
1 SQL-Erweiterungen für Data Warehousing Songbo Wang Januar 2004.
56
1 SQL-Erweiterungen für Data Warehousing Songbo Wang Januar 2004
-
Upload
lennart-ritter -
Category
Documents
-
view
215 -
download
0
Transcript of 1 SQL-Erweiterungen für Data Warehousing Songbo Wang Januar 2004.

1
SQL-Erweiterungenfür Data Warehousing
Songbo Wang Januar 2004

2
Einführung
• Thema SQL-Erweiterungen für Data Warehousing• Inhalte der Erweiterungen 1. Mehrfachgruppierungen SQL für Aggregation im Data Warehousing 2. Spezifikation sequenzbasierter Operationen SQL für Analyse im Data Warehousing

3
1. Mehrfachgruppierungen1.1 Motivation• Einfache Anfragenoperation erfüllen schon
Anforderung der gewünschten Ergebnisse in Data Warehousing nicht.
• Um dieses brennendes Problem zu lösen, wird SQL gezielt erweitet, hierfür wurden insbesondere zwei Erweiterung ––––– Mehrfachgruppierungen und analytische Funktionen – auf Ebene von SQL entwickelt.

4
1.2 Grouping Sets()
Die erweiterte Gruppierungsanweisung Grouping Setskann mehrere nicht notwendigerweise disjunkte Attributkombinationen oder gegebenfalls auch leere Mengen enthalten.
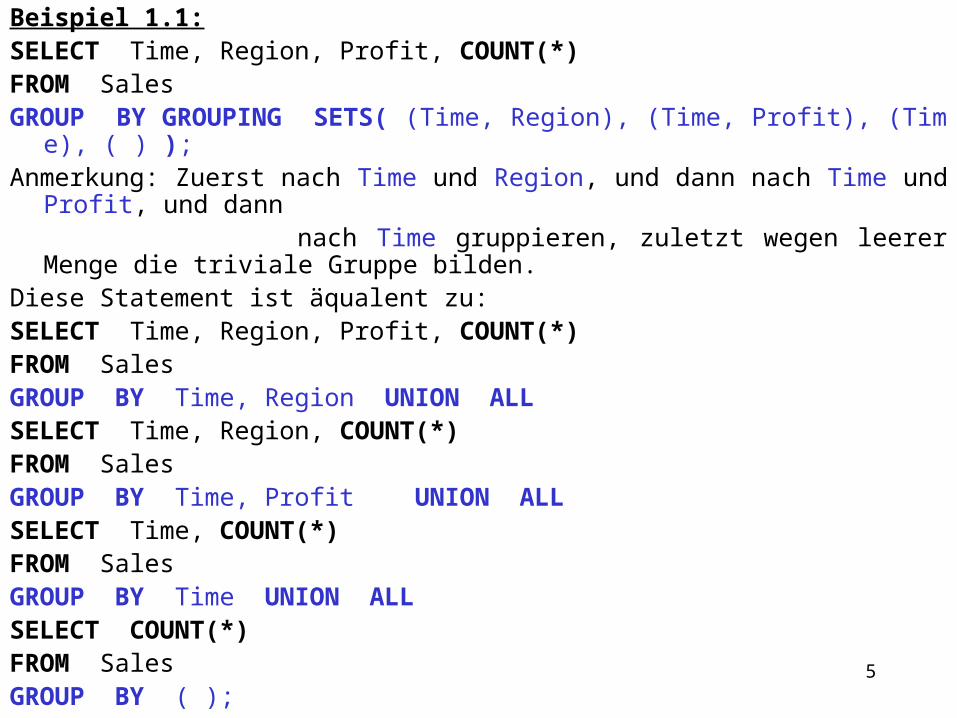
Frage: Welcher Unterschied ist zwischen GROUP BY und Grouping Sets?Dazu das folgende Beispiel:
5
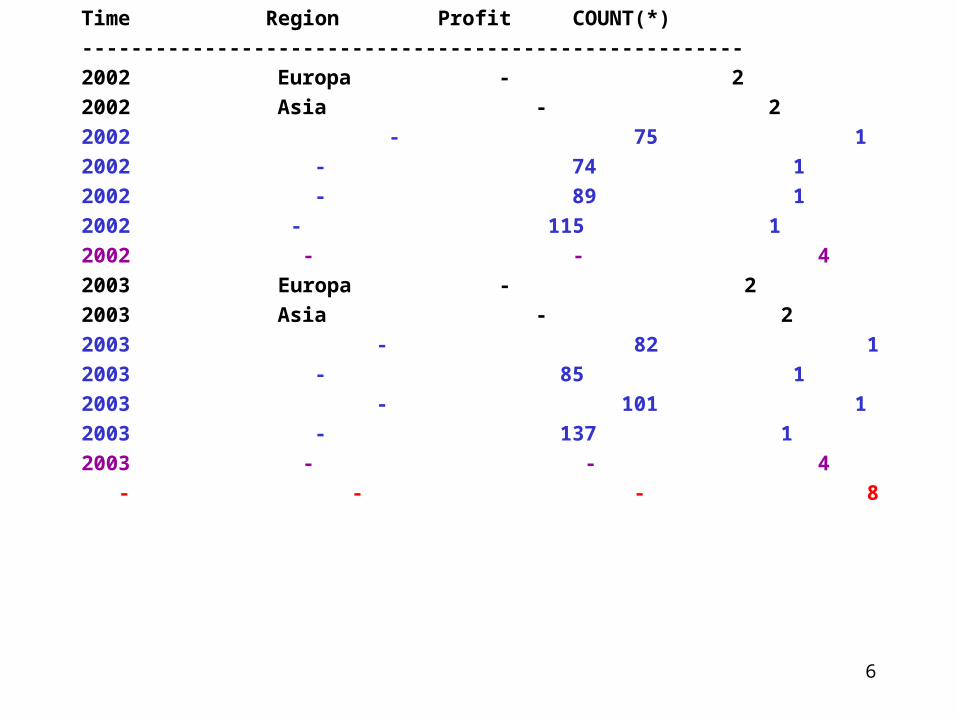
Beispiel 1.1:SELECT Time, Region, Profit, COUNT(*)FROM Sales GROUP BY GROUPING SETS( (Time, Region), (Time, Profit), (Time), ( ) );Anmerkung: Zuerst nach Time und Region, und dann nach Time und Profit, und dann nach Time gruppieren, zuletzt wegen leerer Menge die triviale Gruppe bilden. Diese Statement ist äqualent zu:SELECT Time, Region, Profit, COUNT(*)FROM SalesGROUP BY Time, Region UNION ALLSELECT Time, Region, COUNT(*)FROM SalesGROUP BY Time, Profit UNION ALLSELECT Time, COUNT(*)FROM SalesGROUP BY Time UNION ALLSELECT COUNT(*) FROM SalesGROUP BY ( );
6
Time Region Profit COUNT(*)------------------------------------------------------ 2002 Europa - 22002 Asia - 22002 - 75 12002 - 74 12002 - 89 12002 - 115 12002 - - 42003 Europa - 22003 Asia - 22003 - 82 12003 - 85 12003 - 101 12003 - 137 12003 - - 4 - - - 8
7
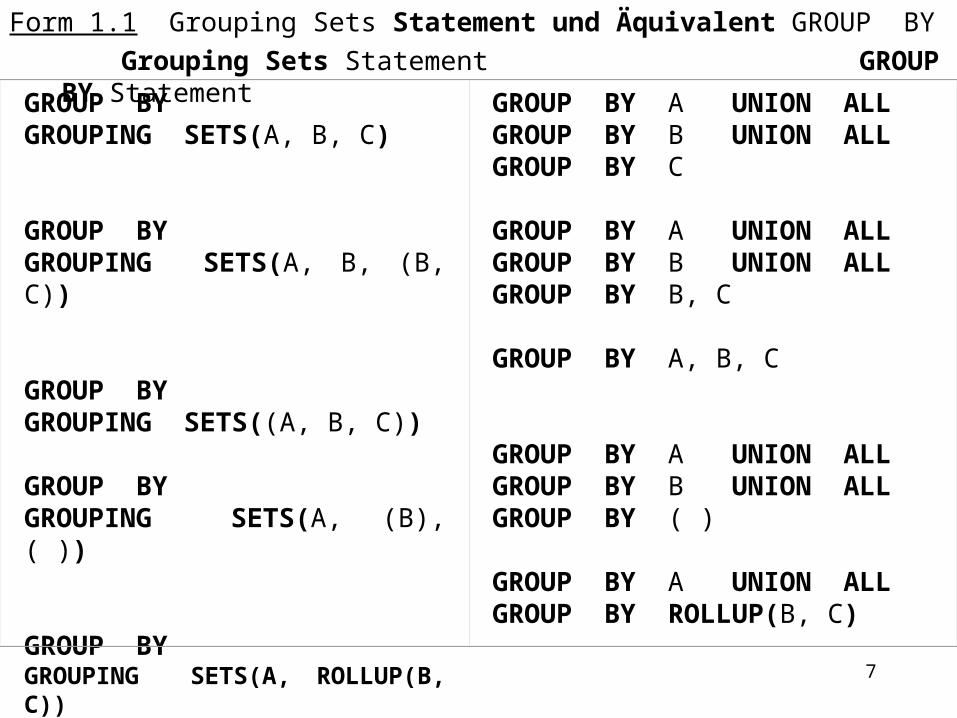
Form 1.1 Grouping Sets Statement und Äquivalent GROUP BY Grouping Sets Statement GROUP BY Statement
GROUP BYGROUPING SETS(A, B, C) GROUP BYGROUPING SETS(A, B, (B, C)) GROUP BYGROUPING SETS((A, B, C)) GROUP BYGROUPING SETS(A, (B), ( )) GROUP BYGROUPING SETS(A, ROLLUP(B, C))
GROUP BY A UNION ALLGROUP BY B UNION ALLGROUP BY C GROUP BY A UNION ALLGROUP BY B UNION ALLGROUP BY B, C GROUP BY A, B, C GROUP BY A UNION ALLGROUP BY B UNION ALLGROUP BY ( ) GROUP BY A UNION ALLGROUP BY ROLLUP(B, C)

8
Grouping Sets hat folgende allgemeine Kombinationssemantiken:
• Multiplikation i.S. der Bildung des kartesischen Produkts bei Gruppierungsattributen innerhalb einer Gruppierungskombination.
• Addition i.S. einer Vereinigung bei Gruppierungskombinationen innerhalb einer Gruppierungsmenge.

