
© MATERNA GmbH 2014 1blogs.gm.fh-koeln.de/faeskorn/.../2014/05/FH-Apache... · Apache Hadoop...
66
© MATERNA GmbH 2014 www.materna.de 1
Transcript of © MATERNA GmbH 2014 1blogs.gm.fh-koeln.de/faeskorn/.../2014/05/FH-Apache... · Apache Hadoop...
© MATERNA GmbH 2014 www.materna.de 1

© Materna GmbH 2014 www.materna.de 2
Agenda
Herausforderungen BigData Größeres Pferd oder Pferdegespann? Apache Hadoop
Geschichte, Versionen, Ökosystem Produkte
HDFS – Daten speichern und verteilen Map/Reduce – parallelisieren der Verarbeitung Pig,Hive – Verarbeitung von Daten HBase – Verteilte und skalierbare Speicherung von Daten
Benchmark: Wie schnell 1TB sortieren? BigData-UseCases mit ORACLE Fazit, Ausblick
© Materna GmbH 2014 www.materna.de 3
Steigende Nutzerzahlen
Daten-quellen
Geschwindigkeit der Datenproduktion
Datenvolumen
Eigenschaften von Big Data
© Materna GmbH 2014 www.materna.de 4
Value
VarietyVelocity
Volumen
Kennzeichen von Big Data: die vier Vs

© Materna GmbH 2014 www.materna.de 5
Größeres Pferd oder Pferdegespann?
vertikal vs horizontal

© Materna GmbH 2014 www.materna.de 6
Agenda
Herausforderungen BigData Größeres Pferd oder Pferdegespann? Apache Hadoop
Geschichte, Versionen, Ökosystem Produkte
HDFS – Daten speichern und verteilen Map/Reduce – parallelisieren der Verarbeitung Pig,Hive – Verarbeitung von Daten HBase – Verteilte und skalierbare Speicherung von Daten
Benchmark: Wie schnell 1TB sortieren? BigData-UseCases mit ORACLE Fazit, Ausblick

© Materna GmbH 2014 www.materna.de 7
Der Elefant hat den Laden verlassen …

© Materna GmbH 2014 www.materna.de 8
Hadoop Entstehung, Hintergründe: Da hinter steckt ein Kopf…
Doug Cutting Lucene-Suche 1997 SourceForge, 2001 ASF Nutch-Webcrawler Hadoop 2003, 2005 ASF Google Labs paper:
– The Google File System, October, 2003– MapReduce algorithm, December 2004– Bigtable: A Distributed Storage System for Structured Data,
November 2006– H-store: a high-performance, distributed main memory
transaction processing system, August 2008– Dremel: Interactive Analysis of WebScale Datasets,
September 2010 Board of directors of the Apache Software Foundation July 2009 Doug Cutting Cloudera August 2009 ASF chairman September 2010

