
Analyse und Auswertung großer heterogener Datenmengen · PDF fileAnalyse und Auswertung...
31
Analyse und Auswertung großer heterogener Datenmengen Herausforderungen für die IT-Infrastruktur Richard Göbel
Transcript of Analyse und Auswertung großer heterogener Datenmengen · PDF fileAnalyse und Auswertung...

Analyse und Auswertung großer heterogener Datenmengen
Herausforderungen für die IT-Infrastruktur
Richard Göbel

Inhalt
Big Data
• Was ist das eigentlich?
• Was nützt mir das?
• Wie lassen sich solche großen Datenmengen effizient analysieren und auswerten?
– Ideen
– Konzepte
• Welche Produkte gibt es?

Big Data
• In einigen Bereichen "explodieren" die Datenmengen
• Herausforderungen für die – Verwaltung – Auswertung – Nutzung
• 4V-Definition von Big Data – Volume sehr große Datenmenge – Variety verschiedene Typen von Daten – Velocity enge zeitliche Rahmenbedingungen – Veracity ungenaue Daten
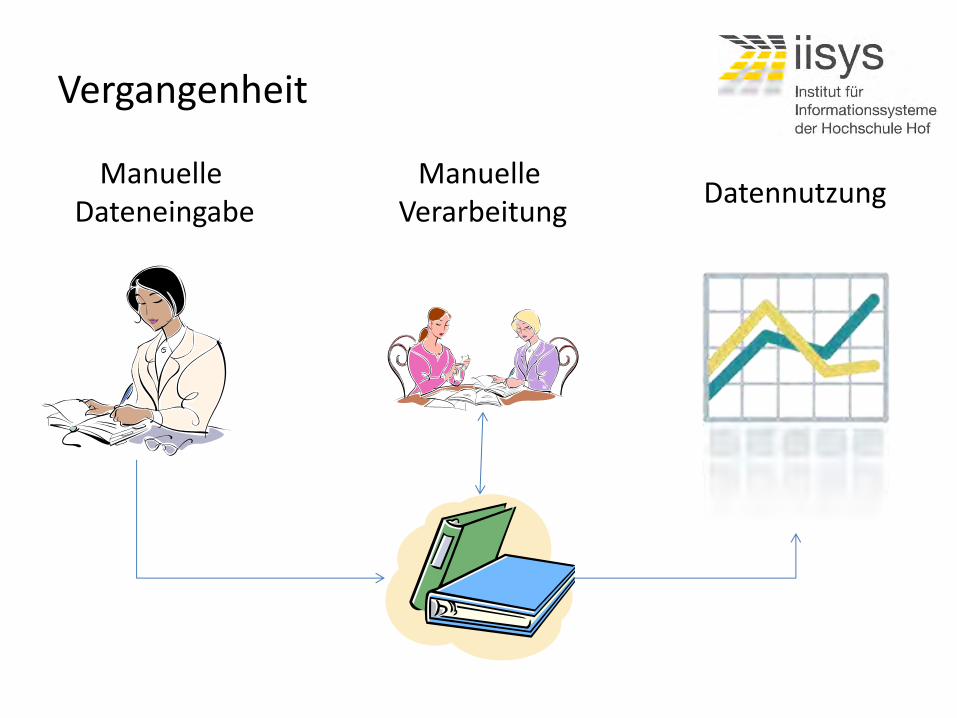
Manuelle Dateneingabe
Manuelle Verarbeitung
Datennutzung
Vergangenheit
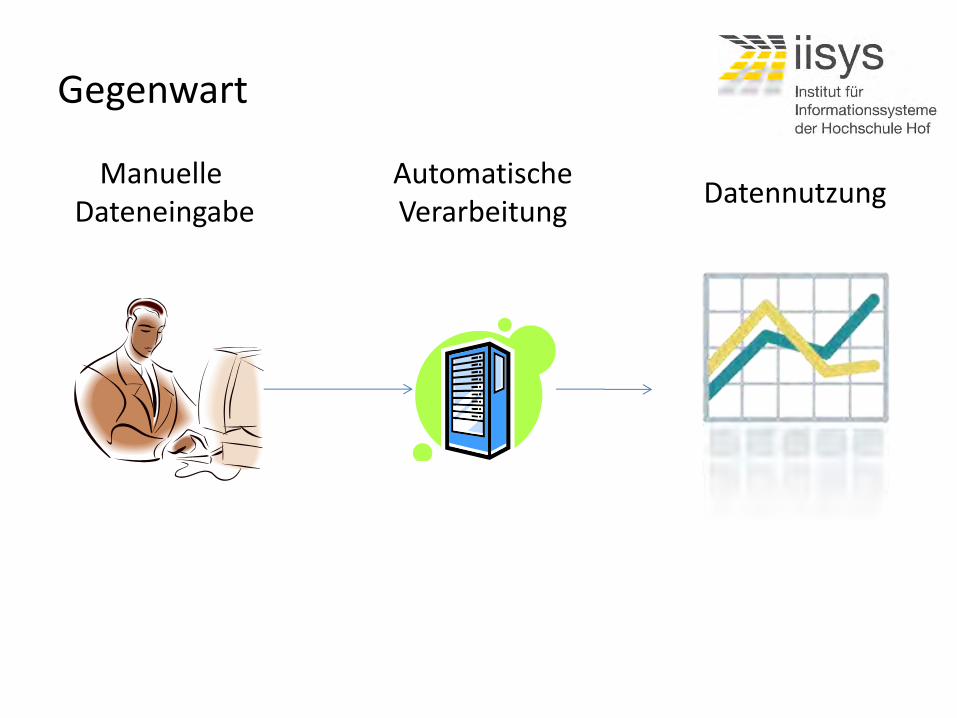
Gegenwart
Manuelle Dateneingabe
Automatische Verarbeitung
Datennutzung
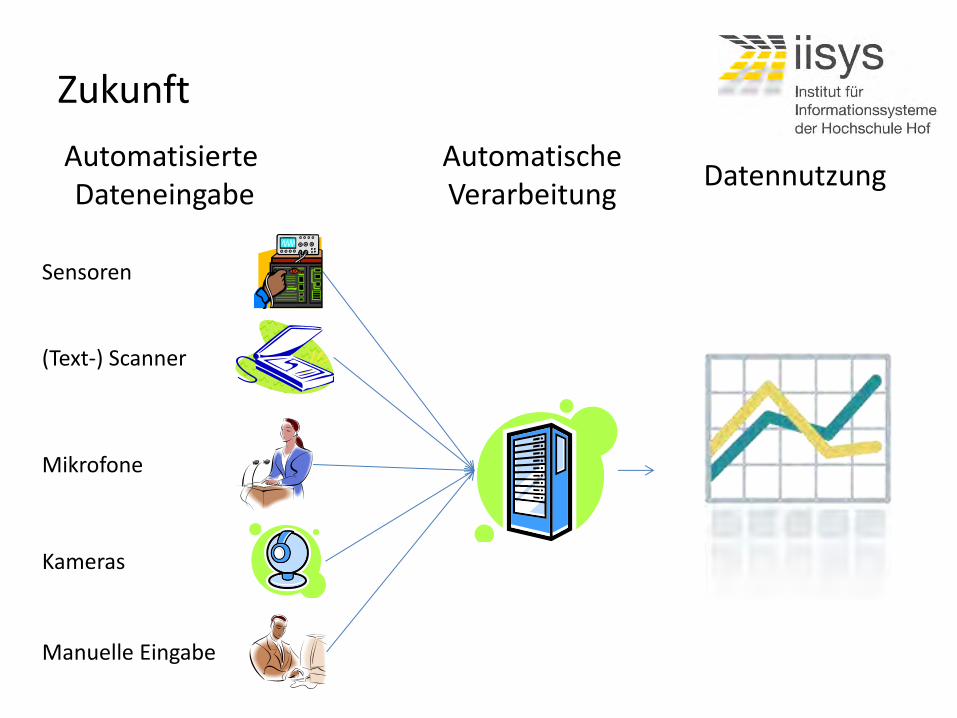
Zukunft
Automatisierte Dateneingabe
Automatische Verarbeitung
Datennutzung
Sensoren
(Text-) Scanner
Kameras
Manuelle Eingabe
Mikrofone

Automatisierte Eingaben: Big Data
• Automatisierte Eingaben ermöglichen – die Akquisition und Auswertung von Daten in Echtzeit
– die Erfassung von mehr Details
– eine deutliche höhere zeitliche Auflösung
• Neben strukturierten Daten werden auch unstrukturierte Daten erfasst – Texte
– Bilder
– Audio- und Videodaten
• Konventionelle IT-Strukturen sind nicht ausreichend für die Verwaltung großer heterogener Datenmengen!

