







Sprachen
Seiten
Rechtliche


Aus dem Institut für Biometrie und Medizinische Informatik
(Direktor Univ.-Prof. Dr. rer. nat. habil. Karl-Ernst Biebler)
der Universitätsmedizin der Ernst-Moritz-Arndt-Universität Greifswald
Thema: Methoden zur Bestimmung von medizinischen Referenz-
bereichen für labordiagnostische Parameter
Inaugural-Dissertation
zur
Erlangung des akademischen
Grades
Doktor der Wissenschaften in der Medizin
(Dr. rer. med.)
der
Universitätsmedizin
der
Ernst-Moritz-Arndt-Universität
Greifswald
2013
vorgelegt von:
Sylvi Lucke, geb. Pollack
geb. am: 02.03.1977
in: Halle/ Saale

Dekan: Prof. Dr. Reiner Biffar
1. Gutachter: Prof. Dr. Karl-Ernst Biebler
2. Gutachter: Prof. Dr. Peter Schuff-Werner
Ort, Raum: Institut für Klinische Chemie und Laboratoriumsmedizin,
Greifswald, Seminarraum P0.76
Tag der Disputation: 15.07.2014

III
Inhaltsverzeichnis
Abbildungsverzeichnis ........................................................................................... VI
Tabellenverzeichnis................................................................................................ VII
Formelverzeichnis ................................................................................................. VIII
Abkürzungsverzeichnis .......................................................................................... IX
1 Einleitung ........................................................................................................ 1
1.1 Begriffsbestimmungen ..................................................................................... 1
1.2 Problematik ...................................................................................................... 2
1.3 Kontext der Untersuchung ............................................................................... 3
1.3.1 Internationale Ebene ........................................................................................ 3
1.3.2 Europäische Ebene .......................................................................................... 6
1.3.3 Nationale Ebene .............................................................................................. 6
1.4 Abgrenzung der Thematik .............................................................................. 10
1.5 Public Health-Relevanz des Themas ............................................................. 11
1.5.1 Auswirkungen der Nierenkrankheit auf die öffentliche Gesundheit ................ 12
1.5.2 Auswirkungen unterschiedlicher Methoden zur Berechnung von
Referenzbereichen auf die öffentliche Gesundheit ........................................ 13
1.5.3 Einfluss biologischer Unterschiede auf Referenzgrenzen von Parametern .... 15
1.6 Aufbau der Dissertation .................................................................................. 16
2 Theoretischer Hintergrund .......................................................................... 18
2.1 Wahrscheinlichkeitstheoretische und statistische Ansätze ............................ 18
2.2 Definitionen statistischer Intervalle für Referenzbereiche .............................. 22
2.2.1 Quantil-Intervall mit Konfidenzintervallen ....................................................... 22
2.2.2 Toleranzintervall ............................................................................................. 24
2.2.3 Prognoseintervall ........................................................................................... 25
2.3 Einordnung der Verfahren zur Berechnung von Referenzbereichen .............. 26
2.3.1 Induktive versus deduktive Methode .............................................................. 26
2.3.2 Direkte versus indirekte Methode ................................................................... 27
2.3.3 Einseitige versus zweiseitige Referenzintervalle ............................................ 27
2.3.4 Bezug zur Normalverteilung ........................................................................... 28
2.3.5 Parametrische versus nicht-parametrische Methode ..................................... 32

IV
2.3.6 Approximative versus exakte Schätzung ....................................................... 33
2.4 Die Entwicklung der Forschung bis zum aktuellen Stand ............................... 34
2.4.1 Das Bootstrap-Verfahren ............................................................................... 35
2.4.2 Kombinierte Verfahren ................................................................................... 38
2.4.3 Quantilregression ........................................................................................... 39
2.5 Umsetzungsdefizite und Forschungslücken ................................................... 40
2.5.1 Mängel in der Umsetzung von der Theorie in die Praxis ................................ 40
2.5.2 Desiderate für die Forschung ......................................................................... 42
2.6 Zielsetzung ..................................................................................................... 47
2.7 Forschungsfrage ............................................................................................ 48
3 Material und Methoden ................................................................................ 50
3.1 Untersuchungskonzept .................................................................................. 50
3.1.1 Festlegung der Laborparameter ..................................................................... 50
3.1.2 Festlegung der geschlechts- und altersspezifischen Subgruppen ................. 51
3.1.3 Festlegung der Stichprobengrößen ................................................................ 52
3.2 Berechnungsmethoden für Referenzbereiche ................................................ 52
3.2.1 Forschungsansätze ........................................................................................ 52
3.2.2 Quantil-Intervall mit Konfidenzintervallen ....................................................... 55
3.2.3 Toleranzintervall ............................................................................................. 59
3.2.4 Quantilregression ........................................................................................... 67
3.3 Datengrundlage.............................................................................................. 68
3.4 Auswerteverfahren ......................................................................................... 70
3.4.1 Computerprogramme und Prozeduren ........................................................... 70
3.4.2 Auswertung der Daten und Bewertung der vorgestellten
Berechnungsmethoden für Referenzbereiche ................................................ 71
3.5 Durchführungsbedingungen ........................................................................... 72
3.6 Kontrollmaßnahmen ....................................................................................... 72
3.7 Ethische Betrachtung ..................................................................................... 73
3.8 Software und Dateien ..................................................................................... 73
4 Ergebnisse .................................................................................................... 75
4.1 Plausibilitätsprüfungen ................................................................................... 75
4.1.1 Geschlecht ..................................................................................................... 75

V
4.1.2 Alter ................................................................................................................ 75
4.1.3 Patientennummer ........................................................................................... 77
4.1.4 Natrium .......................................................................................................... 77
4.1.5 Harnstoff ........................................................................................................ 78
4.1.6 Kreatinin ......................................................................................................... 81
4.2 Datenaufbereitung .......................................................................................... 85
4.2.1 Datenpakete ................................................................................................... 85
4.2.2 Subgruppen ................................................................................................... 86
4.2.3 Zufallsstichproben .......................................................................................... 87
4.3 Referenzbereiche ........................................................................................... 89
4.3.1 Quantil-Intervall mit Konfidenzintervallen ....................................................... 89
4.3.2 Toleranzschätzung ......................................................................................... 91
4.3.3 Quantilregression ........................................................................................... 95
4.4 Einfluss von Alter und Geschlecht auf Referenzgrenzen ............................... 98
4.4.1 Einflüsse auf die Referenzgrenzen für Harnstoff .......................................... 105
4.4.2 Einflüsse auf die Referenzgrenzen für Natrium ............................................ 109
4.4.3 Einflüsse auf die Referenzgrenzen für Kreatinin .......................................... 113
4.5 Fazit ............................................................................................................. 117
5 Diskussion .................................................................................................. 119
5.1 Erörterung der Ergebnisse ........................................................................... 119
5.2 Abgleich mit Referenzbereichen der Universitätsmedizin Greifswald .......... 127
5.3 Herausarbeitung relevanter Phänomene und Trends .................................. 133
5.4 Limitationen der Untersuchung .................................................................... 139
5.5 Schlussfolgerungen ...................................................................................... 144
5.6 Ausblick ........................................................................................................ 150
6 Zusammenfassung .................................................................................... 152
Literaturverzeichnis.............................................................................................. 154

VI
Abbildungsverzeichnis
Abbildung 1: Der 95%-Referenzbereich einer Normalverteilung ............................ 30
Abbildung 2: Normalisierende Transformationsmethoden...................................... 31
Abbildung 3: Nicht-parametrische Konfidenzintervalle für Referenzgrenzen .......... 56
Abbildung 4: Nicht-parametrische 0,95- und 0,90-Toleranzintervalle ..................... 60
Abbildung 5: Überdeckungswahrscheinlichkeit G als Funktion von N
für 0 ≤ N ≤ 2.000 für ein = 0,90-Toleranzintervall mit = 0,95 ........ 63
Abbildung 6: Überdeckungswahrscheinlichkeit G als Funktion von N
für 40 ≤ N ≤ 120 für ein = 0,90-Toleranzintervall mit = 0,95 ......... 64
Abbildung 7: Überdeckungswahrscheinlichkeit G als Funktion von N
für 0 ≤ N ≤ 2.000 für ein = 0,95-Toleranzintervall mit = 0,90 ........ 65
Abbildung 8: Überdeckungswahrscheinlichkeit G als Funktion von N
für 40 ≤ N ≤ 120 für ein = 0,95-Toleranzintervall mit = 0,90 ......... 66
Abbildung 9: Analyseschema ................................................................................. 71
Abbildung 10: Histogramm der Variable ALTER ....................................................... 76
Abbildung 11: Histogramm der Variable NATRIUM für die allgemeine
Bezugsgruppe ................................................................................... 77
Abbildung 12: Histogramm der Variable HARNSTOFF für die allgemeine
Bezugsgruppe – vor der Trunkierung ................................................ 79
Abbildung 13: Histogramm der Variable HARNSTOFF – nach der Trunkierung ...... 80
Abbildung 14: Histogramm der Variable KREA für die allgemeine Bezugsgruppe ... 82
Abbildung 15: Histogramme der Variable KREA für vordefinierte Subgruppen ........ 84
Abbildung 16: Mittelwerte der Kreatininwerte je altersspezifische Bezugsgruppe .... 97
Abbildung 17: Regressionsgeraden der 0,025- und 0,975-Quantile für Harnstoff… 108
Abbildung 18: Regressionsgeraden der 0,025- und 0,975-Quantile für Natrium….. 112
Abbildung 19: Regressionsgeraden der 0,025- und 0,975-Quantile für Kreatinin…116

VII
Tabellenverzeichnis
Tabelle 1: Auszug aus der Publikationsdatenbank der IFCC ................................... 3
Tabelle 2: Auszug aus der Publikationsübersicht der DGKL .................................... 7
Tabelle 3: Beispiele für Referenzgrenzen des Laborparameters CRP ................... 14
Tabelle 4: Auszug aus dem Laborkatalog der Ernst-Moritz-Arndt-Universität
Greifswald von 2011 .............................................................................. 54
Tabelle 5: Nicht-parametrische Konfidenzintervalle für Referenzgrenzen .............. 58
Tabelle 6: Nicht-parametrische 0,95- und 0,90-Toleranzintervalle ......................... 61
Tabelle 7: Mindest-Stichprobenumfänge N für nicht-parametrische
symmetrische 0,99-, 0,95- und 0,90-Toleranzintervalle ......................... 67
Tabelle 8: Zusammenfassung der kategorischen Variable GESCHLECHT ........... 75
Tabelle 9: Zusammenfassung der numerischen Variablen .................................... 75
Tabelle 10: Deskriptive Zusammenfassung der geschlechts- und alters-
spezifischen Subgruppen für den Parameter KREATININ..................... 87
Tabelle 11: Deskriptive Zusammenfassung aller 29 Untersuchungsgruppen ........... 88
Tabelle 12: Quantil-Intervalle mit nicht-parametrischen Konfidenzgrenzen für
alle 29 Untersuchungsgruppen .............................................................. 90
Tabelle 13: Rangnummern für untere und obere Grenzen von Toleranzintervallen.. 92
Tabelle 14: Nicht-parametrische Toleranzintervalle für
alle 29 Untersuchungsgruppen .............................................................. 94
Tabelle 15: Quantil-Intervalle aus vier verschiedenen Regressionsmodellen für
alle 29 Untersuchungsgruppen .............................................................. 96
Tabelle 16: Übersicht über die mittels drei verschiedener Methoden bestimmten
Referenzbereiche für alle 29 Untersuchungsgruppen ......................... 118
Tabelle 17: Übersicht über die Längen der mittels drei verschiedener Methoden
berechneten Referenzintervalle für alle 29 Untersuchungsgruppen .... 124
Tabelle 18: Auszug aus dem Laborkatalog der Ernst-Moritz-Arndt-Universität
Greifswald von 2011 mit Intervalllängen .............................................. 128
Tabelle 19: Auszug aus dem Laborkatalog der Ernst-Moritz-Arndt-Universität
Greifswald von 2013 mit Intervalllängen .............................................. 130

VIII
Formelverzeichnis
Formel 1 - 5: Funktionen und Verteilungen diskreter und stetiger Zufallsgrößen ..... 18
Formel 6: Theoretisches Quantil. ......................................................................... 19
Formel 7: Empirisches Quantil ............................................................................. 22
Formel 8: Konfidenzintervall ................................................................................ 23
Formel 9: Toleranzintervall .................................................................................. 25
Formel 10: Prognoseintervall ................................................................................. 26
Formel 11: Normalverteilung ................................................................................. 28
Formel 12: 95%-Referenzbereich einer Normalverteilung ..................................... 29
Formel 13: Nicht-parametrische Quantilschätzung ................................................ 55
Formel 14: Nicht-parametrische Toleranzschätzung ............................................. 59
Formel 15: β-Toleranzintervall ............................................................................... 59
Formel 16: Quantilregression ................................................................................ 68

IX
Abkürzungsverzeichnis
AG Arbeitsgruppe
BÄK Bundesärztekammer
CDC Englisch: Centers for Disease Control
CLSI Institut für klinische Laborstandards (Englisch: Clinical and Laboratory
Standards Institute)
CRP C-reaktives Protein
DGfN Deutsche Gesellschaft für Nephrologie
DGKL Deutsche Vereinte Gesellschaft für Klinische Chemie und Laboratoriums-
medizin e.V.
EBPG Englisch: European Best Practice Guidelines
EFCC Europäische Föderation für klinische Chemie und Laboratoriumsmedizin
(Englisch: European Federation of Clinical Chemistry and Laboratory Medi-
cine)
EPTRV Englisch: Expert Panel on Theory of Reference Values
GFR Glomeruläre Filtrationsrate
i.Pl. im Plasma
ICD Internationale statistische Klassifikation der Krankheiten und verwandter
Gesundheitsprobleme (Englisch: International Statistical Classification of
Diseases and Related Health Problems)
IFCC Internationale Föderation für klinische Chemie und Laboratoriumsmedizin
(Englisch: International Federation of Clinical Chemistry and Laboratory
Medicine)
IPCS Internationales Programm für chemische Sicherheit (Englisch: International
Programme on Chemical Safety)
ISO Internationale Organisation für Standardisierung (Englisch: International
Organization for Standardization)
IUPAC Internationale Vereinigung für theoretische und angewandte Chemie (Eng-
lisch: International Union of Pure and Applied Chemistry)
KDIGO Englisch: Kidney Disease: Improving Global Outcomes
KDOQI Englisch: Kidney Disease Outcome Quality Initiative
KI Konfidenzintervall

X
N Stichprobengröße
NCCLS Nationales Komitee für klinische Laborstandards (Englisch: National Com-
mittee for Clinical Laboratory Standards)
NKF Englisch: National Kidney Foundation
UBA Umweltbundesamt
WHO Weltgesundheitsorganisation (Englisch: World Health Organization)

1
1 Einleitung
Medizinische Referenzbereiche für labordiagnostische Parameter werden zur Validie-
rung von Laborergebnissen und zur Erstellung von medizinischen Befunden heran-
gezogen. Sie bilden eine essentielle Basis zur Gültigkeitserklärung und Bewertung
von Ergebnissen aus Labormessungen (1). Die Verfügbarkeit von validen Referenz-
bereichen für biologische Parameter ist demzufolge eine Grundvoraussetzung dafür,
anhand ermittelter Laborwerte fundierte Diagnosen stellen und die weitere Therapie
bestimmen zu können.
1.1 Begriffsbestimmungen
Das wissenschaftliche Komitee der Internationalen Föderation für klinische Chemie
und Laboratoriumsmedizin, International Federation of Clinical Chemistry and Labo-
ratory Medicine (IFCC), erschuf im Jahr 1970 ein Gremium namens Expert Panel on
Theory of Reference Values (EPTRV), welches sich mit der Erstellung einer Nomen-
klatur sowie mit der Entwicklung von Prozeduren für die Produktion von Referenz-
werten, wie auch mit deren Verarbeitung und Präsentation befasste. Das EPTRV
verfasste daraufhin im Jahr 1986 in Ermangelung einer weltweit einheitlichen No-
menklatur ein Konzept zu Referenzwerten. Die im Rahmen dieses Konzeptes veröf-
fentlichten, von der IFCC empfohlenen Definitionen haben sich seitdem als internati-
onal gültiger Standard etabliert. Dieses Konzept der Referenzwerte bildet das Fun-
dament für die von der IFCC entwickelten Theorie der Referenzwerte, die in einer
sechsteiligen Serie in Form von genehmigten Empfehlungen im Zeitraum von 1987
bis 1991 publiziert wurde (2-7).
In ihrem Konzept der Referenzwerte stellt die IFCC sämtliche zur Theorie der Refe-
renzwerte beitragenden Begriffe wie folgt in einer Beziehung zueinander dar, um ei-
nerseits den Zusammenhang der empfohlenen Definitionen hervorzuheben und sie
andererseits voneinander abzugrenzen (2): Referenzindividuen bilden eine Refe-
renzpopulation. Aus der Referenzpopulation wird eine Referenzstichprobe selektiert.
Von dieser Referenzstichprobe werden Referenzwerte ermittelt. Anhand dieser Refe-
renzwerte wird eine Referenzverteilung bestimmt. Auf Grundlage dieser angenom-
menen Referenzverteilung werden Referenzgrenzen berechnet. Diese Referenz-

2
grenzen definieren den Referenzbereich. Der Referenzbereich, die Referenzgrenzen,
die Referenzverteilung sowie die Referenzwerte bieten eine Vergleichsbasis für indi-
viduell beobachtete Laborwerte. Die Definitionen der IFCC laut dem Konzept der Re-
ferenzwerte (2) dienen als Ansatz für die vorliegende Forschungsarbeit, um eine ein-
heitliche Ausgangsbasis für das Verständnis der folgenden Untersuchung sowie der
daraus gewonnenen Ergebnisse sicherzustellen.
1.2 Problematik
Medizinische Referenzbereiche für labordiagnostische Parameter sind mittels statis-
tischer Methoden ermittelte und festgelegte Intervalle, die durch obere und untere
Grenzwerte definiert sind. Sie bilden den Normalbereich eines biologischen Parame-
ters ab und werden als Referenz für Laborergebnisse zur Bestimmung medizinischer
Diagnosen und Therapien herangezogen.
„Der Normalbereich hat eine unklare, aber bequeme Rolle in der Laboratoriumsmedi-
zin gespielt. Er wird undeutlich sichtbar am Horizont unseres Bewusstseins, voll-
kommen symmetrisch wie der Berg Fujiyama, ein wenig umnebelt in seiner Bedeu-
tung, trotzdem dankbar verehrt und anerkannt. Weit ab jedoch davon, rein und ein-
fach zu sein wie eine gepflegte Illusion der Kindheit, stellt sich bei näherer Prüfung
heraus, dass er verwirrend komplex ist und so tatsächlich eines der hartnäckigsten
und schwierigsten Probleme darstellt, das die Nützlichkeit klinischer Labordaten be-
grenzt.“ [(8), S. 303]
Der Normalbereich eines biologischen Parameters, wie zum Beispiel dem Gewicht
oder der Körpergröße, ist ein Bereich, innerhalb dessen alle Werte im Allgemeinen
als normal gelten. Dieser Bereich beinhaltet demnach alle Normalwerte und wird
durch Referenzgrenzen begrenzt. Der dem Normalbereich entstammte und ursprüng-
lich grundsätzlich verwendete Begriff Normalwert wird jedoch aufgrund einer eventu-
ell missverständlichen Auslegung des Wortes normal mittlerweile generell durch den
Terminus Referenzwert ersetzt, da andernfalls Messwerte außerhalb dieses Berei-
ches als abnorm angesehen werden würden. (9)
Das maßgebliche Problem bei der Verwendung des Normalbereiches in der Labora-
toriumsmedizin als Vergleichsbasis für die Bewertung von Laborbefunden besteht

3
darin, dass der Normalbereich und folglich die Referenzgrenzen sehr stark von der
angewendeten statistischen Methode sowie der ausgewählten Referenzpopulation
abhängen (10). Des Weiteren kann nicht prinzipiell davon ausgegangen werden,
dass jeder biologische Parameter annähernd normalverteilt ist – denn laut Untersu-
chungen ist dies eher die Ausnahme [vgl. (11-13)].
Die Bestimmung des Normal- beziehungsweise Referenzbereiches eines biologi-
schen Merkmals, medizinischen Messwertes oder labordiagnostischen Parameters
durch die Beantwortung der Frage Was ist normal? stößt demzufolge auf ein metho-
disches Problem, welches durch die in Abschnitt 1.3 aufgeführten internationalen,
europäischen und nationalen Gesetze, Richt- und Leitlinien zu regeln versucht wird.
1.3 Kontext der Untersuchung
1.3.1 Internationale Ebene
Auf der internationalen Ebene ist die IFCC für den rahmengebenden, rechtlichen
Kontext hinsichtlich der oben dargelegten Problematik maßgebend. Eigenen Recher-
chen und Literaturauswertungen zufolge sind die in Tabelle 1 aufgeführten Publikati-
onen der IFCC für die Bearbeitung des gewählten Untersuchungsthemas ausschlag-
gebend.
Tabelle 1: Auszug aus der Publikationsdatenbank der IFCC (14)
Jahr Autor(en) Titel Veröffentlicht in
1986 Solberg HE Approved Recommendation (1986) on
the Theory of Reference Values. Part 1.
The Concept of Reference Values
J Clin Chem Clin
Biochem 1987;
25: 337-42
1987 PetitClerc C,
Solberg HE
Approved Recommendation (1987) on
the Theory of Reference Values. Part 2.
Selection of Individuals for the Production
of Reference Values
J Clin Chem Clin
Biochem 1987;
25: 639-44

4
1987 Solberg HE Approved Recommendation (1987) on
the Theory of Reference Values. Part 5.
Statistical Treatment of Collected Refer-
ence Values. Determination of Reference
Limits
J Clin Chem Clin
Biochem 1988;
26: 645-56
1987 Dybkaer R,
Solberg HE
Approved Recommendation (1987) on
the Theory of Reference Values. Part 6.
Presentation of Observed Values Related
to Reference Values
J Clin Chem Clin
Biochem 1987;
25: 657-62
1988 Solberg HE,
PetitClerc C
Approved Recommendation (1988) on
the Theory of Reference Values. Part 3.
Preparation of Individuals and Collection
of Specimens for the Production of Ref-
erence Values
J Clin Chem Clin
Biochem 1988;
26: 593-8
1991 Solberg HE,
Petit-Clerc C,
Stamm D
Approved Recommendation on the Theo-
ry of Reference Values. Part 4. Control of
Analytical Variation in the Production,
Transfer and Application of Reference
Values
Eur J Clin Chem
Clin Biochem
1991; 29: 531-5
1993 Solberg HE A guide to IFCC Recommendations on
Reference Values
J Int Fed Clin
Chem 1993; 5:
160-64
1998 Büttner J Biological variation and quantification of
health: the emergence of the concept of
normality
Clin Chem Lab
Med 1998; 36:
69-73
2004 Solberg HE The IFCC recommendation on estimation
of reference intervals. The RefVal Pro-
gram
Clin Chem Lab
Med 2004; 42:
710-4
2007 Ceriotti F Prerequisites for Use of Common Refer-
ence Intervals
Clin Biochem
Rev Vol 28 2007;
I: 115-21

5
2008 Kallner A Markers of Kidney Disease. Proceedings
of the 11th Bergmeyer Conference. IFCC-
Roche Diagnostics Master Discussion
Scand J Clin Lab
Invest 2008; 68
(S241): 1-112
2008 Ceriotti F,
Boyd JC,
Klein G, Hen-
ny J, Queraltó
J, Kairisto V,
Panteghini M
Reference intervals for serum creatinine
concentrations: assessment of available
data for global application
Clin Chem. 2008
Mar; 54(3):559-
66. Epub 2008
Jan 17
2008 Ceriotti F,
Henny J
„Are my laboratory results normal?“ Con-
siderations to be Made Concerning Ref-
erence Intervals and Decision Limits
eJIFCC Vol 19
no 2: http://www.
ifcc.org/ejifcc/vol
19no2/19020120
0803.htm
2009 Ceriotti F,
Hinzmann R,
Panteghini M
Reference intervals: the way forward Ann Clin Bio-
chem 2009; 46:8-
17
2010 Ichihara K,
Boyd JC
An appraisal of statistical procedures
used in derivation of reference limits
Clin Chem Lab
Med, 2010; 48:
1537
Das gleichfalls auf internationaler Ebene agierende und mit der IFCC kooperierende
Institut für klinische Laborstandards (CLSI) – das frühere Nationale Komitee für klini-
sche Laborstandards (NCCLS) – hat mit seiner Richtlinie Defining, Establishing, and
Verifying Reference Intervals in the Clinical Laboratory; Approved Guideline – Third
Edition aus dem Jahr 2008 wesentlich zur nachhaltigen Besprechung des methodi-
schen Problems sowie zur weiterführenden Etablierung der IFCC-Empfehlungen bei-
getragen (15).
Auf der internationalen Ebene gleichrangig bedeutsam und richtungsweisend ist die
Publikation der Internationalen Vereinigung für theoretische und angewandte Chemie
(IUPAC) mit dem Titel Calculation and Application of Coverage Intervals for Biologi-
cal Reference Values von Poulsen et al. aus dem Jahr 1997 (16).

6
Ebenso auf internationaler Ebene gibt die Internationale Organisation für Standardi-
sierung (ISO) mit der ISO 15189: Medical laboratories – Particular requirements for
quality and competence aus dem Jahr 2007 einen rechtskräftigen Rahmen betref-
fend der Erfordernisse für medizinische Laboratorien vor, indem sie unter anderem
vorschreibt, dass biologische Referenzintervalle in regelmäßigen Abständen über-
prüft werden müssen (17).
Nicht zuletzt sei hier die Weltgesundheitsorganisation (WHO) als wichtiger, internati-
onal tätiger Akteur genannt, die sich im Rahmen des Internationalen Programms für
chemische Sicherheit (IPCS) dieser Thematik widmet und mit der Veröffentlichung
Environmental Health Criteria. No. 170 – Assessing human health risks of chemicals:
Derivation of guidance values for health-based exposure limits aus dem Jahr 1994
zur Diskussion beiträgt (18).
1.3.2 Europäische Ebene
Auf der europäischen Ebene ist die zuständige Europäische Föderation für klinische
Chemie und Laboratoriumsmedizin (EFCC) aktiv. Laut eigenen Rechercheergebnis-
sen anhand der Publikationsliste der EFCC trägt die EFCC jedoch nicht zur Erörte-
rung der oben erläuterten Thematik bei (19).
1.3.3 Nationale Ebene
Auf der nationalen Ebene ist die Deutsche Vereinte Gesellschaft für Klinische Che-
mie und Laboratoriumsmedizin e.V. (DGKL) auf dem Forschungsgebiet wegweisend.
Eine Arbeitsgruppe (AG) der DGKL – die AG Entscheidungsgrenzen/ Richtwerte –
befasst sich hauptsächlich mit Fragen zur Bewertung von Laborergebnissen, im Spe-
ziellen mit folgenden Themenbereichen (20):
Verfahren zur Ermittlung von Referenzintervallen, Entscheidungs- und Akti-
onsgrenzen
Verfahren zur Abschätzung der Validität dieser Grenzen und Bereiche
Verfahren zur Bewertung von Laborbefunden
Verfahren zur Bewertung von Methodenvergleichen

7
Die AG Entscheidungsgrenzen/ Richtwerte wurde 2007 gegründet und entsprang der
bereits jahrelang existierenden Kooperation zwischen Prof. Dr. Haeckel, Dipl. Math.
Wosniok und Dr. Arzideh aus dem Institut für Statistik der Universität Bremen. Eige-
ner Recherchen und Literaturauswertungen zufolge sind die in Tabelle 2 aufgeliste-
ten Veröffentlichungen der AG Entscheidungsgrenzen/ Richtwerte der DGKL, in de-
nen Methoden zur Ermittlung beziehungsweise Definitionen von Referenzgrenzen
besprochen werden, für den vorliegenden Diskurs maßgeblich.
Tabelle 2: Auszug aus der Publikationsübersicht der DGKL (21)
Jahr Autor(en) Titel Veröffentlicht in
2007 Haeckel R, Wosniok
W, Arzideh F
A plea for intra-laboratory refer-
ence limits. Part 1. General con-
siderations and concepts of deter-
mination
Clin Chem Lab
Med 2007;
45:1033-42
2007 Arzideh F, Wosniok
W, Gurr E, Hinsch
W, Schumann G,
Weinstock N, Hae-
ckel R
A plea for intra-laboratory refer-
ence limits. Part 2. A bimodal ret-
rospective concept for determining
reference limits from intra-
laboratory databases demonstrat-
ed by catalytic activity concentra-
tions of enzymes
Clin Chem Lab
Med 2007;
45:1043-57
2009 Arzideh F, Brand-
horst G, Gurr E, Hin-
sch W, Hoff T, Rog-
genbuck L, Rothe G,
Schumann G, Wol-
ters B, Wosniok W,
Haeckel R
An improved indirect approach for
determining reference limits from
intra-laboratory data bases exem-
plified by concentrations of electro-
lytes
J Lab Med 2009;
33:52-66

8
2009 Arzideh F, Gurr E,
Haeckel R, Hinsch
W, Schumann G,
Wosniok W
Richtwerte bei quantitativen Unter-
suchungen im Medizinischen La-
boratorium. Definition, Klassifikati-
on und Grenzen der Anwendung.
Empfehlung zur Klassifizierung
und Definitionen von Richtwerten
quantitativer Messgrößen
J Lab Med 2009;
33:228-232
2009 Haeckel R, Wosniok
W, Arzideh F
Proposed classification of various
limit values (guide values) used in
assisting the interpretation of quan-
titative test results
Clin Chem Lab
Med 2009;
47:494-7
2010 Arzideh F, Wosniok
W, Haeckel R
Indirect reference limits of plasma
and serum creatinine concentra-
tions from intra-laboratory data
bases of several German and Ital-
ian medical centres. Comparison
between direct and indirect proce-
dures
Clin Chim Acta
2010; 411:215-
21
2010 Haeckel R, Wosniok
W
Observed, unknown distributions of
clinical chemistry quantities should
be considered to be log-normal: a
proposal
Clin Chem Lab
Med 2010;
48:1393-6
2011 Arzideh F, Wosniok
W, Haeckel R
Indirect reference intervals of
plasma and serum thyrotropin
(TSH) concentrations from intra-
laboratory data bases of several
German and Italian medical cen-
tres
Clin Chem Lab
Med 2011;
49:659-64
Parallel dazu befasst sich das Umweltbundesamt (UBA) auf nationaler Ebene mit der
Bestimmung von Referenzbereichen und bezieht sich in dem im Jahr 1996 heraus-
gegebenen Konzept der Referenz- und Human-Biomonitoring-Werte in der Umwelt-
medizin sowie im Addendum zum Konzept der Referenz- und Human-Biomonitoring-

9
Werte in der Umweltmedizin aus dem Jahr 2009 auf die von der WHO, der IUPAC
und dem NCCLS besprochenen Methoden (22;23).
Ebenfalls auf nationaler Ebene trifft die Richtlinie der Bundesärztekammer zur Quali-
tätssicherung laboratoriumsmedizinischer Untersuchungen von der Bundesärzte-
kammer (BÄK) aus dem Jahr 2008 für die aktuelle Problematik zu, nach der jede
Verfahrensanweisung für die Durchführung von laboratoriumsmedizinischen Unter-
suchungen Referenzbereiche gesunder Probanden enthalten muss (24). Hierbei wird
jedoch nicht näher darauf eingegangen, was genau als gesund beziehungsweise
normal zu definieren ist – was wieder das anfangs geschilderte gegenwärtige metho-
dische Problem aufzeigt und einen Forschungsbedarf darstellt.
Zusammenfassend betrachtet ist auffällig, dass es eine Vielzahl verschiedenartige
Instanzen gibt, die mitunter voneinander abweichende Methoden zur Bestimmung
von medizinischen Referenzbereichen für labordiagnostische Parameter anhand un-
terschiedlichster Mittel mehr oder weniger präzise vorgeben. Die Methoden laut Emp-
fehlungen der IFCC in Form der Theorie und des Konzeptes der Referenzwerte ha-
ben sich dabei weltweit als Goldstandard durchgesetzt. Jedoch sind diese Empfeh-
lungen, die seither von der IFCC nicht wieder aufgegriffen, fortgeführt und an den
aktuellen Stand der Forschung (siehe Abschnitt 2.4) angepasst wurden, verhältnis-
mäßig alt. Seit dem Jahr 2004 wurden keine Neuerungen an dem IFCC-
Referenzwertkonzept mehr vorgenommen (25;26). In den Jahren seit der Etablierung
und Umsetzung der IFCC-Empfehlungen in der Praxis wurden einige Schwachstellen
erkannt (27;28).
Diese Faktoren, sowie die Tatsachen, dass es einerseits auf internationaler Ebene
auch andere befürwortete Methoden zur Ermittlung von Referenzbereichen wie zum
Beispiel die der IUPAC (16) gibt, und andererseits besonders auf nationaler Ebene
aktuell stark geforscht wird und neuartige Methodenanregungen veröffentlicht wur-
den – vorwiegend durch die DGKL (21) – begründen einen vordringlichen For-
schungsbedarf auf diesem Sektor.

10
1.4 Abgrenzung der Thematik
Obwohl die im vorherigen Abschnitt 1.3 geschilderten Empfehlungen, Richt- und Leit-
linien im Wesentlichen für alle biologischen Laborparameter gelten, liegen in
Deutschland letztendlich die Hauptverantwortung und Kompetenzen bei den jeweili-
gen wissenschaftlich-medizinischen Fachgesellschaften (29). Aufgrund der Fülle an
Fachrichtungen und Fachgesellschaften im medizinischen Bereich müssen daher bei
der Bearbeitung des Themas Methoden zur Bestimmung von medizinischen Refe-
renzbereichen für labordiagnostische Parameter Einschränkungen vorgenommen
werden, die im Folgenden beschrieben werden.
In der geplanten Untersuchung sollten insbesondere die für Deutschland derzeit gül-
tigen Richt- und Leitlinien sowie die von deutschen Fachgesellschaften gegenwärtig
empfohlenen oder in der Literatur neu diskutierten statistischen Methoden zur Be-
rechnung von Referenzgrenzen für Laborparameter beleuchtet und selektiv gegenei-
nander abgewogen werden. Zudem sollten die zu prüfenden statistischen Methoden
anhand exemplarisch ausgewählter labordiagnostischer Parameter betrachtet wer-
den. Hierfür scheint es sinnvoll, häufig untersuchte biologische Parameter mit hoher
Public Health-Relevanz heranzuziehen.
Zu diesem Zweck eignen sich im Speziellen Nierenwerte. Nierenwerte dienen der
Diagnostik von Nierenfunktionsstörungen. Die Betrachtung der Public Health-
Relevanz des Krankheitsbildes Niereninsuffizienz in Deutschland wird im nächsten
Absatz 1.5 vorgenommen.
Die Deutsche Gesellschaft für Nephrologie (DGfN) übernimmt die international aner-
kannten Leitlinien der gemeinnützigen Stiftung Kidney Disease: Improving Global
Outcomes (KDIGO) (30). Die DGfN schließt sich der Kidney Disease Outcome Quali-
ty Initiative (KDOQI) der amerikanischen National Kidney Foundation (NKF) hinsicht-
lich des Standpunktes an, Kreatinin nicht als alleinigen Laborparameter zur Bestim-
mung der Nierenfunktion heranzuziehen (31). Welche Laborparameter zur Bestim-
mung der Nierenfunktion konkret herangezogen werden sollten stellt eine Übersicht
der KDIGO für einzelne Länder beziehungsweise Regionen dar (32). Die dort aufge-
listeten Richtlinien je Land/ Region und der zugehörigen verantwortlichen Organisati-

11
on zeigen deutlich, dass die für die Diagnose, Beurteilung und Klassifikation einer
chronischen Nierenkrankheit zwingend notwendig zu untersuchenden Laborparame-
ter länderspezifisch oder regional voneinander abweichen. Speziell für Deutschland
sind hier jedoch keine Leitlinien genannt. Allein für Europa ist eine Richtlinie entspre-
chend der European Best Practice Guidelines (EBPG) aus dem Jahr 2002 angege-
ben (33).
Werden sämtliche Richt- und Leitlinien sowie einschlägige Fachliteratur und Heraus-
gaben der zuständigen Fachgesellschaften berücksichtigt ist auffallend, dass die für
die Diagnostik einer Niereninsuffizienz essentiell zu testenden Nierenwerte nicht ein-
deutig definiert sind. Insgesamt sind in der Literatur hauptsächlich folgende labordi-
agnostische Parameter als zu analysierende Nierenwerte angeführt [vgl. (34-39)]:
Albumin
C-reaktives Protein
Cystatin C
Harnsäure
Harnstoff
Kalium
Kalzium
Kreatinin
Natrium
Kleines Blutbild
o Erythrozyten
o Hämatokrit
o Hämoglobin
o Leukozyten
o Mittleres corpuskuläres Hämoglobin
o Mittleres corpuskuläres Volumen
o Thrombozyten
Laut der Stellungnahme Testing for chronic kidney disease der NKF ist bei der hier
beabsichtigten Untersuchung der Methoden zur Bestimmung von medizinischen Re-
ferenzbereichen anhand der vorangehend aufgestellten labordiagnostischen Para-
meter zusätzlich darauf zu achten, dass die Größen Alter, Rasse und Geschlecht als
erhebliche Einflussfaktoren Berücksichtigung finden (40).
1.5 Public Health-Relevanz des Themas
Bei der Erörterung der Public Health-Relevanz des Themas muss einesteils auf das
Krankheitsbild der Nierenerkrankung, seine Prävalenz in Deutschland sowie dessen
Effekt auf das deutsche Gesundheitssystem eingegangen werden.

12
Demgegenüber muss die Wichtigkeit von – mittels verschiedener statistischer Me-
thoden gewonnenen – unterschiedlichen Referenzbereichen für gleiche Laborpara-
meter mitsamt ihrer Auswirkung auf die klinische Praxis wie auch ausdrücklich für die
Patienten selbst aufgezeigt werden.
1.5.1 Auswirkungen der Nierenkrankheit auf die öffentliche Gesundheit
Nierenerkrankungen sind systemische Erkrankungen. Das bedeutet, dass nicht nur
ein Organ – also eine oder beide Nieren – von einer Funktionsstörung betroffen ist,
sondern Reaktionen im gesamten Organismus bestehen und damit Folgekrankheiten
wie zum Beispiel arterielle Hypertonie (Bluthochdruck) oder renale Anämie (Blutar-
mut) einhergehen können. Der Oberbegriff Nierenerkrankung umfasst die nachste-
henden einzelnen Krankheitsbilder: akutes Nierenversagen, chronisches Nierenver-
sagen, entzündliche Erkrankungen der Glomeruli, bakterielle Infekte an Nieren und
Harnwegen, angeborene Nierenerkrankungen (wie beispielsweise Zystennieren),
sowie Hämaturie und Proteinurie (Blut und Eiweiß im Urin) (41). Zu den Hauptrisiko-
faktoren für das Entstehen eines chronischen Nierenversagens gehören die Vorer-
krankungen Diabetes mellitus, arterielle Hypertonie, Herz-Kreislauferkrankung und
chronische Niereninsuffizienz in der Familiengeschichte, sowie ein Alter über 60 Jah-
re (40).
Gemäß des Jahresberichtes 2006/ 2007 der QuaSi Niere gGmbH iL, der im Rahmen
der jährlichen Qualitätsberichte des Projektes zur Förderung der Qualitätssicherung
in der Nierenersatztherapie – von den Bundesverbänden der Krankenkassen und
den Leistungserbringern in der Nierenersatztherapie gemeinsam mit dem Bundes-
verband Niere e.V. initiiert – herausgegeben wurde, befanden sich zum Stichtag
31.12.2006 aufgrund einer chronischen Nierenerkrankung 66.508 Patienten in Dialy-
sebehandlung und 25.210 Patienten in der Nachsorge nach einer Nierentransplanta-
tion. Somit betrug die Gesamtprävalenz von Transplantationsnachsorge-Patienten
und Dialysepatienten zum Ende des Jahres 2006 insgesamt 1.114 Patienten pro ei-
ne Million Einwohner in Deutschland. Darunter waren 862 Kinder und Jugendliche,
die von der Notwendigkeit einer dauerhaften Nierenersatztherapie betroffen waren.
12.124 Erwachsene und 6 Kinder, die sich in einer chronischen Nierenersatztherapie
befanden, verstarben im Jahr 2006 – 522 Patienten davon trotz funktionsfähiger Nie-

13
rentransplantate. Die Inzidenz belief sich im Jahr 2006 auf 213 chronisch Neuer-
krankte je eine Million Einwohner in Deutschland. Seit dem Jahr 1997 bis zum Jahr
2006 ist die Prävalenz von Patienten in Dialyse- oder Nierentransplantationsnach-
sorge-Behandlung durchschnittlich jährlich um 4,4 %, und die Inzidenz um 5,1 % an-
gestiegen – was allein durch den Zuwachs des Bevölkerungsanteils der Älteren in
Deutschland nicht zu erklären ist. Desgleichen ist die Mortalität von circa 80 verstor-
benen Patienten pro eine Million Einwohner, die sich im Jahr 1995 in einer chroni-
schen Nierenersatztherapie befanden, bis zum Jahr 2006 auf knapp 150 verstorbene
Patienten je eine Million Einwohner gestiegen. (42)
Die Auswirkungen dieser beachtlichen Zunahme an Nierenkranken während der letz-
ten 15 Jahre auf das deutsche Gesundheitssystem betreffen vorwiegend die Ge-
sundheitsversorgung, welche konstant an diese neuen Verhältnisse angepasst wer-
den und den wachsenden Versorgungsbedarf decken muss – was wiederum durch
die Gesundheitspolitik reguliert werden muss und somit diese ebenfalls von der Auf-
gabe betroffen ist.
Die NKF betonte in einem Positionspapier aus dem Jahr 2007, dass chronische Nie-
renerkrankungen mittlerweile ein wahres Problem für die öffentliche Gesundheit dar-
stellen und diverse Institutionen, wie unter anderen die KDIGO und die Centers for
Disease Control (CDC), weltweite Screening und Surveillance Programme – beson-
ders für Risikogruppen – befürworten. Sie empfehlen, mit Hilfe von Routinetests bei
Risikopatienten regelmäßig festzustellen, ob ein Nierenschaden vorliegt und wie
ausgeprägt die Nierenfunktion ist. Sie heben hervor, dass die öffentliche Gesundheit
in Bezug auf Nierenerkrankungen durch die kontinuierliche Anwendung derartiger
Tests verbessert werden kann (40).
1.5.2 Auswirkungen unterschiedlicher Methoden zur Berechnung von Refe-
renzbereichen auf die öffentliche Gesundheit
Medizinische Referenzbereiche für labordiagnostische Parameter dienen den Ärzten
zur Diagnose- und Therapiestellung bei der Behandlung ihrer Patienten. Die Refe-
renzgrenzen für die einzelnen biologischen Parameter werden entweder Labor-intern
von den jeweils regional ansässigen Laboratorien [vgl. (43;44)] ermittelt und zur Ver-
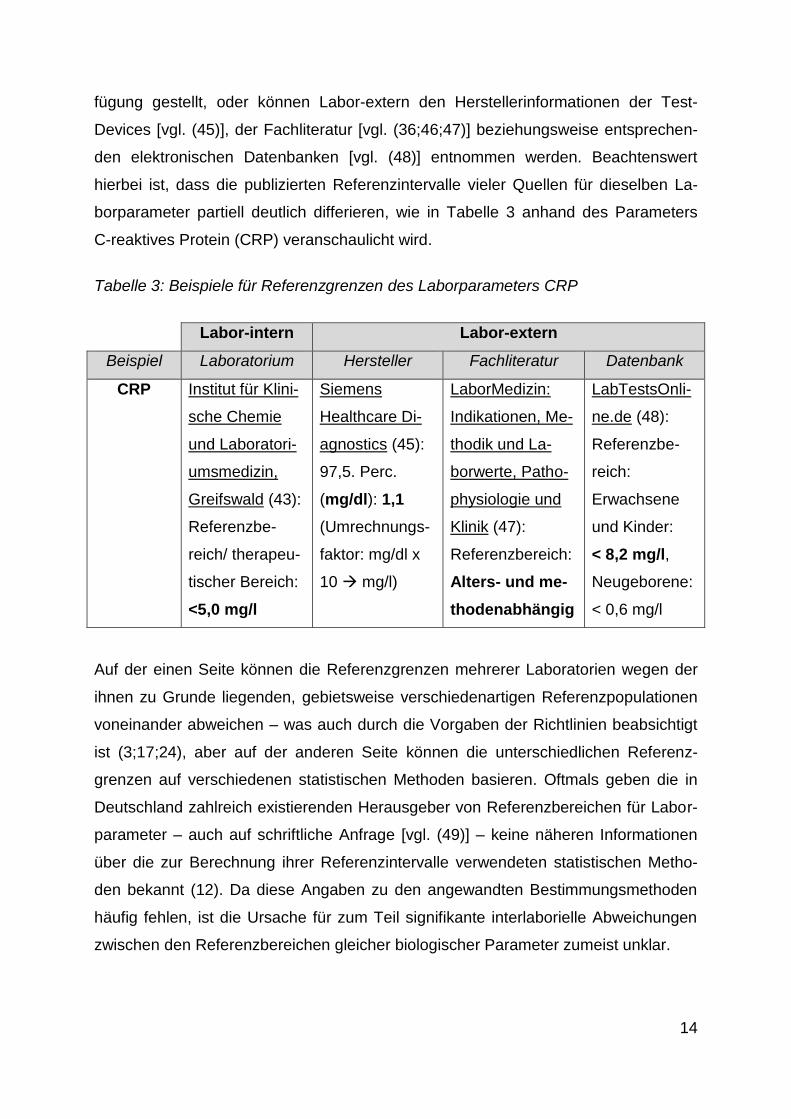
14
fügung gestellt, oder können Labor-extern den Herstellerinformationen der Test-
Devices [vgl. (45)], der Fachliteratur [vgl. (36;46;47)] beziehungsweise entsprechen-
den elektronischen Datenbanken [vgl. (48)] entnommen werden. Beachtenswert
hierbei ist, dass die publizierten Referenzintervalle vieler Quellen für dieselben La-
borparameter partiell deutlich differieren, wie in Tabelle 3 anhand des Parameters
C-reaktives Protein (CRP) veranschaulicht wird.
Tabelle 3: Beispiele für Referenzgrenzen des Laborparameters CRP
Labor-intern Labor-extern
Beispiel Laboratorium Hersteller Fachliteratur Datenbank
CRP Institut für Klini-
sche Chemie
und Laboratori-
umsmedizin,
Greifswald (43):
Referenzbe-
reich/ therapeu-
tischer Bereich:
<5,0 mg/l
Siemens
Healthcare Di-
agnostics (45):
97,5. Perc.
(mg/dl): 1,1
(Umrechnungs-
faktor: mg/dl x
10 mg/l)
LaborMedizin:
Indikationen, Me-
thodik und La-
borwerte, Patho-
physiologie und
Klinik (47):
Referenzbereich:
Alters- und me-
thodenabhängig
LabTestsOnli-
ne.de (48):
Referenzbe-
reich:
Erwachsene
und Kinder:
< 8,2 mg/l,
Neugeborene:
< 0,6 mg/l
Auf der einen Seite können die Referenzgrenzen mehrerer Laboratorien wegen der
ihnen zu Grunde liegenden, gebietsweise verschiedenartigen Referenzpopulationen
voneinander abweichen – was auch durch die Vorgaben der Richtlinien beabsichtigt
ist (3;17;24), aber auf der anderen Seite können die unterschiedlichen Referenz-
grenzen auf verschiedenen statistischen Methoden basieren. Oftmals geben die in
Deutschland zahlreich existierenden Herausgeber von Referenzbereichen für Labor-
parameter – auch auf schriftliche Anfrage [vgl. (49)] – keine näheren Informationen
über die zur Berechnung ihrer Referenzintervalle verwendeten statistischen Metho-
den bekannt (12). Da diese Angaben zu den angewandten Bestimmungsmethoden
häufig fehlen, ist die Ursache für zum Teil signifikante interlaborielle Abweichungen
zwischen den Referenzbereichen gleicher biologischer Parameter zumeist unklar.

15
„Referenzwerte dienen dem Vergleich eines einzelnen klinisch-chemischen Mess-
wertes mit Werten einer ‚gesunden‘ Referenzgruppe. Sie tragen damit zur Erstellung
eines klinisch-chemischen Befundes bei.“ [(12), S. 34]. Wenn nun aber – um das
Exempel aus Tabelle 3 aufzugreifen – ein gemessener CRP-Laborwert eines Patien-
ten beispielsweise 8,0 mg/l beträgt, wird er laut des Referenzbereiches entsprechend
des Laborkatalogs des Instituts für Klinische Chemie und Laboratoriumsmedizin der
Universitätsmedizin Greifswald für „krank“, und laut der Referenzbereiche gemäß der
Siemens Healthcare Diagnostics GmbH sowie nach LabTestsOnline.de für „gesund“
erklärt. Hiermit wird die bestehende Gefahr verdeutlicht, dass durch – mit unter-
schiedlichen statistischen Methoden ermittelte – stark voneinander abweichende Re-
ferenzbereiche für dieselben biologischen Parameter Kranke als gesund und Gesun-
de als krank eingestuft und dementsprechend falsche Diagnosen und Therapien auf-
gestellt werden könnten. Trifft dies nicht nur auf einzelne Patienten sondern auf gro-
ße Patientengruppen zu, könnte infolge von zu niedrig geschätzten Prävalenz-, Inzi-
denz- oder Mortalitätsraten leicht ein Public Health-Problem unterschätzt, eventuell in
Deutschland häufig vorkommende Erkrankungen nicht rechtzeitig erkannt und ihnen
vorgebeugt beziehungsweise begegnet werden.
1.5.3 Einfluss biologischer Unterschiede auf Referenzgrenzen von Parametern
Biologische Unterschiede innerhalb einer Referenzpopulation oder einer Patienten-
gruppe – wie Alter, Geschlecht oder ethnische Zugehörigkeit – können Einflussgrö-
ßen sein, die bei der Ermittlung von medizinischen Referenzbereichen für labordiag-
nostische Parameter berücksichtigt werden sollten. Aber nicht jeder biologische Pa-
rameter wird von den Faktoren Alter, Geschlecht und Ethnizität beeinflusst. Auch
hierzu variieren die Angaben zu den Referenzgrenzen je nach Alters-, Geschlechts-
oder ethnischer Gruppe zwischen den Quellen für Referenzintervalle immens.
Wie in Tabelle 3 erkennbar ist, ist zum Beispiel der Referenzbereich für den Nieren-
parameter CRP nach Bruhn et al. (47) sowie laut LabTestsOnline.de (48) altersab-
hängig. Dagegen unterliegt der Referenzbereich für den Nierenparameter CRP ge-
mäß des Laborkatalogs des Instituts für Klinische Chemie und Laboratoriumsmedizin
der Universitätsmedizin Greifswald (43) und der Siemens Healthcare Diagnostics
GmbH (45) nicht dem Einfluss des Alters.

16
Ein weiteres Beispiel für Nierenparameter, deren Referenzgrenzen von biologischen
Größen abhängen, stellt die Kreatininkonzentration im Serum dar. Ceriotti et al. un-
tersuchten im Auftrag der IFCC in einer systematischen Literaturübersichtsarbeit alle
zwischen 1987 und 2007 veröffentlichten und in der Medline-Datenbank auffindbaren
Referenzbereiche, die mittels valider Studien gewonnen wurden. In ihrer Übersicht
stellen Ceriotti et al. (50) die einzelnen Referenzbereiche von Serum-Kreatinin für
Erwachsene aus drei Studien gegenüber. Hierbei wird ersichtlich, dass der Faktor
Geschlecht Einfluss auf die Referenzgrenzen ausübt. Wieder variieren die oberen
und unteren Referenzgrenzen je Quelle derart, dass keine einheitlichen Referenzin-
tervalle pro Geschlechtsgruppe für Serum-Kreatinin vorzuweisen sind. Darüber hin-
aus berechneten die Autoren selbst Referenzbereiche von Serum-Kreatinin für Kin-
der und konnten dem Faktor Geschlecht dagegen keinen signifikanten Effekt nach-
weisen (50).
Analog zu den Aufführungen unter Punkt 1.5.2 können sich auch diese, die alters-
und geschlechtsabhängigen Referenzintervalle betreffenden, widersprüchlichen An-
gaben nachteilig auf die Diagnose und den Therapieverlauf des einzelnen Patienten
sowie auf die Gesundheit der Öffentlichkeit in Deutschland auswirken, indem sie die
wahren Zusammenhänge und Effekte verzerrt widerspiegeln.
Nicht zuletzt spielt die ethnische Zugehörigkeit bei der Bestimmung von medizini-
schen Referenzbereichen für ausgewählte Laborparameter eine bedeutende Rolle.
Beispielsweise bei der Kalkulation der Glomerulären Filtrationsrate (GFR) muss die
ethnische Herkunft beachtet werden, da sich die GFR je nach Hautfarbe – schwarz
oder weiß – ändert. Der Bezug zur Ethnizität bei der Bestimmung der GFR ist für
Deutschland jedoch von geringerer Public Health-Relevanz, da bei fehlenden Anga-
ben zur ethnischen Zugehörigkeit in der Formel für die GFR von der weißen Hautfar-
be ausgegangen wird, was auch der Mehrheit in der Bevölkerung entspricht. (32)
1.6 Aufbau der Dissertation
Nachdem in diesem 1. Kapitel die derzeitige Sachlage einschließlich der aktuell exis-
tierenden Richtlinien als Rahmenvorgaben sowie die Notwendigkeit der vorliegenden
Forschungsarbeit erörtert wurden, werden im 2. Kapitel die theoretischen Hintergrün-

17
de ausgewählter Verfahren, deren Zusammenhänge oder Abgrenzungen wie auch
deren Schwächen und Stärken aufgezeigt, Forschungslücken beleuchtet und die da-
raus resultierende Forschungsfrage erklärt. Im 3. Kapitel wird der geplante Untersu-
chungshergang detailliert geschildert, indem das vorhandene Untersuchungsmaterial
und die anzuwendenden Methoden ausführlich beschrieben werden. Das Untersu-
chungskonzept, die Durchführungsbedingungen, die Auswerteverfahren sowie Kon-
trollmaßnahmen werden explizit definiert und auf die ethische Betrachtung näher
eingegangen. Im Kapitel 4 werden die Untersuchungsergebnisse sowohl grafisch als
auch numerisch dargestellt. Die Diskussion der Forschungsergebnisse erfolgt in
Form einer Erörterung der Ergebnisse unter Berücksichtigung der Limitationen der
Untersuchung im Kapitel 5. Abschließend werden – ebenfalls im 5. Kapitel – Schluss-
folgerungen gezogen und ein Ausblick auf zukünftige Forschungsschwerpunkte auf
dem bearbeiteten Gebiet geboten. Im 6. Kapitel findet eine kurze Zusammenfassung
der gesamten, hier vorgestellten wissenschaftlichen Abhandlung statt.