9
Form 1.2
Fall 1: GROUP BY A, B ≡ GROUP BY GROUPING SET ( (A, B) ) → (A, B)
Fall 2: GROUP BY GROUPING SET ( (A, B), (A, C), (A) ) ≡ GROUP BY A, GROUP BY GROUPING SET ( (B), (C), ( ) )
↓ ↓(A) × (B) (A, B)
(C) → (A, C) ( ) (A)
Fall 3: GROUP BY GROUPING SET ( (A, B), (B, C) ), GROUP BY GROUPING SET ( (D, E), (D), ( ) ) ↓ ↓ (A, B, D, E)
(A, B) × (D, E) (A, B, D) (B, C) (D) → (A, B) ( ) (B, C, D, E)
(B, C, D) (B, C)

10
1.3 GROUPING-Funktion• Ziel: Um einen systemseitig generierten NULL-Wert von benutzerseitig in der Datenbank repräsentierten NULL- Werten unterscheiden zu können, wird GROUPING() angeboten. z.B. generierte NULL-Werte von ROLLUP und CUBE. • Wert: wenn über dieses Attribute hinwegaggregiert wird, d.h. das Gruppierungsattribut für das aktuelle Tupel an einer Gruppierung nicht beteiligt ist, liefert die GROUPING Funktion den numerischen Wert 1. Andernfalls , wird der Wert 0 zurückgeben, d.h. bei Gruppierung nach dem entsprechenden Attribut.

11
• Syntax:
SELECT ... [GROUPING(grouping_column)...] ...
GROUP BY { grouping_column (| CUBE | ROLLUP| GROUPING SETS) (grouping_column) }

12
Beispiel 1.2:SELECT Time, Region, Department, SUM(Profit) AS Profit, GROUPING(Time) as T, GROUPING(Region) as R, GROUPING(Department) as DFROM Sales GROUP BY GROUPING SETS( (Time, Region, Department), (Time, Region), (Time), ( ) );

13
Time Region Department Profit T R D--------------------------------------------------------------------------2002 Europa VideoRental 75,000 0 0 02002 Europa VideoSales 74,000 0 0 02002 Europa - 149,000 0 0 12002 Asia VideoRental 89,000 0 0 02002 Asia VideoSales 115,000 0 0 02002 Asia - 204,000 0 0 12002 - - 353,000 0 1 12003 Europa VideoRental 82,000 0 0 02003 Europa VideoSales 85,000 0 0 02003 Europa - 167,000 0 0 12003 Asia VideoRental 101,000 0 0 02003 Asia VideoSales 137,000 0 0 02003 Asia - 238,000 0 0 12003 - - 405,000 0 1 1 - - - 758,000 1 1 1

14
1.4 Multidimensionale Gruppierung1.4.1 CUBE()-Operator Ziel: Um die Visualisierung multidimensionaler Datenwürfel in
Form einer statistischen Tabelle alle Zeilen- und Spaltensummen zu berechnen.
Um Teilsummen zu berechnen.
Um Gesamtsummen zu berechnen.Syntax: SELECT ... GROUP BY CUBE ( grouping_column_reference_list)
15
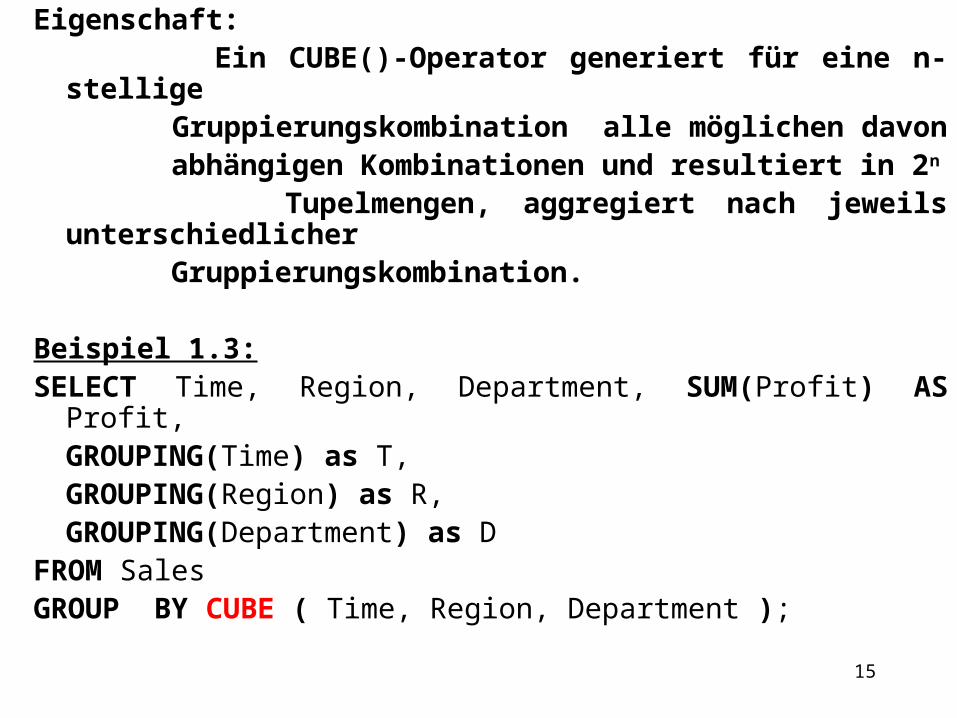
Eigenschaft: Ein CUBE()-Operator generiert für eine n-stellige Gruppierungskombination alle möglichen davon abhängigen Kombinationen und resultiert in 2n
Tupelmengen, aggregiert nach jeweils unterschiedlicher Gruppierungskombination.
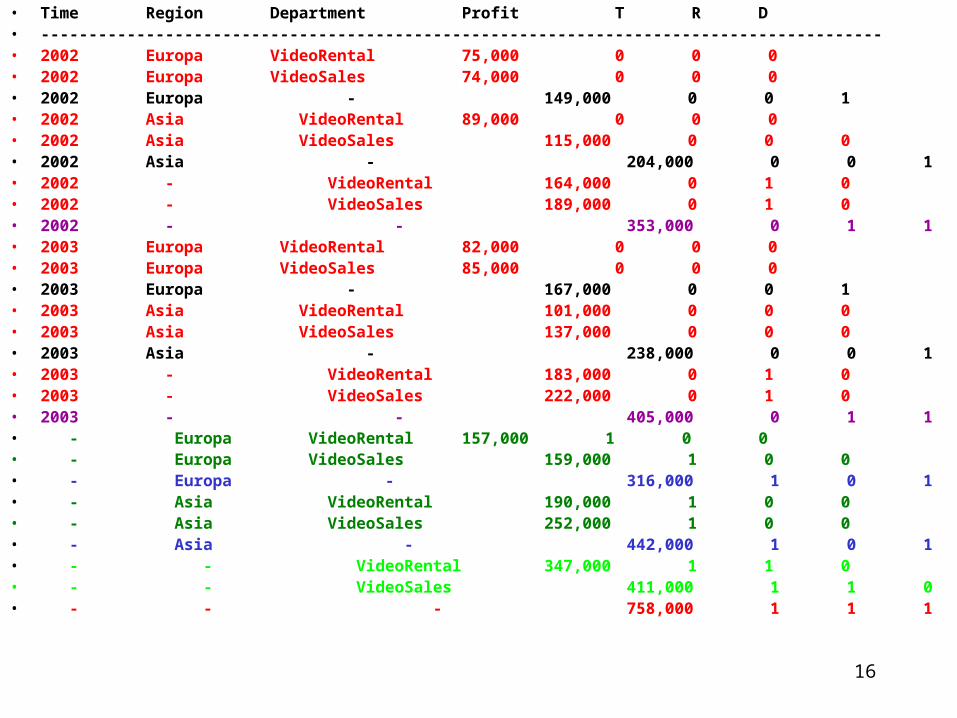
Beispiel 1.3:SELECT Time, Region, Department, SUM(Profit) AS Profit,
GROUPING(Time) as T,GROUPING(Region) as R,GROUPING(Department) as D
FROM Sales GROUP BY CUBE ( Time, Region, Department );
16
• Time Region Department Profit T R D• ----------------------------------------------------------------------------------------• 2002 Europa VideoRental 75,000 0 0 0• 2002 Europa VideoSales 74,000 0 0 0• 2002 Europa - 149,000 0 0 1• 2002 Asia VideoRental 89,000 0 0 0• 2002 Asia VideoSales 115,000 0 0 0• 2002 Asia - 204,000 0 0 1• 2002 - VideoRental 164,000 0 1 0• 2002 - VideoSales 189,000 0 1 0• 2002 - - 353,000 0 1 1• 2003 Europa VideoRental 82,000 0 0 0• 2003 Europa VideoSales 85,000 0 0 0• 2003 Europa - 167,000 0 0 1• 2003 Asia VideoRental 101,000 0 0 0• 2003 Asia VideoSales 137,000 0 0 0• 2003 Asia - 238,000 0 0 1• 2003 - VideoRental 183,000 0 1 0• 2003 - VideoSales 222,000 0 1 0• 2003 - - 405,000 0 1 1• - Europa VideoRental 157,000 1 0 0• - Europa VideoSales 159,000 1 0 0• - Europa - 316,000 1 0 1• - Asia VideoRental 190,000 1 0 0• - Asia VideoSales 252,000 1 0 0• - Asia - 442,000 1 0 1• - - VideoRental 347,000 1 1 0 • - - VideoSales 411,000 1 1 0• - - - 758,000 1 1 1

17
Form 1.3:
Fall 1: GROUP BY CUBE(A, B) ≡ GROUP BY GROUPING SET ( (A, B), (A), (B), ( ) )
Fall 2: GROUP BY CUBE(A, B, C) ≡ GROUP BY GROUPING SET ( (A, B, C), (A, B), (A, C) , (B,C) , (A) , (B) , (C) , ( ) )
Fall 3: GROUP BY CUBE(A, B), CUBE( B, C) ↓ ↓ (A, B, B, C) = (A, B, C) , (A, B, B) = (A, B) , (A, B, C) (A, B) (B, C) (A, B), (A, B, C), (A, B)
(A) × (B) → (A, C), (A), (B, B, C) = (B, C) (B) (C) (B, B), (B), (B, C) ( ) ( ) (B), (B, C) , (B) (C) , ( )Fall 4: GROUP BY GROUPING SET ( CUBE(A, B), CUBE(B, C)) ≡GROUP BY GROUPING SET ( (A, B), (A) , (B) , ( ),
(B,C) , (B), (C) , ( ) )Anmerkung:In Fall 3 wird deutlich, dass es bei der Auflösung zu Duplikaten kommt, wenn die Gruppierungsattributemenge
nicht disjunkt sind.

