
CES - Seminar - mathcces.rwth-aachen.de€¦ · CES - Seminar Computer Vision für...
20
CES - Seminar Computer Vision für Fahrerassistenzsysteme RWTH Aachen University Fakultät für Maschinenwesen Institut für Kraftfahrzeuge Aachen, August 2013 Herrn B.Sc. Julian Bock vorgelegt von:
Transcript of CES - Seminar - mathcces.rwth-aachen.de€¦ · CES - Seminar Computer Vision für...

CES - Seminar
Computer Vision für Fahrerassistenzsysteme
RWTH Aachen University
Fakultät für Maschinenwesen
Institut für Kraftfahrzeuge
Aachen, August 2013
Herrn B.Sc. Julian Bock
vorgelegt von:

Inhalt
Inhalt_08_08.docx
3
Inhalt
1 Einleitung ....................................................................................................................... 4
2 Kamerabasierter Abstandsregeltempomat ..................................................................... 8
3 Spurhalteassistent ....................................................................................................... 11
4 Ampelerkennung ......................................................................................................... 17
5 Literatur ....................................................................................................................... 20

1 Einleitung
Inhalt_08_08.docx
4
1 Einleitung
„Computer Vision“ (CV) ist ein Gebiet, das in der Regel der Informatik zugeordnet wird, und das Ziel verfolgt, mit Hilfe von durch Computer auf Bildern oder Videos ausgeführten Algorithmen die dreidimensionale Welt zu „verstehen“. Verstehen bedeutet hier, korrekte Informationen zu generieren und Schlussfolgerungen zu ziehen.
[GRA11] unterscheidet zwischen drei Teilen des automatischen Verstehens durch Computer Vision:
1. Berechnung von Eigenschaften der dreidimensionalen Welt aus visuellen Daten (Messung)
2. Algorithmen, die es einer Maschine möglich machen, Objekte, Menschen, Szenen und Aktivitäten zu erkennen (Wahrnehmung und Interpretation)
3. Algorithmen zur Verarbeitung und Durchsuchung von visuelle Daten sowie der Interaktion mit diesen (Suche und Organisation)
Im Bereich der Fahrerassistenzsysteme sind insbesondere die ersten beiden Punkte relevant. Die Messung durch CV-Systeme ist z.B. für kamerabasierte Abstandsregeltempomaten (s. Kapitel 2) relevant. Wahrnehmung und Interpretation ist z.B. zur Ampelerkennung (s. Kapitel 4) notwendig. Wichtige Grundlagen und Algorithmen zu Computer Vision sind in [FOR12], [SZE11] und [HAR04] beschrieben.
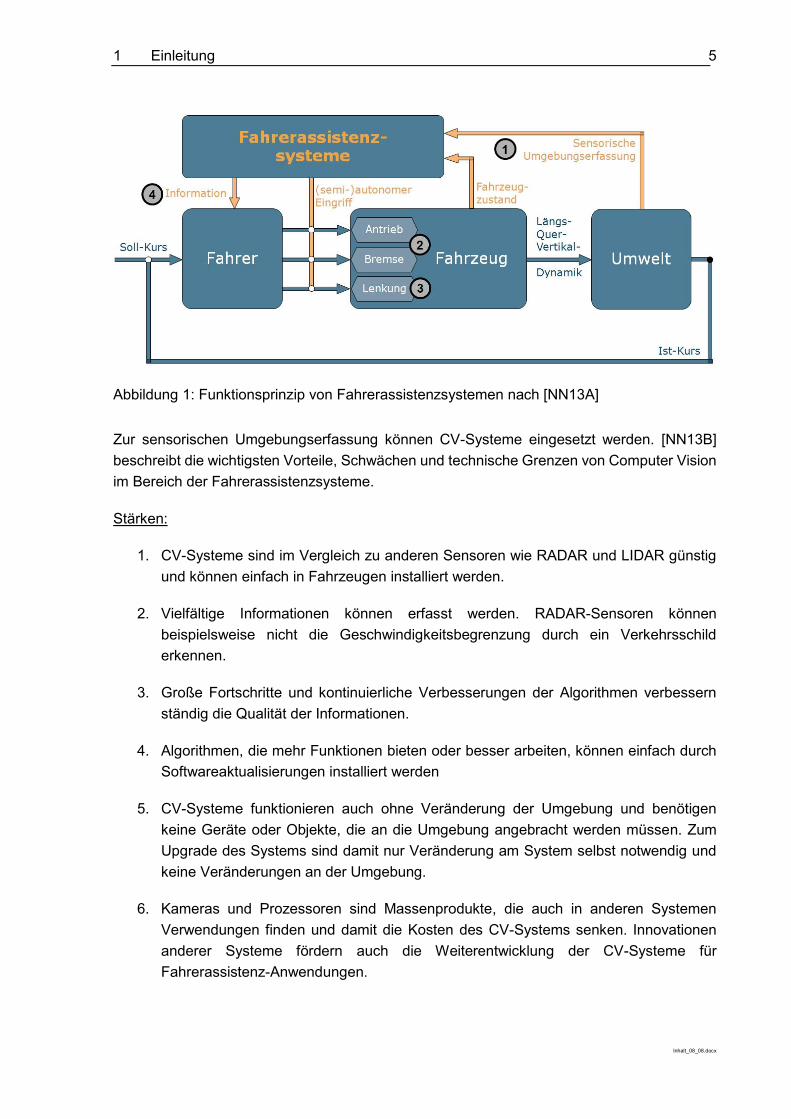
Fahrerassistenzsysteme sind elektronische Systeme in einem Fahrzeug, die den Fahrer entweder durch Ausgabe über eine Mensch-Maschine-Schnittstelle oder durch Eingriff in Antrieb und Steuerung bei der Fahraufgabe unterstützen sollen. Abbildung 1 zeigt das generelle Funktionsprinzip von Fahrerassistenzsystemen. Das Fahrerassistenzsystem erfasst durch Sensoren die Umgebung und den Fahrzeugzustand und berechnet daraus Informationen bzw. Eingriffsstrategien. Der Fahrer wird informiert, um selbst entsprechend der Berechnungen des Fahrerassistenzsystems zu handeln, oder das Fahrerassistenzsystem greif (semi-) autonom ein und beeinflusst neben dem Fahrer den Fahrzeugzustand. Für umfangreiche Grundlagen und vertiefende Referenzen zum Thema Fahrerassistenzsysteme siehe [WIN12].
1 Einleitung
Inhalt_08_08.docx
5
Abbildung 1: Funktionsprinzip von Fahrerassistenzsystemen nach [NN13A]
Zur sensorischen Umgebungserfassung können CV-Systeme eingesetzt werden. [NN13B] beschreibt die wichtigsten Vorteile, Schwächen und technische Grenzen von Computer Vision im Bereich der Fahrerassistenzsysteme.
Stärken:
1. CV-Systeme sind im Vergleich zu anderen Sensoren wie RADAR und LIDAR günstig und können einfach in Fahrzeugen installiert werden.
2. Vielfältige Informationen können erfasst werden. RADAR-Sensoren können beispielsweise nicht die Geschwindigkeitsbegrenzung durch ein Verkehrsschild erkennen.
3. Große Fortschritte und kontinuierliche Verbesserungen der Algorithmen verbessern ständig die Qualität der Informationen.
4. Algorithmen, die mehr Funktionen bieten oder besser arbeiten, können einfach durch Softwareaktualisierungen installiert werden
5. CV-Systeme funktionieren auch ohne Veränderung der Umgebung und benötigen keine Geräte oder Objekte, die an die Umgebung angebracht werden müssen. Zum Upgrade des Systems sind damit nur Veränderung am System selbst notwendig und keine Veränderungen an der Umgebung.
6. Kameras und Prozessoren sind Massenprodukte, die auch in anderen Systemen Verwendungen finden und damit die Kosten des CV-Systems senken. Innovationen anderer Systeme fördern auch die Weiterentwicklung der CV-Systeme für Fahrerassistenz-Anwendungen.

