







Sprachen
Seiten
Rechtliche


Gewichtung in der Umfragepraxis –Das Beispiel SOEP
Jürgen Schupp (DIW Berlin)
Juli 2004

Juli 2004 2
Notwendigkeiten
Warum Gewichtung im SOEP?– Unterschiedliche Auswahlwahrscheinlichkeiten
der verschiedenen Stichproben in der ersten Welle
– Non-response - Ausfälle– Fehlende Teilnahmebereitschaft in der ersten Welle– Unterschiedliche Ausfälle in den Folgewellen
Warum spezielle Varianzschätzer? • Geschichtete (clustered) Stichproben

Juli 2004 3
Literatur zur Gewichtung/ Hochrechnung im SOEP– Rendtel, Ulrich (1995), Lebenslagen im Wandel:
Panelausfälle und Panelselektivität, Frankfurt/M-New York.– Pannenberg, M. (2002), “Documentation of Sample Sizes and
Panel Attrition in the German Socio-Economic Panel (GSOEP) (1984-until 2001)”, DIW Berlin Research Note No. 23.
– Spiess, M. /Rendtel, U. (2000), “Combining an ongoing panel with a new cross-sectional sample”, DIW Berlin Discussion Paper No. 198.
– Spiess, M. (2001),“Derivation of design weights: The case of the German Socio-Economic Panel (GSOEP), DIW Berlin Research Note No. 5.
– Spiess, M. (2001), Description of the variables STRAT1, STRAT2, and SAMPOINT, mimeo (http://www.diw.de/english/sop/service/doku/paper197.pdf).

Juli 2004 4
StichprobenStichprobe A “Westdeutsche”
Ziel: 4500 HaushalteAusschöpfung Welle 1: 61 %
Stichprobe B “Gastarbeiter in West Deutschland”Ziel: 1500 HaushalteAusschöpfung Welle 1: 68 %
Stichprobe C “Deutschen in der ehemaligen DDR”Ziel: 2000 HaushalteAusschöpfung Welle 1: 70 %
Stichprobe D “Zuwanderer seit 1984”Ziel: 500 HaushalteAusschöpfung Welle 1:≈ 55 %
Stichprobe E “Wohnbevölkerung in Deutschland 1998”Ziel: 1000 HaushalteAusschöpfung Welle 1: 54 %
Stichprobe F “Wohnbevölkerung in Deutschland 2000”Ziel: 6000 HaushalteAusschöpfung Welle 1: 51 %

Juli 2004 5
ZufallsauswahlStichprobe A “Westdeutsche”
Ziehungswahrscheinlichkeit ≈ 0.0002 Durchschnittliches Gewicht ≈ 5,000
Stichprobe B “Gastarbeiter in West Deutschland”Ziehungswahrscheinlichkeit ≈ 0.001 Durchschnittliches Gewicht ≈ 800
Stichprobe C “Deutschen in der ehemaligen DDR”Ziehungswahrscheinlichkeit ≈ 0.0003 Durchschnittliches Gewicht ≈ 3,000
Stichprobe D “Zuwanderer seit 1984”Ziehungswahrscheinlichkeit ≈ 0.0002 Durchschnittliches Gewicht ≈ 5,000
Stichprobe E “Wohnbevölkerung in Deutschland 1998”Ziehungswahrscheinlichkeit ≈ 0.00003 Durchschn. Gewicht ≈ 35,000
Stichprobe F “Wohnbevölkerung in Deutschland 2000”Ziehungswahrscheinlichkeit ≈ 0.00015 Durchschnittliches Gewicht ≈ 6,000

Juli 2004 6
Schichtung der SOEP-StichprobenSample A:
Standard Schichtung ADM (vgl. DTC, chapter 5)random-route
Sample B:Adressenregister von Personen
Sample C:Adressen eines zentralen Registers der DDR:
Geschichtetes Random Route Verfahren
Sample D:Ohne Schichtung nach Nationalität Adress sample von Haushalten (im Anschluß an Screening)
Sample E:Standard Schichtung ADM (vgl. DTC, chapter 5)random-route
Sample F:Standard Schichtung ADM (vgl. DTC, chapter 5)random-route mit doppelter Auswahlwahrscheinlichkeit für
Ausländer

