
Probabilistische Fahrzeugumfeldschätzung für Fahrerassistenzsysteme
253
Probabilistische Fahrzeugumfeldschätzung für Fahrerassistenzsysteme Von der Fakultät für Elektrotechnik, Informationstechnik, Physik der Technischen Universität Carolo-Wilhelmina zu Braunschweig zur Erlangung des Grades eines Doktors der Ingenieurwissenschaften (Dr.-Ing.) genehmigte Dissertation von Simon Steinmeyer aus Braunschweig eingereicht am: 06.01.2014 Disputation am: 13.05.2014 Referenten: Prof. Dr.-Ing. Markus Maurer Prof. Dr.-Ing. Klaus Dietmayer Druckjahr: 2014
-
Upload
mia-amalia -
Category
Documents
-
view
267 -
download
1
description
Viele aktuelle Fahrerassistenzsysteme wie beispielsweise die adaptive Geschwindigkeitsregelung, Spurwechselassistenten und Systeme zur Anhaltewegverkürzung sind auf eine verlässliche Detektion anderer Verkehrsteilnehmer und Hindernisse angewiesen.
Transcript of Probabilistische Fahrzeugumfeldschätzung für Fahrerassistenzsysteme

Probabilistische Fahrzeugumfeldschätzung fürFahrerassistenzsysteme
Von der Fakultät für Elektrotechnik, Informationstechnik, Physik
der Technischen Universität Carolo-Wilhelmina zu Braunschweig
zur Erlangung des Grades eines Doktors
der Ingenieurwissenschaften (Dr.-Ing.)
genehmigte Dissertation von
Simon Steinmeyer
aus Braunschweig
eingereicht am: 06.01.2014
Disputation am: 13.05.2014
Referenten: Prof. Dr.-Ing. Markus Maurer
Prof. Dr.-Ing. Klaus Dietmayer
Druckjahr: 2014

Die Ergebnisse, Meinungen und Schlüsse dieser Dissertation sind nichtnotwendigerweise die der Volkswagen AG.

Kurzbeschreibung
Viele aktuelle Fahrerassistenzsysteme wie beispielsweise die adaptive Ge-schwindigkeitsregelung, Spurwechselassistenten und Systeme zur Anhal-tewegverkürzung sind auf eine verlässliche Detektion anderer Verkehrsteil-nehmer und Hindernisse angewiesen. Zukünftige Assistenzsysteme wiebeispielsweise Systeme für das Automatische Fahren erhöhen diese Zu-verlässigkeitsanforderung weiter.
Die Dissertation befasst sich mit der statistisch genauen Bewertung vonObjekthypothesen innerhalb einer Sensordatenfusion, welche aus Mess-daten gewonnen wurden. Für jede Hypothese wird eine Wahrscheinlich-keit bestimmt, welche angibt, ob diese vom Fahrerassistenzsystem berück-sichtigt werden muss. Hierbei werden widersprüchliche Messdaten syste-matisch in probabilistischen Modellen aufgelöst, wobei zur Approximationder Wahrscheinlichkeitsdichtefunktion geeignete Modelle aus dem Bereichdes Maschinellen Lernens eingesetzt werden. Als Ergebnis erhält man ei-nen Schätzer, der eine präzise Relevanzwahrscheinlichkeit für beliebigeObjekthypothesen erzeugt, sodass das Fahrerassistenzsystem frühzeitigund angemessen auf ein aktuelles Umfeld reagieren kann.
Neben dem Objekthypothesenmodell ist als zweiter Typ von Umfeldmo-dellen das Belegungsgitter verbreitet, welches den Raum um das Fahr-zeug in Zellen diskretisiert. Die Messdaten werden mit den jeweiligen ört-lich zugehörigen Zellen assoziiert und deren Zustand wird aktualisiert. AlsErgebnis erhält man eine Menge von Zellen mit unterschiedlichen Zustän-den, die beispielsweise die Überfahrbarkeit repräsentieren. Die Dissertati-on entwickelt formale Eigenschaften, die Fusions- und Abfragealgorithmenaufweisen müssen, um eine statistisch belastbare Aussage über die Be-fahrbarkeit eines aus vielen Zellen bestehenden Korridors liefern zu kön-nen. Zusätzlich werden exemplarische Algorithmen entwickelt, die dieseEigenschaften berücksichtigen und somit eine präzisere Schätzung als be-kannte Ansätze erlauben.
iii

Abstract
Many of today’s driver assistance systems, like adaptive cruise control, la-ne change assistant or collision avoidance and mitigation systems requi-re a reliable perception of other traffic participants and obstacles. Futuredriver assistance systems like automatic driving will further increase therequirement of a reliable environment perception.
This thesis deals with the validation of object hypotheses that are gene-rated on the base of measurements inside a sensor data fusion software.A statistically accurate probability of each object hypothesis is generated,which indicates if it should be considered by the driver assistance system.Contradictory data will be resolved systematically using probabilistic mo-dels. To approximate the underlying probabilistic density function, properMachine Learning algorithms are used. As a result, an estimator can bepresented that generates a accurate relevance probability for every objecthypothesis. Driver assistance systems can now react more early and moreadequately to the current environment.
Beside the object model, a second type of environment model is com-mon: The occupancy grid discretises the space around the vehicle intocells, in which each of them contains a cell state. These cell states are up-dated with measurements that can be associated with the cell’s position.As a result, a set of cell states is generated that may represent, for in-stance, their trafficability. To provide a trafficability estimation of a corridorconsisting of many cells, formal mathematical standards are developed.These standards must be considered from both fusion and query algorith-ms to perform a statistically correct estimation. Additionally, exemplary al-gorithms with these features are developed which can do a more accurateestimation than common approaches.
iv

Inhaltsverzeichnis
1. Einleitung 11.1. Einleitung und Motivation . . . . . . . . . . . . . . . . . . . . 11.2. Aktuelle Fahrerassistenzsysteme . . . . . . . . . . . . . . . . 31.3. Zielsetzung dieser Arbeit . . . . . . . . . . . . . . . . . . . . 51.4. Gliederung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2. Sensorik 92.1. Sensorik zur Fahrdynamikerfassung des Ego-Fahrzeuges . . 9
2.1.1. Raddrehzahlsensor . . . . . . . . . . . . . . . . . . . 92.1.2. Beschleunigungssensor . . . . . . . . . . . . . . . . . 122.1.3. Gierratensensor . . . . . . . . . . . . . . . . . . . . . 132.1.4. Inertialplattformen . . . . . . . . . . . . . . . . . . . . 142.1.5. Bewertung . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2. Sensortechnologien zur Umfelderfassung . . . . . . . . . . . 152.2.1. Monokamerasensor . . . . . . . . . . . . . . . . . . . 152.2.2. Stereokamerasensor . . . . . . . . . . . . . . . . . . . 202.2.3. Radarsensor . . . . . . . . . . . . . . . . . . . . . . . 222.2.4. Lidarsensor . . . . . . . . . . . . . . . . . . . . . . . . 272.2.5. Ultraschallsensoren . . . . . . . . . . . . . . . . . . . 292.2.6. Bewertung . . . . . . . . . . . . . . . . . . . . . . . . 30
2.3. Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . 33
3. Sensordatenfusion 353.1. Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.2. Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . 363.3. Dynamische Zustandsschätzer . . . . . . . . . . . . . . . . . 383.4. Stand der Technik: Sensordatenfusionsarchitekturen . . . . . 383.5. Entwicklung einer Sensordatenfusionsarchitektur . . . . . . . 42
3.5.1. Pipe & Filters-Architektur . . . . . . . . . . . . . . . . 423.5.2. Verwendetes Schichtenmodell . . . . . . . . . . . . . 433.5.3. Eingabeschicht: Abstraktion der Empfangswege . . . 463.5.4. Dekodierungsschicht: Abstraktion durch generische
Formate . . . . . . . . . . . . . . . . . . . . . . . . . . 463.5.5. Fusionschicht: Teilfusionen und Dienste . . . . . . . . 51
v

Inhaltsverzeichnis
3.5.6. Enkodierungsschicht: Trennung von Umfeldmodellund Ausgabeprotokoll . . . . . . . . . . . . . . . . . . 58
3.5.7. Ausgabeschicht: Abstraktion des Sendeweges . . . . 603.5.8. Ablaufsteuerung . . . . . . . . . . . . . . . . . . . . . 60
3.6. Anwendungen und erreichte Modularität . . . . . . . . . . . . 633.7. Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . 64
4. Existenz- und Signifikanzschätzung für Umfeldobjekte 674.1. Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 674.2. Gliederung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 684.3. Existente und signifikante Objekte . . . . . . . . . . . . . . . 694.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer . . . 70
4.4.1. Track Score Funktion nach Sittler . . . . . . . . . . . . 714.4.2. Trackqualität nach Sinha . . . . . . . . . . . . . . . . . 734.4.3. Objektplausibilisierung nach Schoeberl . . . . . . . . 764.4.4. Familie der „Probabilistischen Datenassoziationsal-
gorithmen“ . . . . . . . . . . . . . . . . . . . . . . . . 784.4.5. Entwicklung eines Existenzwahrscheinlichkeits-
schätzer mithilfe von zyklischen Markov-Ketten . . . . 814.4.6. Statische Regeln . . . . . . . . . . . . . . . . . . . . . 854.4.7. Bewertung . . . . . . . . . . . . . . . . . . . . . . . . 87
4.5. Stand der Technik: Signifikanzschätzer . . . . . . . . . . . . . 894.5.1. Bestimmung des Kursverlaufes . . . . . . . . . . . . . 904.5.2. Bestimmung der Fahrschlauchbreite . . . . . . . . . . 914.5.3. Probabilistische Fahrschlauchgenerierung und -
zuordnung . . . . . . . . . . . . . . . . . . . . . . . . 924.5.4. Bewertung . . . . . . . . . . . . . . . . . . . . . . . . 93
4.6. Entwicklung eines integrierten Relevanzschätzer . . . . . . . 944.6.1. Definition des Zustandsraumes . . . . . . . . . . . . . 954.6.2. Prospektive Erzeugung der Trainingsdaten . . . . . . 984.6.3. Anforderungen und Auswahl von Maschinellen Ler-
nalgorithmen . . . . . . . . . . . . . . . . . . . . . . . 1004.6.4. Anwendung der Lernverfahren zur Relevanzklassika-
tion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1044.6.5. Dimensionsreduktion des Zustandsraumes . . . . . . 1054.6.6. Tiefpassfilterung des Ergebnisses . . . . . . . . . . . 1094.6.7. Auswertung mittels Grenzwertoptimierungskurven . . 1104.6.8. Histogrammanalyse und -korrektur . . . . . . . . . . . 1124.6.9. Bewertung . . . . . . . . . . . . . . . . . . . . . . . . 115
4.7. Ableitung von Regeln aus einem integrierten Relevanz-schätzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
vi

Inhaltsverzeichnis
4.8. Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . 123
5. Probabilistische Belegungsgitterfusion 1265.1. Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1265.2. Anforderungen an eine Belegungsgitterfusion . . . . . . . . . 1285.3. Stand der Technik: Algorithmen und Datenstrukturen für Be-
legungsgitter . . . . . . . . . . . . . . . . . . . . . . . . . . . 1295.3.1. Zweidimensionaler Ringpuffer . . . . . . . . . . . . . . 1305.3.2. Punktalgorithmus . . . . . . . . . . . . . . . . . . . . . 1315.3.3. Linienalgorithmus . . . . . . . . . . . . . . . . . . . . 1325.3.4. Entwicklung eines Polygonalgorithmus . . . . . . . . . 134
5.4. Grundlagen: Logikalgorithmen für Belegungsgitter . . . . . . 1405.4.1. Wahrnehmungsrahmen und Massefunktionen . . . . . 1415.4.2. Bayes-Logik . . . . . . . . . . . . . . . . . . . . . . . 1425.4.3. Dempster-Shafer Theorie . . . . . . . . . . . . . . . . 1445.4.4. Dezert-Smarandache Theorie . . . . . . . . . . . . . . 1465.4.5. Zusammenfassung . . . . . . . . . . . . . . . . . . . . 148
5.5. Stand der Technik: Fusionsalgorithmen für Belegungsgitter . 1495.5.1. Belegungsgitterfusion nach Elfes . . . . . . . . . . . . 1505.5.2. Belegungsgitterfusion nach dem MURIEL-Ansatz . . . 1555.5.3. Belegungsgitterfusion mittels erlernter inverser Sen-
sormodelle . . . . . . . . . . . . . . . . . . . . . . . . 1585.5.4. Bewertung . . . . . . . . . . . . . . . . . . . . . . . . 164
5.6. Abhängigkeiten in Belegungsgittern . . . . . . . . . . . . . . 1655.6.1. Inter-Cell Dependency Problem . . . . . . . . . . . . . 1655.6.2. Inter-Measurement Dependency Problem . . . . . . . 1695.6.3. Kombination von ICDP und IMDP . . . . . . . . . . . . 1705.6.4. Zusammenfassung . . . . . . . . . . . . . . . . . . . . 172
5.7. Entwicklung von ICDP-Algorithmen . . . . . . . . . . . . . . . 1725.7.1. Nichtprobabilistischer Algorithmus . . . . . . . . . . . 1735.7.2. Probabilistischer Fusionsalgorithmus . . . . . . . . . . 1765.7.3. Belegungsgitter mit variabler Auflösung . . . . . . . . 1895.7.4. Zusammenfassung . . . . . . . . . . . . . . . . . . . . 192
5.8. IMDP-Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . 1955.8.1. Übersicht existierender IMDP-Algorithmen . . . . . . . 1955.8.2. Entwicklung eines IMDP-Algorithmus . . . . . . . . . 1975.8.3. Zusammenfassung . . . . . . . . . . . . . . . . . . . . 203
5.9. Vergleiche und Anwendungen . . . . . . . . . . . . . . . . . . 2045.9.1. Vergleich mit klassischem Dempster-Shafer-Ansatz . 2045.9.2. Echtzeitfähigkeit . . . . . . . . . . . . . . . . . . . . . 206
5.10.Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . 208
vii

Inhaltsverzeichnis
6. Zusammenfassung und Ausblick 2106.1. Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . 2106.2. Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
A. Anhang 215A.1. Begriffsdefinitionen . . . . . . . . . . . . . . . . . . . . . . . . 215
A.1.1. Echtzeitfähigkeit . . . . . . . . . . . . . . . . . . . . . 215A.1.2. Statistisch korrekte Schätzer . . . . . . . . . . . . . . 215
A.2. Kalmanfilter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217A.3. Maschinelle Lernverfahren . . . . . . . . . . . . . . . . . . . . 219
A.3.1. Bayessches Netz . . . . . . . . . . . . . . . . . . . . . 219A.3.2. k-Nearest-Neighbour . . . . . . . . . . . . . . . . . . . 220A.3.3. Lineare Support Vector Machine . . . . . . . . . . . . 221A.3.4. Support Vector Machine mit Kernelerweiterung . . . . 224A.3.5. Künstliche neuronale Netze . . . . . . . . . . . . . . . 226
viii

Abkürzungsverzeichnis
ABS AntiblockiersystemACC Geschwindigkeitsregeltempomat (engl. „Adaptive Cruise
Control“)ANN Künstliches Neuronales Netz (engl. „Artificial Neuronal Net-
work“)CAN Ein häufig im Automobilbereich eingesetzter Feldbus (engl.
„Controller Area Network“)CCD Lichtempfindliche elektronische Bauelemente (engl.
„Charge-coupled Device“)DARPA Behörde des US-Verteidigungsministerium für Forschungs-
projekte (engl. „Defence Advanced Research ProjectsAgency“)
DSmT Dezert-Smarandache Logik (engl. „Dezert-SmarandacheTheory“)
DST Dempster-Shafer Logik (engl. „Dempster-Shafer Theory“)ESC Fahrdynamikregelung (engl. „Electronic Stability Control“)FAS FahrerassistenzsystemFMCW Dauerstrich-Frequenzmodulation-Verfahren (engl. „Fre-
quency Modulated Continuous Wave“)GPS Globales Satellitennavigationssystem (engl. „Global Positio-
ning System“)ICDP Abhängigkeitsproblem zwischen Zellen (engl. „Inter-Cell-
Dependency-Problem“)IMDP Abhängigkeitsproblem zwischen Messungen (engl. „Inter-
Measurement-Dependency-Problem“)IMU Inertialplattform (engl. „Inertial Measurement Unit“)IPDA Integrierte Probabilistische Datenassoziation (engl. „Inte-
grated Probabilistic Data Association“)JIPDA Vereinheitlichte Integrierte Probabilistische Datenassoziati-
on (engl. „Joint Integrated Probabilistic Data Association“)
ix

JPDA Vereinheitlichte Probabilistische Datenassoziation (engl.„Joint Probabilistic Data Association“)
kNN Klassifikationsalgorithmus „k-Nächste-Nachbarn“ (engl. „k-Nearest-Neighbour“)
LLR Logarithmischer Wahrscheinlichkeitsquotient (engl. „Loga-rithmic Likelihood Ratio“)
LR Wahrscheinlichkeitsquotient (engl. „Likelihood Ratio“)MURIEL Belegungsgitterfusionsmethode, welche bestimmte Abhän-
gigkeiten berücksichtigt (engl. „Multiple Representation, In-dependent Evidence Log“)
PDA Probabilistische Datenassoziation (engl. „Probabilistic DataAssociation“)
PReVENT EU-Förderprojekt zur Steigerung der Verkehrssicherheit(engl. „PReVENTive and Active Safety Applications Integra-ted Project“)
ROC-Kurve Grenzwertoptimierungskurve (engl. „Receiver OperatingCharacteristic“)
SDF SensordatenfusionSVM Stützvektormaschine (engl. „Support-Vector-Machine“)TTC Zeit bis zur Kollision (engl. „Time-To-Collision“)UDP Ein verbindungsloses Internetprotokoll (engl. „User Data-
gram Protocol“)WDF Wahrscheinlichkeitsdichtefunktion
x

Kapitel 1.
Einleitung
1.1. Einleitung und Motivation
Das Automobil ist eines der weitverbreitetsten Produkte zur Wahrnehmungindividueller Mobilität. Es bietet dem einzelnen Menschen die Freiheit,räumlich jederzeit beweglich zu sein und erhöht dessen Wirkungskreis we-sentlich. Der Mensch kann somit aus einer Vielzahl von Arbeits- und Frei-zeitmöglichkeiten wählen, sodass das Automobil zu seiner persönlichenEntfaltung mit beiträgt.
Zur Nutzung dieser Freiheit muss sich der Fahrer im Gegenzug jedochder Fahrzeugführungsaufgabe widmen. Diese kann er einerseits als lästi-ge Pflicht empfinden, beispielsweise bei langen Stau- oder Autobahnfahr-ten. Andererseits beherrscht der Mensch die Regelungsaufgabe nicht per-fekt: Durch Fahrfehler und Fehleinschätzungen kombiniert mit dem hohenSchadenspotenzial eines sich schnell bewegenden Kraftfahrzeuges kommtes immer wieder zu Unfällen zum Teil mit erheblichen Folgen für die Betei-ligten.
Um die Fahrzeugführung komfortabler und sicherer zu gestalten, entwi-ckeln Fahrzeughersteller verschiedenste technische Systeme: Hierbei be-finden sich im aktuellen Fokus der Forschung und Entwicklung insbeson-dere sog. Fahrerassistenzsysteme (FAS), welche direkt Einfluss auf Fahr-zeugregelung oder Fahrer nehmen. Diese haben das Potenzial, den Fah-rer aktiv bei anspruchsvollen Fahrsituationen oder eintönigen Aufgaben zuunterstützen, und so einer Überforderung oder einer Unachtsamkeit direktentgegenzuwirken.
Eine wachsende Anzahl dieser Systeme ist bereits in vielen Fahrzeugenverfügbar: So informieren Navigationssysteme über die kürzeste Routeund auftretenden Verkehrsstörungen, Spurhalte- und Fahrstreifenwechsel-assistent wirken potenziell gefährlichen querdynamischen Fahrmanövernentgegen, der Abstandsregeltempomat (ACC) und Frontalkollisionsschutz-systeme unterstützen den Fahrer bei der Fahrzeuglängsregelung, währenddas Antiblockiersystem (ABS) und die Fahrdynamikregelung (ESC) in fahr-
1

Kapitel 1. Einleitung
dynamischen Grenzsituationen den Fahrer bei der Kontrolle über das Fahr-zeug unterstützt. Verschiedenste Studien weisen auch ein hohes Wirkpo-tenzial für solche Systeme auf das Unfallgeschehen aus [Breuer 2009;Thomas 2007; Bartels 2009].
Neben Aspekten der Sicherheit adressieren Fahrerassistenzsystemeauch Komfortfunktionen: So können Teile der Fahrzeugregelung in be-stimmten Situationen vom Fahrer an solch ein System abgegeben werden,sodass der Fahrer diese nur noch überwachen muss. Eine Ausbaustufeist dabei das „Teilautomatische Fahren“, in der die komplette Fahrzeug-führung in bestimmten Domänen und Situationen vom Fahrzeug übernom-men wird und der Fahrer nur als Überwachungs- und Rückfallebene zurVerfügung stehen muss [Weiser 2009; Gasser 2012]. Langfristig könntedie Überwachungsaufgabe sogar entfallen, sodass der Fahrer sich mit Ne-bentätigkeiten während der Fahrt beschäftigen kann. Diese Fahrfunktionwird als „Hochautomatisches Fahren“ bezeichnet, sofern der Fahrer vordem Erreichen von Systemgrenzen die Fahrzeugführung kurzfristig wiederübernehmen muss. Hat die Fahrfunktion hingegen ausreichend Zeit, beieiner nicht erfolgten Übernahme einen risikominimalen Zustand zu errei-chen, bevor Systemgrenzen erreicht werden, so unterstützt die Fahrfunkti-on „Vollautomatisches Fahren“.
Neben Sicherheit und Komfort können zudem Aspekte der Energieeffizi-enz bei der Umsetzung einer automatisierten Längsregelung mitintegriertwerden. Hierzu kann beispielsweise ein auf den Antriebsstrang optimier-tes und vorausschauendes Geschwindigkeitsprofil erstellt werden, welchesStraßentopologie, Geschwindigkeitsbegrenzungen und andere Verkehrs-teilnehmer berücksichtigt. Zusammen mit Technologien zur intelligentenVerkehrssteuerung können solche Systeme Emissionen verringern und so-mit einen Beitrag zum Umwelt- und Klimaschutz leisten.
Durch die vielen Möglichkeiten auf das Verkehrsgeschehen positiv ein-zuwirken, ist bereits ein Trend zu erkennen, der einen stetig wachsendenWert verkaufter Fahrerassistenzsysteme aufzeigt. Dieser Trend wird einer-seits durch den Käufer erzeugt, der insbesondere der Fahrzeugsicherheiteinen hohen Wert beimisst, andererseits durch gesetzliche Vorgaben bzw.Selbstverpflichtungen der Automobilindustrie gefördert.
So sind seit 2004 alle neuzugelassenen Autos in der EU und in Japanmit ABS ausgerüstet. Seit November 2011 müssen alle Neuzulassungeninnerhalb der EU zusätzlich mit ESC ausgestattet sein; die Vorgabe einesReifendruckkontrollsystems folgte 2012. Für die meisten in der EU neuzu-gelassenen schweren Nutzfahrzeuge sind seit 2013 ein Frontalkollisions-
2

1.2. Aktuelle Fahrerassistenzsysteme
schutzsystem und ein Spurverlassenswarner vorgeschrieben [Gail 2010]1.Weitere gesetzliche Vorgaben, wie beispielsweise im Bereich des Fußgän-gerschutzes, sind in Vorbereitung.
Neben Fortschritten im Insassenschutz und der Verbesserung der Ver-kehrsinfrastruktur sind solche Assistenzsysteme im Bereich der Fahrdy-namikstabilisierung mit dafür verantwortlich, dass sich die Anzahl der Ver-kehrsunfälle bzgl. Schwerverletzten und Toten in der EU trotz höheren Ver-kehrsaufkommens seit Jahren rückläufig entwickelt. Bei der langfristigenFortsetzung dieses positiven Trends werden Fahrerassistenzsysteme einewichtige Rolle spielen, welche eine Umfeldwahrnehmung beinhalten undsomit eine Re- und Interaktion mit dem Fahrzeugumfeld ermöglichen.
Zurzeit ist die Ausstattungsrate solcher Systeme im bundesdeutschenFlottendurchschnitt jedoch eher gering, sodass noch ein hohes Potenzialaktueller und zukünftiger Systeme zur Verbesserung der Sicherheit, derEnergieeffizienz und des Komforts besteht.
1.2. Aktuelle Fahrerassistenzsysteme
Neben den bereits recht weitverbreiteten Systemen zur Fahrdynamiksta-bilisierung sind in einigen Fahrzeugen auch verschiedenste Fahrerassis-tenzsysteme verfügbar. Die meisten dieser Systeme wurden in Oberklas-sefahrzeugen eingeführt, jedoch ist bereits eine Demokratisierung erkenn-bar, sodass diese mittlerweile auch in anderen Fahrzeugklassen angebo-ten werden.
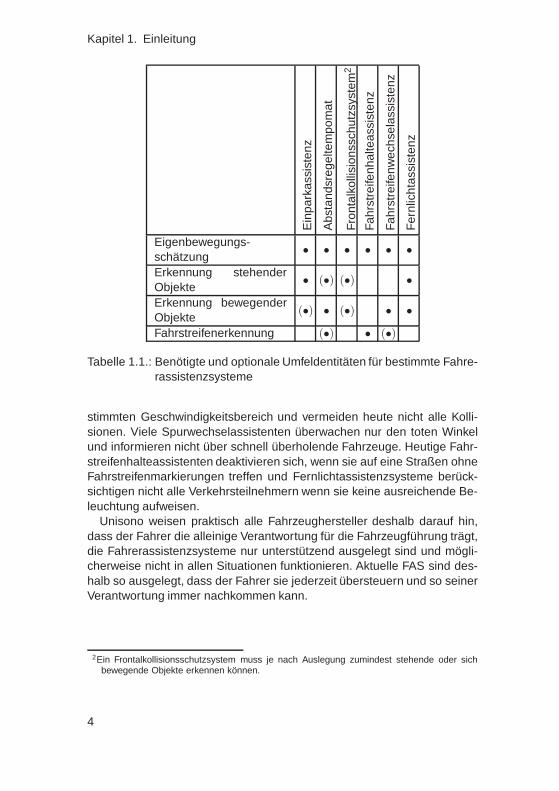
Ein wichtiger Bestandteil dieser Systeme ist eine Umfeldwahrnehmungund dessen Interpretation, welche wichtige Eingangsgrößen liefert. Jenach System werden neben einer Eigenbewegungsschätzung zusätzlichInformationen über andere Hindernisse, Verkehrsteilnehmer oder auchüber Verläufe bestimmter Fahrstreifen benötigt. Eine Übersicht einiger Fah-rerassistenzsysteme und deren benötigten und leistungssteigernden optio-nalen Umfeldentitäten ist in Tabelle 1.1 dargestellt.
Bei vielen Fahrerassistenzsystemen stellt die Leistungsfähigkeit der Um-feldwahrnehmung und der Interpretation einen limitierenden Faktor dar,welcher bei der Auslegung dieser Systeme in Form von Funktionsgren-zen mitberücksichtigt wird: So beachten viele ACC-Systeme keine odernicht alle statischen Objekte und limitieren die maximale Bremsverzöge-rung um Auswirkungen von Fehldetektionen abzuschwächen. Assistenz-systeme zur Vermeidung von Frontalkollisionen arbeiten nur in einem be-
1Bei vielen der hier beschriebenen gesetzlichen Regelungen sind Übergangsfristen und Aus-nahmegenehmigungen noch zu beachten.
3
Kapitel 1. Einleitung
Ein
park
assi
sten
z
Abs
tand
sreg
elte
mpo
mat
Fron
talk
ollis
ions
schu
tzsy
stem
2
Fahr
stre
ifenh
alte
assi
sten
z
Fahr
stre
ifenw
echs
elas
sist
enz
Fer
nlic
htas
sist
enz
Eigenbewegungs-schätzung
• • • • • •
Erkennung stehenderObjekte
• (•) (•) •
Erkennung bewegenderObjekte
(•) • (•) • •
Fahrstreifenerkennung (•) • (•)
Tabelle 1.1.: Benötigte und optionale Umfeldentitäten für bestimmte Fahre-rassistenzsysteme
stimmten Geschwindigkeitsbereich und vermeiden heute nicht alle Kolli-sionen. Viele Spurwechselassistenten überwachen nur den toten Winkelund informieren nicht über schnell überholende Fahrzeuge. Heutige Fahr-streifenhalteassistenten deaktivieren sich, wenn sie auf eine Straßen ohneFahrstreifenmarkierungen treffen und Fernlichtassistenzsysteme berück-sichtigen nicht alle Verkehrsteilnehmern wenn sie keine ausreichende Be-leuchtung aufweisen.
Unisono weisen praktisch alle Fahrzeughersteller deshalb darauf hin,dass der Fahrer die alleinige Verantwortung für die Fahrzeugführung trägt,die Fahrerassistenzsysteme nur unterstützend ausgelegt sind und mögli-cherweise nicht in allen Situationen funktionieren. Aktuelle FAS sind des-halb so ausgelegt, dass der Fahrer sie jederzeit übersteuern und so seinerVerantwortung immer nachkommen kann.
2Ein Frontalkollisionsschutzsystem muss je nach Auslegung zumindest stehende oder sichbewegende Objekte erkennen können.
4

1.3. Zielsetzung dieser Arbeit
1.3. Zielsetzung dieser Arbeit
Bereits heute haben einige Fahrerassistenzsysteme hohe Anforderungenan die Genauigkeit, Robustheit und Umfang der Umfeldwahrnehmung. Esist abzusehen, dass zukünftige Fahrerassistenzsysteme diese Anforderun-gen weiter erhöhen. Dies wird insbesondere bei Systemen der Fall sein, inder der Fahrer keine dauerhafte Überwachungsaufgabe hat, also bei hoch-und vollautomatisierten Fahrfunktionen. Auch kann die Leistungsfähigkeitaktueller Fahrerassistenzsysteme durch eine verbesserte Umfeldwahrneh-mung gesteigert werden.
Eine Umfeldwahrnehmung basiert jedoch auf Messdaten, welche vonverschiedenen Sensoren erzeugt werden und je nach Messprinzip zu ei-nem gewissen Maß immer ungenau sind. Daneben können Witterungs-einflüsse und situationsbezogene Faktoren Messungen negativ beeinflus-sen, sodass eine ungenaue Zustandserfassung einzelner Umfeldentitätenmöglich ist. Dieses kann die Umfeldwahrnehmung insgesamt beeinträch-tigen und somit die Leistungsfähigkeit von Fahrerassistenzsystemen ver-schlechtern: Beispielsweise können andere Fahrzeuge fälschlicherweisedem Fahrstreifen des eigenen Fahrzeuges3 zugeordnet werden, falls dieFahrbahnschätzung oder Fahrzeugpositionsschätzung ungenau ist.
Des Weiteren können Fehlinterpretationen der Messergebnisse dazuführen, dass wesentliche Entitäten übersehen oder sogar Fehlziele im Sin-ne des Fahrerassistenzsystems generiert werden. So können unterfahr-bare Schilderbrücken als stationäre Hindernisse wahrgenommen werden,wenn sie von einem Radarsensor ungünstig erfasst werden. Ebenso kön-nen auch metallische Getränkedosen als relevantes Ziel fehlinterpretiertwerden, obwohl diese überfahrbar sind. Umgekehrt können wesentlicheUmfeldobjekte mit einem sehr geringen Radarquerschnitt nicht oder erstsehr spät durch Radarsensor wahrgenommen werden.
Um die Umfeldwahrnehmung zu verbessern, ist die Weiterentwicklungvon Sensortechnologien möglich, sodass diese idealerweise hochgenaumessen und alle Merkmale korrekt interpretieren ohne Fehlziele zu erzeu-gen und ohne wesentliche Ziele übersehen. Fortschritte in Sensortechno-logien werden voraussichtlich Verbesserungen erreichen, jedoch scheintdie Entwicklung eines solchen idealen Sensors in naher Zukunft unrealis-tisch zu sein.
Eine andere Möglichkeit die Umfeldwahrnehmung zu verbessern, be-steht in der Fusionierung von Messdaten unterschiedlicher Sensoren unddie systematische Auflösung von Messdifferenzen und Widersprüchen. Ein
3Das eigene Fahrzeug aus Sicht des Fahrerassistenzsystems wird im folgenden Ego-Fahrzeuggenannt
5

Kapitel 1. Einleitung
probabilistisches Umfeldmodell kann helfen, diese negativen Einflüsse sta-tistisch genau zu quantifizieren und zu minimieren. Die Entwicklung einessolchen Umfeldmodells ist Ziel dieser Arbeit.
Die in dieser Arbeit entwickelte Umfeldwahrnehmung zielt dabei auf keinbestimmtes Fahrerassistenzsystem ab. Stattdessen versucht die Umfeld-wahrnehmung das Verkehrsgeschehen, Fahrbahn und Befahrbarkeit imRahmen der verfügbaren Daten so genau und aktuell wie möglich zu schät-zen. Konkrete Fahrerassistenzapplikationen4 können dann die benötigtenGrößen aus dem Umfeldmodell extrahieren und verwenden, sodass dieUmfeldwahrnehmung universell verschiedenen Fahrerassistenzsystemendienen kann.
1.4. Gliederung
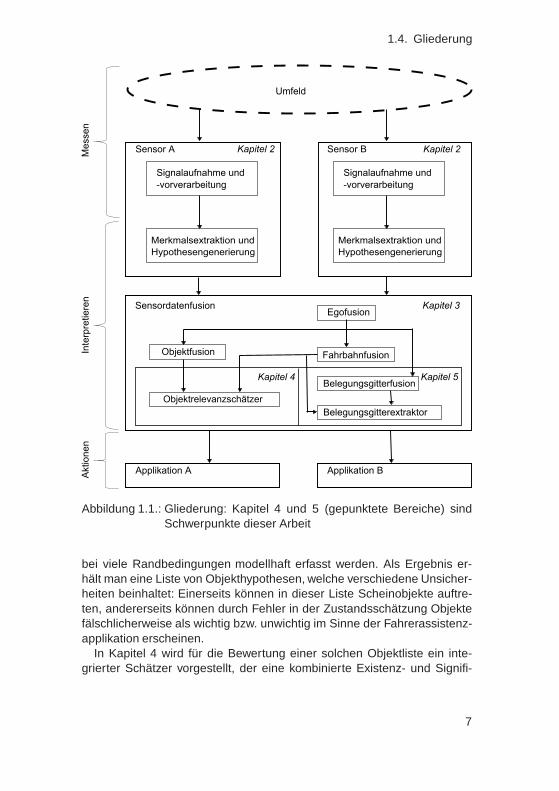
Um ein probabilistisches Umfeldmodell zu entwickeln, ist zunächst die ge-samte Wahrnehmungskette zu betrachten, wobei frühe Störeinflüsse undzu einfache Modellannahmen identifiziert und ggf. durch bessere Modelleund Schätzer ausgetauscht werden müssen. Diese Wahrnehmungskettewird sukzessiv in den einzeln Kapiteln untersucht, was als Übersicht in Ab-bildung 1.1 dargestellt ist.
Hierzu werden in Kapitel 2 verschiedene aktuelle Sensortechnologienvorgestellt, wobei sowohl Sensoren zur Erfassung der Eigenbewegung alsauch Sensoren zur Umfeldwahrnehmung untersucht werden. Hierbei wer-den diverse mögliche Störquellen für das jeweilige Messprinzip bzw. beider Interpretation der Messergebnisse aufgezeigt. Diese können die Basis-ursache in einer Fehlerkette sein, wenn eine Umfeldschätzung zu unge-naue oder fehlerhafte Ergebnisse liefert.
Im anschließenden Kapitel 3 wird eine exemplarische Sensordatenfusi-on vorgestellt, welche u. a Objekte, Hindernisse, Befahrbarkeit, Eigenbe-wegung sowie Fahrbahnverlauf und -eigenschaften schätzt. Hierzu werdendie Messdaten von diversen Sensoren in verschiedenste Teilschätzer ein-gebracht, sodass ein Umfeldmodell mit hohem Detaillierungsgrad erzeugtwird. Aus diesem lassen sich die benötigten Größen für verschiedensteFahrerassistenzapplikationen extrahieren.
Innerhalb der Sensordatenfusion werden unterschiedliche Modelle ver-wendet, um Umfeldobjekte zu berücksichtigen: Ein filterbasierter Objekt-tracker verfolgt und schätzt den Zustand anderer Verkehrsteilnehmer, wo-
4Die Fahrerassistenzapplikation ist der Teil eines FAS, der aufgrund eines aufgetretenen Ego-und Umfeldzustandes agiert. Das Erfassen und Fusionieren von Sensordaten gehört nichtdazu.
6
1.4. Gliederung
Sensor A
Signalaufnahme und
-vorverarbeitung
Merkmalsextraktion und
Hypothesengenerierung
Umfeld
Sensor B
Signalaufnahme und
-vorverarbeitung
Merkmalsextraktion und
Hypothesengenerierung
SensordatenfusionEgofusion
Objektfusion
Belegungsgitterfusion
Fahrbahnfusion
Belegungsgitterextraktor
Objektrelevanzschätzer
Kapitel 2Kapitel 2
Kapitel 3
Me
sse
nIn
terp
retie
ren
Aktio
ne
n
Kapitel 5Kapitel 4
Applikation A Applikation B
Abbildung 1.1.: Gliederung: Kapitel 4 und 5 (gepunktete Bereiche) sindSchwerpunkte dieser Arbeit
bei viele Randbedingungen modellhaft erfasst werden. Als Ergebnis er-hält man eine Liste von Objekthypothesen, welche verschiedene Unsicher-heiten beinhaltet: Einerseits können in dieser Liste Scheinobjekte auftre-ten, andererseits können durch Fehler in der Zustandsschätzung Objektefälschlicherweise als wichtig bzw. unwichtig im Sinne der Fahrerassistenz-applikation erscheinen.
In Kapitel 4 wird für die Bewertung einer solchen Objektliste ein inte-grierter Schätzer vorgestellt, der eine kombinierte Existenz- und Signifi-
7

Kapitel 1. Einleitung
kanzwahrscheinlichkeit für Objekte ermittelt und dabei sämtliche Abhän-gigkeiten der Informationsquellen berücksichtigt. Somit werden beispiels-weise Unsicherheiten, Ungenauigkeiten und Fehler von Messprinzipien, Si-gnalvorverarbeitungen, Hypothesengenerierung, Interpretation, Modellan-nahmen, Umwelteinflüssen und sonstigen Quellen in den probabilistischenSchätzer mit einbezogen. Als Ergebnis erhält die Fahrerassistenzapplikati-on für eine aktuelle Objektliste genaue Relevanzwahrscheinlichkeiten. Bei-spielhaft wird dies für einen Relevanzklassifikator gezeigt, der hochauto-matisches Fahrfunktionen auf Autobahnen und autobahnähnlichen Stra-ßen unterstützt.
Als Alternative zu der stark modellbehafteten Schätzung eines Objekt-trackers und des integrierten Relevanzschätzers verwenden viele Sen-sordatenfusionen ein sog. „Belegungsgitter“, welches eine modellärmereUmfeldrepräsentation darstellt. Das Umfeld wird dabei in Zellen diskreti-siert, welche meist einen Zustand zur Überfahrbarkeit kapseln. In Kapitel5 wird ein neuer Belegungsgitteransatz vorgestellt, der höhere Anforde-rungen an Genauigkeit und Robustheit als bekannte Ansätze bewältigenkann. Die Besonderheit ist, dass er Abhängigkeiten zwischen allen Zell-zuständen und Messungen deutlich genauer berücksichtigt. Im Ergebniskann eine Fahrerassistenzapplikation einen beliebigen Bereich im Bele-gungsgitter abfragen und eine genaue Befahrbarkeitsschätzung erhalten.
Zuletzt werden in Kapitel 6 die vorgestellten Ansätze und Ergebnissedieser Arbeit zusammengefasst und es wird ein Ausblick auf mögliche zu-künftige Entwicklungen im Bereich der Fahrerassistenzsysteme gegeben.
Teile dieser Arbeit sind bereits in Vorabveröffentlichungen dokumentiert:So ist eine Basisbeschreibung der verwendeten Sensordatenfusionsarchi-tektur in [Steinmeyer 2010a] beschrieben, in [Steinmeyer 2010b] sind dieentwickelten Algorithmen zur Relevanzschätzung aus Kapitel 4 veröffent-licht und einige Aspekte zur Belegungsgitterfusion aus Kapitel 5 sind in[Steinmeyer 2009] wiederzufinden.
8

Kapitel 2.
Sensorik
Fahrerassistenzsysteme benötigen sowohl Informationen über den Dyna-mikzustand des Ego-Fahrzeuges als auch über das Umfeld. Hierzu werdenOdometrie- und Umfeldsensoren eingesetzt, welche meist zyklisch ent-sprechende Messdaten erzeugen. Je nach Mess- und Auswertungsprinzipkönnen hier verschiedene Quellen identifiziert werden, die Ungenauigkei-ten und Fehlinterpretationen verursachen können. Diese werden in diesemKapitel für die einzelnen Sensoren dargestellt.
2.1. Sensorik zur Fahrdynamikerfassung desEgo-Fahrzeuges
Für viele Fahrerassistenzsysteme ist die Bestimmung der Fahrzeugeigen-bewegung grundlegende Voraussetzung für deren Funktion. Hierbei sind jenach Fahrerassistenzapplikation die relative Position, die Längs- und Quer-geschwindigkeiten bzw. -beschleunigungen wie auch Gierwinkel und Gier-rate relevant. In diesem Abschnitt werden einige Sensoren vorgestellt, dieeine Schätzung dieser Größen erlauben.
2.1.1. Raddrehzahlsensor
Einer der wichtigsten Sensoren zur Eigenbewegungsschätzung ist der sog.„Raddrehzahlsensor“, welcher in diskreten Schritten misst, inwieweit sichein Rad weiterbewegt hat. Ein Steuergerät zählt die jeweiligen Impulse dereinzelnen Räder und informiert andere Steuergeräte zyklisch über den ak-tuellen Stand.
Heutige Raddrehzahlsensoren sind meist aktive Sensoren, welche nachdem sog. „Hallprinzip“ messen und welche schematisch in Abbildung 2.1dargestellt sind: Bei diesen Sensoren ist am zu messenden Rad ein Pol-ring angebracht, welcher in verschiedene gleichgroße Sektoren unterteiltist. Benachbarte Sektoren weisen eine unterschiedliche Magnetisierung
9

Kapitel 2. Sensorik
Abbildung 2.1.: Schematischer Aufbau eines Raddrehzahlsensors beste-hend aus einem Polring und einem Hall-Element
(Nordpol bzw. Südpol) auf. Das Sensorelement besteht aus einer Leiter-platte, welche mit einer Spannung versorgt wird. Wird diese Leiterplatte ei-nem Magnetfeld ausgesetzt, so kann man dies in Form einer Spannungs-änderung quer zur Leiterplatte feststellen. Die unterschiedliche Magneti-sierung erzeugt bei einer Radbewegung eine Schwingung, wobei dessenFrequenz proportional zur Geschwindigkeit ist. Für genauere Informatio-nen zu Raddrehzahlsensoren sei auf [Zabler 2010, S. 63 ff] verwiesen.
Unter der Annahme, dass das Ego-Fahrzeug die Strecke zurückgelegthat, die die gemessenen Radimpulse suggerieren, lassen sich viele ver-schiedene Größen des Ego-Zustands ableiten. Für die einfache Bestim-mung sind insbesondere die Hinterräder geeignet, wenn diese keine aktiveHinterradlenkung aufweisen. Somit sind nur die beiden Zählervariablen irbzw. il für das rechte bzw. linke Hinterrad die einzigen beiden notwendigenMesswerte zur Eigenbewegungsschätzung.
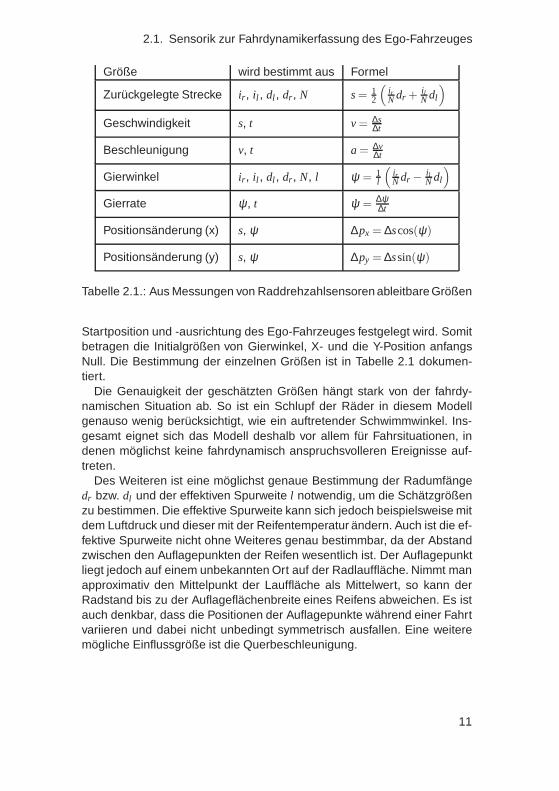
Als zusätzliche Datenquelle bzw. Apriori-Wissen sind ein Zeitgeber zurMessung der Zeit t und das Wissen über die Anzahl der Impulse pro Rad-umdrehung N, die effektive Spurweite l und die Radumfänge dr bzw. dl desrechten und linken Hinterrades notwendig. Daraus lassen sich die zurück-gelegte Strecke s, die Gesamtgeschwindigkeit v, die Beschleunigung a, derGierwinkel ψ und die Gierrate ψ bestimmen.
Der Gierwinkel und die relative Positionsänderungen werden mithilfe ei-nes ortsfesten Koordinatensystems referenziert, dessen Ursprung durch
10
2.1. Sensorik zur Fahrdynamikerfassung des Ego-Fahrzeuges
Größe wird bestimmt aus Formel
Zurückgelegte Strecke ir, il , dl , dr, N s = 12
(irN dr +
ilN dl
)
Geschwindigkeit s, t v = ∆s∆t
Beschleunigung v, t a = ∆v∆t
Gierwinkel ir, il , dl , dr, N, l ψ = 1l
(irN dr − il
N dl
)
Gierrate ψ, t ψ = ∆ψ∆t
Positionsänderung (x) s, ψ ∆px = ∆scos(ψ)
Positionsänderung (y) s, ψ ∆py = ∆ssin(ψ)
Tabelle 2.1.: Aus Messungen von Raddrehzahlsensoren ableitbare Größen
Startposition und -ausrichtung des Ego-Fahrzeuges festgelegt wird. Somitbetragen die Initialgrößen von Gierwinkel, X- und die Y-Position anfangsNull. Die Bestimmung der einzelnen Größen ist in Tabelle 2.1 dokumen-tiert.
Die Genauigkeit der geschätzten Größen hängt stark von der fahrdy-namischen Situation ab. So ist ein Schlupf der Räder in diesem Modellgenauso wenig berücksichtigt, wie ein auftretender Schwimmwinkel. Ins-gesamt eignet sich das Modell deshalb vor allem für Fahrsituationen, indenen möglichst keine fahrdynamisch anspruchsvolleren Ereignisse auf-treten.
Des Weiteren ist eine möglichst genaue Bestimmung der Radumfängedr bzw. dl und der effektiven Spurweite l notwendig, um die Schätzgrößenzu bestimmen. Die effektive Spurweite kann sich jedoch beispielsweise mitdem Luftdruck und dieser mit der Reifentemperatur ändern. Auch ist die ef-fektive Spurweite nicht ohne Weiteres genau bestimmbar, da der Abstandzwischen den Auflagepunkten der Reifen wesentlich ist. Der Auflagepunktliegt jedoch auf einem unbekannten Ort auf der Radlauffläche. Nimmt manapproximativ den Mittelpunkt der Lauffläche als Mittelwert, so kann derRadstand bis zu der Auflageflächenbreite eines Reifens abweichen. Es istauch denkbar, dass die Positionen der Auflagepunkte während einer Fahrtvariieren und dabei nicht unbedingt symmetrisch ausfallen. Eine weiteremögliche Einflussgröße ist die Querbeschleunigung.
11

Kapitel 2. Sensorik
2.1.2. Beschleunigungssensor
Die Längs- und Querbeschleunigung lässt sich zwar aus den Raddreh-zahlsensoren bestimmen (s. Tabelle 2.1), jedoch unterliegt diese ver-schiedenen Störgrößen wie beispielsweise dem Radschlupf. Diese tre-ten verstärkt in fahrdynamischen Grenzsituationen auf, bei denen hoheBeschleunigungs- oder Verzögerungsraten erreicht werden.
Sowohl bei stärkeren Bremssituationen als auch bei sich durchdrehen-den Reifen repräsentiert die Strecke, die die Reifen gerollt sind, nicht mehrdie Strecke, die das Fahrzeug zurückgelegt hat. Somit wird die zurückge-legte Strecke ungenau bestimmt und damit alle von ihr abgeleiteten Grö-ßen, wie beispielsweise die Längs- und Quergeschwindigkeit und entspre-chende Beschleunigungen. Zur genaueren Bestimmung dieser Größen insolchen Szenarien können zusätzliche Beschleunigungssensoren helfen,welche die Beschleunigung in X- und Y-Richtung des Fahrzeuges messen.Durch die zeitliche Integration der Beschleunigung hat man eine weitereQuelle für die Geschwindigkeitsänderung, welche unempfindlicher in sol-chen Fahrsituationen ist.
Abbildung 2.2.: Schematisch dargestellter Beschleunigungssensor beste-hend aus einer seismischen Masse (blau) und verschiede-nen Kapazitäten (rot, grün)
Ein mögliches Messprinzip eines mikromechanischen Beschleunigungs-sensors ist in Abbildung 2.2 dargestellt: Er basiert auf einer seismischen
12

2.1. Sensorik zur Fahrdynamikerfassung des Ego-Fahrzeuges
Masse, welche sich bei Bewegung anderen Kondensatorplatten nähertbzw. entfernt. Dies bewirkt eine kapazitive Änderung, aus der die Beschleu-nigung abgeleitet werden kann. Für genauere Informationen zum physika-lischen Messprinzip sei auf [Zabler 2010, S. 75 ff] verwiesen.
Für die Bestimmung der Geschwindigkeit bzw. der zurückgelegten Stre-cke ist es zwar prinzipiell möglich, die Beschleunigung über die Zeit ein-oder zweimal zu integrieren. Hierbei gilt jedoch, dass sich die Messfehlermitintegrieren und Geschwindigkeit und zurückgelegte Strecke somit sehrungenau werden können.
Als alleiniger Odometriesensor zur Eigenbewegungsschätzung scheidetdieser somit aus, jedoch kann er insbesondere in Situationen, wo starkeBeschleunigungen auftreten, die Dynamikschätzung basierend auf Rad-drehzahlsensoren verbessern.
2.1.3. Gierratensensor
Die Gierrate kann wie die Beschleunigung in fahrdynamisch anspruchsvol-leren Situationen nur unzureichend aus dem Raddrehzahlsensor bestimmtwerden. Für Assistenzsysteme im Bereich der Fahrdynamikstabilisierungist jedoch die Bestimmung dieser Größe in genau solchen Situationen un-abdingbar. Hierbei ist insbesondere das elektronische Stabilitätsprogramm(engl. „Electronic Stability Control (ESC)“) zu nennen, welches ein Schleu-dern des Fahrzeuges erkennen muss.
Als alternativer Sensor eignet sich ein mikromechanischer Drehraten-sensor, welcher bei geeigneter Positionierung im Fahrzeug dessen Dreh-rate um die Z-Achse und somit dessen Gierrate misst. Innerhalb einessolchen Drehratensensors befindet sich eine seismische Masse, welchedurch einen Aktor in eine oszillierende Schwingung versetzt wird. Bei ei-ner Drehbewegung wird diese seismische Masse einer Corioliskraft aus-gesetzt, die die Schwingungsrichtung beeinflusst. Eine Richtungsänderungund dessen Stärke kann durch einen Beschleunigungssensor erfasst wer-den, der die Beschleunigung senkrecht zur ursprünglichen Schwingungs-richtung misst (vgl. [Zabler 2010, S. 130 ff].
Heutige in Fahrzeugen verbaute Beschleunigungs- und Gierratensenso-ren werden hauptsächlich als Eingangsgrößen für die Fahrdynamikstabili-sierung verwendet, welche nur größere Abweichungen zwischen dem vomFahrer gewünschten und tatsächlichen Kurs des Ego-Fahrzeuges feststel-len muss. Das zugrundeliegende Modell bestimmt dabei Schlupf einzel-ner Räder, Kurs- und Gierwinkel des Fahrzeuges mit Hilfe von Messun-gen des Lenkradwinkelsensor und Odometriesensoren (vgl. [von Zanten
13

Kapitel 2. Sensorik
2009]). Für Messungen zwecks genauer Eigenbewegungsschätzung sinddiese Sensoren jedoch nicht ausgelegt, weswegen ein beachtliches Mess-rauschen festgestellt werden muss, welches beispielsweise durch Fahr-zeugvibrationen und Unebenheiten der Fahrbahn verursacht wird.
Aus der zeitlichen Integration der Gierrate ψ kann zwar der Gierwinkel ψbestimmt werden, jedoch integrieren sich auch hier kleine Schätzfehler. ZuUngenauigkeiten kommt es insbesondere dann, wenn kein exakter Null-punktabgleich erfolgt und die Gierrate somit einen systematischen Fehleraufweist. Dies kann unter anderem stärkere Ungenauigkeiten bei der rela-tiven Positionsschätzung hervorrufen.
2.1.4. Inertialplattformen
Inertialplattformen (engl. „Inertial Measurement Unit (IMU)“) integrierenmeist mehrere höherwertige Beschleunigungs- und Gierratensensoren füralle drei Raumachsen und können somit eine relative Bewegung ermitteln.Einige IMUs weisen zusätzlich Empfänger auf, welche Signale globaler Sa-tellitennavigationssysteme und ggf. entsprechende Korrekturdaten aus an-deren Quellen auswerten können.
Durch diese globale Referenzierung gelingt eine Positionsbestimmungteilweise bis in den Zentimeterbereich, was eine genaue Eigenbewegungs-schätzung deutlich vereinfacht. Bei Verwendung mehrerer Antennen ist zu-dem die direkte Messung der Fahrzeugausrichtung möglich, sodass Gier-und sogar Schwimmwinkel leicht bestimmbar sind. Auch ermöglicht die ge-naue globale Positionierung eine ständige Kalibrierung der Odometriesen-soren, sodass beispielsweise ein Nullpunktabgleich schnell und genau er-folgen kann.
Insgesamt erreichen solche Inertialplattformen zwar eine sehr gutePositions- und Dynamikschätzung des Ego-Fahrzeuges, jedoch eignen siesich aus Kostengründen momentan nicht für serientaugliche Fahrerassis-tenzsysteme. Sie sind aber als Referenzsysteme im Forschungs- und Ent-wicklungsbereich prädestiniert.
2.1.5. Bewertung
In heutigen Serienfahrzeugen sind bereits viele Odometriesensoren ver-baut, die eine Eigenbewegungsschätzung erlauben. Sind bestimmte Ka-librationsdaten bekannt, so ist in fahrdynamisch wenig anspruchsvollenSituationen die Auswertung der Radimpulse vielversprechend. Bei star-ken Beschleunigungs- oder Bremsmanövern repräsentieren diese hinge-
14

2.2. Sensortechnologien zur Umfelderfassung
gen nicht mehr die vom Ego-Fahrzeug zurückgelegte Strecke, wobei dannauf mäßig genaue Beschleunigungs- und Gierratensensoren zurückgegrif-fen werden muss.
Insgesamt ist bei der Fusionierung dieser Odometriedaten mit einemSchätzfehlern zu rechnen, wobei hier insbesondere der Gierwinkel hervor-zuheben ist. Einerseits wird dieser nur durch Integration von bestimmtenSchätzgrößen ermittelt, wobei sich Fehler mitintegrieren, andererseits kön-nen bereits kleine Gierwinkelfehler laterale Scheinbewegungen von Objek-ten in größerer Entfernung verursachen und die Assoziation von Objekthy-pothesen erschweren.
Abhilfe schaffen natürlich bessere Sensoren, welche bereits in verschie-denen Kosten- und Genauigkeitsabstufungen innerhalb fertiger Inertial-plattformen verfügbar sind und um Größenordnungen genauere Schätzun-gen erlauben. Um die Verbreitung künftiger Fahrerassistenzsysteme zufördern, sollte jedoch möglichst auf solche aufwendigen Plattformen ver-zichtet und versucht werden, mit der Schätzgüte vorhandener Sensorenumzugehen.
2.2. Sensortechnologien zur Umfelderfassung
Für Fahrerassistenzsysteme ist eine Erfassung des Fahrzeugumfeldes not-wendig, wobei je nach Fahrerassistenzapplikation verschiedenste Aspek-te berücksichtigt werden müssen: Einige benötigen Informationen andererVerkehrsteilnehmer und Hindernisse, aber auch Fahrstreifenverläufe, Ver-kehrszeichen und erkannte Gefahrenstellen können von Interesse sein. Ei-ne solche Umfelderfassung ist nur mittels zusätzlicher Sensorik möglich,welche in diesem Abschnitt vorgestellt wird.
2.2.1. Monokamerasensor
Monokamerasensoren messen mithilfe einer Optik und eines lichtempfind-lichen CCD- oder CMOS-Sensors einstrahlendes Licht. Hierbei werdenHelligkeiten, Azimut- und Elevationswinkel und je nach Funktion auch Farb-werte erfasst, sodass eine zweidimensionale Projektion eines Umgebungs-ausschnitts entsteht. Es können jedoch keine Tiefen- oder Geschwindig-keitsinformationen direkt gemessen werden.
Mithilfe bildverarbeitender Algorithmen wird versucht, aus diesen Bildernbestimmte Größen zu extrahieren, welche für ein Fahrerassistenzsystemhilfreich sein könnten. Hierzu gibt es zwei unterschiedliche Methoden:
15

Kapitel 2. Sensorik
Die erste Methode ist stark modellbehaftet und sucht Entitäten bekann-ter Klassen im gegebenen Bild aufgrund bekannter Merkmale. Dazu gehö-ren beispielsweise:
• Fahrstreifenmarkierungen
• Verkehrszeichen
• Andere Verkehrsteilnehmer einer definierten Klasse (z. B. Autos,Fußgänger)
(a) Originalbild mit Fahrstreifenmarkie-rungen, Teernähten, Verkehrszei-chen, Abschattungen und Fahrzeu-gen
(b) Die Anwendung des Canny-Operators liefert viele möglicheHypothesen
Abbildung 2.3.: Anwendung des Canny-Kantendetektionsalgorithmus[Canny 1987] auf eine Verkehrsszene (Bundesautobahn39, nahe Wolfsburg)
Hierzu werden zunächst recht einfache Bildoperatoren angewendet, diebestimmte allgemeine Merkmale extrahieren, welche sich auch in der zudetektierenden Objektklasse wiederfinden. Für eine Fahrstreifenmarkie-rungserkennung ist beispielsweise ein Kantendetektor hilfreich, der Bildbe-reiche mit starken Gradienten findet (vgl. Abbildung 2.3 und [Canny 1987]).Bildausschnitte, in denen diese Merkmale vorkommen, bilden eine Men-ge von zu validierenden Hypothesen. Die Validierung kann beispielsweiseüber manuell definierte Nebenbedingungen erfolgen:
So erwartet man beispielsweise bei Fahrstreifenmarkierungen aufgrundihrer genormten Strichbreiten zwei in etwa parallel ausgerichtete Kanten,welche einen Abstand in einem bestimmten Intervall aufweisen. Meist sind
16

2.2. Sensortechnologien zur Umfelderfassung
die Fahrstreifenmarkierungen auch heller als der Straßenbelag, sodass zu-sätzliche Randbedingungen definiert werden können, die bestimmte Gra-dientenausrichtungen an den beiden Kanten verlangen. Auch ist die Defini-tion einer Mindestkantenlänge im Bildraum vorteilhaft, um Fehldetektionenweiter zu reduzieren.
Bei Objekten mit vielen komplexen und unterschiedlichen Merkmalen,wie beispielsweise bei Autos aus verschiedenen Perspektiven oder Fuß-gängern, ist die manuelle Definition solcher Randbedingungen sehr auf-wendig. Alternativ bieten sich sog. „überwachte Lernverfahren“ zur Hypo-thesenvalidierung an: Hierbei werden die detektierten Objektmerkmale ei-nes Bildausschnitts auf einen Vektor abgebildet, welcher eine Objekthy-pothese im Zustandsraum des verwendeten Klassifikators darstellt. DerKlassifikator wird dabei aus Lerndaten approximiert, wobei für das An-lernen neben dem Eingabevektor auch eine korrespondierende „GroundTruth“-Objektklasse benötigt wird. Für genauere Informationen zur Merk-malsgenerierung bzw. überwachten Lernverfahren sei auf [Sun 2006] bzw.Abschnitt 4.6.3 verwiesen.
Abbildung 2.4.: Optischer Fluss (rote Pfeile) für ein Verkehrsszenario, indem das Ego-Fahrzeug einen LKW überholt (rechter Fahr-streifen) und gleichzeitig von anderen Fahrzeugen überholtwird (linker Fahrstreifen)
Eine zweite Methode zur Umgebungserfassung ist modellärmer und er-möglicht teilweise die Detektion allgemeiner Objekte. Hierzu wird der sog.„optische Fluss“ aus zwei aufeinanderfolgenden Bildern bestimmt, welcherdie Verschiebung von korrespondierenden Bildpunkten mithilfe eines Vek-torfeldes beschreibt. Das gemittelte Ergebnis einer Bilderserie für einenoptischen Fluss ist beispielhaft in Abbildung 2.4 dargestellt.
17

Kapitel 2. Sensorik
Eine Möglichkeit diesen zu berechnen besteht in der Annahme, dassGrauwerte an korrespondierenden Stellen in den Einzelbildern eine kon-stante Helligkeit aufweisen. Das entsprechende Vektorfeld kann dann mit-hilfe von Helligkeitsdifferenzen berechnet werden. Für Details zu dieserMethode sei auf [Lucas 1985] verwiesen.
Für die Erzeugung des optischen Flusses ist es wichtig, dass bestimmteTeile und Punkte in den Bildern wiedererkannt werden können. So ist bei-spielsweise die Berechnung für eine einfarbige Fläche mit konstanter Hel-ligkeit ohne eindeutige Texturen nicht möglich, wie es bei Straßenbelägenhäufig der Fall ist. Auch sich wiederholende Muster sowie Belichtungsän-derungen erschweren eine eindeutige Bestimmung der Verschiebung.
Das erzeugte Vektorfeld wird anschließend mithilfe weiterer Algorithmenausgewertet: Diese nehmen an, dass der optische Fluss durch eine tat-sächliche Relativbewegung von Umfeldobjekten entstanden ist und nichtdurch andere Projektionseffekte beeinflusst worden ist. Zur Objektdetek-tion wird das Bewegungsfeld, welches sich aus Kameraparametern, derEgobewegung und der Annahme einer planaren Ebene ergibt, mit demtatsächlichen optischen Fluss verglichen. Differenzen deuten auf Umfeld-objekte hin. Für beispielhafte Algorithmen hierzu sei auf [Giachetti 1998]verwiesen.
Zur Objektzustandsbestimmung kann die ermittelte Vektorlänge inner-halb des optischen Flusses herangezogen werden: Diese ist für eine Bild-position von Entfernung und relativer Geschwindigkeit abhängig. Ist Letzte-re aus der bekannten Ego-Geschwindigkeit und statischen Objektannahmebekannt, so lässt sich eine Tiefeninformation generieren. Je nach Kamera-ausrichtung und Relativbewegung können hier unterschiedlich gut ausge-prägte Detektionsbereiche entstehen.
Bei der häufig anzutreffenden frontalen Kameraausrichtung und Vor-wärtsbewegung des Ego-Fahrzeuges gilt: Je größer die Entfernung einesObjektpunktes zur Bewegungsachse ist, desto genauer kann die Tiefenin-formation bestimmt werden. Dies ist durch die stärkere Verschiebung vonBildpunkten in diesen Bereichen begründet, was Störungen durch Nickenund Wanken des Ego-Fahrzeuges und die durch die Bilddiskretisierungverursachten Ungenauigkeiten besser ausgleicht.
Ohne Relativgeschwindigkeitsannahme kann die Entfernung eines Ob-jekts zwar nicht modellarm bestimmt werden, jedoch deren Quotient [Mey-er 1992]. Dieser beschreibt die Zeit bis zur Kollision (engl. „Time-To-Collision (TTC)“) mit dem Ego-Fahrzeug bzw. bei ausreichendem lateralenVersatz die Zeit bis zum Passieren des Objektes. Diese Eigenschaft wirdabgewandelt im Abschnitt 4.4.3 wieder aufgegriffen.
Bei der Bewertung von Monokamerasensoren fällt insbesondere die Lü-
18

2.2. Sensortechnologien zur Umfelderfassung
cke zwischen theoretisch erreichbarer Leistung und Stand der Technik auf:Einerseits werten diese Sensoren den für die menschliche Wahrnehmungwichtigen visuellen Informationskanal aus und erhalten somit fast alle In-formationen, wie sie auch ein Mensch bekommen würde. Da die Verkehrs-infrastruktur besonders für den visuellen Wahrnehmungskanal optimiertist, haben diese Sensoren theoretisch das Potenzial, alle wesentlichenUmfeldaspekte detektieren zu können.
Andererseits ist jedoch die sichere Wahrnehmung von Entitäten mit kom-plexen und variablen Merkmalen problematisch. Diese erfolgt häufig übermustererkennende Algorithmen, welche auf spezielle Klassen trainiert sindund meist keine perfekte Klassifikationsleistung liefern, was beispielsweisein [Schiele 2009] im Bereich der Fußgängererkennung gezeigt wird. Aucherzeugen diese Klassifikatoren keine Entfernungsinformation, sodass die-se über weitere Modellannahmen generiert werden muss. Hierzu kannder Vergleich von Abbildgröße und angenommener realer Größe heran-gezogen werden. Dennoch bleibt die Gewinnung eines genauen Objekt-zustandsvektors mit Monokamerasensoren sehr schwierig, was eine Rele-vanzklassifikation von Objekten erschwert.
Als passiver Sensor ist die Monokamera zudem von nicht steuerba-ren Lichtverhältnissen abhängig, sodass die Detektionsbedingungen in derUmwelt sehr variabel ausfallen können, was eine korrekte Klassifikationweiter erschweren kann.
Neben der Mustererkennung wurde noch die modellarme Möglichkeitvorgestellt, die Objektdetektion mithilfe des optischen Flusses zu bewerk-stelligen. Diese Methode liefert jedoch bei der üblichen frontalen Kame-raausrichtung für Objekte im Bereich des Fahrschlauchkorridors aufgrundder geringen Punktverschiebungen im Bild eine schlechte Detektionsleis-tung, wobei jedoch für viele Fahrerassistenzapplikationen gerade dieserBereich wichtig ist. Des Weiteren ist bei dieser Methode meist die Auswer-tung von mehreren Bildern notwendig, was eine gewisse Verzögerung inerkennbaren Gefahrensituationen bedeuten kann.
In der Vergangenheit wurden Monokameras deshalb vor allem zur De-tektion von Entitäten mit klaren oder gar genormten Merkmalen verwendet,wie Verkehrszeichen und Fahrstreifenmarkierungen. Bei diesen sind bisauf den lateralen Versatz und fahrstreifenrelativer Gierwinkel kaum wei-tere Zustandsinformationen für die Fahrerassistenzapplikationen notwen-dig. Obwohl diese Objekte von den Mustern her recht einfach sind, gibtes auch hier Fehlalarme und ausbleibende Erkennung durch verschmutzteoder teilweise verdeckte Verkehrszeichen bzw. durch Teernähte oder durchabgefahrene Fahrbahnmarkierungen.
19

Kapitel 2. Sensorik
2.2.2. Stereokamerasensor
Stereokamerasensoren bestehen aus zwei Kameras, welche in einem be-stimmten Abstand (Basisbreite) voneinander angeordnet sind und einenUmgebungsausschnitt aus unterschiedlichen Perspektiven vermessen. DieMessungen erfolgen synchron, wobei in den beiden Abbildern eine Tie-fenschätzung durch Vergleich der Verschiebung (Disparität) einzelner Bild-punkte bzw. Muster erzeugt wird. Die Tiefe ist antiproportional zur Dispa-rität und proportional zur Basisbreite und Brennweite der Objektive. Durchdie Synchronität der beiden Messungen wird die Auswertung kaum durchNick- und Wankbewegungen des Ego-Fahrzeuges oder unbekannten Ob-jektdynamiken gestört, wie es beim optischen Fluss der Fall ist. Für einegenauere Beschreibung der geometrischen Grundlagen, die für die Verar-beitung von Stereobildern notwendig sind, sei auf [Faugeras 2004] verwie-sen.
(a) Originalbild (b) Disparitätsbild
Abbildung 2.5.: Beispielhafte Disparitätsberechnung (rechtes Bild) für ei-ne Verkehrsszene (linkes Bild). Korrespondierende Punktesind je nach Entfernung orange (nah) oder blau (fern) ein-gefärbt. Für schwarze Pixel konnte keine Entfernungsinfor-mation generiert werden.
Bei der Bilderauswertung wird versucht, eine möglichst dichte Tiefenkar-te zu erstellen. Wie beim optischen Fluss ist die Disparitätsbestimmungfür monotone Flächen und sich wiederholende Muster jedoch nicht immereindeutig möglich, sodass die Karte eventuell Löcher unbekannter Dispa-rität aufweist, was Abbildung 2.5 beispielhaft zeigt. Um Objektinformatio-nen aus der generierten Tiefenkarte zu erzeugen, wird zunächst eine Ebe-nenschätzung erzeugt. Hierzu wird in der Tiefenkarte ein kontinuierlicherGradient in Höhenrichtung gesucht, der durch die Fahrbahnebene verur-
20

2.2. Sensortechnologien zur Umfelderfassung
sacht wurde. Tiefenschätzungen, die von der Ebenenschätzung abwei-chen, werden einem Clusteralgorithmus unterworfen und zu einzelnen Ob-jekten zusammengefasst. Häufig wird hierbei das Quadermodell verwen-det, sodass die Objekthypothese eine Längen-, Breiten- und Höhenschät-zung aufweist. Bei der Clusterung von Objekten mit monotonen Flächen,für die keine vollständige Disparitätsinformationen generiert wurden, kön-nen Ungenauigkeiten und Mehrdeutigkeiten auftreten: Eine genaue Kon-turschätzung für solche nur teilweise erfassten Objekte ist schwierig undim Extremfall können solche Objekte sogar in mehrere Objekthypothesenzerfallen.
Stereokamerasensoren können zusätzlich Algorithmen zur Auswertungvon Einzelbildern implementieren und erreichen somit mindestens die Leis-tungsfähigkeit einer Monokamera. Durch die Ebenen- und Tiefenschätzungkönnen sogar mehr Randbedingungen in den Klassifikatoren verwendetwerden, sodass diese genauer ausfallen. So können beispielsweise detek-tierte Kanten als Fahrstreifenmarkierung ausscheiden, wenn diese nichtdie Höhe der Ebenenschätzung aufweisen. Auch können die meisten run-den Verkehrszeichen von Rädern anhand der Höhenschätzung unterschie-den werden.
Zur Objektdetektion verwenden Stereokamerasensoren jedoch die mo-dellärmere und robustere Wahrnehmung über die Disparitätskarte, anstatteinen Klassifikator zu verbessern. Die Objektklassifikation kann jedochauch sinnvoll in der Stereokamera eingesetzt werden: Einerseits könnenallgemeine aus der Disparitätskarte gewonnene Umfeldobjekte einer Klas-se zugeordnet werden, die ein Fahrerassistenzsystem unterschiedlich be-handeln kann, andererseits können Monoalgorithmen bei gleicher Auflö-sung höhere Reichweiten erzielen. Letzteres ist damit begründet, dassdie Disparitätsbestimmung auf Pixelebene ab einer bestimmten Entfernungspätestens an der endlichen Bildauflösung scheitert, während Objekte abeiner bestimmten Größe noch als Muster erkennbar sind.
Insgesamt können Stereokamerasensoren wie Monokamerasensorenviele Umfeldentitäten erfassen, besitzen aber zusätzlich eine bessere Ob-jekterkennung und durch eine Kombination von Mono- und Stereokame-raalgorithmen eine vergleichsweise gute Zustandsschätzung. Durch dieBestimmung einer Tiefenkarte können zudem Klassifikatoren für ande-re Umfeldentitäten bessere Randbedingungen nutzen, sodass diese ge-nauer ausfallen. Durch die Ebenenbestimmung können zudem Nick- undWankbewegungen des Ego-Fahrzeuges geschätzt werden, welche u. a.zur Messwertkompensation anderer Sensoren verwendet werden können.
Nachteilig bei aktuellen Stereokamerasensoren ist insbesondere die be-grenzte Reichweite der Disparitätskarte, was eine robuste Objekterken-
21

Kapitel 2. Sensorik
nung nur in einem mittleren Abstand ermöglicht. Eine Reichweitensteige-rung ist aufwendig, da die benötigte Bildauflösung quadratisch zur Entfer-nung ansteigt. Auch erfordert eine Vergrößerung der Auflösung eine ent-sprechend verbesserte Optik und eine genauere Kalibrierung. Eine Erhö-hung der Basisbreite oder Brennweite würde zwar die erzielbare Reichwei-te vergrößern, jedoch gleichzeitig den auswertbaren Öffnungswinkel desSensors reduzieren.
Als passiver Sensor ist die Stereokamera wie die Monokamera auchvon externen Lichtverhältnissen abhängig. So müssen detektierbare En-titäten ein Mindestmaß an Ausleuchtung aufweisen, was insbesondere beiDämmerung oder Dunkelheit problematisch sein kann: Im schlechtestenFall muss hier die Ausleuchtung alleine von den Scheinwerfern des Ego-Fahrzeuges vorgenommen werden, wobei die Lichtintensität mit steigen-der Entfernung abnimmt und somit den Detektionsbereich potentiell weitereinschränkt. Auch starke externe Lichtquellen wie Scheinwerfer könnendie Messergebnisse von schwach beleuchteten Objekten negativ beein-flussen.
Als weiterer Nachteil ist die schlechtere Verbaubarkeit zu nennen, dader Sensor so in ein Fahrzeug integriert werden muss, dass seine Sichtmöglichst vor Schmutz geschützt wird. Hierzu kommt wie bei der Mono-kamera als kostengünstige Lösung praktisch nur der Bereich hinter demInnenspiegel infrage, welcher durch den bereits integrierten Scheibenwi-scher schmutzfrei gehalten werden kann und die freie Sicht des Fahrersnicht behindert. In diesem Bereich sind insbesondere kompakte Sensorengefragt, wobei die Breite einer Stereokamera jedoch prinzipbedingt min-destens so groß sein muss wie dessen Basisbreite. Die Basisbreite kannman ohne Reichweitenverlust jedoch nicht reduzieren, ohne dass man dieBildauflösung wieder entsprechend erhöht.
2.2.3. Radarsensor
Radarsensoren emittieren elektromagnetische Wellen, welche von Objek-ten teilweise reflektiert werden. Diese reflektierte Strahlung kann vom Ra-darsensor detektiert werden, wobei sich abhängig vom Verfahren folgendeMessgrößen direkt gewinnen lassen:
• Frequenz bzw. Phasenlage
• Intensität
• Signallaufzeit (nur bei gepulsten Modulationen)
22
2.2. Sensortechnologien zur Umfelderfassung
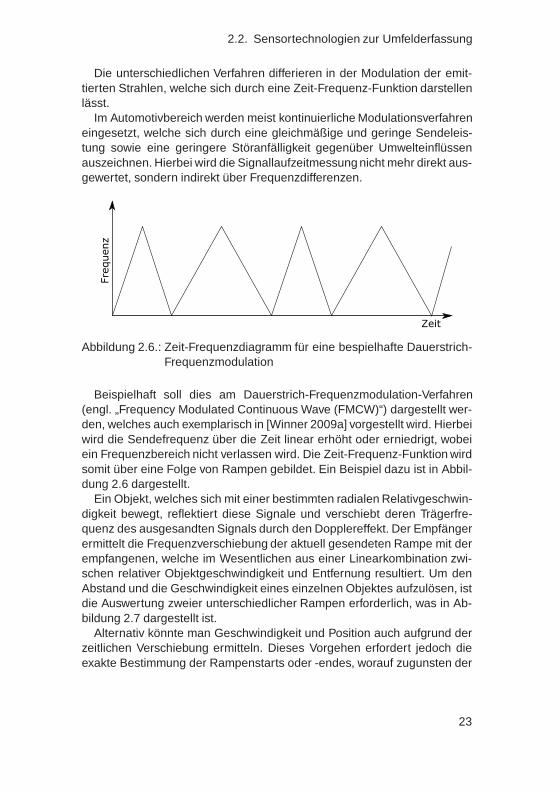
Die unterschiedlichen Verfahren differieren in der Modulation der emit-tierten Strahlen, welche sich durch eine Zeit-Frequenz-Funktion darstellenlässt.
Im Automotivbereich werden meist kontinuierliche Modulationsverfahreneingesetzt, welche sich durch eine gleichmäßige und geringe Sendeleis-tung sowie eine geringere Störanfälligkeit gegenüber Umwelteinflüssenauszeichnen. Hierbei wird die Signallaufzeitmessung nicht mehr direkt aus-gewertet, sondern indirekt über Frequenzdifferenzen.
Zeit
Frequenz
Abbildung 2.6.: Zeit-Frequenzdiagramm für eine bespielhafte Dauerstrich-Frequenzmodulation
Beispielhaft soll dies am Dauerstrich-Frequenzmodulation-Verfahren(engl. „Frequency Modulated Continuous Wave (FMCW)“) dargestellt wer-den, welches auch exemplarisch in [Winner 2009a] vorgestellt wird. Hierbeiwird die Sendefrequenz über die Zeit linear erhöht oder erniedrigt, wobeiein Frequenzbereich nicht verlassen wird. Die Zeit-Frequenz-Funktion wirdsomit über eine Folge von Rampen gebildet. Ein Beispiel dazu ist in Abbil-dung 2.6 dargestellt.
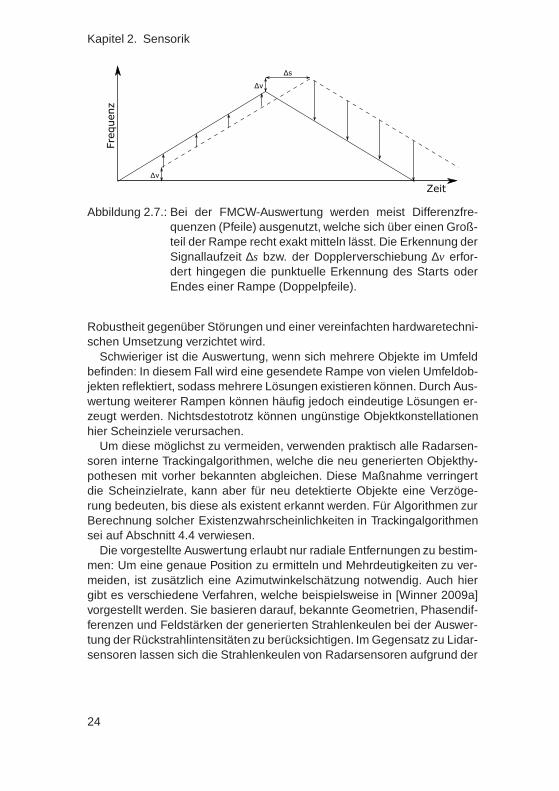
Ein Objekt, welches sich mit einer bestimmten radialen Relativgeschwin-digkeit bewegt, reflektiert diese Signale und verschiebt deren Trägerfre-quenz des ausgesandten Signals durch den Dopplereffekt. Der Empfängerermittelt die Frequenzverschiebung der aktuell gesendeten Rampe mit derempfangenen, welche im Wesentlichen aus einer Linearkombination zwi-schen relativer Objektgeschwindigkeit und Entfernung resultiert. Um denAbstand und die Geschwindigkeit eines einzelnen Objektes aufzulösen, istdie Auswertung zweier unterschiedlicher Rampen erforderlich, was in Ab-bildung 2.7 dargestellt ist.
Alternativ könnte man Geschwindigkeit und Position auch aufgrund derzeitlichen Verschiebung ermitteln. Dieses Vorgehen erfordert jedoch dieexakte Bestimmung der Rampenstarts oder -endes, worauf zugunsten der
23
Kapitel 2. Sensorik
Zeit
Frequenz
Δs
Δv
Δv
Abbildung 2.7.: Bei der FMCW-Auswertung werden meist Differenzfre-quenzen (Pfeile) ausgenutzt, welche sich über einen Groß-teil der Rampe recht exakt mitteln lässt. Die Erkennung derSignallaufzeit ∆s bzw. der Dopplerverschiebung ∆v erfor-dert hingegen die punktuelle Erkennung des Starts oderEndes einer Rampe (Doppelpfeile).
Robustheit gegenüber Störungen und einer vereinfachten hardwaretechni-schen Umsetzung verzichtet wird.
Schwieriger ist die Auswertung, wenn sich mehrere Objekte im Umfeldbefinden: In diesem Fall wird eine gesendete Rampe von vielen Umfeldob-jekten reflektiert, sodass mehrere Lösungen existieren können. Durch Aus-wertung weiterer Rampen können häufig jedoch eindeutige Lösungen er-zeugt werden. Nichtsdestotrotz können ungünstige Objektkonstellationenhier Scheinziele verursachen.
Um diese möglichst zu vermeiden, verwenden praktisch alle Radarsen-soren interne Trackingalgorithmen, welche die neu generierten Objekthy-pothesen mit vorher bekannten abgleichen. Diese Maßnahme verringertdie Scheinzielrate, kann aber für neu detektierte Objekte eine Verzöge-rung bedeuten, bis diese als existent erkannt werden. Für Algorithmen zurBerechnung solcher Existenzwahrscheinlichkeiten in Trackingalgorithmensei auf Abschnitt 4.4 verwiesen.
Die vorgestellte Auswertung erlaubt nur radiale Entfernungen zu bestim-men: Um eine genaue Position zu ermitteln und Mehrdeutigkeiten zu ver-meiden, ist zusätzlich eine Azimutwinkelschätzung notwendig. Auch hiergibt es verschiedene Verfahren, welche beispielsweise in [Winner 2009a]vorgestellt werden. Sie basieren darauf, bekannte Geometrien, Phasendif-ferenzen und Feldstärken der generierten Strahlenkeulen bei der Auswer-tung der Rückstrahlintensitäten zu berücksichtigen. Im Gegensatz zu Lidar-sensoren lassen sich die Strahlenkeulen von Radarsensoren aufgrund der
24

