
4 Verteilte Algorithmen - w3.inf.fu-berlin.de
64
WS 13/14 ALP 5 - Verteilte Algorithmen 1 4 Verteilte Algorithmen 4.1 Plattformen 3 4.2 Beispiel: Verteilter Ausschluss 20 4.3 Beispiel: Wahlalgorithmen 32 4.4 Beispiel: Verteilte Hash-Tabellen 38 4.5 Virtuelle Zeit 47 Zusammenfassung 61 Klaus-Peter Löhr
Transcript of 4 Verteilte Algorithmen - w3.inf.fu-berlin.de

WS 13/14 ALP 5 - Verteilte Algorithmen 1
4 Verteilte Algorithmen!
4.1 Plattformen ! ! ! !3!4.2 Beispiel: Verteilter Ausschluss ! !20!4.3 Beispiel: Wahlalgorithmen ! !32!4.4 Beispiel: Verteilte Hash-Tabellen! !38!4.5 Virtuelle Zeit ! ! ! !47!Zusammenfassung ! ! ! !61!
Klaus-Peter Löhr!

WS 13/14 ALP 5 - Verteilte Algorithmen 2
Verteilter Algorithmus (distributed algorithm, peer-to-peer algorithm): Nichtsequentieller Algorithmus, dessen Prozesse ausschließlich über Nachrichten interagieren und zur Erreichung eines gemeinsamen Ziels unter Kenntnis ihrer Partner kooperieren.
Kommunikationsoperationen (vgl. 2.4): send(message, proc) !recv(mesvar) ! !

WS 13/14 ALP 5 - Verteilte Algorithmen 3
4.1 Plattformen!
1. Beispiel Erlang: funktionale Sprache
2. Beispiel Scala: objektorientiert/funktionale Sprache
3. Beispiel UDP: Internet-Transportdienst

WS 13/14 ALP 5 - Verteilte Algorithmen 4
4.1.1 Beispiel Erlang!
Funktionale Sprache, dynamisch getypt (!) (Ericsson Language, bei Ericsson entwickelt 1987. Dänischer Mathematiker 1878-1929)"
peer ! expression
Die Auswertung dieses Ausdrucks liefert den Wert von expression und hat die Nebenwirkung, dass dieser Wert an den Prozess peer geschickt wird
Jeder Prozess hat eine ausgezeichnete, unbeschränkte mailbox.

WS 13/14 ALP 5 - Verteilte Algorithmen 5
receive pattern1 [ when guard1 ] -> expressions1 ; ! pattern2 -> expressions2 ; ! . . . . . !end !!
durchsucht die mailbox nach der ersten Nachricht, bei der eine Musteranpassung an eines der Muster gelingt und der entsprechende guard gilt, wertet dann den zugehörigen Ausdruck aus und liefert dessen Wert als Ergebnis. Bei Nichtgelingen wird blockiert.

WS 13/14 ALP 5 - Verteilte Algorithmen 6
Variable (variables) beginnen mit Großbuchstaben, z.B. Message Atome (atoms) beginnen mit Kleinbuchstaben, z.B. urgent Terme (terms) sind Atome oder Variable oder: Tupel (tuples) von Termen, z.B. {urgent, Message}!Listen (lists) und weitere .....
Musteranpassung:
Ein Muster (pattern) ist ein Term. Variable in einem Muster werden mit Werten belegt durch
pattern = expression oder receive pattern -> ...!!

WS 13/14 ALP 5 - Verteilte Algorithmen 7
Bemerkungen:
� Ein Erlang-Prozess hat zwar nur eine Mailbox, dies wird aber mehr als aufgewogen durch die Möglichkeiten des receive .
� Es gibt „ports“ in Erlang: das sind die aus Kap. 3
bekannten Datenfluss-Ports, die den Anschluss an Kanäle des Betriebssystems ermöglichen.
� Die Erzeugung von Prozessen in Erlang ist extrem leichtgewichtig (mehr noch als Java Threads). � Das Erlang-System unterstützt in komfortabler Weise auch die physische Verteilung eines Programms auf mehrere vernetzte Rechner („Distributed Erlang“!).
WS 13/14 ALP 5 - Verteilte Algorithmen 8
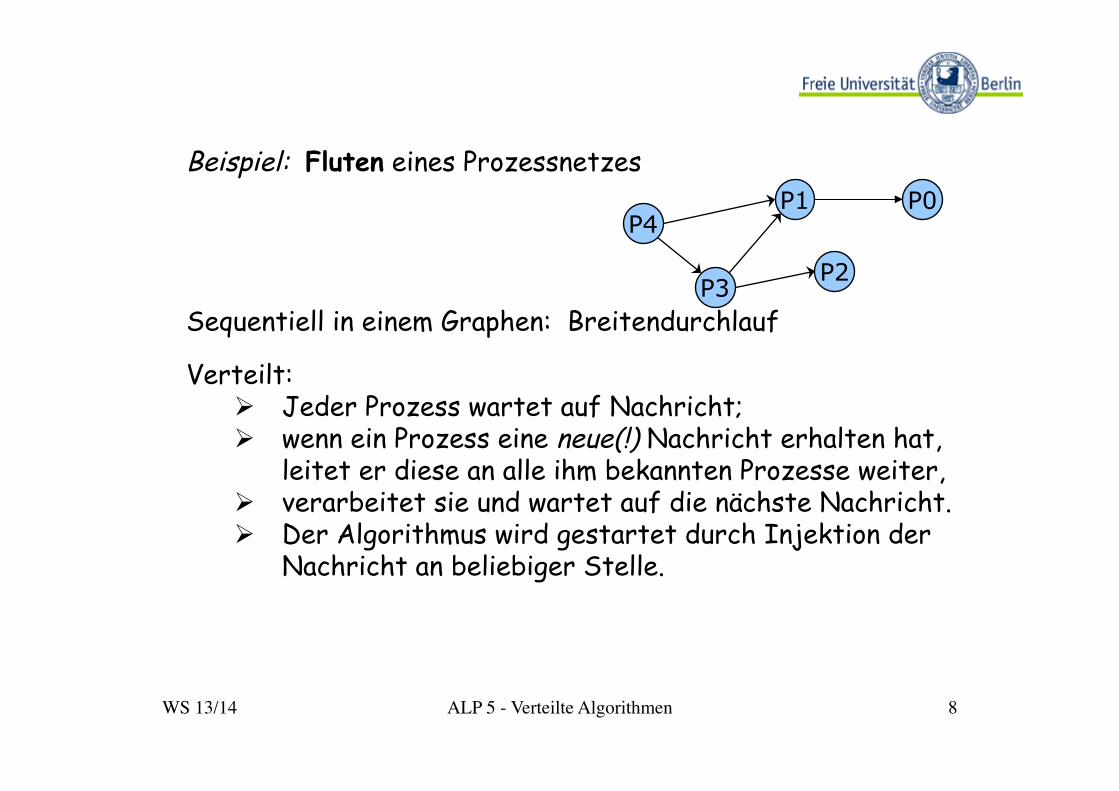
Beispiel: Fluten eines Prozessnetzes Sequentiell in einem Graphen: Breitendurchlauf Verteilt:
Ø Jeder Prozess wartet auf Nachricht; Ø wenn ein Prozess eine neue(!) Nachricht erhalten hat,
leitet er diese an alle ihm bekannten Prozesse weiter, Ø verarbeitet sie und wartet auf die nächste Nachricht. Ø Der Algorithmus wird gestartet durch Injektion der
Nachricht an beliebiger Stelle.
P4
P3 P2
P1 P0

WS 13/14 ALP 5 - Verteilte Algorithmen 9
pass(Peers) -> % Funktion beschreibt Prozessverhalten ! receive Info -> [Peer!Info || Peer<-Peers],! doWork(Info),! pass(Peers)! after 5000 -> dead! end .!
Duplikate werden nicht erkannt!
dowork(X) -> io:format("~w in ~w~n", [X, self()]).! % will write, e.g., "info in <0.37.0>"!

