介護用マッスルスーツ - techno-aids.or.jp16 移乗介助(装着型) 検証の目的(①~⑤共通) 検証の概要 介護用マッスルスーツプロジェクト①

中文降維正負評情感分析方法應用於 PTT 資料
Chinese dimension-reduction based sentiment
analysis method applied to PTT data
摘要
現今的網路上有越來越多的平台提供使用者討論,在這些平台中的文章常
涉及到近期發生的事件,而這些文章都會有正面或負面的傾向,我們希望可以利
用多分類器技術將這些文章分類成正向或負向的文章,藉由分類後的結果可以針
對負面文章的內容找到使用者不滿的事件並加以討論。批批踢實業坊是台灣很大
的討論平台,因此本篇利用組合相異空間(CoDiS)方法將 PTT 八卦版的文章分類,
其中,資料在輸入分類器前用到相異性轉換進行降維。本研究提出三種新的表示
集合選取方法,並比較隨機森林與支持向量機在多分類器系統中的表現。
關鍵字:文本分類、正負文分析、降維分類、集成學習
1
壹、緒論
一、研究背景
在科技的推動下,多數人都有使用社群網站或軟體的習慣,隨著智慧型
手機的普及,新聞媒體與商品行銷更是投入大量的資源於數位化的發展,這
樣的趨勢讓所有人都能更容易且直接接觸各種在網路上傳播的資訊,也更容
易地在網路上與其他人討論或分享。
世新大學於「2012 年媒體風雲排行榜」中公布台灣民眾在五大媒體(電
視、報紙、廣播、雜誌與網路)的使用比例,調查指出電視的使用率最高,總
使用率佔 96.2%,而網路媒體首度打敗報紙,分別為 74.9%、67.7%;「2015
年媒體風雲排行榜」調查中,電視的使用率相較於 2012 年有下降的趨勢,
且網路的使用率上升了 5%,報紙的使用率大幅度的降低。從此調查中可以
看出網路上提供的資訊越來越多且越來越方便取得,而在網路及行動裝置的
快速發展下,網路使用量正在不斷的攀升。
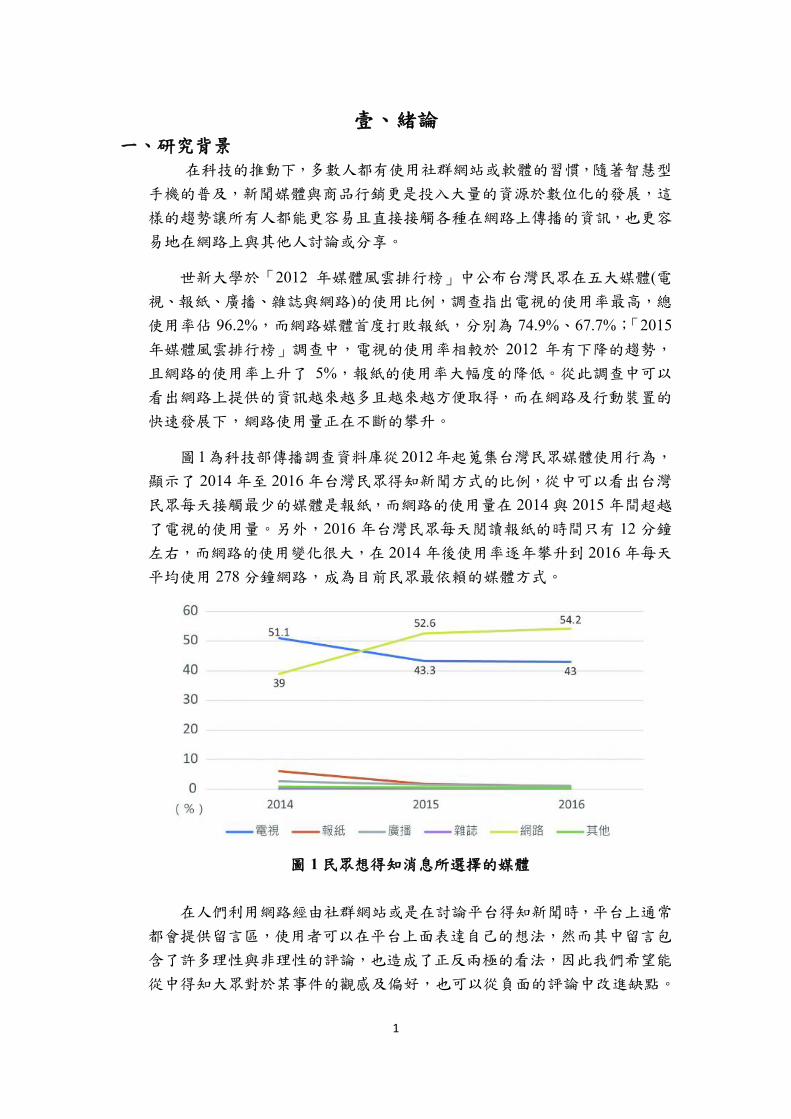
圖1為科技部傳播調查資料庫從2012年起蒐集台灣民眾媒體使用行為,
顯示了 2014 年至 2016 年台灣民眾得知新聞方式的比例,從中可以看出台灣
民眾每天接觸最少的媒體是報紙,而網路的使用量在 2014 與 2015 年間超越
了電視的使用量。另外,2016 年台灣民眾每天閱讀報紙的時間只有 12 分鐘
左右,而網路的使用變化很大,在 2014 年後使用率逐年攀升到 2016 年每天
平均使用 278 分鐘網路,成為目前民眾最依賴的媒體方式。
圖 1 民眾想得知消息所選擇的媒體
在人們利用網路經由社群網站或是在討論平台得知新聞時,平台上通常
都會提供留言區,使用者可以在平台上面表達自己的想法,然而其中留言包
含了許多理性與非理性的評論,也造成了正反兩極的看法,因此我們希望能
從中得知大眾對於某事件的觀感及偏好,也可以從負面的評論中改進缺點。

2
二、研究動機與目的
由於現今網路言論自由的環境,使得網絡中興起許多討論區、部落格與
資訊分享平台,時常可以看到對於某些事件的發生或銷售商品的各種評論或
是批判的留言,這些評論往往反映出民眾或是消費者的真實心態與想法,而
評論的正/負傾向可以看出留言者對於某事件的態度,甚至可以被當作支持或
改進的重要參考,其中負面的評論中也有著不同的強度,因此在知道民眾的
看法後,能夠從不同的負面評論中瞭解事件的趨勢或商品的銷售狀況,並持
續追蹤找出解決問題的方法。
《數位時代》於 2015 年公布 Web 100,即台灣最熱門網站前 100 名,
從榜單中可知 Facebook 與 Youtube 位居一二名,然而以時事分享文章及評論
為主的平台批踢踢實業坊(PTT)與巴哈姆特等知名網站皆有進榜單,其中網
路知名論壇批踢踢實業坊平台上有一萬個以上的主題看板,且每日平均約有
兩萬則文章在此平台上發表,留言推文更超過 50 萬則,因此每天都有大量
的主題在被討論著。然而對於每篇新發表的文章,我們希望在有效的時間內
判斷其屬於正面評論或負面評論,並可以針對負面的文章深入了解做出應對
的解決策略。
情感分析(Sentiment Analysis)是利用語言處理、文字探勘等方式來獲得
文章的訊息,其中主要的方法包含監督式學習(Supervised learning)、半監督
式學習(Semi-supervised learning)、非監督式學習(Unsupervised learning),以
中文情緒分析來說,其目的是希望從文本中利用演算法擷取我們想預測或分