18
2 Theoretischer Hintergrund
Bevor ab Abschnitt 2.2 auf die theoretischen Erklärungen und Festlegungen der
IFCC und IUPAC aus der Sicht der klinischen Chemie eingegangen wird, ihre Me-
thoden und Verfahren zur Berechnung von Referenzbereichen vorgestellt werden,
der aktuelle Stand der Forschung erörtert sowie auf Umsetzungsdefizite und For-
schungslücken geschlossen wird, soll zunächst der Theorieteil aus dem Blickwinkel
der Stochastik erläutert werden.
2.1 Wahrscheinlichkeitstheoretische und statistische Ansätze
Angenommen ein Merkmal, ein Messwert beziehungsweise ein diagnostischer Pa-
rameter X wird als Zufallsgröße aufgefasst. Eine Zufallsgröße, auch als Zufallsvariab-
le benannt, stellt in der Stochastik eine Variable dar, deren Wert von dem Zufall ab-
hängt. „Der Wert, der im konkreten Falle durch diese Zufallsgröße angenommen
wird, heißt Realisierung der Zufallsgröße.“ [(13), S. 44] Der Wertebereich einer Zu-
fallsgröße X entspricht der Grundgesamtheit. Nimmt eine Zufallsvariable nur endlich
viele oder abzählbar unendlich viele verschiedene Werte an, handelt es sich um eine
diskrete Zufallsgröße (13). Formal als Funktion wird eine diskrete Zufallsvariable wie
folgt definiert: „Für eine diskrete Zufallsgröße X mit den Werten x1, x2, x3, … ist ihre
Wahrscheinlichkeitsfunktion durch pi = P(X = xi) gegeben.“ (Formel 1) [(13), S. 45].
Können die Realisierungen einer Zufallsvariable beliebige reelle Zahlen aus einem
Intervall annehmen, wird die Zufallsgröße als stetige Zufallsgröße bezeichnet (13).
Die Verteilung einer Zufallsgröße X – die Wahrscheinlichkeitsverteilung beziehungs-
weise Verteilungsfunktion – wird durch eine Abbildung FX von ℝ in [0, 1] mit FX(x) =
P(X ≤ x) definiert (Formel 2) (13). „Für eine diskrete Zufallsgröße X gilt ( )
∑ ( )“ (Formel 3) [(13), S. 45]. Für eine stetige Zufallsgröße X gilt, dass sie
eine stetige Verteilungsfunktion aufweist – was bedeutet, dass eine einzelne Reali-
sierung x von einer stetigen Zufallsgröße X stets die Wahrscheinlichkeit Null besitzt:
P(X = x) = 0 (Formel 4) (13). Des Weiteren wird eine stetige Zufallsgröße X durch
ihre Dichte gekennzeichnet: „Es sei X eine stetige Zufallsgröße mit der Verteilungs-
funktion FX(x). Eine nichtnegative reelle Funktion fX(x) mit der Eigenschaft
∫ ( )
( ) für alle x ∊ ℝ heißt Wahrscheinlichkeitsdichte, Dichtefunktion oder
Dichte der Verteilungsfunktion FX(x).“ (Formel 5) [(13), S. 47].

19
Kenngrößen der Verteilung einer Zufallsvariablen, die Verteilungsparameter, wie Er-
wartungswert E(X), Varianz Var(X) oder Verteilungsquantile dienen der Charakteri-
sierung der Verteilung der Zufallsgröße (51). Sie erklären eine theoretische Wahr-
scheinlichkeitsverteilung (13). Besonders kennzeichnend sind die Verteilungsquantile
x0,95 und x0,99 sowie der Median x0,5. Ein Quantil wird folgendermaßen definiert: „Es
seien X eine stetige Zufallsgröße, FX ihre Verteilungsfunktion und p eine zwischen
Null und Eins gelegene Zahl. Es heißt xp Quantil der Ordnung p, wenn FX(xp) = p gilt.“
(Formel 6) [(13), S. 51]. Diese, eine Wahrscheinlichkeitsverteilung beschreibenden,
„theoretischen“ Quantile sind von empirischen Quantilen zu unterscheiden (13). Em-
pirische Quantile gehören zu den Stichprobenparametern, die sich auf Stichproben
beziehen und empirisches Wissen widerspiegeln, wohingegen „theoretische“ Quanti-
le zu den Verteilungsparametern gehören und „dem ‚Theoriebereich‘ zugeordnet“
sind [(13), S. 49].
Die in Formel 5 erklärte „Verteilungsfunktion ist das theoretische Analogon zur empi-
rischen Verteilungsfunktion in einer Stichprobe […]. Die gedankliche Brücke für den
Übergang von der empirischen zur theoretischen Verteilungsfunktion bildet die fol-
gende vereinfacht formulierte Überlegung: Die empirische Verteilungsfunktion eines
stetigen Merkmals beobachtet in einer beliebig großen Stichprobe mit beliebig großer
Messgenauigkeit ist gleich der (theoretischen) Verteilungsfunktion.“ [(51), S. 58]
Hieraus lassen sich folgende Überlegungen formulieren: Ist auf der Grundlage der
beobachteten Daten die Aussage berechtigt, dass die Referenzpopulation insgesamt
– das heißt die Grundgesamtheit – bekannt ist? Falls dem so sei, ist davon auszuge-
hen, dass dementsprechend auch die Verteilung der Daten bekannt ist und folglich
keine statistischen Schätzungen erforderlich sind. Das gesuchte statistische Intervall
wäre aus den Daten direkt abzuleiten, denn die empirischen Quantile entsprächen
den theoretischen Quantilen und könnten einfach abgezählt werden. Würde es sich
bei dem zu ermittelnden statistischen Intervall um ein Toleranzbereich handeln, ist in
diesem Fall die Sicherheitswahrscheinlichkeit mit 1 anzugeben. Falls die Aussage,
dass die Referenzpopulation insgesamt bekannt ist, jedoch nicht bestätigt werden
kann, muss das interessierende statistische Intervall geschätzt werden, wofür eine
Stichprobe erforderlich ist. Unter dieser Bedingung entsprächen die empirischen
Quantile nicht den theoretischen Quantilen. Sie müssten mittels einer Punkt- oder

20
Konfidenzschätzung bestimmt werden. Bei der Schätzung eines Toleranzintervalls
als statistisches Intervall müsste dieses mit einer Sicherheitswahrscheinlichkeit un-
ter 1 angegeben werden, was ausdrückt, dass der geschätzte Toleranzbereich nur zu
einer gewissen vorgegebenen Sicherheitswahrscheinlichkeit bekannt ist. (13)
Schätzverfahren sind generell von der Kenntnis der Verteilung der Zufallsgröße ab-
hängig. Wird als Verteilung der Zufallsgröße eine Normalverteilung vorausgesetzt,
sind die zu schätzenden Parameter leicht zu berechnen. Jedoch sind biologische
Daten in der Regel nicht normalverteilt. Häufig werden Transformationen durchge-
führt, um zu erreichen, dass die zu analysierenden Daten einer Normalverteilung fol-
gen. Hierin liegt aber ein großes Fehlerpotential, denn mit einer Transformation der
Zufallsgröße wird im Allgemeinen auch ihre Verteilung transformiert [(52), S. 158 ff.].
Jegliche auf die transformierten Werte angewandten Verfahren gelten hingegen aus-
schließlich für diese, da die rücktransformierten Ergebnisse nicht immer richtig sind.
Beispielsweise ist es von der Transformationsmethode abhängig, ob Konfidenzgren-
zen rücktransformiert werden können. Um diesem Fehlerpotential auszuweichen, ist
den Rang-basierten Methoden Vorzug zu geben. Das Argument von Rechenvorteilen
bei der Kalkulation von statistischen Intervallen auf der Basis normalverteilter Daten
ist in der heutigen Zeit bei den allgemein zur Verfügung stehenden Rechnern und
leistungsfähigen Programmen kein Argument mehr gegen Rang-basierte Methoden.
Ferner gilt, dass bei normalverteilten Daten die zu ermittelnden Referenzbereiche
entsprechend geschätzt werden müssen, was für kategoriale Daten ungeeignet ist.
Aus den vorangehend genannten Gründen sind Rang-basierte Methoden zu favori-
sieren. (13)
Nach Handl (53) gibt es grundsätzlich die folgenden drei Arten statistischer Intervalle:
Konfidenzintervalle, Prognoseintervalle und Toleranzintervalle. Die Konfidenzschät-
zung betrifft sowohl Verteilungsparameter als auch theoretische Quantile. Die Tole-
ranzschätzung betrifft Werte der Zufallsgröße – der Toleranzbereich T enthält einen
vorgegebenen Anteil der Grundgesamtheit. Das Prognoseintervall wird im Kontext
von Regressionsmodellen benutzt. Obwohl Handl die drei statistischen Intervall-Arten
voneinander abgrenzt, fließen sie doch teilweise ineinander über, wenn Referenzbe-
reiche für biologische Parameter bestimmt werden sollen, denn der zentrale Punkt
ist, dass ein Referenzbereich im medizinischen Sinne ein Toleranzbereich im statisti-

21
schen Sinne ist. Ein Prognoseintervall – ein Vorhersageintervall – gibt Auskunft über
die Werte der Zufallsgröße in einer zukünftigen Stichprobe. Rasch et al. (54) stellen
klar, dass ein Vorhersageintervall im Grunde ein Toleranzintervall ist. Konfidenzinter-
valle und Toleranzintervalle sind beide gewissermaßen coverage intervals, da sie
Enthaltenseinsbeziehungen betreffen. Dennoch wird der Begriff coverage interval in
der vorliegenden Arbeit nicht weiterführend verwendet, da er auch in der Topologie
eine konkrete Bedeutung besitzt und es hier nicht zu Verwechslungen kommen soll.
Die Definitionen für Konfidenzintervalle und Quantil-Intervalle, Toleranzintervalle so-
wie Prognoseintervalle werden aus der Perspektive medizinischer Referenzbereiche
für labordiagnostische Parameter nachfolgend ausführlich in Abschnitt 2.2 angeführt.
Prinzipiell ist es eine Standpunktfrage, ob die Referenzpopulation insgesamt bekannt
ist oder nicht. Demnach werden die zwei nachstehenden Situationen unterschieden:
Entweder wird die Grundgesamtheit anhand einer vorliegenden Stichprobe beurteilt,
indem die Konfidenzintervalle bezüglich der Verteilungsparameter beziehungsweise
die Toleranzintervalle in Bezug auf die Werte der Zufallsgröße berechnet werden,
oder die Grundgesamtheit und eine Stichprobe daraus liegen vor und es soll für die
Werte einer zukünftigen Stichprobe zum Beispiel ein Konfidenzintervall für den Stich-
probenmedian angeben werden. Dieses ist dann ein sogenanntes Prognoseintervall.
Ebenso könnte ein Intervall erfragt werden, welches beispielsweise 90 % der Werte
dieser zukünftigen Stichprobe mit der Wahrscheinlichkeit 0,99 überdeckt. Dies wäre
folglich ein Toleranzintervall in Form eines Prognoseintervalles. Von diesen zwei
Blickrichtungen – zum einen mit dem Augenmerk auf die Referenzpopulation und
zum anderen im Hinblick auf das statistische Verfahren zur Toleranzschätzung –
hängt die Qualität eines Referenzbereiches ab.
In den folgenden Absätzen 2.2, 2.3 und 2.4 soll zunächst die theoretische Einord-
nung vorgenommen werden, um eine Übersicht darüber zu geben, welche Möglich-
keiten und Verfahren zur Berechnung von Referenzbereichen bestehen und empfoh-
len werden. Anschließend wird in Absatz 2.6 das Forschungsziel formuliert.

22
2.2 Definitionen statistischer Intervalle für Referenzbereiche
Gemäß der international anerkannten Richtlinie Approved recommendation (1987) on
the theory of reference values. Part 5. Statistical treatment of collected reference va-
lues. Determination of reference limits. aus dem Jahr 1987 von Solberg, die im Auf-
trag der IFCC erschien, wird unter einem Referenzbereich ein Referenzintervall ver-
standen, welches durch zwei Referenzgrenzen definiert ist und in dem sich Refe-
renzwerte der Referenzpopulation befinden. Referenzintervalle werden zumeist
durch die folgenden statistischen Intervallarten definiert: das Quantil-Intervall (Eng-
lisch: inter-fractile interval oder inter-percentile interval), das Toleranzintervall (Eng-
lisch: tolerance interval oder coverage interval) und das Prognoseintervall (Englisch:
prediction interval). Darüber hinaus gibt es noch weitere statistische Methoden, Refe-
renzintervalle zu bestimmen, die allerdings laut Solberg in der Literatur weniger oft
beschrieben und in der Praxis weitaus seltener angewendet werden. (6)
2.2.1 Quantil-Intervall mit Konfidenzintervallen
Bevor anschließend auf das Quantil-Intervall näher eingegangen wird, soll hier zuerst
der statistische Begriff empirisches Quantil anschaulich erläutert werden: Ein empiri-
sches p-Quantil ist allgemein dadurch charakterisiert, dass mindestens der Anteil p
der Stichprobenwerte kleiner oder gleich diesem Wert und mindestens der Anteil 1–p
größer oder gleich diesem Wert ist. Das empirische p-Quantil lässt sich aus der
Rangliste x(1), …, x(n) von n Stichprobenwerten bestimmen. „Dazu wird zunächst das
Produkt n*p berechnet. Ist n*p keine ganze Zahl, so ist das p-Quantil der k-te Wert
x(k) der Rangliste, wobei k die auf n*p folgende ganze Zahl ist. Falls jedoch n*p eine
ganze Zahl ist, so wird zur Bestimmung des p-Quantils zwischen den Werten x(n*p)
und x(n*p+1) interpoliert. Üblicherweise wird als Interpolation der Wert ½ (x(n*p)+x(n*p+1))
gewählt.“ [(51), S. 12].
DEFINITION Quantil:
Es seien X eine diskrete Zufallsgröße mit den Werten xi und den Wahrscheinlichkei-
ten P(X = xi) = pi sowie p ∈ ℝ, 0 < p < 1. Jede reelle Zahl x, für die die Ungleichun-
gen P(X ≤ x) ≥ p und P(X ≥ x) ≥ 1 – p gelten, heißt p-Quantil xp. (Formel 7) (55)

23
Der IFCC-Richtlinie Approved recommendation (1987) on the theory of reference
values. Part 5. Statistical treatment of collected reference values. Determination of
reference limits. zufolge ist es eine häufig angewandte Konvention, dass das Refe-
renzintervall den zentralen 0,95-Anteil (95 %) der Grundgesamtheit beinhalten sollte.
Dementsprechend wird prinzipiell1 ein Quantil-Intervall gebildet, indem das 0,025-
Quantil und das 0,975-Quantil der Referenzverteilung geschätzt und diese als Refe-
renzgrenzen eingesetzt werden. Diesen Referenzgrenzen sollten Angaben zu ihren
Konfidenzintervallen hinzugefügt werden. Üblich sind hierfür 0,90-Konfidenzintervalle
um jede der beiden Referenzgrenzen. Die IFCC empfiehlt, dass der Berechnung ei-
nes Referenzintervalls mindestens 120 Referenzwerte zugrunde liegen sollten. (6)
Demnach besteht ein Referenzbereich, der mittels der Methode des Quantil-Intervalls
bestimmt wurde, aus der unteren Referenzgrenze – dem 0,025-Quantil und seinem
0,90-Konfidenzintervall, sowie der oberen Referenzgrenze – dem 0,975-Quantil und
seinem 0,90-Konfidenzintervall. Er enthält dann 95 % der Grundgesamtheit mit einer
Wahrscheinlichkeit von mindestens 0,90. Eine derartige Qualitätskennzeichnung ist
für Referenzbereiche unbedingt zu fordern und auch angebbar.
DEFINITION Konfidenzintervall:
Seien X1, . . ., Xn unabhängige, identisch verteilte Zufallsvariablen, deren Verteilungs-
funktion FX(x) von einem Parameter θ abhängt. Außerdem seien T1 = g1(X1, . . ., Xn)
und T2 = g2(X1, . . ., Xn) zwei Stichprobenfunktionen.
Dann heißt das Intervall [T1, T2] mit P (T1 ≤ θ ≤ T2) = 1 – α zweiseitiges Konfidenzin-
tervall für θ zum Konfidenzniveau 1 – α. (Formel 8) (53)
Quantil-basierte Referenzbereiche sind laut Ansicht der IFCC die am meisten genutz-
ten Intervalle für labordiagnostische Parameter. Nach Gutachten der IFCC wird zur
Ermittlung von labormedizinischen Referenzbereichen die statistische Methode des
Quantil-Intervalls empfohlen und gegenüber den methodischen Ansätzen des Tole-
ranzintervalls und des Prognoseintervalls bevorzugt, da zum einen sowohl das Tole-
ranzintervall als auch das Prognoseintervall die Annahme einer einfachen Zufalls-
stichprobe voraussetzen, und zum anderen ein Quantil-Intervall recht einfach mit pa-
rametrischen wie auch mit nicht-parametrischen statistischen Methoden geschätzt 1 Verteilungsabhängige Ausnahmen werden in Abschnitt 2.3 besprochen.

24
werden kann – wobei die IFCC für die meisten Untersuchungszwecke den Einsatz
von nicht-parametrischen Intervallen vorschlägt (6). Diesen auf Solberg (6) zurück-
gehenden Argumenten kann sich die Autorin aus zwei Gründen nicht anschließen:
Erstens setzt jede der drei Methoden voraus, dass die Daten als Stichprobe gelten
können. Zweitens ist das einfach zu bestimmende Quantil-Intervall per se nicht quali-
tativ charakterisiert. Diese zu fordernde Charakterisierung, also die Angabe der
Wahrscheinlichkeit, mit der das Quantil-Intervall den vorgegebenen Anteil der
Grundgesamtheit tatsächlich auch enthält, ist nicht trivial ausrechenbar. Die Methode
ist also nicht einfacher in ihrer Anwendung als die anderen genannten Möglichkeiten
zur Berechnung von Referenzbereichen. Es soll hier angemerkt werden, dass die
Veröffentlichung (6) 25 Jahre zurückliegt und dass inzwischen sowohl die statistische
Methodik als auch die rechentechnischen Arbeitsmöglichkeiten eine bedeutende
Weiterentwicklung erfahren haben.
2.2.2 Toleranzintervall
Der technische Bericht Calculation and application of coverage intervals for biological
reference values aus dem Jahr 1997 von Poulsen et al., der unter Federführung der
IUPAC herausgegeben wurde, stellt eine offizielle Ergänzung zu den IFCC-
Empfehlungen zur Theorie der Referenzwerte dar (16).
In den zehn Jahren zwischen der Veröffentlichung der IFCC-Richtlinien und der oben
genannten Publikation der IUPAC haben sich die ISO und mehrere Experten für die
Anwendung von Toleranzintervallen als Äquivalenz zu Prognoseintervallen einge-
setzt. Laut Standpunkt der IUPAC sprechen die folgenden Vorteile für die Nutzung
von Toleranzintervallen zur Bestimmung von Referenzbereichen: 1) Die Wahrschein-
lichkeit, dass das Intervall einen zukünftigen Beobachtungswert einschließt, kann
vorausgesagt werden. 2) Die Unsicherheit des Toleranzintervalls ist – im Gegensatz
zur Methode des Quantil-Intervalls – statistisch klar definiert. Nach Ermessen der
IUPAC ist der hier zuletzt genannte Punkt bei einem Vergleich von Messergebnissen
mit der Verteilung von Referenzwerten zur Beurteilung des Gesundheitsstatus Ein-
zelner beziehungsweise zur Einschätzung von Gefahren für die öffentliche Gesund-
heit von großer Bedeutung. (16)

25
Aufgrund dieses Vorteils des Toleranzintervalls gegenüber dem Quantil-Intervall lau-
tet die Empfehlung der IUPAC, bei Referenzstichproben kleiner als 120, die Methode
des Toleranzintervalls – in Verbindung mit der Angabe der Unsicherheit des Intervalls
– zur Ermittlung von Referenzbereichen zu nutzen. Überdies wird von der IUPAC
vorgeschlagen, auch bei größeren Referenzstichproben das Toleranzintervall ge-
meinsam mit der Information über seine Unsicherheit zusätzlich zum Quantil-Intervall
zu präsentieren, um die Präzision des geschätzten Intervalls darzulegen. (16)
DEFINITION Toleranzintervall:
Sei X1, . . ., Xn eine Stichprobe über die mit der Verteilungsfunktion FX(x) verteilte
Zufallsvariable X. Außerdem seien T1 = g1(X1, . . ., Xn) und T2 = g2(X1, . . ., Xn) zwei
Stichprobenfunktionen.
Ein minimales Intervall [T1, T2] mit P (P(T1 ≤ X ≤ T2) ≥ β) = heißt Toleranzintervall
für den Anteil β der Grundgesamtheit zur Sicherheit . (Formel 9) (53)
Entsprechend der IUPAC ist ein Toleranzintervall als 0,95-Toleranzintervall zusam-
men mit der Angabe zur Unsicherheit der Überdeckung mit einer Konfidenz von 0,95
definiert. Im Falle einer sehr kleinen Referenzmenge wird eine Konfidenz von 0,90
empfohlen. In Anlehnung an die unter 2.2.1 erläuterte IFCC-Richtlinie wird – ebenso
wie für Quantil-Intervalle – der nicht-parametrische methodische Ansatz nahegelegt,
um einen eventuell nötigen Transformationsschritt zu vermeiden. (16)
2.2.3 Prognoseintervall
Ein Prognoseintervall ist ein Intervall für die Realisation einer Zufallsvariablen (56).
Ein derartiges ‚Vorhersageintervall‘ gibt Auskunft darüber, mit welcher Wahrschein-
lichkeit ein einzelner zukünftig gemessener Laborwert eines biologischen Parameters
eines Patienten innerhalb der – auf der Basis einer Referenzpopulation bestimmten –
Referenzgrenzen zu erwarten ist. Der Nachteil gegenüber Toleranzintervallen ist,
dass Prognoseintervalle breiter und daher unsicherer in ihrer Aussagekraft sind.
(53;57)

26
DEFINITION Prognoseintervall:
Seien X1, . . ., Xn, Xn+1 unabhängige, identisch mit Verteilungsfunktion FX(x) verteilte
Zufallsvariablen. Außerdem seien T1 = g1(X1, . . ., Xn) und T2 = g2(X1, . . ., Xn) zwei
Stichprobenfunktionen.
Dann heißt das Intervall [T1, T2] mit P (T1 ≤ Xn+1 ≤ T2) = 1 – α Prognoseintervall für
Xn+1 zur Sicherheit 1 − α. (Formel 10) (53)
2.3 Einordnung der Verfahren zur Berechnung von Referenzbereichen
Bei der Wahl des Verfahrens zur Bestimmung eines medizinischen Referenzberei-
ches für einen biologischen Parameter muss auf eine statistische Methode zurück-
gegriffen werden, die für die Verteilung und den Umfang der Messwerte angemessen
scheint. So ist vorweg zu entscheiden beziehungsweise bei der Auswertung zu be-
achten, ob die Selektion der Referenzstichprobe induktiv oder deduktiv, nach der di-
rekten oder indirekten Methode vollzogen wird, ob es sich um ein einseitiges oder ein
zweiseitiges Intervall handelt, ob die Werte annähernd normalverteilt sind oder sie
transformiert werden müssen und auch können, ob ein parametrischer oder ein nicht-
parametrischer Analyseansatz gewählt wird, und ob die Schätzung approximativ oder
exakt erfolgt.
2.3.1 Induktive versus deduktive Methode
Die Selektion einer Stichprobe aus einer Referenzpopulation kann entweder induktiv
oder deduktiv durchgeführt werden. Wird die induktive Auswahlmethode vorgenom-
men, werden ausschließlich Gesunde einer vordefinierten Population rekrutiert. Hier-
für kommen beispielsweise Blutspender, Probanden oder Angestellte in medizini-
schen Versorgungseinrichtungen in Betracht. Kranke scheiden bei der Selektion von
vorn herein aus. Bei der deduktiven Auswahlmethode wird sich an bereits vorliegen-
den Patientendatenbeständen bedient, die daraufhin mittels vorab festgelegter Ein-
und Ausschlusskriterien beziehungsweise Ausschlusskrankheiten gefiltert werden.
Das daraus resultierende Kollektiv der Nicht-Kranken wird zur Erzeugung der Refe-
renzstichprobe genutzt. (12)
Die induktive Selektion einer Bezugspopulation zur Bestimmung von Referenzgren-
zen erfolgt ergo prospektiv (a priori), indem zuerst die Selektionskriterien festgelegt

27
werden und danach die Auswahl der Probanden stattfindet – bevor die Untersuchun-
gen ausgeführt werden. Die deduktive Selektion einer Bezugspopulation zur Bestim-
mung von Referenzgrenzen erfolgt hingegen retrospektiv (a posteriori), indem die
Festlegung der Selektionskriterien und die Auswahl der Referenzindividuen erst im
Nachhinein – nach der tatsächlichen Durchführung der Untersuchungen passieren.
Die IFCC fordert in ihrer Richtlinie Approved Recommendation (1987) on the Theory
of Reference Values. Part 2. Selection of Individuals for the Production of Reference
Values aus dem Jahr 1987 dazu auf, die induktive Auswahlmethode anzuwenden
und prospektive Referenzgrenzen auf der Basis einer Population von Nicht-Kranken
zu ermitteln (3). Die IUPAC macht die Selektionsmethode nicht zum Gegenstand ih-
res technischen Berichts, in welchem sich vorrangig den Analyseverfahren gewidmet
wird (16).
2.3.2 Direkte versus indirekte Methode
Die Gewinnung einer Referenzstichprobe zur Ermittlung eines Referenzintervalls
kann mit Hilfe der direkten oder der indirekten Methode geschehen. Bei dem direkten
Verfahren erfolgt – aus der Charakteristik der Verteilung von der relevanten Mess-
größe schließend – eine Unterteilung in die zwei Subgruppen Gesunde und Kranke.
Die aus den Primärdaten erzeugte bimodale Verteilung wird folglich in zwei Vertei-
lungen zerlegt. Es entstehen jeweils Referenzgrenzen für eine kranke und eine nicht-
kranke Subpopulation. Bei dem indirekten Verfahren wird indessen die Aufteilung der
Subgruppen anhand von Sekundärdaten vorgenommen. Beispiele dafür sind Ein-
und Ausschlusskriterien, andere begleitende Befunde oder weitere Messgrößen. Es
entstehen Referenzgrenzen für eine nicht-kranke Subpopulation bezüglich einer
unimodalen Verteilung. Die indirekte Selektionsmethode entspricht den Empfehlun-
gen der IFCC im Sinne des Konzepts der Referenzwerte (3).
2.3.3 Einseitige versus zweiseitige Referenzintervalle
Je nach medizinischer Notwendigkeit können einseitige oder zweiseitige Referenzin-
tervalle bestimmt werden. Sind die Laborwerte eines biologischen Parameters nur
nach oben oder nach unten hin für die Diagnosestellung und/ oder Therapieent-
scheidung von Interesse, kann für einen Laborparameter entweder nur die untere

28
oder nur die obere Referenzgrenze, also jeweils ein einseitiges Referenzintervall,
festgelegt werden. Als Beispiel für Nierenwerte ist hier der Laborparameter CRP zu
nennen, der laut Angaben des Instituts für Klinische Chemie und Laboratoriumsme-
dizin Greifswald den einseitigen Referenzbereich von <5,0 mg/l (obere Referenz-
grenze) aufweist (43). Zweiseitige Referenzintervalle umfassen stets eine untere und
eine obere Referenzgrenze. Als Exempel für Nierenwerte kann der Laborparameter
Hämatokrit dienen, dessen zweiseitiger Referenzbereich für die allgemeine Bezugs-
gruppe durch die zweiseitigen Referenzgrenzen 0,35 (untere Referenzgrenze) und
0,51 (obere Referenzgrenze) von dem Institut für Klinische Chemie und Laboratori-
umsmedizin Greifswald definiert ist (43). Die IFCC unterscheidet in ihrer Richtlinie
Approved recommendation (1987) on the theory of reference values. Part 5. Statisti-
cal treatment of collected reference values. Determination of reference limits. nicht
zwischen einseitigen und zweiseitigen Referenzintervallen, sondern definiert ein Re-
ferenzintervall zwecks besseren Verständnis in ihrem Methodenpapier durchgängig
durch zweiseitige Referenzgrenzen (6). Die IUPAC beschränkt sich im Dokument
Calculation and Application of Coverage Intervals for Biological Reference Values
ebenfalls einzig auf die Darlegung der Theorie der zweiseitigen Referenzintervalle,
da sie der Theorie der einseitigen Referenzintervalle annähernd gleichkommt (16).
2.3.4 Bezug zur Normalverteilung
Die aus einer Referenzstichprobe gewonnenen Referenzwerte müssen hinsichtlich
ihrer Verteilung überprüft werden, denn „biologische Werte verschiedener Individuen
zeigen in der Regel keine Normalverteilung […], wo häufigster Wert und arithmeti-
scher Mittelwert gleich sind, die Verteilung symmetrisch ist […]. Biologische Werte
weisen eher kompliziertere Verteilungen auf“ [(12), S. 36].
DEFINITION Normalverteilung:
Eine Zufallsgröße X heißt normalverteilt, s mbolisch geschrieben X ( ), wenn
ihre Wahrscheinlichkeitsdichte durch ( )
√
( )
∈ ℝ
gegeben ist.
Die Wahrscheinlichkeitsverteilung hat somit die Form ( ) ∫
√
( )
Als frei wählbare Parameter treten und auf.
Es gelten E(X) = und D2(X) = . (Formel 11) (13;55)

29
Mit Hilfe der nachfolgenden statistischen Methoden kann geprüft werden, ob die aus-
zuwertenden Referenzwerte normalverteilt sind: mit dem Chi-Quadrat-Test, dem
Kolmogorow-Smirnow-Test, dem Anderson-Darling-Test, dem Lilliefors-Test, dem
Cramér-von-Mises-Test, dem Shapiro-Wilk-Test, dem Jarque-Bera-Test, sowie gra-
phisch mittels eines Q-Q-Plots oder der Maximum-Likelihood-Methode.
Bezüglich der Prüfung auf Normalverteilung rät die IFCC in ihrer Richtlinie Approved
recommendation (1987) on the theory of reference values. Part 5. Statistical treat-
ment of collected reference values. Determination of reference limits. zuerst zu einer
graphischen Überprüfung anhand eines Plots und als zweites zu einem der hier auf-
geführten Anpassungstests: dem Chi-Quadrat-Anpassungstest, dem Kolmogorow-
Smirnow-Anpassungstest beziehungsweise dem Anderson-Darling-Anpassungstest
(6). Indessen zieht die IUPAC in ihrem technischen Bericht Calculation and Applicati-
on of Coverage Intervals for Biological Reference Values den Anderson-Darling-Test
als Anpassungstest dem Kolmogorov-Smirnov-Test aufgrund seiner höheren Aussa-
gekraft vor und befürwortet einen p-Wert größer als 0,05 als Kriterium zur Nichtab-
lehnung einer Normalverteilung der Referenzwerte (16).
Existiert kein Bezug zur Normalverteilung, das heißt – kann mit Hilfe eines der oben
erwähnten Anpassungstests und des daraus resultierenden p-Wertes die Annahme
nicht bestätigt werden, dass die Referenzwerte normalverteilt sind, besteht mitunter
die Möglichkeit, die vorliegende Verteilung der Referenzwerte mittels einer normali-
sierenden Transformation der Daten in eine Normalverteilung umzuwandeln. Somit
wäre die Voraussetzung von normalverteilten Daten, die für viele Verfahren der in-
duktiven Statistik Vereinfachungen bringt, erfüllt.
Für normalverteilte Zufallsgrößen lassen sich die Referenzbereiche unter Bezug auf
den Mittelwert und die Standardabweichung σ leicht berechnen und veranschauli-
chen. Ein 95%-Referenzbereich kann bei normalverteilten Daten leicht gebildet wer-
den: Die untere und obere Grenze des zu symmetrischen Toleranzintervalles wer-
den aus der Standardabweichung σ sowie dem 0,95-Quantil 1,96 der Standardnor-
malverteilung berechnet. Die Wahrscheinlichkeit, dass die Zufallsgröße X in diesem
Intervall liegt, -1,96σ ≤ X ≤ +1,96σ, ist dann 0,95. (Formel 12) (58)
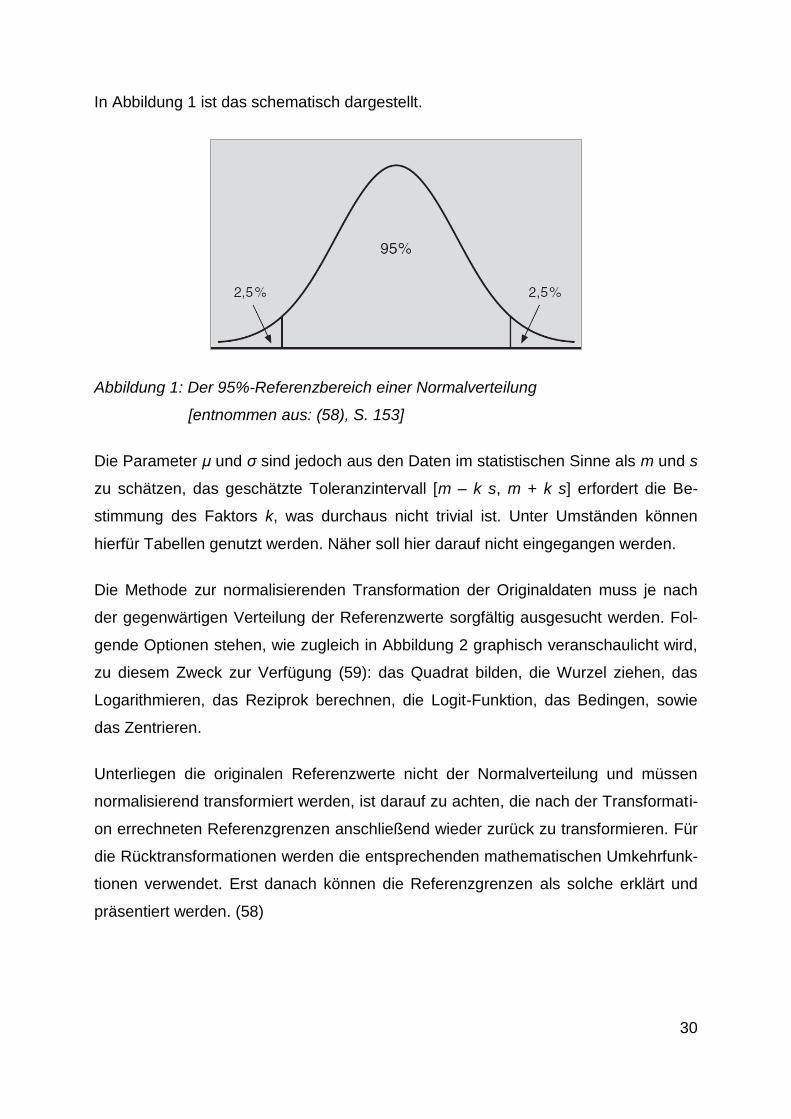
30
In Abbildung 1 ist das schematisch dargestellt.
Abbildung 1: Der 95%-Referenzbereich einer Normalverteilung
[entnommen aus: (58), S. 153]
Die Parameter und σ sind jedoch aus den Daten im statistischen Sinne als m und s
zu schätzen, das geschätzte Toleranzintervall [m – k s, m + k s] erfordert die Be-
stimmung des Faktors k, was durchaus nicht trivial ist. Unter Umständen können
hierfür Tabellen genutzt werden. Näher soll hier darauf nicht eingegangen werden.
Die Methode zur normalisierenden Transformation der Originaldaten muss je nach
der gegenwärtigen Verteilung der Referenzwerte sorgfältig ausgesucht werden. Fol-
gende Optionen stehen, wie zugleich in Abbildung 2 graphisch veranschaulicht wird,
zu diesem Zweck zur Verfügung (59): das Quadrat bilden, die Wurzel ziehen, das
Logarithmieren, das Reziprok berechnen, die Logit-Funktion, das Bedingen, sowie
das Zentrieren.
Unterliegen die originalen Referenzwerte nicht der Normalverteilung und müssen
normalisierend transformiert werden, ist darauf zu achten, die nach der Transformati-
on errechneten Referenzgrenzen anschließend wieder zurück zu transformieren. Für
die Rücktransformationen werden die entsprechenden mathematischen Umkehrfunk-
tionen verwendet. Erst danach können die Referenzgrenzen als solche erklärt und
präsentiert werden. (58)

31
Abbildung 2: Normalisierende Transformationsmethoden
[entnommen aus: (59), S. 14]
In ihrer Richtlinie Approved recommendation (1987) on the theory of reference val-
ues. Part 5. Statistical treatment of collected reference values. Determination of refe-
rence limits. aus dem Jahr 1987 weist die IFCC darauf hin, nach dem Transformati-
onsschritt nochmalig einen Anpassungstest auszuführen, um zu kontrollieren, ob die
transformierten Referenzwerte nun der Voraussetzung einer Normalverteilung genü-
gen. Die IUPAC fügt dem noch hinzu, der schlussendlichen Präsentation der ermittel-
ten Referenzbereiche die Ergebnisse der Anpassungstests von vor und nach der
Transformation inklusive der p-Werte beizufügen. Kann durch einen der oben ge-
nannten Anpassungstest statistisch nicht bestätigt werden, dass die Daten vor und/
oder nach der Transformation normalverteilt sind, muss anstatt der parametrischen
Methode die nicht-parametrische Methode zur weiteren Analyse gewählt werden,
was im nächsten Abschnitt 2.3.5 ausführlicher beschrieben wird. (6;16)
Die hier beschriebene Transformation von Zufallsgrößen zwecks Parameterberech-
nung mit anschließender Rücktransformation des Resultates ist weit verbreitet. Ihre
Berechtigung ist im jeweiligen Anwendungsfalle jedoch mathematisch zu beweisen,
da die Transformation (also auch die Rücktransformation) einer Zufallsgröße ein an-
deres wahrscheinlichkeitstheoretisches Modell ergibt. Daher ist dieses Vorgehen ge-
nerell nicht empfehlenswert.

32
2.3.5 Parametrische versus nicht-parametrische Methode
Wie vorangehend geschildert wurde kann unter der Voraussetzung normalverteilter
Referenzwerte das parametrische Verfahren zur Bestimmung der Referenzgrenzen
Anwendung finden. Kann diese Voraussetzung einer Normalverteilung der Daten
nicht erfüllt werden beziehungsweise ist das Arbeiten ohne eine parametrische Fest-
legung der Verteilungsform erwünscht, muss das nicht-parametrische Verfahren zur
Bestimmung der Referenzgrenzen verwendet werden (51).
Da parametrische Methoden hypothetisch eine normalverteilte Grundgesamtheit vo-
raussetzen und die Verteilung der Zufallsvariablen deshalb bekannt ist, werden nur
bestimmte Parameter – wie beispielsweise Erwartungswerte – ausgewertet. Bei den
nicht-parametrischen Methoden hingegen werden die Prüfgrößen nicht von den ein-
zelnen originalen Referenzwerten sondern von ihren Rangnummern abgeleitet. (58)
Das nicht-parametrische Verfahren – auch bezeichnet als das verteilungsfreie Ver-
fahren – setzt keine spezielle Verteilung der Daten voraus. Für das Schätzen von
Quantilen gibt es mehrere nicht-parametrische Methoden. Die IFCC stellt in ihrer
Richtlinie Approved recommendation (1987) on the theory of reference values.
Part 5. Statistical treatment of collected reference values. Determination of reference
limits. eine Rang-basierte Methode vor, die den Nutzern als zuverlässig wie auch
einfach in ihrer Anwendung anempfohlen wird und auf die in Kapitel 3 detaillierter
eingegangen wird. Betreffs dieser Rang-basierten Methode bedarf es den Hinweis,
dass zu den mittels des Rang-Verfahrens leicht zu bestimmenden 0,025- und 0,975-
Quantilen, welche als Referenzgrenzen dienen, die jeweils dazugehörigen zweiseiti-
gen nicht-parametrischen 0,90-Konfidenzintervalle anzugeben sind, welche aus einer
in der Richtlinie aufgestellten Tabelle entnommen werden können. (6)
Das nicht-parametrische Verfahren, welches die IUPAC in ihrem technischen Bericht
Calculation and Application of Coverage Intervals for Biological Reference Values
darbietet, sollte insbesondere dann angewendet werden, wenn nur wenige Refe-
renzwerte (zirka unter 50) zur Verfügung stehen oder wenn die Referenzverteilung
nicht der Normalverteilung entspricht. Auch das nicht-parametrische Verfahren der
IUPAC basiert auf Rangzahlen. Die IUPAC beschreibt in ihrem Bericht, wie ein nicht-
parametrisches Toleranzintervall in Abhängigkeit von der Anzahl der gegebenen Re-

33
ferenzwerte unter Zuhilfenahme der zwei dort aufgeführten Tabellen – jeweils eine
für ein 0,90-Toleranzintervall sowie für ein 0,95-Toleranzintervall – bestimmt werden
kann. Die genauen Analyseschritte hierzu werden in Kapitel 3 angegeben. (16)
Das parametrische Verfahren, das die IFCC in der oben genannten Richtlinie emp-
fiehlt, stützt sich auf das arithmetische Mittel und die Standardabweichung der Nor-
malverteilung, auf deren Grundlage die 0,025- und 0,975-Quantile geschätzt werden.
Für das Schätzen der Konfidenzintervalle für diese zwei Quantile gibt die IFCC eine
Formel in ihrer Verfahrensanleitung an. (6)
Das parametrische Verfahren, welches die IUPAC befürwortet, beruht indessen auf
Parameter der t-Verteilung und hängt von der Anzahl der Referenzwerte sowie der
Freiheitsgrade ab. Die IUPAC gibt in ihrem oben genannten Bericht zur Bestimmung
eines parametrischen Toleranzintervalls zwei Gleichungen sowie eine Tabelle mit
t-Werten je nach Freiheitsgrad (N-1) an. In einer zweiten Tabelle kann für ein gewähl-
tes β-Toleranzintervall (β = 0,90 oder β = 0,95) die Unsicherheit der Überdeckung ( )
je nach Stichprobengröße (N) abgelesen werden. (16)
Generell sind parametrische Intervalle schmaler und dadurch in ihrer Aussagefähig-
keit präziser als nicht-parametrische Intervalle. Sofern die Referenzwerte die jeweili-
gen Verteilungsannahmen erfüllen, sind parametrische Referenzintervalle infolge-
dessen wertvoller als nicht-parametrische Referenzintervalle. Dennoch empfehlen
sowohl die IFCC als auch die IUPAC der allgemeinen Anwendbarkeit halber sowie
der minimalen Unterschiede wegen das nicht-parametrische Verfahren als Methode
zur Bestimmung von medizinischen Referenzbereichen für Laborparameter. (6;16)
2.3.6 Approximative versus exakte Schätzung
Der hier angesprochene Themenkreis kann nicht verallgemeinernd diskutiert werden.
Er ist in Bezug auf den mathematischen Kontext, die Datenlage sowie die rechen-
technischen Gegebenheiten zu würdigen. Allerdings kann gesagt werden, dass im
Sinne der Theorie exakte Methoden den Vorzug vor auf Näherungsverfahren beru-
henden Toleranzschätzungen haben sollen, insbesondere wenn die Charakteristika
der Approximation nicht quantifiziert sind. Rechentechnische Vorteile dürfen heutzu-
tage nur noch in Ausnahmefällen ein Argument sein.

