
SS 2004 Datenbanken 4W Mi 13:30 – 15:00 G 2.30 Vorlesung #2 Datenbankentwurf.

Rheinische-Friedrich-Wilhelms-Universität Bonn Institut für Informatik III
Diplomarbeit
Ein regelbasiertes System zur Subsumtionsunterstützung
bei Körperverletzungsdelikten
Daniel Köhnen
September 2000
Erstgutachter: Prof. Dr. Rainer Manthey

ii

iii
Inhaltsverzeichnis
1 Einleitung......................................................................................................................1
2 Grundlagen ...................................................................................................................3
2.1 Grundlagen aus der Informatik ...............................................................................3 2.1.1 Expertensysteme .............................................................................................3 2.1.2 Datenbanksysteme ..........................................................................................4 2.1.3 Deduktive Datenbanksysteme..........................................................................7
2.1.3.1 Motivierendes Beispiel ................................................................................7 2.1.3.2 Begriffsbestimmung: Deduktives Datenbanksystem ....................................7 2.1.3.3 Zentrales Element: Regel.............................................................................8 2.1.3.4 Einschub: Integritätsbedingungen................................................................8 2.1.3.5 Änderungsgetriebene und anfragegetriebene Inferenz ..................................9 2.1.3.6 Vorteile Deduktiver Datenbanksysteme.......................................................9
2.1.4 Aktive Datenbanksysteme .............................................................................10 2.1.4.1 Motivation.................................................................................................10 2.1.4.2 Begriffsklärung: Aktives Datenbanksystem (ADBS) .................................10 2.1.4.3 Zentrales Element: Aktive Regel ...............................................................10
2.1.5 Relationale Datenbanksysteme ......................................................................11 2.1.5.1 Relationales Datenmodell ..........................................................................11 2.1.5.2 SQL ..........................................................................................................12
2.1.6 Objektorientiertes Datenmodell .....................................................................13 2.1.7 UML .............................................................................................................14
2.1.7.1 UML-Klassendiagramme ..........................................................................14 2.1.7.2 UML-Sequenzdiagramme..........................................................................16
2.1.8 Logische Programmierung ............................................................................17 2.1.8.1 Prolog .......................................................................................................18 2.1.8.2 Datalog......................................................................................................22
2.1.9 Tcl/Tk ...........................................................................................................23 2.1.9.1 Tcl-Grundlagen .........................................................................................23 2.1.9.2 Tk-Grundlagen ..........................................................................................24
2.2 Rechtswissenschaftliche Grundlagen.....................................................................26 2.2.1 Gesetzesstruktur............................................................................................26 2.2.2 Die juristische Subsumtion: Vorgang der Rechtsfindung ...............................28
2.2.2.1 Gesetzesauslegung ....................................................................................29 2.2.2.2 Unbestimmte Rechtsbegriffe .....................................................................31 2.2.2.3 Sachverhaltsanpassung ..............................................................................31
2.2.3 Prüfungsaufbau im Strafrecht ........................................................................32 2.2.4 Prüfungsreihenfolge ......................................................................................33

iv
3 Ausgewählte juristische Systeme................................................................................35
3.1 LEX-1 ...................................................................................................................35 3.1.1 Systembeschreibung......................................................................................35 3.1.2 Bewertung.....................................................................................................36
3.2 WZ........................................................................................................................37 3.2.1 Systembeschreibung......................................................................................37 3.2.2 Bewertung.....................................................................................................38
3.3 HYPO und darauf aufbauende Ansätze .................................................................39 3.3.1 Beschreibung ................................................................................................39 3.3.2 Bewertung.....................................................................................................40
3.4 Sonstige regelbasierte Ansätze ..............................................................................40
4 Exkurs: Analogie zwischen Rechtsanwendung und wissensbasierten Systemen.....41
5 Formalisierung juristischer Sachverhalte und Normen............................................42
5.1 Datenbanksprachen ..............................................................................................42
5.2 Auswahl des zu modellierenden Gesetzesauschnitts...............................................43
5.3 Eingeschränkter Prüfungsaufbau des juristischen Systems ....................................44
5.4 Formalisierung von Sachverhalten........................................................................45 5.4.1 Konzeptueller Entwurf ..................................................................................47 5.4.2 Logischer Entwurf.........................................................................................54
5.4.2.1 Beziehungen..............................................................................................54 5.4.2.2 Objekt-Klassen..........................................................................................55 5.4.2.3 Klassen-Hierarchien ..................................................................................57 5.4.2.4 Methoden von Objekten ............................................................................58 5.4.2.5 Diskriminator-Metatyp ..............................................................................58 5.4.2.6 Beispiel-Sachverhalt..................................................................................59
5.5 Formalisierung juristischer Normen .....................................................................60 5.5.1 Prinzipieller Aufbau von Gesetz-modellierenden Regeln...............................61 5.5.2 Allgemeines über die Formalisierung von Gesetzen ......................................62 5.5.3 Formalisierung einzelner Gesetze..................................................................63
5.5.3.1 Körperverletzung (§223) ...........................................................................63 5.5.3.1.1 Körperliche Misshandlung (§223 I, 1. Alt.)..........................................64 5.5.3.1.2 Gesundheitsschädigung (§223 I, 2. Alt.) ..............................................66
5.5.3.2 Gefährliche Körperverletzung (§224) ........................................................67 5.5.3.3 Schwere Körperverletzung (§226) .............................................................68 5.5.3.4 Fahrlässige Körperverletzung (§229) .........................................................69
5.5.4 Effizienz .......................................................................................................69 5.5.5 Hierarchie der Körperverletzungsdelikte .......................................................69

v
6 Implementierung des juristischen Systems................................................................71
6.1 Entwicklung des Systems.......................................................................................71
6.2 Planung und erste Systemdefinition.......................................................................72
6.3 Architektur des Systems ........................................................................................74
6.4 Wissensbasis .........................................................................................................75
6.5 Dialogkomponente ................................................................................................75 6.5.1 Benutzerfreundlichkeit ..................................................................................76
6.5.1.1 Abbildung natürlicher Sprache auf Prolog-Klauseln ..................................77 6.5.1.2 Abbildung von Prolog-Klauseln auf natürlichsprachliche Sätze .................78
6.5.2 Die Dialoge des juristischen Systems ............................................................79 6.5.2.1 Sachverhalt bearbeiten...............................................................................80
6.5.2.1.1 Gegenstand-Bearbeitung......................................................................81 6.5.2.1.2 Verhalten-Bearbeitung.........................................................................84 6.5.2.1.3 Person-Bearbeitung .............................................................................85
6.5.2.2 Sachverhalt-DB verwalten.........................................................................86 6.5.2.3 Meinungs-DB verwalten............................................................................86 6.5.2.4 Subsumtion ...............................................................................................86 6.5.2.5 Rückfragen des Systems............................................................................88 6.5.2.6 Schlussbemerkungen zur Dialogkomponente.............................................89
6.6 Event-Handler ......................................................................................................90 6.6.1 ProTcXl ........................................................................................................90 6.6.2 Funktionsweise des Event-Handlers ..............................................................92
6.7 Datenbank-Management-System ...........................................................................96 6.7.1 Datenbankänderungsoperationen: Insert, Delete, Update ...............................96 6.7.2 Verwaltung der Objekt-Schlüssel ..................................................................97 6.7.3 Transaktionen................................................................................................97 6.7.4 Integritätsprüfung..........................................................................................99 6.7.5 Trigger im juristischen System....................................................................101
6.8 Subsumtionskomponente .....................................................................................103 6.8.1 Deduktive Komponente...............................................................................103
6.8.1.1 Top-Down...............................................................................................103 6.8.1.2 Top-Down-Auswertung und Bearbeitung der Ergebnismenge .................104 6.8.1.3 Generate And Test...................................................................................105 6.8.1.4 Constrain And Generate ..........................................................................106
6.8.2 Entscheidungskomponente ..........................................................................108 6.8.3 Subsumtionsstrategie des juristischen Systems ............................................113
7 Zusammenfassung und Ausblick .............................................................................117

1
1 Einleitung
Der Aufbau vieler Gesetze – welche im Folgenden allgemeiner auch als (juristische) Normen bezeichnet werden – und die zahlreich damit zusammenhängenden Begriffshierarchien moti-vieren den Einsatz regelbasierter (deduktiver) Systeme im Recht. So können viele Gesetze in eine wenn-dann-Struktur gebracht werden, wie folgende Beispiele veranschaulichen:
- Wenn jemand eine Straftat begeht, dann wird er bestraft. - Wenn jemand eine Körperverletzung begeht, dann begeht er eine Straftat. - Wenn jemand einen anderen körperlich misshandelt, dann begeht er eine Körper-
verletzung Neben diesen Parallelen zwischen juristischen Gesetzen und ‚Regeln’ besteht darüber hinaus nach Herbert Fiedler und Thomas F. Gordon ([FG87], S. 63 ff.) auch eine gewisse Analogie zwischen juristischer Methodik und wissensbasierten Systemen. Insbesondere sei ein Richter in eingeschränktem Maße mit der Inferenzkomponente eines solchen Systems zu vergleichen. Bei einer solchen Sichtweise verwundert es nicht, dass in der Vergangenheit viele Versuche unternommen wurden, juristische Expertensysteme zu entwickeln, deren hochgestecktes Ziel es war, die Arbeit eines Juristen – zumindest in speziellen Bereichen – von Computern leisten zu lassen. Besonders zahlreich waren diese Versuche Ende der 80er Jahre. Die meisten der so entwickelten Systeme kamen über das Prototypstadium jedoch nicht hinaus, wie eine breit angelegte empirische Auswertung von Thomas Jandach in [Jan93] (S. 20 ff.) ergab. Eine Ur-sache hierfür stellen sicherlich die, in der Vergangenheit häufig zu optimistischen Erwartun-gen an die Künstliche Intelligenz dar; die Ziele der juristischen Systeme waren oft zu hoch gesteckt. So wurde beispielsweise im Rahmen des LEX-Projekts (s. [HL89]) versucht, ein System zu entwickeln, welches bestimmte, in natürlicher Sprache formulierte Fälle beurteilen können sollte. Darüber hinaus scheint es gewisse Aspekte der juristischen Arbeitsweise zu geben, welche sich von Computern nicht, oder nur schwer bewältigen lassen. So ist es zur Klärung von Rechtsfragen häufig erforderlich, Wertungen vorzunehmen oder bestimmte Textstellen zu deuten. Ein System zu entwickeln, welches auch in solchen Situationen die „richtigen“ Ent-scheidungen zu treffen vermag, ist insbesondere auch deshalb sehr problematisch, da im All-gemeinen nicht vollkommen objektiv beurteilt werden kann, ob ein Urteil „richtig“ oder „falsch“ ist. So ist oftmals auch zu erklären, warum in einem Rechtsstreit zunächst die eine Partei, in späterer Instanz aber die andere Partei gewinnt. Man könnte nun zu der Überzeu-gung gelangen, solch unterschiedliche Bewertungen ein und des selben Falles seien grund-sätzlich unerwünscht, die Gesetze müssten von der Legislative klarer formuliert werden und es müssten eindeutige Wertmaßstäbe festgelegt werden, an welchen sich jeder Richter orien-tieren kann. Jedoch kann kein Gesetzgeber alle denkbaren Fallkonstellationen bedenken und somit unter Berücksichtigung seiner rechtspolitischen Zielsetzungen und Wertentscheidungen von vornherein regeln (vgl. [Sir89], S. 43). Darüber hinaus können sich Werte wandeln und rechtspolitische Zielsetzungen verändern. Um das Recht an solche dynamische Prozesse an-passen zu können, ist es wohl geradezu erwünscht, in einem engen Rahmen über gewisse Spielräume im Gesetz zu verfügen, um produktive, rechtsfortbildende Diskussionen über de-ren Ausfüllung zu ermöglichen.

2
Basierend auf dieser Erkenntnis, wurde im Rahmen dieser Arbeit versucht, ein regelbasiertes juristisches System zu entwickeln, welches zwar in der Lage sein sollte, bestimmte Sachver-halte juristisch zu beurteilen, welches dabei aber in Auslegungs- oder Wertungsfragen den Systemanwender in den Inferenzprozess involviert. Ziel der Arbeit war es, auf diese Weise ein juristisches Gutachten zu erstellen. Das System sollte in der Lage sein, die hierzu erforder-liche Subsumtion – also die Unterordnung eines konkreten Falles unter eine abstrakte Rechts-norm – möglichst weitgehend nachzuahmen. Hierbei wurden verschiedene, aber nicht alle Gesichtspunkte der Subsumtion berücksichtigt. Bei dem implementierten System handelt es sich im Grunde um eine Deduktive Datenbank, welche auch über ein einfaches Trigger-Konzept verfügt. Das System kann Lebenssachverhal-te im Hinblick darauf untersuchen, ob der objektive Tatbestand eines Körperverletzungsde-likts verwirklicht wurde. Dazu mussten die Lebenssachverhalte zunächst in eine Form ge-bracht werden, welche vom System behandelt werden kann. Hierzu gibt der Benutzer in vor-gegebene grafische Eingabemasken den Fall in einer standardisierten Form ein, woraus das System anschließend eine interne Repräsentation des Sachverhaltes erzeugt. Mit Hilfe von Regeln kann anschließend die Inferenzkomponente des Systems versuchen, das Vorliegen einzelner Tatbestände aus der internen Fallrepräsentation zu beweisen. Die hierbei verwende-ten Regeln stellen die Modelle der Gesetze dar, welche vom juristischen System „beherrscht“ werden. Die Art und Weise, auf welche diese Regeln von der Inferenzkomponente verwendet werden, orientiert sich an den Eigenarten der juristischen Subsumtion wie beispielsweise der Reihenfolge, in welcher einzelne Tatbestände bei einem juristischen Gutachten zu überprüfen sind. Ein herausragendes Merkmal des Systems ist, dass bei juristischen Meinungsstreitigkei-ten – etwa bei der Frage, ob eine bestimmte Tätigkeit eine Misshandlung darstellt – der Be-nutzer konsultiert wird: Existieren zu einem juristischen Problem verschiedene Ansichten, so werden diese durch das System verwaltet und an gegebener Stelle dem Systembenutzer zur Entscheidung vorgelegt. Dies macht zwar erforderlich, dass der Anwender über gewisse juristische Kenntnisse verfügt, doch erhöht es gleichzeitig die Leistungsfähigkeit des Systems enorm, da bei juristischen Meinungsstreitigkeiten viele andere Systeme an ihre Grenzen stossen ... Die vorliegende Arbeit hat folgenden Aufbau. Im Anschluss an diese Einleitung wird der Le-ser in Kapitel 2 mit den für das Verständnis dieser Arbeit benötigten Grundlagen aus den Be-reichen Informatik beziehungsweise Rechtswissenschaft vertraut gemacht. Auf der Seite der Informatik werden hauptsächlich die im juristischen System zur Anwendung gekommenen Konzepte erläutert, die rechtswissenschaftlichen Grundlagen beziehen sich im Wesentlichen auf die juristische Methodenlehre. Um bestimmte Entwurfsentscheidungen für das juristische System besser begründen zu können und um einen kleinen Überblick über bisherige Ansätze zu vermitteln, werden in Kapitel 3 ausgewählte andere juristische Systeme vorgestellt. In Ka-pitel 4 wird in einem kurzen Exkurs die bereits angesprochene Analogie zwischen juristischer Methodik und wissensbasierten Systemen dargestellt, um eine Verbindung zwischen den Be-reichen Rechtswissenschaft und Informatik herzustellen. Die beiden folgenden Kapitel be-schreiben dann ausführlich das entwickelte juristische System. Kapitel 5 beschäftigt sich mit der formalen Darstellung von Sachverhalten und Normen, welche die Basis für die in Kapitel 6 vorgestellte Implementation des Systems bildet. Die Arbeit schließt in Kapitel 7, wo ein Fazit gezogen wird und Vorschläge zur Weiterentwicklung des Systems gemacht werden.

3
2 Grundlagen
In diesem Kapitel werden die zum Verständnis der Arbeit erforderlichen allgemeinen Grund-lagen aus Informatik und Rechtswissenschaft dargestellt. Im weiteren Verlauf der Arbeit wer-den darüber hinaus an verschiedenen Stellen gewisse speziellere Grundlagen erörtert.
2.1 Grundlagen aus der Informatik
Das im Rahmen dieser Arbeit entwickelte juristische System weist einige Parallelen zu Exper-tensystem-Ansätzen aus den 80er Jahren auf. Daher soll zunächst die Struktur solcher Exper-tensysteme dargestellt werden. Bei dem im Rahmen dieser Arbeit entwickelten juristischen System handelt es sich im Prinzip um ein Datenbanksystem, weshalb in den folgenden Ab-schnitten Grundlagen aus dem Gebiet der Datenbanken vermittelt werden. Hierbei handelt es sich um kurze Einführungen zu klassischen, deduktiven und aktiven Datenbanken. Außerdem werden die zum Datenbankentwurf erforderlichen Grundkenntnisse über das Relationenmo-dell und objektorientierte Datenmodelle vermittelt. Anschließend wird die UML – eine Spra-che zur Software-Modellierung – vorgestellt. Diese Sprache wird an einigen Stellen der Ar-beit verwendet, um einzelne Aspekte des entwickelten Systems mit ihr zu beschreiben. Als nächstes werden Grundlagen der logischen Programmierung vermittelt. Insbesondere wird hierbei auf die Sprache Prolog eingegangen, da große Teile des juristischen Systems mit ihr implementiert wurden. Die zweite verwendete Sprache zur Realisierung des juristischen Sys-tems ist Tcl/Tk. Daher erfolgt zum Abschluss des Abschnittes zur Beschreibung der Grundla-gen aus der Informatik eine kurze Einführung in diese Programmiersprache.
2.1.1 Expertensysteme
In der Vergangenheit – insbesondere in den 80er Jahren – wurde häufig versucht, sogenannte juristische Expertensysteme zu entwickeln. Diese Expertensysteme sind den später beschrie-benen deduktiven Datenbanksystemen teilweise ähnlich. Im folgenden soll daher zunächst der Begriff des Expertensystems klargestellt werden, um später in der Lage zu sein, Parallelen zu deduktiven Datenbanksystemen sichtbar zu machen und so das juristische System besser ein-ordnen und mit den später beschriebenen bisherigen Entwicklungen (Kapitel 3) vergleichen zu können. Eine exakte, einheitliche Definition existiert für Expertensysteme nicht. Stattdessen gibt es verschiedene Ansätze, welche in [Jan93] (S. 6 ff.) ausführlich dargestellt, klassifiziert und bewertet werden. Zu diesen verschiedenen Definitionen soll hier keine Stellung bezogen wer-den. An dieser Stelle soll den weit verbreiteten Sichtweisen gefolgt werden, welche es von der Struktur abhängig machen, ob es sich bei einem System um ein Expertensystem handelt. Hiernach besteht ein Expertensystem aus folgenden Bestandteilen: - Wissensbasis - Inferenz- oder Ableitungsmaschine - Erklärungskomponente - (Wissenserwerbskomponente) - Dialogkomponente

4
Die in Klammern stehenden Bestandteile sind nicht in allen Definitionen enthalten. Die ge-naue architektonische Anordnung dieser Komponenten kann sich von Definition zu Definition geringfügig unterscheiden.
Wissensbasis
Wissenserwerbs- komponente
Dialogkomponente
Erklärungs- komponente
Inferenz- maschine
Abbildung: Ein Architekturmodell eines Expertensystems Das in der Wissensbasis abgelegte Wissen kann in der Regel in fallspezifisches, anwendungs-spezifisches und allgemeines Wissen unterteilt werden. Die Inferenzmaschine wird benötigt, um dem System Schlussfolgerungen zu ermöglichen, welche benötigt werden, um Anfragen von der Dialogkomponente zu verarbeiten oder mit Hilfe der Erklärungskomponente Begrün-dungen zu erzeugen. Die Wissenserwerbskomponente hat die Aufgabe, die Wissensbasis auf-zubauen und neues Wissen einzufügen.
2.1.2 Datenbanksysteme
Da keine anerkannte, einheitliche Definition für Datenbanksysteme existiert, soll in diesem Abschnitt zunächst das „klassische“ Datenbanksystem-Grundmodell dargestellt werden, wel-ches bei den weiteren Betrachtungen zu Grunde gelegt wird. Ein Datenbanksystem (kurz: DBS) setzt sich demnach aus einem Datenbank-Management-System (DBMS) und mindestens einer Datenbank (DB) zusammen. Eine Datenbank besteht aus einer Menge anwendungsspezifischer Fakten. Das DBMS hat die Aufgabe, diese Fakten anwendungsunabhängig zu verwalten und die Kommunikation zwischen Anwendern und/oder Datenbankanwendungen und den Datenbanken zu organisieren. Aufgaben eines DBMS sind beispielsweise Schutz vor Datenverlust, Verwaltung von Transaktionen, Anfrageoptimierung und Autorisierungskontrolle. Auf welche Art die Fakten der DB abgespeichert sind und wel-che Operationen zur Verfügung stehen, um darauf zuzugreifen, hängt von dem zu Grunde liegenden Datenmodell ab (z.B. relationales Datenmodell). Dieses Datenmodell besteht in der

5
Regel1 aus einer Datendefinitionssprache (DDL2), welche die in den DBen verwendeten Da-tentypen beschreibt, und einer Datenmanipulationssprache (DML3), mit welcher Operationen zum Zugriff auf die Daten wie speichern, lesen, löschen und verändern formuliert werden.
DB DB DB DB
Datenbank-Management-System (DBMS)
Anwender
Abbildung: „klassisches“ DBS-Grundmodell Soweit die kurze Einführung in das „klassische“ DBS-Grundmodell. Für ausführliche Be-schreibungen seien die Darstellungen [KE99] und [Vos94] empfohlen. An dieser Stelle folgt nun noch ein kurzer Abschnitt über Transaktionsverwaltung, da dieser im juristischen System größere Relevanz zukommt: Einschub: Transaktionsverwaltung Eine Transaktion besteht aus zu einer Einheit zusammengefassten Datenbankoperationen und muss über die vier Eigenschaften des ACID-Paradigmas „atomicity“ (Atomarität), „con-sistency“ (Konsistenz), „isolation“ (Isolation) und „durability“ (Dauerhaftigkeit) verfügen. - Die „atomicity“-Eigenschaft fordert, dass entweder alle der zu einer Transaktion gehöri-
gen Datenbankoperationen ausgeführt werden sollen oder aber keine einzige. Eine Trans-aktion wird somit als atomare Einheit betrachtet, die nicht zerlegt werden kann.
- Die „consistency“-Eigenschaft stellt sicher, dass die Datenbank nach einer Transaktion
wieder in einen konsistenten Zustand gelangt. Gelingt dies nicht, wird die „atomare“ Transaktion komplett zurückgenommen. Konsistent ist ein Zustand, in welchem alle an den Datenbestand gestellten Integritätsbedingungen eingehalten werden.
1 anders beim objektorientierten Datenmodell: Struktur der Daten und Operationen werden zusammen definiert 2 Data Definition Language 3 Data Manipulation Language

6
- Die „isolation“-Eigenschaft verlangt, dass parallele Transaktionen voneinander unbeein-flusst ablaufen müssen.
- Die „durability“-Eigenschaft schließlich fordert, dass die innerhalb einer Transaktion vor-
genommen Datenbankänderung nach Beendigung der Transaktion dauerhaft erhalten blei-ben. Solche dauerhaften Änderungen können nur noch durch kompensierende Datenbank-operationen rückgängig gemacht werden.
Mit Hilfe der Transaktionen sollen im wesentlichen zwei Ziele verfolgt werden. Das eine Ziel ist die Synchronisation. Im Mehrbenutzerbetrieb soll mit Hilfe des Konzepts der Transaktion dafür gesorgt werden, dass durch die gleichzeitige Arbeit mehrerer Anwender keine Inkon-sistenzen in der Datenbank entstehen. Da es sich beim juristischen System um ein System handelt, welches nicht für den Mehrbenutzerbetrieb ausgelegt ist, spielt dieser Aspekt keine Rolle und erlangt in der vorliegenden Arbeit auch keine weitere Berücksichtigung. Das ande-re Ziel mit Hilfe der Transaktionen verfolgte Ziel heißt Recovery. Nach Fehlern wie zum Bei-spiel dem Absturz des Systems, soll die Datenbank wieder in ihren letzten konsistenten Zu-stand versetzt werden. Andere Arten von „Fehlern“ können beispielsweise unsinnige Benut-zereingaben oder vom Anwender gewünschte Transaktionsabbrüche darstellen. Um diese Ziele mit Hilfe der Transaktionen erreichen zu können, stehen auf der Transaktions-Ebene folgende Operationen zur Verfügung4: - Durch die Operation begin of transaction (kurz: BOT) wird der Anfang einer Transaktion
markiert. - Durch die commit-Operation wird die Beendigung der Transaktion eingeleitet. Alle wäh-
rend der Transaktion vorgenommenen Datenbankänderungen werden dauerhaft in die Da-tenbank aufgenommen.
- Mit der Operation abort wird eine Transaktion abgebrochen. Das DBS kehrt in den Zu-
stand zurück, der vor Transaktionsbeginn bestand. - Mit define savepoint wird ein Sicherungspunkt definiert. - Zu dem Zustand, der vor diesem Sicherungspunkt bestand, kann mit der Operation backup
transaction zurückgekehrt werden. Eine ausführliche Darstellung zur Transaktionsverwaltung befindet sich beispielsweise in [VG93]. Die beiden nun folgenden Beschreibungen zu deduktiven und aktiven Datenbanksystemen erweitern das „klassische“ DBS-Grundmodell. Beide Ansätze sind orthogonal zueinander, was bedeutet, dass sie einander nicht ausschließen. Stattdessen kann ein DBS durchaus de-duktive und aktive Konzepte enthalten.
4 Nur die ersten drei Operationen sind tatsächlich erforderlich.

7
2.1.3 Deduktive Datenbanksysteme
In diesem Abschnitt soll – mangels einheitlicher Definition – zunächst klargestellt werden, was in dieser Arbeit unter einem Deduktiven Datenbanksystem (DDBS) verstanden werden soll. Darüber hinaus sollen einige, für diese Arbeit relevante Aspekte eines DDBS dargestellt werden. Begonnen werden soll dieser Abschnitt jedoch zunächst mit einem motivierenden Beispiel.
2.1.3.1 Motivierendes Beispiel
Angenommen, folgender Sachverhalt liegt vor: „Beim Berlin-Marathon befinden sich alle 5 km und im Ziel sogenannte Versorgungszentren, an welchen die Läufer verpflegt werden.“ Mit Hilfe von Fakten kann dieser Sachverhalt folgendermaßen beschrieben werden:
Beim Berlin-Marathon befindet sich an km 5 ein Versorgungspunkt. Beim Berlin-Marathon befindet sich an km 10 ein Versorgungspunkt. Beim Berlin-Marathon befindet sich an km 15 ein Versorgungspunkt. Beim Berlin-Marathon befindet sich an km 20 ein Versorgungspunkt. Beim Berlin-Marathon befindet sich an km 25 ein Versorgungspunkt. Beim Berlin-Marathon befindet sich an km 30 ein Versorgungspunkt. Beim Berlin-Marathon befindet sich an km 35 ein Versorgungspunkt. Beim Berlin-Marathon befindet sich an km 40 ein Versorgungspunkt. Beim Berlin-Marathon befindet sich an km 42,195 ein Versorgungspunkt.
Man erkennt leicht, dass in dieser Darstellung eine Regelmäßigkeit steckt, welche sich als Regel formulieren lässt. Hierdurch lassen sich beispielsweise folgendermaßen Fakten einspa-ren:
1. Beim Berlin-Marathon befindet sich an km 5 ein Versorgungspunkt. 2. Wenn sich an einer bestimmten Stelle ein Versorgungspunkt befindet,
dann befindet sich (bis ins Ziel) 5 km hinter dieser Stelle ein wei-terer Versorgungspunkt.
3. Beim Berlin-Marathon befindet sich an km 42,195 ein Versorgungspunkt.
Herkömmliche Datenbanksysteme können Regeln (wie 2.) nicht verarbeiten, was die Erweite-rung des klassischen Modells motiviert.
2.1.3.2 Begriffsbestimmung: Deduktives Datenbanksystem
Als DDBS soll in dieser Arbeit ein DBS bezeichnet werden, welches über eine Komponente verfügt, die es dem System erlaubt, mit Hilfe von Regeln neues Wissen herzuleiten5. Diese Komponente wird als Deduktive Komponente (oder Inferenzkomponente) bezeichnet.
5 Dieses Erschließen neuen Wissens wird als Inferenz bezeichnet. Nach C. S. Peirce (s. [Har31]) lassen sich die Inferenzarten Deduktion („Schließen von einem allgemeinen auf einen speziellen Fall“), Induktion („Erschlie-ßung regelhaften Wissens durch Beobachtung“) und Abduktion („Hypothesen über den Sachverhalt werden aus Beobachtung und regelhaftem Wissen gewonnen“) unterscheiden. Da sich Induktion und Abduktion auch als Deduktionsproblem betrachten lassen [BHS93] und diese beiden Inferenzarten die unerwünschten Eigenschaften aufweisen, dass mit ihrer Hilfe hergeleitetes Wissen nicht notwendigerweise wahr ist, kommt im Zusammenhang mit Automatischem Beweisen der Deduktion die größte Bedeutung zu. In dieser Arbeit werden daher die Begrif-fe Deduktion und Inferenz synonym verwendet.

8
Zugegebenermaßen ist dieser Ansatz zur Beschreibung eines DDBS etwas vage. Beispiels-weise wird nicht geklärt, wie die Architektur eines DDBS genau auszusehen hat. Dadurch wird diese Umschreibung aber der Verschiedenartigkeit der Architekturansätze6 gerecht. Es wird nicht vorgeschrieben, wie die Komponente an das herkömmliche DBMS gekoppelt ist („lose Kopplung“ oder „enge Kopplung“). Auch wird nicht ausgeschlossen, dass die Kompo-nente sogar Teil des DBMS ist („integrierter Ansatz“).
2.1.3.3 Zentrales Element: Regel
Zentrales Element deduktiver Datenbanksysteme ist die Regel. Diese wird zwecks Abgren-zung zur weiter unten erläuterten aktiven Regel auch als passive Regel bezeichnet. (Passive) Regeln können auf verschiedene Arten beschrieben werden. Hierzu muss die DDL des deduk-tiven Datenbanksystems die Möglichkeit haben, Regeln zu formulieren. Dies ist in Sprachen „konventioneller“ Systeme nicht möglich. In der Anfragesprache SQL (s. Kapitel 2.1.5.2) können zwar mittels Sichten gewisse, eingeschränkte Regeln formuliert werden, rekursive Anfragen sind damit aber nicht realisierbar7. So gesehen, lassen sich die Regeln eines Deduk-tiven Datenbanksystems auch als Erweiterung der SQL-Sichten auffassen. Unabhängig von der genauen Syntax einer Regel, hat ihre Darstellung stets eine „wenn-dann-Struktur“.
wenn <Bedingung> dann <herleitbares Fakt>
Aufgrund der Zielsetzung deduktiver Datenbanksysteme, Schlussfolgerungen ziehen zu kön-nen, bildet Logik die theoretische Grundlage. Daher besteht ein enger Zusammenhang zwi-schen logischer Programmierung (s. Kapitel 2.1.8) und deduktiven Datenbanksystemen. Diese Verbindung von DDBSen und logischer Programmierung ist zwar nicht zwingend, allerdings eignen sich logische Programmiersprachen wie Prolog besonders gut, Regeln zu formulieren. Eine spezielle Anfragesprache für deduktive Datenbanksysteme stellt Datalog dar. Hierbei handelt es sich zwar nicht um eine Programmiersprache im engeren Sinne, um diese Sprache aber mit Prolog besser vergleichen zu können, wird sie ebenfalls erst in Kapitel 2.1.8 be-schrieben.
2.1.3.4 Einschub: Integritätsbedingungen
Dieser Einschub befasst sich mit semantischer Integrität von Datenbanken. Obwohl dieses Thema auch für herkömmliche Datenbanksysteme von großer Bedeutung ist, soll es aufgrund der Parallelen statischer Integritätsbedingungen zu deduktiven Regeln im Anschluss an die diesbezügliche Beschreibung erläutert werden. Man beachte zunächst, dass beispielsweise die Vereinbarungen von Datentypen bereits als Integritätsbedingungen aufgefasst werden können. Im folgenden soll – wenn nicht anders angegeben – der Begriff der Integritätsbedingung al-lerdings enger verstanden werden: als eine besondere, im folgenden beschriebene Art von Regel. Darüber hinaus spielen die dynamischen Integritätsbedingungen, also Integritätsbedin-gungen welche sich auf Abläufe in Datenbanken beziehen, keine Rolle. Betrachtet werden sollen hingegen statische – sich auf den Datenbankzustand beziehende – Integritätsbedingun-gen. 6 Ein kurzer Überblick über die verschiedenen Architekturansätze erfolgt in [FU1665], Kapitel 10, S. 42 7 Die SQL-3-Spezifikation sieht rekursive Anfragen vor. In DBSen mit rekursiven Sichten könnte insofern also auch keine Rede mehr von „konventionellen“ DBSen sein. Zur Weiterentwicklung des SQL-Standards s. [Mel96]

9
Im Versorgungspunkte-Beispiel könnte man sich beispielsweise folgende Bedingung denken:
Versorgungspunkte dürfen nie näher als 2 km nebeneinander liegen.
Man erkennt schon an diesem Beispiel den normativen Charakter von Integritätsbedingungen. Im Gegensatz zu deduktiven Regeln, welche zur Herleitung von neuen Fakten dienen, spre-chen Integritätsbedingungen Verbote aus und grenzen somit die Menge zulässiger Daten-bankzustände ein. Die Parallele zu deduktiven Regeln offenbart sich erst nach Umformung der Bedingung:
Wenn ein Versorgungspunkt von einem anderen Versorgungspunkt weniger als 2 km entfernt liegt, dann ist der Datenbankzustand inkonsistent.
2.1.3.5 Änderungsgetriebene und anfragegetriebene Inferenz
Man unterscheidet änderungsgetriebene und anfragegetriebene Inferenz. Inferenz wird als änderungsgetrieben bezeichnet, wenn die Inferenz als Folge von Datenbankänderungen ange-stoßen wird, um neues Wissen herzuleiten. Werden die Infernzmechanismen hingegen erst als Reaktion auf Anfragen aktiv, um zu ermitteln, ob ein gewisses Fakt in der Datenbank enthal-ten ist, spricht man von anfragegetriebener Inferenz. Die Begriffe der änderungsgetriebenen und anfragegetriebenen Inferenz sind eng verknüpft mit den Begriffen materialisierte und virtuelle Daten. Daten werden als materialisiert bezeichnet, wenn sie (wie bei der änderungs-getriebenen Inferenz üblich) physisch in der Datenbank vorhanden sind (beispielsweise als Relation). Werden die Daten nicht physisch erzeugt, sondern muss stattdessen bei Anfragen über Inferenz des Systems geprüft werden, ob ein bestimmtes Fakt gegeben ist oder nicht, spricht man von virtuellen Daten.
2.1.3.6 Vorteile Deduktiver Datenbanksysteme
Virtuelle Datenhaltung hat gegenüber der materialisierten den Vorteil der teilweise enormen Speicherplatzersparnis, dafür ist der Zugriff (wegen des Umwegs über die Deduktive Kompo-nente) auf diese Daten häufig langsamer. Aus diesem Grund ist es mitunter sinnvoll, auf Mischformen der Datenhaltung zurückzugreifen. So können beispielsweise die Daten größ-tenteils virtuell gehalten werden, wobei häufig benötigte oder zeitintensiv herzuleitende Daten materialisiert werden. Im Gegensatz zu herkömmlichen Datenbanksystemen kann in einem DDBS auf diese Weise, ein möglichst ideales Verhältnis zwischen Speicherplatz und Daten-Zugriffszeit erreicht werden. Über diesen – aus der Möglichkeit zur virtuellen Datenhaltung resultierenden – Vorteil hinaus haben Deduktive Systeme weitere Vorteile. Ein Vorteil ist beispielsweise, dass die Datenbankinhalte aufgrund ihrer modulareren Struktur besser lesbar sind. Darüber hinaus lassen sich Änderungen der Datenbankinhalte teilweise erheblich einfa-cher vornehmen. Angenommen, die Leitung des Berlin-Marathons gelangt zu der Ansicht, es genüge, alle 7 km einen Versorgungspunkt zur Verfügung zu stellen, so müssten im Beispiel in der ersten Darstellungsart sämtliche Fakten geändert werden. Die Änderung in der Darstel-lung mit Hilfe von Regeln kann hier viel einfacher vorgenommen werden. Dies soll als Einführung genügen. Zur ausführlichen Beschreibung deduktiver Datenbanksys-teme sei auf [CGT90], [Man99] oder [BS96] verwiesen.

10
2.1.4 Aktive Datenbanksysteme
2.1.4.1 Motivation
Manchmal erscheint es wünschenswert, dass ein DBS auf bestimmte Ereignisse oder Konstel-lationen in den Datenbanken selbständig reagiert. In einem beschränkten Maß ist dies zwar auch den oben beschriebenen Deduktiven Datenbanksystemen möglich. So kann das DBMS bei Verletzung einer Integritätsbedingung einen Rollback auslösen und somit auf bestimmte – inkonsistente – Situationen reagieren. Dies reicht jedoch nicht mehr aus, wenn erforderlich wird, dass speziellere Reaktionen ausgelöst werden oder dass auch auf Ereignisse reagiert wird, die keinen inkonsistenen DB-Zustand nach sich ziehen. So könnte der Inhaber eines Supermarktes beispielsweise den Wunsch haben, dass sein DBS automatisch erkennt, wenn gewisse Produkte besonders häufig oder besonders selten verkauft werden und daraufhin au-tomatisch prüft, ob eine Preisanpassung erfolgen sollte.
2.1.4.2 Begriffsklärung: Aktives Datenbanksystem (ADBS)
Für solche Situationen eignen sich aktive Datenbanksysteme. Da sich auch in Bezug auf akti-ve Datenbanksysteme noch keine einheitliche Sichtweise etabliert hat, soll an dieser Stelle zunächst einmal geklärt werden, was in dieser Arbeit unter einem aktivem DBS verstanden wird. Hierbei wird der Begriffsdefinition von [DG96] gefolgt: „Ein Datenbanksystem heißt aktiv, wenn es zusätzlich zu den üblichen DBS-Fähigkeiten in der Lage ist, definierbare Situationen in der Datenbank (und wenn möglich darüber hinaus) zu erkennen und als Folge davon bestimmte (ebenfalls definierbare) Reaktionen auszulösen.“ ([DG96], S.7)
2.1.4.3 Zentrales Element: Aktive Regel
Um Situationen erkennen und passende Reaktionen auslösen zu können, muss zunächst spezi-fiziert worden sein, welche Situationen welche Reaktionen des Systems nach sich ziehen sol-len. Aktive Datenbanken stellen hierzu ECA-Regeln (ECA steht für Event, Condition, Action) oder ähnliche Konzepte zur Verfügung. Diese Regeln, welche auch als Trigger oder aktive Regeln bezeichnet werden, haben folgenden prinzipiellen Aufbau:
ON Event, IF Condition � DO Action
Eine solche ECA-Regel soll bewirken, dass immer, wenn ein Ereignis "Event" stattfindet und die Bedingung "Condition" erfüllt ist, die Aktion "Action" ausgeführt wird. Die genaue Syn-tax der aktiven Regel eines Aktiven Datenbanksystems wird durch die DDL festgelegt. Auch aktive Regeln können mit logischen Programmiersprachen beschrieben werden. Hinsichtlich der Semantik aktiver Regeln gibt es verschiedene betrachtenswerte Aspekte: So ist beispielsweise die Frage zu berücksichtigen, wann eine Regel relativ zum Zeitpunkt des Eintretens eines Ereignisses vom System auszuführen ist oder wie die Ereignisse und Bedin-gungen (EC-Kopplung) beziehungsweise die Bedingungen und die Aktionen (CA-Kopplung) miteinander gekoppelt sind. Hierbei gibt es einerseits die Möglichkeit der direkten Kopplung, was beispielsweise bei einer EC-Kopplung bedeutet, dass direkt nach Auswertung des Ereig-nis-Teils die Bedingung überprüft wird (Kopplungsmodus „immediate“). Bei dem zweiten möglichen Kopplungsmodus, der verzögerten Kopplung („deferred“), wird zunächst das je-

11
weilige Transaktionsende abgewartet. Eine verzögerte CA-Kopplung bedeutet beispielsweise, dass die nach Auswertung des Bedingungs-Teils eventuell fällige Aktion erst kurz vor dem „commit“ der aktuellen Transaktion ausgeführt wird. Ein letzter Kopplungsmodus heißt Ent-kopplung, was bedeutet, dass der entkoppelte Regelteil in einer unabhängigen, separaten Transaktion ausgeführt wird („decoupled“). Da im juristischen System zwar aktive Regeln verwendet werden, diese aber eine sehr einfa-che Semantik haben und nur in einem sehr eingeschränkten Rahmen verwendet werden, endet die Einführung zu Aktiven Datenbanken hier. In [DG96] ist mehr über die Konzepte Aktiver Datenbanken zu erfahren.
2.1.5 Relationale Datenbanksysteme
2.1.5.1 Relationales Datenmodell
Relationale Datenbanksysteme basieren auf dem 1970 von [Cod70] eingeführten Relationen-modell. Aufgrund der Einfachheit dieses Modells ist es in der Praxis zum bedeutendsten Da-tenmodell geworden. Im Relationenmodell wird die modellierte Anwendungswelt mit Hilfe von flachen Relationen beschrieben. Eine Relation kann als Teilmenge des kartesischen Produkts von Wertebereichen aufgefasst werden.8 In flachen Relationen enthalten die Wertebereiche oder Domänen jeweils nur atoma-re Werte, also weder Relationen nach anders strukturierte Werte („Forderung der ersten Nor-malform“). Ein Beispiel für eine flache Relation ist
Fußballspieler ⊆ string × string × {Tor, Abw, Mit, Ang} × integer Man unterscheidet zwar zwischen dem Schema einer Relation, welches sich aus den einzelnen Wertebereichen zusammensetzt, und der Instanz einer Relation, womit die konkrete Teilmen-ge bezeichnet wird. Der Einfachheit halber soll hier jedoch, wo sich die Bedeutung aus dem Zusammenhang ergibt, beides als Relation bezeichnet werden. Relationen lassen sich sehr gut als Tabellen veranschaulichen:
Fußballspieler Name Team Position Rückennummer Volker Vollspann FC Beispiel Ang 9 Didi Dribbling VfB Musterstadt Mit 10 Siggi Sicher FC Beispiel Tor 1
Die einzelnen Spalten stellen die Attribute dar. Die Attributwerte sind jeweils Elemente des dazugehörigen Wertebereichs. Ausführliche Darstellungen des relationalen Datenmodells finden sich in [KE99] (S.59 ff.) und [Heu92] (S. 57 ff.).
8 obwohl diese Sichtweise aufgrund der Reihenfolgeabhängigkeit der einzelnen Wertetypen Probleme mit sich bringen kann, soll sie aufgrund ihrer Griffigkeit in dieser Arbeit verwendet werden

12
2.1.5.2 SQL9
Für relationale Datenbanksysteme existiert die Datenbanksprache SQL, welche gleichzeitig DDL und DML ist. Sie ist die eindeutig am weitesten verbreitete relationale Datenbankspra-che und soll daher im folgenden kurz vorgestellt werden. Eine von vielen ausführlichen Ein-führungen zu SQL ist [KR97]. Abfragen (engl.: queries) werden in SQL mit Hilfe der SELECT-Anweisung durchgeführt. Mit dieser Anweisung kann auf verschiedenste Weisen auf Inhalte von Tabellen zugegriffen werden. Hier ein Beispiel: SELECT name, rueckennummer FROM fussballspieler WHERE team = ’FC Beispiel’ ORDER BY rueckennummer
Die obige Abfrage hat zur Folge, dass aus (FROM) der Tabelle „fussballspieler“ die Spalten „name“ und „rueckennummer“ herausgesucht werden (SELECT). Hierbei sollen allerdings nur die Zeilen betrachtet werden, wo (WHERE) team = ’FC Beispiel’ ist. Die neue Tabelle soll nach „rueckennummer“ sortiert werden (ORDER). Das Ergebnis obiger Anfrage wäre somit – die Relation „fussballspieler“ aus Kapitel 2.1.5.1 zu Grunde gelegt – folgende Tabelle:
Name Rückennummer Siggi Sicher 1 Volker Vollspann 9
Mit Hilfe der DML-Anweisungen INSERT, UPDATE und DELETE lassen sich die Tupel (Zeilen) in den Relationen (Tabellen) einfügen, verändern oder löschen. Ein weiteres wichtiges SQL-Konzept sind die Sichten, welche über CREATE VIEW definiert werden. Im folgenden Beispiel wird eine Sicht „sportler“ erzeugt, welche die Namen von Fußballspielern, Turnern etc. (mittels UNION) zusammenfasst. CREATE VIEW sportler AS ( SELECT name FROM fussballspieler) UNION ( SELECT name FROM turner) UNION ...
Im Gegensatz zu den Basisrelationen in SQL sind die in Sichten enthaltenen Daten nicht ma-terialisiert. Sie stellen lediglich abgeleitete Relationen dar. Viele SQL-basierte relationale Datenbanksysteme bieten die Möglichkeit an, SQL in Pro-grammiersprachen wie beispielsweise Fortran oder C einzubinden. Dies geschieht meist so, dass SQL-Ausdrücke direkt in Programme eingefügt werden können („embedded SQL“).
9 SQL steht für Structured Query Language.

