Die X-Curve und deren Auswirkung auf die...
54
Bachelorthesis Julian Domann Dialog- und Sprachverständlichkeit in Kinos über Lautsprecher hinter Bildwänden mit Einfluss der X-Curve Fakultät Technik und Informatik Department Informations- und Elektrotechnik Faculty of Engineering and Computer Science Department of Information and Electrical Engineering
Transcript of Die X-Curve und deren Auswirkung auf die...

BachelorthesisJulian Domann
Dialog- und Sprachverständlichkeit in Kinos überLautsprecher hinter Bildwänden mit Einfluss der
X-Curve
Fakultät Technik und InformatikDepartment Informations- undElektrotechnik
Faculty of Engineering and Computer ScienceDepartment of Information andElectrical Engineering

Julian Domann
Dialog- und Sprachverständlichkeit in Kinos überLautsprecher hinter Bildwänden mit Einfluss der
X-Curve
Bachelorthesis eingereicht im Rahmen der Bachelorprüfungim Studiengang Informations- und Elektrotechnikam Department Informations- und Elektrotechnikder Fakultät Technik und Informatikder Hochschule für Angewandte Wissenschaften Hamburg
Betreuender Prüfer: Prof. Dr. Robert HeßZweitgutachter: Prof. Dr. Klaus Jünemann
Abgegeben am 24. April 2017

Julian Domann
Thema der BachelorthesisDialog- und Sprachverständlichkeit in Kinos über Lautsprecher hinter Bildwänden mitEinfluss der X-Curve
StichworteKinobeschallungssyteme, Sprachverständlichkeit, Dialog, Sprachübertragungsindex,STI, %ALcons, X-Curve, Bildwand, Logatomtest
KurzzusammenfassungEs wird die Dialog- und Sprachverständlichkeit von Lautsprechern hinter Bildwändenin Kinosälen untersucht und bewertet. Hierfür wird zum Vergleich ein weitgehend fre-quenzgangoptimiertes Bildwandlautsprechersystem herangezogen.
Julian Domann
Title of the paperDialogue and Speech Intelligibility in Cinemas Through Loudspeakers BehindScreens With Influence of the X-Curve
KeywordsCinema Soundsystem, Speech Intelligibility, Dialogue, Speech Transmission Index,STI, %ALcons, X-Curve, Projection Screen, Logatom Articulation Test
AbstractThe dialogue and speech intelligibility of cinemas with loudspeaker behind screenswill be examined and evaluated. For the purpose of comparison a widely frequencyoptimized screen-soundsystem is used.

Danksagung
An dieser Stelle möchte ich mich zunächst bei meiner Familie und meinen Freunden bedan-ken, die mich während der Anfertigung dieser Bachelorarbeit unterstützt und motiviert haben.Ein besonderer Dank geht an Andrea, Janou, Jascha, Kachina, Laura, Maede, Matze, Oleund Sebastian. Ebenfalls möchte ich mich bei Michael Staats bedanken, der mich auf dasThema aufmerksam gemacht hat und mir durch seine Fachkenntnisse und seiner konstrukti-ven Kritik verhalf, dieses Thema zu bearbeiten. Ein weiterer Dank geht an Gunnar Andresenund die Firma Amptown System Company GmbH, die mir die benötigten Messinstrumentezur Verfügung gestellt hat, die Möglichkeit gab, in den Räumlichkeiten zu messen und denKontakt zu den Kinobetreibern hergestellt hat. Den Verantwortlichen der Kinos möchte ichebenso meinen Dank für die Zurverfügungstellung der Kinosäle aussprechen. Ferner dankeich der Firma AFMG Technologies GmbH für die Bereitstellung der Messsoftware. Zuletztein Dankeschön an Prof. Dr. Robert Heß, sowie an Prof. Dr. Klaus Jünemann, die sich bereiterklärt haben, die Prüfung dieser Arbeit zu übernehmen.

Inhaltsverzeichnis
Abkürzungsverzeichnis 7
1 Einleitung 8
2 Grundlagen 102.1 Frequenzaufbau der Sprache . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.1 Formanten von Vokalen . . . . . . . . . . . . . . . . . . . . . . . . 102.1.2 Konsonanten und Plosive . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Auditive Wahrnehmung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.2.1 Lautheitswahrnehmung (Empfindlichkeit des Hörsinns) . . . . . . . 122.2.2 Gesetz der ersten Wellenfront (menschliche Zweiohrigkeit) . . . . . 132.2.3 Maskierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Hintergrund zur X-Curve . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.3.1 Entstehung und Bedeutung . . . . . . . . . . . . . . . . . . . . . . 142.3.2 SMPTE ST 202:2010 und ISO 2969:2015 . . . . . . . . . . . . . . 16
2.4 Interaktion zwischen Lautsprechern und Bildwänden . . . . . . . . . . . . . 182.5 Qualifizierung von Sprachverständlichkeit . . . . . . . . . . . . . . . . . . . 20
2.5.1 Objektive Bewertung der Sprachverständlichkeit . . . . . . . . . . . 202.5.2 Subjektive Bewertung der Sprachverständlichkeit . . . . . . . . . . 242.5.3 Zusammenhang zwischen objektiver und subjektiver Bewertung . . . 26
3 Messvorgang 273.1 Sprachverständlichkeit nach STI und %ALcons . . . . . . . . . . . . . . . . 27
3.1.1 Messsoftware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.1.2 Verwendete Technik . . . . . . . . . . . . . . . . . . . . . . . . . . 283.1.3 Messorte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.1.4 Messaufbau und -methodik . . . . . . . . . . . . . . . . . . . . . . 30
3.2 Logatom-Verständlichkeitstest . . . . . . . . . . . . . . . . . . . . . . . . . 313.2.1 Vorgehen des Hörtests . . . . . . . . . . . . . . . . . . . . . . . . 323.2.2 Auswahl der Test-Logatome und des Störsignals . . . . . . . . . . . 323.2.3 Aufnahme und Zusammenstellung . . . . . . . . . . . . . . . . . . 33
4 Messergebnisse & Diskussion 354.1 Mittelungsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35

Inhaltsverzeichnis 6
4.2 Darstellungsverfahren mit MATLAB . . . . . . . . . . . . . . . . . . . . . . 354.3 Sprachverständlichkeit nach STI und %ALcons . . . . . . . . . . . . . . . . 374.4 Logatom-Verständlichkeitstest . . . . . . . . . . . . . . . . . . . . . . . . . 41
5 Auswertung 435.1 Einfluss des Frequenzgangs auf die objektive Sprachverständlichkeit . . . . 435.2 Relation zwischen parametrischer Messung und Logatomtest . . . . . . . . 45
6 Zusammenfassung und Ausblick 47
Anhang auf dem Datenträger 48
Literaturverzeichnis 49
Tabellenverzeichnis 51
Abbildungsverzeichnis 52

Abkürzungsverzeichnis
%ALcons Articulation Loss of Consonants
ASC Amptown System Company
ASR Automatic Speech Recognizers
DAW Digital Audio Workstation
DCI Digital Cinema Initiative
DCP Digital Cinema Packages
DRT Diagnostic Rhyme Test
EASERA Electronic and Acoustic System Evaluation and Response Analysis
ICRA International Collegium of Rehabilitative Audiology
ISO International Organization for Standardization
LCR Left Center Right
MRT Modified Rhyme Test
MTF Modulations-Transfer-Funktion
OLLO Oldenburg Logatome Speech Corpus
RASTI Room Acoustical Speech Transmission Index
RT reverberation time
SMPTE Society of Motion Picture & Television Engineers
STI Speech Transmission Index
STIPA Speech Transmission Index for Public Adress Systems
STITEL Speech Transmission Index for Telecommunication Systems

1 Einleitung
In der Geschichte des Kinos kam es zu zahlreichen Modifikationen im Bereich der Produk-tion und der Wiedergabe. Ziel dieser Veränderungen war eine weitgehend einheitliche undkompatible Vorführung der Kinoproduktionen zu ermöglichen. Die letzte große Anpassungim Kino war die Digitalisierung der Wiedergabekette (B-Chain). Hierbei wurden aus Filmrol-len Digital Cinema Packages (DCP), Digitalprojektoren kamen zum Einsatz und die Rolle derFilmvorführer übernahmen Software und Server. Die jahrelang entwickelten Standards derDigital Cinema Initiative (DCI), welche später als Norm der Society of Motion Picture & Te-levision Engineers (SMPTE) übernommen wurden, führten besonders bei der Wiedergabedes Bildes zu einer weltweiten Qualitätssteigerung. Die Umstellung von analoger zur volldi-gitalen Signalkette betraf ebenso den Filmton. Die digitale AES/EBU Norm mit diskreten Ein-zelkanälen löste die proprietären analogen Tonübertragungsstandards von konkurrierendenHerstellern ab. Die resultierten Änderungen im Dynamikumfang sorgten für mehr Optionenbei der Tonmischung von Dialog, Musik und Soundeffekten.
Die Wiedergabekette auf der akustischen Seite im Saal hinter der Bildwand wurde jedochkeiner kritischen Betrachtung unterzogen. Die hier installierte Technik ist teilweise bis zu 30Jahre alt und nicht aufeinander abgestimmt. Dies hört das Publikum zum Beispiel an derSprachverständlichkeit von Dialogen. Welche Faktoren tragen dazu bei, dass die Qualitätder Übertragung von Sprache hinter ihrer Zeit zurückbleibt?Dies kann zum einen am grundsätzlichen Qualitätsbewusstsein der Hersteller, Integratorenund Kunden liegen. Zum anderen spielt die akustische Situation direkt im Raum vor Ort einewichtige Rolle. Effekte der Psychoakustik (z.B. Maskierung) bei hohen Pegeln der Hinter-grundgeräusche (Filmton oder Publikum), Einflüsse wie der Zielfrequenzgang der X-Curveund die Verwendung einer Bildwand haben erhebliche Auswirkungen auf die Frequenzanteiledes hörbaren Spektrums und somit auch auf die übertragenen Dialoge.
Diese Bachelorarbeit beschäftigt sich mit der Bewertung der Sprachverständlichkeit von Ki-nobeschallungssystemen, in denen der Dialog über Center-Lautsprecher hinter einer Bild-wand ausgegeben wird. Die Abbildung 1.1 zeigt den systematischen Aufbau eines solchenKinosaals mit den Front-Lautsprechern Left Center Right (LCR). Das Ziel ist die vielfach kri-tisierte, unzureichende Sprachverständlichkeit in deutschen Kinosälen aufzuzeigen. Im Be-sonderen sollen die negativen Auswirkungen alter Korrekturverfahren (X-Curve) im Zusam-

1 Einleitung 9
menhang mit der Bildwand ausgewertet werden. Dies geschieht, um die Notwendigkeit derAbstimmung von akustisch komplexen Bildwand/Lautsprechersystemen zu belegen und einUmdenken von traditionellen Anpassungsmethoden zur Qualitätssteigerung zu erreichen.Zuerst werden die Grundlagen für diese Untersuchungen erläutert. Dies beinhaltet die Dis-kussion der X-Curve und deren abstrakter Idee, welche auch in den Standards SMPTE ST202:2010 und ISO 2969:2015 festgelegt ist. Weiterhin wird der Stand der Forschung zurFrequenzzusammensetzung der Sprache und zur menschlichen auditiven Wahrnehmungzusammengefasst. Danach wird die derzeitige Qualifizierung von Sprachverständlichkeitund der Frequenzgangeinfluss von Bildwänden in einem neuen Zusammenhang diskutiert.Zur Bewertung der Sprachverständlichkeit werden Messungen zur Erfassung der Sprach-übertragungsparameter Speech Transmission Index (STI) und Articulation Loss of Conso-nants (%ALcons) der Bildwand-Lautsprechersysteme in mehreren unterschiedlich großenKinosälen durchgeführt. Diese werden mit den Messwerten eines frequenzgangoptimiertenSystems in einem Referenz-Raum verglichen. Zur Beurteilung des Zusammenhangs zwi-schen der objektiven und subjektiven Verständlichkeit wird ein Logatomtest als A/B-Vergleichim Referenzraum durchgeführt und ausgewertet.
Abbildung 1.1: Skizzierter Lageplan der Räume in denen Messungen stattfinden

2 Grundlagen
Die folgenden Grundlagen dienen zum Verständnis der angewandten Methoden dieser Ba-chelorarbeit. Sie sollen die Einflüsse und Auswirkungen von verschiedenen Faktoren auf dieSprachverständlichkeit darlegen, derzeitige Standards erläutern und die Relevanz des The-mas hervorheben.
2.1 Frequenzaufbau der Sprache
Der folgende Abschnitt erläutert das Spektrum von Sprache und aus welchen Anteilen sichdie einzelnen Frequenzbestandteile zusammensetzen, sowie die Zeitebene um die direkteEinwirkung einer Frequenzgangbeeinflussung auf die Verständlichkeit der Sprache zu zei-gen.
Generell besteht die gesprochene Sprache aus der Grundfrequenz (Schwingen der Stimm-bänder), den einzelnen Formanten der Vokale und den Konsonanten mit ihren Obertönen.Zu beachten ist, dass sich diese Grundlagen, sowie die nachfolgenden Aufgaben, hier nurauf die deutsche Sprache beziehen. Andere Sprachen ähnlicher Herkunft (z.B. GermanischeSprachen) können Parallelen, jedoch auch große Unterschiede aufweisen.
2.1.1 Formanten von Vokalen
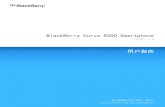
Formanten bezeichnen einen Frequenzabschnitt in dem die akustische Energie besondersverstärkt wird. Abhängig von ihrer Lage sind sie der Hauptbestandteil für die Klangbildungder Stimme bzw. der einzelnen Vokale, welche eine Durchschnittsdauer von 30 ms - 300 mshaben. In Abbildung 2.1 ist eine Übersicht der ersten beiden Formanten zu sehen, wel-che großen Einfluss auf die Verständlichkeit haben. Der Frequenzbereich streckt sich von200 Hz - 2600 Hz. Da die charakteristische Bildung des Vokaltrakts maßgeblich die Reso-nanzen festlegt, handelt es sich um eine Mittelung. Formanten gleicher Vokale weisen seltendie gleichen Werte auf, besonders bei der Unterscheidung von Frau und Mann. So kön-nen durchaus weit höhere Frequenzen bei der Bildung von Vokalen gemessen werden [vgl.Sendlmeier und Seebode (2015)].
2 Grundlagen 11
Abbildung 2.1: Mittelwert von Formanten (weibl. und männl. Sprecher), entnommen aus Ma-chelett (1996)
2.1.2 Konsonanten und Plosive
Die Verständlichkeit der gesprochenen Sprache ist hauptsächlich abhängig von den Konso-nanten, welche eine Dauer von 10 ms - 100 ms besitzen und somit deutlich schneller abklin-gen als Vokale. Außerdem können sie bis zu 27 dB unter der Amplitude von Vokalen liegen,was zu großen Herausforderungen in der Mischung und Präsentation von Dialogen führenkann. Allgemein sind Konsonanten Laute, bei denen es zu einer Verengung des Stimmtrak-tes kommt.Eine besondere Form sind die Plosive. Hier wird der komplette Atemluftstrom mit Hilfe derZungenposition oder der Lippen blockiert. Im deutschen Alphabet sind es die Buchstaben t,d, k, g und p, b. Es handelt sich bei den Plosiven um Laute mit sehr kurzer Dauer in einemFrequenzbereich von 2 kHz - 9 kHz [vgl. MeyerSound (2005)]. Abbildung 2.2 zeigt exempla-risch die Sonagramme (Schall-Spektogramme) von verschiedenen Plosiven.

