
Leitlinie zur (allergen-) spezifischen Immuntherapie bei IgE ...
Upload
nguyenphucCategory
view
213download
0
44
2 Modelle für diskrete und beschränkte abhängige Variablen
Mikrodaten sind sehr häufig dadurch gekennzeichnet, daß neben den metrischen Vari-
ablen für die Individuen bestimmte Eigenschaften, d.h. qualitative bzw. diskrete Merk-
male beobachtet werden. Sehr häufig lassen sich diese qualitativen Merkmale wie z.B.
das Geschlecht einer Person oder die Existenz einer Forschungsabteilung in einem
Unternehmen durch entsprechende 0,1-Variablen (Dummy-Variablen, binäre Variablen)
abbilden.
Andere qualitative Merkmale lassen mehr als zwei Alternativen zu. Diese Alternativen
können entweder ungeordnet sein wie beispielsweise die Berufstätigkeit eines Indivi-
duums (Arbeiter, Angestellter, Beamter etc.) oder die Wahl des Prozeßortes bei Pa-
tentstreitigkeiten (Düsseldorf, München, Mannheim, etc.). Sie können aber auch geord-
net sein wie beispielsweise der höchste Bildungsabschluß einer Person (Hauptschule,
Realschule, Gymnasium, Fachhochschule, Hochschule etc.) oder die subjektive Ein-
schätzung der Bedeutung von Merkmalen (geringe bis große Bedeutung auf einer Skala
von 1 bis 5, sogenannte Likert-Skalen).
Wiederum andere Merkmale sind zwar quantitativ, treten aber nur in diskreten Ausprä-
gungen auf (sogenannte Zähldaten, die im nachfolgenden Kapitel 3 behandelt werden),
wie beispielsweise die Anzahl von Kindern in einem Haushalt oder die Anzahl von Pa-
tenten, die ein Unternehmen hält. Oder sie sind quantitativ, aber beschränkt wie bei-
spielsweise die tägliche Freizeitnachfrage, die nicht 24 Stunden übersteigen kann, oder
aber das tägliche Arbeitsangebot, das nicht unter 0 Stunden sinken kann.
Diese Variablen bereiten in der Regel wenig Probleme, wenn sie auf der rechten Seite
der Gleichung stehen, also erklärende Variablen sind. Dies ändert sich, wenn die Erklä-
rung der Variablen selbst im Mittelpunkt des Interesses steht, die qualitativen oder dis-
kreten Merkmale also selbst endogene Variablen sind. Die Methoden, die für derartige
Modelle entwickelt worden sind, werden häufig unter dem Begriff Mikroökonometrie
zusammengefaßt, obwohl sie nur einen Teil der Methoden für Mikrodaten bilden. Zu die-
sen Methoden sind inzwischen auch etliche Lehrbücher und Monographien entstanden,
in deutscher Sprache beispielsweise Ronning (1991). Auch allgemeine Lehrbücher o-
der Monographien zur Ökonometrie enthalten umfassende Abschnitte, wie insbesonde-

45
re Amemiya (1985) in den Kapiteln 9 und 10, aber auch Greene (1993) im Kapitel 19.
Der immer noch sehr lesenswerte Klassiker in der Literatur ist jedoch zweifelsohne die
Monographie des im Sommer 1999 verstorbenen Maddala (1983).
2.1 Modelle für binäre abhängige Variablen
2.1.1 Das lineare Wahrscheinlichkeitsmodell
Die einfachste Form, ein Modell für binäre abhängige Variablen zu konstruieren, ist das
lineare Wahrscheinlichkeitsmodell (linear probability model). Die abhängige Vari-
able iy ist eine binäre, also 0,1-Variable, die z.B. mißt, ob das Individuum i ein Auto
gekauft hat oder nicht, oder ob Individuum i Gewerkschaftsmitglied ist oder nicht. Es gilt
in diesem Fall
(2.1)1 wenn Gewerkschaftsmitglied0 wenn kein Gewerkschaftsmitglied.i
iy
i
=
Erklärt man die Entscheidungen des Individuums mit Hilfe geeigneter unabhängiger
Variablen iX wie z.B. Alter in Jahren, Schulbildung, Berufserfahrung etc., so läßt sich
die Wahrscheinlichkeit, daß ein Individuum Gewerkschaftsmitglied ist, folgendermaßen
modellieren:
(2.2)( ) ( )( ) ( )
1
0 1i i
i i
P y F X
P y F X
β
β
= =
= = −
wobei ( )iF X β eine kumulierte Verteilungsfunktion ist. Im linearen Wahrscheinlichkeits-
modell wird diese Verteilungsfunktion linear modelliert, d.h. ( )i iF X Xβ β= . Daraus
folgt:
(2.3) y X ui i i= +β
Da iy nur die Werte 1 oder 0 annehmen kann, können die Störgrößen für gegebene
erklärende Variablen iX ebenfalls nur 2 Werte annehmen
(2.4) 1 bzw.i i i iu X u Xβ β= − = − .

46
Daraus folgt, daß für gegebene iX die Störgrößen iu nicht die Bedingungen der Nor-
malverteilung erfüllen können. Die iu folgen dann einer Bernoulli-Verteilung. Ihr Erwar-
tungswert ist:
(2.5) ( ) ( ) ( ) ( )1 1 1 1 1i i i i iE u X P y X P yβ β= − = = − − =
Der Erwartungswert ist nur dann gleich null, wenn ( )1i iP y X β= = ist.
Es ist nicht einmal gewährleistet, daß die prognostizierte Wahrscheinlichkeit
( )1i i iP y X X β= = zwischen 0 und 1 liegt. Sie kann sogar negativ werden. Ferner ist für
( )1|i i iP y X X β= = die Varianz der Störgrößen von iX abhängig (heteroskedastisch),
denn es gilt:
(2.6) ( ) ( ) ( ) ( ) ( ) ( )2 22 | 1 1 1 1 1
1i i i i i i i i
i i
E u X X P y X P y X X
X X
β β β β
β β
= − = + − = = − −
14243 1442443
Der KQ-Schätzer der Gleichung (2.3) ist daher ineffizient. Aufgrund dieser Überlegun-
gen ist klar, daß das lineare Modell eigentlich nicht geeignet ist, eine abhängige 0,1-
Variable zu erklären. Es findet in empirischen Studien daher kaum Anwendung, so daß
man für empirische Illustrationen auf Lehrbuchbeispiele zurückgreifen muß.
Wir benutzen das Beispiel zur Erklärung der Mitgliedschaft in der Gewerkschaft in den
USA (Union) aus dem Lehrbuch Johnston and DiNardo (1997). Die Variablen stammen
aus dem „Current Population Survey“ von 1988 und bedeuten:
- Union Mitgliedschaft in einer Gewerkschaft ( 1Union = )
- Exp Potentielle Erfahrung ( Alter - Schuljahre - 5Exp = )
- 2Exp ( 2Exp )
- Grade Anzahl der vollendeten Schuljahre
- Married verheiratet ( 1Married = )
- High beschäftigt in einem Wirtschaftszweig mit hohem gewerkschaftl. Organi-sationsgrad ( 1High = ).
Man erhält mit in RATS mit dem Befehl LINREG folgende Koeffizienten

47
Tabelle 2.1 Schätzergebnisse für das lineare Wahrscheinlichkeitsmodell
$β t Sign. level
Exp .0200388 5.14 0.000
Exp2 -.0003706 -4.53 0.000
Grade -.0124636 -2.44 0.015
Married .0133428 0.45 0.657
High .1439396 5.61 0.000
constant .1021368 1.36 0.173
R2 = 0.0837; N = 1000
2.1.2 Das Probit-Modell
Sinnvoller ist ein Modell, das die Wahrscheinlichkeit ( )1iP y = direkt aus einer Vertei-
lungsannahme erklärt. Modelle, die auf diese Weise ein dichotomes Wahlverhalten er-
klären wollen, bezeichnet man auch als binäre Wahlhandlungsmodelle oder Binary
Choice-Modelle. Erklärt wird die Wahrscheinlichkeit für den Eintritt bzw. Nichteintritt
eines Ereignisses, z.B. Kaufereignisses, unter der Bedingung gegebener erklärender
Variablen, und es wird analysiert, wie diese bedingte Wahrscheinlichkeit mit den erklä-
renden Variablen variiert.
In der ökonometrischen Literatur werden praktisch nur zwei alternative Verteilungsan-
nahmen verwendet: die Normalverteilung und die logistische Verteilung. Das soge-
nannte Probit-Modell verwendet die kumulierte Verteilungsfunktion der Standardnor-
malverteilung:
(2.7) ( ) ( ) ( )2
211|
2
iX z
i i i iP y X F X X e dzβ
β βπ
−
−∞
= = = Φ = ∫ für 1σ =
Die Grenzwerte 0 und 1 für die Wahrscheinlichkeit ( 1 )i iP y X= sind nicht verletzt. Da es
sich bei der abhängigen Variablen um eine Wahrscheinlichkeit handelt, ist diese Vari-
able auf das Intervall [ ]0,1 beschränkt. Es gilt ferner
(2.8) ( ) ( )i i i iE y x X Xβ β= Φ ≠

