
Vorlesung Rechnernetze II - in.tu-clausthal.de · TCP-Protokoll beim Empfänger muss...
147
1 Vorlesung Rechnernetze II Prof. Dr. Harald Richter Vorwort Es ist zu hoffen, dass dieses Skript einen guten Zugang zu dem nachfolgenden Fach bie- tet. Allerdings ist es kein Buch; es soll nur die Zuhörer davon befreien, von Hand mit- schreiben zu müssen so dass sie sich besser auf den Stoff konzentrieren können. Jeder Student hat unterschiedliche Stärken und Schwächen. Deswegen werden sie persönli- che Bemerkungen und Erklärungen an unterschiedlichen Stellen des Skripts einfügen, je nach Bedarf. Das vorliegende Dokument wird dabei helfen, dies in Ruhe zu tun. Weder das Skript noch das web können den Besuch der Vorlesungen ersetzen. Es hat sich viele Male gezeigt, dass ein autodidaktisches Lernen umfangreichen Stoffs nur Hilfe von Schriften, dem web oder per Video viel mehr Zeit und persönliches Engagement erfordert als die Vorlesungen regelmäßig zu besuchen; insbesonders wenn ein persönli- cher Kontakt während der Vorlesungszeit und den Übungen möglich ist. Gemäß des deutschen Copyright-Gesetzes liegen alle Rechte beim Verfasser. Das Kopie- ren dieses Skripts, das Veröffentlichen oder Weiterreichen in jedweder Form ist nicht gestattet. Zuwiderhandlungen werden strafrechtlich verfolgt. Das Einstellen ins Internet dient zur Erleichterung meiner Studenten. Rechte können davon nicht abgeleitet werden. 2 1 Einleitung und Überblick über Rechnernetze Hinweis: Das erste Kapitel ist für Studierende ohne Rechnernetze-Kenntnisse gedacht 1.1 Wichtige Definitionen Internet = miteinander gekoppelte, öffentliche Teilnetze, die zu einem weltumspannen- den Netz verbunden sind Intranets = interne Netze von Firmen, Organisationen Behörden, Universitäten, Tele- kom-Unternehmen u.s.w. Intranets sind oft, aber nicht immer Teilnetze des Internet Intranets sind im inneren Aufbau und den verwendeten Protokollen oft zueinander in- kompatibel Intranets werden durch sog. Gateway-Rechner und dem IP-Protokoll des Internet ge- koppelt (IP = internet protocol) 1.2 Historie des Internet Ursprünglich wurde das Internet in den späten 1960er-Jahren für das US Department of Defense zur sicheren Kommunikation zwischen Atombunkern entwickelt Es wurde seit den frühen 1970er-Jahren von amerikanischen Behörden, Universitäten und Forschungseinrichtungen für verschiedene Dienste genutzt, wie z.B.:
Transcript of Vorlesung Rechnernetze II - in.tu-clausthal.de · TCP-Protokoll beim Empfänger muss...

1
Vorlesung Rechnernetze IIProf. Dr. Harald Richter
Vorwort
Es ist zu hoffen, dass dieses Skript einen guten Zugang zu dem nachfolgenden Fach bie-tet. Allerdings ist es kein Buch; es soll nur die Zuhörer davon befreien, von Hand mit-schreiben zu müssen so dass sie sich besser auf den Stoff konzentrieren können. JederStudent hat unterschiedliche Stärken und Schwächen. Deswegen werden sie persönli-che Bemerkungen und Erklärungen an unterschiedlichen Stellen des Skripts einfügen, jenach Bedarf. Das vorliegende Dokument wird dabei helfen, dies in Ruhe zu tun.Weder das Skript noch das web können den Besuch der Vorlesungen ersetzen. Es hatsich viele Male gezeigt, dass ein autodidaktisches Lernen umfangreichen Stoffs nur Hilfevon Schriften, dem web oder per Video viel mehr Zeit und persönliches Engagementerfordert als die Vorlesungen regelmäßig zu besuchen; insbesonders wenn ein persönli-cher Kontakt während der Vorlesungszeit und den Übungen möglich ist.
Gemäß des deutschen Copyright-Gesetzes liegen alle Rechte beim Verfasser. Das Kopie-ren dieses Skripts, das Veröffentlichen oder Weiterreichen in jedweder Form ist nichtgestattet. Zuwiderhandlungen werden strafrechtlich verfolgt. Das Einstellen ins Internetdient zur Erleichterung meiner Studenten. Rechte können davon nicht abgeleitet werden.
2
1 Einleitung und Überblick über Rechnernetze
Hinweis: Das erste Kapitel ist für Studierende ohne Rechnernetze-Kenntnisse gedacht
1.1 Wichtige Definitionen
Internet = miteinander gekoppelte, öffentliche Teilnetze, die zu einem weltumspannen-den Netz verbunden sind
Intranets = interne Netze von Firmen, Organisationen Behörden, Universitäten, Tele-kom-Unternehmen u.s.w.
Intranets sind oft, aber nicht immer Teilnetze des Internet Intranets sind im inneren Aufbau und den verwendeten Protokollen oft zueinander in-
kompatibel Intranets werden durch sog. Gateway-Rechner und dem IP-Protokoll des Internet ge-
koppelt (IP = internet protocol)
1.2 Historie des Internet
Ursprünglich wurde das Internet in den späten 1960er-Jahren für das US Departmentof Defense zur sicheren Kommunikation zwischen Atombunkern entwickelt
Es wurde seit den frühen 1970er-Jahren von amerikanischen Behörden, Universitätenund Forschungseinrichtungen für verschiedene Dienste genutzt, wie z.B.:

3
• Zugriff auf entfernte Dateien (FTP) • Login auf entfernte Rechner (Remote Login, Telnet)• Elektronische Post (E-Mail)
1.3 Heutiger Stand
Heutzutage wird das Internet hauptsächlich durch Dienste wie www und E-Mail domi-niert
Alle Internet-Dienste und -Anwendungen beruhen auf Datenübertragung in Rechner-netzen
Die Datenübertragung basiert auf Nachrichtenaustausch mittels Paketen
1.4 Segmentierung
Längere Nachrichten werden in kleinere Pakete zerlegt und vom Internet in maximal 64K Byte großen Portionen übertragen
Beispielnachricht:
Der Mond ist aufge gangen1. Paket 2. Paket 3. Paket 4. Paket 5. Paket
4
Momentaufnahme des Transfers der Beispielnachricht
1.5 Datensicherung
Pakete können durch Übertragungsfehler verfälscht werden
Verwendung von Prüfsummen (CRC), um Fehler zu erkennen
Im Fehlerfall werden Pakete durch das TCP-Protokoll automatisch wiederholt Pakete können verloren gehen
Ziel Länge InhaltB, 5, aufge
4. PaketRechner A Rechner B
Ziel Länge InhaltA, 2, OK
4. Ack Sender Empfänger
Sendepuffer:„gangen“
Empfangspuffer:„Der Mond ist“

5
Für jedes empfangene Paket, das empfangen wurde und korrekt ist, wird eine Quit-tung zurückgeschickt (=Acknowledge, Ack)
1.6 Flusssteuerung
Sender muss Pakete in dem Tempo an den Empfänger senden, das ihn nicht überfor-dert
Flusssteuerung
1.7 Wegewahl (Routing)
Der Datentransport bei Weitverkehrsnetzen verläuft über Zwischenknoten (Routern)
ASender Em=B pfänger
Router
C
D
B, 5, auf-
B, 3, ist
B, 4, Mond
A, 2, OK Empfangspuffer:„Der“
Sendepuffer:„gangen“
Router
6
Die Wegewahl geschieht im Internet durch das IP-Protokoll Jedes Paket wird als autonome Einheit versendet Router müssen Pakete zwischenspeichern, um die Wegewahl vornehmen zu können =
"store-and-forward"-Prinzip
1.8 Ende-zu-Ende-Übertragung
Pakete gehen bei IP unterschiedliche Wege von der Quelle zum Ziel
Pakete können sich überholen
TCP-Protokoll beim Empfänger muss Paketreihenfolge wiederherstellen
Des weiteren leistet TCP u.a. eine Paketwiederholung von der Quelle zum Ziel
1.9 Das ISO-7-Schichten-Modell
Die ISO (International Standardization Organization) hat die Aufgaben, die beim Trans-port von Daten zwischen Rechnern anfallen, in einem Schichtenmodell gegliedert
Nur die ersten 4 Schichten sind in Teilen im Internet implementiert

7
Jede Schicht erbringt einen speziellen Dienst für die darüberliegenden Schichten Sie bietet an ihrer Schnittstelle nach oben einen wohl definierten Funktionsumfang an Die Implementierung einer Schicht heißt Instanz Die Instanz einer Schicht auf einem Rechner kommuniziert nur mit einer Instanz dersel-
ben Schichthöhe
Partnerprotokoll= peer protocol
indirekteKommunikation
direkte Kommunikati-on
Presentation
Session
Transport
Network
Data Link
Physical
Application
Physikalisches Übertragungsmedium
Darstellungsschicht
Sitzungssteuerungs-schicht
Transportschicht
Vermittlungsschicht
Sicherungsschicht
Bitübertragungsschicht
Anwendungsschicht
direkte Kommunikati-
indirekte
indirekteKommunikationindirekteKommunikation
indirekteKommunikation
Rechner A Rechner B
8
Instanzen gleicher Höhe auf verschiedenen Rechnern heißen peers (Partnerinstanzen) Die Kommunikationsregeln zwischen peers werden durch ein Protokoll festgelegt Für die Abwicklung des Protokolls greift jede Instanz auf die Funktionen der unmittel-
bar darunterliegenden Schicht zurück
7-stufige rekursive Aufrufreihenfolge von Unterprogrammen von Schicht 7 bis hinun-ter zu Schicht 1
Nur auf Ebene 1 werden tatsächlich Bits übertragen Die Ebenen 2-7 haben andere Aufgaben
Ausschnitt aus dem Schichten-modell
Rechner A Rechner BInstanz von Schicht i Protokoll i
Protokoll i-1
Instanz von Schicht i-1
.
.
.
Schi
cht i
Schi
cht i
-1
Instanz von Schicht i
Instanz von Schicht i-1
.
.
.

9
1.10 Indirekte Kommunikation im ISO-Modell
Daten werden innerhalb eines Rechners von Schicht zu Schicht transportiert Zwischen 2 Rechnern können Daten nur auf der Schicht 1 transportiert werden Kommunikation zwischen Instanzen höher als Schicht 1 werden indirekt (virtuell) ab-
gewickelt Die indirekte Kommunikation wird mittels eines Protokolls zwischen Partnerinstanzen
durchgeführt, so dass beide Partnerinstanzen „sich verstehen“ können (Protokoll = ge-meinsame Sprache)
1.11 Header und Trailer
Von Schicht zu Schicht kommt ein Paket-Header und evtl. ein Paket-Trailer hinzu Einige der Nachrichtenköpfe (Header) bzw. Trailer können im Allgemeinfall auch leer
sein Ist die zu übertragende Information zu lang, wird sie segmentiert
10
Sendeprozess
Verm.prot.
AH = application headerPH = presentation headerSH = session headerTH = transport headerNH = network headerDH, DT = data link header/trailerPhH, PhT = physical link header/trailer
Anwendungs-schichtDarstellungs-schichtSitzungs-schichtTransport-schichtVermittlungs-schichtSicherung-schichtBitübertragungs-schicht
Anwendungs-schichtDarstellungs-schichtSitzungs-schichtTransport-schichtVermittlungs-schichtSicherung-schichtBitübertra-gungsschicht
Empfängerprozess
Daten DTDH
NH Daten
TH Daten
DatenSH
DatenPH
AH DatenAnwendungsprotokoll
Darstellungsproto-kollSitzungspro-tokollTransport-protokoll
Tatsächlicher Übertragungspfad
Tatsächlich übertra-gene Bits
PhTPhH Daten

11
1.12 Beschreibung der Schichten im ISO-Modell
Nachfolgend werden die einzelnen ISO-Schichten beschrieben
1.12.1 Bitübertragungsschicht (Schicht 1)
Übertragungsmedien:• elektrische Kabel (Zweidrahtleitung, Koaxialkabel, ...)• elektromagnetische Wellen (Richtfunk, Satelliten, Mobilfunktelefonie,...)• Glasfaser (Monomode-Faser, Multimode-Faser)
Art der Übertragung:• synchron oder asynchron zu einem Taktsignal• bitseriell oder bitparallel• unkodiert (rein binär) oder kodiert (Manchester-Code, differentieller Manchester-Code, ...)
Übertragungsverfahren:• nicht moduliert (= „Basisband“)• moduliert (Frequenz-, Amplituden-, Phasen-Modulation)• nicht gemultiplext• gemultiplext (Zeitmultiplex, Frequenzmultiplex)
1.12.1.1 Datenraten verschiedener Netz-Technologien
Bei lokalen Netzen und Stadtnetzen (LANs und MANs) gibt es folgende Datenraten:
12
• Ethernet 10/100/1000 Mbit/s, 10 GBit/s • Token Ring 4/16 Mbit/s • FDDI 100 Mbit/s • Funk-LANs 0,2..50 Mbit/s, sog. WLANs (=Wireless LAN)
Bei Weitverkehrsnetzen (Wide Area Networks, WANs) gibt es folgende Datenraten:• Telefonnetz 56 kbit/s (über Modem) • ISDN 64 kbit/s bzw. 128 kbit/s• xDSL 1,44 .. 50 Mbit/s (DSL = Digital Subscriber Line, x=A,S,...)• Mobilfunk 64 kbit/s ...7 Mbit/s• Mietleitung vom Typ „E1“ von einer Telekomfirma: 2048 kbit/s• SONET/SDH 34 ... 622 Mbit/s ... 2,4 ... 10 Gbit/s
1.12.2 Sicherungsschicht (Schicht 2)
Sicherungsschicht ist in zwei Subschichten 2a und 2b unterteilt:
Beispiel: Sicherungsschichtsprotokolle IEEE 802.11-x für WLAN
Logical Link Control (LLC)
Medium Access Control (MAC)
Schicht 2b
Schicht 2aSicherungsschicht

13
Hinweis: (IEEE = Institute of Electrical and Electronics Engineers = Berufsverband, sehr aktiv im Bereich der Normung)
Die LLC-Schicht ist für die eigentlichen ISO-Schicht-2-Aufgabe der Sicherung zustän-dig
Die MAC-Schicht regelt nur den Zugang mehrerer Rechner zu einem gemeinsam ge-nutzten Übertragungsmedium wie z.B. zu einem gemeinsamen Kabel oder Funkkanal
1.12.2.1 MAC-Subschicht (Medium Access Control)
Man unterscheidet zwischen kollisionsbehafteten und kollisionsfreien Protokollen
1.) Kollisionsbehaftete Protokolle• Jeder Rechner überträgt Daten, ohne sich mit anderen abzusprechen • Bsp.: Ethernet ohne Switch aber mit gemeinsamem Kabel• Durch gleichzeitige Übertragung verschiedener Pakete kommt es zu Kollisionen• Kollisionen resultieren in Paketverlusten• Reduzierung der Paketverluste durch:
· Abhören des Mediums vor dem Senden, ob das Medium frei ist· Zufallsgesteuerte Zeitverzögerung vor erneutem Paketsenden nach Auftreten einer Kol-
lision (CSMA/CD)· CSMA/CD heißt Carrier Sense For Multiple Access With Collision Detection
14
2.) Kollisionsfreie Protokolle• Es gibt eine „Sendeberechtigungsmarke“ (Token), die in einem ringförmigen Netz von Sen-
der zu Sender weitergereicht wird• Nur wer das Token besitzt, darf senden• Da es nur ein Token gibt, ist der exklusive Medienzugriff gesichert• Nach dem Senden eines Paketes muss das Token zum nächsten Nachbarn weitergereicht
werden
Beispiel: Token-Ring (4 bzw. 16 Mb/s), FDDI (Fiber Distributed Data Interface, 100 Mb/s)
1.12.2.2 LLC-Subschicht
Aufgaben von LLC (Logical Link Control):• Portionierung des Bitstroms in Frames• Anhängen einer Prüfsumme an die Daten (CRC, Cyclic Redundancy Check) • Erneute Übertragung bei Fehler oder Verlust eines Pakets zwischen benachbarten Knoten • Senden eines Quittungsrahmens durch den empfangenden Nachbarknoten, um fehlerhaf-
te oder verlorene Pakete beim Sender anzuzeigen (= Acknowledge)• Timeout zum Erkennen von Verlust von Quittungen zwischen benachbarten Knoten• Flusssteuerung zwischen benachbarten Knoten = Bremsen des Senders zur Verhinderung
von Pufferüberlauf beim Empfänger • Vollduplex- oder Halbduplexbetrieb auf der Schicht 2• Vollduplex heißt: Sender und Empfänger können gleichzeitig senden

15
• Beispiel Ethernet: keine Neuübertragung, kein Timeout, keine Flusssteuerung, Halfduplex
1.12.3 Vermittlungsschicht (Schicht 3)
Das Schicht-3-Protokoll im Internet ist IP (IP = Internet Protocol) Aufgaben:
1.) Segmentierung von Datenpaketen, die zu lang sind, in Schicht-2-Datenrahmen und zusam-menbauen der Rahmen beim Empfänger
2.) Je nach der Verbindungsart:• Verbindungslos (Datagram)
· Nachrichtenpakete enthalten Ziel- und Quelladresse· Sie werden unabhängig voneinander durch das Netz geschickt, d.h. sie gehen unter-
schiedliche Wege• Verbindungsorientiert
· Feste Verbindung vom Sender zum Empfänger, Pakete gehen stets denselben Weg
3.) Je nach dem Routing-Algorithmus:• Wegewahl ist adaptiv/nicht adaptiv• Adaptiv heißt, dass die Verkehrsbelastung der Zwischenknoten berücksichtigt und danach
die Route ausgewählt wird• Verbindung ist verklemmungsfrei oder nicht verklemmungsfrei (Deadlocks)
16
• Verbindung nutzt gleichzeitig mehrere Pfade durch das Netz oder nicht (dient zur Band-breiteerhöhung und Fehlertoleranz)
4.) Kopplung von Netzen verschiedener Betreiber
5.) Steuerung des Datenverkehrs bei Staus zur Vermeidung von überlasteten Zwischen-knoten
1.12.4 Transportschicht (Schicht 4)
Beispiele für Transportprotokolle im Internet: TCP (transmission control protocol) undUDP (user datagram protocol)
Bei verbindungsorientiertem Datenaustausch durch TCP wird eine feste Verbindungzwischen Sender und Empfänger über Zwischenknoten quer durch das Netz auf- undwieder abgebaut
Aufgaben:• große Datenmengen werden in transportierbare Pakete zerteilt
Es gibt eine Rahmensegmentierung auf Schicht 3 und eine Paketsegmentierung aufSchicht 4
• Adressierung einzelner Prozesse beim Empfänger durch eine Portnummer Bei verbindungsorientiertem Datenaustausch kommen als weitere Aufgaben hinzu:
• Wiederherstellen der Paketreihenfolge

17
• Erneute Übertragung eines Pakets bei Fehler oder Verlust, nicht zwischen Nachbarknoten,sondern über alle Zwischenknoten hinweg quer durch das Netz
• Flusssteuerung erfolgt zwischen Sender und Empfänger (Ende zu Ende)• Multiplexen bei verbindungsorientiertem Datenaustausch
· Multiplexen = Mehrfachnutzung ein- und derselben Verbindung, um Bandbreite effizientzu nützen
1.12.5 Sitzungsschicht (Schicht 5)
Synchronisierung bei Client/Server-Kommunikation bzgl.:• Beginn einer „Sitzung“ (login) und Ende (logout)• Half Duplex/full Duplex auf Schicht 5• Automatisches Wiederaufsetzen einer gestörten Verbindung an der Stelle der Unterbre-
chung (Recovery) Schicht 5 gibt es nicht im Internet Schicht 5-Funktionalität wird von Schicht 7-Anwendungen nachgebildet
1.12.6 Darstellungsschicht (Schicht 6)
Aufgaben:• Anpassung der unterschiedlichen Datenkodierungen und -Formate zwischen den Rech-
nern, z.B. EBCDIC <-> ASCII, ASCII <-> ISO-Code, <CR><LF> in <LF><CR>, u.s.w.
18
• Anpassung der unterschiedlichen Zahlenrepräsentationen zwischen den Rechnern, z.B.32-Bit-Integer in 64-Bit-Integer u.s.w.
• Datenverschlüsselung und Datenkompression Schicht 6 gibt es nicht im Internet Schicht 6-Funktionalität wird von Schicht 7-Anwendungen nachgebildet
Schicht 7 kann im Internet nur auf den Funktionen der Transportschicht (Schicht 4)aufsetzen
1.12.7 Anwendungsschicht (Schicht 7)
Hier sind alle Internet-Anwendungen, sowie die meisten Internet-Dienste lokalisiertund die Funktionen der Schichten 5 und 6 in Form zahlreicher Einzellösungen angesie-delt
Die Programmierschnittstelle (API) im Internet sind die Berkeley-Sockets bzw. die Win-Sockets der Schicht 4
Neben den 7 Schichten gemäß ISO gibt es noch sehr viele Protokolle und Anwendun-gen, die für den Betrieb des Internet notwendig sind, wie z.B. das Internet Control Mes-sage Protocol (ICMP) oder das Domain Name System (DNS)
ICMP und DNS gehören in die Kategorie des Netzmanagements ICMP und DNS etc. können nicht in das ISO-7-Schichten-Modell einsortiert werden, da
Netzmanagement dort nicht vorgesehen ist
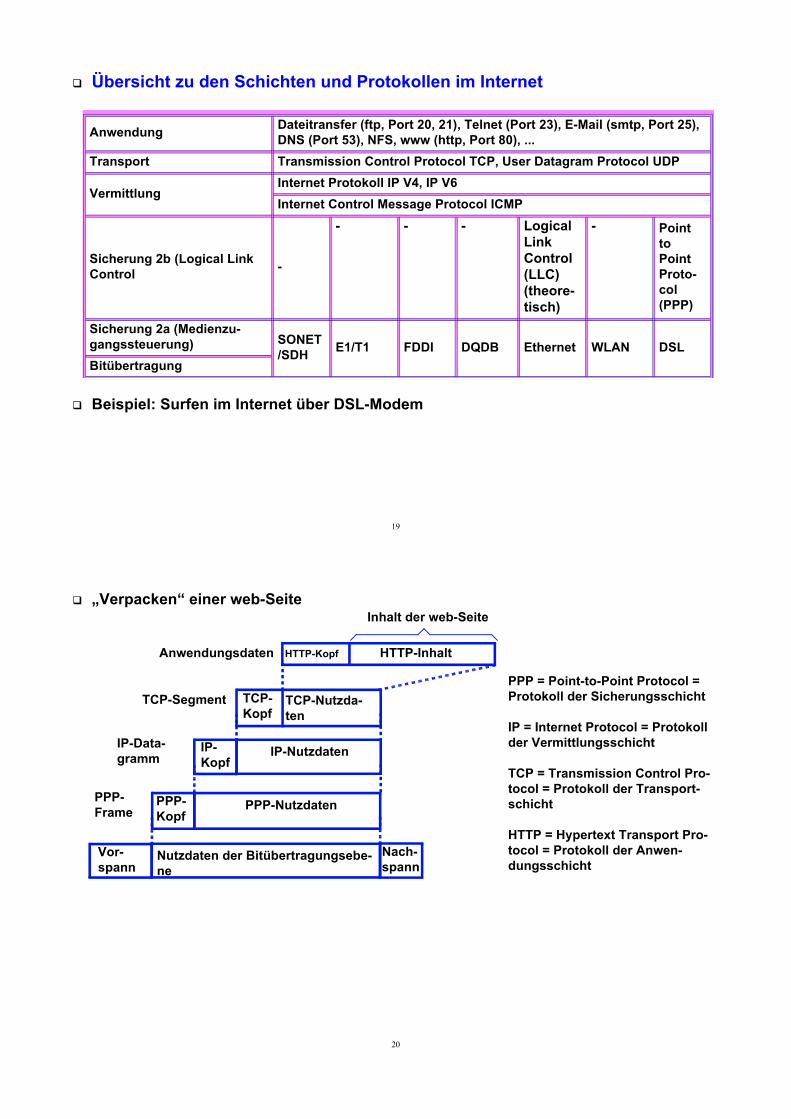
19
Übersicht zu den Schichten und Protokollen im Internet
Beispiel: Surfen im Internet über DSL-Modem
Anwendung Dateitransfer (ftp, Port 20, 21), Telnet (Port 23), E-Mail (smtp, Port 25), DNS (Port 53), NFS, www (http, Port 80), ...
Transport Transmission Control Protocol TCP, User Datagram Protocol UDP
VermittlungInternet Protokoll IP V4, IP V6Internet Control Message Protocol ICMP
Sicherung 2b (Logical Link Control -
- - - Logical Link Control (LLC) (theore-tisch)
- Point to Point Proto-col (PPP)
Sicherung 2a (Medienzu-gangssteuerung) SONET
/SDH E1/T1 FDDI DQDB Ethernet WLAN DSLBitübertragung
20
„Verpacken“ einer web-Seite
PPP-NutzdatenPPP-Kopf
Anwendungsdaten HTTP-Kopf HTTP-Inhalt
Inhalt der web-Seite
TCP-Nutzda-ten
TCP-Segment TCP-Kopf
IP-NutzdatenIP-Data-gramm
IP-Kopf
Nutzdaten der Bitübertragungsebe-ne
Vor-spann
Nach-spann
PPP-Frame
PPP = Point-to-Point Protocol = Protokoll der Sicherungsschicht
IP = Internet Protocol = Protokoll der Vermittlungsschicht
TCP = Transmission Control Pro-tocol = Protokoll der Transport-schicht
HTTP = Hypertext Transport Pro-tocol = Protokoll der Anwen-dungsschicht

21
2 Beschreibung der Darstellungsschicht (ISO-Schicht 6)
Die ISO-Darstellungsschicht wird im Internet durch zahlreiche Einzellösungen in Formvon Internet-Diensten und -Anwendungen nachgebildet
Im folgenden wird die Funktion der Datenkompression anhand von Schicht-7-Anwen-dungen des Internet erläutert
Dabei wird besonderer Wert auf die Kompression multimedialer Daten gelegt
2.1 Multimediale Daten
Multimediale Daten spielen im Internet eine immer wichtigere Rolle Leider ist das Internet nicht für Multimediale Daten ausgelegt Multimedial heißt: mindestens ein zeitdiskretes und ein zeitkontinuierliches Medium
wird für die Darstellung von Information benutzt. Beispiel Audio + Diagramme, Video +PP-Folien
Zahl der gleichzeitig verwendeten Medien ist ≥ 2
Durch die Kombination von ≥ 2 Medien verschiedener Kategorien entsteht eine neueArt der Präsentation von Information
Eine multimediale Präsentation ist interessanter, detaillierter und leichter nachvollzieh-bar
22
Die Kombination von zeitdiskreten mit zeitkontinuierlichen Medien erfordert eine zeit-liche Synchronisation beider Medienarten bei der Übertragung und bei der Wiederga-be
Die zeitliche Synchronisation bei der Übertragung wird durch Echtzeitprotokolle wiez.B. ATM erreicht, die es im Internet aber nicht gibt
Die Erzeugung von Multimediadaten erfolgt mit Hilfe spezieller Anwendungen wie z.B.MS Power Point oder Adobe Director
Aber: wie speichert und überträgt man effizient Multimediadaten im Internet?
Eine erhebliche Erleichterung dieses Problems wird dadurch erzielt, dass man eineKompression der Daten vornimmt
2.2 Kompression von Graphik/Bild/Video-Daten
Für die Speicherung und Kompression von Graphik/Bild/Video-Daten gibt es eine Rei-he von Formaten:• PDF (Portable Document Format): für ganze Dokumente• BMP (Bit Map Picture): für ein Bild, aber ohne Kompression!• GIF (Graphics Interchange Format): für ein Bild, inkl. Metainformation• JPEG (Joint Photographic Expert Group): für ein Bild (Photo)• HTML (Hypertext Markup Language): für ganze web-Seiten• MPEG (Motion Picture Experts Group): für Video

23
• MP3 (MPEG 1 Audio, Layer 3): für Audio• Microsoft WAV (für Audio), AVI (für Audio and Video)• SUN AU (für Audio), Apple Quicktime (für Video)• Real Video, Real Audio• Macromedia Flash (Vektorgraphik)• VRML (Virtual Reality Modeling Language): für perspektivische Wiedergabe von 3D-Sze-
nen• Quicktime Virtual Reality: für perspektivische Wiedergabe von 3D-Szenen
2.3 Gliederung der Formate zur Datenspeicherung
Es gibt firmenabhängige/standardisierte Formate sowie plattformabhängige/-unabhän-gige Formate
Des weiteren gibt es komprimierte/unkomprimierte Formate sowie www-geeignete/www-ungeeignete Formate
Im folgenden werden wichtige Formate zur Datenkompression bei Speicherung undDatenübertragung betrachtet
Datenkompression ist eine Aufgabe der ISO-Schicht 6 Da es diese im Internet nicht gibt, wird Kompression durch zahlreiche Formate zur Da-
tenspeicherung und zahlreiche Internet-Anwendungen nachgebaut
24
2.4 Prinzip der Kompression
Ohne Kompression sind Video-Dienste wie YouTube, Amazon Prime oder Netflix un-möglich
Ohne Kompression ist HDTV unmöglich Ohne Kompression sind Blue Ray Disks unmöglich Ohne Kompression sind Digitalkameras und Handy-Kameras unmöglich
Datenkompression ist wichtig
low delay
uncompressedMultimediaData Input
compressedMultimediaData Output
compressionhigh quality
intrinsic scalability
low complexity (e.g., ease of decoding)efficient implementation (e.g., memory requirements)
lower data rate after compression

25
2.5 Grobgliederung der Kompressionsalgorithmen
Nur verlustbehaftete Kompressionen liefern die nötigen Reduktionsraten für die effizi-ente Speicherung und den effizienten Transport von Multimedia-Daten (Raten > 10 not-wendig).
Kompressionsalgo-rithmen
verlustfrei (lossless)
verlustbehaftet (lossy)
26
2.6 Feingliederung der Kompressionsalgorithmen
2.6.1 Entropie-Kodierungen
Immer verlustfrei. Beispiel: Lauflängenkodierung bei FAX. Semantik (Bedeutung) der Daten spielt für die Kompression keine Rolle Kompressionsraten ≤ 3
2.6.2 Quellen-Kodierungen
Je nach Verfahren und Parameterwahl verlustfrei oder verlustbehaftet. Beispiel: JPEG Semantik der Daten ist für die verlustbehaftete Kompression wichtig Kompressionsraten ≥ 10 Beruht oft auf der Diskreten Cosinus Transformation + dem Wegglassen von Fourier-
koeffizienten mit hoher Frequenz und kleiner Amplitude
Kompressionsalgo-rithmen
Entropie-Kodie-rungen
Quellen-Kodie-rungen
Kanal-Kodie-rungen
Hybride Kodie-rungen

27
Es ändern sich durch Kompression nur die feinen Details eines Bildes von ganzscharf zu etwas weniger scharf, sofern die Rate nicht zu hoch gewählt ist
2.6.3 Kanal-Kodierungen
Verlustbehaftet. Beispiele: MP3-Player oder Subband-Kodierung Physiologische Wirkung der wiedergegebenen Daten auf Augen/Ohren ist für die Kom-
pression wichtigBeispiel: leise Töne unmittelbar nach oder gleichzeitig mit lauten Tönen von ähnlicherHöhe kann das Ohr nicht wahrnehmen
Sie können weggelassen werden
Kompressionsraten ≥ 10
2.6.4 Hybride Kodierungen
Meistens verlustbehaftet. Beispiel: JPEG, MPEG Kombinationen aus den ersten drei Verfahren Damit sind die höchsten Kompressionsraten erzielbar (bis ca. 100)
28
2.7 Verfahren der Entropie-Kodierung
Innerhalb der Entropie-Kodierung kennt man die Lauflängen-Kodierung und die Color-Lookup-Table-Kodierung
Außerdem gibt es noch die große Gruppe der statistische Kodierungen
Entropie-Kodierungen
Lauflängen-Kodierung
Statistische Ko-dierungen
Color-Lookup-Table-Kodierung
Morse-KodeHuffman-KodeZiv-Lempel-KodeArithmetischer Kode

29
2.8 Verfahren der Quellen-Kodierung
Innerhalb der Quellen-Kodierung kennt man die Prädiktive Kodierung und die Vektor-quantisierung
Daneben gibt es noch die Gruppe der Transformations-Kodierungen
Quellen-Kodierungen
Prädiktive Kodie-rung
Transformations-Ko-dierungen
Vektorquanti-sierung
Diskrete FouriertransformationSchnelle Fouriertransf. (FFT)Diskrete Cosinustransformat.
30
2.9 Verfahren der Kanal-Kodierung
Innerhalb der Kanal-Kodierung gibt es das Subsampling und die Subband-Kodierung
2.10 Verfahren der hybriden Kodierung
Als hybrid gelten alle Verfahren, die Entropie-, Quellen und Kanal-Kodierungen zusam-mennehmen
Kanal-Kodierungen
Subsampling Subband-Kodie-rung
Hybride Kodierungen
JPEG MPEG 1, 2, 4, 7 H.261, ...

31
2.11 Beschreibung der Entropie-Kodierungsverfahren
Die wichtigsten Entropie-Kodierungsverfahren sind die Lauflängenkodierung, der Mor-sekode, die Huffman-Kodierung, die Variable Length Integer-Kodierung, die Lempel-Ziv-Kodierung, die Arithmetische Kodierung und die Color-Lookup-Table-Kodierung
2.11.1 Lauflängenkodierung
Die Voraussetzung für die Lauflängenkodierung (run-length-encoding) sind lange Se-quenzen gleicher Zeichen
Wird stets bei der Fax-Datenübertragung eingesetzt Jedes Zeichen, das mehrfach hintereinander kommt, wird nur einmal zusammen mit
der Anzahl der Wiederholungen übertragen Die Anzahl der Wiederholungen wird als Metainformation in der Form „Wiederholungs-
indikator und Anzahl“ übertragen Der Empfänger muss die Metainformation von den eigentlichen Daten unterscheiden
können Dazu gibt es zwei Möglichkeiten:
1.) Der Wiederholungsindikator ist ein spezielles Steuerzeichen, das in den normalenDaten nicht vorkommt. Dadurch wird die Metainformation von den Daten unterschie-den.
32
• Nachteil: Ein solches Steuerzeichen ist nur bei Verwendung eines Codes möglich, der sol-che Zeichen überhaupt enthält, wie z.B. ASCII
Hinweis: ASCII = American Standard Code for Information Interchange
2.) Der Wiederholungsindikator ist eine Folge von normalen Zeichen (=Kennzeichnungs-folge)
• Nachteil: Das Vorkommen dieser Folge von normalen Zeichen muss vom Sender im nor-malen Datensatz z.B. durch Byte Stuffing verhindert werden. Dadurch wird der komprimier-te Datensatz wieder etwas vergrößert.
Byte Stuffing heißt: • Zwischen Sender und Empfänger wird eine Kennzeichnungsfolge vereinbart, z.B. 5 Mal
hintereinander #FF• Der Sender verhindert, dass in den normalen Daten diese Bytefolge übermittelt wird, indem
er z.B. nach dem 4. aufeinanderfolgenden #FF in den Nutzdaten ein Füllbyte einfügt, wiez.B. #00
• Der Empfänger kontrolliert, ob nach dem 4. #FF ein #00 kommt. Wenn ja, wird dieses ausden Nutzdaten wieder entfernt, um die Nutzdaten nicht zu verfälschen.
• Will der Sender die Kennzeichnungsfolge übertragen, erzeugt er 5 Mal hintereinander #FF• Kommen beim Empfänger 5 Mal hintereinander #FF an, weiß er, dass es sich nicht um
Nutzdaten handelt, sondern um die Kennzeichnungsfolge

33
Beispiel für die Verwendung eines Steuerzeichens als Wiederholungsindikator:
2.11.2 Morsekode
Zeichen werden im Morsekode als Kombination von Punkten und Strichen bzw. als Fol-gen von kurzen und langen Tönen codiert
Die Punkt/Strich-Darstellung ist vordergründig äquivalent zu einem 0/1-Kode, aller-dings gibt es beim Morsekode noch ein drittes Zeichen: die Pause zwischen Punktenbzw. Strichen
Sender überträgt zeichenweise im Morsealphabet; der Empfänger dekodiert schritthal-tend
Der Empfänger kann den Beginn jedes Zeichens anhand der Pause erkennen
... A B C E <CNTRL M> 6 D A C B ...
ASCII-Steuerzeichen als Zeichen Anzahl
... A B C E E E E E E D A C B ...
Wiederholungsindikator
34
Die Häufigkeit der Buchstaben A-Z in der englischen Sprache wurde von Samuel Morseanhand von Zeitungsartikeln einmal ermittelt und in ein sog. Kodebuch eingetragen
Das Kodebuch heißt Morsealphabet und ist Sender und Empfänger bekannt Vorteil des Morsekodes: der häufigste Buchstabe hat die kürzeste Kodierung, der sel-
tenste die längste
für die häufigen Buchstaben müssen weniger Punkte und Striche übertragen werdenals für die seltenen (= zeitsparend)
2.11.3 Huffman-Kodierung
Mit dem Huffman-Kode sind ca. 40% Kompressionsrate erreichbar (verlustfrei) Der Huffmann-Kode ist eine Spezialisierung des Morsekodes, bei der das dritte Zeichen
(die Pause) wegfällt. Er eignet sich deshalb für eine digitale Übertragung mit Null undEins.
Die Voraussetzung für den Wegfall der Pause besteht darin, dass die Kodeworte prä-fixfrei sind
Präfixfrei heißt, dass kein Kodewort zugleich den Anfang eines anderen Kodewortesbildet, d.h. kein Kodewort ist im Anfang eines anderen Kodewortes enthalten
Je zwei Kodeworte unterscheiden sich mindestens durch 1 Bit voneinander
Die Kodeworte müssen deshalb präfixfrei sein, damit der Empfänger die Bits im emp-fangenen Bitstrom eindeutig jeweils einem Kodewort zuordnen kann

35
Zur Erzielung der Präfixfreiheit muss für jeden zu übertragenden Datensatz die statis-tische Häufigkeitsverteilung (= wie oft kommt welches Zeichen vor) bestimmt werden
Mathematisches Hilfsmittel für Präfixfreiheit und Kodeworterzeugung ist der Entschei-dungsbaum
2.11.3.1 Definition Entscheidungsbaum
Def.: Ein Entscheidungsbaum ist ein Binärbaum, bei dem die Kanten mit 0 oder 1beschriftet sind. Jeder Pfad von der Wurzel zu einem Blatt des Baumes stellt ein Kode-wort dar.
Der Wert des Kodeworts ergibt sich aus der Aneinanderreihung der auf einem Pfaddurchlaufenen Kantenbeschriftungen
Beim Huffman-Entscheidungsbaum sind zusätzlich die Blätter des Baumes mit den zukodierenden Zeichen beschriftet (=“markiert“)
Die inneren Knoten des Baums, also nicht die Wurzel oder die Blätter des Baumes, sinddarüberhinaus mit der Häufigkeit des Auftretens der zu kodierenden Zeichen markiert,die im Teilbaum unterhalb des betrachteten Knotens liegen
Die Häufigkeit des Auftretens ist eine rationale Zahl zwischen 0 und 1 und repräsentiertdie Wahrscheinlichkeit des Vorkommens eines Zeichens im Datensatz
Das Ziel ist wie beim Morse-Kode, dass der häufigste Buchstabe den kürzesten Kodeerhält und der seltenste Buchstabe den längsten, und dass alle Kodeworte präfixfreisind
36
Der Pfad des häufigsten Buchstabens muss nahe unterhalb der Wurzel enden, undder Pfad des seltensten bis auf die tiefste Ebene des Baumes hinabreichen
Beide Pfade (kurz und lang) münden in „ihrem“ jeweiligen Blatt
2.11.3.2 Algorithmus der Huffman-Kodierung
1.) Zuerst werden senderseitig die im Datensatz verwendeten Zeichen ermittelt
2.) Danach wird die Häufigkeitsverteilung dieser Zeichen im Datensatz durch Abzählenbestimmt und daraus ein Entscheidungsbaum erstellt
3.) Dann wird mit Hilfe des Entscheidungsbaums ein Kodebuch erstellt
4.) Danach wird der Datensatz mit Hilfe des Kodebuchs kodiert und dadurch komprimiert
5.) Zur Dekodierung wird zuerst das Codebuch des Senders dem Empfänger mitgeteilt
6.) Dann werden die Kodeworte einzeln zum Empfänger übertragen
7.) Der Empfänger dekodiert schritthaltend mit dem Sender Kodewort für Kodewortanhand seines Kodebuchs und der Eigenschaft der Präfixfreiheit der Kodeworte
2.11.3.3 Regeln zur Erstellung des Entscheidungsbaums
1.) Der Entscheidungsbaum wird rekursiv von den Blättern zur Wurzel aufgebaut

37
2.) Begonnen wird mit den beiden seltensten Zeichen. Sie dienen 2 benachbarten Blät-tern als Beschriftung.
3.) Falls >2 Zeichen gleich selten sind, entsteht eine Mehrdeutigkeit => es gibt >1 gleich-wertige Entscheidungsbäume
4.) Die beiden seltensten Zeichen werden zu einem Teilbaum zusammengefasst und ihresummierte Häufigkeit an der Wurzel ihres Teilbaums als Knotenmarkierung notiert
5.) Die eine Kante des Teilbaums (z.B. immer die linke bzw. die untere) wird mit 0, dieandere Kante wird mit 1 beschriftet
6.) Das Verfahren, zwei seltene Zeichen zu einem Teilbaum zusammenzufassen, wird mitden beiden dritt- und viertseltensten Zeichen bzw. der Wurzel eines Teilbaums fortge-setzt. D.h., es wiederholen sich in analoger Weise die Schritte 2)-5).
7.) Im weiteren werden jeweils solche Blätter oder Teilbäume zu übergeordneten Teil-bäumen zusammengefasst, deren summierter Markierungswert an der gemeinsamenWurzel am kleinsten ist. Dadurch wird erreicht, dass seltene Zeichen besonders langkodiert werden.
8.) Der Prozess terminiert, sobald alle Zeichen eine Position als Blatt im Entscheidungs-baum erhalten haben, d.h. sobald alle Zeichen als Beschriftung der Blätter verwendetwurden
38
Durch das beschriebene Verfahren wird sichergestellt, dass seltene Zeichen in langePfade übersetzt werden. Dies ist nach Voraussetzung erforderlich, um häufige Zeichenkurz kodieren zu können
Der Empfänger rekonstruiert anhand der erhaltenen Kodeworte eine Kopie des Ent-scheidungsbaums des Senders
Der Empfänger durchläuft den Entscheidungsbaum entlang eines Pfades von der Wur-zel zu einem Blatt
Sobald er an einem Blatt ankommt, ist das Kodewort zu Ende. Der Empfänger weiß da-durch, wie viele Bits in einem Bitstrom zu einem Kodewort gehören.
Da der Baum der einzige kreisfreie Graph unter allen ungerichteten Graphen ist, wirdferner erreicht, dass es für jedes Zeichen genau einen Pfad durch den Baum und damitgenau ein Kodewort gibt
Die Präfixfreiheit wird dadurch erzielt, dass an jeder Verzweigung, d.h. an jedem inne-ren Knoten, sich die beiden Alternativen durch je ein Bit unterscheiden und jeder Pfadan einem Blatt endet.
Selbst wenn zwei Pfade den gleichen Anfang haben, unterscheiden sie sich früheroder später voneinander. Der Code eines Zeichens ist also nie Teil eines anderen Zei-chencodes.
Sobald der Empfänger an einem Blatt angekommen ist, gehört das nächste Bit im Bit-strom zum nächsten Kodewort

39
Beispiel: Datensatz, der zu kodieren ist: A B D C A A E D C.
Im Datensatz verwendete Zeichen: A, B, C, D und E
Häufigkeiten der Zeichen: p(A)=3/9, p(B)=1/9, p(C)=2/9, p(D)= 2/9, p(E)=1/9
Daraus resultiert der unten dargestellte, nicht eindeutige Entscheidungsbaum:
Beispiel: Man könnte auch die Blätter C und D zu einem Teilbaum zusammenfassen, dabeides Mal 4/9 als Häufigkeit auftritt. Ebenso ist es möglich, C statt D zum B/E-Teilbaumzusammenzufassen (=> Mehrdeutigkeit).
Entscheidungsbaum Häufigkeit Zeichen => Kodewort3/9 A 11
2/9 C 10
2/9 D 01
1/9 B 001
1/9 E 000
1
0
1
1
0
01
0
5/9
2/94/9
Wurzel 9/9
40
Daraus resultierendes Kodebuch für die Kodierung von A B D C A A E D C:
2.11.4 Variable Length Integer-Kodierung
Ein wichtiger Variante der Huffman-Kodierung ist die nicht die Darstellung von Zei-chen, sondern die von ganzen Zahlen (Integer) über Bitstrings variabler Länge, die sog.Variable Length Integer-Kodierung
Prinzip: kleine Zahlen sind im täglichen Leben häufiger als große => Sie sollten in we-niger Bits kodiert werden
Beispiel: Es sei in einem Datensatz die nachfolgende Häufigkeitsverteilung von ganzenZahlen gegeben. Hinweis: die nachfolgend angegebene Häufigkeitsverteilung ist durchaus realistisch
Kodebuch:
Zeichen Kode A 11 B 001 C 10 D 01 E 000
A B D C A A E D C11 001 01 10 11 11 000 01 10
Übertragene Bits (= Datensatz-Kodierung)

41
Um innerhalb einer gewählten Häufigkeitsklasse eine Zahl eindeutig zu klassifizieren,ist log2[Anzahl der Fallunterscheidungen] an Bits nötig
Zusätzlich wird jede Häufigkeitsklasse mit einem Vorzeichenbit (VZ) versehen, umauch negative ganze Zahlen kodieren zu können
Zahlen Häufigkeitsklasse
Zahl der Bits für die Anzahl der Fallunter-
scheidungen innerhalb einer Häufigkeitsklasse
0 am häufigsten 0
1 am zweithäufigsten 0
2,3 am dritthäufigsten 1
4,...,7 am vierthäufigsten 2
8,...,15 am fünfthäufigsten 3
16,...,31 am sechsthäufigsten 4
32,...,63 am siebthäufigsten 5
64,...,127 am achthäufigsten 6
. . . . . . . . .
42
Um Kompression zu erzielen, müssen mehrere Variable-Length-Integer aus unter-schiedlichen Häufigkeitsklassen im Originaltext existieren, sonst lohnt sich das Ver-fahren nicht
Kleine Zahlen werden dann mit wenig Bits, große mit mehr Bits kodiert Zur Unterscheidung der einzelnen Variable-Length-Integer in einem Bitstrom ist die
Angabe der Zahl der Bits notwendig, die man pro Variable Length Integer braucht Die Zahl der Bits pro Variable Length Integer gewinnt man aus der Datenstruktur, die
eine Variable Length Integer definiert Diese Datenstruktur ist ein Tripel:
1.) Länge der Datenstruktur = Anzahl der Bits für die Fallunterscheidung innerhalb einerHäufigkeitsklasse + 1 Vorzeichenbit. Die Längenangabe erfolgt im Binärcode.
2.) Vorzeichenbit
3.) Fallunterscheidung innerhalb der Häufigkeitsklasse. Die Auswahlangabe erfolgt imBinärcode.
Die Zahl der Bits, aus denen Feld 1 des Tripels besteht, muss beim Empfängerbekannt sein, damit der Empfänger Beginn und Ende der Datenstrukturen durchAbzählen feststellen kann
Beispiel: Es sollen alle Zahlen zwischen +/-0,...,31 als Variable Length Integer kodiertwerden.