© Materna GmbH 2014 www.materna.de 9
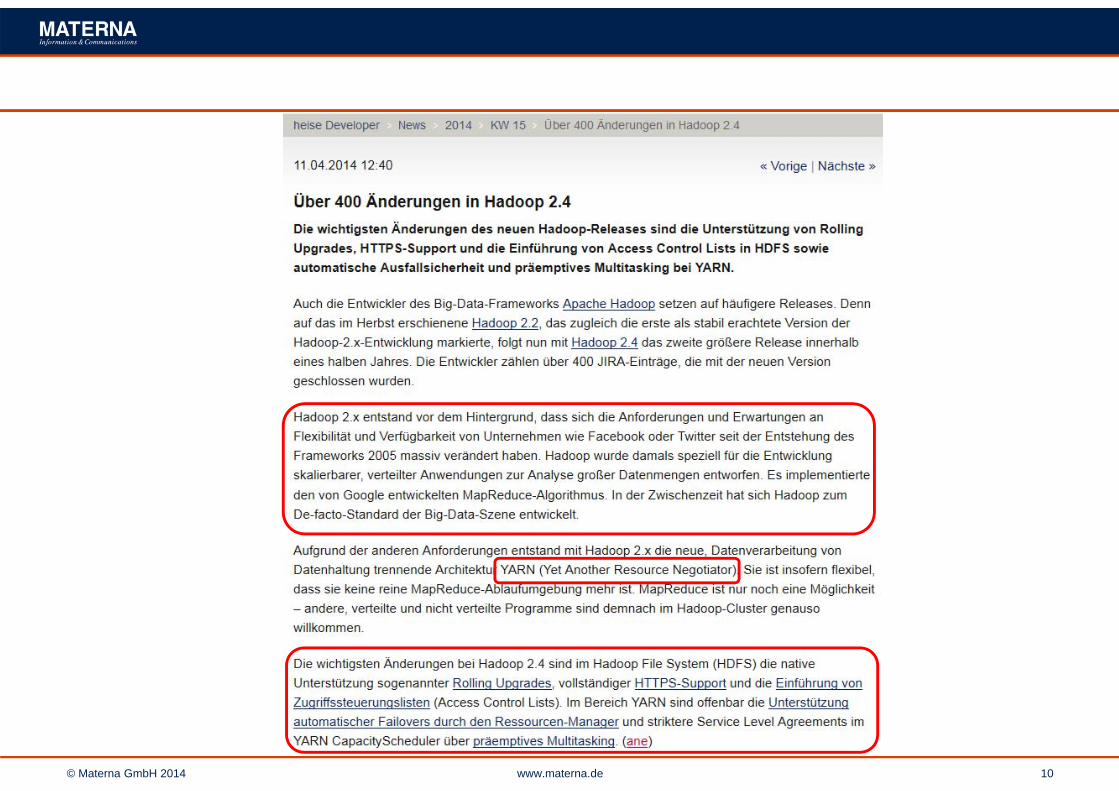
Hadoop Releases
Feature 0.20/1.2 0.22 0.23/2.4Secure authentication X X
Old configuration names X Deprecated DeprecatedNew configuration names X XOld MapReduce API X X XNew MapReduce API (X) X XMapReduce 1 runtime (Classic) X XMapReduce 2 runtime (YARN) XHDFS federation XHDFS high-availability X
02.201308.2013 12.2011
12.201304.2014
© Materna GmbH 2014 www.materna.de 10
© Materna GmbH 2014 www.materna.de 11
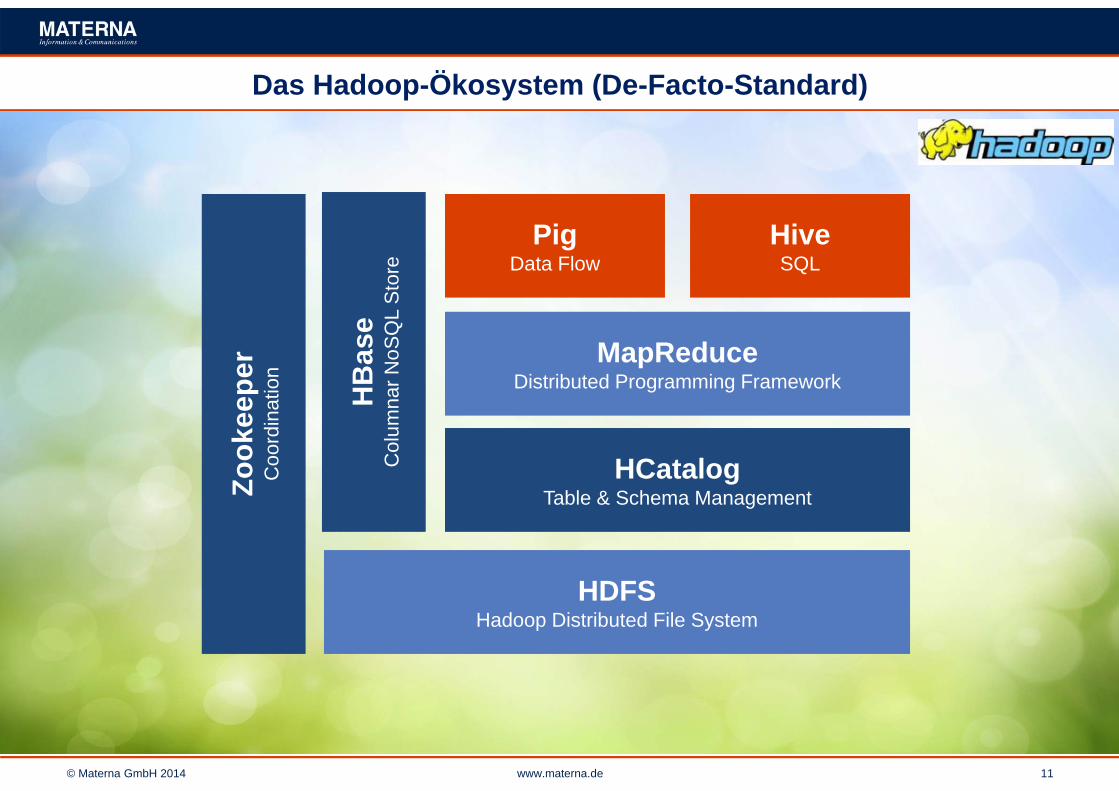
Das Hadoop-Ökosystem (De-Facto-Standard)
PigData Flow
PigData Flow
HiveSQL
HiveSQL
MapReduceDistributed Programming Framework
MapReduceDistributed Programming Framework
HCatalogTable & Schema Management
HCatalogTable & Schema Management
HDFSHadoop Distributed File System
HDFSHadoop Distributed File System
Zook
eepe
rC
oord
inat
ion
Zook
eepe
rC
oord
inat
ion
HB
ase
Col
umna
rNoS
QL
Sto
reH
Bas
eC
olum
narN
oSQ
LS
tore
© Materna GmbH 2014 www.materna.de 12
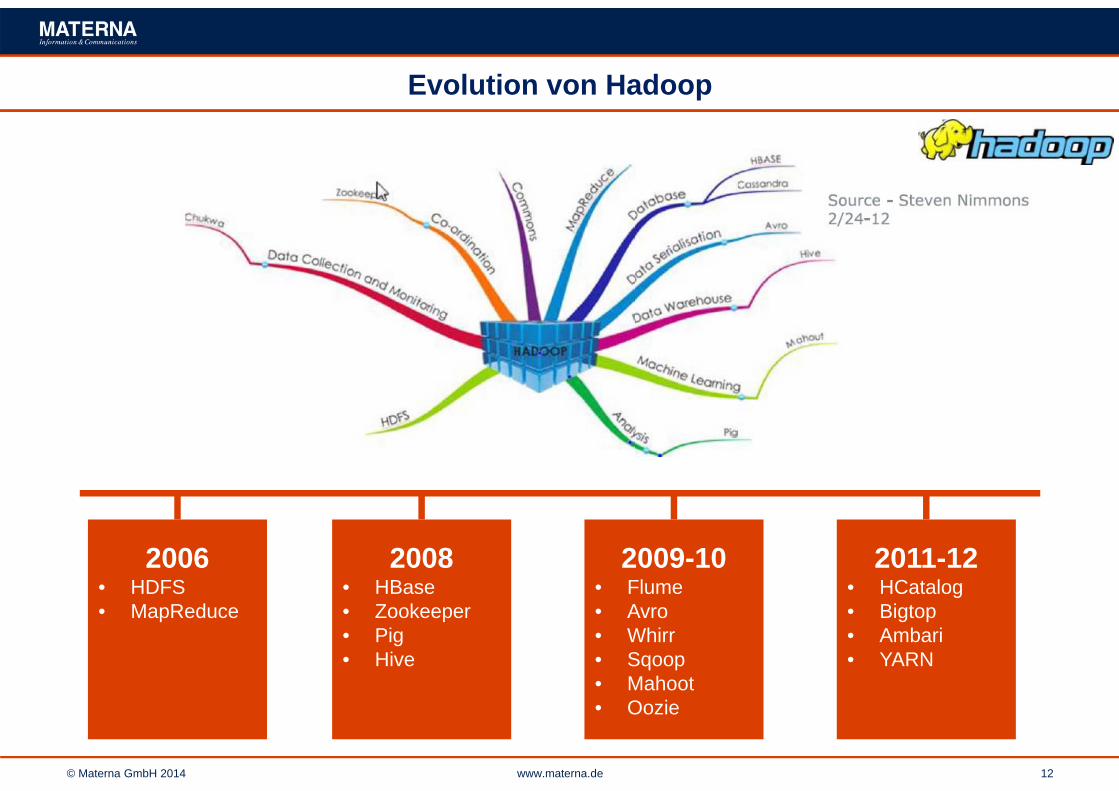
Evolution von Hadoop
2006• HDFS• MapReduce
2008• HBase• Zookeeper• Pig• Hive
2011-12• HCatalog• Bigtop• Ambari• YARN
2009-10• Flume• Avro• Whirr• Sqoop• Mahoot• Oozie
© Materna GmbH 2014 www.materna.de 13
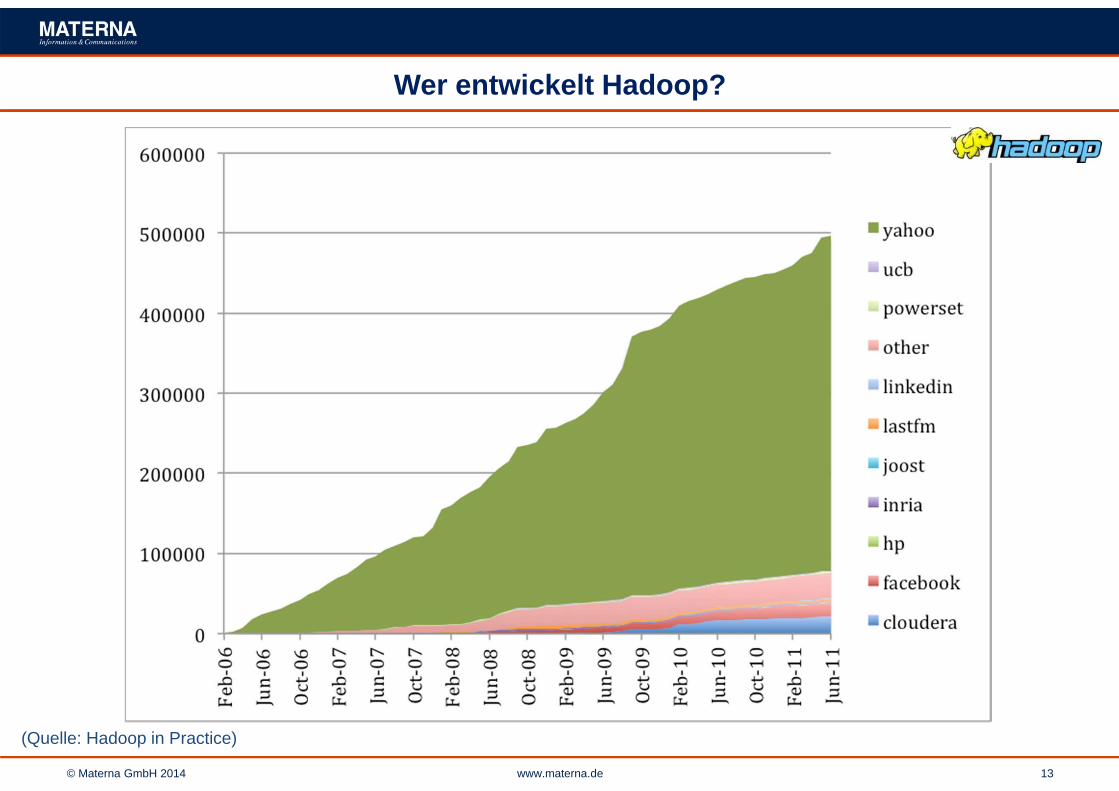
Wer entwickelt Hadoop?
(Quelle: Hadoop in Practice)
© Materna GmbH 2014 www.materna.de 14
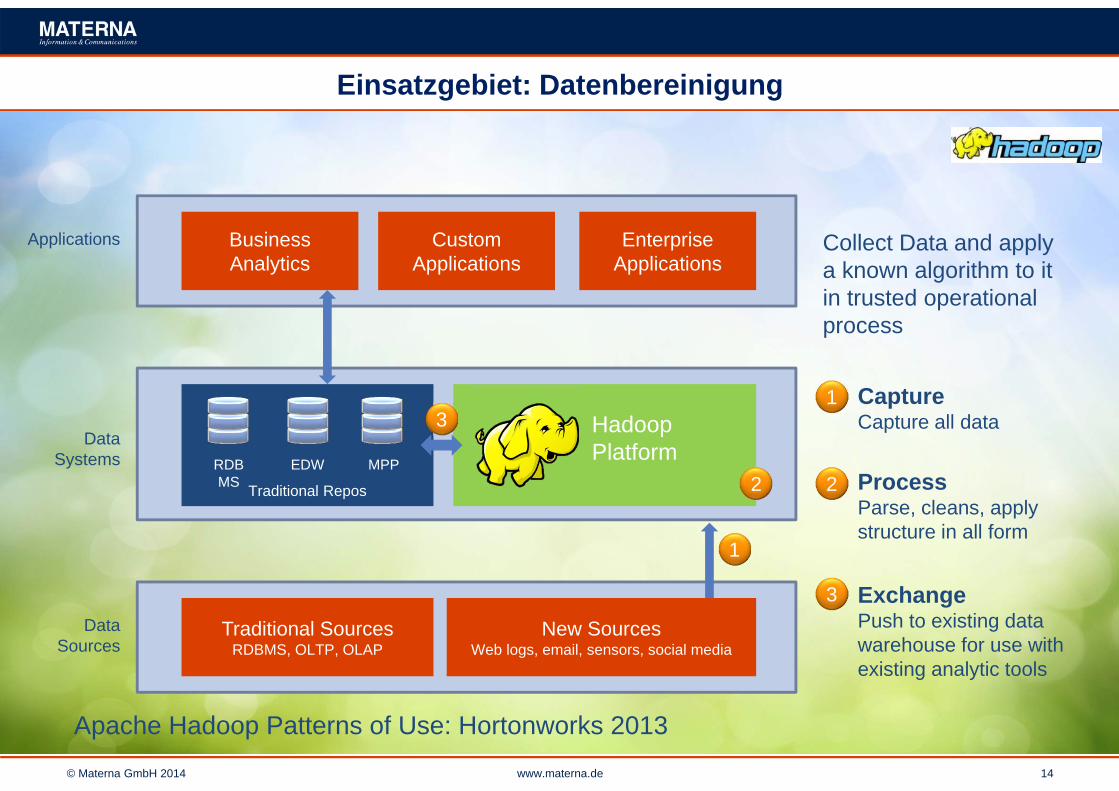
Einsatzgebiet: Datenbereinigung
Business Analytics
Custom Applications
Enterprise Applications
Traditional SourcesRDBMS, OLTP, OLAP
New SourcesWeb logs, email, sensors, social media
RDBMS
EDW MPP
Traditional Repos
Hadoop Platform
Data Systems
Data Sources
Applications Collect Data and applya known algorithm to itin trusted operational process
CaptureCapture all data
ProcessParse, cleans, applystructure in all form
ExchangePush to existing datawarehouse for use withexisting analytic tools
1
2
3
1
2
3
Apache Hadoop Patterns of Use: Hortonworks 2013
© Materna GmbH 2014 www.materna.de 15
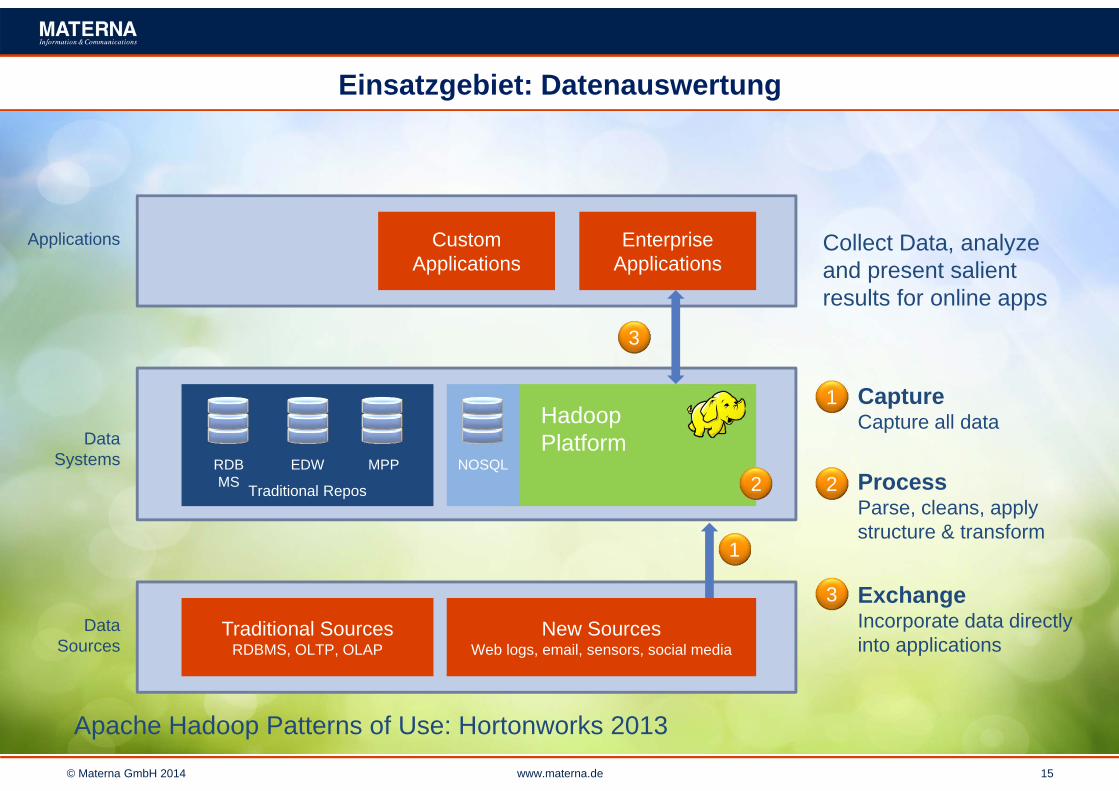
Einsatzgebiet: Datenauswertung
Apache Hadoop Patterns of Use: Hortonworks 2013
Custom Applications
Enterprise Applications
Traditional SourcesRDBMS, OLTP, OLAP
New SourcesWeb logs, email, sensors, social media
RDBMS
EDW MPP
Traditional Repos
Hadoop PlatformData
Systems
Data Sources
Applications
NOSQL
1
2
3
Collect Data, analyzeand present salientresults for online apps
CaptureCapture all data
ProcessParse, cleans, applystructure & transform
ExchangeIncorporate data directlyinto applications
1
2
3
© Materna GmbH 2014 www.materna.de 16
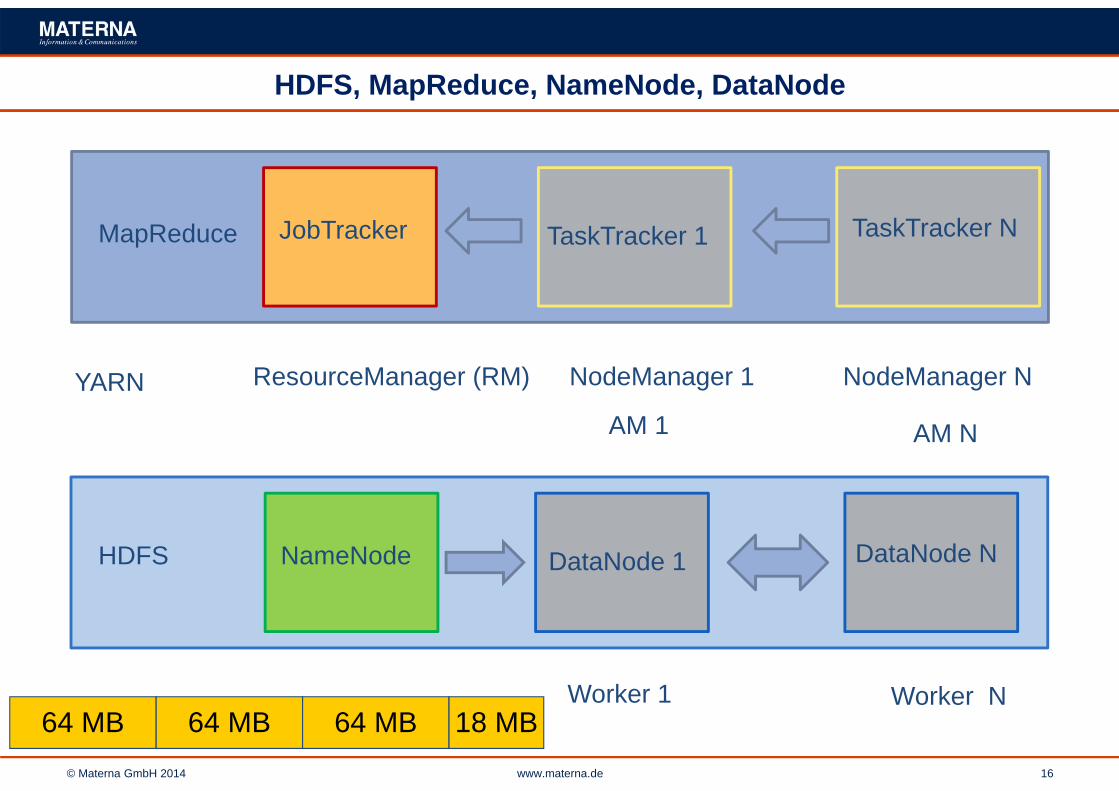
HDFS, MapReduce, NameNode, DataNode
HDFS
MapReduce
NameNode DataNode 1 DataNode N
JobTracker TaskTracker 1 TaskTracker N
ResourceManager (RM)
ApplicationMaster (AM) AM 1 AM N
YARN
Worker 1 Worker N
NodeManager 1 NodeManager N
