
Eine wissensbasierte Benutzerschnittstelle f.r das ... · system for data mining. With it data...
210
Eine wissensbasierte Benutzerschnittstelle für das Invisible Data Mining Der Technischen Fakultät der Universität Erlangen-Nürnberg zur Erlangung des Grades DOKTOR-INGENIEUR vorgelegt von Oliver Mathias Johannes Hogl Erlangen – 2003
Transcript of Eine wissensbasierte Benutzerschnittstelle f.r das ... · system for data mining. With it data...

Eine wissensbasierte Benutzerschnittstelle für das Invisible Data Mining
Der Technischen Fakultät derUniversität Erlangen-Nürnberg
zur Erlangung des Grades
DOKTOR-INGENIEUR
vorgelegt von
Oliver Mathias Johannes Hogl
Erlangen – 2003

Als Dissertation genehmigt vonder Technischen Fakultät der
Universität Erlangen-Nürnberg
Tag der Einreichung: 9. Mai 2003Tag der Promotion: 30. Oktober 2003 Dekan: Prof. Dr. Albrecht Winnacker
Erstberichterstatter: Prof. Dr. Herbert StoyanZweitberichterstatter: Prof. Dr. Stefan Jablonski

VORWORT
Die vorliegende Arbeit entstand vorwiegend während meiner Tätigkeit als wissenschaftlicherMitarbeiter in der Forschungsgruppe Wissenserwerb am Bayerischen Forschungszentrum fürWissensbasierte Systeme (FORWISS) sowie am Lehrstuhl Informatik 8 (Künstliche Intelli-genz) der Friedrich-Alexander-Universität Erlangen-Nürnberg. In der Zeit von 1998 bis 2002habe ich dort verschiedene Projekte in den Bereichen Wissenserwerb, Wissensmanagementund vor allem natürlich Data Mining bearbeitet und geleitet.
An dieser Stelle möchte ich den vielen Menschen Dank sagen, die zum Gelingen dieser Ar-beit beigetragen haben. Mein besonderer Dank gilt dabei Herrn Prof. Dr. Herbert Stoyan, derals Leiter der Forschungsgruppe und als Lehrstuhlinhaber diese Arbeit gefördert hat, jederzeitdiskussionsbereit war und mir den Freiraum gewährt hat, den das Gelingen einer solchen Ar-beit voraussetzt. Nicht weniger danke ich Herrn Prof. Dr. Stefan Jablonski für die Übernahmedes Koreferats.
Unter den vielen Kollegen, die ihren Anteil am Erfolg dieser Arbeit tragen, möchte ich vorallem Herrn Dr. Michael Müller und Herrn Carsten Hausdorf sowie Frau Andrea Stocker,Herrn Dieter Käppel und Herrn Ralf Kokowski nennen. Auch dem Leiter des Qualitätsma-nagements der Tiroler Landeskrankenanstalten GmbH, Herrn Univ.-Doz. Dr. Wolf Stühlinger,sei stellvertretend gedankt für sein Interesse an dieser Arbeit, seinen Input und sein Feedbackaus der Sicht des Fachexperten.
Nicht vergessen möchte ich auch einige Menschen in nah und fern, die es beherrschten,mich im richtigen Moment von den Problemen des Data Mining abzulenken, aber auch dannVerständnis zu zeigen, wenn dies notwendig war. Auch meiner Familie möchte ich an dieserStelle meinen ganz besonderen Dank aussprechen. Ohne ihr Verständnis und ihre nicht zu un-terschätzende Unterstützung wäre vieles nicht möglich gewesen.
Zuletzt – und diese Stelle hat durchaus ihre Bedeutung – möchte ich meinen Dank und mei-ne Anerkennung an Ebba Friedrich richten. Ihre Geduld, ihr Verständnis und ihre Unterstüt-zung haben mir die Kraft gegeben, diese Arbeit zu einem erfolgreichen Ende zu bringen.
Erlangen im Mai 2003 Oliver J. Hogl

.

KURZFASSUNG
Die Analyse von Daten mit Hilfe von Methoden des Data Mining ist ein wissensintensiver Be-reich, der aufgrund seiner hohen Anforderungen bislang vor allem Experten des Data Miningvorbehalten war. Fachexperten aus Bereichen wie Qualitätsmanagement, Marketing und Pro-duktion als die eigentlichen Nutznießer dieser Technologie stehen häufig vor dem Problem,dass sie auf eine umfassende Beratung oder gar auf die vollständige Durchführung der Daten-analyse durch Data-Mining-Experten angewiesen sind. Diese Problematik ist groß genug, dasssie eine weitere Verbreitung der innovativen Data-Mining-Technologien wenn nicht verhin-dert dann doch stark einschränkt.
Vor dieser Problemstellung beschreiben wir in dieser Arbeit einen Ansatz für die Unterstüt-zung von Fachexperten beim Data Mining, der sie in die Lage versetzen kann, Analysen einergewissen Komplexität selbst und ohne Hilfe von außen durchzuführen. Als Hauptaspekt unse-res Ansatzes, den wir auch als Invisible Data Mining bezeichnen, tritt die Methodik des DataMining mit ihren Anforderungen in den Hintergrund und wird sozusagen für den Benutzer un-sichtbar. Stattdessen erlaubt der Ansatz dem Benutzer die Kommunikation mittels zweier ein-facher Konzepte, die ihm als Grundmittel des Erwerbs von Wissen vertraut sind: Fragen undAntworten, formuliert in der jeweiligen Fachsprache.
Auf der Basis eines Modells von Sprachebenen bei der Entdeckung von Wissen in Daten-banken entwickeln wir in dieser Arbeit eine Sprache für die Beschreibung der natürlichsprach-lichen Fragen, die von Fachexperten bei der Datenanalyse formuliert werden. Diese Sprache,die wir Knowledge Discovery Question Language nennen, setzt sich aus bis zu fünf komplexenElementen zusammen und wird detailliert mit ihrer Syntax und Semantik beschrieben.
Fragen, die in der Knowledge Discovery Question Language formuliert sind, können unterEinsatz von umfangreichem Domänenwissen zunächst verfeinert und dann in formale Data-Mining-Anfragen übersetzt werden. Dabei werden unter Berücksichtigung ihrer Einsatzbedin-gungen, Ergebniseigenschaften sowie weiteren Merkmalen und anfangs unabhängig von kon-kreten Implementierungen Data-Mining-Methoden und -Algorithmen ausgewählt und parame-trisiert, die für die Beantwortung der Frage geeignet sind. Im letzten Schritt erfolgt die Anpas-sung an die Anforderungen einer gegebenen Implementierung eines Data-Mining-Algorith-mus. Aus den Ergebnissen, die von den Algorithmen geliefert werden, können wiederAntworten in der Fachsprache des Experten generiert werden.
Das für den Ansatz benötigte Wissen ist in einer komplexen Wissensbasis beschrieben, dieüber drei Spezialisierungsstufen modular aufgebaut ist. Durch diese Trennung von allgemei-nem, domänenspezifischem und unternehmens- bzw. anwenderspezifischem Wissen wird dieÜbertragbarkeit des Ansatzes, z.B. von der Konzeptions- und Evaluierungsdomäne des medi-zinischen Qualitätsmanagements auf andere Anwendungsbereiche, erleichtert.
Der vorliegende Ansatz zur Benutzerunterstützung wurde in einem Assistenzsystem für dasData Mining prototypisch implementiert. Damit können Datenanalysen unter Verwendung derTechnologie des Data Mining erstmals von Fachexperten selbst durchgeführt werden.

.

SUMMARY
Data analysis based on methods of data mining is a knowledge intensive task, which due to itshigh demands on technical knowledge has been left to data mining experts. Experts from do-mains such as quality management, marketing and production who will eventually reap thebenefits of this technology often depend on expensive data mining experts to give advice oreven to let them carry out the analyses themselves. The problematic nature of this dependencyis strong enough to limit the further spreading of data mining technologies.
Against this background, this work describes an approach for the support of domain ex-perts, which can enable them to carry out analyses of a certain complexity without any helpfrom other parties. As a main feature of our approach, the methodology of data mining with itshigh knowledge demands retreats into the background and becomes so to speak invisible. In-stead the approach allows domain users to communicate using two simple concepts, which areall too familiar to him as basic means of knowledge acquisition: questions and answers, ex-pressed in their very own technical language.
Based on a level model of language levels in the area of knowledge discovery in databases,we develop a language for the description of natural language questions, which are being ex-pressed by domain experts during data analysis. This language, which we call Knowledge Dis-covery Question Language, is composed of up to five complex elements and will be describedby its syntax and semantics in detail.
Questions formulated in KDQL can be initially refined and translated into formal data min-ing queries using extensive domain knowledge. This implies the selection of data miningmethods and algorithms to answer the question under consideration of their deployment crite-ria, result properties as well as other characteristic features and is performed independentlyfrom concrete implementations of algorithms. In a final step the adaptation to the specificneeds of a given implementation is carried out. Using the results of the algorithms, answers inthe technical language of domain experts can be generated.
The knowledge which is required for the approach is described in a complex knowledgebase, which is structured over three levels of specialization. By this separation of common, do-main specific and user or company specific knowledge the portability of our approach fromour evaluation domain of medical quality management to other domains is made easier.
The approach for user support in hand has been prototypically implemented in an assistancesystem for data mining. With it data analyses using data mining technology for the first timecan be carried out by domain experts themselves.

.

INHALTSVERZEICHNIS
1 Einleitung 11.1 Business Understanding als Herausforderung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Intelligente Benutzerschnittstellen für Informationssysteme . . . . . . . . . . . . . . . . . 2
1.3 Ein Ansatz für das Invisible Data Mining – Ziele und Beiträge . . . . . . . . . . . . . . 3
1.3.1 Ziele der Arbeit. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.2 Beiträge der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Die praktische Anwendung beim Qualitätsmanagement im Gesundheitswesen . . 6
1.5 Der Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Relevante Ansätze für wissensbasierte Benutzerschnittstellen 92.1 Ansätze zur Unterstützung von Anfragen an Informationssysteme. . . . . . . . . . . 10
2.1.1 Unterstützung beim Zugriff auf Dokumente . . . . . . . . . . . . . . . . . . . . . . 12
2.1.2 Unterstützung beim Zugriff auf Datenbanktupel . . . . . . . . . . . . . . . . . . . 12
2.1.3 Unterstützung beim Zugriff auf Data Mining-Ergebnisse . . . . . . . . . . . . 18
2.2 Ansätze zur Unterstützung der Auswahl von Methoden . . . . . . . . . . . . . . . . . . . 25
2.2.1 Unterstützung der Auswahl von Methoden der Statistik . . . . . . . . . . . . . 25
2.2.2 Unterstützung der Auswahl von Methoden des Maschinellen Lernens . . 26
2.2.3 Unterstützung der Auswahl von Methoden bei der Entdeckung von Wissen in Datenbanken. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28

x INHALTSVERZEICHNIS
3 Relevante Ansätze zur Beschreibung der Semantik von Fragen 313.1 Die erotetische Logik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.2 Theorien zur Semantik von Fragen und Antworten . . . . . . . . . . . . . . . . . . . . . . . 34
3.2.1 Die funktionale Theorie der Semantik . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.2.2 Die propositionale Theorie der Semantik. . . . . . . . . . . . . . . . . . . . . . . . . 36
3.2.3 Die Konstruktion von komplexen Fragebedeutungen . . . . . . . . . . . . . . . 37
3.2.4 Exhaustive und nicht-exhaustive Semantik . . . . . . . . . . . . . . . . . . . . . . . 38
3.3 Fragen als Instrumente des Wissenserwerbs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4 Der QUESTUS-KDD-Ansatz der wissensbasierten Benutzerunterstützung 41
4.1 Die Anforderungen an die Realisierung des Benutzerunterstützung . . . . . . . . . . 41
4.2 Der Prozess der Formulierung und Beantwortung von Fragen . . . . . . . . . . . . . . 42
4.3 Das QUESTUS-KDD-Verarbeitungsmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.4 Die Modellierung der Wissensbasis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5 KDQL und KDAL – Sprachen für Fragen und Antworten von Fachexperten 51
5.1 Die Anforderungen an eine Sprache für Fragen von Fachexperten . . . . . . . . . . . 51
5.2 Die Modellierung von KD-Fragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.2.1 Die Fragewurzel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.2.2 Die optionalen Frageelemente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.3 Die Modellierung von KD-Antworten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
5.3.1 KD-Antworten zu konfirmativen KD-Fragen . . . . . . . . . . . . . . . . . . . . . 73
5.3.2 KD-Antworten zu deskriptiven KD-Fragen . . . . . . . . . . . . . . . . . . . . . . . 73
5.3.3 KD-Antworten zu komplexen KD-Fragen . . . . . . . . . . . . . . . . . . . . . . . . 74
5.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74

xiINHALTSVERZEICHNIS
6 Die Operationalisierung von KD-Fragen 756.1 Die Operationalisierung des Frageobjekts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
6.1.1 KD-Fragen nach einem Zusammenhang . . . . . . . . . . . . . . . . . . . . . . . . . 76
6.1.2 KD-Fragen nach einem Unterschied . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
6.1.3 KD-Fragen nach einer Gemeinsamkeit . . . . . . . . . . . . . . . . . . . . . . . . . . 78
6.1.4 KD-Fragen nach einer Veränderung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
6.1.5 KD-Fragen mit domänenspezifischen Frageobjekten . . . . . . . . . . . . . . . 80
6.2 Die Operationalisierung des Fragetyps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.2.1 Konfirmative KD-Fragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.2.2 Deskriptive KD-Fragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
6.2.3 Komplexe KD-Fragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.3 Die Konstruktion komplexer Bedeutungen von KD-Fragen . . . . . . . . . . . . . . . . 83
6.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
7 Die Abbildung von KD-Fragen auf DM-Anfragen 877.1 Die Modellierung relevanter Objekte für die Abbildung . . . . . . . . . . . . . . . . . . . 87
7.1.1 Die Modellierung von DM-Anfragen. . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
7.1.2 Die Modellierung von Data-Mining-Methoden . . . . . . . . . . . . . . . . . . . . 89
7.1.3 Die Modellierung von Data-Mining-Algorithmen . . . . . . . . . . . . . . . . . . 92
7.2 Die Verfeinerung von KD-Fragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
7.3 Die Übersetzung von KD-Fragen in DM-Anfragen. . . . . . . . . . . . . . . . . . . . . . . 95
7.3.1 Die Ermittlung von Kandidaten von Data-Mining-Methoden . . . . . . . . . 95
7.3.2 Die Einschränkung der Kandidaten von Data-Mining-Methoden . . . . . . 97
7.3.3 Die Auswahl von Konfigurationen der Data-Mining-Methoden . . . . . . . 98
7.3.4 Die Ermittlung von Kandidaten von Data-Mining-Algorithmen . . . . . . 100
7.3.5 Die Spezifikation der Datenbasis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
7.3.6 Die Formulierung der DM-Anfrage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
7.3.7 Die Ermittlung der implementierungsabhängigen DM-System-Anfrage 102
7.4 Der Prozess der Beantwortung von KD-Fragen. . . . . . . . . . . . . . . . . . . . . . . . . 102
7.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104

xii INHALTSVERZEICHNIS
8 Der Knowledge Discovery Assistant 1058.1 Die Gesamtarchitektur des Knowledge Discovery Assistant. . . . . . . . . . . . . . . 105
8.1.1 Der Knowledge-Discovery-Agent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
8.1.2 Der Data-Mining-Agent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
8.1.3 Der Datenbank-Agent. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
8.1.4 Die Berichtsgeneratoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
8.2 Die graphische Benutzeroberfläche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
8.3 Die Realisierung des QUESTUS-KDD-Ansatzes . . . . . . . . . . . . . . . . . . . . . . . .110
8.3.1 Die Eingabe und Verwaltung der KD-Fragen . . . . . . . . . . . . . . . . . . . . .110
8.3.2 Die Verarbeitung von KD-Fragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .113
8.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .114
9 Die Evaluierung des QUESTUS-KDD-Ansatzes 1179.1 Die Kriterien für die Evaluierung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .117
9.2 Die Anwendung der Evaluierungskriterien . . . . . . . . . . . . . . . . . . . . . . . . . . . . .119
9.3 Die Anforderungen an den Benutzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
9.4 Die Integration in den Gesamtprozess . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
9.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
10 Zusammenfassung, Diskussion und Ausblick 13310.1 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
10.2 Diskussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
10.3 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
Anhang A: Empirische Grundlagen 137
A.1 Die Themenhierarchie im Bereich des medizinischen Leistungscontrollings . . 137
A.2 Der Fragekorpus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
Anhang B: Modellierung relevanter Objekte 141
B.1 Modellierung relevanter KDQL-Elemente. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
B.2 Modellierung relevanter allgemeiner Objekte . . . . . . . . . . . . . . . . . . . . . . . . . . 147

xiiiINHALTSVERZEICHNIS
Anhang C: Allgemeine Modellierung der Wissensbasis 153
Anhang D: Modellierung von Wissen über Analysemethoden 157
D.1 Modellierung der Analysemethoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
D.2 Zuordnung von Analysemethoden zu Frageobjekten und Frageargumenten. . . 163
D.3 Versprachlichung von Beschreibungsmaßen . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
Literaturverzeichnis 169
Stichwortverzeichnis 183
Lebenslauf 189

xiv INHALTSVERZEICHNIS

ABBILDUNGSVERZEICHNIS
1. Die Ermittlung von Antworten auf der Basis von Daten, Methoden, Fragen und Domänenwissen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2. Das sprachorientierte Ebenenmodell für die Datenanalyse. . . . . . . . . . . . . . . . . . . . . . . . 4
3. Die Hierarchie der Themen im medizinischen Qualitätsmanagement. . . . . . . . . . . . . . . 7
4. Der Interaktionszyklus nach [Mur98]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
5. Ein beispielhafter Syntaxbaum einer semantischen Grammatik nach [And95]. . . . . . . 15
6. Das CRISP-DM Prozessmodell (aus [CRI01]). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
7. Der Prozess der Textrezeption nach [Ram91]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
8. Der allgemeine Prozess der Formulierung und Beantwortung von Fragen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
9. Das sprachorientierte QUESTUS-KDD-Verarbeitungsmodell. . . . . . . . . . . . . . . . . . . . 43
10. Das QUESTUS-KDD-Begriffsmodell.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
11. Der modulare Aufbau der Wissensbasis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
12. Die Struktur des Elements KD-Frage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
13. Die Struktur des Elements Fragewurzel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
14. Darstellung des Elements TypKonfirmativ im XML-Schema.. . . . . . . . . . . . . . . . 57
15. Die Struktur des Elements PersonalFokus. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
16. Die Struktur des Elements TypOffen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
17. Die Struktur des Elements TypKomplex. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
18. Die Struktur des Elements ObjektStat. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
19. Ausschnitt aus der Operationalisierung des Themas „Korrektheit der Therapeutik“. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
20. Ausschnitt aus der Operationalisierung des Themas“Technische Differenziertheit der Dokumentation“. . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
21. Das Modell der Eigenschaftsargumente und der Gruppenargumente. . . . . . . . . . . . . . . 67
22. Ausschnitt aus dem Domänenmodell. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
23. XML-Darstellung der Frage aus Beispiel 12.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
24. Visualisierung der allgemeinen Frageobjekte. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77

xvi ABBILDUNGSVERZEICHNIS
25. Ausschnitt aus einem bei der KD-Frage-Expansion entstehenden Fragebaum.. . . . . . . 94
26. Der Prozess der KD-DM-Transformation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
27. Überblick über die Zuordnung von Data-Mining-Methoden zu den allgemeinen Frageobjekten. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
28. Der Prozess der Beantwortung von KD-Fragen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
29. Die Gesamtarchitektur des Knowledge Discovery Assistant. . . . . . . . . . . . . . . . . . . . 106
30. Die Konfiguration der Datenquellen im Datenbank-Agenten. . . . . . . . . . . . . . . . . . . . 107
31. Die modulare Integration von Algorithmen in den Data-Mining-Agenten. . . . . . . . . . 107
32. Die Darstellung der Ergebnisse in einem Bericht im HTML-Format. . . . . . . . . . . . . . 108
33. Die graphische Benutzerschnittstelle des KDA.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
34. Die Fensterstruktur des KDA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
35. Die Verwaltung taxonomischer Informationen im KDA. . . . . . . . . . . . . . . . . . . . . . . 111
36. Die Eingabe von Fragen und Generierung von Feedback an den Benutzer. . . . . . . . . 112
37. Die Eingabe einer neuen natürlichsprachlichen Frage in den KDA. . . . . . . . . . . . . . . 112
38. Das Stufenmodell für Änderbarkeit und Portierbarkeit.. . . . . . . . . . . . . . . . . . . . . . . . 121
39. Die Abbildungen zur Überprüfung der Vollständigkeit. . . . . . . . . . . . . . . . . . . . . . . . 122
40. Die Anforderungen an die Benutzer des QUESTUS-KDD-Ansatzes. . . . . . . . . . . . . . 127
41. Der Ausgangsprozess des datenbasierten medizinischen Qualitätsmanagements.. . . . 130
42. Der Prozess des datenbasierten medizinischen Qualitäts-managements unter Verwendung des KDA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
43. Die Themenhierarchie des Medizinischen Leistungscontrollings. . . . . . . . . . . . . . . . . 138
44. Darstellung des Elements TypKonfirmativ im XML-Schema.. . . . . . . . . . . . . . . 141
45. Darstellung des Elements TypDeskriptiv im XML-Schema. . . . . . . . . . . . . . . . . 142
46. Darstellung des Elements TypKomplex im XML-Schema. . . . . . . . . . . . . . . . . . . . 143
47. Darstellung des Elements FrageObjekt im XML-Schema. . . . . . . . . . . . . . . . . . . 144
48. Darstellung des Elements TypOffen im XML-Schema. . . . . . . . . . . . . . . . . . . . . . . 144
49. Darstellung des Elements Zusammenhang im XML-Schema. . . . . . . . . . . . . . . . . . 145
50. Darstellung des Elements Gemeinsamkeit im XML-Schema. . . . . . . . . . . . . . . . . 146
51. Darstellung des Elements Unterschied im XML-Schema. . . . . . . . . . . . . . . . . . . 146
52. Darstellung des Elements Veraenderung im XML-Schema. . . . . . . . . . . . . . . . . . 147
53. Die Datenbankstruktur für die Modellierung des Wissensüber Data-Mining-Methoden und -Algorithmen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156

