VIP+ Validierungsprojekt: ArgumenText
27
1 VIP+ Validierungsprojekt: ArgumenText Entscheidungsunterstützung durch die automatische Extraktion von Argumenten aus großen Textquellen Schlussbericht nach BNBest-BMBF 98 Iryna Gurevych und Johannes Daxenberger Ubiquitous Knowledge Processing Lab Fachbereich Informatik, Technische Universität Darmstadt Zuwendungsempfänger: Technische Universität Darmstadt FKZ: 03VP02540 Laufzeit des Vorhabens: 01.05.2017 - 31.10.2020 Dieses Werk ist verfügbar unter der CC-BY 4.0 Lizenz.
Transcript of VIP+ Validierungsprojekt: ArgumenText

1
VIP+ Validierungsprojekt: ArgumenText
Entscheidungsunterstützung durch die automatische Extraktion von Argumenten aus großen Textquellen
Schlussbericht nach BNBest-BMBF 98
Iryna Gurevych und Johannes Daxenberger Ubiquitous Knowledge Processing Lab
Fachbereich Informatik, Technische Universität Darmstadt Zuwendungsempfänger: Technische Universität Darmstadt
FKZ: 03VP02540 Laufzeit des Vorhabens: 01.05.2017 - 31.10.2020 Dieses Werk ist verfügbar unter der CC-BY 4.0 Lizenz.

2
Abkürzungsverzeichnis
AF Anwendungsfall
AP Arbeitspaket
ML Machine Learning
PM Personenmonate
TUDa Technische Universität Darmstadt

3
Inhaltsverzeichnis I. Kurzdarstellung 4
I.1. Aufgabenstellung 4I.2. Voraussetzungen, unter denen das Vorhaben durchgeführt wurde 4I.3. Planung und Ablauf des Vorhabens 5
I.3.1. Inhaltliche Planung 5I.3.2. Organisation und Ablauf 8
I.4. Wissenschaftlicher und technischer Stand, an den angeknüpft wurde 10I.5. Zusammenarbeit mit anderen Stellen 11
II. Eingehende Darstellung 12II.1. Verwendung der Zuwendung 12II.1.1. Verwertungsstrategische Ergebnisse 12II.1.2. Inhaltlich-technische Ergebnisse 14II.2. Wichtigste Positionen des zahlenmäßigen Nachweises 17II.3. Notwendigkeit und Angemessenheit der geleisteten Arbeit 18II.4. Voraussichtlicher Nutzen, insbesondere der Verwertbarkeit des Ergebnisses im Sinne des fortgeschriebenen Verwertungsplans 18II.5. Während der Durchführung des Vorhabens dem Zuwendungsempfänger bekannt gewordener Fortschritt auf dem Gebiet des Vorhabens bei anderen Stellen 21II.6. Erfolgte oder geplante Veröffentlichungen der Ergebnisse 21
Anhang 25

4
I. Kurzdarstellung
I.1. Aufgabenstellung Alle relevanten Gründe für eine Entscheidung zu berücksichtigen ist aufgrund der vorherrschenden Informationsflut u.a. im Internet zunehmend schwieriger. Existierende Technologien wie Suchmaschinen unterstützen den Entscheidungsprozess zwar, die relevanten Argumente in den Dokumenten gehen dabei aber verloren. Das Validierungsprojekt ArgumenText hatte sich zum Ziel gesetzt, mittels automatischer Extraktion von Argumenten aus großen Textquellen Entscheidungen oder Wissensgenerierungsprozesse effektiv und effizient zu unterstützen. Dabei konnte auf Methoden zur Argumentextraktion aus vorangegangener Grundlagenforschung, die Behauptungen und Begründungen in einzelnen Textdokumenten erkennen, zurückgegriffen werden. Bisher ungenutztes wirtschaftliches Potenzial für innovative Anwendungen in den Bereichen Journalismus und Kaufentscheidungen sollte so erschlossen werden. Ziel war, die Qualität der journalistischen Recherche deutlich zu steigern und den Zeitaufwand für Recherchearbeiten zu verringern. Auch neue oder seltene, aber dennoch entscheidende Argumente sollten so besser identifiziert werden. Des Weiteren war auch die Anwendung auf Produktbewertungen und Rezensionen zur Aggregation von Argumenten für oder gegen ein bestimmtes Produkt zur Erleichterung einer Kaufentscheidung vorgesehen. Im Rahmen der VIP+ Validierungsförderung stand insbesondere die Erarbeitung einer vielversprechenden Verwertungsstrategie im Vordergrund. Entsprechend war das ArgumenText Arbeitsprogramm und Projektmanagement ausgerichtet auf die Definition von Anwendungsfällen, in denen eine Methodenadaption und Evaluation der Technologie stattfand.
I.2. Voraussetzungen, unter denen das Vorhaben durchgeführt wurde
Das Vorhaben wurde vollständig und ausschließlich an der Technischen Universität Darmstadt (TUDa) unter der Leitung des Lehrstuhls für Ubiquitous Knowledge Processing (UKP) durchgeführt. Die Gruppe von Antragstellerin Prof. Dr. Iryna Gurevych gehört zu den weltweit führenden Forschungsgruppen im Bereich Computational Argumentation. In Kombination mit der langjährigen Expertise in der Lösung von komplexen Problemstellungen im Bereich der automatischen Sprachverarbeitung war somit eine exzellente Grundlage für die technologische Weiterentwicklung der Argumentextraktion gegeben. Die Innovation in ArgumenText setzte sich dabei aus der Kombination der Methoden zur Argumentextraktion, dem Knowhow rund um Trainingsdatenerstellung und der Expertise im Bereich Deep Learning zusammen. Entsprechende Vorarbeiten wurden u.a. in den vom BMBF geförderten Projekten „Intelligente Unterstützung für argumentatives Schreiben“ (Software-Campus), „DARIAH-DE: Digitale Forschungsinfrastruktur für Geistes- und Kulturwissenschaften“ sowie dem DFG-Projekt „Information Consolidation: A New Paradigm in Knowledge Search“ (DIP-Exzellenzprogramm) gelegt.

5
Konkret konnte auf Vorarbeiten zur Extraktion von Argumentkomponenten aus Onlinediskussionen und Zeitungsartikeln, sowie zur Erkennung von Argumentstrukturen in Aufsätzen zurückgegriffen werden. Besonders vielversprechend war dabei ein Verfahren zur Erkennung von Argumentstrukturen (Behauptungen, Begründungen und deren Zusammenhänge) in englischen studentischen Aufsätzen, welches zwischen 85 und 95% der menschlichen Genauigkeit für diese Aufgabe erreichte.1 Schwerpunkt der Methodenadaption im Validierungsvorhaben war nun, diese hohe Genauigkeit auch in Szenarien mit heterogenen Dokumentquellen zu erreichen. Auch wenn die Machbarkeit dieser Zielsetzung durch Vorarbeiten, die mit Onlinediskussionen und Zeitungsartikeln arbeiteten, grundsätzlich gezeigt war, lag in dieser Aufgabe eine große Herausforderung, da Machine Learning basierte Algorithmen bekanntermaßen sehr abhängig von der ihnen bekannten Domäne sind. Zusätzlich mussten im Rahmen der Validierung neue Anwendungsfälle erschlossen werden, welche zusätzliche Anforderungen an die Genauigkeit, Effizient und Flexibilität der Verfahren stellten. In allen vorgesehenen Anwendungsfällen war außerdem eine Methode zur Argumentaggregation vonnöten. Diese Aufgabe erforderte eine massive Weiterentwicklung der vorliegenden Grundlagenergebnisse, weil identifizierte Argumente vollautomatisch nach ihrer Ähnlichkeit sortiert werden mussten. Neben den inhaltlichen Vorarbeiten standen dem Vorhaben für eine Laufzeit von drei Jahren ein Projektteam zur Verfügung, das sich aus einer Person in der Projektleitung sowie vier weiteren Mitarbeiterinnen und Mitarbeitern zusammensetzte. Das Projektpersonal war verantwortlich für die Umsetzung der Aufgaben in allen Arbeitspaketen und wurde unterstützt durch studentische Hilfskräfte. Das Vorhaben wurde begleitet durch Dr. Karl-Friedrich Rausch und Prof. Dr. Lorenz Lorenz-Meyer als Innovationsmentoren mit weitreichender Industrieerfahrung. Zur Umsetzung der technischen Infrastruktur wurde ein hochperformantes Rechencluster angeschafft, ausgestattet mit redundanten Knoten und Grafikkarten für die Berechnung von Deep Learning Modellen. Außerdem waren Mittel zur Erstellung von Trainingsdaten vorgesehen, ebenso wie zur Erstellung von graphischen Frontends für die Evaluation mit Validierungspartnern in den Anwendungsfällen. Auch waren Mittel für die Einholung von Gutachten zu rechtlichen Fragestellungen, insbesondere hinsichtlich einer möglichen kommerziellen Verwertung, vorhanden. Für die Durchführung von Evaluations-Workshops, für Reisen zu Validierungspartnern sowie zu Netzwerk- und Disseminationsevents waren weitere Mittel vorgesehen.
I.3. Planung und Ablauf des Vorhabens Das Vorhaben war gegliedert in acht Arbeitspakete (AP) in denen sechs Meilensteine zu nehmen waren. Sämtliche Aufgaben wurden von Projektmitarbeitern der TUDa erbracht.
I.3.1. Inhaltliche Planung Tabelle 1 gibt einen Überblick über die AP und die jeweils veranschlagten Aufwände in Personenmonaten (PM).
1 Stab, C., & Gurevych, I. (2017). Parsing Argumentation Structures in Persuasive Essays. Computational Linguistics, 43(3), 619–659.