析的資訊,並利用這些資訊訓練出有用的模型,而中文的情緒分析包含以下
幾個重要的步驟,(1)在網路平台上利用爬蟲程式取得文章及留言,(2)利用詞
庫將蒐集到的文本斷詞,(3)針對有興趣之方向做分析、結論彙整。然而正負
評分析即為情緒分析中的一種方法,為了能夠瞭解大家對於某事件的觀感是
正向或是負向的,我們可以透過討論平台上相關事件的文章或回覆進行正負
評的判斷,在有效的時間內能夠針對負面評價給予補償或是改進。
三、論文架構
本論文共分為五個章節,第二章為文獻探討,介紹斷詞方法、相異轉換
的降維方法之分類系統架構,以及本篇研究在組合分類系統中用到的分類器:
支持向量機與隨機森林,最後介紹了加權會用到的 N-Gram 理論;第三章為
研究方法,介紹CoDiS組合分類系統在選擇不同 representation set時的表現,
且利用 600 篇隨機抽出的文章來選取最佳的超參數 L 與超參數 Q,並提出利
用 N-Gram 所計算的加權方法;第四章則利用本篇改進的多分類器系統對
1000 篇隨機選取的文章進行分析,以批踢踢實業坊中八卦版的資料進行正負
評文章分類,並比較支持向量機與隨機森林的表現;最後於第五章做出結論
以及未來的研究方向。

3
貳、文獻探討
一、中文斷詞工具
在進行中文自然語言處理時,在進行分析前都需要做資料清理的動作,
其中一項重要的步驟則是斷詞,然而在英文斷詞中我們利用單詞與單詞之間
的空格或標點符號作為斷詞的依據,但中文的特性並沒有詞與詞之間明顯的
依據作為分割點,因此中文的斷詞需要藉由大量的語料庫比對或是特殊的演
算法來達到分割中文詞語的目的。現今有許多公開的斷詞技術能夠幫助我們
達到這樣的處理,接下來會介紹兩種較常用的中文斷詞技術。
CKIP(Chinese Knowledge and Information Processing)斷詞系統為中央研
究院資訊所以及語言所共同建立的中文自然語言處理團隊提出的一個線上
公開斷詞系統,可以利用 CKIP 網站進行即時的中文文章斷詞,另外 CKIP
網站上也有未知詞的偵測、詞性判斷等功能,圖 2 為 CKIP 中文斷詞系統之
結果。
在R 中有許多斷詞系統的套件,如 jiebaR、Rwordseg與 text2vec等套件,
其中 jiebaR 套件為 Python 的斷詞工具中的 R 版本,Rwordseg 則是由 Java
中的斷詞工具 Ansj 改寫的。圖 3 為 jiebaR 斷詞之結果。
圖 2 CKIP 中文斷詞系統結果
圖 3 jiebaR 斷詞結果

4
二、組合相異空間多分類系統(CoDiS)
由 Pinheiro & Cavalcanti & Tsang (2017)提出的組合相異空間多分類器
系(Combined Dissimilarity Spaces, CoDiS)統,其概念是利用抽樣轉換在不同
空間進行文本分類,利用多分類器系統的特性以增加文本分類的準確性,而
此多分類器系統中使用的分類器為支持向量機(SVM)並採用 linear kernal 的
轉換。
(一)相異性轉換
詞袋(Bag-of-words)是用來表示文檔最常用的方法之一,它是將所有出現
過的每個字詞都當作文本的特徵,並且用字詞出現的次數來表示文本,但是
詞袋的生成具有三個主要的缺點:高維度、資料高稀疏性以及高特徵比例
(feature-to-instance ratio),因此組合相異空間(CoDiS)利用相異性轉換來解
決詞袋的缺點,藉由降低維度及降低稀疏性的方式以增加計算效率。
Pekalska & Duin (2005)的研究中提出的相異性轉換表示法,是計算每篇
文本間的歐氏距離作為新的特徵,以此解決詞袋維度過高的缺點。其方法將
所有文本以 Bootstrap aggregating 的方式從資料集合X中抽出等數量的訓練
樣本,再以隨機抽取的方式抽出表示大小為Q × n的表示集合R,然後計算
訓練樣本內的文本與表示集合R內的文本的相異性,相異性的計算方式為歐
氏距離,計算公式如下(2.1)
𝑑(𝑥𝑎, 𝑥𝑏) = √∑ (𝑤ℎ𝑥𝑎 − 𝑤ℎ
𝑥𝑏)2𝑉
ℎ=1 (2.1)
其中𝑤ℎ𝑥𝑎與𝑤ℎ
𝑥𝑏為文本𝑥𝑎與文本𝑥𝑏的第ℎ個特徵。
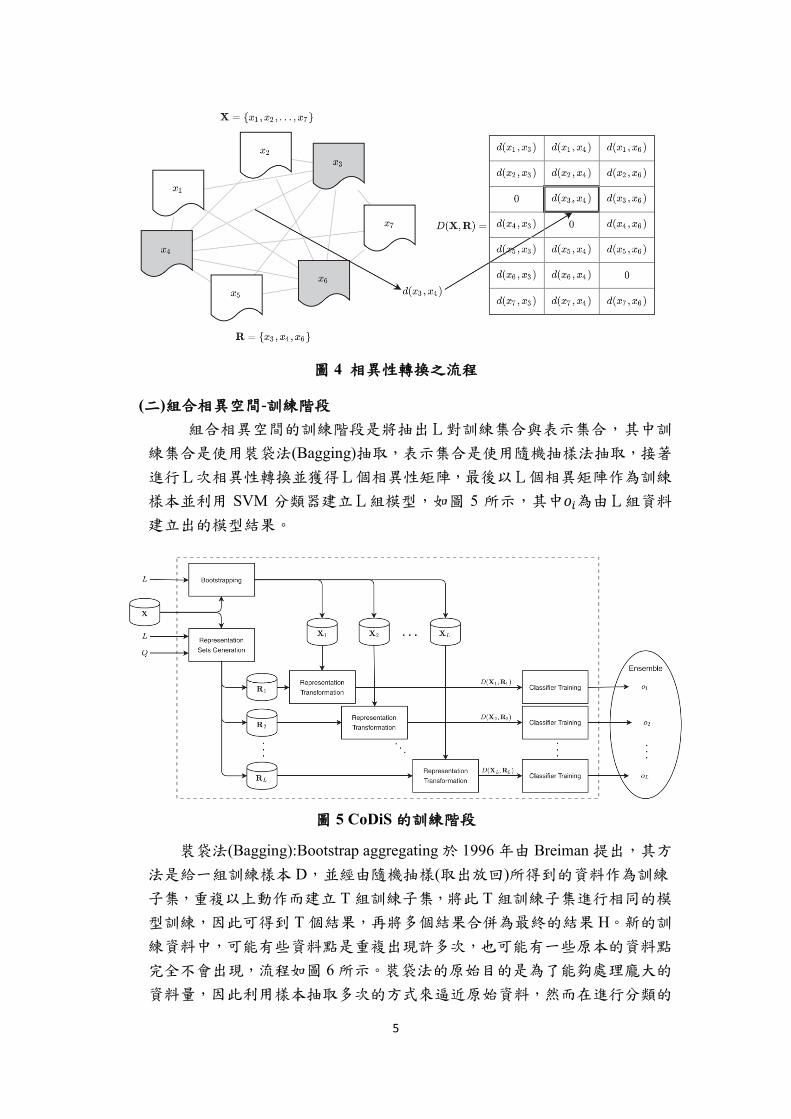
假設訓練樣本中有 N 個文本,表示集合R中有 Q×n 個文本,在相異性
轉換後我們可以得到一個 N×Q 的相異性矩陣如(2.2),而圖 4 為相異性轉換
之流程圖示,圖中𝑥3、𝑥4、𝑥6被隨機選擇成為表示集合R。
𝐷(𝑿,𝑹) = [
𝑑(𝑥1, 𝑟1) ⋯ 𝑑(𝑥1, 𝑟𝑄)
