
Apis Mellifera - ZIB · Zusammenfassung Forschungsergebnisse uber die r aumliche Struktur des...
70
Freie Universit¨ at Berlin - Fachbereich Informatik - - Studiengang Bioinformatik - Aufbau und Analyse eines statistischen Formmodells des Gehirns der Honigbiene Apis Mellifera Abschlussarbeit zur Erlangung des akademischen Grades Bachelor of Science (B.Sc.) vorgelegt von Matthias Lienhard Matrikelnummer 4059510 Gutachter: Prof. Dr. Randolf Menzel Dr. Stefan Zachow
-
Upload
truongkhanh -
Category
Documents
-
view
213 -
download
0
Transcript of Apis Mellifera - ZIB · Zusammenfassung Forschungsergebnisse uber die r aumliche Struktur des...

Freie Universitat Berlin- Fachbereich Informatik -
- Studiengang Bioinformatik -
Aufbau und Analyse eines statistischen
Formmodells des Gehirns der Honigbiene
Apis Mellifera
Abschlussarbeit zur Erlangung des akademischen Grades
Bachelor of Science (B.Sc.)
vorgelegt von
Matthias Lienhard
Matrikelnummer 4059510
Gutachter: Prof. Dr. Randolf Menzel
Dr. Stefan Zachow

Zusammenfassung
Forschungsergebnisse uber die raumliche Struktur des Bienengehirns auszuwerten, darzu-
stellen und zueinander in Beziehung zu setzten erfordert eine aufwandige Analyse und
Verarbeitung mikroskopischer Schnittserien.
Statistische Formmodelle haben sich als vielfaltige und machtige Werkzeuge zur Analyse
von Bilddaten erwiesen. Die Modelle beinhalten a priori Wissen uber die Form der
modellierten Objekte, welches u.a. zur automatischen Segmentierung der Bilddaten
genutzt werden kann.
Mit dieser Arbeit wurde ein statistisches Formmodell der zentralen Gehirnstrukturen
des Bienengehirns aus 16 manuell segmentierten Exemplaren erstellt. Es umfasst die
Pilzkorper, den Protocerebrallobus, das Unterschlundganglion, den Zentralkomplex sowie
deren Subneuropile. Außerdem wurde im Rahmen dieser Arbeit eine Methode entwickelt,
mittels derer beliebige Teile des Modells entnommen und als separate statistische Form-
modelle genutzt werden konnen. Die Qualitat des Modells wurde anhand von statistischer
Analyseverfahren ausgewertet. Durch die Aufnahme von gespiegelten Gehirnen konnte die
Qualitat des Modells einerseits erhoht werden, andererseits wurde so ein symmetrisches
Verhalten des Modells erreicht.
J.Singer stellt in seiner Arbeit [Sin08] einen Algorithmus zur Autosegmentierung vor, der
dieses Modell an konfokale Grauwertbilder anpasst.

Inhaltsverzeichnis
1 Einleitung 1
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Vorarbeiten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Thematik der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Grundlagen 6
2.1 Morphologie des Bienengehirns . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Praparation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Tiere . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.2 Histologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Konfokale Mikroskopie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 3D Modellrekonstruktion . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4.1 Segmentierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.4.2 Oberflachenrekonstruktion . . . . . . . . . . . . . . . . . . . . . . 12
2.5 Statistische Formmodelle (SFM) . . . . . . . . . . . . . . . . . . . . . . . 12
2.5.1 Alignierung der Trainingsdaten . . . . . . . . . . . . . . . . . . . 13
2.5.2 Korrespondenzproblem . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5.3 Finden einer gemeinsamen Parametrisierung . . . . . . . . . . . . 14
2.5.4 Hauptkomponentenanalyse (Principal Component Analysis, PCA) 15
2.5.5 Aufbau eines SFM . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.5.6 Anwendungen statistischer Formmodelle . . . . . . . . . . . . . . 17
2.5.7 Anforderungen an statistische Formmodelle . . . . . . . . . . . . 18
3 Aufbau eines statistischen Formmodells des Bienengehirns 21
3.1 Grundlage des statistischen Formmodells . . . . . . . . . . . . . . . . . . 21
3.2 Aufbau des statistischen Formmodells . . . . . . . . . . . . . . . . . . . . 23
3.2.1 Bedingungen an die Segmentierung . . . . . . . . . . . . . . . . . 23

Inhaltsverzeichnis
3.2.2 Bedingungen an die Oberflachen . . . . . . . . . . . . . . . . . . . 23
3.2.3 Gebietszerlegung . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.3 Erweiterung der Trainingsmenge durch Spiegelung der Daten . . . . . . . 27
3.4 Auflosungsstufen des SFM . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.5 Extrahieren von Teilstrukturen aus dem SFM . . . . . . . . . . . . . . . 30
4 Analyse des statistischen Formmodells 33
4.1 Auswertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.1.1 Formmoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.1.2 Korrelation der Formmoden des SFM in verschiedenen Detailstufen 35
4.1.3 Kompaktheit des Modells . . . . . . . . . . . . . . . . . . . . . . 39
4.1.4 Vollstandigkeit des Modells . . . . . . . . . . . . . . . . . . . . . 41
4.1.5 Auswertung des zeitlichen Aufwands . . . . . . . . . . . . . . . . 43
4.2 Diskussion und Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5 Danksagung 45
A Praktische Anleitung zur Erzeugung von Oberflachen fur das statisti-
sche Formmodell des Bienengehirns mit Amira I
A.1 Segmentierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . I
A.1.1 Materialien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . II
A.1.2 Segmentierungsstrategie . . . . . . . . . . . . . . . . . . . . . . . II
A.1.3 Nachbearbeitung . . . . . . . . . . . . . . . . . . . . . . . . . . . III
A.2 Erzeugung einer Oberflache . . . . . . . . . . . . . . . . . . . . . . . . . IV
A.2.1 Nachbearbeitung einer Oberflache . . . . . . . . . . . . . . . . . . V
A.2.2 Gebietszerlegung einer Oberflache . . . . . . . . . . . . . . . . . . VI
A.2.3 Definition von Oberflachenpfaden . . . . . . . . . . . . . . . . . . VI
A.2.4 Zerlegung der Oberflache . . . . . . . . . . . . . . . . . . . . . . . X
A.2.5 Ordnen der Oberflachenregionen . . . . . . . . . . . . . . . . . . . X
A.3 Erweiterung der Stichprobe durch Spiegelung von Oberflachen . . . . . . X
A.4 Abbilden der Triangulation . . . . . . . . . . . . . . . . . . . . . . . . . . XI
A.5 Erzeugen der”Active Surface“ . . . . . . . . . . . . . . . . . . . . . . . . XII
A.6 Erstellen von Teilmodellen . . . . . . . . . . . . . . . . . . . . . . . . . . XIII
Glossar XIV
Literaturverzeichnis XVI
iv

Abbildungsverzeichnis
1.1 Die Neuropile des statistischen Formmodells . . . . . . . . . . . . . . . . 4
2.1 Pilzkorper . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Zentralkomplex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Protocerebrallobus und Unterschlundganglion . . . . . . . . . . . . . . . 8
2.4 Antennal Loben und optische Loben . . . . . . . . . . . . . . . . . . . . 8
2.5 Konfokaler Schnitt des Bienengehirns . . . . . . . . . . . . . . . . . . . . 10
2.6 Prinzipieller Aufbau eines konfokalen Mikroskops . . . . . . . . . . . . . 10
2.7 Bildstapel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.8 Der Winkel zwischen den Normalen zweier verbundener Dreiecke . . . . . 13
2.9 Korrespondenzfunktion zwischen zwei Oberflachenteilstucken . . . . . . . 15
2.10 Beispielhafter Verlauf der kumulierten Varianz . . . . . . . . . . . . . . . 20
3.1 Das SFM des Bienengehirns . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Kontaktflachen zwischen den Neuropilen . . . . . . . . . . . . . . . . . . 24
3.3 Glattung durch Vergroberung der Dreiecksvernetzung (schematisch) . . . 25
3.4 Beispiel zur Glattung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.5 Genera geschlossener Oberflachen. Aus Wikipedia, die freie Enzyklopadie 25
3.6 Die 7”Henkel“ des PL-SOG . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.7 Deriecksseitenverhaltnis . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.8 Die Einteilung der Bienengehirnoberflache in 89 Teilgebiete . . . . . . . . 28
3.9 Ein gespiegeltes Bienengehirn . . . . . . . . . . . . . . . . . . . . . . . . 29
3.10 Aus dem Gesamtmodell extrahierte Teilstruktur: SFM des rechten Pilzkorpers 31
3.11 Hochauflosender Scan des rechten Pilzkorpers . . . . . . . . . . . . . . . 32
4.1 Variation der ersten Hauptmode . . . . . . . . . . . . . . . . . . . . . . . 34
4.2 Variation der zweiten Hauptmode . . . . . . . . . . . . . . . . . . . . . . 35
4.3 Variation der dritten Hauptmode . . . . . . . . . . . . . . . . . . . . . . 36

Abbildungsverzeichnis
4.4 Variation der vierten Hauptmode . . . . . . . . . . . . . . . . . . . . . . 36
4.5 Relative kumulierte Varianz der Modelle . . . . . . . . . . . . . . . . . . 40
4.6 Abstande der angepassten Modelle zu den Testoberflachen . . . . . . . . 42
4.7 Systematische Verzerrung bei der Abbildung an Beruhrungsflachen . . . . 44
A.1 Parameter des Resample Moduls . . . . . . . . . . . . . . . . . . . . . . III
vi

Tabellenverzeichnis
3.1 Die Neuropile des SFM des Bienengehirns . . . . . . . . . . . . . . . . . 22
3.2 Auflosungsstufen des statistischen Formmodells . . . . . . . . . . . . . . 30
4.1 Auswirkung der ersten Moden auf das Verhaltnis von Hohe zu Breite und
Tiefe. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.2 Korrelation der Modellparameter verschiedener Detailstufen . . . . . . . 38
4.3 Relative 90%-Kompaktheit der Modelle . . . . . . . . . . . . . . . . . . . 39
4.4 Vergleich der Vollstandigkeit der Modelle mit und ohne gespiegelte Instan-
zen mit”leave one out“ Test . . . . . . . . . . . . . . . . . . . . . . . . . 42

Kapitel 1
Einleitung
1.1 Motivation
Am Institut fur Neurobiologie der FU Berlin (AG Prof. Menzel) wird die Dynamik
des Gehirns beim Lernen erforscht. Es ist aufgrund der Komplexitat der neuronalen
Vorgange notwendig, die Prozesse der Bildung eines Gedachtnisses an einem relativ
einfachen Organismus zu untersuchen, welcher dennoch in der Lage ist, schnell zu
lernen und uber ein Langzeitgedachtnis verfugt. Diese Voraussetzungen bietet die Biene
unter experimentellen Bedingungen, welche eine optische und elektrische Messung der
Gehirnaktivitat ermoglichen. Neuronale Phanomene konnten so auf zellulare Prozesse
zuruckgefuhrt werden, welche sich prinzipiell bei allen Tieren beobachten lassen.
Ein wesentlicher Aspekt fur die zusammenfassende Betrachtung experimenteller Daten
(Morphologie, Physiologie, Molekularbiologie) ist die Aufnahme der Daten in einen Da-
tenatlas. Ein erster Schritt ist der Atlas des Honigbienengehirns, Honeybee Standard
Brain (HSB) welcher 2005 von Brandt et al., [BRR+05] vorgestellt wurde. Dieser stellt
eine Durchschnittsform von 20 manuell segmentierten Bienengehirnen dar. Er eignet
sich, raumlich strukturelle Beziehungen zwischen Neuronen aus unterschiedlichen Ex-
perimenten in einem gemeinsamen Kontext darzustellen. Inzwischen enthalt der Atlas
ca. 20 Neurone und Neuronentrakte1, welche in verschiedenen Praparaten angefarbt und
in das Durchschnittsmodell ubertragen wurden. Ein solcher Atlas dient nicht nur dem
1siehe http://www.neurobiologie.fu-berlin.de/beebrain/Register.html

1. Einleitung
Verstandnis der Struktur des Bienengehirns, er stellt auch ein wichtiges Werkzeug fur die
konkrete Versuchsplanung dar. So eignet er sich z.B. als stereotaktisches Instrument fur
die Visualisierung der Einstichstelle bei intra-und extrazellularen Ableitungen definierter
Neuronenpopulationen.
Da die raumliche Struktur der verschiedenen Bienengehirne individuell ist, konnen
Neurone nicht direkt miteinander dargestellt werden, sondern mussen in ein gemeinsames
Modell, das Durchschnittgehirn (HSB) transformiert werden. Um Neurone in den Atlas
zu integrieren sind bislang folgende Schritte notwendig:
• In einem Praparat wird eine Nervenzelle (oder eine Population von Neuronen)
und das umgebende Neuropil mit zwei unterschiedlichen Fluoreszenzfarbstoffen
markiert.
• Im Konfokalmikroskop wird ein Doppel-Kanal Scan durchgefuhrt.
• Die digitalisierten 3D Bildstapel werden als Neuron- und Neuropilkanal getrennt
weiter prozessiert: Das in den Atlas zu transformierende Neuron sowie die Neuropile
werden getrennt segmentiert.
• Die Neuropile werden mittels einer affinen und einer elastischen Transformation des
Volumens derart an das HSB angepasst, sodass der Oberflachenabstand zu dem
Durchschnittsgehirn minimal wird. Diese Transformationsvorschriften werden dann
auch auf das Neuron angewandt.
Die manuelle Segmentierung stellt dabei einen erheblichen Teil der Arbeit dar, je nachdem
wie viele der Neuropile segmentiert werden mussen nimmt sie pro Gehirn 1-2 Arbeitstage
in Anspruch. Sie muss mit großer Sorgfalt durchgefuhrt werden und erfordert sowohl
Fachwissen uber die Form der Neuropilstrukturen und deren spezifische Muster in den
Bilddaten, als auch Erfahrung mit der Software Segmentierungsumgebung. Der enorme
zeitliche Aufwand und die Komplexitat der Strukturen fuhren bei aller Sorgfalt und
Erfahrung zwangslaufig zu mehr oder weniger gravierenden Segmentierfehlern. Außerdem
fuhren verschiedene Erfahrungen und Praferenzen der Segmentierer dazu, dass Rekon-
struktionen verschiedener Personen sich unterscheiden. Selbst von ein und demselben
Segmentierer sind die Ergebnisse nicht zu 100% reproduzierbar. Eine automatische Seg-
2

