
Wissens- und...
79
Institut für Informatik Wissens- und Content-Management XML und Datenbanken Dr. Roman Schneider
Transcript of Wissens- und...

Institut für Informatik
Wissens- und
Content-Management
XML und Datenbanken Dr. Roman Schneider

XML und Datenbanken
Content Management für XML 1/3
• Aufgabe: Verwaltung der Inhalte und der logischen Struktur von XML-
Instanzen
• Layoutinformationen separat
=> flexible Darstellung und effektive Weiterverarbeitung (Medien, Formate, …)
2 Dr. Roman Schneider Modul Wissens- und Contentmanagement

XML und Datenbanken
Content Management für XML 2/3
3 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Was gehört dazu? Spektrum der Teilaufgaben:
• Modellierung: Erstellung/Ableitung von Strukturbeschreibungen
• Manuelle oder automatisierte Generierung von XML-Dokumenten
• Speicherung von (dokumentenzentrierten, semistrukturierten, ggf. auch
datenzentrierten) XML-Dokumenten (CMS, DBMS)
• Indizierungsverfahren (wichtig zur Abfrage-Optimierung)
• Abfragerealisierung (Abfragesprachen für XML-Dokumente)
• Update / Transformation von XML-Dokumenten
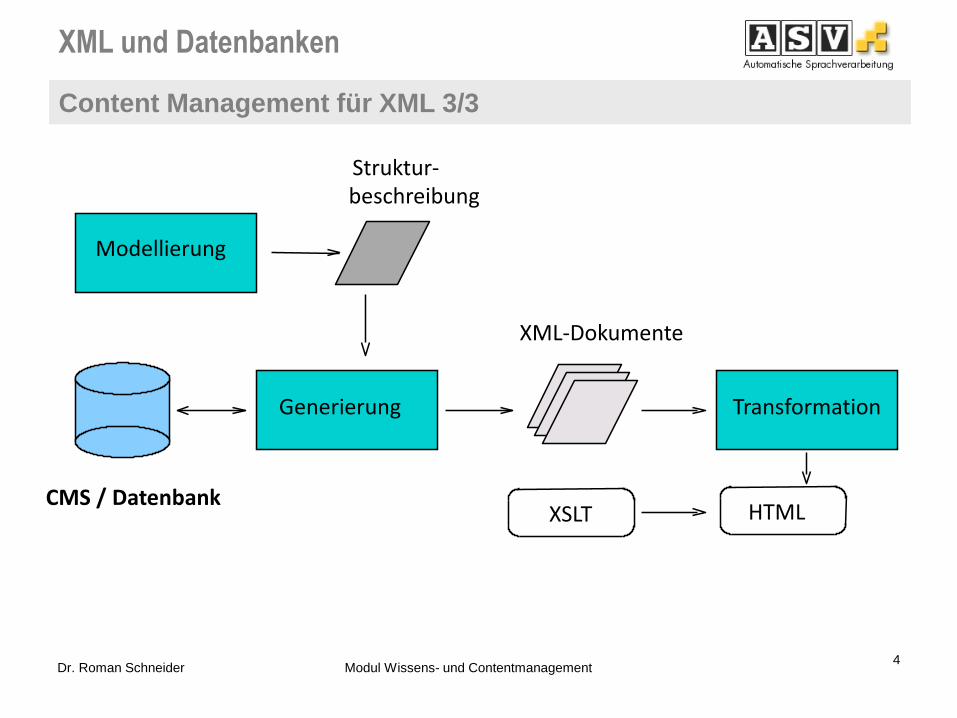
XML und Datenbanken
Content Management für XML 3/3
4 Dr. Roman Schneider Modul Wissens- und Contentmanagement
XML-Dokumente
Generierung
HTML XSLT CMS / Datenbank
Struktur- beschreibung
Modellierung
Transformation

XML und Datenbanken
Problematik
5 Dr. Roman Schneider Modul Wissens- und Contentmanagement
1. XML-Dokumente können für sehr verschiedene Anwendungen
/ Zwecke eingesetzt werden (Kataloge, Webseiten, ...)
=> Aufbau der Dokumente unterscheidet sich stark
2. Oft mehrere Varianten einer Struktur-Modellierung denkbar
3. Es existiert eine Vielzahl von Methoden zur Speicherung
Nachfolgend:
Klassifikation und
Einordnung bekannter Methoden für Entwurf, Generierung &
Speicherung von XML-Dokumenten
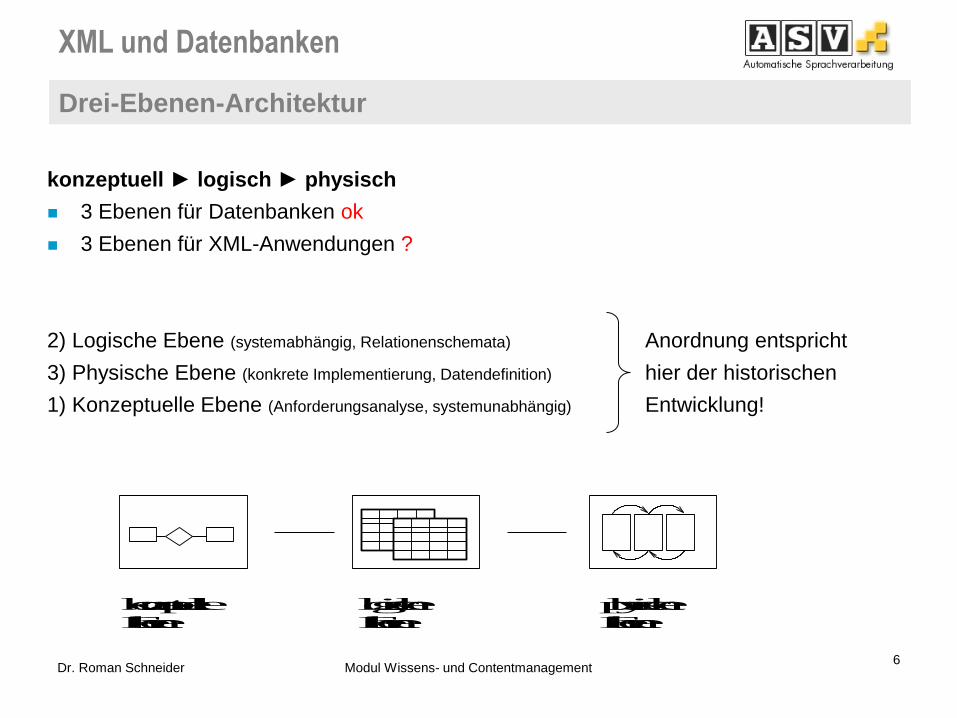
XML und Datenbanken
Drei-Ebenen-Architektur
6 Dr. Roman Schneider Modul Wissens- und Contentmanagement
konzeptuell ► logisch ► physisch
3 Ebenen für Datenbanken ok
3 Ebenen für XML-Anwendungen ?
2) Logische Ebene (systemabhängig, Relationenschemata) Anordnung entspricht
3) Physische Ebene (konkrete Implementierung, Datendefinition) hier der historischen
1) Konzeptuelle Ebene (Anforderungsanalyse, systemunabhängig) Entwicklung!
physische EbeneEbene
logischekonzeptuelleEbene

XML und Datenbanken
Drei Ebenen bei Datenbanken
7 Dr. Roman Schneider Modul Wissens- und Contentmanagement
1. Konzeptuelle Ebene (in der Regel bezogen auf ein
Anwendungsgebiet): Entwurf evtl. bereits mit ERM, ER-
Diagrammen
2. Logische Ebene (logische Strukturen für konkretes System):
relationales Datenmodell, relationale Algebra
3. Physische Ebene (Implementierung): interne Speicherung,
Indizierung, Transaktionsverarbeitung, Anfrageoptimierung
physische EbeneEbene
logischekonzeptuelleEbene
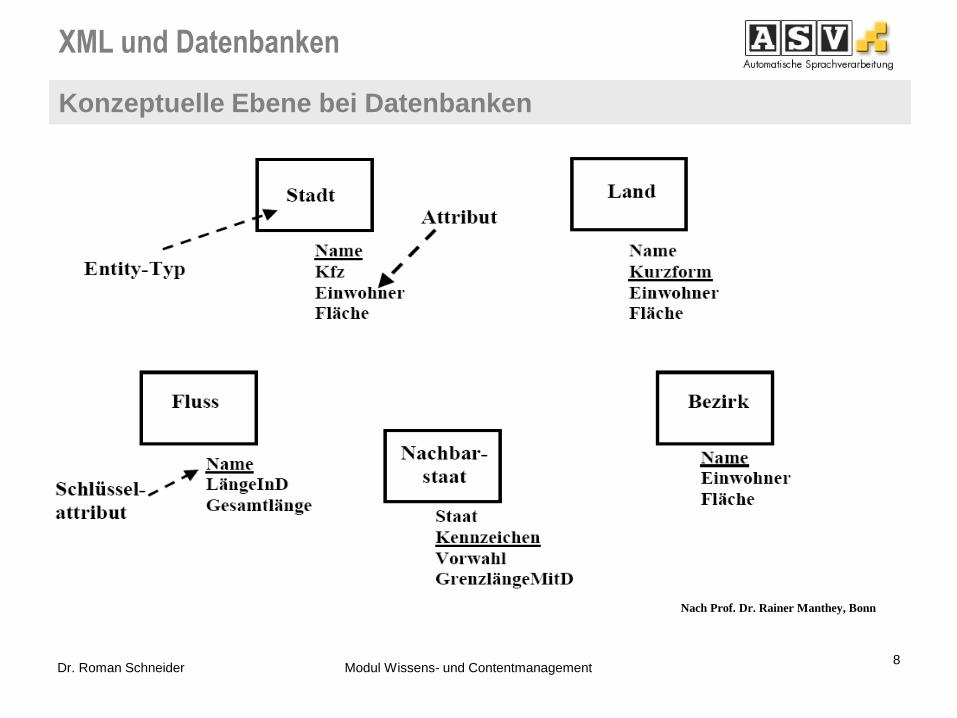
XML und Datenbanken
Konzeptuelle Ebene bei Datenbanken
8 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Nach Prof. Dr. Rainer Manthey, Bonn
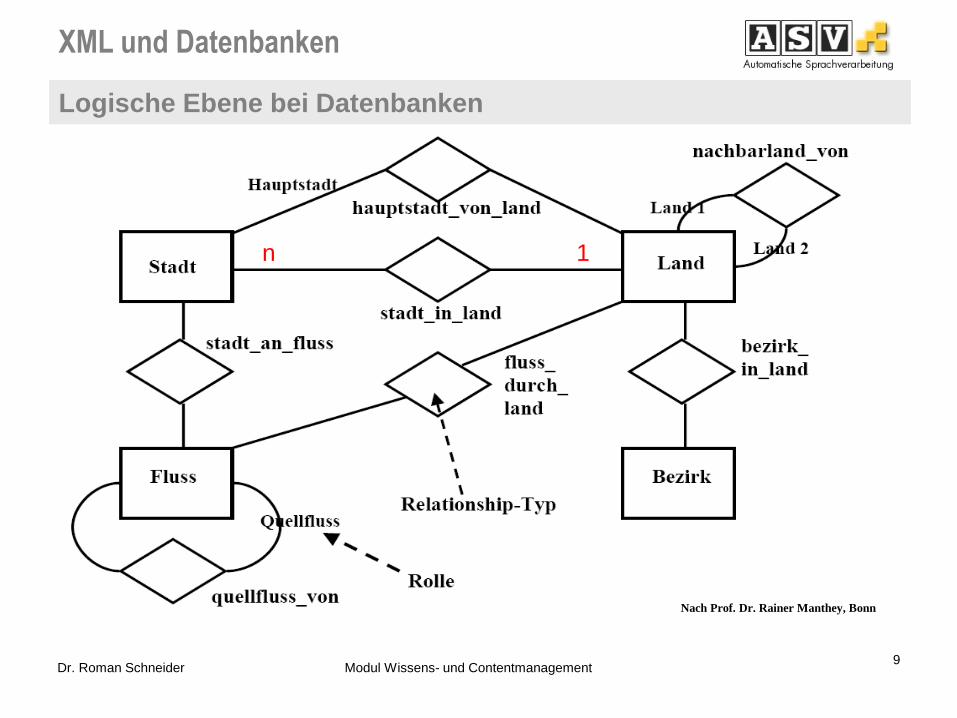
XML und Datenbanken
Logische Ebene bei Datenbanken
9 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Nach Prof. Dr. Rainer Manthey, Bonn
1 n
XML und Datenbanken
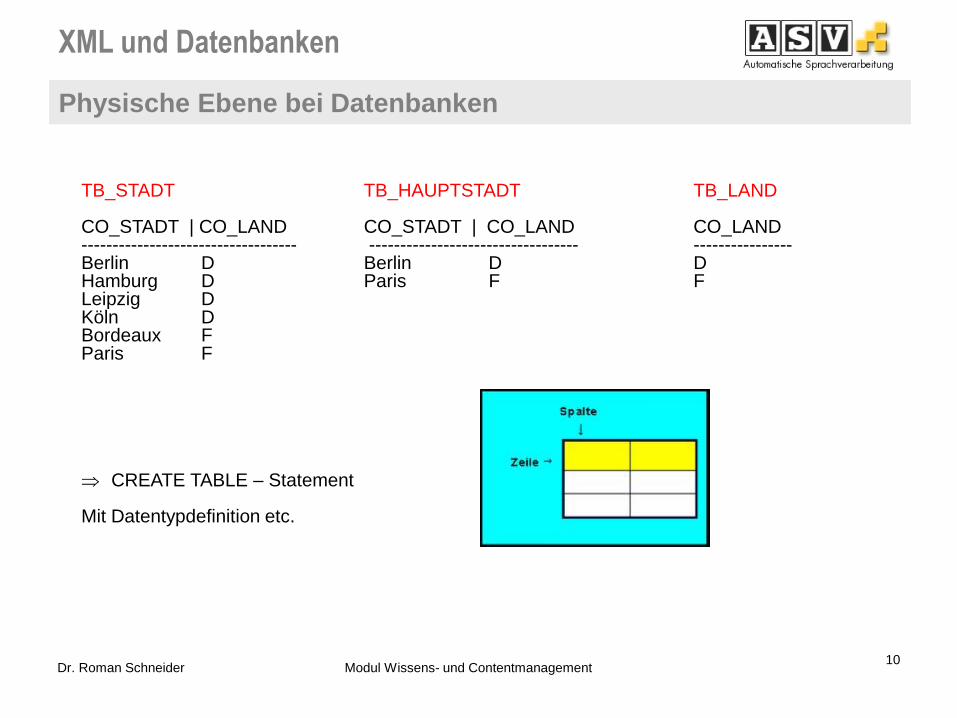
Physische Ebene bei Datenbanken
10 Dr. Roman Schneider Modul Wissens- und Contentmanagement
TB_STADT TB_HAUPTSTADT TB_LAND CO_STADT | CO_LAND CO_STADT | CO_LAND CO_LAND ----------------------------------- ---------------------------------- ---------------- Berlin D Berlin D D Hamburg D Paris F F Leipzig D Köln D Bordeaux F Paris F CREATE TABLE – Statement
Mit Datentypdefinition etc.