43
Lösung: Die oben angegebenen Zahlen fallen in folgende Häufigkeitsklassen:• 0, +/-1, +/-(2, 3), +/-(4,...,7), +/-(8,...15), +/-(16,...,31), d.h. aus 11 Klassen• Die größten Häufigkeitsklassen sind +/-(16,...,31)• Zur Unterscheidung aller Zahlen in der größten Häufigkeitsklasse benötigt man 4 Bit. Hinzu
kommt das VZ => Gesamtzahl der Bits = 5. Die Zahl 5 kann man binär mit 3 Bit kodieren. Für die Datenstrukturen der einzelnen Häufigkeitsklassen ergibt sich:
• Datenstruktur(16,...,31) = {101, 0, abcd}Hinweis: a, b, c, d sind die Bits, die eine bestimmte Zahl in der Häufigkeitsklasse auswählen
• Datenstruktur(8,...,15) = {100, 0, abc}• Datenstruktur(4,...,7) = {011, 0, ab}• Datenstruktur(2,...,3) = {010, 0, a}• Datenstruktur(1) = {001, 0}• Datenstruktur(0) = {000}
Negative Zahlen unterscheiden sich durch eine „1“ im 2. Element Daraus ergeben sich für die Datenstruktur der Variable Length Integer +/-(0,...,31) des
Beispiels folgende Regeln:
1.) Feste Zahl von 3 Bit für die Angabe der Länge aus 2.) + 3.). Mögliche Werte sind 5, 4,3, 2, 1, 0. Der Wert ist Null, wenn es keine Unterscheidung in der Häufigkeitsklassegibt.
44
2.) 0 oder 1 Bit für das VZ: 0 = „+“, 1 = „-“. Der Wert entfällt, wenn es keine Unterschei-dung zwischen Plus und Minus gibt.
3.) 0, 1, 2, 3 oder 4 Bit für die Fallunterscheidungen innerhalb der Häufigkeitsklasse. DerWert entfällt, wenn es keine Unterscheidung in der Häufigkeitsklasse gibt.
Beispiel: Die Kodierung der Zahlen 0, 1, -1, 4, und -21 aus dem Intervall -31,....-1,0,1,...,31 ist:
2.11.5 Lempel-Ziv-Kodierung
Lempel-Ziv-Kodes stellen eine ganze Familie von Kodes dar, die sich mehr oder weni-ger voneinander unterscheiden
Eine bestimmte Variante der Lempel-Ziv-Kodes wird für das Zip-Kompressionspro-gramm verwendet
Zahl Länge/VZ/WertZum Vergleich die 6-Bit Integer-Darstellung
0 000 000000
+1 0010 000001
-1 0011 111111
4 011000 000100
-21 10110101 (=länger!) 101011

45
Lempel-Ziv berücksichtigt nicht nur die Häufigkeit einzelner Zeichen im Datensatz,sondern ganzer Zeichenketten
höhere Kompressionsrate als bei Huffman, da ganze Strings mit einem Kodewort dar-gestellt werden
Besonderheit bei Lempel-Ziv: Ist der Datensatz vom Sender komplett eingelesen, sindzugleich alle Daten komprimiert (= kodiert schritthaltend mit dem Einlesen der Daten)
Eine der bekanntesten Varianten der Lempel-Ziv-Familie ist Lempel-Ziv-Welch (LZW) LZW gewährleistet sowohl bei der Kompression als auch bei der Dekompression eine
hohe Arbeitsgeschwindigkeit LZW setzt voraus, das zu Beginn der Kodierung/Dekodierung für jedes im Eingabe-
alphabet vorkommende Zeichen ein entsprechender Kode in einem Kodebuch existie-ren muss
LZW arbeitet im Gegensatz zum Huffman-Kode über Präfixe (= Textstrings aus 0 u. 1)als Zwischenwerte und über die Verkettung von Textstrings miteinander (=String-Kon-katenation)
Präfix heißt, dass ein Kodewort zugleich den Anfang eines anderen Kodewortes bildet
2.11.6 Arithmetische Kodierung
Patentiertes Verfahren, d.h. kostenpflichtig
46
Ähnlich wie Huffman-Kodierung, jedoch mit noch höherer Kompressionsrate als Huff-man oder Lempel-Ziv
Komprimiert ebenso wie Lempel-Ziv-Welch ganze Zeichenketten, berücksichtigt aberzusätzlich die Häufigkeit ihres Auftretens im Datensatz: „ei“ z.B. ist häufiger als „yw“.
Es werden n-Tupel von Zeichen aus dem Datenstrom mit je einem Kodewort kodiert;mit n = beliebig aber fest
Die Kompression erfolgt dadurch, das die Bitrepräsentation des Kodeworts kürzer istals die des n-Tupels
Das Kodewort des n-Tupels wird indirekt über die Häufigkeit des n-Tupels berechnet Dazu werden die Häufigkeiten aller n-Tupel als Längen auf einem Zahlenstrahl nachei-
nander aufgetragen, z.B. für n= 4 beginnend mit dem 4-Tupel aaaa und endend mit zzzz
Häufige n-Tupel haben eine größere Länge auf dem Zahlenstrahl als seltene
Dann wird der Zahlenstrahl auf das Intervall [0,1] skaliert
Jedes n-Tupel überdeckt ein Teilintervall aus [0,1]
Alle Teilintervalle werden mit einem im Prinzip beliebigen Wert aus dem jeweiligen Teil-intervall kodiert
Dieser Wert ist eine rationale Zahl, die im Rechner als REAL z.B. gemäß IEEE 754 (=Zah-lendarstellung im Rechner) repräsentiert wird. Daher der Name „arithmetische Kodie-rung“.

47
Die Kompression erfolgt dadurch, dass der Codewert so gewählt wird, dass dessen Bit-zahl kleiner ist als die Bits des n-Tupels, das er repräsentiert
Der Wert ist das Kodewort des n-Tupels Da es oft im jeweiligen Teilintervall mindestens eine rationale Zahl gibt, die im gewähl-
ten Zahlenformat der Gleitkomma-Zahl nach nur wenigen Bits der Mantisse mit Nullenweitergeht, kann man sich diese Nullen sparen. Sie können weggelassen werden.
Da häufige n-Tupel ein größeres Teilintervall haben, ist für sie die Wahrscheinlichkeit,eine solche Gleitkomma-Zahl mit besonders wenigen Mantisse-Bits zu finden, höherals für seltene n-Tupel
Häufige n-Tupel werden im Mittel kürzer kodiert als seltene
Dadurch wird komprimiert
2.11.7 Color-Lookup-Table-Kodierung
Bildschirme verwenden zur Farbdarstellung oft 3 Byte pro Pixel => 16 M Farben In einem einzigen Bild sind aber nicht alle 16 M Farben gleichzeitig vertreten, sondern
in der Regel viel weniger Hinzu kommt, dass das Auge nur max. 8 Mio. Farben also ca. 50% von 16 M unterschei-
den kann
Anlegen einer Farbzuordnungstabelle (= Kodebuch)
48
Beispiel: in einem Bild seien nur 200 verschiedene Farben verwendet, der Bildschirmbenötigt jedoch 3 Byte pro Pixel zur Ansteuerung
Es wird eine Tabelle mit 200 Einträgen zu je 3 Byte aufgebaut. Jeder Eintrag kodierteine andere im Bild verwendete Farbe
Anstelle der 3 Byte Farbinformation pro Pixel wird nur ein 1 Byte als Index für die Farb-zuordnungstabelle abgespeichert (mit 1 Byte kann man bis zu 256 Einträge in der Farb-zuordnungstabelle adressieren)
2.12 Beschreibung der Quellen-Kodierungsverfahren
Bekannte Quellen-Kodierungsverfahren sind die Prädiktive Kodierung und die Vektor-quantisierung
Daneben gibt es noch die Gruppe der Transformationskodierungen
2.12.1 Prädiktive Kodierung
Es wird bei der prädiktiven Kodierung ein „Vorhersager“ (Prädiktor) benutzt, der dasjeweils nächste Zeichen im Datenstrom anhand der Zeichen, die in der Vergangenheitgesendet wurden, schätzt (= Extrapolation)
Kodierer/Dekodierer bzw. Sender/Empfänger benutzen denselben Prädiktor Es wird nur der Fehler, d.h. die Differenz zum jeweils vorhergesagten Wert übertragen

49
Wenn sich im Datenstrom nur wenig ändert, bzw. wenn der Prädiktor gut ist, ist die Ab-weichung vom Schätzwert klein (= geringe Differenz)
Kompression wird dadurch erreicht, das die Abweichungen vom Schätzwert i.a. in we-niger Bits kodiert werden können als die Absolutwerte
2.12.2 Transformationskodierung
Innerhalb der Transformationskodierungen sind die DFT, FFT und DCT die wichtigstenVerfahren
2.12.2.1 Diskrete Fouriertransformation (DFT)
Die DFT ist eine Variante der klassischen Fouriertransformation (FT). Die FT ist für zeit-kontinuierliche, periodische Funktionen definiert.
Die DFT hingegen kann auf zeitdiskrete Funktionen angewandt werden, d.h. auf Zah-lenwerte, die in einem Rechner abgespeichert werden können
Die zeitdiskreten Funktionen werden als periodisch angenommen Die Periodizität stellt eine Idealisierung der Wirklichkeit dar, ist aber wichtig für das
Weiterrechnen Die DFT transformiert wie die FT Funktionen (= Signale) in eine Summe von Sinus-
schwingungen unterschiedlicher Frequenz, Phase und Amplitude Diese Frequenzen heissen „Spektrum des Signals“ und bestehen aus Grundwelle und
Oberwellen
50
Die Frequenzen bei FT und DFT sind auf einer f-Achse, auf der man sie auftragen kann,in stets gleichen Abständen angeordnet, haben aber i.a. unterschiedliche Höhe (Amp-litude) und unterschiedliche Phasen
Jedes Paar aus Amplituden-/Phasenwert einer Frequenz auf der f-Achse heißt „Fourier-koeffizient“
Fourierkoeffizienten sind i.a. komplexe Zahlen, was die Arithmetik erschwert Aufgrund dessen, dass die zu transformierenden Signale im Zeitbereich als periodisch
angenommen werden, ergeben sich diskrete Werte mit konstantem Abstand im Spekt-rum
Diskrete Frequenzwerte sind die Voraussetzung für die Berechnung derselben imComputer
2.12.2.2 Mathematischer Hintergrund der DFT
Eine periodische Funktion f wird als Linearkombination von i.a. unendlich vielen sog.Basisfunktionen dargestellt
Basisfunktionen sind bei der Fouriertransformation sin(nx)- und cos(mx)-Funktionen(n, m ∈ N0),
Sinus- und Cosinus-Schwingungen sind in einem Funktionenraum zueinander ortho-gonal
Der Funktionenraum heißt Fourierraum

51
Linearkombination heißt, dass die diversen Schwingungen gewichtet, d.h. mit unter-schiedlicher Amplitude und Phase addiert werden
Die Gewichtungsfaktoren der Basisfunktionen repräsentieren eindeutig die Funktion f Die Gewichtungsfaktoren heißen Fourierkoeffizienten und werden mittels der sog. Fou-
rier-Hintransformation bestimmt Die Gewichtungsfaktoren sind komplexe Zahlen und enthalten die Amplitude und Pha-
se ihrer Basisfunktion (= Sinus-Schwingung) als Information Die Gewichtungsfaktoren erscheinen auf der Frequenzachse in festen Abständen Sie bilden im Fourierraum eine Funktion F, die umkehrbar eindeutig mit f korreliert Die Fourier-Rücktransformation ist die inverse Operation der Hintransformation und
rekonstruiert aus den Gewichtungsfaktoren F wieder die Originalfunktion f
Die Fourier-Rücktransformation ist eine Linearkombination aus Sinus- und Cosinus-Schwingungen verschiedener Amplitude, Phase und Frequenz
Hin- und Rücktransformation sind bis auf ein Minus-Zeichen mathematisch identisch In der Praxis beschränkt man sich auf die Transformation periodischer Signale, die zu-
sätzlich im Fourierraum bandbegrenzt sind, da sonst das sog. Abtasttheorem, das eserlaubt, analoge Signale zu digitalisieren, verletzt werden würde
bei Bandbegrenzung im Eingangssignal werden nur endlich viele Koeffizienten benö-tigt
52
Fouriertransformation ist bei Beachtung der Bandbegrenzung und der Periodizität ver-lustfrei
Verlustbehaftete Kompression entsteht durch Weglassen hoher Frequenzanteile mitkleiner Amplitude; diese Anteile tragen nur wenig zum generellen Signalverlauf bei
Schnelle Sinus-Schwingungen mit kleiner Amplitude sind weniger wichtig
2.12.2.3 2D-DFT für Bilder
Wird die Fouriertransformation nicht auf 1-dimensionale Signale wie z.B. Audio-Signa-le, sondern auf 2-D Bilder angewandt, erhält man Paare von Fourierkoeffizienten
Jedes Koeffizientenpaar repräsentiert dabei 2 Wellen, die sich in x- und in y-Richtungausbreiten
Die x- und y-Richtung zusammen ergeben eine 2-D Ebene, die sog. Bildebene Jeder Koeffizient repräsentiert die Amplitude und Phase einer Welle einer bestimmten
Frequenz, die entweder in x- oder in -y-Richtung verläuft Die Sinus-Schwingungen (= Wellen) sind bei Schwarz/Weiß-Bildern als ansteigende
und abklingende Hell/Dunkel-Verläufe in der Ebene sichtbar Der Helligkeitswert entspricht dabei der Höhe der Sinus-Schwingung, die wiederum
von dem Betrag eines Fourierkoeffizienten im Rechner repräsentiert wird Farbbilder sind die Summe der Helligkeits- und Phasenverläufe der 3 Grundfarben Rot,
Grün u. Blau

53
An jedem Punkt (x|y) der Bildebene überlagern sich die Wellen des Spektrums zur Hel-ligkeit bzw. zur Farbe des Bildes an dieser Stelle
Der Fourierkoeffizient mit der Frequenz F0=0 hat eine besondere Bedeutung:• F0=0 repräsentiert den sog. Gleichanteil des Signals• Der Gleichanteil des Signals ist der Mittelwert über alle Amplitudenwerte
Daneben gibt es noch die sog. Grundfrequenz F1 >0, die den Abstand der Fourierkoef-fizienten auf der f-Achse (=Abszisse), d.h. dem Fourierraum festlegt
F1 wird benötigt, um die Größe des benötigten Speichers im Rechner zur Abspeiche-rung der Fourierkoeffizienten zu ermitteln
Niedrige Grundfrequenz bedeutet ein feines Raster im Fourierraum, d.h. viel Speicher Ein komplexer Koeffizient, der den Index n und den Wert Fn mit Fn>0 hat, repräsentiert
Phase und Amplitude einer Welle mit der Frequenz n*F1 (= n. Oberwelle)
Hinweis: Eine alternative Schreibweis der 1D-Fourierkoeffizitenten ist F(n) = Fn.
Es gilt: Wenn es ein feines Raster und hohe Frequenzen im Fourierraum gibt, dann gibtes eine hohe Auflösung im Ortsraum, d.h. ein scharfes Bild, aber viel Speicherver-brauch
54
2.12.2.4 Schnelle Fouriertransformation (FFT)
Die FFT ist ein sehr effizientes numerisches Verfahren zur Berechnung der 1D oder 2D-DFT, das es schon seit den 1960er Jahren gibt
Die Zeitkomplexität zur Berechnung der DFT wird durch die FFT dramatisch von O(n2)auf O(nlogn) verringert (bei 1D-DFT)
Bei der 2D-FFT, wie sie bei JPEG verwendet wird, ist der Gewinn noch größer Die FFT wird in Technik und Wissenschaft sehr oft eingesetzt Die DFT/FFT ist bei Beachtung des sog. Abtasttheorems, der Bandbegrenzung und der
Periodizität eine verlustfreie Transformation
2.12.2.5 Diskrete Cosinustransformation (DCT)
Die DCT ist ein Spezialfall der diskreten Fouriertransformation DFT und kann über dasVerfahren der FFT numerisch effizient berechnet werden, sofern bestimmte Vorausset-zungen erfüllt sind:• Es sei die zu transformierende Funktion f periodisch und spiegelsymmetrisch zur y-Achse
(= gerade) und bandbegrenzt Da solche Funktionen in der Praxis fast nie vorkommen, tut man so als ob, um Weiter-
rechnen zu können
Das zu transformierende Signal bzw. der zu kodierende Datenstrom wird als perio-disch, gerade und bandbegrenzt angenommen

55
Bei Annahme dieser Voraussetzungen ist die DCT anwendbar und verlustfrei Datenkompression erfolgt durch Weglassen von Fourierkoeffizienten hoher Frequen-
zen mit kleiner Amplitude (= verlustbehaftet) Vorteile der diskreten Cosinustransformation gegenüber der DFT/FFT:
• Nur reelle Koeffizienten, d.h. keine komplexen Zahlen im Computer notwendig• Nur cosinus(mx)-Funktionen als Basisfunktionen, keine sinus-Funktionen• Hin- und Rücktransformationen sind reell (keine Arithmetik mit komplexen Zahlen nötig)
Bei JPEG und MPEG wird die diskrete Cosinustransformation eingesetzt
2.12.3 Vektorquantisierung
Wird speziell zur Bildkompression verwendet• Bild wird in kleine quadratische oder rechteckige Blöcke gleicher Größe aufgeteilt• Jeder Block erhält eine Kennzeichnungs-Nummer• Das Kodebuch besteht aus der Menge verschiedener Blöcke des Bildes und deren Num-
mern• Anstelle des Bildes wird zuerst das Kodebuch und dann die Nummern übertragen, aus de-
nen sich das Bild zusammensetzt• Eine Kompression erfolgt genau dann, wenn mehrfach derselbe Block im Bild vorkommt,
da ab dem zweiten gleichen Block nur noch dessen Nummer übertragen werden muss• Die Nummer des Blocks wird etwas hochtrabend als „Vektor“ bezeichnet
56
2.13 Beschreibung der Kanal-Kodierungsverfahren
Die Kanal-Kodierungsverfahren beruhen darauf,• dass man entweder die feinen Pixel eines Bildes zu gröberen Pixeln zusammenfasst =
Farb-Subsampling• oder dass man das Spektrum der zu komprimierenden Funktion in einzelne Intervalle (Ab-
schnitte) unterteilt, die getrennt komprimiert werden = Subband-Kodierung
2.13.1 Farb-Subsampling
Beruht darauf, dass das Auge sehr feine Farbverläufe schlechter auflösen kann als grö-bere
sehr nah benachbarte Pixel mit ähnlicher Farbe brauchen nicht individuell abgespei-chert werden, sondern können gemittelt als ein einziger Wert gespeichert werden
Üblich sind Mittelungen über je zwei eng benachbarte Pixel, entweder in x oder in y-Richtung oder in beide Richtungen (=Mittelwert aus 2x2 Pixelblock)
Die Mittelung im Ortsraum wirkt wie eine sog. Tiefpassfilterung im Frequenzbereich Dadurch werden die Fourierkoeffizienten mit hoher Frequenz abgeschnitten => Kom-
pression durch Weglassen hoher Frequenzen

57
2.13.2 Subband-Kodierung
2D-Bild oder 1D-Tonsignal wird fouriertransformiert und das Spektrum in einzelne Teil-bereiche aufgeteilt, die als Teilbänder (Subbänder) bezeichnet werden
Jedes Subband wird getrennt komprimiert => Subband-Kodierung• Die Subbänder, bei denen Fourierkoeffizienten mit geringer Amplitude und hoher Fre-
quenz vorkommen, werden stärker verlustbehaftet komprimiert als die Bänder mit hoherAmplitude und niedriger Frequenz
Der größte Informationsverlust tritt da auf, wo er am wenigsten dem Auge auffällt
3 JPEG (= Hybride Kodierung)
Aufgrund der vorangegangenen Kapitel sind jetzt alle Grundlagen vorhanden, umJPEG verstehen zu können
JPEG ist ein sehr gutes Kompressionsverfahren für Farbbilder mit kontinuierlichemFarbverlauf
JPEG wurde 1993 von der Joint Photographic Expert Group (=Untergruppe der ISO)standardisiert
Komprimiert jeweils 1 Bild Ist der Standard bei Kameras und im www
58
Ist für Zeichnungen, Liniengraphiken oder Texte weniger geeignet, da dort der Farbver-lauf springt
Ist ebenfalls weniger geeignet für Bilder mit hohen Kontrasten oder hohem Detailreich-tum
Basiert auf der Kombination der zuvor erläuterten Kompressionsalgorithmen (DiskreteCosinustransformation + Huffman + ...)
Erlaubt verlustfreie Kompression (bis 3:1) und verlustbehaftete Kompression (bis ca.40:1)
Die Rate bei verlustbehafteter Kompression ist frei einstellbar
Bildqualität kann beliebig zwischen gut und schlecht gewählt werden
Zusammenhang zwischen Kompressionsrate und Bildqualität:
Sehr allgemeines Kompressionsschema, da unabhängig von:• Bildauflösung, Bildseitenverhältnis und Pixelgröße• Farbrepräsentation, d.h. wie Farbe im Rechner codiert wird
Rate Bildqualität
5 wie Original
10 sehr gut
20 gut
30 befriedigend

59
• Bildkomplexität und statistischen Eigenschaften des Bildes
Standardisiertes Austauschformat der codierten Daten vorhanden (= .jpg-Dateien) Implementierung des JPEG Encoders/Decoders erfolgt durch Software, sofern ausrei-
chend Prozessorleistung vorhanden ist, ansonsten gibt es spezielle Hardware zur Um-wandlung in .jpg-Format
„MOTION JPEG“ für Videokompression = Erweiterung von JPEG für kurze Sequenzvon JPEG-codierten Bildern. Wird in Digitalkameras oder Handys verwendet.
3.1 Vorteile von JPEG
Farbtiefe kann beliebig groß sein Verschiedene „Operationsmodi“ je nach Anwendungsfall Weit verbreitet; ist de jure- und de facto-Standard in Digitalkameras, Handys und im
www
3.2 Wichtige Begriffe in JPEG
Die von JPEG verwendeten wichtigen Begriffe sind das Farbmodell, das Subsamplingmit der x:y:z-Notation, die JPEG-Komponenten und die JPEG-Dateneinheiten
60
3.2.1 Farbraumdarstellung (Farbmodell)
Fakt: Das Auge kann geringe Helligkeitsunterschiede besser unterscheiden als gerin-ge Farbunterschiede
Rot-Grün-Blau-Darstellung (RGB) von Bildern ist für die Kompression ungünstig, dadabei Farbe und Helligkeit zusammen kodiert werden
Besser ist die Darstellung über Helligkeitssignal (Luminanz) und 2 Farbsignale (Chro-minanz)
Luminanz/-Chrominanzsignale werden mit Y, Cb, Cr, bzw. beim Farbfernsehen mit Y, U,V abgekürzt. Cb, Cr bzw. U, V definieren eindeutig eine Farbe in einem 2D-Farbraum.
JPEG verwendet meist den Luminanz/Chrominanz-Farbraum, ist aber nicht darauffestgelegt
3.2.2 x:y:z-Notation für Farb-Subsampling (CCIR-601)
Farb-Subsampling heißt: es werden die Farben von benachbarten Pixeln gemittelt Dies wird deshalb gemacht, weil das Auge feine Farbverläufe nicht sieht Die x:y:z-Notation bezieht sich auf Subsampling im Luminanz/Chrominanz-Farbraum
(Y, Cb,Cr)
Def.: 4:2:2 heißt: pro 4 Pixel im Y-Signal gibt es zwei gemittelte Pixel bei Cb und Cr. DieMittelung erfolgt in x-Richtung (horizontal) über je zwei Nachbarpunkte.

61
Die Zahl der Pixel in Y, Cb und Cr verhalten sich wie 4:2:2
Die Bildauflösungen von Y, Cb und Cr verhalten sich in x und y-Richtung wie axb, (a/2)xb und (a/2)xb => axb:(a/2)xb:(a/2)xb
Def.: 4:1:1 heißt: pro 4 Pixel im Y-Signal gibt es ein gemitteltes Pixel bei Cb und Cr. DieMittelung erfolgt in x-Richtung (horizontal) über je vier Nachbarpunkte.
Die Zahl der Pixel in Y, Cb und Cr verhalten sich wie 4:1:1.
Die Auflösungen verhalten sich wie axb:(a/4)xb:(a/4)xb
Um eine Mittelung in x- und y-Richtung in der x:y:z-Notation auszudrücken, wird dieNotation „missbraucht“:
Def.: 4:2:0 heißt: pro 4 Pixel im y-Signal gibt es ein gemitteltes Pixel bei Cb und Cr. DieMittelung erfolgt in x- und y-Richtung über je zwei, d.h. insgesamt vier Nachparpunkte.
Die Zahl der Pixel verhalten sich ebenfalls wie 4:1:1.
Die Auflösungen verhalten sich jedoch wie axb:(a/2)x(b/2):(a/2)x(b/2)
Beispiel: Die Pixelauflösungen bei Handy Video Calls sind entweder gemäß 4:2:2, oder4:1:1 oder 4:2:0 gemäß nachfolgender Tabelle:
62
3.2.3 JPEG-Komponenten (Bild-Bestandteile)
Wird bei JPEG der Luminanz/Chrominanz-Farbraum verwendet, werden Y, Cb und Cr in3 „JPEG-Komponenten“ abgespeichert
Bei Verwendung anderer Farbmodelle (z.B. RGB) wird die Farbinformation jedes Pixelsebenfalls getrennt nach Komponenten gespeichert
Jede Komponente ist als 2-dimensionales Feld (Array) implementiert, das Bildinforma-tion enthält und anteilig zum Gesamtbild beiträgt
Bei JPEG sind bis zu 255 solcher Felder, d.h. Komponenten erlaubtBeispiel: Ein Bild verwendet 4 Komponenten: Helligkeit, Farbe Cb, Farbe Cr und Durch-sichtigkeit (Transluzenz) des Bildes. Transluzenz heißt, man sieht etwas durch das Bildhindurch.
Man kann sich die Komponenten wie Ebenen vorstellen, die parallel hintereinander lie-gen
Y Cb, Crje
4:2:2 352 x 288 176 x 288
4:1:1 352 x 288 88 x 288
4:2:0 352 x 288 176 x 144

63
Jede Ebene (= Komponente) trägt an der Stelle (x|y) mit ihrem Informationsgehalt zumPixel (x|y) bei
Wichtig: die Komponenten, d.h. die Werte in den Arrays, werden jede für sich kompri-miert, um Rechenzeit zu sparen, da für die Zeitkomplexität der 1D-FFT O(nlogn) gilt
Dies ist für Bilder im www, in Handys und in Kameras von hoher Bedeutung, weil diekomponentenweise Kompression viel schneller geht, als die Kompression des Bildesals ganzes
3.2.4 JPEG-Farb-Subsampling
Bei Verwendung von Farb-Subsampling haben die Chrominanz-Komponenten eine ge-ringere Auflösung in x- und/oder y-Richtung als die Luminanzkomponente
Wichtig für den Kompressionsfaktor beim Farb-Subsampling sind die Verhältnisse derAuflösungen der einzelnen Komponenten zueinander
Die Verhältniszahl der Auflösung der Komponente i wird in x-Richtung mit Hi, in y-Rich-tung mit Vi bezeichnet (Hi, Vi für horizontal und vertikal)
Beispiel:
• Für 4:2:2 nach CCIR-601 ist Hy:HCr:HCb = 2:1:1 und Vy:VCr:VCb = 1:1:1• Für 4:1:1 nach CCIR-601 ist Hy:HCr:HCb = 4:1:1 und Vy:VCr:VCb = 1:1:1• Für 4:2:0 nach CCIR-601 ist Hy:HCr:HCb = 2:1:1 und Vy:VCr:VCb = 2:1:1
64
Bei Farb-Subsampling gehört jedes Element einer Chrominanzkomponente zu mehre-ren Elementen der Luminanzkomponente
Ein und derselbe Farbwert wird für mehrere benachbarte Pixel verwendet
Beispiel: gegeben sei ein Bild der Größe 4x2 Pixel mit 4:2:2. Es werden drei Komponen-ten pro Pixel verwendet, die die Y-, Cb- und Cr-Signale speichern.
Die verschiedenen Verhältnisse der Auflösungen Hi, Vi sind im Header eines JPEG-ko-dierten Bildes für jede Komponente i angegeben
3.2.5 Dateneinheiten
Bei JPEG können Kompressionsalgorithmen auf 2 Datentypen angewandt werden:
1. Komponente (Y-Signal)Y Y Y YY Y Y Y2. Komponente (Cb-Signal)
Cb1Cb3
Cb2Cb4
3. Komponente (Cr-Signal)Cr1Cr3
Cr2Cr4
4x2 Bild: 2x2 Raster definiert
4x2 Raster definiertHelligkeitsauflösung
Farbauflösung
2x2 Raster definiertFarbauflösung

65
1.) Ein einzelnes Komponentenelement
2.) Einen ganzen Block von Komponentenelementen, z.B. der Größe 8x8
Die JPEG-Algorithmen sprechen deshalb allgemein von Dateneinheiten (Data Units)
Eine Dateneinheit ist entweder ein Element einer Komponente oder ein Block von Ele-menten einer Komponente
Beispiele:• a) Dateneinheit ist ein einzelner Wert des Y-Signals eines Pixels• b) Dateneinheit ist die Menge aller Werte des Y-Signals eines 8x8 Blocks von Pixeln
Einzelne Komponentenelemente werden nur mit verlustfreier Kompression verarbeitet.Wert wird geschätzt = sog. prädiktive Vorhersage.
Bei verlustbehafteter Kompression wird i.d.R. Farb-Subsampling angewandt und Blö-cke der Größe 8x8 von Elementen einer Komponenten verarbeitet (= Diskrete Cosi-nustransformation)
Wichtig ist: Die Kompression erfolgt komponentenweise getrennt
3.2.6 Minimal Coded Units (MCUs)
MCUs sind die Elemente aller Komponenten, die logisch zusammen gehören aber ge-trennt komprimiert werden (Menge zusammengehöriger Komponentenelemente)
66
Beispiel: Ein Element einer Farbkomponente gehört immer zu einem Element der Hel-ligkeitskomponente
Die Elemente einer MCU können parallel verarbeitet werden, wodurch die Kompressi-onsgeschwindigkeit ansteigt
Dies ist speziell für Multicore-Prozessoren interessant
3.2.6.1 MCUs aus einzelnen Komponentenelementen und Farb-Subsampling
Werden einzelne Komponentenelemente als Datenelemente (also keine Blöcke) undFarb-Subsampling verwendet, ist eine MCU eine Menge aus jeweils zusammengehö-renden Elementen aller Komponenten
Beispiel: gegeben sei ein 4x2-Bild mit 4:2:2 Farb-Subsampling
Die Helligkeitskomponente ist ein 4x2-Feld mit den Elementen Y1, Y1, Y3, Y4 in der 1.Zeile und Y5, Y6, Y7, Y8 in der zweiten.
Die Farbkomponente Cb ist ein 2x2-Feld mit den Elementen Cb1, Cb2 in der 1. Zeileund Cb3 und Cb4 in der 2. Zeile (Bei Cr analog).
MCU1 = {Y1, Y2, Cb1, Cr1}MCU2 = {Y3, Y4, Cb2, Cr2}MCU3 = {Y5, Y6, Cb3, Cr3}MCU4 = {Y7, Y8, Cb4, Cr4}
Es gibt 4 MCUs:

67
Sowohl die 4 verschiedenen Elemente in einer MCU können parallel komprimiert wer-den als auch die 4 MCUs untereinander => 16-fache Parallelität => 16-fache Kompres-sionsgeschwindigkeit in einem 16-Core Prozessor
3.2.6.2 MCUs aus Blöcken von Komponentenelementen und Farb-Subsampling
Werden Blöcke von Komponentenelementen als Datenelemente und Farb-Subsamp-ling verwendet, enthält eine MCU die Farb- und Helligkeitssignale eines Blocks von Pi-xeln.
3.3 Kompression mittels diskreter Cosinustransformation (DCT)
Fakt 1: Das Auge kann geringe Farbunterschiede viel schlechter erkennen als geringeHelligkeitsunterschiede => ganz feine Farbverläufe bleiben für das Auge unsichtbar
Wenn Chrominanzsignale fouriertransformatiert werden, haben die Fourierkoeffizien-ten unterschiedliche Wichtigkeit
Chrominanz-Fourierkoeffizienten hoher Frequenz sind weniger wichtig, da sie feineFarbverläufe repräsentieren
Chrominanz-Koeffizienten hoher Frequenz können mit reduzierter Genauigkeit abge-speichert werden (auch wenn sie rel. hohe Amplituden haben) oder ganz weggelas-sen werden
68
Fakt 2: Photos sind in der Regel so strukturiert, dass sich von Pixel zu Pixel wenig än-dert
Wenn das Luminanzsignal fouriertransformatiert wird, haben die Koeffizienten hoherFrequenz meist nur sehr geringe Amplituden, da sich i.d.R. wenig von Pixel zu Pixeländert
Luminanz-Koeffizienten hoher Frequenz können ebenfalls mit reduzierter Genauigkeitabgespeichert werden (=Subband-Kodierung) oder ganz weggelassen werden
Die DCT ist wichtiger Bestandteil von JPEG und trägt wesentlich zur Datenkompressi-on bei
3.4 Verlustfreie Kompression in JPEG
Erlaubt Raten bis 3:1. Wird z.B. beim maschinellen Bild-Erkennen eingesetzt. Wird i.a.nicht zur Kompression von Bildern verwendet, die von Menschen betrachtet werden.
Prinzip:• Zuerst wird das Bild pixelweise prädiktiv kodiert. • Prädiktiv heißt, dass neue Pixelwerte „geschätzt“ d.h. aus bestehenden vorhergesagt wer-
den.• Dabei entstehen 2-Tupel der Form: (Vorhersage, Differenz), (Vorhersage, Differenz), (Vor-
hersage, Differenz), ...• Davon wird nur jeweils die Differenz abgespeichert, da der Dekodierer in derselben Weise
vorhersagt wie der Kodierer.

