
Data Mining -...
155
Lehrgebiet „Datenbanksysteme für neue Anwendungen“ Seminarband zu Kurs 1912 im SS 2008 Data Mining Vorträge der Präsenzphase am 4. und 5. Juli 2008 Betreuer: Prof. Dr. Ralf Hartmut Güting Dipl.-Inform. Christian Düntgen Fakultät für Mathematik und Informatik Datenbanksysteme für neue Anwendungen FernUniversität in Hagen, 58084 Hagen © 2008 FernUniversität in Hagen
Transcript of Data Mining -...

Lehrgebiet „Datenbanksysteme für neue Anwendungen“
Seminarband zu Kurs 1912 im SS 2008
Data Mining
Vorträge der Präsenzphase am 4. und 5. Juli 2008
Betreuer: Prof. Dr. Ralf Hartmut Güting Dipl.-Inform. Christian Düntgen
Fakultät für Mathematik und Informatik Datenbanksysteme für neue Anwendungen FernUniversität in Hagen, 58084 Hagen
© 2008 FernUniversität in Hagen


Inhalt
Themenvorstellung............... ............................................................................................5
Zeitplan Präsenzphase........... ..........................................................................................13
Olga Riener: (1.1.1) Der Apriori-Algorithmus .................................................15
Nicolai Voget: (1.1.2) Frequent Pattern Growth..................................................39
Mathias Krüger: (1.2.1) Decision Tree Induction...................................................55
Constanze Hofmann:(1.3.1) Clustern mit CLARANS und BIRCH..............................79
Bernd Puchinger: (1.4.2) Ähnlichkeitssuche auf Zeitreihen ....................................97
Achim Eisele: (1.4.3) Suche nach Sequentiellen Mustern ................................113
Fatma Akyol: (1.5.1) Suche nach Häufigen Teilgraphen .................................133
- 3 -

- 4 -

Seminar 01912: Data MiningVortragsthemenRalf Hartmut Güting, Christian Düntgenrhg, hristian.duentgenfernuni-hagen.de11. Juni 2008Inhaltsverzei hnis1 Themen1.1 Häuge Muster und Assoziationsregeln1.1.1 Der Apriori-Algorithmus1.1.2 Frequent Pattern Growth1.2 Klassikation und Vorhersage1.2.1 De ision Tree Indu tion: SLIQ und SPRINT1.3 Cluster-Analyse1.3.1 Partitionierendes- und Hierar his hes Clustern: CLARANS und BIRCH1.3.2 Di htebasiertes Clustern: DBSCAN und OPTICS1.4 Datenströme, Zeitreihen und Sequentielle Daten1.4.1 Klassikation auf Datenströmen1.4.2 Ähnli hkeitssu he auf Zeitreihen1.4.3 Sequentielle Muster1.5 Graph Mining1.5.1 Häuge Teilgraphen: gSpan1.5.2 Indizieren von Graphen: GrapGrep und gIndex1.6 Räumli he Daten1.6.1 Räumli he Assoziationsmuster1.7 Data Mining Systeme1.7.1 Data Mining Systeme im Verglei h2 Themenwahl1 ThemenDas Seminar sah ursprüngli h vor, dass zwölf Teilnehmer jeweils einen Beitrag leisten. Lei-der haben nur sieben Teilnehmer und Teilnehmerinnen re htzeitig eine zufriedenstellendeAusarbeitung abgegeben und werden ihre Themen in der Präsenzphase präsentieren.
- 5 -

Bevor wir die Ausarbeitungen zu den sieben Seminarbeiträgen abdru ken, wollen wiehier no h einmal alle zwölf ursprungli h geplanten Vortragsthemen kurz vorstellen.Die ersten elf Seminarbeiträge behandeln bedeutende und interessante Verfahren, diebeim Data Mining Verwendung nden. Da uns nur begrenzt viel Zeit (nämli h 12 Vorträ-ge) zur Verfügung steht, mussten wir bezügli h der zu behandelnden Themen eine strengeAuwahl treen. So bleiben etwa die Themenberei he Data Warehouses und OLAP sowieText Mining, Web Mining und Information Retrieval unberü ksi htigt. Da es jedo h ge-rade zu diesen Berei hen zahlrei he spezielle Veranstaltungen gibt, halten wir dies fürvertretbar.Wir haben uns dazu ents hieden, eine Auswahl wi htiger Themenberei he des DataMining mit jeweils zwei Beiträgen zu bedeutenden Verfahren dieses Berei hs zu berü k-si htigen. Wir hoen, dass dadur h das jeweilige Bild ein wenig plastis her wird.Zu jedem der elf ersten Beiträge haben wir einen oder mehrere grundlegende wissen-s haftli he Artikel (Quellen) ausgewählt. Diese Quellen sollen die Grundlagen für denentspre henden Seminarbeitrag darstellen. Zusätzli h ist es zu einem tieferen Verständ-nis in der Regel sinnvoll, weitere Quellen zu Rate zu ziehen, etwa sol he, auf die si h diegenannten Arbeiten selbst beziehen.Während in nahezu jedem der angegebenen Artikel Anwendungen des jeweiligen Ver-fahrens mit anklingen und wir daher auf eine explizite Darstellung von Data MiningAnwendungen verzi hten, sollen im Rahmen des zwölften Beitrags existierende Data Mi-ning Systeme vorgestellt und vergli hen werden.1.1 Häuge Muster und AssoziationsregelnDie Entde kung von häugen Mustern (frequent itemsets) in Datenbeständen ist ein wi h-tiges Problem des Data Mining. Dessen Lösung ermögli ht etwa eine Warenkorbanalyse,bei der von Kunden häug gemeinsam erworbene Waren oder Warengruppen aus denTransaktionsdaten eines Ges häfts ermittelt werden.Aus häugen Mustern können Assoziationsregeln (asso iation rules) erzeugt werden.Dies sind Regeln der Formkauft(Bier) ∧ kauft(Milch) ⇒ kauft(Babywindeln)1.1.1 Der Apriori-AlgorithmusDerApriori Algorithmus [AS94, MTV94 stellt den ersten Algorithmus zur Entde kungvon frequent itemsets dar. Er erzeugt immer gröÿere Kandidatenmengen, testet die ein-zelnen Kandidaten und s hneidet auszus hlieÿende Berei he des Su hraums ab (pruning).1.1.2 Frequent Pattern GrowthDies ist eine verfeinerte Methode zur Bere hnung von von frequent itemsets [HPY00. Siekonstruiert dazu iterativ eine FP-tree genannte Datenstruktur.
- 6 -

1.2 Klassikation und VorhersageUnter Klassikation versteht man das Problem, Objekte auf Grund ihrer Eigens haftenbestimmten Mengen (Klassen) zuzuordnen. Das Klassikationsproblem besteht beim Da-ta Mining in der Regel darin, ein Verfahren (einen Klassikator) zu bestimmen, na h demman die Zuordnung vornehmen kann. Die Ermittlung des Klassikators wird häug alsLernproblem betra htet. Man unters heidet dabei überwa hte und unüberwa hte Lern-verfahren. Gemeinsam ist diesen Verfahren jedo h das Prinzip Learning by Example,d.h. dass anhand bekannter Beispiele gelernt wird.Bei der Vorhersage geht es darum, anhand bekannter Merkmale eines Objekts eineoder mehrere weitere (aber unbekannte) Eigens haften vorherzusagen.1.2.1 De ision Tree Indu tion: SLIQ und SPRINTDiese Verfahren erzeugen als Klassikator einen Ents heidungsbaum, indem sie die Bei-spielmenge na heinander anhand eines Attributs unterteilen, das jeweils anhand einesbestimmten Kriteriums und der beoba hteten Merkmale ausgewählt wird.Anstelle der einfa hen und grundlegenden Verfahren sollen hier SLIQ [MAR96 undSPRINT [SAM96 behandelt werden. Beide Verfahren eignen si h für die Analyse grö-ÿerer Datenmengen.1.3 Cluster-AnalyseBei der Cluster-Analyse versu ht man, Objekte anhand ihrer Merkmalsausprägungen inGruppen (Cluster) einzuteilen. Die Objekte werden dabei als Punkte dargestellt, die dur hdie Vektoren der Merkmalsausprägungen bes hrieben werden. Als Cluster betra htet mandann sol he Objektmengen, deren Elemente gemäÿ eines gegebenen Distanzmaÿes nahezueinander liegen (si h zu Haufen zusammenballen). Cluster-Verfahren sind sogenannteLearning by Observation-Verfahren, d.h. man benötigt vorab keine bereits klassiziertenBeispiele.1.3.1 Partitionierendes- und Hierar his hes Clustern: CLARANS und BIRCHZu den partinionierenden abstandsbasierten Cluster-Verfahren gehören Medoid-Cluster-verfahren. Sie unterteilen den Merkmalsraum in eine vorgegebene Anzahl von Berei hen,indem eine initiale Zuordnung von Punkten zu Clustern iterativ verbessert wird (iterativerelo ation te hnique). Jeder Cluster wird dur h einen Datenpunkt (Medoid) repräsentiert,dessen Abstand zumMittelwert innerhalb des Clusters minimal ist.CLARANS [EKX95verbindet das k-Medoids-Verfahren mit einem sampling-Ansatz.Hierar his he Clusterverfahren ordnen Cluster hierar his h an, d.h. kleinere Mikro lu-ster werden zu gröÿeren Makro lustern vereinigt (agglomerativ/bottom-up), bzw. letzterewerden in erstere unterteilt (diversiv/top-down). Als Beispiel soll BIRCH [ZRL96 be-handelt werden. BIRCH nutzt lustering features (CF) und CF-trees. Dabei kombiniert eshierar his hes Clustern auf der Mikroebene mit anderen Verfahren auf der Makroebene.- 7 -

1.3.2 Di htebasiertes Clustern: DBSCAN und OPTICSDi htebasierte Verfahren untersu hen die Anzahl potentieller Na hbarpunkte um zu ent-s heiden, ob ein Knoten zu einem Cluster gehört oder ni ht. So können au h asphäris heCluster (und Ausreiÿer) gefunden werden und die Anzahl der Cluster muss ni ht vorge-geben werden.DBSCAN[EKSX97 nutzt dazu die sogenannte Di hte-Errei hbarkeit von Punkten.OPTICS [ABKS99 führt kein Clustering dur h, sondern erzeugt Cluster-Ordnungen zurautomatis hen und interaktiven Parameterbestimmung bei der Clusteranalyse.1.4 Datenströme, Zeitreihen und Sequentielle Daten1.4.1 Klassikation auf DatenströmenWährend es lei ht ist, Daten mit hoher Frequenz und in groÿer Anzahl zu erheben undweiterzuleiten, bereitet die Verarbeitung aufgrund ihrer Komplexität vielfa h gröÿere Pro-bleme. So lassen si h etwa viele Daten aufgrund des Volumens ni ht dauerhaft spei hern.Au h kann man während der Analyse kaum auf alle gesammelten Daten zurü kgreifen.Daher ist Data Mining für derartige Data Streams (Datenströme) ein eigenes, anspru hs-volles Thema. Ansätze zur Lösung sol her Aufgaben liegen darin, Anfragen ni ht exakt,sondern nurmehr approximativ zu lösen.Stellvertretend für Stream Mining Verfahren sollen hier zwei Verfahren zur Klassi-kation auf Datenströmen vorgestellt werden: VFDT [DH00 und CVFDT [HSD01.1.4.2 Ähnli hkeitssu he auf ZeitreihenZeitreihen geben Daten wieder, die in einem funktionalen Zusammenhang zur Zeit ihrerErhebung stehen, etwa Aktienkurse, Temperaturkurven, et . Hierbei ist es von Interesse,regelmäÿige, etwa saisonale S hwankungen zu erkennen und von anderen (interessanteren)Mustern zu unters heiden.Als Beispiel für Data Mining auf Zeitreihen soll hier die Änli hkeitssu he auf Zeitreihen[AFS93 betra htet werden.1.4.3 Sequentielle MusterSequenzdatenbanken spei hern Ereignisse in der Reihenfolge ihres Auftretens, wobei je-do h der exakte Zeitpunkt jedes Ereignisses auÿer Betra ht bleibt. So können etwa Flug-bewegungen oder aufeinanderfolgende Kaufents heidungen auf wiederkehrende Musteruntersu ht werden [AS95, [SA96.1.5 Graph MiningGraphen dienen der Darstellung von Beziehungen unters hiedli hster Natur, z.B. vonsozialen Beziehungen von Individuen und Gruppen, oder zur Modellierung von Netzwer-ken (Kommunikations-, Verkehrsinfrastrukturen, Verweise im WWW, ...). Beim GraphMining versu ht man, interessante Strukturen und Beziehungen in/zwis hen sol hen Gra-phen aufzunden, bzw. herzustellen.- 8 -

1.5.1 Häuge Teilgraphen: gSpanDas Finden häuger Teilgraphen erlaubt es, wiederkehrende Muster zu isolieren oderGraphdaten zu komprimieren. Eine Methode dazu ist gSpan [YH02.1.5.2 Indizieren von Graphen: GrapGrep und gIndexEin Anwendungsszenario für häuge Teilgraphen ist die Su he in Graph-Datenbankenanhand von Substrukturen. GraphGrep [SWG02 ist ein Werkzeug zur Su he in Graph-Datenbanken. Es selektiert Graphen anhand von Teilgraphen. Ein pfadbasiertes Indizie-rungsverfahren ist gIndex [YYH04.1.6 Räumli he DatenBei der Analyse von Geodaten (spatial data) oder raumzeitli hen Daten (spatio-temporaldata) gibt es besondere Fragestellungen und Probleme bei der Datenanalyse. Die benö-tigten Algorithmen haben oft eine hohe Komplexität und die Datenmengen sind häuggroÿ.1.6.1 Räumli he AssoziationsmusterSpatial Data Mining soll hier dur h Verfahren zur Entde kung räumli her Assoziations-muster [KH95, [KN96 vorgestellt werden.1.7 Data Mining SystemeDie Entwi klung von Verfahren ist ein wi htiger Fors hungsbeitrag im Berei h des DataMining. Dabei werden die Verfahren häug als stand-alone-Anwendungen implementiertund getestet. Zur Bewertung der Verfahren wird dann meist nur ein isolierter Verglei hmit einem einzelnen weiteren Verfahren herangezogen.Einen umfassenderen Einbli k in die Leistungsfähigleit unters hiedli her Verfahrenbieten (prototypis he) Implementierungen von Data Mining Systemen. Diese Software-pakete bieten ein Framework zur Entwi klung und Implementierung unters hiedli herData Mining Verfahren und erlauben so deren direkten Verglei h. Zusätzli h bieten sieAnwendern einen ersten Zugang zu innovativen Methoden der Datenauswertung.1.7.1 Data Mining Systeme im Verglei hIn diesem Beitrag sollen daher abs hlieÿend bestehende und frei zugängli he Data MiningSysteme vergli hen und bewertet werden. Wir haben dazu drei Systeme ausgewählt:1. IlliMine 1.1.0 [Ill082. KnowledgeMiner 5.0 [Kno083. RapidMiner4.1beta2 [Rap08- 9 -

Während der Vorbereitung des Seminarbeitrags sollen mindestens zwei dieser Systemeinstalliert und in ihrer Anwendung erprobt werden. Im Vortrag sollen diese Systeme inkurzen Demonstrationen vorgestellt werden. Dabei sollen ihre Vorzüge und Na hteiledargestellt werden. Besondere Aufmerksamkeit verdienen Konzeption, Funktionsumfang,Erweiterbarkeit, S hnittstellen und allgemeine Usability.2 ThemenwahlUm die Themen bestmögli h auf die aktiven Teilnehmer und Teilnehmerinnen verteilenzu können, bitten wie Sie nun, uns Ihre Neigungen mitzuteilen.Ordnen Sie dazu jede der natürli hen Zahlen von 1 bis 12 genau einem derzwölf Themen zu. Die 1 steht für Ihre hö hste Priorität (also das Thema, wel hes Sieam liebsten bearbeiten wollen), die 12 entspre hend für die geringste (das von Ihnenam wenigsten geliebte Thema).Senden Sie uns Ihre Präferenzliste bis allerspätestens Sonntag, den 24.02.2008,per E-Mail an die Adresse hristian.duentgenfernuni-hagen.de.Wir werden dann am darauf folgenden Montag die Themenzuordnung vornehmen undIhnen das Ergebnis unverzügli h mitteilen.Literatur[ABKS99 M. Ankerst, M. M. Breunig, H.-P. Kriegel, and J. Sander. Opti s: Orderingpoints to identify the lustering stru ture. In Pro . ACM SIGMOD Int. Conf.on Management of Data (SIGMOD'99), pages 4960, Philadelphia, PA, 1999.[AFS93 Rakesh Agrawal, Christos Faloutsos, and Arun N. Swami. E ient SimilaritySear h In Sequen e Databases. In D. Lomet, editor, Pro eedings of the 4thInternational Conferen e of Foundations of Data Organization and Algorithms(FODO), pages 6984, Chi ago, Illinois, 1993. Springer Verlag.[AS94 Rakesh Agrawal and Ramakrishnan Srikant. Fast algorithms for mining asso- iation rules. In Jorge B. Bo a, Matthias Jarke, and Carlo Zaniolo, editors,Pro . 20th Int. Conf. Very Large Data Bases, VLDB, pages 487499. MorganKaufmann, 1215 1994.[AS95 Rakesh Agrawal and Ramakrishnan Srikant. Mining sequential patterns. InPhilip S. Yu and Arbee S. P. Chen, editors, Eleventh International Conferen eon Data Engineering, pages 314, Taipei, Taiwan, 1995. IEEE Computer So- iety Press.[DH00 Pedro Domingos and Geo Hulten. Mining high-speed data streams. In Know-ledge Dis overy and Data Mining, pages 7180, 2000.[EKSX97 Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. Density- onne ted sets and their appli ation for trend dete tion in spatial databases.In KDD, pages 1015, 1997.- 10 -

[EKX95 M. Ester, H.-P. Kriegel, and X. Xu. Knowledge dis overy in large spatialdatabases: fo using te hniques for e ient lass identi ation. In M. Egenho-fer and J. Herring, editors, Advan es in Spatial Databases, 4th InternationalSymposium, SSD'95, volume 951, pages 6782, Portland, ME, 1995. Springer.[HPY00 Jiawei Han, Jian Pei, and Yiwen Yin. Mining frequent patterns without andi-date generation. In Weidong Chen, Jerey Naughton, and Philip A. Bernstein,editors, 2000 ACM SIGMOD Intl. Conferen e on Management of Data, pages112. ACM Press, 05 2000.[HSD01 Geo Hulten, Laurie Spen er, and Pedro Domingos. Mining time- hanging da-ta streams. In Pro eedings of the Seventh ACM SIGKDD International Confe-ren e on Knowledge Dis overy and Data Mining, pages 97106, San Fran is o,CA, 2001. ACM Press.[Ill08 IlliMine Web Site. http://illimine. s.uiu .edu/, 2008.[KH95 Krzysztof Koperski and Jiawei Han. Dis overy of spatial asso iation rules ingeographi information databases. In SSD '95: Pro eedings of the 4th Inter-national Symposium on Advan es in Spatial Databases, pages 4766, London,UK, 1995. Springer-Verlag.[KN96 Edwin M. Knorr and Raymond T. Ng. Finding aggregate proximity relati-onships and ommonalities in spatial data mining. IEEE Transa tions onKnowledge and Data Engineering, 08(6):884897, 1996.[Kno08 KnowledgeMiner Web Site. http://www.knowledgeminer.net/, 2008.[MAR96 Manish Mehta, Rakesh Agrawal, and Jorma Rissanen. SLIQ: A fast s alable lassier for data mining. In Extending Database Te hnology, pages 1832,1996.[MTV94 Heikki Mannila, Hannu Toivonen, and A. Inkeri Verkamo. E ient algorithmsfor dis overing asso iation rules. In Usama M. Fayyad and Ramasamy Uthuru-samy, editors, AAAI Workshop on Knowledge Dis overy in Databases (KDD-94), pages 181192, Seattle, Washington, 1994. AAAI Press.[Rap08 RapidMiner Web Site. http://rapid-i. om/, 2008.[SA96 Ramakrishnan Srikant and Rakesh Agrawal. Mining sequential patterns: Ge-neralizations and performan e improvements. In Peter M. G. Apers, MokraneBouzeghoub, and Georges Gardarin, editors, Pro . 5th Int. Conf. ExtendingDatabase Te hnology, EDBT, volume 1057, pages 317. Springer-Verlag, 2529 1996.[SAM96 John C. Shafer, Rakesh Agrawal, and Manish Mehta. SPRINT: A s alableparallel lassier for data mining. In T. M. Vijayaraman, Alejandro P. Bu h-mann, C. Mohan, and Nandlal L. Sarda, editors, Pro . 22nd Int. Conf. VeryLarge Databases, VLDB, pages 544555. Morgan Kaufmann, 36 1996.- 11 -

[SWG02 Dennis Shasha, Jason Tsong-Li Wang, and Rosalba Giugno. Algorithmi sand appli ations of tree and graph sear hing. In Symposium on Prin iples ofDatabase Systems, pages 3952, 2002.[YH02 Xifeng Yan and Jiawei Han. gSpan: Graph-based substru ture pattern mining.In ICDM '02: Pro eedings of the 2002 IEEE International Conferen e on DataMining (ICDM'02), page 721, Washington, DC, USA, 2002. IEEE ComputerSo iety.[YYH04 Xifeng Yan, Philip S. Yu, and Jiawei Han. Graph indexing: A frequentstru ture-based approa h. In SIGMOD '04: Pro eedings of the 2004 ACMSIGMOD international onferen e on Management of data, pages 335346,New York, NY, USA, 2004. ACM.[ZRL96 Tian Zhang, Raghu Ramakrishnan, and Miron Livny. BIRCH: An e ientdata lustering method for very large databases. pages 103114, 1996.
- 12 -

Seminar 01912: Data MiningAblauf der Präsenzphaseam 5./6. Juli 2008, FernUniversität in Hagen11. Juni 2008Aufgrund einiger Ausfälle wird die Präsenzphase nur zwei (statt drei) Tage dauern:Fr., 04.07.2008, 10.00 Uhr - 16.45 UhrSa., 05.07.2008, 9.00 Uhr - 12.30 UhrDur h Verzögerungen im Ablauf kann si h das tatsä hli he Ende gegenüber der Pla-nung mögli herweise na h hinten vers hieben. Wir bitten, dies etwa bei Planung IhrerAbreise zu berü ksi htigen.Ort:FernUniversität in HagenInformatikzentrumRaum H 05Universitätsstraÿe 158097 HagenGeplanter Ablauf: Für den Freitag haben wir 5, für den Samstag 3 Vorträge eingeplant.An jeden 45-minütigen Vortrag s hlieÿt si h eine Diskussionsphase von etwa 15 MinutenDauer an. Zwis hen aufeinander folgenden Vorträgen haben wir kurze Pausen vorgesehen.
1- 13 -

Freitag, 04.07.200810.00 === Begrüÿung ===10.15 Vortrag 1: Olga Riener (Thema 1.1.1)11.15 Kaee-Pause11.30 Vortrag 2: Ni olai Voget (Thema 1.1.2)12.30 === Mittagspause ===(Mögli hkeit zur Verpegung in der Mensa oder Polizeikantine)13.30 Vortrag 3: Mathias Krüger (Thema 1.2.1)14.30 Kaee-Pause14.45 Vortrag 4: Constanze Hofmann (Thema 1.3.1)15.45 Kaee-Pausee16.00 Vortrag 5: Thorsten Edler (Thema 1.4.1)16.45 === S hluss ===Samstag, 05.07.200809.00 === Beginn ===09.00 Vortrag 6: Bernd Pu hinger (Thema 1.4.2)10.00 Kaee-Pause10.15 Vortrag 7: A him Eisele (Thema 1.4.3)11.15 Kaee-Pause11.30 Vortrag 8: Fatma Akyol (Thema 1.5.1)12.30 Abs hlussdiskussion13.00 === S hluss/Abreise ===Falls ein Vortrag entfällt, werden ggf. alle na hfolgenden Vorträge entspre hend vor-gezogen.
2- 14 -