TABELLENVERZEICHNIS
1. Einordnung der Ansätze bezüglich des Paradigmas der Benutzerunterstützung und des unterstützten Datenmodells. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2. Einordnung der Ansätze bezüglich des Paradigmas und des Fokus der Benutzerunterstützung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3. Aufstellung der semiotischen Ebenen für ausgewählte sprachliche Ausdrücke nach [Wal85]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4. Nicht-exhaustive Interpretation nach Hamblin. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5. Exhaustive Interpretation nach Groenendijk und Stokhof. . . . . . . . . . . . . . . . . . . . . . . . 38
6. KDQL-Elemente einer einfachen Frage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
7. Attribute für die Modellierung eines KDQL-Elements. . . . . . . . . . . . . . . . . . . . . . . . . . 54
8. Formale Beschreibung des Elements TypKonfirmativ. . . . . . . . . . . . . . . . . . . . . . 57
9. Gegenüberstellung verschiedener Arten von Ergänzungsfragennach [Kri00] und deren Modellierung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
10. Beispiele für Fragen mit implizitem Variablenbereich unddaraus abgeleiteten expliziten Fragebereichen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
11. Semantische Klassen und ihre Referenzen auf mögliche Variablenbereiche. . . . . . . . . 59
12. Typen des Elements Zusammenhang. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
13. Typen des Elements Unterschied. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
14. Typen des Elements Veränderung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
15. Typen des Elements Gemeinsamkeit. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
16. Modellierung des Elements Frageargumente. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
17. Modellierung des Elements AttributKennzahl. . . . . . . . . . . . . . . . . . . . . . . . . . . 68
18. Modellierung des Elements Fragegruppe. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
19. Modellierung des Elements Fragekontext. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
20. KDAL-Elemente einer einfachen Antwort. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
21. Arten von KD-Antworten. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
22. Gruppierung und Übersetzung von Korrelationskoeffizienten wie beispielsweise Pearson’s r in verbale Beschreibungen (nach [Wit91]). . . . . . . . . . . . . . . . . . . . . . . . . . 82
23. Gruppierung und Übersetzung der Irrtumswahrscheinlichkeit α (nach [Wit91]). . . . . . 82

xviii TABELLENVERZEICHNIS
24. Verwendung der KDQL-Elemente bei der Ermittlung der Semantik. . . . . . . . . . . . . . . 84
25. Charakteristika zur Klassifikation von Data-Mining-Methoden. . . . . . . . . . . . . . . . . . . 90
26. Zuordnung der relevanten Evaluierungskriterien zu den Verarbeitungsschritten . . . . 120
27. Überprüfung der Vollständigkeit der Abbildung von natürlichsprachlichen Fragen . . 123
28. Überprüfung der Vollständigkeit der Abbildung von KD-Fragen . . . . . . . . . . . . . . . . 124
29. Formale Beschreibung des Elements TypKonfirmativ. . . . . . . . . . . . . . . . . . . . . 141
30. Formale Beschreibung des Elements TypDeskriptiv. . . . . . . . . . . . . . . . . . . . . . . 142
31. Formale Beschreibung des Elements TypKomplex. . . . . . . . . . . . . . . . . . . . . . . . . . 142
32. Formale Beschreibung des Elements TypOffen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
33. Formale Beschreibung des Elements FrageObjekt. . . . . . . . . . . . . . . . . . . . . . . . . 144
34. Formale Beschreibung des Elements Zusammenhang. . . . . . . . . . . . . . . . . . . . . . . . 145
35. Formale Beschreibung des Elements Unterschied. . . . . . . . . . . . . . . . . . . . . . . . . 145
36. Formale Beschreibung des Elements Gemeinsamkeit. . . . . . . . . . . . . . . . . . . . . . . 146
37. Formale Beschreibung des Elements Veraenderung. . . . . . . . . . . . . . . . . . . . . . . . 147
38. Attribute des Objekttyps Attribut. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
39. Attribute des Objekttyps Attributwert. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
40. Attribute des Objekttyps Fall. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
41. Attribute des Objekttyps Attributgruppe. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
42. Attribute des Objekttyps Attributwertgruppe. . . . . . . . . . . . . . . . . . . . . . . . . . 149
43. Attribute des Objekttyps Fallgruppe. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
44. Attribute des Objekttyps DM-Anfrage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
45. Attribute des Objekttyps DM-Ergebnis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
46. Attribute des Objekttyps KD-Frage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
47. Attribute des Objekttyps KD-Antwort. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
48. Modularisierung des Wissens. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
49. Übersicht über die Modellierung der Analysemethoden (Teil A). . . . . . . . . . . . . . . . . 157
50. Übersicht über die Modellierung der Analysemethoden (Teil B). . . . . . . . . . . . . . . . . 159
51. Übersicht über die Modellierung der Analysemethoden (Teil C). . . . . . . . . . . . . . . . . 161
52. Übersicht über einige Methoden für die Operationalisierungder allgemeinen Frageobjekte. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
53. Sprachliche Ausdrücke für Wahrheitswerte (nach [Käp02]). . . . . . . . . . . . . . . . . . . . . 165
54. Sprachliche Ausdrücke für Interessantheitswerte (nach [Käp02]). . . . . . . . . . . . . . . . 166
55. Sprachliche Ausdrücke für Häufigkeitswerte (nach [Käp02]). . . . . . . . . . . . . . . . . . . 166
56. Sprachliche Ausdrücke für Korrelationsmaße (nach [Wit91]). . . . . . . . . . . . . . . . . . . 167
57. Sprachliche Ausdrücke für Maße der Irrtumswahrscheinlichkeit (nach [Wit91]). . . . 167

xixTABELLENVERZEICHNIS
58. Sprachliche Ausdrücke für normierte Größen (nach [Käp02]). . . . . . . . . . . . . . . . . . . 168

xx TABELLENVERZEICHNIS

KAPITEL 1 EINLEITUNG
Die Entdeckung von Wissen in Datenbanken oder Data Mining1 ist eine Technologie, die nachder Einführung von leistungsfähigen Data Warehouses in immer mehr Unternehmen vor einerneuen Chance der Anwendung in der betrieblichen Praxis steht: zum einen stehen nach demAbschluss der initialen Befüllung der Data Warehouses jetzt wieder Ressourcen für die Ein-führung von Technologien zur Auswertung der Daten im Allgemeinen und von Data-Mining-Technologien im Speziellen zu Verfügung. Zum anderen bieten die in den Data Warehousesverfügbaren, konsolidierten Daten eine nahezu optimale Grundlage für weit reichende Analy-sen, die zuvor noch aufwändiger Datenvorverarbeitungsschritte bedurft hätten.
Die möglichen Anwendungen der Datenanalyse mit Methoden des Data Mining sind viel-fältig und werden beinahe täglich um neue erweitert: Zur beinahe schon klassischen Analysevon Kunden- und Warenkorbdaten kommen neue Bereiche, wie die Untersuchung des Verhal-tens von Besuchern auf Websites und die Auswertung von Daten zum Zwecke des Qualitäts-managements z.B. im Gesundheitswesen oder in Fertigungsbetrieben, hinzu.
Dabei darf jedoch nicht übersehen werden, dass die korrekte Anwendung von Methodendes Data Mining ebenso wie von Methoden der Statistik eine höchst anspruchsvolle Aufgabeist, bei der das Fachwissen der Anwender durch das Methodenwissen von Data-Mining-Exper-ten ergänzt werden muss. So beschreiben auch Wirth et al. die aktuelle Situation mit den Wor-ten:
„The main bottleneck for KDD-applications is not the lack of techniques. Thechallenge is to exploit and combine existing algorithms effectively, and help theuser during all phases of the KDD process.“ ([Wir97:243])
1.1 Business Understanding als Herausforderung
Tatsächlich wurden im Bereich der Entdeckung von Wissen in Datenbanken in den letzten Jah-ren große Forschungsanstrengungen vor allem in die Entwicklung von effizienten Algorithmenfür die Entdeckung von unterschiedlichen Mustern in großen Datenbeständen investiert. Na-türlich waren diese Bemühungen nicht erfolglos und so existiert heute eine nur schwer über-schaubare Menge an Data-Mining-Algorithmen, die in der Lage sind, immer komplexere Mus-ter in immer größeren Datenbanken in immer kürzerer Zeit zu finden. Dabei wurden aber dieProzessschritte, die dem eigentlichen Entdeckungsprozess vorangehen und ihm folgen – ab-sichtlich oder unabsichtlich – vernachlässigt. Diese Schritte werden im CRISP-DM-Modell,auf das wir in Abschnitt 2.1.3 noch ausführlich eingehen, von Chapman et al. in [Cha00a] de-tailliert beschrieben, sind aber in heutigen Data-Mining-Umgebungen noch weitgehend ohne
1 Dem allgemeinen Sprachgebrauch folgend verwenden wir hier und im Folgenden die Bezeichnungen„Entdeckung von Wissen in Datenbanken“ (auch als Knowledge Discovery in Databases oder KDD be-kannt) und „Data Mining“ synonym.

2 KAPITEL 1. EINLEITUNG
systemische Unterstützung. Vor allem die initiale CRISP-Phase des Business Understanding,in der Fachexperte2 und Datenanalyst3 zu Beginn eines Analyseprojekts zusammenkommen,um die beabsichtigten Ziele und möglichen Methoden der Datenanalyse zu identifizieren, istso komplex wie entscheidend für den Erfolg des Projekts. Denn nur wenn bereits an dieserStelle bei den beteiligten Gruppen (Experten der Anwendungsdomäne und Experten der Da-tenanalyse) ein gemeinsames Verständnis über Erwartungen und Möglichkeiten aufgebautwerden kann, werden die Analysen in eine Richtung führen, die gleichermaßen valide und um-setzbare Ergebnisse erzeugt. Die Interessen des Fachexperten können dann als eine Fokussie-rung auf die ansonsten häufig unüberschaubare Menge an Data-Mining-Ergebnissen, wie siehäufig von Data-Mining-Algorithmen produziert werden, verwendet und deren Nutzung unddie Akzeptanz des Vorgehens dadurch verbessert werden.
Business Understanding ist jedoch aus zwei Gründen eine schwierige Aufgabe: Zum einensprechen die Experten aus der Anwendungsdomäne und die Datenanalysten unterschiedlicheFachsprachen. Zum anderen können die Fachexperten ihre Interessen oft nur vage formulieren.Der direkteste Weg zur Lösung dieses Problem, nämlich die Definition von Zielen und dieDurchführung der Analysen in eine Hand zu geben, scheitert jedoch an dem jeweils tief grei-fenden Wissen, das für beide Aufgaben benötigt wird und nur selten auf eine Person vereinigtgefunden werden kann.
Da auf das Wissen sowohl aus dem Anwendungsbereich als auch aus dem Methodenbe-reich jedoch nicht verzichtet werden kann, bleibt nur die Möglichkeit, eine der beiden Rollenin die Lage zu versetzen, alleine die Data-Mining-Aufgabe durchzuführen, und das dafür benö-tigte Wissen als Teil der Benutzerunterstützung zu integrieren. Welche der beiden Rolle sichbesser für eine selbständige Durchführung des Data Mining eignet, bedarf einer einfachen Ab-wägung: Während das Handeln des Datenanalysten bei der Bewältigung einer komplexenData-Mining-Aufgabe üblicherweise von den verfügbaren Methoden geprägt sein wird (me-thodenorientiertes Vorgehen), wird der Fachexperte vor allem die Erreichung seiner Analyse-ziele im Auge haben (zielorientiertes Vorgehen). Aus diesem Grund wählen wir den Fachex-perten als die Rolle, die – im Rahmen unseres Ansatzes – künftig in der Lage sein soll, dasData Mining selbständig durchzuführen. Das Wissen, das er dafür aus dem Bereich der Data-Mining-Methodik benötigt, soll ihm im Rahmen der Benutzerunterstützung zur Verfügung ge-stellt werden.
1.2 Intelligente Benutzerschnittstellen für Informationssysteme
Die Notwendigkeit einer verbesserten Benutzerunterstützung für Fachexperten ist beim DataMining kein Einzelfall. Generell kann – wie auch in der Zielsetzung des vom Deutschen For-schungszentrums für Künstliche Intelligenz (DFKI) geleiteten Projekts Smartkom in [Sma03]formuliert – die Schaffung intelligenter Benutzerschnittstellen, die den natürlichen Kommuni-kationsstil von Computerlaien akzeptieren und so unterstützen, dass eine für den Menschen in-tuitive und benutzergerechte Mensch-Technik-Interaktion entsteht, als eine der derzeit wich-tigsten Herausforderungen für die Wissensgesellschaft bezeichnet werden.
Die Aufwertung der Rolle des Fachexperten in dem vorgeschlagenen Szenario verursachteinen Bedarf an einer effektiven, effizienten und natürlichen Schnittstelle, um den Zugriff aufMethoden und Informationen zu erleichtern. Dieser Bedarf wird weiter gesteigert durch die
2 Hier und im Folgenden verwenden wir für diese Rolle die Bezeichnung „Fachexperte“. In anderenArbeiten werden diese auch als „Endbenutzer“, „Business User“ oder schlicht als „Client“ und „Custo-mer“ ([Cha00a]) benannt.
3 In Übereinstimmung mit der Terminologie des CRISP-DM-Modells aus [Cha00a] bezeichnen wir dieRolle des Data-Mining-Experten hier und im Folgenden als „Datenanalyst“.

31.3 EIN ANSATZ FÜR DAS INVISIBLE DATA MINING – ZIELE UND BEITRÄGE
rasch zunehmende Komplexität der IT-Systeme und durch die immer geringere Zeit, welcheden Benutzern zum Ausführen von Aufgaben und für das Erlernen von Bedienkonzepten zurVerfügung steht.
1.3 Ein Ansatz für das Invisible Data Mining – Ziele und Beiträge
Auf der Basis der oben beschriebenen Herausforderung stellen wir in dieser Arbeit den QUES-TUS-KDD-Ansatz (Question-Driven User Support für Knowledge Discovery in Databases)vor, der vor allem Fachexperten den direkten Zugriff auf Methoden des Data Mining erleich-tern und damit neue Potentiale der schnellen und einfachen Datenanalyse vor Ort erschließensoll. Die Kernidee des Ansatzes, den Benutzern den Blick auf die formalen Grundlagen vonData-Mining-Anfragen zu ersparen und ihnen die Interaktion auf höherer Ebene zu ermögli-chen, wurde von Umesh Dayal4 als „Invisible Data Mining“ bezeichnet.5 Diese Bezeichnungerscheint prägnant genug, um sie als Leitmotiv dieser Arbeit weiter zu tragen.
Bei der Konzeption des Ansatzes gehen wir von einer Situation aus, die sich durch die fol-genden Elemente beschreiben lässt:
• Daten: Es gibt eine Menge von Daten, die in einer Datenbank für die Analysen verfüg-bar sind. Wir gehen dabei von einem relationalen Datenmodell aus, wie es von Wede-kind in [Wed81] beschrieben wird.
• Domäne: Für die Anwendungsdomäne, aus der die Daten und der Fachexperte stammen,ist Hintergrundwissen in Form von Konzepthierarchien und Begriffsoperationalisierun-gen, wie von Müller in [Mül98] beschrieben, verfügbar.
• Methoden: Es gibt eine Menge von Analysemethoden, deren Anforderungen, Merkmaleund Ergebniseigenschaften sich korrekt und vollständig beschreiben lassen.
• Fragen: Der Fachexperte ist in der Lage, eine Menge von Fragen in natürlicher Sprachezur Verfolgung der Ziele seiner Analysen zu formulieren.
Ziel des Ansatzes ist dann, auf der Basis der Daten, mit dem Wissen der Domäne und unterZuhilfenahme der verfügbaren Methoden auf die Menge der Fragen eine Menge von adäquatenAntworten zu finden, die vom Fachexperten verstanden werden können. Abbildung 1 illustriertdiesen Zusammenhang.
4 Intelligent Information Solutions Group, HP-Labs, Palo Alto, Kalifornien.5 Der Begriff entstand bei der Panel-Diskussion auf dem ACM SIGMOD Workshop on Research Issu-
es in Data Mining and Knowledge Discovery (DMKD 2000) am 14. Mai 2000 in Dallas, Texas.
Abbildung 1: Die Ermittlung von Antworten auf der Basis von Daten, Methoden, Fragen und Domänenwissen.
Fragen Antworten
Daten
Domäne
Methoden

4 KAPITEL 1. EINLEITUNG
Für die Erreichung dieses Ziels werden wir im Folgenden das in Abbildung 2 dargestellteEbenenmodell verwenden. Die darin dargestellten Ebenen in der vertikalen Dimension lassensich auf verschiedene Weisen interpretieren:
• Sprachebene: Ausgehend von der Struktur von Fragen und Antworten, die sich an dernatürlichen Sprache orientiert, werden die Objekte nach unten hin immer formaler be-schrieben: durch Funktionenaufrufe für die Methoden bzw. durch SQL-Ausdrücke aufder Ebene der Datenbank-Anfragen.
• Abstraktionsniveau: Während Datenbank-Anfragen und die zurück gelieferten Tupelaus der Datensicht sehr konkrete Objekte darstellen, lassen sich die darüber liegendenObjekte als Verdichtungen der unteren Stufen betrachten.
• Komplexitätsniveau: Analog zum Abstraktionsniveau nimmt die Komplexität der Ob-jekte in Bezug auf ihre Syntax und Semantik von unten nach oben zu. Damit wächstauch die Menge ihrer Interpretationsmöglichkeiten.
• Verarbeitungsstufen: Für die Lieferung von Ergebnissen zu den auf der linken Seitedes Modells dargestellten Objekten werden jeweils die darunter liegenden Ebenen ver-wendet: Um eine Antwort auf eine Frage auf der höchsten Ebene zu erhalten, werden indiesem Sinne die Fragen durch eine geeignete Menge von Methodenaufrufen operationa-lisiert, deren Ergebnisse wieder in Antworten transformiert werden können. Ebenso wer-den die Methoden-Aufrufe unter Verwendung von Datenbank-Anfragen ausgeführt, diezurück gelieferten Datenbanktupel stellen dann die Grundlage für die Berechnung derErgebnisse im Data Mining dar.
Im Sinne des Invisible Data Mining interagiert der Fachexperte als der intendierte Benutzerdes Systems nur auf der obersten Ebene (KD-Ebene) durch Fragen und Antworten in einerSprache, die ihm näher ist als die formalen Aufrufe auf der Data-Mining- und auf der Daten-bank-Ebene (DM- bzw. DB-Ebene). Der Blick auf die darunter liegenden Schichten wird nuraus Gründen der Transparenz notwendig. Damit steht die Benutzerunterstützung bei der Inter-aktion mit einem Data-Mining-System auf hoher Ebene über Fragen und Antworten im Fokusdieser Arbeit. Die darunter liegenden Schichten werden dabei als Werkzeuge für die Operatio-nalisierung gebraucht und nur soweit beschrieben, wie es die Definition der Schnittstellen er-fordert. Für die Grundlagen des Data Mining verweisen wir deshalb auf die einschlägige Lite-ratur (z.B. [Ber97], [Fay96a], [Fay96b] und [Eng97c]).
Abbildung 2: Das sprachorientierte Ebenenmodell für die Datenanalyse.
Fragen Antworten
Methoden-Aufrufe Ergebnisse
Datenbank-Anfragen Datenbank-Tupel
Beantwortung
Database Querying
Data Mining
Knowledge-Discovery-Ebene (KD)
Data-Mining-Ebene (DM)
Datenbank-Ebene (DB)

51.3 EIN ANSATZ FÜR DAS INVISIBLE DATA MINING – ZIELE UND BEITRÄGE
Dabei soll nicht übersehen werden, dass sich durch die Interaktion auf hoher Ebene in die-sem ersten Ansatz möglicherweise nicht das vollständige Aufgabenspektrum, das bei der Ent-deckung von Wissen in Datenbanken vorgegeben ist, abgedeckt werden kann. Obwohl sich dieArbeit um Vollständigkeit bei der Formulierung von möglichen Fragen im eigentlichen Analy-seschritt bemüht, kann nicht ausgeschlossen werden, dass Analysen, die sich entweder durcheine hohe Domänenabhängigkeit oder Komplexität auszeichnen, weiterhin durch die direkteInteraktion auf Methodenebene und mit der Hilfe eines Datenanalysten durchgeführt werdenmüssen. Zudem bedürfen einige Teilprozesse bei der Entdeckung von Wissen in Datenbankenweiterhin der Unterstützung durch Datenbank- und Data-Mining-Experten, z.B. was die Vor-verarbeitung und Integration der Daten sowie der benötigen Analysemethoden betrifft.
1.3.1 Ziele der Arbeit
Vor dem oben beschriebenen Hintergrund formulieren wir die folgenden Ziele der Arbeit:
1. Ermöglichung von Data Mining für Data-Mining-Laien: Fachexperten mit ihremDomänenwissen aber zugleich eingeschränkten Kenntnissen von Datenanalyse-Techno-logien stehen im Fokus des Ansatzes. Durch die Benutzerunterstützung soll es ihnenermöglicht werden, in einem konfigurierten System, das sich durch eine abgeschlosseneIntegration von Daten und Methoden sowie die Formalisierung des Domänenwissensauszeichnet, und nur mit geringen Analysekenntnissen selbständig Hinweise auf dieBeantwortung ihrer Fragen zu erhalten. Die technologische Zugangsschwelle zum DataMining soll damit für Fachexperten gesenkt werden.
2. Befreiung vom kognitiven Overhead beim Data Mining: Die Benutzer des Systemssollen bei ihrer Analysetätigkeit nicht durch methodische Überlegungen abgelenkt wer-den. Stattdessen sollen sie in der Lage sein, sich auf ihre Interessen in Form von natür-lichsprachlichen Fragen, wie sie auch bei der Kommunikation untereinander formuliertwerden, zu konzentrieren. Dies ermöglicht dann in der Fortsetzung auch einen verein-fachten Umgang mit den Ergebnissen und deren fokussiertere Umsetzung. Damit soll diementale Zugangsschwelle zum Data Mining reduziert werden.
3. Einsparung von Expertenkapazitäten: Aus betriebswirtschaftlicher Sicht stellt derEinsatz von Datenanalyse-Experten für jede Art von Data-Mining-Analysen einebeträchtliche Belastung für die Firmen dar. Vor allem für mittelständische Unternehmenist der Einsatz der Technologie aufgrund der damit verbundenen hohen Beratungskostennur schwer finanzierbar. Aber auch in den Fachabteilungen von Großunternehmen undKonzernen stellen die Kosten, die für Beratungsleistungen oder abgeschlossene Data-Mining-Studien intern verrechnet werden, einen nicht zu unterschätzenden Aufwand dar.Kann durch die verbesserte Benutzerunterstützung nun ein Teil der Analysen in denFachabteilungen vor Ort und ohne externe Beratung durchgeführt werden, lassen sichdiese Kosten deutlich reduzieren. Damit kann auch die betriebswirtschaftliche Zugangs-schwelle zum Data Mining gesenkt werden.
1.3.2 Beiträge der Arbeit
Um die oben beschriebenen Ziele zu erreichen, definieren wir die folgenden Beiträge der Ar-beit:
1. Modellierung von Fragen von Fachexperten für das Data Mining: Ausgehend vonder Analyse eines Korpus von Fragen von Fachexperten entwickeln wir die KnowledgeDiscovery Question Language (KDQL) als kontrollierte Sprache für deren Formulie-