WS 13/14 ALP 5 - Verteilte Algorithmen 10
... und weniger trivial, mit Duplikat-Erkennung: ! node(Peers, State) -> ! receive {info, Info} -> ! if State/=Info -> ! [Peer!{info,Info}||Peer<-Peers],! display(Info);! true -> skip ! end,! node(Peers, Info);! work -> doWork(State), ! node(Peers, State);! shutdown -> [Peer!shutdown||Peer<-Peers],! dead! end.!!
WS 13/14 ALP 5 - Verteilte Algorithmen 11
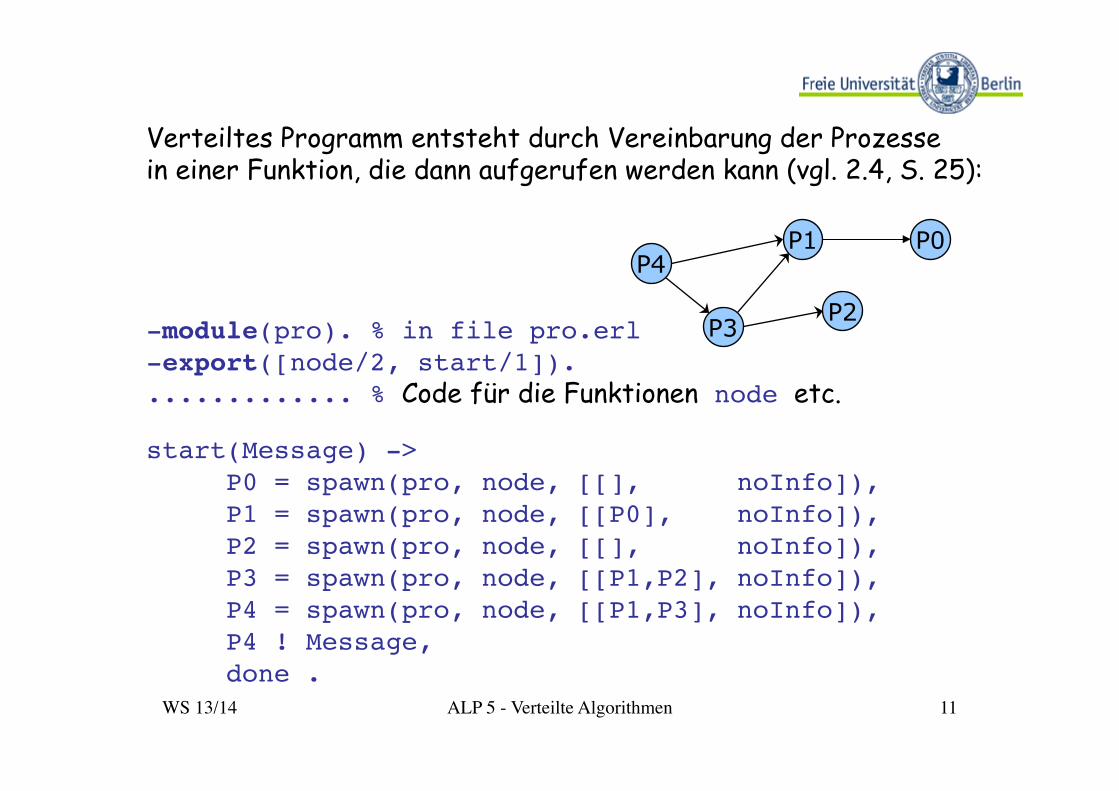
Verteiltes Programm entsteht durch Vereinbarung der Prozesse in einer Funktion, die dann aufgerufen werden kann (vgl. 2.4, S. 25): !!!!-module(pro). % in file pro.erl!-export([node/2, start/1]).!............. % Code für die Funktionen node etc.
P4
P3 P2
P1 P0
start(Message) -> !! P0 = spawn(pro, node, [[], noInfo]), ! P1 = spawn(pro, node, [[P0], noInfo]), ! P2 = spawn(pro, node, [[], noInfo]),! P3 = spawn(pro, node, [[P1,P2], noInfo]),! P4 = spawn(pro, node, [[P1,P3], noInfo]),! P4 ! Message,! done .!
WS 13/14 ALP 5 - Verteilte Algorithmen 12
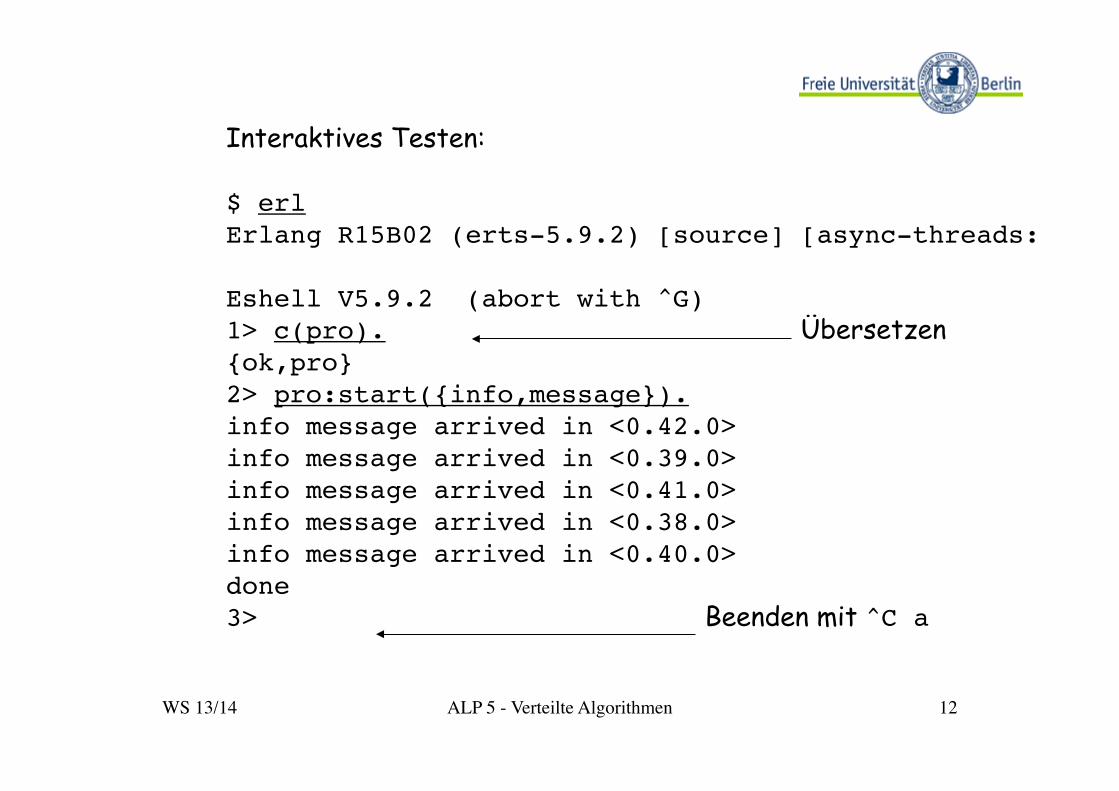
Interaktives Testen: $ erl!Erlang R15B02 (erts-5.9.2) [source] [async-threads:0] [hipe] [kernel-poll:false]!!Eshell V5.9.2 (abort with ^G)!1> c(pro). ! ! ! ! !Übersetzen!{ok,pro}!2> pro:start({info,message}).!info message arrived in <0.42.0>!info message arrived in <0.39.0>!info message arrived in <0.41.0>!info message arrived in <0.38.0>!info message arrived in <0.40.0>!done!3> ! ! ! ! !Beenden mit ^C a

WS 13/14 ALP 5 - Verteilte Algorithmen 13
Bemerkungen:
Ø Der Algorithmus funktioniert auch für zyklische Netze. (In Erlang allerdings etwas umständlicher zu formulieren.)
Ø Es handelt sich tatsächlich um einen verteilten Algorithmus: Ø die Prozesse „kennen“ ihre Partner nicht nur namentlich,
sie kennen auch deren Verhalten und kooperieren.
Ø Dieses Verhalten ist hier identisch mit dem eigenen - nicht ungewöhnlich für verteilte Algorithmen. Ø Das Beispiel ist relativ einfach. Typische verteilte
Algorithmen sind wesentlich kniffliger.