69
• Es kann zwischen 8 verschiedenen Prädiktor-Methoden gewählt werden.• Anschließend werden die Daten der Form (Differenz, Differenz, Differenz, ...) per Huffman-
Kode oder arithmetischer Kodierung weiter verdichtet.
3.5 Prädikatormodi
Beispiel: Beispiele für Prädiktormodi sind X := A, X := B, X := C oder X:=(A+B)/2
3.6 Verlustbehaftete Kompression in JPEG
Dient hauptsächlich der Kompression von Photos Es gibt 3 verschiedene Möglichkeiten, die man je nach Anwendungszweck wählen
kann:• Sequentieller Modus
C BA X
Pixel
70
• Progressiver Modus• Hierarchischer Modus
Alle Modi verwenden u.a. die Diskrete Cosinustransformation (DCT), um das 2-dimen-sionale Bild in den 2-dimensionalen Fourierraum zu transformieren
Unterschiede gibt es in der Gewinnung und Übertragung der Fourierkoeffizienten• Der progressive und der hierarchische Modus enthalten den sequentiellen Modus als
Kernelement und sind insgesamt aufwendiger
3.6.1 Sequentieller Modus
Als JPEG-Datentyp werden Blöcke von Pixel der Größe 8x8 oder 16x16 verwendet,meistens zusammen mit Farb-Subsampling
Begonnen wird mit der Kompression des Blocks links oben und endet mit dem Blockrechts unten im Bild
Bild wird Block für Block separat komprimiert
Liefert die besten Kompressionsraten und ist am leichtesten zu implementieren
3.6.2 Progressiver Modus
Bild wird mehrmals komprimiert, jedesmal etwas „schärfer“ Übertragen wird zuerst ein rel. unscharfes Bild, dessen Kompression und Übertragung
aber schnell vonstatten gehen

71
Mit jeder Übertragung nimmt die Bildschärfe zu, aber auch die Kompressions- undÜbertragungsdauer
Man bekommt schnell einen Überblick über das Bild und kann vorzeitig abbrechen,wenn man genug gesehen hat
Nachteil: aufwendiger zu implementieren Beim progressiven Modus gibt es drei Unterfälle der Implementierung:
1.) Zuerst werden bei der DCT nur die Fourierkoeffizienten niedriger Frequenz berechnetund übertragen (= spektrale Variante)
Bild gewinnt an Schärfe durch schrittweise Hinzunahme der hohen Frequenzen
2.) Zuerst werden nur Fourierkoeffizienten mit reduzierter Genauigkeit (z.B. 16 statt 32Bit) übertragen (= approximative Variante)
Bild gewinnt an Schärfe durch Übertragung genauerer Koeffizienten
3.) Kombination aus spektraler und approximativer Methode (= hybride Variante). Wirdkaum eingesetzt, da zu aufwendig.
72
3.6.2.1 Spektrale Variante des progressiven Modus
Hinweis: DC = Gleichanteil des Bildes, AC = Wechselanteile des Bildes
DCT Koeff. aller 8x8 oder 16x16 Blöcke
01 ... (n-1) z.B. n=32 Bits eines Koeffizienten
0 0
1
2
63
1
z.B. 63
1. Transfer
64.
3.
...
2. TransferDC
AC
0 1
.
.
.
...
DCT Koeff. der Frequenzen n=0...63
AC
AC

73
3.6.2.2 Approximative Variante des Progressiven Modus
3.6.3 Hierarchischer Modus
Zuerst wird ein Bild geringerer Auflösung übertragen Für jede nachfolgende Übertragung wird die Auflösung, d.h. die Zahl der Pixel erhöht.
Bild gewinnt an Schärfe durch Übertragung immer mehr Pixel pro Bild
. . .
6376 7765
0 0 0
63 63
01 ... (n-1) z.B. n=8 Bits eines Koeffizienten
01
z.B. 63
0 1
.
.
.
1. Transfer2. Transfer3. Transfer
...
DCT Koeff. aller 8x8 oder 16x16 Blöcke
DCT Koeff. der Frequenzen n=0...63
74
Optimierung: Die nächstfeinere Auflösung überträgt nur die Differenz zur gröberenAuflösung.
Wo sich nichts ändert, wird nichts übertragen. Es werden keine Daten doppelt über-tragen.
Am aufwendigsten zu implementieren Wird in Bilddatenbanken eingesetzt. Das Inhaltsverzeichnis enthält komprimierte Bil-
der in grober Auflösung, jeder Datensatz enthält ein Bit der Koeffizienten
3.7 Beschreibung des sequentiellen Modus von JPEG
Wird am häufigsten verwendet Besteht aus sechs einzelnen Schritten:
1.) Blockvorbereitung
2.) Diskrete Cosinustransformation jedes Blocks
3.) Quantisierung (Rasterung) der Fourierkoeffizienten jedes Blocks
4.) Prädiktive Kodierung des Gleichanteils („Differential Quantization“)
5.) Lauflängenkodierung der Wechselanteile (Koeffizienten mit Index n>0)
6.) Statistische Kodierung aller Koeffizienten (n≥0)

75
3.7.1 JPEG Blockvorbereitung
Die Blockvorbereitung umfasst fünf Teilschritte:• Konvertierung von RGB in den Y-Cb-Cr-Farbraum, da besser als RGB geeignet• Abspeicherung in drei JPEG-Komponenten mit einer Auflösung von 8 Bit pro Element• Subsampling der Chrominanzkomp. gemäß 4:2:0 (=Mittelung über je zwei Pixel in x und y)• Nullpunktverschiebung der 8-Bit-Zahlen, so dass vorzeichenbehaftete Zahlen im Intervall
-128,...,0,...,127 entstehen• Aufteilung jeder Komponente des Bildes in Blöcke der Größe 8x8
3.7.1.1 Konvertierung in den Y-Cb-Cr-Farbraum
R-G-B- und Y-Cb-Cr-Farbraum sind umkehrbar eindeutig aufeinander abbildbar
das eine kann durch das andere ersetzt werden und umgekehrt
R-G-B-Modell wird umgesetzt in Y-Cb-Cr-Modell durch 3x3-Transformationsmatrix
.
76
3.7.1.2 Abspeicherung in drei JPEG-Komponenten
Jedes Komponentenelement speichert 8 Bit eines Pixels Die 8-Bit-Komponentenelemente sind hier noch vorzeichenlose Zahlen, da es keine ne-
gative Helligkeit und keine negative Farbe gibt
3.7.1.3 Farb-Subsampling
Die Chrominanzkomponenten werden in x und y-Richtung über je zwei Pixelfarben ge-mittelt
Die 1. Kompression des Bildes erfolgt bereits in diesem Teilschritt
3.7.1.4 Nullpunktverschiebung
Für die nachfolgende DCT ist es besser, zu vorzeichenbehafteten Zahlen (8-Bit Integer)überzugehen, da arithmetische Operationen durchgeführt werden müssen
Die Helligkeit „Null“ wird auf den Wert -128 abgebildet
3.7.1.5 Aufteilung in Blöcke der Größe 8x8
Im nachfolgendem Beispiel wird ein Bild der Größe 640x480 zur DCT vorbereitet:

77
Die Luminanz-Komponente hat 4800 Blöcke, Cb und Cr haben je 1200 Blöcke
Für das 640x480-Bild werden insgesamt 7200 Blöcke gebildet
Jede MCU besteht aus 6 Blöcken: 4x Luminanz Y und je ein Chrominanzblock Cb und Cr Jeder Block hat eine Größe von 8x8 Pixel
Cb
Cr
78
3.7.2 DCT jedes Blocks
Jeder 8x8-Block einer Komponentenebene wird über die DCT fouriertransformiert Jede Transformation liefert einen Block von 8x8 Fourierkoeffizienten im 2-D Fourier-
raum Die 8x8-Blöcke der Fourierkoeffizienten überschreiben in der Komponentenebene die
dort zuvor abgespeicherten 8x8-Blöcke (= „in-place-transformation“) DCT-Element F(0,0) ist der Mittelwert über alle Elemente eines Blocks einer Komponen-
te = der sog. „Gleichanteil“ DCT-Element F(n,0) ist die Amplitude der n. Helligkeitswelle oder der n. Farbwelle ent-
lang der x-Achse (0 ≤ n ≤7) DCT-Element F(0,m) ist die Amplitude der m. Helligkeitswelle oder der m. Farbwelle ent-
lang der y-Achse (0 ≤ m ≤7) Die Wellen haben je nach Komponentenebene die Bedeutung der Luminanz oder einer
Chrominanz DCT-Element F(n,m) ist das Produkt aus den n-ten und der m-ten Wellen-Amplitude Das ganze Bild ist die Summe aller DCT-Elemente F(n,m) von allen 3 Komponenten
3.7.3 Berechnung der DCT-Koeffizienten (Hintransformation)
Die Fourierkoeffizienten F(n,m) berechnen sich aus dem Skalarprodukt der Ortsfunkti-on f(x,y) mit den 2-dimensionalen Basisfunktionen cos(nx)⋅cos(my)

79
Beispiel: für n=0, m=1 ist die Basisfunktion in der Helligkeitskomponente eine halbePeriode eines Cosinus, der sich in y-Richtung ausbreitet (nach unten)
Die Rückgewinnung der Ortsfunktion f(x,y) aus den Fourierkoeffizienten ist verlustfreidurch Rücktransformation, d.h. durch die inverse DCT möglich
Die Ortsfunktion entsteht aus dem Skalarprodukt der Fourierkoeffizienten F(n,m) mitdenselben Basisfunktionen cos(nx)⋅cos(my)
80
3.7.3.1 Graphische Darstellung der 2D-Basisfunktionen für die Helligkeitswellen
n=0 n=1 n=2 n=3 n=4 n=5 n=6 n=7 m=0 m=0 m=0 m=0 m=0 m=0 m=0 m=0
m=1 n=0
m=2 n=0
m=3 n=0
m=4 n=0
m=5 n=0
m=6 n=0
m=7 n=0
m
n
m=0n=0
81
Die numerische DCT-Hin- und -Rücktransformation kann über die FFT auf einem Com-puter sehr schnell ausgeführt werden
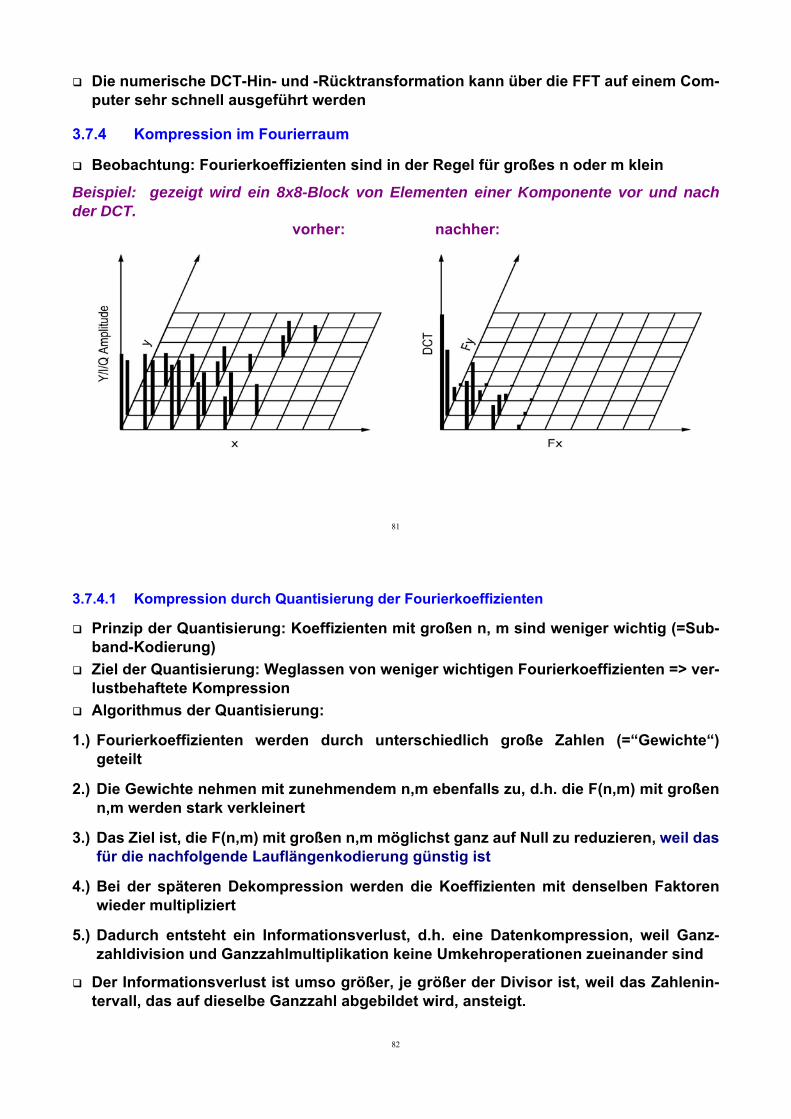
3.7.4 Kompression im Fourierraum
Beobachtung: Fourierkoeffizienten sind in der Regel für großes n oder m kleinBeispiel: gezeigt wird ein 8x8-Block von Elementen einer Komponente vor und nachder DCT.
vorher: nachher:
82
3.7.4.1 Kompression durch Quantisierung der Fourierkoeffizienten
Prinzip der Quantisierung: Koeffizienten mit großen n, m sind weniger wichtig (=Sub-band-Kodierung)
Ziel der Quantisierung: Weglassen von weniger wichtigen Fourierkoeffizienten => ver-lustbehaftete Kompression
Algorithmus der Quantisierung:
1.) Fourierkoeffizienten werden durch unterschiedlich große Zahlen (=“Gewichte“)geteilt
2.) Die Gewichte nehmen mit zunehmendem n,m ebenfalls zu, d.h. die F(n,m) mit großenn,m werden stark verkleinert
3.) Das Ziel ist, die F(n,m) mit großen n,m möglichst ganz auf Null zu reduzieren, weil dasfür die nachfolgende Lauflängenkodierung günstig ist
4.) Bei der späteren Dekompression werden die Koeffizienten mit denselben Faktorenwieder multipliziert
5.) Dadurch entsteht ein Informationsverlust, d.h. eine Datenkompression, weil Ganz-zahldivision und Ganzzahlmultiplikation keine Umkehroperationen zueinander sind
Der Informationsverlust ist umso größer, je größer der Divisor ist, weil das Zahlenin-tervall, das auf dieselbe Ganzzahl abgebildet wird, ansteigt.

83
Beispiel: 8 \ 3 = 2 (Ganzzahldivison); aber 2 * 3 = 6 mit 6 ≠ 8
F(n,m) mit großen n,m werden mehr komprimiert als solche mit kleinen n,m, weil manes dort weniger sieht
Allgemein gilt für die JPEG-Division und JPEG-Multiplikation:
ist der Abrundungsoperator, x+0.5 ist die normale Aufrundung Die Teiler q(n, m) von F werden einer Quantisierungstabelle entnommen Aber: Quantisierungstabelle ist in JPEG nicht vorgegeben, vielmehr muss sie von jeder
Implementierung von JPEG neu festgelegt werden!
JPEG-Implementierung kann die gewünschte Kompressionsrate selbst bestimmen
Generelles Vorgehen dabei:
1.) Abbildung jedes Intervalls von reellen Zahlen auf eine ganze Zahl
84
2.) Verwendung einer Quantisierungstabelle für die DCT-Koeffizienten, um für jedenKoeffizienten eine unterschiedliche hohe Genauigkeit zu erzielen
Beispiel: Quantisierung eines 8x8-Blocks von Fourierkoeffizienten durch eine Quanti-sierungstabelle, die der Benutzer z.B. über einen Schieberegler im Bedienmenü vorge-ben kann.

85
86
3.7.4.2 Wirkung der Quantisierung
Beispiel: Die Wirkung der JPEG-Quantisierung im Photo ist, dass der Schulterübergangnicht mehr so präzise ist wie vorher. Das ganze Bild ist aber nach wie vor gut erkennbar.

87
3.7.5 Prädiktive Kodierung des Gleichanteils
Die Kodierung des Gleichanteils F(0, 0) erfolgt auf eine andere Art als die Kodierungder Frequenzen F(n, m) mit m, n > 0
Der Gleichanteil wird prädiktiv kodiert, wobei der vorgesagte Wert gleich dem aktuellenWert ist (= sehr einfacher Prädiktor). Gespeichert wird nur der Fehler zur Vorhersage
3.7.6 Lauflängenkodierung der Wechselanteile
Durch die vorangegangene Quantisierung sind die Koeffizienten mit großem n, m weg-gefallen (Wert=0) oder zumindest sehr klein geworden
Lauflängenkodierung ist günstig, da sie ein Folge von Nullen effizient kodiert
Um möglichst viele Nullen am Stück zu erhalten, wird darüberhinaus der quantisierteKoeffizientenblock in der Reihenfolge zunehmender Frequenz durchlaufen
Es wird dazu bei der Reihenfolge, in der die Koeffizienten Lauflängen-kodiert werden,eine Zick-Zack-Kurve verwendet (= mäanderförmiger Durchlauf)
88
Reihenfolge der Lauflängenkodierung beim 2-D Spektrum (links oben = Gleichanteil):
3.7.6.1 Statistische Kodierung aller Koeffizienten
Alle Koeffizienten werden zum Schluss gemäß ihrer Häufigkeit im Datensatz mit mehroder weniger Bits kodiert, d.h. komprimiert
Als statistische Kompressionsverfahren stehen bei JPEG die Huffmann-Kodierung(kostenfrei) oder das arithmetische Kodierung (kostenpflichtig) zur Verfügung
Will man sich die Häufigkeitsanalyse sparen, kann man auch die einfachere Kodierungüber Variable-Length-Integer vornehmen

89
4 MPEG (= Hybride Kodierung)
Sehr gute Kompressionsverfahren für Bewegtbilder und Ton (Video und Audio) Bereits 1993 von der Motion Picture Expert Group (=Untergruppe der ISO) standardi-
siert (MPEG-1 und MPEG-2) Komprimiert beliebig lange Sequenzen von Bild und Ton Basiert auf der JPEG-Kompression, d.h. auf Diskrete Cosinustransformation + Lauflän-
gen-Kodierung + Huffman-Kodierung/arithmetische Kodierung/Variable Length Integer Erlaubt verlustbehaftete Kompression von bis 75:1 für Video und 10:1 bei Audio bei gu-
ter bzw. sehr guter Qualität Bildqualität kann durch einstellbare Kompressionsrate beliebig gewählt werden Beinhaltet Unterstandards für verschiedene Anwendungsgebiete: MPEG-1 Video/Au-
dio, MPEG-2 Video/Audio, MPEG 4 und MPEG 7 MPEG-7 ist im Gegensatz zu MPEG-1/2/4 kein Kompressionsstandard für Video- oder
Audiodaten Es wird benutzt, um multimediale Daten mittels XML zu beschreiben (sog. Metadaten) MPEG-1 Audio, Layer 3 ist auch als MP3 in der Konsumelektronik bekannt MPEG-4 ist nicht ein einzlener Standard, sondern eine Sammlung von mehr 20 Stan-
dards, worunter auch die neuesten fallen
90
4.1 Anwendungsbereiche
4.1.1 MPEG-1
Typisch für Video in mittlerer Qualität für preisgünstige Konsumelektronik sowie fürAudio
Wird beim Digital Audio Broadcast (DAB), d.h. beim digitalen Hörfunk und beim MP3-Player („iPOD“ etc.) verwendet
Sonstige typische Anwendungsfelder:• mittelteure Video-Spiele• TV-Übertragung über das Internet (life web-TV)• Video-on-Demand über das Internet (web-TV über video-Datenbank)• Video-E-Mails
4.1.2 MPEG-2
Typisch für Video in guter Qualität wie hochauflösendes Fernsehen (HDTV) sowie für• Satelliten-Fernsehen• 500-Kanal-Kabelfernsehen• Video-on-Demand über Breitbandkabel
MPEG2-Audio bietet 5-Kanal-Surround-Ton + 7-Fremdsprachenkanäle

91
4.1.3 MPEG 4
Ursprünglich für Video niederer Qualität bei extrem niedriger Bitrate:• Bildtelefon über S-ISDN oder Mobilfunktelefon (Video Call)• Skype video calls (Bild und Ton sind bereits bei 35 Kbit/s akzeptabel)• Videokonferenzen über S-ISDN oder Mobilfunktelefon• Elektronische Zeitung über Mobilfunktelefon• Mobile Multimedia-Player mit kleinem Bildschirm• einfache Video-Spiele• Multimediale E-Mail• einfache multimediale Datenbanken
Deckt mittlerweile breites Spektrum von Anwendungen ab:• von Video in niederer Qualität bei extrem niedriger Bitrate bis HDTV
Hat die besten Audio- und Videoencoder/-decoder
4.2 Gemeinsame Eigenschaften von MPEG-1 und 2
Wahlfreier Zugriff auf jedes einzelne Bild innerhalb eines Videofilms Schnelles Vor- und Rückspulen mit Bildanzeige Bildrücklauf in Originalgeschwindigkeit (reverse play) Sichere Synchronisation zwischen Bild und Ton Fehlertoleranz gegenüber Übertragungsfehlern
92
Unempfindlichkeit gegenüber Verzögerungen (delays) bei Kodierung, Übertragungund Dekodierung
Elektronisches Editieren von Bild und Ton („Schneiden“) ist möglich Vielfalt hinsichtlich Bildgröße und Bildwiederholrate ist gegeben preisgünstig, da nur geringe Rechenressourcen nötig
4.3 Unterschiede zwischen MPEG 1,2 und 4
MPEG-1 und 2 sind für verschiedene Anwendungsgebiete. Sie konkurrieren nicht mit-einander, sondern ergänzen sich, wobei MPEG2 heutzutage das Wichtigere ist.
MPEG-1 und 2 haben eine gemeinsame Schnittmenge von Algorithmen. Gemäß ihrerspezifischen Aufgaben unterscheiden sie sich jedoch in einigen Details.
MPEG 4 basiert auf völlig anderen Algorithmen: morphologische, fraktale, wavelet- undmodellbasierte Kompression.
4.3.1 MPEG-1
Ursprünglich für eine Auflösung von 360 x 288 bei 25 Bildern pro Sekunde Dabei ist die Bitrate ≤ 1,862 Mbit/s Kein Interlacing von zwei Halbbildern zu einem Vollbild Audio: nur 2 Kanäle (Stereo)

93
4.3.2 MPEG-2
Auflösungen 1440 x 1152 (HDTV 4:3) und 1920 x 1080 (HDTV 16:9) Bitrate: 2 - 80 Mbit/s Interlacing vorhanden + 5 Surround Audio-Kanäle
4.3.3 MPEG-4
Im Low-Quality-Format ist die benötigte Bandbreite nur 4,8 kbit/s!! Der Bandbreitebedarf steigt bis max. 64 kbit/s bei einer Auflösung von 176 x 144 pixel
x 10 Hz = Video Call per Smartphone Im High-Quality-Format H.264 wird Spitzenqualität auf dem Niveau einer blue ray disk
erreicht
MPEG-4 deckt alle Anforderungen ab
4.4 Übersicht MPEG-1
MPEG-1 umfasst drei Teile: Audio, Video und System Audio- und Video-Teil komprimieren unabhängig voneinander Ton und Bild, verwen-
den jedoch eine gemeinsame Zeitbasis zur Synchronisation, damit Lippenbewegungenund Ton nicht auseinanderlaufen, wie es ansonsten im Internet der Fall wäre
Zeitbasis arbeitet mit 90 KHz und verteilt 33 Bit große Zeitstempel an Datenpakete
94
Der Systemteil integriert die komprimierten Datenströme von Audio- und Video zu ei-nem ununterbrochenen Paketstrom (sog. streaming data)
Systemmultiplexer besteht aus 2 Schichten: Der Paket- und der Packschicht
1.) Die Paketschicht gliedert die Bitströme von Audio- und Video-Teil in Pakete und ver-sieht jedes Paket mit einem Header
2.) Die Packschicht fasst mehrere Pakete der Paketschicht zu einem neuen übergeord-neten Paket zusammen, das ebenfalls einen Header hat und Audio und Videopaketezusammenfasst

95
Die Pakete der Packschicht variieren in der Länge, da die Kompression datenabhängigist
Größenordnungsmäßig ist die Paketlänge 188 Byte, also sehr kurz
4.5 MPEG-1/Video
MPEG-1/Video beruht auf zwei Tatsachen:
1.) Bei einem einzelnen Bild eines Videofilms unterscheiden sich benachbarte Pixel oftnur wenig
Packschicht
Header 3 Videoda-ten
Audioda-ten
Header 1 Header 2
Paketschicht
Videoda-ten
Header 1 Audioda-ten
Header 2
96
2.) Aufeinander folgende Bilder eines Videofilms unterscheiden sich ebenfalls oft nurwenig
Filme haben Redundanz, und zwar sowohl innerhalb jedes Bildes als auch von Bildzu Bild (=örtliche und zeitliche Redundanz)
Die örtliche Redundanz wird bei MPEG dadurch eliminiert, dass einzelne Bilder JPEGkomprimiert werden
Die zeitliche Redundanz wird durch die sog. Bewegungskompensation eliminiert: Prinzip der Bewegungskompensation:
• Anstatt je zwei aufeinanderfolgende Vollbilder mit hohem Speicheraufwand zu kodieren,werden lediglich die veränderten Bilddetails erfasst und weiterverarbeitet
• Bildteile, die unverändert oder nahezu unverändert geblieben sind, aber eine andere Posi-tion im Nachfolgebild haben, werden nur durch Angabe ihrer neuen Position und ggf. derUnterschiede zum vorherigen Bildteil charakterisiert
Verwenden unterschiedlicher Bildtypen für verschobene und „normale“ Bildteile
Prüfung aller Bildteile in Vorgänger- und Nachfolgebild erforderlich, ob sich ihrePosition geändert hat. Erfolgt durch die Bewegungskompensation.
4.5.1 Bewegungskompensation
Bewegungskompensation ist dann nützlich, wenn im Film bzw. Video folgende zwei Si-tationen vorkommen:

97
1.) Der Bildhintergrund ist fest. Es bewegen sich nur einige Objekte im Vordergrund oder:
2.) Die Kamera bewegt sich über eine Szenerie mit festem Bildhinter- und -vordergrund
Beide Arten der Relativbewegung werden von der Bewegungskompensation eliminiert Die Vorgehensweise bei der Bewegungskompensation ist folgende:
• Ein Bild i wird in Macroblöcke zerlegt (ähnlich der Blöcke bei JPEG)• Macroblöcke für die Luminanzkomponente haben allerdings jetzt die Größe 16x16• Macroblöcke für die Chrominanzkomponenten haben bei 4:2:0-Farb-Subsampling die Grö-
ße 8x8.• Im Bild i+1 wird versucht, jeden Macroblock des Bildes i wiederzuentdecken• Um die Rechenzeit zu begrenzen, wird nicht das ganze Bild abgesucht, sondern nur die
Umgebung des Macroblocks• Der Suchbereich für einen Macroblock, dessen geometrische Mitte P im Bild i an der Stelle
P(x|y) war, ist im Bild i+1 das Intervall (x±Δx|y±Δy)
die geometrische Mitte P des Macroblocks, und damit der ganze Macroblock, wird inx-Richtung um ±Δx und in x-Richtung um ±Δy verschoben und mit den dort befindli-chen Pixeln verglichen
• Die überdeckte Gesamtfläche, in der nach einem Nachfolgemacroblock gesucht werden,wird aus dem Suchbereich und der Größe des Macroblocks berechnet
98
Beispiel: Δx = Δy =8 Pixel => Suchbereich für P(x|y) ist x-8<x<x+8, y-8<y<y+8. Die über-deckte Gesamtfläche, in der Macroblöcke für die Luminanzkomponente gesucht werden,ist (8+8+16)*(8+8+16) Pixel.
Hinweis: Im Bild ist der Suchbereich 48x48 Pixel. Das Bild ist nicht maßstabsgerecht gezeichnet.
Für jede neue Position P‘(x’|y’) innerhalb des Suchbereichs wird geprüft, ob dorthin derMacroblock gewandert ist
Wird ein Macroblock im Bild i+1 wiedergefunden, wird er durch den Wert seiner Positi-onsverschiebung ersetzt
Die Positionsverschiebung wird als Bewegungsvektor bezeichnet
P(x|y)y
xx-Δx
y-Δx
x+Δx
y+Δx

99
Der Bewegungsvektor zeigt an, wie weit sich ein Macroblock von Position (x|y) in Bildi im Folgebild i+1 entfernt hat
Beispiel: Bewegungsvektor.
4.5.1.1 Vorteile der Bewegungskompensation
Bildhintergrund und sich bewegende Macroblöcke müssen nur einmal kodiert werden,wenn die Bewegungsvektoren der Macroblöcke bekannt sind
100
Beispiel: Bewegungskompensation
Männchen besteht aus drei Macroblöcken, die sich von links nach rechts auf festemBildhintergrund bewegen.
Ihre Positionsverschiebung beträgt von Bild zu Bild jeweils n Pixel nach rechts und 0Pixel nach oben.
Problem: • Ein verschobener Macroblock soll auch dann wiedererkannt werden, wenn sich seine Pi-
xelwerte z.B. durch Bildrauschen leicht geändert haben In MPEG ist jedoch nicht spezifiziert, wie nach ähnlichen Macroblöcken gesucht wer-
den soll, wie groß der Suchraum ist, und was ähnlich heißt Dies wird der jeweiligen Implementierung von MPEG überlassen

101
4.5.1.2 Wann sind zwei Macroblöcke ähnlich?
Entscheidungskriterium ist z. B. die Zahl gleicher Pixel Ist die Zahl gleicher Pixel oberhalb eines Schwellwerts, gelten zwei Blöcke als ähnlich Alternatives Entscheidungskriterium ist der mittlere quadratische Abstand der Pixel-
werte der beiden Macroblöcke (= Euklidische Metrik bzw. Gauss-Metrik) Berechnen der Gauss-Metrik:
1.) Für jede neue Position P‘(x’|y’) innerhalb des Suchbereichs werden die Differenz-werte der Luminanz zwischen Original und Kandidatenblock gebildet, quadriert undaufsummiert = „quadratischer Abstand“
2.) Dasselbe wird für die Chrominanz gemacht
3.) Es wird der Kandidatenblock mit dem kleinsten quadratischen Abstand zum Original-block als die beste Entsprechung ausgewählt, sofern der Gauss-Abstand insgesamtnicht zu groß ist
4.) Andernfalls gilt die Ähnlichkeit als zu gering, und der Macroblock hat keine Entspre-chung im Nachfolgebild.
4.5.1.3 Suche nach ähnlichen Macroblöcken
Üblich ist die sog. brute-force-Methode (einfach aber langsam) und die Methode mitmehreren Gittern, die unterschiedlich grob bzw. fein den Suchraum abprüfen (schnell)
102
4.5.1.4 „Brute-force“-Methode
• Innerhalb des Suchraums wird an jeder Bitposition geprüft, wie ähnlich ein dortiger Macro-block mit dem zu suchenden Block ist
• Dann wird der ähnlichste Block genommen, sofern das Schwellwertkriterium erfüllt ist• Ist das Schwellwertkriterium nicht erfüllt, gilt der Macroblock als fehlend und wird nicht
weiter gesucht Nachteil: Die brute-force-Methode erfordert sehr hohe Rechenleistung, bzw. sie ist
sehr zeitaufwendig, da sie mit O(N2) skaliert, wobei N ungefähr die Zahl der Pixel im Ma-croblock bzw. auch im Suchraum ist
4.5.1.5 Methode mit mehreren Gittern
Innerhalb des Suchraums wird zunächst ein grobes Raster mit einem Abstand vonmehreren Pixeln benutzt, um die Ähnlichkeit von Blöcken zu vergleichen, die auf demgroben Raster liegen
Werden zwei ähnliche „Grobblöcke“ gefunden, wird das Raster um diese Blöcke herumschrittweise verfeinert
Nach jedem Verfeinerungsschritt des Rasters wird geprüft, ob die beiden Blöcke immernoch ähnlich sind
Sehr viele Blöcke können so mit wenig Rechenaufwand vorab aussortiert werden, dasie bereits bei groben Gitter nicht mehr ähnlich sind
Vorteil: weniger rechenintensiv

103
Nachteil: ein ähnlicher Macroblock wird dann nicht gefunden, wenn das Raster in Be-zug auf den Macroblock ungünstig liegt
4.5.2 Elimination der zeitlichen Redundanz
Wurde ein ähnlicher Macroblock mit Hilfe der Bewegungskompensation wiedergefun-den, beginnt folgender Algorithmus:
1.) Speichern des Bewegungsvektors des Macroblocks
2.) Bilden der Differenz zum Originalblock des Vorgängerbildes
3.) JPEG-Kodierung des Differenz-Macroblocks
Theoretisch könnte ein einmal kodierten Macroblock so oft wiederverwendet werden,wie es in einem Nachfolgebild einen Bewegungsvektor sowie den JPEG-kodierten Dif-ferenz-Macroblock gibt
In der Praxis ist dies aber wegen der Akkumulation von kleinen Fehlern nicht möglich
4.5.3 Macroblock ohne Entsprechung
Hat ein Macroblock keine Entsprechung im Vorgängerbild, beginnt folgender alternati-ve Algorithmus:
1.) Speichern des Bewegungsvektors entfällt
104
2.) Es wird der Block selbst anstelle seiner Differenz JPEG-kodiert. Damit wird wenigs-tens der Kompressionsgrad von JPEG für den Macroblock erreicht, auch wenn Bewe-gungskompensation nicht möglich ist
Der Video-Kodierer liefert entweder einen Bewegungsvektor gefolgt von JPEG-kom-primiertem Differenz-Macroblock oder nur den Bitstrom für einen Original JPEG-Mac-roblock
Bei MPEG ist eine Unterscheidung zwischen verschiedenen Bildtypen nötig
Das Gesamtbild nach Bewegungskompensation besteht aus der Menge der Original-JPEG-Macroblöcke, sowie der Differenz-JPEG-Macroblöcke und ihren Bewegungsvek-toren.
Problem: Bei der Wiederverwendung von Macroblöcken schleichen sich durch Run-dung und Quantisierung der Differenz-JPEG-Macroblöcke und ihren Bewegungsvekto-ren jedesmal kleine Fehler ein.
Die Wiederverwendung von Blöcken ist nicht beliebig oft möglich
Ab und zu muss ein Bild komplett neu ohne Bewegungskompensation, aber mit JPEG-Komprimierung übertragen werden (= Übertragung ohne akkumulierte Fehler)
Ein JPEG-Bild ohne Bewegungskompensation dient als Startpunkt für nachfolgendeBilder mit Bewegungskompensation
Der MPEG-Video-Kodierer liefert einen Bitstrom mit unterschiedlich kodierten Bil-dern.

105
Diese werden als MPEG Frames bezeichnet Zusätzlich wird der Bitstrom durch den Systemteil von MPEG in Datenpakete unter-
schiedlichen Typs strukturiert.
4.5.4 MPEG-1-Frames
Es gibt aufgrund der Bewegungskompensation und der Anforderungen an MPEG ver-schiedene Frame-Typen, die sich bei der Übertragung auf dem Internet abwechseln:• I Frames (Intracoded Frames als Startpunkt)• P Frames (Predicted Frames als Differenzmacroblöcke)• B-Frames (Bidirectional predicted Frames als Differenzmacroblöcke mit doppelter Verzei-
gerung)• D Frames(DC-coded Frames für grobe Bilddarstellung)
Beispiel: zeitlicher Wechsel von I-, P- und B-Frames
106
4.5.4.1 Intracoded Frames (I Frames)
Intrakodierte Rahmen (I Frames) enthalten ein Bild komplett ohne Bewegungskompen-sation, aber mit JPEG-Komprimierung
I Frames dienen als Ausgangspunkt für die Ermittlung von Predicted- und Bidirectionalpredicted-Frames (P und B Frames)
Alle 1-2 Sek. wird ein I Frame in den Ausgabestrom eingefügt, d.h. ein neuer Startpunktgesetzt

107
Weitere Aufgaben von I Frames sind:
1.) Startbild für jeden neuen Teilnehmer einer MPEG-Übertragung im Internet. Startbilddient zur Synchronisation des neuen Empfängers auf den ununterbrochen eintreffen-den Rahmenstrom.
2.) Re-Synchronisation eines Empfängers nach einem Übertragungsfehler
3.) I Frames erlauben schnelles Vor- und Zurückspulen des Videos unter visueller Kont-rolle, da I Frames sich nicht auf andere Rahmen beziehen
4.5.4.2 Predicted Frames
Ein P Frame besteht aus Original-JPEG-Macroblöcken + Differenz-JPEG-Macroblöckenmit Bewegungsvektoren
P Frames werden durch Bewegungskompensation aus zeitlich zurückliegenden Bil-dern vom Typ I oder P abgeleitet
P Frames dienen wie I Frames als Referenzbilder für die Bewegungskompensation
Die Differenz-Macroblöcke bei P Frames werden allerdings anders JPEG-komprimiertals die Macroblöcke der I Frames
Der Unterschied besteht in der Verwendung einer anderen JPEG-Quantisierungstabel-le mit den Eigenschaften:
1.) Geringe Differenzen werden durch deren Quantisierungstabelle zu Null gemacht
108
2.) Der Zahlenbereich, der bei Differenz-Macroblöcken auf Null abgebildet wird, ist dop-pelt so groß wie die Zahlenbereiche, die auf Zahlen ≠0 abgebildet werden => weitereKompression
Der Grund liegt darin, dass das Auge geringe Differenzen in zwei auffeinanderfolgen-den Macroblöcken nicht sehen kann
Der MPEG-Encoder kodiert bei aufeinanderfolgender P Frames mit kleineren Differen-zen keinen Unterscheid
4.5.4.3 Bidirectional predicted Frames
B-Frames sind mit P Frames vergleichbar, sie haben jedoch eine doppelte Referenz Ein Referenzrahmen ist entweder ein Vorgänger- oder Nachfolgerbild oder beides (= bi-
direktionale Referenz)
Berechnung der Verschiebungsvektoren ist verbessert, da der jeweils beste Refe-renzblock aus zweien (Forward und Backward) gesucht werden kann
B-Frames dienen ihrerseits nicht als erneute Referenz, da Verkettung zu kompliziertwäre
B-Frames tragen im Gegensatz zu P-Rahmen nicht zur Fehlerfortpflanzung bei
Ein B Frame kann wegen der fehlenden Fehlerfortpflanzung mit weniger Bits codiertwerden als ein P Frame

109
B-Frames dienen auch zur Regulierung des Bitstroms hinsichtlich seiner Geschwin-digkeit bei der Übertragung
Sobald langsamer gesendet werden soll, wird ein B Frame gesendet, da dieser wenigerBits benötigt
I- oder P Frames erhöhen dagegen die Datenrate, da mehr Daten zu senden sind MPEG-Encoder haben darauf zu achten, dass eine maximale Datenrate nicht über-
schritten wird, um das Internet, den Decoder und den Empfänger nicht zu überlasten Es werden mindestens zwei B-Frames zwischen einem I- oder P-Frame platziert, die
wiederum als Referenz dienen
110
4.5.4.4 Rückwärtsverzeigerung bei B- Frames
4.5.4.5 Problem bei B-Rahmen
Da sich ein B-Rahmen auch auf ein Nachfolgebild beziehen kann, ist das Nachfolgebildnötig, um den B-Rahmen zu dekodieren
Nachfolgebild muss vor der Berechnung des B-Rahmens zur Verfügung stehen

111
Die Reihenfolge bei der Übertragung eines MPEG-Paketstroms muss permutiert wer-den
Hinweis: Im Beispiel wird angenommen, dass sich je zwei B-Rahmen auf die P-Rahmen 4 bzw. 7 beziehen.
4.5.4.6 DC-coded Frames
Jedes Element (= Pixel) in einem DC-kodierten Rahmen ist der Mittelwert eines ganzenMacroblocks, d.h. alle Elemente eines Macroblocks sind gleich
112
DC-Rahmen haben zwar eine viel niedrige Pixel-Auflösung, erlauben aber die momen-tane Position des Films grob zu erkennen, was für einen Schnelldurchlauf meist aus-reicht
Wird verwendet, um bei schnellem Vor- oder Rückspulen eine einfache visuelle Kont-rolle des Films zu haben
4.5.5 MPEG-Datenstrom
Ein MPEG-Datenstrom ist hierarchisch in 6 Schichten organisiert Jede Schicht hat einen eigenen Header, in dem Verwaltungsinformation steht Die Daten aller 6 Schichten zusammen bilden ein MPEG Video-Paket, das in einem
UDP-Pakete im Internet übertragen wirdHinweis: Es wird meist UDP zur Übertragung verwendet, da dann keine automatische Paketwiederholung im Fehlerfall gemacht wird, wie es bei TCP der Fall wäre. Paketwiederholungen sind dem Echtzeitverhalten abträglich, da sie beim Empfänger eintreffen können, wenn das fehlerhafte Bild bereits dargestellt wurde.
Aufgrund der Kürze der Videopakete von ca. 188 Byte, ist es im Prinzip möglich, meh-rere MPEG-Pakete in einem einzigen UDP-Paket zu übertragen, eine einigermaßen feh-lerfreie Übertragungsstrecke vorausgesetzt
Jedes MPEG 1-Video-Paket wird vom MPEG-Systemteil über eine 90 KHz-Systemuhrmit einem MPEG Audio-Paket starr gekoppelt, d.h. synchronisiert
Bei MPEG 2-Video-Paketen kann allerdings zwischen starrer Synchronisation undohne Synchronisation gewählt werden

113
4.5.6 Schichten des MPEG-Datenstroms:
4.5.6.1 Block-Layer
Die Blockebene enthält Original-JPEG-Macroblöcke (I Frames) und Differenz-JPEG-Ma-croblöcke (P-, B-Frames) mit Bewegungsvektoren
4.5.6.2 Makroblock-Layer
In der Makroblockebene wird beschrieben, wo der Makroblock im Bild liegt, und umwelche Art von Makroblock es sich handelt (I-, B-, P- oder D)
oben
unten
114
Es gibt Makroblöcke für I-, B-, P- oder D-Rahmen
4.5.6.3 Slice-Layer
Slices (engl. Scheiben) sind Sequenzen von aufeinanderfolgenden Makroblöcken imselben Bild
Der Header der Slice-Ebene sagt, wo Slices anfangen und aufhören Slices müssen nicht an der linken Bildkante beginnen und mit der rechten aufhören,
d.h. eine Zeile komplett übertragen, sondern können beliebig im Bild positioniert sein Ein MPEG-Decoder kann jeden Slice für sich dekodieren, ohne auf andere Slices zu-
rückgreifen zu müssen => Parallelverarbeitung mehrerer Slices durch einen Multicore-Prozessor ist möglich
Mit Beginn eines neuen Slices, das auf ein fehlerhaftes folgt, ist ein MPEG-Dekoder inder Lage, wieder korrekte Daten zu liefern => Bilder sind selten komplett gestört
Übertragungsfehler können sich nicht über das ganze Bild fortsetzen (= Fehlertoleranz)
4.5.6.4 Picture-Layer
Die Bildebene enthält alle Informationen, die benötigt werden, um ein Bild zu dekodie-ren
Der Header der Bildebene gibt den Rahmentyp (I, B, P oder D) an Der Header enthält auch die Information, als wievieltes Bild einer ''Group of Pictures''
das Bild dargestellt werden soll