6 KAPITEL 1. EINLEITUNG
rung. Darüber hinaus beschreiben wir mit der Knowledge Discovery Answer Language(KDAL) eine Sprache für die Formulierung entsprechender Antworten.
2. Abbildung von Fragen von Fachexperten auf Data-Mining-Anfragen: Für dieBeantwortung von Fragen von Fachexperten, die in KDQL formuliert sind, stellen wirumfangreiche Methoden für deren schrittweise Operationalisierung durch Data-Mining-Anfragen bereit.
3. Modellierung des Wissens auf verschiedenen Spezialisierungsebenen: Das für dieFormulierung und Operationalisierung der Fragen benötigte Wissen stellen wir in einermodularen Wissensbasis zur Verfügung. Dabei unterscheiden wir zwischen allgemeinen,domänenspezifischen und anwenderspezifischen Objekten.
4. Integration des Ansatzes als Front-End in den Knowledge Discovery Assistant: Derin dieser Arbeit entwickelte Ansatz wird in das am Bayerischen Forschungszentrum fürWissensbasierte Systeme (FORWISS) entstandene Data-Mining-Werkzeug KnowledgeDiscovery Assistant (KDA) integriert und mit einer Benutzerschnittstelle für die interak-tive Formulierung von Fragen versehen.
1.4 Die praktische Anwendung beim Qualitätsmanagement im Gesundheitswesen
Die Liste möglicher Anwendungen für die Technologien des Data Mining ist lang und wirdlaufend erweitert. Neben der rein wissenschaftlichen Suche nach neuem Wissen, wie sie bei-spielsweise in der Soziologie, der Chemie und der Medizin betrieben wird, hält diese Techno-logie auch immer mehr in Unternehmen ihren Einzug. Im Vordergrund steht dabei die Aus-schöpfung von bisher nicht genutzten Effizienzreserven, wie sie sich durch die vorhandenenDatenbestände ergeben und im Bereich des Customer Relationship Management (CRM) bei-spielsweise zur Akquisition von Neukunden und der Bindung von bestehenden Kunden ver-wendet werden können. Aber auch für die Verbesserung der vom Unternehmen erbrachtenQualität birgt die Analyse der bestehenden Datenbestände großes Potential. Dies ist sowohl inProduktionsbetrieben, vor allem bei der Herstellung von technologieorientierten Produkten, alsauch bei Dienstleistungsbetrieben, zu denen wir auch Einrichtungen des Gesundheitswesenszählen, der Fall.
Als Grundlage für die Illustration der Problemstellung und des Vorgehens dienen deshalbim Folgenden die seit Dezember 1998 am FORWISS laufenden Studien zum medizinischenLeistungscontrolling, die in Zusammenarbeit mit der Tiroler Landeskrankenanstalten GmbHin Innsbruck durchgeführt wurden. Das Ziel der Studien ist es, vermutete qualitätsrelevanteKriterien für das medizinische Leistungscontrolling in Patientendaten zu überprüfen und neueKriterien zu entdecken. In den Studien wurden in den drei Themenbereichen Diagnosen undTherapien, Komplikationen und Dokumentationsqualität Fragestellungen, die von der dortigenAbteilung für Qualitätsmanagement formuliert wurden, bearbeitet. Abbildung 3 enthält dieThemenhierarchie des medizinischen Qualitätsmanagements auf oberster Ebene, wie sie alsHintergrund zu den Studien auf der Basis von [Don92] erarbeitet wurde. Im Anhang A.1 findetsich die vollständige Hierarchie der Themen für das medizinische Leistungscontrolling als Un-teraufgabe des Qualitätsmanagements.
Grundlage für die Analysen sind die aus dem Data Warehouse des Klinikverbunds stam-menden Daten in relationaler Form. Ein Patient ist darin unter anderem beschrieben durch Ein-träge zu seinem Alter, Geschlecht, Geburtsland und Krankenversicherungsträger. Die Attribu-te, mit denen ein Klinikaufenthalt beschrieben wird, lassen sich u.a. in die Gruppen Diagnosen(z.B. Hauptdiagnose, Zusatzdiagnosen), medizinische Leistungen (z.B. Art und Anzahl der er-

71.5 DER AUFBAU DER ARBEIT
brachten ambulanten und stationären Leistungen) sowie Aufenthaltsinformation (z.B. Gesamt-verweildauer, behandelnde Abteilungen) unterteilen. Für eine genauere Beschreibung der Stu-dien verweisen wir auf [Stü2000].
1.5 Der Aufbau der Arbeit
Die vorliegende Arbeit gliedert sich nach dieser Einleitung wie folgt:• Kapitel 2: In diesem Kapitel untersuchen wir bestehende Ansätze für wissensbasierte
Benutzerschnittstellen. Dabei behandeln wir zum einen Anfragesysteme für verschiede-ne Arten von Informationssystemen, die beispielsweise den Zugriff auf Ergebnisse aufDatenbanktupel und Data-Mining-Ergebnisse erleichtern sollen. Zum anderen beschrei-ben wir Ansätze, die im Bereich der Statistik, des maschinellen Lernens und des DataMining Benutzerunterstützung bei der Auswahl von Methoden, die sich für die Lösungeiner gegebenen Problemstellung eignen, leisten.
• Kapitel 3: Fragen und Antworten als das Mittel der Kommunikation zwischen Fachex-perten und Data-Mining-System sind Gegenstand der Analysen in diesem Kapitel. DerSchwerpunkt liegt dabei auf Mitteln zur Beschreibung der Logik von Fragen und Ant-worten (erotetische Logik) im Allgemeinen sowie auf der Formalisierung ihrer Semantikim Speziellen.
• Kapitel 4: Nach den Analysen bestehender Ansätze legen wir die Anforderungen an un-seren Ansatz der Benutzerunterstützung fest, beschreiben sein Grundgerüst und definie-ren die wichtigsten Objekte und Methoden. Darüber hinaus stellen wir das Konzept fürdie Modellierung der Wissensbasis vor.
• Kapitel 5: Als Hauptbestandteil unseres Ansatzes beschreiben wir in diesem Kapitel dieKnowledge Discovery Question Language für die Formulierung von Fragen von Fachex-perten sowie der Knowledge Discovery Answer Language (KDAL) für die entsprechen-den Antworten.
Abbildung 3: Die Hierarchie der Themen im medizinischen Qualitätsma-nagement.
MedizinischesQualitätsmanagement
Prozess-bewertung
Ergebnis-bewertung
Struktur-bewertung
Einrichtung
Personal
Ausrüstung
FinanzielleAusstattung
MaterielleRessourcen
DiagnostischeMaßnahmen
TherapeutischeMaßnahmen
Patienten-zufriedenheit
Gesundheits-zustand

8 KAPITEL 1. EINLEITUNG
• Kapitel 6: Nach der Syntax von Fragen und Antworten leisten wir in diesem Kapitel dieBeschreibung ihrer Operationalisierung. Dabei untersuchen wir zunächst die Umsetzungder KDQL-Einzelelemente und erschließen dann nach dem Prinzip der Komposition dieOperationalisierung der ganzen Frage.
• Kapitel 7: Dieses Kapitel beschreibt detailliert die Abbildung von Fragen, die in KDQLformuliert sind, auf eine Menge geeigneter Data-Mining-Anfragen. Dabei expandierenwir die gegebene Frage zunächst in eine Menge von konkreteren Unterfragen und leitenaus diesen dann in mehreren Schritte die für die Formulierung einer Data-Mining-Anfra-ge benötigten Elemente ab. Die Methoden zur Beantwortung einer Frage runden das Ka-pitel ab.
• Kapitel 8: Als Nachweis der Umsetzbarkeit des vorgestellten Ansatzes integrieren wirseine Objekte und Methoden in den Knowledge Discovery Assistant, den wir in diesemKapitel beschreiben. Dabei gehen wir auf seine grundlegende Architektur, die graphi-sche Benutzeroberfläche und die Implementierung unseres Ansatzes ein.
• Kapitel 9: In diesem Kapitel stellen wir Ansätze für eine weitergehende Evaluierung derbeschriebenen Konzepte vor und führen diese teilweise durch. Der Schwerpunkt liegt da-bei auf der Untersuchung der Vollständigkeit der Menge der formulierbaren Fragen.
• Kapitel 10: Abschließend fassen wir die Ergebnisse der Arbeit zusammen, diskutierendie Vorteile und Nachteile des Ansatzes und geben einen Ausblick auf zukünftige Arbei-ten in diesem Themenbereich.
• Anhang: In den Anhängen finden sich empirische Grundlagen für die Konzeption sowiedetaillierte Informationen über die Syntax von KDQL und die Modellierung der Wis-sensbasis.
Die theoretischen Konzepte der Arbeit werden durchgängig durch Beispiele aus dem Be-reich des medizinischen Qualitätsmanagements veranschaulicht.

KAPITEL 2 RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
In diesem Kapitel wollen wir einen Überblick über abgeschlossene und laufende Forschungs-arbeiten geben, die einen inhaltlichen Bezug zur vorliegenden Arbeit aufweisen. Den über die-ser Arbeit liegenden Rahmen bildet das Forschungsgebiet der Human-Computer-Interactionoder eingedeutscht der Mensch-Maschine-Interaktion, das sich mit dem Verständnis, dem Ent-wurf, der Bewertung und der Umsetzung interaktiver Computersysteme beschäftigt. Mit demBegriff „Benutzerschnittstelle“ werden vor allem die technologischen Aspekte des Computer-systems betrachtet, mit denen der Benutzer unmittelbar in Berührung kommt ([Pre94]).
Der grundlegende Begriff „Wissensbasierte Benutzerschnittstelle“ wird im Folgenden mitdem Begriff „intelligente Benutzerschnittstelle“ (engl. Intelligent User Interface) synonym be-trachtet, da sich intelligente Systeme im Allgemeinen durch den Einsatz einer (möglichst de-klarativen) Wissensbasis auszeichnen. Wir bevorzugen jedoch die Wissensbasiertheit alskennzeichnendes Attribut, da eine Definition des Intelligenz-Begriffs als höchst umstritten an-zusehen ist.
Intelligente bzw. wissensbasierte Benutzerschnittstellen werden bereits 1993 von Dieterichet al. sehr eng als
„...the integration of an adaptive user interface [...] both with an intelligent helpsystem (IHS), making context-sensitive and active help available, and with an in-telligent tutoring system, supporting the user in learning the use of the system.''([Die93])
definiert, also als Kombination einer adaptiven Benutzerschnittstelle mit einem intelligen-ten Hilfesystem und einem intelligenten Tutorsystem. Tyler et al. beschreiben die Anforderun-gen an intelligente Benutzerschnittstellen mit den folgenden Komponenten ([Tyl91]):
• Wissensbasiertheit und Modularität• Schlussfolgerungs- und Bewertungsfähigkeit für die Pläne und Absichten der Nutzer• Anpassungsfähigkeit des Verhaltens an den individuellen Nutzer und seine aktuellen
Aufgaben• Unterstützung multimodaler Eingabe und ErgebnispräsentationDiese beiden sehr restriktiven Definitionen wurden in den letzten Jahren dahingehend auf-
geweicht, dass nicht mehr die Gesamtmenge der genannten Bestandteile gefordert wird, son-dern diese Menge nur noch den Vorrat möglicher Realisierungen darstellt. Diese Menge dermöglichen Bestandteile einer intelligenten Benutzerschnittstelle wird von Encarnação um diefolgenden Komponenten erweitert ([Enc97]):
• Multimodale Kommunikation• Dynamische Präsentation

10 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
• Natürlichsprachlicher Dialog• Interface-Adaptivität• Benutzermodellierung• Erkennung der Pläne der Benutzer Der Begriff „Wissensbasiertes System“ (engl. Knowledge-Based System) wird im American
National Standard Dictionary of Information Technology (ANSDIT) wie folgt definiert:
„A computer system that provides for solving problems in a given field or applica-tion area by drawing inferences from a knowledge base. (...)“ ([ANS02])
Dies greifen auch Borgelt et al. auf und erweitern die Definition des Begriffs um das Zielder Benutzerunterstützung:
„Wissensbasierte Systeme sind Programme, die auf der Grundlage von Wissenüber einen bestimmten Anwendungsbereich Schlussfolgerungen ziehen können,und die so einem Benutzer helfen, ein Problem zu lösen oder eine Entscheidung zutreffen.“ ([Bor00])
Die generelle Idee von wissensbasierten oder intelligenten Benutzerschnittstellen besteht inder Unterstützung der Nutzer von Computersystemen bei der Lösung großer und komplexerAufgaben und stellt damit eines der Grundthemen der Anwendung künstlicher Intelligenz dar.Miller et al. beschreiben bereits 1991 die Ziele intelligenter Benutzerschnittstellen [Mil91]:
• Interaktionen klarer und effizienter gestalten,• die Aufgaben, Pläne und Ziele des Benutzers besser unterstützen und• Informationen effektiver darstellen.Während diese Ziele über die Jahre ihre Gültigkeit bewahrt haben, unterlag die Art der Un-
terstützung einem steten Wandel. Die frühen Arbeiten auf diesem Gebiet waren geprägt vonder Idee quasi-natürlichsprachlicher Mensch-Maschine-Kommunikation in der Form von An-fragen und Antworten. Durch die Schwierigkeiten bei der Verarbeitung natürlicher Sprachekombiniert mit der Verfügbarkeit neuer graphischer Interaktionsmethoden erfolgte ein Para-digmenwechsel. Anstatt Aufgaben und Konzepte einer linguistischer Art der Interaktion zuüberlassen und Referenzen darauf nur über Namen oder Beschreibungen zu ermöglichen, kanndie Domäne graphisch dargestellt und mit visuellen Methoden greifbarer gemacht werden. Dersich entwickelnde Wettbewerb zwischen den beiden Paradigmen hatte eine genauere Untersu-chung ihrer relativen Stärken zur Folge. Eine natürliche Konsequenz stellt die Verbindung bei-der Ansätze in Form einer Einbindung linguistischer Arten der Konversation in graphische Be-nutzerschnittstellen. Aktuelle Arbeiten, wie das vom DFKI in Saarbrücken geleitete Smart-Kom-Projekt, konzentrieren sich vor allem auf das Prinzip der Multimodalität, also der Inter-aktion und der Kommunikation über verschiedene sensorische und effektorische Kanäle wieSprechen und Hören oder Zeigen und Sehen ([Sma03]).
2.1 Ansätze zur Unterstützung von Anfragen an Informationssysteme
In den folgenden Abschnitten werden wir die wichtigsten Forschungsansätze für die Unterstüt-zung von Anfragen an Informationssysteme6 auf zwei Arten einordnen: zum ersten werden wireine Klassifikation aufgrund der Art der Ergebnisse vornehmen, die auf eine entsprechende

112.1 ANSÄTZE ZUR UNTERSTÜTZUNG VON ANFRAGEN AN INFORMATIONSSYSTEME
Anfrage zurückgeliefert werden, und zum zweiten aufgrund der Art der Unterstützung für denBenutzer.
Wir verwenden das in Abbildung 4 gezeigte Modell von Murray et al. ([Mur98]), um denallgemeinen Interaktionszyklus zwischen dem Benutzer und dem (Informations-)System mitdessen Ein- und Ausgaben darzustellen. Der Zyklus beginnt mit der Entscheidung des Benut-zers über eine geplante Anfrage und der Formulierung der Aufgabe an der Benutzerschnittstel-le über dafür geeignete Mechanismen. Diese Handlung wird dann an das System übertragen,das die Anfrage bearbeitet. Als Ergebnis der Anfrage sendet das System seine Ausgabe an dieBenutzerschnittstelle, damit sie diese über ihre Ausgabemechanismen dem Benutzer präsen-tiert.
Gastner beschreit in [Gas93] zwei grundlegende Dialogmetaphern für die Mensch-Maschi-ne-Kommunikation, die auch für die vorliegende Aufgabenstellung relevant ist:
• Arbeit in der konversationellen Welt: Hier beschreibt der Mensch üblicherweise miteiner Kommandosprache die Aufgaben, die vom Computer erledigt werden sollen. Fürdie Ausführung der Aufgabe wird dann ein Anfrage-Antwort-Dialog eingesetzt. DieseForm der Eingabe wird von Dennebouy et al. auch als prozedurales Vorgehen bei derAnfrageformulierung bezeichnet ([Den95]).
• Arbeit in der Modellwelt: In diesem Fall zeigt der Mensch, was getan werden soll, in-dem er beispielsweise mit der Maus graphische Repräsentationen von Objekten manipu-liert. Dennebouy et al. verwenden für die Arbeit in der Modellwelt den Begriff der asser-torischen Anfrageformulierung ([Den95]).
Bei der folgenden Untersuchung von Benutzerschnittstellen von Informationssystemenwollen wir unter Berücksichtigung der verschiedenen Dialogmetaphern vor allem auf die Ge-staltung der Eingabe- und Ausgabemechanismen eingehen. Bei der Klassifikation der Anfra-gesysteme nach dem Ergebnistyp unterscheiden wir solche, die Texte und Dokumente, solche,die einfach strukturierte Datenbanktupel, und solche, die komplexere Data-Mining-Ergebnisseliefern.
6 Hier und im Folgenden bezeichnen wir Informationssysteme als Systeme, die die Verwaltung struk-turierter, semi-strukturierter und unstrukturierter Daten und Informationen sowie den Zugriff darauf mit-tels einer Retrieval-Komponente erlauben.
Abbildung 4: Der Interaktionszyklus nach [Mur98].
Interaktion
Eingabesystem
Ausgabesystem
Präsentation
BearbeitungSystemBenutzerAufgaben-formulierung
Aktion Eingabe
AusgabeWahrnehmung
Mensch Schnittstelle System

12 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
2.1.1 Unterstützung beim Zugriff auf Dokumente
Die Benutzerunterstützung beim Zugriff auf unstrukturierte Informationen, also vor allem aufDokumente und Texte, ist Teil der Untersuchungen des Information Retrieval und des TextRetrieval. Diese Ansätze erwähnen wir nur aus Gründen der Vollständigkeit. Aufgrund ihrerEntfernung zum Gegenstand dieser Arbeit wollen nicht im Detail darauf eingehen. Einen aus-führlichen Überblick geben jedoch beispielsweise Baeza-Yates und Ribeiro-Neto in [Bae99].
Zusätzlich zu klassischen Information-Retrieval-Systemen sind in den letzten Jahren vor al-lem Web-Retrieval-Systeme entstanden, die als Grundlage sichtbare (d.h. für die Allgemein-heit zugängliche) bzw. unsichtbare (d.h. nur einer beschränkten Öffentlichkeit zugängliche)Informationen aus dem WWW verwenden: AskJeeves ([Jee03]), das inzwischen nicht mehrverfügbare CHAT ([CHA02]) und andere natürlichsprachliche Zugriffssysteme verwenden da-bei die Struktur von Web-Dokumenten mit Tags und Links für die Informationssuche. Im Un-terschied zur vorliegenden Arbeit konzentrieren sie sich, wie alle Suchmaschinen aber auf dasWiederfinden von explizit vorhandenen Elementen in der Informationsquelle, die vorher inden Index aufgenommen wurden.
Chai et al. versuchen in [Cha00b] den Vergleich eines natürlichsprachlichen und eines men-übasierten Systems für den Zugriff auf Informationen über verschiedene angebotene Produkte.Das dabei eingesetzte Beratungssystem HappyAssistant verwendet ein Domänenlexikon undeine Wissensbasis für die Beratungsregeln. Anders als AskJeeves, das ein reines Frage-und-Antwortsystem ist, modelliert der HappyAssistant die Dialoge, um dem Benutzer zu ermögli-chen, seine anfangs vagen Interessen mit fortschreitendem Beratungsstand genauer zu formu-lieren. Beim Vergleich der Paradigmen natürlichsprachlich vs. menübasiert wird deutlich, dassvor allem für unerfahrene Benutzer der Zugriff über die natürliche Sprache der schnellere undeinfachere Weg ist.
2.1.2 Unterstützung beim Zugriff auf Datenbanktupel
Im Bereich von Benutzerschnittstellen, die den Zugriff auf Datenbanktupel ermöglichen underleichtern sollen, wurde eine große Menge unterschiedlicher Ansätze entwickelt. Murray etal. schlagen in [Mur98] einen konzeptionellen Rahmen für die Beschreibung vor allem graphi-scher Benutzerschnittstellen für Datenbanken vor. Sie berücksichtigen dabei das zugrunde lie-gende Datenmodell, die verwendeten Präsentationsmethoden und die Menge der bearbeitbarenAufgaben. Diesem nahe liegenden Ansatz fügen wir als weiteres Merkmal die Zielgruppe zu,so dass sich die folgende Aufstellung von Unterscheidungskriterien ergibt:
• Paradigma der Benutzerunterstützung, z.B. formale Sprache, natürliche Sprache7,graphische Unterstützung.
• Zugrunde liegendes Datenmodell, z.B. relational, funktional, objektorientiert.• Unterstützte Aufgaben, z.B. Datenbankabfrage, Datenbankmanipulation, Datenbank-
definition.• Zielbenutzergruppe, z.B. Experten, Gelegenheitsnutzer, Laien.Dabei ist im Rahmen der vorliegenden Arbeit das jeweilige Paradigma der Benutzunterstüt-
zung das entscheidende Merkmal. Aus diesem Grund verwenden wir es im Folgenden, um denÜberblick über wichtige Ansätze und Systeme für die Benutzerunterstützung bei der Arbeitmit Datenbanken zu strukturieren. Dabei gehen wir von folgenden Paradigmen aus:
• Formale Anfragesprachen
7 Selbstverständlich wird auf der Realisierungsebene eine scheinbar natürlichsprachliche Benutzerun-terstützung immer durch eine kontrollierte Sprache gelöst.