48
Somit ist auch der Erwartungswert auf das Intervall [ ]0,1 beschränkt.
Um das klassische Regressionsmodell auf diesen Fall anzuwenden, wird zwischen ei-
nem latenten Modellteil und einem beobachteten Modellteil unterschieden.
Der latente Modellteil erklärt eine nicht beobachtbare (latente) Variable *iy , die man
als stetige Neigung beispielsweise ein Konsumgut zu kaufen interpretieren kann, wie im
klassischen Regressionsmodell.
Latenter Modellteil
(2.9) *i i iy X uβ= + mit ( )20,iu N σ∼
Der latente Modellteil sagt, daß die unbeobachtbare Variable *iy einer stetigen Ver-
teilung über den Wertebereich ( , )−∞ +∞ folgt wie im klassischen Regressionsmodell. Im
Probit-Modell gibt *iy im latenten Modellteil an, mit welcher Intensität der Haushalt i den
Kauf des Konsumgutes wünscht bzw. ihn ablehnt. Für * 0iy > wünscht er den Kauf, für
* 0iy ≤ lehnt er ihn ab. Beobachtbar ist aber im Probit-Modell lediglich die Variable iy ,
nämlich ob der Haushalt das Konsumgut kauft ( 1iy = ) oder nicht ( 0iy = ). Der Haushalt
kauft das Gut nur, wenn die Bedingung * 0iy > bzw. i iu Xσ β σ> − gilt. Für die beob-
achtbare Variable gilt daher:
Beobachtbarer Modellteil
(2.10)*
*
1 , wenn 0 bzw.0 , wenn 0 bzw.
i i ii
i i i
y u Xy
y u Xσ β σσ β σ
> > −=
≤ ≤ −
Wir erklären das Probit- und Logit-Modell im folgenden am Beispiel eines Haushalts,
der in der Untersuchungsperiode entweder ein langlebiges Gebrauchsgut kauft ( 1iy = )
oder nicht kauft ( 0iy = ). Die Idee des Probit-Modells kann dann wie folgt beschrieben
werden:
Haushalte haben ein bestimmtes Einkommen, das zu Ausgaben z.B. für die Anschaf-
fung eines Autos führt bzw. nicht führt. Es wird angenommen, daß der kritische Wert der
latenten Variablen *iy , bei dem ein Haushalt sich zu einer solchen Ausgabe entschließt,

49
von Haushalt zu Haushalt variiert. Folgen diese kritischen latenten Werte *iy einer
Normalverteilung, so daß sich wegen
(2.11)( ) ( ) ( ) ( )( ) ( )
*0 0 1 ( / )
1 1 ( / )
i i i i i i
i i i
P y P y P u X X X
P y X X
σ β σ β σ β σ
β σ β σ
= = ≤ = ≤ − = Φ − = − Φ
= = − Φ − = Φ
die folgende Likelihoodfunktion für das Probit-Modell nach Sortierung in M Haus-halte mit Beobachtung 0iy = und N M− Haushalte mit 1iy = ergibt:
(2.12) ( ) ( ) ( ) ( ) ( )1 2 10 0 0 1 1probit M M NL P y P y P y P y P y+= = ⋅ = = ⋅ = =L L
( ) ( )
( ) ( )
( ) ( )
* *
1 1
1 1
1 1
0 0
1
M N
probit i ii i M
M N
i i i ii i M
M N
i ii i M
L P y P y
P u X P u X
X X
σ β σ σ β σ
β σ β σ
= = +
= = +
= = +
= ≤ >
= ≤ − > −
= − Φ − Φ −
∏ ∏
∏ ∏
∏ ∏
wobei ( / )iX β σΦ die kumulierte Verteilungsfunktion der Normalverteilung für einen
Haushalt mit Merkmalsvektor iX ist. Die Maximierung der logarithmierten Likelihood-
funktion durch Differentiation nach den Parametern β und σ sowie Nullsetzen der 1.
Ableitung, führt zu nichtlinearen Funktionen, aus denen die zu schätzenden Parame-
ter iterativ ermittelt werden können. Die Maximierung dieser Likelihoodfunktion ist ein
nichtlineares Schätzproblem ähnlich der nichtlinearen KQ-Schätzung, wie sie in Ökono-
metrie I behandelt wurde. Wir betrachten die Log-Likelihoodfunktion
(2.13) ( ) ( )1 1
ln ln 1 lnM N
probit i ii i M
L X Xβ σ β σ= = +
= − Φ + Φ ∑ ∑
sowie deren Ableitung nach β
(2.14)1 1
ln
1
N Mprobit i i i i
i M ii i
L X X∂ φ φ∂ β σ σ= + =
= −Φ − Φ∑ ∑ .
Dabei stellen iφ und iΦ auch im weiteren Verlauf des Skripts vereinfachte Schreibwei-
sen der Dichte ( )iXφ β σ sowie der kumulierten Verteilungsfunktion der Normalvertei-
lung ( )iX β σΦ dar. Das iterative Verfahren schätzt dann die Gleichung

50
(2.15) $ $ ln ln$ $
β β∂∂ β∂ β
∂∂ ββ β
j jL L
jj
+
−
= −′
1
21
wobei sich die Matrix der 2. Ableitungen als
(2.16)( )
2
2 21 1
ln1
M Ni i i i i i i i
i ii i Mi i
X X X X X XL φ β φ β∂φ φ
∂ β∂ β σ σ σ σ= = +
′ ′ = − − + ′ − Φ Φ ∑ ∑
ergibt. ˆjβ ist ein Anfangswert, der z.B. aus den linearen Wahrscheinlichkeitsmodell
stammen kann.
Diese Iterationen, z.B. mittels der Newton-Raphson-Methode oder des Verfahrens von
Berndt, Hall, Hall and Hausmann (1974) konvergieren nur dann zuverlässig gegen ein
globales Maximum der logarithmierten Likelihoodfunktion, wenn diese global konkav
bezüglich ihrer Parameter ist. Olsen (1978) hat nachgewiesen, daß diese Bedingung für
die obigen Modelle erfüllt ist.
Allerdings sind in Probit-Modellen nur standardisierte Koeffizienten βσ identifiziert.
2.1.3 Das Logit-Modell
Im Probit-Modell wird eine Normalverteilung des kritischen Wertes unterstellt, der durch
die die Entscheidung beeinflussenden unabhängigen Variablen bestimmt wird. Im Lo-
git-Modell geht man demgegenüber von einer logistischen Verteilung aus:
(2.17)i
i
i X /
i i i X /
1f ( y )
1 e1
P( y 1 | X ) F ( X / )1 e
β σ
β σβ σ
−
−
=+
= = =+
Ansonsten ist die Vorgehensweise einschließlich deren Interpretation vollständig analog
zum Probit-Modell.
2.1.4 Vergleich und empirische Beispiele für das Probit- und Logit-Modell
In RATS sind einfache Prozeduren für beide Verfahren enthalten, die der LINREG-
Prozedur entsprechen, indem sie LINREG durch LGT (Logit) oder PRB (Probit) erset-
zen:

51
Das folgende Programm schätzt das lineare, das Probit- und das Logit-Modell für das
oben genannte Beispiel der Mitgliedschaft in einer Gewerkschaft:
allocate 1000open data cps.ratdata(format=rat,org=var)/age exp2 grade ind1 married Inwage occ1 $partt exp union weigh high* Lineares Wahrscheinlichkeitsmodelllinreg union /‘exp exp2 grade married high constant* Probit-Modellprb union /‘exp exp2 grade married high constant* Logit-Modelllgt union /#exp exp2 grade married high constant
Die Ergebnisse lauten für das lineare Wahrscheinlichkeitsmodell:
Tabelle 2.2 Schätzergebnisse für das lineare Wahrscheinlichkeitsmodell
Variable Coeff Std Error T-Stat Signif
1. EXP 0.020038767 0.003896914 5.14221 0.00000033
2. EXP2 -0.000370581 0.000081883 -4.52572 0.00000675
3. GRADE -0.012463581 0.005100452 -2.44362 0.01471364
4. MARRIED 0.013342779 0.030000989 0.44474 0.65660113
5. HIGH 0.143939577 0.025678520 5.60545 0.00000003
6. Constant 0.102136788 0.074933713 1.36303 0.17318220
für das Probit-Modell:
Tabelle 2.3 Schätzergebnisse für das Probit-Modell
Variable Coeff Std Error T.Stat Signif
1. EXP 0.083509133 0.015608799 5.35013 0.00000009
2. EXP2 -0.001530796 0.000317877 -4.81569 0.00000147
3. GRADE -0.042077965 0.018908978 -2.22529 0.02606175
4. MARRIED 0.062251606 0.112583951 0.55293 0.58030792
5. HIGH 0.561295261 0.099662392 5.63197 0.00000002
6. Constant -1.468412409 0.295812594 -4.96400 0.00000069