13
Als DDL/DML für relationale Datenbanksysteme eignen sich außer SQL auch die logischen Programmiersprachen. Da diese ausführlicher beschrieben werden sollen, wurde darauf ver-zichtet, sie bereits an dieser Stelle zusammen mit SQL vorzustellen.
2.1.6 Objektorientiertes Datenmodell
Innerhalb des Datenbankentwurfs10 unterscheidet man unter anderem die Phasen des konzep-tuellen und logischen Entwurfs. In relationalen Datenbanken basiert der logische Entwurf auf dem in Kapitel 2.1.5.1 beschriebenen Relationenmodell. Ein auf dem Relationenmodell basie-render Entwurf ist häufig schwierig, da dieses Modell sich an Eigenschaften von Maschinen orientiert und daher als unnatürlich empfunden wird (vgl. [Oes98], S. 25 ff.; [KE99], S. 55). Aus diesem Grunde sollte zunächst ein konzeptueller Entwurf vorgenommen werden, welcher im Anschluss in den logischen Entwurf überführt werden kann. Für einen konzeptuellen Ent-wurf eignen sich die deutlich stärker an die menschliche Denkweise angelehnten objektorien-tierten Datenmodellen besonders gut. Da in dieser Arbeit der konzeptuelle Entwurf der Sach-verhalt-Datenbank auf einem objektorientierten Datenmodell basiert, sollen die für diese Ar-beit wichtigen objektorientierten Konzepte nun vorgestellt werden. Eine detailliertere Darstel-lung findet sich in [Oes98] (S. 35 ff.). Gegenstände11 (wie z.B. Fußballmannschaft) aus der realen Welt können als Objekte aufge-fasst werden. Ein Objekt verfügt über Attribute (wie z.B. Vereinsname, Tabellenplatz) und Operationen, welche mögliche „Verhaltensweisen“ von Objekten beschreiben. Ein im Ver-gleich zum relationalen Datenmodell herauszuhebendes Merkmal von Objektattributen ist, dass ein solches durchaus wiederum ein Objekt als Wert haben kann12. Dies ist in relationalen Datenmodellen unter Einhaltung der Forderung der ersten Normalform nicht auf solch direkte Art darzustellen. In objektorientierten Datenmodellen kann aber so beispielsweise ein Attri-but eines Objektes „Fußballmannschaft“ die Bezeichnung „Elfmeterschütze“ tragen und als Wertemenge die Menge aller möglichen „Fußballspieler“-Objekte haben. Ein einzelnes Ele-ment aus einer solchen Menge wird auch als Objekt-Instanz bezeichnet. Man unterscheidet zwischen diesen Objektinstanzen und Objektklassen: Objektinstanzen modellieren jeweils einen „Gegenstand“ der realen Welt. In einer Objektklasse sind hingegen Objektinstanzen, welche über die gleiche Datenstruktur verfügen, zusammengefasst (Klassifikation); eine Ob-jektklasse ist sozusagen eine Schablone für Objektinstanzen.
class Fussballmannschaft {
string vereinsname; int tabellenplatz; fussballspieler elfmeterschuetze;
public void tabellenplatz_aendern (int neu_tabellenplatz) { tabellenplatz = neu_tabellenplatz;
} }
Abbildung: Eine Objektklasse in Java
10 Eine genaue Beschreibung zum Datenbankentwurfs findet sich in [KE99] (S. 27 ff.) 11 oft macht es darüber hinaus auch Sinn, abstrakte Begriffe (Stundenplan, Straftat) als Objekte aufzufassen 12 In Sprachen wie beispielsweise Smalltalk, wo jedes Attribut wieder ein Objekt ist, muss der Wert eines Attri-buts sogar wieder ein Ob jekt sein

14
Eine wichtige Eigenschaft von Objektinstanzen ist die Objektidentität: jedes Objekt muss ein-deutig von jedem anderen unterscheidbar sein. Um dies zu gewährleisten werden Schlüssel verwendet. Mit Schlüssel wird eine minimale Menge von Attributen eines Objektes bezeich-net, deren Werte die Objektinstanz innerhalb aller Objektinstanzen einer Objektklasse eindeu-tig identifiziert (vgl. [KE99], S.35). Legt man das Fußballspieler-Beispiel aus Kapitel 2.1.5.1 zu Grunde, so bilden die Attribute „Team“ und „Rueckennummer“ einen Schlüssel, vorausge-setzt jeder Spieler hat innerhalb eines Teams eine eindeutige Rückennummer. Klassen können hierarchisch angeordnet werden. Ist eine Klasse einer anderen hierarchisch untergeordnet, „erbt“ sie die Attribute und Operationen der übergeordneten Klasse (Vererbung), kann zusätz-lich aber auch neue Eigenschaften (Attribute, Methoden) aufweisen. So ist beispielsweise eine Klasse „Sportler“ denkbar, welche über Attribute wie „Name“ und „Gewicht“ verfügt. Die untergeordnete Klasse „Fußballspieler“ verfügt dann auch über diese Attribute, könnte zusätz-lich allerdings beispielsweise das Attribut „Rückennummer“ einführen. Dies soll als kurze Einführung genügen. Im nun folgenden Kapitel wird eine Möglichkeit vorgestellt, objektorientierte Datenmodelle zu beschreiben.
2.1.7 UML
Da komplexe Software-Systeme in ihrer Gesamtheit nur schwer zu erfassen sind, ist es zur Beschreibung und damit auch zur Entwicklung solcher Systeme erforderlich, geeignete Dar-stellungsarten für die verschiedenen Aspekte eines Software-Systems zur Verfügung zu haben (vgl. [UML1.3], S. 2). Aus dieser Notwendigkeit heraus wurden in der Vergangenheit ver-schiedenste Modellierungs-Sprachen entwickelt. Nachdem die wohl beliebtesten Beschrei-bungsarten der „Amigos“ Grady Booch ([Boo91]), James Rumbaugh ([Rum91]) und Ivar Jacobsen ([Jac92]) 1997 zusammengeführt wurden, steht nun mit der so entstandenen „Uni-fied Modeling Language“ (UML) ein Quasi-Standard zur Verfügung (vgl. [Oes98], S. 19). Die UML legt Notation und Semantik einer „Sprache“ zur Beschreibung verschiedener Ge-sichtspunkte von Software-Modellen fest. Sie basiert auf dem objektorientierten Datenmodell. Ein Teil der mit dieser Sprache erzeugbaren Diagrammarten soll im folgenden so weit, wie für das Verständnis der in dieser Arbeit vorkommenden Diagramme erforderlich, erläutert werden. Die Darstellung der Diagrammtypen orientiert sich hauptsächlich an [UML1.3] und [Oes98].
2.1.7.1 UML-Klassendiagramme
Klassendiagramme sind dazu da, Objekt-Klassen und die Beziehungen zwischen diesen Klas-sen darzustellen. Mit Hilfe dieses Diagrammtyps lassen sich so objekt-orientierte Datenmo-delle visualisieren. Basiselement des Klassendiagramms ist die Objekt-Klasse, welche in der UML durch ein Rechteck, das durch waagerechte Linien in maximal drei Bereiche eingeteilt ist, dargestellt wird. Im obersten Teil des Rechtecks steht der Name der Klasse. Im zweiten Teil des die Klasse darstellenden Rechtecks finden sich die Klassen-Attribute. Im dritten Teil stehen die Methoden der Klasse. Durch Linien zwischen zwei Klassen werden Beziehungen zwischen den entsprechenden Klassen dargestellt. Neben solch einer Linie kann der Name der Beziehung angegeben sein. Eine besondere Art der Beziehung ist die Spezialisierung. Diese wird durch einen Pfeil darge-stellt, dessen Spitze unausgefüllt ist und auf die sogenannte Oberklasse zeigt. Die dazugehö-rende Unterklasse erbt sämtliche Attribute und Methoden der Oberklasse, kann darüber hin-

15
aus aber zusätzliche eigene Attribute und Methoden enthalten. Gehört ein Objekt einer Unter-klasse an, so gehört es gleichzeitig auch zur entsprechenden Oberklasse. Eine Klasse heißt abstrakte Klasse, wenn in ihr keine Instanzen erzeugt werden können. Alle Elemente einer solchen Klasse müssen auch zu einer ihrer Unterklassen gehören. Zur Kennzeichnung einer abstrakten Klasse schreibt man ihren Namen in kursiver Schrift.
Klassendiagramm: Standardsituationen Man betrachte das Klassendiagramm „Standardsituationen“. Eine Instanz der Klasse Fußball-spieler könnte beispielsweise folgende Attribute besitzen:
name: Volker Vollspann team: FC Beispiel position: Ang rückennummer: 9 verwarnstatus: {}
Darüber hinaus existiert die Klasse „Standardsituation“. Sie ist als abstrakte Klasse model-liert, was zur Folge hat, dass jede Standardsituation Instanz einer der Klassen „Anstoß“, „Eckball“, „Einwurf“, „Elfmeter“ und „Freistoß“ sein muss. Eine Instanz der Klasse „Eck-ball“ hat demnach auch die Eigenschaften der Klasse „Standardsituation“ und könnte bei-spielsweise über folgende Attributwerte verfügen:
ausführendes_Team: Heim seite: rechts
Zwischen diesem Eckball und Volker Vollspann könnte nun die Beziehung „führt_aus“ be-stehen, was natürlich nur Sinn machte, wenn der FC Beispiel die Heimmannschaft wäre. Die meisten Objektklassen im Klassendiagramm „Standardsituationen“ verfügen über keine Me-thoden, manche – wie Einwurf – führen auch keine neuen Attribute ein, sondern erben nur aus der Oberklasse. Einzig die Klasse „Spieler“ verfügt über eine Methode. Über „verwarnsta-tus_ändern(neuer_Verwarnstatus)“ kann der „verwarnstatus“ eines Spielers verändert werden. Soweit die ersten Erläuterungen zu UML-Klassendiagrammen. Auf speziellere Probleme wird an entsprechender Stelle genauer eingegangen.
Freistoß direkt: {ja, nein}
Standardsituation ausführendes_Team: {Heim, Gast}
Fußballspieler name: STRING team: STRING position: {Tor, Abw, Mit, Ang} rückennummer: INTEGER verwarnstatus: {{}, gelb, rot, gelb-rot} verwarnstatus_ändern(neuer_Verwarnstatus)
Eckball seite: {links, rechts}
Elfmeter
Einwurf
Anstoß
führt_aus

16
2.1.7.2 UML-Sequenzdiagramme
Mit Sequenzdiagrammen lässt sich in der UML die Zusammenarbeit einzelner Objekte insbe-sondere unter zeitlichen Gesichtspunkten beschreiben. Da man einzelne Komponenten eines Softwaresystems auch als Objekte auffassen kann, lässt sich auch die Kooperation einzelner Systemteile wie beispielsweise Dialog- und Inferenzkomponente mit Hilfe dieses Diagramm-typs veranschaulichen.
Dialog_Personalien_aufnehmen
Dialog_Eingabe_Geburtsdatum
neu()
datum_erfragen()
geburtsdatum
Sequenzdiagramm: Eingabe-Dialoge Ein Objekt wird im Sequenzdiagramm durch ein Rechteck dargestellt, in welchem der Name des Objektes steht. Unter diesem Objektsymbol beginnt die Lebenslinie des Objektes. Diese ist gestrichelt dargestellt und verläuft entlang einer imaginären Zeitachse von oben nach un-ten. Wird die gestrichelte Linie durch einen grauen Balken – den Steuerungsfokus – überla-gert, bedeutet dies, dass das entsprechende Objekt für den Zeitraum der Überlagerung aktiv ist und somit Programmkontrolle besitzt. Mitunter können mehrer Objekte gleichzeitig aktiv sein. Dieser Fall ist auch in der Beispielabbildung zu erkennen. Ein Kreuz am unteren Ende eines grauen Balkens signalisiert das Ende der Lebensdauer eines Objektes. Die Entstehung eines neuen Objektes wird dadurch dargestellt, dass ein Pfeil mit geschlossener Spitze vom Steuerungsfokus eines anderen Objektes aus auf das neu erschaffene Objekt zeigt. Diese Art von Pfeilen kann nicht nur zur Objektkonstruktion verwendet werden, sondern steht prinzi-piell für jede Nachricht, die ein Objekt an ein anderes sendet. Über einem solchem Pfeil steht stets die Bezeichnung der dazugehörigen Nachricht. Durch Pfeile mit offenen Spitzen werden Rücksprünge beschrieben. Der Text über diesen Pfeilen bezeichnet den dazugehörigen Rück-gabewert. Die Beispielabbildung soll folgenden Vorgang darstellen. Der Benutzer befindet sich im Dia-log mit dem Programm: er möchte seine Personalien eingeben. Dazu wird ein entsprechender Dialog benötigt, in welchem er beispielsweise Vor- und Nachnamen eingeben kann. Möchte er nun sein Geburtsdatum eingeben, muss dazu eigens ein weiterer Dialog gestartet werden. In der Beispielabbildung existiert zunächst nur das Objekt „Dialog_Personalien_aufnehmen“. Dieses sendet eine als Konstruktor fungierende Nachricht „neu()“, um ein Objekt vom Typ

17
„Dialog_Eingabe_Geburtsdatum“ zu erschaffen. Nun existieren zwei Objekte nebeneinander, wobei das Objekt „Dialog_Personalien_aufnehmen“ den Steuerungsfokus besitzt. Erst in dem Moment, wo die Nachricht „datum_erfragen()“ versendet wird, enthält auch das zweite Ob-jekt Programmkontrolle, was am zweiten senkrechten Balken zu erkennen ist. Nun kann der Benutzer mit beiden Objekten interagieren. Beendet er die Eingabe des Geburtsdatums, wird dieses („geburtsdatum“) an „Dialog_Personalien_aufnehmen“ zurückgegeben und „Dia-log_Eingabe_Geburtsdatum“ wird zerstört.
2.1.8 Logische Programmierung
Bei der imperativen13 Programmierung werden durch Algorithmen genaue Anleitungen spezi-fiziert, welche einer Maschine vorgeben (befehlen), wie sie ein bestimmtes Problem bearbei-ten soll. Solche imperativen Programme basieren daher, abhängig vom Abstraktionsgrad der konkret verwendeten Programmiersprache, mehr oder weniger deutlich erkennbar auf der zu Grunde liegenden Maschinenstruktur (z.B. von Neumann-Rechner). Im Gegensatz dazu fußt die deklarative14 (oder deskriptive15) Programmierung auf mathematischen Theorien. Als de-klarativ wird diese Art der Programmierung deshalb bezeichnet, weil mit Hilfe der zu Grunde liegenden mathematischen Theorien das zu bearbeitende Problem beschrieben wird. Ein de-skriptives Programm besteht dann im Idealfall – welcher in der Praxis aus Effizienzgründen jedoch nicht ganz erreicht wird – lediglich aus Problembeschreibungen, welche keine Infor-mationen über den von der Maschine vorzunehmenden Problemlösungsvorgang enthalten. Dadurch werden Programme häufig leichter lesbar und in Folge dessen einfacher zu entwi-ckeln, warten und verifizieren. Ein ausführlicher Überblick über deklarative Programmierung findet sich beispielsweise in [Loo99] oder [Man98]. Bei der deklarativen Programmierung unterscheidet man hauptsächlich zwischen den Berei-chen funktionale und logische Programmierung, jedoch existieren auch Ansätze, welche diese Richtungen in einer Sprache vereinen. In diesem Abschnitt soll die logische Programmierung genauer betrachtet werden. Logische Programme bestehen aus logischen Formeln. Ein solches Programm wird nicht im klassischen Sinne gestartet. Stattdessen wird eine Anfrage formuliert, welche wiederum aus einer logischen Formel besteht. Das System versucht mit Hilfe der anderen Formeln zu be-weisen, dass diese Anfrage-Formel „wahr“ ist. Enthält die zu beweisende Formel (das „Goal“) Variablen, so sucht das System nach Belegungen, für welche die durch die Formel ausgedrückte Aussage gilt. Der von der Programmiersprache abhängige Vorgang des Bewei-sens entspricht der „Ausführung“ des Programms. An dieser Stelle sollen zwei auf Logik basierende Sprachen vorgestellt werden. Dies sind die Sprachen Prolog und Datalog. Letztere stellt zwar keine Programmiersprache im engeren Sinn dar; vielmehr handelt es sich bei dieser Sprache um eine relationale Anfragesprache. Da Data-log aber mit Prolog verglichen werden soll, um später in Kapitel 5.1 besser beurteilen zu kön-nen, welche Sprache sich besser als Datenbanksprache des juristischen Systems eignet, wird auch Datalog in diesem Kapitel beschrieben.
13 „imperare“ (lat.) bedeutet befehlen 14 „declarare“ (lat.) bedeutet erklären, deutlich machen 15 „describere“ (lat.) bedeutet beschreiben

18
2.1.8.1 Prolog
Die folgende Darstellung der Grundlagen der Prolog-Programmierung ist stark zusammenge-fasst und spiegelt nur einen Ausschnitt der Möglichkeiten wider. Zur vertiefenden Lektüre können [SG98] und [StS94] empfohlen werden. Da die Programmiersprache Prolog auf der Prädikatenlogik erster Stufe basiert, werden gewisse Grundlagen aus der mathematischen Lo-gik benötigt, welche zum Teil als bekannt vorausgesetzt werden. Diese Grundlagen können in [Sch94] nachgelesen werden. Man unterscheidet folgende Arten von Prolog-Termen: - Konstanten:
Konstanten sind im Prinzip 0-stellige Funktionssymbole und werden in Prolog durch ei-nen kleinen Buchstaben am Anfang gekennzeichnet. Außerdem werden Zahlen als Kon-stanten betrachtet und alles was durch Hochkommata umschlossen ist.
- Variablen:
Variablen werden in Prolog durch einen großen Buchstaben oder einen Unterstrich am Anfang gekennzeichnet. Ein alleinstehender Unterstrich („_“) steht für eine anonyme Va-riable, wobei zu beachten ist, dass zwei solcher anonymer Variablen trotz gleicher Schreibweise für verschiedene Variablen stehen.
- Zusammengesetzte Terme (Funktionen): Diese Terme bestehen aus einem kleingeschriebenen Funktionsnamen und einer Argu-mentliste, welche wiederum Terme enthält. Ein Beispiel für eine Funktion ist: f(X, a, g(auto), 123, _). In Prolog werden Funktionen nicht interpretiert; man kann auch sagen, sie interpretieren sich selbst. So steht ein Term wie beispielsweise f(4) nicht für einen be-stimmten Wert, sondern für f(4).
Mit Hilfe verschiedener Umformungsschritte können Formeln der Prädikatenlogik in erfüll-barkeitsäquivalente Formeln in Klauselform gebracht werden. Eine Klausel, welche genau ein positives Literal enthält, nennt sich definite Hornklausel. Ein Prolog-Programm besteht nun aus einer Menge von Klauseln dieser besonderen Art, welche alle implizit als allquantifiziert zu betrachten sind. In Prolog unterscheidet man definite Hornklauseln weiter in: - Fakten:
Definite Hornklauseln, welche aus einem einzigen positiven Literal bestehen, werden Fak-ten genannt. Somit entsprechen Fakten atomaren Formeln, welche aus einem Prädikaten-symbol und einer Liste von Termen bestehen. Prolog-Prädikate werden notiert wie Funk-tionen in Prolog; jedoch ergibt sich aus dem Zusammenhang, was im Einzelfall gemeint ist.
- Regeln: Als Regel werden definite Hornklauseln bezeichnet, welche mindestens ein negatives Li-teral enthalten. Regeln werden in Prolog in implikativer Schreibweise notiert. Die Impli-kation „⇐ “ wird in Prolog durch „:-“ und die Konjunktion „ ∧ “ durch ein Komma ausge-drückt.
Dies sind Beispiele für Prolog-Fakten:
nachbar(ned, homer). mitbewohner(bart, maggie). mitbewohner(homer, maggie). maennlich(ned). weiblich(maggie).

19
... und dies ist ein Beispiel für eine Prolog-Regel:
nachbar(X,Z) :- mitbewohner(Y,Z), nachbar(X,Y).
Der linke Teil einer Regel wird als Kopf (engl. Head), der rechte Teil als Rumpf (Tail) be-zeichnet. Durch Regeln und Fakten werden Bedeutungen von Prädikaten festgelegt. So wird durch das Beispiel-Fakt nachbar(ned, homer) ausgedrückt, dass zwischen ned und homer eine nachbar/2-Beziehung besteht. Über Regeln können solche Relationen ebenfalls definiert wer-den. Die Regel im Beispiel drückt aus, dass X und Z in „nachbar/2“-Beziehung zueinander stehen, wenn X und Y in „nachbar/2“-Beziehung stehen und Y und Z an der Relation „mit-bewohner/2“ beteiligt sind. Wie gerade bereits geschehen, werden in Prolog zur Bezeichnung von Relationen, ihr Name und – durch einen Schrägstrich getrennt – ihre Stelligkeit angege-ben, also etwa „weiblich/1“ oder „nachbar/2“. Relationen mit gleichem Namen aber unter-schiedlichen Stelligkeiten sind in Prolog verschiedene Relationen. Mittels Anfragen (engl. queries) kann das in Prolog-Programmen enthaltene Wissen erfragt werden. Eine Anfrage sieht aus wie ein Fakt oder – bei zusammengesetzten Anfragen – wie eine Konjunktion von Fakten, doch ist immer aus dem Kontext klar, ob ein Fakt oder eine Anfrage vorliegt. Wird eine Anfrage in das Prolog-System eingegeben, so versucht dieses, die Anfrage zu beweisen. Die Klausel, welche jeweils aktuell zu beweisen versucht wird, be-zeichnet man als Goal oder Zielklausel. Anfragen können auch Variablen enthalten, für wel-che während des im folgenden genauer beschriebenen Beweisverfahrens geeignete Werte gesucht werden. SLD-Resolution Die definiten Hornklauseln sind Grundlage für ein spezielles Beweisverfahren, welches Pro-log verwendet. Mit diesem Verfahren kann die Semantik eines Prolog-Programms operational beschrieben werden. Hierzu definiert man die Bedeutung eines Programms als die Menge aller variablenfreien Prädikate, welche mit diesem Verfahren bewiesen werden können. Das entsprechende Beweisverfahren heißt SLD-Resolution16 und soll im folgenden beschrieben werden. Zunächst müssen aber die hierfür erforderlichen Begriffe Unifikation und allgemeins-ter Unifikator erläutert werden. Wird durch Substitution eine Menge von Literalen L identisch gemacht, so nennt man dies Unifikation. Der Vorgang wird als unifizieren bezeichnet. Die dabei vorgenommenen Substi-tutionen werden als Unifikator bezeichnet. Ein Unifikator u heißt allgemeinster Unifikator oder most general unifier (kurz: MGU) von L, wenn zu jedem anderen Unifikator v eine Sub-stitution w existiert, so dass gilt: w � u = v. Beispiel: Durch die Substitution {[X|g(a)] , [Z|a], [Y|a]} können die Elemente der Literalm-enge {f(X, g(a)), f(g(Y), g(Z))} identisch gemacht werden zu f(g(a),g(a)). Diese Substitution ist somit ein Unifikator, allerdings nicht der allgemeinste. MGU ist {[X|g(Y)], [Z|a]}. Um mit (SLD-)Resolution eine gegebene Formel (Anfrage) zu beweisen, wird versucht, deren Negation zu widerlegen. Gelingt dies, so ist die ursprüngliche Formel bewiesen. Eine Formel ist widerlegbar, wenn sie im Widerspruch zur vorliegenden Klauselmenge (dem Prolog-Programm) steht. In solch einem Fall kann durch Resolution von der Negation der Anfrage-Formel auf die leere Klausel („��� ��������� erden. Dies geschieht durch wiederholte Anwendung der Resolventenregel, welche eine Verallgemeinerung des modus ponens dar-stellt. 16 SLD steht für „linear resolution with selection function for definite clauses”

20
},...,,{ 11 LAA m ¬ , },,...,{ 21 LBB n sind Klauseln
u ist MGU der Literale 1L und 2L
)}(...,),({)}(,...,)({
},,...,{},,,...,{
11
2111
nm
nm
BuBuAuAu
LBBLAA
∪¬
Abbildung: Resolventenregel Die Suche nach einem Resolutionsbeweis kann mitunter sehr schwierig sein. Dies liegt daran, dass die Resolventenregel im Allgemeinen bei jedem Schritt auf mehrere verschiedene Arten zur Anwendung kommen kann. Die SLD-Resolution nutzt die Tatsache aus, dass Prolog-Programme aus definiten Hornklauseln bestehen und kann auf diese Weise effizienter arbei-ten: Beim zu beweisenden Goal wird zuerst das am weitesten links stehende Literal ausge-wählt. Dieses wird mit einem Regelkopf unifiziert und anschließend durch den dazugehörigen Regelrumpf ersetzt. Existieren mehrere „passende“ Regeln, wird zunächst die am weitesten oben stehende gewählt. Dieser Vorgang wird solange wiederholt, bis alle Literale des Goals von links nach rechts bewiesen sind. Man sagt daher, die Berechnungsregel von Prolog lautet „von links nach rechts“. Kann ein Literal an einer beliebigen Stelle des Beweises nicht mehr mit einem Regelkopf unifiziert werden, so werden soviele Resolutionsschritte zurückgenom-men (einschließlich der Substitutionen), bis der Beweis an einer Stelle angekommen ist, wo das ausgewählte Literal mit einer anderen (der nächsttieferen) Regel unifiziert werden kann. Aufgrund dieser Reihenfolge der Regelauswahl in Prolog sagt man, die Auswertungsstrategie von Prolog ist „von oben nach unten“. Nach Durchführung der Unifikation fährt der Beweis fort. Gibt es keine alternativen Regeln mehr, so kann das Goal nicht bewiesen werden. Der Vorgang des Zurücknehmens von Resolutionsschritten und Ausprobierens von anderen Mög-lichkeiten heißt Backtracking. Die Abbildung „Beispielanfrage“ zeigt den Verlauf einer SLD-Resolution. Zunächst wird Y mit bart unifiziert, dies muss später allerdings zurückgenommen werden, um mit dem Beweis fortfahren zu können.
?- nachbar(ned, maggie). ned = X, maggie = Z mitbewohner(Y, maggie), nachbar(ned, Y)
mitbewohner(Y, maggie) Y = bart true nachbar(ned,bart) false mitbewohner(Y, maggie), nachbar(ned, Y)
mitbewohner(Y, maggie) Y = homer true
nachbar(ned, homer) true
Abbildung: Beispielanfrage Die SLD-Beweisstrategie zieht gewisse Reihenfolgeabhängigkeiten nach sich. Die verschie-denen Variablenbindungen, die während eines Beweises entstehen, führen teilweise zu unter-schiedlichen Lösungen für eine Anfrage. Diese werden in einer von der SLD-Resolution ab-hängigen Reihenfolge entdeckt. Der Programmierer kann über die Anordnung der Regeln und Klauseln in Prolog-Programmen die Reihenfolge, in welcher die Lösungen gefunden werden, beeinflussen. Es kann sogar vorkommen, dass Prolog bei einem Beweis in eine endlose, re-

21
kursive Schleife gerät ohne vorher Lösungen gefunden zu haben, bei einer anderen Anord-nung der Regeln aber zunächst Lösungen entdeckt. In Verbindung mit den im folgenden be-schriebenen „außer-logischen“ Konstrukten – insbesondere den roten Cuts – treten solche Reihenfolgeabhängigkeiten noch stärker zu Tage. Nicht-pures Prolog Die bisherigen Ausführungen bezogen sich auf „pures“ Prolog. Mit purem Prolog können im Prinzip „nur“ auf Klauselmengen basierende Beweise durchgeführt werden. Um eine vollwer-tige Programmiersprache zu erhalten, wurden Prädikate eingeführt, welche mit Seiteneffekten operieren, also neben ihrer logischen Bedeutung eine weitere Funktion haben. - Write:
So kann beispielsweise das Prädikat write/1, welches immer „wahr“ ist, verwendet wer-den, um Text auf den Bildschirm zu schreiben. Wenn der Beweismechanismus an eine Stelle kommt, wo dieses Prädikat bewiesen werden soll, so wird Text auf den Bildschirm ausgegeben. Solche Seiteneffekte können nicht mehr über das Backtracking zurückge-nommen werden.
- Assert und retract: Zwei weitere wichtige „außer-logische“ Prädikate sind assert/1 und retract/1. Mit dem ers-ten Prädikat werden Klauseln in das Prolog-Programm eingefügt, mit letzterem entfernt.
- Negation As Failure:
Ein besonders wichtiges „außer-logisches“ Prädikat, ist not/1. Es erfordert ein Prädikat als Argument und gehört somit nicht mehr zur Prädikatenlogik erster Stufe. „not/1“ wird ver-wendet, um eine besondere Art der Negation unter Prolog verwendbar zu machen. Hierbei handelt es sich um Negation As Failure. Nach der Closed World Assumption gilt alles, was nicht explizit über Fakten angegeben ist oder über Regeln hergeleitet werden kann, als „falsch“. Das Prädikat not/1 dient dazu, solche negative Informationen zu nutzen. Die Anfrage
not Goal
ist „wahr“, wenn der Beweis von „Goal“ mißlingt. Mit Hilfe des Prädikats not/1 können teilweise Regeln verwirklicht werden, welche zu erheblicher Speicherplatzersparnis füh-ren. So kann beispielsweise in einer Personendatenbank durch Verwendung der folgenden Regel auf materialisierte Darstellung des Geschlechts verzichtet werden, wenn alle Frauen von der Relation weiblich/1 erfasst sind:
maennlich(Person) :- not weiblich(Person).
- Cuts:
Als letztes “außer-logisches“ Konzept soll an dieser Stelle der Cut (notiert als „!“) vorge-stellt werden. Der ursprüngliche Zweck von Cuts ist es, den Suchraum von Prolog-Berechnungen zu begrenzen. Dies hat zum einen den Vorteil, dass der Beweis schneller durchgeführt werden kann. Zum anderen wird weniger Speicherplatz für die Verwaltung des Backtrackings benötigt. Die Bedeutung des Cuts lässt sich folgendermaßen beschrei-ben. Angenommen, es wird versucht, die folgende Klausel K zu beweisen.
K :- A1, ... ,Ai ,! , Ai+1, ... , An.

22
Nachdem „!“ erreicht ist, stehen alle Variablenbindungen links vom Cut fest. Alternativen zu K werden nicht mehr berücksichtigt. Scheitert der Beweis von K an einem Literal Ai+1, ... , An, so erfolgt Backtracking höchstens bis zum Cut. Genügt dies nicht, scheitert der Beweis von K und der Beweis des übergeordneten Goals wird an der Stelle fortgesetzt, bevor K ausgewählt wurde. Man unterscheidet grüne und rote Cuts. Als grün wird ein Cut bezeichnet, der die Seman-tik des Programms nicht verändert. Solche Cuts wirken sich nur auf die Laufzeit aus und begrenzen den Suchraum, wo klar ist, dass keine Lösungen gefunden werden. Rote Cuts hingegen ändern die Semantik eines Prolog-Programms, indem möglicherweise noch nicht entdeckte Lösungen „abgeschnitten“ werden.
Alle hier vorgestellten nicht-puren Konzepte haben gemeinsam, dass sie imperative Aspekte in Prolog integrieren und somit den deklarativen Charakter der Sprache beschädigen. Aus diesem Grunde sollte der Einsatz solcher Konzepte immer gründlich durchdacht werden.
2.1.8.2 Datalog
Datalog17 ist eine relationale Anfragesprache, welche – wie der Name erkennen lässt – von logischen Programmiersprachen wie Prolog beeinflusst ist. Im Gegensatz zu Prolog verfügt Datalog aber nicht über dessen „außer-logischen“ Konzepte und stellt damit eine Reinform einer logischen Programmiersprache dar. Es folgt ein kurzer Überblick über weitere Unter-schiede zur Programmiersprache Prolog. Eine weiterführende Informationsquelle für Datalog ist [CGH94]. Die Syntax von Prolog entspricht im wesentlichen der von “purem” Prolog. Funktionssymbo-le sind im ursprünglichen Datalog jedoch nicht zugelassen, damit der direkte Zusammenhang zu den Relationen einer relationalen Datenbank nicht verloren geht. In seiner ursprünglichen Definition verfügt Datalog auch nicht über Negation. Sowohl für Funktionen als auch für die Negation gibt es allerdings erweiterte Sprachdefinitionen. Die Datalog-Semantik ist im Gegensatz zur instanzorientierten18 Semantik von Prolog men-genorientiert. Dies bedeutet, dass Datalog die Lösungen zu einem Goal nicht sequenziell son-dern gleichzeitig erhält. Hieraus folgt auch, dass – anders als in Prolog – Reihenfolgenunab-hängigkeit für die Anordnung der Regeln und Klauseln besteht. Ein weiterer Unterschied zu Prolog ist, dass die Resolventenregel in umgekehrter Richtung zur Anwendung kommt. An-statt in einer „top-down“-Strategie – ausgehend von einer Anfrage – diese durch wiederholte Resolution zu beweisen, kommt in Datalog in der Regel eine “bottom-up”-Strategie zur An-wendung, welche – ausgehend von den Basisfakten – die Regeln verwendet, um neue Fakten herzuleiten. Die Deklarativität von Datalog-Programmen kann ausgenutzt werden, um die Effizienz zu steigern. Durch Äquivalenztransformationen von Datalog-Programmen – die durch die pure Deklaritivität möglich werden – können Anfragen optimiert werden. Hier endet die Darstellung der logischen Programmiersprachen Datalog und Prolog. Weshalb Prolog vor Datalog letztlich im juristischen System den Vorzug bekommt, wird in Kapitel 5.1 erläutert. Der Abschnitt über die Grundlagen der Informatik soll nun mit einer Einführung in Tcl/Tk beschlossen werden.
17 Datalog steht für Database Prolog 18 Lösungen werden der Reihe nach ermittelt

23
2.1.9 Tcl/Tk
Tcl19/Tk20 wurde Ende der 80er Jahre von John K. Ousterhout entwickelt. Es setzt sich zu-sammen aus der interpretativen, stringbasierten Skriptsprache Tcl und dem Toolkit Tk. Dieses Toolkit erlaubt es, grafische Oberflächen (GUIs21) für „X windows“ zu erzeugen. Tcl/Tk ist relativ einfach zu erlernen und frei verfügbar. Darüber hinaus verfügt es über Schnittstellen zu den verschiedensten Programmiersprachen. Die Entscheidung, Tcl/Tk zu verwenden, um die grafische Oberfläche des juristischen Systems damit zu implementieren, fiel daher vor allem wegen der guten Schnittstelle zu ECLiPSe, sehr leicht (vgl. [Mei96], S. 1). Diese Verbindung zwischen Tcl/Tk und Prolog nennt sich ProTcXl22. Zu ProTcXl gehören auf der einen Seite Tcl-Kommandos, die es erlauben Prolog-Prädikate von Tcl/Tk aus aufzurufen. Auf der ande-ren Seite werden von ProTcXl aber auch Prolog-Prädikate definiert, mit welchen auf Tcl/Tk-Kommandos zugegriffen werden kann. Auf Details, welche die Schnittstelle zwischen EC-LiPSe und Tcl/Tk betreffen, wird bei der Beschreibung des Eventhandlers genauer eingegan-gen. An dieser Stelle soll eine sehr kurze Einführung in Tcl/Tk erfolgen. Zur vertiefenden Lektüre sei [Wel95] empfohlen.
2.1.9.1 Tcl-Grundlagen
Ein Tcl-Programm wird „Script“ genannt und besteht aus einer Folge von Tcl-Kommandos, welche allesamt aus dem Kommandonamen und einer Liste von Argumenten bestehen. Ein-zelne Elemente einer Liste werden durch ein Leerzeichen getrennt, so dass ein typisches Tcl-Kommando folgendes Format hat:
command argument1 argument2 ... argument_n
Variablen können mit Hilfe des set-Kommandos belegt werden. Da alle Argumente stets als Zeichenketten aufgefasst, vom Interpreter also nicht ausgewertet werden, hätte ein Komman-do der Form
set x a+1
zur Folge, dass die Variable x mit der Zeichenkette a+1 belegt würde. Sollen arithmetische Ausdrücke ausgewertet werden, ist das expr-Kommando erforderlich. Um Kommandos aus-zuwerten, werden eckige Klammern („[ ]“) benötigt. Der Wert einer Variable wird mit Hilfe des Dollarzeichens („$“) ermittelt. Die Kommandos
set a 4 set x [expr $a + 1]
hätten somit zur Folge, dass die Variable x mit dem Wert 5 belegt würde. Anführungszeichen und geschweifte Klammern („{ }“) haben in Tcl die Funktion, mehrere Argumente zusam-menzufassen. Die Ausdrücke
„$x $a hallo“ {$x $a hallo}
19 Tcl steht für Tool Command Language 20 Tk steht für Toolkit 21 graphical user interfaces 22 Prolog und Tcl, das X steht für den direkten Zugriff auf die X11-Bibliothek Xlib

24
stellen daher jeweils nur ein einziges Argument dar. Der Unterschied zwischen den Anfüh-rungszeichen und den geschweiften Klammern besteht darin, dass innerhalb geschweifter Klammern keine Auswertungen stattfinden, innerhalb von Anführungszeichen jedoch schon. Weitere Programmierkonstrukte wie „proc“, „if ... then ... else“,“foreach“, „while“ und „puts“ entsprechen in ihren Bedeutungen ihren Gegenstücken aus anderen Programmiersprachen und werden daher hier nicht näher erläutert.
2.1.9.2 Tk-Grundlagen
In diesem Abschnitt sollen kurz die wichtigsten Grundkonzepte des Toolkits Tk beschrieben werden. Tk besteht aus einer Menge zusätzlicher Tcl-Kommandos, die es erlauben, grafische Objekte – sogenannte Widgets – darzustellen und zu verwalten. Es gibt verschiedene Arten dieser grafischen Objekte. Aufgrund der großen Anzahl verschiedener Arten von Tk-Widgets werden an dieser Stelle nur einige Beispiele aufgeführt und ihre Bedeutung kurz erläutert: - Toplevel-Window: Alle anderen Widgets müssen sich in einem solchen Fenster befinden. - Frames: Enthalten andere Widgets. - Buttons: Je nach Button-Art ändert ein Mausklick auf einen Button bestimmte Variablen-
werte (Radiobutton und Selectbutton) oder sorgt dafür, dass Tcl-Scripts oder Kommandos ausgeführt werden (Commandbutton).
- Scrollbars: Mit ihnen lassen sich, wenn nicht alle Inhalte eines Widgets auf einmal sicht-
bar sein können, die sichtbaren Bereiche verschieben. - Listboxes: Dienen der Darstellung von Listen sowie der Auswahl der darin enthaltenen
Elemente. - Entry-Widgets: Stehen für Text-Eingaben zur Verfügung. Die Eigenschaften der Widgets können bei ihrer Erschaffung direkt angegeben werden. Bei-spielsweise wird mit dem Kommando
button .knopf –text „drück’ mich und es klingelt“ –command bell
ein neuer Commandbutton mit der Bezeichnung „.knopf“ erzeugt, welcher die Aufschrift „drück’ mich und es klingelt“ trägt. Über den letzten Teil der Zeile wird bestimmt, dass bei Druck auf den Button das Kommando „bell“ ausgeführt wird, was ein akustisches Signal be-wirkt. Die Widget-Eigenschaften können über das configure-Kommando modifiziert werden.
.knopf configure –text „ich bin ein Button“
bewirkt, dass der oben erzeugte Button fortan die Aufschrift „ich bin ein Button“ trägt. Ein äußerst wichtiges Kommando ist das pack-Kommando. Es weist den Tk-Fenstermanager an, ein bereits erzeugtes Widget auf dem Bildschirm darzustellen. Hierzu muss der Name des entsprechenden Widgets angegeben werden. Ausserdem kann eine pack-Anweisung wie

25
pack .knopf –side left
Informationen darüber enthalten, wie das Widget genau auf dem Bildschirm erscheinen soll (z.B. linksbündig). Je nach Widget gibt es noch viele andere Kommandos, welche an gegebener Stelle kurz erläu-tert werden. An dieser Stelle soll lediglich noch erwähnt werden, dass die Widgets hierar-chisch angeordnet sind. An der Spitze dieser Hierarchie befindet sich das Hauptfenster der Anwendung. Dieses trägt stets die Bezeichnung „.“. Am Namen des Widgets lässt sich seine Position in der Hierarchie ablesen. Ein Button „b“, der sich in einem Frame „f“ befindet, wel-cher in einem Toplevel-Window „w“ angesiedelt ist, trägt die Bezeichnung „.w.f.b“.

26
2.2 Rechtswissenschaftliche Grundlagen
Im kommenden Abschnitt wird das Ziel verfolgt, den Anwendungsbereich des juristischen Systems zu erläutern. Hierzu wird als erstes die allgemeine Struktur des Gesetzes dargestellt. Da das entwickelte System die juristische Subsumtion nachzuahmen versucht, wird diese im weiteren Verlauf dieses Kapitels ausführlich beschrieben. Um später auf einzelne Entschei-dungen aus der Phase des System-Entwurfs genauer eingehen zu können, ist es erforderlich, in diesem Abschnitt auch Aspekte der Subsumtion zu erläutern, die vom tatsächlich imple-mentierten System nicht nachgeahmt werden können. Der Anwendungsbereich der in dieser Arbeit entwickelten Software ist das Strafgesetz. Die folgenden Ausführungen über Gesetze und deren Anwendung beziehen sich daher teilweise schwerpunktmäßig auf das Strafrecht. Daher ist zu beachten, dass in anderen Teilgebieten des Rechts, wie beispielsweise im Bürgerlichen Recht, Unterschiede bestehen.
2.2.1 Gesetzesstruktur
Das Strafgesetzbuch ist unterteilt in einen Allgemeinen Teil und einen Besonderen Teil. Der Allgemeine Teil (§§231-79b) enthält im wesentlichen Regeln, die für jede Straftat glei-chermaßen gelten.
§1. Keine Strafe ohne Gesetz. Eine Tat kann nur bestraft werden, wenn die Strafbar-keit gesetzlich bestimmt war, bevor die Tat begangen wurde. §12. Verbrechen und Vergehen. (1) Verbrechen sind rechtswidrige Taten, die im Mindestmaß mit Freiheitsstrafe von einem Jahr oder darüber bedroht sind. (2) Vergehen sind rechtswidrige Taten, die im Mindestmaß mit einer geringen Frei-heitsstrafe oder die mit Geldstrafe bedroht sind. (3) ... §23. Strafbarkeit des Versuchs. (1) Der Versuch eines Verbrechens ist stets strafbar, der Versuch eines Vergehens nur dann, wenn das Gesetz es ausdrücklich bestimmt. (2) ... §25. Täterschaft. (1) Als Täter wird bestraft, wer die Straftat selbst oder durch einen anderen begeht. (2) Begehen mehrere die Straftat gemeinschaftlich, so wird jeder als Täter bestraft (Mittäter). §52. Tateinheit. (1) Verletzt dieselbe Handlung mehrere Strafgesetze oder dasselbe Strafgesetz mehrmals, so wird nur auf eine Strafe erkannt. (2) ...
23 Soweit nicht anders angegeben, sind alle §§ solche des Strafgesetzbuches (StGB).

27
Hauptsächlich beschreiben die Paragraphen des Besonderen Teils (§§80-358) einzelne straf-würdige Verhaltensweisen und geben das Strafmaß für diese Delikte an.
§223. Körperverletzung. (1) Wer eine andere Person körperlich mißhandelt oder an der Gesundheit schädigt, wird mit Freiheitsstrafe bis zu fünf Jahren oder mit Geldstra-fe bestraft. (2) Der Versuch ist strafbar. §224. Gefährliche Körperverletzung. (1) Wer die Körperverletzung 1. durch Beibringung von Gift oder anderen gesundheitsschädlichen Stoffen, 2. mittels einer Waffe oder eines anderen gefährlichen Werkzeugs, ... begeht, wird mit Freiheitsstrafe von sechs Monaten bis zu zehn Jahren, in minder schweren Fällen mit Freiheitsstrafe von drei Monaten bis zu fünf Jahren bestraft. (2) Der Versuch ist strafbar. §242. Diebstahl. (1) Wer eine fremde bewegliche Sache einem anderen in der Absicht wegnimmt, diesselbe sich rechtswidrig zuzueignen, wird mit Freiheitsstrafe bis zu fünf Jahren oder mit Geldstrafe bestraft. (2) Der Versuch ist strafbar.
Wie man leicht sieht, haben die Paragraphen des Besonderen Teils eine Art wenn-dann-Struktur. Außerdem ist zu beobachten, dass gewisse juristische Begriffe wie zum Beispiel „gesundheitsschädlicher Stoff” in §224 I Alt. 1 oder „gefährliches Werkzeug” in Alternative 2 Bestandteil von Hierarchen sind. So lassen sich „gesundheitsschädlicher Stoff” als Oberbeg-riff von „Gift” und „gefährliches Werkzeug” als Oberbegriff von „Waffe” ausmachen. Viele juristische Begriffe definieren sich darüber hinaus über Unterbegriffe, so dass sich baumartige Strukturen bilden lassen.
Abbildung: Baumstruktur des Gesetzes
§242. Diebstahl
Wegnahme einer fremden, beweglichen, Sache
Bruch fremden Gewahrsams Begründung neuen Gewahrsams
Vom Herrschaftswillen getragene tatsächliche Sachherrschaft

28
Beispielsweise ist der Begriff „Diebstahl“ definiert als „Wegnahme einer fremden, bewegli-chen Sache.“ Die einzelnen Tatbestandsmerkmale „Wegnahme“, „fremd“, „beweglich“ und „Sache“ lassen sich wiederum genauer beschreiben. So ist der juristische Begriff der „Weg-nahme“ in §242 gleichbedeutend mit „Bruch fremden und Begründung neuen Gewahrsams“. „Gewahrsam“ ist „vom Herrschaftswillen getragene tatsächliche Sachherrschaft“ und so wei-ter.
2.2.2 Die juristische Subsumtion: Vorgang der Rechtsfindung
Der Begriff der Subsumtion bedeutet im juristischen Kontext die Unterordnung eines konkre-ten Sachverhaltes unter eine abstrakte Rechtsnorm (vgl. [Kau87], S. 1206). Dies soll nun nä-her erläutert werden. Ziel der Rechtsfindung ist es, ausgehend von einem Sachverhalt, eine Rechtsfolge zu ermit-teln und somit ein Urteil fällen zu können. Die für das Strafrecht typische Rechtsfolge ist die Strafe, beispielsweise Freiheitsentzug oder Geldbuße; Rechtsfolgen des Bürgerlichen Rechts sind häufig Ansprüche. Eine solche Rechtsfolge wird ermittelt, indem versucht wird, einen abstrakten Tatbestand, welcher eine abstrakte Rechtsfolge nach sich zieht, mit einem tatsäch-lichen Sachverhalt zur Deckung zu bringen. Man bezeichnet die Kombination eines abstrak-ten Tatbestandes mit einer daraus folgenden abstrakten Rechtsfolge als Obersatz. Der konkre-te Sachverhalt, welcher damit zur Deckung gebracht werden soll, heisst Untersatz. Der Vor-gang des „zur-Deckung-bringens“ von Ober- und Untersatz ist der eigentliche Subsumti-onsschritt. Gelingt dieser Subsumtionsschritt, so lässt sich das Urteil – also die konkrete Rechtsfolge – aus der abstrakten Rechtsfolge des Obersatzes und dem konkreten Sachverhalt des Untersatzes herleiten. Dieses Urteil nennt sich auch Schluss(-satz) (vgl. [Sir89], S. 10). Der oben beschriebene Vorgang der juristischen Subsumtion soll nun anhand eines Beispieles verdeutlicht werden:
Obersatz: § 223 I 2. Alt. StGB: Wer eine andere Person ... an der Gesundheit schä-digt, wird mit Freiheitsstrafe bis zu fünf Jahren oder mit Geldstrafe bestraft. Untersatz: Peter Müller fügt Lieschen Müller eine Verletzung zu.
Der abstrakte Tatbestand wird im Obersatz mit den Worten „wer eine andere Person an der Gesundheit schädigt“ beschrieben. Der abstrakte Tatbestand ist mit der abstrakten Rechtsfol-ge „Freiheitsstrafe bis zu fünf Jahren oder Geldstrafe“ (für diese Person) verknüpft. Der Un-tersatz – also der konkrete Sachverhalt – kann mit dem abstrakten Tatbestand zur Deckung gebracht werden, indem für „wer“ Peter Müller und für „eine andere Person“ Lieschen Müller eingesetzt wird. Ferner entspricht das Zufügen einer Verletzung dem Vorgang des Schädigens an der Gesundheit, so dass sich abstrakter und konkreter Tatbestand überdecken. Dadurch folgt letztlich als Schlusssatz:
Schlusssatz: Peter Müller wird mit Freiheitsstrafe bis zu fünf Jahren oder mit Geld-strafe bestraft.
Der Vorgang der Subsumtion ist damit abgeschlossen. Leider ist es im Allgemeinen nicht möglich, die Subsumtion so problemlos durchzuführen, wie dies im obigen Beispiel geschehen ist. Der Grund hierfür liegt darin, dass Sachverhalt und Norm meist nicht direkt so gut zueinander passen wie im obigen Beispiel. Daher müssen

29
Sachverhalt und Norm einander angepasst werden. Die Norm muss im Hinblick auf den Sachverhalt konkretisiert werden. Das Gesetz muss ausgelegt werden. Auf der anderen Seite muss der Sachverhalt im Hinblick auf die Norm angepasst werden. Beispielsweise müssen aus dem Sachverhalt die rechtlich unerheblichen Tatsachen ausgesondert werden. Diese beiden unterschiedlichen Vorgänge – Gesetzesauslegung einerseits und Sachverhalts-anpassung andererseits – werden nun näher erläutert. Dabei ist allerdings zu beachten, dass diese beiden Tätigkeiten nicht nacheinander vorgenommen werden. Stattdessen versucht der Jurist „durch Hin- und Herwandern des Blickes“ Sachverhalt und Norm durch wechselseitige Anpassungen zur Deckung zu bringen.
2.2.2.1 Gesetzesauslegung
Das Gesetz kann bei der Subsumtion nur richtig angewendet werden, wenn bekannt ist, was es meint, wenn also der Sinn des Gesetzes klar ist. Da Gesetze mit natürlicher Sprache be-schrieben werden, diese aber oft mehrdeutig oder unklar ist, muss dieser Gesetzessinn häufig erst ermittelt werden, bevor die Subsumtion eines Sachverhaltes unter der Rechtsnorm vorge-nommen werden kann. So ist ein Blick in den Gesetzestext des §248b allein nicht ausrei-chend, um zweifelsfrei sagen zu können, ob eine Staftat bereits vorliegt, wenn jemand unbe-fugt in dem Auto eines anderen übernachtet24.
§248b. Unbefugter Gebrauch eines Fahrzeugs. (1) Wer ein Kraftfahrzeug oder ein Fahrrad gegen den Willen des Berechtigten in Gebrauch nimmt, wird mit Freiheitsstra-fe bis zu drei Jahren oder mit Geldstrafe bestraft, ...
Fraglich ist hier, wie der Begriff des „Ingebrauchnehmens“ zu interpretieren ist. Legte man den Begriff restriktiv also einschränkend aus, so wäre „Gebrauch“ als bestimmunggemäßer Gebrauch zu interpretieren. In diesem Fall umschlösse der Begriff nur das Führen des Ge-fährts. Ein zweckentfremdendes Übernachten im Auto wäre damit von der Norm nicht erfasst. Anders stellte sich dies bei einer extensiven oder ausdehnenden Auslegung dar. Würde man „Gebrauch“ als irgendwie geartetes Verwenden auffassen, läge im Beispiel ein „Ingebrauch-nehmen“ vor. Das Beispiel zeigt, dass in solchen Fällen eine Entscheidung nur dann getroffen werden kann, wenn zuvor die Bedeutung des Gesetzes geklärt wurde. Die juristische Metho-denlehre stellt hierzu gewissermassen eine Anleitung zur Verfügung, wie diese Bedeutung im Rahmen der Auslegung zu ermitteln ist (s. z.B. [Wes95], Rn. 56 ff.; [Bro95], Rn. 58 ff.; [Lar91] S. 312 ff., BVerfGE 11, 126). Zunächst werden im allgemeinen folgende Auslegungsarten unterschieden (vgl.z.B. [Bro95], Rn. 59-62):
- grammatische Auslegung (Wortlaut der Norm) - systematische Auslegung (Gesetzeszusammenhang) - historische Auslegung (Entstehungsgeschichte des Gesetzes) - objektiv-teleologische Auslegung (Sinn und Zweck der Norm)
Grammatische Auslegung Der Wortlaut der Norm umgrenzt die möglichen Interpretationen der Norm. Nur was nach den Regeln des allgemeinen Sprachgebrauchs oder der juristischen Fachsprache möglicher-weise durch den Gesetzes-Wortlaut gemeint sein kann, ist potentielle Bedeutung der Norm. 24 s. BGHSt 11, 44 und 47

30
Eine Berücksichtigung der weiteren Auslegungsarten kommt damit erst in Betracht, wenn der Wortlaut mehrdeutig ist, die grammatische Auslegung also kein eindeutiges Ergebnis liefert.
Im obigen Beispiel erlaubt der Wortlaut zwei Interpretationen. Ob „Gebrauch“ restrik-tiv als „bestimmungsgemäßer Gebrauch“ oder extensiv als „irgendwie geartete Ver-wendung“ zu interpretieren ist, ist vom Wortlaut her offen. Somit müssen die weiteren Auslegungsarten herangezogen werden.
Die weiteren Auslegungsarten systematische, historische und objektiv-teleologische Ausle-gung dienen dazu, einer von mehreren möglichen Interpretationen den Vorzug zu geben. Hierbei besteht zwischen den weiteren Arten der Auslegung keine bestimmte Rangordnung ([Sir89], S. 37). Systematische Auslegung Im Rahmen der systematischen Auslegung wird anhand der Gesetzessystematik zu erkennen versucht, was der Gesetzgeber mit der Norm bezwecken möchte.
Im Beispiel bietet der Gesetzeskontext einen Anhaltspunkt. Da §248b zu dem 19. Ab-schnitt des Strafgesetzbuches gehört, welcher sich mit „Diebstahl und Unterschla-gung“ beschäftigt, könnte man der Ansicht sein, dass §248b nicht das bloße Übernach-ten im Auto behandelt.
Historische Auslegung oder subjektiv-teleologische Auslegung Weitere Hinweise auf die beabsichtigte Bedeutung eines Gesetzes kann manchmal die Entste-hungsgeschichte der Norm geben25. Diese ist in Dokumenten wie Entwürfen, Motiven und Protokollen26 dokumentiert. Auch Vorgänger einer Norm können Hinweise enthalten, wie sie zu interpretieren ist. Objektiv-teleologische Auslegung Die objektive-teleologische Auslegung versucht – mitunter in Verbindung anderer Ausle-gungsarten – zu ermitteln, welchen rechtspolitischen Zweck ein Gesetz verfolgt. Im Strafrecht wird bei der objektiv-teleologischen Auslegung der Versuch unternommen, herauszufinden, was der Schutzzweck der Norm ist, um so Rückschlüsse auf die richtige Interpretation des Gesetzes ziehen zu können.
Der bestimmungsgemäße Zweck des §248b besteht darin, Schwarzfahrten entgegenzu-treten. Der Schutzzweck der Norm ist, der damit verbundenen Gefährdung der öffent-lichen Sicherheit entgegenzutreten.27 Für das Beispiel bedeutet dies, dass der Begriff des „Gebrauchs“ restriktiv auszulegen ist. In einem fremden Auto zu übernachten stellt somit lediglich eine straflose Gebrauchsanmaßung dar.
25 Hierbei ist jedoch umstritten, ob der subjektive Wille des Gesetzgebers bei der Gesetzesauslegung berücksic h-tigt werden darf (so aber die subjektive Theorie) oder ob bloß der objektivierte Wille des Gesetzgebers ermittelt werden darf. Nach der zweiten Ansicht (objektive Theorie) ist nicht ausschlaggebend, was der Gesetzgeber ur-sprünglich beabsichtigte, da Gesetzestext „nicht toter Buchstabe, sondern lebendig sich entwickelnder Geist“ sei, welcher „mit den Lebensverhältnissen fortschreiten und ihnen sinnvoll angepasst weitergelten will“ (BGHSt 10, 159). 26 Das heutige BGB hat in der langen Zeit seines Bestehens viele Veränderungen erfahren. Bevor es am 1.1.1900 verabschiedet wurde, durchlief es drei Entwurfsstadien (Entwürfe I-III). Die Begründungen zum 1. Entwurf sind in den sogenannten Motiven dokumentiert. Die Beratungen zum 2. Entwurf sind in den sogenannten Protokollen festgehalten. (vgl. [Bro95], Rn. 20) 27 s. BGH 11, 49

31
Verhältnis zwischen den verschiedenen Auslegungsarten Wie bereits erwähnt, ist zuerst die grammatische Auslegungsart anzuwenden. Eine feste Rangfolge unter den anderen Auslegungsarten besteht nicht, jedoch wird vereinzelt gefordert, dass eine historische Auslegung erst dann vorzunehmen ist, wenn die anderen Auslegungsme-thoden zu keiner Lösung führen (vgl. [Ste84], S. 115 ff. m.w.N.).
2.2.2.2 Unbestimmte Rechtsbegriffe
Eine Anleitung – wie bei der Auslegung von Gesetzen – gibt es für den Umgang mit unbe-stimmten Rechtsbegriffen nicht. Bei den unbestimmten Rechtsbegriffen handelt es sich um Begriffe, deren Bedeutung ohne Wertung nicht eindeutig zu bestimmen ist (vgl. [Sir89], S. 16). Beispiele für unbestimmte Rechtsbegriffe sind die „guten Sitten“ in §138 BGB, „Treu und Glauben“ aus §242 BGB und der Begriff der „angemessenen Wartezeit“ in §142 StGB.
§138 I BGB. Sittenwidriges Rechtsgeschäft. Ein Rechtsgeschäft, das gegen die guten Sitten verstößt, ist nichtig. §242 BGB. Leistung nach Treu und Glauben. Der Schuldner ist verpflichtet, die Leis-tung so zu bewirken, wie Treu und Glauben mit Rücksicht auf die Verkehrssitte es erfor-dern.
§142 StGB. Unerlaubtes Entfernen vom Unfallort. (1) Ein Unfallbeteiligter, der sich nach einem Unfall im Straßenverkehr vom Unfallort entfernt, bevor er ... 2. eine nach den Umständen angemessene Zeit gewartet hat ... wird mit Freiheitsstrafe bis zu drei Jahren oder mit Geldstrafe bestraft.
Zur Ermittlung der Bedeutung unbestimmter Rechtsbegriffe ist nach dem Bundesverfas-sungsgericht eine an der Wertordnung des Grundgesetzes orientierte Wertung vorzunehmen (vgl. [Ste84], S. 116). Somit unterscheidet sich die Ausfüllung unbestimmter Rechtsbegriffe wesentlich von der oben beschriebenen Methode der Auslegung, „wenn auch im Einzelfall der Übergang flüssig ... sein mag“ ([Sir89], S. 40).
2.2.2.3 Sachverhaltsanpassung
Die Auslegung der Norm bildet die eine oft notwendige Vorleistung, die bei einer Subsumtion zu erbringen ist. Auf der anderen Seite muss häufig der Sachverhalt an die Norm angepasst werden. Hierbei müssen einerseits rechtlich unerhebliche Tatsachen ausgesondert werden. Hinzu kommt, dass Sachverhaltsbeschreibungen teilweise anders ausgedrückt werden müs-sen, damit sie zum Obersatz passen.
Sachverhalt: Peter begeht eine Körperverletzung, indem er Lieschen anschießt. Obersatz: § 224 I 2. Alt. StGB: Wer die Körperverletzung ... mittels einer Waffe ... begeht, wird mit Freiheitsstrafe von sechs Monaten bis zu zehn Jahren ... bestraft. Untersatz: Peter begeht eine Körperverletzung, indem er Lieschen mit einer Schuss-waffe verletzt. Schlussatz: Peter wird mit Freiheitsstrafe von sechs Monaten bis zehn Jahren bestraft.