132.1 ANSÄTZE ZUR UNTERSTÜTZUNG VON ANFRAGEN AN INFORMATIONSSYSTEME
• Natürlichsprachliche Anfragesysteme• Syntaktisches Editieren• Formularbasierte Benutzerschnittstellen, Query-by-Example und Query-by-Template• Graphische Benutzerschnittstellen• Hybride BenutzerschnittstellenDiese Paradigmen stellen wir im Folgenden mit ihren wichtigsten Eigenschaften und rele-
vanten Vertretern dar.
Formale AnfragesprachenDer traditionelle Ansatz für Schnittstellen zu Datenbanken besteht in einer Vielzahl von Anfra-gesprachen. Die wohl bekannteste Sprache stellt der SQL-Standard (Structured Query Lan-guage; [Dat87], [Can92]) dar, der seine Bedeutung vor allem durch die Verbreitung des relati-onalen Datenmodells aus [Cod70] erreichte. Dabei ist SQL nicht nur auf die reine Anfrage-funktionalität beschränkt, sondern unterstützt die Definition, die Manipulation und die Über-wachung (Sicherheit, Integrität) der Daten. Zu erwähnen ist an dieser Stelle der enormeEinfluss, den SQL auf die Entwicklung von Anfragesprachen für eine große Menge von unter-schiedlichen Datenmodellen (z.B. objekt-orientierte oder multidimensionale Datenmodelle)ausüben konnte.
Neben SQL konnte sich vor allem die auf dem funktionalen Datenmodell basierende Daten-definitions- und -manipulationssprache DAPLEX durchsetzen ([Shi81]). Ähnlich wie SQL er-hebt DAPLEX den Anspruch,
„to provide a ’conceptually natural’ database interface language“ ([Shi81:140]),
um Nicht-Experten die Formulierung ihrer Aufgaben zu erlauben, ohne zu erklären, wie dasgewünschte Ergebnis erzeugt wird. Die deklarative High-Level-Anfragesprache hat die Ent-wicklung aller späteren fortgeschrittenen Anfragesprachen vor allem objektorientierter Art be-einflusst. Weitere, weniger verbreitete Anfragesprachen für Datenbanksysteme sind SDM([Ham81]), Galileo ([Alb85]), Napier88 ([Dea89]) und NOODL ([Bar92]).
Die meisten dieser Sprachen erheben den Anspruch, auch von Laien einsetzbar zu sein.Diese Sprachen verlassen sich jedoch zu einem großen Teil auf das Wissen der Nutzer über dieStruktur der Datenbank und die Syntax der Befehle. Sie sind deshalb ohne vertiefte Kenntnisdieses Interaktionsstils sehr schwer zu verwenden.
Eine zumindest nach den Aussagen von Systemanbietern mehr an der Expertise von Fach-experten ausgerichtete Möglichkeit des Datenzugriffs ist das ebenfalls von Codd geprägte On-Line Analytical Processing (OLAP; [Cod93] [Ber97]). Diese auch als Fast Analysis of SharedInformation (FASMI) bezeichnete Technologie erlaubt die schnelle Generierung deskriptiveroder vergleichender Zusammenfassungen oder Sichten von Daten und verwendet dafür einmultidimensionales Datenmodell. Die für OLAP und das multidimensionale Datenmodell ent-wickelten Anfragesprachen bestehen im Wesentlichen aus Anpassungen von SQL an die je-weiligen Ausprägungen des Datenmodells und die gegenüber dem relationalen Modell erwei-terten Anfragemöglichkeiten (Aggregierungsfunktionen, Roll-Up, Drill-Down). In Ermange-lung eines Standards existieren eine Vielzahl von Anfragesprachen, die vor allem durch dieAnbieter von OLAP-Systemen geprägt werden, z.B. MDSQL (Multidimensional Query Lan-guage) von Platinum Technologies, MDX (Multidimensional Expressions) von Microsoft undRISQL (Red Brick Intelligent SQL) von IBM Informix. Blaschka et al. geben in [Bla99] einenÜberblick über die wichtigsten multidimensionalen Datenmodelle und die jeweiligen Anfra-gesprachen.

14 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
Zur Verbesserung der Nutzerfreundlichkeit von formalen Sprachen wurden verschiedeneAnsätze entwickelt, die eine einfacher zu bedienende Benutzerschnittstelle und meist dieÜbersetzung der damit formulierten Operationen und Anfragen auf formale Sprachen (meistSQL) realisieren. Auf diese Ansätze gehen wir in den folgenden Abschnitten ein.
Natürlichsprachliche AnfragesystemeNatürlichsprachliche Benutzerschnittstellen zu Datenbanken (Natural Language Interfaces toDatabases, NLIDB) erlauben ihren Benutzern den Zugriff auf Informationen in einer Daten-bank durch die Eingabe von Anfragen in einer natürlichen Sprache (z.B. Englisch). Da auchdie Ergebnisse der Anfrage natürlichsprachlich aufbereitet werden und in einigen Systemensogar eine Diskursmodellierung verwendet wird, erfolgt also die gesamte Nutzerinteraktiondialogähnlich. Androutsopoulos et al. geben in [And95] einen fundierten Überblick überNLIDB-Systeme.
Wie zu Beginn des Kapitel 2 geschildert, stellt das Paradigma der natürlichsprachlichen In-teraktion einen der ersten Ansätze der Benutzerunterstützung dar. Erste prototypische NLIDB-Systeme, wie zum Beispiel LUNAR ([Woo72]), ein domänenspezifischer Ansatz für den Zu-griff auf Datenbanken mit chemischen Analysen von Mondgestein, reichen bis in die späten60er Jahre zurück. Die in den folgenden Jahren entwickelten Systeme zeichneten sich durcheine zunehmende Domänenunabhängigkeit und Flexibilität bezüglich des zugrunde liegendenDatenbanksystems aus: LADDER ([Hen78]) und CHAT-80 ([War82]) erlauben die Kopplungder natürlichsprachlichen Anfragekomponente an verschiedene Datenbanken und Janus([Bob90]) sogar an Datenbanken und Expertensysteme.
Trotz der Entstehung zahlreicher NLIDB-Systeme in den 80er Jahren konnten diese nichtdie erhoffte und teilweise auch vorhergesagte kommerzielle Verbreitung erreichen. Sie wurdenimmer noch mehr als Forschungsprototypen anstelle von Standardkomponenten von Daten-banksystemen betrachtet. Dies lässt sich zum Teil auch auf die Entwicklung von Alternativen,wie die in den folgenden Abschnitten geschilderten graphischen Benutzerschnittstellen, undauf einige intrinsische Probleme zurückführen. Durch neue Ergebnisse bei der Verarbeitungnatürlicher Sprache, die Entwicklung von Architekturen für die Abbildung von NLIDB-Syste-men auf Agententechnologien und die Kombination von Sprache und Graphik zur Nutzung derVorteile beider Modalitäten hat die Forschung auf diesem Gebiet jedoch neuen Auftrieb erhal-ten ([And95]).
Bezüglich ihrer Architektur lassen sich bei NLIDB-Systemen im Wesentlichen drei Ansätzeunterscheiden:
• Pattern-Matching- oder Keyword-Spotting-Systeme, bei denen aus Mustern von Schlüs-selwörtern in der Anfrage auf deren Semantik geschlossen wird, zeichnen sich vor allemdurch ihre einfache Realisierung aus, weil auf eine komplexe Analyse der Anfrage (Par-sing) verzichtet wird. Bei Anfragen jedoch, die die Muster von Schlüsselwörtern durch-brechen, führt diese Einfachheit zu groben Fehlinterpretationen. Ein typisches Beispielfür NLIDB-Systeme, die diesen Ansatz realisieren, ist SAVVY ([Joh85]).
• Bei syntaxbasierten Systemen wird die Benutzerfrage syntaktisch analysiert und der dar-aus entstehende Syntaxbaum auf einen Ausdruck in der Datenbank-Anfragesprache (z.B.SQL) abgebildet. Zur Beschreibung möglicher syntaktischer Strukturen von Benutzer-fragen wird eine Grammatik verwendet. Die Abbildung auf Datenbank-Anfragen erfolgtdurch feste Regeln. Die Ermittlung geeigneter Regeln, die die Abbildung auf Ausdrückeder formalen Anfragesprachen erlauben, stellt das Hauptproblem bei der Entwicklungsyntaxbasierter NLIDB-Systeme dar. LUNAR ([Woo72]) ist ein typisches Beispiel fürein solches System.

152.1 ANSÄTZE ZUR UNTERSTÜTZUNG VON ANFRAGEN AN INFORMATIONSSYSTEME
• NLIDB-Systeme, die eine semantische Grammatik verwenden, analysieren ebenfalls dieEingabe syntaktisch und bilden den Syntaxbaum auf eine Datenbank-Anfrage ab. Im Un-terschied zu den syntaxbasierten Systemen entsprechen die Kategorien der Grammatikaber nicht notwendigerweise rein syntaktischen Konzepten, wie Verb oder Nomen, son-dern können bereits neben syntaktischen auch semantische Informationen über die An-wendungsdomäne enthalten (siehe Abbildung 5). Dadurch lassen sich semantische Con-straints leichter realisieren. Mit einer geeigneten Wahl von Kategorien kann zudem dieAbbildung auf die zugrunde liegende Datenbank und deren Anfragesprache erleichtertwerden. Durch die feste Einbindung von Wissen über die Anwendungsdomäne wird dieÜbertragung auf andere Domänen jedoch deutlich erschwert. Semantische Grammatikenwerden unter anderem verwendet in PLANES ([Wal78]), LADDER ([Hen78]) und REL([Tho75]).
Androutsopoulos et al. beschreiben in [And95] die Vorteile von NLIDB-Systemen gegenü-ber anderen Ansätzen:
• Der Benutzer ist nicht gezwungen, eine weitere künstliche Sprache zu erlernen.• Vor allem für Fragestellungen, die Negationen8 oder Universalquantoren9 enthalten, ist
die natürlichsprachliche Formulierung von Fragen besser geeignet als die Eingabe übergraphische und formularbasierte Schnittstellen. Da durch natürliche Sprache auch Iterati-onen und Rekursionen abgedeckt werden, sind NLIDB-Systeme, sofern sie dies unter-stützen, auch ausdrucksstärker als Anfragesysteme mit formalen Sprachen wie SQL.
• Die meisten NLIDB-Systeme sehen eine Diskursmodellierung vor und erlauben damitdie Verwendung von kurzen, unterspezifizierten Fragen, deren Bedeutung durch denDiskurskontext vervollständigt wird.
Dem werden unter anderem die folgenden Nachteile gegenüber gestellt:• Die linguistische Abdeckung eines NLIDB-Systems ist nicht erkennbar. Benutzern fällt
es schwer zu verstehen, welche Arten von Fragen vom System verstanden werden kön-nen und welche nicht.
• Aufgrund dieser Intransparenz wird auch die Unterscheidung von linguistischen und be-grifflichen Schwächen erschwert. Wenn eine Frage vom System nicht oder falsch beant-wortet wurde, ist nicht klar, ob dies auf eine mangelnde linguistische oder begrifflicheAbdeckung zurückzuführen ist.
Abbildung 5: Ein beispielhafter Syntaxbaum einer semantischen Gram-matik nach [And95].
8 z.B. Welche Abteilung hat keine Programmierer?9 z.B. Welche Firma beliefert jede Abteilung?
S
Specimen_question
Specimen_spec Contains_info
which rock contains Substance
magnesium

16 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
• Durch die Fähigkeit der Systeme, natürliche Sprache zu verarbeiten, vermuten Benutzerweitere intelligente Eigenschaften, wie Allgemeinwissen und Schlussfolgerungsfähig-keiten, die aber in den meisten Systemen nicht vorhanden sind.
Bell und Rowe verglichen in einem Experiment die Verwendbarkeit von NLIDB-Systemenmit der anderer Ansätze ([Bel92]). Die Ergebnisse dieser Studie fassen wir am Ende diesesAbschnitts zusammen.
Syntaktisches EditierenDie syntaktische Anfragebearbeitung stellt einen assertorischen Ansatz für die visuelle Unter-stützung textbasierter Anfrageformulierung dar ([Den95]). Dies lässt sich sowohl für formaleals auch für natürlichsprachliche Anfragen einsetzen: Für formale Sprachen schlagen Larsonund Wallick in ([Lar85]) ein System vor, das die Anfrageformulierung visuell durch die Dar-stellung von Syntaxdiagrammen zusammen mit dem Entity-Relationship-Diagramm unter-stützt. Die Anfrage wird durch die Verknüpfung von Elementen des Syntaxdiagramms undElementen des Datenbankschemas komponiert und kann auch in textueller Form vom Benut-zer verändert werden. IQL von Ramos kombiniert syntaktisches Editieren mit graphischer For-mulierung von SQL-Anfragen ([Ram92]). In einem Menü ist die Menge der verfügbaren Ope-rationen (z.B. SELECT, JOIN, GROUP BY) erkennbar, die auf visuellen Repräsentationen vonRelationen anwendbar sind. Der Benutzer kann Attribute, die bei Projektionen und Selektionenberücksichtigt werden sollen, durch Mausklick spezifizieren. Der Formulierungsaufwandsteigt hier jedoch überproportional mit der Komplexität der Anfragen.
Auch bei der Formulierung natürlichsprachlicher Anfragen gibt es Ansätze zur Benutzerun-terstützung mittels syntaktischen Editierens: NLMENU erlaubt die Konstruktion von Anfragenüber die Auswahl von Operationen, Prädikaten usw. aus Menüs ([Ten83]). Dies hat den Vor-teil, dass nur Fragen und Anfragen, die auch tatsächlich vom System bearbeitbar sind, eingege-ben werden können. Der Benutzer kann durch die Menüs navigieren um die Menge der bear-beitbaren Fragen und Anfragen zu erkennen. Die Menge und Komplexität möglicher Menüs istaber begrenzt durch Anforderungen der Übersichtlichkeit.
Formularbasierte Benutzerschnittstellen, Query-by-Example und Query-by-Template Bei der ebenfalls assertorischen Anfrageformulierung über Beispiele (Query-by-Example) gibtder Benutzer ein Beispiel für ein Ergebnis ein, das er auf die Anfrage erwartet. Die Retrieval-Komponente sucht dann in der Datenbank für die Daten, die auf das gegebene Beispiel passen.Vor allem bei relationalen Datenbanken ist dies ein erfolgreicher Ansatz, weil die Tabellen-struktur der Datenbank gut mit den Tabellenskeletten der Benutzerschnittstelle zur Deckunggebracht werden kann. Die Benutzerschnittestelle von QBE von Zloff besteht vor allem aussolchen Tabellenskeletten, die die Tabellen in der Datenbank darstellen ([Zlo97]). Der Benut-zer füllt die entsprechenden Spalten mit typischen Werten oder Beispielen aus, um die Ergeb-nisfelder sowie die Werte für die Selektionskriterien und die Verknüpfungsbedingungen zukennzeichnen. Diese Art von Unterstützung für die Anfrageformulierung ist leicht für einfacheAnfragen einsetzbar; komplexere Anfragen erfordern aber vertieftes Verständnis.
Eine Variante von Query-by-Example stellen formularbasierte Benutzerschnittstellen dar.Bei diesem Ansatz wird dem Benutzer ein Formular bestehend aus einer Liste von suchbarenFeldern präsentiert. Dieses Vorgehen entspricht der Detail-Suche bei verschiedenen Internet-und Intranet-Suchmaschinen. Wir verzichten deshalb an dieser Stelle auf weitere Erläuterun-gen.
Sengupta und Dillon schlagen in [Sen97] die Query-by-Template-Methode (QBT) vor, dieeine Verallgemeinerung des auf relationale Datenbanken fokussierten Query-by-Example dar-stellt. Die generelle Grundlage der Benutzerschnittstelle besteht dabei in einem visuellen Tem-plate, das eine Instanz der Datenbank repräsentiert: Bei relationalen Datenbanken besteht das

172.1 ANSÄTZE ZUR UNTERSTÜTZUNG VON ANFRAGEN AN INFORMATIONSSYSTEME
Template aus der bereits oben erwähnten Tabelle. Bei einer Gedichtdatenbank nennt [Sen97]ein kurzes Gedicht als Template und bei einer bibliographischen Datenbank einen beispielhaf-ten Eintrag. Damit lassen sich die geschilderten Vorzüge von QBE, also die Einfachheit, dieÄquivalenz des Datenmodells mit der Visualisierung, die Abgeschlossenheit von Anfragefor-mulierung und Ergebnisausgabe in derselben Form und die Vollständigkeit auf QBT im Allge-meinen übertragen.
Graphische BenutzerschnittstellenGraphische Editoren unterstützen den Benutzer bei der Anfragformulierung durch die Darstel-lung des Datenbankschemas und die direkte Manipulierbarkeit der Objekte. Operationen kön-nen entweder über Menüs oder über visuelle Techniken spezifiziert werden ([Den95]). Im Be-reich graphischer Benutzerschnittstellen gibt es Ansätze, die sowohl assertorisches als auchprozedurales Vorgehen unterstützen.
Die Anfrageeditoren beruhen auf einem semantischen Datenmodell für die Visualisierungdes Datenbankschemas. Durch die Anzeige der einzelnen Datenbankrelationen zusammen mitihren Attributen wird die Auswahl der Elemente, die in der Anfrage enthalten sein sollen, überZeige-und-Klick-Operationen unterstützt. Papantonakis und King schlagen in [Pap95] mitGQL eine graphbasierte graphische Anfragesprache als Benutzerschnittstelle vor. Die Darstel-lung besteht dabei aus einem Graph, der das Datenbankschema10 repräsentiert und in dem dieEntitäten und deren Attribute als Knoten eingetragen sind. Zusätzlich zum Fenster mit demDatenbankschema gibt es ein Fenster, in dem die Datenbank-Anfrage unter Verwendung vonOperanden, die per drag-and-drop aus dem Datenbankfenster geholt werden, und Operatoren,die in einer Werkzeugleiste verfügbar sind, formuliert wird. Die Ergebnisse auf eine Anfragewerden dann in einem weiteren Fenster textuell dargestellt.
Hybride BenutzerschnittstellenIn Ergänzung zu den reinen Formen von Benutzerschnittstellen für Datenbanken entstehen vorallem in jüngerer Zeit auch verschiedene hybride Ansätze, also solche, die die Vorteile ver-schiedener Paradigmen kombinieren: Adam und Gangopadhyay schlagen in [Ada97] einFront-End für relationale Datenbanken vor, das eine natürlichsprachliche Anfrageformulie-rung auf der Basis von SQL-Formularen benutzt. Dabei wird die natürlichsprachliche Anfragezunächst bottom-up durchsucht, um über einen Index der Bedeutung jedes Formulars ein ge-eignetes Formular zu identifizieren. Anschließend wird die natürlichsprachliche Anfrage desBenutzers noch einmal top-down analysiert, um mittels einer Menge von Grammatikregeln,die mit dem zuvor ausgewählten Formular verbunden sind, die relevanten Informationen zuextrahieren. Für objektorientierte Datenbanken entwickelten Doan et al. in [Doa95] einen An-satz, der die Formulierung von Anfragen alternativ in der formalen Anfragesprache DAPLEXund formular- und graphbasiert erlaubt sowie jederzeit den Wechsel zwischen den Paradigmenunterstützt.
Vergleich der verschiedenen AnsätzeTabelle 1 ordnet die oben erwähnten Ansätze bezüglich des Paradigmas der Benutzerunterstüt-zung und des unterstützten Datenmodells ein. In der Literatur geben Catarci et al. einen Über-blick und eine grobe Klassifikation für graphische Benutzerschnittstellen für Datenbanken([Cat95]). Sie unterscheiden dabei auf erster Ebene zwischen formularbasierten, diagrammba-sierten, iconbasierten und hybriden Ansätzen und führen auch eine vergleichende Usability-Studie durch. Bei einem von Bell und Rowe durchgeführten Experiment zum Vergleich derBenutzerfreundlichkeit von formalen Anfragesprachen, formularbasierten Benutzerschnittstel-
10 GQL beruht auf dem funktionalen Datenmodell nach [Pou90].
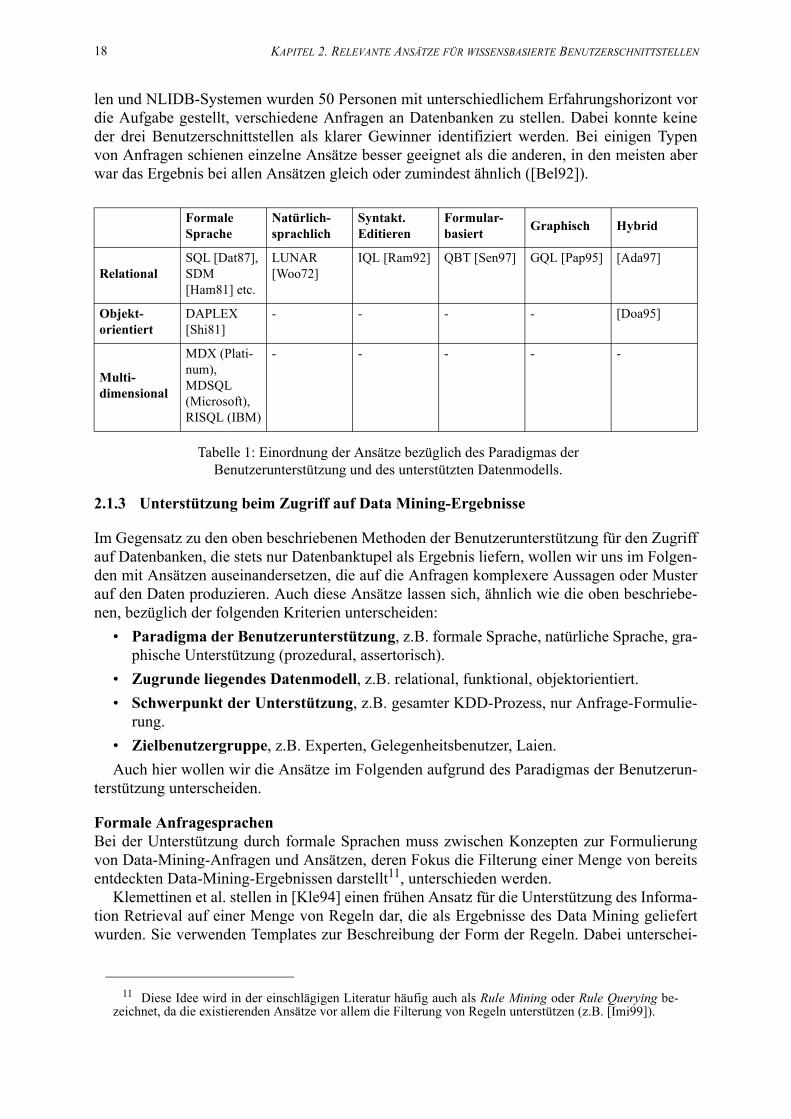
18 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
len und NLIDB-Systemen wurden 50 Personen mit unterschiedlichem Erfahrungshorizont vordie Aufgabe gestellt, verschiedene Anfragen an Datenbanken zu stellen. Dabei konnte keineder drei Benutzerschnittstellen als klarer Gewinner identifiziert werden. Bei einigen Typenvon Anfragen schienen einzelne Ansätze besser geeignet als die anderen, in den meisten aberwar das Ergebnis bei allen Ansätzen gleich oder zumindest ähnlich ([Bel92]).
2.1.3 Unterstützung beim Zugriff auf Data Mining-Ergebnisse
Im Gegensatz zu den oben beschriebenen Methoden der Benutzerunterstützung für den Zugriffauf Datenbanken, die stets nur Datenbanktupel als Ergebnis liefern, wollen wir uns im Folgen-den mit Ansätzen auseinandersetzen, die auf die Anfragen komplexere Aussagen oder Musterauf den Daten produzieren. Auch diese Ansätze lassen sich, ähnlich wie die oben beschriebe-nen, bezüglich der folgenden Kriterien unterscheiden:
• Paradigma der Benutzerunterstützung, z.B. formale Sprache, natürliche Sprache, gra-phische Unterstützung (prozedural, assertorisch).
• Zugrunde liegendes Datenmodell, z.B. relational, funktional, objektorientiert.• Schwerpunkt der Unterstützung, z.B. gesamter KDD-Prozess, nur Anfrage-Formulie-
rung.• Zielbenutzergruppe, z.B. Experten, Gelegenheitsbenutzer, Laien.Auch hier wollen wir die Ansätze im Folgenden aufgrund des Paradigmas der Benutzerun-
terstützung unterscheiden.
Formale AnfragesprachenBei der Unterstützung durch formale Sprachen muss zwischen Konzepten zur Formulierungvon Data-Mining-Anfragen und Ansätzen, deren Fokus die Filterung einer Menge von bereitsentdeckten Data-Mining-Ergebnissen darstellt11, unterschieden werden.
Klemettinen et al. stellen in [Kle94] einen frühen Ansatz für die Unterstützung des Informa-tion Retrieval auf einer Menge von Regeln dar, die als Ergebnisse des Data Mining geliefertwurden. Sie verwenden Templates zur Beschreibung der Form der Regeln. Dabei unterschei-
FormaleSprache
Natürlich-sprachlich
Syntakt. Editieren
Formular-basiert Graphisch Hybrid
RelationalSQL [Dat87], SDM [Ham81] etc.
LUNAR [Woo72]
IQL [Ram92] QBT [Sen97] GQL [Pap95] [Ada97]
Objekt-orientiert
DAPLEX [Shi81]
- - - - [Doa95]
Multi-dimensional
MDX (Plati-num), MDSQL (Microsoft), RISQL (IBM)
- - - - -
Tabelle 1: Einordnung der Ansätze bezüglich des Paradigmas der Benutzerunterstützung und des unterstützten Datenmodells.
11 Diese Idee wird in der einschlägigen Literatur häufig auch als Rule Mining oder Rule Querying be-zeichnet, da die existierenden Ansätze vor allem die Filterung von Regeln unterstützen (z.B. [Imi99]).

