
3. Mikroprozessor 8086 - alt.ife.tugraz.atalt.ife.tugraz.at/LV/Skripten/gemp1_kap3.pdf ·...
29
GEMP1 Kap3 - 1 3. Mikroprozessor 8086 • 16bit Datenbus (extern und intern) • 20bit Adressbus (2 20 byte physikalischer Speicher adressierbar) • Getrennter I/O – Adressraum (64 kbyte, keine Segmentierung)
Transcript of 3. Mikroprozessor 8086 - alt.ife.tugraz.atalt.ife.tugraz.at/LV/Skripten/gemp1_kap3.pdf ·...

GEMP1 Kap3 - 1
3. Mikroprozessor 8086
• 16bit Datenbus (extern und intern) • 20bit Adressbus (220 byte physikalischer Speicher adressierbar) • Getrennter I/O – Adressraum (64 kbyte, keine Segmentierung)

GEMP1 Kap3 - 2

GEMP1 Kap3 - 3

GEMP1 Kap3 - 4
Schnittstellenbausteine haben häufig einen 8Bit Datenport. Sie können an einen 16Bit Datenbus entweder an die untere oder an die obere Datenbushälfte angeschlossen werden. Entsprechend belegen ihre Register entweder nur gerade oder ungerade Adressen. Eine andere Möglichkeit besteht in der Konvertierung des 16Bit Datenbusses in einen 8Bit Datenbus für einen bestimmten Bereich des I/O-Adressraumes.
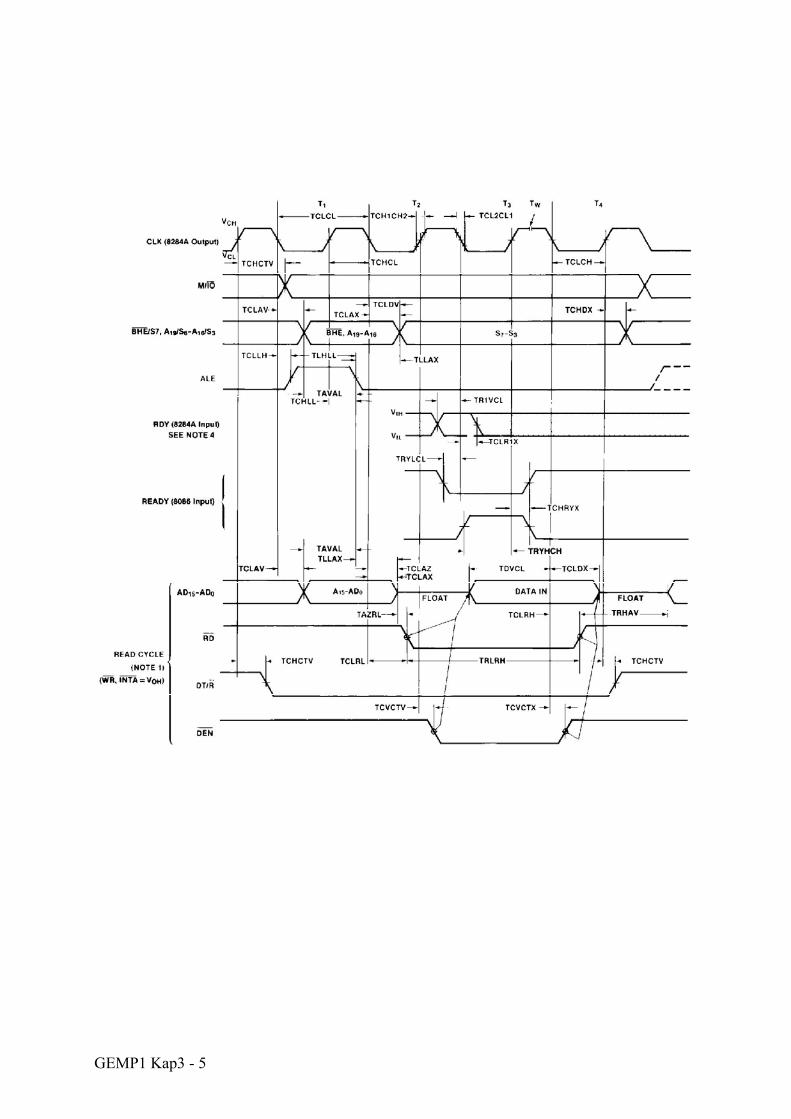
GEMP1 Kap3 - 5