2 Grundlagen 12
Abbildung 2.2: Sonagramme der Plosive „p“, „t“ und „k“, entnommen aus Machelett (1996)
2.2 Auditive Wahrnehmung
Der Mensch und sein Gehör haben spezifische Eigenschaften im Umgang mit der Wahrneh-mung von Schall. Dieses Ohr-Gehirn-System ist hochkomplex und bei weitem nicht komplettanalysiert und verstanden. Nachstehend werden wichtige Aspekte der auditiven Wahrneh-mung hinsichtlich der Frequenzgänge, der Schallausbreitung im Raum und psychoakusti-scher Effekte beschrieben.
2.2.1 Lautheitswahrnehmung (Empfindlichkeit des Hörsinns)
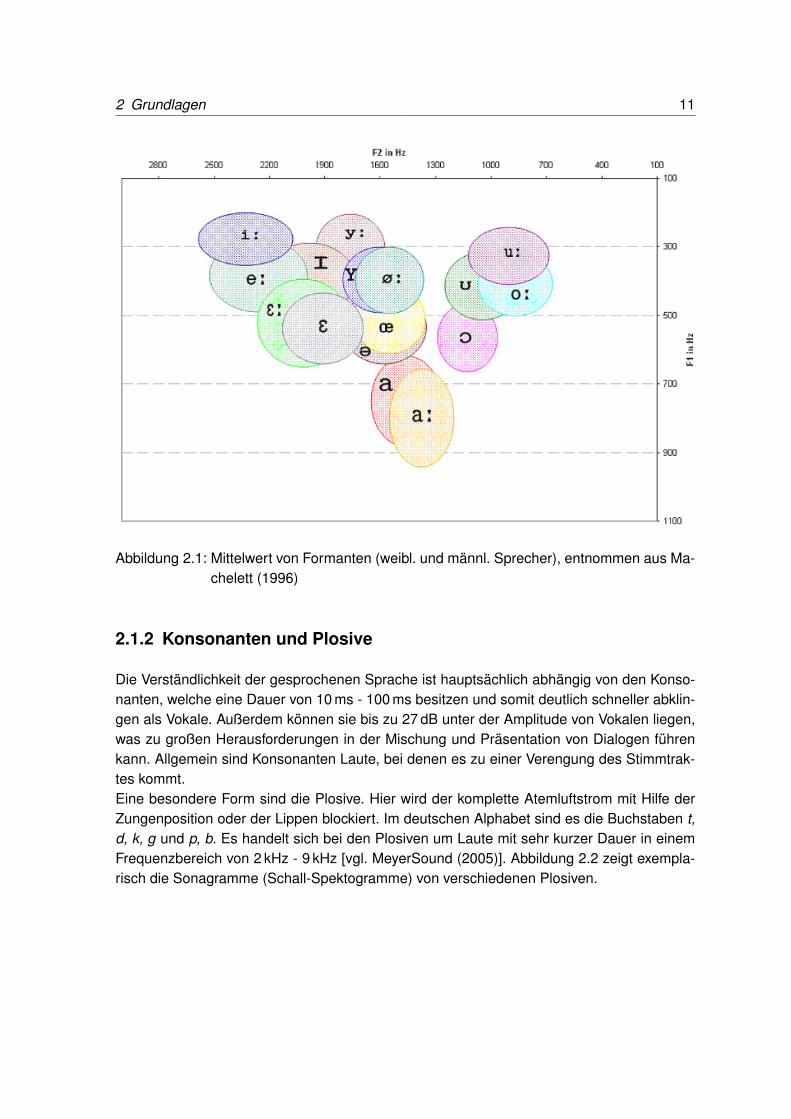
Die Lautheit bzw. empfundene Lautstärke wird vom menschlichen Gehör und Hörsinn starkfrequenzabhängig wahrgenommen. Zusätzlich variiert diese Wahrnehmung mit Änderungdes Lautstärkepegels. In Abbildung 2.3 ist die Abnahme der Empfindlichkeit bei gleicherLautheit ab einer Frequenz von 1,6 kHz zu sehen, welche bei einem geringeren Pegel stärker
2 Grundlagen 13
ausfällt. Ab einer Frequenz von 4 kHz steigt die Empfindlichkeit an. Dies führt dazu, dassgerade im Hochtonbereich eine Differenz von bis zu 20 dB bei gleichem Lautstärkeempfindenvon verschiedenen Frequenzen vorliegen kann.
Abbildung 2.3: Kurven gleicher Lautheit nach Fletcher und Munson, entnommen aus ISO(2003)
2.2.2 Gesetz der ersten Wellenfront (menschliche Zweiohrigkeit)
Das Gesetz der ersten Wellenfront beschreibt den psychoakustischen Effekt des Richtungs-hörens bei zeitlicher Differenz von eintreffenden Schallwellen des gleichen Signals zwischen2 ms - 50 ms (bei Sprache). Hier wird die wahrgenommene Richtung durch das zuerst ein-treffende Signal festgelegt. Die räumliche Ausbreitung und zeitliche Differenz einer Welleentsteht durch Reflexionen an Wänden, Decken und Böden (nicht im Freifeld). Durch dieÜberlagerungen von Direktschall und Reflexionen kann es zur Auslöschung im Frequenz-gang kommen. Ein Spezialfall stellt das Kammfilter dar, das zu einem sehr störenden undklanglich schlechten Hörerlebnis führt. Signale, die eine Differenz größer als 50 ms aufwei-sen, werden meist als störende Echos wahrgenommen.

2 Grundlagen 14
2.2.3 Maskierung
Bei unterschiedlich großen Schalldruckpegeln von verschiedenen Frequenzen kommt eszu Maskierungen. Durch die Maskierung werden Frequenzen geringerer Intensität von Fre-quenzen höherer Intensität verdeckt, sodass das menschliche Ohr diese Anteile nicht odernur mit verringerter Intensität wahrnimmt. Dies tritt vor allem bei Stör- und Hintergrundrau-schen (Bezug zum Kino: Publikumsgeräusche, Spezial-Effekte des Films, Zumischung vonUmgebungsgeräuschen, Ablenkungen durch Parallelhandlungen, etc.) auf. HochfrequentesStörspektrum maskiert nur Konsonanten, während niederfrequentes Störspektrum bei ho-hen Pegeln auch Auswirkungen auf Vokale haben kann. Die Intensität der Maskierung hängtebenfalls von der relativen Richtung, aus der Signale und Störungen kommen, ab. Ist dieRichtung des Störsignals gleich der des Nutzsignals, ist die Auswirkung am Größten.
2.3 Hintergrund zur X-Curve
2.3.1 Entstehung und Bedeutung
Früh in den Anfängen des Tonfilms wurde die Notwendigkeit einer Standardisierung derWiedergabe über das Medium deutlich, um damit die einheitliche Wiedergabe von Tonspu-ren weltweit zu gewährleisten. 1937 setzte sich ein Komitee des Motion Picture ResearchCouncil zusammen und ermittelte aus einer großen Menge an unterschiedlichem Audiomate-rial eine Hochfrequenzdämpfung, die das ausgeglichenste und angenehmste Klangerlebnisbot. Über das Ausgangssignal mit einem flachen Frequenzverlauf des Leistungsverstärkerswurde die definierte Dämpfung dann gemessen. Die resultierte Kurve wurde unter dem Na-men "The Academy Curve" bekannt und als Standard deklariert [vgl. Allen (2006)].In den folgenden Jahrzehnten gab es einige Anpassungen. Neben der Unterscheidung vonLautsprecherarten wurden neue Techniken zur Messung der elektro-akustischen Raumant-wort entwickelt. White- bzw. Pink-Noise war nun das Messsignal, die Wiedergabekette wurdein A-Chain und B-Chain unterteilt und es wurde mit einem 1/3-Oktaven Echtzeit Analysatorgemessen.
Das Vorhaben war die Kurve im nieder- und hochfrequenten Bereich zu erweitern und die500 Hz Absenkung (hervorgerufen vom passiven Crossover des Lautsprechers) zu glätten.Daraus resultierte die X-Curve, welche zu dem Zeitpunkt (1972) noch wide-range B-Chaincharacteristic genannt wurde. Laut Allen resultiert die gewollte Abnahme der tiefen Fre-quenzen aus der sonstigen Überladung der damalig qualitativ minderwertigen Lautspre-cher mit niederfrequenter Energie und der daraus folgenden Entstehung von Verzerrungen.

2 Grundlagen 15
Die erwünschte Schwächung der hochfrequenten Anteile sind schwieriger nachzuvollzie-hen. Folgende drei Aspekte spielen hierbei einzeln oder in Kombination eine Rolle [vgl. Allen(2006)]:
• Effekte der Psychoakustik
• HF-Verzerrungen des Lautsprechers (mit damaliger geringer Qualität)
• Folgen des Nachhalls im Raum
1977 wurde nach weiteren Änderungen die X-Curve zum ersten Mal veröffentlicht und alsISO 2969 ratifiziert und ein Jahr später von der SMPTE als SMPTE 202M übernommen.Nach jahrelanger Diskussion wurde die X-Curve bis 16 kHz erweitert und ein weiterer Knick-punkt bei 10 kHz eingeführt.
Wichtig hervorzuheben ist, dass es sich bei der X-Curve nicht um eine Equalisation-Kurvehandelt, sondern um den Zielfrequenzgang der eingeschwungenen Raumantwort im statio-nären Zustand. Diese Messung wird nur in der B-Chain an einem Referenzpunkt mit einemPink Noise Messsignal durchgeführt. Die A-Chain ist hierbei nicht einbezogen [vgl. Leem-bruggen u. a. (2011)]. Genaueres wird in Abschnitt 2.3.2 erläutert.
In der heutigen Zeit soll die X-Curve eine Ziel-Übertragungsfunktion vorgeben, die dem Kino-Techniker hilft, den Sound im Vorführungssaal möglichst dem gehörten Sound im MixingRoom anzupassen. Allerdings gibt es auch kritische Meinungen, die den Einsatz der X-Curveals kontraproduktiv beurteilen. Leembruggen u.a. schreiben in ihrem Aufsatz „Is The X Cur-ve Damaging Our Enjoyment of Cinema“, dass es hierbei zur Verstärkung von Maskierungs-effekten (siehe 2.2.3) kommt, die folglich die Sprachverständlichkeit von Dialogen senken.Dies geschieht vor allem, wenn sie während Musik oder Effekten auftreten [vgl. Leembrug-gen u. a. (2011)]. Hierzu wurden jedoch keine Messergebnisse veröffentlicht, die speziell aufdie Sprachverständlichkeit abzielen. Ein weiterer Punkt ist die unbestimmte Menge an Hoch-frequenzenergie, die der Tonmischer kompensieren muss.Allen schrieb in seinem Aufsatz von 2006 "The X-Curve: Its Origins and History": „TheX-Curve is probably not perfect, and neither are the measurement techniques employed. Butit should be remembered that the introduction of the X-Curve represented a radical changein film sound practice and led to a revolution in film sound quality“ [vgl. Allen (2006)].Die X-Curve scheint in der Vergangenheit berechtigt gewesen zu sein, da sie nichtlineareSysteme in akustisch stark abweichenden Kinosälen harmonisiert hat. Durch die großenFortschritte in der Lautsprecherentwicklung seit Ende der 80er Jahre und dem Einfluss eineroptimierten, standardisierten Raumakustik in Kinosälen, ist der ursprünglich positive Effektder X-Curve überholt.
2 Grundlagen 16
2.3.2 SMPTE ST 202:2010 und ISO 2969:2015
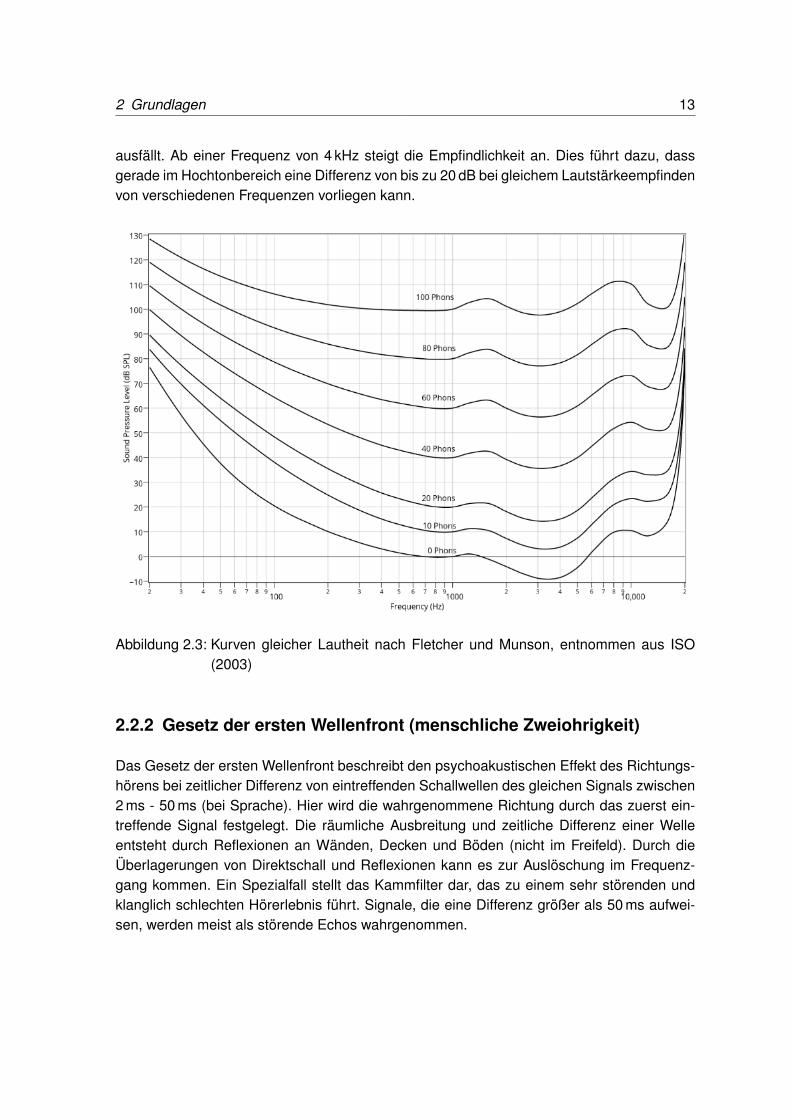
Folgende Anweisungen für die Anwendung der X-Curve als elektro-akustische Raumantwortin Kinos sind in der Standardisierung SMPTE ST 202:2010 und ISO 2969:2015 festgelegtund können dort nachgelesen werden [vgl. SMPTE (2010)].
Die Reproduktionskette im Kino besteht aus der A-Chain und der B-Chain (siehe Abbildung2.4). Die X-Curve bezieht sich nur auf den Abschnitt der B-Chain. Sie beginnt mit dem InputSource Selector und endet im Zuhörerraum.
Abbildung 2.4: Audioreproduktionskette des digitalen Kinos
Die elektro-akustische Raumantwort ist (in diesem Fall) der in 1/3-Oktaven mit breitbandigemPink Noise gemessene, räumlich und zeitlich durchschnittliche Schalldruckpegel in dB. DieMessmethode ist in Abbildung 2.5 zu sehen. Pink Noise wird von einem Rauschgenerator alsErregersignal am Eingang des Input-Source-Selektors bereitgestellt. Es hat die Eigenschaft,die gleiche Energie pro Oktave zu besitzen, während White Noise die gleiche Energie bei je-der Frequenz bereitstellt. Ein Mensch nimmt dieses Rauschen im hörbaren Frequenzbereich