32
Im Beispiel musste der Sachverhalt anders ausgedrückt werden, damit er genau zum Obersatz passt.28 Die Verwendung einer Schusswaffe lässt sich aus dem Verb „anschießen“ erschlie-ßen.
2.2.3 Prüfungsaufbau im Strafrecht
Im Rahmen einer strafrechtlichen Subsumtion wird in der Regel zu prüfen sein, ob eine ge-wisse Verhaltensweise zu bestrafen ist oder nicht. Hierbei sind meistens drei Prüfungsschritte zu berücksichtigen. Die nun folgende Darstellung des Prüfungsaufbaus im Strafrecht orien-tiert sich an [Wes95], wo ausführliche Darstellungen (z.B. Rn. 860 ff.) zu finden sind Zunächst erfolgt eine Prüfung der Tatbestandsmäßigkeit. Im Anschluss an diesen (häufig um-fangreichsten) Prüfungspunkt wird die Rechtswidrigkeit der Tat und zum Abschluss die Schuld des Täters geprüft. Erst wenn ein Tatbestand rechtswidrig und schuldhaft verwirklicht wurde, ist ein Verhalten zu bestrafen. Die drei Prüfungsschritte werden nun kurz beschrieben. Tatbestandsmäßigkeit Bei der Prüfung, ob ein bestimmtes Delikt verwirklicht wurde, ist zunächst zu prüfen, ob der zu dem entsprechenden Delikt gehörende (abstrakte) Tatbestand29 im Sachverhalt konkret eingetreten ist. Der Tatbestand besteht aus einem objektiven und einem subjektiven Teil. Der objektive Tatbestand besteht aus den Umständen, „die das äußere Erscheinungsbild einer Tat bestimmen“ ([Wes95], Rn. 133). Diese Umstände sind meist im „wenn-Teil“ einer Norm des Besonderen Teils benannt.
Beispiel: Würde man §223 StGB in einer wenn-dann-Schreibweise darstellen, könnte dies so aussehen:
Wenn eine Person eine andere Person körperlich misshandelt oder an der Gesundheit schädigt, dann wird diese (die handelnde) Person ... bestraft.
Der objektive Tatbestand ist in diesem Beispiel eine körperliche Misshandlung oder eine Schädigung an der Gesundheit.
Der subjektive Tatbestand besteht aus den Umständen, „die dem psychisch-seelischen Bereich und der Vorstellungswelt des Täters angehören“ ([Wes95], Rn. 136). In der Regel sind die subjektiven Tatbestandsmerkmale nicht in der Norm des geprüften Delikts selbst aufgeführt. Zum Beispiel ist in §15 – einer Norm des Allgemeinen Teils des Strafgesetzbuches – für alle Normen festgelegt, dass in der Regel nur vorsätzliches Handeln bestraft werden darf.
§15. Vorsätzliches und fahrlässiges Handeln. Strafbar ist nur vorsätzliches Handeln, wenn nicht das Gesetz fahrlässiges Handeln ausdrücklich mit Strafe bedroht.
28 Bei der juristischen Subsumtion kann dieser Schritt in solch trivialen Fällen häufig einfach ausgelassen we r-den, da sich dem Leser die Bedeutung auch so erschliessen müsste. 29 Mit Tatbestand ist hier der Tatbestand im engeren Sinne gemeint, welcher aus den Merkmalen besteht, „die dem jeweiligen Delikt das individuelle Gepräge geben und seinen typischen Unrechtsgehalt charakterisieren“ (s. [Wes95], Rn. 116 ff.).

33
Wird nun beispielsweise geprüft, ob ein Verhalten den Tatbestand der Körperverletzung (§223) erfüllt, so ist innerhalb der Prüfung der subjektiven Tatbestandsmäßigkeit zu ermitteln, ob der Täter mit Vorsatz gehandelt hat. Gelegentlich tauchen subjektive Tatbestandsmerkmale allerdings auch direkt in der Beschreibung des entsprechenden Delikts auf. Beispiel:
§ 229. Fahrlässige Körperverletzung. Wer durch Fahrlässigkeit die Körperverlet-zung einer anderen Person verursacht, wird mit Freiheitsstrafe bis zu drei Jahren oder mit Geldstrafe bestraft.
Rechtswidrigkeit Im nächsten Schritt erfolgt die negative Prüfung, „ob die ‚unrechtsindizierende’ Wirkung der Tatbestandsverwirklichung durch Rechtfertigungsgründe ausgeschlossen wird“ ([Wes95], Rn. 861).
Beispiele: §32. Notwehr. (1) Wer eine Tat begeht, die durch Notwehr geboten ist, handelt nicht rechtswidrig. (2) Notwehr ist die Verteidigung, die erforderlich ist, um einen gegen-wärtigen rechtswidrigen Angriff von sich oder einem anderen abzuwenden. §33. Überschreitung der Notwehr. Überschreitet der Täter die Grenzen der Notwehr aus Verwirrung, Furcht oder Schrecken, so wird er nicht bestraft. § 228. Einwilligung. Wer eine Körperverletzung mit Einwilligung der verletzten Per-son vornimmt, handelt nur dann rechtswidrig, wenn die Tat trotz der Einwilligung ge-gen die guten Sitten verstößt.
Schuld Im Rahmen der Schuld-Prüfung wird ermittelt, ob dem Täter die rechtswidrige Tat persönlich vorzuwerfen ist ([Wes95], Rn. 395). Nur wenn dies der Fall ist, darf der Täter letztlich be-straft werden. Es gibt verschiedenste Gründe, warum eine Tat ohne „Schuld“ begangen wor-den sein kann.
Beispiele: §19. Schuldunfähigkeit des Kindes. Schuldunfähig ist, wer bei der Begehung der Tat noch nicht vierzehn Jahre alt ist. §35. Entschuldigender Notstand. (1) Wer in einer gegenwärtigen, nicht anders ab-wendbaren Gefahr für Leben, Leib oder Freiheit eine rechtswidrige Tat begeht, um die Gefahr von sich, einem Angehörigen oder einer anderen ihm nahestehenden Person abzuwenden, handelt ohne Schuld...
2.2.4 Prüfungsreihenfolge
Die oben beschriebene juristische Subsumtion dient dazu, einem abstrakten Tatbestand einen Sachverhalt unterzuordnen. Häufig wird es allerdings erwünscht sein, dass ein gegebener Sachverhalt gleich unter mehrere Normen subsumiert wird, da zur Ermittlung der Rechtsfolge

34
eines Verhaltens zunächst geklärt werden muss, gegen welche Gesetze verstoßen wurde. Bei umfangreicheren Sachverhalten müssen mehrere Normen im Hinblick auf mehrere verschie-dene Lebensvorgänge überprüft werden. So könnten in einem strafrechtlichen Fall gleich mehrere Verhaltensweise auf Strafbarkeit zu überprüfen sein. Um die juristische Arbeitsweise nachvollziehbar zu gestalten, bietet es sich an, die erforderlichen Prüfungen sinnvoll zu ord-nen. Hier kommen nach [Wes95] (Rn. 855-858) drei verschiedene Arten der Darstellung in Betracht: Chronologischer Aufbau Die Lebensvorgänge werden in ihrer zeitlichen Abfolge untersucht. Vorteil dieser Vorge-hensweise ist, dass der Bearbeiter hierbei kaum vergessen kann, einen Sachverhaltsaspekt zu bearbeiten. Allerdings werden bei dieser Methode Tatkomplexe mitunter auseinander geris-sen.
Person A schlägt Person B. Dann zerschlägt Person A eine Flasche und benutzt die so gewonnene Waffe für einen Stich in den Arm von Person B.
Hier würde nun in einem chronologischen Aufbau zunächst der Schlag hinsichtlich einer Körperverletzung zu überprüfen sein. Bevor dann der Stich geprüft würde, müsste streng ge-nommen erörtert werden, ob das zerschlagen der Flasche eine Sachbeschädigung darstellt. Aufbau nach Tätern und Beteiligten Bei dieser beliebten Methode werden die Strafbarkeiten nach Personen geordnet untersucht. Diese Vorgehensweise ist sehr übersichtlich. Dies gilt allerdings nur für weniger verwickelte Fälle.
Person A schlägt Person C, welche von Person B festgehalten wird. Danach hält Person A Person C fest und Person B schlägt zu.
Person A hat durch den Schlag eine Körperverletzung und durch das Festhalten eine Teil-nahme an einer Körperverletzung begangen. Für Person B gilt das gleiche. Die Teilnahme kann aber sinnvoll nur geprüft werden, wenn die Haupttat (an der sich beteiligt wird) bereits erörtert wurde. Im vorliegenden Fall ist dies nicht möglich, wenn der Aufbau nach Tätern geordnet werden soll. Aufbau nach Tatkomplexen Der Sachverhalt wird bei einem Aufbau nach Tatkomplexen zunächst hinsichtlich Sachver-haltsabschnitten, die eine in sich geschlossene Einheit bilden, geordnet. Diese Komplexe wer-den dann der Reihe nach geprüft. Im letzten Beispiel lassen sich die kleinen Komplexe „Per-son A schlägt Person C mit Hilfe von Person B“ und „Person B schlägt Person C mit Hilfe von Person A“ ausmachen. Innerhalb dieser Komplexe kann dann nach Personen geordnet werden. Hierbei kann nun darauf geachtet werden, dass jeweils die Strafbarkeiten der Person zuerst geprüft werden, welche die Haupttat begangen hat.

35
3 Ausgewählte juristische Systeme
In diesem Abschnitt soll dargestellt werden, welche Bemühungen bereits unternommen wur-den, Computer einzusetzen, um die Arbeit eines Juristen zu unterstützen oder nachzuahmen. Hierbei sind solche Projekte von Interesse, die das Ziel haben, „künstliche Intelligenz“ einzu-setzen, um die juristische Methodik oder Teilaspekte dieser zu modellieren. Diese meist als juristische Expertensysteme bezeichneten Projekte wurden insbesondere in den 80er Jahren zu entwickeln versucht. Aus der Menge der hauptsächlich in dieser Zeit entwickelten Systeme, werden in diesem Kapitel insbesondere solche Ansätze dargestellt, welche für bestimmte Entwurfsentscheidungen des juristischen Systems von Bedeutung waren. So wird beispiels-weise im LEX-Projekt die Machbarkeit einer natürlichsprachlichen Schnittstelle erprobt und das System WZ versucht sich am Umgang mit unbestimmten Rechtsbegriffen. Im Anschluss an die Beschreibung eines Systems wird jeweils eine kurze Bewertung vorg enommen. Ausserdem werden in Unterkapitel 3.4 einige regelbasierte Ansätze in einer kürzeren Darstel-lungsform zusammengefasst, einen Eindruck davon zu vermitteln, wofür regelbasierte Ansät-ze im Recht verwendet werden. Da Literatur zu den verschiedenen Projekten teilweise nur schwer zugänglich ist, orientieren sich die kurzen Darstellungen der Projekte CABARET, HYPO und KOKON einzig an der der Sekundärquelle [Jan93], welche auch zur Vermittlung eines weitergehenden Überblicks über die Entwicklung juristischer Expertensysteme zu emp-fehlen ist.
3.1 LEX-1
3.1.1 Systembeschreibung
LEX30-1 ist der Prototyp eines juristischen Expertensystems auf natürlichsprachlicher Basis. Der Beschreibung basiert auf der Darstellung in [HL89]. Der Systementwicklung lag das Ziel zu Grunde, bessere Erkenntnisse über das menschliche Informations- und Entscheidungsverhalten zu gewinnen und dieses nachzuahmen. Darüber hinaus sollte das System in der Lage sein, natürliche Sprache zu verstehen. Später entwickelte sich dieser Versuch des Sprachverstehens als Schwerpunkt des Projekts heraus. Den juristi-schen Anwendungsbereich von LEX-1 stellt der „Unfallfluchtparagraph“ §142 I, IV StGB dar; dennoch war ein Ziel des Projektes die Anwendungsunabhängigkeit des Systems. So soll-te es prinzipiell möglich sein, durch Austausch der Daten in der Wissensbasis auch andere Anwendungen mit ihm zu verwirklichen. Die Architektur des Systems entspricht der in Kapitel 2.1.1 dargestellten Expertensystemar-chitektur. Allerdings verfügt LEX-1 darüber hinaus über jeweils eine Komponente zur Analy-se (NLA31) beziehungsweise Synthese (NLS32) natürlicher Sprache, welche zwischen der Dia-logkomponente und den anderen Komponenten des Systems in die Systemarchitektur einge-bunden sind.
30 LEX steht für „Linguistik- und logikbasiertes juristisches Expertensystem. LEX ist ein gemeinsames For-schungsprojekt der Universität Tübingen und der IBM Deutschland GmbH. ist ein gemeinsames Forschungsprojekt der Universität Tübingen und der IBM Deutschland GmbH, an welchem Informatiker, Logiker, Linguisten und Juristen beteiligt waren. 31 Natural Language Analyzer 32 Natural Language Synthesizer

36
Das in der Wissensbasis von LEX-1 enthaltene Wissen ist in die drei Bereiche Fallwissen, Allgemeinwissen und juristisches Wissen unterteilt und wird durch sogenannte Diskursreprä-sentationsstrukturen (kurz: DRSen), welche vom NLA und NLS analysiert beziehungsweise erzeugt werden, dargestellt. Eine DRS stellt entweder eine Regel oder ein Fakt dar. Durch Deduktion wird über die Infernzkomponente unter Verwendung des Wissens in der Wissens-basis zu beweisen versucht, dass der im Fallwissen enthaltene Sachverhalt den Tatbestand der Unfallflucht erfüllt. Gelingt dies, so ist die Erklärungskomponente mit Hilfe des während der Inferenz erstellten Beweisbaumes in der Lage, Fragen zu dem bearbeiteten Sachverhalt zu beantworten. Die Leistungsmöglichkeit des letztlich implementierten Systems ist stark begrenzt. LEX-1 ist in der Lage, eine Fallbeschreibung (mit kleinen Änderungen) – auf welche die Wissensbasis speziell zugeschnitten wurde – zu bearbeiten. Eine weitere Fallbeschreibung konnte von ei-nem Systemkenner so modifiziert werden, dass eine Bearbeitung möglich wurde.
3.1.2 Bewertung
Die wohl schwerwiegendste Ursache, für das praxisuntaugliche Resultat von LEX-1 ist, dass der Versuch, Computersysteme in die Lage zu versetzen, natürliche Sprache zu „verstehen“, die Systementwickler vor viele Schwierigkeiten stellt. Ein Teil dieser Schwierigkeiten soll anhand eines kleinen Beispieles aufgezeigt werden. „Frau Müller fährt Herrn Maier auf der Landstraße mit ihrem Wagen an. Dieser stürzt und verliert einen Zahn.“ Für den menschlichen Leser ist es leicht, den obigen Sachverhalt zu verstehen, ihn in seiner Bedeutung zu erfassen. Ein wissensbasiertes System, welches einen solchen Sachverhalt „ver-stehen“ soll, muss diesen in geeignete Repräsentationsstrukturen umsetzen können. Hierzu genügt es nicht, die deutsche Grammatik zu beherrschen und über einen großen Wortschatz zu verfügen. Stattdessen können einzelne Satzteile häufig nur unter Beachtung des Kontextes interpretiert werden. Mit Kontext kann hierbei ein Satz gemeint sein; es kann aber auch vor-kommen, dass andere Sätze zum Verständnis hinzugezogen werden müssen. Diese Abhängig-keit vom Kontext soll nun am obigen Beispiels gezeigt werden. So bedeutet „einen Zahn zu verlieren“ in der Regel, dass man ihn aus dem Mund verliert. Denkbar wäre allerdings auch, dass Herr Maier den Zahn im obigen Sachverhalt in der Tasche mit sich trug. Da dies aber nicht extra erwähnt wurde, genügt das Indiz, dass Herr Maier ge-stürzt ist, um die intendierte Bedeutung zu erschliessen. Die Bedeutung des Begriffs „Wagen“ ist ebenfalls nicht eindeutig. Theoretisch könnte auch ein Einkaufswagen gemeint sein. Diese Möglichkeit wird allerdings durch Auswertung der Tatsache, dass sich der Unfall auf einer Landstraße ereignete, zu unwahrscheinlich. Drittens ist nicht klar, wer genau stürzt. Mit „die-ser“ kann aus grammatikalischer Sicht auch der Wagen gemeint sein. Dies wäre sogar wahr-scheinlich, da „Wagen“ das letztgenannte Wort ist, auf welches „dieser“ referenzieren könnte. Da man aber wohl eher nicht davon spricht, dass ein Wagen stürzt und ein Wagen auch keine Zähne hat, die er verlieren könnte, muss Herr Maier gemeint sein. Aus diesen Beobachtungen ergibt sich, dass ein wissensbasiertes System wesentlich mehr Wissen benötigt, als man zunächst annehmen könnte. Dieses Wissen, welches bei der wis-

37
sensbasierten Sprachanalyse33 explizit in einer Wissensbasis gespeichert ist, lässt sich unter-teilen in Wortschatz, Grammatikregeln, Wortbedeutungen, semantische Regeln, Ableitungs-regeln, Inferenzregeln (vgl. [Sag90], S. 3 ff.). Abgesehen von den Problemen der Sprachanalyse erscheint der Ansatz, Regeln einzusetzen, um juristisches Wissen zu repräsentieren, vielversprechend. Ein schwerwiegendes Problem ist hierbei nach Angaben der an der Entwicklung der Regeln in LEX-1 Beteiligten, diese Regeln durch eine angemessene Modellierung des Rechts zu erarbeiten.
3.2 WZ
3.2.1 Systembeschreibung
Ein großes Problem bei der automatisierten Subsumtion stellen die sogenannten unbestimm-ten Rechtsbegriffe dar. Ein Versuch, ein System zu entwickeln, dass einen solchen Begriff „beherrscht“, wurde in [Ger87] unternommen. Das im Rahmen dieses Versuchs entwickelte System WZ34 basiert auf der Idee, es sei prinzi-piell möglich, die Merkmale, welche entscheidend für die Einordnung eines Falles unter einen unbestimmten Rechtsbegriff sind, herauszufinden und anhand dieser Merkmale auf irgendeine Art zu ermitteln, ob der entsprechende Fall unter diesen Rechtsbegriff fällt oder nicht. An-wendungsbereich des Systems ist wie schon bei LEX-1 §142 StGB. Der in §142 enthaltene unbestimmte Rechtsbegriff ist die „angemessene Wartezeit“. Durch WZ soll gezeigt werden, dass dieser Begriff und prinzipiell auch andere unbestimmte Begriffe durch exakte Berech-nungsregeln modelliert werden könnten (vgl. [Ger87], S. 147).
Wartezeit
Tageszeit
Wartezeit
...
<38 >=38
unangemessen unangemessen
keine Angabe
untertags abends
Unfallort
nachts
unangemessen angemessen
>=13 <13
Wartezeit
inner- oder außerorts in bebautem Gebiet
unangemessen
sonst
unangemessen angemessen
>=15 <15
Abbildung: Teil des Entscheidungsbaumes von WZ
33 Alternative Systemkonzeptionen können beispielsweise Neuronale Netze als Grundlage haben. Bei diesen Systemen wird Wissen nicht explizit abgelegt, sondern implizit: es „befindet“ sich in der Vernetzungsstruktur der Neuronen. 34 WZ wurde im Rahmen einer Dissertation von Peter Gerathewohl entwickelt.

38
WZ fußt auf einer zunächst vorgenommenen Analyse richterlicher Entscheidungen, bei wel-cher die in den Urteilsbegründungen genannten relevanten Merkmale ermittelt wurden. Bei-spiele für solche Merkmale sind Tageszeit, zur Wartezeit vorherrschende Witterungslage, Unfallort und Verkehrsdichte. Die einzelnen Merkmale jeweils in verschiedenen Ausprägun-gen vorkommen. So kann das Merkmal „Verkehrsdichte“ in den Ausprägungen „wenig oder kein Verkehr“, „normaler, fließender Verkehr“, „lebhafter/dichter Verkehr“ und „keine An-gabe hierzu“ auftreten. Mittels „RuleMaker“ (einem Regelgenerator innerhalb der Shell „Ru-leMaster“) wurde auf Basis der Daten der analysierten Beispielfälle ein Entscheidungsbaum geschaffen. Teilt der Systemanwender WZ mit, welche Merkmale in welcher Ausprägung vorliegen, kann WZ (vermeintlich) über diesen Entscheidungsbaum feststellen, ob eine be-stimmte Wartezeit angemessen war.
3.2.2 Bewertung
Ein ähnlicher Ansatz ließe sich auch mit Hilfe „Neuronaler Netze“ verwirklichen, wobei zu-nächst wieder die relevanten Merkmale gefunden werden müssten. Nachfolgend könnten die entsprechenden Netze mit Musterfällen trainiert werden. Beide Ansätze weisen allerdings grundsätzliche Probleme auf, worauf [Jan93] zutreffend hinweist (S. 42 f.): Ein großes Problem stellt dar, dass zunächst die relevanten Merkmale ermittelt werden müss-ten. Hierbei ist es sehr fraglich, ob dies überhaupt gelingen kann. Selbst wenn alle richterli-chen Entscheidungen analysiert würden, könnte es sein, dass in der als nächstes folgenden Entscheidung ein neues Merkmal von Relevanz ist. Es ist daher wohl nicht zu beweisen, dass eine Liste relevanter Merkmale vollständig ist. Ein anderes Problem ist, dass bei der Zerlegung eines Begriffes in bedeutsame Merkmale teilweise wiederum unbestimmte Begriffe gebraucht werden. So benötigt das System WZ beispielsweise die Information, ob die Witterung während der Wartezeit normal oder extrem war, was wiederum ohne (Be-)Wertung der Witterungslage nicht möglich ist. Die Verwen-dung neuer unbestimmter Begriffe lässt sich auch nicht ohne weiteres verhindern, schon gar nicht, wenn man nur Merkmale verwenden möchte, welche Urteilsbegründungen entnommen wurden. Letztlich würden insbesondere „Neuronale Netze“ gegen die Maxime verstoßen, die Ent-scheidungen des Expertensystems durchschaubar und nachvollziehbar zu gestalten. Aber auch in WZ ist die Berechnungsregel undurchsichtig und das Resultat – die „angemessene Warte-zeit“ – wird nicht begründet. Über die genannten Kritikpunkte hinaus ist es sehr fragwürdig, ob es überhaupt wünschens-wert wäre, unbestimmte Rechtsbegriffe von einem Computer bestimmbar zu machen. So un-terliegt der Rechtsbegriff der „guten Sitten“ auch dem Wandel der Zeit. Was heute als sitten-konform gilt, kann vor einigen Jahren noch gegen die „guten Sitten“ verstoßen haben. Hier kann ein Richter nicht auf Präjudizien beharren, sondern muss den Begriff an aktuelle Bege-benheiten anpassen, damit nicht die Dynamik des Rechts verloren geht. Ebensowenig kann ein unbestimmter Rechtsbegriff von einer (statischen) Berechnungsregel „bestimmt“ werden. Zwar gilt das Gebot der Gleichmäßigkeit und Beständigkeit der Rechtsprechung, doch ist die-se stets aufs Neue zu überprüfen, sonst kommt es zu einer Versteinerung des Rechts (vgl. zur Ausfüllung unbestimmter Rechtsbegriffe [Sir89], S. 41).

39
Aus diesen Erwägungen resultiert, dass die Subsumtion unter unbestimmte Rechtsbegriffe in der Zuständigkeit des Menschen verbleiben sollte. Allenfalls wäre eine Beratung des Men-schen durch den Computer denkbar, obgleich diese auch zu einer ungeprüften Übernahme des Ratschlages verführen könnte.
3.3 HYPO und darauf aufbauende Ansätze
3.3.1 Beschreibung
HYPO ist ein fallvergleichendes System. Dies bedeutet, dass es versucht, Erfahrungen aus Fällen aus der Vergangenheit für neue Fälle zu nutzen. HYPO vergleicht hierzu einen gege-benen Fall mit „Präzedenzfällen“. In der angloamerikanischen Rechtssprechung spielen zwar Präzedenzfälle eine wesentlich wichtigere Rolle als beispielsweise im deutschen Recht, den-noch haben Systeme wie HYPO auch in Deutschland ihre Berechtigung. Wird unter einen unbestimmten Rechtsbegriff subsumiert, so werden – dem Gebot der Beständigkeit und Gleichmäßigkeit der Rechtsprechung folgend – Präzedenzfälle zur Beratung herangezogen, wenngleich diese keine gesetzesgleiche oder gesetzesähnliche Kraft besitzen. Dennoch dienen gerade höchstrichterliche Entscheidungen häufig als Musterprozesse und erhalten so im deut-schen Recht praktische Bedeutung (vgl. [Sir89], S. 41). Ähnlich wie bei dem System WZ werden bei HYPO Fälle mittels verschiedener, abgestufter Merkmale charakterisiert. Der Anwendungsbereich des Systems ist der „Schutz von Ge-schäftsgeheimnissen“. Das System ist in der Lage, (bei Vorliegen einer Fall-Charakterisierung) eine Anklage mit Hilfe von Präzedenzfällen zu stützen oder zu verteidigen (vgl. [Jan93], S. 43 ff.). Das Fallvergleichskonzept von HYPO wurde beispielsweise in [PS97], [PS98] und [Ben99] weiter untersucht und verfeinert. An dieser Stelle soll lediglich die Darstellung aus [Ben99] zusammengefasst werden, welche die Ideen aus [PS97]/[PS98] aufgreift. Demnach besteht ein Fall jeweils aus mehreren Argumenten, die sich jeweils entweder als Argument des Klägers oder als Argument des Angeklagten einordnen lassen. Angenommen, ein Fall bestünde aus den Argumenten A,B,C,D und E, wobei A, B, C anklagestützende Ar-gumente („pro-plaintiff“ (p)) und die anderen Argumente anklageverteidigende Argumente („pro-defendant“ (d)) darstellen. Dies würde durch folgende Regeln dargestellt:
R1: A & B & C -> p. R2: D & E -> d.
Sei weiter angenommen, der Fall sei von der Verteidigung gewonnen worden. Nach dem hier dargestellten Ansatz, würde dies bedeuten, dass die Argumente aus R2 zusammen stärker wiegen als die Argumente aus R1. Dies würde folgendermaßen dargestellt:
R3: R1 < R2
Unter der Annahme, dass alle Argumente voneinander unabhängig sind und entweder vorlie-gen oder nicht, können, wenn darüber hinaus angenommen wird, dass zusätzliche Argumente für eine bestimmte Seite die entsprechende Position niemals abschwächen, die Argumente in eine partielle Ordnung gebracht werden. Hier ein Auszug der sich daraus ergebenden Folge-rungen für das obige Beispiel:
R1a: A & B -> p.

40
R1b: A & C -> p. R2a: D -> d. R3a: R1a < R2. R3b: R1b < R2.
Durch jeden neu hinzu kommenden Fall wird die Ordnung verfeinert, so dass immer mehr Fälle beurteilt werden können. Probleme treten beispielsweise auf, wenn Fälle ergänzt wer-den, aus welchen Widersprüche resultieren. Diese Situation träte beispielsweise ein, wenn ein Fall mit den Argumenten A,B,D und E für den Ankläger entschieden würde, was im Wider-spruch zu R3 in Verbindung mit der Forderung, dass zusätzliche Argumente die entsprechen-de Position nicht abschwächen dürfen, steht.
3.3.2 Bewertung
Wie schon im System WZ, so muss auch bei HYPO im vorhinein geklärt werden, was mögli-che relevante Merkmale sind. Dieser Mangel wird jedoch von den anderen Ansätzen behoben. Alle Ansätze haben derzeit noch Probleme mit der Skalierung von Argumenten, da hier eine Darstellung gefunden werden muss, welche sich in die partielle Ordnung einbinden lässt (vgl. hierzu den Versuch in [Ben99], S.38 ff.). Schwerer wiegt allerdings wohl die bereits ange-sprochene Tatsache, dass sich verschiedene Fälle widersprechen können. Es wird vorgeschla-gen, diese Situation zu lösen, indem ein an dem Widerspruch beteiligter Präzedenzfall oder der neue Fall als falsch beurteilt eingestuft wird und somit aus der Präzedenzfall-Datenbank zu entfernen ist. Als zweite Alternative wird vorgeschlagen, in solchen Situationen weitere Argumente einzuführen, welche eine Unterscheidung der „widersprüchlichen“ Fälle erlauben. Dies erscheint sinnvoll, doch ist wohl fraglich, ob eine eventuell später (wegen Auftretens eines Widerspruches) abzuändernde Fallcharakterisierung als Grundlage für Entscheidungen dienen darf. Eine Verwendung der vorgestellten Ansätze als Basis für eine Argumentations-hilfe, welche diese Ansätze ursprünglich motivierte, erscheint hingegen denkbar.
3.4 Sonstige regelbasierte Ansätze
CABARET35 ist ein Nachfolgeprojekt des oben beschriebenen Systems HYPO. Es verwendet klassische und probabilistische Regeln nebeneinander und kann daher auch als hybrides Sys-tem klassifiziert werden. Es kann verwendet werden, um einen Standpunkt zu vertreten oder um Argumente gegen die diesen Standpunkt stützenden Argumente aufzuzeigen (vgl. [Jan93], S. 276). Das System KOKON36 stellt ein System dar, welches dazu dienen soll, Grundstückskaufver-träge aufzusetzen. Der Anwender trägt in einem Formular die Daten des Kaufs ein und sieht parallel zur Dateneingabe die jeweils aktuelle Version des Vertrages. Regeln dienen dazu, aus den Eingaben Daten zu gewinnen, welche in einem Grundstückskaufvertrag anzugeben sind. So kann KOKON beispielsweise aus Daten wie dem Alter oder dem Personenstand ableiten, ob die Vertragspartei geschäftsfähig ist, ob behördliche Genehmigungen erforderlich sind oder ob eine Ehegattenzustimmung (§1365 BGB) benötigt wird (vgl. [Jan93], S. 273 f.). De-fault-Reasoning wird verwendet, um immer eine aktuelle Vertragsversion anzeigen zu kön-nen, welche anfangs ausschließlich aus den Default-Werten ermittelt wird.
35 CABARET steht für „Case-Based Reasoning Tool“und stammt von Edwina L. Rissland und David B. Skalak (University of Massachusetts). 36 KOKON wurde von Systemtechnik Berner und Mattner entworfen und in Zusammenarbeit mit der TU Mün-chen im Rahmen des WISDOM-Verbundprojektes verwirklicht.

41
4 Exkurs: Analogie zwischen Rechtsanwendung und wissensbasierten Systemen
An dieser Stelle erfolgt ein kurzer Exkurs, welcher zeigen soll, dass zwischen juristischer Me-thodik und wissensbasierten Systemen gewisse Parallelen existieren. Zwar sollte man diese Erkenntnis nicht überbewerten, doch motivieren diese Parallelen auch den Aufbau des juristi-schen Systems – welcher in den beiden folgenden Kapiteln beschrieben wird – mit. Der nun dargestellt Vergleich wurde 1987 von [FG87] (S. 63 ff.) angestellt. Repräsentiert man einen Fall über gegebene Fakten in einer Wissensbasis, so sei dies zu ver-gleichen mit der tatsächlichen Situation vor Gericht, wenn alle Aussagen vorliegen. Diese von den verschiedenen Parteien oder Zeugen getätigten Aussagen liegen in einem wissensbasier-ten System in Faktenform vor. Während in der Praxis der Richter nun den Fall im Lichte der Gesetze betrachten muss, kön-nen in regelbasierten Systemen Regeln verwendet werden, um zu Urteilen zu gelangen. Sol-che Regeln seien vergleichbar mit (bestimmten) Gesetzen. Wie ein Richter auf verschiedene Arten mit Hilfe der ihm vorliegenden Fakten und Gesetze zu seinem Urteil kommt, kann mitunter unterschiedlich sein. Zwar wird in einem juristischen Gutachten zunächst die Norm genannt und dann versucht, diese an die Fakten „anzupassen“ (top-down), doch stellt ein juristisches Gutachten nur eine Darstellungsform des Ergebnisses juristischen Schließens dar. Die Schlüsse, über welche der Richter zu seinem Urteil gelangte, können durchaus auch in umgekehrter Richtung, also von den Sachverhaltsfakten ausgehend, vorgenommen worden sein (bottom-up). Ebenso ist es denkbar, dass der Richter, um zu sei-nem Urteil zu gelangen, Sachverhalt und Norm aneinander anzupassen versucht hat und dabei teilweise von den Gesetzesnormen und teilweise von den Sachverhaltsfakten ausging (ge-mischte Strategie). Wie der Richter nun genau das Urteil erarbeitet, könne verglichen werden mit der von der Inferenzkomponente verwendeten Regel-Anwendungs-Strategie. Insofern entspräche die Judikative in gewissem Sinne solch einer Inferenzkomponente. Es dürfte wohl offensichtlich sein, dass die oben aufgezeigten Parallelen zwischen wissensba-sierten Systemen und dem Rechtsfindungsvorgang von mehr oder weniger starken Vereinfa-chungen ausgehen. So können beispielsweise Aussagen einander widersprechen. In solchen Fällen können nun nicht einfach die Gesetze beziehungsweise Regeln angewendet werden, um zu einem Urteil zu gelangen. Der Grund dafür ist, dass dann der Fall eintreten könnte, dass verschiedene, widersprüchliche Urteile hergeleitet werden. Dieser Fall ist auch in Situa-tionen denkbar, wo die Entscheidung eines Falles der Gesetzesauslegung bedarf. Um hier eindeutige Entscheidungen treffen zu können, sind zum einen Mechanismen erforderlich, welche es ermöglichen, Gesetze auszulegen. Außerdem muss eine Inferenzkomponente he-rausfinden können, wem geglaubt werden kann und wem nicht. Trotz solcher Probleme darf wohl zu Recht von gewissen Parallelen zwischen Rechtsanwen-dung und wissensbasierten Systemen gesprochen werden. Bei der Entwicklung solcher Sys-teme darf diese Erkenntnis allerdings nicht dazu verführen, zu stark zu vereinfachen und die Rechtsanwendung somit wichtiger Facetten zu berauben. Stattdessen ist zu versuchen, Prob-leme wie die oben angesprochenen, angemessen zu behandeln oder die Funktionalität des Systems in problematischen Bereichen einzuschränken und den menschlichen Jurist in die Entscheidungsfindung des Systems zu involvieren.

42
5 Formalisierung juristischer Sachverhalte und Normen
In diesem Kapitel und in Kapitel 6 wird das im Rahmen dieser Arbeit entwickelte wissensba-sierte juristische System vorgestellt. Während sich Kapitel 6 mit der Implementierung und der Architektur beschäftigt, geht es in diesem Kapitel darum, darzustellen, auf welche Weise das Wissen aus dem Anwendungsbereich innerhalb des Systems dargestellt wird. Um hierauf ge-nau eingehen zu können, muss zunächst geklärt werden, welche Datenbanksprache(n) inner-halb des Systems verwendet werden soll(en) (Kapitel 5.1). Ferner ist der genaue Anwen-dungsbereich des Systems einzugrenzen. Dazu wird zunächst in Kapitel 5.2 der zu modellie-rende Gesetzesausschnitt ausgewählt. Anschließend wird in Kapitel 5.3 dargelegt, welche der bei einer juristischen Subsumtion üblichen Prüfungs-Schritte von dem hier behandelten juris-tischen System tatsächlich durchgeführt werden. Erst im Anschluss an diese Vorbereitungen wird in Kapitel 5.4 und Kapitel 5.5 gezeigt, auf welche Weise der Sachverhalt beziehungs-weise die juristischen Normen formal dargestellt werden.
5.1 Datenbanksprachen
Wie angekündigt, wird nun diskutiert, welche Sprache(n) als DDL und DML des juristischen Systems verwendet werden soll(en). Aufgrund der Eigenschaft, Handlungsabfolgen in beliebiger Länge („horizontal extensibili-ty“) und in beliebiger Detailliertheit („vertical extensibility“) darstellen zu können, bietet sich die Prädikatenlogik erster Stufe beziehungsweise darauf basierende logische Sprachen wie Prolog oder Datalog zur Beschreibung von Sachverhalten an (vgl. [Bra99], S. 1). Diese bei-den Sprachen wurden in den Kapiteln 2.1.8.1 und 2.1.8.2 dargestellt. Es gibt verschiedene Argumente, welche Prolog gegenüber Datalog zur Verwendung im juristischen System favo-risieren. Die Reihenfolgeunabhängigkeit von Datalog mag für viele Anwendungen von Vorteil sein. Im juristischen System soll aber mit Hilfe von Ableitungsregeln hauptsächlich die juristische Subsumtion nachgeahmt werden. Hierbei sollen juristische Gutachten erstellt werden, bei welchen es in der Regel nicht gleichgültig ist, in welcher Reihenfolge die einzelnen Prüfungs-schritte durchgeführt werden (vgl. Kapitel 2.2.4). Eine mengenorientierte Semantik – wie in Datalog – wird vermutlich nicht so häufig benötigt, daher genügt es, in solchen Fällen auf Prädikate wie findall/3 zurückzugreifen, mit welchen alle Lösungen zu einer Anfrage „ge-sammelt“ werden können. Ebenso von Vorteil für eine juristische Subsumtion ist die „top-down“-Auswertungsstrategie von Prolog. In einem juristischen Gutachten wird ausgehend von einer Norm versucht, diese mit einem Sachverhalt zur Deckung zu bringen. Betrachtet man die Abbildung in Kapitel 2.2.1, so erkennt man, dass es sich hierbei auch um eine „top-down“-Auswertung handelt. Außerdem kann Prolog durch seine außer-logischen Konzepte nicht nur als Datenbankspra-che, sondern darüber hinaus auch besonders gut als Programmiersprache für das gesamte ju-ristische System verwendet werden. Diese außer-logischen Konzepte lassen es auch zu, die Ableitungsreihenfolge zu beeinflussen und so an das jeweilige Problem anzupassen. So lassen sich Prolog-Regeln beispielsweise im Wechsel auf Sachverhalt und Norm anwenden, um so das in Kapitel 2.2.2 beschriebene „Hin-und-Herwandern des Blickes“ zu simulieren. Der gro-

43
ße Nachteil der außer-logischen Prolog-Konzepte ist allerdings, dass durch ihre Verwendung die Deklarativität in ihrer Reinheit verloren geht. Daher sollten diese Konzepte nur zur Da-tenmanipulation auf einer Meta-Ebene verwendet werden, nicht jedoch zur Beschreibung von Gesetzen oder Aspekten des Sachverhalts. Als populärste Datenbanksprache käme eventuell noch SQL in Frage, im juristischen System verwendet zu werden. Leider existieren in SQL-2 keine rekursive Sichten. Aber selbst wenn man die neueste SQL-3-Spezifikation zu Grunde legen würde, könnte man mit SQL immer noch nicht die Ableitungsreihenfolge so elegant beeinflussen, wie dies in Prolog möglich ist. Somit wird lediglich Prolog verwendet37, um das juristische System zu implementieren. Als DDL dient reines Prolog. Im juristischen System wurde der Prolog-Compiler ECLiPSe ver-wendet.
5.2 Auswahl des zu modellierenden Gesetzesauschnitts
Bevor nun genauer darauf eingegangen werden kann, wie mit Hilfe von Prolog Gesetze und Sachverhalte modelliert werden, muss zunächst geklärt werden, welche Normen überhaupt modelliert werden sollen. Das juristische System soll zwar anhand konkreter Gesetze arbei-ten, im Vordergrund soll aber die Imitation juristischer Methodik stehen. Insofern spielt die Wahl der Gesetze, welche vom juristischen System bearbeitet werden können sollen, nur eine untergeordnete Rolle. An das System darf nicht die Anforderung gestellt werden, dass es alle erdenklichen Normen „beherrscht“. Damit soll gemeint sein, dass das System nicht unter alle real existierenden Normen subsumieren können muss. Dies ist angesichts der Flut von Geset-zen wohl selbstverständlich, hat aber zur Folge, dass ein bestimmter Bereich des Gesetzes ausgewählt werden muss. Die Gesetze sollten so ausgewählt werden, dass bei einem juristischen Gutachten möglichst viele Aspekte juristscher Methodenlehre zur Anwendung kommen. Auf diese Weise wird erzwungen, dass für die verschiedensten Schwierigkeiten, welche im Rahmen der Subsumtion auftreteten können, Lösungen gefunden werden müssen. Zu diesen Aspekten gehören bei-spielsweise Auslegung und Wertungen im Zusammenhang mit unbestimmten Rechtsbegrif-fen. Die verschiedenen Gesetze sind in unterschiedlichem Maße auslegungsbedürftig und in längst nicht allen Gesetzen kommen wertungsbedürftige unbestimmte Rechtsbegriffe vor. Hierzu zunächst zwei extreme Beispiele:
§4 HeizAnlV38. Einbau und Aufstellung von Wärmeerzeugern. (3) Zentralheizungen mit einer Nennwärmeleistung von mehr als 70 kW sind mit Ein-richtungen für eine mehrstufige oder stufenlos verstellbare Feuerungsleistung oder mit mehreren Wärmeerzeugern auszustatten. ... §157 BGB. Auslegung von Verträgen. Verträge sind so auszulegen, wie Treu und Glauben und Rücksicht auf die Verkehrssitte es erfordern.
Die Vorschrift aus der Heizungsanlagen-Verordnung enthält keine auslegungs- oder wer-tungsbedürftigen Passagen. Zwar ist in diesem Beispiel keine Rechtsfolge angegeben – diese findet sich in einem anderen Paragraphen der Heizungsanlagen-Verordnung –, doch sollte 37 Ausnahme: Dialogkomponente (s. Kapitel 6.5) 38 Heizungsanlagen-Verordnung

44
erkennbar sein, dass sich solche Gesetze sehr einfach mit Regeln darstellen lassen. Anders sieht die Situation im zweiten Beispiel aus. Im Gegensatz zu §4 HeizAnlV enthält §157 BGB unbestimmte Rechtsbegriffe („Treu und Glauben“, „Rücksicht auf die Verkehrssitte“). Hier stößt die Darstellung durch Regeln auf Probleme (vgl. Kapitel 3.2.2). Da solche Probleme in einem gewissen Maß in fast allen Gesetzen auftauchen, muss ein Sys-tem, welches die juristische Subsumtion nachahmen möchte, in der Lage sein, mit diesen Problemen umzugehen. Daher sollten die Normen der Wissensbasis des juristischen Systems unbestimmte und auslegungsbedürftige Begriffe enthalten. Rechtssätze, welche solche Begrif-fe enthalten, nennt man auch billiges Recht (lat. ius aequum) (vgl. [Bro95], Rn. 32). Auf der anderen Seite sollte dieses billige Recht auch nicht überwiegen, da auch gezeigt werden soll, dass Regeln prinzipiell zur Darstellung von Gesetzen gut geeignet sind. Würden ausschließ-lich Gesetze modelliert, welche nur bis zu einem bestimmten Punkt zu formalisieren sind, entstünde ein falscher Eindruck. Somit ist eine Anforderung an die zu modellierenden Geset-ze, dass diese in einem „durchschnittlichen Maße“ billiges Recht (lat. ius aequum) enthalten. Eine weitere Anforderung folgt daraus, dass nur ein Teilbereich eines Rechtsgebietes model-liert wird. Es sollten Gesetze ausgewählt werden, welche isoliert betrachtet werden können. So gibt es Gesetze wie etwa im Bürgerlichen Gesetzbuch, die zu einem hohen Maße mitein-ander verflochten sind, mit der Folge, dass aus dem Versuch, einzelne Normen zu formalisie-ren, die Notwendigkeit andere Normen miteinzubeziehen resultiert. Letztlich wurden die Körperverletzungsdelikte39 aus dem 17. Abschnitt des Strafgesetzbuchs ausgewählt. Die Delikte sind in den Paragraphen 223-233 enthalten, welche auch im Anhang abgebildet sind. Diese Wahl genügt der Forderung nach einem „durchschnittlichem Maß“ an billigem Recht. Begriffe wie „hinterlistiger Überfall“ aus §224 I Nr. 3 oder „gute Sitten“ aus §228 sind in hohem Maße auslegungs- beziehungsweise wertungsbedürftig. Dennoch lassen sich in vielen Gesetzen Baumstrukturen erkennen und der ganze 17. Abschnitt stellt eine Hie-rarchie von Paragraphen dar, so dass ein großes Potential für den Einsatz von Regeln besteht. Ein weiterer Punkt, der für die Körperverletzungsdelikte spricht, ist ihr Bekanntheitsgrad. Unter dem juristischen Begriff der Körperverletzung kann sich wohl beinahe jeder etwas vor-stellen. Würden unbekanntere Normen ausgewählt, so könnte eher der Eindruck entstehen, dass nur ganz spezielle Gesetze dem hier verfolgten Ansatz zugänglich seien. Letztlich lassen sich die Körperverletzungsdelikte auch recht gut isoliert betrachten. Schränkt man den im Strafrecht üblichen Prüfungsaufbau ein wenig ein, so kann man ein System entwickeln, wel-ches (fast) ausschließlich auf der Modellierung der Körperverletzungsdelikte basiert. Wie diese Einschränkung auszusehen hat, wird nun dargestellt.
5.3 Eingeschränkter Prüfungsaufbau des juristischen Systems
Wie in Kapitel 2.2.1 dargestellt, unterteilt sich das Strafgesetzbuch in einen Allgemeinen und einen Besonderen Teil. Während der Besondere Teil verschiedene Straftaten auflistet, enthält der Allgemeine Teil Vorschriften, wie damit umzugehen ist. Diese allgemeinen Vorschriften, sind bei der Prüfung jeder Straftat zu berücksichtigen. So ergibt sich der in Kapitel 2.2.3 be-schriebene Prüfungsaufbau im Strafrecht zu einem großen Teil aus Vorschriften aus dem All-gemeinen Teil des Strafgesetzbuches. Dies hat zur Folge, dass sehr viele allgemeine Vor-schriften dem juristischen System bekannt sein müssten, wenn es eine vollständige Überprü-fung eines Körperverletzungsdelikts vornehmen wollte.
39 genauer: Straftaten gegen die körperliche Unversehrtheit