Konkrete Anwendungsbeispiele
• Verbesserte Absatzprognosen der Otto Gruppe aus Daten zu Bewerbungsgrad der Artikel, Artikeleigenschaften sowie Informationen aus dem Umfeld
• Verkehrsmanagement in Stockholm zur Verkehrsleitung auf der Basis von „ Verkehrs- und Wetterdaten (GPS, Sensoren, Unfall- und Staumeldungen, Videos …)
• Nebenwirkungen von Medikamenten sowie Patientenzufriedenheit mit Behandlungsmethoden durch Analyse von Internet Foren und Blogs durch die Treato / First Life Ltd
• Erkennen von Betrugsversuchen bei der Paymint AG bei Kreditkartentransaktionen

Weitere Beispiele für Anwendungen
• Ausfallwahrscheinlichkeiten von Anlagen Betriebsdaten, Protokolle, E-Mails, …
• Kundenmeinungen über eigene und Konkurrenzprodukte Kundenemails, Blogs, soziale Netzwerke,…
• Markforschung: Was wollen Kunden? CRM, Kundenemails, Vertriebsberichte,…
• Erkennen von Unregelmäßigkeiten in Finanztransaktionen Daten Rechnungswesens, Kommunikation, Korrespondenz, …
• Effizienz von Geschäftsprozessen Protokolle, Verbesserungsvorschläge, interne E-Mails,… …

Beispielszenario
• Aufzeichnung von Telefongesprächen im Vertrieb/Support • Stimmanalyse • Umwandlung der Gespräche in Texte • Text Mining
– Warum ruft der Kunde an? Topic Detection
– Welches Produkt? Named Entity Recognition
– Welches Problem hat der Kunde? Ontology
– Bewertung des Produkts Opinion Mining
• Auswertung der Telefongespräche in Echtzeit – Anzahl Probleme pro Produkt – Veränderung der Kundenmeinung

Eine Beispielanwendung
• Überwachung einer Vielzahl von Anlagen in einer Produktionsumgebung
• Erfassung von Daten im Millisekundentakt – Stromverbrauch – Betriebstemperatur – Betriebsmodus – …
• Beispielanwendungen – Ausfallwahrscheinlichkeiten von Anlagen – Qualitätskontrolle – …
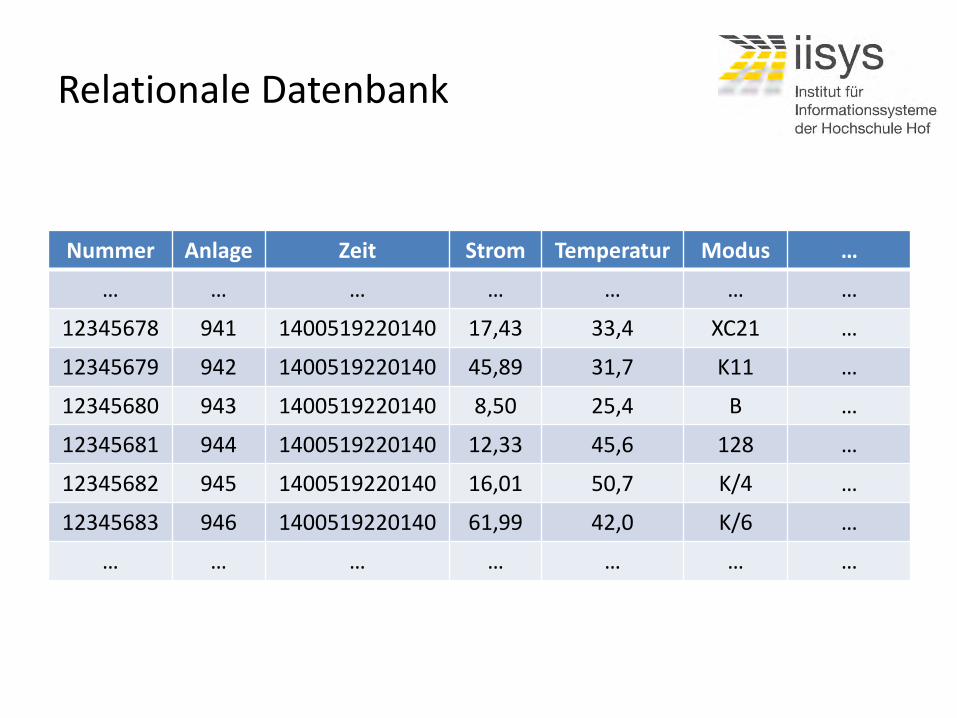
Relationale Datenbank
Nummer Anlage Zeit Strom Temperatur Modus …
… … … … … … …
12345678 941 1400519220140 17,43 33,4 XC21 …
12345679 942 1400519220140 45,89 31,7 K11 …
12345680 943 1400519220140 8,50 25,4 B …
12345681 944 1400519220140 12,33 45,6 128 …
12345682 945 1400519220140 16,01 50,7 K/4 …
12345683 946 1400519220140 61,99 42,0 K/6 …
… … … … … … …