FernUniversität in Hagen
Seminar 01912 „Data Mining“ im Sommersemester 2008
„Häufige Muster und Assoziationsregeln“
Thema 1.1.1 Der Apriori-Algorithmus
(Ausarbeitung)
Referentin: Olga Riener
- 15 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 2
Inhaltsverzeichnis 1. Einführung............................................................................................................. 3
2. Formale Notationen............................................................................................... 6
2.1. Transaktionen, Attribute (items) ..........................................................................................6
2.2. Assoziationsregeln (association rules) .................................................................................7
2.3. Unterstützungsgrad (support) ...............................................................................................7
2.4. Konfidenz bzw. Vertrauensgrad (confidence)......................................................................8
2.5. Häufige Muster (frequent itemsets)......................................................................................9
3. Formale Definition des Assoziationsproblems ................................................... 10
4. Basisalgorithmen zur Entdeckung von Assoziationsregeln............................... 11
4.1. AIS-Algorithmus ................................................................................................................11
4.2. SETM-Algorithmus............................................................................................................11
4.3. Nachteile der Basisalgorithmen..........................................................................................11
5. Apriori-Ansatz zur Entdeckung von Assoziationsregeln.................................... 12
5.1. Grundidee des Apriori-Ansatzes ........................................................................................12
5.2. Apriori-Algorithmus...........................................................................................................13
5.3. Erkennung der Assoziationsregeln.....................................................................................16
6. Apriori-Erweiterungen ........................................................................................ 18
6.1. AprioriTID..........................................................................................................................18
6.2. AprioriHybrid.....................................................................................................................19
7. Sonstige Effizienzsteigerung des Apriori-Verfahrens ........................................ 20
7.1. Hashbasierte Techniken (DHP)..........................................................................................20
7.2. Reduzierung der Transaktionen..........................................................................................20
7.3. Partitionierung ....................................................................................................................20
7.4. Sampling.............................................................................................................................21
7.5. Dynamische Aufzählung der Attributenwertmenge (DIC) ................................................22
8. Fazit ..................................................................................................................... 23
Literaturliste ............................................................................................................ 24
- 16 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 3
1. Einführung Der Erfolg vieler Aktivitäten in unserem Leben wird heutzutage primär vom Vorhandensein und der richtigen Auswertung diverser Informationen bestimmt. Bei der Geschäftsführung, bei wissenschaftlichen Recherchen oder bei staatlichen sozial-wirtschaftlichen Programmen sind solche Erkenntnisse besonders wichtig für den Erfolg. Der Einsatz von Datenbanktechnologien ermöglicht die Aufnahme größerer Datenbestände wie Lagerbestände, Auftragsdaten, Verkaufs- und Umsatzdaten, Personendaten, usw. Der KDD-Einsatz („Knowledge Discovery in Databases“) stellt entsprechend den gesamten Prozess der interaktiven und iterativen Entdeckung und Interpretation von nützlichem Wissen aus diesen Daten dar. Das Data Mining an sich ist das Herzstück des KDD-Prozesses.
„Unter Data Mining versteht man das systematische (in der Regel automatisierte oder halbautomatische) Entdecken und Extrahieren von Strukturen und Beziehungen in großen Datenmengen.“ ([6])
Bei Data Mining geht es also um die Auswahl und Anwendung geeigneter Methoden zur Entdeckung von Mustern und Beziehungen in den betrachteten Daten. Die hierduch gewonnenen Aussagen werden nach der entsprechenden Plausibilitätskontrolle in Erkenntnisse bzw. Wissen umgesetzt. Beispiel 1.1. Anwendungsbeispiel für Data Mining Eines der geläufigsten Anwendungsbeispiele für Data Mining findet man bei der Warenkorbanalyse, wo es um die folgende Frage geht: „Welche Produkte werden häufig zusammen gekauft?“ Abbildung 1.1 Die Antwort auf die obige Frage kann dann wie folgt aussehen: “Kauft ein Kunde Milch und Butter, besteht eine große Wahrscheinlichkeit, dass er sich auch noch für Brot entscheidet.”
Hm-m-m, welche Produkte werden
bei uns häufig zusammen gekauft?
Kunde 1: Brot, Milch, Butter
Kunde 2: Brot, Zucker, Milch
Kunde 3: Brot, Milch, Butter, Mehl
Kunde 4: Zucker, Sahne
- 17 -
Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 4
Es haben sich im Wesentlichen vier Aufgabenbereiche des Data Mining herausgebildet, und zwar die Segmentierung, die Klassifikation, die Vorhersage sowie der Ansatz der Assoziation. In der Tabelle 1.1. werden diese Aufgabenbereiche überblicksartig beschrieben. ([6]) Tabelle 1.1. Aufgabenbereiche und Methoden des Data Mining. Aufgabe Aufgabenstellung/Beispiel Wesentliche Methoden
Segmentierung
Bildung von Klassen aufgrund von Ähnlichkeiten der Objekte. Beispiel: Kundensegmentierung, um Produkte, Dienste und Kommunikationsmaßnahmen auf die Bedürfnisse der gefundenen homogenen Zielgruppen abstimmen zu können.
- Clusteranalyse - Neuronale Netze
Klassifikation
Identifikation der Klassenzugehörigkeit von Objekten auf der Basis gegebener Merkmale. Beispiel: Eine klassifikatorische Bonitätsbeurteilung ordnet einen Kunden in die Klassen der kreditwürdigen oder der kreditunwürdigen Personen ein.
- Diskriminanzanalyse - Neuronale Netze - Entscheidungsbäume
Vorhersage
Prognose der Werte einer abhängigen kontinuierlichen Variable auf Basis einer funktionalen Beziehung. Beispiel: Bei einer vorhersagenden Bonitätsbeurteilung wird die Bonität z.B. als maximal einräumbares Forderungsvolumen definiert.
- Regressionsanalyse - Neuronale Netze - Entscheidungsbäume
Assoziation
Aufdeckung von strukturellen Zusammenhängen in Datenbasen mit Hilfe von Regeln. Beispiel: Hier werden häufige Muster gefunden, z.B.: – Produkt/Kunden Muster (Warenkorbanalyse) – Sequenzmuster in Zeitreihen, Texten.
- Assoziationsanalyse
Generell haben sich in den letzten 10 Jahren die Methoden des Data Mining in vielen Einsatzgebieten etabliert. Herausragende Bedeutung haben jedoch die folgenden betriebswirtschaftlichen Anwendungen ([6]): 1) Marketing
Kundensegmentierung Responseanalyse von Werbemitteln Warenkorbanalyse Storno-/Reklamations-/Kündigungsanalyse
2) Beschaffung/Produktion
Materialbedarfsplanung Qualitätssicherung und Kontrolle
- 18 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 5
3) Controlling
Ergebnisabweichungsanalyse Entdecken von Controlling-Mustern
4) Finanzdienstleistungen
Kreditrisikobewertung Prävention des Kreditkartenmissbrauchs Bildung von Versicherungsrisikoklassen
Im Folgenden wird nur auf die Assoziationsanalyse näher eingegangen.
- 19 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 6
2. Formale Notationen Bevor wir uns mit den tatsächlichen Regeln und Algorithmen zur Entdeckung interessanter Zusammenhänge in großen Datenbeständen beschäftigen, werfen wir einen Blick auf die formalen Definitionen der hierfür interessanten Kenngrößen und betrachten ihre Nutzung am Beispiel der Warenkorbanalyse.
2.1. Transaktionen, Attribute (items) Gegeben seien eine Menge F von Transaktionsbezeichnern (Transaktionsschlüsseln) und eine Menge O von Objektbezeichnern (items). Eine Transaktion T ist ein Paar T=(TID, I), wobei TID F ein eindeutiger Bezeichner für die Transaktion und I O eine endliche Menge von items ist. Die Elemente i1 , i2 , ... , ik von I bezeichnen wir als items der Transaktion und schreiben I = i1 , i2 , ... , ik. Die Menge aller Transaktionen bezeichnen wir als D. Diese formale Definitionen wird sehr anschaulich am Beispiel vom Kaufvorgang eines Kunden. Die Menge der zu einem Einkauf gehörenden Produkte wird als eine Menge von items aufgefasst, wobei jedem Produkt genau ein item entspricht. Jedem Kaufvorgang wird ein eindeutiger Schlüssel im Kassensystem zugeordnet (TID). Für jeden Kaufvorgang speichert das Kassensystem einen Datensatz T, bestehend aus dem Schlüssel TID und einem mengenwertigen Attribut I, das alle items i1 , i2 , ... , ik enthält, die Gegenstand des Kaufvorgangs sind. Für unsere weitere Recherchen betrachten wir die Menge D aller Transaktionen aus der Tabelle 2.1.1.: Tabelle 2.1.1. Einkaufstransaktionen TID Items 100 Brot, Milch, Butter 200 Brot, Milch, Käse 300 Brot, Marmelade 400 Milch, Butter, Brot 500 Brot, Milch, Butter, Käse 600 Marmelade
- 20 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 7
2.2. Assoziationsregeln (association rules) Bei einer Assoziationsregel handelt es sich allgemein um eine Aussage der Form: „Wenn ein Ereignis X eingetreten ist, dann besteht eine hohe Wahrscheinlichkeit, dass auch Ereignis Y eintritt“. ([2]) Definition: Assoziationsregel Gegeben seien eine Menge F von Transaktionsbezeichnern und eine Menge O von Objektbezeichnern (items). Für X,Y O, X Y= ist die Implikation X Y eine Assoziationsregel. Eine Transaktion T=(TID,I) erfüllt eine Transaktionsregel R: X Y genau dann, wenn gilt: (X Y) . Wir schreiben T R. Es werden die folgenden Arten von Assoziationsregeln unterschieden ([3]):
Nützliche Assoziationsregeln enthalten Information über bislang unbekannte, aber nachvollziehbare Zusammenhänge.
Semantisch triviale Assoziationsregeln enthalten korrekte Information über bereits allgemein bekannte Zusammenhänge.
Syntaktisch triviale Assoziationsregeln enthalten Information über Zusammenhänge, die allein aufgrund des syntaktischen Aufbaus der Assoziationsregel und unabhängig von deren Inhalt korrekt sind.
Unerklärliche Assoziationsregeln entziehen sich einer plausiblen Erklärung. Die Zugehörigkeit der Assoziationsregeln zu einer der obengenannten Gruppen kann unter anderem durch die Auswertung unter Verwendung von Metriken wie dem Unterstützungsgrad (siehe Kapitel 2.3) und Vertrauensgrad (siehe Kapitel 2.4.) bestimmt werden. Beispiel 2.2.1. Aus den Einkaufstransaktionen der Tabelle 2.1.1. können wir z.B. die Abhängigkeit „Kauft ein Kunde Brot und Butter, so kauft er höchstwahrscheinlich auch Milch“ als Assoziationsregel Brot, Butter Milch ableiten.
2.3. Unterstützungsgrad (support)
Gegeben seien eine Menge F von Transaktionsbezeichnern, eine Menge O von Objektbezeichnern (items) und eine Menge von Transaktionen D. Dann ist für eine itemset X O der Unterstützungsgrad (support) von X in D wie folgt definiert:
| TD| T=(TID,I), X I | supportD(X) = ([4])
|D|
- 21 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 8
Offensichtlich misst supportD(X) den (prozentualen) Anteil der Transaktionen mit X in der Menge aller Transaktionen D an. Der Unterstützungsgrad (support) einer Assoziationsregel R: (A B) in D ist wie folgt definiert:
|T D | T=(TID,I), (A ) I | supportD(A = = support D(A ([4])
|D| Offensichtlich misst supportD(A die statistische Signifikanz der Regel R und wird als der (prozentuale) Anteil der Transaktionen mit (A B) in der Menge aller Transaktionen D berechnet. Ein hoher Unterstützungsgrad signalisiert tendenziell, dass die Assoziationsregel einen bereits bekannten Zusammenhang beschreibt. Da auch Assoziationsregeln mit geringem Unterstützungsgrad interessante Zusammenhänge repräsentieren können, ist der Unterstützungsgrad für sich allein genommen nicht geeignet, die Relevanz von Assoziationsregeln zu messen. Beispiel 2.3.1. Aus den Einkaufstransaktionen der Tabelle 2.1.1. bekommen wir z.B. die folgenden Werte für den Unterstützungsgrad:
support(Brot) = 5/6 = 83.3% support(Milch,Butter) = 3/6 = 50% support(Brot,Milch) = 4/6 = 66,6 %
2.4. Konfidenz bzw. Vertrauensgrad (confidence) Die Konfidenz misst die Sicherheit der entdeckten Assoziationsregel und präsentiert somit die Stärke bzw. den Vertrauensgrad für dieser Regel. Die Konfidenz ist der (prozentuale) Anteil der Transaktionen mit (X Y) in der Menge der Transaktionen D, deren Itemsets X enthalten :
|T D | T=(TID,I), (X Y) I | supportD(X Y) confidenceD(X Y) = = ([4])
|T D | T=(TID,I), X I | supportD(X) Der Vertrauensgrad einer Assoziationsregel ist unempfindlich gegenüber einer Veränderung der Anzahl der Tupel von D bei gleichbleibender Anzahl der Tupel, die die Assoziationsregel bzw. deren linke Seite erfüllen. Der Vertrauensgrad einer Assoziationsregel ist unempfindlich gegenüber einer proportionalen Veränderung des Unterstützungsgrads der Assoziationsregel und ihrer linken Seite. Beispiel 2.4.1. Aus den Einkaufstransaktionen der Tabelle 2.1.1. bekommen wir z.B. die folgenden Werte für den Vertrauensgrad:
- 22 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 9
support(BrotMilch) 2/3 confidence(Brot Milch) = = = 80%
support(Brot) 5/6
support(MilchBrot) 2/3
confidence(Milch Brot) = = = 100% support(Milch ) 2/3
2.5. Häufige Muster (frequent itemsets) Eine Menge aus einem oder mehreren items einer Transaktion wird als Muster oder als Attributwertmenge (itemset) bezeichnet (z.B. Muster Milch, Brot in einer Kauftransaktion). Eine aus k items bestehende Attributwertmenge wird als k-Attributwertmenge bezeichnet. Ein häufiges Muster ist eine Attributwertmenge M O mit einem Unterstützungsgrad grösser als eine vorgegebene minimale Unterstützung min_sup. D.h. der Anteil der Transaktionen in D mit dieser Attributwertmenge muss mindestens min_sup sein (supportD(X) ≥ min_sup). Beispiel 2.5.1. Aus den Einkaufstransaktionen der Tabelle 2.1.1. und bei der vorgegebenen minimalen Unterstützung min_sup=45% können wir folgende Besipiele betrachten:
Die Attributwertmengen (Brot), (Milch,Butter), (Brot,Milch) sind häufige Muster.
Die Attributwertmengen (Butter, Käse),(Marmelade) sind keine häufigen Muster.
- 23 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 10
3. Formale Definition des Assoziationsproblems Die Entdeckung interessanter Zusammenhänge in grösseren Datenbeständen erfolgt durch die Suche nach allen Assoziationsregeln mit mindestens:
einem vorgegebenen Unterstützungsgrad (support) min_sup; einem vorgegebenen Vertrauensgrad (confidence) min_conf.
Die Werte für min_sup und min_conf sind dabei frei wählbar. ([1], [4]) Das Assoziationsproblem an sich kann somit wie folgt formal definiert werden: In der gegebenen Menge D der Transaktionen, mit vorgegebenen min_sup und min_conf finde alle Assoziationsregeln X Y, so dass
support(X Y) min_sup confidence(X Y) min_conf
Eine enumerative Problemlösung hierzu kann in folgenden Schritten realisiert werden:
Auflistung aller möglichen Assoziationsregeln Berechnung vom Unterstützungs- und Vertrauensgrad für jede Assoziationsregel Entfernen aller Assoziationsregeln, deren Unterstützungs- oder Vertrauensgrad kleiner
als die geforderten Werte min_sup und min_conf sind. Solch eine Umsetzung verbietet sich jedoch bei grösseren Datenbeständen auf Grund der Rechenintensivität, da allein die Anzahl aller möglichen Kombinationen von Attributwerten der Ausgangs-Attributwertmenge im Allgemeinen sehr groß ist. Die Aufgabe von Assoziationsregelalgorithmen besteht daher darin, möglichst effizient alle häufigen Attributwertmengen zu finden, ohne jedoch alle grundsätzlich möglichen Attributwertmengen auf ihren Unterstützungsgrad hin untersuchen zu müssen. Sind schließlich alle häufigen Attributwertmengen gefunden, werden im zweiten Schritt aus jeder häufigen Attributwertmenge alle möglichen Regeln generiert, deren Vertrauensgrad größer gleich dem geforderten Mindestwert ist.
- 24 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 11
4. Basisalgorithmen zur Entdeckung von Assoziationsregeln Die ersten Algorithmen zur Entdeckung von Assoziationsregeln waren der AIS- und SETM-Algorithmus. Da diese Algorithmen heutzutage kaum noch praktische Bedeutung besitzen, betrachten wir diese nur oberflächlich um die historische Entwicklung dieses Problembereichs darzustellen.
4.1. AIS-Algorithmus Im Jahre 1993 wurde von den Mitarbeitern der Research IMB Almaden Center (Agrawal, Imielinski and Swami) das Problem der Assoziationsregeln eingeführt und der erste nach den Erfindern benannter Algorithmus (AIS-Algorithmus) zur Generierung von Einfachen Assoziationsregeln vorgeschlagen. Im AIS-Algorithmus werden die Kandidaten für häufige Itemsets beim Scannen der Datenbank „on the fly" generiert und gezählt, was eine sehr rechenintensive Operation darstellt. ([1], [5], [7])
4.2. SETM-Algorithmus Ebenfalls im Jahre 1993 wurde ein anderer Algorithmus namens SETM von Houtsma und Swami vorgestellt. Die Entwicklung dieses Algorithmus’ wurde mit dem Wunsch der SQL-Nutzung für die Suche nach den Assoziationsregeln motiviert. Im SETM-Algorithmus werden die potentiell häufigen Attributwertmengen analog dem AIS-Algorithmus basierend auf den Transformationen der Datenbank so zu sagen „on the fly" generiert. Abweichend vom AIS-Algorithmus trennt der SETM-Algorithmus das Generieren der Kandidaten von deren Aufzählung, um die Standardoperation „Union" (Vereinigung) der SQL-Sprache für die Generierung der Kandidaten zu benutzen. ([1], [5], [7])
4.3. Nachteile der Basisalgorithmen Der Nachteil der beiden Algorithmen (AIS und SETM) ist das überflüssige Generieren und Aufzählen von Kandidaten, die sich später als nicht häufig erweisen. ([5], [7])
- 25 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 12
5. Apriori-Ansatz zur Entdeckung von Assoziationsregeln Der Apriori-Algorithmus wurde 1994 von Rakesh Agrawal und Ramakrishnan Srikant entwickelt. Zur Zeit ist er der meistgenutzte Algorithmus zur Entdeckung der Assoziationsregeln aus Datenbeständen. Er zeichnet sich durch seine Einfachheit und ein gutes Laufzeitverhalten bei kleinen und mittleren Datenmengen aus. Dabei stellt er eine Weiterentwicklung und eine Verbesserung des AIS-Algorithmus dar. Die Entdeckung der Assoziationsregeln wird wiederum in die zwei Teilprobleme aufgeteilt welche dann separat gelöst werden können. In der ersten Phase kommt der eigentliche Apriori-Algorithmus in Einsatz für die Suche nach den häufige Muster (Attributwertmengen). In der zweiten Phase werden aus diesen häufigen Muster die Regeln gebildet.
5.1. Grundidee des Apriori-Ansatzes Der Apriori-Algorithmus ermittelt zu einer vorgegebenen Relation R und einem geforderten minimalen Unterstützungsgrad min_sup die Menge L aller häufigen Attributwertmengen, die in R vorkommen. Dies geschieht mit Hilfe eines iterativen Verfahrens, das zur Untersuchung der k-Attributwertmenge die bereits untersuchten (k-1)-Attributwertmengen verwendet. Am Anfang wird die Menge L1 aller häufigen 1-Attributwertmengen L1 gefunden. L1 wird zur Bestimmung aller häufigen 2-Attributwertmengen L2 verwendet und so weiter, bis keine häufige n-Attributwertmenge mehr gefunden werden kann. Die Bestimmung jeder Lk-Menge benötigt einen kompletten Datenbankdurchlauf bzw. Datenbankscan. Der Name „Apriori“ wurde diesem Algorithmus auf Grund der Tatsache vergeben, dass folgendes „a priori“ gesetzte Wissen (vorausgesetztes Wissen) bei der Ermittlung der häufigen Attributwertmengen verwendet wird ([7]):
Jede nichtleere Teilmenge einer häufigen Attributwertmenge muss auch eine häufige Attributwertmenge sein (z.B., wenn Milch, Brot eine häufige Attributwertmenge in den Kauftransaktionen ist, so müssen Milch und Brot auch häufig sein)
Dieses „a priori“-Wissen wird als folgende nicht-monotone Eigenschaft des Unterstützungsgrads aufgefasst:
X,Y : ( X Y ) support(X) support(Y) Die Verwendung dieser Eigenschaft im Apriori-Algorithmus hilft den Suchraum zu verkleinern und alle Obermengen der aussichtslosen k-elementigen Attributwertmengen für weitere Iterationen zu ignorieren. Dies kann am Beispiel 5.1.1. verdeutlicht werden:
- 26 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 13
Beispiel 5.1.1 . Apriori–Eigenschaft im Einsatz (auf Basis der Einkaufstransaktionen aus der Tabelle 2.1.1.) geforderter minimaler Unterstützungsgrad min_sup=50%
1. Iteration 1-Itemset Support Brot 5/6=83,3% 2. Iteration Milch 4/6=66,6% 2-Itemset support Butter 3/6=50% Brot, Milch 4/6=66,6% 3. Iteration Käse 2/6=33.3% Milch, Butter 3/6=50% 3-Itemset support Marmelade 2/6=33.3% Brot, Butter 3/6=50% Brot, Milch, Butter 3/6=50%
5.2. Apriori-Algorithmus Die eigentliche Ausführung vom Apriori-Algorithmus verwendet dabei im wesentlichen die folgenden Hilfsmengen ([1], [5]):
Ck (k 1) ist die Menge aller k-elementigen potentiell häufigen Attributwertmengen. Lk (k 1) ist die Menge aller k-elementigen häufigen Attributwertmengen.
Der Durchlauf jeder Iteration k im Apriori-Algorithmus erfolgt in 3 Schritten:
Im ersten Schritt, der sogenannten Join-Phase, wird die Ck–Menge erzeugt, indem die (k-1)-Attributwertmenge Lk-1 mit sich selbst vereinigt wird.
Im zweiten Schritt, der sogenannten Pruning-Phase, werden aus der Ck–Menge alle k-elementigen Attributwertmengen entfernt, die eine Teilmenge enthalten, welche nicht häufig ist. D.h. in diesem Schritt werden die Kandidaten aus Ck mit Hilfe der Apriori-Eigenschaft abgeschnitten.
Als abschließender Schritt wird für die übrig gebliebenen Kandidaten aus Ck an Hand der Datenbasis überprüft, ob sie häufig sind. Die Kandidaten, die diesen Test bestehen, werden in die Menge Lk aufgenommen.
Wie bereits im Kapitel 4.1. erwähnt wird dieses iterative Vorgehen so oft wiederholt , bis keine weitere häufige Attributwertmenge gefunden werden kann. Die Realisierung dieses Algorithmus kann mit dem folgenden Pseudo-Code ([1], [5]) verdeutlicht werden: ( 1) L1 = häufige 1-Attributenwertmenge; ( 2) for ( k=2 ; Lk-1 ≠ ; k++ ) do begin ( 3) Ck= apriori-gen(Lk-1 ); // Berechnung neuer Kandidaten ( 4) for all Transaktionen t D do begin ( 5) Ct = subset(Ck,t) ; // Berechnung aller in t enthaltene Kandidaten ( 6) for all Kandidaten c Ct do ( 7) c.count++; // ( 8) end ( 9) Lk = c Ck | c.count >= minsup (10) end (11) return: k Lk
- 27 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 14
In Zeile (1) wird mit der Menge der einelementigen häufigen Attributwertmenge gestartet. Diese Menge wird durch einfaches Zählen der Häufigkeit der einzelnen Attributwerte im Datenbestand D und anschließendem Vergleich mit der Größe min_sup bestimmt. Ausgangspunkt ist dann eine nichtleere Menge aller häufigen (k-1)-Attributwertmengen Lk-1 (Zeile 2). Um die häufige k-Attributwertmengen Lk zu finden, werden zunächst die sogennaten k-elementigen Kandidaten Ck bestimmt, die potentielle häufige k-Attributwertmengen sein können. Dazu wird die weiter unten beschriebene Funktion apriori-gen verwendet, welche die Menge der k-elementigen Kandidaten Ck zurückgibt (Zeile 3). Zu diesen k-elementigen Kandidaten werden dann die im Datenbestand vorkommenden Häufigkeiten (support-Werte) berechnet (Zeilen 4-8). Dies geschieht, indem zunächst in der Prozedur subset für jede Transaktion t alle in t vorkommenden k-elementigen Attributwertmengen bestimmt werden, die zugleich in der Menge der k-elementigen Kandidaten Ck enthalten sind. Anschließend wird für jede dieser Mengen ein Zähler inkrementiert (Zeile 6,7), der nach Durchlauf aller Transaktion angibt, wie oft ein bestimmter k-elementiger Kandidat durch die Transaktionen unterstützt wird. Diejenigen k-elementigen Kandidaten, die sich durch Vergleich der Auftretenshäufigkeit mit der Größe min_sup als häufige k-Attributwertmengen herausstellen, werden in die Menge der häufigen k-Attributwertmengen Lk aufgenommen. Wenn Lk nicht leer ist, so wird mit dieser Menge die Schleife ab Zeile 2 wiederholt. Der Algorithmus terminiert, wenn die Menge der häufigen k-Attributwertmengen Lk leer ist und somit keine weiteren Obermengen, welche die min_sup-Bedingung erfüllen könnten, gefunden werden können. Die Berechnung der neuen k-elementigen Kandidaten erfolgt in der folgenden apriori-gen Funktion ([5]): procedure apriori-gen(Lk-1: (k-1)-Attributwertmenge)
//Join-Schritt ( 1) insert into Ck ( 2) select p.item1 , p.item2 , …p.itemk-1 , q.itemk-1 ( 3) from Lk-1 p , Lk-1 q ( 4) where p.item1=q.item1 ,….,.p.item k-2=q. item k-2 , p.item k-1<q. item k-1
// Prune-Schritt ( 5) for all itemsets c Ck do ( 6) for all (k-1)–subset s of c do ( 7) if ( s Lk-1) then ( 8) delete c from Ck end procedure Die apriori-gen Funktion besteht aus 2 Phasen: dem Join-Schritt und dem Prune-Schritt. Im Join-Schritt (Zeilen 1-4) wird die als Input übergebene (k-1)-Attributwertmenge Lk-1 mit sich selbst vereinigt, um einen neuen Kandidat der Größe k zu erzeugen. Dabei werden solche häufigen (k-1)-elementigen Attributwertmengen verknüpft, welche in den ersten k-2 Elementen identisch
- 28 -
Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 15
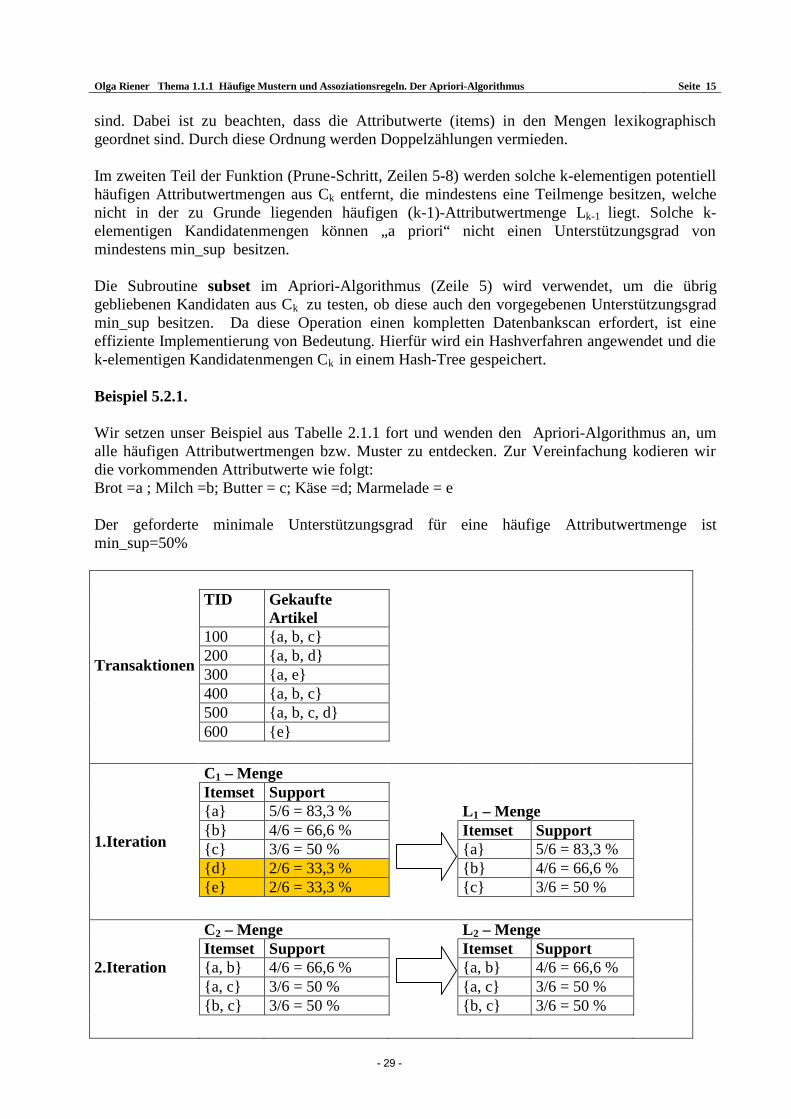
sind. Dabei ist zu beachten, dass die Attributwerte (items) in den Mengen lexikographisch geordnet sind. Durch diese Ordnung werden Doppelzählungen vermieden. Im zweiten Teil der Funktion (Prune-Schritt, Zeilen 5-8) werden solche k-elementigen potentiell häufigen Attributwertmengen aus Ck entfernt, die mindestens eine Teilmenge besitzen, welche nicht in der zu Grunde liegenden häufigen (k-1)-Attributwertmenge Lk-1 liegt. Solche k-elementigen Kandidatenmengen können „a priori“ nicht einen Unterstützungsgrad von mindestens min_sup besitzen. Die Subroutine subset im Apriori-Algorithmus (Zeile 5) wird verwendet, um die übrig gebliebenen Kandidaten aus Ck zu testen, ob diese auch den vorgegebenen Unterstützungsgrad min_sup besitzen. Da diese Operation einen kompletten Datenbankscan erfordert, ist eine effiziente Implementierung von Bedeutung. Hierfür wird ein Hashverfahren angewendet und die k-elementigen Kandidatenmengen Ck in einem Hash-Tree gespeichert. Beispiel 5.2.1. Wir setzen unser Beispiel aus Tabelle 2.1.1 fort und wenden den Apriori-Algorithmus an, um alle häufigen Attributwertmengen bzw. Muster zu entdecken. Zur Vereinfachung kodieren wir die vorkommenden Attributwerte wie folgt: Brot =a ; Milch =b; Butter = c; Käse =d; Marmelade = e Der geforderte minimale Unterstützungsgrad für eine häufige Attributwertmenge ist min_sup=50%
TID Gekaufte Artikel
100 a, b, c 200 a, b, d 300 a, e 400 a, b, c 500 a, b, c, d
Transaktionen
600 e
C1 – Menge Itemset Support a 5/6 = 83,3 % L1 – Menge b 4/6 = 66,6 % Itemset Support c 3/6 = 50 % a 5/6 = 83,3 % d 2/6 = 33,3 % b 4/6 = 66,6 % e 2/6 = 33,3 % c 3/6 = 50 %
1.Iteration
C2 – Menge L2 – Menge Itemset Support Itemset Support a, b 4/6 = 66,6 % a, b 4/6 = 66,6 % a, c 3/6 = 50 % a, c 3/6 = 50 %
2.Iteration
b, c 3/6 = 50 % b, c 3/6 = 50 %
- 29 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 16
C3 – Menge L3 – Menge Itemset Support Itemset Support 3.Iteration a, b, c 3/6 = 50 % a, b, c 3/6 = 50 %
C4 – Menge L4 – Menge Itemset Support Itemset Support 4.Iteration
5.3. Erkennung der Assoziationsregeln Mit dem Apriori-Algorithmus ist es möglich, sämtliche häufigen Muster eines Datenbestandes zu erzeugen. In der zweiten Phase der Bestimmung der Assoziationsregeln werden nun aus diesen häufigen Mustern die Regeln generiert, die auch mindestens den vorgegebenen Vertrauensgrad min_conf haben. Dies kann mit Hilfe der Konfidenz-Gleichung (siehe Kapitel 2.4) erfolgen:
| support(X Y) | confidence(X Y) =
| support(X) | Ausgehend von dieser Gleichung, können dann die Assoziationsregeln wie folgt generiert werden:
Für jede häufige Attributwertmenge l werden nicht leere Teilmengen von l gebildet Für jede nicht leere Teilmenge s von l wird die Regel „s (l/s)“ generiert, falls
support(l) ≥ min_conf, support(s)
wo min_conf ein vorgegebener Vertrauensgrad (confidence) ist. ([1], [8]) Wie bereits im Kapitel 2 erwähnt soll eine Assoziationsregel mindestens den vorgegebenen Unterstützungsgrad (support) min_sup und den vorgegebenen Vertrauensgrad (confidence) min_conf besitzen. Da die Erstellung der Assoziationsregeln bereits auf den häufigen Attributwertmengen erfolgt, erfüllt jede dieser Regeln diese Forderung im Bezug auf den vorgegebenen Unterstützungsgrad automatisch. Beispiel 5.3.1. (Fortführung des Beispiels 5.2.1.) Im zweiten Schritt werden die Assoziationsregeln aus den im Beispiel 5.2.1. durch den Apriori -Algorithmus gewonnenen häufigen Attributwertmengen abgeleitet. Als Ergebnis des
- 30 -
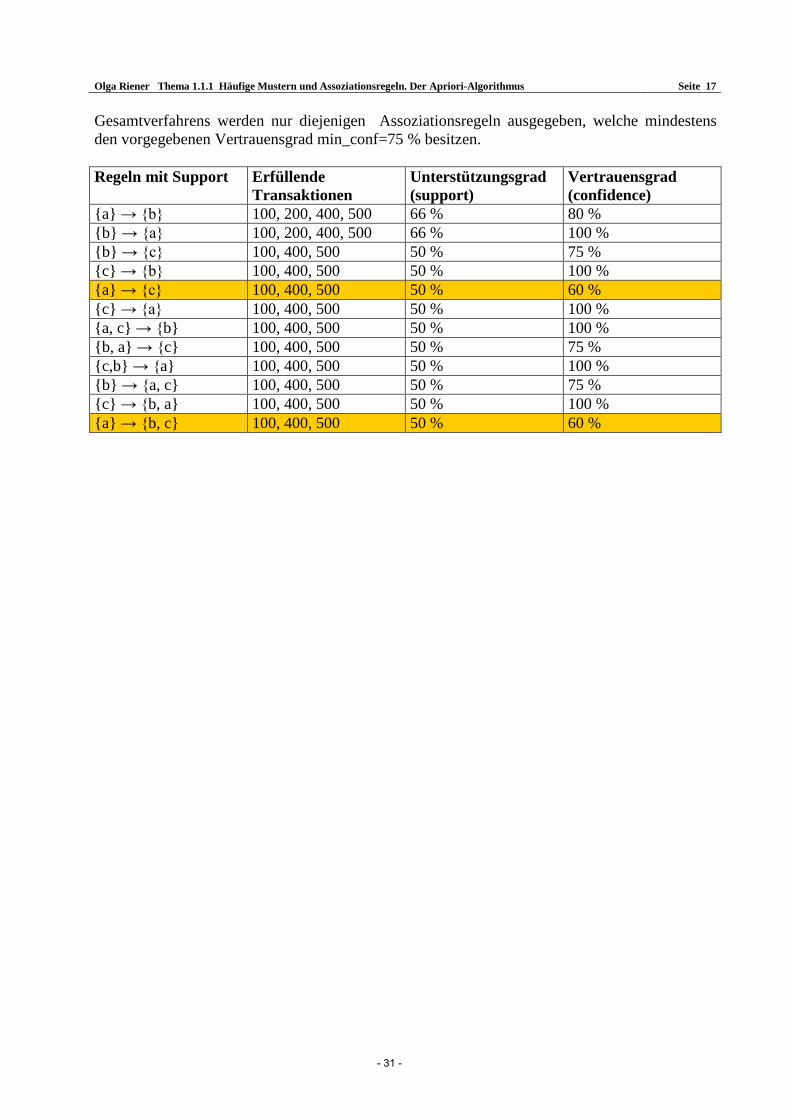
Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 17
Gesamtverfahrens werden nur diejenigen Assoziationsregeln ausgegeben, welche mindestens den vorgegebenen Vertrauensgrad min_conf=75 % besitzen. Regeln mit Support Erfüllende
Transaktionen Unterstützungsgrad (support)
Vertrauensgrad (confidence)
a → b 100, 200, 400, 500 66 % 80 % b → a 100, 200, 400, 500 66 % 100 % b → c 100, 400, 500 50 % 75 % c → b 100, 400, 500 50 % 100 % a → c 100, 400, 500 50 % 60 % c → a 100, 400, 500 50 % 100 % a, c → b 100, 400, 500 50 % 100 % b, a → c 100, 400, 500 50 % 75 % c,b → a 100, 400, 500 50 % 100 % b → a, c 100, 400, 500 50 % 75 % c → b, a 100, 400, 500 50 % 100 % a → b, c 100, 400, 500 50 % 60 %
- 31 -
Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 18
6. Apriori-Erweiterungen Der Apriori-Algorithmus zeigt ein gutes Laufzeitverhalten bei kleinen und mittleren Datenmengen. Um sein schlechtes Laufzeitverhalten bei sehr großen Datenmengen zu überwinden wurden Apriori-Modifikationen wie AprioriTID und AprioriHybrid vorgenommen.
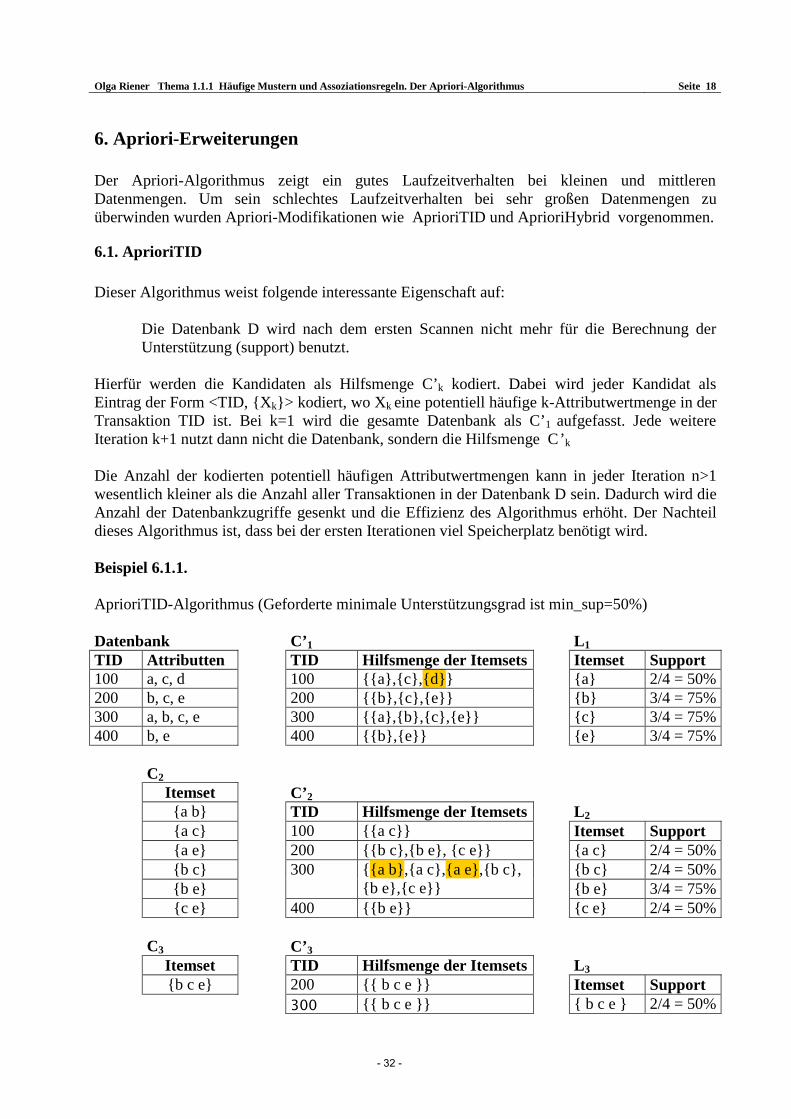
6.1. AprioriTID Dieser Algorithmus weist folgende interessante Eigenschaft auf:
Die Datenbank D wird nach dem ersten Scannen nicht mehr für die Berechnung der Unterstützung (support) benutzt.
Hierfür werden die Kandidaten als Hilfsmenge C’k kodiert. Dabei wird jeder Kandidat als Eintrag der Form <TID, Xk> kodiert, wo Xk eine potentiell häufige k-Attributwertmenge in der Transaktion TID ist. Bei k=1 wird die gesamte Datenbank als C’1 aufgefasst. Jede weitere Iteration k+1 nutzt dann nicht die Datenbank, sondern die Hilfsmenge C’k Die Anzahl der kodierten potentiell häufigen Attributwertmengen kann in jeder Iteration n>1 wesentlich kleiner als die Anzahl aller Transaktionen in der Datenbank D sein. Dadurch wird die Anzahl der Datenbankzugriffe gesenkt und die Effizienz des Algorithmus erhöht. Der Nachteil dieses Algorithmus ist, dass bei der ersten Iterationen viel Speicherplatz benötigt wird. Beispiel 6.1.1. AprioriTID-Algorithmus (Geforderte minimale Unterstützungsgrad ist min_sup=50%) Datenbank C’1 L1 TID Attributten TID Hilfsmenge der Itemsets Itemset Support 100 a, c, d 100 a,c,d a 2/4 = 50% 200 b, c, e 200 b,c,e b 3/4 = 75% 300 a, b, c, e 300 a,b,c,e c 3/4 = 75% 400 b, e 400 b,e e 3/4 = 75% C2 Itemset C’2 a b TID Hilfsmenge der Itemsets L2 a c 100 a c Itemset Support a e 200 b c,b e, c e a c 2/4 = 50% b c b c 2/4 = 50% b e
300 a b,a c,a e,b c, b e,c e b e 3/4 = 75%
c e 400 b e c e 2/4 = 50% C3 C’3 Itemset TID Hilfsmenge der Itemsets L3 b c e 200 b c e Itemset Support 300 b c e b c e 2/4 = 50%
- 32 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 19
6.2. AprioriHybrid Die Analyse der Ausführungszeit von Apriori- und AprioriTid zeigt, dass in den früheren Iterationen Apriori effektiver als AprioriTID ist und in den späteren Iterationen AprioriTID besser als Apriori arbeitet. Beide Algorithmen benutzen ein und dieselbe Prozedur zur Bildung der potentiell häufigen k-Attributwertmengen. Basierend auf dieser Beobachtung wurde der AprioriHybrid-Algorithmus vorgeschlagen, um die besten Eigenschaften von Apriori und AprioriTID in einem Verfahren zu kombinieren. AprioriHybrid verwendet den Apriori-Algorithmus in frühen Iterationen und wechselt zum AprioriTID-Algorithmus in späteren Iterationen. Der Wechsel zum AprioriTID-Algorithmus ist vor allem dann effektiv, wenn die kodierten Kandidaten der Hilfsmenge C’k in den operativen Speicher passen. Der Nachteil des AprioriHybrid-Algorithmus ist der Verbrauch an zusätzlichen Ressourcen beim Umschalten von Apriori zu AprioriTID.
- 33 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 20
7. Sonstige Effizienzsteigerung des Apriori-Verfahrens Hauptansätze für die Effizienzsteigerung des Apriori-Verfahrens:
Reduktion der Anzahl der Datenbankzugriffe/Datenbankscans Reduktion der Anzahl der Kandidaten Beschleunigung der Berechnung des Unterstützungsgrads für die Kandidaten
7.1. Hashbasierte Techniken (DHP) Hashbasiertes Verfahren (DHP-Algorithmus, „direkt hashing and pruning“) wurde 1995 von J. Park, M. Chen and P. Yu entwickelt. Die hashbasierte Technik kann für die Reduzierung der potentiell häufigen k-Attributwertmenge Ck für k>1 Kandidaten benutzt werden. So wird zum Beispiel durch Scannen jeder Transaktion in der Datenbank aus der 1-Kandidatenmenge C1 die häufige 1-Attributtenwertmenge L1 erstellt. Parallel können wir für jede Transaktion alle potentiellen häufigen 2-Attributtenwertmengen C2 generieren und diese in die unterschiedlichen Behälter einer Hashtabelle abbilden und den zugehörigen Behälterzähler entsprechend inkremetieren. Eine potentiell häufige 2-Attributwertmenge, deren zugehöriger Behälterzähler in der Hashtabelle unterhalb von min_supp liegt, kann nicht häufig sein und sollte deshalb aus der Kandidatenmenge entfernt werden. Solch eine hashbasierte Technik kann die Anzahl der untersuchten potentiellen häufigen k-Attributwertmengen wesentlich reduzieren (besonders wenn k=2). ([5], [8])
7.2. Reduzierung der Transaktionen Dieses Verfahren reduziert die Anzahl der Transaktionen, die in den künftigen Iterationen gescannt werden. Eine Transaktion, die keine häufige k-Attributwertmengen beinhaltet kann auch keine häufigen k+1-Attributwertmengen beinhalten. Somit kann eine solche Transaktion gekennzeichnet werden oder bei weiteren Überlegungen ausgenommen werden, da die nachfolgenden DB-Durchläufe für j-Attributwertmengen bei j>k diese Transaktion nicht mehr benötigen. ([5], [8])
7.3. Partitionierung Der Partitionierungs-Algorithmus wurde 1995 von A. Savasere, E. Omiecinski and S. Navathe entwickelt. Die Suche nach häufigen Attributwertmengen mit Hilfe der Partitionierungstechnik benötigt nur 2 DB-Durchläufe. Dieser Vorgang besteht aus 2 Phasen.
- 34 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 21
In der ersten Phase verteilt der Algorithmus die Transaktionen von D in n disjunkte Partitionen. Wenn der minimal geforderter Unterstützungsgrad für Attributwertmengen in D min_sup ist, so wird die minimale Attributwertmengen-Unterstützung für eine Partition folgendermaßen berechnet:
min_sup(Partition X) = min_sup * #_der_Transaktionen_in_der_PartitionX Mit Hilfe der min_sup(Partition X) werden für jede Partition X alle häufigen Attributwertmengen innerhalb dieser Partition gefunden. Diese werden lokale häufige Attributwertmengen genannt. Dieses Prozedere benutzt eine spezielle Datenstruktur, so dass für jedes Itemset die Primärschlüssel (TIDs) der relevanten Transaktionen festgehalten werden. Dieses Vorgehen ermöglicht die Feststellung aller lokalen häufigen k-Attributtenwertmengen für k=1,2,... in nur einem DB-Durchlauf. Die lokalen häufigen Attributwertmengen können sowohl häufig, als auch unhäufig im Bezug auf die ursprüngliche Datenbank D auftreten. Aber alle potenziell häufigen Attributwertmengen in D sollen mindestens in einer der Partitionen als häufig vorkommen. Somit sind alle lokalen häufigen Attributwertmengen die möglichen Kandidat-Attributwertmengen für D. Die Sammlung der lokalen häufigen Attributwertmengen aus allen Partitionen bildet die Mengen der globalen potentiellen häufigen Attributwertmenge für D. In der zweiten Phase wird der DB-Durchlauf von D vorgenommen, um die tatsächliche Unterstützung jedes Kandidaten zu berechnen und die endgültige Menge der globalen häufigen Attributwertmengen festzustellen. Die Partitionsgröße und die Anzahl der Transaktionen sind so gewählt, dass jede Partition in den Hauptspeicher passen kann. Somit muss eine Partition in jeder Phase nur einmal gelesen werden. ([5], [8])
7.4. Sampling Der Sampling-Algorithmus wurde 1996 von Toivonen vorgestellt. Die Grundidee von Sampling sind Recherchen auf einer Teilmenge der gegebenen Daten. Hierfür wird durch Stichproben eine Teilmenge S der gegebenen Daten D gebildet. Die anschließende Suche nach den häufigen Attributwertmengen erfolgt in S anstelle von D. Dieses Verfahren stellt somit einen Kompromiss dar, indem die Effizienz auf Kosten der Genauigkeit erhöht wird. Die Größe der Teilmenge S ist so gewählt, dass die Suche nach häufigen Attributtenwertmengen im Hauptspeicher durchgeführt werden kann und insgesamt nur ein einziger Durchlauf der Transaktionen in S erforderlich ist. Die Suche nach häufigen Attributwertmengen in S anstelle von D kann dazu führen, dass wir am Ende manche globale häufige Attributwertmengen übersehen. Um die Wahrscheinlichkeit dieses Übersehens zu reduzieren, verwenden wir einen geringeren Unterstützungsgrad für die Suche nach den häufigen Attributwertmengen (LS) in S als den ursprünglich geforderten minimalen Unterstützungsgrad min_sup für D. Die übrige Datenbank wird dann nur zur Berechnung der tatsächlichen Häufigkeit jeder Attributwertmenge aus LS benutzt. Der Sampling-Ansatz ist vor allem dann vorzuziehen, wenn gerade die Effizienz von höchster Bedeutung ist. (Wie z.B. in rechenintensiven Applikation mit häufiger Ausführung)
- 35 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 22
([5], [8])
7.5. Dynamische Aufzählung der Attributenwertmenge (DIC) Im Jahre 1997 wurde von S. Brin R. Motwani, J. Ullman und S. Tsur eine Erweiterung des Apriori-Algorithmus unter dem Namen „dynamic itemset counting“ (DIC) veröffentlicht. Die Grundidee hinter diesem Verfahren ist, in der Kandidatengenerierungsphase nicht den genauen Unterstützungsgrad zu bestimmen, sondern die Berechnung des Unterstützungsgrads zu stoppen, sobald eine Attributwertmenge eine Unterstützung größer als den vorgegebenen Unterstützungsgrad min_sup besitzt. ([5], [8])
- 36 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 23
8. Fazit Wir haben gesehen, dass die Assoziationsregeln eine wichtige Analysemöglichkeit für die Datenbestände darstellt. Wir haben diverse Ansätze zur Entdeckung der Assoziationsregeln kennen gelernt. Insbesondere haben wir mit dem Apriori-Algorithmus eine gut anwendbare und verständliche Methode zur Entdeckung der Assoziationsregeln kennen gelernt, die im Vergleich zur früheren Ansätzen (AIS, SETM) mit hoher Performanz arbeitet. Auch der Apriori ist noch nicht optimal. Hierfür existieren diverse Erweiterungen des Apriori –Algorithmus wie AprioriTID und AprioriHybrid sowie weitere Ansätze zur Reduzierung der Anzahl der Datenbankzugriffe, Reduzierung der Kandidatengenerierung, usw.
- 37 -

Olga Riener Thema 1.1.1 Häufige Mustern und Assoziationsregeln. Der Apriori-Algorithmus Seite 24
Literaturliste [1] Rakesch Agrawal, Ramikrishan Srikant. “Fast algorithms for mining association rules in large databases.” Proc. 20th Int. Conf. Very Large Data Bases, VLDB, Pages 467-490. Morgan Kaufmann, 12-15 1994. [2] Heikki Mannila, Hannu Toivonen, A. Inkeri Verkamo. „Efficient algorithms for discovering association rules.” AAAI Workschop on KDD-94, pages 181-192, Seattle, Washington, 1994, AAAI Press [3] Prof. Dr. Jürgen M. Janas “Vorlesung: Wrapup Data Mining” PDF-Download [4] Dr. Jörg-Uwe Kietz. Data Mining zur Wissensgewinnung aus Datenbanken. Teil 7: Assoziationsregelverfahren (Vorlesung im Sommersemester 2005) PDF-Download: http://www.kietz.ch/DataMining/Vorlesung/ [5] Frank Beekmann „Stichprobebasierte Assoziationsanalyse im Rahmen des Knowledge Discovery in Databases“. ISBN 3-8244-2168-2, S. 58-68 [6] Udo Bankhofer "Data Mining und seine betriebswirtschaftliche Relevanz", in: Betriebswirtschaftliche Forschung und Praxis : BFuP. - Herne, Westf. : Verl. Neue Wirtschaftsbriefe, ISSN 0340-5370, 56. Jg. (2004), S. 395-412 [7] Chubukova Irina „Data Mining: Assoziationsregeln“ (Russisches Online-Lehrbuch unter http://www.intuit.ru/lector/118.html ) [8] Jiawei Han, Micheline Kamber „Data Mining. Concepts and Techniques“. ISBN 1-55860-489-8, Seiten 230-239
- 38 -

Seminarbeitrag
von
Nicolai Voget
DerFrequent-Pattern-Growth-
Algorithmus
angefertigt amLehrstuhl Datenbanksysteme für neue Anwendungen
FernUniversität HagenJuni 2008
Betreuer: Christian Düntgen- 39 -

ii Der Frequent-Pattern-Growth-Algorithmus Nicolai Voget
Kurzzusammenfassung
Seitdem es möglich ist, große Datenmengen in Datenbanken zu speichern, wird rege geforscht,
wie man diese Daten effektiv auswerten kann. Ein Forschungsbereich beschäftigt sich dabei mit
der Suche nach effizienten Algorithmen, die wiederkehrende Muster und, darauf aufbauend,
Assoziationsregeln aufdecken.
Mit Hilfe dieser Algorithmen ist es beispielsweise möglich, Zusammenhänge im
Konsumverhalten von Kunden aufzudecken, indem man ermittelt, welche Kombinationen von
Waren besonders häufig gekauft wurden. Des Weiteren kann man darauf aufbauend feststellen,
bei welchen Waren bestimmte Waren oft mit gekauft werden. Eine mögliche Aussage wäre: „In
3% aller Käufe war Brot und Wurst dabei.“ (wiederkehrendes Muster) oder „Bei 80% der
Einkäufe, bei denen Bier gekauft wurde, waren auch Chips dabei.“ (Assoziationsregel). Darauf
aufbauend kann dann kundenspezifisch geworben werden oder die Chips im Supermarkt neben
das Bier gestellt werden.
Einer der ersten Algorithmen, die dieses Problem der Suche nach häufigen Mustern („frequent
pattern“) lösen, war der Apriori-Algorithmus. Dabei ist jedoch nicht ganz klar, wer diesen
erfunden hat, da sowohl ein Forscherteam aus Kalifornien, als auch ein Forscherteam aus
Finnland im Jahre 1994 unabhängig voneinander ihre Algorithmen präsentierten, die im Grunde
äquivalent sind.
Im Jahre 2000, nach einer Reihe weiterer Veröffentlichungen aus aller Welt, veröffentlichten
Jiawei Han, Jian Pei und Yiwen Yin von der Simon Fraser University in Kanada ihren
Forschungsbericht mit dem Namen „Mining Frequent Patterns without Candidate Generation“,
in dem sie einen neuartigen Algorithmus vorstellen, den sie „frequent pattern growth“
(FP-Growth) nennen.
In meiner Arbeit werde ich nun zuerst eine kurze Übersicht über den Apriori-Algorithmus geben,
um, ausgehend von seinen Schwächen, die Motivation des FP-Growth-Ansatzes
herauszuarbeiten.
Daraufhin werde ich die Datenstruktur FP-Tree, die als Grundlage für den FP-Growth-
Algorithmus dient, vorstellen, gefolgt von der Vorstellung des FP-Growth-Algorithmus.
Zuletzt werde ich nach einem Vergleich des FP-Growth-Algorithmus mit dem Apriori-
Algorithmus noch die verbleibenden Nachteile des FP-Growth-Algorithmus anschneiden.
- 40 -

Nicolai Voget Der Frequent-Pattern-Growth-Algorithmus iii
Inhaltsverzeichnis 1. Der Apriori-Algorithmus............................................................................................................1
1.1. Grundlagen..........................................................................................................................1 1.2. Der Apriori-Algorithmus.....................................................................................................1 1.3. Nachteile.............................................................................................................................2
2. FP-Tree.......................................................................................................................................3 2.1. Überlegungen......................................................................................................................3 2.2. Definition und Aufbau des FP-Tree....................................................................................5 2.3. Beispiel................................................................................................................................6
3. FP-Growth..................................................................................................................................8 3.1. Beispiel................................................................................................................................8 3.2. Der Algorithmus FP-Growth...............................................................................................9
4. Vergleich von FP-Tree/FP-Growth mit Apriori........................................................................11 A Literaturangaben.......................................................................................................................12
- 41 -

1 Der Frequent-Pattern-Growth-Algorithmus Nicolai Voget
1. Der Apriori-Algorithmus
Wie bereits weiter oben erwähnt, war der Apriori-Algorithmus einer der ersten wirklich
effektiven Algorithmen für die Suche nach häufigen Mustern. Da sich (fast) alle nach ihm
entwickelten Algorithmen mit ihm gemessen haben, werde ich hier einen kurzen Einblick in
seine Funktionsweise geben. Doch bevor ich in die Details eintauche, kommen noch einige
Grundlagen, die in den weiteren Ausführungen immer wieder auftreten werden.
1.1. Grundlagen
Bei der Suche nach häufig wiederkehrenden Mustern stellt sich immer die Frage, ab wann ein
Muster relevant ist. Beispielsweise ist bei einer Menge von 10000 Transaktionen nicht klar, ob
die Tatsache, dass in 10 Transaktionen ein Muster auftaucht, wichtig ist oder nicht. Um nun eine
Grenze zu ziehen gibt es eine Kenngröße: den support (Da in diesem Forschungsbereich wenig
deutschsprachige Literatur veröffentlicht wurde und es daher auch keine häufig benutzten
deutschen Äquivalente gibt, werde ich im Folgenden den englischen Begriff verwenden).
Der support gibt an, wie oft ein Muster auftaucht. Dabei wird dieser manchmal absolut (Anzahl
der Vorkommnisse des Musters) und manchmal relativ (zur Anzahl aller Transaktionen in der
Datenbank) angegeben.
Liegt nun der support eines Musters über einem bestimmten minimalen support (oft mit ξ
bezeichnet), so ist dieses Muster häufig (engl. strong, frequent).
1.2. Der Apriori-Algorithmus
Nun stellt sich die Frage, wie man mit einem unkomplizierten Algorithmus möglichst schnell
alle häufigen Muster aufzählen kann. Die sicherlich algorithmisch einfachste Lösung wäre es,
jede mögliche Kombination von Elementen als Muster zu generieren und dann zu prüfen, welche
dieser Muster häufig sind. Es fällt jedoch recht schnell auf, dass dieser Algorithmus schon für
recht kleine Datenbanken unverhältnismäßig lange braucht, da viel zu viele Kombinationen
generiert werden.
Wir können uns dafür eine kleine, aber nicht ganz unwichtige Beobachtung zu Nutze machen:
Ein Muster kann nur dann häufig sein, wenn alle seine Teilmengen auch häufige Muster sind.
Das heißt, dass wir ein Muster, das k Elemente enthält, überhaupt nur weiter untersuchen
müssen, wenn alle seine (k-1)-elementigen Teilmengen auch häufig sind. Somit haben wir nun
- 42 -

Nicolai Voget Der Frequent-Pattern-Growth-Algorithmus 2
einen iterativen Ansatz zur Lösung des Problems (vgl. [2]):
1) Bestimme alle 1-elementigen häufigen Muster (das sind gerade alle häufigen Elemente)
2) k=2
3) Nimm als Menge der möglichen k-elementigen Muster alle Kombinationen aus (k-1)-
elementigen häufigen Mustern mit häufigen 1-elementigen Mustern
4) Entferne alle Kandidaten, von denen mindestens eine (k-1)-elementige Teilmenge kein
Muster ist.
5) Prüfe für alle restlichen Kandidaten, ob support des Kandidaten über dem minimalen
support liegt. Wenn nein, entferne den Kandidaten.
6) Die übrig gebliebenen Kandidaten sind genau die häufigen k-elementigen Muster.
7) Wenn die Menge der häufigen k-elementigen Muster nicht leer ist, erhöhe k, und gehe
zurück zu 3.
Das ist nun schon fast der Apriori-Algorithmus. Dieser hat nur noch den Unterschied, dass in
Schritt 3 unseres Ansatzes nicht (k-1)-elementige Muster mit 1-elementigen Mustern kombiniert
werden, sondern dass immer zwei (k-1)-elementige Muster, die sich nur in einem Element
unterscheiden, kombiniert werden. Dadurch wird die Menge der Kandidaten kleiner gehalten,
obwohl immer noch alle tatsächlich häufigen k-elementigen Muster enthalten sind.
1.3. Nachteile
Obwohl der Apriori-Algorithmus schon eine starke Reduzierung des Problems mit sich bringt,
bleiben doch noch zwei Probleme, die bei großen Datenbanken einen starken Einfluss auf die
Rechenzeit und den Speicherbedarf haben:
1. Es werden immer noch viele Muster generiert, die nicht häufig sind.
2. Die Datenbank muss mehrfach durchlaufen werden, nämlich für jedes k einmal. Bei
großen Datenbanken dauert solch ein Durchlauf unverhältnismäßig lange, bei großem k
muss die Datenbank oft durchlaufen werden.
Es ist also eine andere Herangehensweise an das Problem nötig, bei der der Algorithmus, wenn
möglich, die Datenbank nur einige wenige Male durchläuft und bei der Generierung der Muster
Rücksicht auf die Informationen der Datenbank nimmt.
- 43 -

3 Der Frequent-Pattern-Growth-Algorithmus Nicolai Voget
2. FP-Tree
Wie am Ende des letzten Kapitels zusammengefasst, suchen wir also eine Möglichkeit, mit
möglichst wenig Datenbankdurchläufen alle häufigen Muster zu finden. Außerdem wollen wir
nur genau die häufigen Muster generieren.
Diese Möglichkeit haben Jiawei Han, Jian Pei und Yiwen Yin von der Simon Fraser University
in Kanada im Jahre 2000 in ihrem Forschungsbericht „Mining Frequent Patterns without
Candidate Generation“ veröffentlicht. Den Kern dieses Berichts bildet die Entwicklung einer
neuen Datenstruktur, von ihnen „frequent pattern tree“ (FP-Tree) genannt, mit der sie alle
notwendigen Informationen der Datenbank sehr kompakt speichern. Aufbauend auf diesem FP-
Tree generiert dann ein Algorithmus, „frequent pattern growth“ (FP-Growth), genau alle
häufigen Muster.
In diesem Kapitel werde ich nun darstellen, wie ein FP-Tree aufgebaut wird. Danach werde ich
im nächsten Kapitel den FP-Growth-Algorithmus präsentieren, bevor ich abschließend in Kapitel
4 einen kurzen Vergleich zwischen dem Apriori-Ansatz und dem FP-Growth-Ansatz ziehen
werde.
2.1. Überlegungen
Han, Pei und Yin kamen nach gründlichen Überlegungen über Möglichkeiten zur Verbesserung
des Apriori-Algorithmus zu dem Schluss, dass der kritische Punkt des Algorithmus die
Generierung von Kandidaten ist. Es ging ihnen also primär um die Suche nach einer
Möglichkeit, die Informationen der Datenbank so in einer Struktur darzustellen, dass diese
Struktur schon alle Informationen über die häufigen Muster enthält. Bei der Frage, welche
Informationen der Datenbank überhaupt in diese Struktur gehören, beobachteten sie einige
Eigenschaften:
1. Elemente, die nicht häufig sind, müssen gar nicht abgebildet werden, da sie niemals in
einem häufigen Muster vorkommen können.
2. Wenn zwei Transaktionen die gleiche Menge häufiger Elemente haben (Achtung: Diese
Menge muss nicht unbedingt ein häufiges Muster sein!), so kann man sie als eine
Transaktion speichern, wenn man vermerkt, dass die zweimal vorkommt.
3. Wenn die beiden Mengen häufiger Elemente von zwei Transaktionen gleich beginnen
(bezogen auf eine feste Sortierung der häufigen Elemente), kann man diesen Präfix als
- 44 -