Juli 2004 7
2.000
4.000
6.000
8.000
10.000
12.000AnzahlHaushalte
Jahr: 84 85 86 87 88 89 90 91 92 93 94 97 98 99 00 01 02 03 04 05 06 0795 96
KonsolidierungEinbeziehung neuerPopulationen
D
C
Aufbauphase
A
B
Vergrößerung desStichprobenumfangs
E
FG
und Stärkung der Interdisziplinarität
Die Stichproben des SOEP von 1984 bis 2007
Design und Prognose: TNS-Infratest Sozialforschung

Juli 2004 8
Gewichtungs- und Hochrechnungsprozeduren1) Auswahlwahrscheinlichkeiten
(“Einfache” Design Gewichte)
2) Querschnittgewichtung von Welle 1
3) Längsschnittgewichtung
4) Querschnittgewichtung von Welle 2ff.

Juli 2004 9
1. Auswahlwahrscheinlichkeiten
§ Entsprechend der jeweiligen Grundgesamtheit haben SOEP-Haushalte in der jeweiligen Startwelle unterschiedliche Auswahlwahrscheinlichkeiten (Stichproben A-G)§ Diese Unterschiede können kontrolliert werden, indem
entsprechende Design-Gewichte genutzt werden (vgl. Spiess 2001) §Diese Gewichte kompensieren NICHT für die Selektivität in
der ersten Welle oder für Folgewellen§ Aber diese Gewichte liefern einen sinnvollen Startpunkt für
nutzerdefinierte Kalkulationen eigener Ausfallanalysen

Juli 2004 10
2. Querschnitt-Gewichtung für Welle 1
§Die Berechnung der Auswahlwahrscheinlichkeit kann erweitert werden indem die realisierte Stichprobe mit Haushalts- oder Personencharakteristiken anderer vergleichbarere Stichproben verglichen werden – folgende Annahmen liegen dabei zugrunde:
• Populationsschätzer anderer Stichproben sind “besser” als die Panel-Schätzung
• Eine Anpassung an bestimmte Merkmale verbessern auch die andere – nicht angepasste – Charakteristika
§So wird bspw. die rund 50fach größere Stichprobe des Mikrozensus und die Auskunftspflicht als “bessere” Information gewertet

Juli 2004 11
2. Querschnitt-Gewichtung für Welle 1
Eine Anpassung der geschätzten Ergebnisse an bestimmte Randverteilungen geht von der Annahme aus, dass sämtliche Antwortwahrscheinlichkeiten den Anpassungen an die Merkmale der Randverteilungen sinnvoll entsprechen und zu keinen Verzerrungen führen

Juli 2004 12
2. Querschnitt-Gewichtung für Welle 1
Overview 1: Marginal distributions used to adjust the first waves of the German Socio-Economic Panel (GSOEP) – only for private households –
Sample A + B Sample C Sample D Sample E
Sample F
Households • Sex of the head of household (sample A only)
• Age of the head of household, Size of the household
• Nationality of the head of household (sample B only)
• Country of origin
Resident population in private households
• Sex, age, martial status • Nationality of the head of
household (sample B only)
• Sex, Age
Foreign institutionalized population of sample B
• Sex
Pupils total • Sex, type of school • Nationality of the head of
household (sample B only)
Gainfully employed persons residing in private households
• Sex, age • Job (main ISCO groups) • Nationality (sample B only)
Resident population • Counties • Size of
Community
Separated for East and West Germany
• Size of the household
• Sex • German /
foreign • 3 age
groups
• Size of the household
• Sex • German /
foreign • 18 age
groups

