Direkte Loser und ihre Nachteile III.1 III.2 Klassische ... · L¨osung des linearen...
23
Prof. Dr. Barbara Wohlmuth Lehrstuhl f¨ ur Numerische Mathematik III. Iterative L¨oser III.1 Direkte L¨ oser und ihre Nachteile III.2 Klassische lineare Iterationsverfahren – Typeset by Foil T E X – 1
Transcript of Direkte Loser und ihre Nachteile III.1 III.2 Klassische ... · L¨osung des linearen...

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
III. Iterative Loser
III.1 Direkte Loser und ihre Nachteile
III.2 Klassische lineare Iterationsverfahren
– Typeset by FoilTEX – 1

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Erinnerung: Lineares Gleichungssystem bei FDM
Diskretisierung einer linearen PDGL 2. Ordnung mit Finiten Differenzen/FEMfuhrt zu einem linearen Gleichungssystem Ahuh = h2fh, welches
• groß ist (typischerweise: Dimension = O(h−2d)),
• dunn besetzt ist (O(h−d) nicht-Null Eintrage)
• schlecht konditioniert ist (κ(Ah) = O(h−2)),
• haufig symmetrisch, positiv definit ist, und
• bei geeigneter Nummerierung eine Bandstruktur besitzt.
– Typeset by FoilTEX – 2

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Verschiedene Loser: MATLAB
Aus der Matlab Dokumentation: Direkte Loser
– Typeset by FoilTEX – 3

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Verschiedene Loser: MATLAB
Aus der Matlab Dokumentation: Iterative Loser
– Typeset by FoilTEX – 4

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Gauß-Elimination
Zerlege die invertierbare Matrix A ∈ Rn×n in das Produkt zweier Dreiecksmatrizen
L (untere Dreiecksmatrix mit 1 als Diagonaleintrage) und U (obereDreiecksmatrix), so dass
PA = LU,
mit einer Permutationsmatrix P . Damit lasst sich das Gleichungssystem durchSubstitution losen:
Lz = P T b, Ux = z
Aufwand bei vollbesetzten Matrizen:
• Berechnung der LU–Zerlegung: O(n3)
• Ruckwarts/Vorwarts–Substitution: O(n2)
– Typeset by FoilTEX – 5