52
und für das Logit-Modell:
Tabelle 2.4 Schätzergebnisse für das Logit-Modell
Variable Coeff Std Errir T-Stat Signif
1. EXP 0.147402074 0.028097014 5.24618 0.00000016
2. EXP2 -0.002686919 0.000565428 -4.75201 0.00000201
3. GRADE -0.0704320887 0.032142049 -2.18782 0.02868301
4. MARRIED 0.115463002 0.196778961 0l.58676 0.55736156
5. HIGH 0.980141109 0.180049032 5.44375 0.00000005
6. Constant -2.581435858 0.518685883 -4.97688 0.00000065
Man erkennt erhebliche Differenzen in den drei Schätzungen, d.h. die Schätzer sind
nicht indifferent gegenüber der Spezifikation. Die Parameter der drei Modelle haben
jeweils eine andere Interpretation. Das Probit- und das Logit-Modell liefern im allgemei-
nen ähnliche Ergebnisse. Das Probit-Modell unterstellt eine Normalverteilung mit Vari-
anz 2 1σ = , das Logit-Modell eine logistische Verteilung mit einer Varianz 223
πσ = , so
daß die Ergebnisse des Probit-Modells multipliziert mit σ π= / 3 annähernd den Er-
gebnissen des Logit-Modells entsprechen. Größere Unterschiede treten nur auf, wenn
das Datenmaterial eine sehr hohe Schiefe aufweist. In diesem Fall ist das Logit-Modell
der adäquatere Ansatz.
Im Gegensatz zum lineare Wahrscheinlichkeitsmodell sind die geschätzten Koeffizien-
ten des Probit-Modells und des Logit-Modells nicht als marginale Effekte zu interpretie-
ren, diese müssen auf Basis der Schätzung erst noch berechnet werden. Es gilt allge-
mein:
(2.18)( ) ( )
( )i i
kik i
E y F Xx X
ββ
β∂ ∂
=∂ ∂
.

53
Also im linearen Wahrscheinlichkeitsmodell
(2.19)( )i
kik
E yx
∂β
∂=
im Probit-Modell:
(2.20)( )
( )ii k
ik
E yX
x∂
φ β β∂
=
und im Logit-Modell:
(2.21) ( ) ( )( )( )1i
i i ikik
E yX X
x∂
β β β∂
= Λ − Λ ⋅ mit ( )1
i
i
X
i X
eX
e
β
ββΛ =+
.
Die marginalen Effekte hängen also im Probit- und im Logit-Modell von den exogenen
Variablen iX ab und sind daher für jedes Individuum unterschiedlich. Es gibt prinzipiell 2
Wege, die marginalen Effekte zu berechnen. Man evaluiert die marginalen Effekte je-
weils am arithmetischen Mittel der erklärenden Variablen X oder man evaluiert für je-
des Individuum den marginalen Effekt und mittelt anschließend über die marginalen Ef-
fekte. Die Evaluation am arithmetischen Mittel der erklärenden Variablen ist für 0/1-
Variablen nicht sinnvoll. Daher berechnet man den marginalen Effekt einer 0/1 Variab-
len iD häufig als ( ) ( )1 0i i i iF X D F X Dβ β= − = . Die Schätzungen der marginalen Ef-
fekte stimmen im Probit-Modell und im Logit-Modell häufig weitgehend überein.
Man kann die binären Choice-Modelle auch benutzen, um Prognosen für die Wahr-
scheinlichkeiten ( ) 1iP y = abzuleiten. Es gilt:
(2.22) ( )( )
ˆ im linearen Wahrscheinlichkeitsmodell
ˆ( 1) im Probitmodell
ˆ im Logitmodell
i
i i
i
X
P y X
X
β
β
β
= = ΦΛ
Die Ursache der wesentliche Unterschiede kann z.B. Heteroskedastizität der Störgröße
sein. Für das lineare Modell haben wir diese bereits gezeigt. Dort hat eine Heteroske-
dastie aber nur Effekte auf die Schätzfehler. In nichtlinearen Modellen wie dem Probit-
und Logit-Modell führt Heteroskedastie auch zu inkonsistenten Schätzern. Dies er-
gibt sich für das Probit-Modell unmittelbar aus

54
(2.23) ( 1)( )i
ii
XP y
g Xβ
σ
= = Φ ⋅ .
Heteroskedastie ist also ein wesentlich ernsteres Problem als im linearen Modell. Da-
her sollte im Rahmen von Analysen mit dem Probit- bzw. des Logit-Modell möglichst ein
Heteroskedastietest durchgeführt werden. Die Maximum-Likelihood-Schätzung ist aber
immer dann konsistent und effizient, wenn wir die richtige Likelihoodfunktion maxi-
miert haben. In den meisten empirischen Anwendungen unterscheiden sich die Para-
meter des Probit- und Logit-Modells nur geringfügig. Daraus kann dann auf eine gewis-
se Robustheit gegenüber den unterschiedlichen Annahmen geschlossen werden.
Im Gegensatz zum linearen Regressionsmodell ist im Probit- und im Logit-Modell das
klassische Bestimmtheitsmaß 2R nicht als Maß für die Güte der Schätzung anwendbar.
Daher verwendet man sogenannte Pseudo-Bestimmtheitsmaße oder auch Pseudo- 2R .
Das einfachste Pseudo-Bestimmtheistmaß ist der Likelihood-Ratio-Index:
(2.24)0
ln1
lnL
LRIL
= −
0ln L ist dabei die Log-Likelihood eines Probit- oder Logit-Modells, das nur eine Kon-
stante und sonst keine erklärenden Variablen enthält. Es ist wie das klassische Be-
stimmtheitsmaß auf den Wertebereich [ ]0,1 . Allerdings sind selten Pseudo- 2R zu er-
warten, die größer sind als 0,2 . Sehr häufig sind sie sogar kleiner als 0,1 .
Ein Beispiel für die Anwendung des Probit-Modells ergibt sich aus einer jüngeren Stu-
die des ZEW zum Technologietransfer von Hochschulen und öffentlichen Forschungs-
einrichtungen an private Unternehmen. Beise und Stahl (1999) haben mit einem Quer-
schnitt des Mannheimer Innovationspanels untersucht, ob Forschungsergebnisse von
Hochschulen und öffentlichen Forschungseinrichtungen maßgeblich für die Innovations-
tätigkeit privater Unternehmen sind. Dazu wurden die Unternehmen gefragt, ob es Pro-
dukt- oder Prozeßinnovationen gibt, die ohne die Ergebnisse der jüngeren Forschung
von Hochschulen oder öffentlichen Forschungseinrichtungen nicht zustandegekommen
wären.

55
Die Probitschätzung führte zu folgenden Ergebnissen (die Werte stellen die marginalen
Effekte dar):
Tabelle 2.5 Technologietransfer an private Unternehmen
Transfer vonHochschulen undöffentlichen For-schungseinrich-tungen
Transfer vonUniversitäten
Transfer vonFachhochschu-len
Transfer vonöffentlichen For-schungseinrich-tungen
Beschäftigten-zahl (in logs)
0,0240*** 0,022*** 0,0038 0,014***
FuE-Intensität 0,0042*** 0,0016 -0,0000 0,0026**
Produktlebens-zyklus
-0,0011 -0,0006 -0,0018** -0,0010
Breite der Pro-duktpalette
-0,0110** -0,0058** -0,0044** -0,0032
Wissenschaft-lerdichte
-0,2070
Wissenschaft-lerdichte (Uni)
-0,387 -0,471** -0,482
Wissenschaft-lerdichte (FHs)
0,197 0,586*** 0,377
Wissenschaft-lerdichte (Insti-tute)
0,017 -0,127 0,038
Investitionsgüter-sektor (Dummy)
0,038 0,039** 0,016** -0,0053
Neue Bundes-länder (Dummy)
-0.028 0,0034 0,0012 0,032
N 892 891 889 890
ln L -371,4 -213,4 -136,9 -206,4
Pseudo R2 0,0377 0,0931 0,1276 0,0605
*,**,*** bezeichnet ein Signifikanzniveau von 1%, 5% bzw. 10%.
Einige Ergebnisse seien nur exemplarisch diskutiert. Die Neigung der Unternehmen,
sich Spillovers der öffentlichen Forschung anzueignen, steigt mit der Größe und der
FuE-Intensität der Unternehmen (gemessen als Anteil der FuE-Ausgaben am Umsatz).
Insbesondere die Fähigkeiten, sich die Ergebnisse der Forschung öffentlicher Institute