Nicolai Voget Der Frequent-Pattern-Growth-Algorithmus 4
gemeinsamen Präfix speichern, wenn man vermerkt, dass er zweimal vorkommt, und die
unterschiedlichen Suffixe mit dem Präfix verknüpfen. Was die Sortierung betrifft, ist
ersichtlich, dass man meistens mehr gemeinsame Präfixe findet, wenn die häufigen
Elemente nach absteigender Häufigkeit sortiert werden.
Es ist nicht schwer zu sehen, dass die bisherigen Überlegungen den Informationsgehalt der
Datenbank nur an Stellen verkürzen, die sowieso nicht von Bedeutung sind (nämlich das
„Überlesen“ nicht häufiger Elemente, 1.). Außerdem ist 2. ein Spezialfall von 3.
Bevor wir nun jedoch unsere Überlegungen weiter verfolgen können, stellt sich die Frage, wie
wir zu diesen Mengen häufiger Elemente der Transaktionen kommen. Dafür müssen wir die
Datenbank einmal komplett durchlaufen und für jedes Element seinen support bestimmen. Nach
dem Durchlauf werden alle Elemente, deren support unter dem minimalen support liegt, gelöscht
und die übrig gebliebenen Elemente nach absteigendem support geordnet. Damit haben wir dann
eine ab jetzt feste Sortierung der Elemente. In einem zweiten Durchlauf können wir dann für
jede Transaktion alle Elemente, die in der Menge der häufigen Elemente vorkommen, der
Sortierung nach in eine Menge einfügen. Damit haben wir dann unsere Menge der häufigen
Elemente, die wir jetzt nur noch in einer Struktur abspeichern müssen.
Aus 3. wird leicht ersichtlich, dass wir einen Baum benötigen, da wir ja einen Präfix mit
mehreren Suffixen verknüpfen können müssen. Damit alle Transaktionen den gleichen Anfang
haben, also alle von einem Knoten aus zu erreichen sind, wird die Wurzel ein leerer Knoten. Eine
Menge häufiger Elemente einer Transaktion wird nun in den Baum eingefügt, indem, von der
Wurzel ausgehend, die Menge als Pfad abgebildet wird. Das heißt, wir gucken für das jeweils
aktuelle Element der Menge, ob der aktuelle Knoten schon einen Sohn mit dem Namen des
Elements enthält. Wenn ja, gehen wir zu diesem Knoten, erhöhen seine Anzahl, die gemeinsam
mit dem Namen abgespeichert wird, um 1. Existiert jedoch kein Sohn mit dem richtigen Namen,
so fügen wir einen neuen Sohn ein, den wir mit dem Namen des Elements benennen, und setzen
seine Anzahl auf 1. Danach betrachten wir das nächste Element der Menge.
Am Ende entspricht damit jeder Durchlauf durch den Baum vom Wurzelknoten zu einem Blatt
mindestens einer Transaktion. (Die Anzahl der Transaktionen, die tatsächlich dem gewählten
Pfad entsprechen, lässt sich anhand der Anzahl des Blattes bestimmen). Es gibt jedoch auch
Transaktionen, deren entsprechender Pfad gar nicht bis zu einem Blatt geht, sondern in einem
Knoten endet. Das ist dann der Fall, wenn die Menge häufiger Elemente der Transaktion ein
Präfix einer Menge häufiger Elemente einer anderen Transaktion ist.
- 45 -

5 Der Frequent-Pattern-Growth-Algorithmus Nicolai Voget
2.2. Definition und Aufbau des FP-Tree
Abschließend zu den bisherigen Überlegungen gebe ich noch die genaue Definition des FP-Tree,
gefolgt von einem Algorithmus zum Aufbau desselben, an (vgl. [1]):
Ein frequent pattern tree (oder FP-Tree) ist eine Baumstruktur, die wie folgt definiert ist:
1. Es gibt eine Wurzel, die mit „null“ beschrieben ist, mehrere item prefix subtrees und
eine frequent-item header table.
2. Jeder Knoten in einem item prefix subtree besteht aus drei Feldern: Elementname, Anzahl
und node-link, wobei der Elementname angibt, für welches Element der Knoten steht,
Anzahl die Nummer der Transaktionen speichert, die von dem Teilpfad, der bis zu diesem
Knoten geht, repräsentiert werden, und der node-link zum nächsten Knoten im FP-Tree
mit dem gleichen Namen zeigt, wenn dieser existiert, und sonst null ist.
3. Jeder Eintrag der frequent-item header table besteht aus zwei Feldern, nämlich (1)
Elementname und (2) head of node-link, der zum ersten Knoten im FP-Tree mit diesem
Namen verweist.
Ein FP-Tree wird wie folgt konstruiert:
1. Durchlaufe die Datenbank einmal und sammle dabei die Menge der häufigen Elemente
und die zugehörigen supports. Sortiere die Menge nach absteigendem support und
speichere sie als L, die Liste der häufigen Elemente.
2. Erzeuge die Wurzel eines FP-Tree, T, und benenne sie mit „null“.
3. Mache folgendes für jede Transaktion Trans in der Datenbank:
1. Wähle alle häufigen Elemente aus Trans und sortiere sie gemäß der Reihenfolge in L.
2. Sei [p|P] die geordnete Liste der häufigen Elemente aus Trans, wobei p das erste
Element und P die restliche Liste ist. Rufe insert_tree([p|P], T ) auf.
Dabei ist die Funktion insert_tree([p|P], T ) wie folgt implementiert:
Wenn T einen Sohn N hat, sodass N.Elementname = p.Elementname, dann erhöhe N.Anzahl um
1; sonst erzeuge einen neuen Knoten N, und setze seine Anzahl auf 1. Registriere dann N als
neuen Sohn von T und T als Vater von N.
Sei K der Knoten, auf den der head of node-link von N.Elementname zeigt. Setze dann
N.node-link := K und head of node-link(N.Elementname) := N. gleichen Elementnamen, der
über die frequent-item header table verfügbar ist.
- 46 -

Nicolai Voget Der Frequent-Pattern-Growth-Algorithmus 6
Wenn P nicht leer ist, rufe insert_tree([P], N ) auf.
Jetzt, wo wir eine kompakte Datenstruktur haben, die alle relevanten Informationen abbildet,
stellt sich die Frage, wie wir diese so auswerten, dass wir genau die häufigen Muster erhalten.
Diese Aufgabe übernimmt der Algorithmus FP-Growth, den ich im nächsten Kapitel vorstellen
werde.
2.3. Beispiel
Zunächst jedoch wollen wir den FP-Tree zu einer kleinen Beispieldatenbank aufbauen:
Angenommen, wir hätten eine Datenbank mit folgenden Transaktionen:
T1 d, e, h, n, r, k, m, uT2 s, e, t, b, rT3 w, e, r, n, c, l, oT4 d, u, f, r, nT5 b, i, u, s, e, n
TABELLE 1: BEISPIELDATENBANK
Der erste Durchlauf durch die Datenbank ergibt folgende Häufigkeit der Elemente:
d:2, e:4, h:1, n:4, r:4, k:1, m:1, u:3, s:2, t:1, b:2, w:1, c:1, l:1, o:1, f:1, i:1.
Lässt man nun alle Elemente weg, deren support nicht über dem minimalen support (in diesem
Fall ξ = 2 (absolut angegeben)) liegt, und sortiert die verbleibenden Elemente nach absteigendem
support, so erhält man:
L = (e:4, n:4, r:4, u:3, d:2, s:2, b:2).
Ein zweiter Durchlauf ergibt nun folgenden FP-Tree (Tabelle 2 gibt die Transaktionen aus
Tabelle 1 nach L sortiert an):
T1 e, n, r, u, dT2 e, r, s, bT3 e, n, rT4 n, r, u, dT5 e, n, u, s, b
TABELLE 2: TRANSAKTIONEN NACH L SORTIERT
- 47 -
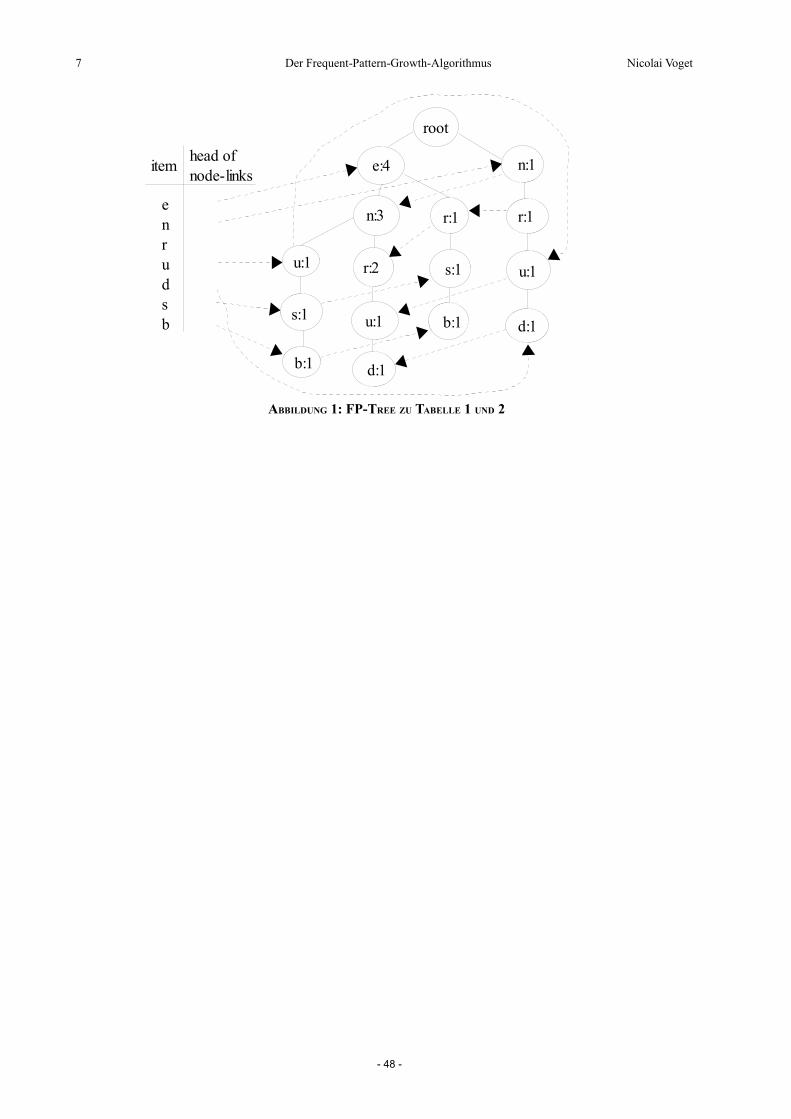
7 Der Frequent-Pattern-Growth-Algorithmus Nicolai Voget
ABBILDUNG 1: FP-TREE ZU TABELLE 1 UND 2
item
enrudsb
head of node-links
root
n:3
r:2 s:1
d:1
r:1
s:1 b:1u:1
u:1
b:1
d:1
u:1
r:1
n:1e:4
- 48 -

Nicolai Voget Der Frequent-Pattern-Growth-Algorithmus 8
3. FP-Growth
Im letzten Kapitel habe ich dargestellt, wie man mit Hilfe des FP-Tree alle relevanten
Informationen der Datenbank kompakt gespeichert bekommt. Jetzt stellt sich aber die Frage, wie
man aus einem FP-Tree möglichst effizient alle häufigen Muster erhält, ohne Muster zu
generieren, die nicht häufig sind.
Am Anfang der weiteren Überlegungen steht die Beobachtung, dass für jedes Element alle
häufigen Muster, in denen dieses Element auftaucht, über die node-link-Struktur des Elements
auffindbar sind. Das heißt, wenn wir zum einem Element alle häufigen Muster, in denen dieses
auftaucht, finden wollen, müssen wir nur die Pfade weiter untersuchen, die man erreicht, wenn
man die node-link-Struktur des Elements durchläuft. Eine weitere wichtige Beobachtung ist die
Tatsache, dass wir, um alle häufigen Muster zu entdecken, immer nur den Pfad, der bis zu einem
Knoten hingeht, untersuchen müssen und den weiteren Pfad von dem Knoten ausgehend
ignorieren können, da ja alle Muster mit Elementen, die in dem weitergehenden Pfad auftauchen,
schon untersucht werden, wenn die unteren Elemente untersucht werden. Somit wird auch
verhindert, dass ein Muster mehrfach untersucht wird, was natürlich viel Zeit spart.
Um nun alle Muster, die sich für ein Element, das wir n nennen, ergeben, zu entwickeln, müssen
wir zuerst die abhängige Musterbasis von n bestimmen. Die abhängige Musterbasis besteht aus
allen Präfixen der Pfade, in denen n auftaucht, wobei die Anzahl der Elemente in den Pfaden auf
die Anzahl, die n in diesem Pfad hat, gesetzt wird, da zwar die Elemente öfter vorkommen
können, aber nur n.Anzahl mal in Verbindung mit n. Aus dieser abhängigen Musterbasis bilden
wir nun einen neuen FP-Tree, auch von n abhängiger FP-Tree genannt, bei dem wir wiederum
alle Muster, die dieser FP-Tree enthält, entwickeln, und erweitern alle so entwickelten Muster
mit n. Außerdem haben wir als Muster noch n selber. Wenn wir diesen Vorgang für alle n aus der
frequent-item header table wiederholen, haben wir zum Schluss alle häufigen Muster, die in der
Datenbank auftreten.
3.1. Beispiel
Betrachten wir den FP-Tree aus Beispiel 2.3. Für b ergeben sich folgende Pfadpräfixe:
<e:4, n:3, u:1, s:1, b:1> und <e:4, r:1, s:1, b:1>
Daraus ergibt sich die folgende abhängige Musterbasis von b:
(e:1, n:1, u:1, s:1), (e:1, r:1, s:1)
- 49 -

9 Der Frequent-Pattern-Growth-Algorithmus Nicolai Voget
In dieser sind e und s häufig (ξ ist immer noch 2). Der daraus aufgebaute von b abhängige FP-
Tree besitzt einen Pfad, nämlich <e:2, s:2>:
ABBILDUNG 2: VON B ABHÄNGIGER FP-TREE ABBILDUNG 3: VON SB ABHÄNGIGER FP-TREE
Aus diesem Pfad bekommt man die Muster (e:2), (s:2), was, in Verbindung mit b, (eb:2) und
(sb:2) ergibt. Für bs bekommt man die abhängige Musterbasis (e:2) und den in Abbildung 3
dargestellten abhängigen FP-Tree, aus dem man das Muster (e:2) bekommt, also, in Verbindung
mit sb, (esb:2). Außerdem gibt es noch das häufige Muster (b:2), so dass alle in diesem
Durchgang gefundenen Muster (b:2), (eb:2), (sb:2) und (esb:2) sind.
Die Durchgänge für die anderen Elemente ergeben folgende häufigen Muster:
s: (s:2) und (es:2)
d: (d:2), (nd:2), (rd:2), (ud:2), (nrd:2), (nud:2), (rud:2) und (nrud:2)
u: (u:3), (eu:2), (ru:2), (nu:3), (neu:2), (rnu:2)
r: (r:4), (er:3), (nr:3), (enr:2)
Zum Schluss des Kapitels werde ich noch den Algorithmus zur Berechnung der Muster, FP-
Growth genannt, angeben:
3.2. Der Algorithmus FP-Growth
FP-Growth(Tree, α)
1. Wenn Tree einen einzigen Pfad P hat, gehe zu 2., sonst zu 4.
2. Wiederhole 2.1 für jede Kombination β der Knoten in P.
1. Erzeuge das Muster ∪ und setze support auf die kleinste Anzahl aus β.
3. Return.
4. Wiederhole 4.1.-4.3. für jedes a in der frequent-item header table von Tree.
1. Generiere β = a∪ mit β.support = a.support.
itemhead of node-link
es
root
e:2
s:2
itemhead of node-link
e
root
e:2
- 50 -

Nicolai Voget Der Frequent-Pattern-Growth-Algorithmus 10
2. Konstruiere βs abhängige Musterbasis und damit βs abhängigen FP-Tree Treeβ .
3. Wenn Treeβ nicht leer ist, rufe FP-Growth( Treeβ , β ) auf.
Alle häufigen Muster erhält man dann bei Aufruf von FP-Growth(FP-Tree, null ) (vgl. [1]).
- 51 -

11 Der Frequent-Pattern-Growth-Algorithmus Nicolai Voget
4. Vergleich von FP-Tree/FP-Growth mit Apriori
Nachdem ich nun zuerst in Kapitel 1 einen kurzen Überblick über den Apriori-Algorithmus
gegeben habe und danach in den Kapiteln 2 und 3 ausführlich auf die FP-Tree-Struktur und den
FP-Growth-Algorithmus eingegangen bin, kommt nun ein kleiner Vergleich der beiden Ansätze.
Zu Ende von Kapitel 1 habe ich zwei Nachteile des Apriori-Algorithmus angegeben, die es zu
beheben galt. Das waren
1. die Generierung von Mustern, die nicht häufig sind und
2. die hohe Anzahl an Datenbankdurchläufen.
FP-Tree generiert keine Muster und läuft immer genau zwei Mal durch die Datenbank, während
FP-Growth nur Muster generiert, die häufig sind und komplett ohne Datenbankdurchläufe
auskommt. Damit sind die beiden Schwachstellen also behoben. Jetzt stellt sich die Frage, ob in
dem FP-Ansatz neue Schwächen auftreten, die in Apriori nicht zu finden sind.
Das Hauptproblem beim FP-Ansatz ist, dass der FP-Tree, der ja mit der Anzahl der Elemente in
den Transaktionen wächst, immer als Ganzes vorhanden sein muss, was bei großen Datenbanken
zu Speicherproblemen führen kann. Dieses Problem werde ich hier aber nicht weiter
untersuchen.
Vergleicht man nun den FP-Ansatz mit dem Apriori-Ansatz auf Basis der Rechenzeit, so stellt
man fest (vgl. [1], S. 9), dass die Zeit, die ein Apriori-Algorithmus für die Mustergenerierung
benötigt, zwischen zehn bis 100 mal so groß ist, wie die Zeit, die ein FP-Algorithmus benötigt.
- 52 -

Nicolai Voget Der Frequent-Pattern-Growth-Algorithmus 12
A Literaturangaben
[1] Jiawei Han, Jian Pei, Yiwen Yin. Mining Frequent Patterns Without Candidate
Generation. In 2000 ACM SIGMOD Intl. Conference on Management of Data, S. 1-12
[2] R. Agrawal, R. Srikant. Fast Algorithms for Mining Association Rules. In VLDB '94, S.
487-499
- 53 -

- 54 -

Entscheidungsbaume mit SLIQ und SPRINT
Mathias Kruger
9. Juni 2008
Inhaltsverzeichnis
1 Einleitung 21.1 Klassifikationsproblem . . . . . . . . . . . . . . . . . . . . . . 21.2 Entscheidungsbaume . . . . . . . . . . . . . . . . . . . . . . . 4
1.2.1 Algorithmische Grundlagen . . . . . . . . . . . . . . . 5
2 SLIQ 72.1 Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2 Datenstrukturen . . . . . . . . . . . . . . . . . . . . . . . . . 82.3 Algorithmus zum Aufbau . . . . . . . . . . . . . . . . . . . . . 8
2.3.1 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . 122.4 Pruning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4.1 Datenkodierung: . . . . . . . . . . . . . . . . . . . . . 152.4.2 Modellkodierung: . . . . . . . . . . . . . . . . . . . . . 162.4.3 Pruning Algorithmen . . . . . . . . . . . . . . . . . . . 162.4.4 Parallelisierung von SLIQ . . . . . . . . . . . . . . . . 17
2.5 Leistungsmerkmale von SLIQ . . . . . . . . . . . . . . . . . . 182.5.1 Komplexitat der Aufbauphase . . . . . . . . . . . . . . 182.5.2 MDL Pruning . . . . . . . . . . . . . . . . . . . . . . . 182.5.3 Benchmarks . . . . . . . . . . . . . . . . . . . . . . . . 18
3 SPRINT 193.1 Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.2 Datenstrukturen . . . . . . . . . . . . . . . . . . . . . . . . . 193.3 Algorithmische Details . . . . . . . . . . . . . . . . . . . . . . 203.4 Parallelisierung . . . . . . . . . . . . . . . . . . . . . . . . . . 203.5 Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4 Zussammenfassung 24
1
- 55 -

1 EINLEITUNG 2
1 Einleitung
Die Klassifikation von Objekten ist neben der Segmentierung, Prognose,Abhangigkeits- und Abweichungsanalyse1 eine Teilaufgabe im Bereich desData-Mining. Eine einfache Methode zur ihrer Losung bieten Entscheidungs-baume. Mit ihrer Hilfe konnen einfach zu verstehende Klassikationsregelnerstellt werden. Diese Arbeit wird zwei Algorithmen zum Aufbau von Ent-scheidungsbaumen beleuchten und vergleichen. In den nachsten beiden Un-terabschnitten der Einleitung werde ich kurz das Klassifikationsproblem undden grundlegenden Algorithmus fur den Aufbau der Entscheidungsbaumedarstellen und in ein Beispiel einfuhren, welches sich durch die Arbeit zie-hen wird. Im Abschnitt 2 und 3 werden dann die beiden Algorithmen SLIQund SPRINT betrachtet, welche auch die Klassifikation großer Datenmen-gen erlauben. Durch die Untergliederung der Abschnitte 2 und 3 werdenAhnlichkeiten und Unterschiede deutlich gemacht.
1.1 Klassifikationsproblem
Bei der Klassifikation soll einem Objekt anhand bekannter Merkmale einweiteres Merkmal zugeordnet werden, daß die Zugehorigkeit des Objektes zueiner Klasse oder Kategorie kenntlich macht.
Es sei D eine Menge von Objekten mit den Attributen Ai, 1 ≤ i ≤ e, und essei C = c1, . . . , ck eine Menge von Klassen. Weiterhin ist k : D → C einesurjektive Funktion, die jedes Objekt in Abhangigkeit von seinen AttributenA1, . . . , Ae auf eine Klasse cj abbildet. Die Funktion k nennt man Klassifika-tor.
Wenn man nun eine Instanz von d ∈ D eingibt, d = (a1 . . . ae)T wird durch
den Vektor der Attributbelegungen reprasentiert, dann will man mithilfe vonk auf die Klasse ci ∈ C schließen. Nur ist leider k unbekannt.
Man versucht nun ein k′
zu bestimmen, und daraus eine Hypothese h : D ⇒
C abzuleiten, welche k sehr ahnlich ist. Dabei sei O ⊂ D undL =< (o1, c1), . . . , (om, cm) > mit o ∈ O eine Menge von Trainingsdaten undk
′
: O → C eine surjektive Funktion, die Objekte aus O in Abhangigkeit vonihren Attributen A1, . . . , Ae auf eine Klasse cj abbildet. Von L schließt mannun auf k
′
.
1Vgl. Paul Alpar (2000, S. 9ff).
- 56 -

1 EINLEITUNG 3
ID Alter Autotyp Risiko (Klasse)1 23 Familie hoch2 17 Sport hoch3 43 Sport hoch4 68 Familie niedrig5 32 LKW niedrig6 20 Familie hoch
Tabelle 1: Beispiel fur das Klassifikationsproblem nach Shafer et al. (1996,S.2)
Wenn h bei einer Instanz d ∈ D und k bei der selben Instanz auf unter-schiedliche Klassen ci, cj schließen, also ci = cj , dann ist das ein Fehler. h istk umso ahnlicher, je kleiner der Fehler ist. Die Hypothese h wird dann alsKlassifikator verwendet.
Der Prozess der Klassifikation besteht also aus zwei Grundphasen. Als ers-tes wird ein Modell konstruiert. Dazu wertet ein Klassifikationsalgorithmuseinen Satz von Traingsdaten aus und bestimmt so den Klassifikator. Als Ein-gabe hat man die Trainingdaten und als Ergebnis den Klassifikator. In der 2.Phase wird das Modell angewandt. Dazu bestimmt man nun aus Daten mitunbekannter Klassenzugehorigkeit und dem in Phase 1 ermittelten Klassifi-kator die Klassenzugehorigkeit.
Die Aufgabe der Klassifikation ist vom Clustering abzugrenzen. Beim Clus-tering will man erst geeignete Klassen finden, wahrend diese bei der Klassi-fikation bereits bekannt sind.
Beispiel: Die Tabelle 1.1 zeigt einige Datensatze mit einem Index, demnumerischen Attribut
”Alter“ und den kategoriellen Attributen
”Autotyp“
und”Risiko“. Das Attribut
”Risiko“ hat als Klassenattribut die zwei Aus-
pragungen”hoch“ und
”niedrig“. Zunachst wird also ein Klassifikator be-
stimmt. Hier handelt es sich um eine Abbildung (Alter, Autotyp) → Risiko.Mogliche Klassifikatoren fur diese Tabelle waren dann z.B.:
if Alter > 50 or Autotyp = LKW then Risiko = niedrig
if Alter ≤ 50 and Autotyp = LKW then Risiko = hoch
Definition 1 Es sei h : D ⇒ C eine Hypothese auf der Objektmenge D und
- 57 -

1 EINLEITUNG 4
k : D → C eine Funktion wie oben. Es sei X := d ∈ D|h(d) = k(d). Dannist die Fehlerrate FD(h, k) := |X|.
Uberanpassung (Overfitting)
Definition 2 Sei H ein Hypothesenraum und h ∈ H eine Hypothese. Esheißt h uberangepasst (overfit) genau dann, wenn eine Hypothese h
′
∈ H
existiert, sodass h auf den Trainingsdaten eine kleinere Fehlerrate hat als h′
und h′
eine kleinere Fehlerrate auf allen Instanzen hat als h, also FO(h, k′
) <
FO(h′
, k′
) und FD(h, k) > FD(h′
, k).
Mit anderen Worten entsteht eine Uberanpassung dann, wenn der Klassifi-kator zu sehr auf den Trainingsdaten optimiert wurde und fur die Grundge-samtheit dann aber schlechtere Ergebnisse erzeugt. Um dem Problem zu be-gegnen, muss man die Klassifikatoren validieren.2 Dazu kann man zum einendie Traingsdaten (in denen die Klassen schon bekannt sind) in eine Trai-ningsmenge und eine Testmenge unterteilen. Mit der Trainingsmenge wirddann das Modell konstruiert. Mit der Testmenge wird es validiert. Leider istdieses
”Train-and-Test-Verfahren“ nicht anwendbar, wenn nur bei wenigen
Objekten die Klassenzugehorigkeit bekannt ist. Offensichtlich werden danndie Ergebnisse zu ungenau. Alternativ dazu besteht die Moglichkeit einerm-fachen Uberkreuz-Validierung. Dazu wurde man die Trainingsdaten in m
gleichgroße Teilmengen teilen. Nun verwendet man jeweils eine Teilmengezur Validierung und den Rest (also m − 1 Teilmengen) zum Training. Manerhalt dann m Modelle und die dazugehorigen Klassifikationsgenauigkeiten(bzw. -fehler) welche man miteinander kombiniert. Die Klassifikatoren unddie Methoden ihrer Gewinnung lassen sich als Klassifikationsgute nach derKlassifikationsgenauigkeit, der Kompaktheit des Modells, seiner Interpretier-barkeit, der Effizienz in der Konstruktion und in der Anwendung des Modells,der Skalierbarkeit von Datenmengen und der Robustheit bewerten.
1.2 Entscheidungsbaume
Eine einfache, effiziente und genaue Methode zur Klassifikation ist der Auf-bau von Entscheidungsbaumen. Besondere Vorteile von Entscheidungsbaumensind die Moglichkeit zur Konversion zu einfach zu verstehenden Regeln oder
2Vgl. Mehta et al. (1996, S.21).
- 58 -

1 EINLEITUNG 5
auch SQL-Anfragen3. Abbildung 1.2 zeigt einen Entscheidungsbaum fur dasEingangsbeispiel. Jeder innere Knoten einschließlich der Wurzel reprasentiertein Attribut. Die Klassen werden durch die Blatter dargestellt. Jede Kanteist eine Reprasentation eines Tests auf dem Attribut des Vaterknotens. DieKlassifikatoren konnen dann durch die Konjunktion der Tests entlang desPfades der Wurzel zu einem Blatt gebildet werden. Fur das Beispiel ware einKlassifikator als Regel dann:
if Autotyp = LKW and Alter ≤ 60 then Risiko := hoch
Autotyp
AlterRisiko = niedrig
= LKW
Risiko = niedrig Risiko = hoch
≤ 60< 60
= LKW
Abbildung 1: Entscheidungsbaum fur das Eingangsbeispiel
Die folgende SQL-Anfrage wurde alle Indizes der Datensatze mit niedrigemRisiko ausgeben:
Select id FROM table
WHERE Autotyp = LKW or Autotyp != LKW and Alter > 60
1.2.1 Algorithmische Grundlagen
Es sind eine Anzahl von Algorithmen zum Aufbau von Entscheidungsbaumenpubliziert worden (z.B. ID34, C4.55, CART6). Ziel dieser Arbeit ist es nichtjeden einzelnen Algorithmus im Detail zu besprechen. Man kann einen ge-meinsamen Grundablauf feststellen. Man Unterscheidet jeweils eine Aufbau-phase und eine Pruningphase.7
3Vgl. Mehta et al. (1996, S.19).4Vgl. Quinlan (1986).5Vgl. Quinlan (1993).6Vgl. Breiman et al. (1984).7Vgl. Mehta et al. (1996, S.20).
- 59 -

1 EINLEITUNG 6
i) Aufbauphase: Die Trainingsmenge wird sukzessiv partitioniert, bis injeder Partition alle Datensatze moglichst einer Klasse angehoren.
Grundalgorithmus zur Aufbauphase:
Prozedur makeTree(Trainingsdaten T)
Partition(T);
Prozedur Partition(Data S)if alle Objekte in S sind in der gleichen Klasse oder nur noch einAttribut then
return;endberechne splits fur jedes Attribut;nimm den besten Split und partioniere S nach S1 und S2;Partition(S1);Partition(S2);
Man baut den Baum also mit einem rekursiven”Top-Down“-Algorithmus
auf, der sich beendet, wenn alle Objekte der unteren Knoten eindeutig einerKlasse zugeordnet werden konnten oder wenn es kein Attribut mehr gibt,wonach man weiter partitionieren kann.
Die zentrale Aufgabe der Prozedur Partition(Data S) besteht darin, S inzwei Teilmengen S1 und S2 zu teilen. Hierbei wird man sich wird man sichzwischen verschiedenen Strategien entscheiden. Zunachst sind dabei die At-tributtypen von Bedeutung, d.h. numerische Attribute vs. kategorische At-tribute. Wahrend man bei den numerischen Attributen einen Wert v sucht,so dass S1 = SLA≤vS und S2 = SLA>vS
8, sucht man bei kategorischen At-tributen ein M1 ⊂ M und ein M2 = M \ M1 wobei M(A) alle moglichenWerte des Attributs A sind. Man teilt dann S entsprechend M1 und M2.
Definition 3 Es sei
P = p ∈ RC : pc ≥ 0,
C∑
c=1
pc = 1.
8Dabei bezeichnet SLF R die Selektion, angewandt auf R unter Anwendung der Selek-tionsformel F (Vgl. Dadam (1996, S. 39)).
- 60 -

2 SLIQ 7
Eine Unreinheitsfunktion ist eine Funktion φ : P → R.
φ hat die Eigenschaften:
1. φ hat bei ( 1
C, . . . , 1
C) ihr einziges Maximum,
2. φ(1, 0, . . . , 0) = φ(0, . . . , 0, 1, 0, . . . , 0) = φ(0, . . . , 0, 1) = minpφ(p),
3. φ ist symetrisch in p.
Auf Grundlage Unreinheitsfunktion9 lasst sich das Unreinheitmaß an einemKnoten k definieren:
Definition 4 u(k) = φ(p(1|k), . . . , p(C|k)).
Als Unreinheitmaße wurden z.B. der Informationsgewinn10 oder der Gini-Index11 entwickelt.
ii) Pruning : Die 2. Phase bezeichnet man als Pruning. Es dient zur Re-duzierungs des Overfittings. Hierbei wird der Entscheidungsbaum wieder
”zuruckgeschnitten“. Es werden diejenigen Teilbaume wieder entfernt, wel-
che eine geringe Klassifikationsgute aufweisen.
Ein Nachteil dieser klassischen Algorithmen ist, dass die Datensatze im Haupt-speicher gehalten werden mussen und sie damit ungeeignet fur rosse Da-tensatze sind. Sie haben also ein großes Problem mit der Skalierbarkeit.
2 SLIQ
2.1 Eigenschaften
Der SLIQ-Algorithmus12 zeichnet sich dadurch aus, dass der Großteil der Da-ten nicht im Hauptspeicher gehalten werden muss. Dadurch wird eine bessereSkalierbarkeit als bei den klassischen Algorithmen erreicht. Die Anzahl der
9Vgl. Breiman et al. (1984).10Siehe Breiman et al. (1984, S. 25, 103) oder Beierle and Kern-Isberner (2006, S. 116).11Vgl. Breiman et al. (1984, S. 38, 103) und Abschnitt 2.3.12SLIQ steht fur
”Supervised Learning In Quest“, Quest ist ein Data-Mining Projekt
beim IBM Almaden Research Center.
- 61 -

2 SLIQ 8
Tupel bleibt trotzdem limitiert, kann aber sehr groß werden. Es besteht dieMoglichkeit der Verarbeitung numerischer und kategorieller Attribute.
Der elementare Unterschied zu den klassischen Algorithmen besteht in denDatenstrukturen, einer Vorsortierung der Attribute und der Benutzung ei-ner Breitenwachstumsstrategie, welche sekundarspeicherresident Datensatzeermoglicht. SLIQ verwendet binare Splits.
2.2 Datenstrukturen
Es werden drei verschiedene Datenstrukturen verwendet: Fur jedes Attributgibt es eine Attributliste. Es gibt eine Klassenliste und es gibt Histogramme.
Klassenliste:Die Klassenliste ist die einzige Datenstruktur, welche uber die ganze Lauf-zeit im Hauptspeicher gehalten werden muss. Sie enthalt fur jeden Datensatzdie zugehorige Klasse, sowie einen Verweis auf das korrespondierende Blattim Entscheidungsbaum. Am Anfang werden alle Verweise auf die Wurzel imEntscheidungsbaum zeigen. Wie der Algorithmus zeigen wird, muss der Zu-griff wahlfrei erfolgen. Deshalb besteht die Notwendigkeit einer Ablegung imHauptspeicher.
Attributlisten:Fur jedes Attribut wird eine Liste angelegt. In jeder dieser Listen wird fur je-des Objekt ein Tupel bestehend aus dem Attributwert zu diesem Objekt undeiner Referenz auf den zugehorigen Eintrag in der Klassenliste gespeichert.Die Tupel werden nach den Attributwerten aufsteigend sortiert. Der Zugrifferfolgt sequenziell. Die Attributlisten konnen somit im Sekundarspeicher ge-halten werden.
Histogramme:Fur jedes Blatt im Entscheidungsbaum wird ein Histogramm angelegt. Dortwerden im Entscheidungsbaum die Haufigkeiten der einzelnen Klassen aufdie Trainingsdatenobjekte der Partition gespeichert.
2.3 Algorithmus zum Aufbau
Der Algorithmus verfolgt eine Breadth-First-Strategie, das bedeutet, es er-folgt eine Aufteilung aller vorhandenen Blattknoten in jedem einzelnen Schritt.
- 62 -

2 SLIQ 9
Alter classlist
index
17 220 623 132 543 368 4
Attributliste von Alter
Risiko Blatt
hoch K1
hoch K1
hoch K1
niedrig K1
niedrig K1
hoch K1
Klassenliste
hoch niedrigFamilie 2 1Sport 2 0LKW 0 1
Histogramm fur kate-gorielles Attribut
hoch niedrigS1 3 1S2 1 1
Histogramm fur Altere ∈ S1|v <= 32; e ∈ S2
sonst
Abbildung 2: Datenstrukturen fur das Beispiel
Gini-Index Als Split-Kriterium benutzt SLIQ den Gini-Index. Er ist einMaß fur die Unreinheit einer Partitionierung. Je kleiner er ist, desto wenigerunrein in Bezug auf die Klassenzugehorigkeit sind Werte in den Partitionen.Fur eine Datensatzmenge S mit n unterschiedlichen Klassen gilt:13
gini(S) = 1 −
n∑
j=1
p2
j .
Nach einer binaren Partitionierung berechnet sich:14
ginisplit(S) =n1
ngini(S1) +
n2
ngini(S2).
pj ist dabei die relativen Haufigkeit der Klasse j in S. Der Vorteil des Gini-Index ist, dass er nur die Verteilung der Klassenwerte in jeder Partitionbenotigt.
Der Algorithmus durchlauft nun vier Phasen.15
13Vgl. Mehta et al. (1996, S.21).14Vgl. Shafer et al. (1996, S.4).15Vgl. Mehta et al. (1996, Abschnitt 4.2).
- 63 -

2 SLIQ 10
i) Initialisierung
1. Erstellung und Vorsortierung der Attributlisten
2. Fur jeden Eintrag in der Klassenliste verweist die Referenz auf dieWurzel im Entscheidungsbaum
Bei der Initialisierung werden nun die Attributlisten und die Klassenlisteerstellt. Bei den Klassenlisten wird fur jeden Eintrag eine Referenz auf dieWurzel im Entscheidungsbaum (dem augenblicklichen Blatt) gesetzt. Wie inAbschnitt 1.2.1 beschrieben, wird bei den numerischen Attributen ein Wertgesucht der S moglichst gut partitioniert, sodass alle Datensatze die kleinergleich diesem Wert sind zu S1 und alle die großer sind zu S2 gehoren. Umdie Attributlisten bei der Splitevaluation nur einmal durchlaufen zu mussen,werden alle Attributlisten fur numerische Attribute vorsortiert.
ii) Split berechnenIn der zweiten Phase werden nun fur jedes aktuelle Blatt die besten Splits
berechnet. Dazu werden alle Attributlisten einmal durchlaufen. Fur jedenWert wird zuerst der korrenspondierende Eintrag in der Klassenliste ermit-telt und das Histogram von dem Blatt, auf das der Eintrag (in der Klassen-liste) zeigt, aktualisiert. Da die Werte sortiert sind, kann bei den numeri-schen Attributen jetzt schon gleichzeitig der Splitting-Index fur das jeweiligeBlatt berechnet werden. Man wird sich immer den besten Splitting-Indexund die dazugehorige Aufteilung pro Blatt merken. Bei den kategoriellenAttributen wird man zuerst die ganze Liste durchlaufen und dabei die Auf-trittshaufigkeiten in den Klassen zahlen. In Abbildung 2 wird ein Histogrammfur das Attribut
”Autotyp“ gezeigt. Danach konnen fur alle moglichen Teil-
mengen die Gini-Indexe berechnet und vergleichen werden. Man wahlt danndie Mengenaufteilung mit dem besten Index. Nach der Ausfuhrung von Eva-luateSplits steht an jedem Blattknoten die beste Aufteilung zur Verfugung.
iii) Kinderknoten erstellen und die Klassenliste aktualisierenIn diesem Schritt werden zunachst fur jedes Blatt, dass zusammen mit
einem Split-Test gespeichert wurde, zwei neue Kinder erstellt. Danach wirddie Prozedur UpdateLabels() ausgefuhrt, dabei der Split nun an jedem Blattangewendet und die Referenzen in der Klassenliste den neuen Blattern zuge-ordnet.
- 64 -

2 SLIQ 11
Prozedur EvaluateSplits
Ausgabe : Menge von Split-Testsforeach A ist Attribut do
durchlaufe Attributliste von A;foreach Wert v ∈ A do
finde den zugehorigen Wert in der Klassenliste, also diezugehorige Klasse und den Blattknoten l;if Es existiert noch kein Histogramm fur l then
erstelle Histogramm fur l;endaktualisiere das Klassenhistogramm in l;if A ist ein numerisches Attribut then
berechne den Splitting-Index i fur den Test(A ≤ v) fur l;if i ist bester Splitting-Index fur Blatt l then
speichere Split-Test mit l;end
end
endif A ist ein kategorielles Attribut then
foreach Blatt des Baums dofinde die Teilmenge von A mit dem besten Split;if i ist bester Splitting-Index fur Blatt l then
speichere Split-Test mit l;end
end
endentferne alle Histogramme;
end
- 65 -

2 SLIQ 12
Prozedur UpdateLabels
Eingabe : Menge von Split-TestsEingabe/Ausgabe : Klassenlisteforeach Attribut A in einem Split do
durchlaufe die Attributliste von A;foreach Wert v in der Liste do
finde den korrespondierenden Eintrag e in der Klassenliste;finde das neue Kind c, zu der v bei Anwendung desSplitting-Tests am Knoten referenziert von e gehort;aktualisiere den Blattzeiger in der Klassenlisten am Eintrag e,so dass er auf das Kind c zeigt;
end
end
iv) gehe zu ii) wenn es noch was zu splitten gibt sonst Ende.Falls nach allen Attributen gesplittet wurde oder die Klassen rein sind
(Gini-Index = 0), dann beende den Aufbau des Baumes, sonst gehe zurucknach ii).
2.3.1 Beispiel
Es soll nun der Aubau nach dem SLIQ-Algorithmus an dem Beispiel durchge-gangen werden. Dazu wird noch die Attributliste fur den
”Autotyp“ benotigt.
Sie ist kategoriell und muss deswegen nicht sortiert weden.
Autotyp classFamilie 1Sport 2Sport 3
Familie 4LKW 5
Familie 6
Am Anfang zeigt jede Referenz in der Klassenliste auf die Wurzel (alsoK1). Nach Durchlaufen der Attributliste
”Autotyp“ wurde das in Abbil-
dung 2 gezeigte Histogramm erstellt. Hier ergeben sich nun folgende Tei-lungsmoglichkeiten:
I:S1 = e|e.Autotyp = Familie ∨ e.Autotyp = Sport
S2 = e|e.Autotyp = LKW
- 66 -

2 SLIQ 13
II:S1 = e|e.Autotyp = Familie ∨ e.Autotyp = LKW
S2 = e|e.Autotyp = Sport
III:S1 = e|e.Autotyp = Sport ∨ e.Autotyp = LKW
S2 = e|e.Autotyp = Familie
Die anderen drei waren spiegelverkehrt und brauchen nicht weiter betrachtetzu werden.
Ich berechne nun fur alle den Gini-Index, dabei ist :
Moglichkeit gini(S1) gini(S2) ginisplit(S) p1h p1n p2h p2n
I 0, 32 0 0, 266 0, 8 0, 2 0 1II 0, 5 0 0, 33 0, 5 0, 5 1 0III 0, 46 0, 46 0, 46 0, 66 0, 33 0, 66 0, 33
Somit ware fur das Attribut”Autotyp“ der beste Split die Moglichkeit I.
Fur das Attribut”Alter“ erhalt man nach durchlaufen von
”EvaluateSplits()“
folgende Werte fur die relativen Haufigkeiten und den Gini-Index:
Alter gini(S1) gini(S2) ginisplit(S) p1h p1n p2h p2n
17 0 0, 48 0, 4 1 0 0, 6 0, 420 0 0, 5 0, 3333 1 0 0, 5 0, 523 0 0, 44 0, 22 1 0 0, 333 0, 66632 0, 375 0, 5 0, 41 0, 75 0, 25 0, 5 0, 543 0, 32 0 0, 266 0, 8 0, 2 0 168 0, 44 0, 44 0, 666 0, 33 n.d. n.d.
Also hat in der ersten Runde das”Attribut“ Alter gewonnen. Die Wurzel be-
kommt also das Attribut”Alter“ und es werden zwei Kinder erstellt, außer-
dem werden in der Klassenliste die Referenzen auf die neuen Kinder gesetzt.
Abbildung 3 zeigt den Baum nach der ersten Teilung. Tabelle 2 zeigt dieaktualisierte Klassenliste.
Im nachsten Schritt ware dann noch nach dem Attribut”Autotyp“ zu parti-
tionieren. Dabei konnte an Knoten K2 nichts mehr verbessert werden (Dortergibt sich ein Gini-Index von 0.). Am Knoten K3 wurde ein neue Teilung
- 67 -

2 SLIQ 14
Alter
Alter <= 23 Alter > 23
K_2 K_3
Abbildung 3: Entscheidungsbaum nach dem 1. Split
Risiko Blatt
hoch K2
hoch K2
hoch K3
niedrig K3
niedrig K3
hoch K2
Tabelle 2: Klassenliste nach dem 1. Durchlauf
entstehen, so dass die Teilmengen rein werden:
S1 = e|e.Autotyp = Sport
S2 = e|e.Autotyp = Familie ∨ e.Autotyp = LKW
Den Ergebnisbaum zeigt Abbildung 4.
2.4 Pruning
In der Einleitung wurde schon zwei grundlegende Methoden fur das Pruninggenannt. Der Pruning-Algorithmus von SLIQ basiert auf der
”Minimum De-
scription Length“.Minimum Description Length (MDL):16
Definition 5 Das beste Modell fur einen gegebenen Datensatz minimiert diefolgende Summe: die Lange der im Modell kodierten Daten plus die Langedes Modells.
16Vgl. http://www-agrw.informatik.uni-kl.de/damit/m/mdl.html (Zugriff am20.5.2008)
- 68 -