6
AP Titel Veranschlagte PM 1 Projektmanagement 22 2 Markt- und Anforderungsanalyse 18 3 Erstellung von anwendungsspezifischen Trainingsdaten 24 4 Sprachanpassung 12 5 Anwendungsspezifische Optimierung 24 6 Aggregation von Argumenten 24 7 Demonstrator zur Realtime-Analyse 30 8 Evaluation und Tauglichkeitsanalyse 26
Tabelle 1: Arbeitspakete und Ressourcenplanung
AP1: Projektmanagement Dieses AP beinhaltete die strategische Projektleitung. Neben organisatorischem Projektmanagement gehörten dazu v.a. die Identifikation, Bewertung und Ausarbeitung von Verwertungsstrategien für die an das Projekt anschließende Verwertungs- und Anwendungsphase. Hier sollte außerdem die zentrale Erfassung der Projektergebnisse sowie die Vorstellung der Projektergebnisse auf Messen und nationalen und internationalen Events geplant und umgesetzt werden. AP2: Markt- und Anforderungsanalyse Zentrales Anliegen des Validierungsprojekts war die Definition einer vielversprechenden Verwertungsstrategie. Dazu sollten in AP2 Markt- und Anforderungsanalysen zur frühzeitigen Erkennung von Konkurrenten und Bewertung des Marktpotentials der Technologie in konkreten Anwendungsfällen durchgeführt werden. Im Rahmen von Workshops mit Validierungspartnern sollten außerdem die Anforderungen für Anwendungsfälle und Demonstratoren erhoben werden. AP3: Erstellung von anwendungsspezifischen Trainingsdaten AP3 war verantwortlich für die Identifikation von Textquellen für die Anwendungsfälle (siehe unten). Je nach Anwendung waren unterschiedliche Quellen vonnöten welche einer Qualitäts- und Machbarkeitsprüfung unterzogen werden mussten. Zur Vorbereitung der Machine Learning Modelle mussten dann die entsprechende Annotation von Trainingsdaten mittels Crowdsourcing erfolgen. AP4: Sprachanpassung Die Schlüsselergebnisse aus der Findungsphase (Vorarbeiten) wurden ausschließlich auf englischen Dokumenten erzielt. Ziel dieses AP war die Anpassung der Argumentextraktion für weitere Sprachen, insbesondere das Deutsche mit dem Ziel der Erschließung von neuem Anwendungspotential. AP5: Anwendungsspezifische Optimierung Hier stand die Optimierung der Argumentextraktion mittels Deep Learning im Vordergrund. Dazu mussten die bestehenden Methoden grundlegend umgeschrieben und auf einer neuen

7
Infrastruktur evaluiert werden. Ziel war die Verbesserung der Performanz zur Steigerung des Nutzens in den Anwendungsfällen. AP6: Aggregation von Argumenten Zum Gruppieren von Argumenten mussten grundlegend neue Verfahren entwickelt werden. Dabei sollten insbesondere unüberwachte Ansätze (Clustering) zum Einsatz kommen. Das Ergebnis dieser Aufgabe zielte ab auf eine massive Steigerung der Übersichtlichkeit der Argumentzusammenfassung, weil ähnliche Argumente automatisch in Gruppen gegliedert werden können. AP7: Demonstrator zur Realtime-Analyse Für den Einsatz in Workshops mit Validierungspartnern und zur Evaluation in Anwendungsfällen war die Entwicklung einer bzw. mehrerer Benutzerschnittstellen geplant. Hier sollte eine einfach zu bedienende graphische Oberfläche geschaffen werden. Außerdem mussten die Komponenten zur Realtime-Analyse von dynamischen Textquellen implementiert werden und die zentrale Serverarchitektur für das Vorhaben aufgebaut werden. AP8: Evaluation und Tauglichkeitsanalyse Als zentrales Element der Validierung gehörten zu diesem AP die Evaluation des Demonstrators mittels Nutzerstudien und Workshops mit Validierungspartnern in allen Anwendungsfällen (extrinsische Evaluation). Außerdem sollte auch eine intrinsische Evaluation zur Beurteilung der Performanz der angepassten Methoden zur Argumentextraktion mittels neu geschaffener Trainingsdaten stattfinden. Meilensteine Über die Projektlaufzeit waren sechs Meilensteine im Abstand von jeweils sechs Monaten zu nehmen:
• M6: Spezifikation der Anwendungsfälle (vorläufige Spezifikation der Anwendungsfälle inkl. Datenquellen und absehbarer Mehrwert für Nutzergruppe)
• M12: Trainingsdaten (Trainingsdaten für Anwendungsfälle liegen vor) • M18: Anwendungsspezifische Argumentextraktion (Adaption der Deep Learning
Modelle für Argumentextraktion ist abgeschlossen und für Deutsch und Englisch verfügbar)
• M24: Realtime-Demonstrator (Graphische Benutzerschnittstelle ist entwickelt für bisher unbekannte und dynamische Textquellen)
• M30: Tauglichkeitsprüfung (Erste Ergebnisse aus Benutzerstudien in den Anwendungsfällen mit dem oder den Demonstratoren liegen vor)
• M36: Vollständige Verwertungsstrategie (Optimaler Verwertungsweg ist definiert und Vorbereitungsaktivität zur eigentlichen Verwertung ist aufgenommen)
Aus den Meilensteinen ergeben sich die Abhängigkeiten unter den AP sowie deren zeitliche Abfolge.

8
Anwendungsfälle Als Schlüsselanwendungen waren die Anwendungsfälle (AF) Journalismus (Zusammenstellung von Argumenten in der Recherche) und Kaufentscheidung (Unterstützung bei Entscheidungen im eCommerce) vorgesehen. Im AF Journalismus sollte ein Thema durch das Aggregieren von Argumenten zusammengefasst werden, um so den Zeitaufwand für Journalisten bei der Recherche erheblich zu reduzieren. Im AF Kaufentscheidung war vorgesehen, die dafür notwendigen Informationen effektiver aus Produktbewertungen zu extrahieren und auch Argumente zu Konkurrenzprodukten automatisch zu identifizieren. Im Effekt könnten Marketingmaßnahmen fokussierter ausgerichtet werden und die Wirksamkeit einer Werbekampagne gezielt gesteigert werden. Weitere mögliche Anwendungsfälle, u.a. im Bereich Finanzdienstleistungen oder zur Meinungsbildung in Politik und Industrie waren vorgeschlagen und sollten nachgelagert und sukzessive erschlossen werden.
I.3.2. Organisation und Ablauf Die Projektmitarbeiterinnen und -mitarbeiter wurden aufgeteilt in fünf Task Forces, welchen wiederum die Umsetzung der AP zugeordnet wurde. Die zentrale Task Force „Definition and Evaluation“ übernahm dabei die Funktion der Projektkoordination. Die Task Forces und Zuordnung von AP findet sich in Tabelle 2. Innerhalb der Task Forces wurde die Arbeitsteilung agil und durch den oder die Leiter oder Leiterin der Task Force koordiniert (Kanban). In der Regel fanden wöchentliche Treffen statt und die Hauptverantwortlichen aller Task Forces kamen zusätzlich einmal die Woche zur Abstimmung zusammen. Neben der Projektplanung via Kanban und schriftlichen Status-Berichten wurde zum Wissensaufbau und -austausch ein Wiki und ein Dateiablagesystem verwendet. Im Rahmen der wissenschaftlichen Projektarbeit bestand enger Austausch im Rahmen einer Special Interest Group zum Thema Argument Mining, an der auch Mitglieder des Lehrstuhls, die nicht im ArgumenText Projekt beschäftigt waren, teilnahmen. Zwischen Prof. Dr. Iryna Gurevych und den Projektkoordinatoren fanden zum Zwecke der Projektsteuerung ebenfalls wöchentliche Treffen statt. Die Projektkoordination wurde während der gesamten Laufzeit von Dr. Johannes Daxenberger übernommen.
Task Force Beteiligte AP Zentrale Funktion Definition and Evaluation 1, 2, 8 Projektsteuerung und Verwertungsstrategie Method Adaptation 3, 4, 5 Umsetzung der Deep Learning Modelle Training Data 3, 4, 5 Erstellung von Trainingsdaten Realtime Analysis & UI 7 Demonstrator und Infrastruktur Aggregation 6 Argumentgruppierung
Tabelle 2: Übersicht über die Task Forces und deren zentrale Aufgaben.
Innerhalb der Task Forces konnte die erfolgreiche Umsetzung der Aufgaben sichergestellt werden. Projektlaufzeit Die geplante Projektlaufzeit von drei Jahren wurde aufgrund von Verzögerungen beim Abschluss der Evaluationsstudien in zwei Anwendungsfällen mit Genehmigung des

9
Projektträgers um sechs Monate kostenneutral verlängert. Dadurch ergaben sich Verschiebungen in AP6, AP8 und AP1. Meilensteine Die Meilensteine M6 – M30 (siehe I.3.1) wurden erfolgreich genommen. M36 (Vollständige Verwertungsstrategie) verzögerte sich aufgrund der Laufzeitverlängerung um sechs Monate, konnte durch die Verlängerung aber letztlich auch erfolgreich genommen werden. Anwendungsfälle Im Laufe der Validierung wurden die vorgesehenen Anwendungsfälle neu bewertet und priorisiert. Der AF Journalismus wurde mangels nachweisbarem Verwertungspotenzial verworfen, stattdessen haben wir den AF Kaufentscheidung aufgeteilt in die konkreten Fälle Innovations- und Technologiebewertung (Argumentsuche in großen Dokumentsammlungen) und Kundenfeedbackanalyse (Argumentsuche in Kundenrückmeldungen zu Produkten). Dissemination und Verwertung Im Rahmen der Zielsetzung des Validierungsvorhabens stand die Erarbeitung einer möglichst vielversprechenden Verwertungsstrategie an erster Stelle. Die Meilensteine orientieren sich in ihrer Reihenfolge an dieser Zielsetzung: zunächst stand die Definition und Vorbereitung von Anwendungsfällen für Argumentextraktion und -aggregation im Vordergrund (Spezifikation der Anwendungsfälle und Erstellung benötigter Trainingsdaten), sodann die technisch-inhaltliche Vorbereitung dieser Anwendungsfälle (Deep Learning für Argumentextraktion und Aggregation sowie Demonstrator) und zuletzt die Evaluation in den Anwendungsfällen (Workshops mit Validierungspartnern und Evaluationsstudien). Um eine möglichst breite Menge an potenziellen Validierungspartnern und Validierungsmöglichkeiten zu erreichen, haben wir im Laufe des Vorhabens Projektergebnisse auf mehr als 40 nationalen und internationalen Foren vorgestellt (siehe Anhang A). In Folge dieser Anstrengungen konnten rund 40 Workshops oder ähnliche Veranstaltungen mit ca. 20 Validierungspartnern durchgeführt werden. Aus den Erkenntnissen dieser Aktivität wurde die Verwertungsstrategie festgelegt: die kommerzielle Verwertung im Rahmen einer Unternehmensgründung in den Anwendungsfällen Kundenfeedbackanalyse (primär) und Innovations- und Technologiebewertung (sekundär). Zusammenfassung Im Laufe der Validierung wurden für zentrale Projektziele entscheidende Durchbrüche erzielt, welche im Folgenden kurz dargelegt sind:
1. Hochqualitative Argumentextraktion auf heterogenen Textquellen (Flexibilität): Anstelle der existierenden Schemata zur Definition von diskursiven Argumentstrukturen wurde ein einfacheres, aber dafür wesentlich flexibleres Schema geschaffen, das Pro- und Kontra-Argumente immer mit Bezug auf ein gegebenes Thema definiert.
2. Effiziente Argumentextraktion aus massiv großen Datenbeständen (Skalierbarkeit): Anstelle einer themenunabhängigen Vorabklassifikation wurde ein zweistufiges Verfahren geschaffen, welches in Echtzeit zunächst Dokumente nach Relevanz zum