45
Ein großer Teilbereich einer solchen Prüfung kann allerdings weitestgehend ohne den Allge-meinen Teil vorgenommen werden. Hierbei handelt es sich um die Prüfung des objektiven Tatbestands. Da die Menge der vom juristischen System beherrschten Gesetze eingeschränkt werden soll, wurde darauf verzichtet, die Prüfungsschritte Rechtswidrigkeit und Schuld mit-einzubeziehen. Auch die subjektive Tatbestandsmäßigkeit wird vom juristischen System nicht geprüft. Stattdessen wird „nur“ ermittelt, ob die in den „wenn-Teilen“ der Gesetze des 17. Abschnitts des Strafgesetzbuches enthaltenen objektiven Tatbestandsmerkmale vorliegen oder nicht.
5.4 Formalisierung von Sachverhalten
Nun ist also klargestellt, welche Gesetze das juristische System in welchem Umfang bearbei-ten können soll. Als nächstes gilt es zu beschreiben, wie Sachverhalt und Normen im juristi-schen System modelliert werden sollen. Es ist schwierig, eine geeignete Darstellungsform für die Modelle von Sachverhalt und Normen zu finden, welche auch beschreibt, wie diese Mo-dellierung entwickelt wird. Der Grund hierfür ist, dass Sachverhalt und Normen streng ge-nommen nicht getrennt betrachtet werden können, da sie in wechselseitiger Abhängigkeit stehen:
- So ist für die Entwicklung der Gesetzes-Modelle entscheidend, wie der Sachverhalt modelliert ist, da Gesetze ja abstrakte Tatbestände beschreiben, welche sich mit kon-kreten Tatbeständen – also den Sachverhalten – decken sollen.
- Auf der anderen Seite kann auch die Entwicklung der Sachverhaltsdarstellung nicht
effizient erfolgen, ohne zu wissen, wie die Modelle der Gesetze aussehen. Man könnte zwar gewiss Konzepte erarbeiten, mit welchen man eine große Menge von Sachver-halten beschreiben könnte, da es aber nicht nötig ist, Sachverhalte beschreiben zu können, welche – im Fall des juristischen Systems – nichts mit Körperverletzungsde-likten „zu tun“ haben, ist es wohl sinnvoller, lediglich die Konzepte genau herauszu-arbeiten, welche den Anwendungsbereich – den 17. Abschnitt des Strafgesetzbuches – tangieren. Zwar sollen nicht ausschließlich Sachverhalte darstellbar sein, welche aus Körperverletzungen „bestehen“, es genügt aber, solche Sachverhalte repräsentieren zu können, welche es „wert“ sind, hinsichtlich der Körperverletzungsdelikte überprüft zu werden. In der Regel können „prüfenswerte“ Sachverhalte allerdings mit den gleichen Konzepten beschrieben werden, wie die Sachverhalte, welche tatsächlich tatbestands-mäßig sind.
Letztlich wurde die Entscheidung getroffen, zunächst die Modellierung des Sachverhaltes zu beschreiben. Der ausschlaggebende Grund hierfür ist, dass bereits bekannt ist, welche Gesetze vom System „beherrscht“ werden sollen. Hiermit steht prinzipiell bereits fest, welche Kon-zepte erforderlich sind, um die Sachverhalte zu beschreiben, welche im System dargestellt werden können müssen. Es ist jedoch zu beachten, dass dennoch viele Entscheidungen im Rahmen des Entwurfs der Sachverhalt-Modellierung im Hinblick auf die parallel dazu entwi-ckelte Modellierung der „Körperverletzungsgesetze“ getroffen wurden. Auf diesen Aspekt wird in der nun folgenden Beschreibung der Sachverhalt-Modellierung im einzelnen immer wieder eingegangen.
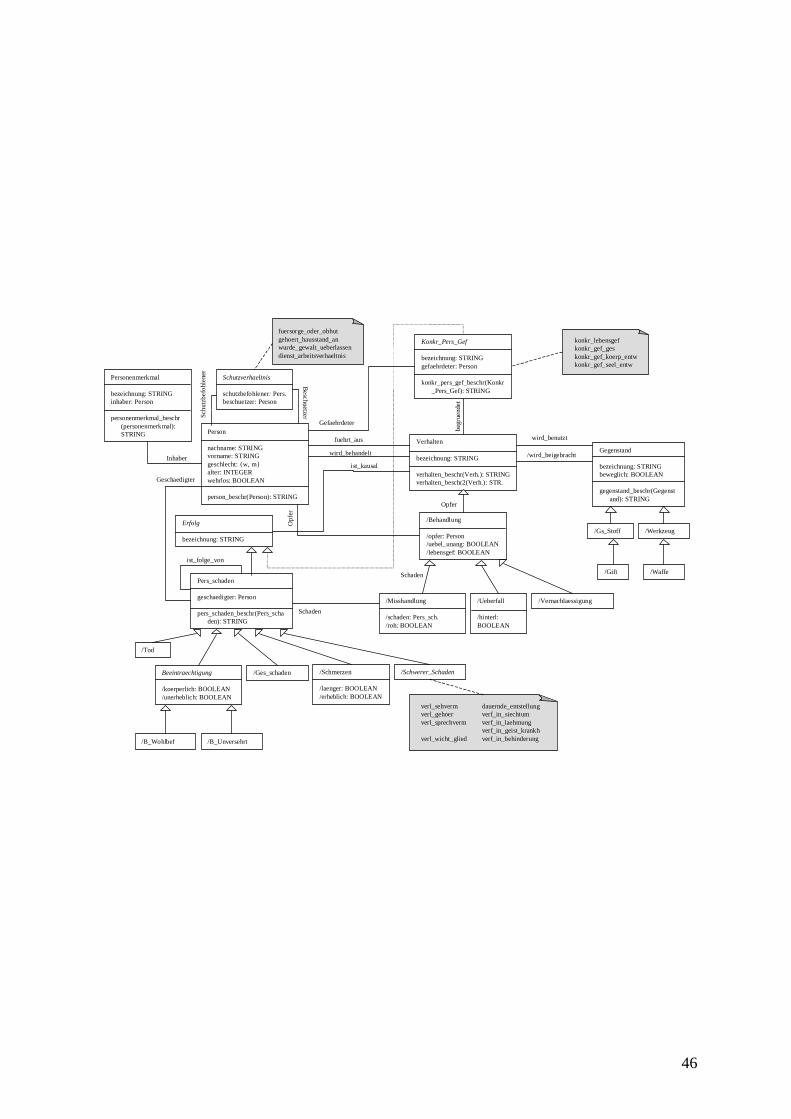
46
Pers_schaden
geschaedigter: Person
pers_schaden_beschr(Pers_scha___den): STRING
Gegenstand
bezeichnung: STRINGbeweglich: BOOLEAN
gegenstand_beschr(Gegenst___and): STRING
/Waffe/Gift
Person
nachname: STRINGvorname: STRINGgeschlecht: {w, m}alter: INTEGERwehrlos: BOOLEAN
person_beschr(Person): STRING
Verhalten
bezeichnung: STRING
verhalten_beschr(Verh.): STRINGverhalten_beschr2(Verh.): STR.
fuehrt_aus
/Ueberfall
/hinterl: BOOLEAN
/Behandlung
/opfer: Person/uebel_unang: BOOLEAN/lebensgef: BOOLEAN
wird_benutzt
/wird_beigebracht
ist_kausal
wird_behandelt
Beeintraechtigung
/koerperlich: BOOLEAN/unerheblich: BOOLEAN
/Ges_schaden
/B_Unversehrt/B_Wohlbef
/Misshandlung
/schaden: Pers_sch./roh: BOOLEAN
Konkr_Pers_Gef
bezeichnung: STRINGgefaehrdeter: Person
konkr_pers_gef_beschr(Konkr____Pers_Gef): STRING
/Schmerzen
/laenger: BOOLEAN/erheblich: BOOLEAN
/Tod
ist_folge_von
begr
uend
et
Schutzverhaeltnis
schutzbefohlener: Pers.beschuetzer: Person
BeschuetzerS
chut
zbef
ohl
ener
Geschaedigter
/Gs_Stoff /Werkzeug
/Vernachlaessigung
Gefaehrdeter
/Schwerer_Schaden
Personenmerkmal
bezeichnung: STRINGinhaber: Person
personenmerkmal_beschr ___(personenmerkmal): ___STRING
Erfolg
bezeichnung: STRING
Opfer
Schaden
Opf
er
Schaden
verl_sehverm dauernde_entstellungverl_gehoer verf_in_siechtumverl_sprechverm verf_in_laehmung
verf_in_geist_krankhverl_wicht_glied verf_in_behinderung
konkr_lebensgefkonkr_gef_geskonkr_gef_koerp_entwkonkr_gef_seel_entw
fuersorge_oder_obhutgehoert_hausstand_anwurde_gewalt_ueberlassendienst_arbeitsverhaeltnis
Inhaber

47
5.4.1 Konzeptueller Entwurf
Auf der vorigen Seite ist das komplette konzeptuelle Sachverhalt-Schema in UML dargestellt. Dieses wird nun im Folgenden Schritt für Schritt hergeleitet beziehungsweise erläutert und anschließend in Kapitel 5.4.2 in den logischen Entwurf überführt. Hierbei wird ausführlich auf ausgesuchte Probleme eingegangen, mit welchen man bei der Entwicklung eines solchen Schemas zwangsläufig konfrontiert wird. Dies geschieht auch, um dem Leser ein Gespür da-für zu vermitteln, wie schwierig es ist, einen komplexen juristischen Anwendungsbereich zu modellieren. Am Ende dieses Kapitels wird der Versuch unternommen, die Gründe für diese Schwierigkeit zu benennen. Auf der anderen Seite werden auch einige Entwurfsentscheidun-gen ohne Begründung getroffen. Dies liegt in der Regel nicht daran, dass sie „aus dem Bauch heraus“ getroffen worden wären, sondern vielmehr daran, dass diese Entscheidungen nur um-ständlich zu begründen sind (etwa nur durch Vorgriff auf das später präsentierte Normen-Modell). In Fällen, wo dieser Aufwand in keinem vernünftigen Verhältnis zur Wichtigkeit der Entscheidung steht, fehlt daher eine Begründung gelegentlich ganz. Die zentralen Konzepte: Verhalten, Person, Erfolg Innerhalb des Strafgesetzbuches werden rechtswidrige „Straftaten“ aufgezählt und unter Stra-fe gestellt. Dadurch dient das Strafrecht insbesondere dem Zweck, Verbote oder – in be-stimmten Fällen – auch Gebote auszusprechen und die Menschen zu normgerechtem Verhal-ten zu bestimmen (vgl. [Wes95], Rn. 80). Um dem juristischen System die Möglichkeit zu geben, Rechtsverstöße zu erkennen, muss daher zunächst die Möglichkeit bestehen, rechts-widriges Verhalten – beziehungsweise Verhalten im Allgemeinen – innerhalb des Systems darzustellen. Daher muss ein Verhalten-Konzept existieren. Man beachte die Namensgebung: das Konzept wird bewusst mit „Verhalten“ und nicht etwa mit „Handlung“ oder – wie es der Begriff der Straftat motivieren könnte – mit „Tat“ bezeichnet, da im Strafrecht durchaus auch Untätigbleiben strafbar sein kann. Man unterscheidet daher zwischen Tun und Unterlassen40 (§13 StGB); Verhalten sei der Oberbegriff hierfür. (Menschliches) Verhalten ist immer mit irgendeiner „ausführenden“ Person verbunden. Daher könnten Personen als „Teil“ von Verhalten angesehen werden. Dennoch sollten zur Darstel-lung von Verhalten und Personen verschiedene Konzepte bereitstehen, da eine bestimmte Person immer auch in anderen Rollen als der des „Täters“ (z.B. Opfer, Anstifter ...) an einem bestimmten Verhalten beteiligt sein kann. Ein weiteres zur Beschreibung von Sachverhalten innerhalb des juristischen Systems benötig-tes Konzept ist „Erfolg“. Man unterscheidet im Strafrecht Erfolgsdelikte von den schlichten Tätigkeitsdelikten dadurch, dass bei Erfolgsdelikten im gesetzlichen Tatbestand ein vom je-weiligen Verhalten abgrenzbarer Erfolg in der Außenwelt gefordert wird (s. [Wes95], Rn. 22). Ein Beispiel für ein Tätigkeitsdelikt ist §231 („Beteiligung an einer Schlägerei“). Hier wird bereits das bloße Verhalten, sich an einer Schlägerei zu beteiligen, unter Strafe gestellt, unab-hängig davon, ob irgendwelche Folgen wie Verletzungen oder ähnliches eingetreten sind. Die weiteren Körperverletzungsdelikte sind allerdings Erfolgsdelikte. So wird in §223 („Körper-verletzung“) – grob gesprochen – verlangt, dass eine Verletzung vorliegt. Die Bezeichnung beispielsweise einer Verletzung als „Erfolg“ erscheint unangebracht, da dieser Begriff häufig mit etwas Positivem assoziiert wird. Im juristischen Kontext ist er allerdings wertfrei zu ver-stehen.
40 Im Rahmen des juristischen Systems wird allerdings keine komplette Unterlassungsdelikt-Prüfung vorge-nommen.

48
Die zur Darstellung von Körperverletzungsdelikten benötigten zentralen Konzepte sind hier-mit bereits aufgezählt. Dies sind „Verhalten“, „Person“ und „Erfolg“. Die einzelnen Konzepte sind in der folgenden Abbildung als Klassen dargestellt. Als Attribut der Elemente der Klas-sen Verhalten und Erfolg ist nur das Attribut „bezeichnung“ angegeben. Eine typische Ver-halten-Bezeichnung ist beispielsweise „schlagen“ eine Bezeichnung für einen Erfolg könnte z.B. „Schürfwunde am Bein“ heißen. Die Klasse Person verfügt über die Attribute Nachname, Vorname und einige Attribute, auf die erst später eingegangen wird. Alle41 Klassen des die-sem Kapitel vorangestellten UML-Schemas verfügen neben den jeweils angegebenen Attribu-ten über ein weiteres, nicht eigens angegebenes Schlüssel-Attribut namens „schluessel“ mit dem Wertebereich „Integer“. Die Funktion dieses Attributs ist die Wahrung der Objektidenti-tät für die Instanzen der verschiedenen Objektklassen. In der nun folgenden Abbildung sollen neben den Klassen mit ihren Attributen auch die im Rahmen von Körperverletzungsdelikten interessierenden Beziehungen zwischen diesen Klas-sen dargestellt werden:
Person
nachname: STRING vorname: STRING ...
Verhalten bezeichnung: STRING
Erfolg bezeichnung: STRING
fuehrt_aus
wird_behandelt
ist_kausal
Abbildung: Die zentralen Sachverhalts-Konzepte Eine Person kann ein Verhalten ausführen oder durch ein Verhalten „behandelt“ werden, etwa wenn eine Person eine andere schlägt. Ein Erfolg (z.B. eine Verletzung) muss, damit er straf-rechtliche Relevanz erlangen kann, in einem Zusammenhang mit dem Verhalten des „Täters“ stehen. Wie dieser Zusammenhang genau auszusehen hat, ist umstritten. Im Allgemeinen wird zumindest gefordert, dass das Verhalten kausal (=ursächlich) für den Erfolg ist. Darüber, wann ein Verhalten in kausalem Zusammenhang mit einem Erfolg steht, existieren verschiedene Ansichten. An dieser Stelle sollen lediglich drei von vielen verschiedenen An-sichten dargestellt werden, um ein Gespür für die Problematik entwickeln zu können. Im An-schluss daran wird festgelegt, welche Beziehungen im juristischen System mit „ist_kausal“ gemeint sein sollen. Ein ausführlicher Überblick über die verschiedenen Kausalitäts-Theorien ist in [Wes95] (Rn. 152 ff., mwN) zu finden. Angelehnt an diese Quelle erfolgten auch die nun folgenden Kurzzusammenfassungen:
- Bedingungs- oder Äquivalenztheorie: Nach dieser Ansicht ist Ursache im Sinne des Strafrechts jede Bedingung eines Erfol-ges, die nicht hinweggedacht werden kann, ohne dass der Erfolg in seiner konkreten Gestalt entfiele („condicio-sine-qua-non-Formel“). Ein Mangel dieser Theorie ist, dass er in Fällen, wo mehrere unabhängige Bedingungen zusammenkommen, wobei jede für sich geeignet ist, den Erfolg herbeizuführen, beide Bedingungen nicht als Ursache angesehen werden können. Werden beispielsweise von zwei Personen Schüsse auf ein Opfer abgegeben und jeder Schuss für sich genommen, wäre mit Sicherheit ein tödli-
41 Eine Ausnahme bilden hier lediglich die Schutzverhältnisse (s.u.), da diese eigentlich Beziehungen modelli e-ren.

49
cher, so kann auch jeder Schuss hinweggedacht werden, ohne dass der Tod des Opfers entfiele. Eine andere Schwäche dieser Theorie ist, dass ein Geschehen, welches in Folge eines atypischen, unvorhersehbaren Kausalverlaufs zu einem tatbestandsmäßi-gen Erfolg führt, als dessen Ursache betrachtet werden muss und somit eventuell zu einer Bestrafung des „Täters“ führt, wo dies nicht angebracht erscheint. Bricht Person A Person B beispielsweise ein Bein und diese Person verstirbt durch einen Unfall des Krankenwagens auf dem Weg ins Hospital, so liegt nach der conticio-sine-qua-non-Formel in dem Verhalten, welches zum Beinbruch von Person B geführt hat, auch die Ursache für deren Tod.
- Adäquanztheorie:
Ein Verhalten ist nach der Adäquanztheorie dann („adäquate“) Bedingung des konkre-ten Erfolges, wenn es die objektive Möglichkeit seines Eintritts generell in nicht uner-heblicher Weise erhöht hat. Nach dieser Theorie wird bei einem atypischen Kausalver-lauf wie im Krankentransport-Beispiel der Kausalzusammenhang verneint. Im Ergeb-nis führt diese Theorie damit zu „besseren“ Resultaten, doch erscheint es nicht ange-bracht, einen Kausalzusammenhang in Fällen mit atypischem Verlauf zu leugnen. Hier erscheint die Lehre von der objektiven Zurechnung der bessere Ansatz zu sein.
- Lehre von der objektiven Zurechnung:
Nach der Lehre von der objektiven Zurechnung genügt der Begriff der Kausalität al-lein nicht, um eine Person für einen Erfolg verantwortlich zu machen. Stattdessen müsse neben der Kausalität das Merkmal der objektiven Zurechnung vorliegen. Ein Erfolg ist einem Verhalten – grob gesprochen – dann objektiv zurechenbar, wenn durch das Verhalten eine rechtlich verbotene Gefahr geschaffen und die Gefahr sich in dem tatbestandsmäßigen Erfolg realisiert hat.
Die letztgenannte Ansicht entspricht der heute (vor-)herrschenden Meinung (abgekürzt hM). Somit wäre es durchaus angebracht, zwischen Verhalten und Erfolg sowohl eine Kausalitäts- als auch eine (objektive) Zurechenbarkeits-Beziehung zu haben. Da allerdings im Rahmen dieser Arbeit auf die Probleme des Allgemeinen Teils – und um ein solches handelt es sich bei der Kausalitätsproblematik – nicht näher eingegangen wird, wurde auf diese umständli-chere Vorgehensweise verzichtet. Stattdessen bestehe nun zwischen einem Verhalten und einem Erfolg dann eine Beziehung „ist_kausal“, wenn die Person durch ihr Verhalten für den Erfolg verantwortlich gemacht werden kann. Durch diese Vereinbarung wird die Kausalitäts-problematik vom juristischen System ferngehalten. Der Anwender muss im Einzelfall daher selbst wissen, ob eine Person durch ihr Verhalten für einen Erfolg verantwortlich gemacht werden darf. Man erkennt bereits an dieser Stelle, dass bei der Erarbeitung des konzeptuellen Schemas die rechtlichen Grundlagen von einiger Bedeutung sind und genauestens bekannt sein sollten, bevor eine Modellierung des Sachverhaltes vorgenommen werden kann. Weitere Konzepte: Gegenstand, Personenmerkmal, Schutzverhältnis Die drei bisher eingeführten Basiskonzepte reichen noch nicht aus, um alle relevanten Sach-verhalte zu beschreiben. Betrachtet man §224 („Gefährliche Körperverletzung“), so entdeckt man die Begriffe „Gift“, „gesundheitsschädliche Stoffe“, „Waffe“ und „gefährliches Werk-zeug“. Diese Begriffe können mit den oben eingeführten Konzepten nicht modelliert werden. Allerdings kommen die Begriffe in §224 nur in Verbindung mit einer Körperverletzung vor, was bedeutet, dass sie notwendigerweise an ein Verhalten gekoppelt sein müssen. Somit könnte man auf die Idee kommen, sie in das Verhalten-Konzept zu integrieren. Wird bei-

50
spielsweise ein Hammer verwendet, um eine Person damit zu schlagen, so könnte dies durch ein Verhalten – etwa mit der Bezeichnung „schlagen mit Hammer“ – dargestellt werden. Da aber Gift oder eine Waffe etwas prinzipiell anderes ist, als ein Verhalten, sollten im Sinne der Objektorientiertheit verschiedene Konzepte dafür eingeführt werden. Die oben genannten Begriffe sind teilweise hierarchisch angeordnet. So ist am Wortlaut des §224 zu erkennen, dass „Werkzeug“ ein Oberbegriff für „Waffe“ ist.42 Außerdem wird „ge-sundheitsschädlicher Stoff“ als Oberbegriff von „Gift“ verwendet. Da die Funktionen von „Werkzeugen“ und „gesundheitsschädlichen Stoffen“ innerhalb des Gesetzes sehr ähnlich sind, erscheint es sinnvoll, diese Begriffe zu einem Oberbegriff zusammenzufassen. Fraglich ist hierbei jedoch, wie ein solcher Oberbegriff heißen kann. Da alle diese Begriffe in irgend-einer Form verwendet werden, also gewissermaßen „Handlungs-Objekte“ sind, böte sich die Bezeichnung „Objekt“ an, wäre dieser Begriff in der Informatik nicht schon eindeutig belegt. Letztlich fiel die Entscheidung auf den Namen „Gegenstand“, auch wenn beispielsweise Ga-se, welche auch gesundheitsschädliche Stoffe sein können, sicherlich keine Gegenstände dar-stellen. Der alternativ in Frage kommende Konzept-Name „Stoff“ erschien zu nichtssagend, weshalb die Ungenauigkeit des Namens „Gegenstand“ in Kauf genommen wurde.
Gegenstand
bezeichnung: STR. beweglich: BOOL.
Gs_Stoff
Werkzeug
Gift
Waffe
Abbildung: „Gegenstände“ Gegenstände haben die Attribute „bezeichnung“ und „beweglich“. Letzteres Attribut enthält die Information, ob der entsprechende Gegenstand beweglich ist oder nicht. Ein Objekt der Klasse „Gegenstand“ kann zu einem Verhalten in der Beziehung „wird_benutzt“ stehen, was bedeutet, dass der Gegenstand bei dem Verhalten verwendet wird. Darüber hinaus können Gegenstände auf eine besondere Weise benutzt werden: sie können einer anderen Person bei-gebracht werden, wobei hierbei „beibringen“ im Sinne von „in den Körper eines anderen ein-führen“ (vgl. [DT95], Rn. 4 zu §229) zu verstehen ist. Gelegentlich wird im Strafgesetzbuch Bezug auf bestimmte Merkmale von Personen genom-men. So sind in §225 („Misshandlung von Schutzbefhohlenen“) der Passage „Wer eine Per-son unter achtzehn Jahren oder eine ... wehrlose Person“ die Merkmale Alter und Wehrlosig-keit zu entnehmen. Auch spielt gelegentlich das Geschlecht einer Person eine Rolle (§177. Vergewaltigung. „Wer eine Frau ...“). Solche Merkmale lassen sich bequem als Attribut der Klasse Person modellieren (s. komplettes UML-Sachverhalt-Schema). Es gibt aber auch Be-züge auf Personenmerkmale, die so verschiedenartig sind, dass sie nicht einfach als Attribut der Person-Klasse modelliert werden können. So ist im Rahmen der Überprüfung, ob eine Vergiftung erfolgt ist, die „Körperbeschaffenheit“ des Opfers zu berücksichtigen (vgl. [LK99], Rn. 1a zu §224). Diese „Körperbeschaffenheit“ umfasst Merkmale wie Allergie oder Überemfindlichkeit gegen einen bestimmten Stoff und ähnliches. Solche Personenmerkmale, die in unbegrenzter Anzahl einer Person „anhängen“ können, werden durch Instanzen der
42 Eigentlich ist zu erkennen, dass „gefährliches Werkzeug“ ein Oberbegriff von „Waffe“ ist. Dies ist aber – wie später gezeigt wird - nicht ganz exakt. Wenn ein „gefährliches Werkzeug“ aber Oberbegriff von „Waffe“ ist, dann auch ein „Werkzeug“.

51
Klasse „Personenmerkmal“ modelliert. Diese Instanzen haben wieder ein Attribut „bezeich-nung“. In diesem Attribut ist jeweils die Spezifikation des Merkmals angegeben (z.B. „Aller-gie gegen Bienengift“). Außerdem gehört zur Klasse „Personenmerkmal“ das Attribut „inha-ber“ vom Typ „Person“, womit der Bezug zu der Person hergestellt wird, welcher das ent-sprechende Merkmal anhängt. Letztlich existiert noch die abstrakte Klasse „Schutzverhaeltnis“. Wie der Name schon vermu-ten lässt, handelt es sich hierbei eher um eine Beziehung als um eine Klasse, doch wird ein Schutzverhältnis als Klasse modelliert, da es ein Oberbegriff für verschiedene Arten von Schutzverhältnissen43 ist. Zwar lassen sich in der UML auch Hierarchien von Beziehungen bilden, doch Klassenhierarchien stellen das bekanntere Konzept dar. Ohnehin wird nach der Überführung des konzeptuellen in das logische Schema der Unterschied zwischen den beiden alternativen Modellierungsformen (Klasse oder Beziehung) nicht mehr zu erkennen sein. Ein Objekt der „Schutzverhaeltnis“-Klasse verfügt über zwei Attribute vom Typ Person. Das eine heisst „schutzbefohlener“, das andere „beschuetzer“. Mit dieser Klasse kann dargestellt wer-den, dass eine Person („schutzbefohlener“) dem Schutze einer anderen Person („beschuetzer“) unterstellt ist. Dies ist etwa der Fall, wenn die Person „beschuetzer“ als Babysitter für die Per-son „schutzbefohlener“ eingesetzt wurde. Die zu diesem Beispiel gehörende Unterklasse von „Schutzverhaeltnis“ ist „fuersorge_oder_obhut“. Unterklassen der bisher eingeführten Klassen Die bisher eingeführten Klassen werden innerhalb des juristischen Systems teilweise noch untergliedert. Bevor diese Untergliederungen dargestellt werden, soll erläutert werden, welche grundsätzlichen Maßstäbe hierbei angesetzt wurden. Ein Verhalten beispielsweise lässt sich ja sehr fein untergliedern: so könnte es jeweils eine Klasse für verschiedenste Arten von Verhalten wie beispielsweise „singen“, „spazieren ge-hen“, „treten“ und „schlagen“ geben. Personen könnten in Klassen wie „Schüler“, „Polizist“, „Astronaut“ etc. unterteilt werden. Bei der Entwicklung des konzeptuellen Schemas des juris-tischen Systems wurde allerdings versucht, einen ganz konsequenten Weg zu gehen: abhängig von den modellierten (Körperverletzungs-)Normen werden nur solche Untergliederungen vorgenommen, welche von rechtlicher Relevanz sein können. Am Beispiel der Unterteilung von Gegenständen wurde diese Vorgehensweise bereits demonstriert. Die Unterteilung von Objekten der Klasse Verhalten ist dennoch problematisch. Da es durch-aus von rechtlicher Relevanz sein kann, ob ein Verhalten „singen“ oder „schlagen“ ausgeführt wird, könnte man hier mit Recht Unterklassen wie „schlagen“ und „singen“ einführen. Hier-von wurde aber aus folgenden Gründen abgesehen:
- Verhalten-Objekte sind keine Verben, sondern werden lediglich mit Hilfe von Verben „bezeichnet“. Die Namen der Unterklassen müssten nun aber Verben oder zumindest substantivierte Verben sein. Eine Instanz einer Unterklasse wie „Schlagen“ stünde dann für einen konkreten Vorgang, bei welchem eine Person eine andere schlägt. Eine solche Modellierung wirkte sehr gekünstelt.
- Außerdem müssten sehr viele Unterklassen eingeführt werden. Je nach vorliegendem
Sachverhalt würden diese Klassen zu einem großen Teil ohne konkrete Instanzen sein.
43 Diese Arten sind in §225 aufgelistet, welcher im Anhang abgebildet ist.

52
- Ein anderes Problem ist, dass im Voraus nicht gesagt werden kann, welche Klassen er-forderlich sind, da das Spektrum verschiedener Verhaltensarten riesig ist. Allenfalls wäre es möglich, je nach Sachverhalt neue Klassen einzuführen.
Aus den oben genannten Gründen, erscheint es angebracht, keine so weit reichende Unter-gliederung der Klasse „Verhalten“ vorzunehmen. Stattdessen werden im juristischen System Objekte der „Verhalten“-Klasse nicht in erster Linie nach Zugehörigkeit zu einer Unterklasse bewertet, sondern nach ihrer „bezeichnung“. Hierauf wird aber erst in Kapitel 5.5 genauer eingegangen. Als Resultat obiger Ausführungen existiert zu der Klasse „Verhalten“ nicht eine große Anzahl von Unterklassen, sondern lediglich die Unterklasse „Behandlung“44. Diese Klasse ist erforderlich, um körperliche Misshandlungen – eine spezielle Art von Körperver-letzungen – zu definieren.
„[Eine] körperliche Misshandlung ist eine üble, unangemessene Behandlung, ...“ ([LK99], Rn. 4 zu §223).
Eine Behandlung verfügt über die BOOL’schen Attribute „uebel_unang“ und „lebensgef“, welche den Wert ‚ja’ haben, wenn die Behandlung übel und unangemessen beziehungsweise lebensgefährlich für die behandelte Person ist. Grundbedingung für jede Instanz der „Behand-lung“-Klasse ist, dass eine Person in „wird_behandelt“-Beziehung zu ihr steht, da eine Be-handlung ein Verhalten ist, bei welchem eine Person behandelt wird. Diese behandelte Person stellt den Wert des Attributs „opfer“ dar. Es ist notwendig, das Opfer der Behandlung an-zugeben, obwohl die durch ein Verhalten behandelten Personen durch die „wird_behandelt“-Beziehung identifizierbar sind. Der Grund hierfür ist, dass durch ein Verhalten grundsätzlich mehrere Personen zugleich behandelt werden können, ein Objekt der Klasse „Behandlung“ aber jeweils nur für die Behandlung einer einzelnen Person steht. An dieser Stelle liegt somit ein Modellierungsproblem vor:
Verhalten schluessel: 1 bezeichnung: „ärgern“ ...
Behandlung schluessel: 1 opfer: Lieschen
Behandlung schluessel: 1 opfer: Justus
?
Verhalten schluessel: 1 bezeichnung: „ärgern“ ...
Behandlung von Lieschen schluessel: 1 opfer: Lieschen
Behandlung von Justus schluessel: 1 opfer: Justus
Opfer
Abbildung: Modellierungsproblematik - Diskriminator-Metatyp Angenommen, Peter ärgert seine Kinder Lieschen und Jonas. Dann stellt dies ein Verhalten dar. Dieses Verhalten habe den Schlüssel 1 und ist in der Abbildung dargestellt. Gleichzeitig stellt dieses Verhalten zwei verschiedene Behandlungen dar (linke Seite der Abbildung), die
44 Dies ist nicht ganz korrekt ausgedrückt, wie gleich zu sehen sein wird.

53
aber – modellierte man Behandlung als Unterklasse von Verhalten – aufgrund der Vererbung jeweils den selben Schlüssel aber unterschiedliche „opfer“-Attribute hätten, was einen Ver-stoß gegen die Objektidentität darstellte. Dennoch erscheint es „natürlich“, eine Behandlung als eine spezielle Form von Verhalten anzusehen. Einen Ausweg aus diesem Dilemma eröffnet das Konstrukt des Diskriminator-Metatyps (s. dazu [Oes98], S. 265). Neben dem Spezialisierungspfeil im kompletten Sachverhalt-UML-Diagramm steht „Opfer“. Dies soll bedeuten, dass die spezielle (Unter-)Klasse erst durch das „Opfer“ genau definiert wird. Opfer sei, wer durch ein Verhalten behandelt wird. Im Beispiel-fall existieren dann die Opfer Lieschen und Jonas45 und somit zwei Unterklassen „Behand-lung von Lieschen“ und „Behandlung von Jonas“ (s. rechte Seite der Abbildung). Durch den Diskriminator-Metatyp werden also gewissermaßen mehrere Unterklassen erzeugt. Zum Abschluss dieses Abschnittes sollen nun noch kurz die restlichen Unterklassen der bis-lang dargestellten Klassen aufgezählt werden. Im Übrigen sei auf das UML-Diagramm ver-wiesen, welches eingangs dieses Kapitels abgebildet ist. Die Klasse (bzw. die Menge der Klassen) „Behandlung“ kann unterteilt werden in Überfälle, Vernachlässigungen und Miss-handlungen, wobei letztgenannte wieder eines Diskriminator-Metatyps bedürfen: ist ein Ver-halten kausal für mehrere Personenschäden (s.u.), so stellt jede entsprechende Behandlung in Verbindung mit einem der Schäden eine eigene Misshandlung dar. Die Erfolge lassen sich ebenfalls noch in Unterklassen aufteilen. So gibt es Personenschäden, welche ihrerseits durch die Klassen „Tod“, „Beeintraechtigung“, „Ges_schaden“ (= Schaden an der Gesundheit), „Schmerzen“ und „Schwerer_Schaden“ spezialisiert werden. Beeinträchtigungen werden un-terteilt in Beeinträchtigungen des Wohlbefindens oder der Unversehrtheit. Schwere Schäden unterteilen sich in die in §226 genannten Schäden. Alle Personenschäden können neben der „ist_kausal“-Beziehung an einer weiteren Beziehung teilnehmen. Diese Beziehung zwischen jeweils zwei Personenschäden trägt den Namen „ist_folge_von“. Mit ihr kann ausgedrückt werden, dass ein Personenschaden, die Folge eines anderen Personenschadens (der selben Person) ist. Somit kann beispielsweise dargestellt werden, dass eine Person an den Folgen ihrer Verletzungen stirbt. Außer den Personenschäden existieren noch die konkreten Perso-nengefahren („Konkr_Pers_Gef“): löst ein Verhalten beispielsweise Lebensgefahr für ein Op-fer aus, so wird dies mit der Beziehung „begruendet“46 dargestellt. Die Spezialisierungsbezie-hung zwischen Erfolg und „Konkr_Pers_Gef“ ist im UML-Diagramm gestrichelt dargestellt, weil sie im logischen Entwurf nicht berücksichtigt wurde. Die konkreten Personengefahren unterteilen sich noch einmal in Lebensgefahr, Gefahr für die Gesundheit, Gefahr für die kör-perliche und Gefahr für die seelische Entwicklung. Gründe für die Schwierigkeiten beim konzeptuellen Entwurf Dies soll als Beschreibung des konzeptuellen Schemas genügen. Wie zu Anfang dieses Kapi-tels angekündigt, wird dieses Kapitel nun mit dem Versuch beschlossen, Gründe für die mehr oder weniger bereits im Vorausgegangenen angesprochenen Schwierigkeiten bei der Entwick-lung eines konzeptuellen Schemas für einen juristischen Anwendungsbereich zu benennen. Das größte Problem ist es, die Konzepte herauszuarbeiten, welche zur Sachverhaltsbeschrei-bung benötigt werden. Zwar mag in diesem Abschnitt der Eindruck entstanden sein, dass sich diese Konzepte einigermaßen direkt aus den im Gesetz verwendet Begriffen herleiten lassen, dem ist aber häufig nicht so. Ohnehin genügt es nicht, den Gesetzestext alleine zu betrachten.
45 Korrekterweise sollten ihre Schlüssel angegeben werden. Zur besseren Übersicht wird allerdings der jeweilige Name benannt. 46 „begruendet“ ist vergleichbar mit „ist_kausal“ doch bestehen hier in der juristischen Sichtweise kleine Unter-schiede, weshalb verschieden Beziehungen erforderlich sind.

54
Wie es bei der bereits betrachteten Kausalitätsproblematik der Fall ist, so kommt es häufig vor, dass um das Gesetz herum verschiedene Theorien erarbeitet wurden, wie mit dem ent-sprechenden Gesetz umzugehen ist (s. hierzu Kapitel 5.5). Um die Erfahrungen aus diesen Theorien für das juristische System nutzbar zu machen, müssen die Konzepte zur Sachver-haltsdarstellung so gewählt werden, dass sie zu diesen Theorien „passen“. So wurde oben eine körperliche Misshandlung als „üble, unangemessene Behandlung, ...“ definiert. Um diese De-finition im juristischen System verwenden zu können, ist es beispielsweise erforderlich, über ein Konzept „Behandlung“ zu verfügen. Die so benötigten Konzepte zur Sachverhaltsdarstellung sind häufig nicht einfach zu handha-ben. Dies zeigte sich bereits am Konzept der „Behandlung“. Teilweise ist dieses Problem die Folge davon, dass die juristischen Begriffe, aus denen die Konzepte entwickelt wurden, nicht die Bedeutung haben, die sie zu haben scheinen. Häufig ist es so, dass die natürlicherweise mit ihnen assoziierte Bedeutung in der Regel passt, aber in speziellen Fällen nicht. Ein Bei-spiel hierfür ist der Begriff des „gefährlichen Werkzeugs“. Eine Körperverletzung ist nach §224 I Nr. 2 dann eine gefährliche Körperverletzung, wenn sie mit einem gefährlichen Werk-zeug begangen wurde. „Normalerweise“ müsste man nun davon ausgehen können, dass die Gefährlichkeit eine Eigenschaft des Werkzeuges ist. Dies ist allerdings tatsächlich nicht ganz richtig. Stattdessen gilt ein Werkzeug als gefährlich, wenn die gesamte Situation, in welcher das Werkzeug verwendet wird, durch die Verwendung des Werkzeuges „gefährlich“ wird (näheres in Kapitel 5.5). So kann es in einzelnen Fällen sein, dass nicht einmal ein Messer, welches in der alten Fassung des Strafgesetzbuches noch als Beispiel für gefährliche Werk-zeuge ausdrücklich genannt wurde, als gefährliches Werkzeug einzustufen ist. Darüber hinaus operieren die Theorien über die richtige Interpretation von Gesetzen teilweise auf einer sehr abstrakten Ebene. Möchte man diese abstrakte Ebene mit der sprachlichen Ebe-ne verknüpfen, führt dies an den Schnittstellen teilweise zu erheblichen Problemen. Diese Problematik wird sich an einigen in Kapitel 5.5 entwickelten Gesetzes-Modellen zeigen, wo auch die Diskussion über die Formalisierungs-Probleme an verschiedenen Stellen wieder auf-genommen wird. Hiermit ist das Kapitel über den konzeptuellen Entwurf des Sachverhalt-Schemas zu Ende. Wie dieses Schema in ein relationales umgewandelt wird, wird im nun folgenden Kapitel dar-gestellt.
5.4.2 Logischer Entwurf
Die Erläuterung des konzeptuellen Entwurfs erfolgt, indem nacheinander die Umsetzungen der verschiedenen konzeptuellen Entwurfselemente in Relationen beschrieben werden.
5.4.2.1 Beziehungen
Beziehungen (mit Grad n) des konzeptuellen Schemas lassen sich mit Hilfe der Objektschlüs-sel der an der jeweiligen Beziehung beteiligten Objekte folgendermaßen als Relation darstel-len:
Beziehung ⊆ Schlüssel1 × Schlüssel2 × ... × Schlüsseln Die Objekte werden hierbei durch ihre jeweiligen Schlüsselwerte repräsentiert. Wie bereits erwähnt, verfügt jedes Objekt im konzeptuellen Sachverhalt-Schema über einen „künstlichen“ Schlüssel vom Typ Integer. Darüber hinaus kommen dort nur binäre Beziehungen vor. Somit

55
kann beispielsweise die Kausalitätsbeziehung zwischen Verhalten und Erfolg in Prolog durch eine Menge von Fakten von folgender Form dargestellt werden: ist_kausal(Schluessel_V,Schluessel_E).
Schluessel_V und Schluessel_E stehen für den Schlüssel des jeweiligen Verhalten- bezie-hungsweise Erfolg-Objektes. Insbesondere weil alle Objekt-Schlüssel im juristischen System vom gleichen Typ sind und somit prinzipiell zwei Objekte aus verschiedenen Klassen den gleichen Schlüsselwert haben können, ist es bei der oben beschriebenen Darstellungsart wich-tig, genau festzulegen, an welcher Position einer Relation welcher Schlüsselwert zu stehen hat. Jede Beziehung des konzeptuellen Sachverhalt-Schemas wird im juristischen System durch Angabe der entsprechenden Fakten in oben angegebener Form definiert. Eine Ausnahme bil-det hier lediglich die abgeleitete Beziehung „wird_beigebracht“, welche durch eine Ablei-tungsregel definiert wird:
wird_beigebracht(Verhalten,Gegenstand):- wird_benutzt(Verhalten,Gegenstand), ...
Diese Regel besagt, dass jedes Verhalten, welches zu einem bestimmten Gegenstand in der Beziehung „wird_benutzt“ steht und darüber hinaus bestimmte Bedingungen („...“) erfüllt, zu diesem Gegenstand auch in der Beziehung „wird_beigebracht“ steht.
5.4.2.2 Objekt-Klassen
Etwas problematischer ist die Darstellung von Objekten mittels Relationen. Insbesondere tritt hierbei die Frage auf, wie Objektattribute behandelt werden sollen (vgl. hierzu [GL96], S. 6 ff.; [Man00], Kap. 3, S. 7). Man unterscheidet zwischen extensionalen und intensionalen Att-ributen. Im juristischen System sind im Gegensatz zu den extensionalen Attributen die inten-sionalen oder abgeleiteten Attribute nicht physisch in der Datenbank vorhanden, sondern können mit Hilfe bestimmter Regeln aus anderen Attributen errechnet werden. Extensionale Attribute Die extensionalen Attribute eines Objekts werden im juristischen System durch eine Relation dargestellt, deren erstes Argument der Schlüssel des dazugehörenden Objekts ist. Die weite-ren Argumente entsprechen den extensionalen Attributen des Objektes. Der Name der Relati-on entspricht dem Klassennamen des Objekts. Sei folgendes Objekt gegeben:
Person
schluessel: 1 nachname: „Müller“ vorname: „Lieschen“ geschlecht: w alter: 12 wehrlos: nein

56
Dieses Objekt würde dann durch folgendes Fakt dargestellt:
person(1, „Müller“, „Lieschen“, w, 12, nein).
Man beachte, dass bei dieser Darstellungsart die Namen der Attribute nicht auftauchen. Um welches Attribut es sich bei den einzelnen Werten handelt, ergibt sich implizit aus der jewei-ligen Position. Eine nicht-positionsabhängige Alternative zu dieser Darstellungsart wäre, die einzelnen Attribute als „Funktion“ des Objektschlüssels aufzufassen. Dies geschieht bei den abgeleiteten Attribute und wird unten näher erläutert. Der Vorteil der hier aufgezeigten Dar-stellungsart ist aber, dass hiermit pro Objekt nur ein47 Fakt in der Wissensbasis abgespeichert werden muss. Außerdem lässt sich auf diese Weise die Vererbung sehr bequem implementie-ren, was in Kapitel 5.4.2.3 zu sehen sein wird. Abgeleitete Attribute Wie bereits erwähnt, werden abgeleitete Attribute anders dargestellt. Diese Attribute sind im UML-Diagramm durch einen Schrägstrich („/“) gekennzeichnet, der ihrem Namen vorange-stellt ist. Ein abgeleitetes Attribut wird im juristischen System durch eine binäre Relation rep-räsentiert, deren erstes Argument wieder der Schlüssel des entsprechenden Objektes ist. Das zweite Argument entspricht dem Wert des abgeleiteten Attributs. Der Name der Relation setzt sich zusammen aus dem (abgekürzten) Namen der Klasse, zu welcher das Attribut gehört, und dem Attributnamen. Die Bedeutung der Relation wird über eine Regel bestimmt, welche dazu dient, den Attributwert herzuleiten. Sei folgendes Objekt gegeben:
Quadrat schlüssel: 1 seitenlänge: 5 /fläche: { seitenlänge * seitenlänge } /umfang: { seitenlänge * 4 }
Das extensionale Attribut („seitenlänge“) würde – wie gewohnt – durch folgendes Fakt darge-stellt: quadrat(1, 5).
Zur Berechnung der abgeleiteten Attribute stünden folgende Regeln zur Verfügung: quadr_flaeche(Schluessel, Flaeche):- quadrat(Schluessel, seitenlaenge), Flaeche is seitenlaenge*seitenlaenge. quadr_umfang(Schluessel, Umfang):- quadrat(Schluessel, seitenlaenge), Umfang is seitenlaenge*4.
47 Ausnahme: abgeleitete Attribute

57
Diese Darstellungsart für abgeleitete Attribute ist nicht-positionsabhängig. Stattdessen exis-tiert für jedes Attribut eine eigene „Funktion“, welche den jeweiligen Attributwert errechnet. An dieser Stelle soll noch kurz erläutert werden, warum es von Vorteil ist, für jedes abgeleite-te Attribut eine eigene Funktion zu haben. Hierdurch wird nämlich ermöglicht, dass Objekte behandelt werden können, ohne dass der Attributwert berechnet werden muss. Stattdessen wird dieser nur ermittelt, wenn er tatsächlich benötigt wird. Dies ist im juristischen System besonders wichtig, da für die Berechnung der abgeleiteten Attributwerte gelegentlich Fragen an den Anwender gerichtet werden müssen und es selbstverständlich ärgerlich wäre, wenn diese Fragen überflüssig wären.
5.4.2.3 Klassen-Hierarchien
Die Klassen des juristischen Systems lassen sich in drei verschiedene Arten unterteilen.
- Zum einen gibt es die extensionalen Klassen. Zwar ist dies nicht zwingend erforder-lich, doch verfügen diese Klassen im juristischen System nur über extensionale Attri-bute.
- Darüber hinaus existieren im juristischen System Klassen, welche nur den Zweck ha-
ben, einzelne Klassen zusammenzufassen. Dies sind die in Kapitel 2.1.7.1 beschriebe-nen abstrakten Klassen. Spezialisierungs-Beziehungen zwischen abstrakten Klassen und ihren Unterklassen werden im juristischen System durch Regeln von folgender Form realisiert:
abstr_klasse(Schluessel, Attr_1, ..., Attr_n):- klasse(Schluessel, Attr_1, ..., Attr_n, Attr_n+1, ...).
Auf diese Weise verfügt die Klasse „klasse“ über alle Attribute ihrer Oberklasse „abstr_klasse“ und eventuell über weitere Attribute („Attr_n+1“, ...).
- Letztlich gibt es Klassen, deren jeweilige Population –also die Menge ihrer Instanzen–
automatisch berechnet wird. Diese abgeleiteten Klassen werden im UML-Diagramm durch einen Schrägstrich („/“) gekennzeichnet, der ihrem Namen vorangestellt ist. Die abgeleiteten Klassen sind im Prinzip Teilmengen ihrer Oberklassen, verfügen teilwei-se allerdings noch über weitere abgeleitete Attribute. Diese Attribute sind wie oben beschrieben durch besondere „Funktionen“ dargestellt. Die abgeleitete Klasse ergibt sich aus einer Populationsregel von folgender Struktur.
abgel_klasse(Schluessel, Attr_1, ..., Attr_n):-
oberklasse(Schluessel, Attr_1, ..., Attr_n), ... .
Die letzte Zeile der Populationsregel („...“) steht für beliebige Bedingungen, welche gelten müssen, damit eine Objekt Element der abgeleiteten Klasse ist. So könnte man beispielsweise eine Klasse „Quadrat_groß“ als Unterklasse von „Quadrat“ einführen, in welcher nur die Quadrate enthalten sind, die eine Fläche haben, die mindestens 20 beträgt:
quadrat_gross(Schluessel, Seitenlaenge):- quadrat(Schluessel, Seitenlaenge), quadr_flaeche(Schluessel, Flaeche), Flaeche >= 20.

58
An diesem Beispiel erkennt man auch, wie abgeleitete Attribute vererbt werden. „Quadrat_groß“ ist ja Unterklasse von „Quadrat“. Eine „Funktion“ mit Namen „quad-rat_gross_flaeche“ existiert nicht, stattdessen wird über die Funktion der Oberklasse auf dieses Attribut zugegriffen.
5.4.2.4 Methoden von Objekten
Im UML-Diagramm ist zu erkennen, dass einige Klassen über Methoden verfügen. Diese Me-thoden berechnen jeweils aus Merkmalen eines Objekts eine ausführliche Beschreibung die-ses Objektes. Nach dieser Beschreibung können einzelne Objekte später (juristisch) klassifi-ziert werden. Eine ausführliche Beschreibung eines Verhalten-Objektes besteht beispielswei-se nicht nur aus der Objekt-Bezeichnung sondern enthält zusätzlich die Informationen, welche Gegenstände bei dem Verhalten benutzt wurden (z.B. „schlagen mit Knüppel“). Die Namen der Methoden sind so gewählt, dass sie für jedes Objekt eindeutig sind, was auch erforderlich ist, da die Methoden – ähnlich wie die abgeleiteten Attribute – durch Relationen realisiert werden, welche „Funktionen“ darstellen. Anstelle der Methoden hätten diese Funktionen auch durch abgeleitete Attribute dargestellt werden können. Davon wurde aber abgesehen, da diese Funktionen, welche nun durch Methoden realisiert wurden, lediglich zur Textausgabe benö-tigt werden und somit eigentlich keine Objektattribute im strengen Sinne mehr darstellen.
5.4.2.5 Diskriminator-Metatyp
Bevor zum Abschluss des Kapitels über den logischen Sachverhalt-Entwurf noch auf ein aus-führliches Beispiel verwiesen wird, soll nun noch dargestellt werden, auf welche Weise mit Diskriminator-Metatypen umgegangen wird. Dies soll am Beispiel der „Behandlung“-Klasse(n) geschehen:
behandlung(Schluessel,Bezeichnung,Opfer):- verhalten(Schluessel,Bezeichnung), wird_behandelt(Schluessel,Opfer).
Es erscheint fast so, als wäre die Behandlung eine ganz „normale“ Spezialisierung von Ver-halten. Allerdings wird scheinbar ein neues Attribut „Opfer“ eingefügt, welches aus der Be-ziehung „wird_behandelt“ gewonnen wird. Da ein Verhalten zu mehreren Personen in einer solchen Beziehung stehen kann, ist es durchaus möglich, dass Behandlungen mit dem selben Schlüssel unterschiedliche Attributwerte für „Opfer“ besitzen. Dieser scheinbare Widerspruch wird allerdings dadurch aufgelöst, dass Opfer nicht als Attribut, sondern als Klassen-Unterscheidungsmerkmal aufgefasst wird. Somit gibt es im Allgemeinen also verschiedene Klassen „Behandlung“, die beispielsweise als „Behandlung_von_Lieschen“, „Behand-lung_von_Jonas“ usw. bezeichnet werden könnten.