GEMP1 Kap3 - 6

GEMP1 Kap3 - 7
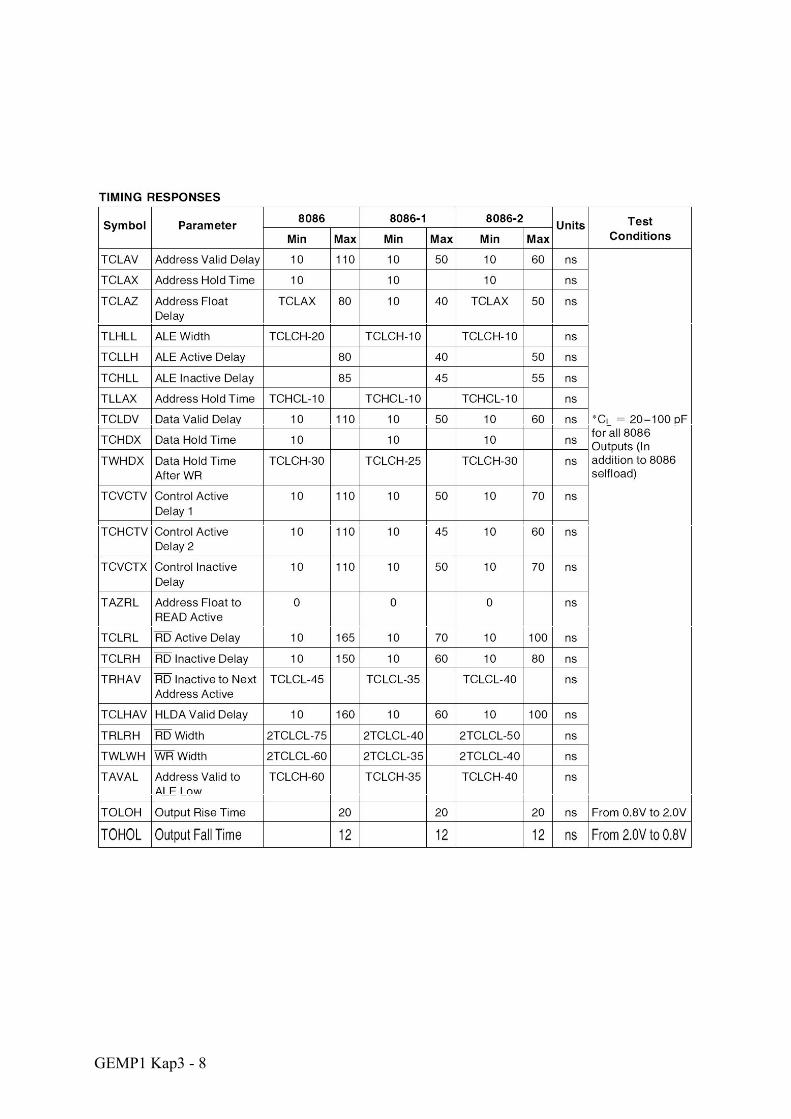
GEMP1 Kap3 - 8
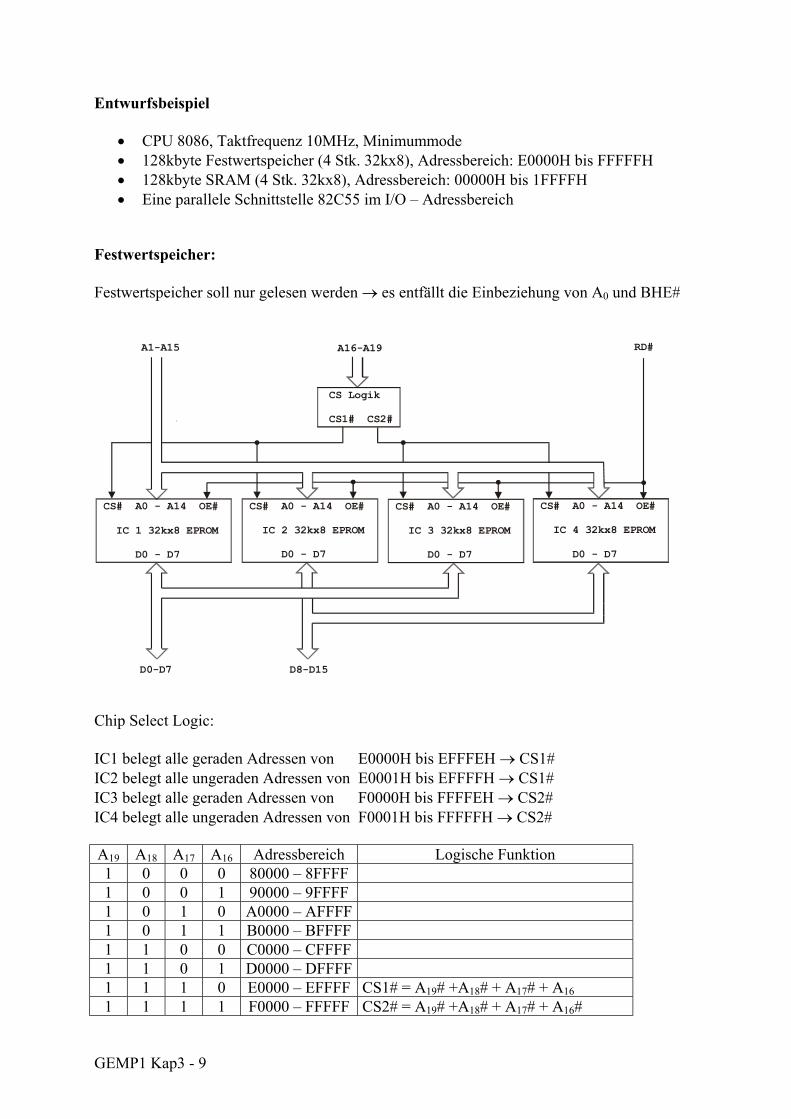
GEMP1 Kap3 - 9
Entwurfsbeispiel
• CPU 8086, Taktfrequenz 10MHz, Minimummode • 128kbyte Festwertspeicher (4 Stk. 32kx8), Adressbereich: E0000H bis FFFFFH • 128kbyte SRAM (4 Stk. 32kx8), Adressbereich: 00000H bis 1FFFFH • Eine parallele Schnittstelle 82C55 im I/O – Adressbereich
Festwertspeicher: Festwertspeicher soll nur gelesen werden → es entfällt die Einbeziehung von A0 und BHE#
Chip Select Logic: IC1 belegt alle geraden Adressen von E0000H bis EFFFEH → CS1# IC2 belegt alle ungeraden Adressen von E0001H bis EFFFFH → CS1# IC3 belegt alle geraden Adressen von F0000H bis FFFFEH → CS2# IC4 belegt alle ungeraden Adressen von F0001H bis FFFFFH → CS2# A19 A18 A17 A16 Adressbereich Logische Funktion 1 0 0 0 80000 – 8FFFF 1 0 0 1 90000 – 9FFFF 1 0 1 0 A0000 – AFFFF 1 0 1 1 B0000 – BFFFF 1 1 0 0 C0000 – CFFFF 1 1 0 1 D0000 – DFFFF 1 1 1 0 E0000 – EFFFF CS1# = A19# +A18# + A17# + A16 1 1 1 1 F0000 – FFFFF CS2# = A19# +A18# + A17# + A16#
CS# A0 - A14 OE#
IC 1 32kx8 EPROM
D0 - D7
CS# A0 - A14 OE#
IC 2 32kx8 EPROM
D0 - D7
CS# A0 - A14 OE#
IC 3 32kx8 EPROM
D0 - D7
CS# A0 - A14 OE#
IC 4 32kx8 EPROM
D0 - D7
CS Logik
CS1# CS2#
A1-A15 A16-A19 RD#
D0-D7 D8-D15