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Einfluss der Bandstruktur auf Fill-In
• Permutationsmatrizen P erlauben die Vertauschung der Zeilen (beiMultiplikation von links) und der Spalten (bei Multiplikation von rechts) einerMatrix A. Fur diese gelten P−1 = P⊤.
Ax = b ⇔ (PA)x = Pb,
AP⊤Px = b ⇔ (AP⊤)x = b mit x = Px.
• Die Bandstruktur der Matrix A bleibt bei der LU-Zerlegung erhalten, d.h.außerhalb der Bandstruktur treten keine weiteren Eintrage auf, jedoch konnendie Nulleintrage innerhalb der Bandstruktur verschwinden (Fill-In).
• Ziel: Finden von geeigneten Permutationen der Matrix A, so dass moglichstgeringe Bandbreite entsteht. Hierzu gibt es Minimierungsalgorithmen z.B. vonCuthill-McKee.
– Typeset by FoilTEX – 6
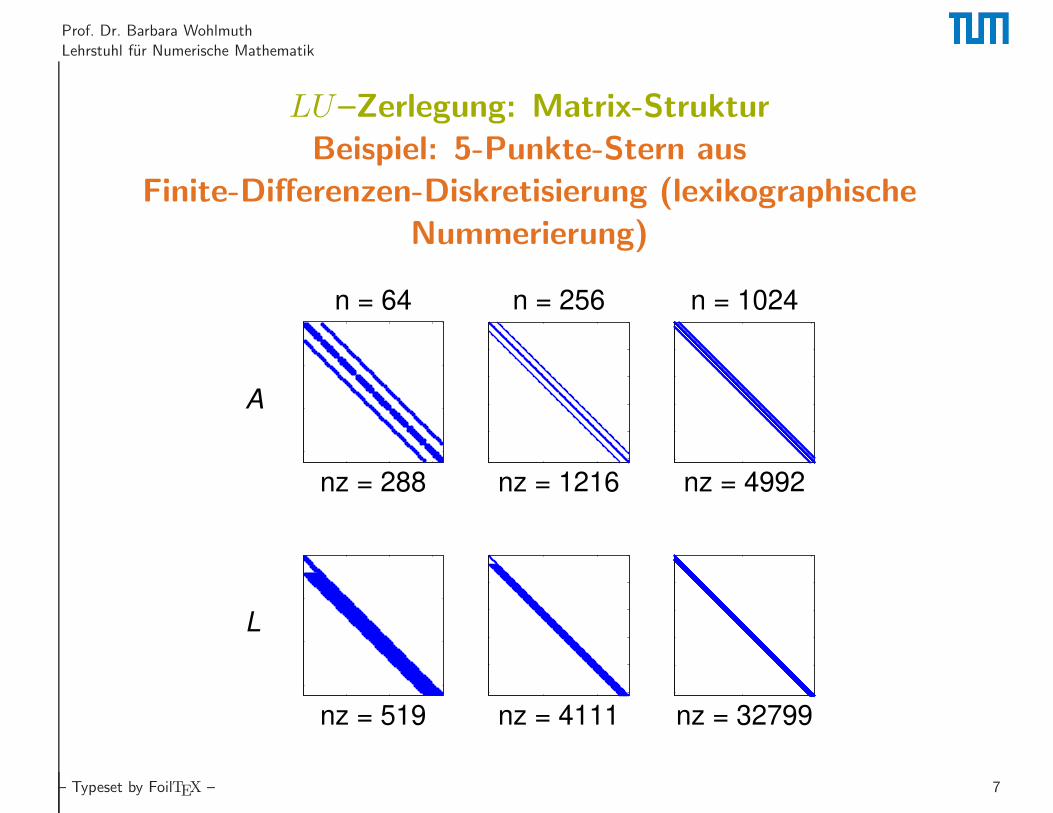
Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