2.2. Sensortechnologien zur Umfelderfassung
größeren Wellenlänge weniger fein fokussieren, sodass dieses Verfahreneine im Allgemeinen schlechtere Objektdiskriminierung über Azimutwinkelerlaubt.
Besonders schwierig für Radarsensoren ist deshalb die Erkennung sog.„Gassensituationen“, in denen zwei Objekte mit annähernd der gleichenGeschwindigkeit nebeneinander fahren. Diese Objekte weisen einen an-nähernd gleichen radialen Abstand und Geschwindigkeit auf, weshalb sienur über den Azimutwinkel unterschieden werden können. Ist die Auflö-sung zu grob, können diese beiden interferierenden Objekte als ein einzel-nes großes aufgefasst werden, wobei sich scheinbar die Lücke zwischenden beiden Objekten schließt. Dieser Fall kann insbesondere auch bei sta-tischer Randbebauung auftreten, da diese exakt die gleiche relative Ob-jektgeschwindigkeit aufweisen.
Die vorgestellte Messwertauswertung basiert insgesamt darauf, dass je-des relevante Objekt möglichst in seinem definierten Ursprung oder gleich-mäßig über seine gesamte Fläche einen gewissen Anteil der Radarwellenzum Sensor reflektiert.
Einerseits kann je nach Geometrie und Ausrichtung des Objektes derRadarquerschnitt variieren und möglicherweise so wenig Signalleistungzurückreflektiert werden, dass diese unterhalb der Detektionsschwelleliegt: So beschreiben auch die ISO-Normen für ACC [ISO 2002, 2008],dass Radarsensoren nur Objekte in einem definierten Bereich detektie-ren müssen, welche einen Radarquerschnitt von mindestens 10 m2± 3 m2
aufweisen. Dies entspricht lt. den ISO-Normen nur 95 % aller Fahrzeuge,sodass für diese keine sichere Detektion gefordert wird.
Andererseits können an einem ausgedehnten Objekt bestimmte Berei-che die Radarwellen deutlich besser zurückreflektieren als andere: So wer-den in [Winner 2009a] die Einstiegstreppen von Lkws genannt, welche häu-fig einen erhöhten Radarquerschnitt aufweisen. Aber auch andere konkaveFlächen, wie beispielsweise Radkästen und Gehäuse von konventionellenRücklichtern können bevorzugte Reflexionsflächen darstellen. Diese befin-den sich häufig an Ecken der Objektkontur, sodass trotz einer geanuen Azi-mutwinkelauflösung die Interpretation schwierig bleibt, wie eine Objektkon-tur unbekannten Ausmaßes an diesen ausgewerteten Punkt anzuordnenist. Erkennt der Radarsensor mehrere Reflexionspunkte der Objektkontur,so kann die Konturschätzung mithilfe von Clusteralgorithmen verbessertwerden (vgl. [Maurer 2004]).
Neben Objekten, die einen schlechten Radarquerschnitt aufweisen,existieren auch Scheinobjekte im Sinne der Fahrerassistenzapplikation mitzum Teil hohen Radarquerschnitten. Hierbei sind einerseits überfahrba-re Objekte wie beispielsweise Getränkedosen [Jordan 2006; Steinmeyer
25

Kapitel 2. Sensorik
Abbildung 2.8.: Systematisches, durch Tracking aufrechterhaltenes Radar-Fehlziel (rotes Kreuz, mitte) verursacht durch Schilderbrü-cke
2009] oder Bahnschienen zu nennen, andererseits auch unterfahrbare Ob-jekte wie eine in Abbildung 2.8 dargestellte Schilderbrücke.
Um die Probleme mit statischen Scheinzielen zu vermeiden, blendenviele Radarsensoren statische Objekte aus bzw. solche, bei denen wäh-rend des Trackings keine Bewegung festgestellt werden konnte. DiesesVorgehen wird auch von den ISO-Normen [ISO 2002, 2008] für ACC un-terstützt.
Andere Radarsensoren versuchen Scheinziele herauszufiltern, indemsie Rückstrahlintensitäten und Winkelmessungen über eine längere Stre-cke beobachten. So werden in [Jordan 2006] Gassensituationen erkannt,indem im Trackingalgorithmus eine hohe Varianz der Messwerte zur Ob-jekthypothese festgestellt wird, was durch einzelne Winkelmessfehler in-terferierender Objekte verursacht wird. Über- und unterfahrbare Objektewerden hingegen über eine Verteilungsanalyse der Rückstrahlintensitätenklassifiziert, welche sich von relevanten Hindernissen unterscheidet. Dieunterschiedlichen Verteilungen resultieren aus einer unterschiedlich star-ken Änderung des Elevationsmesswinkels über die Strecke bei über- oderunterfahrbaren Objekten im Vergleich zu relevanten Hindernissen auf Hö-he des Radarsensors. Problematisch an der Methode ist jedoch die Not-wendigkeit der längeren Objektbeobachtung, was im Vergleich zur Sensor-reichweite eine späte Hindernisklassifikation zur Folge haben kann. Auchkönnen vom Klassifikator relevante Ziele als irrelevant angesehen werden(vgl. [Jordan 2006]).
26

2.2. Sensortechnologien zur Umfelderfassung
2.2.4. Lidarsensor
Lidarsensoren basieren auf der Aussendung eines Lichtimpulses, welchevon einem oder mehreren Objekten reflektiert wird. Die Laufzeit des reflek-tierten Lichtimpulses misst der Lidarsensor und ermittelt daraus die Ob-jektentfernung. Die meisten Lidarsensoren sind mehrzielfähig und somit inder Lage, mehrere Reflexionen eines Lichtimpulses auszuwerten.
Aufgrund der geringen Wellenlänge von Infrarotlicht lassen sich dieseLichtstrahlen besser fokussieren als dieses bei Radarsensoren der Fall ist.Vorteilig an diesem Messprinzip ist die Möglichkeit, genaue Objektkontu-ren vermessen zu können, nachteilig die teilweise hohe Empfindlichkeitgegenüber Nick- und Wankbewegungen des Ego-Fahrzeuges. Dies kannden Messpunkt beim Zielobjekt leicht verschieben, was bei Objekten mitnicht senkrecht zum Sensor ausgerichteten Oberflächen zu geringen Ab-standsänderungen führen kann. Da die Dynamikeigenschaften von keinemLidarsensor direkt gemessen, sondern über Trackingverfahren abgeleitetwerden, können solche Effekte Scheinbeschleunigen hervorrufen.
Für den Automotivbereich existieren verschiedene Lidarsensoren, wel-che sich vor allem in der Methodik zur Abtastung der Umgebung und derAnzahl der Scan-Ebenen unterscheiden:
• Feste Lidarsensoren: Diese Lidarsensoren enthalten ein Array vonSende- und Empfangseinheiten,welche jeweils einen konstanten Be-reich abdecken. Sie sind sehr robust, da sie keine bewegliche Me-chanik enthalten.
• Schwenkende Lidarsensoren: Diese Lidarsensoren weisen einebewegliche Optik auf, mit der die Strahlen zu einem gewissen Gradgelenkt werden können. Sie erlauben es somit einen größeren Be-reich mit weniger Sende- und Empfangseinheiten abzudecken, alsfeste Lidarsensoren.
• Laserscanner: Bei Laserscannern rotiert die Ausrichtung derSende- und Empfangseinheit. Dies kann direkt durch eine Rotationdes gesamten Sensors geschehen oder indirekt über einen rotieren-den Spiegel, der die emittierten und reflektierten Laserstrahlen in dieentsprechende Richtung bzw. Empfangseinheit lenkt. Laserscannerweisen hohe Öffnungswinkel von bis zu 360 auf und werden häufigim Forschungsbereich eingesetzt.
Schwenkende Lidarsensoren und Laserscanner haben den Nachteil,dass zur Synchronisation eines Messzyklus eine Eigenbewegungsschät-zung notwendig ist, da die einzelnen Messungen sich über einen gewissen
27

Kapitel 2. Sensorik
Messzeitraum verteilen. Ungenaue Eigenbewegungsschätzungen könnensomit Schereffekte hervorrufen.
Alle Lidarsensoren benötigen freie Sicht auf ein Objekt, um dieses zudetektieren. Einschränkungen durch Nebel, starker Niederschlag oder Ver-schmutzungen am Sensor können Detektionen von Objekten verhindern.Allerdings sind die meisten Sensoren selbstdiagnosefähig, sodass solcheStörungen erkannt und an die Fahrerassistenzapplikation gemeldet wer-den können (vgl. [Geduld 2009]).
(a) Schwarze Limousinen sind für Li-darsensoren potenziell Ziele mit ge-ringer Reflektivität
(b) Im Laserscan können kaum Refle-xionen (weiße Punkte) für diesesZiel detektiert werden
Abbildung 2.9.: Nichtdetektiertes Ziel eines Laserscanners (Bilder aus [Pe-trovskaya 2009])
Wie bei Radarsensoren hängt die Detektierbarkeit anderer Objekte vonder Reflektivität bzgl. der emittierten Strahlung ab, weshalb die Geome-trie und Ausrichtung des Objektes auch hier ein wesentlicher Faktor dar-stellt. Als weiterer Einflussfaktor kommt bei Lidarsensoren jedoch einehohe Lichtabsorbtionsfähigkeit von einigen Objekten hinzu: Während diemeisten Fahrzeuge für Radarsensoren viele gut reflektierende Metallober-flächen aufweisen, können Autos mit schwarzen Oberflächen nicht immerdetektiert werden (vgl. Abbildung 2.9).
Neben Objekten können bei entsprechender Sensorausrichtung auchFahrstreifenmarkierungen detektiert werden, indem neben Signallaufzeitzusätzlich die Intensität der Reflexion gemessen wird (vgl. [Dietmayer2005b]). Hierbei wird der Umstand ausgenutzt, dass Fahrbahnmarkierun-gen speziell darauf optimiert sind, möglichst viel Licht zurückzureflektieren,damit sie der Fahrer gut wahrnehmen kann. Vorteilhaft gegenüber der ka-merabasierten Fahrstreifenerkennung ist das aktive Messprinzip, sodass
28

2.2. Sensortechnologien zur Umfelderfassung
die Erkennung weitestgehend unabhängig von den Lichtverhältnissen derUmgebung ist.
2.2.5. Ultraschallsensoren
Ultraschallsensoren nutzen sog. „piezoelektrische Materialien“, welchebeim Anlegen einer Spannung Schallwellen emittieren können und um-gekehrt eine Spannung erzeugen, wenn sie durch reflektierte Schallwellenverformt werden.
Das Messprinzip zur Objekterkennung beruht insgesamt auf einer Lauf-zeitmessung der emittierten und reflektierten Schallwellen, wobei im Ge-gensatz zu Lidarsensoren statt der Lichtgeschwindigkeit nur die viel lang-samere Schallgeschwindigkeit in der Luft berücksichtigt werden muss, wasgeringere Anforderungen an den Zeitgeber in der Signalverarbeitung nachsich zieht. Als Ergebnis liefern Ultraschallsensoren radiale Abstände vonObjekten im Messsektor oder sie lassen auf einen leeren Sektor bei nichtdetektierter Reflexion schließen. Für Genaueres zum piezoelektrischen Ef-fekt und dessen Anwendung in Ultraschallsensoren sei auf [Noll 2009] ver-wiesen.
Ultraschallsensoren haben eine vergleichsweise kurze Reichweite, sinddafür aber relativ kostengünstig und kompakt, weshalb sie vielfach im Be-reich der Parkassistenzsysteme verwendet werden. Um ausgedehnte Ob-jekte und Objektpositionen genauer bestimmen zu können, werden meh-rere mit bekanntem Abstand angeordnete Ultraschallsensoren verwendet,welche die unterschiedlichen Laufzeiten eines einzelnen Sendeimpulsesmessen und durch eine Multilateration eine bessere Schätzung erreichen.
Neben Objektabstandsbestimmungen verwenden einige Fahrerassis-tenzsysteme die inverse Belegungsinformation und validieren damit, obein bestimmter Bereich frei oder belegt ist. Anwendungen hierbei sind dieParklückenvermessung und Spurwechselassistenz. Bei Letzterer wird auf-grund der geringen Reichweite nur der tote Winkel überwacht, sodass vorschnell überholenden Fahrzeugen nicht rechtzeitig gewarnt werden kann.
Ultraschallsensoren haben wie alle aktiven Sensoren den Nachteil, dassihre emittierten Signale ausreichend zum Empfänger zurückreflektiert wer-den müssen. Diese Eigenschaft kann bei einigen Objekten eingeschränktsein, wie beispielsweise bei Metallketten, welche Parktaschen begrenzen.Auch müssen diese Sensoren verstärkt mit Fremdsignalen umgehen kön-nen, da andere dynamische Objekte und insbesondere das Ego-Fahrzeugselbst ständig präsente Störschallquellen darstellen, wobei unterschied-lichste Frequenzen auftreten können.
29

Kapitel 2. Sensorik
2.2.6. Bewertung
Zur Umfeldwahrnehmung werden technologisch unterschiedliche Umfeld-sensoren eingesetzt, wobei jede Sensortechnologie ihre Stärken undSchwächen aufweist. Exemplarisch wird dies hier für die Zustandsbestim-mung für Umfeldobjekte dargestellt, da viele Fahrerassistenzsysteme aufdessen genaue Schätzung angewiesen sind: So kann beispielsweise ei-ne ungenaue Objektpositionsschätzung die Ursache dafür sein, dass einSpurwechselassistent fälschlicherweise annimmt, dass sich ein Objekt imNachbarfahrstreifen befindet und unnötig warnt.
Die Sensoren unterscheiden sich einerseits in der maximalen Reich-weite, in der sie typische Umfeldobjekte detektieren können, andererseitshaben sie aufgrund ihres Messprinzips unterschiedliche Genauigkeiten inder Zustandsbestimmung von detektierten Objekten. So können bestimm-te Radarsensoren hohe Reichweiten von 200 m oder mehr erzielen. Eben-so erreichen viele Lidarsensoren diese Reichweite bei gut reflektierendenZielen.
Bei der Genauigkeit der Zustandsbestimmung ist hingegen keine allge-meingültige Aussage möglich: Diese hängt stark von einzelnen Zustands-attributen ab. So erlauben Kameras aufgrund ihrer hohen Auflösung einesehr gute Winkelschätzung, ebenso wie gut fokussierbare Lidarsensoren.Dadurch kann ebenfalls eine Objektkontur geschätzt werden, wobei diesbei der Monokamera aufgrund der fehlenden Tiefeninformation nur unge-nau mit Hilfe von Modellannahmen gelingt.
Eine Geschwindigkeitsschätzung hingegen gelingt diesen Sensoren nurüber die zeitliche Ableitung der Positionsschätzung, sodass diese unge-nauer ist als bei Radarsensoren. Insbesondere Monokamerasensoren wei-sen eine nur ungenaue Entfernungsschätzung auf, sodass die longitudina-le Komponente eines Geschwindigkeitsvektors mit größerer Unsicherheitbehaftet ist.
Für die praktische Nutzung der Sensoren für Fahrerassistenzsysteme istneben deren Leistungsfähigkeit auch eine leichte Verbaubarkeit und einehohe Robustheit gegenüber Umwelteinflüssen wichtig. So sollten Senso-ren möglichst kompakt und an universell vielen Orten im Fahrzeug verbautwerden können und gleichzeitig möglichst unempfindlich gegenüber Re-gen, Schnee, Dunkelheit und Verschmutzungen sein. Hier sind die aktu-ell häufig genutzten Radar- und Ultraschallsensoren im Vorteil, da diesenahezu unsichtbar hinter durchlässigen Kunststoffen versteckt bzw. ent-sprechend lackiert werden können. Kamera- und Lidarsensoren hingegenbenötigen freie Sicht, welche auch nicht durch Verschmutzungen beein-trächtigt werden sollte, weshalb häufig nur Verbauorte hinter Scheiben mit
30

2.2. Sensortechnologien zur Umfelderfassung
Rei
chw
eite
Ent
fern
ungs
schä
tzun
g
Win
kels
chät
zung
Ges
chw
indi
gkei
tssc
hätz
ung
Kon
turs
chät
zung
Um
feld
entit
äten
Um
wel
tein
flüss
e
Ver
baub
arke
it
Monokamera +1 - ++ - - o + o oStereokamera2 o1 + ++ o ++ ++ o o/-3
Radar ++4 ++ + ++5 - - ++ +Lidar ++ ++ + + + o + oUltraschall - + o - - - - + ++
Tabelle 2.2.: Bewertung der Sensortechnologien
Wischanlage infrage kommen. Kamerasensoren sind als passive Senso-ren zusätzlich empfindlich gegenüber einer schlecht ausgeleuchteten Um-gebung. Eine Übersicht der vorgestellten Sensoren und deren Bewertungist in Tabelle 2.2 dargestellt. Weitere Bewertungen einzelner Sensortech-nologien sind in [Rasshofer 2005] zu finden.
Neben der genauen Schätzung des Objektzustandes ist für Fahrerassis-tenzsysteme ebenso wichtig, dass der Sensor alle relevanten Ziele mög-lichst zuverlässig detektiert. Scheinziele („Falsch positive Objekte“) alsauch nicht erkannte relevante Ziele („Falsch negative Objekte“) könnensich negativ auf die Qualität der Umfeldwahrnehmung und somit nega-tiv auf das gesamte Fahrerassistenzsystem auswirken: Wird beispielswei-se eine Messung für ein ACC-System so missinterpretiert, dass im Fahr-schlauch ein Objekt fälschlicherweise wahrgenommen wird, so erfolgt eine
1Die Reichweite von Kamerasensoren kann mithilfe entsprechender Objektive auf Kosten desverfügbaren Öffnungswinkels in erhöht werden. Hierbei ist die Fahrzeugeigenbewegung zubeachten, welche den auswertbaren Bildbereich in dynamischen Situationen einschränkenkann. Hier sind typische Konfigurationen bewertet.
2In Stereokameras können auch Monobildverarbeitungsalgorithmen eingesetzt werden, so-dass sich diese nach erschöpfter Stereoreichweite wie eine Monokamera verhält.
3Die Verbaubarkeit hängt wesentlich von der verwendeten Basisbreite ab4Hohe Reichweiten erzielen einige Radarsensoren, welche im 77 GHz-Bereich arbeiten.5Radarsensoren können sehr gut relative Radialgeschwindigkeiten messen. Um einen kartesi-
schen Geschwindigkeitsvektor zu erhalten, muss zusätzlich die Winkeländerung betrachtetwerden.
31
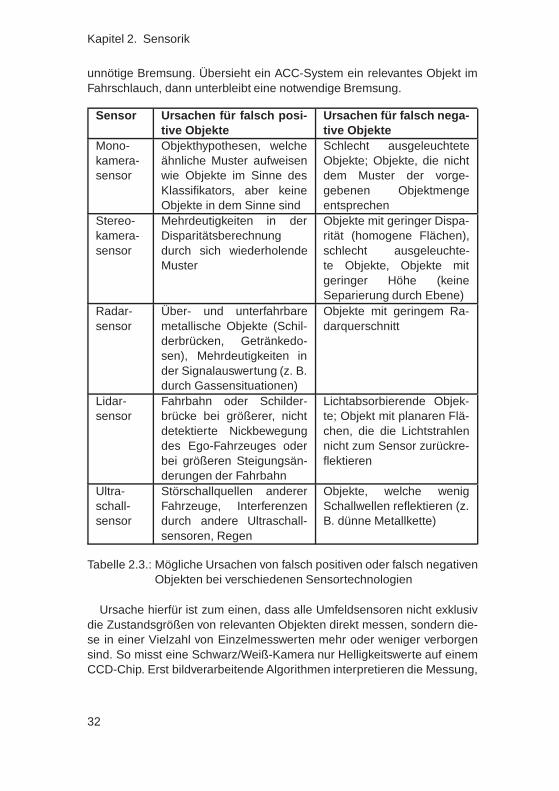
Kapitel 2. Sensorik
unnötige Bremsung. Übersieht ein ACC-System ein relevantes Objekt imFahrschlauch, dann unterbleibt eine notwendige Bremsung.
Sensor Ursachen für falsch posi-tive Objekte
Ursachen für falsch nega-tive Objekte
Mono-kamera-sensor
Objekthypothesen, welcheähnliche Muster aufweisenwie Objekte im Sinne desKlassifikators, aber keineObjekte in dem Sinne sind
Schlecht ausgeleuchteteObjekte; Objekte, die nichtdem Muster der vorge-gebenen Objektmengeentsprechen
Stereo-kamera-sensor
Mehrdeutigkeiten in derDisparitätsberechnungdurch sich wiederholendeMuster
Objekte mit geringer Dispa-rität (homogene Flächen),schlecht ausgeleuchte-te Objekte, Objekte mitgeringer Höhe (keineSeparierung durch Ebene)
Radar-sensor
Über- und unterfahrbaremetallische Objekte (Schil-derbrücken, Getränkedo-sen), Mehrdeutigkeiten inder Signalauswertung (z. B.durch Gassensituationen)
Objekte mit geringem Ra-darquerschnitt
Lidar-sensor
Fahrbahn oder Schilder-brücke bei größerer, nichtdetektierte Nickbewegungdes Ego-Fahrzeuges oderbei größeren Steigungsän-derungen der Fahrbahn
Lichtabsorbierende Objek-te; Objekt mit planaren Flä-chen, die die Lichtstrahlennicht zum Sensor zurückre-flektieren
Ultra-schall-sensor
Störschallquellen andererFahrzeuge, Interferenzendurch andere Ultraschall-sensoren, Regen
Objekte, welche wenigSchallwellen reflektieren (z.B. dünne Metallkette)
Tabelle 2.3.: Mögliche Ursachen von falsch positiven oder falsch negativenObjekten bei verschiedenen Sensortechnologien
Ursache hierfür ist zum einen, dass alle Umfeldsensoren nicht exklusivdie Zustandsgrößen von relevanten Objekten direkt messen, sondern die-se in einer Vielzahl von Einzelmesswerten mehr oder weniger verborgensind. So misst eine Schwarz/Weiß-Kamera nur Helligkeitswerte auf einemCCD-Chip. Erst bildverarbeitende Algorithmen interpretieren die Messung,
32

2.3. Zusammenfassung
sodass Objekte und deren Zustand wahrgenommen werden können. Auf-grund der nahezu unendlich großen Menge von möglichen Bildzuständenist es jedoch für solche Algorithmen schwierig, aus jedem Bild immer dierichtigen Objekte und deren Zustandsgrößen zu extrahieren. Ähnliches giltfür Lidar- und Radarsensoren, welche eine Vielzahl von Reflexionsinforma-tionen korrekt interpretieren müssen.
Zum anderen können je nach Sensortechnologie bestimmte Objektenicht oder nur sehr spät erfasst werden. So müssen Objekte ein Mindest-maß an Texturierung aufweisen, damit sie von einer Stereokamera erfasstwerden können. Frühzeitig durch einen Radarsensor detektierbare Objektemüssen einen bestimmten Mindestradarquerschnitt zum Radarsensor hinbesitzen. Umgekehrt gibt es Objekte, die zwar irrelevant für das Fahreras-sistenzsystem sind, aber gleichzeitig sehr gut emittierte Strahlen reflektie-ren. So können überfahrbare Getränkedosen und Gullydeckel Ursache fürFehlziele für einen Radarsensor sein, genauso wie unterfahrbare Schilder-brücken. Eine Übersicht möglicher Ursachen für falsch positive und falschnegative Objekte ist in Tabelle 2.3 zusammengefasst.
Als weitere Fehlerquelle sind verletzte Modellannahmen zu erwähnen,welche in weiteren Verarbeitungsschritten erfolgen. Die Darstellung dieserFehlerquellen erfolgt im folgenden Kapitel 3.
2.3. Zusammenfassung
In diesem Kapitel sind verschiedene Sensortechnologien sowohl zurSchätzung der relativen Position und Dynamik des Ego-Fahrzeuges alsauch zur Detektion und Zustandsbestimmung von Umfeldobjekten be-schrieben worden. Um ein genaues Umfeldmodell zu erstellen, ist sowohldie Schätzung der relativen Objektzustände als auch der Eigenbewegungnotwendig, was eine Trennung der Dynamik von Ego-Fahrzeug und Umfel-dobjekten erlaubt. Zusätzlich verwenden viele Fahrerassistenzsysteme dieEgozustandsgrößen direkt als Eingangsgrößen in deren jeweiligen Appli-kation.
Bereits bei der Ego-Zustandsschätzung existieren jedoch einige spora-dische und auch systematische Fehlerquellen: Neben nicht gemessenenRadschlupf, unbekannten Radumfang und Radstand bei Verwendung vonRaddrehzahlsensoren, sind auch viele im Fahrzeug verwendete Gierraten-und Beschleunigungssensoren empfindlich gegenüber Vibrationen, Fahr-bahnunebenheiten oder Fahrbahnneigungen. Somit kann ein aus diesenDaten gewonnener Zustandsvektor je nach Dynamik des Ego-Fahrzeugesund Fahrbahnbeschaffenheit mehr oder weniger ungenau sein. Abhilfe
33

Kapitel 2. Sensorik
könnte eine darauf spezialisierte Inertialplattformschaffen, welche um Grö-ßenordnungen genauere Messwerte liefert, jedoch ist hierbei mit deutli-chen Zusatzkosten zu rechnen.
Wie bei den Odometriesensoren müssen auch bei Umfeldsensoren ver-schiedene mögliche Ursachen berücksichtigt werden, wenn man die Gü-te der Messungen bewerten möchte. Neben Ungenauigkeiten in der Zu-standsbestimmung ist hier jedoch noch eine weitere Unsicherheitsquellezu berücksichtigen: Während Odometriesensoren von der Existenz desEgo-Fahrzeuges ausgehen können, können einzelne Umfeldsensoren un-ter Umständen falsch positive Objekte im Sinne des Fahrerassistenzsys-tems liefern oder relevante Objekte nicht wahrnehmen.
Dabei ist eine heterogene Sensorkonfiguration vorteilhaft, um den Ein-fluss dieser Unsicherheitsquellen zu minimieren: Einerseits können be-kannte Stärken von Sensoren bei der Bestimmung einzelner Zustandsattri-bute berücksichtigt werden, andererseits sollte es in den meisten Fällen zuwidersprüchlichen Informationen zwischen einzelnen Sensoren kommen,wenn ein Sensor ein Scheinziel liefert oder ein relevantes Ziel übersieht.Herausfordernd sind hierbei die genaue Zustandsschätzung und die Auf-lösung auftretender Widersprüche zu einem statistisch genauen Ergebnis,wobei möglichst alle verfügbaren Messungen, deren Abhängigkeiten undandere Informationen berücksichtigt werden sollten.
Um dieses zu erreichen, wird im folgenden Kapitel eine Sensordatenfu-sionmodul vorgestellt, welches ein umfangreiches Umfeldmodell in Formverschiedener Teilschätzer beinhaltet. Diese Teilschätzer werden in dar-auf folgenden Kapiteln dann so kombiniert, dass eine breite Bewertungs-grundlage für daraus aufbauende Schätzalgorithmen gegeben ist. Letzterewerden ebenfalls in den beiden Kapiteln 4 und 5 dargestellt.
34

Kapitel 3.
Sensordatenfusion
3.1. Einleitung
Für die Umsetzung Fahrerassistenzsystemen ist eine Umfeldwahrneh-mung elementare Voraussetzung: Wie im vorherigen Kapitel vorgestellt,werden zu diesem Zweck Sensoren eingesetzt, die bestimmte Aspekte desUmfeldes messen können. Aus diesen Messdaten werden die Hypothesenerzeugt, welche validiert und anschließend an die Fahrerassistenzapplika-tionen weitergeleitet werden müssen. Hierzu existieren im Wesentlichenzwei unterschiedliche Konzepte, wobei aber auch Hybridformen und ver-teilte Systeme denkbar sind:
Im ersten Konzept wird jeweils ein Steuergerät für ein Assistenzsystemverwendet, an dem exklusiv die relevanten Sensoren zur Umfeldwahrneh-mung und entsprechende Aktoren bzw. Informationssysteme angebundensind. Deren Umfeldmodell ist soweit optimiert, dass ausschließlich die fürdas einzelne Fahrerassistenzsystem relevanten Größen bestimmt werden.Häufig ist dieses Steuergerät direkt im Sensor zu finden, sodass dieseszusätzlich die Signalvorverarbeitung bewältigt. Vorteil dieses Konzeptes istdie Unabhängigkeit der Systeme untereinander. Durch die konzeptionellbedingte Modularität arbeitet beispielsweise ein ACC-System unabhängigvon einem Fahrstreifenverlassenswarner, sodass diese auch separat ver-baut und verkauft werden können. Nachteilig an diesem Konzept ist, dassvorhandene Informationen nicht vollständig genutzt werden. So könnte bei-spielsweise die Fahrstreifenschätzung hilfreich für eine Fahrschlauchgene-rierung sein, sodass die Zielauswahl für ACC-Systeme verbessert wird.
Ein zweites Konzept sieht dagegen ein zentrales Umfeldmodell für ver-schiedene Fahrerassistenzsysteme vor, welches diverse Aspekte des Um-feldes enthält. Dieses Umfeldmodell wird meist in einem zentralen Soft-waremodul implementiert, welches auf der einen Seite die Sensordatenvon allen relevanten Umfeld- und Fahrzeugsensoren verarbeitet und aufder anderen Seite das Umfeldmodul bereitstellt. Aus dieser Software kön-nen die benötigten Informationen für verschiedene Fahrerassistenzsys-
35

Kapitel 3. Sensordatenfusion
teme extrahiert werden. Dieses Softwaremodul heißt Sensordatenfusion(SDF). Vorteilhaft an diesem Konzept ist vor allem die Möglichkeit, mehrInformationen aggregieren zu können, sodass das Umfeldmodell eine po-tenziell höhere Qualität und einen größeren Umfang aufweist.
Insgesamt kann solch Sensordatenfusion je nach Anzahl und Granula-rität der integrierten Modelle ein sehr komplexes System darstellen undsomit einen beträchtlichen Entwicklungsaufwand nach sich ziehen. Um dieKomplexität zu beherrschen, erfolgt eine funktionale Dekomposition in Ein-zelkomponenten, welche so verknüpft sind, dass sie definierten Hierarchi-en und Anordnungen unterliegen. Diese Gesamtstruktur bezeichnet manals zugrunde liegende Architektur des Systems. Großen Einfluss auf dieKomplexität und somit auf die Systemarchitektur haben die Anforderungenan eine Sensordatenfusion, welche sich aus den umzusetzenden Fahre-rassistenzsystemen ergeben.
In diesem Kapitel werden typische Anforderungen an eine Sensordaten-fusion untersucht, existierende Ansätze vorgestellt und eine eigene Sen-sordatenfusionsarchitektur dargestellt. Diese bildet die Basis für die fol-genden Kapitel, in denen bestimmte Schätzer genauer untersucht werden.
3.2. Anforderungen
Die Anforderungen an eine Software haben großen Einfluss auf dessenArchitektur und die zu integrierenden Algorithmen. Sie vollständig vorherzu erfassen, erleichtert die Entwicklung, da nachträgliche Anforderungenmitunter große Änderungen an der Softwarearchitektur und damit an Zeitund Kosten verursachen können.
Für eine Sensordatenfusion für Fahrerassistenzapplikationen sind fol-gende allgemeine Anforderungen sinnvoll:
• Genau : Die verwendeten Modelle sollten in der Lage sein, die Zu-standsgrößen der Umfeldschätzung in einer Güte zu generieren, diefür das Fahrerassistenzsystem ausreichend sind1.
• Robust : Die Sensordatenfusion sollte gegenüber Störungen mög-lichst unempfindlich sein, wie z. B. ein kurzzeitig ausgefallener Sen-sor oder bei einzelnen Fehlmessungen.
• Probabilistisch : Die Umfeldmodellabstraktion und die Imperfektionder Sensordaten schränken die Genauigkeit der Umfeldschätzung
1Eine formalere Definition des Genauigkeitsbegriffes ist beispielsweise in [Brahmi 2013] zufinden
36

3.2. Anforderungen
ein. Dessen Unsicherheit sollte quantitativ mitgeschätzt werden, bei-spielsweise in Form von Varianzen und Existenwahrscheinlichkei-ten2.
• Echtzeitfähig : Fahrerassistenzapplikationen sollten mit einer defi-nierten maximalen Latenz alle notwendigen Informationen über einhinreichend aktuelles Umfeldmodell bei einer bestimmten Zielplatt-form erhalten3
• Modular : Neue Sensoren oder neue Modellaspekte sollten sich mitmöglichst wenig Aufwand in die Sensordatenfusion integrieren las-sen.
Die genannten Anforderungen lassen sich zum Teil nicht unabhängigbetrachten. So hängt es dann von der Applikation ab, welche Anforderun-gen einen hohen und welche einen niedrigeren Stellenwert besitzen, wasunterschiedliche Architekturen zur Folge haben kann.
So vereinfacht sich beispielsweise die Umsetzung der Genauigkeits- undEchtzeitanforderung, wenn sog. „synchrone Sensoren“ eingesetzt werdenvgl. [Darms 2007, S. 20]. Diese messen gleichzeitig, was zeitliche Prädik-tionen reduziert und Retrodiktionen ausschließt. Eine Synchronitätsanfor-derung an Sensoren schränkt allerdings die Modularität ein, da die Sen-soren dann eine gleiche Zyklusrate aufweisen und sich an einem einheit-lichen Synchronisationssignal orientieren müssen. Die Messungen „asyn-chroner Sensoren“ können hingegen in beliebiger Reihenfolge mit unter-schiedlicher Latenz die Sensordatenfusion erreichen. Hier ist eine Erweite-rung der Sensordatenfusion in Form eines Messwertepufferspeichers oderretrodiktionsfähiger Algorithmen notwendig (vgl. [Stüker 2004, S. 63 ff] und[Muntzinger 2011]). Diese können aber Echtzeitfähigkeit und die Genauig-keit der Schätzung einschränken.
Weiteren Einfluss auf die Architektur und Algorithmen hat der Ort der Si-gnalvorverarbeitung. Sensoren enthalten häufig Steuergeräte, die aus denRohdaten Merkmalsdaten extrahieren oder sogar ein internes Tracking be-sitzen. Je stärker die Sensorsteuergeräte die Messdaten vorverarbeiten,desto geringer ist der Aufwand der Sensordatenfusion. Dies kann die Ent-wicklung echtzeitfähiger Algorithmen erleichtern, schränkt allerdings dieGenauigkeit der Umfeldschätzung ein: Je stärker die Sensoren Messdatenvorverarbeiten, desto höher ist der Informationsverlust (vgl. [Darms 2007,S. 18 f]).
2Eine formale Definition von probabilistischen und statistisch korrekten Schätzern ist im An-hang A.1.2 zu finden
3Eine Definition zu harter Echtzeitfähigkeit ist im Anhang A.1.1 dokumentiert.
37

Kapitel 3. Sensordatenfusion
Auch die Auswahl der Schätzalgorithmen für das Umfeldmodell musssorgfältig aufgrund der Anforderungen erfolgen. Hierbei ist die Genauig-keitsanforderung eines Fahrerassistenzsystems mit der Echtzeitanforde-rung bzgl. einer Zielplattform auszubalanzieren. Im folgenden Abschnittwird beispielsweise das sog. „Kalmanfilter“ als dynamischer Zustands-schätzer vorgestellt, zu dem es auch ein Monte-Carlo-Pendant gibt, das„Partikelfilter“ heißt. Letzteres kann bei idealer Modellierung eine höhereGenauigkeit liefern, ist jedoch meist viel speicher- und rechenaufwendiger.
3.3. Dynamische Zustandsschätzer
Um die Anforderung der genauen und robusten Umfeldmodellierung Rech-nung zu tragen, verwenden praktisch alle Sensordatenfusionen sog. „Dy-namische Zustandsschätzer“. Diese bilden eine Algorithmenklasse, welcheMessreihen von einem oder mehreren Sensoren nutzen, um bestimmteAspekte eines sich dynamisch ändernden Umfeldes zu approximieren. Diemeisten Zustandsschätzer liefern zusätzlich eine Schätzgüte in Form einerWahrscheinlichkeitsdichtefunktion. Die Varianz dieser Verteilung repräsen-tiert die Unsicherheit dieser Schätzung.
Dynamische Zustandsschätzer sind modellbasiert: Sie enthalten u. a.ein Dynamikmodell, mit dem ein Zustand beispielsweise in der Zeitdomänevorhergesagt werden kann. Auch die Unsicherheiten des Dynamikmodellsund der Messungen werden meist in Form von System- bzw. Messrau-schen modelliert.
Eine häufig genutzter dynamische Zustandsschätzer ist das „Kalmanfil-ter“, dessen Algorithmus im Anhang A.2 vorgestellt wird. Dieses Filter bil-det meist einen guten Kompromiss aus Echtzeitfähigkeit und Genauigkeit,weshalb es auch in vielen existierenden SensordatenfusionsarchitekturenVerwendung findet, welche im folgenden Abschnitt 3.4 vorgestellt werden.Das Kalmanfilter bildet auch eine wichtige Grundlage für die im Abschnitt3.5 entwickelte Sensordatenfusionsarchitektur.
3.4. Stand der Technik:Sensordatenfusionsarchitekturen
Sensordatenfusionsarchitekturen können nach verschiedenen Kriterienklassifiziert werden, wobei Art (synchrone oder asynchrone Sensoren) undSichtbereiche (komplementär, konkurrierend oder kooperativ) Unterschei-dungsmerkmale darstellen können. Auch können zentrale Sensordatenfu-
38

3.4. Stand der Technik: Sensordatenfusionsarchitekturen
sionsmodule von verteilten Architekturen unterschieden werden. Für eineÜbersicht möglicher Architekturen sei auf [Dietmayer 2005a] verwiesen.
Bisher wurden diverse Sensordatenfusionen im automotiven Bereich fürunterschiedlichste Projekte und Anforderungen entwickelt. Allerdings fin-det man in der Literatur wenig über komplexe Sensordatenfusionsarchitek-turen, welche sehr viele Umfeldaspekte gleichzeitig berücksichtigen undkombinieren. Häufig wird ausschließlich das Tracking dynamischer Umfeld-objekte mit dem Kalmanfilter beschrieben (siehe beispielsweise [Stüker2004; Darms 2007]).
Im Zusammenhang mit Wettbewerben der DARPA4 sind Sensordaten-fusionen entstanden, die neben dem Objekttracking auch eine Überfahr-barkeitsschätzung mittels Belegungsgitter enthalten [Effertz 2009; Thrun2006; Urmson 2008; Rojo 2007; Kammel 2008]. Dies ist damit begrün-det, dass diese Wettbewerbe in komplexen5 Umgebungen wie Wüste oderurbanen Bereich stattfanden und somit modellarme Umgebungsrepräsen-tationen vorteilhaft waren. Insbesondere bei der „Urban Challenge“ warauch mit anderen sich bewegenden Verkehrsteilnehmern zu rechnen, so-dass ein zusätzliches klassisches Objekttracking Erfolg versprechend war.
Viele Arbeiten enthalten zwar eine Fahrbahnschätzung und kombinierendiese mit anderen Teilfusionen. Diese Schätzung basiert bei vielen Archi-tekturen jedoch auf einer hochgenauen Ortung in Kombination mit genau-em digitalem Kartenmaterial. Letzteres ist entweder a priori bekannt (vgl.Projekt „iCar“ in [Weiser 2009]) oder wird vorher aufgrund von detektier-ten Begrenzungen generiert (vgl. Projekt „GTI 53+1“ in [Kompaß 2008]).Auch bei den Fusionen der „Urban Challenge“-Teilnehmer spielten Fahr-bahnverlaufsschätzungen mittels lokaler Messdaten eine eher untergeord-nete Rolle: So wird beispielsweise in [Rojo 2007] beschrieben, dass auf-grund der hohen Dichte von vorgegebenen GPS-Wegpunkten diese in derWettbewerbsdomäne unnötig seien und die Fahrbahnmarkierungsinforma-tionen hauptsächlich für eine laterale fahrbahnrelative Positionsschätzungdes Ego-Fahrzeuges verwendet wurden. Auch in [Kammel 2008] wird einähnlicher Ansatz verfolgt, welcher aus akkumulierten Fahrbahnmarkierun-gen und Bordsteinen den Versatz zum gegebenen Kartenmaterial schätzt.
Einige andere Fusionen integrieren die lokal ermittelten Fahrbahnda-ten in bestimmte Teilschätzer: So werden in [Kolski 2006] die detektiertenFahrstreifenmarkierungen in ein Belegungsgitter mit geringer Gewichtung
4Die „Defense Advanced Research Projects Agency“ (DARPA) ist eine Technologieabteilungdes US-Verteidigungsministerium. Sie hat verschiedene Wettbewerbe veranstaltet, in denenFahrzeuge bestimmte Strecken autonom und auf Zeit zurücklegen mussten. Diese befandensich in der Mohave-Wüste (Grand Challenge) bzw. im städtischen Umfeld (Urban Challenge).
5Komplexe Umgebungen lassen sich nicht mit Modellen beschreiben, die nur wenige freie Pa-rameter aufweisen.
39

Kapitel 3. Sensordatenfusion
eingetragen, sodass diese bevorzugt nicht überfahren werden. Diese mo-dellarme Repräsentation ermöglicht die Einbringung von Fahrbahnmarkie-rungen beliebiger Geometrie, hat jedoch den Nachteil, dass aufgrund desfehlenden Fahrbahnmodells weder eine Assoziation von Messungen nocheine Prädiktion des Fahrbahnverlaufes möglich ist. Dies mach den Schät-zer empfindlich gegenüber Messrauschen, fehlinterpretierten Messungenund fehlenden Messungen.
Wenige andere Arbeiten integrieren eine lokale modellbehaftete Fahr-bahnschätzung: So ist im Rahmen des Teilprojektes SAFELANE des EU-Förderprojektes PReVENT die Fusionierung von Fahrbahn- und Objektda-ten untersucht worden (s. [Ahrholdt 2006; Polychronopoulos 2005b,a]).
Dabei wird einerseits die Fahrbahnschätzung durch die gemessenenTrajektorien vorausfahrender Fahrzeuge verbessert, andererseits ermög-licht die Fahrbahnschätzung selbst eine bessere Fahrstreifenzuordnunganderer Verkehrsteilnehmer. Als weitere Informationsquelle zur Fahrbahn-schätzung dienen neben detektierten Fahrstreifenmarkierungen auch digi-tale Kartendaten und die Krümmung der Egotrajektorie. Letztere Daten-quelle bietet sich nur an, wenn die Fahrzeugquerregelung nicht auf denfusionierten Fahrbahndaten basiert, da ansonsten Rückkopplungen denk-bar sind.
Als Fahrbahnmodell wird das sog. „Klothoidenmodell“ genutzt, welchesals Basisparameter durch Krümmung und Krümmungsänderung spezifi-ziert ist. Um es zum Ego-Fahrzeug korrekt anzuordnen, ist zusätzlich dieAngabe der Drehung und Ablage notwendig. Als dynamischer Zustands-schätzer finden mehrere erweiterte Kalmanfilter Anwendung, wobei sie dieKlothoide mithilfe eines Polynom dritten Grades approximieren. Auf einedirekte Verwendung des Klothoidenmodells wird verzichtet, da dieses un-günstige mathematische Eigenschaften aufweist6.
Die Kalmanfilter schätzen für jede einzelne Informationsquelle mit Aus-nahme der digitalen Karte die Krümmung und Krümmungsänderung se-parat. Die Ergebnisse werden über eine dynamische Gewichtung zu ei-ner Klothoide fusioniert. Diese Gewichtung richtet sich u. a. nach Varianzder Schätzung, Entfernung und Verfügbarkeit der Informationsquelle. EineÜbersicht dazu ist in Abbildung 3.1 dargestellt.
Neben den in SAFELANE verwendeten Datenquellen wird in [Schuberth2010] vorgeschlagen, zusätzlich statische Randbebauungen zu berück-sichtigen. Diese seien häufig parallel zur Fahrbahn angeordnet, sodasssie dessen Verlauf widerspiegeln. Als Beispiel werden Bäume, Leitplan-
6Eine allgemeine Klothoide kann nicht durch eine Funktion beschrieben werden, sondern nurdurch eine Kurve.
40

3.4. Stand der Technik: Sensordatenfusionsarchitekturen
Krümmung aus
Objekttrajektorien
Krümmung aus
Ego-Trajektorie
Krümmung aus
digitaler Karte
Krümmung aus
Bildverarbeitung
Dynamische
Gewichtung
Fusionierte
Krümmung
Distanz der
Datenquelle
Informationen
des Nachbarfahr-
streifens
Laterale
Dynamik des
Ego-Fahrzeuges
Varianz der
Datenquelle
Abbildung 3.1.: Fahrbahnschätzung für SAFELANE (vgl. [Polychronopou-los 2005b])
ken und Leitpfosten genannt. Im Gegensatz zu SAFELANE werden dieInformationsquellen in [Schuberth 2010] nicht durch Kalmanfilter, sondernanhand selbstdefinierter Gütemaße gewichtet.
Alle vorgestellten Fusionen zeichnen sich dadurch aus, dass sie eineOdometrieschätzung vornehmen. Diese wird häufig durch eine separatehochgenaue Inertialplattform durchgeführt, welche meist mit einer hoch-genauen Ortung mittels „Differential GPS“ kombiniert wird. Solche fertigenPlattformen verwendeten praktisch alle DARPA-Wettbewerber (vgl. [Thrun2006; Effertz 2009; Rojo 2007; Urmson 2008]) und andere Versuchsträ-ger, die auf genauem Kartenmaterial (vgl. [Weiser 2009]) basieren. DiesePlattformen zeichnen sich durch einen sehr geringen Fehler in der Egozu-standsbestimmung aus, sind aber aus Kostengründen in der hohen Quali-tät für einen massenhaften Einsatz in Serienfahrzeugen heute ungeeignet.
Im Rahmen industrienaher Arbeiten wird deshalb vermehrt auf bereitsim Fahrzeug bestehende Odometriesensoren zurückgegriffen (s. [Mählisch2009; Kolski 2006] und PREVenT-Projekt). Bei diesen ist zusätzlich die Ent-wicklung eines auf die Fahrzeugsensorik abgestimmten Schätzers erfor-derlich. Herausfordernd ist der Umgang mit der geringeren Schätzgüte, dadieser Schätzfehler auf viele andere Teilfusionen propagiert wird.
Im Folgenden soll eine Sensordatenfusion entwickelt werden, welcheein möglichst umfangreiches Umfeldmodell liefert und dabei vielverspre-chende Aspekte vorhandener Ansätze kombiniert. Die verwendeten Sen-soren sollen möglichst seriennah sein: So soll die Sensordatenfusion bei-
41

Kapitel 3. Sensordatenfusion
spielsweise auf eine hochgenaue Ortung und Inertialplattform verzichtenund auch kein hochgenaues Kartenmaterial verwenden. Stattdessen sol-len heute übliche Kartendaten mit begrenzter Genauigkeit genutzt werden,welche heutige Navigationssysteme verwenden. Gleiches gilt für Umfeld-sensoren, welche einerseits möglichst kostengünstig sein müssen und an-dererseits unauffällig im Auto verbaut werden können.
3.5. Entwicklung einer Sensordatenfusionsarchitektur
Im vorherigen Abschnitt sind einige Sensordatenfusionen vorgestellt wor-den, welche sich auf unterschiedliche Aspekte konzentrieren. Im Hinblickauf eine umfangreiche Umfeldrepräsentation wird in diesem Abschnitt ei-ne Sensordatenfusion vorgestellt, welche einige dieser Ansätze aufgreift,diese kombiniert und erweitert7.
Die Sensordatenfusion soll dabei in einzelne Schätzer unterteilt werden,die folgende Umfelddaten bereitstellen:
• Egofusion : Eigenbewegungsschätzung
• Objektfusion : Verfolgung und Zustandsschätzung von Umfeldobjek-ten
• Belegungsgitterfusion : Befahrbarkeitsschätzung
• Fahrbahnfusion : Fahrbahnverlaufsschätzung
• Digitale Karte : Straßenvorausschau
Hierbei sollen die genannten Anforderungen beachtet werden. Zunächstwerden jedoch die verwendeten Architekturmuster beschrieben, die hilf-reich sind, die Modularitätsanforderung zu bewältigen.
3.5.1. Pipe & Filters-Architektur
Als dominierendes Architekturmuster wurde für diese Sensordatenfusiondie sog. „Pipe & Filter-Architektur“ gewählt, in der Teilkomponenten durchsog. „Filter“ dargestellt werden. Diese sind über sog. „Pipes“ miteinanderverbunden, über welche Daten ausgetauscht werden. Ein Beispielgraph istin Abbildung 3.2 dargestellt.
7Die Schätzer dieser Sensordatenfusion wurden von einer Gruppe von Mitarbeiter aus demKonzernverbund der Volkswagen AG entwickelt. Der Autor gehört dieser Entwicklergruppean und hat mit Ausnahme der Egofusion an allen Modulen mitgewirkt. Der Relevanzschätzerzur Objektfusion (vgl. Kapitel 4) und das Belegungsgittermodul (vgl. Kapitel 5) und hat ereigenständig konzeptioniert und implementiert.
42

3.5. Entwicklung einer Sensordatenfusionsarchitektur
Filterinstanz A1 Filterinstanz A2
Filterinstanz C1
Filterinstanz B1
Abbildung 3.2.: Filtergraphbeispiel mit 4 Instanzen von 3 Filtern A, B und C.Filterinstanzen haben links Eingangspins und rechts Aus-gangspins
Ein Filter hat verschiedene Eingangsempfangs- und Ausgangssende-stellen, in denen ein Datenstrom entgegengenommen, verarbeitet, gege-benenfalls zwischengespeichert und versendet wird. Diese Stellen werdenim verwendeten Framework (s. [Schabenberger 2007]) als „Pins“ bezeich-net.
Die Filter werden in einer Filtergraphkonfiguration instanziiert und mit-einander verbunden. Dieser sog. „Filtergraph“ stellt einen gerichteten Gra-phen dar, wobei die Knoten die Filterinstanzen und die Kanten die Pipessind. Die Erstellung und die äußere Ablaufsteuerung des Graphens werdendabei durch einen sog. „Filtergraphmanager“ aufgrund einer vom Benutzererstellten Konfiguration vorgenommen.
Die Pipe & Filter-Architektur erlaubt die lose Kopplung verschiedenerKomponenten. Diese müssen weder die Funktion noch die interne Strukturvon Nachbarfiltern kennen. Die gemeinsame Schnittstelle ist über die Da-tenstruktur definiert, welche dem zu empfangenden Datenstrom zugrundeliegt.
Pipe & Filter-Architekturen unterstützten die Parallelisierung von Soft-ware: So können unterschiedliche Zweige im gerichteten Graphen parallelauf unterschiedlichen Prozessoren berechnet werden und somit bestimm-te Echtzeitanforderungen leichter erfüllen. Dieses wird in Abschnitt 3.5.8genauer behandelt.
3.5.2. Verwendetes Schichtenmodell
In der entwickelten Sensordatenfusion existieren über 90 verschiedene Fil-ter, welche miteinander interagieren, weshalb mögliche Filtergraphen dem-entsprechend komplex aufgebaut sein können. Um eine weitere Ordnungin die Architektur zu bringen, ist fast jedes Filter einer sog. „Software-schicht“ zugeordnet. Eine Softwareschicht umfasst eine grundlegendereZuständigkeit als ein einzelnes Filter und hat maximal zwei Nachbarschich-ten, mit denen sie kommuniziert.
43
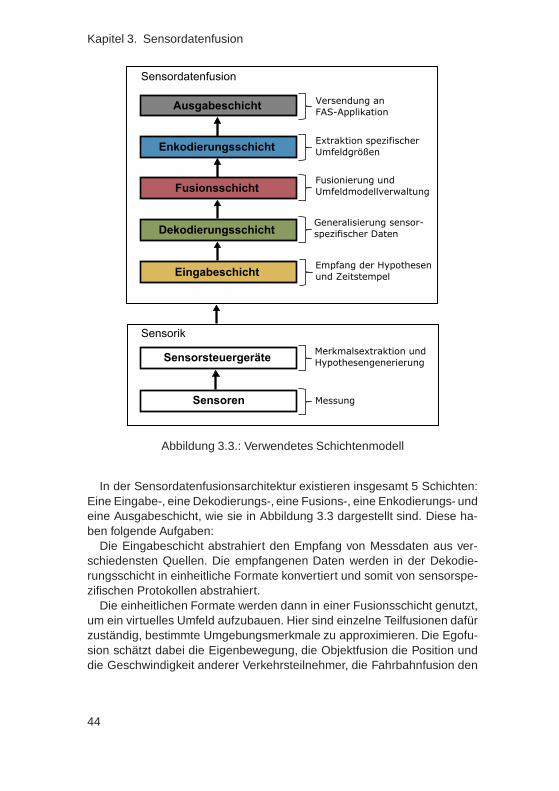
Kapitel 3. Sensordatenfusion
Fusionsschicht
Dekodierungsschicht
Eingabeschicht
Enkodierungsschicht
Ausgabeschicht
Sensoren
Sensorsteuergeräte
Versendung an
FAS-Applikation
Extraktion spezifischer
Umfeldgrößen
Fusionierung und
Umfeldmodellverwaltung
Generalisierung sensor-
spezifischer Daten
Empfang der Hypothesen
und Zeitstempel
Merkmalsextraktion und
Hypothesengenerierung
Messung
Sensorik
Sensordatenfusion
Abbildung 3.3.: Verwendetes Schichtenmodell
In der Sensordatenfusionsarchitektur existieren insgesamt 5 Schichten:Eine Eingabe-, eine Dekodierungs-, eine Fusions-, eine Enkodierungs- undeine Ausgabeschicht, wie sie in Abbildung 3.3 dargestellt sind. Diese ha-ben folgende Aufgaben:
Die Eingabeschicht abstrahiert den Empfang von Messdaten aus ver-schiedensten Quellen. Die empfangenen Daten werden in der Dekodie-rungsschicht in einheitliche Formate konvertiert und somit von sensorspe-zifischen Protokollen abstrahiert.
Die einheitlichen Formate werden dann in einer Fusionsschicht genutzt,um ein virtuelles Umfeld aufzubauen. Hier sind einzelne Teilfusionen dafürzuständig, bestimmte Umgebungsmerkmale zu approximieren. Die Egofu-sion schätzt dabei die Eigenbewegung, die Objektfusion die Position unddie Geschwindigkeit anderer Verkehrsteilnehmer, die Fahrbahnfusion den
44
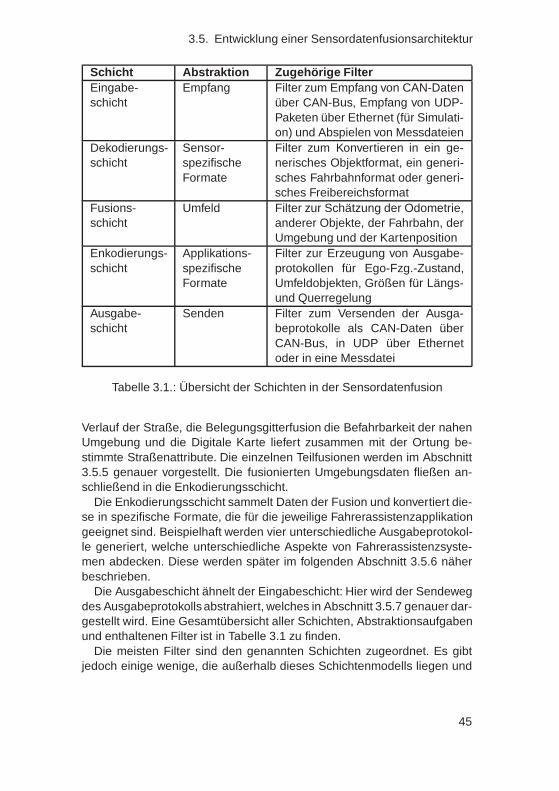
3.5. Entwicklung einer Sensordatenfusionsarchitektur
Schicht Abstraktion Zugehörige FilterEingabe-schicht
Empfang Filter zum Empfang von CAN-Datenüber CAN-Bus, Empfang von UDP-Paketen über Ethernet (für Simulati-on) und Abspielen von Messdateien
Dekodierungs-schicht
Sensor-spezifischeFormate
Filter zum Konvertieren in ein ge-nerisches Objektformat, ein generi-sches Fahrbahnformat oder generi-sches Freibereichsformat
Fusions-schicht
Umfeld Filter zur Schätzung der Odometrie,anderer Objekte, der Fahrbahn, derUmgebung und der Kartenposition
Enkodierungs-schicht
Applikations-spezifischeFormate
Filter zur Erzeugung von Ausgabe-protokollen für Ego-Fzg.-Zustand,Umfeldobjekten, Größen für Längs-und Querregelung
Ausgabe-schicht
Senden Filter zum Versenden der Ausga-beprotokolle als CAN-Daten überCAN-Bus, in UDP über Ethernetoder in eine Messdatei
Tabelle 3.1.: Übersicht der Schichten in der Sensordatenfusion
Verlauf der Straße, die Belegungsgitterfusion die Befahrbarkeit der nahenUmgebung und die Digitale Karte liefert zusammen mit der Ortung be-stimmte Straßenattribute. Die einzelnen Teilfusionen werden im Abschnitt3.5.5 genauer vorgestellt. Die fusionierten Umgebungsdaten fließen an-schließend in die Enkodierungsschicht.
Die Enkodierungsschicht sammelt Daten der Fusion und konvertiert die-se in spezifische Formate, die für die jeweilige Fahrerassistenzapplikationgeeignet sind. Beispielhaft werden vier unterschiedliche Ausgabeprotokol-le generiert, welche unterschiedliche Aspekte von Fahrerassistenzsyste-men abdecken. Diese werden später im folgenden Abschnitt 3.5.6 näherbeschrieben.
Die Ausgabeschicht ähnelt der Eingabeschicht: Hier wird der Sendewegdes Ausgabeprotokolls abstrahiert, welches in Abschnitt 3.5.7 genauer dar-gestellt wird. Eine Gesamtübersicht aller Schichten, Abstraktionsaufgabenund enthaltenen Filter ist in Tabelle 3.1 zu finden.
Die meisten Filter sind den genannten Schichten zugeordnet. Es gibtjedoch einige wenige, die außerhalb dieses Schichtenmodells liegen und
45

Kapitel 3. Sensordatenfusion
mit Filtern agieren, die in verschiedenen Schichten anzutreffen sind. Da-zu gehört beispielsweise der sog. „Scheduler“, der die Ablaufsteuerungder Fusion maßgeblich regelt und im Abschnitt 3.5.8 dokumentiert ist. Da-neben existieren Visualisierungs- und Debuggingkomponenten, die Infor-mationen an vielen Stellen schichtenübergreifend darstellen können. AlsBeispiel sei eine 3D-Visualisierung genannt, die sowohl Messdaten im ge-nerischen Format (Schicht 2), fusionierte Daten (Schicht 3) und Daten desAusgabeprotokolls (Schicht 4) anzeigen kann.
3.5.3. Eingabeschicht: Abstraktion der Empfangswege
Die Eingabeschicht abstrahiert den Empfang von Messdaten. Diese kön-nen über einen CAN-Bus empfangen werden, wie es im Fahrzeug oderbei Hardware-in-the-loop-Simulationen der Fall ist. In einer Offlinekonfigu-ration können auch Messdateien abgespielt werden, welche dann in dasFramework eingespeist werden. Für Simulationszwecke ist die Kommuni-kation mit anderen Programmen sinnvoll. Hierbei wird das verbindungsloseUDP-Protokoll über Ethernet genutzt, welches einzelne Messdatenpaketein UDP-Paketen kapselt.
Die Eingabeschicht ist zusätzlich verantwortlich für die Bereitstellungder Zeitquelle: Während die Messdaten vom CAN-Bus ihren Zeitstempeldurch einen Zeitgeber auf der Empfangshardware erhalten, enthalten dieaufgenommenen Messdateien und die simulierten Daten bereits definierteZeitstempel. Diese wurden während der Messdatenaufnahme bzw. durchdie Simulation festgelegt. In diesen beiden Fällen kann die Sensordaten-fusion somit auch schneller oder langsamer als in Realzeit laufen. Die sogenerierte Zeitquelle ist Basis für die später in Abschnitt 3.5.8 vorgestellteAblaufsteuerung der Sensordatenfusion.
3.5.4. Dekodierungsschicht: Abstraktion durch generisch eFormate
Da jeder Sensor in seinem spezifischen Format seine Messdaten sendet,sind Anpassungen der Sensordatenfusion an neue Sensoren notwendig.Um Adaptionen in der Fusionsschicht möglichst zu vermeiden und somitden Aufwand zu minimieren, werden im Folgenden verschiedene generi-sche Formate definiert, welche die wesentlichsten Aspekte der Messdatenim Sinne der Sensordatenfusion vereinheitlichen und kapseln. Hierbei wirddavon ausgegangen, dass bereits eine Signalvorverarbeitung stattgefun-
46

3.5. Entwicklung einer Sensordatenfusionsarchitektur
den hat oder dass diese in dem Dekodierungsfilter erfolgt, sodass tiefereSchichten keine Rohdaten verarbeiten müssen.
Exemplarisch werden hierzu Formate für Objektinformationen, Freiberei-che und Fahrbahninformationen vorgestellt. Diese ermöglichen nicht nureinheitliche und definierte Schnittstellen für einzelne Zustandsschätzer,sondern auch für generische Visualisierungs- und Protokollierungskompo-nenten.
Nachteilig an diesen Formaten ist jedoch, dass nicht immer alle Mes-sattribute in das jeweilige generische Format abgebildet werden könnenund somit ein Informationsverlust eintritt. Die Abbildung solcher Informa-tionen ist jedoch nur sinnvoll, wenn sie später in den Zustandsschätzernauch Verwendung findet. Hierzu ist dann zusätzlich eine Erweiterung derFusionsschicht notwendig.
Alle Messdaten werden von den Dekodierungsfiltern vom Sensorkoordi-natensystem in das Fahrzeugkoordinatensystem transformiert, wobei be-kannte Einbaupositionen und Ausrichtungen berücksichtigt werden. Au-ßerdem erhalten diese einen aus der Zeitquelle abgeleiteten Zeitstempel,welcher den Messzeitpunkt repräsentieren soll. Hierbei werden bekannteVerzögerungen durch Signalvorverarbeitungen im Sensor oder Synchroni-sationsdaten beachtet.
Zusätzlich ist in allen generischen Formaten ein Sensoridentifier vorge-sehen, sodass diese jederzeit einem Sensor wieder zugeordnet werdenkönnen.
Generische Objektdaten
Bei der Interpretation von Messdaten werden verschiedene Objekthypothe-sendarstellungen abhängig vom Messprinzip verwendet. So erzeugen bei-spielsweise viele Radarsensoren punktförmige Objekthypothesen mit Ge-schwindigkeitsinformationen, während Laserscanner und Stereokamera-sensoren keine Geschwindigkeiten messen, dafür aber häufig zusätzlicheKonturinformationen liefern können. Ultraschallsensoren hingegen liefernnur radiale Entfernungsinformationen, was durch ein Kreissegment darge-stellt werden kann.
Um möglichst viele Attribute kapseln zu können, beschreibt das generi-sche Format für jedes Objekt nicht nur einen umfangreichen Zustandsvek-tor, sondern auch, ob ein Attribut im Zustandsvektor gültig ist. Nachfolgen-de Module müssen vor der Verarbeitung zunächst prüfen, ob die notwen-digen Attribute auch im Objekt enthalten sind.
Für jede gültige Zustandsgröße kann auch deren Unsicherheit in Formeiner Varianz abgelegt werden, welche beispielsweise mithilfe eines in-
47

Kapitel 3. Sensordatenfusion
versen Sensormodells8 und des Zustandsvektors festgelegt werden kann.Wie beim Zustandsvektor auch gibt es für jedes Element im Varianzvektorein Gültigkeitsattribut, sodass dieses Element nicht zwangsweise generiertwerden muss.
Abbildung 3.4.: Die Position jeder Objekthypothese (grüne Fahrzeuge) wirddurch einen (roter Stern) von acht möglichen Referenz-punkten (alle Sterne) angegeben. Die Festlegung des Re-ferenzpunktes erfolgt durch ein inverses Sensormodell,welches den Messvektor berücksichtigt.
Bei einigen Messungen kann der Fall auftreten, dass Objekte teilweiseverdeckt oder sich teilweise außerhalb des Messfeldes befinden. Hierzuunterstützt das Format einen variablen Referenzpunkt bzgl. eines Recht-eckmodells, auf welches sich der Positionsvektor bezieht. Breiten- undLängenschätzungen sind dann als Schätzungen von diesem Referenz-punkt anzusehen. Ein Beispiel hierzu ist in Abbildung 3.4 dargestellt.
Damit das Format nicht nur Sensordaten kapseln kann, sondern auchals Ausgabeformat für einen Objekttracker verwendet werden kann, ist die-ses noch um einige Attribute erweitert worden. So ist neben der Tracking-dauer auch ein Flag vorgesehen, welches beschreibt, ob das Objekt imletzten Zyklus gemessen oder nur prädiziert worden ist. Ein weiteres Attri-but dokumentiert, ob ein Objekt neu initialisiert worden ist oder sich bereitsin der Objektliste des letzten Trackingzyklus befand.
Insgesamt lassen sich durch das Format sehr viele Objektinformationenbeschreiben: So ist durch das Setzen entsprechender Attribute ein Punkt-,
8Ein inverses Sensormodell schließt von der Messung ausgehend auf die Umgebung, währendein Sensormodell von der Umgebung ausgehend auf die Messung schließt. Inverse Sensor-modelle werden zur Sensordatenfusion benötigt, während Sensormodelle beispielsweise fürSimulationsumgebungen genutzt werden.
48

3.5. Entwicklung einer Sensordatenfusionsarchitektur
Linien- oder Rechteckmodell möglich. Außerdem ist es möglich, die Positi-onsinformation entweder kartesisch oder radial anzugeben.
Die generischen Objekte werden zuletzt in einer Objektliste zusammen-gefasst, welche einen Messzyklus eines Sensors oder eine Umfeldobjekt-liste des Trackers repräsentiert. Diese Liste wird noch mit einem Mess-bzw. Schätzzeitpunkt und einem Quellidentifier angereichert.
Generische Freibereichsdaten
Zur Beschreibung von Freibereichen, die direkt oder indirekt gemessenworden sind, dient ein generisches Freibereichsformat. Zur Approximationeines solchen Bereiches eignen sich besonders konkave Polygone: Diesist einerseits dadurch begründet, dass einige Sensoren wie beispielswei-se Laserscanner in bekannten diskreten Winkelschritten Entfernungsmes-sungen vornehmen, welche durch ein solches Polygon exakt rekonstru-iert werden können, andererseits ist es damit möglich, jede andere Frei-bereichsform beliebig genau anzunähern. Letzteres ist für sektorförmigeFreibereichsinformationen notwendig, welche beispielsweise durch Ultra-schallsensoren generiert werden können.
Um die Unsicherheit einer Messung darzustellen, kann man jedem Eck-punkt des Polygons eine Varianz zuweisen. Die entfernungsabhängige Va-rianz bezieht sich auf einen vorher definierten Referenzpunkt, der bei-spielsweise im Sensorursprung liegt. Um komplexe Evidenzberechnungeninnerhalb eines Polygons zu vereinfachen, wird statt einer Normalvertei-lung eine Dreiecksverteilung angenommen. Die Evidenz innerhalb einesSektors in solch einem Polygon wird durch lineare Interpolation der Vari-anzinformationen der Eckpunkte berechnet. Zusätzlich wird dem gesamtenFreibereich noch eine Gesamtevidenz zugeordnet.
Durch dieses modellarme Format können viele Freibereiche flexibel an-genähert werden. Eingeschränkt wird dieses nur durch die angenomme-ne Dreiecksverteilung und dessen singulären Referenzpunkt. Letztereskann beispielsweise die Freibereichsgenerierung durch ein Sensorarrayeinschränken, wenn man jeden Sensor nicht einzeln betrachten möchte.
Generische Fahrbahndaten
Um Information über einen Fahrbahnverlauf möglichst modellarm darzu-stellen, wurde für das generische Fahrbahndatenformat eine Linienzug-darstellung mithilfe von Stützpunkten gewählt. Dieses kann indirekt auchmodellbehaftete Darstellungen repräsentieren, indem alle Stützpunkte bei-spielsweise auf einem Kreis- oder Klothoidensegment abgebildet werden.
49
Kapitel 3. Sensordatenfusion
Jeder Linienzug kann durch diverse Attribute angereichert werden:Wenn dieser Fahrbahnmarkierungen repräsentieren soll, ist es beispiels-weise möglich, die Art, Breite und Farbe der Markierung anzugeben. Sokönnen weiße gestrichelte Linien beispielsweise von gelben durchgezo-genen Linien unterschieden werden. Solche Informationen sind u. a. hilf-reich um festzustellen, auf welchem Fahrstreifen einer mehrspurigen Stra-ße man sich befindet oder ob ein Fahrstreifenwechsel erlaubt ist.
Neben Fahrstreifenmarkierungen können auch andere Informationsquel-len dargestellt werden. So ist es möglich, den Linienzügen eine Höhe zu-zuweisen, sodass beispielsweise der Verlauf einer Bordsteinkante oder ei-ner direkt am Fahrstreifen befindlichen Leitplanke dargestellt werden kann.Diese Informationen können beispielsweise die Existenz von entsprechen-den Nachbarfahrstreifen verneinen.
Wie bei dem generischen Objektformat werden die Linienzüge einerMessung zu einer Liste zusammengefasst und mit einem Messzeitpunktversehen.
Zusammenfassung
Die generischen Formate erlauben eine Abstrahierung der sensorspezi-fischen Formate, was die Modularitätsanforderung berücksichtigt. Tabelle3.2 zeigt eine Übersicht der verwendeten Formate und in welchen Teilmo-dulen sie verwendet werden. Sie erlauben die schnelle Integration neuerSensoren in die Sensordatenfusion.
Format Abstrahierung Verwendung inGenerischeObjektdaten
Objekthypothesenals Punkt-, Linien,Box- oder radialesModell
Visualisierung, Ob-jektfusion, Fahr-bahnfusion, Bele-gungsgitterfusion
GenerischeFahrbahndaten
Fahrbahnverlaufs-hypothesen alsStützpunktmodell
Visualisierung, Fahr-bahnfusion
GenerischeFreibereichsdaten
Freibereichs-hypothesen als Poly-gonmodell
Belegungsgitterfusion
Tabelle 3.2.: Generische Datenformate und Verwendung innerhalb derSensordatenfusion
50

3.5. Entwicklung einer Sensordatenfusionsarchitektur
3.5.5. Fusionschicht: Teilfusionen und Dienste
Das Umfeldmodell besteht aus mehreren unabhängigen Teilen, von de-nen jedes in einer eigenen Fusionskomponente geschätzt und aktualisiertwird. Jede Fusionskomponente erfüllt einen spezifischen Informationsbe-darf und verwendet eine entsprechende Modellabstraktion.
Da einige Teilfusionen große Datenmengen kapseln, ist es ineffizient,diese komplett an nachfolgende Filter zu schicken. Deshalb verwenden vie-le Teilfusionen Dienstschnittstellen, über die andere Filter die gewünschtenDaten von den Teilfusionen beziehen können. Diese enthalten Methoden,welche die gekapselten Daten aufbereiten: So bieten viele Teilfusionen bei-spielsweise eine Zustandsprädiktion auf andere Zeitpunkte an.
Die Dienstschnittstellen erlauben zusätzlich eine Änderung der inter-nen Datenrepräsentation oder gar den kompletten Austausch eines Schät-zers: So muss ein anderer Schätzalgorithmus nur die Dienstschnittstellereimplementieren, um transparent eingesetzt werden zu können. Dieseswird beispielsweise zu Simulationszwecken genutzt.
Egofusion
Die Egofusion schätzt den Zustand des Ego-Fahrzeuges ausschließlichmithilfe von Messungen der Odometriesensoren. Dabei werden Messun-gen von den Raddrehzahlsensoren der Hinterräder und vom Gierraten-sensor verwendet, welche in ein erweitertes Kalmanfilter eingehen. Dergeschätzte Zustandsvektor umfasst eine relative Position, die zurückgeleg-te Strecke, eine Geschwindigkeit, eine Beschleunigung, eine Gierrate undeinen relativen Gierwinkel. Die Position und der Gierwinkel werden relativzur Startposition bzw. Startausrichtung angegeben.
Da keine globale Positionsinformationen in die Schätzung mit eingeht,erfolgt eine rein integrierende Zustandsschätzung. Diese zeichnet sichdurch eine praktisch kontinuierliche Zustandsänderung und durch einensich integrierenden Fehler aus. Schwerpunkt dieser Zustandsschätzung istsomit die Minimierung des relativen Fehlers zwischen zwei zeitlich nahenSchätzungen ohne Rücksicht auf einen globalen Fehler zu nehmen. Abbil-dung 3.5 zeigt beispielhaft Trajektorien zweier Schätzer mit und ohne sichintegrierenden Fehler.
Die Minimierung dieses relativen Schätzfehlers ist entscheidend für dieMinimierung der Schätzfehler anderer Teilfusionen: So wird der relati-ve Fehler auf den Dynamikzustand im Objekttracker propagiert, währendGierwinkelfehler wiederholte Zellassoziationen in der Belegungsgitterfusi-
51

Kapitel 3. Sensordatenfusion
Abbildung 3.5.: Relative Odometrieschätzung (blaue Trajektorie) und glo-bale Schätzung mittels GPS (rote Trajektorie) nach meh-reren Umrundungen eines ovalen und ca. 1,7 km langenTestgeländes
on erschweren. In der Fahrbahnfusion kann eine fehlerhafte Gierrate hin-gegen Scheinkrümmungen verursachen.
Die Egofusion liefert eine Dienstschnittstelle, mit welcher der Egozu-stand eines bestimmten Zeitpunktes abgefragt werden kann. Dieses er-folgt durch Prädiktion bzw. Retrodiktion des aktuellen Zustandes, was an-deren Schätzern ermöglicht, den Egozustand zu spezifischen Mess- oderSchätzzeitpunkten anzunähern. Hiervon machen alle weiteren vorgestell-ten Teilfusionen Gebrauch.
Objektfusion
Die Objektfusion schätzt den Zustand von Umfeldobjekten mittels generi-scher Objektdaten. Für die Zustandsschätzung wird ein erweitertes Kal-manfilter eingesetzt, welches neben der kartesischen Position und Objekt-kontur auch die Geschwindigkeit und Beschleunigung in Längs- und Quer-richtung für jedes Objekt schätzt.
Als Ergebnis erhält man eine Liste von Objekthypothesen, welche je-weils aus einem Zustandsvektor und dessen korrespondierender Kovari-anzmatrix besteht. Letztere dokumentiert die Unsicherheit der Zustands-schätzung, was die Bewältigung der Anforderung an eine probabilistischeSensordatenfusion unterstützt.
52

3.5. Entwicklung einer Sensordatenfusionsarchitektur
Im Gegensatz zur Egofusion muss die Objektfusion mehrere Zuständeparallel schätzen: Hierzu ist die Assoziation einer Messung mit bereits vor-handenen Umfeldobjekten notwendig. Als Grundlage dient die sog. Maha-lanobisdistanz, welche Objekthypothese (Track) und Messung vergleicht.Das Abstandsmaß gewichtet die Innovation zwischen Trackzustand undMessung yt (s. Gleichung A.5) mit dessen Residualkovarianz St (s. Glei-chung A.6) im Messraum. Zusätzlich wird der Logarithmus der Residual-kovarianzdeterminante als additiver Term zum Abstandsmaß hinzugefügt,um eine geringe Trackunsicherheit positiv zu gewichten (vgl. [Stüker 2004,S. 49 f]):
d2(yt ,St ) = yTt S−1
t yt + ln(|St |) (3.1)
Als Ergebnis erhält man eine Assoziationsdistanz: Je kleiner diese Dis-tanz ist, desto geringer ist die Erwartungswertdifferenz zwischen Track undMessung gemäß der Verteilungserwartung im Messraum und desto gerin-ger ist die Trackunsicherheit.
Diese Distanz entscheidet auch über den Lebenszyklus eines Tracks:Der Track mit der geringsten Entfernung zur Messung wird mit dieser as-soziiert. Überschreitet diese Entfernung einen bestimmten Schwellwert,so wird von einem neu gemessenen Objekt ausgegangen, was eineTrackinitialisierung zur Folge hat. Kann ein Track in mehrere Zyklen mitkeiner Messung assoziiert werden, so wird dieser gelöscht. Dieses kannbeispielsweise auftreten, wenn ein Objekt sich aus dem Sichtbereich derSensoren entfernt oder längerfristig verdeckt wird.
Eine Übersicht über die Trackverwaltung bietet das in Abbildung 3.6dargestellte Flussdiagramm9. Der verwendete Objekttracker nutzt zusätz-lich einen variablen Referenzpunkt für partielle Assoziationen und unter-stützt asynchrone Sensoren, wobei zugunsten der Echtzeitfähigkeit aufeinen Messdatenpuffer mithilfe retrodiktionsfähiger Algorithmen verzichtetwerden konnte. Er kann auch radiale Abstandsinformationen verarbeiten,welche beispielsweise durch Ultraschallsensoren erzeugt werden. Für ge-nauere Informationen zu Objekttrackingalgorithmen sei beispielsweise auf[Bar-Shalom 2001; Stüker 2004] verwiesen. Einen weiteren Ansatz zur par-tiellen Assoziation und zur Konturschätzung wird in [Ohl 2011] vorgestellt.
Neben dem ungenauen Objektzustand ergeben sich beim Objekt-tracking weitere Unsicherheits- und Fehlerquellen: Messungen könneneventuell nicht eindeutig zu benachbarten Objekthypothesen zugeordnetwerden, sodass bei Fehlassoziation eine inkorrekte Zustandsaktualisie-
9Durch die Rekursivität des Algorithmus ist die Terminierung von der Sensordatenmenge ab-hängig. Deshalb wurde auf Start- und Stoppsymbole im Flussdiagramm verzichtet.
53
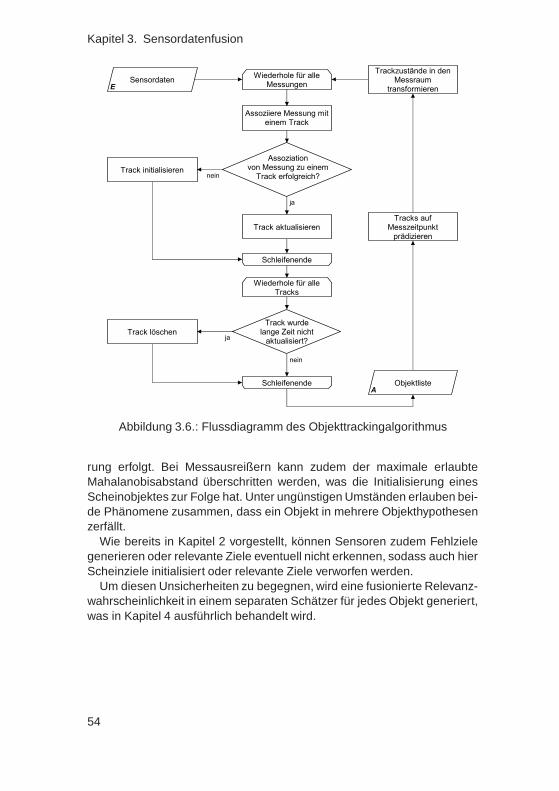
Kapitel 3. Sensordatenfusion
nein
ja
nein
ja
E
Sensordaten
Track initialisieren
Track löschen
Wiederhole für alle Messungen
Assoziiere Messung mit einem Track
Assoziationvon Messung zu einem
Track erfolgreich?
Track aktualisieren
Schleifenende
Wiederhole für alle Tracks
Track wurdelange Zeit nicht
aktualisiert?
Schleifenende
Trackzustände in den Messraum
transformieren
Tracks auf Messzeitpunkt
prädizieren
A
Objektliste
Abbildung 3.6.: Flussdiagramm des Objekttrackingalgorithmus
rung erfolgt. Bei Messausreißern kann zudem der maximale erlaubteMahalanobisabstand überschritten werden, was die Initialisierung einesScheinobjektes zur Folge hat. Unter ungünstigen Umständen erlauben bei-de Phänomene zusammen, dass ein Objekt in mehrere Objekthypothesenzerfällt.
Wie bereits in Kapitel 2 vorgestellt, können Sensoren zudem Fehlzielegenerieren oder relevante Ziele eventuell nicht erkennen, sodass auch hierScheinziele initialisiert oder relevante Ziele verworfen werden.
Um diesen Unsicherheiten zu begegnen, wird eine fusionierte Relevanz-wahrscheinlichkeit in einem separaten Schätzer für jedes Objekt generiert,was in Kapitel 4 ausführlich behandelt wird.
54