XML und Datenbanken
Drei Ebenen für XML-Applikationen
11 Dr. Roman Schneider Modul Wissens- und Contentmanagement
konzeptuelle Ebene
logische Ebene Ebene
physische
<..> <..>
</..>
</..> <..> </..>
Konzeptueller
Entwurf von XML-
Dokumenten ? ?
XML-Dokumente: Welche Methoden und Werkzeuge für...
– Entwurf/Konzeption ?
– Speicherung ?
– Anfragen, Updates ?
– Transformation ?
Historisch: logische Ebene (Spezifikation Dokumentenmodell) prominent…
XML und Datenbanken
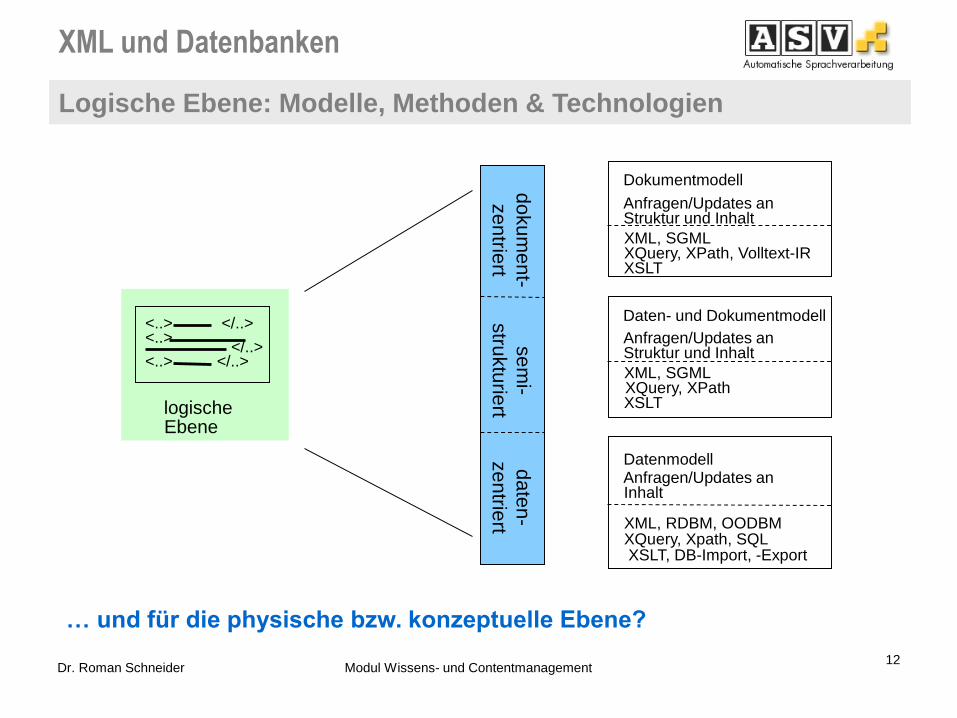
Logische Ebene: Modelle, Methoden & Technologien
12 Dr. Roman Schneider Modul Wissens- und Contentmanagement
logische Ebene
<..> <..>
</..>
</..> <..> </..>
da
ten
-
ze
ntrie
rt
se
mi-
stru
ktu
riert
do
ku
me
nt-
ze
ntrie
rt Datenmodell Anfragen/Updates an Inhalt
XML, RDBM, OODBM XQuery, Xpath, SQL XSLT, DB-Import, -Export
Daten- und Dokumentmodell
Struktur und Inhalt Anfragen/Updates an
XML, SGML XQuery, XPath XSLT
Dokumentmodell
Anfragen/Updates an Struktur und Inhalt
XML, SGML XQuery, XPath, Volltext-IR XSLT
… und für die physische bzw. konzeptuelle Ebene?

XML und Datenbanken
Anforderungen an die physische Ebene
13 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Anforderungen an die Speicherung von XML-Dokumenten:
effektive Speicherung
effizienter Zugriff auf XML-Dokumente oder -Fragmente
durch
– Transaktionsverwaltung
– Unterstützung von XPath und XQuery
– Unterstützung von SAX (Simple API for XML) oder DOM (Document
Object Model, W3C-Standard), beide spezifizieren Methoden für den
Zugriff auf XML-Instanzen
Wiederherstellbarkeit der Dokumente (bzw. der enthaltenen Informationen)
Nach Fiebig, Kanne, Moerkotte (2002): Anatomy of a native XML base management system.
Ebene physische
XML und Datenbanken
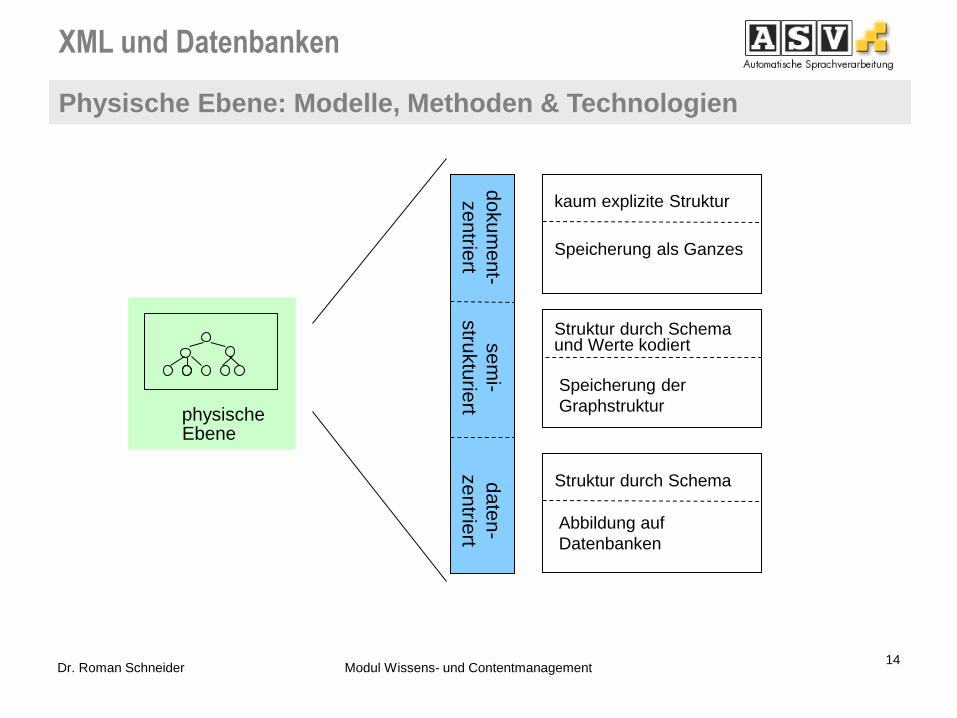
Physische Ebene: Modelle, Methoden & Technologien
14 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Ebene physische
Struktur durch Schema
Struktur durch Schema und Werte kodiert
kaum explizite Struktur
Abbildung auf
Datenbanken
Speicherung der
Graphstruktur
Speicherung als Ganzes
da
ten
-
ze
ntrie
rt
se
mi-
stru
ktu
riert
do
ku
me
nt-
ze
ntrie
rt

XML und Datenbanken
Realisierungen für die physische Ebene
15 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Speicherung der XML-Dokumente als
Ganzes (textbasiert native)
– Dateisystem
– Volltextindex
– Strukturindex
Speicherung der Graphenstruktur
(modellbasiertes natives Verfahren)
– generische Graphspeicherung
– Speicherung der DOM-Informationen
strukturierte Abbildung auf Datenbanken
– relationale Datenbanken
– objekt-orientierte und objekt-relationale Datenbanken
– Einsatz von Mappingverfahren (manuell oder automatisiert)
Ebene physische
XML-Datenbanken?
XML und Datenbanken
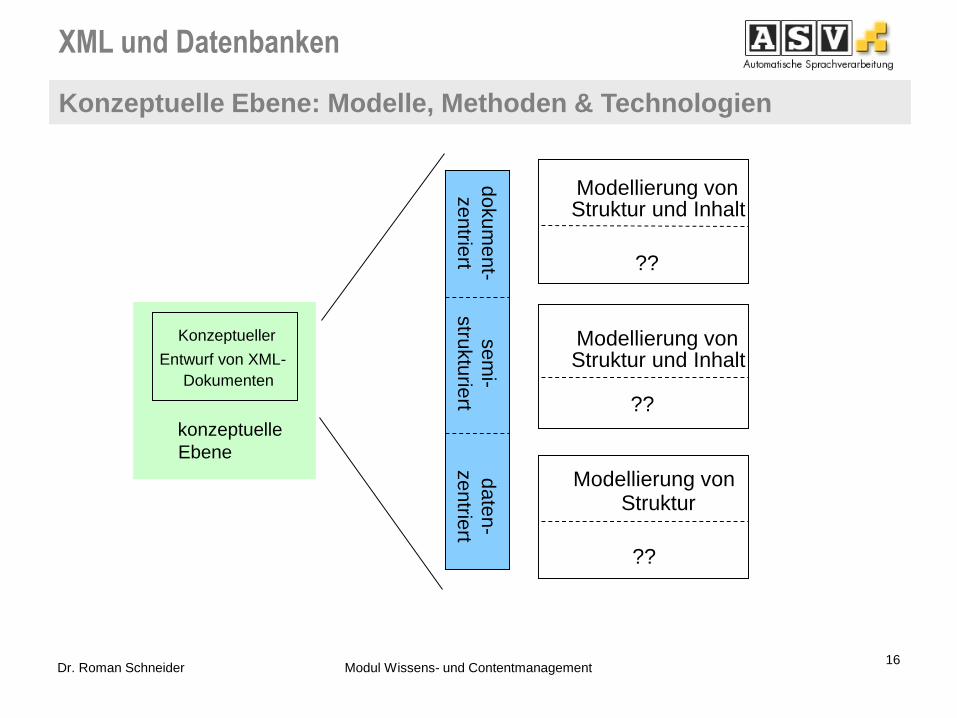
Konzeptuelle Ebene: Modelle, Methoden & Technologien
16 Dr. Roman Schneider Modul Wissens- und Contentmanagement
?? konzeptuell
e
Ebene
??
Modellierung von Struktur
??
Struktur und Inhalt Modellierung von
Struktur und Inhalt Modellierung von
?? konzeptuelle
Ebene
Konzeptueller
Entwurf von XML-
Dokumenten
da
ten
-
ze
ntrie
rt
se
mi-
stru
ktu
riert
do
ku
me
nt-
ze
ntrie
rt

XML und Datenbanken
Realisierungen für die konzeptuelle Ebene
17 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Dokumentzentrierte XML-Dokumente – Graphische Entwurfswerkzeuge
– Visualisierung von Baum- und Graphstruktur
Semistrukturierte XML-Dokumente – Graphendarstellungen, …?
Datenzentrierte XML-Dokumente – UML (Unified Modelling Language)
– Erweiterung von ER
– Erweiterung von ORM (Object-Relational Mapping, einem Konzept zum Abbilden von Objekten in relationale Datenbanken)
Hier besteht (insbesondere für semistrukturiertes XML) noch Forschungsbedarf, bislang keine etablierte Entwurfsmethode!
konzeptuelle Ebene
Konzeptueller
Entwurf von XML- Dokumenten
XML und Datenbanken
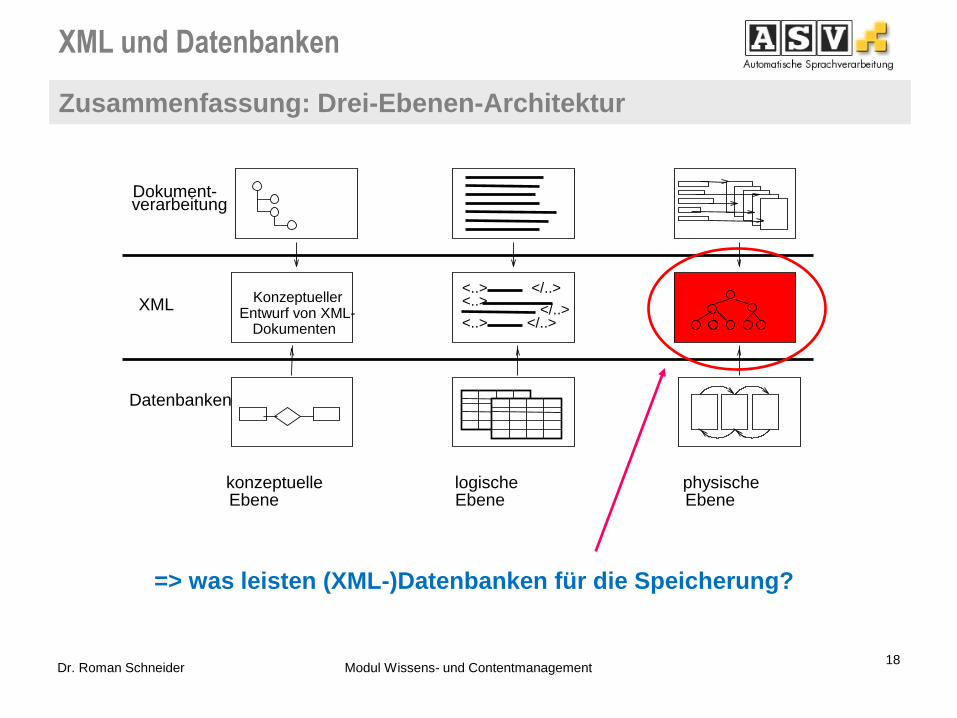
Zusammenfassung: Drei-Ebenen-Architektur
18 Dr. Roman Schneider Modul Wissens- und Contentmanagement
<..>
physische Ebene Ebene
Dokument- verarbeitung
Dokumenten Entwurf von XML-
Konzeptueller
</..> </..>
logische Ebene
<..>
konzeptuelle
</..> <..> XML
Datenbanken
=> was leisten (XML-)Datenbanken für die Speicherung?