115
Diese Information ist notwendig, da wegen der Rückwärtsbezüge bei B-Rahmen die Bil-der in einer anderen Reihenfolge gesendet werden als bei der Wiedergabe auf demSchirm
4.5.6.5 Group-of-Picture-Ebene
In dieser-Ebene wird eine beliebige Anzahl von Bildern in der Reihenfolge der Wieder-gabe zu einer Gruppe zusammengefasst
Diese Ebene leistet die inverse Permutation, die nach der Übertragung nötig wird Voraussetzung: In jeder Gruppe muss mind. ein I-Rahmen zur Synchronisation existie-
ren Der Header gibt auch an, ob Standard- oder anwenderdefinierte Quantisierungstabel-
len zur Anwendung kommen Es können ferner sog. geschlossene Gruppen definiert werden, in die keine Referenz
hinein- oder hinausweist Eine geschlossene Bildgruppe ist ohne jeden anderen Bezug für sich dekodierbar Sie erleichtern den Zugriff auf Einzelbilder im Speichermedium und erlauben die Paral-
lelverarbeitung mehrerer geschlossener Bildgruppen durch mehrere Multicore-Prozes-soren eines Rechners
doppelte Parallelität möglich: mehrere slices in einem Bild durch eine Multicore-CPUund mehrere geschlossene Gruppen in einer Videosequenz durch mehrere Multicore-CPUs in einem Rechner
116
4.5.6.6 Sequenz-Layer
Die Sequenzschicht dient der Zusammenfassung einer oder mehrere Bildgruppen zueinem ganzen Film
Diese werden in zahlreichen MPEG-Paketen übertragen Im Header werden darüberhinaus allgemeine Parameter des Films gespeichert wie:
• Bildbreite und -höhe in pixel• Bildformat (z.B. 4:3, 16:9) • Bildwiederholrate (pictures per second) • Bit-Rate (bits per second)• Puffergröße, die zum Dekodieren nötig ist
4.6 MPEG-1/Audio
Wird u.a. beim MP3 Player, bei digitalen Hörfunksendungen gemäß Digital AudioBroadcast (DAB) und bei digitalen Aufzeichnungssystemen in Tonstudios verwendet,aber nicht bei DAB+
Erreicht Kompressionsraten bis 22:1 ohne größeren Hörverlust Bietet 3 verschiedene Kompressionsstufen mit wachsender Komplexität an: Layer I, II
und III MPEG-1/Audio Layer III ist besser bekannt als MP3 MPEG-1/Audio unterstützt 2 Audiokanäle mit jeweils 16 Bit Auflösung pro Abtastpunkt

117
Die Abtastrate kann 48 kHz, 44.1 kHz oder 32 kHz betragen Das Format ist bitorientiert (bit stream), eine Ausrichtung auf Bytes findet nicht statt Die Audiodaten werden hintereinander in Frames übertragen, die abhängig von der Ab-
tastrate eine feste Anzahl Abtastpunkte haben Achtung: aus einer festen Zahl von Abtastpunkten pro Frame, kann nicht geschlossen
werden, dass die Datenrate bei einer MPEG-Audioübertragung konstant ist Bei Layer II z.B. besteht ein Frame aus 1152 Abtastpunkten, was bei 44,1 kHz einer zeit-
lichen Hördauer von ungefähr 26 ms entspricht (Dauer schwankt je nach Inhalt) Die Frames besitzen neben Audiodaten zusätzliche Informationen, die z.B. den Text der
Lieder speichern können. Diese werden mit einer 16-Bit Prüfsumme gesichert.
4.6.1 WIe funktioniert der MP 3-Player?
Nutzt die Eigenschaften des Gehörs, bestimmte Hörinformation auszublenden Beruht auf einem sog. psychoakustisches Modell des Ohres, nämlich:
1.) Eigenart des Ohres• Bei lautenTönen ist ein Rauschen weniger störend als bei leisen
· Um das auszunutzen, wird der „Rauschabstand“ (Verhältnis von Signal zu Rauschen)von lauten Tönen verschlechtert. Spart Daten und damit Bandbreite.
• Leise Töne sind bei gleichzeitigem lauten Ton ähnlicher Frequenz nicht hörbar (= Maskie-rung im Frequenzbereich)· Um die Maskierung im Frequenzbereich auszunutzen, wird folgendermaßen eine Sub-
118
band-Kodierung vorgenommen:· Der Frequenzbereich zwischen 20 Hz und 20 kHz wird in 32 Unterbänder zu je 625 Hz
aufgeteilt· Jedes Band wird getrennt komprimiert· Leise Töne neben gleichzeitigen lauten ähnlicher Frequenz werden dabei weggelassen
2.) Eigenart des Ohres• Ein kleiner Lautstärkesprung unmittelbar nach einem großen Lautstärkesprung ist nicht zu
hören (= Maskierung im Zeitbereich)• Um die Maskierung im Zeitbereich auszunutzen, werden kleine Lautstärkesprünge (Töne),
die unmittelbar nach einem großen Lautstärkesprung folgen, kurzzeitig ausgeblendet.Während dieser Zeit werden keine Daten übertragen
Nach der Maskierung im Zeit- und Frequenzbereich werden folgende Schritte ausge-führt:
· Quantisierung der Abtastwerte je nach Subband. Die Quantisierung wird ebenfalls voneinem psychoakustischen Ohrmodell gesteuert.
Hinweis: psychoakustisches Ohrmodell heißt hier, dass weitere physiologische Charakteristika des Ohres herangezogen werden, wie z.B. die unterschiedliche Empfindlichkeit auf verschiedenen Tonhöhen.
· DCT zur Berechnung der FourierkoeffizientenHinweis: D.h., Töne werden über eine 1D-DCT in den Fourierraum transformiert und dann ähnlich wie Bilddaten behandelt.
· Entropie-Kodierung der Fourierkoeffizienten über Huffman-Kode

119
Aufgrund der Maskierungen hat MPEG-1 Audio eine leicht schwankende Datenrate beider Übertragung, die vom jeweiligen Musikstück abhängt
Darüberhinaus verwendet MP3 zusätzliche „Hybridfilter“, nichtlineare Quantisierungund andere Techniken zur Verbesserung von Qualität und Kompressionsrate
MPEG1/Audio ist teilweise kompatibel zu den Kodierungen, die für CD und Digital Au-dio Tape (DAT) existieren
CD and DAT haben nämlich wie MPEG1 Abtastraten von 32 kHz, 44,1 kHz und 48 kHzund eine Abtast-Genauigkeit von 16 bit/Sample
4.6.2 MPEG1-Audio-Kanäle
Es gibt Mono und Stereo (2 Kanäle)• Der Zweikanal-Modus kann auch unabhängig voneinander betrieben werden, z.B. für zwei
Sprachen
Festlegung von 3 Qualitätsstufen:
• Level I: max. 448 Kbit/s• Level II: max. 384 Kbit/s, wird u.a. für das sog. MUSICAM-Format von DAB verwendet• Level III: max. 320 Kbit/s, wird im MP3-Player verwendet (iPOD etc.)
4.7 MPEG-2
MPEG-2 ist eine Variante von MPEG-1 mit zusätzlichen Leistungsmerkmalen
120
Wie bei MPEG1 werden Audio- und Video-Signale zu einem Datenstrom zusammenge-mischt
Dafür ist der Systemmultiplexer zuständig, der bei MPEG2 allerdings zwei Ausgangs-datenströme, sog. PES, erzeugt
PES Nr. 1 heißt Programmstrom, PES Nr. 2 heißt Transportstrom Der Benutzer kann wählen, welchen PES er haben will Der Programmstrom entspricht dem MPEG-1-Systemstrom, der Transportstrom ist neuDef.: Der Transportstrom besteht aus Paketen fester Länge und koppelt Audio und Videonur asynchron, hat aber den Vorteil konstanter Bandbreite bei der Übertragung
schlecht für die Lippensynchronizität, aber gut für die Übertragung im Netz
Def.: Der Programmstrom besteht aus Paketen variabler Länge, koppelt Audio und Videosynchron über einen gemeinsamen Systemtakt und hat den Nachteil, dass der Bandbrei-tebedarf schwankt
gut für die Lippensynchronizität, aber schlecht für die Übertragung im Netz
Der Transportstrom enthält Pakete einer Länge von 188 Byte Der Transportstrom wird bei fehlerträchtiger Speicherung oder Übertragung der Pake-
te eingesetzt, da die feste Paketlänge eine Paketwiederholung zur Fehlerkorrektur imPrinzip erlauben würde, sofern das Internet genügend Bandbreite zwischen Senderund Empfänger hat

121
D.h., Voraussetzung für eine Paketwiederholung ist, dass ausreichend viel Bandbreitezur Verfügung steht, um auch im Fehlerfall eine Datenübertragung in Echtzeit zu er-möglichen
Der Programmstrom wird bei fehlerfreier Speicherung und Übertragung der Daten ein-gesetzt, da eine Korrektur durch Paketwiederholung wg. der variablen Paketlängen,d.h. notwendigen variablen Bandbreiten schwieriger zu realisieren ist
Ein Transportstrom ist insgesamt flexibler: er kann mehrere Programmströme enthal-ten, sowie externe zeitdiskrete Multimedia-Datenströme einkoppeln
Konvertierung von Programmstrom zu Transportstrom ist unter Verlust der Synchro-nizität möglich
122
4.7.1 Blockschaltbild der MPEG2 Audio- und Video-Signalmischung
4.7.2 MPEG-2/Audio
Surround-Ton heißt bei MPEG-2/Audio: 5 Kanäle mit voller Audio-Bandbreite für• 2x Lautsprecher links und rechts vorne• 1x Lautsprecher Mitte oder vorne• 2x Lautsprecher links und rechts hinten
Audio

123
professionelles System für Kino-Filme
Sowie 7 mehrsprachige Kanäle, die auch als Kommentar-Kanäle verwendet werdenkönnen
Verbesserte Tonqualität auch bei niedriger Datenrate (kleiner 64 kbit/s) MPEG-2/Audio ist aufwärtskompatibel zu MPEG-1/Audio:
• alle MPEG-1 Audioformate können auch von MPEG-2 verarbeitet werden• aber MPEG-2 Audioformate haben keine Abwärtskompatibilität zu MPEG 1
4.8 MPEG-4
MPEG-4 (ISO 14496) zielte ursprünglich auf Systeme mit sehr wenig Ressourcen ab Einsatzgebiete waren Mobilkommunikation (Handys), Videotelefonie und Video-E-Mail
Mittlerweile gibt es ca. 25 MPEG 4-Unterstandards, inkl. des hochauflösenden undhochkomprimierenden H.264-Standards für HDTV über blue ray disk, sowie einer Spe-zifikation für 3D-Videos
H.264 ist auch als Advanced Video Coding (AVC) bekannt Im Audioteil eines der MPEG 4-Unterstandards ist das Advanced Audio Coding (AAC)
enthalten, das bei gleicher Qualität besser komprimiert als MP3 AVC und AAC gemeinsam ist die höhere Kompressionsrate, aber auch der höhere Re-
chenaufwand im Vergleich zu MPEG1/2
124
4.8.1 MPEG-4-Kompressionsverfahren
Grundidee: Die Pixel eines Objekts haben in der Regel ähnliche Eigenschaften
Objekte lassen sich mit weniger Bits kodieren als willkürlich gezogene Pixelbereiche(Blöcke)
Bei MPEG-4 werden folgende 3 Schritte durchlaufen:
1.) Erfasse die Semantik der Bildinhalte durch die Identifikation von Videoobjekten undAudioobjekten (schwierig!)
2.) Komprimiere ganze Objekte anstelle von willkürlich gezogenen Blöcken. Die Objekt-kompression erfolgt mit einer Vielzahl auswählbarer Methoden.
Beispiel: Fraktale Kompression von Objekten

125
3.) Verwende eine formale Sprache (MSDL) zur Beschreibung der Szene, die aus kompri-mieren Objekten besteht
Hinweis: MSDL = MPEG-4 Syntactic Description Language, um einzelne Objekte zu beschreiben, sowie um Operationen durchzuführen wie Dekodierung, Manipulation oder Kombination von Objekten
MPEG 4 stellt einen Satz von Werkzeugen und Methoden bereit für:• Identifikation von Objekten• Kompression von Objekten• Operationen auf Objekten• Szenenbeschreibungen aus Objekten
Diese sind von kleinen zu großen Bildern skalierbar und robust gegen Rauschen undsonstige Fehler
MPEG 4 erlaubt schließlich auch das Mischen von natürlichen und synthetischen Ob-jekten, d.h. von Fotos mit Virtual Reality d.h. mit Computergrafik
126
5 Anwendungsschicht (ISO-Schicht 7)
Die Anwendungsschicht im Internet ist unüberschaubar groß Im Folgenden erfolgt daher zuerst eine Klassifikation in Dienste und Anwendungen
5.1 Klassifizierung nach Diensten und Anwendungen
Def.: Dienste sind Programme und Protokolle, die allgemein im Internet verfügbar sindund deren Funktion und Datenaustauschformat in einer Norm oder einer sog. RFC fest-gelegt istHinweis: RFC = Request for Comment; siehe dazu http://www.rfc.net
Beispiel: FTP, E-Mail und http sind über RFCs festgelegt und damit Dienste
Def.: Anwendungen sind individuelle Programme von Firmen, Institutionen oder Einzel-personen, die aufgrund ihrer Client/Server-Struktur ein Rechnernetz brauchen, und dievon einem begrenzten öffentlichen Benutzerkreis verwendet werden
Beispiel: Audio/Video-on-Demand, web-TV, Flugbuchungssysteme, Hotelbuchungspor-tale, Video-Konferenzsysteme, SW für verteilte Dokumentenbearbeitung, SW für Auktio-nen im Netz sind Anwendungen.
Ebenso sind selbstgeschriebene Programme, die ein Rechnernetz benützen, Anwen-dungen

127
Suchmaschinen haben eine Sonderrolle und sind zugleich Dienste und Anwendungen Ist eine Internet-Anwendung weit verbreitet und von allgemeinem Interesse, kann im
Laufe der Zeit eine öffentliche RFC-Definition daraus entstehen
Aus der Anwendung wird ein Dienst
Beispiel: das NFS (Network File System) dient zum Aufbau eines verteilten Dateisys-tems; es wurde ursprünglich von SUN für deren UNIX-Rechner entwickelt und danachvon SUN freigegeben.
5.1.1 Weitere Beispiele für Internet-Dienste
• FTP = File Transfer Protocol, dient zum Dateitransfer; moderne Variante WINSCP• Telnet: dient zum Einloggen auf entfernte Rechner; moderne Variante putty• SMTP = Simple Mail Transfer Protocol für einfachen mail-Dienst• MIME = Multipurpose Internet Mail Extension für multimediale E-Mail-Erweiterungen• DNS = domain name system: dient zur Abbildung von symbolischen Rechnernamen auf IP-
Adressen und umgekehrt; basiert auf UDP• NTP = network time protocol: zur Verteilung der Uhrzeit im Internet• HTTP = hypertext transport protocol. Dient u.a. zum Übertragen von web-Seiten. Wird auch
intensiv zum Cloud Computing verwendet.• Ping: dient zum Testen, ob ein bestimmter Rechner online ist; basiert auf ICMP (siehe un-
ten)
128
• BOOTP = Boot Protocol: dient zum Herunterladen eines Betriebssystems von einem Ser-ver auf einen Discless Client
5.2 Steuerungsprotokolle
Daneben gibt es sog. Steuerungsprotokolle, die der Schicht 3 zugerechnet werden,weil es im ISO-Modell keinen richtigen Platz dafür gibt
Ohne diese Steuerungsprotokolle würde das Internet nicht funktionieren Beispiele von Steuerungsprotokollen:
• ICMP = Internet Control Message Protocol: dient zur Kommunikation zwischen Routern• NSP = name server protocol: zur Kommunikation zwischen einzelnen Name Servern des
Domain Name Systems DNS• ARP = Address Resolution Protocol: dient zur Kommunikation zwischen Name Server und
Client, um die Abbildung IP-Adresse -> MAC-Adresse vorzunehmen• RARP = Reverse ARP: dient zur Abbildung MAC-Adresse-> IP-Adresse • SNMP = simple network management protocol: dient zur Verwaltung von Netzwerk-Kom-
ponenten wie Router oder Switches; basiert auf UDP• RSVP = resource reservation protocol: zur Reservierung von Bandbreite und Pufferplatz
auf einem Router, z.B. für Audio on Demand oder Video on Demand; mit RSVP kann einesog. Quality of Service (Garantie einer bestimmen Qualität bei der Übertragung) zumindestbei IPv6 erreicht werden

129
5.3 Vergleich zwischen dem ISO 7-Schichten-Modell und dem Internet
Im Internet gibt es keine Schicht 5 und 6, sondern nur 1-4 und 7:
5.4 Verzeichnisdienste (Namensdienste)
Ein Verzeichnisdienst macht die Abbildung von Rechnernamen auf Netzadressen undist für ein Rechnernetz ähnlich wichtig wie ein Telefonbuch für das Telefonnetz
Beispiel: Verzeichnisdienste sind das Domain Name System (DNS) im Internet, sowiedas alte X.500 im ISO 7-Schichten-Netz.
Bitübertragung, z.B.: Ethernet, SONET/SDH
Sicherung, z.B.: SLIP, PPP, PPPoE
Vermittlung: IP oder SNMP
Transport: TCP, UDP
Anwendung, z.B.: www, ftp, E-Mail
Schicht 1
Schicht 2
Schicht 3
Schicht 4
Schicht 7
130
5.5 Domain Name System (DNS)
Der Internet-Verzeichnisdienst DNS bildet die Basis vieler Dienste und -Anwendungen Aufgaben des Domain Name Systems (DNS) sind:
• normale und inverse Abbildung von Rechnernamen auf Netzadressen für die· einfache Zustellung von E-Mail durch symbolische Mail-Adressen· einfache Abfrage von Web-Seiten durch symbolische ULRs
• Auskünfte über die im jeweils eigenen LAN existierenden Name Server und Mail Server
Das DNS ist als weltweit verteilte „Datenbank“ implementiert Die Abfrage und das Management der „Datenbank“ erfolgt dezentral und an vielen Stel-
len gleichzeitigBeispiel: BIND und PowerDNS sind weit verbreitete Programme zum Lesen und Schrei-ben der DNS-“Datenbank“ auf der Seite der DNS Server (Backend). Der Resolver ist einProgramm zum Abfragen von DNS-Servern auf der Seite der Benutzerrechner (Frontend).
Die Einträge in die DNS-„Datenbank“ sind komplex strukturiert Zur Geschwindigkeitssteigerung bei Abfragen der „Datenbank“ werden frühere Abfra-
geergebnisse in lokalen Caches gespeichert, die als Dateien auf der Festplatte imple-mentiert sind
Zur Zuverlässigkeitssteigerung wird i.d.R. eine Verdopplung des jeweiligen lokalenDNS-Servers vorgenommen (primary and secondary name server)

131
5.6 Abbildung von Rechnernamen auf Netzadressen bei DNS
In WANs werden alle Rechner über ihre IP-Adresse angesprochenHinweis: in LANs und MANs sind alle Pakete Multicast. Es gibt kein Routing durch Router.
Jeder Rechner hat zumindest theoretisch eine weltweit eindeutige 4-Byte IP-Adresse(=32 Bit => 232 verschiedene IP-Adressen); gilt nur für IP V4, bei IP V6 gibt es 16 Byte-Adressen.
Bsp.: 198.41.0.4 = IP-Adresse des .edu Name Servers in den USA Jeder Rechnername ist zumindest theoretisch ebenfalls weltweit eindeutig Wegen der Vielzahl existierender Rechner kann keine zentrale Instanz alle IP-Adressen
und Rechnernamen verwalten Problem: Wie kann man - ohne den globalen Überblick zu haben - erreichen, dass es
nicht 2 gleiche Adressen od. Namen gibt? Lösung: die Vergabe von Namen und Adressen erfolgt modular und hierarchisch Das graphische Äquivalent zu dieser Vorgehensweise ist ein Baum Die Hierarchieebenen im Baum entsprechen der hierarchischen Namensvergabe Die dezentralen Stellen der Namensvergabe entsprechen den Baumknoten (Module) Die eindeutigen Namen entsprechen den Baumblättern
Jeder Knoten, der nicht Blatt ist, ist für einen ganzen Bereich von Namen zuständig,d.h. für seinen Unterbaum
132
Eigenschaften des Namensbaums:• Die Baumtiefe ist „unbeschränkt“ (der String für den DNS-Namen ist allerdings in seiner
Länge beschränkt)• Die Zahl der Söhne pro Vaterknoten ist „unbeschränkt“• Die Gesamtzahl der Blätter ist wg. der Limitierung auf 32-Bit-IPV4-Adressen max. 232 (ohne
Berücksichtigung von alias-Namen von Rechnern und ohne Berücksichtigung von dyna-mischer IP-Adressvergabe)
• Die zweitoberste Baumebene wird als Top-Level Domain bezeichnet und hat einen festge-legten Aufbau
• Die oberste Baumebene ist der sog. Root-Knoten
5.6.1 Root-Knoten im DNS
Der Root-“Knoten“ besteht aus 13 festgelegten Rechner-Clustern, den sog. Root-Ser-vern
Die 13 Root-Server kennen alle Top-Level Domain Name-Server bzgl. Name und IP-Ad-resse
Ein einzelner Root-Server besteht aus einigen Dutzend weltweit verteilten Einzel-Rech-nern
Aufgabe der Root Server ist es, DNS-Anfragen von Computern aus aller Welt zu denDNS-Servern der zuständigen Top Level Domain umzuleiten
Sie beantworten keine DNS-Anfragen sondern leitern nur weiter

133
5.6.2 DNS-Namen
Jeder DNS-Name entsteht aus einem Baumdurchlauf, der vom Blatt bis zur Top-LevelDomain erfolgt
Der Baumdurchlauf der Namensgebung geht hoch bis zur Top-Level Domain, nicht biszu root, daher die Namensgebung „Top Level“ Domain
In die DNS-Namen werden die Top Level Domain-Namen eingebaut, nicht die Namender Root Server
Der resultierende DNS-Name ist die Verkettung der durchlaufenen Knotennamen, diejeweils durch Punkt verbunden sind
Beispiel: s2.informatik.tu-clausthal.de bedeutet: s2=Blatt, informatik=Baumebene 4, tu-clausthal=Baumebene 3, de=Top-level Domain
Wichtige Knotennamen der Top-Level Domain sind:• .int für weltweite Organisationen (UNO, ... ), .org für internationale Organisationen (IEEE,
ACM, ... )• .mil für das US-Militär, .gov. für die US-Regierung, .edu für US-Universitäten, .net für spe-
zielle Internet-Adressen, • .eu für Firmen, Institutionen und Privatpersonen der European Community, .com für Fir-
men (weltweit)
Länderkennungen:
134
• u.a.: .fr für Frankreich, .it für Italien, .at für Österreich, .ch für Schweiz, .uk für Großbritan-nien, .jp für Japan, .ru für Russland, u.s.w.
Insgesamt gibt es mehr als 200 Top Level Domains
5.6.3 Der DNS-Namensbaum
Jeder vollständige DNS-Name besteht aus dem eigentlichen Rechnernamen sowie ei-ner Folge von Domain-Namen
Um eine neue Domain anzulegen, braucht man die Genehmigung des übergeordnetenVaterknotens im Namensbaum (= übergeordnete Domäne) und muss diese bei einerspeziellen Instanz registrieren lassen
Die Registrierung erfolgt kostenpflichtig entweder bei einem sog. Network InformationCenter (NIC) oder bei Firmen, die damit Geld verdienen
.eu .edu .gov .mil .int .org .net .com . fr. .it .de .uk . . .
stanford harvard ACM IEEEIBM Google uni- tu-goettingenmuenchen
CS EE TJWatson ... ifi
Top-Level Domain Länderkennungen

135
Der Preis für die Registrierung beträgt größenordnungsmäßig einige Euro bis DutzendEuro pro Jahr
Für .de ist das NIC www.denic.de, für .com, .net, .org ist das NIC die Firma www.net-worksolutions.com
136
Beispiel: Vergabe der Domänen im DNS-Namensbaum .
ICANN (IANA)
ARIN APNIC AfriNIC LACNIC RIPE NIC Regional Internet Registries
NIR
LIR
ISP
End-Users End-Users
Several NationalInternet Registries on Level 3 NIRNIRNIR
Many Local Internet RegistriesMany Local Internet Registries on Level 4
Many More Internet Service Providers on Lev. 5
Really Many Users on Level 6

137
Bemerkung: Seit längerem sind die 232-IP-Adressen knapp geworden. Deshalb werdenbei IPV4 bei Einwahl ins Internet IP-Adressen dynamisch mittels eines Providers ver-geben => DHCP
Dadurch entsteht die Situation, dass mehrere DNS-Namen dieselbe IP-Adresse habenkönnen, allerdings kann sich von diesen zu einer Zeit immer nur einer unter dieser IP-Adresse ins Internet einwählen => öffnet Hackern Tür und Tor
Wollen sich zwei Rechner gleichzeitig einwählen, bekommen beide vom Provider ver-schiedene IP-Adressen zugewiesen
5.6.4 Realisierung des DNS
Jeder Knoten im Namensbaum, der nicht Blatt ist, ist ein sog. Name Server und sorgtfür seine Sohnknoten
Die Sohnknoten sind entweder weitere Name Server oder im Fall von Blättern Clients Die Informationen zur Abbildung von Namen auf IP-Adressen ist in Teilen in jedem
Name Server in Form von sog. Resource Records gespeichert Resource Records existieren aus Sicherheitsgründen oft mehrfach (1 Original + 1-2 Ko-
pien)
5.6.4.1 Resource Records
Resource Records sind lokale Datensätze auf jedem Name Server, in denen die jeweilsnotwendigen Adressabbildungen zur Namens“auflösung“ stehen
138
vereinfachtes Bsp. für 2 Resource Records: lokaler Rechnername1 -> IP-Adresse1 lokaler Rechnername2 -> IP-Adresse2
5.6.4.2 Zonen
Soll ein Name Server eine Domäne verwalten, die kleiner als ein Unterbaum ist, also nureinige, aber nicht alle Sohnknoten umfasst, dann teilt man die Sohnknoten und derenUnterbäume in sog. Zonen ein
Beispiel:
Zonen

139
Beispiel: An der Yale-Universität gibt es einen Namens-Server xxx.yale.edu, deryyy.eng.yale.edu aber nicht zzz.cs.yale.edu verwaltet.
5.6.5 Namens“auflösung“
Es gibt es 2 Methoden zur Adressabbildung:
1.) rekursive Auflösung
2.) iterative Auflösung
Rekursiv heißt, dass der Namensbaum maximal hoch bis zur Wurzel und wiederabwärts bis zu demjenigen Server durchlaufen wird, zu dessen Zone der gesuchteRechner gehört
Wird vor Ende des kompletten Baumdurchlaufs ein Server erreicht, der die Namensauf-lösung vornehmen kann, wird der Durchlauf an diesem Knoten vorzeitig beendet
Für die Durchführung des Baumdurchlaufs ist der lokale Name Server verantwortlich,nicht der anfragende Client
Bei der iterativen Namensauflösung hingegen muss der Client selbst einen Server fin-den, der die Adressauflösung kennt
Er fragt dazu zuerst den lokalen Name-Server und dann, wenn nötig, die jeweils über-geordneten Name-Server
Iterative Namensauflösung wird dann eingesetzt, wenn der lokale Name-Server die re-kursive Auflösung nicht vornehmen kann
140
Die iterative Namensauflösung ist für den Client aufwendiger als für den Server; beider rekursiven Auflösung ist es umgekehrt
5.6.5.1 Schema der rekursiven Namensauflösung
Um Baumdurchläufe abzukürzen, hat sowohl der Resolver als auch der Name Servereine DNS-Cache-Datei, in der die Ergebnisse früherer Anfragen gespeichert sind
Zur besseren Zuverlässigkeit existieren lokal i.d.R. primäre und sekundäre Namens-Server
Um Konsistenzprobleme zwischen primärem und sekundärem NS zu vermeiden, gibtes das Konzept des autoritativen Name Servers
Antwort
Aufruf Re-sol-ver
Prozess Bibliotheks-funktion
Internet- Dienst/An-wendung
autoritativer Ressourcen-satz
Cache-Datei
BENUTZERRECH-NER (= Client)
Demon
PRIMÄRER LOKALER NAMENS-SERVER
Namens-Server der nächsthöheren Ebene
ggfs.Anfrage
ggfs.Antwort
ggfs.Anfrage
ggfs.Antwort
Anfrage
Antwort
1.
2.

141
5.6.6 Autoritativer Namens-Server
Def.: der autoritativer Namens-Server ist derjenige, der für eine Zone maßgebend verant-wortlich ist. Seine Resource Records gelten. Alle anderen Server dieser Zone haben nurKopien der autoritativen Ressourcensätze.
5.6.6.1 Aufgaben des autoritativen Namens-Servers
Für jeden Rechner einer Zone verwaltet dessen Name Server mehrere ResourceRecords für folgende Aufgaben:
1.) Abbildung Rechnername -> IP-Adresse
2.) Inverse Abbildung IP-Adresse -> Rechnername
3.) Korrekte Zustellung von E-Mail
4.) Erteilen allgemeiner Auskünfte über die Rechner einer Zone (Prozessortyp, Betriebs-system, ...)
5.6.7 Anfragen an den autoritativen Name Server (Query)
Jede Name Server Query wird über ein sog. Query-Protokoll zwischen Client undName-Server abgewickelt
Das Query-Protokoll ist wie jedes Protokoll eine Datenstruktur, die im Wechsel zwi-schen Sender und Empfänger ausgetauscht wird
142
Die Query-Datenstruktur hat 5 Elemente: Query Header, Question, Answer, Authorityund Additional
Def.: Query Header enthält Steuerinformationen zur Anfrage
Def.: Question enthält die Anfrage, z.B. IP-Adresse zu einem Rechnernamen
Def.: Answer enthält die Resource Record(s), die die Antwort auf die Anfrage darstellen
Def.: Authority sind spezielle Resource Records, die den Weg zu einem autoritativenName Server angeben
Def.: Additional sind zusätzliche Resource Records, die der Client in Zukunft vielleichtbrauchen wird, wie z.B. die IP-Adresse des Mail Servers der Zone
5.6.8 Aufbau des Query Headers
Der Header der Query hat folgenden Aufbau: · ID: eine 16-Bit Nummer, anhand derer der Client eine empfangene Antwort einer zuvor
gestellten Anfrage zuordnen kann (= Zuordnung von Query und Response)· QR: 0 für Query, 1 für Response· OPCODE: 0=Standardanfrage, 1=inverse Anfrage, 2=Server Status Request, 3-15 Reser-
ved· AA (Authoritative Address): ist gesetzt, wenn es sich bei dem antwortenden Server um
den autoritativen Server der RRs handelt. Für AA = 0 sind die Informationen aus demCache des Servers zu nehmen (der Cache enthält nur Kopien)

143
· TC (TrunCation): die Antwort wurde in mehrere Pakete aufgeteilt · RD (Recursion Desired): der Client verlangt eine rekursive Namensauflösung · RA (Recursion Available): gibt an, ob der Server rekursive Anfragen unterstützt (=1)
oder nicht (=0)· Z: reserviert - muss immer 0 sein · RCODE (Response Code): gibt an, ob eine Anfrage erfolgreich bearbeitet werden konn-
te, oder ob Fehler aufgetreten sind · QDCOUNT: Anzahl der Einträge in der nachfolgenden Question Section der Query =
Länge· ANCOUNT: Anzahl der Einträge in der Answer Section
1 1 1 1 1 1 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | ID | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ |QR| Opcode |AA|TC|RD|RA| Z | RCODE | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | QDCOUNT | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | ANCOUNT | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | NSCOUNT | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | ARCOUNT | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
144
· NSCOUNT: Anzahl der Einträge in der Nameserver Section · ARCOUNT: Anzahl der Einträge in der Additional Section
5.6.9 Dateien, die jeder Name Server braucht
1.) eine Boot-Datei
2.) zwei Zonen-Dateien
3.) eine Root-Datei
Boot-Datei: enthält Konfigurationsparameter für den Server und die Angabe, welcheZone(n) der Name Server verwalten soll
Zonen-Dateien: · Für den autoritativen Name Server gibt es zwei Dateien zur Speicherung der autoritati-
ven Ressourcensätze; Die erste Datei ist für die Abbildung Name->Adresse, die zweitefür die inverse Abbildung zuständig.
· Für den nicht-autoritativen Name Server gibt es zwei Dateien zur Speicherung der nichtautoritativen Ressourcensätze; diese dienen als DNS-Caches.
Root-Datei: enthält die Namen und IP-Adressen aller 13 Root-Server des DNS
5.6.10 Aufbau eines Resource Records
Jeder Resource Record (RR) besteht aus einem 5-Tupel (Owner, TTL, Class, Type,RDATA)

145
1.) Owner: Name der Zone, zu der der RR gehört
2.) TTL (Time To Live): 32-Bit-Wert, der die Lebensdauer des RRs in Sekunden angibt.Damit kann man festlegen, wie lange der RR im Cache von Resolvern stehen darf..
3.) Class: 16-Bit-Wert, der die Protokollfamilie angibt, für die der RR gültig ist. Hier wirdnur "IN" für Internet verwendet, auch wenn es prinzipiell jedem anderen Netz offen-stünde, das DNS zu verwenden.
4.) Type: 16-Bit-Wert, der den Typ des RRs angibt, z.B. Adresstyp für die Adressabbil-dung, Aliastyp für synonyme Namen, u.s.w
5.) RDATA (Resource Data): Hier werden in Abhängigkeit von type und class die eigentli-chen Informationen gespeichert, beispielsweise:
• die IP-Adresse, falls type = A = Adresstyp• ein synonymer Name, falls type = CNAME (=Aliastyp)
5.6.10.1 Aufbau des Typ-Feldes eines Resource Records
Es sind viele Typen von Ressourcensätzen definiertBeispiel: Adresstyp, Canonical Name, Host Info, Mail Exchanger, Name Server, Pointer,Start of Authority.
1.) A (Adresstyp): enthält Name und IP-Adresse eines Rechners. Dient zur AbbildungRechnername -> IP-Adresse
146
2.) CNAME (Canonical NAME): definiert ein Synonym (Alias) für einen Rechner. Damit istes möglich, unter zwei Namen auf einen Rechner zuzugreifen. Pro Rechner ist nur einAlias zulässig.
3.) HINFO (Host Info): gibt den Prozessortyp und das Betriebssystem eines Rechnersder Zone an
4.) MX (Mail Exchanger): gibt den Server an, der in der Zone für E-Mails zuständig ist.Dort landet alle Post, die an den Rechner geschickt wird.
Hinweis: Durch die zusätzliche Angabe einer Priorität für den Server kann Ausfallsicherheit erreicht werden, sofern in einer Zone mehrere Mail Server existieren.
5.) NS (Name Server): gibt den autoritativen Name Server für die Domain an
6.) PTR (Pointer): Zeiger auf einen Rechner. Dient u.a. zur inv. Abbildung IP-Adresse ->Rechnername
7.) SOA (Start Of Authority): zeigt den Beginn von zusätzlicher Verwaltungsinformationfür die Zone an
5.6.11 Beispiel einer manuellen DNS Query
Die manuelle DNS Query wird mittels des Linux/Unix-Programms DIG ausgeführt:jonny@pluto:~ > dig www.uni-ulm.de -- dig = Domain Information Groper; <<>> DiG 8.1 <<>> www.uni-ulm.de;; res options: init recurs defnam dnsrch

147
;; got answer:;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 6;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 3, ADDITIONAL: 3;; QUERY SECTION:www.uni-ulm.de, type = A, class = IN;; ANSWER SECTION:www.uni-ulm.de 1h31m24s IN CNAME orion-fddi.rz.uni-ulm.de.orion-fddi.rz.uni-ulm.de d22h3m8s IN A 134.60.240.13;; AUTHORITY SECTION:rz.uni-ulm.de 14h10m46s IN NS titania.mathematik.uni-ulm.de.rz.uni-ulm.de 14h10m46s IN NS theophys.physik.uni-ulm.de.rz.uni-ulm.de 14h10m46s IN NS ns.informatik.uni-ulm.de.;; ADDITIONAL SECTION:titania.mathematik.uni-ulm.de 22h3m8s IN A 134.60.66.21theophys.physik.uni-ulm.de 04h3m8s IN A 134.60.10.01ns.informatik.uni-ulm.de 04h3m8s IN A 134.60.68.63
5.7 Telnet (Telecommunication Network)/Putty
Über den Telnet/Putty-Dienst kann ein Anwender - bei entsprechender Berechtigung -von seinem Rechner aus über das Netz die Leistungen eines anderen Computers nut-zen
Telnet vereint drei Konzepte, die bei Rechnernetzen immer wieder verwendet werden:
1.) Virtualisierung der Kommunikation mit dem Benutzer durch ein virtuelles Terminal:
148
Beispiel: web Browser mit html-Interpreter für ein virtuelles Terminal
2.) Verhandelbare Optionen: Beispiel: PPP (point-to-point protocol) bei DSL-Modems zur Aushandlung der Bitratenetc.
3.) Symmetrische Verbindungen (peer-to-peer): Beispiel: Musiktauschbörsen, um Songs zwischen gleichberechtigten Benutzern aus-zutauschen
Def.: Virtuelles Terminal heißt, dass Telnet die Eigenschaften eines idealisierten Termi-nals auf die konkreten Hardware-Möglichkeiten des Client-Rechners abbildet (=Abstrak-tion der zugrunde liegenden Hardware)
Vorteil: der Server braucht bei der Kommunikation keine Kenntnis über die Client-Hard-ware, sondern kann sich auf einen immer vorhandenen Satz von Funktionen verlassen
Methode ist identisch zum Konzept von web BrowsernDef.: Verhandelbare Optionen: Der Server handelt mit dem Client die Parameter der Kom-munikation aus, z.B. zusätzliche Terminaleigenschaften
Methode ist identisch zum Konzept von PPP, das Parameter der Datenübertragung zwi-schen DSL Modem und Ortsvermittlungsstelle auf der Schicht 2 aushandelt

149
Def.: Symmetrische Verbindungen: Client und Server sind aus der Sicht des Protokollsgleichberechtigt, d.h. das Client/Server-Konzept wird ersetzt durch Peer-to-Peer
Nachteil des Telnet-Protokolls: keine Verschlüsselung der Daten
Besser: Secure-Socket-Shell-Protokoll (SSH)
5.7.1 Telnet-Programme
Telnet-Client: normales Anwendungsprogramm wie z.B. „Windows Telnet“ oder „PuT-TY“
5.8 FTP (File Transfer Protocol)
Netzwerkprotokoll zur Übertragung von Dateien über TCP/IP-Netzwerke FTP erlaubt folgende Funktionen:
• Senden, Empfangen, Löschen und Umbenennen von entfernten Dateien• Einrichten und Löschen von Verzeichnissen und Wechseln des Verzeichnisses auf dem
entfernten Rechner Aber: Keine Integration des Dateisystems des entfernten Rechners in das lokale Datei-
system. Das leistet erst NFS.
FTP ist nicht „transparent“
150
Das Ausführen von Programmen (z.B. zum Entpacken von Dateien oder Verzeichnis-sen) ist auf dem entfernten Rechner nicht möglich
Kein Verschlüsselung der Daten Nur Authentifizierung am entfernten Rechner Die Dateiübertragung kann binär- oder im ASCII-Modus erfolgen Im binären Modus ("image file type") wird ein Bitstrom aus dem Speicher des Senders
ausgelesen und unverändert übertragen Im ASCII-Modus werden alphanumerische Zeichen gemäß folgenden Regeln übertra-
gen:
1.) Ein Zeilenende wird als <CR><LF> dargestellt. Wenn der Empfänger eine anderelokale Darstellung hat (z.B. <LF><CR>), wird automatisch in dessen Darstellung kon-vertiert
2.) Wenn der Empfänger einen anderen Code als ASCII hat (z.B. ISO 8859), wird automa-tisch konvertiert
Der ASCII-Modus implementiert einfache Funktionen der ISO-Darstellungsschicht
Beispiele für Verzeichnisbefehle: cd, ls, rmdir, mkdir. Alle Befehle sind ASCII-Strings,d.h. das Protokoll ist von Menschen lesbar
Befehle für Dateien: (m)put, (m)get, ... (m = multiple) Befehle zur Authentifizierung: user, bye

151
D.h., der Zugang zum entfernten Rechner erfolgt über Benutzerkennung und Passwort Zusätzlich gibt es help-Funktionen Als Antwort für jeden Befehl wird ein Statuskode in ASCII zurückgeliefert Verwendet das Client/Server-Prinzip und Port-Adressierung zur Kommunikation
Es werden 2 separate TCP-Verbindungen für Datenübertragung und für die Steuerungder Datenübertragung aufgebaut
Der Grund liegt in erhöhter Handhabbarkeit: • Abbruch einer gestörten Datenübertragung ist über den Steuerkanal leicht möglich
lokaler Rechner entfernter Rechner
ftp Client für Daten-übertra-gung
TCP/IP proto-col stack
Port 21
ftp Clientfür Steue-rung
Port 20
ftp serverfür Daten-übertra-gung
TCP/IP pro-tocol stack
ftp serverfür Steue-rung
Port 20Port 21Steuerung
Daten
152
5.8.1 Sichere Übertragung bei FTP
Es gibt diverse Varianten für sichere Übertragung bei FTP:
1.) SecureFTP• Sichert die FTP-Steuerung mit Hilfe von SSH (Secure Socket Shell), allerdings ist nur die
Steuerung verschlüsselt und nicht die eigentliche Datenübertragung = nicht sicher• Datentransfer erfolgt über einen zufällig ausgewählten Port, den Client und Server vorher
aushandeln. Die einzige Sicherheit beim Transfer besteht in einer zufälligen Portnr.
2.) FTPS (= FTP über SSL)• Verwendet eine SSL-Verbindung (Secure Socket Layer), um Steuerdaten und Nutzdaten zu
sichernHinweis: Secure Socket Layer (SSL) ist eine alte Bezeichnung für das Transport Layer Security-Protokoll (TLS)
3.) SCP (= Secure Copy Protocol)• Sichert die Steuerdaten und die Nutzdaten via SSH. Wird häufig verwendet.
4.) SFTP (= SSH FTP)• Erweitert SCP und bietet zusätzliche Dateioperationen