34
2.4 Die Entwicklung der Forschung bis zum aktuellen Stand
Nachdem in den Jahren 1987/ 1988 der mehrheitliche Teil der sechs offiziellen Emp-
fehlungen der IFCC zu ihrem Referenzwertkonzept herausgegeben wurden (2-7),
gab es rund zehn Jahre lang keine großen Neuerungen auf diesem Forschungsge-
biet – bis zur Veröffentlichung der IUPAC im Jahr 1997 (16), die als Addendum zum
IFCC-Referenzwertkonzept gelten sollte.
Erst im Jahr 2000 wurden erste Kritiken an dem IFCC-Konzept der Referenzwerte
verlautet, da inzwischen hinreichende Erfahrungen aus der Umsetzung der IFCC-
Richtlinien in die Praxis vorlagen und impraktikable Vorgaben aufgedeckt wurden. So
berichteten Henny et al. in ihrem Opinion Paper Need for Revisiting the Concept of
Reference Values aus dem Jahr 2000, dass die Empfehlungen der IFCC viel zu theo-
retisch sind und weitaus praktischer gestaltet werden sollten, damit sie von den An-
wendern wie klinischen Chemikern oder Herstellern von Diagnose-Kits besser ver-
standen und noch ausnahmsloser befolgt werden. Henny et al. schilderten, dass vie-
le kleinere Laboratorien die IFCC-Richtlinien nicht umsetzen und ihre eigenen Refe-
renzbereiche produzieren, sondern stattdessen externe Referenzintervalle überneh-
men, da die von der IFCC aufgeführten Prozesse zu kostenintensiv und zu komplex
sind und daher zu viel Aufwand abverlangen. Nach der Auffassung von Henny et al.
kommt daher der nicht länger haltbare Zustand, dass diverse Laboratorien aus der-
selben Region mit derselben Bezugspopulation für den gleichen biologischen Para-
meter voneinander abweichende Referenzbereiche nutzen. Henny et al. merkten des
Weiteren an, dass die Methoden zur Festlegung der Referenzgrenzen nicht ausrei-
chend definiert sind und die Verfahren zur Schätzung von Referenzintervallen ver-
bessert werden müssen. Fraglich sei beispielsweise, ob nicht noch zusätzlich zum
2,5- und 97,5-Perzentil weitere Perzentile wie zum Beispiel 5, 10, 20, 75, 80, 85, 90
oder 95 präsentiert werden müssten, um Ausreißer, Asymmetrie oder Bimodalität in
der Verteilung der Referenzwerte – insbesondere bei heterogenen Gruppen – auf-
zeigen zu können. (27)

35
2.4.1 Das Bootstrap-Verfahren
Ebenfalls im Jahr 2000 publizierte Linnet in seinem Artikel Nonparametric
Estimation of Reference Intervals by Simple and Bootstrap-based Procedures
einen Vergleich zwischen der herkömmlichen, einfachen, nicht-
parametrischen IFCC-Methode zur Schätzung von Referenzintervallen mit der
moderneren, Computer-gestützten, nicht-parametrischen Prozedur nach dem
Bootstrap-Prinzip – vornehmlich für schiefe und Normalverteilungen. Das
Bootstrap-Prinzip beruht auf wiederholten, zufälligen Stichprobenziehungen
aus den Originalwerten mit Zurücklegen, und wird mit Hilfe von Computerpro-
grammen ausgeführt. Für jeden gezogenen Stichprobensatz werden die
Quantile mittels bekannter Methoden geschätzt. Diese Prozedur wird etwa 50-
bis 500-mal wiederholt. Die Bootstrap-Schätzer werden anschließend aus dem
Mittel aller geschätzten Quantile gebildet. Nach Linnet zeigte der Vergleich der
Methoden, dass ab einer Stichprobengröße von 100 die Bootstrap-Methode
der herkömmlichen Quantilschätzung laut den IFCC-Empfehlungen vorzuzie-
hen ist, da hierdurch – für den nicht-parametrischen Ansatz – eine geringfügig
höhere Präzision der geschätzten Referenzgrenzen erlangt werden kann. (60)
Da Bootstrap-Methoden empirischen Charakter haben, also auf Stichproben-
Daten basieren, ist allerdings der Bezug der Resultate zur beobachteten
Wahrscheinlichkeitsverteilung jeweils mathematisch zu begründen.
Vier Jahre später, im Jahr 2004, bezog Gräsbeck – einer der Hauptbegründer des
Referenzwertkonzeptes der IFCC – in seinem Artikel The evolution of the reference
value concept Stellung zu den bislang verlauteten Kritiken, besprach viele kursieren-
de Missverständnisse sowie entstandene Unklarheiten bezüglich der IFCC-Theorie,
bot Lösungswege an und ersuchte Verständnis für die Komplexität des weiten Feldes
der Referenzwerte zu erlangen. Gräsbeck räumte ein, dass die Vorgaben der IFCC –
zum Beispiel hinsichtlich der Selektion einer gesunden Referenzpopulation – nicht
konkret genug wären, betonte diesbezüglich jedoch die Schwierigkeit und sogar Un-
lösbarkeit einer allumfassenden Definition von Gesundheit für den Zweck des Refe-
renzwertkonzeptes. Er hob außerdem den bis dahin nicht erkannten Fakt hervor,
dass der Großteil der Laborergebnisse der Bevölkerung scheinbar log-normalverteilt

36
ist und nicht der Gauß-Verteilung folgt. Darüber hinaus versuchte Gräsbeck den be-
troffenen Fachkreisen bei Bedarf den gezielten Einsatz von multivariaten Referenzin-
tervallen und Überlebensreferenzintervallen nahezulegen. Letztendlich appellierte er
an die Skeptiker des IFCC-Programmes, lieber Modifikationen an dem IFCC-Konzept
vorzuschlagen oder konstruktive Alternativen zu den IFCC-Empfehlungen anzubieten
anstatt sie einfach nicht zu implementieren. (25)
Im selben Jahr, 2004, gab Solberg eine neue, das IFCC-Referenzwertkonzept er-
gänzende Empfehlung mit dem Titel The IFCC recommendation on estimation of re-
ference intervals. The RefVal Program heraus. Hierin befasste er sich konzentriert
mit den statistischen Methoden zur Analyse von Referenzwerten und Schätzung von
Referenzintervallen, die im 5. Teil (Approved recommendation (1987) on the theory
of reference values. Part 5. Statistical treatment of collected reference values. De-
termination of reference limits.) der Serie der IFCC-Empfehlungen erläutert wurden
und stellte hierfür das Computerprogramm RefVal im Detail vor. Nachdem Solberg
am Anfang des Artikels die Resonanz der Fachwelt auf die IFCC-Empfehlungen in
den vorangegangen Jahren rekapitulierte, stellte er klar heraus, dass der 5. Teil der
IFCC-Empfehlungen der bisher in der Literatur am häufigsten diskutierte wie auch
der einflussreichste Teil der Serie ist. Er stellte die oftmals missverstandene Regel –
dass gemäß des IFCC-Referenzwertkonzeptes mindestens 120 Referenzwerte vor-
handen sein müssen, um vertrauenswürdige Schätzer zu erzielen – richtig und be-
tonte, dass die Anzahl von 120 Referenzwerten nicht als absolute Beschränkung in-
terpretiert werden sollte. Solberg begründete diese Mindestwertangabe der IFCC
damit, dass mit weniger als 119 Referenzwerten eine Konfidenz von 0,90 mittels der
nicht-parametrischen Methode nicht erreicht werden kann. Weiterhin befasste er sich
in dieser Veröffentlichung mit der Problematik von Ausreißern und ihrer statistischen
Behandlung sowie mit beobachteten beziehungsweise berichteten Transformations-
schwierigkeiten bei einigen Verteilungsarten unter Anwendung der parametrischen
Methode. Das Kernstück der Publikation beschilderte das RefVal Computerpro-
gramm inklusive seiner geschichtlichen Entstehung anhand der einzelnen herausge-
brachten Versionen, sein Leistungsvermögen, und zuletzt allen notwendigen Erweite-
rungen oder Anpassungen des Softwarepaketes für spätere Releases. Solberg wies
ausdrücklich darauf hin, dass das RefVal Programm nicht als Ersatz für die ge-

37
bräuchlichen Statistikprogramme entworfen wurde, sondern komplementär einge-
setzt werden sollte, und dass es hauptsächlich die von der IFCC empfohlenen Pro-
zeduren und Algorithmen umsetzt – ausgenommen des nicht-parametrischen
Bootstrap-Verfahrens und des Cramér-von Mises-Anpassungstests, welche in der
Software zusätzlich angeboten werden. (26)
Drei Jahre später, im Jahr 2007, veröffentlichten Mitglieder der AG Entscheidungs-
grenzen/ Richtwerte der DGKL ihre ersten Ergebnisse auf diesem Forschungsgebiet
in Deutschland. Im Gegensatz zur IFCC und IUPAC, deren bedeutsamsten heraus-
gegebenen Empfehlungen auf dem Gebiet im Jahr 2007 schon zwanzig (betrifft die
IFCC) beziehungsweise zehn (betrifft die IUPAC) Jahre zurücklagen, forschten die
Mitglieder der AG Entscheidungsgrenzen/ Richtwerte der DGKL seit 2007 bis ein-
schließlich 2011 überaus intensiv im Bereich der Methoden zur Bestimmung von Re-
ferenzbereichen und publizierten eine Reihe von neuartigen methodischen Konzep-
ten zur Festlegung von Referenzgrenzen für Laborparameter (siehe auch Abschnitt
1.3.3 und Tabelle 2).
Die Mitglieder der AG Entscheidungsgrenzen/ Richtwerte der DGKL setzten sich für
eine klare Abgrenzung zwischen den einzelnen bestehenden Richtwerten ein und
unterschieden strikt zwischen Referenzgrenzen, Entscheidungsgrenzen, Aktions-
grenzen und therapeutischen Grenzen. Entsprechend den Definitionen der AG sind
Referenzgrenzen unimodale Richtgrenzen, die von einer nicht-kranken Referenzpo-
pulation abstammen und darüber entscheiden, ob ein Laborwert der Referenzgruppe
zugeordnet werden kann oder nicht. Entscheidungsgrenzen sind hingegen bimodale
Richtgrenzen, die von zwei Untergruppen der Bezugspopulation – einer kranken und
einer nicht-kranken – abgeleitet werden, anhand derer mit einer spezifizierten diag-
nostischen Effizienz zwischen krank und nicht-krank diskriminiert werden kann. Akti-
onsgrenzen sind klinisch relevante Grenzen, mittels derer eine Person einer oder
keiner Risikogruppe zugeordnet wird und bei deren Unter- oder Überschreitung wei-
tere diagnostische oder therapeutische Maßnahmen folgen sollten. Therapeutische
Grenzen werden ausschließlich bei kranken Personen, welche medikamentös be-
handelt werden, ermittelt und zur Medikamentenüberwachung/ Medikamentenspie-
gelbestimmung herangezogen. Sie definieren das optimale Konzentrationsintervall
für den bestmöglichen Effekt einer therapeutischen Substanz. (61;62)

38
Des Weiteren stimmten die Mitglieder Haeckel und Wosniok der AG Entscheidungs-
grenzen/ Richtwerte der DGKL in ihrem Artikel Observed, unknown distributions of
clinical chemistry quantities should be considered to be log-normal: a proposal der
Ausführung von Gräsbeck in seinem Artikel The evolution of the reference value con-
cept zu, und befürworteten für unbekannte Verteilungstypen bei biologischen Quanti-
täten die Annahme einer log-normalen Verteilung (63).
2.4.2 Kombinierte Verfahren
Wie zuvor in Abschnitt 2.3.2 dargelegt wurde, werden Referenzbereiche im Wesentli-
chen entweder nach dem direkten Ansatz oder nach dem indirekten Ansatz ermittelt.
Bei Anwendung des direkten Verfahrens erfolgt die Identifikation und Auswahl der
Nicht-Kranken mit Hilfe einer Verteilungszerlegung. Bei Anwendung des indirekten
Verfahrens erfolgen die Inklusion von Nicht-Kranken und die Exklusion von Kranken
auf der Basis von vordefinierten Selektionskriterien. Wie desgleichen bereits in Ab-
satz 2.3.1 erläutert wurde, können entweder prospektive Referenzgrenzen oder ret-
rospektive Referenzgrenzen bestimmt werden. Die IFCC empfiehlt in ihrem Refe-
renzwertkonzept die Schätzung von prospektiven Referenzgrenzen mittels des indi-
rekten Ansatzes – was sich seither auch als Goldstandard durchgesetzt hat.
Die Mitglieder der AG Entscheidungsgrenzen/ Richtwerte der DGKL setzten seit Be-
ginn ihrer Gemeinschaftsarbeit im Jahr 2007 ihren Forschungsschwerpunkt auf kom-
binierte Modelle zur Bestimmung von Referenzintervallen – primär auf die Kombina-
tion von retrospektiven Referenzgrenzen nach dem indirekten Prinzip. Im Vorder-
grund ihrer Forschungsarbeit steht prioritär das Verfahren der Bestimmung von retro-
spektiven Referenzgrenzen, die aus großen intra-laboratoriellen Datenpools – ent-
weder nach dem unimodalen oder nach dem bimodalen Ansatz – ermittelt werden
(64-68). Dieses Konzept der retrospektiven Referenzgrenzen entspricht nicht dem
IFCC-Referenzwertkonzept, in welchem die Bestimmung von prospektiven Refe-
renzgrenzen rein nach dem unimodalen Ansatz als Norm festgelegt ist.
Unter dem Aspekt der methodischen Forschungsaktivitäten auf dem Feld der retro-
spektiven Referenzgrenzen, die aus intra-laboratoriellen Datenpools gewonnen wer-
den, ist an dieser Stelle die Dissertation von Arzideh mit dem Thema Estimation of

39
Medical Reference Limits by Truncated Gaussian and Truncated Power Normal Dis-
tributions aus dem Jahr 2008 ergänzend zu nennen. Arzideh untersuchte in seiner
Arbeit Datensätze mit nicht-pathologischen wie auch pathologischen Laborwerten
von Krankenhauspatienten und ergründete daran eine neue indirekte Methode zur
Schätzung von Referenzgrenzen. Aus den Datensätzen wurde ein bestimmter Teil,
der sich über- beziehungsweise unterhalb gewisser Werte befand, herausgetrennt,
da die restlichen – mutmaßlich pathologischen – Beobachtungswerte der Stichprobe
in der darauffolgenden Auswertung nicht berücksichtigt werden sollten. Die Daten
aus dem herausgetrennten Teil – der trunkierten Verteilung – wurden anschließend
modelliert. Zur Modellierung der Daten nutzte Arzideh die trunkierte Gaußverteilung
und die trunkierte Gauß-Mischverteilung und schätzte die Parameter mit Hilfe der
Maximum-Likelihood-Methode. Er entwickelte einen Algorithmus zur Optimierung der
daraus gewonnen Parameter und evaluierte anhand einer Test-Statistik die Güte des
erzeugten Modells. Den für die Test-Statistik notwendigen kritischen Wert berechnete
Arzideh mittels der Monte-Carlo-Simulationsmethode. Für schiefe Verteilungen ver-
wendete er die trunkierte Power-Normal-Verteilung und die trunkierte Power-Normal-
Mischverteilung stattdessen. Mit den von Arzideh entwickelten Modellen sollte aus
Krankenhausdatensätzen die Verteilung der nicht-pathologischen Laborwerte her-
ausgetrennt und deren Referenzbereich geschätzt werden können. (69)
2.4.3 Quantilregression
Im Jahr 2010 befasste sich Frieß in ihrer Dissertation zum Thema Bestimmung der
99sten Perzentile für kardiales Troponin I am Dimension Vista mit der Ermittlung von
konditionalen Quantilen als Referenzgrenzen für biologische Parameter, die von wei-
teren Variablen wie zum Beispiel dem Alter und/ oder dem Geschlecht abhängen.
Konditionale Quantile können durch das Verfahren der Quantilregression geschätzt
werden. Dabei werden für definierte Quantile – wie beispielsweise für das 99%-
Perzentil in der Arbeit von Frieß – geschlechts- und altersspezifische Kurven berech-
net. Im Gegensatz zu anderen nicht-parametrischen Methoden zur Bestimmung von
Referenzbereichen wie etwa dem Bootstrap-Verfahren besteht hierbei der Vorteil,
dass vorab keine geschlechts- und/ oder altersbezogenen Subgruppen erzeugt wer-
den müssen und einzelne Unterklassen nicht durch hohe Ausreißer-Werte falsch ge-
bildet werden, da in die Berechnung der spezifischen Referenzgrenzen die Refe-

40
renzwerte aller Referenzindividuen der Referenzstichprobe – gewichtet nach deren
Häufigkeit – eingehen. Hierdurch entstehen, gerade die Darstellung des Altersgangs
betreffend, robustere Schätzungen für Referenzgrenzen als bei Verfahren mit Klas-
senbildung. (70)
Der bedeutende Vorteil der Quantilregression ist, dass durch die Kenntnis über die
Lageparameter und Streuungsmaße eine gezielte Analyse und Aussage einer – auch
nicht-linearen – Beziehung zwischen den Kovariablen und deren Einfluss auf den zu
bestimmenden biologischen Parameter möglich ist. Mittels der Quantilregression
werden die betreffenden Quantile, die von Interesse sind, modelliert, um Informatio-
nen über die gesamte Verteilung zu gewinnen. (71)
Die mit Hilfe der Quantilregression geschätzten konditionalen Quantile, die als Refe-
renzgrenzen interpretiert werden können, sind demgemäß robuster gegen Extrem-
werte, mit ihr können Interaktionen zwischen Variablen erkannt und Beziehungen
zueinander vorhergesagt werden. Für die Definition von Referenzbereichen wichtige
Einflussvariablen wie Alter und Geschlecht können Berücksichtigung finden ohne
dafür stratifizieren zu müssen und Fehler bei der Klassenbildung zu begehen. Die mit
dieser Methode kalkulierten Referenzintervalle gehören zu den Prognoseintervallen
(siehe Absatz 2.2.3).
Offenbar hängen die Ergebnisse einer Quantilregression vom gewählten statistischen
Modell ab. Über die Eigenschaften der Schätzer gibt es nur asymptotische Aussa-
gen. Das macht für eine subtile Bewertung konkreter Berechnungsergebnisse zu-
sätzliche Aufwendungen (Modellvergleiche, Methodenvergleiche, Simulationen) er-
forderlich.
2.5 Umsetzungsdefizite und Forschungslücken
2.5.1 Mängel in der Umsetzung von der Theorie in die Praxis
Defizite bei der Umsetzung von den Richt- und Leitlinien in die praktische Arbeit der
Laboratorien, klinischen Chemiker und Hersteller von Diagnose-Kits gibt es erhebli-
che. Die als Goldstandard geltenden Empfehlungen der IFCC werden in der klini-
schen Routine nicht oder nur teilweise umgesetzt und etabliert (27). Gründe dafür
sind einerseits der als zu hoch erachtete personelle und zeitliche Aufwand sowie an-

41
dererseits die oftmals nicht tragbaren Kosten für die Implementierung (16). Dies be-
trifft besonders kleinere Laboratorien. Obwohl laut der von der IFCC entwickelten
Theorie der Referenzwerte jedes Labor seine eigenen, internen Referenzbereiche
auf der Basis der dort ansässigen Population bestimmen (3) und diese periodisch
überprüfen (17) sollte, übernehmen viele Laboratorien aus den oben genannten
Gründen häufig externe Referenzintervalle aus den Herstellerinformationen der diag-
nostischen Geräte, aus Publikationen oder der gegenwärtigen Fachliteratur wie bei-
spielsweise aus dem Werk von Thomas mit dem Titel Labor und Diagnose: Indikation
und Bewertung von Laborbefunden für die medizinische Diagnostik (36) oder aus
Lehrbüchern wie zum Beispiel dem Buch Klinische Chemie. Laborwerte in der klini-
schen Praxis von Graf und Gürkov (39), oder aber sie transferieren Referenzgrenzen
von anderen Laboratorien und nutzen diese als ihre eigene Grundlage. Hierbei treten
etliche Probleme auf und ziehen weitreichende Folgen nach sich. Nach Haeckel et al.
stellen sich die Probleme bei dem Transfer von externen Referenzbereichen wie folgt
dar: Zum einen herrscht die Unsicherheit betreffs einer adäquaten Referenzpopulati-
on in Bezug auf das Alter, das Geschlecht, den Ernährungsstatus, den Drogenmiss-
brauch, die ethnische Homogenität, et cetera. Zum anderen besteht die Ungewiss-
heit, ob identische analytische Verfahren angewendet wurden. Nicht zuletzt könnte
sich das Analysesystem nach der Etablierung der Referenzintervalle als langfristig
instabil gestalten. In der Folge reduzieren diese Fehler bei dem Transfer der Refe-
renzbereiche die gesamte diagnostische Effizienz (64).
Des Weiteren fallen durchgehend deutliche Mängel bei der Präsentation der Refe-
renzgrenzen auf. Die IFCC-Empfehlung Approved recommendation (1987) on the
theory of reference values. Part 6. Presentation of observed values related to refer-
ence values von Dybkoer und Solberg (7) wird beinahe ausnahmslos nicht in die
Praxis umgesetzt und befolgt. Hinreichende Angaben zu den verwendeten statisti-
schen Methoden fehlen grundsätzlich. Dörner stellt fest, dass zu den in den Normal-
werttabellen angegebenen Intervallen nie die analytischen Methoden zur Bestim-
mung dieser Werte dargelegt werden, und dass zudem niemals ersichtlich ist, ob die
Referenzwerte der Stichprobe tatsächlich normalverteilt waren (12). Außerdem
kommt es prinzipiell vor, dass die Konfidenzintervalle zu den einzelnen Referenz-
grenzen/ Quantilen und die Unsicherheit der Schätzung nicht angeführt werden. Fer-

42
ner werden generell keine Informationen zu der Herkunft der Referenzwerte vermit-
telt – ob es sich um intern ermittelte oder von extern übernommene Referenzinterval-
le handelt, wie die Referenzpopulation zusammengesetzt wurde und auf welcher Re-
ferenzstichprobengröße die Referenzbereiche basieren. Ohne diese bedeutsamen
Angaben können indes keine oder nur unzureichende Aussagen über die Präzision
und die Zuverlässigkeit der Referenzbereiche getroffen werden – was aber für die
Bewertung der Laborergebnisse eines Patienten äußerst wichtig ist.
Bei der Betrachtung der bisherigen Erkenntnisse zum Forschungsthema – basierend
auf der gesichteten Literatur und der Recherche zu den rechtlichen Rahmenbedin-
gungen – ist auffallend, dass die Qualitätssicherung der Referenzbereiche noch im-
mer regelrecht vernachlässigt wird oder gar gänzlich unbeachtet ist, während die
Qualitätssicherung in der Analytik fortwährend im Vordergrund steht, an Bedeutung
gewonnen und sich in den letzten Jahren bemerkenswert entwickelt hat – wie an-
hand der Richtlinie der Bundesärztekammer zur Qualitätssicherung laboratoriums-
medizinischer Untersuchungen klar erkennbar ist (24;72). Die Qualitätssicherung der
Referenzbereiche hingegen scheint sich auf dem Entwicklungsstand von vor 25 Jah-
ren zu befinden. Zu bedenken ist dabei aber, dass vertrauenswürdige, qualitätsgesi-
cherte Analysenergebnisse wenig nützen, wenn die Referenzintervalle als Kriterium
für diagnostische Entscheidungen nicht zuverlässig sind oder sogar zu Fehlentschei-
dungen führen (64).
2.5.2 Desiderate für die Forschung
1) Wahl der statistischen Methode
Wie eingangs in Abschnitt 1.2 in der Aufführung der Problematik einer einheitlichen
Definition des Normalbereiches geschildert wurde, ist in Fachkreisen bis heute um-
stritten, was als normal – das bedeutet hinsichtlich des zu bewertenden Parameters
gesund – gilt, und dass diese Definition sehr stark von den eingesetzten statistischen
Methoden und der zugrunde liegenden Referenzstichprobe abhängt.
Reed et al. sagen zum Beispiel in ihrem Artikel Influence of Statistical Method Used
on the Resulting Estimate of Normal Range aus, dass die Wahl der statistischen Me-
thode sehr großen Einfluss auf den Normalbereich ausübt: „The choice of statistical

43
method can greatly influence the calculated normal range“ [(10), S. 275]. Derselben
Auffassung sind Poulsen et al., die in ihrer Veröffentlichung Calculation and applica-
tion of coverage intervals for biological reference values zwei Methoden zur Bestim-
mung von Referenzintervallen – IFCC versus IUPAC – vergleichen und anhand di-
verser Rechenbeispiele mit verschiedenen Stichprobengrößen nachweisen, dass
beträchtliche Unterschiede in den ermittelten Referenzbereichen entstehen – speziell
bei kleinen Stichprobengrößen im Umfang von etwa 50 Referenzindividuen (16).
Ähnliche Abweichungen in den Resultaten von unterschiedlichen Verfahren zur Be-
rechnung von Referenzintervallen sind in der Publikation Reference limits of plasma
and serum creatinine concentrations from intra-laboratory data bases of several
German and Italian medical centres: Comparison between direct and indirect proce-
dures von Arzideh et al. zu finden, die Referenzgrenzen von Kreatinin, welche mittels
der indirekten und der direkten Methode bestimmt wurden, miteinander abglichen
(67).
Demgegenüber behauptet Solberg in der IFCC-Empfehlung Approved recommenda-
tion (1987) on the theory of reference values. Part 5. Statistical treatment of collected
reference values. Determination of reference limits, dass die Wahl der Art des Refe-
renzintervalls – ob Quantil-Intervall, Toleranzintervall oder Prognoseintervall – in der
alltäglichen klinischen Situation keine entscheidende Rolle spielt, da ein Referenzin-
tervall lediglich als Basis für eine intuitive Beurteilung dient, und dass die relativen
numerischen Unterschiede zwischen diesen Intervallarten zu klein und für die Praxis
unwesentlich sind – sofern das Referenzintervall auf mehr als 100 Referenzwerten
basiert: „Several types of reference intervals have been proposed in the literature
[…]: inter-fractile interval, tolerance interval, and prediction interval. The choice be-
tween these kinds of intervals may be important for certain well-defined statistical
problems. In the usual clinical situation, however, the reference interval merely
serves as a basis for a, more or less, intuitive assessment of the biological infor-
mation given by an observed value. Furthermore, the relative numerical differences
between these intervals are too small to be practically important when based on 100
reference values or more.“ [(6), S. 15].
Dieser Aspekt der Festlegung einer grundlegenden Definition des Normalbereiches
und der Klärung der Frage, was als normal gilt, sowie der damit verbundenen und in

44
der Wissenschaft noch immer ausstehenden Kür der einzig „richtigen“, als Standard
für alle Anwender in der klinischen Chemie anerkannten und sich als sowohl zuver-
lässig als auch vertrauenswürdig bewährten statistischen Methode nach einem prak-
tikablen Verfahren stellt nach wie vor eine Forschungslücke dar.
2) Wahl der Referenzstichprobengröße
Wie viele Referenzindividuen insgesamt oder pro Subgruppe definitiv vorhanden sein
müssen, um verlässliche Referenzintervalle zu erzielen, variiert in den sich mit der
Thematik befassenden Literaturquellen außerordentlich. Laut der IFCC-Empfehlung
Approved recommendation (1987) on the theory of reference values. Part 5. Statisti-
cal treatment of collected reference values. Determination of reference limits, Absatz
5.2 Partition müssen die gesammelten Referenzwerte entsprechend charakterisie-
render Faktoren wie Alter und Geschlecht in Unterklassen aufgeteilt werden, um die
Variation zwischen den Referenzwerten zu reduzieren, denn eine geringere Variation
innerhalb einer Klasse hat schmalere und genauere Referenzbereiche zum Ergebnis.
Mit Hilfe von statistischen Tests wie dem t-Test oder dem F-Test sollte das Erforder-
nis der Klassenbildung indiziert werden. Die entstandenen Subgruppen sollten unbe-
dingt eine ausreichende Anzahl von Werten enthalten. Gemäß der IFCC-Richtlinie
muss zur Bestimmung der 0,025- und 0,975-Quantile eine Gruppenstärke von min-
destens 40 Referenzwerten gegeben sein. Um zuverlässige Schätzer zu erhalten
sollten jedoch mindestens 120 Referenzwerte je Subgruppe vorliegen. Entsprechend
der IFCC-Empfehlung müssten zuerst alle Referenzwerte gewonnen und anschlie-
ßend die nötigen Subgruppen gebildet werden. (6) Wird aber dieser IFCC-Methode
gefolgt und insgesamt nur von einem begrenzten, kleinen Referenzstichprobenum-
fang in der Höhe von der IFCC geforderten 120 Individuen ausgegangen, kann es
geschehen, dass eine Subgruppe aus weniger als das von der IFCC verlangte Mini-
mum im Umfang von 40 Referenzindividuen besteht.
In der IFCC-Publikation mit dem Titel An appraisal of statistical procedures used in
derivation of reference intervals. von Ichihara et al. (siehe Abschnitt 1.3.1, Tabelle 1)
wird sich dafür ausgesprochen, dass jede Subgruppe der Referenzstichprobe min-
destens 400 Referenzindividuen umfassen sollte, um vertrauenswürdige Referenz-
grenzen aus multizentrischen Studien beziehen zu können (73). Arzideh et al. (61)

45
beschreiben in ihrem Artikel Richtwerte bei quantitativen Untersuchungen im medizi-
nischen Laboratorium: Definitionen, Klassifikation und Grenzen der Anwendung.
Empfehlungen zur Klassifizierung und Definitionen von Richtwerten quantitativer
Messgrößen, dass für das von ihnen vorgestellte kombinierte Verfahren zur Bestim-
mung von Richtgrenzen mit dem retrospektiven Ansatz nach dem indirekten Konzept
zwar eine Stichprobengröße von wenigstens 2.000 Referenzwerten zur Verfügung
stehen sollte, dafür aber die Stratifizierung „[…] nach Geschlecht und Alter, insbe-
sondere bei Kindern und Älteren (ab 60 Jahre nach WHO)“ – im Gegensatz zum
prospektiven Ansatz nach dem IFCC-Konzept – leicht möglich ist [(61), S. 231]. Das
Fazit, welches Henny in seiner Publikation Die IFCC-Empfehlungen für die Bestim-
mung von Referenzbereichen: Stärken und Schwächen zieht, lautet: „The minimum
number of reference values remains a challenge.“ [(28), S. 47], was sinnentspre-
chend bedeutet, dass die Festlegung der Mindestanzahl von Referenzwerten nach
wie vor eine Herausforderung ist und bleibt.
Nachdem in dieser Passage die Forschungslücke in Bezug auf den Referenzstich-
probenumfang – im Wesentlichen in Hinsicht auf die klassifizierten Subgruppen –
und der damit einhergehenden Präzision der berechneten Referenzgrenzen je nach
statistischer Methode aufgezeigt wurde, soll anschließend auf die Problematik der
Zusammensetzung der Referenzstichproben und deren Repräsentativität für die
Grundgesamtheit eingegangen werden.
3) Wahl der Referenzstichprobenzusammensetzung
Üblicherweise orientieren sich Referenzgrenzen an einer jungen Bezugspopulation
von erwachsenen, nicht-kranken Männern in einem Alter zwischen 18 und 60 Jahren.
Nicht abgebildet werden dabei vornehmlich Frauen, Kinder und alte Menschen – was
auf ethischen Gesichtspunkten beruht und auf entsprechende Einschränkungen bei
der Rekrutierung der Referenzindividuen zurückzuführen ist. Diese genannten Sub-
gruppen sind in den Referenzstichproben, welche als Grundlage für die Bestimmung
von Referenzbereichen dienen, zumeist unterrepräsentiert oder fehlen im Ganzen.
Daher sind die gegenwärtig gängigen Referenzgrenzen generell nicht sehr repräsen-
tativ für die Bevölkerungsgruppen der Frauen, Kinder und alten Menschen. Dass auf
diesem Feld weiterführender Forschungsbedarf besteht haben auch Henny et al. er-

46
kannt, die in ihrer Veröffentlichung Need for revisiting the concept of reference values
von internationalen Organisationen wie der IFCC fordern, dass sie Richtlinien für die
Produktion von Referenzwerten von älteren Menschen etablieren – gerade in Anbe-
tracht einer alternden Bevölkerung und dem Anstieg chronischer Erkrankungen (27).
Gleichermaßen schildert Dörner in seinem Buch, dass für einige Bevölkerungsgrup-
pen wie bettlägerige Patienten oder Greise kaum Referenzwerte existieren, da „es
keine speziell anhand eines ‚passenden Kollektivs‘ erstellten Referenzwerte für alle
Patienten(gruppen) gibt“ [(12), S. 35].
Der IFCC-Empfehlung Approved recommendation (1987) on the theory of reference
values. Part 2. Selection of individuals for the production of reference values zufolge
sollten die in die Analyse eingeschlossenen Referenzindividuen möglichst zwischen
20 und 30 Jahre alt sein, einen idealen Body-Mass-Index haben, seit 10 Stunden
nüchtern sein, keine Medikamente einnehmen, weniger als 45 g Alkohol pro Trag
konsumieren, weniger als 12 Zigaretten pro Tag rauchen und keine offensichtlichen
Krankheiten besitzen (3). Dass diese nach dem prospektiven IFCC-Ansatz generier-
te, gewissermaßen gesunde Bezugspopulation tatsächlich als Referenzpopulation für
Kranke, die in ihrer Altersstruktur, ihrem Geschlecht, ihren Diätgewohnheiten, et
cetera deutlich davon abweichen, ungeeignet ist, ist plausibel – im Besonderen im
Hinblick auf die hier aufgezeigte Forschungslücke der mangelhaften Referenzberei-
che für Kinder, Frauen und Ältere.
4) Wahl der Referenzstichprobensubgruppen
Nachdem bisher die Forschungslücken bezüglich der Wahl einer korrekten statisti-
schen Methode, der exakten Referenzstichprobengröße (je Subgruppe) sowie der
richtigen Zusammensetzung der Referenzstichprobe dargestellt wurden, folgt zuletzt
die Forschungslücke der Determination von Subgruppen bei der Klassenbildung.
Gräsbeck bekräftigt, dass die Relevanz von Referenzwerten beträchtlich steigt, wenn
sie derart angemessen stratifiziert werden, dass die gebildeten Gruppen in den be-
treffenden Merkmalen der Charakteristik der Bezugspopulation gleichen, indem sie
dieselben Verteilungen des Geschlechts, des Alters, der ethnischen Zugehörigkeit
und so weiter abbilden (25). Henny (28) bestätigt diese Bedeutsamkeit der Gruppen-
bildung nur unter der Bedingung, dass sie klinisch nutzbringend oder physiologisch

47
fundiert ist. Er stellt zwei methodische Ansätze für die Gruppenaufteilung vor, aber
stellt doch fest, dass beide Herangehensweisen das Problem der Gruppenbildung
nicht lösen (28). Dieses Phänomen der nicht einheitlich gehandhabten Klassenbil-
dung resultiert in widersprüchlichen Angaben zu Referenzbereichen je Alters- und/
oder Geschlechtskategorie, was ebenso in Tabelle 3: Beispiele für Referenzgrenzen
des Laborparameters CRP unter Absatz 1.5.2 beispielhaft veranschaulicht ist.
2.6 Zielsetzung
Unter Beachtung der obig erläuterten Problemstellungen sollen Vergleiche von aus-
gewählten und vorangehend diskutierten Methoden und Verfahren zur Bestimmung
von Referenzbereichen erfolgen. Diese Methoden sind auf einen Datensatz anzu-
wenden, die Resultate den in der Praxis genutzten Referenzbereichen gegenüberzu-
stellen. Die zu vergleichenden Methoden und Verfahren müssen bei verschieden
großen Stichprobenumfängen und für die nach biologischen Faktoren, hier beispiel-
haft Alter und Geschlecht, stratifizierten Subgruppen berechnet werden.
Das Hauptuntersuchungsziel besteht darin, den effektivsten Ansatz und die zuverläs-
sigste Methode zur Bestimmung von medizinischen Referenzbereichen für labordi-
agnostische Parameter für alle Subpopulationen – explizit die der Frauen, Kinder und
alten Menschen – zu finden, die insbesondere auch auf der Grundlage von kleinen
Stichprobenmengen vertrauenswürdige Referenzgrenzen liefern. Die Wahl der bes-
ten Methode hängt dabei von dem jeweiligen Fall ab. Eine Methode ist als gut einzu-
stufen, wenn die Methode richtig und angemessen ist, die zu gewährleistenden Vo-
raussetzungen erfüllt sind und sie einen Referenzbereich in minimaler Länge liefert,
was bedeutet, dass die Informationen der Daten optimal ausgenutzt werden. Eine
Methode ist als schlecht anzusehen, wenn ungerechtfertigte Umrechnungen vorge-
nommen werden, indem die Daten ohne mathematischen Beweis der Berechtigung
transformiert und rücktransformiert werden, oder die geforderten Voraussetzungen
nicht geprüft oder erfüllt werden. Um die Güte einer jeweiligen Methode einordnen zu
können, sollen konkrete Beispiele – das heißt reale Daten – studiert werden, anhand
derer die nach unterschiedlichen Methoden berechneten Referenzbereiche anschlie-
ßend einander gegenübergestellt werden.

48
2.7 Forschungsfrage
Den vordringlichsten Forschungsbedarf und in diesem Diskurs thematisierten For-
schungsschwerpunkt begründet nach Erachten der Autorin der Disput um die erfor-
derliche – auch die letztendlich in der Laborpraxis realisierbare Größe einer Refe-
renzstichprobe und die damit steigende oder fallende Präzision der gewonnenen Re-
ferenzgrenzen je Methode und je Subpopulation, da es den in Verantwortung ste-
henden Laboratorien scheinbar nicht oder nur erschwert möglich ist, die geforderte
Anzahl an Referenzindividuen – hauptsächlich auch für jede notwendige Altersklasse
und Geschlechtsgruppe – zusammenzustellen (siehe Punkt 2.5.1).
Die vier in Abschnitt 2.5.2 herausgearbeiteten Forschungslücken sowie das unter
2.5.1 dargelegte Umsetzungsdefizit, dass viele Laboratorien die IFCC-Richtlinien
nicht befolgen und aus Kapazitäts- und Kostengründen keine eigenen Referenzbe-
reiche bestimmen können, sprechen gegen die Praktikabilität und Zuverlässigkeit des
prospektiven IFCC-Ansatzes (induktive Selektion einer Bezugspopulation) und be-
gründen die Befürwortung eines retrospektiven Forschungsansatzes (deduktive Se-
lektion einer Bezugspopulation). Die weiteren von der IFCC empfohlenen Prozeduren
des indirekten Verfahrens und der nicht-parametrischen Methode erscheinen nicht
defizitär und sind als Forschungsansatz zu übernehmen. Die in Abschnitt 2.2 defi-
nierten statistischen Intervalle für Referenzbereiche – das Quantil-Intervall mit Kon-
fidenzintervallen, das Toleranzintervall und das Prognoseintervall – sollen nach dem
voranstehend fixierten Forschungsansatz miteinander verglichen und hinsichtlich ih-
rer Präzision und Zuverlässigkeit für verschiedene Stichprobengrößen bewertet wer-
den. Ein zusätzlicher Abgleich mit adäquaten Referenzintervallen aus dem Laborka-
talog des Instituts für Klinische Chemie und Laboratoriumsmedizin der Universitäts-
medizin Greifswald ist für die Kontrolle der Ergebnisse sachdienlich.
Als Prognoseintervall im Kontext von Regressionsmodellen soll das nach dem Stand
der Forschung (siehe Absatz 2.4) als erfolgversprechend herausgestellte Verfahren
der Quantilregression dienen, um biologische Einflussfaktoren wie den Alterseinfluss
auf die Referenzbereiche berücksichtigen zu können. Die biologischen Faktoren Alter
und Geschlecht sollen als Partitionskriterien (Stratifizierungsvariablen beziehungs-
weise Einflussgrößen) herangezogen werden. Anhand der Ergebnisse der Quantilre-

49
gression ist zu zeigen, ob das Alter und das Geschlecht signifikanten Einfluss auf
den jeweiligen Laborparameter ausüben. Hierbei soll von der Annahme eines linea-
ren Zusammenhangs ausgegangen werden, diesbezüglich ein linearer Ansatz ge-
wählt und mit einem linearen Modell dargestellt werden. Da die Ergebnisse von der
Modellierung des Zusammenhanges beeinflusst werden, sollen die auszuwertenden
Daten zudem nach Alter geschichtet und die Referenzbereiche je Schicht berechnet
werden. Es ist zwischen Referenzbereichen ohne Berücksichtigung von Kovariablen
und Referenzbereichen mit Berücksichtigung von Kovariablen zu unterscheiden.
Die Grundsatzfrage in der klinischen Chemie und Laboratoriumsmedizin lautet: Was
ist normal?. Gesucht ist die Kenntnis des „normalen“ Bereiches für die Werte eines
Laborparameters – der Referenzbereich. Die Beantwortung dieser Frage nach dem
„normalen“ Bereich gilt es zu finden, indem aus biologischer Sicht argumentiert wird:
Man betrachte die Werte von Gesunden und sehe von extremen Werten ab. Refe-
renzbereiche sind aus Daten zu berechnen – aus einer Stichprobe aus Gesunden.
Unter diesem Blickwinkel erfolgt die vorliegende Forschungsarbeit im empirischen
Bereich, an empirischen Daten. Unter Beachtung der stetigen/ diskreten Datentypen
werden somit empirische Quantile als Referenzgrenzen der Referenzbereiche ermit-
telt. Referenzbereiche entsprechend verschiedenen statistischen Definitionen sollen
verglichen werden.
Die übergreifende Forschungsfrage lautet daher wie folgt: Welche der drei vorselek-
tierten Methoden zur Bestimmung von Referenzbereichen – Quantilschätzung, Tole-
ranzschätzung und Quantilregression – ist, in Bezug auf eine Kombination mit dem
retrospektiven Ansatz zur Gewinnung der Referenzpopulation, zu empfehlen?

50
3 Material und Methoden
3.1 Untersuchungskonzept
Bezugnehmend auf die in Abschnitt 2.7 aufgestellte Forschungsfrage sowie das un-
ter Punkt 2.6 erklärte Hauptuntersuchungsziel wird das folgende Untersuchungsmo-
dell entwickelt. Es soll eine vergleichende Betrachtung von medizinischen Referenz-
bereichen für geschlechts- und altersspezifische Subgruppen sowie für eine allge-
meine Gruppe anhand beispielhafter Laborparameter vorgenommen werden, die im
Rahmen der Untersuchung mittels verschiedener Methoden auf der Grundlage vor-
liegender Labordaten in variierenden Stichprobengrößen bestimmt werden. Quantil-
Intervall mit Konfidenzintervallen, Toleranzschätzung und Quantilregression sind
wahrscheinlichkeitstheoretisch beziehungsweise statistisch zu charakterisieren.
3.1.1 Festlegung der Laborparameter
Der geplante Vergleich der zu ermittelnden Referenzintervalle kann nur auf wenigen,
ausgesuchten Laborparametern basieren, da der Umfang aller existierenden labordi-
agnostischen Parameter zu groß ist. Aus den in Absatz 1.4 wie auch unter 1.5.1 er-
wähnten Gründen sollen hierfür Nierenparameter herangezogen werden. Die beiden
geläufigsten Nierenparameter sind Kreatinin und Harnstoff. „Die Bestimmung von
Kreatinin und Harnstoff im Serum werden als Suchtests zur Überprüfung der Nieren-
funktion eingesetzt.“ [(39), S. 54]. Zusätzlich kann als Indikator für eine Einschrän-
kung der Nierenfunktion der Laborparameter Natrium dienen, indem die Natrium-
Blut-Konzentration bestimmt wird (48). Für den Zweck der Zielerreichung ist es nicht
ratsam, Laborparameter zu untersuchen, die zwar auf eine Nierenschädigung hin-
weisen mögen, die aber auch andere Erkrankungen indizieren können. Ein derartiger
unspezifischer Parameter ist zum Beispiel CRP. CRP hat die Funktion der unspezifi-
schen Immunabwehr und dient als Indikation für akute Infektionen im Körper (39). Da
CRP nicht ausschließlich als Nieren-spezifischer Parameter in der Diagnostik einge-
setzt wird und daher die Voraussetzung einer gänzlich gesunden Bezugspopulation
nicht garantiert werden kann, ist CRP in dieser Untersuchung nicht einzubeziehen.
Folglich sollen in der gesamten Untersuchung Referenzbereiche für die Nierenpara-
meter Kreatinin, Harnstoff und Natrium berechnet und für den anschließenden
Vergleich der Methoden genutzt werden. Datensätze mit fehlenden Kreatinin-, Harn-
stoff- und Natriumwerten sind von der Analyse auszuschließen.

51
3.1.2 Festlegung der geschlechts- und altersspezifischen Subgruppen
„Die Referenzwerte [Kreatinin und Harnstoff, Anm. des Verf.] […] variieren nach Alter
und Geschlecht.“ [(39), S. 54].
Die geschlechtsspezifischen Subgruppen sollen je nach Geschlechtszugehörigkeit in
die zwei Gruppen Männer und Frauen aufgeteilt werden. Datensätze mit fehlender
Geschlechtsangabe sind von der Untersuchung auszuschließen. Außerdem soll eine
allgemeine, geschlechtsunabhängige Gruppe erstellt werden, in der sowohl Männer
als auch Frauen repräsentiert sind. Die altersspezifischen Subgruppen sollten sich an
der Untergliederung der Altersklassen gemäß dem Laborkatalog von dem Institut für
Klinische Chemie und Laboratoriumsmedizin der Ernst-Moritz-Arndt-Universität
Greifswald orientieren, um die regionale Charakteristik der Bezugspopulation in den
auszuwertenden Labordaten widerzuspiegeln und der IFCC-Empfehlung betreffend
der Erzeugung lokaler Referenzbereiche gerecht zu werden (3). Datensätze ohne
Altersangabe sind von der Auswertung auszuschließen.
Für den Analyt Kreatinin im Plasma (i.Pl.) werden folgende geschlechts- und alters-
spezifischen Bezugsgruppen im Laborkatalog von dem Institut für Klinische Chemie
und Laboratoriumsmedizin angegeben: bis 30 Tage, 1 bis 11 Monate, 1 bis 3 Jahre,
4 bis 6 Jahre, 7 bis 9 Jahre, 10 bis 12 Jahre, 13 bis 15 Jahre, 16 bis 18 Jahre, Män-
ner: 19 bis 50 Jahre, Männer: 51 Jahre bis ins Alter, Frauen: 19 Jahre bis ins Alter,
sowie eine allgemeine Gruppe (43). Für den Analyt Harnstoff i.Pl. werden keine ge-
schlechtsspezifischen Subgruppen deklariert. Die altersspezifischen Bezugsgruppen
für Harnstoff sind wie folgt: bis 180 Tage, sowie eine allgemeine Gruppe (43). Für
den Analyt Natrium i.Pl. werden im Laborkatalog der Ernst-Moritz-Arndt-Universität
Greifswald weder geschlechts- noch altersspezifische Bezugsgruppen angezeigt, es
wird nur eine allgemeine Gruppe abgebildet (43).
Mit Hilfe der Quantilregression soll an konkreten Beispielen überprüft werden, ob die
Variablen Alter und Geschlecht wahrhaftig keinen signifikanten Einfluss auf die Refe-
renzgrenzen der Parameter Harnstoff und Natrium ausüben und ob die für Kreatinin
angegebenen geschlechts- und altersspezifischen Subgruppen den in den realen
Daten tatsächlich vorliegenden Verhältnissen entsprechen.

52
3.1.3 Festlegung der Stichprobengrößen
Wie in Abschnitt 2.5.2 unter 2) Wahl der Referenzstichprobengröße diskutiert wurde,
werden für verschiedene Verfahren und Methoden – beispielsweise je nachdem ob
die Selektion der Bezugspopulation prospektiv oder retrospektiv erfolgt – unter-
schiedliche Stichprobengrößen vorgeschlagen. So fordert die IFCC mindestens 40
Referenzindividuen pro Subgruppe, empfiehlt aber für präzisere Referenzbereiche
wenigstens 100 bis 120 Referenzindividuen pro Subgruppe. Ferner werden Stichpro-
benumfänge von 400 und 2.000 Referenzindividuen in den Fachkreisen als ange-
messen betrachtet. Um das Hauptuntersuchungsziel bearbeiten und aussagekräftige
Ergebnisse erlangen zu können, sollen in der Untersuchung Stichproben in den Um-
fängen von 40, 120 und 2.000 Referenzindividuen analysiert und anschließend ver-
glichen werden, wobei jedes Referenzindividuum mit nur einem Referenzwert vertre-
ten ist. Diese Stichprobengrößen gelten je Subgruppe – sofern es die Datenlage er-
laubt. Überdies ist darauf zu achten, dass die Referenzstichproben als einfache Zu-
fallsstichproben gezogen werden.
3.2 Berechnungsmethoden für Referenzbereiche
3.2.1 Forschungsansätze
In dem Fachbuch Klinische Chemie. Laborwerte in der klinischen Praxis von Graf
und Gürkov steht die Aussage: „Die Referenzwerte [Kreatinin und Harnstoff, Anm.
des Verf.] sind deutlich methodenabhängig“ [(39), S. 54]. Dass dem so ist und Refe-
renzintervalle grundlegend von den angewendeten Methoden und Verfahren abhän-
gen, wurde umfassend in den vorangehenden Kapiteln demonstriert. Um dies nach-
zuweisen und dem Hauptuntersuchungsziel und der Forschungsfrage nachzugehen,
sollen in der vorliegenden Untersuchung Referenzbereiche nach unterschiedlichen
Methoden an realen Daten berechnet und einander gegenübergestellt werden. Für
die Gewinnung der realen Daten wird der retrospektive Ansatz gewählt. Wie zuvor
in Absatz 2.3.1 erklärt wurde, werden bei der deduktiven Methode für die Auswahl
der Referenzpopulation bereits vorliegende Patientendatenbestände genutzt, welche
mit Hilfe von Ein- und Ausschlusskriterien gefiltert werden. Für die geplante Untersu-
chung dient das Vorhandensein des Krankheitsbildes der Nierenerkrankung bei ei-
nem Patienten als Ausschlusskriterium. Das daraus hervorgehende Kollektiv der Nie-

53
ren-Gesunden stellt die Bezugspopulation dar und wird als Grundlage zur Erzeugung
der Referenzstichprobe verwendet.
Die Selektion der Referenzpopulation erfolgt durch das indirekte Verfahren, wel-
ches in Abschnitt 2.3.2 vorgestellt wurde. Die Aufteilung der Gruppen in Kranke und
Nicht-Kranke wird bei dem indirekten Verfahren anhand von Sekundärdaten wie Be-
funde oder Messgrößen vorgenommen. Durch den Ausschluss der Nieren-Kranken
mittels der Befunde sowie durch die Einschränkung auf Nieren-spezifische Parame-
ter mittels der Messgrößen können prinzipiell ausschließlich unimodale Referenz-
grenzen für eine nicht-kranke Subpopulation entstehen. Um unimodale Referenzver-
teilungen sicherzustellen, sollen in der anstehenden Analyse die Verteilungen der
Laborwerte der drei Nierenparameter Kreatinin, Harnstoff und Natrium grafisch als
Histogramme angezeigt und auf Mehrgipfligkeit überprüft werden. Würden Nieren-
unspezifische Parameter wie CRP in die Untersuchung eingeschlossen werden,
könnten bimodale Referenzgrenzen für anderweitig Erkrankte einerseits und Nieren-
Gesunde andererseits entstehen und die Durchführung einer Verteilungszerlegung
nach dem direkten Verfahren erfordern, was hier möglichst vermieden werden soll.
Bei dem obig beschriebenen methodischen Zugang handelt es sich um eine Sekun-
därdatenanalyse.
Weitere methodische Bestimmungen, die als Untersuchungsansatz zu treffen sind,
betreffen die unter Punkt 2.3.3 erwähnte Festlegung, ob einseitige oder zweiseitige
Referenzintervalle ermittelt werden sollen. Entsprechend der Vorgaben aus dem La-
borkatalog von dem Institut für Klinische Chemie und Laboratoriumsmedizin der
Ernst-Moritz-Arndt-Universität Greifswald sind für die drei Nierenparameter Kreatinin,
Harnstoff und Natrium ausnahmslos zweiseitige Referenzintervalle zu
berechnen (43), wie in Tabelle 4 in der dritten Spalte ‚Referenzbereich/ therapeuti-
scher Bereich‘ zu sehen ist.

54
Tabelle 4: Auszug aus dem Laborkatalog der Ernst-Moritz-Arndt-Universität Greifs-
wald von 2011 (43)
Analyt Bezugsgruppe Referenzbereich/
therapeutischer Bereich
Harnstoff i.Pl. bis 180 Tage 2,0 - 4,5 mmol/l
allgemein 2,5 - 6,4 mmol/l
Natrium i.Pl. allgemein 135 - 145 mmol/l
Kreatinin i.Pl. bis 30 Tage 44 - 106 µmol/l
1 bis 11 Monate 35 - 62 µmol/l
1 bis 3 Jahre 35 - 62 µmol/l
4 bis 6 Jahre 44 - 71 µmol/l
7 bis 9 Jahre 53 - 80 µmol/l
10 bis 12 Jahre 53 - 88 µmol/l
13 bis 15 Jahre 53 - 106 µmol/l
16 bis 18 Jahre 71 - 123 µmol/l
Frauen: 19 Jahre bis ins Alter 58 - 96 µmol/l
Männer: 19 bis 50 Jahre 74 - 110 µmol/l
Männer: 51 Jahre bis ins Alter 72 - 127 µmol/l
allgemein 58 - 127 µmol/l
Da das nicht-parametrische Verfahren sowohl von der IFCC (siehe Absatz 2.2.1) als
auch von der IUPAC (siehe Abschnitt 2.2.2) als das zweckdienlichste Verfahren emp-
fohlen wird und dem parametrischen Verfahren vorzuziehen ist, wird die beabsichtig-
te Untersuchung gleichermaßen auf nicht-parametrische Verfahrensweisen limi-
tiert. Konkret für die Schätzung der Quantil- und Toleranzintervalle bedeutet dies,
dass die zur Bestimmung der Referenzbereiche genutzten statistischen Methoden
auf Rang-basierten Prozeduren ohne Verteilungsannahmen beruhen. Die einzelnen
Arbeitsschritte für die zu prüfenden Methoden werden in den nachstehenden drei
Teilabschnitten angeordnet.

55
3.2.2 Quantil-Intervall mit Konfidenzintervallen
Der Anweisung der IFCC zufolge müssen für die nicht-parametrische Quantilschät-
zung als Erstes alle N Referenzwerte entsprechend ihres numerischen Wertes auf-
steigend geordnet werden. Den geordneten Referenzwerten werden Rangnummern
zugeordnet, sodass der niedrigste Referenzwert die Rangnummer 1 erhält und der
höchste Referenzwert die Rangnummer N: x1 ≤ x2 ≤ … ≤ xN. Auch für zwei oder meh-
rere gleiche Referenzwerte sollen fortlaufende Rangnummern vergeben werden.
Gleiche Referenzwerte können vermieden werden, sobald mehr Nachkommastellen
verwendet werden. Ein Referenzbereich, der einen Anteil β = 0,95 der Grundge-
samtheit enthält, ist beispielsweise durch die Quantile x0,025 und x0,975 markiert. Da
die Wahrscheinlichkeitsverteilung der Referenzwerte nicht bekannt ist, sind diese
Quantile aus der Stichprobe wie folgt zu berechnen: Die Rangnummer des 0,025-
Quantils wird durch 0,025 * (N+1) und die Rangnummer des 0,975-Quantils durch
0,975 * (N+1) bestimmt (Formel 13). Die untere Grenze des Referenzbereiches wird
durch den Referenzwert definiert, der zur Rangnummer des 0,025-Quantils gehört –
sofern diese Nummer eine ganze Zahl ist. Anderenfalls wird die Grenze durch eine
Interpolation zwischen zwei Referenzwerten determiniert. Die obere Grenze des Re-
ferenzbereiches wird analog durch den Referenzwert abgebildet, der zur Rangnum-
mer des 0,975-Quantils gehört – sofern diese Nummer eine ganze Zahl ist. Ansons-
ten muss hier ebenso interpoliert werden. Die so ermittelten Grenzen des gesuchten
Referenzbereiches, der einen Anteil β = 0,95 der Grundgesamtheit enthält, sind
Punktschätzungen im Sinne der Stichprobenstatistik. Über die Sicherheit für diese
Enthaltenseinsrelation ist nichts bekannt. Man kann diesen Mangel jedoch beheben,
indem man die -Konfidenzintervalle für die beiden Stichprobenquantile verwendet.
Das zweiseitige nicht-parametrische 0,90-Konfidenzintervall des 0,025-Quantils er-
mittelt man, indem die den – in der IFCC-Tabelle I siehe Abbildung 3 je nach unter-
suchter Stichprobengröße aufgelisteten – Rangnummern entsprechenden Referenz-
werte als Konfidenzgrenzen angegeben werden (6).
Die Konfidenzgrenzen für das 0,975-Quantil werden äquivalent bestimmt. Die Ta-
belle I aus der IFCC-Veröffentlichung Approved Recommendation (1987) on the
Theory of Reference Values. Part 5. Statistical Treatment of Collected Reference

56
Values. Determination of Reference Limits, welche nachfolgend in Abbildung 3 ge-
zeigt wird, listet Rangnummern von 0,90-Konfidenzintervallen der 0,025-Quantile für
Stichproben im Umfang von 119 bis 1.000 Referenzwerten auf. Um die dazugehöri-
gen Rangnummern von 0,90-Konfidenzintervallen der 0,975-Quantile zu erhalten,
muss die jeweilige Rangnummer aus der IFCC-Tabelle I von N+1 subtrahiert werden,
wobei N die Stichprobengröße darstellt. (6)
Abbildung 3: Nicht-parametrische Konfidenzintervalle für Referenzgrenzen
[entnommen aus: (6), S. 21], Erläuterungen siehe Text
Indem die linke Grenze des 0,90-Konfidenzintervalles für das 0,025-Quantil und die
rechte Grenze des 0,975-Quantiles gewählt werden, erhält man einen Referenzbe-
reich, der den Anteil = 0,95 der Grundgesamtheit mit einer Sicherheit von mindes-
tens = 0,90 enthält, sofern N groß genug ist.

57
Damit ist klar:
1) Eine Stichprobenumfangsplanung ist erforderlich, um die geforderte Qualität
des Referenzbereiches zu gewährleisten.
2) Ein so konstruierter Referenzbereich ist zu groß, falls die tatsächliche Sicher-
heit den geforderten Wert = 0,90 übersteigt.
Die in Abbildung 3 dargestellten Rangnummern aus den Berechnungen der IFCC,
welche laut ihrer Richtlinie als untere und obere Grenzen von nicht-parametrischen
0,90-Konfidenzintervallen der 0,025-Quantile für die dort aufgeführten 882 Stichpro-
bengrößen im Umfang zwischen 119 und 1.000 Referenzwerten/ -individuen empfoh-
len werden, wurden mit Hilfe eines eigens dafür generierten SAS®-Programmes
nachgeprüft. Ein Teil des erzeugten SAS®-Skriptes Macro_Konfidenzbereiche.sas
(siehe Programmliste in Abschnitt 3.8) wurde der Autorin für diese Untersuchung von
dem Institut für Biometrie und Medizinische Informatik der Medizinischen Fakultät der
Ernst-Moritz-Arndt-Universität Greifswald zur Verfügung gestellt. Die mitwirkenden
Programmierer sind in der Kopfzeile des Programm-Skriptes benannt.
Mittels dieses SAS®-Programmes wurden für verschiedene Stichprobenumfänge N,
ein Quantil xp und ein Konfidenzniveau 1– α zweiseitige Konfidenzgrenzen als Rang-
nummern ausgegeben, wobei p auf 0,025, α auf 0,1 und N auf 119 bis 1.000 gesetzt
wurden. Die Rechenergebnisse wurden in Tabelle 5 so zusammengefasst, dass Ver-
gleiche mit den Daten aus Abbildung 3 unterstützt werden.
Ein Abgleich der von der IFCC herausgegebenen Rangnummern aus Abbildung 3
mit den selbst ermittelten Rangnummern aus Tabelle 5 zeigt mehrheitlich Überein-
stimmungen der Werte. Bei den unteren Konfidenzgrenzen gibt es für 440 Stichpro-
bengrößen keine Abweichungen in den Rangzahlen, für 409 Stichprobengrößen nur
einen Unterschied von einem Rangplatz und bei geringfügigen 33 von insgesamt 882
verschiedenen Stichprobengrößen einen Abstand von zwei Rangplätzen. Die Be-
trachtung der oberen Konfidenzgrenzen ergibt überwiegend einen Abstand von einer
Rangnummer, was zusammen 733 Stichprobengrößen betrifft. Ein Unterschied von
jeweils zwei Rangplätzen ist bei 75 Stichprobengrößen zu finden. Keine Abweichun-
gen in den Rängen für die oberen Konfidenzgrenzen liegen bei 74 Stichprobengrö-
ßen vor.