Herausforderungen
• Anzahl neuer Werte pro Sekunde – 1000 Messwerte / Sekunde
– 100 Anlagen
– 10 Parameter / Anlage
– 1.000.000 Werte pro Sekunde
• Anzahl Werte pro Jahr: 31.536.000.000.000
• Schnelles Gruppieren und Auswerten von Daten – Maximaler Stromverbrauch einer Anlage in einem Jahr
– Energieverbrauch jeder Anlage über die letzten 100 Tage
– Verschleiß als Funktion von Stromverbrauch, Temperatur und Betriebsmodus

Relationale Datenbanken - Probleme
• Einfügen von Daten
– Speicherung der Daten direkt auf der Festplatte
– Transaktionskonzept mit „write-ahead logging“
• Auswertung der Daten
– Laden der Daten von der Festplatte
– (Fast) alle Daten müssen für eine Auswertung angefasst werden

Idee - Vorausberechnung
• Anordnung der Werte in einer Tabelle
• Vorausberechnen der Summen für alle Spalten und Zeilen
• Allgemein: OLAP-Hypercube
• Problem: nicht alle relevanten Funktionen sind vorher bekannt
7,2 12 1,1 6 4 30,3
7,3 11 1 6 4,1 29,4
7,4 12 0,9 6 4,2 30,5
7,5 11 0,8 6 4,3 29,6
7,6 11 0,7 6 4,4 29,7
37 57 4,5 30 21 149,5
Anlagen
Zeit
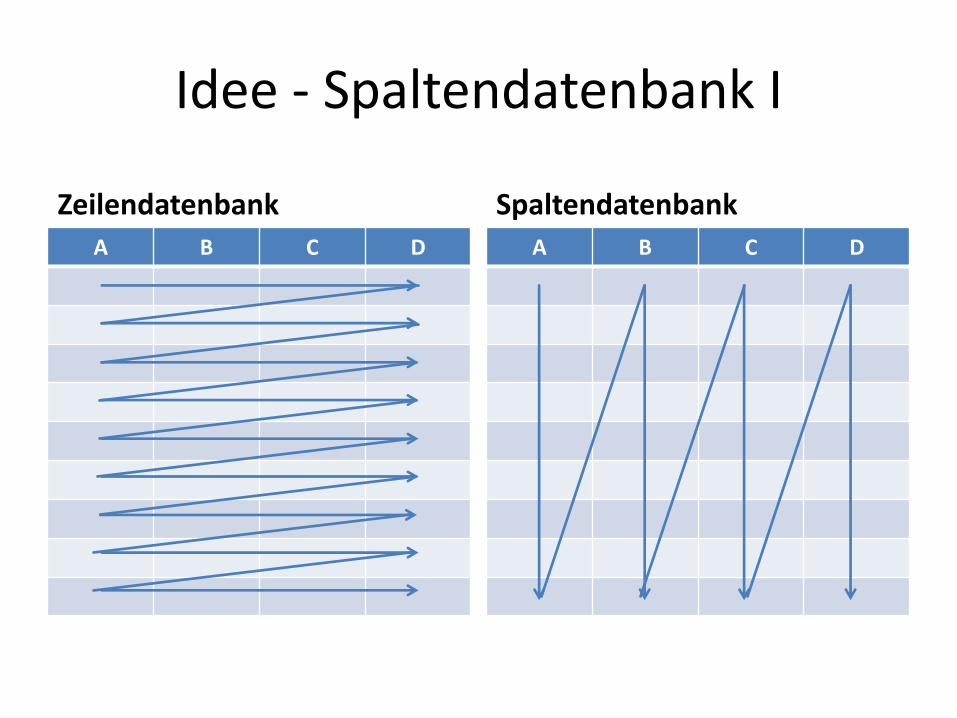
Idee - Spaltendatenbank I
Zeilendatenbank Spaltendatenbank
A B C D A B C D