1 Einleitung
Inhalt_08_08.docx
6
7. Da von einer Gültigkeit von Moore‘s Law weiterhin ausgegangen werden kann, wird die kostenwirksame Rechenleistung in Zukunft weiter deutlich steigen und damit auch bessere CV-Systeme ermöglichen.
Schwächen und technische Grenzen:
1. Kamerabasierte Systeme erfordern eine hohe Rechenleistung. Für Fahrerassistenzsysteme ist es in der Regel notwendig, dass die visuellen Daten sehr schnell und direkt verarbeitet werden und erlauben keine Speicherung und spätere Berechnung.
2. Besonders kritisch ist jedoch, eine hohe Robustheit bei sich ändernden Umgebungsbedingungen zu erhalten. Fahrerassistenzsystemen müssen auch unter solch stark ändernden Umgebungsbedingungen durch Tageszeit, Wetter und andere Objekte funktionieren. Dabei vorkommende starke Helligkeitsschwankungen erschweren das Bildverstehen und sind als größte Herausforderung bei der Verwendung von Computer Vision für Fahrerassistenzsysteme anzusehen. Abbildung 2 zeigt Beispiele für Herausforderungen durch unterschiedliche Gegebenheiten der Bilder.
Abbildung 2: Herausforderungen durch sich ändernde Gegebenheiten nach [GRA11]
Die vorgestellten Herausforderungen bei der Verwendung von Computer Vision für Fahrerassistenzsysteme werden in der Regel durch zwei Ansätze gelöst. Mit Hilfe der Sensorfusion (s. [WIN12]) können die Informationen und Daten der CV-Systeme mit Daten von anderen Sensoren und Informationsquellen wie RADAR, LIDAR, Ultraschall, digitale

1 Einleitung
Inhalt_08_08.docx
7
Karten und V2X-Kommunikation kombiniert werden. Zur Objekterkennung (Fahrzeuge, Personen, Hindernisse) können beispielsweise RADAR-Sensoren verwendet werden, die zuverlässige Daten über Geschwindigkeit und Distanz zu anderen Objekten liefern. Außerdem kann durch die Verbesserung von Algorithmen die Zuverlässigkeit und Funktionalität der Systeme stark erhöht werden. Ein wichtiger Aspekt ist hier die Größe und Qualität der Trainings- und Testdaten anhand deren die Algorithmen entwickelt und verbessert werden. Haben diese Daten eine hohe Qualität und decken das gesamte Spektrum der möglichen Szenarien ab, können genaue und zuverlässige Algorithmen entwickelt werden.
Im Folgenden werden verschiedene Beispiele für den Einsatz von Computer Vision im Bereich der Fahrerassistenzsysteme vorgestellt. Die dabei verwendeten Lösungsverfahren und Algorithmen funktionieren häufig nur unter vereinfachenden Annahmen zuverlässig und sollen anstatt den Stand der Technik zu präsentieren, Grundprinzipien und Vorgehensweisen beispielhaft zeigen. Die Anwendungsbeispiele sind der Abstandsregeltempomat, Spurhalteassistent und Ampelerkennung.

