
Cache Blöcke und Offsets - Uni Koblenz-Landauunikorn/lehre/gdra/ss15/05 Speich… ·...
37
Cache‐Blöcke und Offsets SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 16 Ein Cache‐Eintrag speichert in der Regel gleich mehrere im Speicher aufeinander folgende Bytes. Grund: räumliche Lokalität wird wie folgt besser ausgenutzt: • Bei Cache‐Miss gleich mehrere Bytes laden • Anschließende Zugriffe auf benachbarte Bytes sind dann ein Hit Konsequenz auf die Aufteilung der Adresse der Form Tag|Index? Beispiel: Cache mit einem Word pro Eintrag (auf nächster Folie) Tag Index Offset
Transcript of Cache Blöcke und Offsets - Uni Koblenz-Landauunikorn/lehre/gdra/ss15/05 Speich… ·...

Cache‐Blöcke und Offsets
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 16
Ein Cache‐Eintrag speichert in der Regel gleich mehrere im Speicher aufeinander folgende Bytes.
Grund: räumliche Lokalität wird wie folgt besser ausgenutzt:• Bei Cache‐Miss gleich mehrere Bytes laden• Anschließende Zugriffe auf benachbarte Bytes sind dann ein Hit
Konsequenz auf die Aufteilung der Adresse der Form Tag|Index?
Beispiel: Cache mit einem Word pro Eintrag (auf nächster Folie)
Tag Index Offset
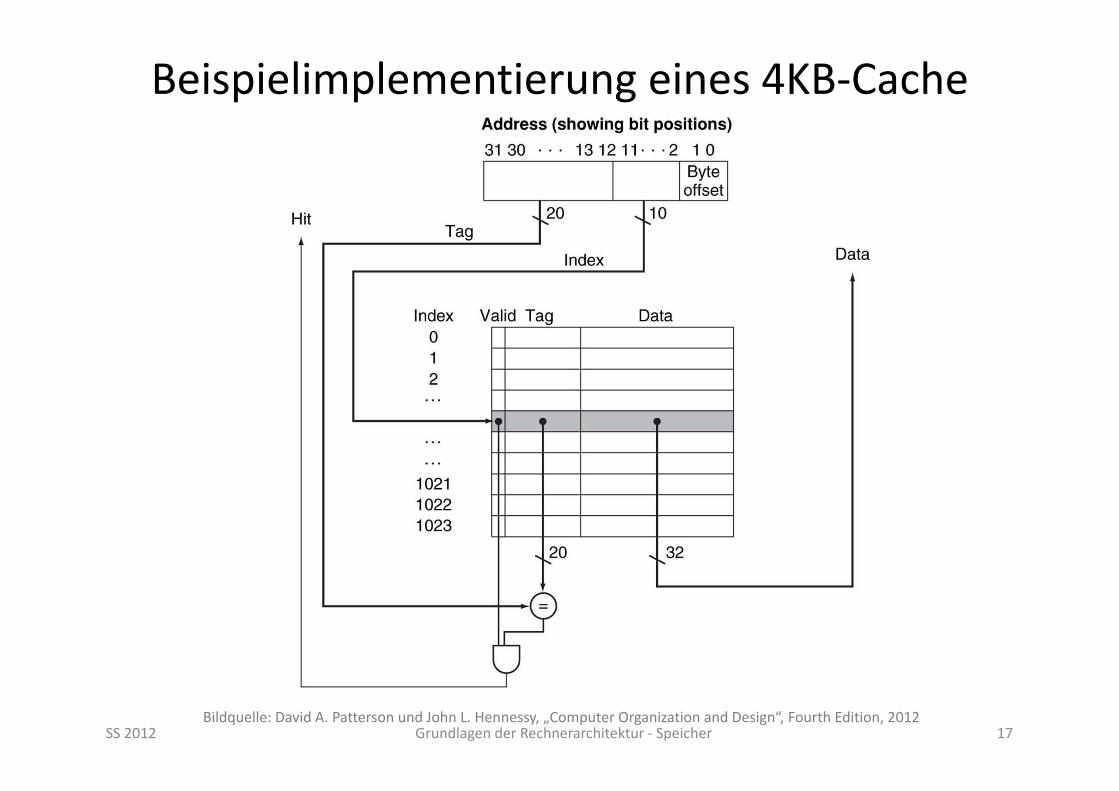
Beispielimplementierung eines 4KB‐Cache
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 17Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
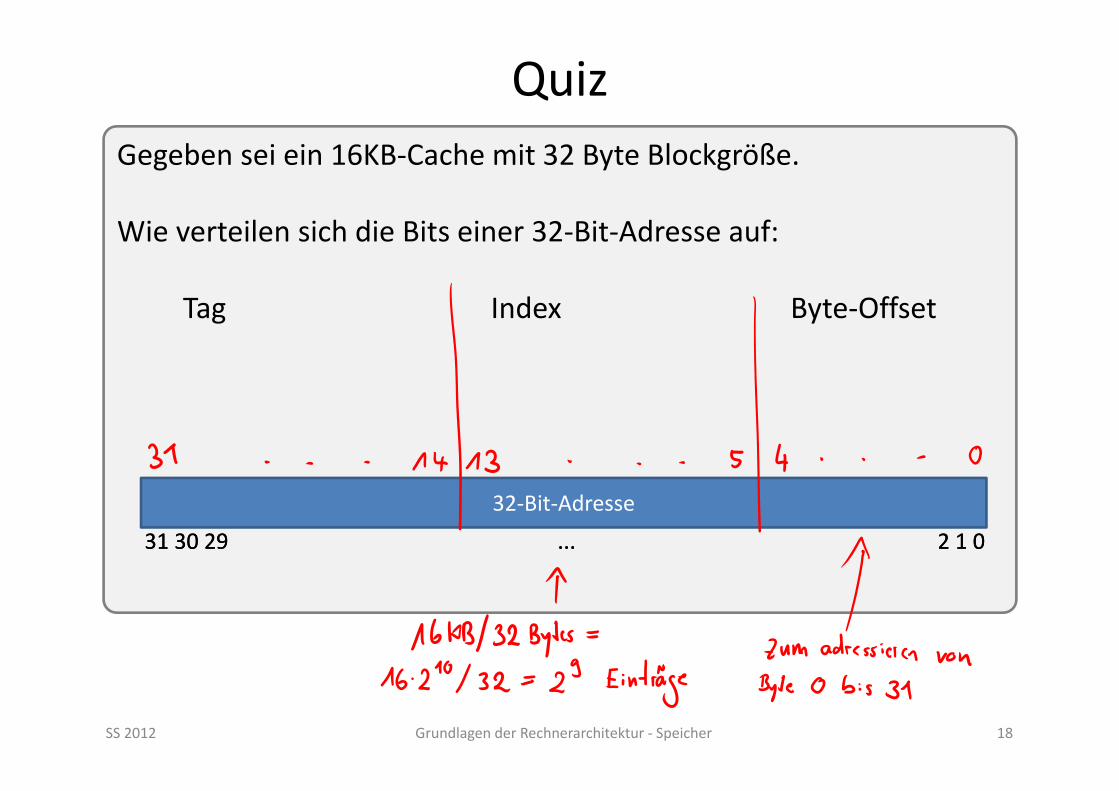
Quiz
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 18
Gegeben sei ein 16KB‐Cache mit 32 Byte Blockgröße.
Wie verteilen sich die Bits einer 32‐Bit‐Adresse auf:
Tag Index Byte‐Offset
32‐Bit‐Adresse
31 30 29 ... 2 1 031 30 29 ... 2 1 0