59
5.4.2.6 Beispiel-Sachverhalt
Im Anhang ist ein ausführliches Beispiel zu sehen, welches den gleich folgenden Sachverhalt darstellt, durch welchen ein Gefühl dafür vermittelt werden soll, wie die vom juristischen System bearbeitbaren Fälle aussehen:
Peter Müller schlägt die in seinem Haus wohnende Lieschen Müller, welche besonders empfindlich ist, und fügt ihr so leichte Blessuren zu. Anschließend tritt er sie mit sei-nem schweren Arbeitsschuh, wodurch sie innere Verletzungen und erhebliche, länger andauernde Schmerzen erleidet. Durch die inneren Verletzungen schwebte sie vorü-bergehend in Lebensgefahr. Berta B. sticht mit einer Gabel, einem Löffel, einem Messer und einem Messerchen Friedhelm F., was diesem eine tiefe Wunde einbringt. Daraufhin schlägt Friedhelm F. Berta B., welche seiner Obhut überlassen wurde, mit einer Eisenstange so stark, dass diese einen Schädelbruch und erhebliche, länger andauernde Schmerzen erleidet. Am Schädelbruch stirbt sie später. Im gemeinsamen Haushalt von Jürgen und Gerda Schmidt leben Willy und Karsten Schmidt zur Untermiete. Eines Tages kommt es zu einem handfesten Streit. Zunächst schlägt Gerda Schmidt Karsten Schmidt, welcher zusammen mit seiner Freundin Julia J. in Gerdas Betrieb beschäftigt sind, mit einer aufgerollten Zeitung. Julia J. berührt den so gereizten Karsten Schmidt mit einem Messerchen, woraufhin dieser zusammen mit Willy Schmidt Julia J. mit Salzsäure beschüttet und ihr so Verätzungen im Gesicht zufügt, welche bleibende Narben verursachen. Willy Schmidt wird von dem dazwi-schenspringenden Jürgen Schmidt gegen einen Kachelofen gestoßen, wodurch er sich eine Rippe bricht.

60
5.5 Formalisierung juristischer Normen
Um mit Sachverhalten wie dem oben beschriebenen umgehen zu können, ist neben der Mo-dellierung des Sachverhalts auch eine Formalisierung der Gesetze erforderlich, welche in die-sem Kapitel beschrieben werden soll. In Kapitel 5.2 wurde dargestellt, warum die Körperverletzungsdelikte modelliert werden sol-len. Einige Gesetze aus dem, diese Delikte enthaltenden, 17. Abschnitt des Strafgesetzbuches wurden aus verschiedenen Gründen nicht berücksichtigt. Diese nicht berücksichtigten Gesetze seien zunächst benannt:
- § 228. Einwilligung. Dieser Paragraph besagt, dass ein Körperverletzungsdelikt nicht rechtswidrig ist, wenn das Opfer gesetzeswirksam in die Tat eingewilligt hat. Da Rechtswidrigkeit in der eingeschränkten Prüfung des juristischen Systems (vgl. Kapitel 5.3) nicht geprüft wird, wurde dieser Paragraph nicht formalisiert.
- § 230. Strafantrag.
Dieser Paragraph regelt, welche Anträge bei welchen Delikten gestellt werden müssen, damit diese verfolgt werden. Hier gilt ähnliches wie für §228. Das juristische System überprüft nur die objektive Tatbestandsmäßigkeit und somit auch nicht, ob erforderliche Anträge richtig gestellt wurden.
- § 231. Beteiligung an einer Schlägerei.
Dieses Gesetz stellt die Beteiligung an einer Schlägerei unter Strafe. Schlägereien können im juristischen System nicht dargestellt werden. Für den juristisch komplexen Begriff der Schlägerei wären zu viele neue Sachverhalts-Konzepte erforderlich gewe-sen. Daher wurde der kompletten §231 im juristischen System nicht berücksichtigt.
Somit bleiben folgende Gesetze, welche vom System behandelt werden können sollen:
- § 223. Körperverletzung. (s. Kapitel 5.5.3.1) - § 224. Gefährliche Körperverletzung. (s. Kapitel 5.5.3.2) - § 225. Mißhandlung von Schutzbefohlenen. - § 226. Schwere Körperverletzung. (s. Kapitel 5.5.3.3) - § 227. Körperverletzung mit Todesfolge. - § 229. Fahrlässige Körperverletzung. (s. Kapitel5.5.3.4)
Der komplette Text der Körperverletzungsdelikte findet sich im Anhang. Bevor in Kapitel 5.5.3 auf die formalen Darstellungen einzelner Gesetze eingegangen wird, soll zunächst erläu-tert werden, wie ein beliebiges Gesetz prinzipiell in Regel-Form gebracht wird (Kapitel 5.5.1 und 5.5.2).

61
5.5.1 Prinzipieller Aufbau von Gesetz-modellierenden Regeln
In der Einleitung und im Exkurs aus Kapitel 4 wurde auf die Ähnlichkeiten von Regeln und Gesetzen hingewiesen. Viele Gesetze sind so beschaffen, dass sie Tatbestandsmerkmale und eine Rechtsfolge benennen. Wenn eine bestimmte Menge von Tatbestandsmerkmalen konkret (d.h. im Sachverhalt) vorliegt, dann gelte die Rechtsfolge wie beispielsweise eine bestimmte Strafe. Dies lässt sich folgendermaßen in einer Prolog-Regel ausdrücken: rechtsfolge(SV_Ausschnitt):-
tatbestandsmerkmal_1(SV_Ausschnitt_1), tatbestandsmerkmal_2(SV_Ausschnitt_2), ... tatbestandsmerkmal_n(SV_Ausschnitt_n).
Diese Regel besagt, dass ein Ausschnitt aus einem Sachverhalt „SV_Ausschnitt“ (z.B. eine bestimmte Tat) die Rechtsfolge „rechtsfolge“ nach sich zieht, wenn die Tatbestandsmerkmale 1 bis n in nicht zwingenderweise untereinander disjunkten Sachverhaltsausschnitten 1 bis n verwirklicht sind. Der Sachverhaltsausschnitt „SV_Ausschnitt“ setzt sich hierbei aus Teilen der anderen Sachverhaltsausschnitte zusammen. Das folgende Diebstahl-Beispiel (vgl. Kapi-tel 2.2.1) soll dazu dienen, diese etwas verwirrende Erläuterung zu verdeutlichen:
freiheitsstrafe(Handlung):- wegnahme_von(Handlung, Sache), fremd(Sache), beweglich(Sache), sache(Sache),
vorsaetzlich(Handlung), rechtswidrig(Handlung), schuldhaft(Handlung).
Eine Handlung „Handlung“ zieht die Rechtsfolge „freiheitsstrafe“ nach sich, wenn eine frem-de, bewegliche Sache durch diese Handlung weggenommen wurde und dies vorsätzlich, rechtswidrig und schuldhaft geschah. Im juristischen System werden Rechtsfolgen allerdings nicht berücksichtigt. Dies liegt daran, dass nicht bestraft werden kann, bevor nicht eine komplette Prüfung vorgenommen wurde, welche im juristischen System nicht erfolgt. Stattdessen wird nur geprüft, ob bestimmte ob-jektive Tatbestände verwirklicht wurden (s. Kapitel 5.3). Dies kann allerdings genauso durch eine Regel ausgedrückt werden, wie wieder am Diebstahl-Beispiel gezeigt werden kann: diebstahl_obj_tb(Handlung):-
wegnahme_von(Handlung, Sache), fremd(Sache), beweglich(Sache), sache(Sache).
Diese Regel besagt, dass der objektive Tatbestand des Diebstahls erfüllt ist, wenn eine „Sa-che“ weggenommen wird, die fremd und beweglich (und eine Sache) ist. Da im juristischen System nur objektive Tatbestände geprüft werden, wird der Zusatz „_obj_tb“ der Einfachheit halber bei der Gesetzesdarstellung in Zukunft weggelassen. Die einzelnen Tatbestandsmerkmale „Wegnahme einer Sache“, „Fremdheit der Sache“ etc. können wiederum durch Regeln genauer definiert werden, wie am Beispiel von „wegnah-me_von“ zu sehen ist:

62
wegnahme_von(Handlung, Sache):- bruch(Gewahrsam_Alt, Handlung, Sache),
begruendung(Gewahrsam, Handlung, Sache), fremd_Gewahrsam(Gewahrsam_Alt).
Die in dieser Regel eingeführten (Unter-)Tatbestandsmerkmale können wieder und wieder durch Regeln definiert werden. Auf diese Weise entsteht eine baumartige Regelstruktur. Die Wurzel dieser Struktur ist im Beispiel der „diebstahl“; die Blätter entsprechen Konzepten der Sachverhaltsdarstellung. So könnten zur Beschreibung von Diebstahl-Sachverhalten bei-spielsweise die Konzepte „fremd“, „beweglich“ und „sache“ zur Verfügung stehen. Diese Begriffe würden dann nicht weiter durch Regeln beschrieben. Erwähnt werden sollte auch noch, dass für einzelne Tatbestandsmerkmale durchaus Definiti-onen existieren können, welche Alternativen enthalten. So ist eine „gefährliche Körperverlet-zung“ beispielsweise eine Körperverletzung welche mit einer Waffe (§223 I Nr. 2 StGB) oder mittels eines hinterlistigen Überfalls (§223 I Nr. 3 StGB) verübt wurde. Solche Definitionen lassen sich über AND-OR-Graphen veranschaulichen. In Regel-Schreibweise würde eine De-finition, in welcher verschiedene Alternativen vorkommen, in etwa folgendermaßen aussehen: gef_koerperverletzung(...):- koerperverletzung(...), ... waffe(...).
gef_koerperverletzung(...):- koerperverletzung(...), ... ueberfall(...).
Dies soll zur Beschreibung des prinzipiellen Aufbaus von Prolog-Modellen juristischer Nor-men genügen. Im fogenden Kapitel wird genauer erläutert, wie diese Prolog-Regeln aus dem Gesetzestext entwickelt werden.
5.5.2 Allgemeines über die Formalisierung von Gesetzen
Wie bereits in Kapitel 5.4.1 im Rahmen der Erörterung der Kausalitätsproblematik angedeutet wurde, so können die oben dargestellten „Regelbäume“ nicht allein aus dem Gesetzestext gewonnen werden. Der Grund hierfür ist, dass in den Gesetzestexten häufig Formulierungen enthalten sind, welche sich nicht selbst erklären. Zwar gibt es Tatbestandsmerkmale, welche auch Nicht-Juristen sofort verstehen; hierzu zählen beispielsweise Begriffe wie „eine andere Person“ in §223 StGB. Häufiger ist jedoch, dass im Gesetzestext Formulierungen vorkom-men, welche von Nicht-Juristen nicht verstanden werden. Manchmal sind dies Begriffe, wel-che zwar verständlich erscheinen, wo aber dennoch nicht genau klar ist, was gemeint ist. Ein Beispiel hierfür ist „wichtiges Glied des Körpers“ in §226 I Nr. 2 StGB. Nicht-Juristen wer-den hier in der Regel nicht mit Sicherheit sagen können, ob beispielsweise ein Finger als „wichtig“ oder ein Organ als „Glied“ zu betrachten ist. Solche Formulierungen sind teilweise durch das Gesetz erklärt. So wird beispielsweise in §12 StGB festgelegt, was ein „Vergehen“ und was ein „Verbrechen“ ist. §11 StGB enthält sogar gleich eine ganze Reihe von Begriffs-definitionen wie „Angehöriger (§11 Nr. 1 StGB) oder „Amtsträger“ (§11 Nr. 2 StGB). Solche expliziten Begriffsdefinitionen bilden allerdings eher die Ausnahme. Wesentlich häufiger kommt es vor, dass unklare Formulierungen durch Rechtssprechung und Rechtslehre klarge-stellt wurden. So wurde häufig im Laufe der Zeit ein Konsens bezüglich der Bedeutung ge-wisser fraglicher Formulierungen erarbeitet.

63
Möchte man nun ein Gesetz durch Regeln modellieren, so sind diese von Rechtsprechung und Rechtslehre erarbeiteten Gesetzesinterpretationen genauso wie die Gesetzestexte selbst zu beachten. Diese Interpretationen finden sich in Urteilen von Gerichten, in juristischen Lehr-büchern oder Kommentaren zu den Gesetzen. Ein kurzes Beispiel: aus §223 StGB lässt sich entnehmen, dass es einer Körperverletzung gleich kommt, wenn man eine andere Person „an der Gesundheit schädigt“. Was damit ge-meint ist, steht beispielsweise in dem Gesetzeskommentar [LK99] (S. 1063 f., Rn. 5 zu §223): „Gesundheitsschädigung ist jedes Hervorrufen oder Steigern eines vom normalen Zustand der körperlichen Funktionen nachteilig abweichenden (pathologischen) Zustandes, gleichgültig, auf welche Art und Weise er verursacht wird und ob das Opfer dabei Schmerz empfindet...“ Um Gesetze also formalisieren zu können, ist neben der Kenntnis des Gesetzestexts auch aus-führliches Wissen über die darum entwickelten Theorien erforderlich. An dieser Stelle soll nicht verschwiegen werden, dass sich Theorien zur „richtigen“ Interpretation von Gesetzen teilweise widersprechen und somit nicht ohne weiteres eindeutige Regeln erarbeitet werden können. Dies war schon im Rahmen der Kausalitätsproblematik zu beobachten. Nicht selten existieren zu einem Zeitpunkt verschiedene Ansichten darüber, wie eine Gesetzespassage zu interpretieren ist. Im Rahmen dieses Kapitels über die Formalisierung von Gesetzen wird al-lerdings die einschränkende Annahme gemacht, dass stets ein Konsens über die „richtige“ Interpretation existiert. Diese Einschränkung wird in Kapitel 6.8.2 bei Erläuterung der Ent-scheidungskomponente des juristischen Systems wieder zurückgenommen.
5.5.3 Formalisierung einzelner Gesetze
In diesem Kapitel soll nun an einigen Beispielen gezeigt werden, wie die Formalisierung der Gesetze, welche dem juristischen System als Grundlage dienen, erfolgt ist. Hierbei soll unter anderem gezeigt werden, dass die einzelnen Tatbestandsmerkmale, welche zur Erstellung von Regeln benötigt werden, zwar durch den Gesetzestext beziehungsweise durch Interpretationen des Gesetzestextes motiviert sind, dass aber prinzipiell verschiedene Möglichkeiten bestehen, ein Gesetz mittels Tatbestandsmerkmalen zu beschreiben.
5.5.3.1 Körperverletzung (§223)
Begonnen werden soll mit dem ersten Paragraphen des 17. Abschnittes des Strafgesetzbuches: §223 StGB.
§ 223. Körperverletzung. (1) Wer eine andere Person körperlich mißhandelt oder an der Gesundheit schädigt, wird mit Freiheitsstrafe bis zu fünf Jahren oder mit Geldstrafe be-straft. (2) Der Versuch ist strafbar.
Wie in Kapitel 4 beschrieben wurde, existieren zur Beschreibung von Sachverhalten unter anderem die Objekte Person, Verhalten und Erfolg. Da im Rahmen einer Subsumtion Sach-verhalt und Norm zur Deckung gebracht werden sollen, müssen die Regeln so geschaffen sein, dass sie an den Sachverhalt – also die Objekte, durch welchen dieser beschrieben wird – anknüpfen. Das Wort „Wer“ in §223 steht für eine Person, ebenso die Umschreibung „eine andere Per-son“. Durch „andere“ wird festgelegt, dass es sich hierbei um verschiedene Personen handeln

64
muss. Darüber hinaus ist die Körperverletzung ein Erfolgsdelikt, weswegen zur Beschreibung von Körperverletzungen unbedingt ein „Erfolg“ benötigt wird. In §223 sind zwei Alternativen genannt, wann eine Körperverletzung vorliegt. Daher lassen sich folgende Regeln aufstellen: koerperverletzung(Taeter, Verhalten, Erfolg, Opfer):- verschieden(Taeter, Opfer), koerperl_missh(Taeter, Verhalten, Erfolg, Opfer). koerperverletzung(Taeter, Verhalten, Erfolg, Opfer):- verschieden(Taeter, Opfer), ges_schaedigung(Taeter, Verhalten, Erfolg, Opfer).
Hiernach liegt also eine Körperverletzung vor, wenn eine körperliche Misshandlung oder eine Gesundheitsschädigung erfolgt ist. Körperliche Misshandlung und Gesundheitsschädigung werden bei dieser Darstellung jeweils nicht als Sonderform eines Verhaltens aufgefasst, son-dern als Deliktart wie etwa „Körperverletzung“. Diese Modellierung ist durchaus nicht zwin-gend. Es wurde lediglich auf diese Weise modelliert, um für die beiden Gesetzesalternativen Entsprechungen zur Verfügung zu haben. Dies ermöglicht es später, gezielt nach diesen Al-ternativen zu fragen. In diesem Zusammenhang sollte folgendes angemerkt werden: Juristische Begriffe wie „Kör-perverletzung“, „körperliche Misshandlung“ und „Gesundheitsschädigung“ können ihrem Wortlaut nach auf verschiedene Weisen verstanden werden. So kann zum einen das spezielle Delikt gemeint sein. Auf der anderen Seite kann hiermit aber auch ein Erfolg (die spezielle Verletzung) oder ein Verhalten (das Zufügen der Verletzung) gemeint sein. In der Rechtswis-senschaft werden diese Begriffe auf alle verschiedenen Arten gebraucht, doch ist es für eine Modellierung wichtig, die verschiedenen Bedeutungen auseinanderzuhalten. 5.5.3.1.1 Körperliche Misshandlung (§223 I, 1. Alt.)
Die oben aufgestellten Regeln wurden mehr oder weniger direkt aus dem Gesetzestext abge-leitet. Anders sieht dies aus, wenn die beiden Alternativen „körperliche Misshandlung“ und „Gesundheitsschädigung“ modelliert werden sollen. Eine Erläuterung dieser Begriffe sucht man im Gesetzestext vergebens. Stattdessen finden sich in den verschiedenen Gesetzeskom-mentaren Definitionen wie die folgende für „körperliche Misshandlung“ (s. [DT95], §223, Rn. 3; [LK99], §223, Rn. 4; vgl. außerdem BGH 14, 269; Bay NJW 70, 769):
„Eine körperliche Misshandlung ist eine üble, unangemessene Behandlung, durch die das körperliche Wohlbefinden nicht nur unerheblich beeinträchtigt wird.“
Um diesen Satz zu modellieren, kann nun das Sachverhalt-Konzept „Misshandlung“ (s. UML-Sachverhalt-Diagramm) verwendet werden. Eine Misshandlung ist eine Spezialisierung einer Behandlung, welche Verhalten spezialisiert. Eine Misshandlung verfügt daher neben dem Schlüsselattribut und der Beschreibung über die abgeleiteten bool’schen Attribute na-mens „uebel_unang“, „lebensgef“ beziehungsweise „roh“. Diese Attribute sind durch eigene Relationen realisiert. Somit wäre die Relation „misshandlung“ binär (wegen der Attribute „schluessel“ und „beschr“), würden nicht durch die Diskriminator-Metatypen zwei weitere Parameter (Opfer und Erfolg) erforderlich. Außerdem taucht in obigem Satz die Formulierung „körperliches Wohlbefinden“ auf. Körper-liches Wohlbefinden kann mit den zur Verfügung stehenden Sachverhalts-Konzepten nicht direkt ausgedrückt werden. Es wurde davon abgesehen, hierfür ein zusätzliches Konzept be-

65
reit zu stellen, da sich der obige Satz derart umformulieren lässt, dass dieses Konzept nicht mehr benötigt wird:
„Eine körperliche Misshandlung ist eine üble, unangemessene Behandlung, durch die eine nicht unerhebliche Beeinträchtigung des körperlichen Wohlbefindens erfolgt.“
Somit braucht das Wohlbefinden an sich nicht mehr betrachtet zu werden. Es interessiert nur noch, ob eine „nicht unerhebliche Beeinträchtigung des körperlichen Wohlbefindens“ vor-liegt. Hierzu dient das spezielle Personenschaden-Objekt namens „b_wohlbef“, welches über die abgeleiteten bool’schen Attribute „koerperlich“ und „unerheblich“ verfügt. Für die Regel zu „körperlicher Misshandlung“ ergibt sich damit:
koerperl_missh(Taeter,Verhalten,Erfolg,Opfer):- misshandlung(Verhalten,_,Opfer,Erfolg), beh_uebel_unang(Verhalten,"ja"), ist_kausal(Verhalten,Erfolg), b_wohlbef(Erfolg, Bez, Opfer), beeintr_koerperlich(Erfolg,"ja"),
fuehrt_aus(Verhalten,Taeter), wird_behandelt(Verhalten,Opfer).
Eine körperliche Misshandlung liegt damit nach dieser Regel vor, wenn eine Misshandlung von „Opfer“ mit dem Resultat „Erfolg“ gegeben ist. Zusätzlich dazu muss die Behandlung (jede Misshandlung ist auch eine Behandlung) übel und unangemessen sein. Der durch die Misshandlung verursachte („ist_kausal“) Erfolg muss eine Beeinträchtigung des Wohlbefin-dens darstellen, wobei diese körperlich zu sein hat (also nicht bloß seelisch). Um den jeweili-gen Bezug zwischen Täter und Verhalten beziehungsweise zwischen Opfer und Verhalten zu garantieren, sind „fuehrt_aus/2“ und „wird_behandelt/2“ erforderlich. An obiger Regel ist zu erkennen, dass „uebel_unang/2“ nur ein einzelnes Attribut darstellt, obwohl es naheliegend erscheint, zwei verschiedene Attribute für „übel“ und „unangemessen“ einzuführen. Hiervon wurde abgesehen, da die beiden Begriffe im Zusammenhang mit Be-handlungen stets als Einheit begriffen werden. So wird bei einer Behandlung, welche (bei-spielsweise durch die Rechtsprechung) als nicht „übel und unangemessen“ eingestuft wird, im Allgemeinen nicht aufgeführt, ob die Behandlung nicht übel oder nicht unangemessen (oder weder übel noch unangemessen) war. An dieser Stelle soll nun – stellvertretend für andere abgeleitete Klassen – gezeigt werden, wie die Population der abgeleiteten Klasse „Misshandlung“ ermittelt wird. Dies geschieht durch folgende Regel:
misshandlung(Verhalten,VerhBeschr,Opfer,Erfolg):- behandlung(Verhalten,VerhBeschr,Opfer), ist_kausal(Verhalten,Erfolg), beeintraechtigung(Erfolg,_,Opfer), beeintr_unerheblich(Erfolg,"nein").
Jede Behandlung, für welche zusätzlich folgendes gilt, ist eine Misshandlung:
a) durch die Behandlung wird ein Erfolg verursacht, welcher b) eine Beeinträchtigung des Opfers darstellt und c) nicht unerheblich ist.

66
Wie abgeleitete Attribute (z.B. „beeintr_unerheblich“) ermittelt werden, wird in Kapitel 6.8.2 gezeigt. 5.5.3.1.2 Gesundheitsschädigung (§223 I, 2. Alt.)
Wie die „Gesundheitsschädigung“ modelliert wird, soll an dieser Stelle nicht so ausführlich dargestellt werden, da das Prinzip ähnlich ist wie oben. Eine Gesundheitsschädigung wird folgendermaßen definiert (z.B. [LK99], §223, Rn. 5):
„[Eine] Gesundheitsschädigung ist jedes Hervorrufen oder Steigern eines vom norma-len Zustand der körperlichen Funktionen nachteilig abweichenden (pathologischen) Zustandes, gleichgültig, auf welche Art und Weise er verursacht wird und ob das Op-fer dabei Schmerz empfindet.“
Die dazugehörige Regeldarstellung hat folgendes Aussehen:
ges_schaedigung(Taeter,Verhalten,Erfolg,Opfer):- fuehrt_aus(Verhalten,Taeter), verhalten(Verhalten,_VerhBeschr), wird_behandelt(Verhalten,Opfer), ist_kausal(Verhalten,Erfolg), ges_schaden(Erfolg,_ErfBeschr,Opfer).
Die implizite Angabe von Sachverhaltsmerkmalen An dieser Stelle sei auf ein wichtiges Modellierungsproblem hingewiesen. Genau wie bei der körperlichen Misshandlung die Existenz einer Beeinträchtigung des Wohlbefindens gefordert wurde, so wird auch bei der Gesundheitsschädigung verlangt, dass ein Erfolg vorliegt. Dieser Erfolg ist in diesem Fall der Gesundheitsschaden, welcher in obiger Formulierung als „abwei-chender Zustand“ umschrieben wurde. Die Notwendigkeit der Existenz eines Erfolges folgt schon allein aus der Tatsache, dass es sich bei der Körperverletzung um ein Erfolgsdelikt handelt. Bei der Eingabe von Sachverhalten (vgl. Kapitel 6.5.2.1) kann es nun zu folgender problematischen Situation kommen. Der Anwender gibt ein, dass eine Person einer anderen eine schallende Ohrfeige gibt und glaubt, er hätte damit den Sachverhalt vollständig beschrie-ben. Das System kann aber in diesem Fall keine Körperverletzung beweisen, da ihm der dazu nötige Erfolg fehlt. Korrekterweise hätte der Anwender angeben müssen, dass durch die Ohr-feige eine Beeinträchtigung des körperlichen Wohlbefindens verursacht wurde. Ähnliche Probleme treten auch an anderen Stellen auf. So glaubt möglicherweise ein Anwen-der, welcher dem System mitteilt, dass eine Person ein Verhalten „vergiften“ ausführt, dass er hierdurch beschrieben hat, dass dem Opfer Gift „beigebracht“ wurde. Zu einem ähnlichen Problem könnte beispielsweise auch der Begriff „erschießen“ führen ... Das Problem hierbei ist jeweils, dass in solchen Formulierungen gewisse Sachverhaltsmerk-male implizit enthalten sind, diese aber vom System in expliziter Form gefordert werden. Dieses Problem wurde im Rahmen dieser Arbeit nicht gelöst. Somit hat der Anwender bei der Eingabe von Sachverhalten selbst darauf zu achten, dass er diese vollständig (in expliziter Form) beschreibt.

67
5.5.3.2 Gefährliche Körperverletzung (§224)
Die gefährliche Körperverletzung (§224) stellt eine sogenannte qualifizierte Körperverletzung dar. Hierbei handelt es sich um eine Körperverletzung, welche aber aufgrund besonders ge-fährlicher Art der Tatausführung mit einem höheren Strafmaß bewehrt ist. In diesem Ab-schnitt soll beispielhaft die Umsetzung der 2. Alternative gezeigt werden:
§ 224. Gefährliche Körperverletzung. (1) Wer die Körperverletzung 1. mittels einer Waffe oder eines anderen gefährlichen Werkzeugs, 2. mittels eines hinterlistigen Überfalls, 3. mit einem anderen Beteiligten gemeinschaftlich oder 4. mittels einer das Leben gefährdenden Behandlung
begeht, wird mit Freiheitsstrafe von sechs Monaten bis zu zehn Jahren, in minder schwe-ren Fällen mit Freiheitsstrafe von drei Monaten bis zu fünf Jahren bestraft. (2) Der Versuch ist strafbar.
Die verschiedenen Alternativen (1.-4.) stellen allesamt gefährliche Körperverletzungen dar:
gefaehrliche_kv(Taeter,Verhalten,Erfolg,Opfer):- gkv_gs_stoff(Taeter,Verhalten,Erfolg,Opfer,_Gs_Stoff). gefaehrliche_kv(Taeter,Verhalten,Erfolg,Opfer):- gkv_gef_werkzeug(Taeter,Verhalten,Erfolg,Opfer,_Werkzeug). gefaehrliche_kv(Taeter,Verhalten,Erfolg,Opfer):- gkv_ueberfall(Taeter,Verhalten,Erfolg,Opfer). gefaehrliche_kv(Taeter,Verhalten,Erfolg,Opfer):- gkv_gemeinsch(Taeter,Verhalten,Erfolg,Opfer). gefaehrliche_kv(Taeter,Verhalten,Erfolg,Opfer):- gkv_lebensgef(Taeter,Verhalten,Erfolg,Opfer).
In diesem Abschnitt soll lediglich die 2. Alternative etwas genauer betrachtet werden. Wie bereits in Kapitel 5.4.1 angesprochen wurde, ist „gefährlich“ keine reine Werkzeugeigen-schaft, auch wenn der Wortlaut des Gesetzes dies vermuten lässt. Stattdessen gilt (s. [LK99], §224, Rn. 5):
„Gefährlich ist ein Werkzeug, das nach objektiver Beschaffenheit und nach Art der Benutzung im konkreten Fall erhebliche Verletzungen herbeizuführen geeignet ist.“
Hierbei sind Eigenschaften des Opfers und die der Art der Verwendung von Bedeutung:
- Wird eine Person mit einer starken Überempfindlichkeit gegen einen bestimmten Stoff, ein solcher Stoff verabreicht, so ist dieser Stoff im konkreten Fall gefährlich.
- Eine Schere, welche dazu verwendet wird, einen Zopf abzuschneiden, ist kein gefähr-
liches Werkzeug (s. [DT95], §223a, Rn. 2).

68
Dies sei folgendermaßen modelliert:
gkv_gef_werkzeug(Taeter,Verhalten,Erfolg,Opfer,Werkzeug):- koerperverletzung(Taeter,Verhalten,Erfolg,Opfer), wird_benutzt(Verhalten,Werkzeug), werkzeug(Werkzeug,WerkzeugBez,"ja"), kv_ist_iVm_werkzeug_gefaehrlich(Verhalten,Werkzeug,Opfer).
Eine Körperverletzung ist demnach eine gefährliche, wenn ein Werkzeug verwendet wird, welches in Verbindung mit dem Verhalten und dem Opfer (bzw. bestimmten Opfer-Merkmalen) zu einem gefährlichen Werkzeug wird. Dies sei zunächst etwas unelegant mit Hilfe des Prädikats „kv_ist_iVm_werkzeug_gefaehrlich/3“ dargestellt. Die genaue Modellie-rung unterscheidet sich an dieser Stelle von der oben abgebildeten, kann aber erst nach Erläu-terung der Entscheidungskomponente (s. Kapitel 6.8.2) sinnvoll erklärt werden.
5.5.3.3 Schwere Körperverletzung (§226)
Eine genaue Darstellung der Modellierung schwerer Körperverletzungsdelikte soll an dieser Stelle nicht erfolgen, da sie sich nur in einem Punkt wesentlich von den bisherig präsentierten Modellen unterscheidet.
§ 226. Schwere Körperverletzung. (1) Hat die Körperverletzung zur Folge, daß die ver-letzte Person
1. das Sehvermögen auf einem Auge oder beiden Augen, das Gehör, das Sprechvermögen oder die Fortpflanzungsfähigkeit verliert,
2. ein wichtiges Glied des Körpers verliert oder dauernd nicht mehr gebrauchen kann oder
3. in erheblicher Weise dauernd entstellt wird oder in Siechtum, Lähmung oder geis-tige Krankheit oder Behinderung verfällt,
so ist die Strafe Freiheitsstrafe von einem Jahr bis zu zehn Jahren. (2) Verursacht der Täter eine der in Absatz 1 bezeichneten Folgen absichtlich oder wis-sentlich, so ist die Strafe Freiheitsstrafe nicht unter drei Jahren. (3) In minder schweren Fällen des Absatzes 1 ist auf Freiheitsstrafe von sechs Monaten bis zu fünf Jahren, in minder schweren Fällen des Absatzes 2 auf Freiheitsstrafe von ei-nem Jahr bis zu zehn Jahren zu erkennen.
Die schwere Körperverletzung ist – wie die gefährliche – eine qualifikazierte Körperverlet-zung. Der Grund für die Verschärfung des Strafmaßes ist in diesem Fall jedoch ein anderer: Ist durch die Verletzung eine besonders schwerer Folgeschaden (Alt. 1-3) eingetreten, so gilt das erhöhte Strafmaß des §226. Zur Modellierung solcher Folgeschäden wurde in Kapitel 5.4 die Beziehung „ist_folge_von“ eingeführt worden. Hiermit kann modelliert werden, dass ein Erfolg einen anderen nach sich zieht. Ein Problem tritt ein, wenn ein Erfolg nicht direkte sondern bloß indirekte Folge eines anderen Erfolgs ist. Dies kann beispielsweise der Fall sein, wenn eine Person eine Schnittver-letzung erleidet, diese Schnittverletzung als Folgeschaden eine Entzündung nach sich zieht, welche wiederum eine Blutvergiftung verursacht. In diesem Fall ist die Blutvergiftung streng genommen auch eine Folge der Schnittverletzung.

69
Um solche Fälle modellieren zu können, existiert im juristischen System die Relation „ist_indir_folge_von/2“:
ist_indir_folge_von(PS1,PS2):- ist_folge_von(PS1,PS2). ist_indir_folge_von(PS1,PS2):- ist_folge_von(PS1,PS3), ist_indir_folge_von(PS3,PS2).
5.5.3.4 Fahrlässige Körperverletzung (§229)
Eine Körperverletzung, die fahrlässig begangen wird, ist eine fahrlässige Körperverletzung. Da Fahrlässigkeit ein subjektives Tatbestandsmerkmal ist, im juristischen System aber nur objektive Merkmale berücksichtigt werden, gleicht die Modellierung der fahrlässigen Körper-verletzung der des Grundtatbestandes.
5.5.4 Effizienz
Zum Abschluss des Kapitels über die Formalisierung einzelner juristischer Normen soll noch erwähnt werden, dass die hier angegeben Regeln im implementierten Prolog-System noch leicht modifiziert wurden. Im Hinblick auf schnellere Beweise wurde an verschiedenen Stel-len versucht, die Klauseln möglichst effektiv anzuordnen.
a) koerperl_missh(Taeter,Verhalten,Erfolg,Opfer):- misshandlung(Verhalten,_,Opfer,Erfolg),
... fuehrt_aus(Verhalten,Taeter),
... .
b) koerperl_missh(Taeter,Verhalten,Erfolg,Opfer):- fuehrt_aus(Verhalten,Taeter),
... misshandlung(Verhalten,_,Opfer,Erfolg), ... .
Angenommen, eine Anfrage lautet: ?- koerperl_missh(1, Verhalten, Erfolg, Opfer).
Hier arbeitet Regel b) im Allgemeinen wesentlich effektiver, da nicht alle Misshandlungen der Reihe nach geprüft werden, sondern nur die, welche vom Täter mit Schlüssel „1“ began-gen wurden.
5.5.5 Hierarchie der Körperverletzungsdelikte
Man erkennt bereits an den oben aufgeführten Beispielen, dass die Körperverletzungsdelikte hierarchisch angeordnet sind. Darüber hinaus lassen sie sich auch als abgeleitete Klassen auf-fassen. Die Parameter der einzelnen Deliktarten bilden dann zusammen den jeweiligen Ob-jekt-Schlüssel. In der nachfolgenden Abbildung ist dies veranschaulicht.
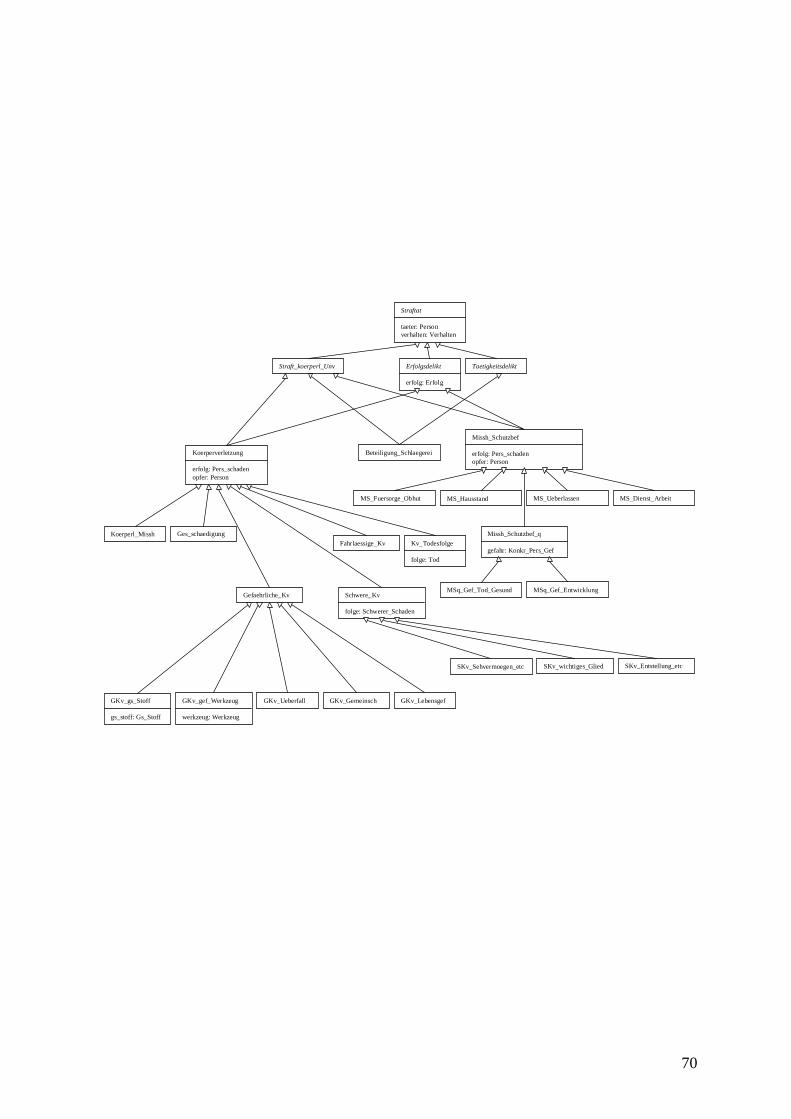
70
Koerperverletzung
erfolg: Pers_schadenopfer: Person
Koerperl_Missh Ges_schaedigung
Gefaehrliche_Kv Schwere_Kv
folge: Schwerer_Schaden
Beteiligung_Schlaegerei
Straft_koerperl_Unv
Straftat
taeter: Personverhalten: Verhalten
Erfolgsdelikt
erfolg: Erfolg
Taetigkeitsdelikt
Kv_Todesfolge
folge: Tod
Fahrlaessige_Kv
Missh_Schutzbef
erfolg: Pers_schadenopfer: Person
GKv_gs_Stoff
gs_stoff: Gs_Stoff
GKv_UeberfallGKv_gef_Werkzeug
werkzeug: Werkzeug
GKv_Gemeinsch GKv_Lebensgef
SKv_Entstellung_etcSKv_wichtiges_GliedSKv_Sehvermoegen_etc
Missh_Schutzbef_q
gefahr: Konkr_Pers_Gef
MSq_Gef_Tod_Gesund MSq_Gef_Entwicklung
MS_Fuersorge_Obhut MS_Hausstand MS_Ueberlassen MS_Dienst_Arbeit

71
6 Implementierung des juristischen Systems
In diesem Kapitel soll zunächst (Kapitel 6.1) dargestellt werden, nach welcher Vorgehenswei-se die Entwicklung des juristischen Systems erfolgte. Da dieses Kapitel insbesondere auch die Entwicklung des Systems nachzeichnen soll, könnte die Ansicht vertreten werden, es sei sinnvoll, die verschiedenen Entwicklungsphasen als Leitfaden für die Darstellung des Sys-tems zu verwenden. In Kapitel 6.1 wird dargelegt, warum davon abgesehen wird. Der tatsäch-liche Aufbau der Darstellung orientiert sich zwar teilweise auch an Aspekten der Entwick-lung, hauptsächlich ist er aber entlang der Architektur des Systems ausgerichtet. Bevor aller-dings die genaue Systemarchitektur in Kapitel 6.3 vorgestellt wird, soll in Abschnitt 6.2 („Planung und erste Systemdefinition“) eine Art Anforderungsanalyse erfolgen. Entlang der daraus im folgenden abgeleiteten Architektur sollen in den weiteren Abschnitten die ver-schiedenen Komponenten des Systems genau beschrieben werden. Innerhalb dieser Abschnit-te werden dann auch jeweils Aspekte der Systementwicklung dargestellt.
6.1 Entwicklung des Systems
Die Entwicklung von Software-Projekten folgt häufig dem Wasserfallmodell48. Hierbei wer-den zuerst die Anforderungen analysiert und das zu erstellende System wird definiert. An-schließend wird das System entworfen und danach implementiert. Bevor es zum Einsatz kommt, wird es getestet. Bei dieser Vorgehensweise sind die einzelnen Entwicklungsphasen voneinander getrennt und werden der Reihe nach durchlaufen (vgl. [PaS94], S.36 ff.). In der Praxis – insbesondere bei größeren Projekten – stößt diese Vorgehensweise jedoch auf Prob-leme. So kann es beispielsweise sein, dass die Anforderungen zu Projektbeginn nicht klar umrissen sind, sondern erst durch die im Projekt gemachten Erfahrungen präzisiert werden können. Gerade innerhalb experimenteller Projekte wird dies regelmäßig der Fall sein. Ein rein sequentielles Durchlaufen der einzelnen Phasen wie zum Beispiel Anforderungsanalyse und Implementierung macht hier keinen Sinn. Stattdessen bietet sich in solchen Fällen eine evolutionäre Softwareentwicklung ([PaS94], S. 66 ff.) an. Hierbei wird zunächst das Projekt in groben Zügen geplant. Außerdem wird eine vorläufige Systemdefinition vorgenommen. Dieser Definition folgend, wird die erste System-version erstellt. Nachdem diese getestet wurde, ist zu überdenken, ob Änderungen der Sys-temdefinition vorgenommen werden sollen. Dies ist erforderlich, wenn eine Weiterentwick-lung beabsichtigt ist. Soll weiterentwickelt werden, so muss zunächst eine Abänderung der Systemdefinition erfolgen. Hiernach wird in die Implementierungsphase zurückgekehrt und eine neue Version des entwickelten Softwaresystems wird realisiert, welche im Anschluss wieder getestet wird. Sollen an einer Systemversion keine Änderungen mehr vorgenommen werden, liegt dieses in der Endversion vor. Der hier beschriebene Entwicklungsprozess wird durch die aus [PaS94] (S. 67) stammende, leicht abgeänderte Abbildung veranschaulicht (s.u.). Bei der Entwicklung des juristischen Systems wurde gemäß dem Modell der evolutionären Softwareentwicklung vorgegangen. Orientierte sich der Aufbau der nun folgenden Beschrei-bung des Systems an den einzelnen – in der Realität jeweils mehrfach durchlaufenen – Ent-wicklungsphasen, so würde der Anschein einer „wasserfallartigen“ Entwicklung erweckt.
48 auch klassisches Phasenmodell genannt

72
Würde man das Systems entlang der evolutionären Entwicklung beschreiben, ginge dies vermutlich auf Kosten der Übersichtlichkeit. Basis der System-Darstellung ist daher dessen Endversion, welche im folgenden komponentenweise vorgestellt wird. Auf interessante As-pekte der Systementwicklung wird dabei in den jeweiligen Kapiteln eingegangen. Die nicht am Entwicklungszyklus beteiligte „Planung und erste Systemdefinition“ wird jedoch zuvor im nun folgenden Unterkapitel vorgenommen.
Planung und erste Systemdefinition
Implementierung einer Systemversion
Validierung
Endversion des Systems
Modifikation der Produktdefinition
neue Implementierung
erforderlich?
JA
NEIN
Abbildung: Darstellung der evolutionären Entwicklung des juristischen Systems
6.2 Planung und erste Systemdefinition
Bevor mit der Entwicklung eines Systems begonnen werden kann, sollte unbedingt – zumin-dest in groben Zügen – geklärt sein, was es leisten soll beziehungsweise für welche Aufga-be(n) es eingesetzt werden soll. In einer Vorstudie sind daher zunächst unter anderem die An-forderungen an das zu entwickelnde System zu beschreiben und das Problemfeld ist abzu-grenzen. Darüber hinaus sollte geklärt werden, wer mit dem zu entwickelnden System arbei-ten soll und wie die in Zukunft vom System zu erbringende Leistung bislang bewältigt wird. Hierbei gilt es auch, Informationen über das Anwendungsgebiet einzuholen. In den vorangegangenen Kapiteln wurden auf die oben angesprochenen Probleme zum Teil schon eingegangen. So wurde beispielsweise in Kapitel 5.2 festgelegt, welche juristischen Fragen vom System bearbeitet werden können sollen. Dennoch soll an dieser Stelle noch einmal aufgezählt werden, was das System in groben Zügen leisten soll. Hauptziel des zu entwickelnden Systems ist es, den Vorgang der juristischen Subsumtion nachzuahmen. Hierdurch soll dem Systemanwender dabei geholfen werden, ein juristisches Gutachten zu erstellen. Als Anwender soll nach Möglichkeit jeder – also auch der juristische Laie – in Betracht kommen. Da das System nicht nur für Informatiker sondern auch für Juris-ten eine Hilfe darstellen soll, ist darüber hinaus wünschenswert, dass auch im Umgang mit Computern weniger erfahrene Personen das System bedienen können.

73
Das System sollte so konzipiert sein, dass die von ihm bearbeitbaren Gesetze (also die Kör-perverletzungsdelikte) prinzipiell austauschbar sind. Daher muss die Subsumtion so model-liert werden, dass sie unabhängig von den konkret „beherrschten“ Gesetzesnormen operiert. Aufgrund gewisser Unterschiede in der Methodik der einzelnen Rechtsgebiete wird es zwar schwierig sein, hier totale Unabhängigkeit zu realisieren, doch sollte sie zumindest möglichst weitreichend sein. Die in Kapitel 5.5 vorgestellte Darstellung von Gesetzen durch Regeln scheint ein vielversprechender Ansatz zu sein, diesem Ziel nahe zu kommen. Ebenso sollten die zu bearbeitenden Fälle beliebig ausgetauscht werden können. Darüber hin-aus muss der Benutzer konkrete Fälle in das System eingeben können. Dies sollte möglichst komfortabel und weitestgehend unabhängig von der Struktur des den Fall repräsentierenden Datenmodells geschehen. Der Benutzer darf nicht gezwungen sein, dieses Modell zu kennen. Hingegen sollte es nicht möglich zu sein, dass der Anwender auch juristisches Wissen bear-beiten kann. Dies folgt daraus, dass juristische Laien mit dem System arbeiten können sollten. Allenfalls denkbar wäre, dass für einen eingeschränkten Benutzerkreis eine Bearbeitung des juristischen Wissens möglich ist. Im folgenden seien die oben herausgearbeiteten Anforderungen an das juristische System noch einmal stichwortartig zusammengefasst. Hinter den einzelnen Stichpunkten ist in Klammern angegeben, an welcher Stelle der Arbeit auf die jeweilige Anforderung genauer eingegangen wird. Diese Anforderungen sind:
- Verschiedenste Aspekte der juristischen Methodenlehre sollen vom System bewältigt werden können. (Kapitel 7117)
- Ein juristischer Laie soll mit dem System arbeiten können. (Kapitel 7) - Nicht-Informatiker sollen mit System arbeiten können und eine komfortable – vom
Datenmodell unabhängige – Fallbearbeitung muss möglich sein. (Kapitel 6.5)
- Die Gesetze sollen von der Subsumtion möglichst unabhängig sein. (Kapitel 6.3)
- Die Gesetze und auch der Sachverhalt sollten ausgetauscht werden können. (Kapitel 6.3)
- Eventuell sollte es einem eingeschränkten Benutzerkreis möglich sein, juristisches
Wissen zu bearbeiten. (Kapitel 7) Wie eine juristische Subsumtion in der Praxis durchgeführt wird, wurde ausführlich in den Kapiteln 2.2.2 und 2.2.4 über die juristische Methodenlehre dargelegt. Welche dort genannten Aspekte der Subsumtion in das System integriert werden können, ist in den folgenden Kapi-teln unter Berücksichtigung der in Kapitel 3 geschilderten Erfahrungen zu überprüfen. Hierbei wird immer wieder Bezug auf die in Kapitel 2.2 dargestellten Grundzüge juristischer Methodenlehre zu nehmen sein.
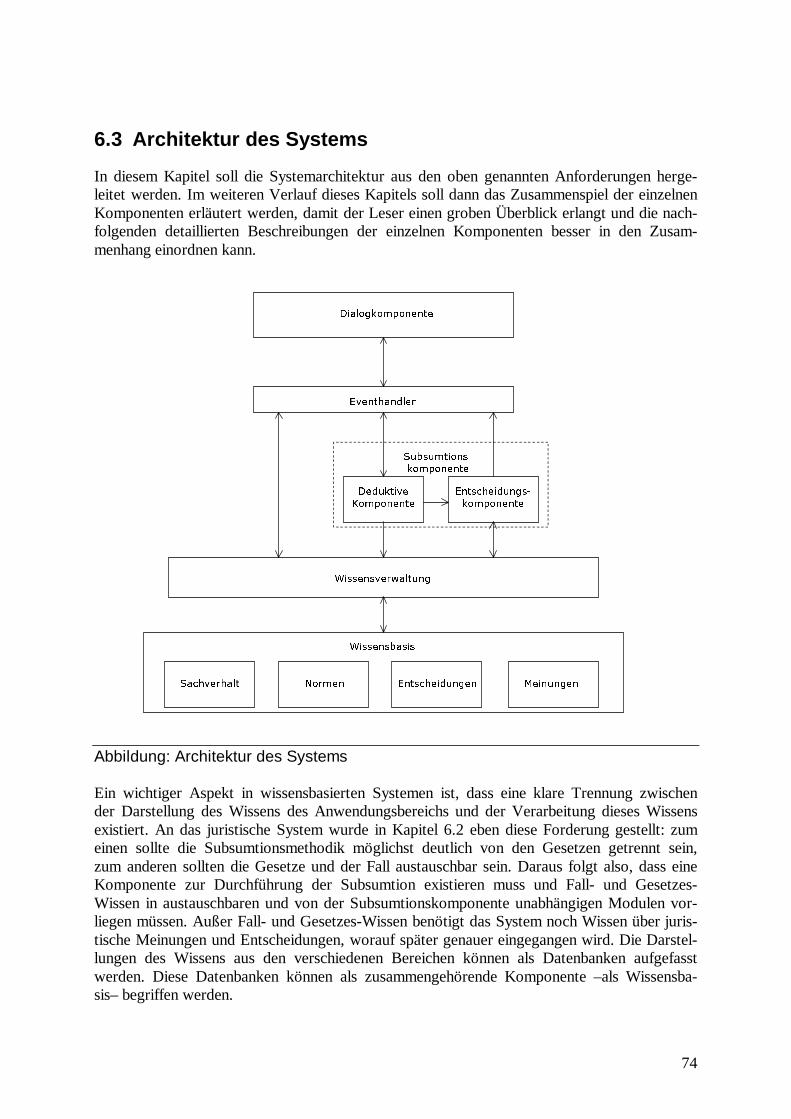
74
6.3 Architektur des Systems
In diesem Kapitel soll die Systemarchitektur aus den oben genannten Anforderungen herge-leitet werden. Im weiteren Verlauf dieses Kapitels soll dann das Zusammenspiel der einzelnen Komponenten erläutert werden, damit der Leser einen groben Überblick erlangt und die nach-folgenden detaillierten Beschreibungen der einzelnen Komponenten besser in den Zusam-menhang einordnen kann.
��������������
�����������
�������� ������ ����������� �� ������ ��
��� ����������
����������� ��
����������
���������
����������
������������
����������
����������
Abbildung: Architektur des Systems Ein wichtiger Aspekt in wissensbasierten Systemen ist, dass eine klare Trennung zwischen der Darstellung des Wissens des Anwendungsbereichs und der Verarbeitung dieses Wissens existiert. An das juristische System wurde in Kapitel 6.2 eben diese Forderung gestellt: zum einen sollte die Subsumtionsmethodik möglichst deutlich von den Gesetzen getrennt sein, zum anderen sollten die Gesetze und der Fall austauschbar sein. Daraus folgt also, dass eine Komponente zur Durchführung der Subsumtion existieren muss und Fall- und Gesetzes-Wissen in austauschbaren und von der Subsumtionskomponente unabhängigen Modulen vor-liegen müssen. Außer Fall- und Gesetzes-Wissen benötigt das System noch Wissen über juris-tische Meinungen und Entscheidungen, worauf später genauer eingegangen wird. Die Darstel-lungen des Wissens aus den verschiedenen Bereichen können als Datenbanken aufgefasst werden. Diese Datenbanken können als zusammengehörende Komponente –als Wissensba-sis– begriffen werden.