18
1.4.2 ROLLUP()-Operator Fragen: Eine multidimensionale Gruppierung mit dem CUBE()-
Operator resultiert in einer ungewünschten Redundanz in der Ergebnisrelation, d.h. alle Kombinationen sind bedingt redundant (obiges Beispielszenario), da zwischen den Gruppierungsattributen vielleicht funktionale Abhängigkeiten vorliegen.
Lösung: Zur redundanzfreien Konstruktion eines hierarchischen
Datenwürfels wird der ROLLUP()-Operator jeweils angewandt auf die Klassifikationsattribute einer Dimension herangezogen.
Syntax: SELECT ... GROUP BY ROLLUP ( grouping_column_reference_list)
19
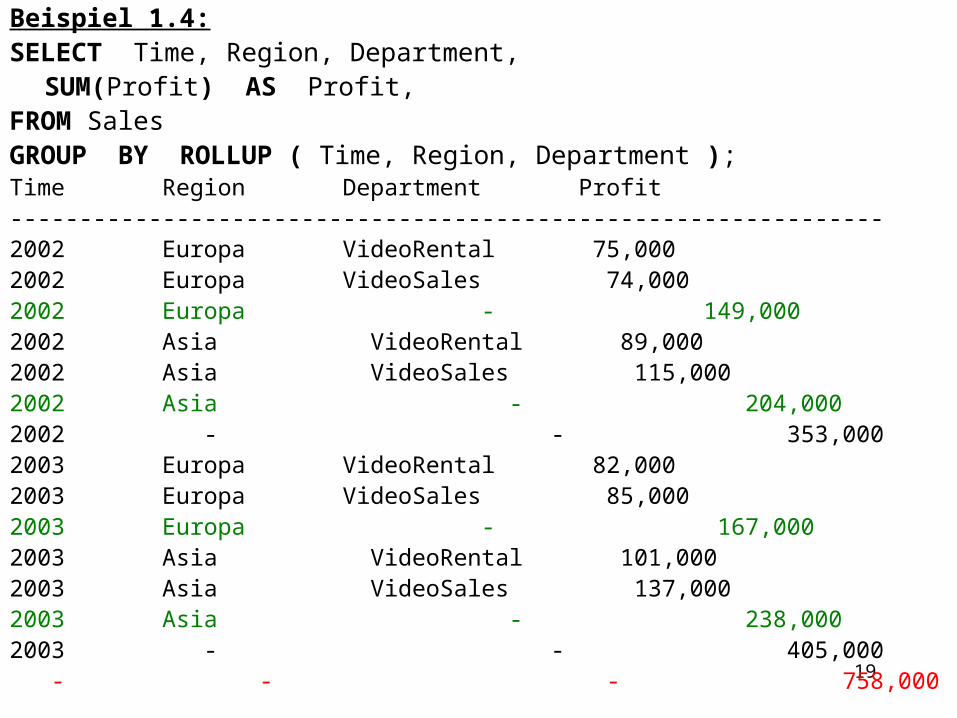
Beispiel 1.4:SELECT Time, Region, Department,
SUM(Profit) AS Profit,FROM SalesGROUP BY ROLLUP ( Time, Region, Department ); Time Region Department Profit ---------------------------------------------------------------2002 Europa VideoRental 75,000 2002 Europa VideoSales 74,000 2002 Europa - 149,000 2002 Asia VideoRental 89,000 2002 Asia VideoSales 115,000 2002 Asia - 204,000 2002 - - 353,000 2003 Europa VideoRental 82,000 2003 Europa VideoSales 85,000 2003 Europa - 167,000 2003 Asia VideoRental 101,000 2003 Asia VideoSales 137,000 2003 Asia - 238,000 2003 - - 405,000 - - - 758,000

20
Form 1.4:Fall 1: ROLLUP (A1 ,…., An –1, An)
≡ GROUPING SETS ( ( ), (A1 ), (A1, A2), (A1 ,…., An -1 ), (A1 ,…., An –1, An ) )
Fall 2: GROUP BY ROLLUP (A1, A2 ,…., An ), ROLLUP (B1, B2 ,…., Bm ) ↓ ↓
() () (A1) × (B1)
… … (A1, A2 ,…., An-1) (B1, B2 ,…., Bm-1) (A1, A2 ,…., An-1, An) (B1, B2 ,…., Bm-1, Bm)
Fall 3: CUBE(A, B) ≡ GROUPING SETS ( (A, B), (A) , (B) , ( ) )
≡ GROUPING SETS ( ( ), (A) ), GROUPING SETS ( ( ), (B) ) ≡ ROLLUP (A), ROLLUP (B)

21
1.5 Partielle multidimensionale Gruppierung Motivation: Manchmal sind nicht alle Einträge einer Dimension oder alle Kombinationen einer komplexen Gruppierungsbedingung immer gewünscht. Lösung: Der Begriff partielle multidimensionale Gruppierung wird eingeführt. Es gibt drei unterschiedliche Weisen für partielle multidimensionale Gruppierung.
Partielle Gruppierung auf Schemaebene Partielle Gruppierung auf Ebene einzelner Klassifikationsstufen Partielle Gruppierung einzelner Dimensionsknoten

22
1.5.1 Partielle Gruppierung auf Schemaeben Konzeption: Wie beim swiss cheese cube sind nicht alle Kombinationen bei
ein Übergang von vollständigen zu partiellen Datenwürfeln enthalten, d.h. Partielle Gruppierung basieren direkt auf originaler Datenbanktabelle.
Methode: partielle Datenwürfel sind durch explizite Angabe der gewünschten Gruppierungsbedingungen in Form von Group by-Klausel mit Grouping Sets/CUBE/ ROLLUP zu beschreiben. können einzelne Gruppierungskombinationen auch in der HAVING-Klausel durch Anwendung der GROUPING()-Funktion eliminiert werden.
Siehe Beispiel 1.7.