Quiz
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 19
Gegeben sei ein Cache mit 64 Blöcken mit Block‐Größe 16 Bytes.
Was ist die Cache‐Größe in KB?
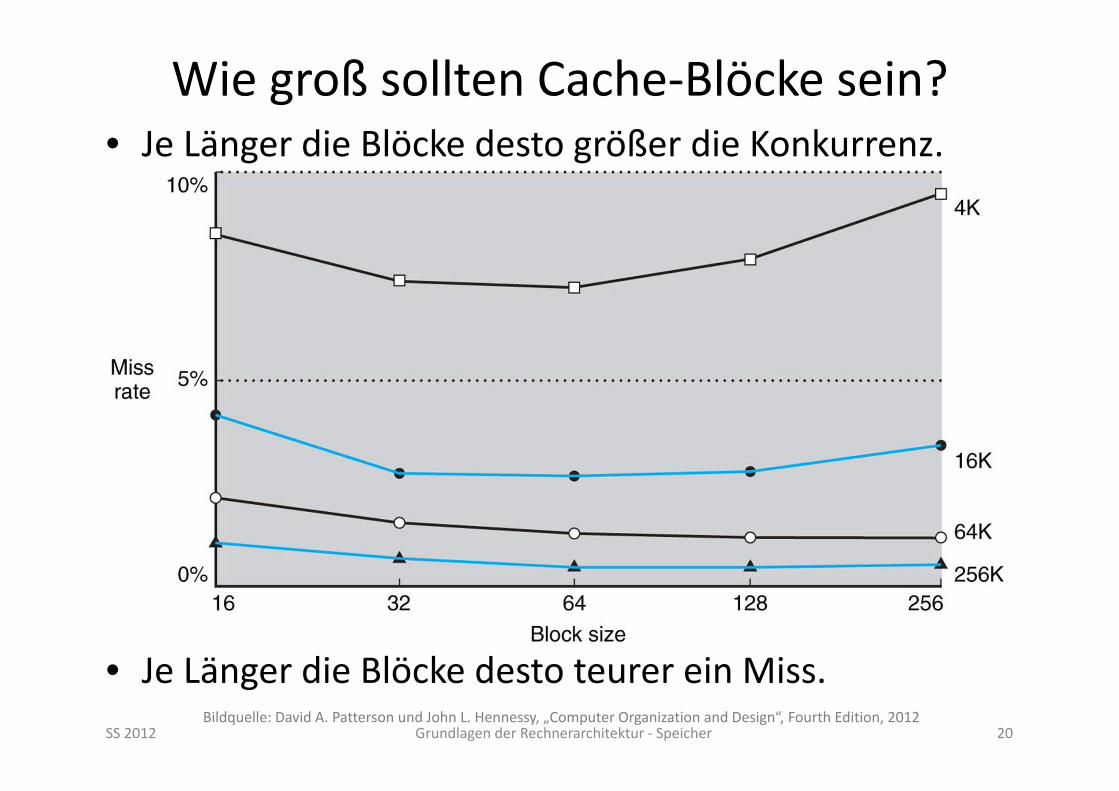
Wie groß sollten Cache‐Blöcke sein?• Je Länger die Blöcke desto größer die Konkurrenz.
• Je Länger die Blöcke desto teurer ein Miss.SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 20
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Ergänzung: Split‐Caches
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 21
Split‐Cache: besteht aus zwei unabhängigen Caches• Ein Cache für die Instruktionen• Ein Cache für die Daten
Vorteil: die Cache‐Bandbreite (d.h. wie viel Daten pro Zeiteinheit können ausgelesen/geschrieben werden) wird erhöht.Erinnerung: unsere MIPS‐CPU konnte auch gleichzeitig einen Instruction‐Fetch und einen Datenzugriff machen.
Nachteil: die Miss‐Rate erhöht sich, da die Aufteilung in Bytes für Instruction‐ und Daten‐Cache fest ist und ggf. nicht optimal für das aktuelle Programm ist.
Beispiel: Miss‐Raten für einen Intrinsity FastMATH Prozessor• Split‐Cache (32 KB aufgeteilt): 3,24% Miss‐Rate• Combined‐Cache (32 KB für einen Cache): 3,18% Miss‐Rate

Cache‐GrundlagenSchreibender Cache‐Zugriff
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 22

Eine einfache Strategie• Schreibt man nur in den Cache, werden Cache und darunter
liegender Speicher inkonsistent. Wie erreicht man Konsistenz?
• Write‐Through– Schreibe immer sofort in den Speicher zurück– Einfach aber schlechte Performance
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 23
Beispiel: 10% Store‐Instruktionen, CPI ohne Miss = 1 und CPI bei Speicherzugriff = 100. Was ist der Gesamt‐CPI‐Wert?

Verbesserungen• Write‐Buffer
– Ergänzung zu Write‐Through– Ausstehende Writes werden in einem kleinen Puffer zwischengespeichert– CPU kann nach schreiben in den Puffer sofort weiter machen– Parallel werden Daten aus dem Puffer in den Speicher geschrieben– CPU muss nur stallen, wenn der Puffer voll ist.
• Write‐Back– Alternative zu Write‐Through– Speichere Änderungen zunächst nur im Cache– Schreibe Änderung in Speicher nur dann, wenn der Cache‐Block ersetzt wird
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 24

Behandlung von Cache‐Misses• Was passiert beim Schreiben (sowohl bei Write‐Through als auch
Write‐Back) eines Bytes bei einem Cache‐Miss?
• Eine naheliegende Lösung– Lade den gesamten Block aus dem Speicher– Überschreibe das Byte in dem Block
• Alternative: No‐Write‐Allocate– Aktualisiere nur den darunter liegenden Speicher aber nicht den Cache– Ist sinnvoll, wenn lesender Zugriff nicht zu erwarten ist
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 25

Cache‐GrundlagenSpeicherunterstützung für Caches
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 26