153
5.9 List Server
Verwalten Listen von E-Mail-Adressen. Alle Teilnehmer einer Liste werden automatischüber ein Kürzel wie z.B. „IfIStudenten“ angesprochen
E-Mails an den List Server erlauben das automatische An- und Abmelden. d.h. Ein- undAustragen in die Liste, sowie die Abfrage von Statusinformation
5.10 E-Mail (Electronic Mail)
E-Mail dient zum Versenden von Textnachrichten, Graphiken, Bildern sowie multimedi-aler Audio- und Video-Nachrichten
Im Internet gibt es 2 Mail-Formate: das ältere RFC 822 und das neuere, aufwärtskom-patible MIME
Eine E-Mail-Nachricht nach RFC 822 besteht aus:• einem Umschlag (envelope), einem Kopfteil (header) und der eigentlichen Nachricht (body)
Typische Einträge im Kopfteil sind: • To: E-Mail-Adresse der Empfängers (können auch mehrere sein) • Cc: E-Mail-Adressen derjenigen, die eine Kopie der Nachricht erhalten (Carbon Copy) • Bcc: Wie Cc, nur dass dieses Feld bei den Empfängern in To: und Cc: leer bleibt (Blind CC) • From: Adresse desjenigen, der die Nachricht erzeugt hat • Sender: Adresse desjenigen, der die Nachricht tatsächlich verschickt hat • Received: Je eine-Zeile für jeden Mail-Transfer-Server entlang der Route
154
• Date: Datum und Zeit des Absendens • Subject: Kurze Zusammenfassung des Inhalts (eine Zeile) • Reply-To: E-Mail-Adresse, an die eventuelle Antworten geschickt werden sollen
E-Mail basiert auf miteinander kommunizierenden Programmen, den sog. Mail-Agents Es gibt 2 Typen von Mail-Agents:
• Benutzeragenten (User Agents) und Nachrichtentransferagenten (Mail Transfer Agents) Der Benutzeragent ist auf dem Benutzerrechner angesiedelt, der Nachrichtentransfer-
agent auf dem jeweiligen lokalen Mail Server
5.10.1 Benutzeragent
Programme, mit dem Benutzer E-Mails erstellen, lesen und speichern können. Beispiel: Mozilla Thunderbird, MS Outlook
Der Benutzeragent ist ein Client-Programm
5.10.2 Nachrichtentransferagent
Def.: Ein Nachrichtentransferagent (Mail Server) ist ein Programm des Senders, das imVerbund mit dem Nachrichtentransferagenten des Empfänger dafür sorgt, dass E-Mailszugestellt werden.
Der Nachrichtentransferagent ist ein Server-Programm

155
Wenn in den Resource Records einer Internet-Adressdomäne das MX-Feld definiert ist,gibt es in dieser Domäne bzw. Zone einen Mail Server, der die E-Mails aller Rechner die-ser Domäne verwaltet und auf dem ein Nachrichtentransferagent läuft
Der Mail Server besteht aus drei Teilen:
1.) Einem Briefkasten (Mailbox) für jede E-Mail-Adresse der Domäne (speichert ankom-mende und abgehende E-Mails)
2.) Einem Protokoll zur Kommunikation mit dem Benutzeragenten
3.) Einem Protokoll zur Kommunikation mit dem Nachrichtentransferagenten des MailServers des Empfängers
Der Mail Server kann physikalisch auf dem Gateway oder dem 1. Router in der Zustell-kette der Wegewahl (Routing) angesiedelt sein, muss aber nicht
Die Nachrichtentransferagenten, die für den sendenden bzw. den empfangenden Clientverantwortlich sind, verwenden das Simple Mail Transfer Protocol (SMTP) zur Kommu-nikation untereinander
Dazu baut der Nachrichtentransferagent des Mail-Servers des Senders eine TCP-Ver-bindung zu dem Nachrichtentransferagenten des Mail-Servers des Empfängers auf
SMTP verwendet TCP-Port 25 bei Sender und Empfänger Der Benutzeragent kommuniziert mit seinem lokalen Mail Server über das ältere POP3-
oder das neuere IMAP-Protokoll
156
Für das Senden von Mail vom Client zum lokalen Mail Server kann alternativ auchSMTP anstelle von IMAP oder POP3 verwendet werden
Alle 3 Protokolle basieren auf TCP/IP

157
5.10.3 Beispiel für die Zustellung einer E-Mail
Benutzer (Sender)
Benutzer (Empfänger)
Benut-zeragent
TCP/IP-Stack
Rechner A
Benut-zeragent
TCP/IP-Stack
Rechner B
Mail Server
Nachrichtentrans-feragent
TCP/IP-Stack
Port 25
Internet
Port
25
TCP/IP-Stack
Mail Server
Nachrichtentrans-feragent
TCP/IP-Stack
Port 25Port
110
(pop
3)Po
rt 1
43 (i
map
)
TCP/IP-Stack
SMTP
SMTP
POP3 oder IMAP
158
5.10.4 POP3-Protokoll (Post Office Protocol Version 3)
Dient zum Lesen von E-Mails auf lokalem Mail Server mit Hilfe des mail Client Einfaches Protokoll, das nur ASCII-Zeichen überträgt erlaubt An- und Abmelden beim Mail Server, Herunterladen und Löschen von E-Mails
aus der Mailbox des Benutzers Ist veraltet
5.10.5 IMAP (Interactive Mail Access Protocol)
Hat bedeutend mehr Möglichkeiten als POP3:• Abfrage der Mail Box von mehreren Rechnern desselben Benutzers aus (Bsp.: Laptop,
Standgerät, Mobiltelefon)• Sortiert und filtert eingehende E-Mail nach Attributen (Bsp.: alle E-Mails von Sender xy sor-
tiert nach Datum, alle E-Mails mit Schlüsselwort abc)
5.10.6 SMTP (Simple Mail Transfer Protocol)
Ist normalerweise das Protokoll zwischen Nachrichtentransferagenten Wird manchmal auch für das Senden von E-Mail zwischen Client und Server verwendet Hat die folgenden ASCII-String-Kommandos zur Steuerung des E-Mail-Versands:
• HELO: zum Verbindungsaufbau• MAIL: zur Angabe des Absenders der E-Mail

159
• RCPT (recipient): zur Angabe des Empfängers der E-Mail• VRFY (verify): zur Bestätigung der Empfängeradresse• DATA: danach folgt die eigentliche E-Mail-Nachricht (body)• <CR LF>.<CR LF>: Endezeichen des Nachrichtentextes• QUIT: zum Verbindungsabbau
Jedes Kommando muss vom Empfänger quittiert werden. Dazu dienen die 2 ASCII-Zeichen „OK“.
Zum Aufbau von Verteilerlisten gibt es das EXPN (expand)-Kommando (= Verteilerlistean mehrere Adressaten derselben E-Mail)
Alle Daten werden als 7-Bit-ASCII-Zeichen in 8-bit-Bytes übertragen
E-mail ist bzgl. der Geschwindigkeit ineffizient
Für E-Mails, die Binärdaten enthalten, ist entweder eine vorherige Kodierung in ASCII(z.B mit uuencode/uudecode) erforderlich oder die Verwendung von MIME-E-Mails nö-tig
SMTP wird technisch als System Demon (=verborgener Systemprozess) implementiert,der eingehende E-Mails von TCP-Port 25 liest
5.10.6.1 Beispiel für SMTP-Dialog
R: Receiver, S: SenderR: 220 Beta.GOV Simple Mail Transfer Service S: HELO Alpha.EDU
160
R: 250 OK Beta.GOV S: MAIL FROM:<[email protected]> R: 250 OK S: RCPT TO:<[email protected]> R: 550 No such user here S: RCPT TO:<[email protected]> R: 250 OK S: DATA R: 354 Start mail input; end with <CR>LF>.<CR><LF> S: ...sends body of mail message... S: ...continues for as many lines as message contains S: <CR><LF>.<CR><LF> R: 250 OK S: QUIT R: 221 Beta.GOV Service closing transmission channel
5.10.7 MIME (Multipurpose Internet Mail Extensions)
Erweiterung von E-Mails nach RFC 822 für verschiedene Arten von Nachrichten Überträgt Text, Graphiken, Bilder sowie Audio- und Video-Nachrichten (Multimedia-
Übertragung möglich) Verwendet spezielle Codierungen für die Übertragung von Nicht-ASCII-Nachrichten:
das Quoted Printable Encoding oder das Base64 Encoding

161
5.10.7.1 Quoted Printable Encoding
Verwendet einen 8-Bit-Zeichencode, den sog. ISO 8859-1-Code, der eine Erweiterungvon ASCII ist
Der ISO 8859-1-Code verpackt Zeichen entweder als einzelne ASCIIs oder als Folge von3 ASCII-Zeichen („Dreierfolge“)
Mit einer ASCII-Dreierfolge nach ISO 8859-1 können Sonderzeichen wie ö,ä,ü,ß,Ö,Ä,Ü,d.h. die sog. Umlaute übertragen werden, was in Standard-ASCII nicht geht
Das Gleichheitszeichen = hat bei Quoted Printable Encoding eine Sonderrolle, weil esdas einleitende Kennzeichen für eine ASCII-Dreierfolge ist
Das bedeutet, dass das erste ASCII-Zeichen einer ASCII-Dreierfolge stets ein Gleich-heitszeichen ist, gefolgt von der hexadezimalen Darstellung des ISO 8859-1-codiertenZeichens
Der Hex-Code von ISO 8859-1 ist dabei ziffernweise in ASCII codiert Dafür werden 2 Bytes benötigt, von denen jeweils 7 Bit belegt sind Insgesamt gilt, dass alle ISO 8859-1-Zeichen, die außerhalb der dezimalen Bereiche 32-
60 und 62-126 in ihrer ASCII-Darstellung liegen, bei Quoted Printable Encoding in eineFolge von 3 ASCII-Zeichen zerlegt werden müssen. Die Gründe dafür sind:• Die Zeichen von 0-31 sind nicht darstellbare ASCII-Steuerzeichen und können deshalb
nicht zur Datenübertragung bei E-mails verwendet werden• 61 ist der ASCII-Code für = und hat bei Quoted Printable Encoding eine Spezialbedeutung• 127 ist der ASCII-Code für Delete, also ebenfalls ein Steuerzeichen
162
• ab 160 fangen die ISO 8859-1-Erweiterungen von ASCII, d.h. die Sonderzeichen an
Beispiel: =E4 ist die ASCII-Dreierfolge für ä; =FC für ü; =F6 für ö und =DF für ß

163
5.10.7.2 ISO 8859-1-Tabelle
Code …0
…1
…2
…3
…4
…5
…6
…7
…8
…9
…A
…B
…C
…D
…E
…F
0…nicht belegt
1…2… SP ! " # $ % & ' ( ) * + , - . /
3… 0 1 2 3 4 5 6 7 8 9 : ; < = > ?
4… @ A B C D E F G H I J K L M N O
5… P Q R S T U V W X Y Z [ \ ] ^ _
6… ` a b c d e f g h i j k l m n o
7… p q r s t u v w x y z { | } ~
8…nicht belegt
9…A… NB ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ SH ® ¯
B… ° ± ² ³ ´ µ ¶ · ¸ ¹ º » ¼ ½ ¾ ¿
C… À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï
164
5.10.7.3 Base64Encoding
Beschreibt ein Verfahren zur Kodierung von 8-Bit-Binärdaten in 7-Bit-ASCII-Bytes Je 3 aufeinanderfolgende Bytes werden umgepackt zu 4 Zeichen von je 6 Bit
Jeder dieser 6-Bit-Zeichen bildet eine Zahl zwischen 0 und 63 Die Zahl wird als ein darstellbares 7-Bit-ASCII-Zeichen in einem 8-Bit-Byte übertragen Die Zuordnung zwischen 6-Bit-Zahl und darstellbarem ASCII-Zeichen erfolgt mittels ei-
ner Tabelle
4 ASCII-Zeichen pro 3 Binärbytes, die in 4 Bytes übertragen werden
D… Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß
E… à á â ã ä å æ ç è é ê ë ì í î ï
F… ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ ÿ

165
Die 6-Bit-Zeichentabelle lautet:
Wert ASCII-Zeichen
Wert ASCII-Zeichen
Wert ASCII-Zeichen
Wert ASCII-Zeichen
0 A 16 Q 32 g 48 w
1 B 17 R 33 h 49 x
2 C 18 S 34 i 50 y
3 D 19 T 35 j 51 z
4 E 20 U 36 k 52 0
5 F 21 V 37 l 53 1
6 G 22 W 38 m 54 2
7 H 23 X 39 n 55 3
8 I 24 Y 40 o 56 4
9 J 25 Z 41 p 57 5
10 K 26 a 42 q 58 6
11 L 27 b 43 r 59 7
12 M 28 c 44 s 60 8
13 N 29 d 45 t 61 9
14 O 30 e 46 u 62 +
15 P 31 f 47 v 63 /
166
MIME unterstützt sog. mehrteilige Nachrichten Damit können Nachrichten unterschiedlichen Typs, wie z.B. einfache RFC 822-E-Mails
und Multimedia-E-Mails in ein und derselben MIME-E-Mail versendet werden MIME definiert neue Felder zusätzlich zum alten RFC 822-Header:
• MIME-Version, Content ID, Content Transfer Encoding und Content Type
Content-Id: eindeutige Nummer zur Kennzeichnung einer E-Mail Content-Transfer-Encoding: gibt an, wie die E-Mail aufbereitet werden muss, um sie le-
sen zu können; es stehen mehrere Kodiermöglichkeiten zur Verfügung: ASCII, Base64Encoding, Quoted Printable Encoding, ...
Content-Type: gibt den Typ der Nachricht an. Es sind zahlreiche Typen mit mehrerenUntertypen definiert
Das Content-Type-Feld wird vom E-mail User Agent ausgewertet, um den Inhalt richtigdarstellen zu können
5.10.7.4 Typen von MIME-E-Mails (kleiner Auszug)
Text/Plain: einfacher ASCII-Text Text/Richtext: Richtext (RTF) ist Text mit Formatierungen. Es wird die Standard Gene-
ralized Markup Language (SGML) als Auszeichnungssprache verwendet (= Übermengevon html)
Image/GIF: Bild im GIF-Format Image/JPEG: Bild im JPEG-Format

167
Audio: Tondaten (MP3, AAC, WAV, ...) Video: Bilddaten (MPEG 1, 2 oder 4) Application/pdf: E-Mail enthält pdf-Datei Message/RFC 822: E-Mail enthält im Nachrichtenteil komplette andere E-Mail im RFC
822-Stil, inkl. deren Header. Wird zum Weiterleiten von E-mails benutzt. Message/Partial: Nachricht wurde in mehrere kleine E-Mails zerlegt, da sie zu lang war Message/External-Body: Nachricht muss separat vom Internet geholt werden, z.B. von
einem ftp-Server. Wird für sehr lange Nachrichten oder große Attachments (z.B. Video-filme) verwendet.
Multipart/Mixed: Nachricht aus mehreren Teilen, die verschiedenen Typs sein können.In jedem Teil muss der Typ angegeben werden. Wird zum Versenden von Attachments(Anhängen) verwendet.
Multipart/Alternative: Gleiche Nachricht in verschiedenen Kodierformaten oder Spra-chen
Multipart/Parallel: Alle Teile der E-Mail müssen gleichzeitig ausgegeben werden (Multi-media-Präsentation)
Multipart/Digest: Jeder Teil der E-Mail ist vom Typ RFC 822. Wird verwendet, wennmehrere Text-E-Mails zu einer MIME E-Mail zusammengesetzt werden sollen.
Beispiel für eine MIME E-mail:• From: [email protected]• To: [email protected]
168
• Subject: der Betreff der Nachricht• MIME-Version: 1.0• Content-type: multipart/mixed; boundary="example-1"• --example-1• Content-type: text/plain; charset=utf-8• (Art der Nachricht, z. B. Klartext, Bilder, Videos etc.)• (Hier steht der Text dieser Beispielnachricht.)•• --example-2• Content-type: image/gif; name="bild.gif" (Bild als Anhang)• Content-Transfer-Encoding: base64 (Hier wird das verwendete Codierungsverfahren ange-
geben)
5.11 World Wide Web (www)
Das www ist heute der mit Abstand wichtigste Dienst des Internet
5.11.1 Was ist das www?
Aus World Wide Web FAQ: „The www project is a distributed hypermedia system. Inpractice, the web is a vast collection of interconnected documents, spanning theworld“• Offenes, verteiltes „Hypermedia“-System

169
• Basierend auf Client/Server-Anwendungen• Eine riesige weltweite Sammlung von Dokumenten• Organisiert in „web-Seiten“ (pages)• Jede Seite kann Links zu anderen Seiten enthalten (= Kennzeichen von „Hypertext“)• Der beliebteste Internet-Dienst und das am schnellsten wachsende Medium aller Zeiten
Das www ist beliebt, weil einfach zu bedienen, multimedial, unterhaltsam, informativund „in“
Hinweis: Es gibt fast alles im www, aber nicht alles ist richtig oder objektiv!!
5.11.2 Komponenten des www
HTML (Hypertext Markup Language): sog. Auszeichnungssprache, in der die Erschei-nung, d.h. das Layout von Dokumenten in Form von Web-Seiten beschrieben werdenkann
HTTP (Hypertext Transfer Protocol): ASCII Protokoll der Schicht 7, das auf TCP aufsitzt Web-Browser: Client mit grafischer Benutzeroberfläche Web-Server: Server zur Verwaltung und Generierung der Dokumente
5.11.3 Die wichtigsten Ziele des www
Ziel 1: Hypermedia-basierend, formatunabhängig und rechnerunabhängig
html-Seitenbeschreibungssprache
170
Ziel 2: Einfacher Zugriff auf weltweit verteilte Informationen
URL-Adressierung + Client-Server-Betriebsweise
Ziel 3: Plattform- und betriebssystemunabhängiger Transfer
http-Protokoll zum Transport des HTML-Protokolls
Ziel 4: Gleiche Benutzungsoberfläche für alle Arten von Informationen => virtuelles Ter-minal wie bei Telnet aber mit Graphik
Browser zur Informationsdarstellung als virtuelles Terminal mit Graphik und Maus
Ziel 5: Einbindung einer Vielzahl von Technologien und Dokumenttypen + leichte Er-weiterbarkeit
Browser Plug-Ins + Java-Applets + verschiedene URL-Protokolle wie www, ftp, ...
Ziel 6: Bereits existierende Objekte wie z.B. ein Dateisystem sollen auch als Hypertextdarstellbar sein und dadurch für www zugänglich werden
URL-Format geht nahtlos in die Notation für den lokalen Dateibaum über
5.11.4 Wichtige Entwicklungen im www
1.) Mobiles Internet:• Alle mobilen Endgeräte (Smart Phones, Tablets) haben schnellen Internet- und www-Zu-
gang zu moderaten Preisen

171
Beispiel: Video Streaming auf dem Mobilfunktelefon für jedermann, jederzeit an allenOrten
2.) Applications Web:• Mini-Programme („apps“) begleiten den Benutzer situations- und ortsabhängig als sog.
Personal Agents.
Beispiel: Apple iPhone apps, Android apps, Whatsapp
3.) All-IP-Vernetzung:• Adressraum des Internets wird durch IPv6 erheblich erweitert• Alle technischen Gebrauchsgüter (Handy, Kühlschrank, Auto, ...) werden über IPv6 ver-
netzt
Beispiel: Internet der Dinge (IOT) bzw. Cyber-Physical Systems
4.) Zunahme sozialer Netzwerke und virtueller Umgebungen im www• Menschen verbringen den größten Teil ihrer Freizeit in der virtuellen Welt des Internets und
nicht mehr mit anderen Menschen• Man hat Hunderte von „Freunden“ ohne jemals einen getroffen zu haben
Beispiel: Facebook, Twitter, ...
5.) Cloud Computing• Speicher, Rechenleistung und Anwendungen werden in einer Cloud zur Verfügung gestellt
172
Beispiel: S3-Dienst des Amazon Web Service (AWS)
• Anwendungen sind von überall und auf allen Endgeräten mit Browser benützbar
Beispiel: MS Office wird nicht mehr auf dem eigenen PC gespeichert und ausgeführt,sondern in einem Rechenzentrum eines Cloud Service-Dienstleisters. Auf MS WebOffice, MS Office365 oder Google Docs wird über das Internet zugegriffen.
• Für Benutzer-Ein- und Ausgaben wird ein web-Formular verwendet• Ausgabe ist unabhängig vom realen Endgerät, da nur ein web-Browser verwendet wird• Dienst ist als Anreiz zunächst kostenfrei aber kostenpflichtig, sobald man mehr will• Aber: es gibt erhebliche Probleme mit der Datensicherheit bei US-amerikanischen Cloud-
Providern. Dieselben Probleme gibt es auch vielen anderen Ländern (Russland, China, ...)
6.) Web 2.0• „Semantisches Web“• Verknüpfung von Informationen nicht als Bits sondern anhand ihres Sinns (= Semantik)• Durch semantische Verknüpfung von Informationen können neue Zusammenhänge auto-
matisch generiert werden, d.h. Software soll die Bedeutung von Daten interpretieren und„verstehen“
• Der Umgang mit dem www und der Nutzen des www soll dadurch wesentlich verbessertwerden
• Ist seit vielen Jahren Zukunftsmusik

173
5.11.5 www als Hypermedium
Def.: ein Hypermedium ist ein Hypertextsystem mit Text, Graphik, Audio und Video, d.h.multimedial
Das www ist ein einziger, zusammenhängender Hypermedium-Graph Der Graph des www wird über das „Link“ feature von html realisiert Die Kanten des Hypermedium-Graphen werden auch als Hyperlinks bezeichnet
5.11.5.1 Was ist ein Hypermedium?
Def.: Hypermedium := Hypertext + Multimedia
Def.: Multimedia := ≥ 1 zeitkontinuierliches Medium + ≥ 1 zeitdiskretes Medium, die zeit-lich synchronisiert sind
Bsp. für Multimedia: Video + Text oder Audio + Graphik
5.11.5.2 Hypertext
Hypertext bietet Informationen nicht linear dar sondern delinearisiert als vernetztesDokument
Def.: Hypertext := Graph aus markierten Knoten und markierten, gerichteten Kanten
Graph => Bezeichnung: „web“ => World Wide WebDef.: Knotenmarkierungen des Graphen := Textpassage
174
Def.: Kantenmarkierungen (sog. Textanker) des Graphen := unterstrichener oder farbighervorgehobener Text.
Das „Anklicken“ eines Textankers bewirkt ein Übergang von einem Knoten (=Textpas-sage) zu einem Nachbarknoten (= verwandte Textpassage)
Der Übergang erfolgt entlang einer gerichteten Kante „Lesen“ eines Hypertext-Dokuments besteht mindestens aus einer sog. Hamilton-Tour
im Graphen des wwwHinweis: Hamilton-Tour: genau einmaliger Besuch aller Knoten eines Graphen. Kanten dürfen mehrfach durchlaufen werden.
5.12 URL-Adressierung
Web-Seiten werden weltweit eindeutig über einen Universal Resource Locator (URL)adressiert
Jede Web-Seite, die zu einer URL gehört, ist ein Hypermedia-Dokument
Die URL beantwortet die Fragen:
• Wie heißt die page?• Wo befindet sich die page?• Wie kann auf die page zugegriffen werden?

175
5.12.1 Einfaches URL-Format
Eine einfache URL hat das Format: <Protokoll>://<host>[:<port>] [/<path>]Hinweis: „<symbolische Name>“ heißt: muss durch eine definierte String-Konstante ersetzt werden. „[...]“ heißt: ist optional. Siehe dazu auch die sog. Backus-Naur-Notation.
Eine einfache URL besteht mindestens aus dem Tripel:
1.) verwendetes Protokoll, z.B. http
2.) DNS-Name des web Servers, z.B. www.example.org
3.) lokaler Dateiname auf dem Server, z.B. /demo/index.html
5.12.2 Komplexes URL-Format
Zusätzlich können, durch ? eingeleitet, Parameter an die URL angehängt werden. Meh-rere Parameter werden durch & unterschieden
Parameter sind notwendig, um Eingaben des Benutzers in einer web-Seite zurück zumServer zu übermitteln
Als weitere Eigenschaft des komplexen URL-Formats ist die Angabe von Benutzerna-me und Passwort möglich
Def.: Eine komplexe URL hat das Format: <Protokoll>://[<U>:<PWD>@]<host>[:<port>][/<path>]{?<Parameter>}
176
Hinweis: Hier wird die erweiterte Backus-Naur-Form verwendet. Sie verwendet geschweifte Klammern {…} für die optionale Wiederholung.
1.) Protocol: verwendetes Netzwerkprotokoll (HTTP, HTTPS, FTP, ...)
2.) U: Username
3.) PWD: Password
4.) host: Zielrechner (symbolische Adresse gemäß DNS oder numerische Adressegemäß IP)
5.) port: Adresse des Empfangsprozesses im Betriebssystem des Host (Bsp.: HTTP hat80, HTTPS hat 443, FTP hat 21)
6.) path: gibt den Weg im Verzeichnisbaum des Hosts zu einer Datei an
7.) Parameter: String für weitere Informationen gemäß des Common Gateway Interfaces(CGI)
Beispiel: für komplexe URL http://hans:[email protected]:80/demo/example.cgi?land=de&stadt=aa
Beispiel: für komplexe URL: Suchstring bei Google: http://www.google.de/search?hl=de&q=CGI-Skript+Java-Servlet+Apache&btnG=Google-Suche

177
5.13 Aufruf einer statischen web-Seite bei einem web-Server über die URL
1.) Der Browser erhält vom Benutzer die URL (Uniform Resource Locator) der web-Seite
2.) Der Browser fragt das DNS nach der IP-Adresse des URL Servers
3.) Das DNS gibt die IP-Adresse des Servers zurück
4.) Der Browser baut zu Port 80 des Servers eine TCP-Verbindung auf
5.) Er sendet eine Anforderung bzgl. der Datei in dem Verzeichnis, das die web-Seite ent-hält
6.) Der Server sendet die Datei aus seinem Verzeichnis
7.) Der Browser zeigt den Inhalt der Datei an, indem er html interpretiert
8.) Der Browser ruft in derselben oder zusätzlichen TCP-Verbindungen alle Bilder derweb-Seite ab, baut sie gemäß html ein und zeigt sie an
9.) Alle TCP-Verbindungen werden getrennt
6 Wichtige Web-Technologien
Es gibt eine sehr große Zahl von Web-Technologien, die als wichtig bezeichnet werdenkönnen
178
Eine Auswahl davon sind Client-Server-Architektur, Peer-to-Peer-Architektur, CGI, ht-tp, html, Applets, Servlets, Portlets, Java Server Pages, MS.net, Web Browser undCloud Computing
Diese Technologien werden nachfolgend erläutert
6.1 Client-Server-Architektur
Das gesamte www basiert auf dem Client/Server-Modell Auf der Benutzerseite gibt es Client Browser Auf der Server-Seite gibt es sog. CGI-Skripte oder Java-Servlets und/oder Java-Server
Pages und/oder Web Server-Software wie z.B. Apache Tomcat

179
Der Client Browser läuft auf dem lokalem Rechner und hat folgende Aufgaben:• Anfragen an den www-Server stellen• Die empfangenen Daten aufbereiten und auf virtuellem Terminal darstellen • Navigationshilfen durch das web zur Verfügung zu stellen
Der www-Server hat die Aufgaben:• Anfragen von Clients beantworten, indem er die angefragten web-Seiten bereitstellt
ISP = Internet Ser-vice Provider (T-Online, 1und1, ...)
180
• Operationen auf den angefragten web-Seiten durchzuführen, z.B. Eintragen von Werten inTabellen oder Durchsuchen von Datenbanken
Die erste Spezifikation für die Interaktion zwischen Client und Server war das Com-mon Gateway Interface (CGI)
CGI wurde 1995 spezifiziert und sitzt auf dem Hypertext Transport-Protokoll (http) auf CGI definiert Art und Syntax der Parameterübergabe zwischen Client und Server sowie
einen Satz von Umgebungsvariablen beim Server und beim Client Server-Programme für CGI werden i.d.R. in sog. Skriptsprachen geschrieben (Python,
PHP, ...) und heißen dann CGI-Skripte Es gibt Frameworks für die Server-Software, die wiederkehrende Aufgaben abnehmenBeispiel: cakePHP ist ein Rahmenwerk für server-seitige Software, das nach dem klas-sischen Model-View-Controller-Prinzip aufgebaut ist. Der Controller-Teil beinhaltet diesog. Geschäftsprozess-Software, die für jeden web Shop spezifisch ist.
Clients kommunizieren mit dem Server-CGI-Skript, das interpretativ ausgeführt wird Ein CGI-Skript leistet Server-seitig folgende Aufgaben:
• Entgegennehmen der Anfrage nach einer web-Seite durch einen Browser (= Client)• Auswerten der vom Client gesendeten Parameter hinsichtlich Syntax und Semantik (= Par-
sen der URL)Hinweis: to parse = „zerpflücken“, parsing = Begriff aus dem Compilerbau
• Prüfen der Zugriffsrechte des Clients auf die Web-Seiten und die Dateien des Servers

181
• Suchen und Übertragen von durchnummerierten Web-Seiten in einer Menge von vorgefer-tigten web-Seiten (kommt nur bei statischen web-Seiten von Firmen und Universitäten vor)
• Erstellen und Übertragen von dynamischen Web-Seiten (ist der Regelfall bei online shops)
Dynamische Web-Seiten sind oft aus einer Datenbank generiert, wie z.B. bei Reservie-rungssystemen für Hotel-/Flugbuchungen oder bei Warenbestellungen bei eCom-merce
Der Vorteil dynamisch erzeugter web-Seiten ist, dass der web-Server auf die Eingabendes Benutzers reagieren kann, die dieser in Felder eines web-Seiten-Formulars ge-macht hat
Beispiel: Der web-Server lässt den Benutzer zwischen VISA Card und Mastercard aus-wählen. Der Benutzer wählt Mastercard. Der web-Server erzeugt daraufhin das web-Sei-ten-Formular zur Eingabe der Kartennr. für eine Mastercard.
6.2 HTML
HTML ist eine Auszeichnungssprache (Markup Language), in der das Layout von Do-kumenten in Form von Web-Seiten beschrieben werden kann
HTML ist eine vereinfachte Untermenge der sog. Standard Generalized Markup Lan-guage (SGML) von IBM aus den 1970er Jahren
182
6.3 Java Servlet
Kunstwort aus Server + Applicationlet (Applicationlet = kleines Anwendungspro-gramm)
Wird benutzt, um die Funktionalität von CGI-Skripten im Server zu erweitern Ist Instanz einer Java-Klasse, die die CGI-Schnittstelle implementiert und die http als
Protokoll benützt Vorteil: Es können alle existierenden Java-Bibliotheken wie z.B. die Java Database
Connectivity (JDBC) für Datenbankanbindung oder die graphische Benutzerschnitt-stelle Swing verwendet werden, was die Funktionalität gegenüber CGI-Skripten erhöht
Servlets werden nach Aufruf der web-Seite durch den Client dynamisch von der Java-Laufzeitumgebung des Servers - dem sogenannten Web Server Container - instanziiertund ausgeführt
Der Web Server Container kommuniziert seinerseits entweder mit einem nicht auf Javabasierenden Web Server oder ist integraler Bestandteil eines Java-basierten Web Ser-vers
Zur Erzeugung eines Java Servlets wird durch Kompilation aus der Servlet-Klasse einJava-Bytecode erstellt und in eine Datei geschrieben, das sog. Web-Archiv

183
6.4 Java Portlets
Ein Java Portlet ist die Erweiterung eines Servlets und benützt einen sog. Portlet Con-tainer
Der Portlet-Container ist die Erweiterung eines Servlet-Containers Ein Portlet wird clientseitig vom Browser nur in einem Teilbereich der web-Seite ange-
zeigt Der Teilbereich heißt „Kachel“ Eine portlet-gesteuerte web-Seite besteht aus vielen von einander unabhängigen Ka-
cheln, d.h. Portlets, die gleichzeitig völlig verschiedene Dinge machen und anzeigenkönnen
Beispiel: auf einer web-Seite wird gleichzeitig ein Kalender, der Wetterbericht und dieTageschau angezeigt. Diese Informationen stammen von drei verschiedenen URLs.
Def.: Ein Web Server, der Portlets unterstützt, heißt Portal Server und seine Web-Seitenheißen Portal.
6.5 Java Server Pages (JSP)
Java Server Pages erlauben genau wie CGI-Skripte, Java Servlets oder Portlets web-Seiten dynamisch nach Aufruf vom web Server zu erzeugen
184
Die dynamisch erzeugte web-Seite beruht dabei auf einem vorgefertigten statischenTeil in html, der das Aussehen der web-Seite vorgibt, z.B. im Stil einer Firma (sog. Cor-porate Design)
Def.: Die waldgrüne Farbe auf den Web-Seiten der TU Clausthal ist das Corporate Designder TU Cl.
Der html-Code, der das Aussehen der web-Seite vorgibt, wird dazu um einen dyna-misch erzeugten Teil erweitert, der Java-Code und sog. JSP-Aktionen erhalten kann
Der Java-Code und die JSP-Aktionen ermöglichen, genau wie CGI-Skripte oder JavaServlets, eine auf Benutzereingaben abgestimmte Reaktion des web-Servers
Der erste Vorteil von JSP ist, dass die dynamisch erzeugten Seiten vom Design her im-mer genau gleich aussehen und dass letzteres nur einmal in html programmiert werdenmuss
Der zweite Vorteil von JSP ist, dass die JSP-Aktionen dynamisches Verhalten ermögli-chen, ohne dass dazu der Ersteller der web-Seite Java programmieren muss, denn dieJSP-Aktionen werden über extra xml-Tags definiert und aufgerufen
Aus einer Java Server Page - bestehend aus html/xhtml und extra xml-Tags - generiertein spezieller JSP-Compiler dann Java-Code, der ein Java Servlet ist
Java Server Pages können ohne eigene Programmierkenntnisse erzeugt werden, dasie vollautomatisch auf Java Servlets zurückgeführt werden
Vorteil von JSP: Erstellung von dynamisch erzeugten web-Seiten wird vereinfacht

185
6.6 Applets
Def.: Applet = Applicationlet = kleines Anwendungsprogramm, das bei der Interpretationeiner web-Seite durch den Browser vom Server heruntergeladen und beim Client ausge-führt wird
Applets werden benutzt, um web-Seiten interaktiver zu gestalten bzw. mit Animationenzu versehen
Beispiel: für Applets: Taschenrechner, bewegte Animationen
Applets können in verschiedenen Sprachen geschrieben werden; am häufigsten wirdJava oder Javaskript verwendet
Ausführung von Java Applets erfordert im Browser eine Java-VM als EinschubmodulHinweis: Java VM = virtuelle Java Maschine zur Interpretation des Java Bytecodes.
6.7 Sonstige Open Source Technologien für das www
Für die Erstellung von web-Seiten mit gleichem Design: „Cascaded Style Sheets, CSS“ Zur Verbesserung der Interaktion zwischen Benutzer und Server: „Ajax“ Zur Erstellung eines web Servers: Apache „http Server“, Microsoft „IIS“ oder Linux
„nginx“ Zur Erstellung eines Web-Server Gateway-Interfaces: das Python-basierte „WSGI“ WSGI standardisiert die Schnittstelle zwischen Web Server und der Server-Anwendung
186
6.8 Hypertext Transport-Protokoll
Tim Berners-Lee: "The Hypertext Transfer Protocol (HTTP) is an application-level pro-tocol for distributed, collaborative hypermedia information systems."
HTTP ist das Protokoll, mit dem HTTP-Client und HTTP-Server auf Schicht 7 kommuni-zieren
HTTP ist zusammen mit FTP und SMTP eines der wenigen Schicht-7-Protokolle, die un-gehindert eine Firewall passieren können und wird deshalb sehr oft für Middleware inverteilten Anwendungen zweckentfremdet eingesetzt
HTTP überträgt HTTP-Requests (=Anforderung von web-Seiten) und HTTP-Responses(=HTML-Seiten und dazugehörige Dateien wie z.B. Bilder)
Mittlerweile werden über http Requests nicht mehr nur web-Seiten per URL angefor-dert, sondern auch sog. web-Ressourcen über eine „URI“ (Uniform Resource Identifier)
Web-Ressourcen können z.B. auch online-Festplatten sein, die über erweiterte http-Methoden gelesen und geschrieben werden können.
Beispiel: Web-Ressourcen sind: Amazon S3, Google Storage, Microsoft Azure Storage,DropBox, BitBucket, Ubuntu One, ...Hinweis: Amazon S3, Google Storage und Microsoft Azure Storage sind nicht nur Web-Ressourcen sondern sogar Cloud-Dienste.
Zu http gibt es mittlerweile substantielle Erweiterungen wie REST oder WebDAV

187
Hinweis: REST = Representational State Transfer. WebDAV = Web-based Distributed Authoring and Versioning.
6.8.1 HTTP-Entwurfsziele
HTTP-Entwurfsziele waren:
1.) Einfaches Zweiphasen-Handshake-Protokoll mit Request/Response im ASCII-Format(rein textbasiert)
2.) Minimale Belastung des Servers bei Transaktionen durch Zustandslosigkeit vonRequest und Response (= stateless protocol)
3.) Die für einen Dialog zwischen Client und Server immer notwendige Zustandsinforma-tion wird Client-seitig in einer speziellen Datei in Form von sog. Cookies gespeichert
• Alternative zu Cookies: der Client hat sich beim Server registriert und dort in einer Daten-bank seine Daten hinterlegt
6.8.2 Nachteile von http
Cookies speichern zusätzlich vertrauliche Information über den Benutzer (Daten-schutz!)
Durch ASCII- und MIME-Codierung ineffizient im Datentransfer Daten werden nicht verschlüsselt => https ist entstanden
188
6.8.3 HTTP-Transaktion (Phasen 1-4)
Eine sog. HTTP-Transaktion besteht aus 4 Phasen Für die Übertragung jeder web-Seite müssen alle 4 Phasen durchlaufen werden
1.) HTTP-Connect des Clients• Aufbau einer TCP-Verbindung zu einem HTTP-Server (geht über TCP-Port 80)
2.) HTTP-Request des Clients (Anfrage nach einer web-Seite)• Anforderung einer web-Ressource wie z.B. einer Datei oder web-Seite mittels URL • Client sendet dazu Request-Kommandos wie z.B. GET oder POST
3.) HTTP-Response des Servers• Übertragung der angeforderten web-Ressource oder einer Fehlermeldung zum Client• d.h. Server sendet Ressource wie z.B. web-Seite und Statuscode zurück
4.) HTTP-Close des Servers• Abbau der TCP-Verbindung zum HTTP-Client. • Ab http V1.1 können beliebig viele Requests und Responses zwischen dem Auf- und dem
Abbau der TCP-Verbindung sein = „Persistente TCP-Verbindung“
V1.1 ist viel effizienter, wenn es um die Übertragung vieler Daten oder Bilder etc. geht
5.) Aktuelle Version: http V2

189
6.8.4 Raum-/Zeitdiagramm des http-Protokolls
Die einzelnen Phasen laufen im Detail wie folgt ab:
6.8.4.1 1. Connection
Der Client stellt zum Verbindungsaufbau eine TCP/IP-Verbindung zum Server über Port80 mit Hilfe der Informationen aus den Parametern in der URL her
6.8.4.2 2. Request
Der Client sendet eine Anfrage in der HTTP-Syntax
190
Grundsätzliche Syntax einer http Anfrage in Backus-Naur-Notation:<Request> := <Simple-Request>|<Full-Request>
Simple Request<Simple-Request> := <Method> <URL> CRLF<Method> := GET
Beim simple request gibt es nur GET als Methode Die Parameter für <Method> werden durch ? getrennt an die URL angehängt und im
CGI-Stil codiert CRLF sind die beiden ASCII-Zeichen Carriage Return und Life Feed Full Request<Full-Request> :=<Request-Line> * (<Header> CRLF) [Data]<Request-Line> := <Method> <URL> [<HTTP-Version>] CRLF<Method> := GET|HEAD|PUT|POST|DELETE|TRACE|OPTIONS|CONNECT|sowie in v2: PATCH
<Header> enthält u.a. den MIME-Datentyp der web-Seite, oder die Unterscheidung, obes sich um klassisches http oder um Erweiterungen wie REST oder WebDAV handelt
[Data] ist für die Methoden POST- und PUT erforderlich <HTTP-Version> gibt die verwendete HTTP-Version an
Beim full request gibt es mehr Methoden als beim simple request. Diese sind:• HEAD = Holt den Header einer web-Seite vom Server
· Der Header einer web-Seite dient u.a. Suchmaschinen wie Google zum Auffinden pas-