GEMP1 Kap3 - 10
Auszug aus dem Datenblatt FM27C256:
Aus den jeweiligen Datenblättern: Address latch: TIVOVlatch max = 35ns Bus buffer: TIVOVbuffer max = 35ns Chip Select Logic: TIVOVCS-Logic = 18ns Für einen Zugriff ohne Wartezyklen sind vom EPROM folgende Zeiten einzuhalten:
• Address to Output Delay (tACC): TAVDV = 3TCLCL – TDVCL – TCLAVmax – TIVOVlatch – TIVOVbuffer = = 300ns – 5ns – 50ns – 35ns –35ns = 175ns
• Chip Enable to Output Delay (tCE):
TSVDV = TAVDV – TIVOVCS-Logic = 175ns – 18ns = 157ns
• Output Enable to Output Delay (tOE): TRLDV = 2TCLCL – TCLRLmax – TDVCL – TIVOVbuffer = = 200ns – 70ns – 5ns – 35ns = 90ns

GEMP1 Kap3 - 11
• Output Disable to Output Float (tDF):
Für ungepufferten Datenbus: TRHAV = TCLCL – 35ns = 100ns – 35ns = 65ns • Output Hold (tOH):
TRHDX = TCLDX – TCLRHmin = 10ns –10ns = 0ns Das verwendete EPROM genügt den Anforderungen. Schreib-/Lesespeicher: Chip Select Logic: IC5 belegt alle geraden Adressen von 00000H bis 0FFFEH → CS3# IC6 belegt alle ungeraden Adressen von 00001H bis 0FFFFH → CS3# IC7 belegt alle geraden Adressen von 10000H bis 1FFFEH → CS4# IC8 belegt alle ungeraden Adressen von 10001H bis 1FFFFH → CS4# A19 A18 A17 A16 M/IO# Adressbereich Logische Funktion 0 0 0 0 1 00000 – 0FFFF CS3# = A19 + A18 + A17 + A16 + (M/IO#)# 0 0 0 1 X 10000 – 1FFFF CS4# = A19 + A18 + A17 + A16# 0 0 1 0 X 20000 – 2FFFF 0 0 1 1 X 30000 – 3FFFF 0 1 0 0 X 40000 – 4FFFF 0 1 0 1 X 50000 – 5FFFF 0 1 1 0 X 60000 – 6FFFF 0 1 1 1 X 70000 – 7FFFF
CS# A0-A14 OE# WE#
IC 5 32kx8 SRAM
D0 - D7
CS# A0-A14 OE# WE#
IC 6
D0 - D7
32kx8 SRAM
CS# A0-A14 OE# WE#
IC 7
D0 - D7
32kx8 SRAM
CS# A0-A14 OE# WE#
IC 8
D0 - D7
32kx8 SRAM
CS Logik
CS3# Cs4#
A1-A15 A16-A19 RD#
D0-D7 D8-D15
M/IO#
= =1 1
A0 WR# BHE#

GEMP1 Kap3 - 12
Auszug aus dem Datenblatt IS62C256: Lesezyklus:
Für den Lesezugriff sind die selben Betrachtungen anzustellen wie beim EPROM. Die Zeiten sind hier durchwegs kürzer, sodass die Bedingungen sicher erfüllt sind. Schreibzyklus:

GEMP1 Kap3 - 13
Für den Schreibzugriff sind folgende Zeiten zu ermitteln:
• Write Cycle Time (tWC): TAVAV = 4TCLCL = 400ns
• Address Setup Time to Write End (tAW):
TAVWH = 3TCLCL – TCLAVmax + TCVCTXmin – TIVOVlatch = = 300ns – 50ns + 10ns – 35ns = 225ns
• CS# to Write End (tSCS):
TSVWH = TAVWH – TIVOVCS-Logic = 225ns – 18ns = 207ns
• Address Hold from Write End (tHA): TWHAX = TCLCL –TCVCTXmax + TCLLHmin – tPDmaxLS32 = = 100ns – 50ns + 0ns – 11ns = 39ns
• Address Setup Time (tSA):
TAVWL = TCLCL – TCLAVmax + TCVCTVmin – TIVOVlatch + tPDminLS32= = 100ns – 50ns + 10ns – 35ns + 0ns = 25ns
• WE# Pulse Width (tPWE):
TWLWH = 2TCLCL – 35ns = 200ns –35ns = 165ns
• Data Setup to Write End (tSD): TDVWH = 2TCLCL – TCLDVmax + TCVCTXmin – TIVOVbuffer + tPDminLS32= = 200ns – 50ns + 10ns – 35ns + 0ns = 125ns
• Data Hold from Write End (tHD):
TWHDX – tPDmaxLS32 = TCLCH –25ns –11ns = 53ns – 25ns – 11ns = 17ns Die erforderlichen Zeiten werden alle eingehalten.
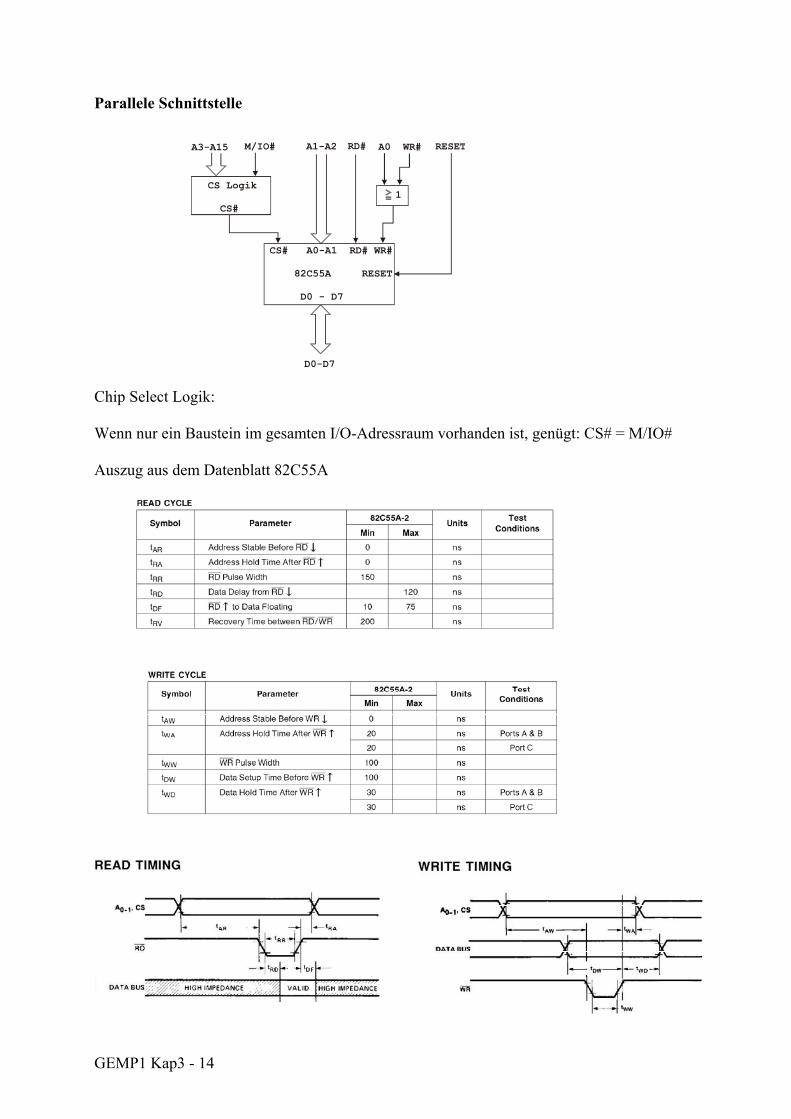
GEMP1 Kap3 - 14
Parallele Schnittstelle Chip Select Logik: Wenn nur ein Baustein im gesamten I/O-Adressraum vorhanden ist, genügt: CS# = M/IO# Auszug aus dem Datenblatt 82C55A
CS Logik
CS#
A1-A2A3-A15 RD#
D0-D7
M/IO#
CS# A0-A1 RD# WR#
82C55A RESET
D0 - D7
= 1
A0 WR# RESET