Motivation
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 27
Erinnerung: CPU und Speicher kommunizieren über einen Bus.
Was beeinflusst die Miss‐Penalty?• Geschwindigkeit des Busses.• Speicherorganisation (siehe gleich).
Ein angenommenes Beispiel von Speicherzugriffswerten:• 1 Speicherbuszyklus die gewünschten Adressen zu senden• 15 Speicherbuszyklen für jeden initiierten DRAM‐Zugriff• 1 Speicherbuszyklus ein Datenwort zu senden
Was ist die Miss‐Penalty bei einem Cache mit vier Word Breite und sequentiellem Zugriff auf ein DRAM mit einem Word Breite?
Kann man das verbessern?
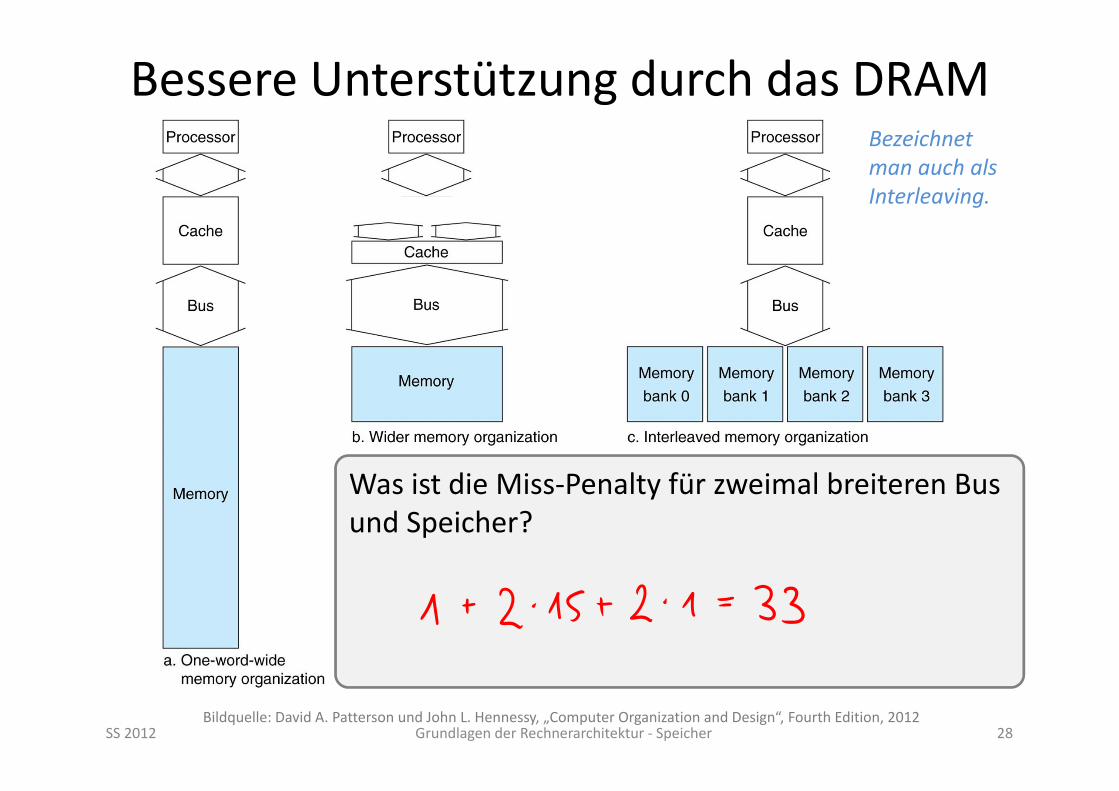
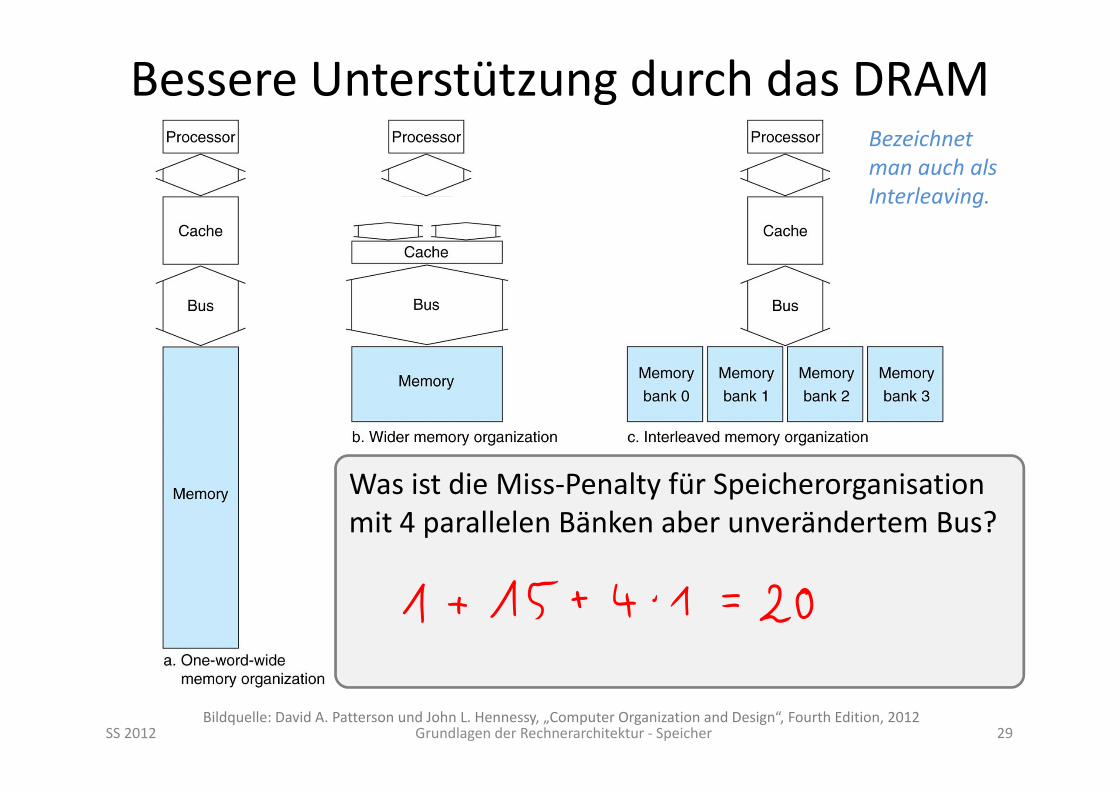
Bessere Unterstützung durch das DRAM
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 28Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
Was ist die Miss‐Penalty für zweimal breiteren Bus und Speicher?
Bezeichnet man auch als Interleaving.
Bessere Unterstützung durch das DRAM
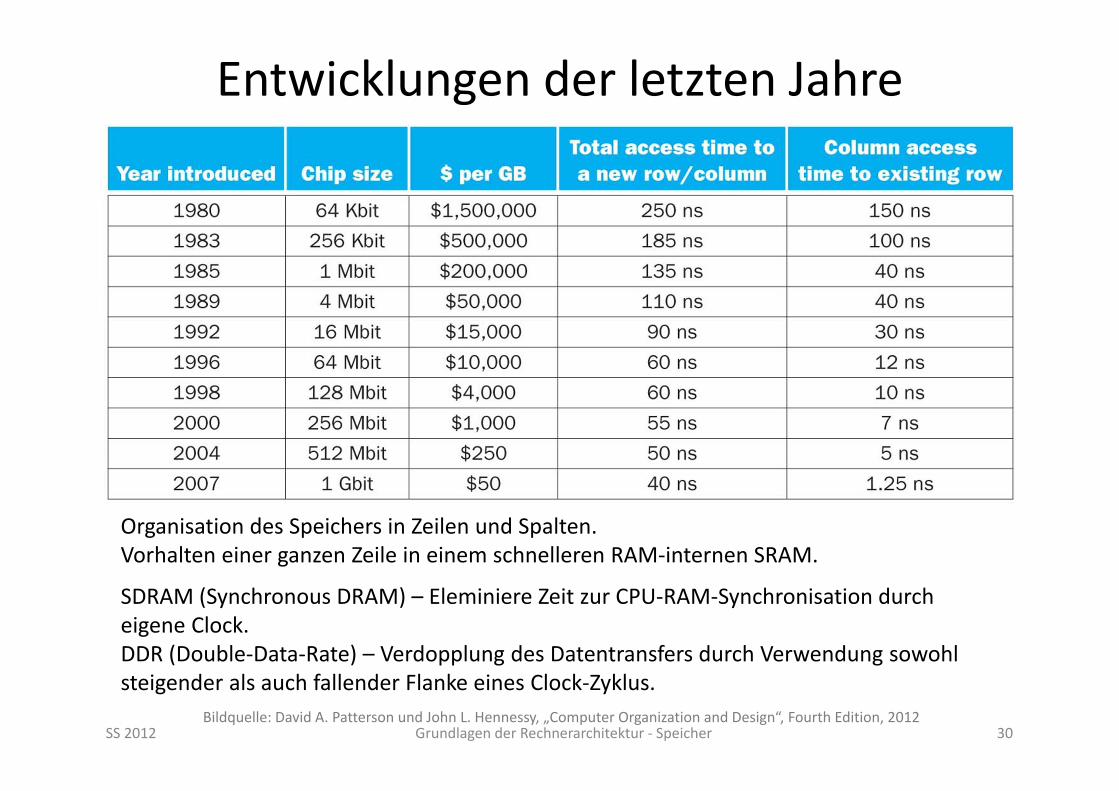
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 29Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
Was ist die Miss‐Penalty für Speicherorganisation mit 4 parallelen Bänken aber unverändertem Bus?
Bezeichnet man auch als Interleaving.
Entwicklungen der letzten Jahre
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 30Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
Organisation des Speichers in Zeilen und Spalten.Vorhalten einer ganzen Zeile in einem schnelleren RAM‐internen SRAM.
SDRAM (Synchronous DRAM) – Eleminiere Zeit zur CPU‐RAM‐Synchronisation durch eigene Clock.DDR (Double‐Data‐Rate) – Verdopplung des Datentransfers durch Verwendung sowohl steigender als auch fallender Flanke eines Clock‐Zyklus.