58
Tabelle 5: Nicht-parametrische Konfidenzintervalle für Referenzgrenzen
[eigene Berechnungen], Erläuterungen siehe Text
Stichprobengröße N
Rangnummern Stichprobengröße N
Rangnummern
Untere Obere Untere Obere
119-146 1 7 560-599 8 21
147-183 1 8 600-629 9 22
184-193 2 9 630-638 8 22
194-216 1 9 639-648 10 23
217-241 2 10 649-675 9 23
242-278 2 11 676-704 10 24
279-303 3 12 705-730 11 25
304-312 2 12 731-750 12 26
313-315 4 13 751-759 11 26
316-342 3 13 760-799 12 27
343-368 4 14 800-834 13 28
369-387 5 15 835-838 12 28
388-399 4 15 839-856 14 29
400-436 5 16 857-878 13 29
437-438 4 16 879-912 14 30
439-459 6 17 913-940 15 31
460-475 5 17 941-965 16 32
476-504 6 18 966-979 17 33
505-531 7 19 980-999 16 33
532-552 8 20 1000 17 34
553-559 7 20
Die minimalen Unterschiede der SAS®-Programmergebnisse gegenüber den im Jahr
1987 von der IFCC veröffentlichten Zahlen könnten auf inzwischen präziseren Com-
puterberechnungen und Algorithmen beziehungsweise weniger Rundungsfehler be-
ruhen, da die Statistiksoftware seit den IFCC-Kalkulationen vor nunmehr 25-26 Jah-
ren weiterentwickelt und optimiert wurde. Für die vorliegende Forschungsarbeit sol-
len die neu berechneten Daten beziehungsweise weitere Daten aus dem zu diesem
Zweck erstellten SAS®-Programm praktische Verwendung finden.

59
3.2.3 Toleranzintervall
Das schrittweise Vorgehen bei der Ermittlung von nicht-parametrischen Toleranzin-
tervallen wird in dem technischen Bericht Calculation and Application of Coverage
Intervals for Biological Reference Values der IUPAC im Detail besprochen. Auch hier
wird als erster Schritt die Sortierung der Referenzwerte in aufsteigender Reihenfolge
genannt, was mit Hilfe von Standard-Tabellenkalkulationsprogrammen ausgeführt
werden kann. Die Kalkulation der Referenzgrenzen und Ermittlung der Überde-
ckungsunsicherheit ( ) ist von der Größe N der auszuwertenden Stichprobe, dem zu
überdeckenden Anteil der Grundgesamtheit zusammen mit einer für zugestan-
denen Unsicherheit sowie von der ersuchten Konfidenz abhängig. Die Grenzen
eines Toleranzintervalls [A;B] werden gewonnen, indem der entsprechende Wert m
aus einer der beiden IUPAC-Tabellen siehe Abbildung 4 verwendet wird. Er ist die
Gesamtzahl der außerhalb des Referenzintervalls liegenden, aufsteigend geordneten
Stichprobenwerte. Für N = 50 liest man beispielsweise in den Tabellen aus Abbil-
dung 4 die Werte = 0,95, = 0,90, = 0,049 und m = 2 ab. Zwischen dem zweit-
kleinsten und zweitgrößten der geordneten Stichprobenwerte liegt mit einer Wahr-
scheinlichkeit von mindestens 0,95 demnach ein Anteil zwischen 0,901 und 0,999
der Grundgesamtheit.
Bei einem zweiseitigen Toleranzintervall liegen mlow Referenzwerte unterhalb der
unteren Referenzgrenze und mup Referenzwerte oberhalb der oberen Referenzgren-
ze. Insgesamt beträgt die Anzahl der Referenzwerte außerhalb des Toleranzinter-
valls m = mlow + mup (Formel 14), wobei darauf zu achten ist, dass für eine zentrale
Lage des Toleranzintervalls die Anzahl der Referenzwerte unterhalb des Toleranzin-
tervalls (mlow) etwa gleichgroß wie die Anzahl der Referenzwerte oberhalb des Tole-
ranzintervalls (mup) sein sollte. Für eine gegebene Stichprobengröße können ver-
schiedene Toleranzintervalle als Referenzbereiche infolge von diversen möglichen
Kombinationen von β, und entstehen, wie von den zwei Tabellen der IUPAC in
Abbildung 4 abzulesen ist. Zudem wird die Anzahl der Referenzwerte N als Minimum
erklärt. Dies bedeutet, dass die Stichprobe mindestens der Größe N entsprechen
muss, damit die Wahrscheinlichkeit wenigstens beträgt, dass das β-
Toleranzintervall die Verteilung zwischen β - und β + überdeckt (Formel 15). (16)

60
Abbildung 4: Nicht-parametrische 0,95- und 0,90-Toleranzintervalle
[entnommen aus: (16), S. 1605], Erläuterungen siehe Text
Auch hierfür wurde – wie zu dem in Absatz 3.2.2 beschriebenen Abgleich – eine Ge-
genrechnung zu den von der IUPAC publizierten Zahlen angestrebt. Zu diesem
Zweck wurde das SAS®-Skript Macro_Toleranzbereiche.sas programmiert (siehe
Programmliste in Abschnitt 3.8). Die Mitwirkenden des SAS®-Programmes, dessen
Hauptteil der Autorin von dem Institut für Biometrie und Medizinische Informatik der
Ernst-Moritz-Arndt-Universität Greifswald für ihre Promotionsarbeit bereitgestellt wur-
de, sind im Header des Skriptes aufgeführt. Dieses Makro ermittelt verteilungsfreie
zweiseitige Toleranzintervalle für verschiedene Stichprobenumfänge N, bestimmte
Stichprobenanteile sowie vorgegebene Irrtumswahrscheinlichkeiten α, indem unte-
re und obere Toleranzgrenzen als Rangnummern berechnet, und zusammen mit der
Überdeckungswahrscheinlichkeit des jeweiligen Intervalls ausgegeben werden. Der
daraus abgeleitete Wert m – die Anzahl der Referenzwerte außerhalb des Toleran-
zintervalls laut Formel 14 – wird gemeinsam mit der auf Basis von Formel 15 erlang-

61
ten Überdeckungsunsicherheit je Stichprobenumfang, Irrtumswahrscheinlichkeit und
Stichprobenanteil in Tabelle 6 aufgelistet.
Tabelle 6: Nicht-parametrische 0,95- und 0,90-Toleranzintervalle
[eigene Berechnungen], Erläuterungen siehe Text
0,95-Toleranzintervall
0,90-Konfidenz ( ) 0,95-Konfidenz ( )
Stichpro-bengröße (N)
m Überdeckungs-
unsicherheit ( )
Stichpro-bengröße (N)
m Überdeckungs-
unsicherheit ( )
1361 56 0,04 1889 77 0,01
343 10 0,02 471 14 0,01
146 2 0,01 210 4 0,004
84 0 0,02 111 0 0,03
47 0 0,26 71 0 0,07
0,90-Toleranzintervall
0,90-Konfidenz ( ) 0,95-Konfidenz ( )
Stichpro-bengröße (N)
m Überdeckungs-
unsicherheit ( )
Stichpro-bengröße (N)
m Überdeckungs-
unsicherheit ( )
650 53 0,02 903 74 0,05
290 21 0,002 403 29 0,05
170 10 0,03 224 13 0,07
102 4 0,05 144 7 0,06
71 2 0,03 95 3 0,07
52 1 0,003 74 1 0,08
41 0 0,03 54 0 0,08
31 0 0,07 44 0 0,04
22 0 0,24 26 0 0,15
Für eine bestmögliche Vergleichbarkeit mit den seitens der IUPAC empfohlenen
Werten wurden folgende vier Kombinationen zur Plausibilisierung durchgerechnet:
1.) Irrtumswahrscheinlichkeit 5 % (0,95-Konfidenz), Stichprobenanteil 90 % (0,90-
Toleranzintervall), 2.) Irrtumswahrscheinlichkeit 10 % (0,90-Konfidenz), Stichproben-
anteil 90 % (0,90-Toleranzintervall), 3.) Irrtumswahrscheinlichkeit 5 % (0,95-
Konfidenz), Stichprobenanteil 95 % (0,95-Toleranzintervall), 4.) Irrtumswahrschein-
lichkeit 10 % (0,90-Konfidenz), Stichprobenanteil 95 % (0,95-Toleranzintervall). Die
für die Berechnungen gewählten Stichprobenumfänge wurden entsprechend der
Stichprobengrößen N aus den IUPAC-Tabellen siehe Abbildung 4 festgelegt.

62
Die im Rahmen der Plausibilitätskontrolle errungenen, im Verhältnis zu den IUPAC-
Zahlen leicht divergierenden m-Werte indizieren keine fehlerhafte Programmierung,
sondern sind auf einen von der Rechenmethode der IUPAC abweichenden Algorith-
mus zurückzuführen, welcher auf einer anderen Definition eines Toleranzintervalls
beruht als die der IUPAC. Grundlegend ist ein Toleranzintervall ein Intervall T aus
dem Wertebereich der betrachteten Zufallsgröße X. A = A(T) ist der Anteil der
Grundgesamtheit, der in T enthalten ist, also die Wahrscheinlichkeit
A = A(T) = P(X∊T). Hauptsächlich gibt es folgende zwei unterschiedliche Typen eines
Toleranzintervalls:
1) T heißt Toleranzbereich mit erwartetem Anteil β, wenn ( ) > 0 gilt, E(A)
bezeichnet den Erwartungswert.
2) T heißt p-Anteil-Toleranzbereich zum Koeffizienten , wenn ( )
gilt. A enthält also mit Mindestwahrscheinlichkeit den Anteil p der Grund-
gesamtheit. [(74), S. 41 f.]
Die festgestellten, von den Werten von Poulsen et al. (siehe IUPAC-Tabellen in Ab-
bildung 4) abweichenden Resultate der eigenen Nachrechnungen (siehe Tabelle 6)
begründen sich demnach in den verschiedenen Definitionen eines Toleranzintervalls.
Während die eigenen Berechnungen der Definition 2) folgen und diesbezüglich „pa-
rameterfrei“ die Toleranzintervalle berechnen, liegt der Arbeit von Poulsen et al. (16)
eine dritte Definition für ein Coverage Interval zugrunde, die dem Typ 1) ähnlich ist.
Poulsen et al. (16) definieren ein Toleranzintervall insofern anders, als dass dort der
erwartete Anteil der Grundgesamtheit gemeint wird. Des Weiteren können für Abwei-
chungen zwischen den selbst entwickelten Rangplätzen und den Rangzahlen der
IUPAC die folgenden Gründe erklärend sein: Es gibt mehrere Möglichkeiten, den
empirischen Median zu definieren und zu berechnen. In der Statistiksoftware SAS®
gibt es insgesamt sechs Angebote hierzu. Diese Auswahl ist für die Rechenergebnis-
se von Bedeutung. Zudem kann nicht in Erfahrung gebracht werden, was zu jener
Zeit im Auftrag der IUPAC wie berechnet wurde. Die Tabellen von Poulsen et al. (16)
berufen sich auf Zahlen von Kirkpatrick (75).
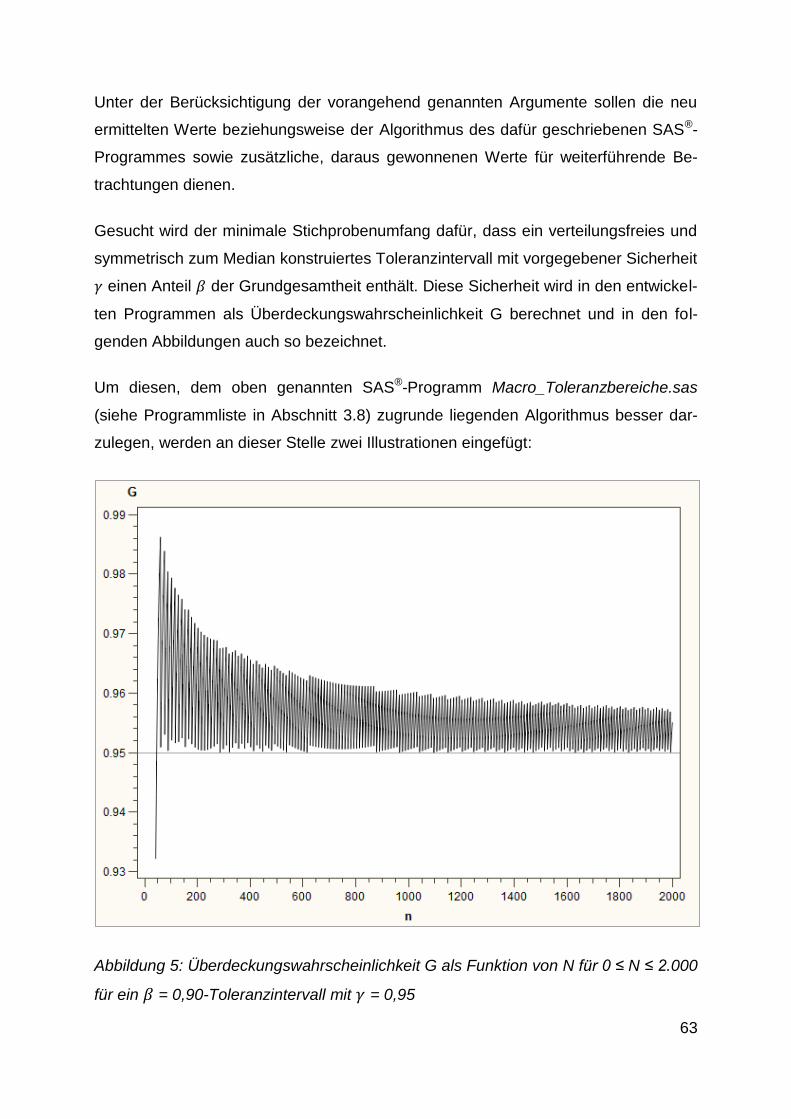
63
Unter der Berücksichtigung der vorangehend genannten Argumente sollen die neu
ermittelten Werte beziehungsweise der Algorithmus des dafür geschriebenen SAS®-
Programmes sowie zusätzliche, daraus gewonnenen Werte für weiterführende Be-
trachtungen dienen.
Gesucht wird der minimale Stichprobenumfang dafür, dass ein verteilungsfreies und
symmetrisch zum Median konstruiertes Toleranzintervall mit vorgegebener Sicherheit
einen Anteil der Grundgesamtheit enthält. Diese Sicherheit wird in den entwickel-
ten Programmen als Überdeckungswahrscheinlichkeit G berechnet und in den fol-
genden Abbildungen auch so bezeichnet.
Um diesen, dem oben genannten SAS®-Programm Macro_Toleranzbereiche.sas
(siehe Programmliste in Abschnitt 3.8) zugrunde liegenden Algorithmus besser dar-
zulegen, werden an dieser Stelle zwei Illustrationen eingefügt:
Abbildung 5: Überdeckungswahrscheinlichkeit G als Funktion von N für 0 ≤ N ≤ 2.000
für ein = 0,90-Toleranzintervall mit = 0,95
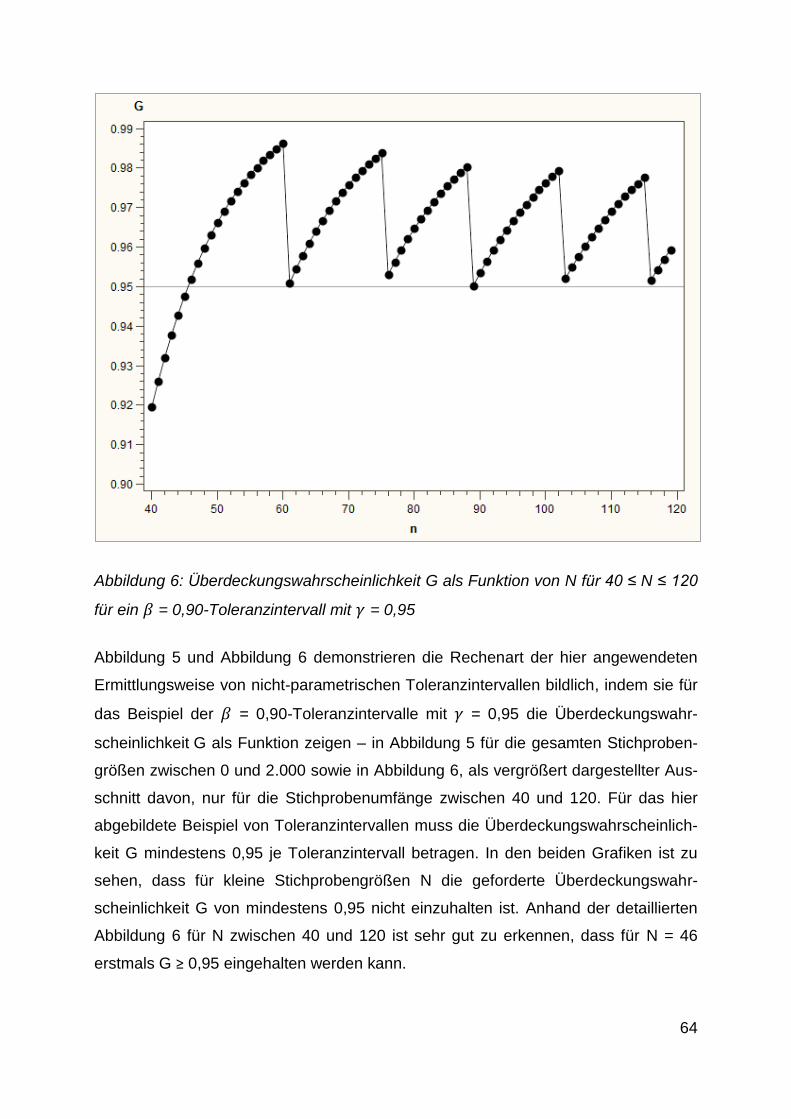
64
Abbildung 6: Überdeckungswahrscheinlichkeit G als Funktion von N für 40 ≤ N ≤ 120
für ein = 0,90-Toleranzintervall mit = 0,95
Abbildung 5 und Abbildung 6 demonstrieren die Rechenart der hier angewendeten
Ermittlungsweise von nicht-parametrischen Toleranzintervallen bildlich, indem sie für
das Beispiel der = 0,90-Toleranzintervalle mit = 0,95 die Überdeckungswahr-
scheinlichkeit G als Funktion zeigen – in Abbildung 5 für die gesamten Stichproben-
größen zwischen 0 und 2.000 sowie in Abbildung 6, als vergrößert dargestellter Aus-
schnitt davon, nur für die Stichprobenumfänge zwischen 40 und 120. Für das hier
abgebildete Beispiel von Toleranzintervallen muss die Überdeckungswahrscheinlich-
keit G mindestens 0,95 je Toleranzintervall betragen. In den beiden Grafiken ist zu
sehen, dass für kleine Stichprobengrößen N die geforderte Überdeckungswahr-
scheinlichkeit G von mindestens 0,95 nicht einzuhalten ist. Anhand der detaillierten
Abbildung 6 für N zwischen 40 und 120 ist sehr gut zu erkennen, dass für N = 46
erstmals G ≥ 0,95 eingehalten werden kann.

65
Da, wie zuvor unter 2.2.2 beschrieben wurde, entsprechend der IUPAC ein Toleran-
zintervall als 0,95-Toleranzintervall mit einer Konfidenz von 0,95 definiert ist, aber bei
sehr kleinen Referenzmengen eine Sicherheit von 0,90 empfohlen wird, werden im
Folgenden die obigen zwei Beispiele zusätzlich für einen Stichprobenanteil von 95 %
und einer Irrtumswahrscheinlichkeit von 10 % ausgegeben und insbesondere für
kleine Stichprobenumfänge ab N = 40 untersucht.
Für die Erstellung dieser insgesamt vier exemplarischen Darstellungen wurde das
SAS®-Programm Macro_Toleranzbereiche.sas als Grundlage genutzt und im Aufruf
verändert. In Zusammenarbeit mit dem Institut für Biometrie und Medizinische Infor-
matik der Universitätsmedizin der Ernst-Moritz-Arndt-Universität Greifswald entstand
das SAS®-Skript Macro_Toleranzbereiche_ÜberdeckungG.sas (siehe Programmliste
in Abschnitt 3.8). Mitwirkende sind im Header betitelt. Die vier Grafiken wurden mit
der Software SAS® Enterprise Guide in der Version 4.3 erzeugt.
Abbildung 7: Überdeckungswahrscheinlichkeit G als Funktion von N für 0 ≤ N ≤ 2.000
für ein = 0,95-Toleranzintervall mit = 0,90

66
Abbildung 8: Überdeckungswahrscheinlichkeit G als Funktion von N für 40 ≤ N ≤ 120
für ein = 0,95-Toleranzintervall mit = 0,90
Auch in Abbildung 7 und Abbildung 8 ist zu beobachten, dass für kleine Stichpro-
benumfänge N die – infolge der ersuchten 0,90-Konfidenz – hier geforderte Überde-
ckungswahrscheinlichkeit G von mindestens 0,90 nicht einzuhalten ist. Mit Hilfe der
detaillierten Abbildung 8 für N zwischen 40 und 120 ist deutlich sichtbar, dass erst ab
einer Stichprobengröße von N = 77 erstmalig G ≥ 0,90 gegeben ist.
Die in Abbildung 5 bis Abbildung 8 erfassten, unterschiedlich verlaufenden Säge-
zahnkurven gaben den Anlass, für verschiedene Intervalle – je nach Kombination
aus Stichprobenanteil und Überdeckungswahrscheinlichkeit – nach dem Stichpro-
benumfang zu fragen, ab dem die Überdeckungswahrscheinlichkeit stets eingehalten
wird. Hierfür wurde, ebenfalls in Kooperation mit dem Institut für Biometrie und Medi-
zinische Informatik in Greifswald, ein SAS®-Makro generiert, welches mit Nennung
der Beteiligten unter dem Namen Macro_Toleranzbereiche_Mindest_n.sas aufgeführt
ist (siehe Programmliste in Abschnitt 3.8).
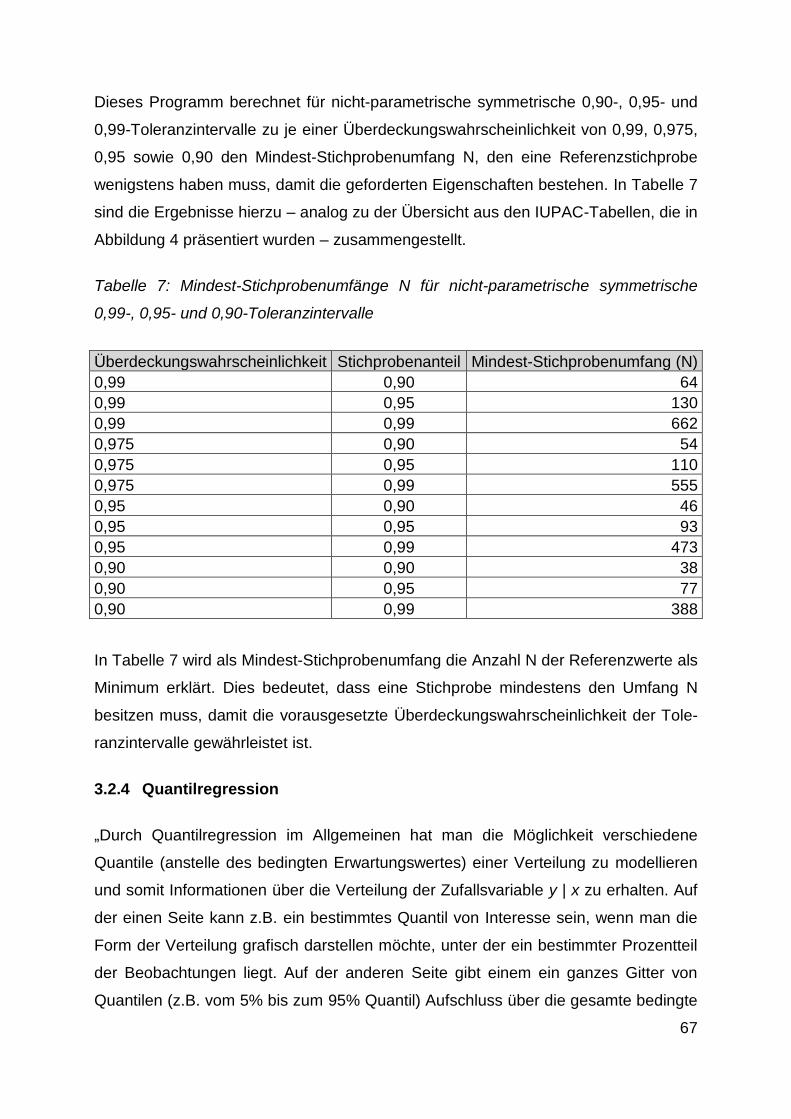
67
Dieses Programm berechnet für nicht-parametrische symmetrische 0,90-, 0,95- und
0,99-Toleranzintervalle zu je einer Überdeckungswahrscheinlichkeit von 0,99, 0,975,
0,95 sowie 0,90 den Mindest-Stichprobenumfang N, den eine Referenzstichprobe
wenigstens haben muss, damit die geforderten Eigenschaften bestehen. In Tabelle 7
sind die Ergebnisse hierzu – analog zu der Übersicht aus den IUPAC-Tabellen, die in
Abbildung 4 präsentiert wurden – zusammengestellt.
Tabelle 7: Mindest-Stichprobenumfänge N für nicht-parametrische symmetrische
0,99-, 0,95- und 0,90-Toleranzintervalle
Überdeckungswahrscheinlichkeit Stichprobenanteil Mindest-Stichprobenumfang (N)
0,99 0,90 64
0,99 0,95 130
0,99 0,99 662
0,975 0,90 54
0,975 0,95 110
0,975 0,99 555
0,95 0,90 46
0,95 0,95 93
0,95 0,99 473
0,90 0,90 38
0,90 0,95 77
0,90 0,99 388
In Tabelle 7 wird als Mindest-Stichprobenumfang die Anzahl N der Referenzwerte als
Minimum erklärt. Dies bedeutet, dass eine Stichprobe mindestens den Umfang N
besitzen muss, damit die vorausgesetzte Überdeckungswahrscheinlichkeit der Tole-
ranzintervalle gewährleistet ist.
3.2.4 Quantilregression
„Durch Quantilregression im Allgemeinen hat man die Möglichkeit verschiedene
Quantile (anstelle des bedingten Erwartungswertes) einer Verteilung zu modellieren
und somit Informationen über die Verteilung der Zufallsvariable y | x zu erhalten. Auf
der einen Seite kann z.B. ein bestimmtes Quantil von Interesse sein, wenn man die
Form der Verteilung grafisch darstellen möchte, unter der ein bestimmter Prozentteil
der Beobachtungen liegt. Auf der anderen Seite gibt einem ein ganzes Gitter von
Quantilen (z.B. vom 5% bis zum 95% Quantil) Aufschluss über die gesamte bedingte

68
Verteilung. Quantilregression bietet eine systematische Strategie zur Untersuchung
des Einflusses von Kovariablen auf die Lokation, Skala und Form der gesamten
Response-Verteilung.“ [(76), S. 2]
Da für die Schätzung der Quantilfunktion keine Verteilung für den Response ange-
nommen wird, handelt es sich um eine nicht-parametrische Quantilregression (76).
Die Quantilregression abstrahiert das Konzept eines univariaten Quantils auf ein
konditionales Quantil – vorausgesetzt es existieren eine oder mehrere Kovariaten.
Für eine Zufallsvariable Y mit der Wahrscheinlichkeitsverteilungsfunktion
F(y) = Prob (Y ≤ y) ist das -te Quantil von Y als die Umkehrfunktion
( ) = inf {y : F(y) ≥ } mit 0 < < 1 definiert. Der Median ist (
). Für eine Zufalls-
stichprobe {y1, …, yn} von Y minimiert der Stichprobenmedian die Summe der abso-
luten Abweichungen; median = arg minξ∊ℝ ∑ ξ . Gleichermaßen ist das all-
gemeine -te Stichprobenquantil ξ( ), analog zu ( ), als Minimizer formuliert:
ξ( ) = arg minξ∊ℝ ∑ ( ξ) mit ( ) ( ( )) , wobei I( )
die Indikatorfunktion bezeichnet. Die Verlustfunktion weist Gewichtungen von auf
positive Residuen ξ und von 1 auf negative Residuen zu. Durch die Nutzung
dieser Verlustfunktion erhebt die lineare konditionale Quantilfunktion das -te Stich-
probenquantil ξ( ) auf den Regressionsansatz. Die Quantilregression schätzt die li-
neare konditionale Quantilfunktion ( ) ( ) durch das Lösen der Glei-
chung ̂( ) arg minβ∊ℝp ∑ ( )
für ∈ (0, 1). Die Quantität ̂( ) wird
das -te Regressionsquantil genannt. Der Regressionsquantilssatz { ( ) : ∈ (0, 1)}
wird als Quantilprozess bezeichnet. (Formel 16) (77)
3.3 Datengrundlage
Wie zuvor in Absatz 3.2.1 dargetan wurde, wird beabsichtigt, den Vergleich der Me-
thoden zur Bestimmung von medizinischen Referenzbereichen für labordiagnosti-
sche Parameter auf der Grundlage echter Labordaten vorzunehmen, um den retro-
spektiven Ansatz zu vollführen. Hierzu wird ein bereits bestehender Patientendaten-
bestand herangezogen, welcher dem Institut für Biometrie und Medizinische Informa-
tik der Medizinischen Fakultät der Ernst-Moritz-Arndt-Universität Greifswald für For-

69
schungszwecke zur Verfügung gestellt wurde. Hierbei handelt es sich um Labordaten
von Nieren-gesunden Patienten aus dem Universitätsklinikum Greifswald, die im Jahr
2005 aufgenommen wurden. Die Charakterisierung der Patienten als Nieren-gesund
erfolgte anhand ihrer nach der Internationalen statistischen Klassifikation der Krank-
heiten und verwandten Gesundheitsprobleme (ICD) verschlüsselten Enddiagnosen,
wobei alle Diagnosen mit möglichem Bezug zu Nierenerkrankungen berücksichtigt
wurden. In den auszuwertenden Daten ist jeder Patient mit nur einem Datensatz ver-
treten – bei mehreren Krankenhausaufnahmen im Jahr 2005 wurden die Laborwerte
der ersten registrierten Aufnahme verwertet. Die Identifikation eines Patienten erfolgt
anhand einer Patientennummer. Um sicherstellen zu können, dass in den Patienten-
datensätzen keine Duplikate enthalten sind, müssen Datensätze mit fehlender Pati-
entennummer von der Analyse ausgeschlossen werden.
Die Datengrundlage für die Referenzpopulation schaffen demzufolge alle im Jahr
2005 im Universitätsklinikum Greifswald untersuchten Personen jeden Alters und
Geschlechts, die hinsichtlich der zu bewertenden Parameter Kreatinin, Harnstoff und
Natrium – welche zur Indikation von Nierenerkrankungen dienen – als gesund und
unbelastet gelten. Aus dieser Nieren-gesunden Referenzpopulation werden reprä-
sentative Stichproben in den vorab begründeten, festgelegten Größen gezogen (sie-
he Abschnitt 3.1.3). Die aus den repräsentativen Stichproben resultierenden Refe-
renzwerte zeigen natürlich vorkommende, normale biologische Variationen, auf de-
ren Basis Referenzbereiche ermittelt werden.
Insgesamt umfasst der Datenbestand 10.899 Patientendatensätze mit den folgenden
26 Variablen: ALTER, CHLORID, CRP, CYSTC, DIAGNOSE, ERYTHROZYTEN,
GEBURTSDATUM, GESCHLECHT, HAEMATOKRIT, HAEMOGLOBIN, HARN-
STOFF, INR, KALIUM, KREA, LEUKOZYTEN, MCH, MCV, NATRIUM, PATIEN-
TENNR, PHOSPHAT, PTH, PTHI, PTHI_EDTA, PTT, QUICK, THROMBOZYTEN.
In der geplanten Untersuchung werden explizit die 6 Variablen PATIENTENNR, AL-
TER, GESCHLECHT, HARNSTOFF, KREA und NATRIUM berücksichtigt und aus-
gewertet. Von den 10.899 Patientendatensätzen haben 228 keine Patientennummer
(Variable PATIENTENNR), 16 keine Angaben zum Geschlecht (Variable GE-
SCHLECHT), 4.821 keine Harnstoffwerte (Variable HARNSTOFF), 1.792 keine Krea-
tininwerte (Variable KREA) sowie 1.440 keine Natriumwerte (Variable NATRIUM).

70
Diese Datensätze mit fehlenden Werten müssen von der weiteren Datenverarbeitung
ausgenommen werden. Alle der 10.899 Patientendatensätze besitzen Informationen
zum Alter (Variable ALTER) als Jahresangaben. Größen, die das genaue Alter von
unter 1-Jährigen in Tagen, Wochen oder Monaten beschreiben, liegen nicht vor. Aus
diesem Anlass wird es nicht möglich sein, die Klassenbildung aus dem Laborkatalog
des Instituts für Klinische Chemie und Laboratoriumsmedizin der Universitätsmedizin
Greifswald exakt zu übernehmen und die zwei altersspezifischen Subgruppen
‚bis 30 Tage‘ für Kreatinin und ‚bis 180 Tage‘ für Harnstoff abzubilden. Sie können in
der Analyse keine Berücksichtigung finden. Die Variable GESCHLECHT ist als 1 und
2 kodiert. Die Ziffer 1 wird als männlich und die Ziffer 2 als weiblich dekodiert.
53 % der Patienten sind weiblich und 47 % der Patienten sind männlich.
3.4 Auswerteverfahren
3.4.1 Computerprogramme und Prozeduren
Als Datenbanksystem und Software für die Bearbeitung der Daten sowie die statisti-
schen Analysen werden SAS® für Windows in der Version 9.2 wie auch SAS® Enter-
prise Guide in der Version 4.3 von dem SAS Institute Inc., Cary, NC, USA – lizenziert
für die Medizinische Fakultät der Ernst-Moritz-Arndt-Universität Greifswald – genutzt.
Für die drei zu vergleichenden Methoden zur Bestimmung von Referenzbereichen für
Laborparameter liegen geeignete Programme und Prozeduren in SAS® vor. Die
Quantilschätzung kann mit Hilfe der SAS®-Prozedur UNIVARIATE gemeinsam mit
der Option PCTLDEF für die Berechnung der 0,025- und 0,975-Quantile vorgenom-
men werden. Die dazugehörigen nicht-parametrischen Konfidenzintervalle für diese
Quantile sind durch die Angabe der CIPCTLDF-Option erhältlich. Parameterfreie To-
leranzschätzungen können unter Zuhilfenahme der SAS®-Funktionen CDF oder
PROBBETA erfolgen. Die Quantilregression kann mittels der SAS®-Prozedur
QUANTREG durchgeführt werden. Die QUANTREG-Prozedur der Statistiksoftware
SAS® berechnet die Quantilfunktion ( ) und leitet davon statistische Inferenz
für die Schätzparameter ̂( ) ab. (77-79)
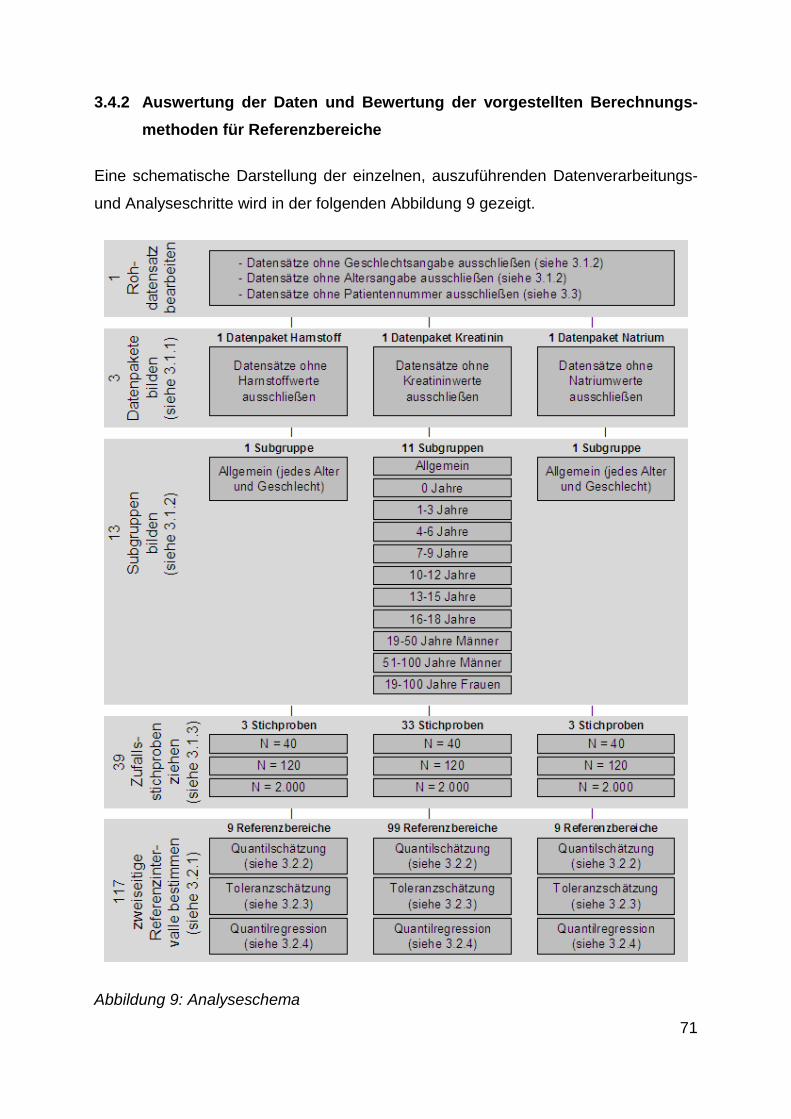
71
3.4.2 Auswertung der Daten und Bewertung der vorgestellten Berechnungs-
methoden für Referenzbereiche
Eine schematische Darstellung der einzelnen, auszuführenden Datenverarbeitungs-
und Analyseschritte wird in der folgenden Abbildung 9 gezeigt.
Abbildung 9: Analyseschema

72
Die Bewertung der drei Methoden Quantil-Intervall mit Konfidenzbereichen, Tole-
ranzschätzung sowie Quantilregression erfolgt unter den folgenden Gesichtspunkten:
1) allgemeine Anwendbarkeit beziehungsweise einschränkende Voraussetzun-
gen und Modellannahmen
2) wahrscheinlichkeitstheoretische Charakterisierung der Resultate
3) praktische Durchführbarkeit.
Die Durchführung der Verfahren wird an realen Daten aus der klinischen Praxis vor-
genommen und ermöglicht die vergleichende Betrachtung der Resultate. Eine Be-
wertung der klinischen Relevanz auftretender Unterschiede ist nicht Gegenstand der
vorliegenden Arbeit.
3.5 Durchführungsbedingungen
Der Ort der Untersuchung ist Berlin. Der Autorin liegen die zu untersuchenden Daten
als sas7bdat-Datei vor. Die Übergabe der Daten fand persönlich im Institut für Bio-
metrie und Medizinische Informatik in Greifswald statt. Via VPN-Zugang hat die Auto-
rin Zugriff auf die online-Bibliothek der Ernst-Moritz-Arndt-Universität Greifswald. Der
zeitliche Ablauf der Datenanalysen ist für November und Dezember 2012 geplant.
3.6 Kontrollmaßnahmen
Maßnahmen der Qualitätssicherung und Qualitätsüberprüfung der auszuwertenden
Labordaten werden vorab im Rahmen der deskriptiven Statistik in SAS® getroffen
und konzentrieren sich auf folgende Punkte:
1) Plausibilitätsprüfungen für die Variablen ALTER und GESCHLECHT:
a) Gibt es Altersangaben (in Jahren) unter 0 und über 100?
b) Gibt es Angaben zum Geschlecht, die nicht als 1 oder 2 kodiert sind?
2) Prüfen der Variable PATIENTENNR auf doppelte Patienteneinträge.
3) Prüfen der Parameter HARNSTOFF, KREA und NATRIUM auf Ausreißer-
Werte.
4) Prüfen der Histogramme der Parameter HARNSTOFF, KREA und NATRIUM
auf Mehrgipfligkeit.

73
3.7 Ethische Betrachtung
Die Sicherstellung des Datenschutzes ist gewährleistet, da es sich bei der Daten-
grundlage um anonymisierte Daten handelt. Die Patienten sind ausschließlich mit
einer anonymen Nummer identifizieret, ohne Angabe der Vor- und Nachnamen oder
Adressen der Patienten. Weil es sich zudem um eine Sekundärdatenanalyse han-
delt, ist die Einholung eines Votums der Ethikkommission nicht erforderlich.
3.8 Software und Dateien
Die für die vorliegende Arbeit von der Autorin geschriebenen, modifizierten oder ver-
wendeten SAS®-Programme (siehe nachstehende Programmliste) sowie die verar-
beiteten oder generierten Dateien werden mit Fertigstellung dieser Arbeit vollständig
an das Institut für Biometrie und Medizinische Informatik der Universitätsmedizin
Greifswald übergeben und dort archiviert. Die Autorin besitzt danach weder die Pro-
gramme noch die Dateien.
Damit ist sichergestellt, dass der Datenschutz gewährleistet ist und dass rechtliche
Fragen der Anwendung der Software in der klinischen Praxis oder die Verwertung
von möglicherweise bestehenden Nutzungsrechten durch die Universität gegebenen-
falls noch geklärt werden können.
Liste der SAS®-Programme und SAS®-Dateien:
Konfidenzbereiche.sas
Macro_Konfidenzbereiche.sas
Macro_Toleranzbereiche.sas
Macro_Toleranzbereiche_Mindest_n.sas
Macro_Toleranzbereiche_ÜberdeckungG.sas
Quantilregression.sas
Quantilschätzung_Macro.sas
Toleranzschätzung.sas

74
Zufallsstichproben:
o sample_na_allg_40.sas7bdat
o sample_na_allg_120.sas7bdat
o sample_na_allg_2000.sas7bdat
o sample_ha_allg_40.sas7bdat
o sample_ha_allg_120.sas7bdat
o sample_ha_allg_2000.sas7bdat
o sample_kr_allg_40.sas7bdat
o sample_kr_allg_120.sas7bdat
o sample_kr_allg_2000.sas7bdat
o sample_kr_0J_40.sas7bdat
o sample_kr_0J_120.sas7bdat
o sample_kr_1bis3J_40.sas7bdat
o sample_kr_1bis3J_120.sas7bdat
o sample_kr_4bis6J_40.sas7bdat
o sample_kr_4bis6J_120.sas7bdat
o sample_kr_7bis9J_40.sas7bdat
o sample_kr_7bis9J_120.sas7bdat
o sample_kr_10bis12J_40.sas7bdat
o sample_kr_10bis12J_120.sas7bdat
o sample_kr_13bis15J_40.sas7bdat
o sample_kr_13bis15J_120.sas7bdat
o sample_kr_16bis18J_40.sas7bdat
o sample_kr_16bis18J_120.sas7bdat
o sample_kr_M19bis50J_40.sas7bdat
o sample_kr_M19bis50J_120.sas7bdat
o sample_kr_M51bis100J_40.sas7bdat
o sample_kr_M51bis100J_120.sas7bdat
o sample_kr_F19bis100J_40.sas7bdat
o sample_kr_F19bis100J_120.sas7bdat

75
4 Ergebnisse
4.1 Plausibilitätsprüfungen
Sämtliche in Absatz 3.6 aufgelisteten Kontrollmaßnahmen wurden im Programm
SAS® Enterprise Guide 4.3 unter Zuhilfenahme der darin angebotenen Oberflächen-
anwendungen vorgenommen. Die nachfolgenden Resultate der deskriptiven Unter-
suchung der Rohdaten inkludieren fehlende Werte, welche erst im nächsten Schritt
der Datenaufbereitung (siehe 4.2) ausgeschlossen wurden.
4.1.1 Geschlecht
Die Plausibilitätsprüfung für die Variable GESCHLECHT ergab, dass keine anderen
Werte als 1 (männlich) oder 2 (weiblich) fälschlicherweise in den Patientendaten ein-
getragen wurden (siehe Tabelle 8). Es bestehen 16 Datensätze ohne Angabe zum
Geschlecht, welche zur Stichprobenziehung exkludiert werden mussten.
Tabelle 8: Zusammenfassung der kategorischen Variable GESCHLECHT
Variable Wert Absolute Häufigkeit Prozentuale Häufigkeit
GESCHLECHT 1 5.141 47,17 %
2 5.742 52,68 %
***Fehlt*** 16 0,15 %
4.1.2 Alter
Die Plausibilitätskontrolle für die Variable ALTER ergab, dass keine unplausibelen
Altersangaben unter 0 oder über 100 Jahre existieren (siehe Tabelle 9).
Tabelle 9: Zusammenfassung der numerischen Variablen
Variable Absolute Häufigkeit
fehlende Werte
Minimum Mittelwert Median Maximum
ALTER 10.899 0 0 34,91 34,0 97
PATIENTENNR 10.671 228
NATRIUM 9.459 1.440 119,0 139,28 139,0 157,0
HARNSTOFF 6.078 4.821 0,2 4,59 4,2 36,0
KREA 9.107 1.792 4,0 66,65 66,0 568,0
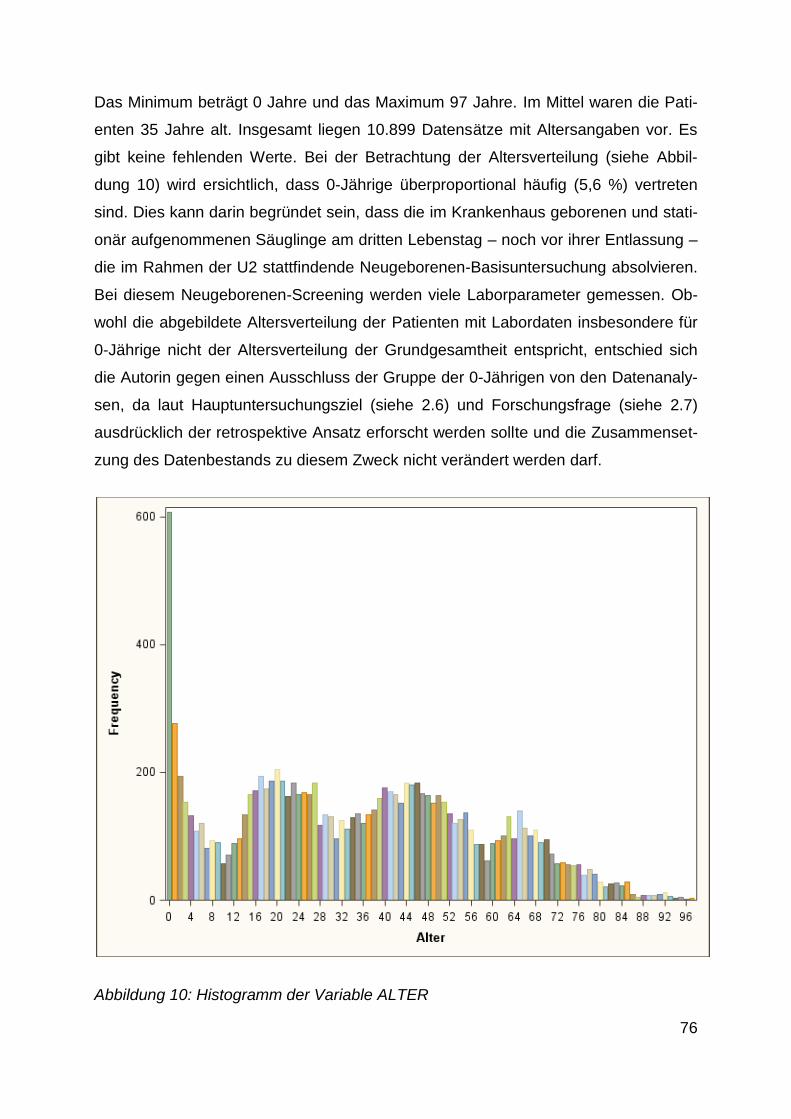
76
Das Minimum beträgt 0 Jahre und das Maximum 97 Jahre. Im Mittel waren die Pati-
enten 35 Jahre alt. Insgesamt liegen 10.899 Datensätze mit Altersangaben vor. Es
gibt keine fehlenden Werte. Bei der Betrachtung der Altersverteilung (siehe Abbil-
dung 10) wird ersichtlich, dass 0-Jährige überproportional häufig (5,6 %) vertreten
sind. Dies kann darin begründet sein, dass die im Krankenhaus geborenen und stati-
onär aufgenommenen Säuglinge am dritten Lebenstag – noch vor ihrer Entlassung –
die im Rahmen der U2 stattfindende Neugeborenen-Basisuntersuchung absolvieren.
Bei diesem Neugeborenen-Screening werden viele Laborparameter gemessen. Ob-
wohl die abgebildete Altersverteilung der Patienten mit Labordaten insbesondere für
0-Jährige nicht der Altersverteilung der Grundgesamtheit entspricht, entschied sich
die Autorin gegen einen Ausschluss der Gruppe der 0-Jährigen von den Datenanaly-
sen, da laut Hauptuntersuchungsziel (siehe 2.6) und Forschungsfrage (siehe 2.7)
ausdrücklich der retrospektive Ansatz erforscht werden sollte und die Zusammenset-
zung des Datenbestands zu diesem Zweck nicht verändert werden darf.
Abbildung 10: Histogramm der Variable ALTER
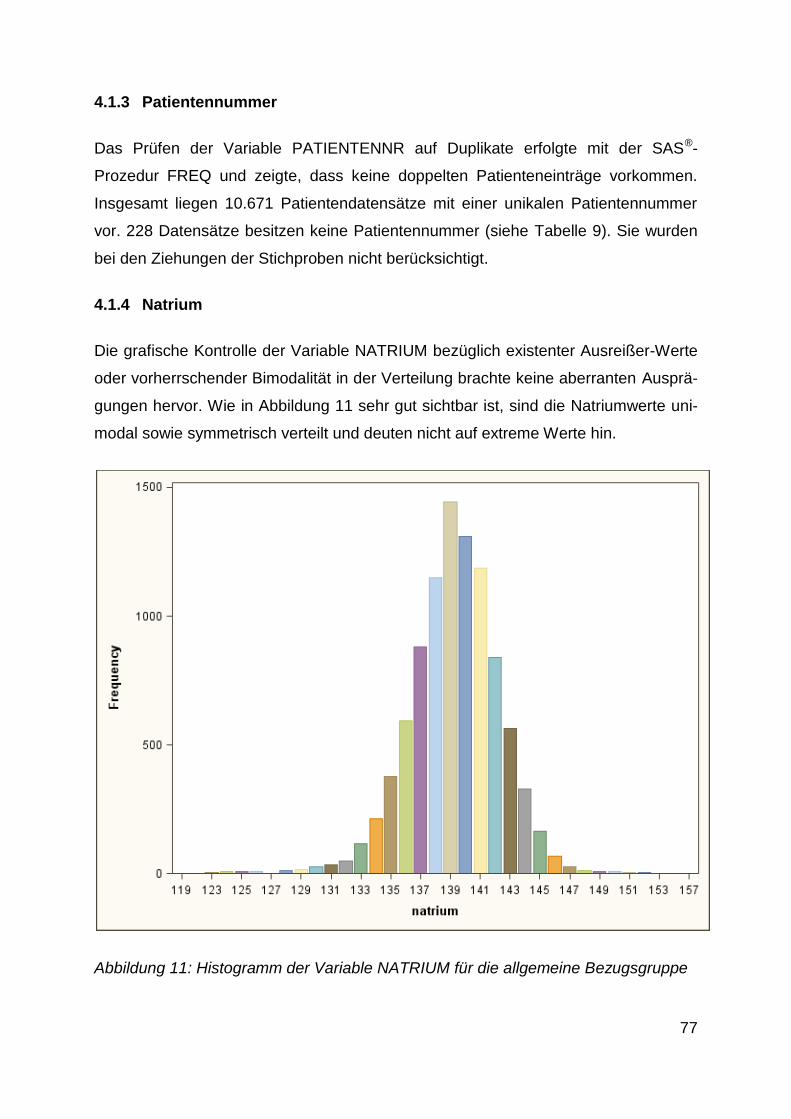
77
4.1.3 Patientennummer
Das Prüfen der Variable PATIENTENNR auf Duplikate erfolgte mit der SAS®-
Prozedur FREQ und zeigte, dass keine doppelten Patienteneinträge vorkommen.
Insgesamt liegen 10.671 Patientendatensätze mit einer unikalen Patientennummer
vor. 228 Datensätze besitzen keine Patientennummer (siehe Tabelle 9). Sie wurden
bei den Ziehungen der Stichproben nicht berücksichtigt.
4.1.4 Natrium
Die grafische Kontrolle der Variable NATRIUM bezüglich existenter Ausreißer-Werte
oder vorherrschender Bimodalität in der Verteilung brachte keine aberranten Ausprä-
gungen hervor. Wie in Abbildung 11 sehr gut sichtbar ist, sind die Natriumwerte uni-
modal sowie symmetrisch verteilt und deuten nicht auf extreme Werte hin.
Abbildung 11: Histogramm der Variable NATRIUM für die allgemeine Bezugsgruppe

78
Wie in Tabelle 9 aufgeführt wird, standen insgesamt 9.459 Natriumwerte für die
Stichprobenziehungen zur Verfügung. Die 1.440 Datensätze mit fehlenden Natrium-
werten wurden dabei nicht eingeschlossen. Der Minimum-Wert für NATRIUM beträgt
119,0 mmol/l. Der Maximum-Wert für NATRIUM ist 157,0 mmol/l. Mittelwert und Me-
dian liegen dicht beieinander bei 139 mmol/l. Verglichen mit dem Referenzbereich für
Natrium für die allgemeine Bezugsgruppe von 135 bis 145 mmol/l aus dem Laborka-
talog von dem Institut für Klinische Chemie und Laboratoriumsmedizin der Ernst-
Moritz-Arndt-Universität Greifswald (siehe Tabelle 4) liegen scheinbar keine gravie-
rend abnormen Werte vor.
4.1.5 Harnstoff
Die Variable HARNSTOFF umfasst 6.078 Laborwerte. In 4.821 Patientendatensätzen
fehlen Harnstoffwerte, welche infolgedessen in den nachstehenden Analysen Aus-
schluss fanden. Mittelwert (4,59 mmol/l) und Median (4,2 mmol/l) liegen annähernd
beisammen. Die Untersuchung der Variable HARNSTOFF in Bezug auf bestehende
Ausreißer-Werte ergab Folgendes: Die Variable HARNSTOFF weist ein Minimum-
Wert von 0,2 mmol/l und einen Maximum-Wert von 36,0 mmol/l auf (siehe Tabelle 9).
Dem Vergleich mit dem Referenzbereich für Harnstoff für die allgemeine Bezugs-
gruppe von 2,5 bis 6,4 mmol/l aus dem Laborkatalog der Universitätsmedizin Greifs-
wald (siehe Tabelle 4) zufolge liegen offensichtlich beachtenswerte Abweichungen
von der oberen Referenzgrenze und somit vermutlich Ausreißer-Werte vor. Die IFCC
definiert Ausreißer in ihrer Richtlinie Approved Recommendation (1987) on the Theo-
ry of Reference Values. Part 5. Statistical Treatment of Collected Reference Values.
Determination of Reference Limits als Werte, die sich unerwartet weit weg von den
meisten anderen Referenzwerten befinden und empfiehlt als zuverlässige Methode
zur Begutachtung und Identifikation von Ausreißern die visuelle Inspektion des His-
togramms des Parameters (6). Das Histogramm der Variable HARNSTOFF zeigt
keine einzelnen Werte, die fernab stehen (siehe Abbildung 12), was zu dem Schluss
führen könnte, dass keine extremen Ausreißer-Werte existieren. Jedoch lässt das
Histogramm eine bimodale Verteilung erkennen. Bimodalität in der Verteilung der
Laborwerte eines Parameters ist ein starker Hinweis auf eine inhomogene Untersu-
chungsgruppe.