LU–Zerlegung: Matrix-Struktur
Beispiel: 5-Punkte-Stern aus
Finite-Differenzen-Diskretisierung (lexikographische
Nummerierung)
nz = 288
n = 64
nz = 519
nz = 1216
n = 256
nz = 4111
nz = 4992
n = 1024
nz = 32799
A
L
– Typeset by FoilTEX – 7
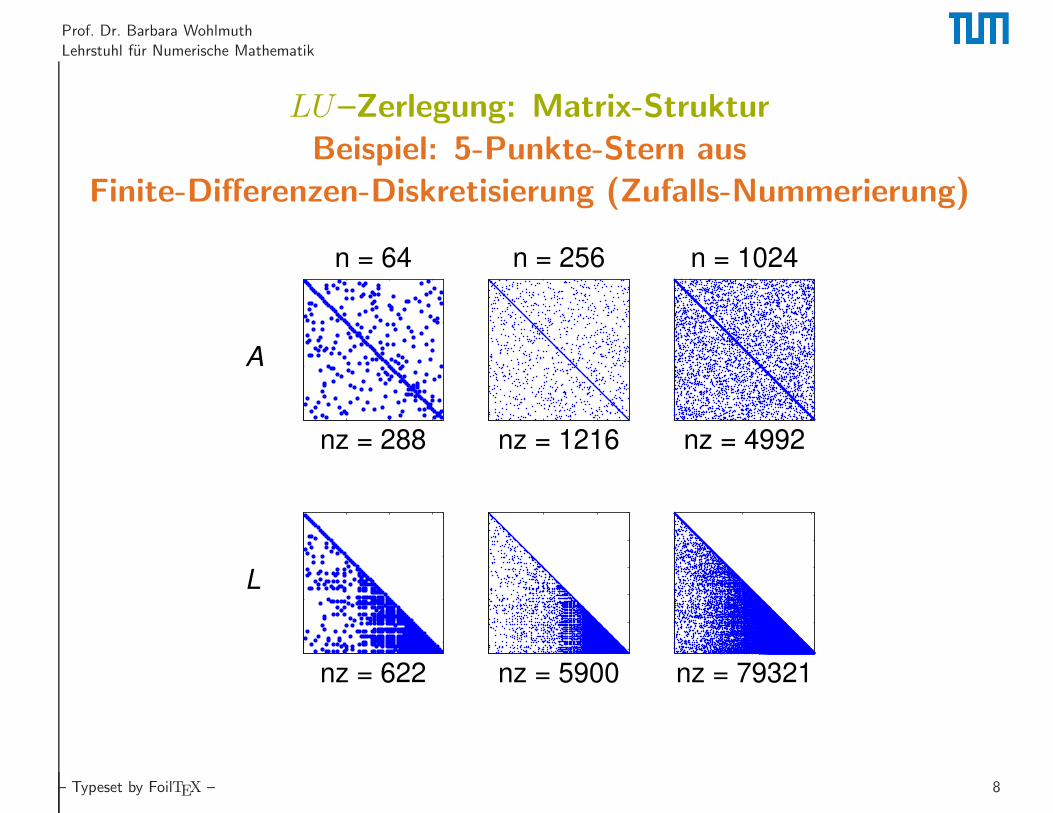
Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
LU–Zerlegung: Matrix-Struktur
Beispiel: 5-Punkte-Stern aus
Finite-Differenzen-Diskretisierung (Zufalls-Nummerierung)
nz = 288
n = 64
nz = 622
nz = 1216
n = 256
nz = 5900
nz = 4992
n = 1024
nz = 79321
A
L
– Typeset by FoilTEX – 8
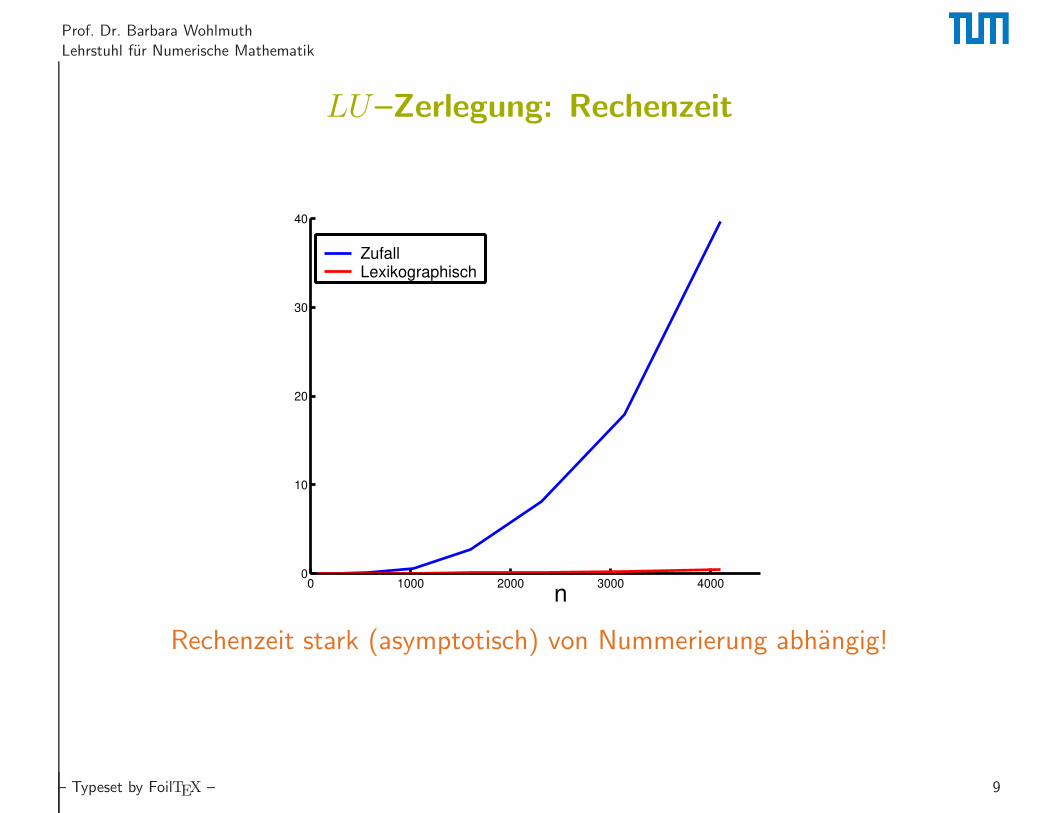
Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
LU–Zerlegung: Rechenzeit
n0 1000 2000 3000 4000
0
10
20
30
40
ZufallLexikographisch
Rechenzeit stark (asymptotisch) von Nummerierung abhangig!
– Typeset by FoilTEX – 9