Idee - Spaltendatenbank II
Hauptspeicher
Cache
CPU

Idee - Datenkompression
• Wenige unterschiedliche Werte Speicherung kurzer Codes anstatt der langen Werte
• Wiederholung von Werten Speicherung von Werten mit Wiederholungsfaktor
• Geringe Differenzen zwischen Werten Start mit einem Basiswert Speicherung von Differenzen
• Einige Kompressionsverfahren beschleunigen die Auswertung der Daten!

Idee - Clustercomputer
• Verteilung der Daten auf unterschiedliche Server – Parallele Verarbeitung und Analyse der Daten möglich
– Aggregation eines Gesamtergebnis aus den Teilergebnissen
– Verwaltung der Daten im Hauptspeicher
– Speicherung der Daten auf Festplatten nur für die Persistenz
– Redundante Speicherung von Daten
• Transparenter Zugriff für Anwender auch über Schnittstellen wie SQL

Konzept - Map
• Zuordnung
– Schlüssel (Key) als beliebiger Datentyp
– Wert (Value) als beliebiger Datentyp
• Operationen
– Put: ordne einem Schlüssel einen Wert zu
– Get: den Wert eines Schlüssels abfragen
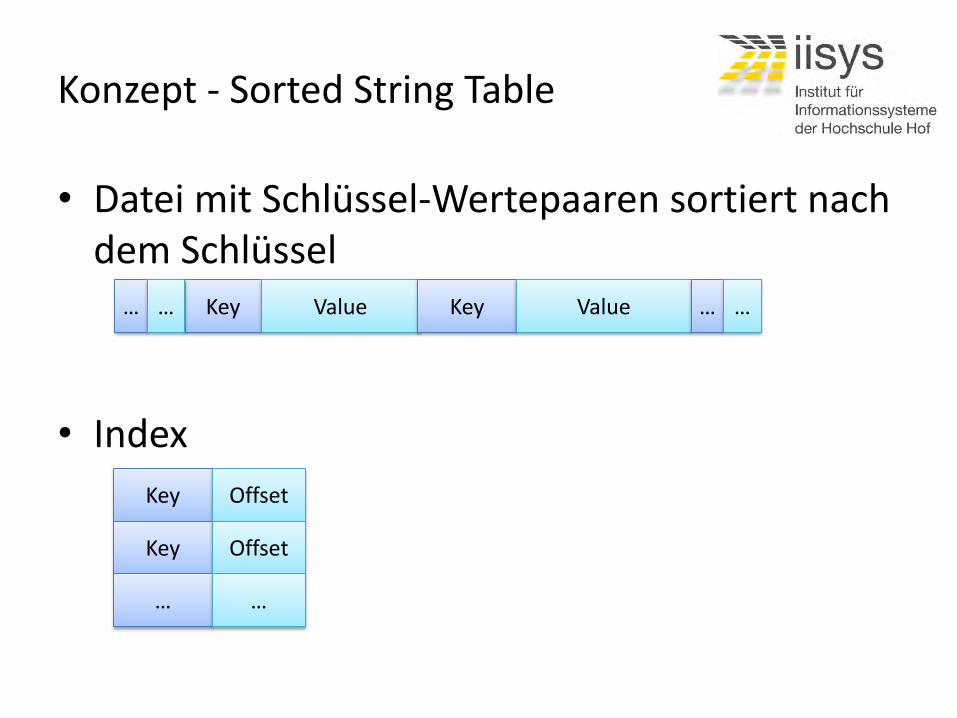
Konzept - Sorted String Table
Key Value Key Value … … … …
• Datei mit Schlüssel-Wertepaaren sortiert nach dem Schlüssel
• Index
Key Offset
Key Offset
… …
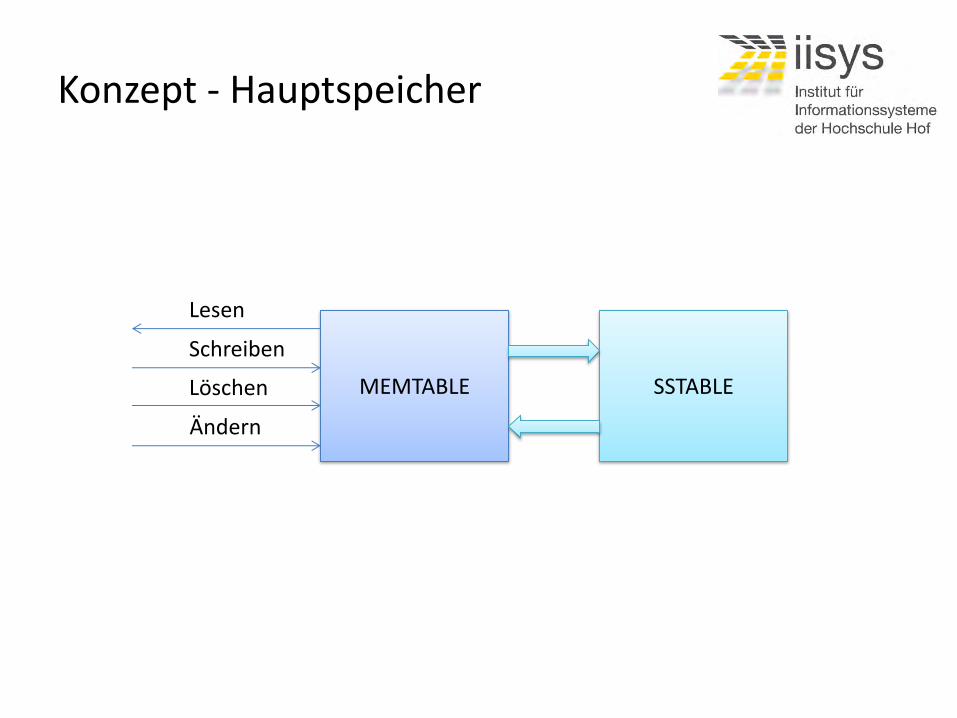
Konzept - Hauptspeicher
MEMTABLE SSTABLE
Lesen
Schreiben
Löschen
Ändern