Verbessern der Cache‐Performance
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 31
Verbesserte Cache Strategien
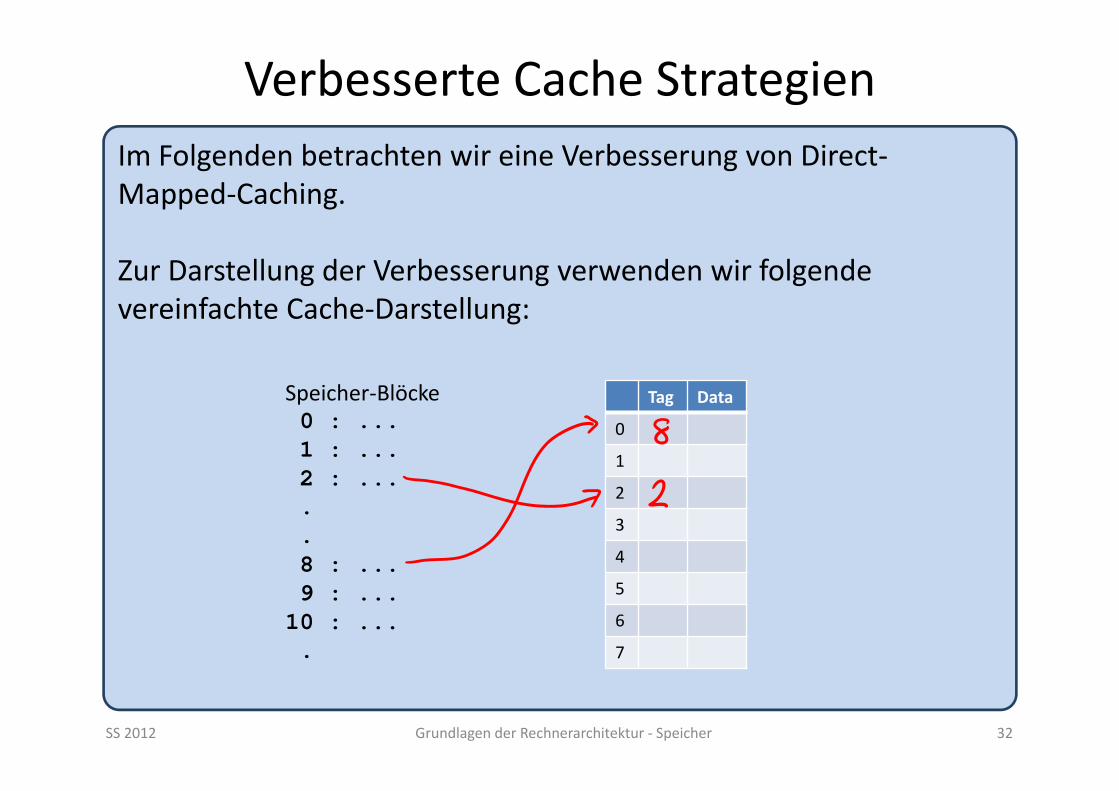
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 32
Im Folgenden betrachten wir eine Verbesserung von Direct‐Mapped‐Caching.
Zur Darstellung der Verbesserung verwenden wir folgende vereinfachte Cache‐Darstellung:
Tag Data
0
1
2
3
4
5
6
7
Speicher‐Blöcke0 : ...1 : ...2 : .....8 : ...9 : ...10 : ....
Fully‐Associative‐Cache
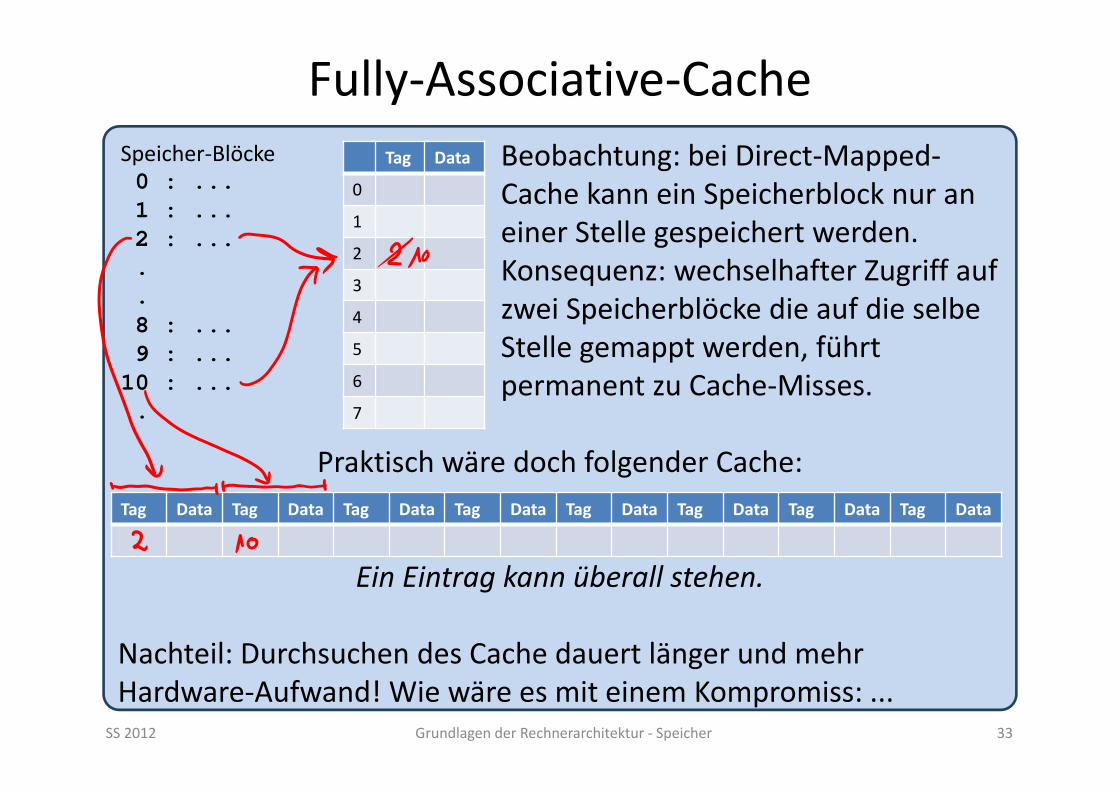
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 33
Beobachtung: bei Direct‐Mapped‐Cache kann ein Speicherblock nur aneiner Stelle gespeichert werden.Konsequenz: wechselhafter Zugriff aufzwei Speicherblöcke die auf die selbeStelle gemappt werden, führtpermanent zu Cache‐Misses.
Praktisch wäre doch folgender Cache:
Ein Eintrag kann überall stehen.
Nachteil: Durchsuchen des Cache dauert länger und mehr Hardware‐Aufwand! Wie wäre es mit einem Kompromiss: ...
Tag Data
0
1
2
3
4
5
6
7
Speicher‐Blöcke0 : ...1 : ...2 : .....8 : ...9 : ...10 : ....
Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data
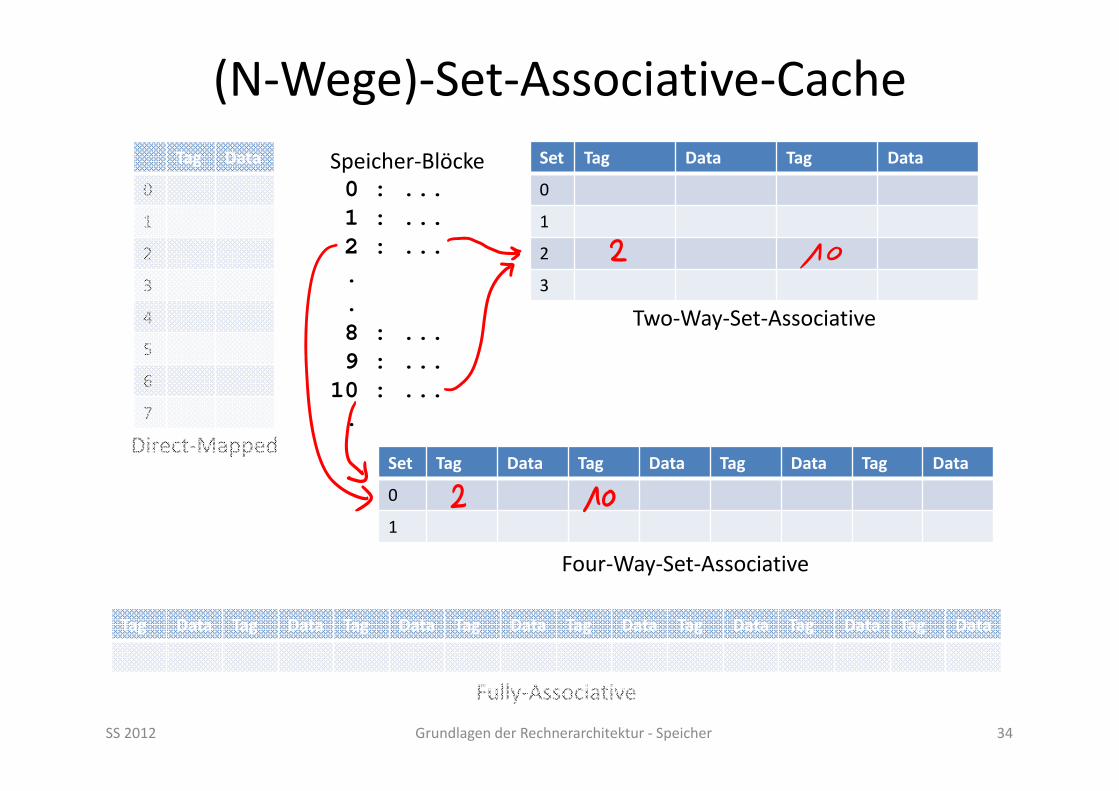
(N‐Wege)‐Set‐Associative‐Cache
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 34
Tag Data
0
1
2
3
4
5
6
7
Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data
Fully‐Associative
Direct‐Mapped
Set Tag Data Tag Data
0
1
2
3
Set Tag Data Tag Data Tag Data Tag Data
0
1
Two‐Way‐Set‐Associative
Four‐Way‐Set‐Associative
Speicher‐Blöcke0 : ...1 : ...2 : .....8 : ...9 : ...10 : ....