3.5. Entwicklung einer Sensordatenfusionsarchitektur
Fahrbahnfusion
Die Fahrbahnfusion schätzt den nahen Verlauf der Fahrbahn, die An-zahl der vorhandenen Fahrstreifen und deren Breite. Hierzu nutzt sie ver-schiedene Informationsquellen: Diese bestehen aus Fahrbahnmarkierun-gen in Form von generischen Fahrbahndaten, Karteninformationen überdie Dienstschnittstelle der digitalen Karte und generische Objektdaten.Letztere werden daraufhin untersucht, ob sie eine Trajektorie eines dy-namischen Objektes beschreiben oder aber Randbebauungen darstellen.Beides weist auf einen möglichen Fahrbahnverlauf hin. Eine beispielhafteVisualisierung dieser Informationsquellen und die resultierende Fahrbahn-schätzung ist in Abbildung 3.7 darstellt.
Abbildung 3.7.: Aus Radarreflexen von Leitplanken (rote Punkte) kanneine Schätzung der Randbebauung (grüne Linien) erfol-gen. Diese gehen zusammen mit Fahrbahnmarkierungen(schwarze Linienzüge) und Kartendaten (blaue Linien) indie Fahrbahnschätzung (rote Straße) ein.
Insgesamt ist die Fahrbahnfusion für Autobahnen und autobahnähnli-che Straßen optimiert, sodass durch ein mehrsegmentiges Klothoidenmo-dell implizierte Randbedingungen Verwendung finden. Die entsprechen-den Klothoidenparameter werden durch ein erweitertes Kalmanfilter ge-schätzt.
Die Fahrbahnfusion bietet eine Dienstschnittstelle, mit der andere Filter
55

Kapitel 3. Sensordatenfusion
Informationen über den aktuellen Verlauf der Straße und der relativen Ego-position erhalten. Zusätzlich ermöglicht der Dienst die Transformation vonkartesischen Vektoren in das Fahrbahnkoordinatensystem. Dieses ist bei-spielsweise für Objekte der Objektfusion interessant, welche somit auf derStraße positioniert werden. Für ein Beispiel dazu sei auf Abschnitt 4.6.1verwiesen.
Belegungsgitterfusion
Die Belegungsgitterfusion betrachtet die Überfahrbarkeit des näheren Um-feldes: Hierzu werden alle generischen Objekt- und Freibereichsdaten be-achtet, welche in diese Teilfusion einfließen.
Die Belegungsgitterfusion kann mithilfe einer Polygonschnittstelle abge-fragt werden, welche fusionierte Überfahrbarkeitsinformationen für den be-schriebenen Bereich liefert. Hierbei ist eine inkrementelle Abfrage möglich,sodass beispielsweise die Befahrbarkeit eines Fahrschlauches in diskretenSchritten mit geringer Latenz analysiert werden kann. Für genauere Infor-mationen zu den verwendeten Fusions- und Abfragealgorithmen sei aufKapitel 5 verwiesen.
Digitale Karte
Um der Fahrzeugumfeldschätzung eine weitreichende Straßenvoraus-schau zu ermöglichen, wird eine digitale Karte zusammen mit einer globa-len Positions- und Gierwinkelschätzung eingesetzt. Im ersten Schritt wirddie Positionsschätzung dazu verwendet, eine Menge von Straßensegmen-thypothesen aus der digitalen Karte mithilfe von Abstandsmaßen zu ex-trahieren. Die Gierwinkelschätzung erlaubt anschließend die Eliminierungunplausibler Hypothesen: Hierzu wird der Gierwinkel des Ego-Fahrzeugesmit dem Richtungswinkel des Straßensegmentes verglichen. Bei Über-schreitung eines Schwellwertes wird davon ausgegangen, dass das Ego-Fahrzeug nicht auf dieser Straße fährt: Hierdurch können beispielsweiseStraßen, die über Autobahnbrücken führen, von Autobahnen unterschie-den werden können.
Die Position und der Gierwinkel werden hauptsächlich durch Satelli-tennavigationssysteme geschätzt: Entsprechende Empfänger werten da-zu in diskreten Zeitabständen Laufzeitmessungen von Satellitensignalenaus und senden die Ergebnisse in die Sensordatenfusion. Um für beliebi-ge Zeitpunkte eine Schätzung zu generieren, werden mithilfe der Egofusi-on die Positions- und Gierwinkelschätzungen inter- oder extrapoliert. Da-durch können auch kurze Unterbrechungen des GPS-Signals überbrückt
56
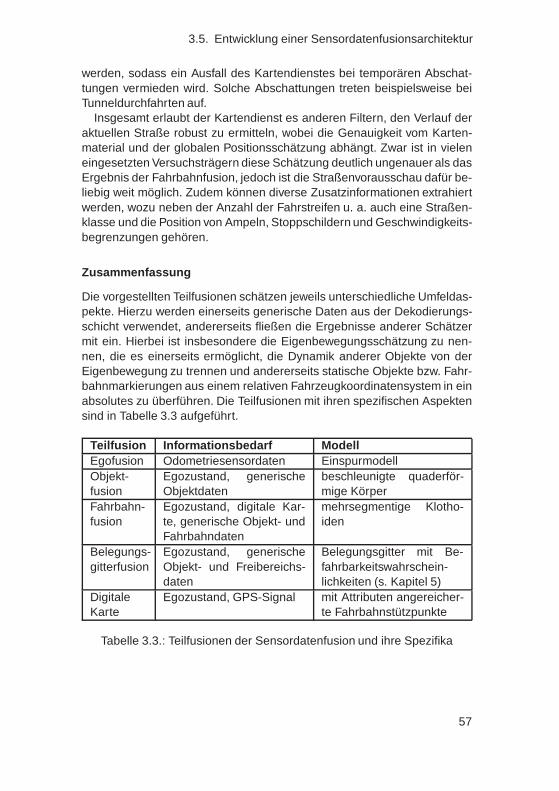
3.5. Entwicklung einer Sensordatenfusionsarchitektur
werden, sodass ein Ausfall des Kartendienstes bei temporären Abschat-tungen vermieden wird. Solche Abschattungen treten beispielsweise beiTunneldurchfahrten auf.
Insgesamt erlaubt der Kartendienst es anderen Filtern, den Verlauf deraktuellen Straße robust zu ermitteln, wobei die Genauigkeit vom Karten-material und der globalen Positionsschätzung abhängt. Zwar ist in vieleneingesetzten Versuchsträgern diese Schätzung deutlich ungenauer als dasErgebnis der Fahrbahnfusion, jedoch ist die Straßenvorausschau dafür be-liebig weit möglich. Zudem können diverse Zusatzinformationen extrahiertwerden, wozu neben der Anzahl der Fahrstreifen u. a. auch eine Straßen-klasse und die Position von Ampeln, Stoppschildern und Geschwindigkeits-begrenzungen gehören.
Zusammenfassung
Die vorgestellten Teilfusionen schätzen jeweils unterschiedliche Umfeldas-pekte. Hierzu werden einerseits generische Daten aus der Dekodierungs-schicht verwendet, andererseits fließen die Ergebnisse anderer Schätzermit ein. Hierbei ist insbesondere die Eigenbewegungsschätzung zu nen-nen, die es einerseits ermöglicht, die Dynamik anderer Objekte von derEigenbewegung zu trennen und andererseits statische Objekte bzw. Fahr-bahnmarkierungen aus einem relativen Fahrzeugkoordinatensystem in einabsolutes zu überführen. Die Teilfusionen mit ihren spezifischen Aspektensind in Tabelle 3.3 aufgeführt.
Teilfusion Informationsbedarf ModellEgofusion Odometriesensordaten EinspurmodellObjekt-fusion
Egozustand, generischeObjektdaten
beschleunigte quaderför-mige Körper
Fahrbahn-fusion
Egozustand, digitale Kar-te, generische Objekt- undFahrbahndaten
mehrsegmentige Klotho-iden
Belegungs-gitterfusion
Egozustand, generischeObjekt- und Freibereichs-daten
Belegungsgitter mit Be-fahrbarkeitswahrschein-lichkeiten (s. Kapitel 5)
DigitaleKarte
Egozustand, GPS-Signal mit Attributen angereicher-te Fahrbahnstützpunkte
Tabelle 3.3.: Teilfusionen der Sensordatenfusion und ihre Spezifika
57

Kapitel 3. Sensordatenfusion
Die Ego-, Objekt- und Fahrbahnfusion basieren hauptsächlich auf Kal-manfilter, die neben dem Zustand auch dessen Unsicherheit automatischmitschätzen. Unter den gegebenen Randbedingungen liefern diese Zu-standsschätzer bei entsprechender Parametrisierung ausreichend genaueErgebnisse, was auf eine begrenzte Nichtlinearität der Modelle und auf inetwa normalverteilte Messungen schließen lässt. Diese Teilfusionen habenmit diesen bekannten Ansätzen somit bereits das Potenzial, eine möglicheGenauigkeitsanforderung eines Fahrerassistenzsystems in Echtzeit zu er-füllen, sodass diese im Folgenden nicht genauer untersucht werden.
Zwei andere Schätzer integrieren jedoch komplexe alternative Schätzal-gorithmen, die nicht auf Kalmanfilter basieren. Hierbei ist einerseits die Re-levanzschätzung für Objekte des Objekttrackers zu nennen und anderer-seits die Überfahrbarkeitsschätzung mithilfe eines Belegungsgitters. BeideSchätzer werden in den kommenden beiden Kapiteln detailliert vorgestellt.
3.5.6. Enkodierungsschicht: Trennung von Umfeldmodell un dAusgabeprotokoll
Im verwendeten Umfeldmodell existieren sehr viele Zustandsvariablen, diesich hochfrequent ändern. Die kompletten Umfeldmodelldaten zyklisch zurApplikation zu senden ist deshalb sehr aufwendig. Auch würden Änderun-gen der Schätzrepräsentation Änderungen in der Fahrerassistenzapplika-tion nach sich ziehen.
Die folgende Enkodierungsschicht trennt daher die Umfeldmodelldarstel-lung von Fahrerassistenzapplikationen: Hierzu wird zunächst für eine spe-zifische Applikation ein Protokoll entworfen, welches die benötigten Regel-größen enthält. Dieses wird von einem sog. „Kollektorfilter“ in der Enko-dierungsschicht generiert, wobei dieser die entsprechenden Zustandsva-riablen aus dem Umfeldmodell extrahiert und kombiniert. Die Regelgrößenwerden mithilfe der Dienstschnittstellen auf den Ausgabezeitpunkt prädi-ziert, sodass die Abhängigkeit vom genauen Alter des Umfeldmodells mi-nimiert wird.
Als beispielhaftes Fahrerassistenzsystem sei das HochautomatischeFahren auf Autobahnen genannt, welches eine kontinuierliche Längs- undQuerregelung in dieser Domäne ermöglichen soll. Längs- und Querrege-lung werden im Folgenden als zwei Fahrerassistenzapplikationen aufge-fasst. Diese beiden Applikationenwerden von insgesamt vier Protokollenverwendet, welche in Tabelle 3.4 in einer Übersicht dargestellt sind.
So liefert das Egoprotokoll ein Abbild des geschätzten Egozustandes,welches von beiden Applikationen benötigt wird. Zusammen mit dem Quer-
58
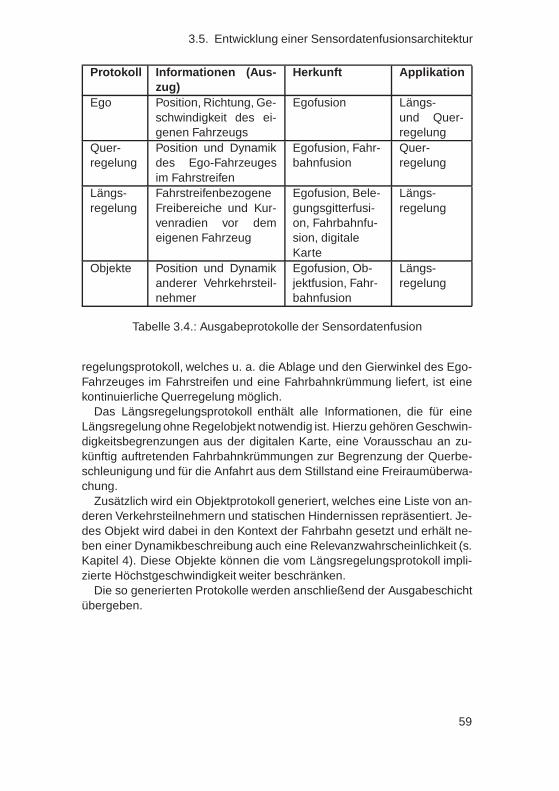
3.5. Entwicklung einer Sensordatenfusionsarchitektur
Protokoll Informationen (Aus-zug)
Herkunft Applikation
Ego Position, Richtung, Ge-schwindigkeit des ei-genen Fahrzeugs
Egofusion Längs-und Quer-regelung
Quer-regelung
Position und Dynamikdes Ego-Fahrzeugesim Fahrstreifen
Egofusion, Fahr-bahnfusion
Quer-regelung
Längs-regelung
FahrstreifenbezogeneFreibereiche und Kur-venradien vor demeigenen Fahrzeug
Egofusion, Bele-gungsgitterfusi-on, Fahrbahnfu-sion, digitaleKarte
Längs-regelung
Objekte Position und Dynamikanderer Vehrkehrsteil-nehmer
Egofusion, Ob-jektfusion, Fahr-bahnfusion
Längs-regelung
Tabelle 3.4.: Ausgabeprotokolle der Sensordatenfusion
regelungsprotokoll, welches u. a. die Ablage und den Gierwinkel des Ego-Fahrzeuges im Fahrstreifen und eine Fahrbahnkrümmung liefert, ist einekontinuierliche Querregelung möglich.
Das Längsregelungsprotokoll enthält alle Informationen, die für eineLängsregelung ohne Regelobjekt notwendig ist. Hierzu gehören Geschwin-digkeitsbegrenzungen aus der digitalen Karte, eine Vorausschau an zu-künftig auftretenden Fahrbahnkrümmungen zur Begrenzung der Querbe-schleunigung und für die Anfahrt aus dem Stillstand eine Freiraumüberwa-chung.
Zusätzlich wird ein Objektprotokoll generiert, welches eine Liste von an-deren Verkehrsteilnehmern und statischen Hindernissen repräsentiert. Je-des Objekt wird dabei in den Kontext der Fahrbahn gesetzt und erhält ne-ben einer Dynamikbeschreibung auch eine Relevanzwahrscheinlichkeit (s.Kapitel 4). Diese Objekte können die vom Längsregelungsprotokoll impli-zierte Höchstgeschwindigkeit weiter beschränken.
Die so generierten Protokolle werden anschließend der Ausgabeschichtübergeben.
59

Kapitel 3. Sensordatenfusion
3.5.7. Ausgabeschicht: Abstraktion des Sendeweges
Ähnlich wie in der Eingabeschicht kann man die erzeugten Ausgabepro-tokolle auf verschiedene Wege aus der Sensordatenfusion senden: Auchin der Ausgabeschicht stehen CAN-Bus, Messdatei und Ethernet für Si-mulationszwecke zur Verfügung. Für einfache Testzwecke ist es möglich,diese Schicht leer zu lassen, sodass keine Protokollausgabe erfolgt, aberbeispielsweise Visualisierungen erzeugt werden.
Zusammen mit der Eingabeschicht lässt sich die Sensordatenfusion inverschiedene Umgebungen transparent einfassen: Neben einer Fahrzeug-Konfiguration und einer Konfiguration zum Abspielen von Messdaten lässtsich die Sensordatenfusion insbesondere auch für „Software-in-the-Loop-Tests (SiL-Tests)“ einbinden. Hierbei werden mithilfe einer virtuellen Fahrtdurch eine virtuelle Umgebung Messdaten simulativ erzeugt und per Ether-net zur Sensordatenfusion gesendet. Die Zeitquelle gibt dabei die Simu-lationsumgebung vor. Die Sensordatenfusion erzeugt die entsprechendenAusgaben, welche mit der virtuellen Umgebung verglichen werden können.
Insgesamt ermöglichen flexible Ein- und Ausgabeschichten die Modula-ritätsanforderung zu erfüllen, sodass die Sensordatenfusion verschiedens-te Rollen einnehmen kann, ohne dass Unterscheidungen in den dazwi-schenliegenden Schichten notwendig sind.
3.5.8. Ablaufsteuerung
Viele Assistenzfunktionen benötigen aktuelle Umfelddaten, um eine qua-litativ hochwertige Funktion zu gewährleisten: Für die Querregelung beimHochautomatischen Fahren sind beispielsweise hohe Anforderungen bzgl.Echtzeitfähigkeit zu erfüllen, da der Querregler in kurzen Zeitabständenmit aktuellen Größen des Querregelungsprotokolls versorgt werden muss.Verzögerungen bedeuteten erhöhte Totzeiten im Regelkreis, was direkt ei-ne Verminderung der Regelungsqualität zur Folge hat.
Um die Protokolle rechtzeitig zu generieren, muss die Sensordatenfu-sion den Kontrollfluss zum Ausgabezeitpunkt an die Kollektorfilter der En-kodierungsschicht übergeben. Hierbei müssen die relevanten Teilfusioneneinen konsistenten Zustand aufweisen, damit alle Regelgrößen korrekt ex-trahiert werden können. Problematisch ist hierbei der externe Einfluss derUmfeldsensoren: Deren Ausgabe kann von der Sensordatenfusion nichtgesteuert werden, sodass eine Teilfusion aufgrund empfangener Sensor-daten möglicherweise gerade Schätzalgorithmen ausführt, während aberein Protokoll mit zeitlich hoher Priorität erzeugt werden soll. Letzteres muss
60
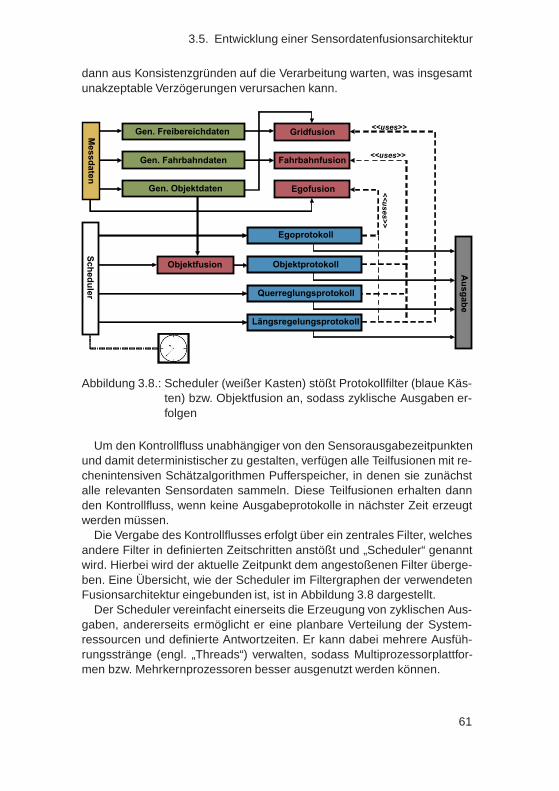
3.5. Entwicklung einer Sensordatenfusionsarchitektur
dann aus Konsistenzgründen auf die Verarbeitung warten, was insgesamtunakzeptable Verzögerungen verursachen kann.
Egoprotokoll
Objektfusion Objektprotokoll
Querreglungsprotokoll
Längsregelungsprotokoll
Egofusion
Fahrbahnfusion
Gridfusion
<<uses>>
<<uses>>
Au
sg
ab
e
Gen. Freibereichdaten
Gen. Fahrbahndaten
Gen. Objektdaten
Mes
sd
ate
nS
ch
ed
ule
r
<<uses>>
Abbildung 3.8.: Scheduler (weißer Kasten) stößt Protokollfilter (blaue Käs-ten) bzw. Objektfusion an, sodass zyklische Ausgaben er-folgen
Um den Kontrollfluss unabhängiger von den Sensorausgabezeitpunktenund damit deterministischer zu gestalten, verfügen alle Teilfusionen mit re-chenintensiven Schätzalgorithmen Pufferspeicher, in denen sie zunächstalle relevanten Sensordaten sammeln. Diese Teilfusionen erhalten dannden Kontrollfluss, wenn keine Ausgabeprotokolle in nächster Zeit erzeugtwerden müssen.
Die Vergabe des Kontrollflusses erfolgt über ein zentrales Filter, welchesandere Filter in definierten Zeitschritten anstößt und „Scheduler“ genanntwird. Hierbei wird der aktuelle Zeitpunkt dem angestoßenen Filter überge-ben. Eine Übersicht, wie der Scheduler im Filtergraphen der verwendetenFusionsarchitektur eingebunden ist, ist in Abbildung 3.8 dargestellt.
Der Scheduler vereinfacht einerseits die Erzeugung von zyklischen Aus-gaben, andererseits ermöglicht er eine planbare Verteilung der System-ressourcen und definierte Antwortzeiten. Er kann dabei mehrere Ausfüh-rungsstränge (engl. „Threads“) verwalten, sodass Multiprozessorplattfor-men bzw. Mehrkernprozessoren besser ausgenutzt werden können.
61

Kapitel 3. Sensordatenfusion
Das verwendete Scheduling ist statisch, nicht-präemptiv und prioritäts-orientiert: D. h. die Zeitschritte und -abstände der geplanten Prozessaufru-fe werden vorher festgelegt und werden zur Laufzeit nicht mehr verändert.Sobald Prozesse gestartet sind, können diese nicht unterbrochen werden,sondern müssen den Kontrollfluss von selbst wieder zurückgeben. Pro-zesse mit niedriger Priorität (Visualisierung, Fusionierung) erhalten keinenKontrollfluss, wenn Prozesse mit hoher Priorität (Erzeugung von Ausgabe-protokolle) anstehen.
0 10 20
Zeit
Abbildung 3.9.: Nicht-präemptives statisches Scheduling für drei Prozes-se mit unterschiedlicher Priorität. Pfeile symbolisieren denjeweils geplanten Start, Kästen die zeitliche Prozessoraus-lastung (ein Kern).
Ein Beispiel für solch einen Schedule mit drei Prozessen (rot/grün/blau)ist in Abbildung 3.9 dargestellt. Diese weisen unterschiedliche geplanteStartzeiten (0/1/2), Zykluszeiten (4/10/8), Rechendauer (1/3/2) und Priori-täten (hoch/niedrig/niedrig) auf. In dem Beispiel werden die Prozesse häu-fig zeitverzögert gestartet, was u. a. mit einer hohen durchschnittlichenProzessorkernauslastung von 80% begründet ist.
Auf der Zielplattform liegt die Prozessorkernauslastung trotz einer deut-lich höheren Anzahl an Prozessen deutlich niedriger10, sodass solche Ver-zögerungen durch ein geschickt gewähltes statisches Schedule größten-teils vermieden werden können. Je mehr Prozesse und je höher die durch-schnittliche Systembelastung, desto schwieriger ist es allerdings, ein gutesoder gar optimales Schedule zu finden: So ist nach [Garey 1979] das Ent-scheidungsproblem, ob ein optimales Schedules für nicht unterbrechbareProzesse existiert, im Allgemeinen NP-vollständig. Durch die Verwendungeines Mehrkernprozessors und durch die geringe Anzahl von Prozessenmit hoher Priorität konnte jedoch problemlos ein Schedule mit ausreichen-der Qualität für diese Sensordatenfusionsinstanz erstellt werden.
10Die vorgestellte Sensordatenfusion verwendet 19 Prozesse, welche den Prozessor auf derZielplattform im Schnitt zu 17,5% auslasten
62

3.6. Anwendungen und erreichte Modularität
Der Scheduler bildet eine wesentliche Komponente zur Erfüllung derEchtzeitanforderung. Er ermöglicht eine kontrollierte Rechenlastverteilungund die zyklische Protokollausgabe zu definierten Zeitpunkten. Durch eineinterne Statistikkomponente erleichtert er zudem die Bewertung der Echt-zeitfähigkeit verwendeter Algorithmen, indem er die Zeit misst, bis ein Filterden Kontrollfluss wieder zum Scheduler zurückgibt.
3.6. Anwendungen und erreichte Modularität
Die Modularität und lose Kopplung der Sensordatenfusionarchitektur er-laubt die einfache Adaption an neue Sensoren und Funktionen und diePortierung auf verschiedene Versuchsträger. Von dieser Eigenschaft wur-de intensiv Gebrauch gemacht, indem die Sensordatenfusion bisher aufacht verschiedenen Versuchsfahrzeugen portiert worden ist. Dort bedientdie Sensordatenfusion unterschiedlichste Fahrerassistenzfunktionen11:
• Hochautomatisches Fahren auf der Autobahn und autobahnähnli-chen Straßen [Steinmeyer 2010a; Hoeger 2011]
• Vorausschauende energieeffiziente Fahrzeuglängsregelung12 [Dor-nieden 2012]
• Nothalteassistenz bei medizinisch bedingter Fahrunfähigkeit [Mir-waldt 2012]
• Fahrstreifenwechselassistenz [Degerman 2012; Meinecke 2013],Fahrstreifenhalteassistenz und hochautomatisches Fahren in Stau-situationen für schwere Nutzfahrzeuge
Die Versuchsträger weisen je nach Anforderungen der Assistenzfunk-tionen unterschiedlichste Sensorkonfigurationen auf: So finden sich al-le im Kapitel 2 erwähnten Sensortechnologien in diesen wieder. Für dieEgoschätzung kommen in einigen Versuchsträgern Inertialplattformen zumEinsatz, während bei anderen Fahrzeugen ausschließlich die serienmäßi-gen Odometriesensoren genutzt werden.
11Aufgrund der vielen verschiedenen Funktionen, Sensoren und Versuchsträger wird in dieserArbeit auf die Darstellung von spezifischen Anforderungen und Gesamtarchitekturen verzich-tet. Es sei aber darauf verwiesen, dass diese für eine hochautomatische Fahrfunktion miteiner Sensorkonfiguration im Rahmen des EU-Förderprojekt HAVEit dokumentiert wordensind [To 2010b,a; Hoeger 2011].
12Hier kam eine vereinfachte Version der Sensordatenfusion zum Einsatz, da es nur geringeAnforderungen an die Genauigkeit der Fahrstreifenschätzung gab und auch kein Belegungs-gitter notwendig war.
63

Kapitel 3. Sensordatenfusion
(a) Versuchsträger für das HAVEit-Projekt ausgerüstet mit Laserscan-ner, Radarsensor, Ultraschallsen-soren, GPS und digitaler Karte
(b) Versuchsträger ausgerüstet mitStereokamera, zwei Monokame-ras, fünf Radarsensoren, zehnUltraschallsensoren, zwei Inerti-alplattformen, GPS und digitalerKarte
Abbildung 3.10.: Zwei Versuchsträger mit unterschiedlichen Sensorkonfi-gurationen (Bild aus [Meinecke 2013])
Zwei Beispiele für verwendete Versuchsträger sind in Abbildung 3.10dokumentiert: Diese unterstützen hochautomatische Fahrfunktionen bzw.Fahrstreifenwechsel- und Fahrstreifenhalteassistenz. Obwohl in beidenVersuchsträgern viele neue Sensoren verbaut worden sind, sind die Ver-bauorte nicht direkt offensichtlich. Der Hintergrund dafür ist, dass nur sol-che Verbauorte ausgewählt worden sind, die auch für einen späterem Se-rieneinsatz in Frage kämen. Deshalb fällt beispielsweise das Autodach alsSensorverbauort aus, obwohl Sensoren dort sehr große Sichtbereiche ab-decken könnten.
3.7. Zusammenfassung
Die gezeigte Softwarearchitektur tariert die Komplexität einer generischenSensordatenfusion mit der benötigten Flexibilität aus. Wesentliche Merk-male sind die lose und konfigurierbare Kopplung von Filtern und die Zu-sammenfassung in Schichten mit genau definierten Verantwortlichkeiten.
So ist es mit möglich, die Sensordatenfusion auf andere Versuchsträ-ger mit unterschiedlicher Sensorik zu portieren. Hier ist im Wesentlichendie Sensorabstraktionsschicht anzupassen, welche die sensorspezifischenProtokolle auf generische Strukturen abbildet.
64
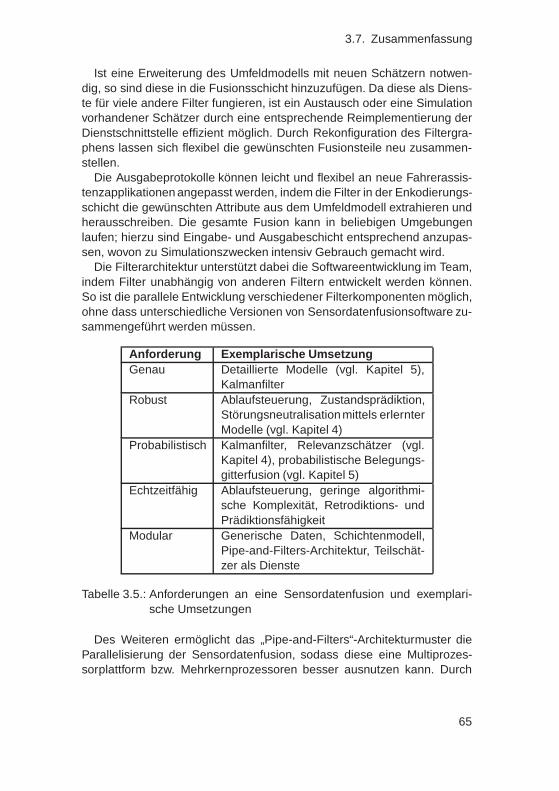
3.7. Zusammenfassung
Ist eine Erweiterung des Umfeldmodells mit neuen Schätzern notwen-dig, so sind diese in die Fusionsschicht hinzuzufügen. Da diese als Diens-te für viele andere Filter fungieren, ist ein Austausch oder eine Simulationvorhandener Schätzer durch eine entsprechende Reimplementierung derDienstschnittstelle effizient möglich. Durch Rekonfiguration des Filtergra-phens lassen sich flexibel die gewünschten Fusionsteile neu zusammen-stellen.
Die Ausgabeprotokolle können leicht und flexibel an neue Fahrerassis-tenzapplikationen angepasst werden, indem die Filter in der Enkodierungs-schicht die gewünschten Attribute aus dem Umfeldmodell extrahieren undherausschreiben. Die gesamte Fusion kann in beliebigen Umgebungenlaufen; hierzu sind Eingabe- und Ausgabeschicht entsprechend anzupas-sen, wovon zu Simulationszwecken intensiv Gebrauch gemacht wird.
Die Filterarchitektur unterstützt dabei die Softwareentwicklung im Team,indem Filter unabhängig von anderen Filtern entwickelt werden können.So ist die parallele Entwicklung verschiedener Filterkomponenten möglich,ohne dass unterschiedliche Versionen von Sensordatenfusionsoftware zu-sammengeführt werden müssen.
Anforderung Exemplarische UmsetzungGenau Detaillierte Modelle (vgl. Kapitel 5),
KalmanfilterRobust Ablaufsteuerung, Zustandsprädiktion,
Störungsneutralisation mittels erlernterModelle (vgl. Kapitel 4)
Probabilistisch Kalmanfilter, Relevanzschätzer (vgl.Kapitel 4), probabilistische Belegungs-gitterfusion (vgl. Kapitel 5)
Echtzeitfähig Ablaufsteuerung, geringe algorithmi-sche Komplexität, Retrodiktions- undPrädiktionsfähigkeit
Modular Generische Daten, Schichtenmodell,Pipe-and-Filters-Architektur, Teilschät-zer als Dienste
Tabelle 3.5.: Anforderungen an eine Sensordatenfusion und exemplari-sche Umsetzungen
Des Weiteren ermöglicht das „Pipe-and-Filters“-Architekturmuster dieParallelisierung der Sensordatenfusion, sodass diese eine Multiprozes-sorplattform bzw. Mehrkernprozessoren besser ausnutzen kann. Durch
65

Kapitel 3. Sensordatenfusion
das explizite Scheduling sind Echtzeitanforderungen in einzelnen Verarbei-tungssträngen kontrolliert umsetzbar. So lassen sich verschiedene Filter zudefinierten Zeiten auf solchen Plattformen parallel anstoßen, sodass dieverfügbare Rechenkapazität optimal zur Latenzzeitoptimierung ausgenutztwerden kann. Dieses ist beispielsweise für die Güte einer Querregelungvon erheblicher Bedeutung. Eine Übersicht, wie die allgemeinen Anforde-rungen in der Sensordatenfusion berücksichtigt werden, ist in Tabelle 3.5dokumentiert.
Die erfolgreiche Umsetzung der Anforderungen zeigt sich dadurch, dassdie entworfene Sensordatenfusion nicht nur auf mittlerweile acht Versuchs-träger mit unterschiedlicher Sensorik portiert werden konnte, sondern dassdiese auch verschiedenste Fahrerassistenzapplikationen bewältigen.
Insgesamt hat sich dieses Kapitel hauptsächlich mit der Modularitäts-und Echtzeitsfähigkeitsanforderung befasst, wobei auch exemplarisch ei-nige Teilfusionen vorgestellt wurden, die größtenteils auf Kalmanfilter ba-sieren. Diese zeichnen sich durch eine gute Zustandsschätzung und Unsi-cherheitsberechnung aus und bilden damit bereits eine wichtige Säule zurErfüllung der Anforderung an eine genaue, robuste und probabilistischeSensordatenfusion. Der Kalmanfilter ist jedoch kein idealer Schätzer für al-le möglichen Umfeldaspekte. Deshalb werden weitere Methoden zur derUmfeldschätzung in den nächsten beiden Kapiteln vorgestellt.
66

Kapitel 4.
Existenz- und Signifikanzschätzung fürUmfeldobjekte
4.1. Einleitung
Mit der im vorherigen Kapitel vorgestellten Objektfusion ist es möglich, Ob-jektdaten von verschiedenen Sensoren durch Kalmanfilter zu einer Objekt-liste zu fusionieren. Durch diese Filterung wird die Zustandsunsicherheitverkleinert und quantifiziert. Insgesamt ist durch diese Methode das Pro-blem der Messungenauigkeiten von Sensoren behandelt worden.
Die resultierende Objektliste beinhaltet jedoch weitere Unsicherheiten:Wie in Kapitel 2 erwähnt worden ist, können vermeintliche Objekte erfasstwerden, welche jedoch keine relevanten Objekte im Sinne einer Fahre-rassistenzapplikation darstellen, da sie beispielsweise über- oder unter-fahrbar sind. Umgekehrt ist es möglich, dass unter Umständen wichtigeObjekte nicht oder nicht in allen Messungen detektiert wurden. In Kapitel3 sind weitere Fehlerquellen bei der Objektverfolgung erwähnt worden. Sokönnen durch Assoziationsfehler sowohl Scheinobjekte entstehen als auchObjekte unerkannt bleiben.
Insgesamt bleibt bei widersprüchlichen und ungenauen Sensordaten dieBewertung schwierig, ob eine Objekthypothese von der Fahrerassistenz-applikation berücksichtigt werden muss oder nicht. Um diesem zu begeg-nen, befasst sich dieses Kapitel mit der statistisch genauen Bewertung derObjektdaten der vorgestellten Sensordatenfusion. Für jede Objekthypothe-se wird eine Wahrscheinlichkeit bestimmt, welche angibt, ob dieses im Sin-ne des Fahrerassistenzsystems berücksichtigt werden muss.
Die probabilistische Ausgabe ist nicht nur Ausdruck und Quantifizierungder Imperfektion der Umfeldwahrnehmung. Ihr Nutzen besteht in der An-wendungsmöglichkeit von Schwellwerten, sodass beispielsweise die Fehl-auslösungsrate auf Kosten der fehlerhaften Nichtauslösungsrate vorher-sagbar gesenkt werden kann oder umgekehrt.
Als Domäne werden in diesem Kapitel Autobahnen und autobahnähn-liche Szenarien gewählt, da diese besonders strukturiert und somit für
67

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Ansätze mit vielen Modellannahmen geeignet sind. Diese werden in die-sem Kapitel untersucht. Für schwach strukturierte Umgebungen eignensich belegungsgitterbasierte Ansätze, welche detailliert im Kapitel 5 vorge-stellt werden. Herausfordernd bei der angenommenen Autobahndomäneist insbesondere die sichere Objektdetektion in großen Entfernungen. Dienachfolgend vorgestellten Methoden können aber auch auf andere Domä-nen übertragen werden.
4.2. Gliederung
In diesem Kapitel werden zunächst verschiedene Typen von Objekthypo-thesen definiert, welche existente bzw. signifikante Objekte repräsentierenkönnen. Sind diese Objekte sowohl existent als auch signifikant, so müs-sen diese vom Fahrerassistenzsystem berücksichtigt werden und geltenals relevant. Genaue Definitionen zur Existenz, Signifikanz und Relevanzerfolgen im nächsten Abschnitt 4.3.
Die Typklassifikation der Objekthypothesen erfolgt durch Schätzer, wel-che ausschließlich auf mehr oder weniger unsichere und ungenaue Infor-mationen zurückgreifen und somit keine perfekten Ergebnisse liefern kön-nen. In den folgenden Abschnitten werden bekannte und neue Ansätzevorgestellt, die eine solche Schätzung leisten können.
Zunächst werden bekannte Ansätze aus der Literatur untersucht, wo-bei insbesondere zur Existenzschätzung eine Vielzahl von Ansätzen ent-wickelt worden sind. Einige Vielversprechende davon werden im Abschnitt4.4 vorgestellt und bewertet. Hier stellt sich heraus, dass viele AnsätzeObjektexistenz als dynamischen Zustand betrachten und deshalb entspre-chende Schätzer nutzen. Nur wenige Ansätze sehen Existenzschätzungals auf Klassifikationsproblem und diese arbeiten nicht probabilistisch.
Weiterhin werden verschiedene Signifikanzschätzer speziell für Ab-standsregeltempomaten (ACC) im Abschnitt 4.5 vorgestellt und untersucht.
Existenz- und Signifikanzschätzungen müssen kombiniert werden, umzu entscheiden, ob eine Objekthypothese relevant ist. Als alternativer An-satz wird ein integrierter Relevanzschätzer vorgestellt, welcher nicht überden Umweg von Existenz- und Signifikanzschätzung arbeitet, sondern dieRelevanz direkt ermittelt. Dieser approximiert mittels Maschinellem Lerneneine Klassifikatorfunktion aus Trainingsdaten, womit er alle vorgestelltenund auch unbekannten Fehlerquellen integriert. Dieser Ansatz wird im Ab-schnitt 4.6 vorgestellt, an realen Messdaten getestet und bewertet.
Die Transparenz von Klassifikatoren, die mittels maschinellen Lernver-fahrens erzeugt werden, ist häufig gering. Um zu analysieren, welche Zu-
68

4.3. Existente und signifikante Objekte
sammenhänge dieser Klassifikator gelernt hat, werden im Abschnitt 4.7Schnittbilder durch den Zustandsraum eines solchen Klassifikators berech-net und interpretiert.
Die dargestellten Ansätze, Ergebnisse und Bewertungen dieses Kapitelswerden im letzten Abschnitt 4.8 zusammengefasst.
4.3. Existente und signifikante Objekte
Die im Kapitel 3 erzeugte Objektliste besteht aus einer Menge von Ob-jekthypothesen. Jede enthält einen Zustandsvektor, der u. a. Dynamik undPosition des Objektes dokumentiert. Es fehlt allerdings eine Schätzung, obsich hinter dem Objekt ein Scheinobjekt oder ein Ziel im Sinne des Fahre-rassistenzsystems verbirgt.
Deshalb ist die Bestimmung der Objektexistenz für jede Objekthypothe-se der Sensordatenfusion notwendig. Diese unterscheidet die Klasse derScheinziele (z. B. Schilderbrücke) von der Klasse der existenten Ziele (z.B. Fahrzeug) ausdrücklich im Sinne des Fahrerassistenzsystems. DiesesVorgehen betont, dass nicht die Fahrerassistenzapplikation an eine Um-feldwahrnehmung angepasst werden soll, sondern dass die Fahrerassis-tenzapplikation Anforderungen an die Umfeldwahrnehmung stellt, die eszu erfüllen gilt1:
Definition 1 (Objektexistenz).Eine Objekthypothese wird im Sinne einer Fahrerassistenzapplikation ge-nau dann als existent klassifiziert, wenn diese zu einem realen Objekt kor-respondiert, welches unabhängig vom aktuellen Zustand einen Typ auf-weist, auf den das Fahrerassistenzsystem potenziell reagieren muss.
Ist das Objekt existent, so bedeutet das aber noch nicht, dass die Fah-rerassistenzapplikation direkt auf dieses reagieren muss. Zusätzlich mussnoch geprüft werden, ob dieses auch signifikant im Sinne des Fahreras-sistenzsystems ist. So sind beispielsweise Fahrzeuge für ein ACC nichtsignifikant, wenn sich diese außerhalb des Fahrschlauches befinden. ImBereich Fußgängerschutz sind nur die Fußgänger signifikant, welche sichim unmittelbaren Nahbereich aufhalten.
Definition 2 (Objektsignifikanz).Eine Objekthypothese wird im Sinne einer Fahrerassistenzapplikation ge-nau dann als signifikant klassifiziert, wenn das zugrundeliegende Objekt
1In [Munz 2011, S. 31 f] wird eine ähnliche Definition zur Existenz von Objekten aufgestellt.Munz fordert allerdings zusätzlich die Detektierbarkeit durch mindestens einen Sensor desEgofahrzeuges. Darauf wird hier bewußt verzichtet, da die Objektexistenz hier unabhängigvon der Beobachtbarkeit sein soll.
69

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
einen Zustand aufweist, bei dem das Fahrerassistenzsystem bei angenom-mener Existenz reagieren muss.
Offensichtlich sind für Fahrerassistenzsysteme nur solche Objekte zuberücksichtigen, welche existent und signifikant sind. Diese beiden Eigen-schaften werden zur Objektrelevanz zusammengefasst:
Definition 3 (Objektrelevanz).Eine Objekthypothese ist im Sinne einer Fahrerassistenzfunktion genaudann relevant, wenn diese existent und signifikant ist.
Da die Information einzelner Sensoren sowohl zur Objektexistenz alsauch Objektsignifikanz aus potenziell unsicheren Sensordaten stammen,ist eine jederzeit fehlerfreie Klassifikation praktisch nicht möglich, da zwi-schen Objekthypothese und zugrunde liegendem Objekt stets eine mehroder weniger große Abweichung besteht. Aus diesem Grund sollten mög-lichst viele Informationsquellen genutzt werden, um die Unsicherheiten beider Schätzung von Existenz, Signifikanz und Relevanz eines Objektes zuminimieren. Die Stärke der Unsicherheit sollte durch ein Wahrscheinlich-keitsmaß möglichst genau wiedergegeben werden.
Dieser probabilistische Ansatz ermöglicht die Auflösung und Quantifi-zierung von widersprüchlichen Informationen und liefert zur Klassifikationzusätzlich eine Schätzgüte.
4.4. Stand der Technik:Existenzwahrscheinlichkeitsschätzer
Existenzwahrscheinlichkeitsschätzer haben im Wesentlichen zwei Aufga-ben. Zum einen müssen sie Objekte vom Hintergrundrauschen separie-ren, sodass Scheinobjekte ohne kausalen Zusammenhang in der Umweltunterdrückt werden.
Wie in Kapitel 2 gezeigt, gibt es zum anderen Phänomene in der Umwelt,welche keine Objekte im Sinne des Fahrerassistenzsystems sind, aberdennoch systematische Quellen für eine positive Objekthypothese darstel-len können. Diese zu eliminieren ist die zweite und wohl anspruchsvollereAufgabe eines Existenzwahrscheinlichkeitsschätzers.
In diesem Abschnitt werden insgesamt sechs verschiedene existierendeAnsätze vorgestellt und bewertet, wobei fünf bekannte Ansätze aus derLiteratur sind.
70

4.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer
4.4.1. Track Score Funktion nach Sittler
Eine der ersten Arbeiten zur Bewertung von Objekthypothesen mittels ei-nes Gütemaßes ist in [Sittler 1964] zu finden, welches später in [Blackman1999] und [Altendorfer 2010] weiter vertieft wird. Ursprünglich wurde die-ses Maß als Entscheidungshilfe im Tracking verwendet, um Messungen mitObjekthypothesen besser assoziieren zu können. Es kann außerdem dazuverwendet werden, den Lebenszyklus einer Objekthypothese zu verwalten:Sinkt das Gütemaß unter einen Schwellwert, so wird die Objekthypotheseverworfen.
Die vorgeschlagene Gütefunktion („Likelihood Ratio“) gibt den Quotien-ten der Wahrscheinlichkeiten P(H1|Mk) und P(H0|Mk) an, dass ein Objektexistiert bzw. nicht existiert. Hierzu wird eine Wahrscheinlichkeitsdichte-funktion erzeugt, welche die Existenzwahrscheinlichkeit aufgrund einesMessvektors und der im Tracking erzeugten zugehörigen Kovarianzmatrixabbildet. Über einen Markov-Ketten-Ansatz wird die Wahrscheinlichkeit fürdie beiden Hypothesen bestimmt, ob das Objekt existiert bzw. nicht exis-tiert.
Sei Mk = m1, . . . ,mk die Menge der Messungen, H1 bzw. H0 die Hypo-these, dass das Objekt existiert bzw. nicht existiert und P0(H1) bzw. P0(H0)die Grundwahrscheinlichkeit eines Tracks, dass es sich um ein existieren-des Objekt bzw. um ein Scheinobjekt handelt.
Dann sei eine „Likelihood Ratio“-Funktion LR definiert, die das Verhältnisder Wahrscheinlichkeiten PH1 und PH0 beschreibt, ob ein Track existiert bzw.nicht existiert:
LR(Mk) =p(Mk|H1) ·P0(H1)
p(Mk|H0) ·P0(H0)=
p(Mk|H1) ·P0(H1)
1− p(Mk|H1) ·P0(H1)
∆=
P(H1|Mk)
P(H0|Mk)(4.1)
Diese Funktion basiert auf einer Unabhängigkeitsannahme der einzel-nen Messungen bezüglich der beiden Objekthypothesen H1 und H0:
p(Mk|H1) =k
∏i=1
p(mi|H1) (4.2)
Herausfordernd bleibt die genaue Modellierung der Wahrscheinlichkeits-dichtefunktion basierend auf einem potenziell hochdimensionalen Mess-vektor. Hierzu wird in [Blackman 1999] die LR-Funktion in die TeilfunktionenLRK und LRS aufgetrennt, die die unterschiedlichen Existenzwahrschein-lichkeiten bzgl. Kinematik des beobachteten Tracks und für die Signalcha-rakteristik beschreiben. Dieses Vorgehen vereinfacht die Modellierung derkorrespondierenden Wahrscheinlichkeitsdichtefunktion.
71

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
In die auf kinematischen Attributen basierende Wahrscheinlichkeits-dichtefunktion fließen verschiedene Schätzungen aus dem Tracking undder assoziierten Messung ein: Hierzu gehört die Determinante der Kovari-anzmatrix S des Zustandsvektors z (s. Abschnitt A.2). Je geringer diese ist,desto geringer ist die Zustandsunsicherheit und desto häufiger wurde dasObjekt mit übereinstimmenden Messungen bestätigt. Des Weiteren wirdder mit der Kovarianzmatrix gewichtete Mahalanobisabstand d(mi,S)2 derassoziierten Messung mi = Hmi zum Trackzustand mit d(mi,S)2 = mi S−1 mi
berücksichtigt. Als letztes Attribut fließt ein messwertabhängiger Korrektur-faktor VC(mi) ein, der für einen diskreten Bereich im Zustandsraum die un-terschiedliche Auftretenswahrscheinlichkeit von Scheinzielen kompensiert.
Die Teilfunktion LRK ergibt sich zu:
LRK(mi,S) =VC(mi) · e
−d(mi ,S)2
2
(2π)dim(mi)
2√
|S|(4.3)
Die Modellierung der Wahrscheinlichkeitsdichtefunktion für die Berech-nung von LRS ist abhängig von der Sensortechnologie. In [Blackman 1999]wird beispielsweise das ermittelte Signal-Rausch-Verhältnis eines Radar-sensors während der Signalverarbeitung genutzt, um diese zu ermitteln.
Allgemein wird ein Signalvektor mS(m) aus dem Messvektor m generiert,der die signalspezifischen Daten enthält; mA(m) ist die aus dem Messvek-tor generierte Amplitude und T H eine Schwelle, ab der mA als positiveDetektion klassifiziert wird. Dann ergibt sich LRS zu:
LRS(z) =p(mS(z),mA(z)≥ T H|H1)
p(mS(z),mA(z)≥ T H|H0)(4.4)
Die Zusammenfassung von LRK und LRS eines Tracks, mit dem k Einzel-messungen assoziiert worden sind, erfolgt durch:
LR(Mk,Sk) =P0(H1)
P0(H0)
k
∏i=1
(LRK(mi,Si) ·LRS(mi)) (4.5)
Um aus dem LR-Funktionsergebnis eine Existenzwahrscheinlichkeit zubestimmen, kann man durch Umformung der Gleichung 4.1 und der to-talen Wahrscheinlichkeit mit P(H1|Mk)+P(H0|Mk) = 1 folgende Beziehungableiten:
P(H1|Mk,Sk) =LR(Mk,Sk)
LR(Mk,Sk)+1(4.6)
72

4.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer
In der Literatur wird häufig die „Logarithmic Likelihood Ratio“(LLR) ange-geben, welche durch Logarithmieren der LR-Funktion erzeugt wird. Dieseerlaubt einen summarischen Aktualisierungsalgorithmus. LLR(Mk,Sk) undP(H1|Mk) ergeben sich dann zu:
LLR(Mk,Sk) = ln(LR(Mk,Sk) (4.7)
P(H1|Mk,Sk) =eLLR(Mk ,Sk)
eLLR(Mk,Sk)+1(4.8)
Die von Sittler vorgeschlagene Gütefunktion berücksichtigt bereits vie-le Faktoren, insbesondere alle Attribute des Messvektors m und dieZustandsunsicherheit innerhalb des Trackings in Form der Determinanteder Kovarianzmatrix. Somit lassen sich viele wesentliche Attribute in die-sem Gütemaß vereinen, sodass dieses potenziell eine hohe Funktionsap-proximation erreichen kann.
Nachteilig an diesem Verfahren ist die Erfordernis der genauen Modellie-rung der beiden Wahrscheinlichkeitsdichtefunktionen LRK und LRS. Wäh-rend bei LRK nur die Scheinzielkompensation VC aufgrund eines potenzi-ell hochdimensionalen Messvektors aufwendig zu ermitteln erscheint, istbei LRS sehr viel sensorspezifisches Expertenwissen notwendig, um eineausreichende Approximation der Wahrscheinlichkeitsdichtefunktion zu er-reichen.
Eine wohl größere Fehlerquelle liefert jedoch die Unabhängigkeitsan-nahme zwischen einzelnen Messungen entsprechend Gleichung 4.2. Da-durch können systematische Scheinziele, wie beispielsweise eine Schilder-brücke, in diesem Verfahren nicht berücksichtigt werden. Sie werden nurunzureichend über die Scheinzielrate VC gemittelt kompensiert. So wird fürdieses Verfahren nach [Blackman 1999] auch eine gleichverteilte Auftre-tenswahrscheinlichkeit für Scheinziele in einem Teilbereich im Zustands-raum VC und für die gemessenen Objektzustände eine Normalverteilungvorausgesetzt.
4.4.2. Trackqualität nach Sinha
Ein weiteres Gütemaß zur Schätzung der „Trackqualität“ ist in [Sinha 2006]angegeben. Die Schätzung soll ebenfalls mit der Existenzwahrscheinlich-keit des Tracks korrelieren.
Wird ein Track das erste Mal initialisiert, erhält er eine konstanteoder messwertabhängige Startexistenzwahrscheinlichkeit P0. Die Prädik-tion folgt einem einfachen Markov-Modell gemäß Abbildung 4.1, welches
73

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Objekt
existiert
Objekt
existiert
nicht
1 -
1
Abbildung 4.1.: Markov-Kette nach Sinha für Ereignis A1
durch einen einzelnen konstanten Faktor α parametrisiert ist. Dieser be-schreibt die Wahrscheinlichkeit, dass ein existierendes Objekt im nächstenPrädikationsschritt noch existiert.
Gemäß dem Markov-Modell kann sich eine Objekthypothese mit derWahrscheinlichkeit von 1−α von existent zu nicht existent wandeln, jedochnicht umgekehrt. Sinha nimmt an, dass eine Objekthypothese im Messrau-schen nach einer gewissen Trackingdauer als existierendes Objekt bestä-tigt werden kann und dann nur eine gewisse Zeitspanne existiert, bevor eseinen Ort einnimmt, wo es nicht mehr detektierbar ist. Die Nichtdetektier-barkeit setzt Sinha mit der Nichtexistenz gleich.
Insgesamt ergibt sich durch das Markov-Modell eine einfache Prädikti-on pro Zeitschritt. Gegeben sei ein Track mit der Existenzwahrscheinlich-keit P(k|k) und ein Persistenzfaktor α, welcher die Wahrscheinlichkeit be-schreibt, dass ein existenter Track immer noch existiert, wenn dieser imaktuellen Messzyklus nicht bestätigt werden konnte. Die prädizierte Exis-tenzwahrscheinlichkeit beträgt dann:
P(k|k+1) = P(k|k)α (4.9)
Im Aktualisierungsschritt werden die beiden Ereignisse A1 und A2 unter-schieden: Entweder konnte der Track mit einer Messung assoziiert werdenoder nicht. Diese beiden Ereignisse A1 und A2 lassen sich noch in 5 unbe-kannte Teilereignisse A1 = A11,A12,A13 und A2 = A21,A22 unterteilen,welche zwei Attribute mit unbekanntem Zustand enthalten.
Das eine Attribut besagt, ob das getrackte Objekt tatsächlich existiert.Das andere Attribut beinhaltet, ob der Sensor ein existierendes Objektwahrgenommen hat oder aber ein falsch positives Objekt durch eine fehlin-terpretierte Messung geliefert hat. Die Zusammensetzung der 5 Teilereig-nisse ist in Tabelle 4.1 dokumentiert.
Sinha nimmt an, dass die Ereignisse A11, A12, A13, in denen eine Mes-sung erfolgreich assoziiert werden konnte, disjunkt und vollständig sind.
74

4.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer
A11 A12 A13 A21 A22
Assoziation möglich Ja Ja Ja Nein NeinObjekt existiert Ja Ja Nein Ja NeinMessung stammt von einemexistierenden Objekt
Ja Nein Nein Nein Nein
Tabelle 4.1.: Auftretende Teilereignisse bei einer Messassoziation
Der Fall, dass eine auf einem existierenden Objekt basierende Messungeine Fehlassoziation verursacht, wird vernachlässigt.
Auf Basis der Auftretenswahrscheinlichkeit dieser Teilereignisse wird dieneue Existenzwahrscheinlichkeit P(k+1|k+1) bestimmt. Bei der Berech-nung wird eine Fallunterscheidung vorgenommen, ob das Ereignis A1 (Ob-jekt assoziiert) oder das Gegenereignis A2 eingetreten ist:
P(k+1|k+1) =
pA11+pA12pA11+pA12+pA13
, wenn A1 eingetreten istpA21
pA21+pA22, sonst
Hierbei sind die Wahrscheinlichkeiten pA11, pA12, pA13, pA21 und pA22 dereinzelnen Teilereignisse genau zu modellieren. Um eine gute Funktionsap-proximation zu erreichen, sollten möglichst viele relevante Eingangspara-meter genutzt werden.
Dafür verwendet Sinha die a-priori zu bestimmenden Detektionswahr-scheinlichkeiten π1 und π2 für die Ereignisse A1 bzw. A2 und die Wahr-scheinlichkeit π0, dass kein Scheinziel im Bereich einer Objekthypotheseaufgetreten ist. Als weitere Funktion wird f (zk+1|xk+1) definiert, welche dieWahrscheinlichkeit bestimmt, dass die Messung zk+1 zu der auf den Zeit-punkt der Messung prädizierten Objekthypothese xk+1 gehört. Wie die imvorherigen Abschnitt vorgestellte „Track Score Function“ von Sittler, wirdals weiterer Faktor noch die Auftretenswahrscheinlichkeit von ScheinzielenVC(z) abhängig vom Messvektor z berücksichtigt:
pA11 = π1 · f (zk+1|xk+1) ·P(k+1|k) (4.10)
pA12 = (1−π1) ·VC(zk+1) ·P(k+1|k) (4.11)
pA13 = VC(zk+1) · (1−P(k+1|k)) (4.12)
pA21 = (1−π2) ·π0 ·P(k+1|k) (4.13)
pA22 = π0 · (1−P(k+1|k)) (4.14)
75

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Der vorgestellte Algorithmus zur Berechnung der Trackqualität von Sinhakann ähnliche Faktoren wie die „Track Score Function“ von Sittler nutzen.Die Funktion f zur Berechnung der Wahrscheinlichkeit, ob eine Messungeinem Track angehört, ist in [Sinha 2006] nicht weiter spezifiziert. Ein of-fensichtlicher Ansatz ist den mit der Kovarianzmatrix gewichteten Maha-lanobisabstand von Messvektor und prädizierter Objekthypothese zu nut-zen. Auch die Verwendung sensorspezifischer Gütefunktionen, wie die imvorherigen Abschnitt vorgestellte LRS-Funktion, ist denkbar. Weiterhin ge-meinsam haben beide Funktionen, dass sie die gemittelte Auftretensratevon Scheinzielen in definierten Teilbereichen des Zustandsraumes verwen-den.
Nachteilig ist die eventuell komplexe oder ungenügend approximativeModellierung von f . Wie bei Sittler ist auch die messvektorabhängigeScheinzielrate VC bei hochdimensionalen Messvektoren eventuell nur auf-wendig zu ermitteln. Auch das Problem der systematischen Scheinzieleoder systematisch nicht erkannten Ziele wird nur unzureichend berücksich-tigt. Diese werden hier, wie die gemittelte Scheinzielrate zeigt, als gleich-verteilt angenommen.
4.4.3. Objektplausibilisierung nach Schoeberl
Die beiden vorausgegangenen Verfahren haben sich im Wesentlichen dar-auf konzentriert, die Objektexistenzschätzung basierend auf einer Messfol-ge mit bestimmten Verteilungs- und Unabhängigkeitsvoraussetzungen zuaktualisieren.
Ein einfaches Verfahren, welches effektiv auch systematische Schein-ziele unterdrückt, ist in [Schoeberl 2008] beschrieben. Es setzt eine Mono-kamera und einen Radarsensor voraus, welche unterschiedliche Messprin-zipien haben. Dadurch ist das gleichzeitige Auftreten von systematischenScheinzielen in den beiden Messfolgen deutlich seltener. Die Messfolgenwerden separat ausgewertet, sodass zwei Listen von Objekthypothesenerzeugt werden.
Für jede Objekthypothese wird die Zeit bis zur Kollision mit dem Ego-Fahrzeug (engl. „Time-To-Collision (TTC)“) bestimmt. Diese ergibt sich ap-proximativ aus dem Verhältnis von Abstand d und der Relativgeschwindig-keit v.
Da ein Monokamerasensor weder die Geschwindigkeit noch den Ab-stand direkt messen kann, muss dieser Parameter anderweitig bestimmtwerden. Dieses ist einerseits über die Auswertung des optischen Flussesmöglich (vgl. Abschnitt 2.2.1), andererseits über die zeitliche Beobachtung
76

4.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer
der Objektkonturgröße.Bei letzterem Ansatz approximiert der Monokamerasensor für ein Ob-
jekt eine Silhouette, wobei bildverarbeitende Algorithmen auf Daten desdigitalen Abbildes angewandt werden. Im einfachsten Fall wird hierbei einKastenmodell verwendet, sodass nur die Breite und Länge als freie Para-meter ermittelt werden müssen.
Es seien zwei aufeinanderfolgende Messungen mit dem zeitlichen Ab-stand ∆t gegeben. Der Abstand des Objektes zum Ego-Fahrzeug sei inden beiden Messungen d1 bzw. d2 und dessen Breite b. Es sei ferner ange-nommen, dass die gemessene scheinbare Objektbreite eines assoziiertenObjektes in der ersten und zweiten Messung s1 bzw. s2 ist. Für s1 bzw. s2gilt dann:
s1 =bd1
(4.15)
s2 =bd2
(4.16)
Aufgrund der Messdaten der Kamera und der Annahmen lässt sich danndie Zeit bis zur Kollision T TCK berechnen:
T TCK(s1,s2) =d2
v= ∆t
d2
d1−d2
= ∆tbs2
bs1− b
s2
= ∆ts1
s2− s1(4.17)
Um die T TCR für eine Radarsensormessung zu bestimmen, kann auf be-kannte Verfahren zurückgegriffen werden, welche Abstand und Relativge-schwindigkeit zurückliefern [Winner 2009a]. Hierbei ist allerdings die Aus-wertung zweier rampenförmig modulierter Signale notwendig. Wenn dabeimehrere Objekte auftreten, kann es zu Assoziationsfehlern kommen, so-dass eine fehlerhafte T TCR ermittelt wird.
In [Schoeberl 2008] wird ein verbessertes Verfahren vorgestellt, welchesdie T TCR als Quotient aus Abstand und Relativgeschwindigkeit direkt auseinem einzigen empfangenen rampenförmig modulierten Signal bestimmt(vgl. Abschnitt 2.2.3).
Die TTCs in den erzeugten Objektlisten werden miteinander verglichen.Wenn in beiden Objektlisten sich zwei Objekthypothesen mit vergleichba-rer TTC finden lassen, so sind diese plausibilisiert und gelten somit alsexistent.
77

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Das vorgestellte Verfahren ist sehr sensorspezifisch: Mittels speziel-ler Signalverarbeitung lassen sich Objekthypothesen mit stabiler TTC fürMonokamera- und Radarsensordaten generieren, welche als Assoziati-onskriterium genutzt werden können. Bei einer anderen Sensorplattformkönnte dieses Verfahren weniger performant sein.
Insgesamt basiert es auf dem Grundgedanken, dass ein Objekt erstplausibel ist, wenn es von einem zweiten Sensor mit anderem Messprin-zip erfasst worden ist. Dieses lässt sich auch in klassischen Trackingver-fahren als Plausibilisierungskriterium leicht nutzen. Eine probabilistischeAngabe über die Existenzwahrscheinlichkeit bietet dieses Verfahren in die-ser Form leider nicht. Sein Fokus liegt im Unterdrücken von Scheinzielenbeispielsweise für Assistenzsysteme zur Vermeidung von Kollisionen. Hiersind Fehlauflösungen möglichst zu vermeiden, notfalls auf Kosten fehlen-der Nichtauslösungen.
4.4.4. Familie der „ProbabilistischenDatenassoziationsalgorithmen“
Einer der fortschrittlichsten Ansätze zur Existenzwahrscheinlichkeitsschät-zung ist in [Mušicki 2004] beschrieben. Der Schätzer ist Teil einesObjekttrackingalgorithmus und hat in seiner Entstehungsgeschichte ver-schiedene Einflüsse von anderen Arbeiten geerbt.
Er basiert auf dem Probabilistischen Datenassoziation-Algorithmus(engl. „Probabilistic Data Association (PDA)“) von Bar-Shalom [Bar-Shalom1975], welcher von Mušicki um den Existenzschätzungsaspekt zum sog.„Integrated Probabilistic Data Association (IPDA)“-Algorithmus erweitertworden ist [Mušicki 1994].
Beide Algorithmen können maximal nur ein einzelnes Ziel verfolgen.Für die Mehrzielfähigkeit wurde der PDA-Algorithmus bereits früh vonBar-Shalom zum „Joint Probabilistic Data Association (JPDA)“-Algorithmusweiterentwickelt [Bar-Shalom 1988]. Eine solche Weiterentwicklung erfolg-te auch für den IPDA-Algorithmus durch Mušicki, wodurch letztendlich dersog. „Joint Integrated Probabilistic Data Association (JIPDA)“-Algorithmus[Mušicki 2004] entstand.
Alle Algorithmen der PDA-Familie versuchen im Trackingprozess durcheine probabilistische Darstellung möglichst vieler Aspekte die Anzahl derdiskreten Entscheidungen zu minimieren (vgl. Tabelle 4.2). Hierdurch sol-len möglichst wenig diskrete Fehlerquellen entstehen. Alle haben vomPDA-Ursprungsalgorithmus eine probabilistische Assoziation zwischenMessungen und Objekthypothesen geerbt.
78
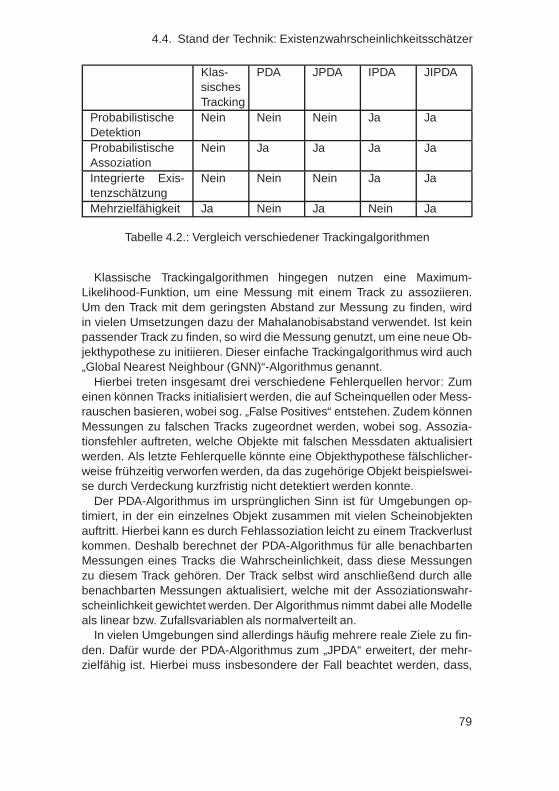
4.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer
Klas-sischesTracking
PDA JPDA IPDA JIPDA
ProbabilistischeDetektion
Nein Nein Nein Ja Ja
ProbabilistischeAssoziation
Nein Ja Ja Ja Ja
Integrierte Exis-tenzschätzung
Nein Nein Nein Ja Ja
Mehrzielfähigkeit Ja Nein Ja Nein Ja
Tabelle 4.2.: Vergleich verschiedener Trackingalgorithmen
Klassische Trackingalgorithmen hingegen nutzen eine Maximum-Likelihood-Funktion, um eine Messung mit einem Track zu assoziieren.Um den Track mit dem geringsten Abstand zur Messung zu finden, wirdin vielen Umsetzungen dazu der Mahalanobisabstand verwendet. Ist keinpassender Track zu finden, so wird die Messung genutzt, um eine neue Ob-jekthypothese zu initiieren. Dieser einfache Trackingalgorithmus wird auch„Global Nearest Neighbour (GNN)“-Algorithmus genannt.
Hierbei treten insgesamt drei verschiedene Fehlerquellen hervor: Zumeinen können Tracks initialisiert werden, die auf Scheinquellen oder Mess-rauschen basieren, wobei sog. „False Positives“ entstehen. Zudem könnenMessungen zu falschen Tracks zugeordnet werden, wobei sog. Assozia-tionsfehler auftreten, welche Objekte mit falschen Messdaten aktualisiertwerden. Als letzte Fehlerquelle könnte eine Objekthypothese fälschlicher-weise frühzeitig verworfen werden, da das zugehörige Objekt beispielswei-se durch Verdeckung kurzfristig nicht detektiert werden konnte.
Der PDA-Algorithmus im ursprünglichen Sinn ist für Umgebungen op-timiert, in der ein einzelnes Objekt zusammen mit vielen Scheinobjektenauftritt. Hierbei kann es durch Fehlassoziation leicht zu einem Trackverlustkommen. Deshalb berechnet der PDA-Algorithmus für alle benachbartenMessungen eines Tracks die Wahrscheinlichkeit, dass diese Messungenzu diesem Track gehören. Der Track selbst wird anschließend durch allebenachbarten Messungen aktualisiert, welche mit der Assoziationswahr-scheinlichkeit gewichtet werden. Der Algorithmus nimmt dabei alle Modelleals linear bzw. Zufallsvariablen als normalverteilt an.
In vielen Umgebungen sind allerdings häufig mehrere reale Ziele zu fin-den. Dafür wurde der PDA-Algorithmus zum „JPDA“ erweitert, der mehr-zielfähig ist. Hierbei muss insbesondere der Fall beachtet werden, dass,
79

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
wenn eine Messung im Bereich mehrerer Tracks liegt, diese auch zu meh-reren Tracks assoziiert werden kann. Die Existenz aller Tracks gilt als si-cher.
Die Erweiterung des PDA-Algorithmus um den Existenzaspekt erfolgtüber die bayessche Schätzung der Eintrittswahrscheinlichkeit eines zu-sätzlichen Ereignisses. Dieses Ereignis betrifft das Vorhandensein undBeobachtbarkeit bzw. Nichtvorhandensein eines einzelnen Objektes. IPDAnimmt dabei eine gleichverteilte Falschalarmrate im beobachteten Bereichan.
Um den IPDA-Algorithmus um den Aspekt der Mehrzielfähigkeit und so-mit zum JIPDA-Algorithmus zu erweitern, ist in der Praxis eine komplexereTrackverwaltung notwendig. Eine große Herausforderung ist dabei, dassim Laufe des Trackingprozesses sehr viele Tracks mit zum Teil geringerExistenzwahrscheinlichkeit entstehen. Die Anzahl möglicher Tracks steigtdurch die probabilistische Assoziation und Existenzschätzung während derrekursiven Objektschätzung exponentiell mit der Anzahl der Schritte. Intel-ligente Strategien sind notwendig, um den entstehenden Hypothesenbaumauf vielversprechende Zweige zu beschneiden (vgl. [Mählisch 2009; Munz2011]).
Abbildung 4.2.: Zwei Objekthypothesen (rote Punkte) konkurrieren um eineMessung (blauer Stern), sodass die Existenzmasse aufge-teilt wird. Die Aufteilung folgt nach Gewichtung von Mahala-nobisabstand (Ellipsen) und aktueller Existenzwahrschein-lichkeit der Tracks.
Das Beschneiden des Hypothesenbaumes hat Auswirkungen auf dieverbleibenden Tracks. Falls beispielsweise die Existenzmasse einer Mes-sung auf zwei konkurrierende Objekthypothesen aufgeteilt worden ist, undeine dieser beiden Hypothesen im Laufe des Trackings später verworfenwird, so erhält der verbleibende Track dessen Existenzmasse (s. Abbil-dung 4.2). Um diese genau zu bestimmen, muss die Fehlentscheidungkorrigiert werden, die Glaubensmasse auf zwei Tracks aufzuteilen. Letzt-endlich müssen alle betroffenen Knoten in der Baumstruktur bis zu den
80

4.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer
Blättern aktualisiert werden. Die Blätter des Baumes repräsentieren dieaktuelle Schätzhypothese.
Der JIPDA-Algorithmus vereint alle Aspekte der probabilistischen PDA-Algorithmen. Im Vergleich zu anderen Trackingalgorithmen müssen im ge-samten Algorithmus theoretisch keine diskreten Entscheidungen mehr ge-fällt werden. In der Praxis ist eine Begrenzung der exponentiell steigen-den Trackhypothesenanzahl jedoch notwendig, sodass bei Erreichung be-stimmter Existenzwahrscheinlichkeitsschwellwerte oder beim Überschrei-ten einer maximalen Anzahl von Trackhypothesen diese nicht weiter ver-folgt werden.
Nachteilig ist jedoch, dass keine systematischen Störungen berücksich-tigt werden. So wird auch hier eine gleichverteilte Fehlzielrate angenom-men. Ebenso finden sich die üblichen Annahmen zu linearen Modellen undnormalverteilten Zufallsvariablen wieder.
4.4.5. Entwicklung einesExistenzwahrscheinlichkeitsschätzer mithilfe vonzyklischen Markov-Ketten
Der folgende Existenzwahrscheinlichkeitsschätzer verwendet zyklischeMarkov-Ketten, um Messabhängigkeiten zu modellieren. Zur Bestimmungder Existenzwahrscheinlichkeit nutzt er allein die Ereignisfolge Mk einesTracks. Diese gibt an, ob eine Messung erfolgreich zu diesem Track zu-geordnet werden konnte oder nicht. Diese besteht aus n Einzelereignissenmit mi ∈ M und mi = +,−. „+“ bedeutet, dass in einem Updateschritt min-destens eine Messung erfolgreich mit dem Track assoziiert werden konnte,während bei dem Ereignis „-“ dies bei keiner Messung möglich war.
Die Markov-Kette hat zwei Zustände und somit ein Gedächtnis, ob beimletzten Updateschritt die Assoziation erfolgreich war (Zustand A) oder nichterfolgreich war (Zustand A). Insgesamt werden zwei Markov-Ketten ver-wendet. Die eine repräsentiert die Zustandsübergänge für die Situation,dass das Objekt existiert (H1), während die zweite Markov-Kette von ei-nem nicht existenten Objekt (H0) ausgeht. Die beiden Markov-Ketten undihre Transitionswahrscheinlichkeiten sind in Abbildung 4.3 dokumentiert.
Die Markov-Ketten lassen sich durch vier Parameter beschreiben, wel-che die Persistenzwahrscheinlichkeiten für die jeweiligen Zustände der bei-den Markov-Ketten repräsentieren. Diese geben die jeweilige Wahrschein-lichkeit an, ob im nächsten Traversierungsschritt die Markov-Kette in demaktuellen Zustand verharrt. Zusätzlich zu den Persistenzwahrscheinlichkei-
81

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
P(-|H1,+)
P(+|H1,-)
P(-|H1,-)P(+|H1,+) A A
P(-|H0,+)
P(+|H0,-)
P(-|H0,-)P(+|H0,+) A A
Abbildung 4.3.: Zwei zyklische Markov-Ketten: Die obere modelliert die Si-tuation, dass ein Objekt existiert (H1) während die unterenichtexistente Objekte (H0) beschreibt.
ten ist ein Parameter für die initiale Existenzwahrscheinlichkeit notwendig.Eine Beschreibung der Parameter ist aus Tabelle 4.3 zu entnehmen.
Der Wechsel des Zustandes innerhalb einer der beiden Markov-Ketten wird durch das entsprechende Gegenereignis modelliert. DerenWahrscheinlichkeit kann komplementär berechnet werden. Für die ersteMarkov-Kette gilt für die Zustandswechselwahrscheinlichkeiten:
P(−|H1,+) = 1−P(+|H1,+) (4.18)
P(+|H1,−) = 1−P(−|H1,−) (4.19)
Gleiches gilt entsprechend für die zweite Markov-Kette. Aus diesenKonstanten lassen sich die Aufenthaltswahrscheinlichkeiten ΩH1(A) bzw.ΩH0(A) ermitteln. Diese beschreiben die relative Häufigkeit für repräsenta-tive Messfolgen, dass bei der Traversierung der Markov-Ketten der ZustandA eingenommen wird:
ΩH1(A) =
(P(+|H1,−)
P(−|H1,+)+1
)−1
(4.20)
ΩH0(A) =
(P(+|H0,−)
P(−|H0,+)+1
)−1
(4.21)
82

4.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer
Ist eine Messfolge Mk gegeben, so lassen sich die relativen Wahrschein-lichkeiten bestimmen, ob diese bei einem existenten Objekt P(Mk|H1) odernichtexistenten Objekt P(Mk|H0) auftritt. Hierbei ist zu beachten, dass eineMessfolge immer mit einer Detektion „+“ beginnt, da ohne eine Erstde-tektion keine Trackinitialisierung stattfindet. Somit startet die Markov-Ketteim Zustand A mit der a-priori bestimmten AufenthaltswahrscheinlichkeitΩA(H1) bzw. ΩA(H0). Anschließend werden die Markov-Ketten anhand derMessfolge traversiert, wobei die Kantengewichte multiplikativ in die Wahr-scheinlichkeitsberechnung einfließen:
P(Mk|H1) = ΩA(H1) ·k
∏i=2
P(mi−1|H1,mi) (4.22)
P(Mk|H0) = ΩA(H0) ·k
∏i=2
P(mi−1|H0,mi) (4.23)
Je länger die Messfolge ist, desto geringer sind die relativen Wahr-scheinlichkeiten P(Mk|H1) bzw. P(Mk|H0). Ein sinnvolles Maß, die dieseWahrscheinlichkeiten in Bezug setzt, ist die „Likelihood-Ratio“ LR(Mk). Die-ses wird beispielsweise auch in [Sittler 1964] verwendet und ergibt sich ausdem Quotienten der relativen Wahrscheinlichkeiten:
LR(Mk) =P(Mk|H1)
P(Mk|H0)(4.24)
=P(Mk|H1)
1−P(Mk|H1)(4.25)
Die LR(Mk) lässt sich mittels Bayes so darstellen, dass der Termausschließlich die Initialwahrscheinlichkeiten P0(H1) bzw. P0(H0) und dieExistenz- bzw. Nichtexistenzwahrscheinlichkeit beinhaltet. Die Detektions-wahrscheinlichkeit P(Mk) kürzt sich dabei heraus und muss somit nichtparametrisiert werden:
LR(Mk) =P(Mk|H1)
P(Mk|H0)(4.26)
=P0(H1)
P0(H0)· P(H1|Mk)
P(H0|Mk)(4.27)
Mittels der Gleichungen 4.25 und 4.27 lässt sich aus der Likelihood-Ratiound den A-priori-Wahrscheinlichkeiten eine Existenzwahrscheinlichkeit er-mitteln:
83

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
P(H1|Mk) =
(1+
P0(H0)
P0(H1)LR(Mk)−1
)−1
(4.28)
Parameter BeschreibungP0(H1) Initiale Existenzwahrscheinlichkeit einer ObjekthypotheseP(+|H1,+) Persistenzwahrscheinlichkeit eines existierenden Objekts
(„Persistent True Positive“)P(−|H1,−) Persistenzwahrscheinlichkeit einer Nichtdetektion eines
existierenden Tracks („Persistent False Negative“)P(+|H0,+) Persistenzwahrscheinlichkeit eines Scheinziels („Persis-
tent False Positive“)P(−|H0,−) Persistenzwahrscheinlichkeit einer Nichtdetektion eines
nichtexistierenden Objekts („Persistent True Negative“)
Tabelle 4.3.: Parametrisierbare Attribute für den auf einen zyklischenMarkov-Ketten-Ansatz beruhenden Existenzschätzers
Für die Parametrisierung dieses Schätzers müssen die 5 Attribute ausTabelle 4.3 bestimmt werden. Hierzu sind Ground Truth-Daten2 notwendig,aus denen sich leicht die initiale Trackexistenzwahrscheinlichkeit P(H1) er-mitteln lässt.
Um die Persistenz- bzw. Übergangswahrscheinlichkeiten zu bestimmen,muss mit den Ground Truth-Daten die jeweils zugehörige Markov-Kette tra-versiert werden. Jedes Mal wenn eine Kante besucht wird, erhöht sich de-ren Gewicht um eins. Nach Abschluss aller Traversierungen werden dieKanten normiert, sodass die Summe aller Kantengewichte die einen Kno-ten verlassen, eins ergibt.
Das vorgestellte Verfahren ist das bisher einzige, welches systematischeFehlziele berücksichtigt, da es die Persistenzwahrscheinlichkeit eines Fehl-ziels explizit als Parameter nutzt. Es ist leicht zu implementieren und para-metrisieren, weshalb es in der im vorherigen Kapitel vorgestellten Sensor-datenfusion intern als Gütemaß Verwendung findet.
Nachteilig ist, dass es als einzigen Faktor nur das Ereignis der erfolgrei-chen Assoziation einer Messung zu einem Track berücksichtigt und somitviele andere mögliche Parameter außer Acht lässt. Es ist fraglich, ob dieser
2„Ground Truth“-Daten sind Referenzdaten, die auf Messdaten basieren. So kann ein Exper-te beispielsweise Ground Truth-Daten für Existenzschätzer erzeugen, indem er Messdatenmanuell entsprechend klassifiziert.
84