⋮ ⋱ ⋮𝑑(𝑥𝑁 , 𝑟1) ⋯ 𝑑(𝑥𝑁 , 𝑟𝑄)
] (2.2)
5
圖 4 相異性轉換之流程
(二)組合相異空間-訓練階段
組合相異空間的訓練階段是將抽出L對訓練集合與表示集合,其中訓
練集合是使用裝袋法(Bagging)抽取,表示集合是使用隨機抽樣法抽取,接著
進行L次相異性轉換並獲得L個相異性矩陣,最後以L個相異矩陣作為訓練
樣本並利用 SVM 分類器建立L組模型,如圖 5 所示,其中𝑜𝑖為由L組資料
建立出的模型結果。
圖 5 CoDiS 的訓練階段
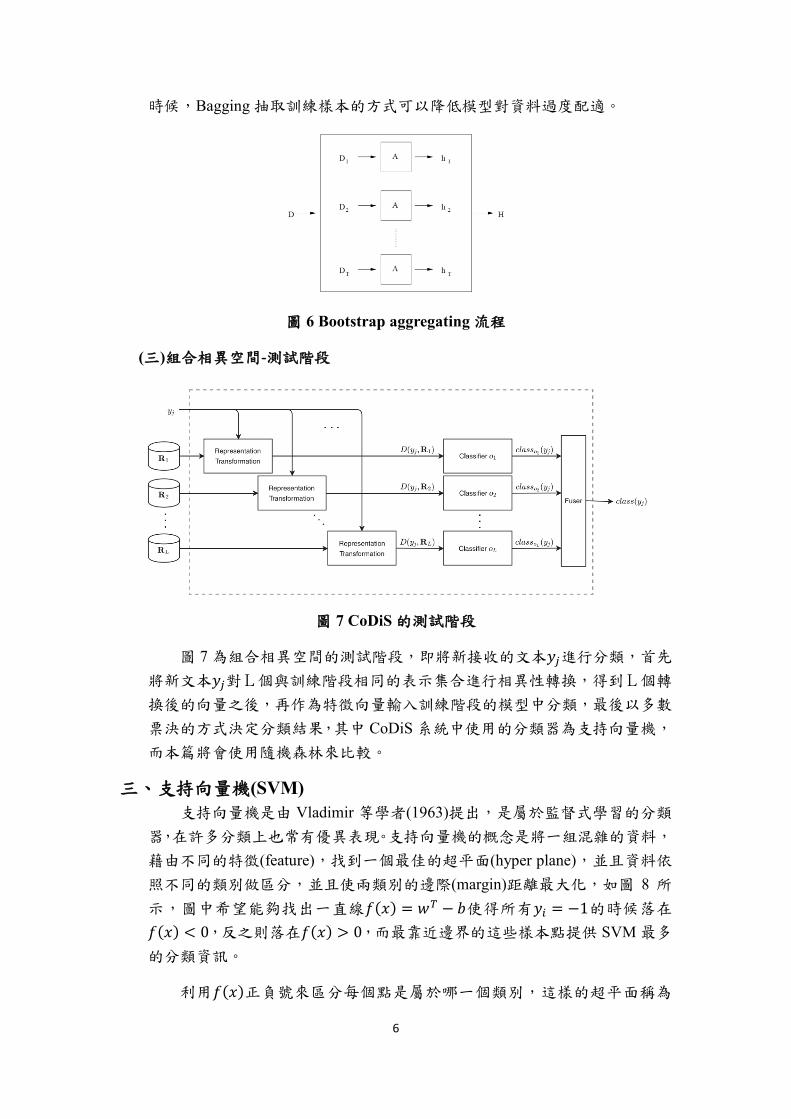
裝袋法(Bagging):Bootstrap aggregating 於 1996 年由 Breiman 提出,其方
法是給一組訓練樣本 D,並經由隨機抽樣(取出放回)所得到的資料作為訓練
子集,重複以上動作而建立 T 組訓練子集,將此 T 組訓練子集進行相同的模
型訓練,因此可得到 T 個結果,再將多個結果合併為最終的結果 H。新的訓
練資料中,可能有些資料點是重複出現許多次,也可能有一些原本的資料點
完全不會出現,流程如圖 6 所示。裝袋法的原始目的是為了能夠處理龐大的
資料量,因此利用樣本抽取多次的方式來逼近原始資料,然而在進行分類的
6
時候,Bagging 抽取訓練樣本的方式可以降低模型對資料過度配適。
圖 6 Bootstrap aggregating 流程
(三)組合相異空間-測試階段
圖 7 CoDiS 的測試階段
圖 7 為組合相異空間的測試階段,即將新接收的文本𝑦𝑗進行分類,首先
將新文本𝑦𝑗對L個與訓練階段相同的表示集合進行相異性轉換,得到L個轉
換後的向量之後,再作為特徵向量輸入訓練階段的模型中分類,最後以多數
票決的方式決定分類結果,其中 CoDiS 系統中使用的分類器為支持向量機,
而本篇將會使用隨機森林來比較。
三、支持向量機(SVM)
支持向量機是由 Vladimir 等學者(1963)提出,是屬於監督式學習的分類
器,在許多分類上也常有優異表現。支持向量機的概念是將一組混雜的資料,
藉由不同的特徵(feature),找到一個最佳的超平面(hyper plane),並且資料依
照不同的類別做區分,並且使兩類別的邊際(margin)距離最大化,如圖 8 所
示,圖中希望能夠找出一直線𝑓(𝑥) = 𝑤𝑇 − 𝑏使得所有𝑦𝑖 = −1的時候落在
𝑓(𝑥) < 0,反之則落在𝑓(𝑥) > 0,而最靠近邊界的這些樣本點提供 SVM 最多
的分類資訊。
利用𝑓(𝑥)正負號來區分每個點是屬於哪一個類別,這樣的超平面稱為

7
separating hyperplane,距離兩邊邊界最大的就稱為 optimal separating
hyperplane(OSH);support hyperplane 是指與 optimal separating hyperplane 平
行,並且最靠近兩邊樣本點的超平面。以二維的例子來說,圖 8 中的兩條虛
線就是 support hyperplane,因此可以將 separating hyperplane 與兩邊的
support hyperplane 的距離為 d 定義如(2.3)、(2.4)所示,然而支持向量機就是
希望在最大化距離之下找出的‖�⃑⃑� ‖最小值。
𝑑 =(||𝑏+1|−|𝑏||)
‖�⃑⃑� ‖=
1
‖�⃑⃑� ‖ 𝑖𝑓 𝑏 ∉ (−1,0) (2.3)
𝑑 =(||𝑏+1|+|𝑏||)
‖�⃑⃑� ‖=
1
‖�⃑⃑� ‖ 𝑖𝑓 𝑏 ∈ (−1,0) (2.4)
圖 8 支持向量機之邊際
四、隨機森林(Random Forest)
隨機森林是一種基於決策樹分類的集成學習方法,最早由 Brieman(1992)
提出,集成學習(Ensemble Learning)是將多個弱分類器結合成一個較強大的
分類器系統,然而這種方法有兩個限制(1) 各個分類器之間須具有差異性、
(2) 每個分類器的準確度必須大於 0.5。
然而使多個分類器有差異性主要有 Boosting 與 Bagging 兩種方法,隨機
森林所用的是多棵決策樹的 Bagging 方法,由多個決策樹的合併結果作為最
後的分類,圖 9 為隨機森林的架構。
圖 9 隨機森林之架構

8
五、N-Gram 模型
語言模型(Language Model)經常被使用在自然語言處理(NLP)方面的應
用,然而 N-Gram 就是一個常見語言模型,N-Gram 是一種統計語言模型的
算法,它是將文本裡面的內容按照字詞進行大小為 N 的視窗擷取,形成了每