XML und Datenbanken
Stand der Kunst bei XML-Datenbanken
19 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Nach wie vor ist vieles in der Entwicklung:
Beim W3C: Abfragesprachen, Updatesprachen, Schemaevolutionssprachen
Entsprechend auch bei XML-Datenbanksystemen
Diverse Verfahren und Techniken existieren nebeneinander
Im Produkt-Portfolio großer Anbieter gibt es z.T. mehrere parallel angebotene Lösungen
Technologie oft aus den „etablierten“ Sparten DBMS und Textverarbeitung
Generell: es gibt keinen „Königsweg“
Beste Lösung für Anwender ist abhängig von konkreten Erfordernissen (und Vorkenntnissen)

XML und Datenbanken
Speicherung von XML-Instanzen in Datenbanken 1/2
20 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Vorstellung von verschiedenen Speicherungs-Methoden
– Grundprinzip der Speicherung (als Ganzes ↔ Struktur ↔ feingranular)
– Untersch. Anwendungsbereiche
– Spezifische Eigenschaften der Speicherungs-Methoden
– Abfragemöglichkeiten
Klassifikation der Methoden folgt…
XML und Datenbanken
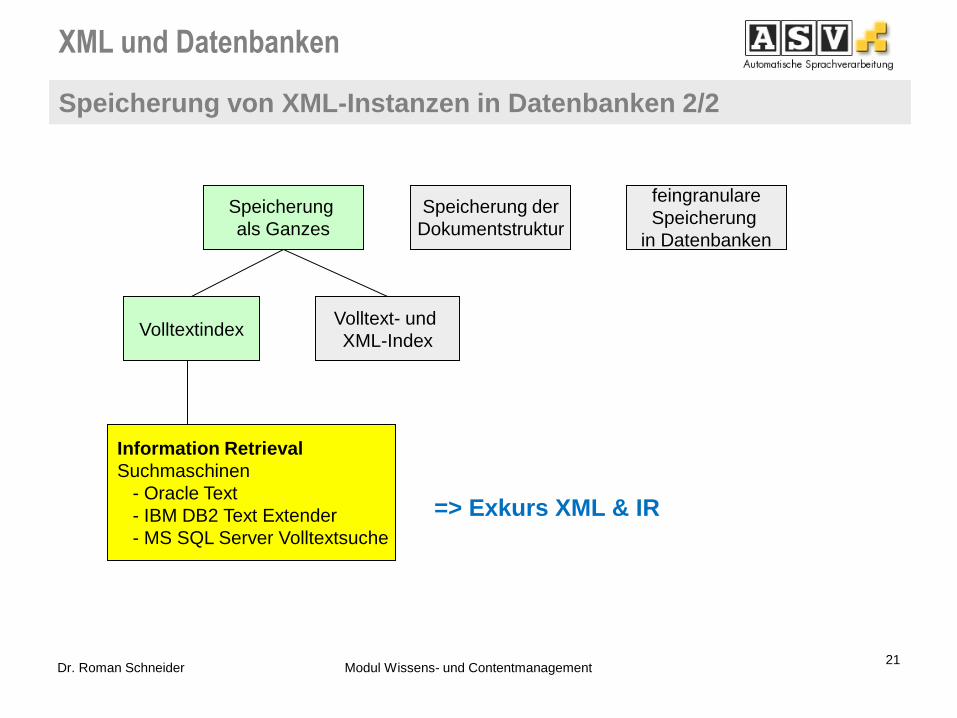
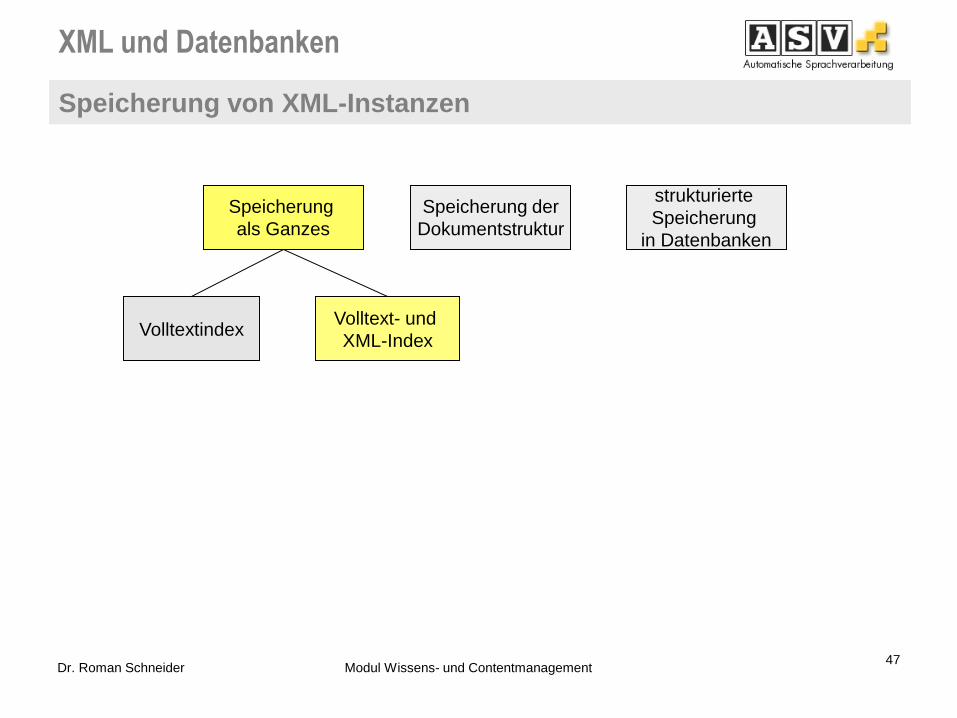
Speicherung von XML-Instanzen in Datenbanken 2/2
=> Exkurs XML & IR
21 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Volltext- und
XML-Index Volltextindex
Speicherung
als Ganzes
Information Retrieval
Suchmaschinen
- Oracle Text
- IBM DB2 Text Extender
- MS SQL Server Volltextsuche
Speicherung der
Dokumentstruktur
feingranulare
Speicherung
in Datenbanken

XML und Datenbanken
Exkurs: Information Retrieval 1/4
22 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Information Retrieval beschäftigt sich mit Verarbeitung solcher
Informationsanfragen:
„Wo findet man Informationen über Kühlschränke?“
„Wie ist der Begriff Airflow-System definiert?“
„Wo ist der Zusammenhang zwischen Kühlsystem und
Energieverbrauch erläutert?“
Norbert Fuhr: „inhaltliche Suche in Texten“
(http://www.is.inf.uni-due.de/courses/ir_ss06/folien/irskall.pdf)
Varianten der Anfrageformulierung: Satz vs. Stichwort vs. ...
Beachten muss man stets die Effizienz, denn in der Regel liegen
große Textmengen zugrunde (”Google doch mal danach...”)!
XML und Datenbanken
23 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Exkurs: Information Retrieval 2/4
Bibliotheken: Volltext- und
Metasuche
Anwendung z.B. in Suchmaschinen,
dabei spezielle Anforderungen
(Textformate, Versionen,
Dokumentstrukturen, ...)
XML und Datenbanken
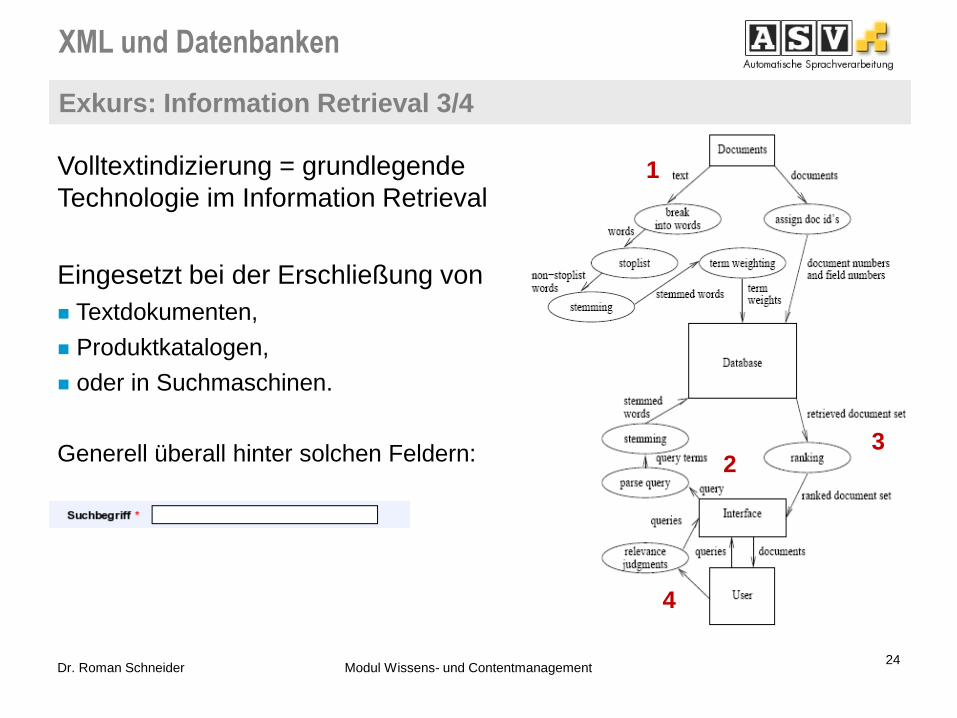
Exkurs: Information Retrieval 3/4
24 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Volltextindizierung = grundlegende
Technologie im Information Retrieval
Eingesetzt bei der Erschließung von
Textdokumenten,
Produktkatalogen,
oder in Suchmaschinen.
Generell überall hinter solchen Feldern:
1
2 3
4