10
Thema und dann innerhalb dieser Dokumente nach passenden Argumenten sucht. Als Dokumentquellen kommen aus urheberrechtlicher Sicht für die kommerzielle Verwertung nur kundeneigene Daten oder lizenzierte Datensammlungen in Frage.
3. Argumentgruppierung anhand argumentativer Aspekte (Aggregation): Anstelle existierender Verfahren zur Erkennung von semantischer Ähnlichkeit wurden Modelle zur Erkennung argumentspezifischer Ähnlichkeit trainiert, welche dann in einem Clustering-Verfahren zum Einsatz kommen, um ähnliche Argumente zum selben Aspekt zu gruppieren.
4. Entscheidungsunterstützung durch Argument Mining (Validierung): Der AF Journalismus wurde aufgrund mangelnder Verwertungschancen zugunsten des AFs Kaufentscheidung verworfen. Letzterer wurde, getrieben durch die Ergebnisse der Evaluationsstudien, Marktanalysen und rechtlichen Gutachten unterteilt in die Fälle Innovations- und Technologiebewertung sowie Kundenfeedbackanalyse.
I.4. Wissenschaftlicher und technischer Stand, an den angeknüpft wurde
Der für das hier beschriebene Vorhaben zentrale Forschungsbereich Argument Mining bzw. Computational Argumentation existiert seit etwa 2009 (Mochales-Palau and Moens, 20092). Dabei lag der Fokus zunächst auf der Erkennung von Argumentation in juristischen Texten. Neuere Arbeiten konzentrierten sich auch auf andere Textsorten wie Onlinekommentare (Florou et al., 20133), Wikipedia (Levy et al., 20144), oder soziale Medien (Goudas et al., 20145). Allerdings deckt keine dieser Arbeiten alle nötigen Schritte für die Argumentextraktion ab. Sie setzen entweder voraus, dass die argumentativen Textstellen bereits erkannt wurden und die Argumentkomponenten bereits segmentiert und als Argument gruppiert vorliegen, oder sind nicht in der Lage, argumentative Relationen zwischen den Argumentkomponenten zu identifizieren. Das VIP+ Vorhaben baute naturgemäß auf die Ergebnisse einer Findungsphase auf. Dabei konnte die Arbeitsgruppe auf weitreichende eigene Vorarbeiten und methodisches Know-How aus dem Bereich Computational Argumentation zurückgreifen, welche bis in das Jahr 2014 zurückreichen. Im Fokus unserer eigenen Arbeiten stand die automatische Extraktion und Analyse von Argumenten in homogenen Datenquellen, bspw. Schüleraufsätze (Stab und Gurevych, 20146), Nachrichtentexte (Eckle-Kohler et al., 20157), oder wissenschaftliche
2 Mochales-Palau, R., & Moens, M.-F. (2009). Argumentation Mining: The Detection, Classification and Structure of Arguments in Text. Proceedings of the 12th International Conference on Artificial Intelligence and Law, 98–107. 3 Florou, E., Konstantopoulos, S., Koukourikos, A., & Karampiperis, P. (2013). Argument extraction for supporting public policy formulation. Proceedings of the 7th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities, 49–54. 4 Levy, R., Bilu, Y., Hershcovich, D., Aharoni, E., & Slonim, N. (2014). Context Dependent Claim Detection. Proceedings of the 25th International Conference on Computational Linguistics (COLING), 1489–1500. 5 Goudas, T., Louizos, C., Petasis, G., & Karkaletsis, V. (2014). Argument Extraction from News, Blogs, and Social Media. In A. Likas, K. Blekas, & D. Kalles (Eds.), Artificial Intelligence: Methods and Applications (pp. 287–299). Springer International Publishing. 6 Stab, C., & Gurevych, I. (2014). Identifying Argumentative Discourse Structures in Persuasive Essays. Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), 46–56. 7 Eckle-Kohler, J., Kluge, R., & Gurevych, I. (2015). On the Role of Discourse Markers for Discriminating Claims and Premises in Argumentative Discourse. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2249–2255.

11
Publikationen (Kirschner et al., 20158). Dabei wurden für verschiedene Datenquellen jeweils eigene Schemata für die Auszeichnung und automatische Erkennung der Argumentstrukturen verwendet. Mittels der „Joint-Modeling-Methode“ wurde auf Schüleraufsätzen eine Genauigkeit von 83% F1-Score für die Klassifikation von Argumentkomponenten und 75% für die Erkennung von argumentativen Relationen erreicht. Das entspricht 95% bzw. 88% der menschlichen Performanz. Da diese Methode einen großen Teil der notwendigen Schritte einer Argumentanalyse abdeckt und dem damaligen Stand der Technik bei der Genauigkeit für automatische Klassifikation entspricht, stellte diese Methode den Ausgangspunkt für die Arbeiten im Vorhaben dar. Unsere Arbeitsgruppe hatte zu Projektbeginn bereits eine Führungs- und Vorreiterrolle im Bereich Computational Argumentation inne und war auch fortlaufend auf den national und international wichtigen Foren für diesen Forschungsbereich vertreten (u.a. Argument Mining Workshops der Association for Computational Linguistics, Dagstuhl-Seminar Debating Technologies). Vorhandene Schutzrechte wurden nicht in Anspruch genommen.
I.5. Zusammenarbeit mit anderen Stellen Das Vorhaben wurde inhaltlich ausschließlich an der TU Darmstadt umgesetzt. An der Evaluation in den Anwendungsfällen hat eine Vielzahl von externen Validierungspartnern teilgenommen. Das Team an der TU Darmstadt wurde außerdem unterstützt von zwei Innovationsmentoren (siehe I.2). Weitere Akteure im Umfeld des Vorhabens waren die Gründungsberatung sowie das Dezernat Forschung und Transfer der TUDa, welche ArgumenText eng hinsichtlich rechtlicher Fragen rund um die Verwertung und Validierung beraten haben. Extern wurden wir außerdem durch die Hessen Trade & Invest GmbH (HTAI, Wirtschaftsentwicklungsgesellschaft des Landes Hessen) unterstützt, u.a. durch eine Delegationsreise ins Silicon Valley sowie durch logistische Unterstützung von Messeauftritten. Im Forschungsbereich haben wir eng mit der Bauhaus-Universität in Weimar, welche ebenfalls im Gebiet Argument Mining aktiv ist, sowie dem Institut für Publizistik der Johannes-Gutenberg-Universität Mainz zusammengearbeitet. Letztere unterstützten das Vorhaben bei der Validierung im AF Journalismus. Enger Austausch bestand außerdem mit dem DFG Schwerpunktprogramm „Robust Argumentation Machines (RATIO)“, welches neue semantische Modelle und Ontologien zur tiefen Repräsentation von Argumenten entwickelt. Im Ausland haben wir u.a. mit dem Natural Language Processing Lab der Bar-Ilan-Universität in Tel Aviv (Israel) zusammengearbeitet, welche im für Argument Mining relevanten Bereich Textuelle Inferenz führend ist.
8 Kirschner, C., Eckle-Kohler, J., & Gurevych, I. (2015). Linking the Thoughts: Analysis of Argumentation Structures in Scientific Publications. Proceedings of the 2nd Workshop on Argumentation Mining Held in Conjunction with the 2015 Conference of the North American Chapter of the Association for Computational Linguistics – Human Language Technologies (NAACL HLT 2015), 1–11.