1. Einleitung
mentierung der konfokalen Bildserien wurde diese Probleme umgehen. Daher ist die
zentrale Motivation der Erstellung des statistischen Formmodells die Anwendung zur
Autosegmentierung.
1.2 Vorarbeiten
Der erste Ansatz, deformierbare Modelle zur Analyse von Bilddaten einzusetzen, wurde
von 1987 von Kass et al., [KWT87] vorgestellt. Bei diesem Verfahren wird die Form von
Objekten automatisch durch sich den Bilddaten anpassende Kurven –sogenannte Snakes–
erkannt. Diese Snakes passen sich abhangig von dem Gradienten in den Bilddaten an die
Form des abgebildeten Objekts an.
Von Cootes et al., [CT92] wurde dieser Ansatz aufgegriffen und die Modelle um statistische
Informationen der Form erweitert, um ihre Deformierbarkeit einzuschranken und damit
die Spezifitat zu erhohen.
2002 stellte Lamecker et al. [LLS02] ein statistisches 3D Formmodell der Leber zur
Autosegmentierung vor. Ein Algorithmus, welcher das Modell iterativ an Computertomo-
graphiedaten (CT) anpasst wurde von der Arbeitsgruppe 2003 vorgestellt [LLS+03b].
Die CT Bilder haben bezuglich der Signalstarke und Qualitat grundsatzlich Ahnlichkeit
zu den konfokalen Schnittserien des Bienengehirns, was nahe legt, dass der Algorithmus
auch fur die automatische Segmentierung dieser Bilddaten eingesetzt werden kann.
2007 wurde dieser Ansatz von K. Neubert [Neu07] auf ein Neuropil des Bienengehirns,
den medialen Calyx des linken Pilzkorpers ubertragen.
Um die zeitaufwandige Prozedur der Neuropil Hintergrundsmarkierung und Registrierung
des individuellen segmentierten Gehirns in den HSB zu vereinfachen, wurde die Synapsin
Hintergrundsmarkierung [BRR+05] durch eine Lucifer Neuropil Markierung [Ste81] ersetzt.
Hierdurch verkurzt sich die histologische Prozedur von 7 Tagen auf einen Tag.
3

1. Einleitung
1.3 Thematik der Arbeit
Um ein statistisches Formmodell des Bienengehirns in der Praxis nutzbar zu machen
muss es einen großeren Bereich des Gehirns darstellen. Dies ist wichtig fur die Anwen-
dung des Modells zur Autosegmentierung, da sich die zu transformierenden Neurone
meist uber Neuropilgrenzen hinweg erstrecken. Daher wird mit dieser Arbeit ein neues
statistisches Formmodell erstellt, welches den Großteil des Bienengehirns darstellt. Es soll
die beiden Pilzkorper inklusive Calyces und Pedunkuli sowie den Protocerebrallobus, das
Unterschlundganglion und den Zentralkomplex umfassen (siehe Abb. 1.1). Aus zeitlichen
Grunden wurde zunachst auf die Integration der Antennalloben sowie der optischen
Loben in das statistische Formmodell verzichtet.
Abbildung 1.1: Die Neuropile des statistischen Formmodells
Die Grundlage des Modells bilden 16 manuell segmentierte konfokale Bildstapel. Das
Modell ist jedoch flexibel konzipiert und erlaubt sowohl die Erweiterung um weitere
Gehirnregionen als auch um weitere Bienengehirne.
4

1. Einleitung
Das statistische Formmodell kann fur verschiedene Anwendungen genutzt werden (siehe
Abschnitt 2.5.6). Da die Anforderungen an das Modell dafur unterschiedlich sein konnen,
ist es wichtig, dass das Modell eine hierarchische Struktur aufweist:
Es wird eine Methode vorgestellt und diskutiert, welche einen flexiblen Wechsel zwischen
den Detailstufen des Modells ermoglicht (siehe Abschnitt 3.4). Die Anwendung eines
grob aufgelosten Modells ist weniger speicher- und rechenintensiv, allerdings werden
dabei auch weniger Details dargestellt. Durch das Verfahren kann der Detailgrad an die
Anforderungen der Anwendung angepasst werden.
Fur einige Anwendungen ist es notig, dass nur bestimmte Teilstrukturen des Modells
dargestellt werden. Mit dieser Arbeit wird eine Methode vorgestellt, welche es erlaubt,
Teilstrukturen aus dem Modell herauszunehmen und diese separat zu nutzen (siehe
Abschnitt 3.5). Beispielsweise konnen mit diesen Teilmodellen hoch auflosenden Scans
von Ausschnitten des Bienengehirns genauer automatisch segmentiert werden.
Durch die zusatzliche Aufnahme der Spiegelbilder der Gehirne kann einerseits die Stichpro-
bengroße des statistischen Formmodells erhoht werden. Andererseits fuhrt das Verfahren
zu einem Modell, dass sich symmetrisch verhalt.
Fur das komplette Modell sowie fur einen exemplarischen Ausschnitt wird die Vollstandig-
keit und Kompaktheit des Modells diskutiert. Diese Qualitatsmerkmale des statistischen
Modells sind u.a. Indizien fur die Moglichkeit, dieses zur Autosegmentierung einsetzen zu
konnen.
J. Singer beschreibt in [Sin08] den Algorithmus, welcher dieses Modell an die zu segmen-
tierenden Grauwertbilder anpasst.
5

Kapitel 2
Grundlagen
2.1 Morphologie des Bienengehirns
Das Gehirn der Arbeiterinnenbiene misst ca. 1,8 mm in der Breite, 1 mm in der Hohe
und 0,6 mm in der Tiefe. Es hat ein Volumen von ca. 0,33 mm3 und besteht aus ca.
800.000 Neuronen. Die Einteilung des Bienengehirns in Regionen (Neuropile) wurde 1982
durch Mobbs [Mob82] wie folgt vorgeschlagen.
Die Pilzkorper (siehe Abb. 2.1) sind symmetrische Strukturen, welche sich in vielen
Insektengehirnen wieder finden. Bei der Biene bestehen sie aus je zwei kelchformigen
Calyces und einem Schaft (Pedunkel), welcher in der Mitte der Calyces beginnt und
sich in α- und β-Lobus fortsetzt. In den Pilzkorpern werden Informationen aus den
sensorischen Neuropilen verarbeitet. Außerdem spielen sie eine Rolle bei der Bildung des
Gedachtnisses [Men01]. Die Pilzkorper bestehen aus 170.000 intrinsischen Neuronen, den
Kenyon Zellen, deren Dendriten die Calyces, und deren Axone die Pedunkuli und die α-
und β-Loben bilden.
Der Zentralkomplex (siehe Abb. 2.2) ist eine Gehirnstruktur in der Mitte des Bienenge-
hirns. Er besteht aus dem Zentralkorper, welcher sich in”Fan Shape Body“ und
”Ellipsoid
Body“ unterteilen lasst, sowie den beiden Noduli. Zentralkorper und Noduli werden als
Zentralkomplex bezeichnet. Die Brucke (protocerebral bridge) wird bei [BRR+05] dem
Protocerebrallobus zugeordnet, eine Konvention welche wir ubernahmen.

2. Grundlagen
Abbildung 2.1: Der linke Pilzkorper mit lateralem (latC) und medilalem Calyx (medC)sowie dem Pedunkulus (Pe). Modifiziert nach [BRR+05]
Abbildung 2.2: Der Zentralkomplex mit Fan Shape Body (Fan), Ellipsoid Body (Eli),Noduli (Nod) und Brucke (Br, transparent). Modifiziert nach [BRR+05]
7

2. Grundlagen
Der Protocerebrallobus und das Unterschlundganglion (siehe Abb. 2.3) wurden in
unserem Modell wie im Atlas [BRR+05] zu einem Neuropil zusammengefasst. Ersterer
umfasst verschiedene bilaterale symmetrische Subneuropile: die lateralen Horner, die
optischen Tuberkel und die Dorsalloben.
Abbildung 2.3: Der Protocerebrallobus (PL) mit den lateralen Hornern (LH), den opti-schen Tuberkeln (OT) sowie den Dorsalloben (DL) und das Unterschlund-ganglion (USG). Modifiziert nach [BRR+05]
Zunachst nicht in das Modell aufgenommen wurden die Antennalloben und die Optischen
Loben welche aus Lobula und Medulla bestehen (Abb. 2.4).
Abbildung 2.4: Antennalloben (AL) und Optische Loben (OL) bestehend aus Lobula(Lo) und Medulla (Me). Modifiziert nach [BRR+05]
8

2. Grundlagen
2.2 Praparation
2.2.1 Tiere
Es wurden adulte Arbeiterinnen (Flugbienen) der westlichen Honigbiene Apis mellifera
carnica verwendet.
2.2.2 Histologie
Eine Farbemethode, welche auf Inkubation des Gehirns mit dem Fluoreszensfarbstoff Lu-
cifer Yellow [Ste81] beruht, wurde angewandt (siehe Abb. 2.5). Der wesentliche praktische
Vorteil ist, dass die Inkubationszeit im Vergleich zu der Synapsin Antikorpermethode
welche bei [BRR+05] eingesetzt wurde mit maximal 1 Tag versus 7 Tagen deutlich geringer
ist. Allerdings liefert diese Methode weniger starke Kontraste, was bezuglich der Arbeit
von K. Neubert [Neu07] eine Adaptierung der Strategie zur Anpassung des statistischen
Modells an die zu segmentierenden Grauwertbilder notig macht (siehe [Sin08]). Der Ein-
fluss dieser Farbemethode auf die Form der Gehirne und damit auch auf das statistische
Modell ist jedoch vernachlassigbar1.
2.3 Konfokale Mikroskopie
Die Bienengehirne wurden mit einem konfokalen Laser-Raster-Mikroskop gescannt. Durch
den speziellen Aufbau wird die Optik hierbei auf eine spezifische Raumebene innerhalb
des Objekts fokussiert, sodass virtuelle optische Schnitte erzeugt werden konnen. Ein
Laserstrahl rastert bei dieser Technik Punkt fur Punkt die fokussierte Ebene des Objekts
ab. Das durch den Farbstoff emittierte Licht wird durch eine Lochblende maskiert,
wodurch nur das Licht aus der Fokusebene auf den Detektor fallt (siehe Abb. 2.6).
1J. Rybak, personliche Mitteilung
9

2. Grundlagen
Abbildung 2.5: Konfokaler Schnitt des Bienengehirns welches mit der Lucifer YellowMethode gefarbt wurde
Abbildung 2.6: Prinzipieller Aufbau eines konfokalen Mikroskops (modifiziert nachhttp://www.sinnesphysiologie.de/methoden/fluo/conepil.htm)
10

2. Grundlagen
Fur die dem Modell zu Grunde liegenden Scans wurde ein Konfokalmikroskop vom Typ
Leica SP2 verwendet und mit einem 10 x Wasserobjektiv bei einer optischen Auflosung
von ca. 1, 5µm in der XY-Ebene und 5, 6µm in der z-Ebene gescannt (siehe Abb. 2.7).
Durch optische Brechung des Lichts im Wasserobjektiv wird die z-Ebene um den Faktor
0,7 gestaucht.
Bei dem Bienengehirn fuhrt der Scan zu einer Bildserie aus ca. 100 Schnitten, welche eine
Auflosung von 1024*1024 Punkten haben. Da jedem Bildpunkte zusatzlich eine Hohe
und damit ein Volumen zugeordnet werden kann, spricht man von Volumenpixeln oder
Voxeln.
Abbildung 2.7: Bildstapel
2.4 3D Modellrekonstruktion
Die gescannten Bilddaten mussen nun digital ausgewertet und verarbeitet werden. In
diesem Kapitel wird eine allgemeine Ubersicht uber die durchzufuhrenden Schritte
gegeben. Informationen bezuglich der konkreten Vorgehensweise bei der Verarbeitung
unserer Bilddaten finden sich im Kapitel 3.2 ab Seite 23. Die fur diese Schritte notwendigen
Verfahren sowie die in Abschnitt 2.5 beschriebenen Grundlagen zur Erstellung statistischer
Formmodelle werden vollstandig von dem Softwaresystem Amira [Ami08] bereitgestellt.
Eine praktische Anleitung zur Erstellung und Erweiterung des statistischem Formmodells
mit dieser Software befindet sich im Anhang A.
11

2. Grundlagen
2.4.1 Segmentierung
Zunachst mussen in den Grauwertbildern die Voxel den entsprechenden Teilstrukturen
des Objekts zugeordnet werden. Hierzu werden manuell die entsprechenden Regionen
in den Bildschichten markiert und zu Segmenten zusammengefasst. Diese Einteilung
impliziert eine Beschreibung der Form des Objektes, welches sich aus den Teilstrukturen
zusammensetzt.
2.4.2 Oberflachenrekonstruktion
Um die Form weiter verarbeiten zu konnen muss eine geometrische Beschreibung der
Oberflache gefunden werden. Ein Verfahren zur Parametrisierung von 3D Oberflachen ist
die Triangulation: Die Form S wird beschrieben durch eine Menge V von p Punkten (vi)
auf der Oberflache welche durch Kanten zu einer Menge T von q Dreiecken (tj) verbunden
sind.
S = (V, T )
V = {vi = (x1, x2, x3)T} mit i = 1..p
T = {tj = (v1, v2, v3)} mit j = 1..q
(2.1)
Damit die Triangulation eine organische Form angemessen beschreiben kann, muss sie
die Bedingung an die Glattheit erfullen. Glattheit wird hierbei definiert uber den Winkel
der verbundenen Dreiecke: Eine Oberflache ist nach [DM92] ε-glatt, wenn der Winkel
zwischen den Normalen verbundener Dreiecke kleiner ε ist (siehe Abb. 2.8).
2.5 Statistische Formmodelle (SFM)
Die ersten statistischen Formmodelle wurden 1992 unter dem Namen”Active Shape
Models“(ASM) von Cootes et al. [CT92] eingefuhrt. Sie beinhalten Informationen uber die
Form eines Objekts sowie deren Variabilitat. Ein SFM beinhaltet eine Durchschnittsform
und gibt vor, in welchem Rahmen sich diese Form verandern darf. Der zentrale Ansatz
12