個字詞長度為 N 的序列,每個字詞片段稱為 gram,對所有 gram 的出現頻率
進行統計形成 gram 列表,也就是這個文本的特徵向量空間,列表中的每一
種 gram 就是一個特徵向量。
假設文本中有𝑛個詞,若將文本中的字詞視為沒有關聯時,文本出現的
機率可以表示成(2.5)式,若將文本中的字詞視為有關聯時,文本出現的機率
可以由馬可夫鏈(Markov chain)表示成(2.6)式。由於(2.6)式的計算較複雜,
因此 N-Gram 模型提出了一些假設,其將文本中的字詞視為有關連且每個字
詞只對前𝑁 − 1個字詞有相關,因此字詞間的關係可以寫成(2.7)式,其中的𝑤𝑖
為文章中的第𝑖個字詞。
𝑃(𝑤1, 𝑤2, … , 𝑤𝑛) = 𝑃(𝑤1)𝑃(𝑤2)…𝑃(𝑤𝑛) (2.5)
𝑃(𝑤1, 𝑤2, … , 𝑤𝑛) = 𝑃(𝑤1)𝑃(𝑤2|𝑤1)𝑃(𝑤3|𝑤1, 𝑤2)…𝑃(𝑤𝑛|𝑤1, … , 𝑤𝑛−1) (2.6)
𝑃(𝑤𝑖|𝑤1, … , 𝑤𝑖−1) = 𝑃(𝑤𝑖|𝑤𝑖−𝑁+1, … , 𝑤𝑖−1) (2.7)
其中𝑃(𝑤𝑖|𝑤1, … , 𝑤𝑖−1) =𝐶𝑜𝑢𝑛𝑡(𝑤1,…,𝑤𝑖−1,𝑤𝑖)
𝐶𝑜𝑢𝑛𝑡(𝑤1,…,𝑤𝑖−1)
常 用 的 2-Gram 模 型 (bigram model) 為 例 , 假 設 有 一 句 話 為
"今天的天氣很好",且被已斷詞為{"今天", "的", "天氣", "很好"},因此這一句
話出現的機率可以寫成(2.8)式。
𝑃(𝑤1, 𝑤2, … , 𝑤𝑛) = ∏𝑃(𝑤𝑖|𝑤𝑖−1)
𝑛
𝑖=1
= 𝑃(今天|𝑏𝑒𝑔𝑖𝑛)𝑃(的|今天)𝑃(天氣|的)𝑃(很好|天氣)𝑃(𝑒𝑛𝑑|很好) (2.8)
9
參、研究方法
一、方法與架構
第三章主要討論由 Pinheiro 等學者(2017)提出的 CoDiS 多分類器系統應
用在中文上的情感分析並加以改進,圖 10 為研究方法之流程圖。第二節與
第三節分別介紹資料處理以及相異性轉換前的資料選取;第四節討論 CoDiS
中不同的表示集合(Represent set)選擇方式的表現;第五節比較 CoDiS 中的兩
個超參數Q與L在不同選擇下的表現,其中超參數Q決定表示集合(Represent
set)與訓練樣本之間的比例,而超參數 L 決定多分類器系統中重複使用分類
器次數;為了考慮字詞之間的相關,第六節提出一種基於 N-Gram 的加權方
法,此方法計算出的矩陣包含了原始 dtm 矩陣的資訊,也加入了 N-Gram 的
概念以改進多分類器系統在中文上的表現;第五節為對於應用在中文文本上
的多分類器系統的簡單結論。
二、資料處理
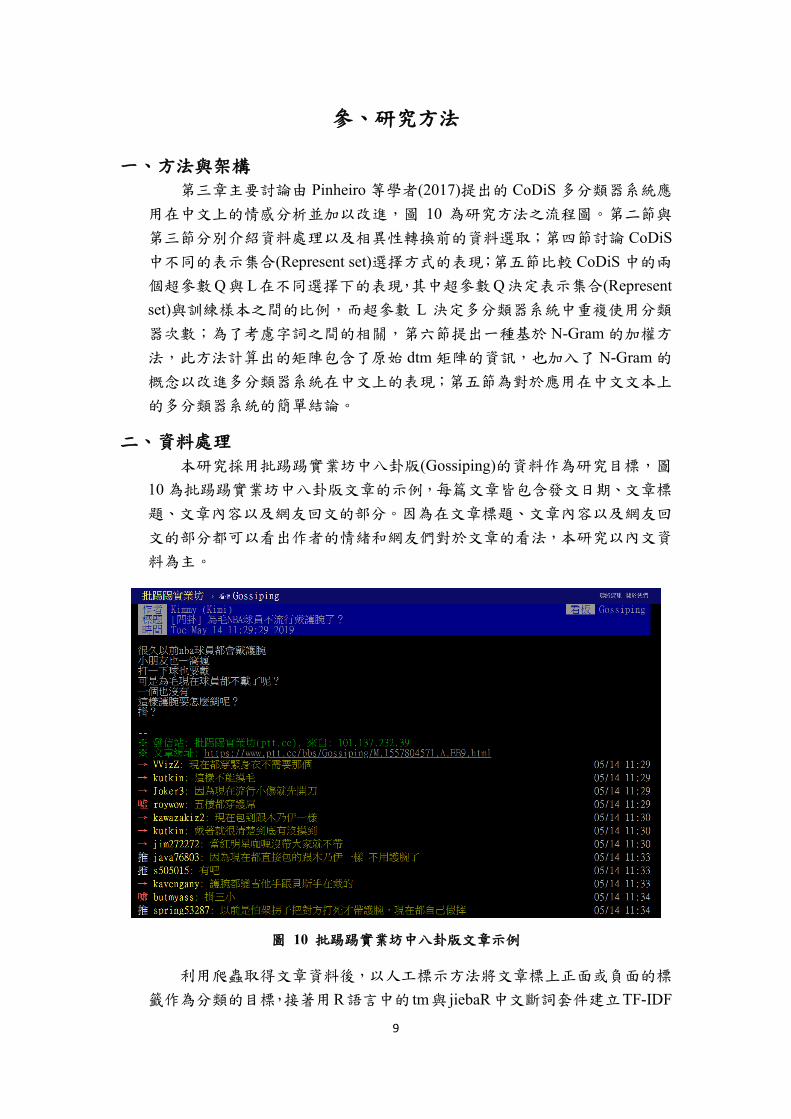
本研究採用批踢踢實業坊中八卦版(Gossiping)的資料作為研究目標,圖
10 為批踢踢實業坊中八卦版文章的示例,每篇文章皆包含發文日期、文章標
題、文章內容以及網友回文的部分。因為在文章標題、文章內容以及網友回
文的部分都可以看出作者的情緒和網友們對於文章的看法,本研究以內文資
料為主。
圖 10 批踢踢實業坊中八卦版文章示例
利用爬蟲取得文章資料後,以人工標示方法將文章標上正面或負面的標
籤作為分類的目標,接著用R語言中的 tm與 jiebaR中文斷詞套件建立TF-IDF

10
權重的 dtm(Document Term Matrix)矩陣,並計算出文本相似矩陣作為模型的
輸入,其中取 10%資料做為測試樣本。
TF-IDF(term frequency–inverse document frequency)是一種常用於中文
語言處理的加權方法,利用每個詞在單篇文章中出現的頻率以及出現的文章
數,可以看出每個詞重要性。詞頻(TF)是指某一個給定的詞語在該檔案中出
現的頻率指標,公式為(3.1)式,當 TF 值越大時,表示該給定的字詞對於某
文章的重要性越高;逆向文件頻率(IDF)是指某一個給定字詞的普遍性指標,
當 IDF 值越大時,表示該詞出現的文章數越少,綜合上述,因此會有以下幾
種情況:
(1) 給定的字詞在某文本中的出現次數高,普遍性也高
(2) 給定的字詞在某文本中的出現次數低,普遍性也低
(3) 給定的字詞在某文本中的出現次數高,但普遍性低
(4 )給定的字詞在某文本中的出現次數低,但普遍性高
將兩指標相乘得到 TF-IDF,表示每個字詞的重要性,如式(3.3)。
𝑡𝑓𝑤,𝑡 =𝑛𝑤,𝑡
∑ 𝑛𝑘,𝑡𝑘 (3.1)
其中𝑛𝑤,𝑡為字詞𝑤在文本𝑡中出現的次數,
𝑖𝑑𝑓𝑤 = 𝑙𝑜𝑔𝐷
𝑑𝑤 (3.2)
其中𝐷為總文本數, 𝑑𝑤為出現𝑤出現的文本數,