WS 13/14 ALP 5 - Verteilte Algorithmen 14
4.1.2 Beispiel Scala!
Amalgam aus objektorientierten und funktionalen Elementen (läuft auf der Java Virtual Machine)
Nichtsequentialität: Prozesse („actors“) interagieren sowohl
über gemeinsame Daten als auch mit Kommunikation: object MyActor extends Actor {! def act() { ... receive Fallunterscheidung ... }!}!!... MyActor.start(); ... MyActor ! "hello!“; ...
[Odersky et al. 2011]

WS 13/14 ALP 5 - Verteilte Algorithmen 15
receive ist Methode von Actor : Argument ist eine partielle Funktion f (Fallunterscheidung mit Musteranpassung) Ergebnis ist f(message)
Beispiel: receive {!
! !case Colour(arg) => ...!! !case Complex(arg1, arg2) => ...!! !case msg => ...!
! }! receive blockiert, bis eine passende Nachricht eintrifft, tätigt die Musteranpassung und wertet den zugehörigen Ausdruck aus. Nirgends passende Nachrichten werden ignoriert.

WS 13/14 ALP 5 - Verteilte Algorithmen 16
4.1.3 Beispiel UDP!
Zur Erinnerung an TI 3: Internet-Transportdienst UDP (user datagram protocol):
Ø sprachunabhängig, vom Betriebssystem angeboten Ø ... zwischen schwergewichtigen Prozessen im Netz Ø keine Gütegarantie (Datenverlust, Reihenfolgeänderung!) Ø auch lokal einsetzbar
Sender adressiert einen Port des Empfängers (≈ Mailbox); Prozess kann aber auch mehrere Ports haben.
WS 13/14 ALP 5 - Verteilte Algorithmen 17
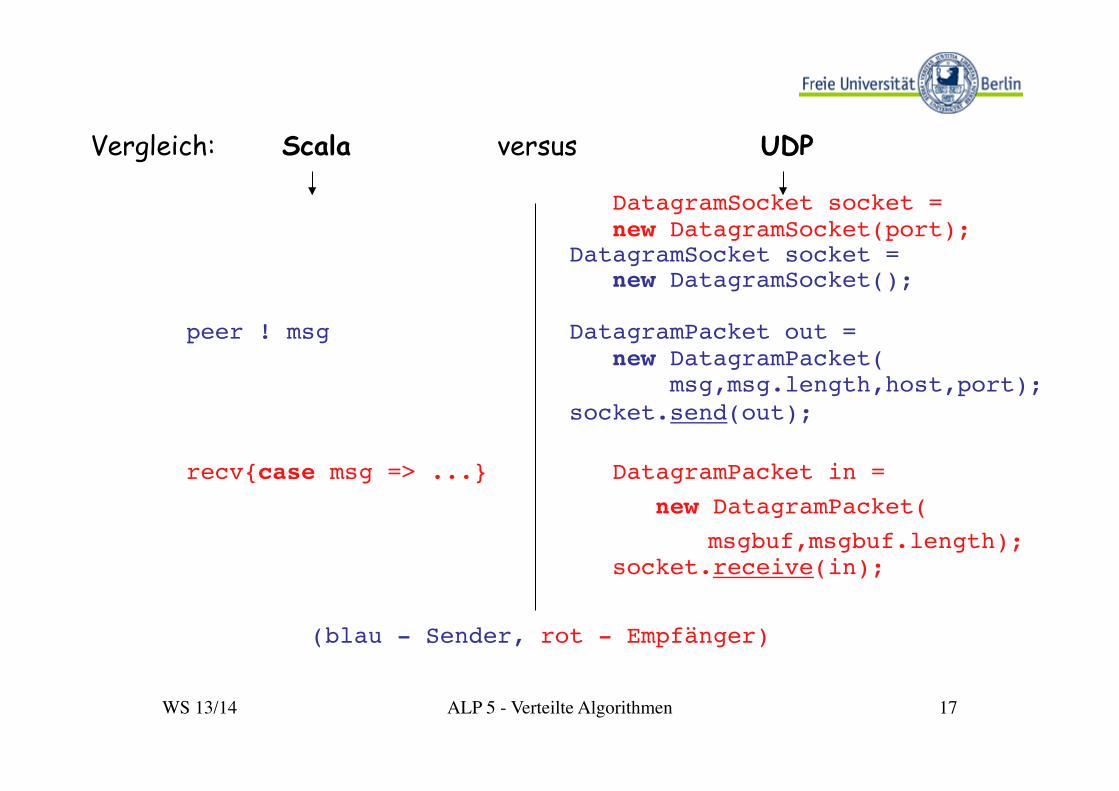
Vergleich: Scala versus UDP
! ! ! ! ! DatagramSocket socket = !! ! new DatagramSocket(port);!! ! ! ! !DatagramSocket socket = !! ! ! ! ! new DatagramSocket();!
!!peer ! msg ! ! !DatagramPacket out = !! ! ! ! ! new DatagramPacket(!! ! ! ! ! msg,msg.length,host,port);!! ! ! ! !socket.send(out);!
! !recv{case msg => ...} ! DatagramPacket in = !
! ! ! ! ! new DatagramPacket(!! ! ! ! ! ! msgbuf,msgbuf.length);!! ! ! ! ! socket.receive(in);!
!
! ! (blau - Sender, rot - Empfänger)

WS 13/14 ALP 5 - Verteilte Algorithmen 18
import java.net.*;!!public class SenderExample {!public static void main (String arg[]) {!
!String message = arg[0];!!int port = Integer.parseInt(arg[1]); // destination!!InetAddress local = InetAddress.getByName(localhost);!!byte[] outData = message.getBytes();!!DatagramPacket out = new DatagramPacket(outData, !! ! ! ! outData.length, local, port);!!DatagramSocket socket = new DatagramSocket();!! ! ! ! // gets any available local port!!socket.send(out);!!.....!!}!
}!