2 Kamerabasierter Abstandsregeltempomat
Inhalt_08_08.docx
8
2 Kamerabasierter Abstandsregeltempomat
Ein Abstandsregelautomat (engl. Adaptive Cruise Control, ACC) ist ein System, das bei freier Fahrt eine vom Fahrer eingestellte Wunschgeschwindigkeit einregelt (Tempomat) und bei Vorderfahrzeug den Abstand und die Relativgeschwindigkeit zu dem Vorderfahrzeug derart überwacht und die eigene Geschwindigkeit regelt, so dass ein sicherer Fahrzeugabstand eingehalten wird (Abstandsregelung) und die Wunschgeschwindigkeit eine Geschwindigkeitsobergrenze darstellt. Das ACC soll den Fahrer vor allem auf der Autobahn und auf Landstraßen unterstützen.
Abbildung 3 zeigt verschiedene Zustände eines ACCs. Das oberste Teil zeigt die freie Fahrt mit auf 140 km/h eingestellter Wunschgeschwindigkeit. Der mittlere Teil zeigt die Verzögerung auf 110 km/h auf Grund eines langsameren Vorderfahrzeugs, zu dem der Sicherheitsabstand eingehalten werden muss. Der untere Teil zeigt die Beschleunigung zurück auf 140 km/h, da das Vorderfahrzeug die Autobahn verlassen und wieder freie Fahrt möglich ist.
Abbildung 3: Abstandsregelautomat, Quelle: Bosch
Die Bestimmung des Abstands sowie der Relativgeschwindigkeit zum Vorderfahrzeug erfolgt im Serieneinsatz in der Regel durch Radarsensoren. Der Einsatz von CV-Systemen ist jedoch auch möglich und wird im Folgenden beispielhaft an einer Microsoft Kinect (siehe Abbildung 4) gezeigt, die häufig für Roboter und autonome Modellfahrzeuge von Hobby- und Freizeitentwicklern verwendet wird.
Die Microsoft Kinect ist ursprünglich ein Zubehör zur Videospielkonsole Microsoft Xbox 360 zur Erkennung von Körperbewegungen. Die Kinect verfügt über einen auf Infrarotstrahlung basierendem Tiefensensor, eine Farbkamera und mehrere Mikrofone. Da das System generell kompatibel mit PCs ist und der Tiefensensor im Verhältnis zum Preis der Kinect sehr gute Ergebnisse liefert, wurden Treiber entwickelt, so dass auch eine Verwendung der Kinect unter

2 Kamerabasierter Abstandsregeltempomat
Inhalt_08_08.docx
9
Linux- und Windows-Systemen möglich ist. Daraufhin fand die Kinect eine sehr hohe Beliebtheit bei Hobby- und Freizeitentwicklern. Daraus entstanden einige Open Source Projekte zur Anwendung und auch zum einfachen Auslesen der Daten der Kinect in verschiedenen Programmiersprachen und auch mit Software wie MATLAB.
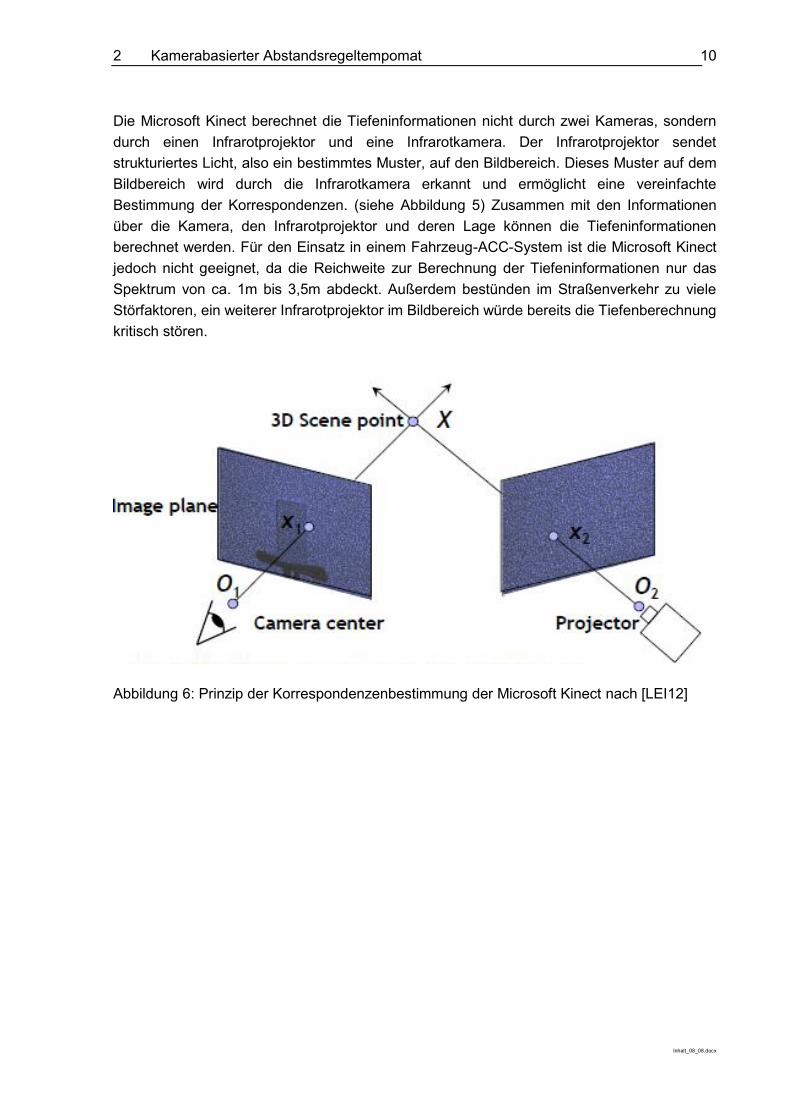
Die Berechnung von Tiefeninformationen mit Hilfe von Kameras (auch „Computer stereo vision“ genannt) ist ein nicht triviales Problem und kann klassisch durch die Verwendung von zwei Kameras analog zum menschlichen Stereoskopischen Sehen erfolgen. Ein wichtiges Problem bei der Berechnung von Tiefeninformationen durch zwei Kameras ist die korrekte Bestimmung der Bildkorrespondenzen. Zur Berechnung der Tiefe an einem Bildpunkt ist es notwendig, den zugehörigen Punkt auf dem durch die andere Kamera aufgenommenen Bild zu bestimmen. Anhand der horizontalen Verschiebung der Bildpunkte zueinander kann die Tiefe berechnet werden, die umgekehrt proportional zur Verschiebung ist. (siehe Abbildung 5) Für
Abbildung 4: Microsoft Kinect, Quelle: Microsoft
Abbildung 5: Tiefeninformation durch Verschiebung, Quelle: [NN13C]
2 Kamerabasierter Abstandsregeltempomat
Inhalt_08_08.docx
10
Die Microsoft Kinect berechnet die Tiefeninformationen nicht durch zwei Kameras, sondern durch einen Infrarotprojektor und eine Infrarotkamera. Der Infrarotprojektor sendet strukturiertes Licht, also ein bestimmtes Muster, auf den Bildbereich. Dieses Muster auf dem Bildbereich wird durch die Infrarotkamera erkannt und ermöglicht eine vereinfachte Bestimmung der Korrespondenzen. (siehe Abbildung 5) Zusammen mit den Informationen über die Kamera, den Infrarotprojektor und deren Lage können die Tiefeninformationen berechnet werden. Für den Einsatz in einem Fahrzeug-ACC-System ist die Microsoft Kinect jedoch nicht geeignet, da die Reichweite zur Berechnung der Tiefeninformationen nur das Spektrum von ca. 1m bis 3,5m abdeckt. Außerdem bestünden im Straßenverkehr zu viele Störfaktoren, ein weiterer Infrarotprojektor im Bildbereich würde bereits die Tiefenberechnung kritisch stören.
Abbildung 6: Prinzip der Korrespondenzenbestimmung der Microsoft Kinect nach [LEI12]