2. Grundlagen
Abbildung 2.8: Der Winkel zwischen den Normalen zweier verbundener Dreiecke
ist hierbei, dass die Dimensionalitat der Form mittels einer Hauptkomponentenanalyse
reduziert wird. Im Folgenden beschreibe ich die Grundlagen eines statistischen 3D
Formmodells.
2.5.1 Alignierung der Trainingsdaten
Die die triangulierten Oberflachen mussen in ein gemeinsames Koordinatensystem ge-
bracht und gleich ausgerichtet werden. Durch eine Translation werden die Schwerpunkte
der Oberflachen ubereinander gebracht. Die Orientierung im Raum wird durch eine
Rotation angepasst. Außerdem konnen die Objekte auf die selbe Große skaliert werden.
Dieser Schritt ist abhangig von den Anforderungen an das statistische Formmodell: Soll
die Variabilitat der Große oder der Zusammenhang von Form und Große des Objekts
durch das Modell dargestellt werden konnen, so durfen die Objekte nicht skaliert werden.
Ein SFM zur Autosegmentierung muss jedoch diese Informationen nicht enthalten, durch
die Skalierung werden sie zugunsten einer großeren Deformierbarkeit aufgegeben.
2.5.2 Korrespondenzproblem
Um das Modell erstellen zu konnen, mussen die Trainingsdaten, also die Menge der
Oberflachen, aus denen das Modell erstellt wird, als Merkmalsvektor vorliegen. Dabei
mussen die einzelnen Eintrage des Vektors in sinnvoller Korrespondenz zueinander stehen.
13

2. Grundlagen
Die ursprunglich von Cootes et al. [CT92] veroffentlichten ASM sind 2D Modelle, bei
denen die Parametrisierung der Trainingsdaten, in diesem Fall das Setzen der korres-
pondierenden Landmarken, manuell erfolgte. Da fur 3D Modelle zur Beschreibung der
Form wesentlich mehr Parameter benotigt werden, ist dieser Ansatz - gerade bei solch
komplexen Geometrien wie der des Bienengehirns - nicht moglich. Die großte Schwie-
rigkeit bei der Erstellung statistischer 3D Formmodelle bereitet daher die Losung des
Korrespondenzproblems. Jedem der p Punkte einer Oberflache muss eine Identifikation
zugeordnet werden, welche die anatomische Lage auf der Oberflache bestimmt. Homologe
Punkte auf verschiedenen Oberflachen bekommen die selbe Identifikation.
2.5.3 Finden einer gemeinsamen Parametrisierung
Lamecker et al. [LLS03a] stellte 2003 ein Verfahren vor, welches die korrespondierende
Dreiecksvernetzung von 3D Oberflachen findet, indem die Triangulation einer Referenzo-
berflache mittels eine Abbildung auf eine 2D Hilfsflache auf alle Trainingsoberflachen
ubertragen wird (siehe Abb. 2.9). Hierfur mussen alle Oberflachen S1..N gleichsinnig in
M korrespondierende Teilflachen P Si1..M zerlegt werden, welche homoomorph zu Kreis-
scheiben sind. Diese Teilflachen konnen uber ein Teilstuck ihres Randes zu sich selbst
bzw. einem oder mehreren anderen Teilflachen benachbart sein. Die Triangulation ei-
nes jeden Oberflachenteilstucks wird nach einem Verfahren von Floater [Flo97] mittels
einer stetigen bijektiven Abbildung φ so auf eine Kreisscheibe B abgebildet, dass die
entsprechenden Teilstucke auf den Randern korrespondierender Oberflachenteilstucke
aufeinander fallen. Durch eine Abbildung γ wird die Triangulation einer Kreisscheibe
auf eine andere ubertragen. Diese kann nun mittels der Umkehrfunktion von φ auf
die andere Teilflache ubertragen werden. Daraus resultiert eine Abbildung f zwischen
beiden Teilflachen, welche, da sowohl φ als auch γ stetig und bijektiv sind, ebenfalls
stetig und bijektiv ist. Die Korrespondenzfunktion, welche die Triangulation von P S1j
auf P S2j ubertragt ist also gegeben durch (φS2
j )−1 ◦ γ ◦ φS1j . Da f sowohl stetig als auch
bijektiv ist, stellt sie einen Homoomorphismus zwischen den Teilflachen dar. Durch die
Ubertragung der Dreiecksvernetzung aller Oberflachenteilstucke einer Referenzoberflache
auf die korrespondierenden Teilstucke aller Trainingsoberflachen wird eine gemeinsame
Parametrisierung der Trainingsmenge gefunden.
14

2. Grundlagen
Abbildung 2.9: Korrespondenzfunktion zwischen zwei Oberflachenteilstucken (nach[LLS+03b])
2.5.4 Hauptkomponentenanalyse (Principal Component
Analysis, PCA)
Da die einander entsprechenden Punkte nun miteinander korrespondieren, konnen die
N Trainingsoberflachen ~x1...N nun als d-dimensionale Vektoren (mit d = 3 · p) aufgefasst
werden. Somit ist die Trainingsmenge X eine Punktwolke im d-dimensionalen Raum. Um
die Dimensionalitat von X zu reduzieren werden nun wie folgt ihre Hauptkomponenten
berechnet.
Zunachst wird der Mittelwert x aller ~xi und die Kovarianzmatrix W der mittelwertsbe-
reinigten Daten X berechnet.
x =1
N
N∑i=1
~xi, x ∈ Rd (2.2)
W =1
N − 1·N∑i=1
(~xi − x) · (~xi − x)T =1
N − 1·XXT ; W ∈ Rd×d
mit X = (~x1 − x|~x2 − x|...|~xN − x)
(2.3)
Die Trainigsmenge X wird nun als Realisierung einer normalverteilten Zufallsvariable
aufgefasst.
X ∼ N (µ,Σ) (2.4)
15

2. Grundlagen
x und W sind die Schatzer der Parameter µ und Σ der Verteilung, welche die Menge
samtlicher moglichen Bienengehirne modelliert. Die Hauptkomponentenanalyse ist ein
Verfahren zur Dekorrelation dieser Verteilung. Geometrisch wird dabei eine Hauptach-
sentransformation durchgefuhrt, wobei die erste Achse in Richtung der großten Varianz
und jede weitere Achse in Richtung der großten Varianz orthogonal zu allen vorherigen
Achsen ausgerichtet wird. Die Orthogonalitat der Hauptachsen wird erreicht, indem S
mittels einer Eigenwertzerlegung so transformiert wird, dass alle Kovarianzen 0 werden.
W~ei =λi~ei ⇐⇒ W = E × Λ× ET
mit den Eigenwerten Λ = diag(λ1, λ2, ..., λd), λ1 ≥ λ2... ≥ λd ≥ 0,
den Eigenvektoren ~ei ∈ Rd;
E =(~e1| ~e2| ...| ~ed
)∈ Rd×d stellt die Matrix der Eigenvektoren dar.
(2.5)
Der i. Eigenwert λi entspricht dabei der in Richtung der i. Hauptkomponente enthal-
tenen Varianz ~ei. Jedes Datum ~xi kann nun durch eine Linearkombination der ersten q
Hauptkomponenten angenahert werden:
~xi ≈ x+ E~b mit
~b = (b1, ..., bq)T ∈ Rq; bi = ~eTi (~xi − x)
E = (~e1|...|~eq) ∈ Rd×q
(2.6)
Es kann gezeigt werden, dass die Gesamtvarianz einer Verteilung der Summe der Achsen-
varianzen (kumulierte Varianz) entspricht. Demnach werden durch die ersten q (mit q < d)
Dimensionen der maximale Anteil der Gesamtvarianz der Projektion der Verteilung in
den entsprechenden Unterraum abgedeckt.
Bei den gegebenen Daten ist die Dimensionalitat d sehr groß. Daher ist es problematisch,
die Kovarianzmatrix W zu speichern und ihre Eigenwerte zu berechnen. Da die Anzahl
der Trainingsinstanzen N kleiner ist als die Dimensionalitat d kann folgendes Verfahren
zur Bestimmung der Eigenwerte benutzt werden:
Sei U =1
N − 1·XTX mit X = (~x1 − x|~x2 − x|...|~xN − x), U ∈ RN×N (2.7)
16

2. Grundlagen
Fur die Hilfsmatrix U werden nun die Eigenwerte berechnet
U ~ei = λi ~ei (2.8)
Diese Gleichung kann wie folgt umgeformt werden
1
N − 1·XTX~ei =λi ~ei
⇐⇒1
N − 1·XXTX~ei =λiX~ei
⇐⇒
WX~ei =λiX~ei
(2.9)
Somit ist X~ei ein Eigenvektor von W zu dem Eigenwert λi mit i = 1...N . Es kann gezeigt
werden, dass alle weiteren Eigenwerte λ(N+1)..d von W gleich Null sind.
2.5.5 Aufbau eines SFM
Durch die Hauptkomponentenanalyse erhalt man ein ein lineares Modell der Formvariabili-
tat der Trainingsdaten. x stellt dabei die durchschnittliche Form aller Trainingsoberflachen
dar, ihre Variabilitat wird beschrieben durch die Gewichte ~b der Hauptkomponenten,
welche in der Matrix E gespeichert sind. Zusatzlich kann das Modell uber eine affine
Abbildung τ transformiert (z.B. skaliert und rotiert) werden:
S(~b, τ) = τ(x+ Eb) (2.10)
2.5.6 Anwendungen statistischer Formmodelle
Die haufigste Anwendung finden SFM bei der automatischen Segmentierung von
Bilddaten ([CT92], [LLS+03b], [KLL07],[Neu07], [Sin08], [Lam08]). Dabei wird das Modell
entsprechend der Merkmale in den Bilddaten angepasst. Das Finden der optimalen
17

2. Grundlagen
Transformation τ ∗ und der Parameter ~b∗, welche das Modell am besten an die zu
segmentierenden Bilddaten I anpassen, ist aquivalent zur Autosegmentierung.
(~b∗I , τ∗I ) = argmin~b,τd(I, S(~b, τ)) (2.11)
Der Abstand d(I, S) zwischen den Bilddaten und dem SFM ist in der Bachelorarbeit von
J.Singer [Sin08] uber 1D Grauwertprofile auf den Normalen der Dreiecke des Modells
definiert. ~b∗ und τ ∗ werden bestimmt, indem dieser Abstand iterativ minimiert wird.
Des Weiteren eignen sich SFM zur Darstellung der naturlichen Formvariabilitat
des Objekts und zur Klassifikation von Subtypen, z.B. in medizinischen Bilddaten
[HXPHA07].
Ein Ansatz von Lamecker zielt darauf ab, aus Bilddaten pathologischer Strukturen
die”normale“ Form zu rekonstruieren [Lam08]. Hierbei wird das SFM in den Regionen,
in denen die Strukturen intakt sind, an die Bilddaten angepasst. Fur die pathologische
Region liefert das Modell eine individuelle Rekonstruktion.
2.5.7 Anforderungen an statistische Formmodelle
Der Nutzwert eines SFM ist nach Davis [Dav02] abhangig von der Fahigkeit des Modells,
die Klasse der modellierten Objekte zu charakterisieren. Danach sollte ein ideales Modell
die folgenden Eigenschaften besitzen:
• Vollstandigkeit: Das Modell soll in der Lage sein, jede theoretisch mogliche Form
eines Objekts der modellierten Klasse darzustellen. Dazu muss das Modell in
der Lage sein, von der Trainingsmenge aus, auf neue, unbekannte Objekte zu
generalisieren.
• Spezifitat: Das Modell soll nur Objekte der modellierten Klasse darstellen.
• Kompaktheit: Die Modellierung der Form soll mit so wenig Parametern wie moglich
auskommen.
18