GEMP1 Kap3 - 15
Lesezugriff:
• Address Stable Before RD# (tAR): TAVRL = TCLCL + TCLRLmin – TCLAVmax – TIVOVlatch = = 100ns + 10ns – 50ns – 35ns = 25ns
• Address Hold Time After RD# (tRA):
TRHAX = TCLCL – TCLRHmax + TCLLHmin = 100ns – 60ns + 0ns = 40ns
• RD# Pulse Width (tRR): TRLRH = 2TCLCL – 40ns = 200ns – 40ns = 160ns
• Data Delay from RD# (tRD):
TRLDV = 2TCLCL – TCLRLmax – TDVCL – TIVOVbuffer = = 200ns – 70ns – 5ns – 35ns = 90ns
• RD# to Data Floating (tDF): Für ungepufferten Datenbus: TRHAV = TCLCL – 35ns = 100ns – 35ns = 65ns !!
• Recovery Time between RD#/WR# (tRV):
TRLRL = 4TCLCL = 400ns Schreibzugriff:
• Address Stable bfore WR# (tAW): TAVWL = TCLCL + TCVCTVmin – TCLAVmax – TIVOVlatch =
= 100ns + 10ns – 50ns – 35ns = 25ns
• Address Hold Time After WR# (tWA): TWHAX = TCLCL – TCVCTXmax + TCLLHmin = 100ns – 50ns + 0ns = 50ns
• WR# Pulse Width (tWW): TWLWH = 2TCLCL –35ns = 200ns – 35ns = 165ns
• Data Setup before WR# (tDW):
TDVWH = 2TCLCL – TCLDVmax + TCVCTXmin – TIVOVbuffer + tPDminLS32= = 200ns – 50ns + 10ns – 35ns + 0ns = 125ns
• Data Hold after WR# (tWD): TWHDX – tPDmaxLS32 = TCLCH –25ns –11ns = 53ns – 25ns – 11ns = 17ns
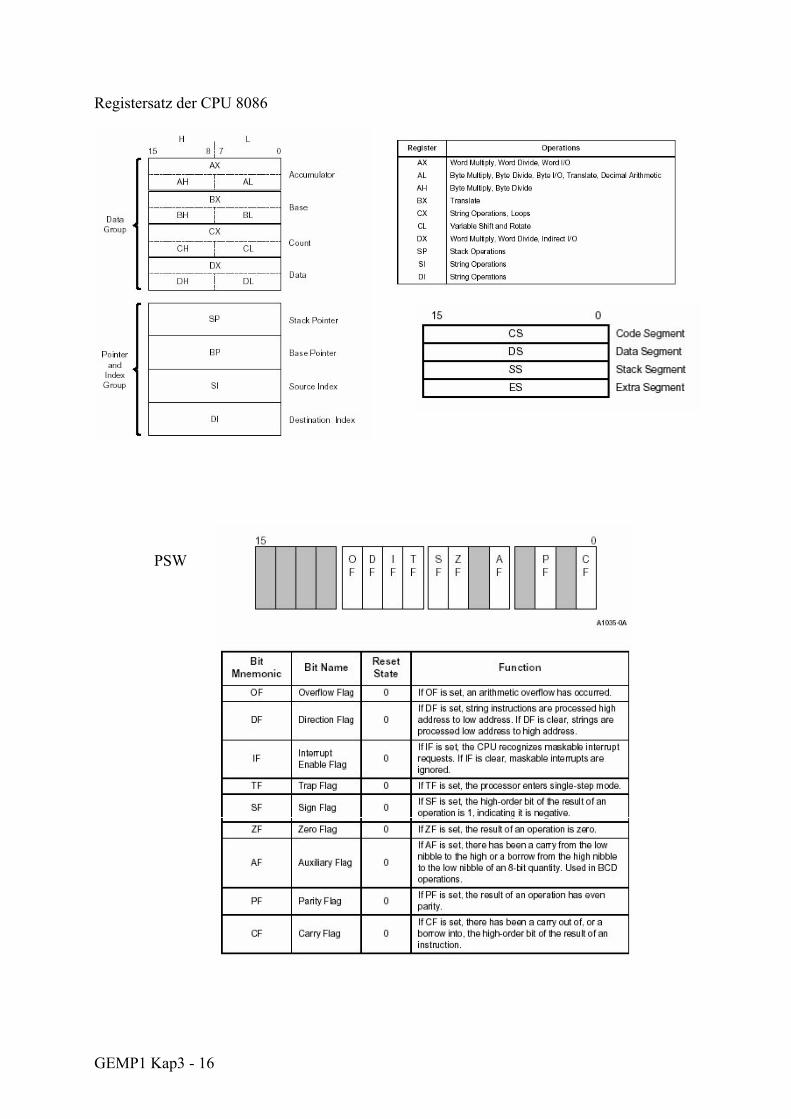
GEMP1 Kap3 - 16
Registersatz der CPU 8086
PSW
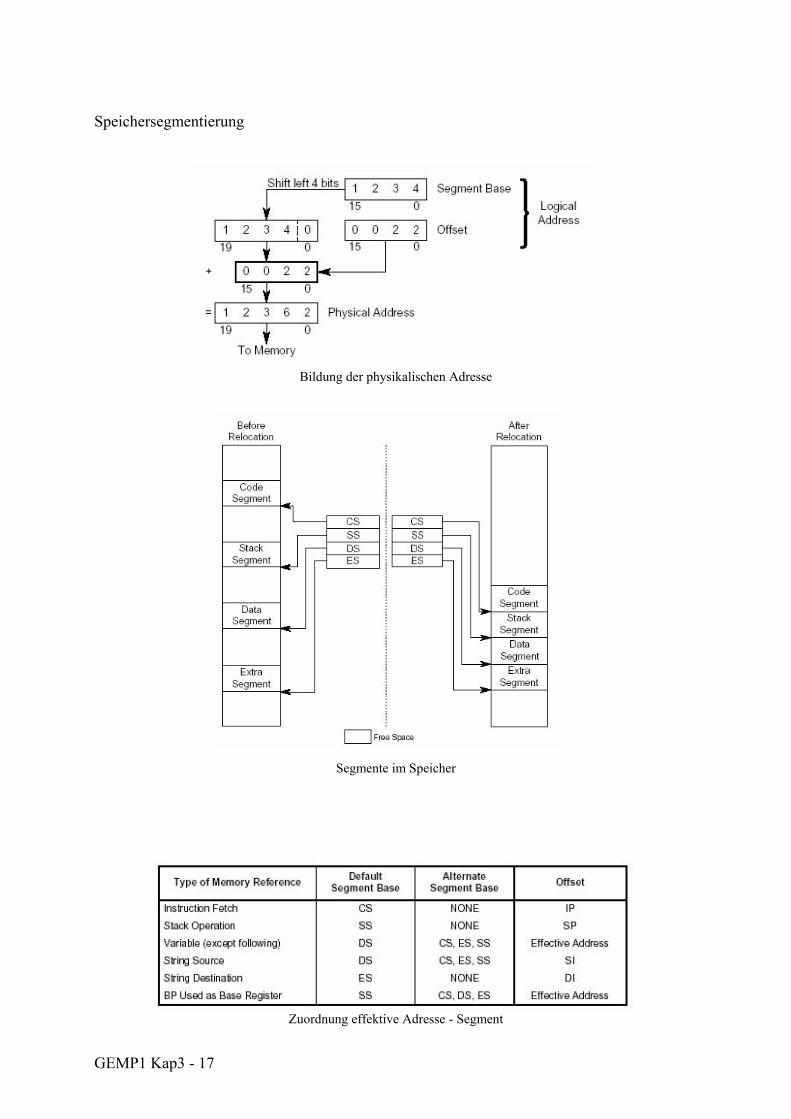
GEMP1 Kap3 - 17
Speichersegmentierung
Bildung der physikalischen Adresse
Segmente im Speicher
Zuordnung effektive Adresse - Segment