XML und Datenbanken
25 Dr. Roman Schneider Modul Wissens- und Contentmanagement
<a href=„kuehlung.html“>
Kühlschränke</a>
... Airflow-System
... Energieverbrauch
... Watt
... Kühlung
Dokument mit Markup:
Situation: Man sucht Dokumente (html, doc,
pdf, ps, etc.), in denen die in der Suche
angegebenen Begriffe auftauchen.
Keine semantische Suche: Computer
„versteht“ die Texte nicht, man kann also
nur danach suchen, welche Wörter in den
Texten vorkommen, wie oft, in welchem
Zusammenhang...
Wie funktioniert (inhaltsbasierte) Suche in
solchen Dokumenten?
=> Deskribierung & Indizierung
Exkurs: Information Retrieval 4/4
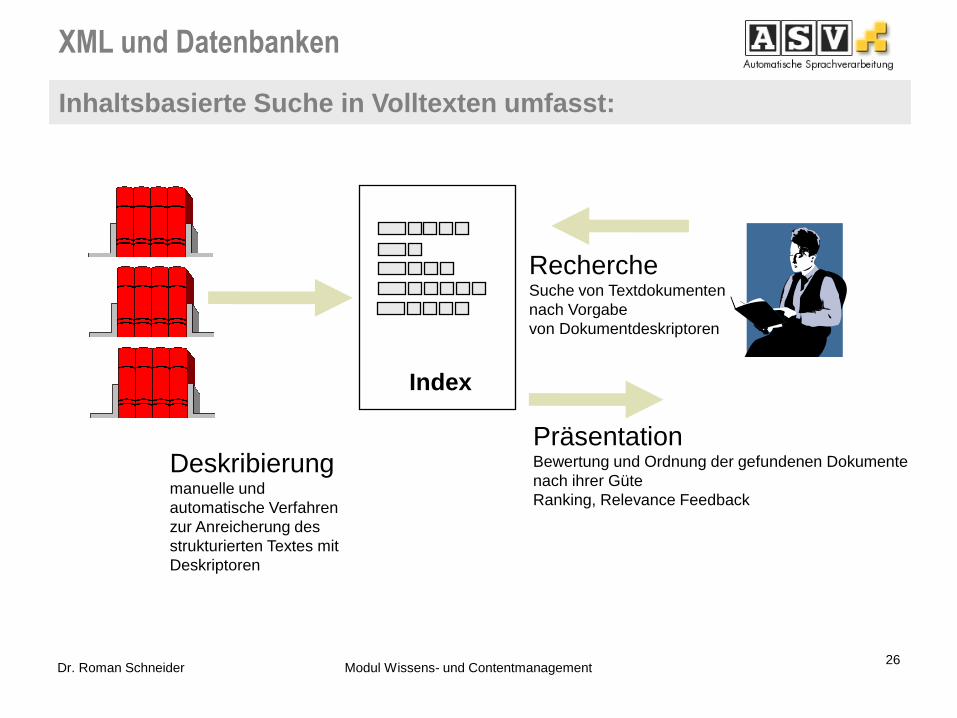
XML und Datenbanken
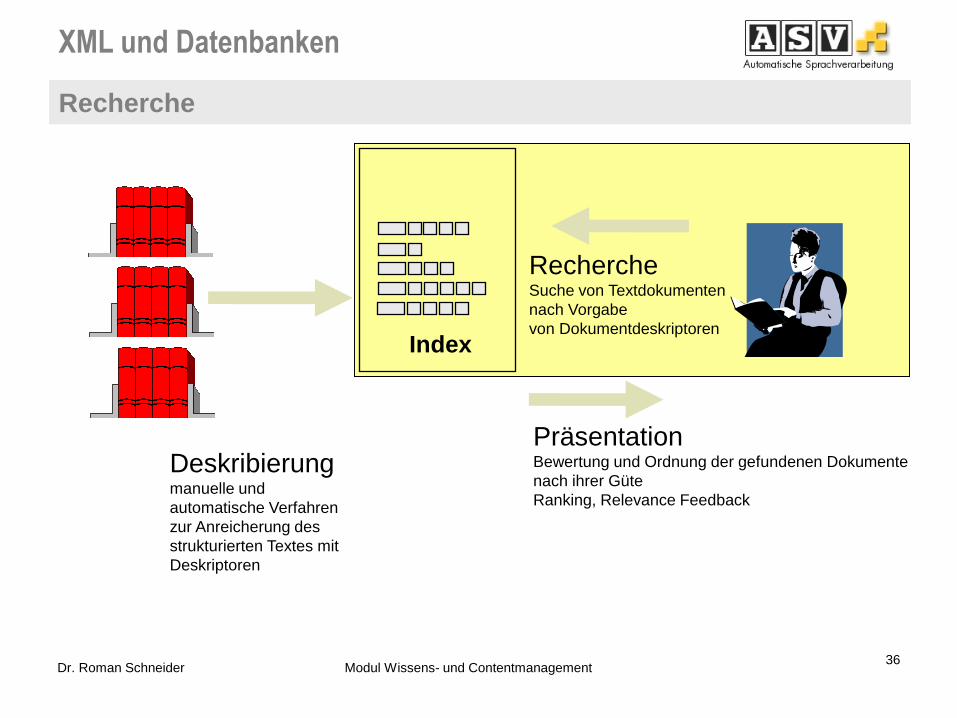
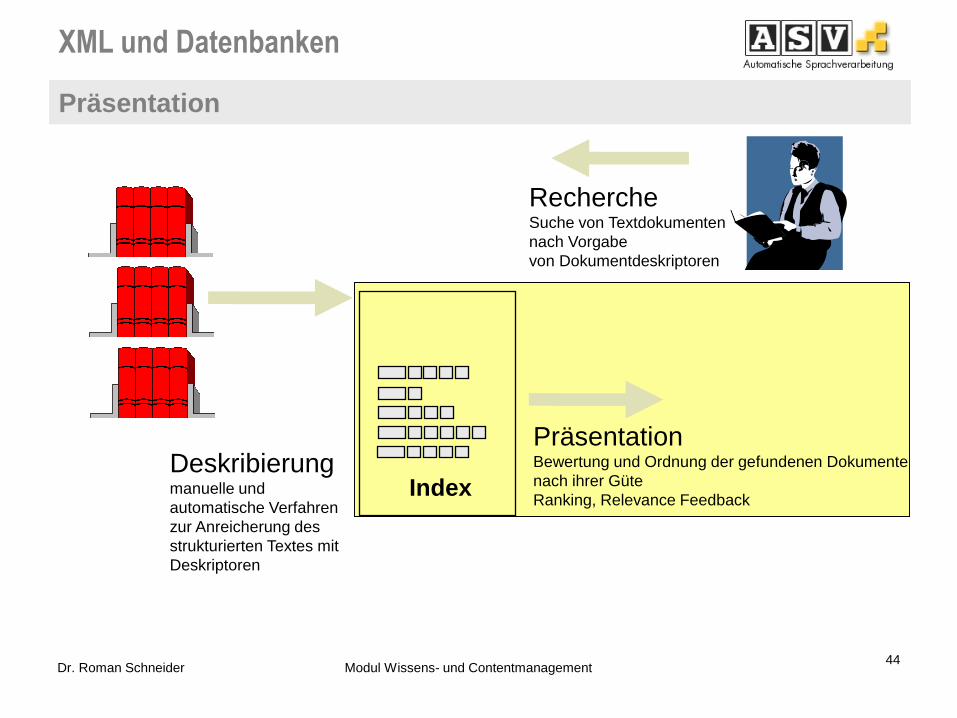
Inhaltsbasierte Suche in Volltexten umfasst:
26 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Index
Deskribierung manuelle und
automatische Verfahren
zur Anreicherung des
strukturierten Textes mit
Deskriptoren
Recherche Suche von Textdokumenten
nach Vorgabe
von Dokumentdeskriptoren
Präsentation Bewertung und Ordnung der gefundenen Dokumente
nach ihrer Güte
Ranking, Relevance Feedback
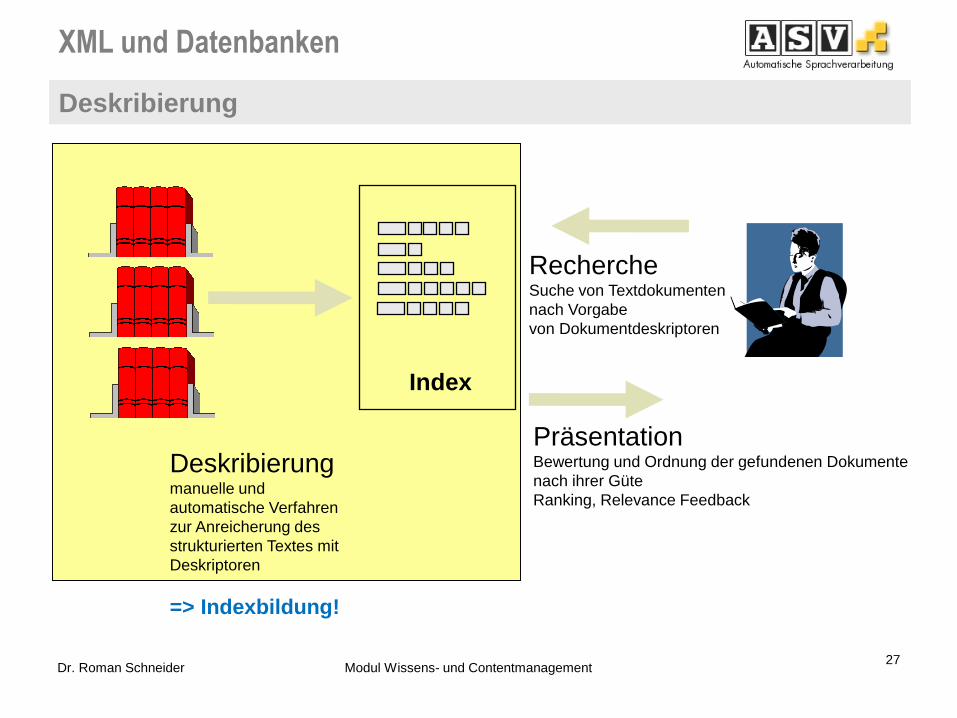
XML und Datenbanken
Deskribierung
27 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Index
Deskribierung manuelle und
automatische Verfahren
zur Anreicherung des
strukturierten Textes mit
Deskriptoren
=> Indexbildung!
Recherche Suche von Textdokumenten
nach Vorgabe
von Dokumentdeskriptoren
Präsentation Bewertung und Ordnung der gefundenen Dokumente
nach ihrer Güte
Ranking, Relevance Feedback

XML und Datenbanken
Indexbildung 1/4
28 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Suchmaschinen für das WWW nutzen indizierte Webdokumente.
Information-Retrieval-Systeme und Datenbanksysteme führen
ebenfalls eine Indexbildung nach der Speicherung von
Dokumenten durch.
Ggf. verschiedene Formate (HTML, PDF, Text, ...)!
Vor der Indexbildung muss bereits feststehen:
– welche Arten von Informationen angefragt werden
– wie die Anfragen aussehen (Einwort, Mehrwort, Phrasen, ...)
Anfragen sind zeitkritisch, Indexbildung nicht!
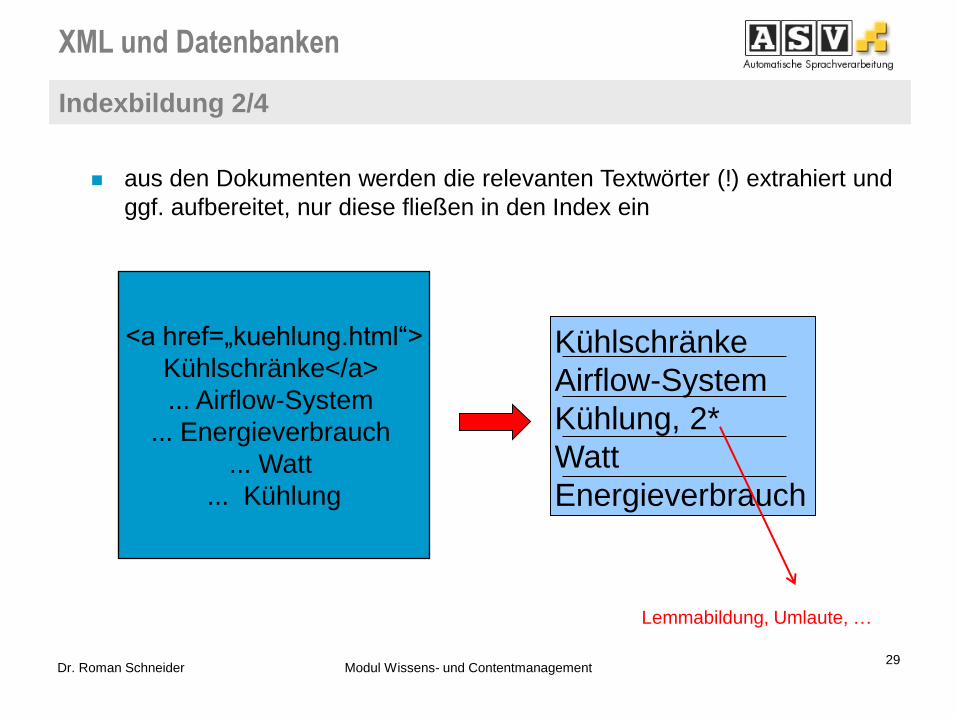
XML und Datenbanken
Indexbildung 2/4
29 Dr. Roman Schneider Modul Wissens- und Contentmanagement
aus den Dokumenten werden die relevanten Textwörter (!) extrahiert und
ggf. aufbereitet, nur diese fließen in den Index ein
Lemmabildung, Umlaute, …
Kühlschränke
Airflow-System
Kühlung, 2*
Watt
Energieverbrauch
<a href=„kuehlung.html“>
Kühlschränke</a>
... Airflow-System
... Energieverbrauch
... Watt
... Kühlung

XML und Datenbanken
Indexbildung 3/4
30 Dr. Roman Schneider Modul Wissens- und Contentmanagement
• verschiedene Optimierungen der Indexstrukturen (B-Tree, Bitmap-Index etc.)
• Anfragen sind zeitkritisch, die Indexbildung weniger: Ziel sind effiziente Zugriffe!
Implementierung als invertierte Liste
1
2
2
1
3
1
A
B
D
E
C
F
2
1
3
A D F
3
3
3 C D B
A C D E
2
Bestimmung der Stichworte
der Dokumente
Dokumente Stichworte
Invertierte Speicherung der Stichworte
und der zugehörigen Dokumente
Stichworte Dokumente

XML und Datenbanken
Indexbildung 4/4
31 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Index
Deskribierung
Verfahren zur Deskribierung (Anreicherung um Deskriptoren)
statistische, wortbasierte Verfahren
– Häufigkeit von Wörtern auswerten
linguistische Verfahren
– Stammwortreduktion (Lemmabildung)
– Phonetische Ähnlichkeit (Soundex)
– Ähnliche Schreibung (fuzzy)
– Erkennen von Satzzusammenhängen (Thema-Rhema, Folgerungen, ...)
wissensbasierte Verfahren
– Klassifikationen, Thesauri, Wortnetze, Ontologien

XML und Datenbanken
Häufigkeit der Wörter berücksichtigen 1/2
32 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Stoppwortliste eliminiert häufige Worte (z.B. Funktionswörter)
– diese würden sehr viele Einträge im Index bewirken, sind aber für die
Recherche zumeist ungeeignet
– 10 häufigste Wörter im Deutschen laut Wikipedia:
• der, die, und, in, den, von, zu, das, mit, sich
Vgl.: DeReWo – Korpusbasierte Grund-/Wortformenlisten
http://www.ids-mannheim.de/kl/projekte/methoden/derewo.html
sehr seltene Begriffe werden gestrichen
– haben zwar die höchste Selektivität, würden die Anzahl der Begriffe im Index
unverhältnismäßig erhöhen und sind für die Recherche oft zu speziell
– Beispiele:
• kennte
• Külschrank
• Kuhlschrank
• Mogelpower
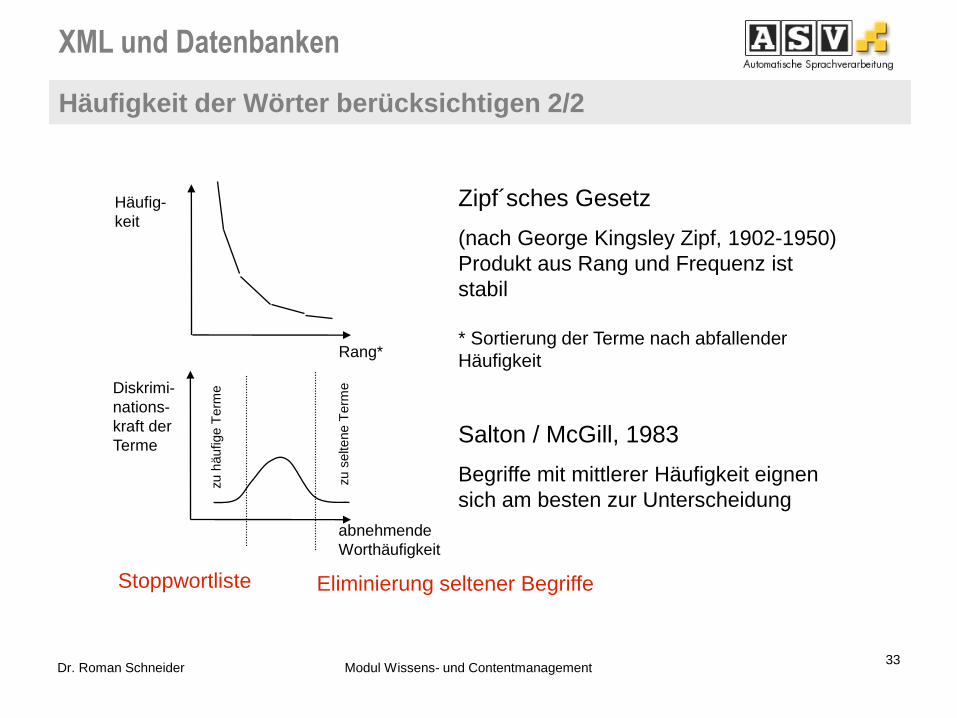
XML und Datenbanken
Häufigkeit der Wörter berücksichtigen 2/2
33 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Eliminierung seltener Begriffe
Zipf´sches Gesetz
(nach George Kingsley Zipf, 1902-1950)
Produkt aus Rang und Frequenz ist
stabil
* Sortierung der Terme nach abfallender
Häufigkeit
Salton / McGill, 1983
Begriffe mit mittlerer Häufigkeit eignen
sich am besten zur Unterscheidung
Häufig-
keit
Rang*
Diskrimi-
nations-
kraft der
Terme
abnehmende
Worthäufigkeit
zu s
eltene T
erm
e
zu h
äufige T
erm
e
Stoppwortliste