2. Grundlagen
Abstands- und Fehlermaße: Um diese Merkmale des SFM quantitativ bewerten zu
konnen, werden nun einige Abstandsmaße von 3D Oberflachen eingefuhrt.
Sei d(v, S) = minv′∈S(||v−v′||) der Abstand zwischen einem Punkt v und einer Oberflache
S und |S| der Oberflacheninhalt. Die mittlere Oberflachendistanz (Mean Surface
Deviation, MSD) von zwei Oberflachen S und S’ ist definiert als
MSD(S, S ′) =1
|S|+ |S ′|
(∫v∈S
d(v, S ′)dS +
∫v′∈S′
d(v′, S)dS ′)
(2.12)
Entsprechend ist die maximale Oberflachendistanz (dmax) definiert als
dmax(S, S′) = maxv∈S;v′∈S′(d(v, S ′), d(v′, S)) (2.13)
Die Wurzel des mittleren quadratischen Fehlers (Root Mean Square Deviation,
RMSD) gewichtet großere Abweichungen starker und ist somit ein Maß fur lokale Unter-
schiede:
RMSD(S, S ′) =
√1
|S|+ |S ′|
(∫v∈S
d(x, S ′)2dS +
∫v′∈S′
d(v′, S)2dS ′)
(2.14)
Bewertung der Vollstandigkeit: Die Vollstandigkeit kann mit dem Verfahren der
Kreuzvalidierung getestet werden: Das Modell wird aus einer Teilmenge der ursprunglichen
Trainingsdaten neu berechnet. Dieses reduzierte Modell wird nun so gut wie moglich
an die verbleibenden Oberflachen angepasst, indem der mittlere quadratische Abstand
(siehe Gleichung 2.14) minimiert wird. Der Oberflachenabstand des angepassten Modells
zum Testdatum ist nun ein Maß fur den Fehler, den das Modell bei der Anpassung an
neue Oberflachen macht. Eine spezielle Variante der Kreuzvalidierung ist der”leave one
out“ Test: Hierbei besteht die Testmenge aus nur einer Oberflache, das Modell, das an
dieses Testobjekt angepasst wird, besteht aus samtlichen anderen Oberflachen.
Bewertung der Spezifitat: Um die Spezifitat eines SFM zu beurteilen, konnen mittels
des Modells neue Objekte generiert werden und diese von fachkundigen Personen bewertet
19
2. Grundlagen
werden. Durch diese Beurteilung kann ein Intervall der Modellparameter festgelegt werden,
in der die erzeugten Objekte als”gultig“ angesehen werden konnen.
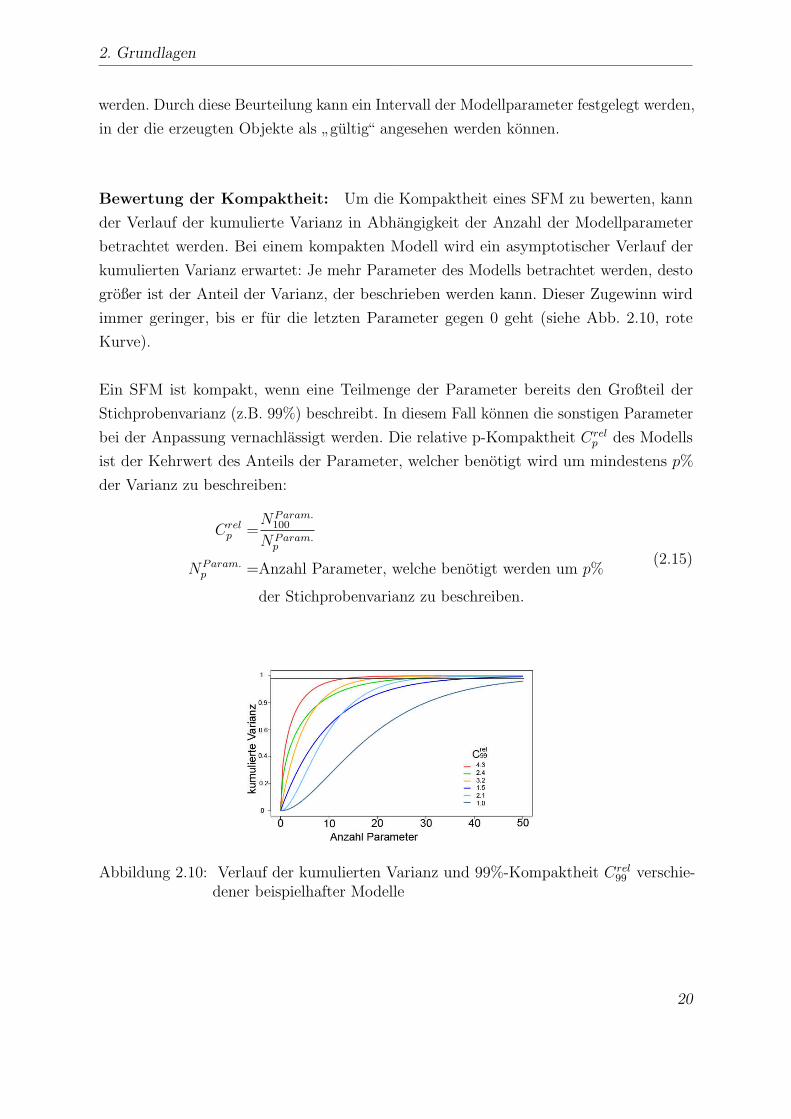
Bewertung der Kompaktheit: Um die Kompaktheit eines SFM zu bewerten, kann
der Verlauf der kumulierte Varianz in Abhangigkeit der Anzahl der Modellparameter
betrachtet werden. Bei einem kompakten Modell wird ein asymptotischer Verlauf der
kumulierten Varianz erwartet: Je mehr Parameter des Modells betrachtet werden, desto
großer ist der Anteil der Varianz, der beschrieben werden kann. Dieser Zugewinn wird
immer geringer, bis er fur die letzten Parameter gegen 0 geht (siehe Abb. 2.10, rote
Kurve).
Ein SFM ist kompakt, wenn eine Teilmenge der Parameter bereits den Großteil der
Stichprobenvarianz (z.B. 99%) beschreibt. In diesem Fall konnen die sonstigen Parameter
bei der Anpassung vernachlassigt werden. Die relative p-Kompaktheit Crelp des Modells
ist der Kehrwert des Anteils der Parameter, welcher benotigt wird um mindestens p%
der Varianz zu beschreiben:
Crelp =
NParam.100
NParam.p
NParam.p =Anzahl Parameter, welche benotigt werden um p%
der Stichprobenvarianz zu beschreiben.
(2.15)
Abbildung 2.10: Verlauf der kumulierten Varianz und 99%-Kompaktheit Crel99 verschie-
dener beispielhafter Modelle
20

Kapitel 3
Aufbau eines statistischen
Formmodells des Bienengehirns
Um ein statistisches Formmodell des Gehirns der Honigbiene zu erstellen, muss zu-
nachst eine Trainingsmenge generiert werden. Dies beinhaltet das Segmentieren der
Grauwertbilder, das Erzeugen und Nachbearbeiten der Oberflachen sowie das Finden der
Korrespondenzen. Dabei bedingt jeder Arbeitsschritt gewisse Voraussetzungen an den
Vorherigen. Im folgenden Abschnitt werden die Uberlegungen, welche hinter den Verar-
beitungsschritten der Daten stehen, erlautert. Eine praktische Anleitung zur Erzeugung
der Trainingsoberflachen mit der Software”Amira“ befindet sich im Anhang A.
3.1 Grundlage des statistischen Formmodells
Die Basis des von uns erstellten SFM bilden die Neuropile des HSB von Brandt et
al. [BRR+05]. Aus praktischen Grunden wurde jedoch im Gegensatz zum HSB auf die
feine Unterteilung der Calyces in Lippe, Kragen und Basaler Ring verzichtet. Außerdem
findet sich im HSB ein schmales vertikales Loch, das zwischen den medialen Calyces im
Protocerebrallobus beginnt, hinter dem Zentralkorper hindurch fuhrt und im Schlundloch
endet. Dieses wurde nicht ubernommen. Das von uns erstellte SFM besteht aus acht Neu-
ropilen des Zentralgehirns ohne die Antennalloben. In Tabelle 3.1 sind die segmentierten
Regionen sowie die verwendeten Abkurzungen aufgelistet.

3. Aufbau eines statistischen Formmodells des Bienengehirns
Neuropil Abkurzung Farberechter lateraler Calyx rlC dunkelrotrechter medialer Calyx rmC hellrotlinker medialer Calyx lmC hellgrunlinker lateraler Calyx llC dunkelgrunrechter Pedunkulus lMB orangelinker Pedunkulus rMB gelbZentralkorper CB cyanProtocerebrallobus und Unterschlundganglion PL-SOG hellblau
Tabelle 3.1: Die Neuropile des SFM des Bienengehirns
Abbildung 3.1: Das SFM des Bienengehirns
22

3. Aufbau eines statistischen Formmodells des Bienengehirns
3.2 Aufbau des statistischen Formmodells
3.2.1 Bedingungen an die Segmentierung
Die Methode zum Finden der Korrespondenzen bedingt, dass die Lagebeziehungen der
Strukturen bei allen Oberflachen einheitlich sind. Insbesondere mussen die Kontakt-
flachen zwischen den Neuropilen definiert werden: Wenn sich zwei Neuropile in einer
Oberflache beruhren, so mussen sich diese Neuropile in allen segmentierten Gehirnen
beruhren. Dies macht es zum Teil notwendig, dass, entgegen der visuellen Analyse der
Grauwertbilder, Neuropile kunstlich getrennt oder verbunden werden mussen. Bei den
gegebenen Grauwertbildern bot sich folgende Definition der Kontaktflachen an:
• Die beiden Calyces eines Pilzkorpers beruhren sich dorsal und ventral. Die medialen
Calyces haben ventral eine Kontaktflache zum PL.
• Alle Calyces haben eine Kontaktflache mit dem ipsilateralen Pedunkulus, welcher
wiederum mit dem PL Kontakt hat.
• Zudem beruhren beide Pedunkuli am β-Lobus den Zentralkorper sowie sich gegen-
seitig. - Der Zentralkorper hat eine Kontaktflache zum PL.
Zur Uberprufung der Beruhrungsflachen gibt es die Moglichkeit, die Berandungen der
Kontaktflachen zu betrachten. Die 16 Kontaktflachen werden von 22 Berandungskurven
begrenzt. Abbildung 3.2 visualisiert zwischen welchen Neuropilen Kontakt besteht.
3.2.2 Bedingungen an die Oberflachen
Damit die Dreiecksvernetzung der Oberflache verzerrungsarm auf Hilfsflachen abgebildet
werden kann (siehe Abschnitt 2.5.3), muss sie gewisse Bedingungen erfullen.
Zum Einen muss sie, um die organische Oberflache angemessen darzustellen, ausreichend
glatt sein (siehe Abschnitt 2.4.2). Dies haben wir erreicht, indem wir die Dreiecksvernet-
23

3. Aufbau eines statistischen Formmodells des Bienengehirns
Abbildung 3.2: Kontaktflachen zwischen den Neuropilen
zung vergrobert haben, um Treppenartefakte, welche durch die grobe Voxelauflosung
entstanden sind, zu beseitigen (siehe Abb. 3.3). Wir reduzierten die Anzahl der Facetten
von 1,5 Mio. auf ca. 90.000, was sich fur die Beschreibung der Struktur als ausreichend
erwiesen hat. Außerdem wurden sowohl die Flachen als auch deren Berandungskurven au-
tomatisch geglattet. Topologische Unterschiede zwischen den Formen, welche aus Fehlern
bei der Segmentierung hervorgehen, lassen sich so jedoch nicht berichtigen, sodass die
Segmentierung vorab korrigiert werden muss (siehe Abb. 3.4). Durch die Vergroberung
kann es passieren, dass sich Dreiecke verschiedener Neuropiloberflachen uberschneiden.
Diese Fehler im Dreiecksnetz mussen gefunden und entfernt werden. Hierfur stellt der
Oberflacheneditor von Amira verschiedene Werkzeuge bereit.
Besonders ist darauf zu achten, dass die Genera der Oberflachen ubereinstimmen,
da nur dann die Triangulationen aufeinander abgebildet werden konnen. Der Genus
einer geschlossenen Oberflache ist die maximale Anzahl sich nicht uberschneidender,
geschlossener Kurven auf der Oberflache, welche diese nicht in mehrere Flachen teilen
(siehe Abb. 3.5). Dies entspricht der Anzahl an Lochern bzw. Henkeln einer Oberflache.
Die in dieser Hinsicht komplexeste Form des SFM bildet das PL-SOG mit sieben Henkeln.
(siehe Abb. 3.6)
24

3. Aufbau eines statistischen Formmodells des Bienengehirns
(a) Feine Dreiecksvernetzung (b) Vergroberte Dreiecksvernet-zung
Abbildung 3.3: Glattung durch Vergroberung der Dreiecksvernetzung (schematisch)
(a) Eine fehlerhafte Oberflache (b) nach dem Uberarbeiten der Seg-mentierung
Abbildung 3.4: Beispiel zur Glattung
(a) Sphere, Genus=0 (b) Torus, Genus=1 (c) Doppeltorus, Ge-nus=2
(d) Tripeltorus, Ge-nus=3
Abbildung 3.5: Genera geschlossener Oberflachen. Aus Wikipedia, die freie Enzyklopadie
25

3. Aufbau eines statistischen Formmodells des Bienengehirns
Abbildung 3.6: Die 7”Henkel“ des PL-SOG
Wichtig fur eine verzerrungsarme Abbildung einer Oberflachenregion auf eine Kreis-
scheibe ist, dass das Verhaltnis von Außen- zum Innenkreisradius ((R/r) ∈]2,∞])
der Dreiecke moglichst klein ist (siehe Abb. 3.7). Dies kann durch eine manuelle oder
automatische [ZLZ08] Bearbeitung der Dreiecksvernetzung erreicht werden.
(a) Ideales Seitenver-haltnis: (R/r)=2
(b) ungunstigeresSeitenverhaltnis:(R/r)>2
Abbildung 3.7: Deriecksseitenverhaltnis
26

3. Aufbau eines statistischen Formmodells des Bienengehirns
3.2.3 Gebietszerlegung
Der nachste Schritt zur Modellerzeugung ist die Korrespondenzbestimmung, d.h. anato-
misch entsprechende Gebiete auf den Trainingsoberflachen werden einander zugeordnet.
Die Voraussetzung dafur ist, dass die Oberflachen in Regionen eingeteilt sind, welche
sich auf Kreisscheiben abbilden lassen. Die komplexe Struktur des Gehirns bedingt, dass
die Oberflache in viele Teile zerlegt werden muss. Zudem sollten anatomisch auffallige
Merkmale wie charakteristische Krummungen und Kanten, welche in allen Oberflachen
auftreten, genutzt werden, um diese weiter einzuteilen, da so die Abbildungsfehler redu-
ziert werden konnen. Beispielsweise wurden dem Lateralen Horn, dem Optischen Tuberkel
und dem Dorsallobus jeweils eine eigene Region zugeordnet, da die Strukturen bei allen
Reprasentanten auftreten und deutlich zu erkennen sind. Insgesamt wurde die Oberflache
so in 89 Gebiete zerlegt (siehe Abb. 3.8).
Um eine Oberflache in Teilflachen zu zerlegen mussen deren Berandungen auf der Ober-
flache definiert werden. Die Anordnung der Gebiete muss bei jeder Instanz genau uber-
einstimmen, da das Verfahren die Nachbarschaftsverhaltnisse der Gebiete auswertet. Das
bedeutet, dass Berandungskurven immer auf demselben Teilstuck bzw. Schnittpunkt
anderer Berandungskurven enden mussen.
Die Parametrisierung einer Referenzoberflache wird gemaß des in Abschnitt 2.5.3 be-
schriebenen Verfahrens auf alle anderen Oberflachen ubertragen. Die Oberflachen werden
aligniert, indem der Abstand der korrespondierenden Vertices durch Rotation und Skalie-
rung minimiert wird. Danach kann, wie in Abschnitt 2.5.4 beschrieben, das SFM erzeugt
werden.
3.3 Erweiterung der Trainingsmenge durch
Spiegelung der Daten
Je mehr Instanzen ein SFM enthalt, desto mehr Variation kann es beschreiben. Allerdings
ist das manuelle Segmentieren eines so komplexen Objekts wie des Bienengehirns ein
sehr zeitaufwandiger Prozess, vor allem unter den Bedingungen, die die Erstellung
27