3 Spurhalteassistent
Inhalt_08_08.docx
11
3 Spurhalteassistent
Ein Spurhalteassistent (engl. Lane Keeping System, LKS) ist ein Fahrerassistenzsystem, das entweder rein bei Verlassen der Spur gegenlenkt oder sogar eine möglichst mittlere bzw. einem Normalfahrer üblichen Spurposition einregelt (s. Abbildung 7). Das LKS erkennt zunächst den Fahrspurverlauf und bestimmt aktuelle fahrdynamische Größen. Damit werden die aktuelle Position auf der Fahrspur und eine neue Fahrer-Soll-Reaktion berechnet. Diese Soll-Reaktion wird mit der Fahrer-Ist-Reaktion verglichen und daraus berechnete Stellgrößen werden durch die Lenkaktorik umgesetzt (siehe [ECK11]). Im Folgenden wird ein mögliches System zur Fahrspurerkennung beschrieben. Dabei wird von Fahrspuren ausgegangen, die für hohe Geschwindigkeit ausgelegt sind und dadurch kleine Krümmungen besitzen.
Abbildung 7: Spurhalteassistent, Quelle: Audi Electronics Venture
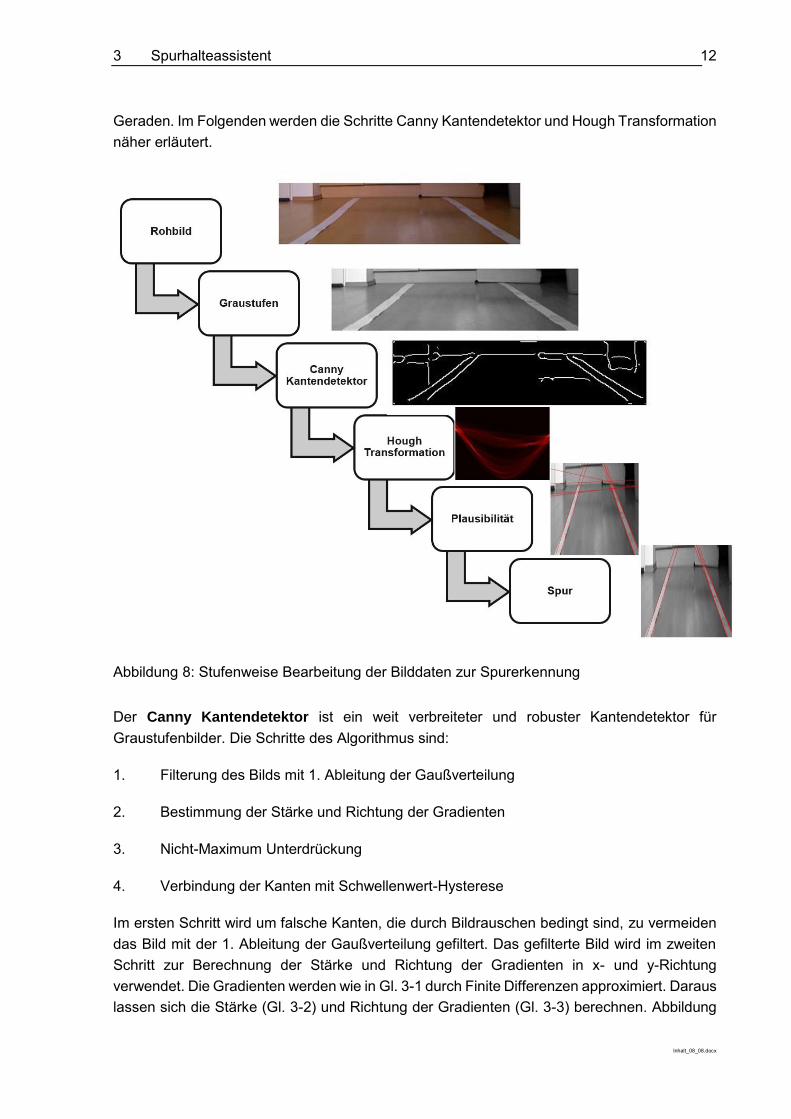
Die Annahme von Fahrspuren mit kleinen Krümmungen ermöglicht die Annäherung der Fahrspur durch Geraden. Für Geraden existieren Erkennungsalgorithmen, die grundlegende Algorithmen und Prinzipien des Computer Vision einfach verdeutlichen. Für die Fahrspurerkennung wird, wie auch bei anderen CV-Verfahren üblich, eine stufenweise Bearbeitung der Bilddaten durchgeführt (siehe Abbildung 8). Als erster Schritt wird das farbige Rohbild in ein Graustufenbild konvertiert, da die Farbinformationen zur Spurerkennung nicht notwendig sind und mit Graustufen einfacher und schneller gerechnet werden kann. Auf dieses Graustufenbild wird ein Kantendetektor angewandt, wofür hier der sehr weit verbreitete Kantendetektor von John F. Canny verwendet wird. Der Kantendetektor liefert eine 1-0-Repräsentation des Bildes, wobei der Wert 1 eines Pixels für die Existenz einer Kante an diesem Pixel und umgekehrt der Wert 0 für keine Kante an diesem Pixel steht. Mit dieser Kantenrepräsentation können durch die Hough Transformation Kandidaten für mögliche Geraden, die den Kanten folgen, berechnet werden. Aus den besten Geradenkandidaten müssen noch durch Plausibilitätsprüfung Gerade herausgefiltert werden, die nicht durch die Fahrspur erzeugt wurden. Das Resultat sind mehrere zur Fahrspur bestmöglich passende
3 Spurhalteassistent
Inhalt_08_08.docx
12
Geraden. Im Folgenden werden die Schritte Canny Kantendetektor und Hough Transformation näher erläutert.
Abbildung 8: Stufenweise Bearbeitung der Bilddaten zur Spurerkennung
Der Canny Kantendetektor ist ein weit verbreiteter und robuster Kantendetektor für Graustufenbilder. Die Schritte des Algorithmus sind:
1. Filterung des Bilds mit 1. Ableitung der Gaußverteilung
2. Bestimmung der Stärke und Richtung der Gradienten
3. Nicht-Maximum Unterdrückung
4. Verbindung der Kanten mit Schwellenwert-Hysterese
Im ersten Schritt wird um falsche Kanten, die durch Bildrauschen bedingt sind, zu vermeiden das Bild mit der 1. Ableitung der Gaußverteilung gefiltert. Das gefilterte Bild wird im zweiten Schritt zur Berechnung der Stärke und Richtung der Gradienten in x- und y-Richtung verwendet. Die Gradienten werden wie in Gl. 3-1 durch Finite Differenzen approximiert. Daraus lassen sich die Stärke (Gl. 3-2) und Richtung der Gradienten (Gl. 3-3) berechnen. Abbildung