192.1 ANSÄTZE ZUR UNTERSTÜTZUNG VON ANFRAGEN AN INFORMATIONSSYSTEME
den sie zwischen inkludierenden Templates für die Spezifikation interessanter Regeln und ex-kludierenden Templates für die Spezifikation generell uninteressanter Regeln.
Im Bereich der Sprachen für die Formulierung von Data-Mining-Anfragen hat sich wieschon bei den Sprachen für Datenbank-Anfragen SQL als allgegenwärtige Basis durchsetzenkönnen: Meo et al. beispielsweise erweitern in [Meo96] den Standard-Umfang von SQL umden Operator MINE RULE, der jedoch auf die von Agrawal et al. in [Agr93] vorgeschlagenenAssoziationsregeln auf Warenkorbdaten beschränkt ist. Wie in Beispiel 1 gezeigt, erlaubtMINE RULE die Spezifikation der Kardinalitäten der beiden Seiten der Regel, sowie die Anga-be von Minimalforderungen an Konfidenz und Support.12 Darüber hinaus können die Stan-dard-SQL-Primitive wie GROUP BY, CLUSTER, WHERE und FROM verwendet werden. Durchdie Verwendung von eigenen Tabellen, die die Hierarchie beschreiben, und eingebettete SQL-Anfragen lassen sich auch taxonomische Informationen bei der Anfrageformulierung verwen-den. Die operationale Semantik von MINE RULE wird beschrieben durch eine erweiterte relati-onale Algebra, durch die sich die Transformation der Datentabelle für die Entdeckung von As-soziationsregeln nachvollziehen lässt.
Beispiel 1: MINE-RULE-Operator. Die folgende, unter Verwendung des MINE-RULE-Operators formulierte Data-Mining-Anfrage sucht nach allenRegeln in der Relation „Tab_Behandlungen“, die beliebig viele Elementein der Vorbedingung und genau ein Element in der Nachbedingunghaben. Als minimale Konfidenz wird ein Wert von 0,3 gefordert. Für dieVerwaltung der entdeckten Regeln wird die Tabelle „Tab_Assoziationen“angelegt:
MINE RULE Tab_Assoziationen ASSELECT DISTINCT 1...n item AS BODY,1...1 item AS HEAD,SUPPORT, CONFIDENCEFROM Tab_BehandlungenEXTRACTING RULES WITH CONFIDENCE: 0.3
Die von Han et al. in [Han96] vorgeschlagene Data Mining Query Language (DMQL) er-laubt im Gegensatz zum MINE-RULE-Operator bereits den Zugriff auf verschiedene Regelty-pen13 (generalisierende, charakterisierende und diskriminierende Regeln, Klassifikations- undAssoziationsregeln). Bei den einzelnen Regeltypen können die jeweils benötigten Schwellwer-te für die Filterung nicht-signifikanter Ergebnisse angegeben werden. Neben einer genauenSpezifikation der Menge der für die Lösung der Data-Mining-Problemstellung relevanten At-tribute, erlaubt DMQL auch die Verwendung von taxonomischem Hintergrundwissen für dieFormulierung generalisierter Anfragen und die Abstraktion von Ergebnissen. Mechanismenzur Abstraktion der Ergebnisse werden allerdings nicht beschrieben.
Zwischen den einzelnen Sprachprimitiven von DMQL besteht eine starke Interdependenz.Die Struktur einer konkreten Data-Mining-Anfrage ist damit immer sehr stark von den Ausprä-gungen der beteiligten Primitive (z.B. der Spezifikation des zu betrachtenden Regeltyps) ab-hängig. Ein uniformeres syntaktisches Netzwerk wird spätestens dann notwendig, wenn die
12 Die Konfidenz einer Regel ist definiert als das Verhältnis der Anzahl der Fälle, die beide Seiten einerRegel erfüllen, zur Anzahl der Fälle, die nur die linke Seite erfüllen. Der Support einer Regel ist definiertals die Anzahl der Fälle, die die linke Seite einer Regel erfüllen.
13 Han et al. beschreiben in [Han96] die Regeltypen interessanterweise als „kinds of knowledge to bediscovered“.

20 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
bisher noch begrenzte Anzahl von ansprechbaren Data-Mining-Aussagetypen erweitert wird.Beispiel 2 zeigt die Formulierung einer einfachen Data-Mining-Anfrage in DMQL.
Beispiel 2: DMQL-Anfrage. Die folgende DMQL-Anfrage sucht, ähnlich wie die inBeispiel 1 gezeigte Anfrage, nach allen Assoziationsregeln in der Rela-tion „Tab_Behandlungen“. Bedingung für die Regeln ist aber das Enthal-tensein eines der Attribute Geschlecht, Alter, Diagnose oder Klinik. AlsMinimal-Konfidenz wird auch hier ein Wert von 0,3 gefordert:
find association rulesrelated to Geschlecht, Alter, Diagnose, Klinikfrom Tab_Behandlungenwith confidence threshold = 0.3
Der Idee hybrider Ansätze, wie wir sie auch schon in Abschnitt 2.1.2 bei der Benutzerunter-stützung für den Zugriff auf Datenbanken beschrieben haben, folgend, schlagen Han et al. be-reits die Verwendung von DMQL zur Unterstützung von graphischen Benutzerschnittstellenvor.
Auch Imielinski und Virmani verfolgen die Idee einer SQL-nahen, aber für den Zugriff aufRegeln spezialisierten, formalen Sprache ([Imi96], [Imi99]). Im Gegensatz zu früheren Ansät-zen unterstützen sie aber sowohl den Zugriff auf die früher entdeckten und jetzt in einer Regel-basis abgelegten Regeln (rule querying) als auch die Entdeckung neuer Regeln auf einer Da-tenbank (rule generation). Dafür führen sie die SelectRules- bzw. GetRules-Operatorenein, die sich durch eine identische Syntax auszeichnen und nur durch die Quelle der Regeln(Regelbasis oder Datenbasis) unterscheiden. Weitere, für die Gestaltung von M-SQL entschei-dende Anforderungen sind die Möglichkeiten, SQL-Ausdrücke innerhalb der Data-Mining-Anfragen (ability to nest SQL) und Ergebnisse einer Anfrage als Basis für eine neue Anfrageverwenden zu können (closure). M-SQL unterstützt die Spezifikation von Bedingungen für
• das Regelformat, d.h. die in der Vor- und Nachbedingung der Regeln enthaltenen Attri-bute und evtl. Attributwerte sowie -intervalle,
• die Werte von Support und Konfidenz sowie die Anzahl der Vor- und Nachbedingungen,• Mengen von zwei oder mehreren Attributen, deren Vorkommen innerhalb einer Regel
sich gegenseitig ausschließen, und• die in SQL formulierten, eingebetteten Datenbank-Anfragen für die Selektion der rele-
vanten Daten.Beispiel 3 greift die Beispiele von MINE RULE und DMQL wieder auf und illustriert die
zusätzlichen Möglichkeiten von M-SQL bei der Spezifikation der Vor- und Nachbedingungender gesuchten Regeln. Dabei ist M-SQL aber wieder auf einen Aussagentyp beschränkt und er-laubt darüber hinaus nur die Verwendung diskreter Attribute.

212.1 ANSÄTZE ZUR UNTERSTÜTZUNG VON ANFRAGEN AN INFORMATIONSSYSTEME
Beispiel 3: M-SQL-Anfrage. Die folgende M-SQL-Anfrage sucht nach allen Regelnin der Relation „Tab_Behandlungen“, deren Vorbedingung genau dieAttribute Geschlecht und Alter und deren Nachbedingung entweder dieAttribute Diagnose oder Klinik enthalten. Als Minimal-Konfidenz wirdwieder ein Wert von 0,3 gefordert:
GetRules (Tab_Behandlungen)where Body is {(Geschlecht=*), (Alter=*)}and Consequent in {(Diagnose=*), (Klinik=*)}and Confidence >= 0.3
Im direkten Vergleich zu DMQL bietet M-SQL damit zwar umfangreichere Möglichkeitenfür die Beschreibung der gesuchten Regeln, ist aber durch die fehlende Verwendbarkeit von ta-xonomischem Hintergrundwissen und die Beschränkung auf nur einen Aussagentyp im Nach-teil. Aufgrund ihres formalen, SQL-nahen Charakters sind die beschriebenen Ansätze für dieVerwendung durch Endbenutzer ohne Wissen über Datenbank-Anfragesprachen nur begrenztgeeignet.
Abweichend von diesen drei Ansätzen gehen Shen et al. in [She96] aus holistischer Sichtvon den folgenden Annahmen aus:
• Induktives Lernen ist unabdingbar für die automatische Generierung von Hypothesenauf einem Datenbestand.
• Deduktive Datenbanktechnologien stellen ein nahe liegendes Werkzeug für den Nach-weis der Korrektheit von bestehenden Hypothesen.
• Menschliche Intuition (evtl. inspiriert durch die Ergebnisse maschineller Entdeckungs-prozesse) wird schließlich benötigt, um die vielversprechendsten Hypothesen zu generie-ren und zu selektieren.
Sie stellen deshalb einen Ansatz vor, der induktive Lernmethoden und deduktive Daten-banktechnologie im Kontext der Wissensentdeckung in Datenbanken durch die Verwendungvon Meta-Regeln (metaqueries) integriert. Metaqueries sind dabei Prädikate zweiter Ordnungoder Templates, die den gesuchten Typ von Mustern beschreiben. Die Anfragen können alseine zweiteilige Spezifikation gesehen werden: die linke Seite enthält ein Constraint, wie dieDaten vorzubereiten sind, und die rechte Seite eine Aktion, die auf den vorbereiteten Datenausgeführt werden soll. Bei den Aktionen kann dabei zwischen der Berechnung von Regeln,dem Plotten der Daten, der Klassifikation der Daten und dem Finden von Clustern gewähltwerden. Metaqueries können entweder vom Benutzer formuliert oder automatisch generiertwerden.
Formularbasierte ProzessunterstützungNeben dem von Fayyad et al. in [Fay96b] vorgestellten Prozessmodell für das Data Miningwird mit dem Cross Industry Standard Process for Data Mining (CRISP-DM), der von eineminternationalen Konsortium von industriellen Anwendern, Tool-Herstellern und Forschungs-partnern entwickelt wurde, erstmals versucht, ein durchgängiges Prozessmodell für die Entde-ckung von Wissen in Datenbanken zu entwerfen. Abbildung 6 illustriert die sechs Kernphasendes Prozesses ([Cha00a], [CRI01]):
• Business Understanding: Formulierung des eigentlichen Projektziels aus der Perspekti-ve des Anwenders.

22 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
• Data Understanding: Datenauswahl gefolgt von Aktivitäten mit dem Ziel, die Datenkennen zu lernen, Probleme der Datenqualität oder interessierende Teilmengen der Da-ten zu entdecken.
• Data Preparation: Aktivitäten zur Generierung der endgültigen Analysedaten. Darinenthalten ist die Auswahl von Daten, sowohl von Variablen als auch von Datensätzen,wie auch Transformationen und das Entfernen von Datenschmutz.
• Modeling: Auswahl und Anwendung verschiedener Verfahren sowie Festsetzung derzugehörigen Parameter.
• Evaluation: Gründliche Beurteilung der vorhergehenden Schritte um sicherzustellen,dass die Ergebnisse der vorgegebenen Zielsetzung gerecht werden.
• Deployment: Aufbereitung des gefundenen Wissens in einer dem Auftraggeber ver-ständlichen Form und soweit möglich Umsetzung der Ergebnisse.
CRISP-DM liefert eine umfassende Strukturierung und detaillierte Beschreibung der Pro-zessschritte zusammen mit den zugehörigen Aufgaben. Bis dato konnte jedoch kein Ansatz füreine durchgängige Softwareunterstützung des vorgeschlagenen Prozesses identifiziert werden.
Der interessanteste Ansatz im Bereich der prozessbasierten Benutzerunterstützung, der je-doch nicht ausdrücklich auf das CRISP-Modell aufbaut, stammt von Engels und wird als UserGuidance Module (UGM) bezeichnet ([Eng96], [Eng97a], [Eng97b], [Eng99]). UGM beab-sichtigt eine durchgängige Unterstützung des Nutzers durch alle Phasen des KDD-Prozesseshindurch: bei der Beschreibung und beim Reduzieren der Komplexität der Data-Mining-Auf-gabe, bei der Definition einer Lösung, bei der Auswahl einer geeigneten Methode und bei derDokumentation und Speicherung erfolgreicher Anwendungen für die spätere Wiederverwen-dung.
Der Schwerpunkt der Unterstützung, wie er auch für den Rahmen der vorliegenden Arbeitrelevant ist, liegt auf der Auswahl und Anwendung geeigneter Data-Mining-Methoden undVorverarbeitungsschritte auf ein Problem. Dies erfolgt in Form der Überprüfung von Annah-
Abbildung 6: Das CRISP-DM Prozessmodell (aus [CRI01])a.a. CRISP-DM ist das alleinige Eigentum der Partner des CRISP-DM Konsortiums: NCR Systems Engi-
neering Kopenhagen (USA und Dänemark), DaimlerChrysler AG (Deutschland), SPSS Inc. (USA) und OHRA Verzekeringen en Bank Groep B.V (Niederlande), Copyright © 1999-2003.

232.1 ANSÄTZE ZUR UNTERSTÜTZUNG VON ANFRAGEN AN INFORMATIONSSYSTEME
men und die Initialisierung der Parameter der Methoden. Darüber hinaus werden das Wieder-auffinden und die Wiederverwendung von früheren Lösungen für ein Problem unterstützt. Fürdiesen Zweck werden Teilmodule für die Benutzerschnittstelle, die Problembeschreibung undfür die Aufgabenzerlegung sowie Repositories für die Verwaltung früherer Lösungen bereitge-stellt.
Typischerweise ist ein Problem durch einen Ausgangs- und einen Zielzustand definiert, wo-bei der Ausgangszustand durch geeignete Prozessschritte in den Zielzustand transformiert wer-den soll. Das Problem ist gelöst, sobald der Zielzustand vom Ausgangszustand aus erreichtwerden kann. Für die Beschreibung verwendet UGM funktionale und nicht-funktionale Anfor-derungen für den Zielzustand und funktionale Anforderungen für den Ausgangszustand:
• Als funktionale Anforderungen werden solche bezeichnet, die unabhängig von pragmati-schen Überlegungen und von realisierungsspezifischen Anforderungen sind. Sie be-schreiben also, was die Anwendung im Sinne von system- und datenunabhängigen Zie-len leisten soll, z.B. ihren Fokus (explorative Analysen oder Hypothesenverifikation)oder die gewünschte Form der Ergebnispräsentation.
• Nicht-funktionale Anforderungen dagegen beziehen sich auf alle Anforderungen, dienicht aufgabenabhängig sind, die aber das System in einer anderen Weise beeinflussen.Sie werden pragmatisch im Sinne von Kontexteinflüssen und Implementierungsaspektenverstanden. Beispiele für nicht-funktionale Anforderungen sind die verfügbare CPU-Zeitfür die verschiedenen Prozessphasen und die gewünschte Genauigkeit der Lösungen.
Wie auch andere Ansätze aus dem Bereich der Wissensrepräsentation verfolgt UGM dieIdee der Komplexitätsreduktion des Ausgangsproblems durch schrittweise Zerlegung in eineMenge von weniger komplexen Teilaufgaben. Ziel der Zerlegung ist in diesem Fall die Abbil-dung auf zehn primitive Aufgaben, z.B. Induktion, Fusion von Datenquellen oder Sortieren derDaten, die von Engels als einfache Aufgaben (simple tasks) bezeichnet werden. Diese lassensich dann direkt auf einzelne Datenvorverarbeitungs- und Data-Mining-Methoden abbilden,wobei für die Auswahl gegebene Eingabeconstraints (input constraints) und gewünschte Aus-gabeeffekte (output effects) berücksichtigt werden. Beispiel 4 zeigt die Modellierung der Ein-und Ausgaben einer Methode.
Beispiel 4: UGM-Formalisierung der Induktion. Die Induktion wird im UGM-Ansatz von Engels formal mit den folgenden Eingabeconstraints beschrie-ben ([Eng99]):
(1)
(2)
Dies besagt, dass die Menge der Attribute zu jedem Datenbanktupel (Fall)nicht-leer ist und die Anzahl der Datenbanktupel mindestens 2 beträgt.Die Ausgabeeffekte für die Induktion lauten dann:
(3)
Nach der Induktion ist also ein Modell vorhanden, das die Daten be-schreibt, und für jedes Datenbanktupel aus der Gesamtmenge gilt, dassdie Menge der im Modell enthaltenen Attribute eine Teilmenge der in denDatenbanktupeln enthaltenen Attribute ist.
ATTDT ∅≠
DT 2≥
MODEL ∅ dt DT∈ ATTmodel ATTdt⊆{ }∧≠ DT=