75
Um mit dem Wissen aus der Wissensbasis angemessen „hantieren“ zu können, sollte das Sys-tem über eine Komponente zur Verwaltung dieses Wissens verfügen. Diese Komponente ent-spricht dann dem Datenbank-Management-System eines Datenbanksystems. Darüber hinaus benötigt das juristische System noch eine Dialogkomponente, welche es dem Informatik-Laien ermöglicht mit dem System zu kommunizieren. Aufgrund der Problematik der Datenübergabe zwischen ECLiPSe und Tcl/Tk folgt außerdem die Notwendigkeit eines Eventhandlers. Hierauf wird in Kapitel 6.5 eingegangen. Der Eventhandler bildet die Schnitt-stelle zwischen der Dialogkomponente und dem restlichen System. Aus den obigen Ausführungen lassen sich folgende Komponenten identifizieren, welche in den in Klammern angegebenen Kapiteln dargestellt werden:
- Wissensbasis (Kapitel 6.4) - Dialogkomponente (Kapitel 6.5) - Eventhandler (Kapitel 6.6) - Wissensverwaltung oder DBMS (Kapitel 6.7) - Subsumtionskomponente (Kapitel 6.8)
6.4 Wissensbasis
In Kapitel 6.3 wurde bereits erwähnt, dass sich die Wissensbasis des juristischen Systems aus vier verschiedenen Datenbanken zusammensetzt. Wie die Sachverhalt- und die Normen-Datenbank aussehen, wurde bereits in Kapitel 5 beschrieben. Daneben existieren noch eine Datenbank für juristische Meinungen (enthält Meinung-Objekte) und eine für Entscheidungen (mit Entscheidung-Objekten). Diese Datenbanken kön-nen im Prinzip nur in Verbindung mit der Subsumtionskomponente (s. Kapitel 6.8) sinnvoll dargestellt werden, weshalb an dieser Stelle lediglich kurz angedeutet werden soll, welchem Zweck sie dienen. Die Datenbank für juristische Meinungen enthält alle Informationen über verschiedene An-sichten bezüglich eines juristischen Meinungsstreits. Ein solcher Meinungsstreit liegt vor, wenn kein Konsens bezüglich der Interpretation von Gesetzen besteht. Die Datenbank für Entscheidungen dient dazu, die erforderlichen Entscheidungen, welche der Anwender des Systems in Streitfragen zu treffen hat, zu verwalten.
6.5 Dialogkomponente
Wie in Kapitel 5 dargestellt wurde, wird das Wissen des juristischen Systems in Prolog-Fakten und –Regeln dargestellt. Daher kann auf dieses Wissen über Prolog-Anfragen auf Ba-sis dieser Regeln und Fakten zugegriffen werden. Solche Anfragen könnten dann beispiels-weise folgendermaßen aussehen:
?- person(Schluessel,Nachname,“Tim“,Geschlecht,Alter,Wehrlos). ?- koerperverletzung(Taeter,Verhalten,Erfolg,Opfer).
Die erste Anfrage würde als Resultat alle Personen liefern, die mit Vornamen „Tim“ heissen. Die zweite Anfrage würde die Frage beantworten, welche Körperverletzungen begangen wur-den.

76
Das Wissen des Systems kann darüber hinaus auf Prolog-Ebene mittels der Prädikate assert/2 und retract/2 modifiziert werden. So könnte beispielsweise folgendermaßen das Attribut „Al-ter“ eines Person-Objekts aus dem Datenbestand verändert werden:
retract(person(4,“Schuster“,“Tim“,m,24,nein)). assert(person(4,“Schuster“,“Tim“,m,27,nein)).
Insofern ist es also prinzipiell nicht unbedingt nötig, eine besondere Dialogkomponente zur Verfügung zu stellen. Wie jedoch an den Beispielen zu erkennen ist, sind solche Zugriffe auf das Wissen des Systems umständlich und ohne Kenntnis des zu Grunde liegenden relationalen Datenmodells nicht möglich. Insbesondere ist zu beachten, dass die Attributwerte der Relati-onen häufig Schlüssel sind, also meist bloße Zahlen, die den Anwender häufig vor die Frage stellen dürften, was sich dahinter verbirgt. In Kapitel 6.2 wurde die Anforderung formuliert, dass auch Nicht-Informatiker mit dem Sys-tem arbeiten können sollen und eine komfortable – vom Datenmodell unabhängige – Fallbe-arbeitung muss möglich sein muss. Um einen solchen Umgang mit dem System zu ermögli-chen, ist es somit nötig, eine spezielle Dialogkomponente bereitzustellen, über welche die gesamte Kommunikation des Anwenders mit dem System abgewickelt werden kann. Diese Dialogkomponente muss folgende Aufgaben bewältigen können:
- Ein Sachverhalt muss eingegeben werden können. Dabei muss es nicht möglich sein, dem System jeden denkbaren Lebensvorgang vermitteln zu können. Vielmehr ist er-forderlich, dass die Fälle eingegeben werden können, die mit Körperverletzungsdelik-ten in Verbindung stehen könnten.
- Der Sachverhalt soll in der Folge auch verändert werden können. Schon deswegen
muss es auch möglich sein, den Sachverhalt anzusehen.
- Das System muss dem Anwender in Rechtsstreitigkeiten die verschiedenen Ansichten präsentieren und Entscheidungen des Anwenders erfragen können. Ausserdem muss der Anwender (neue) Meinungen zu einem Streit eingeben und bearbeiten können.
- Letztlich muss auch der Anwender die Möglichkeit haben, Fragen an das System zu
stellen und Antworten darauf zu erhalten. Hierunter fällt auch, dass der Anwender das System dazu auffordern können muss, eine Fallbearbeitung vorzunehmen.
Bevor in Kapitel 6.5.2 dargestellt wird, wie die Dialogkomponente des juristischen Systems implementiert wurde und die oben aufgeführten Aufgaben bewältigt, sollen zuvor noch einige ergonomische Gesichtspunkte Berücksichtigung finden.
6.5.1 Benutzerfreundlichkeit
Da die Dialogkomponente die Arbeit mit dem System erleichtern soll und eine unkomfortable Dialogkomponente die Handhabbarkeit des Systems und somit auch seinen Nutzen stark ein-schränken kann, sind bei ihrer Entwicklung stets gewisse ergonomische Überlegungen zu berücksichtigen. Auch unerfahrenen Anwendern sollte es möglich sein, mit dem System zu interagieren und dabei alle Aktionen einigermassen zügig auszuführen. Daher empfiehlt es sich, eine grafische Anwendungsoberfläche zur Verfügung zu stellen, da viele Anwender mit dem Umgang von „Fenstern“, „Buttons“, „Schiebereglern“ und ähnlichem vertraut sind und

77
diese Techniken in der Regel eine im Vergleich zu textbasierten Systemen intuitivere und schnellere Handhabung erlauben. Dennoch ist bei der Realisierung der Dialogkomponente auch zu berücksichtigen, dass Benut-zerfreundlichkeit teilweise durch einen erheblichen Entwicklungsaufwand erkauft werden muss. Hier gilt es also besonders, einen sinnvollen Mittelweg zwischen Aufwand und Nutzen zu finden. In den Beschreibungen der einzelnen Dialoge wird hierauf weiter einzugehen sein. Ein Aspekt dieser Prolbematik soll allerdings bereits an dieser Stelle berücksichtigt werden. Hierbei geht es um die „Analyse und Synthese natürlicher Sprache“. Bei jeder Form des Dia-loges des Systems stellt sich die Frage, inwieweit natürliche Sprache verwendet werden kann. In der Regel wird der Anwender den Sachverhalt in schriftlicher Form in natürlicher Sprache vorliegen haben. Auch Fragen, die er an das System stellen möchte, wird er zunächst als Vor-stellung im Kopf haben, die –zumindest ansatzweise– in natürlicher Sprache formuliert ist. Daher wäre es sicher sehr komfortabel, wenn er beispielsweise einen Sachverhalt oder eine Frage in natürlicher Sprache in das System eingeben könnte und dieses die Sprache analysier-te und in die interne Repräsentation überführen könnte, also die entsprechenden Prolog-Klauseln generieren könnte. Ebenso wäre es schön, wenn die Ergebnisse oder Rückfragen des Systems dem Anwender in natürlicher Sprache präsentiert würden, das System also selbst-ständig aus Prolog-Klauseln vernünftige natürlichsprachliche Sätze erzeugte. Wollte man dies realisieren, wären also Systemkomponenten zur Analyse beziehungsweise Synthese natürlicher Sprache erforderlich, wie dies beim LEX-Projekt (s. Kapitel 3.1) erfor-derlich war. Allerdings stellt die natürliche Sprache die Informatik derzeit vor große Proble-me. Ohne hierauf näher eingehen zu wollen (vgl. dazu Kapitel 3.1.2), scheint es wohl nicht möglich zu sein, in vernünftiger Weise die natürliche Sprache zu analysieren. Zumindest le-gen die Erfahrungen des LEX-Projekts dies nahe, wo das implementierte System vor allem aufgrund des Versuchs, natürliche Sprache zu verarbeiten – gemessen an juristischen Maßstä-ben – nur geringe Leistungsfähigkeit erzielte. Die Erzeugung von (mehr oder weniger) natür-licher Sprache aus Prolog-Klauseln scheint hier ein kleineres Problem darzustellen. In den folgenden beiden Abschnitten soll nun dargestellt werden, auf welche Weise im juristi-schen System der Übergang von natürlicher Sprache zu Prolog-Klauseln (in beide Richtun-gen) realisiert wurde.
6.5.1.1 Abbildung natürlicher Sprache auf Prolog-Klauseln
Wie bereits dargelegt, scheint es zu aufwendig zu sein, das System mit der Fähigkeit zur Sprachanalyse auszustatten. Der Schwerpunkt der Arbeit würde hierdurch zu stark verscho-ben. Es ist daher notwendig, die Sprachanalyse gewissermassen auf den Anwender zu verla-gern. Dies scheint durchaus angebracht zu sein, da der Mensch über die Bedeutung einzelner Satzteile Bescheid weiss und die in natürlichsprachlichen Sätzen transportierten Informatio-nen ermitteln kann. Es sollte daher Aufgabe des Anwenders sein, die Sätze, die er dem Sys-tem vermitteln möchte, auf seine Informationen hin zu untersuchen. Das System muss dem Anwender nun lediglich eine Möglichkeit bieten, diese Informationen unmissverständlich eingeben zu können. Genügen sollten hier gewisse Sachverhalt-Eingabe-Formulare, die es ermöglichen, die relevanten Informationen eines Falles einzugeben. Da das Problemfeld (die Körperverletzungsdelikte) einigermassen klar umgrenzt ist und im Prinzip hauptsächlich Ver-haltensweisen klassifiziert werden können müssen, kann die Menge der verschiedenen Kon-zepte zur Darstellung von Sachverhalten und somit auch die Menge der verschiedenen Einga-

78
be-Formulare relativ klein gehalten werden, so dass der Anwender den Umgang mit ihnen relativ schnell beherrschen lernen kann.
6.5.1.2 Abbildung von Prolog-Klauseln auf natürlichsprachliche Sätze
Wie bereits gesagt, scheint zumindest die Erzeugung natürlichsprachlicher Sätze aus Prolog-Klauseln machbar zu sein. Dennoch sind auch hier noch einige grammatikalische Informatio-nen nötig. So müssten beispielsweise Verben dekliniert werden können und die Geschlechter der Nomen im Sachverhalt müssten bekannt sein. Angenommen, folgende Sachverhaltsfakten lägen dem System vor:
person(24,“Müller“,“Dieter“,m,33,nein). person(12,“Schmidt“,“Ulla“,w,35,nein). gegenstand(9,“Knüppel“,ja). verhalten(18,“schlagen“). pers_schaden(87,“Beule“,12). fuehrt_aus(18,24). wird_behandelt(18,12). ist_kausal(18,87).
In natürlicher Sprache soll dies bedeuten: „Dieter Müller schlägt Ulla Schmidt mit einem Knüppel und fügt ihr so eine Beule zu.“ Um diesen Satz bilden zu können, benötigt das Sys-tem folgendes Sprachwissen:
- das Verb „schlagen“ in der dritten Person Singular heisst „schlägt“, - das Geschlecht von „Knüppel“ ist männlich, - das Geschlecht von „Beule“ ist weiblich.
Das Sprachwissen müsste dem System als Faktenmenge zur Verfügung stehen. Entweder, es verfügte über eine riesige Wissensbasis mit allen Informationen zu allen Wörtern oder der Anwender müsste eine solche Faktenmenge sukzessiv aufbauen, indem er bei jeder Datenein-gabe dem System auch die notwendigen grammatikalischen Informationen zu den eingegebe-nen Daten mitliefert. Auch eine Mischform wäre denkbar. So könnte das System über ein aufbaubares Grundwissen verfügen. Unabhängig davon, welche Alternative realisiert werden sollte, entstünde sehr großer Auf-wand. Entweder die Systementwicklung würde grossen zusätzlichen Aufwand erfordern oder der Anwender hätte mehr Arbeit bei der Eingabe zu leisten. Fraglich ist daher, ob es nicht besser ist, ganz auf das Grammatikwissen zu verzichten, böte sich doch immerhin noch die Möglichkeit, pseudo-natürlichsprachliche Sätze im folgenden Stil zu bilden:
Dieter Müller führt das Verhalten <schlagen> gegen Ulla Schmidt aus und verwendet dabei den Gegenstand <Knüppel> und verursacht den Scha-den <Beule>.
Zwar klingt ein solcher „Satz“ nicht elegant, dennoch ist vollkommen klar, was gemeint ist. Da auf eine Sprachanalyse des Systems verzichtet wird, scheint es konsequent zu sein, auch in die Sprachsynthese nicht allzu großen Aufwand zu investieren. Der Nutzen der besser formu-lierten Sätze wiegt den zu leistenden Aufwand wohl nicht auf. Daher wird auf diese pseudo-natürlichsprachlichen Sätze zurückgegriffen. Dadurch, dass diese „Sätze“ noch in eine norma-le Form gebracht werden müssen, ist in einem gewissen Sinne auch die Sprachsynthese zu einem Teil vom Anwender zu leisten.

79
6.5.2 Die Dialoge des juristischen Systems
Die Dialogkomponente wurde mittels Tcl/Tk (s. Kapitel 2.1.9) implementiert. Tcl/Tk wird vom Prolog-Programm aus gestartet. Wie die Interaktion zwischen ECLiPSe und Tcl/Tk ge-nau realisiert wurde, wird in Kapitel 6.6 beschrieben. In diesem Teil der Arbeit, werden die Dialoge vorgestellt, mit welchen der Benutzer bei der Arbeit mit dem System konfrontiert werden kann. Somit fungiert dieser Abschnitt auch als Bedienungsanleitung für das juristische System. Das juristische System wird mit
[’jur_system’], top.
geladen und gestartet. Als erstes wird dann dem Benutzer das Hauptmenü präsentiert (s. Ab-bildung). Dieses besteht hauptsächlich aus vier Spalten von Buttons. Diese Spalten tragen die Überschriften
- Sachverhalt bearbeiten - Sachverhalt-DB verwalten - Meinungs-DB verwalten - Subsumtion
Ausserdem existiert im Hauptmenü ein Button mit der Aufschrift „Sachverhalt ansehen“ und einer mit der Aufschrift „fertig“. Ein Druck auf den letztgenannten beendet das juristische System. Genaugenommen sorgt er lediglich dafür, dass die grafische Oberfläche geschlossen wird und der Anwender in den ECLiPSe-Terminal-Modus zurück gelangt, von wo aus immer noch auf die Daten des Systems zugegriffen beziehungsweise – mittels „top/0“ – die GUI erneut gestartet werden kann. Über den Button „Sachverhalt ansehen“ gelangt der Anwender zu einer textuellen Darstellung des Sachverhalts.
Dialog: Hauptmenü

80
Im folgenden sollen die vier oben genannten Button-Spalten und die sich hinter den einzelnen Buttons verbergenden Funktionen des Programms näher beschrieben werden.
6.5.2.1 Sachverhalt bearbeiten
Mit den Buttons unter der Überschrift „Sachverhalt bearbeiten“ werden Dialoge gestartet, die zur Bearbeitung der Sachverhalt-Daten in der entsprechenden Wissensbasis dienen. Der An-wender hat die Wahl zwischen folgenden Dialogen:
- Person bearbeiten - Verhalten bearbeiten - Gegenstand bearbeiten
Um alle Aspekte eines Sachverhalts bearbeiten zu können, müssen alle Sachverhalt-Prädikate (bis auf die abgeleiteten) bearbeitet werden können. Über die drei oben aufgeführten Dialoge kann auf die Prädikate „person/6“, „verhalten/2“ und „gegenstand/3“ zugegriffen werden. Die restlichen Prädikate können über Dialoge bearbeitet werden, welche von den anderen Dialo-gen aus erreicht werden können. Die folgende Übersicht soll veranschaulichen, über welche Dialoge welche Prädikate bearbei-tet werden können.
Person bearbeiten � person/6
� schutzverhaeltnis/2 � personenmerkmal/3 � konkr_pers_gef/3 � pers_schaden/2 � ist_folge_von/2
Gegenstand bearbeiten � gegenstand/3 Verhalten bearbeiten � verhalten/2
� fuehrt_aus/2 � wird_behandelt/2 � ist_kausal/2 � wird_benutzt/2 � begruendet/2
Abbildung: Übersicht über die Navigation der Sachverhaltsbearbeitung Die Navigation zur Bearbeitung der einzelnen Prädikate wird bei den Beschreibungen zu den einzelnen Dialogen genauer dargestellt werden. Der Grund dafür, dass vor Bearbeitung man-cher Sachverhaltsaspekte zunächst ein Umweg über einen oder sogar zwei (im Falle von „ist_folge_von/2“) andere Dialoge gemacht werden muss, ist, dass hierdurch die Übersicht-lichkeit gesteigert werden soll. Zum einen ist es wenig übersichtlich, wenn der Anwender bereits im Hauptmenü zwischen zu vielen verschiedenen Dialogen auswählen muss. Anderer-seits wird durch den Umweg über die drei Hauptdialoge zur Sachverhaltsbearbeitung der wünschenswerte Effekt herbeigeführt, dass der Anwender ein Prädikat, welches über einen untergeordneten Dialog bearbeitet wird (wie beispielsweise pers_schaden/2), mit dem ent-sprechenden Prädikat des übergeordneten Dialogs (person/6) assoziiert, so dass in diesen Fäl-len der jeweilige Objektbezug klar wird.

81
Bei Prädikaten, die binäre Beziehungen zwischen Objekten darstellen (wie zum Beispiel „ist_kausal/2“ oder „fuehrt_aus/2“), ist offensichtlich, dass die zur Bearbeitung erforderlichen Dialoge prinzipiell über zwei verschiedene übergeordnete Dialoge erreichbar sein müssten. So wäre es durchaus sinnvoll, wenn das Prädikat „fuehrt_aus/2“ mit den an dieser Relation betei-ligten Objekten „Verhalten“ und „Person“ über die zu diesen Objekten gehörenden Dialoge oder diesen untergeordnete Dialoge bearbeitet werden könnte. Stattdessen wird allerdings von der Dialogkomponente jeweils nur eine von mehreren Möglichkeiten zur Verfügung gestellt. Auf das Prädikat „fuehrt_aus/2“ kann beispielsweise nur über den Dialog zur Bearbeitung von „Verhalten“-Objekten zugegriffen werden (s. dort). Der Grund hierfür ist, dass alternative Zugriffsmöglichkeiten auf die einzelnen Prädikate einen erheblichen Mehraufwand bei der Erstellung der Dialogkomponente bedeutet hätten. Da für jedes Prädikat eine sinnvolle Zugriffsmöglichkeit besteht, erscheint der hier erforderliche Mehraufwand in keinem vernünf-tigen Verhältnis zu dem Vorteil verschiedener Zugriffsmöglichkeiten mehr zu stehen. Das Vorhandensein nur einer Eingabemöglichkeit dürfte darüber hinaus nur in wenigen Fällen tatsächlich zu Unbequemlichkeiten bei der Sachverhaltsbearbeitung führen. Möchte man zum Beispiel ein Verhalten-Objekt eingeben, also in der Regel die Handlung einer Person beschreiben, ist selbstverständlich, dass man hierbei auch angeben möchte, wer das Verhalten „ausführt“, wer hierdurch „behandelt“ wird und welche Gegenstände dabei benutzt werden. Aus diesem Grund, sollten die Prädikate „fuehrt_aus/2“, „wird_behandelt/2“ und „wird_benutzt/2“ auch über den Dialog „Verhalten bearbeiten“ erreicht werden können. Auf der anderen Seite wird es wohl eher selten der Fall sein, dass jemand einen Gegenstand eingeben möchte und an dieser Stelle direkt bestimmen möchte, bei welchem „Verhalten“ dieser zur Anwendung kommt. Dies hat zur Folge, dass im Dialog „Gegenstand bearbeiten“ nur wenige Eingaben gemacht werden können, was zu Beginn der nun folgenden Beschrei-bungen der einzelnen Dialoge zur Sachverhalt-Bearbeitung zu sehen sein wird. 6.5.2.1.1 Gegenstand-Bearbeitung
Dialog: Auswahl der zu bearbeitenden Instanz Allen Dialogen zur Bearbeitung einzelner Sachverhaltsaspekte wie Gegenstand-, Person- oder Verhalten-Objekte ist gemein, dass zunächst eine bestehende Instanz ausgewählt werden

82
kann, die bearbeitet werden soll. Ausserdem besteht die Möglichkeit, eine neue Instanz zu erschaffen. Die Beispielabbildung zeigt den Dialog zur Auswahl eines Gegenstand-Objektes. Wird auf den „neu“-Button gedrückt, gelangt der Anwender zum Gegenstand-Bearbeitungs-Dialog. Dies geschieht auch, wenn er auf den „bearbeiten“-Button drückt und zuvor eine In-stanz markiert hat. In diesem Fall sind jedoch die Attribute und gegebenfalls andere mit der jeweiligen Instanz zusammenhängende Werte in das entsprechende Dialog-Formular einge-tragen. Bevor nun der Dialog zur Bearbeitung einzelner Gegenstand-Objekte (wie er in obiger Abbil-dung zu sehen ist) erläutert wird, soll dargestellt werden, auf welche Weise die Auswahl von Objektinstanzen in Tcl/Tk programmiert wurde. Hierzu wurde die Prozedur „schluesselbox“ entwickelt, die in einer stark vereinfachten Form hier abgebildet ist:
proc schluesselbox {bezeichnung fenster cmd1 cmd2 cmd3 inhalt} { global schluesselbox_inhalt frame $fenster -relief ridge -borderwidth 3 frame $fenster.rahmen label $fenster.rahmen.bez -text $bezeichnung pack $fenster.rahmen.bez -side left -anchor w pack $fenster.rahmen -fill x pack $fenster -fill x neue_listbox $fenster schlbox
foreach element $inhalt { $fenster.schlbox.inhalt insert end [lindex $element 1]
set i [lindex $element 1] set e [lindex $element 0]
set schluesselbox_inhalt($i) $e } set b $fenster.buttons frame $b; pack $b button $b.add -text neu –“command” $cmd1 pack $b.add -side left
button $b.edit -text “bearbeiten” -command $cmd2 pack $b.edit -side left button $b.remove -text “löschen” -command $cmd3 pack $b.remove -side left }
Abbildung: Tcl/Tk-Prozedur „schluesselbox“ Die genaue Funktionsweise der Prozedur ist nicht so wichtig und soll nicht näher erläutert werden. Wichtig ist, dass (über die Prozedur „neue_listbox“) eine „Listbox“ geöffnet wird, in welche die Elemente eingefügt werden („foreach element ...“), welche innerhalb der Listbox bearbeitet werden sollen. Diese Elemente sind im juristischen System meist Beschreibungen von Objekten (wofür die bereits beschriebenen Objekt-Methoden erforderlich sind). Die „but-ton“-Anweisungen am Ende der Prozedur sorgen dafür, dass die Knöpfe „neu“, „bearbeiten“ und „löschen“ auf dem Bildschirm erscheinen. Was bei einem Druck auf einen der Knöpfe geschieht, steht in den Argumenten „cmd1“, „cmd2“ und „cmd3“. Diese drei Kommandos stellen jeweils Prozeduraufrufe dar. Die so aufrufbaren Prozeduren operieren auf dem Inhalt (meistens auf dem jeweils selektierten Element) der Listbox und sorgen so dafür, dass der Inhalt der Listbox verändert werden kann. Damit gleichzeitig auch eventuell erforderliche Datenbankanpassungen erfolgen können – beispielsweise wenn ein bestimmtes Element ent-

83
fernt wird und somit auch aus der Datenbank gelöscht werden muss – ist es erforderlich, die Schlüssel der einzelnen Objekte zu kennen. Dazu werden die Objektschlüssel in dem Array „schluesselbox_inhalt“ verwaltet. Ein Problem, welches im Rahmen der aktuellen Version des juristischen Systems noch nicht vollständig gelöst wurde, ist, dass die Objektbeschreibungen im Allgemeinen nicht die Schlüsseleigenschaft besitzen und so in Einzelfällen verschiedene Objekte innerhalb der Listbox nicht auseinandergehalten werden können. Immerhin verbes-sern die ausführlichen Objektbeschreibungen, welche in der Listbox stehen, die Unterscheid-barkeit im Vergleich zu den bloßen Objekt-Bezeichnungen, so dass der Mangel des Systems nur selten in Erscheinung tritt. Dennoch müsste dieser Mangel in einer Nachfolgeversion be-hoben werden. Geplant ist, Objekte mit identischen Bezeichnungen mit Indizes zu versehen. Dieser Plan wurde aus Zeitmangel jedoch noch nicht verwirklicht. Nun aber zur Bearbeitung einzelner Gegenstand-Objekte.
Dialog: Gegenstand-Eingabe In diesem Dialog muss der Anwender lediglich eine Bezeichnung für das Gegenstand-Objekt in das dafür vorgesehene „Entry-Widget“ eintippen und über den „Select-Button“ angeben, ob dieses Objekt beweglich ist oder nicht. Wie in allen anderen Eingabe-Formularen befinden sich an unterster Stelle des Dialog-Fensters drei Buttons. Diese tragen die Aufschriften „fertig“, „übernehmen“ und „abbrechen“. Mit „übernehmen“ werden die Eingabe-Daten in die Datenbank übernommen. Der „fertig“-Button dient dem gleichen Zweck, mit dem einzigen Unterschied, dass er darüber hinaus den Dialog beendet. Dies passiert auch, wenn auf den „abbrechen“-Button geklickt wird, aller-dings erfolgt in diesem Fall keine Anpassung der Datenbank. Die genaue Semantik dieser drei Buttons wird in dem Kapitel 6.7.3 über die Transaktionen im juristischen System beschrieben.

84
6.5.2.1.2 Verhalten-Bearbeitung
Dialog: Verhalten-Eingabe Die Bearbeitung eines Verhaltens geschieht folgendermaßen. Zum einen muss selbstverständ-lich eine Bezeichnung für das Verhalten eingegeben werden. Über weitere Attribute verfügt das Konzepts „Verhalten“ nicht. Allerdings steht es, wie oben beschrieben, zu ein paar anderen Objektklassen in Beziehung. Da über diese Beziehungen das Verhalten näher beschrieben wird (wer ist/sind Täter, wer ist/sind Opfer etc.) werden diese Beziehungen über den Verhalten-Dialog bearbeitet. Dies geschieht, indem in die Listboxes die Objekte hinzugefügt oder entfernt werden, die zu dem bearbeiteten Verhalten-Objekt in der dazugehörigen Beziehung stehen. Die Überschriften der einzelnen Listboxes entsprechen hierbei nicht den Bezeichnungen der entsprechenden Prädi-kate, sondern orientieren sich an den Rollen, in welcher das jeweilige Objekt an der entspre-chenden Relation beteiligt ist:
Überschrift der Listbox entsprechendes Prädikat Ausführende Personen Behandelte Personen Benutzte Gegenstände Verursachte Schäden Ausgelöste konkrete Gefahren
fuehrt_aus/2 wird_behandelt/2 wird_benutzt/2 ist_kausal/2 begruendet/2
Um ein neues Objekt in eine Listbox einzufügen, muss diese gegebenenfalls zunächst aufge-klappt werden. Dies geschieht durch Druck auf den Button mit der Beschriftung „...“. Exis-tiert kein solcher Button neben der Überschrift der jeweiligen Listbox, ist diese bereits aufge-

85
klappt und kann über einen Druck auf den Button mit der Beschriftung „X“ wieder zuge-klappt werden. Unter aufgeklappten Listboxes befinden sich jeweils Buttons mit den Aufschriften „hinzufü-gen“ und „entfernen“. Drückt der Anwender auf den Button „hinzufügen“, öffnet sich eine Listbox, in welcher alle Objekte der an der Beziehung beteiligten Klasse aufgelistet sind. Der Anwender kann nun ein Element auswählen und es so in die entsprechende Beziehung mit dem gerade bearbeiteten Verhalten-Objekt setzen. Ein Druck auf den Button „entfernen“ ent-fernt das jeweils markierte Element der Listbox. 6.5.2.1.3 Person-Bearbeitung
Dialog: Person-Eingabe Die vom Anwender bearbeitenden Daten, welche unmittelbar zur Relation „person/6“ gehö-ren, können im Dialog oben eingegeben beziehungsweise bearbeitet werden: Vorname, Nach-name und Alter können in die entsprechenden Textfelder getippt werden. Über einen „Select-Button“ kann eingestellt werden, ob die Person wehrlos ist oder nicht. Ausserdem kann mit-tels sogenannter „Radio-Buttons“ das Geschlecht ausgewählt werden. Über den unteren Teil des „Dialog-Formulars“ können Daten eingegeben werden, die mit dem „person/6“-Prädikat in Beziehungen stehen. Hierzu zählen einerseits die Schutzverhält-nisse an denen die Person als „schützende Person“ beteiligt sein kann. Drückt der Anwender den Button mit der Aufschrift „Schutzverhältnisse ...“, wird ein Dialog zur Bearbeitung der Schutzverhältnisse geöffnet, welcher nicht näher beschrieben werden muss, da er prinzipiell genauso funktioniert, wie die Bearbeitung der Beziehungen von Verhalten-Objekten (s.o.). Die weiteren Beziehungen, an welchen ein Person-Objekte beteiligt sein kann, werden über den Verhalten-Dialog bearbeitet. Allerdings existieren Objekte, welche als Attribut eine Referenz auf „Person“-Objekte haben. Da sie ausser dieser Referenz und ihres eigenen Schlüsselwertes nur über ein weiteres Attri-but verfügen (jeweils „bezeichnung“), werden diese Objekte über den Dialog „Person bear-beiten“ mitverwaltet.

86
Dies geschieht – wie bei der Bearbeitung von Beziehungen – über Listboxes:
Überschrift der Listbox entsprechendes Prädikat Besondere Merkmale Erlittene Schäden Erfahrene konkrete Gefahren
personenmerkmal/3 pers_schaden/3 konkr_pers_gef/3
Der einzige Unterschied ist, dass bei Druck auf den Button „hinzufügen“ unter der jeweiligen Listbox keine Listbox zur Auswahl eines Objektes geöffnet wird, sondern ein Entry-Widget, in welches der Anwender die Bezeichnung des Personenmerkmals, Personenschadens bezie-hungsweise der konkreten Personengefahr eingibt und somit zugleich dieses Objekt erschafft. Eine Ausnahme bildet hierbei die Bearbeitung von Personenschäden. Da Objekte dieser Klas-se an der Beziehung „ist_folge_von“ beteiligt sind, können bei der Bearbeitung solcher Ob-jekte darüber hinaus, die Personenschäden angegeben werden, welche Folge des derzeit bear-beiteten Personenschadens sind.
6.5.2.2 Sachverhalt-DB verwalten
Da es je nach Sachverhalt relativ aufwendig sein kann, diesen einzugeben, besteht die Mög-lichkeit, Sachverhalte durch Druck auf den entsprechenden Button und Angabe des Pfad- und Dateinamens in eine Datei zu schreiben und ihn daraus zu laden. Ausserdem können Sachver-halte gelöscht werden, damit ein neuer Fall eingegeben und bearbeitet werden kann. Wird ein Sachverhalt gespeichert, so werden neben den Sachverhaltsfakten auch die Zähler gespei-chert, welche die Informationen enthalten, was der nächste zu vergebene Schlüsselwert für neu zu erschaffene Objekte ist, obwohl diese Werte streng genommen nicht zur Sachverhalt-Datenbank zu rechnen sind. Entsprechend werden die Zähler bei Löschung eines Sachverhal-tes auf ihre Ausgangswerte zurück gesetzt.
6.5.2.3 Meinungs-DB verwalten
Gleiches gilt für die Datenbank, welche die Informationen über verschiedene juristische Mei-nungen enthält. Auch diese Daten können gesichert, geladen und gelöscht werden.
6.5.2.4 Subsumtion
Unter Rückgriff auf die zur Verfügung stehenden Datenbanken wie der Sachverhalt-Datenbank ist das juristische System in der Lage, juristische Fragen zu beantworten. Die Ent-scheidungen (für jeweils eine Ansicht in einem Meinungsstreit), die während dieser Beant-wortungen von Fragen an das System vom Anwender getroffen werden, können über den But-ton „Subsumtion zurücksetzen“ revidiert werden. Für die Beantwortung der Fragen selbst stehen dem System hauptsächlich die Prädikate „constrain_and_test/1“ und „subsumtionen/2“ zur Verfügung. Mit der „Constrain And Test“-Methode lassen sich schnell alle Antworten zu einer Anfrage ermitteln. Mit Hilfe des Prädi-kats „subsumtionen/2“ können diese Antworten nicht ganz so effizient, dafür aber in der bei einem juristischen Gutachten üblichen Reihenfolge gefunden werden. Darüber hinaus wird bei Anfragen mittels „subsumtionen/2“ ein Subsumtionstext erstellt, welcher auf dem Bild-schirm ausgegeben wird. Dieser Text kann bearbeitet und in einer Textdatei gespeichert wer-den. Wie die beiden Inferenzmethoden genau funktionieren, wird in Kapitel 6.8 beschrieben.

87
An dieser Stelle soll lediglich beschrieben werden, wie die Methoden an die grafische Ober-fläche angebunden sind. Hinter dem Button „(Delikt prüfen)“ verbirgt sich das Prädikat „constrain_and_test/1“. Die Klammern um die Beschriftung des Buttons sollen signalisieren, dass die Anbindung an die grafische Oberfläche nicht richtig abgeschlossen ist. Wird der Button gedrückt, erscheint zu-nächst ein einfacher Dialog, in welchem der Anwender das Delikt49 auswählen kann, von welchem geprüft werden soll, ob es im vorliegenden Sachverhalt begangen wurde. Das zu dem Delikt gehörende Prolog-Prädikat bildet dann das Argument für „constrain_and_test/1“. Das Prädikat wird dann mit dem entsprechenden Argument angefragt und im ECLiPSe-Terminal wird dargestellt, was genau überprüft wird und zu welchen Resultaten die jeweili-gen Überprüfungen gelangen.50 Das Prädikat „subsumtionen/2“ kann über den Button „Subsumtion durchführen“ angefragt werden. Zunächst wird der Anwender wieder mit dem Deliktauswahl-Dialog konfrontiert, über welchen das System das erste Argument für „subsumtionen/2“ gewinnt: den Funktorna-men des Prädikats, welches die Norm repräsentiert, die überprüft werden soll. Entscheidet sich der Anwender beispielsweise dafür, den Sachverhalt hinsichtlich des Vorhandenseins einer gefährlichen Körperverletzung zu untersuchen, so lautet dieses erste Argument „ge-faehrliche_kv“. Das zweite Argument des Prädikats „subsumtionen/2“ sollte ursprünglich die zu dem Funktor gehörenden Argumente enthalten. Diese Argumente waren in einer Liste angeordnet. Aus dem Funktor (erstes Argument von „subsumtionen/2“) und den Argumenten aus dem zweiten Argument von „subsumtionen/2“ konnte nun ein Prolog-Term gebildet werden. Die Anfrage
?- subsumtionen(gefaehrliche_kv,[13,5,2,47]).
hatte dann zur Folge, dass versucht wurde folgendes Goal zu beweisen:
gefaehrliche_kv(13,5,2,47).
Die Argumentliste konnte gewonnen werden, indem der Anwender in einem weiteren Dialog (s. Abbildung) aus mehreren Listboxes die entsprechenden Instanzen auswählte. Wurde kein Element ausgewählt, so wurde das entsprechende Argument als nicht instanziiert betrachtet. Im vorliegenden System wurde die Anbindung der Subsumtion an die grafische Oberfläche verbessert: anstatt nur die Auswahl eines oder keines Objektes je Argument zuzulassen, ist es nun möglich eine beliebige Anzahl von Objektinstanzen auszuwählen. Der Sachverhalt wird dann hinsichtlich aller möglichen Kombinationen von hieraus erzeugbaren Termen unter-sucht:
?- subsumtionen(gefaehrliche_kv,[[13,69],[5],[2,7,9],[47]]).
ergibt nun folgende zu beweisende Goals:
gefaehrliche_kv(13,5,2,47). gefaehrliche_kv(13,5,7,47). gefaehrliche_kv(13,5,9,47). gefaehrliche_kv(69,5,2,47).
49 ebenso können Deliktgruppen wie Straftaten, Körperverletzungsdelikte oder Erfolgsdelikte geprüft werden 50 genaueres hierzu bei der Beschreibung der Deduktiven Komponente

88
gefaehrliche_kv(69,5,7,47). gefaehrliche_kv(69,5,9,47).
Da die Auswahl aller Instanzen somit die gleiche Bedeutung hat, wie die Auswahl keiner In-stanz, muss im Dialog jeweils mindestens eine Instanz ausgewählt werden. Voreingestellt ist jeweils, dass alle Elemente ausgewählt sind.
Dialog: Auswahl der bei der Subsumtion zu berücksichtigen Instanzen
6.5.2.5 Rückfragen des Systems
Während der soeben beschriebenen Anfragen mittels „constrain_and_test/1“ oder „subsumti-onen/2“ kann es vorkommen, dass das System bei der juristischen Subsumtion zu einem Punkt gelangt, wo es verschiedene Ansichten und somit verschiedene Möglichkeiten, einen Sachverhalt zu bewerten, gibt. In einem solchen Fall muss der Anwender eine Entscheidung treffen, damit das System den Sachverhalt weiter untersuchen kann (näheres hierzu in Kapitel 6.8.2). Dazu wird dem Benutzer der in der Abbildung zu sehende Dialog präsentiert.

89
Dialog: Bearbeitung von Meinungen und Entscheidungen Ganz oben steht zunächst die eigentliche Frage, welche es zu beantworten gilt. Über den „Se-lect-Button“ kann eingestellt werden, ob diese Frage umstritten ist oder nicht. Nur wenn die-ser Button eingedrückt ist, die Frage also strittig ist, wird der mittlere Teil angezeigt. Dieser enthält zum einen eine Übersicht über die zu diesem Problem vertretenen Meinungen. Diese Meinungen können in einem anderen Dialog bearbeitet werden. Klickt man auf den Button mit der Aufschrift „ansehen“ öffnet sich ein Fenster, in welchem die Argumente der selektier-ten Meinung zu sehen sind. Auf diese Weise lassen sich mehrere solcher Fenster öffnen, was dabei helfen soll, eine Stellungnahme abzugeben, welche in einem Textfeld eingegeben wer-den kann. Auch dieses ist nur zu sehen ist, wenn die Frage umstritten ist. Im unteren Teil des Dialogs kann der Anwender zum Schluss angeben, ob die von ihm einge-gebene Stellungnahme die Frage mit „ja“ oder „nein“ beantwortet. Diese Antwort ist aus-schlaggebend dafür, wie das System mit der Subsumtion fortfährt.
6.5.2.6 Schlussbemerkungen zur Dialogkomponente
Bevor im nächsten Kapitel unter anderem erläutert wird, auf welche Weise die Datenbank-sprache in die soeben beschriebenen Dialoge eingebettet ist, soll nun noch einmal kurz her-vorgehoben werden, dass diese Dialogkomponente lediglich ein Kompromiss zwischen gro-ßer Benutzerfreundlichkeit und geringem Entwicklungsaufwand darstellt. Zwar erorderte die

90
Entwicklung der Komponente in ihrer jetzigen Form schon einen erheblichen zeitlichen Auf-wand, doch wäre dieser sicherlich wesentlich größer gewesen, hätte man beispielsweise alle Anfragen, welche im Prolog-Terminal-Modus möglich sind, auch in die grafische Oberfläche integriert. Dennoch sollte deutlich geworden sein, dass die grafische Oberfläche den Anwen-der in die Lage versetzt, wesentlich einfacher mit dem System zu interagieren.
6.6 Event-Handler
In diesem Kapitel wird der Event-Handler beschrieben, welcher das Bindeglied zwischen gra-fischer Oberfläche und dem Rest des juristischen Systems darstellt. Die grafische Oberfläche ist ja in Tcl/Tk, der Rest des Systems in Prolog implementiert.
6.6.1 ProTcXl
Das Bindeglied zwischen Tcl/Tk und Prolog stellt ProTcXl51 dar. Wie bereits in Kapitel 2.1.9 erwähnt, gehören zu ProTcXl auf der einen Seite Tcl-Kommandos, die es erlauben Prolog-Prädikate von Tcl/Tk aus aufzurufen. Auf der anderen Seite werden von ProTcXl aber auch Prolog-Prädikate definiert, mit welchen auf Tcl/Tk-Kommandos zugegriffen werden kann. Somit gibt es zwei prinzipiell unterschiedliche Möglichkeiten der Interaktion von Tcl/Tk und Prolog, die eigentlich beliebig miteinander kombiniert werden können. Es ist sogar möglich, beispielsweise von einem Tcl/Tk-Programm aus ein Prolog-Prädikat aufzurufen, welches dann wiederum Tcl/Tk-Prozeduren aufruft. Allerdings ist eine solche Vorgehensweise nicht empfehlen. Zum einen könnten gegenseitige rekursive Aufrufe für eine Überlastung des Heaps sorgen, vor allem aber litte die Übersichtlichkeit und Sauberkeit der Systemarchitektur. Stattdessen sollte eine Entscheidung getroffen werden, ob man entweder von Tcl/Tk aus Pro-log-Prädikate aufrufen oder umgekehrt von Prolog aus auf Tcl/Tk-Prozeduren zugreifen möchte. Die Empfehlung des ProTcXl 2.1 User Manuals hierzu lautet, Tcl/Tk als „Master“, also als die aufrufende Sprache, zu verwenden, wenn Anwendungen implementiert werden, in denen Prolog nur für gelegentliche Anfragen benötigt wird. Hingegen sei in Anwendungen, in welchen viel Interaktion zwischen Prolog und Tcl/Tk stattfinden soll, eine Verwendung von Prolog als „Master“ ratsam ([Mei96], S. 30, 35). Das juristische System fällt eindeutig in die zweite Kategorie. Die Anfragen an die Wissens-basis stellen einen wesentlichen Nutzen des ganzen Systems dar, mit der Folge, dass es sich bei diesen Anfragen nicht bloss um gelegentliche Anfragen handelt. Der Sinn des Systems besteht hauptsächlich darin, mit ihm zu kommunizieren. Da diese Kommunikation über die durch Tcl/Tk realisierte grafische Oberfläche geschehen soll und dabei ständig auf die Prolog-Wissensbasis zugegriffen werden muss, findet zwangsläufig viel Interaktion zwischen Prolog und Tcl/Tk statt. Da das Wissen des juristische Systems in Prolog-Fakten und Prolog-Regeln vorliegt, hätte ein System, welches Tcl/Tk als Master verwendet, zur Folge, dass ständig über ProTcXl-Schnittstellenprozeduren auf die Daten zugegriffen werden müsste, was der Forderung nach einer möglichst kleinen Schnittstelle wiederspräche. Somit fällt die Entscheidung, dass Prolog als Master verwendet wird. 51 Prolog und Tcl, das X steht für den direkten Zugriff auf die X11-Bibliothek Xlib

91
Datenübergabe von ECLiPSe nach Tcl/Tk Diese Entscheidung hat zur Folge, dass es „erlaubt“ ist, Tcl/Tk-Prozeduren von Prolog aus aufgzurufen. Dies geschieht in der Regel, um Dialoge zu starten. Beispielsweise könnte der Dialog, der benötigt wird, um eine neue Person in die Wissensbasis einzugeben, folgender-maßen gestartet werden:
tcl('tcl_person_neu ##',[Schluessel]).
Diese Zeile bewirkt, dass die Tcl/Tk-Prozedur mit dem Namen „tcl_person_neu“ mit dem Argument „Schluessel“ (der Schlüsselwert der neu einzugebenden Person) aufgerufen wird. Über die Argumentliste (im Beispiel „[Schluessel]“) werden Daten von ECLiPSe an Tcl/Tk übergeben. Nachdem die Prozedur ausgeführt (und der Dialog generiert) wurde, fährt das Pro-log-System fort. Datenübergabe von Tcl/Tk nach ECLiPSe Abhängig von der Art des gestarteten Dialogs, kann der Anwender bestimmte Eingaben ma-chen. Alle Dialoge sind dazu da, Daten des Anwenders entgegenzunehmen. Das System muss in der Folge auf diese Eingaben reagieren können, so dass es erforderlich ist, die Daten, die der Benutzer während eines Dialoges eingibt, an das den „Prolog-Teil“ des System weiterzu-leiten. Es muss also eine Übergabe der Daten von Tcl/Tk nach ECLiPSe stattfinden. Die Möglichkeit, die Prolog-Daten von der Tcl/Tk-Seite aus direkt zu manipulieren, scheidet aus, da bewusst darauf verzichtet wird, Prolog-Prädikate von Tcl/Tk aus zu verwenden (s.o.). Stattdessen wird die Datenübergabe realisiert, indem zum Abschluss eines Dialoges Ereignis-se erzeugt werden, die das Prolog-System empfängt und verarbeitet. Ein solches Ereignis wird auf Tcl/Tk-Seite folgendermaßen produziert:
prolog_event arg1 arg2 ... .
Die Argumente „arg1 arg2 ...“ können hierbei beliebige Zeichenketten sein und auch die Da-ten enthalten, die an das Prolog-System übergeben werden sollen. So liesse sich, nachdem in einem Dialog zur Eingabe von Personendaten die entsprechenden Werte eingegeben wurden, folgendermaßen über ein Ereignis dem Prolog-System mitteilen, dass ein Person-Objekt („Doris Meier“) in die Datenbank eingefügt werden soll:
prolog_event Person_einfuegen 1 Meier Doris w 12 nein
Das erste Argument („Person_einfuegen“) enthält die Information für das Prolog-System, dass eine Person in die Datenbank eingefügt werden soll, die weiteren Argumente enthalten die zu der Person gehörenden Daten wie Geschlecht und Alter. Damit das Ereignis überhaupt ausgelöst werden kann, muss es zuvor an eine Aktion „gebunden“ worden sein. Dies kann so aussehen. button dialog.ok -command "prolog_event Person_einfuegen $key $name ..." pack dialog.ok
Hierdurch wird ein „Button“ mit Namen „dialog.ok“ erzeugt. Sobald mit der Maus auf diesen geklickt wird, wird das hinter „command“ stehende Kommando ausgeführt; es wird also das Prolog-Ereignis „Person_einfuegen ...“ ausgelöst.

92
Selbstverständlich sind auf der Prolog-Seite entsprechende Prädikate erforderlich, um die er-haltenen Informationen sinnvoll zu verwerten. Ausserdem muss das Ereignis zunächst emp-fangen werden. Während ein Tcl/Tk-Dialog läuft, blockiert das Prolog-System nicht, sondern läuft normal weiter. Um Ereignisse empfangen zu können, muss das System zunächst in einen Wartezustand versetzt werden, was mit Hilfe des von ProTcXl bereit gestellten Prädikats „tk_next_event/1“ geregelt wird:
tk_next_event(Ereignis).
Hierdurch wird das Prolog-System angehalten bis ein Tcl/Tk-Ereignis empfangen wird. Dabei wird dann die Argumentliste des von Tcl/Tk ausgelösten Ereignisses mit der Prolog-Variable („Ereignis“) unifiziert. Die Variable enthält nun die Informationen, die das System benötigt, um zu wissen, was es tun soll. Zusammengefasst, wird also zuerst ein Dialog gestartet. Direkt danach wird das Prolog-System in einen Zustand versetzt, in dem es auf Ereignisse wartet. Die durch den Aufruf der Dialog-Prozedur erzeugte Oberfläche gibt dem Anwender die Möglichkeiten, Eingaben zu tätigen und die Eingabe – in der Regel durch einen Mausklick auf einen bestimmten „But-ton“– abzuschliessen. Die Aktion, die benötigt wird, um die Eingabe abzuschliessen, löst ein Ereignis aus, das vom Prolog-System empfangen wird. Das Ereignis enthält Informationen, welche das System benötigt, um zu „wissen“, wie es fortfahren soll.
6.6.2 Funktionsweise des Event-Handlers
Sollen während eines Dialoges mehrere Ereignisse an das System gesendet werden, so muss dieses nach Empfang eines Ereignisses ständig über das Prädikat „tk_next_event/1“ in den Wartezustand zurückversetzt werden, um empfangsbereit zu bleiben. Dies wird durch den „Event-Handler“ geleistet. Ausserdem ist der Event-Handler dafür zuständig, die eigentlichen Reaktionen auf die empfangenen Ereignisse auszulösen, also auch die über die Tcl/Tk-Ereignisse empfangenden Informationen zu interpretieren. Der Event-Handler hat folgenden prinzipiellen Aufbau:
event_handler:- tk_next_event(EventDescription),!,
event_handler(EventDescription).
event_handler([EventName|EventParameters]):- handle_event(EventName,EventParameters),!,
event_handler.
Das Prädikat event_handler/1 bewirkt, dass auf ein Ereignis „EventDescription“ gewartet wird und dieses danach von dem Prädikat „event_handler/2“ verarbeitet wird. Das Ereignis „EventDescription“ setzt sich zusammen aus einem Ereignisnamen „EventName“ und dazu-gehörigenden Argumenten „EventParameters“. Das Prädikat „handle_event/2“ besteht aus einigen Klauseln, die für jeweils eine gewisse Art von Ereignissen stehen. Eine dieser Klau-seln sieht beispielsweise folgendermaßen aus:
handle_event("Person_einfuegen",[S,N,V,G,A,W]):- db_insert(person(S,N,V,G,A,W)), naechster_schluessel(person,_), tcl('destroy .person_eingabe').