WS 13/14 ALP 5 - Verteilte Algorithmen 19
import java.net.*;!!public class ReceiverExample {!public static void main (String arg[]) {!
!int port = Integer.parseInt(arg[0]); // my port!!DatagramSocket socket = new DatagramSocket(port);!!byte[] inData = new byte[1024]; !!DatagramPacket in = new DatagramPacket(inData, 1024);!!socket.receive(in);!// wait for message and get it!!int senderPort = in.getPort();!!.....!!}!
}!
evtl. hilfreich für verteilten Algorithmus

WS 13/14 ALP 5 - Verteilte Algorithmen 20
4.2 Beispiel: Verteilter Ausschluss!
Verteilter wechselseitiger Ausschluss:
Ø Prozesse haben kritische Abschnitte, z.B. wegen Zugriffs auf gemeinsame Ressourcen wie Peripheriegeräte, Funkverbindungen, ...
Ø Ausschluss verklemmungsfrei und fair Ø verschiedene Ansätze:
- zentraler Koordinator-Prozess - Berechtigungs-Token wird herumgereicht - Prozesse einigen sich direkt

WS 13/14 ALP 5 - Verteilte Algorithmen 21
Voraussetzungen:
Ø Wir betrachten kommunizierende Stationen
Ø ... bestehend aus Anwendungsprozess und Begleitprozess
Ø ... mit gemeinsamen Daten
Ø Anwendungsprozess befolgt Protokoll für Ausschluss
Ø Begleitprozess erledigt Teil des Protokolls
Ø jede Station hat eine Mailbox

WS 13/14 ALP 5 - Verteilte Algorithmen 22
4.2.1 Algorithmus von Ricart/Agrawala!
Lösungsidee: Stationen kennen einander und einigen sich über Eintritt
� eintrittswillige Station A sendet Anfrage mit Zeitstempel an alle Partner und wartet auf Zustimmung aller Partner.
� Ein Partner B stimmt zu, wenn er selbst nicht an einem
kritischen Abschnitt interessiert ist. � Wenn B selbst im kritischen Abschnitt ist, merkt er sich die Anfrage und beantwortet sie nach
Verlassen des kritischen Abschnitts.
� Wenn B aber selbst auch in der Anfragephase ist, entscheiden die Zeitstempel, ob � oder � erfolgt !

WS 13/14 ALP 5 - Verteilte Algorithmen 23
Protokoll in Pseudocode:
recv(xyz, ...) bedeutet wie in Erlang „entnimm der Mailbox die nächste mit xyz beginnende Nachricht, sobald vorhanden“
Variablen und Code jeder Station: Clock % actual time Time % time of request N = . . . % number of stations Peers = . . . % set of all stations Deferred = emptyset % set of waiting stations Critical = false % entering or inside critical section enter: . . . . . % prologue of critical section leave: . . . . . % epilogue of critical section helper: . . . . . % code of helper process

WS 13/14 ALP 5 - Verteilte Algorithmen 24
enter: < Critical = true Time = Clock > for P ∈ Peers - Me do send(request, Me, Time, P) for I ∈ [1..N-1] do recv(reply)
leave: < Critical = false > for P ∈ Deferred do send(reply, P) Deferred = emptyset
helper: repeat
recv(request, Requester, T) < if Critical and Time<T then Deferred += Requester else send(reply, Requester) >
Animation: http://cs.gmu.edu/cne/workbenches/ricart/ricart.html

WS 13/14 ALP 5 - Verteilte Algorithmen 25
Schönheitsfehler:
Verteilte Systeme kennen keine globale Zeit
Ú Problem der Uhrensynchronisation Ú Problem Time==T (evtl. Stationsnummer anhängen!) Ú Lösung: virtuelle Zeit verwenden Ú 4.5

WS 13/14 ALP 5 - Verteilte Algorithmen 26
Analyse
Aufwand: für jeden kritischen Abschnitt:
2(n-1) Nachrichten Korrektheit:
� Ausschluss garantiert ? � kein Verhungern ?

WS 13/14 ALP 5 - Verteilte Algorithmen 27
� Ausschluss garantiert ? Fall 1: A sendet in seinem Prolog eine Anfrage mit Zeit TA,
B antwortet und tritt dann auch in seinen Prolog ein.
Folgerung: B sendet Anfrage mit TB > TA , die deshalb von A erst im Epilog beantwortet wird P
Fall 2: A und B sind beide in ihre Prologe eingetreten, bevor einer der beiden eine Anfrage des anderen beantwortet hat.
Folgerung: Im Fall TB > TA wird B antworten, im Fall TB < TA wird A antworten P

WS 13/14 ALP 5 - Verteilte Algorithmen 28
� kein Verhungern ? Unter den Prozessen, die ihren Prolog noch nicht abgeschlossen haben, gibt es einen Prozess P mit kleinstem Zeitstempel. Dessen Anfrage wird daher von allen anderen beantwortet - irgendwann auch vom eventuellen kritischen Prozess. P kann dann selbst in seinen kritischen Abschnitt eintreten.
Das Gleiche gilt jeweils für den Prozess mit dem nächsten Zeitstempel. P Bemerkung: Die jeweils in ihrem Prolog hängenden Prozesse bilden eine virtuelle Warteschlange gemäß den Zeitstempeln.

WS 13/14 ALP 5 - Verteilte Algorithmen 29
4.2.2 Einfacher Token Ring!
Lösungsidee: Stationen bilden einen Ring, auf dem eine spezielle Marke (token) permanent herumgereicht wird. Wer in seinen kritischen Abschnitt eintreten will, greift sich die Marke; beim Austritt schickt er sie wieder auf die Reise (wie beim LAN Token Ring).
Kommunikationsoperationen:
send() schickt Marke an den Nachfolger im Ring recv() empfängt Marke vom Vorgänger
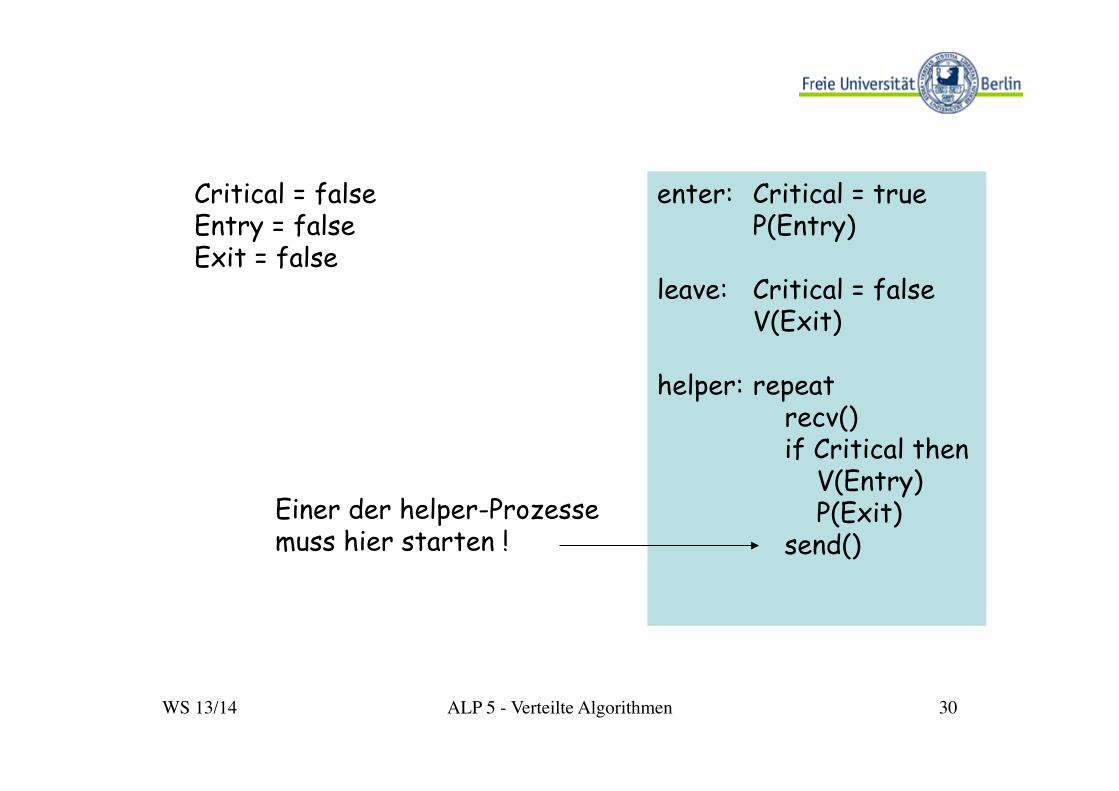
WS 13/14 ALP 5 - Verteilte Algorithmen 30
enter: Critical = true P(Entry)
leave: Critical = false
V(Exit) helper: repeat
recv() if Critical then
V(Entry) P(Exit)
send()
Critical = false Entry = false Exit = false
Einer der helper-Prozesse muss hier starten !