2 SLIQ 15
Alter
Alter <= 23 Alter > 23
hoch Autotyp
hoch niedrig
Sport Familie oder LKW
Abbildung 4: Entscheidungsbaum nach Ausfuhrung von SLIQ
Wenn also M das Modell ist, und D die Daten, die von dem Modell kodiertwerden, dann sind die Kosten, die minimiert werden sollen:
cost(M, D) = cost(D|M) + cost(M)17
Die Kosten werden in”bit“ angegeben. Der Pruningalgorithmus besteht aus
2 Komponenten:
1. Das Kodierungsschema bestimmt die Kosten der Daten- und Mo-dellkodierung.
2. Der Algorithmus vergleicht die Kosten verschiedenen Unterbaume.
2.4.1 Datenkodierung:
Die Kosten bei der Kodierung des Trainingssets werden aus der Summe al-ler Klassifizierungsfehler bestimmt. Sie konnen schon in der Aufbauphasesukzessiv jedem Knoten im Entscheidungsbaum zugeordnet werden. NachSchritt 3 wird man sich also bei jedem Blatt fur eine Klasse entscheiden (an-hand der Mehrheit der Referenzen in der Klassenliste) und wird dann dieKlassifizierungsfehler mit der Testmenge zahlen. Der Zeitaufwand dazu istim Vergleich zum Baumaufbau also unkritisch.
17Vgl. Mehta et al. (1996, S.26).
- 69 -

2 SLIQ 16
2.4.2 Modellkodierung:
Die Kosten der Kodierung des Entscheidungsbaum, also des Modells setzensich aus den Kosten zur Kodierung des Baums und den Kosten der Kodie-rung der Tests an jedem Knoten zusammen.
Nach der Aufbauphase hat jeder Knoten zwei Kinder als Wurzel eines Teil-baums oder er ist ein Blatt. Man kann nun entweder beide Teilbaume be-lassen, beide entfernen oder auch nur einen Teilbaum entfernen. Deswegenwerden zur Kodierung der Kosten L drei Moglichkeiten angegeben:18
1. Code1: Ein Knoten hat entweder 0 oder 2 Kinder. Weil es hier nur 2Moglichkeiten gibt kostet die Kodierung 1 bit.
2. Code2: Ein Knoten hat kein Kind, sein rechtes, sein linkes oder allebeiden Kinder. Die 4 Moglichkeiten kosten 2 bits.
3. Code3: Es werden nur interne Knoten betrachtet. Also hat jeder Knotenein linkes oder ein rechtes Kind oder beide Kinder. Diese Kodierungkostet log(3) bits.
Bei der Kodierung der Tests Ltest werden die Kosten bei jedem Test auf einnumerisches Attribut mit 1 bemessen. Bei kategoriellen Attributen wird dieAnzahl nA der Tests A ∈ S gezahlt, wobei A ein kategorielles Attribut istund S eine Teilmenge der moglichen Werte von A. Die Kosten sind dann log(nA).
2.4.3 Pruning Algorithmen
Ein Pruning-Algorithmus vergleicht dann fur jeden Knoten die Kosten, jenach dem ob er zu einem Blatt gestutzt wird (1), oder den linken (2), rech-ten Teilbaum (3) oder beide Teilbaume (4) behalt. Die Kosten berechnensich dann:19
1. CBlatt(t) = L(t) + Fehlert
2. Clinks(t) = L(t) + Ltest + C(t1) + C′
(t2)
3. Crechts(t) = L(t) + Ltest + C′
(t1) + C(t2)
18Vgl. Mehta et al. (1996, S.27).19Vgl. Mehta et al. (1996, S.27).
- 70 -

2 SLIQ 17
4. Cbeide(t) = L(t) + Ltest + C(t1) + C(t2)
C(t) bezeichne dabei die Kosten des jeweiligen Teilbaums und C′
(t) die Kos-ten eines Teilbaumes, der geloscht wird, und dessen Objekte jetzt t zugeord-net werden. Es gibt, wie schon angedeutet, nun 3 mogliche Algorithmen:
1. Volles Pruning wird, wenn es den Baum stutzt, immer beide Teilbaumeabschneiden. Bei der Kostenberechnung spielen also nur die Formeln 1und 4 eine Rolle. L wird mit Code1 bestimmt.
2. Partielles Pruning vergleicht alle 4 Optionen, hier wird L mit Code2
berechnet.
3. Hybrid Pruning benutzt in einer ersten Phase volles Pruning und ent-scheidet in einer zweiten Phase mit den Formeln 2, 3 und 4.
2.4.4 Parallelisierung von SLIQ
Die Autoren von SPRINT machten zwei Vorschage20 fur die Parallelisierungvon SLIQ. Das Problem hierbei ist die zentrale, hauptspeicherresidente Klas-senliste, auf die beiden Prozeduren (EvaluateSplits() und UpdateLabels()) injedem Einzelschritt zugreifen.
Man hat nun einerseits die Moglichkeitkeit die Klassenliste an jedem Prozes-sor zu replizieren. Dann mussen jedoch auch alle anderen Prozessoren vonjedem Prozessor uber Updates in UpdateLabels() informiert werden. Außer-dem muss an jedem Prozessor der gesamte Speicherplatz bereitgestellt wer-den, um die ganze Klassenliste zu halten. Diese Modifikation wird SLIQ/Rgenannt.
Die andere Moglichkeit ist die Klassenliste auf alle Prozessoren gleichmaßigzu verteilen (SLIQ/D). Da aber die Eintrage der horizontal verteilten (vgl.Abschnitt 3.4) Attributlisten nicht mit den Eintragen der Klassenliste aufdem jeweiligen Prozessor korrespondieren, muss bei fast allen Zugriffen aufdie Klassenliste die Information bei einem anderen Prozessor angefordertwerden bzw. dort aktualisiert werden.
20Vgl. Shafer et al. (1996, Abschnitt 3.4).
- 71 -

2 SLIQ 18
2.5 Leistungsmerkmale von SLIQ
2.5.1 Komplexitat der Aufbauphase
In der Initialisierungsphase hat das Sortieren der Attributlisten die maß-gebliche Komplexitat. Sie betragt fur jedes numerische Attribut O(n log n).Danach wird fur jedes Attribut die Teilung (Split) berechnet. Hier unterschei-det sich die Komplexitat zwischen numerischen und kategoriellen Attibutenerheblich.
Bei den numerischen Attributen wird die Liste durchlaufen, bei jedem Schrittdas Histogramm aktualisiert, der Gini-Index berechnet und mit dem gemerk-ten verglichen. Man hat also eine Komplexitat von O(n).
Bei den kategoriellen Attributen21 muss jede Teilmenge S′
⊂ S ausgewer-tet werden, wobei S die Menge der moglichen Merkmalsauspragungen ei-nes Attributs ist. Die Komplexat hangt also von der Kardinalitat von S
ab. Bei k moglichen Merkmalsauspragungen von S und m Knoten im Ent-scheigunsbaum entsteht so eine Komplexitat von O(m · 2k). Um diesemProblem zu begegnen, verwendet SLIQ einen Schwellwert fur die Anzahlder moglichen Auspragungen. Wird dieser uberschritten benutzt SLIQ einenGreedy-Algorithmus. Dieser beginnt mit einer leeren Menge S
′
und fugt im-mer wieder das Element aus S hinzu, welches den besten Split ergibt, bis derSplit nicht mehr verbessert werden kann.
2.5.2 MDL Pruning
Das MDL-Pruning benotigt weniger als 1 % der Zeit im Vegleich zur Auf-bauphase. Es kann deswegen vernachlassigt werden.
2.5.3 Benchmarks
Es wurden Vergleiche von SLIQ mit den Algorithmen CART und C4 (einemVorganger von C4.5) angestellt. Da bei diesen Algorithmen die Daten spei-cherresident vorliegen mussen, konnten nur kleinere Datensatze miteinanderverglichen werden. Dabei wurden drei Parameter gemessen: die Genauigkeit,die Ausfuhrungszeit und die Baumgrosse. Bei der Genauigkeit waren alledrei Algorithmen etwa gleich gut. Der C4 Algorithmus produzierte wesent-lich grossere Baume, als SLIQ und CART. Dagegen war die Ausfuhrungszeit
21Vgl. Mehta et al. (1996, Abschnitt 4.3).
- 72 -

3 SPRINT 19
bei Cart wegen der Uberkreuzvalidierung beim Pruning erheblich grosser alsbei den anderen beiden. Insgesamt ließ sich feststellen, dass SLIQ bei keinemParameter schlechter ist, als einer der anderen beiden Algorithmen.
Bei der Skalierbarkeit hinsichtlich der Tupel- und Attributenanzahl verzeich-nete die Ausfuhrungszeit bei SPRINT jeweils einen linearen Anstieg.
3 SPRINT
3.1 Eigenschaften
Obwohl SLIQ schon fur sehr große Datenmengen geeigent war, wurde amIBM Almaden Research Center noch nach einem Algorithmus fur beliebiggroße Datenmengen gesucht. Dieser sollte SLIQ nicht unbedingt in der Leis-tung uberbieten. Das Augenmerk lag deswegen in der Skalierbarkeit fur be-liebig große Datenbanken und in der Parallelisierbarkeit des Verfahrens.
3.2 Datenstrukturen
Bei SLIQ muss die Klassenliste immer noch permanent im Hauptspeicherliegen. Daher wird sie bei SPRINT22 entfernt und bei den Attributlisten einzusatzliches Attribut
”Klasse“ eingefugt. Jede Attributliste hat jetzt die At-
tribute: Wert, Klassenlabel, Eintrags-Id. Die Listen werden wie bei SLIQvorsortiert.
Abbildung 5 zeigt die Attributlisten fur das Beispiel.
Alter Klasse id17 hoch 220 hoch 623 hoch 132 niedrig 543 hoch 368 niedrig 4
Autotyp Klasse idFamilie hoch 1Sport hoch 2Sport hoch 3
Familie niedrig 4LKW niedrig 5
Familie hoch 6
Abbildung 5: Attributlisten SPRINT fur das Beispiel
22Scalable, PaRallelizable INduction of decision Trees
- 73 -

3 SPRINT 20
Ausserdem gibt es zwei Histogramme fur numerische Attribute Cabove undCbelow. Bei dem Durchlaufen einer Attributliste werden in den Histogrammendie Klassenhaufigkeiten gezahlt. Cbelow enthalt die Haufigkeiten der schonbetrachteten Tupel und Cabove die der noch nicht betrachteten Tupel. DasHistogramm fur kategorielle Attribute ist dem von SLIQ aquivalent, die Au-toren nennen es
”Count Matrix“.
3.3 Algorithmische Details
Der wesentliche Unterschied zu SLIQ besteht nun darin, dass nach einemSplit nicht die Referenzen in der Klassenliste auf die neuen Blatter gesetztwerden, sondern die Attributlisten entsprechend der Splitmengen geteilt undden neuen Blattern zugeordnet werden. Deswegen gibt es anstelle der Proze-dur UpdateLabels() die Prozedur SplitLists(). Als Teilungsmaß dient wiederder Gini-Index.
Die Prozedur EvaluateSplitsSprint() berechnet die Splitpradikate. Weil dieAttributlisten fur jedes neue Blatt geteilt werden, ist es zu vermuten, dassSPRINT auch mit einer Tiefensuchen-Strategie durchfuhrbar ist. Hier wirder mit einer Breadth-First-Strategie dargestellt. Das Pruning erfolgt analogzu SLIQ. Ich werde darauf hier nicht nocheinmal eingehen.
Da nun jedes Blatt seine eigenen Attributlisten bekommt, muss Evaluate-Splits() nun fur jedes Blatt ausgefuhrt werden. Die Anzahl der zu durchlau-fenden Datensatze bleibt aber insgesamt gleich. Nachdem nun die Splitat-tribute und die Teilungspradikate bestimmt worden sind, mussen noch alleanderen Attributlisten entprechend den zugehorigen Datensatzen aufgeteiltwerden. Dies geschieht in der Prozedur SplitLists23.
3.4 Parallelisierung
Wie schon erwahnt, wurde SPRINT so konstruiert, dass er sich leicht paralle-lisieren laßt. Dabei ist die Aufbauphase von Interesse. Bei der Pruningphasewird nur der Zugriff auf den gewonnenen Entscheidungsbaum benotigt. Sie
23Die Autoren von SPRINT haben keine solche Prozedur angegeben, sondern diesenSchritt nur informell beschrieben. Dort betonen sie auch, dass wenn die Hashtabelle nichtin den Hauptspeicher passen sollte, dieser Schritt in mehreren Schritten vollzogen wer-den konne. Dies wurde aber eine Nachsortierung der Attributlisten erfordern. Auf dieseNachsortierung gehen sie in Ihrem Artikel nicht ein.
- 74 -

3 SPRINT 21
Prozedur SplitLists(Attributliste A, Splitmenge S1, Blattknoten l1,l2)
durchlaufe die Attributliste A;foreach Wert v in der Liste do
if v ∈ S1 thenlege id in eine Hashtabelle;verschiebe das Tupel nach A1;A1 gehort zum neuen linken Blatt;
endelse
verschiebe das Tupel nach A2;A2 gehort zum neuen rechten Blatt;
end
enddurchlaufe alle anderen Attributlisten;foreach Attributliste B = A do
foreach Tupel in der Liste doif id ∈ Hashtabelle then
verschiebe Tupel von B nach B1;B1 gehort zum neuen linken Blatt;
endelse
verschiebe Tupel von B nach B2;B2 gehort zum neuen rechten Blatt;
end
end
end
- 75 -

3 SPRINT 22
Prozedur EvaluateSplitsSprint(Queue von Blattknoten q)
foreach Blatt in q doforeach A ist Attribut do
erstelle Histogramm(e) fuer A und das aktuelle Blatt;durchlaufe Attributliste von A;foreach Wert v ∈ A do
selektiere die Klasse;aktualisiere das Klassenhistogramm;if A ist ein numerisches Attribut then
berechne den splitting-index fur den Test(A ≤ v) fur lend
endif A ist ein kategorielles Attribut then
foreach Blatt des Baums dofinde die Teilmenge von A mit dem besten Split
end
end
endif ¬(alle Objekte die zu diesem Blatt gehoren sind rein oder dieObjektmenge ist zu klein) then
erstelle 2 neue Blatter l1, l2;q := q ∪ l1 ∪ l2;A := gefundenes Splitattribut;SplitLists(Attributliste von A, Splitpradikat S1, Blattknoten l1,
l2) /* z.B. S1 := v ≤ 23 */
;endentferne Histogramm(e);
end
- 76 -

3 SPRINT 23
ist verhaltnismaßig einfach und wird nicht parallelisiert. Wie schon im Abb-schitt 3.3 deutlich wurde, liegt das Hauptproblem von SPRINT im Findeneines guten Splitpunktes und dem anschliessenden Partitionieren der Attri-butlisten. Im Gegensatz zu SLIQ gibt es keine zentralisierten und speicherre-sidenten Datenstrukturen. Somit ist es moglich eine Parallelisierung mit einerShared-Nothing-Architektur zu erreichen. Dazu lassen sich die Attributlistengleichmaßig horizontal auf alle Prozessoren aufteilen. Die (Teil-)Listen wer-den dann wie in der seriellen Version durchlaufen um die besten Splits zufinden. Uber die Histogramme muss jedoch kommuniziert werden. Cbelow undCabove mussen in der Initialisierung bei den numerischen Attributen mit denentsprechenden Werten der Sektion der Listen versorgt werden. Dazu wer-den beim Vorgangersplit die Haufigkeiten gesammelt, unter den Prozessorenausgetauscht und mit den Blatten gespeichert. Sie stehen dann beim aktu-ellen Split wieder zur Verfugung. Nach Berechnung der lokalen besten Splitstauschen sich die Prozessoren noch uber das niedrigste Ergebnis aus. Bei denkategoriellen Attributen werden die gesammelten Haufigkeiten an einem Kno-ten aufsummiert. Dort wird dann auch die beste Splitmenge bestimmt. Nach-dem nun das Splitattribut und das Splitpradikat bestimmt wurden, mussennoch die Nicht-Splitattribute geteilt werden dazu wird an jedem Prozessordie gesamte Haschtabelle zur Verfugung gestellt. Die Prozessoren versorgensich dafur mit den jeweiligen ID’s.
3.5 Performance
Obwohl sich die Datenstrukturen und die Art des Wachstums bei SLIQ undSPRINT sehr unterscheiden, berechnen sie die gleichen Splits an jedem Kno-ten24. Da sie auch den gleichen Pruningalgorithmus verwenden, sind ihre Ent-scheidungsbaume im Ergebnis identisch, also auch deren Genauigkeit und dieBaumhohe.Bei der seriellen Ausfuhrung schneidet SLIQ leicht besser ab als SPRINT.Sobald die Klassenliste aber nicht mehr in den Hauptspeicher passt, mussSLIQ aufgeben. Die Ausfuhrungszeit steigt mit der Anzahl der Tupel beiSPRINT etwa linear an.
Bei der parallelen Ausfuhrung wird deutlich, dass SLIQ/D gegenuber SLI-Q/R und SPRINT sehr langsam arbeitet. SPRINT hat eine wesentlich bes-sere Antwortzeit als SLIQ/R.
24Vgl. Shafer et al. (1996, S. 8).
- 77 -

4 ZUSSAMMENFASSUNG 24
4 Zussammenfassung
Mit SLIQ und SPRINT wurden zwei Algorithmen vorgestellt, welche diefur das Data-Mining sehr wichtige Eigenschaft haben, große Datensatze zuklassifizieren. Sie sind dabei so genau und schnell, dass sie die klassischenAlgorithmen auch bei kleinen Datensatzen ersetzen konnen, wobei sich diePerformance bei SLIQ noch etwas besser darstellt. Mit SPRINT wurde je-doch ein Algorithmus vorgestellt, der sich auf beliebig große Datensatze an-wenden lasst, der sich sehr leicht parallelisieren lasst und dabei sehr guteEigenschaften an den Tag legt.
Literatur
Beierle, C. and Kern-Isberner, G. (2006). Methoden wissensbasierter Systeme- Grundlagen, Algorithmen, Anwendungen. Vieweg-Verlag, 3., erweiterteAuflage.
Breiman, L., Friedman, J., Olshen, R., and Stone, C. (1984). Classificationand Regression Trees. Wadsworth and Brooks, Monterey, CA.
Dadam, P. (1996). Verteilte Datenbanken und Client/Server-Systeme –Grundlagen, Konzepte und Realisierungsformen. Springer-Verlag.
Mehta, M., Agrawal, R., and Rissanen, J. (1996). SLIQ: A fast scalableclassifier for data mining. In Extending Database Technology, pages 18–32.
Paul Alpar, J. N. (2000). Data Mining im praktischen Einsatz. Vieweg,Deutschland.
Quinlan, J. R. (1986). Induction of decision trees. In Machine Learning,pages 81–106.
Quinlan, J. R. (1993). C4.5: programs for machine learning. Morgan Kauf-mann Publishers Inc., San Francisco, CA, USA.
Shafer, J. C., Agrawal, R., and Mehta, M. (1996). SPRINT: A scalableparallel classifier for data mining. In Vijayaraman, T. M., Buchmann,A. P., Mohan, C., and Sarda, N. L., editors, Proc. 22nd Int. Conf. VeryLarge Databases, VLDB, pages 544–555. Morgan Kaufmann.
- 78 -

FernUniversitat in Hagen—
Seminar 01912im Sommersemester 2008
Data Mining
Thema 1.3.1
Partitionierendes und Hierarchisches Clustern:CLARANS und BIRCH
Constanze Hofmann
- 79 -

Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern Seite 1
Inhaltsverzeichnis
1 Einleitung — Begriffsklarungen 2
1.1 Begriffe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Kriterien zur Beurteilung von Clusteringverfahren . . . . . . . . . . . . . 3
2 Partitionierendes Clustern — CLARANS 4
2.1 Begriffe und Datenstrukturen . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Kostenbetrachtung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3.1 Ansatze zur Beschleunigung des Algorithmus . . . . . . . . . . . . 7
3 Hierarchisches Clustern — BIRCH 10
3.1 Begriffe und Datenstrukturen . . . . . . . . . . . . . . . . . . . . . . . . 10
3.2 Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.3 Kostenbetrachtung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4 Vergleich der Methoden, Vorteile und Grenzen 14
4.1 CLARANS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.2 BIRCH . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
- 80 -

Seite 2 Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern
1 Einleitung — Begriffsklarungen
Die Cluster-Analyse zerlegt eine Datenmenge in Gruppen. Die Zuordnung zu einer be-stimmten Gruppe erfolgt aufgrund der Merkmalsauspragungen der zu klassifizierendenObjekte. Jedes Objekt wird dabei als Punkt in einem Vektorraum dargestellt. Die ge-genseitige Entfernung der Punkte aufgrund eines vorgegebenen Distanzmaßes wird danndazu genutzt, die Punkte einem Cluster zuzuordnen. Die Cluster-Analyse benotigt keinevorab klassifizierten Daten. Ziel ist dabei, dass Objekte im gleichen Cluster unterein-ander moglichst ahnlich und Objekte aus verschiedenen Clustern moglichst unahnlichsind.
Ziel der hier vorgestellten Methoden ist es, eine effektive Analyse auf großen Daten-mengen zu ermoglichen, d. h. auf Datenmengen, die nicht komplett im Hauptspeichergehalten werden konnen.
Abbildung 1 gibt einen Uberblick uber verschiedene Cluster-Algorithmen. Von diesenwerden CLARANS als Beispiel fur partitionierendes und BIRCH als Beispiel fur hierar-chisches Clustern vorgestellt.
Abbildung 1: Uberblick uber Clustering-Algorithmen [Kolatch, 2001].
- 81 -

Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern Seite 3
1.1 Begriffe
Voraussetzung fur die Clusteranalyse ist die Definition eines Distanzmaßes oder einerDistanzfunktion, die die Ahnlichkeit zwischen zwei Objekten modelliert. Eine kleineDistanz charakterisiert dabei ahnliche, eine große Distanz unahnliche Objekte.
Fur die Distanzfunktion dist mussen mindestens folgende Bedingungen fur alle Objekteo1, o2 aus der Objektmenge O gelten ([Ester und Sander, 2000], Kap. 3.1.2):
1. dist(o1, o2) = d ∈ R≥0,
2. dist(o1, o2) = 0 gdw. o1 = o2,
3. dist(o1, o2) = dist(o2, o1) (Symmetrie).
Gilt zusatzlich die Dreiecksungleichung, ist dist eine Metrik. Dies ist dann der Fall, wennfur alle o1, o2, o3 ∈ O gilt:
dist(o1, o3) ≤ dist(o1, o2) + dist(o2, o3)
Die zu clusternden Daten konnen sowohl metrische als auch nichtmetrische Attributeenthalten. Die hier beschriebenen Algorithmen konzentrieren sich auf metrische Distanz-maße.
Alternativ zur Distanzfunktion kann auch eine Ahnlichkeitsfunktion verwendet werden.In diesem Fall ist der Wert der Funktion um so großer, je ahnlicher zwei Objekte sind.Die unten beschriebenen Algorithmen verwenden aber jeweils Distanzfunktionen.
1.2 Kriterien zur Beurteilung von Clusteringverfahren
[Kolatch, 2001] nennt eine Reihe von Anforderungen, die Clusteringalgorithmen furgroße Datenmengen erfullen sollten:
1. Der Algorithmus soll effizient und skalierbar sein, um die Verarbeitung von großenDatenmengen zu ermoglichen.
2. Es muss moglich sein, irregulare und verschachtelte Formen zu erkennen, insbe-sondere auch solche mit konkaven Begrenzungen.
3. Der Algorithmus soll nicht empfindlich gegen Rauschen sein.
4. Der Algorithmus soll unabhangig von der Reihenfolge sein, in der die Daten vor-liegen.
5. Es soll kein a-priori Wissen uber die zu analysierenden Daten benotigt werden,insbesondere uber die Anzahl der zu erzeugenden Cluster.
6. Es soll moglich sein, Daten mit einer großen Anzahl von Eigenschaften, d. h.hoherdimensionale Daten, zu verarbeiten.
- 82 -

Seite 4 Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern
2 Partitionierendes Clustern — CLARANS
Beim partitionierenden Clustern wird der Merkmalsraum in eine vorgegebene Anzahl vonBereichen unterteilt. Mit Hilfe eines iterativen Ansatzes wird eine initiale Zuordnung vonPunkten zu Clustern schrittweise verbessert.
CLARANS steht fur “Clustering Large Applications based on RANdomized Search”.
2.1 Begriffe und Datenstrukturen
Notation:
– O: Menge der n zu clusternden Objekte
– M ⊆ O: Menge der k ausgewahlten Medoide
– NM = O−M: Menge der Nicht-Medoide
Medoid wird ein Objekt genannt, das eine Gruppe von Objekten (einen Cluster)reprasentiert. Jedes Objekt, das kein Medoid ist, wird dem Medoid zugeordnet,von dem es den geringsten Abstand hat:
medoid(o) = mi, mj ∈ M,∀mj ∈ M : dist(o,mi) ≤ dist(o,mj)
Als Cluster des Medoiden mi wird die Teilmenge aller Objekte aus O bezeichnet,fur die gilt: medoid(o) = mi. Ein Clustering ist eine Menge von Clustern, die Oaufteilen. Jedes Clustering kann somit durch Angabe von M eindeutig beschriebenwerden, da die Zuordnung der ubrigen Objekte dann eindeutig bestimmt ist.
Die Gesamtdistanz eines Clusterings c ist die Summe der Distanzen aller Objektezu ihrem jeweiligen Medoiden:
total distance(c) =∑
mi∈M
∑o∈cluster(mi)
dist(o,mi)
Die Gesamtdistanz wird genutzt, um die Qualitat eines Clusterings zu ermitteln.Sie ist allerdings nur dazu geeignet, die Qualitat von Clusterings mit der gleichenAnzahl von Clustern zu vergleichen.
Ein R*-Baum ist ein balancierter Vielweg-Suchbaum, der den Datenraum in dis-junkte Bereiche unterteilt. Objekte konnen dabei uber mehrere Blattknoten ver-teilt werden. In einem R*-Baum konnen sowohl Objekte, die durch Punkte, alsauch Objekte, die durch das minimale, sie vollstandig umschließende achsenparal-lele Rechteck (minimum bounding box) reprasentiert werden, effektiv gespeichertwerden. Abbildung 2 zeigt ein Beispiel fur die Speicherung von zweidimensionalenRechtecken.
Als Distanzmaß dist verwendet CLARANS den euklidischen Abstand zwischenden Zentren zweier Objekte.
- 83 -

Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern Seite 5
Abbildung 2: R*-Baum mit 2-dimensionalen Rechtecken [Ester et al., 1995b].
2.2 Algorithmus
Der Algorithmus zu CLARANS wurde erstmals von [Ng und Han, 1994] vorgestellt. Diefolgende Beschreibung lehnt sich an [Ester et al., 1995a] an.
Eingabedaten:
- O — Menge der zu partitionierenden Objekte
- k — Anzahl der zu erzeugenden Cluster
- dist — Distanzfunktion
- numlocal — Anzahl der Durchlaufe des Algorithmus mit verschiedenen zufalliggenerierten Anfangsclustern.
- maxneighbor — Anzahl der maximal untersuchten “benachbarten” Clusterings,um eine Verbesserung gegenuber der bestehenden Aufteilung zu finden.
Ein Clustering wird als “Nachbar” eines anderen Clusterings bezeichnet, wenn genau einMedoid durch ein Objekt, das bisher nicht Medoid war, ersetzt wird.
Fur jeden der numlocal Durchlaufe des Algorithmus (außere Schleife) wird folgender-maßen verfahren:
- Erzeugen einer zufallig ausgewahlten Menge von k Medoiden. Somit erfolgt jederder numlocal Durchlaufe des Algorithmus mit neuen Anfangsbedingungen, dieunabhangig von vorherigen Durchlaufen sind.
- Solange die Anzahl der Durchlaufe j kleiner maxneighbor (innere Schleife):
- Ersetzen eines zufallig ausgewahlten Medoids durch einen ebenfalls zufalligausgewahlten Nicht-Medoid. Dies erzeugt einen Nachbarn zum aktuellen Clu-stering.
- 84 -

Seite 6 Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern
- Berechnung der Gesamtdifferenz der Distanzen
total distance(cnew)− total distance(cold),
die durch die Ersetzung entsteht. Dabei wird total distance(c) nicht fur beideClusterings berechnet, sondern die Summe der Distanzdifferenzen fur alleObjekte: ∑
oi∈O
dist(oi, medoidnew(oi))− dist(oi, medoidold(oi))
- Ist die Differenz kleiner 0, ersetzt der neue Medoid den alten, j wird auf 1zuruckgesetzt. Andernfalls wird j um 1 erhoht.
- Berechnung von total distance(cnew)
- Ist total distance(cnew) kleiner der aktuell kleinsten Gesamtdistanz, ersetzt dieneue Clusterung die bis jetzt beste Clusterung.
2.3 Kostenbetrachtung
Die Kostenbetrachtung erfolgt unter folgenden Annahmen:
- Die Menge der Medoiden kann im Hauptspeicher gehalten werden, wahrend dierestlichen Objekte vom Datentrager gelesen werden mussen.
- c sei die durchschnittliche Zahl von Objekten, die auf eine Seite des Sekundar-speichers passen.
- Die I/O-Kosten fur Lesezugriffe auf die Platte sind wesentlich hoher als die CPU-Kosten, deshalb wird nur die Anzahl der benotigten Plattenzugriffe analysiert.
Die Anzahl der Durchlaufe der inneren Schleife kann aufgrund der angewandten Heuri-stik nicht analytisch ermittelt werden. Deshalb wird nur unterschieden, ob eine bestimm-te Funktion in der inneren oder außeren Schleife aufgerufen wird. Fur jeden Durchlaufder außeren Schleife wird die innere Schleife mindestens maxneighbor mal durchlaufen,wenn keine Verbesserung der ursprunglichen Aufteilung gefunden wird. Bei jeder gefun-denen Verbesserung wird der Schleifenzahler j auf 1 zuruckgesetzt, somit wird die innereSchleife im Normalfall sehr oft durchlaufen. Aufrufe innerhalb dieser Schleife dominierendeshalb die Kosten. Innerhalb der inneren Schleife muss fur die Berechnung der Gesamt-differenz der Distanzen auf jedes Objekt zugegriffen werden, die Kosten dafur sind O(n).Da die innere Schleife oft durchlaufen wird, verhalt sich die Gesamtlaufzeit des Algo-rithmus in der Praxis nahezu quadratisch zur Anzahl der Objekte. Verbesserungen beider Differenz-Berechnung fuhren deshalb zu wesentlichen Laufzeitverbesserungen undwerden im Folgenden genauer betrachtet.
- 85 -

Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern Seite 7
2.3.1 Ansatze zur Beschleunigung des Algorithmus
[Ester et al., 1995a] stellt verschiedene Optimierungsmoglichkeiten vor, wie die Laufzeitvon CLARANS verbessert werden kann:
Konzentration auf reprasentative Objekte: Bei dieser Optimierung wird das Cluste-ringverfahren nicht auf alle Objekte, sondern nur auf eine Teilmenge angewendet. Furdas Verfahren ist es erforderlich, dass die zu clusternden Objekte durch einen R*-Baumindiziert sind. Jede Datenseite des R*-Baumes wird durch das Objekt reprasentiert, dasdem Zentrum der Bounding Box der Seite am nachsten liegt. Anstatt von n Objek-ten mussen somit nur noch n/c Objekte durch den Algorithmus geclustert werden. In[Ester et al., 1995a] wird an einem Beispiel gezeigt, dass diese Vorgehensweise zwischen48- und 158-mal schneller ist als die Verwendung aller Objekte, der entstehende Qua-litatsverlust aber nur zwischen 1.5% und 3.2% liegt. Als Qualitatskriterium wird diedurchschnittliche Distanz der Objekte zum Medoiden genutzt:∑n
i=1 dist(oi, medoid(oi))
n
In [Ester et al., 1995b] wird gezeigt, dass die Reprasentation jedes Blattknotens des R*-Baumes durch genau ein Objekt in der benutzten Datenbank ausreichend ist. Werdenmehrere Reprasentanten pro Seite benutzt, erhoht sich die Laufzeit mehr als quadratisch,ohne zu einer wesentlichen Qualitatsverbesserung zu fuhren.
Konzentration auf relevante Cluster: In der inneren Schleife wird die Differenz derGesamtdistanz zwischen zwei benachbarten Clusterings berechnet, d. h. solchen, bei de-nen sich nur ein Medoid unterscheidet. Fur die Differenzberechnung sind nur die Objekterelevant, deren Zuordnung zu einem Medoid sich durch den Austausch geandert hat. Eskann also eine Einschrankung der zu betrachtenden Objekte erfolgen, wenn untersuchtwird, fur welche Objekte sich die Zuordnung uberhaupt geandert haben kann, und nurdiese mussen dann fur die Differenzberechnung von der Datenbank gelesen werden. Da-bei ist old der Medoid, der ersetzt wird, new der Nicht-Medoid, durch den old ersetztwerden soll, und o das betrachtete Objekt. Folgende Falle werden unterschieden:
1. Der derzeitige Medoid von o ist old, und o liegt naher am zweitnachsten Medoidals an new. o wird dementsprechend in den Cluster des zweitnachsten Medoideneingefugt.
2. Der derzeitige Medoid von o ist old, und o liegt naher an new als am zweitnachstenMedoid. o wird also in den Cluster von new eingefugt.
3. Der derzeitige Medoid von o ist nicht old, und o liegt naher an diesem Medoid alsan new. o bleibt in seinem derzeitigen Cluster.
- 86 -

Seite 8 Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern
4. Der derzeitige Medoid von o ist nicht old, und o liegt naher an new als an seinemderzeitigen Medoid. o wird also in den Cluster von new eingefugt.
Abbildung 3 zeigt die verschiedenen Varianten.
Abbildung 3: Anderung der Zuordnung von Objekten bei Austausch eines Medoids (aus[Ester und Sander, 2000], Kap. 3.4.2.).
Die Differenz der Distanzen wird also nur von den Punkten beeinflusst, die entwederold oder new zugeordnet werden. Nur diese mussen von der Datenbank gelesen werden.Benotigt wird dazu eine Methode, wie die zu einem Cluster gehorenden Objekte effektivselektiert werden konnen.
Selektion der Objekte eines Clusters: Aufgrund der Zugehorigkeit jedes Objekteszum Medoiden mit dem geringsten Abstand mussen alle zu einem Medoiden gehorendenObjekte innerhalb des Voronoi-Polygons dieses Medoiden liegen (Abbildung 5). EinVoronoi-Polygon hat die Eigenschaft, dass alle Punkte, die innerhalb des Polygons liegen,naher am zugehorigen Medoiden liegen als an jedem anderen Medoiden. Dies ist abergenau die Definition, wie ein Objekt dem zugehorigen Medoiden zugeordnet wird. DieKonstruktion des Voronoi-Diagramms zu einer Menge von Medoiden wird im folgendenam Beispiel des zweidimensionalen Falles gezeigt:
Es werden jeweils Paare von Medoiden (mi, mj) betrachtet. Die Menge aller Punkte, dievon beiden Medoiden den gleichen Abstand haben, ist die Mittelsenkrechte der Strecke,die mi und mj verbindet. Die Flache, die durch diese Gerade begrenzt wird und in dermi liegt, enthalt alle Punkte mit
x ∈ R2|dist(x, mi) ≤ dist(x, mj).
Diese Betrachtung wird fur alle Paare (mi, mj) durchgefuhrt. Das Voronoi-Polygon zumi ist durch die Schnittmenge der Flachen fur alle mj definiert. Abbildung 4 zeigt
- 87 -
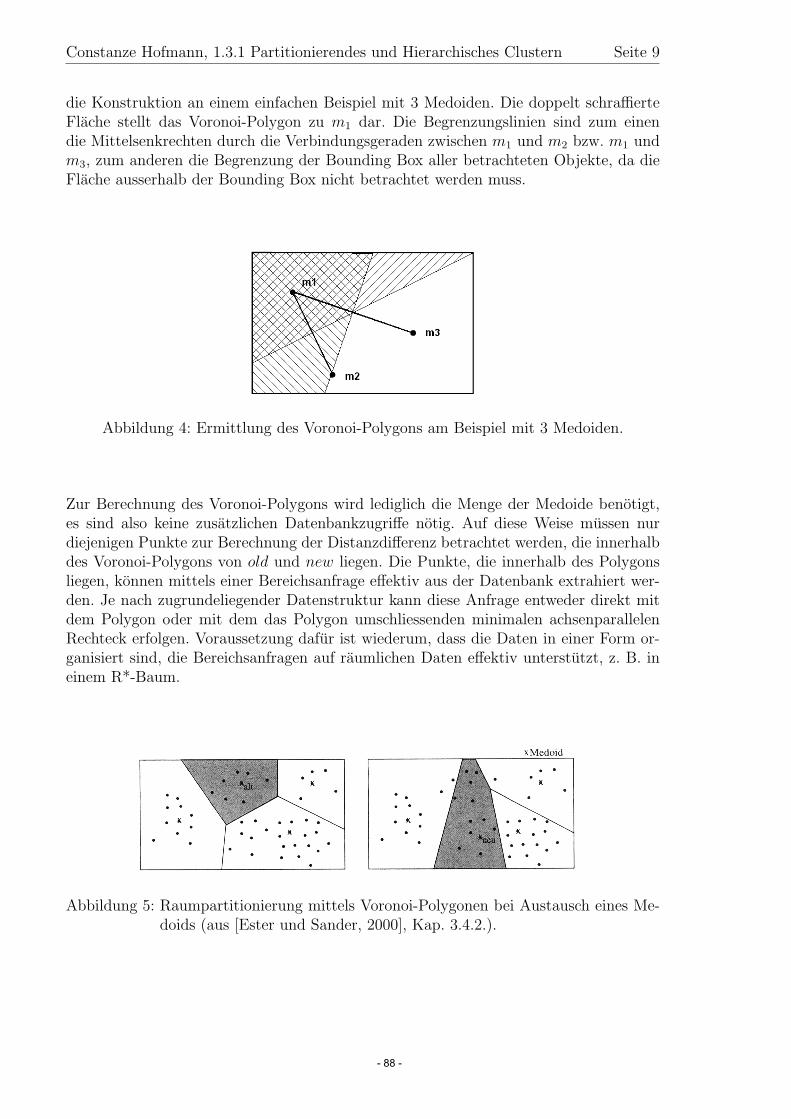
Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern Seite 9
die Konstruktion an einem einfachen Beispiel mit 3 Medoiden. Die doppelt schraffierteFlache stellt das Voronoi-Polygon zu m1 dar. Die Begrenzungslinien sind zum einendie Mittelsenkrechten durch die Verbindungsgeraden zwischen m1 und m2 bzw. m1 undm3, zum anderen die Begrenzung der Bounding Box aller betrachteten Objekte, da dieFlache ausserhalb der Bounding Box nicht betrachtet werden muss.
Abbildung 4: Ermittlung des Voronoi-Polygons am Beispiel mit 3 Medoiden.
Zur Berechnung des Voronoi-Polygons wird lediglich die Menge der Medoide benotigt,es sind also keine zusatzlichen Datenbankzugriffe notig. Auf diese Weise mussen nurdiejenigen Punkte zur Berechnung der Distanzdifferenz betrachtet werden, die innerhalbdes Voronoi-Polygons von old und new liegen. Die Punkte, die innerhalb des Polygonsliegen, konnen mittels einer Bereichsanfrage effektiv aus der Datenbank extrahiert wer-den. Je nach zugrundeliegender Datenstruktur kann diese Anfrage entweder direkt mitdem Polygon oder mit dem das Polygon umschliessenden minimalen achsenparallelenRechteck erfolgen. Voraussetzung dafur ist wiederum, dass die Daten in einer Form or-ganisiert sind, die Bereichsanfragen auf raumlichen Daten effektiv unterstutzt, z. B. ineinem R*-Baum.
Abbildung 5: Raumpartitionierung mittels Voronoi-Polygonen bei Austausch eines Me-doids (aus [Ester und Sander, 2000], Kap. 3.4.2.).
- 88 -

Seite 10 Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern
3 Hierarchisches Clustern — BIRCH
Bei hierarchischen Clusteringverfahren wird nicht jedes Objekt einem bestimmten Clu-ster zugeordnet, sondern es wird eine Hierarchie von Clustern aufgebaut. Beginnend mitden einzelnen Objekten, werden schrittweise kleinere Cluster zu großeren zusammen-gefasst, bis schließlich die gesamte Objektmenge in einem Cluster liegt. Es sind alsoverschiedene Detailtiefen des Clusterings erkennbar.
Der hier betrachtete Algorithmus BIRCH (“Balanced Iterative Reducing and Clusteringusing Hierarchies”) wurde erstmals in [Zhang et al., 1996] vorgestellt.
3.1 Begriffe und Datenstrukturen
Folgende Eigenschaften eines Clusters, bestehend aus N d-dimensionalen Datenpunkten,werden definiert:
- der Centroid ~X0 =PN
i=1~Xi
N,
- der Radius R =
√PNi=1( ~Xi− ~X0)2
Nist der durchschnittliche Abstand der Punkte im
Cluster vom Centroid,
- der Durchmesser D =
√PNi=1
PNj=1( ~Xi− ~Xj)2
N(N−1)ist die durchschnittliche Distanz zwi-
schen je zwei Punkten eines Clusters.
Sowohl R als auch D mussen als im Rahmen des in [Zhang et al., 1996] vorgestelltenVerfahren als so definiert angenommen werden. Bei R handelt es sich nicht um den mitHilfe einer Distanzfunktion dist berechneten durchschnittlichen Abstand der Punkteeines Clusters zum Centroiden. Dieser musste wie folgt berechnet werden:
R′ =
∑Ni=1 dist( ~Xi, ~X0)
N
R und R′ konnen unabhangig von der Definition von dist nicht zueinander aquivalentsein. Dies wird im Folgenden gezeigt:
- 89 -

Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern Seite 11
Angenommen, R′ = R:
∑Ni=1 dist( ~Xi, ~X0)
N=
√∑Ni=1(
~Xi − ~X0)2
N
N∑i=1
dist( ~Xi, ~X0) = N
√∑Ni=1(
~Xi − ~X0)2
N
=√
N
√√√√ N∑i=1
( ~Xi − ~X0)2
=
√√√√N
N∑i=1
( ~Xi − ~X0)2
=
√√√√ N∑i=1
N( ~Xi − ~X0)2
∑Ni=1 dist( ~Xi, ~X0) musste folglich von N abhangig sein, was der Definition der Distanz-
funktion dist widerspricht, die nur von den Eigenschaften der Punkte abhangig ist.
Die angegebenen Definitionen fur R und D sind aber fur den im folgenden beschriebenenAlgorithmus notwendig, da nur so die Berechnung der Großen auf Grundlage des CF-Vektors des Clusters moglich ist.
Zusatzlich wird eine Distanzfunktion benotigt, die den Abstand zweier Cluster unterein-ander misst. Folgende Varianten werden in [Zhang et al., 1996] angegeben:
- Euklidischer Abstand zwischen den Centroiden ~X01 und ~X02:
D0 =
√( ~X01 − ~X02)2
- Manhattan distance zwischen den Centroiden:
D1 = | ~X01 − ~X02|
- Der durchschnittliche Inter-Cluster-Abstand (average inter-cluster distance) wirddefiniert als
D2 =
√∑N1
i=1
∑N1+N2
j=N1+1(~Xi − ~Xj)2
N1N2
mit N1, N2 Anzahl der Punkte in den beiden betrachteten Clustern.
- 90 -

Seite 12 Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern
- Der durchschnittliche Intra-Cluster-Abstand (average intra-cluster distance) wirddefiniert als
D3 =
√∑N1
i=1
∑N1+N2
j=N1+1(~Xi − ~Xj)2
(N1 + N2)(N1 + N2 − 1)
- Die “variance increase distance” wird definiert als:
D4 =
N1+N2∑k=1
(~Xk−
∑N1+N2
l=1~Xl
N1 + N2
)2
−N1∑i=1
(~Xi−
∑N1
l=1~Xl
N1
)2
−N1+N2∑j=N1+1
(~Xj−
∑N1+N2
l=N1+1~Xl
N1
)2
Ein Clustering Feature ist ein Tripel CF = (N, ~LS, SS), mit dessen Hilfe die wesent-lichen Informationen zu einem Cluster zusammengefasst werden. Dabei ist
- N die Anzahl der d-dimensionalen Punkte im Cluster,
- ~LS die lineare Summe der N Punkte:∑N
i=1~Xi und
- SS die Quadratsumme der N Punkte:∑N
i=1~Xi
2.
Es gilt das Additivitatstheorem fur Clustering Features: Wenn CF1 = (N1, ~LS1, SS1)
und CF2 = (N2, ~LS2, SS2) die CF-Vektoren zweier Cluster sind, die keine Objekte ge-meinsam haben, so gilt:
CF1 + CF2 = (N1 + N2, ~LS1 + ~LS2, SS1 + SS2).
Aufgrund dieser Eigenschaft lassen sich ~X0, R, D sowie die verschiedenen Distanzmaßenur aus der Kenntnis der CF-Vektoren berechnen sowie Cluster zusammenfassen, ohnedass man zusatzliche Informationen uber die Cluster benotigt.
Ein CF-Baum ist ein hohenbalancierter Baum mit zwei Parametern:
- dem Verzweigungsgrad B, der festlegt, wie viele Eintrage der Form [CFi, childi]jeder innere Knoten des Baumes maximal haben kann, und
- dem Schwellwert T , der den maximalen Radius oder Durchmesser fur die Clusterin den Blattknoten festlegt.
Der CF-Baum ist eine sehr kompakte Darstellung der Daten, da jeder Eintrag einesBlattknotens nicht einzelne Punkte, sondern den CF-Vektor eines Subclusters enthalt,der viele Datenpunkte zusammenfassen kann. Wie in Abbildung 6 zu erkennen, sind dieBlattknoten des CF-Baumes durch Zeiger auf den vorherigen und nachsten Blattknotenverknupft, um einen sequentiellen Durchlauf durch die Blattknoten zu unterstutzen.
- 91 -

Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern Seite 13
Abbildung 6: Struktur eines CF-Baumes (aus [Ester und Sander, 2000], Kap. 3.4.4.).
Aufbau eines CF-Baumes [Ester und Sander, 2000]: Der Aufbau eines CF-Baumeserfolgt durch sukzessives Einfugen aller Datensatze. Der CF-Baum verhalt sich dabeianalog einem B+-Baum. Jeder einzufugende Datensatz ~X wird zuerst in den zugehorigenCF-Vektor CFX = (1, ~X, ~X2) umgewandelt. Beginnend mit der Wurzel wird anschlie-ßend der CF-Baum durchlaufen und jeweils derjenige Sohnknoten ausgewahlt, der demeinzufugenden CF-Vektor gemaß der verwendeten Distanzfunktion fur Abstande zwi-schen Clustern (D0–D4) am nachsten ist. Ist ein Blatt erreicht, wird der dem neuen Da-tensatz am nachsten liegende Eintrag in diesem Blatt gesucht und gepruft, ob der Daten-satz diesem Eintrag zugeordnet werden kann, ohne den Schwellwert T zu uberschreiten.Ist dies der Fall, wird das Additivitatstheorem fur Clustering Features angewandt undCFX wird mit dem Eintrag verschmolzen. Ist T uberschritten, wird CFX als neuer Ein-trag in das Blatt eingefugt. Entsteht dabei ein Uberlauf, wird der Blattknoten gesplittet.Dies erfolgt, indem das Paar von Eintragen, welches entsprechend dem verwendeten Di-stanzmaß den großten Abstand hat, den beiden neuen Knoten zugewiesen wird. Anschlie-ßend werden alle anderen Eintrage dem Knoten zugewiesen, der naher liegt. Wenn dieEinfugeoperation im Blatt beendet ist, werden die CF-Vektoren aller daruberliegendenKnoten aktualisiert, indem CFX zum entsprechenden Eintrag addiert wird.
3.2 Algorithmus
Der Algorithmus besteht aus 4 Phasen:
1. Lesen aller Daten und Aufbau eines initialen CF-Baumes im Hauptspeicher,
2. Optional: Weiteres Komprimieren der Daten in einen kleineren CF-Baum,
3. Anwendung eines globalen oder semi-globalen Clustering-Verfahrens auf die Blatt-knoten des CF-Baumes und
4. Optional: Weitere Verfeinerung des Clusterings.
- 92 -

Seite 14 Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern
In Phase 1 kann es notwendig sein, den CF-Baum mehrfach neu aufzubauen, wenn derinitiale Schwellwert T zu klein ist, um den gesamten Baum im Speicher halten zu konnen.In diesem Fall wird T erhoht. Ein neuer Baum wird aufgebaut, indem die Blattknoten desalten Baumes von links nach rechts durchlaufen und die Eintrage in dieser Reihenfolgein den neuen Baum eingefugt werden. Dabei wird uberpruft, ob aufgrund des hoherenSchwellwertes der jeweils einzufugende Eintrag mit einem bereits bestehenden Eintragverschmolzen werden kann.
Phase 2 ist sinnvoll, wenn die Anzahl der Eintrage im CF-Baum nach Phase 1 zu großist als Eingabe fur das in Phase 3 anzuwendende Clusterverfahren. Die Komprimierungerfolgt durch eine weitere Erhohung von T und anschließenden Neuaufbau des CF-Baumsanalog zu Phase 1.
Die Menge von Subclustern, die durch die CF-Vektoren in den Blattknoten des CF-Baumes reprasentiert werden, entspricht normalerweise nicht den in den Daten wirklichvorhandenen Mustern. Deshalb wird in Phase 3 eine weitere globale oder semi-globaleClusteringmethode angewendet, um die Eintrage der Blattknoten zu clustern. Viele exi-stierende Algorithmen konnen so angepasst werden, dass sie direkt mit CF-Vektorenarbeiten.
Phase 4 kann dazu benutzt werden, um weitere Verfeinerungen an dem ermittelten Clu-stering vorzunehmen. Dazu sind weitere Durchlaufe durch die gesamte Datenmenge not-wendig. Die Centroide der in Phase 3 ermittelten Cluster werden dazu genutzt, alle Ob-jekte dem Cluster mit minimaler Distanz von dessen Centroiden zuzuordnen. Zusatzlichkonnen die einzelnen Objekte in diesem Schritt mit der Information, zu welchem Clustersie gehoren, gekennzeichnet werden.
3.3 Kostenbetrachtung
In Phase 1–3 mussen die Daten lediglich einmal komplett gelesen werden, namlich inPhase 1 fur den Aufbau des initialen CF-Baumes. Die I/O-Kosten verhalten sich dem-nach wie O(n).
Weitere Durchlaufe durch die Daten konnen in Phase 4 durchgefuhrt werden, um das Er-gebnis zu verfeinern. Auch eine Zuordnung der einzelnen Objekte zum jeweiligen Clusterist in dieser Phase moglich.
4 Vergleich der Methoden, Vorteile und Grenzen
Die Beurteilung der beiden betrachteten Algorithmen erfolgt mit Hilfe der unter 1.2genannten Kriterien.
- 93 -

Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern Seite 15
4.1 CLARANS
Effizienz: Der ursprungliche Algorithmus hat quadratische Laufzeit und ist dadurch furgroße Datenmengen nicht geeignet. Die unter 2.3.1 beschriebenen Fokussierungstechni-ken verbessern die Laufzeit allerdings erheblich. Insbesondere durch die Ausnutzung vonIndexstrukturen fur raumliche Datenbanken (R*-Baum) kann eine Verbesserung in derGroßenordnung einer Zehnerpotenz erreicht werden.
Identifizierung komplexer Formen: Da der Datenraum mittels CLARANS in Voronoi-Polygone bzw. im mehrdimensionalen Fall in Voronoi-Zellen aufgeteilt wird, lassen sichdurch den Algorithmus nur konvexe Cluster ermitteln. Fur komplexe Clusterformen,beispielsweise lineare oder verschachtelte Formen, ist der Algorithmus nicht geeignet.
Rauschen: Der Algorithmus ordnet immer alle Objekte der Datenmenge einem Clusterzu. Rauschen kann deshalb nicht erkannt und unterdruckt werden.
Reihenfolge der Eingabedaten: Die Qualitat des Algorithmus sollte unabhangig seinvon der Ordnung, in der die Daten vorliegen. [Zhang et al., 1996] stellt allerdings fest,dass sowohl Qualitat als auch Effizienz von CLARANS stark abnehmen, wenn die Ein-gabedaten geordnet vorliegen.
Eine Datenbankstruktur mit geeigneten raumlichen Indexstrukturen erhoht die Effizienzdes Algorithmus erheblich.
A-priori Wissen: CLARANS benotigt die Anzahl der zu erzeugenden Cluster k alsEingabeparameter. Diese Anzahl wird aber im Normalfall nicht von vornherein bekanntsein. Oft wird der Algorithmus deshalb fur verschiedene k durchgefuhrt und anschließenddas beste Clustering ausgewahlt. Um das zu ermoglichen, ist es notwendig, ein Maß furdie Gute eines Clusterings zu finden, das unabhangig von der Anzahl der erzeugtenCluster ist.
Verarbeitung hoherdimensionaler Daten: Die Verarbeitung hoherdimensionalerDaten ist moglich, wenn eine entsprechende Distanzfunktion definiert werden kann.
4.2 BIRCH
Effizienz: Hauptziel von BIRCH ist die Minimierung von I/O-Zugriffen bei der Ver-arbeitung von großen Datenmengen. Dies wird erreicht, indem zum Aufbau des CF-Baumes die Daten nur einmal gescannt werden und die weitere Verarbeitung komplettim Speicher erfolgen kann. Lediglich in Phase 4 werden unter Umstanden weitere Da-tendurchlaufe benotigt.
Identifizierung komplexer Formen: Der Algorithmus erzeugt lediglich eine Hier-archie von Clustern. Das eigentliche Clustering wird in Phase 3 mit einem geeignetenglobalen Clustering-Algorithmus erzeugt. Von der Wahl dieses Algorithmus hangt es ab,ob komplexe Formen erkannt werden konnen.
- 94 -

Seite 16 Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern
Rauschen: Phase 2 des Algorithmus kann dazu genutzt werden, Blattknoten mit we-sentlich geringerer Dichte als der Durchschnitt als Rauschen zu identifizieren und zuentfernen.
Reihenfolge der Eingabedaten: Der in Phase 1 erzeugte initiale CF-Baum hangtvon der Reihenfolge, in der die Eingabedaten verarbeitet werden, ab. Dabei kann eszu Anomalien in der Zuordnung der Datenpunkte zu Blattknoten kommen, indem zumBeispiel mehrere identische Punkte verschiedenen Knoten zugeordnet werden. DerartigeProbleme konnen durch zusatzliche Datendurchlaufe in Phase 4 behoben werden.
A-priori Wissen: Der einzige initiale Eingabeparameter ist der Schwellwert T . Wirddieser zu 0 gesetzt (Default), werden keinerlei Annahmen uber die Daten vorausgesetzt.
Verarbeitung hoherdimensionaler Daten: Da der Algorithmus lediglich die Exi-stenz eines Abstandsmaßes voraussetzt, dessen Berechnung aus CF = (N, ~LS, SS)moglich ist, spricht nichts gegen eine Anwendung auf hoherdimensionalen Daten, so-lange die Distanzfunktion zwischen zwei Objekten entsprechend definiert werden kann.
4.3 Zusammenfassung
CLARANS ist ein partitionierendes Clusterverfahren, im Speziellen ein k-Medoid-Verfahren. Als solches ist es nur zum Erkennen konvexer Cluster geeignet. Ausserdemmuss die Anzahl der zu erzeugenden Cluster von vornherein bekannt sein oder durchaufwandiges Probieren ermittelt werden. Der ursprungliche Algorithmus ist fur großeDatenmengen nicht geeignet, die Laufzeit kann aber durch die beschriebenen Optimie-rungen erheblich verbessert werden.
BIRCH als hierarchisches Clusterverfahren erstellt eine Hierarchie ineinander verschach-telter Cluster. Um aus dieser Hierarchie die eigentliche Struktur der Daten zu extrahie-ren, ist die Anwendung eines weiteren globalen Clusterverfahrens in Phase 3 notwendig.Der Algorithmus wurde speziell fur effizientes Arbeiten mit großen Datenmengen ent-worfen.
Literatur
[Ester et al., 1995a] M. Ester, H. P. Kriegel and X. Xu. Knowledge Discovery in LargeSpatial Databases: Focusing Techniques for Efficient Class Identification, LectureNotes in Computer Science (Proc. Fourth International Symposium on Large SpatialDatabases, Portland, Maine, USA), Vol. 591, Springer, 1995, pp. 67–82.
[Ester et al., 1995b] M. Ester, H. P. Kriegel, and X. Xu. A Database Interface for Clu-stering in Large Spatial Databases, Proceedings of 1st International Conference onKnowledge Discovery and Data Mining, AAA1 Press, Menlo Park, CA, pp. 194–198.
- 95 -

Constanze Hofmann, 1.3.1 Partitionierendes und Hierarchisches Clustern Seite 17
[Ester et al., 1998] M. Ester, H. P. Kriegel, J. Sander and X. Xu. Clustering for Miningin Large Spatial Databases, KI Kunstliche Intelligenz (Themenheft Data Mining)1, 1998, ScienTec Publishing, Bad Ems, pp. 18–24.
[Ester und Sander, 2000] M. Ester, J. Sander. Knowledge Discovery in Databases: Tech-niken und Anwendungen. Springer, Berlin, 2000.
[Ng und Han, 1994] R. T. Ng, J. Han. Efficient and Effective Clustering Methods forSpatial Data Mining, Proceedings of the 20th International Conference on VeryLarge Data Bases, Santiago, Chile, 1994.
[Kolatch, 2001] E. Kolatch. Clustering Algorithms for Spatial Databases: A Survey. De-partment of Computer Science, University of Maryland, College Park, 2001.
[Zhang et al., 1996] Tian Zhang, Raghu Ramakrishnan, and Miron Livny. BIRCH: AnEfficient Data Clustering Method for Very Large Databases. Proceedings of the1996 ACM SIGMOD International Conference on Management of Data, Montreal,Canada, 1996, ACM Press, New York, pp. 103–114.
- 96 -

FernUniversität in Hagen
Seminar 01912im Sommersemester 2008
“Datamining“
Thema 1.4.2Ähnlichkeitssuche auf Zeitreihen
Referent: Bernd Puchinger
- 97 -

Seite 2 Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen
Abstract
Ein Problem des Datamining ist es, Ähnlichkeitssuchen über großen Datenbeständen durch-zuführen. Eine etablierte Methode für den effizienten Zugriff ist es, die Objekte eines Daten-bestandes zu indizieren, beispielsweise in einem mehrdimensionalen Raum, in dem die Objektedurch Ortspunkte repräsentiert werden; der räumliche Abstand der Ortspunkte stellt dabei einMaß für die Ähnlichkeit dieser Objekte dar. Es wurden verschiedene Indexstrukturen hierfür vor-geschlagen, insbesondere R-Trees und hierbei insbesondere der R*-Tree. Alle diese Methodenleiden jedoch unter den Fluch der Dimensionen (dimensionality curse), das heißt, sie sindineffizient für große Anzahl an Dimensionen (etwa jenseits zehn Dimensionen). Um diesenAnsatz auf Zeitreihen anwenden zu können, wird die diskrete Fouriertransformation vorge-schlagen, die die Zeitreihe in ein Frequenzspektrum überführt. Es wird dargestellt, dass die erstenzwei bis drei Frequenzen dabei ausreichen, um einen effizienten Index zu erstellen.
Einordnung in das Themengebiet Datamining
Begriff und Bedeutung
Nach [WI1-06] versteht man unter Datamining „die Anwendung (mathematischer) Methoden aufeinen [üblicherweise großen] Datenbestand, mit dem Ziel der Mustererkennung“. In [KTXX]findet sich folgende, engere Definition: „[Datamining is] the automated extraction of predictiveinformation from (large) databases“. Es geht also einmal um Methoden, die ohne intelligentesZutun eines Anwenders auskommen, was Datamining insbesondere von Ad-hoc SQL Abfragen
unterscheidet. Es geht weiters um Ansätze mit Voraussage-Charakter, das heißt um Ansätze, diees erlauben aus unüberblickbar umfänglichen Datenbeständen die versteckt enthaltenen Infor-mation – im Sinne von Handlungs- und Entscheidungsrelevanz – aufzufinden. Datamining ver-sucht jedoch nicht, die aufgefundenen Zusammenhänge zu erklären oder zu bewerten, wie esbeim Knowledge Discovery in Databases der Fall ist.
Die Bedeutung des Datamining nimmt praktisch immer mehr zu. Dies ist nach [KTXX] dreiUmständen geschuldet: der steigenden Verfügbarkeit geeigneter Datenbestände, der noch immersteigenden Rechenleistung eingesetzter IT-Infrastruktur, und den Verbesserungen bei statisti-schen Verfahren sowie den Fortschritten bei lernenden Systemen (insbesondere neuronaleNetze). Typische praktische Anwendungsgebiete sind vor allem aus dem Bereich der Betriebs-wirtschaft, insbesondere für Marktsegmentierung und Warenkorbanalysen bekannt, mutmaßlichdeshalb, da hier Entscheidungsbedarf besteht, ohne dass andere Methodiken oder geeigneteModelle zur Verfügung stehen. Im Zusammenhang mit der Betrachtung von Zeitreihen werdenzuvorderst Börsenkurse und Klimakurven genannt.
Techniken und Methoden
In [KTXX] sind als wichtigste Techniken des Datamining Entscheidungs- und Klassifikations-bäume, Neuronale Netze, Rule-Induction und Clustering genannt. Bei der Technik derEntscheidungs- und Klassifikationsbäume soll ein Datenbestand klassifiziert werden, wobei dierelevanten Klassifikationskriterien dabei noch herausgefunden werden müssen. Die Wurzel desentstehenden Baumes wird auf Zweige der ersten Ebene anhand des am meisten signifikantenKriteriums aufgeteilt; diese wiederum auf Zweige der nächsten Ebene anhand des nächstwichtigen Kriteriums, und so weiter. Die Relevanz bestimmt sich aufgrund der Fragestellung,
- 98 -

Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen Seite 3
mit der der Datenbestand untersucht wird, oft ein Entscheidungs-Problem. Neuronale Netze sindSysteme, die vor allem zum Erkennen von Mustern in Datenbeständen eingesetzt werdenkönnen. Dabei muss ein neuronales Netz zunächst trainiert werden, das heißt es wird mit einemSatz an beispielhaften Daten und den gewünschten Ergebnissen beaufschlagt; das neuronale Netzkonfiguriert sich dadurch so, dass es nach dem Training für echte Datensätze eingesetzt werdenkann. Bei der Rule-Induction geht es darum, (Implikations-) Regeln in Regelsystemen zu finden,die bislang nicht aufgestellt (und bekannt) sind. Zuletzt genannt ist Clustering: hierbei geht esgrundsätzlich darum, Objekte mit ähnlichen Eigenschaften zu gruppieren. Als Basis-Problem-stellung hierzu ist auch die Ähnlichkeitssuche auf Zeitreihen einzuordnen.
Ein spezieller Fall des Clustering ist das k-Means-Clustering. Dabei legt der Anwender dieAnzahl der zu bildenden Cluster fest, das ist k. Das k-Means-Clustering identifiziert dann kCluster, so dass über Alles betrachtet die „kompaktesten“ Cluster entstehen. Die Frage nach der„Kompaktheit“ der Clustern basiert dabei auf Ähnlichkeits- beziehungsweise Distanzmaßen, wiesie auch für die Ähnlichkeitssuche verwendet werden. Bei Ähnlichkeitssuchen unterscheidet manmehrere Arten von Anfragen: Eine k-Nearest-Neighbours Anfrage liefert zu einem gegebenenObjekt diejenigen k Objekte, die dem gegebenen Objekt am ähnlichsten sind. Dabei istunbekannt, wie ähnlich diese Nachbarn sein werden, die Schranke ergibt sich durch die Anzahl.Legt man im Gegensatz dazu eine Ähnlichkeits-Schranke fest, in der Regel als die maximalerlaubte Distanz ε, so nennt man das eine Range-Query. Hierbei ist unbekannt, wie viele Objekteals Ergebnis geliefert wird. Die in [AFS93] genannte All-Pairs-Query ist lediglich eineRange-Query über alle in einem Datenbestand enthaltenen Objekte, zu denen jeweils eine Ergeb-nismenge angegeben wird, also konzeptionell nichts neues.
Ähnlichkeitssuche auf Zeitreihen In [AFS93], welches als Basis für diesen Seminarbeitrag vorgegeben ist, wird dargelegt, wieRange-Queries über Datenbeständen von Zeitreihen durch eine Index-Struktur, den so genanntenF-Index, unterstütz werden können. Unter Zeitreihen werden in [AFS93] Folgen von Zahlen-werten verstanden, wobei diese Zahlenwerte den jeweils aktuellen Zustand einer beobachteten Eigen-schaft eines Objekts zu äquidistanten Zeitpunkten wiedergeben. Beispiele für Zeitreihen in diesemSinne sind Verläufe von Börsenkursen, in denen der Kurswert von Wertpapieren am Ende einesjeden Handelstages dargestellt wird. Klimakurven, in denen der durchschnittliche monatlicheNiederschlag oder die Durchschnittstemperatur erfasst sind, seismographische Wellen zur Erdbeben-forschung, oder der Verlauf gemeldeter Fehler einer in Entwicklung befindlichen Software zurPrognose des weiteren Projektverlaufs sind weitere praxisrelevante Beispiele. Auch digitalgesampelte Musik, wie es auf Musik-CDs der Fall ist, stellt eine Zeitreihe in diesem Sinne dar;es handelt sich dabei um die Werte eins mit 44 kHz (das heißt im zeitlichen Abstand von jeweils1/44.000 s) abgetasteten analogen elektrischen Signals, welches die Schallauslenkung dargestellt.
Die in [AFS93] dargestellte Methode ist nicht geeignet für nicht-äquidistante Zeitreihen, wiebeispielsweise der Verlauf eines Lagerbestandes, der sich durch zeitlich variabel gelagerteWareneingangs- und Warenausgangs-Ereignisse ändert. Im Gegensatz zu äquidistantenZeitreihen benötigt man hier unbedingt zusätzliche Zeit-Information, die bei äquidistantenZeitreihen durch die Position implizit gegeben ist. Im linken Teil in Abbildung 1 ist eine solchenicht-äquidistante Zeitreihe dargestellt: jeder Eintrag besteht aus einer Zeitangabe (hier jeweilsein Datum) und dem resultierenden Bestand. Eine solche Zeitreihe kann durch Pseudo-Sampling
in eine äquidistante Zeitreihe umgewandelt werden, wie sie beispielhaft im rechten Teil derAbbildung 1 dargestellt ist. Wählt man die „Sampling-Rate“, das ist das Inverse des Abstandszwischen den „Messpunkten“, zu groß, verliert man Information, im Beispiel der Abbildung 1 im
- 99 -

Seite 4 Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen
Juli (Wareneingang am 5. und Entnahme am 6.) und Oktober (Entnahme am 13. und Warenein-gang am 14.). Diese Tatsache ist vor allem im Zusammenhang mit Untersuchungen in derNachrichtentechnik unter dem Begriff Shannon'sches Abtast-Theorem untersucht. Wählt man dieSampling-Rate hingegen zu hoch, erhält man sehr lange äquidistante Zeitreihen. Im Falle desBeispiels der Abbildung 1 benötigt man Tage, bekommt also 356 Samples, obwohl insgesamtnur 11 Ereignisse im ganzen Jahr stattgefunden haben.
Abbildung 1: Lagerbestand als äquidistante Zeitreihe und ereignisbezogener Zeitreihe
Die in [AFS93] dargestellte Methode ist weiters limitiert auf die Ähnlichkeitssuche in Daten-beständen mit Zeitreihen identischer Länge und mit einer Anfrage-Zeitreihe der gleichen Länge.In [FRM94] ist eine Fortentwicklung der in [AFS93] dargestellte Methode beschrieben, dieDatenbestände und Abfragen mit Zeitreihen unterschiedlicher Länge ermöglicht. Die dabeiverwendete Index-Struktur wird bereits in [FRM94] als ST-Index bezeichnet. Eine kurzeBeschreibung des Ansatzes wird im Abschnitt „Suche auf Teil-Zeitreihen“ auf Seite 15 gegeben.
Effiziente Ähnlichkeitssuche auf Zeitreihen nach [AFS93]
Überblick über die Grundidee
Wie bereits im voranstehenden Abschnitt dargestellt, erlaubt die in [AFS93] beschriebene MethodeÄhnlichkeitssuchen über einen Bestand von äquidistanten Zeitreihen identischer Länge. Direktunterstütz werden Range Queries und All-Pairs Queries mit einer äquidistanten Anfrage-Zeitreiheder gleichen Länge, jedoch keine k-Nearest Neighbours Queries (vgl. Seite 3). Um Effizienz beider Ähnlichkeitssuche zu erreichen, wird der Bestand der gespeicherten Zeitreihen indiziert. AlsÄhnlichkeits-Merkmal, welches diesem Index zu Grunde gelegt wird, wird das Frequenzspektrumder Zeitreihen herangezogen. Um das Frequenzspektrum zu ermitteln, wird die aus der Nach-richtentechnik wohl bekannte Fouriertransformation angewandt. Die Fouriertransformation ist aufanaloge kontinuierliche Signale anwendbar und transformiert ein Zeitsignal in ein Frequenz-spektrum. Die diskrete Fouriertransformation (DFT) kann auf „gesampelte“ Signale angewandt wer-den, das sind äquidistante Zeitreihen; als Ergebnis liefert die DFT ein diskretes Frequenzspektrum.Aus diesem diskreten Frequenzspektrum werden die niedrigsten zwei bis drei Frequenzen (charak-terisiert durch jeweils Amplitude und Phasenverschiebung) für den Index herangezogen. Diese sindin der Regel differenzierend genug, um im Tradeoff zwischen Index-Treffsicherheit und Nachlese-Aufwand im Postprocessing ein optimales Ergebnis zu zeitigen. Die zwei bis drei niedrigstenFrequenzen spannen also einen vier- bis sechs-dimensionalen Suchraum auf (Amplitude undPhasenverschiebung), den so genannten Feature-Raum. Wegen der moderaten Anzahl anDimensionen kann eine Datenstruktur aus der Gruppe der R-Trees (Original-Vorschlag in[GUT84]) verwendet werden, es wird der R*-Tree (Original-Vorschlag in [BKSS90]) eingesetzt.
Lagerbestand
29. 0
1.'0
7
17. 0
2.'0
7
15. 1
2.'0
6
02.0
6.'0
7
10. 0
6.'0
7
20. 0
6.'0
7
05. 0
7.'0
706
. 07.
'07
13.1
0.'0
714
.10.
'07
21.1
0.'0
7
01.1
1.'0
7
Lagerbestand bei Veränderungen ab dem jeweils angegebenen Datum
≈ ≈
Janu
ar
Feb
ruar
Mär
z
Apr
il
Mai
Juni
Juli
Aug
ust
Sep
tem
ber
Okt
ober
Nov
emde
r
Dez
embe
r
Lagerbestand zum Monatsletzten
Lagerbestand
- 100 -
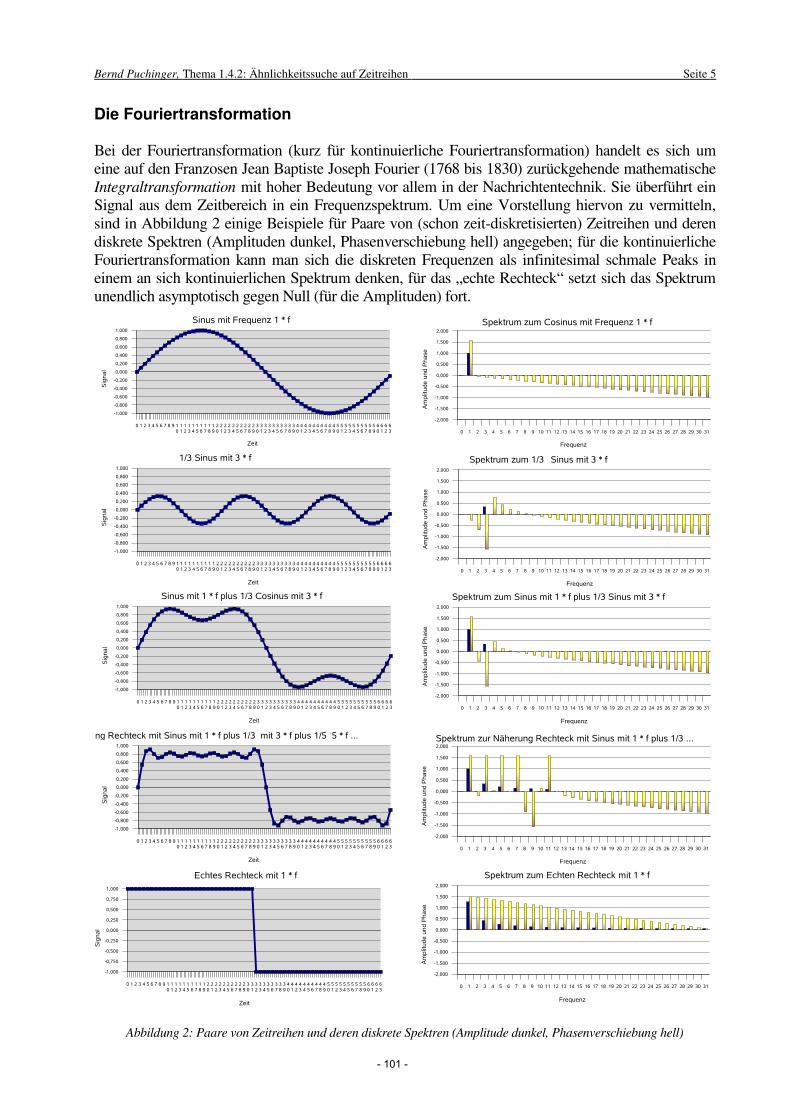
Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen Seite 5
Die Fouriertransformation
Bei der Fouriertransformation (kurz für kontinuierliche Fouriertransformation) handelt es sich umeine auf den Franzosen Jean Baptiste Joseph Fourier (1768 bis 1830) zurückgehende mathematischeIntegraltransformation mit hoher Bedeutung vor allem in der Nachrichtentechnik. Sie überführt einSignal aus dem Zeitbereich in ein Frequenzspektrum. Um eine Vorstellung hiervon zu vermitteln,sind in Abbildung 2 einige Beispiele für Paare von (schon zeit-diskretisierten) Zeitreihen und derendiskrete Spektren (Amplituden dunkel, Phasenverschiebung hell) angegeben; für die kontinuierlicheFouriertransformation kann man sich die diskreten Frequenzen als infinitesimal schmale Peaks ineinem an sich kontinuierlichen Spektrum denken, für das „echte Rechteck“ setzt sich das Spektrumunendlich asymptotisch gegen Null (für die Amplituden) fort.
Abbildung 2: Paare von Zeitreihen und deren diskrete Spektren (Amplitude dunkel, Phasenverschiebung hell)
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Echten Rechteck mit 1 * f
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zur Näherung Rechteck mit Sinus mit 1 * f plus 1/3 ...
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
Näherung Rechteck mit Sinus mit 1 * f plus 1/3 mit 3 * f plus 1/5 5 * f ...
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
1/3 Sinus mit 3 * f
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
Sinus mit Frequenz 1 * f
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum 1/3 Sinus mit 3 * f
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Cosinus mit Frequenz 1 * f
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Sinus mit 1 * f plus 1/3 Sinus mit 3 * f
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,750
-0,500
-0,250
0,000
0,250
0,500
0,750
1,000
Echtes Rechteck mit 1 * f
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
Sinus mit 1 * f plus 1/3 Cosinus mit 3 * f
Zeit
Signal
- 101 -

Seite 6 Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen
Dabei ist als grundlegende Tatsache festzustellen, dass Sinus- und Cosinus-Schwingungen imZeitbereich mit einem Peak im Frequenzbereich korrespondieren. Bei einer „unendlich langen“Schwingung ist so ein Peak infinitesimal schmal, bei einer gedämpften Schwingung verbreitert ersich. Die beiden oberen Paare in Abbildung 2 stellen jeweils eine einzelne Cosinus-Schwingungdar; im ersten Fall weist das Spektrum einen Peak beim 1-fachen der Frequenz auf, im zweitenFall beim 3-fachen dieser Frequenz, zudem mit einem Drittel der Amplitude. Das dritte Paar inAbbildung 2 zeigt die Überlagerung der beiden vorgenannten Signale; das Spektrum enthält ent-sprechend zwei Frequenz-Peaks. Mathematischer ausgedrückt handelt es sich mit der Fourier-Transformation um eine lineare Transformation, was bedeutet, dass die Transformation einerSumme von Zeitsignalen gleich der Summe der transformierten Zeitsignale ist. Bei „zusammen-gesetzten“ Zeitsignalen ergibt sich also ein „aufsummiertes“ Spektrum. Das vierte Paar ist dieÜberlagerung der 1-, 3-, 5-, 7-, 9- und 11-fachen Frequenz mit 1/1, 1/3, 1/5, 1/7, 1/9beziehungsweise 1/11 der Amplitude; man erkennt, dass das Zeitsignal sich der Form einesRechtecks nähert. Die letzte Zeile in Abbildung 2 schließlich zeigt ein „echtes“ Rechteck-Signal;in dem korrespondierenden Spektrum finden sich die gleichen Amplituden wie im vorherigenFall, jedoch „unendlich“ fortgesetzt. Da die Darstellung als diskrete Fourieranalyse berechnetwurde, ist dies nur andeutungsweise bis zur 31-fachen Frequenz zu sehen.
Die mathematischen Grundlagen der kontinuierlichen Fouriertransformation im Rahmen einesSeminarbeitrags darzustellen und zu erklären, ist sicher nicht möglich. Um den Übergang zurdiskreten Fouriertransformation jedoch plausibel zu machen, seien hier die beiden grund-legenden, so genannten vereinheitlichten Formeln mit Abbildung 3 (nach [WI2-06]) aufgeschrie-ben, links für die Transformation vom Zeitbereich in den Frequenzbereich und rechts umgekehrt,die so genannte inverse Fouriertransformation.
X ω=1
2π∫−∞
∞
x te−iωt dt x t=1
2π∫−∞
∞
X ω eiωt dω
Abbildung 3: Kontinuierliche Fouriertransformation (links) und inverse kontinuierliche Fouriertransformation (rechts)
Dabei ist ω die so genannte Kreisfrequenz, das ist die Frequenz multipliziert mit 2π, und i ist dieimaginäre Einheit der komplexen Zahlen. Die Formeln erschließen sich etwas vor dem Hinter-grund der Definition der trigonometrischen Funktionen Sinus und Cosinus als Exponentialfunk-tionen, wie sie in Abbildung 4 (nach [WI2-06]) aufgeschrieben sind. Dabei entspricht der Sinusdem Imaginärteil ℑ und der Cosinus dem Realteil ℜ , die man in Amplitude und Phasenver-schiebung umrechnen kann (vergleiche Abbildung 7).
sin x =1
2ieix−e− ix cos x =
1
2eixe− ix
Abbildung 4: Darstellung von Sinus und Kosinus als Exponentialfunktionen
Die diskrete Fouriertransformation
Als diskrete Fouriertransformation (DFT) bezeichnet man die Anwendung der Fouriertransfor-mation über nicht kontinuierlichen Signalen, also äquidistanten Zeitreihen, wie sie beispielsweisebeim Sampeln von Signalen entstehen, aber auch, wie in Abbildung 1 dargestellt, in betriebswirt-schaftlichem Umfeld gegebenenfalls durch Pseudo-Sampling anfallen. Im Gegensatz zur Fourier-analyse ist es nicht notwendig, die „Funktion“, die das zu analysierende Signal beschreibt, zukennen. Gerade im Datamining ist diese ja gar nicht bekannt. In Abbildung 5 (aus [WI2-06]) sind
- 102 -

Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen Seite 7
die Basis-Gleichungen der DFT aufgeschrieben, links für die Transformation vom Zeitbereich inden Frequenzbereich, und rechts umgekehrt. Man beachte die Analogie zu den Formeln ausAbbildung 3: Die Integration von –∞ bis +∞ wird dabei durch eine Summation über alle Werteder Zeitreihe der Länge N ersetzt, beziehungsweise durch eine Summation über alle Spektral-werte, von denen es ebenfalls N gibt. Das Ergebnis jeder einzelnen Anwendung der Formelnergibt jedoch keine Spektral-Funktion X(ω) beziehungsweise Zeitfunktion x(t), sondern eineeinzelne (komplexzahlige) Amplitude Xk zum Vielfachen k der Basis-Frequenz, beziehungsweiseeinen einzelnen (möglicherweise komplexzahligen) Zeitwert xn an der Position n der Zeitreihe.Für eine vollständige (inverse) DFT muss die Formel in Abbildung 5 also N mal angewandtwerden, wobei jedes mal eine Summation über N Summanden durchgeführt werden muss.
Xk=∑n=1
N
xne−i2π
kn
N xn=1
N∑k=1
N
Xkei2π
kn
N
Abbildung 5: Diskrete Fouriertransformation (links) und inverse diskrete Fouriertransformation (rechts)
In Abbildung 6 ist die Formel zur DFT unter Anwendung der Formeln in Abbildung 4 umgeformt,so dass Real- und Imaginärteil der Spektralwerte besser erkennbar und jeweils als reelle Zahlendirekt berechenbar sind. Mittels der Formeln zur Umwandlung der kartesischen in die polare Dar-stellungsart komplexer Zahlen lässt sich daraus die Amplitude als Betrag und die Phasen-verschiebung als Winkel berechnen, wie in Abbildung 7 visualisiert und als Formeln angegeben.
Xk=∑n=1
N
xn⋅[cos
2π k n
N−isin
2π k n
N]
Abbildung 6: Diskrete Fouriertransformation mit trigonometrischen Funktionen
Abbildung 7: Komplexe Zahlen in kartesischer und polarer Darstellungsart
Abschließend zur DFT soll angemerkt sein, dass sich verschieden skalierte Formel in derLiteratur finden, also Formeln mit anderen als den hier angegebenen Faktoren vor derSummation. Für das hier vorgestellte Verfahren ist das ohne Bedeutung. Für die imaginäreEinheit der komplexen Zahlen wird häufig j statt i benutz, vor allem in der Elektrotechnik. AlsFormelzeichen für die Fourier-Transformierte werden unterschiedliche Formelzeichen ver-wendet, oft x , hier wurde X gewählt.
Realteil
Imaginärteil
.φ
∣x∣= ℜ x 2ℑ x 2
ℜ x φ=arctan ℑ x /ℜ x
ℜ x =∣ x ∣sin φℑ x
ℑ x =∣ x ∣cosφ
∣ x ∣
- 103 -
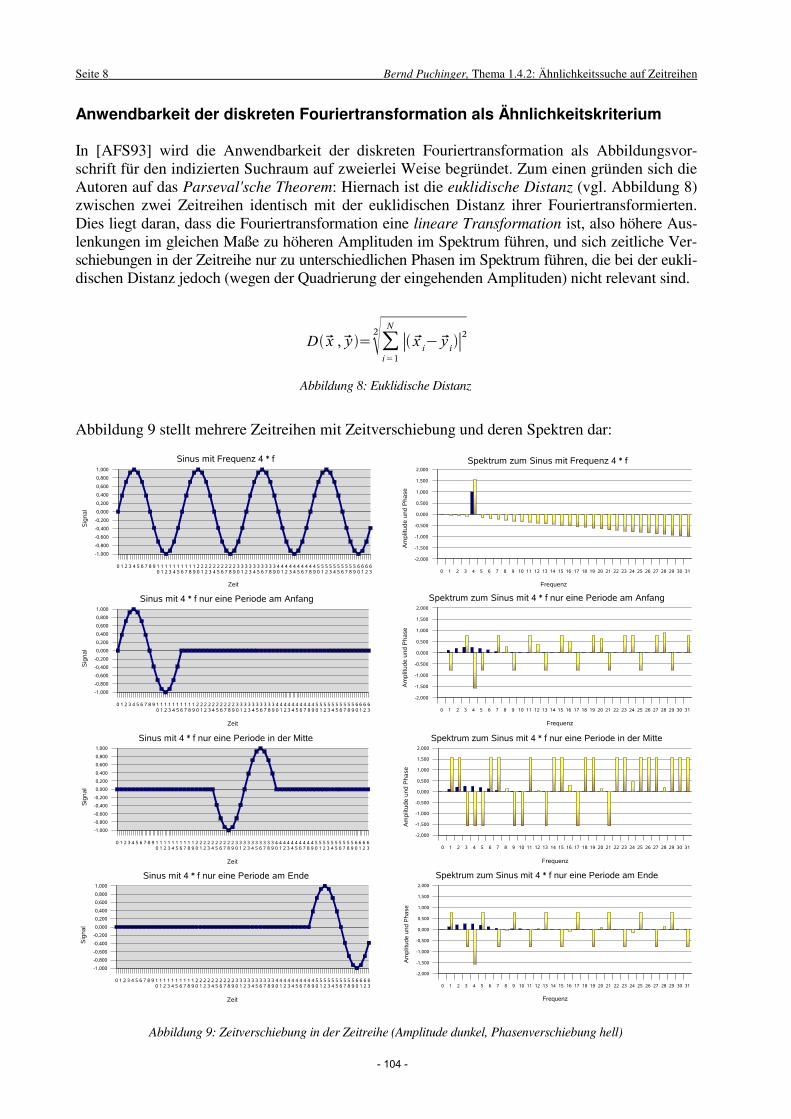
Seite 8 Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen
Anwendbarkeit der diskreten Fouriertransformation als Ähnlichkeitskriterium
In [AFS93] wird die Anwendbarkeit der diskreten Fouriertransformation als Abbildungsvor-schrift für den indizierten Suchraum auf zweierlei Weise begründet. Zum einen gründen sich dieAutoren auf das Parseval'sche Theorem: Hiernach ist die euklidische Distanz (vgl. Abbildung 8)zwischen zwei Zeitreihen identisch mit der euklidischen Distanz ihrer Fouriertransformierten.Dies liegt daran, dass die Fouriertransformation eine lineare Transformation ist, also höhere Aus-lenkungen im gleichen Maße zu höheren Amplituden im Spektrum führen, und sich zeitliche Ver-schiebungen in der Zeitreihe nur zu unterschiedlichen Phasen im Spektrum führen, die bei der eukli-dischen Distanz jedoch (wegen der Quadrierung der eingehenden Amplituden) nicht relevant sind.
Abbildung 8: Euklidische Distanz
Abbildung 9 stellt mehrere Zeitreihen mit Zeitverschiebung und deren Spektren dar:
Abbildung 9: Zeitverschiebung in der Zeitreihe (Amplitude dunkel, Phasenverschiebung hell)
Dx ,y=2
∑i=1
N
∣ x i−y i∣2
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
Sinus mit 4 * f nur eine Periode am Ende
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Sinus mit 4 * f nur eine Periode am Anfang
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Sinus mit Frequenz 4 * f
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
Sinus mit Frequenz 4 * f
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
Sinus mit 4 * f nur eine Periode am Anfang
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
Sinus mit 4 * f nur eine Periode in der Mitte
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum Sinus mit 4 * f nur eine Periode in der Mitte
Frequenz
Amplitude
und
Phase
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Sinus mit 4 * f nur eine Periode in der Mitte
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Sinus mit 4 * f nur eine Periode am Ende
Frequenz
Amplitude und Phase
- 104 -

Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen Seite 9
Der Vergleich der Auswirkungen einer zeitlichen Verschiebung einer einzelnen Sinus-Periodemit 4-facher Frequenz findet sich im zweiten bis vierten Paar: Die dunkel dargestelltenAmplituden bilden einen „Buckel“ um die 4-fache Frequenz, der Richtung höhere Frequenzenasymptotisch ausläuft. Die hell dargestellten Phasen unterscheiden sich jedoch erheblich.
Das erste Paar ist angegeben, um zu zeigen, dass ein durchgängiges Sinus-Signal mit 4-facherFrequenz eine Amplitude bei 4-facher Grundfrequenz und einem Phasenwinkel von π/2 hat(Cosinus hätte 0) und sich bereits in den niederfrequenten Amplituden von den Impuls-Reihenunterscheidet. Diese Beobachtung ist wichtig, um die Reduktion auf einige wenige nieder-frequente Amplituden zu rechtfertigen. Eine Reduktion führt potentiell zu zwei Arten möglicherFehlern eines Index, den false alarms und den false dismissals. Unter einem false alarm verstehtman, dass der Index einen Treffer anzeigt, der tatsächlich gar keiner ist. Unter einem false
dismissal versteht man, dass der Index für ein indiziertes Element keinen Treffer anzeigt, obwohles tatsächlich einer ist. Mathematischer ausgedrückt liegt die durch den Index ermittelte DistanzDIndex im ersten Fall unter der anzuwendenen Schwellen-Distanz ε, obwohl die wahre DistanzDZeitreihe über dieser liegt. Die in [AFS93] vorgeschlagene Methode sieht, wie in “Überblick überdie Grundidee“ auf Seite 4 dargestellt, ein Postprocessing vor, welches false alarms aussortiert,indem für alle angezeigten Treffer die Distanz auf den originalen Zeitreihen berechnet wird, alsodie wahre Distanz DZeitreihe, und diese gegen ε getestet wird. Um die Effizienz der Methode zugewährleisten, darf die Anzahl der false alarms nicht zu hoch sein, da sonst das Postprocessingzu aufwändig wird. Kritischer sind false dismissals, denn diese könnten allenfalls durch einkomplettes Durchsuchen der Zeitreihen behoben werden, was den Index jedoch sinnlos machenwürde. Das Weglassen von Amplituden führt jedoch niemals zu false dismissals, sondern nureventuell zu mehr false alarms, weil es dazu führt, dass sich eine kleinere Distanz ergibt alsdiejenige, die sich bei Einbezug aller Amplituden ergibt. Man sagt auch, die Distanz wirdunterschätzt. Das ist deshalb so, da das Weglassen von Amplituden dazu führt, dass Summanden inder Formel aus Abbildung 8 wegfallen, wobei alle Summanden positiv sind. Der sich ergebende Dis-tanzwert ist also immer kleiner oder gleich demjenigen bei Berücksichtigung aller Amplituden.
Zum anderen begründen die Autoren die Anwendbarkeit der diskreten Fouriertransformation alsAbbildungsvorschrift für den indizierten Suchraum auf deren intuitiver Einsichtigkeit. Bei derAnwendung der Fouriertransformation spricht man auch von Fourieranalyse; dieser Begriff trägtder Tatsache Rechnung, dass der Vorgang die in einem Kurvenverlauf beziehungsweise einerZeitreihe enthaltenen Schwingungssignale herausstellt, auf deren Basis man umgekehrt diesenKurvenverlauf beziehungsweise diese Zeitreihe auch wieder synthetisieren könnte. Dabei habendie niedrigen Amplituden die größten Beträge (bei den Phasen ist das nicht so) und die höherentypischerweise asymptotisch abfallende Amplituden-Beträge. Letzteres kann man in Abbildung 2insbesondere beim fünften Paar von Zeitreihen und Spektren gut sehen: Die niedrigenAmplituden sind auch diejenigen Amplituden, die die Form des korrespondierenden Signals ammeisten beeinflussen. Dies kann man wieder anhand Abbildung 2 bei dem dritten bis fünften Paarvon Zeitreihen und Spektren gut sehen: Bereits bei nur zwei überlagerten Sinus-Schwingungenergibt sich eine ansatzweise rechteckförmige Kurve (drittes Paar); mit sechs überlagerten Sinus-Schwingungen, entsprechend elf Amplituden, entsteht schon eine Kurve, die nur unwesentlichvom idealen Rechteck abweicht (viertes Paar).
Ein weiteres Indiz dafür, dass die höherfrequenten Amplituden weniger aussagekräftig sind, alsdie niederfrequenten, ist die Tatsache, dass reale Zeitreihen durch Störungen in Gestalt vonRauschen überlagert sind. So genanntes weißes Rauschen ist ein Signal, dessen Werte völligzufällig sind, und dessen Frequenzspektrum zumindest theoretisch über alle Frequenzen (desrelevanten Frequenzbereichs) gleich ist. Es ist der typische Fall für Störungen. Das erste Paar inAbbildung 10 stellt ein Beispiel für weißes Rauschen dar. Man kann erkennen, dass sich bei der
- 105 -
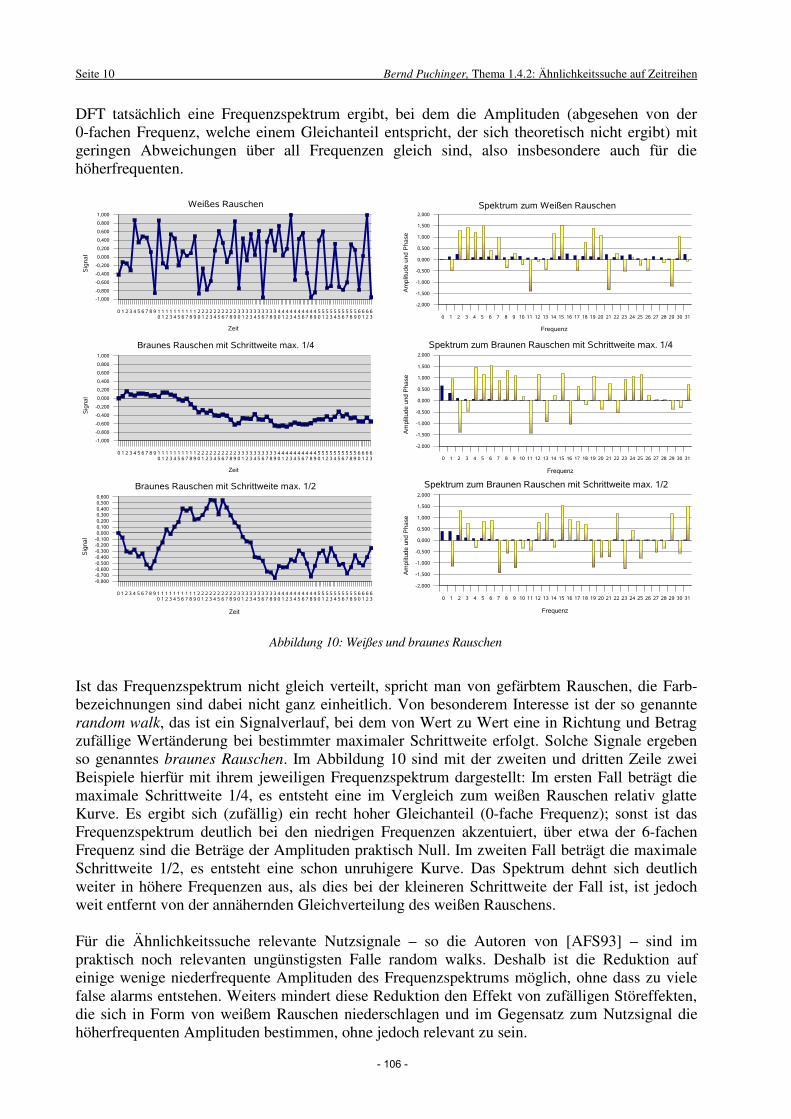
Seite 10 Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen
DFT tatsächlich eine Frequenzspektrum ergibt, bei dem die Amplituden (abgesehen von der0-fachen Frequenz, welche einem Gleichanteil entspricht, der sich theoretisch nicht ergibt) mitgeringen Abweichungen über all Frequenzen gleich sind, also insbesondere auch für diehöherfrequenten.
Abbildung 10: Weißes und braunes Rauschen
Ist das Frequenzspektrum nicht gleich verteilt, spricht man von gefärbtem Rauschen, die Farb-bezeichnungen sind dabei nicht ganz einheitlich. Von besonderem Interesse ist der so genannterandom walk, das ist ein Signalverlauf, bei dem von Wert zu Wert eine in Richtung und Betragzufällige Wertänderung bei bestimmter maximaler Schrittweite erfolgt. Solche Signale ergebenso genanntes braunes Rauschen. Im Abbildung 10 sind mit der zweiten und dritten Zeile zweiBeispiele hierfür mit ihrem jeweiligen Frequenzspektrum dargestellt: Im ersten Fall beträgt diemaximale Schrittweite 1/4, es entsteht eine im Vergleich zum weißen Rauschen relativ glatteKurve. Es ergibt sich (zufällig) ein recht hoher Gleichanteil (0-fache Frequenz); sonst ist dasFrequenzspektrum deutlich bei den niedrigen Frequenzen akzentuiert, über etwa der 6-fachenFrequenz sind die Beträge der Amplituden praktisch Null. Im zweiten Fall beträgt die maximaleSchrittweite 1/2, es entsteht eine schon unruhigere Kurve. Das Spektrum dehnt sich deutlichweiter in höhere Frequenzen aus, als dies bei der kleineren Schrittweite der Fall ist, ist jedochweit entfernt von der annähernden Gleichverteilung des weißen Rauschens.
Für die Ähnlichkeitssuche relevante Nutzsignale – so die Autoren von [AFS93] – sind impraktisch noch relevanten ungünstigsten Falle random walks. Deshalb ist die Reduktion aufeinige wenige niederfrequente Amplituden des Frequenzspektrums möglich, ohne dass zu vielefalse alarms entstehen. Weiters mindert diese Reduktion den Effekt von zufälligen Störeffekten,die sich in Form von weißem Rauschen niederschlagen und im Gegensatz zum Nutzsignal diehöherfrequenten Amplituden bestimmen, ohne jedoch relevant zu sein.
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-0,800
-0,700
-0,600
-0,500
-0,400
-0,300
-0,200
-0,100
0,000
0,100
0,200
0,300
0,400
0,500
0,600
Braunes Rauschen mit Schrittweite max. 1/2
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Braunen Rauschen mit Schrittweite max. 1/4
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
Braunes Rauschen mit Schrittweite max. 1/4
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
-1,000
-0,800
-0,600
-0,400
-0,200
0,000
0,200
0,400
0,600
0,800
1,000
Weißes Rauschen
Zeit
Signal
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Weißen Rauschen
Frequenz
Amplitude und Phase
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-2,000
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
Spektrum zum Braunen Rauschen mit Schrittweite max. 1/2
Frequenz
Amplitude und Phase
- 106 -

Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen Seite 11
Der R*-Tree
Im voranstehenden Abschnitt wurde dargestellt, dass die in [AFS93] dargestellte Vorgehens-weise äquidistante Zeitreihen von einheitlicher Länge mittels diskreter Fouriertransformationwandelt, und plausibel gemacht, dass eine Reduktion auf die ersten zwei bis drei komplex-zahligen Spektralwerte möglich ist, so dass diese Werte als Ortspunkte in einem entsprechendvier- bis sechs-dimensionalen Raum genutzt werden können. In [AFS93] wird vorgeschlagen,einen Index mit der Datenstruktur R*-Tree aufzubauen, wie sie in [BKSS90] dargestellt ist. DerR*-Tree basiert auf dem R-Tree, wie er in [GUT84] dargestellt ist, der wesentliche Unterschiedbesteht in einer verbesserten Einfüge- und Lösch-Operation.
Ursprünglich ist der R-Tree dazu gedacht, Referenzen auf räumlich ausgedehnte Objekte so ineiner Baumstruktur (dem R-Tree) anzuordnen, dass man bei bekannter räumlicher Positionmöglichst eindeutig durch den Baum zu den betreffenden Referenzen traversieren kann. Der ersteSchritt bei der Katalogisierung ist dabei der, eine so genannte bounding box um die Objekte zulegen. Abbildung 10 stellt für den zweidimensionalen Fall eine Reihe von Objekten mit denzugehörigen bounding boxes dar. Die Grenzen einer bounding box verlaufen immer parallel zuden Raumachsen, hier also horizontal und vertikal. Bei orthogonalen Raumachsen ergeben sichalso Rechtecke im zweidimensionalen Fall, im dreidimensionalen Fall Quader (nicht dargestellt),fortsetzbar auf beliebig-dimensionale Räume zu Hyper-Rechtecken. Die Grenzen werden dabeiso gewählt, dass das Objekt vollständig innerhalb der bounding box liegt und die räumlicheAusdehnung der bounding box in jeder Raumachse minimal ist. Man spricht deshalb exakter vonminimum bounding boxes.
Abbildung 10: Bounding Boxes im zweidimensionalen Raum
Die bounding boxes von Objekten können wiederum zu bounding boxes zusammengefasstwerden, wodurch sich eine in der Regel räumlich ausgedehntere bounding box ergibt, die diebounding boxes aller enthaltener Objekte beinhaltet. Dies ist hierarchisch über beliebig vieleEbenen möglich.
Im R-Tree entsprechen den ursprünglichen räumlichen Objekten die Einträge in den Blattknoten,Jeder Blattknoten enthält eine (variable) Anzahl an Objekt-Einträgen, die jeweils aus einerReferenz auf das Objekt und aus der jeweiligen bounding box bestehen. Weiters enthält einBlattknoten die zusammengefasste bounding box seiner Objekt-Einträge. Die Einträge in Nicht-blattknoten sind Referenzen auf Knoten (Blattknoten oder Nichtblattknoten). Weiters enthält einNichtblattknoten die zusammengefasste bounding box seiner enthaltenen Knoten. Abbildung 11stellt hierfür ein Beispiel dar, bei dem die sieben Objekte aus Abbildung 10 in den (nur in derZeichnung benannten) Blattknoten „Knoten L“ und „Knoten R“ katalogisiert sind. Diese sindwiederum angedeutet in Nichtblattknoten „Knoten RL“ enthalten.
Horizontale Raumachse
Ver
tika
le R
aum
achs
e
- 107 -

Seite 12 Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen
Abbildung 11: Organisation eine R-Tree
Beim Traversieren einer solchen Hierarchie anhand einer Suchposition müssen immer nurdiejenigen Knoten berücksichtigt werden, in deren bounding box die Suchposition enthalten ist,alle anderen Knoten enthalten keine Objekte, die an dem betreffenden Raumpunkt liegen, dennsonst hätten sie eine andere bounding box. Bei einer Range-Query ist der Suchbereich räumlichausgedehnt, und zwar eigentlich ein sphärischer Bereich mit Radius ε in allen Raumrichtungenum eine Suchposition. Praktisch werden aus Effizienzgründen aber meist hyper-rechteckigeSuchbereiche verwendet. Abbildung 12 stellt dies für den zweidimensionalen Fall dar. BeimTraversieren müssen alle Knoten berücksichtigt werden, deren bounding box sich mit demSuchbereich schneiden, die also ganz oder teilweise in diesem Suchbereich liegen.
Abbildung 12: Räumlich ausgedehnter Suchbereich im zweidimensionalen Fall
Für den in Abbildung 12 dargestellten Suchbereich müssen also folgende Knoten aus Abbildung11 durchsucht werden: „Knoten RL“, darin beide Knoten „Knoten L“ und „Knoten R“, weil beide
Spinnennetz -10 ; 6 ; -6 ; 2
Bleistift -7 ; 8 ; -4 ; 5
Hand -3 ; 8 ; -1 ; 3
Tropfen -3 ; 3 ; -2 ; 1
Wolke 2 ; 3 ; 8 ; 1
Sonnenkern 10 ; 5 ; 12 ; 3
Strahlen 9 ; 6 ; 13 ; 2
Knoten L -10 ; 8 ; -1 ; 1
Knoten R 2 ; 6 ; 13 ; 1
Knoten RL -10 ; 6 ; 13 ; 1
- 108 -

Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen Seite 13
sich mit dem Suchbereich überschneiden. Für Knoten „Knoten R“ stellt sich heraus, dass alleObjekte außerhalb des Suchbereichs liegen. In „Knoten L“ liegt Objekt „Hand“ ganz imSuchbereich, das Objekt „Bleistift“ teilweise, während die Objekte „Tropfen“ und „Spinnennetz“außerhalb liegen. Ob das Suchergebnis auf vollständiges oder teilweises Enthaltensein einesObjekts abstellt, hängt von der Anwendung ab. Für die in [AFS93] dargestellte Methode stellt sichdiese Frage nicht, da die indizierten Objekte, die Zeitreihen also, nur einzelne Raumpunkte sind;sie können als Objekte mit einer bounding box mit einer räumlichen Ausdehnung von Null in jederRaumrichtung aufgefasst werden, die also immer ganz oder gar nicht in einem Suchbereich liegen.
Die Anzahl der bei einer Suche zu traversierenden Knoten hängt neben der Größe des Such-bereichs entscheidend davon ab, wie die Objekte in Knoten gruppiert werden. Es ist günstig,wenn möglichst wenige Knoten bei einer Suche einbezogen werden müssen, und das istinformell ausgedrückt dann der Fall, wenn Gruppen mit möglichst kleinen bounding boxesgebildet werden, da sie sich in diesem Falle weniger wahrscheinlich mit einem Suchbereich über-schneiden. In [BKSS90] werden weitere Optimierungskriterien für die bounding boxes genannt,worauf hier nicht eingegangen werden soll. Da es sich beim R-Tree um einen Datenbank-Indexhandelt, wird dieser nicht komplett aufgebaut (bestenfalls einmal über einem initialen Daten-bestand), sondern muss vielmehr fortlaufend aktualisiert werden, nämlich immer dann, wenn einObjekt hinzugefügt oder gelöscht wird. Weiters kann jeweils ein Knoten des R-Tree nur einemaximale Anzahl an Einträgen halten, die sich durch die Größe einer Speicherseite für denSekundärspeicherzugriff der benutzten Hardware und die Größe eines Eintrags bestimmt; inrealen Systemen hat eine Speicherseite beispielsweise 4096 Byte, sodass sich nicht mehr als 200Einträge pro Knoten ergeben – je nach dem, wie viele Dimensionen für eine bounding boxgespeichert werden müssen. Diese Bedingung ist bei der Gruppierung der Objekte zu berück-sichtigen. Der wesentliche Unterschied zwischen dem R-Tree und seinen Varianten, insbesonderedem R*-Tree, besteht in den Algorithmen zur Gruppierung der Objekte und Knoten in Knotenbeim Hinzufügen und Löschen von Objekten. Dabei ist der Tradeoff zwischen dem Aufwand beiÄnderungsoperationen, der damit verbundenen Beschleunigung bei Leseoperationen, und demSpeicherbedarf für die Indexstruktur zu berücksichtigen.
An dieser Stelle sollen die Vorgänge, die bei den beiden Änderungsoperationen ablaufen, nurskizziert werden. Es sei vorweg angemerkt, dass diese Aktionen auch provoziert durchgeführtwerden können mit dem Ziel der Verbesserung der Gruppierung der Objekte, insbesondere als sogenannte Reinserts, bei denen ein Objekt gelöscht und sofort neu eingefügt wird.
Beim Einfügen eines neuen Objekts wird zunächst derjenige Blattknoten gesucht, dessenbisherige bounding box durch das Hinzufügen des neuen Objekts am wenigsten vergrößertwerden muss. Ist in dem identifizierten Knoten noch Platz für diesen Eintrag, so wird erhinzugefügt und die bounding box wird aktualisiert. Ist jedoch kein Platz, muss der Knoteneinem Split unterzogen werden. Dabei werden die Objekte des Blattknotens und das hinzuzu-fügende Objekt auf zwei Gruppen aufgeteilt, sodass sich für beide möglichst kleine boundingboxes ergeben. In [GUT84] werden für den R-Tree mehrere Split-Verfahren gegenübergestellt,wobei der so genannte „Quadratic Split“ als optimal identifiziert wird; in [BKSS90] wird für denR*-Tree ein deutlich komplexeres Vorgehen angegeben, das hier nicht dargestellt werden soll.Beim „Quadratic Split“ werden zunächst die beiden Objekte mit der größten Distanz gesucht, dieso genannten „Seeds“, die das jeweils erste Element der beiden neuen Gruppen bilden. Dieverbleibenden Objekte werden nacheinander jeweils einer der Gruppen zugeordnet, und zwarderjenigen, bei der sich die kleinere Erweiterung der bounding box ergib, solange, bis entwederalle Objekte zugeordnet sind, oder eine der Gruppen einen festgelegten Füllstand (mindestens 1/2mal und kleiner 1 mal die Knoten-Kapazität) erreicht; in letzterem Falle werden die restlichenObjekte der anderen Gruppe zugeordnet. Für die beiden neuen Gruppen wird jeweils ein Blatt-
- 109 -
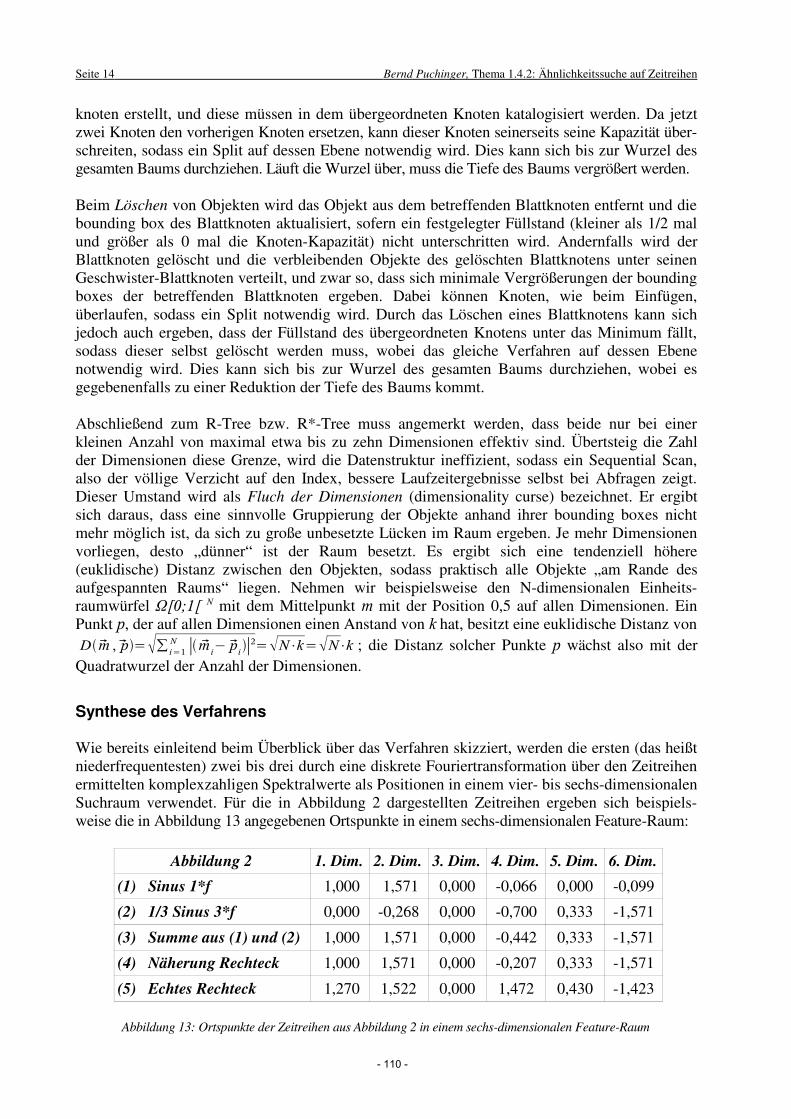
Seite 14 Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen
knoten erstellt, und diese müssen in dem übergeordneten Knoten katalogisiert werden. Da jetztzwei Knoten den vorherigen Knoten ersetzen, kann dieser Knoten seinerseits seine Kapazität über-schreiten, sodass ein Split auf dessen Ebene notwendig wird. Dies kann sich bis zur Wurzel desgesamten Baums durchziehen. Läuft die Wurzel über, muss die Tiefe des Baums vergrößert werden.
Beim Löschen von Objekten wird das Objekt aus dem betreffenden Blattknoten entfernt und diebounding box des Blattknoten aktualisiert, sofern ein festgelegter Füllstand (kleiner als 1/2 malund größer als 0 mal die Knoten-Kapazität) nicht unterschritten wird. Andernfalls wird derBlattknoten gelöscht und die verbleibenden Objekte des gelöschten Blattknotens unter seinenGeschwister-Blattknoten verteilt, und zwar so, dass sich minimale Vergrößerungen der boundingboxes der betreffenden Blattknoten ergeben. Dabei können Knoten, wie beim Einfügen,überlaufen, sodass ein Split notwendig wird. Durch das Löschen eines Blattknotens kann sichjedoch auch ergeben, dass der Füllstand des übergeordneten Knotens unter das Minimum fällt,sodass dieser selbst gelöscht werden muss, wobei das gleiche Verfahren auf dessen Ebenenotwendig wird. Dies kann sich bis zur Wurzel des gesamten Baums durchziehen, wobei esgegebenenfalls zu einer Reduktion der Tiefe des Baums kommt.
Abschließend zum R-Tree bzw. R*-Tree muss angemerkt werden, dass beide nur bei einerkleinen Anzahl von maximal etwa bis zu zehn Dimensionen effektiv sind. Übertsteig die Zahlder Dimensionen diese Grenze, wird die Datenstruktur ineffizient, sodass ein Sequential Scan,also der völlige Verzicht auf den Index, bessere Laufzeitergebnisse selbst bei Abfragen zeigt.Dieser Umstand wird als Fluch der Dimensionen (dimensionality curse) bezeichnet. Er ergibtsich daraus, dass eine sinnvolle Gruppierung der Objekte anhand ihrer bounding boxes nichtmehr möglich ist, da sich zu große unbesetzte Lücken im Raum ergeben. Je mehr Dimensionenvorliegen, desto „dünner“ ist der Raum besetzt. Es ergibt sich eine tendenziell höhere(euklidische) Distanz zwischen den Objekten, sodass praktisch alle Objekte „am Rande desaufgespannten Raums“ liegen. Nehmen wir beispielsweise den N-dimensionalen Einheits-raumwürfel Ω[0;1[ N mit dem Mittelpunkt m mit der Position 0,5 auf allen Dimensionen. EinPunkt p, der auf allen Dimensionen einen Anstand von k hat, besitzt eine euklidische Distanz vonD m , p= ∑
i=1
N ∣ m i− p
i∣2= N⋅k= N⋅k ; die Distanz solcher Punkte p wächst also mit der
Quadratwurzel der Anzahl der Dimensionen.
Synthese des Verfahrens
Wie bereits einleitend beim Überblick über das Verfahren skizziert, werden die ersten (das heißtniederfrequentesten) zwei bis drei durch eine diskrete Fouriertransformation über den Zeitreihenermittelten komplexzahligen Spektralwerte als Positionen in einem vier- bis sechs-dimensionalenSuchraum verwendet. Für die in Abbildung 2 dargestellten Zeitreihen ergeben sich beispiels-weise die in Abbildung 13 angegebenen Ortspunkte in einem sechs-dimensionalen Feature-Raum:
Abbildung 2 1. Dim. 2. Dim. 3. Dim. 4. Dim. 5. Dim. 6. Dim.
(1) Sinus 1*f 1,000 1,571 0,000 -0,066 0,000 -0,099
(2) 1/3 Sinus 3*f 0,000 -0,268 0,000 -0,700 0,333 -1,571
(3) Summe aus (1) und (2) 1,000 1,571 0,000 -0,442 0,333 -1,571
(4) Näherung Rechteck 1,000 1,571 0,000 -0,207 0,333 -1,571
(5) Echtes Rechteck 1,270 1,522 0,000 1,472 0,430 -1,423
Abbildung 13: Ortspunkte der Zeitreihen aus Abbildung 2 in einem sechs-dimensionalen Feature-Raum
- 110 -

Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen Seite 15
Dabei sind die Werte der Dimensionen 1, 3 und 5 die Amplituden und die Werte der Dimensionen2, 4 und 6 die Phasenverschiebungen der drei niederfrequentesten Vielfachen der Grundfrequenz.Diese Reihenfolge ist natürlich beliebig wählbar, muss jedoch für alle Zeitreihen identisch sein.
Im Teilabschnitt „Anwendbarkeit der diskreten Fouriertransformation als Ähnlichkeitskriterium“ abSeite 8 wurde dargestellt, dass der Verzicht auf Spektralwerte dazu führt, dass die Distanz unter-schätz wird und somit zu false alarms führt, also dazu, dass Zeitreihen als Treffer aufgeführt werden,die gar keine Treffer sind. Um dieses Problem zu beheben, sieht die Methode nach [AFS93] einso genanntes Postprocessing vor, welches false alarms aussortiert, indem für alle angezeigtenTreffer die Distanz auf den originalen Zeitreihen berechnet, also die wahre Distanz berechnetwird, und diese gegen die Anfrage getestet wird. Um die Effizienz der gesamten Methode zugewährleisten, darf die Anzahl der false alarms nicht zu hoch sein, da sonst das Postprocessingzu aufwändig wird. Das diese Bedingung erfüllt ist, wurde in [AFS93] empirisch festgestellt.
Suche auf Teil-Zeitreihen
Die Methode nach [AFS93] ist grundsätzlich nur anwendbar auf Datenbestände mit Zeitreihenjeweils identischer Länge und für Abfragen anhand von Zeitreihen mit ebendieser Länge.Allenfalls bietet sich Resampling (Sampling über einer interpolierten Zeitreihe mit einemanderen zeitlichen Abstand zwischen den Werten, als dies in der ursprünglichen Zeitreihevorliegt) an, um auch Zeitreihen unterschiedlicher Länge oder mit unterschiedlichem zeitlichenAbstand zwischen den Werten zu indizieren. Die durch Resampling erzeugten Zeitreihen werdendabei nur für die Ermittlung des jeweiligen Raumpunktes im Feature-Raum für den F-Indexbenötigt. Ob Resampling anwendbar ist, hängt jedoch von der Art des Inhalts der Zeitreihen undder Fragestellung ab. Eine Abfrage auf Teil-Zeitreihen ist damit nicht möglich.
In [FRM94] ist eine Fortentwicklung der in [AFS93] dargestellte Methode beschrieben, dieDatenbestände und Abfragen mit Zeitreihen unterschiedlicher Länge ermöglicht und Abfragenauf Teil-Zeitreihen ermöglicht. Im Folgenden wird dieser Ansatz skizziert.
Als erstes wird eine minimale Länge für Zeitreihen, die angefragt werden können, festgelegt, w.Für alle Zeitreihen Si des Datenbestandes werden length(Si )–w+1 diskrete Fouriertransforma-tionen mit jeweils w Samples durchgeführt, das sind alle möglichen Teil-Zeitreihen der Länge w.Da jeweils benachbarte Teil-Zeitreihen sich kaum voneinander unterscheiden, ergeben sich auchjeweils ähnliche Spektren, die „räumlich“ nahe beieinander liegen und in [FRM94] als Trailsbezeichnet werden. Die Trails werden in Teil-Trails zerlegt, die jeweils zu einer (variablen)Anzahl von Teil-Sequenzen korrespondieren. Referenzen auf die Teil-Zeitreihen jeweils einesTeil-Trails werden als räumlich ausgedehnte Objekte in einem R*-Tree Index abgelegt. DieserIndex wird in [FRM94] als ST-Index bezeichnet.
Für Anfragen der Länge w liegt der Fall sehr einfach: im R*-Tree wird nach Teil-Trail-Objektengesucht, deren bounding box sich mit dem Suchbereich schneidet. In einem Postprocessingwerden die false alarms aussortiert, also jene Teil-Sequenzen, die zwar zu einem Teil-Trailgehören, aber selbst nicht im Suchraum liegen.
Für Anfragen mit einer Länge größer w könnte als trivialer Ansatz eine Prefix-Suche angewandtwerden. Dabei wird nur der Anfang der Suchanfrage mit der Länge w für die Suche verwendet. Diesführt dazu, dass die Distanz der Teil-Zeitreihen unterschätz wird, da Unterschiede in dem nicht be-achteten Teil der Teil-Zeitreihen, die die ermittelte Distanz jedenfalls nicht verkleinern würden, nichteingehen. Dieser Ansatz ist also korrekt in dem Sinne, dass es nicht zu false dismissals kommenkann, leidet aber erheblich unter false alarms, die das Postprocessing aufwändig werden lassen.
- 111 -

Seite 16 Bernd Puchinger, Thema 1.4.2: Ähnlichkeitssuche auf Zeitreihen
Als verbesserter Ansatz für Anfragen mit einer Länge größer w wird in [FRM94] folgender als„Multi Piece“ bezeichneter Ansatz beschrieben: Die Anfrage Q wird in p=lengthQ/w Teil-abfragen zerlegt, wobei der gegebenenfalls bei der Ganzzahldivision nicht berücksichtigte letzteTeil der Anfrage mit Länge lenghtQmod w wie bei der Prefix-Suche die Korrektheit nichtbeeinträchtigt. Das Gesamtergebnis der Abfrage mit Distanz-Range ε ist die Vereinigung derErgebnisse aller Teilabfragen, wobei der Suchbereich für die Teilabfragen auf ε / p reduziertwerden kann. Insgesamt ergeben sich damit in der Regel weniger false alarms, die beimPostprocessing ausgefiltert werden müssen, als dies für die triviale Prefix-Suche der Fall ist.
Referenzen
[AFS93] Rakesh Agrawal, Christos Faloutsos, and Arun N. Swami:Efficient Similarity Search In Sequence Databasesin Proceedings of the 4th Intern. Conference of Foundations of Data Organization and AlgorithmsSeiten 69-841993
[BKSS90] Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, Bernhard Seeger:The R*-Tree: An Efficient and Robust Access Method for Points and RectanglesACMSeiten 322-3311990
[FRM94] Christos Faloutsos, M. Ranganathan, and Yannis Manolopoulos:Fast Subsequence Matching in Time-Series Databasesin Proceedings of the 1994 ACM SIGMOD Intern. Conference on Management of DataSeiten 419-4291994.
[GUT84] Antonin Guttman:R-Trees – A Dynamic Index Structure for Spatial Searchingin Proceeding of the ACM SIGMOID Intern. Conference on Management of DataSeiten 47-571984
[MLH01] Magnus Lie Hetland:A Survey of Recent Methods for Efficient Retrieval of Similar Time Sequencesin Proceedings of the First NTNU CSGSC2001
[WI1-06] Wikipedia - Die freie Enzyklopädie (Hrsg.)Wikipedia DVD-Ausgabe vom 20. September 2006Artikel “Data-Mining“
[WI2-06] Wikipedia - Die freie Enzyklopädie (Hrsg.)Wikipedia DVD-Ausgabe vom 20. September 2006Artikel “Fourier-Transformation“
[KTXX] Kurt Thearling, Ph.D.An Introduction to Data MiningPräsentationsfolien
- 112 -