Zwischenbilanz
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 35
Finden der Cache‐Zeile c des Speicher‐Blocks n in einem Direct‐Mapped‐Cache der Größe k?
(Vergleiche anschließend n mit dem in Zeile c gespeicherten Tag)
Finden der Set s des Speicher‐Blocks n in einem N‐Way‐Set‐Associative‐Cache mit k Sets?
(Durchlaufe dann die Set s und suche nach einem Tag der n entspricht)
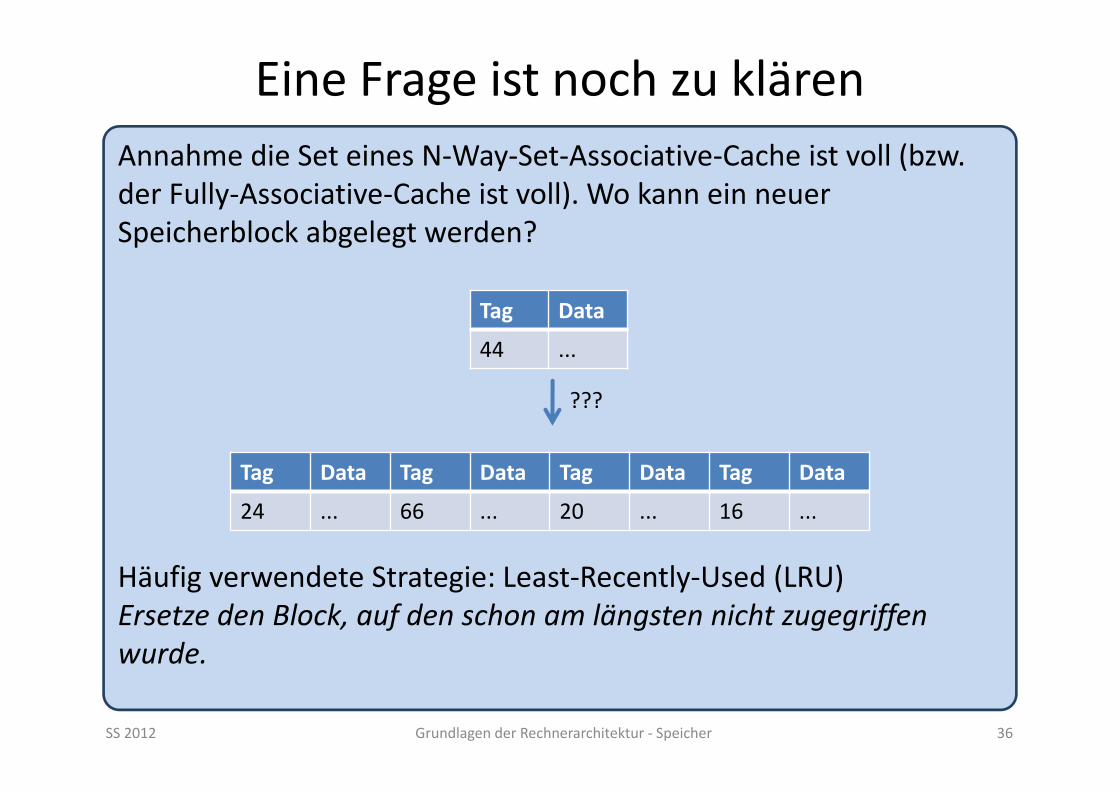
Eine Frage ist noch zu klären
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 36
Annahme die Set eines N‐Way‐Set‐Associative‐Cache ist voll (bzw. der Fully‐Associative‐Cache ist voll). Wo kann ein neuer Speicherblock abgelegt werden?
Häufig verwendete Strategie: Least‐Recently‐Used (LRU)Ersetze den Block, auf den schon am längsten nicht zugegriffen wurde.
Tag Data Tag Data Tag Data Tag Data
24 ... 66 ... 20 ... 16 ...
Tag Data
44 ...
???

Mehr Wege resultieren in weniger Misses
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 37
Beispiel: betrachte Cache‐Varianten mit vier Speicherblöcken
Wie viele Cache‐Misses erzeugt die folgende Sequenz von Speicherblockzugriffen?
0 , 8 , 0 , 6 , 8
Tag Data Tag Data Tag Data Tag Data
Tag Data
0
1
2
3
Set Tag Data Tag Data
0
1
Direct‐Mapped Set‐Associative Fully‐Associative
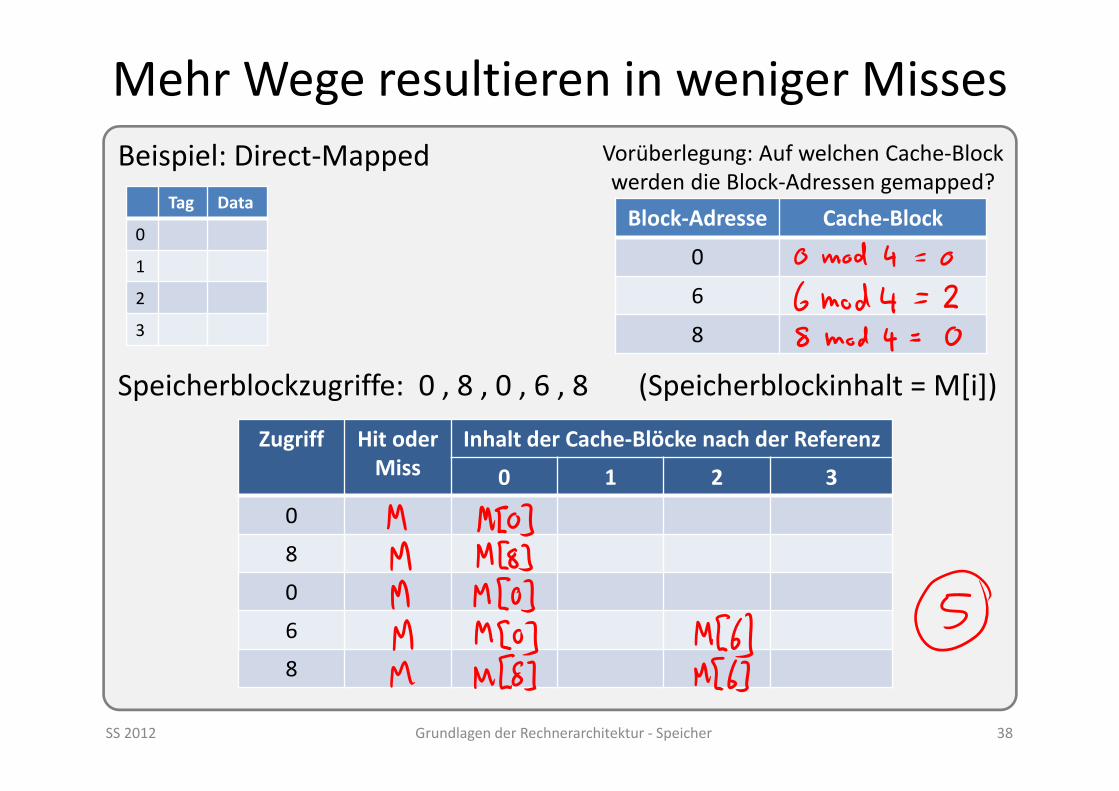
Mehr Wege resultieren in weniger Misses
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 38
Beispiel: Direct‐Mapped
Speicherblockzugriffe: 0 , 8 , 0 , 6 , 8 (Speicherblockinhalt = M[i])
Tag Data
0
1
2
3
Zugriff Hit oder Miss
Inhalt der Cache‐Blöcke nach der Referenz
0 1 2 3
0
8
0
6
8
Block‐Adresse Cache‐Block
0
6
8
Vorüberlegung: Auf welchen Cache‐Block werden die Block‐Adressen gemapped?
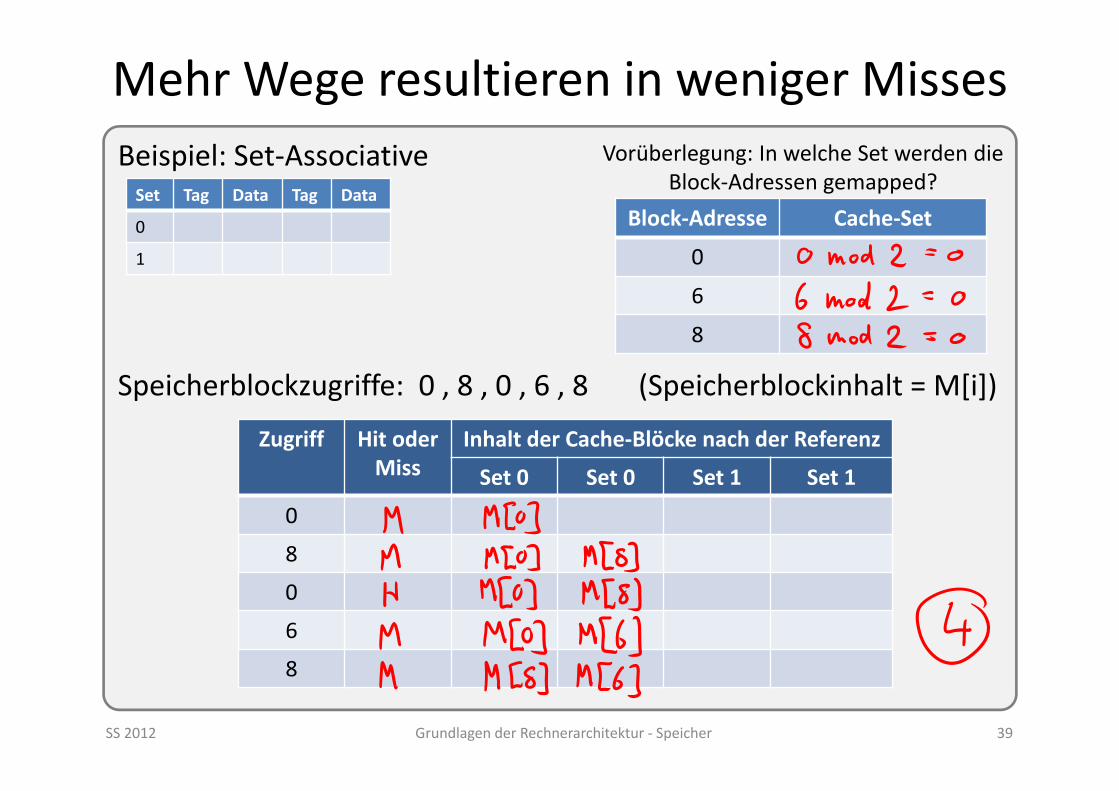
Mehr Wege resultieren in weniger Misses
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 39
Beispiel: Set‐Associative
Speicherblockzugriffe: 0 , 8 , 0 , 6 , 8 (Speicherblockinhalt = M[i])
Zugriff Hit oder Miss
Inhalt der Cache‐Blöcke nach der Referenz
Set 0 Set 0 Set 1 Set 1
0
8
0
6
8
Block‐Adresse Cache‐Set
0
6
8
Vorüberlegung: In welche Set werden die Block‐Adressen gemapped?Set Tag Data Tag Data
0
1