3. Aufbau eines statistischen Formmodells des Bienengehirns
Abbildung 3.8: Die Einteilung der Bienengehirnoberflache in 89 Teilgebiete
28

3. Aufbau eines statistischen Formmodells des Bienengehirns
eines statistischen Formmodells mit sich bringt. Die Neuropile des Bienengehirns sind
bilateral symmetrisch angeordnet. Das heißt, es kann davon ausgegangen werden, dass
eine Formvariation am rechten medialen Calyx theoretisch auch am linken medialen Calyx
auftreten kann (siehe Abb. 3.9). Diese Tatsache kann ausgenutzt werden, um die Anzahl
der Freiheitsgrade des Modells zu erhohen, ohne neue Bilddaten segmentieren zu mussen:
Alle in das Modell aufgenommenen Instanzen konnen gespiegelt und die Bezeichnung
der bilateral symmetrischen Neuropile vertauscht werden. Auch die Berandungspfade der
Gebietszerlegung konnen gespiegelt und auf die gespiegelten Oberflachen projiziert werden.
Auf diese Weise lasst sich der Umfang der Stichprobe des Modells mit unerheblichem
Mehraufwand verdoppeln.
Abbildung 3.9: Ein gespiegeltes Bienengehirn
3.4 Auflosungsstufen des SFM
Das Modell ist in drei verschiedenen Detailstufen erstellt worden (siehe Tabelle 3.2)
Die Form eines groben Modell aus den Gewichten zu berechnen (z.B. zur Anpassung an
Bilddaten bei der Autosegmentierung) ist weniger aufwandig, allerdings werden dabei
weniger Details wiedergegeben. Um die Detailstufen flexibel anwenden zu konnen, muss
es moglich sein, die Form eines groberen Modells Mx uber seine Parameter (~b∗Mx, τ ∗) auf
29

3. Aufbau eines statistischen Formmodells des Bienengehirns
Modell Anzahl Facetten Anzahl PunkteM1 15713 32330M2 29469 60078M3 91680 185235
Tabelle 3.2: Auflosungsstufen des statistischen Formmodells
ein feinere Modell My zu ubertragen. Beispielsweise konnte dann die Autosegmentierung
zunachst mit einem groben Modell durchgefuhrt werden, um danach mit einem feinen
Modell Details anzupassen.
Wahrend die Transformation τ ubernommen werden kann, ist dies bei dem Gewichts-
vektor ~b nicht ohne weiteres moglich, da die PCA der Modelle unabhangig voneinander
durchgefuhrt wurden. Wenn jeweils zwischen den Gewichten der Hauptkomponenten bk
der verschiedenen Modelle ein linearer Zusammenhang besteht, konnen diese uber einen
Faktor umgerechnet werden. Dieser Zusammenhang wird in Abschnitt 4.1.2 untersucht.
Fur den Umrechnungsfaktor fMx→My eines Gewichts bk aus Modell Mx in ein Gewicht des
Modells My liefert der mittlere quadratische Fehler eine Schatzfunktion (siehe Gleichung
3.1).
fMx→My =argminf (||f ·~bMxk −~b
My
k ||)⇔ fMx→My =(~bMxk )T ·~bMy
k
||~bMy
k ||2
mit den Gewichten der Trainingsmenge fur die k. Hauptkomponente ~bMxk
(3.1)
3.5 Extrahieren von Teilstrukturen aus dem SFM
Oft ist es notig, Abschnitte des Gehirns oder einzelne Neuropile von hochauflosenden
Teilscans des Gehirns (siehe 3.11) zu segmentieren. Dies erfordert die Moglichkeit, Teil-
formen aus dem Modell herauszunehmen und ein neues SFM mit dieser Teilstruktur zu
erzeugen. Diese konnen dann separat behandelt werden. Da diese Funktionalitat bisher
30

3. Aufbau eines statistischen Formmodells des Bienengehirns
nicht vorgesehen war, wurde im Rahmen dieser Arbeit ein Modul entwickelt, welches
einen beliebigen Ausschnitt des Gesamtmodells extrahieren kann (siehe Abb. 3.10).
Abbildung 3.10: Aus dem Gesamtmodell extrahierte Teilstruktur: SFM des rechtenPilzkorpers
31

3. Aufbau eines statistischen Formmodells des Bienengehirns
Abbildung 3.11: Hochauflosender Scan des rechten Pilzkorpers
32

Kapitel 4
Analyse des statistischen
Formmodells
Basierend auf 16, wie in Abschnitt 2.2.2 beschrieben, gefarbten und gescannten Bie-
nengehirnen sowie deren Spiegelungen (siehe Kapitel 3.3) wurde, wie in Abschnitt 3.2
beschrieben, ein SFM des Bienengehirns erstellt. Außer dem Gesamtmodell wird exem-
plarisch ein, wie in Abschnitt 3.5 beschrieben, erstelltes Teilmodell, welches den linken
Pilzkorper sowie das umgebende Protocerebrum enthalt, untersucht (Abbildung 3.10).
4.1 Auswertung
4.1.1 Formmoden
Die Abbildungen 4.1 bis 4.4 zeigen die Variation der Form des Modells durch die Variation
der ersten 4 Hauptmoden des Modells. Durch die Aufnahme der Spiegelungen in das
Modell verhalten sich alle Moden entweder symmetrisch oder antisymetrisch. Variiert
man z.B. bei den Moden 1, 2 oder 3 das entsprechende Gewicht, so bleibt das Modell
stets spiegelsymmetrisch, die Formanderungen betreffen beide Seiten gleichermaßen
(siehe Abbildungen 4.1– 4.3). Andere Moden wirken sich antisymmetrisch, also genau
entgegengesetzt auf die beiden Halften des Gehirns aus: Setzt man z.B. das Gewicht der

4. Analyse des statistischen Formmodells
vierten Mode auf einen Wert, so ist das Modell spiegelsymmetrisch zu dem Modell, bei
dem das Gewicht der vierten Mode auf den gleichen Wert mit geandertem Vorzeichen
gesetzt wurde (siehe Abbildung 4.4).
Das Volumen und die raumlichen Ausmaße des Modells andern sich bei Variation der
Moden nur geringfugig, da die Trainingsoberflachen vor der Erstellung des Modells auf
die selbe Große skaliert wurden. Jedoch verandert sich das Verhaltnis der Ausdehnung in
den verschiedenen raumlichen Ausrichtungen.
Beispielsweise fallt auf, dass sich bei der Variation des Gewichts der ersten Mode
das Verhaltnis von Hohe (Ausdehnung in X) zu Breite (Y) und Tiefe (Z) des Modells
verandert: Wahlt man das Gewicht der ersten Hauptmode +2Sd, so wirkt das Modell
deutlich hoher und schmaler als wenn es auf −2Sd gesetzt ist (siehe Abbildung 4.1).
Dieses Verhaltnis bleibt bei der Variation der anderen Moden annahernd konstant (siehe
Tabelle 4.1).
(a) −2Sd: nieder und breit (b) +2Sd: hoch und schmal
Abbildung 4.1: Variation der ersten Hauptmode
Die auffalligste Veranderung der Form bei Variation des Gewichts der zweiten Haupt-
mode ist, dass sich die Achsen der Beruhrungsflachen der Calyces zueinander verdrehen:
Wahrend sie bei einem Gewicht von −2Sd etwa in einem Winkel von 55◦ zueinander
stehen, ist der Winkel bei +2Sd mit ca. 35◦ deutlich spitzer (siehe Abbildung 4.2).
34

4. Analyse des statistischen Formmodells
1.Mode 2.Mode 3.Mode 4.Modehb+t
−2Sd 0.74 0.77 0.78 0.79
+2Sd 0.82 0.76 0.78 0.79Dif. 0.08 0.01 0 0
Tabelle 4.1: Auswirkung der ersten Moden auf das Verhaltnis von Hohe zu Breite undTiefe.
(a) −2Sd: Winkel ca. 55◦ (b) +2Sd: Winkel ca. 35◦
Abbildung 4.2: Variation der zweiten Hauptmode
Durch die dritte Mode werden strukturelle Details auf der Oberflache, wie z.B. die
Form der Optischen Tuberkel modelliert. Diese sind bei negativem Gewicht nach innen
gewolbt, wahrend sie bei positivem Gewicht nach außen gewolbt sind (siehe Pfeile in
Abbildung 4.3).
Die vierte Mode ist die großte antisymmetrische Mode. Sie wirkt sich nicht symmetrisch
auf die beiden Halften des Gehirns aus und modelliert somit asymmetrische Oberflachen-
merkmale. Beispielsweise ist bei negativem Gewicht der linke Dorsallobus flacher als der
rechte (siehe Pfeile in Abbildung 4.4). Wegen der Antisymmetrie verhalt sich die Form
bei positivem Gewicht genau entgegengesetzt.
4.1.2 Korrelation der Formmoden des SFM in verschiedenen
Detailstufen
Wie in Abschnitt 3.4 beschrieben ist eine Voraussetzung fur die flexible Anwendung der
Detailstufen, dass die Gewichtsvektoren der verschiedenen Modelle in Zusammenhang
35

4. Analyse des statistischen Formmodells
(a) −2Sd: konkave Form der Optischen Tu-berkel
(b) +2Sd: konvexe Form der Optischen Tu-berkel
Abbildung 4.3: Variation der dritten Hauptmode
(a) −2Sd: linker Dorsallobus abgeflacht (b) +2Sd: rechter Dorsallobus abgeflacht
Abbildung 4.4: Variation der vierten Hauptmode
36

4. Analyse des statistischen Formmodells
stehen. Nur dann konnen aus den angepassten Gewichten ~b∗M1des groberen Modells
Gewichte des feineren Modells ~b(1)M2
berechnet und weiter optimiert werden.
Ein Trainigsdatum Si wird in einem SFM Mj durch einen Gewichtsvektor ~bMj
Si=
(bMj
Si,1, ..., b
Mj
Si,(N−1))T ∈ RN−1 reprasentiert. Die Menge der Gewichte der k. Mode al-
ler Trainingsoberflachen ~bMj
k = (bMj
S1,k, ..., b
Mj
SN ,k)T ∈ RN kann als Zufallsvariable aufgefasst
werden. Wenn ein starker linearer Zusammenhang zwischen den Gewichten der entspre-
chenden Moden zweier Modelle Mx und My besteht, konnen die Gewichte des einen
Modells My mittels eines Faktors fMx→My aus den Gewichten des ersten Modells Mx
geschatzt werden (siehe Gleichung 3.1).
Der Determinationskoeffizient R2 beschreibt den Anteil der durch einen linearen Zusam-
menhang erklarten Varianz zweier Zufallsvariablen:
R2(X, Y ) =Cov(X, Y )2
V ar(x)V ar(Y )(4.1)
Tabelle 4.2 zeigt die Korrelation der einzelnen Parameter R2(~bMxk ,~b
My
k ) zwischen den
Detailstufen des Gesamtmodells.
Der Determinationskoeffizient der meisten Moden liegt zwischen 95% und 99%. Die
Koefizienten der 17., 18. 20., 21. und 22. Moden weichen jedoch stark nach unten ab. Dies
kann daran liegen, dass das grobere Modell die in diesen Moden dargestellten Details nicht
auflosen kann. In drei Fallen korrelieren einander nominell nicht entsprechneden Moden
miteinander. Die Varianz dieser Moden ist so ahnlich, dass sich durch die Veranderung
durch die Vergroberung ihre Reihenfolge geandert hat: Da die Moden absteigend nach dem
Anteil an der Varianz sortiert werden, werden dann sich tatsachlich nicht entsprechnede
Moden einander zugeordnet.
Die Analyse der Korrelation zwischen den Gewichten der Trainingsdaten zeigt, dass die
meisten Moden ohne nennenswerten Fehler ineinander umgerechnet werden konnen.
37

4. Analyse des statistischen Formmodells
Moden R2 M1 → M2 R2 M1 → M3 R2 M2 → M3
1 0.99 0.99 0.992 0.99 0.99 0.993 0.99 0.99 0.994 0.99 0.99 0.995 0.99 0.99 0.996 0.96 0.98 0.977 0.97 0.97 0.938 0.97 0.95 0.939 0.98 0.97 0.9610 0.99 0.99 0.9911 0.98 0.98 0.9812 0.98 0.99 0.9913 0.95 0.97 0.9714 0.95 0.98 0.9715 0.97 0.85 0.9316 0.98 0.89 0.9417 0.74 0.79 0.9418 0.74 0.82 0.9819 0.98 0.97 0.9820 0.73 0.73 0.611
21 0.35 0.61 0.942
22 0.53 0.40 0.623
23 0.99 0.99 0.9924 0.99 0.98 0.9925 0.96 0.96 0.9926 0.95 0.96 0.9827 0.98 0.99 0.9828 0.99 0.97 0.9829 0.99 0.98 0.9830 0.86 0.94 0.9731 0.86 0.94 0.97
Tabelle 4.2: Korrelation der Modellparameter der drei Detailstufen des Modells desgesamten Bienengehirns1 Korrelation der 21. Mode des 2. Modells mit der 20. Mode des 3. Modells2 Korrelation der 22. Mode des 2. Modells mit der 21. Mode des 3. Modells3 Korrelation der 20. Mode des 2. Modells mit der 22. Mode des 3. Modells
38