WS 13/14 ALP 5 - Verteilte Algorithmen 31
Bemerkungen:
Ø Ausschluss ist gesichert, da nur eine Station im Besitz der Marke sein kann.
Ø Verhungern ist ausgeschlossen, da die Marke nach jedem
kritischen Abschnitt weitergereicht wird.
Ø Fairness: höchstens n-1 Stationen können sich vordrängeln
Ø Die heftige Kommunikation kann dadurch abgemildert werden, dass die helper-Prozesse Pausen einlegen

WS 13/14 ALP 5 - Verteilte Algorithmen 32
4.3 Beispiel: Wahlalgorithmen!Klaus-Peter Löhr!
(election algorithms)
Wird für irgendeinen Zweck ein zentraler Koordinator benötigt, so müssen sich die Stationen auf einen einigen. Voraussetzungen:
- Stationen tragen verschiedene Nummern „ID“ - als Koordinatorin gesucht ist die „größte“ Station - Stationen bilden einen gerichteten Ring wie in 4.2.2 - Variable max ist mit ID initialisiert
Ú [Chang/Roberts 1979]

WS 13/14 ALP 5 - Verteilte Algorithmen 33
Funktionsweise:
� Einige Stationen schicken unabhängig voneinander einen Aufruf (Wählen!, ID) an die jeweiligen Nachfolgerinnen und betrachten sich als wählend.
� Empfängerin eines Aufrufs (Wählen!, x) mit x>max leitet
diese Nachricht weiter (sie kommt als Koordinatorin nicht in Frage), setzt max:=x und betrachtet sich als wählend.
a) Ist aber x<max, dann könnte sie in Frage kommen: war sie nicht wählend, leitet sie die Nachricht (Wählen!, max) weiter; war sie bereits wählend, ist nichts zu tun (weil max bereits gesendet wurde).

WS 13/14 ALP 5 - Verteilte Algorithmen 34
b) Ist x=max, dann ist max=ID durch den ganzen Ring gelaufen, alle Stationen haben das gleiche max, und ID ist zur Koordinatorin gewählt. Sie betrachtet sich als nicht mehr wählend und schickt die Nachricht (fertig) an ihre Nachfolgerin.
� Empfängerin dieser Nachricht merkt sich max als neue Koordinatorin, betrachtet sich als nicht mehr wählend und schickt die Nachricht weiter - sofern sie nicht selbst die Koordinatorin ist.

WS 13/14 ALP 5 - Verteilte Algorithmen 35
Analyse
Aufwand: a(n) = Anzahl der Nachrichten bei n Stationen
2n ≤ a(n) ≤ 3n-1 (ÚS. 36)
Korrektheit:
� Safety: nur eine wird gewählt
� Liveness: eine wird gewählt (und alle sind informiert) (ÚS. 37)
Animation: http://visidia.labri.fr/examples/animations/Chang_roberts(10).html

WS 13/14 ALP 5 - Verteilte Algorithmen 36
Aufwand : am günstigsten: größte Station x startet die Wahl
Ú n Aufrufe (Wählen!, x) (1 Umlauf) n Meldungen (Ergebnis:, x) (1 Umlauf)
am ungünstigsten: Nachfolgerin y der größten Station x startet die Wahl Ú n-1 Aufrufe (Wählen!,..) (fast 1 Umlauf) n Aufrufe (Wählen!, x) (1 Umlauf) n Meldungen (Ergebnis:, x) (1 Umlauf)

WS 13/14 ALP 5 - Verteilte Algorithmen 37
Korrektheit:
� Safety: nur eine wird gewählt ? Wäre mehr als eine gewählt worden, etwa x und y, dann wären beider Wahlaufrufe vollständig durch den Ring gelaufen, also der x-Aufruf durch y weitergeleitet - d.h. x>y - und der y-Aufruf durch x - d.h. y>x - Widerspruch!. P
� Liveness: eine wird gewählt und alle informiert ? Die größte Station muss erfolgreich sein, denn ihre ID wird überall weitergeleitet, bis sie wieder bei ihr ankommt. Die ID ist dann als max bei allen bekannt. P

WS 13/14 ALP 5 - Verteilte Algorithmen 38
4.4 Beispiel: Verteilte Hash-Tabellen!
Zur Erinnerung: Hash-Tabelle =
Ø Implementierung einer tabellierten Abbildung Key→Data
Ø Spezifikation: rechtseindeutige, endliche Relation ⊆ Key×Data mit Operationen put(k,d) und d=get(k)
Ø Implementierung: offene Streuspeicherung unter Verwendung einer Hash-Funktion h:
endlich viele Behälter (buckets), bucket[i] enthält alle (k,d) mit h(k) = i („bei i kollidierende Einträge“)

WS 13/14 ALP 5 - Verteilte Algorithmen 39
Vorsicht mit dem Begriff Hash-Funktion! Entweder kryptographische Hash-Funktion, z.B. SHA-1:
Kollision hash(x) = hash(y) mit x≠y ist so extrem unwahrscheinlich, dass ein Wert hash(x) nur mit Kenntnis von x berechnet worden sein kann. Salopp gesagt: hash ist „quasi-injektiv“.
Oder Streuspeicherungs-Funktion: Kollisionen h(k1) = h(k2) mit k1≠k2 kommen vor und werden speziell behandelt, z.B. mit buckets. Wenn man möchte, kann man bei N buckets h(k) = hash(k) mod N wählen.

WS 13/14 ALP 5 - Verteilte Algorithmen 40
Verteilte Hash-Tabelle: kryptographische Hash-Funktion hash:
Ø Die Tabelleneinträge (k,d) sind über N Stationen verteilt.
Ø hash(k) entscheidet, wo (hash(k), d) (!) gespeichert wird.
Motivation: Peer-to-Peer-Systeme im Netz
Ø Verteilte Speicherung großer Datenmengen (file sharing, e.g., Gnutella, Napster, ...): k = global eindeutiger Dateiname, d = Stationsname
Ø beliebige umfangreiche Verzeichnis-Dienste