Mehr Wege resultieren in weniger Misses
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 40
Beispiel: Fully‐Associative
Speicherblockzugriffe: 0 , 8 , 0 , 6 , 8 (Speicherblockinhalt = M[i])
Zugriff Hit oder Miss
Inhalt der Cache‐Blöcke nach der Referenz
Block 0 Block 1 Block 2 Block 3
0
8
0
6
8
Tag Data Tag Data Tag Data Tag Data
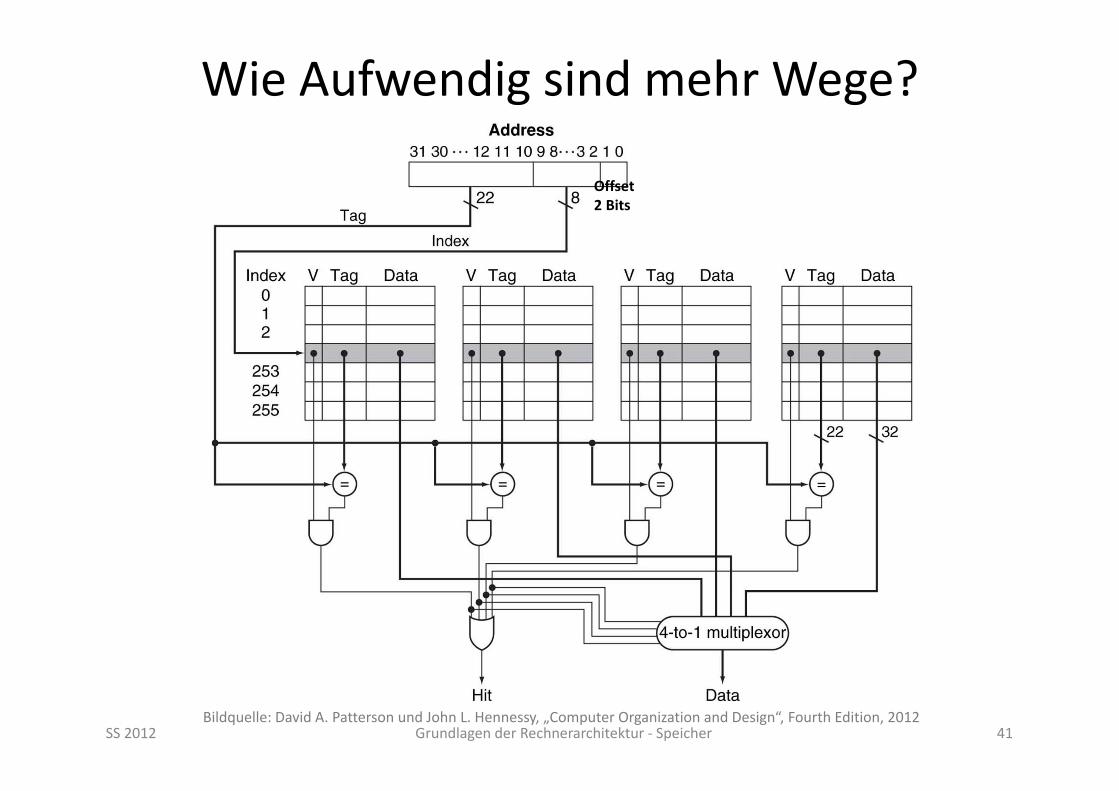
Wie Aufwendig sind mehr Wege?
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 41Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
Offset2 Bits
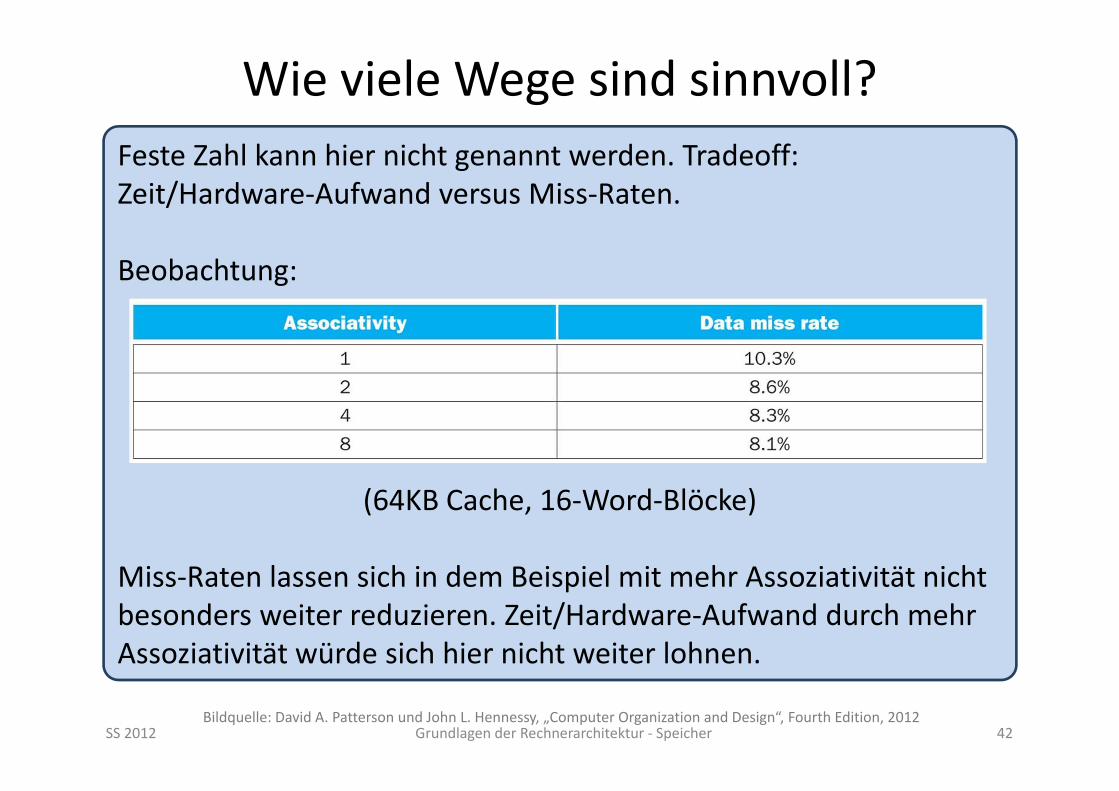
Wie viele Wege sind sinnvoll?
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 42
Feste Zahl kann hier nicht genannt werden. Tradeoff: Zeit/Hardware‐Aufwand versus Miss‐Raten.
Beobachtung:
(64KB Cache, 16‐Word‐Blöcke)
Miss‐Raten lassen sich in dem Beispiel mit mehr Assoziativität nicht besonders weiter reduzieren. Zeit/Hardware‐Aufwand durch mehr Assoziativität würde sich hier nicht weiter lohnen.
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
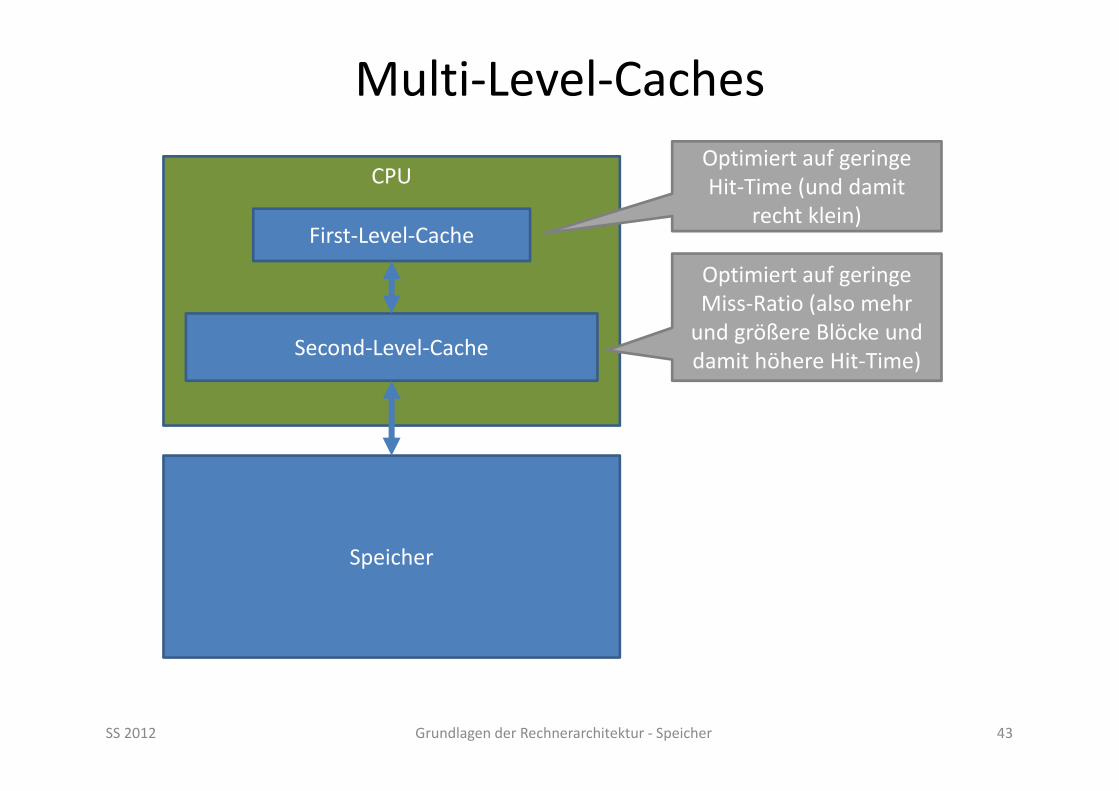
CPU
Multi‐Level‐Caches
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 43
First‐Level‐Cache
Second‐Level‐Cache
Speicher
Optimiert auf geringe Hit‐Time (und damit
recht klein)
Optimiert auf geringe Miss‐Ratio (also mehr und größere Blöcke und damit höhere Hit‐Time)