Konzept – Tabellenstruktur I
• Aufbau – Zeilen (Row)
– Spalten (Column)
– Zeilenschlüssel (Row ID)
• Spaltengruppen – Gruppe von Spalten mit identischen Inhaltstyp
– Jede Zeile kann unterschiedliche Spalten haben
• Es können unterschiedliche Versionen von Spaltenwerten existieren
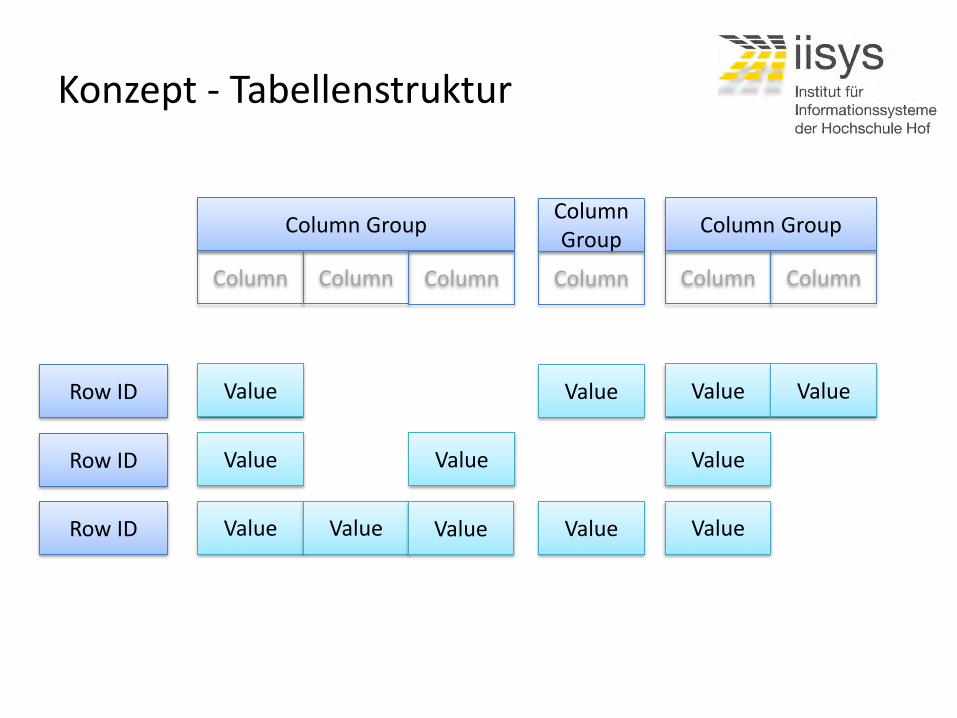
Konzept - Tabellenstruktur
Column Group
Row ID
Column Column Column
Column Group
Column
Column Group
Column Column
Value Value Value Value
Row ID Value Value Value
Row ID Value Value Value Value Value
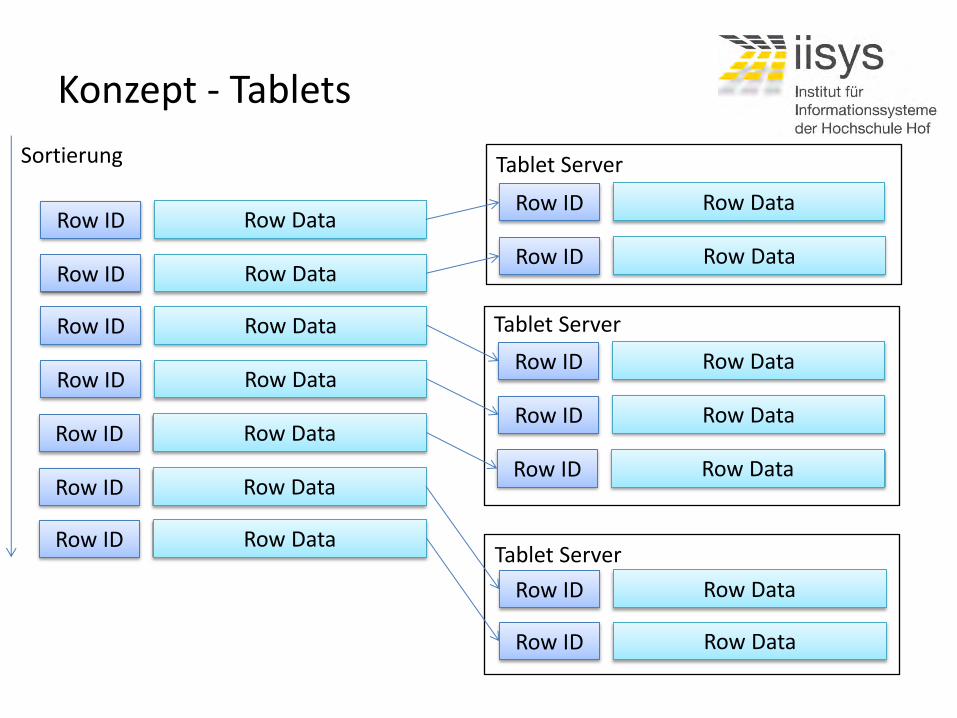