23
1.5.2 Partielle Gruppierung auf Ebene einzelner Klassifikationsstufen Konzeption: Gruppierungen werden nur nach bestimmten Einträgen
innerhalb einer Klassifikationsstufe vorgenommen. Diese Technik heißt bedingte Verfeinerung (conditional drill-down).
Bedingte Verfeinerung: Bei der bedingten Verfeinerung wird eine Ausweisung von Detailinformation nur für bestimmte, explizit vorgegebene Dimensionselemente vorgenommen.Syntax: …CASE WHEN grouping _column IN (determinate _column_ reference_list) THEN grouping _column ( | ELSE others_ grouping _column ) END
24
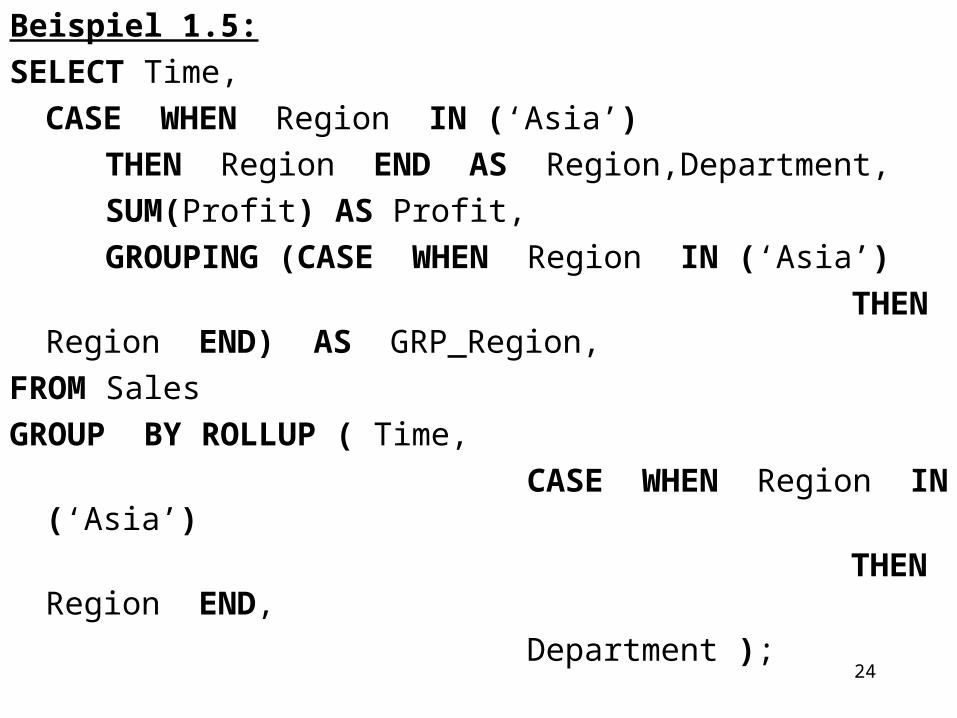
Beispiel 1.5:SELECT Time,
CASE WHEN Region IN (‘Asia’) THEN Region END AS Region,Department, SUM(Profit) AS Profit, GROUPING (CASE WHEN Region IN (‘Asia’) THEN Region END) AS GRP_Region,FROM Sales GROUP BY ROLLUP ( Time, CASE WHEN Region IN (‘Asia’) THEN Region END, Department );
25
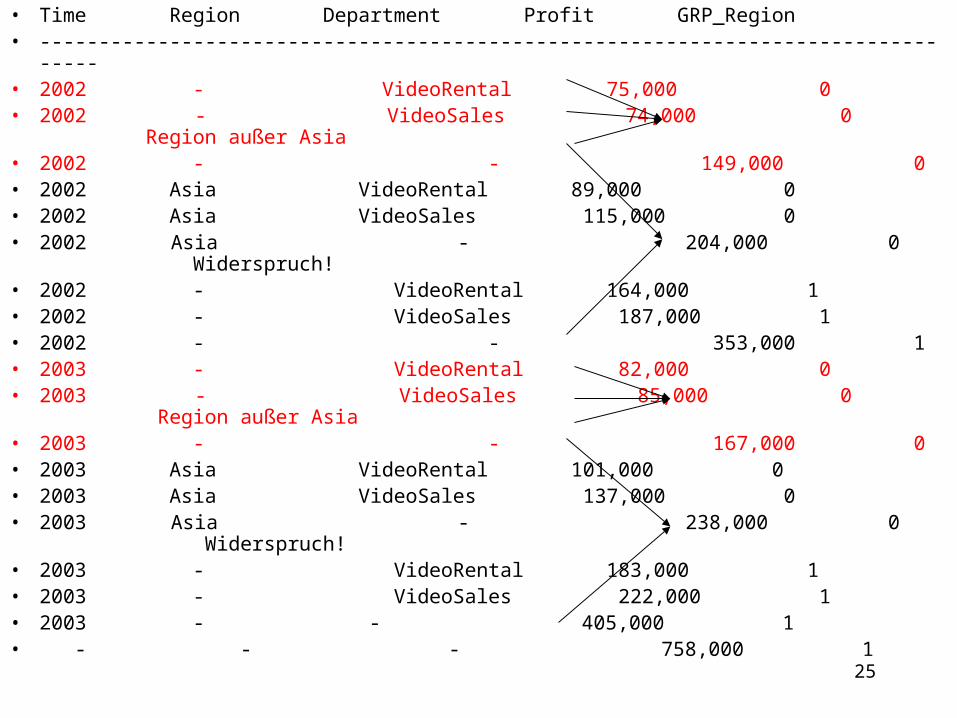
• Time Region Department Profit GRP_Region• ---------------------------------------------------------------------------------• 2002 - VideoRental 75,000 0• 2002 - VideoSales 74,000 0 Region außer Asia• 2002 - - 149,000 0• 2002 Asia VideoRental 89,000 0• 2002 Asia VideoSales 115,000 0• 2002 Asia - 204,000 0 Widerspruch! • 2002 - VideoRental 164,000 1• 2002 - VideoSales 187,000 1• 2002 - - 353,000 1• 2003 - VideoRental 82,000 0• 2003 - VideoSales 85,000 0 Region außer Asia• 2003 - - 167,000 0• 2003 Asia VideoRental 101,000 0• 2003 Asia VideoSales 137,000 0• 2003 Asia - 238,000 0 Widerspruch!• 2003 - VideoRental 183,000 1• 2003 - VideoSales 222,000 1• 2003 - - 405,000 1• - - - 758,000 1

26
In obiger Beispiel wird deutlich, dass es entweder Widerspruch oder redundanter Eintrag vorhanden ist. Diese lassen sich jedoch Anwendung der GROUPING()-Funktion identifizieren. Für eine explizite Ausweisung der nicht explizit genannten Dimensionseinträge benutzt man einerseits die ELSE-Klausel der CASE()-Anweisung. Eine verbessere Beispiel wird wie folgt angeboten:

27
• Beispiel 1.6:• SELECT Time, • CASE WHEN Region IN (‘Asia’) • THEN Region • ELSE ‘OTHERS’ END AS Region,• Department, • SUM(Profit) AS Profit,• GROUPING (CASE WHEN Region IN (‘Asia’)
• THEN Region END) AS GRP_Region,• FROM Sales • GROUP BY ROLLUP ( Time,• CASE WHEN Region IN (‘Asia’) • THEN Region END, • Department );

28
• Time Region Department Profit GRP_Region• ---------------------------------------------------------------------------------• 2002 OTHERS VideoRental 75,000 0• 2002 OTHERS VideoSales 74,000 0 • 2002 OTHERS - 149,000 0• 2002 Asia VideoRental 89,000 0• 2002 Asia VideoSales 115,000 0• 2002 Asia - 204,000 0 • 2002 - VideoRental 164,000 1• 2002 - VideoSales 187,000 1• 2002 - - 353,000 1• 2003 OTHERS VideoRental 82,000 0• 2003 OTHERS VideoSales 85,000 0 • 2003 OTHERS - 167,000 0• 2003 Asia VideoRental 101,000 0• 2003 Asia VideoSales 137,000 0• 2003 Asia - 238,000 0 • 2003 - VideoRental 183,000 1• 2003 - VideoSales 222,000 1• 2003 - - 405,000 1• - - - 758,000 1

29
Der Method der Partielle Gruppierung auf Schemaeben kann für Eliminieren der nicht erwünschter Tupel hinzugefügt werden. Eine verbessere Beispiel wird wie folgt angeboten: Beispiel 1.7:SELECT Time,
CASE WHEN Region IN (‘Asia’) THEN Region END AS Region, Department,
SUM(Profit) AS Profit, GROUPING (CASE WHEN Region IN (‘Asia’)
THEN Region END) AS GRP_Region,FROM Sales GROUP BY ROLLUP ( Time,
CASE WHEN Region IN (‘Asia’) THEN Region END,
Department );HAVING NOT (CASE WHEN Region IN (‘Asia’) THEN Region END IS NULL AND GROUPING (CASE WHEN Region IN (‘Asia’)
THEN Region END) = 0)