Virtueller Speicher
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 44
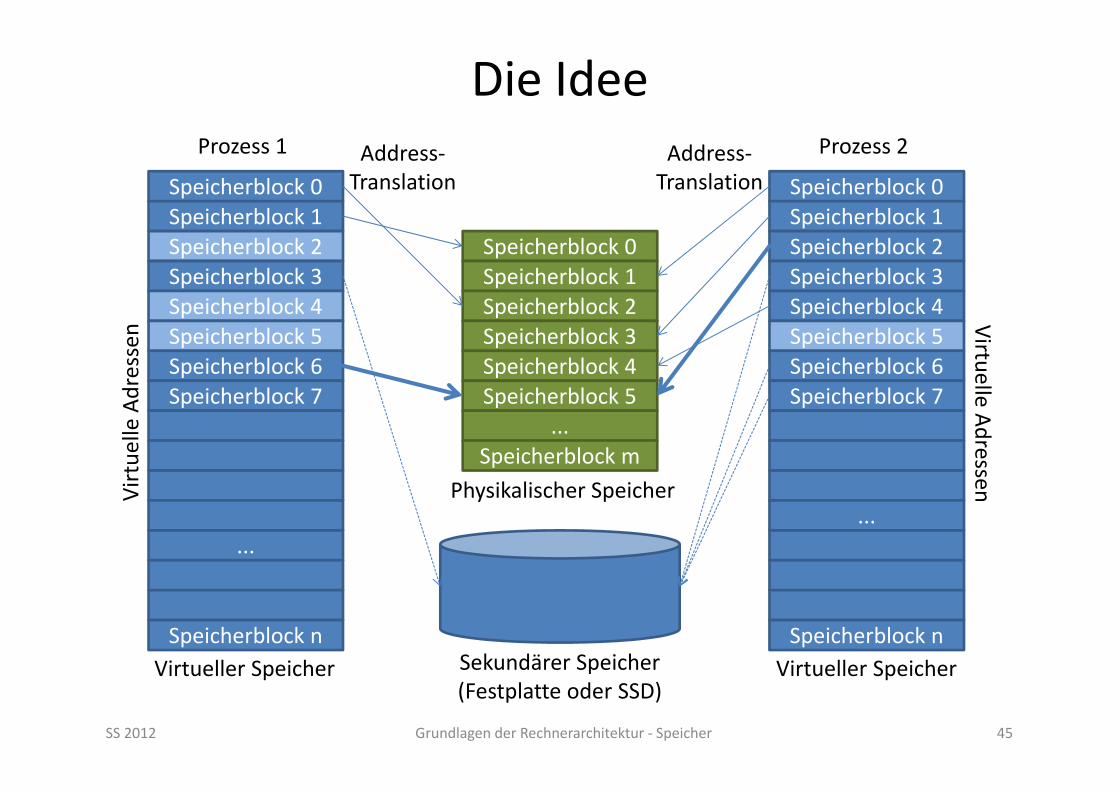
Die Idee
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 45
Speicherblock 0
Virtue
lle Adressen
Speicherblock 1Speicherblock 2Speicherblock 3Speicherblock 4Speicherblock 5Speicherblock 6Speicherblock 7
...
Speicherblock n
Prozess 1
Speicherblock 0
Virtuelle Adressen
Speicherblock 1Speicherblock 2Speicherblock 3Speicherblock 4Speicherblock 5Speicherblock 6Speicherblock 7
...
Speicherblock n
Prozess 2
Speicherblock 0Speicherblock 1Speicherblock 2Speicherblock 3Speicherblock 4Speicherblock 5
...Speicherblock m
Virtueller Speicher Virtueller SpeicherSekundärer Speicher (Festplatte oder SSD)
Physikalischer Speicher
Address‐Translation
Address‐Translation
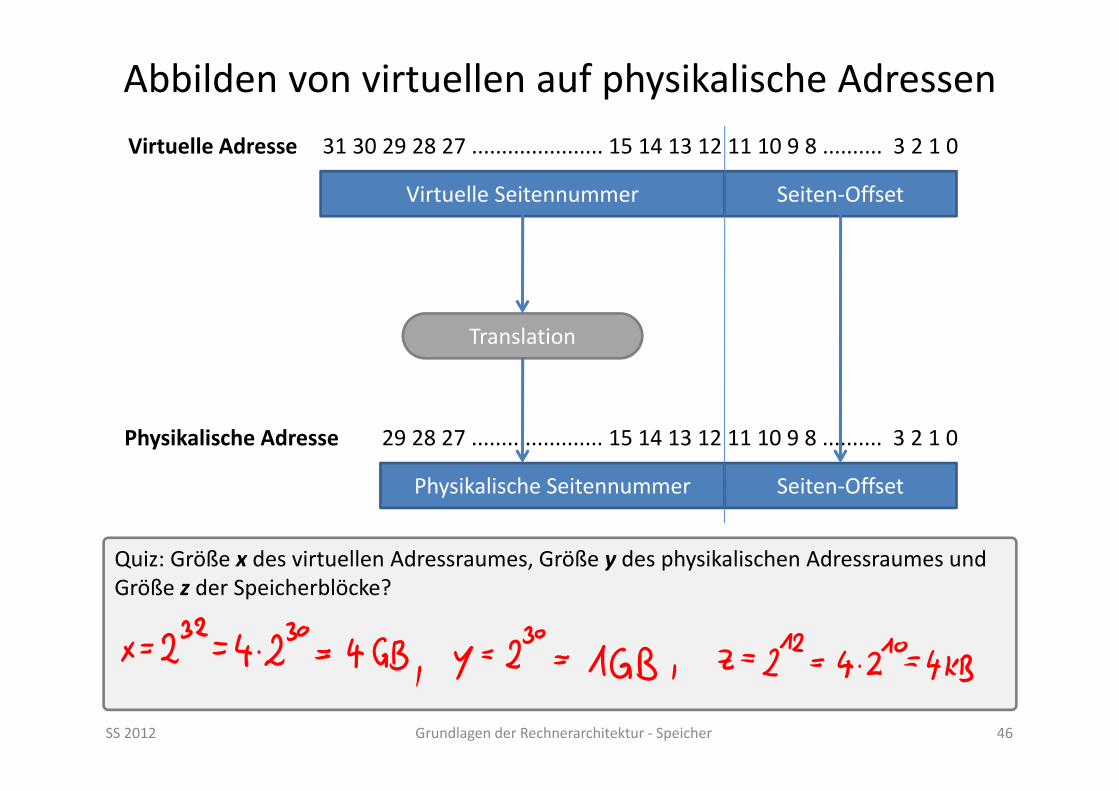
Abbilden von virtuellen auf physikalische Adressen
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 46
Virtuelle Seitennummer Seiten‐Offset
Translation
Physikalische Seitennummer Seiten‐Offset
31 30 29 28 27 ...................... 15 14 13 12 11 10 9 8 .......... 3 2 1 0Virtuelle Adresse
29 28 27 ...................... 15 14 13 12 11 10 9 8 .......... 3 2 1 0Physikalische Adresse
Quiz: Größe x des virtuellen Adressraumes, Größe y des physikalischen Adressraumes und Größe z der Speicherblöcke?
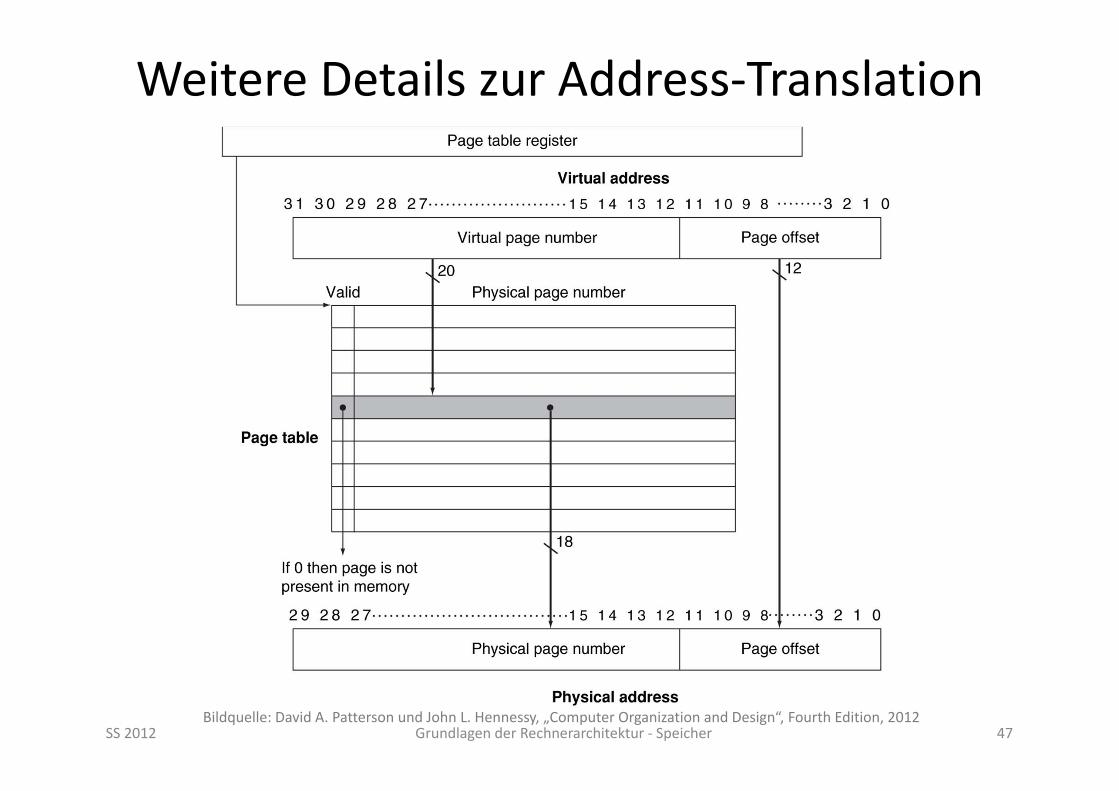
Weitere Details zur Address‐Translation
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 47Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Page‐Faults
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 48
Page‐Fault: die Page muss in eine freie Page im Speicher geladen werden. Was, wenn keine Page mehr frei ist?
Andere Page im Speicher muss ausgelagert werden. Mögliche Ersetzungsstrategie: LRU (siehe voriges Thema Caching).
Woher weiß man eigentlich, welche Page schon lange nicht mehr adressiert wurde?
Manche Prozessoren können die Page‐Table mit einem Reference/Use‐Bit taggen. Den Rest muss das Betriebssystem übernehmen (mehr dazu in der Vorlesung Betriebssysteme)