64 MB 64 MB 64 MB 18 MB
© Materna GmbH 2014 www.materna.de 17
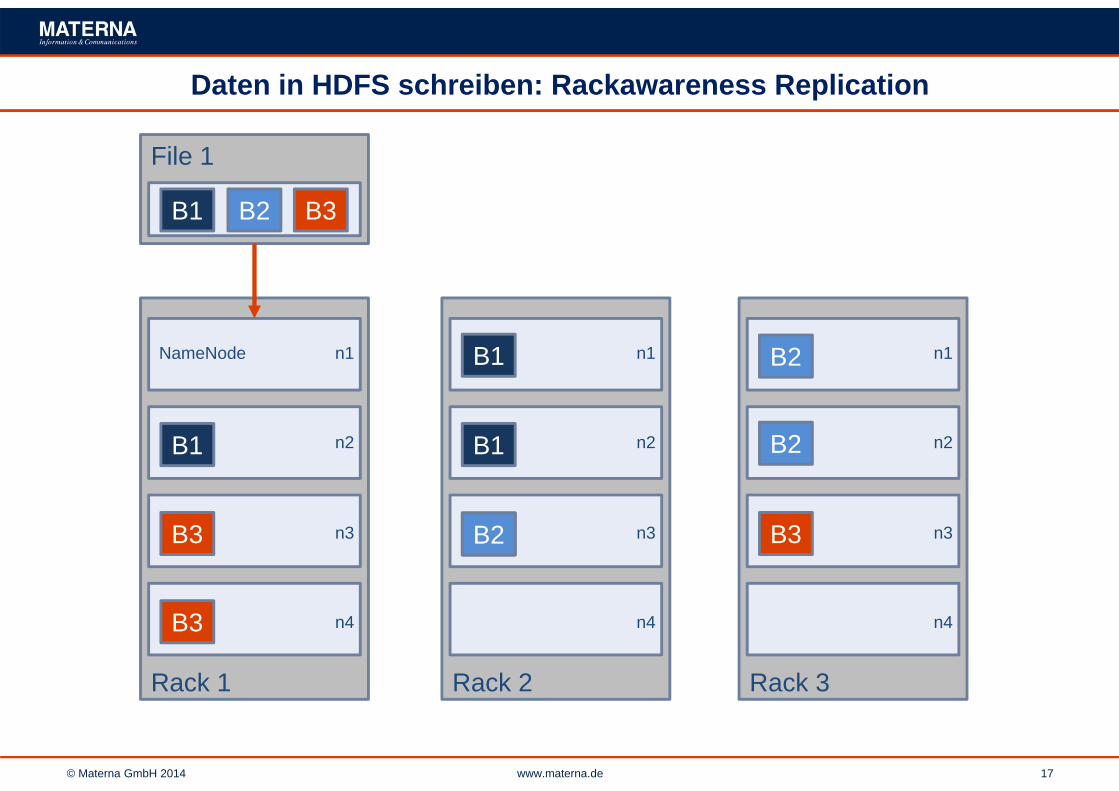
Daten in HDFS schreiben: Rackawareness Replication
File 1
B1 B2 B3
NameNode n1
n2
n3
n4
B1
B3
B3
Rack 1
n1
n2
n3
n4
B1
Rack 2
n1
n2
n3
n4
Rack 3
B1
B2B2
B2
B2
B3
© Materna GmbH 2014 www.materna.de 18
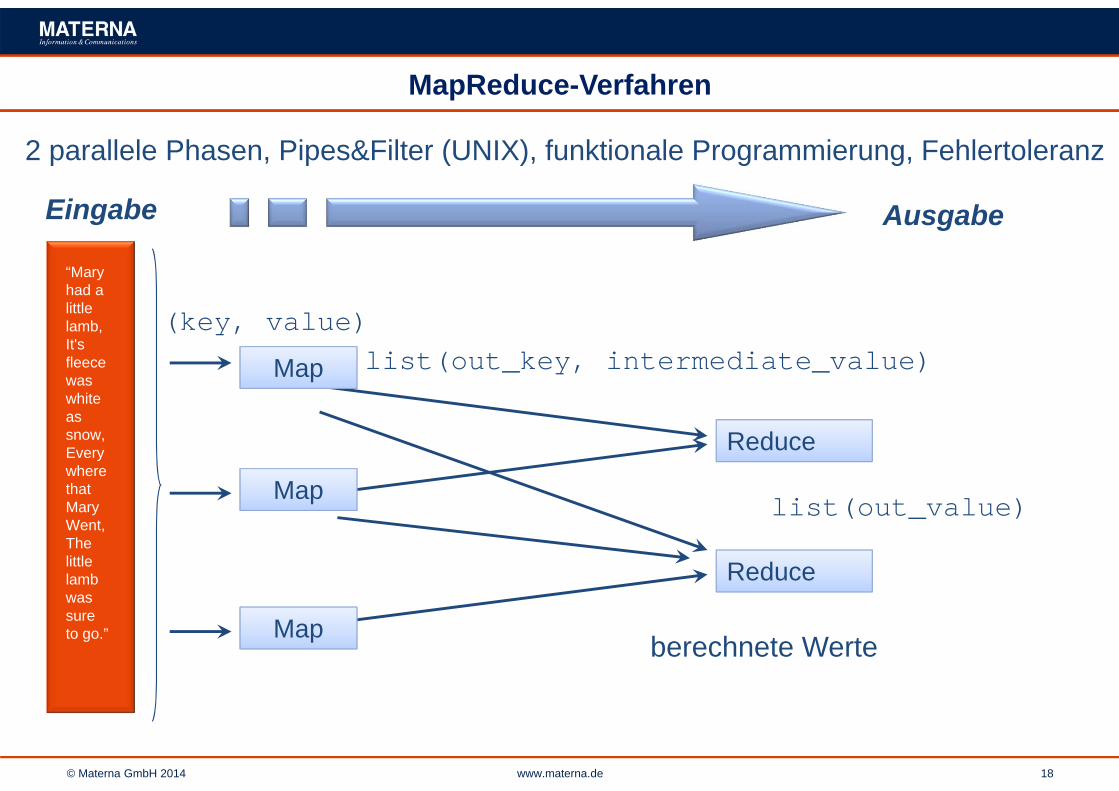
MapReduce-Verfahren
“Mary had a little lamb, It's fleece was white as snow, Everywhere that Mary Went, The little lamb was sure to go.”
Reduce
Reduce
(key, value)list(out_key, intermediate_value)
list(out_value)
Eingabe Ausgabe
Map
Map
Map
2 parallele Phasen, Pipes&Filter (UNIX), funktionale Programmierung, Fehlertoleranz
berechnete Werte
© Materna GmbH 2014 www.materna.de 19
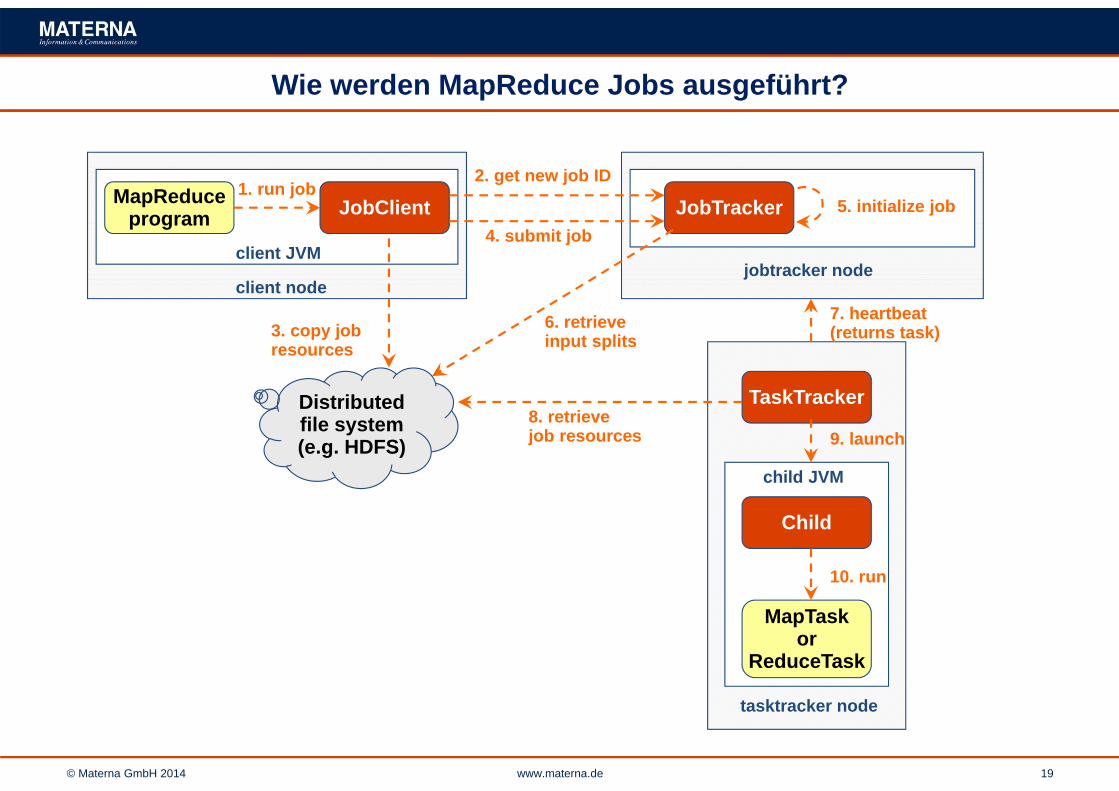
Wie werden MapReduce Jobs ausgeführt?
MapReduceprogram JobClient
1. run job
client JVM
client node
JobTracker 5. initialize job
jobtracker node
2. get new job ID
3. copy jobresources
Distributed file system (e.g. HDFS)
4. submit job
6. retrieve input splits
child JVM
MapTaskor
ReduceTask
TaskTracker
Child
tasktracker node
8. retrieve job resources
7. heartbeat(returns task)
9. launch
10. run
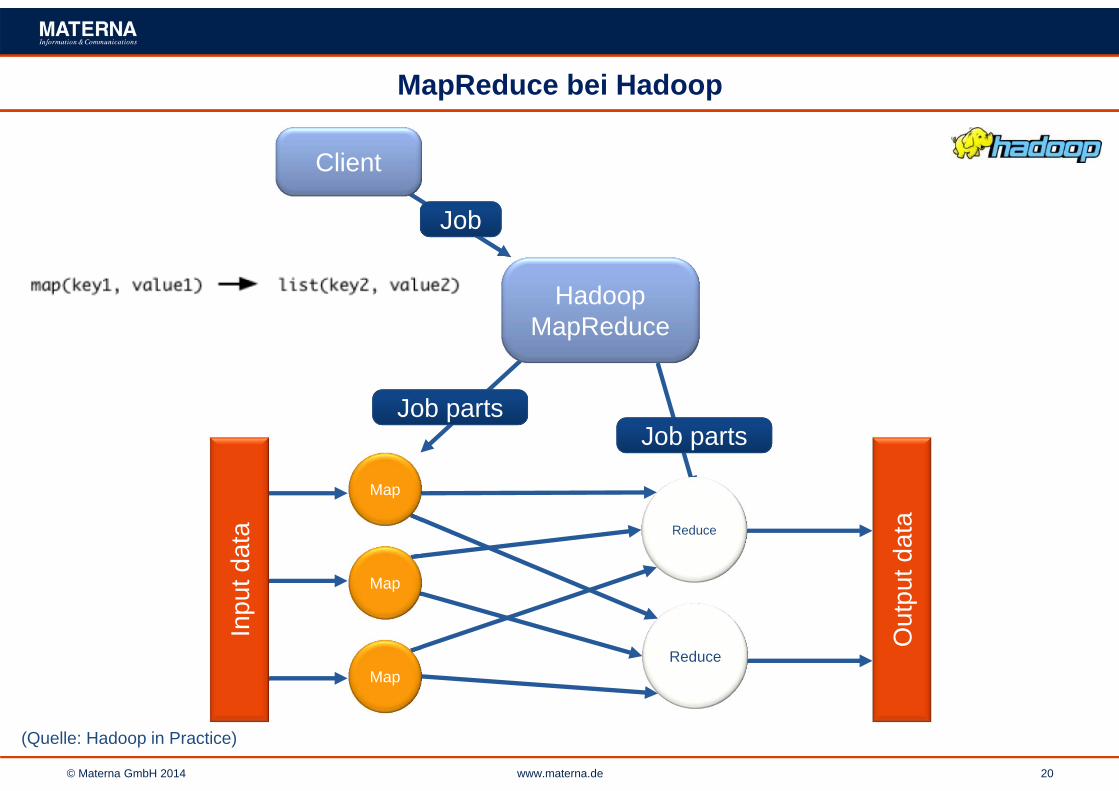
© Materna GmbH 2014 www.materna.de 20
MapReduce bei Hadoop
(Quelle: Hadoop in Practice)
Client
Job
HadoopMapReduce
Job partsJob parts
Out
put d
ataReduce
Reduce
Inpu
t dat
a
Map
Map
Map
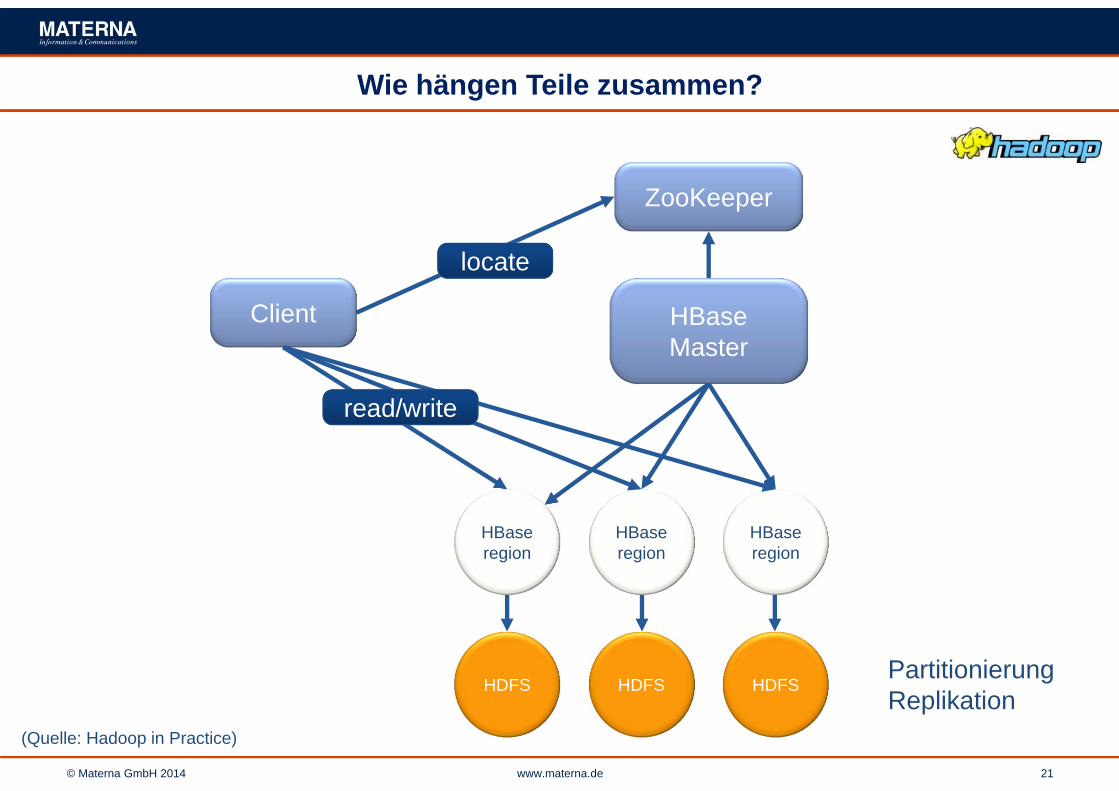
© Materna GmbH 2014 www.materna.de 21
Wie hängen Teile zusammen?
(Quelle: Hadoop in Practice)
Client
locate
HBaseMaster
HBaseregion
ZooKeeper
HBaseregion
HBaseregion
HDFS HDFS HDFS
read/write
PartitionierungReplikation
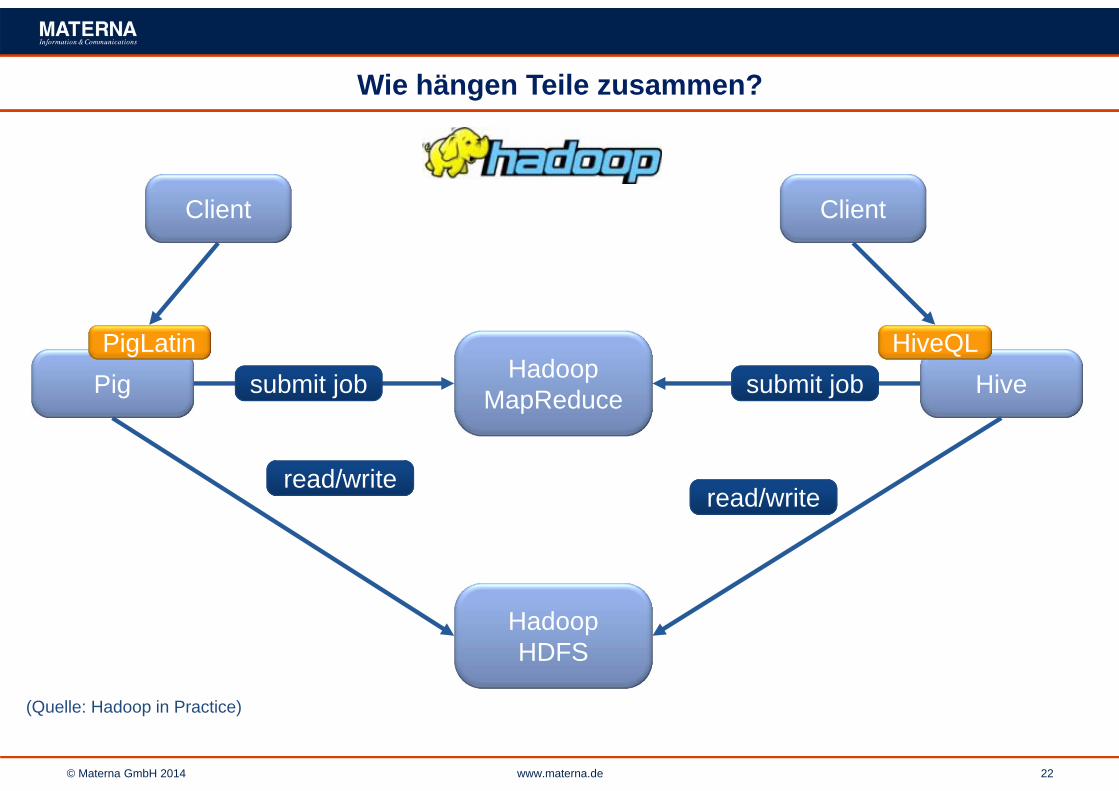
© Materna GmbH 2014 www.materna.de 22
Wie hängen Teile zusammen?
(Quelle: Hadoop in Practice)
Client Client
HivePig submit job submit job
read/writeread/write
HadoopMapReduce
HadoopHDFS
HiveQLPigLatin
© Materna GmbH 2014 www.materna.de 23
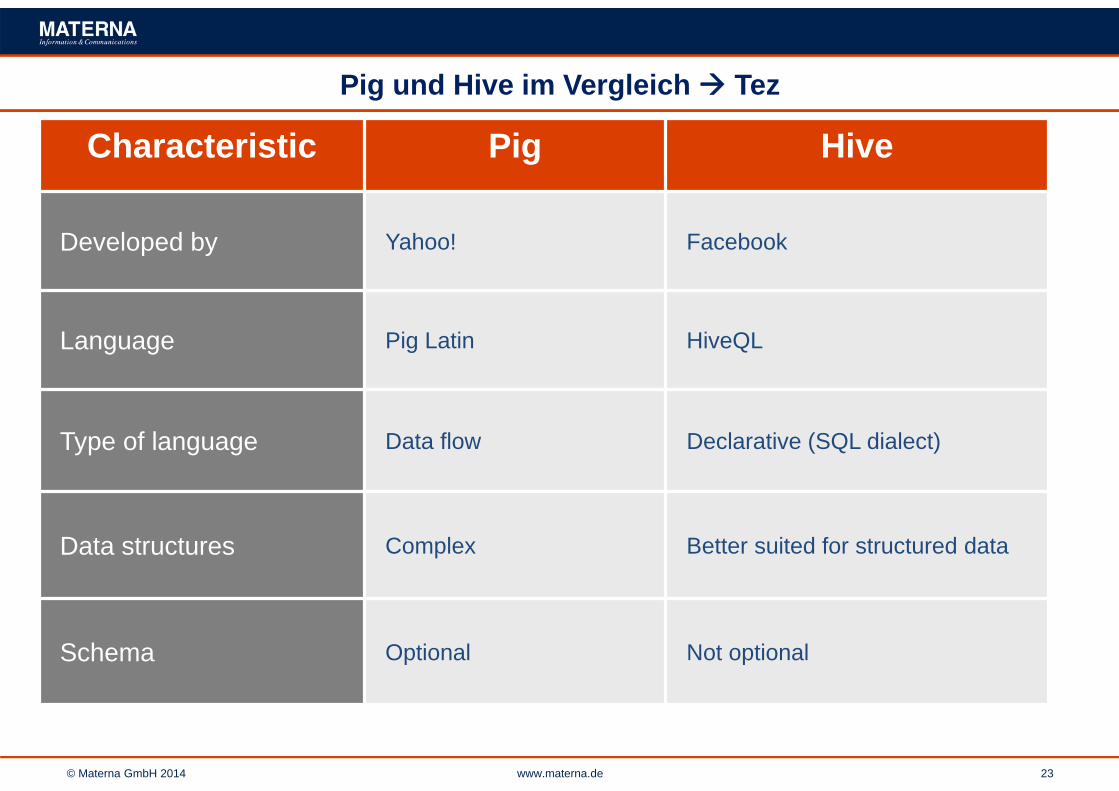
Pig und Hive im Vergleich Tez
Characteristic Pig Hive
Developed by Yahoo! Facebook
Language Pig Latin HiveQL
Type of language Data flow Declarative (SQL dialect)
Data structures Complex Better suited for structured data
Schema Optional Not optional
© Materna GmbH 2014 www.materna.de 24
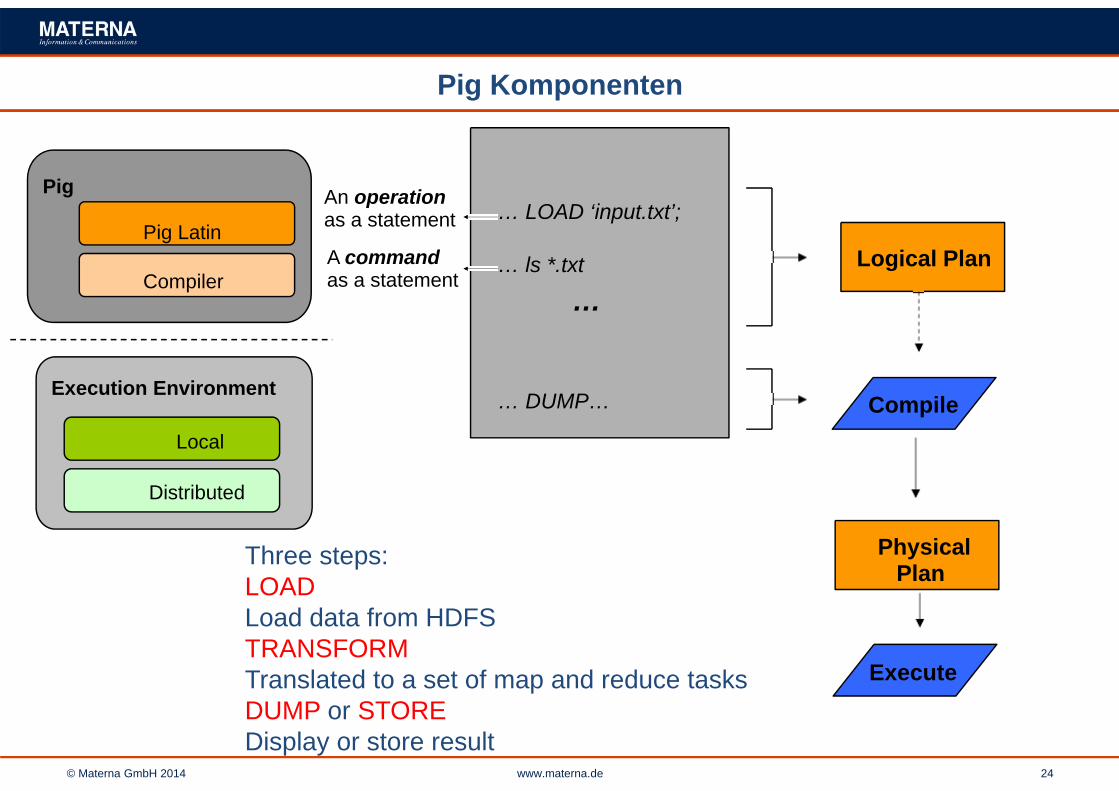
Pig Komponenten
Pig
Pig Latin
Compiler
Execution Environment
Local
Distributed
… LOAD ‘input.txt’;
… ls *.txt
…
… DUMP…
An operationas a statement
A commandas a statement
Logical Plan
Compile
PhysicalPlan
Execute
Three steps:LOADLoad data from HDFSTRANSFORMTranslated to a set of map and reduce tasksDUMP or STOREDisplay or store result
© Materna GmbH 2014 www.materna.de 25
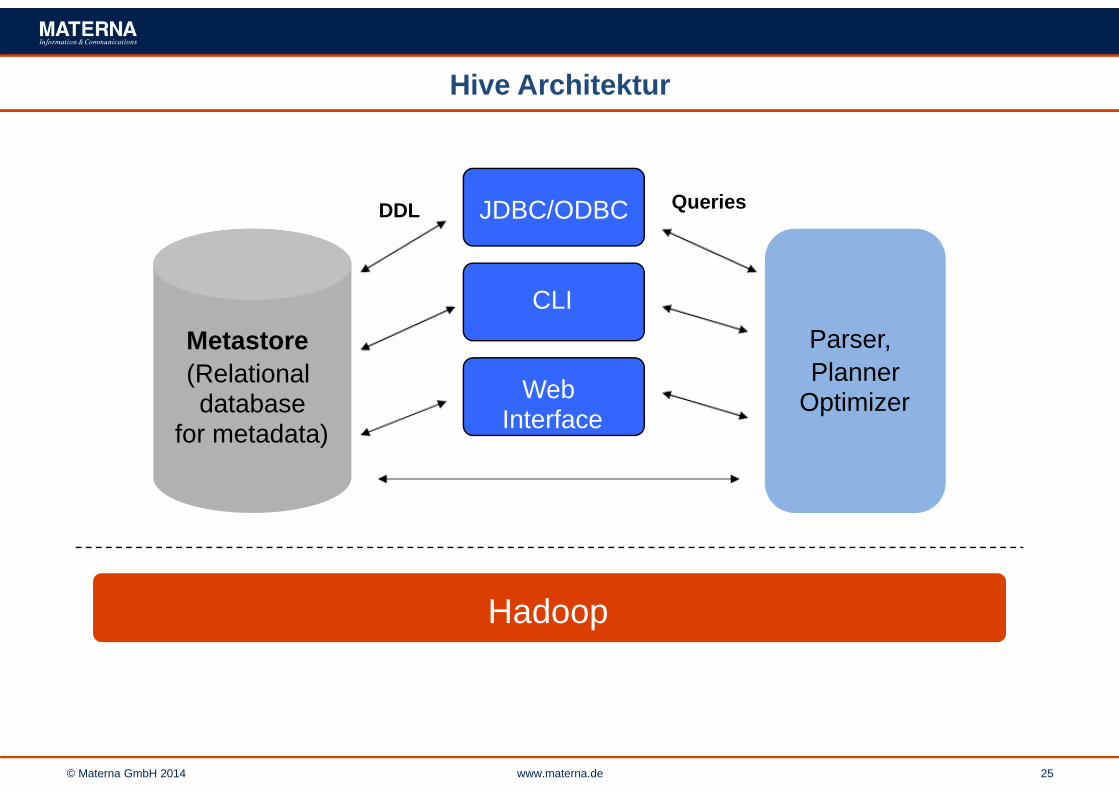
Hive Architektur
Metastore(Relationaldatabase
for metadata)
JDBC/ODBC
CLI
WebInterface
Hadoop
Parser,Planner
Optimizer
DDL Queries