4. Analyse des statistischen Formmodells
4.1.3 Kompaktheit des Modells
Die Kompaktheit ist ein Maß dafur, wie viele Formmoden benotigt werden, um die
Variabilitat der Form zu beschreiben.
Wie in Abschnitt 3.3 beschrieben wurde der Stichprobenumfang verdoppelt, indem alle
Trainingsdaten zusatzlich gespiegelt in das Modell mit aufgenommen wurden. Dadurch
erwarten wir eine Erhohung der Vollstandigkeit. Vor diesem Hintergrund wird das SFM,
welches nur aus den nicht gespiegelten Trainingsdaten besteht (MN=16) mit dem Modell,
das auch die gespiegelten Oberflachen enthalt (MN=32) verglichen.
Um die Kompaktheit des SFM zu veranschaulichen wird die kumulierte Varianz in
Abhangigkeit der Anzahl der Moden betrachtet (siehe 4.5). Fur einen direkten Vergleich
der Modelle untereinander wird hier die relative 90%-Kompaktheit Crel90% (siehe Gleichung
2.15) herangezogen. Auf diese Weise wird ausgewertet, wie sich die Aufnahme der
Spiegelungen in das Modell auf die Kompaktheit auswirkt.
Abbildung 4.5 zeigt fur das Gesamt- sowie fur das Teilmodell ohne Spiegelungen, dass
auch die letzten Moden noch einen erheblichen Anteil der Varianz beschreiben. Dieser
Effekt ist bei den Modellen mit Spiegelungen nicht so groß, allerdings ist der Verlauf der
Kurveen auch hier nicht asymptotisch (Vergleiche Abbildung 2.10).
Tabelle 4.3 zeigt, dass die Crel90% Kompaktheit der Modelle durch die Aufnahme der
Spiegelungen gesteigert werden konnte.
MN=16 MN=32
Gesamtmodell 1.33 1.52Teilmodell 1.45 1.68
Tabelle 4.3: Relative 90%-Kompaktheit der Modelle
39

4. Analyse des statistischen Formmodells
Abbildung 4.5: Relative kumulierte Varianz der Modelle1: Modell mit Spiegelungen (MN=32)2: Modell ohne Spiegelungen (MN=16)
40

4. Analyse des statistischen Formmodells
4.1.4 Vollstandigkeit des Modells
Die Vollstandigkeit beschreibt die Generalisierungsfahigkeit des SFM, also seine Fahig-
keit sich an unbekannte Oberflachen anzupassen. Dies ist das fur die Anwendung zur
Autosegmentierung entscheidende Qualitatsmerkmal des statistischen Formmodells: Ein
unvollstandiges Modell schrankt den Algorithmus zu sehr ein und verhindert so, dass er
sich an die Bilddaten anpassen kann.
Bei dem verwendeten Test wird jede der Trainingsoberflachen durch das Modell MN=32,
um die Testoberflache sowie ihr Spiegelbild reduziert, sowie an das Modell MN=16,
um die Testoberflache reduziert, angepasst (”leave one out Test“). Dieser Test wurde
sowohl fur das Modell des gesamten Bienengehirns (Gesamtmodell), als auch fur das
in Abschnitt 3.5 beschriebene Ausschnittsmodell (Teilmodell), welches einen Pilzkorper
umfasst, durchgefuhrt.
Fur das angepassten Modelle wurde der mittlere (MSD, siehe Gleichung 2.12) und der
maximale Oberflachenabstand (dmax, siehe Gleichung 2.13) sowie die Wurzel des durch-
schnittlichen quadratischen Fehlers (RMSD, siehe Gleichung 2.14) zu der Testoberflache
berechnet. Außerdem wurde ausgewertet, welcher Anteil der Oberflachen mehr als 4
µm auseinander liegen (d>4µm). Abbildung 4.6 veranschaulicht die Ergebnisse in einem
Box-Whisker-Plot.
Die durchschnittlichen Unterschiede der Abstande der Modelle MN=16 und MN=32 wurden
jeweils mittels eines T-Tests fur verbundene Stichproben auf Signifikanz uberpruft.
Wie Tabelle 4.4 zeigt, ist sowohl beim Teilmodell als auch beim Gesamtmodell die
Uberschreitungswahrscheinlichkeit p des T-Tests fur den MSD, den d>4µm und fur den
RMSD <0.05. Damit ist die Verbesserung dieser Oberflachendistanzen signifikant. Fur
die Verbesserung des maximalen Oberflachenabstandes dmax lasst sich zumindest eine
klare Tendenz erkennen.
41

4. Analyse des statistischen Formmodells
Abbildung 4.6: Abstande der angepassten Modelle ohne (MN=16) und mit (MN=32) ge-spiegelten Oberflachen zu den Testoberflachen im leave one out Test
MN=16 MN=32 AD t pGesamtmodell MSD [µm] 8.1 ±0.77 7.3 ±0.62 0.8∗∗∗ 4.14 8.66 E-4
RMSD [µm] 10.6 ±0.92 9.5 ±0.76 1.1∗∗∗ 4.82 2.24 E-4dmax [µm] 63.2 ±10.8 55.7 ±11.2 7.6 1.87 8.04 E-2d>4µm [%] 67.3 ±3.44 64.1 ±3.19 3.2∗∗ 3.23 5.64 E-3
Teilmodell MSD [µm] 6.9 ±0.69 6.0 ±0.47 0.9∗∗∗ 7.36 0.02 E-4RMSD [µm] 8.9 ±0.86 7.8 ±0.62 1.2∗∗∗ 7.16 0.03 E-4dmax [µm] 49.4 ±8.40 44.1 ±8.47 5.3 1.93 7.33 E-2d>4µm [%] 62.2 ±3.46 57.2 ±3.33 5.0∗∗∗ 7.21 0.03 E-4
Tabelle 4.4: Vergleich der Vollstandigkeit der Modelle mit und ohne gespiegelte Instanzenmit
”leave one out“ Test
AD: durchschnittliche Abweichung der Abstandet: Teststatistik eines t-Test fur gepaarte Stichprobenp: Die Uberschreitungswahrscheinlichkeit des t-Tests∗∗∗: Signifikant auf dem 0.1 % Niveau∗∗: Signifikant auf dem 1 % Niveau∗: Signifikant auf dem 5 % Niveau
42

4. Analyse des statistischen Formmodells
4.1.5 Auswertung des zeitlichen Aufwands
Die Erstellung eines statistischen Formmodells einer so komplexen Geometrie wie der
des Bienengehirns ist trotz der gegebenen Methoden mit großem Aufwand verbunden:
Die manuelle Segmentierung der Grauwertbilder hat daran erheblichen Anteil (ca. 6-10
Arbeitsstunden1 pro Gehirn), aber auch die Nachbearbeitungsschritte der Oberflachen
(ca. 4-8 Arbeitsstunden pro Gehirn) sowie die Definition und Zuordnung der Oberflachen-
regionen (ca. 2-4 Arbeitsstunden pro Gehirn) sind aufwandig.
4.2 Diskussion und Ausblick
Es konnte gezeigt werden, das durch die Aufnahme der gespiegelten Oberflachen sowohl
die Kompaktheit als auch die Vollstandigkeit des Modells erhoht. Außerdem fuhrt das
Verfahren zu einem symmetrischen Verhalten des Modells. Diese Tatsache konnte helfen,
strukturelle Forschungsergebnisse aus den beiden Gehirnhalften zu integrieren, indem sie
von einer Seite auf die andere ubertragen werden.
Schwierig zu beurteilen ist die Frage, welcher Teil der Formvariabilitat naturliche Ursachen
(Individualitat der Bienengehirne) oder technische Ursachen (verschiedenen Umstande
bei der Praparation) hat und welcher aufgrund von Artefakten und fehlerhafter Modell-
rekonstruktion aus den Bilddaten entsteht. Wie eingangs beschrieben, ist die manuelle
Segmentierung sehr abhangig von subjektiven Faktoren. Außerdem haben die verschiede-
nen Nachbearbeitungsschritte Einfluss auf die Form der Bienengehirne.
In einem Modell mit großerer Stichprobe ware es eventuell moglich, die Moden, welche
die naturliche und technische Formvariabilitat beschreiben, zu selektieren um nur diese
bei der Autosegmentierung anzupassen.
Allerdings unterliegt die Form des Modells auch einem systematischen Fehler: Aufgrund
der Methodik zum Aufbau statistischen Formmodells muss, z.T. entgegen der visuellen
Analyse der Bilddaten, die Segmentierung dem definierten Schema angepasst werden.
1die Zeitangaben beziehen sich auf die reine Arbeitszeit ohne Vorarbeit fur geubte Anwender
43

4. Analyse des statistischen Formmodells
Dadurch wird die Formvariabilitat des Modells eingeschrankt. Außerdem kann aufgrund
dieser Methode nicht modelliert werden, dass sich korrespondierende Landmarken einer
Trainingsoberflache auf einer Kontaktflache befinden und einer anderen auf einer Außen-
flache. Dies ist nicht notig fur innere Strukturen, bei zwei sich beruhrenden Strukturen,
wie den Calyces, fuhrt das Verfahren jedoch zu Verzerrungen an den Kontaktflachen(siehe
Abbildung 4.7). Die Kontaktflachen waren jedoch bei allen Bienengehirnen relativ re-
gelmaßig vorhanden, sodass zu hoffen ist, dass sich dieser Fehler nicht sehr gravierend
auswirkt.
(a) Referenz: Oberflache 1 (b) Abbildung der Landmar-ken auf Oberflache 2
(c) Tatsachliche Lage derLandmarken in Oberflache 2
Abbildung 4.7: Verzerrung bei der Abbildung an BeruhrungsflachenSchwarze Punkte stellen Landmarken dar
Der mittlere Oberflachenabstand von 7.3 µm beim leave one out Test lasst darauf schließen,
dass der Fehler, den ein Anpassungsalgorithmus zur Autosegmentierung aufgrund der
Beschrankung des Modells macht, in der selben Großenordnung liegt. Ist dies praktisch
nicht zufriedenstellend, kann die Vollstandigkeit durch die Vergroßerung der Stichprobe
weiter erhoht werden. Hierdurch konnte unter Umstanden die Kompaktheit des Modells
ebenfalls erhoht werden.
Die Erweiterung des Modells um die fehlenden Neuropile eroffnet zwei verschiedene
Moglichkeiten: Einerseits kann das Modell dann auch zur Autosegmentierung dieser
Regionen genutzt werden. Andererseits konnte ein vollstandiges SFM des Bienengehirns
als deformierbarer 3D Formatlas dienen. Dieser wurde einen Rahmen zur kohasiven
Darstellung rekonstruierter Neurone bieten, welche mittels verallgemeinerter mean value
Koordinaten [JSW05] abhangig von der Form der Oberflache deformiert werden. Dies
wurde den aufwandigen und fehleranfalligen Schritt der volumenbasierten Transformation
der Neurone in den Atlas von Brandt et al. [BRR+05] umgehen.
44

Kapitel 5
Danksagung
Ich danke allen, welche mich bei der Erstellung dieser Arbeit unterstutzt haben.
Insbesondere danke ich meinen Gutachtern, Prof. Randolf Menzel und Dr. Stefan Za-
chow.
Fur die Ausgabe des Themas, die individuelle Betreuung sowie fur die Bereitstellung der
Laborraume mochte ich Dr. Jurgen Rybak meinen Dank aussprechen.
Hans Lamecker danke ich fur die Unterstutzung und die zahlreichen Erklarungen.
Außerdem danke ich Astrid Klawitter fur die zur Verfugung gestellten Praparate.
Ein weiterer Dank geht an alle Lektoren, und Korrektoren meiner Arbeit.

Anhang A
Praktische Anleitung zur Erzeugung
von Oberflachen fur das statistische
Formmodell des Bienengehirns mit
Amira
Diese Anleitung bezieht sich auf die Benennungen in ZIBAmira 2008.01. In anderen
Versionen konnen Bezeichnungen abweichen oder Module nicht vorhanden sein. Die
Basisfunktionen von Amira werden als bekannt vorausgesetzt. Fur eine ausfuhrliche
Erklarung der Funktionen von Amira verweise ich auf die Dokumentation [Ami08].
A.1 Segmentierung
Fur die Segmentierung stellt Amira den”Segmentation Editor“ bereit. Er ist
uber ein Symbol (rechts) oberhalb des Pools zu erreichen. Zunachst muss zu dem
Grauwertdatensatz ein neues”Labelfield“ erzeugt werden, das die Segmentierung
speichert. Dazu bei”Label Data“ auf den Button
”New“ drucken.