XML und Datenbanken
Bildung eines linguistischen Indexes 1/2
34 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Motivation: Begriffsuche soll auch Deklinationen (Beugung von Substantiven /
Adjektiven) bzw. Konjugationen (Beugung von Verben) einbeziehen.
Beispiele:
– bei Eingabe des Suchbegriffes „Kühlschrank“ sollen auch Dokumente mit dem
Begriff „Kühlschränke“ gefunden werden
– bei der Suche nach „fehlschlagen“ soll auch „fehlschlug“ und „fehlgeschlagen“
gefunden werden
Ergänzend zum exakten Begriff wird die Grundform der Textwörter
gespeichert
Außerdem evtl.: phonetische Ähnlichkeit oder ähnliche Schreibungen
beachten
Ziele:
– Zusammenführung sprachlich zusammengehöriger Textwörter zu einem
Eintrag
– dadurch Verkleinerung der invertierten Listen

XML und Datenbanken
Bildung eines linguistischen Indexes 2/2
35 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Verfahren:
– Wortnormalisierung (Groß- und Kleinschreibung, Umlaute)
– Wortdekomposition (besonders für deutsche Sprache wichtig)
• Komposita (zusammengesetzte Begriffe) werden auseinandergenommen,
• Beispiele:
– Haupt-bahnhof, Ost-bahnhof (Hauptbahn-hof?)
– Einzel-zimmer, Doppel-zimmer, Zweibett-zimmer
– Stammformreduktion (Verfahren zur Bestimmung der Grundformen) durch:
• Regeln (sprachabhängige Verfahren mit untersch. Güte) oder
• Wörterbücher (besonders für Sprachen mit vielen Unregelmäßigkeiten)
• Abkürzungen auflösen?
XML und Datenbanken
Recherche
36 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Index
Deskribierung manuelle und
automatische Verfahren
zur Anreicherung des
strukturierten Textes mit
Deskriptoren
Recherche Suche von Textdokumenten
nach Vorgabe
von Dokumentdeskriptoren
Präsentation Bewertung und Ordnung der gefundenen Dokumente
nach ihrer Güte
Ranking, Relevance Feedback
XML und Datenbanken
Verfahren zur Recherche
37 Dr. Roman Schneider Modul Wissens- und Contentmanagement
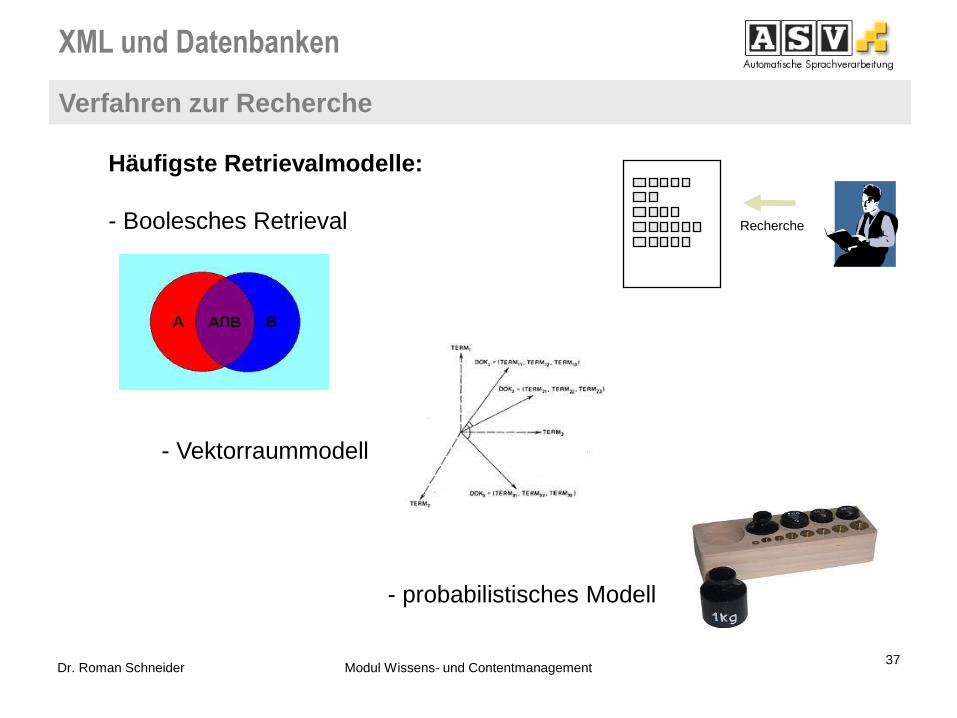
Recherche
Häufigste Retrievalmodelle:
- Boolesches Retrieval
- Vektorraummodell
- probabilistisches Modell

XML und Datenbanken
Boolesches Retrieval 1/2
38 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Dokumente werden als Wort-Mengen modelliert
Abfrage-Grundbaustein: Paar aus Attribut & Attributwert
verknüpft durch: and, or, not
exakt, logisch klar, einfach programmierbar
Suchmaschinen-Statistiken weisen aus, dass Anfragen
durchschnittlich 1,7 Wörter enthalten
Nachteile:
relativ geringe Möglichkeiten, komplexere Anfragen (präzise) zu
formulieren, evtl. Abfragesprachen mit Klammerung etc.
Häufigkeit und Relevanz der Terme bleiben unberücksichtigt
Boolesches Retrieval erlaubt kein Ranking (Ergebnis 0 oder 1),
dieses wird ggf. nachträglich in einem zweiten Schritt ermittelt
XML und Datenbanken
Boolesches Retrieval 2/2
39 Dr. Roman Schneider Modul Wissens- und Contentmanagement

XML und Datenbanken
Vektorraummodell 1/2
40 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Dokumente und Anfragen werden nicht als Wortmengen, sondern als
Vektoren (mit Länge und Richtung) betrachtet
Abbildung auf jeweils genau einen Eintrag im Vektorraum
(hochdimensional in Abhängigkeit von Zahl der indizierten Terme)
Merkmalsgewichtungsmodelle berücksichtigen die Häufigkeit von
Textwörtern, Lemmata oder n-Grammen
Reihenfolge der Wörter wird ignoriert (“bag of words”)
d1 = ( 1 , 3 , 3 , 0 , 0 )
d2 = ( 0 , 2 , 1 , 0 , 1 )
d3 = ( 1 , 0 , 0 , 1 , 0 )
d4 = ( 0 , 4 , 2 , 7 , 0 )
d5 = ( 0 , 0 , 1 , 1 , 1 )
q = query

XML und Datenbanken
Vektorraummodell 2/2
41 Dr. Roman Schneider Modul Wissens- und Contentmanagement
mit einem Ähnlichkeitsmaß (Vektordistanz) werden zu einer Anfrage-
Vektor die ähnlichsten Dokumenten-Vektoren ermittelt
es gibt zahlreiche Ähnlichkeitsmaße
Vagheit von Anfragen wird berücksichtigt ("best match"-Prinzip, d. h. es
erfolgt ein Ranking der Dokumente nach der Wahrscheinlichkeit in wieweit
ein Dokument auf die Anfrage zutrifft)
Ergebnis der Ähnlichkeitsfunktion kann für das Ranking verwendet werden
Relevance-Feedback

XML und Datenbanken
Probabilistisches Modell
42 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Ermittlung der Wahrscheinlichkeit, ob ein Dokument für die
Suchanfrage relevant ist
Hauptkriterium: Häufigkeiten (Suchterm, Terme in Dokument, ...)
Terme der Anfrage können gewichtet werden, damit hat der
Benutzer die Möglichkeit, wichtigere und unwichtigere Teile einer
Anfrage explizit zu spezifizieren
Wörter des Dokumentes werden ebenfalls gewichtet
– manuelle Verfahren: für Indizierende stellt die Angabe solcher
Wahrscheinlichkeiten eine schwierige Aufgabe dar
– automatische Verfahren: verwenden Worthäufigkeiten,
Dokumentgröße, Position des Worts im Dokument
(Überschrift?), ..
XML und Datenbanken
Übersicht der Retrievalmodelle
43 Dr. Roman Schneider Modul Wissens- und Contentmanagement
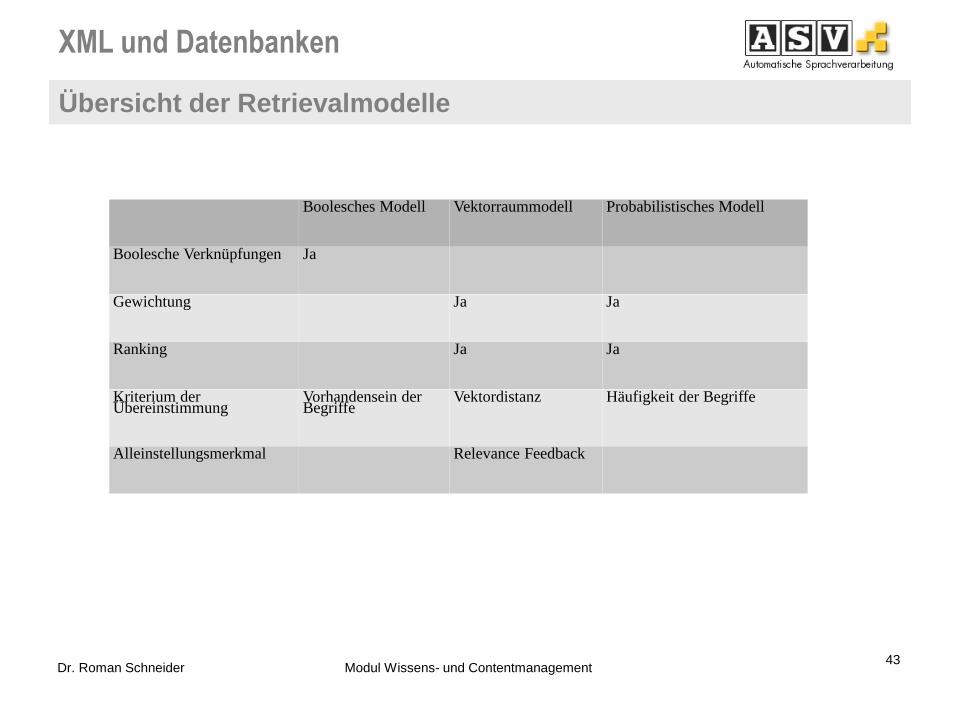
Boolesches Modell Vektorraummodell Probabilistisches Modell
Boolesche Verknüpfungen Ja
Gewichtung Ja Ja
Ranking Ja Ja
Kriterium der Übereinstimmung
Vorhandensein der Begriffe
Vektordistanz Häufigkeit der Begriffe
Alleinstellungsmerkmal Relevance Feedback
XML und Datenbanken
Präsentation
44 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Index Deskribierung manuelle und
automatische Verfahren
zur Anreicherung des
strukturierten Textes mit
Deskriptoren
Recherche Suche von Textdokumenten
nach Vorgabe
von Dokumentdeskriptoren
Präsentation Bewertung und Ordnung der gefundenen Dokumente
nach ihrer Güte
Ranking, Relevance Feedback

XML und Datenbanken
Präsentation
45 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Ranking: Bestimmung, in welcher Reihenfolge die ermittelten Ergebnisse
präsentiert werden.
Grundlegende Maße (kombinierbar):
Häufigkeit des Suchterms im Dokument
Anzahl der verschiedenen Suchterme eines Dokumentes
Anzahl der Dokumente, in denen der Suchterm auftritt
Dokumentgröße
Relevance Feedback:
Dialog mit dem Benutzer
Klassifizierung von relevanten und nicht relevanten Dokumenten
anschließend nochmalige Ergebnisermittlung.
Recherche
Bewertung
Index