93
Diese Klausel dient der Einfügung einer Person in die Wissensbasis. Das Prädikat „db_insert/1“ erledigt hierbei das Wesentliche: die Einfügung in die Datenbank. Das Prädikat „naechster_schluessel/2“ sorgt dafür, dass der nächste Schlüssel, der an ein neu erschaffenes Person-Objekt vergeben wird, um eins erhöht wird (s. Kapitel 6.7.2). So gibt es zu den verschiedensten Datenbankänderungen eigene „handle_event/2“-Klauseln. Fast allen ist gemein, dass sie – nachdem sie die Datenbankänderung bewirkt haben – die Dia-logoberfläche anpassen. Beispielsweise könnte ein soeben eingefügtes Element in eine Liste in der Bildschirmansicht eingefügt werden müssen. Im vorliegenden Beispiel wird der Dialog zur Personeneingabe („.person_eingabe“) über das „destroy“-Kommando komplett geschlos-sen. Wichtig ist bei diesen Oberflächen-Anpassungen, dass sie vom Event-Handler aus ausge-führt werden. Prinzipiell hätten sie schon vorher, nämlich vom eigentlichen Tcl/Tk-Dialog aus, befohlen worden sein können. Dies geschieht jedoch nicht, da ansonsten im Falle des Scheiterns eines Datenbank-Updates dieser Schritt wieder zurückgenommen werden müsste. Scheitert im Beispiel das „db_insert/1“-Prädikat aus irgendwelchen Gründen, wird die Ober-flächenanpassung erst gar nicht ausgeführt, der Dialog im Beispiel also nicht geschlossen. Nachdem das Prädikat „handle_event/2“ erfolgreich war, wird „event_handler/0“ erneut auf-gerufen. Somit liegt hier im Prinzip eine Endlosschleife – die sogenannte „Event-Loop“ – vor. Diese kann jedoch über das Ereignis „exit_eventhandler“ und die dazugehörige hand-le_event/1-Klausel
handle_event("exit_eventhandler"):- !, fail.
verlassen werden. Das genaue Zusammenspiel von ECLiPSe und Tcl/Tk soll nun noch einmal an einem Beispiel erläutert werden (vgl. Sequenzdiagramm). Am Anfang steht der Systemstart. Der Anwender möchte nun ein neues Person-Objekt einge-ben. Daher wird vom Prolog-System52 aus das Kommando gegeben, einen Dialog zur Perso-neneingabe zu starten. Diese Aufgabe erledigt Tcl/Tk. Es wird eine Oberfläche zur Personen-eingabe angezeigt. Das Prolog-System erhält nun die Kontrolle zurück. Gleichzeitig ist aller-dings auch die Tcl/Tk-Oberfläche aktiv. Damit die hier generierten Ereignisse verarbeitet werden können, wird also als nächstes der Event-Handler gestartet. Dieser gibt nun die Kon-trolle über das „tk_next_event/1“-Prädikat an Tcl/Tk ab. Angenommen, der Anwender gibt nun Personendaten ein. Die Oberfläche, mit der Anwender dabei interagiert, enthält unter anderem einen Button mit der Aufschrift „übernehmen“ und einen mit der Aufschrift „abbrechen“. Der Button mit der Aufschrift „übernehmen“ soll dazu dienen, die getätigten Eingaben in die Datenbank zu übernehmen, wobei der Dialog aber ge-öffnet bleiben soll. Der Button mit der Aufschrift „abbrechen“ soll den Eingabe-Dialog schließen. Sobald der Anwender nun beispielsweise auf den Button „übernehmen“ klickt, sendet Tcl/Tk das Ereignis „person_einfuegen ...“ an den Event-Handler. Dieser erledigt das Datenbank-Update und wartet durch „tk_next_event/1“ auf das nächste Ereignis. Der Dialog zur Person-Objekt-Eingabe bleibt dabei geöffnet, so dass der Anwender nun weitere Daten eingeben kann. So könnte es als nächstes sein, dass der Anwender eingeben möchte, dass ein Schaden, der Person, die gerade eingegeben wird, einen bestimmte Folgeschaden verursacht hat. In diesem
52 genauer wäre: der Prolog-Anteil des Systems ohne den Event-Handler

94
Fall sollte dem Anwender nun eine Liste von Schäden präsentiert werden, von denen er einen auswählen muss. Das Problem hierbei ist nun, dass der Personeneingabe-Dialog erst einmal nicht über die notwendigen Daten verfügt: Er kennt nicht die Liste der Schäden, die er dem Anwender zur Auswahl präsentieren soll. Diese Liste kann er jedoch der Datenbank entneh-men. Hierzu muss der Dialog nun ein Ereignis an das Prolog-System senden („prolog_event folgen_bearbeiten ...“). Als Folge auf dieses Ereignis wird ein weiterer Tcl/Tk-Dialog gestar-tet: der Dialog zur Auswahl des Folgeschadens. Danach wird das Prolog-System wieder in den Wartezustand versetzt („tk_next_event/1“). Wenn der Anwender die Folge ausgewählt hat, wird ein Ereignis zur Einfügung der Folge in die Datenbank ausgelöst („fol-ge_einfuegen“) und der Folgeauswahldialog geschlossen. Der übergeordnete Personeneinga-bedialog bleibt geöffnet. Damit die von ihm produzierten Ereignisse weiter entgegengenom-men werden können, wird abermals „tk_next_event/1“ aufgerufen.
�������
����
����
�������
������
�����������
���� ������ �������
��������������� �������
����������� ���������������� ���
������������
���
������������
����������� ����������������� ���
����������� ��������������� ���
������������
������ �������
����������� ����������������
������ ��������!��������� �������
������������
����������� ��������������
Sequenzdiagramm: Beispielinteraktion zwischen ECLiPSe und Tcl/Tk Drückt der Anwender nun auf den „abbrechen“-Button, so wird das Ereignis „dia-log_beenden“ ausgelöst. Hierauf reagiert der Event-Handler, indem er eine Tcl/Tk-Prozedur aufruft, die zum einen den Dialog zur Eingabe von Person-Objekten schließt, zum anderen das Ereignis „exit_eventhandler“ produziert. Hierauf antwortet der Event-Handler, indem er die Event-Loop verlässt, wodurch der Event-Handler verlassen wird. Probleme bei der Datenübergabe Bei der Datenübergabe zwischen Prolog und Tcl/Tk können aufgrund der unterschiedlichen Typ-Konzepte einige Probleme auftreten. So sind Leerzeichen in Tcl/Tk-Zeichenketten Trennsymbole für Listen. Eine Zeichenkette mit Leerzeichen wird in Tcl/Tk daher als Liste interpretiert, was es erforderlich macht, Zeichenketten zu konvertieren.

95
Ein größeres Problem bei der Datenübergabe zwischen Prolog und Tcl/Tk tritt auf, wenn ver-sucht wird, mehrere Ereignisse hintereinander auszulösen. Werden in Tcl/Tk beispielsweise mehrere Prolog-Ereignisse an einen Mausklick gebunden, so wird tatsächlich nur eines dieser Ereignisse ausgelöst. Das Auslösen mehrerer Ereignisse kann aber erforderlich sein, wenn als Resultat eines Dialoges mehrere Datenbankänderungen durchgeführt werden sollen. Bei-spielsweise könnte ein Dialog geöffnet sein, in welchem der Anwender ein Verhalten-Objekt eingeben soll. Hierzu muss zum einen angegeben werden, wie die Bezeichnung des Verhal-ten-Objekts lautet (z.B. „schlagen“), zum anderen muss angegeben werden, wer die ausfüh-rende Person des Verhaltens ist. Möchte man nun die nötigen Datenbankeinfügungen vor-nehmen und die Fakten
verhalten(Verhalten_Schluessel,“schlagen“). fuehrt_aus(Verhalten_Schluessel,Person_Schluessel).
einfügen, so sind zwar zwei Datenbankeinfügungen erforderlich, diese können aber nicht durch zwei hintereinander ausgelöste Prolog-Ereignisse veranlasst werden. Der Grund hierfür ist, dass ECLiPSe-Code im Gegensatz zu Tcl/Tk-Programmen nicht „reentrant“ ist, was be-deutet, dass nicht auf mehreren Kopien des ECLiPSe-Code gleichzeitig operiert werden kann. Stattdessen werden in einem solchen Fall, die Ereignisse zu Ereignis-Listen zusammengefügt, so dass nur ein Ereignis (die Liste von Ereignissen) ausgelöst werden muss.
prolog_event „. $ereignis1 $ereignis2“
Der Punkt („.“) dient hierbei als Listenoperator. Der Event-Handler verfügt über folgende Klausel, um solche Ereignislisten (oder Listen von Ereignislisten) zu verarbeiten:
handle_event(".",[[E1H|E1T],[E2H|E2T]]):- handle_event(E1H,E1T), handle_event(E2H,E2T).

96
6.7 Datenbank-Management-System
In obigen Kapitel 6.6 wurde dargestellt, dass die Dialogkomponente Ereignisse an den Event-Handler verschickt, welcher daraufhin bestimmtes System-Verhalten auslöst. Auf diese Weise wird insbesondere das Datenbank-Management-System angesprochen. Wie diese Komponen-te des juristischen Systems funktioniert, soll hier dargestellt werden. Das Datenbank-Management-System des juristischen Systems hat beispielsweise die Aufga-be, die Vergabe der Objekt-Schlüssel zu verwalten. Eine der wichtigsten Aufgaben des DBMS ist es, Änderungen an den Datenbankinhalten zu organisieren. So wird über das DBMS Wissen in die Datenbanken eingefügt, gelöscht oder verändert. Diese Operationen können darüber hinaus in Transaktionen zusammengefasst werden, für deren Verwaltung auch das DBMS zuständig ist. Außerdem überwacht das DBMS die Integrität der Datenban-ken. Zum einen geschieht dies durch die Überwachung der explizit formulierten Integritätsbe-dingungen, zum anderen werden als Reaktion auf bestimmte Situationen mit Hilfe von Trig-gern konsistente Datenbankzustände aktiv erzeugt.
6.7.1 Datenbankänderungsoperationen: Insert, Delete, Update
Im juristischen System können Prolog-Klauseln mit dem Prädikat „db_insert/1“ in die Wis-sensbasis eingefügt werden. So kann die Einfügung eines Person-Objektes über db_insert(person(1,"Müller","Peter","m",30,"nein")).
erfolgen. Realisiert wird diese Einfügung mit Hilfe des Meta-Prädikats „assert/2“:
db_insert(Clause):- assert(Clause), log_entry(ta(assert(Clause),retract(Clause))).
Über „assert(Clause)“ wird die entsprechende Klausel in die Wissensbasis geschrieben. Das Prädikat „log_entry/1“ protokolliert die Datenbankänderung. Dies wird in Kapitel 6.7.3 genau beschrieben. Auf ähnliche Weise kann Wissen aus der Wissensbasis auch wieder entfernt werden. Dies geschieht durch „retract(Clause)“, wodurch die erste zu „Clause“ passende Klausel aus der Wissensbasis entfernt wird:
db_delete(Clause):- retract(Clause), log_entry(ta(retract(Clause),assert(Clause))).
Letztlich ist es auch möglich, Elemente der Wissensbasis zu verändern. Realisiert wird dies dadurch, dass die Klausel in ihrer alten Form entfernt wird und in der veränderten Form ein-gefügt wird.
db_update(Clause,NewClause):- retract(Clause), assert(NewClause),
log_entry(ta((retract(Clause),assert(NewClause)), (retract(NewClause),assert(Clause)))).

97
6.7.2 Verwaltung der Objekt-Schlüssel
Wie in Kapitel 5.4.2 beschrieben wurde, besitzt jedes Objekt des juristischen Systems einen Schlüssel. Diese Schlüssel sind für den Anwender des Systems unsichtbar. Das DBMS hat dafür zu sorgen, dass niemals ein und der selbe Schlüsselwert für zwei verschiedene Objekte der selben Klasse vergeben wird. Zu diesem Zweck merkt sich das System mit Hilfe des Prä-dikats „schluessel_nr/2“ den Schlüssel, welcher als nächstes an ein neu erschaffenes Objekt einer bestimmten Klasse zu vergeben ist. Die Fakten, in welchen dieses Wissen gespeichert ist, können in etwa so aussehen:
% schluessel_nr(Klasse, Nr):- % Nr ist der Schlüssel, welcher an das nächste neue Objekt der % Klasse „Klasse“ zu vergeben ist.
schluessel_nr(person,2). schluessel_nr(personenmerkmal,1). schluessel_nr(gegenstand,3). schluessel_nr(verhalten,1). ...
Das DBMS stellt Prädikate zur Verfügung, mit welchen diese Fakten manipuliert werden können. Wird etwa ein neues Person-Objekt erschaffen, so wird mit dem Prädikat „naechster_schluessel(Klasse)“ der zu Klasse gehörende Schlüssel-Zähler um eins erhöht.
6.7.3 Transaktionen
Die in Kapitel 6.7.1 beschriebenen Datenbankänderungsoperationen können zu Transaktionen zusammengefasst werden. Der einzige Zweck, welcher im juristischen System durch die Transaktionen verfolgt wird, ist das Recovery. Nach „Fehlern“ soll die Datenbank wieder in ihren letzten konsistenten Zustand versetzt werden. Im juristischen System können zwei Arten von „Fehlersituationen“ eintreten:
a) Die Datenbank befindet sich in einem inkonsistenten Zustand. Ein solcher Zustand kann eintreten, wenn beispielsweise „unsinnige“ Eingaben gemacht wurden.
b) Der Benutzer bricht eine Transaktion ab.
Beide Fehler führen dazu, dass das DBMS den letzten konsistenten Zustand wiederherstellt. Auf inkonsistente Datenbankzustände wird in Kapitel 6.7.4 genauer eingegangen. Die Be-schreibung der Funktionsweise des Transaktionssystems im juristischen System orientiert sich daher im Folgenden hauptsächlich an manuellen Transaktionsabbrüchen. Die Bedienung des juristischen Systems wurde in Kapitel 6.5.2 ausführlich beschrieben. Dort wurde unter anderem auch dargestellt, dass die meisten Dialoge über die Buttons „überneh-men“, „abbrechen“ und „fertig“ verfügen. Die genaue Semantik dieser Buttons wird nun er-läutert:
- „übernehmen“: Drückt der Anwender „übernehmen“, so werden alle Datenbankänderungen, welche innerhalb des Dialoges vorgenommen wurden, „endgültig“ in die Datenbank über-nommen.

98
- „abbrechen“: Der „abbrechen“-Button wird verwendet, um den Dialog abzubrechen. Alle Änderun-gen die innerhalb dieses Dialoges bereits erfolgt sind, sollen zurückgenommen wer-den.
- „fertig“:
Ein Druck auf den Button „fertig“ hat zur Folge, dass einerseits alle Datenbankände-rungen – wie bei „übernehmen“ – „endgültig“ in die Datenbank übernommen werden. Gleichzeitig bewirkt ein solcher Knopfdruck, dass der Dialog beendet wird.
Wie man leicht sieht, ähneln die Bedeutungen der Buttons den Operationen, welche auf Transaktionsebene zur Verfügung stehen. So entspricht ein „fertig“ oder „übernehmen“ in etwa der „commit“-Operation; der „abbrechen“-Button hat den gleichen Effekt wie die Opera-tion „abort“. Diese Ähnlichkeiten legen es nahe, alle Änderungen, welche innerhalb eines Dialoges vorgenommen werden, als Transaktion zusammenzufassen. Wird ein Dialog dann beendet, so auch die Transaktion. Je nach dem, ob der Dialog über „abbrechen“ oder „fertig“ beendet wird, ist eine „abort“- beziehungsweise „commit“-Operation auszuführen. Ursprüng-lich war beabsichtigt, die (ansatzweise im juristischen System implementierte) „savepoint“-Operation dazu zu verwenden, den „übernehmen“-Button zu realisieren. Dies ist allerdings nicht erforderlich, da die gewünschte Funktionalität des „übernehmen“-Buttons durch eine „commit“-„BOT“-Folge erreicht werden kann. Zur Implementierung von Transaktionen ist eine Log-Datei erforderlich, in welcher Daten-bank- und Transaktions-Operationen protokolliert werden. Dies war bereits in Kapitel 6.7.1 zu sehen. Eine solche Log-Datei kann beispielswesie folgendermaßen aussehen:
Transaktions-Log
Log-Eintrag Schritt Operation Redo Undo
1 „Dialog starten” BOT 2 db_insert(Clause1) assert(Clause1) retract(Clause1) 3 db_insert(Clause2) assert(Clause2) retract(Clause2)
retract(Clause1) assert(Clause1) 4 db_update(Clause1,NewClause1) assert(NewClause1) retract(NewClause1) COMMIT 5 „übernehmen“ BOT
6 db_delete(Clause1) retract(Clause1) assert(Clause1) 7 „abbrechen“ ABORT
Hier wurde zunächst eine Transaktion mit „BOT“ begonnen, danach wurden über „db_insert/1“ zwei verschiedene Klauseln eingefügt. Der Log-Eintrag hierfür besteht aus ei-nem Redo- und einem Undo-Teil. Der Redo-Teil enthält die Informationen darüber, wie die Operation wiederholt werden könnte; im Undo-Teil steht, wie die Operation rückgängig ge-macht werden kann. Letztere Information ist wichtig, um bei einem etwaigen Rollback, die vorgenommenen Änderungen zu revidieren. In Schritt 4 wird eine Änderung vorgenommen. Dies wird durch eine Löschung und eine Einfügung realisiert, weswegen auch zwei Log-

99
Einträge benötigt werden. In Schritt 5 wird der „übernehmen“-Button gedrückt. Dies hat zur Folge, dass ein „commit“ und ein „abort“ erfolgt. Im vorletzten Schritt erfolgt eine Löschung, ehe in Schritt 7 der „abbrechen“-Knopf gedrückt wird, was ein „abort“ nach sich zieht. Der „abort“ bewirkt, dass – in umgekehrter Reihenfolge – die Undo-Operationen ausgeführt wer-den, bis das letzte „BOT“ erreicht wird. Somit werden im Beispiel die Schritte 1-4 nicht zu-rückgenommen. Zu beachten ist allerdings, dass die Dialoge in einer hierarchischen Struktur angeordnet sind. Wird ein Vaterdialog abgebrochen, so sollen alle Eingaben, die in Unterdialogen getätigt wurden – unabhängig davon, ob sie schon mit „fertig“ oder „übernehmen“ bestätigt wurden –, zurückgenommen werden. Dies macht geschachtelte Transaktionen erforderlich. Ausführliche Informationen über geschachtelte Transaktionen finden sich in [VG93] (S. 251 ff.). Solche Transaktionen können sogenannte Subtransaktionen enthalten, welche aus Sicht der jeweili-gen Vater-Transaktion eine atomare Einheit darstellen. Dadurch, dass Subtransaktionen wie-derum geschachtelte Transaktionen sein können, gibt es verschiedene Schachtelungsstufen. Im juristischen System korrespondiert der so entstehende Schachtelungsbaum mit der Dialog-hierarchie. Hier ein Beispiel für eine geschachtelte Transaktion:
[BOT ... [BOT [BOT ... COMMIT] ... [BOT ... COMMIT] COMMIT] COMMIT]
Eine Folge daraus, dass im juristischen System geschachtelte Transaktionen erlaubt sind, ist, dass bei einem „abort“ nicht lediglich das letzte „BOT“ gesucht werden darf, wie oben be-schrieben wurde. Stattdessen muss genau der „BOT“ gesucht werden, welcher zu der aktuel-len Transaktionsebene gehört. Dies wurde im vorliegenden System folgendermaßen imple-mentiert: Ein Zähler wird auf null gesetzt. Das Transaktions-Log wird rückwärts abgearbeitet und alle Undo-Operationen werden ausgeführt. Bei jedem „commit“ oder „abort“ wird der Zähler um eins erhöht und bei jedem „BOT“ um eins reduziert. Ist bei Entdeckung eines „BOT“ der Zähler auf null, so ist der Vorgang beendet.
6.7.4 Integritätsprüfung
In obigem Kapitel wurde die Aussage gemacht, das im juristischen System zwei verschiedene „Fehlersituationen“ eintreten können. Auf den Abbruch durch den Benutzer wurde bereits ausführlich eingegangen. Dieses Kapitel beschäftigt sich mit inkonsistenten Datenbankzu-ständen, der anderen Fehlersituation. Führt eine Benutzereingabe zu einem inkonsistenten Zustand, so ist diese Eingabe vom DBMS zurückzuweisen. Daher muss das DBMS, bevor es Datenbankänderungen endgültig akzeptiert, prüfen, ob die Integritätsbedingungen erfüllt sind. Wie bereits in Kapitel 2.1.3.4 gesagt wurde, sollen hier unter Integritätsbedingungen nur be-stimmte, durch besondere Regeln beschriebene Integritätsbedingungen verstanden werden. Durch diese Regeln lässt sich das Prädikat „inconsistent/0“ herleiten. Der jeweilige Regel-rumpf beschreibt einen inkonsistenten Datenbankzustand. Diese Regel besagt beispielsweise, dass ein Datenbankzustand inkonsistent ist, wenn zwei Personen den gleichen Vor- und Nachnamen besitzen:
inconsistent:- person(S1,N1,V1,_,_,_), person(S2,N2,V2,_,_,_), not S1=S2, N1=N2,
V1=V2.

100
Zwar sollten auch solche Eingaben prinzipiell möglich sein (vgl. Kapitel 6.5.2.1.1), da aber Personen mit gleichem Namen in der aktuellen Systemversion nicht auseinandergehalten werden können, wurde diese Bedingung formuliert. Hier zwei weitere Beispiele für Integri-tätsbedingingen, welche unsinnige Eingaben abfangen:
inconsistent:- schutzverhaeltnis(P,P). inconsistent:- ist_indir_folge_von(A,B), ist_indir_folge_von(B,A).
Die erste Bedingung drückt aus, dass eine Person nicht in einem Schutzverhältnis zu sich selbst stehen kann, die zweite schließt Zyklen in der Relation „ist_indir_folge_von/2“ aus: Kein Erfolg darf (indirekt) sich selbst bedingen. Viel mehr Integritätsbedingungen existieren im juristischen System nicht. Daher wurde auch davon abgesehen, eine inkrementelle Integritätsprüfung vorzunehmen. Somit werden stets alle Bedingungen überprüft und nicht nur die Bedingungen, welche durch die vorgenomme-nen Datenbankänderungen betroffen sein könnten. Weiter oben wurde bereits gesagt, dass der Datenbankzustand nur zu Ende einer Transaktion konsistent zu sein hat. Der Grund dafür ist, dass der Fall eintreten kann, dass während eines komplexeren Dialoges mehrere Eingaben getätigt werden müssen, welche erst in ihrer Gesamtheit wieder zu einem konsistenten Zu-stand führen. Daher sind die Integritätsbedingungen unmittelbar vor jedem „commit“ zu prü-fen. Dies wird im juristischen System durch folgende Implementation des Prädikats „db_commit“ gewährleistet:
db_commit:- if_then_else(
not inconsistent, log_entry(commit), (bell,fail)
).
Dieses Prädikat besagt, dass ein „commit“ nur dann durchgeführt wird (indem der entspre-chende Eintrag in die Log-Datei erfolgt), wenn der Datenbankzustand nicht inkonsistent ist. Ansonsten erfolgt ein Signalton („bell“) und „db_commit“ scheitert. Ein Problem tritt im Zusammenhang mit geschachtelten Transaktionen auf: Es kann vorkom-men, dass in einem Unterdialog alles korrekt eingegeben wurde und dennoch ein inkonsisten-ter Datenbankzustand vorliegt. Der Grund hierfür ist, dass ein übergeordneter Dialog ungülti-ge oder unvollständige Eingaben enthält. In solchen Fällen soll der Unterdialog natürlich ab-geschlossen werden können, da im übergeordneten Dialog ja noch Änderungen vorgenommen werden können. Ein Beispiel: Der Dialog zur Person-Eingabe wird gestartet. Ohne irgendeine Eingabe zu ma-chen wird von diesem Dialog aus der Dialog zur Eingabe von Folgeschäden aufgerufen. An-genommen, hier werden nur gültige Eingaben vorgenommen. Wenn nun die untergeordnete Transaktion beendet werden soll, fällt bei der Integritätsprüfung auf, dass die soeben eingege-benen Folgeschäden zu einem inkonsistenten Zustand führen, da die Person, welche diese Schäden erlitten haben soll, nicht existiert. Der Grund hierfür ist, dass der Person-Eingabe-Dialog noch nicht beendet wurde.

101
Dieses Problem ist für geschachtelte Transaktionen typisch und lässt sich nicht so leicht ver-meiden. Daher werden in der Regel von Subtransaktionen nur die Eigenschaften A und I des ACID-Prinzips verlangt (s. [VG93], S. 254). Stattdessen könnte man beispielsweise auch In-tegritätsbedingungen an bestimmte Dialoge koppeln. Da das oben beschrieben Problem aber nur in einem speziellen Fall im juristischen System auftreten kann, wird – wie oben beschrie-ben – in diesem Fall das ACID-Prinzip gelockert und auf die Integritätsprüfung verzichtet.
6.7.5 Trigger im juristischen System
Ein besonderes Integritätsproblem stellt die referenzielle Integrität dar. Damit ist gemeint, dass nicht auf Objekte verwiesen werden darf, welche nicht existieren. Beispielsweise kann kein Personenmerkmal existieren, wenn es den dazugehörigen „Inhaber“ des Merkmals nicht gibt. Die referenzielle Integrität kann – wie in obigem Beispiel beschrieben – durch Integri-tätsbedingungen überwacht werden. Diese Vorgehensweise ist in bestimmten Fällen aller-dings nicht praktikabel beziehungsweise sehr umständlich. Diese Fälle treten bei der Lö-schung von Objekten ein. Wird ein Objekt gelöscht, so müssen zur Wahrung der referenziel-len Integrität alle Elemente, welche auf dieses Objekt verweisen, ebenfalls gelöscht werden. Dies stellt mitunter eine große, dem Anwender nicht zumutbare Arbeit dar. In solchen Fällen bieten sich Kaskaden-Löschungen an. Dies sind Löschungen, bei welchen Objekte, welche auf das gelöschte Element verweisen, gleich mitgelöscht werden. Kaskaden-Löschungen kön-nen, wie im juristischen System geschehen, bequem über Trigger realisiert werden. Ein Trig-ger hat in diesem System folgendes Aussehen:
trigger(Event,Condition,Action).
Wird beispielsweise ein Person-Objekt gelöscht, ist gleich eine ganze Menge von Triggern betroffen. Ein interessantes Exemplar stellt dabei diese aktive Regel dar:
trigger( db_delete(person(Pers,_N,_V,_G,_A,_W)),
( fuehrt_aus(Verh,Pers), not (fuehrt_aus(Verh,Pers2),not Pers=Pers2)
), db_delete(verhalten(Verh,_B) )
).
Die Regel besagt, dass bei Löschung einer Person automatisch jedes Verhalten-Objekt ge-löscht werden soll, welches von dieser Person ausgeführt wurde, außer an diesem Verhalten war noch eine andere Person beteiligt. Durch die so eventuell vorzunehmende Verhalten-Löschung können neue Trigger aktiviert werden, beispielsweise dieser:
trigger(db_delete(verhalten(Verh,_B)), fuehrt_aus(Verh,P), db_delete(fuehrt_aus(Verh,P))).
Im Folgenden soll nun beschrieben werden, wie dieses aktive Konzept in das DBMS des ju-ristischen Systems integriert wurde. Jedes DBMS-Prädikat wird über das Meta-Prädikat „dbms/1“ aufgerufen. Ein solcher Aufruf kann dann beispielsweise so aussehen:
dbms(db_delete(fuehrt_aus(12,3))).
Das Meta-Prädikat „dbms/1“ ist folgendermaßen definiert:

102
dbms(Aktion):- aktion(Aktion), reaktion(Aktion).
Durch das Prädikat „aktion/1“ wird das jeweilige Prädikat „Aktion“ ausgeführt. Danach wird im Prädikat „reaktion/1“ geprüft, ob das System auf die soeben ausgeführte Aktion (welche aus Trigger-Sicht das Ereignis darstellt) zu reagieren hat. Dies geschieht mit Hilfe folgender Prädikate:
reaktion(Event):- findall(
ca(Condition,Action), event_condition(ec(Event,Condition),Action), CAs
), checklist(condition_action,CAs),
!. % keine Reaktion (Trigger) definiert reaktion(_). event_condition(ec(Event,Condition),Action):- trigger(Event,Condition,Action), Condition.
condition_action(ca(Condition,Action)):-
Condition,!, dbms(Action). condition_action(_).
Anstatt diese Prädikate im Einzelnen genau zu erklären, wird an dieser Stelle lediglich erläu-tert, was durch sie gemeinsam geleistet wird:
- Alle Trigger werden gefunden, deren Ereignisteil auf das konkrete Ereignis „passt“. - Die jeweiligen Condition-Action-Paare der einzelnen Trigger werden in einer Liste
„CAs“ zusammengefasst. - Nach der Reihe werden die Bedingungen aus der Liste „CAs“ überprüft. Ist eine Be-
dingung erfüllt, so wird die entsprechende Aktion ausgeführt, was eventuell neue Trigger betrifft ...
Dieses Trigger-System ist sehr einfach, weshalb es an dieser Stelle auch nicht genauer erläu-tert werden braucht. Für den verfolgten Zweck (die Kaskaden-Löschung) ist dieses System vollkommen ausreichend.

103
6.8 Subsumtionskomponente
Bislang wurde dargestellt, wie das Wissen des juristischen Systems organisiert ist, wie darauf zugegriffen wird und wie es bearbeitet werden kann. In diesem Kapitel soll nun erläutert wer-den, auf welche Weise mit Hilfe der juristischen Normen und Sachverhalts-Fakten ermittelt werden kann, ob eine bestimmte Straftat begangen wurde oder nicht. Dazu werden zunächst im Rahmen der Erläuterung der deduktiven Komponente die vom System zur Verfügung ge-stellten Inferenzmethoden vorgestellt. Die Subsumtionskomponente besteht allerdings nicht nur aus dieser deduktiven Komponente. Der Grund dafür ist, dass zur Entscheidung gewisser Fragen der Anwender zu Rate gezogen wird. Wie dies genau realisiert wurde, steht in Kapitel 6.8.2. Im Anschluss daran wird in Kapitel 6.8.3 genau dargestellt, wie das System eine juristi-sche Subsumtion unter Verwendung der deduktiven Komponente und der Entscheidungs-komponente vornimmt.
6.8.1 Deduktive Komponente
In diesem Kapitel soll erläutert werden, auf welche Weise die Deduktive Komponente zu ih-ren Schlüssen kommt, wie also genau überprüft wird, ob eine juristische Norm im Sachverhalt verwirklicht ist. Hierzu sollen der Reihe nach verschiedene Inferenzstrategien vorgestellt werden, die nach und nach verbessert werden.
6.8.1.1 Top-Down
Am einfachsten ist es, die Normen von Prolog top-down auswerten zu lassen. Die Klauseln sind so aufgebaut, dass dies relativ effizient geschehen kann (s. Kapitel 5.5.4). Angenommen, dem System läge ein Sachverhalt, wie in Kapitel 5.4.2.6 und im Anhang dargestellt, vor. Sei weiter angenommen, das System benötige nicht den Anwender, um gewisse Entscheidungen zu treffen. Stattdessen würde es die Fragen des Sachverhaltes selbstständig beantworten. Durch Eingabe von beispielsweise
koerperverletzung(T,V,E,O).
könnte man erfragen, welche Körperverletzungen begangen wurden. Man erhielte folgende Ausgabe (auszugsweise), wobei „T“ für den Schlüssel des Täters, „V“ für den Schlüssel des Verhaltens, „E“ für den Schlüssel des Erfolges und „O“ für den Schlüssel des Opfers steht:
T=1, V=1, E=1, O=2 T=1, V=1, E=1, O=2 ... T=1, V=1, E=1, O=2 ... T=9, V=3, E=4, O=7 T=9, V=3, E=5, O=7 ... T=3, V=8, E=9, O=8 ... T=9, V=3, E=4, O=7 ...

104
Die beiden Nachteile dieser top-down-Inferenzmethode sind offensichtlich: Zum einen wer-den die Antworten nicht in gewünschter Reihenfolge gegeben. Die Reihenfolge, in welcher die Antworten auf die Anfrage gegeben werden, entspricht nicht der, die bei einer juristischen Fallbearbeitung üblich ist. So kann es kaum erwünscht sein, dass zwischen zwei Taten der selben Person (mit Schlüssel 9) die Tat einer anderen Person (mit Schlüssel 3) genannt wird. Der andere offensichtliche Nachteil dieser Methode besteht darin, dass identische Antworten mehrfach angegeben werden (siehe die ersten Reihen). Dies geschieht, da die Antworten auf verschiedenen Wegen hergeleitet werden können. So kann beispielsweise eine Körperverlet-zung vorliegen, weil eine körperliche Misshandlung vorliegt. Gleichzeitig kann die selbe Handlung aber auch als Gesundheitsschädigung einzustufen sein, so dass mehrere Herlei-tungsmöglichkeiten bestehen. Ohne Nennung der Herleitungsumstände erscheint eine solche doppelte Aufzählung kaum sinnvoll. Zumindest die Mehrfachableitungen liessen sich vermeiden, wenn in die Klauseln, welche juristische Normen darstellen, „Cuts“ („!“) eingefügt würden, so dass der Suchbaum dyna-misch beschränkt würde. Dies könnte folgendermassen aussehen:
koerperverletzung(Taeter,Verhalten,Erfolg,Opfer):- koerperl_missh(Taeter,Verhalten,Erfolg,Opfer),!. koerperverletzung(Taeter,Verhalten,Erfolg,Opfer):- ges_schaedigung(Taeter,Verhalten,Erfolg,Opfer).
Der „Cut“ in der ersten Klausel bewirkt, dass nicht überprüft wird, ob eine Gesundheitsschä-digung vorliegt, wenn eine körperliche Misshandlung gegeben ist und somit eine Körperver-letzung bereits auf diesem Wege hergeleitet wurde. Eine solche Vorgehensweise ist jedoch nicht akzeptabel, da die Semantik der Norm verändert würde. Daher wurde auch in Kapitel 5.1 entschieden, „reines“ Prolog als DDL zu verwenden. Im vorliegenden Beispiel wäre der „Cut“ kein Problem, wenn man bloß herausfinden wollte, ob eine Körperverletzung vorliegt oder nicht. Es mag allerdings auch Fälle geben, in welchen der Anwender alle verschiedenen Herleitungen einer Norm wissen möchte, was mit den obi-gen Klauseln nicht mehr möglich wäre. Ein solches Interesse des Anwenders ist durchaus denkbar. So könnte beispielsweise eine Herleitung einer Körperverletzung über eine körperli-che Misshandlung nur mit schwachen Argumenten belegt sein, so dass es Sinn machen wür-de, einen weiteren Herleitungsweg zu entdecken und die Argumentation nachvollziehbarer zu gestalten beziehungsweise das Vorliegen einer Körperverletzung zu untermauern. Da nicht von vorhinein festgelegt sein soll, was mit den juristischen Normen geschieht und die Normen auch nicht eine Art „Algorithmus“ sein sollen, sondern juristisches Wissen beschreiben sol-len, verbietet es sich, „Cuts“ innerhalb der Normen zu verwenden. Stattdessen kann man allerdings auf einer Meta-Ebene die Standard-Beweisstrategie von Pro-log optimieren, was bei den im Folgenden beschriebenen Strategien geschehen ist.
6.8.1.2 Top-Down-Auswertung und Bearbeitung der Ergebnismenge
Der oben aufgezeigte Nachteil der Mehrfachableitungen könnte auf recht naheliegende Weise behoben werden. Zunächst könnten alle Antworten gesammelt und danach Duplikate aussor-tiert werden. Dabei ließe sich direkt auch der Nachteil der ungewünschten Ergebnisreihenfol-ge beheben, wenn die Antwortreihenfolge im nachhinein der „üblichen“ juristischen Prü-fungsreihenfolge angepasst würde. Die beschriebenen Schritte ließen sich mit Built-In-

105
Prädikaten wie findall/3 oder setof/3 recht einfach vornehmen. Da, wie in Kapitel 6.8.2 zu sehen sein wird, im juristischen System der Anwender in den Inferenzprozess eingebunden ist, brächte eine solche Vorgehensweise neue Probleme mit sich. Eines dieser Probleme besteht darin, dass Ableitungspfade beschritten werden, obwohl sie zu einer Antwort führen, die später aussortiert wird. Dies geschieht zwar im Allgemeinen sehr schnell, allerdings wird es wohl nicht selten vorkommen, dass auf diesem Ableitungspfad Entscheidungen vom Benutzer verlangt werden, die eigentlich nicht mehr zur Beantwortung der Frage notwendig sind. Hier könnten dem Anwender beispielsweise Fragen gestellt wer-den, die ermitteln sollen, ob eine bestimmte Handlung als körperliche Misshandlung einzustu-fen ist. Das System könnte zu diesem Schluss kommen, würde aber dennoch andere Ablei-tungspfade beschreiten und dabei Fragen stellen, die herausfinden sollen, ob eine Gesund-heitsschädigung gegeben ist. Dies ist nicht nur lästig für den Anwender, sondern verstößt auch gegen die übliche juristische Vorgehensweise, in einem Fall nur auf die zur Lösung die-ses Falles erforderlichen Probleme einzugehen. Das zweite Problem, welches durch die oben beschriebene Vorgehensweise entstehen würde ist, dass der Zusammenhang zwischen vom Anwender getroffenen Entscheidungen und den daraufhin gegebenen Antworten nicht mehr zu erkennen ist, wenn erst zu Ende aller Herlei-tungen – also nach Beantwortung aller Fragen – die Lösungsmenge präsentiert wird. Aufgrund der genannten Probleme ist dieser naheliegende Lösungsansatz zur Vermeidung von Mehrfachableitungen und Sortierung der Antworten zu verwerfen.
6.8.1.3 Generate And Test
Vielmehr scheint erforderlich, dass Mehrfachableitungen schon zur Laufzeit erkannt und vermieden werden und nach Möglichkeit die Lösungen direkt in der richtigen Reihenfolge gesucht werden. Eine Möglichkeit, dies zu gewährleisten, besteht darin, alle denkbaren Er-gebnisse einer Anfrage zu erzeugen und dann in der richtigen Reihenfolge zu überprüfen. Denkbar ist dabei jede Variablenbelegung, zu welcher die entsprechenden Objekte (wie bei-spielsweise ein bestimmter Erfolg) im Sachverhalt existieren. Um dies zu ermöglichen wird das Meta-Prädikat „jur_norm_inst/1“ benötigt. Wird es mit dem Kopf einer juristischen Norm aufgerufen, deren Parameter nicht instanziiert sind, so nimmt es eine Instanziierung vor. Bei-spielsweise wird durch jur_norm_inst(koerperverletzung(T,V,E,O))
als erstes folgende Instanziierung vorgenommen: T=1
V=1 E=1 O=1 More? (;)
Weitere Ergebnisse werden dann in der Reihenfolge erzeugt, wie sie bei einer juristischen Prüfung erwünscht ist. Die so gewonnenen Goals werden der Reihe nach zu beweisen ver-sucht, was mit Hilfe eines Meta-Interpreters geschieht. Auf diese Weise werden die Ergebnisse in der gewünschten Reihenfolge erzeugt, außerdem erfolgen keine Mehrfachableitungen mehr, da jede Instanziierung ja nur einmal getestet wird.

106
Insofern erzielt diese Inferenzstrategie sehr schöne Ergebnisse. Allerdings hat sie einen ent-scheidenden Nachteil: Da sie alle Instanzen zunächst generiert und diese jeweils testet, ist sie sehr langsam. Bei größeren Sachverhalten dauert die Ermittlung der Ergebnisse insbesondere dann sehr lange, wenn Deliktarten mit vielen Parametern – wie beispielsweise die schwere Körperverletzung – bewiesen werden sollen. Hauptursache ist hierbei die „kombinatorische Explosion“: In einem Sachverhalt mit nur jeweils 7 Objekten der Klassen Person, Verhalten und Personenschaden bestehen schon 16807 verschiedene Arten, ein Goal für die „schwere Körperverletzung“ zu erzeugen.
6.8.1.4 Constrain And Generate
Die oben beschriebene Strategie kann jedoch weiter optimiert werden. Hierzu muss die Men-ge der zu testenden Goals beschränkt werden. Die Idee dabei ist, dass beispielsweise Perso-nen, welche gar kein Verhalten ausüben, nicht als Täter eines Verbrechens in Frage kommen. In gleicher Weise kann niemand Opfer eines Körperverletzungsdelikts sein, der nicht auch einen Personenschaden erlitten hat. Hierzu wird das Meta-Prädikat „constrain_and_-generate/1“ verwendet:
constrain_and_generate(Goal):- constrain(Goal,Goals),
checklist(test,Goals).
Zu einem (im Allgemeinen uninstanziierten) Goal werden zunächst über „constrain/2“ dieje-nigen Instanzen von Goal gesucht, welche als Lösung überhaupt in Frage kommen. Jedes die-ser Goals wird anschließend über „test/1“ getestet. Dies entspricht der Testphase bei der Ge-nerate-And-Test-Strategie. Allerdings werden nicht alle Instanzen erzeugt („generate“), son-dern nur eine eingeschränkte Menge („constrain“):
constrain(Goal,Goals):- setof(Goal,moeglich(Goal),Goals).
Dieses Prädikat hat folgende Bedeutung: „Goals“ sind die (sortierten) Instanzen von „Goal“, welche möglicherweise bewiesen werden können. Die eigentliche Einschränkung findet somit über das Meta-Prädikat „moeglich/1“ statt. Das Prolog-Goal „moeglich(Goal)“ ist erfolgreich, wenn „Goal“ unter der Voraussetzung bewiesen werden kann, dass der Anwender alle Ent-scheidungen „ideal“ trifft. Hängt beispielsweise die Frage, ob eine körperliche Misshandlung vorliegt, davon ab, wie der Anwender eine bestimmte Situation beurteilt, so wird unabhängig davon die Frage nach dem Vorliegen der Misshandlung bejaht. Dieses Systemverhalten wird über folgende Klausel erreicht:
moeglich(Goal):- functor(Goal,entschluss,_),!.
Wenn es sich bei dem zu beweisenden Goal um eine Frage an den Benutzer handelt („ent-schluss“), so ist dieses Goal „moeglich“. Um dies genau zu verstehen, muss an dieser Stelle kurz erläutert werden, wie der Anwender in den Beweisprozess eingebunden ist. Die in Kapi-tel 5 entwickelten Prolog-Regeln haben prinzipiell folgende Struktur: TBM(...):- TBM1(...), TBM2(...),
...

107
Ein Tatbestandsmerkmal (TBM) liegt vor, wenn gewisse Unter-Tatbestandsmerkmale vorlie-gen. Ein solches Unter-Tatbestandsmerkmal kann nun auch ein sogenannter Entschluss sein. Dies kann dann in etwa so aussehen: TBM(...):- TBM1(...), TBM2(...), entschluss(Die Handlung „schlagen“ ist eine Misshandlung).
Damit liegt ein Tatbestandsmerkmal „TBM“ vor, wenn die Merkmale „TBM1“ und „TBM2“ vorliegen und der Anwender der Ansicht ist, dass die Handlung „schlagen“ eine Misshand-lung darstellt. Wie man sich denken kann, wird der Anwender befragt, wenn das System ver-sucht, ein Goal mit Funktor „entschluss“ zu beweisen. Genauer wird dies in Kapitel 6.8.2 dar-gestellt. Das Prädikat „moeglich/1“ besteht nicht nur aus der oben angegebenen Klausel. Ansonsten wäre das „TBM“ im eben genannten Beispiel nicht „moeglich“. Es sind weitere Klauseln er-forderlich, um ein vorliegendes Goal hinsichtlich seiner Beweisbarkeit zu untersuchen:
moeglich((A,B)):- !,moeglich(A), moeglich(B). moeglich(A):- clause(A,B), moeglich(B). moeglich(fail):- fail.
...
Die erste Klausel besagt, dass eine Konjunktion von Goals (im Beispiel also z.B. „TBM1(...),TBM2(...)“) dann „moeglich“ ist, wenn die beiden darin enthaltenen Goals jeweils diese Eigenschaft besitzen. Die zweite Klausel drückt aus, dass ein Goal möglich ist, wenn es in einem Resolutionsschritt durch ein mögliches Goal ersetzt werden kann. Durch die letzte der hier aufgeführten Klauseln wird formuliert, dass ein Goal „fail“ nicht beweisbar ist. Über das Meta-Prädikat „moeglich/1“ können somit „Regelbäume“ komplett inspiziert werden. Die folgende Tabelle zeigt, wieviel Zeit die oben beschriebenen Strategien benötigen. Gemes-sen wurde der Zeitbedarf für folgende Goals: koerperverletzung(T,V,E,O). schwere_kv(T,V,E,O,F).
Den Messungen zu Grunde lag jeweils der in Kapitel 5.4.2.6 vorgestellte Beispiel-Sachverhalt, dessen logische Darstellung im Anhang zu finden ist. Die Zeiten sind in Sekun-den angegeben. Top-Down Generate & Test Constrain & Generate koerperverletzung 0,017 2,780 0,029 schwere_kv 0,081 112,320 0,121

108
An der Tabelle ist deutlich zu erkennen, dass eine größere Anzahl von Parametern den Zeit-bedarf erhöht. Dies fällt insbesondere bei der Generate-And-Test-Strategie besonders unange-nehm auf, welche ohnehin sehr schlechte Ergebnisse erzielt. Deutlich zu erkennen ist aber auch, dass die Constrain-And-Generate-Strategie im Vergleich dazu wesentlich besser ab-schneidet und sogar mit „Top-Down“ mithalten kann, obwohl „Constrain & Generate“ sogar die „richtige“ Ableitungsreihenfolge berücksichtigt...
6.8.2 Entscheidungskomponente
In Kapitel 3.2.2 wurde darauf eingegangen, weshalb bestimmte juristische Entscheidungen nur von einem Menschen getroffen werden sollten. Bereits in der Einleitung wurde darauf hingewiesen, dass zur Erhaltung der „Dynamik des Rechts“ in bestimmten Fällen Meinungs-streitigkeiten durchaus erwünscht sind. So dürfen Wertungen im Zusammenhang mit unbe-stimmten Rechtsbegriffen und die Auslegung von Gesetzen nicht von einem Computersystem übernommen werden. Dies schränkt die Leistungsfähigkeit solcher Systeme in einem gewis-sem Sinne ein. Stattdessen besteht allerdings die Möglichkeit, ein System zu entwickeln, wel-ches Meinungsstreitigkeiten verwaltet und dem Anwender bei seinen Entscheidungen assis-tiert. Dies ist im Fall des juristischen Systems geschehen. Problem-Objekte Um gewisse Entscheidungen treffen zu können, muss zunächst ein Problem vorliegen, zu wel-chem verschiedene Standpunkte existieren. Eine Entscheidung ist dann die Beantwortung eines solchen Problems unter Berücksichtigung der verschiedenen Standpunkte. An folgendem Beispiel soll gezeigt werden, wie Probleme im juristischen System modelliert werden:
problem(p(15,[Gegenstandbeschr]),Problemtext):- stringlist_string(
["ein_Gegenstand_<",Gegenstandbeschr,">_ein_Werkzeug"], Text
).
Ein Problem besteht demnach aus einem zusammengesetzten Schlüssel und einer Problembe-schreibung. Der komplexe Schlüssel setzt sich aus einer Problem-Nummer und einer Liste von Argumenten zusammen. Die Problem-Nummer klassifiziert das Problem grob, die Argu-mente spezifizieren es genauer. So kann – wie in obigem Beispiel – eine Problemkategorie existieren, welche für das Problem steht, ob ein bestimmter Gegenstand ein Werkzeug ist oder nicht. Im juristischen System hat dieses Problem die Nummer 15. Das Problem wird erst dadurch komplett beschrieben, dass dazu die Beschreibung eines Gegenstandes angegeben wird. Das Problem, ob ein Klebeband ein Werkzeug ist, wird somit durch die Instanz der Problem-Klasse mit dem zusammengesetzten Schlüssel „p(15,[’Klebeband’])“ dargestellt. Bei dem Attribut Problembeschreibung handelt es sich um ein abgeleitetes Attribut. Die entsprechende Ableitungsvorschrift kann der oben abgebildeten Regel entnommen werden. Die Problembeschreibung besteht demnach aus einer Umschreibung des Problems mit Hilfe der Argumentbeschreibung(en) („Klebeband“). Im Beispiel ist der so gebildete Problemtext:
„ein_Gegenstand_<Klebeband>_ein_Werkzeug“.

