

![Compressed Sensing and Machine Learning · The following introductions to omprcessed sensing and machine learning are inspired and held in the manner of the references [DDEK12] and](https://static.fdokument.com/doc/165x107/5ed31e0ae87f8f56a1275a19/compressed-sensing-and-machine-the-following-introductions-to-omprcessed-sensing.jpg)





Sprachen
Seiten
Rechtliche


Machine Learning
Neuronale Netze 2
(Mitchell Kap. 4)

Kombination mehrerer Neuronen
• zwei Klassen, die nicht linear separierbar sind:
• zwei innere Knoten und ein Output-Knoten
• Beispiel
• h h y Klasse B
andernfalls y Klasse A
1 20 0 0
1
: ( )
: ( )
y
h1 h2
A
A
A AA
A
AA
A
B
BB
B
A
B B
A
A
A
A
A A
B
B
10
1
0

Mehrschichtiges Netzwerk
n Eingabeneuronen
X1
X2
…
Xn
W11
W12W1p
Wn1Wn2
Wnp
Y1
Y2
Ym
……
V11
V12
V1m
Vp1Vp2
Vpm
m Ausgabeneuronenp verborgene Neuronen
(Hidden layer)
Gewichtsmatrix W Gewichtsmatrix V

Design der Netztopologie• Bestimmung von
• Anzahl der Input-Knoten
• Anzahl der inneren Schichten und jeweilige Anzahl der Knoten
• Anzahl der Output-Knoten
• starker Einfluß auf die Klassifikationsgüte:
• zu wenige Knoten
• niedrige Klassifikationsgüte
• zu viele Knoten
• Overfitting

Aktivierungsfunktionen
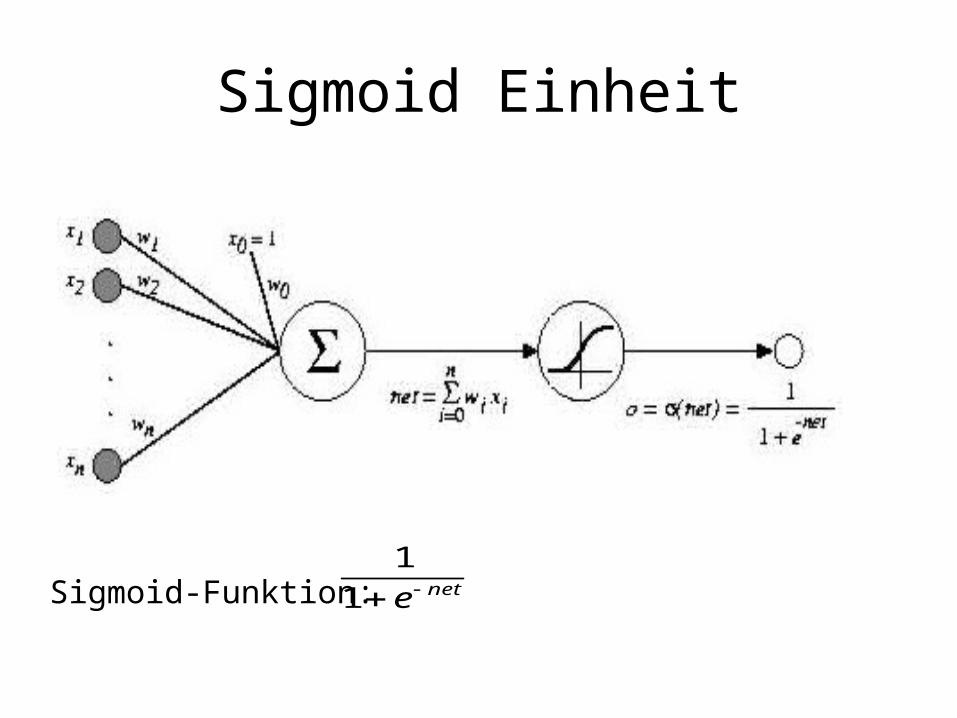
Sigmoid Einheit
Sigmoid-Funktion: nete1
1