3 Spurhalteassistent
Inhalt_08_08.docx
13
9 zeigt links das Originalbild in Graustufen und rechts die Gradientenstärke. Das verwendete Bild ist das wohl bekannteste und meist verbreitete Testbild in der Computer Vision Gemeinschaft. Das Bild wird nach der abgebildeten Person Lena genannt.
𝜕𝑓(𝑥,𝑦)
𝜕𝑥≈
𝑓(𝑥+1,𝑦)−𝑓(𝑥,𝑦)
1
‖∇𝑓‖ = √(𝜕𝑓
𝜕𝑥)2 + (
𝜕𝑓
𝜕𝑦)2
𝜃 = 𝑡𝑎𝑛−1(𝜕𝑓
𝜕𝑦/
𝜕𝑓
𝜕𝑥)
Abbildung 9: Graustufenbild (links) und Gradientenstärke (rechts), Quelle: [GRA11]
Im dritten Schritt des Canny Kantendetektors findet eine Nicht-Maximum Unterdrückung statt. Eine Kante soll der Algorithmus durch eine einzelne Linie mit der Breite von einem Pixel darstellen. In dem Gradientenstärkebild haben Kanten noch eine Dicke von meist einigen Pixeln. Um von diesen Pixeln die beste Repräsentation für die Kanten zu finden, wird entlang der Gradientenrichtung der Pixel in der nächsten Umgebung nach dem lokalen Maximum der Gradientenstärke gesucht (siehe Abbildung 10). Dieser Pixel stellt dann einen Kantenkandidat dar.
Aus den Kandidaten werden durch die Verbindung der Kanten mittels einer Schwellenwert-Hysterese die „besten“ Kanten ausgewählt, um nicht zu viele Kanten darzustellen. Dabei werden zwei Schwellenwerte für die Gradientenstärke ausgewählt. Ein hoher Schwellenwert um „starke“ Kanten zu finden und ein niedriger Schwellenwert, um schwache Kanten zu finden, die die „starken“ Kanten weiterführen (Hysterese, s. Abbildung 11). Damit wird vermieden, dass abschnittsweise schwache Kanten unterdrückt werden, obwohl sie zu einer stärkeren
Gl. 3-1
Gl. 3-2
Gl. 3-3