𝑡𝑓𝑖𝑑𝑓𝑤,𝑡 = 𝑡𝑓𝑤,𝑡 × 𝑖𝑑𝑓𝑤 (3.3)
許多文獻會再進行 TF-IDF 的加權調整以優化分析表現,因此本章第六節也
會提出一種 N-Gram 加權的方法來改進中文分類。
三、表示集合(Represent set)比較
在相異性轉換中,表示集合扮演著重要的角色,不同的表示集合選擇
會影響到分類器的表現,表示集合的概念就像是標準,當我們選出一些文本
作為表示集合後,它們會被用來與訓練樣本中的文本比較,並將訓練樣本中
的文本與表示集合中文本的相似性作為新的特徵,利用相似性建立降維矩陣
並分析。因此本論文除了隨機選取表示集合的方法之外,提出了三種不同的
選取方式:
(1) 隨機選取
(2) 正向文章選取
(3) 負向文章選取
本研究將利用支持向量機分類器搭配 sigmoid 核心與隨機森林分類器來
比較不同選取方法的表現,本節的實驗資料為半年內批踢踢實業坊八卦版文
章並隨機挑選出600篇文章,其中包含239篇正向文章以及361篇負向文章。
11
四、多分類器系統超參數比較
本節介紹在 CoDiS 多分類器系統中的兩個超參數,分別是 Q 與 L,其
中 Q 為抽取表示集合時的比例,影響到表示集合的大小與降低的維度;L 為
系統中重複使用分類器次數,影響系統的穩定與表現,但當 L 太大時會造成
大量的計算時間,本節中我們加入第四節的表示集合選取並討論在不同的超
參數下,多分類器系統的表現,資料和分類器皆與前一節相同,其中正向文
章有 239 篇,負向文章有 361 篇。
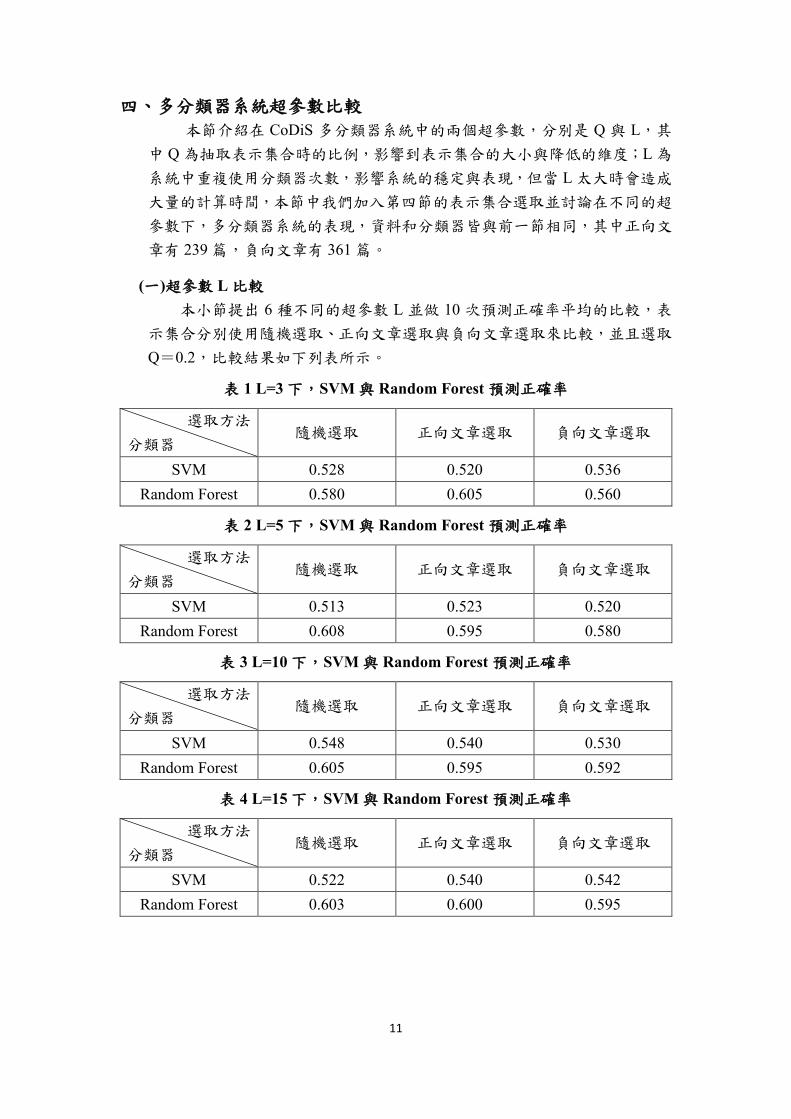
(一)超參數 L 比較
本小節提出 6 種不同的超參數 L 並做 10 次預測正確率平均的比較,表
示集合分別使用隨機選取、正向文章選取與負向文章選取來比較,並且選取
Q=0.2,比較結果如下列表所示。
表 1 L=3 下,SVM 與 Random Forest 預測正確率
選取方法
分類器 隨機選取 正向文章選取 負向文章選取
SVM 0.528 0.520 0.536
Random Forest 0.580 0.605 0.560
表 2 L=5 下,SVM 與 Random Forest 預測正確率
選取方法
分類器 隨機選取 正向文章選取 負向文章選取
SVM 0.513 0.523 0.520
Random Forest 0.608 0.595 0.580
表 3 L=10 下,SVM 與 Random Forest 預測正確率
選取方法
分類器 隨機選取 正向文章選取 負向文章選取
SVM 0.548 0.540 0.530
Random Forest 0.605 0.595 0.592
表 4 L=15 下,SVM 與 Random Forest 預測正確率
選取方法
分類器 隨機選取 正向文章選取 負向文章選取
SVM 0.522 0.540 0.542
Random Forest 0.603 0.600 0.595
12
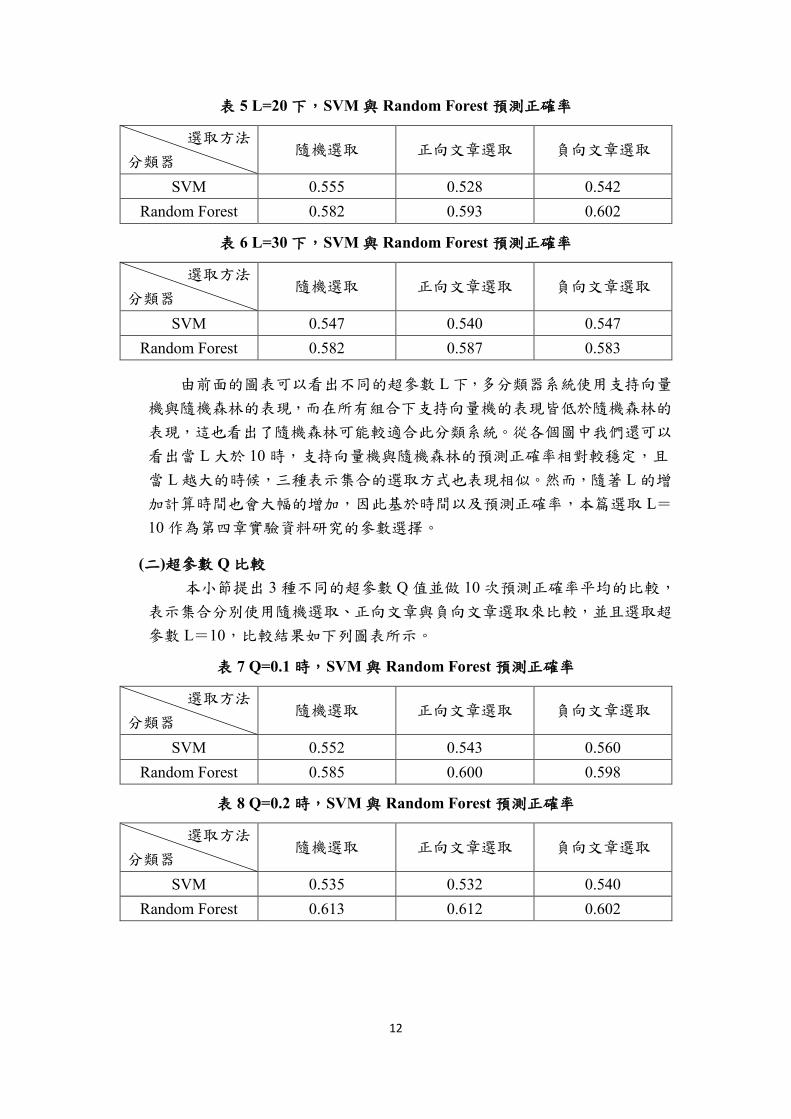
表 5 L=20 下,SVM 與 Random Forest 預測正確率
選取方法
分類器 隨機選取 正向文章選取 負向文章選取
SVM 0.555 0.528 0.542
Random Forest 0.582 0.593 0.602
表 6 L=30 下,SVM 與 Random Forest 預測正確率
選取方法
分類器 隨機選取 正向文章選取 負向文章選取
SVM 0.547 0.540 0.547
Random Forest 0.582 0.587 0.583
由前面的圖表可以看出不同的超參數 L 下,多分類器系統使用支持向量
機與隨機森林的表現,而在所有組合下支持向量機的表現皆低於隨機森林的
表現,這也看出了隨機森林可能較適合此分類系統。從各個圖中我們還可以
看出當 L 大於 10 時,支持向量機與隨機森林的預測正確率相對較穩定,且
當 L 越大的時候,三種表示集合的選取方式也表現相似。然而,隨著 L 的增
加計算時間也會大幅的增加,因此基於時間以及預測正確率,本篇選取 L=
10 作為第四章實驗資料研究的參數選擇。
(二)超參數 Q 比較
本小節提出 3 種不同的超參數 Q 值並做 10 次預測正確率平均的比較,
表示集合分別使用隨機選取、正向文章與負向文章選取來比較,並且選取超
參數 L=10,比較結果如下列圖表所示。
表 7 Q=0.1 時,SVM 與 Random Forest 預測正確率
選取方法
分類器 隨機選取 正向文章選取 負向文章選取
SVM 0.552 0.543 0.560