79
Abbildung 12: Histogramm der Variable HARNSTOFF für die allgemeine Bezugs-
gruppe – vor der Trunkierung
Da das Alter und das Geschlecht den Informationen des Laborkataloges der Univer-
sitätsmedizin Greifswald gemäß keinen erheblichen Einfluss auf den Referenzbe-
reich von Harnstoff und insofern auch auf die Verteilung der Referenzwerte ausübt,
kann diese bimodale Verteilung der Laborwerte bedeuten, dass die Datenmenge so-
wohl Gesunde als auch Kranke repräsentiert. Obwohl die Patienten der Stichprobe
mit Blick auf die ICD-Klassifikation der Enddiagnose als Nieren-gesund ausgewählt
wurden, könnten andere Erkrankungen oder medikamentöse Behandlungen unbe-
kannte Auswirkungen auf die Harnstoffwerte der Patienten haben. Beispielsweise
wird die Bestimmung des Harnstoffspiegels neben der „Überprüfung der Nierenfunk-
tion […] zudem als Kontrollparameter […] bei der Gabe nephrotoxischer Medikamen-
te wie Z tostatika (Cisplatin) und Antibiotika (Aminogl koside)“ eingesetzt [(39),
S. 54]. Des Weiteren können zu hohe Harnstoffwerte auf „übermäßige Eiweiß-
Aufnahme mit der Nahrung und hohes Fieber hindeuten“ [(80), S. 1]. Demzufolge

80
fällte die Autorin den Entschluss, die in der Grafik rechts gelegene, kleinere Vertei-
lungskurve (siehe Abbildung 12) als die der Kranken zu interpretieren – da diese
Werte weit oberhalb der oberen Referenzgrenze von 6,4 mmol/l (siehe Tabelle 4)
liegen – und diese als Ausreißer-Werte von den weiterführenden Analysen auszu-
schließen. Eine mehrgipflige Verteilungsform verlangt eine Verteilungszerlegung.
Dafür wurde der Cutoff-Wert von 9,5 festgelegt. Demgemäß wurden alle Laborwerte
größer oder gleich 9,6 im weiteren Verlauf nicht evaluiert. Nach der Trunkierung der
Verteilung entstand eine neue Verteilungsform der Harnstoffwerte, die in Abbildung
13 dargestellt ist. Insgesamt wurden 165 Patienten mit zu hohen Harnstoffwerten
ausgeschlossen, so dass 5.913 Harnstoffwerte im Patientendatenbestand verblie-
ben. Mittelwert (4,31 mmol/l) und Median (4,1 mmol/l) haben sich erwartungsgemäß
einander mehr angenähert. Der Minimum-Wert liegt unverändert bei 0,2 mmol/l. Der
neue Maximum-Wert beträgt nun 9,5 mmol/l.
Abbildung 13: Histogramm der Variable HARNSTOFF – nach der Trunkierung

81
4.1.6 Kreatinin
Die Variable KREA enthält 9.107 Datensätze mit Kreatininwerten sowie 1.792 Da-
tensätze ohne Kreatininwerte, welche im Datenaufbereitungsschritt ausgeschlossen
wurden (siehe Abschnitt 4.2). Der niedrigste Kreatininwert ist mit 4,0 µmol/l und der
höchste Kreatininwert mit 568,0 µmol/l angegeben (siehe Tabelle 9). Im Vergleich
zum Laborkatalog der Universitätsmedizin Greifswald, in welchem der niedrigste
Wert für die untere Referenzgrenze einer Subgruppe 35 µmol/l ist und der höchste
Wert für die obere Referenzgrenze einer Subgruppe 127 µmol/l beträgt (siehe Tabel-
le 4), weichen die Minimum- und Maximum-Werte der Kreatininwerte des Patienten-
datenbestands – im Speziellen von der oberen Referenzgrenze – außergewöhnlich
ab, was ein Indiz für Ausreißer-Werte sein könnte. Gleichwohl ist Folgendes zu be-
denken: „Zu hohe Kreatinin-Werte können auf eine Nierenschwäche, Verletzungen
der Muskulatur, Muskeldystrophie oder eine Entzündung der Haut und Muskulatur
(Dermatomyositis, Polymyositis) hindeuten. Auch nach Sport, Krampfanfällen und
nach Injektionen in die Muskulatur (z.B. Impfungen) können die Werte erhöht sein“
[(80), S. 1]. Überdies steigt der Kreatininwert proportional zur Muskelmasse, „was bei
der Interpretation erhöhter Serumwerte zu berücksichtigen ist“ [(39), S. 54]. Aus die-
sen voranstehend genannten Gründen sowie der Unkenntnis der Begleitumstände
der Patienten – wie zum Beispiel vorhandene Muskelmasse, sportliche Aktivitäten,
Krämpfe oder Impfreaktionen im Muskel – entschied sich die Autorin, die hohen Kre-
atininwerte nicht als Ausreißer-Werte zu erklären. Sie verblieben im Datenvolumen,
um eine unverfälschte Repräsentativität der Grundgesamtheit zu ermöglichen.
Die Lageparameter Mittelwert (66,65 µmol/l) und Median (66,0 µmol/l) zeigen einan-
der ähnelnde Werte an (siehe Tabelle 9). Bei dem Abgleich mit dem Referenzbereich
für Kreatinin von 58 bis 127 µmol/l für die allgemeine Bezugsgruppe laut dem Labor-
katalog der Universitätsmedizin Greifswald (siehe Tabelle 4) war auffällig, dass die
Verteilung der vorliegenden Kreatininwerte nach links verschoben erscheint (siehe
Abbildung 14), denn entsprechend der Referenzintervalle des Laborkatalogs der
Universitätsmedizin Greifswald würde der Mittelwert beziehungsweise Median für die
allgemeine Bezugsgruppe etwa zwischen 92 und 93 µmol/l liegen – und nicht zwi-
schen 66 und 67 µmol/l, wie in der folgenden Grafik zu beobachten ist.

82
Abbildung 14: Histogramm der Variable KREA für die allgemeine Bezugsgruppe
Das Prüfen des Histogramms des Parameters KREA auf Mehrgipfligkeit zeigte auf
den erst Blick keine eindeutige unimodale Verteilung der Kreatininwerte (siehe Abbil-
dung 14). Eher schienen die Beobachtungswerte zu zwei sich gegenseitig überlap-
penden Verteilungen zu gehören und bimodale Formen anzunehmen – eine kleinere
Glockenkurve links sowie eine große Glockenkurve mittig, was auf eine heterogene
Untersuchungsgruppe hingewiesen hätte. Auf den zweiten Blick jedoch ließ sich die
nicht klare unimodale Verteilungskurve der Kreatininwerte den unterschiedlichen Ein-
flüssen der Größen Alter und Geschlecht zuschreiben. Die Abbildung 15 veranschau-
licht die einzelnen Verteilungen der Kreatininwerte für die nach dem Laborkatalog der
Universitätsmedizin Greifswald eingeteilten Subgruppen. Hieran wird ersichtlich, dass
die Kreatininwerte von allen Kindern bis zu dem Alter von circa 18 Jahren einer ande-
ren Verteilung folgen (breiter und niedriger) als die gesamten Kreatininwerte der Er-
wachsenen ab dem Alter von 19 Jahren (schmaler und höher).

83
Bezugsgruppe: 0 Jahre
vgl. Referenzbereich (43): 35 - 62 µmol/l
Bezugsgruppe: 1 - 3 Jahre
vgl. Referenzbereich (43): 35 - 62 µmol/l
Bezugsgruppe: 4 - 6 Jahre
vgl. Referenzbereich (43): 44 - 71 µmol/l
Bezugsgruppe: 7 - 9 Jahre
vgl. Referenzbereich (43): 53 - 80 µmol/l
Bezugsgruppe: 10 - 12 Jahre
vgl. Referenzbereich (43): 53 - 88 µmol/l
Bezugsgruppe: 13 - 15 Jahre
vgl. Referenzbereich (43): 53 - 106 µmol/l

84
Bezugsgruppe: 16 - 18 Jahre
vgl. Referenzbereich (43): 71 - 123 µmol/l
Bezugsgruppe: Frauen ab 19 Jahre bis ins Alter
vgl. Referenzbereich (43): 58 - 96 µmol/l
Bezugsgruppe: Männer 19 - 50 Jahre
vgl. Referenzbereich (43): 74 - 110 µmol/l
Bezugsgruppe: Männer ab 51 Jahre bis ins Alter
vgl. Referenzbereich (43): 72 - 127 µmol/l
Abbildung 15: Histogramme der Variable KREA für vordefinierte Subgruppen
Die Abbildung 15 weist zudem darauf hin, dass besonders die 7- bis ungefähr
12-Jährigen in den Patientendaten unterrepräsentiert sind. Die Verteilung der Krea-
tininwerte der Erwachsenen gleicht dem Referenzbereich des Laborkatalogs der Uni-
versitätsmedizin Greifswald für Kreatinin für die allgemeine Bezugsgruppe am ehes-
ten. Diese in Abbildung 15 demonstrierte Abhängigkeit der Laborwerte von dem Ge-
schlecht und dem Alter der Patienten kann – sobald einige Subgruppen weniger
stark vertreten sind als andere – die sich in Abbildung 14 abgezeichnete Verschie-
bung beziehungsweise Verzerrung in der Verteilungskurve der Kreatininwerte für die
allgemeine Bezugspopulation verursacht haben.

85
4.2 Datenaufbereitung
Die Vorbereitung der Daten für die anstehenden Analysen erfolgte ebenfalls im SAS®
Enterprise Guide 4.3 mittels der Oberflächenanwendungen des Programms.
4.2.1 Datenpakete
Nachdem aus der Quelldatei Labordaten.sas7bdat, welche ursprünglich die unter 3.3
aufgezählten 26 Spalten enthielt, nur die sechs zu betrachtenden Variablen ALTER,
GESCHLECHT, HARNSTOFF, KREA, NATRIUM und PATIENTENNR herausgefiltert
wurden, um die in Abschnitt 4.1 angeführten Plausibilitätsprüfungen sowie deskripti-
ven Statistiken durchführen zu können, folgte als nächstes der Ausschluss jeglicher
Datensätze, die keine Alters- oder Geschlechtsangaben besaßen oder die keine Pa-
tientennummer hatten. Auf dieser Grundlage wurden anschließend drei Datenpakte
gebildet, wobei jeweils nur die Datensätze herausgefiltert und genutzt wurden, die
keine fehlenden Werte in den betreffenden Spalten ‚HARNSTOFF‘, ‚KREA‘ bezie-
hungsweise ‚NATRIUM‘ aufwiesen.
Das erste Datenpaket namens ALLGEMEIN NATRIUM enthält die Variablen ALTER,
GESCHLECHT, NATRIUM und PATIENTENNR. Insgesamt liegen – nach den vo-
rangehend erläuterten Ausschlüssen von Datensätzen mit fehlenden Werten –
9.259 Patientendatensätze mit Angaben zum Alter und Geschlecht sowie je einem
Natriumwert und einer Patientennummer vor, von denen 49,02 % männlich und
50,98 % weiblich sind. Die Minimum-, Maximum-, Median- und Mittelwerte der Vari-
ablen NATRIUM und ALTER blieben unverändert (siehe 4.1.2 und 4.1.4) – bis auf
den Fakt, dass das mittlere Alter der Patienten nun 37 Jahre beträgt.
Das zweite Datenpaket namens ALLGEMEIN HARNSTOFF umfasst die Variablen
ALTER, GESCHLECHT, HARNSTOFF und PATIENTENNR. Insgesamt existieren –
nach den zuvor dargelegten Ausschlüssen von Datensätzen mit fehlenden Einträgen
– 5.808 Patientendatensätze mit Angaben zum Alter und Geschlecht sowie je einem
Harnstoffwert und einer Patientennummer, von denen 53,22 % männlich und
46,78 % weiblich sind. Die Minimum-, Maximum-, Median- und Mittelwerte der Vari-
ablen HARNSTOFF und ALTER blieben im Vergleich zu den Werten nach der Trun-

86
kierung der Verteilung unverändert (siehe 4.1.2 und 4.1.5) – bis auf die Gegebenheit,
dass das mittlere Alter der Patienten nun bei 33 Jahren liegt.
Das dritte Datenpaket mit dem Namen ALLGEMEIN KREA besteht aus den Variab-
len ALTER, GESCHLECHT, KREA und PATIENTENNR. Insgesamt gibt es – nach
den vorherig aufgezeigten Ausschlüssen von Datensätzen mit fehlenden Daten –
8.912 Patientendatensätze mit Angaben zum Alter und Geschlecht sowie je einem
Kreatininwert und einer Patientennummer, von denen 49,14 % männlich und
50,86 % weiblich sind. Die Minimum-, Maximum-, Median- und Mittelwerte der Vari-
ablen KREA und ALTER blieben nahezu alle gleich (siehe 4.1.2 und 4.1.6) – bis auf
das mittlere Alter der Patienten, welches nun 37 Jahre ist.
4.2.2 Subgruppen
Entsprechend des Analyseschemas, welches unter 3.4.2 vorgestellt wurde, geht aus
dem Datenpaket NATRIUM eine Subgruppe für die allgemeine Bezugsgruppe hervor,
aus dem Datenpaket HARNSTOFF entsteht gleichfalls eine Subgruppe für die allge-
meine Bezugsgruppe, und aus dem Datenpaket KREATININ werden 10 geschlechts-
und altersspezifische Subgruppen sowie eine Subgruppe für die allgemeine Bezugs-
gruppe gebildet. Die drei allgemeinen Subgruppen aus den Datenpakten HARN-
STOFF, NATRIUM und KREATININ, die jedes Alter und jedes Geschlecht abdecken,
wurden bereits in Absatz 4.2.1 ausführlich beschrieben. An dieser Stelle sollen er-
gänzend die 10 geschlechts- und altersspezifischen Subgruppen aus dem Datenpa-
ket KREATININ deskriptiv erfasst werden.
Die 10 nach Alter und teilweise auch Geschlecht stratifizierten Subgruppen für den
Parameter KREATININ wurden wie folgt aufgegliedert (in Anlehnung an Tabelle 4):
0 Jahre, 1 bis 3 Jahre, 4 bis 6 Jahre, 7 bis 9 Jahre, 10 bis 12 Jahre, 13 bis 15 Jahre,
16 bis 18 Jahre, Frauen: 19 Jahre bis ins Alter, Männer: 19 bis 50 Jahre, Männer:
51 Jahre bis ins Alter. Da der Maximum-Wert der Variable ALTER 97 beträgt (siehe
4.1.2), wurde der Ausdruck ‚bis ins Alter‘ durch den Wert 100 operationalisiert. Die
Gruppe der 0-Jährigen repräsentiert – in Ermangelung von Tages- und Monatsanga-
ben im Datenbestand – die zwei Bezugsgruppen ‚bis 30 Tage‘ sowie ‚1 bis 11 Mona-
te‘ aus dem Laborkatalog der Universitätsmedizin Greifswald (43). In Tabelle 10 sind

87
die charakterisierenden Daten je alters- und geschlechtsspezifischer Subgruppe zu-
sammenfassend dargestellt.
Tabelle 10: Deskriptive Zusammenfassung der geschlechts- und altersspezifischen
Subgruppen für den Parameter KREATININ
GESCHLECHT ALTER KREATININ
Subgruppe N männlich weiblich Min Mittel Median Max Min Mittel Median Max
0 J. 452 53,76% 46,24% 0 0,00 0,0 0 4 31,94 30,0 134
1 bis 3 J. 525 55,43% 44,57% 1 1,78 2,0 3 8 32,79 32,0 64
4 bis 6 J. 293 57,00% 43,00% 4 4,98 5,0 6 15 39,41 39,0 116
7 bis 9 J. 221 55,20% 44,80% 7 8,02 8,0 9 19 46,51 46,0 82
10 bis 12 J. 187 57,75% 42,25% 10 11,15 11,0 12 28 54,54 55,0 95
13 bis 15 J. 340 48,82% 51,18% 13 14,16 14,0 15 30 62,95 63,0 111
16 bis 18 J. 434 46,31% 53,69% 16 16,98 17,0 18 23 69,06 68,5 126
Männer: 19 bis 50 J.
1.785 100,00% 0,00% 19 35,52 37,0 50 27 80,10 79,0 365
Männer: 51 bis 100 J.
1.296 100,00% 0,00% 51 63,85 63,0 94 25 85,26 81,0 568
Frauen: 19 bis 100 J.
3.379 0,00% 100,00% 19 46,27 45,0 97 16 66,42 64,0 426
Die insgesamt 13 Subgruppen stellten die Datenbasis für die darauffolgenden Zie-
hungen der Zufallsstichproben dar, welche fortan als Untersuchungsgruppen dienten.
4.2.3 Zufallsstichproben
Wie aus Tabelle 10 abzuleiten ist, konnten für die überwiegende Zahl der Subgrup-
pen des Parameters KREATININ keine Stichproben im Umfang von N = 2.000 gezo-
gen werden, da alle Subgruppen – mit der Ausnahme von einer – über weitaus weni-
ger Datensätze als 2.000 verfügen. Aus diesem Grund wurden nur 29 Untersu-
chungsgruppen durch einfache Zufallsstichproben gebildet, anstatt 39 – wie anfäng-
lich laut Analyseschema angedacht wurde (siehe 3.4.2). Tabelle 11 charakterisiert
die entstandenen 29 Untersuchungsgruppen, welche im weiteren Verlauf als Refe-
renzpopulationen mit ihren Referenzwerten zur Bestimmung von Referenzbereichen
eingesetzt werden (siehe Liste der Zufallsstichproben unter Punkt 3.8).
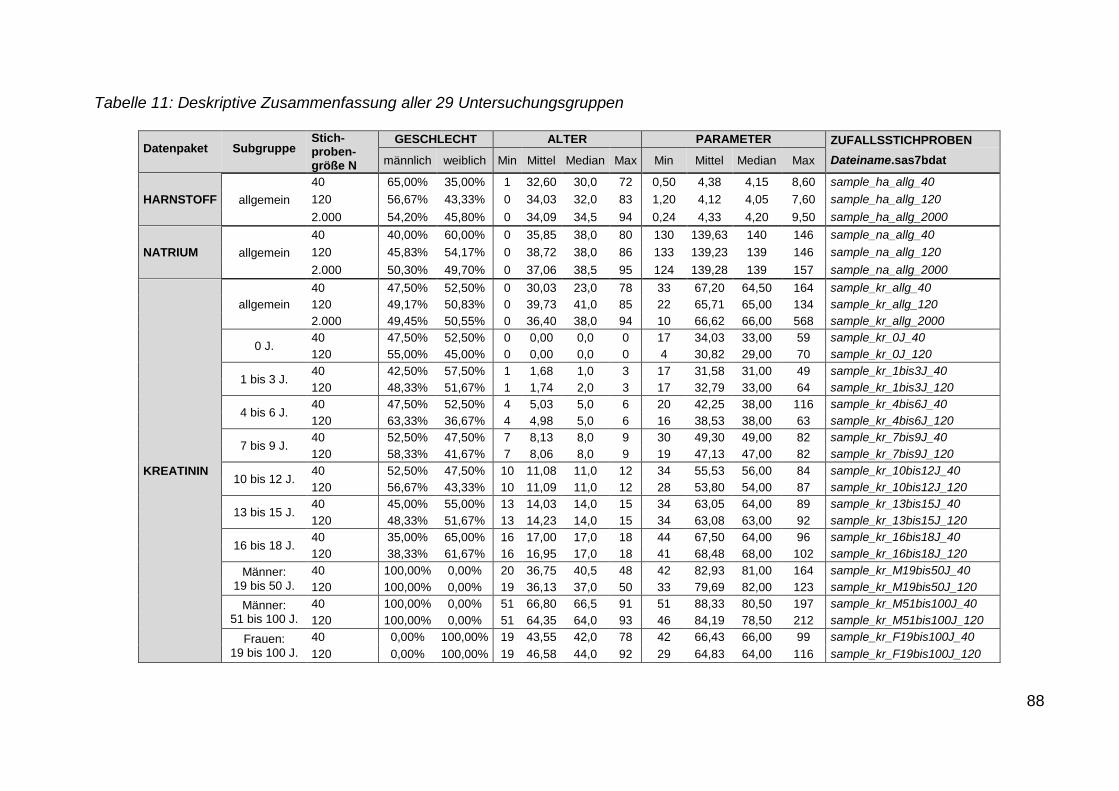
88
Tabelle 11: Deskriptive Zusammenfassung aller 29 Untersuchungsgruppen
Datenpaket Subgruppe Stich- proben- größe N
GESCHLECHT ALTER PARAMETER ZUFALLSSTICHPROBEN
männlich weiblich Min Mittel Median Max Min Mittel Median Max Dateiname.sas7bdat
HARNSTOFF allgemein
40 65,00% 35,00% 1 32,60 30,0 72 0,50 4,38 4,15 8,60 sample_ha_allg_40
120 56,67% 43,33% 0 34,03 32,0 83 1,20 4,12 4,05 7,60 sample_ha_allg_120
2.000 54,20% 45,80% 0 34,09 34,5 94 0,24 4,33 4,20 9,50 sample_ha_allg_2000
NATRIUM allgemein
40 40,00% 60,00% 0 35,85 38,0 80 130 139,63 140 146 sample_na_allg_40
120 45,83% 54,17% 0 38,72 38,0 86 133 139,23 139 146 sample_na_allg_120
2.000 50,30% 49,70% 0 37,06 38,5 95 124 139,28 139 157 sample_na_allg_2000
KREATININ
allgemein
40 47,50% 52,50% 0 30,03 23,0 78 33 67,20 64,50 164 sample_kr_allg_40
120 49,17% 50,83% 0 39,73 41,0 85 22 65,71 65,00 134 sample_kr_allg_120
2.000 49,45% 50,55% 0 36,40 38,0 94 10 66,62 66,00 568 sample_kr_allg_2000
0 J. 40 47,50% 52,50% 0 0,00 0,0 0 17 34,03 33,00 59 sample_kr_0J_40
120 55,00% 45,00% 0 0,00 0,0 0 4 30,82 29,00 70 sample_kr_0J_120
1 bis 3 J. 40 42,50% 57,50% 1 1,68 1,0 3 17 31,58 31,00 49 sample_kr_1bis3J_40
120 48,33% 51,67% 1 1,74 2,0 3 17 32,79 33,00 64 sample_kr_1bis3J_120
4 bis 6 J. 40 47,50% 52,50% 4 5,03 5,0 6 20 42,25 38,00 116 sample_kr_4bis6J_40
120 63,33% 36,67% 4 4,98 5,0 6 16 38,53 38,00 63 sample_kr_4bis6J_120
7 bis 9 J. 40 52,50% 47,50% 7 8,13 8,0 9 30 49,30 49,00 82 sample_kr_7bis9J_40
120 58,33% 41,67% 7 8,06 8,0 9 19 47,13 47,00 82 sample_kr_7bis9J_120
10 bis 12 J. 40 52,50% 47,50% 10 11,08 11,0 12 34 55,53 56,00 84 sample_kr_10bis12J_40
120 56,67% 43,33% 10 11,09 11,0 12 28 53,80 54,00 87 sample_kr_10bis12J_120
13 bis 15 J. 40 45,00% 55,00% 13 14,03 14,0 15 34 63,05 64,00 89 sample_kr_13bis15J_40
120 48,33% 51,67% 13 14,23 14,0 15 34 63,08 63,00 92 sample_kr_13bis15J_120
16 bis 18 J. 40 35,00% 65,00% 16 17,00 17,0 18 44 67,50 64,00 96 sample_kr_16bis18J_40
120 38,33% 61,67% 16 16,95 17,0 18 41 68,48 68,00 102 sample_kr_16bis18J_120
Männer: 19 bis 50 J.
40 100,00% 0,00% 20 36,75 40,5 48 42 82,93 81,00 164 sample_kr_M19bis50J_40
120 100,00% 0,00% 19 36,13 37,0 50 33 79,69 82,00 123 sample_kr_M19bis50J_120
Männer: 51 bis 100 J.
40 100,00% 0,00% 51 66,80 66,5 91 51 88,33 80,50 197 sample_kr_M51bis100J_40
120 100,00% 0,00% 51 64,35 64,0 93 46 84,19 78,50 212 sample_kr_M51bis100J_120
Frauen: 19 bis 100 J.
40 0,00% 100,00% 19 43,55 42,0 78 42 66,43 66,00 99 sample_kr_F19bis100J_40
120 0,00% 100,00% 19 46,58 44,0 92 29 64,83 64,00 116 sample_kr_F19bis100J_120

89
4.3 Referenzbereiche
Alle Referenzgrenzen für die gesuchten Referenzbereiche zu den in Tabelle 11 an-
geführten 29 Untersuchungsgruppen wurden mit Hilfe der Statistiksoftware SAS® für
Windows in der Version 9.2 berechnet.
4.3.1 Quantil-Intervall mit Konfidenzintervallen
Die Bestimmung der Referenzbereiche für alle 29 Untersuchungsgruppen erfolgte als
erste zu untersuchende Methode durch die Bildung von Quantil-Intervallen mittels der
SAS®-Prozedur PROC UNIVARIATE, indem die jeweiligen 2,5- und 97,5-Perzentile
der Referenzverteilungen ermittelt wurden. Als Definition für die Berechnung der
Perzentile wurde die PCTLDEF-Option 2 gewählt (77). Der SAS®-Quellcode hierfür
wurde von der Autorin verfasst (siehe Quantilschätzung_Macro.sas unter Punkt 3.8).
Die zu den gewonnenen 0,025- sowie 0,975-Quantilen gehörigen nicht-
parametrischen 0,90-Konfidenzintervalle wurden unter Zuhilfenahme eines SAS®-
Skriptes erzeugt, welches der Autorin für diesen Untersuchungszweck von dem Insti-
tut für Biometrie und Medizinische Informatik der Medizinischen Fakultät der Ernst-
Moritz-Arndt-Universität Greifswald zur Verwendung freigestellt wurde und das sie
leicht modifizierte. Die Namen der Programmierer und Mitwirkenden werden im Hea-
der des Skriptes genannt (siehe Konfidenzbereiche.sas unter Punkt 3.8).
Die im ersten Programmschritt angewendete SAS®-Prozedur PROC UNIVARIATE
lieferte konkrete Parameter-Werte als Ergebnisse. Der zweite Programmschritt hin-
gegen erzielte ausschließlich die Rangnummern der Konfidenzgrenzen als Ergebnis.
Infolgedessen musste als letzter Schritt die Zuweisung der entsprechenden, geord-
neten und mit Rangnummern versehenen Parameter-Werte aus den Zufallsstichpro-
ben zu den Rangzahlen der Konfidenzgrenzen für jede Untersuchungsgruppe je
Quantil durchgeführt werden. Diese Zuordnung wurde manuell anhand der jeweiligen
Rangzahl aus der extra vorab im Programm generierten Spalte ‚RANGNR‘ in den
Tabellen der einzelnen Untersuchungsgruppen verrichtet.
Die hieraus resultierenden Referenzgrenzen inklusive ihrer Konfidenzintervalle (KI)
für die gesamten 29 Untersuchungsgruppen wurden in Tabelle 12 festgehalten.
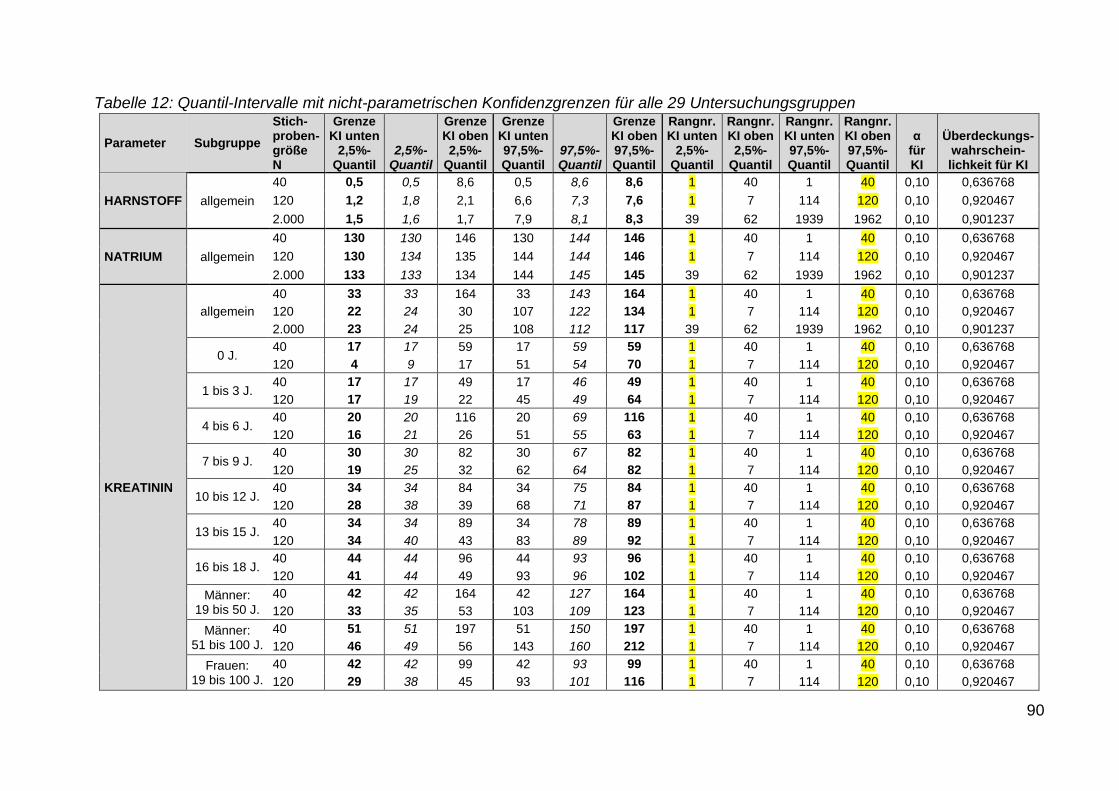
90
Tabelle 12: Quantil-Intervalle mit nicht-parametrischen Konfidenzgrenzen für alle 29 Untersuchungsgruppen
Parameter Subgruppe
Stich- proben- größe N
Grenze KI unten
2,5%-Quantil
2,5%-Quantil
Grenze KI oben 2,5%-
Quantil
Grenze KI unten 97,5%-Quantil
97,5%-Quantil
Grenze KI oben 97,5%-Quantil
Rangnr. KI unten
2,5%-Quantil
Rangnr. KI oben 2,5%-
Quantil
Rangnr. KI unten 97,5%-Quantil
Rangnr. KI oben 97,5%-Quantil
α für KI
Überdeckungs- wahrschein- lichkeit für KI
HARNSTOFF allgemein
40 0,5 0,5 8,6 0,5 8,6 8,6 1 40 1 40 0,10 0,636768
120 1,2 1,8 2,1 6,6 7,3 7,6 1 7 114 120 0,10 0,920467
2.000 1,5 1,6 1,7 7,9 8,1 8,3 39 62 1939 1962 0,10 0,901237
NATRIUM allgemein
40 130 130 146 130 144 146 1 40 1 40 0,10 0,636768
120 130 134 135 144 144 146 1 7 114 120 0,10 0,920467
2.000 133 133 134 144 145 145 39 62 1939 1962 0,10 0,901237
KREATININ
allgemein
40 33 33 164 33 143 164 1 40 1 40 0,10 0,636768
120 22 24 30 107 122 134 1 7 114 120 0,10 0,920467
2.000 23 24 25 108 112 117 39 62 1939 1962 0,10 0,901237
0 J. 40 17 17 59 17 59 59 1 40 1 40 0,10 0,636768
120 4 9 17 51 54 70 1 7 114 120 0,10 0,920467
1 bis 3 J. 40 17 17 49 17 46 49 1 40 1 40 0,10 0,636768
120 17 19 22 45 49 64 1 7 114 120 0,10 0,920467
4 bis 6 J. 40 20 20 116 20 69 116 1 40 1 40 0,10 0,636768
120 16 21 26 51 55 63 1 7 114 120 0,10 0,920467
7 bis 9 J. 40 30 30 82 30 67 82 1 40 1 40 0,10 0,636768
120 19 25 32 62 64 82 1 7 114 120 0,10 0,920467
10 bis 12 J. 40 34 34 84 34 75 84 1 40 1 40 0,10 0,636768
120 28 38 39 68 71 87 1 7 114 120 0,10 0,920467
13 bis 15 J. 40 34 34 89 34 78 89 1 40 1 40 0,10 0,636768
120 34 40 43 83 89 92 1 7 114 120 0,10 0,920467
16 bis 18 J. 40 44 44 96 44 93 96 1 40 1 40 0,10 0,636768
120 41 44 49 93 96 102 1 7 114 120 0,10 0,920467
Männer: 19 bis 50 J.
40 42 42 164 42 127 164 1 40 1 40 0,10 0,636768
120 33 35 53 103 109 123 1 7 114 120 0,10 0,920467
Männer: 51 bis 100 J.
40 51 51 197 51 150 197 1 40 1 40 0,10 0,636768
120 46 49 56 143 160 212 1 7 114 120 0,10 0,920467
Frauen: 19 bis 100 J.
40 42 42 99 42 93 99 1 40 1 40 0,10 0,636768
120 29 38 45 93 101 116 1 7 114 120 0,10 0,920467

91
Ein zur Kontrolle vorgenommener Vergleich zwischen den in Abbildung 3 gelisteten
Rangnummern der 0,90-Konfidenzintervalle für die Stichprobengröße N = 120 und
den mittels des SAS®-Programmes Konfidenzbereiche.sas kalkulierten Rangzahlen
der Konfidenzintervalle mit α = 0,10 für den Stichprobenumfang N = 120 aus Tabelle
12 wies eine 100 %-ige Übereinstimmung auf. Die Rangnummern für die Stichpro-
bengrößen N = 40 sowie N = 2.000 wurden in der veröffentlichten Tabelle der IFCC
siehe Abbildung 3 unter Punkt 3.2.2 nicht angegeben und konnten nicht abgeglichen
werden.
Der Referenzbereich für eine Untersuchungsgruppe wird durch die untere Referenz-
grenze (siehe kursiv-gedruckte Zahlen aus der Spalte ‚2,5%-Quantil‘ in Tabelle 12)
und die obere Referenzgrenze (siehe kursiv-gedruckte Zahlen aus der Spalte
‚97,5%-Quantil‘ in Tabelle 12) definiert. Werden die Konfidenzintervalle der Quantile
gemäß der Vorschrift der IFCC mit einbezogen, ergibt sich der Referenzbereich für
eine Untersuchungsgruppe aus der unteren Konfidenzintervallgrenze des 0,025-
Quantils (siehe fett-gedruckte Werte in der Spalte ‚Grenze KI unten 2,5%-Quantil‘ in
Tabelle 12) und der oberen Konfidenzintervallgrenze des 0,975-Quantils (siehe fett-
gedruckte Werte in der Spalte ‚Grenze KI oben 97,5%-Quantil‘ in Tabelle 12).
Die letzte Spalte von Tabelle 12 gibt die Wahrscheinlichkeit dafür an, dass das vertei-
lungsfrei berechnete Konfidenzintervall das Quantil der Verteilung enthält. Diese
Wahrscheinlichkeit ist nur vom Stichprobenumfang abhängig. Die Wiederholungen
der Werte erklären sich daraus. Gleichzeitig wird sichtbar, welche Unsicherheiten
den Toleranzbereichen basierend auf Quantilen und deren Konfidenzbereichen in-
newohnen.
4.3.2 Toleranzschätzung
Die Bestimmung der Referenzbereiche für alle 29 Untersuchungsgruppen erfolgte als
zweite zu untersuchende Methode durch die Bildung von nicht-parametrischen Tole-
ranzintervallen erstens mittels der SAS®-Funktion PROBBETA, und zweitens indem
als Intervallgrenzen die den unteren und oberen Rangnummern entsprechenden
Werte aus den geordneten Referenzwerten jeder Referenzverteilung entnommen
wurden. Das SAS®-Programm zur Erzeugung dieser Rangzahlen wurde der Autorin
von dem Institut für Biometrie und Medizinische Informatik der Medizinischen Fakul-
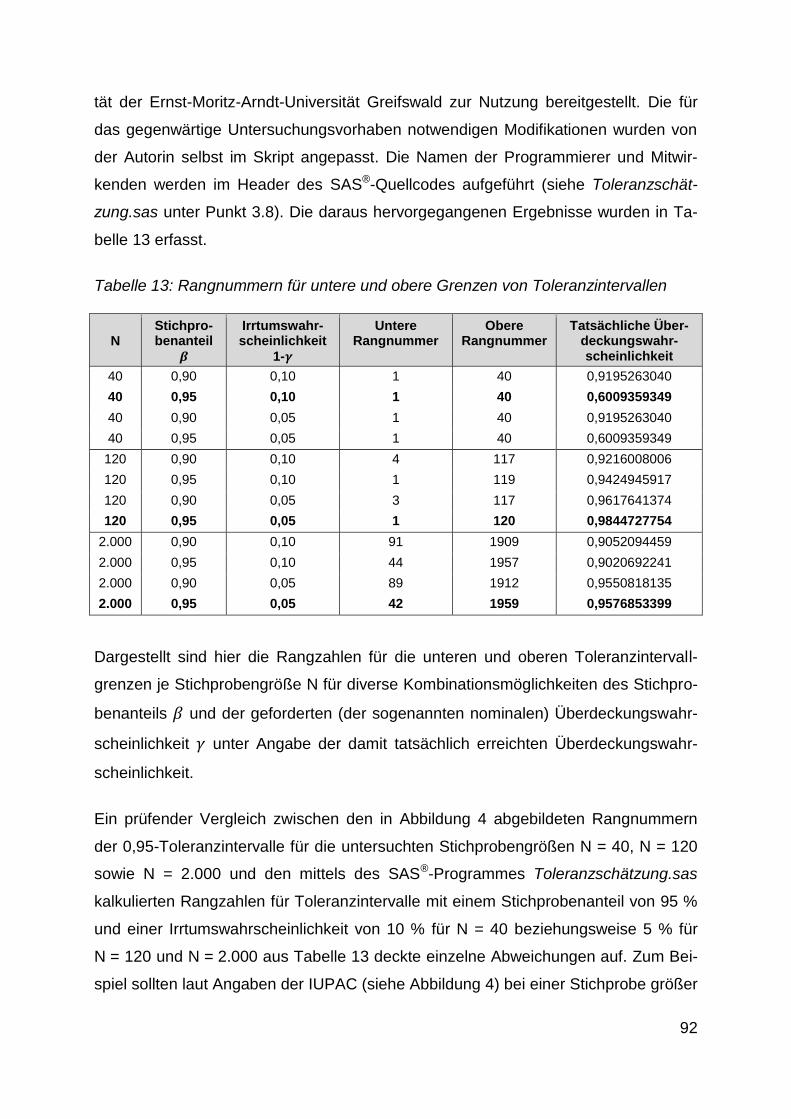
92
tät der Ernst-Moritz-Arndt-Universität Greifswald zur Nutzung bereitgestellt. Die für
das gegenwärtige Untersuchungsvorhaben notwendigen Modifikationen wurden von
der Autorin selbst im Skript angepasst. Die Namen der Programmierer und Mitwir-
kenden werden im Header des SAS®-Quellcodes aufgeführt (siehe Toleranzschät-
zung.sas unter Punkt 3.8). Die daraus hervorgegangenen Ergebnisse wurden in Ta-
belle 13 erfasst.
Tabelle 13: Rangnummern für untere und obere Grenzen von Toleranzintervallen
N Stichpro-benanteil
Irrtumswahr-scheinlichkeit
1-
Untere Rangnummer
Obere Rangnummer
Tatsächliche Über-deckungswahr-scheinlichkeit
40 0,90 0,10 1 40 0,9195263040
40 0,95 0,10 1 40 0,6009359349
40 0,90 0,05 1 40 0,9195263040
40 0,95 0,05 1 40 0,6009359349
120 0,90 0,10 4 117 0,9216008006
120 0,95 0,10 1 119 0,9424945917
120 0,90 0,05 3 117 0,9617641374
120 0,95 0,05 1 120 0,9844727754
2.000 0,90 0,10 91 1909 0,9052094459
2.000 0,95 0,10 44 1957 0,9020692241
2.000 0,90 0,05 89 1912 0,9550818135
2.000 0,95 0,05 42 1959 0,9576853399
Dargestellt sind hier die Rangzahlen für die unteren und oberen Toleranzintervall-
grenzen je Stichprobengröße N für diverse Kombinationsmöglichkeiten des Stichpro-
benanteils und der geforderten (der sogenannten nominalen) Überdeckungswahr-
scheinlichkeit unter Angabe der damit tatsächlich erreichten Überdeckungswahr-
scheinlichkeit.
Ein prüfender Vergleich zwischen den in Abbildung 4 abgebildeten Rangnummern
der 0,95-Toleranzintervalle für die untersuchten Stichprobengrößen N = 40, N = 120
sowie N = 2.000 und den mittels des SAS®-Programmes Toleranzschätzung.sas
kalkulierten Rangzahlen für Toleranzintervalle mit einem Stichprobenanteil von 95 %
und einer Irrtumswahrscheinlichkeit von 10 % für N = 40 beziehungsweise 5 % für
N = 120 und N = 2.000 aus Tabelle 13 deckte einzelne Abweichungen auf. Zum Bei-
spiel sollten laut Angaben der IUPAC (siehe Abbildung 4) bei einer Stichprobe größer

93
als N = 1.889, einem Stichprobenanteil von 95 % und einer Konfidenz von 95 % ins-
gesamt 94 Referenzwerte außerhalb des Toleranzintervalls liegen – möglichst
gleichmäßig verteilt auf ungefähr die Hälfte der Referenzwerte (etwa 47) unter der
unteren Toleranzgrenze und die Hälfte der Referenzwerte (etwa 47) über der oberen
Toleranzgrenze. Entsprechend des angewendeten SAS®-Programmes Toleranz-
schätzung.sas befinden sich indessen insgesamt 82 Referenzwerte außerhalb des
Toleranzintervalls – 41 Referenzwerte liegen darunter und 41 Referenzwerte liegen
darüber. Dieser Aspekt wird anschließend in der Diskussion und Interpretation der
Ergebnisse bei der Behandlung der Frage nach den wahren Referenzgrenzen be-
rücksichtigt. Der wesentliche Grund für etwaige Divergenzen wurde bereits unter Ab-
satz 3.2.3 erörtert.
Wie vorangehend in Abschnitt 2.2.2 erläutert wurde, ist die Kalkulation der Referenz-
grenzen von der Größe der auszuwertenden Stichprobe, des zu bestimmenden
Überdeckungsintervalls und der ersuchten Konfidenz abhängig. Die IUPAC empfiehlt
ein 0,95-Toleranzintervall zusammen mit einer Konfidenz von 0,95. Bei sehr kleinen
Referenzmengen wird eine Konfidenz von 0,90 angeraten (16). Demgemäß wurden
für die anstehenden Betrachtungen folgende Kombinationen gewählt (siehe fett-
markierte Zeilen in Tabelle 13): Für Untersuchungsgruppen mit einem Umfang von
N = 40 gilt der Stichprobenanteil von 0,95 und die Irrtumswahrscheinlichkeit von 0,10
als Definition zur Ermittlung von Toleranzintervallgrenzen. Für Untersuchungsgrup-
pen mit einer Größe von N = 120 sowie N = 2.000 gilt der Stichprobenanteil von 0,95
und die Irrtumswahrscheinlichkeit von 0,05 als Definition zur Bestimmung der Tole-
ranzintervalle als Referenzbereiche. Die Zuordnung der errungenen oberen und un-
teren Rangnummern der Toleranzintervallgrenzen aus Tabelle 13 zu den Referenz-
werten aus den verschiedenen Stichproben je Parameter und Subgruppe wurde ma-
nuell anhand der jeweiligen Rangzahl aus der vorab im Programm generierten Spalte
‚RANGNR‘ in den Tabellen der einzelnen Untersuchungsgruppen durchgeführt.
Die erarbeiteten Ergebnisse sind in Tabelle 14 abgedruckt. Ein Referenzbereich für
eine Untersuchungsgruppe wird durch die untere Referenzgrenze (siehe fett-
geschriebene Zahlen aus der Spalte ‚untere Toleranzgrenze‘ in Tabelle 14) und die
obere Referenzgrenze (siehe fett-markierte Zahlen aus der Spalte ‚obere Toleranz-
grenze‘ in Tabelle 14) definiert.

94
Tabelle 14: Nicht-parametrische Toleranzintervalle für alle 29 Untersuchungsgruppen
Parameter Subgruppe N untere Toleranzgrenze
obere Toleranzgrenze
untere Rangnummer
obere Rangnummer
Stichproben- anteil
Irrtums- wahrscheinlichkeit
Überdeckungs- wahrscheinlichkeit
HARN-STOFF
allgemein
40 0,5 8,6 1 40 0,95 0,10 0,6009359349
120 1,2 7,6 1 120 0,95 0,05 0,9844727754
2.000 1,5 8,2 42 1959 0,95 0,05 0,9576853399
NATRIUM allgemein
40 130 146 1 40 0,95 0,10 0,6009359349
120 133 146 1 120 0,95 0,05 0,9844727754
2.000 133 145 42 1959 0,95 0,05 0,9576853399
KREATININ
allgemein
40 33 164 1 40 0,95 0,10 0,6009359349
120 22 134 1 120 0,95 0,05 0,9844727754
2.000 23 116 42 1959 0,95 0,05 0,9576853399
0 J. 40 17 59 1 40 0,95 0,10 0,6009359349
120 4 70 1 120 0,95 0,05 0,9844727754
1 bis 3 J. 40 17 49 1 40 0,95 0,10 0,6009359349
120 17 64 1 120 0,95 0,05 0,9844727754
4 bis 6 J. 40 20 116 1 40 0,95 0,10 0,6009359349
120 16 63 1 120 0,95 0,05 0,9844727754
7 bis 9 J. 40 30 82 1 40 0,95 0,10 0,6009359349
120 19 82 1 120 0,95 0,05 0,9844727754
10 bis 12 J. 40 34 84 1 40 0,95 0,10 0,6009359349
120 28 87 1 120 0,95 0,05 0,9844727754
13 bis 15 J. 40 34 89 1 40 0,95 0,10 0,6009359349
120 34 92 1 120 0,95 0,05 0,9844727754
16 bis 18 J. 40 44 96 1 40 0,95 0,10 0,6009359349
120 41 102 1 120 0,95 0,05 0,9844727754
Männer: 19 bis 50 J.
40 42 164 1 40 0,95 0,10 0,6009359349
120 33 123 1 120 0,95 0,05 0,9844727754
Männer: 51 bis 100 J.
40 51 197 1 40 0,95 0,10 0,6009359349
120 46 212 1 120 0,95 0,05 0,9844727754
Frauen: 19 bis 100 J.
40 42 99 1 40 0,95 0,10 0,6009359349
120 29 116 1 120 0,95 0,05 0,9844727754

95
4.3.3 Quantilregression
Die Bestimmung der Referenzbereiche für alle 29 Untersuchungsgruppen erfolgte als
dritte zu untersuchende Methode durch die Bildung von Quantil-Intervallen mittels der
SAS®-Prozedur PROC QUANTREG, indem die 2,5- und 97,5-Perzentile für ver-
schiedene Regressionsmodelle unter Hinzunahme der Variablen ALTER und/ oder
GESCHLECHT beziehungsweise durch die Gruppierung nach GESCHLECHT be-
rechnet wurden. Als Algorithmus zur Optimierung für die Regressionsschätzungen
wurde das Innere-Punkte-Verfahren gewählt, da es gegenüber dem in SAS® als
Default voreingestellten Simplex-Algorithmus eine bessere Performanz für größere
Stichproben zeigt und diverse Berechnungen für Stichproben im Umfang von
N = 2.000 durchgeführt werden mussten. Alle drei von der SAS®-Prozedur PROC
QUANTREG angebotenen Algorithmen – das Innere-Punkte-Verfahren, das Glät-
tungsverfahren wie auch das Simplex-Verfahren – liefern jedoch gleiche Schätzwerte
für die Parameter (77). Das Signifikanzniveau wurde auf α = 0,05 gesetzt. Als Me-
thode zur Bestimmung der Konfidenzintervalle für die Regressionsparameter je
Quantil wurde die Resampling-Methode festgelegt, da sie auf dem Bootstrap-Prinzip
beruht und die Rang-Methode nur in Kombination mit dem Simplex-Verfahren ange-
wendet werden kann (77).
Der SAS®-Programmcode hierzu wurde eigenständig von der Autorin geschrieben
(siehe Quantilregression.sas unter Punkt 3.8). Die Ergebnisse der Quantilregressio-
nen für die insgesamt vier Regressionsmodelle für alle 29 Untersuchungsgruppen
wurden in Tabelle 15 zusammengefasst. Die mit einem Stern * versehenen Refe-
renzgrenzen sind laut p-Wert im Programm-Output signifikant von den Einflussvari-
ablen ALTER und/ oder GESCHLECHT abhängig – mit einer Konfidenz von 95 %.
Auf den Einfluss von Alter und Geschlecht auf die Referenzgrenzen der drei unter-
suchten Laborparameter je Subgruppe und Stichprobengröße wird in Absatz 4.4 nä-
her eingegangen. Der Referenzbereich für eine Untersuchungsgruppe wird durch die
untere Referenzgrenze (siehe Werte aus den Spalten ‚2,5%-Quantil‘ in Tabelle 15)
und die obere Referenzgrenze (siehe Werte aus den Spalten ‚97,5%-Quantil‘ in Ta-
belle 15) je nach gewähltem Regressionsmodell definiert. Die Spalte mit den fett-
gedruckten Werten bezieht sich auf das 3. Regressionsmodell, in dem Alter und Ge-
schlecht berücksichtigt sind.