Juli 2004 13
3. Längsschnittgewichtung
§Das Konzept der Längsschnittgewichtung setzt direkt am Konzept der Querschnittgewichtung an. Um einen Schätzer für t+x zu erhalten ist es lediglich notwendig zu wissen, wie groß die Ausfallwahrscheinlichkeiten für spezifische Subgruppe ist. Der inverse Faktor für den Drop-Out ergibt den Gewichtungsfaktor als Bleibewahrscheinlichkeit§Die Kalkulation von Ausfallraten erfolgt entweder durch Tabellenanalyse oder – wie im Fall des SOEP – durch logistische Regressionsanalysen
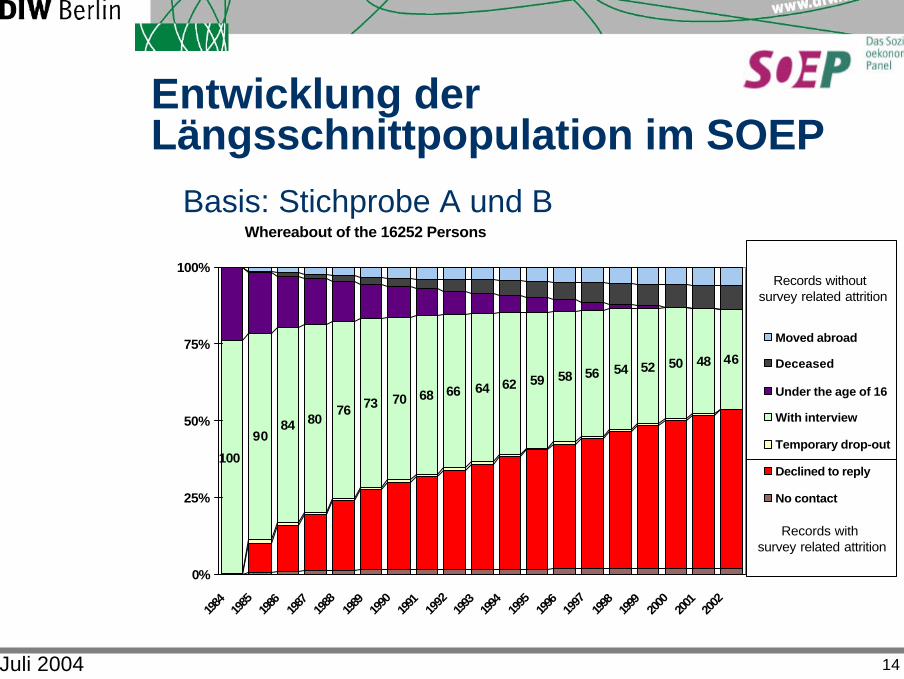
Juli 2004 14
Whereabout of the 16252 Persons
525456
100
62
9084 80
76 73 70 68 66 6459 58
50 48 46
0%
25%
50%
75%
100%
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
Moved abroad
Deceased
Under the age of 16
With interview
Temporary drop-out
Declined to reply
No contact
Records without survey related attrition
Records with survey related attrition
Entwicklung der Längsschnittpopulation im SOEP
Basis: Stichprobe A und B
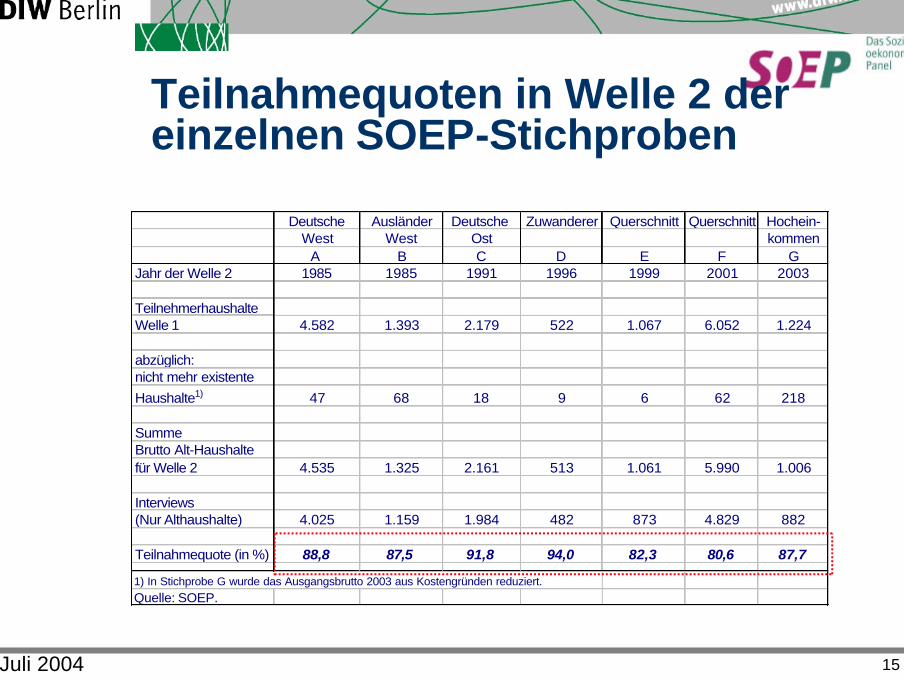
Juli 2004 15
Teilnahmequoten in Welle 2 der einzelnen SOEP-Stichproben
Deutsche Ausländer Deutsche Zuwanderer Querschnitt Querschnitt Hochein-West West Ost kommen
A B C D E F GJahr der Welle 2 1985 1985 1991 1996 1999 2001 2003
TeilnehmerhaushalteWelle 1 4.582 1.393 2.179 522 1.067 6.052 1.224
abzüglich:nicht mehr existente Haushalte1) 47 68 18 9 6 62 218
Summe Brutto Alt-Haushalte für Welle 2 4.535 1.325 2.161 513 1.061 5.990 1.006
Interviews(Nur Althaushalte) 4.025 1.159 1.984 482 873 4.829 882
Teilnahmequote (in %) 88,8 87,5 91,8 94,0 82,3 80,6 87,7
1) In Stichprobe G wurde das Ausgangsbrutto 2003 aus Kostengründen reduziert.Quelle: SOEP.