30
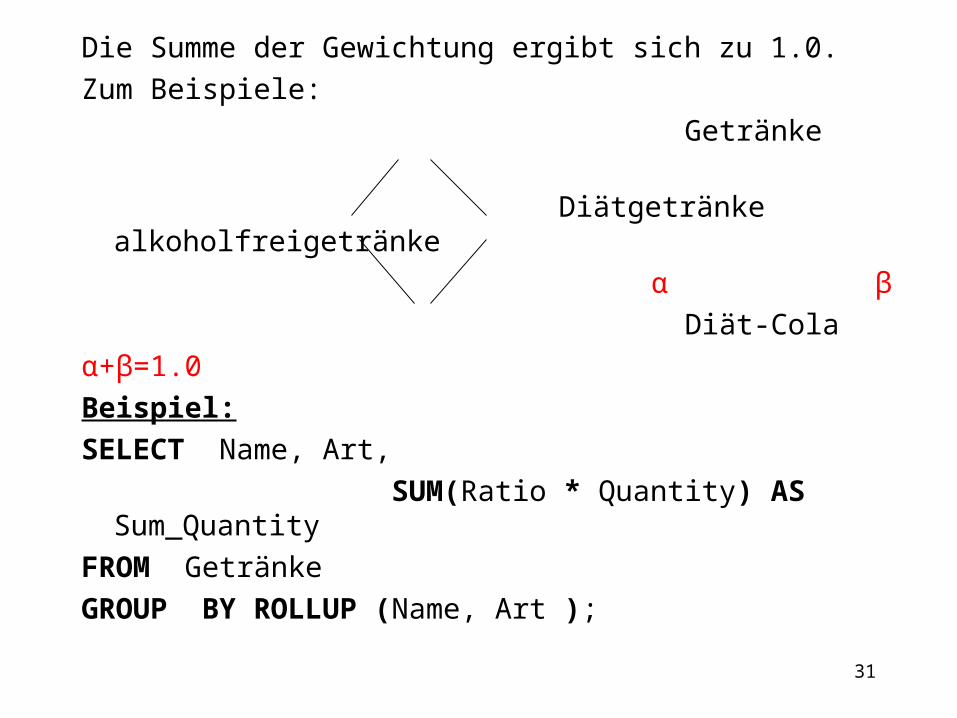
1.5.3 Partielle Gruppierung einzelner Dimensionsknoten Hierarchische Datenwürfel mit irregulären Dimensionen
Diamond Dimensions
Getränke Diätgetränke alkoholfreigetränke Diät-Cola Falls ein einzelnes Dimensionselement mehreren übergeordneten Klassifikationsknoten zugeordnet ist, kommt es zu Mehrfachzählungen.
Lösung: Gewichtungen angeben Dazu wird eine Spalte, die die Gewichtung repräsentiert, der Tabelle hinzugefügt: ALTER TABLE Getränke ADD COLUMN Ratio DECIMAL(3,2);
31
Die Summe der Gewichtung ergibt sich zu 1.0. Zum Beispiele: Getränke
Diätgetränke alkoholfreigetränke α β Diät-Colaα+β=1.0Beispiel:SELECT Name, Art, SUM(Ratio * Quantity) AS Sum_QuantityFROM GetränkeGROUP BY ROLLUP (Name, Art );
32
2 Spezifikation sequenzbasierter Operationen (SQL Für Analyse im Data Warehousing) Motivation:
Welche Ansätze für Analyse nach der Mehrfachgruppierung im Data Warehouse angewendet werden. Wie werden SQL-Anfragen für Analyse im Data Warehouse verbessert.
2.1 Konzept der attributlokalen und tupelbasierten Aggregation (Drei Gattung der Aggregation) Im attributbasierte Ordnung existieren drei zentrale Bausteine
beim SQL-Sprachentwurf, d.h. es gibt drei Gattung für Aggregation: Skalarfunktionen, Aggregationsfunktionen und OLAP-Funktionen.
33
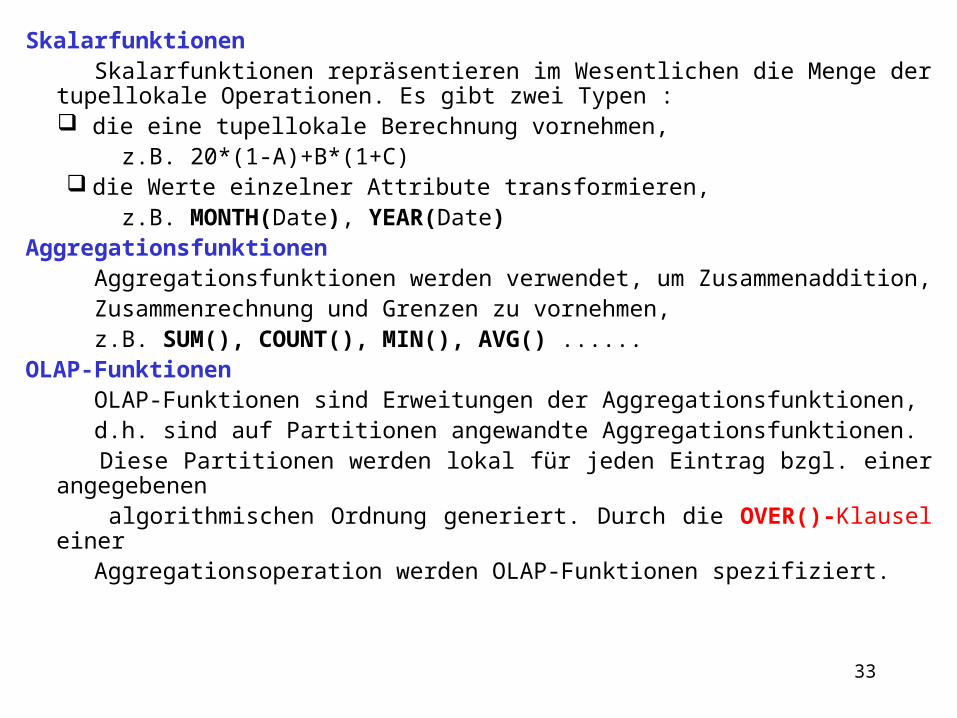
Skalarfunktionen Skalarfunktionen repräsentieren im Wesentlichen die Menge der tupellokale Ope
rationen. Es gibt zwei Typen : die eine tupellokale Berechnung vornehmen, z.B. 20*(1-A)+B*(1+C) die Werte einzelner Attribute transformieren, z.B. MONTH(Date), YEAR(Date)
Aggregationsfunktionen Aggregationsfunktionen werden verwendet, um Zusammenaddition, Zusammenrechnung und Grenzen zu vornehmen, z.B. SUM(), COUNT(), MIN(), AVG() ......OLAP-Funktionen OLAP-Funktionen sind Erweitungen der Aggregationsfunktionen, d.h. sind auf Partitionen angewandte Aggregationsfunktionen. Diese Partitionen werden lokal für jeden Eintrag bzgl. einer angegebenen algorithmischen Ordnung generiert. Durch die OVER()-Klausel einer Aggregationsoperation werden OLAP-Funktionen spezifiziert.
34
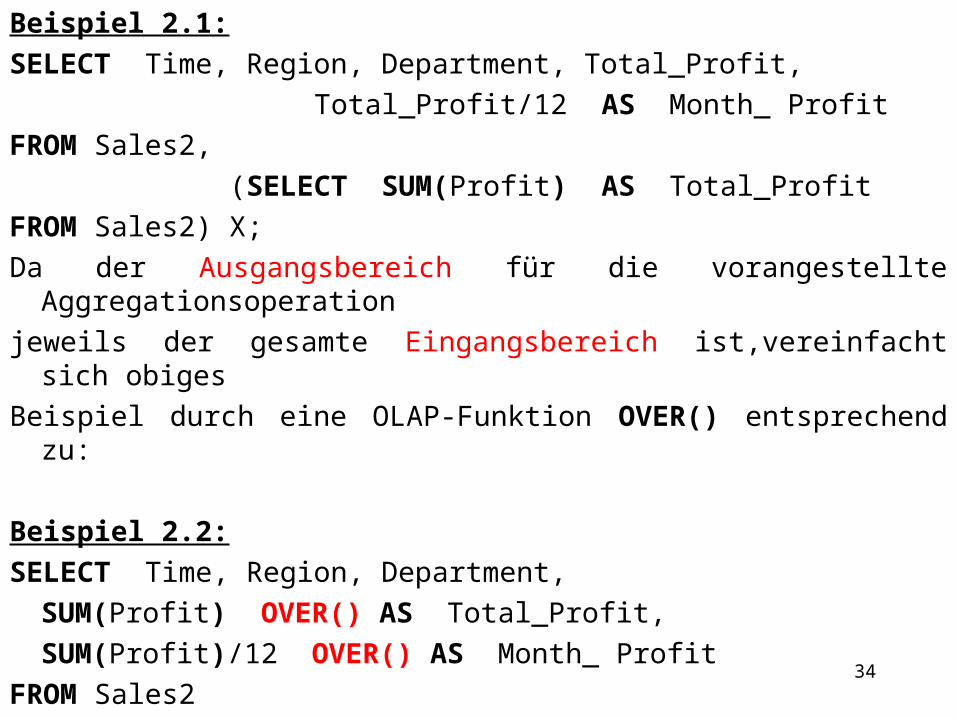
Beispiel 2.1:SELECT Time, Region, Department, Total_Profit, Total_Profit/12 AS Month_ ProfitFROM Sales2, (SELECT SUM(Profit) AS Total_ProfitFROM Sales2) X; Da der Ausgangsbereich für die vorangestellte Aggregationsoperationjeweils der gesamte Eingangsbereich ist,vereinfacht sich obiges Beispiel durch eine OLAP-Funktion OVER() entsprechend zu:
Beispiel 2.2:SELECT Time, Region, Department,
SUM(Profit) OVER() AS Total_Profit,SUM(Profit)/12 OVER() AS Month_ Profit
FROM Sales2

35
2.2 Attributlokale Partitionierung Analog zur Gruppierung auf Anweisungsebene erlauben
OLAP-Funktionen die Partitionierung des eingehenden Datenstromes hinsichtlich einer Menge von Partitionier-ungsattributen.
Wir können die attributlokale Partitionierung als zweite Gruppierung nach GROUP BY-Klausel(oder ohne)auffassen.
36
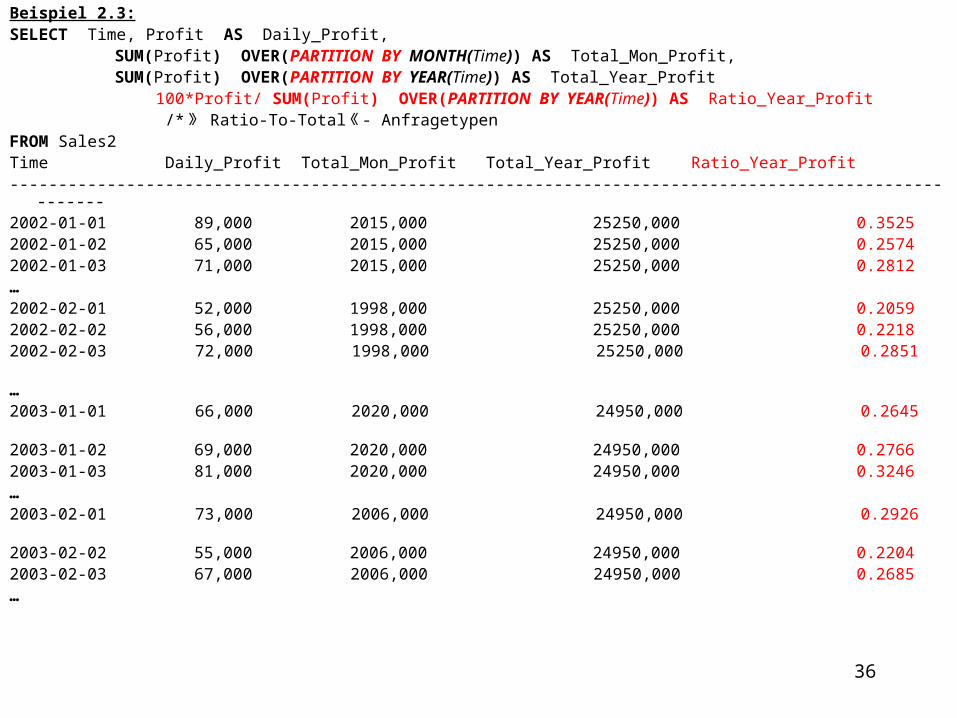
Beispiel 2.3:SELECT Time, Profit AS Daily_Profit,
SUM(Profit) OVER(PARTITION BY MONTH(Time)) AS Total_Mon_Profit, SUM(Profit) OVER(PARTITION BY YEAR(Time)) AS Total_Year_Profit
100*Profit/ SUM(Profit) OVER(PARTITION BY YEAR(Time)) AS Ratio_Year_Profit /* 》 Ratio-To-Total《 - Anfragetypen FROM Sales2Time Daily_Profit Total_Mon_Profit Total_Year_Profit Ratio_Year_Profit -------------------------------------------------------------------------------------------------------2002-01-01 89,000 2015,000 25250,000 0.3525 2002-01-02 65,000 2015,000 25250,000 0.2574 2002-01-03 71,000 2015,000 25250,000 0.2812 …2002-02-01 52,000 1998,000 25250,000 0.2059 2002-02-02 56,000 1998,000 25250,000 0.2218 2002-02-03 72,000 1998,000 25250,000 0.2851 … 2003-01-01 66,000 2020,000 24950,000 0.2645 2003-01-02 69,000 2020,000 24950,000 0.2766 2003-01-03 81,000 2020,000 24950,000 0.3246 …2003-02-01 73,000 2006,000 24950,000 0.2926 2003-02-02 55,000 2006,000 24950,000 0.2204 2003-02-03 67,000 2006,000 24950,000 0.2685 …