96
Tabelle 15: Quantil-Intervalle aus vier verschiedenen Regressionsmodellen für alle 29 Untersuchungsgruppen
1. MODELL Parameter
= Alter 2. MODELL Parameter
= Geschlecht 3. MODELL Parameter
= Alter Geschlecht
4. MODELL Parameter = Alter BY Geschlecht:
Männlich
4. MODELL Parameter = Alter BY Geschlecht:
Weiblich
Parameter Subgruppe N 2,5%-
Quantil 97,5%-Quantil
2,5%-Quantil
97,5%-Quantil
2,5%-Quantil
97,5%-Quantil
2,5%-Quantil
97,5%-Quantil
2,5%-Quantil
97,5%-Quantil
HARN- STOFF
allgemein
40 1,9 7,4 0,9 8,6 2,3 7,1 2,2 7,0 2,6* 6,7
120 1,8 6,8 1,9 7,3 1,9 6,8 1,9 7,4 2,0 6,5
2.000 1,8* 7,6* 1,6 8,0 1,7* 7,5* 1,7* 7,7* 1,8* 7,4*
NATRIUM allgemein
40 133 145 134 145 135 145 133 145 137 144
120 134 145 134 145 134 145 134 144 134 145
2.000 133 145* 133 145 133 145 132* 145 133 145*
KREATININ
allgemein
40 43 99* 34 133 45 99* 53* 97 43 100
120 35 111 26 119 36 106 26 133 42* 95
2.000 34* 110* 24 109* 35* 108* 39* 132* 33* 97*
0 J. 40 19 59 20 59 20 59 24 59 17 59
120 10 65 10 58 10 58 9 52 11 66
1 bis 3 J. 40 20 48 19 48 21 47 23 43 20 47
120 21* 48 19 49 20 48 21 46 22 59
4 bis 6 J. 40 21 83 21 91 21 78 27 51 28 82
120 23 56 21 58 20 54 22 57 23 50
7 bis 9 J. 40 32 80 35 74 36 73 41 64 32 78
120 23 66 22 66 25 66 22 69 25 62
10 bis 12 J. 40 39 73 39 80 42 73 39 72 45 67
120 37 74 38 74 37 73 36 78 34 70
13 bis 15 J. 40 38 83 38 80 39 79 52 83 45 73
120 39 89 41 85 39 85 39 90 43 81
16 bis 18 J. 40 46 94 44 93 47 91 52 92 46 86
120 45 97 44 96 45 97 43 98 45 97
Männer: 19 bis 50 J.
40 44 159 44 157 44 159 44 159
120 46* 112 36 114 46 112 46* 112
Männer: 51 bis 100 J.
40 56 171 51 187 56 171 56 171
120 52 141 49 165 52 141 52 141
Frauen: 19 bis 100 J.
40 43 90 44 96 43 90
43 90
120 40 89 38 104 40 89
40 89*

97
Die Berechnungen der Quantilregressionen basieren auf einem linearen Ansatz. Die
generelle Annahme eines linearen Zusammenhangs zwischen Alter und Laborwerten
beruht auf den Referenzbereichen der nach Alter stratifizierten Bezugsgruppen für
den Parameter KREATININ. Gemäß Laborkatalog des Instituts für Klinische Chemie
und Laboratoriumsmedizin der Universitätsmedizin Greifswald (43) ist Kreatinin der
einzige der drei untersuchten Laborparameter, dessen Referenzwerte bei der Be-
stimmung von Referenzbereichen nach Alter geschichtet auszuwerten sind. Auf der
Grundlage der in Tabelle 10 zusammengefassten deskriptiven Daten zu den Mini-
mum-, Maximum-, Median- und Mittelwerten der geschlechts- und altersspezifischen
Subgruppen für den Parameter KREATININ, welche auf den gesamten 8.912 Patien-
tendatensätzen basieren, entstand die nachfolgende Abbildung 16. Die Grafik illus-
triert die Mittelwerte der Kreatininwerte je altersspezifische Bezugsgruppe für Männer
und für Frauen, und legt – abgebildet durch die die einzelnen Punktwerte verbinden-
de Linie – einen linearen Zusammenhang zwischen Alter und Kreatininwert nahe.
Abbildung 16: Mittelwerte der Kreatininwerte je altersspezifische Bezugsgruppe
,000
10,000
20,000
30,000
40,000
50,000
60,000
70,000
80,000
90,000
0 1-3 4-6 7-9 10-12 13-15 16-18 19-50 51-100
Kre
ati
nin
we
rt in
µm
ol/
l
Alter der Bezugsgruppe in Jahren
Mittel (Frauen)
Mittel (Männer)

98
4.4 Einfluss von Alter und Geschlecht auf Referenzgrenzen
Der Einfluss der Variablen ALTER und GESCHLECHT auf die als Referenzgrenzen
definierten 2,5- und 97,5-Perzentile der Referenzverteilungen aller 29 Untersu-
chungsgruppen wurde zuvor im Rahmen der unter Absatz 4.3.3 abgefassten Quantil-
regression zusammen mit den dort ermittelten Quantil-Intervallen mittels des bereits
ausgeführten SAS®-Programmes Quantilregression.sas berechnet (siehe auch Pro-
grammliste in Abschnitt 3.8). Zur Erzielung einer besseren Qualität der nachfolgen-
den Grafiken wurde dieses SAS®-Programm nochmals in der Statistiksoftware SAS®
Enterprise Guide in der Version 4.3 laufen gelassen. Die durch vier verschiedene
Regressionsmodelle bestimmten unteren und oberen Quantile wurden schon in Ta-
belle 15 vorgestellt – gemeinsam mit einem Hinweis auf existente signifikante Zu-
sammenhänge zwischen Alter und/ oder Geschlecht und den entsprechenden Refe-
renzgrenzen, welche im Falle von signifikanten p-Werten für den beziehungsweise
die Regressionskoeffizienten mit einem Stern * markiert wurden.
Mit Hilfe der vier verschiedenen Quantilregressionsmodelle wurde der Einfluss von
Alter und/ oder Geschlecht auf die Lage der unteren und oberen Referenzgrenzen
pro Laborparameter, Subgruppe und Stichprobengröße untersucht. Hierbei stellte je
Regressionsanalyse das 0,025- beziehungsweise das 0,975-Quantil die abhängige
Variable dar und ALTER und/ oder GESCHLECHT die unabhängigen Variablen (die
Regressoren). Der Einfluss der Variablen ALTER und/ oder GESCHLECHT wurde
als Ergebnis jeder Quantilregression durch den beziehungsweise die Regressions-
koeffizienten zusammen mit einem p-Wert, der auf einem t-Test basiert, ausgedrückt.
Insgesamt lieferten die 116 durchgeführten Quantilregressionen (29 Untersuchungs-
gruppen à 4 Regressionsmodelle) zu 29 Quantilen signifikante p-Werte, die indizie-
ren, dass diese 29 Referenzgrenzen signifikant von den Variablen ALTER und/ oder
GESCHLECHT beeinflusst wurden – zum Konfidenzniveau von 0,95.
1) Das erste Quantilregressionsmodell schloss ausschließlich die Variable ALTER
als unabhängige Variable in das Modell ein. Sechs Regressionsanalysen ergaben
folgende, zum Signifikanzniveau α = 0,05 signifikante Regressionskoeffizienten
und p-Werte:

99
HARNSTOFF, allgemeine Bezugsgruppe, N = 2.000:
o untere Referenzgrenze: 0,025-Quantil: 1,7682 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 1,2000 0,0973 1,0092 1,3908 12,33 <,0001
Alter 1 0,0167 0,0022 0,0123 0,0210 7,48 <,0001*
o obere Referenzgrenze: 0,975-Quantil: 7,5740 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 6,6000 0,1527 6,3005 6,8995 43,22 <,0001
Alter 1 0,0286 0,0027 0,0233 0,0338 10,66 <,0001*
NATRIUM, allgemeine Bezugsgruppe, N = 2.000:
o obere Referenzgrenze: 0,975-Quantil: 144,7885 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 144,0000 0,4557 143,1062 144,8938 315,97 <,0001
Alter 1 0,0213 0,0099 0,0019 0,0407 2,15 0,0317*
KREATININ, allgemeine Bezugsgruppe, N = 40:
o obere Referenzgrenze: 0,975-Quantil: 99,4518 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 59,0545 6,9844 44,9154 73,1937 8,46 <,0001
Alter 1 1,3455 0,2843 0,7699 1,9210 4,73 <,0001*
KREATININ, allgemeine Bezugsgruppe, N = 2.000:
o untere Referenzgrenze: 0,025-Quantil: 33,9576 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 19,1884 0,9476 17,3300 21,0468 20,25 <,0001
Alter 1 0,4058 0,0190 0,3685 0,4431 21,35 <,0001*
o obere Referenzgrenze: 0,975-Quantil: 109,6636 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 74,6415 7,6370 59,6642 89,6188 9,77 <,0001
Alter 1 0,9623 0,2646 0,4433 1,4813 3,64 0,0003*

100
KREATININ, Bezugsgruppe der 1 bis 3 Jährigen, N = 120:
o untere Referenzgrenze: 0,025-Quantil: 20,7083 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 12,0000 3,3493 5,3674 18,6326 3,58 0,0005
Alter 1 5,0000 2,2691 0,5065 9,4935 2,20 0,0295*
KREATININ, Bezugsgruppe der Männer von 19 bis 50 Jahre, N = 120:
o untere Referenzgrenze: 0,025-Quantil: 46,1111 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 106,3333 26,9425 52,9798 159,6869 3,95 0,0001
Alter 1 -1,6667 0,7027 -3,0582 -0,2751 -2,37 0,0193*
Diese acht signifikanten Regressionskoeffizienten (siehe obig aufgeführte
Schätzwerte) für die Einflussgröße ALTER geben an, um wie viel mmol/l sich die
dazugehörigen drei Referenzgrenzen für die Parameter NATRIUM und HARN-
STOFF beziehungsweise um wie viel µmol/l sich die dazugehörigen fünf Refe-
renzgrenzen für den Parameter KREATININ für die oben genannten Bezugsgrup-
pen und Stichprobengrößen nach unten oder oben verschieben, wenn sich das
Alter in der entsprechenden Subgruppe um ein Jahr erhöht.
2) Das zweite Quantilregressionsmodell schloss ausschließlich die Variable GE-
SCHLECHT als unabhängige Variable in das Modell ein. Eine Regressionsanaly-
se brachte folgenden, zum Signifikanzniveau α = 0,05 signifikanten Regressions-
koeffizienten und p-Wert hervor:
KREATININ, allgemeine Bezugsgruppe, N = 2.000:
o obere Referenzgrenze: 0,975-Quantil: 109,3955 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 138,0000 10,9414 116,5423 159,4577 12,61 <,0001
Sex 1 -19,0000 6,1704 -31,1012 -6,8988 -3,08 0,0021*
Dieser signifikante Regressionskoeffizient (siehe oben als Schätzwert bezeichnet)
für die Einflussgröße GESCHLECHT (Sex) bedeutet, dass sich die obere Refe-
renzgrenze für den Parameter KREATININ für die allgemeine Bezugsgruppe mit
der Stichprobengröße N = 2.000 um 19,00 µmol/l nach unten verschiebt, wenn
sich das Geschlecht von Mann auf Frau verändert.
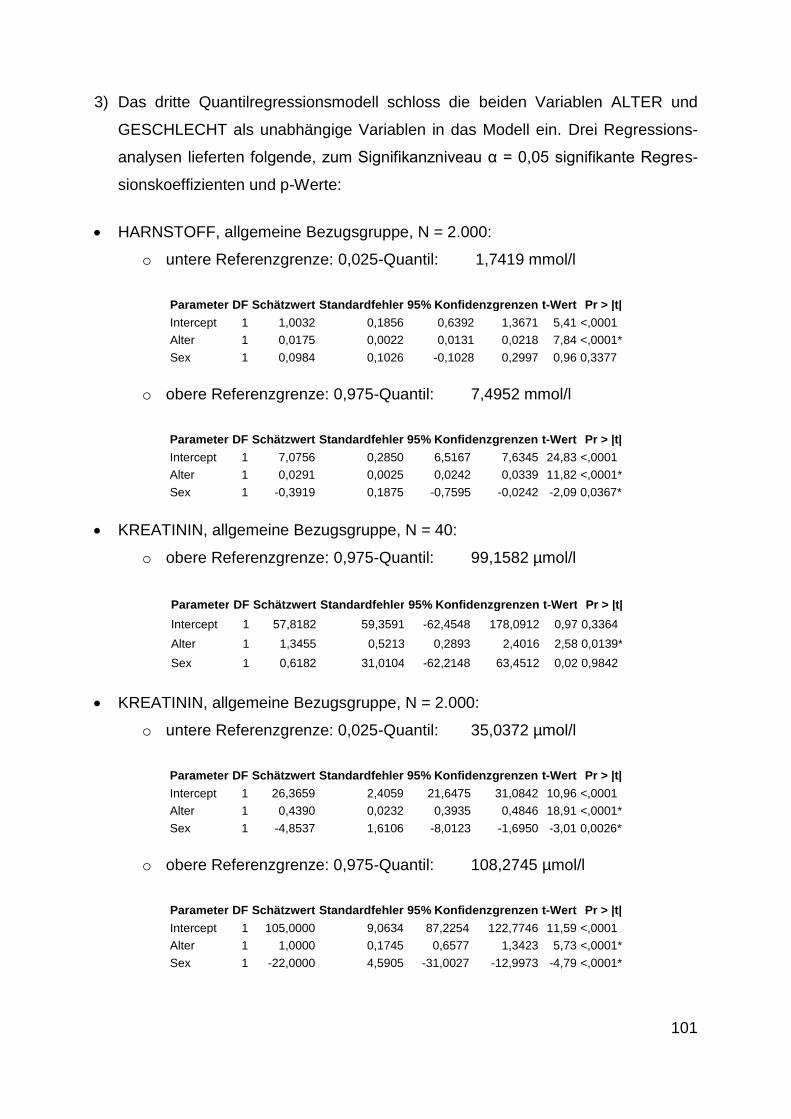
101
3) Das dritte Quantilregressionsmodell schloss die beiden Variablen ALTER und
GESCHLECHT als unabhängige Variablen in das Modell ein. Drei Regressions-
analysen lieferten folgende, zum Signifikanzniveau α = 0,05 signifikante Regres-
sionskoeffizienten und p-Werte:
HARNSTOFF, allgemeine Bezugsgruppe, N = 2.000:
o untere Referenzgrenze: 0,025-Quantil: 1,7419 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 1,0032 0,1856 0,6392 1,3671 5,41 <,0001
Alter 1 0,0175 0,0022 0,0131 0,0218 7,84 <,0001*
Sex 1 0,0984 0,1026 -0,1028 0,2997 0,96 0,3377
o obere Referenzgrenze: 0,975-Quantil: 7,4952 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 7,0756 0,2850 6,5167 7,6345 24,83 <,0001
Alter 1 0,0291 0,0025 0,0242 0,0339 11,82 <,0001*
Sex 1 -0,3919 0,1875 -0,7595 -0,0242 -2,09 0,0367*
KREATININ, allgemeine Bezugsgruppe, N = 40:
o obere Referenzgrenze: 0,975-Quantil: 99,1582 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 57,8182 59,3591 -62,4548 178,0912 0,97 0,3364
Alter 1 1,3455 0,5213 0,2893 2,4016 2,58 0,0139*
Sex 1 0,6182 31,0104 -62,2148 63,4512 0,02 0,9842
KREATININ, allgemeine Bezugsgruppe, N = 2.000:
o untere Referenzgrenze: 0,025-Quantil: 35,0372 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 26,3659 2,4059 21,6475 31,0842 10,96 <,0001
Alter 1 0,4390 0,0232 0,3935 0,4846 18,91 <,0001*
Sex 1 -4,8537 1,6106 -8,0123 -1,6950 -3,01 0,0026*
o obere Referenzgrenze: 0,975-Quantil: 108,2745 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 105,0000 9,0634 87,2254 122,7746 11,59 <,0001
Alter 1 1,0000 0,1745 0,6577 1,3423 5,73 <,0001*
Sex 1 -22,0000 4,5905 -31,0027 -12,9973 -4,79 <,0001*

102
Diese insgesamt acht signifikanten Regressionskoeffizienten (siehe Schätzwerte)
für die Einflussgrößen ALTER und GESCHLECHT (Sex) zeigen an, um wie viel
mmol/l sich die dazugehörigen zwei Referenzgrenzen für den Parameter HARN-
STOFF und um wie viel µmol/l sich die dazugehörigen drei Referenzgrenzen für
den Parameter KREATININ für die oben aufgelisteten Bezugsgruppen und Stich-
probengrößen nach unten oder oben verschieben, wenn sich das Alter in der ent-
sprechenden Subgruppe um ein Jahr erhöht beziehungsweise wenn sich das Ge-
schlecht von Mann auf Frau verändert.
4) Das vierte Quantilregressionsmodell schloss die Variable ALTER als unabhängi-
ge Variable in das Modell ein und gruppierte nach der Variable GESCHLECHT.
Acht Regressionsanalysen gaben folgende, zum Signifikanzniveau α = 0,05 signi-
fikante Regressionskoeffizienten und p-Werte aus:
HARNSTOFF, allgemeine Bezugsgruppe, N = 40:
o untere Referenzgrenze: 0,025-Quantil – für Frauen: 2,6359 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 1,3355 0,0000 1,3355 1,3355 1,71E11 <,0001
Alter 1 0,0548 0,0000 0,0548 0,0548 6,72E11 <,0001*
HARNSTOFF, allgemeine Bezugsgruppe, N = 2.000:
o untere Referenzgrenze: 0,025-Quantil – für Männer: 1,7004 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 1,0820 0,1728 0,7429 1,4211 6,26 <,0001
Alter 1 0,0180 0,0049 0,0083 0,0277 3,65 0,0003*
o obere Referenzgrenze: 0,975-Quantil – für Männer: 7,6745 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 6,6068 0,1839 6,2459 6,9676 35,92 <,0001
Alter 1 0,0311 0,0039 0,0233 0,0388 7,88 <,0001*
o untere Referenzgrenze: 0,025-Quantil – für Frauen: 1,8091 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 1,2564 0,1038 1,0527 1,4600 12,11 <,0001
Alter 1 0,0164 0,0022 0,0121 0,0206 7,56 <,0001*

103
o obere Referenzgrenze: 0,975-Quantil – für Frauen: 7,3960 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 6,5757 0,3005 5,9860 7,1654 21,88 <,0001
Alter 1 0,0243 0,0045 0,0155 0,0331 5,41 <,0001*
NATRIUM, allgemeine Bezugsgruppe, N = 2.000:
o untere Referenzgrenze: 0,025-Quantil – für Männer: 132,4595 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 134,4286 0,7718 132,9141 135,9430 174,18 <,0001
Alter 1 -0,0536 0,0215 -0,0958 -0,0113 -2,49 0,0130*
o obere Referenzgrenze: 0,975-Quantil – für Frauen: 144,8655 mmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 143,4815 0,3834 142,7291 144,2338 374,25 <,0001
Alter 1 0,0370 0,0114 0,0147 0,0594 3,26 0,0012*
KREATININ, allgemeine Bezugsgruppe, N = 40:
o untere Referenzgrenze: 0,025-Quantil – für Männer: 53,1943 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 29,3462 0,4436 28,4102 30,2821 66,15 <,0001
Alter 1 0,8077 0,0165 0,7730 0,8424 49,10 <,0001*
KREATININ, allgemeine Bezugsgruppe, N = 120:
o untere Referenzgrenze: 0,025-Quantil – für Frauen: 41,9129 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 22,5625 7,5025 7,5501 37,5749 3,01 0,0039
Alter 1 0,4375 0,1828 0,0717 0,8033 2,39 0,0199*
KREATININ, allgemeine Bezugsgruppe, N = 2.000:
o untere Referenzgrenze: 0,025-Quantil – für Männer: 38,8704 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 19,2794 1,6088 16,1223 22,4365 11,98 <,0001
Alter 1 0,5441 0,0300 0,4852 0,6030 18,13 <,0001*
o obere Referenzgrenze: 0,975-Quantil – für Männer: 131,5248 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 69,9677 10,3216 49,7130 90,2225 6,78 <,0001
Alter 1 1,7097 0,3722 0,9794 2,4400 4,59 <,0001*

104
o untere Referenzgrenze: 0,025-Quantil – für Frauen: 32,6463 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 19,2727 1,4089 16,5081 22,0374 13,68 <,0001
Alter 1 0,3636 0,0290 0,3068 0,4205 12,55 <,0001*
o obere Referenzgrenze: 0,975-Quantil – für Frauen: 96,9503 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 62,5079 5,2599 52,1864 72,8295 11,88 <,0001
Alter 1 0,9365 0,1721 0,5988 1,2742 5,44 <,0001*
KREATININ, Bezugsgruppe der Männer von 19 bis 50 Jahre, N = 120:
o untere Referenzgrenze: 0,025-Quantil – für Männer: 46,1111 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 106,3333 29,9189 47,0858 165,5809 3,55 0,0005
Alter 1 -1,6667 0,8147 -3,2800 -0,0533 -2,05 0,0430*
KREATININ, Bezugsgruppe der Frauen von 19 bis 100 Jahre, N = 120:
o obere Referenzgrenze: 0,975-Quantil – für Frauen: 89,3407 µmol/l
Parameter DF Schätzwert Standardfehler 95% Konfidenzgrenzen t-Wert Pr > |t|
Intercept 1 61,7407 14,6833 32,6639 90,8176 4,20 <,0001
Alter 1 0,5926 0,2184 0,1602 1,0250 2,71 0,0077*
Diese zusammen 15 signifikanten Regressionskoeffizienten (siehe Schätzwerte)
für die Einflussgröße ALTER – gruppiert nach der Variable GESCHLECHT – ge-
ben vor, um wie viel mmol/l sich die dazugehörigen sieben Referenzgrenzen für
die Parameter HARNSTOFF und NATRIUM beziehungsweise um wie viel µmol/l
sich die dazugehörigen acht Referenzgrenzen für den Parameter KREATININ für
die oben aufgestellten Bezugsgruppen und Stichprobengrößen nach unten oder
oben justieren, wenn sich das Alter in der gegebenen Bezugsgruppe um ein Jahr
erhöht – wobei die Referenzgrenzen für Frauen und Männer je nach obig stehen-
den Angaben getrennt voneinander berechnet werden.
Prinzipiell verlagern sich die Referenzgrenzen bei signifikanten positiven Schätzwer-
ten für die Regressoren nach oben und bei signifikanten negativen Schätzwerten für
die Regressoren nach unten.

105
4.4.1 Einflüsse auf die Referenzgrenzen für Harnstoff
Die dreiseitige Abbildung 17 demonstriert die Regressionsgeraden für die geschätz-
ten 0,025- und 0,975-Quantile als untere und obere Referenzgrenzen für den Para-
meter HARNSTOFF in Abhängigkeit von der Variable ALTER und veranschaulicht
damit den Zusammenhang zwischen den unteren und oberen Referenzgrenzen und
dem Alter. Dargestellt sind dabei die Punktewolken der Referenzwerte mit den Re-
gressionsgeraden für die 0,025- und 0,975-Quantile aus zwei verschiedenen Re-
gressionsmodellen für die allgemeine Bezugsgruppe von HARNSTOFF mit jeweils
drei Stichprobengrößen N = 40, N = 120 sowie N = 2.000. Die mit einem Stern * mar-
kierten Variablen weisen auf signifikante Abhängigkeiten der jeweiligen Quantile von
den gekennzeichneten unabhängigen Variablen laut Regressionsanalysen hin.
Das erste grafisch abgebildete Regressionsmodell schloss die unabhängige Variable
ALTER ein, ohne Berücksichtigung des Geschlechts. Die ersten drei Grafiken der
Abbildung 17 zeigen einen Anstieg der unteren wie auch oberen Referenzgrenzen
mit steigendem Alter. Besonders deutlich ist dies bei den Untersuchungsgruppen mit
den Umfängen N = 40 und N = 2.000 zu beobachten. Das zweite grafisch dargestell-
te Regressionsmodell schloss die Variable ALTER ein und gruppierte nach der Vari-
able GESCHLECHT. Die vierte, fünfte und sechste Grafik in der Abbildung 17 stellen
die Punktewolken der Referenzwerte mit den Regressionsgeraden für Männer vor,
und die letzten drei Grafiken der Abbildung 17 präsentieren diese für die Gruppe der
Frauen. Hier ist für beide Geschlechter der gleiche Trend wie im ersten abgebildeten
Regressionsmodell zu erkennen, welcher wie folgt lautet: Mit steigendem Alter erhöht
sich die untere sowie die obere Referenzgrenze für HARNSTOFF. Besonders klar
war dies erneut für die Untersuchungsgruppen N = 40 und N = 2.000 ersichtlich. Die
Untersuchungsgruppe mit der Stichprobengröße N = 120 lieferte bei beiden Regres-
sionsmodellen leicht differente Ergebnisse, was durch Ausreißer-Werte bedingt sein
könnte. Die hier besprochenen Beobachtungen decken sich mit den vorgestellten
Ergebnissen aus Tabelle 15. Generell scheinen beide, den Referenzbereich des La-
borparameters HARNSTOFF definierende, Referenzgrenzen abhängig vom Alter zu
sein. Eine Abhängigkeit der Referenzgrenzen vom Geschlecht war grafisch nicht
nachweisbar, wird jedoch durch signifikante Werte (siehe Spalte ‚3. MODELL Para-
meter = Alter Geschlecht‘ in Tabelle 15; siehe Schätzwert auf Seite 101) bekräftigt.

106
HARNSTOFF,
ALLGEMEIN,
N = 40:
MODEL =
Alter
HARNSTOFF,
ALLGEMEIN,
N = 120:
MODEL =
Alter
HARNSTOFF,
ALLGEMEIN,
N = 2.000:
MODEL =
Alter * [u,o]
* [u,o]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil,
sowie der
oberen Gren-
ze (o), dem
0,975-Quantil

107
HARNSTOFF,
ALLGEMEIN,
N = 40:
MODEL =
Alter BY Ge-
schlecht:
Männlich
HARNSTOFF,
ALLGEMEIN,
N = 120:
MODEL =
Alter BY Ge-
schlecht:
Männlich
HARNSTOFF,
ALLGEMEIN,
N = 2.000:
MODEL =
Alter BY Ge-
schlecht:
Männlich * [u,o]
* [u,o]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil,
sowie der
oberen Gren-
ze (o), dem
0,975-Quantil

108
HARNSTOFF,
ALLGEMEIN,
N = 40:
MODEL =
Alter BY Ge-
schlecht:
Weiblich * [u]
* [u]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil
HARNSTOFF,
ALLGEMEIN,
N = 120:
MODEL =
Alter BY Ge-
schlecht:
Weiblich
HARNSTOFF,
ALLGEMEIN,
N = 2.000:
MODEL =
Alter BY Ge-
schlecht:
Weiblich * [u,o]
* [u,o]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil,
sowie der
oberen Gren-
ze (o), dem
0,975-Quantil
Abbildung 17: Regressionsgeraden der 0,025- und 0,975-Quantile für Harnstoff(Alter)

109
4.4.2 Einflüsse auf die Referenzgrenzen für Natrium
Die 3-Seiten-lange Abbildung 18 illustriert die Regressionsgeraden für die geschätz-
ten 0,025- und 0,975-Quantile als untere und obere Referenzgrenzen für den Para-
meter NATRIUM in Abhängigkeit von der Variable ALTER und verbildlicht damit ei-
nen möglichen Zusammenhang zwischen den unteren und oberen Referenzgrenzen
und dem Alter. Gezeigt werden hier die Punktewolken der Referenzwerte mit den
Regressionsgeraden für die 0,025- und 0,975-Quantile aus zwei unterschiedlichen
Regressionsmodellen für die allgemeine Bezugsgruppe von NATRIUM zu den drei
Stichprobengrößen N = 40, N = 120 sowie N = 2.000. Die mit einem Stern * vermerk-
ten Variablen indizieren signifikante Abhängigkeiten konkreter Quantile von den ge-
kennzeichneten unabhängigen Variablen gemäß der Regressionsanalysen.
Das erste grafisch dargestellte Regressionsmodell schloss die unabhängige Variable
ALTER ein, ohne Bezug zum Geschlecht. Die ersten drei Grafiken der Abbildung 18
zeigen für die untersuchten Gruppen keinen klaren Anstieg oder Abfall der unteren
und oberen Referenzgrenzen mit steigendem Alter. Allein die Untersuchungsgruppe
mit dem Umfang N = 2.000 weist auf eine signifikante Assoziation zwischen dem Al-
ter und dem 0,975-Quantil hin, was mit einer genügend großen Stichprobe und/ oder
Ausreißer-Werten begründet sein könnte. Das zweite grafisch dargestellte Regressi-
onsmodell schloss die Variable ALTER ein – klassifiziert nach der Variable GE-
SCHLECHT. Die vierte, fünfte und sechste Grafik in der Abbildung 18 demonstrieren
die Punktewolken der Referenzwerte mit den geschätzten Regressionsgeraden für
Männer, und die letzten drei Grafiken der Abbildung 18 die für Frauen. Darin ist für
sowohl Männer als auch Frauen ebenfalls kein eindeutiger Zusammenhang zwischen
der Lage der unteren und oberen Referenzgrenzen für den Parameter NATRIUM und
dem Alter oder dem Geschlecht erkennbar.
Die hier festgehaltenen Beobachtungen stimmen mit den in Tabelle 15 zusammenge-
fassten, aus allen Regressionsmodellen stammenden Resultaten überein. Allgemein
scheinen beide, den Referenzbereich des Laborparameters NATRIUM abgrenzende,
Referenzgrenzen nicht abhängig von dem Alter zu sein. Eine Abhängigkeit der Refe-
renzgrenzen von dem Geschlecht war gleichermaßen nicht zu belegen.

110
NATRIUM,
ALLGEMEIN,
N = 40:
MODEL =
Alter
NATRIUM,
ALLGEMEIN,
N = 120:
MODEL =
Alter
NATRIUM,
ALLGEMEIN,
N = 2.000:
MODEL =
Alter * [o]
* [o]
signifikante
Assoziation
zwischen dem
Alter und der
oberen Grenze
(o), dem 0,975-
Quantil

111
NATRIUM,
ALLGEMEIN,
N = 40:
MODEL =
Alter BY Ge-
schlecht:
Männlich
NATRIUM,
ALLGEMEIN,
N = 120:
MODEL =
Alter BY Ge-
schlecht:
Männlich
NATRIUM,
ALLGEMEIN,
N = 2.000:
MODEL =
Alter BY Ge-
schlecht:
Männlich * [u]
* [u]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil

112
NATRIUM,
ALLGEMEIN,
N = 40:
MODEL =
Alter BY Ge-
schlecht:
Weiblich
NATRIUM,
ALLGEMEIN,
N = 120:
MODEL =
Alter BY Ge-
schlecht:
Weiblich
NATRIUM,
ALLGEMEIN,
N = 2.000:
MODEL =
Alter BY Ge-
schlecht:
Weiblich * [o]
* [o]
signifikante
Assoziation
zwischen dem
Alter und der
oberen Grenze
(o), dem 0,975-
Quantil
Abbildung 18: Regressionsgeraden der 0,025- und 0,975-Quantile für Natrium(Alter)

113
4.4.3 Einflüsse auf die Referenzgrenzen für Kreatinin
Die sich über drei Seiten erstreckende Abbildung 19 veranschaulicht die Regressi-
onsgeraden für die geschätzten 0,025- und 0,975-Quantile als untere und obere Re-
ferenzgrenzen für den Parameter KREATININ in Abhängigkeit von der Variable AL-
TER und beleuchtet damit den Zusammenhang zwischen den unteren und oberen
Referenzgrenzen und dem Alter. Abgebildet sind hierbei die Punktewolken der Refe-
renzwerte mit den Regressionsgeraden für die 0,025- und 0,975-Quantile aus zwei
verschiedenen Regressionsmodellen für die allgemeine Bezugsgruppe von KREA-
TININ mit jeweils den Stichprobenumfängen N = 40, N = 120 sowie N = 2.000. Die
mit einem Stern * markierten Variablen geben Hinweise auf signifikante Abhängigkei-
ten der entsprechenden Quantile von den gekennzeichneten unabhängigen Variab-
len laut Regressionsanalysen.
Das erste grafisch dargestellte Regressionsmodell schloss die unabhängige Variable
ALTER ein, nicht bezugnehmend auf das Geschlecht. In den ersten drei Grafiken der
Abbildung 19 ist ein Anstieg der unteren wie auch oberen Referenzgrenze mit zu-
nehmendem Alter zu beobachten. Das zweite abgezeichnete Regressionsmodell
schloss die Variable ALTER ein – unterteilt für die Variable GESCHLECHT. Die vier-
te, fünfte und sechste Grafik in der Abbildung 19 illustrieren die Punktewolken der
Referenzwerte mit den Regressionsgeraden für Männer, und die letzten drei Grafiken
der Abbildung 19 präsentieren diese für die Klasse der Frauen. Hier ist für beide Ge-
schlechter die gleiche Tendenz wie im ersten abgebildeten Regressionsmodell zu
sehen, welche wie folgt ist: Mit steigendem Alter erhöht sich die untere sowie die
obere Referenzgrenze für KREATININ.
Die oben beschriebenen Beobachtungen bekräftigen die in Tabelle 15 aufgelisteten
Ergebnisse. Grundsätzlich sind sichtlich beide, den Referenzbereich des Laborpara-
meters KREATININ umfassende Referenzgrenzen abhängig von dem Alter. Eine Ab-
hängigkeit der Referenzgrenzen von dem Geschlecht war grafisch nicht feststellbar.
Jedoch sprechen die mittels der Quantilregressionen erzeugten signifikanten Werte
für eine Abhängigkeit der Referenzgrenzen des Parameters KREATININ von dem
Geschlecht (siehe Spalte ‚3. MODEL Parameter = Alter Geschlecht‘ in Tabelle 15;
siehe Schätzwerte des 3. Quantilregressionsmodells auf Seite 101).

114
KREATININ,
ALLGEMEIN,
N = 40:
MODEL =
Alter * [o]
* [o]
signifikante
Assoziation
zwischen dem
Alter und der
oberen Grenze
(o), dem
0,975-Quantil
KREATININ,
ALLGEMEIN,
N = 120:
MODEL =
Alter
KREATININ,
ALLGEMEIN,
N = 2.000:
MODEL =
Alter * [u,o]
* [u,o]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil,
sowie der
oberen Grenze
(o), dem
0,975-Quantil
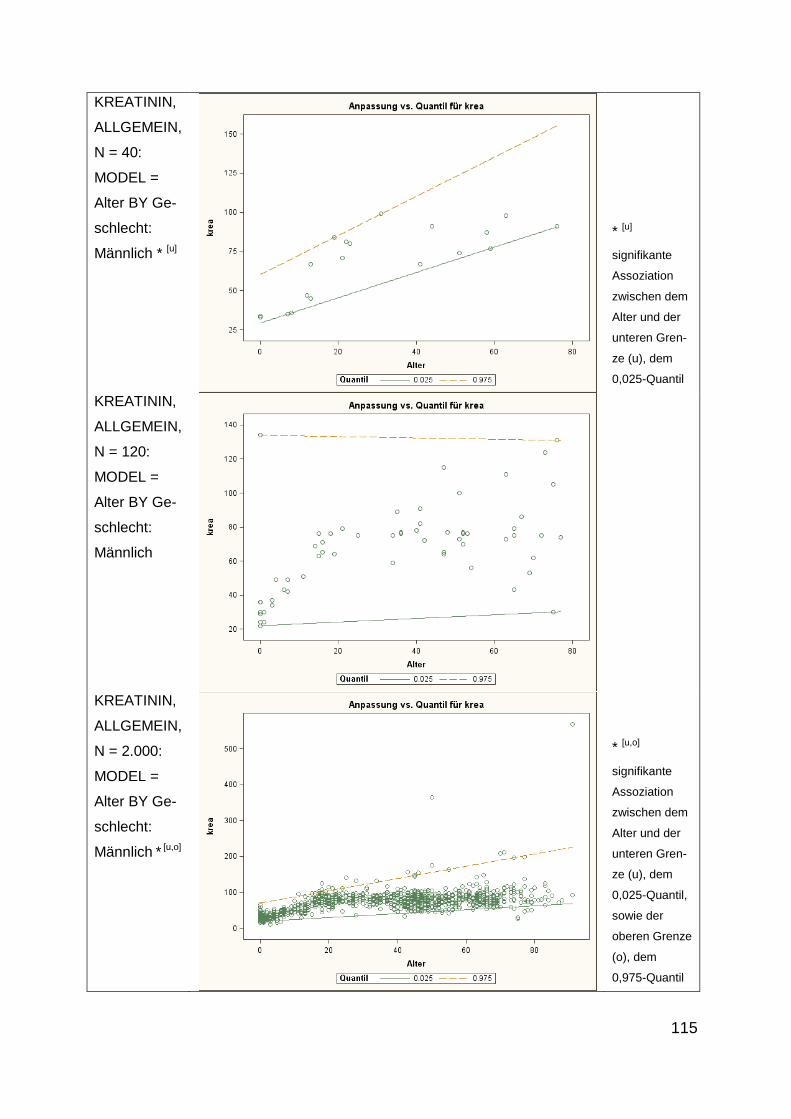
115
KREATININ,
ALLGEMEIN,
N = 40:
MODEL =
Alter BY Ge-
schlecht:
Männlich * [u]
* [u]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil
KREATININ,
ALLGEMEIN,
N = 120:
MODEL =
Alter BY Ge-
schlecht:
Männlich
KREATININ,
ALLGEMEIN,
N = 2.000:
MODEL =
Alter BY Ge-
schlecht:
Männlich * [u,o]
* [u,o]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil,
sowie der
oberen Grenze
(o), dem
0,975-Quantil

116
KREATININ,
ALLGEMEIN,
N = 40:
MODEL =
Alter BY Ge-
schlecht:
Weiblich
KREATININ,
ALLGEMEIN,
N = 120:
MODEL =
Alter BY Ge-
schlecht:
Weiblich * [u]
* [u]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil
KREATININ,
ALLGEMEIN,
N = 2.000:
MODEL =
Alter BY Ge-
schlecht:
Weiblich * [u,o]
* [u,o]
signifikante
Assoziation
zwischen dem
Alter und der
unteren Gren-
ze (u), dem
0,025-Quantil,
sowie der
oberen Grenze
(o), dem
0,975-Quantil
Abbildung 19: Regressionsgeraden der 0,025- und 0,975-Quantile für Kreatinin(Alter)

117
4.5 Fazit
Eine Zusammenfassung der Berechnungsergebnisse für Referenzbereiche aus den
Labordaten von Nieren-gesunden Patienten aus dem Universitätsklinikum Greifswald
aus dem Jahr 2005 bietet Tabelle 16.
Für kleine (N = 40), mittlere (N = 120) und große (N = 2.000) Stichprobenumfänge
sind die Referenzbereiche, die aus Quantilschätzungen mit Konfidenzintervall bezie-
hungsweise aus Toleranzschätzungen berechnet wurden, übereinstimmend.
Referenzintervalle aus der Quantilregression weisen mehrheitlich Unterschiede zu
den vorher genannten Referenzbereichen auf.
Die aus den Quantilschätzungen erhaltenen Referenzbereiche besitzen keine statis-
tische Gütekennzeichnung (Überdeckungswahrscheinlichkeit). Sie sind durchgängig
(siehe Tabelle 16) in den Referenzbereichen aus den Toleranzschätzungen enthal-
ten. Die Frage, ob sie dennoch den geforderten Anteil der Grundgesamtheit mit der
angeforderten Sicherheit überdecken, kann nicht beantwortet werden.
Die mit Hilfe der Methode der Quantilregression stattgefundenen Analysen zu Ab-
hängigkeiten der Referenzbereiche von signifikanten Einflussgrößen ergaben auf der
vorliegenden Datengrundlage, dass die Referenzgrenzen der Parameter HARN-
STOFF und KREATININ von den Einflussgrößen Alter und Geschlecht abhängen
und die Referenzgrenzen des Parameters NATRIUM wahrscheinlich unabhängig von
dem Alter und dem Geschlecht sind (siehe Abschnitt 4.4). Dass die Referenzgrenzen
des Parameters HARNSTOFF von dem Alter und dem Geschlecht abhängen steht
im Widerspruch zu den Vorgaben aus dem Laborkatalog von dem Institut für Klini-
sche Chemie und Laboratoriumsmedizin der Ernst-Moritz-Arndt-Universität Greifs-
wald und muss in Kapitel 5 interpretiert werden.
Eine Diskussion der Berechnungsergebnisse in Bezug auf die Eigenschaften der
verwendeten Methoden und das Hauptuntersuchungsziel befindet sich im folgenden
Kapitel.

118
Tabelle 16: Übersicht über die mittels drei verschiedener Methoden bestimmten Referenzbereiche für alle 29 Untersuchungsgruppen
Quantilschätzung Toleranzschätzung Quantilregression
Quantil-Intervall Konfidenzintervall Toleranzintervall nach
ALTER nach GE-
SCHLECHT nach ALTER u. GESCHLECHT
Parameter Subgruppe N 2,5%-
Quantil 97,5%- Quantil
untere KI-grenze des 2,5%-Quantils
obere KI-grenze des 97,5%-
Quantils
untere Grenze
obere Grenze
2,5%- Quantil
97,5%- Quantil
2,5%- Quantil
97,5%- Quantil
2,5%- Quantil
97,5%- Quantil
HARNSTOFF allgemein
40 0,5 8,6 0,5 8,6 0,5 8,6 1,9 7,4 0,9 8,6 2,3 7,1
120 1,8 7,3 1,2 7,6 1,2 7,6 1,8 6,8 1,9 7,3 1,9 6,8
2.000 1,6 8,1 1,5 8,3 1,5 8,2 1,8 7,6 1,6 8,0 1,7 7,5
NATRIUM allgemein
40 130 144 130 146 130 146 133 145 134 145 135 145
120 134 144 130 146 133 146 134 145 134 145 134 145
2.000 133 145 133 145 133 145 133 145 133 145 133 145
KREATININ
allgemein
40 33 143 33 164 33 164 43 99 34 133 45 99
120 24 122 22 134 22 134 35 111 26 119 36 106
2.000 24 112 23 117 23 116 34 110 24 109 35 108
0 J. 40 17 59 17 59 17 59 19 59 20 59 20 59
120 9 54 4 70 4 70 10 65 10 58 10 58
1 bis 3 J. 40 17 46 17 49 17 49 20 48 19 48 21 47
120 19 49 17 64 17 64 21 48 19 49 20 48
4 bis 6 J. 40 20 69 20 116 20 116 21 83 21 91 21 78
120 21 55 16 63 16 63 23 56 21 58 20 54
7 bis 9 J. 40 30 67 30 82 30 82 32 80 35 74 36 73
120 25 64 19 82 19 82 23 66 22 66 25 66
10 bis 12 J. 40 34 75 34 84 34 84 39 73 39 80 42 73
120 38 71 28 87 28 87 37 74 38 74 37 73
13 bis 15 J. 40 34 78 34 89 34 89 38 83 38 80 39 79
120 40 89 34 92 34 92 39 89 41 85 39 85
16 bis 18 J. 40 44 93 44 96 44 96 46 94 44 93 47 91
120 44 96 41 102 41 102 45 97 44 96 45 97
Männer: 19 bis 50 J.
40 42 127 42 164 42 164 44 159 44 157 44 159
120 35 109 33 123 33 123 46 112 36 114 46 112
Männer: 51 bis 100 J.
40 51 150 51 197 51 197 56 171 51 187 56 171
120 49 160 46 212 46 212 52 141 49 165 52 141
Frauen: 19 bis 100 J.
40 42 93 42 99 42 99 43 90 44 96 43 90
120 38 101 29 116 29 116 40 89 38 104 40 89

119
5 Diskussion
Beginnend mit einer kurzen Rekapitulation der Ansatzpunkte dieser Forschungsar-
beit, folgt eine Wiederholung des Kerns der Zielsetzung und der Forschungsfrage,
um schlussendlich die gelieferten Ergebnisse angemessen interpretieren zu können.
Die vier essentiellen Ausgangspunkte für die Bestimmung von medizinischen Refe-
renzbereichen für labordiagnostische Parameter sind: die Wahl der statistischen Me-
thode, die Wahl der Referenzstichprobengröße, die Wahl der Referenzstichproben-
zusammensetzung sowie die Wahl der Referenzstichprobensubgruppen. Diese vier,
das Fundament bildenden Eckpfeiler, von deren einzelnen Festlegung aber auch ih-
rer Zusammensetzung insgesamt jegliche berechneten Referenzgrenzen abhängen,
stellen aktuell die Desiderate für die Forschung dar (siehe 2.5.2). Obwohl sich – ent-
sprechend des Dissertationsthemas – der Forschungsschwerpunkt der Wahl der sta-
tistischen Methode widmen sollte, wurde bei der Ausarbeitung des Standes der For-
schung und der Aufdeckung von Umsetzungsdefiziten und Forschungslücken ver-
ständlich, dass die Festsetzung der Referenzstichprobengröße, der Referenzstich-
probenzusammensetzung wie auch der Referenzstichprobensubgruppen als Voraus-
setzung für daraus resultierende Referenzbereiche gleichermaßen bedeutsam sind.
Folglich lautete das Hauptuntersuchungsziel, den effektivsten Ansatz und die zuver-
lässigste Methode zur Bestimmung von medizinischen Referenzbereichen für labor-
diagnostische Parameter für alle Subpopulationen – explizit die der Frauen, Kinder
und alten Menschen – zu finden, die insbesondere auch auf der Grundlage von klei-
nen Stichprobenmengen vertrauenswürdige Referenzgrenzen liefern (siehe 2.6). Die
Forschungsfrage hieß demgemäß: Welche der drei vorselektierten Methoden zur
Bestimmung von Referenzbereichen – Quantilschätzung mit Konfidenzbereichen,
Toleranzschätzung und Quantilregression – ist, in Bezug auf eine Kombination mit
dem retrospektiven Ansatz zur Gewinnung der Referenzpopulation, zu empfehlen?
(siehe 2.7).
5.1 Erörterung der Ergebnisse
Für die Evaluation der Erreichung des Untersuchungsziels und finalen Beantwortung
der Forschungsfrage werden ausschließlich die diesbezüglich relevanten Ergebnisse

120
aus den in Kapitel 4 umfassend aufgestellten Ergebnissen extrahiert und in Bezug
auf den theoretischen Kontext der Methoden diskutiert.
Die Kriterien, anhand derer die in Kapitel 3 vorgestellten Verfahren zur Bestimmung
von Referenzbereichen maßgeblich verglichen und charakterisiert werden, lauten wie
folgt: 1.) Enthalten die Referenzbereiche die vorgegebenen Anteile der Realisierun-
gen der Zufallsgröße mit der geforderten Sicherheit [ja/ nein]? 2.) Wie lang ist der
Referenzbereich [bestmöglich kurz]? Aus den drei untersuchten Methoden – der Er-
mittlung der Referenzbereiche aus den Konfidenzgrenzen der Quantilschätzer, der
parameterfreien Toleranzschätzung und der Quantilregression – wird je nach Stich-
probenzusammensetzung, Stichprobengröße und Subgruppe die beste Methode für
den jeweiligen Fall gewählt. Diese Beurteilung der Methoden erfolgt empirisch in Be-
zug auf die vorliegenden Daten und den daraus berechneten Referenzbereichen.
Die Betrachtung der Ergebnisse vor dem Hintergrund des ersten Kriteriums (1.)
ergibt folgendes Bild: Von den drei oben aufgezählten und in dieser Forschungsar-
beit umgesetzten Methoden ist die parameterfreie Toleranzschätzung die einzige
Methode, mit deren Output die Frage, ob der Referenzbereich den vorgegebenen
Anteil der Grundgesamtheit der Zufallsgröße mit der geforderten (nominalen) Si-
cherheit enthält, eindeutig beantwortet werden kann. Die parameterfreie Toleranz-
schätzung liefert für jedes Toleranzintervall – also den Referenzbereich – stets die
dazugehörige Angabe der Überdeckungswahrscheinlichkeit, also die tatsächliche
Sicherheit, des Intervalls. Darüber hinaus besteht die Möglichkeit einer Stichpro-
benumfangsplanung. Sie gewährleistet für vorgegebenes die Einhaltung von .
Damit ist man in der Lage, die Ermittlung von Referenzbereichen minimaler Länge zu
gewährleisten.
Die Methode der Quantil- und Konfidenzschätzung gewährleistet, dass der so be-
rechnete Referenzbereich mindestens den vorgegebenen Anteil der Grundge-
samtheit der Zufallsgröße mit der geforderten (nominalen) Sicherheit enthält. Sol-
che Referenzbereiche können größer sein als die aus der Toleranzschätzung resul-
tierenden. Eine Stichprobenumfangsplanung ist hier nicht bekannt. Würde man allein
aus den Stichprobenquantilen die Grenzen eines Referenzbereiches festlegen, hätte
man keine Möglichkeit, die Wahrscheinlichkeit , dass der Referenzbereich einen

121
vorgegebenen Anteil der Grundgesamtheit enthält, anzugeben. In der Sprache der
Statistik gesagt: Quantilschätzer sind keine Intervallschätzer.
Die Methode der Quantilregression berechnet ebenfalls nicht den gesamten Refe-
renzbereich, sondern die unteren und oberen Quantile separat als Bereichsgrenzen.
Sie gibt ebenso wie die Quantilschätzung keine exakte Überdeckungswahrschein-
lichkeit des Referenzbereiches an.
Insofern ist die Methode der parameterfreien Toleranzschätzung formal gesehen die
am besten geeignete Methode dafür, die Frage, ob die Referenzbereiche die vorge-
gebenen Anteile der Realisierungen der Zufallsgröße mit der geforderten Sicherheit
enthalten, fachgerecht zu beantworten. Inwieweit die drei Methoden bei unterschied-
lichen Stichprobengrößen bezüglich des ersten Kriteriums (1.) zuverlässig nutzbar
sind, wird im Folgenden ausgewertet.
Die mittels der Quantil- und Konfidenzschätzung als Referenzbereiche bestimmten
Quantil-Intervalle mit nicht-parametrischen Konfidenzgrenzen enthalten für die Unter-
suchungsgruppen mit der Stichprobengröße N = 40 nicht den vorgegebenen 0,95-
Anteil der Realisierungen der Zufallsgröße mit der geforderten 0,90-Sicherheit, da die
Überdeckungswahrscheinlichkeit für die Konfidenzintervalle der geschätzten 0,025-
und 0,975-Quantile einheitlich nur 0,636768 beträgt (siehe Tabelle 12). Für die Un-
tersuchungsgruppen mit den Stichprobengrößen N = 120 sowie N = 2.000 hingegen
enthalten die mittels der Quantil- und Konfidenzschätzung als Referenzbereiche be-
stimmten Quantil-Intervalle mit nicht-parametrischen Konfidenzgrenzen offenbar den
vorgegebenen 0,95-Anteil der Realisierungen der Zufallsgröße mit der geforderten
0,90-Sicherheit, da die Überdeckungswahrscheinlichkeiten für die Konfidenzintervalle
der geschätzten 0,025- und 0,975-Quantile 0,920467 (für N = 120) beziehungsweise
0,901237 (für N = 2.000) betragen (siehe Tabelle 12). Die mit Hilfe der Toleranz-
schätzung als Referenzbereiche bestimmten nicht-parametrischen Toleranzintervalle
enthalten ebenfalls für alle Untersuchungsgruppen mit dem Stichprobenumfang
N = 40 nicht den vorgegebenen 0,95-Anteil der Realisierungen der Zufallsgröße mit
der geforderten 0,90-Sicherheit, da die Überdeckungswahrscheinlichkeit für diese
Toleranzintervalle nur 0,6009359349 beträgt (siehe Tabelle 14). Dagegen enthalten
die für die Untersuchungsgruppen mit den Stichprobengrößen N = 120 sowie

122
N = 2.000 mit Hilfe der Toleranzschätzung als Referenzbereiche bestimmten nicht-
parametrischen Toleranzintervalle faktisch den vorgegebenen 0,95-Anteil der Reali-
sierungen der Zufallsgröße mit der geforderten 0,95-Sicherheit, da die Überde-
ckungswahrscheinlichkeiten für diese Toleranzintervalle 0,9844727754 (für N = 120)
beziehungsweise 0,9576853399 (für N = 2.000) betragen (siehe Tabelle 14). Ob die
mittels der Quantilregression als Referenzbereiche bestimmten Quantil-Intervalle den
vorgegebenen 0,95-Anteil der Realisierungen der Zufallsgröße mit der geforderten
0,95-Sicherheit enthalten, ist für alle drei unterschiedlichen Stichprobengrößen nicht
festzustellen, da in den Ergebnissen hierzu keine Überdeckungswahrscheinlichkeit
angegeben werden kann (siehe Tabelle 15).
An den hier in Hinblick auf das erste Kriterium (1.) zusammengefassten Resultaten
ist klar zu erkennen, dass die Methode der parameterfreien Toleranzschätzung für
die Stichprobenumfänge N = 120 und N = 2.000 der Methode der Quantil- und Kon-
fidenzschätzung überlegen ist, da – obwohl die Referenzbereiche beider Methoden
einen gleichen Anteil von 95 % der Realisierungen der Zufallsgröße beinhalten – die
parameterfreie Toleranzschätzung mit einer niedrigeren Irrtumswahrscheinlichkeit
(5 %) als die Quantil- und Konfidenzschätzung (10 %) eine höhere Überdeckungs-
wahrscheinlichkeit der Referenzintervalle erzielt (0,9844727754 Überdeckungswahr-
scheinlichkeit für Toleranzintervalle bei N = 120 und 0,9576853399 bei N = 2.000
versus 0,920467 Überdeckungswahrscheinlichkeit für Konfidenzintervalle der Quanti-
le bei N = 120 und 0,901237 bei N = 2.000). Damit die zur Erfüllung des ersten Krite-
riums (1.) vorangehend als am geeignetsten erklärte Methode der parameterfreien
Toleranzschätzung für alle Stichprobenumfänge – speziell auch für kleine Stichpro-
bengrößen mit N = 40 – universell einsetzbar ist, müsste von der Empfehlung der
IUPAC für generell 0,95-Toleranzintervalle abgesehen werden. Stattdessen sollten
bei sehr kleinen Referenzmengen grundsätzlich 0,90-Toleranzintervalle mit einer
Konfidenz von 0,90 definiert und berechnet werden, um somit eine ausreichende
Überdeckungswahrscheinlichkeit von 0,9195263040 gewährleisten zu können (siehe
Tabelle 13). Unter diesen Bedingungen wäre die Methode der parameterfreien Tole-
ranzschätzung unter dem Aspekt der Sicherstellung des ersten Kriteriums (1.) allge-
meingültig für alle Stichprobengrößen ab N = 40 die zuverlässigste Methode.