56
(Großforschungseinrichtungen, Fraunhofer-Institute) anzueignen, erfordert eine eigene
FuE-Tätigkeit der Unternehmen.
Der Transfer von Fachhochschulen unterscheidet sich davon jedoch deutlich. Die Größe
des Unternehmens spielt keine Rolle, kleine und mittlere Unternehmen können in glei-
chem Maße profitieren. Die räumliche Nähe gemessen als Wissenschaftlerdichte in
einem Umkreis von 100km ist signifikant. Im übrigen konnte im Rahmen der Studie, die
weitere Schätzungen enthält, dem Technologietransfer öffentlicher an private Einrichtun-
gen kein besonders gutes Zeugnis ausgestellt werden. Dies betraf insbesondere den
Transfer von sogenannten Großforschungseinrichtungen. Die wesentlichen Transfers
finden nur von Fraunhofer-Instituten sowie einigen Technischen Universitäten statt.
2.1.5 Bivariate und Simultane Probit-Modelle
Häufig stehen jedoch verschiedene diskrete Entscheidungen von Individuen oder Unter-
nehmen in einem direkten oder indirekten Zusammenhang, wie beispielsweise die Ent-
scheidung über Erwerbsbeteiligung und das Kinderkriegen von Frauen oder die Ent-
scheidung über Produkt- und Prozeßinnovationen von Unternehmen. Es ist dabei zwi-
schen genisteten und nicht-genisteten Modellen zu unterscheiden.
In einem genisteten Modell hängt die zweite Entscheidung vom Ergebnis der ersten
Entscheidung ab. Es ergibt sich also ein zweistufiges Entscheidungsmuster, wie bei-
spielsweise auf der ersten Stufe die Entscheidung über eine Fahrt mit dem eigenen
Auto oder einem öffentlichen Verkehrsmittel und auf der zweiten Stufe die Entscheidung
zwischen dem Bus und der Bahn, gegeben eine Entscheidung für öffentliche Verkehrs-
mittel auf der ersten Stufe. Derartige Modelle werden hier nicht behandelt. Sie können
beispielsweise in Ronning (1991) nachgelesen werden.
Das bivariate Probit-Modell entspricht einer Übertragung des bekannten Modells mit
scheinbar unabhängigen Gleichungen auf das Probit-Modell. Es hat folgende Struktur
für den beobachtbaren Modellteil:

57
(2.25)
*1
1 *1
*2
2 *2
1 wenn 0
0 wenn 0
1 wenn 0
0 wenn 0
ii
i
ii
i
yy
y
yy
y
>= ≤
>=
≤
und folgende für den latenten Modellteil:
(2.26)*1 1 1 1 1 1
*2 2 2 2 1 1 1 2
mit ( ) 0, ( ) 1
mit ( ) 0, ( ) 1, ( )i i i i i
i i i i i i i
y X u E u V u
y X u E u V u Cov u u
β
β ρ
= + = =
= + = = =
Die Varianzen können auf 1 normiert werden, da wie im gewöhnlichen Probit-Modell nur
die standardisierten Koeffizienten identifiziert sind. ρ beschreibt wie im SUR-Modell
die Korrelation zwischen den Störgrößen der beiden Gleichungen. Das bivariate Probit-
Modell kann mit der Maximum-Likelihood-Methode geschätzt werden. Die individuellen
Eintrittswahrscheinlichkeiten der beiden Ereignisse werden folgendermaßen gebildet:
(2.27) 1 1 2 2 1 2( , ) ( , , )i i i i i i iP Y y Y y w w ρ+= = = Φ
mit 1 2i i iq qρ ρ+ = , 1 1 1 1i i iw q X β= , 2 2 2 2i i iw q X β= und 1 12 1i iq y= − , 2 22 1i iq y= − .
Im Gegensatz zum bivariaten Probit-Modell hängt beim simultanen Probit-Modell die
latente Variable der einen Gleichung von der latenten Gleichung der jeweils anderen
Gleichung ab. D.h. es gilt weiterhin das beobachtbare Modell (2.25), aber statt des la-
tenten Modells (2.26) gilt jetzt:
(2.28)* *1 2 1 1 1 1 1 1
* *2 1 2 2 2 2 1 1 1 2
mit ( ) 0, ( ) 1
mit ( ) 0, ( ) 1, ( )i i i i i i
i i i i i i i i
y y X u E u V u
y y X u E u V u Cov u u
γ β
γ β ρ
= + + = =
= + + = = =
Das simultane Probit-Modell ist damit ein simultanes Modell in den latenten Variablen,
nicht in den beobachtbaren. Mann kann zeigen, daß ein simultanes Modell in den beob-
achtbaren Variablen nur dann logisch konsistent ist, wenn es eine rekursive Struktur
aufweist. Ansonsten sind die sogenannte Kohärenzbedingungen verletzt (Blundell and
Smith, 1994).
Das simultane Probit-Modell kann beispielsweise mit der zweistufigen Methode von
Mallar (1977) oder Maddala (1983) geschätzt werden. Bei diesem Verfahren wird zu-
erst die reduzierte Form des Gleichungssystems (2.28) abgeleitet:

58
(2.29)
* 1 1 21 2 11 2 1
1 2 1 2 1 2
* 2 1 22 1 22 1 2
1 2 1 2 1 2
1 1 1
1 1 1
i ii i i
i ii i i
u uy X X
u uy X X
γγ β βγ γ γ γ γ γ
γγ β βγ γ γ γ γ γ
+= + +
− − −+
= + +− − −
Tatsächlich werden im ersten Schritt also die latenten Variablen 1iy und 2iy mit dem
ML-Probit-Schätzer auf das gesamte Set exogener Variablen regressiert:
(2.30)*1 1 1
*2 2 2
i i i
i i i
y X
y X
υ
υ
= Π +
= Π +
Im zweiten Schritt werden die Schätzungen der Latenten in die strukturelle Gleichung
(2.28) eingesetzt. Bei der gegebenen Normierung der Varianzen auf 1 können die Pa-
rameter somit konsistent geschätzt werden durch
(2.31)* *1 2 1 1 1 1
* *2 1 2 2 2 2
ˆ
ˆi i i i
i i i i
y y X u
y y X u
γ β
γ β
= + +
= + + .
Die Schätzung der korrekten Form der Standardfehler ist Maddala (1983) im Abschnitt
7.3 zu entnehmen.
In einer aktuellen ZEW-Studie (Ebling und Janz, 1999) wurde mit diesem Ansatz der
Zusammenhang zwischen Exporttätigkeit und Innovationsverhalten im Dienstleistungs-
sektor simultan untersucht. Ausgangspunkt ist dabei die Analyse der Bestimmungsfak-
toren für die Exportentscheidung von Dienstleistungsunternehmen. Die Innovationsfreu-
digkeit eines Unternehmens wird generell als wichtige Bestimmungsgröße für die Ex-
portentscheidung eines Unternehmens angesehen: Nach Posner (1961) kann (gerade
intra-industrieller) Handel durch Unterschiede in der Technologie, also Innovationen,
begründet werden. Umgekehrt kann jedoch auch argumentiert werden, daß Handel den
Umsatzanteil eines Unternehmens mit seinen neuen Produkten erhöht. Das Unterneh-
men wird daher die Innovationsaktivitäten intensivieren. Die Wirkungsrichtung, ob Ex-
porterfolg durch Innovationsaktivitäten begründet wird oder Exporte vielmehr Innovati-
onsaktivitäten verstärken, ist somit a priori nicht eindeutig.
Die Anwendung des vorgestellten simultanen Probitansatzes auf einen Querschnitt des
Mannheimer Innovationspanels im Dienstleistungssektor führte zu folgenden Ergebnis-
sen:
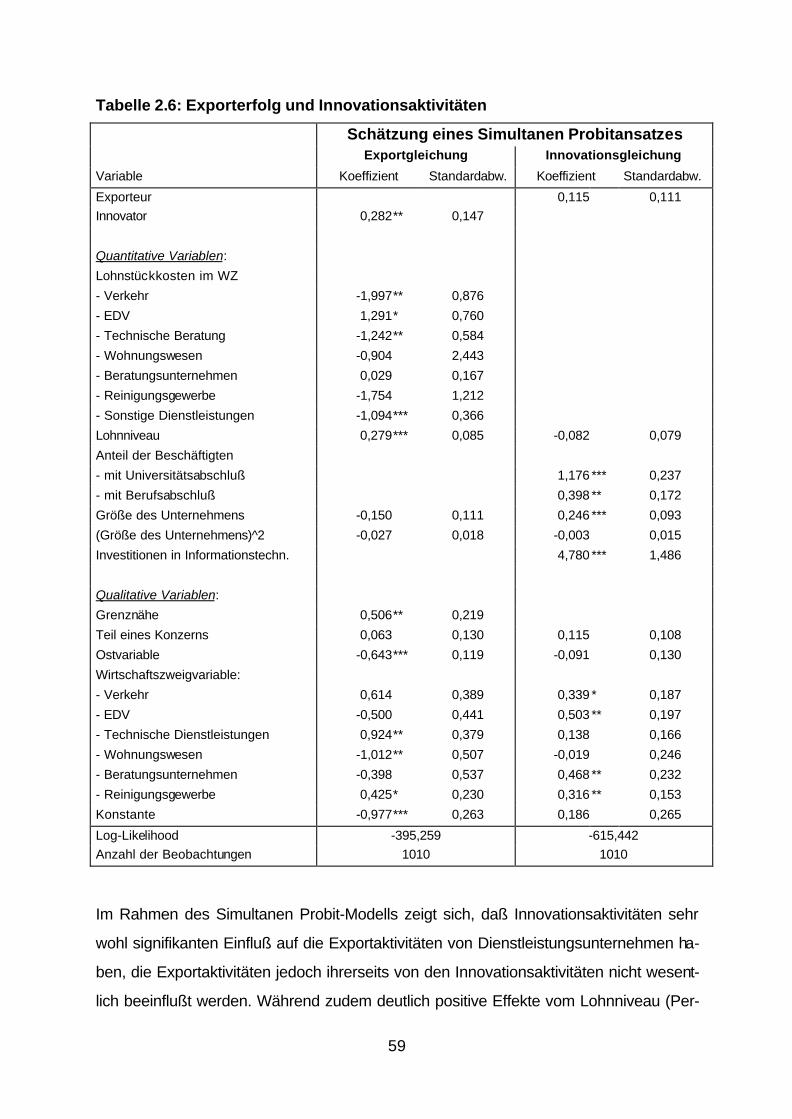
59
Tabelle 2.6: Exporterfolg und Innovationsaktivitäten
Schätzung eines Simultanen ProbitansatzesExportgleichung Innovationsgleichung
Variable Koeffizient Standardabw. Koeffizient Standardabw.
Exporteur 0,115 0,111Innovator 0,282** 0,147
Quantitative Variablen:
Lohnstückkosten im WZ
- Verkehr -1,997** 0,876
- EDV 1,291* 0,760
- Technische Beratung -1,242** 0,584
- Wohnungswesen -0,904 2,443
- Beratungsunternehmen 0,029 0,167
- Reinigungsgewerbe -1,754 1,212
- Sonstige Dienstleistungen -1,094*** 0,366
Lohnniveau 0,279*** 0,085 -0,082 0,079
Anteil der Beschäftigten
- mit Universitätsabschluß 1,176 *** 0,237
- mit Berufsabschluß 0,398 ** 0,172
Größe des Unternehmens -0,150 0,111 0,246 *** 0,093
(Größe des Unternehmens)^2 -0,027 0,018 -0,003 0,015
Investitionen in Informationstechn. 4,780 *** 1,486
Qualitative Variablen:
Grenznähe 0,506** 0,219
Teil eines Konzerns 0,063 0,130 0,115 0,108
Ostvariable -0,643*** 0,119 -0,091 0,130
Wirtschaftszweigvariable:
- Verkehr 0,614 0,389 0,339 * 0,187
- EDV -0,500 0,441 0,503 ** 0,197
- Technische Dienstleistungen 0,924** 0,379 0,138 0,166
- Wohnungswesen -1,012** 0,507 -0,019 0,246
- Beratungsunternehmen -0,398 0,537 0,468 ** 0,232
- Reinigungsgewerbe 0,425* 0,230 0,316 ** 0,153
Konstante -0,977*** 0,263 0,186 0,265
Log-Likelihood -395,259 -615,442Anzahl der Beobachtungen 1010 1010
Im Rahmen des Simultanen Probit-Modells zeigt sich, daß Innovationsaktivitäten sehr
wohl signifikanten Einfluß auf die Exportaktivitäten von Dienstleistungsunternehmen ha-
ben, die Exportaktivitäten jedoch ihrerseits von den Innovationsaktivitäten nicht wesent-
lich beeinflußt werden. Während zudem deutlich positive Effekte vom Lohnniveau (Per-