Konzept - Tablets
Row ID Row Data
Row ID Row Data
Row ID Row Data
Row ID Row Data
Row ID Row Data
Row ID Row Data
Row ID Row Data
Sortierung
Row ID Row Data
Row ID Row Data
Row ID Row Data
Row ID Row Data
Row ID Row Data
Row ID Row Data
Row ID Row Data
Tablet Server
Tablet Server
Tablet Server
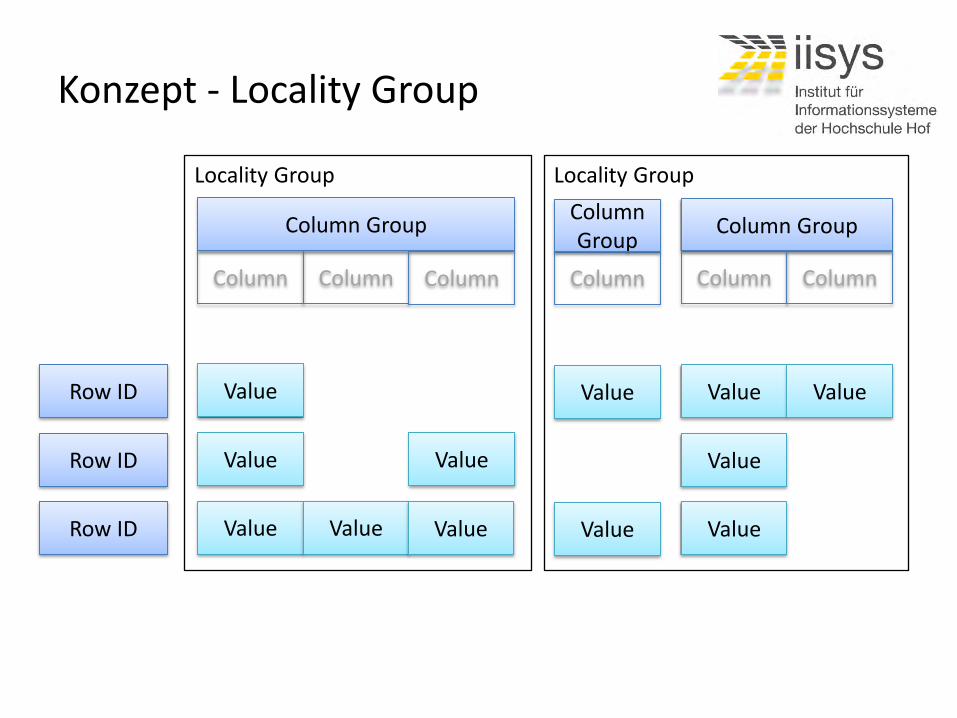
Konzept - Locality Group
Column Group
Row ID
Column Group
Column Group
Value Value Value Value
Row ID Value Value Value
Row ID Value Value Value Value Value
Locality Group Locality Group
Column Column Column Column Column Column