Random Forest 0.585 0.600 0.598
表 8 Q=0.2 時,SVM 與 Random Forest 預測正確率
選取方法
分類器 隨機選取 正向文章選取 負向文章選取
SVM 0.535 0.532 0.540
Random Forest 0.613 0.612 0.602
13
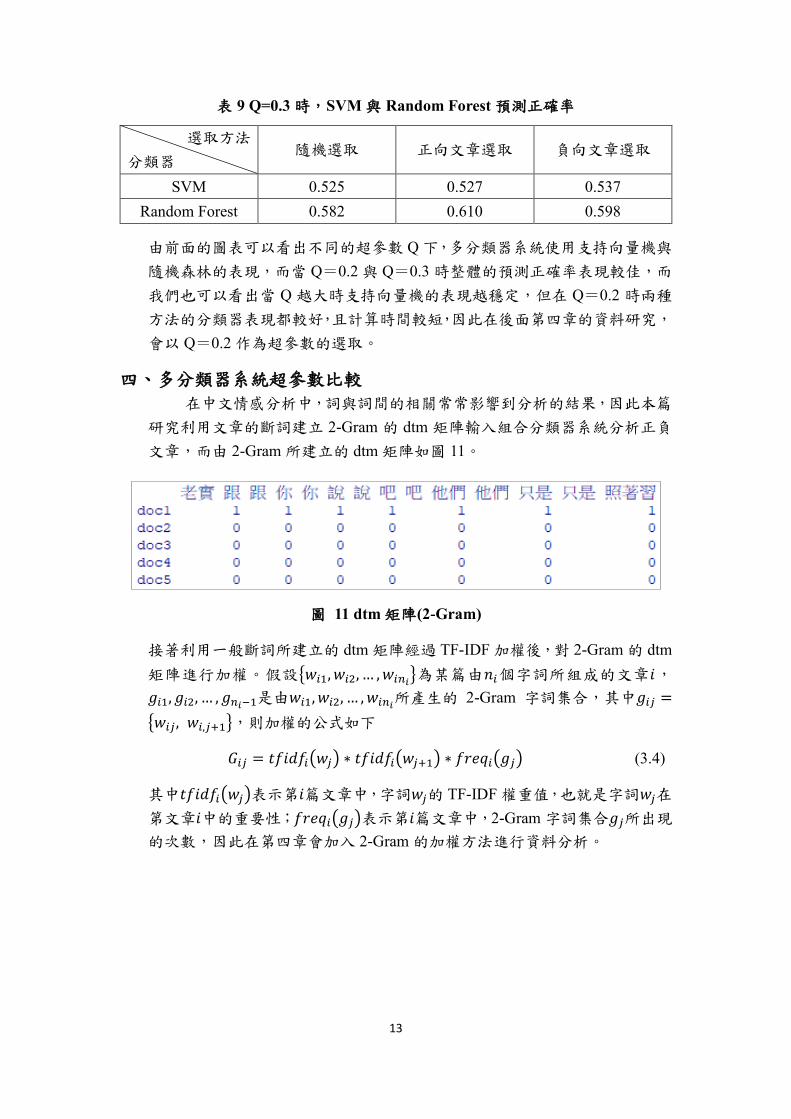
表 9 Q=0.3 時,SVM 與 Random Forest 預測正確率
選取方法
分類器 隨機選取 正向文章選取 負向文章選取
SVM 0.525 0.527 0.537
Random Forest 0.582 0.610 0.598
由前面的圖表可以看出不同的超參數 Q 下,多分類器系統使用支持向量機與
隨機森林的表現,而當 Q=0.2 與 Q=0.3 時整體的預測正確率表現較佳,而
我們也可以看出當 Q 越大時支持向量機的表現越穩定,但在 Q=0.2 時兩種
方法的分類器表現都較好,且計算時間較短,因此在後面第四章的資料研究,
會以 Q=0.2 作為超參數的選取。
四、多分類器系統超參數比較
在中文情感分析中,詞與詞間的相關常常影響到分析的結果,因此本篇
研究利用文章的斷詞建立 2-Gram 的 dtm 矩陣輸入組合分類器系統分析正負
文章,而由 2-Gram 所建立的 dtm 矩陣如圖 11。
圖 11 dtm 矩陣(2-Gram)
接著利用一般斷詞所建立的 dtm 矩陣經過 TF-IDF 加權後,對 2-Gram 的 dtm
矩陣進行加權。假設{𝑤𝑖1, 𝑤𝑖2, … , 𝑤𝑖𝑛𝑖}為某篇由𝑛𝑖個字詞所組成的文章𝑖,
𝑔𝑖1, 𝑔𝑖2, … , 𝑔𝑛𝑖−1是由𝑤𝑖1, 𝑤𝑖2, … , 𝑤𝑖𝑛𝑖所產生的 2-Gram 字詞集合,其中𝑔𝑖𝑗 =
{𝑤𝑖𝑗, 𝑤𝑖,𝑗+1},則加權的公式如下
𝐺𝑖𝑗 = 𝑡𝑓𝑖𝑑𝑓𝑖(𝑤𝑗) ∗ 𝑡𝑓𝑖𝑑𝑓𝑖(𝑤𝑗+1) ∗ 𝑓𝑟𝑒𝑞𝑖(𝑔𝑗) (3.4)
其中𝑡𝑓𝑖𝑑𝑓𝑖(𝑤𝑗)表示第𝑖篇文章中,字詞𝑤𝑗的 TF-IDF 權重值,也就是字詞𝑤𝑗在
第文章𝑖中的重要性;𝑓𝑟𝑒𝑞𝑖(𝑔𝑗)表示第𝑖篇文章中,2-Gram 字詞集合𝑔𝑗所出現
的次數,因此在第四章會加入 2-Gram 的加權方法進行資料分析。

14
肆、實驗資料與研究評估
一、研究資料介紹
本章節是從批踢踢實業坊中八卦版(Gossiping)上爬取的資料作為研究
資料,並且從半年內的文章中隨機挑選 1000 篇文章內文並進行人工標籤,
其中包含 625 篇正向文章以及 375 篇負向文章,並選取 10%資料當作測試樣
本,另外 90%資料將會作為表示集合與訓練樣本所抽取的資料。
二、評估指標
在做文本分類的時候,會用到一些指標來評判算法的優劣,最簡單的
就是預測正確的文本數與總文本數的比值,但這樣的方法過於簡單,因此
本文還使用幾個常用的文本分類評估指標 recall、precision 以及 F-score 三
種指標。
(一)正確率
正確率(accuracy)為判斷預測正確率最簡單且最直觀的方法,也就是計
算正確分類的比例,如(4.1)式。
𝑎𝑐𝑐𝑢𝑟𝑎𝑐𝑦 =正確分類的文本數
所有分類的文本數 (4.1)
(二)F-measure
F-score 是由兩個主要指標所組成,分別為召回率(recall)與精準率
(precision),F1 的公式如下(4.2)
𝐹 − 𝑠𝑐𝑜𝑟𝑒 =2
1
𝑟𝑒𝑐𝑎𝑙𝑙+
1
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛
= 2 ×𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛×𝑟𝑒𝑐𝑎𝑙𝑙
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑟𝑒𝑐𝑎𝑙𝑙 (4.2)
召回率與精準率的計算需用到三個指標:TP、FP 及FN ,TP 是正確將正
向文章分類至正向文章的數量,FP 是將負向文章分類至正向文章的數量,
而FN 將正向文章分類至負向文章的數量,如下表 11 所示,其中的𝑟𝑒𝑐𝑎𝑙𝑙與
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛分別為(4.3)與(4.4)式。
表 10 TP、FN、FP 及 TN 指標
真實文本為正向文章 真實文本為負向文章
分類器分類文本為
正向文章
正確正例篇數
(true positive, TP)
錯誤負例篇數