3 Spurhalteassistent
Inhalt_08_08.docx
14
Kante gehören. Abbildung 12 zeigt abschließend das Ergebnis des Canny Kantendetektors auf das Testbild „Lena“.
Abbildung 10: Nicht-Maximum Unterdrückung, Quelle: [GRA11]
Abbildung 11: Kantenstärke-Hysterese [LEI12]
Abbildung 12: Ergebnis des Canny Kantendetektors auf das Testbild "Lena" [GRA11]
Die Hough Transformation ist ein Verfahren benannt nach dem Erfinder Paul V.C. Hough, welches auf durch einen Kantendetektor berechnete Schwarz/Weiß-Bilder Kreise, Geraden und andere einfach parametrierbare geometrische Figuren erkennt. Im Folgenden wird das

3 Spurhalteassistent
Inhalt_08_08.docx
15
Prinzip der Hough Transformation für Geraden beschrieben. Die Grundidee des Hough Transformation Algorithmus nach [LEI12] ist:
1. Ein Punkt stimmt für alle möglichen Linien ab, die durch diesen Kantenpunkt verlaufen könnten.
2. Suche nach Linien, für die am meisten abgestimmt wurde.
Abbildung 13 zeigt beispielhaft die Hough Transformation für Geraden. Die Punkte im x-y-Raum auf der linken Seite stellen Punkte auf einer Kante dar. Für jeden einzelnen Punkt wird die Gerade im m-n-Raum berechnet, die sämtliche mögliche Parameter für die Zugehörigkeit des Punktes zu einer Gerade im x-y-Raum darstellt. Da für Punkte, die im x-y-Raum auf einer Gerade liegen, nur ein Parametersatz zu dieser Gerade passt, schneiden sich die zugehörigen Geraden in einem Punkt im m-n-Raum. Da zwischen
Abbildung 13: Hough Transformation für Geraden [LEI12]
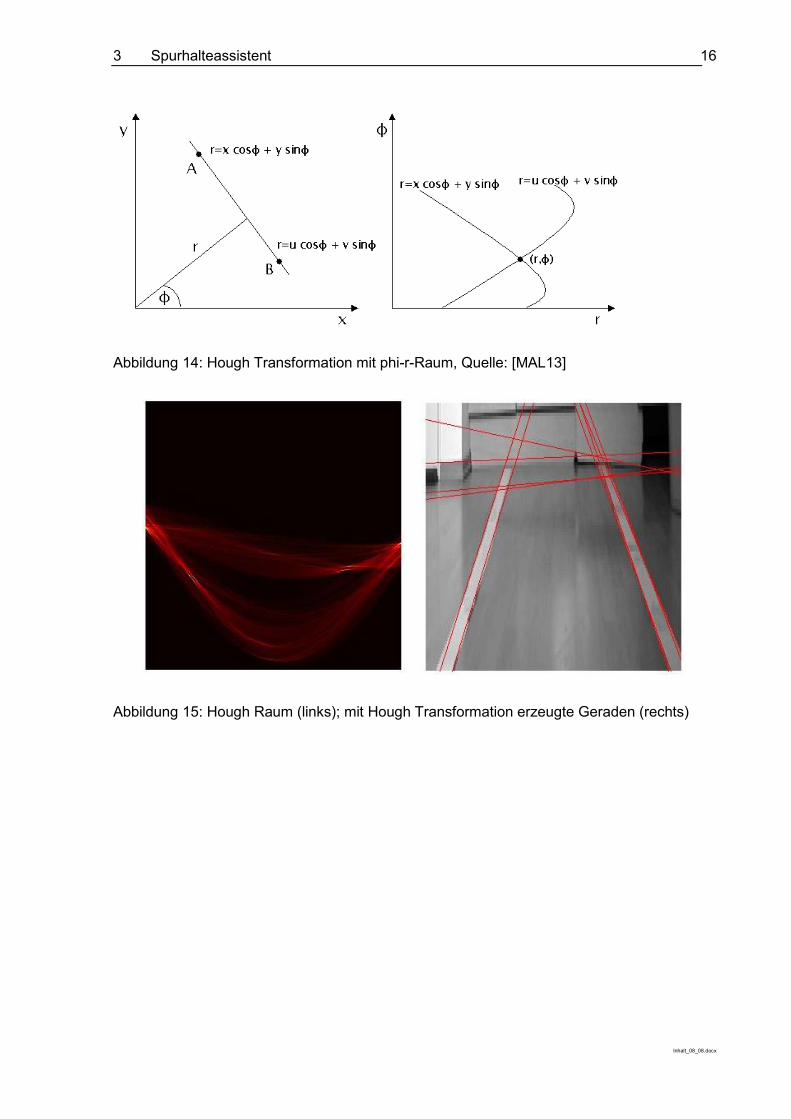
Um auch senkrechte Geraden darstellen zu können, wird in der Praxis ein phi-r-Raum mit dem Radius r und dem Winkel phi zwischen x-Achse und der Verbindung Koordinatenursprung-Punkt verwendet (s. Abbildung 14) Dies ist im m-n-Raum nicht möglich, da eine senkrechte Gerade eine Steigung m=∞ hätte. Abbildung 15 zeigt schließlich das Ergebnis einer Hough Transformation mit dem Hough Raum auf der linken Seite und ein Beispiel mit den „besten“ Geraden für ein Testbild auf der rechten Seite.
3 Spurhalteassistent
Inhalt_08_08.docx
16
Abbildung 14: Hough Transformation mit phi-r-Raum, Quelle: [MAL13]
Abbildung 15: Hough Raum (links); mit Hough Transformation erzeugte Geraden (rechts)
m