12
II. Eingehende Darstellung
II.1. Verwendung der Zuwendung Die Zuwendung wurde verwendet, um die inhaltlich-technischen Arbeiten zu erbringen, die dem vorrangigen Ziel der Erarbeitung einer vielversprechenden Verwertungsstrategie dienten. Der folgende Abschnitt ist entsprechend in diese beiden Bereiche untergliedert.
II.1.1. Verwertungsstrategische Ergebnisse In AP1 wurde ein agiler Entwicklungsprozess zur Projektsteuerung entwickelt. Um die Sichtbarkeit des Projektes zu stärken, wurde die Erstellung einer Projektwebseite (www.argumentext.de) beauftragt. Die Projektergebnisse wurden auf internationalen und hoch-sichtbaren Foren vorgestellt (siehe II.6). Das Projekt wurde mehrfach in der Presseberichterstattung (u.a. mit einem Artikel in der Computerzeitschrift c‘t) aufgegriffen. Es wurden mehrere rechtliche Gutachten zu den Themen Urheberrecht und Datenschutz in Auftrag gegeben. Ausgehend von den Ergebnissen wurden die Systemkomponenten auf die Verarbeitung von proprietären Datenquellen und spezifischen Kundendaten ausgerichtet. Mit der erfolgreichen Einwerbung einer Anschlussförderung im EXIST Programm des BMWi wurde auch die weiterlaufende Verwertung sichergestellt. In AP2 wurden Workshops mit Stakeholdern aus der Industrie durchgeführt. Die Ergebnisse dieser Workshops war die Definition der Anwendungsfälle (siehe Tabelle 3 und Abschnitt „Anwendungsfälle“), außerdem wurden für die Entwicklung des Demonstrators die funktionalen und nicht-funktionalen Nutzeranforderungen erhoben.
Anwendungsfall Zielgruppe Evaluation Verwertung Mgl. Verwertung
Innovations- und Technologiebewertung
Innovationsmanager Nutzerstudien via API-Schnittstelle und Dashboard
Ja Kommerziell
Journalismus Zeitungsverlage Nutzerstudien via API-Schnittstelle
Nein Kommerziell
Patent- und Knowhow-Recherche
Wissenschaft - Nein OpenSource
Kundenfeedbackanalyse Qualitätssicherung, Produktentwicklung
Nutzerstudien via Dashboard
Ja Kommerziell
Finanzdienstleistungen Finanzanalysten Fragebogen Nein Kommerziell Tabelle 3: Evaluation in den Anwendungsfällen
AP8 diente der Evaluation der Arbeitsergebnisse in den Anwendungsfällen. Diese erfolgte auf zwei Wegen: unsere Validierungspartner konnten entweder auf eine ArgumenText-Schnittstelle zur Klassifikation von eigenen Argumenten zugreifen (Classify-API), oder auf ein personalisierbares Dashboard (siehe AP7 und Abb. 4). Im ersteren Fall kamen Quelldaten der Validierungspartner zum Einsatz, diese wurden über unsere API ausgewertet und das

13
Ergebnis direkt in der Umgebung der Validierungspartner integriert. Im AF Innovations- und Technologiebewertung kamen beide Zugriffsmethoden zum Einsatz. Im AF Kundenfeedbackanalyse haben wir ausschließlich mit dem Dashboard gearbeitet (vgl. Tab. 3). Sowohl im AF Innovations- und Technologiebewertung als auch im AF Kundenfeedbackanalyse wurde die Evaluation mehrstufig durchgeführt – insb. wurde die Extraktion von Argumenten und deren Aggregation getrennt untersucht. Auch die Bedienbarkeit der Weboberflächen wurde untersucht. Die Ergebnisse der Evaluationsstudien wurden, wo möglich, strukturiert bspw. durch Fragebögen erhoben. Wo eine strukturierte Evaluation nicht möglich oder sinnvoll war, wurde ein Bericht oder eine Abschlusspräsentation erstellt. Neben der Classify-API wurde auch eine Search-API bereitgestellt, welche es erlaubt in den von ArgumenText bereitgestellten Datensätzen nach Argumenten zu suchen. Diese kam vorwiegend für den öffentlichen Demonstrator zum Einsatz (siehe Abb. 1). Die Arbeitsergebnisse wurden aber nicht nur im Rahmen von Nutzerstudien evaluiert, sondern auch intrinsisch durch entsprechende Benchmarks (Training- und Testdaten zu verschiedenen Themen) und Qualitätssicherungsmaßnahmen (bei der Erstellung von Trainingsdaten, bspw. durch die Messung der Übereinstimmung mehrerer Annotatoren). Tabelle 4 fasst die Evaluation der Arbeitsergebnisse zusammen.
AP Inhalt Intrinsisch Extrinsisch Publikation (siehe Verz. in II.6)
3 Trainingsdaten Qualitätssicherung beim Crowdsourcing
AP4 und AP5 (trainierte Modelle)
-
4 Mehrsprachigkeit Transferqualität auf Benchmark-Datensatz
- Eger et al. (2017)
5 Argument-erkennung
Modellqualität auf Benchmark-Datensatz
Manuell (Validität von Pro- und Kontra-Argumenten)
Reimers et al. (2019), Stab et al. (2018b)
6 Argument-aggregation
Modellqualität auf Benchmark-Datensatz
Manuell (Zuweisung von Argumenten zu Clustern)
Reimers et al. (2019)
7 Bedienung Demonstrator
- Fragebogen zur Benutzerfreundlichkeit
-
Tabelle 4: Evaluation der Arbeitsergebnisse in der AP.
Anwendungsfälle Trotz diverser Unterstützungszusagen zur Validierung der Technologie für Anwendungen im Bereich Journalismus (Zusammenstellung von Argumenten zu beliebigen Themen bei der journalistischen Recherche) konnten wir kein hohes Verwertungspotenzial in dieser Hinsicht feststellen. Die Hintergründe sind vielfältig, lassen sich aber u.a. mit einer sehr hohen Erwartung an die Genauigkeit automatischer Werkzeuge zur Recherche erklären. Eine Evaluation mit einem Validierungspartner zur automatischen Suche von Argumenten zu Themen rund um Volksabstimmungen in der Schweiz führte zu keinem positiven Ergebnis. Außerdem ist die ArgumenText Technologie nicht geeignet um Fake News zu identifizieren, was im Projektzeitraum ein beherrschendes Thema im Bereich Data Journalism darstellte. Ein mit Unterstützung unseres Innovationsmentors Prof. Dr. Lorenz Lorenz-Meyer im Frühjahr 2019 angedachter Workshop mit Journalisten musste mehrfach verschoben werden und ist schließlich aufgrund der Verschiebung der Prioritäten bei den Verwertungsszenarien komplett entfallen. Hinsichtlich der Verwertungschancen besteht im AF Journalismus außerdem das Problem der Beschaffung der Quelldaten, in welchen Argumente identifiziert werden können. Dieses Problem ließ zumindest die kommerzielle Verwertung ohne einen Sparring-Partner zur

14
Datenbeschaffung wenig attraktiv erscheinen. Entsprechend haben wir über den gesamten Projektzeitraum mit mehreren Datenanbietern zusammengearbeitet, u.a. überregionalen deutschen Wirtschaftszeitungen, Presseagenturen und einem internationalen Anbieter von Informationslösungen. Trotz der prototypischen Integration der jeweiligen Datenquellen in unsere Infrastruktur konnten hier keine Win-Win Szenarien zur Zusammenarbeit festgestellt werden. Der ursprüngliche geplante AF Kaufentscheidung sah einen Einsatz der ArgumenText Technologie zur Unterstützung von Verbrauchern im eCommerce Bereich vor. Allerdings stellten wir bereits früh in der Projektlaufzeit auch Interesse von Technologieherstellern (v.a. für den Bereich Mobilität) fest. Insbesondere für die Bewertung von innovativen und noch wenig bekannten Technologien schien die Suche nach Pro- und Kontra-Argumenten in heterogenen Echtzeitdaten ein bislang wenig bearbeitetes und vielversprechendes Feld. Als Konsequenz wurde der neue AF Innovations- und Technologiebewertung geschaffen und dem AF Kaufentscheidung zugeordnet. Für die Unterstützung von Verbrauchern im eCommerce Bereich waren als Datengrundlage Produktbewertungen (Online Reviews) vorgesehen. Als Konsequenz der rechtlichen Problematik bei der Beschaffung externer Daten inkl. Webcrawl mit Reviews wurde dieser Anwendungsfall modifiziert und konkretisiert für den B2B Bereich und auf unternehmenseigenen Daten. So entstand der AF Kundenfeedbackanalyse, welcher zusammen mit dem AF Innovations- und Technologiebewertung letztlich zentraler Bestandteil der Validierung und Fokus der Evaluationsstudien wurde. Außerdem wurden Anwendungsfälle im Bereich Finanzdienstleistungen untersucht. Dazu haben wir mit Validierungspartnern bei einem Bankhaus sowie einer deutschen Wirtschafts- und Finanzzeitung als Datenanbieter zusammengearbeitet. Untersucht wurde die Unterstützung von Finanzanalysten beim Verfassen von Berichten zu Technologie-lastigen Themen. Auch der AF Patent- und Knowhow-Recherche zur Analyse von Argumenten in Patenten wurde untersucht mit einer möglichen Verwertung als Open Source Software. Aufgrund der speziellen Gegebenheiten in Patentschriften und sich daraus ergebenden notwendigen Aufwände zur Anpassung der Trainingsdaten wurde dieser Anwendungsfall aber nicht weiterverfolgt.
II.1.2. Inhaltlich-technische Ergebnisse In AP3 wurde ein neues Annotationsschema entwickelt, das die Extraktion von themen-relevanten Argumenten aus Texten ermöglicht. Es wurde gezeigt, dass dieses neue Annotationsschema sowohl von Experten als auch Crowdworkern verlässlich auf heterogene Webdaten anwendbar ist und sich mittels Crowdsourcing eine große Datenmenge mit hoher Qualität in kurzer Zeit erstellen lässt. Insgesamt wurden Datensätze mit mehr als 100,000 englischen Instanzen über mehr als 70 Themenbereiche erstellt. Unter den Themenbereichen sind vorwiegend solche zu Technologie und Innovation, aber auch politisch, gesellschaftlich und finanzwirtschaftlich relevante Themen.
15
In AP4 wurden zur Sprachanpassung der Argumentextraktionsmethoden für das Deutsche maschinelle Lernverfahren basierend auf bilingualen Repräsentationen erprobt und mit Modellen, die auf maschinell übersetzten Trainingsdaten trainiert wurden, verglichen. Die Ergebnisse zeigten, dass das Trainieren auf übersetzten Trainingsdaten eine bessere Performance bietet, wodurch eine große Menge von Sprachen mit geringem Aufwand erschlossen werden können. Außerdem wurden im Rahmen interner Nutzerstudien das deutsche und englische Modell u.a. für den AF Innovations- und Technologiebewertung auf proprietären Dokumentsammlungen evaluiert. Das Ergebnis zeigte, dass beide Sprachen ähnlich gut abschneiden. In AP5 wurden mehrfach neue maschinelle Lernverfahren für die Argumenterkennung aus heterogenen Daten entwickelt. Das zuletzt eingesetzte Modell basiert auf einer Transformer-Architektur und erzielt Bestergebnisse auf den verfügbaren Benchmark-Datensätzen. Es wurde zudem gezeigt, dass die neuen Modelle deutlich robuster gegenüber thematischen Änderungen sind als herkömmliche neuronale Netze. Zusätzlich wurden anwendungsspezifische Trainingsdaten für den AF Kundenfeedbackanalyse erstellt und darauf ein entsprechendes Modell trainiert.
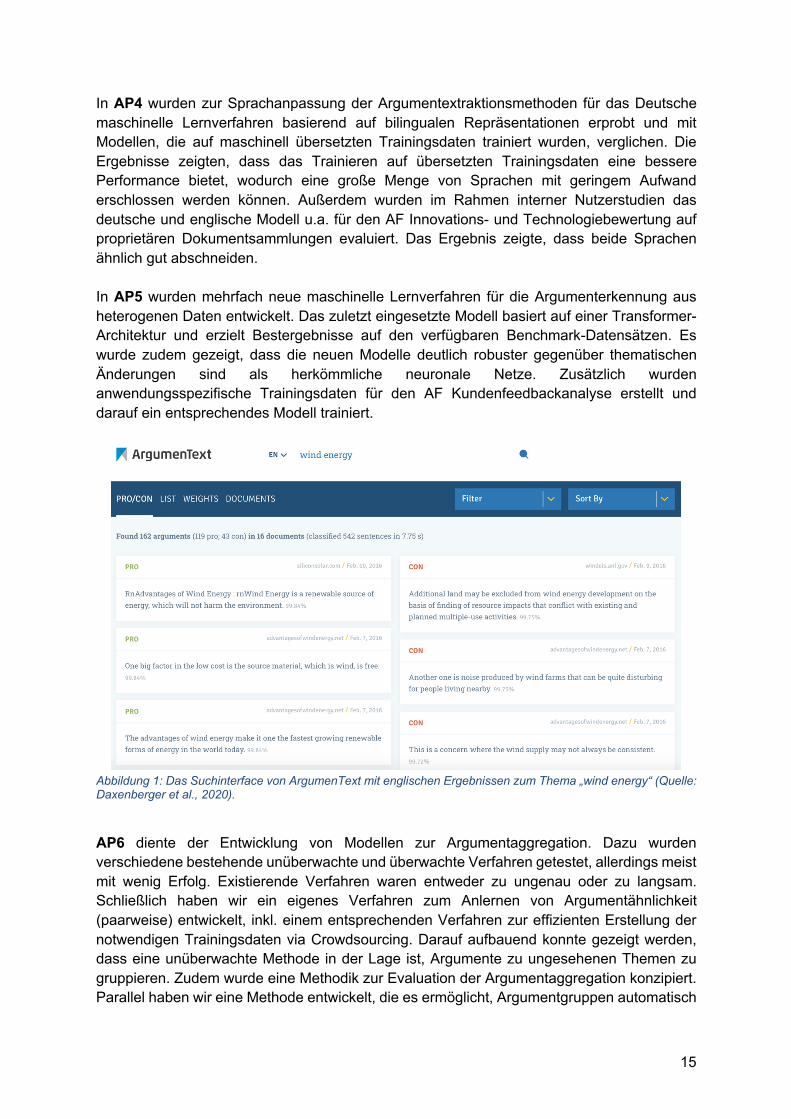
Abbildung 1: Das Suchinterface von ArgumenText mit englischen Ergebnissen zum Thema „wind energy“ (Quelle: Daxenberger et al., 2020).
AP6 diente der Entwicklung von Modellen zur Argumentaggregation. Dazu wurden verschiedene bestehende unüberwachte und überwachte Verfahren getestet, allerdings meist mit wenig Erfolg. Existierende Verfahren waren entweder zu ungenau oder zu langsam. Schließlich haben wir ein eigenes Verfahren zum Anlernen von Argumentähnlichkeit (paarweise) entwickelt, inkl. einem entsprechenden Verfahren zur effizienten Erstellung der notwendigen Trainingsdaten via Crowdsourcing. Darauf aufbauend konnte gezeigt werden, dass eine unüberwachte Methode in der Lage ist, Argumente zu ungesehenen Themen zu gruppieren. Zudem wurde eine Methodik zur Evaluation der Argumentaggregation konzipiert. Parallel haben wir eine Methode entwickelt, die es ermöglicht, Argumentgruppen automatisch