(false positive, FP)
分類器分類文本為
負向文章
錯誤正例篇數
(false negative, FN)
正確負例篇數
(true negative, TN)
15
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =𝑇𝑃
𝑇𝑃+𝐹𝑃 (4.3)
𝑟𝑒𝑐𝑎𝑙𝑙 =𝑇𝑃
𝑇𝑃+𝐹𝑁 (4.4)
三、方法結果與評估
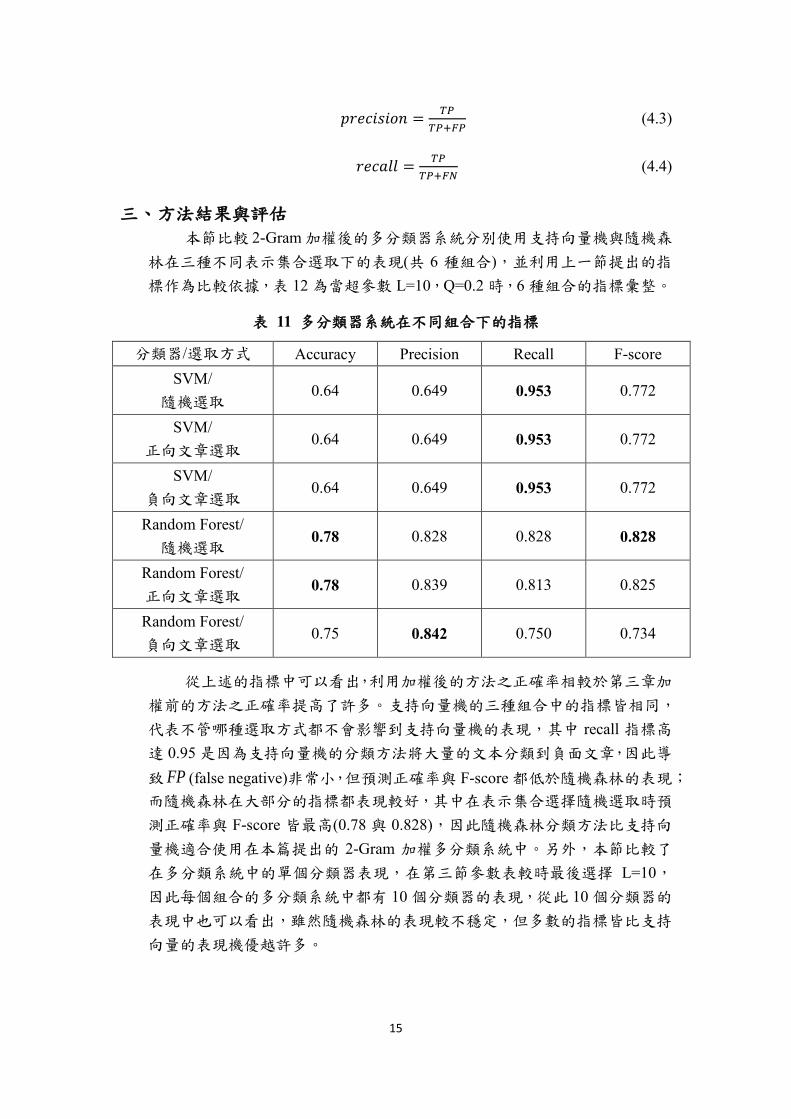
本節比較 2-Gram 加權後的多分類器系統分別使用支持向量機與隨機森
林在三種不同表示集合選取下的表現(共 6 種組合),並利用上一節提出的指
標作為比較依據,表 12 為當超參數 L=10,Q=0.2 時,6 種組合的指標彙整。
表 11 多分類器系統在不同組合下的指標
分類器/選取方式 Accuracy Precision Recall F-score
SVM/
隨機選取 0.64 0.649 0.953 0.772
SVM/
正向文章選取 0.64 0.649 0.953 0.772
SVM/
負向文章選取 0.64 0.649 0.953 0.772
Random Forest/
隨機選取 0.78 0.828 0.828 0.828
Random Forest/
正向文章選取 0.78 0.839 0.813 0.825
Random Forest/
負向文章選取 0.75 0.842 0.750 0.734
從上述的指標中可以看出,利用加權後的方法之正確率相較於第三章加
權前的方法之正確率提高了許多。支持向量機的三種組合中的指標皆相同,
代表不管哪種選取方式都不會影響到支持向量機的表現,其中 recall 指標高
達 0.95 是因為支持向量機的分類方法將大量的文本分類到負面文章,因此導
致 FP (false negative)非常小,但預測正確率與 F-score 都低於隨機森林的表現;
而隨機森林在大部分的指標都表現較好,其中在表示集合選擇隨機選取時預
測正確率與 F-score 皆最高(0.78 與 0.828),因此隨機森林分類方法比支持向
量機適合使用在本篇提出的 2-Gram 加權多分類系統中。另外,本節比較了
在多分類系統中的單個分類器表現,在第三節參數表較時最後選擇 L=10,
因此每個組合的多分類系統中都有 10 個分類器的表現,從此 10 個分類器的
表現中也可以看出,雖然隨機森林的表現較不穩定,但多數的指標皆比支持
向量的表現機優越許多。

16
伍、結論
一、總結
在中文的文章分析中,字詞的順序也有可能影響到文章的語意,因此本
文利用了原始的 tfidf 矩陣對 2-Gram 的詞頻矩陣進行加權,雖然 2-Gram 矩
陣比一般 dtm 矩陣的維度還要大,但矩陣在進入分類器前經過了相異性轉換
的步驟,因此大大的降低了分類器的輸入,縮短在分類時使用的時間。在第
三章中可以看出進行 2-Gram 加權前的多分類器系統分別使用支持向量機與
隨機森林的表現,並比較不同超參數下的預測正確率,最後選擇超參數L=10,
Q=0.2 作為本篇研究的超參數。另外,本篇提出兩種不同的表示集合的選擇
與 CoDiS 中的隨機選擇比較,且加入了隨機森林分類方法與 CoDiS 中的支
持向量機比較,從第四章中的指標可以看出隨機森林在的表現比支持向量機
還要好,而隨機森林使用負向文章的表示集選取方式表現比其他兩種選取方
式差。
二、未來研究
在建立 2-Gram 矩陣時因為考慮到詞與詞之間的組合,因此在進行相異
轉換前的維度非常高,導致在相異性轉換中的歐式距離計算需要較多的時間,
因此未來會考慮其他方式來測量兩文本之間的相異性;另外,系統中不同的
分類器會有不同的效果,本篇的分類器只選擇隨機森林與支持向量機,因此
未來研究可以加入其他分類器的比較。
本篇研究只考慮了文本是正面或是負面的狀況,因此在做分類時皆為二
分類,當資料超過兩個類別時可能需要做一些調整,因此未來可以研究三個
分類以上的多分類器系統以及其合適的分類器與適合的超參數。

17
參考文獻
Ghiassi, M., Lee, S. A domain transferable lexicon set for Twitter sentiment analysis
using a supervised machine learning approach. Expert Systems with
Applications. Volume 106, 15 September 2018, Pages 197-216