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
III. Iterative Loser
III.1 Direkte Loser und ihre Nachteile
III.2 Klassische lineare Iterationsverfahren
– Typeset by FoilTEX – 10

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Lineare Iterationsverfahren
Voruberlegung: Eigentlich ist man gar nicht an einer exakten Losung desGleichungssystems interessiert, sondern an einer guten Approximation der PDGL.Sei u∗
h eine Naherung von uh mit Ahuh = fh, so gilt fur den Fehler
‖u− u∗
h‖h≥≤‖u− uh‖h
−+‖uh − u∗
h‖h
d. h. es genugt, wenn ‖uh − u∗
h‖h ∼ ‖u− uh‖h.
Idee: Berechne uh nicht direkt, sondern wiederum uber ein Naherungsverfahren.
– Typeset by FoilTEX – 11

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Lineare Iterationsverfahren: Definitionen
1. Ein Losungsverfahren zur Berechnung von Ax = b heißt iterativ, falls ausgehendvon einem Startwert x0 eine Folge xk von Iterierten bestimmt wird.
2. Ein Iterationsverfahren heißt konvergent, falls unabhangig vom Startwert gilt
limk → ∞
xk = x,
wobei x die exakte Losung ist.
3. Es heißt konsistent, falls aus xk = x folgt, dass xk+1 = x.
4. Es heißt linear, falls xk+1 linear von xk und b abhangt, d.h. es gibt zweiMatrizen M,N ∈ R
n×n mit xk+1 = Mxk +Nb
– Typeset by FoilTEX – 12

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Lineare IterationsverfahrenEin allgemeines konsistentes lineares Iterationsverfahren zur Losung von Ax = b
hat die Form
xk+1 = Mxk +Nb mit M = (Id−NA).
Mit der Zerlegung A = L+D + U erhalten wir folgende Verfahren:
• Jacobi-Verfahren: N = D−1
xk+1 = −D−1(L+ U)xk +D−1b
• vorwartiger Gauß–Seidel: N = (D + L)−1
xk+1 = −(D + L)−1Uxk + (D + L)−1b
• ruckwartiger Gauß–Seidel: N = (D + U)−1
xk+1 = −(D + U)−1Lxk + (D + U)−1b
• SOR-Verfahren fur ω ∈ (0, 2): N = ω(D + ωL)−1
(D + ωL)xk+1 =(
(1− ω)D − ωU)
xk + ωb
– Typeset by FoilTEX – 13

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Definition: Konvergenzrate und Fehlerreduktion
Sei ρ(M) := max{|λj| : λj EW von M} der Spektralradius der Matrix M .
1. ρ(M) heißt Konvergenzrate
2. It(M) := − 1ln(ρ(M)) definiert ein Maß fur die Fehlerreduktion
Bemerkung:
1. Je kleiner ρ(M), desto weniger Iterationen werden benotigt, um den Fehler umeinen vorgegebenen Faktor zu reduzieren.
2. It(M) gibt an, wieviele Iterationen notwendig sind, um den Fehler um denFaktor 1
ezu reduzieren.
Folgerung: ρ(M1) = ρ(M2)2 ⇒ It(M1) =
12It(M2)
– Typeset by FoilTEX – 14

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Historische Bemerkungen
C.F. Gauß in einem Brief vom 26.12.1823 an Gerling:Ich empfehle Ihnen diesen Modus zur Nachahmung. Schwerlich werden Sie jewieder direct eliminieren, wenigstens nicht, wenn Sie mehr als 2 Unbekanntehaben. Das indirecte Verfahren lasst sich halb im Schlafe ausfuhren, oder mankann wahrend desselben an andere Dinge denken.
[C.F. Gauß: Werke Bd. 9, S. 280f, Gottingen 1903]
Block Gauß–Seidel Verfahren: (1819-1822)Supplementum theoriae combinationis observationum erroribus minime obnoxiae
C.G. Jacobi: 1845Uber eine neue Auflosungsart der bei der Methode der kleinsten Quadratevorkommenden linearen Gleichungen
– Typeset by FoilTEX – 15

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Vergleich iterativer Losungsverfahren
Poisson-Matrix
Ah ∈ RN2
h×N2h, Ah = AT
h ,
Ah :=
B −I
−I . . . . . .. . . . . . −I
−I B
mit I,B ∈ RNh×Nh,
B :=
4 −1−1 . . . . . .
. . . . . . −1−1 4
.
– Typeset by FoilTEX – 16