16
mit einem kurzen Stichwort zu benennen (diese Anforderung ergab sich aus den frühen Validierungsstudien). Kurz vor Projektende konnte das Verfahren zur Argumentaggregation signifikant beschleunigt werden, ein ebenfalls wichtiges Merkmal für den Praxiseinsatz. Zudem wurden anwendungsspezifische Trainingsdaten erstellt (AF Kundenfeedbackanalyse).
Abbildung 2: Übersicht über die Software-Komponenten von ArgumenText (Quelle: Daxenberger et al., 2020).
In AP7 wurde der zentrale Demonstrator für die Validierungsstudien entwickelt. Dazu wurde zunächst eine Serverarchitektur eingerichtet, mit der dynamische Inhalte in Echtzeit verarbeitet und die anwendungsrelevanten Texte effizient aus großen Datenmengen extrahiert werden können. Es wurde ein Suchinterface erstellt, welches 400 Mio. englische und 7 Mio. deutsche Texte aus existierenden Webkorpora nach Argumenten zu beliebigen Themen durchsucht. Abb. 1 zeigt den öffentlich zugänglichen Webdemonstrator zur Argumentsuche.
Abbildung 3: Die Zeitstrahlkomponente des ArgumenText Dashboards zeigt die Entwicklung der Pro- und Kontra-Argumente über einen gewissen Zeitraum (Quelle: Daxenberger et al., 2020).

17
Im nächsten Schritt wurde der Demonstrator signifikant erweitert um eine Dashboard-Komponente und deren Backend. Das neue Frontend erlaubt die Verwaltung von Suchanfragen und -ergebnissen, eine spezifische Anpassung von Suchanfragen (verschiedenen Modelle, Textquellen, Filter etc.) und die Gruppierung von Argumenten zu einer Suchanfrage (vgl. AP6). Argumente aus Datenquellen, die Dokumente aus einem längeren Zeitraum umfassen, lassen sich an einem Zeitstrahl darstellen (siehe Abb. 3). Als Backbone zur Dashboard-Komponente wurde eine komplexe Service-basierte Infrastruktur entwickelt, welche Suchanfragen in Echtzeit über ein Queuing-System abarbeitet. Abb. 2 gibt einen konzeptuellen Überblick über die einzelnen Softwarekomponenten. Das Dashboard kam im Rahmen zahlreicher Nutzerstudien (siehe AP8) zum Einsatz (siehe Abb. 4). Neben dem Webcrawl wurden auch andere Dokumentsammlungen als Textquellen integriert, u.a. Wikipedia-Artikel, Pressemitteilungen, Soziale Medien, sowie proprietäre Datenanbieter. Ursprünglich waren getrennte Demonstratoren für zwei Anwendungsfälle vorgesehen. Aus der Entscheidung, den AF Journalismus nicht weiterzuverfolgen und stattdessen den AF Kaufentscheidung in zwei AF zu unterteilen (Innovations- und Technologiebewertung und Kundenfeedbackanalyse), ergab sich auch eine Änderung an den Demonstratoren: mit Genehmigung des Projektträgers wurden die für zwei getrennte Demonstratoren vorgesehenen Mittel eingesetzt, um einen gemeinsamen Demonstrator zu entwickeln, der in beiden Anwendungsfällen eingesetzt werden kann und einen erweiterten Funktionsumfang bietet (Quellenauswahl, Auswahl von ML-Modellen, Clustering).
Abbildung 4: Argumente und Cluster zum Thema „E-Scooter“, wie sie im ArgumenText Dashboard dargestellt werden.
II.2. Wichtigste Positionen des zahlenmäßigen Nachweises
Der größte Kostenfaktor des Projekts umfasst die Personalkosten für die Mitarbeiterinnen und Mitarbeiter während der gesamten Projektlaufzeit. Das Projektpersonal hat unter der Leitung von Dr. Johannes Daxenberger die inhaltlich-technischen Arbeiten erledigt sowie

18
Validierungsstudien, Netzwerkevents und Workshops durchgeführt und die Verwertungsstrategie erarbeitet. Das Projektpersonal wurde dabei während der gesamten Projektlaufzeit von studentischen Hilfskräften unterstützt, welche insbesondere an Programmierarbeiten, Datenannotation und logischer Organisation beteiligt waren. Zu den größten Posten unter den verausgabten Sachmitteln gehören die Vergabe von Aufträgen und die Beschaffung von Projekthardware. Zu erstem gehören Ausgaben zur professionellen Außendarstellung (Website, GUI für Demonstrator), der Erstellung von Trainingsdaten via Crowdsourcing (AP3), sowie die Erstellung von rechtlichen Gutachten zu essenziellen Fragen der Verwertung (AP2, Urheberrecht und Datenschutz). Hardware wurde zu Projektbeginn beschafft, um eine dem Projekt dauerhaft und ausschließlich zur Verfügung stehende Entwicklungs- und Produktivinfrastruktur zu ermöglichen. Diese Hardware besteht im Wesentlichen aus einem Berechnungscluster und Daten-Speicher. Auf dieser Hardware wird der Demonstrator betrieben, welcher ausfallsicher und reaktionsschnell für die Evaluationsstudien zur Verfügung stehen musste. Weitere Sachmittel wurden für nationale und internationale Dienstreisen verausgabt. Ziele waren entweder Foren auf denen Projektergebnisse vorgestellt wurden und welche auch Networking-Charakter hatten (siehe Anhang A), oder Veranstaltungen die unmittelbar der Validierung bzw. Evaluation der Projektergebnisse dienten. Letztere führten immer zu Validierungspartnern im Inland. Weitere Sachausgaben entstanden durch Lizenzierungsgebühren für Dokumentquellen, welche zur Validierung im AF Innovations- und Technologiebewertung benötigt wurden.
II.3. Notwendigkeit und Angemessenheit der geleisteten Arbeit
Die geleisteten Arbeiten folgten der Projektplanung laut Antrag, alle gesetzten Meilensteine wurden erfolgreich abgeschlossen, lediglich M36 verzögerte sich um 6 Monate. Der gesetzte Kostenrahmen wurde eingehalten, auch wenn es im Laufe des Projekts zu (genehmigten) Mittelumwidmungen kam. Eine inhaltliche Verzögerung in der zweiten Hälfte der Projektlaufzeit (v.a. in AP7 und als Folge dessen auch in AP8) veranlasste uns dazu, eine kostenneutrale Verlängerung zu beantragen. Durch die Gewährung dieser Verlängerung konnte sichergestellt werden, dass die vorgesehenen Ziele vollständig erreicht werden und eine anschließende Verwertung der Ergebnisse gesichert ist.
II.4. Voraussichtlicher Nutzen, insbesondere der Verwertbarkeit des Ergebnisses im Sinne des fortgeschriebenen Verwertungsplans
Eine fundierte Beurteilung der Verwertungsmöglichkeiten der ArgumenText Technologie war eines der wesentlichen Ziele der Förderung. Entsprechend wurde der Verwertungsplan