WS 13/14 ALP 5 - Verteilte Algorithmen 41
Das Beispiel Chord [I. Stoica et al. 2001]:
Ø Jede der N Stationen trägt eine Nummer s = hash(stationId).
Ø Die Stationen kooperieren in einem Ring in Richtung aufsteigender Nummern (z.B. modulo 2160 mit SHA-1) („overlay network“ innerhalb des physischen Netzes): s0, s1, s2, . . . , sN-1
Ø Eine Station si ist jeweils zuständig für alle k mit
si-1 < hash(k) ≤ si
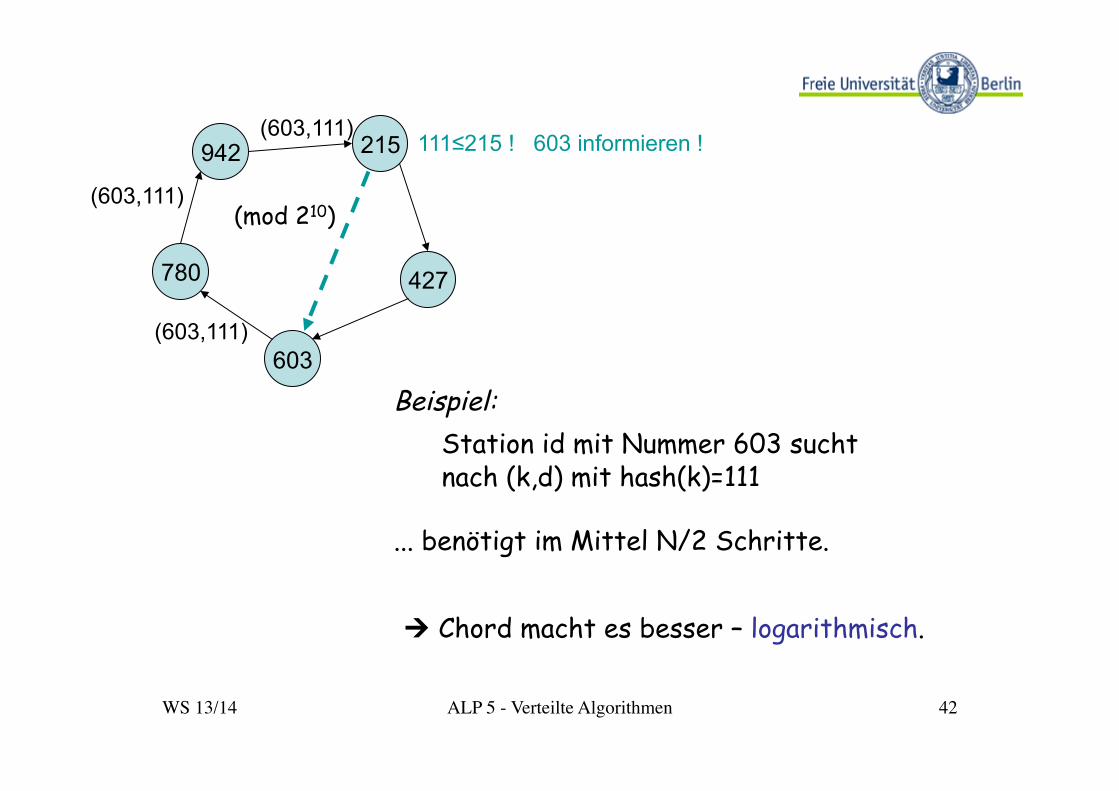
WS 13/14 ALP 5 - Verteilte Algorithmen 42
942
780
603
427
215
(mod 210)
Beispiel: Station id mit Nummer 603 sucht nach (k,d) mit hash(k)=111
... benötigt im Mittel N/2 Schritte.
(603,111)
(603,111)
(603,111)
111≤215 ! 603 informieren !
Ú Chord macht es besser – logarithmisch.

WS 13/14 ALP 5 - Verteilte Algorithmen 43
Idee: größere Schritte in Richtung auf das Ziel machen
Ø ... erfordert Kenntnis weiterer Stationen, nicht nur des direkten Nachfolgers;
Ø damit: Anfrage für h an die höchstnumerierte
lokal bekannte Station s mit s<h schicken - und von dort entsprechend weiter.
Ø Präzisierung: „finger table“ mit log2(N) Einträgen: (s + 2i , z) , i=0, ..., log2(N)-1 mit pred(z) < s+2i ≤ z
(für s+1 ist z der direkte Nachfolger im Ring)
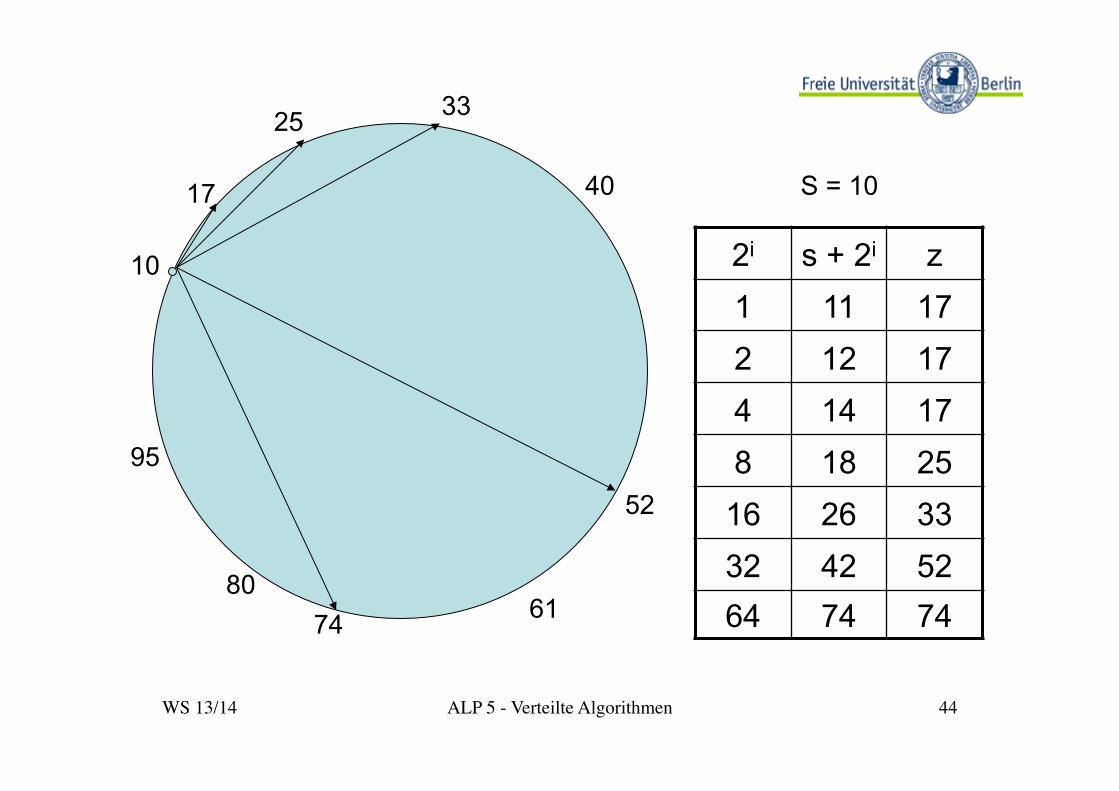
WS 13/14 ALP 5 - Verteilte Algorithmen 44
2i s + 2i z 1 11 17 2 12 17 4 14 17 8 18 25
16 26 33 32 42 52 64 74 74
17
61 74
40
80
52
95
10
33 25
S = 10

WS 13/14 ALP 5 - Verteilte Algorithmen
Algorithmus zum Auffinden der für h zuständigen Station, ausgehend von nicht zuständiger Station s: z = s while succ(z) < h do t = fingertable of z z = farthest station in t with z<h od return succ(z)
Bemerkung: Um der Klarheit willen ist das Protokoll als sequentieller Algorithmus auf den beteiligten finger tables formuliert. Die Umsetzung in den Code eines helper-Prozesses ist einfach.