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Iterative Loser: Einfuhrung
Aufwandsabschatzung
• Bandbreite: ω = O(Nh)
• Die Anzahl der Nicht-Nulleintrage wachst mit O(Nh)
• Anwendung von z.B. LU-Zerlegung erfordert Aufwand von O(N2h)
• Matrix-Vektor-Multiplikation hat Aufwand von O(Nh)
– Typeset by FoilTEX – 17
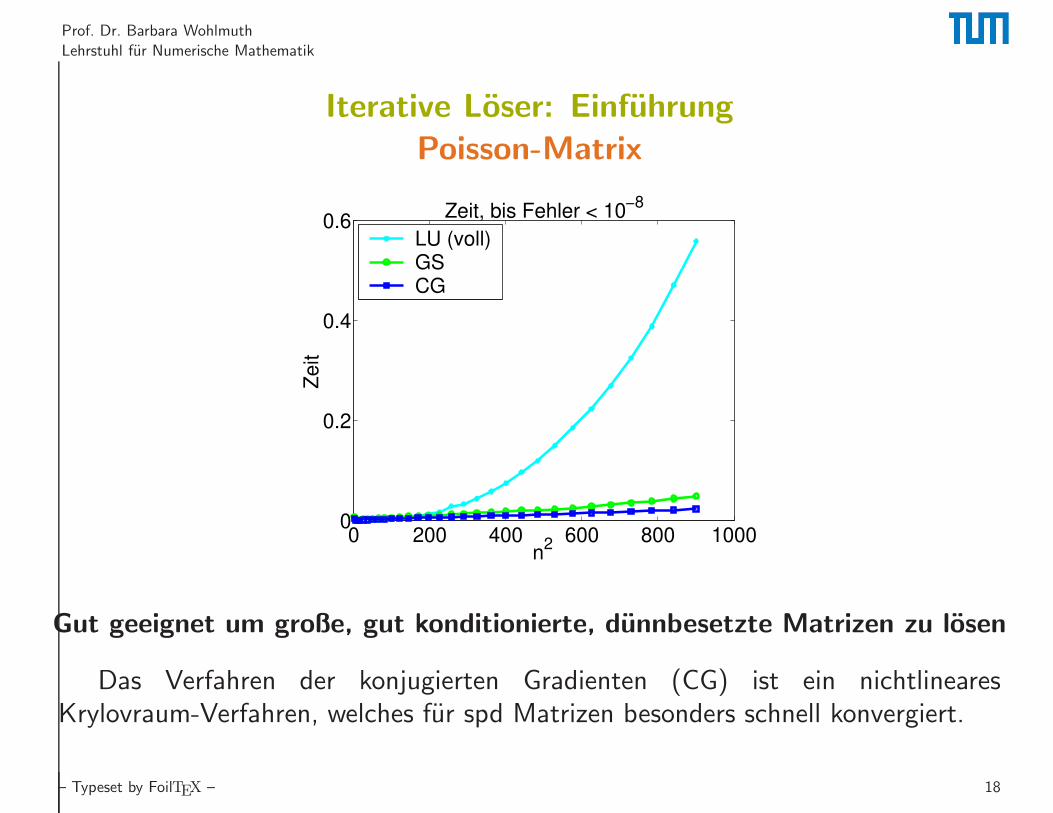
Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Iterative Loser: Einfuhrung
Poisson-Matrix
0 200 400 600 800 10000
0.2
0.4
0.6Zeit, bis Fehler < 10
−8
n2
Ze
it
LU (voll)GSCG
Gut geeignet um große, gut konditionierte, dunnbesetzte Matrizen zu losen