Juli 2004 16
3. Längsschnittgewichtung
§Zur Ermittlung der Bestimmungsgründe für Ausfälle in t1 kann bei einem Paneldesign auf die Charakteristika der Haushalte in Welle t0 zurückgegriffen werden§Zusätzlich stehen Charakteristica der Feldarbeit in t1 (Umzug oder Wechsel des Interviewers) zur Schätzung zur Verfügung
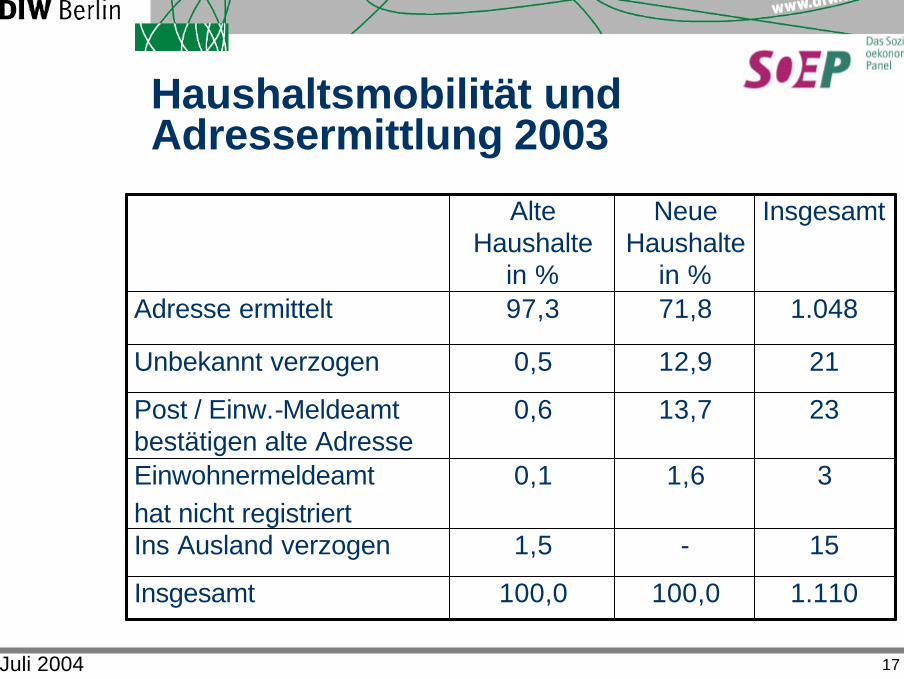
Juli 2004 17
Haushaltsmobilität und Adressermittlung 2003
1.110100,0100,0Insgesamt
15-1,5Ins Ausland verzogen
31,60,1Einwohnermeldeamthat nicht registriert
2313,70,6Post / Einw.-Meldeamtbestätigen alte Adresse
2112,90,5Unbekannt verzogen
1.04871,897,3Adresse ermittelt
InsgesamtNeue Haushalte
in %
Alte Haushalte
in %
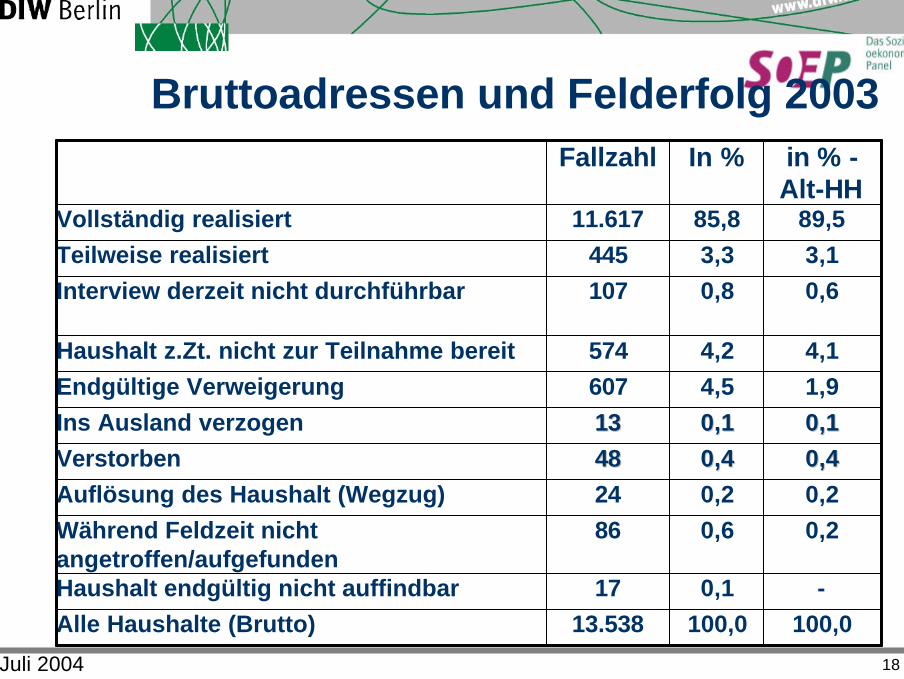
Juli 2004 18
Bruttoadressen und Felderfolg 2003
100,00,1
0,60,20,40,40,10,14,54,2
0,83,3
85,8
In %
100,013.538Alle Haushalte (Brutto)-17Haushalt endgültig nicht auffindbar
0,286Während Feldzeit nicht angetroffen/aufgefunden
0,224Auflösung des Haushalt (Wegzug)0,40,44848Verstorben0,10,11313Ins Ausland verzogen1,9607Endgültige Verweigerung4,1574Haushalt z.Zt. nicht zur Teilnahme bereit
0,6107Interview derzeit nicht durchführbar3,1445Teilweise realisiert
89,511.617Vollständig realisiert
in % -Alt-HH
Fallzahl