WS 13/14 ALP 5 - Verteilte Algorithmen 46
Was fehlt für den Einsatz in der Realität? Verwaltung der finger tables angesichts
Ø hinzukommender Stationen Ø ausscheidender Stationen Ø zusammenbrechender Stationen Ø zusammenbrechender Kommunikation
Ú [I. Stoica et al. 2001]

WS 13/14 ALP 5 - Verteilte Algorithmen 47
4.5 Virtuelle Zeit!
Ø keine globale Zeit
Ø absolute Zeit interessiert aber auch wenig
Ø relative Zeitpunkte einzelner Ereignisse können wichtig sein
Ø è Virtuelle Zeit (virtual time)

WS 13/14 ALP 5 - Verteilte Algorithmen 48
4.5.1 Kausalität!
Def.: Ereignis (event) - drei verschiedene Arten:
local - eine prozessinterne Aktion (z.B. „Zuweisung“) send - Abschicken einer Nachricht (als Folge von send) recv - Empfangen einer Nachricht (als Folge von recv)
E Dienstgüte des Nachrichtensystems bleibt dabei offen
Ereignismenge, nicht näher spezifiziert: E

WS 13/14 ALP 5 - Verteilte Algorithmen 49
Def.: Kausale Abhängigkeit
Zwei Ereignisse a,b ∈ E stehen in der Beziehung a Ú b („a vor b“, „a happened before b“, „b ist kausal abhängig von a“) zueinander, wenn gilt:
entweder � a und b gehören zum selben Prozess und geschehen in dieser Reihenfolge
oder � a ist das Abschicken einer Nachricht, b ist das Empfangen dieser Nachricht
oder � es gibt ein Ereignis c mit a Ú c und c Ú b (Transitivität von Ú)

WS 13/14 ALP 5 - Verteilte Algorithmen 50
Bemerkung: Die Relation „gleich oder vor“
ist partielle Ordnung auf E: Kausalordnung Def.: Zwei Ereignisse a,b sind voneinander unabhängig
(auch nebenläufig, concurrent, causally unrelated), wenn weder a Ú b noch b Ú a
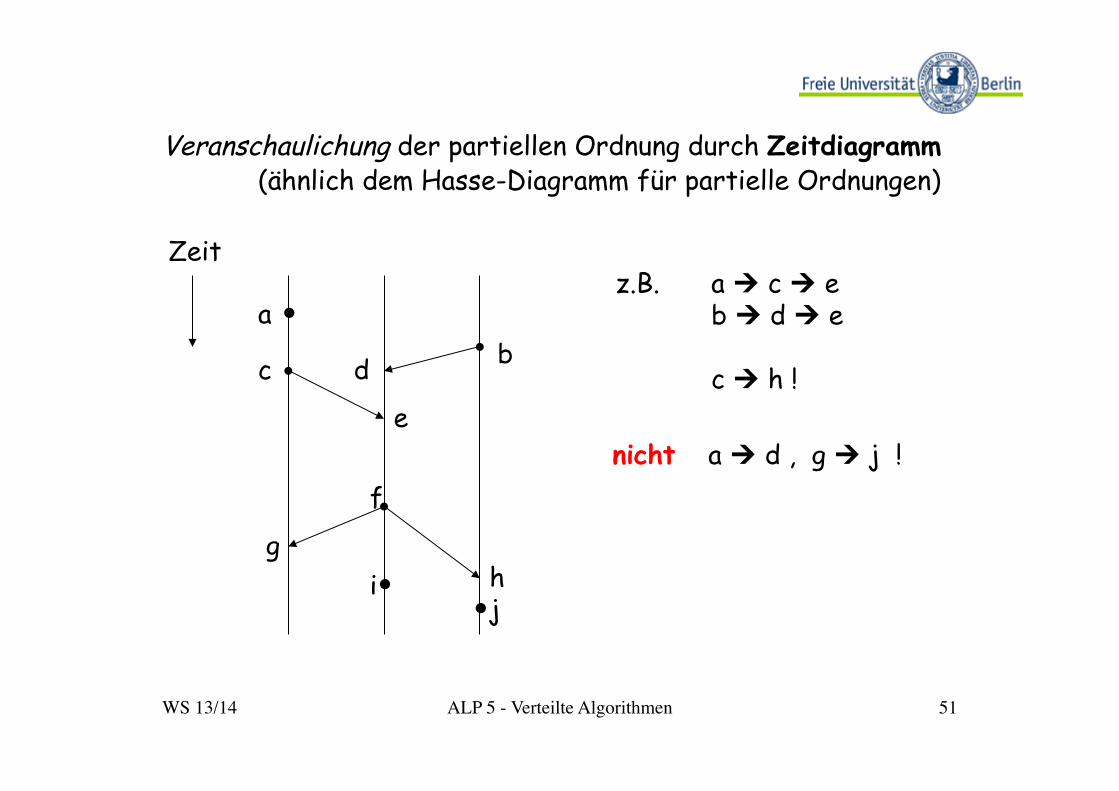
WS 13/14 ALP 5 - Verteilte Algorithmen 51
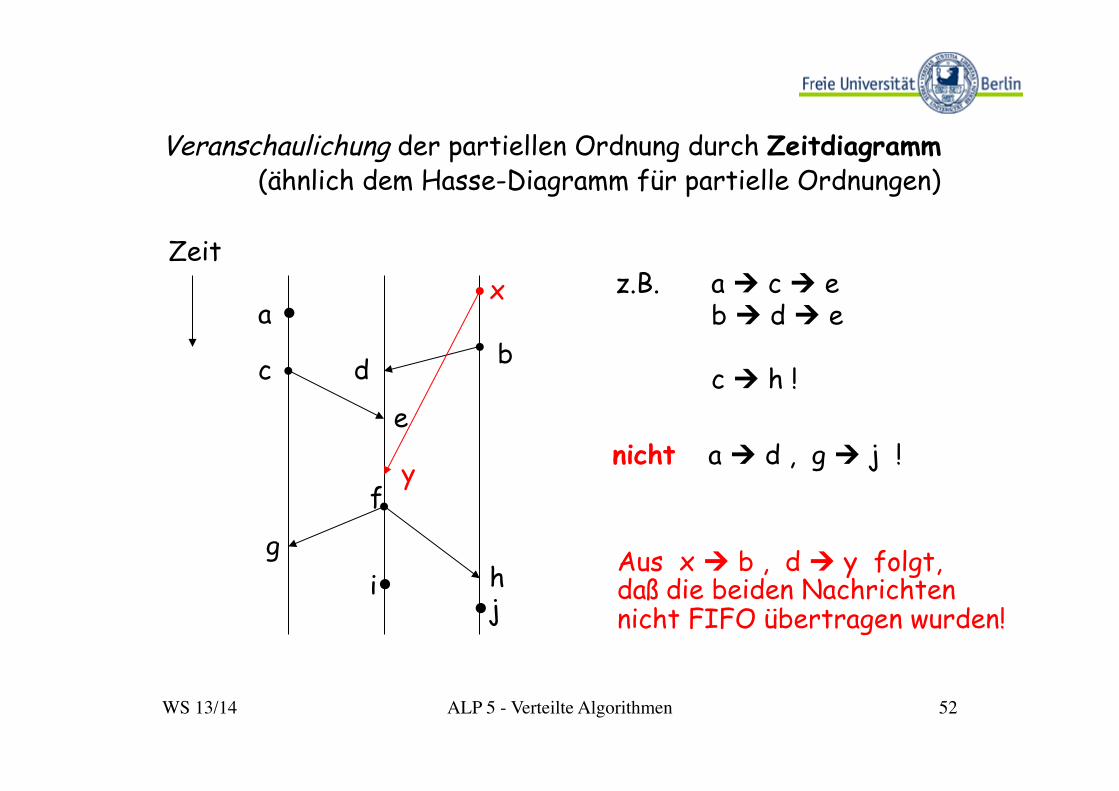
Veranschaulichung der partiellen Ordnung durch Zeitdiagramm (ähnlich dem Hasse-Diagramm für partielle Ordnungen)
Zeit
�
� �
a
j
f
e
d c b
h g
i
z.B. a Ú c Ú e b Ú d Ú e
c Ú h !
nicht a Ú d , g Ú j !
WS 13/14 ALP 5 - Verteilte Algorithmen 52
Veranschaulichung der partiellen Ordnung durch Zeitdiagramm (ähnlich dem Hasse-Diagramm für partielle Ordnungen)
Zeit
�
� �
a
j
f
e
d c b
h g
i
z.B. a Ú c Ú e b Ú d Ú e
c Ú h !
y
x
Aus x Ú b , d Ú y folgt, daß die beiden Nachrichten nicht FIFO übertragen wurden!
nicht a Ú d , g Ú j !