© Materna GmbH 2014 www.materna.de 27
Agenda
Herausforderungen BigData Größeres Pferd oder Pferdegespann? Apache Hadoop
Geschichte, Versionen, Ökosystem Produkte
HDFS – Daten speichern und verteilen Map/Reduce – parallelisieren der Verarbeitung Pig,Hive – Verarbeitung von Daten HBase – Verteilte und skalierbare Speicherung von Daten
Benchmark: Wie schnell 1TB sortieren? BigData-UseCases mit ORACLE Fazit, Ausblick
© Materna GmbH 2014 www.materna.de 28
Hadoop Cluster Hardwareanforderungen: eine Menge Blech …
Intel Cloud Builders Guide: Apache Hadoophttp://software.intel.com/en-us/articles/intel-benchmark-install-and-test-tool-intel-bitt-tools/
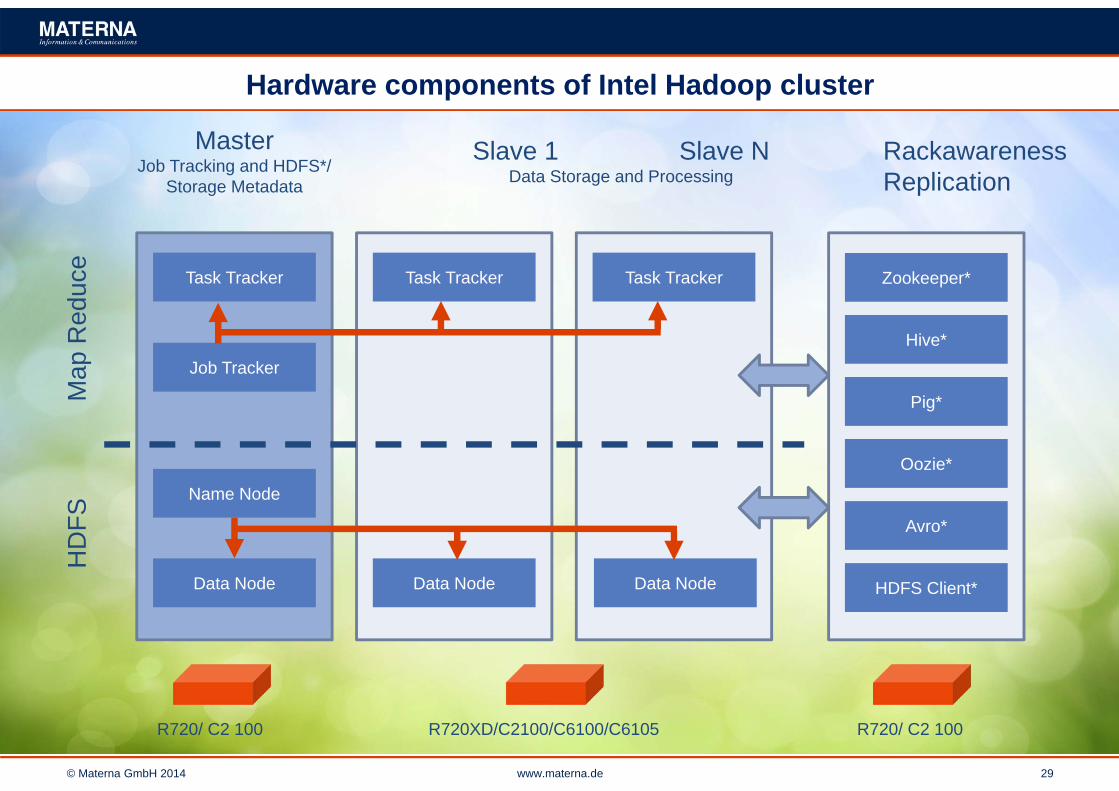
© Materna GmbH 2014 www.materna.de 29
Hardware components of Intel Hadoop cluster
MasterJob Tracking and HDFS*/
Storage Metadata
Slave 1 Slave NData Storage and Processing
Map
Red
uce
Task Tracker Task Tracker Task Tracker
Job Tracker
Data Node Data Node Data Node
Name Node
HD
FS
Zookeeper*
Hive*
Pig*
Oozie*
Avro*
HDFS Client*
R720/ C2 100 R720XD/C2100/C6100/C6105 R720/ C2 100
RackawarenessReplication
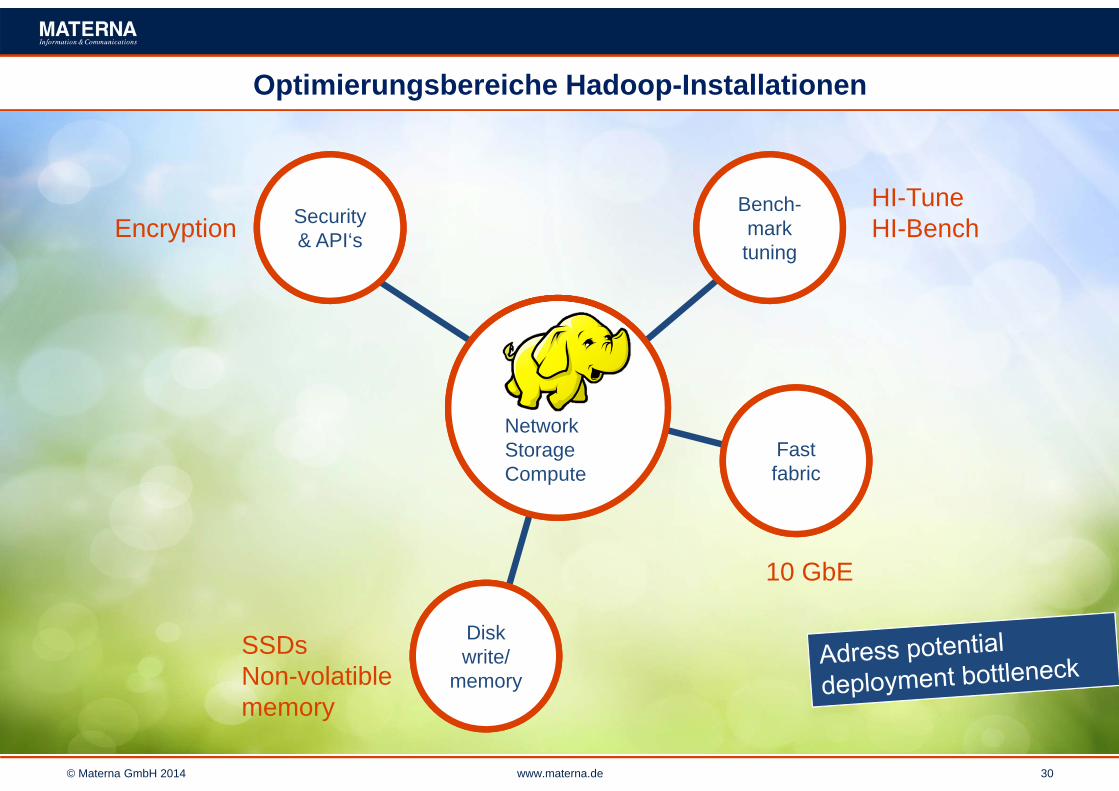
© Materna GmbH 2014 www.materna.de 30
Optimierungsbereiche Hadoop-Installationen
Bench-marktuning
NetworkStorage Compute
Security & API‘s
Disk write/
memory
Fast fabric
HI-TuneHI-BenchEncryption
SSDsNon-volatiblememory
10 GbE
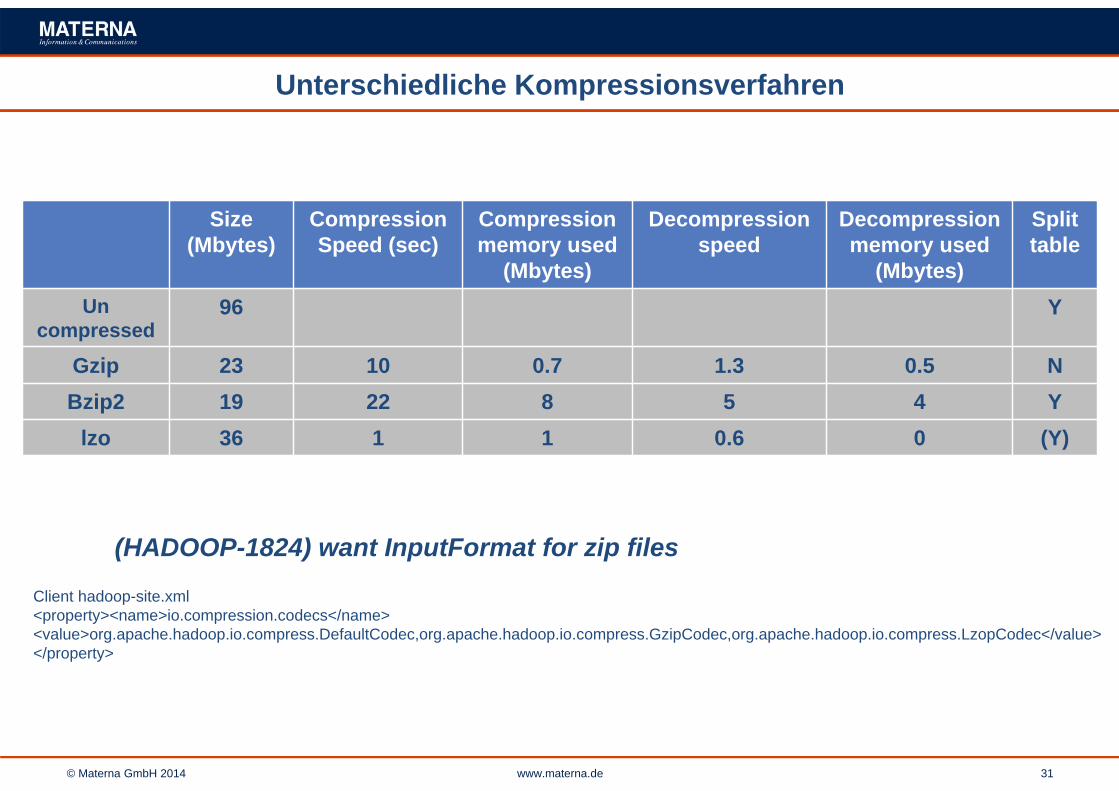
© Materna GmbH 2014 www.materna.de 31
Unterschiedliche Kompressionsverfahren
Size (Mbytes)
Compression Speed (sec)
Compression memory used
(Mbytes)
Decompression speed
Decompression memory used
(Mbytes)
Splittable
Uncompressed
96 Y
Gzip 23 10 0.7 1.3 0.5 NBzip2 19 22 8 5 4 Y
lzo 36 1 1 0.6 0 (Y)
(HADOOP-1824) want InputFormat for zip files
Client hadoop-site.xml<property><name>io.compression.codecs</name><value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.LzopCodec</value></property>