GEMP1 Kap3 - 18
Stack operation Adressierungsarten Ein Operand kann sich befinden:
• in einem Register • im Operandenfeld eines Befehls • im Speicher oder einem I/O-Baustein
Registeradressierung: Kein weiterer Speicherzugriff notwendig, die Angabe des Registers erfolgt mit wenigen bits im Operationsfeld des Befehls → schnellste Befehlsausführung. Unmittelbare (immediate) Adressierung: Operand ist Teil des Befehls → kein weiterer Speicherzugriff notwendig. Speicheradressierung: Die effektive (logische) Adresse eines Operanden wird aus dem Inhalt eines Registers und/oder einem im Befehl angegebenen displacement gebildet.

GEMP1 Kap3 - 19
Direkte Adressierung Register indirekte Adressierung
Adressierung mit Basisregister Adressierung mit Indexregister
Zugriff auf Strukturen Zugriff auf Arrays

GEMP1 Kap3 - 20
Adressierung von Zeichenketten: Befehle zur Verarbeitung von Zeichenketten (Kopieren, Vergleichen, etc.) sind 1-byte-Befehle und verwenden die Inhalte von SI und DI als effektive Operandenadresse. Dabei werden SI und DI automatisch inkrementiert oder dekrementiert. I/O Adressierung: Zur Adressierung des getrennten I/O-Adressraumes stehen nur die Transferbefehle „IN“ und „OUT“ zur Verfügung. Der Transfer läuft immer über AX.
• Direkte I/O-Adressierung: Portadresse (8bit) ist Teil des Befehls • Indirekte I/O-Adressierung: Inhalt von DX ist die Portadresse.
Adressierung bei Programmverzweigung:
• Intrasegment: IP wird verändert, CS bleibt unverändert
- Relativ zu IP: um angegebenes Displacement (1 byte mit Vorzeichen oder 2 byte ohne Vorzeichen)
- Direkt: angegebenes Displacement wird neuer Inhalt von IP - Register: Der Inhalt des angegebenen Registers wird neuer Inhalt von IP - Indirekt: Durch eine der oben angeführten Adressierungsarten wird eine
Speicheradresse bestimmt. Der Inhalt dieser Speicherstelle wird nach IP geladen.
• Intersegment: IP und CS werden verändert.
- Direkt: Neuer IP- und neuer CS-Inhalt sind Teil des Befehls - Indirekt: Wie bei Intrasegment, jedoch sind 4 byte im Speicher nötig
Struktur eines Maschinenbefehls: Ein Maschinenbefehl besteht aus 1 bis 6 byte:
1.byte: Opcode 2.byte: Adressmodusbyte 3. bis 6.byte: Displacement oder Operand

GEMP1 Kap3 - 21
Unterbrechungsanforderung Interrupts (externe asynchrone Ereignisse) und exceptions (Fehler bei einer Befehlsausführung, z.B. Division durch null) ändern den Programmfluss. Ein gerade laufender Befehl wird zu Ende geführt, PSW und die Adresse (IP und CS) des nächsten Befehls werden automatisch auf den Stapel gerettet und das Programm verzweigt zum Beginn eines, dem auslösenden Ereignisses zugeordneten, Programmteiles (Interrupt service routine). Nach Durchlaufen dieser Routine kehrt das Programm an die ursprüngliche Stelle zurück.

GEMP1 Kap3 - 22
Hardware Interrupts:
• Non Maskable Interrupt (NMI) – Type 2: Nicht sperrbarer Interrupt höchster Priorität ausgelöst durch steigende Flanke am Eingang NMI → verwendet z.B. zur Sicherung wichtiger Daten bei Spannungsausfall.
• Maskable Interrupt: Ausgelöst durch aktiven Pegel am Eingang INTR. Keinem bestimmten Interrupt-Vektor zugeordnet, die Zuordnung erfolgt über einen speziellen Mechanismus mit Hilfe eines externen Interrupt-Controllers. Sperrbar mittels bit I im PSW.