Wie groß ist die Page‐Table?
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 49
Im vorigen (typischen) Beispiel verwenden wir 20 Bits zum indizieren der Page‐Table. Typischerweise spendiert man 32 Bits pro Tabellen‐Zeile (im Vorigen Beispiel brauchten wir mindestens 18 Bits). Damit benötigen wir insgesamt:
Anzahl Page‐Table‐Einträge:
Größe der Page‐Table:
Wir benötigen so eine Page‐Table pro Prozess!
Noch gravierender ist es natürlich für 64‐Bit‐Adressen!
Größe der Page‐Table:

Techniken zur Reduktion der Page‐Table‐Größe
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 50
Page‐Table‐Größe ist limitiert durch ein spezielles Limit‐Register: Adressen erst mal nur bis maximal dem Inhalt des Limit‐Registers erlaubt. Limit‐Register wird nur bei Bedarf (also überschreiten) erhöht. Sinnvoll, wenn Speicher nur in eine Richtung wächst.
Page‐Table ist in zwei Segmenten organisiert:Beide Segmente wachsen wie vorhin beschrieben mittels eines Limit‐Registers nur bei Bedarf. Ein Segment wird für den Stack verwendet und wächst von oben nach unten. Das andere Segment wird für den Heap verwendet und wächst von unten nach oben. Höchstes Adress‐Bit bestimmt welches der beiden Segmente verwendet wird. (Also: Speicher in zwei gleich große Teile unterteilt)

Techniken zur Reduktion der Page‐Table‐Größe
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 51
Invertierte Page‐Tables:Es wird eine Hash‐Funktion auf die virtuelle Adresse angewendet. Die Größe der Page‐Table entspricht der Anzahl Seiten im physikalischen Speicher. Jeder Eintrag speichert die aktuellen High‐Order‐Bits der Adressen zu den die aktuelle Page gehört.
Mehrere Level von Page‐Tables:Oberster Level zeigt zunächst auf sehr große Blöcke (auch als Segmente bezeichnet). Innerhalb eines Segments wird wiederum mittels Page‐Table feiner (dann als Pages bezeichnet) unterteilt. Referenzieren einer Page: High‐Order‐Bits bestimmen das Segment (wenn vorhanden); die nächsten Bits dann die richtige Page in diesem Segment. Nachteil dieses Verfahrens: Adress‐Translation ist aufwendiger.

Techniken zur Reduktion der Page‐Table‐Größe
SS 2012 Grundlagen der Rechnerarchitektur ‐ Speicher 52
Paged‐Page‐Tables:Page‐Table befindet sich selber im virtuellen Speicher. Mögliche rekursive Page‐Faults müssen durch geeignete Betriebssystem‐Mechanismen verhindert werden. (Keine weiteren Details hier)


