FernUniversitat in HagenSeminar 01912
im Sommersemester 2008
Erkennung Sequenzieller Muster -Algorithmen und Anwendungen
Thema 1.4.3
Sequenzielle Muster
Referent: Achim Eisele
- 113 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 1
Inhaltsverzeichnis
1 Einleitung 2
2 Data Mining und KDD 2
3 Sequenzielle Muster 43.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43.2 Losungsansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63.3 Abgrenzung All/Some . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
4 Algorithmen 84.1 Generierung von Sequenzkandidaten . . . . . . . . . . . . . . . . . . . . . . 84.2 AprioriAll . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94.3 AprioriSome . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.4 DynamicSome . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124.5 GSP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134.6 Weitere Entwicklungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5 Diskussion 155.1 Speicherverwaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155.2 Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165.3 Einordnung des Problems . . . . . . . . . . . . . . . . . . . . . . . . . . . 165.4 Kommerzieller Einsatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
6 Zusammenfassung 17
Literatur 18
- 114 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 2
1 Einleitung
Die Erkennung sequenzieller Muster (sequential patterns) dient der Findung interessanterMuster in großen Datenbanken, die in zeitlicher Abhangigkeit zueinander stehen. DasThema wurde erstmals 1995 von Agrawal und Skrikant [AS95] vorgestellt.
Ein Muster im Kontext eines Videoverleihs konnte zum Beispiel sein, dass Kunden ty-pischerweise erst
”Krieg der Sterne“, dann
”Das Imperium schlagt zuruck“, gefolgt von
”Die Ruckkehr der Jedi-Ritter“ ausleihen. Dabei muss der Verleih nicht streng aufeinan-
der folgend geschehen, es konnen zwischendurch auch andere Videos ausgeliehen werden,um das Muster zu erfullen.
Diese Auswertung des Kundenverhaltens ist im kommerziellen Umfeld als Warenkorb-analyse bekannt geworden. Mit der Weiterentwicklung der Barcode Technologie in Ver-bindung mit personalisierten Kunden- oder Kreditkarten wurde Ende der 80er Jahre dieSpeicherung individuellen Kaufverhaltens ermoglicht. So werden pro Einkauf eine Kun-dennummer, die Zeit des Einkaufs und die Produkte im Warenkorb erfasst. Im e-commercewerden diese Daten schon implizit erhoben.
Neben dem Einsatz im kommerziellen Umfeld, wird die Erkennung sequenzieller Musterauch im wissenschaftlichen Bereich genutzt. Beispielsweise bei der DNA-Analyse gilt es,Ahnlichkeiten in Codesequenzen im Genom zu erkennen, die Proteine verschlusseln unddurch eine variable Anzahl von Storsymbolen voneinander getrennt sind.
Ein ebenfalls vergleichbares Problem ist das Auffinden von Teilfolgen eines Textes, dieeinem vorgegebenen regularen Ausdruck genugen1.
Im Folgenden werden Begrifflichkeiten und Regeln im Zusammenhang mit sequenziellenMustern vorgestellt. Darauf aufbauend werden Algorithmen zur Erkennung dieser Musterbesprochen.
2 Data Mining und KDD
Die Erkennung sequenzieller Muster ist im Kontext eines Datenanaylseprozesses zu be-trachten. Ein weit verbreitetes Konzept zur Gewinnung von Erkenntnissen — und damitneuen Wissens — ist Knowledge Discovery in Databases (KDD). KDD umfasst im Allge-meinen das Data Mining sowie vorbereitende (Daten-) Analysen.
Somit ist das Data Mining ein Teilschritt innerhalb des KDD. Das Data Mining bestehtaus Algorithmen, die in akzeptabler Rechenzeit aus der vorgegebenen Datenbasis eineMenge von Mustern liefert. Alle Verfahren des Data Mining — auch die Erkennung se-quenzieller Muster — unterliegen einem solchen Prozess, der mindestens die folgendenPhasen umfasst (Abbildung 1):
1Zum Beispiel UNIX grep.
- 115 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 3
• Selektion der Daten
• Exploration und Modifikation der Daten
• Transformation der Daten
• Analyse der Daten
• Interpretation der Ergebnisse
Muster
Wissen
Trans-formierteDaten
VorbereiteteDaten
Daten
Analyse-daten
Selektion
Transformation
Data Mining /Analyse
Interpretation
Modifikation
Abbildung 1: Der KDD-Prozess
Bei der Selektion der Daten werden geeignete Datenquellen identifiziert und erforder-liches Datenmaterial bereitgestellt. Zur Bereitstellung der Daten bedient man sich derOperationen der Relationenalgebra2. Qualitativ hochwertiges Datenmaterial ist dabei ei-ne Grundvoraussetzung fur den Erfolg des Analyseprozesses.
Wahrend der Exploration und Modifikation der Daten versucht der Analyst sich einenUberblick uber die Struktur der Daten zu verschaffen. Neckel und Knobloch bezeichnenes mit
”ein Gefuhl fur das Datenmaterial bekommen“[NK05, S. 185]. Dieses
”Gefuhl“
soll bei der Einordnung der Analyseergebnisse in Bezug auf Relevanz, Reprasentativitatund Plausibilitat helfen. Das erhaltene Ausgangsmaterial kann mit Daten aus weiterenQuellen angereichert werden. Oftmals ist es notwendig, fehlende Attribute zu berechnenoder fehlerhafte Daten zu korrigieren.
In der Phase der Transformation werden die Eingabedaten in eine fur den Algorithmusadaquate Datenstruktur transformiert. Die Transformation der Eingabedaten kann unterUmstanden eine beachtliche Laufzeitverbesserung der Algorithmen bedeuten3.
2Siehe hierzu Kurs 1671, 1665[Sch03].3Siehe auch Kapitel 3.2, 3.3.
- 116 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 4
Das anzuwendende Verfahren wahrend der Analyse kann vom Analysproblem oder Ana-lyseziel abgeleitet werden. Es extrahiert die vorhandenen Muster. Jedes Verfahren mussvor seiner Anwendung konfiguriert werden. Diese Parametrisierung bezieht sich auf dieVorgabe methodenspezifischer Werte, wie z.B. die Festlegung minimaler relativer Haufig-keiten oder die Einstellung von Gewichtungsfaktoren einzelner Eingabevariablen.
In der Phase der Interpretation wird eine Bewertung der Analyseergebnisse vorgenom-men.Da Verfahren des Data Mining u.U. triviale oder
”uninteressante“ Aussagen und
Muster zutage fordern, ist dieser Schritt unablasslich. Eine grafische Darstellung der Er-gebnisse4 erleichtert die Interpretation wesentlich.
3 Sequenzielle Muster
Dieses Kapitel beschaftigt sich mit allgemeinen Vorgehensweisen zur Erkennung sequen-zieller Muster. Nach den formellen Grundlagen dieses speziellen Problems werden diegrundsatzliche Schritte zu seiner Losung aufgezeigt, die fur alle im folgenden vorgestell-ten Algorithmen grundlegend sind.
3.1 Grundlagen
Gegeben ist eine Datenbank D mit Kundentransaktionen. Jede Transaktion umfasstdie Felder KundenNr, Transaktionszeit und Bestellpositionen (items) (Tabelle 1). ProZeiteinheit kann maximal eine Transaktion eines Kunden stattgefunden haben. D.h. einKunde kann keine zwei Transaktionen zur gleichen Zeit durchfuhren. Die absolut bestellteAnzahl eines items (Produkts) wird nicht beachtet.
KundenNr Produkte (items) Transaktionszeit4 (3) 2008-03-08 13:46:323 (3,5,7) 2008-03-11 16:03:011 (3) 2008-04-23 09:12:494 (4,7) 2008-04-30 22:51:232 (1,2) 2008-05-01 11:20:211 (9) 2008-05-22 14:24:512 (3) 2008-03-12 20:01:445 (9) 2008-03-11 08:04:534 (9) 2008-04-16 15:33:122 (4,6,7) 2008-05-13 07:47:37
Tabelle 1: Kundentransaktionen
4Meist mit Hilfe von Reporting-Tools.
- 117 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 5
Ein itemset oder auch Artikelmenge ist eine nicht-leere Menge von items. Diese Daten-struktur reprasentiert den Warenkorb einer einzelnen Transaktion, i = (i1i2...in). Dabeiwerden die items auf einen integer Wert (die ProductID), den Primarschlussel der Produkt-tabelle, abgebildet. Eine Sequenz ist eine geordnete Liste von itemsets, s = 〈s1s2...sn〉.
Eine Sequenz 〈a1a2...an〉 ist in einer zweiten Sequenz 〈b1b2...bn〉 enthalten, wenn i1 < i2 <.. < in existieren, so dass a1 ⊆ bi1 , a2 ⊆ bi2 , .., an ⊆ bin . Beispielsweise ist die Sequenz〈(2, 3)(5)(8, 9)〉 in 〈(2, 3, 4)(5, 6)(8, 9)〉 enthalten, da (2, 3) ⊆ (2, 3, 4), (5) ⊆ (5, 6) und(7, 8) ⊆ (7, 8) gilt. Ist die Sequenz a in der Sequenz b enthalten, so ist a eine Teilsequenz(subsequence) von b.
Eine zusammenhangende Teilsequenz (contiguous subsequence) c einer Sequenz s = 〈s1s2..sn〉erhalt man, wenn man das erste s1 oder das letzte Element sn aus s entfernt bzw. einitem aus einem Element si entfernt, das wenigstens zwei items enthalt.
Jedoch ist die Sequenz 〈(3)(5)〉 nicht in 〈(3, 5)〉 enthalten und umgekehrt. Die erste Se-quenz bedeutet, dass die items 3 und 5 in zwei Transaktionen gekauft wurden, wahrenddie items 3 und 5 bei der zweiten Sequenz innerhalb einer einzigen Transaktion erstandenwurden. In einer Menge von Sequenzen ist s maximal, wenn s in keiner anderen Sequenzenthalten ist.
Alle nach der Transaktionszeit sortierten Warenkorbe (itemsets) eines Kunden nennt manKundensequenz (Tabelle 2). Ein Kunde unterstutzt (supports) eine Sequenz s, wenn s inder Kundensequenz enthalten ist. Die Unterstutzung einer Sequenz als relativer Anteilvon Kunden, die diese Sequenz unterstutzen, nennt man Unterstutzung (Support) einerSequenz.
KundenNr Kundensequenz1 〈(3)(9)〉2 〈(1, 2)(3)(4, 6, 7)〉3 〈(3, 5, 7)〉4 〈(3)(4, 7)(9)〉5 〈(9)〉
Tabelle 2: Transformierte Datenbank mit Kundensequenzen
Gesucht werden zu der gegebenen Datenbank D die maximalen Sequenzen, die einer be-nutzerdefinierten minimalen Unterstutzung genugen5. Jede dieser maximalen Sequenzenreprasentiert ein sequenzielles Muster und wird auch große Sequenz (large sequence) ge-nannt [AS95]. Da jedes itemset einer großen Sequenz dieser Minimalunterstutzung genugt,werden diese als litemset (large itemset) bezeichnet. Tabelle 3 zeigt sequenzielle Mustermit einer benutzerdefinierten relativen Unterstutzung von 25% (bzw mit einer absolutenUnterstutzung von 2).
5 Die Angabe dieser Unterstutzung wird in der Literatur als relativer Anteil von Kunden, die diemaximalen Sequenzen unterstutzen, zu der Gesamtzahl der Kunden angegeben [AS95], manchmalaber auch als absoluter Wert (Anzahl der Kunden, die maximalen Sequenzen unterstutzen) [GRS99].
- 118 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 6
Sequenzielle Muster mit einer Unterstuzung von 25%1-Sequenzen 〈(3)〉 〈(4)〉 〈(7)〉 〈(9)〉2-Sequenzen 〈(3)(9)〉3-Sequenzen 〈(3)(4, 7)〉
Tabelle 3: Muster, die einer benutzerdefinierten Unterstutzung genugen
Die Große einer Sequenz entspricht der Anzahl der enthaltenen itemsets (Warenkorbe).Die Anzahl der enthaltenen items (Produkte) bezeichnet man mit Lange der Sequenz. Mitk-Sequenz bezeichnet man Sequenzen der Lange k. x.y kennzeichnet die Konkatenationder Sequenzen x und y.
3.2 Losungsansatz
Das Problem der Erkennung sequenzieller Muster wird in funf Phasen gelost:
1. Sortierphase
2. litemset-Phase
3. Transformationsphase
4. Sequenzierungsphase
5. Maximierungsphase
Die Sortierphase bereitet die Daten fur die Weiterverarbeitung vor, indem sie die Da-tenbank D mit Kundentransaktionen erst nach der KundenNr, dann nach der Transakti-onszeit sortiert.
In der litemset-Phase werden alle litemsets (große Sequenzen) gefunden. Dabei wird dieMenge der litemsets auf eine Menge von integer-Werten abgebildet (Tabelle 4). DieseAbbildung eines mehrdimensionalen litemset auf einen eindimensionalen integer Wertermoglicht den Vergleich in konstanter Zeit, was bei der Prufung, ob ein litemset in einemanderen enthalten ist, einen erheblichen Performancegewinn bedeutet.
litemsets abgebildet auf(3) 1(9) 2(1,2) 3(4,6,7) 4(3,5,7) 5(4,7) 6
Tabelle 4: Abbildung der litemsets auf integer-Werte
- 119 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 7
Wie spater noch naher erlautert wird, muss mehrfach ermittelt werden, welche litemsetsin den Kundensequenzen enthalten sind. Um diese Vergleiche zu beschleunigen werdendie Kundensequenzen in der Transformationsphase in eine alternative Darstellung ge-bracht.
In einer Kundensequenz wird jede Transaktion durch eine Menge von litemsets ersetzt.Wenn eine Transaktion kein litemset enthalt, so wird diese verworfen, gehort aber weiter-hin zu der Gesamtzahl der Transaktionen, aus denen die Unterstutzung ermittelt wird.Die Kundensequenz wir nun als Liste von litemset-Mengen reprasentiert.
Diese transformierte Datenbank wird mit DT bezeichnet. DT kann physikalisch auf derFestplatte gespeichert werden, aber auch on-the-fly generiert werden.
Die im nachsten Kapitel vorgestellten Algorithmen unterscheiden sich hauptsachlich in derSequenzierungsphase. Allen gemein ist, dass sie auf die transformierte Datenbank DT
aufsetzen, um die gewunschten Sequenzen zu finden. Dabei benotigen alle Algorithmenmehrere Durchlaufe uber die Daten.
In der Maximierungsphase werden die maximalen Sequenzen aus der Menge der großenSequenzen gefunden. Einige Algorithmen verwenden aus Performancegrunden eine kombi-nierte Sequenzierungs-/Maximierungsphase, bei der das Berechnen von nicht-maximalenSequenzen entfallt.
Algorithmus 1 reduziert eine Menge großer Sequnezen S auf die Menge der maximalenSequenzen der Lange 1 ≤ k ≤ n. Dabei ist n die Lange der großten Sequenz.
Algorithmus 1 Maximierungsphase nach [AS95]
maximiere (S, n)Eingabe:
S: eine Menge von großen Sequenzenn: großte zu betrachtende Sequenzlange
Ausgabe:S: die auf die Menge der maximalen Sequenzen reduzierte Eingabe
1: for k = n downto 2 do2: for all k-sequences sk ∈ S do3: Losche alle Teilsequenzen von sk aus S4: end for5: end for
3.3 Abgrenzung All/Some
Im Folgenden werden zwei Familien von Algorithmen vorgestellt, welche mit count-allund count-some bezeichnet werden. Die Algorithmen der Count-all-Familie berechnen
- 120 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 8
alle großen Sequenzen, auch die nicht-maximalen. Die nicht-maximalen Sequenzen mussendeshalb in der Maximierungsphase aussortiert werden.
Count-some-Algorithmen verfolgen den Ansatz, lediglich die maximalen Sequenzen zuberechnen; denn nur diese sind bei dem hier beschriebenen Problem von Interesse. Somitentfallt das Berechnen von Sequenzen, die in großeren Sequenzen enthalten sind. Jedochsollte beachtet werden, dass nicht allzu viele große Sequenzen berechnet werden, die nichtder minimalen Unterstutzung genugen.
Alle Count-some-Algorithmen besitzen eine Vorwartsphase (forward phase), in der allegroße Sequenzen einer bestimmten Lange gefunden werden, und eine Ruckwartsphase(backward phase), die alle ubrigen großen Sequenzen findet.
Die Algorithmen der Count-some-Familie unterscheiden sich hauptsachlich in der Gene-rierung der Sequenzkandidaten (candidate sequences) wahrend der Vorwartsphase. MitSequenzkandidaten bezeichnet man neue, potenziell große Sequenzen.
4 Algorithmen
Algorithmen sind das zentrale Thema bei der Erkennung sequenzieller Muster. Aus derFamilie der Count-all-Algorithmen stellen wir den AprioriAll vor. Aus der Count-some-Familie betrachten wir die Algorithmen AprioriSome und DynamicSome. Diese drei Al-gorithmen wurden von Agrawal und Srikant bereits 1995 vorgestellt [AS95]. Im Anschlusswird ein komplexerer Algorithmus, GSP, der Time-Constraints und Klassifizierung derErgebnisse zulasst, angerissen. Zuvor betrachten wir im Detail die eingesetzten Moglich-keiten zur Generierung von Sequenzkandidaten.
4.1 Generierung von Sequenzkandidaten
Die Generierung der Sequenzkandidaten ist ein Hauptunterscheidungsmerkmal der vor-gestellten Algorithmen. Wie schon kurz angedeutet, wird das geschilderte Problem derErkennung sequenzieller Muster in mehreren Durchlaufen gelost. Im ersten Durchlaufwird die in der litemset-Phase gefundene Menge der 1-Sequenzen als Eingabemenge ver-wendet. Alle weiteren Durchlaufe arbeiten auf der im vorherigen Durchlauf gefundenenMenge von großen Sequenzen. Aus dieser Menge von großen Sequenzen werden die Se-quenzkandidaten generiert. Am Ende des Durchlaufs wird deren Unterstutzung ermittelt.Genugen ermittelte Sequenzkandidaten der minimalen Unterstutzung, so werden dieseKandidaten in die Menge der großen Sequenzen aufgenommen; alle anderen werden ver-worfen [AS95]. Um die Laufzeit in Grenzen zu halten, sollte versucht werden, so wenigeSequenzkandidaten wie moglich zu berechnen, jedoch ohne große Sequenzen zu vergessen[SA96].
- 121 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 9
Die beiden Apriori-Algorithmen nutzen zu Generierung ihrer Sequenzkandidaten die Funk-tion apriori-generate (Algorithmus 2). Diese verknupft die Menge der großen Sequen-zen Lk−1 mit sich selbst (Join Phase).
Algorithmus 2 apriori-generate nach [AS95]
Eingabe:Lk−1: Menge der großen Sequenzen der Lange k − 1
Ausgabe:Ck: Menge der Sequenzkandidaten der Lange k
INSERT INTO Ck
SELECT p.litemset1, ... ,p.litemsetk−1, q.litemsetk−1
FROM Lk−1 p, Lk−1 qWHERE p.litemset1 = q.litemset1, ... , p.litemsetk−2 = q.litemsetk−2
Danach werden alle Sequenzen c ∈ Ck, deren k− 1-Teilsequenzen nicht in Lk−1 enthaltensind verworfen (Prune Phase).
Der Algorithmus DynamicSome nutzt zur Generierung von Sequenzkandidaten — nebenapriori-generate — noch einen on-the-fly-Ansatz. Eine auf diesem Ansatz basierteFunktion erwartet als Eingabeparameter Lk, Lj und die Kundensequenz c. Daraus werdenk+j Sequenzkandidaten berechnet, die in c enthalten sind. Die Idee hinter dieser Funktionist, wenn sk ∈ Lk und sj ∈ Lk in c enthalten sind, und sich diese in c nicht uberlappen,dann ist 〈sk.sj〉 ein k + j-Sequenzkandidat. Dabei bezeichnet man mit Lk die Menge allergroßen k-Sequenzen und mit Ck die Menge aller k-Sequenzkandidaten.
Um Sequenzkandidaten, die in Kundensequenzen enthalten sind, schnell auffinden zukonnen, werden diese in der Datenstruktur hash-tree abgelegt. Dies wurde von Agra-wal schon 1994 vorgeschlagen [AS94]. Der Algorithmus GSP, 1996 von Srikant vorgestellt[SA96], nutzt ein optimiertes Verfahren, um die Menge der Sequenzkandidaten zu redu-zieren, und somit schneller zu terminieren. Dieses Verfahren ahnelt apriori-generate,jedoch werden nur Kandidaten generiert, die potenziell neue große Sequenzen sind.
4.2 AprioriAll
Der AprioriAll-Algorithmus ist — im Vergleich mit den anderen vorgestellten Algorithmen— der einfachste. Wie alle weiteren Algorithmen benotigt er mehrere Durchlaufe uber dieDaten. Er gehort zur Count-all-Familie und verwendet die Funktion apriori-generate zurGenerierung der Sequenzkandidaten. Algorithmus 3 zeigt die Implementierungsdetails.
Als Eingabemenge dienen die zuvor gefundenen große 1-Sequenzen. Solange die Mengeder großen k−1-Sequenzen Lk−1 nicht leer ist, werden die k-Sequenzkandidaten generiert.Fur jede Kundensequenz c wird uberpruft, ob Kandidaten aus Ck in c enthalten sind. DieKandidaten, die in c enthalten sind, werden in die Menge Lk ubernommen.
- 122 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 10
Algorithmus 3 AprioriAll nach [AS95]
Eingabe:L1: Menge der großen 1-Sequenzen // Ergebnis der litemset-Phase
Ausgabe:Lk: Menge der großen Sequenzen der Lange k
1: L1 = große 1-Sequenzen // Ergebnis der litemset-Phase2: for k = 2; Lk−1 6= ∅ ; k + + do3: Ck = apriori-generate(Lk−i)4: for all Kundensequenz c in der Datenbank do5: Inkrementiere den Zahler aller Kandidaten in Ck, die in c enthalten sind6: end for7: Lk = Kandidaten in Ck mit minimaler Unterstutzung8: end for9: return maximiere(Lk, k)
4.3 AprioriSome
AprioriSome gehort zur Count-some-Familie. Deshalb besitzt er eine Vorwarts- und eineRuckwartsphase (Algorithmus 4). In der Vorwartsphase werden nur Sequenzen bestimm-ter Lange bearbeitet. Dabei versucht man durch Uberspringen bestimmter Langen dieGeamtlaufzeit des Algorithmus zu reduzieren. So konnten wir in der Vorwartsphase z.B.Sequenzen der Lange 1, 2, 4 und 6, und in der Ruckwartsphase Sequenzen der Lange3 und 5 bearbeiten. Zur Generierung von Sequenzkandidaten wird apriori-generate
verwendet. Jedoch konnte im k-ten Durchlauf die erforderliche Eingabemenge Lk−1 nichtzur Verfugung stehen, da moglicherweise die (k − 1)-Sequenzkandidaten nicht bearbeitetworden sind. In diesem Fall wird die Menge der (k− 1)-Sequenzkandidaten Ck−1 verwen-det.
Interessant ist hier die Funktion next. Diese erwartet als Eingabeparameter die Langeder in diesem Durchlauf bearbeiteten Sequenzen und gibt die Lange der im nachstenDurchlauf zu bearbeitenden Sequenzen zuruck. Da next genau untersucht, welche Se-quenzen gerade bearbeitet wurden, kann sie einen Kompromiss zwischen der Bearbeitungnicht maximaler Sequenzen und der Bearbeitung von Erweiterungen kleiner Sequenzkan-didaten ermitteln. Algorithmus 5 beschreibt die Funktion next mit willkurlich belegtenVergleichsparametern.
Bei next(k) = k + 1 degeneriert AprioriSome zu AprioriAll. Das andere Extrem ware z.B.fur next(k) = 100 ∗ k, was bedeuten wurde, dass fast keine nicht-maximalen Sequenzenbearbeitet werden, aber viele Erweiterung kleiner Sequenzkandidaten. hitk bedeutet indiesem Zusammenhang das Verhaltnis der Anzahl der großen k-Sequenzen zu der An-zahl der k-Sequenzkandidaten (|Lk| / |Ck|). Die Idee hinter dieser Heuristik ist: Wenn derAnteil der bearbeiteten Kandidaten im derzeitigen Durchlauf steigt, so reduziert sich die
- 123 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 11
Algorithmus 4 AprioriSome nach[AS95]
Eingabe:L1: Menge der großen 1-Sequenzen // Ergebnis der litemset-Phase
Ausgabe:Lk: Menge der großen Sequenzen der Lange k
1: // Vorwartsphase2: C1 = L1
3: last = 14: for k = 2; Lk−1 6= ∅ und Llast 6= ∅ ; k + + do5: if Lk−1 bekannt then6: Ck = apriori-generate(Lk−i)7: else8: Ck = apriori-generate(Ck−i)9: end if
10: if k == next(last) then11: for all Kundensequenz c in der Datenbank do12: Inkrementiere den Zahler aller Kandidaten in Ck, die in c enthalten sind13: end for14: Lk = Kandidaten in Ck mit minimaler Unterstutzung15: last = k16: end if17: end for18:19: // Ruckwartsphase20: for k −−; k ≥ 1; k −− do21: if Lk in der Vorwartsphase nicht gefunden then22: Losche alle Sequenzen in Ck, die in mindestens einem Li, i > k23: for all Kundensequenz c in der Datenbank DT do24: Inkrementiere den Zahler aller Kandidaten in Ck, die in c enthalten sind25: end for26: Lk = Kandidaten in Ck mit minimaler Unterstutzung27: else28: // Lk schon bekannt29: Losche alle Sequenzen in Lk, die in mindestens einem Li, i > k30: end if31: end for32: return maximiere(Lk, k)
- 124 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 12
Algorithmus 5 next nach[AS95]
next(k: integer)Eingabe:
k: Lange der im letzten Durchlauf berechneten SequenzenAusgabe:
knext: Lange der im nachsten Durchlauf zu berechnenden Sequenzen k
1: if hitk < 0.666 then2: return k + 13: else if hitk < 0.75 then4: return k + 25: else if hitk < 0.80 then6: return k + 37: else if hitk < 0.85 then8: return k + 49: else
10: return k + 511: end if
Zeitverschwendung fur das Bearbeiten der Erweiterungen kleiner Sequenzkandidaten beimUberspringen einer Lange.
In der Ruckwartsphase werden die Sequenzen bearbeitet, die in der Vorwartsphase uber-sprungen wurden. Zuvor werden aber alle Sequenzen, die in einer großen Sequenz enthaltensind, geloscht. Diese kleinere Sequenzen konnen nicht in der Antwortmenge enthalten sein,da lediglich die maximalen Sequenzen von Interesse sind. Deshalb werden auch alle nicht-maximalen großen Sequenzen aus der Vorwartsphase aussortiert. Um den Speicherplatzzur Haltung der Sequenzkandidaten zu minimieren, konnen die Vorwarts- und Ruckwarts-phase ineinander verschachtelt werden.
4.4 DynamicSome
Wie AprioriSome gehort auch DynamicSome zur Familie der Count-some-Algorithmen.Auch hier werden in der Vorwartsphase Sequenzkandidaten bestimmter Lange ubersprun-gen. Die Sequenzkandidaten, die bearbeitet werden sollen, werden von der Variable stepabgeleitet. Wahrend der Initialisierungsphase werden alle Sequenzkandidaten bis zu einerLange von step bearbeitet. In der Vorwartsphase werden dann alle Langen, die ein Viel-faches von step sind, betrachtet. Bei step = 3 werden in der Initialisierungphase also dieSequenzkandidaten der Lange 1, 2 und 3 bearbeitet; und wahrend der Vorwartsphase dieLangen 6, 9, 12, ... . Dabei konnen Sequenzkandidaten der Lange 6 aus Verknupfung vonSequenzen der Lange 3 mit sich selbst erzeugt werden. Sequenzkandidaten der Lange 9
- 125 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 13
konnen aus Verknupfung von Sequenzen der Lange 6 mit Sequenzen der Lange 3 generiertwerden.
Ebenso wie AprioriSome bearbeitet auch DynamicSome in der Ruckwartsphase die Langenvon Sequenzen, die in der Vorwartsphase ubersprungen wurden. Im Gegensatz zu Aprio-riSome werden die Sequenzkandidaten nicht in der Vorwartsphase erzeugt. Dafur gibt esbei DynamicSome eine Zwischenphase.
DynamicSome verwendet die Funktion apriori-generate zur Generierung der Sequenz-kandidaten in der Initialisierungsphase; die Vorwartsphase nutzt die on-the-fly-Kandidatengenerierungsfunktion.
4.5 GSP
GSP (Generalized Sequential Patterns) ist ein erweiterter Algorithmus zur Erkennungsequenzieller Muster. Er basiert auf dem Apriori-Algorithmus und unterscheidet sich vonden bisher vorgestellten Algorithmen durch folgende Merkmale:
• Taxonomien erlauben die Einfuhrung einer Vererbungshierarchie fur Produkte.Muster konnen somit auf verschiedenen Ebenen der Taxonomie gefunden werden(Abbildung 2).
• Mit sliding window konnen Zeitfenster fur die zeitliche Folge von Transaktionenangegeben werden.
• Zeitbindungen (time constraints) definieren bestimmte zeitliche Mindest- und Ma-ximalabstande. Diese Zeitbindung wird auch mit gap bezeichnet.
Produktebene
Taxomie / Klassifizierung
Computer & Software Bücher Musik
Chemie
Praktische Inf Technische Inf Theoretische Inf
Theoretische Inf Eine Einführung
Einführung in die Automatentheorie
Grundkurs Theoretische Inf
Informatik Mathematik
Abbildung 2: Taxonomie
- 126 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 14
Ein weiteres Merkmal des GSP ist eine Laufzeitoptimierung gegenuber den Apriori-Algorithmen. GSP versucht so wenig wie moglich Sequenzkandidaten zu generieren, ohnegroße Sequenzen auszulassen. Die Generierung der Sequenzkandidaten ahnelt der Funkti-on apriori-generate. Jedoch werden beim GSP in der Join-Phase zwei k−1-Sequenzenmiteinander verknuft, die gleiche zusammenhangende Teilsequenzen enthalten. Bei derVerknupfung kann das neue item einmal als eigenes Element eingefugt werden, aber auchals Teil eines Elements. Beispielsweise haben 〈(1, 2)(3)〉 und 〈(1, 2)(4)〉 die gemeinsa-me zusammenhangende Teilsequenz 〈(1, 2)〉. Die generierten Sequenzkandidaten warennun 〈(1, 2)(3, 4)〉 und 〈(1, 2)(3)(4)〉. In der Prune-Phase werden die Knadidaten ausge-schlossen, deren zusammenhangende Teilsequenzen der benutzerdefinierten minimalenUnterstutzung nicht genugen. Weiterhin nutzt der GSP eine hash-tree-Struktur, um dieAnzahl der Sequenzkandidaten zu minimieren, die beim nachsten Durchlauf uberpruftwerden mussen [SA96].
Beim AprioriAll ist es sehr einfach die Unterstutzung der Sequenzkandidaten zu berech-nen, da alle Sequenzen in der Datenbank durch ihre enthaltenen Teilsequenzen darge-stellt werden. Durch die Einfuhrung von Constraints wie Minimal- und Maximalabstandist diese Berechnung beim GSP komplizierter. Die Prufung, ob ein Sequenzkandidat cin einer Kundensequenz s enthalten ist, bedarf mehreren Phasen: eine Vorwarts- und ei-ner Ruckwartsphase, die solange wiederholt werden, bis alle Elemente gefunden wurden[ZB03].
Wahrend der Vorwartsphase werden aufeinander folgende Elemente von c ind s gefunden,solange der zeitliche Abstand des gefundenen Elementes und des vorherigen Elementesinnerhalb des Maximalabstandes liegt. Falls der zeitliche Abstand großer als der Maxi-malabstand ist, so wird zur Ruckwartsphase gesprungen.
In der Ruckwartsphase wird das vorherige Element herangezogen und uberpruft, ob diesesin einer fuheren Transaktion schon einmal aufgetreten ist. Ist dies der Fall, so werdenalle bisherigen Elemente auf die Einhaltung des Maximalabstandes uberpruft. Ist diesePrufung erfolgreich, so wird zuruck zur Vorwartsphase gesprungen.
Um Taxonomien der items zu beachten, werden die Kundensequenzen um die entsprechen-den Taxonomien erweitert. Dies fuhrt jedoch dazu, dass bei der Berechnung die Anzahlder zu beachtenden Regeln sehr groß wird, wobei viele Regeln redundant sind. Deshalbist eine Vorberechnung notwendig, die nicht interessanter Sequenzen aussortiert.
4.6 Weitere Entwicklungen
Nach der Veroffentlichung des GSP im Jahr 1996 wurden viele weitere Algorithmen zurErkennung sequenzieller Muster vorgestellt. In [CYH04] wird mit IncSpan ein inkremen-teller Algorithmus vorgeschlagen. Wenn eine Datenbasis organisch wachst, so ist es nichtnotwendig, jede Analyse erneut uber den kompletten Datenbestand auszufuhren. Der in-krementelle Ansatz dieses Algorithmus’ startet mit Ergebnissen aus einer fruheren Analyseund bearbeitet lediglich die neu hinzugekommenen Sequenzen. Der CCSM [OPS04] nutzt
- 127 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 15
ein Zwischenspeicherung (Caching) der generierten Sequenzkandidaten, um die Laufzeitweiter zu verbessern. Spade findet in nur drei Durchlaufen alle große Sequenzen, was ihnim Vergleich mit dem GSP um ein Vielfaches schneller macht [Zak01]. Auch PrefixSpanverbessert das Laufzeitverhalten gegenuber dem GSP, vor allem bei sehr langen Sequenzen[PHMA+01].
Neben den beim GSP vorgestellten Contstraints — Taxonomien und Zeitbeschrankungen— wurden Algorithmen entwickelt, die weitere Klassen von Constraints unterstutzen. DieFamilie der SPIRIT Algorithmen verarbeitet Regulare Ausdrucke[GRS99]. In [PHW02]werden insgesamt sieben verschiedene Constraint-Klassen behandelt.
5 Diskussion
Bei der Definition des Begriffs Data Mining wird in der Literatur von Algorithmen ge-sprochen, die in akzeptabler Rechenzeit aus der vorgegebenen Datenbasis eine Menge vonMustern liefern. Im Folgenden wird auf die Speicherverwaltung und die Laufzeitkomple-xitat der vorgestellten Algorithmen eingegangen, bevor eine Einordnung des Problems indas moderne Arbeitsumfeld geliefert wird.
5.1 Speicherverwaltung
Bei großen Kundendatenbanken und einer niedrigen Unterstutzung konnten die generier-ten Sequenzkandidaten Ck nicht mehr im Arbeitsspeicher vorgehalten werden. Ein Teil derSequenzkandidaten musste auf den Hintergrundspeicher ausgelagert werden. Ohne Spei-cherverwaltung musste der Algorithmus standig auf diesen Hintergrundspeicher zugreifen,was die Laufzeit erheblich beeintrachtigen wurde.
Wahrend der Phase der Generierung von k-Sequenzkandidatengenerierung wird Speicherzur Vorhaltung der litemsets Lk−1 und der Sequenzkandidaten Ck benotigt. Angenom-men, dass Lk−1 vollstandig im Arbeitsspeicher gehalten werden kann, aber fur die gesam-te Menge der Ck kein Platz vorhanden ist. Dann kann die Funktion zur Generierung derSequenzkandidaten so modifiziert werden, dass immer nur so viele Kandidaten generiertwerden, wie aktuell in den Arbeitsspeicher passen. Diese Kandidaten werden dann unter-sucht, die großen Sequenzen auf dem Hintergrundspeicher abgelegt, und die Kandidaten,die der minimalen Unterstutzung nicht genugen, verworfen. Dieser Vorgang wird solangewiederholt, bis alle Sequenzkandidaten aus Ck untersucht wurden.
Falls selbst die Menge der großen k − 1-Sequenzen nicht im Arbeitsspeicher vorgehaltenwerden kann, so kann ein relationales Merge/Join Verfahren zur Generierung der Sequenz-kandidaten wahrend der Join-Phase eingesetzt werden. Eine detailliertere Beschreibungdes Merge/Join Verfahrens ist bei Srikant [SA96] nachzulesen.
- 128 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 16
5.2 Performance
Jede Vorstellung eines Algorithmus zur Erkennung sequenzieller Muster beinhaltet eineEvaluation der Performance des Algorithmus’ (vergleiche hierzu [AS95] fur die Algorith-men AprioriAll, AprioriSome und DynamicSome, [SA96] fur den GSP). Die wichtigsteErkenntnis ist, dass die Laufzeit zur Erkennnung sequenzieller Muster linear mit der An-zahl der Kunden bzw. der Anzahl der Kundensequenzen wachst.
5.3 Einordnung des Problems
Ein ahnliches Problem ist die Erkennung von Assoziationsregeln. Assoziationsregeln be-achten jedoch nur die items innerhalb einer einzigen Transaktion. Deshalb nennt mansie auch Intratransaktionsmuster. Im kommerziellen Umfeld wird bei der Erkennung vonAssoziationsregeln auch vom
”Kaufverbund“ gesprochen. Dagegen betrachten Sequenti-
elle Muster — oder auch Intertransaktionsmuster — das Auftreten bestimmter items imZeitverlauf.
Data Mining und der zugehorige Prozess der Wissensentdeckung sind durch ein daten-getriebenes Vorgehen gekennzeichnet. Da hier ein Ziel ohne konkrete Annahmen verfolgtwird, spricht man auch von einem Bottom-up Vorgehen[NK05, S. 81]. Eine Fragestellungin diesem Zusammenhang konnte z.B. sein:
”Welche Kunden soll ich in einer Direktwer-
bekampagne anschreiben?“.
Hat man dagegen eine konkrete Vorstellung davon, was man durch eine Datenanalyse er-fahren mochte, so hat man implizit eine Hypothese formuliert. In solchen Fallen ist relativklar, wonach man in den Daten suchen muss, und die Analyse beschrankt sich prinzipiellauf ein Abrufen und Zusammenfassen von Datenwerten nach in der Fragestellung enthal-tenen Kriterien. Hypothesengetriebene Analysen werden auch mit
”Top-down-Verfahren“
bezeichnet. Eine Fragestellung aus diesem Bereich konnte z.B. sein:”Wieviele Kunden,
die Bier gekauft haben, kauften auch Windeln?“. Solche Fragestellungen werden nichtuber ein Verfahren des Data Mining gelost, sondern durch statistische Auswertungen.
Data Mining als Verfahren im Analyseprozess ist also nicht die alleinige Losung fur Proble-me dieser Anwendungsdomane. Vielmehr sind weitere Aufgaben im Rahmen eines Wissen-sentdeckungsprozess durchzufuhren, die in Abhangigkeit des konkreten Analyseproblemszu gestalten sind [NK05, S. 182]. Man kann hier auch von der Anwendungsebene sprechen.Dorian Pyle formuliert dies sehr treffend:
”Die Technik selbst ist nicht die Antwort, sondern nur das Werkzeug, das den
Analytiker dabei unterstutzen soll, eine Antwort zu finden.“ [Pyl03, S.1]
Vor der eigentlichen Analyse sind Aspekte der Datenselektion, der Datenbereinigung undder Datenreprasentation zu beachten. Dabei betragt der Anteil des Data Mining gerade
- 129 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 17
einmal 10-20% des Gesamtaufwands. Die restlichen 80-90% verteilen sich auf die vorgela-gerten Arbeiten und die anschließende Interpretation der Ergebnisse. Somit ist der kom-plette KDD-Prozess fur den Erfolg der Datenanalyse entscheidend. Ebenso wichtig ist dieQualitat des verarbeiteten Datenmaterials und die Zusammenfuhrung der Unternehmens-/Kundendaten in einem Data Warehouse.
5.4 Kommerzieller Einsatz
Die Erkennung sequenzieller Muster — als Teil der Warenkorbanalyse — liefert fur das Di-rektmarketing sehr interessante Informationen. Durch solche Analysen konnen Affinitatenvon Kunden zu speziellen Themengebieten entdeckt werden. Das Wissen uber die Inter-essen der Kunden fuhrt zu gezielteren Werbemaßnahmen mit dem positiven Nebeneffektder Steigerung der Conversion Rate einer Werbeaktion. So werden lediglich potenzielleInteressenten eines beworbenen Produkts angeschrieben. So spart das werbende Unter-nehmen z.B. Portokosten ein (im Falle eines Printmailings) und der Kunde profitiert vonauf seine Interessen zugeschnittenen Produktwerbung.
In den letzten Jahren ist ein Trend Richtung Automatisierung der Mustererkennung,vor allem im Bereich des e-commerce, zu erkennen. So versendet ein bekannter Online-Buchhandler Werbemails, die aus der Historie der Einkaufe ermittelt werden. Dieser auto-matisierte Ansatz wurde in Empfehlungsdiensten (Recommendation Engines) implemen-tiert.
Ein weiterer Ansatz ist die Erstellung von Benutzerprofilen anhand der Logfiles vonWebservern. Jeder Kunde kann anhand von Cookies im Browser uber einen bestimmtenZeitraum verfolgt werden, auch uber mehrere Sitzungen (Sessions) hinweg. Diese gewon-nen Informationen konnen im Data Warehouse die bisherigen Kundendaten erweitern.
6 Zusammenfassung
Seit der Einfuhrung des Problems der Erkennung sequenzieller Muster Agrawal und Sri-kant im Jahr 1995 wurde eine ganze Reihe von Algorithmen zur Losung des Problems vor-geschlagen. Diese unterscheiden sich hauptsachlich in der Unterstutzung von Constraintsund der Laufzeit. Dabei bedeutet eine bessere Laufzeit auch eine hohere Kompliziertheitder Algorithmen.
Die Erkennung sequenzieller Muster ist inzwischen ein beliebter Gegenstand der For-schung und wird in vielen wissenschaftlichen und kommerziellen Anwendungsgebieten zurFindung neuen Wissens eingesetzt. Dabei kann eine gewisse Verwandtschaft mit der Er-kennung von Assoziationsmustern festgestellt werden.
- 130 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 18
Literatur
[AS94] Agrawal, Rakesh ; Srikant, Ramakrishnan: Fast Algorithms for MiningAssociation Rules. In: Bocca, Jorge B. (Hrsg.) ; Jarke, Matthias (Hrsg.); Zaniolo, Carlo (Hrsg.): Proc. 20th Int. Conf. Very Large Data Bases,VLDB, Morgan Kaufmann. – ISBN 1–55860–153–8, 487–499
[AS95] Agrawal, Rakesh ; Srikant, Ramakrishnan: Mining sequential patterns.In: Yu, Philip S. (Hrsg.) ; Chen, Arbee S. P. (Hrsg.): Eleventh InternationalConference on Data Engineering. IEEE Computer Society Press, 3–14
[CYH04] Cheng, Hong ; Yan, Xifeng ; Han, Jiawei: IncSpan: incremental miningof sequential patterns in large database. In: Proceedings of the tenth ACMSIGKDD international conference on Knowledge discovery and data mining,ACM. – ISBN 1–58113–888–1, 527–532
[GRS99] Garofalakis, Minos N. ; Rastogi, Rajeev ; Shim, Kyuseok: SPIRIT:Sequential Pattern Mining with Regular Expression Constraints. In: TheVLDB Journal, 223-234
[NK05] Neckel, Peter ; Knobloch, Bernd: Customer Relationship Analytics.dpunkt, 2005. – ISBN 3898643093
[OPS04] Orlando, Salvatore ; Perego, Raffaele ; Silvestri, Claudio: A new algo-rithm for gap constrained sequence mining. In: Proceedings of the 2004 ACMsymposium on Applied computing, ACM. – ISBN 1–58113–812–1, 540–547
[PHMA+01] Pei, J. ; Han, J. ; Mortazavi-Asl, B. ; Pinto, H. ; Chen, Q. ; Dayal, U.; Hsu, M.-C.: PrefixSpan Mining Sequential Patterns Efficiently by PrefixProjected Pattern Growth, 215–226
[PHW02] Pei, J. ; Han, J. ; Wang, W.: Mining Sequential Patterns with Constraintsin Large Databases
[Pyl03] Pyle, Dorian: Data Preparation for Data Mining. Morgan Kaufmann, 2003.– ISBN 1558605290
[SA96] Srikant, Ramakrishnan ; Agrawal, Rakesh: Mining Sequential Pat-terns: Generalizations and Performance Improvements. In: Apers, PeterM. G. (Hrsg.) ; Bouzeghoub, Mokrane (Hrsg.) ; Gardarin, Georges(Hrsg.): Proc. 5th Int. Conf. Extending Database Technology, EDBT Bd.1057, Springer-Verlag. – ISBN 3–540–61057–X, 3–17
[Sch03] Schlageter: Datenbanken I. Wintersemester 2003/2004. Hagen, Germany: FernUniversitat in Hagen, 2003 (Kurs 1671)
[Zak01] Zaki, Mohammed J.: SPADE: An Efficient Algorithm for Mining FrequentSequences. In: Machine Learning 42 (2001), Nr. 1/2, 31–60. citeseer.ist.psu.edu/zaki00spade.html
- 131 -