GEMP1 Kap3 - 23
Exceptions:
• Divide Error – Type 0: Wird ausgelöst, wenn das Ergebnis einer Division den möglichen Zahlenbereich des Resultats (8bit bzw. 16bit) überschreitet. Nicht sperrbar.
• Single Step – Type 1: Ausgelöst nach einer Befehlsausführung, wenn TF im PSW gesetzt ist. TF wird bei Verzweigung in die zugehörige ISR rückgesetzt und beim Rücksprung wieder restauriert. Hardware-Unterstützung für Debugger.
• Array Bounds Check – Type 5 (nicht bei 8086): Wird durch den Befehl BOUND ausgelöst, wenn eine Speicherreferenz außerhalb angegebener Grenzen liegt.
• Invalid Opcode – Type 6 (nicht bei 8086): Ausgelöst bei ungültigem Opcode • Escape Opcode – Type 7 (nicht bei 8086): Wird, wenn freigeschaltet, durch einen
Befehl für den Numerischen Coprocessor 80C187 ausgelöst. Für die Emulation dieses Coprocessors.
• Numerics Coprocessor Fault – Type 16 (nicht bei 8086): Ausgelöst vom 80C187 Software Interrups:
• INTn: Dieser Befehl löst die entsprechende ISR aus. Die Vektornummer wird im Befehl angegeben.
• Breakpoint Interrupt – Type 3: Der Befehl INT besteht nur aus einem byte und wird von Debuggern zum Setzen von Breakpoints verwendet.
• Interrupt on Overflow –Type 4: Der Befehl INTO löst diesen Interrupt aus, wenn das OF im PSW gesetzt ist.