60
sonalkosten pro Beschäftigtem), das im Rahmen der Studie als Qualifikationsniveau
interpretiert wird, auf die Exportwahrscheinlichkeit festzustellen sind, beeinflussen die
Lohnstückkosten (Personalkosten pro Umsatzeinheit) nur in einzelnen Branchen die
Exportaktivitäten negativ. Hohe Löhne verschlechtern demnach nicht die Exportchancen
von Dienstleistungsunternehmen, wenn sie das Qualifikationsniveau der Unternehmen
reflektieren.
2.2 Modelle für kategoriale abhängige Variablen
2.2.1 Das geordnete Probit-Modell
Das binäre Wahlmodell ist ein Spezialfall allgemeiner Wahlmöglichkeiten. Fragt man
z.B. nach der Erwerbstätigkeit, so ließen sich folgende drei Antworten unterscheiden:
nicht erwerbstätig ( )niy
teilweise (z.B. Teilzeit) erwerbstätig ( )tiy
voll erwerbstätig ( )viy
Das latente Modellteil, das die Neigung eine Erwerbstätigkeit aufzunehmen be-
schreibt, hat wieder folgende Gestalt:
(2.32) * 2mit ~ (0, )i i i iy X u u Nβ σ= +
Der beobachtbare Modellteil läßt sich jetzt durch zwei 0,1 Variable beschreiben, näm-
lich
(2.33)1 wenn die Person erwerbstätig ist0 wenn die Person nicht erwerbstätig ist
eiy
=
1 wenn die Person voll erwerbstätig ist0 wenn die Person teils erwerbstätig ist
viy
=
Alternativ können wir iy in einer Variablen mit 3 Ausprägungen wie folgt kodieren:
(2.34)
0 nicht erwerbstätig
1 Teilzeit beschäftigt2 Vollzeit beschäftigt
iy
=

61
Beide Kodierungen führen zum gleichen Ergebnis. In der ökonometrische Literatur ver-
wendet man in der Regel die Codierung (2.34). Die beobachtbare Variable iy ist dann
ordinal skaliert. Allgemein können wir das latente Modell für 1J + ordinale Kategorien
wie folgt schreiben:
(2.35)
*1*
1 2
*
0 für1 für
für
i
ii
J i
y cc y c
y
J c y
≤ < ≤
= <
M
Für die latente Variable *iy gilt Gleichung (2.32). Die beobachtbaren Zustände ergeben
sich wie folgt aus dem latenten Modell:
(2.36)
1
1
*1*
1 2 2
*
0 bzw.
1 bzw.
bzw.
i i
i i i
J i i
u Xci
X u Xci
i
c X uJ i
y c
c y c cy
J c y
βσ σ σ
β βσ σ σ σ
βσ σ σ
< < −
< < − < < −=
< − <
M
Die Koeffizienten jc werden als Schwellenparameter (Threshold parameter) bezeich-
net, für die gelten muß
(2.37) 1 2 Jc c c< < <L
Man kann zeigen, daß bei 1J > Wahlmöglichkeiten ein Schwellenparameter beliebig
gewählt werden kann, z.B. 1 0c = . Wir sehen sofort, daß es sich beim geordneten Pro-
bit-Modell um eine direkte Verallgemeinerung des Probit-Modells handelt, das für 1J =
das Probit-Modell als Spezialfall enthält. Für die Eintrittswahrscheinlichkeiten gilt im ge-
ordneten Probit-Modell:
(2.38)2
( 0) ( )( 1) ( ) ( )
( ) 1 ( )
i
i i
J i
Xi
X Xci
c Xi
P yP y
P y J
βσ
β βσ σ σ
βσ σ
= = Φ −= = Φ − − Φ −
= = − Φ −M M
Zusätzlich zu den Parametern β und σ werden auch die Schwellenparameter 2 , , Jc cLgeschätzt, die genauso wie die Parameter bis auf einen konstanten Faktor identifiziert
sind. Man setzt daher in der Regel 1σ = .

62
Genau so wie im Probit-Modell der Gleichung (2.11) lassen sich auch für das geordnete
Probit-Modell der Gleichung (2.38) analog zu (2.20) marginale Effekte berechnen. Die-
se lauten im geordneten Probit-Modell:
(2.39)( )2
( 0)( )
( 1)( ) ( )
( )( )
ii k
ik
ii i k
ik
iJ i k
ik
P yX
xP y
X c Xx
P y Jc X
x
φ β β
φ β φ β β
φ β β
∂ == −
∂∂ =
= − − −∂
∂ == −
∂
M M
Kaiser (1998) hat mit den Daten des Mannheimer Innovationspanels untersucht, wel-
chen Einfluß der Einsatz von neuen Technologien auf die erwartete Arbeitsnachfrage
von Dienstleistungsunternehmen hat. Im Rahmen des MIP wurde die Unternehmen ge-
fragt, ob sie für verschieden vorgegebene Qualifikationsstufen (heterogene Arbeit) pla-
nen die Beschäftigung zu senken oder zu erhöhen. Dazu wurde ihnen eine 5er-Likert-
Skala vorgegeben. Die Mitte als der Wert 3 kennzeichnet dabei eine konstante ge-
plante Beschäftigung. Die folgende Tabelle zeigt die Auszüge der Schätzergebnisse für
2 Qualifikationsgruppen (Universitätsabsolventen und Beschäftigte mit abgeschlossener
Berufsausbildung).