Aufgaben des Datenbankentwicklers
• Datenmodell entwerfen – Tabellen – Spalten/Spaltengruppen (erweiterbar) – Versionsverwaltung für Werte
• Abbildung des Datenmodells definieren – Verteilung der Daten auf verschiedene Rechner – Redundante Datenhaltung – Gruppieren von Spaltengruppen – Datenkompression – …
• Zugriff und Auswertung – Klassisch deklarativ (z.B. mit SQL) – Zusätzlich prozedurale Programme zur optimalen Nutzung der
Abbildung des Datenmodell

Konzept - Datenkompression
• Identische Werte für konsekutive Schlüssel werden nicht redundant gespeichert
• Standardkompression zum Beispiel mit dem ZIP-Verfahren
• Anwendung kann zusätzlich eigene Verfahren definieren

Beispiel Spaltendatenbanken
• Kommmerziell – Oracle 12c – IBM DB2 with BLU Acceleration – Microsoft SQL Server 2014 – SAP Hana – Sybase IQ – …
• Open Source – Apache Accumulo – Apache Cassandra – MonetDB – …

Zusammenfassung
• Schnelle Erfassung und Auswertung sehr großer Datenmengen mit neuen Technologien möglich
• Größere Freiheiten und höherer Aufwand zur Anpassung der Datenbanken an Anwendungen
• Aktuell noch sehr unterschiedliche Konzepte und Produkte (kein Standard in Sicht!)
• Kontakt
www.iisys.de

Vielen Dank für ihre Aufmerksamkeit!


