2 Grundlagen 17
als gleich laut wahr. In einer doppelt logarithmischen Darstellung entspricht dies einem Abfallvon 3 dB/Oktave. Eine Oktave bezeichnet ein Frequenzintervall mit dem Verhältnis zwischenunterer und oberer Frequenz von 1/2.
Abbildung 2.5: B-Chain Messmethode
In Abbildung 2.6 ist der gewünschte Amplitudengang der B-Chain in Abhängigkeit von derFrequenz zu erkennen. Sie zeigt die Amplitude zwischen den Frequenzen 31,5 Hz und16 kHz. Bis 50 Hz wird eine Steigung von 3 dB/Oktave empfohlen. Im Bereich von 50 Hz- 2 kHz ist ein linearer Verlauf gewünscht mit anschließendem Abfall von 3 dB/Oktave biszu 10 kHz und 6 dB/Oktave bis 16 kHz. Die Toleranzen betragen zwischen 80 Hz und 8 kHz�3 dB. Außerhalb dieses Bereichs steigt die untere Toleranz.
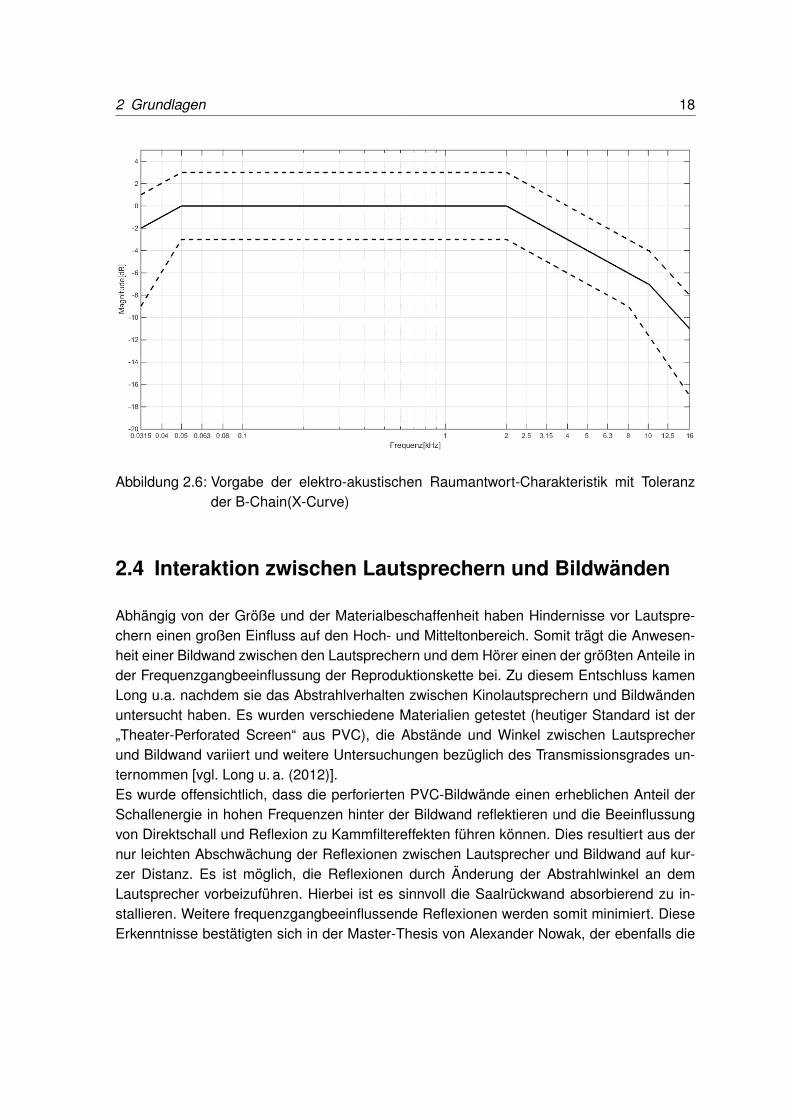
2 Grundlagen 18
Abbildung 2.6: Vorgabe der elektro-akustischen Raumantwort-Charakteristik mit Toleranzder B-Chain(X-Curve)
2.4 Interaktion zwischen Lautsprechern und Bildwänden
Abhängig von der Größe und der Materialbeschaffenheit haben Hindernisse vor Lautspre-chern einen großen Einfluss auf den Hoch- und Mitteltonbereich. Somit trägt die Anwesen-heit einer Bildwand zwischen den Lautsprechern und dem Hörer einen der größten Anteile inder Frequenzgangbeeinflussung der Reproduktionskette bei. Zu diesem Entschluss kamenLong u.a. nachdem sie das Abstrahlverhalten zwischen Kinolautsprechern und Bildwändenuntersucht haben. Es wurden verschiedene Materialien getestet (heutiger Standard ist der„Theater-Perforated Screen“ aus PVC), die Abstände und Winkel zwischen Lautsprecherund Bildwand variiert und weitere Untersuchungen bezüglich des Transmissionsgrades un-ternommen [vgl. Long u. a. (2012)].Es wurde offensichtlich, dass die perforierten PVC-Bildwände einen erheblichen Anteil derSchallenergie in hohen Frequenzen hinter der Bildwand reflektieren und die Beeinflussungvon Direktschall und Reflexion zu Kammfiltereffekten führen können. Dies resultiert aus dernur leichten Abschwächung der Reflexionen zwischen Lautsprecher und Bildwand auf kur-zer Distanz. Es ist möglich, die Reflexionen durch Änderung der Abstrahlwinkel an demLautsprecher vorbeizuführen. Hierbei ist es sinnvoll die Saalrückwand absorbierend zu in-stallieren. Weitere frequenzgangbeeinflussende Reflexionen werden somit minimiert. DieseErkenntnisse bestätigten sich in der Master-Thesis von Alexander Nowak, der ebenfalls die
2 Grundlagen 19
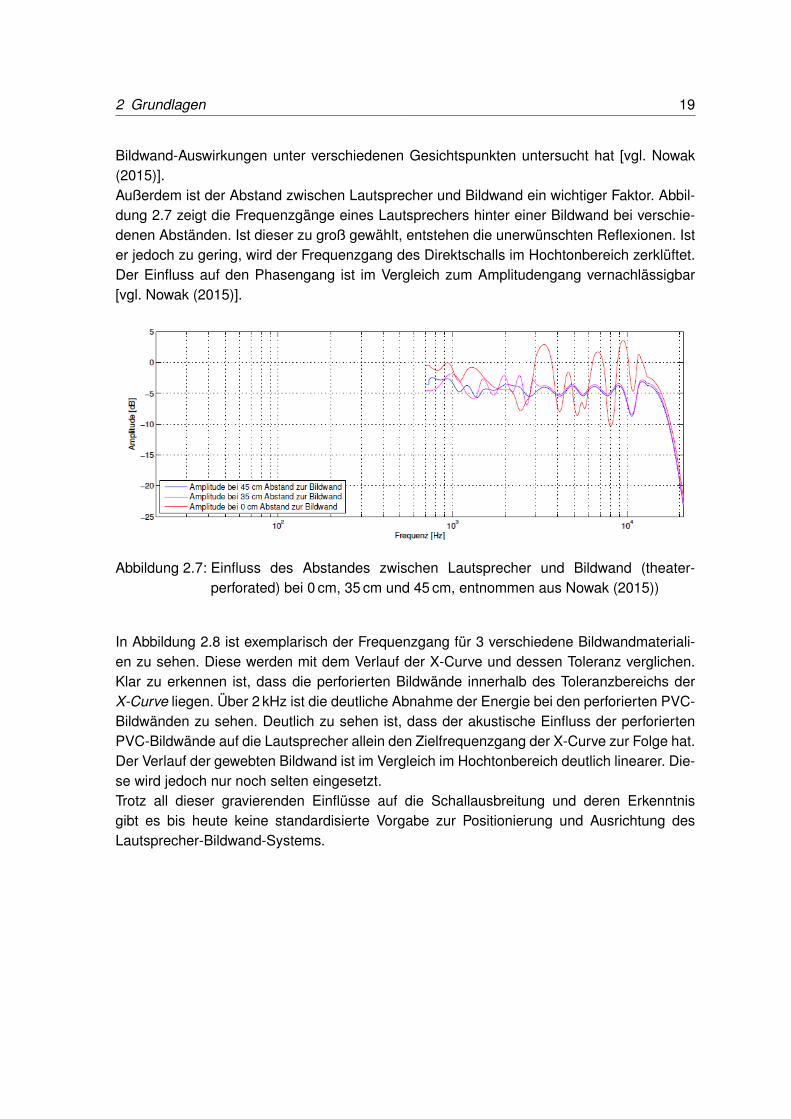
Bildwand-Auswirkungen unter verschiedenen Gesichtspunkten untersucht hat [vgl. Nowak(2015)].Außerdem ist der Abstand zwischen Lautsprecher und Bildwand ein wichtiger Faktor. Abbil-dung 2.7 zeigt die Frequenzgänge eines Lautsprechers hinter einer Bildwand bei verschie-denen Abständen. Ist dieser zu groß gewählt, entstehen die unerwünschten Reflexionen. Ister jedoch zu gering, wird der Frequenzgang des Direktschalls im Hochtonbereich zerklüftet.Der Einfluss auf den Phasengang ist im Vergleich zum Amplitudengang vernachlässigbar[vgl. Nowak (2015)].
Abbildung 2.7: Einfluss des Abstandes zwischen Lautsprecher und Bildwand (theater-perforated) bei 0 cm, 35 cm und 45 cm, entnommen aus Nowak (2015))
In Abbildung 2.8 ist exemplarisch der Frequenzgang für 3 verschiedene Bildwandmateriali-en zu sehen. Diese werden mit dem Verlauf der X-Curve und dessen Toleranz verglichen.Klar zu erkennen ist, dass die perforierten Bildwände innerhalb des Toleranzbereichs derX-Curve liegen. Über 2 kHz ist die deutliche Abnahme der Energie bei den perforierten PVC-Bildwänden zu sehen. Deutlich zu sehen ist, dass der akustische Einfluss der perforiertenPVC-Bildwände auf die Lautsprecher allein den Zielfrequenzgang der X-Curve zur Folge hat.Der Verlauf der gewebten Bildwand ist im Vergleich im Hochtonbereich deutlich linearer. Die-se wird jedoch nur noch selten eingesetzt.Trotz all dieser gravierenden Einflüsse auf die Schallausbreitung und deren Erkenntnisgibt es bis heute keine standardisierte Vorgabe zur Positionierung und Ausrichtung desLautsprecher-Bildwand-Systems.
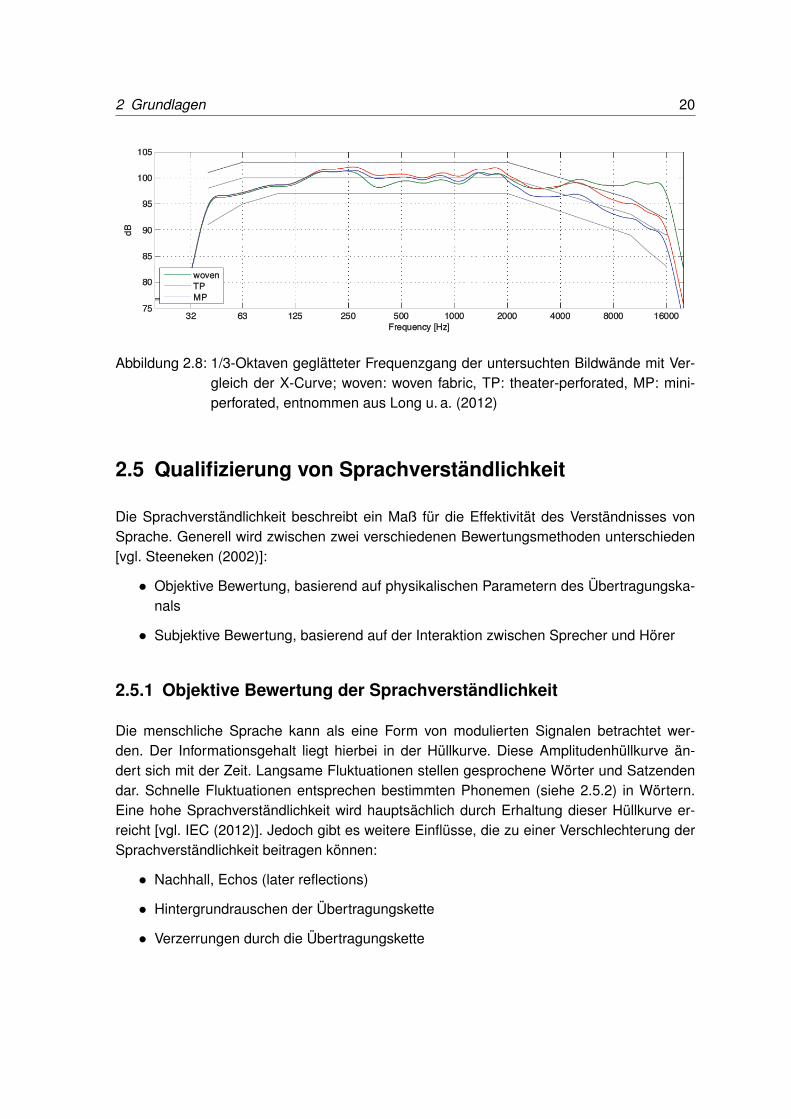
2 Grundlagen 20
Abbildung 2.8: 1/3-Oktaven geglätteter Frequenzgang der untersuchten Bildwände mit Ver-gleich der X-Curve; woven: woven fabric, TP: theater-perforated, MP: mini-perforated, entnommen aus Long u. a. (2012)
2.5 Qualifizierung von Sprachverständlichkeit
Die Sprachverständlichkeit beschreibt ein Maß für die Effektivität des Verständnisses vonSprache. Generell wird zwischen zwei verschiedenen Bewertungsmethoden unterschieden[vgl. Steeneken (2002)]:
• Objektive Bewertung, basierend auf physikalischen Parametern des Übertragungska-nals
• Subjektive Bewertung, basierend auf der Interaktion zwischen Sprecher und Hörer
2.5.1 Objektive Bewertung der Sprachverständlichkeit
Die menschliche Sprache kann als eine Form von modulierten Signalen betrachtet wer-den. Der Informationsgehalt liegt hierbei in der Hüllkurve. Diese Amplitudenhüllkurve än-dert sich mit der Zeit. Langsame Fluktuationen stellen gesprochene Wörter und Satzendendar. Schnelle Fluktuationen entsprechen bestimmten Phonemen (siehe 2.5.2) in Wörtern.Eine hohe Sprachverständlichkeit wird hauptsächlich durch Erhaltung dieser Hüllkurve er-reicht [vgl. IEC (2012)]. Jedoch gibt es weitere Einflüsse, die zu einer Verschlechterung derSprachverständlichkeit beitragen können:
• Nachhall, Echos (later reflections)
• Hintergrundrauschen der Übertragungskette
• Verzerrungen durch die Übertragungskette

2 Grundlagen 21
• Frequenzgang der Übertragungskette
Zurzeit werden u.a. folgende Messmethoden und Parameter, die unter bestimmten Bedin-gungen eindeutige Anwendungen finden, benutzt und werden als technische maßgebendeRegelprüfungen verwendet [vgl. Houtgast und Steeneken (2002)]:
• Speech Transmission Index (STI)
• Speech Transmission Index for Public Adress Systems (STIPA)
• Speech Transmission Index for Telecommunication Systems (STITEL)
• Room Acoustical Speech Transmission Index (RASTI) (veraltet)
Die folgenden Parameter werden in dieser Bachelorarbeit ermittelt, da die Verschlechterungder Sprachverständlichkeit, wie in 2.3.1 beschrieben, in verschiedenen Artikeln angemerktwurde, es jedoch zu keiner Veröffentlichung von Messergebnissen gekommen ist.
STI
Der STI bewertet die auftretenden Auswirkungen des Übertragungskanals auf die Hüllkur-ve des Sprachsignals. Während der Messung entspricht dies dem Modulationsverlust desMesssignals auf der Übertragungsstrecke.Zur Erfassung dieses Parameters gibt es zwei verschiedene Methoden:
• Direkte Methode: Verwendung eines sprachähnlichen Testsignals zur Berechnung derModulations-Transfer-Funktion (MTF)
• Indirekte Methode: Verwendung des Schroeder-Integrals zur Ableitung der MTF ausder Impulsantwort
Bei der direkten Methode wird der Frequenzbereich in 7 Oktavbänder (125 Hz - 8 kHz) auf-geteilt und jedes Band mit 14 sinusoiden Signalen (0,63 Hz - 12,5 Hz) moduliert. Die resultie-renden modulierten Signale simulieren die Fluktuationen der Hüllkurve eines realen Sprach-signals. Bei der Übertragung auf dem Kanal wird eine schlechte Sprachverständlichkeit miteiner Minderung des Modulationsspektrums dargestellt. Dies entspricht einer niedrigerenModulationstiefe in ein oder mehreren Modulationsfrequenzen. Aus dieser Abnahme werdendie MTF-Indizes pro Oktavband berechnet. Gemäß IEC (2012) entspricht die Summierungnach Gewichtung und Redundanz dem STI. Die Gewichtungs- und Redundanzfaktoren sindin der Tabelle 2.1 dargestellt und gleichen denen einer männlichen Stimme. Der weightingfactor � entspricht dem relativen Beitrag und der redundancy factor � dem Anteil der Infor-mationsüberlagerung pro Oktavband zum STI [vgl. IEC (2012)].