Juli 2004 19
3. Längsschnittgewichtung
§Die Längsschnittgewichtung wird für jede Erhebungswelle erstellt; der Längsschnittgewichtungsfaktor passt ab Welle 2 von der Basiswelle zur Folgewelle an§Um einen korrekten Gewichtungsfaktor für Längsschnittanalysen zu erhalten, sollten die Längsschnittfaktoren der herangezogenen Wellen miteinander multipliziert werden

Juli 2004 20
Ausfallgründe über die Zeit (für Welle 2 ff.)
Ausfälle bei:• Umzug • Haushaltsabspaltung• Großstadt• Einpersonenhaushalt

Juli 2004 21
Ausfallgründe über die Zeit (für Welle 2 ff.)
Individuelle Verweigerungsmerkmale:• Ostdeutsche • Hohes Lebensalter des Haushaltsvorstands• Frauen als Haushaltsvorstand• Umzug des Haushalts• Haushaltsplitt• Trennung vom Partner• Interviewerwechsel• Wenige bisherige Interviews mit gleichem Interviewer• Befragter ist relativ neu in der Stichprobe• Niedrigeinkommenshaushalt• Verweigerung des Betrages bei Haushaltseinkommen• Erwarteter Verlust des Jobs

Juli 2004 22
Methodologie für die Bildung der LängsschnittgewichteErster Schritt: Design Auswahl (initialize the sample) P(D=1)Zweiter Schritt: Response in Welle 1 P(R1=1|D)Dritter Schritt: Erfolgreiche Kontaktwahrscheinlichkeit in der
Folgewelle P(K2=1|D, R1)Vierter Schritt: Response in der Folgewelle P(R2=1|D, R1, K2)
.
.
.Schritt T: Response in Welle T
P(RT=1|D, R1, ..., RT1, K2, ..., KT)