XML und Datenbanken
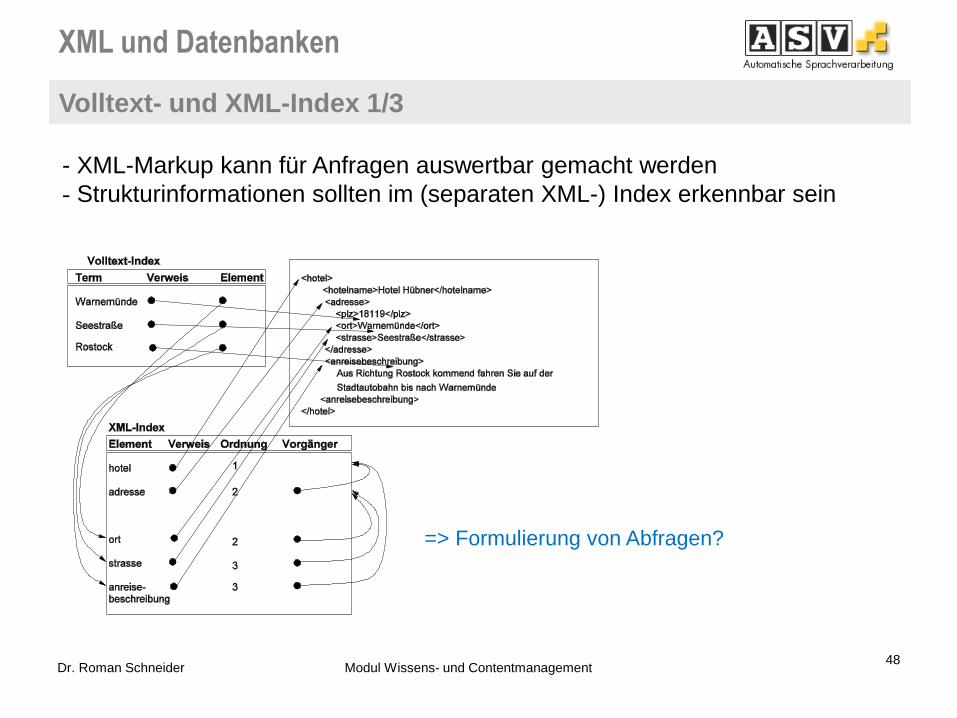
Anwendung von Volltextsuchen auf XML-Dokumente
46 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Volltext-Index
bekannte Methode (älter als relationale Datenbanken)
Verfahren aus dem Bereich der Dokumentverarbeitung
Problem: wie soll mit Bezeichnern von XML-Elementtypen/-Attributtypen
umgegangen werden?
Verweis
Warnemünde
<adresse>
<plz>18119</plz> <ort>Warnemünde</ort>
<nummer>12</nummer>
</adresse>
<anreisebeschreibung>
</anreisebeschreibung>
</hotel>
<hotelname>Hotel Hübner</hotelname>
Aus Richtung Rostock kommend ...
<hotel>
Begriff
anreisebeschreibung
ort
Rostock
hotel <strasse>Seestraße</strasse>
=> Volltextindex plus XML-Index!
XML und Datenbanken
Speicherung von XML-Instanzen
47 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Volltext- und
XML-Index Volltextindex
Speicherung
als Ganzes
Speicherung der
Dokumentstruktur
strukturierte
Speicherung
in Datenbanken
XML und Datenbanken
Volltext- und XML-Index 1/3
48 Dr. Roman Schneider Modul Wissens- und Contentmanagement
- XML-Markup kann für Anfragen auswertbar gemacht werden
- Strukturinformationen sollten im (separaten XML-) Index erkennbar sein
=> Formulierung von Abfragen?

XML und Datenbanken
Volltext- und XML-Index 2/3
49 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Einsatz von XPath
und XQuery möglich.
Anfragen, die das
gesamte Dokument
als Ergebnis liefern
sollen, lassen sich
einfach bedienen.
Andernfalls muss das
Dokument geparst
und das Ergebnis
daraus generiert
werden.
/hotel/adresse/ort/text()=“Warnemünde“

XML und Datenbanken
Volltext- und XML-Index 3/3
50 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Schemabeschreibung Nicht zwingend erforderlich
Dokumentrekonstruktion XML-Dokumente bleiben im Original erhalten
Anfragen Anfragen des Information Retrieval
Volltextanfragen
XML-Anfragen / Auswertung des Markups
Updates Austausch kompletter XML-Dokumente
Anwendungen dokumentzentriertes / semistrukturiertes XML
XML und Datenbanken
Speicherung von XML-Instanzen
51 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Speicherung
als Ganzes
Speicherung der
Dokumentstruktur
strukturierte
Speicherung
in Datenbanken
(einfache)
Abbildung der
Graphstruktur
Speicherung der
Informationen
des DOM
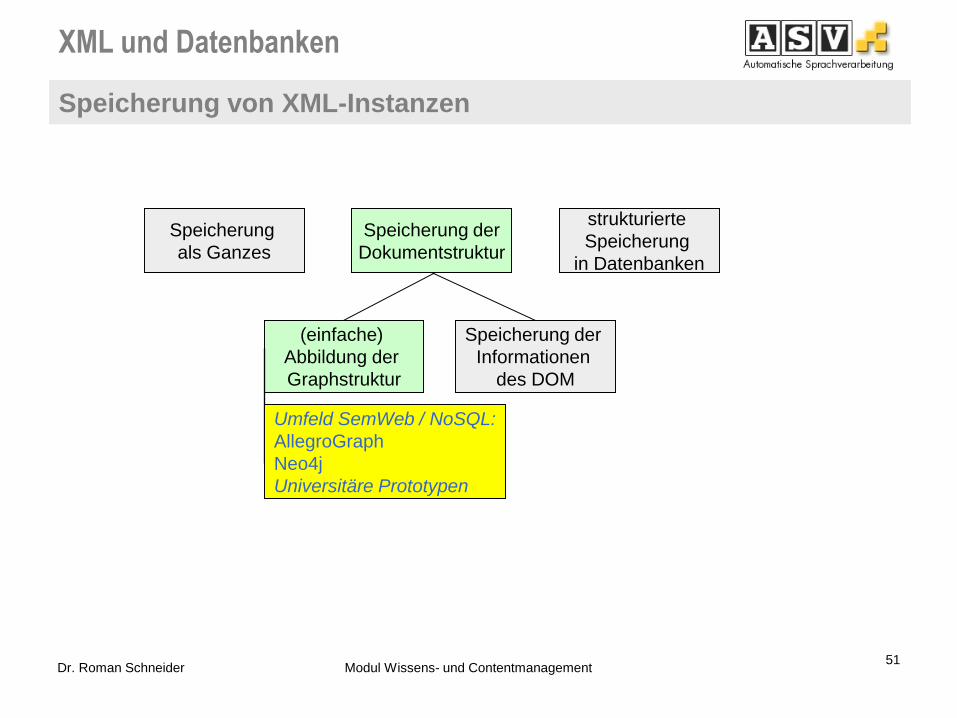
Umfeld SemWeb / NoSQL:
AllegroGraph
Neo4j
Universitäre Prototypen
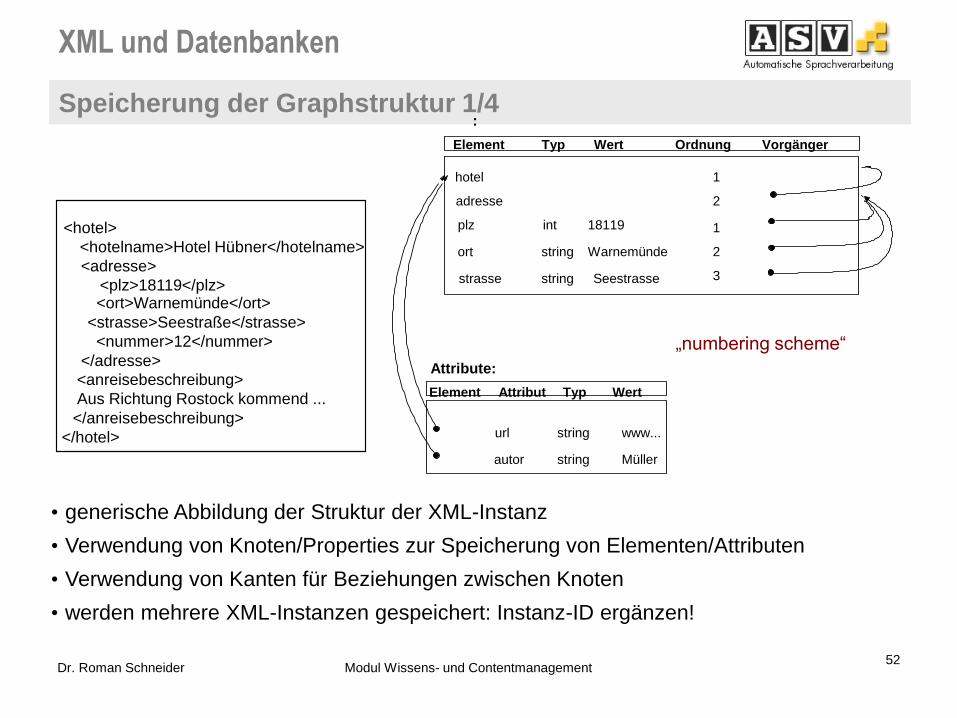
XML und Datenbanken
Speicherung der Graphstruktur 1/4
52 Dr. Roman Schneider Modul Wissens- und Contentmanagement
• generische Abbildung der Struktur der XML-Instanz
• Verwendung von Knoten/Properties zur Speicherung von Elementen/Attributen
• Verwendung von Kanten für Beziehungen zwischen Knoten
• werden mehrere XML-Instanzen gespeichert: Instanz-ID ergänzen!
ort
plz
adresse
Warnemünde
Seestrasse
Wert Typ
string
string
Element
Element Typ
hotel
url
autor
3 strasse
int 18119
string
string
www...
Attribut Wert
2
Müller
Vorgänger Ordnung
1
2
1
Attribute:
:
„numbering scheme“
<adresse>
<plz>18119</plz>
<nummer>12</nummer>
</adresse>
</anreisebeschreibung>
</hotel>
Aus Richtung Rostock kommend ...
<hotel>
<strasse>Seestraße</strasse>
<hotelname>Hotel Hübner</hotelname>
<anreisebeschreibung>
<ort>Warnemünde</ort>