2 Grundlagen 22
Octave Band [Hz] 125 250 500 1000 2000 4000 8000� 0,085 0,127 0,230 0,233 0,309 0,224 0,173� 0,085 0,078 0,065 0,011 0,047 0,095 -
Tabelle 2.1: STI weighting und redundancy factor der männlichen Stimme
Die indirekte Methode erfolgt durch Berechnung der MTF aus der Impulsantwort unter Ver-wendung des Schroeder-Integrals.Folgende Gleichung beschreibt diese Berechnung [vgl. IEC (2012)]:
mk(fm) =
∣∣∣∣ ∫10 hk(t)e�j2�fmtdt
∣∣∣∣∫1
0hk(t)2dt
� [1 + 10�SNRk=10]�1 (2.1)
mit hk(t) : Impulsantwort in Oktavband kfm : ModulationsfrequenzSNRk : Signal-Rausch-Abstand in dB in Oktavband k
und kann weitergeführt werden zu [vgl. Ahnert und Schmidt (2005)]:
mk(fm) =1√
1 + (2�fm � RTk=13; 8)2� [1 + 10�SNRk=10]�1 (2.2)
mit RTk : Nachhallzeit in s in Oktavband k
Die weitere Berechnung entspricht dem Vorgehen der direkten Methode.
%ALcons
Der Parameter %ALcons beschreibt den Artikulationsverlust für Konsonanten und wird in% angegeben. Ein hoher Wert entspricht einem hohem Verlust an Konsonanten und somiteiner schlechten Sprachverständlichkeit. Es wird der aufgenommene Direktschall mit denverspäteten Reflexionen des Diffusfeldes verglichen und daraus die zu erwarteten Verlusteder Konsonanten berechnet.
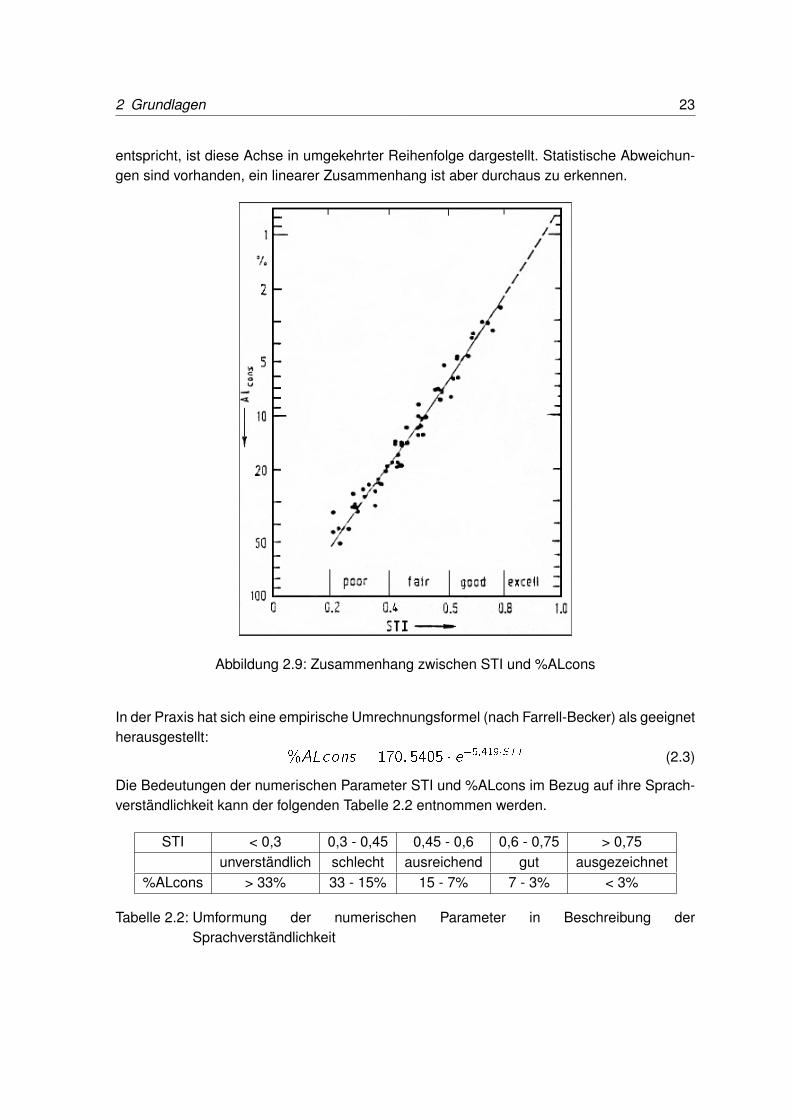
Abbildung 2.9 zeigt den statistischen Zusammenhang zwischen den Parametern STI und%ALcons. Der Parameter STI ist auf der Abszisse aufgetragen, %ALcons in % in logarith-mischer Darstellung auf der Ordinate. Da %ALcons, im Gegensatz zu STI, einem Verlust
2 Grundlagen 23
entspricht, ist diese Achse in umgekehrter Reihenfolge dargestellt. Statistische Abweichun-gen sind vorhanden, ein linearer Zusammenhang ist aber durchaus zu erkennen.
Abbildung 2.9: Zusammenhang zwischen STI und %ALcons
In der Praxis hat sich eine empirische Umrechnungsformel (nach Farrell-Becker) als geeignetherausgestellt:
%ALcons = 170; 5405 � e�5;419�ST I (2.3)
Die Bedeutungen der numerischen Parameter STI und %ALcons im Bezug auf ihre Sprach-verständlichkeit kann der folgenden Tabelle 2.2 entnommen werden.
STI < 0,3 0,3 - 0,45 0,45 - 0,6 0,6 - 0,75 > 0,75unverständlich schlecht ausreichend gut ausgezeichnet
%ALcons > 33% 33 - 15% 15 - 7% 7 - 3% < 3%
Tabelle 2.2: Umformung der numerischen Parameter in Beschreibung derSprachverständlichkeit
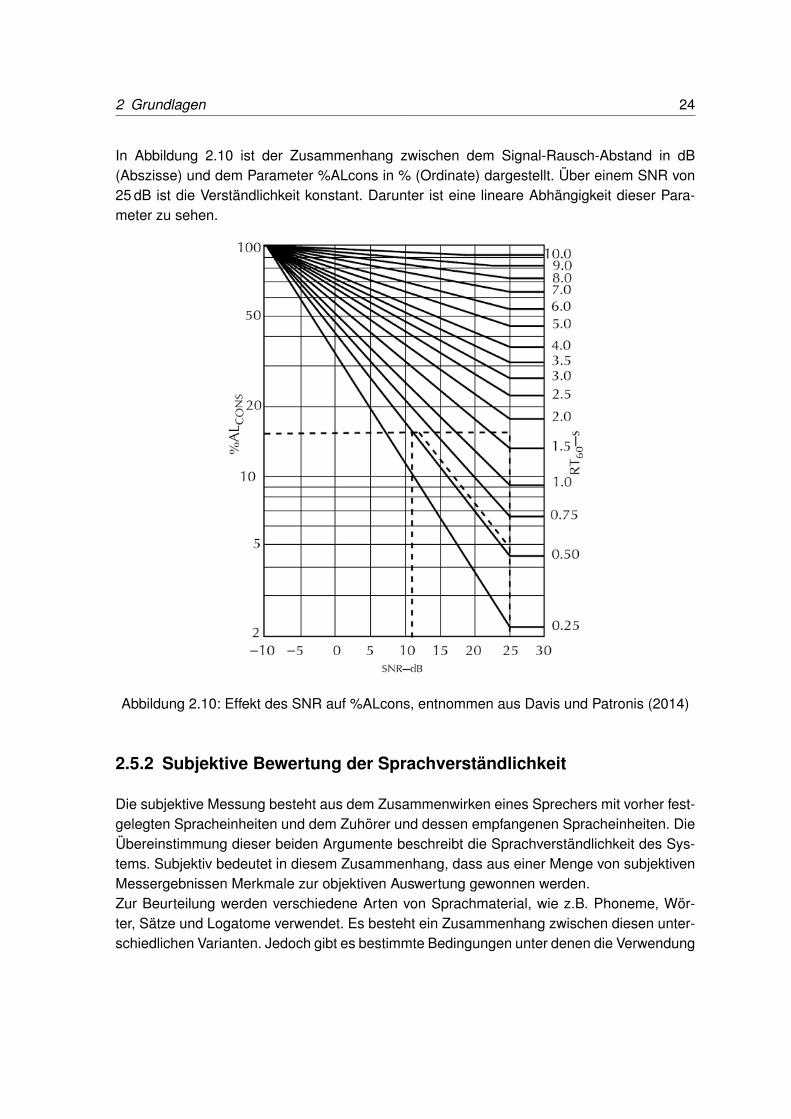
2 Grundlagen 24
In Abbildung 2.10 ist der Zusammenhang zwischen dem Signal-Rausch-Abstand in dB(Abszisse) und dem Parameter %ALcons in % (Ordinate) dargestellt. Über einem SNR von25 dB ist die Verständlichkeit konstant. Darunter ist eine lineare Abhängigkeit dieser Para-meter zu sehen.
Abbildung 2.10: Effekt des SNR auf %ALcons, entnommen aus Davis und Patronis (2014)
2.5.2 Subjektive Bewertung der Sprachverständlichkeit
Die subjektive Messung besteht aus dem Zusammenwirken eines Sprechers mit vorher fest-gelegten Spracheinheiten und dem Zuhörer und dessen empfangenen Spracheinheiten. DieÜbereinstimmung dieser beiden Argumente beschreibt die Sprachverständlichkeit des Sys-tems. Subjektiv bedeutet in diesem Zusammenhang, dass aus einer Menge von subjektivenMessergebnissen Merkmale zur objektiven Auswertung gewonnen werden.Zur Beurteilung werden verschiedene Arten von Sprachmaterial, wie z.B. Phoneme, Wör-ter, Sätze und Logatome verwendet. Es besteht ein Zusammenhang zwischen diesen unter-schiedlichen Varianten. Jedoch gibt es bestimmte Bedingungen unter denen die Verwendung

2 Grundlagen 25
eines Wortes ein besseres Ergebnis liefert, als z.B. ein CVC-Logatom (engl. für consonant-vowel-consonant; Konsonant-Vokal-Konsonant). Ein Logatom bezeichnet eine menschlicheLautäußerung, die aus einer Zusammenstellung von Buchstaben und Silben besteht, jedochin der jeweiligen (für den Test genutzten) Sprache keine Bedeutung hat.Werden die Testwörter auf die kleinsten Spracheinheiten (Phonem) der natürlichen Sprachereduziert, können zusätzliche Hinweise, die durch die Testhörer ausgenutzt werden, auf einMinimum reduziert werden. Wenn die Äußerungen keine Bedeutung beinhalten, wird nur derreine, neurosensorische Prozess des Hörens und Verstehens, ohne weitere kognitive Verar-beitung oder Fehlerkorrektur, betrachtet und bewertet [vgl. Wesker u. a. (2005)].Die Antwortmöglichkeiten des Hörers können ebenfalls variieren. Ein offener Test gibt demHörer eine uneingeschränkte Auswahl. Beim geschlossenen Test wird eine Multiple Choi-ce Auswahl angeboten, an denen sich der Hörer orientieren, von denen er sich aber auchbeeinflussen lassen kann.
Folgende Methoden stehen u.a. zur Verfügung:
• Diagnostic Rhyme Test (DRT)
– Diagnose und Vergleichsbewertung der Verständlichkeit von einfachen Anfangs-konsonanten mit bedeutsamen CVC-Wörtern
– Geschlossene Antwortmöglichkeit mit 2 Alternativen
• Modified Rhyme Test (MRT)
– Diagnose und Vergleichsbewertung der Verständlichkeit von einfachen Anfangs-und Endkonsonanten mit bedeutsamen CVC-Wörtern
– Geschlossene Antwortmöglichkeit mit 6 Alternativen und offener Antwortmöglich-keit
• Harvard Phonetically Balanced Word Test (PB)
– Vergleichsbewertung von Satz-Verständlichkeit mit bedeutsamen syntaktisch va-riablen Sätzen
– Offene Antwortmöglichkeit
Grundlegend ist zu sagen, dass eine Auswahl von mindestens 50 bis 100 Logatomen unterVerwendung von 5 Testpersonen ein repräsentatives Ergebnis liefern kann. Die verwende-ten Spracheinheiten müssen phonetisch und strukturell ausgeglichen sein und das Hinter-grundrauschen muss einen realistischen Wert annehmen. Die Testhörer dürfen nicht unterSchwerhörigkeit leiden und der Test sollte in der Muttersprache dieser Person durchgeführtwerden. Der Sprecher hat die Aufgabe die Logatome klar, deutlich und ohne Betonung vor-zutragen [vgl.Brachmanski (2004)].
2 Grundlagen 26
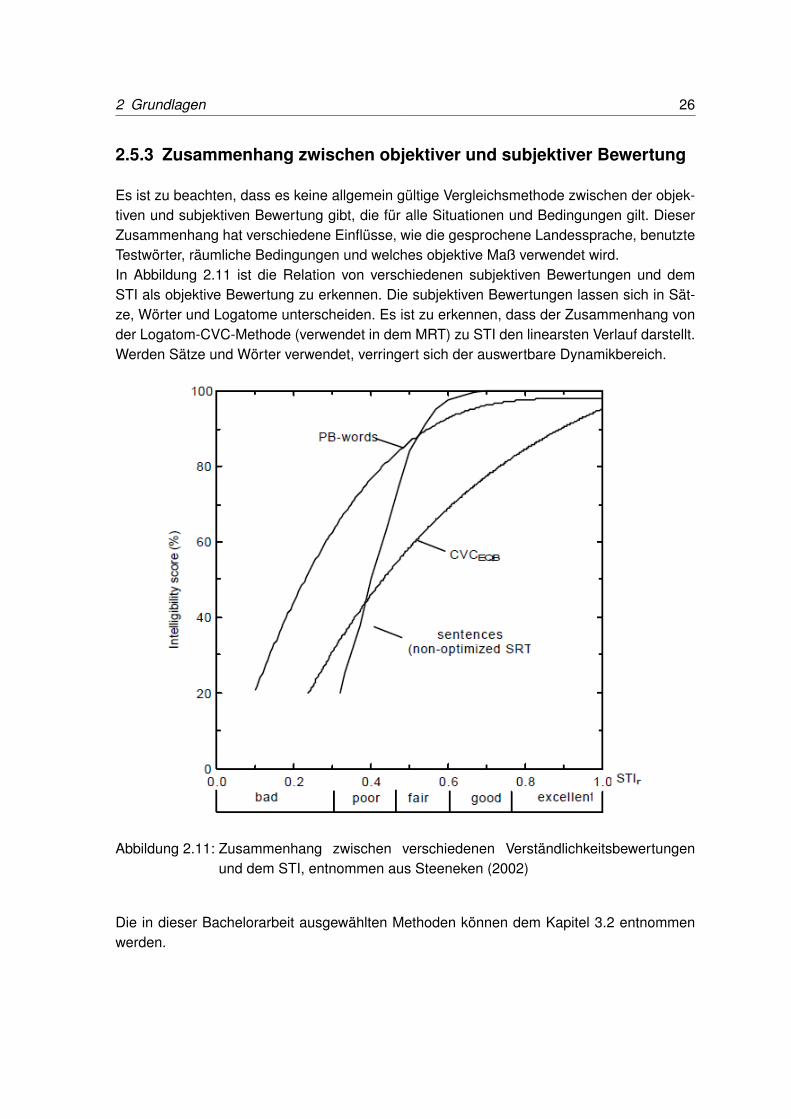
2.5.3 Zusammenhang zwischen objektiver und subjektiver Bewertung
Es ist zu beachten, dass es keine allgemein gültige Vergleichsmethode zwischen der objek-tiven und subjektiven Bewertung gibt, die für alle Situationen und Bedingungen gilt. DieserZusammenhang hat verschiedene Einflüsse, wie die gesprochene Landessprache, benutzteTestwörter, räumliche Bedingungen und welches objektive Maß verwendet wird.In Abbildung 2.11 ist die Relation von verschiedenen subjektiven Bewertungen und demSTI als objektive Bewertung zu erkennen. Die subjektiven Bewertungen lassen sich in Sät-ze, Wörter und Logatome unterscheiden. Es ist zu erkennen, dass der Zusammenhang vonder Logatom-CVC-Methode (verwendet in dem MRT) zu STI den linearsten Verlauf darstellt.Werden Sätze und Wörter verwendet, verringert sich der auswertbare Dynamikbereich.
Abbildung 2.11: Zusammenhang zwischen verschiedenen Verständlichkeitsbewertungenund dem STI, entnommen aus Steeneken (2002)
Die in dieser Bachelorarbeit ausgewählten Methoden können dem Kapitel 3.2 entnommenwerden.