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
A.1.1 Materialien
Folgende Neuropile mussen segmentiert werden:
l-vMB r-vMB CB LPL-SOG r-medCal r-latCal l-latCal l-medCal
Um sicherzustellen, dass die Materialbenennung konsistent ist sollte nach der Erzeugung
des Labelfields das Compute Modul”Relabel“ verwendet werden. Dazu wechselt man
zuruck in den Pool, und wahlt dort fur das neue Labelfield das compute/relabel aus.
Der Template Port wird mit einem beliebigen Labelfield verbunden, bei welchem die
Materialbenennung bereits korrekt ist und die Option”modify input“ wird ausgewahlt.
Durch”apply“ werden die Materialbezeichnungen von dem Template auf das neue
Labelfield ubertragen.
A.1.2 Segmentierungsstrategie
Nun kann mit der Segmentierung begonnen werden. Es empfiehlt sich, mit den Calices
anzufangen, dann die Pedunkuli und den Zentralkorper und zuletzt das PL-SOG zu
labeln. Beim Labeln haben wir uns an die Vorgaben des Standards nach Brandt et al.
gehalten [BRR+05], mit Ausnahme des vertikalen Lochs durch das PL-SOG hinter dem
Zentralkorper, welches wir weggelassen haben. Der Film, welcher im Rahmen dieser
Publikation erstellt wurde, gibt Aufschluss uber Unklarheiten bei der Segmentierung.
Wie in Abschnitt 3.2 beschrieben mussen die Kontaktflachen zwischen den Neuropilen ex-
akt bei allen Segmentierungen ubereinstimmen. Insbesondere mussen alle Kontaktflachen
ununterbrochen, d.h. ohne Locher sein.
Die Abbildung 3.2 stellt dar, zwischen welchen Neuropilen Kontakt bestehen muss. Bei
den lateralen und medialen Calyces ist darauf zu achten, dass diese sich an zwei Stellen
beruhren. Diese Kontaktflachen durfen nicht verschmelzen.
Beim Segmentieren an Kontaktflachen sollte das bereits vorhandene Material geschutzt
werden (Schloß bei den Materialien unter”Lock“) und das neue ein Stuck uber die Grenze
II

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
hinweg gemalt werden. Dies stellt sicher, dass die Kontaktflache auch bei interpolierten
Schichten vorhanden ist.
Grundsatzlich sollte zunachst in jeder dritte bis funfte Schicht ein Neuropil mit dem Pinsel
markiert werden. Nach der letzten Schicht werden die Zwischenschichten interpoliert
(”Selection/Interpolate“) und dann das Material zugewiesen (Strg+A).
A.1.3 Nachbearbeitung
Sind alle Materialien segmentiert sollte die xz und die yz Ebenen betrachtet werden um
festzustellen, ob die Segmentierung kontinuierlich durchgefuhrt wurde: Die Materialgren-
zen sollten eben und gleichmaßig sein. Ist dies nicht der Fall konnen die entsprechenden
Materialien mittels Segmentation/smoothLabels in 3 d geglattet werden (die anderen
Materialien sperren). Beim”size“-Parameter empfiehlt sich ein Wert zwischen 3 (leichte
Unebenheiten) und 7 (grobere Unebenheiten). Nach dem Glatten mussen noch ein-
mal feinere Strukturen wie die Brucke (hinten am PL-SOG uber dem CB) uberpruft
werden, da sie”weggeglattet“ werden konnen. Am Ende konnen nochmals alle Mate-
rialien geglattet werden um auch die Kontaktflachen zu glatten. Nun sollten in den
MaterialStatistics (Segmentation/MaterialStatistics) 9 Materialien (inkl. Exterior) und
9 Regions vorhanden sein. Uberzahlige Regionen konnen mittels”remove islands (3d)“
(Segmentation/RemoveIslands) entfernt werden.
Nach der Segmentierung haben wir die Auflosung in X und Y von 512 auf 512 Punkte
halbiert, sowohl bei den Labelfields als auch bei den Grauwertbildern (siehe Abb. A.1).
Bei den Grauwerten wird dabei der”Lacerus“ Filter verwendet, bei den Labeln kann
keine Methode angegeben werden, hier kommt ein nearest neigbour Algorithmus zum
Einsatz. compute -> resample
(a) Grauwertbilder (b) Labelfields
Abbildung A.1: Parameter des Resample Moduls
III

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
Dies sorgt dafur, dass die Voxel eine gleichmaßigere Kantenlange haben und damit
Treppenartefakte bei der Erzeugung der Oberflache reduziert werden.
A.2 Erzeugung einer Oberflache
Sind alle Materialien segmentiert kann mit dem SurfaceGen Modul eine Oberflache
erzeugt werden. Die Surface sollte erzeugt werden mit den Einstellungen”constrained
smoothing“ und”add border“ (die restlichen Optionen nicht ausgewahlt bzw. 0). Anhand
dieser kann nun noch einmal uberpruft werden, ob die Segmentierung glatt war: Die
Oberflache sollte glatt sein, von der Seite betrachtet sollten keine groben Unebenheiten
vorhanden sein. Gegebenenfalls muss das Labelfield uberarbeitet werden. Abb. 3.4 zeigt
solche Fehler.
Auf die Oberflache kann jetzt das checkSurfaces-Script (Rechtsklick im Pool/create/sur-
faceAtlas/checkSurfaces) angewandt werden. Dieses wird mittels einer Textdatei konfigu-
riert. Das Beispiel in Listing A.1 zeigt den Aufbau dieser Datei. Das Script geht davon aus,
dass die Dateien alle in einem eigenen Unterordner liegen, z.B.”C:/myBeeBrains/LY 01/LY 01.surf“.
#Das Verzeichnis, in welchem die Dateien liegenset dir "C:/myBeeBrains/"
#die Erweiterung der Oberflachen-Dateienset surfExt ".surf"
#Liste aller Oberflachen, welche getestet werden sollenset surfaces {LY_01
LY_02LY_03}
Listing A.1: checkSurfaces Konfigurationsdatei
Das Script testet verschiedene Eigenschaften der Oberflachen. Zu diesem Zeitpunkt
sind die Genus-Tests sowie die Anzahl der Kontaktflachenberandungen interessant: Eine
korrekte Oberflache hat 22 Kontaktflachenberandungen, welche als”Contours“ bezeichnet
werden. Diese Contours lassen sich nach dem Test mit Display/ContourView anzeigen.
Sind mehr bzw. falsche Pfade vorhanden muss das Labelfield uberarbeitet werden.
IV

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
Der”Genus Test“ uberpruft, ob die Neuropile die richtige Anzahl an
”Henkeln“ haben. Ist
dies nicht der Fall so ist die Struktur falsch und die Labels mussen uberarbeitet werden.
Das PL-SOG hat 7 Henkel (siehe Abb. 3.6), die Calyces jeweils einen und die anderen
Neuropile keinen.
Außerdem wird bei dem Test das”AspectRatio“ der Dreiecke und die Uberschneidungen
(”Intersections“) gepruft. Diese sind jedoch zum jetzigen Zeitpunkt noch unerheblch.
A.2.1 Nachbearbeitung einer Oberflache
Nachdem die Tests erfolgreich durchgefuhrt wurden kann die Oberflache mittels”Simpli-
fier“ vergrobert werden. Als Grenze fur die Simplifizierung haben wir eine”max dist“ von
13 eingestellt. Dies fuhrt zu einer Simplifizierung auf etwa 150000 Dreiecke. Die dabei
entstehende Oberflache kann nochmals mittels”compute/SmoothSurface“ Modul in 10
Iterationen bei lamda=0.5 geglattet werden. Zuletzt werden die Konturen geglattet: Das
Modul”compute/SmoothSurfaceContours“ wird zweimal mit den Standardeinstellungen
auf die Oberflache angewandt. Nun muss die Oberflache im Surface-Editor uberarbei-
tet werden: Alle Uberschneidungen von Dreiecken mussen aufgelost werden sowie das
Verhaltnis zwischen Innen- und Aussenkreis der Dreiecke (Aspect Ratio) auf maximal
100 verringert werden. Dazu stellt der Editor entsprechende Tests zur Verfugung: Der
AspectRatio Test sucht die Dreiecke mit dem schlechtesten Verhaltnis und markiert diese
rot. Oft sind die Dreiecke so schmal, dass sie nur als Linie zu erkennen sind. Die meisten
Dreiecke lassen sich mit dem Flip-Edges-Tool verbessern.
Der Intersections Test sucht nach Dreiecken, welche sich uberschneiden. Diese Fehler
aufzulosen erfordert Ubung mit den Werkzeugen des Surface Editors.
Jetzt wird der Test”checkSurfaces“ ein weiteres mal durchgefuhrt, um zu testen, ob alle
Eigenschaften der Oberflache korrekt sind und alle Fehler entfernt wurden. Insbesondere
ist zu uberprufen, ob sich durch das Simplifizieren oder Entfernen der Intersections die
Anzahl der Contours nicht verandert hat.
V

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
A.2.2 Gebietszerlegung einer Oberflache
Ist alles in Ordnung kann die Zerlegung der Oberflache in Gebiete, sogenannte”Patches“,
durchgefuhrt werden.
A.2.3 Definition von Oberflachenpfaden
Fur die Gebietszerlegung mussen zunachst die Randkurven der Gebiete als Pfade auf
der Oberflache definiert werden. Zunachst wird ein”SurfacePath/ArbitrayPathsEditor“
geoffnet und die Gebietsrander als Pfade importiert (”importContours“). Der Editor
erlaubt die Definition von Oberflachenpfaden. Dies geschieht uber Kontrollpunkte (CP),
welche zu Pfaden verbunden werden. Durch einen Klick auf die Oberflache bei gedruckter
Umschalt-Taste wird ein neuer CP hinzugefugt. Falls ein Pfad ausgewahlt ist wird
dieser mit dem neuen Kontrollpunkt mithilfe des ausgewahlten Verbindungsalgorithmus
verbunden. Als Verbindungsalgorithmus empfiehlt sich”plane cut“, da dieser im Gegensatz
zu”localy shortest“ keine Probleme an Nichtmanigfaltigkeiten hat.
Auf diese Weise mussen die folgenden 71 Pfade auf die Oberflache gezeichnet werden.
Dabei ist darauf zu Achten, dass Pfade, welche auf einem Kontrollpunkt (CP) oder Pfad
enden sollen, wirklich genau auf diesem CP/Pfad enden, da die Nachbarschaftsverhaltnisse
der Patches, ansonsten nicht ubereinstimmen.
PL-SOG
VI

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
1 PL-SOG Symmetrieebene –> PL und
2 –> SOG
3 Um das Schlundloch: Ring vorne und
4 hinten (auf dem SOG entlang)
–> Brucke
5/6 –> Ringe um die Kontakte zum PL
7 –> oben auf Brucke
8 –> Kamm unter Brucke
9 Mittig Alpha Loben Austritte verbinden
10/11 Mittig Alpha Loben mit Kontaktflache zu medialen Calyces verbinden
12/13 Kontaktflachen (KF) zu medialen Calyces mittig mit Austritt medialen Pedunculus
verbinden
14 KF der medialen Calyces mittig verbinden
15/16 Austritt Pedunkuli mit Brucke an Kontrollpunkt (CP) von 7 verbinden
17/18 Austritt Pedunkuli diagonal mit CB verbinden
–> Dorsallobus:
19/20 Oben: Vorne oben am Schlund beginnen, durch Tal auf die Ruckseite, etwa in der
Mitte des Schlundlochs enden
21/22 Unten: Vorne Mittig am Schlund beginnen, durch Tal auf Ruckseite und hinten
unten am Schlund oberhalb USG enden.
23/24 Optischer Tuberkel umrunden und
VII

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
25/26 diagonal auf kurzestem Weg mit Alpha Lobus Austritt verbinden
27/28 Laterales Horn umrunden und
29/30 diagonal mit optischem Tuberkel verbinden
31/32 Laterales Horn von unterster Stelle mit dem Knick der vordersten Schicht des
oberen Pfads des Dorsallobus verbinden
MB
33/34 Mitte oben Alpha Loben an CP von 10/11 mit Mitte (hinten) zw. Calyces verbinden
35/36 Alpha mit Beta Lobus verbinden (mittig unten)
37 KF von CB links uber Beta Lobus KF mit KF von CB rechts verbinden.
38/39 Kontaktflache von CB mit Austritt aus PL verbinden.
40–44 Mittig die Aufsicht der KF zu Exterior zwischen PL und Calyces und KF zu den
Calyces trennen
CB
45 Kontaktflachen von Beta Loben uber vorderste Schicht des Fanshapebody
46/47 CP von 17/18 mit CP von 37/38 verbinden -> Dreieck
laterale Calyces
48/49 Kontaktflachen zu medialen Calyces verbinden
50–53 Entlang der Langsachse teilen
54/55 Auf der Lippe entlang ganz herum.
VIII

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
–> KF zu medialen Calyces mit Schnittlinie (50-53) verbinden, in der Mitte des
Kragens:
56/57 dorsal und
58/59 ventral
mediale Calyces
60/61 Kontaktflachen zu medialen Calyces verbinden
–> Entlang der Langsachse teilen:
62/63 dorsal und
64/65 ventral mittig bei KF zu PL beginnen (CP 10/11) und enden (CP 12/13)
66/67 Auf der Lippe entlang ganz herum.
68/69 Kontaktflache zu lateralen Calyces dorsal in der Mitte des Kragens mit Schnittlinie
(62/63) verbinden.
70/71 Kontaktflache zu lateralen Calyces ventral in der Mitte des Kragens mit KF zu PL
verbinden.
Zusammen mit den 22 importierten Contours ergeben sich so 93 Pfade. Nun kann”Split
Paths at Intersections“ durchgefuhrt werden. Die sich schneidenden Pfade werden getrennt.
Nun sollten 227 Pfade vorhanden sein. Oft ergeben sich zu viele Pfade, da Pfade, welche
auf einem CP enden sollten dicht daneben enden. Die falschen Pfade sind oft sehr kurz
und bestehen nur aus zwei Punkten. Sie sind leicht zu finden, indem die Pfade der Lange
nach sortiert werden (TCL-Befehl”sortPathsByLength“). Die uberzahligen Pfade mussen
dann durch Versetzten der Kontrollpunkte entfernt werden.
IX

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
A.2.4 Zerlegung der Oberflache
Das Pathset sollte zur Sicherheit vor dem nachsten Schritt abgespeichert werden. Wenn
davon ausgegangen werden kann, dass Einteilung korrekt vorgenommen wurde, wird
nun”Snap Nodes“ mit einem Epsilon von 0.001 durchgefuhrt. Dadurch werden die
Kontrollpunkte auf benachbarte Kanten oder Eckpunkte in diesem Radius gesetzt. Dann
konnen mit”CDT“ die Dreiecke der Oberflache entlang der Pfade geschnitten werden.
Jetzt kann die Oberflache mittels”Patchify“ zerlegt werden. Dabei sollten sich 89 Patches
ergeben. Die so eingeteilte Oberflache sowie der dazugehorige Pfad sollten beide unter
neuem Namen (mit dem Postfix”
patched.pathset“ bzw.”
patched.surf“ ) abgespeichert
werden. Zur Kontrolle der Patches und zum Finden von Fehlern konnen nun von der
eingeteilten Oberflache wiederum die Konturen importiert werden. Da der Pfad, der auf
der Brucke verlauft keine Grenzflache zu einem anderen Patch bildet sollten nun 226
Konturen importiert werden. Eine weitere Moglichkeit, falsche Patches zu finden ist, sich
die kleinsten Exemplare mit den niedrigsten IDs im SurfaceViewer anzusehen.
A.2.5 Ordnen der Oberflachenregionen
Wenn die Zerlegung korrekt ist mussen die Patches mittels des”Experimental / reorder-
Patches“ Modul in die richtige Reihenfolge gebracht werden. Das Schema in Abb. 3.8
stellt die ID der verschiedenen Patches da. Die fertige Oberflache ist mit dem postfix
”patched ro.surf“ abzuspeichern.
A.3 Erweiterung der Stichprobe durch Spiegelung
von Oberflachen
Das Spiegeln wird durch die Transformation der nachbearbeiteten und eingeteilten Ober-
flache mit”setTransform -1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1“ erreicht. Durch
”applyTransform“
wird die Transformation angewendet.
X