4.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer
Klassifikator mit so wenig Informationen den Zustandsraum so gut trennenkann, dass er nach kurzer Zeit Scheinziele von existenten Zielen sicherunterscheidet.
Nachteilig ist außerdem, dass für verschieden lange Messfolgen keineunterschiedlichen Markov-Ketten existieren. So scheint es wahrscheinli-cher, dass je länger ein Objekt getrackt werden kann, dieses auch stabilpersistent gemessen werden kann, da es ansonsten früher oder späterverworfen werden würde. Dieser einzelne Track würde aber als GroundTruth-Track die Persistenzwahrscheinlichkeit für existierende Objekte mas-siv ändern, welche nur durch sehr viele kurze Tracks mit Scheinzielen wie-der ausgeglichen werden könnte. Die Kantengewichte bilden somit ein Mit-tel über alle Assoziationen, sodass das Ergebnis wohl nur statistisch kor-rekt ist, wenn der zu untersuchende Track genau die mittlere Trackdaueraufweist.
Das gleiche Phänomen der Mittelung tritt bei der Betrachtung einzel-ner Kantengewichte auf. So wird beispielsweise die Persistenzwahrschein-lichkeit von Scheinzielen über alle Störphänomene in den Trainingsdatengemittelt, ohne dass diese Wahrscheinlichkeit beispielsweise anhand vonMessfolgelängen differenziert wird.
4.4.6. Statische Regeln
Ein weitverbreiteter Ansatz zur diskreten Existenzbestimmung ist die Ver-wendung statischer Regeln, die die Objekthypothesen erfüllen müssen, umals existent betrachtet werden zu können. Während des Objekttrackingsist jede dieser Hypothesen durch verschiedene Parameter gekennzeich-net, die als Faktoren zur Existenzklassifikation genutzt werden können.Diese werden in einem Regelkatalog in Form von verknüpften booleschenAusdrücken ausgewertet. Hierbei müssen diese Faktoren sorgsam gewähl-te Schwellwerte über- oder unterschreiten, damit die Objekthypothese alsexistent gelten darf.
Als ein Teilfaktor für die Existenzbetrachtung wird bei vielen Assistenz-systemen die Dynamik der Objekthypothese ausgewertet. Dabei werdenhäufig stationäre Objekte herausgefiltert, was die überwiegend meist sta-tionären Scheinziele eliminiert. Um Fehlauslösungen durch solche Schein-ziele zu vermeiden, ist bei vielen Systemen die Nichtbetrachtung statio-närer Objekte Teil der Spezifikation geworden. So betont die ISO-Normzum Abstandsregeltempomaten [ISO 2002], dass die Betrachtung solcherObjekte keine Anforderung ist und dass dieser Umstand nur geeignet imHandbuch dokumentiert werden muss. Neuere ACC-Systeme („Full Speed
85

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Range Adaptive Cruise Control“) beachten zumindest noch stationäre Ob-jekte, die sich im Laufe des Trackings bewegt hatten [Winner 2009b]. Aufdiese kann die Geschwindigkeit des Ego-Fahrzeuges dann bis zum Still-stand geregelt werden.
Abbildung 4.4.: Objekthypothesen müssen je nach Position unterschiedli-che Bedingungen erfüllen. Die Gültigkeitsbereiche dieserBedingungen sind durch Polygone dargestellt (vgl. [Effertz2009, S. 98 ff]).
Als weitere statische Regel kann die Plausibilisierung durch mehrereSensoren genutzt werden, wie in Abschnitt 4.4.3 exemplarisch beschrie-ben worden ist. In [Effertz 2009, S. 98 ff] ist der Ansatz durch die Definitionvon Polygonen verfeinert worden, die fest im Fahrzeugkoordinatensystemliegen und mit den Sichtbereichen der Umfeldsensoren korrelieren. Viersolcher Polygone sind beispielhaft in Abbildung 4.4 dargestellt. Für jedesdieser Polygone wird ein boolescher Ausdruck definiert, der eine Stützungeiner Objekthypothese durch einzelne Sensoren fordert oder auch aus-schließt. Nur wenn dieser Ausdruck je nach Konfiguration ein- oder mehr-fach während des Objekttrackings erfüllt worden ist, gilt die zugehörigeObjekthypothese als existent. Durch eine solche Polygondefinition wird diePosition der Objekthypothese berücksichtigt. Um sinnvolle Bedingungenaufstellen zu können, erfordert dieser Ansatz jedoch ein hohes Maß tech-nologisch möglichst heterogener Sensoren mit redundanten Detektionsbe-reichen.
Als weiteres Kriterium kann eine minimale Trackingdauer festgelegt wer-den. Der Unterschied zum Kriterium der Mindestzahl von Messassozia-tionen ist, dass der Track mit wenigen aber zeitlich gleichmäßig verteil-ten Messungen plausibilisiert werden kann. Dies kann unter Umständenvor systematischen Fehlzielen schützen, da sich existente Objekte wäh-
86

4.4. Stand der Technik: Existenzwahrscheinlichkeitsschätzer
rend der minimalen Trackingdauer komplett im Sichtbereich befinden müs-sen. So kann beispielsweise eine Schilderbrücke aus dem Erfassungsbe-reich eines Radarsensors und Laserscanners verschwinden, wenn sichdas Fahrzeug dieser genügend angenähert hat. Geschieht dies innerhalbder minimalen Trackingdauer, so wird die Objekthypothese zu keinem Zeit-punkt als existent angesehen.
Weitere denkbare Regeln können Höchstunsicherheiten von einzelnenZustandsvarianzen betreffen oder deren Kombination in Form der Deter-minante der Kovarianzmatrix, wie sie Sittler (vgl. Abschnitt 4.4.1) und Sin-ha (vgl. Abschnitt 4.4.2) auch nutzen. Des Weiteren können die Ausgabenanderer Existenzwahrscheinlichkeitsschätzer in den Regelkatalog einflie-ßen, indem diese beispielsweise bestimmte Schwellwerte über- bzw. un-terschreiten müssen, bevor ein Objekt als existent bzw. nichtexistent ange-sehen wird.
Die Vorteile des Verfahrens der statischen Regeln liegen in der hohenTransparenz und schnellen Anpassbarkeit. So lassen sich praktisch alleRegeln leicht parametrisierbar in Software implementieren. Die Adaptionder Parametrisierung an die Sensorik, an das Assistenzsystem und dessenUmgebung kann dann schnell erfolgen.
Nachteilig an dem Verfahren ist, dass komplexere Zusammenhängeeventuell nur schwer von einem Experten zu erfassen sind, um daraus kor-rekte Regeln abzuleiten. Häufig werden deshalb einfache Schwellwertre-geln erstellt, die mit „UND“ bzw. „ODER“ verknüpft werden. Die Trennmög-lichkeit solcher Funktionen für komplexere Zustandsräume ist allerdingsbegrenzt, sodass diese eventuell eine schlechtere Performance aufweisenals andere Verfahren. Die Regeln sind zudem stark abhängig vom Typ desAssistenzsystems und der Sensorik, sodass die Schwellen für Existenzbzw. Nichtexistenz bereits implizit in den Regeln integriert werden müssen.
Auch ist bei der Festlegung der Schwellwertparameter für die einzelnenRegeln häufig eine unsystematische evolutionäre Entwicklung festzustel-len. Hierbei wird durch mehrstufige Parametervariation versucht, die Ratenvon Fehlauslösungen und fehlerhaften Nichtauslösungen zu optimieren. Jenach Komplexität des Klassifikationsproblemes kann diese Vorgehenswei-se sehr aufwendig und uneffizient sein.
4.4.7. Bewertung
Das Unterdrücken nichtexistenter Ziele ist in vielen wissenschaftlichen Ar-beiten bereits früh untersucht worden. Der vorwiegende Anwendungsbe-reich der meisten Arbeiten liegt jedoch im Luftfahrtbereich und hier ins-
87

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
besondere bei der Überwachung von Lufträumen mittels Radaranlagenim militärischen Kontext. Alle Verfahren sind somit geeignet, sehr kurzeScheinziele zu unterdrücken, die aus Messrauschen stammen. Besonderspositiv ist bei JIPDA zudem die Integration in einem Trackingalgorithmuszu erwähnen, sodass der Zustand einzelner Trackhypothesen durch sol-che Scheinziele möglichst wenig negativ beeinflusst wird.
Im Vergleich zur Fahrzeugumfelddomäne ist die Domäne des Luftrau-mes weniger komplex strukturiert. Wie bereits erwähnt, ist im Fahrzeugum-feld mit Artefakten zu rechnen, die systematische Scheinziele verursachen.Auch tritt eine Vielfalt von existenten Objekttypen auf, die alle von den sys-tematischen Scheinzielen unterschieden werden müssen. Des Weiterenspielen Verdeckungen hier eine größere Rolle.
Sitt
ler
Sin
ha
Sch
oebe
rl
JIP
DA
zykl
.Mar
kov-
Ket
ten
stat
isch
eR
egel
n
Probabilistische Schätzung • • • •Berücksichtigung systemati-scher Scheinziele
• • •
Berücksichtigung einer he-terogenen Sensorkonfigura-tion
• • •
Berücksichtigung vieler Attri-bute
• • • •
Existenz als Klassifikations-problem
• •
Tabelle 4.4.: Vergleich verschiedener Existenzschätzer
Dementsprechend sind viele der vorgestellten Verfahren für eine Exis-tenzschätzung im Sinne von Definition 1 weniger geeignet. Dieses zeigtsich insbesondere dann, wenn diese für Messfolgen bestimmte Unab-hängigkeitsannahmen machen, wie beispielsweise gleichverteilte Schein-zielraten. Eine Ausnahme bildet die Existenzschätzung mittels zyklischerMarkov-Ketten, welche explizit die Persistenzwahrscheinlichkeiten model-lieren.
88

4.5. Stand der Technik: Signifikanzschätzer
Zu kritisieren ist auch, dass viele Schätzer hauptsächlich das Ereignisder Trackassoziation bzw. Nichtassoziation nutzen, um ein Existenzgüte-maß zu ermitteln. Dies hat zur Folge, dass diese vielmehr ein „Beobacht-barkeitsgütemaß“ anstatt eines Existenzmaßes liefern: So verringern vieleSchätzer beim Ereignis der Nichtassoziation dessen Gütemaß, auch wennder Track in der Vergangenheit bereits zweifelsohne als existenter Trackklassifiziert worden ist. Wird ein Objekt verdeckt oder verlässt ein Ob-jekt den Sichtbereich der Sensoren, so wird die Existenzwahrscheinlich-keit kontinuierlich verringert, bis das Objekt als nichtexistent angesehenwird. Dennoch kann bezweifelt werden, dass das Objekt aufgehört hat zuexistieren, nur weil es nicht mehr wahrgenommen werden kann.
Nachteilig an vielen Verfahren ist außerdem die Erfordernis, dass alleZustandsunsicherheiten genau bestimmt werden müssen, um eine guteExistenzschätzung treffen zu können. Da insbesondere bei einer heteroge-nen Sensorplattform sehr viele Faktoren zu berücksichtigen sind, ist einemanuelle Modellierung sehr herausfordernd. Außerdem werden teilweiseunrealistische Modellannahmen gemacht, sodass es fraglich ist, ob einestatistisch korrekte Existenzwahrscheinlichkeit3 in der Realität durch einenSchätzer tatsächlich geliefert wird. Hierbei ist insbesondere zu kritisieren,dass keine einzige bekannte Arbeit anhand von realen Mess- und Ground-True-Daten den jeweiligen Schätzer probabilistisch validiert hat.
4.5. Stand der Technik: Signifikanzschätzer
Wenn ein Objekt als existent angesehen wird, muss noch bestimmt wer-den, ob es im Sinne des Fahrerassistenzsystems signifikant ist (vgl. Defi-nition 2 im Abschnitt 4.3). Die Signifikanzanalyse ist im hohen Maße ab-hängig vom Typ des Assistenzsystems: Für einen Spurwechselassistentensind beispielsweise nur Objekte signifikant, die sich in Nachbarfahrstrei-fen befinden. Für Assistenzsysteme zur Vermeidung von Kollisionen sindnur Objekte wesentlich, die sich vor dem Ego-Fahrzeug befinden und beidenen eine geringe TTC gegeben ist.
Exemplarisch werden im Folgenden bekannte Ansätze für einen Ab-standsregeltempomaten (ACC) vorgestellt. Dabei wird ein Korridor, dersog. Fahrschlauch definiert, in dem Objekte potenziell als signifikant klas-sifiziert werden. Diese können dann den Regelkreis der Längsaktorik maß-geblich beeinflussen. Dieser Korridor ist durch einen Kursverlauf und einekonstante Breite oder durch eine distanzabhängige Breitefunktion definiert.
3Vergleiche hierzu die Definition von statistisch korrekten Klassifikatoren im Anhang A.1.2.
89

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Fehler in der Kursverlaufs- und Fahrschlauchbreitenschätzung könnensich negativ auf die Signifikanzanalyse und somit negativ auf das Fah-rerassistenzsystem auswirken. Dieses kann zu unnötigen Reaktionen aufscheinbare Objekte in der Längsregelung führen bzw. eine notwendige Re-aktion auf relevante Objekte unterlassen. In beiden Fällen muss der Fahrerdas System überstimmen und übersteuern. Geschieht dies zu häufig, kanndas den Komfort und die Sicherheit mindern und somit die Akzeptanz fürdieses System verringern.
Verschiedene diskrete Ansätze zur Bestimmung des Kursverlaufes undder Fahrschlauchbreite werden in den beiden nachfolgenden Abschnittenbeschrieben. Um ein Gütemaß der Signifikanzschätzung zu ermitteln undsomit die Signifikanzanalyse zu verbessern, werden anschließend probabi-listische Erweiterungen zu diesen diskreten Schätzern vorgestellt und be-wertet.
4.5.1. Bestimmung des Kursverlaufes
Viele ACC-Systeme schätzen den zukünftigen Kursverlauf anhand derKrümmung der Fahrbahn. Da das Ego-Fahrzeug auf dieser fährt, kannapproximativ dessen Odometriesensorik eingesetzt werden, um die Krüm-mung auf der Höhe des Ego-Fahrzeuges zu bestimmen. Hierzu bieten sichDaten aus dem Gierratensensor, dem Querbeschleunigungssensor, demLenkradwinkelsensor und den Raddrehzahlsensoren an (s. Kapitel 2 und[Winner 2009b]).
Eine solche Krümmungsbestimmung allein erlaubt ausschließlich eineFahrschlauchgenerierung in Kreisform. Durch die Ableitung der Krümmungüber die zurückgelegte Strecke ist zusätzlich eine Approximation der Krüm-mungsänderung möglich, welche die Erweiterung des Kreismodells auf einKlothoidenmodell ermöglicht.
Dieses Vorgehen ist von der Kostenseite her sehr attraktiv, da die Odo-metriesensoren meist bereits im Fahrzeug vorhanden sind. Eine weiterebereits vorhandene Datenquelle sind stationäre Ziele (z. B. Leitplanken),die aus dem ACC-Umfeldsensor gewonnen werden können. Diese begren-zen häufig den Fahrbahnrand und liefern somit einen Anhaltspunkt überden zukünftigen Fahrbahnverlauf. Auch die Mittelung der Quergeschwin-digkeiten von mehreren vorausfahrenden Objekten gibt einen Hinweis überdie zukünftige Fahrbahnkrümmung.
Nichtsdestotrotz wird die Fahrbahngeometrie nur indirekt bestimmt, wo-bei diese indirekten Quellen zwar häufig aber nicht immer mit dem Fahr-bahnverlauf korrelieren. So können sich ohne direkte Informationsquellen
90

4.5. Stand der Technik: Signifikanzschätzer
über den Fahrbahnverlauf in bestimmten Situationen Doppeldeutigkeitenergeben, welche eine sichere Signifikanzbestimmung beeinträchtigen.
Als Beispiel sind dazu zwei identische Objektkonstellationen in Abbil-dung 4.5 bei unterschiedlichen Fahrbahnen dargestellt. Diese indirekteInformationsquellen suggerieren eine Kurve, jedoch ist auch eine gera-de Straße möglich. Je nach Fahrbahnhypothese können sich somit unter-schiedliche Objektsignifikanzen einstellen.
Abbildung 4.5.: Gleiche Objektkonstellationen weisen bei unterschiedli-chen Fahrbahnen unterschiedliche Signifikanzen auf (vgl.[Winner 2009b]).
Um solche Fehleinschätzungen zu vermeiden und eine genauere Be-stimmung des Kursverlaufes zu ermöglichen, ist die Fusionierung direkterDatenquellen, wie digitaler Karte und Fahrstreifenmarkierungen aus einemKamerasensor notwendig. Für eine exemplarische Beschreibung einer sol-chen Teilfusion sei dazu auf Abschnitt 3.5.5 verwiesen.
4.5.2. Bestimmung der Fahrschlauchbreite
Der Fahrschlauch wird aus dem prädizierten Kurs und einer Fahrschlauch-breite erzeugt. Letztere kann konstant oder auch variabel über der Streckesein, sodass der Fahrschlauch komplexere Formen annehmen kann.
91

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Bei der Festlegung der Fahrschlauchbreite tritt ein Zielkonflikt auf: Wirddieser zu groß gewählt, so reagiert das ACC-System evtl. auf nicht signifi-kante Objekte. Umgekehrt können bei einer zu kleinen Fahrschlauchbrei-te fälschlicherweise Objekte ignoriert werden, welche sich auf dem Ego-Fahrstreifen befinden.
Eine variable Fahrschlauchbreite kann die Wahrscheinlichkeit vonFalschzuordnungen verkleinern. So ist eine Aufweitung des Fahrschlau-ches nach links bzw. rechts sinnvoll, wenn dort keine befahrbaren Nach-barfahrstreifen sind. Auf das Vorhandensein bzw. Nichtvorhandensein sol-cher Nachbarfahrstreifen kann aus der Beobachtung von Fremdobjektenbzw. stationären Randobjekten geschlossen werden (vgl. [Urban 2006]).
Auch die Beobachtung von Fahrstreifenmarkierungsarten mithilfe einesKamerasensors kann einen Hinweis auf das Vorhandensein von Nachbar-fahrstreifen geben (vgl. [Weiser 2011]). Als weitere Informationsquelle kannder Straßentyp dienen, der beispielsweise aus einer digitalen Karte ent-nommen werden kann. So ist auf Autobahnen, gut ausgebauten Landstra-ßen und auf wichtigen Verbindungsstraßen im innerstädtischen Bereich mitmehreren Fahrstreifen pro Richtung zu rechnen, während auf den meistenanderen Straßen nur ein Fahrstreifen pro Richtung zur Verfügung steht.
4.5.3. Probabilistische Fahrschlauchgenerierung und-zuordnung
Im einfachsten Fall kann direkt aus der Fahrschlauchbreite und dem prädi-zierten Kursverlauf der Fahrschlauch generiert werden. In [Winner 2009b]wird außerdem vorgeschlagen, dem Fahrschlauch eine unscharfe Konturzu geben, sodass eine probabilistische Aussage möglich ist, inwieweit sichein Objekt in diesem befindet. Abbildung 4.6 zeigt diesen Ansatz exempla-risch. Zu beobachten ist, dass sich die Signifikanzdichte in der Entfernungverringert, sodass die tendenziell ungenaue Fahrbahnschätzung in großerEntfernung zum Tragen kommt.
In [Urban 2006] werden weitere Faktoren bestimmt, um das probabilis-tische Fahrschlauchmodell zu verfeinern. Hierzu gehören die Wahrschein-lichkeiten, ob sich links bzw. rechts vom Ego-Fahrstreifen Fahrbahnbegren-zungen befinden. Auch werden Wahrscheinlichkeiten bestimmt, ob Par-allelspuren beispielsweise durch überholende Fahrzeuge erkannt wordensind. Nachgeschaltete Tiefpassfilter mitteln die bestimmten Einzelwahr-scheinlichkeiten, um ein konsistenteres Umgebungsmodell zu erhalten.
Ebenso wird ein Tiefpassfilter dazu verwendet, die Objektzuordnungsgü-te stabiler zu schätzen. Dadurch kann eine kurzfristige Fehleinschätzung
92

4.5. Stand der Technik: Signifikanzschätzer
0,0
0,2
0,4
0,6
0,8
1,0
dx
dy
Abbildung 4.6.: Unscharfe Kontur zur Signifikanzmodellierung (vgl. [Win-ner 2009b])
des Kurses oder der Objektposition kompensiert werden, ohne dass dasRegelobjekt verloren geht.
Um zu vermeiden, dass Objekte bei einer geringfügigen Schwankungder Objektzuordnungsgüte verworfen und kurze Zeit später neu initialisiertwerden, ist die Nutzung einer Hysteresefunktion vorteilhaft. Um ein Ob-jekt erstmalig als signifikant zu klassifizieren, muss dieses einen höherenGütewert erreichen als beim Verwerfen der Signifikanzhypothese.
4.5.4. Bewertung
Viele eingesetzte Signifikanzschätzer für ACC-Systeme nutzen sehr weni-ge Daten aus: Häufig werden nur die Daten eines Radarsensors mit denEgo-Fahrzeug-Odometriedaten verknüpft. Die Fusionierung und Ausgabeder Regelgrößen erfolgt meist gleich im Steuergerät des Sensors, sodassdie adaptive Geschwindigkeitsregelung mit nur einer zusätzlichen Hard-ware umgesetzt werden kann.
Wie vorgestellt, gibt es weitere Ergänzungen durch digitale Karten undKameradaten, welche die Entscheidungsgrundlage verbreitern und einegenauere Signifikanzbestimmung ermöglichen.
Alle vorgestellten Verfahren verwenden statische Regeln oder nur sehrrudimentäre probabilistische Verfahren, um die Signifikanz zu bewerten.So gibt es beispielsweise in [Winner 2009b] weder eine Angabe darüber,wie man die unscharfe Fahrschlauchkontur festlegen soll, noch wie manverschiedene Signifikanzwerte über die Zeit fusioniert. Noch schwierigerwird es, alle vorgeschlagenen probabilistischen Quellen zu einer statistischkorrekten Aussage zu fusionieren, da diese Quellen nicht als unabhängigangenommen werden können.
93

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
4.6. Entwicklung eines integrierten Relevanzschätzer
Um die Objektrelevanz zu bestimmen, nutzen klassische Verfahren dieindirekte Herleitung über die in den vorherigen Abschnitten aufgeführtenExistenz- und Signifikanzwahrscheinlichkeiten. Relevant ist ein Objekt ge-nau dann, wenn beide Schätzer dies bestätigen.
Die analytische Modellbildung der Objektexistenz und -signifikanz ist je-doch durch Vereinfachungen und Annahmen der statistischen Abhängig-keit bzw. Unabhängigkeit geprägt. Die Berücksichtigung von in der Umweltvorkommenden Artefakten, die die Umfeldwahrnehmung negativ beeinflus-sen, findet kaum oder gar nicht statt. Die einfache Kombination der Ob-jektexistenz und -signifikanz erzeugt zudem einen Klassifikator, der davonausgeht, dass beide Schätzergebnisse unabhängig voneinander sind.
In diesem Abschnitt wird alternativ ein Klassifikator vorgestellt, der dieKlasse der relevanten von der Klasse der irrelevanten Objekte direkt imSinne einer spezifischen Fahrerassistenzapplikation zu separieren ver-mag. Durch diese Klassenreduzierung erscheint es potenziell möglich, die-sen leistungsfähiger zu gestalten.
Die analytische Modellerstellung für einen direkten Relevanzschätzer er-scheint aufgrund der hochgradig unbekannten inneren Struktur des Ge-samtsystems sehr komplex: Hier müssen beispielsweise die Auftretens-wahrscheinlichkeiten von systematischen Störphänomenen berücksichtigtwerden, die statistischen Abhängigkeiten verschiedener Informationsquel-len sowie deren Ungenauigkeiten. Möchte man deshalb auf die manuelleModellierung dieser Klassifikationsfunktion verzichten, so bieten sich Lern-verfahren zu deren Approximation an.
Bei diesem Ansatz wird das Klassifizierungsproblem als mehrdimensio-naler Vektor dargestellt, in dem die empirischen Daten abgebildet wer-den. Eine Menge dieser Vektoren bildet zusammen mit einer zugeordnetenKlasse eine Trainingsbasis. Diese Trainingsbasis wird in einem überwach-ten Lernverfahren genutzt, um eine Funktion zu generieren, welche auseinem gegebenen Eingabevektor möglichst genau die zugehörige Klasseermittelt.
Diese Lernverfahren ermöglichen die Erzeugung eines integriertenSchätzers, welcher die Funktion zur Relevanzschätzung direkt enthält,ohne dass die Existenz- und Signifikanzwahrscheinlichkeiten separat be-stimmt werden müssen. Da ein so erzeugter Relevanzschätzer genau dieAnforderungen einer einzelnen Fahrerassistenzapplikation berücksichtigt,muss für jede Fahrerassistenzapplikation ein eigener Relevanzschätzer in-nerhalb der Sensordatenfusion generiert werden.
94

4.6. Entwicklung eines integrierten Relevanzschätzer
Die Eigenschaften eines solchen Schätzers sollen hierbei die im Ab-schnitt 3.2 genannten allgemeinen Anforderungen für eine Sensordatenfu-sion widerspiegeln. Im Speziellen muss dieser dann folgende Eigenschaf-ten aufweisen:
• Genau : Der Relevanzschätzer soll bereits nach wenigen Messzyklenrelevante Objekte von irrelevanten möglichst sicher trennen können.
• Robust : Der Relevanzschätzer soll gegenüber Störungen, Messrau-schen und Messausreißern möglichst unempfindlich sein.
• Probabilistisch : Der Relevanzschätzer soll eine statistisch korrekteAussage über die Relevanzwahrscheinlichkeit liefern.
• Echtzeitfähig : Der Relevanzschätzer soll innerhalb einer definiertenZeitschranke eine Objekthypothese klassifizieren.
• Modular : Der Relevanzschätzers soll leicht auf andere Sensorik undauf andere Relevanzdefinitionen adaptierbar sein.
Um einen integrierten Schätzer zu generieren, sind verschiedene Schrit-te notwendig. Diese bestehen aus der Definition des Zustandsraumes, derErzeugung von Trainingsdaten, der Anwendung von Algorithmen aus demBereich des „Maschinellen Lernens“, deren Verifikation und evtl. Nachbe-arbeitung der Schätzergebnisse. Diese einzelnen Schritte werden in dennachfolgenden Abschnitten beschrieben. Im Fokus bleiben dabei die ge-nannten Anforderungen, sodass die Teilschritte auch daraufhin untersuchtwerden, ob sie diese negativ beeinträchtigen.
Um die Modularitätsanforderung zu beachten, basiert die folgende Klas-sifikation auf eine reine Parametrisierung, sodass der Relevanzschätzerfür unterschiedliche Sensorkonfigurationen und Funktionen in unterschied-lichen Instanzen verwendet werden kann. Die Relevanzschätzer werdenzum einen aus Parametern des Klassifikationsverfahrens (z. B. Gewichtefür ein künstliches neuronales Netz oder Stützvektoren für eine SupportVector Machine) und zum anderen aus Parametern zur Beschreibung desEingabevektors instanziiert: Eine Änderung der Implementation des Rele-vanzschätzers ist nicht notwendig.
4.6.1. Definition des Zustandsraumes
Bevor der Zustandsraum zur Relevanzbestimmung definiert wird, ist es zu-nächst notwendig, relevante Objekte für ein Fahrerassistenzsystem nachDefinition 3 zu beschreiben. Im Folgenden ist ein Fahrerassistenzsystem
95

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
zum hochautomatischen Fahren auf Autobahnen und autobahnähnlichenDomänen exemplarisch im Fokus. Als relevant anzunehmen seien alle Ob-jekte, die sich auf einem durchgehenden Fahrstreifen befinden. Hierzu zäh-len keine Objekte, die über- oder unterfahrbar sind und auch keine Objekte,die sich komplett auf Stand-, Verzögerungs- oder Beschleunigungsstreifenbefinden.
Abbildung 4.7.: Koordinatensystem der Fahrbahn
Um einen Zustandsvektor zu erzeugen, der alle wesentlichen Faktorenzur Relevanzbestimmung enthält, ist die Kombination verschiedener Teilfu-sionen notwendig.
Die Objekte in der Objektfusion werden in einem kartesischen Koordina-tensystem gemäß [ISO 2011] verfolgt. Für die Entscheidung, ob ein Objektsignifikant sein könnte, ist entscheidend, ob es sich auf der Straße bzw. imFahrstreifen des Ego-Fahrzeuges befindet. Hierzu findet eine Koordinaten-transformation auf Basis der Fahrbahnschätzung statt, welche die Objekt-hypothesen in Bezug zur Fahrbahnschätzung setzt.
Das Fahrbahnkoordinatensystem zeichnet sich dadurch aus, dass des-sen X-Achse dem Fahrbahnverlauf folgt und die y-Achse jeweils senkrechtauf der X-Achse steht. Es kann auch als eine Akkumulation von Fahrzeug-koordinatensystemen nach [ISO 2011] betrachtet werden, sofern das Re-ferenzfahrzeug eine konstante Ablage zur Fahrbahn einhält. Ein solchesFahrbahnkoordinatensystem für eine Straße ist exemplarisch in Abbildung4.7 dargestellt.
Die Transformation ist theoretisch nicht immer eindeutig: Dort wo sichdie Y-Achsen schneiden, gibt es Punkte, die verschiedene X-Werte nachder Transformation erzielen können. Um eine solche Konstellation zu er-reichen, sind praktisch aber Kurven mit sehr starker Krümmung erforder-
96
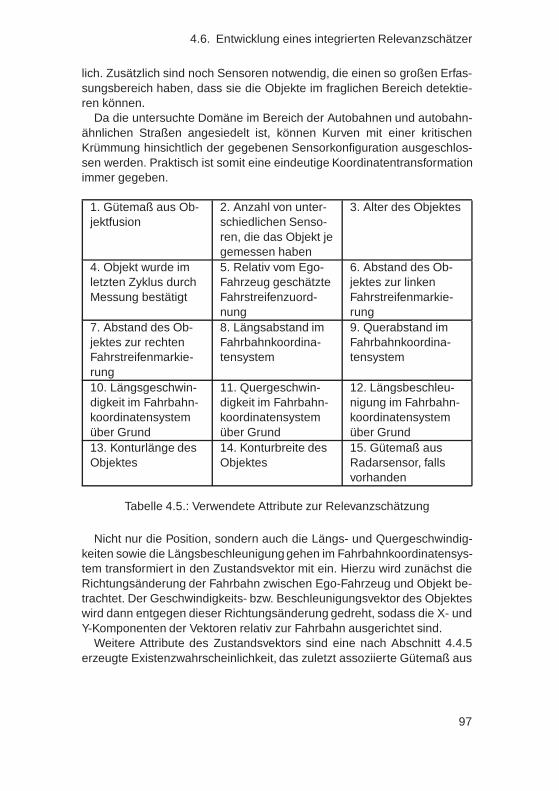
4.6. Entwicklung eines integrierten Relevanzschätzer
lich. Zusätzlich sind noch Sensoren notwendig, die einen so großen Erfas-sungsbereich haben, dass sie die Objekte im fraglichen Bereich detektie-ren können.
Da die untersuchte Domäne im Bereich der Autobahnen und autobahn-ähnlichen Straßen angesiedelt ist, können Kurven mit einer kritischenKrümmung hinsichtlich der gegebenen Sensorkonfiguration ausgeschlos-sen werden. Praktisch ist somit eine eindeutige Koordinatentransformationimmer gegeben.
1. Gütemaß aus Ob-jektfusion
2. Anzahl von unter-schiedlichen Senso-ren, die das Objekt jegemessen haben
3. Alter des Objektes
4. Objekt wurde imletzten Zyklus durchMessung bestätigt
5. Relativ vom Ego-Fahrzeug geschätzteFahrstreifenzuord-nung
6. Abstand des Ob-jektes zur linkenFahrstreifenmarkie-rung
7. Abstand des Ob-jektes zur rechtenFahrstreifenmarkie-rung
8. Längsabstand imFahrbahnkoordina-tensystem
9. Querabstand imFahrbahnkoordina-tensystem
10. Längsgeschwin-digkeit im Fahrbahn-koordinatensystemüber Grund
11. Quergeschwin-digkeit im Fahrbahn-koordinatensystemüber Grund
12. Längsbeschleu-nigung im Fahrbahn-koordinatensystemüber Grund
13. Konturlänge desObjektes
14. Konturbreite desObjektes
15. Gütemaß ausRadarsensor, fallsvorhanden
Tabelle 4.5.: Verwendete Attribute zur Relevanzschätzung
Nicht nur die Position, sondern auch die Längs- und Quergeschwindig-keiten sowie die Längsbeschleunigung gehen im Fahrbahnkoordinatensys-tem transformiert in den Zustandsvektor mit ein. Hierzu wird zunächst dieRichtungsänderung der Fahrbahn zwischen Ego-Fahrzeug und Objekt be-trachtet. Der Geschwindigkeits- bzw. Beschleunigungsvektor des Objekteswird dann entgegen dieser Richtungsänderung gedreht, sodass die X- undY-Komponenten der Vektoren relativ zur Fahrbahn ausgerichtet sind.
Weitere Attribute des Zustandsvektors sind eine nach Abschnitt 4.4.5erzeugte Existenzwahrscheinlichkeit, das zuletzt assoziierte Gütemaß aus
97

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
dem verwendeten Radarsensor4, das Alter der Objekthypothese und wei-tere Attribute, welche in Tabelle 4.5 dargestellt sind. Für diesen Zustands-vektor wird im Folgenden eine Relevanzwahrscheinlichkeit bestimmt, wel-che direkt für das Fahrerassistenzsystem genutzt werden kann.
Bei der Auswahl der Attribute sind solche berücksichtigt worden, die dieRelevanzschätzung positiv beeinflussen könnten. Ob dieses bei allen Attri-buten wirklich der Fall ist, wird später in Abschnitt 4.6.5 untersucht. Insge-samt ist bei diesem Auswahlschritt nur ein geringes Expertenwissen not-wendig: Dieser darf dem Maschinellen Lernverfahren keine wesentliche At-tribute unterschlagen, und sollte möglichst wenig irrelevante Attribute vor-geben. Eine Vorgabe, wie die einzelnen Attribute zu gewichten sind, istnicht nötig.
4.6.2. Prospektive Erzeugung der Trainingsdaten
Die Ergebnisqualität von Algorithmen aus dem Bereich des „MaschinellenLernens“ ist wesentlich von der Güte der Trainingsdaten abhängig. Die-se sollten sowohl repräsentativ als auch umfassend sein. Aufgrund dervielen möglichen Zustände von Fahrbahn und anderen Objekten und derhohen Dimension des Zustandsraumes ist hierfür eine große Menge vonTrainings- und Referenzdaten notwendig.
Um diese mit einem begrenzten Aufwand zu erzeugen, sind Verfahrennotwendig, die diese zum größten Teil aus Messdaten automatisch gene-rieren. Eine Möglichkeit besteht in der Verwendung zusätzlicher Referenz-sensorik, welche bei widersprüchlichen Messdaten einen Hinweis auf dierichtige Tendenz gibt. Nachteilig an dem Verfahren ist jedoch, dass man ei-ne Referenzsensorik benötigt, die um Größenordnungen besser ist, als dieverwendete. Auch der zusätzliche Aufwand durch Verbau und Auswertungdarf nicht vernachlässigt werden.
Alternativ kann man das Mittel der Prospektion verwenden, um Refe-renzdaten zu erzeugen. Hierbei wird der Umstand genutzt, dass in auf-gezeichneten Messdaten für jeden Messzeitpunkt jederzeit in die Zukunftgeschaut werden kann. Mittels dieser prospektiven Analyse können prak-tisch alle Objekte korrekt als relevant oder als nicht relevant klassifiziertwerden.
Die Prospektion erzeugt zum einen für die gesamten Messdaten ei-ne Ground Truth-Fahrbahn auf Basis der Stützpunkte nahe dem Ego-Fahrzeug. Dort ist die Fahrbahnschätzung um ein Vielfaches genauer als
4Der Algorithmus zur Generierung des Gütemaßes ist unbekannt, da er vom Sensorherstellernicht offen gelegt wurde.
98

4.6. Entwicklung eines integrierten Relevanzschätzer
Abbildung 4.8.: Aktuelle und prospektive Fahrbahnverlaufsschätzung(Straße bzw. rote Linie). Je paralleler die Straße zurReferenzlinie verläuft, desto genauer ist die aktuelleFahrbahnverlaufsschätzung.
die nichtprospektive Schätzung in großer Entfernung. Abbildung 4.8 zeigteine Straßenschätzung und die prospektive Fahrbahnreferenzlinie (roteLinie). Die Ground Truth-Fahrbahn wird beispielsweise dazu verwendet,Randbebauungen nahe der Fahrbahn zu erkennen und als irrelevant zumarkieren.
Weitere Regeln betreffen den prospektiven Objektzustand. So werdenbeispielsweise stationäre Objekthypothesen nur dann als relevant ange-nommen, wenn diese von mindestens zwei Messungen aus unterschied-lichen Sensoren assoziiert worden sind, sich dem Ego-Fahrzeug bis auf15 Meter Luftlinie nähern und eine Position aufweisen, die das Objekt si-gnifikant macht. Dynamische Objekte werden aufgrund des prospektivenTrackingalters klassifiziert. Sehr schnelle Objekte benötigen ein deutlichgeringeres prospektives Alter, wenn diese das Ego-Fahrzeug mit hoherGeschwindigkeit passieren. Von Ultraschallsensoren generierte Objekthy-pothesen im Seitenbereich werden nur als relevant betrachtet, wenn sichauf der entsprechenden Seite ein Fahrstreifen befindet, das Objekt in die-sen erheblich hineinragt und eine minimale Trackingdauer prospektiv er-reicht wird.
99

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Falls ein Objekt durch die zahlreichen Regeln trotzdem falsch klassifi-ziert worden ist, gibt es noch die Möglichkeit, diese Objekthypothese ma-nuell zu kennzeichnen. Zu diesem Zweck wurden alle Daten gesichtet undmit synchron aufgezeichnetem Videomaterial oder mit einem bekanntenTestaufbau verglichen und gegebenenfalls korrigiert.
Als Trainingsbasis dienen diverse Autobahnfahrten inklusive Schilder-brücken und Baustellen. Auf Autobahnen ist als kritisches Szenario einStauende denkbar, bei dem sich das Ego-Fahrzeug einem stationären Zielmit hoher Geschwindigkeit nähert. Um solch ein Szenario erlernen zu kön-nen, sollte es auch in den Trainingsdaten enthalten sein. Da ein Stauendein realen Messdateien selten vorkommt, wurde es mit Prüfkörpern auf zweiverschiedenen Testgeländen nachgestellt. Hierbei wurden Einschränkun-gen bzgl. der Repräsentativität der Trainingsdaten in Kauf genommen.
Insgesamt sind dabei über 700.000 Objekthypothesen mit zugehörigerRelevanzklasse erzeugt worden, wobei deutlich mehr irrelevante Objekteals relevante verzeichnet worden sind: Der Anteil der relevanten Objektebetrug dort 21,6%.
4.6.3. Anforderungen und Auswahl von MaschinellenLernalgorithmen
Die im vorherigen Abschnitt erzeugten Datensätze sollen im Folgendengenutzt werden, um einen Klassifikator zu konstruieren, der relevante Ob-jekte von nichtrelevanten zu unterscheiden vermag. Da es beispielsweisebei Scheinzielen und stationären Zielen denkbar ist, dass diese auf gleicheoder sehr ähnliche Muster basieren, ist ein perfekter Klassifikator unrealis-tisch. In diesem Fall sollte dieser eine Wahrscheinlichkeit ausgeben, diedem Anteil der relevanten Objekte in der Gesamtmenge der Objekte ent-spricht, die ein solches Klassifikationsmuster aufweisen. Der Klassifikatorsoll also eine realitätsnahe probabilistische Schätzung unterstützen.
Hierzu sollte die probabilistische Ausgabe idealerweise auf einer quadra-tischen Minimierung der Fehlerfunktion zwischen Ein- und Ausgabemusterbasieren (vgl. [Alpaydin 2004, S. 29 ff]). Hierzu sei κ(x) die Klassifikator-funktion, M = m1, . . . ,mn die Menge der Muster und oi die jeweils eindi-mensionale erwartete Ausgabe. Die Klassifikatorfunktion ist genau dannstatistisch korrekt, wenn sie trotz einer konstanten Fehlklassifikationsrate5
darauf basiert, folgende durchschnittliche Fehlerfunktion e(M) zu minimie-ren:
5Eine Fehlklassifikation liegt im probabilistischen Fall genau dann vor, wenn |κ(mi)− oi| > 0,5beträgt
100

4.6. Entwicklung eines integrierten Relevanzschätzer
e(M) =1n
n
∑i=1
(κ(mi)−oi)2 (4.29)
Dass ein Ergebnis statistisch korrekt ist, wenn die Gleichung 4.29 er-füllt ist, sei an einer Menge von ähnlichen Mustern erläutert. Diese Musterliegen aufgrund ihrer Ähnlichkeit dicht im Merkmalsraum beieinander undbilden einen sog. „Cluster“. Gegeben sei ein solcher Cluster MC , der eineMultimenge von n = |MC | nicht unterscheidbaren Klassifikationsmustern menthält. In dieser Multimenge befinden sich t Muster, hinter denen sich re-levante Objekte verbergen. Da die Klassifikationsmuster nicht unterscheid-bar sind, liefert die Klassifikatorfunktion κ für jedes Element m des Clustersdas gleiche Funktionsergebnis. Für dessen Fehlerfunktion gilt:
e(MC) =1n
((n− t) ·κ(m)2+ t · (κ(m)−1)2
)(4.30)
Durch Ableitung der Fehlerfunktion e(MC) kann man zeigen, dass κ(m)
Gleichung 4.29 genau dann minimiert, wenn:
κ(m) =tn,∀m ∈ MC (4.31)
Damit die statistische Korrektheit nicht nur für einen Cluster gilt, son-dern für den gesamten Merkmalsraum, müssen alle Klassifikationsmustereinem Cluster zugeordnet werden. Für die Berechnung der Relevanzwahr-scheinlichkeiten für die einzelnen Cluster gilt dann 4.30 entsprechend.
Liefert die Klassifikatorfunktion nur ein statistisch ungenaues Gütemaß,so lässt sich dieses dennoch durch eine Korrekturfunktion nutzen. Die Er-stellung einer solchen Korrekturfunktion wird später in Abschnitt 4.6.8 be-schrieben.
Neben einer gewichteten Klassifikation muss ein geeigneter Algorith-mus noch weitere Kriterien erfüllen: Zum einen sollte er keine weiterenModellannahmen benötigen, da auf eine expertenbasierte Modellannah-me hier verzichtet werden soll. Solche Ansätze gehören der Kategorie dersog. „statistischen mustererkennenden Algorithmen“ an. Zum anderen soll-te der Algorithmus auch bei höherdimensionalen Klassifikationsproblemenechtzeitfähig sein. Dieses Kriterium betrifft nur den Klassifikationsteil desAlgorithmus, nicht aber dessen Trainingsphase.
Im Folgenden sollen verschiedene Klassifikationsalgorithmen bewertetwerden, ob diese potenziell als Relevanzklassifikator dienen könnten. Ei-ne Auswahl wird später genauer untersucht und mit Referenzdaten unter-einander verglichen. Bekannte probabilistische Klassifikationsalgorithmensind unter anderen:
101

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
• Bayessches Netz (s. Anhang A.3.1)
• k-Nearest-Neighbour (s. Anhang A.3.2)
• Lineare Support Vector Machine (s. Anhang A.3.3)
• Support Vector Machine mit Kernelerweiterung (s. Anhang A.3.4)
• Künstliches neuronales Netz (s. Anhang A.3.5)
Zwar sind die genannten Machine-Learning-Verfahren in der Lage, mit-tels Lerndaten gewichtete Klassifikatorfunktionen bereitzustellen. Einigedavon scheinen jedoch die speziellen Anforderungen, die ein Relevanz-klassifikator mit sich bringt, weniger gut umzusetzen als andere:
Eine wichtige Anforderung für solch einen Klassifikator ist seine Echt-zeitfähigkeit,welche insbesondere für den kNN-Algorithmus schwierig um-zusetzen ist. Prinzipbedingt muss dieser auf eine im Vorfeld unbekannteTeilmenge der Trainingsmenge in Echtzeit zugreifen können. Je nach Spei-chertechnologie, Suchalgorithmus und Menge der Trainingsdaten kanndieses Kriterium schwierig zu erfüllen sein. Da später eine sehr große Men-ge an Trainingsdaten verwendet wird, ist eine mangelnde Echtzeitfähigkeitzu erwarten, weshalb auf die weitere Untersuchung dieses Klassifikatorsverzichtet wird.
Als weitere Anforderung galt es, dass dieser möglichst genaue gestal-tet werden soll. Problematisch können dabei expertenbasierte Modellan-nahmen und -vereinfachungen sein, da hierbei das komplexe Problem derObjektrelevanz genau verstanden werden muss. Ist dieses nicht fehlerfreimöglich, so können falsche Randbedingungeneinen negativen Einfluss aufdie Genauigkeit des Schätzers ausüben.
Das Bayessche Netz erfordert jedoch die Definition der Netztopologieund der Diskretisierung kontinuierlicher Attribute. Wie dargestellt, gibt eszwar verschiedene Algorithmen, welche die einzelnen Aspekte schätzenkönnen, falls kein gutes expertenbasiertes Modell generiert werden kann.Problematisch ist jedoch die kombinatorische Komplexität, die ohne Rand-bedingungen zu bewältigen ist: So sind die Erlernung einer guten Diskre-tisierung, einer guten Netztopologie und die daraus ermittelten Verbund-wahrscheinlichkeiten der einzelnen Knoten nicht unabhängig. Damit ist eininsgesamt multiplikativer Aufwand bei einer großen Trainingsbasis festzu-stellen, um diese Optimierungsalgorithmen zu kombinieren.
Da dem Bayesschen Netz außerdem bei vielen Klassifizierungsproble-men eine unterdurchschnittliche Genauigkeit im Vergleich zu vielen ande-
102
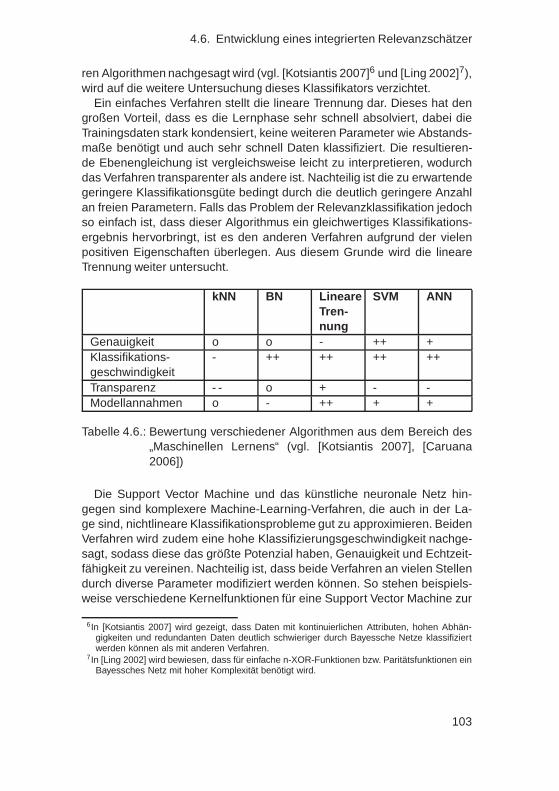
4.6. Entwicklung eines integrierten Relevanzschätzer
ren Algorithmen nachgesagt wird (vgl. [Kotsiantis 2007]6 und [Ling 2002]7),wird auf die weitere Untersuchung dieses Klassifikators verzichtet.
Ein einfaches Verfahren stellt die lineare Trennung dar. Dieses hat dengroßen Vorteil, dass es die Lernphase sehr schnell absolviert, dabei dieTrainingsdaten stark kondensiert, keine weiteren Parameter wie Abstands-maße benötigt und auch sehr schnell Daten klassifiziert. Die resultieren-de Ebenengleichung ist vergleichsweise leicht zu interpretieren, wodurchdas Verfahren transparenter als andere ist. Nachteilig ist die zu erwartendegeringere Klassifikationsgüte bedingt durch die deutlich geringere Anzahlan freien Parametern. Falls das Problem der Relevanzklassifikation jedochso einfach ist, dass dieser Algorithmus ein gleichwertiges Klassifikations-ergebnis hervorbringt, ist es den anderen Verfahren aufgrund der vielenpositiven Eigenschaften überlegen. Aus diesem Grunde wird die lineareTrennung weiter untersucht.
kNN BN LineareTren-nung
SVM ANN
Genauigkeit o o - ++ +Klassifikations-geschwindigkeit
- ++ ++ ++ ++
Transparenz - - o + - -Modellannahmen o - ++ + +
Tabelle 4.6.: Bewertung verschiedener Algorithmen aus dem Bereich des„Maschinellen Lernens“ (vgl. [Kotsiantis 2007], [Caruana2006])
Die Support Vector Machine und das künstliche neuronale Netz hin-gegen sind komplexere Machine-Learning-Verfahren, die auch in der La-ge sind, nichtlineare Klassifikationsprobleme gut zu approximieren. BeidenVerfahren wird zudem eine hohe Klassifizierungsgeschwindigkeit nachge-sagt, sodass diese das größte Potenzial haben, Genauigkeit und Echtzeit-fähigkeit zu vereinen. Nachteilig ist, dass beide Verfahren an vielen Stellendurch diverse Parameter modifiziert werden können. So stehen beispiels-weise verschiedene Kernelfunktionen für eine Support Vector Machine zur
6In [Kotsiantis 2007] wird gezeigt, dass Daten mit kontinuierlichen Attributen, hohen Abhän-gigkeiten und redundanten Daten deutlich schwieriger durch Bayessche Netze klassifiziertwerden können als mit anderen Verfahren.
7In [Ling 2002] wird bewiesen, dass für einfache n-XOR-Funktionen bzw. Paritätsfunktionen einBayessches Netz mit hoher Komplexität benötigt wird.
103

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Auswahl, während beim künstlichen neuronalen Netz die Anzahl der ver-steckten Schichten und deren Neuronenzahl als Parameter festgelegt wer-den müssen. Hier muss ein Experte eine günstige Parametrisierung fin-den. Im Unterschied zum Bayesschen Netz haben sich aber einige wenigeStandardparametrisierungen unabhängig vom speziellen Problem heraus-kristallisiert, welche bei vielen Klassifikationsproblemen gute Ergebnisseliefern. Diese werden in den folgenden Abschnitten verwendet, um diesebeiden Verfahren zu untersuchen.
Eine Übersicht über die Vor- und Nachteile der einzelnen Verfahren istin Tabelle 4.6 zusammengefasst.
4.6.4. Anwendung der Lernverfahren zurRelevanzklassikation
Die im Abschnitt 4.6.2 erzeugte Lernbasis wird in Trainings-, Referenz- undTestdaten getrennt und normiert, sodass sich jedes Attribut im Intervall [0,1] befindet. Diese Daten werden anschließend in verschiedenen Lernver-fahren genutzt, die die Klassifizierungsfunktion approximieren. Insgesamtsind die drei im vorherigen Abschnitt ausgewählten Verfahren getestet wor-den: Lineare Trennung, künstliche neuronale Netze und Support VectorMachine.
Wie erwartet, zeichnet sich die lineare Trennung während des Lernver-fahrens durch eine sehr hohe Geschwindigkeit aus. Diese beträgt nur einenBruchteil der anderen Lernverfahren.
Einen recht hohen Trainingsaufwand verzeichnete das künstliche neuro-nale Netz. Hierbei wurden verschiedene Parametrisierungen getestet, wo-bei sich eine einzelne versteckte Schicht mit 30 Neuronen als geeignetherausstellte. Bei der Verwendung von deutlich mehr oder weniger Neu-ronen zeigte das künstliche neuronale Netz ein schlechteres Klassifikati-onsergebnis bei den Testdaten, was durch Überanpassung bzw. Unteran-passung erklärt werden kann. Es wurden auch verschiedene Aktivierungs-funktionen getestet: Hierbei lieferte die logistische sigmoide Aktivierungs-funktion das beste Ergebnis auf den Testdaten.
Als Ergebnis sind die Netzstruktur und die erlernten Verbindungsgewich-te in Abbildung 4.9 dargestellt. Je stärker das Gewicht zwischen zwei Neu-ronen, desto dicker ist die Verbindungslinie zwischen diesen dargestellt.Positive Gewichte (blaue Verbindungen) erhöhen die elektrische Aktivitätbei den verbundenen Neuronen und erhöhen damit auch insgesamt ten-denziell die Netzaktivität. Umgekehrt dämpfen negative Gewichte (rote Ver-bindungen) bei entsprechender Eingabe diese.
104

4.6. Entwicklung eines integrierten Relevanzschätzer
Abbildung 4.9.: Eingesetztes künstliches neuronales Netz mit 48 Neuro-nen. Blau: Positive Gewichte, Rot: Negative Gewichte.
Den höchsten Trainingsaufwand verzeichnete die Support Vector Machi-ne. Hierbei fällt der Nachteil auf, dass die Anzahl der verwendeten Support-vektoren nicht begrenzt ist und diese tendenziell mit zunehmender Lern-menge ansteigt. Da die Lernmenge mit ca. 300.000 Datensätzen sehr großist, und die Support Vector Machine potenziell eine sehr große Anzahl anfreien Parametern aufweist, kommt es hier möglicherweise zur Überanpas-sung: Wie die Übersicht über die einzelnen Verfahren in Tabelle 4.7 zeigt,sind während der Lernphase über 20.000 Supportvektoren mit je 15 Di-mensionen entstanden. Hierbei wurden auch verschiedene C-Konstantengetestet (vgl. Gleichung A.17), jedoch lieferten diese sehr ähnliche Ergeb-nisse. Bei den Kernelfunktionen hat die radiale Kernelfunktion die besteKlassifikationsleistung erbracht.
Als Ergebnis bzgl. Genauigkeit liefert das künstliche neuronale Netz dasbeste Ergebnis mit 95,7% auf die Referenzmenge. Ein mittleres Ergebnisliefert die Support Vector Machine gefolgt von der linearen Trennung.
4.6.5. Dimensionsreduktion des Zustandsraumes
Bei der Erzeugung des Zustandsraumes in Abschnitt 4.6.1 sind solche At-tribute ausgewählt worden, die potenziell den Zustandsraum so erweitern,dass eine Trennung durch funktionsapproximierende Algorithmen erleich-tert wird. Unklar ist bisher, ob dafür alle Attribute mit der Objektrelevanz
105
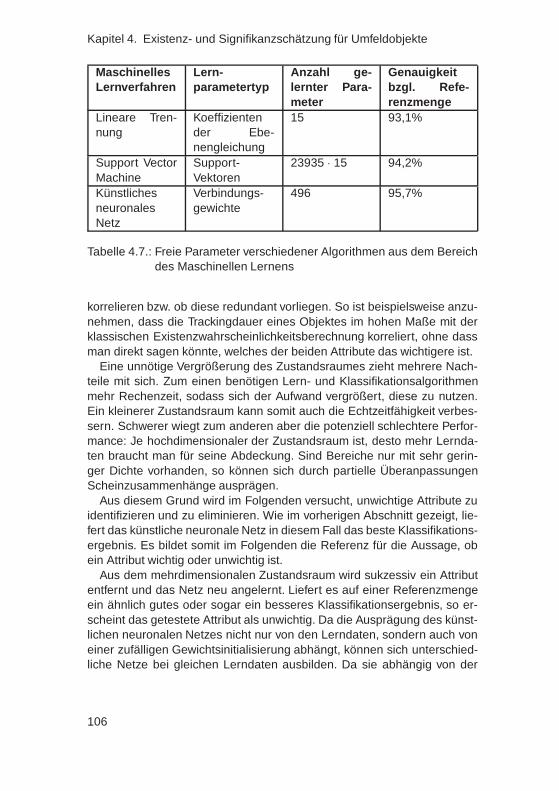
Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
MaschinellesLernverfahren
Lern-parametertyp
Anzahl ge-lernter Para-meter
Genauigkeitbzgl. Refe-renzmenge
Lineare Tren-nung
Koeffizientender Ebe-nengleichung
15 93,1%
Support VectorMachine
Support-Vektoren
23935 · 15 94,2%
KünstlichesneuronalesNetz
Verbindungs-gewichte
496 95,7%
Tabelle 4.7.: Freie Parameter verschiedener Algorithmen aus dem Bereichdes Maschinellen Lernens
korrelieren bzw. ob diese redundant vorliegen. So ist beispielsweise anzu-nehmen, dass die Trackingdauer eines Objektes im hohen Maße mit derklassischen Existenzwahrscheinlichkeitsberechnung korreliert, ohne dassman direkt sagen könnte, welches der beiden Attribute das wichtigere ist.
Eine unnötige Vergrößerung des Zustandsraumes zieht mehrere Nach-teile mit sich. Zum einen benötigen Lern- und Klassifikationsalgorithmenmehr Rechenzeit, sodass sich der Aufwand vergrößert, diese zu nutzen.Ein kleinerer Zustandsraum kann somit auch die Echtzeitfähigkeit verbes-sern. Schwerer wiegt zum anderen aber die potenziell schlechtere Perfor-mance: Je hochdimensionaler der Zustandsraum ist, desto mehr Lernda-ten braucht man für seine Abdeckung. Sind Bereiche nur mit sehr gerin-ger Dichte vorhanden, so können sich durch partielle ÜberanpassungenScheinzusammenhänge ausprägen.
Aus diesem Grund wird im Folgenden versucht, unwichtige Attribute zuidentifizieren und zu eliminieren. Wie im vorherigen Abschnitt gezeigt, lie-fert das künstliche neuronale Netz in diesem Fall das beste Klassifikations-ergebnis. Es bildet somit im Folgenden die Referenz für die Aussage, obein Attribut wichtig oder unwichtig ist.
Aus dem mehrdimensionalen Zustandsraum wird sukzessiv ein Attributentfernt und das Netz neu angelernt. Liefert es auf einer Referenzmengeein ähnlich gutes oder sogar ein besseres Klassifikationsergebnis, so er-scheint das getestete Attribut als unwichtig. Da die Ausprägung des künst-lichen neuronalen Netzes nicht nur von den Lerndaten, sondern auch voneiner zufälligen Gewichtsinitialisierung abhängt, können sich unterschied-liche Netze bei gleichen Lerndaten ausbilden. Da sie abhängig von der
106
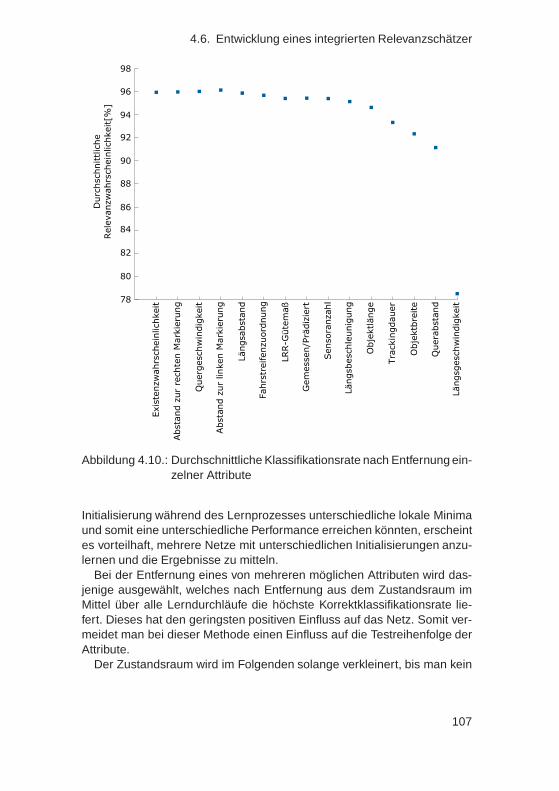
4.6. Entwicklung eines integrierten Relevanzschätzer
78
80
82
84
86
88
90
92
94
96
98
Exis
tenzw
ahrs
chein
lichkeit
Absta
nd z
ur
rechte
n M
ark
ieru
ng
Querg
eschw
indig
keit
Absta
nd z
ur
linken M
ark
ieru
ng
Längsabsta
nd
Fahrs
treifenzuord
nung
LRR-G
üte
maß
Gem
essen/P
rädiz
iert
Sensora
nzahl
Längsbeschle
unig
ung
Obje
ktlänge
Tra
ckin
gdauer
Obje
ktb
reite
Quera
bsta
nd
Längsgeschw
indig
keit
Durc
hschnittlic
he
Rele
vanzw
ahrs
chein
lichkeit[%
]
Abbildung 4.10.: Durchschnittliche Klassifikationsrate nach Entfernung ein-zelner Attribute
Initialisierung während des Lernprozesses unterschiedliche lokale Minimaund somit eine unterschiedliche Performance erreichen könnten, erscheintes vorteilhaft, mehrere Netze mit unterschiedlichen Initialisierungen anzu-lernen und die Ergebnisse zu mitteln.
Bei der Entfernung eines von mehreren möglichen Attributen wird das-jenige ausgewählt, welches nach Entfernung aus dem Zustandsraum imMittel über alle Lerndurchläufe die höchste Korrektklassifikationsrate lie-fert. Dieses hat den geringsten positiven Einfluss auf das Netz. Somit ver-meidet man bei dieser Methode einen Einfluss auf die Testreihenfolge derAttribute.
Der Zustandsraum wird im Folgenden solange verkleinert, bis man kein
107

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Attribut mehr findet, welches man entfernen kann, ohne dass sich die Kor-rektklassifikationsrate verschlechtert. Es zeigt sich, dass es nur wenige At-tribute gibt, bei deren Entfernung sich eine bemerkbare Verschlechterungdes Klassifikationsergebnisses ergibt. Hierzu zählen die Längsgeschwin-digkeit und der Querabstand. Die anderen Merkmale scheinen nur einengeringen Beitrag zur korrekten Klassifikation beizusteuern. Abbildung 4.10zeigt die Veränderung der Klassifikationsrate nach sukzessiver Entfernungeinzelner Attribute.
Aus dieser Abbildung ist auch zu entnehmen, dass der Zustandsraumbis auf 11 Dimensionen reduziert werden kann. Der Abstand zur linkenund rechten Markierung, die nach konventionellen Methoden berechne-te Existenzwahrscheinlichkeit und die Quergeschwindigkeit des Objektessind danach unwichtige bzw. kompensierbare Attribute. Der Klassifikatorerreicht hierbei eine durchschnittliche Klassifikationsrate von 96,1%.
Die wichtigsten Attribute sind nach dieser Analyse die Längsgeschwin-digkeit, der Querabstand, Objektbreite und Trackingdauer. Während dieLängsgeschwindigkeit stationäre Ziele von dynamischen separiert und so-mit ein wichtiges Kriterium für die Erkennung existierender Objekte ist,trennt der Querabstand vermutlich nicht signifikante von signifikanten Ob-jekten. Die Trackingdauer kann kurzfristige Scheinziele unterdrücken undkompensiert somit wohl die Existenzwahrscheinlichkeit nach konventionel-len Methoden.
Anhand der Objektbreite hat das Netz indirekt einen Anhaltspunkt, vonwelchen Sensoren der Objekttrack aktualisiert worden ist. Der Radarsen-sor und der Ultraschallsensor können keine Objektkontur schätzen, sodasshier bestimmte Vorgabewerte genutzt werden. Die Stereokamera kann hin-gegen eine Breite bzw. Länge messen, sodass die Objekthypothese meisteine Konturschätzung ungleich der Vorgabewerte aufweist.
Das gezeigte Verfahren liefert insgesamt allerdings nur ein lokales Mini-mum bei der Bestimmung der optimalen Attributmenge. Die Suche nachdiesem hat nur eine polynomielle Komplexität zur Attributanzahl n vonO(n) = n2. Um das globale Minimum zu finden, müssten hingegen alle Net-ze mit allen möglichen Attributkombinationen getestet werden. Dieses Ver-fahren weist eine exponentielle Komplexität von O(n) = 2n auf und ist somitbei einer größeren Anzahl von Attributen zu aufwendig. Diese Grenze istbereits im vorliegenden Fall überschritten, sodass die Suche nach demlokalen Minimum als Optimierungsmethode mit geringerer Komplexität ge-wählt worden ist.
108

4.6. Entwicklung eines integrierten Relevanzschätzer
4.6.6. Tiefpassfilterung des Ergebnisses
Der zu klassifizierende Zustandsvektor enthält zum einen Attribute, die ku-mulativ während des Trackings erzeugt werden. Hierzu zählen beispiels-weise die Trackingdauer oder auch die Anzahl von unterschiedlichen Sen-soren, die das Objekt je zuvor gemessen haben.
Die meisten anderen Attribute bilden jedoch nur eine Momentaufnah-me der Schätzung, wobei aktuelle Schätzungen der Objektfusion und derFahrbahnfusion einfließen, ohne dass frühere Ergebnisse berücksichtigtwerden. Insbesondere bei weit entfernten Objekten kann dies dazu füh-ren, dass bei schlechter Fahrbahnschätzung diese Objekte mal mehr oderweniger mit einem Fahrstreifen assoziiert werden. Dadurch kann sich imVerlauf der Relevanzschätzung eine hohe Varianz ergeben. Dieses ist vorallem bei konstanten Schwellen problematisch, da das Fahrerassistenzsys-tem dann das Objekt alternierend als relevant und nicht relevant betrachtet.
Das Einbringen alter Relevanzschätzungen in Lernalgorithmen ist nichtohne Weiteres möglich, da diese zum Lernzeitpunkt nicht feststehen. Au-ßerdem verändern sie sich mit jedem Lernschritt, sodass sie theoretischnach jeder Iteration neu erzeugt werden müssen. Es ist zusätzlich frag-lich, ob die einzelnen Verfahren bei sich ständig verändernden Lerndatenkonvergieren.
Aus diesem Grund wurde ein einfaches Tiefpassfilter erster Ordnunghinter der Relevanzschätzung implementiert, welcher die Relevanzwertemittelt. Sei rn die vorherige gefilterte Relevanzschätzung, p die ungefilter-te neue Relevanzschätzung und F ∈ [0,1] ein Faktor, der die Stärke desTiefpassfilters angibt. Dann wird der neue gefilterte Relevanzwert rn+1 wiefolgt berechnet:
rn+1 = F · rn + p · (1−F) (4.32)
Vorteilig ist eine robustere und zum Teil auch genauere Relevanzschät-zung, welche insgesamt konsistentere Ergebnisse liefert. Nachteilig ist ei-ne je nach Stärke des Filters mehr oder weniger verzögerte Detektion re-levanter Objekte: Erstmalig initialisierte Objekte haben häufig eine geringeRelevanzwahrscheinlichkeit. Wenn sich mit zunehmenden Objekthypothe-senalter aus Sicht des Machine Learning Algorithmus herausstellt, dassdiese doch relevant sind, verhindert das Tiefpassfilter eine schnelle Adap-tion an die aktuellen Schätzungen. Dieses ist insbesondere bei stationärenObjekten nachteilig, da diese für das Fahrerassistenzsystem erst späterrelevant werden.
109
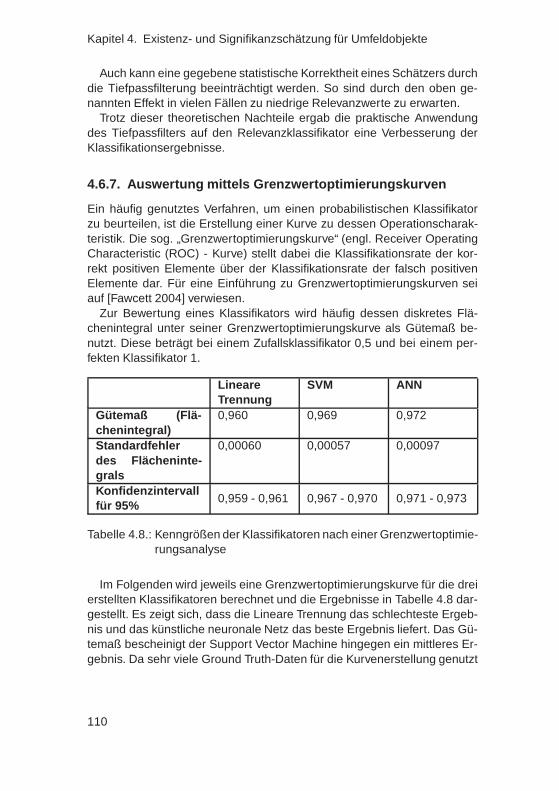
Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Auch kann eine gegebene statistische Korrektheit eines Schätzers durchdie Tiefpassfilterung beeinträchtigt werden. So sind durch den oben ge-nannten Effekt in vielen Fällen zu niedrige Relevanzwerte zu erwarten.
Trotz dieser theoretischen Nachteile ergab die praktische Anwendungdes Tiefpassfilters auf den Relevanzklassifikator eine Verbesserung derKlassifikationsergebnisse.
4.6.7. Auswertung mittels Grenzwertoptimierungskurven
Ein häufig genutztes Verfahren, um einen probabilistischen Klassifikatorzu beurteilen, ist die Erstellung einer Kurve zu dessen Operationscharak-teristik. Die sog. „Grenzwertoptimierungskurve“ (engl. Receiver OperatingCharacteristic (ROC) - Kurve) stellt dabei die Klassifikationsrate der kor-rekt positiven Elemente über der Klassifikationsrate der falsch positivenElemente dar. Für eine Einführung zu Grenzwertoptimierungskurven seiauf [Fawcett 2004] verwiesen.
Zur Bewertung eines Klassifikators wird häufig dessen diskretes Flä-chenintegral unter seiner Grenzwertoptimierungskurve als Gütemaß be-nutzt. Diese beträgt bei einem Zufallsklassifikator 0,5 und bei einem per-fekten Klassifikator 1.
LineareTrennung
SVM ANN
Gütemaß (Flä-chenintegral)
0,960 0,969 0,972
Standardfehlerdes Flächeninte-grals
0,00060 0,00057 0,00097
Konfidenzintervallfür 95%
0,959 - 0,961 0,967 - 0,970 0,971 - 0,973
Tabelle 4.8.: Kenngrößen der Klassifikatoren nach einer Grenzwertoptimie-rungsanalyse
Im Folgenden wird jeweils eine Grenzwertoptimierungskurve für die dreierstellten Klassifikatoren berechnet und die Ergebnisse in Tabelle 4.8 dar-gestellt. Es zeigt sich, dass die Lineare Trennung das schlechteste Ergeb-nis und das künstliche neuronale Netz das beste Ergebnis liefert. Das Gü-temaß bescheinigt der Support Vector Machine hingegen ein mittleres Er-gebnis. Da sehr viele Ground Truth-Daten für die Kurvenerstellung genutzt
110

4.6. Entwicklung eines integrierten Relevanzschätzer
werden konnten, ist die Standardabweichung des diskreten Flächeninte-grals sehr gering. Bei wenigen Ground Truth-Daten können größere Dis-kretisierungsfehler auftreten, welche sich in der Standardabweichung nie-derschlagen.
10,10,010,0010
0,9
0,99
0,999
Quote scheinbar relevanter Objekte
Quote
wir
klic
h r
ele
va
nte
r O
bje
kte
ANN
SVM
Lineare Trennung
Abbildung 4.11.: Doppellogarithmische Darstellung von Grenzwertoptimie-rungskurven für verschiedene Klassifikatoren
Insgesamt liefern alle Verfahren so gute Korrektklassifikationsraten, so-dass für die Visualisierung der Grenzwertoptimierungskurve in Abbildung4.11 eine doppellogarithmische Darstellung gewählt worden ist, um dieUnterschiede besser herauszuheben. Durch diese Darstellung fehlen be-stimmte Bereiche: So haben alle Kurven (0/0) als Startpunkt und (1/1) alsEndpunkt, welche hier fehlen.
Aus dieser Abbildung kann man entnehmen, dass das künstliche neu-ronale Netz in allen wesentlichen Bereichen stets besser als die SupportVector Machine und die lineare Trennung ist. Die Lineare Trennung hinge-
111
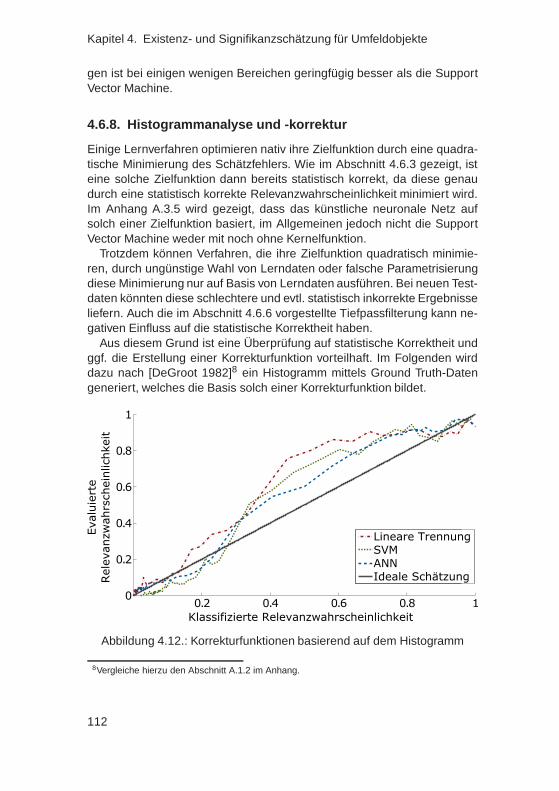
Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
gen ist bei einigen wenigen Bereichen geringfügig besser als die SupportVector Machine.
4.6.8. Histogrammanalyse und -korrektur
Einige Lernverfahren optimieren nativ ihre Zielfunktion durch eine quadra-tische Minimierung des Schätzfehlers. Wie im Abschnitt 4.6.3 gezeigt, isteine solche Zielfunktion dann bereits statistisch korrekt, da diese genaudurch eine statistisch korrekte Relevanzwahrscheinlichkeit minimiert wird.Im Anhang A.3.5 wird gezeigt, dass das künstliche neuronale Netz aufsolch einer Zielfunktion basiert, im Allgemeinen jedoch nicht die SupportVector Machine weder mit noch ohne Kernelfunktion.
Trotzdem können Verfahren, die ihre Zielfunktion quadratisch minimie-ren, durch ungünstige Wahl von Lerndaten oder falsche Parametrisierungdiese Minimierung nur auf Basis von Lerndaten ausführen. Bei neuen Test-daten könnten diese schlechtere und evtl. statistisch inkorrekte Ergebnisseliefern. Auch die im Abschnitt 4.6.6 vorgestellte Tiefpassfilterung kann ne-gativen Einfluss auf die statistische Korrektheit haben.
Aus diesem Grund ist eine Überprüfung auf statistische Korrektheit undggf. die Erstellung einer Korrekturfunktion vorteilhaft. Im Folgenden wirddazu nach [DeGroot 1982]8 ein Histogramm mittels Ground Truth-Datengeneriert, welches die Basis solch einer Korrekturfunktion bildet.
0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
Lineare TrennungSVMANNIdeale Schätzung
Klassifizierte Relevanzwahrscheinlichkeit
Abbildung 4.12.: Korrekturfunktionen basierend auf dem Histogramm
8Vergleiche hierzu den Abschnitt A.1.2 im Anhang.
112

4.6. Entwicklung eines integrierten Relevanzschätzer
Die Histogrammerstellung erfolgt folgendermaßen: Von einer großenMenge von neuen Trainingsdaten wird die Relevanzwahrscheinlichkeit be-stimmt. Nun werden diese in gleich große Mengen unterteilt, sodass sichin jeder Teilmenge die Datensätze befinden, die eine möglichst ähnli-che Relevanzwahrscheinlichkeit haben. Die Relevanzwahrscheinlichkeits-schätzung von Datensätzen einer Teilmenge ist genau dann statistischkorrekt, wenn diese äquivalent zum Quotienten von relevanten Datensät-zen und der Gesamtmenge an Datensätzen ist. Ein Schätzer ist immerdann statistisch korrekt, wenn das Schätzergebnis auf dieses Verhältnisabgebildet wird. Die Abbildungsfunktionen für die lineare Trennung, dieSupport Vector Machine und das künstliche neuronale Netz sind in Ab-bildung 4.12 dargestellt. Die geschätzte Relevanzwahrscheinlichkeit nachdem Tiefpassschritt wird auf die evaluierte Relevanzwahrscheinlichkeit ab-gebildet.
Mithilfe der Histogrammanalyse können die Ergebnisse jeder beliebigeKlassifikationsfunktion statistisch korrekt abgebildet werden, sodass mandie Relevanzwerte direkt verwenden kann. So würde eine Zufallsfunktionnach Histogrammanalyse und -korrektur beispielsweise jeden Relevanz-wert auf einen konstanten Wert abbilden, da in jeder Teilmenge das Ver-hältnis zwischen relevanten und irrelevanten Objekten gleich groß ist.
Wichtig bei der Erstellung ist außerdem eine abgestimmte Wahl derKlassengröße. Ist diese zu klein, kommt es zur Überanpassung. Ist die-se zu groß, wird der Wertebereich, welcher die Teilmenge repräsentiertunnötig vergrößert. Dies hat zur Folge, dass bestimmte Relevanzwerte in-nerhalb dieses Wertebereiches schlechter diskriminiert werden.
Um die Diskriminierung naher Relevanzwerte zu verbessern, wird einelineare Interpolation zwischen den Klassen benachbarter Wertebereichedurchgeführt. In Abbildung 4.13 ist die Methode dargestellt: Die lineareInterpolation (rote Linie) der Relevanzwahrscheinlichkeit p(x) erfolgt zwi-schen zwei benachbarten Klassen (gestrichelte Rechtecke), die jeweils ei-nen Relevanzbereich repräsentieren. Die Höhe der Rechtecke basiert aufdem Verhältnis von relevanten Objekten (blaue Quadrate) zur Gesamtzahlder Objekte dieser Klasse. Diese lineare Interpolation nimmt an, dass dieRelevanzfunktion eine gewisse Stetigkeit aufweist.
Angewandt auf die drei Klassifizierungsfunktionen lineare Trennung,Support Vector Machine und künstliches neuronales Netz ergeben sichdie in Abbildung 4.12 dargestellten Korrekturkurven. Bei diesen ist insbe-sondere zu sehen, dass alle drei Schätzfunktionen keine sicheren relevan-ten Ereignisse schätzen können: Die Schätzwerte „0“ und „1“ werden nurauf nichtsichere Werte nahe „0“ bzw. „1“ korrigiert. Auch sind die Rele-vanzschätzungen in weiten Teilen des Wertebereiches zu niedrig, sodass
113
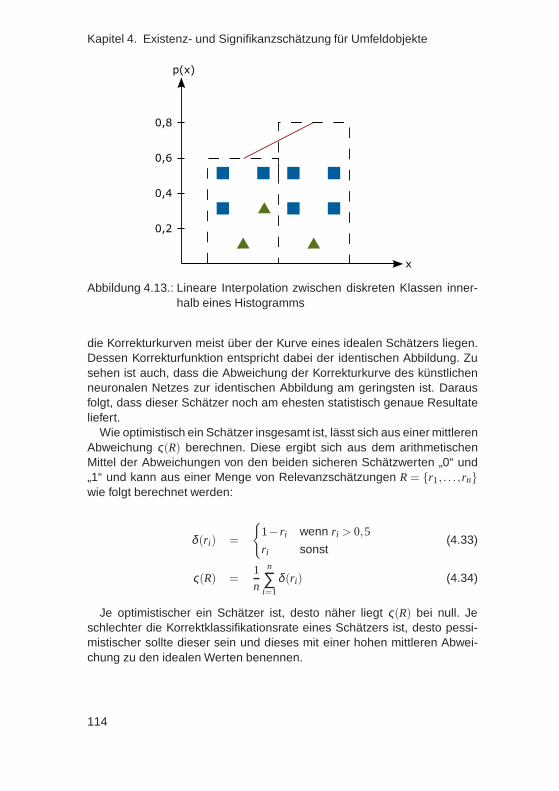
Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
0,2
0,4
0,6
0,8
p(x)
x
Abbildung 4.13.: Lineare Interpolation zwischen diskreten Klassen inner-halb eines Histogramms
die Korrekturkurven meist über der Kurve eines idealen Schätzers liegen.Dessen Korrekturfunktion entspricht dabei der identischen Abbildung. Zusehen ist auch, dass die Abweichung der Korrekturkurve des künstlichenneuronalen Netzes zur identischen Abbildung am geringsten ist. Darausfolgt, dass dieser Schätzer noch am ehesten statistisch genaue Resultateliefert.
Wie optimistisch ein Schätzer insgesamt ist, lässt sich aus einer mittlerenAbweichung ς(R) berechnen. Diese ergibt sich aus dem arithmetischenMittel der Abweichungen von den beiden sicheren Schätzwerten „0“ und„1“ und kann aus einer Menge von Relevanzschätzungen R = r1, . . . ,rnwie folgt berechnet werden:
δ (ri) =
1− ri wenn ri > 0,5
ri sonst(4.33)
ς(R) =1n
n
∑i=1
δ (ri) (4.34)
Je optimistischer ein Schätzer ist, desto näher liegt ς(R) bei null. Jeschlechter die Korrektklassifikationsrate eines Schätzers ist, desto pessi-mistischer sollte dieser sein und dieses mit einer hohen mittleren Abwei-chung zu den idealen Werten benennen.
114
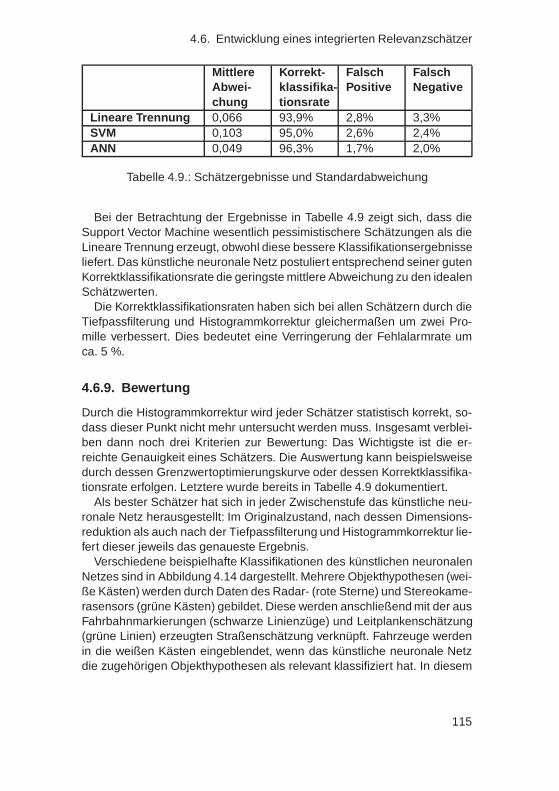
4.6. Entwicklung eines integrierten Relevanzschätzer
MittlereAbwei-chung
Korrekt-klassifika-tionsrate
FalschPositive
FalschNegative
Lineare Trennung 0,066 93,9% 2,8% 3,3%SVM 0,103 95,0% 2,6% 2,4%ANN 0,049 96,3% 1,7% 2,0%
Tabelle 4.9.: Schätzergebnisse und Standardabweichung
Bei der Betrachtung der Ergebnisse in Tabelle 4.9 zeigt sich, dass dieSupport Vector Machine wesentlich pessimistischere Schätzungen als dieLineare Trennung erzeugt, obwohl diese bessere Klassifikationsergebnisseliefert. Das künstliche neuronale Netz postuliert entsprechend seiner gutenKorrektklassifikationsrate die geringste mittlere Abweichung zu den idealenSchätzwerten.
Die Korrektklassifikationsraten haben sich bei allen Schätzern durch dieTiefpassfilterung und Histogrammkorrektur gleichermaßen um zwei Pro-mille verbessert. Dies bedeutet eine Verringerung der Fehlalarmrate umca. 5 %.
4.6.9. Bewertung
Durch die Histogrammkorrektur wird jeder Schätzer statistisch korrekt, so-dass dieser Punkt nicht mehr untersucht werden muss. Insgesamt verblei-ben dann noch drei Kriterien zur Bewertung: Das Wichtigste ist die er-reichte Genauigkeit eines Schätzers. Die Auswertung kann beispielsweisedurch dessen Grenzwertoptimierungskurve oder dessen Korrektklassifika-tionsrate erfolgen. Letztere wurde bereits in Tabelle 4.9 dokumentiert.
Als bester Schätzer hat sich in jeder Zwischenstufe das künstliche neu-ronale Netz herausgestellt: Im Originalzustand, nach dessen Dimensions-reduktion als auch nach der Tiefpassfilterung und Histogrammkorrektur lie-fert dieser jeweils das genaueste Ergebnis.
Verschiedene beispielhafte Klassifikationen des künstlichen neuronalenNetzes sind in Abbildung 4.14 dargestellt. Mehrere Objekthypothesen (wei-ße Kästen) werden durch Daten des Radar- (rote Sterne) und Stereokame-rasensors (grüne Kästen) gebildet. Diese werden anschließend mit der ausFahrbahnmarkierungen (schwarze Linienzüge) und Leitplankenschätzung(grüne Linien) erzeugten Straßenschätzung verknüpft. Fahrzeuge werdenin die weißen Kästen eingeblendet, wenn das künstliche neuronale Netzdie zugehörigen Objekthypothesen als relevant klassifiziert hat. In diesem
115
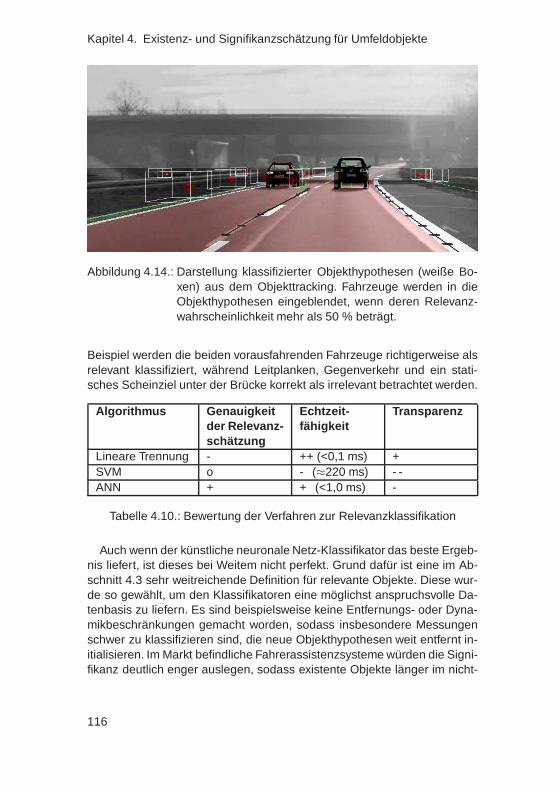
Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Abbildung 4.14.: Darstellung klassifizierter Objekthypothesen (weiße Bo-xen) aus dem Objekttracking. Fahrzeuge werden in dieObjekthypothesen eingeblendet, wenn deren Relevanz-wahrscheinlichkeit mehr als 50 % beträgt.
Beispiel werden die beiden vorausfahrenden Fahrzeuge richtigerweise alsrelevant klassifiziert, während Leitplanken, Gegenverkehr und ein stati-sches Scheinziel unter der Brücke korrekt als irrelevant betrachtet werden.
Algorithmus Genauigkeitder Relevanz-schätzung
Echtzeit-fähigkeit
Transparenz
Lineare Trennung - ++ (<0,1 ms) +SVM o - (≈220 ms) - -ANN + + (<1,0 ms) -
Tabelle 4.10.: Bewertung der Verfahren zur Relevanzklassifikation
Auch wenn der künstliche neuronale Netz-Klassifikator das beste Ergeb-nis liefert, ist dieses bei Weitem nicht perfekt. Grund dafür ist eine im Ab-schnitt 4.3 sehr weitreichende Definition für relevante Objekte. Diese wur-de so gewählt, um den Klassifikatoren eine möglichst anspruchsvolle Da-tenbasis zu liefern. Es sind beispielsweise keine Entfernungs- oder Dyna-mikbeschränkungen gemacht worden, sodass insbesondere Messungenschwer zu klassifizieren sind, die neue Objekthypothesen weit entfernt in-itialisieren. Im Markt befindliche Fahrerassistenzsysteme würden die Signi-fikanz deutlich enger auslegen, sodass existente Objekte länger im nicht-
116