3 Messvorgang
3.1 Sprachverständlichkeit nach STI und %ALcons
3.1.1 Messsoftware
Die hier verwendete Messsoftware wird von der Firma AFMG Technologies GmbH bereit-gestellt. Bei Electronic and Acoustic System Evaluation and Response Analysis (EASERA)handelt es sich um eine professionelle Software für akustische und elektro-akustische An-wendungen, die sich zu einem Standard für Beschallungstechnik und Raumakustik entwi-ckelt hat.
EASERA besteht aus vier logischen Baugruppen:
• Signalgenerator, mit der Auswahl von verschiedenen Stimuli- und Messsignalen (u.a.Sweeps, Rauschen, .wav-Datei)
• Messmodul mit Konfigurationsparametern und Kalibrierungsoption
• Echtzeit-Datenanalyse
• Datenauswertung
Die Messung von STI und %ALcons erfolgt bei EASERA als indirekte Methode über dieAufnahme der Impulsantwort (siehe 2.5.1). Diese wird durch Ausgabe eines geeignetenStimulus-Signals und der Aufzeichnung der Antwort gewonnen. Das hier verwendete Anre-gungssignal ist Pink Noise (siehe 2.3.2). Entsprechend den Vorgaben von IEC (2012) beträgtdas Verhältnis von Scheitelwert zu Effektivwert (Crest-Faktor) 12 dB.Es werden ebenfalls die Frequenzgänge der Kinosäle gemessen. Dies geschieht zur Über-prüfung der Vorgaben nach SMPTE ST 202:2010 und späteren Auswertung der Messergeb-nisse. Die Frequenzgänge errechnen sich durch eine FFT der Impulsantwort.Außerdem wird zur Vollständigkeit die Nachhallzeit RT der Kinosäle erfasst, um möglicheAbhängigkeiten zur Sprachverständlichkeit aufzuzeigen. Bei EASERA wird die NachhallzeitT30 gemessen. Dies entspricht dem Zeitintervall einer Schalldruckpegelabnahme um 30 dBim Raum. Diese Zeit wird auf den Wert für 60 dB extrapoliert und als RT60 angegeben.
3 Messvorgang 28
Die Kalibrierung des Messsystems erfolgt ebenfalls über die Software. Hierfür wird einMikrofon-Kalibrator mit einem konstanten 94 dB Ausgangspegel auf das Messmikrofon ge-steckt und dessen Empfindlichkeit/Übertragungsfaktor zur Kalibrierung des Inputs gemes-sen. Die Einstellung zur maximalen Ausgangsspannung berechnet sich automatisch. DieOutput-Kalibrierung erfolgt über ein Loopback des Interface-Outputs zum Input.
Für die folgenden Messungen wurde die Version EASERA 1.2.13 verwendet.
3.1.2 Verwendete Technik
Für alle Messungen zur Sprachverständlichkeit nach STI und %ALcons wird dieselbe Technikverwendet, um gerätetechnische Abweichungen auszuschließen. Außerdem werden gleicheKabellängen bei der Übertragung des Stimulussignals und des aufgenommenen Signalsbenutzt, auch wenn die Distanz kürzere Kabellängen zulassen würde.Die Datenblätter der Technik können dem Anhang entnommen werden. Tabelle 3.1 zeigt dieÜbersicht der benutzen Geräte.
Gerät Hersteller Modell BeschreibungMessmikrofon Earthworks M23 KugelcharakteristikAudiointerface Roland OCTA-CAPTURE High-Speed, USB
Laptop HP ProBook 430 G2 ConsumerSchallpegelmessgerät Brüel & Kjaer 2236 Handgerät, Klasse 2
Mikrofonkalibrator Galaxy Audio CM-C200 HandgerätAudioprozessor* Dolby CP750 Cinema Audio ProzessorAudioprozessor* Dolby CP65 Cinema Audio ProzessorAudioprozessor* Datasat AP20 Cinema Audio Prozessor
Tabelle 3.1: Übersicht der verwendeten Technik
* für weitere Bemerkungen zum Audioprozessor siehe 3.1.4
3.1.3 Messorte
Kinosäle
Die Messungen zur Sprachverständlichkeit über die Auswertung von STI und %ALcons mitEASERA werden in 8 Kinosälen der größten deutschen Kinobetreiber durchgeführt. Um sta-tistisch einen größeren Bereich abzudecken, unterscheiden sich diese Säle in der Zahl ihrer
3 Messvorgang 29
Sitzplätze, ihren geometrischen Abmessungen und ihrem Raumvolumen. Der Aufbau derKinosäle ist schematisch überall gleich (siehe Abbildungen 1.1 und 3.1) und unterschei-det sich bei den Lautsprechern, Verstärkern und Kinoprozessoren lediglich in den Modellenund Herstellern. Eine genauere Analyse des Einflusses auf die Sprachqualität der Audiopro-zessoren, Leistungsverstärker und Lautsprecher soll hier nicht geschehen, da die Kinosaal-Lautsprecher-Systeme beispielhaft als Status-Quo dienen sollen.Tabelle 3.2 zeigt die Einteilung der Kinosaalgröße und Anzahl der Säle, in denen eine Mes-sung gemacht wurde, sowie deren Bezeichnungen in der folgenden Auswertung.
Sitzplätze < 150 150 - 250 250 - 350 > 350Anzahl der Säle 1 3 2 2
Nachfolgende Bezeichnung ai bi ci di
Tabelle 3.2: Anzahl der Kinosäle und der Sitzplätze
Die genauen Standorte und Betreiber bleiben anonym.
Referenzraum
Als Referenzraum dient ein optimierter Vorführungsraum, nicht zu verwechseln mit einemschalltoten Raum, der Firma Amptown System Company (ASC). Durch die Eigenschaft ei-nes realen, nicht toten Raumes können die beobachteten Phänomene genauer untersuchtwerden und der Bezug zu den ebenso nachhallenden Kinosälen wird somit ermöglicht. DerRaum hat eine gleichmäßige Nachhallzeit von 0,45 s bis 80 Hz. Er hat die Abmessung von10,5 m x 9,6 m, bei einer gekrümmten Deckenhöhe an der Seite von 5,9 m und 4,5 m.Die installierten Lautsprecher sind Screen-Channel-Lautsprechersysteme der Marke CINESOUND LAB. Sie wurden für die Verwendung hinter perforierten Kunststoff-Bildwänden ent-wickelt. Dies kompensiert den Einfluss der perforierten PVC-Bildwand und vereinfacht demSystemingenieur eine finale Lautsprecher/Raum-Equalisation. Die in der Kontrollelektronikdes Leistungsverstärkers integrierte Bildwand-Entzerrung im Zusammenhang mit dem opti-malen Abstand zwischen Lautsprecher und Bildwand sorgen für die vollständige Kompensa-tion des Bildwandeinflusses.Durch die abgerundeten Kanten und das kompakte Design wird erreicht, dass weniger aus-geprägte Reflexionen zwischen Lautsprecher und Bildwand erzeugt werden (siehe 2.4).Die Lautsprecher weisen einen sehr flachen Amplitudenfrequenzgang auf und beherrschendurch den großen Dynamikumfang die verzerrungsfreie Übertragung auch bei hohen Laut-stärken. Der Leistungsverstärker bietet mit 1100 W / 8 und 32 dB Gain auch die Reserven,die es für eine derartige Equalisation benötigt. Die integrierte Kontrollelektronik schützt dieLautsprecher und optimiert deren Frequenz- und Phasenverhalten.

3 Messvorgang 30
Im Nachfolgenden wird die Bezeichnung x1 (mit Screen-Entzerrung) und x2 (ohne Screen-Entzerrung, siehe 3.1.4) für diesen Raum verwendet.
3.1.4 Messaufbau und -methodik
Der Messaufbau ist, wie in 3.1.2 beschrieben, zu jeder Messung einheitlich. Abbildung 3.1zeigt den systematischen Aufbau der Messung. Der Laptop sendet das Stimulus-Signal derMess-Software per USB an das Audiointerface, welches es durch den Output über ein XLR-Kabel an den Audioprozessor weiterleitet. Dieser überträgt das bearbeitete Signal an denLeistungsverstärker, der es über den Center-Lautsprecher ausgeben lässt. Die Schallwellendurchdringen die Bildwand und breiten sich im Raum aus. Das Messmikrofon mit Kugelcha-rakteristik ist auf die Mitte des Lautsprechers, welcher sich bis 4,5 m in der Höhe befindenkann, ausgerichtet und die Höhe des Stativs beträgt 1,2 m. Die aufgenommenen Schallwel-len werden ebenfalls über ein XLR-Kabel an den Input des Audiointerfaces zurückgesendetund an den Laptop weitergeleitet.
Abbildung 3.1: Skizzierter technischer Messaufbau
Bei den Messungen in den Kinosälen werden 9 verschiedene Positionen ausgewertet. Zen-traler Ausgangspunkt ist die Mitte des Sitzbereichs in vertikaler und horizontaler Richtung.

3 Messvorgang 31
Dies ist der akustisch und statistisch ausgeglichenste Platz, da der Abstand zu den Begren-zungen gleich ist und somit auch der Weg für die entstehenden Reflexionen. Zudem ist diesder Referenzpunkt, an dem die Tonfilmmischung erarbeitet wird. Danach verteilen sich dieanderen Positionen im Abstand von 2 m - 3 m umher. Sollte eine dieser Messungen ein un-gewöhnlich akustisches Verhalten aufweisen, werden diese Ergebnisse nicht in die weitereBerechnung und Mittelung mit einfließen [vgl. SMPTE (2010)].
In dem ASC-Referenzraum werden aufgrund seiner Größe nur 6 Positionen ausgewertet.Zusätzlich wird hier eine A/B-Vergleichsmessung durchgeführt. Zunächst wird das ursprüng-liche System, wie in 3.1.3 beschrieben, ausgewertet. Danach wird das System ohne Bild-wandentzerrung der gleichen Messung unterzogen. Dies geschieht durch Austausch desLeistungsverstärkers mit einem üblichen Kino-Verstärker ohne Bildwand-Entzerrung. Hiermitkönnen direkte Schlussfolgerungen des Einflusses einer Bildwandentzerrung auf die ermit-telten STI und %ALcons-Parameter gezogen werden.
Zu den Audioprozessoren ist zu sagen, dass der Dolby 750 und diverse Vorgänger in denuntersuchten Kinos große Verbreitung hat. In den meisten Projektierungsräumen befindetsich das Modell CP-750, seltener der CP-65. Im optimierten Raum von ASC kam der Audio-prozessor AP20 von Datasat zum Einsatz. Der Audioprozessor ist für die Signalverarbeitungverantwortlich. Dazu gehören die Quellenwahl, Vorverstärkung, Lautstärkeeinstellung. Esist ebenfalls ein Grafik-EQ enthalten, der Raum/Lautsprecherkorrekturen ermöglichen soll.Nachfolgend ist in Abbildung 3.2 das Anschlussfeld des CP750 dargestellt. Hierbei wird dasStimulus-Signal über den 25-Pin D-Sub-Connector am Multi-Channel Analog Input einge-speist. Die Anschlussart der anderen Prozessoren erfolgt komparabel.
Abbildung 3.2: Hinteres Anschlussfeld des CP750 Cinema-Audioprozessor
3.2 Logatom-Verständlichkeitstest
In dem Logatomtest dieser Bachelorarbeit wird aufgrund der Ausführungen in 2.5.2 der MRTunter Verwendung von Logatomen der Form CVC und VCV durchgeführt mit geschlossener

3 Messvorgang 32
Antwortmöglichkeit. Im Folgenden wird das Vorgehen und die Vorbereitung zum Logatom-Verständlichkeitstest erläutert.
3.2.1 Vorgehen des Hörtests
Einem Publikum von 8 Testhörern wird in mehreren Durchgängen 100 Logatome über denCenter-Lautsprecher des optimierten Screening-Rooms vorgetragen. Ziel dieser Testperso-nen ist, die gehörten Logatome den richtigen Auswahlmöglichkeiten zuzuordnen. Hierfür ste-hen 6 Alternativen zur Auswahl (siehe Tabelle 3.3). Zu Beginn wird ein Antwortbogen ausge-teilt, der pro gehörtem Logatom eine Auswahl von 5 tonal ähnlichen Logatomen, sowie derAuswahlmöglichkeit "nicht verstanden", anbietet. Dann werden die Audiospuren (siehe 3.2.3)über das Lautsprecher-System ausgegeben. Die Testpersonen sind aufgefordert innerhalbvon 5 Sekunden eine intuitive Entscheidung zu treffen und diese auf den Antwortbögen zumarkieren. Nach jeweils 10 Logatomen wird eine kurze Pause eingelegt.Die Testpersonen haben ein Alter zwischen 20 und 29 Jahren, haben ein nicht beschädigtesGehör und sind mit der deutschen Sprache aufgewachsen.Dieser Test wird mehrmals unter verschiedenen Bedingungen wiederholt. Zum einen wer-den 2 verschiedene Pegel für ein Störsignal, welches über die restlichen Lautsprecherdes Systems (Front Right, Front Left, Surround Right, Surround Left, Surround Back Rightund Surround Back Left) ausgegeben wird, bei einem konstanten Logatompegel getestet(SNR = 0 dB und SNR = 6 dB). Dies geschieht zur Simulation von Dialog-Unterlegung mit Mu-sik, Effekten oder Hintergrundgesprächen. Zum anderen wird der Leistungsverstärker desCenter-Kanals und der zugehörigen Screen-Entzerrung durch einen gängigen Leistungsver-stärker für Kinos ohne Entzerrung für eine weitere Messung ausgetauscht (siehe 3.1.4), umden direkten Einfluss dieser Eigenschaft auf die subjektive Sprachverständlichkeit zu zeigen.Folglich werden 4 Testdurchgänge durchlaufen:
• System mit Bildwand-Entzerrung und SNR = 0 dB
• System ohne Bildwand-Entzerrung und SNR = 0 dB
• System mit Bildwand-Entzerrung und SNR = 6 dB
• System ohne Bildwand-Entzerrung und SNR = 6 dB
3.2.2 Auswahl der Test-Logatome und des Störsignals
In der Sprach-Audiometrie werden zumeist Wort- und Satztests durchgeführt. Diese liefernjedoch aufgrund der Redundanz von Sprache, d.h. der Mehrfachinformation über die vorkom-menden Laute in Worten, keine differenzierte Betrachtung einzelner Frequenzbereiche [vgl.Holube u. a. (2010)]. Deswegen werden für den Test 100 verschiedene Logatome, die aus
3 Messvorgang 33
jeweils 3 Phonemen bestehen, verwendet. Es gibt 2 Strukturen dieser Logatome. Die VCV-Wörter bestehen aus der Reihenfolge Vowel-Consonant-Vowel, die CVC aus Consonant-Vowel-Consonant. Die äußeren 2 Laute sind zur Minimierung der Wechselwirkung identisch.Durch diese Eigenschaft kann ebenfalls die Ko-Artikulation (Beeinflussung eines Lautesdurch den lautlichen Kontext) berücksichtigt werden [vgl. Wesker u. a. (2005)].
In der nachstehenden Tabelle 3.3 werden 4 Beispiel-Logatome mit ihren Auswahlmöglichkei-ten aufgelistet.
Struktur Test-Logatom Auswahlm. 1 2 3 4 5 6vcv ubbu uppu uddu ubbu uwwu uttu "nicht verstanden"vcv esse esche enne ette esse ezze "nicht verstanden"cvc bebb pepp bebb pehp gegg behb "nicht verstanden"cvc fiff siss fihf fehf feff fiff "nicht verstanden"
Tabelle 3.3: Beispiel von Test-Logatomen mit ihren Auswahlmöglichkeiten
Zur Vereinfachung der Einordnung erfolgt die schriftliche Darstellung dieser Logatome inverlängerter Form. Hiermit werden ebenfalls phonetische Unterschiede in ihrer Aussprachedeutlich (z.B. ein kurzes e bei „bebb“ im Vergleich zu „behb“). Die vollständige Liste derbenutzten Logatome und den Auswahlmöglichkeiten, können dem Anhang entnommen wer-den.
Das Störsignal wurde für das International Collegium of Rehabilitative Audiology (ICRA) zurBereitstellung von sprachähnlichen Hintergrundrauschen für Hörtests entwickelt. Es setztsich aus einer gewichteten Überlagerung von einem künstlichen breitbandigen sprachsimu-lierten Rauschen, sowie einem zusammengefassten Korpus von 30 Frauen- und 30 Männer-stimmen zusammen. Das Langzeitspektrum und das fluktuierende Zeitverhalten des Rau-schens entspricht dem einer natürlichen Stimme.
3.2.3 Aufnahme und Zusammenstellung
Das Oldenburg Logatome Speech Corpus (OLLO) ist eine Sprachdatenbank, die für den Ver-gleich von Verständlichkeit zwischen Automatic Speech Recognizers (ASR) und menschli-chen Zuhörern entwickelt wurde. Diese Datenbank der Audiodateien ist auf der Internetseitedes Departements für Medizinische Physik und Akustik der Universität Oldenburg frei ver-fügbar.Die Aufnahme der Sprachsamples erfolgte in einem akustisch isolierten Aufnahmeraum miteinem hochqualitativen Kondensatormikrofon und Recording-Equipment in Studioqualität.