63
Tabelle 2.7 Beispiel geordnetes Probit-Modell: Heterogene Arbeitsnachfrage
Hochschulab-solventen
Beschäftigtemit abge-schlossenerBerufsausbil-dung
Arbeitskosten der Qualifikationsgruppe 0,001 -0,004***
IT-Investitionen als Anteil an den Gesamt-investitionen
0,004*** -0,003**
Investitionen pro Kopf 0,020 0,006
Beschäftigte mit Hochschulabschluß (inLogs)
0,035*** -0,033***
Beschäftigte mit abg. Berufsausbildung (inLogs)
-0,001 0,000
potentielle Kreditrationierung (Dummy) 0,022 -0,067
Neue Bundesländer (Dummy) -0,159* -0,197**
Schwellenparameter 1 -1,220 -0,867
Schwellenparameter 2 0,821 0,938
Anzahl der Beobachtungen 1037 1059
Log-Likelihood -829,797 -992,685
*, **, *** kennzeichnen ein Signifikanzniveau von 0,10; 0,05 und 0,01.
Im Rahmen der Schätzung wird für Branchen und Umsatzerwartungen kontrolliert.
Es zeigen sich deutliche Unterschiede zwischen den beiden gewählten Qualifikations-
gruppen in den Beschäftigungserwartungen bzw. -planungen der Unternehmen. Wäh-
rend sich für Beschäftige mit abgeschlossener Berufsausbildung ein negativer Effekt
der Arbeitskosten nachweisen läßt, findet man keinen Effekt bei Hochschulabsolventen.
Die entscheidende Variable war jedoch im Rahmen der untersuchten Fragestellung der
Effekt des Einsatz neuer Technologie (hier: Informations- und Kommunikationstechnolo-
gien). Im Rahmen der Schätzung des geordnete Probit-Modells der Beschäftigungser-
wartungen sehen wir, daß Unternehmen, die relativ viel in Informations- und Kommuni-
kationstechnologien investieren, die Beschäftigung von Hochschulabsolventen auszu-
weiten planen und die Beschäftigung „einfacher“ Mitarbeiter zu senken. Dies läßt sich
sehr vorsichtig als Anzeichen dafür interpretieren, daß der vermehrte Einsatz von IT-
Technologien auch im Dienstleistungssektor einfache Arbeitsplätze vernichtet und an-

64
spruchsvolle schafft. Man spricht in diesem Zusammenhang vom sogenannten skill bias
of technological change (Bound and Johnson, 1992).
2.2.2 Das multinomiale Logit-Modell
Viele mehrdimensionale Kategorien lassen sich jedoch nicht oder nur sehr schwer ge-
eignet ordnen. Konsumentscheidungen für verschieden Marken wie z.B. Automobile
sind hier ein klassisches Beispiel. Modelle für derartige ungeordnete binäre Alternativen
bezeichnet man als multinomiale Modelle. Das kurz hier beschriebene multinomiale
Logit-Modell geht auf Theil (1969) und McFadden (1974) zurück. McFadden (1974)
bezeichnet sein Modell jedoch als konditionales Logit-Modell. Der wesentliche Unter-
schied ist, daß man im multinomialen Logit-Modell die Wahlhandlungen durch die unter-
schiedlichen Eigenschaften der Individuen erklärt, während bei Entscheidungen im kon-
ditionalen Logit-Modell auch spezifische Eigenschaften der Alternativen berücksichtigt
werden können. Beide Modelle sind jedoch sehr ähnlich, so daß wir hier nur kurz auf das
multinomiale Logit-Modell eingehen. Ein einfache Darstellung mit einem Vergleich der
beiden Ansätze findet man bei Greene (1993) in Kapitel 19.7 und sehr viel ausführlicher
bei Maddala (1983) in Kapitel 3. Dort findet man auch weitere Alternativen wie bei-
spielsweise das Multinomiale Probit-Modell (Hausman and Wise, 1978).
Im multinomialen Logit-Modell sind folgende Auswahlwahrscheinlichkeiten in Verallge-
meinerung zu (2.17) für ein Modell mit 1J + Alternative definiert:
(2.40)1
1
1( 0)
1
( ) für 1, ,1
i k
i j
i k
i JX
j
X
i JX
j
P ye
eP y j j J
e
β
β
β
=
=
= =+
= = =+
∑
∑…
Man beachte dabei einen wesentlichen Unterschied zu den bisher betrachteten Model-
len. Die Koeffizienten jβ variieren mit den Alternativen. Im geordneten Probit-Modell
waren die Koeffizienten unabhängig von der betrachteten Alternative. Die Variabilität

65
der Koeffizienten führt im multinomialen Logit-Modell zu erheblichen Interpretations-
problemen.
Die Koeffizienten sind somit nur relativ interpretierbar. In Gleichung (2.40) wurden die
Parameter 0β willkürlich zu Normierungszwecken auf 0 gesetzt. Wir hätten ebenso
auch jeden anderen Parametervektor wählen können. Die Koeffizienten erklären daher
nur die Unterschiede in den Präferenzen zur gewählten Normierung:
(2.41)( )
ln( 0)
ii j
i
P y jX
P yβ
== =
Insbesondere diese Einschränkung macht die Anwendung des Multinomialen Logit-
Modells für die Praxis nicht sehr attraktiv. Die Schätzung des Multinomialen Logit-
Modells ist wie auch im Logit-Modell die übliche Maximum-Likelihood-Schätzung bei
der die individuellen Beiträge über die Gleichung (2.40) definiert sind.
2.3 Modelle für beschränkte abhängige Variablen
2.3.1 Das Tobit-Modell
Typisch für Mikrodaten im allgemeinen und Querschnittsdaten im besonderen sind auch
sogenannte beschränkte abhängige Variablen (limited dependent variables). Will
man beispielsweise auf der Mikroebene das Arbeitsangebot von Individuen erklären, so
läßt es sich nur für diejenigen Personen beobachten, die auch tatsächlich arbeiten. Bei
Arbeitslosen ist das beobachtbare Arbeitsangebot auf den Wert Null beschränkt. Ein
weiteres Beispiel sind Kaufentscheidungen für dauerhafte Konsumgüter, die nicht in
jeder Periode erfolgen, die Höhe der Ausgaben ist also in vielen Perioden auf den Wert
Null beschränkt.
Ein Modellansatz, der mit derartigen Beobachtungen für abhängige Variable umgehen
kann, wurde von Tobin (1958) entwickelt. Tobin (1958) erweitert das binäre Probit-
Modell insofern, als – um im Beispiel der dauerhaften Konsumgüter zu bleiben − neben
der Entscheidung, dauerhafte Konsumgüter zu kaufen oder nicht, die Entscheidung über
die Ausgabenhöhe simultan berücksichtigt wird. Es wird daher nach ihm auch Tobit-
Modell genannt. Die erklärenden Variablen iX beeinflussen in diesem Ansatz sowohl
die Wahrscheinlichkeit des Ausgabenereignisses als auch die unterschiedliche Höhe

66
der Ausgaben. Einen sehr lesenswerten Überblick über verschiedene Spezifikationen
des Tobit-Modells findet man bei Amemiya (1985) in Kapitel 10.
Die Nullbeobachtungen im Tobit-Modell führen zu einer Konzentration von Beob-
achtungen im Punkt Null, die das Problem mit sich bringt, daß eine gewöhnliche KQ-
Schätzung zu verzerrten und inkonsistenten Schätzergebnissen führt. Die Verzerrtheit
und Inkonsistenz rühren daher, daß in einer Regression über alle Individuen die KQ-
Schätzung einen linearen Zusammenhang erzwingt, der aufgrund der Beobachtungs-
konzentration unangebracht ist. Doch selbst wenn die Regression nur über die Individu-
en erfolgt, für die Ausgaben bzw. Arbeitsangebote beobachtbar sind, treten verzerrte
und inkonsistente Schätzer auf. Denn in dem Fall ist die KQ-Schätzung mit einem sam-
ple selection bias (vgl. dazu auch Heckman, 1976 und 1979) behaftet, da die Schät-
zung annimmt, die Stichprobe bestünde nur aus den verwendeten Beobachtungen, ob-
gleich auch die vernachlässigten "Nullbeobachtungen" der Stichprobe angehören.
Im folgenden wird anhand eines einfachen Modells zur Erklärung der Ausgaben für dau-
erhafte Konsumgüter veranschaulicht, wie Nachfragegleichungen in Querschnittsmo-
dellen unter Beachtung der Konzentration von Beobachtungswerten im Punkt Null ge-
schätzt werden können. Ein solches Modell, das der Beobachtungskonzentration ge-
recht wird, läßt sich wie folgt formulieren.
Für die endogene Variable, die in diesem Fall als Konsumneigung interpretiert werden
kann, nehmen wir wie im Probit-Modell (vgl. Gleichung (2.11)) ein latentes Modell an:
Latenter Modellteil
(2.42) * 2mit (0, )i i i iy X u u Nβ σ= + ∼
Beobachtet werden kann jedoch nur eine positive Kaufentscheidung:
Beobachtbarer Modellteil
(2.43)* *
*
wenn 0 bzw.0 wenn 0 bzw.
i i i i i ii
i i i
y X u y u Xy
y u Xβ σ β σ
σ β σ
= + > > −=
≤ ≤ −
*iy bezeichnet die latente endogene Variable, hier die gewünschten Ausgaben für ein
dauerhaftes Konsumgut, wie sie sich z.B. aus der Maximierung einer Nutzenfunktion
unter Berücksichtigung einer Budgetbeschränkung ergeben. Sie ist nicht direkt beob-