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodelldes Bienengehirns mit Amira
Nach dem Spiegeln der Bienengehirne mussen die bilateral symmetrischen Neuropile
vertauscht werden: Die linken Neuropile werden zu den rechten und andersherum.
Um die entsprechenden symmetrischen Neuropile liegt dieser Arbeit das Compute-
Modul”FlipMaterials“ bei. Es erlaubt, Paare von Materialien auszuwahlen, welche dann
vertauscht werden. Es mussen die lateralen und die medialen Calyces sowie die Pedunkuli
getauscht werden.
Nach dem Vertauschen muss die Orientierung der Beruhrungsflachen der Calyces sowie
die Kontaktflache der β-Loben invertiert werden. Auch hierfur liegt ein Compute-Modul
(”FlipPatches“) bei: Mittels der Leiste kann der gewunschte Patch ausgewahlt werden,
bei welchem dann das Material der Innen- und der Außenseite vertauscht wird. Dies ist
fur die Patches 19–22 sowie fur Patch 0 notig.
Nun mussen die Patches umgeordnet werden. Da die Patches der Original Oberfla-
che bereits gemaß des Schemas angeordnet waren, genugt es bei”reorderPatches“ die
vorbereitete Tabelle”flip.table“ anzuwenden.
Analog zu der Oberflache wird nun das dazugehorige Pathset gespiegelt. Danach muss
dieses mittels”ProjectPathSet“ auf die gespiegelte Oberflache projiziert werden. Ge-
gebenenfalls mussen Fehler, welche durch die Projektion des Pathsets entstanden sind
im”PathSetEditor“ entfernt werden. In jedem Fall mussen auch nach
”Split Pathes at
Intersections“ 227 Pfade vorhanden sein.
Die so bearbeitete Oberflache kann nun analog zu dem in A beschrieben Verfahren in
das statistische Modell mit aufgenommen werden.
A.4 Abbilden der Triangulation
Wenn die Ordnung der Patches mit den Schemata ubereinstimmt kann das Script zum
Abbilden der Triangulation der Patches angewendet werden. Als Referenz muss der Daten-
satz LY 09 angegeben werden. Das Beispiel in A.2 zeigt, wie dazu die Konfigurationsdatei
aufgebaut sein muss.
XI

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodelldes Bienengehirns mit Amira
# base directoryset dir "d:/projects/beebrain/patch/"
# set referenceset refName "LY_09"
# extension for input surfacesset inputSurfExt "_patched_ro.surf"
# extension for input surface pathsset inputPathExt "_patched.pathset"
# extension for morphed surfacesset morphSurfExt "_morphed.surf"
# Surfaceset patchedSurfaces {
LY_XX...
}
Listing A.2: Morphing Konfigurationsdatei
A.5 Erzeugen der”Active Surface“
Da die Korrespondenz nun hergestellt ist kann eine Active Surface neu erzeugt oder die
Vorhandene erweitert werden. Um eine neue”active surface“ zu erstellen empfielt sich das
Script”createActiveSurface“. Dieses muss ebenfalls mit einer Datei nach dem Beispiel in
A.3 konfiguriert werden.
# name of this projectset projectName "BeeBrain"
# base directoryset dir "d:/projects/Beebrain/patch/"
# label separator for name creationset needle "_morphed"
# extension for surfacesset surfExt "_morphed.surf"
# transformation class (one of rigid=0/rigidScale=1/affine=2/none=3)set trafo 1
XII

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
# multi-alignment ?set doMulti 1
# training dataset trainingSet {
LY_XX...
}
Listing A.3: Morphing Konfigurationsdatei
Um eine vorhandene Active Surface zu erweitern kann das Compute-Modul”addToActi-
veSurface2“ verwendet werden. Die Active Surface muss uber ihren”Master“-Connection
Port mit dem Modul verbunden werden, die neue Oberflache wird an den”Data“-Port
des”addToActiveSurface2“ verbunden. Nun kann sie in den
”Buffer“ hinzugefugt werden.
Durch”create“ wird das statistische Modell neu berechnet.
A.6 Erstellen von Teilmodellen
Um Teilmodelle des SFM des Bienengehirns erstellen zu konnen liegt dieser Arbeit das
Modul”extractFromActiveSurface“ bei. Es sieht drei verschiedene Wege, Teilstrukturen
auszuwahlen vor, welche uber die Liste”Selection Mode“ wahlbar sind: Zunachst konnen
Materialien hinzugefugt und entfernt werden. Dazu erscheint eine weitere Liste, in derer
die Materialien ausgewahlt und dann mit”add“ dem Teilmodell hinzugefugt und mit
”remove“ wieder entfernt werden. Wird
”Patches“ als Modus gewahlt, so kann uber die
erscheinenden Buttons oder uber die Konsole (”setPatchBeyond“) ein Patch ausgewahlt
werden und analog zu dem Materialien hinzugefugt oder entfernt werden. Dabei sind nur
Patches wahlbar, die zu Materialien gehoren, welche dem Modell hinzugefugt wurden. Im
”Free Hand Modus“ kann durch eine geschlossene Linie, welche in den Viewer gezeichnet
wird, eine beliebig Mengen von Dreiecken ausgewahlt werden. Ist die Option”Half selected
Patches“ aktiv, so werden zusatzlich alle Patches, von denen mindestens ein Dreieck
ausgewahlt wurde markiert. Auch diese Auswahl kann nun dem Modell entfernt bzw.
wieder hinzugefugt werden.
XIII

Glossar
bijektiv . . . . . . . . . . . . . umkehrbar eindeutig
Formmode . . . . . . . . . . ‘Richtung’ der Formvarianz
Formparametrisierung Beschreibung der Form durch Parameter, z.B. zu Dreiecken
verbundene Punkte auf der Oberflache
Geometrie . . . . . . . . . . raumliche Eigenschaften eines Gegenstandes
homoomorph . . . . . . . Beschreibung der Beziehung zweier Objekte, welche sie sich durch
einen Homoomorphismus aufeinander abbilden lassen.
Homoomorphismus . bijektive, stetige Abbildung zwischen zwei Objekten, deren Um-
kehrabbildung ebenfalls stetig ist, z.B. Dehnen, Stauchen, Verbie-
gen, Verzerren oder Verdrillen.
Instanz . . . . . . . . . . . . . konkretes Exemplar einer Klasse
Kompaktheit . . . . . . . Eigenschaft des SFM, auch mit einer Teilmenge der Moden voll-
standig zu sein
Korrelation . . . . . . . . . Abhangigkeit zweier Zufallsvariablen. Bei korrelierten Zufallsva-
riablen lasst der Wert der einen Variable Ruckschlusse auf den
Wert der zweiten Zufallsvariable zu.
Merkmalsvektor . . . . vektorielle Form der parametrisch beschreibbaren Eigenschaften
des Objekts. Im Fall von 3D Oberflachen die Koordinaten der
Punkte auf der Oberflache.

A. Praktische Anleitung zur Erzeugung von Oberflachen fur das statistische Formmodell
des Bienengehirns mit Amira
Neuropile . . . . . . . . . . . bei der Biene Gehirnareale, welche aus dichtem Nervengeflecht
bestehen
Segmentierung . . . . . . Einteilung der Bilddaten in Regionen nach bestimmten Kriterien
Stetigkeit . . . . . . . . . . . genugend kleine Anderungen der Argumente fuhren zu beliebig
kleinen Anderungen des Funktionswerts
topologische Aquivalenz siehe homoomorph
Trainingsmenge . . . . . die Menge aller dem Modell zu Grunde liegenden Instanzen
Vollstandigkeit . . . . . . Fahigkeit des SFM, die Form beliebiger Instanzen der modellierten
Klasse zu beschreiben
XV

Literaturverzeichnis
[Ami08] Visage Imaging GmbH: Amira,Visualization and Modelling System. http:
//www.amiravis.com/. Version: 5.0, 2008
[BRR+05] Brandt, Robert ; Rohlfing, Torsten ; Rybak, Jurgen ; Krofczik,
Sabine ; Maye, Alexander ; Westerhoff, Malte ; Hege, Hans-Christian ;
Menzel, Randolf: Three-dimensional average-shape atlas of the honeybee
brain and its applications. In: The Journal of Comparative Neurology 492
(2005), Nr. 1, 1–19. http://www3.interscience.wiley.com/journal/
112093922/abstract?CRETRY=1, Abruf: 16.08.2008
[CT92] Cootes, T.F. ; Taylort, C.J.: Active Shape Models - ‘Smart Snakes’. In:
Proc. British Machine Vision Conference, 1992, S. 266–275
[Dav02] Davies, R. H.: Learning Shape: Optimal Models for Analysing Natural
Variability, University of Manchester, Diss., 2002
[DM92] DeRose, T. ; Mann, S.: An approximately G1 cubic surface interpolant.
In: Lyche, Tom (Hrsg.) ; Schumaker, Larry L. (Hrsg.): Mathematical
methods in computer aided geometric design II. San Diego, CA, USA :
Academic Press Professional, Inc., 1992. – ISBN 0–12–460510–9, S. 185–196
[Flo97] Floater, M.: Parametrization and smooth approximation of surface
triangulations. In: Comp. Aided Geometric Design 14(3) (1997), 231–
250. http://www.multires.caltech.edu/teaching/courses/cs101.3.
spring02/cs101_files/resources/Parameterization/Floater.pdf,
Abruf: 16.08.2008

Literaturverzeichnis
[HXPHA07] Hufnagel, H. ; X. Pennec, and J. E. ; Handels, H. ; Ayache, N.: Shape
analysis using a point-based statistical shape model built on correspondence
probabilities. In: Med Image Comput Comput Assist Interv Int Conf Med
Image Comput Comput Assist Interv. (2007), S. 959–967
[JSW05] Ju, Tao ; Schaefer, Scott ; Warren, Joe: Mean Value Coordinates for
Closed Triangular Meshes. In: ACM SIGGRAPH (2005), 561–566. http:
//www.cs.wustl.edu/~taoju/research/meanvalue.pdf, Abruf: 1.9.2008
[KLL07] Kainmuller, D. ; Lange, T. ; Lamecker, H.: Shape Constrained
Automatic Segmentation of the Liver based on a Heuristic Intensity Model.
In: Proc. MICCAI Workshop on 3D Segmentation in the Clinic: A Grand
Challenge (T. Heimann at al., eds.), 2007, 109–116
[KWT87] Kass, M. ; Witkin, A. ; Terzopoulos, D.: Snakes: Active contour models.
In: International Journal of Computer Vision 1 (1987), Nr. 4, S. 321–331
[Lam08] Lamecker, Hans: Variational and Statistical Shape Modeling for 3D
Geometry Reconstruction, Zuse Institute Berlin, Diss., 2008
[LLS02] Lamecker, Hans ; Lange, Thomas ; Seebass, Martin: A Statistical Shape
model for the liver. In: Proc. Medical Image Computing and Computer
Assisted Intervention (MICCAI) (T. Dohi, R. Kikinis, eds.), Lecture Notes
in Computer Science Bd. 2489, 2002, 422–427
[LLS03a] Lamecker, Hans ; Lange, Thomas ; Seebass, Martin: Erzeugung sta-
tistischer 3D-Formmodelle zur Segmentierung medizinischer Bilddaten. In:
Proc. BVM (T. Wittenberg et al., eds.), Informatik aktuell, 2003, 398–403
[LLS+03b] Lamecker, Hans ; Lange, Thomas ; Seebass, Martin ; Eulenstein,
Sebastian ; Westerhoff, Malte ; Hege, Hans-Christian: Automatic
Segmentation of the Liver for Preoperative Planning of Resections. In:
Proc. Medicine Meets Virtual Reality (MMVR) (J.D. Westwood et al., eds.),
Studies in Health Technologies and Informatics 94, 2003, 171-174
XVII

Literaturverzeichnis
[Men01] Menzel, Randolf: Searching for the memory trace in a mini-
brain, the honeybee. In: Learning & Memory (2001), 53–62. http:
//www.neurobiologie.fu-berlin.de/menzel/Pub_AGmenzel/Menzel_
2001_Learning&Memory_8_53_62_Review_SearchingMemoryTrace.pdf,
Abruf: 16.08.2008
[Mob82] Mobbs, P. G.: The Brain of the Honeybee Apis Mellifera. In: Biological
Sciences 298 (1982), Nr. 1091, 309–354. http://www.jstor.org/pss/
2395972, Abruf: 16.08.2008
[Neu07] Neubert, Kerstin: Model-based autosegmentation of brain structures in the
honeybee, Apis mellifera. Bachelorarbeit FU-Berlin, 2007
[Sin08] Singer, Jochen: Entwicklung einer Anpassungsstrategie zur Autosegmentie-
rung des Gehirns der Honigbiene Apis Melifera mittels eines statistischen
Formmodells. Bachelorarbeit FU-Berlin, 2008
[Ste81] Stewart, Walter W.: Lucifer dyes - highly fluorescent dyes for biological
tracing. In: Nature 292 (1981), 17–21. http://www.nature.com/nature/
journal/v292/n5818/abs/292017a0.html, Abruf: 16.08.2008
[ZLZ08] Zielske, Michael ; Lamecker, Hans ; Zachow, Stefan: Adaptive Remes-
hing of Non-Manifold Surfaces. In: Proc. EUROGRAPHICS 2008, 2008
XVIII


