24 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
Für die Parametrisierung der einmal ausgewählten Methode steht eine Menge von Initiali-sierungs- und Anpassungsregeln zur Verfügung. Die Benutzerinteraktion folgt dem Prinzipdes Hierarchical Questioning: Der Benutzer definiert das Problem mittels der Beantwortungeines Baums von Fragen zu den Daten und den Zielen der Analyse, die ihm das System stellt.Damit soll die Verfeinerung der Eigenschaften des Problems in geeigneter Weise dargestelltwerden.
Aufgrund der Durchgängigkeit der Prozessunterstützung ist UGM ein interessanter Ansatz.Dennoch bedarf die Einsatzfähigkeit des Werkzeugs für vollständige Data-Mining-Laien einerweitergehenden Untersuchung.
Menü- und Listenbasierte BenutzerschnittstellenEin einfaches Konzept der Benutzerunterstützung verfolgt der Intelligent Miner der IBM Inc.Ein Projekt wird dabei durch eine Baumstruktur repräsentiert, die alle verfügbaren Methodenin einer zweistufigen Hierarchie enthält. Aus dieser kann der Benutzer die Methoden-Knotenauswählen, die er als relevant für seine Anfrage betrachtet, und damit eine Methode instantiie-ren. Durch einen formularbasierten Wizzard werden dann die für die Konfiguration der Metho-de benötigten Daten und Parameter abgefragt. Die Bewertung der Eignung einzelner Metho-den sowie deren Parametrisierung bleiben dabei vollständig dem Benutzer überlassen.
Graphische BenutzerschnittstellenDie prozedurale Modellierung von Data-Mining-Anfragen mit Mitteln der Visuellen Program-mierung (visual programming) wird vor allem von kommerziellen Data-Mining-Tools unter-stützt. Der Enterprise Miner der SAS Inc. basiert dabei auf einem eigenen Prozessmodell, dersog. SEMMA-Methodik. Diese geht aber von einer deutlich lokaleren Prozesssicht aus, als sievom CRISP-Modell beschrieben wird. Die fünf Hauptprozessschritte sind in diesem Fall: Zie-hen von Stichproben (sample), Exploration der Daten (explore), deren Modifikation undTransformation (modify), Modellbildung (model) und Auswertung der Ergebnisse (assess).Die Instantiierung eines Prozesses erfolgt prozedural durch den schrittweisen Aufbau einerFolge von Einzeloperationen wie Zugriff auf Quelldaten, Selektion einer Menge von relevan-ten Attributen, Anwendung einer Data-Mining-Methode oder Darstellung der Ergebnisse in ei-ner bestimmten Form. Dabei wird der Benutzer durch eine Visualisierung des Datenflussesdurch die verschiedenen Prozessschritte unterstützt. Der Datenfluss lässt sich mittels Drag-and-Drop-Operationen auf den Operationen manipulieren.
Dieser Ansatz wird in vergleichbarer Form aber mit abgewandelten Prozessbeschreibungenauch von anderen Data-Mining-Tools wie beispielsweise Clementine von SPSS Inc. verfolgt.Durch die Visualisierung der Anfrageformulierung erfolgt jedoch streng genommen keine Pro-zessunterstützung. Die Auswahl, Parametrisierung und Kombination geeigneter Vorverarbei-tungs-, Data-Mining- und Ergebnispräsentationsmethoden bleibt auch bei diesen Ansätzenweiterhin dem Benutzer überlassen, der dieser Aufgabe vor allem mit zunehmender Komplexi-tät der Anfrage ohne Methodenkenntnis nur schwerlich gewachsen sein wird.
Weitere Ansätze zur KDD-BenutzerunterstützungEinen wichtigen Ansatz für die Repräsentation abstrakterer Interessen stellen Adomavicius etal. in [Ado97] vor. Wie auch Engels gehen sie von einer Dekomposition von Aufgaben aus undentwickeln dafür den Begriff der Handlungshierarchie (action hierarchy). Im Vordergrund ih-rer Betrachtungen steht dabei das Prinzip der direkten Umsetzbarkeit von Erkenntnissen inkonkrete Handlungen (actionability). Durch eine Hierarchie von Aktionen oder Aufgaben ineiner Domäne und der Assoziation der Aktionsknoten mit Regelmustern, für die eine Umsetz-barkeit in Handlungen gewährleistet ist, bzw. mit Klassen dieser Muster können die Interessenvon Benutzern konkretisiert werden. Es findet also eine interessengesteuerte Auswahl von Re-
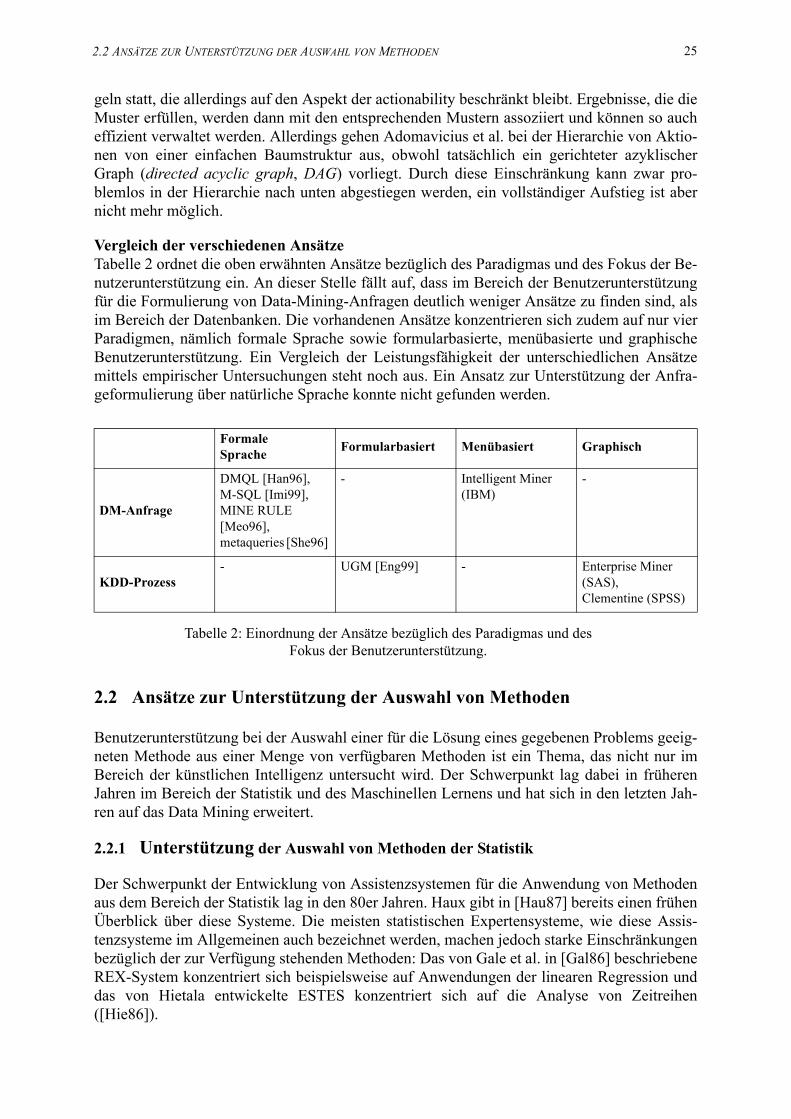
252.2 ANSÄTZE ZUR UNTERSTÜTZUNG DER AUSWAHL VON METHODEN
geln statt, die allerdings auf den Aspekt der actionability beschränkt bleibt. Ergebnisse, die dieMuster erfüllen, werden dann mit den entsprechenden Mustern assoziiert und können so aucheffizient verwaltet werden. Allerdings gehen Adomavicius et al. bei der Hierarchie von Aktio-nen von einer einfachen Baumstruktur aus, obwohl tatsächlich ein gerichteter azyklischerGraph (directed acyclic graph, DAG) vorliegt. Durch diese Einschränkung kann zwar pro-blemlos in der Hierarchie nach unten abgestiegen werden, ein vollständiger Aufstieg ist abernicht mehr möglich.
Vergleich der verschiedenen AnsätzeTabelle 2 ordnet die oben erwähnten Ansätze bezüglich des Paradigmas und des Fokus der Be-nutzerunterstützung ein. An dieser Stelle fällt auf, dass im Bereich der Benutzerunterstützungfür die Formulierung von Data-Mining-Anfragen deutlich weniger Ansätze zu finden sind, alsim Bereich der Datenbanken. Die vorhandenen Ansätze konzentrieren sich zudem auf nur vierParadigmen, nämlich formale Sprache sowie formularbasierte, menübasierte und graphischeBenutzerunterstützung. Ein Vergleich der Leistungsfähigkeit der unterschiedlichen Ansätzemittels empirischer Untersuchungen steht noch aus. Ein Ansatz zur Unterstützung der Anfra-geformulierung über natürliche Sprache konnte nicht gefunden werden.
2.2 Ansätze zur Unterstützung der Auswahl von Methoden
Benutzerunterstützung bei der Auswahl einer für die Lösung eines gegebenen Problems geeig-neten Methode aus einer Menge von verfügbaren Methoden ist ein Thema, das nicht nur imBereich der künstlichen Intelligenz untersucht wird. Der Schwerpunkt lag dabei in früherenJahren im Bereich der Statistik und des Maschinellen Lernens und hat sich in den letzten Jah-ren auf das Data Mining erweitert.
2.2.1 Unterstützung der Auswahl von Methoden der Statistik
Der Schwerpunkt der Entwicklung von Assistenzsystemen für die Anwendung von Methodenaus dem Bereich der Statistik lag in den 80er Jahren. Haux gibt in [Hau87] bereits einen frühenÜberblick über diese Systeme. Die meisten statistischen Expertensysteme, wie diese Assis-tenzsysteme im Allgemeinen auch bezeichnet werden, machen jedoch starke Einschränkungenbezüglich der zur Verfügung stehenden Methoden: Das von Gale et al. in [Gal86] beschriebeneREX-System konzentriert sich beispielsweise auf Anwendungen der linearen Regression unddas von Hietala entwickelte ESTES konzentriert sich auf die Analyse von Zeitreihen([Hie86]).
FormaleSprache Formularbasiert Menübasiert Graphisch
DM-Anfrage
DMQL [Han96],M-SQL [Imi99], MINE RULE [Meo96],metaqueries [She96]
- Intelligent Miner (IBM)
-
KDD-Prozess- UGM [Eng99] - Enterprise Miner
(SAS), Clementine (SPSS)
Tabelle 2: Einordnung der Ansätze bezüglich des Paradigmas und des Fokus der Benutzerunterstützung.

26 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
Nelder stellt 1987 in [Nel87] GLIMPSE als ein Expertensystem zur Benutzerunterstützungbei der Auswahl von Methoden des bestehenden Software-Pakets GLIM (Generalized LinearInteractive Modeling, [NAG02]) vor. Für die Formulierung der Aufgaben wird eine Komman-dosprache auf hoher Ebene zur Verfügung gestellt. GLIMPSE leistet zusätzlich die Aufberei-tung der Ergebnisse. Aufgaben des Benutzers (tasks) werden mit einer Komponente in GLIM-Befehle übersetzt, die explizite Beschreibungen der Aufgaben im Sinne von Überprüfungen,Ergebnissen und notwendige Aktionen enthalten. Die Menge der Aufgaben wird dabei einzel-nen Aktivitäten (activities) zugeordnet, zu denen unter anderem die Eingabe von Daten (datainput), die Datenexploration (data exploration), die Modellauswahl (model selection) und dieModellüberprüfung (model checking) gehören.
GLIMPSE berät und unterstützt den Benutzer auf verschiedenen Ebenen: Im reminder mo-de wird lediglich die Syntax der Anweisungen angezeigt; er eignet sich damit für erfahrene Be-nutzer. Im prompting mode wird eine Liste der im aktuellen Kontext verfügbaren Anweisun-gen angeboten und im handholding mode wird eine schrittweise Entwicklung von Anweisun-gen ermöglicht, ohne dass vom Benutzer die Kenntnis der zugrunde liegenden Kommando-sprache verlangt wird. GLIMPSE beruht auf der Idee, die komplexe Sprache eines statistischenAnalysesystems für den Benutzer leichter handhabbar zu machen. Statistik-Kenntnisse werdenaber in gleichem Maße erwartet wie für das zugrunde liegende System GLIM.
Als Nachfolger von GLIMPSE wurde das System FAST mit einer verbesserten Benutzer-schnittstelle entwickelt, das die Anbindung auch an beliebige Software-Bibliotheken erlaubensoll ([Sta94], [Sta97]). Für die Gestaltung der Beratungskomponente wurde ein endlicher Zu-standsautomat verwendet. Für jede Aktivität, die FAST in neu organisierter Form von GLIMP-SE erbt, enthält das System eine explizite Folge von Zielbeschreibungen. Komplexe Ziele kön-nen, auf diesen Beschreibungen basierend, auch Kontrollstrukturen für die Definition vonSchleifen oder Bedingungen enthalten. Die Kontrolle der domänenspezifischen, interaktivenProzeduren sorgt dafür, dass versucht wird, die Ziele abzuarbeiten. Nach einer Interaktion zwi-schen dem Benutzer und dem System wird ein Ziel als „versucht“ (tried) oder „erreicht“(achieved) gekennzeichnet. Wenn die Erreichung aller Ziele versucht wurde, ist die Spezifika-tion der Beratungsstrategie abgeschlossen.
Einen Schritt weiter gehen Schnittstellensysteme, die die semantische Korrektheit der An-weisungen überprüfen, wie etwa das von Jida und Lemaire in [Jid85] vorgestellte System. SE-TUP, das von Naeve und Steinecker in [Nae86] beschrieben wird, und EXPRESS von Carlsenund Heuch aus [Car96] betonen sogar die statistische Expertise in ihrem Ansatz. Hand be-schäftigt sich in [Han94] dagegen vorwiegend mit der Zerlegung statistischer Fragen für dieMethodenauswahl.
Im Bereich kommerzieller Systeme setzt der SigmaStat-Ansatz auf die Empfehlung einesgeeigneten Tests für vordefinierte Aufgaben (z.B. Vergleich zweier Gruppen, Trendprädiktionund Korrelation) aufgrund der Häufigkeit der Verwendung des Tests ([Sta02]). Das Web-ba-sierte STATIBOT erlaubt die Analyse einer gegebenen Menge von Daten und die Auswahl da-für geeigneter Methoden unter interner Verwendung mehrerer Entscheidungsbäume, die umSchleifen, Rücksprünge und Querverbindungen ergänzt werden ([Hee02]). Darüber hinaus ge-hend versucht das System Statex sogar die Interpretation der Ergebnisse in der Sprache des Be-nutzers ([AIA98]).
2.2.2 Unterstützung der Auswahl von Methoden des Maschinellen Lernens
Im Bereich des Maschinellen Lernens existieren verschiedene Ansätze, die sich mit dem Pro-blem der Algorithmenauswahl beschäftigen. Die beiden wichtigsten sind die Ergebnisse desProjekts Machine Learning Toolbox (MLT) mit seinem Beratungssystem Consultant und desESPRIT-Projekts StatLog.

272.2 ANSÄTZE ZUR UNTERSTÜTZUNG DER AUSWAHL VON METHODEN
Der Machine Learning Toolbox Ansatz stellt eine Sammlung von zehn verschiedenen Lern-algorithmen zur Verfügung ([Usz92], [MLT93]). Um den Einsatz der Methoden zu vereinfa-chen, wurde zudem das wissensbasierte Assistenzsystem Consultant entwickelt ([Cra92]). Da-mit soll Benutzern, die mit dem Bereich des Maschinellen Lernens nicht vertraut sind, die Ver-wendung dieser Technologie bei der Lösung ihrer Aufgabenstellungen erleichtert werden.Consultant verwendet für die Entscheidung zwischen verschiedenen potenziell anwendbarenAlgorithmen eine statische Regelmenge. Dies bringt deutliche Nachteile für die Wartung mitsich, da bei jedem Hinzufügen eines neuen Algorithmus, alle Regeln neu berechnet werdenmüssen. Zudem ist dieser Ansatz ist jedoch sehr abhängig von der Technologie des Maschinel-len Lernens.
Im ESPRIT-Projekt StatLog wurde die Leistungsfähigkeit von Verfahren des MaschinellenLernens, von neuronalen Netzten und statistischen Algorithmen bewertet. Das Ziel war zumeinen die objektive Einschätzung des Potentials von Klassifikationsalgorithmen für die Lösungvon kommerziellen und industriellen Aufgabenstellungen. Zum anderen sollten die Grundla-gen für die kommerzielle Anwendung dieser und verwandter Algorithmen erweitert werden.Neben der Einführung einer Menge von Kriterien für die Bewertung und den Vergleich der 23Algorithmen, wurden vor allem auch die Vor- und Nachteile der Algorithmen beschrieben, so-wie relevante Anwendungsbereiche zugeordnet ([Mic94]).
In diesem Rahmen beschäftigten sich vor allem Brazdil, Gama et al. in [Bra94] und[Gam95] mit der Charakterisierung der Anwendbarkeit der Klassifikationsalgorithmen. Dabeisetzen sie in einem Meta-Lernschritt wiederum Methoden des Maschinellen Lernens für dieOrganisation des Wissens über die Anwendbarkeit der Algorithmen ein. Aus den Testergeb-nissen sowie verschiedenen statistischen und informationstheoretischen Maßen werden Regelnüber die Anwendbarkeit abgeleitet. Wird das System auf neue Daten angewandt, werden demBenutzer Empfehlungen bezüglich der Eignung verschiedener Algorithmen gemacht, die nacheinem Eignungsmaß geordnet sind. Der dafür verwendete a-posteriori-Ansatz stößt bei derpraktischen Anwendung aber an seine Grenzen.
Hoppe stellt in [Hop96] verschiedene Kriterien zur Auswahl maschineller Lernverfahrenvor und führt dabei eine Menge von Dimensionen ein, die für die Beschreibung der Lernalgo-rithmen verwendet werden können. Eine Anwendung, Evaluierung der Ideen und ihre Imple-mentierung in einem System stehen aber noch aus. Einen Ansatz für die Auswahl von Metho-den im Bereich des Knowledge Engineering stellen Thonnat et al. in [Tho94] bereit.
2.2.3 Unterstützung der Auswahl von Methoden bei der Entdeckung von Wissen in Datenbanken
Im Bereich der Entdeckung von Wissen in Datenbanken sind sowohl Ansätze für die Unter-stützung der Auswahl von Vorverarbeitungsmethoden wie auch von Data-Mining-Methodenzu finden.
VorverarbeitungBeim Ansatz von Theusinger, Engels und Lindner ([The98], [Eng98]) basiert die Auswahlent-scheidung, wie auch bei anderen Ansätzen, auf Charakteristika der Daten (Metadaten), die ei-nen vorliegenden Datensatz möglichst genau beschreiben. Für die Ermittlung der Metadatenwurde das Data Characterisation Tool (DCT) entwickelt, das auch Teil des von Engels in[Eng99] vorgestellten und in Abschnitt 2.1.3 erörterten UGM-Ansatzes ist. Die Vorverarbei-tung der Daten besteht aus Methoden, die sich in die drei Klassen Datenbereinigung (Behand-lung von Noise, Extremwerten, Redundanzen usw.), Veränderung der Dimension der Daten(durch Generierung neuer Attribute, Filtern, Transformation usw.) und Veränderung der Da-tenmenge (durch Selektion, Sampling usw.) einteilen lassen. Aufgrund der Anwendbarkeitsbe-

28 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN
dingungen der einzelnen Vorverarbeitungsmethoden lassen sich diese in einem Entscheidungs-baum beschreiben. Die Entscheidung wird dann durch die Metadaten der zu verarbeitendenDaten parametrisiert. Die Metadaten werden als einfache Maße (Anzahl der Klassen, Anzahlder numerischen Attribute usw.), informationstheoretische Maße (Attributentropie, Klassen-entropie usw.) und statistische Maße (Lageparameter, also Minimum, Maximum, Mittelwert,Quantilswert usw. sowie Streuungsparameter, also Standardabweichung, Quantilsabstandusw.) klassifiziert. Die Bedeutung der statistischen Maße wächst dabei mit dem Anteil der nu-merischen Attribute in der Datenmenge.
Data MiningAufbauend auf die Ergebnisse von StatLog entwickelten Nakhaeizadeh und Schnabl in[Nak97] und [Nak98] einen Ansatz zur Personalisierung der Algorithmenbewertung im DataMining. Im Gegensatz zu früheren Ansätzen verwenden sie dabei aus mehreren Kriterien zu-sammengesetzte, komplexe Maße. Schwerpunkt dabei ist die Berücksichtigung von qualitati-ven Eigenschaften der Data-Mining-Algorithmen und von Präferenzen von Benutzern, wie siebeispielsweise die Erklärungskraft der Ergebnisse betreffen.
Ähnlich wie der StatLog-Ansatz rät auch der MLC++-Ansatz von Kohavi et al., alle verfüg-baren Algorithmen zu bewerten, um für die vorliegende Aufgabenstellung den Algorithmus zuwählen, der das beste Modell erzeugt ([Koh97). Die Kriterien für die Algorithmenbewertungsind dabei Klassifikationsgenauigkeit, Verständlichkeit und Kompaktheit des Modells sowiedie Trainings- und Klassifikationsdauer. Basierend auf diesen Einflussfaktoren kann dann eineFunktion zur Bewertung der Algorithmen entwickelt werden, auf die jedoch in der Literaturnicht weiter eingegangen wird.
Lindner und Studer stellen in [Lin99] einen konkreteren Ansatz zur Unterstützung der Aus-wahl von Algorithmen beim Data Mining mit Mitteln des Case-Based-Reasoning vor. Basie-rend auf den Erfahrung aus dem MLT- und dem StatLog-Projekt wird die Algorithmenauswahlanhand von Anforderungen der Aufgabenstellung (top-down), der Menge der verfügbaren Da-ten mit ihren charakteristischen Eigenschaften (bottom-up) und Wissen über die verfügbarenAlgorithmen getroffen. Die Erfahrungen bei der Anwendung eines bestimmten Algorithmusauf eine bestimmte Datenmenge werden in einem Fall dokumentiert. Die Beschreibung einesFalles besteht aus Erfahrungswerten über die Anwendung, grobe Charakteristika des Algorith-mus (Interpretierbarkeit des entstehenden Modells, Trainingszeit, Testzeit) und Charakteristikader Daten.
2.3 Zusammenfassung
In diesem Kapitel haben wir die wichtigsten Systeme für die Unterstützung von Benutzern beider Formulierung von Anfragen an Datenbank- und Data-Mining-Systeme gesammelt, sienach ihren primären Unterstützungsparadigmen klassifiziert und deren Vor- und Nachteile ge-genüber gestellt. Dabei lässt sich erkennen, dass, obwohl sich für eine solche Anwendungdurchaus Vorteile aufzählen und nachweisen lassen, vor allem die Benutzerunterstützung mit-tels natürlicher Anfragesprachen kaum und wenn dann nur im Bereich von Datenbanksyste-men vertreten ist.
Neben der Unterstützung bei der Formulierung von Anfragen war auch die Untersuchungvon Ansätzen und Systemen zur Unterstützung bei der Auswahl von Methoden der Statistik,des Maschinellen Lernens und des Data Mining Thema dieses Kapitels. In diesem Bereich las-sen sich Ansätze identifizieren, die eine konzeptionelle Basis auch für diese Arbeit darstellenkönnen. Dabei sind vor allem die Versuche zu erwähnen, die die verfügbaren Data-Mining-Methoden auf der Basis ihrer Anwendbarkeit und weiterer Eigenschaften bewerten und in Ab-

292.3 ZUSAMMENFASSUNG
hängigkeit von der Beschreibung einer gegeben Problemstellung eine Auswahl vornehmen.Dies wird dann auch Gegenstand unserer Ausführungen in Kapitel 7 sein.