109
Dieses Satzfragment kann später vom juristischen System dazu verwendet werden, danach zu fragen, ob ein Klebeband ein Werkzeug ist.
Problem schluessel: p(INT., Argumente: STR.-LISTE) /problembeschreibung: TEXT
Abbildung: Problem-Klasse Zu beachten ist, dass sich die Argumentlisten von Problemen (im Beispiel [’Klebeband’]) nicht aus konkreten Objekte beziehungsweise deren Schlüsseln zusammensetzen, sondern textuelle Beschreibungen von Objekten enthalten. Dadurch wird erreicht, dass Regeln erzeugt werden können, die bestimmte Objekte (nämlich solche mit identischen Beschreibungen) i-dentisch behandeln. Wurde beispielsweise während des Beweises eines Goals für ein be-stimmtes Klebeband die Entscheidung getroffen, dass es sich hierbei um ein Werkzeug han-delt, so „weiss“ das System beim nächsten Klebeband, dass auch dieses ein Werkzeug dar-stellt. Daher ist darauf zu achten, dass die textuellen Objekt-Beschreibungen (die Objekt-Methoden) in einer eindeutigen Form erzeugt werden. Was damit gemeint ist, soll an diesem kurzen Beispiel gezeigt werden: Angenommen, eine Person führt ein Verhalten aus, welches die Bezeichnung „bogenschie-ßen“ trägt. Die dabei verwendeten Gegenstände seien „Pfeil“ und „Bogen“. Nun können hier-aus zwei verschiedene textuelle Repräsentationen erzeugt werden:
a) „bogenschießen mit Pfeil, Bogen“ b) „bogenschießen mit Bogen, Pfeil“
In solchen Fällen sollte eine eindeutige Form gefunden werden, was in diesem Beispiel durch alphabetische Sortierung der Gegenstände geschieht (Beschreibung b). Meinung-Objekte Zu den oben beschriebenen Problemen können jeweils verschiedene Meinungen existieren. So kann es Meinungen geben, die das Problem bejahen beziehungsweise verneinen. Meinun-gen werden im juristischen System durch Fakten dargestellt: meinung(m(Schluessel),Problem,Bezeichnung,Antwort,Begruendung).
Das erste Argument ist der Schlüssel der Meinung. Das zweite Argument enthält einen Fremdschlüssel: den Schlüssel des Problems, auf welches sich die Meinung bezieht. Im Attri-but „Bezeichnung“ ist der Name der Meinung angegeben. „Antwort“ ist entweder „ja“ oder „nein“, je nach dem, ob durch diese Meinung die Auffassung vertreten wird, dass das Prob-lem zu bejahen oder zu verneinen ist. Letztlich sollte im Attribut „Begruendung“ Text enthal-ten sein, welcher diese Antwort begründet.

110
Meinung schluessel: m(INTEGER) problem: Problem bezeichnung: STRING antwort: BOOL+ begruendung: TEXT
Abbildung: Meinung-Klasse Ein Beispiel-Objekt der Klasse Meinung könnte so aussehen: meinung(
m(1),p(15,[’Klebeband’]), ‚Meinung_von_Micha_Schmidt’, ja, ‚Klebeband_ist_ein_Werkzeug,_da_...’
).
Entscheidung-Objekte Stößt das juristische System während eines Beweises auf ein Problem (dazu später genaue-res), so muss der Anwender eine Entscheidung treffen. In dem er dies tut, erschafft er ein Ob-jekt, welches folgendermaßen aussieht:
Entscheidung schluessel: e(Problem) stellungnahme: TEXT antwort: BOOL
Abbildung: Entscheidungen-Klasse Das entsprechende Prolog-Fakt hat folgende Struktur: entscheidung(e(Problem),Stellungnahme,Antwort).
Das erste Argument ist wieder der Schlüssel. Dieser Schlüssel wird aus dem Schlüssel eines Problems gebildet, was zur Folge hat, dass zu jedem Problem maximal eine Entscheidung existieren kann. Das zweite Attribut enthält eine Stellungnahme, das dritte die Antwort auf das Problem. Ein direkter Bezug zu einer bestimmten Meinung wird also innerhalb einer Ent-scheidung nicht hergestellt. So kann nicht einfach einer bestimmten Meinung zugestimmt werden. Der Grund hierfür ist, dass Entscheidungen auch dadurch entstehen können, dass Argumente aus verschiedenen Begründungen (einzelner Meinungen) gemischt werden und zusammen in die Stellungnahme einfließen.

111
Hier ein Beispiel für eine Entscheidung: entscheidung(
e(p(15,[’Klebeband’])), ‚Der_Meinung_von_Micha_Meier_ist_Recht_zu_geben,_da_...’, ja
)
Der Entscheidungsprozess In diesem Abschnitt soll nun soll dargestellt, auf welche Weise die eben beschriebenen Klas-sen Problem, Meinung und Entscheidung in die Inferenz des juristischen Systems integriert sind. Hierzu ist das Prädikat „entschluss/3“ erforderlich, welches überprüft, ob gewisse Ent-scheidungen vorliegen. Liegen diese nicht vor, so sorgt dieses Prädikat dafür, dass der An-wender eine Entscheidung trifft. Bevor „entschluss/3“ weiter unten genau erläutert wird, soll an Beispielen gezeigt werden, in welchem Zusammenhang es benötigt wird.
- Zur Ermittlung von Klassen-Populationen: Es sei folgende Regel zur Ermittlung der Population der Werkzeug-Klasse betrachtet:
werkzeug(Geg,GegBez,Ist_beweglich):- gegenstand(Geg,GegBez,Ist_beweglich), entschluss(e(p(15,[GegBez])),_,"ja").
Diese Regel liest sich folgendermaßen: Ein Werkzeug ist ein Gegenstand, der durch eine entsprechende Problem-Entscheidung als solcher eingestuft ist.
- Zur Berechnung abgeleiteter Attribute:
Auch abgeleitete Attribute werden im juristischen System über das Prädikat „ent-schluss/3“ berechnet:
beh_uebel_unang(Verhalten,Uebel_unang):- verhalten_beschr(Verhalten,AusfBeschr), entschluss(e(p(6,[AusfBeschr])),_,Uebel_unang).
Das Attribut „Uebel_unang“ ist dann ‚ja’, wenn eine bestimmte Entscheidung ‚ja’ lau-tet. Lautet sie ‚nein’, so ist dies auch der Wert des Attributs.
- Zur Entscheidung für eine bestimmte juristische Sichtweise:
Denkbar ist auch, dass von einer bestimmten juristischen Sichtweise abhängt, welche Unter-Tatbestandsmerkmale vorliegen müssen, damit ein bestimmtes Tatbestands-merkmal erfüllt ist. So könnte beispielsweise von der Frage, ob man der Adäquanzthe-orie (s. Kapitel 5.4.1) folgt oder nicht abhängen, welche Modellierung einer Norm zu Grunde zu legen ist. Solche Situationen ließen53 sich beispielsweise folgendermaßen umsetzen:
TBM(...):- entschluss(..., ..., Entschluss), if_then_else( Entschluss = ‘ja’, TBM1(...), TBM2(...)
).
53 eine existiert juristischen System allerdings nicht

112
Dies bedeutet: Wird ein bestimmtes Problem mit ‚ja’ beantwortet (und somit bei-spielsweise der Adäquanztheorie zugestimmt), so muss „TBM1“ vorliegen, damit „TBM“ erfüllt ist. Wird der Theorie nicht gefolgt, so muss „TBM2“ vorliegen...
Wie das Prädikat „entschluss/3“ genau arbeitet, wird jetzt erläutert. Dazu sei seine Implemen-tierung Klausel für Klausel betrachtet:
entschluss(e(Problem),Stellungnahme,Antwort):- entscheidung(e(Problem),S,A),!, S=Stellungnahme,A=Antwort.
Diese erste Klausel erfüllt den Zweck, dass in dem Fall, dass zu einem Problem bereits eine Entscheidung getroffen wurde, diese Entscheidung übernommen wird. Zu beachten ist in die-ser Klausel die verspätete Unifikation. Man könnte der Ansicht sein, in der ersten Zeile des Klauselrumpfes könnte anstelle von „S“ bereits „Stellungnahme“ und anstelle von „A“ „Ant-wort“ stehen. Dies wurde aus folgendem Grund nicht getan: In dem Fall, dass „Antwort“ be-reits instanziiert ist, würde der Cut nicht erreicht, wenn diese Antwort nicht zu der bereits getroffenen Entscheidung passen würde. Angenommen folgendes Goal sollte bewiesen wer-den:
entschluss(e(p(15,[’Klebeband’])),_,"ja").
In der Wissensbasis würde bereits folgendes Fakt eingetragen sein: entscheidung(e(p(15,[’Klebeband’])),“...“,“nein“).
In diesem Fall würde die oben angegebene Klausel nicht bewiesen werden können, der Cut würde aber erreicht, so dass die im Anschluss vorgestellten weiteren Klauseln von „ent-schluss/3“ nicht mehr berücksichtigt würden. Dies wäre aber der Fall, wenn die Unifikationen von „S“ und „A“ mit „Stellungnahme“ beziehungsweise „Antwort“ früher (vor dem Cut) er-folgt wären. Als nächstes seien folgende Klauseln betrachtet:
entschluss(e(Problem),"ohne_Stellungnahme",Ja):- meinung(_,Problem,_,"ja+",_),!, Ja="ja". entschluss(e(Problem),"ohne_Stellungnahme",Nein):- meinung(_,Problem,_,"nein+",_),!, Nein="nein".
Die Bedeutung dieser Klausel erscheint zunächst etwas verwirrend. Bislang wurde ja auch nicht erwähnt, dass das Attribut „Antwort“ in Meinung-Objekten nicht wirklich vom Typ BOOL ist. Der tatsächliche Datentyp sei als BOOL+ bezeichnet, was bedeuten soll, dass ne-ben „ja“ und „nein“ auch die Werte „ja+“ und „nein+“ erlaubt sind. Hat eine „Antwort“ einen dieser Werte, so bedeutet dies, dass das juristische Problem, auf welches sich diese Meinung bezieht, nicht umstritten ist und mit „ja“ beziehungsweise „nein“ zu beantworten ist, was durch obige Klauseln ausgedrückt ist. Im Rahmen der Darstellung der Dialogkomponente (s. Kapitel 6.5.2.5) wurde bereits erwähnt, das juristische Probleme umstritten sein können oder auch nicht. Da es bei unumstrittenen Problemen keinen Sinn macht, vom Benutzer eine Ent-scheidung zu verlangen, wird stattdessen auf die oben beschriebene Weise innerhalb einer Meinung vermerkt, dass die Meinung nicht zur Diskussion steht.

113
Bislang kann der Benutzer noch keine neuen Entscheidung-Fakten erzeugen. Dies wird durch die letzte Klausel ermöglicht:
entschluss(e(p(PNr,Argumente)),Stellungnahme,Antwort):- problem(p(PNr,Argumente),Problembeschr), tcl_string(Argumente,Tcl_Argumente), schluessel_nr(meinung,SNr), findall(
[M,Bez,Antw], meinung(m(M),p(PNr,Argumente),Bez,Antw,_), Meinungen
), tcl_string(Meinungen,Tcl_Meinungen), tcl(
'tcl_entschluss ## ## ## ## ##', [PNr,Problembeschr,Tcl_Argumente,SNr,Tcl_Meinungen]
), event_handler,!, entschluss(e(p(PNr,Argumente)),Stellungnahme,Antwort).
Diese Klausel ist aufgrund der Tatsache, dass sie sehr eng mit Tcl/Tk verknüpft ist etwas komplizierter zu lesen. Im Wesentlichen leistet sie jedoch folgendes: Zunächst wird aus der Problembeschreibung eine Frage erzeugt. Als nächstes werden alle Meinungen zu dem ent-sprechenden Problem gesammelt (über „findall/3“). Die Tcl/Tk-Prozedur „tcl_entschluss“ wird aufgerufen. Diese Prozedur präsentiert dem Anwender die Frage und die verschiedenen Meinungen. Diese kann er im Rahmen des in Kapitel 6.5.2.5 beschriebenen Dialoges bear-beiten. Außerdem kann er den Dialog verlassen, indem er eine Entscheidung trifft, bezie-hungsweise das Problem als unsumstritten kennzeichnet und es beantwortet. Dies soll zur Beschreibung der Entscheidungskomponente genügen. Es soll lediglich noch angemerkt werden, dass diese Komponente offensichtlich nicht nur verwendet wird, um juris-tische Probleme im engeren Sinne zu entscheiden. Stattdessen wird sie auch verwendet, um „Probleme“ zu bearbeiten, welche nur aufgrund des fehlenden Sprachverständnisses des Sys-tems Probleme darstellen. So ist ein Messer natürlich ein Werkzeug und ein Personenschaden mit der Bezeichnung „Tod“ steht selbstverständlich für den Tod eines Menschen. Solche Fra-gen stören natürlich den Anwender, sind aber erforderlich, um nach und nach eine Wissens-basis aufzubauen...
6.8.3 Subsumtionsstrategie des juristischen Systems
Die Subsumtionskomponente besteht aus den bereits beschriebenen Komponenten deduktive Komponente und Entscheidungskomponente. Ziel des juristischen Systems war es, Subsumti-onen möglichst weitreichend nachahmen zu können. In diesem Kapitel soll nun beschrieben werden, auf welche Weise bei einer solchen Subsumtion ein juristisches Gutachten erstellt wird. Auf der nächsten Seite ist zunächst zu sehen, wie ein solches Gutachten aussieht. Dem Gut-achten liegt wieder der Beispielfall aus Kapitel 5.4.2.6 zu Grunde. Man erkennt schnell, dass diesem Gutachten der Feinschliff fehlt, doch lässt sich die darin enthaltene Prüfung nachvoll-ziehen. Gelegentlich kommt im Gutachtentext das Symbol „+“ oder auch „-“ vor. Dies bedeu-tet, dass ein bestimmtes Tatbestandsmerkmal vorliegt beziehungsweise nicht vorliegt.

114
§223 Obersatz: Fraglich ist, ob gilt: Es ist das Verhalten <schlagen> von Person <Peter Müller> gegen Person <Lieschen Müller> mit der Folge <leichte Blessuren> eine Kör-perverletzung. §223 I 1.Alt. Obersatz: Fraglich ist, ob gilt: Es ist das Verhalten <schlagen> von Person <Peter Müller> gegen Person <Lieschen Müller> mit der Folge <leichte Blessuren> eine kör-perliche Misshandlung. > Person <Peter Müller> führt Verhalten <schlagen> aus (+) > Person <Lieschen Müller> wird behandelt durch Verhalten <schlagen> (+) > Verhalten <schlagen> ist Ursache von <leichte Blessuren> (+) > Person <Lieschen Müller> wird behandelt durch Verhalten <schlagen> (+) > Verhalten <schlagen> ist Ursache von <leichte Blessuren> (+) Obersatz: Fraglich ist, ob gilt: Es ist ein Personenschaden <leichte Blessuren> ei-ne Beeinträchtigung des Wohlbefindens. > Meinung: BGH St ... (ja) > Leichte Blessuren stellen eine Beeinträchtigung des Wohlbefindens dar, weil ... > Meinung: Meinung 1 (nein) > Leichte Blessuren beeinträchtigen das körperliche Wohlbefinden nicht, da ... > Frage: Ist ein Personenschaden <leichte Blessuren> eine Beeinträchtigung des Wohlbefindens? > Antwort: ja > Stellungnahme: Der Ansicht des BGH ist zuzustimmen, da ... (Untersatz:) ja Schluss: Somit ist ein Personenschaden <leichte Blessuren> eine Beeinträchtigung des Wohlbefindens. ... (Untersatz:) ja Schluss: Somit ist das Verhalten <schlagen> von Person <Peter Müller> gegen Person <Lieschen Müller> mit der Folge <leichte Blessuren> eine körperliche Misshandlung. (Untersatz:) ja Schluss: Somit ist das Verhalten <schlagen> von Person <Peter Müller> gegen Person <Lieschen Müller> mit der Folge <leichte Blessuren> eine Körperverletzung. §224 Obersatz: Fraglich ist, ob gilt: Es ist das Verhalten <schlagen> von Person <Peter Müller> gegen Person <Lieschen Müller> mit der Folge <leichte Blessuren> eine ge-fährliche Körperverletzung. §224 I Nr.3 Obersatz: Fraglich ist, ob gilt: Es ist das Verhalten <schlagen> von Person <Peter Müller> gegen Person <Lieschen Müller> mit der Folge <leichte Blessuren> eine ge-fährliche Körperverletzung mittels eines hinterlistigen Überfalls. Obersatz: Fraglich ist, ob gilt: Es ist das Verhalten <schlagen> von Person <Peter Müller> gegen Person <Lieschen Müller> mit der Folge <leichte Blessuren> eine Kör-perverletzung. > s.o. (Untersatz:) ja Schluss: Somit ist das Verhalten <schlagen> von Person <Peter Müller> gegen Person <Lieschen Müller> mit der Folge <leichte Blessuren> eine Körperverletzung. Obersatz: Fraglich ist, ob gilt: Es ist eine Behandlung <schlagen> ein Überfall. > Frage: Ist eine Behandlung <schlagen> ein Überfall? > Antwort: nein > Stellungnahme: ohne Stellungnahme Schluss: Es gilt nicht: Es ist eine Behandlung <schlagen> ein Überfall. Schluss: Es gilt nicht: Es ist das Verhalten <schlagen> von Person <Peter Müller> gegen Person <Lieschen Müller> mit der Folge <leichte Blessuren> eine gefährliche Körperverletzung mittels eines hinterlistigen Überfalls. §224 I Nr.5 ...
Abbildung: Ausschnitt eines Gutachtens des juristischen Systems

115
Die Subsumtion des Systems basiert im Wesentlichen auf der Constrain-And-Generate-Strategie. Diese wurde jedoch um einige Aspekte erweitert. Die genaue Vorgehensweise des Systems bei der Subsumtion ist nur sehr umständlich zu erklären. Daher werden im Folgen-den lediglich die interessantesten Gesichtspunkte dargestellt. Auf die Frage, wie die Gutach-tentexte entstehen wird aber beispielsweise gar nicht eingegangen. Bei einer juristischen Subsumtion wird häufig erwartet, dass ein Sachverhalt im Hinblick auf alle Tatbestände untersucht wird, welche in irgendeiner Weise vom konkreten Fall betroffen sein könnten. Im Rahmen des juristischen Systems wurde dem Anwender daher auch die Möglichkeit eingeräumt, alle Körperverletzungsdelikte überprüfen zu lassen. Er hat allerdings auch die Möglichkeit, die zu prüfenden Delikte einzugrenzen. Im Rahmen dieser Darstellung soll auf diese Möglichkeit allerdings nicht näher eingegangen werden. Bei einer „kompletten“ Subsumtion der Körperverletzungsdelikte ist zunächst das Grundde-likt (§223) zu überprüfen. Hierzu genügt es, eine der beiden in §223 enthaltenen Alternativen zu „beweisen“. Wurde während der Subsumtion gezeigt, dass ein bestimmter Tatbestand im Sachverhalt vorliegt, so sind anschließend auch etwaige Qualifikationen (z.B. gefährliche Körperverletzung nach „bewiesener“ Körperverletzung) zu überprüfen. Die juristischen Nor-men können also zueinander in verschiedenartigen hierarchischen Beziehungen stehen. Je nach dem, um was für eine solche Beziehung es sich hierbei handelt, ist bei Erstellung eines Gutachtens unterschiedlich zu verfahren. Aus diesem Grunde ist es erforderlich, dem System mitzuteilen, in was für einer hierarchischen Beziehung zwei Normen zueinander stehen. Zu-nächst soll an Beispielen gezeigt werden, welche verschiedenen Arten hierbei existieren:
straftat(Taeter,Verhalten):- straft_koerperl_unv(Taeter,Verhalten). koerperverletzung(Taeter,Verhalten,Erfolg,Opfer):- koerperl_missh(Taeter,Verhalten,Erfolg,Opfer). gefaehrliche_kv(Taeter,Verhalten,Erfolg,Opfer):- koerperverletzung(Taeter,Verhalten,Erfolg), ...
Die erste Klausel drückt aus, dass alle Straftaten gegen die körperliche Unversehrtheit auch Straftaten sind. Diese Hierarchie-Beziehung sei als „unterbegriff“ bezeichnet. Die zweite Klausel besagt ähnliches: Jede körperliche Misshandlung ist eine Körperverletzung. Der Un-terschied hierbei ist jedoch, dass es sich bei der körperlichen Misshandlung um eine soge-nannte Gesetzesalternative handelt, welche im Gutachten anders zu behandeln ist als „unter-begriffe“. Die dritte Klausel schließlich beschreibt einen Qualifikationstatbestand („qualifika-tion“). Qualifikationen werden erst geprüft, wenn das zu Grunde liegende Delikt hergeleitet wurde. Alle hierarchischen Beziehungen, die nicht unter eines der genannten Muster fallen, werden als „definition“ bezeichnet, da der Klauselrumpf jeweils den Klauselkopf definiert. Das im Rahmen der Subsumtion benötigte Prädikat „pruefung/1“ sorgt dafür, dass der in Gut-achten übliche Prüfungsaufbau entsteht. Dabei greift das Prädikat auf die Relation „ste-hen_in_beziehung/3“ zurück, worin die Informationen über die jeweilige Art der Hierarchie-Beziehung enthalten sind.

116
pruefung(A):- findall(B,stehen_in_beziehung(A,B,alternative),Alternativen), findall(D,stehen_in_beziehung(A,D,unterbegriff),Unterbegriffe), findall(E,stehen_in_beziehung(A,E,definition),Definitionen), if_then_else( not is_empty(Unterbegriffe), min_1_successful_goal(subsumtion_top,Unterbegriffe), true ), if_then_else( not is_empty(Definitionen), first_successful_goal(subsumtionsschritt,Definitionen), true ), if_then_else( not is_empty(Alternativen), first_successful_goal(subsumtion_top,Alternativen), true ).
Abbildung: „pruefung/1“ sorgt für einen „richtigen“ Gutachtenaufbau Durch den besonderen Aufbau juristischer Gutachten ist es häufig erforderlich, dass Tatbe-stände mehrmals zu überprüfen sind. So ist nach erfolgreicher Subsumtion unter §223 bei-spielsweise §224 – eine Qualifikation zu §223 – zu prüfen. Diese Prüfung des §224 erfordert das Vorliegen von §223. In solchen Situationen kann in juristischen Gutachten auf die bereits erfolgte Prüfung verwiesen werden, damit nicht die komplette Prüfung erneut durchgeführt werden muss. Im anfangs abgebildeten Ausschnitt eines juristischen Gutachtens ist diese Vorgehensweise bei §224 I Nr. 3 zu erkennen. Dort ist an einer Stelle der Verweis „s.o.“ zu finden. Damit das System weiss, was es schon geprüft hat und zu welchen Ergebnissen es dabei ge-kommen ist, kann es die bereits erörterten Prüfungen in einer Relation („schon_eroertert/2“) abspeichern:
assert(schon_eroertert(Goal,ja))
Das erste Argument des so eingefügten Fakts ist das bereits überprüfte Goal, das zweite Ar-gument drückt aus, ob die Prüfung erfolgreich war. Hiermit endet die Beschreibung der Implementation des juristischen Systems. Der Arbeit liegt eine Diskette bei, auf welcher der komplette Quellcode des Systems enthalten ist.

117
7 Zusammenfassung und Ausblick
Im Rahmen der vorliegenden Arbeit wurde ein regelbasiertes System entworfen und imple-mentiert, welches dazu dienen sollte, die juristische Subsumtion zu unterstützen. Es sollte beispielhaft an einem kleinen Ausschnitt des Strafgesetzes – den objektiven Tatbeständen der Körperverletzungsdelikte – gezeigt werden, welche Möglichkeiten bestehen, bestimmte Ge-sichtspunkte der Arbeit eines Juristen durch ein regelbasiertes System nachzuahmen. Im System wurde ein computerunterstützter Umgang mit verschiedenen Aspekten juristischer Methodik realisiert. So kann das System Meinungsstreitigkeiten verwalten. Dadurch, dass es den Anwender in die Subsumtion involviert, verfügt es über eine Möglichkeit, mit Wertungen und Auslegungen umzugehen. Außerdem berücksichtigt das System viele Regeln, die im Zu-sammenhang mit der Erstellung eines Gutachtens zu berücksichtigen sind. Die relativ komfortable Benutzerschnittstelle erlaubt es auch Nicht-Informatikern, mit dem System zu interagieren. Dem Anspruch, dass ein juristischer Laie ein computerunterstütztes Gutachten erstellen können soll, wurde allerdings nicht genügt. Viele Fragen des Systems wird er nicht beantworten können. Immerhin kann ein solcher Laie aber durch das System gewisse Erkenntnisse über den Aufbau eines Gutachtens gewinnen. Die Einbeziehung des Anwenders in den Subsumtionsprozess erschwert einen fairen Ver-gleich mit anderen Systemen. WZ versucht beispielsweise gerade in den Bereichen, in wel-chen das juristische System auf die Entscheidungen des Anwenders zurückgreift, Fortschritte zu erzielen. LEX büßt durch den Versuch, eine natürlichsprachliche Schnittstelle zu realisie-ren, an Leistungsfähigkeit ein. Das im Rahmen dieser Arbeit implementierte System ist durch den Verzicht auf Funktionalitäten wie in WZ oder LEX zu einer recht ansprechenden Leis-tungsfähigkeit im Stande. Zumindest bei Vorhandensein einer großen Wissensbasis sollte es möglich sein, sehr viele Fälle aus dem Bereich der Körperverletzungsdelikte zu bearbeiten. Allerdings stößt das System an manchen Stellen auch an seine Grenzen. Sollen beispielsweise mehr verschiedene Gesetze bearbeitet werden können, so wird es erforderlich sein, die Menge der zur Darstellung von Sachverhalten zur Verfügung stehenden Konzepte zu vergrößern. Da dadurch der Anwender vermutlich in vielen Situationen mehrere verschiedene Möglichkeiten zur Sachverhaltsbeschreibung haben wird, muss ein Weg gefunden werden, diese ineinander zu überführen. Dieses Problem trat bereits in Kapitel 5.5.3.1.2 bei Begriffen wie „vergiften“ oder „erschießen“ auf. Vermutlich werden in solchen Fällen viele weitere Systemfragen er-forderlich. Damit diese den Arbeitsfluss nicht zu stark behindern, wird es immer dringender erforderlich, über sehr große Wissensbasen zu verfügen. Im Zusammenhang mit solch großen Wissensbasen werden auch neue Anforderungen an das Datenbank-Management-System – wie beispielsweise leistungsstarke Indexstrukturen – entstehen... Die vorliegende Version des juristischen Systems lässt an vielen Stellen Erweiterungen sinn-voll erscheinen. Zunächst könnten offensichtliche kleinere Schwachpunkte behoben werden. So kann die Dialogkomponente an vielen Stellen verbessert werden. Es sollte möglich sein, Subsumtionen abzubrechen. Außerdem kann die Einbettung der Anfragesprache in die grafi-sche Oberfläche an einigen Stellen noch erweitert werden. Es ist darüber hinaus dringend ge-boten, im Zusammenhang mit juristischen Entscheidungen Hilfetexte zur Verfügung zu stel-len, welche die Fragen des Systems konkretisieren können. Dadurch würde insbesondere der Nutzen des Systems für den juristischen Laien vergrößert.

118
Auch die juristischen Normen bedürfen der Überarbeitung. Zwar wurden sie mit großer Mühe erarbeitet, doch sollten sie in Zusammenarbeit mit juristischen Experten überprüft werden. Darüber hinaus sind manche strafrechtlichen Theorien noch nicht in den Modellierungen der Gesetze enthalten. Aufgrund der vielen Schwierigkeiten bei der Entwicklung der Normen scheint es nicht angebracht zu sein, innerhalb des Systems eine Bearbeitung der Gesetze zuzu-lassen. Vom juristischen System wird hauptsächlich die nach außen sichtbare Vorgehensweise des Juristen nachgeahmt. Es könnte allerdings durchaus sinnvoll sein, auch typische juristische Gedankengänge zu imitieren. Insbesondere für den Fall, dass sehr viele Normen in modellier-ter Form vorliegen, scheint es empfehlenswert, vom Sachverhalt ausgehend in einer bottom-up-Strategie diejenigen Tatbestände zu ermitteln, welche überhaupt vom entsprechenden Fall tangiert sein könnten. Dadurch könnte man die Effizienz des Systems steigern, da es in seiner derzeitigen Form alle ihm bekannten Normen überprüft. Ein weiterer Verbesserungsvorschlag für das juristische System ist, ihm die Möglichkeit zu geben, gezielt nach bestimmten Sachverhaltsmerkmalen zu fragen. So kann beispielsweise bei der Sachverhaltseingabe leicht vergessen werden, ein bestimmtes Personenmerkmal ein-zugeben. Es wäre sicherlich in vielen Situationen praktisch, wenn das System selbstständig erkennen könnte, dass bestimmte Tatbestände fast erfüllt sind und lediglich gewisse Merkma-le fehlen, die – wie beispielsweise Personenmerkmale – nachgefragt werden können. Es ist darüber hinaus zu prüfen, ob der in Systemen wie HYPO verfolgte Ansatz (s. Kapitel 3.3) zum Fallvergleich in das juristische System zu integrieren ist. Zwar sollten die durch ei-nen solchen Fallvergleich gewonnenen Schlüsse mit Rücksicht auf die „Dynamik des Rechts“ nicht ungeprüft übernommen werden, doch könnten sich in bestimmten Situationen fallver-gleichende Ansätze als nützlich erweisen. So könnte bei der Frage, ob eine Konstellation von Werkzeug, Tathandlung und Opfer aus einem Werkzeug ein gefährliches Werkzeug werden lässt, ein Fallvergleich Sachverhalte mit vergleichbaren Konstellationen aufzeigen und somit bei der Entscheidung, ob das Werkzeug in dieser Situation als gefährlich einzustufen ist, be-hilflich sein. Ausser der genannten gibt es sicherlich noch viele weitere Ansätze – wie beispielsweise das Default-Reasoning in KOKON (s. Kapitel 3.4) –, welche im juristischen System zur Anwen-dung kommen könnten. Diese Ansätze sollten im Hinblick auf ihren Nutzen für das in dieser Arbeit entwickelte juristische System überprüft werden...

119
Anhang
Siebzehnter Abschnitt des Strafgesetzbuches. Körperver-letzung § 223. Körperverletzung. (1) Wer eine andere Person körperlich mißhandelt oder an der Ge-sundheit schädigt, wird mit Freiheitsstrafe bis zu fünf Jahren oder mit Geldstrafe bestraft. (2) Der Versuch ist strafbar. § 224. Gefährliche Körperverletzung. (1) Wer die Körperverletzung
5. durch Beibringung von Gift oder anderen gesundheitsschädlichen Stoffen, 6. mittels einer Waffe oder eines anderen gefährlichen Werkzeugs, 7. mittels eines hinterlistigen Überfalls, 8. mit einem anderen Beteiligten gemeinschaftlich oder 9. mittels einer das Leben gefährdenden Behandlung
begeht, wird mit Freiheitsstrafe von sechs Monaten bis zu zehn Jahren, in minder schweren Fällen mit Freiheitsstrafe von drei Monaten bis zu fünf Jahren bestraft. (2) Der Versuch ist strafbar. § 225. Mißhandlung von Schutzbefohlenen. (1) Wer eine Person unter achtzehn Jahren oder eine wegen Gebrechlichkeit oder Krankheit wehrlose Person, die
1. seiner Fürsorge oder Obhut untersteht, 2. seinem Hausstand angehört, 3. von dem Fürsorgepflichtigen seiner Gewalt überlassen worden oder 4. ihm im Rahmen eines Dienst- oder Arbeitsverhältnisses untergeordnet ist,
quält oder roh mißhandelt, oder wer durch böswillige Vernachlässigung seiner Pflicht, für sie zu sorgen, sie an der Gesundheit schädigt, wird mit Freiheitsstrafe von sechs Monaten bis zu zehn Jahren bestraft. (2) Der Versuch ist strafbar. (3) Auf Freiheitsstrafe nicht unter einem Jahr ist zu erkennen, wenn der Täter die schutzbefohlene Person durch die Tat in die Gefahr
1. des Todes oder einer schweren Gesundheitsschädigung oder 2. einer erheblichen Schädigung der körperlichen oder seelischen Entwicklung
bringt. (4) In minder schweren Fällen des Absatzes 1 ist auf Freiheitsstrafe von drei Monaten bis zu fünf Jahren, in minder schweren Fällen des Absatzes 3 auf Freiheitsstrafe von sechs Monaten bis zu fünf Jahren zu erkennen. § 226. Schwere Körperverletzung. (1) Hat die Körperverletzung zur Folge, daß die verletzte Person
4. das Sehvermögen auf einem Auge oder beiden Augen, das Gehör, das Sprechvermö-gen oder die Fortpflanzungsfähigkeit verliert,
5. ein wichtiges Glied des Körpers verliert oder dauernd nicht mehr gebrauchen kann o-der
6. in erheblicher Weise dauernd entstellt wird oder in Siechtum, Lähmung oder geistige Krankheit oder Behinderung verfällt,

120
so ist die Strafe Freiheitsstrafe von einem Jahr bis zu zehn Jahren. (2) Verursacht der Täter eine der in Absatz 1 bezeichneten Folgen absichtlich oder wissent-lich, so ist die Strafe Freiheitsstrafe nicht unter drei Jahren. (3) In minder schweren Fällen des Absatzes 1 ist auf Freiheitsstrafe von sechs Monaten bis zu fünf Jahren, in minder schweren Fällen des Absatzes 2 auf Freiheitsstrafe von einem Jahr bis zu zehn Jahren zu erkennen. § 227. Körperverletzung mit Todesfolge. (1) Verursacht der Täter durch die Körperverlet-zung (§§ 223 bis 226) den Tod der verletzten Person, so ist die Strafe Freiheitsstrafe nicht unter drei Jahren. (2) In minder schweren Fällen ist auf Freiheitsstrafe von einem Jahr bis zu zehn Jahren zu erkennen. § 228. Einwilligung. Wer eine Körperverletzung mit Einwilligung der verletzten Person vor-nimmt, handelt nur dann rechtswidrig, wenn die Tat trotz der Einwilligung gegen die guten Sitten verstößt. § 229. Fahrlässige Körperverletzung. Wer durch Fahrlässigkeit die Körperverletzung einer anderen Person verursacht, wird mit Freiheitsstrafe bis zu drei Jahren oder mit Geldstrafe be-straft. § 230. Strafantrag. (1) Die vorsätzliche Körperverletzung nach § 223 und die fahrlässige Körperverletzung nach § 229 werden nur auf Antrag verfolgt, es sei denn, daß die Strafver-folgungsbehörde wegen des besonderen öffentlichen Interesses an der Strafverfolgung ein Einschreiten von Amts wegen für geboten hält. Stirbt die verletzte Person, so geht bei vorsätz-licher Körperverletzung das Antragsrecht nach § 77 Abs. 2 auf die Angehörigen über. (2) Ist die Tat gegen einen Amtsträger, einen für den öffentlichen Dienst besonders Verpflich-teten oder einen Soldaten der Bundeswehr während der Ausübung seines Dienstes oder in Beziehung auf seinen Dienst begangen, so wird sie auch auf Antrag des Dienstvorgesetzten verfolgt. Dasselbe gilt für Träger von Ämtern der Kirchen und anderen Religionsgesellschaf-ten des öffentlichen Rechts. § 231. Beteiligung an einer Schlägerei. (1) Wer sich an einer Schlägerei oder an einem von mehreren verübten Angriff beteiligt, wird schon wegen dieser Beteiligung mit Freiheitsstrafe bis zu drei Jahren oder mit Geldstrafe bestraft, wenn durch die Schlägerei oder den Angriff der Tod eines Menschen oder eine schwere Körperverletzung (§ 226) verursacht worden ist. (2) Nach Absatz 1 ist nicht strafbar, wer an der Schlägerei oder dem Angriff beteiligt war, ohne daß ihm dies vorzuwerfen ist. § 232. (weggefallen) § 233. (weggefallen)

121
Logisches Schema des Sachverhalts aus Kapitel 5.4.2.6 personenmerkmal(10,"besonders_empfindlich",2). person(1,"Müller","Peter","m",30,"nein"). person(2,"Müller","Lieschen","w",7,"nein"). person(3,"Schmidt","Karsten","m",18,"nein"). person(4,"Schmidt","Willy","m",77,"nein"). person(5,"Schmidt","Jürgen","m",43,"nein"). person(6,"Schmidt","Gerda","w",38,"nein"). person(7,"B.","Berta","w",55,"nein"). person(8,"J.","Julia","w",20,"nein"). person(9,"F.","Friedhelm","m",67,"ja"). % Berta ist Friedhelms Betreuerin fuersorge_oder_obhut(7,9). % Lieschen wohnt bei Peter gehoert_hausstand_an(2,1). % Willy und Karsten wohnen im Haus von Juergen und Gerda gehoert_hausstand_an(3,5). gehoert_hausstand_an(4,5). gehoert_hausstand_an(3,6). gehoert_hausstand_an(4,6). % Karsten und Julia arbeiten im Betrieb von Gerda dienst_arbeitsverhaeltnis(3,6). dienst_arbeitsverhaeltnis(8,6). % 1. Peter schlaegt Lieschen. % Lieschen erleidet leichte Blessuren. % 2. Peter tritt mit schwerer Arbeitsschuh Lieschen. % Lieschen erleidet innere Verletzungen und ... Schmerzen. % 3. Friedhelm schlaegt mit Eisenstange Berta. % Berta erleidet einen Schaedelbruch, ... Schmerzen und stirb.t % 4. Juergen stoesst vor Kachelofen Willy. % Willy erleidet einen Rippenbruch. % 5. Gerda schlaegt mit aufgerollte Zeitung Karsten. % 6. Berta sticht mit Messer, Gabel und Löffel Friedhelm. % Friedhelm erleidet eine tiefe Wunde. % 7. Julia beruehrt mit Messer Karsten. % 8. Karsten und Willy beschuetten mit Salzsaeure Julia. % Julia erleidet Veraetzungen und bleibende Narben im Gesicht. verhalten(1,"schlagen"). verhalten(2,"treten"). verhalten(3,"schlagen"). verhalten(4,"stoßen_vor"). verhalten(5,"schlagen"). verhalten(6,"stechen"). verhalten(7,"berühren"). verhalten(8,"beschütten").

122
fuehrt_aus(1,1). fuehrt_aus(2,1). fuehrt_aus(3,9). fuehrt_aus(4,5). fuehrt_aus(5,6). fuehrt_aus(6,7). fuehrt_aus(7,8). fuehrt_aus(8,3). fuehrt_aus(8,4). wird_behandelt(1,2). wird_behandelt(2,2). wird_behandelt(3,7). wird_behandelt(4,4). wird_behandelt(5,3). wird_behandelt(6,9). wird_behandelt(7,3). wird_behandelt(8,8). wird_benutzt(2,6). wird_benutzt(3,4). wird_benutzt(4,3). wird_benutzt(5,5). wird_benutzt(6,1). wird_benutzt(6,7). wird_benutzt(6,8). wird_benutzt(6,9). wird_benutzt(7,1). wird_benutzt(8,2). gegenstand(1,"Messerchen","ja"). gegenstand(2,"Salzsäure","ja"). gegenstand(3,"Kachelofen","nein"). gegenstand(4,"Eisenstange","ja"). gegenstand(5,"aufgerollte_Zeitung","ja"). gegenstand(6,"schwerer_Arbeitsschuh","ja"). gegenstand(7,"Gabel","ja"). gegenstand(8,"Löffel","ja"). gegenstand(9,"Messer","ja"). ist_kausal(1,1). ist_kausal(2,2). ist_kausal(2,3). ist_kausal(3,4). ist_kausal(3,5). ist_kausal(4,7). ist_kausal(6,8). ist_kausal(8,9). ist_kausal(8,10). ist_folge_von(6,4). ist_folge_von(10,9). pers_schaden(1,"leichte_Blessuren",2). pers_schaden(2,"innere Verletzungen",2). pers_schaden(3,"erhebliche,_länger_andauernde_Schmerzen",2). pers_schaden(4,"Schädelbruch",7). pers_schaden(5,"erhebliche,_länger_andauernde_Schmerzen",7). pers_schaden(6,"Tod",7). pers_schaden(7,"Rippenbruch",4). pers_schaden(8,"tiefe_Wunde",9). pers_schaden(9,"Verätzungen_im_Gesicht",8). pers_schaden(10,"bleibende_Narben_im_Gesicht",8).

123
konkr_pers_gef(1,"Lebensgefahr",2). begruendet(2,1). schluessel_nr(person,100). schluessel_nr(personenmerkmal,100). schluessel_nr(pers_schaden,100). schluessel_nr(konkr_pers_gef,100). schluessel_nr(gegenstand,100). schluessel_nr(verhalten,100).

124
Literaturverzeichnis
[Ben99] Bench-Capon: Some Observations on Modelling Case Based Reasoning With Formal Argument Models, in: The Seventh International Conference on Artifi-cial Intelligence and Law, Proceedings of the Conference,1999
[BHS93] W. Bibel, S. Hölldobler und T. Schaub (1993). Wissensrepräsentation und Infe-
renz: Eine grundlegende Einführung. Vieweg & Sohn Verlagsgesellschaft mbH, Braunschweig/Wiesbaden.
[Boo91] Grady Booch: Object-oriented design with applications, 1991 [Bra99] Branting, L. Karl: A General Model Of Narrative Cases, in: The Seventh Inter-
national Conference On Artificial Intelligence and Law, Proceedings of The Conference
[Bro95] Brox, Hans: Allgemeiner Teil des Bürgerlichen Gesetzbuchs / Hans Brox. -
19., verb. Aufl. - Köln; Berlin ; Bonn ; München ; Heymann, 1995 [BS96] Vorlesung „Deduktive Datenbanken“, Prof. Dr. Franςois Bry, Dr. Heribert
Schütz. Wintersemester 1996/97 [CGH94] Cremers, A. B. / Griefahn, U. / Hinze, R. Deduktive Datenbanken – Eine Ein-
führung aus der Sicht der logischen Programmierung. Verlag Vieweg, Braun-schweig/Wiesbaden, 1994
[CGT90] Ceri, S. / Gottlob, G. / Tanca, L.: Logic Programming and Databases. Springer -
Verlag Berlin Heidelberg, 1990 [Cod70] E.F. Codd. A relational model for large shared data banks. Communications of
the ACM, 13(6):377-387, Juni 1970 [DG96] Dittrich, Klaus R.; Aktive Datenbanksysteme, Konzepte und Mechanismen /
Klaus R. Dittrich; Stella Gatziu. – Bonn; Albany; Attenkirchen: Internat. Thomson Publ., 1996
[DT95] Dreher, Eduard / Tröndle, Herbert : Strafgesetzbuch und Nebengesetze, 47.,
neubearbeitete Auflage des von Otto Schwarz begründeten Werkes. Aus der Reihe Beck’sche Kurz-Kommentare, Band 10, München, 1995
[FeU1665] FernUni-Kurs 1665 “Datenbanksysteme“ [FeU1695] FernUni-Kurs 1695 “Deduktions- und Inferenzsysteme“ [FG87] Fiedler, Herbert / Gordon, Thomas F.: Recht und Rechtsanwendung als Para-
digma wissensbasierter Systeme, in: W. Brauer / W. Wahlster (Hrsg.), Wis-sensbasierte Systeme, Proceedings, Berlin/Heidelberg 1987

125
[Ger87] Gerathewohl, Peter: Erschließung unbestimmter Rechtsbegriffe mit Hilfe des
Computers. Ein Versuch am Beispiel der „angemessenen Wartezeit“ bei §142 StGB, 1987
[Gre94] Greinke, Andrew: Legal Expert Systems: A Humanistic Critique of Mechanical
Legal Inference – The Australian National University, (ISSN: 131-8247), 1994 (gopher://infolib.murdoch.edu.au:70/00/.ftp/pub/subj/law/jnl/elaw/refereed/greinke.txt)
[GL96] Griefahn, Ulrike / Lemke, Thomas: Implementing Chimera on Top of an Ac-
tive Relational Database System (IDEA.WP.22.O.005), 1996 [Har31] Hartshorn et. al., Hrsg. (1931). Collected Papers of C. Sanders Peirce, Band 2.
Harvard University Press, Cambridge (zitiert nach [FeU1695], S. 3) [Heu92] Heuer, Andreas: Objektorientierte Datenbanken; Konzepte, Modelle, Systeme /
Andreas Heuer. – Bonn; München; Paris [u.a.] : Addison-Wesley, 1992 [HL89] Haft, Fritjof / Lehmann, Hein (Hrsg.): Das LEX-Projekt. Entwicklung eines
Expertensystems – Tübingen: Attempto-Verlag, 1989 (Neue Methoden im Recht; Band 6)
[Jac92] Jacobsen, Christerson, Jonsson, Övergaard: Object-Oriented Software Engi-
neering - A Use Case Driven Approach, 1992 [Jan93] Jandach, Thomas: Juristische Expertensysteme: methodische Grundlagen ihrer
Entwicklung / Thomas Jandach – Berlin; Heidelberg; New York; London; Pa-ris; Tokyo; HongKong; Barcelona; Budapest: Springer, 1993
[Kau87] Creifelds Rechtswörterbuch, 13. Aufl. (Hrsg. von Hans Kaufmann, Bearb.:
Dieter Guntz ...); Münchener Recht-Lexikon [in 3. Bd.]/Red. Horst Tilch (Bd. 3: R-Z) (1987)
[KR97] Kleinschmidt, Peter / Rank, Christian: Relationale Datenbanksysteme. Eine
praktische Einführung. Springer Verlag Berlin , Heidelberg; 1997 [KE99] Kemper, Alfons: Datenbanksysteme : eine Einführung / von Alfons Kemper ;
André Eickler. – 3., korr. Aufl. – München ; Wien : Oldenbourg, 1999 [Lar91] Larenz, Karl: Methodenlehre der Rechtswissenschaft, 6. Aufl., Ber-
lin/Heidelberg 1991 [LK99] Lackner, Karl / Kühl, Kristian : Strafgesetzbuch mit Erläuterungen. 23. Aufl. /
C.H. Beck’sche Verlagsbuchhandlung, München, 1999 [Loo99] Loogen, Rita: Informatik IIIb (Deklarative Programmierung), Skript zur Vorle-
sung Wintersemester 1999/2000 (http://www.mathematik.uni-marburg.de/~loogen/Skripten/inf3bskript99klein.ps)
[Man98] Manthey, Rainer: Folien zur Vorlesung „Grundlagen der deskriptiven Pro-
grammierung – Sommersemester 1998“, Rheinische Friedrich-Wilhelms-Universität Bonn

126
[Man99] Manthey, Rainer: Folien zur Vorlesung „Deduktive Datenbanken I – Sommer-
semester 1999“, Rheinische Friedrich-Wilhelms-Universität Bonn [Man00] Manthey, Rainer: Folien zur Vorlesung „Informationssysteme – Wintersemes-
ter 1999-2000“, Rheinische Friedrich-Wilhelms-Universität Bonn [Mei96] Meier, Micha: ProTcXl 2.1 User Manual, 1996 [Mel96] Melton, J.: An SQL Snapshot. Proceedings of the 1996 International Confer-
ence on Data Engineering (ICDE ‘96), 1996 [Oes98] Oestereich, Bernd: Objektorientierte Softwareentwicklung: Analyse und De-
sign mit der Unified modeling language / von Bernd Oesterreich. – 4., aktuali-sierte Aufl. – München ; Wien : Oldenbourg, 1998
[PaS94] Pagel, Bernd-Uwe: Software Engineering: Die Phasen der Softwareentwick-
lung / Bernd-Uwe Pagel; Hans-Werner Six. – Bonn ; Paris ; Reading, Mass. [u.a.] : Addison-Wesley, 1994
[Phi86] Philipps, Lothar : Rechtssätze in einem Expertensystem in: Fiedler, Herbert /
Traunmüller, Roland (Hrsg.), Formalisierung im Recht und juristische Exper-tensysteme, München, 1986, zitiert nach: [Jan93]
[PS97] Prakken, H. / Sartor, G.: Reasoning With Precedents in a Dialogue Game, in:
Proceedings of the Sixth International Conference on AI and Law, ACM Press New York, S. 1-9,1997, zitiert nach: [Ben99]
[PS98] Prakken, H. / Sartor, G.: Modelling Reasoning With Precedents in a Formal
Dialogue Game, in: Artificial Intelligence and Law, Vol. 6, Nos 2-4, S. 231-287,1998, zitiert nach: [Ben99]
[Rum91] Rumbaugh, Blaha, Premerlani, Eddy, Lorenson: Objektorientiertes Modellieren
und Entwerfen, 1991 [Sag90] Sagerer, Gerhard: Automatisches Verstehen gesprochener Sprache / von Ger-
hard Sagerer. – Mannheim ; Wien ; Zürich : BI-Wiss.Verl., 1990 (Reihe Infor-matik ; Bd. 74)
[Sch94] Schöning, Uwe: Logik für Informatiker. Spektrum Akademischer Verlag, Hei-
delberg , Berlin , Oxford; 4. Auflage, 1994 [SG98] Scholl, Marc H. / Grust, Torsten: Deklarative Programmierung – Vorlesung im
Sommer 1998 (http://www.informatik.uni-konstanz.de/dbis/Courses-old/Courses-ss98/decl-ss98.html)
[Sir89] Sirp, Wilhelm: Bericht, Gutachten und Urteil: e. Einf. in d. Rechtspraxis / von
Wilhelm Sirp. - 31., überarb. u. erg. Aufl. d. 1884 von Hermann Daubenspeck begr., von d. 12.-18. Aufl. von Paul Sattelmacher u. von d. 19.-25. Aufl. von Paul Lüttig u. Gerhard Beyer bearb. Werkes. - München: Vahlen, 1989.

127
[Ste84] Stein, Ekkehart: Methoden der Verfassungsinterpretation und der Verfassungs-konkretisierung, Reihe Alternativkommentare, Bd. I, - Neuwied, 1984
[StS94] Sterling, Leon: The art of Prolog : advanced programming techniques / Leon
Sterling, Ehud Shapiro; 1994 [UML1.3] UML-Summary Version 1.3 (http://www.rational.com/uml) [VG93] Vossen, Gottfried: Grundlagen der Transaktionsverarbeitung / Gottfried Vos-
sen; Margret Gross-Hardt.- Bonn; Paris; Reading, Maas. [u.a.] : Addison-Weseley, 1993
[Vos94] Gottfried Vossen. Datenmodelle, Datenbanksprachen und Datenbank-
Management-Systeme / Gottfried Vossen. – Bonn; Paris; Reading, Maas. [u.a.]: Addison-Wesley, 1994
[Wel95] Welch, Brent. Practical Programming in Tcl and Tk / Brent Welch, 1995 [Wes95] Wessels, Johannes: Strafrecht, allgemeiner Teil : die Straftat und ihr Aufbau /
von Johannes Wessels. - 25., überarb. Aufl. - Heidelberg : Müller, Jur. Verl., 1995

128

129
Schriftliche Erklärung Hiermit erkläre ich, dass ich meine Arbeit selbstständig durchgeführt habe und keine anderen als die angegebenen Quellen und Hilfsmittel benutzt sowie Zitate kenntlich gemacht habe.


