Juli 2004 23
Methodologie für die Bildung der Längsschnittgewichte
Die Selektionswahrscheinlichkeit P(C=1) für den gesamten mehrstufigen Prozess kann als Produkt der einzelnen Wahrscheinlichkeiten aufgefasst werden

Juli 2004 24
4. Querschnittgewichtung von Folgewellen
Die Berechnung der Auswahlwahrscheinlichkeiten für Folgewellen als Querschnitte ist hingegen komplizierter wegen der Weiterverfolgungsregeln im SOEPEs ist notwendig die Auswahlwahrscheinlichkeit für Haushalte für die Folgewelle zu errechnen h2. Für die Person j die in diesen Haushalt hinzugezogen ist, sind lediglich Personencharakteristika PXj verfügbar. Es wird unterstellt, dass die Auswahlwahrscheinlichkeit Pj in der ersten Welle durch ein logit model spezifiziert werden kann. Für die Person j die in den Haushalt zugezogen ist, sind sowohl die Personencharakteristika PXj als auch die unbekannten Haushaltsinformationen HXj aus dem früheren Haushalt von j folgendermaßen spezifiziert:

Juli 2004 25
4. Querschnittgewichtung von Folgewellen
Der unbekannte Haushaltsteil εj= HXj’ β2 ist dabei der Fehlerterm der Spezifikation:
Diese Beziehung wird sowohl für Personen, die in Welle 1 befragt wurde angewandt wie für Personen, die erst in Folgewellen hinzukommen. Solange beide Personencharakteristika und die logits Yi für die Personen der ersten Welle bekannt sind, kann b1 für diese Gruppe bestimmt werden. Dieses Verfahren wird für sämtliche Folgewellen äquivalent angewandt.
2'1'1ln ββ jj
j
j HXPXP
P+=
−
jjj
jj PX
P
Py εβ +=
−= 1'1
ln

Juli 2004 26
4. Querschnittgewichtung von Folgewellen
Zusätzliche Annahmen:Welle für Welle werden die Querschnitthochrechnungsfaktorenan die Zahl aller Personen und Haushalte gemäß Mikrozensusdesselben Jahres angepasst
Bis 1994 wurde bei der Querschnittgewichtung die Annahmegetroffen, dass Immigranten nicht die Struktur derWohnbevölkerung verändern (sprich die Längsschnittpopulation wird nicht durch Zuwanderungtangiert).

Juli 2004 27
Top Coding fürQuerschnittgewichteZiel ist die Reduktion der Varianz in den Gewichtungsfaktoren um den Einfluß von Ausreißern zu mildern . Deshalb werden die Faktoren am Ende noch “top coded” (see chapter 5 at the DTC):
– Für jedes Sample, A-F, werden die Gewichte “top coded” mit einem Wert, der das 10 fache des jeweiligen Medians nicht überschreitet
– Alle Gewichte werden an eine externeRandverteilung nach Alter, Haushaltsgröße, Geschlecht, Nationalität des Haushaltsvorstandsangepasst

Juli 2004 28
5. Schlussbetrachtung aus derAnwenderInnen-Perspektive
Je Befragungswelle sind für Haushalte und Personen im SOEP-Datensatz
• Querschnittgewichtungsfaktor• Längsschnittgewichtungsfaktor

Juli 2004 29
Gewichten im SOEP
Die folgenden Variablen sollten für eineQuerschnittgewichtung von 18 Wellen herangezogen(Welle A=1) (Welle R=18):
• In PHRF: APHRF;BPHRF; ... RPHRF• In HHRF: AHHRF; BHHRF; ... RHHRF

Juli 2004 30
Gewichtung von Längsschnitten
Für die Längsschnittgewichtung stehtim SOEP eine flexible Methode zurVerfügung
Die zur Verfügung gestelltenGewichtungsfaktoren können leicht als“Bleibewahrscheinlichkeiten” aufgefasst werden. Sie sind zu finden in den Variablen:
• In PRHRF: BPBLEIB; CPBLEIB; ... RPBLEIB• In HHRF: BHBLEIB; CHBLEIB; ... RHBLEIB