4 Ampelerkennung
Inhalt_08_08.docx
17
4 Ampelerkennung
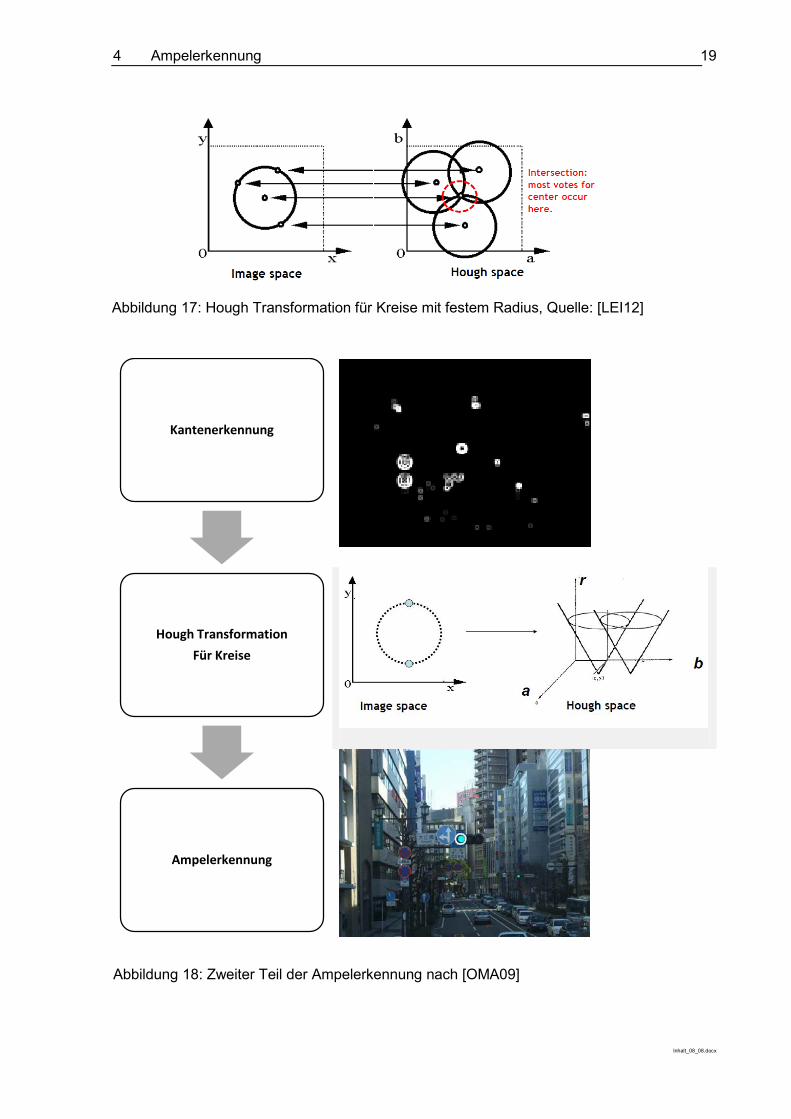
Ein System zur Ampelerkennung hat das Ziel, den aktuellen Status einer Lichtsignalanlage (Ampel) korrekt mit CV-Methoden zu erkennen. Fahrerassistenzsysteme mit Ampelerkennung können den Fahrer in komplexen Umgebungssituationen und bei Ablenkung dabei unterstützen, korrekt auf den aktuellen Status der Ampel zu reagieren. Fährt das Fahrzeug mit hoher Geschwindigkeit auf eine rote Ampel zu, kann das Fahrerassistenzsystem den Fahrer beispielsweise akustisch und optisch warnen. Zur Ampelerkennung gibt es einige verschiedene Algorithmen und Lösungsansätze. Im Folgenden wird ein verhältnismäßig einfacher Lösungsansatz vorgestellt. Abbildung 16 zeigt den ersten Teil dieses Algorithmus.
Abbildung 16: Erster Teil der Ampelerkennung, Quelle: [OMA09]
Rohbild
Farbraum-Konvertierung
Erkennung von Bereichen möglicher Kandidaten