Das Verfahren der konjugierten Gradienten (CG) ist ein nichtlinearesKrylovraum-Verfahren, welches fur spd Matrizen besonders schnell konvergiert.
– Typeset by FoilTEX – 18
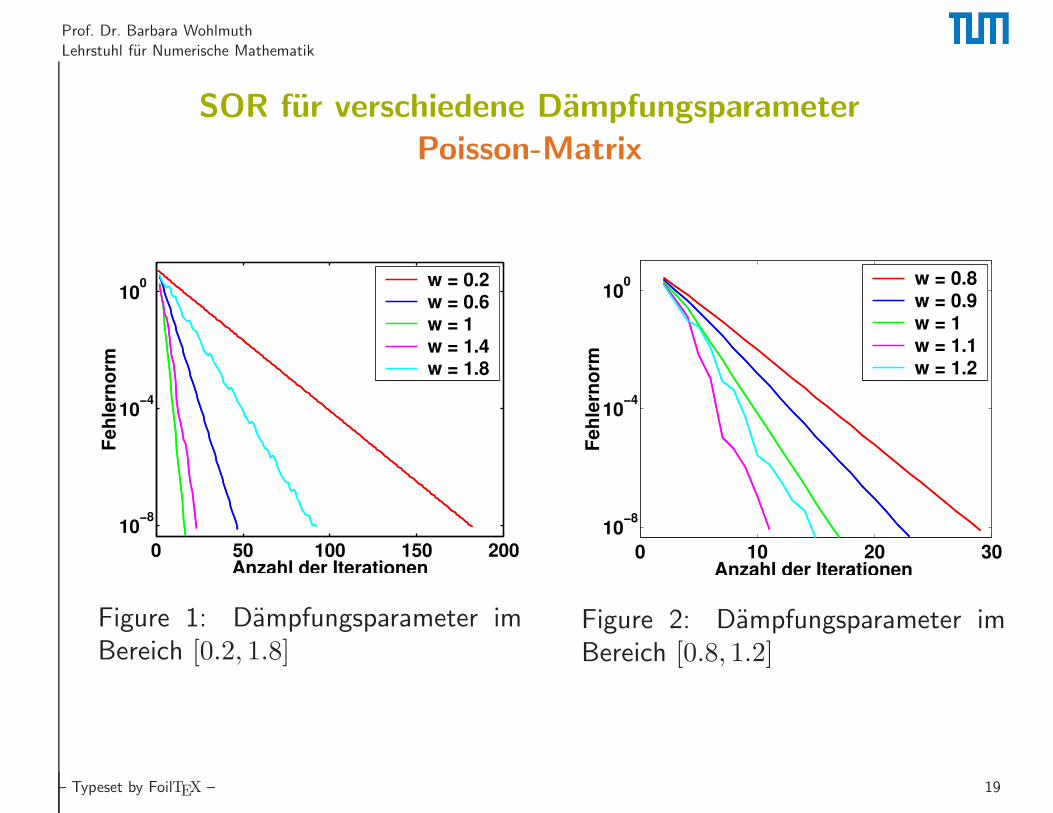
Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
SOR fur verschiedene Dampfungsparameter
Poisson-Matrix
0 50 100 150 200
10−8
10−4
100
Anzahl der Iterationen
Fe
hle
rn
orm
w = 0.2
w = 0.6
w = 1
w = 1.4
w = 1.8
Figure 1: Dampfungsparameter imBereich [0.2, 1.8]
0 10 20 30
10−8
10−4
100
Anzahl der Iterationen
Feh
lern
orm
w = 0.8
w = 0.9
w = 1
w = 1.1
w = 1.2
Figure 2: Dampfungsparameter imBereich [0.8, 1.2]
– Typeset by FoilTEX – 19

Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Konvergenz fur SOR-Verfahren
Fur die Matrix Mω des SOR-Verfahrens gilt
Mω = (D + ωL)−1(
(1− ω)D − ωU)
.
Konvergenz liegt vor, falls fur den Spektralradius ρ(Mω) < 1 ⇔ 0 < ω < 2gilt. Der Spektralradius ρ(Mω) nimmt sein Minimum fur den optimalenDampfungsparameter
ωopt =2
1 +√
1− ρ2J
an, wobei ρJ den Spektralradius der Iterationsmatrix MJ = −D−1(L+ U) desJacobi-Verfahrens bezeichnet. Dann gilt fur die Konvergenzrate
ρ(Mωopt) =1−
√
1− ρ2J
1 +√
1− ρ2J.
Allgemein gilt
ρ(Mω) =
{
ω − 1 fur ωopt ≤ ω ≤ 2,
1− ω + 12ω
2ρ2J + ωρJ
√
1− ω + 14ω
2ρ2J fur 0 ≤ ω ≤ ωopt.
– Typeset by FoilTEX – 20
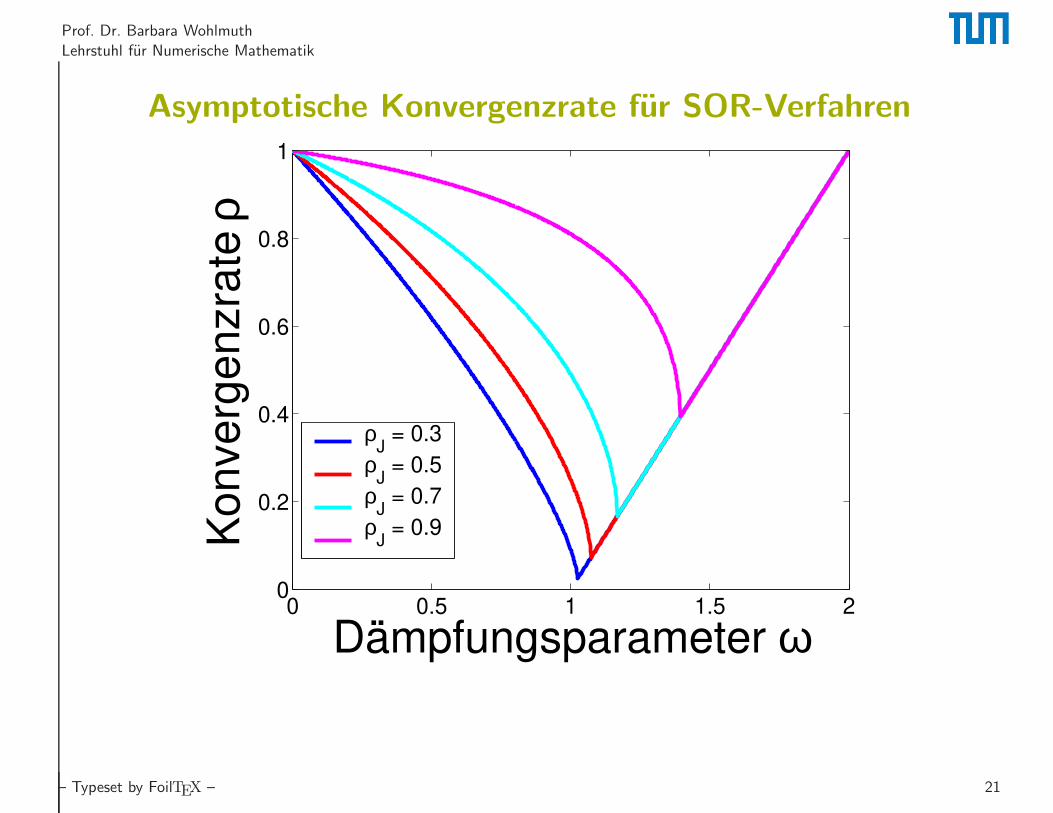
Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Asymptotische Konvergenzrate fur SOR-Verfahren
0 0.5 1 1.5 20
0.2
0.4
0.6
0.8
1
Dämpfungsparameter ω
Konverg
enzra
te ρ
ρJ = 0.3
ρJ = 0.5
ρJ = 0.7
ρJ = 0.9
– Typeset by FoilTEX – 21