191
sender web-Seiten• GET = Holt den Header und den Inhalt einer web-Seite vom Server. Erlaubt bis zu 255 Byte
im CGI-Format als Parameter an die URL der angeforderten web-Seite anzuhängen. Dientdann zur Übergabe von Benutzereingaben an den Server.
• PUT =Speichert eine web-Seite beim Server ab· Geht nur, wenn das Zugriffsrecht des Client auf dem Server dies erlaubt, d.h. wird i.d.R.
vom web-Server ignoriert (außer bei REST und WebDAV)• POST ist ähnlich wie PUT nur ohne Speichern. Ganze Web-Seiten in html oder beliebig vie-
le Benutzereingaben in CGI werden so vom Client zurück zum Server übertragen. Erlaubtebenfalls Parameter an die URL anzuhängen.· Dient zum temporären Speichern von Benutzereingaben, nicht zum permanenten· Ist nützlich für das Ausfüllen eines mehrseitigen web-Formulars, das mehrere Transak-
tions-Schritte zwischen Client und Server erfordert• DELETE = löscht eine web-Seite auf dem Server
· Geht nur, wenn das Zugriffsrecht des Client auf dem Server dies erlaubt, d.h. wird meistvom web-Server ignoriert (außer bei REST und WebDAV)
• TRACE = Server schickt den http Request so an den Client zurück, wie er ihn empfangenhat· Dient zum Feststellen von Übertragungsfehlern
• OPTIONS = Server antwortet mit einer Liste der Request-Methoden, die er unterstützt• CONNECT = Wird u.a. auch beim Verschlüsseln von Daten mit Hilfe des TLS/SSL-Proto-
kolls benötigt• PATCH = ändert ein bestehendes Dokument (geht bei REST und WebDAV)
192
6.8.4.3 3. Response
Der Server sendet eine Antwort (=Response) als ASCII-String im HTTP-Format und ggf.MIME-codiert zurück
Backus-Naur-Notation der Antwort:<Full-Response> :=<Status-Line> * (<Header> CRLF) [Data]<Status-Line> := <HTTP-Version> <Status> <Reason>CRLF<HTTP-Version> = aktuell verwendete Version des Protokolls<Status> = Ein dreistelliger Status-Code (alle Ziffern in ASCII!)<Reason> = Ein ASCII-Text zur Erläuterung des Status-Codes
Header enthält u.a. den MIME-Datentyp und die Länge der Antwort (siehe unten) [Data] enthält die angefragte web-Seite, sofern die Anfrage erfolgreich war
6.8.4.4 4. Disconnection
Der Server beendet die TCP/IP- Verbindung, sobald die Web-Seite übertragen ist

193
6.8.5 Beispiele von Elementen im Response-Header
Der Request Header ist formal ähnlich wie der Response Header aufgebaut
Element Bedeutung
Version http-Versionsnr.
Server:<server-type>
Name des Server-Programms, das den Hea-der erzeugt hat (z.B. Apache http Server). Dient der besseren Kompatibilität zwischen Browser und Server
Content-Length:<length> Die Länge der Antwort in Byte
Content-Type:<MIME-Type> Der MIME-Type der web-Seite, z.B. pdf, jpg, ...
Title:<title> Der Titel der web-Seite
Date:<date> Das Erstellungs- oder Änderungsdatum der web-Seite
Expires:<date> Gibt an, wann web-Seite ungültig wird.
Pragma schaltet das Caching der web-Seite ein oder aus
Status Status der http-Anforderung (ggf. Fehler-code)
Set-Cookie Kommando zur Cookie-Erstellung beim Cli-ent
194
6.8.6 Unterschied zwischen http und REST
REST ist eine Übermenge von http REST ist dann zwischen Client und Server möglich, wenn beide das Protokoll unter-
stützenBeispiel: REST erlaubt es, einen Online-Speicher zu implementieren.
Anstelle einer URL wird eine URI (Uniform Resource Identifier) verwendetDef.: Eine URI ist die Verallgemeinerung einer ULR und adressiert anhand einer vorgege-benen Syntax eine konkrete oder eine abstrakte Web Ressource.Hinweis: Eine abstrakte web Ressource ist z.B. ein Online-Speicher. Der Benutzer einer solchen Ressource weiß nur, wie viel Speicher er dort hat, aber nicht, wo dieser Speicher tatsächlich ist.
Parameter werden bei REST i.d.R. nicht per POST an die URI angehängt, sondern perPUT an den Server übergeben
Es können mit REST Übergabewerte vom Client an den Server transferiert, sowie ganzeWeb-Ressorcen auf dem Server gelöscht werden
bei REST funktionieren auch PUT, DELETE und PATCH, die bei http vom Server abge-blockt werden
Als response vom Server können nicht nur html- sondern auch xml-Daten verarbeitetwerden

195
6.8.7 Unterschied zwischen REST und WebDAV
WebDAV ist eine Übermenge von REST und erlaubt die komfortable Verwaltung vonWeb-Ressourcen, die von mehreren Benutzern gleichzeitig gelesen und geschriebenwerden können
Bei WebDAV funktionieren ebenfalls PUT und DELETE Es gibt außerdem zusätzliche Methoden:
1.) PROPFIND: wird benutzt, um in XML-spezifizierte Eigenschaften einer web-Res-source zu erfahren. Wird auch benutzt, um die Verzeichnisstruktur eines entferntenRechners herauszufinden.
2.) PROPPATCH: ändert oder löscht Eigenschaften einer web-Ressource in einer zeitlichnicht unterbrechbaren Operation (=atomare Aktion)
3.) MKCOL: erstellt ein Dateiverzeichnis (directory)
4.) COPY: kopiert eine web-Ressource, die als URL spezifiziert wird
5.) MOVE: verschiebt eine web-Ressource, die als URL spezifiziert wird
6.) LOCK: sperrt eine web-Ressource auf dem web-Server. Ist nötig, für Exclusive Writeauf die Ressource.
7.) UNLOCK: entfernt die Sperre auf die web-Ressource
196
7 Middleware für verteilte Anwendungen im Internet
Def.: Middleware ist die Software zwischen Betriebssystem und Benutzeranwendung
Middleware hilft durch die Bereitstellung allgemein benötigter Infrastruktur bei der Er-stellung und dem Betrieb von im Internet verteilten Anwendungen
Die im Internet als Open Source verfügbare Middleware ist unüberschaubar groß Anbei wird eine Übersicht zur wichtigsten Middleware gegeben
Transport/Wege-wahlTCP/UDP/IP
Client (= Prozess im Benutzerrech-ner)
Middleware
Transport/Wege-wahl
Bitübertragungs-schicht
Server (= Prozess z.B. auf Firmen-rechner)
Middleware
Bitübertra-gungsschicht
Anwendungsprotokoll
RPCs, http, REST, ...
physik. Daten-transferHardware
Betriebssystem
Anwendung

197
7.1 Übersicht
Viele Internet-Anwendungen beruhen auf einer oder mehrerer folgende Middleware-Technologien:• CGI-Skripte• http und html bzw. XHTML oder XML bzw. REST oder WebDAV• Applets, Java Servlets, Java Portlets und Java Server Pages• Microsoft .net• OASIS Web Services, Amazon Web Services (AWS)• Virtuelle Maschinen• Cloud Computing
Ältere Software-Technologien, die immer noch eingesetzt werden, sind:• Remote Procedure Calls (RPCs)• Remote Method Invocations (RMIs) in Java• Network File System (NFS)
RMI und NFS beruhen auf RPCs als Basis Online-Festplatten (Storage Clouds) beruhen oft auf WebDAV Cloud Computing beruht u.a. auf RPCs, XML und REST
198
7.2 Status und Verwendbarkeit bekannter Middleware
http, XML und CGI sind oft verwendete Standards im www
Java RMI (= Remote Method Invocation = Methodenfernaufruf): Entwicklung von Sun• Java RMIs sind Methodenfernaufrufe und Teil der Sprache Java, um verteilte Anwendun-
gen leichter erstellen zu können• Java RMIs sind RPC-basiert
Web Services: Standard der „Organisation for the Advancement of Structured Infor-mation Standards“ (OASIS) und des „World Wide Web Consortiums“ (W3C)• Web Services funktionieren als Marktplatz für weltweit verteilte Software-Funktionen, die
bei Bedarf von einer Anwendung aufgerufen werden können• Wegen http ist eine Firewall kein Hindernis für Web Services• Probleme: langsam und ressourcenverbrauchend, da gleichzeitig http, XML und SOAP als
Schicht 7-Protokolle verwendet werdenHinweis: Es gibt den Fachbegriff „Web Services“ noch ein zweites Mal und zwar bei den am meisten verbreiteten Cloud Diensten, den Amazon Web Services (AWS). Diese stellen eine erhebliche Erweiterung der OASIS Web Services dar. Sie beruhen zwar noch auf http als Low Level-Benutzerschnittstelle aber nicht mehr auf SOAP, sondern gehen eigene Wege.
Grid Computing: erlaubt es, weltweit verteilte Rechenzeit und Speicherplatz von(Groß)rechnern und PCs zu nutzen• Status: in der Praxis sehr kompliziert anzuwenden. Hat sich nicht durchgesetzt. Wird nur
vom CERN standardmäßig zur Datenauswertung beim LHC eingesetzt.

199
Cloud Computing: umfangreiche Middleware, die manchmal schwierig zu installierenist, aber tatsächlich eine einfache Nutzung von Web-Ressourcen erlaubt• Web-Ressourcen sind Festplattenspeicher, Rechenleistung, Netzwerkverwaltungsdienste
und allgemeine Software-Anwendungen, die unter Web URLs angeboten werden• Es gibt Public Clouds, Private Clouds, Community Clouds und Hybrid Clouds
Beispiel: für Public Clouds: Microsoft Azure, iCloud, Amazon EC2, Google ComputeCloud, Google Storage Cloud
Beispiel: für Cloud Computing-Anwendungen: Google Docs, Microsoft Office 365
Beispiel: für Middleware, die es erlaubt, eine private oder hybride Cloud zu errichten:OpenStack. Das ist das am weitesten verbreitete Open-Source Cloud-OS.
Beispiel: die am weitesten verbreiteten und technologisch führenden, kommerziellenCloud-Dienste für Web-Ressourcen sind die Amazon Web Services (AWS).
• Status: Cloud Computing ist Stand der Technik und für Rechenzentren und Benutzer wich-tig.
Hinweis: Im weiteren werden folgende Middleware-Beispiele präsentiert: das Network File System, das Common Gateway Interface und Remote Procedure Calls. Danach folgen Microsoft.net, virtuelle Maschinen (VMs) und Cloud Computing.
200
7.3 Das Network File System (NFS)
Implementiert ein verteiltes Dateisystem, das nach einer Initialisierungsphase für denBenutzer „transparent“ ist
Transparent heißt, dass der Benutzer sieht nicht mehr sieht, ob Dateien lokal oder ent-fernt gespeichert sind
Alle nicht-lokalen Dateien werden in einem virtuellen Dateisystem verwaltet und er-scheinen dadurch dem Benutzer wie lokale Dateien
Es gibt Software-Konverter und Protokolle wie z.B. Samba, die NFS für Unix/Linux-Rechner mit einem verteilten Windows-Dateisystem koppeln können
Der kommerzielle Nachfolger von NFS ist das Andrew File System (AFS) AFS zählt zur Klasse der Internet-Anwendungen, da es keine RFCs gibt
7.3.1 Merkmale von NFS
Ist für heterogene Netzwerke (=gemischte LINUX/Windows/MacOS-Dateisysteme) Portierung auf neue Betriebssysteme wie z.B. Android ist rel. einfach Basiert auf einem zustandslosen Client/Server-Modell Kommunikation erfolgt über UDP- und TCP-Transportprotokolle Peer-to-Peer-Rechner importieren/exportieren ihre Dateiverzeichnisse oder Teile da-
von als Unterbäume ins NFS und damit ins InternetHinweis: Exportieren heißt: für NFS freigeben, importieren heißt: exportierte Dateien lokal bekanntmachen

201
Es gibt keine Funktionen der ISO-Darstellungsschicht, nur Lesen und Schreiben vonByte-Strömen ist möglich
Records werden nicht unterstützt Funktionalität ist analog zu readf and printf in C
7.3.2 Funktionsweise von NFS
In der Regel werden nicht einzelne Dateien nach NFS exportiert, sondern ganze Unter-verzeichnisse
Jeder Rechner fungiert als NFS-Server für seine lokalen NFS-Dateien, d.h. er sorgt da-für, dass andere Rechner auf die Dateien zugreifen können, die er ins NFS exportierthat
Bezüglich des Zugriffs auf nicht-lokale Dateien ist er zugleich auch NFS-Client, soferner seinerseits auf entfernte NFS-Dateien zugreift
symmetrische Client/Server-Beziehung = peer-to-peer
NFS-Server und NFS-Client kommunizieren über NFS-Protokolle miteinander Ein Rechner, der auf eine nichtlokale Datei zugreifen möchte, muss zuvor dasjenige ex-
portierte Unterverzeichnis „mounten“, in dem sich die gewünschte Datei befindet.Hinweis: to mount: anbringen, befestigen
202
NFS abstrahiert das lokale Dateisystem jedes angeschlossen NFS-Rechners zu einemvirtuellen File-System, das unabhängig von Betriebssystem, Dateisystem und Zeichen-formaten ist
Alle Dateioperationen gehen zuerst an das virtuelle Dateisystem, indem sie von NFS„abgefangen“ werden
Lokale Dateizugriffe werden von NFS an das reale File-System weitergereicht, entfernteDateizugriffe gehen an den NFS-Server auf dem Rechner, der diese Dateien exportierthat

203
NFS besteht aus vier Komponenten:• Network File System, Mount, Status Monitor und Lock Manager
NFS benützt bis zur Version 3 für die vier Komponenten vier Protokolle Jedes Protokoll benutzt Remote Procedure Calls (RPC) und einen sog. PortmapperDef.: Der Portmapper wandelt sog. RPC-Programmnummern in Portnummern um, diedas lokale Betriebssystem verwaltet
Benutzer-prozess
Betriebssystemaufruf
NFS
Virt. Dateisystemlokal entfernt
Lokales Dat-eisystem
NFS Client
Lokale Festplatte
NFS
Virt. Dateisystem
Entferntes Dateisystem
NFS Server
Entfernte Festplatte
NFS-Protokolle
204
7.3.3 NFS-Protokoll (bis NFS-Version 3)
Dieses Protokoll ist die Basis von NFS und erlaubt das Erzeugen, Suchen, Lesen oderSchreiben von Dateien.
Es verwaltet auch die Authentifizierung und sog. Dateistatistiken Jeder Server ist aus Fehlertoleranzgründen „zustandslos“
Er speichert weder die Historie der Zugriffswünsche noch den Status ihrer Erfüllung
Bei entfernten Datei-Zugriffen gibt es keine „open“- oder „close“-Operation, sondernnur read, write und lookup (= dir-Befehl, bzw. ls -la)
Das Mounten von Unterverzeichnissen wird über ein anderes Protokoll durchgeführt(Mount), da es zustandsbehaftet ist (mounted/not mounted)
Mount- und NFS-Protokoll werden über SUN Remote Procedure Calls (RPCs) realisiert
7.3.4 Mount-Protokoll (bis NFS-Version 3)
Mount verbindet ein entferntes Datensystem mit einem lokalen Verzeichnis, d.h. der ge-samte entfernte Datei-Unterbaum wird in das lokale Verzeichnis „eingehängt“
Mount speichert als Zustand, was „eingehängt“ wurde, ist also nicht zustandslos Danach kann über NFS auf die entfernten Dateien wie auf lokale zugegriffen werden Nach Ende eines Mount-Vorgangs stellt Mount einige Informationen für NFS zur Verfü-
gung, z.B. Rechnernamen und Pfad

205
Mount basiert wie NFS auf dem Client/Server-Modell Mount- und NFS-Server-Prozesse sind als System-Demons realisiert und werden beim
Hochfahren des Servers automatisch gestartet Beim MOUNT-Vorgang wird auf der Server-Seite ein eindeutiger Dateisystem-Steuer-
block, der sog. File Handle, erzeugt und an den Client übergeben (Schritte 1 und 2) Der NFS- Client verwendet bei allen späteren Zugriffen auf den entfernten Verzeichnis-
teil nur den File Handle (Schritte 3b, 4a-4c)
Beispiel: Ablauf einer NFS-Kommunikation:
1.) Client kontaktiert den sog. Portmapper auf dem festen Port 111 und fragt nach demPort des Mount-Demons (Prozessname: „mountd“)
Mount-Client
1) Mount-Anforderung
2) File Handle erzeu-gen und übergeben
Mount-Server
3a) File Hand-le weiterrei-chen
3b) Mit File Handle zu-greifen
4a) remote write
4b) remote read 4c) remote lookup
NFS-Cli-ent
NFS-Ser-ver
206
2.) Portmapper gibt Portnummer des mountd
3.) Client kontaktiert mountd über dessen Portnummer und fragt nach dem File Handlefür "/<Unterverzeichnispfad">/<Unterverzeichnis>
4.) mountd gibt das File Handle 0 zurück
5.) Client kontaktiert Portmapper und fragt nach dem Port für NFS (Prozessname:„nfsd“)
6.) Portmapper gibt Portnummer des nfsd
7.) Client führt LOOKUP-Prozedur aus mit den Parametern File Handle 0 und Dateinamen<Dateinamen>.txt
8.) nfsd gibt als Resultat von LOOKUP das File Handle 1 für Datei <Dateinamen>.txtzurück
9.) Client führt READ auf dem File Handle 1 aus
10.)nfsd gibt ein oder mehrere Bytes von der Datei <Dateinamen>.txt zurück, d.h. Daten
7.3.5 Netzwerk Lock-Manager und Lock-Protokoll (bis NFS-Version 3)
Problem: Was passiert, wenn gleichzeitig mehrere Klienten auf dieselbe Datei schrei-bend zugreifen wollen?

207
Fehler
Lösung: Ein zusätzlicher NFS-Lock-Manager ermöglicht exklusiven Schreibzugriff ei-nes Klienten auf eine Datei durch wechselseitigen Ausschluss anderer Klienten
Neues Problem: wechselseitige Blockierung der Klienten kann dann entstehen, wennder Zugriff-habende darauf wartet, dass der ausgesperrte auf die exklusive Dateischreibt (=Deadlock)
Lösung ist nicht vorhanden; das Problem wird als Programmier- oder Bedienfehler desBenutzers betrachtet
7.3.6 Ab NFS-Version 4 (RFC 3530)
Ab Version 4 sind das Mount- und Lock-Protokoll Bestandteil des NFS-Protokolls Das NFS-Protokoll benützt den festen TCP-Port 2049, UDP wird nicht mehr unterstützt Die Verbindung ist nicht mehr zustandslos, was die Programmierung und die Netz-
werksicherheit z.B. durch Firewalls erleichtert, aber die Fehlertoleranz verringert Benutzer-Authentifikation wird ermöglicht
7.3.7 NFS und Datensicherheit (security)
Der Anschluss an ein Rechnernetz ist ein potentielles Sicherheitsrisiko, z.B. lassensich Ethernet-Rahmen oder IP-Pakete abfangen
NFS unterstützt Verschlüsselung und Authentifizierung über Kerberos
208
Hinweis: Kerberos ist ein verteilter Authentifizierungsdienst sowie ein Protokoll, um auf diesen Dienst zuzugreifen
Zusätzliche Sicherheitsmaßnahmen sind:• Mount- und NFS-Zugriffe sind nur von sog. privilegierten Ports erlaubt, die exklusiv von
bekannten Anwendungen und dem Betriebssystem benützt werden dürfen
Def.: privilegierte Ports sind alle Ports mit Port-Nr. <1024
• Bei jedem Mount- und NFS-Zugriff werden Rechnernamen und IP-Adressen mit den lokalenListen der „friendly hosts“ und der „unfriendly hosts“ verglichen (diese stehen bei UNIXin /etc/hosts.allow bzw. /etc/hosts.deny)
7.3.8 Netzwerk Status-Monitor
Wird benutzt, um den aktuellen Zustand eines an NFS angeschlossenen Rechners (Cli-ent oder Server) zu erfahren
Informiert z.B. über Herunterfahren oder Neustart eines Rechners (shut down/reboot)
7.4 Das Common Gateway Interface (CGI)
Def.: CGI ist eine Software-Schnittstelle zur Übergabe von Parametern für http Requestsund Responses zwischen Client und Server
Der Zweck von CGI ist es, Inhalte von web-Seiten (= http responses) an die Eingabendes Benutzers anpassen zu können (wichtig z.B. bei Suchmaschinen)

209
CGI erlaubt es auch, Server-Programme wie z.B. ein Java Servlet von demjenigenHTML-Dokument aus zu starten, das im Browser des Client angezeigt wird
Abhängig von den Eingaben, die der Benutzer auf seinem Web-Formular macht, kön-nen Server-seitig unterschiedliche Programme gestartet werden
Durch CGI können Programme in beliebigen Sprachen und beliebige Middleware vomBrowser auf dem Server aufgerufen werden: Skripte, Java-Servlets, Java Server Pages(JSP), Aktive Server pages (ASP), Programme in C, C++, C#, Java, ...
7.4.1 Erstellen einer dynamischen web-Seite (Web-Formular) über CGI
Der Server erzeugt nach der Eingabe in ein Web-Formular just-in-time eine neue Web-Seite und transferiert diese über das CGI-Protokoll zurück zum Client
Dazu schreibt der Server per printf auf seinen „stdout“ Output, und CGI sorgt zusam-men mit http dafür, dass diese Daten vom Browser Client angezeigt werden
CGI und http sorgen ferner dafür, dass die Client-seitigen Benutzereingaben in dasWeb-Formular vom Server über ein einfaches readf von seinem „stdin“ Input gelesenwerden können (= IO redirection von stdin und stdout)
Dabei spielen die Header von http Requests und Responses, sowie das durch CGI de-finierte Datenübertragungsformat eine zentrale Rolle
Hinweis: Die Request und Response Header sind Datenstrukturen, genau wie alle anderen Teile des http-Protokolls, die zwischen Client und Server ausgetauscht werden
210
Nach Erstellen und Übertragen der dynamisch erzeugten web-Seite (=http Response)wird diese vom Client-Browser interpretiert und visualisiert

211
7.4.2 Ablauf bei einer dynamischen web-Seite mit CGI
Client-RechnerAnfrage nach einer Web-Seite
Antwort: HTML-Da-tei zur Visualisierung
Web Browser z.B. Firefox
URL+Parameter per CGI und http senden
Ergebnisübertragen
Web Serverz.B. Apache
CGI-Benutzeran-wendung starten
html-Seite erzeu-gen
Bei Bedarf: SQL-Query erzeugen
Query-Ergebnis passend forma-tieren
CGI-Anwendung
Datenbankabfra-ge starten
Query-Ergeb-nis
Datenbank z.B. Oracle, mySQL
Server-Rechner
Eingabedatenparsen und aus-werten
html-Inhalt CGI- und http-gerecht formatieren
Internet
212
Die dynamische web-Seiten-Erzeugung umfasst folgende Schritte:
1.) Übertragen der Benutzereingaben vom Client zum Server durch http+CGI
2.) Server-seitig: Parsen und Auswerten der Eingaben durch CGI-Anwendung (Servlet,CGI-Skript, ...)
Hinweis: to parse: zerpflücken, hier: auf syntaktische Korrektheit prüfen
3.) Server-seitig: Prüfen der Zugriffsrechte des Benutzers durch die CGI-Anwendung
4.) Server-seitig: Erstellen der web-Seite durch CGI-Anwendung
5.) Server-seitig: Transfer der web-Seite zum Client durch http+CGI
6.) Speichern der Benutzereingaben beim Client durch Cookies auf der Festplatte oderüber versteckten Felder in web-seiten => zustandsbehaftetes Verfahren
Hinweis: die Speicherung in Cookies kann entfallen, wenn der Client beim Server registriert ist und dort in einer Datenbank seine (persönlichen) Daten hinterlassen hat.
Das Prüfen und Auswerten der Benutzereingaben ist wichtig, aber in konventionellenProgrammiersprachen aufwendig, da Parsen der Texteingaben durch Code erfolgt
Verwendung von speziellen Skriptsprachen (PERL, Python, PHP, etc.) beim Server,die komfortable String-Verarbeitung der Benutzereingaben erlauben

213
7.4.3 Serverseitiger Aufruf von CGI zur Bearbeitung eines html- Formulars
Das Starten einer CGI-Anwendung beim Server erfolgt nach dem Einlesen der Benut-zer-Eingaben in ein web-Formular über das html-Kommando:
<FORM ACTION = „URL“ METHOD = „HTTP-Methode“> </FORM>
Dabei ist:• „URL“: die Angabe einer Datei auf dem Server, die das Programm enthält, das aufgerufen
werden soll• „HTTP-Methode“: die Art der Parameterübergabe an das CGI-Programm. Üblich sind POST
und GET
Beispiel:<FORM ACTION="http://www.informatik.tu-clausthal.de/cgi-bin/programm.pl" METHOD="POST"> </FORM>
7.4.4 Parameterübergabe zwischen Web Client und Web Server
METHOD=POST:
1.) Der Web Client (=Browser) verpackt alle Benutzereingaben als Parameter im CGI-For-mat in einem http request, zusammen mit dem POST-Kommando
214
2.) Stdout und stdin des Servers werden durch CGI+HTTP mit stdin und stout des Clientüber das Internet verbunden => bidirektionale Kommunikation durch Überkreuzkopp-lung der stdins mit den stdouts
3.) Der Client schreibt den http request auf stdout. Im Header des http requests wirddabei die Zahl der übertragenen Bytes an den Server übermittelt.
4.) Von CGI wird die Zahl der übertragenen Bytes in der UmgebungsvariableCONTENT_LENGTH des Web Servers gespeichert
5.) Der Web Server liest die Zahl der übertragenen Bytes von CONTENT_LENGTH, damiter weiß, wie viele Bytes er von stdin lesen muss
6.) Der Web Server liest danach den http request von stdin, führt ihn aus und beantwor-tet ihn mit einer http response, indem er die response auf sein stdout schreibt
METHOD=GET:
1.) Der Client hängt die Benutzereingaben im CGI-Format an die URL an und verpackt dieverlängerte URL in einem http request, zusammen mit dem GET-Kommando und denBenutzereingaben
2.) Die Benutzereingaben werden von CGI dem http request entnommen, in die Umge-bungsvariable QUERY_STRING des Servers eingetragen und dort von der Server-Anwendung gelesen.

215
3.) Zum Zurückschicken der angefragten web-Seite vom Server zum Client werden eben-falls Umgebungsvariablen mit denselben Namen benützt, diesmal sind sie jedoch aufder Client-Seite, und der Client liest daraus. Dazu beschreibt CGI die Umgebungsvari-ablen des Clients, und die Client-Anwendung (=Browser) wertet die http Responsedes Servers aus.
Darüberhinaus gibt es sowohl für GET und POST zusätzliche Umgebungsvariablenbeim Server, deren Wert von der Client-Anwendung über http+CGI geschrieben wer-den
Durch CGI ist festgelegt, in welchem Format die Parameter und Umgebungsvariablenauf stdout geschrieben bzw. an die URL angehängt werden
7.4.5 Das CGI-Parameterformat
Die Felder der Formulare mit den Benutzereingaben werden als Paare der Form Schlüs-selwort = Wert dargestellt
Diese Paare wurden zuvor durch html-Tags und durch die Eingaben des Benutzersfestgelegt:
Beispiel: für html-Tag „Straße“ in einem web-Formular:
Straße: <INPUT TYPE = "text" NAME = "Straßenname"> Die Eingabe des Benutzers für das tag Straße, wie z.B. der String "Maximilianstr.", wird
in der Variablen "Straßenname" gespeichert
216
Das Variablenpaar Schlüsselwort = Wert wird zu Straßenname="Maximilianstr."
Der Beginn der Parameter wird von der eigentlichen URL durch ? abgetrennt Stehen mehrere Variablenpaare hinter einem ?, werden sie durch & getrennt Leerzeichen in den Werten werden durch + ersetzt Umlaute, Sonderzeichen usw. werden genau wie bei Quoted Printable Encoding mittels
des UTF-8-Codes übertragenHinweis: UTF-8 ist ein Zeichencode aus 1-4 Byte. Deutsche Umlaute erfordern zwei Byte.
Der UTF-8-Code wird ziffernweise in Form von ASCII-codierten, hexadezimalen Zahlen(0...9, A-F) übertragen
Beispiel: Die Ziffer „0“ hat in ASCII den Wert #30, und das Anführungszeichen “ ist #22
Im Gegensatz zu Quoted Printable Encoding wird ein % als einleitende Kennung jederASCII-Nummer vorangestellt, die wiederum hexadezimal ausgedrückt wird
Beispiel:
Vorname=Michael+J%C3%BCrgen&Nachname=Gr%C3%BCndlerBeispiel: Eine Google-Suche nach „Michael Jürgen Gründler“ (in Anführungszeichen)wird von der Suchmaschine übersetzt in:

217
https://www.google.de/search?q=%22Michael+J%C3%BCrgen+Gr%C3%BCnd-ler%22&ie=utf-8&oe=utf-8&rls=org.mozilla:en-US:official&client=firefox-a&gws_rd=cr&ei=b3HFUq7FHai54ASyk4GIBQ
7.4.6 Speicherung der Benutzereingaben
Eine TCP-Verbindung besteht nur für die Dauer von der Anforderung einer web-Seitebeim Server bis zu deren Übertragung zurück zum Client (= http V1.1)
Vor und nach der Übertragung von web-Seiten speichert der Server keine Informatio-nen des Client (=zustandsloser Client)
Bei Formularen und Transaktionen, die mehrere web-Seiten umfassen, müssen jedochBenutzereinträge zwischengespeichert werden
Die Zwischenspeicherung erfolgt in versteckten html-Feldern oder beim Client in„Cookies“ oder beim Server in dessen Benutzerdatenbank, wenn der Client registriertist
7.4.6.1 Versteckte Felder
Vertrauliche Informationen über den Benutzer werden u.a. in versteckten Felder abge-speichert
In einer Web-Seite werden versteckte Felder vom Browser nicht angezeigt. Deswegenheißen sie „versteckt“.
218
Versteckte Felder werden allerdings beim Seitenabruf (Request) und bei der Rücküber-tragung zum Server durch die http-post-Methode mit transferiert
Vertrauliche Daten werden mit POST von einer web-Seite zur nächsten durch Anhän-gen an die mit GET geholte Seite weitergereicht
7.4.6.2 Cookies
Alternative Möglichkeit zur Speicherung von Benutzereingaben sind CookiesHinweis: Cookie=süßer Keks, Plätzchen
Web-Server legen beim Client mit Hilfe des Client Browsers Textdateien an, in denen(vertrauliche) Informationen über den Benutzer gespeichert werden
Benutzereingaben werden in solchen Cookies ähnlich wie bei CGI als Paare der FormSchlüsselwort = Wert gespeichert, z.B. Kontonummer="xxx."
Alle nachfolgenden http Requests und Responses können auf diese Dateien zugreifen,sofern rel. leicht zu erfüllende Bedingungen zum Schutz des Benutzers zutreffen
Diese Bedingungen sind eine Browser-Einstellung, die den Cookie-Zugriff erlaubt, so-wie die Information, ob die DNS-Domain des Servers und der Pfad, in dem die Web-Sei-te liegt, „zugelassen“ sind
„zugelassen“ heißt, dass vom Browser kontrolliert wird, ob die DNS-Domain des Ser-vers und sein Pfad mit den Wertepaaren Domain = <DNS-Name> und path = Pfadanga-be in dem Cookie übereinstimmen, das der Server zuvor angelegt hat

219
Aufgrund dieser schwachen Schutzes sind Cookies eine große Sicherheitslücke, so-fern sie nicht vom Server verschlüsselt abgelegt werden, was oft, aber nicht immer derFall ist
Cookies sind weit verbreitet, da einfach zu realisieren und für E-Commerce wichtig Heutzutage werden Cookies oft durch Server-seitige Datenbanken ersetzt, in denen der
Client nach einer Registrierung seine persönlichen Daten hinterlegt hat
7.4.6.3 Erstellen eines Cookies
Ein Cookie wird vom Server beim Client z.B. dadurch erstellt, dass das „Set-Cookie“-Schlüsselwort im Header der http-Response steht
Syntax des Set-Cookie-Schlüsselworts: Set-Cookie: NAME=VALUE; expires=DATE;path=PATH; domain=DOMAIN_NAME; secure
220
7.4.6.4 Bedeutung der Datenfelder im Set-Cookie-Schlüsselwort
Beim Anfordern einer web-Seite (URL) sendet der Client automatisch die bei ihm ge-speicherten Cookies an den Server, sofern sie folgende Bedingungen erfüllen:
1.) Der Server muss in der im Domain-Schlüsselwort angegebenen DNS-Domain liegen.Seine Domain ist aus der URL ersichtlich.
Beispiel: Wenn Domain = tu-clausthal.de gesetzt ist, dann wäre ein Zugriff für den Ser-ver informatik.tu-clausthal.de zugelassen
2.) Die Pfadangabe in der angeforderten URL muss als Zeichenkette bei der path = Pfa-dangabe enthalten sein
Beispiel: Wenn path = /TechnischeInformatik gesetzt ist, dann wäre eine URL der Arthttp://www.informatik.tu-clausthal.de/TechnischeInformatik.html zulässig
Datenfeld Beschreibung
Name Name des Cookies
Value Definition des Namens
Expires Verfallsdatum des Cookies
Domain DNS-Domain, an welche dieses Cookie automatisch gesendet werden soll
Secure wenn TRUE, darf Cookie nur mit HTTPS, d.h. verschlüsselt gesendet werden
path Pfadangabe auf dem Server-Rechner, wohin das Cookie transferiert werden soll

221
Nach dem Senden des Cookies vom Client zum Server wird dessen Inhalt durchCGI+http in die Umgebungsvariable HTTP_COOKIE des Servers kopiert
Die CGI-Anwendung des Servers kann anschließend HTTP_COOKIE lesen Cookies können vom Server beim Client auf insgesamt 2 Arten geschrieben werden:
1.) Durch das Set-Cookie-Schlüsselwort im Header der http Response. Dann schreibt derBrowser das Cookie, nachdem er den http Response Header interpretiert hat.
2.) Durch ein spezielles HTML-Kommando im Quelltext der dynamischen web-Seite
Im Fall 2 interpretiert der Browser die html-Seitenbeschreibung und wird internumkonfiguriert, so als ob im http Response Header das Set-Cookie-Schlüsselwortgesetzt wäre = schlechter Programmierstil, da nach aussen nicht sichtbar ist, waspassiert
7.4.6.5 HTML-Kommando zur Cookie-Erstellung
Das HTML-Kommando zur Cookie-Erstellung ist Teil des sog. META-tags von HTML:<META HTTP-EQUIV="FieldName" CONTENT="value">
Es können in "FieldName" verschiedene Response-Header-Schlüsselworte angegebenwerden, z.B auch „Set-Cookie“
Beispiel: <META HTTP-EQUIV="Set-Cookie" CONTENT="Kreditkartennr=yyy";expires=Friday, 31-Dec-16 23:59:59 GMT; path=/">
222
Das Löschen eines Cookies beim Client durch den Server erfolgt dadurch, dass dasgleiche Cookie noch einmal geschrieben wird, aber mit einer Expires-Zeitangabe, diein der Vergangenheit liegt = ebenfalls schlechter Programmierstil, da nicht klar erkenn-bar ist, was passiert
7.5 Remote Procedure Calls (RPCs)
Internet-Anwendungen werden grundsätzlich in einem Rechnernetz verteilt ausge-führt, oft nach dem Client/Server-Modell, manchmal aber auch gemäß Peer-to-Peer
zwischen den Rechnern ist Kommunikation erforderlich (= Interprozesskommunika-tion)
Zur Durchführung der Kommunikation sind verschiedene Verfahren üblich:
1.) Anwendungsspezifische Protokolle, die auf der Transportschicht aufsitzen (smtp, ftp,http, CGI, REST, WebDAV, SOAP, ...)
2.) Client-/Server-Konzept mit Prozedur- oder Methodenfernaufrufen
Beide Verfahren realisieren einen Botschaftenaustausch nach dem Rendezvous- oderdem Mailbox-Modell (Rendezvouz = synchron, Mailbox = asynchron)
Hier soll nur das Client-/Server-Konzept mit Prozedurfernaufrufen diskutiert werden
Es gibt dabei mindestens zwei beteiligte Partner: einen Client- und einen Server-Rechner

223
Zusätzlich kann der Server aus Geschwindigkeits- und/oder Zuverlässigkeitsgründenauf mehrere Rechner verteilt oder als Parallelrechner implementiert sein
Client und Server sind i.a. heterogen, d.h. verschieden bzgl. Hard- und SoftwareHinweis: Heterogen bedeutet: anderer Prozessortyp, anderes Betriebssystem, andere interne Zahlendarstellung, andere Hardware-/Software-Ausstattung, u.s.w.
7.5.1 Definition von RPCs
RPCs sind i.a. genau wie lokale Prozeduraufrufe blockierend (="synchron")
Client muss warten, bis Prozedur fertig ausgeführt ist (gibt auch Ausnahmen)
Client-Rechner Server-Rechner
Fernaufruf
Ergebnis
Steuerfluß- und Da-tenübergabe
angebotene Prozeduren
getrennte Adreßräume!
224
7.5.2 Eigenschaften von RPCs
RPCs existieren für fast jedes Betriebssystem und sind weit verbreitet RPCs sind eine Erweiterung von normalen Prozeduraufrufen, damit Unterprogramme
auf einem anderen Rechner als dem aufrufenden ausgeführt werden können Der Rechner, der eine entfernte Prozedur aufruft, hat die Rolle eines Klienten (Auftrag-
geber) Der Rechner, der einen RPC ausführt, ist ein Server bzgl. dieses RPC (Auftragnehmer) Die Rollen von Client und Server können fest vergeben sein (=Client/Server-Modell)
oder dynamisch wechseln (=Peer-to-Peer-Modell) Die Heterogenität der Rechner muss dabei Client und Server verborgen bleiben
Für RPCs ist eine Zusatzsoftware erforderlich. Diese dient für:
1.) die automatische Formatkonversion
2.) zum Starten von Unterprogrammen auf dem entfernten Rechner
3.) zum Rücktransfer von Ergebnissen
7.5.3 Unterschiede zu lokalen Prozeduraufrufen
Client- und Server-Programme laufen in verschiedenen Adressräumen, da getrennteRechner

225
Parameterübergabe ist kompliziert bzw. geht bei Zeigern als Parameter gar nicht
Netzwerkkommunikation ist involviert
Transfer von Parametern und Ergebnis dauert aufgrund der Internet-Latenz lang
Netzwerkprobleme können zu RPC-Fehlern führen
Erweiterte "Fehlersemantik" zur sinnvollen Nutzung von RPCs
Zusätzlich gibt es asynchrone (nicht blockierende) RPC-Varianten Diese erfordern eine komplexere Programmierung, erlauben aber Nebenläufigkeit zwi-
schen Client und ServerHinweis: Nebenläufigkeit ist der Oberbegriff sowohl für Parallelverarbeitung, d.h. für echte Gleichzeitigkeit, als auch für zeitliche Verzahnung im Sinne eines time-sharings
Hinzu kommen Inkompatibilitäten aufgrund der Heterogenität von Client und Server
7.5.3.1 Inkompatibilitäten bei der Rechnerkommunikation
Es gibt zahlreiche Möglichkeiten für Inkompatibilitäten bei der Rechnerkommunikation:
1.) Bit-Anordnung im Byte: Das MSB kann im Byte links oder rechts stehen. Beispiel: Xilinx Microblaze: MSB steht rechts; Intel Pentium: MSB steht links
2.) Byte-Anordnung im Wort:
226
• „Big endian“: Most significant Byte liegt auf der niedrigsten Speicheradresse (SUN-Pro-zessoren)
• „Little endian“: Least significant Byte ist auf der niedrigsten Speicheradresse (Intel-Pro-zessoren)
3.) Wort-Anordnung im Adressraum. Beispiel für 32-Bit-Worte:• Wort kann bei jeder Byte-Adresse im Speicher beginnen• Wort kann bei jeder durch 2 teilbaren Byte-Adresse (=gerade Adresse) beginnen• Wort kann bei jeder durch 4 teilbaren Byte-Adresse beginnen
4.) Ungleiche Wortbreiten der Prozessoren. Beispiele:• Prozessor 1 hat 32 Bit Wortbreite => Datentyp INT hat 32 bit• Prozessor 2 hat 64 Bit Wortbreite => Datentyp INT hat 64 bit• Prozessor 2 will Prozessor 1 ein INT schicken. Was wird passieren?
5.) Repräsentation von ZeichenBeispiel: 7-Bit ASCII, UTF-8, ISO 8859-1, ...
6.) Repräsentation von Zeichenketten (Strings). Beispiele:• Länge des Strings wird als erstes Zeichen im String vermerkt• String wird mit spez. Zeichen abgeschlossen, z.B. #00 oder ASCII-Zeichen EOT (End of
Text)• String wird mit <CR><LF> abgeschlossen (Windows)

227
• String wird mit <LF><CR> abgeschlossen (MacOS)
7.) Repräsentation von Datenstrukturen (structs bzw. records)• Je nach Compiler werden Datenstrukturen unterschiedlich im Speicher abgelegt. Das
Hauptproblem hierbei sind die sog. Füllbytes (Paddings).
Beispiel: der GNU C-Compiler erzeugt auf einem 32-Bit Rechner für eine struct aus denElementen BOOL und CHAR ein Byte für char und vier Byte für BOOL. D.h. BOOL wirdwie INT behandelt => 3 Füllbytes, aber wo steht die BOOL-Information in den vier Byte?
Alle aufgeführten Inkompatibilitäten können einzeln oder in Kombination auftreten underschweren den Austausch von E-mails sowie die Kommunikation bei verteilten An-wendungen erheblich
Trotzdem funktionieren E-mail und verteilte Anwendungen meistens gut. Warum?
Durch automatische Konversion zwischen den verschiedenen Formaten in denAnwendungen nach den stets gleichen Regeln
7.5.4 Parameterübergabe bei RPCs
1.) Problem: Aufrufparameter und Ergebnis (return values) können nicht wie bei einemnormalen Unterprogrammaufruf auf dem Stack abgelegt werden
Lösung:• Call-by-Value-Parameter wie INT oder CHAR werden als Werte über das Netz übertragen
228
• Datenstrukturen aus INT oder CHAR, wie Bäume, Listen oder Keller werden Element fürElement als Werte übertragen
• Zeiger auf Datenstrukturen (Call-by-Reference-Parameter) werden dereferenziert, und dieInhalte der Datenstrukturen werden Wert für Wert übertragen
• Beim Server wird eine Kopie der Datenstruktur wieder aufgebaut, anschließend erfolgteine neue Referenzierung auf die Kopie im Server-Adressraum
Die Semantik von Zeigern ändert sich von Call-By-Reference zu Call-By-Copy-and-Restore
2.) Problem: Aufgrund der Heterogenität der vernetzten Rechner sind u.a. Bit-Anord-nung, Byte-Anordnung, Wort-Anordnung, Zeichen- und Stringkodierung unterschied-lich
Parameter müssen in einer vereinbarten Rechner- und BetriebssystemunabhängigenSyntax ausgetauscht werden
Dazu gibt es zwei Möglichkeiten:
1.) Symmetrisches Verfahren: Client und Server verwenden ein gemeinsames, drittesFormat
Konvertierungsroutinen sowohl bei Client als auch bei Server erforderlich
2.) Asymmetrisches Verfahren: Man einigt sich auf das Format des Client oder des Ser-ver

229
Konvertierungsroutinen nur bei Client oder nur bei Server erforderlich
Bei SUN RPCs wird ein gemeinsames drittes Format verwendet, die sog. External DataRepresentation, XDR
In beiden Fällen müssen die Aufruf und Return-Parameter erst konvertiert und dann ei-ner nach dem anderen in einer vorab bekannten Reihenfolge über das Netz geschicktwerden (= Serialisierung bzw. „marshalling“)
Hinweis: to marshall = anreihen
Bei der Serialisierung muss zwischen Client und Server vorab vereinbart werden oderfest in die Anwendungen programmiert sein, in welcher Reihenfolge die Elemente derDatenstrukturen übertragen werden
7.5.5 Aufruf einer entfernten Prozedur
Für Konversion u. Serialisierung der Parameter und des eigentlichen Prozeduraufrufsbeim Server ist Zusatz-Software bei Client und bei Server erforderlich
„Client Stub“ und „Server Stub“Hinweis: stub = Stummel
Prozedurfernaufruf mündet zunächst in einen Aufruf des lokalen Client Stubs Client Stub initiiert dann den Fernaufruf
230
Client Stub kommuniziert dazu mit dem Server Stub auf der Gegenseite durch Transferder konvertierten und serialisierten Parameter
Server Stub de-serialisiert die Parameter (unmarshalling) und ruft die gewünschte Pro-zedur auf dem Server als lokale Prozedur auf

231
7.5.5.1 Ablaufdiagramm des Fernaufrufs
Client-Prozesslokaler Unterprogrammauf-ruf
lokal verfügbares Er-gebnis
Client-StubParameterliste pak-ken (marshalling)
Ergebnis auspacken (unmarshalling)
Parameterliste übertragen
Ergebnis empfangen
UDP/TCP/IPWarten
Empfangen lokal verfügbares Er-gebnis senden
Server-StubParameterliste auspak-ken (unmarshalling)
Ergebnis einpacken (marshalling)
lokales Unter-programm auf-rufen
Server-Prozess
Datenpaket(e) mit Aufruf und Parameterliste via Internet über-tragen
Datenpaket(e) mit Ergebnis via In-ternet übertragen
UDP/TCP/IP
Aufruf aus-führen und auf Ergebnis warten
Aufruf ausge-führt, Ergeb-nis da
Client-Rechner mit Client Anwen-dung als Prozess
Server-Rechner mit Serverpro-zess
232
1.) Der Client ruft die lokale Stub-Prozedur auf. Der Stub erzeugt eine Funktionskenn-nummer zur Identifikation der gewünschten Prozedur und verpackt deren Parameterals Nachricht und serialisiert das Ganze (marshalling)
2.) Netzwerkfunktion des Betriebssystems zum Nachrichten senden wird vom Client-Stub aufgerufen (dazu Prozess-Kontextwechsel und Socket-Kommunikation)
3.) Das Betriebssystem verschickt die Nachricht über eine verbindungslose oder verbin-dungsorientierte Kommunikation, d.h. über IP und UDP oder TCP
4.) Der Server erhält einen Interrupt von der Netzwerkkarte, der passende Server-Stubwird aus der Liste der wartenden Prozesse herausgesucht und aktiviert. Danach de-serialisiert der Server-Stub die Parameter (unmarshalling)
5.) Der Server ruft lokal die gewünschte Prozedur mit den empfangenen Parametern auf
6.) Nach Beendigung der Prozedur erhält der Server-Stub erneut die Kontrolle über denProgrammfluss
7.) Der Server-Stub verpackt die Ergebnisse als serielle Nachricht
8.) Verschicken der Nachricht an den Client
9.) Empfangen der Nachricht vom Client
10.)De-serialisieren der Nachricht durch die Stub-Prozedur des Clients. Empfange Wertewerden dem Anwendungsprogramm zur Verfügung gestellt.