4.7. Ableitung von Regeln aus einem integrierten Relevanzschätzer
signifikanten Bereich beobachtet werden können. Würde man für solcheFahrerassistenzsysteme abgestimmte starke Randbedingungen integrie-ren, so würden sich die Klassifikationsergebnisse noch wesentlich verbes-sern.
Da die Relevanzschätzung bei bestimmten Fahrerassistenzsystemenein Bestandteil der Längsregelung ist, ist eine geringe Totzeit für dessenRegelungsqualität vorteilhaft. Aus diesem Grund müssen alle Schätzer be-stimmte Echtzeitkriterien erfüllen. So müssen sie innerhalb sehr kurzerZeit für eine größere Objektmenge deren jeweilige Relevanz bestimmt ha-ben9. Dieses Kriterium erfüllt natürlich die lineare Trennung, aber auch daskünstliche neuronale Netz kann bei einer optimierten Implementation die-se Anforderung bewältigen. Bei der Support Vector Machine hingegen istaufgrund der vielen Support-Vektoren eine deutliche Latenz messbar, wasdieses Verfahren in dieser Form ungeeignet macht.
Wünschenswert wäre auch eine größere Transparenz der Verfahren. Sobilden sowohl Support Vector Machine als auch das künstliche neuronaleNetz eine Art „Black-Box“, die auf vielen Parametern basiert. Beim künst-lichen neuronalen Netz lassen sich noch wichtige Verbindungspfade her-ausfinden, hingegen ist bei der Support Vector Machine aufgrund der vie-len Support-Vektoren keine Transparenz mehr vorhanden.
Eine Zusammenfassung der Vor- und Nachteile der einzelnen Verfahrenist in Tabelle 4.10 beschrieben.
4.7. Ableitung von Regeln aus einem integriertenRelevanzschätzer
Der vorgestellte integrierte Schätzer bildet eine hochdimensionale Wahr-scheinlichkeitsdichtefunktion, die je nach Machine-Learning-Algorithmusmehr oder weniger intransparent ist. Um diese zu verstehen, werden imFolgenden Schnitte durch den hochdimensionalen Raum durchgeführt undvisualisiert.
Die nicht visualisierten Dimensionen sollen dabei vernachlässigt wer-den. Exemplarisch wird der künstliche neuronale Netz-Klassifikator darge-stellt; das Verfahren ist jedoch auf beliebig andere probabilistische Klassi-fikatoren anwendbar.
Während die Support Vector Machine unbekannte Attribute unterstützt,ist dieses bei der linearen Trennung und beim künstlichen neuronalen
9Als Test wurden 32 Tracks auf einem CompactPCI-Computer ausgerüstet mit einem bis zu2,2 GHz getakteten x86-Doppelkernprozessor und 4 GB Arbeitsspeicher klassifiziert. DieErgebnisse des Tests sind in Tabelle 4.10 zusammengefasst.
117
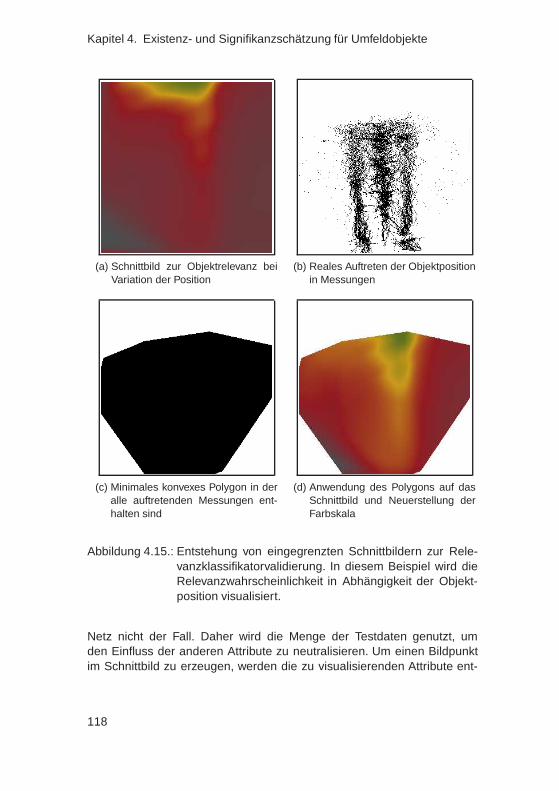
Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
(a) Schnittbild zur Objektrelevanz beiVariation der Position
(b) Reales Auftreten der Objektpositionin Messungen
(c) Minimales konvexes Polygon in deralle auftretenden Messungen ent-halten sind
(d) Anwendung des Polygons auf dasSchnittbild und Neuerstellung derFarbskala
Abbildung 4.15.: Entstehung von eingegrenzten Schnittbildern zur Rele-vanzklassifikatorvalidierung. In diesem Beispiel wird dieRelevanzwahrscheinlichkeit in Abhängigkeit der Objekt-position visualisiert.
Netz nicht der Fall. Daher wird die Menge der Testdaten genutzt, umden Einfluss der anderen Attribute zu neutralisieren. Um einen Bildpunktim Schnittbild zu erzeugen, werden die zu visualisierenden Attribute ent-
118

4.7. Ableitung von Regeln aus einem integrierten Relevanzschätzer
Laterale Distanz [m]
Longitudin
ale
Dis
tanz [
m]
−10 −5 0 5 10
0
20
40
60
80
100
120
140
160
180
200
Rele
vanzw
ahrs
chein
lichkeit
0.1
0.15
0.2
0.25
0.3
0.35
0.4
Abbildung 4.16.: Durchschnittliche Relevanz bei variabler fahrstreifenbezo-gener Objektposition
sprechend der Bildkoordinate in der gesamten Datenmenge gesetzt. An-schließend wird diese Menge durch ein künstliches neuronales Netz klas-sifiziert. Die durchschnittliche Relevanzwahrscheinlichkeit entspricht danndem arithmetischen Mittel der Klassifikationsergebnisse. Für jeden einzel-nen Bildpunkt muss das künstliche neuronale Netz somit ca. 200.000 un-terschiedliche Testdaten durchlaufen.
Beim systematischen Setzen von mehreren Attributen tritt das Problemauf, dass diese nicht zwingend in der Lernmenge repräsentiert sind. Da-durch können Bereiche auftreten, die aus der Extrapolation weit entfernterLernpunkte stammen. Diese Bereiche wurden im Lernprozess durch Datennicht gestützt, sodass der Klassifikator hier beliebige Funktionsergebnisseliefern kann, ohne dass dieses während des überwachten Lernens bestraftwird. Aus diesem Grund wird zumindest das Auftreten der zu visualisieren-den Attribute berücksichtigt: Hierzu wird ein minimales konvexes Polygonaus den Messwerten gebildet, welches als Maske für das finale Schnittbilddient.
119
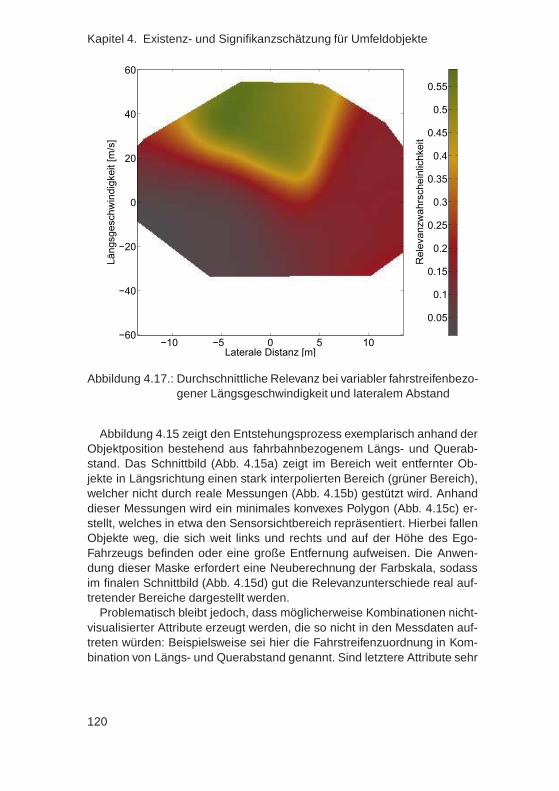
Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Laterale Distanz [m]
Längsgeschw
indig
keit [m
/s]
−10 −5 0 5 10−60
−40
−20
0
20
40
60
Rele
vanzw
ahrs
chein
lichkeit
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
Abbildung 4.17.: Durchschnittliche Relevanz bei variabler fahrstreifenbezo-gener Längsgeschwindigkeit und lateralem Abstand
Abbildung 4.15 zeigt den Entstehungsprozess exemplarisch anhand derObjektposition bestehend aus fahrbahnbezogenem Längs- und Querab-stand. Das Schnittbild (Abb. 4.15a) zeigt im Bereich weit entfernter Ob-jekte in Längsrichtung einen stark interpolierten Bereich (grüner Bereich),welcher nicht durch reale Messungen (Abb. 4.15b) gestützt wird. Anhanddieser Messungen wird ein minimales konvexes Polygon (Abb. 4.15c) er-stellt, welches in etwa den Sensorsichtbereich repräsentiert. Hierbei fallenObjekte weg, die sich weit links und rechts und auf der Höhe des Ego-Fahrzeugs befinden oder eine große Entfernung aufweisen. Die Anwen-dung dieser Maske erfordert eine Neuberechnung der Farbskala, sodassim finalen Schnittbild (Abb. 4.15d) gut die Relevanzunterschiede real auf-tretender Bereiche dargestellt werden.
Problematisch bleibt jedoch, dass möglicherweise Kombinationen nicht-visualisierter Attribute erzeugt werden, die so nicht in den Messdaten auf-treten würden: Beispielsweise sei hier die Fahrstreifenzuordnung in Kom-bination von Längs- und Querabstand genannt. Sind letztere Attribute sehr
120
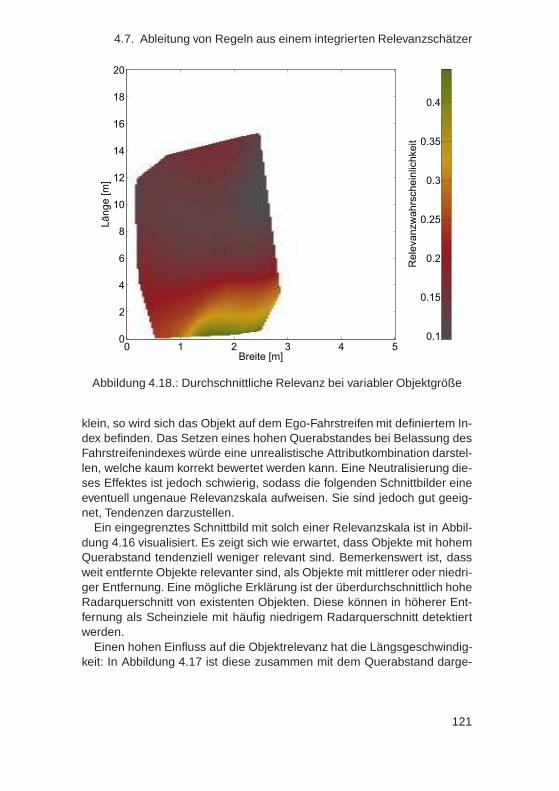
4.7. Ableitung von Regeln aus einem integrierten Relevanzschätzer
Breite [m]
Lä
ng
e [
m]
0 1 2 3 4 50
2
4
6
8
10
12
14
16
18
20
Rele
va
nzw
ah
rsche
inlic
hke
it
0.1
0.15
0.2
0.25
0.3
0.35
0.4
Abbildung 4.18.: Durchschnittliche Relevanz bei variabler Objektgröße
klein, so wird sich das Objekt auf dem Ego-Fahrstreifen mit definiertem In-dex befinden. Das Setzen eines hohen Querabstandes bei Belassung desFahrstreifenindexes würde eine unrealistische Attributkombination darstel-len, welche kaum korrekt bewertet werden kann. Eine Neutralisierung die-ses Effektes ist jedoch schwierig, sodass die folgenden Schnittbilder eineeventuell ungenaue Relevanzskala aufweisen. Sie sind jedoch gut geeig-net, Tendenzen darzustellen.
Ein eingegrenztes Schnittbild mit solch einer Relevanzskala ist in Abbil-dung 4.16 visualisiert. Es zeigt sich wie erwartet, dass Objekte mit hohemQuerabstand tendenziell weniger relevant sind. Bemerkenswert ist, dassweit entfernte Objekte relevanter sind, als Objekte mit mittlerer oder niedri-ger Entfernung. Eine mögliche Erklärung ist der überdurchschnittlich hoheRadarquerschnitt von existenten Objekten. Diese können in höherer Ent-fernung als Scheinziele mit häufig niedrigem Radarquerschnitt detektiertwerden.
Einen hohen Einfluss auf die Objektrelevanz hat die Längsgeschwindig-keit: In Abbildung 4.17 ist diese zusammen mit dem Querabstand darge-
121
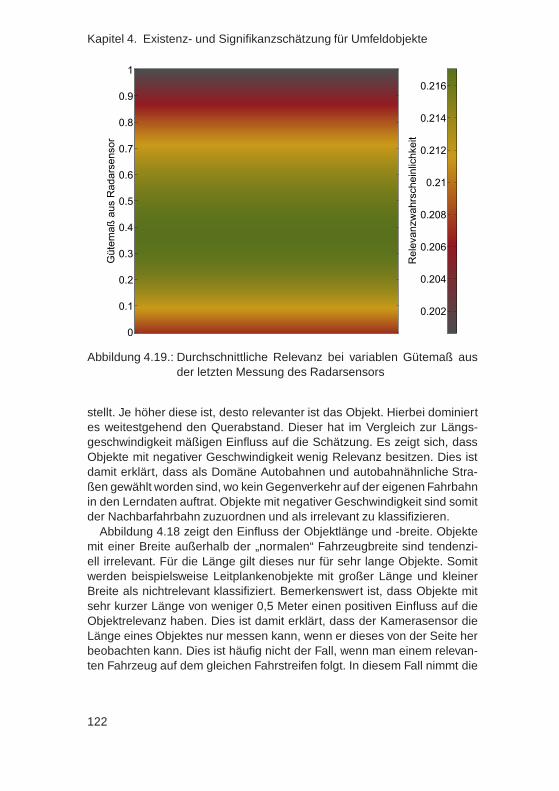
Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
Gü
tem
aß
au
s R
ad
ars
enso
r
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Rele
va
nzw
ah
rsche
inlichke
it
0.202
0.204
0.206
0.208
0.21
0.212
0.214
0.216
Abbildung 4.19.: Durchschnittliche Relevanz bei variablen Gütemaß ausder letzten Messung des Radarsensors
stellt. Je höher diese ist, desto relevanter ist das Objekt. Hierbei dominiertes weitestgehend den Querabstand. Dieser hat im Vergleich zur Längs-geschwindigkeit mäßigen Einfluss auf die Schätzung. Es zeigt sich, dassObjekte mit negativer Geschwindigkeit wenig Relevanz besitzen. Dies istdamit erklärt, dass als Domäne Autobahnen und autobahnähnliche Stra-ßen gewählt worden sind, wo kein Gegenverkehr auf der eigenen Fahrbahnin den Lerndaten auftrat. Objekte mit negativer Geschwindigkeit sind somitder Nachbarfahrbahn zuzuordnen und als irrelevant zu klassifizieren.
Abbildung 4.18 zeigt den Einfluss der Objektlänge und -breite. Objektemit einer Breite außerhalb der „normalen“ Fahrzeugbreite sind tendenzi-ell irrelevant. Für die Länge gilt dieses nur für sehr lange Objekte. Somitwerden beispielsweise Leitplankenobjekte mit großer Länge und kleinerBreite als nichtrelevant klassifiziert. Bemerkenswert ist, dass Objekte mitsehr kurzer Länge von weniger 0,5 Meter einen positiven Einfluss auf dieObjektrelevanz haben. Dies ist damit erklärt, dass der Kamerasensor dieLänge eines Objektes nur messen kann, wenn er dieses von der Seite herbeobachten kann. Dies ist häufig nicht der Fall, wenn man einem relevan-ten Fahrzeug auf dem gleichen Fahrstreifen folgt. In diesem Fall nimmt die
122

4.8. Zusammenfassung
Objektfusion nur eine sehr kurze Länge des Fahrzeuges an.Abbildung 4.19 zeigt den alleinigen Einfluss des Radarsensorgütema-
ßes. Obwohl dieses bei praktisch allen Objekten verfügbar ist, hat es nureinen minimalen Einfluss auf die Objektrelevanz, was der geringe Skalen-unterschied zeigt. Es kann somit durch andere Parameter aus Objekt- undFahrbahnfusion größtenteils kompensiert werden. Wenig erwartet wurde,dass Objekte mit hohem Gütemaß tendenziell eine geringere Objektrele-vanz besitzen als Objekte mit mittlerem Gütemaß. Eine mögliche Erklärungist, dass der Radarsensor bei vielen existenten stationären Randobjektendirekt nach der ersten Messung ein hohes Gütemaß liefert. Diese Objek-te werden aber auch nach kurzer Zeit direkt verworfen, da sie den Sicht-bereich schnell verlassen. Relevante dynamische Objekte hingegen kön-nen ein mittleres Gütemaß erreichen, indem sie den Sichtbereich langsamverlassen. Hier prädiziert der Radarsensor intern weiter und verringert imTracking das Gütemaß.
Insgesamt können die Schnittbilder bei dem Verständnis der generier-ten Wahrscheinlichkeitsdichtefunktion helfen. Sie können zusätzlich einenExperten dabei unterstützen, statische Regeln aus diesen zu generieren.Diese sind transparenter als die hochdimensionale Wahrscheinlichkeits-dichtefunktion und lassen sich auch auf Plattformen mit geringer Speicher-und Rechenleistung portieren.
4.8. Zusammenfassung
Dieses Kapitel hat sich damit beschäftigt, eine statistisch genaue Wahr-scheinlichkeit zu berechnen, ob ein Objekt von einem Fahrerassistenz-system berücksichtigt werden muss oder nicht. Hierzu wurden diverseklassische Verfahren zur Existenz- und Signifikanzschätzung vorgestelltund bewertet. Diese zeichnen sich durch viele Modellvereinfachungen und-annahmen aus und berücksichtigen teilweise nur wenige Attribute.
Im Gegensatz dazu wurde das Konzept eines integrierten Relevanz-schätzers vorgestellt. Dieser erstellt aus Lerndaten ein implizites Umge-bungsmodell, wobei komplexe lineare und nichtlineare Zusammenhängeerfasst und integriert werden. Dadurch kann dieser Schätzer eine Genau-igkeit erreichen, wie sie nur schwer durch manuell festgelegte Regeln über-troffen werden kann.
Seine Schätzgrundlage basiert nicht nur auf den Messdaten eines ein-zelnen Umfeldsensors, sondern auf einer komplexen Sensordatenfusionfür eine technologisch heterogene Sensorkonfiguration. Hierbei fließt unteranderem eine Straßenschätzung mit in die Bewertung ein, womit detektier-
123

Kapitel 4. Existenz- und Signifikanzschätzung für Umfeldobjekte
te Fahrstreifenmarkierungen, digitale Karten und andere Faktoren berück-sichtigt werden können. Im Gegensatz dazu verwenden klassische Verfah-ren nur eine geringe Anzahl von Attributen und machen viele Annahmen zuAbhängigkeiten, Unabhängigkeiten und Verteilungen. Auch bei der Verei-nigung von Existenz- und Signifikanzwahrscheinlichkeit werden bei diesenVerfahren ähnliche Annahmen getroffen.
Der vorgestellte Schätzer hingegen integriert beide Teilwahrscheinlich-keiten zur Relevanzwahrscheinlichkeit und berücksichtigt viele Attribute.Eine Erweiterung um neue Attribute ist leicht möglich. Viel Aufwand wur-de betrieben, um den probabilistischen Schätzer auch statistisch genau zugestalten. Somit liefert er eine echte Wahrscheinlichkeit und kein Gütemaßmit unbekannter Skala.
Das Verfahren zeichnet sich ferner dadurch aus, dass der Kern desKlassifikationsalgorithmus austauschbar ist. Bei den untersuchten Kernal-gorithmen erscheint das künstliche neuronale Netz als geeignet: Es ver-einigt eine gute Klassifizierungsrate mit einer geringen Berechnungsla-tenz. Nachteilig ist eine verminderte Transparenz des Verfahrens. Ein sehrschnelles und transparenteres Verfahren stellt die lineare Trennung dar,welche allerdings eine geringere Genauigkeit aufweist.
Die Klassifikatoren wurden anhand einer sehr weitreichenden Definitionrelevanter Objekte getestet. So wurde von ihnen auch gefordert, erstmaliginitialisierte Objekte in großer Entfernung korrekt zu klassifizieren. Unterdiesen schwierigen Bedingungen erreichen diese eine Korrektklassifikati-onsrate von bis zu 96,3%, wobei der Klassifikationsschwellwert bei 50%lag. Für die meisten Fahrerassistenzapplikationen ist diese Rate noch zuniedrig, sodass der Schwellwert entsprechend angehoben werden muss.Dies führt meist zu einer verzögerten Relevanzklassifikation, da Objekthy-pothesen tendenziell eine längere Beobachtungsdauer aufweisen müssen,bevor diese hohe Schwellwerte überschreiten. Neben Objekthypothesenmit sehr kurzen Beobachtungszeiten sind auch stationäre Objekte in hoherEntfernung schwer zu klassifizieren: Diese weisen meist eine Relevanz-wahrscheinlichkeit auf, welche keinen sehr hohen Schwellwert überschrei-tet und bleiben somit in den ersten Messzyklen meist unberücksichtigt.
Diese Eigenschaften sind jedoch nicht von Nachteil, wenn man sie mitkonventionellen Objektklassifikatoren vergleicht. Diese nutzen starke Ne-benbedingungen, welche einen vergleichbaren Effekt erzielen: So wirdhäufig eine minimale Trackingdauer bzw. eine minimale Anzahl an Mess-bestätigungen vorausgesetzt oder es werden stationäre Objekte im Vorfeldherausgefiltert (vgl. [ISO 2002, 2008]). Dies vereinfacht den Zustandsraumerheblich und erlaubt somit eine deutliche Steigerung der Klassifikations-rate, da schwer zu klassifizierende Objekthypothesen aus dem Zustands-
124

4.8. Zusammenfassung
raum ganz einfach herausdefiniert worden sind.Fraglich bei diesen konventionellen Ansätzen ist jedoch, ob wirklich al-
le Objekthypothesen irrelevant sind, die unter solche Nebenbedingungenfallen: So kann beispielsweise ein vor Kurzem verdecktes Objekt sofortfür ein ACC-System relevant werden, auch wenn es noch keine minimaleTrackingdauer erreicht hat. Es scheint außerdem von Kundennutzen, wennein ACC-System auf alle relevanten stationären Objekte verzögern würdeund dabei keine Einschränkungen bzgl. Dynamik und Entfernung macht.
Der vorgestellte Relevanzklassifikator hingegen versucht auf solche ex-pliziten Nebenbedingungen zu verzichten und nutzt das Gesamtbild derObjekthypothese für eine genaue Relevanzschätzung. Bei hohen Schwell-werten können zwar ähnliche Nebenbedingungen implizit entstehen, je-doch hat die maschinell angelernte und nichtlineare Trennfunktionen dasPotential, deutlich komplexere Zustandsräume zu trennen, sodass dieNebenbedingungen weniger restriktiv ausfallen. Der Relevanzklassifikatorkann somit einen Teil der relevanten Hypothesen, die normalerweise unterNebenbedingungen wegfallen würden, der Fahrerassistenzapplikation zurVerfügung stellen.
Insgesamt hat die dynamische Bestimmung von Relevanzwahr-scheinlichkeiten mittels Maschinellen Lernverfahren das Potenzial,Fehlauslösungs- und fehlerhafte Nichtauslösungsraten zu verringern unddie nutzbare Reaktionszeit zu erhöhen.
125

Kapitel 5.
Probabilistische Belegungsgitterfusion
5.1. Einleitung
In den vorherigen Kapiteln wurde eine komplexe Objektfusion mit integrier-tem Relevanzschätzer vorgestellt, welche exemplarisch in der strukturier-ten Umgebung einer Autobahn bzw. autobahnähnlichen Straße ihre Do-mäne findet. Sie beinhaltet viele Modellannahmen, wie beispielsweise dasKlothoidenmodell der Fahrbahn, ein einfaches Dynamikmodell basierendauf beschleunigten Körpern für zu verfolgende Objekte, das Boxmodell alsderen Konturmodell und diverse Rauschmodelle in den einzelnen Kalman-filterschritten. Diese Annahmen bilden Randbedingungen in den einzelnenModellen, wodurch die Anzahl freier Variablen im Umfeldmodell potentiellreduziert wird. In den vorherigen Kapiteln wurde eine komplexe Objekt-fusion mit integriertem Relevanzschätzer vorgestellt, welche exemplarischin der strukturierten Umgebung einer Autobahn bzw. autobahnähnlichenStraße ihre Domäne findet. Sie beinhaltet viele Modellannahmen, wie bei-spielsweise das Klothoidenmodell der Fahrbahn, ein einfaches Dynamik-modell basierend auf beschleunigten Körpern für zu verfolgende Objek-te, das Boxmodell als deren Konturmodell und diverse Rauschmodelle inden einzelnen Kalmanfilterschritten. Diese Annahmen bilden Randbedin-gungen in den einzelnen Modellen, wodurch die Anzahl freier Variablen imUmfeldmodell potentiell reduziert wird.
Die Messdaten werden mithilfe dieser Modelle in ein strukturiertes Um-feldmodell überführt, wobei das Umfeldmodell aber letztendlich nur eineAbstraktion der Wirklichkeit darstellt. Je ungenauer die Modelle die Um-gebung und Sensoreigenschaften umsetzen, desto weniger genau bildetdas Umfeldmodell die Realität ab. Die Modellierung der Umgebung kannin komplex strukturierten Domänen sehr aufwendig sein, wobei die Um-feldmodelle dann sehr viele freie Parameter aufweisen, die alle korrekt ge-schätzt werden müssen.
Als alternativer Ansatz wurde bereits in den 80er Jahren im Robotik-bereich das sog. „Belegungsgitter“ entwickelt (vgl. [Moravec 1985]), wel-
126

5.1. Einleitung
ches eine modellarme und hochdimensionale Umgebungsrepräsentationdarstellt. Dieses ist für komplex strukturierte Umgebungen geeignet, wiesie beispielsweise im urbanen Bereich auftreten.
Belegungsgitter diskretisieren den Raum um den Roboter bzw. um dasFahrzeug in einzelne Zellen. Den einzelnen Messungen werden die örtlichzugehörigen Zellen zugeordnet und deren Zustand wird aktualisiert. AlsErgebnis erhält man eine Menge von Zellen mit unterschiedlichen Zellzu-ständen, die eine Umgebungsschätzung darstellen.
Typischerweise repräsentiert das Umfeldmodell eine statische Umge-bung. Dynamische Objekte werden entweder als Störgröße behandelt odersie bleiben bereits im Vorfeld unberücksichtigt. Einige neuere Ansätze sindaber auch in der Lage, dynamische Objekte zu behandeln (vgl. [Bouzou-raa 2010]). Diese beinhalten jedoch wieder Modellannahmen, meist auchDynamikmodelle ähnlich der Objektfusion.
Belegungsgitter wurden bereits vielfach im Robotik- und Automobilbe-reich erfolgreich eingesetzt. So spielte bei vielen Teilnehmern der DARPAUrban Challenge (vgl. [Effertz 2009] und [Thrun 2006]) diese Form derUmgebungsrepräsentation eine entscheidende Rolle für die Funktionalitätder autonomen Fahrzeuge. Im Robotikbereich wurden diese insbesondereinnerhalb von Gebäuden und begrenzten Geländearealen eingesetzt (vgl.[Elfes 1989b] und [Ferguson 2006]).
Bei praktisch allen Arbeiten steht die Befahrbarkeitsanalyse von Berei-chen im Vordergrund. Die Zellen des Belegungsgitters enthalten zu diesemZweck einen Zustand bestehend aus einem oder mehreren Attributen, derInformationen über die Befahrbarkeit der jeweiligen Zelle bereitstellt.
Um diesen Zellzustand zu schätzen, werden aus den Messungen zweiMessdatentypen generiert. Der eine Typ modelliert Belegtbereiche, wel-ches beispielsweise Objektinformationen sein können, der andere Typ re-präsentiert Freibereiche. Diese werden genutzt, um die mit den Messungenassoziierten Zellen des Belegungsgitters zu aktualisieren und eine lokaleBefahrbarkeitsschätzung zu erzeugen.
Insgesamt beschäftigt sich dieses Kapitel mit der Untersuchung und Ent-wicklung von Algorithmen für solche Belegungsgitter, die bestimmte Anfor-derungen erfüllen müssen. Als Ergebnis soll die Applikation einen Bereichdes Belegungsgitters in Echtzeit abfragen können und eine möglichst pro-babilistische, genaue und statistisch korrekte Schätzung über dessen Be-fahrbarkeit erhalten1.
Wie bei der Relevanzschätzung in Kapitel 4 besteht der Nutzen einer
1Die Begriffe „Echtzeitfähigkeit“ und „statistische Korrektheit“ werden im Anhang A.1.1 bzw.Anhang A.1.2 definiert.
127

Kapitel 5. Probabilistische Belegungsgitterfusion
solchen probabilistischen Schätzung zum einen in der Verringerung vonFehlauslösungs- und fehlerhaften Nichtauslösungsraten und zum anderenin der Möglichkeit mittels Schwellwerten das Verhältnis dieser beiden Ra-ten genau bestimmen zu können.
5.2. Anforderungen an eine Belegungsgitterfusion
In Kapitel 3 sind verschiedene Anforderungen für eine Sensordatenfusionentwickelt worden, die sich insgesamt auf die Softwarearchitektur und alleTeilfusionen erstrecken muss. Für eine Belegungsgitterfusion abgeleitet,sind folgende Kriterien wünschenswert:
• Genau, Probabilistisch : Die Belegungsgitterfusion soll eine genaueBefahrbarkeitsschätzung für eine beliebige Menge von Zellen liefern.Das Verfahren sollte innerhalb der Diskretisierungsgrenzen invariantgegenüber Zellgrößenänderungen sein.
• Robust : Einzelne Messausreißer und systematische Fehlziele ein-zelner Sensoren sollten möglichst kompensiert werden.
• Echtzeitfähig : Die Belegungsgitterfusion soll auf einer bestimmtenZielplattform echtzeitfähig sein.
• Modular : Es sollten verschiedene Sensoren und Anwendungendurch verallgemeinerte Schnittstellen unterstützt werden. Außerdemsollten verschiedene Logiken eingesetzt werden können.
Um diese Anforderungen zu bewältigen, ist zunächst ein Belegungsgitterals solches notwendig. Dazu werden zunächst im folgenden Abschnitt 5.3grundlegende Algorithmen und Datenstrukturen für Belegungsgitter vorge-stellt, welche aus der Computergrafik entnommen und adaptiert wordensind. Mit diesen ist die Verwaltung und der Zugriff auf definierte Zellmen-gen effizient möglich.
Im anschließenden Abschnitt 5.4 werden drei verschiedene Logikalgo-rithmen vorgestellt, welche die Fusionierung der Zellzustände mit Mess-evidenzen zu neuen Zellzuständen ermöglichen. Eine einheitliche mathe-matische Form dieser Algorithmen unterstützt im Sinne der Modularitäts-anforderung die Austauschbarkeit.
Die schwierigste Anforderung ist die der genauen Umfeldschätzung, wo-für im Abschnitt 5.5 verschiedene Ansätze aus der Literatur untersuchtwerden. Hierbei werden neben den Fusionsalgorithmen auch die inversen
128

5.3. Stand der Technik: Algorithmen und Datenstrukturen für Belegungsgitter
Sensormodelle vorgestellt, welche aus Messungen Messevidenzen für Zel-len generieren. Anschließend wird untersucht, welche Stärken und Schwä-chen der gesamte Ansatz bezüglich der genauen und statistisch korrektenUmfeldschätzung hat, wobei die Bewertung sowohl die jeweilige Anwen-dung berücksichtigt als auch eine mögliche Übertragung in den Automo-tivebereich prüft.
Bei der Untersuchung der Ansätze aus der Literatur zeigt sich, dass die-se bestimmte Abhängigkeiten zwischen Zellen und Messungen nicht odernur unzureichend auflösen. In Abschnitt 5.6 werden diese beiden Kernpro-bleme konventioneller Algorithmen identifiziert und formal definiert. Sie zulösen ist der Schlüssel zur Erfüllung der Genauigkeits- und Robustheitsan-forderung.
Die Lösung dieser beiden Probleme kann jeweils unabhängig betrachtetwerden. In den darauf folgenden beiden Abschnitten 5.7 und 5.8 werdenentsprechende Algorithmen vorgestellt, die diese Probleme berücksichti-gen und somit eine genauere Schätzung als konventionelle Belegungs-gitteralgorithmen erreichen. Im Sinne der Modularitätsanforderung unter-stützen diese Algorithmen bis zu drei verschiedene Messtypen und eineallgemeine Polygonabfrageschnittstelle.
Nach der theoretischen Entwicklung dieser Algorithmen wird in Abschnitt5.9 deren Latenz anhand experimenteller Ergebnisse auf einer Zielplatt-form ermittelt, was eine Voraussetzung für die Bewertung der Echtzeitfä-higkeit darstellt. Zum Schluss wird dieses Kapitel im Abschnitt 5.10 zusam-mengefasst.
5.3. Stand der Technik: Algorithmen undDatenstrukturen für Belegungsgitter
Belegungsgitter repräsentieren das Umfeld in Form von Zellen, die jeweilseinen Zustand beinhalten. Da die speichertechnische Realisierung einesunendlich großen Umfeldes nicht möglich ist, wird nur ein Teil des Umfel-des modelliert. Typischerweise wird nur das direkte Umfeld ortsfest model-liert, welches direkt entscheidungsrelevant für eine Fahrerassistenzfunkti-on bzw. Bahnplanung des Roboters ist.
Da sich der Roboter oder das Ego-Fahrzeug im Allgemeinen bewegt,gilt es eine Strategie zu entwerfen, Zellen zu verwerfen, welche irrelevantgeworden sind. Ein weitverbreiteter Ansatz ist die Nutzung sog. Ringpuf-ferspeicher, welcher hier vorgestellt wird. Dieser ermöglicht es, einen kon-stant großen Umgebungsausschnitt mit einer definierten Speichermengedarzustellen.
129

Kapitel 5. Probabilistische Belegungsgitterfusion
Bevor die Aktualisierung von Zellen durch eine Messung möglich ist,müssen in einem ersten Schritt zunächst die relevanten Zellen ermitteltwerden. Hier sind ressourcenarme und echtzeitfähige Algorithmen gefragt,die die entsprechende Menge der Zellen und deren Koordinaten liefern. Jenach Größe und Auflösung des Belegungsgitters und Größe des assoziier-ten Bereiches einer Messung können sehr viele Zellen durch eine einzigeMessung betroffen sein. Als Beispiel sei ein großer Freibereich genannt,der indirekt aus einer Laserscannermessung generiert wurde.
Im Folgenden werden Algorithmen vorgestellt, die Zellzugriffe in Punkt-,Linien oder Polygonform ermöglichen. Diese sind aus der Computergrafikbekannt und wurden auf die Anforderungen eines Belegungsgitters adap-tiert. Neben Algorithmen zur Sensordatenfusion ermöglichen diese Zellzu-griffsmethoden auch das Abfragen von definierten Flächen. Diese Funkti-on ist grundlegend, um beispielsweise die Befahrbarkeit eines Bereicheszu ermitteln.
5.3.1. Zweidimensionaler Ringpuffer
Eine häufig genutzte Datenstruktur für die Belegungsgitterrepräsentationist der sog. zweidimensionale Ringpufferspeicher. Er basiert auf einemzweidimensionalen Feld, wobei jedes Element genau den Zustand einerZelle repräsentiert. Das Ego-Fahrzeug befindet sich approximativ in derMitte dieses ortsfesten Feldes. Bewegt sich das Ego-Fahrzeug, so werdendie Zellen, welche den relevanten Bereich verlassen, als neue Ressourcenwiederverwendet.
Hierzu existieren verschiedene Strategien: In [Effertz 2009, S. 106 ff]werden Gruppen von Zellen zu Sektoren über verkettete Listen zusam-mengefasst und diese als Ganzes entfernt bzw. hinzugefügt. Ein andererAnsatz nach [Kelly 1998] gruppiert die Zellmengen zu Zeilen und Spal-ten und verschiebt diese als Ganzes. Vorteil des sektorbasierten Ansatzesist ein effizienteres Speicherlayout bzgl. Zellzugriffsalgorithmen innerhalbeines Sektors. Nachteilig ist die Notwendigkeit zusätzlicher Zeigerderefe-renzierungschritte innerhalb der übergeordneten Datenstruktur, bevor manauf die eigentlichen Zellen zugreifen kann. Auch macht der sektorbasierteAnsatz es notwendig, für eine garantierte Größe mehr Zellen und somitmehr Speicher zu reservieren, da die Verschiebung nicht unmittelbar er-folgt, sondern erst dann, wenn eine Sektorgrenze überschritten wurde. ImFolgenden wird daher der Ansatz nach [Kelly 1998] weiter verfolgt.
Der zweidimensionale Ringpufferspeicher nutzt im klassischen Ansatzden Modulo-Operator, um eine Zelle innerhalb der Datenstruktur zu lokali-
130

5.3. Stand der Technik: Algorithmen und Datenstrukturen für Belegungsgitter
Abbildung 5.1.: Modulo-Operation bildet direktes Umfeld (schwarzes Qua-drat) auf 4 disjunkte Ringpufferbereiche ab
sieren: Sei PWelt = (iWelt, jWelt) der Zellindex der Zelle in der Welt und n×ndie Größe des Ringpufferspeichers. Dann befindet sich die gesuchte Zellebei PPuffer = (iPuffer, jPuffer) innerhalb des Ringpufferspeichers mit:
iPuffer = iWelt modn (5.1)
jPuffer = jWelt modn (5.2)
Hierbei ist mod der ganzzahlige Modulo-Operator. Diese Abbildungs-operation verursacht bis zu vier Speichergrenzen im direkten Umfeld, wel-che in Abbildung 5.1 zwischen den farbigen Kacheln auftreten. Zu beach-ten ist, dass jeder beliebige Weltzellenindex auf eine Zelle im Ringpuffer-speicher innerhalb des schwarzen Quadrats abgebildet wird, auch wenndieser sich außerhalb dieses Ausschnittes befindet. Sind solche Zellzugrif-fe nicht auszuschließen, so müssen diese vorher mittels Bereichsprüfungabgefangen werden.
5.3.2. Punktalgorithmus
Die Bestimmung einer Zelle zu einer gegebenen Koordinate ist einerseitszur Modellierung von varianzlosen punktförmigen Messungen notwendig,andererseits aber auch grundlegend für spätere Zellzugriffsalgorithmen,die komplexere Formen aufweisen.
Zur Bestimmung einer Zelle, die zu einer gegebenen Weltkoordinatekorrespondiert, ist im Wesentlichen eine Diskretisierung des Raumes er-forderlich. Die Diskretisierungsgröße entspricht dabei der Zellgröße. Die
131

Kapitel 5. Probabilistische Belegungsgitterfusion
Abbildung der ortsfesten Koordinate auf die entsprechenden Weltindizeserfolgt durch eine entsprechende Skalierung.
Sei P = (x,y) die ortsfeste Koordinate der abzufragenden Zelle innerhalbeines s× s großen Belegungsgitters, welches n×n Zellen enthält. Dann hatdie Zelle die Weltindizes I = (iWelt, jWelt) mit:
iWelt =⌊nx
s
⌋(5.3)
jWelt =⌊ny
s
⌋(5.4)
Mittels der Modulo-Operation im vorangegangenem Abschnitt kann die-se dann auf eine Zelle im Ringpufferspeicher abgebildet werden.
5.3.3. Linienalgorithmus
Der Zellzugriffsalgorithmus für Linien ermöglicht die Bestimmung der Men-ge von Zellen, welche je nach Interpretation ganz oder wesentlich von einerdefinierten Linie geschnitten werden.
Praktisch alle Ansätze basieren auf dem sog. Bresenhamalgorithmus,welcher ausschließlich mit Ganzzahloperationen effizient eine Linie von ei-nem Startpunkt zu einem Endpunkt zeichnet (vgl. [Bresenham 1965]). Die-ser Algorithmus bestimmt zunächst, ob die X- oder Y-Richtung die Haupt-richtung der Linie ist:
dx = x2−x1 (5.5)
dy = y2−y1 (5.6)
Ist dx > dy, so verläuft die Hauptrichtung der Linie entlang der X-Achse.Der Bresenhamalgorithmus geht somit immer einen Schritt Richtung X-Achse, und wenn ein bestimmter Fehler ei nicht negativ geworden ist, zu-sätzlich einen Schritt entlang der Y-Achse. Dieser Fehlerwert wird initiali-siert mit:
e0 = 2dy −dx (5.7)
Der Fehlerwert ändert sich mit jedem Schritt nach:
ei =
ei−1−2
(dx −dy
), wenn ei−1 ≥ 0
ei−1+2dy, sonst(5.8)
132

5.3. Stand der Technik: Algorithmen und Datenstrukturen für Belegungsgitter
Der Standardbresenhamalgorithmus hat als wesentlichen Eingabepara-meter einen Start- und einen Endpunkt, aus denen er dann die Haupt- undFehlerrichtung bestimmt. Da die Linie nicht auf einer unendlichen planarenEbene, sondern in einem zweidimensionalen Ringpufferspeicher gezeich-net wird, müssen die Speichergrenzen beachtet werden.
Abbildung 5.2.: Insgesamt ergeben sich vier verschiedene Möglichkeitenzwei Punkte (grau) in einem zweidimensionalen Ringpufferzu verbinden
Dies erfolgt analog zum Punktalgorithmus mithilfe des Modulo-Operators, welcher einen Speicherüber- oder -unterlauf verhindert. Jenach aktueller Verschiebung ergeben sich im Ringpufferspeicher durch dieModulo-Operation vier Möglichkeiten eine Linie zwischen zwei Punkten zuzeichnen, welche in Abbildung 5.2 dargestellt sind.
Abbildung 5.3.: Originale Variante des Bresenhamalgorithmus (blau) unddessen Erweiterung (gelb)
Der vorgestellte Bresenhamalgorithmus hat die Eigenschaft, dass nur
133

Kapitel 5. Probabilistische Belegungsgitterfusion
solche Zellen markiert werden, welche wesentlich auf der Linie liegen. Ei-ne Modifikation wird in [Bouzouraa 2009] verwendet, in der alle Zellen mar-kiert werden, die von der Linie auch nur marginal geschnitten werden. Da-mit wird insgesamt eine andere Diskretisierung erreicht, welche die Mengealler möglichen Zellen erhöht (vgl. Abbildung 5.3).
Je nach Verwendungszweck ist es sinnvoll, die eine oder andere Vari-ante zu wählen: Falls mit der Linie ein Belegtbereich markiert soll oder dieBefahrbarkeit eines Bereiches analysiert werden soll, so garantiert Bou-zouraas Ansatz, dass durch Diskretisierungsungenauigkeiten keine Zellenunbeachtet gelassen werden, welche nur teilweise auf der Linie liegen.Falls jedoch ein Freibereich durch die Linie markiert werden soll, so er-möglicht der klassische Ansatz von Bresenham, dass nur solche Zellenals frei markiert werden, welche auch wesentlich von der Linie geschnittenwerden.
5.3.4. Entwicklung eines Polygonalgorithmus
Viele Sensoren liefern nach Messvorverarbeitungsschritten neben der Po-sition von Objekten auch deren Ausrichtung und Ausdehnung. Diese wei-sen eine Länge und Breite auf und können somit einen ganzen Bereichim Belegungsgitter abdecken. Auch Freibereiche können sich über größe-re Areale erstrecken und auch der prognostizierte Fahrschlauch des Ego-Fahrzeuges bildet eine größere Fläche. Im Folgenden wird deshalb ein Al-gorithmus benötigt, der flexibel alle Zellen zurückliefert, welche sich untereiner beliebig großen definierten Fläche befinden.
Anforderungen
Für den Zugriff auf Zellen solcher Flächen ist zunächst eine Beschreibungdieser Flächen notwendig. Das allgemeine Polygon eignet sich insbeson-dere, da jeder zusammenhängende Bereich durch ein solches beliebiggenau approximiert werden kann. Eine Reduktion auf konvexe Polygonescheint ungeeignet, da unregelmäßige Freibereiche und gekrümmte Fahr-schläuche naturgemäß nur durch konkave Polygone approximiert werdenkönnen. Letztere Annahme macht die Entwicklung eines entsprechendenAlgorithmus deutlich anspruchsvoller.
Als weitere Anforderung soll es problemlos möglich sein, jede Art vonPolygonen abzufragen. Dazu gehören zum einen solche, die über das Be-legungsgitter hinausragen. Auch in diesem Fall soll der Algorithmus alleZellen zurückliefern, die das Polygon im Belegungsgitter überdeckt. Zum
134

5.3. Stand der Technik: Algorithmen und Datenstrukturen für Belegungsgitter
anderen sollen auch entartete Polygone möglich sein, da die auf Zellen dis-kretisierten Polygone unter Umständen sich selbst berühren oder schnei-den könnten. Dies kann verschiedene Gruppen von inneren aber unver-bundenen Zellen zur Folge haben. Auch ist der Fall denkbar, dass Zellenim Inneren der diskretisierten Kontur, aber trotzdem außerhalb des Poly-gons liegen.
Im Folgenden soll ein Algorithmus entwickelt werden, welcher all dieseAnforderungen vereint. Zusätzlich kommen noch die allgemeinen Anforde-rungen für eine Sensordatenfusion zum Tragen. Hier ist insbesondere dieEchtzeitfähigkeits- und Modularitätsanforderung zu nennen. Der Algorith-mus soll somit möglichst effizient und nicht mit speziellen Fusions- oderAbfragealgorithmen fest gekoppelt sein.
Ablauf des Gesamtalgorithmus
Der entwickelte Algorithmus ist in verschiedene Schritte unterteilt. Zu-nächst wird geprüft, ob sich das Polygon vollständig im Belegungsgitterbefindet. Falls nicht, werden die Ecken des Polygons soweit korrigiert, dasssie sich auf einem Rand des Belegungsgitters befinden. Dazu werden dieRänder mit den Kanten des Polygons geschnitten, die das Belegungsgit-ter verlassen. Als Ergebnis erhält man ein neues Polygon, welches sichvollständig im Belegungsgitter befindet.
Als Nächstes wird mittels Bresenham-Algorithmus die Polygonkonturgezeichnet. Dieses erfolgt in einem extra Speicher, da der spätere Füll-algorithmus für beliebige Nachbarzellen verschiedene Typen von Traver-sierungsmarkierungen unterscheiden muss. Diese Traversierungsmarkie-rungsinformation könnte in den Zellen des Belegungsgitters abgelegt wer-den. Analog zum vorgestellten Linienalgorithmus würde dies aber eine be-sondere Behandlung des Ringpuffers mit diversen Fallunterscheidungennach sich ziehen und die Komplexität des Algorithmus unnötig vergrößern.Um dies zu vermeiden, wird ein neues zweidimensionales Feld genutzt,welches zwar genauso viele Einträge wie das Belegungsgitter besitzt, aberkein Ringpufferspeicher darstellt. Nach Abschluss der Fülloperation wirddas Ergebnis mittels Modulo-Operator (vgl. Abschnitt 5.3.1) auf den Ring-pufferspeicher übertragen.
Um die erstellte Polygonkontur wird zunächst ein virtuelles begrenzen-des Rechteck erstellt, welches einen Pixel Abstand zur Polygonkontur hat.Die Begründung dazu liefert der folgende Füllalgorithmus: Anstatt nur dasInnere des Polygons zu füllen, wird auch der Bereich zwischen Polygon-kontur und begrenzendem Rechteck gefüllt. Hintergrund ist, dass der aufganzzahlige Operationen Füllalgorithmus pro Pixel sehr schnell ist, dieser
135

Kapitel 5. Probabilistische Belegungsgitterfusion
ja
nein
ja
ja
neinnein
Start
E
Eingabe von Polygonecken
Wiederhole für alle Zellen
Ist die Zelleunmarkiert?
Schleifenende
A
Ausgabe der inneren Zellen mit
Farbe "A"
Ende
Befinden sich alle Eckeninnerhalb des Belegungsgitters?
Kontur mit Bresenhamalgorithmus und Farbe "A" zeichnen
Liegt dieseZelle innerhalb des
Polygons ?
Füllalgorithmus mit unmarkierter Zelle als Startpunkt und Farbe
"B"
Korrigiere Eckpunkte durch Bestimmung des
Schnittpunktes von Belegungsgitterrand und Polygonkante.
Füllalgorithmus mit unmarkierter Zelle als Startpunkt und Farbe
"A"
Abbildung 5.4.: Flussdiagramm des Polygonalgorithmus
jedoch einen Startpunkt (engl. „Seed Point“) benötigt. Das Bestimmen ei-nes geeigneten Startpunktes innerhalb eines beliebigen konkaven und evtl.selbstschneidenen Polygons kann sehr rechenaufwendig sein: Der ent-sprechende Algorithmus, welcher im nächsten Abschnitt vorgestellt wird,basiert auf Gleitkommaoperationen und ist pro Pixel deutlich langsamer alsder Füllalgorithmus. Um eine lange und eventuell sogar vergebliche Suchenach einem solchen Punkt zu vermeiden, wird der Füllalgorithmus verwen-det, um zusätzlich den äußeren Bereich zu füllen und somit die Anzahlpotenzieller Startpunkte für den inneren Bereich massiv zu reduzieren.
Insgesamt wird für jede Menge verbundener unmarkierter Zellen genaueine Zelle herausgegriffen und festgestellt, ob diese sich innerhalb oderaußerhalb des Polygons befindet. Um die Anzahl solcher Mengen zu re-duzieren, wurde ein Abstand für das begrenzende Rechteck zum Polygon
136

5.3. Stand der Technik: Algorithmen und Datenstrukturen für Belegungsgitter
festgelegt. Somit müssen für die meisten Polygone nur zwei Startpunkteklassifiziert werden.
Sind sämtliche Zellen markiert, so werden die im Belegungsgitter kor-respondierenden inneren Zellen des Polygons zurückgegeben. Wie beimLinienalgorithmus ist es auch möglich, optional die Zellen mit auszuwäh-len, die nur teilweise vom Polygon überdeckt werden.
In Abbildung 5.4 ist der Ablauf des Gesamtalgorithmus als Flussdia-gramm dargestellt. Die Bestimmung, ob ein Punkt innerhalb oder außer-halb des Polygons liegt und der Füllalgorithmus selbst werden in den fol-genden Abschnitten beschrieben.
Bestimmung eines Startpunktes für den Füllalgorithmus
Für den im folgenden Abschnitt beschriebenen Füllalgorithmus wird als Pa-rameter ein Startpunkt benötigt. Der Füllmarkierungstyp ist abhängig da-von, ob sich dieser innerhalb oder außerhalb des Polygons befindet.
Abbildung 5.5.: Die dreieckige diskretisierte Polygonumrandung (blau)suggeriert ein einfaches Dreieck. Das zugrunde liegendePolygon weist die scheinbar inneren Zellen jedoch als äu-ßere aus (roter Linienzug).
Zur Bestimmung, ob ein Punkt innerhalb oder außerhalb des Polygonsliegt, ist es notwendig, das Polygon als Ganzes zu betrachten. Nur auf-grund der mittels Bresenhamalgorithmus erzeugten Umrandung ist einesolche Klassifizierung im Allgemeinen unentscheidbar, was Abbildung 5.5verdeutlicht.
Um zu ermitteln, ob ein Punkt mit den Koordinaten x und y innerhalbeines n-seitigen Polygones mit den Eckpunkten Pn = [(x1,y1), . . . ,(xn,yn)]
liegt, wird eine Methode nach [Haines 1994] verwendet, welche auf demsog. Jordan-Curve-Theorem basiert: Hierbei wird ein semi-unendlicherStrahl beginnend bei (x,y) horizontal durch das Polygon gesendet, sodassy konstant bleibt. Es wird gezählt, wie oft der Strahl eine Kante des Poly-gons trifft. Bei ungerader Anzahl liegt der Punkt innerhalb des Polygons,
137
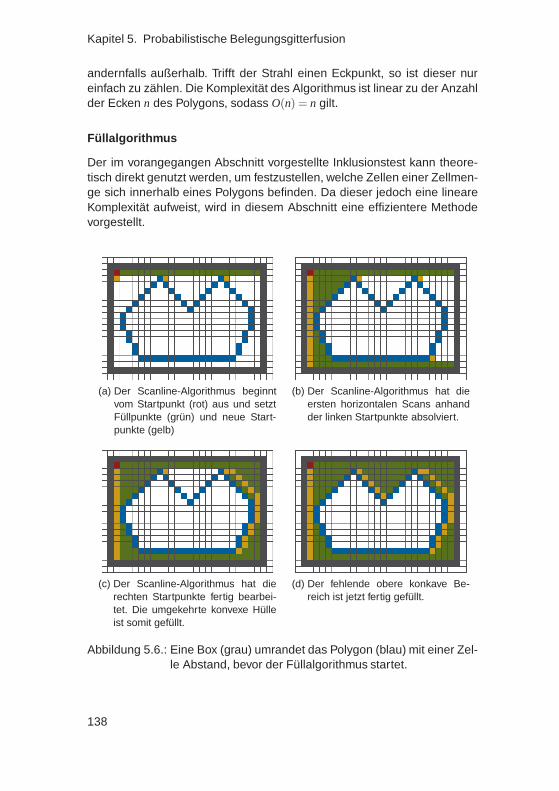
Kapitel 5. Probabilistische Belegungsgitterfusion
andernfalls außerhalb. Trifft der Strahl einen Eckpunkt, so ist dieser nureinfach zu zählen. Die Komplexität des Algorithmus ist linear zu der Anzahlder Ecken n des Polygons, sodass O(n) = n gilt.
Füllalgorithmus
Der im vorangegangen Abschnitt vorgestellte Inklusionstest kann theore-tisch direkt genutzt werden, um festzustellen, welche Zellen einer Zellmen-ge sich innerhalb eines Polygons befinden. Da dieser jedoch eine lineareKomplexität aufweist, wird in diesem Abschnitt eine effizientere Methodevorgestellt.
(a) Der Scanline-Algorithmus beginntvom Startpunkt (rot) aus und setztFüllpunkte (grün) und neue Start-punkte (gelb)
(b) Der Scanline-Algorithmus hat dieersten horizontalen Scans anhandder linken Startpunkte absolviert.
(c) Der Scanline-Algorithmus hat dierechten Startpunkte fertig bearbei-tet. Die umgekehrte konvexe Hülleist somit gefüllt.
(d) Der fehlende obere konkave Be-reich ist jetzt fertig gefüllt.
Abbildung 5.6.: Eine Box (grau) umrandet das Polygon (blau) mit einer Zel-le Abstand, bevor der Füllalgorithmus startet.
138
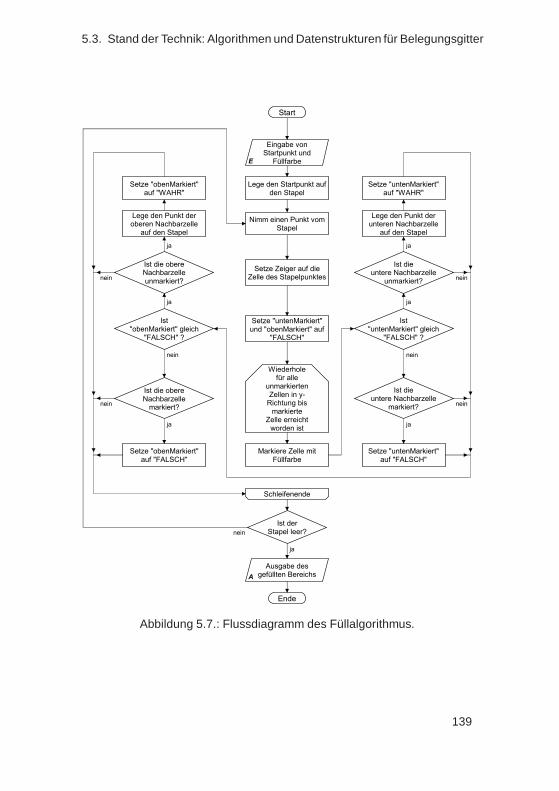
5.3. Stand der Technik: Algorithmen und Datenstrukturen für Belegungsgitter
nein
nein
nein
nein
nein
ja
ja ja
ja
nein
ja
ja
ja
nein
Setze "obenMarkiert" auf "WAHR"
Lege den Punkt der oberen Nachbarzelle
auf den Stapel
Ist die obereNachbarzelleunmarkiert?
Ist"obenMarkiert" gleich
"FALSCH" ?
Ist die obereNachbarzelle
markiert?
Setze "obenMarkiert" auf "FALSCH"
Start
E
Eingabe von Startpunkt und
Füllfarbe
Lege den Startpunkt auf den Stapel
Nimm einen Punkt vom Stapel
Setze Zeiger auf die Zelle des Stapelpunktes
Setze "untenMarkiert" und "obenMarkiert" auf
"FALSCH"
Wiederhole für alle
unmarkierten Zellen in y-
Richtung bis markierte
Zelle erreicht worden ist
Markiere Zelle mit Füllfarbe
Schleifenende
Ist derStapel leer?
A
Ausgabe des gefüllten Bereichs
Ende
Setze "untenMarkiert" auf "WAHR"
Lege den Punkt der unteren Nachbarzelle
auf den Stapel
Ist dieuntere Nachbarzelle
unmarkiert?
Ist"untenMarkiert" gleich
"FALSCH" ?
Ist dieuntere Nachbarzelle
markiert?
Setze "untenMarkiert" auf "FALSCH"
Abbildung 5.7.: Flussdiagramm des Füllalgorithmus.
139

Kapitel 5. Probabilistische Belegungsgitterfusion
Hierzu wird ein Füllalgorithmus verwendet, welcher die Aufgabe hat, aus-gehend von einer Startzelle alle verbundenen Zellen zu markieren. Konkretwird im Folgenden eine Variation des in [Heckbert 1990] vorgestellten Al-gorithmus genutzt, welcher in Abbildung 5.6 beispielhaft visualisiert wird.Da der Füllalgorithmus möglichst effizient ablaufen soll, wurde er als zei-lenbasierter iterativer Ansatz implementiert.
Der Algorithmus nutzt einen Stapel als Datenstruktur, auf dem zunächstder Startpunkt abgelegt wird. Insgesamt wird der Stapel solange mit einemSubalgorithmus abgearbeitet, bis dieser leer ist. Der Subalgorithmus nimmtals Parameter einen Punkt vom Stapel und sucht links und rechts nach Be-grenzungen in Form von markierten Zellen. Zwischen diesen Begrenzun-gen werden die Zellen mit der gewünschten Füllfarbe markiert. Nebenbeiwerden die oberen und unteren Nachbarzellen analysiert und bei Erfüllungbestimmter Kriterien neue Startpunkte auf den Stapel geschrieben. Hierwird genau ein neuer Startpunkt für eine leere Nachbarzeile eingefügt. Istdiese Nachbarzeile jedoch durch Konturmarkierungen unterbrochen, wasbei beispielsweise konkaven Polygonen möglich ist, so erkennt der Algo-rithmus dies und erzeugt entsprechend mehr Startpunkte für diese Zeile.Dieses ist im Beispiel von Abbildung 5.6a der Fall, wo insgesamt drei Start-punkte für eine Zeile neu hinzukommen. Für einen genauen Ablauf desFüllalgorithmus sei auf das Flussdiagramm in Abbildung 5.7 verwiesen.
Der Füllalgorithmus ist offensichtlich unabhängig von der Anzahl der ver-wendeten Polygoneckpunkte, sodass eine konstante Komplexität pro Pixelgegeben ist. Es gilt somit O(n) = 1, was den Algorithmus formal wenigerkomplex macht als den Startpunktalgorithmus. Des Weiteren benutzt erkeine Fließkommaarithmetik, was den Algorithmus insgesamt sehr effizi-ent macht.
5.4. Grundlagen: Logikalgorithmen für Belegungsgitter
Im vorherigen Abschnitt sind Algorithmen vorgestellt worden, welche ge-eignet sind, spezifische Zellen aus einem Belegungsgitter zu extrahieren.Mithilfe dieses Ansatzes können beispielsweise Zellen identifiziert werden,welche mit einer Messung korrespondieren.
Um solche Zellen sinnvoll zu aktualisieren, sind sog. probabilistische Lo-giken hilfreich. Drei solcher Logikalgorithmen werden in diesem Abschnittdargestellt, welche unterschiedliche Zustandsrepräsentationen integrieren.Diese Logikalgorithmen bilden außerdem das Grundgerüst für verschiede-ne andere Fusionsalgorithmen, welche im Laufe des Kapitels vorgestelltwerden.
140

5.4. Grundlagen: Logikalgorithmen für Belegungsgitter
5.4.1. Wahrnehmungsrahmen und Massefunktionen
Die hier vorgestellten Logiken erlauben es, mehrere Zustände entspre-chend eines mathematischen Modells zu einem Zustand zusammenzufas-sen. Diese Algorithmen betrachten dabei einen sog. Wahrnehmungsrah-men (engl. „frame of discernment“) Θ, der verschiedene mögliche Hypo-thesen über einen Zellzustand beinhaltet (vgl. [Shafer 1976]). Dieser wirdim Folgenden insoweit vereinfacht, als dass er auf nur zwei Basishypothe-sen reduziert wird. Diese unterscheiden, ob eine Zelle frei (HF ) oder belegt(HB) ist:
Θ = HF ,HB (5.9)
Aus dem Wahrnehmungsrahmen wird eine Ereignismenge Ω abgeleitet.Diese unterscheidet sich je nach Logik, bildet aber jeweils einen vollständi-gen Ereignishorizont. Auf Basis von Ω wird im Folgenden eine sog. „Mas-sefunktion“ (engl. „mass function“) P definiert (vgl. [Shafer 1976]), für diegilt:
P(H∅) = 0 (5.10)
P(HX ) ∈ [0,1] ,∀X ∈ Ω (5.11)
∑∀X∈Ω
P(HX ) = 1 (5.12)
Die Ergebnismenge der Funktion P(X) heißt dann Massenverteilung2.Bei vielen Ansätzen sind solche Massenverteilungen sowohl das Ergebnisinverser Sensormodelle für einzelne Messungen mi bzgl. bestimmter Zellenals auch für die fusionierten Zellzustände ck.
Im Allgemeinen wird ein solcher Zellzustand ck, der auf dem Initialzu-stand z0 und einer Menge von Messwerten Mk = m0, . . . ,mk basiert, auf-grund einer Messung mk+1 zu einem Zustand ck+1 aktualisiert. Viele Algo-rithmen basieren auf einem Markov-Prozess erster Ordnung:
P(ck+1|Mk+1) = P(ck+1|ck,mk+1) (5.13)
Der Folgezustand ck+1 hängt somit nur vom vorherigen Zustand ck undder Messung mk+1 ab. Alle vorangegangenen Messungen Mk sind bereitsim Zustand ck berücksichtigt.
2Zur Unterscheidung von anderen Tupeln werden Massenverteilungen im Folgenden durchTupel der Form P(X) = 〈. . . 〉 dargestellt
141

Kapitel 5. Probabilistische Belegungsgitterfusion
Welche Attribute der Zustand ck aufweist, hängt von der verwendetenLogik und der daraus resultierenden Massenverteilung ab. Drei verschie-dene Logiken werden in diesem Abschnitt vorgestellt, welche beispielhaftversuchen, freie von belegten Zellen möglichst genau zu unterscheiden.
5.4.2. Bayes-Logik
Beim Bayesansatz entspricht die Ereignismenge ΩBayes dem Wahrneh-mungsrahmen Θ. Die Massenverteilung einer Zelle lässt sich somit mitdem Tupel 〈P(HF |Mk),P(HB|Mk)〉 beschreiben3. Die Elemente des Tupelsenthalten die Frei- und Belegtwahrscheinlichkeiten dieser Zelle, welcheaufgrund der Messungen Mk gebildet worden sind. Diese beiden Wahr-scheinlichkeiten sind gemäß der Massefunktionsdefinition komplementärzu betrachten.
Initial wird meist davon ausgegangen, dass die Zelle mit gleicherWahrscheinlichkeit belegt bzw. frei ist und somit 〈P(HF |M0),P0(HB|M0)〉 =〈1/2,1/2〉 ist. Dieser Zustand repräsentiert die maximale Entropie, die dieZelle erreichen kann, welches gleichzeitig der maximalen Unsicherheit ent-spricht. Vorteilhaft an dieser Annahme ist außerdem, dass für die Berech-nung des sog. „Likelihood-Quotient“ bzw. „ Bayes-Faktor“ LR(Mk) bereitszwei Parameter feststehen. Dieser ergibt sich nach dem Bayes-Theoremzu:
LR(Mk) =P(HF |Mk)
P(HB|Mk)=
P(Mk|HF)·P(HF)P(Mk)
P(Mk|HB)·P(HB)P(Mk)
(5.14)
=P(Mk|HF)
P(Mk|HB)· P(HF)
P(HB)(5.15)
Für die Berechnung des „Likelihood-Quotienten“ benötigt man somit dieDetektionswahrscheinlichkeiten der Frei- und Belegtbereiche und deren In-itialwahrscheinlichkeiten. Diese Parameter lassen sich aus Ground Truth-Daten bestimmen. Die Auftretenswahrscheinlichkeit der Messung P(Mk)
muss nicht bestimmt werden, da sich diese herauskürzt.Der Zellzustand wird rekursiv aktualisiert: Sei 〈P(mk+1|HF),P(mk+1|HB)〉
die Massenverteilung einer neuen Messung mk+1 gemäß inversen Sensor-modells für eine Zelle. Deren Zellzustand 〈P(HF |Mk),P(HB|Mk)〉 aktualisiertsich dann mit:
3Hinsichtlich einer einheitlichen Beschreibung aller Logikalgorithmen wird hier eine alternativeDarstellung des Bayes-Algorithmus gewählt.
142

5.4. Grundlagen: Logikalgorithmen für Belegungsgitter
P(HF |Mk+1) =
(LR(Mk)−1 · P(mk+1|HB)
P(mk+1|HF)+1
)−1
(5.16)
P(HB|Mk+1) = 1−P(HF |Mk+1) (5.17)
Beträgt die Massenverteilung einer Messung 〈1/2,1/2〉, so ändern dieGleichungen 5.16 und 5.17 den Zellzustand nicht, da diese sowohl Hypo-these (Zelle ist frei) als auch Gegenhypothese (Zelle ist belegt) gleicher-maßen stützt. Diese Massenverteilung bildet somit das neutrale Element.
Der Bayes-Algorithmus ist sowohl assoziativ als auch kommutativ. Somitspielt es für das Ergebnis keine Rolle, in welcher Reihenfolge die Messun-gen in den Zellzustand eingebracht werden.
Abbildung 5.8.: Belegungsgitter als Ergebnis einer Parkplatzrundfahrt.Bayes-Algorithmus zeigt belegte und freie Bereiche in rotbzw. grün. Schwarzen Bereichen konnte nie eine Messungzugeordnet werden.
Ein Anwendungsbeispiel des Bayes-Algorithmus ist in Abbildung 5.8 dar-gestellt. Es zeigt ein Belegungsgitter, welches auf einem Parkplatz ent-standen ist. Die Messdaten sind im Winter aufgenommen worden und sinddurch Autos, Büsche, Bäumen, aufgeschüttete Schneeberge und vereisteFlächen beeinflusst. Dieses heterogene Umfeld enthält somit viele Berei-che, in der unklare Objektkonturen, Fehldetektionen und fehlerhafte Nicht-detektionen möglich sind.
143

Kapitel 5. Probabilistische Belegungsgitterfusion
Gemessene Bereiche, deren Belegtwahrscheinlichkeit größer als 1/2 ist,sind rot gefärbt, andernfalls sind sie frei und grün eingefärbt. Nie gemes-sene Bereiche sind schwarz dargestellt.
Bei der Messung wurde eine Eigenbewegungsschätzung aufgrund derRaddrehzahl- und Gierratensensoren erzeugt (vgl. Abschnitt 3.5.5), wel-che einen sich integrierenden Fehler aufweist. Je länger die zurückgelegteStrecke auf einer Rundfahrt ist, desto ungenauer werden die neuen Mess-daten auf das Belegungsgitter abgebildet. Diese Schätzung bildet somiteine weitere potenzielle Fehlerquelle für die ungenaue örtliche Zuordnungeiner Messung.
5.4.3. Dempster-Shafer Theorie
Die vorgestellte Bayes-Logik hat den Nachteil, dass selten gemessene Zel-len nicht von solchen Zellen unterschieden werden können, die im Laufedes Fusionsprozesses widersprüchliche Daten bekommen haben. Es fehlteine Angabe, wie vage die Schätzung ist.
Diesen Nachteil kann man durch die Erweiterung der sog. „Evidenztheo-rie“ von Dempster und Shafer (DST) begegnen (vgl. [Shafer 1976]). Dieseerweitert die Ereignismenge Ω um zusätzliche Elemente, sodass man ex-plizit Unwissen in einer Massenverteilung angeben kann. Diese Elementewerden aus allen möglichen Vereinigungsmengen des Wahrnehmungsrah-mens gebildet:
ΩDST = ∀X ⊆ Θ : P(HX ) (5.18)
Elemente aus ΩDST , die aus der Vereinigung von mehreren nichtleerenElementen des Wahrnehmungsrahmens entstanden sind, repräsentiereneingetretene unsichere Ereignisse. Ein solches unsicheres Ereignis kannauf mehrere Hypothesen aus dem Wahrnehmungsrahmen basieren.
Für den vereinfachten zweielementigen Wahrnehmungsrahmen ergibtsich nur ein einziges weiteres Element für die Ereignismenge ΩDST : NebenHF und HB, die den Frei- bzw. Belegtzustand darstellen, beinhaltet es nunnoch das Ereignis HF∪B. Dieses repräsentiert die vollständige Zustands-unsicherheit, indem eine Zelle gleichzeitig als „frei“ oder „belegt“ deklariertwird.
Liegt eine Messung vor, die eine Belegt- oder Freihypothese fürdie Zelle liefert, so wird der Zellzustand wie folgt aktualisiert: Sei⟨P(HF |Mk),P(HB|Mk),P(HF∪B|Mk)
⟩eine Massenverteilung, die den alten
Zellzustand repräsentiert. Dieser beinhaltet eine Freievidenz, eine Belegt-evidenz und eine Evidenz für den unsicheren Zustand. Diese wird durch
144

5.4. Grundlagen: Logikalgorithmen für Belegungsgitter
eine Massenverteilung 〈P(mk+1|HF ),P(mk+1|HB),P(mk+1|HF∪B)〉 basierendauf einer Messung mk+1 aktualisiert. Zunächst wird aus diesen Variablender Konfliktwert K ermittelt:
K = P(HF |Mk) ·P(HB|mk+1)+P(HB|Mk) ·P(HF |mk+1) (5.19)
Der Konfliktwert gibt an, wie stark sich die beiden Informationsquellenwidersprechen. Da er auf kein Element der Ereignismenge ΩDST komplettabgebildet werden kann, wird er herausnormalisiert und somit proportio-nal auf die Elemente der Ereignismenge verteilt. Der neue Zellzustand⟨P(HF |Mk+1),P(HB|Mk+1),P(HF∪B|Mk+1)
⟩ergibt sich dann zu:
P(HF |Mk+1) =1
1−K·[P(HF |Mk) ·P(HF |mk+1)
+P(HF∪B|Mk) ·P(HF |mk+1)
+P(HF |Mk) ·P(HF∪B|mk+1)]
(5.20)
P(HB|Mk+1) =1
1−K·[P(HB|Mk) ·P(HB|mk+1)
+P(HF∪B|Mk) ·P(HB|mk+1)
+P(HB|Mk) ·P(HF∪B|mk+1)]
(5.21)
P(HF∪B|Mk+1) =1
1−K·P(HF∪B|Mk) ·P(HF∪B|mk+1) (5.22)
Wie beim Bayes-Algorithmus ist das neutrale Element das Element, wel-ches die höchste Entropie aufweist und dem Initialzustand gleicht. Dieseshat keine Information über Belegt- und Freiwahrscheinlichkeiten und weisteine maximale Unwissenheit mit 〈P(HF),P(HB),P(HF∪B)〉= 〈0,0,1〉 auf.
Auch der Dempster-Shafer-Algorithmus ist assoziativ und kommutativ,sodass der Zellzustand von der Reihenfolge der eingebrachten Messungenunabhängig ist.
Das Parkplatzbeispiel aus dem vorherigen Abschnitt ist auch mit derDempster-Shafer Theorie getestet worden. Abbildung 5.9 zeigt das Er-gebnis. Zusätzlich zu den freien und belegten Bereichen gibt es nun nochgraue Bereiche. Diese wurden zwar durch Messungen aktualisiert, jedochdominiert hier noch die Unbekannt-Masse die Zellschätzung.
Der Vergleich der beiden Abbildungen zeigt, dass beim Bayesansatzmehr Bereiche existieren, die als frei oder belegt deklariert werden, dadieser keine Mindestevidenzmasse sammeln muss.
145

Kapitel 5. Probabilistische Belegungsgitterfusion
Abbildung 5.9.: Erzeugtes Belegungsgitter nach einer Parkplatzrundfahrt.Der Dempster-Shafer-Algorithmus zeigt belegte, freie undunbekannte Bereiche in rot, grün bzw. grau. Schwarze Be-reiche sind Bereiche mit maximalen Unwissen.
5.4.4. Dezert-Smarandache Theorie
Die vorgestellte Evidenztheorie von Dempster-Shafer berücksichtigt Un-wissen bereits in einem eigenen Zustand. Eine explizite Modellierung vonwidersprüchlichen Informationen fehlt jedoch. Diese werden zwar im vorge-stellten Aktualisierungsalgorithmus in Gleichung 5.19 mitberechnet, aberletztendlich herausnormalisiert.
Dieser fehlende Aspekt wurde in der Evidenztheorie von Dezert-Smarandache (DSmT) erweitert (vgl. [Smarandache 2006]). Diese berück-sichtigt explizit in zusätzlichen Attributen den Anteil an widersprüchlichenInformationen.
Während bei der Dempster-Shafer Theorie die Ereignismenge ΩDST
aus allen möglichen Vereinigungsmengen des Wahrnehmungsrahmensbesteht, erweitert die Dezert-Smarandache Theorie diese um alle mögli-chen Schnittmengen. Die Ereignismenge ΩDSmT entsteht somit mittels:
ΩDSmT = ∀X ,Y ⊆ Θ : HX∩Y (5.23)
Das Tupel zur Modellierung von Zellzuständen und Messungen wirdbei dem vereinfachten Wahrnehmungsrahmen um ein einzelnes Konflikt-
146