© Materna GmbH 2014 www.materna.de 32
Wichtig: Teste deine Infrastruktur
bin/hadoop jar hadoop-*test*.jar, Benchmarks time hadoop jar ../hadoop-examples-1.1.0.jar wordcount 2 4 hadoop jar hadoop*examples*.jar wordcount
/user/hduser/gutenberg /user/hduser/gutenberg-output time hadoop jar ../hadoop-test-1.1.0.jar
Kontrolle über: http://localhost:50070/ – web UI of the NameNode daemon http://localhost:50030/ – web UI of the JobTracker daemon http://localhost:50060/ – web UI of the TaskTracker daemon

© Materna GmbH 2014 www.materna.de 33
HBase Master user interface

© Materna GmbH 2014 www.materna.de 34
ZooKeeper debugging HBase
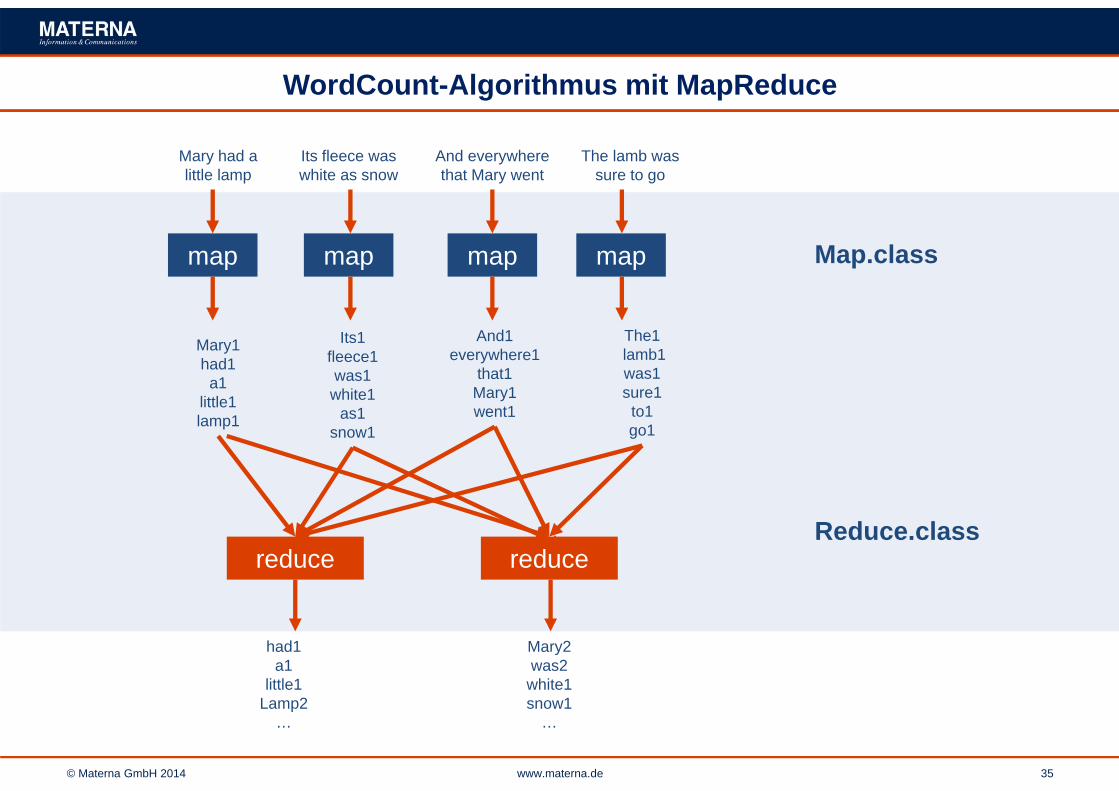
© Materna GmbH 2014 www.materna.de 35
WordCount-Algorithmus mit MapReduce
Map.class
Reduce.class
Mary had a little lamp
Its fleece was white as snow
And everywherethat Mary went
The lamb was sure to go
map map map map
Mary1 had1a1
little1 lamp1
Its1 fleece1 was1 white1
as1 snow1
And1 everywhere1
that1 Mary1 went1
The1lamb1 was1 sure1 to1 go1
had1a1
little1 Lamp2
…
Mary2was2white1snow1
…
reduce reduce

© Materna GmbH 2014 www.materna.de 36
Example: WordCount Hadoop Tutorialpublic class WordCount {
public static class Map extends MapReduceBase implementsMapper<LongWritable, Text, Text, IntWritable> {
……}public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {……}public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);conf.setJobName("wordcount");conf.setOutputKeyClass(Text.class);conf.setOutputValueClass(IntWritable.class);conf.setMapperClass(Map.class);conf.setCombinerClass(Reduce.class);conf.setReducerClass(Reduce.class);conf.setInputFormat(TextInputFormat.class);conf.setOutputFormat(TextOutputFormat.class);FileInputFormat.setInputPaths(conf, new Path(args[0]));FileOutputFormat.setOutputPath(conf, new Path(args[1]));JobClient.runJob(conf); }

© Materna GmbH 2014 www.materna.de 37
Example: WordCount Hadoop Tutorialpublic class WordCount {public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());output.collect(word, one);
}} }public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;while (values.hasNext()) {
sum += values.next().get();}output.collect(key, new IntWritable(sum));
} }

© Materna GmbH 2014 www.materna.de 38
Example: Hive WordCount HQL
CREATE TABLE docs (line STRING);LOAD DATA INPATH ‘/user/cloudera/wordcount/input/file' OVERWRITE INTO TABLE docs;
CREATE TABLE word_counts ASSELECT word, count(1) AS count FROM(SELECT explode(split(line, '\s')) AS word FROM docs) wGROUP BY wordORDER BY word;

© Materna GmbH 2014 www.materna.de 39
Example: Pig WordCount Script
input_lines = LOAD ‘/user/cloudera/wordcount/input/file' AS (line:chararray);words = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word;filtered_words = FILTER words BY word MATCHES '\\w+';word_groups = GROUP filtered_words BY word;word_count = FOREACH word_groups GENERATE COUNT(filtered_words) AS count, group AS word;ordered_word_count = ORDER word_count BY count DESC;STORE ordered_word_count INTO /user/cloudera/wordcount/output/part-00000 ';

© Materna GmbH 2014 www.materna.de 40
Example: WordCount Hadoop Tutorial
$ echo "Hello World Bye World" > file0 $ echo "Hello Hadoop Goodbye Hadoop" > file1 $ hadoop fs -mkdir /user/cloudera /user/cloudera/wordcount/user/cloudera/wordcount/input$ hadoop fs -put file* /user/cloudera/wordcount/input $ hadoop fs -cat /user/cloudera/wordcount/output/part-00000 Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2

© Materna GmbH 2014 www.materna.de 41
Example: WordCount Hadoop Tutorial
first input map : < Hello, 1> < World, 1> < Bye, 1> < World, 1> second input map : < Hello, 1> < Hadoop, 1> < Goodbye, 1> < Hadoop, 1>
first output map: < Bye, 1> < Hello, 1> < World, 2>second output map: < Goodbye, 1> < Hadoop, 2> < Hello, 1>The Reducer sums up the values: < Bye, 1> < Goodbye, 1> < Hadoop, 2> < Hello, 2> < World, 2>

© Materna GmbH 2014 www.materna.de 42
Terasort benchmark Hadoop: Wie lange dauert es 1TB zu sortieren?
http://hadoop.apache.org/docs/current/api/org/apache/hadoop/examples/terasort/package-summary.html
hadoop jar hadoop-*examples*.jar terasort <input dir> <output dir>
2008, 1TB 3,48 minutes910 nodes x (4 dual-core processors, 4 disks, 8 GB memory)
2009, 100 TB in 173 minutes3452 nodes x (2 Quadcore Xeons, 8 GB memory, 4 SATA)
2012 100 TB sort in 10,369 secondsIBM InfoSphere BigInsights 100 TB (1.000 virtual machines, 200 nodes, 2.400 Cores)