67
achtbar und hängt von direkt beobachtbaren Variablen iX ab. Die latente Variable ist
nur dann auch beobachtbar, wenn sie positiv ist: * 0iy > . Im Beispiel: Die Ausgabenent-
scheidung wird nur dann getroffen, wenn die gewünschten Ausgaben positiv sind, bei
negativen optimalen Ausgaben (eine Art Desinvestition) finden keine Ausgaben statt.
Wird die Gleichung i i iy X uβ= + mit Hilfe der KQ-Methode geschätzt, dann wird implizit
unterstellt, daß im Mittel die systematische Komponente iX β gilt, d.h. ( )i iE y X β= . Tat-
sächlich gelten aufgrund der Beobachtungskonzentration unter der Annahme einer nor-
malverteilten Störung 2(0, )iu N σ∼ jedoch die folgenden Erwartungswerte. Dazu sortie-
ren wir die Stichprobe vom Umfang N in die ersten M Individuen, für die die latente
Variable beobachtbar ist, und die N M− Individuen, für die sie nicht beobachtet werden
kann.
Für die Teilstichprobe ( 1, , )i M= … gilt
(2.44)( ) ( )
( )( )
*| 0 |i i i i i i
ii
i
E y y X E u u X
XX
X
β β
φ β σβ σ
β σ
> = + > −
= +Φ
und für die gesamte Stichprobe ( 1, , )i N= …
(2.45)
( ) ( ) ( ) ( )
( ) ( )( )
* * * *
0
( ) 0 | 0 0 | 0
/
i i i i i i i
ii i
i
E y P y E y y P y E y y
XX X
Xφ β σ
β σ β σβ σ
= > ⋅ > + ≤ ⋅ ≤
= Φ ⋅ +
Φ
1442443
Der Ausdruck ( / ) ( / ) / ( / )i i iX X Xλ β σ φ β σ β σ= Φ wird als Inverse von Mills-Ratio be-
zeichnet und hat im Rahmen der Tobit-Modelle eine besondere Bedeutung. Der Erwar-
tungswert (2.44) ist der Erwartungswert einer im Punkt 0iy = abgeschnittenen oder
trunkierten Normalverteilung, der Erwartungswert (2.45) ist der Erwartungswert für eine
im Punkt 0iy = zensierten Normalverteilung. Während bei der trunkierten Normalvertei-
lung alle Beobachtungen 0< nicht beobachtet sind (banal gesprochen: einfach fehlen),
sind diese Beobachtungen bei der zensierten Verteilung auf den Wert 0 gesetzt, d.h.
die gesamte Wahrscheinlichkeitsmasse konzentriert sich im Punkt 0 .

68
Die KQ-Schätzung ist demnach insofern fehlspezifiziert, als mit dem systematischen
Modellteil iX β bestimmte erklärende Variablen vernachlässigt sind. Wird die lineare
Regression i i iy X uβ= + z.B. nur über die ersten M Beobachtungen durchgeführt, dann
rührt die Fehlspezifikation daher, daß die Variable ( / ) ( / ) / ( / )i i iX X Xλ β σ φ β σ β σ= Φ
unberücksichtigt bleibt (Heckman, 1979). Konsistente KQ-Schätzer sind aber möglich,
wenn in einer Regression über alle N Beobachtungen
( / ) [ ( / ) / ( / )]i i i iX X X Xβ σ β σφ β σ β σΦ − ⋅ + Φ bzw. in einer Regression, die ersten M
Beobachtungen umfaßt, ( / ) / ( / )i i iX X Xβ σφ β σ β σ+ Φ als systematischer Modellteil
verwendet wird. Diese Eigenschaften werden uns später im Rahmen der zweistufigen
Heckman-Schätzung zu Nutze machen.
2.3.2 Maximum-Likelihood-Schätzung des Tobit-Modells
Die Likelihoodfunktion des Tobit-Modells wird analog zur Likelihoodfunktion des Probit-
Modells (2.12) gebildet. Sie stellt sich in Form:
(2.46)
* *
1 1
1
1 1
( ) ( 0)
[( ) / ] ( / )
1 ( / )
M N
Tobit i i ii i M
M N
i i ii i M
i
L P y y P y
y X X
X
σ φ β σ β σ
β σ
= = +
−
= = +
= = ⋅ ≤
= − ′ Φ −
−Φ
∏ ∏
∏ ∏ 1442443
dar, wobei das erste Produkt die ersten M Individuen betrifft, für die die latente Vari-
able beobachtbar ist, das zweite Produkt die N - M Individuen, für die sie nicht beo-
bachtet werden kann.
Durch eine Umformulierung der Likelihoodfunktion (2.46) in:
(2.47) 1 [( ) / ]( ) (1 ( ))
( / )i i
Tobit i iM M N Mi
y XL X X
Xφ β σ
σ β ββ σ
−
−
−= Φ − Φ
Φ∏ ∏ ∏
wird ersichtlich, daß das Tobit-Modell 2 Spezialfälle enthält: Der Faktor
(2.48) 1 [( ) / ]( )
i iTrunk
M i
y XL
Xφ β σ
σβ
− −=
Φ∏
beschreibt die Likelihoodfunktion eines trunkierten Modells, in dem Beobachtungen
0iy = gänzlich aus der Analyse ausgeschlossen sind. Der zweite Teil von (2.47)

69
(2.49) ( / ) (1 ( ))probit i iM N M
L X Xβ σ β−
= Φ − Φ∏ ∏
ist hingegen identisch mit der Likelihoodfunktion für das Probit-Modell, wie es in (2.12)
hergeleitet wurde.
Amemiya (1973, 1985) hat gezeigt, daß man durch Maximierung der logarithmierten
Likelihoodfunktion folgende ML-Schätzfunktionen erhält.
(2.50) 1 1 ˆˆ ˆ( ) ( )X X X y X X Xβ σ λ− −= ′ ′ − ′ ′
wobei ( )1 , , MX X X ′′ ′= L , ( )1 , , My y y ′= L ( )1, ,
M NX X X+
′′ ′= L und ( )1ˆ ˆ ˆ,M Nλ λ λ+
′= L mit
ˆˆ
ˆi
ii
φλ =
Φ
Der erste Summand in Gleichung (2.50) ist der KQ-Schätzer der Beobachtungen mit
0iy > . Der ML-Schätzer des Tobit-Modells setzt sich also aus dem KQ-Schätzer der
Fälle mit 0iy > und einem Term zusammen, der die Beobachtungen für 0iy = umfaßt.
Eine Schätzung für 2σ erhält man aus
(2.51) 2 1 ˆˆ ( )y y y XM
σ β= ′ − ′
Amemiya hat gezeigt, daß der Schätzer konsistent, asymptotisch normal und asympto-
tisch effizient ist; er ist gegenüber dem Probit-Schätzer von einer höheren asymp-
totischen Effizienz, da er mehr Informationen verarbeitet. Olsen (1978) hat zudem die
globale Konkavität der Tobit-Likelihoodfunktion nachgewiesen.
Die Konsistenzeigenschaft ist allerdings nicht gewährleistet, wenn eine der Modell-
annahmen (Homoskedastizität, identische Parameter für alle Individuen oder die An-
nahme der Normalverteilung) verletzt ist. Deshalb ist die Überprüfung dieser Annahmen
besonders wichtig. Lee and Maddala (1985) haben für das Tobit-Modell entsprechende
Tests zusammengestellt. Neuere Testverfahren findet man auch bei Greene (1993) in
Kapitel 20 und sehr ausführlich im Sonderheft des Journal of Econometrics von Blundell
(1987). Inzwischen sind Erweiterungen des Tobit-Models, die Heteroskedastizität zulas-
sen, auch in der Standardsoftware relativ einfach umzusetzen und sehr zu empfehlen
(vgl. Czarnitzki und Stadtmann, 1999).

70
In RATS kann die Maximum-Likelihood-Schätzung wie folgt geschrieben werden:
NONLIN SIGMASQ
LINREG Y
# CONSTANT X1 X2
FRML (LASTREG, NAMES = ´B´, ADDPARMS) RHSFRML
COMPUTE SIGMASQ = % SEESQ
FRML TOBIT = (Z=RHSFRML (T)), % IF (%VALID (Y), $
-.5* LOG (SIGMASQ) - .5* (Y-Z) **2/SIGMASQ, $
LOG (%CDF ((TR-RHSFRML)/SQRT ( SIGMASQ)))
MAXIMIZE (METHOD = BFGS) TRUNCATE
2.3.3 Zweistufige Heckman-Schätzung des Tobit-Modells
Da es Zeiten gab, zu denen die Tobit-Schätzung nach der ML-Methode sehr rechen-
zeitaufwendig waren, schlug Heckman (1976) einen Schätzer vor, der weitgehend auf
die KQ-Schätzung zurückgreift. Ausgangspunkt ist der Sample-Selection-Bias für das
Tobit-Modell, wenn man den Teil des Samples mit 0iy > berücksichtigt (vgl. Herleitung
zu (2.44).
(2.52)*( | 0) ( | )
( / ) / ( / )i i i i i i
i i i
E y y X E u u XX X X
β ββ σφ β σ β σ
> = + > −= + Φ
Die Fehlspezifikation, als die Heckman (1979) den Sample-Selection-Bias interpretiert,
besteht also darin, daß das lineare Regressionsmodell i i iy X uβ= + die Variable
( / ) / ( / )i iX Xσφ β σ β σΦ nicht berücksichtigt. Eine konsistente KQ-Schätzung ist mög-
lich, wenn man anstelle des linearen Regressionsmodells das Modell
(2.53)( / )( / )i
ii i
i
Xy X
Xφ β σ
β σ εβ σ
= + +Φ
für diejenigen Beobachtungen mit 0iy > verwendet. Der Störterm *( 0)i i i iy E y yε = − >
der Gleichung (2.53) hat die Eigenschaften ( 0)iE ε = und
( ) ( )( )22 2( ) 1i i i i iV X X Xβ β βσ σ σε σ σ λ λ= Σ = − − . Gleichung (2.53) entspricht also einem
linearen Regressionsmodell mit heteroskedastischen Störgrößen. Das Problem besteht