123
Zunächst sollen die Ergebnisse der Datenauswertungen aus Kapitel 4 unter dem
Gesichtspunkt des zweiten Kriteriums 2.) Wie lang ist der Referenzbereich [bestmög-
lich kurz]? diskutiert werden. Es wird die Methode, welche den Referenzbereich mit
minimaler Länge erzeugt, in diesem Auswahlkriterium als die beste Methode ernannt,
da sie die Information der Daten optimal ausnutzt. „Dabei sollte das Intervall nicht zu
groß sein, da es sonst wenig über den unbekannten wahren Parameter aussagt.“
[(81), S. 253]. Laut der in Absatz 4.5 erstellten Übersicht über die mittels der drei ver-
schiedenen Methoden bestimmten Referenzbereiche für alle Untersuchungsgruppen
sind die Toleranzintervalle für Stichproben mit den Größen N = 120 sowie N = 2.000
prinzipiell geringfügig schmaler als die Intervalle zwischen den unteren Konfidenz-
grenzen der 2,5%-Quantile und den oberen Konfidenzgrenzen der 97,5%-Quantile
(siehe Tabelle 16). Bei kleinen Stichproben im Umfang von N = 40 sind die Längen
der Toleranzintervalle und die Längen der Quantil-Konfidenzintervalle exakt gleich-
groß (siehe Tabelle 17).
Die Bewertung der Längen der Referenzbereiche, die den Quantilregressionen ent-
stammen, muss für drei verschiedene Regressionsmodelle vorgenommen werden –
für das Quantilregressionsmodell mit Einschluss der Variable ALTER, das Regressi-
onsmodell mit ausschließlich der Variable GESCHLECHT, wie auch das Quantilre-
gressionsmodell unter Hinzunahme der beiden Variablen ALTER und GE-
SCHLECHT. Die geschlechtsspezifischen Referenzintervalle aus dem vierten Re-
gressionsmodell, in welchem nach der Variable GESCHLECHT gruppiert wurde (sie-
he Tabelle 15), sind für einen Vergleich bezüglich ihrer Längen mit den geschlechts-
unspezifischen Resultaten aus den anderen untersuchten Methoden zur Referenzbe-
reichsbestimmung ungeeignet. Insgesamt stellen die Quantil-Intervalle aus dem Re-
gressionsmodell mit ausschließlich der Variable GESCHLECHT die längsten Interval-
le von allen drei Regressionsmodellen dar. Die Quantilregressionen mit Einbezug der
beiden Variablen ALTER und GESCHLECHT bringen durchschnittlich die kürzesten
Quantil-Intervalle hervor. Die Längen der Quantil-Intervalle aus dem Regressionsmo-
dell mit Einschluss der einzelnen Variable ALTER liegen ungefähr dazwischen. Fast
ausnahmslos ist – je Untersuchungsgruppe – das längste Intervall aus den drei ver-
schiedenen Quantilregressionsmodellen noch immer kürzer als das kürzeste Intervall
aus der Toleranzschätzung und der Quantilschätzung mit Konfidenzgrenzen. Diese
Sachlage trifft nur bei einer der 29 Untersuchungsgruppen nicht zu (in der Bezugs-

124
gruppe ‚allgemein‘ für den Laborparameter Natrium), bei der die Längen der Refe-
renzbereiche aus allen angewendeten Methoden und Modellen genau gleich sind.
Tabelle 17: Übersicht über die Längen der mittels drei verschiedener Methoden be-
rechneten Referenzintervalle für alle 29 Untersuchungsgruppen
Quantilschätzung Toleranz-schätzung
Quantilregression
Parameter Sub-gruppe
N Quantil-Intervall ohne KI
Quantil-Intervall mit Konfidenz-
grenzen
Toleran-zintervall
nach ALTER
nach GE-SCHLECHT
nach AL-TER u. GE-SCHLECHT
HARN-STOFF
allgemein 40 8,1 8,1 8,1 5,5 7,7 4,8
120 5,5 6,4 6,4 5,0 5,4 4,9
2.000 6,5 6,8 6,7 5,8 6,4 5,8
NATRIUM
allgemein 40 14 16 16 12 11 10
120 10 16 13 11 11 11
2.000 12 12 12 12 12 12
KREA-TININ
allgemein 40 110 131 131 56 99 54
120 98 112 112 76 93 70
2.000 88 94 93 76 85 73
0 J. 40 42 42 42 40 39 39
120 45 66 66 55 48 48
1 - 3 J. 40 29 32 32 28 29 26
120 30 47 47 27 30 28
4 - 6 J. 40 49 96 96 62 70 57
120 34 47 47 33 37 34
7 - 9 J. 40 37 52 52 48 39 37
120 39 63 63 43 44 41
10 - 12 J. 40 41 50 50 34 41 31
120 33 59 59 37 36 36
13 - 15 J. 40 44 55 55 45 42 40
120 49 58 58 50 44 46
16 - 18 J. 40 49 52 52 48 49 44
120 52 61 61 52 52 52
Männer:
19 - 50 J.
40 85 122 122 115 113 115
120 74 90 90 66 78 66
Männer:
51 - 100 J.
40 99 146 146 115 136 115
120 111 166 166 89 116 89
Frauen:
19 - 100 J.
40 51 57 57 47 52 47
120 63 87 87 49 66 49
Summe der Intervalllängen 1.408 1.850 1.846 1.342 1.492 1.286

125
Die Längen der Referenzintervalle aus den verschiedenen Quantilregressionsmodel-
len scheinen – im Gegensatz zu den oben beschriebenen, beobachteten Stichpro-
bengrößen-abhängigen Unterschieden zwischen den Längen der Toleranz- und
Quantil-Intervalle mit Konfidenzgrenzen – nicht abhängig von dem Stichprobenum-
fang zu sein. (Überblick der Intervalllängen siehe Tabelle 17)
Zusammengefasst liefert die Methode der Quantilregression die schmalsten Refe-
renzintervalle für die Daten. Wir wissen aber nichts betreffend die Überdeckungs-
wahrscheinlichkeiten dieser Intervalle. Die Methode der parameterfreien Toleranz-
schätzung ergibt für die Daten die zweitschmalsten Referenzbereiche und die Me-
thode der parameterfreien Quantilschätzung mit Konfidenzgrenzen die breitesten
Referenzintervalle (siehe Tabelle 16 und Tabelle 17). Unter den vorangehend ange-
gebenen Prämissen wäre die Methode der Quantilregression – insbesondere das
Regressionsmodell mit Einschluss der beiden Variablen ALTER und GESCHLECHT
– hinsichtlich der Sicherstellung des zweiten Kriteriums (2.) umfassend für alle Stich-
probengrößen ab N = 40 die präziseste Methode von allen drei getesteten Methoden.
Dieser folgt an zweiter Stelle die Methode der parameterfreien Toleranzschätzung.
Diese Aussage gilt für die Auswertung der betrachteten Daten. Sie kann nicht verall-
gemeinert werden!
Selbstverständlich ist eine Bewertung von Berechnungsmethoden allein anhand von
Rechenergebnissen unzureichend. Hier fehlt der Bezug zu den mathematischen
Grundlagen. Offenbar ist die Länge der Referenzbereiche von dem Stichprobenum-
fang abhängig und wird mit diesem kleiner. Es gilt also, Stichprobenumfang N, gefor-
derten zu überdeckenden Anteil sowie geforderte Überdeckungswahrscheinlich-
keit im Zusammenhang zu sehen (siehe Tabelle 7).
Die Quantilregression bietet den möglicherweise unverzichtbaren Vorteil, Kovariablen
in die Bestimmung von Referenzbereichen einbeziehen zu können. Möchte man auf
den Qualitätsvorteil der verteilungsfreien Toleranzschätzung nicht verzichten, wären
auch geschichtete Toleranzschätzungen denkbar. Das bedeutet aber eine Erhöhung
des Gesamt-Stichprobenumfanges.

126
Die gesamtheitliche Beurteilung der nach den beiden anfangs aufgestellten Kriterien
(1. und 2.) ausgewerteten Forschungsergebnisse ergibt im Endeffekt keine Deklara-
tion einer einheitlich besten Methode zur Bestimmung von Referenzbereichen, son-
dern zeigt eher zwei kontroverse Herangehensweisen auf: Die beste Methode in
Hinblick auf das erste Kriterium mit der Fragestellung 1.) Enthalten die Referenzbe-
reiche die vorgegebenen Anteile der Realisierungen der Zufallsgröße mit der gefor-
derten Sicherheit [ja/ nein]? ist die Methode der parameterfreien Toleranzschätzung,
da sich die parameterfreie Toleranzschätzung als zuverlässigste Methode bezüglich
der erreichten Überdeckungswahrscheinlichkeit herausgestellt hat. Die beste Metho-
de in Bezug auf das zweite Kriterium mit der Fragestellung 2.) Wie lang ist der Refe-
renzbereich [bestmöglich kurz]? ist die Methode der Quantilregression, da sich die
Quantilregression als präziseste Methode betreffs der Intervalllänge erwiesen hat.
Die Kontroverse stellt sich folgendermaßen dar: „Die Suche nach einem geeigneten
Intervall verfolgt somit gegenläufige Ziele: Hohe Anforderung hinsichtlich der ‚Über-
deckungswahrscheinlichkeit‘ erfordert breitere Intervalle, schmalere Intervalle führen
zwangsläufig zu einer kleineren Überdeckungswahrscheinlichkeit.“ [(81), S. 253].
Um schlussendlich das Hauptuntersuchungsziel erfüllen sowie die Forschungsfrage
beantworten und eine Empfehlung abgeben zu können, muss zuvor entschieden
werden, wie mit diesen zwei gegensätzlichen Ansätzen weiter zu verfahren ist: ob die
beste Methode je nach Wichtigkeit des Kriteriums gewählt wird, ob nur eine Methode
befürwortet wird – und wenn ja, welche der beiden und weshalb, oder ob beide Me-
thoden als gegenseitige Alternativen beziehungsweise in Kombination zum stan-
dardmäßigen Einsatz angeraten werden. Diese Entscheidung soll erst nach den Aus-
führungen in den nachfolgenden Absätzen 5.2, 5.3 und 5.4 unter Berücksichtigung
der darin berichteten Feststellungen gefällt, und in Abschnitt 5.5 bekanntgegeben
werden. Endgültig festzuhalten ist an dieser Stelle jedoch schon, dass die Methode
der Ermittlung der Referenzbereiche aus den Konfidenzgrenzen der Quantilschätzer
gemäß der bisher als Goldstandard geltenden IFCC-Empfehlung auf der Basis der
vorliegenden Untersuchungsergebnisse zur weiteren Anwendung in der Laborpraxis
nicht empfohlen werden kann, da diese Methode der Quantilschätzung mit Konfiden-
zintervallen den beiden anderen geprüften Methoden der Toleranzschätzung wie
auch der Quantilregression hinsichtlich der zwei Auswahlkriterien weit unterlegen ist.

127
5.2 Abgleich mit Referenzbereichen der Universitätsmedizin Greifswald
In Abschnitt 2.7 wurde festgelegt, dass ein Abgleich mit adäquaten Referenzinterval-
len aus dem Laborkatalog des Instituts für Klinische Chemie und Laboratoriumsme-
dizin der Universitätsmedizin Greifswald zur Prüfung der Ergebnisse vorzunehmen
ist. Hierfür werden die in Tabelle 4 je Analyt aufgelisteten Referenzbereiche mit den
ermittelten Referenzbereichen der Untersuchungsgruppen aus der Tabelle 16 auf
Bezugsgruppenebene verglichen. Ausgenommen hiervon sind die zwei altersspezifi-
schen Bezugsgruppen ‚bis 30 Tage‘ für Kreatinin sowie ‚bis 180 Tage‘ für Harnstoff –
was unter Punkt 3.3 mit der bestehenden Datenlage begründete wurde. Da im La-
borkatalog wie auch auf den Internetseiten des Instituts für Klinische Chemie und
Laboratoriumsmedizin der Universitätsmedizin Greifswald keine Angaben zum Selek-
tionsverfahren der Referenzindividuen, zu angewendeten statistischen Methoden
sowie bedingten Parametern wie Konfidenz, Stichprobenanteil und Überdeckungs-
wahrscheinlichkeit vorzufinden sind (43), kann sich der Vergleich der Referenzberei-
che nicht auf das erste Kriterium (1.) beziehen, sondern sich nur auf das zweite Krite-
rium (2.) der Intervalllänge, und auf die konkrete Lage der Referenzgrenzen stützen.
Dafür wurden sowohl die Längen der Intervalle der Referenzbereiche entsprechend
des Laborkataloges der Universitätsmedizin Greifswald (siehe Tabelle 18) als auch
die Längen der selbst ermittelten Referenzintervalle bestimmt (siehe Tabelle 17).
Der vorgenommene Abgleich zeigte folgende Tendenzen: Die meisten Übereinstim-
mungen beziehungsweise annähernd gleichen Werte bezüglich der Intervalllängen
zwischen dem Laborkatalog und den selbst bestimmten Referenzbereichen kamen
ausdrücklich bei den Ergebnissen der Methode der Quantilregression vor – am häu-
figsten bei dem Regressionsmodell mit Einschluss der Variablen ALTER und GE-
SCHLECHT (in 10 Untersuchungsgruppen), gefolgt von dem Regressionsmodell mit
Einschluss der einzelnen Variable ALTER (in 7 Untersuchungsgruppen) sowie dem
Regressionsmodell mit Einschluss der einzelnen Variable GESCHLECHT (in 3 Un-
tersuchungsgruppen). Die aus der Methode der Quantilschätzung ohne Berücksichti-
gung der Konfidenzgrenzen ermittelten Intervalllängen zeigten mehr Übereinstim-
mungen beziehungsweise annähernd gleichen Werte (in 3 Untersuchungsgruppen)
als die aus der Methode der Quantilschätzung mit Einbeziehung der Konfidenzgren-

128
zen berechneten Intervalllängen (in 2 Untersuchungsgruppen) und die aus der Me-
thode der Toleranzschätzung kalkulierten Intervalllängen (ebenfalls in 2 Untersu-
chungsgruppen). Exakte Übereinstimmungen zwischen den Intervalllängen aus dem
Laborkatalog und den selbst bestimmten Referenzbereichen liegen bei den drei Be-
zugsgruppen ‚allgemein‘ für Natrium‚ ‚1 bis 3 Jahre‘ für Kreatinin i.Pl. und ‚16 bis 18
Jahre‘ für Kreatinin i.Pl. vor. Die Übereinstimmungen beziehungsweise annähernd
gleichen Werte bezüglich der Intervalllängen treten ausschließlich und zu gleichen
Teilen in den Stichprobengrößen N = 40 und N = 120, keine einzige jedoch in Unter-
suchungsgruppen mit dem Stichprobenumfang N = 2.000 auf.
Tabelle 18: Auszug aus dem Laborkatalog der Ernst-Moritz-Arndt-Universität Greifs-
wald von 2011 mit Intervalllängen (43)
Analyt Bezugsgruppe Referenzbereich/
Therapeutischer
Bereich
Länge des
Intervalls
Harnstoff
i.Pl.
bis 180 Tage 2,0 - 4,5 mmol/l 2,5
allgemein 2,5 - 6,4 mmol/l 3,9
Natrium i.Pl. allgemein 135 - 145 mmol/l 10
Kreatinin
i.Pl.
bis 30 Tage 44 - 106 µmol/l 62
1 bis 11 Monate 35 - 62 µmol/l 27
1 bis 3 Jahre 35 - 62 µmol/l 27
4 bis 6 Jahre 44 - 71 µmol/l 27
7 bis 9 Jahre 53 - 80 µmol/l 27
10 bis 12 Jahre 53 - 88 µmol/l 35
13 bis 15 Jahre 53 - 106 µmol/l 53
16 bis 18 Jahre 71 - 123 µmol/l 52
Frauen: 19 Jahre bis ins Alter 58 - 96 µmol/l 38
Männer: 19 bis 50 Jahre 74 - 110 µmol/l 36
Männer: 51 Jahre bis ins Alter 72 - 127 µmol/l 55
allgemein 58 - 127 µmol/l 69

129
Der Vergleich der konkreten Lagen der unteren und oberen Referenzgrenzen je La-
borparameter und Bezugsgruppe zwischen den Referenzbereichen aus dem Labor-
katalog der Universitätsmedizin Greifswald und den selbst ermittelten Referenzberei-
chen bringt deutlich zum Ausdruck, dass auch unter diesem Blickwinkel die Mehrheit
der Übereinstimmungen beziehungsweise annähernd gleichen Werte in den Ergeb-
nissen aus der Methode der Quantilregression zu finden sind und auch hierbei das
Regressionsmodell mit Einschluss der Variablen ALTER und GESCHLECHT anführt.
Außer bei der Bezugsgruppe ‚allgemein‘ für Natrium, bei der die Referenzgrenzen
weitestgehend von allen drei untersuchten Methoden gleich derer aus dem Laborka-
talog der Universitätsmedizin Greifswald sind, stehen die Methoden der Quantil-
schätzung – sowohl mit als auch ohne Konfidenzgrenzen – und der Toleranzschät-
zung der Methode der Quantilregression in diesem Punkt der Betrachtung nach.
Gleichermaßen wie bei der vorangegangenen Besprechung der Intervalllängen sind
die Übereinstimmungen beziehungsweise annähernd gleichen Werte bezüglich der
Lage der Referenzgrenzen überwiegend in den Ergebnissen aus Stichproben mit
den Größen N = 40 sowie N = 120, und kaum in Untersuchungsgruppen mit dem
Stichprobenumfang N = 2.000 vertreten.
Im Verlauf der sich erstreckenden Phase der Durchführung und Verschriftung der
vorliegenden Forschungsarbeit wurden die auf der Basis des Laborkataloges aus
dem Jahr 2011 in Tabelle 4 definierten und für diese Untersuchung herangezogenen
Bezugsgruppen von dem Institut für Klinische Chemie und Laboratoriumsmedizin der
Universitätsmedizin Greifswald im aktuellen Laborkatalog mit dem Stand vom
17. Mai 2013 für den Analyt Kreatinin (enzymatisch) wie folgt angepasst (82):
Die Bezugsgruppe ‚bis 30 Tage‘ wurde in die zwei Bezugsgruppen ‚bis 7 Tage‘ und
‚8 bis 30 Tage‘ aufgeteilt. Die Bezugsgruppe ‚1 bis 11 Monate‘ wurde in die zwei Be-
zugsgruppen ‚1 bis 6 Monate‘ und ‚7 bis 11 Monate‘ untergliedert. Die sechs Be-
zugsgruppen ‚1 bis 3 Jahre‘, ‚4 bis 6 Jahre‘, ‚7 bis 9 Jahre‘, ‚10 bis 12 Jahre‘, ‚13 bis
15 Jahre‘ und ‚16 bis 18 Jahre‘ wurden in eine Bezugsgruppe ‚1 bis 18 Jahre‘ zu-
sammengelegt. Die zwei Bezugsgruppen ‚Männer: 19 bis 50 Jahre‘ und ‚Männer:
51 Jahre bis ins Alter‘ wurden in einer Bezugsgruppe ‚Männer 19 Jahre bis ins Alter‘
zusammengefasst. Die zwei Bezugsgruppen ‚Frauen: 19 Jahre bis ins Alter‘ sowie
‚allgemein‘ wurden beibehalten. Neben den Anpassungen der Bezugsgruppen ver-

130
änderten sich auch die dazugehörigen Referenzbereiche und Intervalllängen je Be-
zugsgruppe für den Analyt Kreatinin (enzymatisch). Im Mittel sind die aktuellen Refe-
renzbereiche für Kreatinin (enzymatisch) mit einer durchschnittlichen Intervalllänge
von 37 schmaler als die für Kreatinin i.Pl. von 2011 mit der durchschnittlichen Inter-
valllänge 42. Für die Analyten Harnstoff i.Pl. sowie Natrium i.Pl. blieben die Bezugs-
gruppen, Referenzbereiche und Intervalllängen unverändert. Ein Ausschnitt aus dem
gegenwärtigen Laborkatalog ist in Tabelle 19 einzusehen.
Tabelle 19: Auszug aus dem Laborkatalog der Ernst-Moritz-Arndt-Universität Greifs-
wald von 2013 mit Intervalllängen (82)
Analyt Bezugsgruppe Referenzbereich/
Therapeutischer
Bereich
Länge des
Intervalls
Harnstoff
i.Pl.
bis 180 Tage 2,0 - 4,5 mmol/l 2,5
allgemein 2,5 - 6,4 mmol/l 3,9
Natrium i.Pl. allgemein 135 - 145 mmol/l 10
Kreatinin
(enzymat.)
bis 7 Tage 53 - 97 µmol/l 44
8 bis 30 Tage 27 - 62 µmol/l 35
1 bis 6 Monate 18 - 35 µmol/l 17
7 bis 11 Monate 18 - 35 µmol/l 17
1 bis 18 Jahre 18 - 62 µmol/l 44
Frauen 19 Jahre bis ins Alter 42 - 80 µmol/l 38
Männer 19 Jahre bis ins Alter 49 - 97 µmol/l 48
allgemein 42 - 97 µmol/l 55
Der Grund für die Änderungen der Bezugsgruppen und Referenzgrenzen für den
Analyt Kreatinin wurde von dem Institut für Klinische Chemie und Laboratoriumsme-
dizin der Universitätsmedizin Greifswald in einem Rundschreiben an alle Anforderer
labordiagnostischer Untersuchungen kommuniziert. Nauck und Wasner informierten
darin über eine Methodenumstellung bei dem Analyt Kreatinin und gaben Folgendes
bekannt: „die Bestimmung von Kreatinin aus Serum, Lithium-Heparin-Plasma und
Urin wird zukünftig mit einer spezifischen enzymatischen Methode durchgeführt. Die

131
Umstellung erfolgt am 19.11.2012. Die Messwerte der bisherigen und der neuen Me-
thode sind gut vergleichbar, wobei die enzymatische Methode im Serum und Plasma
ca. 10% niedrigere Ergebnisse liefert.“ [(83), S. 1]. Diese Umstellung wurde damit
begründet, dass enzymatische Verfahren zur Kreatininbestimmung „[…] weniger an-
fällig gegenüber Störungen durch Fremdsubstanzen […]“ sind [(83), S. 1]. Scheinbar
nicht gemeldet wurden und werden im Allgemeinen Informationen zu eventuell abge-
änderten Verfahren der Selektion von Referenzindividuen, anderen verwendeten sta-
tistischen Methoden zur Bestimmung von Referenzbereichen, veränderten Definitio-
nen des Konfidenzniveaus, des Stichprobenanteils oder der geforderten Überde-
ckungswahrscheinlichkeit. Somit ist nicht eindeutig erkennbar, ob über die Zeit aufge-
tretene Verschiebungen von Referenzgrenzen – welche nicht wie bei Kreatinin (siehe
oben) auf einer Umstellung der Labormethode beruhen – auf einem Wandel in der
Bezugspopulation und demzufolge in der regionalen Grundgesamtheit basieren.
Insgesamt kann jedoch festgestellt werden, dass der Großteil der selbst bestimmten
Referenzgrenzen den Referenzgrenzen aus dem Laborkatalog des Instituts für Klini-
sche Chemie und Laboratoriumsmedizin der Universitätsmedizin Greifswald annähe-
rungsweise entspricht und die in diesem Abschnitt miteinander verglichenen Refe-
renzbereiche nicht entscheidend voneinander abweichen. In Anbetracht dessen und
unter der Annahme, dass die Referenzbereiche des Instituts für Klinische Chemie
und Laboratoriumsmedizin der Universitätsmedizin Greifswald gemäß der Empfeh-
lung der IFCC generiert wurden, kann die daraus schlussfolgernde Behauptung auf-
gestellt werden, dass die mittels des prospektiven Ansatzes laut der IFCC mit auf-
wändigen und Kosten- wie auch Zeit-intensiven Verfahren erzeugten Referenzberei-
che ebenso gut, aber mit geringerer Belastung für die Laboratorien, mittels des hier
untersuchten retrospektiven Ansatzes gewonnen werden könnten.
Die Studentin Lieckfeldt analysierte im Jahr 2009 während ihrer Praxisarbeit im
Rahmen des Studiengangs Biomathematik an der Hochschule Zittau/ Görlitz (FH) in
Kooperation mit dem Institut für Biometrie und Medizinische Informatik der
Universitätsmedizin der Ernst-Moritz-Arndt-Universität Greifswald ebenfalls
Referenzbereiche klinischer Parameter – desgleichen auf der Grundlage von Labor-
daten von Nieren-gesunden Patienten aus dem Universitätsklinikum Greifswald (84).
Sie verglich die Methode der verteilungsfreien Toleranzschätzung mit der Methode

132
der Quantilschätzung mit verteilungsfreien Konfidenzintervallen, berechnete
Toleranzintervalle für die Parameter CRP, Hämatokrit, Harnstoff, Kreatinin sowie
Natrium und stellte abschließend ihre Ergebnisse den Referenzbereichen aus dem
zu jener Zeit gültigen Laborkatalog der Universitätsmedizin Greifswald gegenüber.
Lieckfeldts Berechnungen bezogen sich allein auf die allgemeinen Bezugsgruppen
der Laborparameter. Zudem beruhten sie nicht auf gezogenen, unterschiedlich
großen Zufallsstichproben, sondern auf dem gesamten Datenbestand mit einem
Umfang von N = 12.556 für Harnstoff, N = 17.048 für Kreatinin und N = 17.483 für
Natrium. Lieckfeldt kam zu dem Resultat, dass die 0,90-Toleranzintervalle mit einer
0,95-Konfidenz näher an den Referenzintervallen des Instituts für Klinische Chemie
und Laboratoriumsmedizin der Universitätsmedizin Greifswald liegen als die ermittel-
ten 0,95-Toleranzintervalle mit einer 0,95-Konfidenz, aber im Ganzen alle
Toleranzintervalle den Referenzbereichen der Universitätsmedizin Greifswald relativ
nahestehen. Sie fasste das Fazit, dass Toleranzintervalle anstelle der mittels der
Quantil- und Konfidenzschätzung bestimmten Referenzbereiche in der Medizin
verwendet werden können (84).
Bereits ein Jahr zuvor, im Jahr 2008, prüfte die Studentin Klassen im Rahmen ihrer
Diplomarbeit im Studiengang Biomathematik an dem Institut für Mathematik und
Informatik an der Ernst-Moritz-Arndt-Universität Greifswald in Zusammenarbeit mit
dem Institut für Biometrie und Medizinische Informatik der Universitätsmedizin der
Ernst-Moritz-Arndt-Universität Greifswald die Anwendung von Toleranzschätzungen
zur Erzeugung von Referenzbereichen mit Hilfe klinischer Daten – anhand von Lab-
ordaten Nieren-gesunder Patienten aus dem Universitätsklinikum Greifswald (85).
Klassen untersuchte verteilungsfreie Toleranzintervalle und Toleranzbereiche für die
Normalverteilung. Sie berechnete verteilungsfreie 0,90-, 0,95-, 0,98- sowie 0,99-
Toleranzintervalle zu jeweils den Sicherheitswahrscheinlichkeiten 0,95 und 0,99 für
die fünf Parameter CRP, Hämatokrit, Harnstoff, Kreatinin und Natrium. Anschließend
glich sie ihre Ergebnisse mit den Referenzbereichen aus dem zur damaligen Zeit
gültigen Laborkatalog der Universitätsmedizin Greifswald ab. Klassen erkannte unter
anderem, „[…] dass sich die approximativen Werte deutlich von den exakt
berechneten Werten unterscheiden.“ [(85), S. 45]. Sie schlug vor, die approximative
Methode erst bei größeren Stichprobenumfängen anzuwenden. Auch Klassens

133
Berechnungen der Referenzgrenzen bezogen sich einzig auf die allgemeinen
Bezugsgruppen der Laborparameter und nicht auf definierte geschlechts- oder al-
tersspezifische Gruppen. Ebenso wie bei Lieckfeldt wurden die Bestimmungen der
Referenzbereiche nicht für verschieden große Zufallsstichproben durchgeführt,
sondern erfolgten nur einmalig bei Untersuchungsgruppen mit den Umfängen
N = 8.888 für Harnstoff, N = 12.690 für Kreatinin und N = 13.110 für Natrium.
Klassens Ergebnisse lassen einen ähnlichen Schluss wie Lieckfeldts Ergebnisse zu:
dass die 0,90-Toleranzintervalle mit einer 0,95-Konfidenz den Referenzbereichen
des Instituts für Klinische Chemie und Laboratoriumsmedizin der Universitätsmedizin
Greifswald mehr entsprechen als die ermittelten 0,95-, 0,98- und 0,99-
Toleranzintervalle. Ferner erreichten die Toleranzintervalle mit einer ersuchten 0,99-
Konfidenz oft nicht die geforderten Stichprobenanteile. Umfassend ist auch an diesen
Untersuchungsergebnissen zu sehen, dass die verteilungsfreien Toleranzgrenzen
den Referenzgrenzen der Universitätsmedizin Greifswald sehr nahe kommen.
Lieckfeldts und Klassens Forschungsergebnisse entstammten verschieden großen
Untersuchungsgruppen, bestehend aus retrospektiv selektierten Referenzindividuen
aus derselben Region, und ließen die einheitliche Aussage zu, dass das
retrospektive Verfahren Referenzbereiche hervorbringt, die den Referenzbereichen
aus dem Laborkatalog der Universitätsmedizin Greifswald annähernd gleichen – bei
denen davon ausgegangen werden kann, dass sie mit dem prospektiven Verfahren
erschaffen wurden. Diese Erkenntnisse bekräftigen die von der Autorin oben
genannte Behauptung, dass die von der IFCC angeratene induktive Selektion einer
Bezugspopulation zur Bestimmung von prospektiven Referenzgrenzen durch die
deduktive Selektion einer Bezugspopulation zur Bestimmung von retrospektiven
Referenzgrenzen ersetzt werden könnte.
5.3 Herausarbeitung relevanter Phänomene und Trends
Wie zu Beginn in der Einleitung (siehe 1.5.2 und 1.5.3) sowie im Methodenteil (siehe
3.1.2) der Dissertation herausgearbeitet wurde, gibt es labordiagnostische
Parameter, deren Referenzgrenzen nachweislich von dem Alter und/ oder dem
Geschlecht abhängen. Dazu gehört zum Beispiel der Parameter Kreatinin i.Pl./ en-
zymatisch bestimmt [vgl. (39;43;82)]. Daneben gibt es Laborparameter, deren

134
Referenzgrenzen eindeutig unabhängig von dem Alter und/ oder Geschlecht sind.
Hierzu gehört beispielsweise der Parameter Natrium i.Pl. [vgl. (39;43;82)]. Es gibt
aber auch Laborparameter, bei denen es vereinzelt Hinweise auf eine Abhängigkeit
der Referenzgrenzen von dem Alter und/ oder dem Geschlecht gibt, diese aber je
nach Laboratorium oder Literaturquelle variieren. Ein Parameter dieser Art ist
Harnstoff i.Pl. [vgl. (39;43;82)]. Für den Analyt Harnstoff i.Pl. werden je nach Quelle
einerseits geschlechtsspezifische, andererseits geschlechtsunspezifische und/ oder
zum einen altersabhängige, zum anderen altersunabhängige Referenzgrenzen
angegeben. Laut dem Institut für Klinische Chemie am Universitätsklinikum Ulm etwa
sind die Referenzgrenzen für Harnstoff i.Pl. geschlechts- und altersspezifisch und
werden für Frauen bis 50 Jahre mit 2,6 - 6,7 mmol/l, für Frauen ab 51 Jahre mit 3,5 -
7,2 mmol/l, für Männer bis 50 Jahre mit 3,2 - 7,3 mmol/l und für Männer ab 51 Jahre
mit 3,0 - 9,2 mmol/l definiert (86). Diese geschlechtsabhängigen Referenzgrenzen
stehen im Widerspruch zu den Vorgaben aus dem Laborkatalog von dem Institut für
Klinische Chemie und Laboratoriumsmedizin der Ernst-Moritz-Arndt-Universität
Greifswald, in denen die Referenzgrenzen für den Parameter Harnstoff ausschließ-
lich von dem Alter und nicht von dem Geschlecht abhängen – wobei auch die Alters-
gruppen gänzlich anders eingeteilt sind [vgl. (43;82)].
Da es relativ unwahrscheinlich ist, dass die biologischen Merkmale innerhalb der Be-
völkerung in Deutschland – welche hier als Grundgesamtheit verstanden werden
könnte – regional derart voneinander abweichen, dass lokale Laboratorien die
Einflüsse auf Referenzgrenzen konträr beurteilen und folglich verschiedenartige
Subgruppen bilden, kann der Grund für diese gegensätzlichen Angaben zu
geschlechts- und altersspezifischen Referenzbereichen für einige Laborparameter –
neben der eventuell von Laboratoriumsmedizinern unterschiedlich bewerteten
klinischen Relevanz einzelner Subgruppendefinitionen – nur in den zu ihrer
Ermittlung angewandten statistischen Methoden oder in Stratifikationsfehlern liegen.
Vor diesem Hintergrund sollten in der vorliegenden Untersuchung die biologischen
Faktoren Alter und Geschlecht als Einflussgrößen herangezogen und ihr Einfluss auf
Referenzgrenzen überprüft werden. Bei Laborparametern wie Kreatinin, von denen
die Einflüsse von Alter und Geschlecht auf den Referenzbereich sicher bekannt sind,
wurden die Variablen ALTER und GESCHLECHT zusätzlich als Stratifizierungsvari-

135
ablen für das Schichten der Patientendaten genutzt, wodurch nach Alter und/ oder
Geschlecht geschichtete Untersuchungsgruppen entstanden. Insbesondere die all-
gemeinen Untersuchungsgruppen, in denen Daten von Patienten jeden Alters und
Geschlechts vertreten waren, wurden mit der Methode der Quantilregression hin-
sichtlich existierender signifikanter Einflüsse von Alter und/ oder Geschlecht auf die
Referenzbereiche von Laborparametern analysiert. Mittels verschiedener Quantilre-
gressionsmodelle wurde der Einfluss von Alter und/ oder Geschlecht auf die Lage der
unteren und oberen Referenzgrenzen für die drei Laborparameter Harnstoff, Natrium
und Kreatinin anhand unterschiedlich großer wie auch zusammengesetzter Untersu-
chungsgruppen erforscht. In Abschnitt 4.4 wurden alle diesbezüglich relevanten Er-
gebnisse der Quantilregressionen aufgeführt und in Tabelle 15 systematisch darge-
stellt. Signifikante Zusammenhänge zwischen Alter und/ oder Geschlecht und Refe-
renzgrenzen wurden mit einem Stern * gekennzeichnet. Da sich das dritte Regressi-
onsmodell mit Einschluss der beiden Variablen ALTER und GESCHLECHT in der
Evaluation der Ergebnisse in den zwei vorherigen Absätzen 5.1 und 5.2 als das bes-
te der vier Regressionsmodelle erwies, sollen die Betrachtungen an dieser Stelle
ebenfalls auf nur dieses Quantilregressionsmodell beschränkt werden.
Die Resultate der Quantilregressionen nach dem dritten Regressionsmodell unter
Berücksichtigung der beiden biologischen Variablen ALTER und GESCHLECHT ge-
ben klare Anhaltspunkte für beziehungsweise gegen geschlechts- und/ oder alters-
abhängige Referenzgrenzen bei den getesteten Laborparametern und können fol-
gendermaßen interpretiert werden:
Die Ergebnisse der Quantilregressionen für den Parameter NATRIUM lassen auf der
Grundlage der verfügbaren Labordaten einheitlich für alle drei ausgewerteten Unter-
suchungsgruppen und Stichprobengrößen die Bestätigung der Annahme zu, dass
das Alter und das Geschlecht keinen signifikanten Einfluss auf die Lage der Refe-
renzgrenzen für den Laborparameter Natrium ausüben (siehe Tabelle 15, Spalte
‚3. MODELL‘ sowie Seite 101). Weder für die Variable ALTER noch für die Variable
GESCHLECHT wurden signifikante p-Werte für die unteren und oberen Quantile aller
Untersuchungsgruppen des Laborparameters Natrium ausgegeben. Ebenso visuell
sind in den neun Streudiagrammen keine mit zunehmendem Alter anwachsenden
oder abfallenden Referenzwerte erkennbar. Regressionsgeraden, die einen anstei-

136
genden oder absinkenden Anschein besitzen, sind höchstwahrscheinlich durch ein-
zelne Ausreißer entstanden (siehe Abbildung 18 unter 4.4.2). Demnach sind die ei-
gens ermittelten Alters- und Geschlechtsspezifika der Referenzbereiche von Natrium
i.Pl. mit denen des Instituts für Klinische Chemie und Laboratoriumsmedizin der Uni-
versitätsmedizin Greifswald identisch (43;82). Dies zeigt, dass retrospektive Refe-
renzgrenzen sogar für alters- und geschlechtsspezifische Referenzbereiche eine gu-
te und nutzbare Alternative für aufwändig generierte prospektive Referenzgrenzen
sein können.
Die Ergebnisse der Quantilregressionen für den Parameter KREATININ lassen auf
der Basis der bereitgestellten Labordaten sowie den bewerteten Untersuchungs-
gruppen aus der allgemeinen Bezugsgruppe mit den Stichprobenumfängen N = 40
und N = 2.000 die Bestätigung der Annahme zu, dass die Referenzgrenzen des La-
borparameters Kreatinin signifikant von dem Alter und dem Geschlecht abhängen
(siehe Tabelle 15, Spalte ‚3. MODELL‘). Gemäß des Outputs der Quantilregressio-
nen zur Bestimmung der Referenzgrenzen für die allgemeine Bezugsgruppe mit
N = 2.000 wird sowohl das untere als auch das obere Quantil von den beiden Variab-
len ALTER und GESCHLECHT beeinflusst (siehe Seite 101). Zugleich konnte für die
allgemeine Bezugsgruppe anhand der Stichprobe mit der Größe N = 40 für das
0,975-Quantil ein signifikanter Zusammenhang zwischen der Variable ALTER und
der Lage der oberen Referenzgrenze für Kreatinin nachgewiesen werden (siehe Sei-
te 101). Parallel dazu zeigen die grafisch in den neun Streudiagrammen dargestell-
ten Referenzwerte aller drei Stichprobengrößen aus der allgemeinen Bezugsgruppe
eindeutig, dass mit zunehmendem Alter auch die unteren und die oberen Referenz-
grenzen von Kreatinin ansteigen (siehe Abbildung 19 unter 4.4.3). Eine einzige Re-
gressionsgerade – das 0,975-Quantil für die Untersuchungsgruppe aus der allgemei-
nen Bezugsgruppe der Stichprobe mit der Größe N = 120 von dem Regressionsmo-
dell mit Einschluss der Variable ALTER, gruppiert nach der Variable GESCHLECHT,
für Männer – nimmt einen leicht sinkenden Verlauf, was jedoch von nur einem Aus-
reißer herrührt.
Der Fakt, dass die Quantilregressionen für die zehn alters- und geschlechtsspezifi-
schen Bezugsgruppen ‚1 bis 11 Monate‘, ‚1 bis 3 Jahre‘, ‚4 bis 6 Jahre‘, ‚7 bis 9 Jah-
re‘, ‚10 bis 12 Jahre‘, ‚13 bis 15 Jahre‘, ‚16 bis 18 Jahre‘, ‚Frauen: 19 Jahre bis ins

137
Alter‘, ‚Männer: 19 bis 50 Jahre‘ sowie ‚Männer: 51 Jahre bis ins Alter‘ des Parame-
ters Kreatinin i.Pl. für die unteren und oberen Quantile in allen Untersuchungsgrup-
pen und jeder Stichprobengröße keine signifikanten p-Werte und somit keine Indizien
für Abhängigkeiten der Referenzgrenzen von dem Alter und dem Geschlecht hervor-
brachten (siehe Tabelle 15, Spalte ‚3. MODELL‘), kann derart gedeutet werden, dass
die alters- und geschlechtsspezifischen Bezugsgruppen aus dem Laborkatalog von
2011 (43) von dem Institut für Klinische Chemie und Laboratoriumsmedizin der Uni-
versitätsmedizin Greifswald adäquat stratifiziert wurden und die wahren regionalen
Strukturen wie auch alters- und geschlechtsabhängigen Effekte auf die Referenz-
grenzen abbilden. Insgesamt sind die selbst bestimmten Alters- und Geschlechts-
spezifika der Referenzbereiche bei dem Parameter Kreatinin i.Pl. mit denen der Uni-
versitätsmedizin Greifswald kongruent und sprechen gleichfalls – wie schon bei dem
Laborparameter Natrium – für das Konzept der retrospektiven Referenzgrenzen.
Die aus den vorhandenen Labordaten für den Parameter HARNSTOFF gewonnenen
Ergebnisse der Quantilregressionen von der Untersuchungsgruppe der allgemeinen
Bezugsgruppe mit dem Stichprobenumfang N = 2.000 bestätigen die vorab diskutier-
ten Hinweise externer Quellen, dass das Alter und das Geschlecht einen signifikan-
ten Einfluss auf die Lage der Referenzgrenzen für den Laborparameter Harnstoff i.Pl.
bewirken (siehe Tabelle 15, Spalte ‚3. MODELL‘ sowie Seite 101). Für das 0,025-
Quantil der allgemeinen Untersuchungsgruppe mit N = 2.000 wurde für die Variable
ALTER ein signifikanter p-Wert ausgegeben, nicht jedoch für die Variable GE-
SCHLECHT. Das heißt, dass die untere Referenzgrenze des Parameters Harnstoff
von dem Alter, nicht aber von dem Geschlecht abhängt. Für das 0,975-Quantil der
allgemeinen Untersuchungsgruppe mit der Größe N = 2.000 wurden für die beiden
Variablen ALTER und GESCHLECHT signifikante p-Werte angegeben. Dies besagt,
dass die obere Referenzgrenze für Harnstoff i.Pl. alters- und geschlechtsabhängig
ist. Die in den neun Streudiagrammen abgebildeten Punktewolken und Regressions-
geraden der drei verschieden großen Untersuchungsgruppen für die allgemeine Be-
zugsgruppe demonstrieren unterschiedliche Erscheinungen und Effekte. Für die
Stichproben in den Umfängen N = 40 sowie N = 2.000 zeigen sowohl die unteren als
auch die oberen Regressionsgeraden mit zunehmendem Alter einen Anstieg der un-
teren und der oberen Referenzgrenzen (siehe Abbildung 17 unter 4.4.1). Für die Un-

138
tersuchungsgruppe mit der Größe N = 120 hingegen sind die Richtungen der Re-
gressionsgeraden nicht gleichförmig, wovon demzufolge kein alters- und ge-
schlechtsspezifischer Anhaltspunkt zu entnehmen ist. Die durch die Quantilregressi-
onen von den Untersuchungsgruppen in den Umfängen N = 40 sowie N = 2.000 er-
rungenen Belege für alters- und geschlechtsspezifische Referenzgrenzen für den
Laborparameter Harnstoff i.Pl. widersprechen dem geschlechtsunabhängigen Refe-
renzbereich aus dem Laborkatalog der Universitätsmedizin Greifswald (43;82). Diese
Abweichung kann auf Unterschiede in der Alters- und Geschlechtsverteilung, dem
Gesundheitsstatus oder der Größe der Referenzpopulationen zurückzuführen sein –
oder aber an den verwendeten statistischen Methoden oder einer fehlerhaften Sub-
gruppenbildung liegen.
Die Wahl des richtigen Ansatzes wie auch der richtigen Methode ist hier entschei-
dend. Laut Arzideh et al. (61) ist die Stratifizierung nach Geschlecht und Alter nach
dem prospektiven IFCC-Ansatz speziell für Kinder und Ältere sehr aufwändig, nach
dem retrospektiven Ansatz hingegen leicht möglich. Fehler bei der Stratifikation kön-
nen somit vermieden werden. In Kombination dazu hat die Methode der Quantilre-
gression gegenüber den Methoden der Toleranzschätzung und der Quantilschätzung
mit Konfidenzgrenzen mehrere Vorteile vorzuweisen: Mittels der Quantilregression
können einzelne Perzentile, die von Interesse sind, unter der Berücksichtigung von
Kovariaten wie dem Alter geschätzt und modelliert werden, was bei zentralen 95%-
Intervallen dagegen nicht machbar ist (87). Damit kann sie ein komplettes Bild der
Verteilung liefern. Des Weiteren ist die Quantilregression robust gegen Ausreißer und
Heterogenität, beruht auf keiner Verteilungsannahme und führt zu einer besseren
Anpassung an die Originaldaten (87). Die Grenzen der mit Hilfe der Quantilregressi-
on erzeugten Quantil-Intervalle sind oftmals nicht symmetrisch und ihre Lage im Ver-
gleich zu den Intervallgrenzen aus der Toleranzschätzung und der Quantilschätzung
mit Konfidenzgrenzen leicht verschoben, was die gute Anpassung an Ausreißer oder
die (Alters-)Verteilung der Referenzpopulation zum Ausdruck bringt. Als zusätzlicher
Vorteil für die Quantilregression ist außerdem zu werten, dass sie sehr einfach mit
den Statistik-Softwarepaketen R und SAS 9.2 – in SAS mittels der verfügbaren Pro-
zedur PROC QUANTREG – anzuwenden ist, wohingegen für die anderen beiden
Methoden der Toleranz- sowie der Quantilschätzung mit Konfidenzintervallen erst

139
eigene Programme erstellt werden müssen. Zudem wurde unterdessen die Weiter-
entwicklung wie auch der Support des in dem Abschnitt 2.4 vorgestellten statisti-
schen Computerprogrammes RefVal, welches die IFCC-Empfehlungen implementiert
hatte und das von Solberg entwickelt und betreut wurde (26), nach fast 30 Jahren im
Einsatz eingestellt und auch nicht durch Neuerungen abgelöst (88).
Die zusammenfassende Evaluation der getesteten unterschiedlichen Stichproben-
größen brachte noch hinzufügend als erwähnenswert hervor, dass in dem erörterten
Regressionsmodell mit Einschluss der zwei Variablen ALTER und GESCHLECHT
ausschließlich die Untersuchungsgruppen mit N = 40 und N = 2.000 signifikante Ab-
hängigkeiten aufdeckten, nie jedoch Untersuchungsgruppen im Umfang von N = 120
(siehe Tabelle 15, Spalte ‚3. MODELL‘) – was fast durchgängig für die Ergebnisse
aller vier Regressionsmodelle gilt und in der kommenden Schlussfolgerung in Absatz
5.5 bei der Abgabe einer Empfehlung bedacht werden muss.
5.4 Limitationen der Untersuchung
In diesem Abschnitt sollen die Grenzen der eigenen Untersuchung, die nicht schon
ausführlich im vorangegangen Teil der Arbeit besprochen wurden, aufgezeigt und
diskutiert werden, wobei insbesondere die methodischen Grenzen im Fokus stehen.
Die Betrachtung der zugänglichen DATEN hinsichtlich ihrer Qualität und Eignung für
den Untersuchungszweck erfolgt als Erstes.
Die zur Auswertung genutzten Labordaten aus dem Universitätsklinikum Greifswald
bildeten den Ursprung für die Referenzpopulationen. Eine Referenzpopulation sollte
immer aus gesunden Referenzindividuen bestehen. Die analysierten Daten stammen
jedoch nicht von vollkommen gesunden Individuen ab, sondern nur von Nieren-
gesunden Patienten. Dies birgt die Gefahr, dass doch kranke Referenzindividuen in
die Berechnungen der Referenzintervalle eingeschlossen wurden und somit die Er-
gebnisse durch pathologische Werte verzerrt wurden. Ebenso können nicht-kranke
Individuen, die beispielsweise schwanger waren und deren Laborwerte in den Da-
tenpool einflossen, zu vielen zu niedrigen Harnstoffwerten führen und die ermittelten
Referenzgrenzen nach unten verzerren. Durch möglicherweise in die Auswertungen
eingeschlossene kranke Referenzindividuen könnten die bestimmten Referenzgren-

140
zen nach unten beziehungsweise oben verschoben worden sein, was bei deren Ver-
wendung in der klinischen Praxis verursachen könnte, dass kranke Patienten fälsch-
licherweise nicht als krank diagnostiziert sondern als gesund erklärt werden.
Des Weiteren waren die aus den Datensätzen als Referenzwerte herangezogenen
Laborwerte bezüglich ihrer Nachkommastellen limitiert – zumindest unter statistisch-
methodischen Gesichtspunkten, denn für die Anwendung Rang-basierter Methoden
sind mehr Nachkommastellen vorteilhaft, um gleiche Referenzwerte vermeiden zu
können (siehe 3.2.2).
Ferner ergab die Durchsicht der Altersangaben und -verteilung in den Datensätzen –
wie bereits unter 4.1.2 erwähnt wurde, dass die Gruppe der 0-Jährigen im Verhältnis
zu den anderen einzelnen Jahrgängen mit einem Anteil von 5,6 % überproportional
groß ist. Ein denkbarer Grund hierfür – dass eine fehlende Altersangabe mit dem
Alter 0 verwechselt wurde, wie es wiederholt bei Dateneingaben vorkommt – konnte
wegen des vorhandenen Geburtsdatums ausgeschlossen werden. Der wahre Grund
dafür sind vermutlich tatsächlich die grundsätzlich in Kliniken durchgeführten Neuge-
borenenscreenings, da Greifswald der Stützpunkt des Neugeborenenscreening-
Labores von Mecklenburg-Vorpommern ist (89). Die Entscheidung der Autorin, diese
überproportional vertretene Altersgruppe der 0-Jährigen von den Analysen nicht aus-
zuschließen, könnte eine Limitation der Untersuchung und eine Verzerrung der ge-
wonnenen Referenzbereiche darstellen, wurde jedoch in Hinblick auf den Versuch,
retrospektive Referenzgrenzen als gut anwendbar zu erweisen, bewusst getroffen.
Eine weitere Limitation der Datenlage in Bezug auf das Alter ist der bereits mehrmals
erwähnte Fakt, dass die 0-Jährigen nicht in die Bezugsgruppen ‚bis 30 Tage‘ für Kre-
atinin i.Pl. und ‚bis 180 Tage‘ für Harnstoff i. Pl. unterteilt werden konnten, was even-
tuell in verzerrten Ergebnissen münden könnte.
Nicht zuletzt sollen die Limitationen bezüglich der aus den Daten erzeugten Untersu-
chungsgruppen behandelt werden. Die Charakterisierung der 29 erstellten Untersu-
chungsgruppen (siehe Tabelle 11) zeigt bei einem Vergleich mit den vollen Datens-
ätzen (siehe Tabelle 9) betreffend bestimmter Eigenschaften wie zum Beispiel dem
Durchschnittsalter, dass das mittlere Alter der einzelnen Untersuchungsgruppen der
allgemeinen Bezugsgruppen nur selten dem mittleren Alter des Gesamtdatenbestan-
des entspricht. Auch die Mittelwerte der drei Laborparameter Natrium, Harnstoff und
Kreatinin der einzelnen Untersuchungsgruppen der allgemeinen Bezugsgruppen

141
weichen – besonders in den kleinen Stichproben mit N = 40 – von den Mittelwerten
der Laborwerte des Gesamtdatenbestandes ab. Ebenfalls ist die durchschnittliche
Geschlechterverteilung in den 23 geschlechtsunspezifischen Untersuchungsgruppen
(siehe Tabelle 11) anders als die des Gesamtdatenbestandes (siehe Tabelle 8), was
speziell für Harnstoff auffällig ist. Zudem scheint die Geschlechterverteilung bei
Stichproben im Umfang von N = 40 nicht sehr ausgewogen zu sein.
Die Beurteilung der selektierten VERFAHREN hinsichtlich ihrer Güte und Tauglich-
keit zur Beantwortung der Forschungsfrage erfolgt als Zweites. Die Frage lautet:
Ist die deduktive Selektion einer Bezugspopulation (das retrospektive Verfahren) zur
Bestimmung von Referenzgrenzen geeignet? In der durchgeführten Forschungsar-
beit wurde der retrospektive Ansatz zur Gewinnung der Referenzpopulation gewählt.
Dieser Ansatz hat zur Folge, dass die daraus ermittelten Referenzbereiche nur so gut
sein können wie die zugrunde liegenden Daten. Die zuvor benannten Vorteile der
deduktiven Selektion einer Bezugspopulation wie Zeit- und Kosten-günstigere Auf-
wendungen für Laboratorien, was langfristig laborinterne Bestimmungen von regiona-
len Referenzgrenzen fördern und leichtfertigen Übernahmen von externen Referenz-
bereichen entgegenwirken könnte, müssen möglichen Nachteilen gegenübergestellt
werden. Ein Nachteil der Nutzung von Labordatenbeständen aus Kliniken für Refe-
renzbereiche ist, dass im Vorfeld ein zumeist großer Datenbereinigungs- und Aufbe-
reitungsaufwand betrieben werden muss, da die Originaldaten oftmals fehlerbehaftet
sind, weil beispielsweise in den Rohdaten Identifikationsnummern doppelt vorkom-
men, Personen ohne Namen und Geburtsdatum zu finden sind, oder erst das Alter
aufwändig berechnet werden muss, weil nur das Geburtsdatum vorliegt. Ein weiterer
Nachteil der deduktiven Selektion einer Bezugspopulation auf der Basis von Klinikda-
ten ist, dass für unspezifische Parameter wie zum Beispiel CRP (siehe 3.1.1) die Ab-
grenzung von Kranken und Gesunden schwierig ist und es zu bimodalen Verteilun-
gen kommen kann, wie es bei dem Parameter Harnstoff vorlag. Bimodale Referenz-
wertverteilungen müssen sodann mittels der direkten Methode zerlegt werden, was
ein Fehlerpotential birgt. Für einen der drei untersuchten Nierenparameter wurde die
direkte Methode angewendet. Nach der Trunkierung bei dem Parameter Harnstoff ist
das durchschnittliche Alter auf 33 Jahre gesunken. Durch willkürliche Trunkierungen
können die wahren Daten verändert und eventuell verfälscht werden.