Sigmoid Einheiten
• Vorteile:– Ausgabefunktion differenzierbar– Einfache Berechnung des Gradienten– Mehrschichtige Netze aus Sigmoid-Einheiten:
Training durch Backpropagation• Propagiere Trainingsbeispiel durchs Netz• Berechne rückwärts Schicht für Schicht
(ausgehend von den Ausgabeneuronen) die Deltas

Beispiel
• 2-schichtiges Netz zur Erkennung von gesprochener Sprache: Laut zwischen h_d

Lernen mehrschichtiger Netze
• Prinzipiell zu lernen:– Entwicklung neuer Verbindungen – Löschen existierender Verbindungen – Modifikation der Verbindungsstärke (Veränderung der
Gewichte) – Modifikation des Schwellenwertes – Modifikation der Aktivierungs- bzw. Ausgabefunktion – Entwicklung neuer Zellen – Löschen bestehender Zellen
• In der Praxis:– Nur Gewichtsmodifikation

Backpropagation Algorithmus
Prinzipiell verläuft der Lernprozess wie bei den Perzeptronen:– Dem Netz werden Beispiele vorgelegt.
– Stimmt der Ausgabevektor mit den erwarteten Werten überein, dann muss nichts gemacht werden.
– Liegt aber ein Fehler vor, d.h. eine Differenz zwischen Ausgabe und Ziel, dann müssen die Gewichte angepasst werden.

Backpropagation Algorithmus
• In einem Rückwärts-Check (Fehlerrückvermittlung) werden nun die einzelnen Gewichte im Netz (durch ) nach oben oder unten korrigiert.
• Der Tendenz nach so, daß das Ergebnis im zurückverfolgten Traingsbeispiel richtiger geworden wäre.
• Dies führt nach einer Anzahl von Trainingsbeispielen zu einem verbesserten Antwortverhalten des Netzes.

Backpropagation Algorithmus
• Belege die Gewichte w1 ...wn sowie die Schwellenwerte mit zufälligen Werten.
• Wähle einen Eingabevektor aus, zu dem es eine Soll-Aktivierung gibt.– 1. Vorwärtsvermittlung:
aktiviere die Eingabeschicht, danach schrittweise die Zwischenschichten 1....m und anschließend die Ausgabeschicht
– 2. Fehlerrückvermittlung:ermittle die -Werte für die Ausgabeschicht, danach schrittweise rückschreitend die -Werte für die Zwischenschichten m .....1 ändere die Gewichte und Schwellenwerte
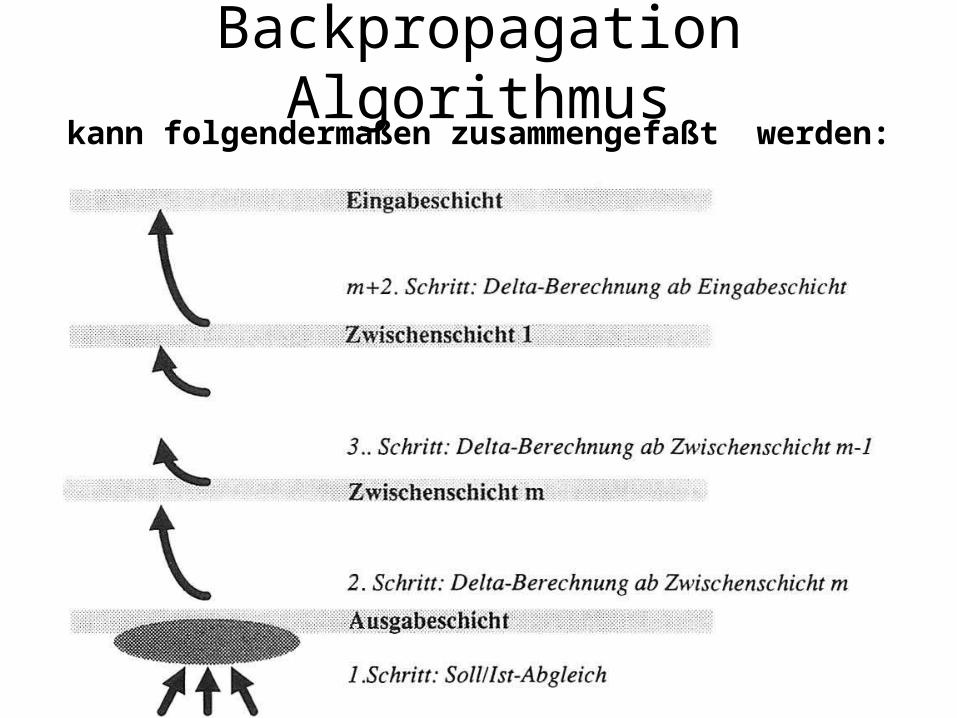
Backpropagation Algorithmuskann folgendermaßen zusammengefaßt werden:

Backpropagation Algorithmus
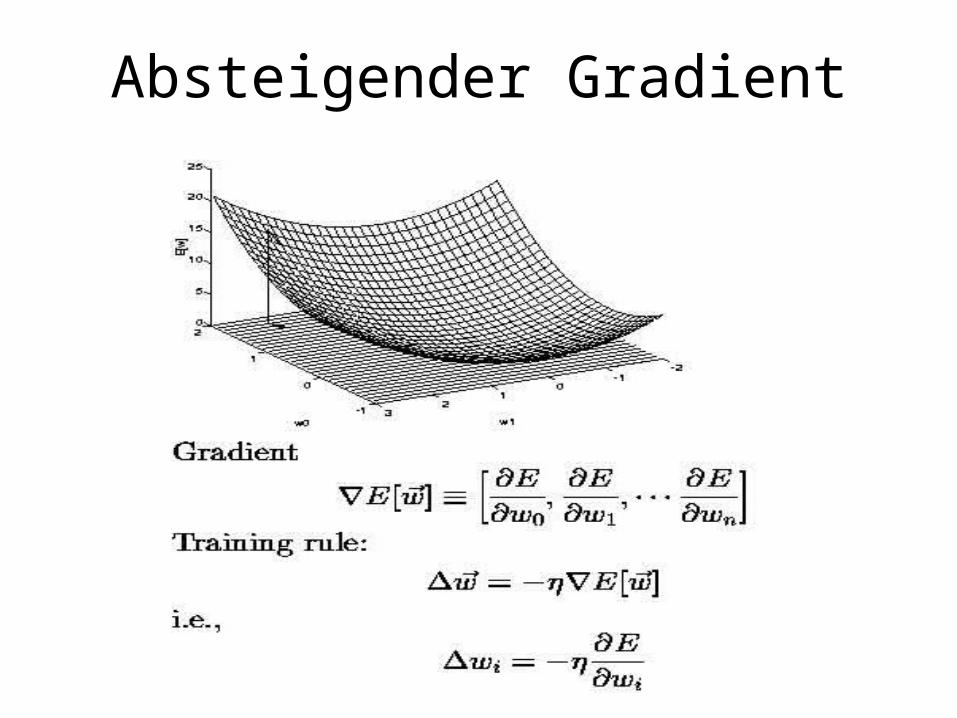
Absteigender Gradient

Abbruchbedingungen
• Anzahl der Iterationen• Schwellenwert für quadratischen Fehler
– In Bezug auf Trainingsmenge (-> große Gefahr von Overfitting)
– In Bezug auf separate Testmenge (-> Vermeidung von Overfitting!) = Cross-Validation
• Schwellenwert für Veränderung zum vorigen Schritt

Probleme
• Lokale Minima
• Flache Plateaus

Verbesserungen
• Momentum– Häufig wird ein zusätzlicher Faktor
(Momentum) hinzugefügt:
– Idee:• Überwindung flacher Plateaus• Evt. Auch Überwindung lokaler Maxima
• Paralleles Training mit versch. Initialwerten

Netztopologie
• Statische Topologie:
– Topologie wird apriori festgelegt
– eine verborgene Schicht reicht in vielen Anwendungen aus
• Dynamische Topologie
– dynamisches Hinzufügen von Neuronen (und verborgenen Schichten)
– solange Klassifikationsgüte signifikant verbessert wird
• Multiple Topologien
– Trainieren mehrer dynamischer Netze parallel
– z.B. je ein Netz mit 1, 2 und 3 verborgenen Schichten