3 Messvorgang 34
Die .wav-Dateien wurden bei einer Samplingrate von 44,1 kHz und einer Auflösung von 32 bitaufgenommen. Nachfolgend im Postprocessing wurde die Amplitude auf 99 % normalisiertund mit 16 bit abgespeichert. Bei allen Aufnahmen wurde auf eine konstante Sprachqualitätgeachtet [vgl. Wesker u. a. (2005)].Zur weiteren Bearbeitung und zum Zusammenfügen der Sprachsamples wird die Demover-sion der Digital Audio Workstation (DAW)-Software REAPER des Entwicklers Cockos Inc.verwendet. Die einzelnen Sprachsamples werden im 5 Sekunden Abstand in zufälliger Rei-henfolge auf einer Spur zusammengefügt und auf den Kanal des Center-Lautsprechers ge-routet. Auf einer weiteren Spur wird das Störsignal integriert und auf die restlichen Kanälegeroutet. Zu Beginn jedes Testdurchlaufs wird nun die Pegeleinstellung für den jeweiligenSNR vorgenommen.Die .wav Dateien können dem Anhang entnommen werden.

4 Messergebnisse & Diskussion
Folgend werden die Messergebnisse der Frequenzgänge, der Nachhallzeiten, der Sprach-übertragungsparameter nach STI und %ALcons und des Logatomverständlichkeitstest gra-fisch und in tabellarischer Form dargestellt. Werden die Ergebnisse in zusammengefassterForm präsentiert, so geschieht dies, da eine ausführliche individuelle Darstellung keinenMehrwert erzielen würde. Die ausführlichen einzelnen Messdaten, sowie weitere Darstellun-gen, können dem Anhang entnommen werden.
4.1 Mittelungsverfahren
Zur Mittelung der Frequenzgänge wird die Average-Funktion von EASERA angewandt. Hier-zu werden die einzelnen positionsabhängigen Frequenzgänge einer 1/12-Oktav-Glättung un-terzogen, die Amplituden in jeder Frequenz aufsummiert und durch die Anzahl der Positionendividiert. Die Darstellungsweise in Form einer 1/3-Oktav-Glättung, auf welche sich der Tole-ranzbereich der X-Curve bezieht, würde die technische Komplexität unnötig vereinfachen.Feinere Glättungen haben die Eigenschaft, das Verhalten von Reflexionen und Verzerrun-gen deutlicher aufzuzeigen und werden deswegen hier gewählt. Hierdurch befinden sich dieFrequenzgänge eventuell nicht mehr im Toleranzbereich der X-Curve, obwohl dies bei einer1/3-Oktav-Glättung der Fall wäre.
Die Parameter STI und %ALcons werden jedoch nicht aus der Average-Funktion gewon-nen, da bei diesen Mittelungsverfahren die Phaseninformationen verloren ginge und so eineweitaus bessere Sprachverständlichkeit suggeriert würde. Daher werden die Werte einer je-den Mess-Position einzeln betrachtet und unter sich gemittelt. Entsprechendes gilt für dieNachhallzeit RT.
4.2 Darstellungsverfahren mit MATLAB
Die Darstellung der Messergebnisse erfolgt mit MATLAB-Skripten. Hierzu werden die Mess-werte des Spektrums mit einer Auflösung von 96 Werte/Oktave exportiert, in eine Excel-Tabelle eingefügt, von MATLAB eingelesen und verarbeitet. Für die Frequenzgänge wird der

4 Messergebnisse & Diskussion 36
für diese Arbeit relevante Bereich von 200 Hz - 16 kHz dargestellt. Weitere Funktionen, wiedie Darstellung der X-Curve-Toleranz und der STI- und %ALcons-Werte, sind hierbei eben-falls enthalten.Zur Darstellung der Ergebnisse des Logatomtests werden die digitalisierten Antworten derTestpersonen ebenfalls aus einer Excel-Tabelle in MATLAB eingelesen und ausgewertet.Es werden verschiedene Darstellungen als Säulendiagramm und Box-Whisker-Plot, aufge-löst nach Testpersonen und in zusammengefasster Form dargestellt. Zum Verständnis desBox-Whisker-Plots zeigt Abbildung 4.1 die Elemente des Aufbaus und Tabelle 4.1 deren Be-deutung.
Abbildung 4.1: Elemente eines Box-Whisker-Plots
Element Bedeutungunteres Whisker kleinster Datenwert (ohne Ausreißer)unteres Quartil 25% der Datenwerte sind kleiner/gleich diesem Wert
Median mittlerer Wert der Datenreiheoberes Quartil 25% der Datenwerte sind größer/gleich diesem Wert
oberes Whisker größter Datenwert (ohne Ausreißer)Ausreißer mehr als 1,5 � Interquartilsabstand entfernt vom oberen/unteren Whisker
Tabelle 4.1: Bedeutung der Elemente eines Box-Whisker-Plots
Die kommentierten MATLAB-Skript-Dateien können dem Anhang entnommen werden.

4 Messergebnisse & Diskussion 37
4.3 Sprachverständlichkeit nach STI und %ALcons
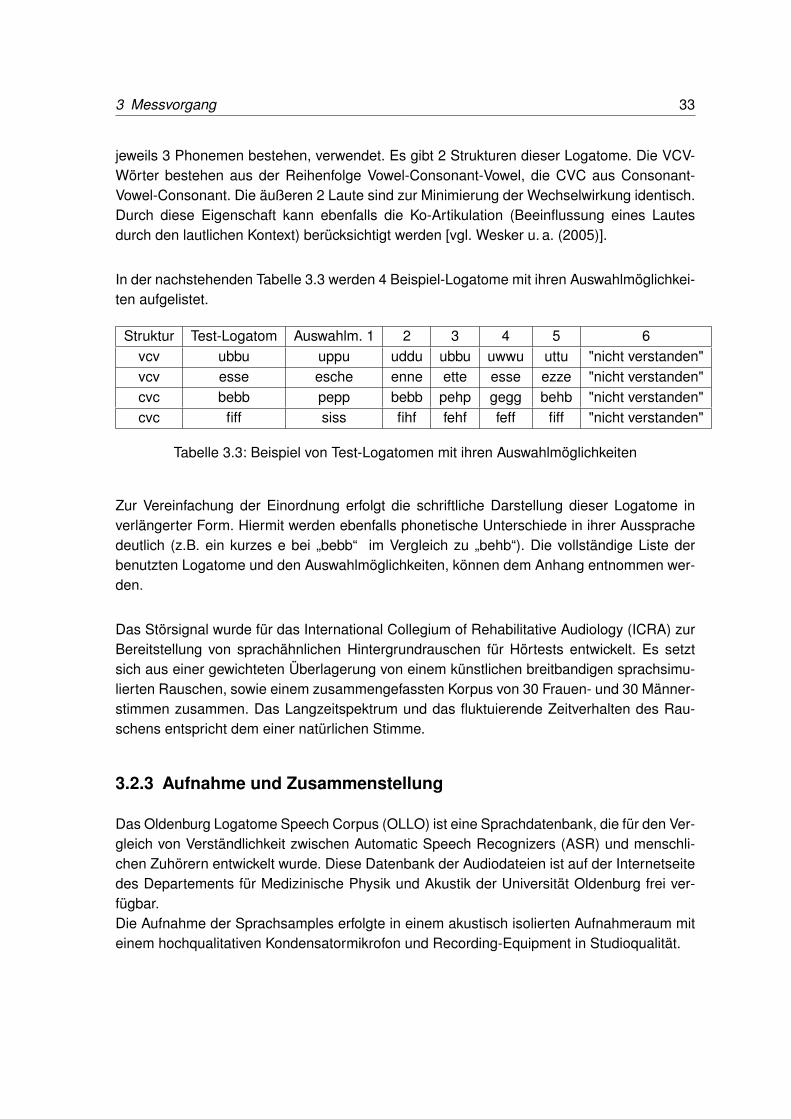
Die Abbildung 4.2 zeigt die 1/12-Oktav geglätteten und gemittelten Amplitudenfrequenz-gänge der Kinosäle in dem Bereich von 200 Hz - 16 kHz, sowie den Zielfrequenzgang derX-Curve mit ihrer Toleranz.
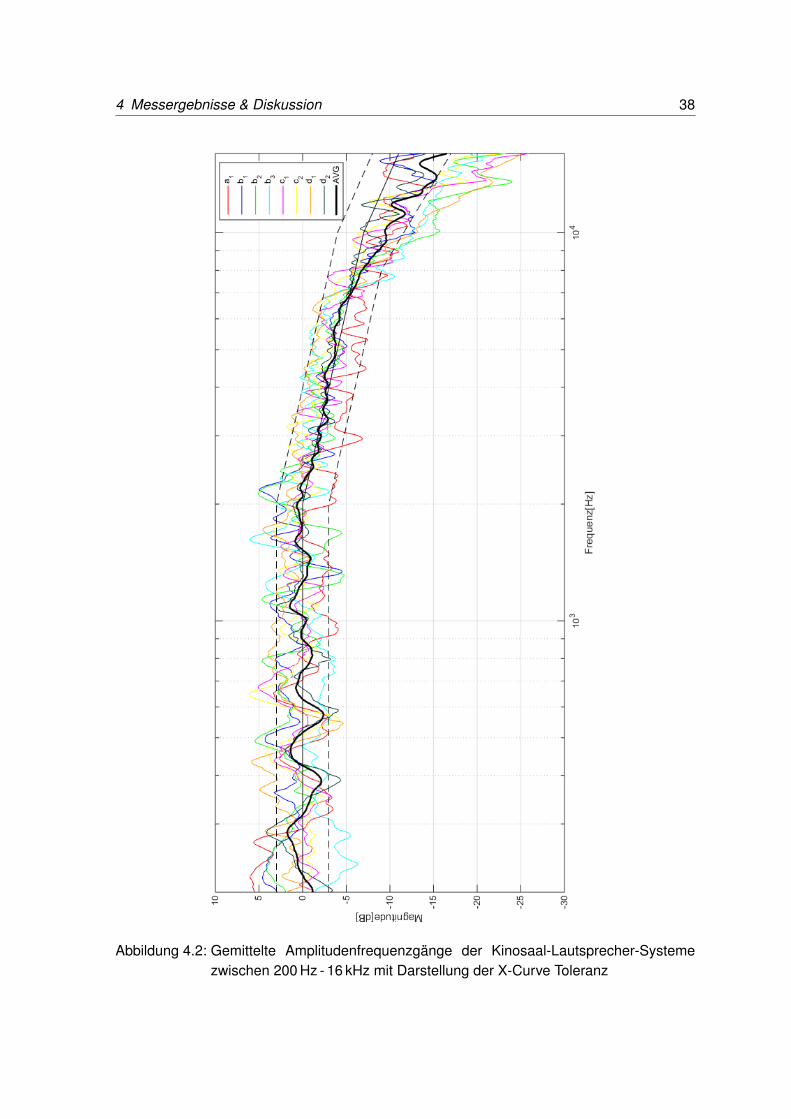
In der Abbildung 4.3 sind die 1/12-Oktav geglätteten und gemittelten Amplitudenfrequenz-gänge des optimierten Screening-Rooms mit und ohne Bildwand-Entzerrung in dem Fre-quenzbereich von 200 Hz - 16 kHz zu sehen. Es ist anzumerken, dass der Verlauf zwischen500 Hz - 1,8 kHz eine Dämpfung zeigt. Diese ist aufgrund von unzureichend temporärenAkustikmaßnahmen und fehlenden Publikum während der Messung durch Bodenreflexionenentstanden. Ohne diese Bedingungen, würde der Frequenzverlauf eine genauere Linearitätzeigen.
Tabelle 4.2 zeigt die Nachhallzeit RT der einzelnen Kinosäle.
Kinosaal a1 b1 b2 b3 c1 c2 d1 d2RT[s] 1,18 0,6 0,67 0,74 0,58 1,08 0,71 0,55
Tabelle 4.2: Extrapolierte Nachhallzeiten RT60(T30) der untersuchten Kinosäle
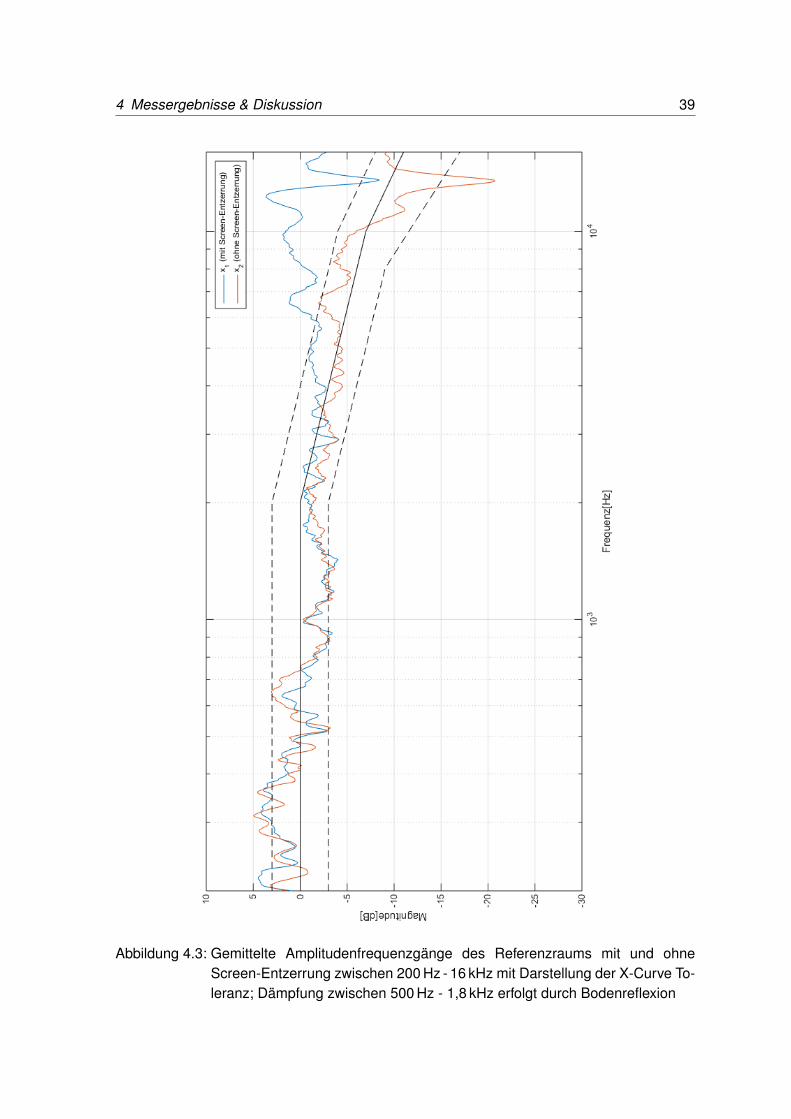
Die Tabelle 4.3 zeigt die über ihre Position gemittelten Werte für die Parameter STI und%ALcons für jeden der untersuchten Kinosäle, sowie des optimierten Screening-Rooms mitund ohne Bildwand-Entzerrung. Abbildung 4.4 zeigt die entsprechende grafische Darstel-lung.
Kinosaal a1 b1 b2 b3 c1 c2 d1 d2 x1 x2STI 0,91 0,85 0,90 0,90 0,88 0,89 0,85 0,86 0,85 0,85
%ALcons[%] 1,21 1,72 1,31 1,32 1,49 1,39 1,73 1,61 1,69 1,69
Tabelle 4.3: Messergebnisse nach STI und %ALcons der verschiedenen Kinosäle und desReferenzraumes
4 Messergebnisse & Diskussion 38
Abbildung 4.2: Gemittelte Amplitudenfrequenzgänge der Kinosaal-Lautsprecher-Systemezwischen 200 Hz - 16 kHz mit Darstellung der X-Curve Toleranz
4 Messergebnisse & Diskussion 39
Abbildung 4.3: Gemittelte Amplitudenfrequenzgänge des Referenzraums mit und ohneScreen-Entzerrung zwischen 200 Hz - 16 kHz mit Darstellung der X-Curve To-leranz; Dämpfung zwischen 500 Hz - 1,8 kHz erfolgt durch Bodenreflexion
4 Messergebnisse & Diskussion 40
Abbildung 4.4: Ermittelte Sprachverständlichkeit nach STI und %ALcons der Kinosaal-Lautsprecher-Systeme und des Referenzraums mit und ohne Screen-Entzerrung
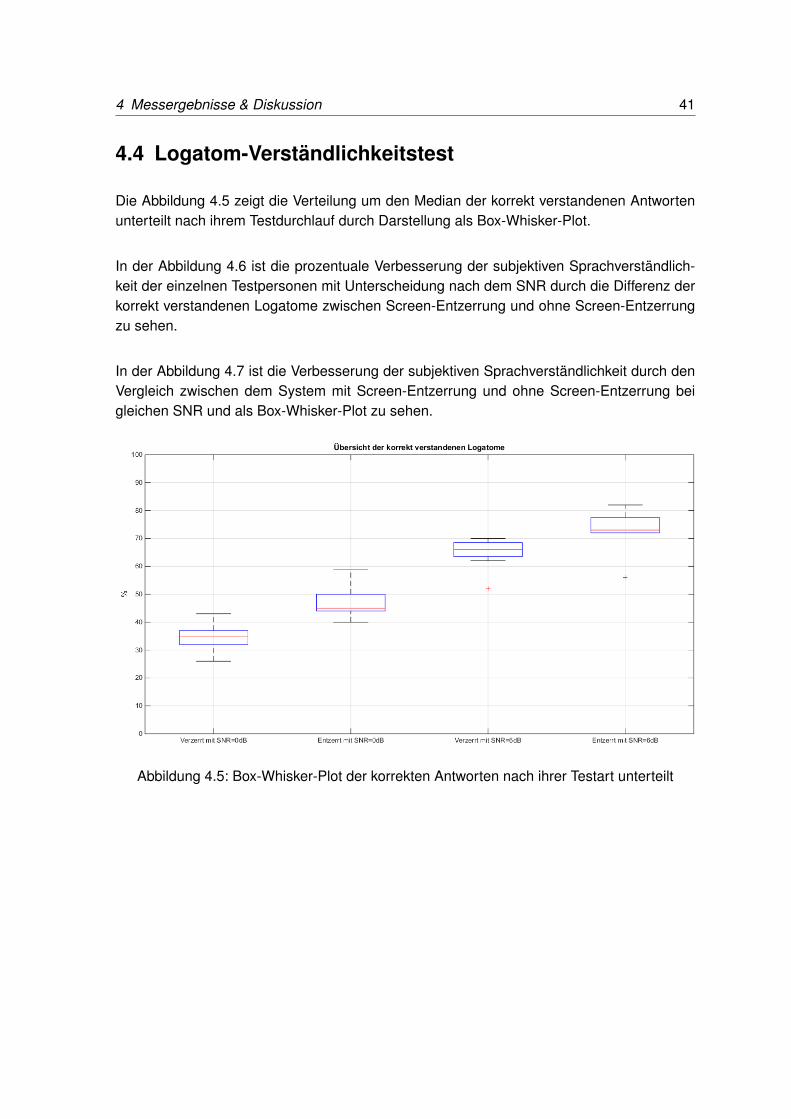
4 Messergebnisse & Diskussion 41
4.4 Logatom-Verständlichkeitstest
Die Abbildung 4.5 zeigt die Verteilung um den Median der korrekt verstandenen Antwortenunterteilt nach ihrem Testdurchlauf durch Darstellung als Box-Whisker-Plot.
In der Abbildung 4.6 ist die prozentuale Verbesserung der subjektiven Sprachverständlich-keit der einzelnen Testpersonen mit Unterscheidung nach dem SNR durch die Differenz derkorrekt verstandenen Logatome zwischen Screen-Entzerrung und ohne Screen-Entzerrungzu sehen.
In der Abbildung 4.7 ist die Verbesserung der subjektiven Sprachverständlichkeit durch denVergleich zwischen dem System mit Screen-Entzerrung und ohne Screen-Entzerrung beigleichen SNR und als Box-Whisker-Plot zu sehen.
Abbildung 4.5: Box-Whisker-Plot der korrekten Antworten nach ihrer Testart unterteilt
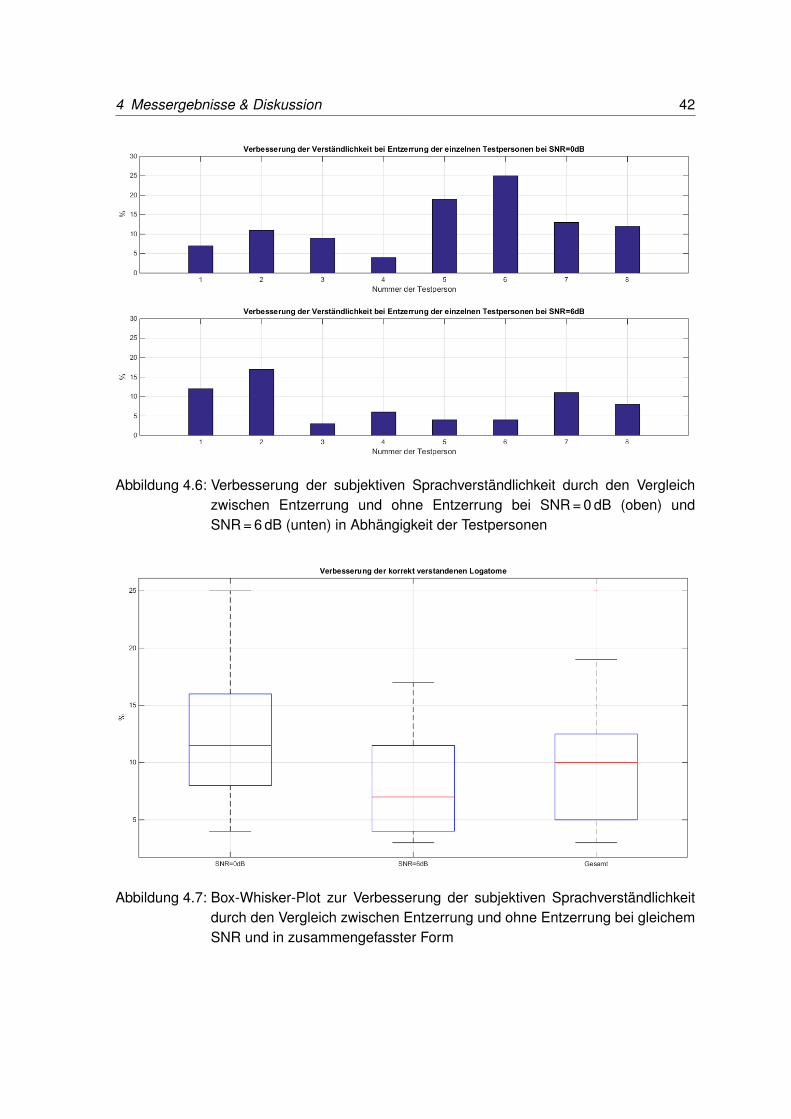
4 Messergebnisse & Diskussion 42
Abbildung 4.6: Verbesserung der subjektiven Sprachverständlichkeit durch den Vergleichzwischen Entzerrung und ohne Entzerrung bei SNR = 0 dB (oben) undSNR = 6 dB (unten) in Abhängigkeit der Testpersonen
Abbildung 4.7: Box-Whisker-Plot zur Verbesserung der subjektiven Sprachverständlichkeitdurch den Vergleich zwischen Entzerrung und ohne Entzerrung bei gleichemSNR und in zusammengefasster Form