© Materna GmbH 2014 www.materna.de 43
Agenda
Herausforderungen BigData Größeres Pferd oder Pferdegespann? Apache Hadoop
Geschichte, Versionen, Ökosystem Produkte
HDFS – Daten speichern und verteilen Map/Reduce – parallelisieren der Verarbeitung Pig,Hive – Verarbeitung von Daten HBase – Verteilte und skalierbare Speicherung von Daten
Benchmark: Wie schnell 1TB sortieren? BigData-UseCases mit ORACLE Fazit, Ausblick
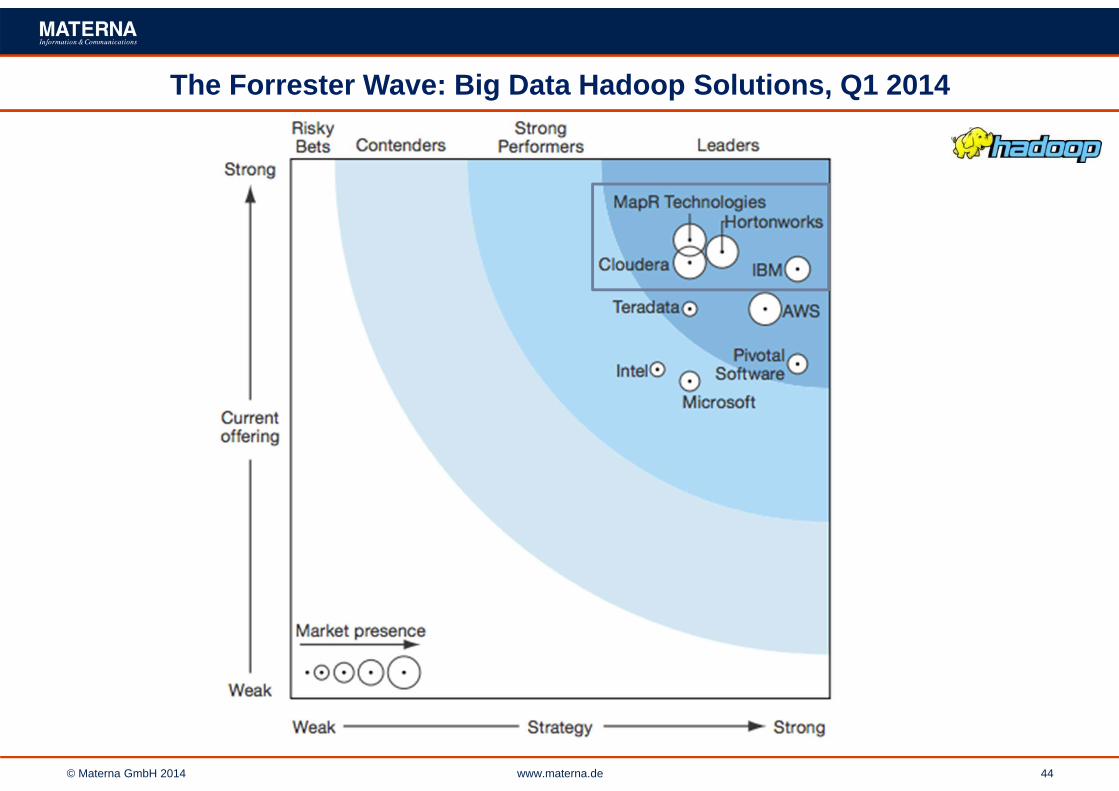
© Materna GmbH 2014 www.materna.de 44
The Forrester Wave: Big Data Hadoop Solutions, Q1 2014
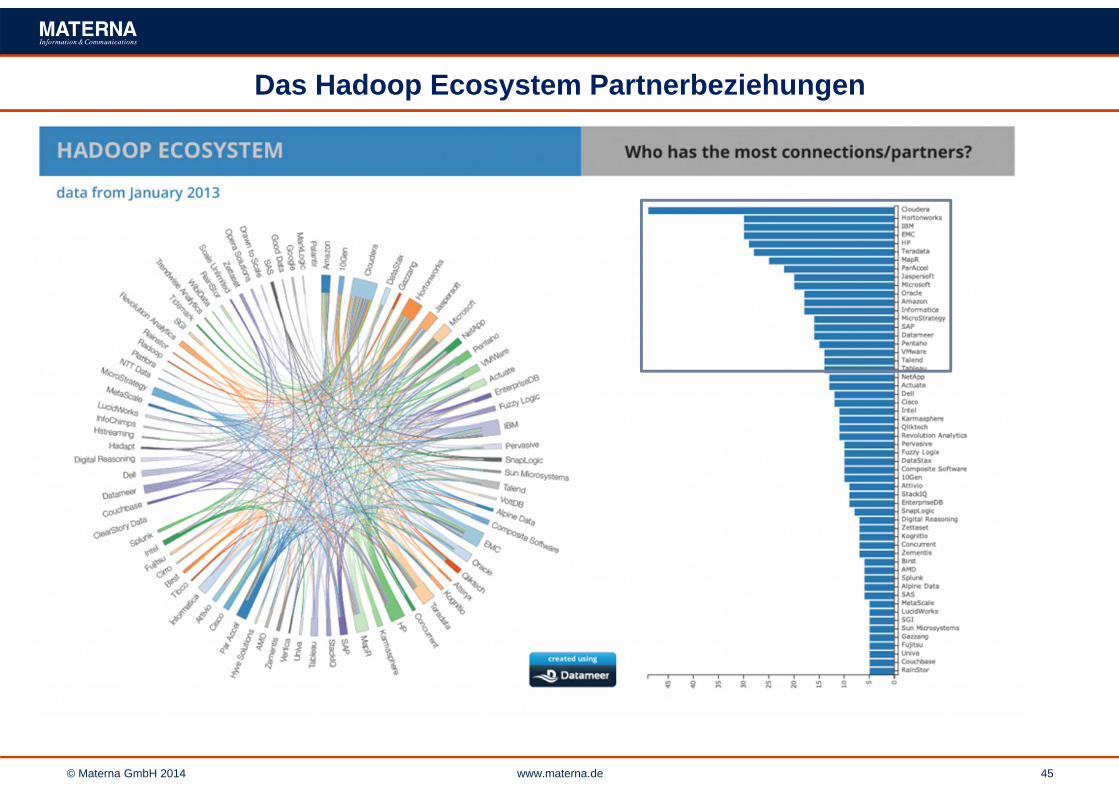
© Materna GmbH 2014 www.materna.de 45
Das Hadoop Ecosystem Partnerbeziehungen
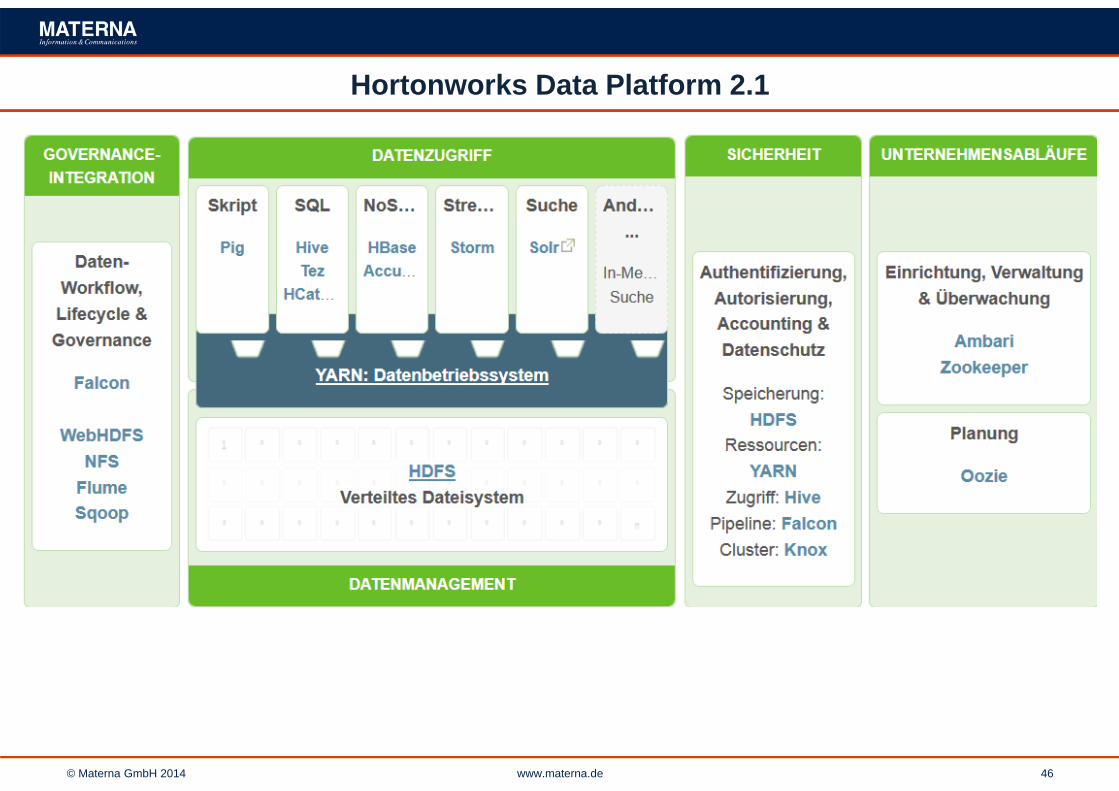
© Materna GmbH 2014 www.materna.de 46
Hortonworks Data Platform 2.1
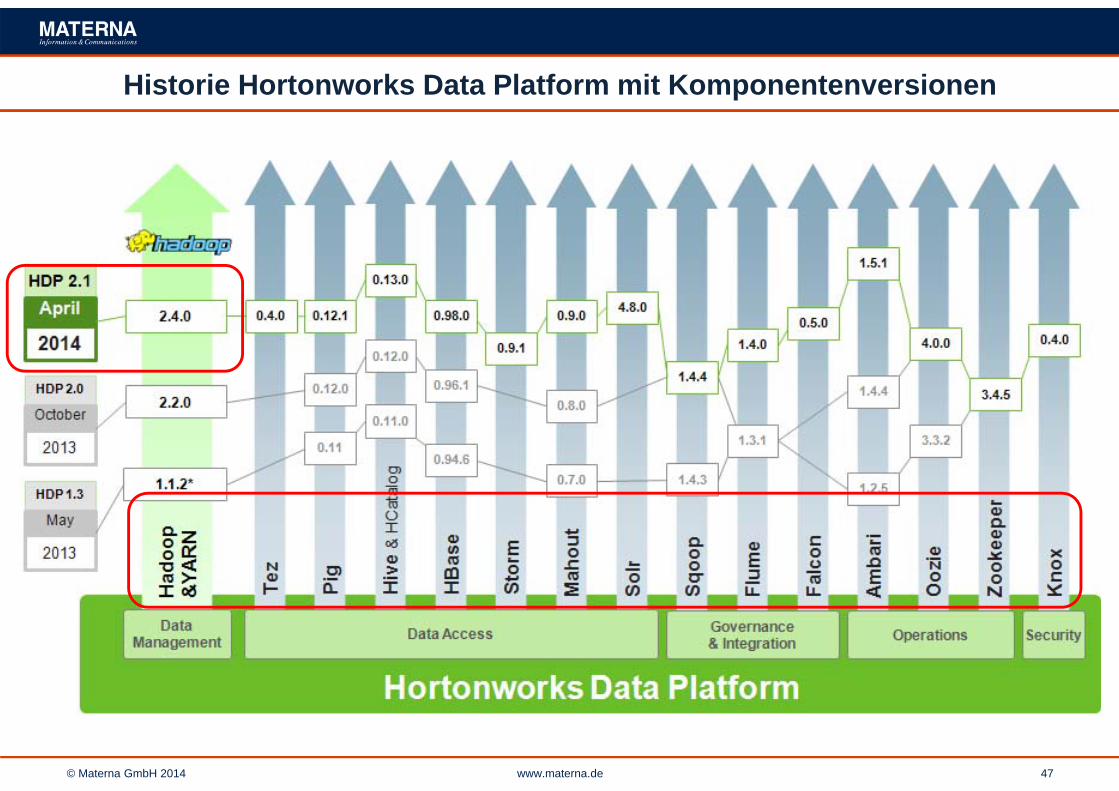
© Materna GmbH 2014 www.materna.de 47
Historie Hortonworks Data Platform mit Komponentenversionen
© Materna GmbH 2014 www.materna.de 48
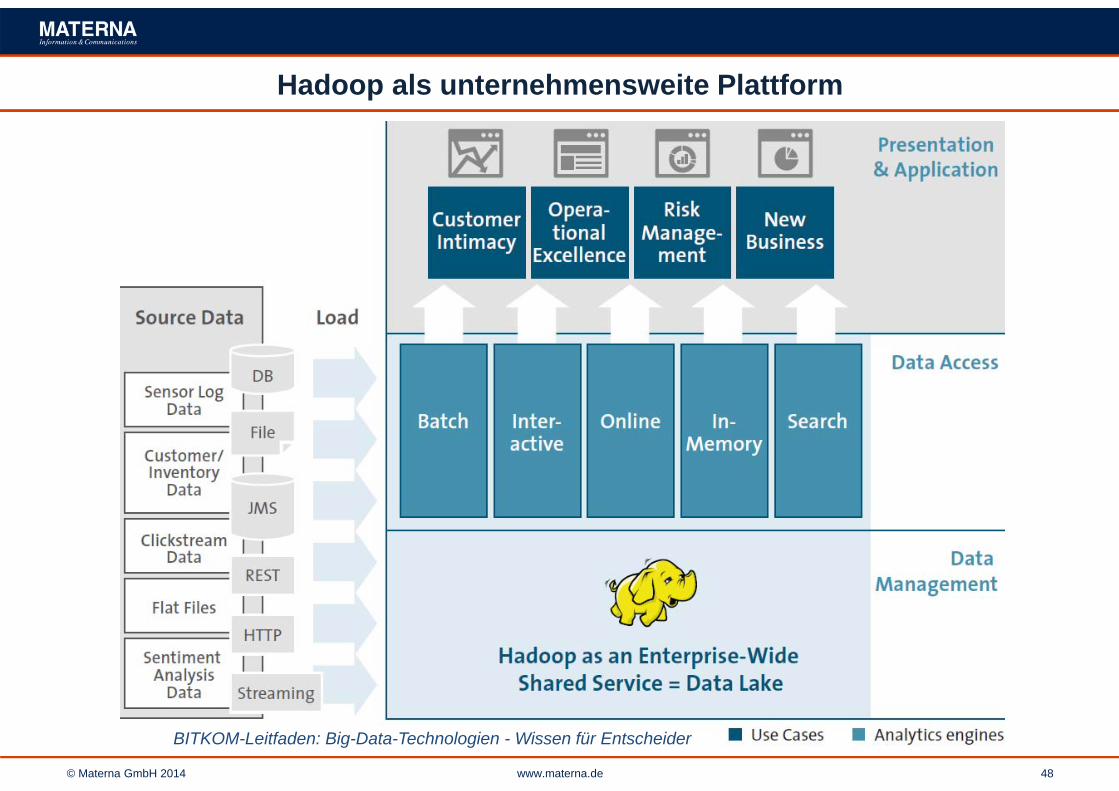
Hadoop als unternehmensweite Plattform
BITKOM-Leitfaden: Big-Data-Technologien - Wissen für Entscheider
© Materna GmbH 2014 www.materna.de 49
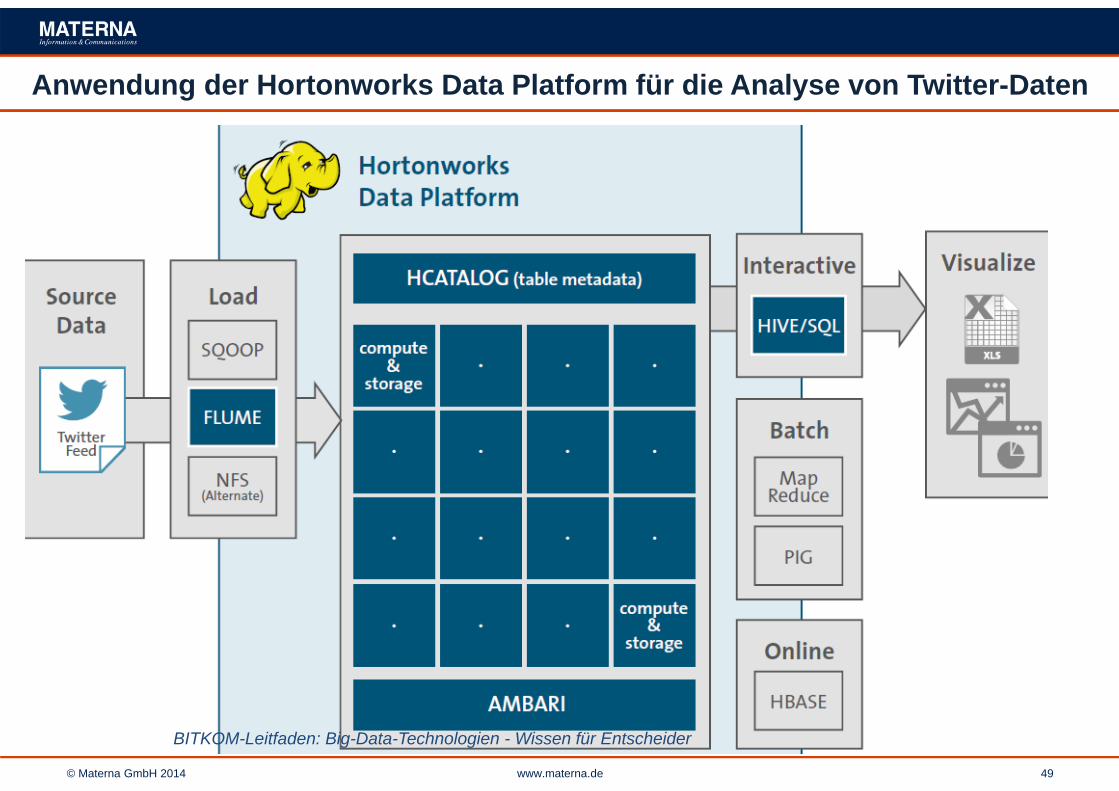
Anwendung der Hortonworks Data Platform für die Analyse von Twitter-Daten
BITKOM-Leitfaden: Big-Data-Technologien - Wissen für Entscheider
© Materna GmbH 2014 www.materna.de 50
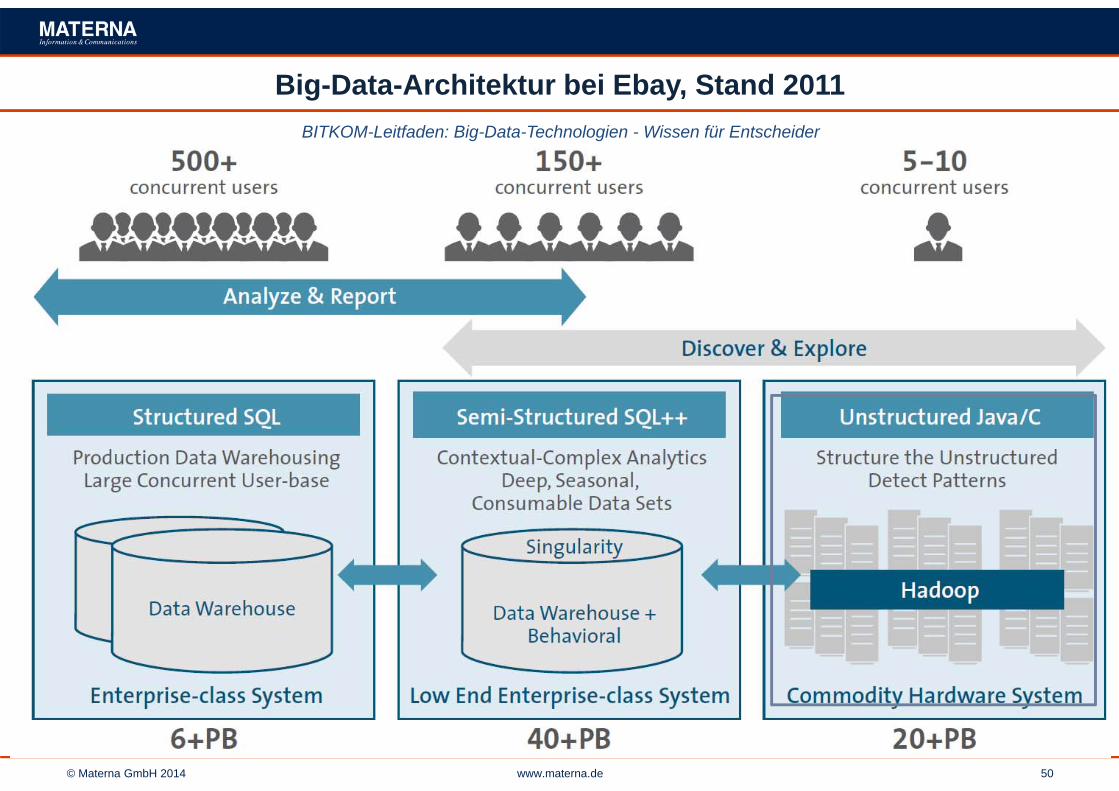
Big-Data-Architektur bei Ebay, Stand 2011BITKOM-Leitfaden: Big-Data-Technologien - Wissen für Entscheider
© Materna GmbH 2014 www.materna.de 51
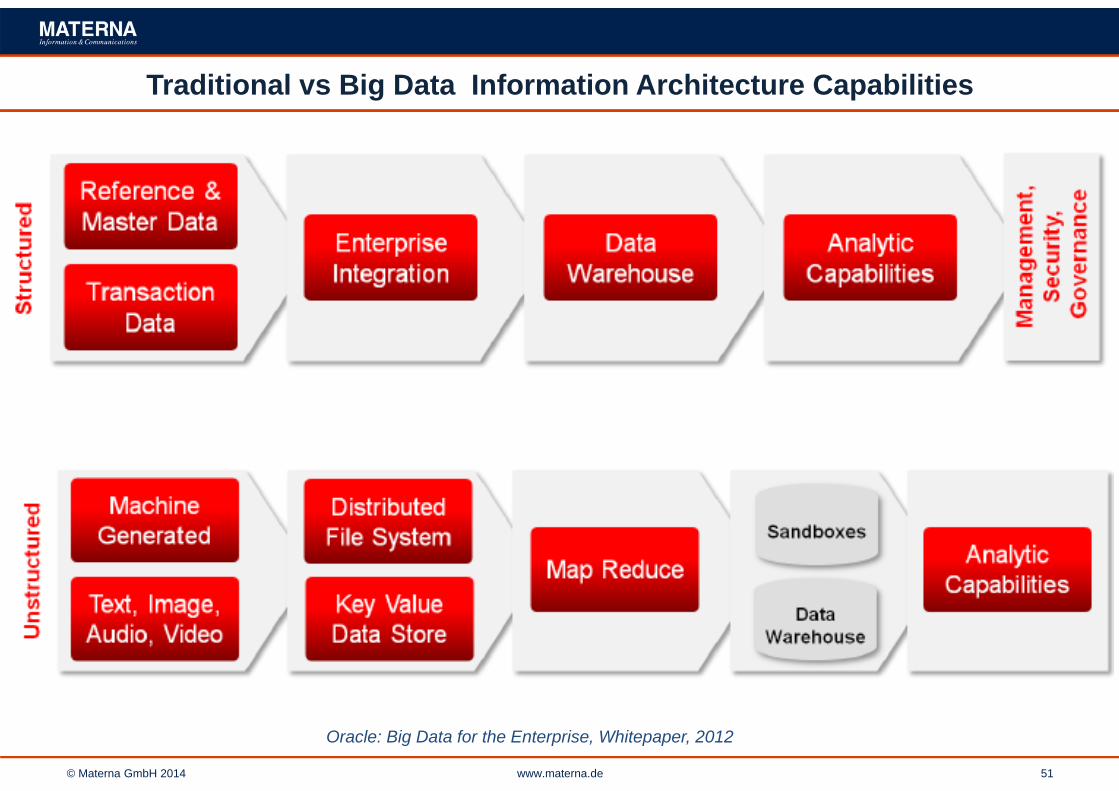
Traditional vs Big Data Information Architecture Capabilities
Oracle: Big Data for the Enterprise, Whitepaper, 2012
© Materna GmbH 2014 www.materna.de 52
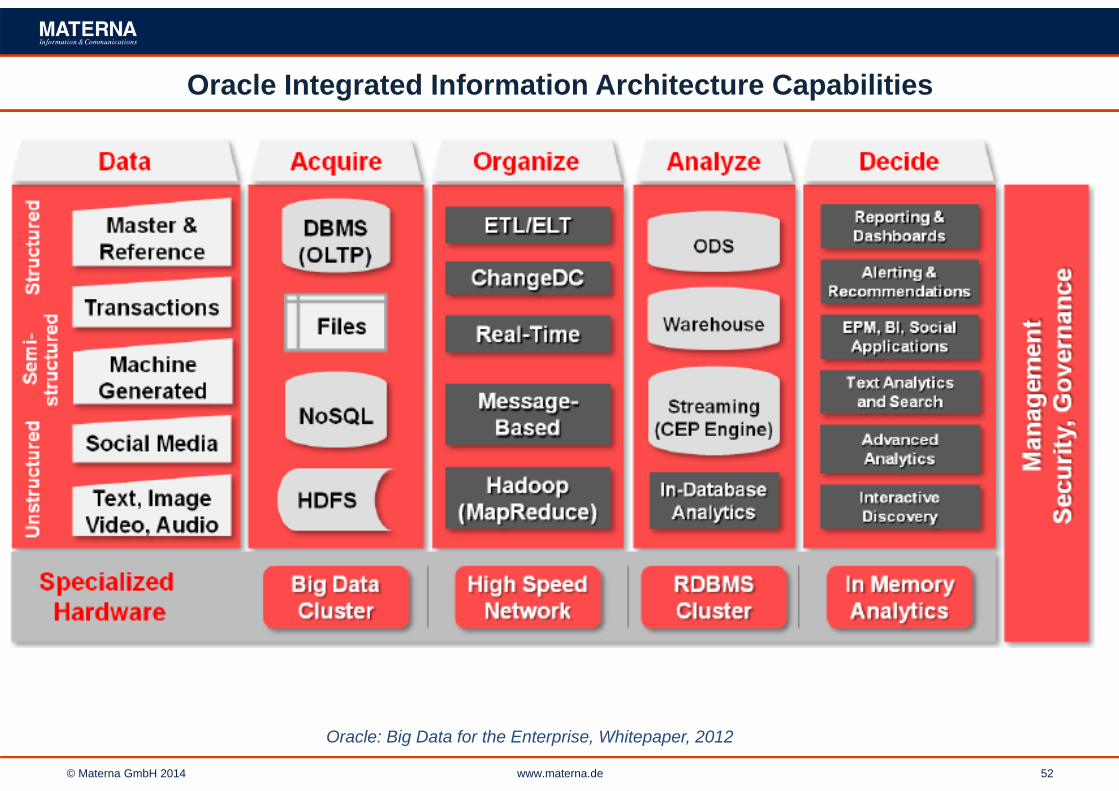
Oracle Integrated Information Architecture Capabilities
Oracle: Big Data for the Enterprise, Whitepaper, 2012
© Materna GmbH 2014 www.materna.de 53
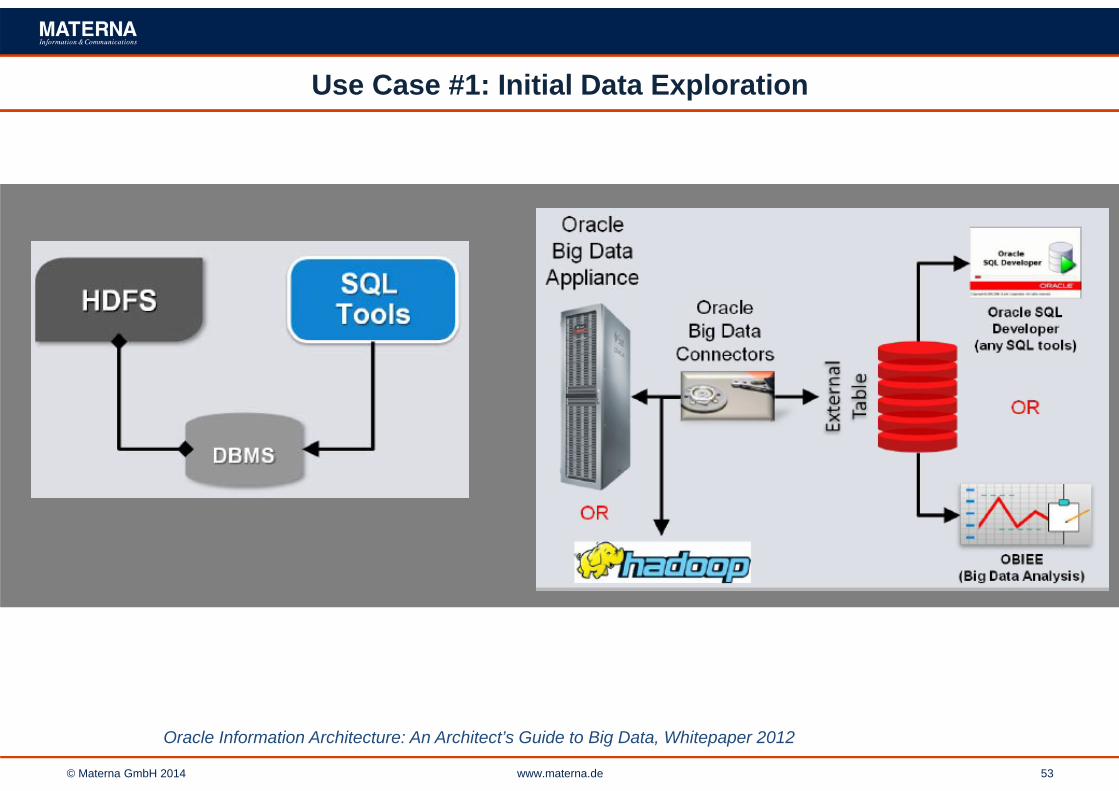