30 KAPITEL 2. RELEVANTE ANSÄTZE FÜR WISSENSBASIERTE BENUTZERSCHNITTSTELLEN

KAPITEL 3 RELEVANTE ANSÄTZE ZUR BESCHREIBUNG DER SEMANTIK VON FRAGEN
Fragen sind im alltäglichen Umgang die gebräuchlichste Art, neues Wissen zu erwerben, aberauch bestehendes Wissen zu erweitern. Mittelstraß formuliert die Vollzugsbedingungen fürden Sprechakt Frage als
„ein Nicht-Wissen bezüglich des Fragethemas als auch ein vorgängiges anfängli-ches Wissen um dieses“
und weiter:
„Aus diesem Grund ist das Fragen als wissendes Nicht-Wissen immer wieder, zu-erst von Sokrates, als paradigmatisch für die menschliche Erkenntnissituation an-gesehen worden.“ ([Mit80:686f.])
Eichler und Bünting beschreiben den Anlass für Fragen als das
„Bewußtsein des Fragenden, etwas nicht zu wissen, wohl aber zu wissen, daß daetwas ist, und eben das wissen zu wollen“
verbunden mit der
„Annahme, der zu Fragende wisse die Antwort.“ ([Eic89:265])
Damit ist die Verwendung des Sprechakts Frage im Zusammenhang mit der Wissensent-deckung in Datenbanken also nicht nur grundsätzlich nahe liegend, sondern der direkteste Wegzur Fokussierung auf Interessenschwerpunkte, der die menschlichen Kommunikationsge-wohnheiten am genauesten abbildet.
Zu Beginn der vertieften Erörterung des Begriffs „Fragen“ folgen wir der Differenzierungvon Groenendijk und Stokhof, die drei unterschiedliche Verwendungen für den Begriff erken-nen ([Gro98]):
1. Interrogativsatz: Art von Sätzen, die sich durch eine bestimmte Wortfolge, Intonationund die Verwendung eines Fragewort und eines Fragezeichens auszeichnen.
2. Interrogativakt (interrogative act): Sprechakt, der durch die Aussprache eines Interro-gativsatzes entsteht. Der Sprecher fordert damit den Adressaten auf, eine Informationeiner bestimmten Art, also die Antwort, zu geben.
3. Objekt, das gefragt und das beantwortet wird: semantischer Inhalt oder Bedeutungeines Interrogativs.

32 KAPITEL 3. RELEVANTE ANSÄTZE ZUR BESCHREIBUNG DER SEMANTIK VON FRAGEN
Walther ordnet in [Wal85] die Benennungen Fragesatz, Frage und Problem auf unterschied-lichen semiotischen Ebenen ein. Auf der in Tabelle 3 gezeigten syntaktischen Ebene ist einFragesatz ein sprachlicher Ausdruck mit einer besonderen syntaktischen Form. Der Fragesatzist nicht identisch mit dem, was er meint (Frage auf der semantischen Ebenen) und nicht iden-tisch mit dem bereits von Groenendijk und Stokhof erwähnten Sprechakt, der vollzogen wird,wenn man den Fragesatz äußert. Damit wird bereits deutlich, dass, wie auch von Belnap undSteele in [Bel76] festgestellt wird, einer Frage eine Menge untereinander gleichwertiger Frage-sätze zugeordnet werden kann. Der Bezug von Fragen zu Aufgaben und Problemen wird so be-schrieben:
„Man kann sagen, daß jemand, der eine Frage zum Ausdruck bringt – etwa indemer einen Fragesatz äußert – , ein Problem entwirft und daß analog dazu, jemand,der eine Aussage zum Ausdruck bringt, einen Sachverhalt entwirft. Eine Frage istein Problementwurf.“ ([Wal85:38f.])
Auf der referentiellen Ebene wird damit einer Aussage ein Sachverhalt und einer Frage einProblem zugeordnet.
Neben den Fragesätzen im engeren Sinne führt Walther auch Fragesätze im weiteren Sinneauf, die keine Antworten erwarten und bezeichnet diese in [Wal85] als Scheinfragesätze:
1. Ausrufe: Was muss das für ein Wesen sein, das die Welt erschaffen hat?
2. Behauptungen: Habe ich Dich nicht immer schon vor ihm gewarnt?14
3. Aufforderungen: Würden Sie mir bitte das Salz reichen?Im Folgenden werden wir von einer Untersuchungen dieser Scheinfragesätze absehen und
uns auf die Fragesätze im engeren Sinn konzentrieren.
3.1 Die erotetische Logik
Der Begriff der erotetischen Logik15 wurde 1955 für die Logik von Fragen und Antworten vonPrior und Prior in [Pri55] geprägt und sollte zunächst in Analogie zur Aussagenlogik verstan-den werden. Dabei ist nach Belnap und Steele aber davon auszugehen, dass sich die Analogieim Wesentlichen auf die Darstellung von Syntax und Semantik, nicht aber auf die Beweistheo-rie der Aussagenlogik bezieht ([Bel76]). Während Belnap und Steele jedoch Fragen einenWahrheitswert in Abhängigkeit von der Existenz wahrer Antworten zuweisen, geht Waltherdavon aus, dass Fragen im Gegensatz zu Aussagen keinen Wahrheitswert haben, also weder
Syntaktische Ebene Wort Aussagesatz Fragesatz
Semantische Ebene Begriff Aussage Frage
Referentielle Ebene Gegenstand Sachverhalt Problem
Tabelle 3: Aufstellung der semiotischen Ebenen für ausgewählte sprachliche Ausdrücke nach [Wal85].
14 Scheinfragesätze dieser Art werden häufig auch als rhetorische Fragen bezeichnet.15 Bei anderen Autoren, z.B. in [Mit80], wird die erotetische Logik auch als Interrogativ-Logik bezeich-
net.

333.1 DIE EROTETISCHE LOGIK
wahr noch falsch sind ([Wal85]). Dafür lassen Fragen nach Krifka noch bestimmte Alternati-ven offen, während eine Aussage alle Alternativen eliminiert ([Kri00]).
Bei einer ersten genaueren Untersuchung des Begriffs „Frage“ geht Frege bereits 1918 aufdie Unterscheidung zwischen Behauptung und Frage ein:
„Fragesatz und Behauptungssatz enthalten denselben Gedanken; aber der Be-hauptungssatz enthält noch etwas mehr, nämlich die Behauptung. Auch der Frage-satz enthält etwas mehr, nämlich eine Aufforderung.“ ([Fre18:62])
Darin begründet sich die später von Stenius in [Ste67] geprägte Idee der Satzradikalmetho-de, die davon ausgeht, dass Aussagen (Propositionen) und Interrogative ein gemeinsames In-halts-Radikal haben und sich nur durch den Modus (deklarativ oder interrogativ) unterschei-den.
Bereits seit Aristoteles wird zwischen dialektischen und nicht-dialektischen Fragen unter-schieden. In modernen Grammatiken der deutschen Sprache (z.B. [Eic89]) wird, dieser Ideefolgend, die Entscheidungsfrage16 von der Ergänzungsfrage17 differenziert:
• Entscheidungsfragen stellen einen Sachverhalt in Frage und zeichnen sich durch dieVoranstellung des finiten Verbs aus (Verb-erst-Stellungstyp, siehe Beispiel 5).
• Ergänzungsfragen dagegen verwenden ein Interrogativpronomen (W-Fragepronomen:wer, was usw.) oder eine adverbielle Ergänzung (W-Adverb: wann, wo usw.), woraufdas Verb folgt (Verb-zweit-Stellungstyp, siehe Beispiel 5). Die Ergänzungsfrage kannnicht mit „Ja“ oder „Nein“ beantwortet werden. Sie verlangt eine Antwort, die eine Er-gänzung entweder in Form eines obligatorischen Satzgliedes (z.B. Wer hat das getan?)oder in Form von adverbiellen Bestimmungen oder Ergänzungen (z.B. Wohin sind siegefahren?) liefert.
• Zusätzlich werden gemeinhin auch Alternativfragen betrachtet (siehe Beispiel 5), die dieAntwortalternativen explizit durch deren Aufzählung vorgeben und die Entscheidung füreine davon fordern.18
Beispiel 5: Arten von Fragen. Entscheidungsfrage: Kommt Hans zum Essen?Ergänzungsfrage: Wer kommt zum Essen?Alternativfrage: Kommt Hans oder kommt Max zum Essen?
Belnap und Steele greifen diese Unterscheidung auf und entwickeln darauf basierend Ob-und Welche-Fragen als Spezialfälle von elementaren Fragen ([Bel76]). Elementare Fragen set-zen sich aus zwei Teilen zusammen:
• dem Subjekt, d.h. der Menge der (wahren und falschen) Antwortalternativen, und• der Anforderung, die angibt, wie viele der wahren Alternativen in der Antwort ge-
wünscht werden und welche Behauptungen über deren Vollständigkeit und Verschieden-heit gemacht werden sollen.
In Abhängigkeit von der Formulierung der Antwortalternativen lassen sich Ob- und Wel-che-Fragen dann folgendermaßen beschreiben:
16 auch als Ja-Nein-Frage oder Satzfrage bezeichnet.17 auch als Bestimmungsfrage, Wortfrage oder W-Frage bezeichnet.18 Alternativfragen werden häufig als Spezialfälle von Entscheidungsfragen betrachtet, spielen deshalb
in der vorliegenden Arbeit eine untergeordnete Rolle und werden in der Folge nicht weiter betrachtet.

34 KAPITEL 3. RELEVANTE ANSÄTZE ZUR BESCHREIBUNG DER SEMANTIK VON FRAGEN
• Ob-Fragen sind Fragen, deren Subjekte eine explizite, endliche Liste von Alternativenpräsentieren (siehe Beispiel 6).
• Welche-Fragen sind Fragen, deren Subjekte eine potenziell unendliche Menge von Al-ternativen präsentiert. Diese Fragen präsentieren ihre Alternativen unter Bezugnahmeauf eine Matrix (im Sinne einer offenen Formel) und eine oder mehrere Kategorienbe-dingungen. Durch die Einsetzung eines Wertes, der die Kategorienbedingung erfüllt, indie Matrix wird eine Antwortalternative erzeugt (siehe Beispiel 6).
Eine direkte Antwort ist ein sprachlicher Ausdruck, der eine Frage vollständig, aber nichtmehr als vollständig und unabhängig von ihrem Wahrheitsgehalt beantwortet. Die Menge derdirekten Antworten bestimmt sich dann aus der Menge der Alternativen, die entsprechend denBedingungen der Anforderungen zusammengesetzt sind.
Beispiel 6: Ob- und Welche-Fragen. Die Ob-Frage Gibt es eine Primzahl, die klei-ner ist als 5? definiert die folgende Menge von direkten Antworten: Esgibt eine Primzahl, die kleiner ist als 5. und Es gibt keine Primzahl, diekleiner ist als 5.Die Welche-Frage Welche positive Zahl ist die kleinste ungerade Prim-zahl? dagegen präsentiert unendlich viele Alternativen unter Bezugnahmeauf die Matrix x ist die kleinste ungerade Primzahl und die Kategorienbe-dingung x ist eine positive ganze Zahl ([Bel76]).
Neben den elementaren Fragen führen Belnap und Steele vier weitere Arten von Fragen ein:quasi-elementare Fragen, Warum-Fragen, zusammengesetzte Fragen und relativierte Fragen,deren Relevanz für die vorliegende Arbeit aber gering ist. Einen erschöpfenden Überblick überdie verschiedenen Ansätze zur Beschreibung der erotetischen Logik geben Bäuerle und Zim-mermann in [Bäu91].
3.2 Theorien zur Semantik von Fragen und Antworten
Bei der Beschreibung verschiedener Theorien zur Formalisierung der Semantik von Fragenund Antworten folgen wir im Wesentlichen der Darstellung von Krifka in [Kri00]. Für die For-malisierung verwenden wir folgende Schreibweisen:
• Φ ist ein Satz.• Die Bedeutung des Satzes Φ wird mit || Φ || bezeichnet. || Φ || kann als die Menge der
möglichen Welten I gesehen werden, in denen Φ wahr ist. Diese Menge auf der semanti-schen Ebene von Tabelle 3 bezeichnen wir als Propositionen oder Aussagen.
• i∈ I ist eine Variable für eine mögliche Welt oder einen möglichen Zustand der Welt, derauch im temporalen Sinne als „die Welt zu einem bestimmten Zeitpunkt“ gesehen wer-den kann.
• Für die Darstellung der charakteristischen Funktionen für die Abbildung auf die Mengeder Wahrheitswerte verwenden wir Lambda-Terme der Form λx [...x...], bei denen x dieVariable ist, die der Lambda-Term bindet.
Die Verwendung dieser Schreibweisen ist in Beispiel 7 mit einem Aussagesatz illustriert.
Beispiel 7: Semantik eines Aussagesatzes. Die Bedeutung der Aussage Paris ist dieHauptstadt von Frankreich. lässt sich folgendermaßen beschreiben:

353.2 THEORIEN ZUR SEMANTIK VON FRAGEN UND ANTWORTEN
|| Paris ist die Hauptstadt von Frankreich. || = {i | Paris ist die Hauptstadt von Frankreich in i} = λi [Paris ist die Hauptstadt von Frankreich in i]
Damit ergibt sich die Menge der Welten i, in denen die Aussage zutrifftund angewendet auf eine bestimmte Welt i0 erhalten wir einen Wahrheits-wert (wahr, wenn Paris in i0 die Hauptstadt von Frankreich ist, und falsch,wenn nicht).
Eine Frage ist ein Sprechakt, der einen anderen Sprechakt, die Antwort, erwartet. Fragenkönnen daher nicht unabhängig von Antworten beschrieben werden. Für die Beantwortungvon Fragen, z.B. Was ist die Hauptstadt von Frankreich?, sind zwei Formen möglich:
• Langantworten: Vollständige Sätze (Aussagen), z.B. „Paris ist die Hauptstadt vonFrankreich.“.
• Kurzantworten: Ein oder zwei Wörter, die als Antwort verstanden werden, z.B. „Pa-ris“.
In den folgenden Abschnitten werden wir verschiedene Theorien zu Darstellung der Seman-tik verschiedener Arten von Fragen darstellen. Wir stützen uns bei der Betrachtung der Seman-tik von Fragen und ihrer Antworten auf die Postulate von Hamblin ([Ham58]):
1. An answer to a question is a statement.
2. Knowing what counts as an answer is equivalent to knowing the question.
3. The possible answers to a question are an exhaustive set of mutually exclusive possibilities.
Groenendijk und Stokhof diskutieren diese Postulate in [Gro98] ausführlich und kritisierenvor allem die Annahmen, dass sich für jede Frage eine Antwort finden lässt (existence assump-tion) und dass es in einer bestimmten Situation zu einer Frage niemals mehr als eine wahre undvollständige Antwort gibt (uniqueness assumption).
3.2.1 Die funktionale Theorie der Semantik
Die funktionale Theorie der Semantik geht auf die Analyse von Ginzburg in [Gin95] zurückund basiert auf der Idee, dass die Bedeutung einer Frage sich aus der Bedeutung der Kurzant-worten auf die Frage ergibt. Damit ist die Bedeutung der Frage eine Funktion, die, wenn sieauf die Bedeutung der Kurzantwort angewendet wird, eine Proposition ergibt, die der Langant-wort entspricht. Die funktionale Theorie legt also Kurzantworten als die eigentlichen Antwor-ten zugrunde. Beispiel 8 nach [Kri00] zeigt die Ableitung der Langantwort aus der Kurzant-wort und die Ermittlung der Semantik mittels der funktionalen Theorie. Der Beitrag des Frage-worts besteht in einer Restriktion der Funktion, die im Sinne von Präsuppositionen19 annimmt,dass es sich beispielsweise bei der Antwort im Falle des Frageworts „wen?“ um eine Personund im Falle von „was?“ um einen Gegenstand handelt.
19 Eine Frage F präsupponiert eine Aussage A genau dann, wenn die Wahrheit von A eine logische Be-dingung dafür ist, dass es eine wahre Antwort auf F gibt ([Bel76]).

36 KAPITEL 3. RELEVANTE ANSÄTZE ZUR BESCHREIBUNG DER SEMANTIK VON FRAGEN
Beispiel 8: Funktionale Theorie der Semantik.Frage: Wen sah Goethe?Kurzantwort: Schiller.Langantwort: Goethe sah Schiller.
|| Wen sah Goethe? || (|| Schiller ||) =λi[Goethe sah Schiller in i] =|| Goethe sah Schiller. ||
Die Bedeutung der Frage ergibt sich dann als:|| Wen sah Goethe? || ≈ || λx[Goethe sah x] || = λxλi[Goethe sah x in i]
Der Wertebereich der Antwort lässt sich schließlich durch das Fragewort einschränken:|| Wen sah Goethe? || = λx∈ PERSON λi[Goethe sah x in i]|| Was sah Goethe? || = λx∈ DING λi[Goethe sah x in i]
3.2.2 Die propositionale Theorie der Semantik
Das in Abschnitt 3.2 aufgeführte zweite Postulat von Hamblin20 bildet die Grundlage für diepropositionale Theorie der Semantik, die von Harrah in [Har84] auch als Antwortmengen-Me-thode (set-of-answers-methodology) bezeichnet wird. Im Sinne von Hamblin argumentierenauch Vanderveken mit
„To understand a question is to understand what counts as an answer.“ ([Van90])
sowie Belnap und Steele mit
„The meaning of a question addressed to a query system […] is to be identifiedwith the range of answers that the question permits.“ ([Bel76:2]).
Dieser Ansatz geht davon aus, dass Antworten Propositionen sind und Fragen damit alsMengen von kongruenten Propositionen21 dargestellt werden können. Im Falle von Entschei-dungsfragen können diese als explizite Aufzählungen und im Fall von Ergänzungsfragen alsEigenschaften von Propositionen angegeben werden. Während die funktionale Theorie dieKurzantworten als Grundlage verwendet, stützt sich die im Folgenden beschriebene propositi-onale Theorie der Semantik auf die Langantworten. Die Definition der Menge der Antwortenlässt noch Varianten zu:
• Alle möglichen oder nur wahre Antworten werden in der Antwortmenge betrachtet.Oder:
• Die Menge der wahren Antworten kann exhaustiv als die Antwort verstanden werdenoder als Menge, aus der ausgewählt werden kann.
20 „Knowing what counts as an answer is equivalent to knowing the question.“ ([Ham58])21 Eine Proposition ist kongruent zu einer Frage, wenn sie ein Element der Fragebedeutung ist. Eine
nicht kongruente Proposition zur Frage Wen sah Goethe? wäre Es regnet!.

373.2 THEORIEN ZUR SEMANTIK VON FRAGEN UND ANTWORTEN
Bei der propositionalen Theorie wird das Fragewort als restringierter Existenzquantor be-trachtet. Die Beispiele 9 und 10 nach [Kri00] stellen die Ermittlung der Semantik von Ent-scheidung- und Ergänzungsfragen mittels der propositionalen Theorie der Semantik dar.
Beispiel 9: Propositionale Theorie der Semantik: Entscheidungsfrage.Frage: Sah Goethe Schiller?Antwortalternativen: {Goethe sah Schiller, Goethe sah Schiller nicht}
|| Sah Goethe Schiller? || = {λi[Goethe traf Schiller in i], λi[Goethe traf Schiller nicht in i]}
Beispiel 10: Propositionale Theorie der Semantik: Ergänzungsfrage.Frage: Wen traf Goethe?Antwortalternativen: {Goethe traf Schiller, Goethe traf Herder, Goethe traf Wieland, ...}
|| Wen sah Goethe? || = {p | ∃ x∈ PERSON und p = λi [Goethe sah x in i]} ={λi[Goethe sah x in i] | x∈ PERSON}
Bäuerle und Zimmermann geben in [Bäu91] einen fundierten Überblick über die Antwort-mengen-Methode und stellen darin vor allem die „Affinität der Methode zu einer formalen Se-mantik, die auf mengentheoretischen Konzepten beruht“ ([Bäu91:341]) heraus.
3.2.3 Die Konstruktion von komplexen Fragebedeutungen
Bei Ermittlung der Semantik von zusammengesetzten Elementen, z.B. komplexen Fragen,wird durchgängig das von Frege in [Fre18] entwickelte Kompositionalitätsprinzip22 verwen-det:
Die Bedeutung eines komplexen Ausdrucks ist abhängig von der Bedeutung seinerunmittelbaren syntaktischen Teile und der Art und Weise, wie sie zusammengefügtsind.
Im Sinne einer kompositionalen Interpretation bedeutet dies, dass die Bedeutung einer Fra-ge auf die Bedeutung der Teilsätze zurückgeführt wird.23 Krifka leitet in [Kri00] daraus eineallgemeine Kompositionalitätsregel ab: die Bedeutung einer komplexen Konstituente errech-net sich damit, indem die Elemente in den Bedeutungen der Teilausdrücke in jeder möglichenWeise kombiniert und die Resultate wieder in einer Menge zusammenfasst werden.
22 Das Kompositionalitätsprinzip von Frege wird auch als „zentrale These der Semantik“ oder „Fre-ge’sches Prinzip“ bezeichnet.
23 Fuhrmann erwähnt in [Fuh98] in diesem Zusammenhang auch das mereologische Frege-Prinzip, dasbesagt, dass der Sinn eines Teilausdrucks eines komplexen Ausdrucks in einer Teil-Ganzes-Beziehungzum Sinn des komplexen Ausdruck steht.