19
während der Projektlaufzeit fortlaufend aktualisiert und sowohl unter wissenschaftlichen als auch unter wirtschaftlichen Gesichtspunkten untersucht. Wissenschaftliche Erfolgsaussichten Auf dem Gebiet Argument Mining und Computational Argumentation konnte das Projekt signifikante Fortschritte erzielen, welche der gesamten Forschungsgemeinschaft zugutekommen. Insbesondere die Ergebnisse aus den AP4, AP5 und AP6 wurden auf hochrangigen internationalen Konferenzen veröffentlicht und erfreuten sich bereits während der Projektlaufzeit einer äußerst hohen Sichtbarkeit.9 Ausgewählte Teile der Software-Architektur und erzeugten Datensätze wurden im Einklang mit der IP-Strategie quellfrei (auf der Plattform github.com, siehe Liste in Anhang B) veröffentlicht. Auch diese Projekte werden von der Forschungsgemeinschaft rege genützt, wie sich bspw. an der hohen Anzahl von Stars auf github.com zeigt.10 Der Demonstrator, welcher erstmalig im Sommer 2018 auf der internationalen A-level Konferenz „Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)“ vorgestellt wurde (siehe Abb. 1), hat bis Anfang 2021 mehr als 150.000 Such-Anfragen beantwortet. Die Search und Classify API (siehe II.1.1), welche zu nicht-kommerziellen Testzwecken verwendet werden konnten, haben insgesamt bislang über 6 Millionen Anfragen bearbeitet. Das enorm hohe wissenschaftliche Interesse zeigt sich auch an den zahlreichen eingeladenen Vorträgen im In- und Ausland, bei denen wir das ArgumenText Projekt vorstellen und so zusätzlich Sichtbarkeit generieren konnten (siehe Anhang A). Im AF Journalismus wurde mit Partnerinnen und Partnern in den Geistes- und Sozialwissenschaften, u.a. an der Universität in Mainz, kooperiert. Auch wenn dieser Anwendungsfall letztlich nicht weiterverfolgt wurde, entstanden Veröffentlichungen aus dieser Zusammenarbeit, siehe II.6. Zusammen mit der Universität Ulm haben wir den Einsatz von ArgumenText für argumentative Dialogsysteme untersucht. Auch hieraus entstand eine wissenschaftliche Publikation (siehe II.6). Im Kernforschungsbereich Argument Mining und Argumentsuche haben wir u.a. mit den Universitäten in München (LMU), Weimar (Bauhaus Universität) und Tel Aviv, Israel (Bar-Ilan) zusammengearbeitet. Allerdings konnte im Rahmen der Projektaktivität bei keiner dieser Anwendungen eine langfristige Verwertungsmöglichkeit gezeigt werden, so dass der Großteil der Evaluationsstudien in den kommerziellen Anwendungsfällen Innovations- und Technologiebewertung und Kundenfeedbackanalyse durchgeführt wurde. Wirtschaftliche Erfolgsaussichten Das Interesse von Validierungspartnern in den Anwendungsfällen Innovations- und Technologiebewertung sowie Kundenfeedbackanalyse führten dazu, dass eine wirtschaftliche Verwertung bspw. im Rahmen einer Unternehmensgründung frühzeitig als vielversprechend eingestuft werden konnte. Konkret konnten wir mit großen Unternehmen aus der Konsumgüterbranche, aus der Verlags- und Medienbrache, aus der Automobilindustrie sowie aus der Finanzbranche zusammenarbeiten. Die Erschließung des kommerziellen
9 Zu Beginn des Jahres 2021 wurden Kern-Publikationen aus dem Vorhaben (siehe II.6) bereits fast tausend Mal zitiert. 10 Zu Beginn des Jahres 2021 weisen Kern-Projekte aus dem Vorhaben über 4700 Stars auf. Knapp 4500 davon stammen aus https://github.com/UKPLab/sentence-transformers. Die vollständige Liste findet sich in Anhang B.

20
Verwertungspotenzials wurde dabei auf die Arbeit mit dem ArgumenText Dashboard und der ArgumenText API (siehe II.1.1) ausgelegt. Im AF Innovations- und Technologiebewertung zeigen die Ergebnisse der Evaluationsstudien, dass die Extraktion von Argumenten aus riesigen Datenbeständen einen massiven Zeit- und Informationsgewinn gegenüber herkömmlicher Suche (bspw. über eine Internet-Suchmaschine) oder Sentimentanalyse schaffen kann. Als Schwachstellen konnte eine teils mangelnde Relevanz der extrahierten Argumente sowie die Beschaffung und Weiterverarbeitung der Quelldatensätze (in denen nach Argumenten gesucht wird) identifiziert werden. Trotz dieser Herausforderungen überwiegen in diesem Fall die kommerziellen Verwertungschancen. Im AF Kundenfeedbackanalyse konnte durch den Einsatz von Argumenterkennung und Aggregation auf Kundenrückmeldungen gezeigt werden, wie ArgumenText die tiefgreifende Analyse von Produktmängeln unterstützen und massiv beschleunigen kann. Hier konnte insbesondere gezeigt werden, dass die vollkommen automatische Analyse im Problemfall tagelange manuelle Arbeit ersetzen kann durch einen Prozess, der nur ein paar Minuten dauert. Herausforderung für diesen Anwendungsfall ist eine erforderliche schnelle und gezielte Erstellung von Trainingsdaten für neue Produktkategorien. Diese konnten wir durch ein zum Patent angemeldetes Verfahren lösen, so dass auch in diesem Anwendungsfall die kommerziellen Verwertungschancen überwiegen. Im Rahmen der IP-Strategie des Vorhabens wurden Teile der erarbeiteten Software und insbesondere der erstellten Trainingsdaten nicht veröffentlicht, außerdem wurde für den Prozess der Trainingsdatenerstellung ein internationales Patent angemeldet. Zur Wahrung des IPs sowie zur Sicherstellung einer zweckgemäßen Verwendung wurden mit allen Validierungspartnern vor Beginn der Studien Geheimhaltungs- und Nutzungsverträge geschlossen. Trotz der regen Forschungsaktivität auf dem Gebiet Argument Mining war uns bis Ende der Projektlaufzeit kein kommerzieller Anbieter dieser Technologie bekannt. Der kommerziell aktivste Player im Gebiet Argument Mining ist IBM.11 Anschlussfähigkeit der Ergebnisse Eine Verwertung der Projektergebnisse ist sowohl im Kontext der Forschung und Bildung sichergestellt als auch im wirtschaftlichen Bereich. Die wissenschaftliche Weiterverwendung der Projektergebnisse wird ermöglicht durch die Veröffentlichung zahlreicher Papiere auf hoch-sichtbaren Foren sowie durch die Bereitstellung von (Teilen) der Ergebnisse als Open-Source Software und Daten. Der Lehrstuhl wird außerdem im Rahmen der nicht-kommerziellen Verwertung der Projekt-Ergebnisse dafür Sorge tragen, dass bspw. der Demonstrator auch der Lehre zum Einsatz kommt. Folgeprojekte im Bereich Argument Mining können auf Teile der ArgumenText Infrastruktur aufbauen. Zur wirtschaftlichen Verwertung konnte im Rahmen des EXIST Programms des BMWi erfolgreich eine Anschlussfinanzierung für eine Unternehmensgründung eingeworben werden. Die am Gründungsvorhaben beteiligten Personen haben auch an der Validierung im Rahmen des VIP+ Projekts mitgewirkt. Es ist die Gründung einer GmbH vorgesehen, die in
11 https://www.research.ibm.com/artificial-intelligence/project-debater/