Backward Netzwerke
= mehrschichtige Netzwerke von Sigmoid-Einheiten• U.U. sehr lange Trainingsphase (mehrere Tausend
Iterationen)• Nach Training extrem schnell• Große Ausdruckskraft:
– Jede Boole‘sche Funktion kann durch ein 2-schichtiges Netz (1 Hidden Layer) repräsentiert werden (-> disjunktive Normalform)
– Jede beschränkte stetige Funktion kann beliebig durch ein 2-schichtiges Netz approximiert werden
– Jede beliebige Funktion kann durch ein 3-schichtiges Netz (2 Hidden Layers) beliebig approximiert werden

Anwendungsbeispiele
• Texterkennung bei OCR Software, die sich auf gewisse Schriftformen trainieren läßt.
• Auch bei der Handschrifterkennung für PDA´s (Personal Digital Assistant), wie dem Apple Newton, kommen NN zu Einsatz.
• 1989: Erkennen von Postleitzahlen auf handgeschriebenen Briefumschlägen.– Das gesamte Netz benutzte nur 9760 Gewichte!– Das Netz wurde mit 7300 Beispielen trainiert und auf
2000 Beispielen getestet.
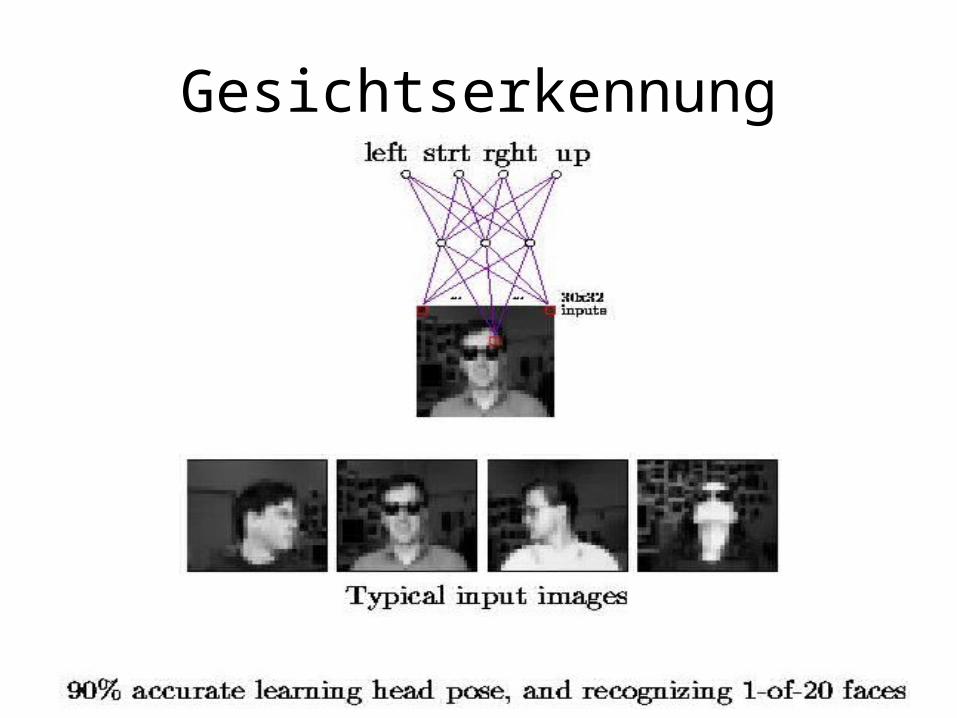
Gesichtserkennung

Gesichtserkennung
Aufgaben
• Bitte installieren und testen Sie die Programme zur Gesichtserkennung (Linux!)
• http://www-2.cs.cmu.edu/~tom/faces.html• Bitte befolgen Sie dabei die Anleitung
http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-8/faceimages/docs/hw97.ps
• Bitte beschreiben Sie Ihre Erfahrungen:– Liess sich das Programm installieren?– Wie ist es zu bedienen?– Was/wie haben Sie das Programm ausprobiert und
was waren die Resultate?
Top Related