Achim Eisele, Thema 1.4.3: Sequenzielle Muster 19
[ZB03] Zhao, Q. ; Bhowmick, S.S.: Sequential pattern mining: a survey. In: Tech-nical Report Center for Advanced Information Systems. School of ComputerEngineering, Nanyang Technological University, Singapore, 2003
- 132 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 1
Fernuniversität in Hagen-
Seminar 01912im SS 2008
Data Mining:Verfahren zum Auffinden
von Mustern in großen Datenmengen
Thema 1.5.1
Graph-Mining/Häufige Teilgraphen gSpan: Graph-Based Substructure Pattern Mining
Referentin: Fatma Akyol
- 133 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 2
Inhaltsverzeichnis 1 Motivation....................................................................................................................................3 2 Einführung...................................................................................................................................3
2.1 Subgraphisomorphismen .....................................................................................................3 2.2 Idee von gSpan ....................................................................................................................5
3 Der gSpan-Algorithmus...............................................................................................................6 3.1 Grundlagen...........................................................................................................................6
3.1.1 DFS-Code ....................................................................................................................6 3.1.2 Lexikographische DFS-Ordnung.................................................................................9 3.1.3 Minimaler DFS-Code.................................................................................................10 3.1.4 DFS-Code-Baum .......................................................................................................11
3.2 Der Algorithmus................................................................................................................13 3.3 Verwendung von gSpan nach graphenbasierter Datenprojektion .....................................17
4 Kritische Bewertung..................................................................................................................17 4.1 Vergleich mit AGM ..........................................................................................................17 4.2 Vergleich mit FSG ............................................................................................................20 4.3 Abschließende Bewertung ................................................................................................22
- 134 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 3
1 MotivationDas Auffinden häufiger Teilgraphen ist eine wichtige Grundlage für verschiedene Anwendungs-domänen von der Chemie bis zur Wirtschaft. Meistens liegen riesige Datenmengen zu Grunde.Die Identifikation häufig vorkommender Teilgraphen kann zur Lösung vieler Probleme beitra-gen. Dabei stellen Knoten und Kanten je nach Anwendungsdomäne verschiedene Sachverhaltedar. In der Chemie stellen die Knoten Atome dar, während die Kanten die Verbindungen zwi-schen den Atomen darstellen. Das Auffinden häufiger Teilgraphen kann hier dazu verwendetwerden, um gleiche Strukturen innerhalb eines Proteins zu identifizieren. In der Medizin können neue Stoffe mit bereits bekannten Mustern verglichen werden und somitbeispielsweise krebserregende Bestandteile einer Substanz analysiert werden. Wegen dieserBreite an Anwendungsmöglichkeiten stößt das Auffinden von häufigen Teilgraphen auf ein brei-tes Interesse.
2 Einführung 2.1 Subgraphisomorphismen Die Grundlage für die Suche nach häufigen Teilgraphen bildet der Subgraphisomorphismustestd.h. das Überprüfen, ob ein Graph Teil eines anderen Graphen ist.
Seien 2 Graphen G1 und G2 gegeben. Seien G1 = (V1., E1), G2 = (V2, E2) Graphen mit Knotenmengen V1, V2 und Kantenmengen E1, E2.G1 ist isomorph zu G2 genau dann wenn es eine bijektive Abbildung f gibt, so daß jede Kante ausG1 durch eine äquivalente aus G2 vertreten ist und umgekehrt. Dabei bildet die Funktion f Knotenaus V1 auf Knoten aus V2 ab. Bei der Subgraphisomorphie reicht eine injektive Funktion f aus.Es müssen nur die Kanten aus G1 in G2 vertreten sein (siehe Abbildung 1). f heißt dann Graphi-somorphismus (Subgraphisomorphismus) zwischen G1 und G2.
Einen primitiver Ansatz für den Subgraphisomorphismustest bildet das Ausprobieren aller mög-lichen Zuordnungen aus der obigen Formel.Dazu würde man im ersten Schritt jedem Knoten aus G1 einen Knoten in G2 zuweisen und imzweiten Schritt prüfen, ob die Eigenschaft für die Kanten erfüllt wird.
Bei dem folgenden Beispiel (Abbildung 2) könnte dem Knoten A durch f einer der Knoten 1,2,3oder 4 zugeordnet werden. Der nächste zuzuordnende Knoten B hätte dann noch nach Wahl A->3 die Zuweisungsmöglichkeiten 1,2 und 4.
Abbildung 1: Isomorphie und Subgraphisomorphie
1 2
1 1 2
1 2
1 1 2
:
:
, : ( , ) ( ( ), ( ))
:
:
, : ( , ) ( ( ), ( ))
Definiton Isomorphie
f V V
a b V a b E f a f b E
Definiton Subgraphisomorphie
f V V
a b V a b E f a f b E
→
∀ ∈ ∈ ⇔ ∈
→
∀ ∈ ∈ ⇒ ∈
- 135 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 4
Abbildung 2: Isomorphie / Subgraphisomorphie
Sei die Anzahl der Knoten |V1| = n; |V2|= mm>n m=n
Probiermöglichkeiten m!/(m-n)! n!
Operationen O(n*m) O(n2)
Zeit O((m!/(m-)!) * (n*m)) O(n!n2)
Das Entscheidungsproblem der Subgraphisomorphie ist NP-vollständig.Für Graphenisomorphismen wird die Laufzeit noch schlechter.
Ein bekannter Algorithmus ist der von Ullman, der hier kurz skizziert wird.
Wir betrachten im folgenden knoten- und kantenmarkierte Graphen.
Seien 2 Graphen wie folgt gegeben: G1 = (V1,E1,L(V1),L(E1)) und G2 = (V2,E2,L(V2),L(E2)) .Seien V1, V2 die Knotenmengen, E1, E2 die Kantenmengen, L(V1) und L(V2) seien die Mengender Knotenbezeichnungen und L(E1) und L(E2) die Mengen der Kantenbezeichnungen.Sei P = (pij) eine Matrix der Größe n∗m mit n = |V1| und m = |V2|.Seien v ϵ V1 und w ϵ V2.
Im ersten Schritt erfolgt die Initialisierung der Matrix dermaßen, dass alle möglichen sinnvollenZuordnungen der Knoten, also z.B. solche mit gleicher Bezeichnung, der beiden Graphen eine 1erhalten, alle anderen Werte bleiben 0. Im folgenden Beispiel hat die Zelle (Zeile 1 und Spalte 2)den Wert 1, da der Knoten 1 aus dem linken Graphen und der Knoten 2 aus dem rechten Gra-phen die gleiche Bezeichnung A haben.
1 2 3 4
1 1 1
2 1
3 1 1
Im zweiten Schritt wird eine Prozedur backtracking(P,i,F) aufgerufen. Die Prozedur backtracking verwendet die Funktion forwardChecking(P',i,F). Erster Aufruf von backtracking erfolgt mit i=1 und F=Ø
Abbildung 3: Subgraphisomorphietest
B A
A
22 3
1
B A
A
22 3
1
22
4B
A
A
C
3
21
D
A
4
1 2
3D
A
4
1 2
3D
A B
C 4
1 2
3
A-3, D-2, B-1, C-4
D
A
4
1 2
3D
A
4
1 2
3D
A
4
1 2
3
- 136 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 5
//Seien P Matrix, i Zeile, F aufgebaute Zuordnung
1. backtracking(P,i,F)
2. if (i>n) return F; //F stellt einen Subgraphisomorphismus von G1 nach G2 dar3. for each Spalte j in Zeile i do
4. if (P[i,j] == 1)then
5. F=F+(vi,wj) //1 in Spalte, füge diese Zuordnung der Menge F hinzu
6. P' = P //erzeuge eine Kopie der Matrix
7. for each k > i do //alle Zeilen unterhalb dieser Zeile den Wert 0
8. p'kj= 0
9. if(forwardChecking(P',i,F) then
10. backtracking(P',i+1,F) //rekursiver Aufruf
11. endif
12.
13. F = F-(vi,wj) //entferne Zurordnung
14. endif15.
1. forwardChecking(P',i,F)
2. for each (v,w) aus F do
3. for k=i+1 to n
4. for l=1 to m
5. if(existingKante(G1,(vk,v))&&existingKante(G2,(wl,w))&& label(vk,v)==label(wl,w)))
6. pkl=1 //mögliche Zuordnung
7. else
8. pkl=0
9. endif
10. //bei induzierten Teilgraphen muß folgende Bedingung auch noch erfüllt sein11. //if(existingKante(G2,(wl,w))&&existingKante(G1,(vk,v) && label(wl,w)==label(vk,v))
12. //for l=1 to m
13. //for k=i+1 to n
14. //for each (v,w) aus F do
15. for k=i+1 to n
16. gefunden=false;
17. for l=1 to m do
18. if(pkl==1)then
19. gefunden=true;//wenn in der Zeile mindestens eine 1 gefunden 20. break;
21. endif
22.
23. if (not gefunden) then
24. return false; //lauter Nuller
25. endif
26. 27. return true;
28.
Induzierte Teilgraphen:
Sei ein knoten- und kantenmarkierter Graph G = (V(G),E(G),L(V(G)),L(E(G))) gegeben.Gs = (V(Gs),E(Gs),L(V(Gs)),L(E(Gs))) ist ein induzierter Teilgraph von G, wenn folgende Eigen-schaften gelten[1]:
( ) ( ), ( ) ( )
, ( ), ( , ) ( ) ( , ) ( )
s s
s s
V G V G E G E G
u v V G u v E G u v E G
⊂ ⊂
∀ ∈ ∈ ⇔ ∈
Mit anderen Worten: Sind 2 Knoten im Teilgraph Gs enthalten, dann muss auch eine Kante imGraphen G, die zwischen den beiden zugeordneten Knoten ist, im Teilgraph Gs enthalten sein.
2.2 Idee von gSpan gSpan ist ein Algorithmus, der Teilgraphen als Knoten in einem Baum geordnet aufbaut. An je-dem Teilgraphen (Knoten) werden zuerst die Kinder der nächsten Generation erzeugt, die an die-sem Teilgraphen am rechtsäußersten Knoten wachsen können. Von diesen Kindern werden nurdiejenigen weiter betrachtet, die einen minimalen DFS-Code haben und die einen GrenzwertminSup überschreiten. Alle anderen Knoten werden nicht mehr betrachtet und abgeschnitten
- 137 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 6
(„pruning“). Der Grenzwert minSup ist die Unterschranke für die Anzahl von Graphen, in denender betrachtete Teilgraph vorkommt, minSup ist somit ein Maß für die Häufigkeit des Vorkom-mens.
Der Subgraphisomorphismustest bildet den Kern für Algorithmen, die nach häufigen Teilgra-phen suchen. Das Problem Subgraphisomorphietest ist ein NP-vollständiges Problem. Zeit lässtsich nur dadurch sparen, daß falsche Kandidaten erst gar nicht geprüft werden müssen. Der Al-gorithmus gSpan reduziert diese Kosten, in dem er keine Graphen einem Subgraphisomorphie-test unterzieht, die nicht häufig sein können[2].
3 Der gSpan-Algorithmus 3.1 Grundlagen 3.1.1 DFS-Code
Bei einer Tiefensuche durch einen Graphen G=(V,E) werden die Knoten ausgehend von einembeliebigen Knoten in Reihenfolge ihres ersten Besuchs nummeriert. Außerdem werden alle Kan-ten klassifiziert: Die Menge der Kanten wird zerlegt in die Menge der Vorwärtskanten Ef, überdie die Knoten erstmalig erreicht werden und die das Gerüst des Graphen, den DFS-Baum, dar-stellen und die Menge der Rückwärtskanten Eb, die alle übrigen Kanten enthält (solche Kantenwährend der Tiefensuche, über die bereits besuchte Knoten erreicht werden).
Da hier nur zusammenhängende Graphen betrachtet werden, kann für jeden Graphen G mindes-tens ein DFS-Baum (bestehend aus den Knoten V und den Vorwärtskanten Ef) bestimmt werden.Im Allgemeinen gibt es für jeden Graphen G jedoch mehrere unterschiedliche DFS-Bäume.
Den zu G isomorphen Graphen, den man durch Umbenennung mittels Tiefensuche erhält, nen-nen wir GT.
Durch den Tiefendurchlauf entsteht eine lineare Ordnung auf den Knoten: es gilt für zwei Knoten vi, vj: i < j g.d.w. vi wurde bei der Tiefensuche vor vj besucht.
Daher gilt: eine Kante e=(vi,vj) ist eine Vorwärtskante g.d.w. i < j oder (vi,vj) ist Rückwärtskanteg.d.w. i≥ j.
Nunmehr wird die abkürzende Notation (i,j) für eine Kante (vi,vj) benutzt.
Definition der Kleiner-Relation:Sei eine lineare Ordnung <T auf den Kanten von GT wie folgt definiert.Zwischen den Kanten e1 = (i1,j1), e2 = (i2,j2) gilt die Kleiner Relation <T unter folgenden Bedin-gungen:(I) i1 = i2 und j1 < j2 => e1 <T e2
(II) i1 < j1 und j1 = i2 => e1 <T e2
(III) e1 <T e2 und e2 <T e3 => e1 <T e3
Der zuerst besuchte Knoten wird v0 genannt, der zuletzt besuchte Knoten wird v(n-1) (für n=|V|)genannt oder der "rechtsäußerste Knoten". Der einfache Pfad von v0 nach v(n-1) wird der "rechts-äußerste Pfad" in GT genannt.
Zu einem DFS-Baum T eines Graphen G nennt man eine Kantenfolge (ei) mit ei <T e(i+1) (0, ..., |E|-1), einen DFS-Code code(G,T).
Es werden von nun an knoten- und kantenmarkierte Graphen G=(V,E,L(V),L(E)) betrachtet.
- 138 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 7
Seien hierbei V eine Menge von Knoten, E eine Menge von Kanten mit E⊆VxV.Seien L(V): V -> L und L(E): E -> L injektive Funktionen, wobei L eine Menge von Markierun-gen (labels) darstellt und L(V) die Markierung der Knoten und L(E) die Markierung der Kantensind.
Dann kann jede Kante (i,j) auch als 5-Tupel (i,j,li,l(i,j),lj) dargestellt werden mit li = LV(i), l(i,j) = LE(i,j) und lj = LV(j).
Organische Verbindungen in einer Chemikalien-Datenbank könnte man folgendermaßen darstel-len:Als Menge der Label verwendet man L = C, N, O, H, S, -, =, ≡.Die Markierungen C,N, O, H, S werden für Knotenmarkierungen verwendet und die Markie-rungen -, =, ≡ für Kantenmarkierungen. Dabei steht "C" für ein Kohlenstoffatom, "N" für ein Stickstoffatom, "O" für ein Sauerstoffatom,"H" für ein Wasserstoffatom und "S" für ein Schwefelatom.Weiterhin steht "-" für eine kovalente Einfachbinding, "=" für eine kovalente Doppelbindungund "≡" für eine kovalente Dreifachbindung.
So könnte man die Chemikalie Harnstoff folgendermaßen als Graph beschreiben:
N HH
C 0N
H
H
5 76
0 12
4
3
In diesem Beispiel können folgende Mengen angegeben werden. Die Knotenmenge V = 0,1,2,3,4,5,6,7Die Kantenmenge E = (0,1),(0,2),(2,3),(2,4),(0,5),(5,6),(5,7)Markierung der Knoten L(V)=(0,C), (1,O), (2,N), (3,H), (4,H), (5,N), (6,H), (7,H)Markierung der Kanten L(E)=((0,1),=),((0,2),-),((2,3),-),((2,4),-),((0,5),-),((5,6),-),((5,7),-)
Die Markierungen (Labels) sind wichtig, weil gSpan bei der Suche nach häufigen Teilgraphendie Anordnung der Label betrachtet d.h. nach häufigen Labelmustern sucht.
- 139 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 8
Die Mengen der Vorwärtskanten Ef,T und die Menge der Rückwärtskanten Eb,T im Graphen GT
sind wie folgt definiet:
Im Beispiel aus der Abbildung 4 ergeben sich folgende Vorwärtskanten, Rückwärtskanten undausgewählte Kleiner-Relationen der Kanten.
, 0 1 1 2 2 3 1 4
1 2 4 6
1 T 2 1 2 1 1
2 T 4 2 4 2 4
1 T 4 1 T 2 2 T 4
( , ), ( , ), ( , ), ( , )
, , ,
(0,1), (1,2), (2,3), (1,4)
e < e , da j =i und i <j (I)
e < e , da j =i und i <j (II)
e < e ,da e < e und e < e (III)
f TE v v v v v v v v
e e e e
=
=
=
2
, 2 0 3 1
3 5
2 3 3 2 2
( , ), ( , )
,
(2,0), (3,1)
, j =i und i <j (II)
b T
T
E v v v v
e e
e e da
=
=
=
<
Um den DFS-Code code(Gα,Tα) zu erhalten, müssen die Kanten gemäß der Kleiner-Relation auf-steigend sortiert werden (siehe folgende Tabelle). Der code(Gα,Tα) ergibt sich dann, indem mandie zweite Spalte von oben nach unten liest.
Abbildung 4: Ausgangsgraph G und konstruierter DFS-Graph GT
vo
X
Y
X
Z
a
c
b
Z
d
a
b
v4
v1
v2
v3
X
Y
X
Z
a
c
b
Z
d
a
b
G GT
α
,
,
| , , , ( , )
| , , , ( , )
f T i j
b T i j
E e i j i j e v v E
E e i j i j e v v E
= ∀ < = ∈
= ∀ > = ∈
- 140 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 9
0 (0,1,X,a,Y)
1 (1,2,Y,b,X)
2 (2,0,X,a,X)
3 (2,3,X,c,Z)
4 (3,1,Z,b,Y)
5 (1,4,Y,d,Z)
Tabelle 3.1: sortierte Kantenfolge ergibt DFS-Code α
3.1.2 Lexikographische DFS-Ordnung
Nach Ermittlung der DFS-Codes aller möglichen DFS-Bäume wird eine lexikographische DFS-Ordnung zwischen diesen ermittelt.
Sei Z = code(G,T) | T ist ein DFS Baum von G .Sei <L eine Relation zur Darstellung einer linearen Ordnung in der Menge der Labels L.
Dann stellt die lexikographische Kombination der Relation <T und der Relation <L eine neue Re-lation <e mit einer linearen Ordnung auf der Menge G mit TE L L L× × × , wobei ET die Mengeder Kanten in GT ist.
Lexikographische DFS-Ordnung ist eine als Folge definierte lineare Ordnung.Seien α = code(Gα,Tα) = (a0,a1,...,am), β = code(Gβ,Tβ) = (b0,b1,...,bn), α,ß ϵ Z(G).
Es gilt die Lexikographische DFS-Ordnung α ≤ β, falls eine der folgenden beiden Bedingungenerüllt ist:
0 0 ( , ) ( , )Für DFS Codes ( ,..., ) und ( ,..., ) mit ( , , , , ) und ( , , , , ) gilt ,
wenn einer der beiden Bedingungen erfüllt ist:
(1)
, 0 min( , ),
a a a a b b b bm n t a a i i j j t b b i i j j
k k
a a b b a i j l l l b i j l l l
t t m n
a b für
α β α β= = = = ≤
∃ ≤ ≤
=
( , ) ( , )
( ,
( )
( )
( ) ,
( )
( ) ,
( ) ,
a a b b
a b
a b a
a a b b
a a b b a b
a a b b a b i j i j
t t a a b b a b
a a b b a b i i
a a b b a b i i i
k t und
i j i j
i j i j und j j
i j i j und j j l l
a b für i j i j und i i
i j i j und i i l l
i j i j und i i l l und l
<
< ∧ >
> ∧ > <
> ∧ > = <
< < ∧ < >
< ∧ < = <
< ∧ < = = ) ( , )
( , ) ( , )
a a b b
( ) , ,
(2) 0
Ist die Kante (i ,j ) eine Rückwärtskante und die Kante (i ,j ) Vorwärtskante
a b b
a b a a b b a b
j i j
a a b b a b i i i j i j j j
k k
l
i j i j und i i l l l l und l l
a b für k m und n m
<
< ∧ < = = = <
= ≤ ≤ ≥
a a b b
a a b b
Ist die Kante (i ,j ) eine Rückwärtskante und die Kante (i ,j ) eine Rückwärtskante
Ist die Kante (i ,j ) eine Vorwärtskante und die Kante (i ,j ) eine Vorwärtskante
a a b b
a a b b
i j i j
i j i j
⇒ < ∧ >
⇒ > ∧ >
a a b b
i j i j⇒ < ∧ <
- 141 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 10
Seien folgende weitere DFS-Bäume neben dem bereits erwähnten DFS-Baum des Ausgangsgra-phen G gegeben (Abbildung 5).
Für diese DFS-Bäume lassen sich folgende DFS-Codes angeben: α,β und γ. Dabei werden diesortierten Kantenfolgen von oben nach unten in der jeweiligen Spalte gelesen.
Kante DFS-Code: α DFS-Code: β DFS-Code: γ
0 (0,1,X,a,Y) (0,1,Y,a,X) (0,1,X,a,X)
1 (1,2,Y,b,X) (1,2,X,a,X) (1,2,X,a,Y)
2 (2,0,X,a,X) (2,0,X,b,Y) (2,0,Y,b,X)
3 (2,3,X,c,Z) (2,3,X,c,Z) (2,3,Y,b,Z)
4 (3,1,Z,b,Y) (3,0,Z,b,Y) (3,0,Z,c,X)
5 (1,4,Y,d,Z) (0,4,Y,d,Z) (2,4,Y,d,Z)
In der 5-Tupeldarstellung lassen sich diese DFS-Codes zu den oben erwähnten DFS-Bäumen wiefolgt angeben:α code(Gα,Tα) (a0,a1,a2,a3,a4,a5) ((0,1,X,a,Y),(1,2,Y,b,X),(2,0,X,a,X),(2,3,X,c,Z),(3,1,Z,b,Y),(1,4,Y,d,Z))
β code(Gβ,Tβ) (b0,b1,b2,b3,b4,b5) ((0,1,Y,a,X),(1,2,X,a,X),(2,0,X,b,Y),(2,3,X,c,Z),(3,0,Z,b,Y),(0,4,Y,d,Z))
γ code(Gγ,Tγ) (c0,c1,c2,c3,c4,c5) ((0,1,X,a,X),(1,2,X,a,Y),(2,0,Y,b,X),(2,3,Y,b,Z),(3,0,Z,c,X),(2,4,Y,d,Z))
α ≤ ß wegen (1), α ≥γ wegen (1) erfüllt wird und ß ≥γ wegen (1) .Das Ergebnis der Vergleiche liefert somit: γ ≤ α ≤ ß[2]
3.1.3 Minimaler DFS-Code
Sei Z(G) = code(G,T) | T ist ein DFS Baum von G.Anhand des Lexikographischen DFS-Ordnung wird der kleinste DFS-Code bezüglich ≤ ermittelt.Dieser wird der minimale DFS-Code, min(Z(G)), genannt[2].
Beispiel: Im Abschnitt 3.1.2 stellt γ den minimalen DFS-Code dar.
Abbildung 5: verschiedene DFS-Codes
vo
X
Y
X
Z
a
c
b z
d
ab
v4
v1
v2
v3
vo
X
Y
X
Z
ac
b
Z
d
a
b
v1
v2
v3
γ
vo X
Y
X
z
c
b
Z
d
a
b
v4
v1
v2
v3
a
α β γ
- 142 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 11
Theorem 1Seien die Graphen G und G' gegeben. G ist isomorph zu G', g.d.w. min(Z(G))=min(Z(G')).
D.h. 2 Graphen sind dann isomorph, wenn ihre DFS-Codes übereinstimmen und minimal sind.Theorem 1 besagt somit, daß das Problem der Suche nach isomorphen Graphen (hohe Komplexi-tät) auf das Problem des Auffindens gleicher minimaler DFS-Codes zurückgeführt werden kann(geringere Komplexität, da sequentielle Suche nach Mustern). Dieses Theorem ist deshalb wich-tig, weil es dem Algorithmus gSpan ermöglicht, DFS-Codes, die nicht minimal sind, beim Iso-morphietest nicht mehr zu berücksichtigen, da diese bereits getestet wurden.
3.1.4 DFS-Code-Baum
Die Knoten eine DFS-Code-Baumes stellen Teilgraphen dar. In der ersten Ebene befinden sichKnoten (Teilgraphen), die nur einen Knoten enthalten. In der nächsten Ebene befinden sich Kno-ten (Teilgraphen), die nur eine Kante enthalten. Mit jeder Stufe wird die Anzahl der Kanten derTeilgraphen um 1 erhöht.Der DFS-Code-Baum hat auch die Eigenschaft, daß alle Kinder eines Knoten einer lexikographi-schen DFS-Ordnung folgen.gSpan nutzt die Eigenschaften eines DFS-Code-Baumes. gSpan baut den DFS-Code-Baum soauf, daß nur häufige Teilgraphen als Knoten des DFS-Code-Baumes vorkommen und die gege-bene lexikographische DFS-Ordnung benutzt gSpan zum Abbrechen der Suche bei nicht mini-malen DFS-Codes.Der gSpan vergrößert den Suchraum für Teilgraphen stufenweise mit Hilfe des DFS-Code-Bau-mes.Der DFS-Code-Baum wächst durch Generierung der Kinder (Generierung größerer DFS-Codes)d.h. Erweiterung von Teilgraphen.
Abbildung 6: DFS-Code-Baum
Die Erweiterung des DFS-Code-Baumes folgt gewissen Regeln, die im Folgenden erläutert wer-den:Um einen korrekten DFS-Code zu erhalten, muss die erweiterte Kante b an einem DFS-Code-Baum-Knoten eine Kante sein, die mit einem Knoten auf dem rechtsäußersten Pfad inzident ist.Als Rückwärtskante kann b ausschließlich vom rechtsäußersten Knoten ausgehen, als
S S'
0-edge
1-edge
0-edge
2-edge
Alle häufigen 1-kantigen Graphen in der Graphenmenge
1 hört die Suche auf, weil dies nicht der minimale DFS- Code ist
1
Alle häufigen Knoten
- 143 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 12
Vorwärtskante kann b von einem beliebigen auf dem rechtsäußersten Pfad liegenden Knotenausgehen. Auf diese Weise kann man mit Hilfe der lexikographischen DFS-Ordnung korrekteDFS-Codes und damit Teilgraphen geordnet wachsen lassen.
(1) (2) (3) (4) (5)
Für eine gegebene Menge von Bezeichnungen L enthält der DFS-Code-Baum im Allgemeineneine unendliche Menge von Graphen. Die Suche von häufigen Teilgraphen erfolgt jedoch in ei-ner endlichen Menge von Graphen, weshalb der DFS-Code-Baum in diesem Falle endlich ist.
Die n-te Ebene eines DFS-Code-Baums enthält jeweils alle Teilgraphen mit (n-1) Kanten. Mit-tels eines Tiefensuchdurchlaufs kann man daher alle minimalen DFS-Codes der häufigen Teil-graphen bestimmen.
Zwischen Eltern und Kindern besteht in einem DFS-Code-Baum folgende Beziehung:Sei ein DFS-Code α=(a0,a1,...,am) gegeben. Dann ist der DFS-Code β=(a0,a1,...,am,b) ein Kind von α und α der Vater von β. Die Kinder von α ist die Menge aller DFS-Codes, für die α der Vater ist.
Eine Tiefensuche auf dem DFS-Code-Baum gemäß Preorder-Reihenfolge (Wurzel, Teilbäumevon links nach rechts) folgt damit der lexikografischen DFS-Ordnung.
Bei dieser Suche werden nur alle minimalen DFS-Codes aller Graphen bearbeitet.In Abbildung 6 seien s und s' unterschiedliche DFS-Codes für denselben Graphen. Dann kann s' nicht der minimale DFS-Code für diesen Graphen sein, da alle Knoten im Baumd.h die DFS-Codes nach der lexikographischen DFS-Ordnung sortiert vorliegen (beginnend mitder Wurzel). Bei der Suche nach häufigen Teilgraphen muss man den Teilbaum, dessen Wurzels' ist, daher nicht weiter berücksichtigen und kann ihn "abschneiden" (pruning).
- 144 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 13
3.2 Der AlgorithmusIm Folgenden wird der Algoritmus gSpan skizziert und erläutert.
Sei eine Menge an Graphen gegeben D = G1,...,Gn (Eingabe).Sei S die Menge der häufigen Teilgraphen (Ausgabe).Sei s.D ist die Menge aller Graphen, in denen der Teilgraph s (DFS-Baum-Knoten s) enthaltenist.
Algorithmus 1: graph_Projection (D,S)
1. Sortiere die Markierungen der Knoten und Kanten nach ihrer Häufigkeit in D, wobei
häufig heisst, dass Markierungen der Knoten und Kanten mindestens minSup-fach in D
vorkommen.
2. Lösche nicht häufige Knoten und Kanten aus D und benenne sie um
3. Ordne die übrig gebliebenen Knoten und Kanten in absteigender Häufigkeit
4. S1=Alle häufigen 1-kantigen Graphen aus D sortiert gemäß lexikographischer DFS-
Ordnung
5. S=S1
6. for each Kante e in S1 do
7. s = e
8. s.D =g|für alle gϵD und eϵE(g) //Menge der Graphen aus D, in denen e vorkommt
9. subgraph_Mining(D,S,s)
10. D = D-e //entferne Kante
11. if (|D|<minSup)then//abbrechen, sobald weniger Graphen verbleiben, als minSup
erfordert.
12. Break
13. endif
14.
Subprocedure 1: subgraph_Mining(D,S,s)1. if (s≠min(s)) then //Wenn nicht minimaler DFS-Code abbruch
2. return //pruning
3. endif
4. //Für diejenigen, die einen minimalen DFS-Code garantieren
5. S= S +s; //füge s in die Menge der häufigen Teilgraphen hinzu
6. C= Alle potentiellen Kinder von s mit 1-Kanten Wachstum
7. enumerate(s)
//zähle Vorkommen von s in jedem Graphen g ϵ s.D, wobei s.D die Menge aller Gra-
phen, in denen dieser Teilgraph s enthalten ist
//s ist der DFS-Code repräsentierte Teilgraph auf dessen rechtsäußersten Pfad eine
Kante e erweitert wurde, c ist ein Kind von s im DFS-Code Baum
8. For each c in C do
9. if(support(c))≥ minSup) //gewisse Häufigkeit vorhanden10. s=c //Kind aufnehmen
11. subgraph_Mining(D,S,s) //rekursiver Aufruf
12. //else
13. //pruning
14. endif
15.
- 145 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 14
Subprocedure 2: enumerate(s)
1. for each g in s.D do //für jeden Graphen g, in denen s Teilgraph ist
2. schau nach, wo der Teilgraph s in g vorkommt
3. für jedes Kind c von s do // s ist der DFS-Code repräsentierte Teilgraph auf
dessen rechtsäußersten Pfad eine Kante e erweitert wurde, c ist ein Kind von s im
DFS-Code Baum
4. schau nach, ob das Kind im Graphen g vertreten ist
5. wenn ja, dann füge den Graphen g zu Menge c.D hinzu
6. if(g ist in allen Kindern von s enthalten)
7. break
8. endif
9.
10.
Algorithmus 1: Vorbereitungen (Zeilen 1-5)Die Menge der Bezeichnungen der Ausgangsgraphen D werden nach der Häufigkeit ihres Vor-kommens sortiert. Durch die separate Betrachtung der Knoten und Kanten kann folgender Fallauftreten: Der Knoten A und die Kante a kommen häufig vor. Die Verbindung (A,a,A) kommthäufig vor, aber nicht die Verbindungen (A,a,B) [2].Diejenigen Knoten und Kanten, die nicht einer vorgegebenen Häufigkeit entsprechen, werdenentfernt. Somit eliminiert der Algorithmus gSpan von vornherein alle Knoten und Kanten, diekeine Chance haben als Bestandteil von Teilgraphen häufig zu sein. Die übriggebliebenen Kno-ten und Kanten werden neu bezeichnet und derart geordnet, so daß die häufigsten Knoten undKanten die kleinsten Labels erhalten. Als nächstes werden alle Teilgraphen mit genau einer Kan-te in die lexikographische DFS-Ordnung gebracht und der Menge S1 zugewiesen. Es wird eineKopie S von S1 erzeugt.
Die Menge S1 enthält zu Beginn alle Teilgraphen, die nur eine Kante haben und einem gewissensupport entsprechen d.h. in einer gewissen Anzahl vertreten sind. Diese Anzahl drückt aus, wiehäufig sie sind.
Algorithmus 1: Betrachtung der Teilgraphen (Zeilen 6-14)Die Bearbeitung einzelner Kanten aus der Menge S1 erfolgt in einer Schleife, welche terminiertnachdem alle Kanten betrachtet worden sind.Jede Kante e aus S1 wird einem s zugewiesen, der einen Knoten im DFS-Code-Baum darstellt.s besitzt als Attribut alle Graphen, die diese Kante e enthalten (Zeile 8). Die Knoten des DFS-Code-Baumes werden ergänzt um die Menge aller Graphen, in denen dieser Teilgraph enthaltenist (im Codetext s.D). Die Kinder von diesem Knoten s können nur noch in diesen Graphen vor-kommen. Damit wird mit s.D der Suchraum für die Kinder auf diese Graphen begrenzt. In die-sem Zusammenhang bildet die Menge S1 den Ausgangspunkt für alle Kinder. Diese Eigenschaftstellt die erste Bedeutung der Menge S1 dar. Die aufgerufene Methode subgraph_Mining() er-zeugt alle Knoten, die auf dem Pfad von s wachsen.Nach dieser Verarbeitung für eine Kante aus S1 kann die betrachtete Kante aus allen Graphen inder Graphenmenge entfernt werden(Zeile 10). Warum die Kante nach jedem Durchlauf der foreach-Schleife aus Zeile 10 entfernt werden kann, sei an einem Beispiel erläutert. Wenn zu Be-ginn der for each-Schleife 3 häufige Kanten gegeben sind, wie (A,a,A), (B,b,C) und (C,c,C) wür-de der erste Durchlauf der for each- Schleife dazu führen, daß die Methode subgraph_Miningalle Teilgraphen finden würde, die (A,a,A) enthalten. Im zweiten Durchlauf der for each-Schleifewürde subgraph_Mining() alle Teilgraphen finden, die (B,b,C) enthalten, jedoch nicht mehr die-jenigen, die (A,a,A) enthalten, da bereits alle Teilgraphen gefunden worden sind, die diese Kante(A,a,A) enthalten.Dieser Vorgang stellt die zweite Bedeutung der Menge S1 dar. Diesen Vorgang nennt man auch
- 146 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 15
die Projektion der gesamten Graphenmenge. Die Entfernung der bearbeiteten Kanten führt dazu,daß die noch zu betrachtenden Graphen kleiner werden. Der Algorithmus wird dadurch immerschneller. Die Abfrage in den Zeilen 11-13 bewirkt, daß abgebrochen wird, sobald weniger Gra-phen verbleiben, als minSup erfordert.
Subroutine 1: subgraph_Mining():Diese Routine läßt im DFS-Code-Baum zuerst die Knoten auf der Ebene 1-edge um eine Kantewachsen und durch den rekursiven Aufruf wiederum den auf der Ebene 2-edge um eine Kantewachsen usw, wobei das Wachsen nach bestimmten Regeln erfolgt (Siehe hierzu die Überschrift„Generierung potentieller Kinder von s mit 1-Kanten Wachstum“).
Die Abbruchbedingung s ≠min(s) sorgt dafür, daß doppelte Teilgraphen und deren Nachkommennicht mehr betrachtet werden. Dieser Vorgang wird Pruning genannt. Durch das Pruning wirdder Suchraum reduziert und es werden redundante Berechnungen vermieden.Der Test auf s ≠min(s) ist zwar rechenzeitintensiv, jedoch kostet es weniger als der Test auf nichthäufige Teilgraphen. Es lässt sich beweisen, daß das Pruning das Ergebnis nicht verändert[2].Wenn es sich bei s um ein Minimum DFS-Code handelt, fügt diese Routine s der Menge derhäufigen Teilgraphen hinzu (Zeile 5).Danach werden alle potentiellen Kinder generiert, die um eine Kante wachsen. Dieser Vorgangist nicht effizient. Es gibt effizientere Ansätze auf die nicht näher eingegangen wird[2]. Die Ge-nerierung der potenziellen Kinder kostet nicht viel. Dabei werden Regeln eingehalten, die dieNachbarschaft im DFS-Code einschränken (Siehe DFS Code Nachbarschaftseinschränkung)[2].Nach Generierung der potentiellen Kinder wird die Subroutine enumerate() aufgerufen.
Danach wird für jedes Kind die Routine subgraph_Mining() rekursiv aufgerufen. In jedem rekur-siven Aufruf erweitert diese Routine den DFS-Code-Baum um eine Kante und findet alle Kindervon s.Die Rekursion folgt der Preorder-Suche, wodurch die häufigen Teilgraphen nach lexikographi-scher DFS-Ordnung gefunden werden, d.h. Der Minimum DFS-Code, der vorher gefundenenTeilgraphen sollte kleiner sein als die später gefundenen[2]. Am Ende dieser Routine ist dieMenge aller häufigen Teilgraphen in einer lexikographischen DFS-Ordnung gefunden.
DFS Code Nachbarschaftseinschränkung:Für einen Graphen G und einen DFS-Baum T sei folgender DFS-Code α=code(G,T)=(ao,a1,...,am)gegeben mit m≥2 und seien 2 Nachbarn ak und ak+1 mit 0≤k≤m gegeben mit ak=(ik,lk,lik,l(ik,jk),ljk)und ak+1=(ik+1,l(k+1),li(k+1),l(i(k+1),j(k+1)),lj(k+1)).Dann gelten für die Nachbarn ak und ak+1 folgende Bedingungen:
Wenn ak eine Rückwärtskante ist:
i) Wenn ak+1 eine Vorwärtskante ist, dann ist i(k+1) ≤ ik und j(k+1)=ik+1
ii) Wenn ak+1 eine Rückwärtskante ist, dann ist i(k+1) = ik und jk<j(k+1)
Wenn ak eine Vorwärtskante ist:
i) Wenn ak+1 eine Vorwärtskante, dann i(k+1) ≤ jk und j(k+1)=jk+1
ii) Wenn ak+1 eine Rückwärtskante, dann i(k+1) ≤ jk und j(k+1)<ik
Diese Einschränkung erlaubt es nicht, dass man Kanten im DFS-Code vertauscht.
- 147 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 16
Einschränkungen bei der Generierung potentieller Kinder:
(1) (2) (3) (4) (5)
Die Generierung der potentiellen Kinder folgt gewissen Regeln. Für den gegeben Ausgangsgra-phen dürfen die Kinder nur am rechtsäußersten Pfad wachen. Der rechtsäußerste Pfad ist derPfad vom Wurzelknoten zu dem Knoten am rechtsäußersten Knoten.
Diese Einschränkung erzeugt nur gültige DFS-Baum-Knoten.
Subroutine enumerate():Diese Subroutine zählt das Vorkommen aller gültigen Kinder von s in einem Graphen. Durch dasZählen der Kinder von s in jedem Graphen G, in dem s enthalten ist, weiß man welche Kinderals häufige Teilgraphen in Frage kommen. Außerdem identifiziert man dadurch alle Graphen, dieden Teilgraphen enthalten. Diese Identifikation wird bei der nächsten Enumeration benötigt, umdie Kinder davon zu erhalten. Wie in Zeile 2 sichtbar wird, wird kein Subgraphisomorphismus-test gefordert[2]. Beginnend mit der ersten Kante werden durch Hinzufügen und erneuter Prü-fung auf Vorkommen dieser Kante im Graphen geprüft, ob der Teilgraph im Graphen enthaltenist. Mit dieser Methode werden die totalen Kosten gesenkt.
Pruning:Es gibt 2 Ansätze für Pruning. Bei Pre-Pruning erfolgt das Absschneiden vor enumerate() undbei post-Pruning erfolgt das Absschneiden nach enumerate(). In gSpan wird ein Trade-off ausbeiden verwendet. Es werden nur Kinder verworfen, die auch tatsächlich gefunden worden sind.Das Pruning erfolgt in 4 Stadien[2]:
Wenn die erste Kante eo in einem minimalen DFS-Code ist, so können Kinder von s kei-ne Kante beinhalten, die in einer Kleiner-Relation zur Kante eo steht
Für jede Rückwärtskante, die von s aus wächst, darf diese Kante nicht in einer Kleiner-Relation zu einer Kante stehen, welche mit dem Zielknoten dieser Rückwärtskante in sverbunden ist
Kanten, die nicht auf dem rechtsäußersten Knoten wachsen, werden verworfen, da siekeine möglichen Kinder darstellen
Post-pruning wird auf die übrig gebliebenen angewendet
Durch Pruning werden alle doppelt auftauchenden DFS-Codes und deren Nachfahren verworfen.
Berechnung von min(s): minimaler DFS-CodeEin einfacher Weg ist hierbei alle DFS-Codes von Graphen zu erzeugen, die s repräsentiert undsich dann für den kleinsten zu entscheiden[2].
- 148 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 17
3.3 Verwendung von gSpan nach graphenbasierter Datenprojektion Der Algorithmus gSpan benötigt zu Beginn die gesamte Datenmenge. Wenn die komplette Gra-phendatenbank in den Arbeitsspeicher geladen werden kann, kann gSpan direkt angewendet wer-den. Falls die Graphdatenbank nicht komplett in Hauptspeicher passt, kann man den gSpan erstnach einer graphenbasierten Datenprojektion anwenden. Dabei können Graphen mit gemeinsa-mer Basis aus der Ausgangsmenge D als Prefix gespeichert werden und die Unterschiede alsPostfix[3].
4 Kritische Bewertung 4.1 Vergleich mit AGM Im Folgenden wird der Algorithmus AGM(Apriori based Algorithmus) skizziert und mit gSpanverglichen.
L1 = Menge aller häufigen 1-kantigen Teilgraphen
1. for (k=2, Lk-1≠Ø;k++) do
2. Ck=apriori-gen(Lk-1) //Candidate Generation
3. for each transaction t in D do //D=G1,G2,..Gn
4. Ct=subset(Ck,t) // Kandidaten in D=G1,.. vertreten
5. for each candidates c in Ct do
6. c.count++ //update Counter
7.
8.
9. Lk= cϵCk|c.count ≥ minSup //prüfe für jeden Kandidaten, ob minSup erfüllt
10.
Antwort= Alle häufigen k-kantigen Teilgraphen
0. Function Ck apriori-gen(Lk-1)
1. Ck=join(Lk-1,Lk-1) //joining
2. for each itemset c in Ck do
3. for each (k-1) subsets s of c do
4. if (s not in Lk-1) then
5. Ck= delete_c_from_Ck //pruning false positives
6. endif
7.
8.
9. return Ck
10.
Sei eine Ausgangsmenge an Graphen D=G1,G2,...,Gn gegeben.Sei Lk-1 eine Menge an Graphen mit (k-1)-Kanten.Sei Ck die Menge der potentiellen Kandidaten mit der Eigenschaft, daß die Menge Lk-1 eine Un-termenge von Ck ist mit k=2,...,m.Sei die Menge Ct eine Menge aus den Kandidaten Ck, die Teilgraph in der Ausgangsmenge Dsind. Sei t=1,..,n.
Die Ausgangsbasis für den Algoritmus AGM liefern 1-kantige häufige Teilgraphen, die MengeLk-1 für k=2. Für jeden dieser Teilgraphen werden Kandidaten generiert. Diese Kandidaten habendie Eigenschaft, daß eine Kante hinzugekommen ist, die Menge Ck. Für jeden Graphen Gt mit t=1, ...,n aus der Ausgangsmenge D wird überprüft, ob der Kandidat k aus Ck im Graphen Gt alsTeilgraph enthalten ist (Subgraphisomorphietest). Für jeden Graphen Gt aus D wird eine neue Menge Ct gebildet. Mit anderen Worten bekommt je-der Graph aus der Ausgangsmenge seine Kandidaten in der Menge Ct zugewiesen. Für jedenGraphen aus der Menge Ct wird ein Zähler hochgezählt, welcher ein Maß für das Vorkommendes Kandidaten in dem Graphen Gt darstellt. Nachdem für alle Graphen in der Ausgangsmeng
- 149 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 18
die Mengen Ct' s gebildet wurden, enthalten die Zähler für jeden Kandidaten eine Zahl, welcherein Maß für die Häufigkeit des Vorkommens des Kandidaten in der gesamten Ausgangsmengeliefert. Diese Zahl wird für jeden Kandidaten mit einem Grenzwert minSup verglichen, welcherdie Unterschranke zur Identifizierung häufiger Teilgraphen bildet. Am Ende wird eine Menge anhäufigen Teilgraphen Lk mit k-Kanten gebildet, welche die neue Ausgangsmenge für den Algo-rithmus liefert. Falls Elemente in der Menge Lk enthalten sind, setzt der Algoritmus das bisherigeVorgehen mit dieser Ausgangsmenge fort, ansonsten terminiert der Algoritmus.Der Algoritmus AGM nutzt prinzipiell den Apriori-Ansatz der iterativen Kandidatengenerierungund Kandidatenevaluierung[2]:
1 Candidate generationKandidatenerzeugung
Die Kandidatengenerierung bedeutet die Erzeugung von k+1 Subgraph-Kandidaten aus k häufigen Teilgraphen. Es werden nur Kandidaten ausdenjenigen Teilgraphen erzeugt, die sich im vorherigen Durchlauf alshäufig erwiesen haben, ohne die Transaktionen zu beachten[4]. Die Ideeist die folgende: Sind alle Untermengen einer Menge häufig vorkom-mende Mengen, so muß auch die Obermenge eine häufig vorkommendesein. Die Menge Lk-1 wird als Untermenge betrachtet (z.B. hat nur eineKante) und mit sich selber gejoint. Es entsteht eine Menge Lk (z.B miteiner Kante mehr).
Die Generierung von k+1 Subgraph-Kandidaten aus k häufigen Teilgra-phen ist kompliziert und kostenaufwändig.
2 Pruning false positivesAusschneiden falscherpositiver Ergebnisse
Lk ist die Menge an Teilgraphen, die man einem Subgraphisomorphietestunterziehen muß. Diejenigen, die sich nicht als häufig herausstellen wer-den entfernt. Mit anderen Worten muß der Subgraphisomorphietest er-folgen, um dann festzustellen, daß die untersuchten Kandidaten sich alsfalsche Kandidaten herausstellen.
Der Subgraphisomorphismustest ist sehr aufwendig.
Der Algorithmus gSpan vermeidet beide oben genannten Kosten, da gSpan weder mit Kandida-tengenerierung noch mit Ausschneiden falscher positiver Ergebnisse arbeitet.
- 150 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 19
Im Folgenden werden skizzenhaft weitere Merkmale von AGM und gSpan angegeben.
gSpan verwendet die Tiefensuche im Gegensatz zu AGM, welcher die Breitensuche nutzt.Die Breitensuche kann in Zeiten der Hochbelastung auf die Festplatte kritisch werden, da einehohe I/O-Belastung vorliegen würde, weil bei der Breitensuche öfter auf die Festplatte zugegrif-fen wird als bei der Tiefensuche[2]. Sowohl gSpan als auch AGM sind im Stande relevanteTransaktionsID's zu identifizieren und damit doppelt vorkommende Graphen nicht unnötig demIsomorphietest zu unterziehen. Jedoch vermeidet gSpan diese redundanten Tests komplett, da ernur die minimalen DFS-Codes im Preorderdurchlauf weiterverfolgt.Die Tiefensuche ist der Grund dafür, warum für gSpan es möglich wird, komplett in den Arbeit-speicher geladen werden zu können. Für Algorithmen, welche die Breitensuche nutzen, wäredies nicht möglich[2].
Es gibt weitere Gründe warum gSpan schneller ist AGM:AGM gSpan
verwendet nur induzierte Teilgraphen Kann induzierte Teilgraphen verwenden, muß keineverwenden
findet alle häufigen Substrukturen sowohl verbun-dene als auch unverbundene Teilgraphen
findet nur häufige verbundene Teilgraphen
update von Zählern notwendig update von Zählern entfällt
verwendet kanonische Labels verwendet DFS-Code
Auf Kanonische Labels und TransaktionsID's wird im Abschnitt FSG eingegangen.
- 151 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 20
4.2 Vergleich mit FSG Im Folgenden wird der Algoritmus FSG (Frequent Subgraph) skizziert und mit gSpan vergli-chen.
F1 = alle häufig vorkommenden 1-kantigen Teilgraphen aus der Graphenmenge D
F2 = alle häufig vorkommenden 2-kantigen Teilgraphen aus der Graphenmenge D
1. k=3
2. while Fk-1≠Ø do
3. Ck = fsg-gen(Fk-1) //candidate generation
4. for each candidate gkϵCk do
5. gk.count=0
6. for each transaction tϵD do //subgraphisomorhietest
7. if (candidate_gk_included_in_t) then
8. gk.count=gk.count+1 //Teilgraph wieder in der Menge D gefunden
9. endif
10.
11.
12. Fk=gkϵCk| gk.count ≥ minSup //nur wenn sie häufig sind
13. k=k+1
14.
Antwort= Alle häufigen k-kantigen Teilgraphen
fsg-gen(Fk) //Candidate Generation
1. Ck+1= Ø
2. For each Paar gik,gj
kϵFk mit i≤j, so daß cl(gik) ≤ cl(gj
k) do
3. for each Kante eϵgik do//erzeugt Teilgraphen mit (k-1)-Kanten
4. gik-1 = gi
k-e
5. if(gik-1 enthalten in gj
k)then // gik-1 und gj
k haben gleiche Teilgraphen
6. Tk+1 =fsg-join(gik,gj
k) //Wenn gik und gj
k gleiche (k-1)-kantige Teilgraphen mergen
7. for each gjk+1 ϵ Tk+1 do //test downward closure property zur Eliminierung
8. flag=true
9. for each Kante f ϵ gjk+1 do
10. hlk =gj
k+1 -f
11. if (istVerbunden(hlk) and h_nichtElement_von_F(Fk, hl
k)) then
12. //closure property false
13. flag=false
14. break
15. endif16.
17. if(flag=true) then
18. Ck+1 =Ck+1+gk+1
19. endif
20.
21. endif
22.
23.
24.return Ck+1
Sei eine Ausgangsmenge an Graphen D=G1,G2,...,Gn gegeben mit t=1,2,...,n.Sei Fk-1 eine Menge an Graphen mit (k-1)-Kanten.Sei gi
k der i-te Teilgraph in der Menge Fk.Sei cl(gi
k) das kanonische Label von gik.
Sei Ck die Menge der Kandidaten.
Der Algorithmus FSG beginnt mit einer Menge von 2-kantigen häufigenTeilgraphen aus D. Imnächsten Schritt erzeugt FSG alle Kandidaten, was im Wesentlichen 3 Schritte beinhaltet: DieIdentifizierung identischer Teilgraphen mit (k-1)-Kanten, einen paarweisen Join über Graphen ineiner definierten Reihenfolge und Nutzung einer Eigenschaft der Hülle zur Eliminierung vonKandidaten[5].
- 152 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 21
Für jeden identifizierten Kandidaten wird überprüft, ob dieser Kandidat in der Ausgangsgraphen-menge enthalten ist. Jeder Kandidat bekommt einen Zähler mit der Information, wie oft dieserKandidat in der Ausgangsmenge als Teilgraph vertreten ist. Diese Zahl kann dann für jeden Kan-didaten mit einem Grenzwert minSup, welcher die Unterschranke zur Identifizierung häufigerTeilgraphen bildet, verglichen werden. Falls eine gewisse Häufigkeit des Vorkommens zutrifft,gehört der Kandidat zur Menge der häufigen Teilgraphen.
Kanonische Labels und Graphinvarianten:FSG nutzt wie AGM kanonische Labels zur eindeutigen Identifizierung von Graphen. Hierfürwird die Adjazenzmatrix, in der der Graph repräsentiert wird, in eine lineare Sequenz von Zei-chen überführt. Die Vergabe dieser Labels, die Kandidatengenerierung und deren Evaluierungwerden bei FSG durch den Einsatz von Graphinvarianten beschleunigt wie z.B. der Grad einesKnotens und das TransaktionsID-Prinzip.
Grad eines Knotens:Der Grad eines Knotens ist die Anzahl der Kanten, die sich an einem Knoten befinden.
TransaktionsID:Das TransaktionsID-Prinzip speichert alle IDs von Transaktionen, an denen ein Teilgraph betei-ligt ist. Dieses bessere Laufzeitverhalten kann aber nur erreicht werden, weil sich FSG im Ge-gensatz zu AGM darauf beschränkt, zusammenhängende Teilgraphen zu finden. Inzusammenhängenden Graphen existiert ein Pfad zwischen allen möglichen Paaren von Kno-ten[5].
Auch bei diesem Algorithmus FSG ist wie bei AGM eine aufwändige Kandidatengenerierungund Eliminierung falscher Kandidaten notwendig. FSG optimiert diese Prozesse im Gegensatzzu AGM[2]. Auch FSG nutzt wie AGM die Breitensuche. Der Algoritmus gSpan spart im Ge-gensatz zu FSG und auch AGM enorm viel Speicherplatz. Dies rührt daher, daß an jedem DFS-Code-Baum-Knoten die Information mitgeliefert wird, an welchem Graphen der bisherige Teil-graph Teilgraph war (s.D , Zeile 8 im Algorithmus 1: graph_Projection (D,S)). Somit wird für je-den erweiterten Knoten im DFS-Code-Code-Baum nur in diesem Graphen ein Isomorphietestvollzogen und nicht mehr in der gesamten Menge. Ausserdem wird eine einmal betrachtete Kan-te aus der Graphenmenge entfernt, somit wird der Suchraum kleiner (G=G-e , Zeile 10 im Algo-rithmus 1: graph_Projection (D,S))
- 153 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 22
4.3 Abschließende Bewertung Der Algorithmus gSpan ist ein schneller Algorithmus im Gegensatz zu den herkömmlichen Me-thoden. Dafür gibt es folgende Gründe:
gSpan ist der erste Algorithmus, der die Tiefensuche (DFS-Search= Depth First Search)beim Auffinden häufiger Teilgraphen nutzt.
gSpan findet alle häufigen Teilgraphen ohne Kandidatengenerierung=candidate generati-on und ohne pruning false positives=Abschneiden falscher Positiver
gSpan beschleunigt den Suchprozess, da in einer Prozedur zwei Algorithmen behandeltwerden, das Wachsen der Teilgraphen und das Suchen nach häufigen Teilgraphen
In gSpan werden mehrere Techniken zur Vorbereitung des eigentlichen Algorithmus ge-nutzt
Jeden Graphen als DFS-Code (String) abbilden Eine lexikographische DFS-Ordnung zwischen den DFS-Codes bilden Einen Suchbaum auf Basis dieser lexikographischen DFS-Ordnung konstruieren
In der heutigen Zeit sind schnelle Algorithmen gefragt, da die Forschung und Entwicklungschnelle Ergebnisse benötigt. Besonders in der Medizin können zeitkritische Prozesse schnelleAlgorithmen benötigen. Zu Beginn benötigt der gSpan zwar viel Speicherplatz für die riesigeDatenmenge, jedoch kann dies durch andere Techniken kompensiert werden wie z.B die Projek-tion der Graphenmenge. Die Generierung potentieller Kinder ist nicht effizient. Man kann abereffizientere Methoden verwenden auf die hier nicht näher eingegangen wird. Durch Verwendungvon induzierten Teilgraphen für den Algorithmus gSpan werden bessere Laufzeiten erreicht[2].
- 154 -

Fatma Akyol ,1.5.1 Häufige Teilgraphen 23
AbbildungsverzeichnisAbbildung 1: Isomorphie und Subgraphisomorphie........................................................................3Abbildung 2: Isomorphie / Subgraphisomorphie.............................................................................4Abbildung 3: Subgraphisomorphietest............................................................................................4Abbildung 4: Ausgangsgraph G und konstruierter DFS-Graph GT................................................8Abbildung 5: verschiedene DFS-Codes ........................................................................................10Abbildung 6: DFS-Code-Baum.....................................................................................................11
TabellenverzeichnisTabelle 3.1: sortierte Kantenfolge ergibt DFS-Code α ...................................................................9
Literaturverzeichnis1: A.Inokuchi, T. Washio, and H. Motoda., An Apriori-based algorithm for mining frequent sub-structures from graph data, 20002: X.Yan and J. Han., gSpan: Graph-based substructure pattern mining, 20023: J.Pei, J.Han, B.Mortazavi-Asl, H.Pinto, Q.Chen, U.Dayal and M.C-Hsu, PrefixSpan: Miningsequential patterns efficiently by prefix-projected pattern growth, April 20014: R.Agrawal and R.Srikant, Fast algorthm for mining association rules, 19945: M.Kuramochi and G. Karypis, Frequent subgraph discovery, Nov 2001
- 155 -


