21
den Anwendungsfällen mit dem größten Marktpotenzial den kommerziellen Arm der Verwertung vorantreibt.
II.5. Während der Durchführung des Vorhabens dem Zuwendungsempfänger bekannt gewordener Fortschritt auf dem Gebiet des Vorhabens bei anderen Stellen
Während der Projektlaufzeit wurde das unmittelbar für das Vorhaben relevante Forschungsgebiet Argument Mining sehr genau verfolgt. Die dynamische Entwicklung dieses Feldes machte eine fortlaufende Anpassung an den State-of-the-Art erforderlich. Wir sind dieser Anforderung durch zahlreiche Studien (siehe II.6) nachgekommen, die neben der eigenen methodischen Weiterentwicklung auch immer den jeweiligen Stand der Technik aufarbeiten - insbesondere im Bereich des Deep Learning. So wurden bspw. im Jahr 2018 neuartige Typen von Embeddings (ein wichtiger Bestandteil unserer Argumentextraktionsmodelle) entwickelt, die auf vielen Text Mining Anwendungen zu signifikanten Verbesserungen führen. Derartige Entwicklungen haben wir schnell aufgegriffen und in die ArgumenText Kerntechnologie integriert. Mittels des Demonstrators wurden diese Neuerungen auch den Validierungsstudien zugänglich gemacht. Der Kreis der relevanten Player im Forschungsbereich Argument Mining war im Berichtszeitraum sehr dynamisch. So wurde das Thema Argumentsuche und-extraktion in Deutschland außer an der TU Darmstadt u.a. von der Bauhaus-Universität in Weimar und der Universität Hamburg behandelt, in Israel von IBM Research („Project Debater“) und in den USA bspw. durch die University of Pennsylvania. Trotz des wachsenden Wettbewerbs war bis zum Ende des Vorhabens keiner dieser Player kommerziell aktiv im Bereich Argument Mining. Auf den einschlägigen Benchmarks erzielte die ArgumenText Technologie außerdem während des gesamten Vorhabens Ergebnisse, die dem Stand der Technik entsprechen. In der Forschung wurde das Thema „Argumentative Suchmaschinen“ auch von dritter Seite bearbeitet, allerdings nicht mit den in ArgumenText validierten Anwendungsfällen (vgl. Tabelle 3). Eine Übersicht über diese Vorhaben findet sich in Tabelle 5.
Name der Suchmaschine Durchsuchte Quellen URL args.me Online-Diskussionsforen www.args.me PerspectroScope Kurierte Online Foren www.perspectroscope.com IBM Debater Nachrichtenartikel, Wikipediaartikel Nicht öffentlich verfügbar
Tabelle 5: Forschungsprojekte von Dritten, die an argumentativen Suchmaschinen arbeiten (Quelle: Daxenberger et al. 2020).
II.6. Erfolgte oder geplante Veröffentlichungen der Ergebnisse
Projektergebnisse aus den AP4 (Multilinguale Argumentextraktion), AP5 (Deep Learning für Argumentextraktion), AP6 (Argumentaggregation) und AP7 (Demonstrator zur Argumentextraktion) wurden in über 25 qualitätsgesicherten Foren veröffentlicht, der Großteil davon in internationalen, hochkompetitiven Konferenzen und Zeitschriften. Neben dem

22
Netzwerk- und Sichtbarkeitseffekt dieser Publikationen war für eine erfolgreiche Verwertung auch eine solide wissenschaftliche Grundlage unabkömmlich. Die folgende Liste der Projektveröffentlichungen ist somit auch ein wesentlicher Bestandteil der Verwertungsstrategie. Daxenberger, J., Eger, S., Habernal I., Stab C., & Gurevych, I. (2017). What is the Essence
of a Claim? Cross-Domain Claim Identification. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2055–2066.
Daxenberger, J., Schiller, B., Stahlhut, C., Kaiser, E., & Gurevych, I. (2020). ArgumenText:
Argument Classification and Clustering in a Generalized Search Scenario. Datenbank-Spektrum, 2, 115–121.
Eger, S., Daxenberger, J., & Gurevych, I. (2017). Neural End-to-End Learning for
Computational Argumentation Mining. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL 2017), 11-22.
Eger, S., Daxenberger, J., Stab, C., & Gurevych, I. (2018a). Cross-lingual Argumentation
Mining: Machine Translation (and a bit of Projection) is All You Need! In Proceedings of the 27th International Conference on Computational Linguistics (COLING 2018), 831–844.
Eger, S., Rücklé, A., & Gurevych, I. (2018b). PD3: Better Low-Resource Cross-Lingual
Transfer By Combining Direct Transfer and Annotation Projection. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 131–143.
Eger, S., Daxenberger, J., & Gurevych, I. (2020). How to Probe Sentence Embeddings in
Low-Resource Languages: On Structural Design Choices for Probing Task Evaluation. Proceedings of the 24th Conference on Computational Natural Language Learning, 108–118.
Lee, J., Eger, S., Daxenberger, J. & Gurevych, I. (2017). UKP TU-DA at GermEval 2017:
Deep Learning for Aspect Based Sentiment Detection. In Proceedings of the GermEval 2017 – Shared Task on Aspect-based Sentiment in Social Media Customer Feedback, 22-29.
Maurer, M., Daxenberger, J., Orlikowski, M., & Gurevych, I. (2019). Argument Mining: A new
method for automated text analysis and its application in communication science. In P. Müller, S. G. C. Schemer, T. K. Naab, & C. Peter (Eds.), Dynamische Prozesse in der Kommunikationswissenschaft: Methodische Herausforderungen, 18–37. Hamburg: Werner Wirth GmbH.
Miller, T., Sukhareva, M., & Gurevych, I. (2019). A Streamlined Method for Sourcing
Discourse-level Argumentation Annotations from the Crowd. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 790–1796.

23
Rach, N., Matsuda, Y., Daxenberger, J., Ultes, S., Yasumoto, K., & Minker, W. (2020). Evaluation of Argument Search Approaches in the Context of Argumentative Dialogue Systems. Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC), 513–522.
Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese
BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 3982–3992.
Reimers, N., Schiller, B., Beck, T., Daxenberger, J., Stab, C., & Gurevych, I. (2019).
Classification and Clustering of Arguments with Contextualized Word Embeddings. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019), 567–578.
Rocha, G., Stab, C., Cardoso, H. L., & Gurevych, I. (2018). Cross-Lingual Argumentative
Relation Identification: from English to Portuguese. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 144–154.
Rücklé, A., Moosavi, N. S., & Gurevych, I. (2019). Neural Duplicate Question Detection
without Labeled Training Data. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 1607–1617.
Schiller, B., Daxenberger, J., & Gurevych, I. (2021a). Aspect-Controlled Neural Argument
Generation. 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics. (im Druck)
Schiller, B., Daxenberger, J., & Gurevych, I. (2021b). Stance Detection Benchmark: How
Robust Is Your Stance Detection? In KI - Künstliche Intelligenz (Issue Preprint). Springer.
Schulz, C., Eger, S., Daxenberger, J., Kahse, T., & Gurevych, I. (2018). Multi-Task Learning
for Argumentation Mining in Low-Resource Settings. In Proceedings of the 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 35–41.
Simpson, E., Pfeiffer, J., & Gurevych, I. (2020). Low Resource Sequence Tagging with Weak
Labels. Proceedings of the AAAI Conference on Artificial Intelligence, 8862–8869. Stab, C. & Gurevych, I. (2017). Parsing Argumentation Structures in Persuasive Essays.
In: Computational Linguistics, Vol. 43, 619—659. Stab, C., Daxenberger, J., Stahlhut, C., Miller, T., Schiller, B., Tauchmann, C., … Gurevych,
I. (2018a). ArgumenText: Searching for Arguments in Heterogeneous Sources. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: System Demonstrations, 21–25.