71
dann nur darin, in einer ersten Stufe standardisierte Parameter βσ zu schätzen um
( / ) / ( / )i iX Xφ β σ β σΦ evaluieren zu können. Heckman (1976) hat daher folgendes
zweistufige Verfahren vorgeschlagen: 1. Schätze mit einer ML-Probit-Schätzung die
standardisierten Koeffizienten βσ und bestimme daraus ( / ) / ( / ).i iX Xφ β σ β σΦ 2.
Schätze die Parameter β und σ aus der Gleichung (2.53) mit der KQ-Methode. Die
Kleinstquadratschätzung von Gleichung (2.53) führt zu einer konsistenten, aber nicht
effizienten Schätzung der Parameter β und σ . Insbesondere sind Standardfehler, die
eine Standardsoftware ausweist, verzerrt, da sie weder die Heteroskedastizität in iε
noch die Tatsache, daß ( / ) / ( / )i iX Xφ β σ β σΦ auf einer ersten Stufe geschätzt und da-
mit selbst mit Schätzfehlern behaftet ist, berücksichtigen. Der zweistufige Heckman-
Schätzer für ( , )γ β σ′ ′= ist asymptotisch normalverteilt.
Das Verfahren von Heckman (1976,1979) läßt sich viel allgemeiner anwenden, um die
Selektionsverzerrung im Rahmen eines linearen Modells zu korrigieren. Die Sample-
Selektion kann beispielsweise von ganz anderen als den Variablen des Modells
( ) / ( )i iX Xφ β βΦ abhängen. Das Vorgehen bleibt gleich.
2.3.4 Marginale Effekte im Tobit-Modell
Ähnlich wie im Probit-Modell messen die Koeffizienten β die marginalen Effekte der
erklärenden Variablen iX auf die latente endogene Variable *iy , nicht die marginalen
Effekte auf die beobachtete Variable iy (vgl. (2.20)). Im Tobit-Modell lassen sich die
Erwartungswerte der latenten Variablen sowie der bedingten und unbedingten beo-
bachteten Variablen unterscheiden:
(2.54) *( )i iE y X β=
(2.55) ( ) ( )*| 0i i i iE y y X Xβ σλ β σ> = +
(2.56) ( ) ( ) ( )i i i iE y X X Xβ σ β σλ β σ= Φ +
Die dazugehörigen partiellen Ableitungen ergeben die marginalen Effekte im Tobit-
Modell:

72
(2.57)*( )i
kik
E yx
∂β
∂=
(2.58) ( ) ( )*
2( | 0)1i i i
k i iik
E y y XX X
x∂ β
β λ β σ λ β σ∂ σ
> = − −
(2.59) ( ) ( ) ( ) ( )| 0( )| 0i i ii
i i iik ik ik
E y y XE yX E y y
x x x∂ ∂ β σ∂
β σ∂ ∂ ∂
> Φ= Φ + <
( ) ( ) ( )
( )( )
( )
2( )1
( )
i ii k i i
ik
i ki i
ki
E y XX X X
xX
X X
X
∂ ββ σ β λ β σ λ β σ
∂ σφ β σ β
β σλ β σσ σ
βφ β σ
σ
= Φ − −
+ +
=
Daraus wird ersichtlich, daß kβ weder den marginalen Einfluß der Variablen ikx auf die
beobachtbare Variable aller Individuen, noch den marginalen Effekt auf die beobachtete
Variable derjenigen Individuen darstellt, für die sie beobachtet werden kann. kβ gibt
lediglich zum Ausdruck, wie sich die latente Variable *iy aufgrund einer marginalen Än-
derung von ikx verändert. Der Ausweis der marginalen Effekte auf die tatsächlich beo-
bachtete Variable ist jedoch für die Interpretation der Schätzergebnisse immer vorzu-
ziehen.
2.3.5 Beispiel: Zuschauerzahlen bei Fußballbundesliga-Spielen
Czarnitzki und Stadtmann (1999) vom ZEW in Mannheim und der WHU in Koblenz ha-
ben im Rahmen einer Studie die Bestimmungsgründe der Zuschauerzahlen von Fußball-
Bundesligaspielen der Saisons 1996/1997 sowie 1997/1998 untersucht. Sie untersu-
chen 2 unterschiedliche Modelle, die bereits in Belgien bzw. Schottland für entspre-
chende Studien verwendet worden sind.
Die latente zu erklärende Variable *iy ist der Zuschauerzuspruch eines Bundesliga-
spiels (die Daten sind über die Saison gepoolt). Der Zuschauerzuspruch ist jedoch im
Unterschied zu den obigen Ausführungen von oben zensiert durch die maximale Kapa-
zität der Stadien. Das Stadion kann also ausverkauft sein:

73
(2.60)* *
*
wennwenn
i i i i ii
i i i
y X u y cy
c y cβ = + ≤
= >
Die Zensierung ist also rechtsseitig und zudem noch individuell variierend. Diese Er-
weiterung führt aber zu keinen weiteren Problemen, solange der Zensierungspunkt be-
kannt ist. Zudem erlauben die Autoren Heteroskedastizität der Form 2 2 iwi e ασ σ= , wobei
iw Teile der erklärenden Variablen iX umfaßt. Die Likelihoodfunktion des Tobit-
Modells (2.46) läßt sich einfach anpassen zu:
(2.61)1
1i i i
i i i i
i i i iTobit w w w
y c y c
y X c XL
e e eα α α
β βφ
σ σ σ≤ >
− − = + − Φ
∏ ∏
Als erklärende Variablen iX dienen:
- Marktgröße der Heimmannschaft (gemessen als Bevölkerung pro Bundesligaklub ineiner Stadt)
- Marktgröße der Gastmannschaft (gemessen wie oben, dividiert durch dieEntfernung vom Austragungsort)
- Tabellenplatz der Heimmannschaft
- Tabellenplatz der Gastmannschaft
- Reputation der Heimmannschaft (gemessen als Performanceindex über dieletzten 6 Jahre)
- Reputation der Gastmannschaft (gemessen wie oben)
- Unsicherheitsmaß für die Heimmannschaft (Funktion, die den Abstand der zumErreichen der Meisterschaft notwendigen Punkte zu den bisher erreichten Punk-ten mißt)
- Unsicherheitsmaß für die Gastmannschaft (gemessen wie oben)
- Spieltag der Saison
- Maß für das Fan-Potential (gemessen als Anzahl der Fanclubs der Auswärtsmann-schaft, invers gewichtet mit der Entfernung zum Austragungsort)
- Temperatur zur Spielzeit
Folgende Ergebnisse ergeben sich für das Tobit-Modell und die heteroskedastische
Erweiterung:

74
Tabelle 2.8: Zuschauerzahlen bei Fußballbundesligaspiele
Variable HomoskedastischesTobit-Modell
HeteroskedastischesTobit-Modell
Marktgröße Heim 9,16*** 7,97***
Marktgröße Gast 22,54*** 17,07***
Tabellenplatz Heim -413,17*** -481,41***
Tabellenplatz Gast -165,94 -162,89
Reputation Heim 766,50*** 765,37***
Reputation Gast 310,05*** 313,00***
Unsicherheit Heim 420,60 222,65
Unsicherheit Gast 321,99** 314,77
Spieltag 195,93*** 187,53***
Fan-Potential 1339,03*** 989,93***
Temperatur 299,07*** 219,15***
Konstante 13205,47 16201,00***
σ 9934,44 9022,72
Log-Likelihood -4339,12 -4302,01
N 513 513
LR-Test auf Heterosked. 74,22***
LM-Test auf Heterosked. 82,10***
Die ausgewiesenen Schätzwerte sind die marginalen Effekte. Die wesentlichen Ergeb-
nisse lassen sich anhand des heteroskedastischen Tobit-Modells folgendermaßen in-
terpretieren: Jede Verbesserung des Tabellenplatzes der Heimmannschaft führt im
Durchschnitt zu 481 Zuschauern mehr, d.h. ein Verein kann als Tabellenführer ungefähr
8.200 Zuschauer mehr erwarten denn als Tabellenletzter. Die Reputation sowohl der
Heim- als auch der Gastmannschaft ist sehr bedeutend für den Zuschauerzuspruch. Ein
Team, das im Vorjahr Meister war, kann gegenüber einer Mannschaft, die Tabellen-
zehnter war, ungefähr 12.000 Zuschauer mehr erwarten. Ebenso spielen Fanclubs eine
bedeutende Rolle. Der Unterschied zwischen dem schlechtesten Potentialmaß und dem
besten betrug ungefähr 14.000 Zuschauer. Natürlich ist, wie zu erwarten, auch das
Wetter gemessen als Temperatur von großer Bedeutung.

75


