Juli 2004 31
Gewichtung von LängsschnttsamplesZum Beispiel soll mithilfe der zur Verfügung
gestellten Faktoren eine Längschnittgewichtungeines Samples der Erhebungsjahre 1988 (WelleE) bis 1993 (Welle J) vorgenommen werden zur Konstruktion:
Wir nennen den individuellen Gewichtungfaktor fürPersonen EJPHRF (dieser Faktor ist NICHT im File PHRF zu finden). Die Variable kann folgendermaßengeneriert werden:

Juli 2004 32
Gewichtung von LängsschnttsamplesEJPHRF = EPHRF * FPBLEIB * GPBLEIB *
HPBLEIB * IPBLEIB * JPBLEIB
Allgemein ist der Gewichtungsfaktor einesLängsschnittsamples das Produkt derQuerschnitthochsrechnungsfaktors der Startwelle mitden Bleibefaktoren der interessierenden Folgewellen

Juli 2004 33
Querschnitte
Aufgepaßt:– Anstaltshaushalte– Umzug von Stichprobenmitgliedern in
andere Sample Regionen!
(so sind seit 2001 etwa 360 Individuen des Samples C nach Westdeutschland umgezogen und mehr als 50 Stichprobenmitglieder aus AB sind nachOstdeutschland umgezogen)

Juli 2004 34
Querschnitte (nach 1998)Besonderheiten :
• Stichproben E und F sind eigenständige random samples derWohnbevölkerung in Deutschland
• Beide haben eigenständige Hochrechnungsfaktoren um die Inhalte der Erhebung stichprobenspezifisch auswerten zu können für A im Vergleichzu D bzw. E
• Querschnittgewichte für A bis D und E sind sog. Integrierte Convex-Gewichte(qA-D=0.8; qE=0.2)
⇒ “blow up factor” für eigenständige Analysen: A-D: 1.25E: 5
• A bis E und F sind ebenfalls interierte Convex-Gewichte (qA-E=0.55; qF=0.45)
⇒ “blow up factor” : A-E: für eigenständige Analysen: A-E: 1.82F: 2.22

Juli 2004 35
Querschnitte (nach 1998)
Für Standard-Analysen kann man diese Besonderheiten jedoch vergessen:
• Längsschnittanalysen werden durch die neuen Stichproben nicht beeinflusst
• Bei Querschnitten bleibt es bei der Regel, der Verwendung von Standardhochrechnungsfaktoren die in PHRF und HHRF zu finden sind:
- xPHRF
- xHHRF

Juli 2004 36
Neuerungen im Release 2004: HHRF and PHRFStandard-Hochrechnungsfaktoren der Wellen S und T
(SPHRF, TPHRF or SHHRF, THHRF) beruhen nur auf den SOEP-Samples A-F
Neue integrierte Gewichtungsfaktoren für die Stichproben A-G ($PHRFAG oder $HHRFAG)
§ Vgl. Dokumentation integrierter Gewichte für A-G versus A-F imFile WEIGHTS_AF.PDF (auf der aktuellen CD)§ contact: Rainer Pischner [email protected]

Juli 2004 37
Schätzung der Stichprobenvarianz
ð Probleme• Schichtung der Startwelle 1• Ausfälle im Zeitverlauf

Juli 2004 38
Schätzung der Stichprobenvarianz
ðAlternative Lösungen im SOEPðRandomization der Stichprobe (cf. Wolter 1985 –
Introduction to Variance Estimation, New York)ðVerwendung der Variablen PRGROUP in PHRF,
HRGROUP in HHRF
ð Explicit Modellierung der Schichtung (cf. Spiess 2001) mit Statistical Packeten wie SUDAAN oder STATAðvariables STRAT1, STRAT2, SAMPOINT, INTNR in file
VARIANZ

Juli 2004 39
Schätzung der Stichprobenvarianz
Der “Random Group Ansatz” ist leicht zur Abschätzung der Varianz anwendbar:
Die Files PHRF sowie HHRF des SOEP enthalten die Variablen PRGROUP und HRGROUP, ihre Verwendung führt zu einer Aufteilung der Gesamtstichprobe in acht gleich große Teilstichproben.
Die Schätzung der Varianz selbst erfolgt folgendermaßen:

Juli 2004 40
Schätzung der Stichprobenvarianz
• Erstelle ein Auswertungsprogramm über das gesamte gewünschte (Längsschnitt-)Sample
• Erstelle eine Kreuztabelle für acht Teilstichproben.• Ordne die Ergebnisse nach ihrer Größe.
ðDie Spanne zwischen dem kleinsten und dem größten Wert repräsentiert ein Konfidenzintervall mit einer Irrtumswahrscheinlichkeit von p =< 0.008.
ðDie Spanne zwischen dem zweitkleinsten und dem zweitgrößten Wert repräsentiert ein Konfidenzintervall mit einer Irrtumswahrscheinlichkeit von =<0.07.ðBei Längsschnittauswertungen ist analog zu verfahren.