5 Auswertung
Folgend werden die Messergebnisse aus 4 ausgewertet, untereinander verglichen undSchlussfolgerungen über ihre Aussagekraft gezogen.
5.1 Einfluss des Frequenzgangs auf die objektiveSprachverständlichkeit
Die Abbildung 4.2 mit den Frequenzgängen der Kinosäle zeigt im Bereich von 200 Hz - 2 kHz(linearer Bereich der X-Curve), dass die Kino-Systeme sich größtenteils im Toleranzbereichder X-Curve befinden. Kinosaal a1 und b3 zeigen zwar Abweichungen von bis zu 6 dB, diesliegt jedoch an der hohen Auflösung der Messauswertung mit einer 1/12-Oktav-Glättung.Bei der traditionellen Glättung mit 1/3-Oktaven würden die Abweichungen nur noch maximal2 dB betragen. Wie in der Vorgabe der X-Curve beschrieben, beginnen die Kurven ab 2 kHzmit einem Abfall von etwa 3 dB/Dekade. Ab 7 kHz kommt es jedoch bei einigen Kinosälenzu einem erhöhten Gefälle der Amplituden, der weit über den Toleranzbereich der X-Curvehinausgeht. Die vorgeschlagene höchste untere Toleranz von -8 dB/Dekade wird nur von denKinosälen a1, b1 und d2 eingehalten. Die anderen Säle haben Gefälle von 9 dB/Dekade (d2)bis zu 18 dB/Dekade (c1), was die Hochtonenergie drastisch verringert. Es wurde ergänzendeine Mittelung über alle Kinosäle angewendet. Sie liegt im gesamten Bereich innerhalb derToleranz, im Hochtonbereich wird allerdings die untere Toleranzgrenze erreicht.Diese Eigenschaften der Amplitudenfrequenzgänge bestätigen die Vermutung, dass eineAnpassung der Lautsprecher-Systeme mit der Bildwand nicht erfolgte. Vielmehr wurde beimAustausch des Bildwandmaterials nicht auf dessen Frequenzgangbeeinflussung geachtetund die Hochtondämpfung weiter verstärkt.
Abbildung 4.3 zeigt bei der Darstellung der Frequenzgänge im optimierten Screening-Roomdeutlich den Einfluss einer Bildwand-Entzerrung. Bis zu 2 kHz gibt es Amplitudenabwei-chungen von bis zu 5 dB. Die rote Kurve (ohne Bildwand-Entzerrung) fällt erst leicht mit1,5 dB/Oktave bis 8 kHz, ab 9 kHz mit ca. 7 dB/Oktave und liegt somit nahe der eigentlichenVorgabe der X-Curve, ohne dass eine Equalisation zur Anpassung der X-Curve-Form vor-genommen wurde. Dies geschieht alleine durch die Anwesenheit der Bildwand und deren

5 Auswertung 44
Einfluss auf den Frequenzgang. Die entzerrte blaue Kurve zeigt jedoch auch oberhalb von2 kHz einen annähernd linearen Verlauf (beachte Bemerkung in Abbildung 4.3).
Die untersuchten Frequenzgänge lassen den Eindruck entstehen, dass es durch die Hoch-tonarmut in den Kinosälen und dessen Einfluss auf die Sprache zu einer vermindertenSprachverständlichkeit kommen muss. Diesen Effekt zu zeigen, ist allerdings durch die Er-mittlung von STI und %ALcons nicht gelungen. In Abbildung 4.4 ist eindeutig zu sehen, dasses kaum Unterschiede in den gemessenen Parametern zur Sprachverständlichkeit gibt. DieSTI-Werte liegen in einem Bereich von 0,85 - 0,91 und die %ALcons-Werte zwischen 1,21 %und 1,73 % (siehe Tabelle 4.3). Geringe Differenzen und teilweise sogar bessere STI- und%ALcons-Werte der Kinosäle im Vergleich zum optimierten Raum liegen zwar vor, könnenjedoch im Bezug auf die absolute Messwertskala vernachlässigt werden. Nach ihrer Be-deutung entsprechen diese Werte für alle Kinosäle und dem optimierten Raum einer aus-gezeichneten Sprachverständlichkeit, was dem subjektiven Eindruck der wahrgenommenenVerständlichkeit widerspricht.Abhängigkeiten bezüglich der Kinosaalgröße oder der Nachhallzeit, welche zwischen 0,55 sund 1,18 s liegen (siehe Tabelle 4.2), sind nicht ersichtlich. Die Differenz von 0,63 s und teilsdoppelt so lange Nachhallzeiten zeigen wiederum, dass es an einer einheitlichen Vorgehens-weise bei der Einrichtung und Installation von Kinosälen mangelt.
Nun stellt sich die Frage, warum diese Messverfahren keine zutreffenden Ergebnisse liefernund möglicherweise ungeeignet sind, das beschriebene Problem zu erfassen.Objektive Messverfahren messen nicht die Sprachverständlichkeit an sich, sondern stellenmit Hilfe von physikalischen Parametern, eine Prognose über die Verständlichkeit für einModell auf. Dieses Modell und der zugehörige Berechnungsalgorithmus unterliegen gewis-sen Beschränkungen in der Aussagekraft. Da die unterschiedlichen Frequenzgänge sichnicht in den ermittelten Werten ausdrücken, muss davon ausgegangen werden, dass ei-ne Frequenzbewertung bei STI und %ALcons eine untergeordnete Rolle einnimmt. Zu Be-ginn der Entstehung dieser Messmethoden war es deren Aufgabe die Sprachverständlichkeitvon Live-Vorträgen, die in sehr großen Räumen (z.B Kirchen, Vortragssälen, Auditorien) mitNachhallzeiten über 2 s stattgefunden haben, zu beurteilen. Hierbei kommt es zu teilweisesehr langen Reflexionswegen und dem daraus resultierenden störenden Nachhall mit Zeit-differenzen von über 50 ms. Somit liegt das Hauptaugenmerk dieser Messtechnik auf derBewertung des Verhältnisses von Direktschall zu Nachhall im Zeitbereich. Die Situation imKino (hier: Nachhallzeit unter 1,2 s) ist jedoch abweichend. Die Sprachverständlichkeit, die inruhigen Szenen durchaus als zufriedenstellend empfunden werden kann, leidet vor allem inSzenen mit Geräuschkulissen in denen der Dialog mit lauten Effekten oder Musik unterlegtwird, was hier im Bezug auf die Kirche mit dem störenden Nachhall vergleichbar ist.Mit dem Hinzufügen eines Störsignals über den Stimulus für die Messungen zu STI und%ALcons würde zwar eine Abnahme der Sprachverständlichkeit erkannt werden, erneute