5.4. Grundlagen: Logikalgorithmen für Belegungsgitter
wertattribut erweitert. Sowohl im Initialzustand als auch in den einzelnenMessungen sollte dieses null betragen, da beides atomare und sich nichtselbst widersprechende Informationen repräsentieren. Die Massenvertei-lung 〈0,0,1,0〉 bildet somit das neutrale und initiale Element für die Dezert-Smarandache Theorie.
Der Zellzustand⟨P(HF |Mk),P(HB|Mk),P(HF∪B|Mk),P(HF∩B|Mk)
⟩wird
nach der Dezert-Smarandache Theorie wie folgt aktualisiert:
P(HF |Mk+1) = P(HF |Mk)P(HF |mk+1)+P(HF |Mk)P(HF∪B|mk+1)
+P(HF∪B|Mk)P(HF |mk+1) (5.24)
P(HB|Mk+1) = P(HB|Mk)P(HB|mk+1)+P(HB|Mk)P(HF∪B|mk+1)
+P(HF∪B|Mk)P(HB|mk+1) (5.25)
P(HF∪B|Mk+1) = P(HF∪B|Mk)P(HF∪B|mk+1) (5.26)
P(HF∩B|Mk+1) = 1−P(HF |Mk+1)−P(HB|Mk+1)−P(HF∪B|Mk+1) (5.27)
Der Algorithmus liefert eine sehr genaue Repräsentation eines Zellzu-standes mit eventuell fehlenden bzw. widersprüchlichen Informationen. Fürdie Praxis hat er jedoch zwei Nachteile.
Zum einen ist er zwar assoziativ, aber nicht kommutativ, sodass dieMessreihenfolge einen Einfluss auf das Ergebnis hat. Je nach Latenz derSensoren können somit unterschiedliche Ergebnisse errechnet werden.
Als zweiter Nachteil ist zu nennen, dass der Konfliktwert monoton steigt.Hat man beispielsweise in großer Entfernung aufgrund von Messunge-nauigkeiten mehrere widersprüchliche Informationen, so kann eine Zel-le schnell einen großen Konfliktwert nahe eins erreichen. Wenn sich dasFahrzeug der Zelle nähert, verringern sich die Messungenauigkeiten zudieser. Somit steigt die Wahrscheinlichkeit, dass keine widersprüchlicheMessungen mehr vorliegen. Dennoch kann der Konfliktwert nicht verrin-gern werden.
In der Praxis müssen deshalb Strategien entwickelt werden, mit denender Konfliktwert über die Zeit verringert werden kann. In zeitlich regelmä-ßigen Abständen kann man beispielsweise einen Teil der Konfliktmassedem unbekannten Zustand zuschlagen und somit neue Messungen hö-her gewichten. Alternativ kann man wie bei der Dempster-Shafer Theoriediesen Konfliktmassenanteil herausnormalisieren und somit über die rest-lichen Attribute verteilen. Dieser Ansatz stärkt somit den alten Zellzustandund erhält die Proportionen der übrigen Attribute.
147

Kapitel 5. Probabilistische Belegungsgitterfusion
Abbildung 5.10.: Berechnetes Belegungsgitter nach Rundfahrt durch einenParkplatz. Der Dezert-Smarandache-Algorithmus zeigtneben belegten, freien und unbekannten Bereichen (rot,grün bzw. schwarz/grau) auch Konfliktbereiche (gelb).
Ein weiterer Ansatz wird später im Abschnitt 5.7.2 vorgestellt. Dieserentfernt alte Messungen aus einer Zelle, sodass Konfliktwerte bei konsis-tenten neuen Daten verschwinden.
In Abbildung 5.10 ist die Dezert-Smarandache Theorie mit diesem An-satz auf das Parkplatzbeispiel aus den vorherigen Abschnitten angewendetworden. Es zeigt neben den freien, belegten und unbekannten Bereichenauch eine Vielzahl von Konfliktbereichen (gelb). Diese sind mit den be-reits erwähnten Odometriefehlern der Eigenbewegungsschätzung und derkomplex strukturierten Domäne begründet. So sind auf dem Parkplatz vie-le Objekte zu finden, die keine klar abgegrenzte Kontur in Rechteckformaufweisen, wie beispielsweise Büsche und aufgeschüttete Schneeberge.
5.4.5. Zusammenfassung
In diesem Abschnitt sind aus der Literatur bekannte Logikalgorithmen vor-gestellt worden, die freie von belegten Bereichen unterscheiden können.Im Sinne der Modularitätsanforderung sind diese einheitlich als Masse-funktionen dargestellt worden, so dass diese leicht austauschbar sind. Die-se bilden zusammen mit den Algorithmen und Datenstrukturen für Bele-
148

5.5. Stand der Technik: Fusionsalgorithmen für Belegungsgitter
gungsgitter die Grundlage für die kommenden Abschnitte.Eine Bewertung der vorgestellten Logiken ist im Speziellen nur zusam-
men mit einer spezifischen Anwendung möglich. So könnte man zum Bei-spiel die Dempster-Shafer Theorie einsetzen, wenn man selten oder unge-messene Bereiche identifizieren möchte, um diese auszuschließen. EineAnwendung für die Dezert-Smarandache Theorie hingegen könnte die Ei-gendiagnose der Umfeldwahrnehmung sein: So könnten häufige und hoheKonfliktwerte beispielsweise auf eine defekte oder dekalibrierte Sensorikhindeuten. Für eine reine Darstellung der Befahrbarkeitswahrscheinlichkeitreicht jedoch die Bayes-Logik aus.
Die Bayes-Logik hat die Eigenschaft, dass diese A-priori-Wahrscheinlichkeiten als Parameter benötigt, welche jedoch unbe-kannt bzw. stark von variablen Faktoren abhängig sein können. DieAnwendung dieser Logik erfordert somit eine genauere Untersuchungdes Zustandsraumes als bei der Dempster-Shafer Theorie oder derDezert-Smarandache Theorie. Dafür liefert die Bayes-Logik bei ausblei-benden Messungen auch direkt A-priori-Wahrscheinlichkeiten und keineUnbekannt-Massen, was für Anwendungen eventuell sinnvoller ist.
Zur Darstellung der Massenverteilungen steigt mit zunehmender Ele-mentanzahl der Ergebnismenge der Speicherbedarf, was besonders beiBelegungsgittern mit vielen Zellen ins Gewicht fallen könnte. So benötigtdie komplementäre Darstellung von Bayes ein Attribut, von der Dempster-Shafer Theorie zwei Attribute und von der Dezert-Smarandache Theoriedrei Attribute.
5.5. Stand der Technik: Fusionsalgorithmen fürBelegungsgitter
Die im vorherigen Abschnitt vorgestellten Logiken sind in der Lage, Infor-mationsquellen in Form von Massenverteilungen zu fusionieren. Hier fehltjedoch noch ein Modell, wie man eine solche Massenverteilung für ein-zelne Messungen generiert. Dazu sind unter anderem inverse probabilis-tische Sensormodelle notwendig, die solche Massenverteilungen erzeu-gen und dabei beispielsweise Messungenauigkeiten und die Zuverlässig-keit des Sensors berücksichtigen.
Ein zweiter Aspekt beschäftigt sich mit der Form, in der das Belegungs-gitter später genutzt wird. Je nach Anforderung der Anwendung könntebeispielsweise die probabilistische Befahrbarkeit eines gewählten Pfadesbestimmt werden. Als Erweiterung ist es denkbar, dass ein Pfad automa-
149

Kapitel 5. Probabilistische Belegungsgitterfusion
tisch bestimmt werden soll, der möglichst viel Abstand zu belegten Zellenhält und somit die Befahrbarkeitswahrscheinlichkeit maximiert.
In diesem Abschnitt werden dazu verschiedene bekannte Ansätze vor-gestellt und bewertet, wobei solche mit einem hohen Rechenaufwandhinsichtlich Echtzeitanforderungen ausgeschlossen wurden. Hierzu ge-hört beispielsweise das Erlernen von Belegungsgitterkarten [Thrun 2003]mittels nicht-inversen Sensormodellen und Expectation-Maximization-Algorithmus.
5.5.1. Belegungsgitterfusion nach Elfes
Die ersten Arbeiten zur Sensordatenfusion mittels Belegungsgittern sinddie Arbeiten [Moravec 1985], [Elfes 1989a], [Elfes 1989b], [Elfes 1991] und[Elfes 1992] von Elfes und Moravec. Die verwendeten Sensorträger bildenRoboter, die sich im Gebäude als auch im freien Gelände zurechtfindensollen. Diese sind mit Ultraschallsensoren ausgestattet, womit sie die naheUmgebung erfassen können. Odometriesensoren ermöglichen eine Eigen-bewegungsschätzung. Einer der genutzten Versuchsträger ist der Roboter„Neptune“, der in Abbildung 5.11 dargestellt ist.
Abbildung 5.11.: Verwendeter Versuchsträger „Neptune“ mit einem Arrayaus 24 Ultraschallsensoren und 2 Kameras (Bild aus [Mo-ravec 1985])
Elfes nimmt an, dass die Messfehler der Ultraschallsensoren normalver-teilt sind (vgl. [Elfes 1989b]). Dies gilt sowohl für die gemessene Entfernung
150
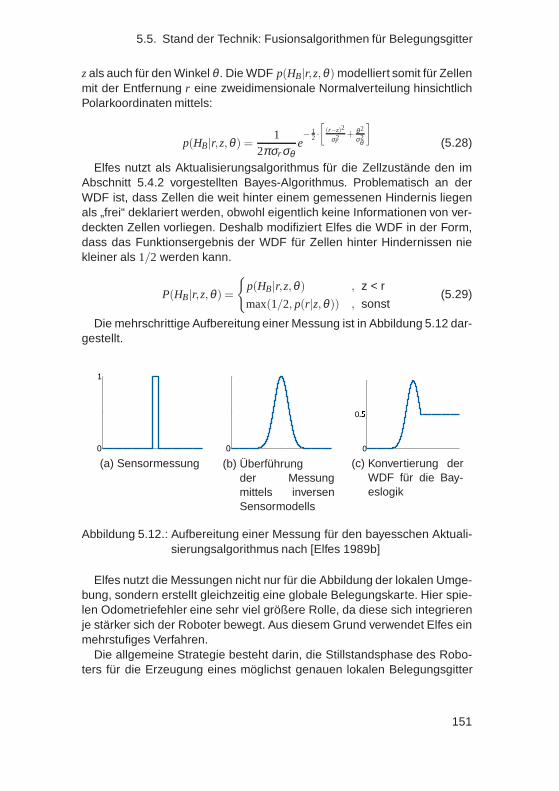
5.5. Stand der Technik: Fusionsalgorithmen für Belegungsgitter
z als auch für den Winkel θ . Die WDF p(HB|r,z,θ ) modelliert somit für Zellenmit der Entfernung r eine zweidimensionale Normalverteilung hinsichtlichPolarkoordinaten mittels:
p(HB|r,z,θ ) =1
2πσrσθe− 1
2 ·[(r−z)2
σ2r
+ θ2
σ2θ
]
(5.28)
Elfes nutzt als Aktualisierungsalgorithmus für die Zellzustände den imAbschnitt 5.4.2 vorgestellten Bayes-Algorithmus. Problematisch an derWDF ist, dass Zellen die weit hinter einem gemessenen Hindernis liegenals „frei“ deklariert werden, obwohl eigentlich keine Informationen von ver-deckten Zellen vorliegen. Deshalb modifiziert Elfes die WDF in der Form,dass das Funktionsergebnis der WDF für Zellen hinter Hindernissen niekleiner als 1/2 werden kann.
P(HB|r,z,θ ) =
p(HB|r,z,θ ) , z < r
max(1/2, p(r|z,θ )) , sonst(5.29)
Die mehrschrittige Aufbereitung einer Messung ist in Abbildung 5.12 dar-gestellt.
0
1
(a) Sensormessung0
(b) Überführungder Messungmittels inversenSensormodells
0
0.
(c) Konvertierung derWDF für die Bay-eslogik
Abbildung 5.12.: Aufbereitung einer Messung für den bayesschen Aktuali-sierungsalgorithmus nach [Elfes 1989b]
Elfes nutzt die Messungen nicht nur für die Abbildung der lokalen Umge-bung, sondern erstellt gleichzeitig eine globale Belegungskarte. Hier spie-len Odometriefehler eine sehr viel größere Rolle, da diese sich integrierenje stärker sich der Roboter bewegt. Aus diesem Grund verwendet Elfes einmehrstufiges Verfahren.
Die allgemeine Strategie besteht darin, die Stillstandsphase des Robo-ters für die Erzeugung eines möglichst genauen lokalen Belegungsgitter
151
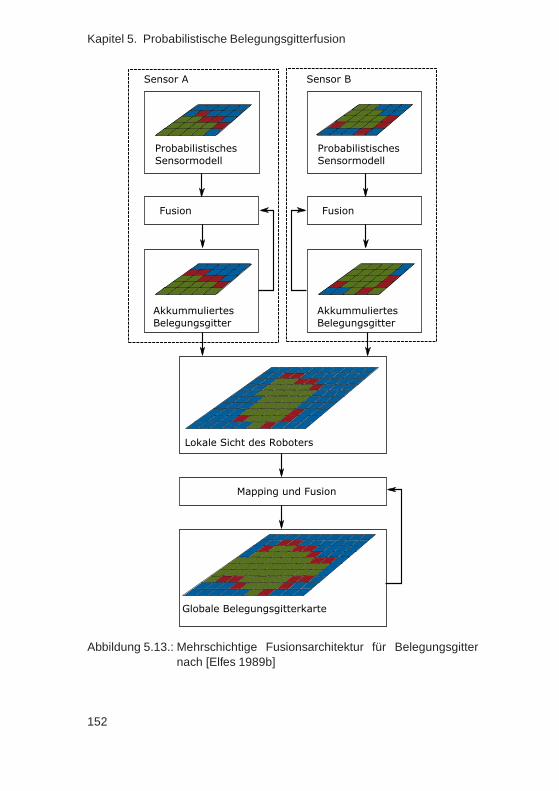
Kapitel 5. Probabilistische Belegungsgitterfusion
Probabilistisches
Sensormodell
Akkummuliertes
Belegungsgitter
Fusion
Probabilistisches
Sensormodell
Akkummuliertes
Belegungsgitter
Fusion
Lokale Sicht des Roboters
Globale Belegungsgitterkarte
Mapping und Fusion
Sensor A Sensor B
Abbildung 5.13.: Mehrschichtige Fusionsarchitektur für Belegungsgitternach [Elfes 1989b]
152

5.5. Stand der Technik: Fusionsalgorithmen für Belegungsgitter
zu nutzen, sodass Odometriefehler keinen Einfluss ausüben können. Kurzbevor der Roboter sich weiterbewegt, wird das lokale Belegungsgitter inein Globales überführt.
Die genaue Vorgehensweise ist in Abbildung 5.13 dargestellt: Zunächstwird für eine einzelne Messung mittels des inversen probabilistischen Sen-sormodells ein lokales temporäres Belegungsgitter erzeugt. Dieses wird inein zweites Gitter fusioniert, welches die akkumulierte Sicht eines einzel-nen Sensors auf die lokale Umgebung repräsentiert.
Bevor der Roboter sich weiterbewegt, werden in einem dritten Schrittdie unterschiedlichen Belegungsgitter der einzelnen Sensoren zu einemweiteren fusioniert. Bei dieser Transformation werden bekannte Einbaupo-sitionen und Ausrichtungen der Sensoren berücksichtigt.
Das so gewonnene Belegungsgitter bildet die aggregierte Sicht des Ro-boters über die lokale Umgebung. Dieses wird in ein globales Belegungs-gitter überführt. Elfes hat einen Alterungsmechanismus in das globale Be-legungsgitter eingeführt, um länger unbeobachtete Bereiche schneller wie-der auf die neue lokale Umgebung aktualisieren zu können.
Besonders schwierig hierbei ist die richtige Transformation zu finden, dasich die Roboterposition nur ungenau bestimmen lässt. Hierzu wird sowohldas Belegungsgitter der globalen Karte im vermuteten Aufenthaltsgebietdes Roboters als auch die lokale Robotersicht in eine geringe Auflösungtransformiert. Als Nächstes werden geeignete Kandidaten für eine Trans-formation gesucht. Hierbei sollte die Differenz der Belegungsgitter mög-lichst gering sein. Eine mögliche Differenzberechnung ist in [Martin 1996]vorgeschlagen worden:
Sei C und D jeweils eine geordnete Menge von n×m Zellen, die vergli-chen werden sollen. Jede Zelle ci, j ∈ C bzw. di, j ∈ D enthält die komple-mentären Wahrscheinlichkeiten für die Frei- und Belegthypothese HF bzw.HB. Das Ähnlichkeitsmaß γ(C,D) liefert dann einen Gütewert im Intervall[0,1] mit:
γ(C,D) =n
∏i=1
m
∏j=1
[P(HF |ci, j) ·P(HF |di, j)+P(HB|ci, j) ·P(HB|di, j)
](5.30)
Volle Ähnlichkeit wird nur zurückgegeben, wenn C =D und alle Zellen ei-ne maximale Konfidenz aufweisen. Dies ist der Fall, wenn P(HB|ci, j)∈0,1für alle Zellen ci, j ∈ C gilt. Um eine volle Unähnlichkeit zu erreichen, reichtbereits ein einziges ungleiches Paar von Zellen mit maximaler Konfidenzaus.
Diese extremen Konfidenzwerte werden bei der Verwendung von nich-tidealen inversen Sensormodellen jedoch nie erreicht. Mit einer endlichen
153

Kapitel 5. Probabilistische Belegungsgitterfusion
Anzahl von Zellaktualisierungen kann die Bayes-Aktualisierungslogik ihreGrenzwerte null und eins zwar beliebig genau annähern, jedoch nie errei-chen.
Bei der Produktbildung sehr vieler Faktoren aus dem Intervall [0, 1]können leicht numerische Ungenauigkeiten auftreten. Aus diesem Grundschlägt Elfes eine modifizierte logarithmische Darstellung vor. Dieser er-laubt einen summarischen Aktualisierungsalgorithmus, welcher eine höhe-re numerische Stabilität aufweist:
Γ(C,D) = m ·n+ log2γ(C,D)
=n
∑i=1
m
∑j=1
[1+ log2
(P(HF |ci, j) ·P(HF |di, j)+P(HB|ci, j) ·P(HB|di, j)
)]
(5.31)
Durch das Gütemaß Γ(C,D) wird eine Auswahl von geeigneten Transfor-mationskandidaten getroffen. Diese werden weiter untersucht, indem dieAuflösung der Belegungsgitter sukzessiv erhöht wird, bis die originale Auf-lösung erreicht worden ist. Der beste Kandidat liefert die zu verwendendeTransformationsmatrix.
Nach der Erzeugung des globalen Belegungsgitters kann dieses als Ent-scheidungsgrundlage für die Pfadplanung dienen. Diese basiert bei Elfesim Wesentlichen auf dem A*-Algorithmus (vgl. [Hart 1968]), welcher in derLage ist, den Pfad zwischen zwei Knoten in einem Graphen zu finden, derdie geringste Summe an Kantengewichten aufweist. Übertragen auf dasBelegungsgitter bildet jede Zelle einen Knoten im Graphen, welcher mitallen Knoten der Nachbarzellen verbunden ist. Deren Kantenverbindungs-gewichte hängen von den Belegungswahrscheinlichkeiten ab.
A* nutzt zur effizienten Suche eine bestimmte Heuristik. Es werden be-vorzugt die Pfade traversiert, die bei einer optimistischen Schätzung diekleinste prospektive Kantengewichtssumme aufweisen. Diese optimisti-sche Heuristik nimmt bei Elfes an, dass auf einem Suchpfad sämtlicheZellen mit unbekannten Zellzustand frei sind.
Zusätzlich basieren die Kantengewichte nicht nur auf den Belegungs-wahrscheinlichkeiten, sondern enthalten auch einen konstanten Faktor.Somit kann der Roboter einen Pfad wählen, der nicht nur frei von Hinder-nissen, sondern auch möglichst kurz ist (vgl. [Elfes 1991]).
Elfes hat insgesamt viele bemerkenswerte Grundlagen entwickelt, wel-che heute noch vielfach in Belegungsgittern eingesetzt werden. SeineKernidee, das Umfeld in quadratische Zellen zu diskretisieren, wird in fast
154

5.5. Stand der Technik: Fusionsalgorithmen für Belegungsgitter
allen Arbeiten im Bereich der Belegungsgitter wieder aufgegriffen. Auf die-se Umfeldrepräsentation hat er viele bekannte Algorithmen adaptiert undgeeignet kombiniert. Zu nennen sind dabei die probabilistischen inversenSensormodelle, die Bayeslogik zur Aktualisierung von belegten und freienZellen, den A*-Algorithmus für die Pfadplanung und die Eigenbewegungs-und Kartenschätzung mittels Landmarken. Er liefert nicht nur eine theo-retische Grundlage, sondern hat diese mit verschiedenen Robotern aucherfolgreich in die Praxis umgesetzt.
Insgesamt konzentriert sich Elfes mit seinen Arbeiten auf den Robotikbe-reich. Besonders die Erstellung von globalen Belegungskarten scheint je-doch für den Automobilbereich ungeeignet. Zum einen befahren Autos viellängere Strecken, sodass diese Karte wenn überhaupt nur äußerst spei-cheraufwendig umgesetzt werden kann. Zum anderen zeichnen sich diemeisten Fahrten dadurch aus, dass keine Straße doppelt befahren wird,sodass man die Belegungskarte zusätzlich persistent speichern muss, umüberhaupt Nutzen aus dieser zu ziehen. Auch kann man es dem Fahrernicht zumuten, dass sein Auto stehen bleibt, nur weil die Umfeldwahrneh-mung längere Zeit von Odometriefehlern ungestört Umfeldinformationensammeln möchte.
Seine probabilistischen Modelle sind noch von vielen Vereinfachungengeprägt: Elfes nimmt beispielsweise an, dass jeder Zellzustand unabhän-gig von anderen ist, und behandelt widersprüchliche und unvollständigeInformationen nur gemäß der Bayeslogik. Die Problematik der systema-tischen Fehlziele werden wenig berücksichtigt und Messungen innerhalbeiner Messreihe werden als unabhängig voneinander betrachtet.
Ein positiver Aspekt ist die separate Behandlung von Sensoren. JedemSensor wird ein eigenes kleines Belegungsgitter zugeordnet, sodass dieMöglichkeit besteht, die Messreihe dieses Sensors von den Messreihender anderen Sensoren zu trennen. Bei der lokalen Umfeldrekonstrukti-on können dann andere Fusionsalgorithmen benutzt werden, sodass bei-spielsweise eine größere Unabhängigkeit angenommen werden kann alsvon Messungen, die von einem Sensor stammen.
5.5.2. Belegungsgitterfusion nach dem MURIEL-Ansatz
In [Konolige 1997] wird ein Ansatz Namens „Multiple Representation, In-dependent Evidence Log (MURIEL)“ vorgestellt, der versucht, bestimmteAbhängigkeiten zwischen Messungen aufzulösen. Der Ansatz ist dabei fürUltraschallsensoren optimiert, sodass in dem verwendeten inversen Sen-sormodell die Eigenschaften dieses Messprinzips berücksichtigt wird.
155

Kapitel 5. Probabilistische Belegungsgitterfusion
Hierbei werden insbesondere Objekte berücksichtigt, die aus bestimm-ten Winkeln heraus schwer zu detektieren sind. Solche Objekte haben bei-spielsweise planare und glatte Oberflächen, welche die Ultraschallwellenin den Raum spiegeln, aber nicht direkt zum Sensorträger zurückreflektie-ren. Solche Objekte können Ursache von Mehrfachreflexionen sein, waseine mehr oder weniger zufällige Positionsinformation des Objektes in derSignalauswertung ergibt.
Im Gegensatz dazu sind Objekte mit einer rauen und gewölbten Ober-fläche leichter zu detektieren, da der Ultraschall diffus in alle Richtungengestreut wird und somit auch direkt zum Sensorträger.
Um u. a. vermeintliche Freibereiche durch Mehrfachreflexionen auszu-schließen, wird für jede Zelle geschätzt, ob diese diffuse oder spiegelndeEigenschaften gegenüber einer Messung aufweist. Dieses erfolgt durchAnalyse des Zellzustandes: Ist eine Zelle beispielsweise bereits von meh-reren Positionen aus als belegt geschätzt worden und eine Messung ver-fehlt diese Zelle, dann wird eine Mehrfachreflexion mit hoher Wahrschein-lichkeit angenommen.
Die genannten Reflexionseigenschaften einer Zelle werden von einemSchätzer rekursiv angenähert und im Zellzustand abgelegt. Die Reflexions-attribute sind Teil des inversen Sensormodells, welches eine Belegungs-wahrscheinlichkeit dynamisch generiert. Diese wird wie bei Elfes rekursivnach Bayes für jede Zelle aktualisiert.
In [Konolige 1997] wird angenommen, dass Belegt- und Freimessun-gen in einer statischen Umgebung stark korrelieren, wenn der Sensorträ-ger die gleiche Position zu einer Zelle aufweist. Dies wird insbesonderemit konstanten Detektionseigenschaften statischer Objekte aus bestimm-ten Winkeln und Entfernungen begründet. So scheint es wahrscheinlich,dass wenn ein Objekt aufgrund hoher spiegelnder Eigenschaften von ei-ner Position aus mit einer Messung nicht detektiert werden kann, diesesauch für wiederholte Messungen gilt.
Um eine Akkumulation von fehlerhaften Nichtdetektionen und falschenPositionen zu vermeiden, soll jede Zelle nur dann aktualisiert werden, wennvon der aktuellen Roboterposition nicht bereits eine Belegt- bzw. Freimes-sung für diese Zelle erfolgte. Insgesamt soll der Einfluss der Aufenthalts-dauer des Roboters in bestimmten Positionen auf den Zellzustand neutra-lisiert werden.
Um dieses zu erreichen, wird in jeder Zelle für Belegt- und Freimes-sungen jeweils eine Umgebungskarte verwaltet, in der die Roboterpositio-nen eingetragen werden, von denen die Zelle aus aktualisiert worden ist.In [Konolige 1997] wird eine diskretisierte Darstellung in Polarkoordinatenvorgeschlagen, wobei 64 Sektoren und 3 Entfernungsbereiche berücksich-
156

5.5. Stand der Technik: Fusionsalgorithmen für Belegungsgitter
Abbildung 5.14.: Zelle mit diskretisierter Umgebungskarte in Polardarstel-lung. Der Sensorträger durchläuft diese (blaue Trajekt-orie) und misst aus bestimmten Sektorabschnitten (ro-te Bereiche) den Zellzustand. Dieser wird pro Sektorab-schnitt nur einmal aktualisiert.
tigt werden. Die Datenstruktur wird als Bitfeld dargestellt, wobei pro Karte192 Bits benötigt werden. Jede Zelle erhöht somit ihren Speicherbedarf fürdie beiden Karten um 48 Bytes. Abbildung 5.14 stellt solch eine Karte undeinen möglichen Zustand exemplarisch dar.
Der vorgestellte Ansatz ist durch die Umgebungskarten in den einzelnenZellen deutlich speicheraufwendiger als konventionelle Ansätze. Er erlaubtdafür eine bessere Auflösung von Messabhängigkeiten, welche darauf ba-siert, ähnlichen Messungen die gleiche Evidenzmasse zuzusprechen wieeiner einzelnen Messung. Auch wird eine wohl genauere Umgebungsdar-stellung dadurch erreicht, dass jede Messung mit dem Belegungsgitterplausibilisiert und entsprechend dynamisch gewichtet wird.
Zu kritisieren ist, dass der Ansatz eine vollständige Abhängigkeit4 derMessungen aus einem Sektorabschnitt annimmt und keine partielle. Sosind aber auch Effekte denkbar, die stochastisch unterschiedliche Mes-sungen verursachen können. Sinnvoller wäre wohl eine Evidenzabnahmefür wiederholte Messungen aus einem Sektorabschnitt heraus. Dies würdeaber zusätzlichen Speicher kosten, da anstatt einer Markierung pro Sek-
4Eine Zufallsvariable y ist von einer anderen Zufallsvariable x vollständig abhängig, wenn yaus x berechnet werden kann (vgl. [Lancaster 1963]). In diesem Fall liefert y keine neueInformation.
157

Kapitel 5. Probabilistische Belegungsgitterfusion
torabschnitt ein Zähler notwendig wäre.In [Konolige 1997] wird nur die Generierung eines Belegungsgitters be-
schrieben, während keine Aussage über Anwendungen oder über Auswer-tungsalgorithmen gemacht wird. Ob mit dem MURIEL-Ansatz eine mess-bar bessere Performance bei spezifischen Anwendungen nach sich zieht,bleibt zu untersuchen.
5.5.3. Belegungsgitterfusion mittels erlernter inverserSensormodelle
Die bereits vorgestellten Ansätze nutzen manuell erstellte inverse Sensor-modelle, welche auf vielen Annahmen beruhen, wie beispielsweise Ver-teilungen von Zufallsvariablen und Gewichtungen. Durch solche Modellekann jedoch eine komplexe Sensorcharakteristik nur mehr oder wenigervereinfacht dargestellt werden. Ein alternativer Ansatz wird in den Arbei-ten von [Thrun 1998], [van Dam 1996] und [Yu 2007] verfolgt, welcher hiervorgestellt wird:
Der allgemeine Aufbau des Belegungsgitters ähnelt in diesen Arbeitendem Ansatz von Elfes: So enthält jede Zelle genau eine Massenvertei-lung, die mittels inversen Sensormodellen und Logikalgorithmen aktuali-siert wird. Die Zellzustände aller Zellen werden als unabhängig angenom-men.
Bei der Generierung der inversen Sensormodelle verfolgen diese Arbei-ten einen genaueren Ansatz als Elfes: Dieser basiert darauf, die Funk-tion zur Belegungsschätzung einer Zelle in einem überwachten Lernpro-zess zu approximieren. Hierzu nutzen alle ein mehrschichtiges künstlichesneuronales Netz mit Fehlerrückführungsalgorithmus, wie es in AbschnittA.3.5 beschrieben wird. Prinzipiell sind aber auch andere probabilistischeAlgorithmen aus dem Bereich des Maschinellen Lernens denkbar, wie bei-spielsweise die SVM (s. A.3.4) oder der kNN-Algorithmus (s. A.3.2).
Eine entscheidende Rolle beim Anlernen dieser Klassifikatoren spielengute Lerndaten, welche repräsentativ und umfassend sein sollten. Bei derErzeugung dieser Daten verfolgen alle drei Arbeiten unterschiedliche Me-thoden, welche in diesem Abschnitt vorgestellt werden.
Belegungsgitterfusion nach Thrun
Das in [Thrun 1998] beschriebene künstliche neuronale Netz soll aus Sen-sorsignalen und einer Zellposition die Belegungswahrscheinlichkeit dieserZelle liefern. Im Detail besteht der Eingabevektor X aus der relativen Po-
158

5.5. Stand der Technik: Fusionsalgorithmen für Belegungsgitter
sition der zu aktualisierenden Zelle (x,y) in Polarkoordinaten und vier syn-chronen Ultraschallabstandsmessungen M = m1, . . . ,m4:
X =
(m1,m2,m3,m4,
√x2+y2,arctan
(yx
))(5.32)
Der Ausgabevektor besteht aus einer einzelnen Belegungswahrschein-lichkeit für die zum Eingabevektor korrespondierenden Zelle c:
Y = P(HB|c) (5.33)
Um das künstliche neuronale Netz anzulernen, werden in [Thrun 1998]Lerndaten aus synthetischen idealen Karten durch manuell erstellte Sen-sormodelle simulativ generiert. Auf solch einer Karte wird der Sensorträgerzufällig positioniert und ausgerichtet. Aus den Kartendaten wird anschlie-ßend eine mögliche Messung gemäß dem stochastischen Modell für denjeweiligen Sensor erzeugt. Die Ground Truth-Belegungsinformation für denAusgabevektor lässt sich aus der Karte entnehmen.
Zur Generierung weiterer Lerndaten werden weitere Positionen und Aus-richtungen für den Sensorträger zufällig generiert und wie beschriebenausgewertet. Hierbei wird eine Gleichverteilung der Zufallsvariable aufmöglichen Kartenpositionen angenommen, was exemplarisch in Abbildung5.15 dargestellt ist.
Abbildung 5.15.: Synthetische Karte mit gleichverteilten Roboterpositionenund -ausrichtungen (blaue Sternchen)
Der Ansatz nach [Thrun 1998] erzeugt unter bestimmten Umständen eingenaueres inverses Sensormodell als eine manuelle Modellierung. Er ba-siert jedoch auch auf ähnlich vielen Modellannahmen:
159

Kapitel 5. Probabilistische Belegungsgitterfusion
Sowohl die repräsentative Modellierung der Karte ist herausforderndals auch die genaue Darstellung des Sensormodells. Für Ersteres müs-sen beispielsweise innerhalb von Gebäuden die Türen, die Einrichtungs-gegenstände und die Räumlichkeiten möglichst realitätsnah und entspre-chend häufig dargestellt werden, während beim Sensormodell für eine ho-he Genauigkeit sämtliche Messphänomene berücksichtigt werden sollten,die in der Domäne auftreten können. Hierzu zählen neben den obligato-rischen Messungenauigkeiten auch Doppeldeutigkeiten durch Mehrfach-reflexionen oder Absorptionen, welche beispielsweise durch Material undAusrichtung von Objektoberflächen verursacht werden können. Außerdemkönnen Unterschiede in der Signalcharakteristik auftreten, welche durchden Dynamikzustand des Sensorträgers, durch Interferenzen mit anderenSensorsignalen oder mit der Verletzung der statischen Umgebungsannah-me durch dynamische Objekte oder temporären Verdeckungen begründetwerden können.
Der Zustandsraum der Lerndaten zeigt, dass zwar zeitgleiche Messun-gen als abhängig angenommen werden, aber zeitlich auseinanderliegendeMessungen als unabhängig. Persistente Scheinziele oder persistent nichtdetektierbare Objekte werden somit nicht berücksichtigt.
Trotz dieser Schwächen ist die Vorgehensweise in [Thrun 1998] attrak-tiv, wenn das Sensormodell deutlich leichter zu generieren ist als desseninverses Pendant. Dies ist bei den verwendeten Ultraschallsensoren derFall, welche ausschließlich eine radiale Entfernungsmessung liefern, ausdenen jedoch keine eindeutige Objektposition und -kontur ermittelt werdenkann. Umgekehrt ist die Generierung einer beispielsweise normalverteil-ten Abstandsmessung zu einer gegebenen Karte recht einfach möglich.Des Weiteren erlaubt der simulative Ansatz die Generierung einer großenLerndatenmenge mit geringem Mehraufwand.
Viele andere Sensoren, wie Laserscanner, Stereokamerasensoren oderauch einige Radarsensoren schätzen bereits in der Signalvorverarbeitungeine mehr oder weniger genaue Objektposition und Objektkontur. Für die-se Sensoren ist die manuelle Generierung eines Sensormodells nicht vielkomplexer zu sein als dessen inverses Pendant. Eine höhere Genauigkeitfür solche inversen Sensormodelle ist wohl nur mit realen Lerndaten zuerwarten.
Die in [Thrun 1998] entwickelten Ansätze sind auf verschiedene Robo-ter portiert worden, sodass die generierten Belegungsgitter auch praktischgenutzt werden. Eine dieser Anwendungen ist der Museumsführer „Rhino“[Burgard 1998], der Besucher von Exponat zu Exponat leitet und Hinter-grundinformationen zu diesen liefert. Er nutzt dazu die erlernten inversenSensormodelle, um eine initiale bekannte Karte des Museums zu erweitern
160

5.5. Stand der Technik: Fusionsalgorithmen für Belegungsgitter
und auf dieser Karte eine möglichst sichere Trajektorie zum nächsten Ex-ponat zu finden. Diese dynamische Erweiterung ist für neue Hindernisse,wie stehende Besucher und verschobene Gegenstände sinnvoll.
Der Pfadplaner basiert wie bei Elfes im Wesentlichen auf dem A*-Algorithmus, wurde jedoch um zwei Aspekte erweitert. Zum einen wirdder berechnete Pfad noch eventuell von einer Routine modifiziert, diezur Kollisionsvermeidung von dynamischen Hindernissen wie Besucherndient, die noch keine ausreichende Evidenz im Belegungsgitter verursachthaben. Eine andere Erweiterung erhöht die Echtzeitfähigkeit, indem je-derzeit eine geeignete Trajektorie mit geringer Latenz abgefragt werdenkann, auch wenn diese aktuell nicht der optimalen Trajektorie nach der A*-Kostenfunktion entspricht.
Insgesamt konnte der Belegungsgitteransatz nach [Thrun 1998] gute Er-gebnisse in der gewählten Domäne erzielen, da er eine recht hohe Ver-fügbarkeit und Funktionalität erreicht hat. Es zeigte sich auch ein großesBesucherinteresse am maschinellen Museumsführer, der nicht nur andereExponate erklären konnte, sondern auch selbst ein solches darstellte.
Einschränken muss man aber, dass die Domäne nur aus einem Teil ei-nes Museums bestand und somit im Vergleich zu typischen Automotive-domänen sehr klein ist. Außerdem wird eine virtuelle Belegungskarte vor-gegeben, die nur noch dynamisch erweitert wird. Eine beliebig große Aus-wahl an Objekten kann dort bereits abgelegt werden, sodass insbesondereschwierig zu detektierende Gegenstände mit dieser Methode problemlosbehandelt werden können. Diese Möglichkeit ist in Automotivedomänenpraktisch nicht gegeben.
Belegungsgitterfusion nach Yu
Die in [Yu 2007] verwendete Netzfunktion ähnelt der von [Thrun 2006]: Eswerden sowohl Zellposition als auch Messungen als Eingangsvektoren ver-wendet und eine einzelne Zellzustandsschätzung wird in Form einer Mas-senverteilung als Ausgabevektor generiert. Auch wird der Ausgabevektorals unabhängig angenommen und mittels Logikalgorithmen mit dem Zell-zustand verknüpft. Als Unterschied ist zu vermerken, dass in den Eingabe-vektor zusätzlich die zwei nächstälteren Messungen einfließen und dasseine Massefunktion nach der Dempster-Shafer Theorie und nicht nachBayes im Ausgabevektor Verwendung findet.
Insgesamt erlaubt der Ansatz die Abhängigkeiten von drei aufeinander-folgenden Messungen zu erlernen. Nachteilig bezüglich der statistischenGenauigkeit ist jedoch, dass eine einzelne Messung dreimal in den Einga-bevektor der Netzfunktion einfließt und die Netzausgaben dennoch als un-
161

Kapitel 5. Probabilistische Belegungsgitterfusion
abhängig voneinander betrachtet werden. Somit kann das künstliche neu-ronale Netz zum Teil einzelne Messausreißer neutralisieren, jedoch liefertes wohl keine Möglichkeit, persistente Abhängigkeiten im finalen Zellzu-stand abzubilden.
Um Lerndaten für das künstliche neuronale Netz zu generieren, wirdin [Yu 2007] ein halbautomatischer Ansatz verfolgt. Die Ausgabevektorenwerden wie in [Thrun 1998] aus einer Ground Truth-Karte generiert: Umdiese zu erzeugen, wird der Roboter in einem Raum positioniert und alleObjekte, Wände und sonstige in Sensorreichweite befindliche Hindernis-se werden manuell ausgemessen. Die Ergebnisse werden in die GroundTruth-Karte übertragen, welche zusammen mit den Messdaten die Lern-basis bildet.
Insgesamt erfordert diese Methode eine Umgebung mit klaren undscharfen Konturen, um eine Ground Truth-Karte eindeutig generieren zukönnen. Um eine Überanpassung an wenige Lerndaten zu vermeiden, istes wohl auch notwendig, mehrere Räume in die Lernbasis mit einfließenzu lassen. Kleinere Ungenauigkeiten könnten sich aus der manuellen Ver-messung der Räumlichkeiten ergeben. Dennoch ist diese aufwändige Me-thode der simulativen Generierung vorzuziehen, da die Lerndaten deutlichrealistischer sind, als die synthetisch generierten.
Für den Automotivebereich ist diese Methode wohl zu aufwendig, damoderne Sensoren eine viel größere Reichweite haben als die im Robotik-bereich verbreiteten Ultraschallsensoren und somit eine deutlich größereGround Truth-Karte erforderlich wäre. Fehlende Wandbegrenzungen ver-größern den Raum zusätzlich. Auch sind Begrenzungen als solche zumTeil schwierig zu definieren, wie beispielsweise bei Rasenflächen mit un-terschiedlich hohem Bewuchs oder bei kleinen aufgeschütteten Schnee-haufen.
In [Yu 2007] ist nur die Erzeugung der Belegungsgitter beschrieben wor-den, jedoch keine spezifische Anwendung. Auf eine Bewertung dieser Me-thode bezüglich einer konkreten Problemstellung wird deshalb verzichtet.
Belegungsgitterfusion nach van Dam
Ein weiterer Ansatz zur Erstellung eines inversen Sensormodells ist in [vanDam 1996] zu finden. Im Gegensatz zu den bisher vorgestellten Ansätzenkommt die dort beschriebene Netzfunktion mit einer einzelnen Messungohne Zellpositionsangabe als Eingabevektor aus.
Der Ausgabevektor besteht dafür aus einem kompletten lokalen Be-legungsgitter, aus dem man die Belegungswahrscheinlichkeit einer ge-
162

5.5. Stand der Technik: Fusionsalgorithmen für Belegungsgitter
Abbildung 5.16.: In [van Dam 1996] verwendetes künstliches neuronalesNetz zur Generierung eines inversen Sensormodells
wünschten Zelle herausextrahieren kann. Dieses Netz ist mit einer bei-spielhaften Messung m in Abbildung 5.16 dargestellt.
Vorteilhaft an diesem Ansatz ist, dass die Netzfunktion des künstlicheneuronale Netz für jede Messung nur einmal ausgeführt werden muss undnicht für jede einzelne Zelle, wie bei den anderen Ansätzen.
Nachteilig ist, dass aufgrund des großen Ausgabevektors eine wohl grö-ßere Menge an Lerndaten notwendig ist, als bei vergleichbaren Ansätzen.Auch die fehlende Positionsangabe im Eingabevektor begründet dies, dadie Abhängigkeiten und Ähnlichkeiten von Nachbarzellen umständlich ausden Ground Truth-Daten abgeleitet werden muss. Eine Interpolation mitHilfe von Zellabstand und -winkel ist somit nicht so einfach möglich wie beianderen Ansätzen.
Wie auch der Ansatz von [Thrun 1998] erlaubt dieser keine Erlernungvon Abhängigkeiten zwischen Messungen. Vielmehr mittelt das künstlicheneuronale Netz diese über die Gesamtheit der Lerndaten.
In [van Dam 1996] werden keine synthetischen sondern reale Lernda-ten erzeugt: Dazu wird der Ansatz einer prospektiven Messdatenanalyse,ähnlich wie in Abschnitt 4.6.2 beschrieben, mit einer Referenzsensorik ge-koppelt. Hierzu befährt der Roboter eine Zufallstrajektorie bis zur Kollisionmit einem Objekt. Letztere kann beispielsweise durch Berührungssenso-ren detektiert werden, welche die Referenzsensorik darstellt. Die befahre-
163

Kapitel 5. Probabilistische Belegungsgitterfusion
ne Trajektorie wird als sicher frei deklariert, während die Zelle, in der dieKollision stattfand, als belegt angesehen wird. Diese Informationen bildenzusammen mit den Messungen, die während der Fahrt aufgenommen wor-den sind, die Lerndaten.
Diese Vorgehensweise ist bei Robotern bei geringen Geschwindigkei-ten Erfolg versprechend, jedoch für Versuchsträger im Automotivebereichaufgrund des hohen Schadenpotenzials nicht akzeptabel.
Auch in [van Dam 1996] ist nur die Belegungsgittergenerierung ohnespezifische Anwendung beschrieben worden, sodass die Bewertung desAnsatzes ohne Problemstellung verzichtet wird.
5.5.4. Bewertung
Die vorgestellten Ansätze aus der Robotik bemühen sich größtenteils umeine genaue Darstellung der inversen Sensormodelle. Allerdings gelingtes diesen nur teilweise die Abhängigkeiten aufzulösen: Während bei Elfesunterschiedliche Sensoren separat betrachtet werden können, wird beimMuriel-Ansatz eine Akkumulation von ähnlichen Messungen verhindert. BeiYu können hingegen einzelne Messausreißer kompensiert werden.
Was allen Ansätzen fehlt, ist eine Abhängigkeitsbeschreibung der Zell-zustände. So können beispielsweise mehrere Zellen durch eine einzelneFehlmessung fälschlicherweise als belegt oder frei angesehen werden:Dass die Zustände benachbarter Zellen deshalb stark miteinander korre-lieren können, wird durch keinen Ansatz dargestellt. Die Konzentration dervorgestellten Arbeiten beschränkt sich darauf, die Abbildungsoperation vonMessungen auf Einzelzellzustände zu perfektionieren, ohne dass das Be-legungsgitter in der Gesamtheit betrachtet wird.
Nur in einem Ansatz wird eine Auswertung des Belegungsgittersbeschrieben: Zur Pfadfindung wird bei Thrun eine Variante des A*-Algorithmus eingesetzt, welcher die Zellzustände als unabhängig betrach-tet und eine Kostenfunktion dementsprechend minimiert.
Bei vielen vorgestellten Ansätzen ist eine Übertragung auf den Auto-motivebereich problematisch, da die natürliche Domäne eines Autos sehrviel größer als die eines Roboters ist. Die Verwaltung eines globalen Bele-gungsgitters würde sehr große Mengen an Speicher kosten und es könn-te wohl auch nur nach mehrmaligem Befahren einer Strecke sinnvoll ge-nutzt werden. Auch erschwert die autotypische Domäne die Ground Truth-Datengenerierung der gesamten Umgebung aufgrund großer Sensorreich-weiten, hoher Geschwindigkeiten und dynamischer Objekte.
164

5.6. Abhängigkeiten in Belegungsgittern
Im Folgenden soll deshalb nur das unmittelbare Umfeld des Autos ineinem Belegungsgitter abgelegt werden; Sensorreichweiten und Applikati-on implizieren hierbei die Größe des Belegungsgitters. Typische Problemeaus der Robotik entfallen damit aus der Betrachtung: Einerseits ist eineLokalisation in einem globalen Belegungsgitter nicht notwendig und ande-rerseits benötigt man keine Algorithmen, die komplexe Pfade in einem sehrgroßen Belegungsgitter finden müssen.
5.6. Abhängigkeiten in Belegungsgittern
Die im Abschnitt 5.2 gesammelten Anforderungen verlangen unter ande-rem eine genaue und statistisch korrekte Schätzung unter realistischenUmgebungen und Anwendungen. Hierzu gehört die Erkennung und Neu-tralisierung von Abhängigkeiten zwischen Zellen und Messungen.
Bevor entsprechende Algorithmen entwickelt werden, werden diese bei-den klassischen Probleme konventioneller Fusionsalgorithmen vorgestelltund formal definiert. Diese treten einerseits bei der Fusionierung mehrererZellen zu einem Gesamtzustand auf und andererseits dann, wenn Messun-gen nicht unabhängig voneinander sind. Diese Phänomene sind praktischbei jeder Belegungsgitteranwendung und in jeder Messreihe eines Sensorsallgegenwärtig.
5.6.1. Inter-Cell Dependency Problem
Häufig verwendete inverse Sensormodelle, die eine unsichere Position imRahmen einer Messung darstellen, basieren auf bestimmten Verteilungs-annahmen, wie beispielsweise einer Normalverteilung (vgl. [Elfes 1989a]).Diese Wahrscheinlichkeitsdichtefunktion wird über das Belegungsgitterprojiziert und die entsprechenden Zellen werden mit der überlappendenFläche oder dem Funktionswert aktualisiert. Aus Performancegründen wer-den meist nur solche Zellen aktualisiert, welche sich signifikant mit dieserVerteilung überlappen.
Diese Algorithmen können eine statistisch genaue Schätzung der Bele-gungswahrscheinlichkeit einer einzelnen Zelle im Gitter leisten. Viele An-wendungen benötigen jedoch eine akkumulierte Schätzung über eine Men-ge von Zellen und nicht eine Menge von Schätzungen einzelner Zellen.Beispielhaft seien Pfadfindungsalgorithmen genannt, welche verschiede-ne Pfadalternativen bewerten müssen. Um die Pfade zu vergleichen, mussdie jeweilige gesamte Zellmenge betrachtet werden, die von diesem Pfad
165
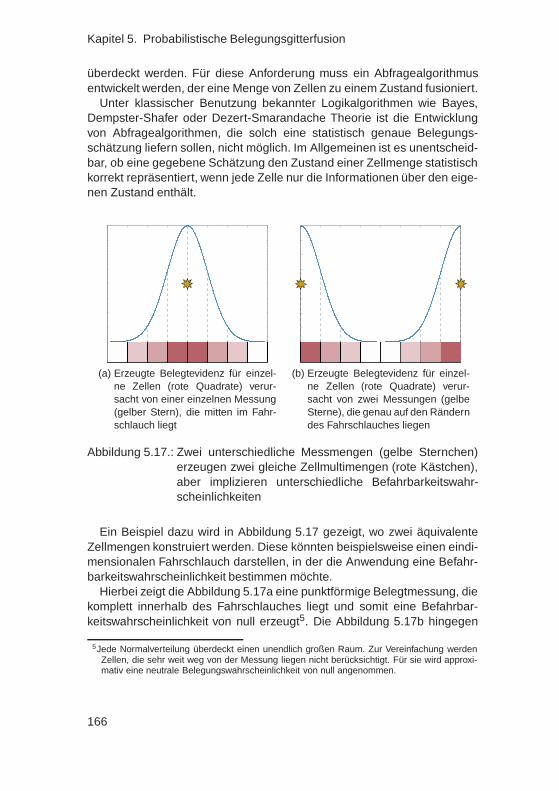
Kapitel 5. Probabilistische Belegungsgitterfusion
überdeckt werden. Für diese Anforderung muss ein Abfragealgorithmusentwickelt werden, der eine Menge von Zellen zu einem Zustand fusioniert.
Unter klassischer Benutzung bekannter Logikalgorithmen wie Bayes,Dempster-Shafer oder Dezert-Smarandache Theorie ist die Entwicklungvon Abfragealgorithmen, die solch eine statistisch genaue Belegungs-schätzung liefern sollen, nicht möglich. Im Allgemeinen ist es unentscheid-bar, ob eine gegebene Schätzung den Zustand einer Zellmenge statistischkorrekt repräsentiert, wenn jede Zelle nur die Informationen über den eige-nen Zustand enthält.
(a) Erzeugte Belegtevidenz für einzel-ne Zellen (rote Quadrate) verur-sacht von einer einzelnen Messung(gelber Stern), die mitten im Fahr-schlauch liegt
(b) Erzeugte Belegtevidenz für einzel-ne Zellen (rote Quadrate) verur-sacht von zwei Messungen (gelbeSterne), die genau auf den Ränderndes Fahrschlauches liegen
Abbildung 5.17.: Zwei unterschiedliche Messmengen (gelbe Sternchen)erzeugen zwei gleiche Zellmultimengen (rote Kästchen),aber implizieren unterschiedliche Befahrbarkeitswahr-scheinlichkeiten
Ein Beispiel dazu wird in Abbildung 5.17 gezeigt, wo zwei äquivalenteZellmengen konstruiert werden. Diese könnten beispielsweise einen eindi-mensionalen Fahrschlauch darstellen, in der die Anwendung eine Befahr-barkeitswahrscheinlichkeit bestimmen möchte.
Hierbei zeigt die Abbildung 5.17a eine punktförmige Belegtmessung, diekomplett innerhalb des Fahrschlauches liegt und somit eine Befahrbar-keitswahrscheinlichkeit von null erzeugt5. Die Abbildung 5.17b hingegen
5Jede Normalverteilung überdeckt einen unendlich großen Raum. Zur Vereinfachung werdenZellen, die sehr weit weg von der Messung liegen nicht berücksichtigt. Für sie wird approxi-mativ eine neutrale Belegungswahrscheinlichkeit von null angenommen.
166

5.6. Abhängigkeiten in Belegungsgittern
repräsentiert zwei punktförmige Belegtmessungen, deren Erwartungswer-te bzgl. Position genau auf den beiden Rändern der Fahrschlauchgren-zen liegen. Somit ergibt sich eine Chance von 1/2 für jede punktförmigeMessung, dass sich dieses außerhalb des Fahrschlauches befindet. Unterder Annahme, dass die beiden Messungen unabhängig sind, ergibt sichdamit eine Wahrscheinlichkeit von 1/4, dass beide Messungen außerhalbdes Fahrschlauches liegen und dieser somit befahrbar ist. Da jedoch beideZellmultimengen äquivalent sind, existiert keine Funktion, die diese beidenFälle unterscheiden könnte.
Abhängig davon, ob die Belegungsevidenz einer Zellmenge von eineroder mehreren Messungen stammt, benötigt man unterschiedliche Ope-ratoren, um die Schätzung genau zu gestalten. Sind zwei Evidenzen e1und e2 in dieser Form stochastisch abhängig, so muss man die verteilteEvidenz der WDF mit Hilfe des Additionsoperators zusammenfassen:
PHB(e1,e2) = e1+e2 (5.34)
Bei stochastisch unabhängigen Evidenzen e1 und e2 ergibt sich die Be-legungswahrscheinlichkeit PHB wie folgt:
PHB(e1,e2) = e1+e2−e1 · e2 (5.35)
Abhängig von der Anzahl der Messungen und deren Konstellation kön-nen große Unterschiede zwischen geschätzten und wahren Belegungs-wahrscheinlichkeiten auftreten, je nachdem wie fehlerhaft die Abhängig-keitsannahme ist. Um den maximalen Fehler zu quantifizieren, wird im Fol-genden ein weiteres Belegungsgitter künstlich erzeugt.
Es sei angenommen, dass n nichtüberlappende Messungen innerhalbeines Belegungsgitters so fusioniert werden, dass jede Einzelne von ihnendie Zellmenge nur partiell überdeckt, die vom Abfragealgorithmus genutztwird. Jede Messung überlappt diese mit einer Fläche von 1
n , sodass dieSumme der Belegungsevidenzen eins ergibt. Unter der Annahme, dassjede Messung unabhängig von den anderen Messungen ist, beträgt dieBelegtwahrscheinlichkeit PHB(n):
PHB(n) = 1−(
1− 1n
)n
(5.36)
Wenn die Anzahl der Messungen erhöht wird, konvergiert die Freiwahr-scheinlichkeit PHB(n) zu einer Konstante:
limn→∞
PHB(n) = 1− 1e
(5.37)
167

Kapitel 5. Probabilistische Belegungsgitterfusion
Als Ergebnis erhält man eine Belegungswahrscheinlichkeit von bis zu0,64 abhängig von der Anzahl der Messungen. Unter der gegensätzlichenAnnahme, dass sämtliche Belegungswerte aus einer einzelnen Messungstammen und somit abhängig sind, würde man eine Belegungswahrschein-lichkeit von 1,0 erhalten. Diese Beispiele führen zu folgendem Theorem:
Theorem 1 (Unentscheidbarkeit der Befahrbarkeit bei klassischen Bele-gungsgitteransätzen).Gegeben sei eine Menge von Messungen, welche die Zellen und Zell-zustände eines Belegungsgitters mit klassischen Logikfunktionen und in-versen Sensormodellen aktualisiert. Ferner sei aus den Messungen ent-scheidbar, ob das gesamte Belegungsgitter überfahrbar ist. Dann existiertkeine Funktion, welche die Befahrbarkeit des Belegungsgitters anhand derZellzustände im Allgemeinen entscheiden kann.
Der Grund für die Schätzunterschiede ist der Informationsverlust inner-halb des Fusionsprozesses: Der Grad der Abhängigkeit eines Zellzustan-des zu anderen Zellen ist nicht in der Belegungswahrscheinlichkeit einereinzelnen Zelle dokumentiert, welches das „Inter-Cell Dependency Pro-blem (ICDP)“ verursacht. Eine sorgfältige Entwicklung von konsistentenFusions- und Abfragealgorithmen ist notwendig, um dieses Problem zu lö-sen.
Für die Entwicklung solcher Algorithmen ist die formale Definition die-ses Problems hilfreich. Hierbei müssen sowohl Fusions- als auch Abfra-gealgorithmus so aufeinander abgestimmt werden, dass diese bestimmteEigenschaften aufweisen. Dazu sei folgende Definition aufgestellt:
Definition 4 (Inter-Cell Dependency Problem).Gegeben seien zwei Mengen von Zellen C und D, welche den gleichenRaum mit unterschiedlichen Zellgrößen bedecken. C und D werden mitder gleichen Menge von Messungen M durch einen Fusionsalgorithmusξ (C,M) bzw. ξ (D,M) aktualisiert.
Ein Abfragealgorithmus β (X) löst das Inter-Cell-Dependency Problem,genau dann wenn β (ξ (C,M)) = β (ξ (D,M)) für alle möglichen Mengen vonC, D und M ist.
Die Definition beinhaltet insbesondere den Fall, dass das Ergebnis desAbfragealgorithmus einer Menge von Zellen C genau dem Ergebnis ent-sprechen muss, als wenn eine einzelne große Zelle D = d den gleichenBereich überdeckt. Bei der Diskretisierungsgenauigkeit verlangt die Defi-nition keine Begrenzung, sodass die Menge der Zellen C theoretisch ausunendlich vielen kleinen Zellen bestehen kann. Insgesamt sind Algorith-men, die das ICDP lösen, invariant gegenüber Zellgrößenveränderungen,
168

5.6. Abhängigkeiten in Belegungsgittern
solange die Diskretisierungsgrenzen genau den Rand des Abfrageberei-ches erreichen.
5.6.2. Inter-Measurement Dependency Problem
Neben Abhängigkeiten von Zellzuständen existieren auch Abhängigkeitenzwischen Messungen einer Messreihe, welche beispielsweise durch per-sistente Scheinziele verursacht werden können. Auch können bei verwand-ten Messprinzipien Abhängigkeiten zwischen Messungen verschiedenerSensoren auftreten. Analog zu ICDP wird dieses Problem im Folgenden„Inter-Measurement Dependency Problem (IMDP)“ genannt.
Die Fusionsalgorithmen Bayes, Dempster-Shafer und Dezert-Smarandache Theorie sind unter klassischer Verwendung nicht inder Lage, die Abhängigkeiten in Messreihen in einem Belegungsgitteraufzulösen. Der Grund dafür ist, dass der Typ der Informationsquelle imZellzustand nicht dokumentiert wird. So ist es schwer oder gar unmöglichzu entscheiden, aufgrund welcher Informationsquellen der Zellzustandentstanden ist. Diese sind aber notwendig, um die Abhängigkeit neuerMessdaten mit dem Zellzustand bestimmen zu können.
So ist beispielsweise eine Zelle sehr wahrscheinlich belegt, wenn die-se durch drei Messungen von technologisch heterogenen Sensoren alssolche bestätigt wird. Eine nicht so hohe Belegungswahrscheinlichkeit istanzunehmen, wenn ein einzelner Sensor dreimal hintereinander eine Zel-le als belegt misst. Dies ist mit persistenten Fehldetektionen und fehler-haften Detektionen aufgrund Umgebungsartefakten für einzelne Sensorenbegründet (vgl. Kapitel 2). Insgesamt ist anzunehmen, dass die Evidenz-masse für wiederholte Messungen unter ähnlichen Messumständen deut-lich sinkt, wenn man den Zellzustand berücksichtigt. Wenn beispielsweiseein Sensor eine Zelle bereits vielfach als belegt postuliert hat, so scheintes kaum ein Mehrwert zu sein, wenn der Sensor dieses ein weiteres Maltut.
Eine besondere Bedeutung erhält die Abhängigkeitsanalyse, wenn wi-dersprüchliche Messungen für eine Zelle vorliegen. Je nach Gewichtungkann der eine oder andere Sensor die Entscheidungshoheit über den Zell-zustand gewinnen.
Wie beim ICDP ist eine formale Definition für Anforderungen an einenAlgorithmus sinnvoll. Im Unterschied zum ICDP werden die Zellen in einemBelegungsgitter nur einzeln betrachtet:
Definition 5 (Inter-Measurement Dependency Problem).Ein Abfragealgorithmus β (c) löst das Inter-Measurement Dependency
169

Kapitel 5. Probabilistische Belegungsgitterfusion
Problem, wenn er eine statistisch genaue und genaue Schätzung für alleeinzelnen Zellen innerhalb eines Belegungsgitters c ∈C liefert.
Zu bemerken ist, dass in der Definition keine Angaben gemacht werden,was „genau“ exakt bedeutet. Dies ist insbesondere bei Massenverteilun-gen mit vielen Attributen wie beispielsweise bei der Dezert-SmarandacheTheorie nicht einfach zu beantworten. Ob die notwendige Genauigkeit er-reicht worden ist, kann zudem nur anhand einer konkreten Fahrerassis-tenzapplikation bewertet werden. Insgesamt bleibt die Definition damit ab-sichtlich etwas unscharf.
Die Genauigkeitsanforderung ist jedoch wichtig, um triviale Massefunk-tionen auszuschließen. So scheint eine Massefunktion im Sinne der De-finition zwar statistisch korrekt zu sein, wenn diese konstant maximalesUnwissen oder A-priori-Wahrscheinlichkeiten als Ergebnis liefert, jedochzu ungenaue für praktisch alle Anwendungen.
5.6.3. Kombination von ICDP und IMDP
Fusions- und Abfragealgorithmen, die die ICDP-Definition erfüllen, erlau-ben zwar die Kombination von Zellen zu einem Ergebnis, welches die Ab-hängigkeiten der Zellzustände auflösen und den Einfluss der Zellgrößenim Rahmen der Diskretisierungsgrenzen neutralisieren. Jedoch werden andas Abfrageergebnis überhaupt keine qualitativen Anforderungen gestellt:So wird die ICDP-Definition beispielsweise von einer Funktion erfüllt, dieunabhängig von der Zellmenge eine konstante Verteilung als Ergebnis zu-rückliefert. Dieses Ergebnis ist jedoch für alle Fahrerassistenzsystemappli-kation praktisch unbrauchbar.
Algorithmen, die die IMDP-Definition erfüllen, erlauben zwar eine ge-naue, robuste und statistisch genaue Befahrbarkeitsschätzung im Sinneder Fahrerassistenzsystemapplikation, jedoch nur für eine einzelne Zelleund nicht für eine Menge von Zellen. Auch hier ist eine Praxisrelevanz nichtgegeben, da das Ego-Fahrzeug praktisch immer mehrere Zellen überfährt.
Insgesamt benötigt die Fahrerassistenzsystemapplikation im Regelfalleinen Abfragealgorithmus, der sowohl die Zellabhängigkeiten einer belie-bigen Menge an Zellen berücksichtigt, als auch eine gute Schätzung imSinne ihrer Anforderungen für diese Zellmenge berechnet. Ein Algorithmuserfüllt diese Anforderung, wenn dieser sowohl die ICDP- als auch IMDP-Definition erfüllt. Hierzu sei folgendes Theorem aufgestellt:
Theorem 2 (Kombination ICDP und IMDP).Ein Abfragealgorithmus β (X) liefert eine genaue, robuste und statistischgenaue Schätzung im Sinne einer Fahrerassistenzsystemapplikation für
170

5.6. Abhängigkeiten in Belegungsgittern
eine Menge von Zellen C, wenn er sowohl das ICDP als auch das IMDPlöst.
Das Theorem folgt direkt aus der Definition von ICDP und IMDP. Sei Ceine Menge von Zellen und d eine Menge bestehend aus einer einzelnenZelle d, welche die gleichen Bereiche abdecken. Beide Mengen werdenmit einer Messreihe M mittels Fusionsalgorithmus ξ (C,M) bzw. ξ (d,M)aktualisiert. Aus der ICDP-Definition folgt:
β (ξ (C,M)) = β (ξ (d,M)) (5.38)
Da der Abfragealgorithmus für die einzelne Zelle d nach der IMDP-Definition statistisch korrekt ist, muss dieses auch für das äquivalente Er-gebnis β (ξ (C,M)) gelten. Dieser Zusammenhang ist in Abbildung 5.18 dar-gestellt.
Abbildung 5.18.: Fusions- und Abfragealgorithmus, der das ICDP exempla-risch löst
Die ICDP- und IMDP-Definition wurde in den vorherigen Schritten sepa-rat definiert, sodass die Möglichkeit besteht, beide Aspekte separat behan-deln zu können. So ist es beispielsweise möglich, einen ICDP-konformenAlgorithmus zu entwickeln und dann für unterschiedliche Applikationen ver-schiedene Varianten von IMDP-Algorithmen auf das Ergebnis darauf an-zuwenden. Genau diese getrennte Betrachtungsweise wird in den nach-folgenden Abschnitten angewendet, in denen ICDP- und IMDP-kompatibleAlgorithmen entwickelt werden.
171

Kapitel 5. Probabilistische Belegungsgitterfusion
5.6.4. Zusammenfassung
In diesem Abschnitt wurden die allgemeinen Anforderungen einer Sensor-datenfusion an das eingebettete Belegungsgitter konkretisiert und dabeidie Aspekte der Genauigkeit und Robustheit genauer untersucht. Die bei-den zugrunde liegenden Teilprobleme ICDP und IMDP wurden dargestelltund formal definiert. Es wurde in einem Theorem bewiesen, dass eini-ge Anforderungen automatisch erfüllt werden, wenn entsprechende Bele-gungsgitteralgorithmen sowohl das ICDP als auch das IMDP lösen.
Die Anforderungen zeigen auch, dass es nicht ausreicht, ausschließlichFusionsalgorithmen für einzelne Zellzustände zu entwickeln. Ausschlagge-bend ist die Kombination von Abfrage- und Fusionsalgorithmus. Die beidenTeilkomponenten einer Belegungsgitterfusion müssen genau aufeinanderabgestimmt werden, um ein genaues Ergebnis zu erhalten.
Solch ein kombinierter Ansatz wird von keinem der im Abschnitt 5.5 vor-gestellten Fusionsalgorithmen verfolgt. Es ist außerdem für diese Fusions-algorithmen unmöglich, einen ICDP-fähigen Abfragealgorithmus mit hoherGenauigkeit zu entwickeln, da die Abhängigkeitsinformationen zwischenden Zellzuständen unwiderruflich verloren gegangen sind. Somit könnendiese Algorithmen die genannten Anforderungen nicht erfüllen.
Einige der vorgestellten Ansätze versuchen zumindest die Messabhän-gigkeiten nach bestimmten Aspekten aufzulösen, scheitern jedoch spä-testens bei der Akkumulation des Zellzustandes durch Verwendung klas-sischer Logikalgorithmen. Diese nehmen eine vollständige Unabhängig-keit der Massenverteilungen von Zellzustand und neuer Messung an, wasZweifel an der statistischen Korrektheit und Genauigkeit der Schätzungaufkommen lässt, da aufeinanderfolgende Messungen praktisch immerpartiell abhängig sind. Je nach Anwendung kann dies Probleme mit derGenauigkeitsanforderung verursachen.
Da die vorgestellten Ansätze aus der Literatur diese Abhängigkeitennicht berücksichtigen, ist das Ziel der nächsten Abschnitte, geeignetereAlgorithmen zu entwickeln. Diese sollen die Genauigkeit und Robustheitder Umgebungsschätzung mittels Belegungsgitter steigern.
5.7. Entwicklung von ICDP-Algorithmen
In diesem Abschnitt werden zwei Algorithmen vorgestellt, welche das ICDPzumindest approximativ lösen. Der eine ist ein einfacher nichtprobabilisti-scher Algorithmus, während der andere verschiedene probabilistische As-
172

5.7. Entwicklung von ICDP-Algorithmen
pekte integriert. Hierzu gehört eine Vertrauensmasse pro Messung und dieMöglichkeit, Messungenauigkeiten mit zu modellieren.
Beide Algorithmen basieren auf der die Dezert-Smarandache Theoriemit dem vereinfachten Wahrnehmungsrahmen Θ aus Abschnitt 5.4.1, so-dass diese eine Massefunktion über vier Attribute zurückliefern. Die Ver-wendung anderer Logiken ist jedoch transparent möglich.
5.7.1. Nichtprobabilistischer Algorithmus
Der nichtprobabilistische Fusionsalgorithmus unterscheidet vier diskreteZustände einer Zelle nach der Dezert-Smarandache Theorie: Entweder istderen Zustand belegt, frei, unbekannt oder konfliktbehaftet. Dieses Modellwird auch beim Abfragealgorithmus β (X) und bei den Messungen ange-wendet, wobei bei Letzterem der konfliktbehaftete Zustand entfällt. Der Al-gorithmus berücksichtigt weder Messungenauigkeiten noch Messunsicher-heiten in Form von Scheinzielen oder fehlerhaften Nichtdetektionen.
Der Zustand einer Zelle bestimmt sich aus der Menge der Messungen,die die Zelle geometrisch betrifft. Für die einzelnen Messungen wird an-genommen, dass mittels inversen Sensormodells eine geometrische Formgeneriert wird. Diese Form beschreibt Frei- oder Belegtbereiche. Die Men-ge der Messungen bestimmt, welche Ereignisse des Wahrnehmungsrah-mens Θ für eine Zelle eingetreten ist. Die Eintrittsbedingungen werden wiefolgt definiert:
P(HF |M,c) =
1, wenn die geometrische Vereinigung aller Frei-
messungen die gesamte Zelle als frei bestätigt
0, sonst(5.39)
P(HB|M,c) =
1, wenn eine Messung einen Teil
der Zelle als belegt bestätigt
0, sonst
(5.40)
Ob HF eingetreten ist, hängt allein von der Menge der Messungen ab,die eine Freihypothese stützen. HB hingegen tritt nur aufgrund einer odermehrerer Messungen ein, die eine Belegthypothese stützen. Der Zellzu-stand einer Zelle c ergibt sich aus den Kombinationsmöglichkeiten der ein-getretenen Ereignisse des Wahrnehmungsrahmens Θ:
173

Kapitel 5. Probabilistische Belegungsgitterfusion
ξ (c,M) =
HF , wenn (P(HF |M,c) = 1)∧ (P(HB|M,c) = 0)
HB , wenn (P(HF |M,c) = 0)∧ (P(HB|M,c) = 1)
HF∪B , wenn (P(HF |M,c) = 0)∧ (P(HB|M,c) = 0)
HF∩B , sonst
(5.41)
Für den Abfragealgorithmus, der die Menge der Zellen C zu einem Zu-stand zusammenfassen soll, ergibt sich folgende Funktion β (C,M) :
β (C,M) =
HF , wenn (∀c ∈C|ξ (c,M) = HF)
HB , wenn (∃c ∈C|ξ (c,M) = HB)∨[(∃c ∈C|ξ (c,M) = HF∪B)∧ (∃c ∈C|ξ (c,M) = HF∩B)]
HF∪B , wenn (∃c ∈C|ξ (c,M) = HB∪F)∧ (∄c ∈C|ξ (c,M) = HB)
HF∩B , sonst(5.42)
Der vorgestellte Algorithmus löst das ICDP formal exakt. Er basiert dar-auf, die Messungen als geometrische Formen in der Ebene zu betrach-ten und diese zu verknüpfen. Hierbei werden die jeweiligen Belegt- undFreimessungen zu jeweils einer Menge vereint. Aus dem Schnitt der bei-den Vereinigungsmengen ergibt sich der Konfliktbereich und aus den Dif-ferenzmengen der Frei- bzw. Belegtbereich. Der Bereich, der durch keineder erzeugten Mengen abgedeckt wird, ist der unbekannte Bereich. DieserZusammenhang ist in Abbildung 5.19 verdeutlicht.
Um zu entscheiden, welchen Zustand eine Zelle hat, muss der Algorith-mus die Gesamtmenge der Frei- und Belegtbereiche betrachten, welchedurch die inversen Sensormodelle und Messungen erzeugt worden sind.Im Gegensatz zu bekannten Ansätzen existiert kein Zellzustand, der effi-zient rekursiv durch neue Messung aktualisiert wird. Eine Begrenzung derbetrachteten Messungen ist somit notwendig, um eine obere Grenze bzgl.Laufzeitverhalten einhalten zu können.
Auch sind je nach geometrischer Form der Frei- und Belegtbereichemehr oder weniger komplexe Algorithmen notwendig, um die Vereini-gungs-, Schnitt- oder Differenzmengen exakt zu bestimmen. Auf Basis sol-cher Algorithmen könnte man direkt den Belegungszustand eines Berei-ches ermitteln, ohne den Umweg über die Zellen zu nutzen. Bei diesemAnsatz kann das Belegungsgitter als solches entfallen und es entsteht kei-ne Diskretisierungsungenauigkeit. Die eigentliche Fusionierung findet bei
174

5.7. Entwicklung von ICDP-Algorithmen
(a) Im einfachsten Fall haben al-le Zellen den gleichen Zustand,welcher bei der Fusionierungerhalten bleibt
(b) Frei- und Konfliktbereiche wer-den zu einem Konfliktbereichfusioniert
(c) Ist eine Zelle belegt, so gilt die-ses für den gesamten Bereich
(d) Konfliktbereiche und unbe-kannte Bereiche werden zueinem Belegtbereich aufgelöst
Abbildung 5.19.: Diskreter ICDP-Algorithmus: Freie, belegte, unbekannteund konfliktbehaftete Zellen (grün/rot/blau/gelb) werdendurch Freibereiche (grünes gestricheltes Dreieck) und Be-legtbereiche (rote gestrichelte Ellipse) erzeugt. Der ICDP-konforme Abfragealgorithmus β (C) liefert für jedes Zell-mengenpaar mit vier und einer Zelle jeweils das gleicheErgebnis.
dieser Methode erst beim Abfragealgorithmus statt, während der Fusions-algorithmus nur einen Messwertepuffer verwalten muss.
Beim vorgestellten Belegungsgitteransatz ist es umgekehrt: Die Fusio-nierung ist der weitaus komplexere Teil, während der Abfragealgorithmusnur wenige Fallunterscheidungen beim Betrachten der Zellzustände ma-chen muss. Dadurch ist eine schnelle Bestimmung des Belegtzustandesvieler unterschiedlicher Zellmengen bei konstanter Messmenge möglich.Dieser Fall tritt beispielsweise bei der Pfadplanung eines Roboters ein, wozu einem Zeitpunkt viele alternative Pfade geprüft werden müssen, ohnedass sich das Belegungsgitter zwischenzeitlich ändert. Das Belegungsgit-ter kann in diesem Fall als eine Art Zwischenspeicher betrachtet werden,
175

Kapitel 5. Probabilistische Belegungsgitterfusion
welches die Laufzeit des Algorithmus auf Kosten von Speicher und Genau-igkeit bei wiederholter Anwendung senkt.
5.7.2. Probabilistischer Fusionsalgorithmus
In diesem Abschnitt wird ein Algorithmus vorgestellt, der im Gegensatzzum vorangegangenen Algorithmus probabilistisch arbeitet. Um eine Echt-zeitfähigkeit für diesen zu ermöglichen, wird keine exakte Lösung desICDP angestrebt, jedoch eine approximative. Auch werden Einschränkun-gen bzgl. der Genauigkeit bei den inversen Sensormodellen gemacht, umdie Laufzeit des Algorithmus zu verringern.
Der Algorithmus unterstützt Belegtbereiche in Form von Punkten undBoxen und Freibereiche in Polygonform. Es werden unterschiedliche Mess-evidenzen und zusätzlich bei den Belegtbereichen Positionsunsicherheitenunterstützt. Zusammen mit dem später vorgestellten Abfragealgorithmusβ (X) formen diese Algorithmen eine approximative Lösung für das ICDP.
Zunächst werden die inversen Sensormodelle für die unterschiedlichenMesstypen vorgestellt. Diese generieren Evidenzen für einzelne Zellen.
Inverses Sensormodell für Freibereiche
Das inverse Sensormodell für Freibereiche generiert eine Evidenzvertei-lung aus einer Freimessung, welche auf unterschiedlichen Sensoren ba-sieren kann (vgl. Kapitel 2). Freibereiche können sehr groß sein und somitviele Zellen enthalten. Sie können gleichzeitig komplexe Formen anneh-men, insbesondere wenn Objekte den Freibereich unregelmäßig unterbre-chen.
Ein geeignetes Modell scheint das Strahlenmodell zu sein, welches aus-gehend vom Sensor einzelne Strahlen solange durch den Raum wirft, bisein Belegtbereich diesen aufhält oder die maximale Sensorreichweite er-reicht worden ist. Falls kein Belegtbereich erkannt worden ist, macht esinsbesondere bei indirekt gemessenen Freibereichen Sinn, die Evidenz fürdie Freihypothese mit steigender Entfernung zu senken. Dies ist mit der un-sicheren Schätzung der maximalen Sensorreichweite begründet, die vondiversen unbekannten Faktoren abhängig ist, wie beispielsweise Reflekti-vität eines möglichen Ziels oder Witterungseinflüsse.
Im folgenden Modell wird ein Kernbereich von 0 bis RMin definiert, in demeine maximale Evidenz für einen Freibereich erreicht wird. Mit steigenderReichweite fällt die Freievidenz linear ab bis RMax erreicht worden ist. Abdiesem Punkt ist die maximale Sensorreichweite erreicht worden, sodass
176
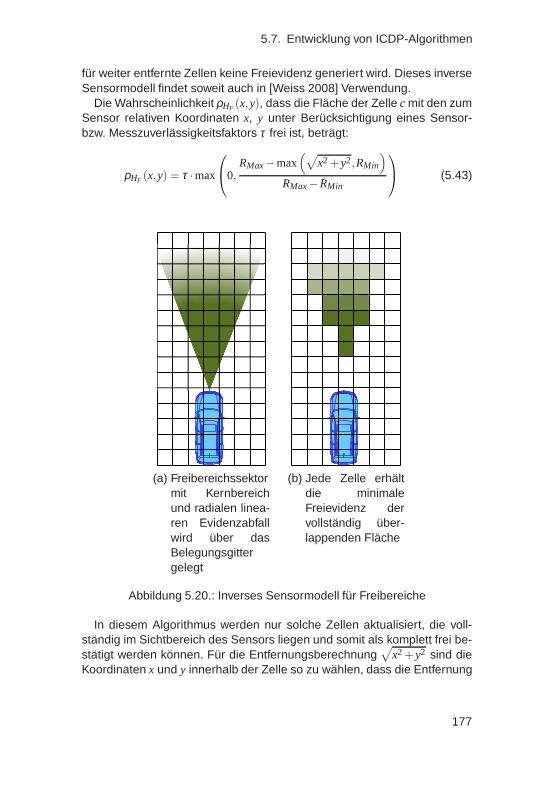
5.7. Entwicklung von ICDP-Algorithmen
für weiter entfernte Zellen keine Freievidenz generiert wird. Dieses inverseSensormodell findet soweit auch in [Weiss 2008] Verwendung.
Die Wahrscheinlichkeit ρHF (x,y), dass die Fläche der Zelle c mit den zumSensor relativen Koordinaten x, y unter Berücksichtigung eines Sensor-bzw. Messzuverlässigkeitsfaktors τ frei ist, beträgt:
ρHF (x,y) = τ ·max
0,
RMax −max(√
x2+y2,RMin
)
RMax −RMin
(5.43)
(a) Freibereichssektormit Kernbereichund radialen linea-ren Evidenzabfallwird über dasBelegungsgittergelegt
(b) Jede Zelle erhältdie minimaleFreievidenz dervollständig über-lappenden Fläche
Abbildung 5.20.: Inverses Sensormodell für Freibereiche
In diesem Algorithmus werden nur solche Zellen aktualisiert, die voll-ständig im Sichtbereich des Sensors liegen und somit als komplett frei be-stätigt werden können. Für die Entfernungsberechnung
√x2+y2 sind die
Koordinaten x und y innerhalb der Zelle so zu wählen, dass die Entfernung
177