Juli 2004 41
Variablenübersicht der SOEP-Files PHRF und HHRF
Meaning Variable Name in file PHRF HHRF original household-ID HHNR HHNR Sort-ID PERSNR HHNRAKT Random Group PRGROUP HRGROUP APPROXIMATED DESIGN WEIGHT DESIGN cross-sectional weighting factor 1984 APHRF AHHRF cross-sectional weighting factor 1985 BPHRF BHHRF ... cross-sectional weighting factor 2000 QPHRF QHHRF cross-sectional weighting factor 2001 RPHRF RHHRF sample D-specific cross-section wgt. 1995 LPHRFD LHHRFD sample D-specific cross-section wgt. 1996 MPHRFD MHHRFD … sample D-specific cross-section wgt. 2000 QPHRFD QHHRFD sample D-specific cross-section wgt. 2001 RPHRFD RHHRFD sample A-E-specific cross-section wgt. 2000 QPHRFAE QHHRFAE sample A-E-specific cross-section wgt. 2001 RPHRFAE RHHRFAE sample F-specific cross-section wgt. 2000 QPHRFF QHHRFF sample F-specific cross-section wgt. 2001 RPHRFF RHHRFF
Juli 2004 42
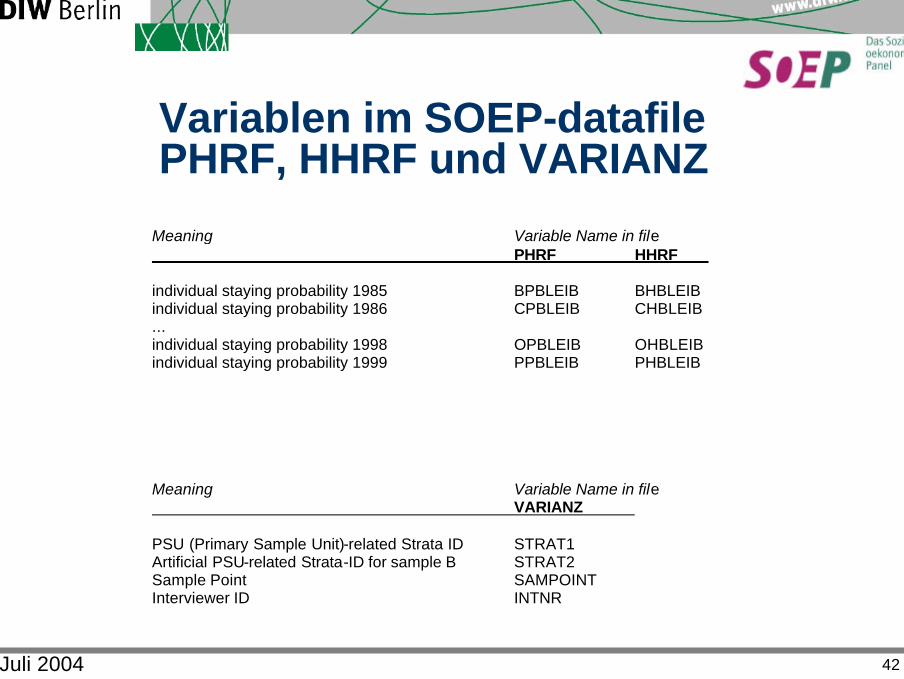
Variablen im SOEP-datafile PHRF, HHRF und VARIANZ
Meaning Variable Name in file PHRF HHRF individual staying probability 1985 BPBLEIB BHBLEIB individual staying probability 1986 CPBLEIB CHBLEIB ... individual staying probability 1998 OPBLEIB OHBLEIB individual staying probability 1999 PPBLEIB PHBLEIB Meaning Variable Name in file VARIANZ PSU (Primary Sample Unit)-related Strata ID STRAT1 Artificial PSU-related Strata-ID for sample B STRAT2 Sample Point SAMPOINT Interviewer ID INTNR
Top Related