Zhou, S., Chen, Q., Wnag, X. Active deep learning method for semi-supervised
sentiment classification. Neurocomputing. Volume 120, 23 November 2013,
Pages 536-546
Weidi Xu, Ying Tan, Semi-supervised Target-oriented Sentiment Classification,
Neurocomputing, doi: https://doi.org/10.10-16/j.neuc-om.2019.01.059
Venkateswarlu Naik, M., Vasumathi, D., Siva Kumar, A.P. An enhanced unsupervised
learning approach for sentiment analysis using extraction of tri-co-occurrence
words phrases. Volume 712, 2018, Pages 17-26
Jochen Hartmann, Juliana Huppertz, Christina Schamp, Mark Heitmann. (2018)
Comparing automated text classification methods. International Journal of
Research in Marketing. IJRM-01274; No of Pages 26.
Xingtong Ge, Xiaofang Jin, Bo Miao, Chenming Liu, & Xinyi Wu. (2019). Research
on the Key Technology of Chinese Text Sentiment Analysis. Proceedings of the
IEEE International Conference on Software Engineering and Service
Sciences, ICSESS. 2018-November,8663744, 395-398.
Pinheiro, R. H. W., Cavalcanti, G. D. C., & Tsang, I. R. (2017). Combining
dissimilarity spaces for text categorization. Information Sciences, 406-407,
87-101.
E. Pekalska and R.P.W. Duin. (2005) The Dissimilarity Representation for Pattern
Recognition, Foundations and Applications, World Scientific, Singapore, 607
pages, ISBN 981-256-530-2.
Roul, R. K., Sahoo, J. K., & Arora, K. (2017). Modified TF-IDF Term Weighting
Strategies for Text Categorization. 2017 14th IEEE India Council
International Conference.
Ying-Tse Sun, Chien-Liang Chen, Chun-Chieh Liu, Chao-Lin Liu, & Von-Wun Soo.
(2010). Sentiment Classification of Short Chinese Sentences. Proceedings of
the 22nd Conference on Computational Linguistics and Speech Processing
(ROCLING 2010). 184–198
Xiao, Z., Li, X., Wang, L., Yang, Q., Du, J., & Sangaiah, A. K. (2018). Using
convolution control block for Chinese sentiment analysis. Journal of Parallel
and Distributed Computing, 116, 18–26.


