24
Stab, C., Miller, T., Schiller, B., Rai, P., & Gurevych, I. (2018b). Cross-topic Argument Mining from Heterogeneous Sources. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 3664–3674.
Stahlhut, C. (2018). Searching Arguments in German with ArgumenText. In Proceedings of
the First Biennial Conference on Design of Experimental Search & Information Retrieval Systems (Vol. 2167), 104.
Stahlhut, C., Stab, C., & Gurevych, I. (2018). Pilot Experiments of Hypothesis Validation
Through Evidence Detection for Historians. In Proceedings of the First Biennial Conference on Design of Experimental Search & Information Retrieval Systems (Vol. 2167), 83–89.
Thakur, N., Reimers, N., Daxenberger, J., & Gurevych, I. (2021). Augmented SBERT: Data
Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks. 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics. (im Druck)
Trautmann, D., Daxenberger, J., Stab, C., Schütze, H., & Gurevych, I. (2020). Fine-Grained
Argument Unit Recognition and Classification. Proceedings of the AAAI Conference on Artificial Intelligence, 9048–9056.
Ziegele, M., Daxenberger, J., Quiring, O., & Gurevych, I. (2018). Developing Automated
Measures to Predict Incivility in Public Online Discussions on the Facebook Sites of Established News Media. Proceedings of the 68th Annual Conference of the International Communication Association (ICA).
25
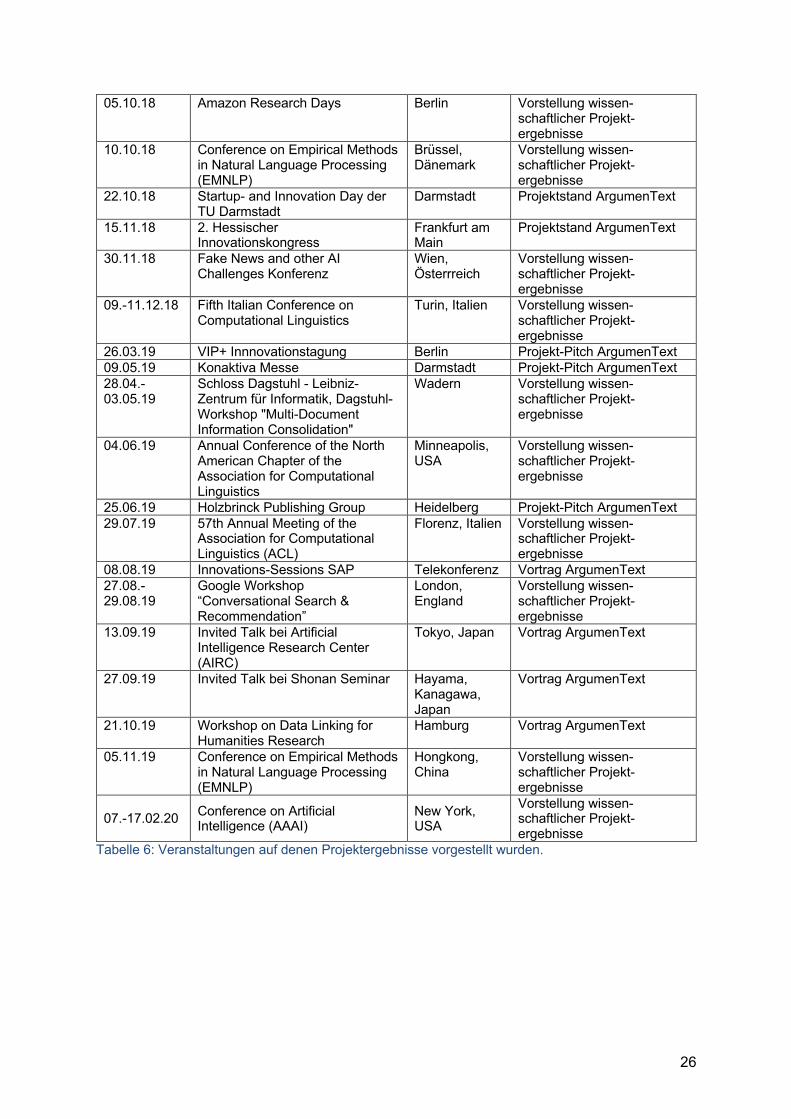
Anhang A: Vorstellung von Projektergebnisse (Auswahl)
Datum Veranstaltung Ort Details
23.06.17 Innovationsallianz TU Darmstadt Darmstadt Kurzer Pitch zur Argument-extraktion und deren Anwendungsfälle
31.07.17 55th Annual Meeting of the Association for Computational Linguistics (ACL)
Vancouver, Canada
Vorstellung wissen-schaftlicher Projekt-ergebnisse
10.09.17 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Kopenhagen, Dänemark
Vorstellung wissen-schaftlicher Projekt-ergebnisse
21.09.17 Digital Humanities im RMU-Verbund Mainz
Vorstellung von ArgumenText für Anwendungen in diversen geisteswissenschaftlichen Disziplinen
11.10.17 Language Technology Industry Summit 2017
Brüssel, Belgien
Vortrag zur Optimierung von Entscheidungen durch Argument Mining
11.10.17 Innovationsummit der Alexander Thamm GmbH München
Vortrag zu Argument Mining und dessen Einsatzmöglichkeiten
06.12.17 Hessischer Innovationskongress Frankfurt Projekt-Pitch ArgumenText 20.02.18 Projekt-Workshop mit Bar Ilan
Universität Tel Aviv, Israel Projekt-Pitch ArgumenText
01.03.18 BigData.AI Summit Hanau Vortrag ArgumenText 29.03.18 HOLM (House of Logistics and
Mobility) Frankfurt am Main
Projekt-Pitch ArgumenText
25.-28.04.18 Hannovermesse Hannover Vorstellung der Projektergebnisse
04.06.18 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)
New Orleans, USA
Vorstellung wissen-schaftlicher Projekt-ergebnisse
12.-31.07.18 56th Annual Meeting of the Association for Computational Linguistics (ACL)
Melbourne, Australien / Hamilton, Neuseeland und Singapur
Vorstellung wissen-schaftlicher Projekt-ergebnisse
06.08.18 Gespräch mit Innovationsmentor Prof. Dr. Lorenz Lorenz-Meyer
Berlin Vorstellung Projektstatus
20.-26.08.18 International Conference on Computational Linguistics (COLING)
Santa Fe, USA Vorstellung wissen-schaftlicher Projekt-ergebnisse
18.09.18 Projekt-Workshop mit Web Technology & Information Systems Network (Webis) Group (Bauhaus-Universität Weimar)
Heidelberg Brainstorming zum Thema Argumentative Suchmaschinen und deren Verwertung
26.09.18 Wissenschaftlicher Kongress des Deutschen Dialogmarketing Verbands (DDV) e.V.
Hamburg Vorstellung wissen-schaftlicher Projekt-ergebnisse
26
05.10.18 Amazon Research Days Berlin Vorstellung wissen-schaftlicher Projekt-ergebnisse
10.10.18 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Brüssel, Dänemark
Vorstellung wissen-schaftlicher Projekt-ergebnisse
22.10.18 Startup- and Innovation Day der TU Darmstadt
Darmstadt Projektstand ArgumenText
15.11.18 2. Hessischer Innovationskongress
Frankfurt am Main
Projektstand ArgumenText
30.11.18 Fake News and other AI Challenges Konferenz
Wien, Österrreich
Vorstellung wissen-schaftlicher Projekt-ergebnisse
09.-11.12.18 Fifth Italian Conference on Computational Linguistics
Turin, Italien Vorstellung wissen-schaftlicher Projekt-ergebnisse
26.03.19 VIP+ Innnovationstagung Berlin Projekt-Pitch ArgumenText 09.05.19 Konaktiva Messe Darmstadt Projekt-Pitch ArgumenText 28.04.-03.05.19
Schloss Dagstuhl - Leibniz-Zentrum für Informatik, Dagstuhl-Workshop "Multi-Document Information Consolidation"
Wadern Vorstellung wissen-schaftlicher Projekt-ergebnisse
04.06.19 Annual Conference of the North American Chapter of the Association for Computational Linguistics
Minneapolis, USA
Vorstellung wissen-schaftlicher Projekt-ergebnisse
25.06.19 Holzbrinck Publishing Group Heidelberg Projekt-Pitch ArgumenText 29.07.19 57th Annual Meeting of the
Association for Computational Linguistics (ACL)
Florenz, Italien Vorstellung wissen-schaftlicher Projekt-ergebnisse
08.08.19 Innovations-Sessions SAP Telekonferenz Vortrag ArgumenText 27.08.-29.08.19
Google Workshop “Conversational Search & Recommendation”
London, England
Vorstellung wissen-schaftlicher Projekt-ergebnisse
13.09.19 Invited Talk bei Artificial Intelligence Research Center (AIRC)
Tokyo, Japan Vortrag ArgumenText
27.09.19 Invited Talk bei Shonan Seminar Hayama, Kanagawa, Japan
Vortrag ArgumenText
21.10.19 Workshop on Data Linking for Humanities Research
Hamburg Vortrag ArgumenText
05.11.19 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Hongkong, China
Vorstellung wissen-schaftlicher Projekt-ergebnisse
07.-17.02.20 Conference on Artificial Intelligence (AAAI)
New York, USA
Vorstellung wissen-schaftlicher Projekt-ergebnisse
Tabelle 6: Veranstaltungen auf denen Projektergebnisse vorgestellt wurden.
27
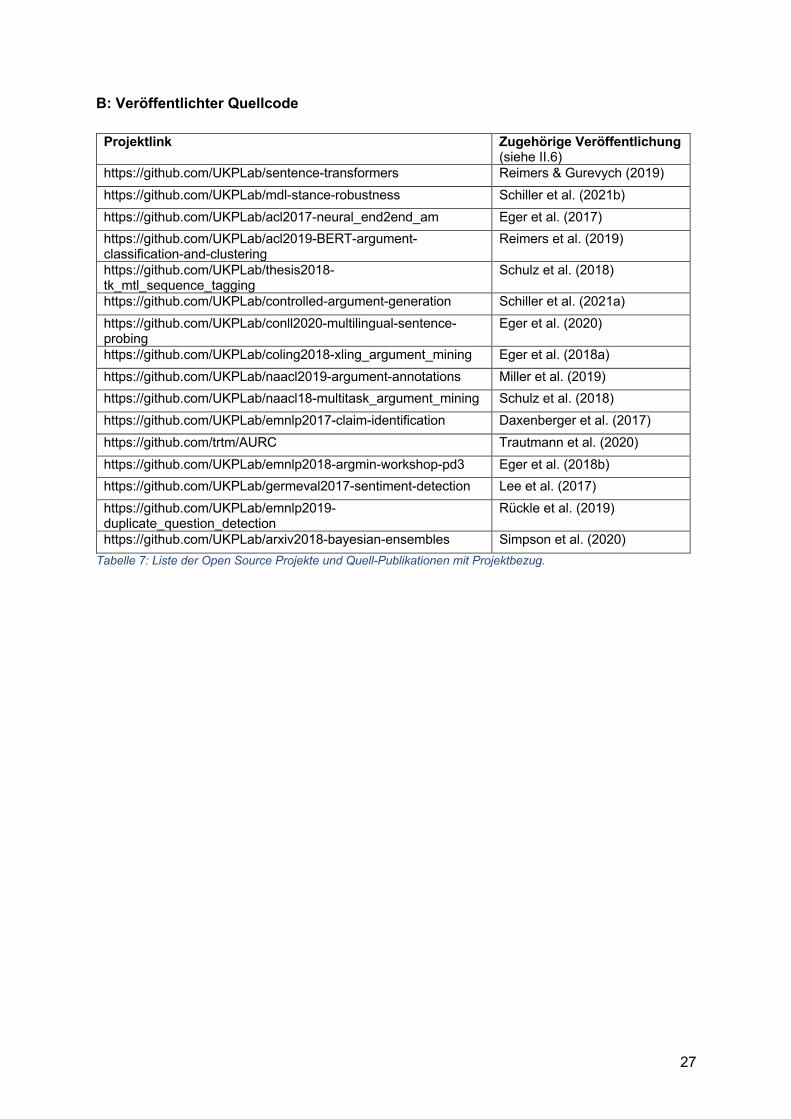
B: Veröffentlichter Quellcode
Projektlink Zugehörige Veröffentlichung (siehe II.6)
https://github.com/UKPLab/sentence-transformers Reimers & Gurevych (2019) https://github.com/UKPLab/mdl-stance-robustness Schiller et al. (2021b) https://github.com/UKPLab/acl2017-neural_end2end_am Eger et al. (2017) https://github.com/UKPLab/acl2019-BERT-argument-classification-and-clustering
Reimers et al. (2019)
https://github.com/UKPLab/thesis2018-tk_mtl_sequence_tagging
Schulz et al. (2018)
https://github.com/UKPLab/controlled-argument-generation Schiller et al. (2021a) https://github.com/UKPLab/conll2020-multilingual-sentence-probing
Eger et al. (2020)
https://github.com/UKPLab/coling2018-xling_argument_mining Eger et al. (2018a) https://github.com/UKPLab/naacl2019-argument-annotations Miller et al. (2019) https://github.com/UKPLab/naacl18-multitask_argument_mining Schulz et al. (2018) https://github.com/UKPLab/emnlp2017-claim-identification Daxenberger et al. (2017) https://github.com/trtm/AURC Trautmann et al. (2020) https://github.com/UKPLab/emnlp2018-argmin-workshop-pd3 Eger et al. (2018b) https://github.com/UKPLab/germeval2017-sentiment-detection Lee et al. (2017) https://github.com/UKPLab/emnlp2019-duplicate_question_detection
Rückle et al. (2019)
https://github.com/UKPLab/arxiv2018-bayesian-ensembles Simpson et al. (2020) Tabelle 7: Liste der Open Source Projekte und Quell-Publikationen mit Projektbezug.