XML und Datenbanken
Speicherung der Graphstruktur 2/4
53 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Umsetzung der Speicherung von Elementen & Attributen:
Elemente:
XML-ID Elementname Typ Wert Ordnung Verweis auf Vorgänger
Attribute:
Attributname Typ Wert Verweis auf Element
damit ist die Zuordnung von Inhalten zur Struktur sowie die vollständige
Wiederherstellung der Struktur (auch ohne DTD) möglich
GraphenDBs: Knoten/Kanten anstatt relationalen Tabellen/Fremdschlüsseln
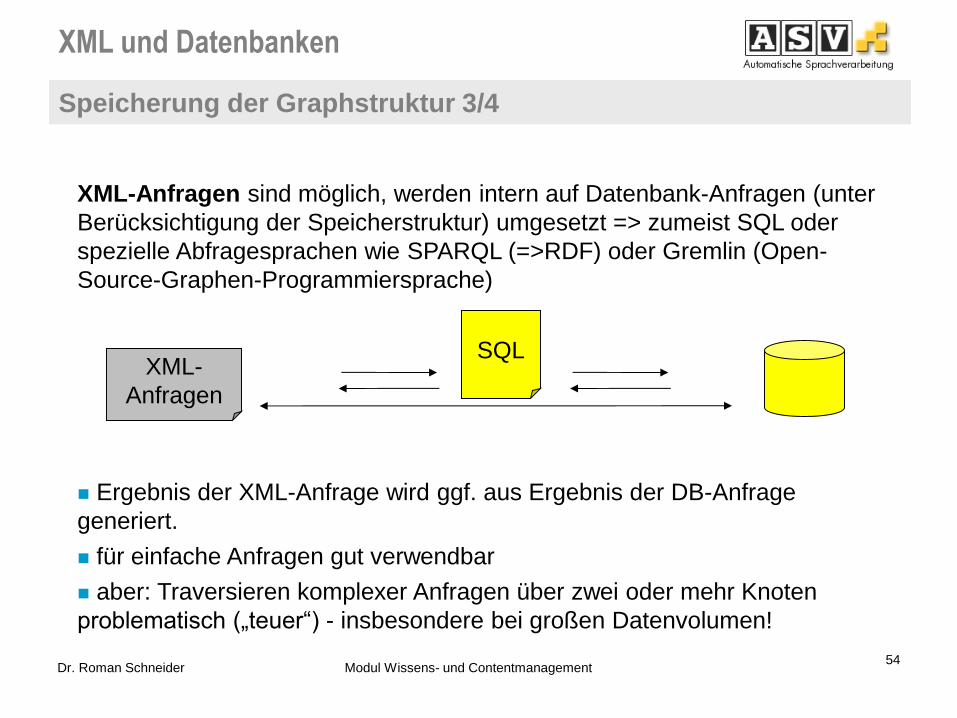
XML und Datenbanken
Speicherung der Graphstruktur 3/4
54 Dr. Roman Schneider Modul Wissens- und Contentmanagement
XML-
Anfragen
SQL
XML-Anfragen sind möglich, werden intern auf Datenbank-Anfragen (unter
Berücksichtigung der Speicherstruktur) umgesetzt => zumeist SQL oder
spezielle Abfragesprachen wie SPARQL (=>RDF) oder Gremlin (Open-
Source-Graphen-Programmiersprache)
Ergebnis der XML-Anfrage wird ggf. aus Ergebnis der DB-Anfrage
generiert.
für einfache Anfragen gut verwendbar
aber: Traversieren komplexer Anfragen über zwei oder mehr Knoten
problematisch („teuer“) - insbesondere bei großen Datenvolumen!
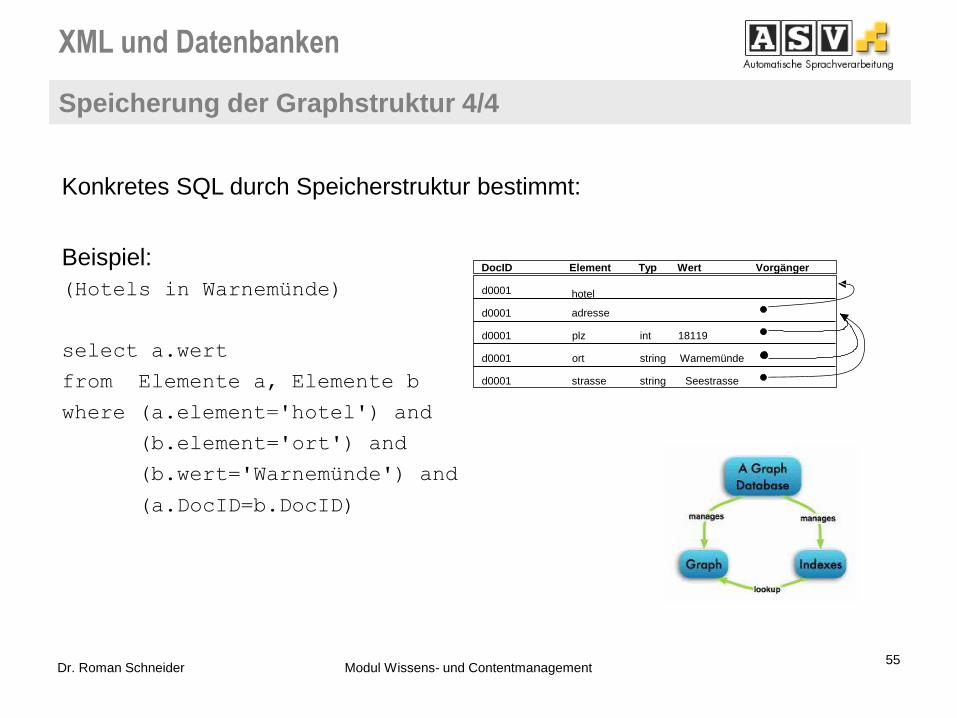
XML und Datenbanken
Speicherung der Graphstruktur 4/4
55 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Konkretes SQL durch Speicherstruktur bestimmt:
Beispiel:
(Hotels in Warnemünde)
select a.wert
from Elemente a, Elemente b
where (a.element='hotel') and
(b.element='ort') and
(b.wert='Warnemünde') and
(a.DocID=b.DocID)
Element
ort
plz
Wert Typ Vorgänger
string
string strasse
Warnemünde
Seestrasse
hotel
adresse
int 18119
DocID
d0001
d0001
d0001
d0001
d0001
XML und Datenbanken
Speicherung von XML-Instanzen
56 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Excelon
Berkeley-DB XML
Infonyte-DB
Speicherung
als Ganzes
Speicherung der
Dokumentstruktur
strukturierte
Speicherung
in Datenbanken
(einfache)
Abbildung der
Graphstruktur
Speicherung der
Informationen
des DOM
XML und Datenbanken
Speicherung basierend auf DOM 1/4
57 Dr. Roman Schneider Modul Wissens- und Contentmanagement
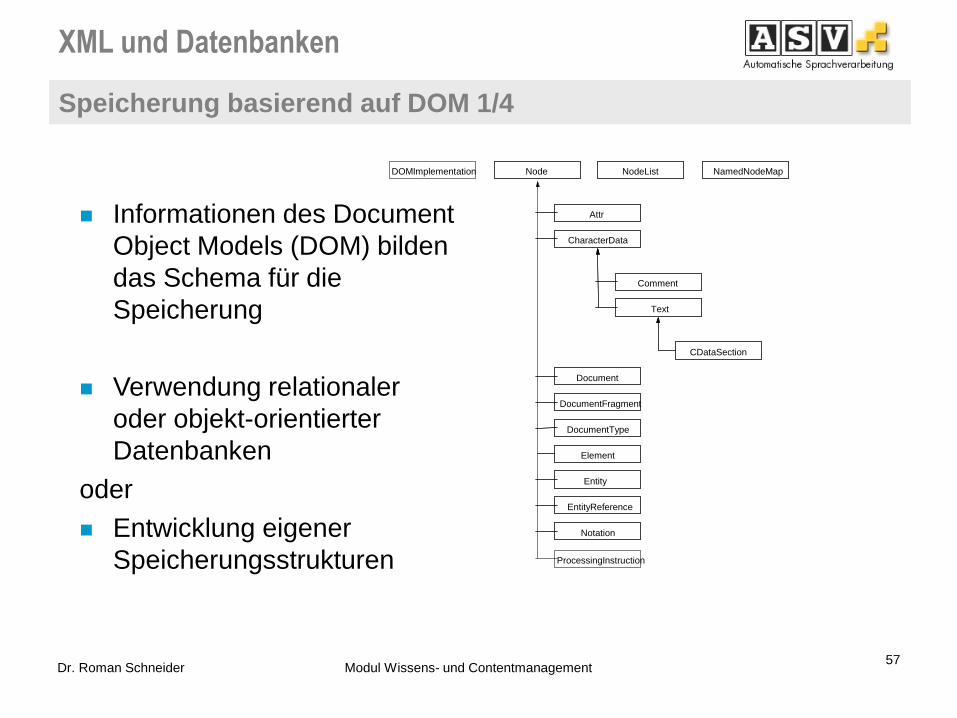
Informationen des Document
Object Models (DOM) bilden
das Schema für die
Speicherung
Verwendung relationaler
oder objekt-orientierter
Datenbanken
oder
Entwicklung eigener
Speicherungsstrukturen
Comment
ProcessingInstruction
Document
DocumentFragment
DocumentType
Element
Entity
EntityReference
Notation
Text
CDataSection
DOMImplementation Node NodeList NamedNodeMap
CharacterData
Attr
XML und Datenbanken
Speicherung basierend auf DOM 2/4
58 Dr. Roman Schneider Modul Wissens- und Contentmanagement
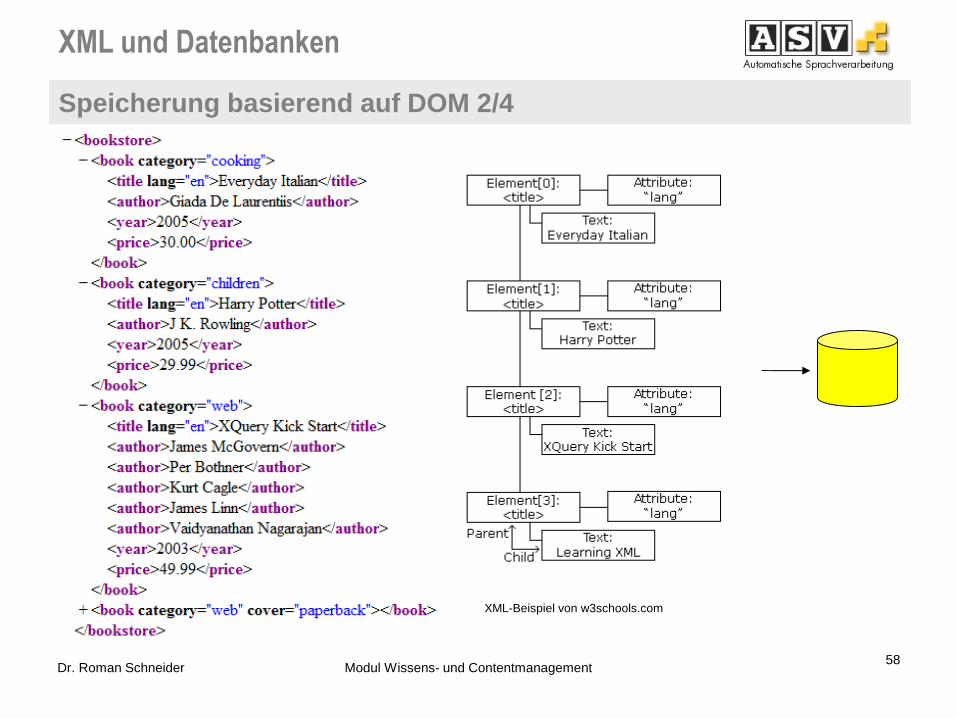
XML-Beispiel von w3schools.com

XML und Datenbanken
Speicherung basierend auf DOM 3/4
59 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Infonyte-DB
verwendet zur Speicherung von XML-Dokumenten ein persistentes Document Object Model (PDOM)
baut nicht auf existierende DBMS auf, sondern entwickelt Komponenten zur physischen Speicherung, die an die XML-Dokumente optimal angepasst sind
Anfragesprache: Richtung XQuery
Sonic XML Server (früher unter den Namen eXcelon)
verwendet zur Speicherung von XML-Dokumenten das Document Object Model
alle Informationen, die in dieser API enthalten sind, werden in einer objektorientierten Datenbank gespeichert.
Berkeley DB XML
Generische Speicherung, Anfragen via XPath, XQuery
XML und Datenbanken
Speicherung basierend auf DOM 4/4
60 Dr. Roman Schneider Modul Wissens- und Contentmanagement
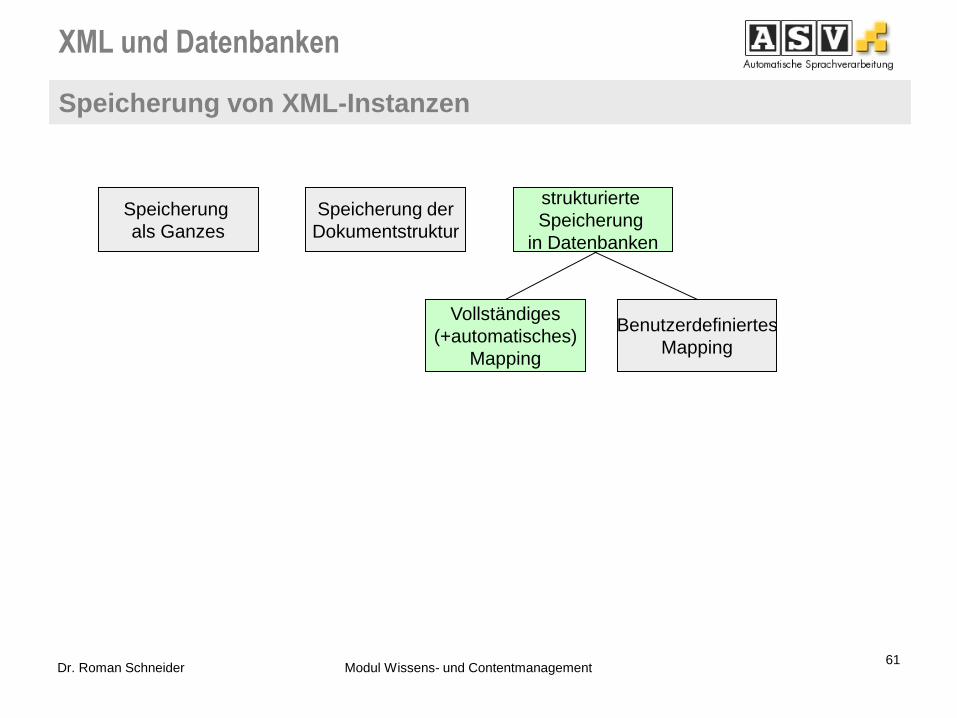
DOM-Methoden
(getChildren(),
hasChild(), ...)
XML-Anfragen
(XQuery / XPath)
XML-
Anfragen SQL
Angepasste
Datenbankanfragen (unter
Kenntnis der
Speicherungsstruktur)
XML und Datenbanken
Speicherung von XML-Instanzen
61 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Speicherung
als Ganzes
Speicherung der
Dokumentstruktur
strukturierte
Speicherung
in Datenbanken
Vollständiges
(+automatisches)
Mapping
Benutzerdefiniertes
Mapping

XML und Datenbanken
Automatisierte strukturierte Speicherung in Datenbanken 1/8
62 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Ansatz: Abbildung der XML-Struktur auf Struktur (relationaler oder
objektorientierter) Datenbanken
- DTD oder XML-Schema (besser wg. Datentypen!) ist erforderlich
- typgerechte Speicherung einzelner Element-/Attributtypen
- Kodierung von hierarchischen Informationen
- gut abbildbar: Sequenzen von Elementen, Attribute
- schlecht abbildbar: mixed content
Objekttypen vs. strenge Relationierung

XML und Datenbanken
Automatisierte strukturierte Speicherung in Datenbanken 2/8
63 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Regeln zur Erzeugung des Datenbankschemas aus einer DTD:
XML-Element wird Attribut (Spalte) einer Relation (Tabelle)
Element mit Quantifizierer ? wird Attribut mit Nullwerten
Zusätzliche Relation für Element mit Quantifizierer * oder +
...
XML-Attribute:
XML-Attribut Attribut einer Relation
IMPLIED Nullwert erlaubt
REQUIRED Nullwert nicht erlaubt (NOT NULL)
Defaultwert Defaultwert
XML und Datenbanken
Automatisierte strukturierte Speicherung in Datenbanken 3/8
64 Dr. Roman Schneider Modul Wissens- und Contentmanagement
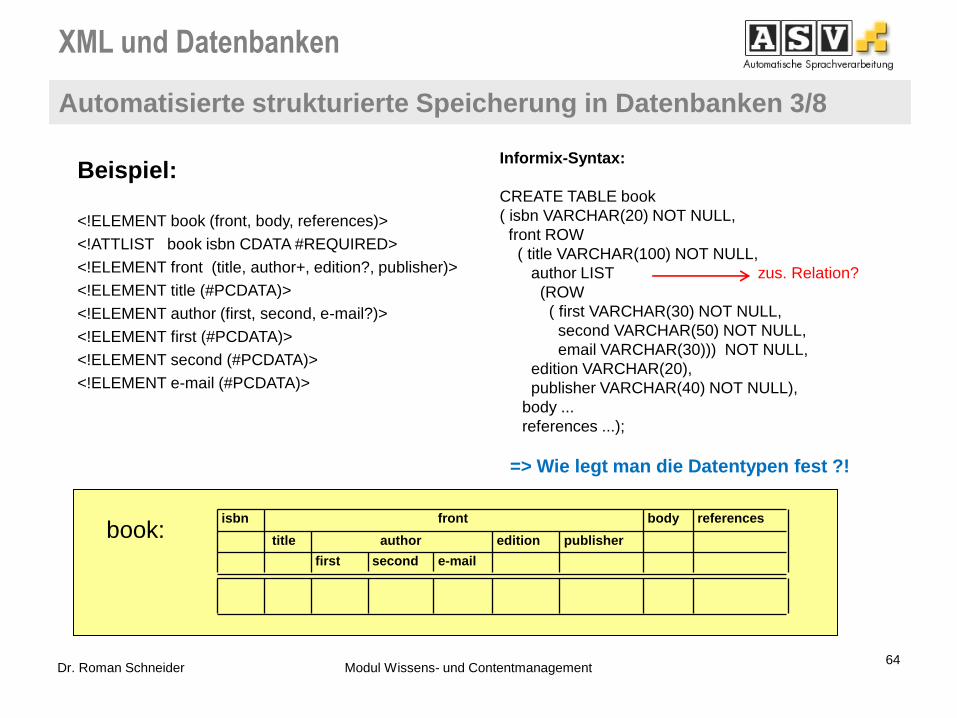
Beispiel:
<!ELEMENT book (front, body, references)>
<!ATTLIST book isbn CDATA #REQUIRED>
<!ELEMENT front (title, author+, edition?, publisher)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (first, second, e-mail?)>
<!ELEMENT first (#PCDATA)>
<!ELEMENT second (#PCDATA)>
<!ELEMENT e-mail (#PCDATA)>
book: e-mail second first
publisher edition author title
references body front isbn
Informix-Syntax:
CREATE TABLE book
( isbn VARCHAR(20) NOT NULL,
front ROW
( title VARCHAR(100) NOT NULL,
author LIST zus. Relation?
(ROW
( first VARCHAR(30) NOT NULL,
second VARCHAR(50) NOT NULL,
email VARCHAR(30))) NOT NULL,
edition VARCHAR(20),
publisher VARCHAR(40) NOT NULL),
body ...
references ...);
=> Wie legt man die Datentypen fest ?!