GEMP1 Kap3 - 24
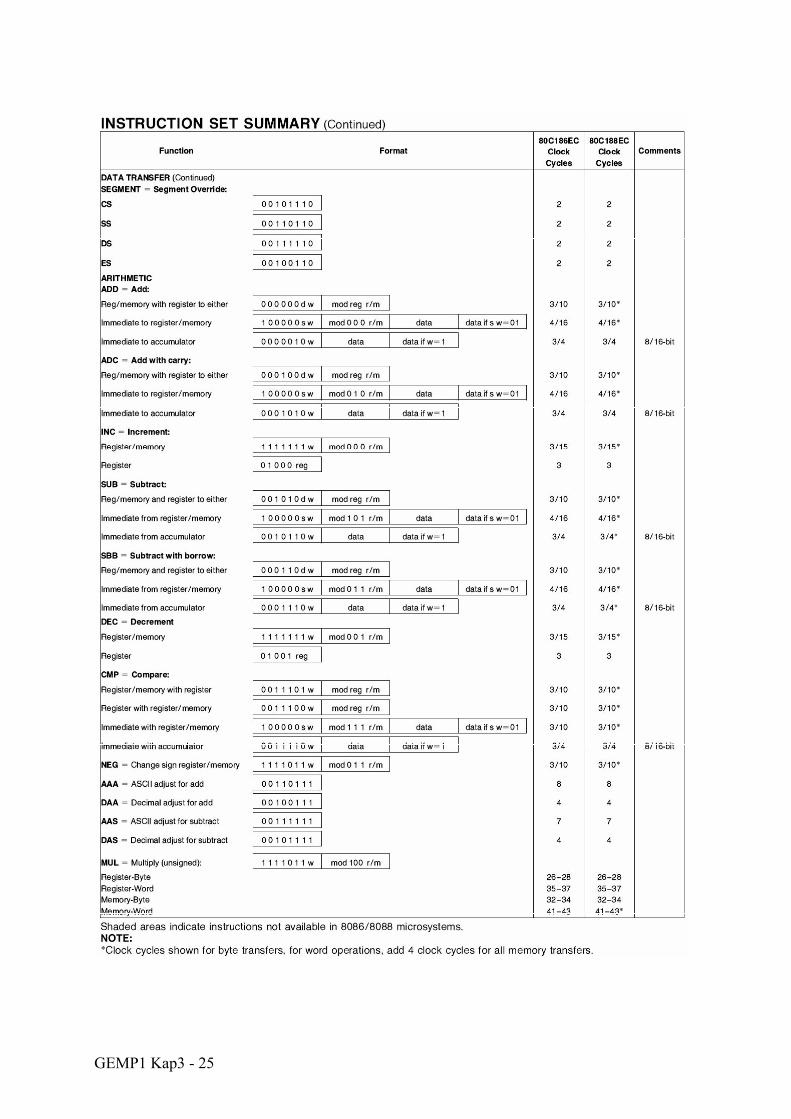
GEMP1 Kap3 - 25

GEMP1 Kap3 - 26
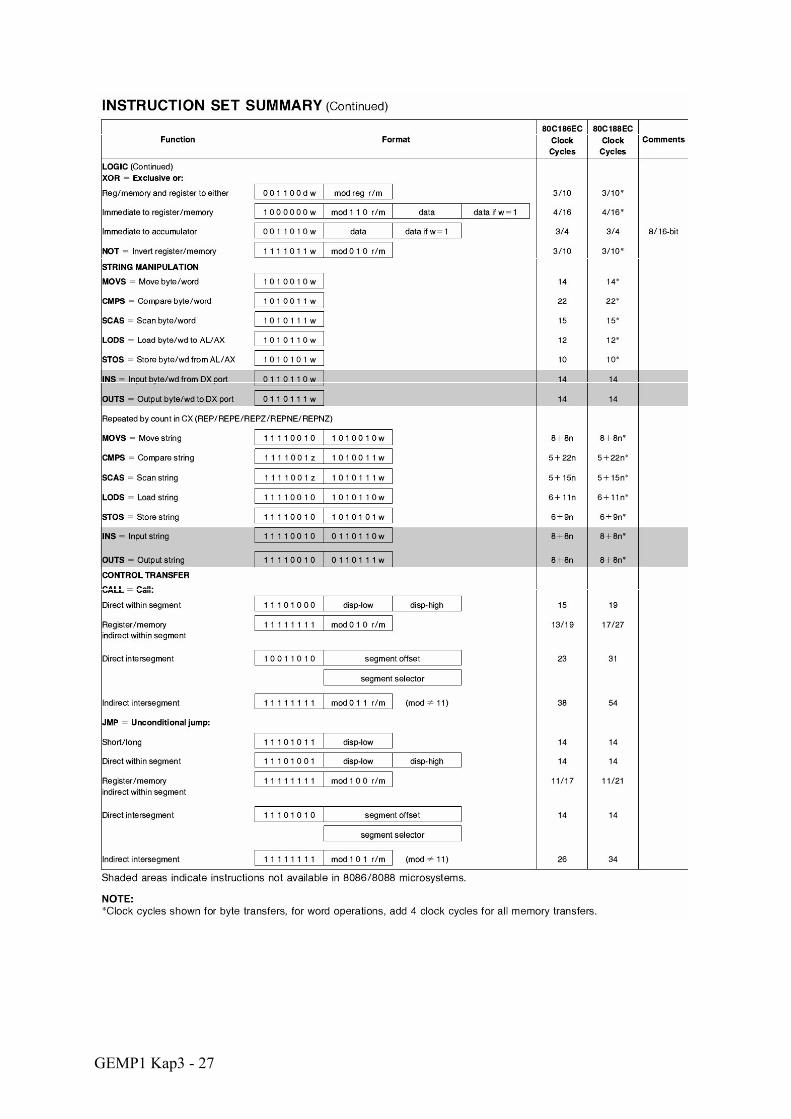
GEMP1 Kap3 - 27
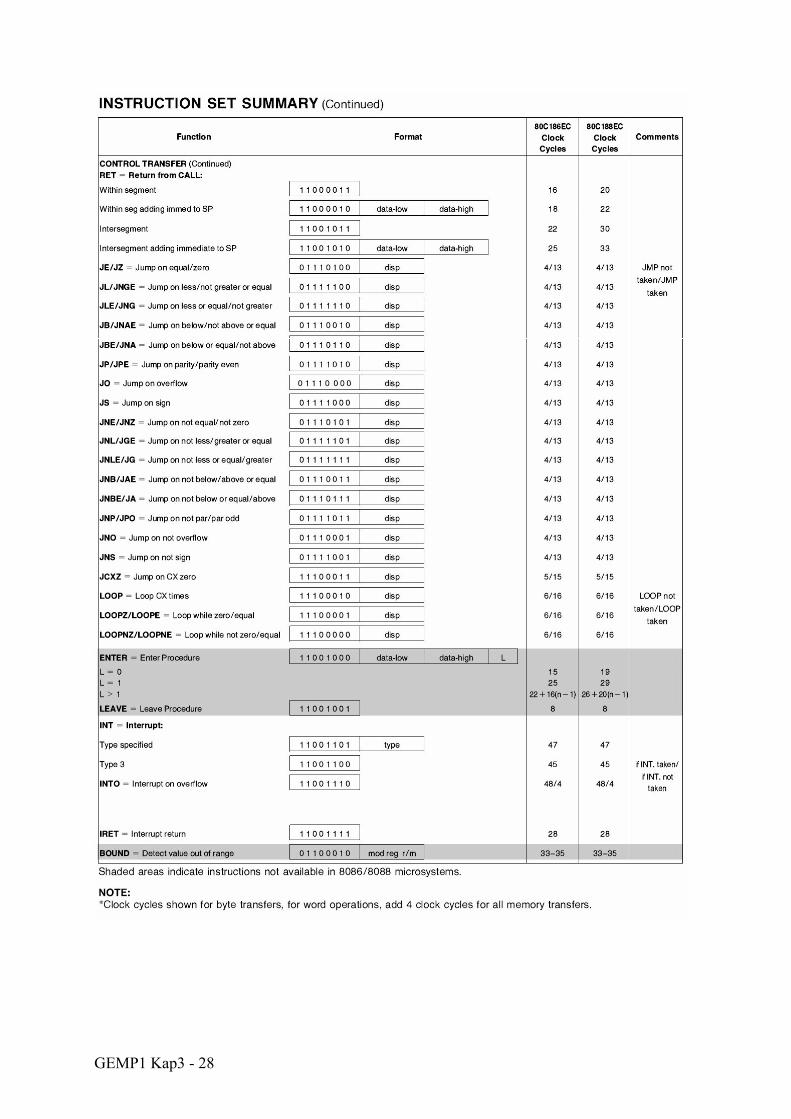
GEMP1 Kap3 - 28

GEMP1 Kap3 - 29
Eine genaue Beschreibung der einzelnen Befehle befindet sich im Dokument 80C186 Instruction Set.pdf


