WS 13/14 ALP 5 - Verteilte Algorithmen 53
Dienstgüte des Nachrichtensystems: Reihenfolgetreue (FCFS, FIFO) bei Sender/Empfänger-Paar:
gegebenenfalls erzwingen mit Durchnumerieren der Nachrichten (vgl. TCP versus UDP)
(m,0)
(n,1)
(k,2) (n,1) zurückstellen m zustellen n zustellen k zustellen

WS 13/14 ALP 5 - Verteilte Algorithmen 54
Dienstgüte des Nachrichtensystems: Reihenfolgetreue (FCFS, FIFO) bei Sender/Empfänger-Paar:
Kausalitätstreue bei mehreren Beteiligten:
m
k
m wird vor k gesendet, also auch vor k empfangen
n
wie erzwingen ?
(m,0)
(n,1)
(k,2) (n,1) zurückstellen m zustellen n zustellen k zustellen
gegebenenfalls erzwingen mit Durchnumerieren der Nachrichten (vgl. TCP versus UDP)

WS 13/14 ALP 5 - Verteilte Algorithmen 55
4.5.2 Skalar- und Vektor-Zeit!
Ziel: Jedem Ereignis e ∈ E wird eine „Zeit“ C(e) ∈ T mit gewissem T zugeordnet.
Die Zeiten sind partiell geordnet, und die Ordnung sollte isomorph zur Kausalordnung sein:
(E, Ú) ≅ (T, <)
Die Abbildung C: E → T heißt logische Uhr.
in Anlehnung an die Kausalitätsbeziehung

WS 13/14 ALP 5 - Verteilte Algorithmen 56
1. Versuch: Skalare Zeit [Lamport 1978] T = natürliche Zahlen
(totale Ordnung - daher zum Scheitern verurteilt)
Ø Jeder Prozess führt in einer lokalen Uhr eine lokale Zeit c (anfangs 0).
Ø Jeder Prozess versieht jede versendete Nachricht mit einem Zeitstempel (timestamp) t = c.
Ø Zwischen je zwei Ereignissen wird c um 1 erhöht.
Ø Zusätzlich wird bei einem recv-Ereignis mit Zeitstempel t die Zeit c auf max(c,t+1) gesetzt.

WS 13/14 ALP 5 - Verteilte Algorithmen 57
Für beliebige Ereignisse a,b ∈ E gilt
a Ú b ⇒ C(a) < C(b) , aber nicht die Umkehrung! Damit gilt
C(a) = C(b) ⇒ ¬ (a Ú b ∨ b Ú a) , aber nicht C(a) = C(b) ⇒ a = b
Feststellung: Unabhängige Ereignisse können gleiche Zeiten haben!
3
4 3
1 (7)
4 (7) 5 (8)
5
3
4

WS 13/14 ALP 5 - Verteilte Algorithmen 58
Skalarzeit kann in verteilten Algorithmen anstelle der - nicht vorhandenen - globalen Zeit eingesetzt werden:
Hängt man an die Skalarzeit die Stationsnummer an, so kann man die Ereignisse gemäß dieser Kennung linear anordnen – verträglich mit ihrer Kausalordnung, z.B. 31 < 41 < 42 < ... („topologisches Sortieren“).
Damit ist wenigstens garantiert, dass alle Zeitstempel verschieden sind und dass der Fall „a vor b“ in den zugehörigen Zeitstempeln mit C(a)<C(b) reflektiert wird.

WS 13/14 ALP 5 - Verteilte Algorithmen 59
2. Versuch: Vektorzeit [Fidge, Mattern]
T = n-Tupel natürlicher Zahlen (bei n Prozessen 1,..,n)
t ≤ s : ti ≤ si für alle i=1,..,n Ú Halbordnung ! Z.B. weder (1,0,2) < (2,1,1) noch umgekehrt
Jeder Prozess p Ø führt in einer lokalen Uhr eine lokale Vektorzeit c (anfangs (0,0,..) ), Ø versieht jede versendete Nachricht mit Zeitstempel t = c. Ø Vor jedem Ereignis wird cp um 1 erhöht. Ø Nach recv mit Zeitstempel t werden für alle i=1,..,n die ci auf max(ci,ti) gesetzt.

WS 13/14 ALP 5 - Verteilte Algorithmen 60
Mit der Vektorzeit C erreichen wir die gewünschte Isomorphie: (E, Ú) ≅ (T, <)
Skalarzeit und Vektorzeit sind vielfältig einsetzbar Ú Verteilte Systeme SS 2013

WS 13/14 ALP 5 - Verteilte Algorithmen 61
Zusammenfassung!
Ø Verteilte Algorithmen sind i.d.R. schwierig
Ø ... insbesondere bei physischer Verteilung
Ø i.d.R. nicht Teil von Anwendungssoftware
Ø Hilfreich sind - virtuelle Ringe - logische Uhren

WS 13/14 ALP 5 - Verteilte Algorithmen 62
Quellen!
Erlang: www.erlang.org/doc.html Einführung: queue.acm.org/detail.cfm?id=1454463
M. Odersky et al.: Programming in Scala. Artima 2011 (2. ed.)
www.scala-lang.org en.wikipedia.org/wiki/Scala_(programming_language)
AB-Protokoll: en.wikipedia.org/wiki/Alternating_bit_protocol G. Ricart, A.K. Agrawala: An Optimal Algorithm for Mutual Exclusion
in Computer Networks. CACM 24.1, January 1981, dl.acm.org/citation.cfm?id=358537 Ferner: CACM 24.9, September 1981

WS 13/14 ALP 5 - Verteilte Algorithmen 63
E. Chang, R. Roberts: An Improved Algorithm for Decentralized Extrema-finding in Circular Configurations of Processes. CACM 22.5, May 1979 dl.acm.org/citation.cfm?id=359108
DHTs: en.wikipedia.org/wiki/Distributed_hash_table I. Stoica et al.: Chord: A Scalable Peer-to-peer Lookup Service for
Internet Applications. Proc. ACM SIGCOMM 2001, pdos.csail.mit.edu/papers/ton:chord/paper-ton.pdf
L. Lamport: Time, clocks, and the ordering of events in a
distributed system. CACM 21.7, July 1978 dl.acm.org/citation.cfm?doid=359545.359563

WS 13/14 ALP 5 - Verteilte Algorithmen 64
C. J. Fidge: Timestamps in Message-Passing Systems That Preserve the Partial Ordering. Proc. 11. Australian Computer Science Conf, February 1988
F. Mattern: Virtual Time and Global States of Distributed Systems.
Proc. Workshop on Parallel and Distributed Algorithms, Elsevier, October 1988 ... und die Hinweise in
www.inf.fu-berlin.de/lehre/WS13/alp5/literatur.html

![Persönlichkeitstypen - inf.fu- · PDF file•Die Typen und der MBTI sind millionenfach bewährt ... • ENTJ ("Field Marshall") Lutz Prechelt, prechelt@inf.fu-berlin.de [18] 31](https://static.fdokument.com/doc/165x107/5a9e040a7f8b9ad2298c21b0/persnlichkeitstypen-inffu-die-typen-und-der-mbti-sind-millionenfach-bewhrt.jpg)















![Risiken bei Informatiksystemen - inf.fu-berlin.de · Lutz Prechelt, prechelt@inf.fu-berlin.de [5] 2 / 42 Perspektive • Bisher haben wir eine sehr breite Sicht auf die Auswirkungen](https://static.fdokument.com/doc/165x107/5e10cf5be4e54a40d941b2b1/risiken-bei-informatiksystemen-inffu-lutz-prechelt-precheltinffu-berlinde.jpg)