Use Case #1: Initial Data Exploration
Oracle Information Architecture: An Architect’s Guide to Big Data, Whitepaper 2012
© Materna GmbH 2014 www.materna.de 54
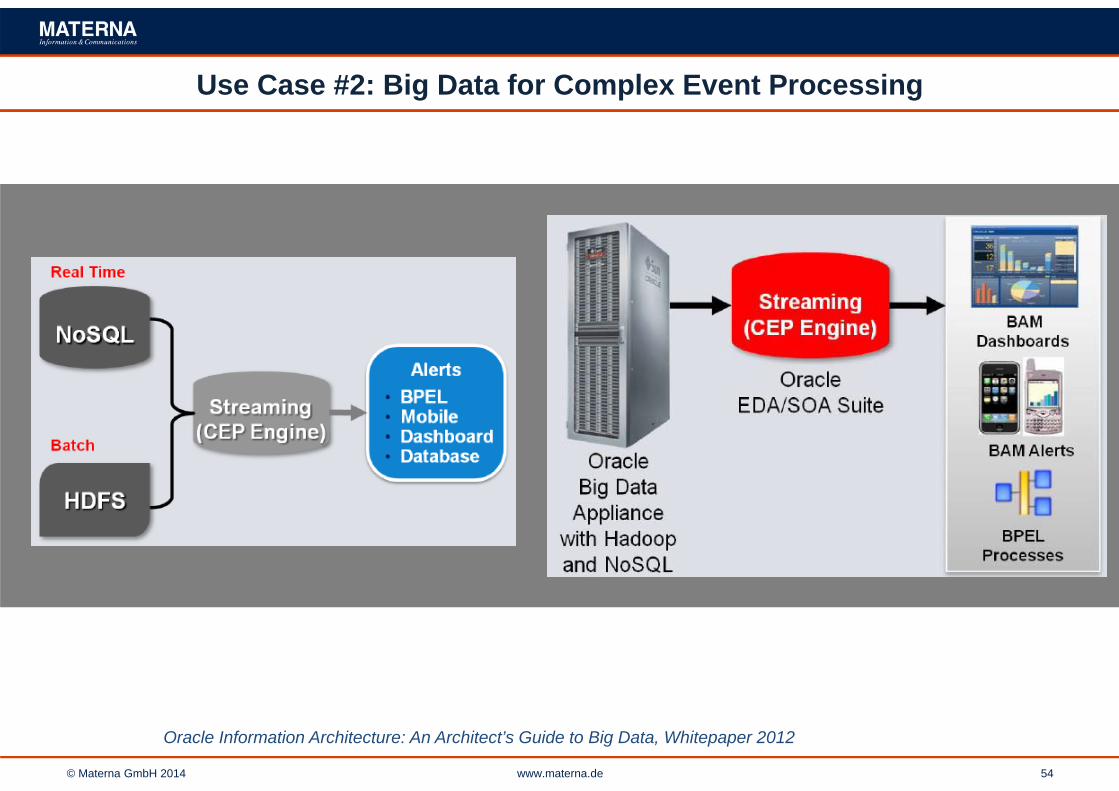
Use Case #2: Big Data for Complex Event Processing
Oracle Information Architecture: An Architect’s Guide to Big Data, Whitepaper 2012
© Materna GmbH 2014 www.materna.de 55
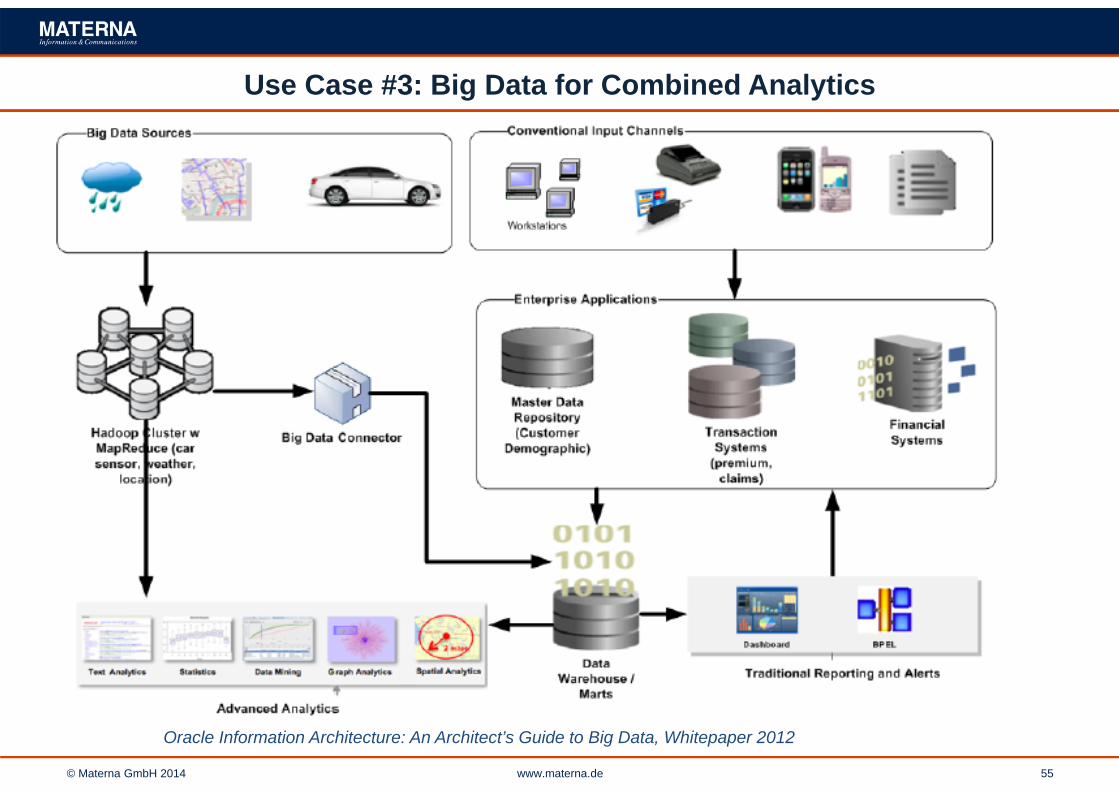
Use Case #3: Big Data for Combined Analytics
Oracle Information Architecture: An Architect’s Guide to Big Data, Whitepaper 2012
© Materna GmbH 2014 www.materna.de 56
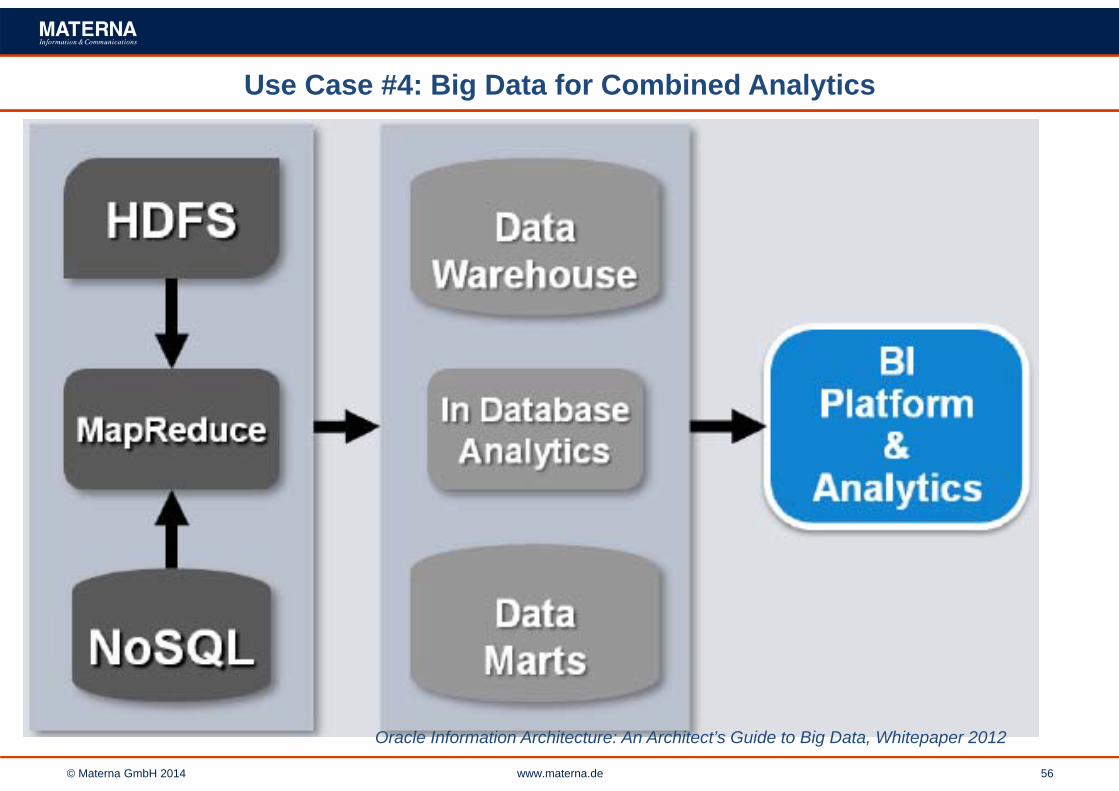
Use Case #4: Big Data for Combined Analytics
Oracle Information Architecture: An Architect’s Guide to Big Data, Whitepaper 2012
© Materna GmbH 2014 www.materna.de 57
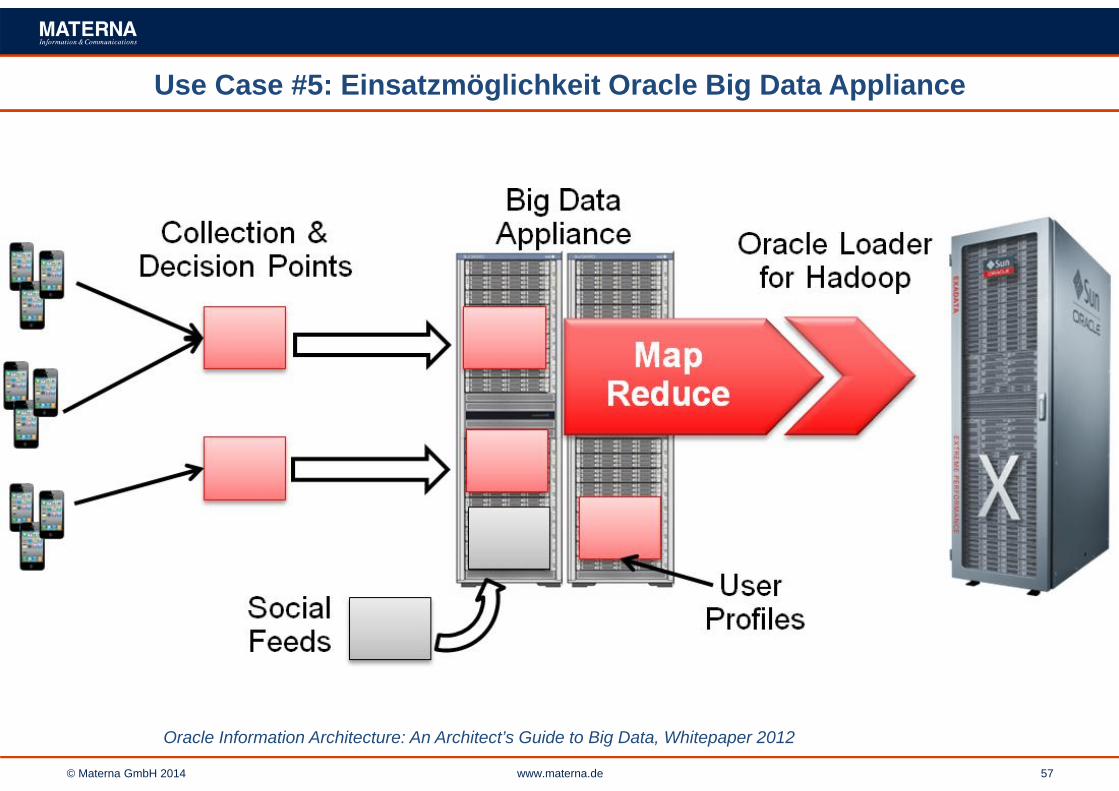
Use Case #5: Einsatzmöglichkeit Oracle Big Data Appliance
Oracle Information Architecture: An Architect’s Guide to Big Data, Whitepaper 2012
© Materna GmbH 2014 www.materna.de 58
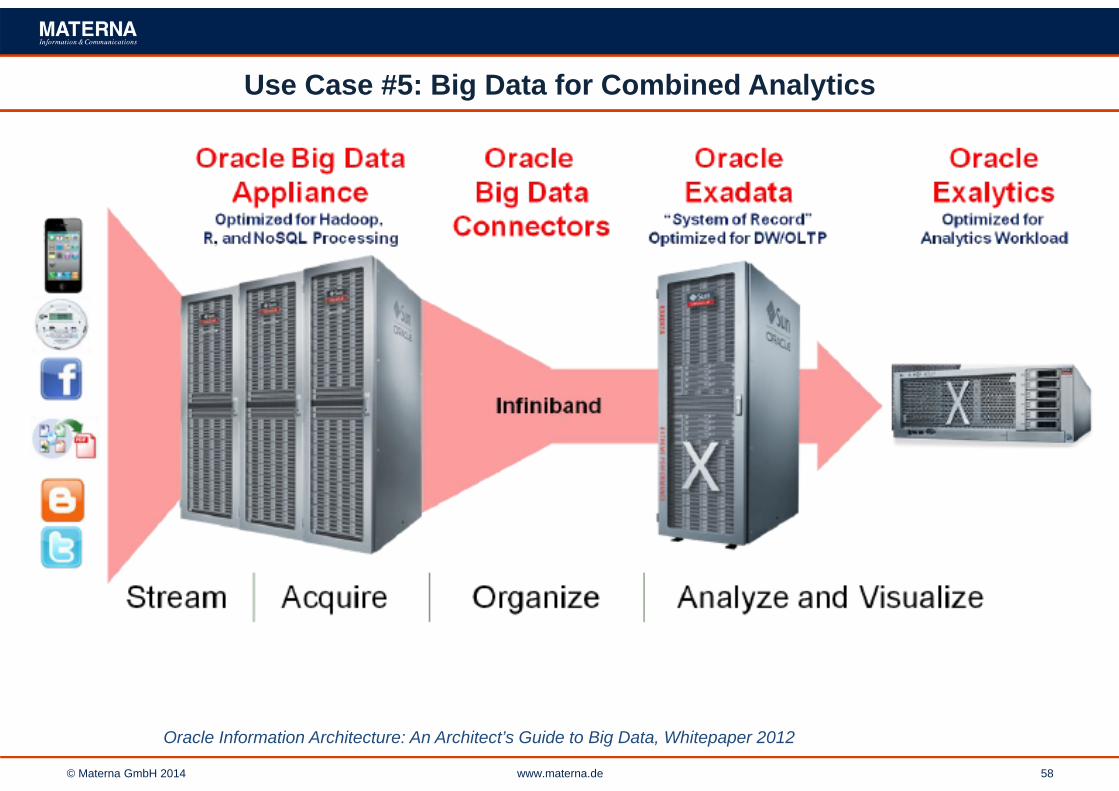
Use Case #5: Big Data for Combined Analytics
Oracle Information Architecture: An Architect’s Guide to Big Data, Whitepaper 2012
© Materna GmbH 2014 www.materna.de 59
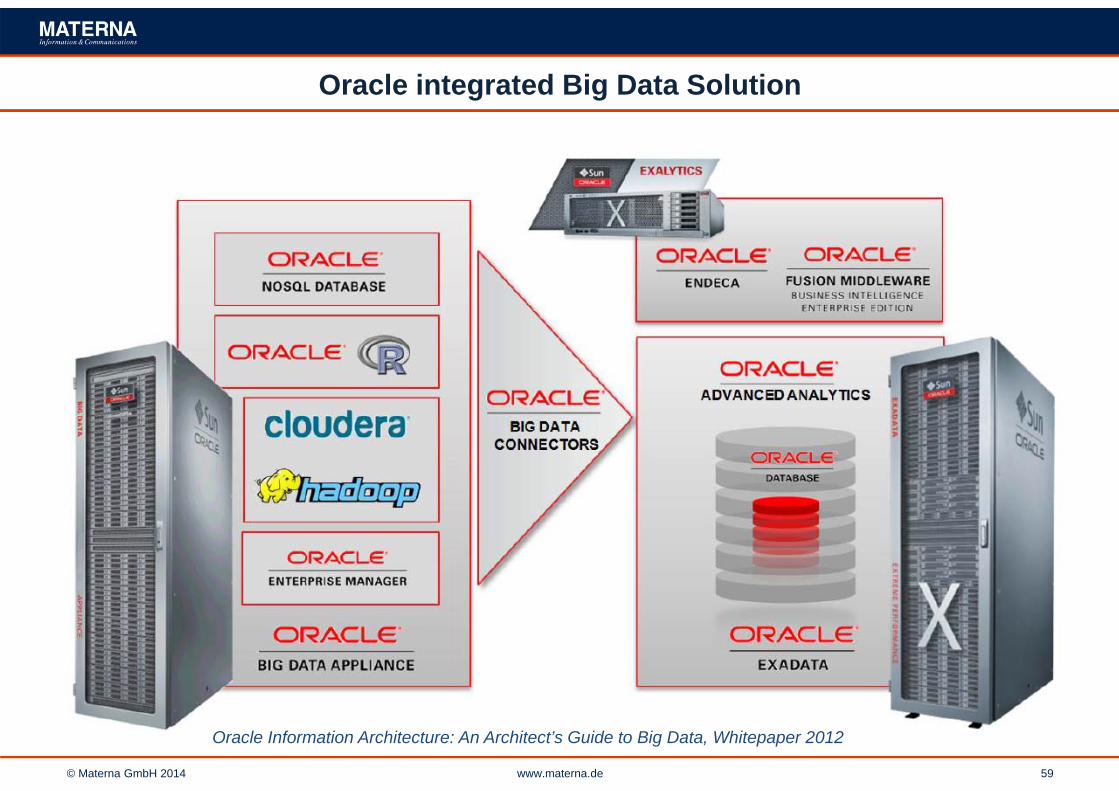
Oracle integrated Big Data Solution
Oracle Information Architecture: An Architect’s Guide to Big Data, Whitepaper 2012
© Materna GmbH 2014 www.materna.de 60
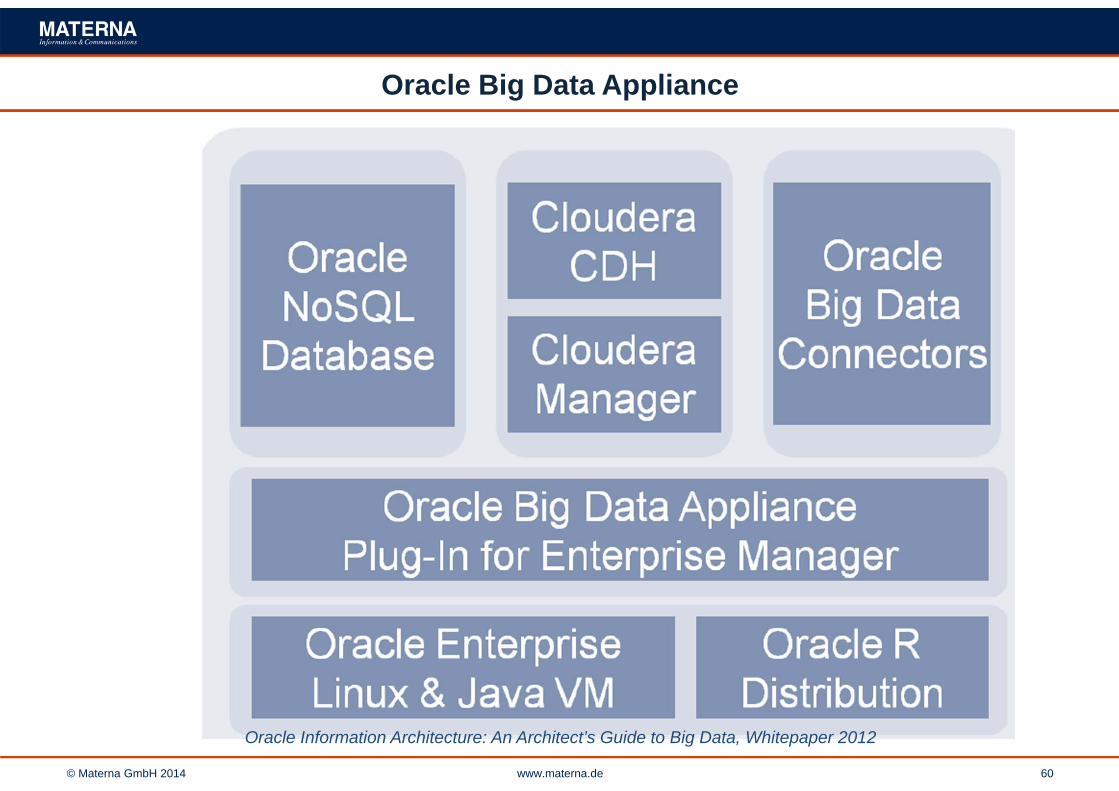
Oracle Big Data Appliance
Oracle Information Architecture: An Architect’s Guide to Big Data, Whitepaper 2012
© Materna GmbH 2014 www.materna.de 61
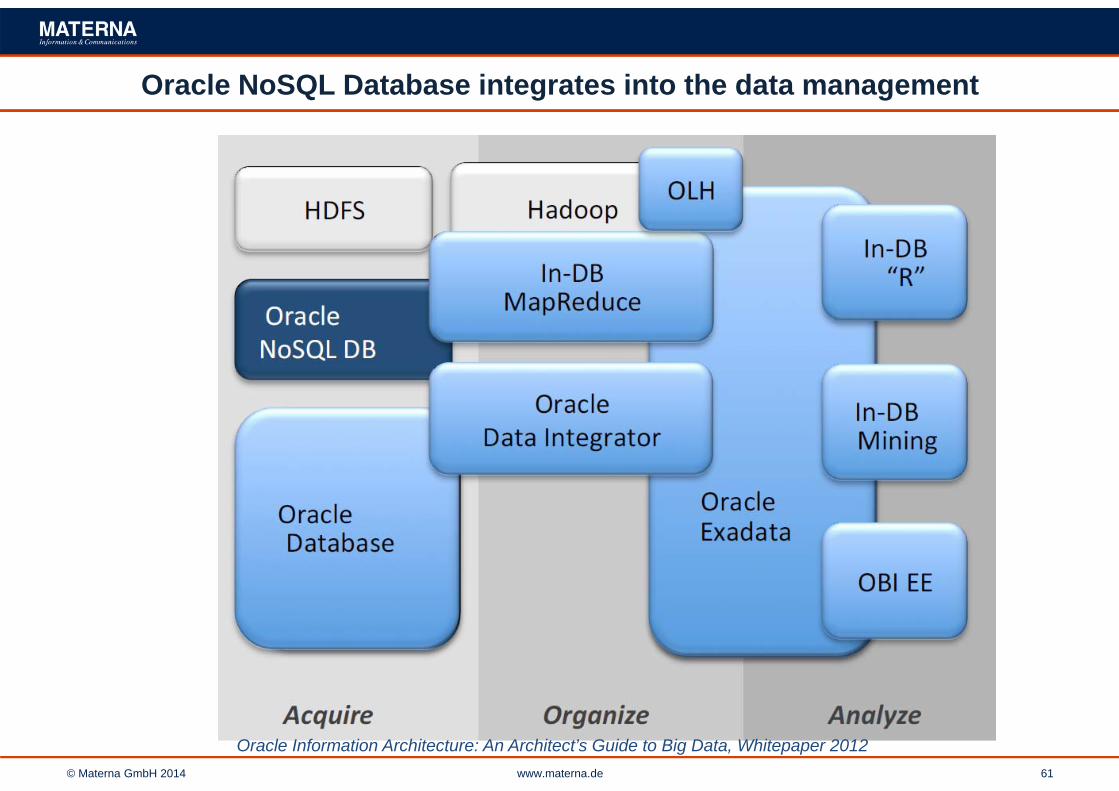
Oracle NoSQL Database integrates into the data management
Oracle Information Architecture: An Architect’s Guide to Big Data, Whitepaper 2012
© Materna GmbH 2014 www.materna.de 62
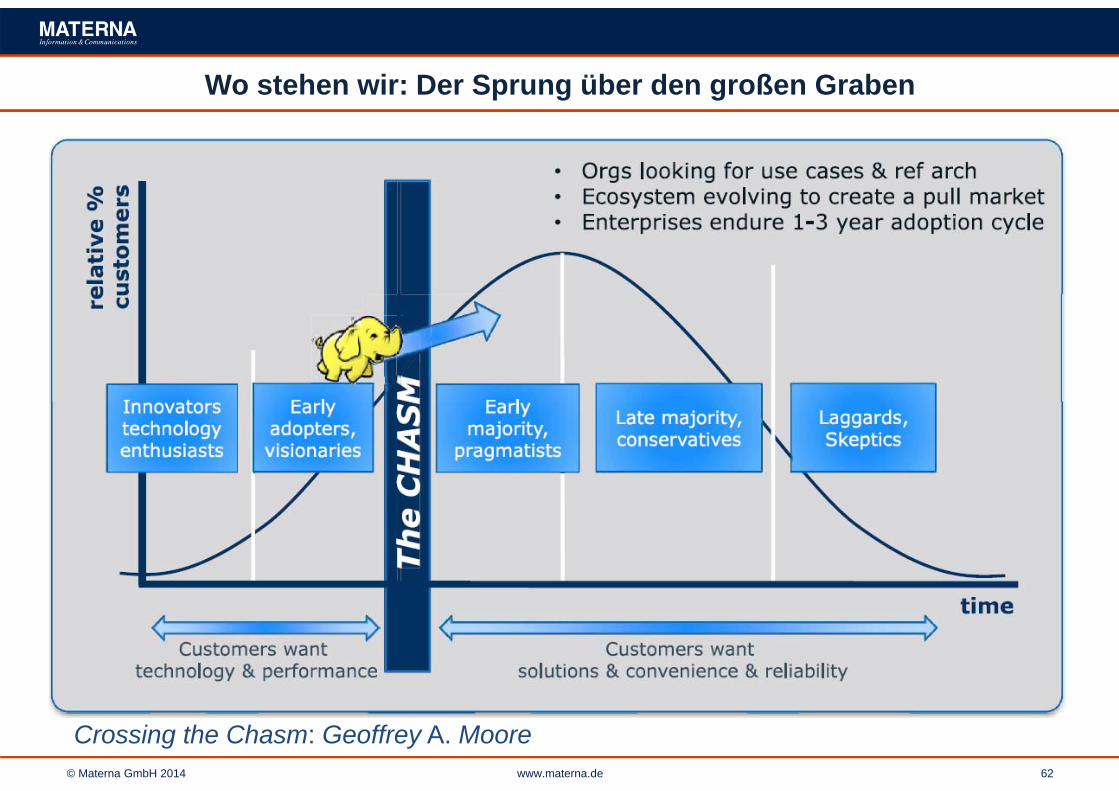
Wo stehen wir: Der Sprung über den großen Graben
Crossing the Chasm: Geoffrey A. Moore