233
7.5.5.2 RPC-Aufruf inkl. der Betriebssystemdienste
Für einen korrekten RPC-Ablauf muss außerdem das darunterliegende Betriebssystemdiverse Dienste bereitstellen
Diese sind nachfolgend dargestellt:
Client-Rechner Server-Rechner
Client-Stub rufen
Clie
nt/
Serv
er
Server-Prozedur ausführen
Marshalling, Resolver aufrufen um IP-Adresse zu bestimmen,Berkeley Socket Aufrufpara-meter erzeugen, Berkeley Sok-ket aufrufen
4. Server-Anwendung aufru-fen 3. Aufrufparameter auf den Stack pushen1. Unmarshalling
Stub
s
Kontextwechsel zum BS, Nachricht in BS-Puffer kopie-ren, Netzwerkkarte starten,Timeout-Überwachung starten
6. Kontextwechsel zum Stub 5. Nachricht zum Stub kopie-ren4. TCP/IP Instanzen schedu-len 3. Interrupt Service Routine schedulen1. Netzwerk-Interrupt da?
Bet
riebs
syst
em
TCP/IP
Client-Anwen-dung
Server-Anwen-dung
234
7.5.6 Zusammenbinden des Client mit dem RPC Server
Wie erfährt ein Client, welcher Server die gewünschte Fernprozedur ausführt? Im einfachsten Fall kennt der Client a priori die Netz- und Port-Adresse des Servers
(statisch) Im Allgemeinfall erfährt der Client die Adressen durch das sog. verteilte Binden (= dy-
namisches Linken)Hinweis: als Binden („Linken“) wird das Zusammenbinden einer Benutzeranwendung mit Bibliotheksfunktionen bezeichnet. Das Ergebnis des Linkens ist ein ausführbares Programm.
7.5.6.1 Statisches Binden
Serveradresse und Portnummer sind statisch im Code des Client verankert
Client und Server werden bereits bei der Codierung aneinander gebunden
Nachteil: Neukodierung und Neukompilation notwendig, sobald sich etwas ändert
7.5.6.2 Dynamisches Binden
Die von Servern angebotenen Fernaufrufe werden in einem lokalen Netz einer zentralenInstanz, dem sog. Binder (Linker) bekannt gemacht. Im globalen Internet ist dies jedochnicht so einfach
Zur Beschreibung eines lokalen Aufrufs (Calls) ist die Angabe von Name und Aufrufpa-rameter notwendig

235
Im globalen Internet müssen aber wesentlich mehr Metainformationen zur Verfügungstehen, sonst kommt es zu keinem Fernaufruf
Über spez. „Schnittstellenbeschreibungssprachen“ (Interface Definition language,IDL) wird deshalb vom Server für den Binder die sog. Signatur jedes Fernaufrufs spe-zifiziert und dieser beim Binder angemeldet
7.5.7 Signatur einer RPC-Funktion
Die Signatur einer Prozedur besteht aus:
1.) Name der Prozedur
2.) Namen, Reihenfolge und Typ der Parameter
3.) Vorschriften zum Verhalten im Fehlerfall (exceptions)
Mit Hilfe der Schnittstellenbeschreibungssprache können die Client und Server Stubsautomatisch erzeugt werden
Spezielle RPC-Compiler erzeugen aus der Schnittstellenbeschreibung den Code derStubs, entweder als C Source Code oder als Object Code
7.5.8 Beispiel SUN RPCs
Die von Sun entwickelten RPCs setzten sich im wesentlichen aus den folgenden Be-standteilen zusammen:
236
1.) Der betriebssystemunabhängigen Datendarstellung „XDR“ (= external data represen-tation) für den Datentransfer zwischen den beteiligten Rechnern
2.) Einer XDR-Bibliothek, welche die auf der lokalen Maschine benutzten Datendarstel-lung nach XDR konvertiert und vice-versa
3.) XDR wurde darüberhinaus zu einer Schnittstellenbeschreibungssprache (IDL) erwei-tert
4.) Das Programm „rpcgen“, das aus einer XDR-Schnittstellenbeschreibung C-Quellcodefür Client- und Server-Stub erzeugt (= RPC-Compiler)
5.) Einer Bibliothek mit RPC-Dienstfunktionen
6.) Zwei Verwaltungsinstanzen „Portmapper“ und „rpcbind“ für die zur Verfügung ste-henden RPC-Aufrufe auf einem Server
• der Portmapper verwaltet auf dem Server die TCP/UDP-Port-Adressen für die SUN RPCs • rpcbind registriert die auf dem Server verfügbaren SUN RPCs und bringt Client und Server
zusammen
7.5.9 Automatische Stub-Code-Erzeugung für RPCs
Der Client- und Server Stub eines RPCs wird automatisch von einem RPC-Compiler ausder Schnittstellenbeschreibung erzeugt

237
Außerdem wird automatisch vom RPC-Compiler eine Include-Datei für den Linker er-zeugt
Zuletzt werden vom Linker alle Teile zu zwei lauffähigen Programmen für Client undServer zusammengebunden
Der Server Stub bleibt wie er ist, für jede neue Client-Anwendung hingegen muss einneuer Client Stub erzeugt und hingebunden („linked“) werden
7.5.10 Verteiltes Binden von Client und Server
Die Information, wo der Server zu einer Fernprozedur zu finden ist, erhält der Clientdurch sog. verteiltes Binden, z.B. über rpcbind
Der Server macht dazu seine Prozeduren einer dritten Instanz (rpcbind) bekannt Alle drei Instanzen, Client, Server und rpcbind können irgendwo im Internet verteilt
sein Das Bekanntmachen heißt auch „Registrieren“ bei rpcbind bzw. „Exportieren“ der
Schnittstellenbeschreibung durch den Server Der Binder rpcbind ist eine zentrale Software-Instanz, die in jedem lokalen Netz min-
destens einmal vorhanden sein muss (bei Anwendungen ohne fest kodierte Server-Ad-ressen)
Durch verteiltes Binden entsteht eine Zuordnung zwischen Client-Prozeduraufruf undServer-Prozeduren
238
Sinn des verteilten Binden ist, dass der Client dynamisch erfährt, welcher Server imNetz die benötigte Prozedur hat und wie sie angesprochen wird
Der Client fragt dazu den Binder rpcbind, welcher Server einen RPC mit passenderSchnittstellenbeschreibung hat
Vorteil 1 der Methode: Änderungen der Server-Adresse, Umschalten auf Backup-Ser-ver oder Systemumkonfigurationen bleiben dem Klienten verborgen
Vorteil 2: Der Client bleibt up-to-date hinsichtlich des RPC-Angebots und der RPC-Ver-sionen des Servers
Nach dem Binden kommunizieren Client und Server direkt über ein sog. „Handle“ mit-einander (verbindungslos über UDP oder verbindungsorientiert über TCP)
Durch verteiltes Binden mittels rpcbind erfährt der Client:• Das Protokoll, das auf dem Netz verwendet wird (TCP oder UDP)• Den symbolischen DNS-Namen bzw. die IP-Adresse des Servers• Die Port-Adresse jeder Prozedur des Servers
Die Vergabe der passenden Server IP-Adresse erfolgt zu Beginn des Programmab-laufs des Klienten oder sogar erst bei dessen erstem Fernaufruf (= late binding)

239
7.5.10.1 Ablauf des verteilten Bindens
1.) Server ruft im Server Stub eine Registrierungsprozedur auf
2.) Dadurch wird beim Binder rpcbind eine Registrierung der exportierten Prozedur mitHilfe der Schnittstellenbeschreibung der Prozedur vorgenommen
• Die Registrierungstabelle des Binders enthält folgende Tripel:• (DNS-Server-Name, Schnittstellenbeschreibung in einer IDL, TCP-/UDP-Port)
3.) Client ruft im Client Stub eine Anfrageprozedur auf
Binder rpcbindRegistrierungstabelle
Server
Server-Anwendung
Server Stub
TCP-/UDP-Protokoll
Client
Client-Anwendung
Client Stub
TCP-/UDP-Protokoll
1
2
3
4
56
7
240
4.) Dadurch wird der Binder nach einem Server mit passender Prozedurbeschreibunggefragt
5.) Client Stub erhält gewünschte Serveradresse zusammen mit dem Protokoll und einerPort-Nr., dem sog. Handle (= „Griff“), falls das Gewünschte vorhanden ist
• Danach kommunizieren Client und Server direkt
6.) Client Stub schickt TCP-/UDP-Paket, das Prozedurnamen und Aufrufparameter ent-hält, zum Server Stub
7.) Server Stub antwortet mit TCP-/UDP-Paket, das das Ergebnis des Aufrufs enthält
7.5.11 Fehlersituationen bei RPCs
Es gibt bei RPCs verschiedene Möglichkeiten für das Auftreten eines Fehlers:
1.) Absturz eines beteiligten Rechners (Client oder Server) • ist besonders kritisch, wenn der Ausfall während der Ausführung einer Operation auftritt,
da unklarer Zustand hinterlassen wird
2.) Plötzliche Unerreichbarkeit eines Rechners wegen Probleme im Netz oder im Rech-ner
• Handhabung durch sicheres Transportprotokoll (TCP) und/oder RPC-Laufzeitumgebung• Reaktion von TCP: Paketwiederholung

241
• Reaktion der RPC-Laufzeitumgebung: dynamisches Binden an Backup-Server (sofern vor-handen)
3.) Eingestellter Export einer Prozedur (= Prozedur gibt es nicht mehr, z.B. aufgrundeines Updates im Server)
• Reaktion auf RPC-Ebene: Binden an anderen Server im Netz, der die gewünschte Prozedurebenfalls hat (sofern vorhanden)
Zwei grundlegende Anforderungen dabei: • Kein endloses Warten des Clients auf einen abgestürzten oder unerreichbaren Server• Keine verwaisten Prozeduren beim Server nach abgestürztem Client, d.h. kein endloses
Warten des Servers auf einen abgestürzten Client
7.5.11.1 RPC-Fehlersemantik Es gibt bei verteilten Anwendungen verschiedene Möglichkeiten, wie auf eine Fehler-
situationen reagiert werden kann Bei RPCs wird meist die At-Most-Once-Strategie verwendetDef.: At-Most-Once: höchstens einmalige Ausführung des aufgerufenen Unterpro-gramms, d.h. Ausführung erfolgt entweder ganz oder gar nicht (= atomare Strategie)
At-Most-Once versucht negative Auswirkungen im Fehlerfall zu vermeiden: es passiertim schlimmsten Fall gar nichts
Wird meist kombiniert mit ein. Fehlermeldung, falls nichts passiert ist (sofern möglich)
242
7.5.12 Geschwindigkeit von RPCs
RPCs sind nicht besonders schnell, sondern benötigen Millisekunden oder sogar Hun-derte von Millisekunden, um über das Internet eine Prozedur aufzurufen (nicht auszu-führen!) und die Ergebnisse zurück zu transportieren
Nichstdestotrotz basieren große Programmsysteme wie z.B. das cloud OS OpenStacku.a. auf RPCs, was problematisch ist
7.5.13 Maßnahmen zur Effizienzsteigerungen bei RPCs
Ursachen für RPC-Effizienz-Probleme:• RPCs sind prinzipiell zeitaufwendig, da ihre Implementierung zahlreiche Befehle erfordert• Bei RPCs ist die Antwortzeit für einen Fernaufruf (= Latenz) wichtiger als die Datenrate bei
der Parameterübergabe, da i.d.R. nur wenige und kurze Parameter (= wenige Daten) über-geben werden
• Bei TCP und UDP wird aber die Datenrate auf Kosten der Latenz optimiert, da die langenHeader der TCP- und UDP-Pakete sich nur bei großen Paketlängen rentieren
• Je nach RPC-Implementierung werden außerdem die Parameter mehr oder weniger oft ko-piert, bevor sie übertragen werden, z.B. Kopieren vom Benutzeradressraum -> Betriebssy-stemadressraum -> Netzwerkkarte
• Beim Empfangen des Ergebnisses erfolgt alles nochmal in umgekehrter Reihenfolge
Ziel: Minimierung der Kopiervorgänge

243
• Weiteres Problem: Wird ein Fernaufruf rekursiv verwendet, entsteht zusätzlich eine Blok-kadesituation, da ein Server sich nicht selbst aufrufen kann
• Dazu verwandtes Problem Nr. 1:· Trifft ein zweiter Fernaufruf bei einem Server ein, während dieser noch einen ersten Auf-
ruf bearbeitet, muss der zweite warten • Verwandtes Problem Nr. 2:
· Durch den blockierenden (=”synchronen”) Charakter der Fernaufrufe kann keine Paral-lelverarbeitung zwischen Client und Server entstehen
Es gibt drei alternative Lösungsmöglichkeiten:• Verwendung von sog. Vater- und Kindprozessen beim Client und/oder Server und Verteilen
derselben auf mehrere Cores• Verwendung von „leichtgewichtigen Prozessen“ (Threads) beim Client und/oder Server,
um Wartezeiten bei Ein-/Ausgabevorgängen durch Umschalten auf einen anderen Threadzu verdecken
• Erweiterung auf asynchrone (= nicht-blockierende) Fernaufrufe, was aber programmier-technisch auf der Client-Seite schwer zu beherrschen und zu testen ist
Hinweis: Child-Prozesse bzw. Threads sind Methoden zur Effizienzsteigerung durch Nebenläufigkeit, echte Parallelität kann aber nur durch Multicore-CPUs erzielt werden
7.5.13.1 Verminderung der Kopienzahl
Neben des Overheads durch Kontextwechsel, Datentransfer, Prüfsummenberechnungetc. stellen Kopiervorgänge im selben Rechner einen bremsenden Faktor dar
244
Die Anzahl der Kopiervorgänge ist abhängig von der Unterstützung durch die Spei-cherverwaltungseinheit (MMU) der CPU und des Betriebssystems:
1.) Best case: • kein Client-seitiges Kopieren: Benutzer verwendet direkt den Transferpuffer der Netzwerk-
karte, um dort seine Datenstruktur für die Parameterübergabe abzulegen• Dazu muss von der MMU der Transferpuffer in den Prozessadressraum des Benutzers ein-
geblendet werden• zusätzlich kein Server-seitiges Kopieren: es wird der Empfangspuffer der Empfänger-Netz-
werkkarte von der dortigen MMU in den Adressraum des Server-Prozesses eingeblendet• Nachteil: Beide Netzwerkkarten stehen anderen Prozessen nicht mehr zur Verfügung!
2.) Worst case:• 5x kopieren nötig: Client-Stub -> Client-BS-> Client-Netzwerkkarte-> Server-Netzwerkkarte
-> Server-BS -> Server-Stub • Dazu kommt nochmal 5x kopieren für den Rückweg
7.5.13.2 Einführen von Vater- und Kindprozessen
Der Vaterprozess des Client (Hauptprozess) erzeugt für jeden Fernaufruf einen Kind-prozess, der auf die Rückantwort wartet

245
Entkopplung des Fernaufrufs und seine Ausführung vom aufrufenden Hauptpro-gramm
Parallelverarbeitung zwischen Client und Server
Zur weiteren Effizienzsteigerung kann der Vaterprozess des Servers für jeden einge-henden Aufruf einen neuen Kindprozess erzeugen, der dann den Aufruf bearbeitet
ruft aufKindpro-
zeß
Antwort da
erzeugt
Client
Fernaufruf
Vaterprozeß
wartet
arbeitet
arbeitet weiter
arbeitet
Rückmel-dung
Antwort
Server
rechnet
246
Server ist auch dann nicht blockiert, wenn er bereits einen Fernaufruf bearbeitet
Nachteile:
1.) Das Erzeugen der Kindprozesse und das Time Sharing zwischen Vater- und Kindpro-zessen bewirken Zeitverluste durch Betriebssystemaufrufe
2.) Kommunikation zwischen Vater- und Kindprozessen muss synchronisiert werden
er-zeugtFernauf-
ruf
Antwort da
Vaterprozeß
Kindpro-zeß
wartet
arbeitet
arbeitet wei-ter
arbeitet
Rückmel-dung Antwort
ruft auf
Client Server
wartet auf Auf-ruf
bearbei-tet
wartet auf Aufruf
Antwort fertig
Aufruf er-zeugt
Vaterprozeß
Kindpro-

247
3.) Sie ist ggf. nur über Interprozessskommunikation zu realisieren, falls Vater- undKindprozess eigene Adressräume haben
7.5.13.3 Einführen von leichtgewichtigen Prozessen
Leichtgewichtige Prozesse (Threads) laufen im selben Adressraum ab (es besteht keinSpeicherschutz zwischen ihnen)
die Umschaltzeit von thread zu thread ist sehr kurz, da kein Kontextwechsel nötig
Kommunikation zwischen threads ist einfacher und schneller als zwischen Prozes-sen mit eigenen Adressräumen
Kommunikation erfolgt über gemeinsame Variable und Semaphore zwischen zweienoder mehreren Threads und dem Vaterprozess „=Multithreading“
Nebenläufigkeit entsteht durch zeitliche Verzahnung der threads und des Vaterprozes-ses bei ihrer Abarbeitung
Threads werden entweder• innerhalb der Zeitscheibe, die dem Server-Prozess zur Verfügung steht, reihum abgearbei-
tet (= Thread Scheduling)• oder wie normale Prozesse vom Betriebssystem gescheduled (= Linux)
Durch Multithreading werden die Nachteile von Vater-/Kindprozessen umgangen
Multithreading ist sehr gute Methode zur Effizienzsteigerung, erschwert aber das De-bugging
248
7.5.14 Zusammenfassung der Probleme bei RPCs
1.) Es gibt bei RPCs deutlich mehr potentielle Fehlerquellen als bei lokalen Prozeduren:• Aufgrund der meistens verwendeten „at-most-once-Semantik“ bleiben Aufrufe ab und zu
ohne Ergebnis (at-most heißt, dass jeder Fernaufruf beim Server im Fehlerfall höchstenseinmal ausgeführt wird)
Überwachung der RPC-Ergebnisse durch Timeout notwendig
• Bei Ausfall des Client bleiben beim Server verwaiste Aufrufe übrig => wohin mit dem Er-gebnis?
2.) Einschränkungen bei der Parameterübergabe:• Zeiger sind problematisch, da Client und Server keinen gemeinsamen Arbeitsspeicher ha-
ben
Zeigerreferenzen werden de-referenziert, linearisiert, die Daten, auf die der Zeigerzeigt, werden über das Netz geschickt, auf der Gegenseite wiederhergestellt und überneue Zeigeradressen wieder referenziert
3.) Einschränkungen bei der Programmierung verteilter Anwendungen, da RPCs lang-sam sind
4.) Im Falle paralleler Anwendungen auf den Cores einer Multi Core CPU: Kommunika-tion über gemeinsame Variable geht nicht, da dieselbe globale Variable nicht beimClient und beim Server zur Verfügung steht

249
7.6 Microsoft .net
Microsoft .net ist eine sehr große Plattform für Software-Entwickler, die für ihre Anwen-dungen das Internet benötigen („Framework“)
MS .net besteht aus:• einer Laufzeitumgebung• vielen Klassenbibliotheken mit ca. 11 Tsd. Klassen, die als „Shared Source“ öffentlich ver-
fügbar sind• zahlreichen Programmierschnittstellen• diversen Dienstprogrammen
Die damit erstellten Benutzeranwendungen sind über das Internet verteilt Für die Kommunikation zwischen Anwendungsteilen ist eine einheitliche .net API vor-
handen .net ist unabhängig von der verwendeten Programmiersprache und der Anwendung, da
die Anwender Source-Codes in eine Microsoft-eigene Zwischensprache (Common In-termediate Language, CIL) übersetzt werden
.net unterstützt die Standardsprachen C++, JavaSkript, und Python sowie viele andere
Die Zwischensprache ist ähnlich wie Java Byte-orientiert und wird später währendAusführung durch einen einzigen Just-in-Time Compiler in Maschinencode übersetzt
250
Def.: Ein Just-in-Time Compiler ist ein Zwitter aus Compiler und Interpreter und verbes-sert die Ausführungsgeschwindigkeit des erzeugten Codes gegenüber einer reinen Inter-pretation.
Beispiel: Anwendungsentwicklung bei Microsoft .net
.NET-Sprache w ie z.B . C#
C#Com piler
Com m on Interm ediateLanguage (C IL)
Just-In-Tim eCom piler
Run
Native Im age G enerator
Run
A lternativ

251
Alternativ ist auch eine Kompilation in Maschinencode vor der Ausführung möglich,um die Ausführungsgeschwindigkeit nochmals zu verbessern
Das Laufzeitsystem hat wie bei Java eine automatische Speicherbereinigung .net ist primär für Windows-Betriebssysteme gemacht, steht aber in eingeschränktem
Umfang auch für andere OSe zur Verfügung
8 Virtuelle Maschinen
Eine wichtige Technologie auf der ISO-Schicht 7 sind die sog. virtuellen Maschinen(VMs), die insbesonders für Rechenzentren und Clouds relevant sind
Virtuelle Maschinen wurden ursprünglich in Rechenzentren u.a. aus Gründen bessererServerauslastung und höherer Energieeffizienz eingeführt
Die Serverauslastung wird durch die sog. „Server Consolidation“ erreicht, was als„Server-Zusammenführung“ übersetzt wird
Gemeint ist damit, dass schlecht ausgelastete Server ihre VMs auf besser ausgelasteteServer verschieben, um diese noch besser auszulasten
Anschließend gehen die schlecht ausgelasteten Server in den Ruhemodus und sparenStrom
Strom zu sparen ist für ein Rechenzentrum sehr wichtig, denn die Stromkosten sind diehöchsten Ausgaben, die im Rechenzentrum entstehen und nicht die Rechner!
252
Def.: Eine virtuelle Maschine (VM) ist eine Sammlung virtueller Ressourcen in einem rea-len Server. Jede VM wird von einem sog. Emulator in Form eines „PCs in Software“bereitgestellt. Auf jedem virtuellen PC läuft ein eigenes Betriebssystem, das sog. GuestOS, sowie Benutzeranwendungen genau wie auf einer realen Maschine.
Beispiel: für virtuelle Maschinen
P hys ical D isk1 T B
P hys ical M em ory6 G B
P hysical C P U8 C ores
W indow s 10
One
Phy
sica
l Mac
hine
W indow s 10
V irtua l D isk500 G B
V irtua l M em ory3 G B
V irtua l C P U3 C ores
U buntu
V irtua l D isk250 G B
V irtua l M em ory1.5 G B
V irtua l C P U2 C ores
C entO S
V irtual D isk250 G B
V irtua l M em ory1.5 G B
V irtua l C P U1 C ores
V irtual M achine V irtua l M achine V irtua l M achine

253
Es werden von der realen Hardware mehrere oder sogar viele verschiedene PCs emu-liert, und in jedem virtuellen PC wird ein Guest OS und viele Benutzeranwendungenausgeführt
8.1 Vorteile der Virtualisierung
Für den Kunden des Rechenzentrums oder der Cloud bleibt alles, wie es ist Er bemerkt nur, dass seine Anwendungen etwas langsamer geworden sind Auch seine Software-Lizenzen kann er weiter verwenden, diesmal in der VM Der Systemadministrator eines Rechenzentrums oder einer Cloud hat außerdem fol-
gende Vorteile:
1.) Eine Reduzierung des Stromverbrauchs ist möglich· Anwendungen auf schlecht ausgelasteten Servern werden zu gut ausgelasteten Ser-
vern migriert, so dass diese maximal ausgelastet sind (=Server Consolidation)
2.) Die Systemstabilität ist deutlich größer· selbst wenn einzelne VMs fehlerhafte Anwendungen ausführen, stört dies nicht, da die
VMs voneinander isoliert sind
3.) Backups sind vereinfacht· die ganze VM kann in einer einzigen Datei gespeichert werden, inkl. aller Benutzeran-
wendungen und Kundendateien. Die Datei heißt VM Image.
254
4.) Neustarts sind vereinfacht· Im Fehlerfall kann ein einzelnes VM Image neu gestartet werden: der VM Launch. Ein
kompletter Server-Reset ist nicht erforderlich
5.) Migration auf einen anderen Rechner ist vereinfacht· es muss nur das VM Image auf den anderen PC kopiert werden: Checkpoint and Restart· dies erleichtert die Wartung und die Server Consolidation
6.) Datensicherheit gegen Hacker ist verbessert· die VM kann von außen viel schwerer als echte Hardware erreicht werden, weil der Zu-
gang nicht über ein Passwort sondern über einen RSA-Schlüssel erfolgt· Einen RSA-Schlüssel kann man weder erraten noch ausspähen, da er sehr lang ist
7.) Erzeugte VMs kann man auch für eine eigene Cloud sichtbar und administrierbarmachen
• VMs sind auch mit Hilfe der eigenen Cloud-Services administrierbar, was eine weitere Ar-beitserleichterung für den Systemadministrator bedeutet, denn diese Dienste sind sehrkomfortabel
alle Vorteile, die eine Cloud bietet, sind gegeben, sobald die Rechnerressourcen vir-tualisiert sind
8.) Die erzeugten VMs sind frei konfigurierbar. Jede denkbare Aufbau ist möglich, danichts real ist.

255
• Der Systemadministrator kann fast jeden Wunsch seiner Kunden erfüllen, was den Aufbaueiner VM anbetrifft, · Es kann ein realer Server auch mehrere virtuelle Server als VMs emulieren, nicht nur
PCs· Allerdings führt das Überbuchen der realen Ressourcen durch zu viele virtuelle zu teil-
weise gravierenden Problemen
Beispiel: Eine Überbuchen der realen Festplatte durch virtuelle Festplatten mit in derSumme mehr Speicherplatz als es real gibt, führt zum Systemabsturz derjenigen VM, dieauf den nicht vorhandenen Speicher zugreifen will.
Deshalb sind emulierte Server die Ausnahme
8.2 Aufbau einer VM
Eine VM besteht üblicherweise aus:
1.) einem oder mehreren virtuellen Sockeln für virtuelle CPU-Chips
2.) einem oder mehreren virtuellen Cores pro virtuellem CPU-Chip, die als vCPUsbezeichnet werden
Hinweis: >1 virtuelle Sockel gibt es nur dann, wenn virtuelle Server emuliert werden sollen.
Hinweis: Reale Server verfügen heutzutage über zwei oder mehr Sockel zum Einstecken von CPU-Chips für dementsprechend viele reale CPUs. Jede reale CPU wiederum besteht aus ca. 4-16 realen Cores.
256
• Eine vCPU heißt manchmal auch „logical processing unit“
3.) einem virtuellem Hauptspeicher, inkl. einer virtuellen Speicherverwaltungseinheit(virtual MMU)
4.) virtueller Peripherie bestehend aus virt. Festplatten, virt. Netzwerkkarten (sog. vNICs)und anderen virt. Benutzerendgeräten
Beispiel: Im Falle einer Intel CPU mit Hyperthreading und einem Hypertthreading-Faktorvon 2 kann jeder reale Core 2 vCPUs bzw. 2 logical processing units (vCPUs) emulierenohne „over-committed“ zu sein.Hinweis: to over-commit: überbuchen
8.3 Nachteile der Virtualisierung
Die Nachteile der Virtualisierung sind:• enormer Software-Overhead, der zur Realisierung notwendig ist
sehr hohe strukturelle Komplexität + längere Ausführungszeiten
• Um Leistungseinbußen zu reduzieren, sind außerdem Hardware-Hilfen auf dem Mother-board, in der Peripherie und im Prozessor notwendig, die als Virtualisierungsbeschleuni-ger dienen
Man geht z.T. wieder von der Virtualisierung ab und ersetzt VMs durch sog. LinuxContainer oder durch hybride Lösungen aus VMs und Containern

257
Container sind zwar bei weitem nicht so Hacker-sicher wie VMs und haben nicht so vie-le Vorteile wie VMs, sind aber viel einfacher zu realisieren
8.4 Host OS und Guest OS
Auf jedem realen Server mit sog. „Typ 2-Hypervisor“ läuft zunächst ein einziges Basis-betriebssystem, das als Host OS bezeichnet wird
Das Host OS ist oft aber nicht immer ein Standardbetriebssystem wie Windows oderLinux
Das Host OS ist i.d.R. die Voraussetzung für eine oder mehrere emulierte PCs und da-mit VMs
Auf jedem emulierten PC läuft ein Guest OS sowie Anwendungen Die Guest OSes können völlig verschieden sein, genau wie die emulierten PCs, die sie
ausführen, ganz unterschiedlich konfiguriert sein können Technisch betrachtet existieren die emulierten PCs in voneinander getrennten Adress-
räumen im virtuellen Speicher des Host OS und sind deswegen sowohl voneinanderals auch vom Host OS isoliert
Eine Kommunikation zwischen VMs auf demselben Server ist auf einfache Weise nurüber das Internet mittels TCP/IP möglich, da jeder emulierte PC auch eine vNIC mitrealen MAC- und IP-Adressen haben kann
Hinweis: Jede vNIC verhält sich genau wie die ganze VM wie reale Hardware und kann somit auch echte MAC- und IP-Adressen haben.
258
Im Host OS läuft neben den VMs mit ihren Guest OS auch der sog. Hypervisor, sowie -sofern vorhanden- auch ein Cloud-Betriebssystem wie z.B. OpenStack
8.5 Hypervisor
Ein Hypervisor ist eine Software-Schicht, die von den emulierten PCs benötigt wird Der Hypervisor ist unterhalb der emulierten PCs angesiedelt und erbringt Dienstleis-
tungen für diese Man unterscheidet zwischen Typ 1- und Typ 2-Hypervisoren Beide Typen von Hypervisoren erlauben das Konfigurieren, Starten, Verwalten, Stop-
pen und Beenden von emulierten Rechnern, d.h. VMs auf demselben realen Rechner Ein Typ 1-Hypervisor, wie z.B. XEN, benötigt kein Host OS, vielmehr sitzt er direkt auf
der realen Maschine auf und hat eigene Gerätetreiber• Er stellt ein rudimentäres Betriebssystem (einen sog. Micro Kernel) dar und vereint die
Funktionen eines einfachen Host OS und des Hypervisors in sich
Beispiel: Der Host OS-Teil von XEN besteht aus einer Prozessverwaltung inkl. TimeSharing, einer Speicherverwaltung, Linux-Gerätetreibern und aus einer API.

259
Ein Typ 2-Hypervisor, wie z.B. KVM für Linux oder Hyper-V für Windows ist kein MicroKernel und hat keine Gerätetreiber, weil er innerhalb eines Standard-Betriebssystemsläuft und dessen Gerätetreiber nutzt
Bei beiden Typen gibt es so viele Guest OS wie emulierte Rechner (VMs) existieren Typischerweise emuliert ein Typ 1-Hypervisor mehrere virtuelle Server, allerdings
ohne die reale Festplatte zu überbuchen, während ein Typ 2-Hypervisor mehrere virtu-elle PCs emuliert
Hinweis: Der strukturelle Unterschied zwischen Server und PC liegt in der Zahl der CPU-Sockel und des gemeinsamen Speichers zwischen CPUs. Ein PC hat nur einen CPU-Sockel und damit nur eine CPU und damit auch keinen gemeinsamen Speicher.
Typ 1
Hardware
Hypervisor
G uest O S G uest O S G uest O S
Host O S
Hypervisor
G uest O S G uest O S G uest O S
Hardware
Typ 1 Typ 2
Typ 2
260
Beide Hypervisor-Typen benötigen Betriebssystem-Privilegien, um alle CPU-Befehleausführen und auf alle Daten, Geräte und den ganzen Hauptspeicher zugreifen zukönnnen
Jeder Typ 2-Hypervisor läuft im Host OS als ladbares Kernel-Modul Jeder Typ 1-Hypervisor ist selber Kernel Typ 2-Hypervisoren implementieren mit Hilfe ihrer Betriebssystem-Privilegien und ei-
nes sog. Emulators die Funktionen mehrerer PCs in Software Der von KVM benützte Emulator ist QEMU Typ 1-Hypervisoren benötigen keinen extra Emulator Mit beiden Typen kann man eine sog. Server-Virtualisierung durchführen
8.6 ESXi, KVM, QEMU und Hyper-V
ESXi ist der aktuelle Typ 1-Hypervisor der Fa. VMWare Hyper-V ist der Standard-Typ 1-Hypervisor für Windows KVM ist der Standard-Typ 2-Hypervisor für Linux QEMU ist der Standard-PC-Emulator für KVM Für jeden zu emulierenden PC wird eine QEMU-Instanz benötigt KVM hat zwei Schnittstellen, eine für alle QEMUs gemeinsam und eine zweite namens
virtio

261
Hinter der virtio-Schnittstelle verbirgt sich eine Virtualisierungs-API und -Bibliothek,die eigene Gerätetreiber enthält
Sobald diese API aufgerufen wird, ist KVM kein reinrassiger Typ 2-Hypervisor mehr,denn die virtio-Gerätetreiber erlauben u.a. einen indirekten Zugriff des Guest OS auf diereale Peripherie durch die sog. „Paravirtualisierung“, die später beschrieben wird
9 Server-Virtualisierung
Ohne Server-Virtualisierung hat man einen klassischen Rechner, wie er in nachfolgen-dem Block-Diagramm dargestellt ist:
Mit einer Server-Virtualisierung ist alles ganz anders: Für den Fall von Linux als Host OS und KVM als Typ 2-Hypervisor gilt dann:
PC-HardwareWindows OS/Linux Host OS
Benutzer-anwen-dung 1
Benutzer-anwen-dung 2
Benutzer-anwen-dung n
. . .Klassisch
262
1.) Ein KVM Hypervisor läuft als geladenes Kernel-Modul mit Systemprivilegien im HostOS
Hinweis: siehe Kasten in obigem Blockdiagramm in hellgrüner Farbe
2.) Mehrere Software-Emulatoren (QEMUs) laufen als Host OS-Benutzerprozesse ohneSystemprivilegien
3.) Jeder QEMU emuliert genau einen PC in Software• es wird dabei ein älterer PC nachgeahmt, der noch mit IDE-Schnittstelle für die Festplatte
und mit PCI-Bus für die Peripherie ausgestattet ist
PC-HardwareLinux Host OS
KVM-Hy-pervisor
System-Pri-vilegien
Nur Benut-zer-Privilegi-en
Virtualisiert
. . .
k PC-Emulationen durch k QEMUs
k Guest OSe in k virtuellen Maschi-nen
QEMU 1
Guest OS 1
Benut-zeran-wendun-gen 1-m
QEMU k
Guest OS k
Benut-zeran-wendun-gen 1-n

263
• bei der Hardwareausstattung des emulierten PCs gibt es bei der Größe der virtuellen Fest-platten eine Grenze:· DIe Summe der Speicherkapazitäten aller emulierten Festplatten darf die Größe der re-
alen Festplatte des Servers nicht überschreiten
4.) Auf jedem der emulierten PCs läuft ein Guest OS• das Guest OS ist ein Child-Prozess von QEMU im Benutzeradressraum (User Space)
5.) In jedem Guest OS laufen i.d.R. mehrere Benutzeranwendungen
6.) KVM kommuniziert mit allen QEMUs
7.) KVM und die QEMUs leisten gemeinsam die Virtualisierung
8.) Die VMs sind völlig isoliert voneinander und können i.d.R. nur über TCP/IP miteinan-der kommunizieren
9.1 Emulation von PCI-Geräten durch QEMU
Der wichtigste Schritt bei der Emulation von PCI-Geräten durch QEMU besteht darin,dass QEMU die PCI-Register des virtuellen Geräts als Datenstruktur im eigenen Benut-zeradressraum anlegt
D.h., QEMU klont die PCI-Register in eine Datenstruktur Da das Layout und die Bedeutung von PCI-Geräteregistern standardisiert ist, sind alle
QEMU PCI-Datenstrukturen gleich und die Emulation der Geräte vereinfacht
264
Allerdings kann QEMU alleine keinen Gerätetreiberzugriff auf das emulierte PCI-Gerätdurchführen
Dafür benötigt QEMU den KVM Hypervisor Die Kooperation zwischen QEMU und KVM wird durch das nachfolgende Beispiel eines
Gerätetreiberzugriffs auf ein emuliertes PCI-Netzwerkgerät erläutert
9.1.1 Gerätetreiberzugriff auf emuliertes PCI-Netzwerkgerät
Bei Linux werden alle Datentransfers von oder zu einem Netzwerk wie z.B. Ethernetüber eine einheitliche, Kernel-interne Datenstruktur namens sk_buff abgewickelt
Das Schreiben von zu sendenden Daten auf eine virtuelle PCI Ethernet-Karte bedeutet,dass der Linux Kernel des Guest OS einen gefüllten sk_buff an den Gerätetreiber dervirtuellen Ethernet-Karte übergibt und diesen aufruft
Der Gerätetreiber wandelt sk_buff in einen Ethernet-Rahmen um, die er als Datenstruk-tur bei sich ablegt, um ihn anschließend der virtuellen Ethernet-Karte zum Absendenzu übergeben
Danach versucht er, auf die Register der virtuellen Ethernet-Karte mit IOread, IOwriteoder IOstatus zuzugreifen
Da der Gerätetreiber im Guest OS der VM läuft und die VM samt Guest OS nur ein Be-nutzerprozess im Adressraum des Host OS ist, fehlen ihm die Host OS Kernel-Privile-gien für diese Befehle