Kapitel 5. Probabilistische Belegungsgitterfusion
maximiert wird. Diese Koordinaten befinden sich vom Sensor aus gesehenauf dem am weitesten entfernten Eckpunkt der Zelle. In Abbildung 5.20ist die exemplarische Generierung von Freievidenzen für einzelne Zellendurch dieses inverse Sensormodell dargestellt.
Im Falle einer Reflexion eines Laserpunktes bzw. bei Erkennung einesObjektes durch einen Stereokamerasensor ist RMax und RMin so zu wählen,dass für die Entfernungsschätzung d der Messung gilt:
d = RMin +12(RMax −RMin) (5.44)
RMax − RMin repräsentiert hierbei die Positionsunsicherheit des Objek-tes und somit indirekt die Unsicherheit über die Länge des Freibereiches.Durch die Linearität des Modells ist die Wahrscheinlichkeitsdichtefunktionbzgl. des Abstandes des Objektes zum Sensor dreiecksverteilt.
In diesem Fall ist bei indirekt messenden Sensoren eine Anhebung desGewichtungsfaktors τ zusätzlich sinnvoll, da aufgrund der Objektdetekti-on die Wahrscheinlichkeit verringert worden ist, dass sich im Bereich zwi-schen Objekt und Sensor ein anderes Objekt befindet. Dieses ist durch diebekannte minimale Sensorreichweite und durch eine nicht erfolgte Verde-ckung des detektierten Objektes begründet.
Das vorgestellte Freibereichsmodell ermöglicht die effiziente Berech-nung von Evidenzen für bestimmte Freibereiche. Es unterstützt Strahlen-,Kegel- bzw. Sektormodelle, welche beispielsweise bei Laserscannern, Ste-reokameras und Ultraschallsensoren auftreten. Es ist somit durch entspre-chende Parametrisierung modular für viele Sensoren einsetzbar.
Insgesamt basiert es darauf, eine Fläche mit variabler Evidenz zu gene-rieren und diese den Zellen zuzuweisen. Um später das ICDP zu lösen,ist die Art unwichtig, wie diese Freifläche generiert wird. Entscheidend ist,dass die Freievidenz einer Zelle der minimalen Evidenz des überlappen-den Bereiches entspricht. Es bleibt somit viel Raum, um alternative inverseSensormodelle für Freibereiche zu generieren.
Inverses Sensormodell für punktförmige Objektmessungen
Für Messungen, die nur eine Positionsinformation aber keine Konturinfor-mation wie Breite oder Länge liefern, ist ein Modell notwendig, welchespunktförmige Belegungsinformationen in das Belegungsgitter fusioniert.Dieser Typ von Messungen wird beispielsweise häufig von Radarsensorenerzeugt.
Im Folgenden sei ein Objekt angenommen, welches neben Positionsin-formationen px und py eine Schätzung der zugehörigen Varianzen σx und
178
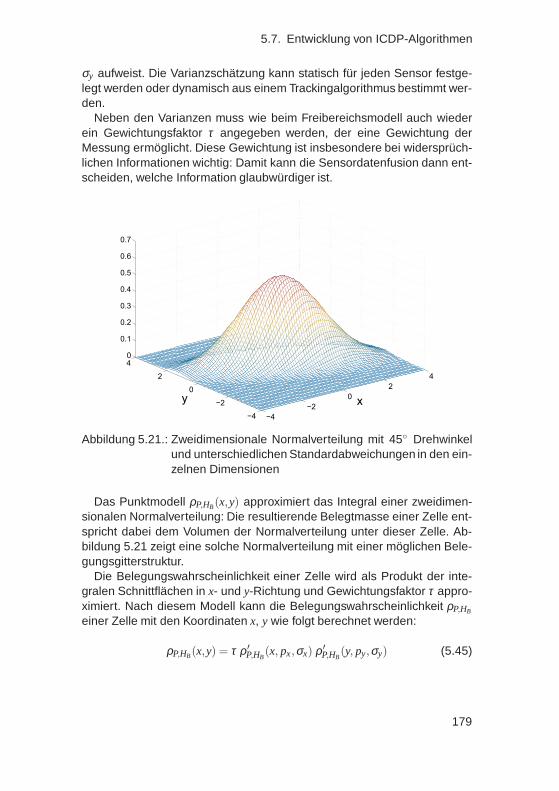
5.7. Entwicklung von ICDP-Algorithmen
σy aufweist. Die Varianzschätzung kann statisch für jeden Sensor festge-legt werden oder dynamisch aus einem Trackingalgorithmus bestimmt wer-den.
Neben den Varianzen muss wie beim Freibereichsmodell auch wiederein Gewichtungsfaktor τ angegeben werden, der eine Gewichtung derMessung ermöglicht. Diese Gewichtung ist insbesondere bei widersprüch-lichen Informationen wichtig: Damit kann die Sensordatenfusion dann ent-scheiden, welche Information glaubwürdiger ist.
−4
−2
0
2
4
−4
−2
0
2
40
0.1
0.2
0.3
0.4
0.5
0.6
0.7
xy
Abbildung 5.21.: Zweidimensionale Normalverteilung mit 45 Drehwinkelund unterschiedlichen Standardabweichungen in den ein-zelnen Dimensionen
Das Punktmodell ρP,HB(x,y) approximiert das Integral einer zweidimen-sionalen Normalverteilung: Die resultierende Belegtmasse einer Zelle ent-spricht dabei dem Volumen der Normalverteilung unter dieser Zelle. Ab-bildung 5.21 zeigt eine solche Normalverteilung mit einer möglichen Bele-gungsgitterstruktur.
Die Belegungswahrscheinlichkeit einer Zelle wird als Produkt der inte-gralen Schnittflächen in x- und y-Richtung und Gewichtungsfaktor τ appro-ximiert. Nach diesem Modell kann die Belegungswahrscheinlichkeit ρP,HB
einer Zelle mit den Koordinaten x, y wie folgt berechnet werden:
ρP,HB(x,y) = τ ρ ′P,HB
(x, px,σx) ρ ′P,HB
(y, py,σy) (5.45)
179

Kapitel 5. Probabilistische Belegungsgitterfusion
Die Belegungswahrscheinlichkeit pro Dimension für eine Zelle der Größes× s wird wie folgt berechnet:
ρ ′P,HB
(a, p,σ) =1
σ√
2π
a+ s2∫
a− s2
e−12(
v−pσ )
2
dv (5.46)
In dem Punktmodell stecken zwei Vereinfachungen, sodass das Volu-men nicht exakt, aber doch recht genau approximiert wird. Diese sind not-wendig, um eine effiziente Berechnung der Masse unter Echtzeitbedingun-gen zu ermöglichen. Zum einen wird die Zelle, über die das Integral be-rechnet wird, um den Zellmittelpunkt so gedreht, dass diese senkrecht bzw.parallel zu den Achsen der Normalverteilung steht. Zum anderen wird nichtdie zweidimensionale Normalverteilung integriert, sondern die eindimen-sionalen Normalverteilungen pro Dimension, die durch den Zellmittelpunktverlaufen.
Die Massebestimmung erfordert insgesamt die Berechnung von zwei be-stimmten Integralen der Normalverteilung. Da solche Integrale nicht ge-schlossen integrierbar sind, werden diese mittels nummerisch approxi-mierten Tabellen angenähert. Durch geschickte Skalierung und Verschie-bung lässt sich das Problem auf die bestimmte Integration einer Standard-normalverteilung bzw. auf die zweimalige Berechnung eines normiertenGaußschen Fehlerintegrals zurückführen. Letzteres wird in einer Tabelle inhoher Auflösung vorgehalten.
Inverses Sensormodell für rechteckförmige Objektmessung en
Neben punktförmigen Belegtmessungen gibt es Sensoren, die bereits beider Signalvorverarbeitung Messpunktwolken so zusammenfassen, dassObjekte mit Konturen entstehen. Für weitere Informationen dazu sei aufKapitel 2 verwiesen. Um für solche Sensoren ein inverses Sensormodellzu schaffen, wird im Folgenden ein Rechteckmodell verwendet.
Dieses inverse Sensormodell soll neben der Objektpositition und denKonturlängen auch probabilistische Faktoren nutzen. Hierzu wird die Vari-anz der Objektposition und wieder ein messungs- bzw. sensorabhängigerGewichtungsfaktor τ berücksichtigt.
Das Rechteckmodell wird auf zwei eindimensionale Linienmodelleρ ′
R,HB(a, p,σ , l) entlang der Richtungsachsen der rechteckförmigen Mes-
sung reduziert. Die Linienmodelle betrachten die jeweilige Wahrscheinlich-keit, dass eine Zelle mit der Position a nicht mit einer Linie mit der Posi-tion (px, py) und der Länge (lx, ly) im eindimensionalen Fall überlappt. Die
180

5.7. Entwicklung von ICDP-Algorithmen
Linien werden aus senkrechten Schnitten des Rechteckes generiert unddurch je zwei Punkte p− l
2 und p+ l2 beschrieben. Die Zelle ist nicht be-
legt, wenn sich der linke Startpunkt der Linie rechts von der Zelle befindetoder wenn der rechte Endpunkt der Linie sich links von der Zelle befindet.Die Belegungswahrscheinlichkeit wird als dazu komplementäres Ereignisangesehen und folgendermaßen berechnet:
ρ ′R,HB
(a, p,σ , l) =
1− 1
σ√
2π
∞∫
a+ s2
e− 1
2
(v−p+ l
2σ
)2
dv
·
1− 1
σ√
2π
a− s2∫
−∞
e− 1
2
(v−p− l
2σ
)2
dv
(5.47)
Durch Umformung der Integrationsgrenzen lässt sich Gleichung 5.47 wiefolgt vereinfachen:
ρ ′R,HB
(a, p,σ , l) =1
2πσ2
a+ s2∫
−∞
e− 1
2
(v−p+ l
2σ
)2
dv
∞∫
a− s2
e− 1
2
(v−p− l
2σ
)2
dv (5.48)
Das Rechteckmodell nimmt die Überlappungswahrscheinlichkeiten in X-und Y-Richtung als unabhängig an und modifiziert die beiden Linienmodel-le mit dem Gewichtungsfaktor τ:
ρR,HB(x,y) = τ ρ ′R,HB
(x, px,σx, lx) ρ ′R,HB
(y, py,σy, ly) (5.49)
Die Belegtevidenzverteilung eines beispielhaften Rechtecks für ein Be-legungsgitter ist in Abbildung 5.22 dargestellt.
Das vorgestellte inverse Sensormodell lässt sich effizient berechnen:Wie beim punktförmigen inversen Sensormodell erfordert es die Produkt-bildung von vier Gaußschen Fehlerintegralen zusammen mit weiteren be-kannten Faktoren. Ebenfalls wie beim Punktmodell werden diese jeweilsauf das normierte Gaußsche Fehlerintegral zurückgeführt, welches in ei-ner hoch aufgelösten Tabelle vorgehalten wird.
Das inverse Sensormodell berücksichtigt zwar einige probabilistischeFaktoren, jedoch nicht die Varianz der Konturlängenschätzung. Diese kannman jedoch approximativ auf die Positionsunsicherheit aufschlagen. Wiebeim inversen Sensormodell für punktförmige Belegtmessungen werden
181

Kapitel 5. Probabilistische Belegungsgitterfusion
−4
−2
0
2
4
−4
−2
0
2
40
0.2
0.4
0.6
0.8
1
xy
Abbildung 5.22.: Inverses Sensormodell für ein 4 × 2 großes Rechteck miteiner Positionsunsicherheit von σx = 0,5 bzw. σy = 0,3.Der Gewichtungsfaktor τ beträgt 1,0.
die Zellen um den Zellmittelpunkt so gedreht, dass diese senkrecht zu denAchsen des Rechtecks liegen. Hierdurch entsteht ein weiterer Approxima-tionsfehler.
Insgesamt wird jedoch eine gute Schätzung der Belegtwahrscheinlich-keit unter den Modellannahmen für eine einzelne Zelle erreicht. Proble-matischer wird später die genaue Schätzung vieler Zellen, die von einerrechteckförmigen Belegtmessung betroffen sind. Hier sind insbesonderebei hohen Varianzen und geringer Konturgröße stärkere Approximations-fehler zu erwarten.
Einbringung der Messevidenzen in eine Zelle
Um das ICDP zu lösen, ist die Modellierung der Abhängigkeiten und Un-abhängigkeiten notwendig. Beim nichtprobabilistischen Algorithmus wurdedazu die betrachtete Menge der Messungen global zwischengespeichert,sodass kein Informationsverlust auftritt. Dieser Ansatz ermöglicht zwar ei-ne exakte Rekonstruktion, ist aber sehr aufwendig und je nach Größe derbetrachteten Messmenge auch nicht echtzeitfähig.
Eine andere Möglichkeit besteht darin, für die jeweilige Zelle an Posi-tion x,y ihre zugeordnete Evidenzmasse dort lokal zu speichern. Hierzu
182

5.7. Entwicklung von ICDP-Algorithmen
muss zunächst für eine Messung mk das passende inverse Sensormodellbestimmt werden:
ρ(mk,c) =
ρHF (x,y) , wenn mk eine Freimessung ist
ρP,HB(x,y) , wenn mk eine punktförmige Belegtmessung ist
ρR,HB(x,y) , sonst
(5.50)
Neben der Evidenzmasse wird die Information benötigt, die eine Zuord-nung der Messevidenz zu einer Messung erlaubt. Hierzu wird eine ein-zigartige Kennung pro Messung id(mk) erzeugt. Diese Kennung wird auseiner Sensoridentifikationsnummer und einem fortlaufenden Zähler gene-riert. Es ist somit möglich, aus solch einer Messkennung sowohl den Typdes inversen Sensormodells als auch den Sensor wieder zu bestimmen.
Der Fusionsalgorithmus ξ (c,Mk) generiert für die Zelle c aus k Messun-gen Mk = m1, . . . mk Tupel, die aus der Zellkoordinate (x, y), einer Mess-kennung id und einer Evidenz ρ(mi,c) bestehen und fügt sie dem Ring-pufferspeicher dieser Zelle hinzu6. Dieser Speicher besitzt eine maximaleKapazität von n Einträgen, sodass bei Überschreitung die ältesten Einträgeaus diesem herausfallen:
ξ (c,Mk) =k⋃
i=max(1,k−n+1)
(x,y, id(mi),ρ(mi,c)) (5.51)
Der Algorithmus kann entgegen der mathematischen Formulierung effi-zient umgesetzt werden, sodass die Aktualisierung des Zellzustandes miteiner Messung in konstanter Zeit möglich ist. Ein beispielhafter Inhalt zwei-er Zellen ist in Tabelle 5.1 dargestellt.
Da alte Messungen automatisch überschrieben werden, wenn der Ring-puffer voll ist, ist indirekt ein Alterungsmechanismus in diesem Algorithmusintegriert. Dieser ist hilfreich, um bei der Dezert-Smarandache Theorie dieKonfliktmasse des Zellzustandes potenziell zu reduzieren. Hierzu müssensolange neue widerspruchsfreie Messungen die Zelle treffen, bis die wi-dersprüchlichen Messungen aus dem Ringpufferspeicher herausgefallensind.
Insgesamt ermöglicht dieser Fusionsalgorithmus eine weitgehende Re-konstruktion der Abhängigkeiten und Unabhängigkeiten. So lässt sich für
6Die Zellkoordinaten in den Tupeln werden später für eine einfachere mathematische Darstel-lung benötigt. Die Softwareimplementation kann diese aus Zellindeces ermitteln, sodass die-se die Zellkoordinaten in den Tupeln nicht benötigt.
183
Kapitel 5. Probabilistische Belegungsgitterfusion
Sensor-ID
Mess-ID
Evidenz
1 (P,HB) 01 0,12 (HF ) 01 0,13 (R,HB) 01 0,32 (HF ) 02 0,1
Sensor-ID
Mess-ID
Evidenz
1 (P,HB) 01 0,152 (HF ) 01 0,13 (R,HB) 01 0,42 (HF ) 03 0,2
Tabelle 5.1.: Beispielhafter Inhalt der Ringpufferspeicher zweier Zellen (oh-ne Zellkoordinaten)
jede Messung, deren Evidenzen noch aus keinem Ringpufferspeicher her-ausgefallen sind, die ursprüngliche Massenverteilung gemäß dem inver-sen Sensormodell approximativ wiederherstellen. Die nicht exakte Lösungist durch die Diskretisierung der Zellen begründet und tritt auf, wenn ei-ne Messung mittels inversen Sensormodells eine nicht homogene Evidenzbzgl. der Zellfläche liefert.
Nachteilig an dem Ansatz ist, dass die Zelle maximal nur soviel Evi-denz sammeln kann, wie der Ringpufferspeicher an Messungen aufneh-men kann. Dieser Nachteil ist je nach Ringpuffergröße hinsichtlich derIMDP-Annahme jedoch zu vernachlässigen. Diese nimmt an, dass Mes-sungen aus einem Sensor korrelieren und somit eine Abhängigkeit auf-weisen. Daraus folgt, dass wenn eine Hypothese bereits von mehrerenMessungen eines Sensors bestätigt worden ist, weitere ähnliche Messun-gen nur eine geringe zusätzliche Evidenz liefern. Wenn man die Messrei-he dann rückwärts betrachtet, so liefern die ältesten Messungen im Durch-schnitt die geringsten zusätzlichen Evidenzen und können am ehesten ent-fallen.
Abfragealgorithmus
Der Fusionsalgorithmus ξ (c,Mk) im vorherigen Abschnitt wurde so entwor-fen, dass er eine approximativ ICDP-konforme Abfrage eines Bereichesermöglicht. Der zugehörige Abfragealgorithmus wird in diesem Abschnittvorgestellt. Hierzu ist eine mathematische Verbunddarstellung des Bele-gungsgitters notwendig:
Der Abfragealgorithmus β (Z) soll im Folgenden eine Befahrbarkeits-schätzung für eine Zellmenge nach der Dezert-Smarandache Theorie be-stimmen. Dazu sei angenommen, dass eine rechteckige Fläche von xmin
und ymin bis xmax und ymax bestehend aus einer Menge von Zellen Z′ be-rücksichtigt werden muss, um eine Befahrbarkeitswahrscheinlichkeit einer
184

5.7. Entwicklung von ICDP-Algorithmen
gegebenen Trajektorie bestimmen zu können7. Wie bereits im vorherigenAbschnitt erwähnt, verwaltet jede Zelle mehrere Tupel in einem Ringpuf-ferspeicher, welche jeweils aus einer Kennung id ∈ I, einer Evidenzmasseρ ∈ E und der Zellkoordinate (x,y) ∈ X ×Y bestehen:
X = xmin,xmin + s,xmin +2s, . . . ,xmax (5.52)
Y = ymin,ymin + s,ymin +2s, . . . ,ymax (5.53)
I = N (5.54)
E = [0,1] (5.55)
Z′ = X ×Y × I ×E (5.56)
Die Größe der Ringpufferspeicher jeder Zelle ist auf n Einträge begrenzt,sodass der unendlich große Zustandsraum Z′ auf einen Zustandsraum Zmit endlich vielen Elementen reduziert werden kann. Zusätzlich gilt, dassdie Kennung id für jede Messung eindeutig ist und somit in jedem Ring-pufferspeicher höchstens einmal auftritt. Für die Elemente in Z ⊂ Z′ kannsomit folgende Relation R definiert werden:
(Z ∈ R)→∀(x,y, id,ρ) ∈ Z :
(|Z ∩ (x×y× I ×E)| ≤ n)∧ (|Z ∩ (x×y× id ×E)| ≤ 1) (5.57)
Die Ringpufferspeicher der Zellen in diesem Bereich werden durch ver-schiedene Messungen und Messtypen gemäß dem vorherigen Abschnitt5.7.2 aktualisiert. Abhängig vom Messtyp müssen verschiedene Abfrage-mechanismen gewählt werden. Der Messtyp lässt sich aus der Dekodie-rung der ID bestimmen.
Wenn das Punktmodell verwendet worden ist, kann eine fusionierte Be-legungsschätzung pro Messung durch einfaches Summieren aller Teilevi-denzen der entsprechenden Zellen berechnet werden. Bei der Verwendungdes Boxmodells approximiert sich die Belegungsevidenz dieser Fläche proMessung durch Maximum-Bildung, welches eine untere Grenze der Bele-gungssschätzung darstellt (vgl. Gleichung 5.49):
7Zur einfacheren mathematischen Darstellung wird angenommen, dass die Fläche rechteckigist und sich senkrecht zum Belegungsgitter befindet. Für die Umsetzung des Abfragealgo-rithmus β (Z) ist es jedoch irrelevant, welche Form die Zellmenge Z impliziert: So wird in derSoftwareimplementation dafür eine allgemeine Polygonbeschreibung benutzt.
185

Kapitel 5. Probabilistische Belegungsgitterfusion
Φ′HB(Z, id) =
∑∀(x,y,id,ρ)∈(X×Y×id×E)∩Z
ρ , wenn id Modell ρP,HB impliziert
max∀(x,y,id,ρ)∈(X×Y×id×E)∩Z
ρ , wenn id Modell ρR,HB impliziert
0 , sonst
(5.58)
Als Ergebnis erhält man eine Belegungsevidenz der Messung mit derKennung id für den Bereich der Zellmenge Z: Hierbei handelt es sich appro-ximativ um die Gewichtung τ der Messung multipliziert mit der Wahrschein-lichkeit, dass diese Messung unter Berücksichtigung der Positionsunsi-cherheit den abgefragten Bereich belegt.
Das Zusammenfassen der Belegtmassen erfolgt nach der Dezert-Smarandache Theorie, wobei eine optimierte Variante möglich ist, da kei-ne Konflikte mit Freimassen auftreten. Es entstehen somit nur die beidenEvidenzen für die Belegt- und Unbekannthypothese. Die Optimierung ba-siert darauf, ausschließlich die Abnahme der Unbekanntmasse zu ermit-teln und die Belegtmasse komplementär zu betrachten. Letztere berechnetsich dann nach:
ΦHB(Z) = 1−∞
∏i=1
(1−Φ′
HB(Z, i)
)(5.59)
Für das Freibereichsmodell müssen zunächst die Freievidenzen Φ′HF
(c)nach der Dezert-Smarandache Theorie für einzelne Zellen c ∈ Z im abge-fragten Bereich bestimmt werden. Auch hier ist aufgrund der konfliktfreienMassen die optimierte Variante möglich:
Φ′HF
(c) = 1−∏∀(x,y,id,ρ)∈c
(1−ρ) , wenn id Modell ρHF impliziert
1 , sonst(5.60)
Die Zelle mit der geringsten Freievidenz der Zellmenge repräsentiert dieFreievidenz der gesamten Fläche:
ΦHF (Z) = min∀c∈Z
(Φ′
HF(c)
)(5.61)
Insgesamt erhält man aus allen Messungen eine kombinierte Freievi-denz für den spezifischen Bereich, wobei die Unsicherheiten des inversenSensormodells für Freibereiche berücksichtigt worden sind. Hierbei wurdedie geometrische Form der Messungen approximativ auf Zellgrößen dis-kretisiert und dessen Evidenzen vereint, sodass je nach Auflösung des
186

5.7. Entwicklung von ICDP-Algorithmen
Belegungsgitters mehr oder weniger Approximationsungenauigkeiten zuerwarten sind.
Um eine endgültige Massenverteilung für den abzufragenden Bereich zugenerieren, werden die beiden erzeugten Evidenzen ΦHF (Z) und ΦHB(Z)in Massenverteilungen konvertiert und als Eingabewert für die Dezert-Smarandache Theorie genutzt:
β (Z) = DSmT(〈ΦHF (Z),0,1−ΦHF (Z),0〉,〈0,ΦHB(Z),1−ΦHB(Z),0〉
)(5.62)
Da die Fusion von widersprüchlichen Massenverteilungen mittelsDezert-Smarandache Theorie nicht kommutativ ist, wurden zuerst alleMessungen für Belegt- und Freibereiche zu einer konfliktfreien Massen-verteilung zusammengefasst. Somit ist der vorgestellte Fusionsalgorith-mus approximativ kommutativ. Die Approximationseinschränkung ergibtsich aus dem endlich großen Ringpufferspeicher der einzelnen Zellen.
Sensor-ID
Mess-ID
EvidenzA
1 (P,HB) 01 0,253 (R,HB) 01 0,4* (HF ) * 0,19
Tabelle 5.2.: Zwischenergebnis des Abfragealgorithmus β nach Traversie-rung der Ringpufferspeicher der beiden Zellen aus Tabelle5.1.
Insgesamt fasst der Abfragealgorithmus β (Z) abhängige Zellinformatio-nen zusammen, die durch einzelne Messungen verursacht wurden. Dieeinzelnen Messungen hingegen werden zunächst als unabhängig betrach-tet. Ein Zwischenergebnis einer beispielhaften Menge ist in Tabelle 5.2 dar-gestellt.
Ist der abzufragende Bereich so klein gewählt, dass er nur eine Zelleumfasst, so lässt sich wie bei klassischen Belegungsgittern der Zustandeinzelner Zellen abfragen. In Abbildung 5.23 sind diese Einzelevidenzenals transparentes Bitmap über dem Umgebungsbild dargestellt. Zusätz-lich wird in diesem Beispiel die Befahrbarkeitswahrscheinlichkeit des Fahr-schlauches in bis zu 16 m Entfernung bestimmt und visualisiert. Hierbeiwurden Hunderte Zellen gemäß dem probabilistischen Algorithmus zu ei-ner Gesamtwahrscheinlichkeit fusioniert.
Der Abfragealgorithmus liefert eine Massenverteilung, welche verschie-dene Szenarien repräsentieren kann. Der häufigste und einfachste Fall
187

Kapitel 5. Probabilistische Belegungsgitterfusion
Abbildung 5.23.: Belegungsgitter der einzelnen Zellzustände in einer in-nerstädtischen Verkehrsszene. Die Befahrbarkeitswahr-scheinlichkeit des Fahrschlauchs wird durch die beidenmagentafarbenen Dreiecke dargestellt.
liegt in einer hohen Evidenzmasse für Belegt- bzw. Freibereiche, welcheeinen entsprechend belegt bzw. freien Raum darstellen.
Falls die Masse für den Unbekanntzustand hoch ist, weist dies auf min-destens eine Zelle hin, für die keine oder nur eine geringe Messevidenzvorliegt. Gleichzeitig sind keine oder nur geringe Belegtevidenzen für an-dere Zellen aufgetreten.
Ein hoher Konfliktwert deutet auf widersprüchliche Sensorinformationenhin: So wurde mindestens eine Zelle im abgefragten Bereich von einer oderverschiedenen Messungen als frei und gleichzeitig als belegt gemessenund es existiert keine weitere Zelle mit einer hohen Belegt- oder Unbe-kanntevidenz. Daraus folgt, dass zu diesem Zeitpunkt keine zuverlässigeAussage über diesen Bereich gemacht werden kann. Muss jedoch einediskrete Entscheidung gefällt werden, so kann man in diesem Fall das Ver-hältnis der Frei- und Belegtmassen betrachten.
188

5.7. Entwicklung von ICDP-Algorithmen
5.7.3. Belegungsgitter mit variabler Auflösung
Der im vorherigen Abschnitt vorgeschlagene Algorithmus ist durch die Ver-wendung von Ringpufferspeichern in den einzelnen Zellen sehr speicher-aufwendig. Eine Möglichkeit dem zu begegnen, ist die Zellauflösung desBelegungsgitters variabel zu gestalten. Diese Grundidee wird soweit auchin [Montemerlo 2004] und [Ferguson 2006] verfolgt.
Die Motivation dieser Arbeiten ist, dass in größerer Entfernung die Po-sitionsunsicherheit von detektierten Hindernissen zunimmt und somit ei-ne hohe Auflösung des Belegungsgitters in großer Entfernung überflüssigerscheint. Zudem wird es Pfadfindungsalgorithmen erleichtert, eine Trajek-torie durch das Umfeld zu finden, da zum einen weniger Zellen zu überprü-fen sind und zum anderen die Auftretenswahrscheinlichkeit von einzelnenvermeintlichen Löchern über lang gestreckte Hindernisse reduziert wird.Ein Beispiel für solch ein Belegungsgitter ist in Abbildung 5.24 dargestellt.
Abbildung 5.24.: Schematisches Beispiel für ein dreischichtiges Bele-gungsgitter mit unterschiedlichen Zellgrößen
In [Montemerlo 2004] werden zur Erzeugung eines solchen Gitters meh-rere Belegungsgitter in Schichten übereinandergesetzt. Das Belegungsgit-ter mit der höchsten Auflösung hat die kleinste Größe und erstreckt sichüber den Nahbereich, während das Belegungsgitter mit der niedrigstenAuflösung den maximalen Aktionsradius des Fahrzeugs repräsentiert. In[Montemerlo 2004] wird dieser Aufbau eine „Pyramide von Belegungsgit-tern“ genannt.
Diese mehrschichtigen Belegungsgitter haben das Problem, dass, wenn
189

Kapitel 5. Probabilistische Belegungsgitterfusion
sich das Fahrzeug bewegt, es zu Zellinitialisierungen in den einzelnenSchichten kommt. Hierbei entstehen Bereiche mit unbekanntem Bele-gungszustand auf den Rändern der einzelnen Belegungsgitter (vgl. blaueZellen in Abbildung 5.25). Für das Belegungsgitter mit der größten Auflö-sung ist dies akzeptabel, nicht jedoch für die kleineren. Um die neu hin-zugekommenen Zellen geschickt zu initialisieren, könnten beispielsweisedie Zellinformationen aus dem nächstgrößeren Belegungsgitter zurate ge-zogen werden. Hierzu müsste die Evidenz einer großen Zelle auf mehrerekleinere übertragen werden.
Abbildung 5.25.: Schnitt durch ein dreischichtiges Belegungsgitter. Dieblauen Zellen werden für die Übergabe der Zellinitiali-sierungen (gestrichelte Linien) benötigt und stehen wiedie zu niedrig aufgelösten gelben Zellen dem eigentlichenBelegungsgitter (unten) nicht zur Verfügung.
Bei der Aufteilung oder beim Zusammenfassen der Evidenzen einer Zell-menge sollten außer den Diskretisierungsungenauigkeiten möglichst keineweiteren Informationen verloren gehen. Hierzu ist eine formale Definitioneiner konsistenten Abbildungsoperation ω(C) hilfreich:
Definition 6 (Konsistente Verschiebung von Belegungsgittern).Seien ξ (X ,M) und β (X) Algorithmen, die das ICDP gemäß Definition 4lösen. Die Abbildung ω(X) → Y einer Zellmenge X auf die Zellmenge Yist im Rahmen einer Belegungsgitterverschiebung genau dann konsistent,wenn β (ξ (ω(ξ (C1,M1))∪ξ (C2,M1),M2)) = β (ξ (ξ (C1∪C2,M1),M2)) für allemöglichen disjunkten Zellmengen C1, C2 und alle Messungen M1 und M2ist.
Da bei einer Verschiebungsoperation die Größe des Bereiches gleichbleibt, den die Zellen X bzw. Y repräsentieren, erfüllt ω diese Definition,wenn es die Fähigkeit von ξ (X ,M) und β (X) zum Lösen des ICDP im All-gemeinen nicht einschränkt. Aus der Definition lassen sich folgende Eigen-schaften für einen konsistenten Abbildungsoperator ableiten:
190

5.7. Entwicklung von ICDP-Algorithmen
• C2 = /0 und M2 = /0 : Die neue Zellmenge ω(C1) muss das gleicheAbfrageergebnis liefern, wie die alte Zellmenge C1.
• C2 = /0 und M2 6= /0 : Die neue Zellmenge ω(C1) verhält sich bzgl.Abfrageergebnis bei weiteren Messungen wie die alte Zellmenge C1.
• C2 6= /0 und M2 = /0 : Wenn die neue Zellmenge ω(C1) und die alteZellmenge C1 mit weiteren Zellen vereinigt werden, liefert der Abfra-gealgorithmus für beide Zellmengen das gleiche Ergebnis.
• C2 6= /0 und M2 6= /0 : Die beiden Mengen liefern auch das gleicheErgebnis, wenn sie durch neue Messungen aktualisiert werden.
Beim Bayesansatz wie ihn [Montemerlo 2004] verwendet, kann der Zell-zustand identisch auf kleinere Zellen übertragen werden. Dieses Vorgehenliefert aber bei dem probabilistischen Algorithmus, welcher in den vorheri-gen Abschnitten vorgestellt worden ist, kein konsistentes Ergebnis.
Im Folgenden wird ein Abbildungsoperator für diesen Algorithmus vor-geschlagen, der eine Konsistenz nach Definition 6 aufweist. Hierzu mussdie Evidenz einer großen Zelle d auf den Zustand von n×n Zellen ci, j ∈Cje nach Messtyp aufgespalten oder übertragen werden.
Die Abbildungsoperation basiert darauf, die Freievidenzen und die Evi-denzen für rechteckförmige Messungen identisch zu übernehmen: Hier istdie Konsistenz durch den min- bzw. max-Operator begründet. Bei punktför-migen Belegtevidenzen, welche durch den Summationsoperator fusioniertworden sind, wird die Evidenz gleichmäßig auf alle Zellen aufgespaltet:
ω ′(d) =⋃
∀(x,y,id,ρ)∈d
(id, ρ
n2 ) , wenn id Modell ρP,HB impliziert
(id,ρ) , sonst(5.63)
Der Abbildungsoperator ω(d) erzeugt n2 ähnliche Zellen. Diese unter-scheiden sich lediglich durch die Zellkoordinaten (x,y), welche die Hilfs-funktion pos(c) für eine Zelle c als Tupel zurückliefert:
ω(d) =⋃
∀ci, j∈C
(pos(ci, j)×ω ′(d)
)(5.64)
Der vorgeschlagene probabilistische Algorithmus unterstützt Belegungs-gitter mit variabler Auflösung, indem die Evidenztabelle mit geringen Ver-lusten auf andere Zellen übertragen werden kann. Um die Informationsver-luste zu minimieren, sollten die Zellgrößen aller Belegungsgitter so gewähltwerden, dass sie einem ganzzahligen Vielfachen von dem Belegungsgitter
191

Kapitel 5. Probabilistische Belegungsgitterfusion
mit der nächstniedrigeren Auflösung entsprechen. In diesem Fall ist nur einDiskretisierungsverlust zu verzeichnen, welcher bei Belegungsgittern mitvariabler Auflösung prinzipbedingt aber in Kauf genommen werden muss.
Neben den theoretischen Grundlagen ist in diesem Abschnitt ein ins-gesamt recht einfacher ω-Algorithmus vorgestellt worden. Dieser erlaubtzwar die konsistente Verwendung von Belegungsgittern mit variabler Auf-lösung und probabilistischen Fusions- und Abfragealgorithmus, ist jedochbzgl. Speicherbedarf und Laufzeit noch nicht optimal. So ist eine Erweite-rung denkbar, die es erlaubt, viele zu niedrig aufgelöste Zellen weder ak-tualisieren noch vorhalten zu müssen. Die Grundidee ist, dass der Zustandsolch einer Zelle im Prinzip schon redundant durch eine Menge höher auf-gelöster Zellen vorliegt. Im Beispiel von Abbildung 5.25 entsprechen solcheredundanten Zellen den gelben Zellen.
Um den Zellzustand der großen Zelle zu erzeugen, ist ein Algorithmusnotwendig, der die Evidenz von vielen kleinen Zellen auf diese überträgt.Für den vorgestellten probabilistischen Algorithmus ist dieses nur approxi-mativ möglich, da es denkbar ist, dass der Inhalt vieler Ringpufferspeicherauf einen Ringpufferspeicher mit jeweils der gleichen Größe nicht verlust-frei übertragen werden kann. Dieser potenzielle Informationsverlust ist je-doch auf die prinzipbedingte und gewollte höhere Diskretisierung zurück-zuführen und ist damit akzeptabel.
Ziel des Algorithmus muss es somit sein, die Evidenzen der Zellmengeauf die große Zelle so zu übertragen, dass diese Zelle höchstens diesenDiskretisierungsverlust erleidet. Dies wird erreicht, wenn diese Zelle dengleichen Zustand annimmt, als wenn sie direkt vom probabilistischen Algo-rithmus mit der gesamten Messmenge aktualisiert worden wäre.
Ein solcher Algorithmus ist approximativ möglich, wenn sich aus denKennungen der Ringpufferspeichereinträge eine zeitliche Abfolge der Mes-sungen ableiten lässt. Auf eine genaue Darstellung dieses Algorithmus seihier verzichtet, da sich dieser dem bereits vorgestellten Abfragealgorith-mus β (X) in großen Teilen ähnelt.
5.7.4. Zusammenfassung
Wie in vorherigen Abschnitten vorgestellt, gibt es in der Literatur keine be-kannten Belegungsgitteransätze, die die Abhängigkeiten zwischen Zellzu-ständen gemäß der ICDP-Definition systematisch auflösen. Deshalb wur-den in diesem Abschnitt zwei Algorithmen vorgestellt, die dieses Problemberücksichtigen.
Es konnte zwar kein probabilistischer Fusions- und Abfragealgorithmus
192

5.7. Entwicklung von ICDP-Algorithmen
geschaffen werden, der dieses Problem in Echtzeit formal löst. Es ist je-doch eine approximative Lösung geschaffen worden, welche deutlich bes-sere Eigenschaften zeigt als die bekannten Ansätze. So ist diese Lösungbeispielsweise in der Lage, die Abhängigkeiten im Beispiel von Abbildung5.17 exakt aufzulösen.
Der vorgestellte probabilistische Algorithmus enthält verschiedene inver-se Sensormodelle, die zusammen mit dem Fusions- und Abfragealgorith-mus je nach Modell, Messung und Zellauflösung einen mehr oder wenigergroßen Fehler bzgl. der ICDP-Definition verursachen.
So werden Punktziele sehr gut approximiert und der Freibereich je nachStärke von Evidenzunterschieden innerhalb einer Zelle und Zellgröße auchgut angenähert. Rechteckförmige Messungen weisen je nach Konturgrö-ße und Varianz jedoch einen mittleren bis großen Fehler auf. Letzteresist damit begründet, dass zu wenig Metainformationen in ein einzelnesEvidenzattribut passen, um eine genaue Abhängigkeitsanalyse solch ei-ner Zellmenge zu generieren. Hier wurde nur die Belegungswahrschein-lichkeit der einzelnen Zelle berechnet, ohne zu berücksichtigen, dass auf-grund der statischen Größe der Objektkontur sich weitere Abhängigkei-ten ergeben. Dennoch ist aufgrund typischer Fahrschläuche der Fehler inder Praxis deutlich geringer als theoretisch möglich. So maximiert sich derFehler, wenn die abzufragende Zellmenge dieses rechteckige Objekt in ge-ringem Abstand möglichst vollständig umfließt, das Objekt möglichst kleinund gleichzeitig eine hohe Positionsvarianz aufweist. Dieses tritt jedoch inAnwendungen praktisch nie auf.
Ein weiterer Approximationsfehler tritt durch die Größenbegrenzung desRingpufferspeichers auf: Sobald dessen Kapazität erreicht ist, fallen die äl-testen Messungen und deren Evidenzen aus der Bewertung. Dies kannbei widersprüchlichen Informationen, wie sie beispielsweise dynamischeObjekte verursachen, aber auch hilfreich sein: So wird eine ehemals be-legte Zelle nach einigen Messungen vollständig wieder freigegeben, wasbeispielsweise in Abbildung 5.26 verdeutlicht wird. Auch liefert unter derIMDP-Annahme eine ältere Messung nur eine geringe zusätzliche Evidenz,wenn bereits viele neuere vorliegen.
Insgesamt ist der Approximationsfehler trotz diverser negativer Einflüs-se sehr gering verglichen mit konventionellen Ansätzen. Fast noch wich-tiger aus Applikationssicht ist jedoch, dass das Belegungsgitter jetzt ei-ne sinnvolle Schnittstelle liefert, den Umgebungszustand abzufragen: DieApplikation kann mittels einer allgemeinen Polygonbeschreibung die Be-fahrbarkeitswahrscheinlichkeit eines beliebigen Korridors ermitteln, wobeidie einzelnen Zellen und deren Zustände vollständig verborgen bleiben.Bei konventionellen Ansätzen wird eine Menge von Einzelzellzuständen
193

Kapitel 5. Probabilistische Belegungsgitterfusion
Abbildung 5.26.: Dynamische Objekte wie fahrende Autos verursachenKonfliktbereiche (gelb). Diese werden freigegeben, so-bald die alten Belegtmessungen durch neue Freimessun-gen aus dem Ringpufferspeicher fallen.
zurückgeliefert, was eine eher künstliche und wenig anwendungsgerechteBeschreibung eines Korridors darstellt und zu stärkeren Ungenauigkeitenführt.
Da bei diesem Ansatz jede Zelle einen kleinen Ringpufferspeicher be-sitzt, ist der Speicherbedarf dieses Belegungsgitters signifikant größer ver-glichen zu bekannten Ansätzen. Die Fusionierung von Messungen in Zell-zuständen ist sehr schnell und kann in konstanter Zeit erfolgen. Im Gegen-satz dazu ist die Abfrage von Bereichen aufwendiger, da bei allen betrof-fenen Zellen die kompletten Ringpufferspeicher abgearbeitet werden müs-sen.
Um sowohl dem hohen Speicherbedarf als auch der hohen Rechenzeitbei der Ausführung des Abfragealgorithmus entgegenzuwirken, sind ver-schiedene Maßnahmen getroffen worden: Zum einen sind nur sehr ein-fache Operationen notwendig, um die Ringpufferspeicher zu verarbeiten.Diese bestehen im Wesentlichen aus dem Minimum-, Maximum- und Addi-tionsoperator. Zum anderen wurde vorgeschlagen, ein Belegungsgitter mitvariabler Auflösung zu verwenden. Im Vergleich zu einem großen hoch auf-gelösten Belegungsgitter senkt dieser Ansatz neben dem Speicherbedarfauch die Laufzeit, da in einem abgefragten Fahrschlauch sich tendenziellweniger Zellen befinden.
Anstatt Belegungsgitter zu verwenden, ist es alternativ denkbar, dassman alle Messungen in einem großen Ringpufferspeicher ablegt. Der Ab-fragealgorithmus berechnet dann den Schnitt dieser Messungen mit ei-
194

5.8. IMDP-Algorithmen
nem Polygon, welches beispielsweise den Fahrschlauch repräsentiert undfasst diese mittels Logikalgorithmen zusammen. Das Ergebnis ist annä-hernd das Gleiche wie beim vorgeschlagenen probabilistischen Algorith-mus. Da keine Diskretisierung und keine Vereinfachungen stattfinden, istdieser Ansatz genauer und verbraucht auch signifikant weniger Speicherabhängig von den Ringpuffergrößen. Allerdings sind Algorithmen, die inder Lage sind, konkave Polygone mit mehrdimensionalen normalverteiltenWahrscheinlichkeitsdichtefunktionen, unscharfen Objektkonturen und Frei-bereichspolygonen mit variabler Evidenz exakt zu schneiden und auszu-werten, schwer zu entwickeln. Außerdem brauchen diese wohl eine deut-lich höhere Laufzeit, was Zweifel an der Echtzeitfähigkeit solcher Algorith-men bei größeren Messmengen aufkommen lässt.
Von diesem Standpunkt aus gesehen ähnelt der vorgestellte Belegungs-gitteransatz einer Art Zwischenspeicher, mit dem man eine geringere Lauf-zeit gegen erhöhten Speicherbedarf und geringere Genauigkeit tauscht.
5.8. IMDP-Algorithmen
In diesem Abschnitt werden die Abhängigkeiten, die zwischen verschiede-nen Messungen auftreten können, behandelt. Ziel ist es, geeignete Metho-den zur Auflösung dieser Abhängigkeiten auf den im vorherigen Abschnittvorgestellten probabilistischen Belegungsgitteralgorithmus zu übertragen.
Aus der IMDP-Definition ergibt sich, dass mindestens die Genauigkeits-anforderung im Sinne der Applikation berücksichtigt werden muss, um ent-scheiden zu können, ob ein Algorithmus zusammen mit einer gegebenenSensorik das IMDP löst. Somit existiert hierfür weder eine allgemeingültigeLösung, noch ist es zwingend mit einer gegebenen Sensorik und Genauig-keitsanforderung immer lösbar. Letzteres ist beispielsweise der Fall, wenndie Applikation praktisch Ground Truth-Daten von der Sensordatenfusionfordert, die Sensorik jedoch nicht annähernd ideale Messdaten liefert.
Insgesamt muss ein IMDP-Algorithmus in der Gesamtheit des komplet-ten Systems betrachtet werden, sodass dieser Abschnitt nur Vorschlägefür solche Algorithmen zeigt, ohne diese genau zu bewerten. Hierzu folgtzunächst eine Vorstellung existierender Verfahren, bevor ein weiteres ent-wickelt wird.
5.8.1. Übersicht existierender IMDP-Algorithmen
In der Literatur sind viele Ansätze zur Auflösung von Messabhängigkeitenbekannt, wobei einige im Abschnitt 5.5 bzw. im vorherigen Kapitel exem-
195

Kapitel 5. Probabilistische Belegungsgitterfusion
plarisch vorgestellt worden sind. Die Zusammenfassung zeigt unterschied-lichste Methoden:
• Für jeden Sensor wird ein eigener Schätzer mit eigenem Belegungs-gitter verwendet (vgl. [Elfes 1989b]).
• Für jede Zelle werden die Messwinkel und -abstände gespeichertund spätere Messungen aus ähnlichen Positionen werden nicht ge-wertet (vgl. [Konolige 1997]).
• Für jede Zelle werden dessen Detektionseigenschaften geschätztund dynamisch in die Evidenzmasse gewichtet (vgl. [Konolige 1997]).
• Die Evidenzmassen werden pro Messung bzw. Messzeitpunkt mittelsMaschinellen Lernens bestimmt (vgl. [Thrun 1998], [van Dam 1996]und [Yu 2007]).
• Ältere Messungen werden in der Massebestimmung berücksichtigt(vgl. [Yu 2007]).
• Mittels zyklischen Markov-Ketten werden persistente Nichtdetek-tionen bzw. persistente Fehlziele explizit modelliert (vgl. Abschnitt4.4.5).
Einige Verfahren lassen sich wohl recht einfach auf den vorgestelltenprobabilistischen Fusionsalgorithmus übertragen: So könnte wie in [Elfes1989b] pro Sensortyp ein separater Ringpufferspeicher verwendet werden,welcher praktisch ein neues Belegungsgitter darstellt. Auch ist die Erstel-lung eines Bitfeldes nach [Konolige 1997] zur Dokumentation von Mess-winkel und Messabstand leicht übertragbar, sodass keine doppelten Mes-sungen von ähnlichen Positionen in den Ringpufferspeicher der Zelle ein-gebracht werden müssen. Auch kann die Messhistorie in den Ringpuffer-speichern rekonstruiert werden, um die zyklischen Markov-Ketten nach Ab-schnitt 4.4.5 zu berechnen. Für Letztere ist die Festlegung einer diskretenAssoziationsschwelle notwendig, was exemplarisch im folgenden Abschnittbehandelt wird.
Die anderen vorgestellten Verfahren greifen jedoch so tief in denKern der inversen Sensormodelle ein, dass eine approximative ICDP-Konformität mit dem Abfragealgorithmus β (X) nicht mehr zwingend ge-geben ist.
Bei der Übertragung der Verfahren nach [Elfes 1989b] und [Konolige1997] ist mit weiteren Speicherkosten zu rechnen, da zusätzliche Datenfür die Abhängigkeitsbeschreibung vorgehalten werden müssen. Jedoch
196

5.8. IMDP-Algorithmen
enthalten die Ringpufferspeicher bereits Informationen, die die Auflösungbestimmter Messabhängigkeiten ermöglichen: So lässt sich aus den Ken-nungen insbesondere bestimmen, wie häufig eine Zelle von welchem Sen-sor gemessen worden ist. Hierdurch können beispielsweise wiederholteMessungen eines einzelnen Sensors erkannt und geringer gewichtet wer-den.
Im Folgenden soll deshalb ein Algorithmus vorgestellt werden, der aus-schließlich aus den bereits vorhandenen Daten versucht, Messabhängig-keiten aufzulösen.
5.8.2. Entwicklung eines IMDP-Algorithmus
Der im vorherigen Abschnitt 5.7 vorgestellte probabilistische Belegungsgit-teralgorithmus ermöglicht bereits die statische Gewichtung von Messun-gen durch einen Faktor τ in den einzelnen inversen Sensormodellen. Je-des dieser Modelle besteht aus dem Produkt von τ und der Belegungs-bzw. Freiwahrscheinlichkeit, die sich aus der Unsicherheit von Positionbzw. Sensorreichweite ergibt.
Im Fusionsalgorithmus ξ (C,M) erfolgt diese Gewichtung direkt bei derEinbringung der Evidenz in den Ringpuffer. Es ist jedoch auch denkbar,diese erst nachgelagert im Abfragealgorithmus β (X) dynamisch durchzu-führen. In diesem Fall wird im Fusionsalgorithmus für alle Messungen τ aufden neutralen Faktor 1,0 gesetzt.
Wie bei Elfes sollen im ersten Schritt die Messreihen einzelner Senso-ren separat ausgewertet werden. Die Abhängigkeiten zwischen den Schät-zungen unterschiedlicher Sensoren werden später untersucht. Analog zumICDP-Algorithmus werden Belegt- und Freimessungen unterschiedlich be-handelt.
Erzeugung einer Belegtevidenz aus Belegtmessungen
Bei der Auswertung von Belegtmessungen soll der Umstand genutzt wer-den, dass eine örtliche Assoziation von Messungen möglich ist: So kanneine Messung mit einer anderen assoziiert werden, wenn beide eine be-stimmte minimale Evidenz K in eine Zelle ablegen. Es wird dann davonausgegangen, dass diese sich auf das gleiche Objekt beziehen und somitzu einem großen Teil abhängig sind.
Die mathematische Darstellung dazu ist wie folgt: Sei Z das Belegungs-gitter in Verbunddarstellung nach Gleichung 5.56 eingeschränkt durch dieRelation R nach Gleichung 5.57. Eine Belegtmessung eines Sensors mitder Kennung a wird mit einer anderen Messung mit der Kennung b des
197

Kapitel 5. Probabilistische Belegungsgitterfusion
gleichen Sensors in einer Zelle assoziiert, wenn folgende Relation S’ er-füllt wird:
a S′ b →∃(x,y) ∈ (X ×Y )∧∃(e1 ∈ E)∧∃(e2 ∈ E) :((x,y,a,e1)∩Z 6= /0
)∧((x,y,b,e2)∩Z 6= /0
)∧ (e1 ≥ K)∧ (e2 ≥ K) (5.65)
Die Relation S erweitert S’ um Transitivität, um Messungen in Nachbar-zellen assoziieren zu können:
a S b →∃c1, . . . ,cn ⊆ ID :
(a S′ c1)∧ (c1 S′ c2)∧·· ·∧ (cn−1 S′ cn)∧ (b S′ cn) (5.66)
Die transitiv assoziierten Ringpufferspeichereinträge werden zu einerMenge Q(Z, id) zusammengefasst. Hierbei wird der daraus entstandeneMesscluster durch die Messung mit der kleinsten Kennungsnummer reprä-sentiert:
Q(Z, id) =
/0 , wenn ∃a ∈ I : (a < id)∧ (a S id)
∀(x,y,b,ρ) ∈ Z : (b S id) , sonst
(5.67)
Die so konstruierte Menge beinhaltet alle Ringpufferspeichereinträge ei-nes Sensors, welche sich auf ein Objekt in der gegebenen Zellmenge be-ziehen. Diese werden im Folgenden so fusioniert, dass eine gemeinsameEinschätzung aller Messungen für das Objekt generiert wird.
Als Beispiel dazu sind vier verschiedene Messungen in Abbildung 5.27dargestellt, welche sich teilweise überlappen. Die Messunterschiede kön-nen beispielweise durch Messungenauigkeiten oder durch Bewegung desObjektes entstehen.
Die aus den Messungen generierten Evidenzen (rote Kästchen) werdenin die Ringpufferspeicher abgelegt. Aus diesen Evidenzen zusammen mitden Kennungen und einem Schwellwert K kann die Assoziationstabelle 5.3gebildet werden. Aus dieser ergibt sich, dass alle vier Messungen transitivassoziierbar sind, sodass Q(Z,1) aus allen in Abbildung 5.27 dargestelltenRingpufferspeichereinträgen (rote Kästchen) besteht.
Da die Evidenzen der assoziierten Messungen mit neutralem Gewich-tungsfaktor τ ausschließlich die Positionsunsicherheit darstellen, wird zurbesseren Approximation der Evidenz eine Mittelung aller Messungen aus
198
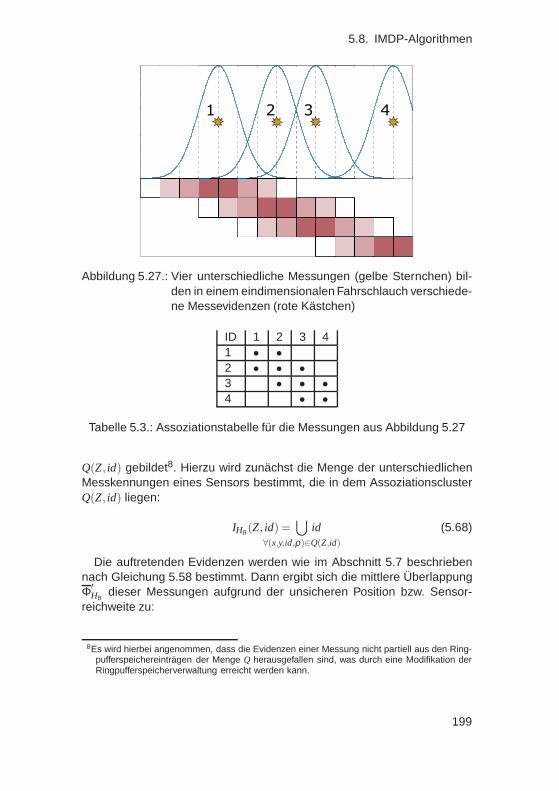
5.8. IMDP-Algorithmen
1 2 3 4
Abbildung 5.27.: Vier unterschiedliche Messungen (gelbe Sternchen) bil-den in einem eindimensionalen Fahrschlauch verschiede-ne Messevidenzen (rote Kästchen)
ID 1 2 3 41 • •2 • • •3 • • •4 • •
Tabelle 5.3.: Assoziationstabelle für die Messungen aus Abbildung 5.27
Q(Z, id) gebildet8. Hierzu wird zunächst die Menge der unterschiedlichenMesskennungen eines Sensors bestimmt, die in dem AssoziationsclusterQ(Z, id) liegen:
IHB(Z, id) =⋃
∀(x,y,id,ρ)∈Q(Z,id)
id (5.68)
Die auftretenden Evidenzen werden wie im Abschnitt 5.7 beschriebennach Gleichung 5.58 bestimmt. Dann ergibt sich die mittlere ÜberlappungΦ′
HBdieser Messungen aufgrund der unsicheren Position bzw. Sensor-
reichweite zu:
8Es wird hierbei angenommen, dass die Evidenzen einer Messung nicht partiell aus den Ring-pufferspeichereinträgen der Menge Q herausgefallen sind, was durch eine Modifikation derRingpufferspeicherverwaltung erreicht werden kann.
199

Kapitel 5. Probabilistische Belegungsgitterfusion
Φ′HB(Z, id) =
1|IHB (Z,id)|
· ∑∀id∈IHB (Z,id)
Φ′HB(Z, id) , wenn IHB(Z, id) 6= /0
0 , sonst(5.69)
Die mittlere Überlappung sei am Beispiel von Abbildung 5.27 erläutert,in der eine Zellmenge dargestellt ist, die beispielsweise einen zu unter-suchenden Fahrschlauch entsprechen kann. In dieser liegen drei Mes-sungen vollständig innerhalb des Fahrschlauchs, während die Vierte sichteilweise außerhalb befindet. Letztere Messung propagiert somit eine be-stimmte Wahrscheinlichkeit, dass das punktförmige Objekt außerhalb desFahrschlauchs liegt. Insgesamt wird diese Wahrscheinlichkeit durch dieanderen drei Messungen geviertelt, sodass die fusionierte Evidenz einehohe Wahrscheinlichkeit für eine Positionierung des Objektes innerhalbdes Fahrschlauchs ergibt. Die vorgestellte Funktion erlaubt somit eine Zu-standsschätzung für Objekte im Belegungsgitter bzgl. einer Zellmenge.
Neben einer Mittelung der Positionen erlauben die vorhandenen Infor-mationen im Belegungsgitter auch die Feststellung, wie häufig ein Objektvon Messungen bestätigt worden ist. Um solche wiederholte Messungenpositiv zu bewerten, kann man die Größe |IHB(Z, id)| des generierten Mess-clusters nutzen, um den Gewichtungsfaktor τ dynamisch zu adaptieren. Jegrößer der Messcluster, desto asymptotisch größer sollte τ sein, bis diemaximale Evidenz τHB,max für den Sensor erreicht worden ist.
Eine mögliche asymptotische Funktion wäre beispielsweise eine Varia-tion der sigmoiden Aktivierungsfunktion A.24 aus dem Bereich der ANNs.Diese wird durch die Konstante ΣHB modifiziert, welche angibt, wie schnelldie asymptotische Näherung der maximalen Evidenz für einen spezifi-schen Sensor erfolgt:
τHB(Z, id) = τHB,max ·1
1+e−ΣHB ·|IHB (Z,id)|(5.70)
Unter der Annahme, dass die Faktoren Φ′HB
(Z, id) und τHB(Z, id) unab-hängig sind und dass unterschiedliche Objekte unabhängige Detektionsei-genschaften aufweisen, lässt sich die propagierte Belegungswahrschein-lichkeit aller Sensoren wie folgt zusammenfassen:
ΦHB(Z) = 1−∞
∏i=1
(1−Φ′
HB(Z, i) · τHB(Z, i)
)(5.71)
Um die Unabhängigkeitsannahmen in dieser Funktion zu neutralisieren,ist es denkbar, diese mittels eines überwachten Lernverfahrens zu approxi-
200

5.8. IMDP-Algorithmen
mieren. Hierzu sollte für jeden Sensor eine konstante Anzahl von Elemen-ten im Eingabevektor reserviert werden, die mit den ermittelten Objekt-evidenzen in aufsteigender Reihenfolge belegt werden. Um eine konstan-te Größe des Eingabevektors zu erreichen, werden bei einer geringerenObjektanzahl die überzähligen Eingänge auf null gesetzt, während bei zuvielen Objekten diejenigen mit der geringsten Evidenz entfallen. Der Aus-gabevektor besteht hingegen aus der Belegungswahrscheinlichkeit.
Erzeugung einer Freievidenz aus Freimessungen
Analog zum probabilistischen ICDP-Algorithmus wird im Folgenden dieFreiwahrscheinlichkeit für jede Zelle einzeln untersucht. Hintergrund istauch hier die Notwendigkeit der komplementären Fusion von örtlich dif-ferierenden Freievidenzen zur Fahrschlauchschätzung.
Im Folgenden wird von einem einzelnen Sensor ausgegangen, der ei-ne Zelle direkt oder indirekt als frei messen kann und eine entsprechendeEvidenz für diese generiert. Anstatt die Messungen als unabhängig anzu-nehmen, wird, wie bei den Belegtmessungen auch, das Mittel der Eviden-zen generiert. Zur leichteren mathematischen Darstellung wird zunächstjedoch die Menge der zu assoziierenden Messkennungen erzeugt:
IHF (c, id) =⋃
(x,y,i,ρ)∈c
i , wenn i und id aus der gleichen Quelle stammen
/0 , sonst
(5.72)
Wie auch bei den Belegtmessungen soll die Messung mit der kleinstenKennung den Messcluster in einer Zelle c repräsentieren. Das arithmeti-sche Mittel seiner Evidenzen berechnet sich dann mit:
Φ′HF
(c, id) =1
|IHF (c, id)|∑
∀(x,y,i,ρ)∈c
ρ , wenn (min(IHF (c, id)) = id)∧(i ∈ IHF (c, id))
0 , sonst
(5.73)
Auch bei Freimessungen sollen wiederholte Messungen des Sensorspositiv bewertet werden. Hierzu wird analog zu den Belegtmessungen ei-ne entsprechende asymptotische Funktion vorgeschlagen, die aus Mess-bestätigungen einen Gewichtungsfaktor τ ableitet. Diese lässt sich mit ΣHF
für einen Sensor parametrisieren, der die Geschwindigkeit der asymptoti-schen Näherung an die maximale Evidenz τHF ,max angibt:
201

Kapitel 5. Probabilistische Belegungsgitterfusion
τHF (c, id) = τHF ,max ·1
1+e−ΣHF ·|IHF (c,id)|(5.74)
Wenn die Freievidenzen unterschiedlicher Sensoren und der jeweiligeGewichtungsfaktor τ als unabhängig angenommen werden, gilt für dieFreievidenz der Zelle:
ΦHF (c) = 1−∏∀(x,y,id,ρ)∈c
(1−Φ′HF
(c, id) · τHF (c, id)) (5.75)
Wie auch bei der Belegtevidenz ist es denkbar, die Unabhängigkeitsan-nahmen zu neutralisieren, indem man diese Funktion mittels überwachtenLernverfahren approximiert. Der Eingangsvektor hat dabei pro Sensor soviele Eingänge, wie der Ringpufferspeicher einer Zelle an Eingängen auf-weist, während der Ausgabevektor aus einer entsprechenden Massenver-teilung für die Freievidenz besteht. Ebenso werden nicht belegte Eingängeauf null gesetzt, während die Evidenzen in aufsteigender Reihenfolge sor-tiert werden, bevor sie in den Eingabevektor geschrieben werden.
Das Zusammenfassen aller Freievidenzen einzelner Zellen erfolgt imletzten Schritt mittels pessimistischem Minimum-Operator:
ΦHF (Z) = min∀c∈Z
(Φ′
HF(c)
)(5.76)
Die Erlernung dieser Funktion mittels überwachtem Lernverfahren ist jenach Größe des Eingabevektors mehr oder weniger problematisch. Die-ser hat potenziell so viele Elemente, wie Z an Zellen maximal aufweist.Alternativ ist es denkbar, stattdessen Statistiken zur Freievidenzmenge alsEingabevektor zu nutzen. Dieser könnte dann beispielsweise Mittelwert,Varianz, größtes und kleinstes Element der Evidenzmenge enthalten.
Fusion der Belegt- und Freievidenz
Das Zusammenfassen der Belegt- und Freievidenzen zu einem Gesamt-zustand kann mittels bekannter Logikalgorithmen erfolgen. Hierzu müs-sen die Evidenzen in Massenverteilungen umgewandelt und verknüpftwerden. Als Beispiel wird im Folgenden eine die Dezert-Smarandache-Massenverteilung erzeugt:
β (Z) = DSmT(〈ΦHF (Z),0,1−ΦHF (Z),0〉,〈0,ΦHB(Z),1−ΦHB(Z),0〉
)(5.77)
202

5.8. IMDP-Algorithmen
Auch hier wird die Unabhängigkeit von Belegt- und Freievidenz ange-nommen. Dies könnte insbesondere verletzt sein, wenn ein einzelner Sen-sor beide Evidenztypen generiert. Dieses ist beispielsweise bei Laserscan-ner und Stereokameras der Fall, welche Belegt- als auch Freibereiche auseiner einzelnen Messung generieren können.
Um die Abhängigkeiten dieser beiden Massenverteilungen aufzulösen,kann auch hier ein überwachtes Lernverfahren zur Anwendung kommen.Basiert die Zielfunktion des Lernverfahrens auf einer quadratischen Mini-mierung der Fehlerfunktion, so strebt diese gleichzeitig eine statistischeKorrektheit an. Andernfalls kann das Ergebnis mittels einer Korrekturfunk-tion statistisch korrekt gestaltet werden (vgl. Abschnitt 4.6.8).
5.8.3. Zusammenfassung
In diesem Abschnitt wurden verschiedene Ansätze aus der Literatur zu-sammengefasst, welche versuchen, genaue Evidenzmassen für Sensorenzu generieren und Messabhängigkeiten bzw. Messakkumulationen zu ver-meiden. Letzteres geschieht jedoch nur sehr rudimentär, da alle Ansätzeeine rekursive Zellzustandsschätzung in einer einzelnen Massenverteilunganstreben. Letztere enthält jedoch keine Information darüber, wie dieserZustand insgesamt erreicht worden ist, sodass Abhängigkeiten neuer In-formationsquellen nicht bestimmt werden können. Wenn überhaupt werdendiese Abhängigkeitsinformationen nur diskret im Zellzustand angereichert(vgl. [Konolige 1997]), was aber nur gleichartige Messakkumulationen ver-hindert.
Abbildung 5.28.: Innerstädtische Szenerie mit vielen Objekten. Die erzeug-ten Messdaten stellen Informationen mit untereinanderunterschiedlichen Abhängigkeitsgraden dar.
203

Kapitel 5. Probabilistische Belegungsgitterfusion
Im Gegensatz dazu ermöglichen die Informationen in den Ringpuffer-speichern der einzelnen Zellen nicht nur die Rekonstruktion der Evidenz-verteilung der inversen Sensormodelle, sondern auch die approximativeErmittlung der Messhistorie für einen begrenzten Zeitraum. Letzteres kannnicht nur genutzt werden, um Messakkumulationen zu vermeiden, sondernauch um eine gefilterte Positionsschätzung zu erzeugen und die Anzahl derMessbestätigungen zu bestimmen.
Insgesamt wurde ein Algorithmus vorgestellt, der diese Aspekte bereitsunter Annahmen berücksichtigt und so auch komplexere Szenarien detail-liert darstellen kann, wie sie beispielsweise in Abbildung 5.28 auftreten.Sind Ground Truth-Daten verfügbar, so wurde bei einigen Funktionen vor-geschlagen, diese mittels überwachten Lernverfahren zu approximieren,sodass die Anzahl von Annahmen reduziert und der Schätzer präzisiertwird.
5.9. Vergleiche und Anwendungen
5.9.1. Vergleich mit klassischem Dempster-Shafer-Ansatz
In diesem Abschnitt wird der probabilistische Fusions- und Abfragealgo-rithmus aus Abschnitt 5.7.2 mit dem klassischen Dempster-Shafer Ansatzverglichen. Um die Nachvollziehbarkeit zu erleichtern, wird im Folgendeneine möglichst einfache Konfiguration vorgestellt: In dieser liefert ein ein-zelner Sensor ein punktförmiges Objekt mitten in einem Fahrschlauch.
Als Extraktionsalgorithmus für den klassischen Dempster-Shafer-Ansatzwird der Maximumoperator verwendet, welcher beispielsweise auch in[Kammel 2008] angewandt wird: Hierbeit repräsentiert die Zelle mit derhöchsten Belegungswahrscheinlichkeit die Befahrbarkeit des gesamtenabgefragten Bereichs. Als inverses Sensormodell wird das Punktmodellaus 5.7.2 verwendet, welches die entsprechenden Evidenzmassen für dieeinzelnen Zellen für beide Ansätze generiert.
Das verwendete Belegungsgitter hat eine Auflösung von 0,25 m × 0,25m. Die Messungen werden mittig auf eine Zelle abgebildet, wobei die Ge-wichtung 0,5 beträgt und die Varianz variabel (0,1 m2 - 0,5 m2) ist. DerAbfragebereich ist 5 m × 5 m, wobei die Messpunkte mittig in diesemBereich liegen. Alle Messungen werden als unabhängig angenommen.Entsprechend der Varianz liegen alle Messungen praktisch vollständig imFahrschlauchbereich, d. h. das Integral über die Wahrscheinlichkeitsdichte-funktion der Zellen im Fahrschlauch entspricht praktisch dem verwendetenGewichtungsfaktor.
204
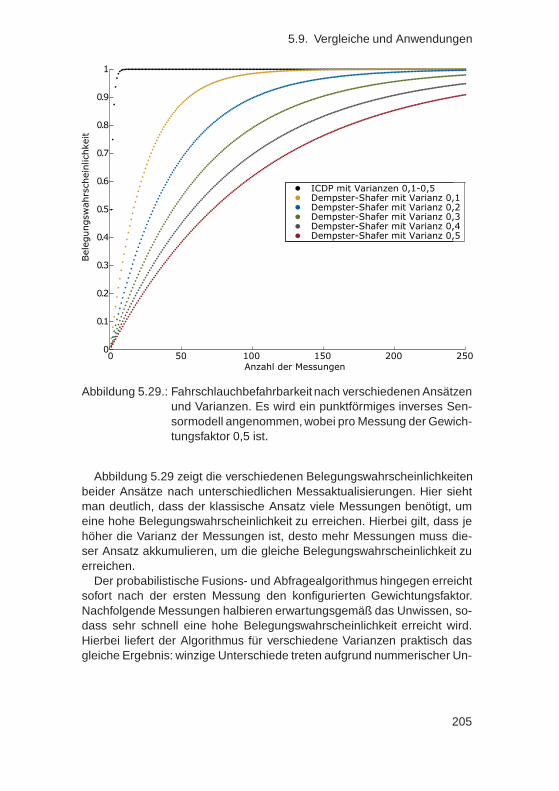
5.9. Vergleiche und Anwendungen
0 50 100 150 200 2500
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Anzahl der Messungen
Bele
gungsw
ahrs
chein
lichkeit
ICDP mit Varianzen 0,1-0,5Dempster-Shafer mit Varianz 0,1Dempster-Shafer mit Varianz 0,2Dempster-Shafer mit Varianz 0,3Dempster-Shafer mit Varianz 0,4Dempster-Shafer mit Varianz 0,5
Abbildung 5.29.: Fahrschlauchbefahrbarkeit nach verschiedenen Ansätzenund Varianzen. Es wird ein punktförmiges inverses Sen-sormodell angenommen, wobei pro Messung der Gewich-tungsfaktor 0,5 ist.
Abbildung 5.29 zeigt die verschiedenen Belegungswahrscheinlichkeitenbeider Ansätze nach unterschiedlichen Messaktualisierungen. Hier siehtman deutlich, dass der klassische Ansatz viele Messungen benötigt, umeine hohe Belegungswahrscheinlichkeit zu erreichen. Hierbei gilt, dass jehöher die Varianz der Messungen ist, desto mehr Messungen muss die-ser Ansatz akkumulieren, um die gleiche Belegungswahrscheinlichkeit zuerreichen.
Der probabilistische Fusions- und Abfragealgorithmus hingegen erreichtsofort nach der ersten Messung den konfigurierten Gewichtungsfaktor.Nachfolgende Messungen halbieren erwartungsgemäß das Unwissen, so-dass sehr schnell eine hohe Belegungswahrscheinlichkeit erreicht wird.Hierbei liefert der Algorithmus für verschiedene Varianzen praktisch dasgleiche Ergebnis: winzige Unterschiede treten aufgrund nummerischer Un-
205

Kapitel 5. Probabilistische Belegungsgitterfusion
genauigkeiten auf und sind im Diagramm nicht visualisierbar. Weitere Testszeigten, dass der ICDP-Algorithmus praktisch die gleichen Ergebnisse beiunterschiedlichen Zellauflösungen erzielt.
5.9.2. Echtzeitfähigkeit
Die vorgestellten Belegungsgitteralgorithmen können in vielfältiger Weiseinstanziiert, parametrisiert und beispielsweise mit einigen vorgestellten An-sätzen aus der Literatur weiter kombiniert werden. Hierbei muss die Bele-gungsgitterinstanz auf die eingesetzten Sensoren und die Anforderungender jeweiligen Anwendung genau abgestimmt werden.
Eine Anwendung ist die Umfeldüberwachung im Bereich des hochauto-matischen Fahrens auf Autobahnen und autobahnähnlichen Straßen beigeringen Geschwindigkeiten und in der Stillstandsphase. Beim Stillstandwird zusätzlich die Veränderung des Freibereiches überwacht: Verkleinertsich dieser, so wird davon ausgegangen, dass Fußgänger oder andere un-gewöhnliche Objekte sich auf der Fahrbahn befinden und die Anfahrüber-wachung wird auf den Fahrer zurückübertragen.
Das verwendete Belegungsgitter hat dabei eine einheitliche Auflösungund garantiert die Einbringung von Messungen in bis zu 100 Meter. Bisauf einige wenige sehr weit entfernte Ziele können somit alle Messungenimmer in das Belegungsgitter eingetragen werden. Die genauen Parametersind aus Tabelle 5.4 zu entnehmen.
Belegungsgitter-größe
200 m × 200 m
Zellgröße 0,25 m × 0,25 mZellanzahl 800 × 800 ZellenRingspeicher-größe
16
Speicherbedarf ca. 91 Megabyte
Tabelle 5.4.: Verwendetes Belegungsgitter
Um das Belegungsgitter mit Evidenzen zu füllen, werden Radar-,Ultraschall- und Stereokamerasensoren eingesetzt, welche verschiedeneObjekt- und Freibereichstypen generieren. Die von diesen Sensoren gene-rierten Messungen werden durch die beschriebenen inversen Sensormo-
206
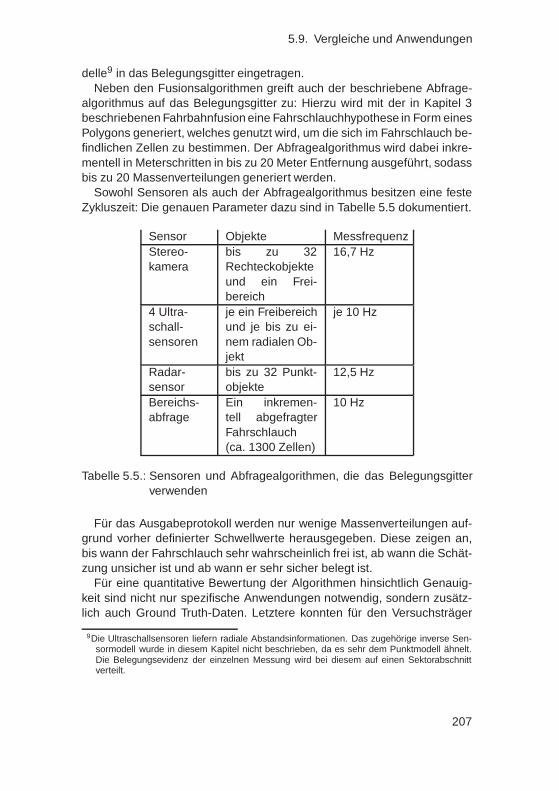
5.9. Vergleiche und Anwendungen
delle9 in das Belegungsgitter eingetragen.Neben den Fusionsalgorithmen greift auch der beschriebene Abfrage-
algorithmus auf das Belegungsgitter zu: Hierzu wird mit der in Kapitel 3beschriebenen Fahrbahnfusion eine Fahrschlauchhypothese in Form einesPolygons generiert, welches genutzt wird, um die sich im Fahrschlauch be-findlichen Zellen zu bestimmen. Der Abfragealgorithmus wird dabei inkre-mentell in Meterschritten in bis zu 20 Meter Entfernung ausgeführt, sodassbis zu 20 Massenverteilungen generiert werden.
Sowohl Sensoren als auch der Abfragealgorithmus besitzen eine festeZykluszeit: Die genauen Parameter dazu sind in Tabelle 5.5 dokumentiert.
Sensor Objekte MessfrequenzStereo-kamera
bis zu 32Rechteckobjekteund ein Frei-bereich
16,7 Hz
4 Ultra-schall-sensoren
je ein Freibereichund je bis zu ei-nem radialen Ob-jekt
je 10 Hz
Radar-sensor
bis zu 32 Punkt-objekte
12,5 Hz
Bereichs-abfrage
Ein inkremen-tell abgefragterFahrschlauch(ca. 1300 Zellen)
10 Hz
Tabelle 5.5.: Sensoren und Abfragealgorithmen, die das Belegungsgitterverwenden
Für das Ausgabeprotokoll werden nur wenige Massenverteilungen auf-grund vorher definierter Schwellwerte herausgegeben. Diese zeigen an,bis wann der Fahrschlauch sehr wahrscheinlich frei ist, ab wann die Schät-zung unsicher ist und ab wann er sehr sicher belegt ist.
Für eine quantitative Bewertung der Algorithmen hinsichtlich Genauig-keit sind nicht nur spezifische Anwendungen notwendig, sondern zusätz-lich auch Ground Truth-Daten. Letztere konnten für den Versuchsträger
9Die Ultraschallsensoren liefern radiale Abstandsinformationen. Das zugehörige inverse Sen-sormodell wurde in diesem Kapitel nicht beschrieben, da es sehr dem Punktmodell ähnelt.Die Belegungsevidenz der einzelnen Messung wird bei diesem auf einen Sektorabschnittverteilt.
207

Kapitel 5. Probabilistische Belegungsgitterfusion
nicht generiert werden, sodass nur eine qualitative Bewertung aus demTestbetrieb möglich ist. Hier zeigte das Belegungsgitter eine sehr hohe Zu-verlässigkeit sowohl auf verschiedenen Testgeländen als auch im öffentli-chen Straßenverkehr. So konnte bei Hunderten von Testkilometern keineFehlfunktion des Belegungsgitters innerhalb der Anwendungsspezifikationfestgestellt werden.
Auf der Zielplattform zeigte es auch eine gerine Latenz: So unter-schreitet die Abfrage des Fahrschlauchs und die Generierung des CAN-Ausgabeprotokolls stets 1 ms bei allen getesteten Messdatensätzen. Ähn-liches gilt für die Einbringung von Messungen mithilfe der inversen Sensor-modelle.
Die zusätzliche Systembelastung auf der Zielplattform10 ist gering: Sobenötigt die Sensordatenfusion wie im Kapitel 3 beschrieben ohne Bele-gungsgitter ca. 10,0 % an Systemleistung, während ca. 17,5 % mit Bele-gungsgitter benötigt wird. Insgesamt konnte der verwendeten Belegungs-gitterinstanz eine ausreichende Echtzeitfähigkeit auf dieser Zielplattformhinsichtlich der Anforderungen des hochautomatischen Fahrens beschei-nigt werden.
5.10. Zusammenfassung
Dieses Kapitel hat sich mit einer genauen und statistisch genauen Umge-bungsschätzung mittels Belegungsgitter beschäftigt. Aus den Anforderun-gen für eine Sensordatenfusion wurde abgeleitet, dass eine solche Schät-zung nicht nur für eine einzelne Zelle ermöglicht werden muss, sonderndass auch eine kombinierte Schätzung für eine Menge von Zellen unter-stützt werden soll. Auch müssen möglichst viele Abhängigkeiten zwischenMessungen erkannt und beseitigt werden, um eine hohe Genauigkeit zugewährleisten. Hierzu wurden verschiedene bekannte Ansätze untersucht,welche teilweise Messabhängigkeiten rudimentär behandeln, jedoch kaumAbhängigkeiten zwischen Zellen.
Diese beiden Probleme wurden formal als ICDP und IMDP definiert undes wurden Algorithmen gesucht, die diese beiden Probleme lösen. Leiderzeigte es sich an einem unentscheidbaren Beispiel, dass konventionelleMethoden zumindest das ICDP nicht lösen können. Diese basieren aufder rekursiven Aktualisierung einer einzelnen Massenverteilung eines Zell-zustandes, wobei jedoch viele Metainformation verloren gehen.
10Die verwendete Plattform besteht aus einem CompactPCI-Computer ausgerüstet mit einembis zu 2,2 GHz getakteten x86-Doppelkernprozessor und 4 GB Arbeitsspeicher
208

5.10. Zusammenfassung
Um diesem zu begegnen, wurde eine neue Umgebungsrepräsentationvon Belegungsgittern vorgestellt, die sich stark von konventionellen An-sätzen unterscheidet: Hierzu wird das Belegungsgitter als Datenstrukturbetrachtet, welche die diskretisierten Ergebnisse der einzelnen inversenSensormodelle möglichst verlustfrei verwalten soll. Hierbei ist ein deutlichgeringerer Informationsverlust zu verzeichnen, was beim Entwurf von Ab-fragealgorithmen genutzt wurde. Diese erkennen die Abhängigkeiten undUnabhängigkeiten bzgl. anderer Zellzustände und Messungen approxima-tiv und berücksichtigen dieses in ihrem Schätzer.
Dieser Schätzer basiert darauf, alle Zellzustände so zu kombinieren,dass diese das gleiche Ergebnis liefern, als wenn eine einzelne Zelle be-trachtet wird, die den gleichen Bereich abdeckt. Als Ergebnis erhält maneinen Algorithmus, der innerhalb der Diskretisierungsgrenzen nicht nur ap-proximativ unabhängig von der Zellauflösung ist, sondern auch eine sta-tistisch genauere Umfeldschätzung ermöglicht, was insgesamt an einemBeispiel gezeigt wurde.
Da beim Abfragealgorithmus genau bestimmt werden kann, welche Sen-soren wie häufig mit welcher Bereichsüberlappung den abgefragten Be-reich detektiert haben, ist es später möglich, Abhängigkeiten zwischenMessungen besser aufzulösen. So filtert der vorgeschlagene Abfrageal-gorithmus nicht nur die Positionsinformation der Messungen, sondern ge-wichtet diese noch aufgrund von Messbestätigungen. Bei vorliegendenGround Truth-Daten ist es zudem möglich, bestimmte Teilfunktionen desSchätzers genauer anzunähern und diesen insgesamt statistisch genauerzu gestalten.
Die vorgeschlagenen Algorithmen haben bei guter Parametrisierungnicht nur das Potenzial, die Genauigkeit der Umfeldschätzung zu erhöhen,sondern zeichnen sich insgesamt auch durch eine geringe Latenz aus, wasan einer Beispielapplikation gezeigt wurde.
209

Kapitel 6.
Zusammenfassung und Ausblick
6.1. Zusammenfassung
Viele aktuelle, aber auch zukünftige Fahrerassistenzsysteme benötigengenaue, robuste und umfangreiche Umfelddaten in Echtzeit. Diese Dis-sertation widmete sich der Generierung eines solchen Umfeldmodells,wobei die komplette Signalkette von Sensormessungen bis zur Fahrer-assistenzapplikation betrachtet worden ist. Insgesamt konnten diverseUngenauigkeits- und Fehlerquellen sowohl bei heutigen Sensortechnolo-gien als auch in bekannten Schätzalgorithmen identifiziert werden, wobeijedoch kein Anspruch auf eine vollständige Aufzählung aller möglichen Ein-flüsse besteht. Hierbei wurden die Sensortechnologien als gegeben ange-sehen, sodass Schätzalgorithmen Rücksicht auf deren Eigenschaften neh-men müssen und nicht umgekehrt.
Bei der Untersuchung bekannter Schätzer zeigte sich jedoch, dassdiese meist bestimmte Annahmen an Eingangsgrößen machen, wel-che in der Realität meist nicht erfüllt werden: Sowohl bei bekanntenObjektverfolgungs- als auch Belegungsgitteransätzen sollte jede als Zu-fallsvariable betrachtete Messung vollständig unabhängig von anderenMessungen sein, womit Abhängigkeiten innerhalb von Messreihen unbe-rücksichtigt bleiben. Auch sollten diese Zufallsvariablen Normalverteilun-gen einnehmen, was jedoch bei einigen Sensoren prinzipbedingt nicht er-reicht wird. Hierbei sind insbesondere Sensoren zu nennen, die diskre-te Messschritte aufweisen, wie beispielsweise Laserscanner und Kame-rasensoren. Bei der Auftretensrate von Scheinzielen verlangen Existenz-schätzer meist eine Gleichverteilung, sodass systematische Einflüsse ausder Umwelt ignoriert werden.
Viele Schätzer weisen zudem Modellschwächen auf, wobei vorhande-ne Informationsquellen unberücksichtigt bleiben oder verloren gehen: Sonutzen viele Signifikanzschätzer nur eine kleine Attributbasis, während be-kannte Belegungsgitteransätze keine Abhängigkeiten zwischen Zellen do-kumentieren und die Extrahierung von Regelgrößen selbst bei idealen Ein-
210