142
Gräsbeck (25) antwortete im Jahr 2004 auf die Frage, ob Patientendaten aus Klini-
ken als Bezugsquelle für Referenzwerte genutzt werden können nach einigem Zö-
gern mit ‚ja‘ und stimmt demzufolge der Bestimmung von retrospektiven Referenz-
grenzen zu. Letztendlich hängt die Angemessenheit des Auswahlverfahrens immer
von der Datengrundlage ab. Wenn die Daten hochwertig und die Population detail-
liert definiert ist, kann auch die Rekrutierung der Untersuchungsgruppen begründet
vollzogen werden. Außerdem bildet eine Klinikpopulation die Wirklichkeit getreuer ab
als auserwählte Gesunde entsprechend der induktiven Auswahlmethode zur Ermitt-
lung von prospektiven Referenzgrenzen im Sinne der IFCC-Empfehlung, da gerade
die „nicht normalen“ Menschen wie Raucher, Kinder, Frauen und Ältere den Großteil
der Bevölkerung ausmachen, für den die Referenzbereiche letztlich erzeugt werden.
Die Bewertung der ausgesuchten METHODEN hinsichtlich ihrer Funktionalität und
Zweckmäßigkeit zur Zielerreichung erfolgt als Drittes. Ein Ziel der Untersuchung war,
die zuverlässigste Methode zur Bestimmung von medizinischen Referenzbereichen
zu finden, die speziell für kleine Stichprobenmengen vertrauenswürdige Referenz-
grenzen liefern, da Randgruppen wie Kinder, Frauen und Ältere bei der Bildung von
Referenzpopulationen häufig unterrepräsentiert sind.
Der durchgeführte Vergleich verschiedener Methoden zur Bestimmung von Refe-
renzbereichen wurde auf drei Methoden eingeschränkt. Dies stellt eine Limitation der
Untersuchung dar, da es – wie zu Beginn in Abschnitt 2.4 beschrieben wurde – noch
mehr Methoden gibt, die zur Ermittlung von Referenzbereichen angewendet werden
könnten, wie etwa das Bootstrap-Verfahren (siehe Punkt 2.4.1). Hinzu kam die Prob-
lematik, dass es zahlreiche Kombinationsmöglichkeiten bei der Berechnung von In-
tervallen gibt, denn je nach Festlegung der Konfidenz, des Stichprobenanteils, der
Überdeckung oder der Regressionsparameter entstehen immer andere Referenzin-
tervalle. Die Wahl der richtigen Kombination hiervon ist diffizil und machte den Ver-
gleich der Methoden und der Ergebnisse sowie die abschließende Empfehlung zu
einer komplexen Aufgabe.
Auch die generelle Annahme eines linearen Zusammenhangs zwischen den Kovari-
ablen und den Referenzgrenzen bei der Methode der Quantilregression ist eine Limi-
tation der Untersuchung, da bei einer Regression alles von der Modellierung des Zu-
sammenhanges beeinflusst wird und der lineare Ansatz lediglich eine Annahme ist.

143
Die Quantilregression betrifft einen speziellen Ansatz, den es weiter zu prüfen gilt,
denn vielleicht ist der Zusammenhang – sofern es einen gibt – nicht linear.
Die Definition der richtigen Stichprobengröße stellte eine weitere Herausforderung
dar. Geprüft wurden die Stichprobenumfänge N = 40, N = 120 wie auch N = 2.000.
Festgestellt werden konnte anhand der Ergebnisse, dass die Untersuchungsgruppen
mit der Stichprobengröße N = 40 aufgrund der angegebenen Überdeckungswahr-
scheinlichkeit den geforderten Stichprobenanteil nicht erreichten (siehe Punkt 5.1),
dass die Untersuchungsgruppen mit der Stichprobengröße N = 120 keine signifikan-
ten Abhängigkeiten von Kovariablen bei den Quantilregressionen aufdeckten (sie-
he Punkt 5.3), und dass die Ergebnisse der Untersuchungsgruppen mit der Stichpro-
bengröße N = 2.000 am wenigsten zu den Referenzbereichen aus dem Laborkatalog
der Universitätsmedizin Greifswald passten (siehe Punkt 5.2).
Desgleichen fiel der Autorin im Prozess der Stichprobenziehung auf, dass eine ein-
malige Ziehung nur einer Zufallsstichprobe eventuell nicht ausreicht, um repräsenta-
tive Referenzwerte zu erhalten, denn bei einem Versuch einer Stichprobenziehung
für die Subgruppe der Frauen zwischen 19 und 100 Jahren für den Parameter Krea-
tinin mit N = 120 betrug der höchste Referenzwert 116 µmol/l und bei dem nächsten
Versuch der Zufallsstichprobenziehung hingegen 127 µmol/l.
Die methodische Berücksichtigung von extremen Werten beziehungsweise Ausrei-
ßern konnte in der gegenwärtigen Untersuchung nicht weitreichend verfolgt werden
und sollte in weiterführenden Forschungsarbeiten vertieft werden.
Die allumfassende Limitation der Untersuchung ist der wahrscheinlich nicht endgültig
zu klärende Disput zwischen den Fachbereichen Medizin und Statistik betreffs der
Frage, ob ein breiteres Intervall besser als ein schmaleres Intervall ist, weil die Wahr-
scheinlichkeit höher ist, dass der Schätzer darin liegt. In dieser Beziehung entspricht
die statistische Sicht nicht der Medizinischen, denn ein breiteres statistisches Inter-
vall vergrößert den medizinischen Referenzbereich – woraufhin wirklich Kranke mög-
licherweise als gesund erklärt werden könnten, weil ihre Laborwerte im Normalbe-
reich liegen würden.

144
5.5 Schlussfolgerungen
Unter diesem Blinkwinkel – des Disputes zwischen der medizinischen und der statis-
tischen Sichtweise – müssen die hier zu treffenden Schlussfolgerungen nicht nur für
die wissenschaftliche Forschung relevant, sondern viel mehr für die klinische Praxis
sinnvoll wie auch umsetzbar, aber vor allem für das Wohl des Patienten förderlich
sein. Die im Folgenden zu gebenden Empfehlungen müssen umsichtig sein, da eine
mögliche Anwendung dieser Forschungsergebnisse Auswirkungen auf die öffentliche
Gesundheit haben kann.
Aufgrund der erarbeiteten Forschungsergebnisse und in Anbetracht der herausge-
stellten Stärken der untersuchten Ansätze und Methoden sowie unter Abwägung der
aufgezeigten Schwächen der geprüften Verfahren können folgende Empfehlungen
abgegeben werden:
1) Der deduktive Ansatz ist dem induktiven Ansatz vorzuziehen. Die Selektion der
Referenzindividuen darf demzufolge deduktiv durchgeführt werden, was heißt,
dass sich bei dieser Auswahlmethode an bereits vorliegenden Patientendatenbe-
ständen bedient werden kann, die daraufhin mittels vorab festgelegter Ein- und
Ausschlusskriterien beziehungsweise Ausschlusskrankheiten gefiltert werden.
Das daraus resultierende Kollektiv der Nicht-Kranken wird zur Erzeugung der Re-
ferenzstichprobe genutzt. Die deduktive Selektion einer Referenzpopulation für
die Bestimmung von Referenzgrenzen erfolgt demnach retrospektiv, indem die
Festlegung der Selektionskriterien und die Auswahl der Referenzindividuen erst
im Nachhinein – nach der tatsächlichen Durchführung der Untersuchungen pas-
sieren (siehe 2.3.1). Diese Empfehlung widerspricht der IFCC-Richtlinie (3).
Ein Grund für diese Wahl des retrospektiven Selektionsverfahrens ist das in Ab-
satz 2.5.1 beschriebene aktuell existierende Defizit in der Umsetzung der IFCC-
Empfehlung, da viele Laboratorien aus Kapazitäts- und Kostengründen keine in-
ternen Referenzbereiche bestimmen können und die Gefahr besteht, dass exter-
ne Referenzbereiche übernommen werden, die mitunter stark von den regionalen
Merkmalen abweichen – wie ein exemplarischer Abgleich zwischen Referenzbe-
reichen gemäß des Laborkataloges der Universitätsmedizin Greifswald (43) und
beispielsweise denen aus dem Buch Klinische Chemie. Laborwerte in der klini-

145
schen Praxis von Graf und Gürkov (39) verdeutlicht hat (vgl. siehe Tabelle 3). Der
zweite Grund für die Befürwortung des retrospektiven Ansatzes ist der, dass an-
hand der Untersuchungsergebnisse gezeigt werden konnte, dass retrospektiv er-
mittelte Referenzgrenzen den prospektiv bestimmten Referenzgrenzen annä-
hernd gleichen (siehe 5.2). Der dritte Grund für die Bevorzugung des retrospekti-
ven Verfahrens ist, dass dies den Laboratorien weniger finanziellen und zeitlichen
Aufwand bedeutet und es ihnen somit ermöglicht wird, eigene regionale Refe-
renzpopulationen abzubilden und adäquate Bezugspopulationen betreffs Alter
und Geschlecht zu erzeugen. Dem Problem des Transfers von externen Refe-
renzgrenzen und der damit einhergehenden Unsicherheit bezüglich der Reprä-
sentativität der Grundgesamtheit kann dadurch begegnet werden. Die AG Ent-
scheidungsgrenzen/ Richtwerte der DGKL empfiehlt große Datenpools als Quelle
für Referenzwerte (siehe 1.3.3). Die Autorin spricht sich für regionale Datenpools
aus, die für ansässige Laboratorien frei zugänglich sein sollten.
2) Das nicht-parametrische Verfahren ist dem parametrischen Verfahren vorzu-
ziehen. Die parameterfreie, Rang-basierte Methode bewährte sich in der vorlie-
gen Untersuchung und lieferte plausible Intervalle. Der Grund für die Empfehlung
der Rang-basierten Methode erschließt sich folgendermaßen: Schätzverfahren
hängen von der Kenntnis der Verteilung der Zufallsgröße ab und setzen eine
Normalverteilung voraus. Da biologische Daten in der Regel nicht normalverteilt
sind, wird die Methode der normalisierenden Transformation der Originaldaten
häufig angewendet, um die Norm zu erzielen (siehe Punkt 2.3.4). Die Transforma-
tion von beliebigen Verteilungen in eine Normalverteilung, die Berechnung der
Grenzen und die anschließende Rücktransformation ist jedoch risikobehaftet,
denn eine Transformation und Rücktransformation kann zu einem ganz anderen
Referenzbereich führen als eine vergleichbare exakte Methode. Viele Anwender
nutzen die Methode der Transformation, da sie praktikabel scheint und es ihnen
an geeigneten alternativen Verfahren mangelt. Hierin liegt jedoch ein großes Feh-
lerpotential, denn laut Rasch [(52), S. 158 ff.] wird mit der Transformation der Zu-
fallsgröße auch ihre Verteilung transformiert, und alle Verfahren, die auf die trans-
formierten Werte angewandt werden, gelten auch nur für diese. Eine Rücktrans-
formation von Ergebnissen ist nicht immer korrekt. Ob Konfidenz- oder Referenz-
grenzen rücktransformiert werden können, hängt von der jeweiligen Transformati-

146
on ab. Daher sind Rang-basierte, nicht-parametrische Verfahren zur Bestimmung
von medizinischen Referenzbereichen für Laborparameter von der Autorin favori-
siert. Diese Empfehlung deckt sich mit denen der IFCC und der IUPAC (siehe
Punkt 2.3.5).
3) Für alters- und geschlechtsspezifische Laborparameter wie Kreatinin und
Harnstoff ist die Methode der Quantilregression (siehe 2.4.3 und 3.2.4) den
Methoden der Toleranzschätzung (gemäß IUPAC, siehe 2.2.2 und 3.2.3) sowie
der Quantilschätzung mit Konfidenzgrenzen (gemäß IFCC, siehe 2.2.1 und 3.2.2)
vorzuziehen. Die Analysen der klinischen Labordaten mittels der drei getesteten
Methoden ergaben, dass die Methode der Quantilregression – insbesondere das
Regressionsmodell mit Einschluss der Variablen ALTER und GESCHLECHT –
zur Bestimmung von Referenzbereichen mit Berücksichtigung von Kovariablen
gegenüber den Methoden der Toleranzschätzung sowie der Quantil- und Kon-
fidenzschätzung zur Bestimmung von Referenzbereichen mit Berücksichtigung
von Kovariablen die größten Vorteile besitzt und die besten Ergebnisse erreicht.
Die drei Faktoren, die diese Empfehlung begründen, sind im Besonderen: Erstens
erwies sich die Methode der Quantilregression hinsichtlich der Intervalllänge als
die präziseste Methode, da sie die schmalsten Referenzintervalle produzierte
(siehe Absatz 5.1, zweites Kriterium). Zweitens zeigten die unteren und oberen
Referenzgrenzen aus den Quantilregressionen die meisten die Übereinstimmun-
gen im Abgleich mit den Referenzbereichen aus dem Laborkatalog der Universi-
tätsmedizin Greifswald (siehe Absatz 5.2). Drittens stellte sich die Methode der
Quantilregression als am geeignetsten heraus, um signifikante Abhängigkeiten
der Referenzgrenzen von Einflussgrößen wie dem Alter oder dem Geschlecht
nachzuweisen (siehe Absatz 5.3).
4) Für alters- und geschlechtsunspezifische Laborparameter wie Natrium ist
die Methode der Toleranzschätzung (gemäß IUPAC, siehe 2.2.2 und 3.2.3) den
Methoden der Quantilregression (siehe 2.4.3 und 3.2.4) sowie der Quantilschät-
zung mit Konfidenzgrenzen (gemäß IFCC, siehe 2.2.1 und 3.2.2) vorzuziehen.
Die Untersuchungen der klinischen Labordaten mittels der drei geprüften Metho-
den offenbarten, dass die Methode der Toleranzschätzung zur Bestimmung von
Referenzbereichen ohne Berücksichtigung von Kovariablen gegenüber den Me-

147
thoden der Quantilregression sowie der Quantil- und Konfidenzschätzung zur Be-
stimmung von Referenzbereichen ohne Berücksichtigung von Kovariablen die
größten Vorzüge aufweist und die besten Resultate erlangt. Die Begründungen,
auf denen diese Empfehlung beruht, lauten wie folgt: Die Methode der Toleranz-
schätzung bewährte sich hinsichtlich der Überdeckungswahrscheinlichkeit als die
zuverlässigste Methode, da sie die vertrauenswürdigsten Referenzintervalle er-
zeugte (siehe Absatz 5.1, erstes Kriterium). Zugleich bewies sich die Methode der
Toleranzschätzung bezüglich der Intervalllänge ebenso als eine präzise Methode,
da sie für alters- und geschlechtsunabhängige Parameter wie Natrium gleich
schmale Referenzintervalle generierte wie die Methode der Quantilregression
(siehe Absatz 5.1, zweites Kriterium). Der Vergleich der mittels der Toleranz-
schätzung errungenen unteren und oberen Referenzgrenzen mit den Referenzbe-
reichen aus dem Laborkatalog der Universitätsmedizin Greifswald bot für alters-
und geschlechtsunabhängige Parameter wie Natrium keine bedeutenden Abwei-
chungen dar (siehe Absatz 5.2). Und da diesbezüglich kein relevanter Unter-
schied besteht, überwiegt der bedeutsamere Aspekt und die für die Methode der
Toleranzschätzung vorteilhafteste Auszeichnung der zuverlässigsten Methode
insgesamt – unter der Voraussetzung, dass die Referenzgrenzen nicht von biolo-
gischen Einflussfaktoren abhängig sind.
5) Die Methode der Quantilschätzung mit Konfidenzintervallen gemäß der bis-
her als Goldstandard geltenden IFCC-Empfehlung wird auf der Basis der vorlie-
genden Untersuchungsergebnisse zur weiteren Anwendung in der Laborpraxis
nicht empfohlen, da zum einen diese Methode der Ermittlung von Referenzbe-
reichen aus den Konfidenzgrenzen der Quantilschätzer den beiden anderen ge-
prüften Methoden der Toleranzschätzung wie auch der Quantilregression unter
Beachtung der oben angeführten Betrachtungspunkte weit unterlegen ist, und
zum anderen die gegenwärtige Problematik noch immer darin besteht, dass die
nach dem IFCC-Konzept erschaffenen Referenzbereiche zumeist nicht mit den
dazugehörigen Konfidenzgrenzen veröffentlicht und verwendet werden, sondern
allein die Quantil-Intervalle als Referenzbereiche gelten. Diese Referenzintervalle
ohne Konfidenzgrenzen sind jedoch nicht hinreichend zuverlässig.

148
6) Zur Feststellung der Erfordernis der Bildung von alters- und geschlechts-
spezifischen Bezugsgruppen für alters- und geschlechtsabhängige Laborpara-
meter wie Kreatinin und Harnstoff ist die Methode der Quantilregression (siehe
2.4.3 und 3.2.4) den Methoden der Toleranzschätzung (gemäß IUPAC, siehe
2.2.2 und 3.2.3) sowie der Quantilschätzung mit Konfidenzgrenzen (gemäß IFCC,
siehe 2.2.1 und 3.2.2) vorzuziehen. Begründet wird diese Empfehlung mit der vo-
rausgehend ausführlich erläuterten Befähigung, mit Hilfe dieser Methode der
Quantilregression, sehr einfach, sicher und schnell signifikante Abhängigkeiten
der Referenzgrenzen von biologischen Einflussgrößen wie dem Alter oder dem
Geschlecht nachweisen und dementsprechend notwendige Subgruppen definie-
ren zu können (vgl. siehe 3.1.2). Die mittels der Methode der Quantilregression
festgestellten Alters- oder Geschlechtseinflüsse auf Referenzbereiche sollten je-
doch nur in Gruppenbildungen münden, wenn die Berücksichtigung von Klassen
klinisch relevant, nutzbringend beziehungsweise physiologisch fundiert ist (28).
7) Zur Festlegung der bestmöglichen Stichprobengröße kann an dieser Stelle
keine endgültige Empfehlung gegeben werden, da – wie unter Punkt 5.4 darge-
legt wurde – für jede der drei erprobten Stichprobengrößen N = 40, N = 120 und
N = 2.000 Grenzen aufgezeigt werden mussten. Definitiv festgehalten werden
kann jedoch die Erkenntnis, dass es zur Anwendung der Methode der Toleranz-
schätzung für 0,90-Toleranzintervalle zum 0,90-Konfidenzniveau ein Mindest-
Stichprobenumfang von N = 38 bedarf, um valide Referenzbereiche zu erstellen
(siehe Tabelle 7). Zusätzlich vermerkt werden kann ebenfalls, dass ein geforder-
ter Stichprobenumfang in Höhe von N = 2.000 nicht realisierbar ist, da die meis-
ten alters- und/ oder geschlechtsspezifischen Subgruppen diese Anforderung
nicht erfüllen können (siehe Tabelle 10). Die sich auf die Mehrheit der Untersu-
chungsergebnisse stützende, als optimal eingeschätzte, empfehlenswerte Stich-
probengröße liegt bei N = 120 – was der Empfehlung der IFCC entspricht. Dieser
Umfang von N = 120 sollte auch in den einzelnen Subgruppen erreicht werden.
Da im Rahmen der durchgeführten Quantilregressionen die signifikanten Abhän-
gigkeiten von Einflussgrößen vornehmlich aus Stichproben mit mehr als 120 Re-
ferenzwerten/ -individuen erhalten wurden (siehe Tabelle 15), sollte in weiterfüh-
renden Forschungsarbeiten der Stichprobenumfang N = 400 ergründet werden

149
(73), wie es in der Literaturübersicht bereits erwähnt wurde (siehe Absätze 2.5.2
und 3.1.3).
8) Die abschließende, alles abrundende Empfehlung betrifft die Regelmäßigkeit der
Bestimmung von Referenzbereichen: Im Routinebetrieb sollten aus den Daten
eines Klinikums beziehungsweise eines Datenpools die Referenzbereiche für die
wesentlichen Parameter und Krankheitsbilder möglichst fortlaufend ermittelt wer-
den, denn es ist wichtig, immer aktuelle Referenzbereiche abzubilden, um auf
eventuelle Änderungen in der Bezugspopulation – der regionalen Grundgesamt-
heit – oder aber auf neue Messmethoden umgehend reagieren zu können.
Nachfolgend zu der bisherigen Diskussion der Ergebnisse und der Argumentation
der oben aufgeführten Handlungsempfehlungen soll nun am Ende des Diskurses
eine Antwort auf die anfangs aufgestellte Forschungsfrage gegeben sowie beurteilt
werden, ob das Hauptuntersuchungsziel schlussendlich erreicht wurde.
Vor dem Hintergrund der gewonnenen Forschungsergebnisse kann die in Absatz 2.7
erstellte Forschungsfrage mit der folgenden Aussage beantwortet werden:
Zur Bestimmung von Referenzbereichen für alters- und geschlechtsunspezifische
Laborparameter ist die Methode der parameterfreien Toleranzschätzung, in Bezug
auf eine Kombination mit dem retrospektiven Ansatz zur Gewinnung der Referenz-
population, als beste Methode zu empfehlen. Zur Bestimmung von Referenzberei-
chen für alters- und/ oder geschlechtsspezifische Laborparameter ist die Methode
der Quantilregression, in Bezug auf eine Kombination mit dem retrospektiven Ansatz
zur Gewinnung der Referenzpopulation, als geeignetste Methode zu empfehlen. Die
Methode der Quantilschätzung mit Konfidenzgrenzen kann aufgrund der erarbeiteten
Forschungsergebnisse zur Bestimmung von Referenzbereichen, in Bezug auf eine
Kombination mit dem retrospektiven Ansatz zur Gewinnung der Referenzpopulation,
nicht empfohlen werden.
In Hinblick auf die voranstehend unter 1) bis 8) gegebenen Empfehlungen kann zu-
sammengefasst werden, dass die in Abschnitt 2.6 gesteckte Zielsetzung erreicht
wurde, denn als effektivster Ansatz wurde das retrospektive Verfahren herausge-
stellt, mit welchem für alle Subpopulationen – explizit die der Frauen, Kinder und al-
ten Menschen – medizinische Referenzbereiche für labordiagnostische Parameter

150
bestimmt werden können. In diesem Zusammenhang wurden die Methoden der pa-
rameterfreien Toleranzschätzung beziehungsweise der Quantilregression als zuver-
lässig benannt, die insbesondere auch auf der Grundlage von kleinen Stichproben-
mengen ab N = 38 vertrauenswürdige Referenzgrenzen liefern.
Letztlich entscheidet jedoch der Mediziner, ob die hier aus dem Blickwinkel der Sta-
tistik geprüften Verfahren, gefundenen Unterschiede, gewonnenen Erkenntnisse so-
wie begründeten Empfehlungen eine klinische Relevanz für seine Patienten und de-
ren Behandlungen besitzen, und inwieweit er sie umzusetzen beabsichtigt.
5.6 Ausblick
Bezugnehmend auf die unter den Limitationen der Untersuchung (siehe Punkt 5.4)
gekennzeichneten offenen Forschungslücken, welche sich während der Bewertung
der erzielten Ergebnisse dartaten, soll zum Schluss ein Ausblick auf zukünftige For-
schungsschwerpunkte auf dem bearbeiteten Gebiet geboten werden.
In weiterführenden Forschungsarbeiten sollte überprüft werden, ob für alters- und/
oder geschlechtsspezifische Parameter die Quantilregression auch dann noch die
beste Methode ist, wenn die Zusammenhänge zwischen den biologischen Einfluss-
faktoren und den Referenzgrenzen nicht linear sind.
Des Weiteren ist zu prüfen, ob sich die Stichprobengröße N = 400 für die beiden Me-
thoden der nicht-parametrischen Toleranzschätzung und der Quantilregression als
angemessen herausstellt, um einerseits sowohl präzise als auch zuverlässige Refe-
renzbereiche zu erzeugen, und um andererseits signifikante Abhängigkeiten von Ein-
flussgrößen ermitteln zu können – und dabei analogen prospektiven Referenzgren-
zen annähernd zu entsprechen.
Für alters- und geschlechtsunabhängige Parameter ist an kleinen Stichproben ab
einem Umfang von N = 38 für die Methode der parameterfreien Toleranzschätzung
zu erforschen, ob die hier empfohlenen 0,90-Toleranzintervalle zu einem 0,90-
Konfidenzniveau trotz der damit erfüllten Überdeckungswahrscheinlichkeit für den
geforderten Stichprobenanteil dennoch präzise und mit prospektiven Referenzgren-
zen vergleichbare Referenzbereiche hervorbringt (siehe Absatz 5.1).

151
Nicht zuletzt sollte für die zur Bestimmung von medizinischen Referenzbereichen für
labordiagnostische Parameter zwei hier empfohlenen Methoden – der nicht-
parametrischen Toleranzschätzung für alters- und geschlechtsunspezifische Parame-
ter sowie der Quantilregression für alters- und/ oder geschlechtsspezifische Parame-
ter – zudem das Prinzip der wiederholten, zufälligen Stichprobenziehungen aus allen
Originalwerten mit Zurücklegen vertiefend untersucht werden, wie es im Bootstrap-
Verfahren vollzogen wird (siehe Absatz 2.4.1). Dafür müssten beispielsweise 10.000-
mal Stichproben mit Zurücklegen von dem Umfang N aus den Klinikdaten gezogen
und deren Referenzbereiche berechnet werden. Die empirische Verteilungsfunktion
der oberen Referenzgrenze minus der empirischen Verteilungsfunktion der unteren
Referenzgrenze gibt dann die Wahrscheinlichkeit p in der Grundgesamtheit an.
Dadurch kann die empirische Beschreibung der Güte der getesteten Methode erhal-
ten werden, und es ist daran erkennbar, ob die jeweiligen Referenzbereiche die ge-
forderte Überdeckungswahrscheinlichkeit der Grundgesamtheit liefern und die getes-
tete Methode vertrauensvolle und präzise Referenzbereiche ausgibt.
Ferner sind weitere Studien betreffend den Wert der Referenzbereiche sowie den
Einfluss von Ungenauigkeiten bei den Referenzbereichen für die Diagnostik wün-
schenswert, wie auch die Anwendung multivariater Klassifikationsverfahren.
Die Umsetzung dieser Empfehlungen für methodisch weitergehende Forschungsan-
sätze dürfte die methodischen Beschränkungen der vorliegenden Untersuchung
überwinden, sie komplettieren und eine wertvolle Ergänzung darstellen.

152
6 Zusammenfassung
Ergebnisse untersuchter Laborwerte von Patienten werden mit Referenzwerten von
Gesunden abgeglichen und anhand vordefinierter Referenzbereiche ausgewertet. Mit
Hilfe der damit gegebenen Information, ob sich ein gemessener Wert innerhalb der
Norm – dem Referenzbereich – oder außerhalb dessen befindet, werden von Medizi-
nern Diagnosen gestellt, Therapieentscheidungen getroffen oder der Krankheitsver-
lauf beurteilt. Wie aber entstehen Referenzbereiche? Wer legt sie wie fest und auf-
grund welcher Daten? Was ist normal? Diese Fragen werden seit Jahrzehnten kont-
rovers diskutiert. Das über 25 Jahre alte, bisher größtenteils weltweit als Standard
anerkannte Konzept zur Gewinnung von gesunden Referenzindividuen und der Er-
mittlung von Referenzgrenzen von der Internationalen Föderation für klinische Che-
mie und Laboratoriumsmedizin (IFCC) wird aus Gründen der schlechten Praktikabili-
tät, eines zu hohen und von kleinen Laboreinrichtungen nicht tragbaren Kosten- und
Zeitaufwandes oftmals nicht angewendet. Statt eigene, laborinterne Referenzberei-
che zu bestimmen werden externe Referenzgrenzen aus der Literatur oder von ande-
ren Laboratorien übernommen – welche aber nicht die regionale Bevölkerung, wie
beispielsweise in ihrer Altersstruktur, repräsentieren. Die von der IFCC befürwortete
prospektive Selektion der Referenzpopulation birgt neben diesem bestehenden Um-
setzungsdefizit auch das Risiko, dass für in dem Probandenkollektiv unterrepräsen-
tierte Subgruppen wie Frauen, Alte und Kinder wegen zu kleiner Stichprobenumfän-
ge gar keine beziehungsweise keine aussagekräftigen Referenzgrenzen bestimmt
werden können. Vermutungen wurden geäußert – zum Beispiel seitens der Internati-
onalen Vereinigung für theoretische und angewandte Chemie (IUPAC), dass die von
der IFCC anempfohlene statistische Methode der Ermittlung der Referenzbereiche
aus den Konfidenzgrenzen der Quantilschätzer speziell für kleine Stichprobengrößen
keine sehr zuverlässigen und präzisen Referenzbereiche liefert.
Basierend auf diesem Verständnis bestand das Untersuchungsziel darin, den effek-
tivsten Ansatz und die zuverlässigste Methode zur Bestimmung von medizinischen
Referenzbereichen für labordiagnostische Parameter für alle Subpopulationen – ex-
plizit die der Frauen, Kinder und alten Menschen – zu finden, die insbesondere auch
auf der Grundlage von kleinen Stichprobenmengen vertrauenswürdige Referenz-
grenzen liefern.

153
Zur Erreichung des Untersuchungszieles wurden Vergleiche von ausgewählten, aus
der Fachliteratur entnommenen, vorangehend im Detail erläuterten Methoden und
Verfahren zur Bestimmung von Referenzbereichen an konkreten Beispielen – an La-
bordaten von Nieren-gesunden Patienten aus dem Universitätsklinikum Greifswald,
die im Jahr 2005 aufgenommen wurden – vorgenommen. Die drei Methoden der
Quantilschätzung mit Konfidenzgrenzen laut der IFCC-Richtlinien, der Toleranz-
schätzung gemäß der IUPAC-Empfehlung sowie der Quantilregression, in Verbin-
dung mit dem retrospektiven Selektionsverfahren für die Gewinnung der Referenz-
population, wurden bei den drei verschieden großen Stichprobenumfängen N = 40,
N = 120 und N = 2.000 angewendet und für 29 nach den biologischen Faktoren Alter
und Geschlecht stratifizierten Subgruppen sowie allgemeinen Bezugsgruppen für die
drei Nierenparameter Kreatinin, Harnstoff und Natrium berechnet. Die Güte der er-
rungenen Referenzbereiche aus den drei verschiedenen Methoden wurde hinsicht-
lich der zwei Kriterien Zuverlässigkeit und Präzision bewertet und mit Referenzberei-
chen aus dem Laborkatalog des Instituts für Klinische Chemie und Laboratoriums-
medizin der Universitätsmedizin Greifswald abgeglichen – auch unter Berücksichti-
gung der ermittelten Alters- und/ oder Geschlechtseinflüsse auf die Referenzgrenzen.
Anhand der gewonnenen Forschungsergebnisse konnte die Forschungsfrage wie
folgt beantwortet werden: Zur Bestimmung von Referenzbereichen für alters- und
geschlechtsunspezifische Laborparameter wie Natrium ist die Methode der parame-
terfreien Toleranzschätzung, in Bezug auf eine Kombination mit dem retrospektiven
Ansatz zur Gewinnung der Referenzpopulation, als beste Methode zu empfehlen.
Zur Bestimmung von Referenzbereichen für alters- und/ oder geschlechtsspezifische
Laborparameter wie Kreatinin oder Harnstoff ist die Methode der Quantilregression,
in Bezug auf eine Kombination mit dem retrospektiven Ansatz zur Gewinnung der
Referenzpopulation, als geeignetste Methode zu empfehlen. Die Methode der Quan-
tilschätzung mit Konfidenzgrenzen nach dem IFCC-Konzept kann aufgrund der erar-
beiteten Forschungsergebnisse zur Bestimmung von Referenzbereichen, in Bezug
auf eine Kombination mit dem retrospektiven Ansatz zur Gewinnung der Referenz-
population, nicht empfohlen werden. Beide als empfehlenswert herausgestellten Me-
thoden sind auch für kleine Stichproben ab N = 40 anwendbar.

154
Literaturverzeichnis
(1) Hallbach J. Klinische Chemie und Hämatologie für den Einstieg. Stuttgart
[u.a.]: Thieme; 2006.
(2) Solberg HE. Approved recommendation (1986) on the theory of reference
values. Part 1. The concept of reference values. Clinica Chimica Acta 1987
May 29;165(1):111-8.
(3) PetitClerc C, Solberg HE. Approved recommendation (1987) on the theory of
reference values. Part 2. Selection of individuals for the production of
reference values. Clinica Chimica Acta 1987 Dec;170(2-3):S1-S11.
(4) Solberg HE, PetitClerc C. Approved recommendation (1988) on the theory of
reference values. Part 3. Preparation of individuals and collection of
specimens for the production of reference values. Clinica Chimica Acta 1988
Oct 31;177(3):S3-S11.
(5) Solberg HE, Stamm D. IFCC recommendation -- theory of reference values.
Part 4. Control of analytical variation in the production, transfer and
application of reference values. Clinica Chimica Acta 1991 Oct 14;202(1-
2):S5-S11.
(6) Solberg HE. Approved recommendation (1987) on the theory of reference
values. Part 5. Statistical treatment of collected reference values.
Determination of reference limits. Clinica Chimica Acta 1987 Dec;170(2-
3):S13-S32.
(7) Dybkoer R, Solberg HE. Approved recommendation (1987) on the theory of
reference values. Part 6. Presentation of observed values related to
reference values. Clinica Chimica Acta 1987 Dec;170(2-3):S33-S41.
(8) Sonntag O. Ist das normal? - Das ist normal! Über die Bedeutung und
Interpretation des so genannten Normalwertes. Laboratoriumsmedizin 2003
Jul;27(7-8):302-10.

155
(9) Williams DL, Nunn RF, Marks V. Scientific Foundations of Clinical
Biochemistry. London: Heinemann Medical Books Ltd.; 1979.
(10) Reed AH, Henry RJ, Mason WB. Influence of statistical method used on the
resulting estimate of normal range. Clin Chem 1971 Apr;17(4):275-84.
(11) Biebler K-E. Biometrie für Mediziner. Gützkow: Ginkgo Press Verlag; 1994.
(12) Dörner K. Klinische Chemie und Hämatologie. Stuttgart [u.a.]: Thieme; 2009.
(13) Biebler K-E, Jäger B. Biometrische und epidemiologische Methoden.
München: Oldenbourg Wissenschaftsverlag; 2008.
(14) The International Federation of Clinical Chemistry and Laboratory Medicine.
IFCC Publications/Documents. IFCC Publications Database.
http://www.ifcc.org/ifcc-communications-publications-division-
%28cpd%29/ifcc-publications/. 2012. 11-4-2013. [Online]
(15) Clinical and Laboratory Standards Institute. Defining, Establishing, and
Verifying Reference Intervals in the Clinical Laboratory; Approved Guideline
- Third Edition. http://www.clsi.org/source/orders/free/c28-a3.pdf 28[30].
2008. 24-1-2012. [Online]
(16) Poulsen OM, Holst E, Christensen JM. Calculation and Application of
Coverage Intervals for Biological Reference Values. Pure & Appl Chem
1997;69(7):1601-11.
(17) International Organization for Standardization. ISO 15189:2007. Medical
laboratories -- Particular requirements for quality and competence.
http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csn
umber=42641. 2007. 11-4-2013. [Online]
(18) World Health Organization. Environmental Health Criteria. No. 170 -
Assessing human health risks of chemicals: Derivation of guidance values
for health-based exposure limits.
http://www.who.int/ipcs/publications/ehc/ehc_numerical/en/index.html. 1994.
26-4-2013. [Online]

156
(19) The European Federation of Clinical Chemistry and Laboratory Medicine.
EFCC Publication List. http://efcclm.eu/publications-and-resources/efcc-
publication-list. 2009. 11-4-2013. [Online]
(20) Die Deutsche Vereinte Gesellschaft für Klinische Chemie und
Laboratoriumsmedizin.AG Entscheidungsgrenzen/Richtwerte. Ziele der
Arbeitsgruppe.
http://www.dgkl.de/PA100139_DE_VAR100?sid=k291041b250731. 2012.
21-3-2013. [Online]
(21) Die Deutsche Vereinte Gesellschaft für Klinische Chemie und
Laboratoriumsmedizin.AG Entscheidungsgrenzen/Richtwerte. Publikationen.
http://www.dgkl.de/PA100142_DE_VAR100?sid=S291041g609361. 2011.
21-3-2013. [Online]
(22) Umweltbundesamt. Konzept der Referenz- und Human-Biomonitoring-Werte
in der Umweltmedizin. Bundesgesundheitsbl 1996;39(6):221-4.
(23) Umweltbundesamt. Addendum zum Konzept der Referenz- und Human-
Biomonitoring-Werte in der Umweltmedizin. Bundesgesundheitsbl
2009;52(8):874-7.
(24) Bundesärztekammer. Richtlinie der Bundesärztekammer zur
Qualitätssicherung laboratoriumsmedizinischer Untersuchungen. Dt Ärztebl
2008;105(7):A 341-55.
(25) Gräsbeck R. The evolution of the reference value concept. Clin Chem Lab
Med 2004;42(7):692-7.
(26) Solberg HE. The IFCC recommendation on estimation of reference intervals.
The RefVal program. Clin Chem Lab Med 2004;42(7):710-4.
(27) Henny J, PetitClerc C, Fuentes-Arderiu X, Petersen PH, Queralto JM,
Schiele F, et al. Need for revisiting the concept of reference values. Clin
Chem Lab Med 2000 Jul;38(7):589-95.

157
(28) Henny J. The IFCC recommendations for determining reference intervals:
strengths and limitations. Laboratoriumsmedizin-Journal of Laboratory
Medicine 2009 Mar;33(2):45-51.
(29) Brüggemann M. Richtlinie der Bundesärztekammer zur Qualitätssicherung
laboratoriumsmedizinischer Untersuchungen. Lucke S, editor.
Bundesärztekammer. 6-10-2011. [E-Mail]
(30) Deutsche Gesellschaft für Nephrologie. Leitlinien.
http://www.dgfn.eu/aerzte/leitlinien. 2011. 9-2-2012. [Online]
(31) National Kidney Foundation. KDOQI Guidelines and Commentaries.
http://www.kidney.org/professionals/kdoqi/guidelines_commentaries.cfm#gui
delines. 2012. 9-2-2012. [Online]
(32) Kidney Disease: Improving Global Outcomes. Guidelines for Diagnosis,
Evaluation, and Classification of CKD.
http://www.kdigo.org/guidelines/topicsummarized/CPG%20Summary%20by
%20Topic_CKD%20Diagnosis%20and%20Evaluation.html. 2012. 11-4-
2013. [Online]
(33) European Renal Association. Section I. Measurement of renal function,
when to refer and when to start dialysis. Nephrol Dial Transplant 2002;17
Suppl 7:7-15.
(34) Herold G. Innere Medizin 2006. Kandern: Narayana Verlag GmbH; 2005.
(35) Pschyrembel W. Pschyrembel Klinisches Wörterbuch. Berlin: Walter de
Gruyter; 2007.
(36) Thomas L. Labor und Diagnose: Indikation und Bewertung von
Laborbefunden für die medizinische Diagnostik. Frankfurt / Main: TH-Books
Verl.-Ges.; 2008.
(37) Mann J. Der große TRIAS-Ratgeber für Nierenkranke. Stuttgart: Trias; 2008.

158
(38) Bioscientia Institut für Medizinische Diagnostik GmbH. Laborparameter der
Nierenfunktionsdiagnostik unter besonderer Berücksichtigung der
Prävention. http://www.bioscientia.de/de/files/2011/07/Bericht-71_Nieren-
Check.pdf [71]. 2008. 11-4-2013. [Online]
(39) Graf N, Gürkov R. Klinische Chemie. Laborwerte in der klinischen Praxis. 2
ed. München: Elsevier, Urban & Fischer; 2010.
(40) Vassalotti JA, Stevens LA, Levey AS. Testing for chronic kidney disease: a
position statement from the National Kidney Foundation. Am J Kidney Dis
2007 Aug;50(2):169-80.
(41) Deutsche Gesellschaft für Nephrologie. Basisinformationen zur Nephrologie.
http://www.dgfn.eu/patienten/basisinformationen-zur-nephrologie/. 2011. 10-
2-2012. [Online]
(42) Bundesverband Niere e.V. Jahresberichte der QuaSi Niere gGmbH iL.
http://www.bundesverband-niere.de/1906/jahresberichte-quasi-niere/. 2012.
12-2-2012. [Online]
(43) Universitätsmedizin Greifswald - Institut für Klinische Chemie und
Laboratoriumsmedizin. Laborkatalog. http://www.medizin.uni-
greifswald.de/klinchem/aktuell/leistungsspektrum/Laborkatalog/Laborkatalog.
html. 5-4-2011. 16-2-2012. [Online]
(44) Institut für Klinische Chemie und Laboratoriumsmedizin des
Universitätsklinikums C.G.Carus an der TU Dresden. Laborkatalog Online.
http://www.tu-dresden.de/medikl/diagnostik/katalog/labk0001.html. 31-3-
2008. 17-2-2012. [Online]
(45) Siemens Healthcare Diagnostics GmbH. Referenzwerte.
http://www.medical.siemens.com/webapp/wcs/stores/servlet/CategoryDispla
y~q_catalogId~e_-
103~a_categoryId~e_1012117~a_catTree~e_100003,1012117~a_langId~e_
-103~a_storeId~e_10001.htm. 2012. 16-2-2012. [Online]

159
(46) Kratz A, Ferraro M, Sluss PM, Lewandrowski KB. Case records of the
Massachusetts General Hospital. Weekly clinicopathological exercises.
Laboratory reference values. N Engl J Med 2004 Oct 7;351(15):1548-63.
(47) Bruhn HD, Junker R, Schäfer H, Schreiber S. LaborMedizin: Indikationen,
Methodik und Laborwerte, Pathophysiologie und Klinik. 3 ed. Stuttgart:
Schattauer; 2011.
(48) Deutsche Vereinte Gesellschaft für Klinische Chemie und
Laboratoriumsmedizin, American Association for Clinical Chemistry. Lab
Tests Online DE. http://www.labtestsonline.de/. 2010. 16-2-2012. [Online]
(49) Lucke S. Frage zur Berechnung der Referenzbereiche aus Ihrem
Laborkatalog. Sekretariat. Institut für Klinische Chemie und
Laboratoriumsmedizin. 27-9-2011. [E-Mail]
(50) Ceriotti F, Boyd JC, Klein G, Henny J, Queralto J, Kairisto V, et al.
Reference intervals for serum creatinine concentrations: Assessment of
available data for global application. Clinical Chemistry 2008 Mar;54(3):559-
66.
(51) Hilgers R-D, Bauer P, Scheiber V. Einführung in die Medizinische Statistik.
2. ed. Berlin, Heidelberg: Springer-Verlag; 2007.
(52) Rasch D. Einführung in die mathematische Statistik I. Berlin: VEB Deutscher
Verlag der Wissenschaften; 1978.
(53) Handl A. Statistische Intervalle. http://www.wiwi.uni-
bielefeld.de/fileadmin/emeriti/frohn/intervals.pdf. 2009. 11-4-2013. [Online]
(54) Rasch D, Herrendörfer G, Bock J, Victor N, Guiard V. Verfahrensbibliothek:
Versuchsplanung und -auswertung. München: Oldenbourg Wissensch.Vlg;
2008.
(55) Biebler K-E, Jäger B. Mathematikkurs zur Biometrie. Gützkow: GinkgoPark
Mediengesellschaft; 1996.

160
(56) Hahn GJ, Meeker WQ. Statistical Intervals. A Guide For Practitioners. New
York: Wiley; 1991.
(57) Ramírez JG. Statistical Intervals: Confidence, Prediction, Enclosure.
http://www.sas.com/resources/whitepaper/wp_4430.pdf. 2009. 11-4-2013.
[Online]
(58) Weiß C. Basiswissen Medizinische Statistik. 4 ed. Heidelberg: Springer
Medizin Verlag; 2008.
(59) Eberhard-Karls-Universität Tübingen, Institut für Medizinische Biometrie.
Einführung in die Statistik für Biochemiker. Wintersemester 2007-2008.
www.uni-tuebingen.de/biometry/Vorlesung2Druck.pdf. 2007. 7-9-2012.
[Online]
(60) Linnet K. Nonparametric estimation of reference intervals by simple and
bootstrap-based procedures. Clin Chem 2000 Jun;46(6 Pt 1):867-9.
(61) Arzideh F, Gurr E, Haeckel R, Hinsch W, Schumann G, Wosniok W. Guide
values for quantitative examinations in medical laboratories: definitions,
classification, and limits of application. Recommendations for classifying and
defining guide values of quantitative measurements. Laboratoriumsmedizin-
Journal of Laboratory Medicine 2009 Jul;33(4):228-32.
(62) Haeckel R, Wosniok W, Arzideh F. Proposed classification of various limit
values (guide values) used in assisting the interpretation of quantitative
laboratory test results. Clin Chem Lab Med 2009;47(4):494-7.
(63) Haeckel R, Wosniok W. Observed, unknown distributions of clinical chemical
quantities should be considered to be log-normal: a proposal. Clin Chem Lab
Med 2010 Oct;48(10):1393-6.
(64) Haeckel R, Wosniok W, Arzideh F. A plea for intra-laboratory reference
limits. Part 1. General considerations and concepts for determination. Clin
Chem Lab Med 2007;45(8):1033-42.

161
(65) Arzideh F, Wosniok W, Gurr E, Hinsch W, Schumann G, Weinstock N, et al.
A plea for intra-laboratory reference limits. Part 2. A bimodal retrospective
concept for determining reference limits from intra-laboratory databases
demonstrated by catalytic activity concentrations of enzymes. Clin Chem Lab
Med 2007;45(8):1043-57.
(66) Arzideh F, Brandhorst G, Gurr E, Hinsch W, Hoff T, Roggenbuck L, et al. An
improved indirect approach for determining reference limits from intra-
laboratory data bases exemplified by concentrations of electrolytes.
Laboratoriumsmedizin-Journal of Laboratory Medicine 2009 Mar;33(2):52-
66.
(67) Arzideh F, Wosniok W, Haeckel R. Reference limits of plasma and serum
creatinine concentrations from intra-laboratory data bases of several
German and Italian medical centres: Comparison between direct and indirect
procedures. Clin Chim Acta 2010 Feb;411(3-4):215-21.
(68) Arzideh F, Wosniok W, Haeckel R. Indirect reference intervals of plasma and
serum thyrotropin (TSH) concentrations from intra-laboratory data bases
from several German and Italian medical centres. Clin Chem Lab Med 2011
Apr;49(4):659-64.
(69) Arzideh F. Estimation of Medical Reference Limits by Truncated Gaussian
and Truncated Power Normal Distributions. Bremen: Universität Bremen,
Fachbereich 3; 2008.
(70) Frieß C. Bestimmung der 99sten Perzentile für kardiales Troponin I am
Dimension Vista. Inaugural-Dissertation. Greifswald: Institut für Klinische
Chemie und Laboratoriumsmedizin der Medizinischen Fakultät der Ernst-
Moritz-Arndt-Universität Greifswald; 2010.
(71) Koenker R. Quantile Regression. New York: Cambridge University Press;
2005.

162
(72) Bundesärztekammer. Richtlinie der Bundesärztekammer zur
Qualitätssicherung laboratoriumsmedizinischer Untersuchungen.
http://www.baek.de/downloads/RiliBAEKLabor201205.pdf. 6-6-2012. 11-4-
2013. [Online]
(73) Ichihara K, Boyd JC. An appraisal of statistical procedures used in derivation
of reference intervals. Clin Chem Lab Med 2010 Nov;48(11):1537-51.
(74) Rasch D, Herrendörfer G, Bock J, Victor N, Guinard V. Verfahrensbibliothek.
Versuchsplanung und -auswertung. Band 1. München: Oldenbourg; 1996.
(75) Kirkpatrick RL. Sample sizes to set tolerance limits. J Qual Tech 1977;(9):6-
12.
(76) Schwitulla J. Nonparametrische Quantilregression. Seminar: Regression -
Von bedingten Erwartungen zu bedingten Dichten.
http://www.statistik.lmu.de/~semwiso/seminare/regressionWiSe2008/downlo
ads/SCHWITULLA-Handout.pdf. 2008. 11-4-2013. [Online]
(77) SAS 9.2 Help and Documentation [computer program]. USA: SAS Institute
Inc.; 2010.
(78) Base SAS® 9.2 Procedures Guide. Statistical Procedures, Third Edition.
Calculating Percentiles.
http://support.sas.com/documentation/cdl/en/procstat/63104/HTML/default/vi
ewer.htm#procstat_univariate_sect028.htm. 2012. 11-4-2013. [Online]
(79) Ortseifen C. Der SAS-Kurs. Heidelberg: International Thomson Publishing
Verlag; 1997.
(80) Berufsverband Deutscher Internisten e.V. Blutbild - Erklärung. Harnstoff.
http://www.internisten-im-netz.de/de_harnstoff_1358.html. 2012. 14-11-
2012. [Online]
(81) Sachs L, Hedderich J. Angewandte Statistik: Methodensammlung mit R.
Berlin Heidelberg: Springer-Verlag; 2006.

163
(82) Universitätsmedizin Greifswald - Institut für Klinische Chemie und
Laboratoriumsmedizin. Laborkatalog. http://www.medizin.uni-
greifswald.de/klinchem/aktuell/leistungsspektrum/Laborkatalog/Laborkatalog.
html. 17-5-2013. 26-8-2013. [Online]
(83) Nauck M, Wasner C. Informationen für alle Anforderer labordiagnostischer
Untersuchungen. Methodenumstellung Kreatinin. http://www.medizin.uni-
greifswald.de/klinchem/fileadmin/user_upload/einsenderinformationen/2012/
Einsenderinformation_15.11.2012.pdf. 15-11-2012. 6-9-2013. [Online]
(84) Lieckfeldt S. Referenzbereiche Klinischer Parameter. Praxisarbeit im
Studiengang Biomathematik. Zittau: Hochschule Zittau/ Görlitz (FH); 2009.
(85) Klassen E. Exakte und approximative Toleranzschätzungen mit
Anwendungen auf klinische Daten. Diplomarbeit im Studiengang
Biomathematik. Greifswald: Institut für Mathematik und Informatik an der
Ernst-Moritz-Arndt-Universität Greifswald; 2008.
(86) Institut für Klinische Chemie am Universitätsklinikum Ulm. Harnstoff.
http://www.uniklinik-ulm.de/struktur/institute/klinische-
chemie/home/praeanalytik/untersuchungen-
leistungsverzeichnis/hij/harnstoff.html. 6-7-2012. 31-8-2013. [Online]
(87) Haring R. Lehre am Institut für Klinische Chemie und Laboratoriumsmedizin.
Downloads. Laborchemische Referenzwerte in der klinischen Versorgung.
http://www.medizin.uni-
greifswald.de/klinchem/fileadmin/user_upload/lehre/2012_Referenzbereiche
_Haring.pdf. 2012. 6-9-2013. [Online]
(88) Solberg HE. The end of RefVal. http://somietspeil.wordpress.com/the-end-of-
refval/. 2013. 10-9-2013. [Online]
(89) Institut für Klinische Chemie und Laboratoriumsmedizin der
Universitätsmedizin Greifswald. Neugeborenenscreening.
http://www.medizin.uni-greifswald.de/klinchem/index.php?id=neoscreen.
2013. 13-9-2013. [Online]
Top Related