265
Der Prozessor führt den IO-Befehl des Guest OS-Gerätetreiber nicht aus und erzeugtstatt dessen einen Host OS System Trap (auch Exception genannt)
Der System Trap wird durch KVM abgefangen Anschließend führt KVM den Guest OS-Gerätetreiber IO-Befehl selber bei der realen
Ethernet-Karte im Host OS aus und gibt das Ergebnis, d.h. den Status an QEMU weiter,der die betreffende Datenstruktur aktualisiert
So wird für jeden Guest OS-Gerätetreiber IO-Befehl ein Trap erzeugt, und KVM undQEMU sind involviert
Die Emulation des virtuellen Ethernet-Karte ist langsam
Jedes Guest OS und seine Anwendungen haben aber das Gefühl, tatsächlich auf einereale Ethernet-Karte zuzugreifen
9.1.2 IO-Virtualisierung und Virtualisierungsbeschleuniger
Der oben beschriebene Vorgang wird als „IO-Virtualisierung“ bezeichnet Eine rein Software-basierte Server-Virtualisierung im allgemeinen und IO-Virtualisie-
rung im speziellen sind technisch sehr aufwendig und deshalb von Haus aus langsam Um die rel. langsame Emulation zu beschleunigen, gibt es in der CPU, den Cores, auf
dem Motherboard und in den PCIe-Karten heutiger Server spezielle Virtualisierungsbe-schleuniger in Hardware
266
Die erwähnte IO-Virtualisierung wird am besten mit dem SR-IOV-Virtualisierungsbe-schleuniger schneller gemacht
SR-IOV ist Stand der Technik bei PCIe-Karten
9.2 Technische Herausforderungen der Server-Virtualisierung
Ursprünglich wurden weder Linux, noch die Linux ausführenden Server, noch derenPeripherie dafür entworfen, dass gleichzeitig mehrere PCs und damit VMs und GuestOSes auf demselben Rechner emuliert werden
Alle VMs, Guest OSe und Benutzeranwendungen wollen im schlimmsten Fall gleichzei-tig auf dieselbe reale Komponenten (CPU, Hauptspeicher oder Peripherie) zugreifen
Es muss für diesen Fall erreicht werden, dass die Zugriffe sequentialisiert ausgeführtwerden
Seit ca. 2005 gibt es deshalb im PC- und Server-Bereich Hardware-basierte Virtualisie-rungshilfen, die den simultanen Zugriff auf reale Hardware-Komponenten aus Soft-ware-Sicht sequentialisieren und vereinfachen
Dies sind die bereits erwähnten Virtualisierungsbeschleuniger, wie z.B SR-IOV Die Implementierung einer virtuellen Maschine in einem Host OS mit Hilfe von KVM/QE-
MUs, Hyper-V oder ESXi stellt allerdings nach wie vor eine Herausforderung dar Besonders schwierig ist die Bereitstellung von virtuellem Speichers in einer VM, denn
bereits der Speicher der realen Maschine ist virtuell, so dass der virtuelle Speicher ei-ner VM eine doppelte Virtualisierung (=doppelte Illusion) darstellt

267
Dem Benutzer ist diese Komplexität nicht bewusst, vielmehr erwartet er von einememulierten PC, dass er dieselbe Funktionalität bzgl. Speichergröße, Speicherver-schnitt, Speicherschutz und Geschwindigkeit bietet wie ein realer PC
Leider stellt dieser Wunsch aus folgenden Gründen ein Problem dar:• Zwar hat jedes Guest OS eine Verwaltung des eigenen virtuellen Speichers in Form von
Seitentabellen (Page Tables) im Guest OS der VM• Diese enthalten jedoch sinnlose Hauptspeicheradressen, da das Guest OS die realen Ver-
hältnisse nicht kennt und der emulierte PC keinen realen Speicher hat• Nur das Host OS hat realen Speicher und weiß, wie dieser aufgeteilt ist• Zudem werden vom Guest OS falsche Page Fault Exceptions bei Seitenfehlen erzeugt
· Die Page Fault Exceptions sind falsch, weil das Guest OS keine Kenntnis über den tat-sächlichen virtuellen Speicher des Host OS und dessen Verteilung in Blöcke im Haupt-speicher und auf Records im Swap Device hat
· Die Page Fault Exceptions sind auch deswegen falsch, weil das Guest OS keinen realenSpeicher verwaltet, weil der emulierte PC, auf dem es ausgeführt wird, keinen hat
• Außerdem erzeugen die virtuellen Geräte in den Gerätetreibern des Guest OS falsche In-terrupts bei virtuellen DMAs· Die Interrupts der virtuellen Geräte sind deswegen falsch, weil die Interrupt-Service-
Vektoren nicht real sind. Dort, wo sie hinzeigen, gibt es im realen Hauptspeicher i.a. kei-ne Interrupt-Service Routinen
Um den Benutzerwunsch, dass ein emulierter PC wie ein realer sein soll, zu erfüllen,wird u.a. jeder lesende oder schreibende Zugriff auf emulierten PC-Speicher vom
268
Hypervisor abgefangen und im realen Speicher so ausgeführt, wie es dort den realenVerhältnissen entspricht
Ebenso werden alle Page Fault Exceptions, DMAs und Interrupts in einem Guest OSvom Hypervisor abgefangen und behandelt
Dies stellt den Kern der Server-Virtualisierung dar Für diese Aufgaben haben Hypervisoren hardware-basierten Virtualisierungshilfen
9.3 Vertiefung der Server-Virtualisierung
Server-Virtualisierung beinhaltet die Emulation vieler virtueller PCs oder Server alsVMs auf demselben physischen Server
Def.: Server-Virtualisierung ist das Schaffen vieler virtueller Maschinen, die sich die rea-len Ressourcen dadurch teilen, dass k voneinander unabhängige PCs oder Server durchSoftware emuliert werden.
Die Server-Virtualisierung erfordert für jeden zu emulierenden PC:
1.) Die Emulation der einzigen CPU eines PCs bestehend aus Hyperthreads und Cores
2.) Die Emulation des Hauptspeichers eines PCs• Dadurch erhält jedes Guest OS und damit jede Benutzeranwendung einen eigenen, priva-
ten, virtuellen Hauptspeicher, obwohl es real nur einen einzigen Hauptspeicher im Servergibt

269
3.) Die I/O-Virtualisierung, die dem Guest OS in einem emulierten PC eine eigene Peri-pherie suggeriert
Zusätzlich erfordert die Server-Virtualisierung für jeden zu emulierenden Server (nichtPC), dass alle virtuellen CPUs des virtuellen Servers emuliert werden, sowie eingemeinsamer virtueller Hauptspeicher
9.4 Inter-VM und Inter-vCPU-Kommunikation auf demselben Server
Die Virtualisierung der Kommunikation betrifft sowohl die VMs desselben Servers alsauch die vCPUs derselben VM
VMs auf demselben Server kommunizieren i.A. so miteinander, als ob sie in verschie-denen realen Rechnern angesiedelt wären, d.h. über TCP/IP
Sogar die vCPUs innerhalb einer VM kommunizieren i.A. so miteinander, als ob sie inverschiedenen realen Rechnern angesiedelt wären, d.h. ebenfalls über TCP/IP
D.h., es wird TCP/IP zusammen mit virtuellen Ethernet-Karten (vNICs) zur Inter-VM-Kommunikation auf demselben Server bzw. zur Inter-vCPU-Kommunikation in dersel-ben VM verwendet
Dazu werden temporär reale MAC und IP-Adressen an die vNIC(s) der VM vergeben Sie existieren nur so lange in der VM, bis sie bei einer anderen VM benötigt werden
270
Hinweis: Die TCP/IP Inter-VM-Kommunikation ist beim sog. Hochleistungsrechnen (HPC) sowie bei Echtzeitanwendungen nicht sinnvoll anwendbar, da TCP/IP zu langsam und zu indeterministisch bzgl. Bandbreite und Latenz ist. In diesen beiden Fällen ist „ivshmem“ für die Inter-VM-Kommunikation sinnvoll.
Die einzige Alternative zur indeterministischen TCP/IP-Kommunikation besteht darin,dass man einen virtuellen gemeinsamer Speicher zwischen den VMs desselben Ser-vers oder zwischen den vCPUs derselben VM generiert und zur Kommunikation nutzt
Dies ist bei KVM/QEMU durch ein virtuelles PCI-Gerät namens Inter-VM Shared Memory(ivshem) möglich
ivshem erzeugt mittels des Host OS einen realen gemeinsamen Speicher im Server Dieser kann von QEMU und einer Guest OS-Anwendung per Linux „mmap“-Komman-
do auf einen VM-Speicherbereich abgebildet werden Der besagte VM-Speicherbereich beginnt dadurch tatsächlich zu existieren: er wird
real ivshmem ist integraler Bestanteil jedes neueren QEMUs Die ivshmem-Funktionalität wird gemeinsam von mehreren QEMUs und zusammen mit
dem KVM-Hypervisor realisiert ivshmem ist technisch außerordentlich kompliziert, aber gegenüber TCP/IP bei der in-
ter-VM-Kommunikation auf demselben Server oder PC ca. 10-fach schneller

271
9.5 Vertiefung der IO-Virtualisierung
Die I/O-Virtualisierung stellt virtuelle Peripherie für jeden einzelnen emulierten PC (VM)zur Verfügung, die letztlich durch reale Peripherie implementiert werden muss
Damit die IO-Virtualisierung gelingt, müssen drei Aufgaben gelöst werden:
1.) Es muss ermöglicht werden, dass mehrere VMs im selben Rechner indirekt auf die-selbe Peripherie des realen Rechners zugreifen können, ohne sich gegenseitig zustören
• Dies deshalb ein Problem, weil die reale Peripherie von Haus aus keinen Multiplexbetriebzwischen VMs kennt
• Dieses Problem wird bei Linux durch einen zentralen KVM-Hypervisor und die dezentralenQEMUs gelöst
2.) Es muss ermöglicht werden, dass die virtuelle Peripherie einer VM über DMA schein-bar auf den virtuellen Speicher der VM zugreifen kann, um dort ihre Eingabedatenabzulegen bzw. von dort ihre Ausgabedaten zu erhalten
• Dies ist deshalb ein Problem, weil dazu das Guest OS den realen DMA-Controller mit derStart- und der Zieladresse des zu transferierenden DMA-Blocks initialisieren müsste
• Der VM-Hauptspeicher ist jedoch nicht real und das Guest OS hat keinerlei Zugriff auf realeHardware, da es nur von einem emulierten PC ausgeführt wird
• Selbst die „physikalischen Adressen“, die die Guest OS MMU erzeugt, werden von KVMauf einen Abschnitt im virtuellen Adressbereich des Host OS abgebildet
272
• Außerdem kann das Guest OS den realen DMA Controller schon deshalb nicht initialisie-ren, weil ihm dazu die Kernel Mode-Privilegien fehlen würden
• Dieses Problem wird bei Linux durch KVM gelöst
3.) Es muss ermöglicht werden, dass die virtuelle Peripherie einer VM über Interrupts miteinem Gerätetreiber des Guest OS kommunizieren kann.
Die letzte Aufgabe ist besonders schwierig zu lösen Die Gründe dafür sind:
1.) Der Gerätetreiber des Guest OS geht davon aus, dass er exklusiv ein reales Gerätbetreibt
• In Wahrheit bedient der Gerätetreiber des Host OS das Gerät
2.) Der VM-Gerätetreiber kennt nicht die realen I/O-Adressen des Geräts, so dass erschon alleine deswegen nicht reale Register ansprechen könnte
• Das Guest OS glaubt jedoch, dass es reale I/O-Adressen ausgibt und mit realer Peripheriearbeitet, was nicht der Fall ist
3.) Der Gerätetreiber des Guest OS kann nicht im Kernel Mode des realen Servers ausge-führt werden, weil er nur in einem emulierten PC läuft und nicht im Host OS· Ohne den Kernel Mode kann in der IA32-, IA32/64-Architektur kein I/O-Befehl ausgeführt
werden

273
4.) Ein Guest OS hat überhaupt keinen Zugriff auf das Host OS und damit auf die HostHardware, denn dazwischen sitzt ein QEMU und KVM, die bereits alle Zugriffe auf denemulierten PC abfangen
• Das Guest OS ist völlig isoliert vom Host OS• Eine Kommunikation zwischen Guest OS und Host OS ist nur über denjenigen QEMU mög-
lich, der für die VM zuständig ist
Durch die I/O-Virtualisierung werden die geschilderten Aufgaben gelöst
9.6 Arten der Server-Virtualisierung
Prinzipiell kann eine Server-Virtualisierung auf vier verschiedene Arten erfolgen:
1.) durch vollständige Simulation der Server-Hardware in Software mit Hilfe vonKVM+QEMUs, Hyper-V oder ESXi
Hinweis: Es gibt einen Unterschied zwischen Simulation und Emulation. DIe Simulation erfolgt rein durch Software und ist nicht echtzeitfähig. Die Emulation erfolgt entweder mit Software und Hardware-Unterstützung oder nur durch Hardware und ist damit echtzeitfähig.
2.) durch sog. Binary Translation in Software
3.) durch Paravirtualisierung in Software
4.) durch sog. Hardware-unterstützte Virtualisierung
274
Die Hardware-unterstützte Virtualisierung emuliert PCs durch KVM+QEMUs und Ser-ver durch ESXi und ist durch die Hardware-Unterstützung schneller als die reine Soft-ware-Lösung von 1.)
Am effizientesten sind die Paravirtualisierung und die Hardware--unterstützte Virtuali-sierung
Beide sind Stand der Technik Die vollständige Simulation der Hardware in Software und die Binary Translation in
Software sind veraltet, da zu langsam Die Binary Translation in Software ist so alt, dass sie hier nicht mehr erläutert wird Das Wissen über die vollständige Simulation der Hardware in Software wird allerdings
im Weiteren benötigt, um die Hardware-Virtualisierung verstehen zu können Die Simulation der Hardware in Software wird deshalb nachfolgend erläutert
9.6.1 Vollständige Simulation der Hardware in Software
Jeder Gerätetreiber der IA32- und IA32/64-Architektur verwendet für den Gerätezugriffspezielle I/O-Befehle, wie z.B. IORead, IOWrite oder IOStatus
Die I/O-Befehle werden im Betriebssystem im priviligierten Modus ausgeführt undspannen einen eigenen I/O-Adressraum auf, der getrennt von den virtuellen und realenHauptspeicheradressen des Betriebssystems ist
Dieser Vorgang wird auch als ported I/O bezeichnet und ist typisch für Intel-Prozesso-ren

275
Immer dann, wenn der Gerätetreiber des Guest OS auf ein virtuelles Gerät zugreifenwill, versucht das Guest OS, auf den Kernel Mode umzuschalten und priviligierte Be-fehle auszuführen
Dieser Versuch ruft eine Exception vom Typ „Access Privilege Violation“ hervor, dieder KVM-Hypervisor abfängt, so dass keine Fehlermeldung erzeugt wird
Danach führt KVM folgende Aktionen aus:
1.) Er übersetzt die Guest OS I/O-Adresse in eine Host OS I/O-Adresse, die real ist und erbeauftragt einen passenden Host OS-Gerätreiber den IO-Vorgang auf der realen Hard-ware auszuführen
2.) Er übersetzt im Falle eines DMA-Transfers die „physikalischen Adressen“ des GuestOS in tatsächliche physikalische I/O-Adressen des realen Servers
3.) Er sorgt dafür, dass bei einem DMA-Transfer der gewünschte Hauptspeicherblock imHauptspeicher vorhanden ist bzw. in den Hauptspeicher geschrieben wird
4.) Er gibt das Ergebnis über QEMU an den Guest OS-Gerätetreiber zurück• Im Falle eines lesenden Zugriffs des Guest OS ist das Ergebnis die gelesenen Daten und
der Gerätestatus• Im Falle eines schreibenden Zugriffs sind es die zu schreibenden Daten und das Geräte-
kommando, die er beide an das reale Gerät weiterreicht
276
5.) Im Falle eines Interrupts von einem realen Gerät, der das Resultat eines Zugriffsver-suchs einer VM ist, ändert er den Interruptvektor, den das Gerät ausgibt, so ab, dasser selber aufgerufen wird und nicht das Host OS, wenn der Interrupt auftritt
6.) Außerdem legt der zuständige QEMU über den virtuellen Interrupt-Controller der VMeinen Interruptvektor an den virtuellen Datenbus der virtuellen CPU des emuliertenPCs an und täuscht so dem Guest OS-Gerätetreiber einen Interrupt vor (virtuellerInterrupt)
7.) KVM nimmt außerdem das Multiplexen und Demultiplexen der Zugriffswünsche undDaten von Guest OSes und Anwendungen vor, d.h. er multiplext die peripherenGeräte zwischen verschiedenen VMs. Dazu muss KVM folgendes machen:
• Er verteilt für den Fall, dass es sich um eine vNIC handelt, von der realen Netzwerkkartetatsächlich empfangene Datenrahmen auf die Ziel-VMs
• Umgekehrt sammelt er zu sendende Datenrahmen von den vNICs der Quell-VMs ein undschickt die Rahmen nacheinander über dieselbe Ethernetkarte ab
• Dazu bildet er einen Ethernet-Switch in Software nach, den sog. vSwitch, der bei n VMs n+1Ports hat. Ein Port ist mit der realen Ethernetkarte verbunden, die übrigen n mit den nGuest OS des Host OS. Damit ermöglicht der vSwitch das Multiplexen.
Alle geschilderten Aktionen erfolgen per Software und kosten viel CPU-Leistung

277
9.6.2 Zusammenfassung Simulation der Hardware in Software
Zugriffe auf die reale Hardware werden vom Hypervisor (KVM) über CPU Exceptions(Traps) abgefangen
Die vom Guest OS beabsichtigte Funktion wird vom Hypervisor selber oder mit Hilfeeines Host OS-Gerätetreibers ausgeführt
Dem Guest OS wird von QEMU und KVM vorgespielt:• es habe einen realen Gerätetreiber aufgerufen• es habe reale Page Tables für die virtuelle Speicherverwaltung konsultiert• es habe den Translation Look-aside Buffer (TLB) einer realen Speicherverwaltungseinheit
(MMU) aktualisiert• es habe einen realen DMA-Transfer zwischen Peripherie und Hauptspeicher durchgeführt• es habe auf einen realen Interrupt des DMA Controllers reagiert
DMA-Interrupts von realer Peripherie, werden sie ebenfalls vom Hypervisor abgefan-gen, sofern sie das Resultat von Guest OS-Gerätetreiberzugriffsversuchen sind
Die Ergebnisse der echten DMA-Interrupts der Gerätetreiber im Host OS werden vonQEMU anstelle der falschen DMA-Interrupts an die Guest OS-Gerätetreiber durchge-reicht, so dass letztere das „Gefühl“ haben, sie würden echte Geräte steuern
Dazu hat der Hypervisor Host OS-Systemprivilegien, für die QEMUs reichen Benutzer-privilegien
278
So wird im Endeffekt die reale Peripherie vom Hypervisor im Time-Sharing-Betrieb ge-nutzt, um die Zugriffswünsche der VMs nacheinander zu befriedigen
Das alles erfordert einen erheblichen Verwaltungszusatzaufwand und ist ohne Hard-ware-unterstützte Virtualisierung nur wenig effizient
9.6.3 Paravirtualisierung
Bei der Paravirtualisierung werden im Guest OS von KVM/QEMU oder von XEN neueBetriebssystemaufrufe in Form von Spezialgerätetreiber zur Verfügung gestellt
Diese Spezialgerätetreiber sind in der API identisch zu den Originalgerätetreibern desGuest OS
Genau wie die Originalgerätetreiber des Guest OS treiben sie kein reales Gerät, da sieim völlig isolierten Guest OS laufen und nur für Geräte in einem emulierten PC zustän-dig sind
Im Gegensatz zu den Originalgerätetreiber des Guest OS sind sie sich aber bewusst,dass sie in einem Guest OS ausgeführt werden und kooperieren deshalb aktiv mit dem-jenigen QEMU, der für das Guest OS zuständig ist
Im Gegensatz zu den Originalgerätetreiber des Guest OS sind die Spezialgerätetreibernur leere Hülsen, die ihre Aufrufparameter an ihren QEMU weiterreichen und sonst kei-nen weiteren Code enthalten
Ein Abfangen von Spezialgerätetreiber-Zugriffen auf den emulierten PC durch KVMist nicht nötig, da sie nicht auf emulierte Peripherie zugreifen wollen

279
Das nicht mehr notwendige Abfangen spart Zeit, weshalb Paravirtualisierung effizien-ter ist als die reine Software-Simulation von Hardware
QEMU reicht die Aufrufparameter des Spezialgerätetreibers an KVM weiter, der wiede-rum den passenden Gerätetreiber des Host OS aufruft
Letzterer treibt das reale Gerät Ergebnisse des realen Geräts, wie z.B. ein TCP/IP-Paket werden über die Kette Host
OS-Gerätetreiber->KVM->QEMU->Spezialgerätetreiber->Guest OS der Benutzeranwen-dung zugestellt
Zur Paravirtualisierung ist eine Änderung des Guest OS erforderlich, da Spezialgeräte-treiber anstelle der Originalgerätetreiber aufgerufen werden müssen
Paravirtualisierung scheitert, wenn der Source Code wie z.B. bei Windows nicht zurVerfügung steht, um Spezialgerätetreiber anstelle der Originalgerätetreiber einbauenzu können, oder wenn der Hersteller des Guest OS keine für Paravirtualisierung ange-passten Treiber bereitstellt (Microsoft)
Beispiel: XEN stellt die sog. VMI-Schnittstelle für Paravirtualisierung zur Verfügung, aufdie die Spezialgerätetreiber der Guest OSe zugreifen.
Beispiel: KVM ermöglicht über seine QEMU-API sowohl eine reine Software-Simulationeines PCs als auch eine Hardware-unterstützte Virtualisierung desselben. Über seine vir-tio-API bietet KVM auch Paravirtualisierung an.
280
9.6.4 Hardware-unterstützte Virtualisierung
Bei der Hardware-unterstützten Virtualisierung geht es im Gegensatz zur Paravirtuali-sierung darum, alle Guest OS-Gerätetreiber unverändert zu lassen und trotzdem effizi-ent zu sein
Dies ist durch ein trickreiche Verzahnung von Hardware-Beschleunigern mit QEMU/KVM bzw. ESXi oder Hyper-V möglich, so dass der Hypervisor wesentlich weniger Auf-gaben zu erledigen hat
KVM/QEMU, ESXi und Hyper-V unterstützen die Hardware-unterstützte Virtualisierung,indem sie mit den Hardware-Hilfen in den Cores, CPUs, Motherboards und in den PCIe-Peripheriegeräten kooperieren
Hardware-unterstützte Virtualisierung beruht auf folgenden Hardware-Hilfen:
1.) einer sog. I/O MMU pro realem Core nur für die Abbildung von IO-Adressen• Die I/O MMU setzt „physikalische“ Guest OS-Adressen, die es nicht gibt, in physikalische
Host OS I/O-Adressen um, die es gibt
2.) einem sog. Address Translation Service (ATS) in der PCIe-Karte, der für PICe-Gerätedasselbe macht wie die I/O MMU für den Core
Hinweis: PCie ist der Nachfolger von PCI-X, was wiederum der Nachfolger von PCI ist
3.) Mehrere Input- und Output-Warteschlangen in Hardware in jeder PCIe-Karte

281
• Mit multiple input und multiple output queues kann das Multiplexen eines PCIe-Geräts zwi-schen VMs in Hardware automatisch vollzogen werden, und der Hypervisor ist entlastet
Es gibt darüber hinaus sogar die Möglichkeit, dass virtuelle Gerätetreiber inkl. derenvirtuelle PCIe-Adressen indirekt ein reales PCIe-Gerät bedienen können
Dies wird als SR-IOV bezeichnet
9.7 SR-IOV
Bei SR-IOV werden die Guest OS-Gerätetreiberkommandos via QEMU/KVM an das re-ale Gerät durchgereicht, ohne dass der Host OS-Gerätetreiber, der eigentlich für dasreale Gerät zuständig ist, beteiligt wäre
Dies ist durch die IO MMU im Core und den Address Translation Service in der PCIe-Karte möglich
SR-IOV erlaubt außerdem, dass mehrere VMs ein reales PCIe-Gerät reihum bedienenkönnen
Dies ist durch die Hardware-Warteschlangen und das Hardware-Multiplexen in denPCIe-Geräten möglich
D.h., bei SR-IOV wird ein Multiplexen von VM-Zugriffswünschen und deren IO-Datenvom peripheren Gerät selber so vorgenommen, dass jede VM „ihre“ Daten erhält
Dadurch können die Gerätetreiber mehrere Guests OSes abwechselnd das reale Gerätbedienen, ohne dass dazu der Hypervisor eingreifen muss
282
Es ist bei SR-IOV nicht mehr nötig, dass der Gerätetreiber des Host OS von KVM/QEMU aufgerufen wird das Gerät steuert
Dadurch wird die Kommunikation zwischen den Guest OS-/Host OS-Gerätetreibernüber QEMU und ein Großteil des KVM-Hypervisor-Overheads eingespart
Damit der direkte Zugriff einer oder mehrerer VMs auf das PCIe-Gerät mittels SR-IOVmöglich ist, müssen zusätzlich auch das BIOS, das Mainboard des Servers und dieCPU SR-IOV unterstützen
SR-IOV ist in neueren PCIe-Geräten enthalten und damit Stand der Technik
9.8 Container anstelle von VMs
Führt man den Effizienzgedanken von SR-IOV weiter, kommt man dazu, die VMs wiederabzuschaffen
Anstelle der VMs treten sog. Container Ein Container ist genau wie eine VM eine selbstständig lauffähige Software-Umgebung,
um Anwendungen auszuführen Ein Container hat aber nicht den Overhead, den eine VM hat, da es kein eigenes Guest
OS gibt Anstelle des Guest OS benützt der Container weitere Funktionen des Kernels des Linux
Host OS, und zwar sog. „Name Spaces“ und „Control Groups (cgroups)“ und ein pri-vates Filesystem pro Container

283
Diese erlauben die Selbstständigkeit verschiedener Container im selben Rechnerdurch „private“ Systemdienste und -Bibliotheken, inkl. eines „privaten“ Laufzeit- undFilesystems, auf die nur je ein Container zugreifen kann
Ein Hypervisor mit Emulator ist für einen Container nicht mehr nötig Es ist aber möglich, dass ein reduzierter Hypervisor zusammen mit Containern existiertBeispiel: die Software „Docker“ ist die am weitesten verbreitete Container-Middleware
10 Cloud Computing
Def.: Als umfassende Definition einer Cloud hat sich die Beschreibung des U.S. NationalInstitute of Standards durchgesetzt. Diese ist unter: http://csrc.nist.gov/publications/nistpubs/800-145/SP800-145.pdf
Im folgenden wird allerdings nur der Fall einer privaten Cloud diskutiert
Eine einfache Definition einer privaten Cloud lautet:Def.: Eine private Cloud besteht aus einem räumlich konzentrierten Rechner-Cluster undeinem sog. Cloud OS, das von allen Rechnern im Cluster in deren Host OS ausgeführtwird. Das Cloud OS stellt dem Eigner eine größere Zahl von IT Management-Funktion aneiner Stelle (zentral) zur Verfügung.Hinweis: Cluster, engl. = Haufen
284
10.1 Vorteile einer Cloud
Es ergeben sich durch die Verwendung einer Cloud zahlreiche Vorteile:
1.) Single Sign-On· auf allen PCs des Clusters kann man sich mit demselben Benutzernamen und Passwort
in gleicher Weise einloggen· das dazu notwendige Werkzeug heißt bei OpenStack „Keystone“.
2.) Single Identity Management· Alle Benutzernamen, Passwörter und Zugriffsrechte der Benutzer werden von einer zen-
tralen Stelle aus vergeben und verwaltet· Ein LDAP kann entfallen· das dazu notwendige Werkzeug ist bei OpenStack ebenfalls „Keystone“.
3.) Single Update· für Updates von MS Windows reicht es aus, eine VM zu aktualisieren· Andere VMs können durch Kopieren von deren VM Image erzeugt werden· das dazu notwendige Werkzeug heißt bei OpenStack „Dashboard“
4.) Single Network Management· die Vergabe von IP-Adressen und von MAC-Adressen (wo nötig) und die Konfiguration
von Ethernet Switches ist zentral möglich· das dazu notwendige Werkzeug heißt bei OpenStack „Neutron“

285
5.) Easy Integration· Integration und Verwaltung neuer Rechner ist vereinfacht, da jede VM zentral sichtbar
und administrierbar ist· das dazu notwendige Werkzeug ist bei OpenStack ebenfalls das Dashboard
6.) Easy Performance Tuning· das Verhalten der Cloud-Rechner und des Netzwerks kann zentral beobachtet und ggf.
verbessert werden· das dazu notwendige Werkzeug heißt bei OpenStack „Ceilometer“
7.) Easy Accounting· Falls eine Abrechnung für verbrauchten Speicherplatz und Rechenzeit notwendig sein
sollte, ist diese vereinfacht, da es dafür ein zentrales Werkzeug gibt· das dazu notwendige Werkzeug ist bei OpenStack ebenfalls das Ceilometer
8.) Single Data Storage and Access· die Einrichtung und Verwaltung von Dateien, die von mehreren PCs gemeinsam gelesen
und geschrieben werden sollen, ist vereinfacht· Jede gemeinsame Datei wird auf ein OpenStack „Share“ abgebildet.
9.) Resource Pooling· erlaubt einen Lastausgleich zwischen den realen Rechnern im Cluster, indem VMs zwi-
schen Rechnern hin- und hergeschoben werden
10.)Rapid Elasticity
286
· erlaubt es, bei Bedarf innerhalb von Sekunden neue VMs zu starten, die wiederum mehrBenutzeranwendungen ausführen können
11.)Easy Overall Administration eines Rechner-Clusters· die zahlreichen Cloud- Services und die zentrale Armaturentafel der Cloud („Dash-
board“) vereinfachen die gesamte Verwaltung eines Rechner-Clusters erheblich
Aufgrund der zahlreichen Vorteile, die eine Cloud bietet, sind viele Firmen-Rechen-zentren intern als Cloud organisiert
10.2 Nachteile einer Cloud
Eine Cloud stellt ein verteiltes System dar, dessen VMs/vCPUs über TCP/IP gekoppeltist, obwohl sich alle VMs/vCPUs der Cloud physikalisch im selben Schrank oder im sel-ben Rechenzentrum befinden
ein effizienter Datenaustausch zwischen VMs ist i.d.R. nicht gegeben, da TCP/IP fürweltweite Kommunikation gemacht ist, was im selben Schrank oder selben Rechen-zentrum gar nicht notwendig wäre
Aufgrund der ineffizienten Datenübertragung ist es normalerweise auch nicht mög-lich, sog. Hochleistungsrechnen (High-Performance Computing, HPC) durchzuführen,außer man wendet spezielle Techniken wie ivshmem an

287
10.3 Das Cloud-Betriebssystem
Das Cloud OS ist die Software zur Realisierung einer Cloud Das Cloud OS ist, einfach gesprochen, eine Sammlung von Management-Diensten Die Management-Dienste erlauben u.a. virtuelle Maschinen Cluster-weit zu erzeugen,
zu betreiben und zu verwalten Das Cloud OS arbeitet dazu mit den Hypervisoren auf den einzelnen Rechnern eng zu-
sammen Das Cloud OS ist quasi ein Hypervisor nicht nur für einen Rechner sondern für eine
Menge von Rechnern Bzgl. der Virtualisierung macht das Cloud OS nur wenig selber, sondern bedient sich
der Dienste, die die lokalen Hypervisoren anbieten Die Cloud ist logisch oberhalb der Hypervisoren, aber unterhalb der Anwendungen an-
gesiedelt Insgesamt erleichtert das Cloud OS die Verwaltung der Cluster-Rechner erheblich Das Cloud OS stellt analog zu einem traditionellen Betriebssystem für reale Hardware
Aufruf-Schnittstellen bereit, allerdings für virtuelle Ressourcen und nicht für reale
Dafür stellt das Cloud OS Cluster-weit zahlreiche Dienste zur Verfügung, die über eineAPI konfiguriert werden können
Beispiel: Die am weitesten verbreiteten kommerziellen Cloud-Dienste sind AmazonWeb Service (AWS) und Microsoft Azure
288
10.4 Das Cloud OS „OpenStack“
OpenStack ist das am meisten verbreitete, nicht kommerzielle Open-Source Cloud-OS OpenStack hat ca. 60 Tausend Entwickler! Alle 6 Monate erscheint eine neue Version („Release“) OpenStack ist in der Skriptsprache „Python“ geschrieben und wird interpretiert Müssen Datenstrukturen ausgetauscht werden, wird dazu „Jason“ verwendet Bei OpenStack existieren zahlreiche Dienste, die unabhängig vom darunterliegenden
Betriebssystem (Linux in allen Varianten) in stets derselben Weise aufgerufen werden
feste Cloud API trotz sich ändernden Linux- und OpenStack-Varianten
Mit der Cloud API kann bei den virtuellen Ressourcen alles konfiguriert werdenBeispiel: Jeder logische Prozessor besteht bei OpenStack aus einem virtuellen Chip-Sockel, der eine vCPU enthält. Virtuelle Multicore-Architekturen werden dadurch reali-siert, dass der VM zusätzliche vCPUs hinzufügt werden.
10.4.1 OpenStack-Dienste
Folgende OpenStack-Dienste dienen dem Cluster-weiten Management virtueller Res-sourcen und sind bei OpenStack besonders wichtig:
1.) Ein Metascheduler namens „Nova“, der VMs realen Cores in realen Servern zuordnet• Damit erhält eine VM statisch einen Core im Cluster zugewiesen, der die VM ausführt

289
2.) Ein Netzwerkdienst namens „Neutron“ für die zentrale Verwaltung virtueller Netzwerk-karten, virtueller Switches und virtueller LANs
Beispiel: durch die zentrale Verwaltung mittels Neutron wird die Vergabe von MAC- undIP-Adressen an VMs vereinfacht.
3.) Ein Benutzer-Verwaltungssystem namens „Keystone“, das einen Benutzer mit Pass-wort auf allen Rechnern im Cluster einrichtet und ihm überall dieselben Zugriffs-rechte gibt
Beispiel: Ein Benutzer muss bei 1000 Rechnern in einer Cloud nur einmal in Keystoneangelegt werden und nicht 1000 Mal in den einzelnen Rechnern.
4.) Eine web-basierte Benutzoberfläche namens „Horizon“, auch „Dashboard“ genannt,über die man von überall die Cloud von Hand konfigurieren und überwachen kann
5.) Einen 1. Speicherdienste namens „Swift“, das ein verteiltes Dateisystem darstellt, umsog. Objekte zu speichern
Hinweis: Swift, engl. = Haspel; Mauersegler
• Objekte sind nach außen hin unstrukturierte Daten wie Photos, E-mails und Festplatten-Backups, die einfach nur aus einer Folge von Bytes bestehen, zusammen mit einer Be-schreibung dieser Daten durch sog. „Metainformation“
• Die Daten werden redundant über das Cluster verteilt abgelegt• Damit können Petabytes zuverlässig gespeichert werden (=„Big Data“)
290
6.) Einen 2. Speicherdienst namens „Cinder“, um sog. Blöcke (Records) im Cluster ver-teilt zu speichern
Hinweis: Cinder, engl. = Zunder, Schlacke
• Cinder ist quasi eine Festplatte, die auf ein ganze Rechner-Cluster ausgedehnt ist und Red-undanz ähnlich wie ein RAID aufweist
Hinweis: RAID = Redundant Array of Inexpensive Disks
• Cinder-Blöcke sind Festplatten-Records gleicher Länge • Sie speichern solche Daten, die man in Records gleicher Länge unterteilen kann, wie z.B.
Datenbank-Daten• Records sind nicht redundant vorhanden sondern nur einmal• Jeder Record hat eine individuelle Adresse auf der Festplatten und kann direkt angespro-
chen werden => schneller Zugriff auf jeden einzelnen Record
Beispiel: Mit Cinder können relationale Datenbanken effizient implementieren werden
7.) Einen 3. Speicherdienst namens „Glance“, um VMs in Form sog. „Images“, d.h. vonHauptspeicherauszügen (Core Dumps) auf Platte abzuspeichern (Snapshot), wiederaufzu-finden und neu zu starten
Hinweis: Glance, engl. = Blick; Glanz
8.) Einen 4. Speicherdienst namens „Trove“, mit dem man auch nicht-relationale Daten-banken im Cluster effizient implementieren kann

291
Hinweis: Trove, engl. = Fund. nicht-relationale Datenbanken sind auch unter dem Namen No-SQL-Datenbanken bekannt. Sie speichern Objekte statt Relationen, d.h. Daten und Metainformationen zu diesen Daten.
9.) Einen Messungsdienst namens „Ceilometer“, mit dem man Leistungsdaten aus demlaufenden Betrieb der Cloud sammeln und darstellen kann
Beispiel: Messdaten in der Cloud sind u.a. die CPU-Auslastung, die Zahl der Festplat-tenzugriffe pro Sekunde, die erreichte Netzwerkbandbreite, etc.
• Ceilometer kann für die Abrechnung von Cloud-Diensten über Gebühren verwendet wer-den
10.)Einen Stapelverarbeitungsdienst namens „Heat“, mit dem man eine beliebige Zahlvon API-Aufrufen ausführen kann, die in einer Batch-Datei („Skript“) gespeichert sind
Beispiel: Heat erlaubt u.a. die automatisierte Erzeugung von VMs, sowie die automati-sierte Nutzung aller Dienste der API über Skripte.
Um die Dienste von OpenStack aufzurufen, existiert eine REST-basierte APIHinweis: REST ist eine Implementierung des http-Protokolls, bei der auch die Methoden PUT & DELETEfunktionieren, sowie ein bestimmter Satz von Regeln („Architekturstil“), die es u.a. erlauben, einenstatuslosen Web Service mit Hilfe von http-Methoden und sog. Uniform Resource Identifiern (URIs) zurealisieren.
Beispiel: Die REST-basierte API erlaubt u.a. das Einrichten, Verwaltung und Löschenvon VMs und von Datenbanken.
292
Die REST API von OpenStack konfiguriert jedoch nur die Objekte, die die Cloud erzeugt Sie erlaubt nicht deren Nutzung Es gibt eine Aufgabenteilung zwischen der Objektkonfiguration durch die REST API
und der Objektnutzung durch existierende Standardmethoden Diese Aufgabenteilung erlaubt die Kompatibilität des Cloud OS mit den existierenden
StandardsBeispiel: Der Zugriff auf eine relationale Datenbank erfolgt über SQL-Aufrufe und nichtüber die REST API. Der Zugriff auf eine VM erfolgt über die Anwendung selber. DerZugriff auf den blockbasierten Speicherdienst Cinder erfolgt über readf/printf.
10.4.2 Eigenschaften des OpenStack Cloud OS
Das OpenStack Cloud OS läuft als Benutzerprozess im Host OS des realen Rechnersohne Systemprivilegien
Alle Guest OSe laufen ebenfalls als Benutzerprozesse im Host OS des realen Rechnersohne Systemprivilegien
Kein Guest OS kann auf reale Ein-/Ausgabegeräte des Rechners zugreifen
Die Benutzeranwendungen laufen im Host OS ebenfalls als Benutzerprozesse ohneSystemprivilegien
Alle Anwendungen eines Guest OS sind im Host OS Threads des Guest OS-ProzessesHinweis: Threads werden bei Linux ähnlich wie Prozesse behandelt.

293
Guest OS-Anwendungen haben im Host OS eine normale Process-ID und ein ParentProcess ID, die die Process ID des Guest OS-Prozesses ist
Auf diese Weise werden Sie im Host OS verwaltet
10.4.3 Unterstützung von OpenStack durch libvirt
OpenStack wird durch eine extern erstellte Bibliothek namens libvirt bei der Verwal-tung von VMs unterstützt
Libvirt bietet einen Kommandozeilen-Benutzerschnittstelle namens virsh und eine gra-phische Schnittstelle namens virt-Manager zum Erzeugen, Starten, Stoppen und Steu-ern von VMs an
Dieselben Funktion können auch vom Horizon Dashboard direkt aufgerufen werden,das dazu die OpenStack-Schnittstelle von libvirt benützt
294
10.4.4 OpenStack im Kontext
Zusammen mit libvirt, KVM/QEMU und dem Horizon Dashboard ergibt sich nachfolgen-des Gesamtschaubild von OpenStack:
Vielen Dank für die Aufmerksamkeit!
Libvirt Virtuali-sierungs-API und -biblio-thek
Horizon zur Cloud- und VM-Steue-rung
Open-Stack OS mit Dien-sten
Realer Rechner mit Hardware-Hilfen für die Virtualisierung und Geräteemulation
Linux Host OSSystem-privilegi-en
Benut-zerprivi-legien
. . .
QEMU 1
Guest OS 1
Benutzer-anwen-dungen 1-m
QEMU k
Guest OS k
Benutzer-anwen-dungen 1-n
KVM-Hy-pervisor










![3. Transformatoren - iee.tu-clausthal.de · Elektrische Energietechnik (S8803) Seite 3.3 Transformatoren _____ Be/Wo 24.10.99 u12 N1]](https://static.fdokument.com/doc/165x107/5ad660217f8b9a1a028e5928/3-transformatoren-ieetu-energietechnik-s8803-seite-33-transformatoren-.jpg)






![REGIONALES RECHENZENTRUM ERLANGEN [RRZE] · Rechner 131.188.79.246 Port 23 TCP (telnet) § „Verbergen“ von Diensten § Keine Überprüfung der IP / TCP / UDP Payload § Keine](https://static.fdokument.com/doc/165x107/5d55d78a88c99353208b48d5/regionales-rechenzentrum-erlangen-rrze-rechner-13118879246-port-23-tcp.jpg)