6.1. Zusammenfassung
gangsdaten mit hohen Ungenauigkeiten behaftet sein kann.Insgesamt widmete sich diese Dissertation mit der realitätsnäheren Ge-
staltung solcher Schätzalgorithmen: Hierzu wurden Annahmen und zu-grunde liegende Modelle hinterfragt, ob sie im Kontext von aktuellen Sen-sortechnologien und auftretenden Objektkonstellationen das Umfeld ge-nau darstellen können. Bei einigen Klassen von Schätzern wurden neueAnsätze vorgeschlagen, die insbesondere eine höhere Präzision gegen-über bekannten Ansätzen versprechen und weniger Annahmen an Ein-gangsdaten machen.
Zu den neu vorgestellten Ansätzen gehört eine Schätzung, ob ein Objektsowohl als existent als auch signifikant anzusehen ist und somit vom Fah-rerassistenzsystem berücksichtigt werden muss. Im Gegensatz zu bekann-ten Ansätzen wird hierbei nicht versucht, Evidenzen verschiedenster Quel-len zu gewichten und mithilfe probabilistischer Logik- und Statistikalgorith-men zu akkumulieren, da dieses Vorgehen eine genaue Abhängigkeits-und Unsicherheitsanalyse aller Quellen zur Folge haben würde.
Stattdessen wird die Bestimmung der kombinierten Existenz- und Signi-fikanzwahrscheinlichkeit als Klassifikationsproblem aufgefasst, wobei einentsprechender probabilistischer Klassifikator durch ein überwachtes Lern-verfahren angenähert wurde. Dieser berücksichtigt automatisch alle in denLerndaten enthaltenen Abhängigkeiten und Unsicherheiten, die beispiels-weise durch Sensortechnologien, Umwelteinflüsse, Signalvorverarbeitungund Schwächen in vorgelagerten Schätzern entstehen. Er weist insgesamteine hohe Präzision und Robustheit auf und ist echtzeitfähig.
Neben der Umfeldrepräsentation durch Objektlisten und Objektverfol-gungsalgorithmen ist als weiterer Schwerpunkt die modellärmere Reprä-sentation mithilfe von Belegungsgittern behandelt worden. Bei der Verbes-serung dieser Algorithmenklasse stand die Beseitigung von Schwächenklassischer Ansätze im Vordergrund: So berücksichtigen diese kaum Ab-hängigkeiten zwischen Zellinformationen und Messreihen. Diese Abhän-gigkeiten wurden formal als „Inter-Cell Dependency Problem“ bzw. „Inter-Measurement Dependency Problem“ definiert, sodass formale Anforderun-gen an Belegungsgitteralgorithmen gestellt werden konnten.
Um diesen Anforderungen zu begegnen, wurde ein neuer Belegungsgit-teransatz vorgestellt: Dieser beruht darauf, das Belegungsgitter nicht alsAnsammlung einzelner unabhängiger Zellen zu betrachten, sondern alsDatenstruktur, welche einen möglichst verlustfreien Zugriff auf die Mess-historie in Form diskretisierter Ergebnisse inverser Sensormodelle erlaubt.Als Ergebnis konnte zu solch einem Belegungsgitter ein entsprechenderAbfragealgorithmus entwickelt werden, welcher viel mehr Informationenberücksichtigt: Er kann nicht nur die Abhängigkeiten zwischen Zellen und
211

Kapitel 6. Zusammenfassung und Ausblick
Messreihen besser auflösen, sondern erlaubt sogar eine Positionsfilterung.Obwohl auch Schwächen in bekannten dynamischen Zustandsschät-
zern identifiziert worden sind, wurde keine direkte Verbesserung dieserAlgorithmenklasse vorgeschlagen. Dies ist einerseits damit begründet,dass Kalman- oder Partikelfilter unter Modellannahmen bereits sehr guteoder sogar optimale Zustandsschätzer darstellen, andererseits sind solcheSchätzer bereits stark im wissenschaftlichen Fokus gewesen, sodass zuden diversen bereits existierenden Varianten wohl nur marginale Verbesse-rungen erreichbar sind. Die Ungenauigkeiten dieser Filter wurden jedochindirekt in nachfolgenden Schätzern (Relevanz, Überfahrbarkeit) berück-sichtigt, welche auf überwachten Lernverfahren basieren.
Die neu entwickelten Ansätze wurden zusammen mit kalmanfilterbasier-ten Schätzern in eine Sensordatenfusion integriert, welche zusammen einumfassendes Umfeldmodell repräsentieren. Die Softwarearchitektur wurdedabei so entworfen, dass hohe Modularitätsanforderungen erfüllt werden:Sie erlaubt die einfache Erstellung von kaskadierten Schätzalgorithmenund unterstützt verschiedenste Sensortechnologien und Fahrerassistenz-applikationen. Eine Einbettung in unterschiedliche Umgebungen zwecksSimulations- und Testzwecken ist durch schichtenbasierte Architekturmus-ter und durch beliebige Zeitquellen möglich.
Insgesamt konnte eine Sensordatenfusion geschaffen werden, die hoheAnforderungen an Präzision, Robustheit, Echtzeitfähigkeit und Modularitäterfüllen kann. Sie wurde bereits auf acht Versuchsträger mit unterschiedli-chen Sensortechnologien portiert, wo sie unterschiedlichste Regelgrößenin hoher Qualität für diverse Fahrerassistenzapplikationen generiert.
6.2. Ausblick
Viele heutige Fahrerassistenzsysteme basieren auf dem Konzept, dassein Sensor genau eine Fahrerassistenzapplikation bedient. Es existierenjedoch bereits einige Systeme, die die Daten mehrerer Umfeldsensorenin einer Sensordatenfusion nutzen, um ein qualitativ besseres Umfeld zuschätzen. Dieser Trend wird sich mit der zunehmenden Anzahl an Fahrer-assistenzapplikationen und deren höheren Anforderungen verstärken.
Eine Herausforderung bleibt es, aus der sich abzeichnenden Flut vonSensordaten und anderer Informationsquellen ein möglichst genaues Um-feldmodell zu erzeugen, wobei Messungenauigkeiten, systematische Feh-ler, Umwelteinflüsse und sonstige Abhängigkeiten stets berücksichtigt wer-den müssen. Diese Faktoren scheinen dabei exponentiell mit der Sensor-anzahl und den zu schätzenden Entitäten in den einzelnen Domänen zu
212

6.2. Ausblick
steigen, sodass eine genaue und robuste Umfeldschätzung bereits heute,aber insbesondere auch in Zukunft einen hohen Forschungs- und Entwick-lungsaufwand nach sich zieht.
Diese Arbeit hat hierzu einen kleinen Baustein geliefert, indem neue ge-nauere Schätzmethoden zur Relevanz von Umfeldobjekten und zur Über-fahrbarkeit von Arealen vorgestellt worden sind. Hierbei wurde eine mög-lichst unabhängige Darstellung von bestimmten Sensortechnologien undFahrerassistenzapplikationen beschrieben, sodass diese Methoden uni-versell anwendbar sind und auch gut mit einer zunehmenden Anzahl vonSensoren skalieren.
Mögliche Fortschritte im Bereich der Sensordatenfusion stoßen jedochirgendwann an Grenzen: Die Schätzbasis besteht schließlich aus einerendlichen Menge nicht idealer Messdaten, aus denen man selbst mit per-fekten Modellen nur im endlichen Umfang endlich genaue Informationenextrahieren kann. Um qualitativ hochwertige Umfeldmodelle zu erstellen,sind deshalb gemeinsame Fortschritte sowohl bei Sensortechnologien undzugehöriger Signalvorverarbeitung als auch im Bereich der Hypothesenge-nerierung und Sensordatenfusion wichtig.
(a) Zwei Fussgänger, welche durch Be-wegung und Perspektive kein ein-heitliches Muster bilden und einemunregelmäßigen Vorder- und Hin-tergrund ausgesetzt sind
(b) Bild von maschinell verzerrten Zah-len auf unregelmäßigem Hinter-grund, welches eine automatischeUnterscheidung von Menschen undMaschinen ermöglicht (Turing-Test)
Abbildung 6.1.: Verschiedene Muster, die für Maschinen schwer wahr-nehmbar sind
Zwar sind Fortschritte in der Umfeldwahrnehmung absehbar, jedoch wirdin naher und mittlerer Zukunft wohl kaum die allgemeine Leistungsfähigkeiteines durchschnittlichen Fahrers in allen Verkehrsszenarien erreicht wer-den. Dies liegt vor allem in der für Menschen optimierten Verkehrsinfra-struktur, die genau dessen Stärken berücksichtigt: Dieser nimmt sehr viele
213

Kapitel 6. Zusammenfassung und Ausblick
analoge Informationen wahr, wie Farben, Licht, Symbole, Markierungenund akustische Signale, die jeweils die hochgradig gut ausgeprägte Mus-tererkennung von Menschen anspricht. Mustererkennung ist jedoch gera-de für Maschinen eine schwere Aufgabe, zumal die Umgebung mit vielenanderen Störmustern und Interferenzen behaftet ist. Dieser Umstand wirdin anderen Bereichen sogar dazu genutzt, Menschen von maschinell simu-lierten Nutzern automatisch zu unterscheiden (s. Abbildung 6.1).
Letztendlich muss man feststellen, dass die Verkehrsinfrastruktur vonMenschen für Menschen gemacht worden ist, und der Versuch diese ge-nauso gut maschinell wahrzunehmen und zu interpretieren dem Versuchgleicht, Maschinen teilweise zu vermenschlichen. Sollte dieses Vorhabenirgendwann gelingen, sind wohl intelligente Systeme im Sinne eines alter-nativen Turing-Tests geschaffen worden.
Einige wenige Domänen im Verkehrsbereich weisen zwar exemplarischbereits eine für Maschinen geeignete Umgebung auf: Hierbei sind bei-spielsweise autonom fahrende U-Bahnen oder Fahrstühle zu nennen, wel-che hauptsächlich in begrenzten und wohldefinierten Umgebungen digi-tal gesteuert bzw. geregelt werden. Ein weltweiter Umbau der komplettenVerkehrsinfrastruktur hin zu einer von Maschinen sehr gut wahrnehmba-ren Umgebung ist jedoch aus Kostengründen unabsehbar. Deshalb wirdes wohl in naher Zukunft kein autonomes Fahrzeug geben, welches in al-len Domänen eine vergleichbar leistungsfähige Fahrzeugführung aufweist,wie der Mensch.
Dennoch können punktuelle maschinelle Stärken genutzt werden, umdie Auswirkungen bestimmter menschlicher Schwächen bei der Fahraufga-be zu verringern: Im Gegensatz zum Menschen werden Maschinen nichtdurch Übermüdung, Gesundheitszustand, Emotionen oder Unachtsamkeitnegativ beeinflusst. Auch eine möglicherweise hohe Reaktionsfähigkeit aufplötzlich auftretende Ereignisse ist von Vorteil. Ziel der nahen und mittlerenEntwicklung muss es deshalb sein, die Kooperation von Fahrerassistenz-systemen und Fahrern zu perfektionieren. Dieses wird im Rahmen einerevolutionären Entwicklung auch gelingen, sodass Fahrern schrittweise ei-ne sicherere, komfortablere und effizientere Fahrzeugführung ermöglichtwird. Dieser Fortschritt wird sich beispielsweise auch in der Reduktion vonVerkehrsunfallzahlen ausdrücken. Eine autonome und sichere Fahrzeug-führung in allen Domänen unter den heutigen verkehrlichen Bedingungenbleibt vorerst jedoch eine Zukunftsvision.
214

Anhang A.
A.1. Begriffsdefinitionen
A.1.1. Echtzeitfähigkeit
In vielen Systemen besteht die Notwendigkeit, dass bestimmte Teilsyste-me innerhalb einer gewissen Zeitspanne eine Messung bzw. Berechnungausführen, damit das Gesamtsystem funktionieren kann. Im Bereich derFahrerassistenzsysteme sind beispielsweise solche Systeme betroffen, dieeine kontinuierliche Querführung erlauben. Werden Messdaten zu spät er-fasst, können hohe Osszilationen in der Querablage auftreten. Für solcheSysteme werden kontinuierlich aktuelle Messdaten benötigt, welche eindefiniertes Alter nicht überschreiten.
Definition (Hart Echtzeitfähigkeit).Ein (Teil-)System ist genau dann hart Echtzeitfähigkeit, wenn es eine be-stimmte vorgegebene Reaktionszeit nicht überschritten wird.
Um eine harte Echtzeitfähigkeit zu erreichen, müssen zum einen Algo-rithmen eingesetzt werden, welche immer voraussagbar terminieren. Zumanderen muss entsprechende Hardware verwendet werden, welche dieAbarbeitung der Algorithmen in der vorgegebenen Zeitspanne immer ge-währleistet. Falls der Terminierungszeitpunkt für einen Algorithmus varia-bel ist, muss der ungünstigste Fall berücksichtigt werden.
Weitere abhängige Anforderungen an ein hartes Echtzeitsystem und dieUnterscheidung zu weichen Echtzeitsysteme ist in [Kopetz 2011, S. 6ff] zufinden.
A.1.2. Statistisch korrekte Schätzer
Die Eigenschaft „Statistisch korrekt“ erlangt ein Schätzer, wenn er immerechte Wahrscheinlichkeiten als Gütemaß liefert und kein Gütemaß unbe-kannter Skalierung.
Hierbei unterscheiden wir zwei Klassen von Schätzern: Die Klassifikato-ren und Zustandsschätzer. Während ein probabilistischer Klassifikator eine
215

Anhang A. Anhang
Wahrscheinlichkeit für eine Klassenzugehörigkeit ermittelt, liefert ein pro-babilistischer Zustandsschätzer zusätzlich zur Schätzgröße beispielsweiseeine Varianz als Gütemaß. Statistisch korrekte Klassifikatoren werden in[DeGroot 1982] behandelt1.
Definition (Statistisch korrekte Klassifikatoren).Sei κ(x) ein probabilistischer Klassifikator, der für einen Merkmalsvektor xdie Wahrscheinlichkeit schätzt, dass er einer bestimmten Klasse angehört.Sei X = x1, . . . eine Menge von Merkmalsvektoren und Y = y1, . . . die bi-näre Beschreibung der Klassenzugehörigkeit (yi ∈ 0,1). Ferner sei X ⊂ Xmit (∀xi ∈ X)|(ε1 < κ(xi)< ε2) und Y ⊂Y die Menge der jeweils assoziiertenKlassenbeschreibung.
Ein Klassifikator ist genau dann statistisch korrekt wenn für alle ε1 < ε2gilt:
∞
∑i=1
κ(xi)− yi = 0 (A.1)
Falls ein Klassifikator statistisch nicht korrekt ist, so kann man diesenmittels Korrekturfunktion statistisch korrekt gestalten.
Definition (Statistisch korrekte probabilistische Zustandsschätzer).Sei ς(x) ein probabilistischer Güteschätzer, der für eine Schätzgröße xdessen Varianz schätzt. Sei X = x1, . . . eine Menge von Schätzgrößenund Y = y1, . . . die Menge der zugehörigen Zustandsgrößen. Ferner sei(X ⊂ X) mit ∀xi ∈ X |(ε1 < ς(xi)< ε2) und Y ⊂Y die Menge der jeweils zuge-hörigen Zustandsgrößen.
Ein Schätzer ist genau dann statistisch korrekt wenn für alle ε1 < ε2 gilt:
∞
∑i=1
ς(xi)− (xi − yi)2 = 0 (A.2)
Analog zur Klassifikatorfunktion kann auch die Schätzgüte mithilfe einerKorrekturfunktion statistisch genau gestaltet werden2.
1Der Artikel stammt aus dem Bereich der Meteorologie, da im Bereich der Robotik bzw. Fahrer-assistenzsysteme keine Quelle gefunden werden konnte, die eine geschätzte Wahrschein-lichkeit aus Ground-True-Daten validiert und gegebenenfalls korrigiert. DeGrooth nennt sol-che Schätzer im Meteologiebereich „perfekt zuverlässige Vorhersager“. Für diese Arbeit wur-de stattdessen der Begriff „statistisch korrekt“ gewählt, da „Zuverlässigkeit“ im Software- undTechnikbereich bereits eine anderweitige Bedeutung hat.
2Zu diesem Aspekt konnte leider keine Literaturquelle gefunden werden und er wird in dieserArbeit auch nicht weiter behandelt.
216

A.2. Kalmanfilter
A.2. Kalmanfilter
Das Kalmanfilter [Kalman 1960] ist ein dynamischer Zustandsschätzer,der in seiner ursprünglichen Form ein lineares Dynamikmodell Ft voraus-setzt. Es ist ein sog. „Prädiktor-Korrektor-Schätzer“, welcher den aktuellgeschätzten Zustand xt−1|t−1 eines Objektes auf den Zeitpunkt t einer Mes-sung prädiziert und diesen anschließend anhand der Messung korrigiert.
Mithilfe des geschätzten Zustandes und des Dynamikmodells könnenfehlende oder fehlerhafte Messungen teilweise kompensiert werden. Hier-zu wird der Zustand auf den aktuellen Zeitpunkt prädiziert, was je nachStärke des Dynamikrauschens eine mehr oder weniger genaue neueSchätzung ohne neu eingebrachte Messungen darstellt. Der Algorithmuserweist sich unter solchen Umständen als sehr robust und vermindert dieNotwendigkeit schneller Messdatenverarbeitung.
Zustands-
vorhersage
Zustands-
korrektur
Abbildung A.1.: Ablauf rekursiver Prädiktor-Korrektor-Schätzer
Die Zustandsschätzung bildet einen rekursiven Algorithmus (s. Abbil-dung A.1), wobei die Prädiktion des Zustandes wie folgt aktualisiert wird:
xt|t−1 = Ft xt−1|t−1 (A.3)
Neben der Zustandsprädiktion erfolgt auch die Prädiktion ihrer Unsicher-heit in Form einer Kovarianzmatrix Pt−1|t−1. Da das Dynamikmodell häufignicht perfekt ist, wird in der Regel noch ein Dynamikrauschen Qt definiert,welches die Zustandsunsicherheit weiter erhöht:
Pt|t−1 = FtPt−1|t−1FTt +Qt (A.4)
Die maximal mögliche Korrektur des Zustandes wird durch die sog. „In-novation“ yt festgelegt. Um diese zu bestimmen, wird der geschätzte Zu-stand xt mit der Messung zt verglichen. Dafür wird der Schätzzustand mit-hilfe der Matrix Ht in den Messraum abgebildet:
yt = zt −Ht xt|t−1 (A.5)
217

Anhang A. Anhang
Die sog. „Residualkovarianz“ St beschreibt die Unsicherheit der Innova-tion in Form ihrer Kovarianzmatrix. Sie berechnet sich aus der geschätztenZustandskovarianz Pt und der apriori bestimmten Messkovarianz Rt folgen-dermaßen:
St = HtPt|t−1HTt +Rt (A.6)
Aus der aktuellen Zustandsunsicherheit Pt|t−1 und der Residualkovari-anz St kann der optimale Kalmanverstärkungsfaktor Kt für den späterenKorrekturschritt berechnet werden:
Kt = Pt|t−1HT S−1t (A.7)
Mit dem optimalen Kalmanverstärkungsfaktor Kt und der Innovation yt
wird der Schätzzustand wie folgt aktualisiert:
xt|t = xt|t−1+Kt yt (A.8)
Kt wird ebenso genutzt, um die zu der Schätzung gehörige Kovarianz-matrix Pt entsprechend zu aktualisieren:
Pt|t = (I −KtHt)Pt|t−1 (A.9)
Das Kalmanfilter ist bewiesenermaßen ein optimaler Zustandsschätzer(vgl. Kalman [1960]), wenn sowohl das Dynamikmodell Ft als auch die Ab-bildung vom Systemraum in den Messraum Ht linear darstellbar sind undalle Unsicherheiten (Qt , Rt) normalverteilt sind. Bei solchen Systemen istdie Genauigkeitsanforderung entweder durch das Kalmanfilter erfüllt odersie ist nicht erfüllbar.
In vielen Anwendungsbereichen sind diese idealen Voraussetzungen je-doch nicht erfüllt. Hierfür wurden im Laufe der Zeit viele Varianten des Kal-manfilters entwickelt, welche versuchen, diese Einschränkung zu kompen-sieren.
So erlaubt beispielsweise das sog. „erweiterte Kalmanfilter“ auch dieVerwendung von nichtlinearen und differenzierbaren Modellen, welchedann approximativ linearisiert werden. Hierbei werden im Kalmanfilter dieMatrizen Ft und Ht durch entsprechende Jacobimatrizen ersetzt, welche alsElemente die partiellen Ableitungen der einzelnen Modellvariablen enthal-ten. Diese werden bei der Kovarianzprädiktion, bei der Residualkovarianz-berechnung, bei der Berechnung des optimalen Kalmanverstärkungsfak-tors und bei Kovarianzmatrixberechnung verwendet. Bei der Zustandsprä-diktion und bei der Innovationsberechnung können die Funktionen direktgenutzt werden.
218

A.3. Maschinelle Lernverfahren
Die Zustandsschätzung ist je nach Stärke der Nichtlinearität der Modellemehr oder weniger suboptimal. Eine weitere Verbesserung stellt das sog.„Unscented Kalman Filter“ dar. Diese Variante nutzt zwei sog. „Sigmapunk-te“ pro Dimension des Zustandsraumes, welche um den Schätzzustandplatziert werden. Diese Punktmenge wird mithilfe des potenziell nichtlinea-ren Dynamikmodells auf einen Messzeitpunkt prädiziert. Aus der transfor-mierten Punktmenge lässt sich eine neue Wahrscheinlichkeitsdichtefunkti-on ableiten, welche für eine genauere Kovarianzaktualisierung genutzt wird(vgl. [Julier 1997]).
A.3. Maschinelle Lernverfahren
A.3.1. Bayessches Netz
Ein Bayessches Netz wird aus einem gerichteten azyklischen Graphen ge-bildet, welcher die Zusammenhänge des zugrunde liegenden Klassifikati-onsproblems repräsentiert. Als Beispiel für solch ein Bayessches Netz istin Abbildung A.2 eine mögliche Struktur für einen Relevanzschätzer dar-gestellt. Während die Knoten des Graphen die Zufallsvariablen beschrei-ben, markieren die Kanten die bedingten Abhängigkeiten zwischen diesen[Pearl 1988, S. 77 ff]. Die Zufallsvariablen werden häufig in diskreter Formin den Knoten abgelegt. Bei dieser Modellierungsform müssen kontinuier-liche Eingangsdaten diskretisiert werden.
Bei einem Bayesschen Netz muss zum einen eine Netzstruktur festge-legt werden, die die Abhängigkeiten des zugrunde liegenden Problems re-präsentieren. Ist diese unbekannt, so kann man auf Algorithmen zurück-greifen, die aus Trainingsdaten eine mögliche Netzstruktur mittels lokalerMinimierung bestimmen. Als Beispiel sei der sog. „K2-Algorithmus“ [Co-oper 1992]) genannt.
Zum anderen muss beim Bayessches Netz eine Merkmalsdiskretisie-rung von kontinuierlichen Eingangswerten bestimmt werden. Ist diese zugrob, so können relevante Zustände nicht mehr differenziert werden. Ist siezu klein, kann es zu einer Überanpassung an die Trainingsdaten kommen[Uusitalo 2007].
Außerdem hat die Zahl der Diskretisierungsschritte einen großen Ein-fluss auf die bedingte Verbundwahrscheinlichkeitstabelle eines Netzkno-tens. So steigt deren Größe exponentiell zur Anzahl der Eingangsknotenn, während die Anzahl der Diskretisierungsschritte di die Basis bildet. DieGröße der Tabelle ist gegeben durch:
219

Anhang A. Anhang
Existent Signifikant
Relevant
Objekt-
alter
Objekt-
position
Objektge-
schwindig-
keit
Fahrbahn-
schätzung
Abbildung A.2.: Mögliche vereinfachte Struktur eines Bayesschen Netzeszur Schätzung der Relevanzwahrscheinlichkeit
O(n) =n
∏i=1
di (A.10)
Diese Größenabschätzung bildet gleichzeitig die untere Schranke für dieKomplexität der Trainingsalgorithmen. Aufgrund der potenziell hohen An-zahl von freien Variablen, die eine Verbundverteilung mit vielen Eingangs-parametern nach sich zieht, ist es für die Trainingsalgorithmen eine Her-ausforderung, keine Überanpassung vorzunehmen.
Die Verwendung von Algorithmen zur optimalen Bestimmung von Diskre-tisierungsschritten ist wenig verbreitet, sodass hier in den meisten Fällenein Experte diese vornimmt.
A.3.2. k-Nearest-Neighbour
Ein weiterer Algorithmus ist der sog. „k-Nearest-Neighbour-Algorithmus(kNN)“, welcher die k nächsten Ground Truth-Daten zurate zieht, um eineKlassifikation zu treffen [Dasarathy 1990]. Die Relevanzwahrscheinlichkeitberechnet sich aus dem Quotienten aus der Anzahl der relevanten Objekteder k nächsten Objekte und k.
Die richtige Wahl von k hat großen Einfluss auf das Klassifikationsergeb-nis: Ist k zu groß gewählt, kann er bestimmte Merkmale bei wenig dichten
220

A.3. Maschinelle Lernverfahren
?
Abbildung A.3.: k-Nearest-Neighbour Klassifikator mit k=3 und k=7 undMahalanobisabstandsmaß
Eingangsdaten nicht mehr differenzieren. Ist k zu klein gewählt, so kann ei-ne Überanpassung erfolgen (s. Abbildung A.3). Zudem benötigt der kNN-Algorithmus eine Abstandsfunktion, um zu entscheiden, welche Objektedem Muster am ähnlichsten sind. Hierbei wird häufig eine Mahalanobisdis-tanz verwendet, dessen Parametrisierung auf einer Verteilungsanalyse derEingangsdaten beruht. Dabei ist der Klassifikator darauf angewiesen, dassdie Eingangsdaten normalverteilt sind. Ist dieses nicht der Fall, kann einExperte versuchen, diese mittels einer Abbildungsfunktion entsprechendaufzubereiten.
Der kNN-Algorithmus besitzt im Prinzip keine Lernphase, welche Trai-ningsdaten kondensiert und überflüssige Daten eliminiert. Er gehört somitder Kategorie der sog. „Lazy Learner“-Algorithmen an, welche die Klas-sifizierungsfunktion direkt auf die Trainingsdaten anwendet. Vorteilhaft ist,dass die Trainingsdatenbasis mit sehr geringem Aufwand erweitert wer-den kann. Insbesondere bei einer großen Trainingsdatenbasis ist es je-doch nachteilig, dass der Klassifikator einen hohen Ressourcenverbrauchin Form von Speicherplatz und je nach Implementation auch in Form vonRechenzeit beansprucht.
A.3.3. Lineare Support Vector Machine
Die zugrunde liegende Struktur einiger Klassifikationsprobleme ist mögli-cherweise weniger komplex, sodass diese bereits von Klassifikatoren miteiner geringen Anzahl an Freiheitsgraden ausreichend approximiert wer-den können. Ein solch einfacher Klassifikator ist die Hyperebene, welche
221

Anhang A. Anhang
für linear separable Daten geeignet ist. Im Folgenden werden Ansätze zurApproximation einer solchen Ebene nach [Fan 2008] und [Burges 1998]vorgestellt.
Eine solche Trennebene kann hierbei durch einen Normalenvektor w undeinen Versatz b dargestellt werden, sodass für alle Punkte xi ∈ X der Trai-ningsmenge X gilt:
w · xi −b ≥ 0 , wenn xi der Klasse A angehört (A.11)
w · xi −b < 0 , sonst (A.12)
Abbildung A.4.: Der Abstand der eigentlichen Trennebene (durchgezoge-ne Linie) und parallelen Trennebenen (gestrichelte Linien)sollte für eine robuste Klassifikation maximiert werden
Bei linear separablen Daten existieren meist unendlich viele möglicheTrennebenen. Um den Klassifikator möglichst robust zu gestalten, solltehierbei die Trennebene gewählt werden, welche den Abstand zu den Trai-ningsdaten maximiert. Hierzu werden zwei weitere parallele Ebenen defi-niert, welche jeweils Abstand von 1
||w|| zur eigentlichen Trennebene aufwei-sen (vgl. Abbildung A.4):
w · xi −b ≥ 1 , wenn xi der Klasse A angehört (A.13)
w · xi −b < −1 , sonst (A.14)
Um den Abstand der Trennebene zu den parallelen Ebenen zu maxi-mieren, ist die Minimierung von ||w|| bzw. ||w||2 = w ·w notwendig. Hierzu
222

A.3. Maschinelle Lernverfahren
kann auf bekannte Verfahren im Bereich der konvexen Optimierung zurück-gegriffen werden. Zu bemerken dabei ist, dass meist nur wenige Punktein den Trainingsdaten die optimale Trennebene definieren: Diese werdenStützvektoren (engl. „support vectors“) genannt, welche mittels Maschinel-len Lernens bestimmt werden. Eine Trennebene kann somit auch durcheine entsprechende Stützvektormenge beschrieben werden, was dem Ver-fahren den Namen „Support Vector Machine (SVM)“ gegeben hat.
Die beschriebene Trennung funktioniert nur bei exakt linear trennbarenDaten, sodass ein einzelner Ausreißer diese Methode bereits unbrauchbarmachen könnte. Um dieses zu vermeiden, wurden Schlupfvariablen ζi inden Nebenbedingungen definiert, welche Ausreißer ermöglichen:
w · xi −b ≥ 1−ζi , wenn xi der Klasse A angehört (A.15)
w · xi −b < −1+ζi , sonst (A.16)
Auftretende Ausreißer werden aber auch gleichzeitig bestraft, indem dieSchlupfvariablen ζi in der zu optimierenden Zielfunktion berücksichtigt wer-den. Wie stark Ausreißer gewichtet werden, wird in dem Parameter C > 0festgelegt:
min||w||,ζ
12||w||2+C
n
∑i=1
ζi
(A.17)
Je nach Gewichtung mittels C kann entweder eine Trennebene priorisiertwerden, welche die Trainingsbeispiele möglichst zahlreich trennt oder abereine Trennebene, die den durchschnittlichen Abstand zu den Datenpunk-ten maximiert.
Die lineare Trennung von Daten hat den Vorteil, dass die Bestimmungder optimalen Hyperebene im Sinne der Zielfunktion effizient möglich ist,sodass sich dieser Klassifikator auch für sehr große und hochdimensionaleDatenbestände eignet. Die Zahl der freien Parameter ist dabei auf die Di-mension des Klassifikationsproblems beschränkt, sodass Überanpassun-gen möglicherweise weniger ausgeprägt sind als bei anderen Ansätzen.Auch ist die Klassifikation selbst sehr schnell möglich, da im Wesentlichennur das Skalarprodukt zwischen dem zu klassifizierenden Punkt und demNormalenvektor der Hyperebene bestimmt werden muss. Echtzeitanforde-rungen lassen sich somit leicht umsetzen.
Nachteilig ist die möglicherweise schlechtere Leistungsfähigkeit bei nichtlinear separablen Klassifikationsproblemen. Abhilfe kann hier eventuell ei-ne Datenanalyse und eine Abbildungsfunktion schaffen, die den Klassifi-kationsraum geeignet transformiert. Dieses ist manuell wohl aber nur bei
223

Anhang A. Anhang
niedrigdimensionalen Problemen effektiv möglich und erfordert Modellwis-sen.
A.3.4. Support Vector Machine mit Kernelerweiterung
Die lineare Trennung erreicht nur bei entsprechend verteilten Daten guteKlassifikationsraten, sodass diese beispielsweise keine n-XOR- bzw. Pari-tätsfunktion darstellen kann. Um komplexere Trennflächen zu ermöglichen,ist eine Erweiterung des Verfahrens notwendig, welche mehr Freiheitsgra-de als die Hyperebene im Merkmalsraum erlaubt. Dieser Ansatz wird bei-spielsweise in [Burges 1998] und [Steinwart 2008] verfolgt und im Folgen-den beschrieben.
Eine Möglichkeit mehr Freiheitsgrade zu erlauben, besteht in der Abbil-dung des Merkmalsraums auf einen euklidischen Raum höherer Dimen-sion, sodass eine Trennebene entsprechend mehr Parameter in Form zu-sätzlicher Stützvektoren aufweist. Durch eine entsprechende Rückabbil-dung können dann allgemeinere Trennflächen im Merkmalsraum beschrie-ben werden.
Da innerhalb der Trainings- und Klassifikationsalgorithmen die Elementedes Merkmalsraums nur mittels Skalarprodukten verknüpft werden, ist dieAbbildung einzelner Elemente in einen höherdimensionalen Raum nichtdirekt notwendig. Stattdessen ist es ausreichend, eine Abbildungsfunkti-on für zwei Elemente des Merkmalsraums in einen Skalarproduktraum zudefinieren, welcher durch einen möglichen höherdimensionalen Raum im-pliziert wird. Eine solche Funktion wird Kernelfunktion genannt.
Kernelfunktionen haben den Vorteil, dass ihre Dimension durch die Di-mension des Merkmalsraums definiert und begrenzt ist, jedoch deutlichhöher- oder gar unendlichdimensionale Abbildungsräume implizieren kön-nen, in denen ein entsprechendes Skalarprodukt definiert werden müsste.Sie erlauben somit eine indirekte, aber effiziente Skalarproduktbildung vonElementen in solchen Räumen und erweitern somit die Echtzeitfähigkeitund Genauigkeit des Klassifikators.
Kernelfunktionen können als eine Art Distanzmaß im Zustandsraum be-trachtet werden: Während beim normierten euklidischen Skalarprodukt derAbstand eines Punktes zu einer Trennebene bestimmt wird, lassen sichmit anderen Kernelfunktionen komplexere Distanzmaße definieren. Gän-gig sind polynomielle, radiale und sigmoide Kernelfunktionen, welche durchKonstanten (p, σ , κ und δ ) parametrisiert werden und teilweise aus demBereich der künstlichen neuronalen Netze bekannt sind:
224

A.3. Maschinelle Lernverfahren
KPoly(x1,x2) = (x1 · x2+1)p (A.18)
KRadial(x1,x2) = e−(x1−x2)
2
2σ2 (A.19)
KSigmoid(x1,x2) = tanh(κx1 · x2−δ ) (A.20)
Während bei der linearen Trennung die Anzahl der benötigten Stützvek-toren durch die Dimension des Merkmalsraums definiert ist, können beiden genannten Kernelfunktionen beliebig viele Stützvektoren verwendetwerden. Hierzu gibt es verschiedene Verfahren, mit denen iterativ eine ge-eignete Stützvektormenge bestimmt werden kann. Für Genaueres sei auf[Burges 1998] verwiesen.
Des Weiteren existieren Ansätze, die eine gewichtete Klassifikation er-lauben. Als Bewertungsgrundlage spielen hierbei die durch Kernelfunktio-nen ermittelten Distanzen eine wichtige Rolle: So wird beispielsweise in[Platt 1999] eine sigmoide Funktion approximiert, welche den Entfernun-gen zur Trennfläche d im Skalarproduktraum entsprechende Wahrschein-lichkeiten p(d) zuordnet:
p(d) =1
1+eA·d+B(A.21)
Die vorgeschlagene Funktion wird jedoch nur durch die beiden Konstan-ten A und B parametrisiert, sodass komplexe statistische Zusammenhängemöglicherweise nicht genau dargestellt werden. Das Ergebnis kann aberzumindest als Gütemaß unbekannter Skala betrachtet werden.
Eine beispielhafte Klassifikation einer SVM mit Kernelerweiterung ist inAbbildung A.5 dargestellt, in der ein zweidimensionaler Raum in diskretenSchritten probabilistisch klassifiziert wird.
Insgesamt eignet sich die SVM mit Kernelerweiterung für komplexe Klas-sifikationsprobleme, wobei die Trainingsmenge begrenzt sein sollte, damititerative Trainingsalgorithmen nicht zu viele mögliche Stützvektoren testenmüssen. Eine wichtige Rolle spielt außerdem die Trennbarkeit: So könnenviele Ausreißer Trainingsalgorithmen verleiten, Überanpassungen durchzusätzliche Stützvektoren vorzunehmen. Dies kann zwar mithilfe des C-Parameters aus Gleichung A.17 möglicherweise abgeschwächt werden,jedoch kann dies auch zu einer schlechteren Klassifikatoradaption führen.
Auch ist es herausfordernd, eine passende Parametrisierung für die Ker-nelfunktion und eine geeignete Stützvektormenge zu finden. Die Parame-trisierung eines Klassifikators auf Basis von SVMs sollte deshalb mithilfe
225

Anhang A. Anhang
Abbildung A.5.: Probabilistische Klassifikation (roter und blauer Bereich)zweidimensionaler Merkmalsvektoren (rote und blaueKreise) mittels radialer Basisfunktion als Kernelfunktion.Berücksichtigt werden 25 Stützvektoren (weiß umrandeteKreise).
von Kreuzvalidierungsverfahren unterstützt werden, sodass ein Parameter-satz mit hoher Genauigkeit erzeugt wird. Eine mögliche Vorgehensweisewird beispielsweise in [Chang 2011] beschrieben.
A.3.5. Künstliche neuronale Netze
Künstliche neuronale Netze (engl. „Artificial Neuronal Networks (ANN)“)bilden eine Klasse von Algorithmen aus dem Bereich des MaschinellenLernens (vgl. [Haun 1998], [Borgelt 2003] und [Nissen 2003]). Ihnen allenist gemeinsam, dass sie biologische Neuronen als Vorbild nehmen, um einkünstliches Neuron zu abstrahieren. Hierbei sammeln Neuronen über sog.„Dendriten“ Energie in Form von elektrischer Aktivität und leitet diese beiÜberschreitung eines Schwellwertes über sog. „Axone“ weiter. Die Den-driten sind mit anderen Axonen über sog. „Synapsen“ verbunden, wobeidiese je nach Typ das elektrische Signal verstärken oder hemmen können.
Ein künstliches Neuron imitiert ein solches Verhalten: Es erhält Aktivitä-ten über verschiedene Eingänge, welche über eine sog. „Übertragungs-funktion“ Σ gewichtet und zusammengefasst werden. Das Ergebnis derÜbertragungsfunktion wird an eine sog. „Aktivierungsfunktion“ ϕ weiter-geleitet. Diese ermittelt die Ausgabeaktivität y des Neurons, wobei einSchwellwertparameter θ berücksichtigt wird. In Abbildung A.6 ist die Ver-arbeitung exemplarisch dargestellt.
226

A.3. Maschinelle Lernverfahren
Axone
anderer
Neuronen
Synapsen /
Dendriten
x1
x2
w1
w2
w3
x3
∑
Zellkörper Axon
yφ
θ
Abbildung A.6.: Abstrahiertes künstliches Neuron
Diese künstlichen Neuronen werden zu ganzen Netzen verknüpft, wel-che mittels Trainingsdaten in der Lage sind, Funktionen zu approximierenoder als Assoziativspeicher zu fungieren.
Im Folgenden soll ein Netztyp aus der Klasse der vorwärtsgekoppeltenNetze mit überwachter Lernfunktion verwendet werden. Es handelt sichum sog. „Fehlerrückführungsnetze“ (engl. „backpropagation nets“), welchesich durch ein Schichtenlayout auszeichnen.
Hierbei werden insgesamt drei Schichttypen unterschieden. In derWahrnehmungs- bzw. Eingabeschicht wird das zu klassifizierende Mus-ter entgegengenommen. Dieses besteht aus so vielen Neuronen, wie Ein-gangsmerkmale verfügbar sind. Am anderen Ende des Netzes befindetsich die Ausgabeschicht, welche so viele Neuronen hat, wie Ausgabewerteerzeugt werden müssen. Im Fall des Relevanzklassifikators besteht dieseraus nur einem Neuron.
Dazwischen befinden sich meist ein bis zwei versteckte Schichten. Die-se ermöglichen es dem Netz, beliebige Funktionsapproximationen zu be-treiben [Pinkus 1999]. Jedes Neuron einer Schicht ist mit mindestens ei-nem Neuron aus den Nachbarschichten verbunden. Häufig wird die Klasseder vollständig verbundenen Fehlerrückführungsnetze genutzt, sodass einNeuron einer Schicht mit allen Neuronen der Nachbarschichten verbundenist. Ein Beispiel für ein solches Netz ist in Abbildung A.7 dargestellt.
Um ein Eingabemuster von solch einem Netz klassifizieren zu lassen,werden die Eingangsmerkmale meist auf das Intervall [0, 1] oder [-1, 1]normiert. Diese bilden die Eingangswerte der Wahrnehmungsschicht.
Die Eingangswerte werden über gewichtete Neuronenverbindungen indie nächste Schicht geleitet und von den dortigen Neuronen entgegen-
227

Anhang A. Anhang
Eingabe-
schicht
Versteckte
Schicht
Ausgabe-
schicht
x1
x2
wI11
wI12
wI13
wI23
wI22
wI21
wH11
wH21
wH31
Abbildung A.7.: Vollständig verbundenes mehrschichtiges künstliches neu-ronales Netz
genommen. Um alle Eingänge zu kombinieren, wird eine Übertragungs-funktion verwendet. Sei X = x1, . . .xn die Menge der Eingangswerte undW = w1, . . . ,wn die Menge der Verbindungsgewichte eines Neurons. DieÜbertragungsfunktion Σ(X ,W ) liefert als Netzeingabe eine Energie nach:
Σ(X ,W ) =n
∑i=1
wixi (A.22)
Während die Eingangswerte der Wahrnehmungsschicht meist nach demEmpfang identisch weitergeleitet werden, wird in den anderen Fällen aufdie Netzeingabe eine sog. „Aktivierungsfunktion“ angewendet. Diese mussfür das später beschriebene Lernverfahren differenzierbar sein.
Meist wird eine sog. sigmoide Aktivierungsfunktion verwendet, welchees dem künstlichen neuronalen Netz ermöglicht, nichtlineare Zusammen-hänge wiederzugeben. Diese zeichnet sich durch ihren beschränkten Wer-tebereich, einer streng monotonen Steigung und genau einen Wendepunktaus. Eine häufig genutzte sigmoide Aktivierungsfunktion ist ein Spezialfallder logistischen Funktion, welche in Abbildung A.8 dargestellt ist. Dieseund deren partielle Ableitung ist beschrieben durch:
228
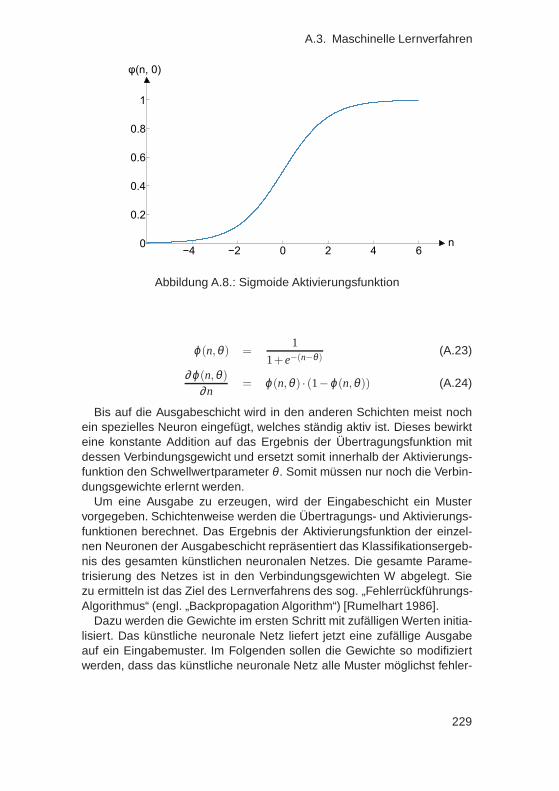
A.3. Maschinelle Lernverfahren
−4 −2 0 2 4 60
0.2
0.4
0.6
0.8
1
n
φ(n, 0)
Abbildung A.8.: Sigmoide Aktivierungsfunktion
ϕ(n,θ ) =1
1+e−(n−θ) (A.23)
∂ϕ(n,θ )∂n
= ϕ(n,θ ) · (1−ϕ(n,θ )) (A.24)
Bis auf die Ausgabeschicht wird in den anderen Schichten meist nochein spezielles Neuron eingefügt, welches ständig aktiv ist. Dieses bewirkteine konstante Addition auf das Ergebnis der Übertragungsfunktion mitdessen Verbindungsgewicht und ersetzt somit innerhalb der Aktivierungs-funktion den Schwellwertparameter θ . Somit müssen nur noch die Verbin-dungsgewichte erlernt werden.
Um eine Ausgabe zu erzeugen, wird der Eingabeschicht ein Mustervorgegeben. Schichtenweise werden die Übertragungs- und Aktivierungs-funktionen berechnet. Das Ergebnis der Aktivierungsfunktion der einzel-nen Neuronen der Ausgabeschicht repräsentiert das Klassifikationsergeb-nis des gesamten künstlichen neuronalen Netzes. Die gesamte Parame-trisierung des Netzes ist in den Verbindungsgewichten W abgelegt. Siezu ermitteln ist das Ziel des Lernverfahrens des sog. „Fehlerrückführungs-Algorithmus“ (engl. „Backpropagation Algorithm“) [Rumelhart 1986].
Dazu werden die Gewichte im ersten Schritt mit zufälligen Werten initia-lisiert. Das künstliche neuronale Netz liefert jetzt eine zufällige Ausgabeauf ein Eingabemuster. Im Folgenden sollen die Gewichte so modifiziertwerden, dass das künstliche neuronale Netz alle Muster möglichst fehler-
229

Anhang A. Anhang
frei klassifiziert. Hierzu ist eine repräsentative Menge von zu klassifizieren-den Mustern und deren gewünschte Ausgabe notwendig. Das künstlicheneuronale Netz minimiert den durchschnittlichen quadratischen Fehler derMustermenge gemäß Gleichung 4.29.
Um die Verbindungsgewichte zu bestimmen, ist zu unterscheiden, obes sich um eine Verbindung zwischen versteckter Schicht und Ausgabe-schicht oder zwischen Eingabeschicht und versteckter Schicht handelt. Imersten Fall hat das Gewicht direkten Einfluss auf die Ausgabe, im anderenFall kann der Einfluss nur indirekt ermittelt werden. Die Gewichtsänderungwird aus dem Fehleranteil ε berechnet, den das Neuron bewirkt hat. Die-ser berechnet sich für ein Neuron nO j der Ausgabeschicht aus der Differenzzwischen Soll-Wert ωnO j
und Ist-Wert νnO jmit:
εnOi= ωnO j
−νnO j(A.25)
Aus dem Fehlerwert εnO jwird ein Korrekturwert δnO j
abgeleitet, welcherspäter sowohl für die Berechnung der Gewichtsänderungen als auch für dieFehlerwertberechnung der Neuronen vorangegangener Schichten benötigtwird. Mittels einschrittigem Newtonverfahren wird die Funktionswertdiffe-renz approximiert, welche den Fehlerwert verkleinert. Hierbei wird die inGleichung A.24 genannte Ableitung der Aktivierungsfunktion verwendet3.
δnO j= εnO j
·ϕ(xnO j,0) · [1−ϕ(xnO j
,0)] (A.26)
Nur ein Bruchteil von δnO jwird genutzt, um die Gewichte anzupassen.
Der Anteil ist durch eine konstante Lernrate η festgelegt. Somit ändert sichdas Gewicht wHi j zwischen einem Neuron nHi der versteckten Schicht undeinem Neuron nO j der Ausgabeschicht mit:
wHi j = wHi j +ηδnO j(A.27)
Die Fehlerwertberechnung für ein Neuron nHi der vorangegangenen ver-steckten Schicht erfolgt indirekt: Dessen Fehlerwert εnHi
entspricht der mitden Neuronenverbindungen wHi j gewichteten Summe der zuvor bestimm-ten Korrekturwerte δnO j
:
εnHi=
n
∑j=1
(wI ji δnOi) (A.28)
Aus dem Fehlerwert εnHiwird analog zu Gleichung A.26 wieder ein Kor-
rekturwert δnHiabgeleitet und mit dessen Hilfe analog zu Gleichung A.27
3Wie beschrieben, wurde der Schwellwert θ in ein zusätzliches Verbindungsgewicht ausgela-gert, sodass dieser Parameter in der Aktivierungsfunktion null ergibt
230

A.3. Maschinelle Lernverfahren
die Gewichte der Neuronenverbindungen zwischen Eingabeschicht undversteckter Schicht angepasst.
Die Methode der Gewichtsanpassung stellt sich insgesamt als Gradien-tenabstiegsverfahren im hochdimensionalen Fehlerfeld dar. Über die Ab-leitungsfunktion des Fehlers wird die Bewegungsrichtung im Feld genutzt,die den steilsten Abstieg verspricht. Die begrenzte Lernrate η sorgt dafür,dass ein nahes lokales Minimum nicht übersprungen wird.
Die Anpassung der Gewichte erfolgt iterativ, wobei als Abbruchkriteriumdie Entwicklung des durchschnittlichen quadratischen Fehlers genutzt wird.Sollte dieser einen stagnierenden oder gar negativen Trend aufweisen, soist das Abbruchkriterium erfüllt. Um eine Überanpassung zu vermeiden,sollte der quadratische Fehler jedoch für eine separate Testmenge undnicht für die Trainingsdaten bestimmt werden.
231

Literaturverzeichnis
[Ahrholdt 2006] AHRHOLDT, M. ; BEUTNER, A.: Advanced Driver Assistan-ce for Trucks by Lane Observation. In: Proceedings of the 3. InternationalWorkshop on Intelligent Transportation, Hamburg, 2006
[Alpaydin 2004] ALPAYDIN, E.: Introduction to machine learning. The MITPress, 2004
[Altendorfer 2010] ALTENDORFER, R. ; MATZKA, S.: A Confidence Measurefor Vehicle Tracking based on a Generalization of Bayes Estimation. In:Proceedings of the IEEE Intelligent Vehicles Symposium, San Diego,USA, 2010, S. 766–772
[Bar-Shalom 1988] BAR-SHALOM, Y. ; FORTMANN, T. E.: Tracking and dataassociation. Academic-Press, Boston, USA, 1988
[Bar-Shalom 2001] BAR-SHALOM, Y. ; LI, X. R. ; KIRUBARAJAN, T.: Esti-mation with Applications to Tracking and Navigation: Theory Algorithmsand Software. Wiley & Sons, 2001
[Bar-Shalom 1975] BAR-SHALOM, Y. ; TSE, E.: Tracking in a ClutteredEnvironment with Probabilistic Data Association. In: Automatica 11, Nr.5, 1975, S. 451–460
[Bartels 2009] BARTELS, A. ; STEINMEYER, S. ; SPICHALSKI, C.: Spur-wechselassistenz. In: [Winner 2009c], S. 562–571
[Blackman 1999] BLACKMAN, S. ; POPOLI, R.: Design and Analysis ofModern Tracking Systems. Artech House Radar Library, 1999
[Borgelt 2003] BORGELT, C. ; KLAWONN, F. ; KRUSE, R. ; NAUCK, D.: Neuro-Fuzzy-Systeme. Vieweg+Teubner, 2003
[Bouzouraa 2009] BOUZOURAA, M. E. ; HOFMANN, U.: Effiziente Kar-tenbasierte Umfeldwahrnehmung mit Laserscanner-Sensoren für Fah-rerassistenzsysteme. In: STILLER, C. (Hrsg.) ; MAURER, M. (Hrsg.):6. Workshop Fahrerassistenzsysteme, Löwenstein/Hößlinsülz, 2009, S.157–165
232

Literaturverzeichnis
[Bouzouraa 2010] BOUZOURAA, M. E. ; HOFMANN, U.: Fusion of Occupan-cy Grid Mapping and Model based Object Tracking for Driver AssistanceSystems using Laser and Radar Sensors. In: Proceedings of the IEEEIntelligent Vehicles Symposium, San Diego, USA, 2010, S. 294–300
[Brahmi 2013] BRAHMI, M.: Reference Systems for Environmental Percep-tion. In: MAURER, M. (Hrsg.) ; WINNER, H. (Hrsg.): Automotive SystemsEngineering. Springer, 2013, S. 205–221
[Bresenham 1965] BRESENHAM, J. E.: Algorithm for Computer Control ofa Digital Plotter. In: IBM Systems journal 4, Nr. 1, 1965, S. 25–30
[Breuer 2009] BREUER, J.: Bewertungsverfahren von Fahrerassistenzsys-temen. In: [Winner 2009c], S. 55–68
[Burgard 1998] BURGARD, W. ; CREMERS, A.B. ; FOX, D. ; HÄHNEL, D. ;LAKEMEYER, G. ; SCHULZ, D. ; STEINER, W. ; THRUN, S.: The InteractiveMuseum Tour-guide Robot. In: Proceedings of the National Conferenceon Artificial Intelligence, Madison, USA, 1998, S. 11–18
[Burges 1998] BURGES, C. J. C.: A Tutorial on Support Vector Machinesfor Pattern Recognition. In: Data mining and knowledge discovery 2, Nr.2, 1998, S. 121–167
[Canny 1987] CANNY, J.: A Computational Approach to Edge Detection.In: Readings in computer vision: issues, problems, principles, and para-digms 184, 1987, S. 87–116
[Caruana 2006] CARUANA, R. ; NICULESCU-MIZIL, A.: An Empirical Com-parison of Supervised Learning Algorithms. In: Proceedings of the 23rdInternational Conference on Machine Learning, Pittsburgh, USA, 2006,S. 161–168
[Chang 2011] CHANG, C.-C. ; LIN, C.-J.: LIBSVM: a Library for SupportVector Machines. In: ACM Transactions on Intelligent Systems and Tech-nology 2, 2011, S. 1–27
[Cooper 1992] COOPER, G. ; HERSKOVITS, E.: A Bayesian Method for TheInduction of Probabilistic Networks from Data. In: Machine Learning 9,1992, S. 309–347
[Darms 2007] DARMS, M.: Eine Basis-Systemarchitektur zur Sensorda-tenfusion von Umfeldsensoren für Fahrerassistenzsysteme, TechnischeUniversität Darmstadt, Diss., 2007
233

Literaturverzeichnis
[Dasarathy 1990] DASARATHY, B. V.: Nearest Neighbor (NN) Norms: NNPattern Classification Techniques. IEEE Computer Society Press, 1990
[Degerman 2012] DEGERMAN, P. ; AH-KING, J. ; NYSTRÖM, T. ; MEINE-CKE, M. ; STEINMEYER, S.: Targeting lane-change accidents for heavyvehicles. In: VDI-Berichte , Nr. 2166, 2012
[DeGroot 1982] DEGROOT, M. ; FIENBERG, S.: The Comparison and Eva-luation of Forecasters. In: The Statistician 32, 1982, S. 12–22
[Dietmayer 2005a] DIETMAYER, K. ; KIRCHNER, A. ; KÄMPCHEN, N.: Fu-sionsarchitekturen zur Umfeldwahrnehmung für zukünftige Fahrerassis-tenzsysteme. In: MAURER, M. (Hrsg.) ; STILLER, C. (Hrsg.): Fahrerassis-tenzsysteme mit maschineller Wahrnehmung. Springer, 2005, S. 661–692
[Dietmayer 2005b] DIETMAYER, K. ; KÄMPCHEN, N. ; FÜRSTENBERG, K.; KIBBEL, J. ; JUSTUS, W. ; SCHULZ, R.: Roadway Detection and La-ne Detection using Multilayer Laserscanner. In: VALLDORF, J. (Hrsg.) ;GESSNER, W. (Hrsg.): Advanced Microsystems for Automotive Applica-tions 2005, Springer, 2005, S. 197–213
[Dornieden 2012] DORNIEDEN, B. ; JUNGE, L. ; PASCHEKA, P.: Voraus-schauende Energieeffiziente Fahrzeuglängsregelung. In: Automobil-technische Zeitschrift 114, Nr. 3, 2012
[Effertz 2009] EFFERTZ, J.: Autonome Fahrzeugführung in urbaner Um-gebung durch Kombination objekt– und kartenbasierter Umfeldmodelle,Technische Universität Braunschweig, Diss., 2009
[Elfes 1989a] ELFES, A.: Occupancy grids: A Probabilistic Frameworkfor Robot Perception and Navigation, Carnegie Mellon University Pitts-burgh, USA, Diss., 1989
[Elfes 1989b] ELFES, A.: Using Occupancy Grids for Mobile Robot Percep-tion and Navigation. In: IEEE Trans. on Computers 22, Nr. 6, 1989, S.46–57
[Elfes 1991] ELFES, A.: Dynamic Control of Robot Perception using Sto-chastic Spatial Models. In: Proceedings of the International Workshopon Information Processing in Mobile Robots, München, 1991, S. 203–218
234

Literaturverzeichnis
[Elfes 1992] ELFES, A.: Dynamic Control of Robot Perception using Multi-property Inference Grids. In: Proceedings of the IEEE International Con-ference on Robotics and Automation, Nizza, Frankreich, 1992, S. 2561–2567
[Fan 2008] FAN, R.-E. ; CHANG, K.-W. ; HSIEH, C.-J. ; WANG, X.-R. ; LIN,C.-J.: LIBLINEAR: A Library for Large Linear Classification. In: Journalof Machine Learning Research 9, 2008, S. 1871–1874
[Faugeras 2004] FAUGERAS, O. ; LUONG, Q. ; PAPADOPOULLO, T.: TheGeometry of Multiple Images: the Laws that Govern the Formation ofMultiple Images of a Scene and some of their Applications. The MITPress, 2004
[Fawcett 2004] FAWCETT, T.: ROC graphs: Notes and Practical Considera-tions for Researchers. In: Machine Learning 31, 2004, S. 1–38
[Ferguson 2006] FERGUSON, D. ; STENTZ, A.: Multi-resolution Field D*. In:Proceedings of the International Conference on Intelligent AutonomousSystems, Tokio, Japan, 2006, S. 65–74
[Gail 2010] GAIL, J.: Notbrems- und Spurverlassenswarnsysteme fürschwere Nutzfahrzeuge - Technische Anforderungen aus Sicht der Ge-setzgebung. In: [VDI Fahrzeug- und Verkehrstechnik 2010], S. 289–302
[Garey 1979] GAREY, M. R. ; JOHNSON, D. S.: Computers and Intractability:A Guide to the Theory of NP-Completeness. W. H. Freeman & Co., 1979
[Gasser 2012] GASSER, T. ; ARZT, C. ; AYOUBI, M. ; BARTELS, A. ; EIER, J. ;FLEMISCH, F. ; HÄCKER, D. ; HESSE, T. ; HUBER, W. ; LOTZ, C. ; MAURER,M. ; RUTH-SCHUMACHER, S. ; SCHWARZ, J. ; VOGT, W.: Rechtsfolgenzunehmender Fahrzeugautomatisierung – Gemeinsamer Schlussberichtder Projektgruppe. In: Berichte der Bundesanstalt für Straßenwesen.Bergisch-Gladbach, 2012
[Geduld 2009] GEDULD, G.: Lidarsensorik. In: [Winner 2009c], S. 172–186
[Giachetti 1998] GIACHETTI, A. ; CAMPANI, M. ; TORRE, V.: The use ofOptical Flow for Road Navigation. In: IEEE Transactions on Roboticsand Automation 14, Nr. 1, 1998, S. 34–48
[Haines 1994] HAINES, E.: Point in Polygon Strategies. In: Graphics GemsIV, 1994, S. 24–46
235

Literaturverzeichnis
[Hart 1968] HART, P. E. ; NILSSON, N. J. ; RAPHAEL, B.: A Formal Basis forthe Heuristic Determination of Minimum Cost Paths. In: IEEE transac-tions on Systems Science and Cybernetics 4, Nr. 2, 1968, S. 100–107
[Haun 1998] HAUN, M.: Simulation Neuronaler Netze. expert-Verlag, 1998
[Heckbert 1990] HECKBERT, P. S.: A Seed Fill Algorithm. In: GraphicsGems 1, 1990, S. 275–277
[Hoeger 2011] HOEGER, R. ; ZENG, H. ; HOESS, A. ; KRANZ, T. ; BOVERIE,S. ; STRAUSS, M. ; JAKOBSSON, E. ; BEUTNER, A. ; BARTELS, A. ; TO, T.; STRATIL, H. ; FÜRSTENBERG, K. ; AHLERS, F. ; FREY, E. ; SCHIEBEN, A.; MOSEBACH, H. ; FLEMISCH, F. ; DUFAUX, A. ; MANETTI, D. ; AMDITIS, A.; MANTZOURANIS, I. ; LEPKE, H. ; SZALAY, Z. ; SZABO, B. ; LUITHARDT,P. ; GUTKNECHT, M. ; SCHOEMIG, N. ; KAUSSNER, A. ; NASHASHIBI, F.; RESENDE, P. ; VANHOLME, B. ; GLASER, S. ; ALLEMANN, P. ; SEGLÖ,F. ; NILSSON, A.: Final Report / HAVEit Project (FP7/2007-2013 grantagreement n 212154). 2011 (D61.1). – Public Deliverable
[ISO 2002] Norm ISO/IEC 15622:2002(E) 2002. Transport Information andControl Systems – Adaptive Cruise Control Systems – Performance Re-quirements and Test Procedures
[ISO 2008] Norm ISO/IEC 22179:2008(E) 2008. Intelligent Transport Sys-tems – Full Speed Range Adaptive Cruise Control (FSRA) Systems –Performance Requirements and Test Procedures
[ISO 2011] Norm ISO/IEC 8855:2011(E) 2011. Road vehicles – Vehicledynamics and road-holding ability – Vocabulary
[Jordan 2006] JORDAN, R. ; AHLRICHS, U. ; LEINEWEBER, T. ; LUCAS, B.; KNOLL, P.: Hindernisklassifikation von stationären Objekten auf Basiseines nichtwinkeltrennfähigen Long-Range-Radar Sensors. In: STILLER,C. (Hrsg.) ; MAURER, M. (Hrsg.): 4. Workshop Fahrerassistenzsysteme,Löwenstein/Hößlinsülz, 2006, S. 153–160
[Julier 1997] JULIER, S. J. ; UHLMANN, J. K.: A new Extension of the KalmanFilter to Nonlinear Systems. In: Proceedings of the 11th InternationalSymposium on Aerospace/Defense Sensing (AeroSense), Simulationsand Controls, Orlando, USA, 1997, S. 182–193
[Kalman 1960] KALMAN, R. E.: A New Approach to Linear Filtering andPrediction Problems. In: Transaction of ASME, Journal of Basic Engi-neering , 1960, S. 25–45
236

Literaturverzeichnis
[Kammel 2008] KAMMEL, S. ; ZIEGLER, J. ; PITZER, B. ; WERLING, M. ;GINDELE, T. ; JAGZENT, D. ; SCHRÖDER, J. ; THUY, M. ; GOEBL, M.; HUNDELSHAUSEN, F. v. ; PINK, O. ; FRESE, C. ; STILLER, C.: TeamAnnieWAY’s autonomous system for the DARPA Urban Challenge 2007.In: Journal of Field Robotics 25, Nr. 9, 2008, S. 615–639
[Kelly 1998] KELLY, A. ; STENTZ, A.: Rough Terrain Autonomous Mobility– part 2: An active Vision, Predictive Control Approach. In: AutonomousRobots 5, Nr. 2, 1998, S. 163–198
[Kolski 2006] KOLSKI, S. ; FERGUSON, D. ; BELLINO, M. ; SIEGWART, R.:Autonomous Driving in Structured and Unstructured Environments. In:Proceedings of the IEEE Intelligent Vehicles Symposium, Tokio, Japan,2006, S. 558–563
[Kompaß 2008] KOMPASS, K.: Fahrerassistenzsysteme der Zukunft – aufdem Weg zum autonomen Pkw? In: SCHINDLER, V. (Hrsg.) ; SIEVERS, I.(Hrsg.): Forschung für das Auto von Morgen, Springer, 2008, S. 261–285
[Konolige 1997] KONOLIGE, K.: Improved Occupancy Grids for Map Buil-ding. In: Autonomous Robots 4, Nr. 4, 1997, S. 351–367
[Kopetz 2011] KOPETZ, H.: Real-time systems: design principles for distri-buted embedded applications. Springer, 2011
[Kotsiantis 2007] KOTSIANTIS, S. B.: Supervised Machine Learning: A Re-view of Classification Techniques. In: Informatika 31, 2007, S. 249–268
[Lancaster 1963] LANCASTER, H.: Correlation and complete dependenceof random variables. In: The Annals of Mathematical Statistics 34, Nr. 4,1963, S. 1315–1321
[Ling 2002] LING, C. X. ; ZHANG, H.: The Representational Power of Dis-crete Bayesian Networks. In: Journal of Machine Learning Research 3,2002, S. 709–721
[Lucas 1985] LUCAS, B. D.: Generalized Image Matching by the Method ofDifferences, Carnegie Mellon University, Diss., 1985
[Martin 1996] MARTIN, M. C. ; MORAVEC, H.P.: Robot Evidence Grids / Car-negie Mellon University, the Robotics Institute. 1996 (6). – Forschungs-bericht
237

Literaturverzeichnis
[Maurer 2004] MAURER, M. ; KIRCHNER, A. ; KOPISCHKE, S. ; MEINECKE,M. ; RANDLER, M. ; SCHOLZ, S. ; STÄMPFLE, M. ; WILHELM, U. ; ANKLAM,C. ; MEINKE, I. ; VON HOLT, V. ; KÜHNLE, G.: Verfahren und Vorrichtungzur Erkennung von Hindernissen und/oder Verkehrsteilnehmern. Deut-sches Patent- und Markenamt, Bundesrepublik Deutschland, 2004. – DEA1 10 242 808
[Meinecke 2013] MEINECKE, M. ; STEINMEYER, S. ; DEGERMAN, P. ; AH-KING, J. ; NYSTRÖM, T. ; DEEG, C. ; MENDE, R.: Experiences with aradar-based side assist for heavy vehicles. In: 14th International RadarSymposium (IRS) Bd. 2, Dresden, 2013, S. 720–725
[Meyer 1992] MEYER, F. ; BOUTHEMY, P.: Estimation of Time-to-collisionMaps from First Order Motion Models and Normal Flows. In: Procee-dings of the 11th International Conference on Pattern Recognition andInformation Processing Bd. 1, Minsk, Weißrussland, 1992, S. 78–82
[Mählisch 2009] MÄHLISCH, M.: Filtersynthese zur simultanen Minimierungvon Existenz-, Assoziations- und Zustandsunsicherheiten in der Fahr-zeugumfelderfassung mit heterogenen Sensordaten, Universität Ulm,Diss., 2009
[Mirwaldt 2012] MIRWALDT, P. ; BARTELS, A. ; TO, T. ; LEMMER, K. ; HUHLE,R. ; MALBERG, H. ; ZAUNSEDER, S.: Gestaltung eines Notfallassistenz-systems bei medizinisch bedingter Fahrunfähigkeit. In: Beiträge zur 5.Tagung Fahrerassistenz, München, 2012
[Montemerlo 2004] MONTEMERLO, M. ; THRUN, S.: A Multi-resolution Py-ramid for Outdoor Robot Terrain Perception. In: Proceedings of the 19thNational Conference on Artifical intelligence, San Jose, USA, 2004, S.464–469
[Moravec 1985] MORAVEC, H. P. ; ELFES, A.: High Resolution Maps fromWide Angle Sonar. In: Proceedings of the IEEE International Conferenceon Robotics and Automatisation, St. Louis, USA, 1985, S. 116–121
[Muntzinger 2011] MUNTZINGER, M. M.: Zustandsschätzung mit chronolo-gisch ungeordneten Sensordaten für die Fahrzeugumfelderfassung, Uni-versität Ulm, Diss., 2011
[Munz 2011] MUNZ, M.: Generisches Sensorfusionsframework zur gleich-zeitigen Zustands- und Existenzschätzung für die Fahrzeugumfelderken-nung, Universität Ulm, Diss., 2011
238

Literaturverzeichnis
[Mušicki 2004] MUŠICKI, D. ; EVANS, R.: Joint Integrated Probabilistic DataAssociation: JIPDA. In: IEEE Transactions on Aerospace and ElectronicSystems 40, 2004
[Mušicki 1994] MUŠICKI, D. ; EVANS, R. ; STANKOVIC, S.: Integrated Pro-babilistic Data Association. In: IEEE Transactions on Automatic Control39, 1994, S. 1237–1241
[Nissen 2003] NISSEN, S.: Implementation of a Fast Artificial Neural Net-work Library (FANN) / Department of Computer Science University ofCopenhagen (DIKU). 2003. – Forschungsbericht. – http://fann.sf.net
[Noll 2009] NOLL, M. ; RAPPS, P.: Ultraschallsensorik. In: [Winner 2009c],S. 110–122
[Ohl 2011] OHL, S. ; MAURER, M.: Ein Kontur schätzendes Kalmanfiltermithilfe der Evidenztheorie. In: MAURER, M. (Hrsg.) ; DIETMAYER, K.(Hrsg.) ; FÄRBER, B. (Hrsg.) ; STILLER, C. (Hrsg.) ; WINNER, H. (Hrsg.):7. Workshop Fahrerassistenzsysteme, Walting/Altmühltal, 2011, S. 83–94
[Pearl 1988] PEARL, J.: Probabilistic Reasoning in Intelligent Systems:Networks of Plausible Inference. Morgan Kaufmann Publishers, 1988
[Petrovskaya 2009] PETROVSKAYA, A. ; THRUN, S.: Model based VehicleDetection and Tracking for Autonomous Urban Driving. In: AutonomousRobots 26, 2009, S. 123–139
[Pinkus 1999] PINKUS, A.: Approximation Theory of the MLP Model inNeural Networks. In: Acta Numerica 8, 1999, S. 143–196
[Platt 1999] PLATT, J. C.: Probabilistic Outputs for Support Vector Machinesand Comparisons to Regularized Likelihood Methods. In: Advances inlarge margin classifiers , 1999, S. 61–74
[Polychronopoulos 2005a] POLYCHRONOPOULOS, A. ; AMDITIS, A. ; TSO-GAS, M. ; ETEMAD, A.: Extended Path Prediction using Camera and MapData for Lane Keeping Support. In: Proceedings of the IEEE IntelligentTransportation Systems, Wien, Österreich, 2005, S. 166–171
[Polychronopoulos 2005b] POLYCHRONOPOULOS, A. ; MÖHLER, N. ;GHOSH, S. ; BEUTNER, A.: System Design of a Situation Adaptive LaneKeeping Support System, the SAFELANE System. In: Advanced Micro-systems for Automotive Applications , 2005, S. 169–183
239

Literaturverzeichnis
[Rasshofer 2005] RASSHOFER, R. H. ; GRESSER, K.: Automotive Radarand Lidar Systems for Next Generation Driver Assistance Functions. In:Advances in Radio Science 3, 2005, S. 205–209
[Rojo 2007] ROJO, J. ; ROJAS, R. ; GUNNARSSON, K. ; SIMON, M. ; WIE-SEL, F. ; RUFF, F. ; WOLTER, L. ; ZILLY, F. ; SANTRAC, N. ; GANJINEH, T.; SARKOHI, A. ; ULBRICH, F. ; LATOTZKY, D. ; JANKOVIC, B. ; HOHL, G. ;WISSPEINTNER, T. ; MAY, S. ; PERVÖLZ, K. ; NOWAK, W. ; MAURELLI, F.; DRÖSCHEL, D.: Spirit of Berlin: An Autonomous Car for the DARPA Ur-ban Challenge - Hardware and Software Architecture / Freie UniversitätBerlin. 2007. – Forschungsbericht
[Rumelhart 1986] RUMELHART, D. E. ; HINTONT, G. E. ; WILLIAMS, R. J.:Learning Representations by Back–propagating Errors. In: Nature 323,1986, S. 533–536
[Schabenberger 2007] SCHABENBERGER, R.: ADTF: Engineering-Framework for Driver Assistance and Safety Systems. In: VDI Berichte2000, 2007
[Schiele 2009] SCHIELE, B. ; WOJEK, C.: Kamerabasierte Fußgängerde-tektion. In: [Winner 2009c], S. 223–236
[Schoeberl 2008] SCHOEBERL, T. ; FOCKE, T. ; MÜLLER, M. ; HILSEBE-CHER, J. ; BECKER, J. ; SPARBERT, J. ; OECHSLE, F. ; ZENDER, A. ;SIMON, A. ; GRIMM, A.: Fahrerassistenzsystem und Verfahren zur Ob-jektplausibilisierung. Deutsches Patent- und Markenamt, Bundesrepu-blik Deutschland, 2008. – DE A1 10 018 470
[Schuberth 2010] SCHUBERTH, S. ; DUBA, G.-P. ; SPARBERT, J. ; RAU, S.:Fahrschlauchfusion. In: [VDI Fahrzeug- und Verkehrstechnik 2010], S.213–229
[Shafer 1976] SHAFER, G.: A Mathematical Theory of Evidence. Bd. 1.Princeton university press Princeton, 1976
[Sinha 2006] SINHA, A. ; KIRUBARAJAN, T. ; DING, Z. J. ; FAROOQ, M.: TrackQuality based Multitarget Tracking Algorithm. In: Proceedings of SPIE6236, 2006, S. 1–12
[Sittler 1964] SITTLER, R. W.: An Optimal Data Association Problem onSurveillance Theory. In: IEEE Trans. on Military Electronics MIL-8, 1964,S. 125–139
240

Literaturverzeichnis
[Smarandache 2006] SMARANDACHE, Florentin ; DEZERT, Jean: Advan-ces and Applications of DSmT for Information Fusion. 2nd. AmericanResearch Press, 2006
[Steinmeyer 2009] STEINMEYER, S.: Handling Contradictory Sensor Da-ta in Environment Maps for Advanced Driver Assistance Systems. In:FISCHER, S. (Hrsg.) ; MAEHLE, E. (Hrsg.) ; REISCHUK, R. (Hrsg.): Infor-matik 2009: Im Focus das Leben, Köllen, Lübeck, 2009, S. 301
[Steinmeyer 2010a] STEINMEYER, S. ; BARTELS, A. ; MUSIAL, M. ; SCHULT-ZE, K. ; TO, T. ; WEISER, A.: Modulare Sensordatenfusions-Architekturam Beispiel des ’Temporary Auto Pilot’. In: AAET 2010, Beiträgezum gleichnamigen 11. Braunschweiger Symposium, Gesamtzentrumfür Verkehr Braunschweig e. V., Braunschweig, 2010, S. 89–104
[Steinmeyer 2010b] STEINMEYER, S. ; MAURER, M.: Dynamische Bestim-mung von Existenz- und Signifikanzwahrscheinlichkeiten für Umfeldob-jekte. In: [VDI Fahrzeug- und Verkehrstechnik 2010], S. 197–212
[Steinwart 2008] STEINWART, I. ; CHRISTMANN, A.: Support Vector Machi-nes. Springer, 2008
[Stüker 2004] STÜKER, D.: Heterogene Sensordatenfusion zur robustenObjektverfolgung im automobilen Straßenverkehr, Carl von Ossietzky-Universität Oldenburg, Diss., 2004
[Sun 2006] SUN, Z. ; BEBIS, G. ; MILLER, R.: On-road Vehicle Detection: aReview. In: IEEE Transactions on Pattern Analysis and Machine Intelli-gence 28, Nr. 5, 2006, S. 694–711
[Thomas 2007] THOMAS, P. ; FRAMPTON, R.: Real-world assessment ofRelative Crash Involvement Rates of Cars equipped with Electronic Sta-bility Control. In: Proceedings of the 20th International Technical Confe-rence on the Enhanced Safety of Vehicles Conference, Lyon, Frankreich,2007
[Thrun 1998] THRUN, S.: Learning Metric-topological Maps for Indoor Mo-bile Robot Navigation. In: Artificial Intelligence 99, Nr. 1, 1998, S. 21–71
[Thrun 2003] THRUN, S.: Learning Occupancy Grid Maps with ForwardSensor Models. In: Autonomous robots 15, Nr. 2, 2003, S. 111–127
241

Literaturverzeichnis
[Thrun 2006] THRUN, S. ; MONTEMERLO, M. ; DAHLKAMP, H. ; STAVENS,D. ; ARON, A. ; DIEBEL, J. ; FONG, P. ; GALE, J. ; HALPENNY, M. ; HOFF-MANN, G. ; LAU, K. ; OAKLEY, C. ; PALATUCCI, M. ; PRATT, V. ; STANG, P.; STROHBAND, S. ; DUPONT, C. ; JENDROSSEK, L. ; KOELEN, C. ; MAR-KEY, C. ; RUMMEL, C. ; NIEKERK, J. v. ; JENSEN, E. ; ALESSANDRINI, P.; BRADSKI, G. ; DAVIES, B. ; ETTINGER, S. ; KAEHLER, A. ; NEFIAN, A. ;MAHONEY, P.: Stanley, the Robot that won the DARPA Grand Challenge.In: Journal of Field Robotics 23, Nr. 9, 2006, S. 661–692
[To 2010a] TO, T. ; BARTELS, A.: Temporary Auto-Pilot: 1st System Func-tionality / HAVEit Project (FP7/2007-2013 grant agreement n 212154).2010 (D53.3). – Public Deliverable
[To 2010b] TO, T. ; KARRENBERG, S. ; STEINMEYER, S. ; WEISER, A. ;JOACHIM, M. ; JUNGE, L. ; BARTELS, A.: Temporary Auto-Pilot: Com-ponents installed, working and tested / HAVEit Project (FP7/2007-2013grant agreement n 212154). 2010 (D53.2). – Public Deliverable
[Urban 2006] URBAN, W. ; HENN, R. ; MOSER, V.: Method for Determi-ning the Plausibility of Objects in A Vehicle Driver Assistance System.Europäisches Patentamt, 2006. – EP 1 853 453 B1
[Urmson 2008] URMSON, C. ; ANHALT, J. ; BAGNELL, D. ; BAKER, C. ; BITT-NER, R. ; CLARK, M. N. ; DOLAN, J. ; DUGGINS, D. ; GALATALI, T. ; GEY-ER, C. ; GITTLEMAN, M. ; HARBAUGH, S. ; HEBERT, M. ; HOWARD, T. M.; KOLSKI, S. ; KELLY, A. ; LIKHACHEV, M. ; MCNAUGHTON, M. ; MILLER,N. ; PETERSON, K. ; PILNICK, B. ; RAJKUMAR, R. ; RYBSKI, P. ; SALES-KY, B. ; SEO, Y. ; SINGH, S. ; SNIDER, J. ; STENTZ, A. ; WHITTAKER, W.; WOLKOWICKI, Z. ; ZIGLAR, J. ; BAE, H. ; BROWN, T. ; DEMITRISH, D. ;LITKOUHI, B. ; NICKOLAOU, J. ; SADEKAR, V. ; ; ZHANG, W. ; STRUBLE,J. ; TAYLOR, M. ; DARMS, M. ; FERGUSON, D.: Autonomous driving inurban environments: Boss and the urban challenge. In: Journal of FieldRobotics 25, 2008, S. 425–466
[Uusitalo 2007] UUSITALO, L.: Advantages and challenges of Bayesiannetworks in environmental modelling. In: Ecological modelling 203, Nr.3-4, 2007, S. 312–318
[van Dam 1996] VAN DAM, J. ; KRÖSE, B. ; GROEN, F.: Neural NetworkApplications in Sensor Fusion for An Autonomous Mobile Robot. In:Reasoning with Uncertainty in Robotics , 1996, S. 263–278
242

Literaturverzeichnis
[VDI Fahrzeug- und Verkehrstechnik 2010] VDI FAHRZEUG-UND VERKEHRSTECHNIK (Hrsg.): Beiträge zur 26. VDI/VW-Gemeinschaftstagung, Fahrerassistenz und Integrierte Sicherheit.VDI Wissensforum GmbH, 2010
[von Zanten 2009] VON ZANTEN, A. ; KOST, F.: Bremsenbasierte Assis-tenzfunktionen. In: [Winner 2009c], S. 356–394
[Weiser 2009] WEISER, A. ; BARTELS, A. ; STEINMEYER, S. ; WEISS, K. ;MAREK, M.: Intelligent Car - Teilautomatisches Fahren auf der Autobahn.In: AAET 2009, Beiträge zum gleichnamigen 10. Braunschweiger Sym-posium, Gesamtzentrum für Verkehr Braunschweig e. V., Braunschweig,2009, S. 11–26
[Weiser 2011] WEISER, A. ; TO, T.: Verfahren zur Zuordnung von Fahrstrei-fen zu einem Fahrzeug. Deutsches Patent- und Markenamt, Bundesre-publik Deutschland, 2011. – DE 10 2009 060 600.9
[Weiss 2008] WEISS, T. ; DIETMAYER, K.: Positionierung eines Fahr-zeugs in unbekannten Gebieten mit Hilfe von Laserscannern (Loca-lization in Unknown Environments Using Laser Scanner). In: at–Automatisierungstechnik 56, Nr. 11, 2008, S. 554–562
[Winner 2009a] WINNER, H.: Radarsensorik. In: [Winner 2009c], S. 123–171
[Winner 2009b] WINNER, H. ; DANNER, B. ; STEINLE, J.: Adaptive CruiseControl. In: [Winner 2009c], S. 478–521
[Winner 2009c] WINNER, H. (Hrsg.) ; HAKULI, S. (Hrsg.) ; WOLF, G. (Hrsg.):Handbuch Fahrerassistenzsysteme. Vieweg+Teubner, 2009
[Yu 2007] YU, H. ; WANG, Y. ; PENG, J.: An Occupancy Grids BuildingMethod with Sonar Sensors Based on Improved Neural Network Model.In: Proceedings of the 4th International Symposium on Neural Networks,Nanjing, China, 2007, S. 592–601
[Zabler 2010] ZABLER, E. ; FINGBEINER, S. ; WELSCH, W. ; KITTEL, H. ;BAUER, C. ; NOETZEL, G. ; EMMERICH, H. ; HOPF, G. ; KONZELMANN,U. ; WAHL, T. ; NEUL, R. ; MÜLLER, W. ; BISCHOFF, C. ; PFAHLER, C. ;WEIBERLE, P. ; PAPERT, U. ; GERHARDT, C. ; MIEKLEY, K. ; FREHOFF,R. ; MAST, M. ; BAUER, B. ; HARDER, M. ; KASTEN, K. ; BRENNER, P.; WOLF, F. ; RIEGEL, J. ; ARNDT, M. ; REIF, K. (Hrsg.): Sensoren imKraftfahrzeug. Vieweg+Teubner, 2010
243


