37
2.3 Sequenzorientierte Analysen(Ranking Funktionen) Im Bereich der Datenanalyse im Data Warehousing gibt es zweiAnfragetypen: Ratio-To-Total Anfragetypen Siehe Beispiel 2.3. Sequenzbasierte Anfragen. Sequenzbasierte Anfragen lassen sich wie folgt einteilen:
die Ermittlung laufender Summen 》 Kumulation 《 ; (Siehe Beispiel 2.4 und 1. Beispiel von Beispiel2.5)
die Berechnung gleitender Durchschnitte (Moving Average Values); (Siehe Beispiel 2.9)
einfache 》 Ranking-Analysen 《 ; (Siehe Beispiel 2. Beispiel von Beispiel2.5)

38
Beispiel 2.4:
SELECT Time, Profit AS Daily_Profit, SUM(Profit) OVER(ORDER BY Time) AS Total _Profit,
SUM(Profit) OVER(PARTITION BY MONTH(Time) ORDER BY Time) AS Total_Mon_Profit
FROM Sales2

39
Beispiel2.5:SELECT Time,
COUNT(*) OVER(ORDER BY Profit) AS RANK _Profit,
FROM Sales2
Obiges Beispiel ist äquivalent zu:
SELECT Time, RANK() OVER(ORDER BY Profit) AS RANK _Profit,
FROM Sales2

40
Ranking FunktionenRANK() die von Duplikaten erzeugte Lücken werden nicht
bewahrt.
DENSERANK() bewahrt die von Duplikate erzeugte Abstände innerhalb der Rangfolge.
ROWNUMBER() liefert eine eindeutige Nummerierung der Tupel, wobei Mehrfachplatzierungen nichtdeterministisch aufgelöst werden.

41
Beispiel 2.6:SELECT A,
RANK() OVER(ORDER BY A) AS RANK _NO, DENSERANK() OVER(ORDER BY A) AS DENSERANK _NO, ROWNUMBER () OVER(ORDER BY A) AS ROWNUMBER _NO
FROM Sales2A RANK _NO DENSERANK _NO ROWNUMBER _NO------------------------------------------------------------------------------------5 1 1 1
10 2 2 2
10 2 2 3
10 2 2 4
15 5 3 5
15 5 3 6
20 7 4 7

42
Sortieren pro Partitionierung
Ranking Funktionen können in einer Partition verwendet werden,
aber bei Änderung einer Partition muss die Sortierenplatzierung wieder zurückgesetzt werden (reset).
Ranking Funktionen wird mit PARTITION BY-Klausel zusammen benutzt.
Eine Partition kann mehrere Ranking Funktionen enthalten. Jeder Ranking Funktionen setzt neue Sortierenplatzierung wiederum zurück.

43
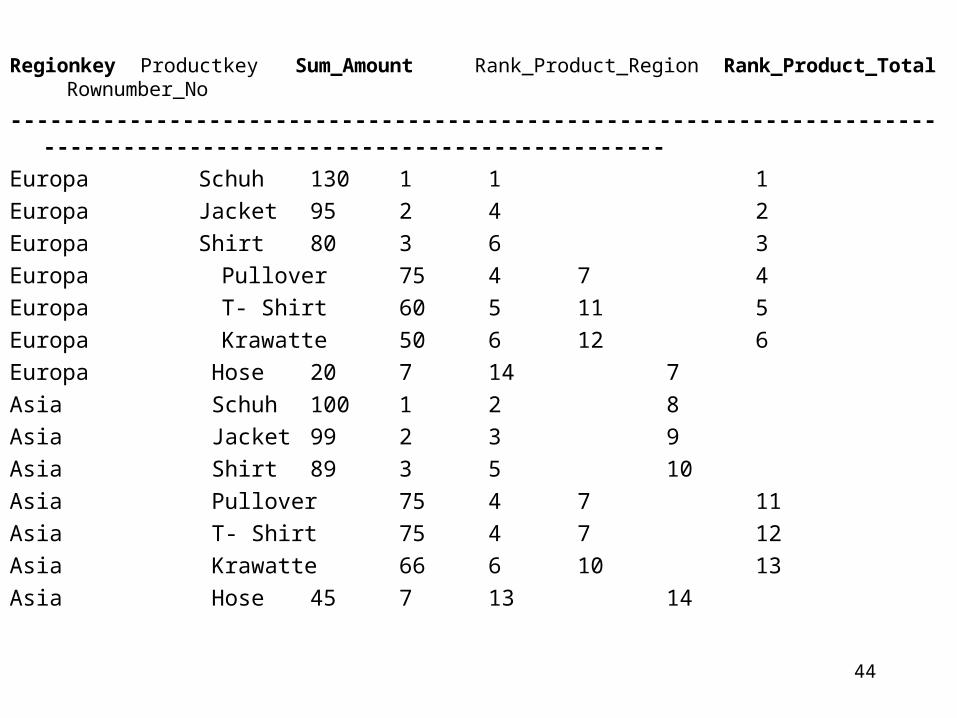
Beispiel 2.7:SELECT Regionkey, Productkey,
SUM(Amount) AS Sum_AmountRANK() OVER(PARTITION BY Regionkey
ORDER BY SUM(Amount) DESC ) AS Rank _ Product_Region,
RANK() OVER(ORDER BY SUM(Amount) DESC) AS Rank _ Product_Total, ROWNUMBER () OVER(ORDER BY A) AS Rownumber_No FROM Region,
Product,SalesWHERE Region. Regionkey= Sales. Regionkey AND Product. Productkey =Sales. ProductkeyGROUP BY Regionkey, ProductkeyORDER BY Regionkey
44
Regionkey Productkey Sum_Amount Rank_Product_Region Rank_Product_Total Rownumber_No
---------------------------------------------------------------------------------------------------------------------Europa Schuh 130 1 1 1Europa Jacket 95 2 4 2Europa Shirt 80 3 6 3Europa Pullover 75 4 7 4Europa T- Shirt 60 5 11 5Europa Krawatte 50 6 12 6Europa Hose 20 7 14 7Asia Schuh 100 1 2 8Asia Jacket 99 2 3 9Asia Shirt 89 3 5 10Asia Pullover 75 4 7 11Asia T- Shirt 75 4 7 12Asia Krawatte 66 6 10 13Asia Hose 45 7 13 14

45
2.4 Bildung dynamischer Fenster(Fensterfunktionen) Motivation: Durch Aggregatfunktionen und Fensterfunktionen ermöglicht eine
weitergehende und flexible Definition der Wertebereiche für Aggregationsoperatoren einzelner Tupel. Aggregatfenster: Wegen Benutzung der Aggregatfunktionen und Fensterfunktionen führen wir den Begriff des Aggregatfensters ein. Für die Festlegung der Größe eines Aggregatfensters gibt es zwei
Metriken: die Anzahl von Tupeln (ROWS); ROWS bestimmt logische Row (die Anzahl der Tupels) der Fenster. die logische Abweichung ders Tupels (RANGE).

46
Für die Größe selbst existieren zwei alternative Möglichkeiten: Alternative 1:Von einem frei wählbaren Startpunkt bis zum aktuellen
Tupel Alternative 2:Frei wählbare obere und untere Schranken Bewegung richtung von Fensters --Startposition von Fensters-------------------------- ... --Current Row ...
--Endposition von Fensters--------------------------
Bew
egungrichtung von Fensters

47
Syntax:{SUM | AVG | MAX | MIN | COUNT |...}({<value expression1> | *})OVER([PARTITION BY <value expression2> [,…]])
ORDER BY <value expression3> [ASC |DESC |…] ROWS |RANGE {{ UNBOUNDED PRECEDING | <value expression4> PRECEDING}| BETWEEN{ UNBOUNDED PRECEDING |<value expression4> PRECEDING} AND{ CURRENT ROW |<value expression4> FOLLOWING}}}