XML und Datenbanken
Automatisierte strukturierte Speicherung in Datenbanken 4/8
65 Dr. Roman Schneider Modul Wissens- und Contentmanagement
<?xml version="1.0" encoding=“ISO-8859-1“?>
<xs:schema xmlns:xdb="http://xmlns.oracle.com/xdb„
xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace=http://www.oracle.com/xsd/auftrag.xsd elementFormDefault="qualified"
attributeFormDefault="unqualified">
<xs:element name="Auftrag" xdb:SQLName="AUFTRAG„ xdb:SQLType="AUFTRAG_T„
xdb:defaultTable="AUFTRAG_TAB">
<xs:complexType>
<xs:sequence>
<xs:element name="Auftragsnr„ type="xs:integer" xdb:SQLName="A_NR"
xdb:SQLType="INTEGER" />
<xs:element name="Kunde" type="xs:string„ xdb:SQLName="KUNDE„
xdb:SQLType="VARCHAR2" />
<xs:element name="Datum" type="xs:date„ xdb:SQLName="DATUM"
xdb:SQLType="DATE" />
<xs:element name="Produkt„ maxOccurs="unbounded„ xdb:SQLName="PRODUKTE"
xdb:SQLType="PRODUKT_T„ xdb:defaultTable="PRODUKT_TAB„
xdb:SQLInline="false">
....
</xs:schema>
Überführung in (objekt-)relationales Schema in Oracle:

XML und Datenbanken
Automatisierte strukturierte Speicherung in Datenbanken 5/8
66 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Problemfälle bei der Abbildung: (1) Alternative Elemente
Beispiel: <!ELEMENT unterkunft (hotel | pension | campingplatz)*>
Generell sind drei Speicherungsvarianten möglich:
alle Alternativen in einer Relation vorsehen (aber: viele Nullwerte!)
Aufspaltung in separate Relationen (Performanz?)
Verwendung eines Attributes vom Typ XML :-)
unterkunft
<pension>
<pensionsname>Zum Kater</pensionsname>
<zimmer>...</zimmer>
...
</pension>
<hotel>
<kategorie>4 </kategorie>
<hotelname>Strand Hotel Hübner </hotelname>
</hotel>

XML und Datenbanken
Automatisierte strukturierte Speicherung in Datenbanken 6/8
67 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Problemfälle bei der Abbildung: (2) Rekursionen (in DTDs)
book references
public. book ...
book references
ID
Beispiel:
<!ELEMENT publications (book | article | conference)*>
<!ELEMENT book (front, body, references)>
<!ELEMENT references (publications+)>
Vorgehensweise:
– Markieren der Knoten
– Aufspaltung in separate Relationen
– Verwendung von Referenzen (primary/foreign key)

XML und Datenbanken
Automatisierte strukturierte Speicherung in Datenbanken 7/8
68 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Problemfälle bei der Abbildung: (3) Mixed content <anreisebeschreibung>
Sie können unser Haus auf verschiedenen Wegen erreichen:
<bahn>per Bahn: 1 km ab Bahnhof Warnemünde</bahn>
<auto>per Auto: 19 km ab Autobahn A19
Rostock--Berlin</auto>
Sie finden uns direkt an der Uferpromenade.
</anreisebeschreibung>
Ordnung #PCDATA Bahn Auto
1 Sie können unser Haus auf
verschiedenen Wegen erreichen:
2 per Bahn: 1 km ab Bahnhof Warnemünde
3 per Auto: 19 km ab Autobahn A19 Rostock—Berlin
4 Sie finden uns direkt an der Uferpromenade.
Problematische Abbildung in
Relationen!
Angemessener: XML-Datentyp

XML und Datenbanken
Automatisierte strukturierte Speicherung in Datenbanken 8/8
69 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Zusammenfassung der automatisierten strukturierten Abbildung
Vorteile: bei der Speicherung strukturierter Daten
Bietet SQL-Anfragen, Datentypen, Aggregatfunktionen, Sichten
Einfache Integration in andere Datenbanken
Nachteile: bei der Speicherung semi- und unstrukturierter Daten
großes Schema, schwach gefüllte Datenbanken, viele Nullwerte
Speicherung von Alternativen problematisch
keine Volltextoperationen möglich
Deshalb besser benutzerdefinierte, flexible Abbildung?
XML und Datenbanken
Speicherung von XML-Instanzen
70 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Speicherung
als Ganzes
Speicherung der
Dokumentstruktur
strukturierte
Speicherung
in Datenbanken
Vollständiges
(+automatisches)
Mapping
Benutzerdefiniertes
Mapping

XML und Datenbanken
Benutzerdefiniertes Mapping 1/5
71 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Bei allen bisherigen Methoden konnte die Art der Speicherung nicht
beeinflusst werden
Oft praktikabler: flexible Methode
Mappingvorschrift wird dabei durch den Benutzer spezifiziert
Struktur der XML-Instanzen und das Datenbankschema können unabhängig
voneinander entworfen werden (und relativ autonom gepflegt werden)
Nebeneffekt: Ermöglicht Speicherung von XML-Dokumenten in bereits
existierenden Datenbanken
XML und Datenbanken
Benutzerdefiniertes Mapping 2/5
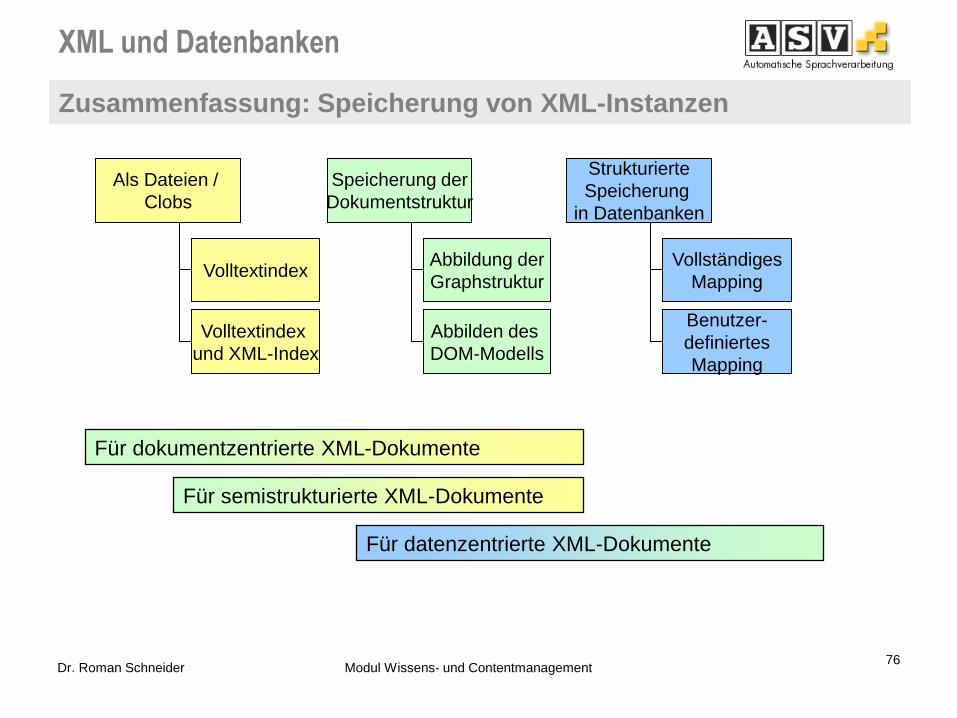
72 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Hotel Hübner
Hotel_URL
Hotelpreise
Name Einzelzimmer
www.hotel-huebner.de 198
Datenbank
<ClassMap>
<ToClassTable>
</ToClassTable>
<Table Name="Hotelpreise"/>
<ElementType Name="hotel"/>
<hotel url="www.hotel-huebner.de">
<hotelname>Hotel Hübner</hotelname>
<adresse>
<ort>Warnemünde</ort>
...
</adresse>
<preise>
<einzelzimmer>198</einzelzimmer>
</preise>
...
</hotel>
<strasse>Seestraße</strasse>
<PropertyMap>
<ToColumn>
</ToColumn>
</PropertyMap>
<PropertyMap>
<ToColumn>
</ToColumn>
</PropertyMap>
...
<Attribute Name="url"/>
<Column Name="Hotel_URL"/>
<ElementType Name="hotelname"/>
<Column Name="Name"/>
</Classmap>
XML-Dokument Mapping Vorschrift
XML-Segmente können auch ignoriert werden => kleinere Datenbasis

XML und Datenbanken
Benutzerdefiniertes Mapping 3/5
73 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Kodierung der Mapping-Regeln; Beispiel nach Ronald Bourret:
<ClassMap>
<ElementType Name="hotel"/>
<ToClassTable>
<Table Name="Hotelpreise"/>
</ToClassTable>
<PropertyMap>
<Attribute Name="url"/>
<ToColumn>
<Column Name="Hotel_URL"/>
</ToColumn>
</PropertyMap>
...
</ClassMap>
Verbindung zwischen
XML-Elementen und
Datenbank-Relationen
(Tabellen)
Verbindung zwischen
XML-Elementen/
-Attributen und
Datenbank-Attributen
(Spalten)

XML und Datenbanken
Benutzerdefiniertes Mapping 4/5
74 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Schemabeschreibung Erforderlich für Generierung der Speicherstrukturen
Dokumentrekonstruktion Nur möglich bei vollständiger Abbildung sowie Protokollierung des Abbildungsprozesses
Updates Als Datenbankupdates realisierbar
Updates, die Strukturen verändern,
bewirken Datenbankevolution!
Weitere Besonderheiten Integration in bestehende DB möglich
XML-Instanzen und DB voneinander unabhängig

XML und Datenbanken
Benutzerdefiniertes Mapping 5/5
75 Dr. Roman Schneider Modul Wissens- und Contentmanagement
IBM DB2 XML-Extender
Aufsplitten von XML-Dokumenten ins relationale Datenbanksystem DB2
über eine Mappingvorschrift (DAD - Data Access Definition) wird angegeben, wie die
Zuordnung von Elementen und Attributen einer XML-Instanz auf die Attribute der
Datenbank erfolgen soll.
Die Syntax der DAD-Dateien ist XML
Oracle RDBMS
• objektrelationale Speicherung / Datentyp XMLType
• Art der Speicherung wird durch ein annotiertes XML-Schema beschrieben, dieses
enthält eine Zuordnung von Datenbankinformationen zu den XML-Bestandteilen
• dadurch benutzerdefinierte Speicherung möglich
Microsoft SQL-Server
anwenderdefiniertes Mapping durch annotiertes Schema
Annotationen bestimmen die Zuordnung von Elementen und Attributen zu
Datenbankrelationen und Datenbankattributen
XML und Datenbanken
Zusammenfassung: Speicherung von XML-Instanzen
76 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Volltextindex
und XML-Index
Volltextindex
Als Dateien /
Clobs
Speicherung der
Dokumentstruktur
Strukturierte
Speicherung
in Datenbanken
Vollständiges
Mapping
Benutzer-
definiertes
Mapping
Abbilden des
DOM-Modells
Abbildung der
Graphstruktur
Für dokumentzentrierte XML-Dokumente
Für datenzentrierte XML-Dokumente
Für semistrukturierte XML-Dokumente

XML und Datenbanken
Native Speicherung 1/2
77 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Volltextindex
und XML-Index
Volltextindex
Als Dateien /
Clobs
Speicherung der
Dokumentstruktur
Strukturierte
Speicherung
in Datenbanken
Vollständiges
Mapping
Benutzer-
definiertes
Mapping
Abbilden des
DOM-Modells
Abbildung der
Graphstruktur
Textbasierte native Modellbasierte native
Speicherung Speicherung
Also: kein Mapping des XML-Formats, sondern direktes Speichern des
XML-Dokuments. Abgrenzung von XML-enabled DBMS schwierig!

XML und Datenbanken
Native Speicherung 2/2
78 Dr. Roman Schneider Modul Wissens- und Contentmanagement
Produkte
Open Source, größtenteils plattformunabhängig:
BaseX (Version 2013: 7.7.2)
eXist (Version 2013: 2.1)
MonetDB (Version 2013: 11.15)
Sedna (Version 2013: 3.5)
Apache Xindice (bis 2011: Version 1.2 )
Kommerziell:
Tamino (Software AG)
zeen-dee-chay

XML und Datenbanken
Zusammenfassung
79 Dr. Roman Schneider Modul Wissens- und Contentmanagement
XML und Datenbanken
– Vielzahl von Verfahren und Techniken existieren nebeneinander
– oft aus den Bereichen Datenbanken und Text-/Dokumentverarbeitung
– generell: es gibt keine „beste Lösung“ für alle XML-Dokumente, geeignetste Lösung ist abhängig von konkreten Projekterfordernissen







![Textdatenbanken12.ppt [Kompatibilitätsmodus]asv.informatik.uni-leipzig.de/uploads/document/file_link/1558/... · Title: Textdatenbanken12.ppt [Kompatibilitätsmodus] Author: Uwe](https://static.fdokument.com/doc/165x107/60161cd8d43d36599830f932/kompatibilittsmodusasvinformatikuni-leipzigdeuploadsdocumentfilelink1558.jpg)