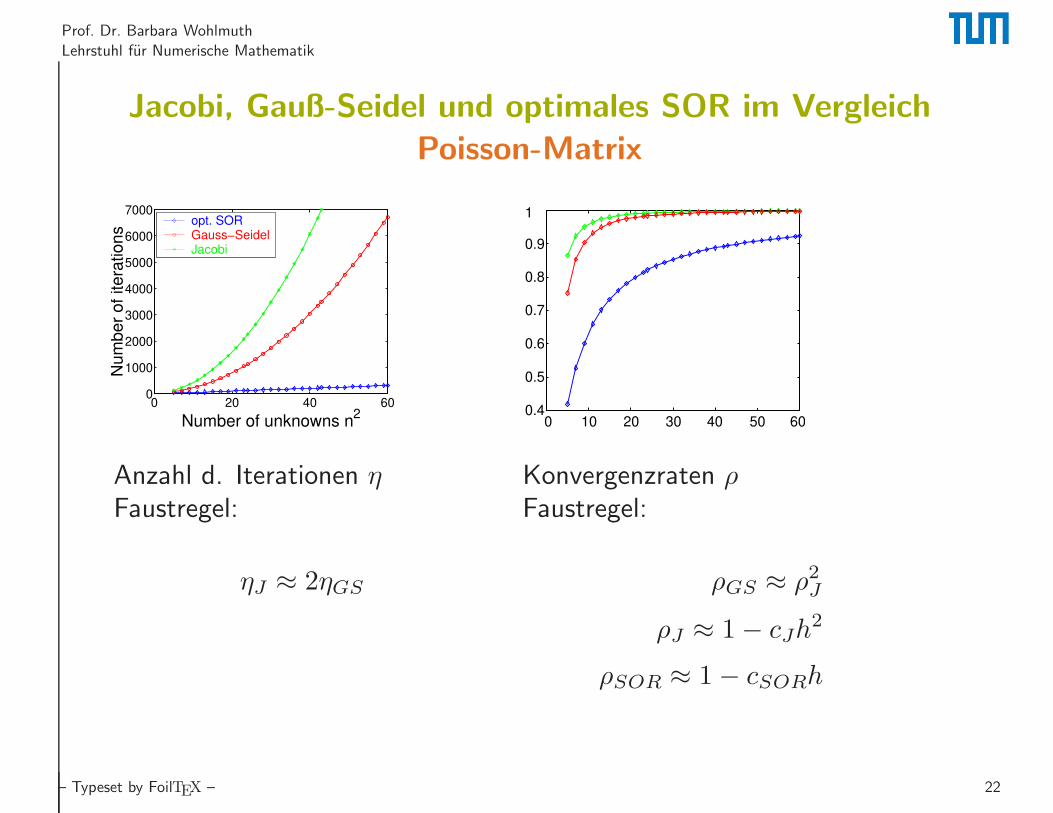
Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Jacobi, Gauß-Seidel und optimales SOR im Vergleich
Poisson-Matrix
0 20 40 600
1000
2000
3000
4000
5000
6000
7000
Number of unknowns n2
Num
ber
of itera
tions
opt. SOR Gauss−SeidelJacobi
0 10 20 30 40 50 600.4
0.5
0.6
0.7
0.8
0.9
1
Anzahl d. Iterationen η
Faustregel:
ηJ ≈ 2ηGS
Konvergenzraten ρ
Faustregel:
ρGS ≈ ρ2J
ρJ ≈ 1− cJh2
ρSOR ≈ 1− cSORh
– Typeset by FoilTEX – 22
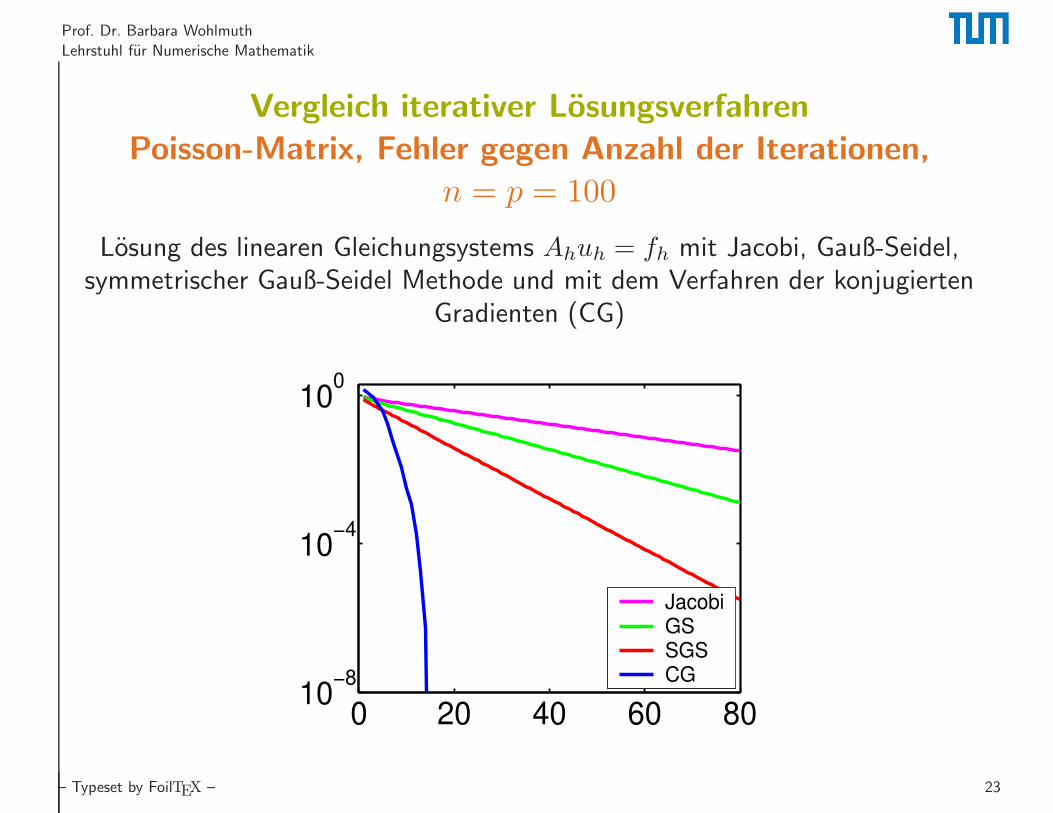
Prof. Dr. Barbara Wohlmuth
Lehrstuhl fur Numerische Mathematik
Vergleich iterativer Losungsverfahren
Poisson-Matrix, Fehler gegen Anzahl der Iterationen,
n = p = 100
Losung des linearen Gleichungsystems Ahuh = fh mit Jacobi, Gauß-Seidel,symmetrischer Gauß-Seidel Methode und mit dem Verfahren der konjugierten
Gradienten (CG)
0 20 40 60 8010
−8
10−4
100
JacobiGSSGSCG
– Typeset by FoilTEX – 23