48
Anmerkung:UNBOUNDED PRECEDING Erste Zeile der Partition wird der Startpunkt des Fensters. z.B: OVER (ROWS UNBOUNDED PRECEDING) ≡ OVER () /* default erste Reihe<n> PRECEDING Als Startpunkt wird der n-te Vorgänger relativ zur aktuellen Position gewählt. /* mit <n> FOLLOWING zusammenbenutzen<n> FOLLOWING Als Endpunkt wird der n-te Nachfolger relativ zur aktuellen Position gewählt./* mit <n> PRECEDING zusammenbenutzenCURRENT ROW Startpunkt ist das aktuelle Tupel.BETWEEN <obere Grenzen> Die Schranken eines Aggregatfensters werden beschreiben,AND < obere Grenzen > wobei die obere Grenzen stets eine höhere Position als die untere Grenzen aufweisen muss.ROWS Die Anzahl von Tupel. ROWS bestimmt logische Row
(die Anzahl der Tupels) der FensterRANGE RANGE ist logisches Interval. Diese logische Abweichung kann wie z.B. RANGE 10 PRECEDING sein, oder eine Ausdruck, die eine Konstante oder Zeitwerte ergibt, sein,
oder wie z.B. RANGE INTERVAL N DAYS/MONTHS/YEARS PRECEDING sein
49
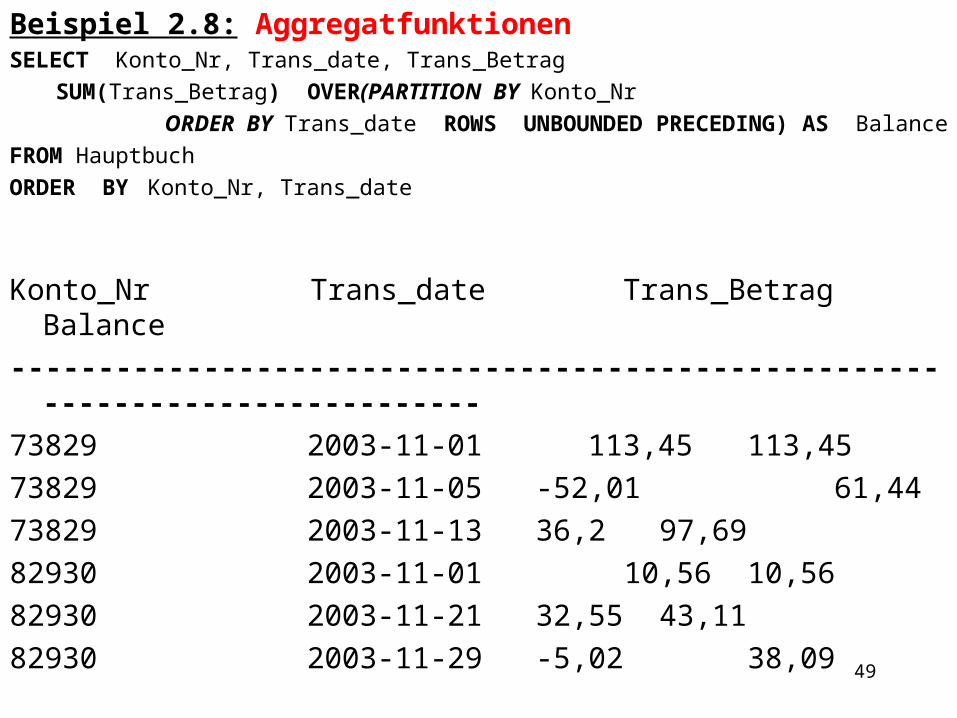
Beispiel 2.8: AggregatfunktionenSELECT Konto_Nr, Trans_date, Trans_Betrag
SUM(Trans_Betrag) OVER(PARTITION BY Konto_Nr ORDER BY Trans_date ROWS UNBOUNDED PRECEDING) AS
Balance FROM HauptbuchORDER BY Konto_Nr, Trans_date
Konto_Nr Trans_date Trans_Betrag Balance------------------------------------------------------------------------------73829 2003-11-01 113,45 113,4573829 2003-11-05 -52,01 61,4473829 2003-11-13 36,2 97,6982930 2003-11-01 10,56 10,5682930 2003-11-21 32,55 43,1182930 2003-11-29 -5,02 38,09
50
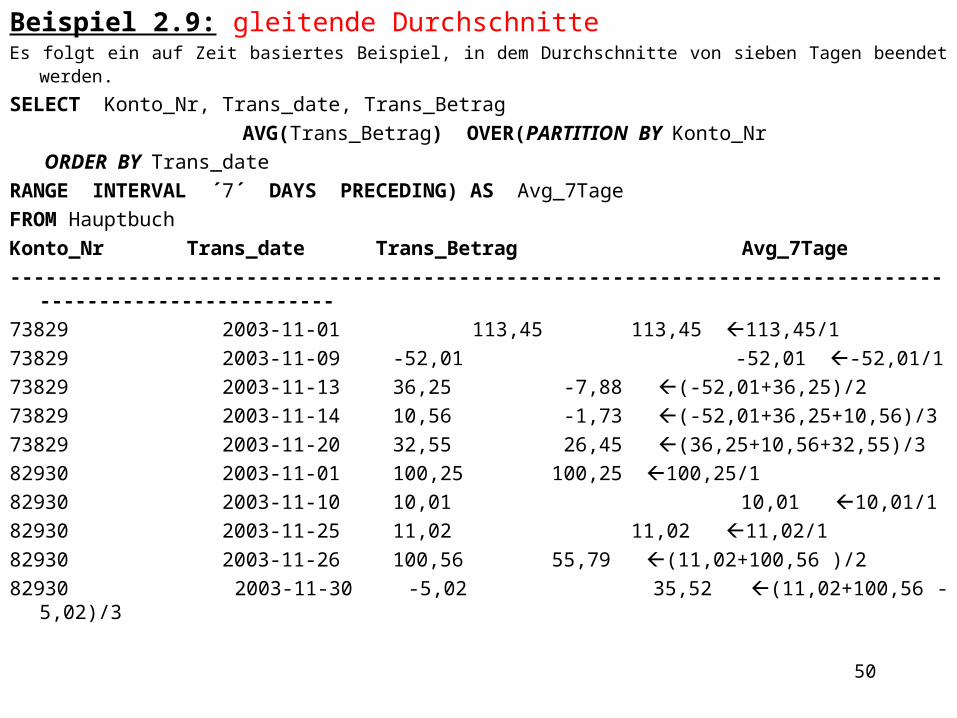
Beispiel 2.9: gleitende DurchschnitteEs folgt ein auf Zeit basiertes Beispiel, in dem Durchschnitte von sieben Tagen beendet werden.SELECT Konto_Nr, Trans_date, Trans_Betrag
AVG(Trans_Betrag) OVER(PARTITION BY Konto_Nr ORDER BY Trans_date
RANGE INTERVAL ´7´ DAYS PRECEDING) AS Avg_7TageFROM HauptbuchKonto_Nr Trans_date Trans_Betrag Avg_7Tage--------------------------------------------------------------------------------------------------------73829 2003-11-01 113,45 113,45 113,45/173829 2003-11-09 -52,01 -52,01 -52,01/173829 2003-11-13 36,25 -7,88 (-52,01+36,25)/273829 2003-11-14 10,56 -1,73 (-52,01+36,25+10,56)/373829 2003-11-20 32,55 26,45 (36,25+10,56+32,55)/382930 2003-11-01 100,25 100,25 100,25/182930 2003-11-10 10,01 10,01 10,01/182930 2003-11-25 11,02 11,02 11,02/182930 2003-11-26 100,56 55,79 (11,02+100,56 )/282930 2003-11-30 -5,02 35,52 (11,02+100,56 -5,02)/3