4 Ampelerkennung
Inhalt_08_08.docx
18
In einem ersten Schritt wird mit dem Rohbild eine Farbraum-Konvertierung aus dem RGB-Raum in den normalisierten RGB-Raum vorgenommen. Dabei werden für jeden einzelnen Pixel die R-,G- und B-Werte des RGB-Raums durch die Gesamtintensität an diesem Punkt geteilt. (Gl.4-1) Dies ermöglicht eine höhere Robustheit bezüglich der Farben der Ampel gegenüber Schwankungen durch Tageszeit, Wetter und anderen Faktoren ([OMA09]).
{
𝑅 = 𝐺 = 𝐵 = 0 (𝑓ü𝑟 𝑠 = 0)
𝑅 =𝑟
𝑠, 𝐺 =
𝑔
𝑠, 𝐵 =
𝑏
𝑠 (𝑠𝑜𝑛𝑠𝑡)
𝑚𝑖𝑡 𝑠 = 𝑟 + 𝑔 + 𝑏
Anhand des Bilds im normalisierten RGB-Raum können nun Regionen bestimmt werden, in denen möglicherweise sich eine Ampel befinden könnte. Diese Kandidaten werden mit den bekannten Farbbereichen der Ampelzustände bestimmt. Dadurch kann der Bereich, in dem weiter nach Ampeln gesucht wird, eingeschränkt werden. Auf dem untersten Bild der Abbildung 16 kann man die Kandidaten für das normalisierte RGB-Bild (mittleres Bild) erkennen. Man sieht, dass der Kandidatenbereich deutlich kleiner gegenüber dem Originalbild ist und nur Farben ähnlich den Ampelsignalen berücksichtigt werden.
Abbildung 18 zeigt die weiteren Schritte des Algorithmus, die das Kandidatenbild weiterverarbeiten. Zunächst wird eine Kantenerkennung wie im vorgehenden Kapitel über den Spurhalteassistent verwendet. Als Kantendetektor wird in diesem Fall der Sobel-Algorithmus verwendet, der im Gegensatz zu dem Canny Kantendetektor beliebig dicke und beliebige starke Kanten und nicht nur Kanten der Dicke und Stärke eins berechnet. Da ein leuchtendes Ampelsignal auf dem Kantenbild einen Kreis mit hoher Intensität darstellt, wird hier die Hough Transformation für Kreise zur Erkennung der Ampel verwendet. Dazu wird die Kreisgleichung (Gl. 4-2) mit den Parametern Zentrum (a,b) und Radius r verwendet. Ist der Radius bekannt,bei der Ampelerkennung beispielsweise durch den Abstand zur Ampel und Größe des Ampelsignals, votet jeder Pixel über jede mögliche Gradientenrichtung (zum Zentrum des Kreises) an diesem Punkt für verschiedene Kreiszentren nach Gl. 4-3. Im Hough Raum entstehen dadurch Kreise (siehe Abbildung 17), deren Schnittpunkt bzw. der Punkt mit den meisten Abstimmungen hat als Ortsparameter (a,b) das Zentrum des Kreises.
(𝑥𝑖 − 𝑎)2 + (𝑦𝑖 − 𝑏)2 = 𝑟²
{𝑎 = 𝑥 − 𝑟 cos (𝜃)𝑏 = 𝑦 + 𝑟 sin (𝜃)
Ist hingegen der Radius des Kreises unbekannt oder kann nur auf einen bestimmten Bereich festlegt werden muss ein erweiterter Hough Raum verwendet werden. Jeder Pixel (x,y) stimmt für jeden möglichen Radius mit der Gradientenrichtung, die wie in Kapitel 3 beschrieben bestimmt werden kann, an diesem Punkt ab. Damit besteht der Hough Raum aus den Parametern a, b und r, die anhand des Abstimmungsmaximums bestimmt werden können (siehe mittleres Bild auf Abbildung 18). Kombiniert mit Plausibilitätsprüfungen können damit schließlich Ampeln erkannt werden.
Gl. 4-1
Gl. 4-2
Gl. 4-3
4 Ampelerkennung
Inhalt_08_08.docx
19
Abbildung 18: Zweiter Teil der Ampelerkennung nach [OMA09]
Kantenerkennung
Hough Transformation
Für Kreise
Ampelerkennung
• Kreisgleichung: Zentrum (a,b) und Radius r
Abbildung 17: Hough Transformation für Kreise mit festem Radius, Quelle: [LEI12]

5 Literatur
Inhalt_08_08.docx
20
5 Literatur
[ECK11] ECKSTEIN, L. Aktive Fahrzeugsicherheit und Fahrerassistenz Vorlesungsumdruck Fahrzeugtechnik III fka, 2011
[FOR12] FORSYTH, D. Computer Vision: A Modern Approach 2012
[GRA11] GRAUMAN, K. Vorlesungsfolien, Computer Vision, http://www.cs.utexas.edu/~grauman/courses/spring2011/index.html
[HAR04] HARTLEY, R. Multiple View Geometry in Computer Vision 2004
[LEI12] LEIBE, B. Vorlesungsfolien Computer Vision http://www.vision.rwth-aachen.de/teaching/lecture_computer_vision/winter-12-13
[MAL13] MALERCZYK, C. Webseite, 07.08.2013 http://www.malerczyk.de/applets/Hough/Hough.html
[NN13A] N.N. Forschungsfeld Fahrerassistenzsysteme Lehrstuhl Fahrzeugmechatronik, TU Dresden Webseite, 07.08.2013 http://tu-dresden.de/die_tu_dresden/fakultaeten/vkw/iad/professuren/fm/forschung/schwpkt/assistenz
[NN13B] N.N. Research and Innovative Technology Administration Connected Vehicle Insights: Trends in Computer Vision U.S. Department of Transportation

5 Literatur
Inhalt_08_08.docx
21
[NN13C] N.N. University of Dayton School of Engineering Webseite, 07.08.2013 http://www.udayton.edu/engineering/vision_lab/research/scene_analysis_and_understanding/3d_scene_creation.php
[OMA09] OMACHI, M. Traffic Light Detection with Color and Edge Information Tohoku University
[SZE11] SZELISKI, R. Computer Vision 2011
[WIN12] WINNER, H. Handbuch Fahrerassistenzsysteme 2012


