© Materna GmbH 2014 www.materna.de 63
„Crossing the Chasm“: Koexistenz & Kooperation
Hadoop
RDBMS ORACLE
„Wenn ich die Menschen gefragt hätte, was sie wollen, hätten sie gesagt schnellere Pferde“
Henry Ford

© Materna GmbH 2014 www.materna.de 64
Fazit
billige Standard-Hardware, Umgang mit Ausfällen billiger Hauptspeicher günstiger als großes Cluster Daten-Lokalitäts-Prinzip Verteiltes parallelisiertes Dateisystem mit Replikation Spezialisierte Datenspeicher (Spalten, Key/Value) Divide-et-Impera, parallelisierter MapReduce-Algorithmus Interaktive SQL-Abfrageengine für HDFS/HBase (Impala) Mehr Realtime-Verarbeitung, weniger Batch Betriebsthemen wichtiger: Update, Monitoring, Sicherheit

© Materna GmbH 2014 www.materna.de 65
Ausblick
Hadoop ist DeFacto-Standard für BigData-Processing LINUX bleibt bevorzugte Hadoop-Plattform Nur wenige Hadoop Distributionen werden überleben Das Hadoop Ökosystem wird wachsen Der Hadoop-Dienstleistungsmarkt wird wachsen Hadoop Appliance reduzieren Kosten, Komplexität Hybride RDBMS werden Lücke schließen Benchmarks wichtig für Sizing, Tuning, Systemauswahl „Keep your ecosystem simple!“

© Materna GmbH 2014 www.materna.de 66
Literatur

© Materna GmbH 2014 www.materna.de 67
Vielen Dank für Ihre/Eure Aufmerksamkeit!
MATERNA GmbHDipl. Inform. Frank PientkaSenior Software ArchitectBusiness Division Applications
Telefon: +49 231 5599-8854Telefax: +49 231 [email protected]://xing.to/frank_pientka


