51
2.5 Wechselwirkung mit Mehrfachgruppierungen Im folgenden wird eine Kombination der global wirkenden Mehrfachgruppierungen und der lokal operierenden analytischen Funktionen skizziert. Solche Kombination ist durchaus sinnvoll, aber relativ komplex zu visualisieren. Um obiges Ergebnis zu ergeben, haben wir dazu zwei Methoden:
52
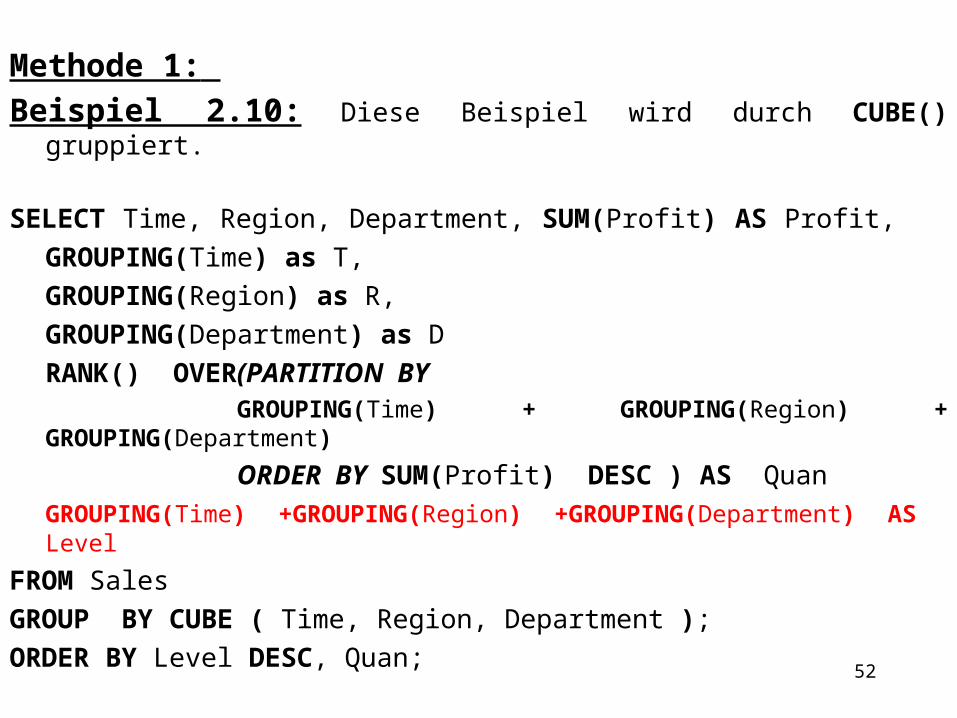
Methode 1: Beispiel 2.10: Diese Beispiel wird durch CUBE() gruppiert.
SELECT Time, Region, Department, SUM(Profit) AS Profit, GROUPING(Time) as T,GROUPING(Region) as R,GROUPING(Department) as DRANK() OVER(PARTITION BY
GROUPING(Time) + GROUPING(Region) + GROUPING(Department)
ORDER BY SUM(Profit) DESC ) AS Quan GROUPING(Time) +GROUPING(Region) +GROUPING(Department) AS Level
FROM Sales GROUP BY CUBE ( Time, Region, Department );ORDER BY Level DESC, Quan;
53
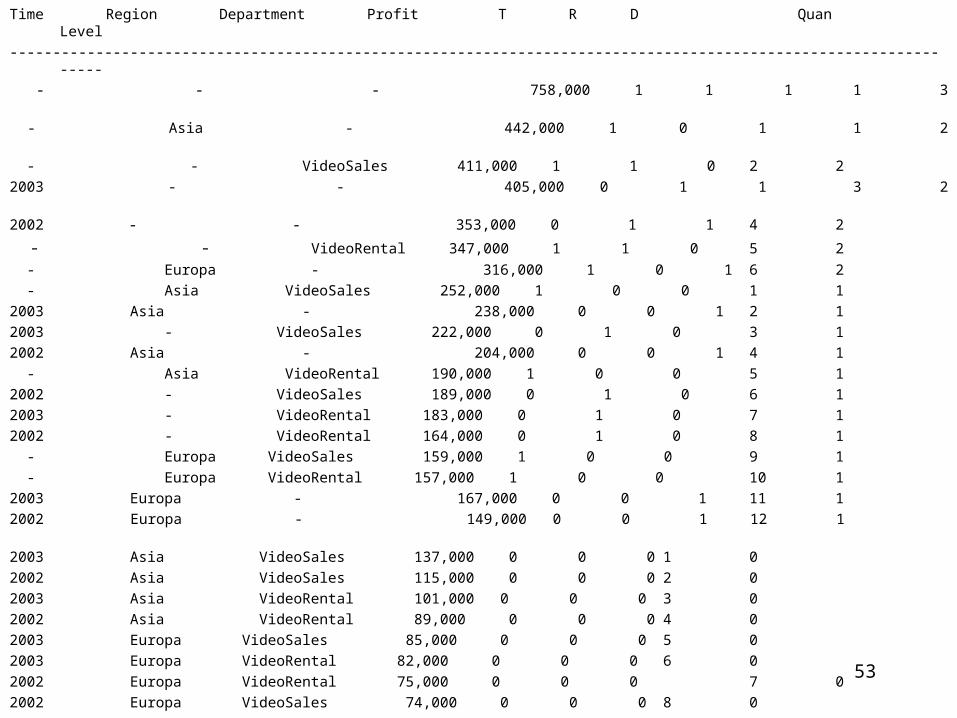
Time Region Department Profit T R D Quan Level ----------------------------------------------------------------------------------------------------------------- - - - 758,000 1 1 1 1 3 - Asia - 442,000 1 0 1 1 2 - - VideoSales 411,000 1 1 0 2 22003 - - 405,000 0 1 1 3 22002 - - 353,000 0 1 1 4 2
- - VideoRental 347,000 1 1 0 5 2 - Europa - 316,000 1 0 1 6 2 - Asia VideoSales 252,000 1 0 0 1 12003 Asia - 238,000 0 0 1 2 12003 - VideoSales 222,000 0 1 0 3 12002 Asia - 204,000 0 0 1 4 1 - Asia VideoRental 190,000 1 0 0 5 12002 - VideoSales 189,000 0 1 0 6 12003 - VideoRental 183,000 0 1 0 7 12002 - VideoRental 164,000 0 1 0 8 1 - Europa VideoSales 159,000 1 0 0 9 1 - Europa VideoRental 157,000 1 0 0 10 12003 Europa - 167,000 0 0 1 11 12002 Europa - 149,000 0 0 1 12 1 2003 Asia VideoSales 137,000 0 0 0 1 02002 Asia VideoSales 115,000 0 0 0 2 0 2003 Asia VideoRental 101,000 0 0 0 3 02002 Asia VideoRental 89,000 0 0 0 4 0 2003 Europa VideoSales 85,000 0 0 0 5 02003 Europa VideoRental 82,000 0 0 0 6 02002 Europa VideoRental 75,000 0 0 0 7 0 2002 Europa VideoSales 74,000 0 0 0 8 0
54
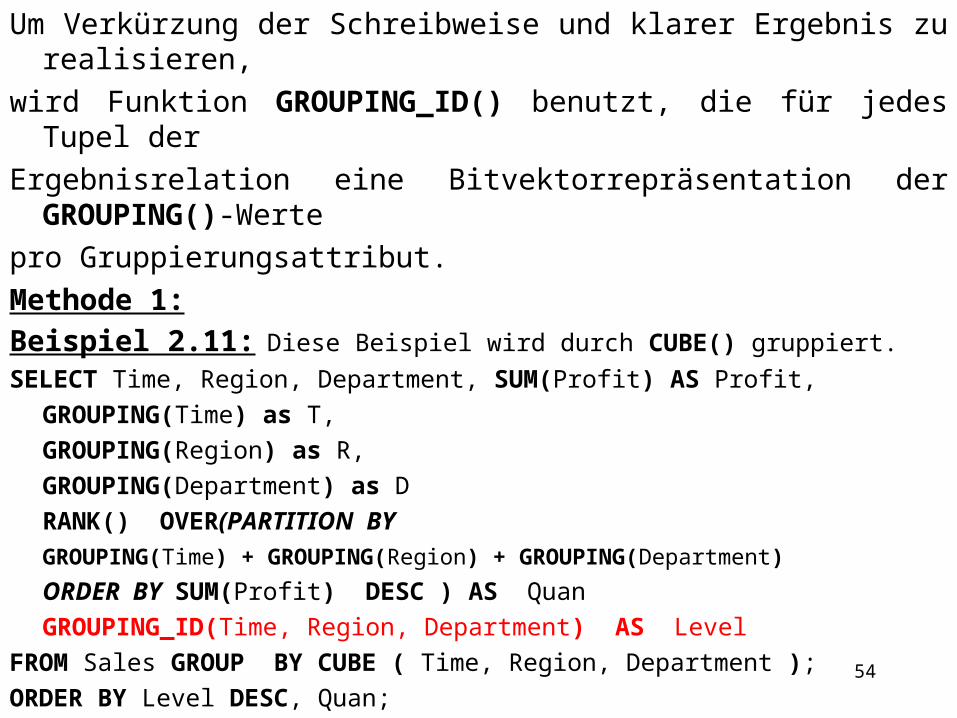
Um Verkürzung der Schreibweise und klarer Ergebnis zu realisieren,wird Funktion GROUPING_ID() benutzt, die für jedes Tupel derErgebnisrelation eine Bitvektorrepräsentation der GROUPING()-Wertepro Gruppierungsattribut. Methode 1:Beispiel 2.11: Diese Beispiel wird durch CUBE() gruppiert.SELECT Time, Region, Department, SUM(Profit) AS Profit,
GROUPING(Time) as T,GROUPING(Region) as R,GROUPING(Department) as DRANK() OVER(PARTITION BY
GROUPING(Time) + GROUPING(Region) + GROUPING(Department)
ORDER BY SUM(Profit) DESC ) AS Quan GROUPING_ID(Time, Region, Department) AS Level
FROM Sales GROUP BY CUBE ( Time, Region, Department );ORDER BY Level DESC, Quan;
55
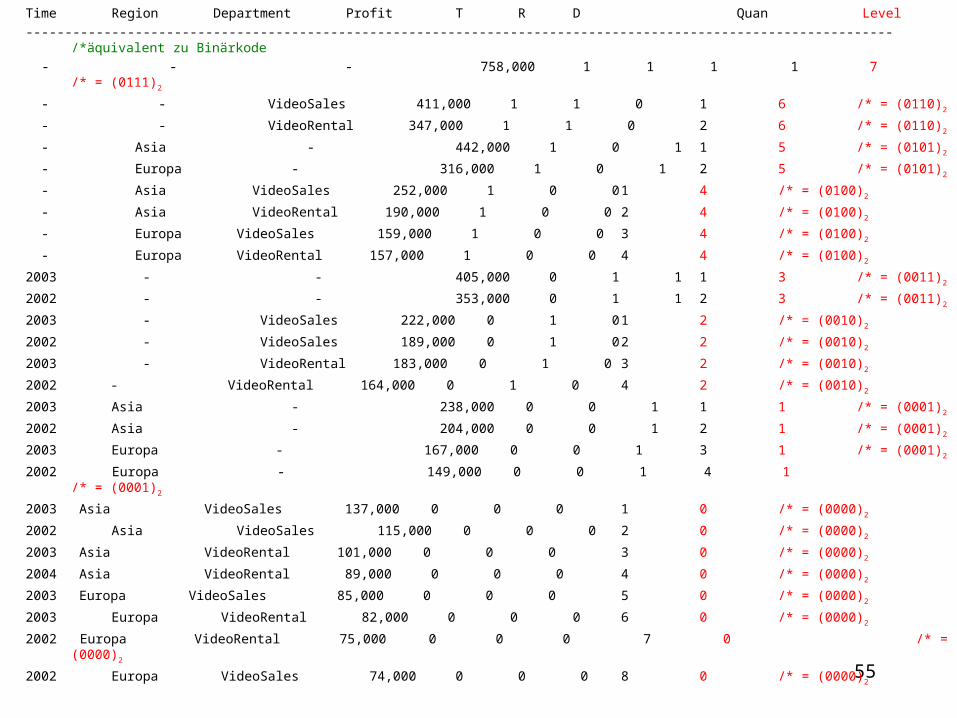
Time Region Department Profit T R D Quan Level --------------------------------------------------------------------------------------------------------------- /*äquivalent zu Binärkode - - - 758,000 1 1 1 1 7 /* = (0111)2
- - VideoSales 411,000 1 1 0 1 6 /* = (0110)2
- - VideoRental 347,000 1 1 0 2 6 /* = (0110)2
- Asia - 442,000 1 0 1 1 5 /* = (0101)2
- Europa - 316,000 1 0 1 2 5 /* = (0101)2
- Asia VideoSales 252,000 1 0 0 1 4 /* = (0100)2
- Asia VideoRental 190,000 1 0 0 2 4 /* = (0100)2
- Europa VideoSales 159,000 1 0 0 3 4 /* = (0100)2
- Europa VideoRental 157,000 1 0 0 4 4 /* = (0100)2
2003 - - 405,000 0 1 1 1 3 /* = (0011)2
2002 - - 353,000 0 1 1 2 3 /* = (0011)2
2003 - VideoSales 222,000 0 1 0 1 2 /* = (0010)2
2002 - VideoSales 189,000 0 1 0 2 2 /* = (0010)2
2003 - VideoRental 183,000 0 1 0 3 2 /* = (0010)2
2002 - VideoRental 164,000 0 1 0 4 2 /* = (0010)2
2003 Asia - 238,000 0 0 1 1 1 /* = (0001)2
2002 Asia - 204,000 0 0 1 2 1 /* = (0001)2
2003 Europa - 167,000 0 0 1 3 1 /* = (0001)2
2002 Europa - 149,000 0 0 1 4 1 /* = (0001)2
2003 Asia VideoSales 137,000 0 0 0 1 0 /* = (0000)2
2002 Asia VideoSales 115,000 0 0 0 2 0 /* = (0000)2
2003 Asia VideoRental 101,000 0 0 0 3 0 /* = (0000)2
2004 Asia VideoRental 89,000 0 0 0 4 0 /* = (0000)2
2003 Europa VideoSales 85,000 0 0 0 5 0 /* = (0000)2
2003 Europa VideoRental 82,000 0 0 0 6 0 /* = (0000)2
2002 Europa VideoRental 75,000 0 0 0 7 0 /* = (0000)2
2002 Europa VideoSales 74,000 0 0 0 8 0 /* = (0000)2

56
Vielen Dank!


