5 Auswertung 45
Messungen mit dieser Eigenschaft sind jedoch so nicht zweckmäßig. Es würden keine wei-teren Erkenntnisse gewonnen werden, da nur der in 2.5.1 beschriebene lineare Zusammen-hang ermittelt werden würde.
Ein weiterer Punkt sind die unterentwickelten Messverfahren für elektro-akustische Anwen-dungen. Im Vergleich sind elektronische Messverfahren und deren Bestandteile (z.B. SNR,Intermodulation, Klirrfaktoren, etc.) wesentlich eindeutiger spezifiziert und ersichtlicher. Auf-grund von unterschiedlicher Relevanz und Auswirkung lassen sich diese Bestandteile nichtdirekt auf die Elektro-Akustik übertragen. In der Akustik gibt es weiterhin große Unklarheitenund gegensätzliche Auffassungen über grundlegende Funktionsweisen. Zum Beispiel sinddie Schallverarbeitung des Gehörs und die Weiterverarbeitung im Gehirn bis heute nichtvollständig geklärt und umstritten.
5.2 Relation zwischen parametrischer Messung undLogatomtest
In Abbildung 4.5 ist zu sehen, dass die Mediane für die zusammengefassten korrekten Ant-worten des Durchgangs mit Screen-Entzerrung über dem Durchgang ohne Entzerrung lie-gen. Dies gilt für beide getesteten SNRs. Jedoch ist ebenfalls zu erkennen, dass der obe-re Whisker der Daten für „verzerrt SNR = 0 dB“ über dem unteren Whisker der Daten für„entzerrt SNR = 0 dB“ liegt, was eine mögliche Verschlechterung der Sprachverständlichkeitbedeuten würde. Dies kann jedoch mit dem Vergleich der Abbildung 4.6 widerlegt werden.Diese zeigt, dass im Vergleich zwischen Ent- und Verzerrung bei jeder einzelnen Testper-son unabhängig von dem eingestellten SNR eine Verbesserung der subjektiven Sprachver-ständlichkeit durch die Bildwand-Entzerrung erreicht wurde. In den Testdurchgängen derProbanden wurden bei Verwendung der Screen-Entzerrung zwischen 4 % - 25 % mehr rich-tige Antworten gegeben. Die irreführende Darstellung erfolgt, da zum Beispiel Testperson 5im Vergleich zu Testperson 2 generell niedrigere Ergebnisse liefert. Das bedeutet, diese bei-den Whisker-Werte stammen von verschiedenen Personen und stehen daher nicht für eineVerschlechterung der Sprachverständlichkeit.Zusammenfassend zeigt Abbildung 4.7, dass in diesem Test bei einem SNR von 0 dB einemittlere Sprachverständlichkeitsverbesserung von 11,5 % beobachtet wurde, für einen SNRvon 6 dB 7 % und die mittlere Gesamtverbesserung des Logatomtest ergab eine Steigerungder richtigen Antworten um 10 %. Diese Bewertung entspräche im oberen Bereich in der für%ALcons geltenden Skala dem Unterschied zwischen ausreichender und ausgezeichneterSprachverständlichkeit.

5 Auswertung 46
Die Auswertung des hier durchgeführten Logatomtests zeigt die Einflussnahme der Entzer-rung des Frequenzgangs. Durch die Bereitstellung von mehr Hochtonenergie, wurde in die-sem Fall die subjektive Sprachverständlichkeit verbessert. Verfahren wie die X-Curve undeine nicht entzerrte Bildwand tragen demnach zu einer Verschlechterung der subjektivenSprachverständlichkeit bei. Aufgrund dieser Eigenschaft müsste es folglich Unterschiede beiden Messungen nach STI und %ALcons im ASC-Raum geben. Dies ist nicht der Fall undfestigt daher die Aussage der fehlenden Frequenzgangbewertung.

6 Zusammenfassung und Ausblick
Diese Bachelorarbeit hat zum Ziel, die unzureichende Sprachverständlichkeit in deutschenKinosälen mit parametrischen Mitteln darzustellen. Dieses Vorhaben konnte nur teilweise er-reicht werden. Die untersuchten Kinosäle zeigten in ihrem Frequenzgang die Auswirkungender X-Curve im Zusammenhang mit der Bildwandbeeinflussung. Teilweise verstärkten sichdiese Einflüsse, sodass es im Hochtonbereich zu einer Verringerung der Energie kommt,die weit über den Vorgaben nach SMPTE ST 202:2010 und ISO 2969:2015 liegen. Die Er-mittlung der Sprachverständlichkeit nach STI und %ALcons konnte im Vergleich zwischenden Kinosälen und dem frequenzgangoptimierten System im Mess-Raum keine auswertba-ren Ergebnisse liefern. Dies liegt an der unzulänglichen Eignung dieser Parameter für dieseFragestellung. Allerdings konnte im A/B-Vergleich des durchgeführten Logatomtests eineVerbesserung der subjektiven Sprachverständlichkeit durch Entzerrung und Linearisierungdes Frequenzgangs beobachtet werden. Der subjektive Logatomtest bewertet die Sprach-verständlichkeit hierbei nicht nur, wie bei STI und %ALcons, in der Zeitebene, sondern legteine hohe Gewichtung auf den Frequenzgang. Für diese Aufgabenstellung ist der Logatom-test im Vergleich zur hier durchführten parametrischen Messung weitaus geeigneter.Die Notwendigkeit der Anpassung vom Lautsprechersystem und der Bildwand wurde eben-falls deutlich. Hierbei müssen Standardisierungen entwickelt werden, um eine einheitlicheVerbesserung der Sprachverständlichkeit zu erreichen.
Zusammenfassend ist zu sagen, dass Leembruggen u. a. (2011) mit ihren Schlussfolge-rungen zur Verschlechterung der Sprachverständlichkeit durch die Anwendung der X-CurveRecht haben. Es wird empfohlen weitere Untersuchungen zu diesem Thema im größerenMaßstab durchzuführen. Es ist sinnvoll den Logatomtest mit mehreren Testpersonen in ver-schiedenen Kinosälen unter Verwendung mehrerer SNR zu wiederholen und die Beobach-tungen zu verifizieren. Dies war als Teil dieser Arbeit aus Budgetgründen nicht möglich.Die unterschiedlichen Untersuchungen zu diesem Thema mit gleichen Ergebnissen müs-sen zwangsläufig zusammengeführt werden, um die Aufmerksamkeit der SMPTE sicher zustellen.

Anhang auf dem Datenträger
Der Anhang, welcher auf dem beiliegenden Datenträger einzusehen ist, beinhaltet:
• Bachelorarbeit als PDF in Volltext
• EASERA Messdaten
– Messdaten der Einzelmessungen und der gemittelten Frequenzgänge derKinosäle
– Messdaten der Einzelmessungen und der gemittelten Frequenzgänge desReferenzraums
• Messtabellen und MATLAB-Skripte
– Excel-Tabellen mit Messwerten der Frequenzgänge, der Nachhallzeiten, derSTI- und %ALcons-Werte und des Logatomtests
– Excel-Tabelle des Logatomtests mit Übersicht der Logatome, desAntwortbogens und der einzelnen digitalisierten Antworten
– Kommentierte MATLAB-Skripte zur Darstellung der Messergebnisse aus denTabellen
• Datenblätter der verwendeten Technik
• Abbildungen
– Abbildungen der gemittelten Frequenzgänge mit verschiedenenGlättungsverfahren
– Abbildungen der einzelnen Frequenzgänge der Kinosäle
– Weitere Abbildungen zur Auswertung des Logatomtests und der STI- und%ALcons-Werte
• Audiodateien (.wav) des Logatomtests

Literaturverzeichnis
[Ahnert und Schmidt 2005] AHNERT, DR. W. ; SCHMIDT, Dr. W.: Fundamentals to performacoustical measurements - Appendix to EASERA. Software Design Ahnert GmbH. 2005
[Allen 2006] ALLEN, Ioan: The X-Curve: Its Origins and History. In: SMPTE Motion PicturesJournal (2006), Jul/Aug, S. 1–24
[Brachmanski 2004] BRACHMANSKI, Stefan: Estimation of logatom intelligibility with theSTI method for Polish speech transmitted via communication channels. In: Archives ofAcoustics (2004), Sep, S. 555–562
[Davis und Patronis 2014] DAVIS, Don ; PATRONIS, Eugene: Sound System Engineering.Third Edition. Taylor & Francis, 2014. – ISBN 9781136119330
[Everest 2001] EVEREST, F. A.: Master Handbook of ACOUSTICS. Fourth Edition.McGraw-Hill, 2001. – ISBN 0-07-136097-2
[Holube u. a. 2010] HOLUBE, Inga ; BITZER, Jörg ; FÖRSTEL, Alexander ; HEITKÖTTER,Felix ; KNOTHE, Benina ; MUNCKE, Jan ; OTTINK, Marco ; STEVER, Johanna: Erstellungeines Logatomtests für die Konsonantenverständlichkeit. 13. Jahrestagung der DeutschenGesellschaft für Audiologie, Jade Hochschule, Institut für Hörtechnik und Audiologie, Ol-denburg. 2010
[Houtgast und Steeneken 2002] HOUTGAST, Tammo ; STEENEKEN, Herman: Past, presentand future of the Speech Transmission Index. TNO Human Factors, 2002. – ISBN 90-76702-02-0
[IEC 2012] IEC: 60268-16:2011 - Objective rating of speech intelligibility by speech trans-mission index. 2012. – European Standard
[ISO 2003] ISO: 226:2003 - Acoustics - Normal equal-loudness-level contours. 2003. –International Standard
[Leembruggen u. a. 2011] LEEMBRUGGEN, Glenn ; NEWELL, Philip ; NEWELL, Joules ;GILFILLAN, David ; HOLLAND, Dr. K. ; MCCAARTY, Brian: Is the X Curve Damaging OurEnjoyment of Cinema? In: SMPTE Motion Pictures Meeting Presentation (2011)

Literaturverzeichnis 50
[Long u. a. 2012] LONG, Brian ; SCHWENKE, Roger ; SOPER, Peter ; LEEMBRUGGEN,Glenn: Further Investigations Into the Interactions Between Cinema Loudspeakers andScreens. In: SMPTE Motion Pictures Journal (2012), Nov/Dez, S. 46–62
[Machelett 1996] MACHELETT, Kirsten: Das Lesen von Sonagrammen. Universitaet Mu-enchen, Institut fuer Phonetik und sprachliche Kommunikation. 1996
[MeyerSound 2005] MEYERSOUND: Speech Intelligibility. Meyer Sound Website. 2005.– URL http://meyersound.de/support/papers/speech/intro.htm. –Zugriffsdatum: 14.03.2017
[Nowak 2015] NOWAK, Alexander: Einfluss von Aufprojektionsbildwänden auf das Abt-strahlverhalten von Lautsprechern, Technische Universität Berlin, Institut für Sprache undKommunikation: Fachgebiet Audiokommunikation, Master-Thesis, 2015
[Sendlmeier und Seebode 2015] SENDLMEIER, Walter F. ; SEEBODE, Julia: Formantkartendes deutschen Vokalsystems. TU Berlin, Institut fuer Sprache und Kommunikation. 2015
[SMPTE 2010] SMPTE: ST 202:2010 - Dubbing Stages, Mixing Rooms, ScreeningRooms and Indoor Theaters - B-Chain Electroacoustic Response. 2010. – Standardfor Motion-Pictures
[Steeneken 2002] STEENEKEN, Herman: The Measurement of Speech Intelligibility. TNOHuman Factor. 2002
[Wesker u. a. 2005] WESKER, Thorsten ; MEYER, Bern ; WAGENER, Kirsten ; ANEMUEL-LER, Joern ; MERTINS, Alfred ; KOLLMEIER, Birgit: Oldenburg Logatome Speech Corpus(OLLO) for Speech Recognition Experiments with Humans and Machines. Interspeech.2005

Tabellenverzeichnis
2.1 STI weighting und redundancy factor der männlichen Stimme . . . . . . . . . 222.2 Umformung der numerischen Parameter in Beschreibung der Sprachverständ-
lichkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1 Übersicht der verwendeten Technik . . . . . . . . . . . . . . . . . . . . . . 283.2 Anzahl der Kinosäle und der Sitzplätze . . . . . . . . . . . . . . . . . . . . 293.3 Beispiel von Test-Logatomen mit ihren Auswahlmöglichkeiten . . . . . . . . . 33
4.1 Bedeutung der Elemente eines Box-Whisker-Plots . . . . . . . . . . . . . . 364.2 Extrapolierte Nachhallzeiten RT60(T30) der untersuchten Kinosäle . . . . . . 374.3 Messergebnisse nach STI und %ALcons der verschiedenen Kinosäle und des
Referenzraumes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37

Abbildungsverzeichnis
1.1 Skizzierter Lageplan der Räume in denen Messungen stattfinden . . . . . . 9
2.1 Mittelwert von Formanten (weibl. und männl. Sprecher), entnommen aus Ma-chelett (1996) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Sonagramme der Plosive „p“, „t“ und „k“, entnommen aus Machelett (1996) . 122.3 Kurven gleicher Lautheit nach Fletcher und Munson, entnommen aus ISO (2003) 132.4 Audioreproduktionskette des digitalen Kinos . . . . . . . . . . . . . . . . . . 162.5 B-Chain Messmethode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.6 Vorgabe der elektro-akustischen Raumantwort-Charakteristik mit Toleranz der
B-Chain(X-Curve) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.7 Einfluss des Abstandes zwischen Lautsprecher und Bildwand (theater-
perforated) bei 0 cm, 35 cm und 45 cm, entnommen aus Nowak (2015)) . . . 192.8 1/3-Oktaven geglätteter Frequenzgang der untersuchten Bildwände mit Ver-
gleich der X-Curve; woven: woven fabric, TP: theater-perforated, MP: mini-perforated, entnommen aus Long u. a. (2012) . . . . . . . . . . . . . . . . . 20
2.9 Zusammenhang zwischen STI und %ALcons . . . . . . . . . . . . . . . . . 232.10 Effekt des SNR auf %ALcons, entnommen aus Davis und Patronis (2014) . . 242.11 Zusammenhang zwischen verschiedenen Verständlichkeitsbewertungen und
dem STI, entnommen aus Steeneken (2002) . . . . . . . . . . . . . . . . . 26
3.1 Skizzierter technischer Messaufbau . . . . . . . . . . . . . . . . . . . . . . 303.2 Hinteres Anschlussfeld des CP750 Cinema-Audioprozessor . . . . . . . . . 31
4.1 Elemente eines Box-Whisker-Plots . . . . . . . . . . . . . . . . . . . . . . . 364.2 Gemittelte Amplitudenfrequenzgänge der Kinosaal-Lautsprecher-Systeme
zwischen 200 Hz - 16 kHz mit Darstellung der X-Curve Toleranz . . . . . . . . 384.3 Gemittelte Amplitudenfrequenzgänge des Referenzraums mit und ohne
Screen-Entzerrung zwischen 200 Hz - 16 kHz mit Darstellung der X-CurveToleranz; Dämpfung zwischen 500 Hz - 1,8 kHz erfolgt durch Bodenreflexion . 39
4.4 Ermittelte Sprachverständlichkeit nach STI und %ALcons der Kinosaal-Lautsprecher-Systeme und des Referenzraums mit und ohne Screen-Entzerrung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.5 Box-Whisker-Plot der korrekten Antworten nach ihrer Testart unterteilt . . . . 41

Abbildungsverzeichnis 53
4.6 Verbesserung der subjektiven Sprachverständlichkeit durch den Vergleich zwi-schen Entzerrung und ohne Entzerrung bei SNR = 0 dB (oben) und SNR = 6 dB(unten) in Abhängigkeit der Testpersonen . . . . . . . . . . . . . . . . . . . 42
4.7 Box-Whisker-Plot zur Verbesserung der subjektiven Sprachverständlichkeitdurch den Vergleich zwischen Entzerrung und ohne Entzerrung bei gleichemSNR und in zusammengefasster Form . . . . . . . . . . . . . . . . . . . . . 42

Versicherung über die Selbstständigkeit
Hiermit versichere ich, dass ich die vorliegende Arbeit im Sinne der Prüfungsordnung nach§16(5) APSO-TI-BM ohne fremde Hilfe selbstständig verfasst und nur die angegebenen Hilfs-mittel benutzt habe. Wörtlich oder dem Sinn nach aus anderen Werken entnommene Stellenhabe ich unter Angabe der Quellen kenntlich gemacht.
Hamburg, 24. April 2017Ort, Datum Unterschrift