38 KAPITEL 3. RELEVANTE ANSÄTZE ZUR BESCHREIBUNG DER SEMANTIK VON FRAGEN
3.2.4 Exhaustive und nicht-exhaustive Semantik
Hamblin geht in [Ham58] davon aus, dass die Menge der Antworten zu einer Frage nicht-ex-haustiv verstanden wird, dass also bei der Frage „Wer geht?“ die Antwort „Goethe geht.“vollständig ist und nicht ausschließt, dass auch andere Personen gehen.
Bei einer exhaustiven Interpretation wäre die Antwort „Goethe geht“ dagegen unvollstän-dig, wenn weitere Personen gehen. Groenendijk und Stokhof schlagen deshalb vor, dass eineFragen die Menge aller möglichen Welten partitioniert, d.h. in nicht überlappende und dieMenge aller Welten ausschöpfenden Zellen zerlegt ([Gro84]). Es ist bleibt aber fragwürdig, obAntworten immer exhaustiv verstanden werden können (selbst wenn sie nicht durch Zusätzewie „zum Beispiel“ als unvollständig markiert werden), wie Beispiel 11 zeigt. Die beiden An-sätze sind in den Tabellen 4 und 5 graphisch aufbereitet.
Beispiel 11: Probleme der exhaustiven Interpretation.Frage: Wo kann ich in Berlin die New York Times kaufen?Antwort: Am Bahnhof Friedrichstraße.
Als Kompromisslösung zwischen den beiden Ansätzen schlägt Krifka in [Kri00] vor, Fra-gen nicht generell als exhaustiv zu definieren, sie aus Gründen der pragmatischen Informati-onsmaximierung aber exhaustiv zu verstehen.24
Nach dieser Untersuchung von unterschiedlichen Ansätzen zur Beschreibung der Semantikvon Fragen wenden wir uns nunmehr dem Einsatz von Fragen als „wissendes Nicht-Wissen“beim Wissenserwerb zu.
3.3 Fragen als Instrumente des Wissenserwerbs
Im Bereich des Textverstehens führt Ram in [Ram91] den Begriff der Wissensziele (know-ledge goals) ein, also die Ziele einer Person bei der Lektüre von Texten, sich bestimmte Wis-senselemente für die Lösung von bestimmten Denkaufgaben anzueignen. Fragen bilden dieGrundlage für die Erreichung dieser Wissensziele und entstehen aus der Interaktion zwischenInteressen und Zielen des Menschen und Information aus der Umgebung. Vor allem, wenn dasModell des Menschen über eine Domäne in irgendeiner Weise inadäquat oder unvollständigerscheint, werden Wissensziele definiert, um diese Unzulänglichkeiten zu korrigieren. Im De-
Goethe und Schiller gehen.
Goethe geht. Schiller geht.
Niemand geht.
Tabelle 4: Nicht-exhaustive Interpretation nach Hamblin.
Goethe und Schiller gehen.
Goethe geht. Schiller geht.
Niemand geht.
Tabelle 5: Exhaustive Interpretation nach Groenendijk und Stokhof.
24 im Sinne von: Make your contribution as informative as is required!

393.3 FRAGEN ALS INSTRUMENTE DES WISSENSERWERBS
tail beschreibt Ram drei Arten, wie durch Lücken im Domänenwissen des Menschen Fragenentstehen können:
• Neuartige Situation: Die Person hat keinen anwendbaren Fall und kein Schema für dievorliegende Situation zur Verfügung.
• Fehlindiziertes Wissen: Die Person hat zwar einen anwendbaren Fall oder ein Schemazur Verfügung, kann darauf aber nicht zugreifen, weil die Kriterien, unter denen der Falloder das Schema abgelegt wurden, nicht auf die Situation passen.
• Falsches oder nur teilweise verstandenes Wissen: Frühere Erfahrungen in neuartigenSituationen wurden nicht oder nur teilweise verstanden. Damit sind die Fälle oder dieSchemata inkorrekt oder unvollständig.
Die Wissensziele im Bereich des Textverstehens teilt Ram in die Kategorien Textziele (syn-taktische und semantische Analyse des Textes), Gedächtnisziele (Assoziation zwischen neuenund bestehenden Aspekten), Erklärungsziele (Herstellen von kausalen Zusammenhängen zwi-schen Elementen des Textes) und Relevanzziele (Suche nach Textaspekten, die für die eigeneSituation relevant sind) ein. Der Zweck der Textrezeption besteht für den Leser natürlich darin,Antworten auf seine Fragen zu finden, um zu einem lückenloseren Verständnis in der durchden Text beschriebenen Domäne zu gelangen. In dem in Abbildung 7 nach [Ram91] illustrier-ten Prozess der Textrezeption entstehen aber kontinuierlich neue Fragen, die das Verständnisweiterer Texte leiten und deren Interpretation beeinflussen werden.
Graesser et al. entwickeln in [Gra92a] eine Taxonomie von Fragen aufgrund von abstraktenKategorien ihrer Semantik und nicht aufgrund von syntaktischen oder lexikalischen Kriterien(z.B. Art des Fragepronomens). Die theoretische Grundlage dafür bilden die von Lehnert in[Leh78] gesammelten zwölf Fragekategorien für eine Berechnungstheorie für die Beantwor-tung von Fragen im Bereich der künstlichen Intelligenz. Zu den 18 von Graesser et al. gesam-melten Kategorien, die sich für diese Arbeit als relevant erweisen, zählen:
• die Verifikation (Ist eine Tatsache wahr?), • der Vergleich (Wie ähnelt Instanz X Instanz Y?), • die Spezifikation von qualitativen und quantitativen Eigenschaften (Welche Eigenschaf-
ten hat eine Instanz?) und • kausale Nachfolgebeziehungen (Was sind die kausalen Folgen eines Ereignisses?).Wie auch schon Ram begeben sich Graesser et al. auf die Suche nach Mechanismen, die
Fragen erzeugen, und stoßen dabei auf vier Hauptkategorien:• Überprüfung des gemeinsamen Standpunkts,• Soziale Absprache von Handlungen,• Steuerung von Konversationen und Handlungen und
Abbildung 7: Der Prozess der Textrezeption nach [Ram91].
Parser
Gedächtnis
Text
Fragen Antworten
Neue Fragen

40 KAPITEL 3. RELEVANTE ANSÄTZE ZUR BESCHREIBUNG DER SEMANTIK VON FRAGEN
• Korrektur von Wissensdefiziten, die auf Unvollständigkeit oder Fehlern beruhen.Im Falle dieser letzten Kategorie wird eine Frage gestellt in der Hoffnung, durch deren Ant-
wort Informationen für die Korrektur der Wissenslücke zu finden. Diese Kategorie, die wiraufgrund ihrer thematischen Relevanz für die vorliegende Arbeit gesondert betrachten wollen,lässt sich weiter in die folgenden Unterkategorien zerlegen:
• Hindernisse bei der Planung oder Problemlösung,• Entscheidungen zwischen Alternativen, die gleichermaßen attraktiv erscheinen,• Verständnislücken und• Widersprüche.Diese Vorüberlegungen werden von Graesser et al. in [Gra92b] für die Konzeption des Fra-
ge-Antwort-Systems QUEST verwendet, das sich damit den folgenden Annahmen unterwirft:Es gibt eine begrenzte Menge von Fragekategorien (siehe oben), jede Kategorie hat eine ein-deutige Menge von Fragebeantwortungsstrategien und jede Frage ist einer der oben genanntenFragekategorien zugeordnet.
3.4 Zusammenfassung
In diesem Kapitel haben wir die Natur und das Wesen von Fragen und Antworten als Instru-mente des täglichen Sprachgebrauchs betrachtet. Dafür sind wir nach einer kurzen Beschrei-bung der Syntax von Fragen in der deutschen Sprache auf verschiedene Methoden zur Be-schreibung ihrer Semantik eingegangen. Für die Beschreibung der Semantik von komplexerenFragebedeutungen stellten wir das Frege’sche Kompositionalitätsprinzip vor. Den Abschlussdes Kapitels bildete eine Untersuchung von Zielen, die bei der Formulierung von Fragen allge-mein und beim Lesen von Texten im Speziellen verfolgt werden.
Für die vorliegende Arbeit sind besonders die syntaktische Analyse und Klassifikation vonFragen sowie die Methoden zur Beschreibung ihrer Semantik von Bedeutung. Diese werdenwir in den Kapiteln 5 und 6 wieder aufgreifen und bei der Konzeption der Sprache für die For-mulierung von Fragen von Fachexperten als methodische Grundlage verwenden. Davor wer-den wir aber im nun folgenden Kapitel die Grundidee des QUESTUS-KDD-Ansatzes vorstel-len.

KAPITEL 4 DER QUESTUS-KDD-ANSATZ DER WISSENSBASIERTEN BENUTZERUNTERSTÜTZUNG
Nachdem wir in den vorhergehenden Kapitel bestehende Ansätze von wissensbasierten Benut-zerschnittstellen in verschiedenen Bereichen analysiert und uns mit Syntax, Semantik und Zie-len von Fragen beim Erwerb von Wissen beschäftigt haben, wollen wir in den folgenden Kapi-teln unseren Ansatz vorstellen: Der Ansatz des Question-Driven User Support für KnowledgeDiscovery in Databases (QUESTUS-KDD) erlaubt es Fachexperten mit geringem Datenbank-und Data-Mining-Wissen, auf diese Technologien zuzugreifen und in weitgehend natürlicherSprache über Fragen und Antworten mit dem System zu kommunizieren.
In diesem Kapitel beschreiben wir das Konzept des QUESTUS-KDD-Ansatzes mit den An-forderungen, die in die Konzeption eingeflossen sind, dem Prozess von Anfrageformulierungund Ergebnislieferung und dem konzeptionellen Rahmenmodell. In den darauf folgenden Ka-piteln werden wir auf die wichtigsten Bestandteile des QUESTUS-KDD-Ansatzes im Detaileingehen.
4.1 Die Anforderungen an die Realisierung des Benutzerunterstützung
Aus der Analyse bestehender Ansätze aber vor allem auch aus den Erfahrungen in verschiede-nen Projekten haben sich die folgenden Anforderungen an die Realisierung der Benutzerunter-stützung ergeben:
Erfassbarkeit komplexer Aussagen und MusterZiel bei der Konzeption der Benutzerunterstützung bei der Entdeckung von Wissen in Daten-banken ist es, dem Benutzer Hilfsmittel für die gesamte Breite und Funktionalität der zugrundeliegenden Analysealgorithmen zur Verfügung zu stellen, soweit dies mit vertretbarem Auf-wand möglich ist. Das beinhaltet, dass auch die Formulierung von Anfragen, die nur durch dieErmittlung komplexerer Ergebnisse beantwortet werden können, unterstützt wird und auchdiese Ergebnisse wiederum in entsprechende Antworten übersetzt werden können.
TransparenzUm den Eindruck des Systems für den Benutzer als „Black Box“ zu vermeiden und bei denFolgen von Transformationsschritten die Gefahr einer „Stillen-Post“-Übermittlung zu reduzie-ren, müssen die Prozessschritte und deren Ergebnisse – soweit dies mit den Zielen des Invisib-le Data Mining vereinbar ist – für den Benutzer transparent gemacht werden. So müssen dieErgebnisse interner Transformationsschritte für den Nutzer zumindest auf Anfrage möglichstfachexpertengerecht dargestellt werden, um zum einen Verständnis und Akzeptanz des Vorge-hens zu fördern und zum anderen eine Überprüfung der Korrektheit der Transformationen zuermöglichen.

42 KAPITEL 4. DER QUESTUS-KDD-ANSATZ DER WISSENSBASIERTEN BENUTZERUNTERSTÜTZUNG
Modularität Durch die generelle Anforderung nach Erweiterbarkeit und Portierbarkeit des Ansatzes ergibtsich die Notwendigkeit eines modularen Aufbau des Gesamtsystems aber vor allem auch derWissensbasis. Darüber hinaus wird eine weitere Modularisierung entsprechend der Allgemein-gültigkeit der Konzepte notwendig: Allgemeine Konzepte wie Standardfragen oder Standard-methoden sind dabei von solchen zu trennen, die nur im Rahmen einer Anwendungsdomäneverwendbar sind. Daraus ergibt sich die Forderung nach Modulen der Wissensbasis, die allge-meine Objekte beschreiben, und ebenfalls modularen, domänenspezifischen Erweiterungen.
Diese weiterführenden Anforderungen nehmen wir zusammen mit den in Abschnitt 1.3.1beschriebenen Zielen als Grundlage für die Konzeption des Ansatzes.
4.2 Der Prozess der Formulierung und Beantwortung von Fragen
Für den Aufbau eines konzeptionellen Rahmens für die Unterstützung bei der Sammlung vonInformationen durch Fragen und Antworten beschreiben wir zunächst in Abbildung 8 den all-gemeinen Prozess unabhängig vom technologischen Hintergrund von Datenbanken und DataMining.
Abbildung 8: Der allgemeine Prozess der Formulierung und Beantwortung von Fragen.
Fragebeantwortet? Nein
Ja
Vorwissen(Hypothesen,
etc.)
Wissensziel
Ausgangs-zustand
Stellender Frage
Erweiterung desWissenskontexts
Aufgabe
Erklärungsversuch
Strukturieren derneuen Fragen
AuswahlAbstraktionsniveauund Formulierung
der Frage
Aufwerfen neuerFragen
Erklärungplausibel?
Ja
Nein
Beantwortungder Frage

434.3 DAS QUESTUS-KDD-VERARBEITUNGSMODELL
In diesem Modell gehen wir davon aus, dass der Benutzer den Prozess des Wissenserwerbsvor dem Hintergrund einer konkreten Aufgabe beginnt. Diese Aufgabe ist domänenabhängigund könnte im Bereich des medizinischen Qualitätsmanagements beispielsweise die Steige-rung der Effizienz therapeutischer Maßnahmen darstellen. Diese Aufgaben sind Teile des Do-mänenmodells, das Müller in [Mül98] aufbaut, und stellen die Grundlage für die Ableitungvon Wissenszielen dar. Im vorliegenden Fall könnte ein solches Wissensziel die Erforschungder Ursachen von Komplikationen als effizienzreduzierende Ereignisse sein. In Kombinationmit dem Vorwissen des Experten, z.B. dass Komplikationen vor allem in einer bestimmtenKlinik auftreten und die Ursachen möglicherweise mit der Reihenfolge der Leistungserbrin-gung zusammenhängen, definiert das Wissensziel den Ausgangszustand für einen Analysezyk-lus.25
Der Ausgangszustand stellt also das „wissende Nicht-Wissen“ ([Mit80], siehe auch Kapitel3) des Experten dar. Dieses erlaubt ihm die Formulierung einer Frage auf einem geeignetenAbstraktionsniveau. Nachdem diese gestellt und von einer unabhängigen Instanz eine Antwortdarauf geliefert wurde, ist vom Experten zu entscheiden, ob die Frage damit für ihn ausrei-chend beantwortet ist. Falls dem so ist, wird der Experte mit Hilfe der Antwort versuchen, denhinterfragten Sachverhalt zu erklären. Falls eine plausible Erklärung gefunden werden kann,wird der Experte damit seinen Wissenskontext erweitern, was sich beim erneuten Stellen einerFrage als verändertes Vorwissen äußern wird. Reicht die Antwort nicht aus, um die Frage zubeantworten, oder lassen sich keine plausiblen Erklärungen finden, werden neue Fragen aufge-worfen. Diese wird der Experte zunächst mental strukturieren und ordnen, bevor er eine Fragedavon auswählt und stellt.
4.3 Das QUESTUS-KDD-Verarbeitungsmodell
Wir verwenden nun das allgemeine Prozessmodell sowie das in Abbildung 2 dargestellte Ebe-nenmodell und fokussieren vor dem technologischen Hintergrund von Datenbanken und DataMining das in Abbildung 9 dargestellte QUESTUS-KDD-Verarbeitungsmodell.
25 Hier erkennen wir eine Parallele zu den in [Ram91] vorgeschlagenen knowledge goals (siehe dazuauch Abschnitt 3.3).
Abbildung 9: Das sprachorientierte QUESTUS-KDD-Verarbeitungsmo-dell.
KD-Fragen
DM-Anfragen DM-Ergebnisse
KD-Antworten
q1
q2q3 q4
q5 q6 q7 q8 q9
u1 u2 u3 u4 u5 u6
u7 u8 u9 u10 u11 u12
u13 u14 u15 u16 u17 u18
u19 u20 u21 u22 u23 u24
u25 u26 u27 u28 u29 u30
u31 u32 u33 u34 u35 u36
r25
r33
r26
r34
r27
r35
r28
r36
r29
r37
r30
r38
r31
r39
r1 r2 r3 r4 r5 r6 r7 r8
r9 r10 r11 r12 r13 r14 r15 r16
r17 r18 r19 r20 r21 r22 r23 r24
r32
r40
r41 r42 r43 r44 r45 r46 r47 r48
r49 r50 r51 r52 r53 r54 r55 r56
r57 r58 r59 r60 r61 r62 r63 r64
a1
a2
a5
a3 a4
a6 a7 a8 a9
Prozessablauf
Beziehung von KD-Antwortenzu KD-Fragen
Verfeinerung
Transformation
qi KD-Frageui DM-Anfrageri DM-Ergebnisai KD-Antwort
Rücktransformation
Abstraktion
Erzeugung von DM-Ergebnissenaus DM-Anfragen

44 KAPITEL 4. DER QUESTUS-KDD-ANSATZ DER WISSENSBASIERTEN BENUTZERUNTERSTÜTZUNG
Wie bereits in Abschnitt 1.1 beschrieben, sind in den Prozess der Entdeckung von Wissenin Datenbanken verschiedene Experten involviert, z.B. Fachexperten und Analyseexperten, diejedoch unterschiedliche Fachsprachen sprechen. Aus diesem Grund führen wir, wie in Abbil-dung 9 gezeigt, eine sprachorientierte vertikale Trennung der Ebenen durch. Die horizontaleAchse trennt damit die Sprachwelt eines Domänen- oder Fachexperten und die eines Statisti-kers oder Data-Mining-Experten: Wie ebenfalls schon in früheren Abschnitten beschrieben,formuliert der Fachexperte seine Fragen üblicherweise ohne vertieftes Wissen über Daten, Sta-tistik und Data-Mining-Methoden in der für seine Domäne typischen Fachsprache. Die obereSprachebene, die wir als Knowledge-Discovery-Ebene (KD-Ebene) bezeichnen, erlaubt Fach-experten die Formulierung von Fragen, die von spezieller Datenbank- und Data-Mining-Ter-minologie abstrahiert, und die Beantworten in derselben Sprache. Auf der unteren Sprachebe-ne, die wir Data-Mining-Ebene (DM-Ebene) nennen, werden in einer formaleren Sprache Auf-rufe von statistischen Tests oder Data-Mining-Methoden formuliert. Die vertikale Achse trenntFragen von Antworten auf der KD-Ebene bzw. Anfragen und Ergebnisse als Analogon auf derDM-Ebene.
Für die Bezeichnung der Objekte auf der Frageseite der KD-Ebene führen wir den Begriffder KD-Frage ein und definieren ihn unter Verwendung der Knowledge Discovery QuestionLanguage (KDQL), die wir in den folgenden Kapiteln im Detail beschreiben, wie folgt:
Definition 1: KD-Frage. Eine KD-Frage ist die auf KDQL abgebildete natürlich-sprachliche Frage des Fachexperten.
KD-Fragen werden vom Fachexperten formuliert und stoßen den Beantwortungsprozess an.Die KD-Fragen werden anschließend im QUESTUS-KDD-Ansatz analysiert und mit der KD-Frage-Expansion schrittweise in neue KD-Fragen auf einem niedrigeren Abstraktionsniveauübersetzt.
Definition 2: KD-Frage-Expansion. Der Prozess der KD-Frage-Expansion ist die Er-zeugung einer Menge von KD-Fragen, bei denen jeweils genau eines derElemente von KDQL durch ein spezielleres Konzept belegt ist, aus einerKD-Frage.
Hat eine ausreichende Expansion (siehe dazu auch Abschnitt 7.2) stattgefunden, können dieexpandierten KD-Fragen in eine Menge von DM-Anfragen, die auf der Frageseite der DM-Ebene in das Modell eingeordnet sind, übersetzt werden. Diese Übersetzung bezeichnen wirals KD-DM-Transformation und definieren sie folgendermaßen:
Definition 3: KD-DM-Transformation. Der Prozess der KD-DM-Transformation istdie Erzeugung einer Menge von DM-Anfragen aus einer KD-Frage, wo-bei die Ergebnisse der Ausführung der DM-Anfrage geeignet sind, Hin-weise für die Beantwortung der KD-Frage zu liefern.
Den Begriff der DM-Anfrage definieren wir unter Verwendung der Data Mining AlgorithmQuery Language (DMAQL), die wir im Detail in Abschnitt 7.1.1 beschreiben, wie folgt:
Definition 4: DM-Anfrage. Eine DM-Anfrage ist ein in DMAQL formulierter Aus-druck, der, unabhängig von den Anforderungen einer konkreten Imple-mentierung eines Data-Mining-Algorithmus, alle Elemente für die kor-rekte und vollständige Konfiguration eines Datenanalyselaufs liefert.

454.3 DAS QUESTUS-KDD-VERARBEITUNGSMODELL
Aufgrund ihrer Unabhängigkeit von Implementierungen von Algorithmen müssen DM-An-fragen noch einmal transformiert werden, bevor sie von einem Data-Mining-System als Einga-be verstanden werden können.26 Diese Eingaben bezeichnen wir als DM-System-Anfragen:
Definition 5: DM-System-Anfrage. Eine DM-System-Anfrage ist ein für eine kon-krete Implementierung eines Data-Mining-Algorithmus formulierterAusdruck in einer implementierungsabhängigen Sprache, der alle Ele-mente für die korrekte und vollständige Konfiguration eines Daten-analyselaufs liefert.
Die Abbildung auf implementierungsabhängige Anfrageformulierungen geschieht im Pro-zess der DM-Anfrage-Spezialisierung, den wir folgendermaßen definieren:
Definition 6: DM-Anfrage-Spezialisierung. Der Prozess der DM-Anfrage-Speziali-sierung ist die Erzeugung einer implementierungsabhängigen DM-Sys-tem-Anfrage aus einer DM-Anfrage.
Die dem Datenanalyseprozess zugrunde liegenden statistischen und Data-Mining-Algorith-men verwenden die DM-System-Anfragen als Spezifikation der Eingabeparameter und lieferndaraufhin eine Menge von Ergebnissen zurück, die wir als DM-System-Ergebnis bezeich-nen:27
Definition 7: DM-System-Ergebnis. Ein DM-System-Ergebnis ist die Ausgabe einerkonkreten Implementierung eines Data-Mining-Algorithmus aufgrundder Eingabe einer DM-System-Anfrage.
Aus dieser Definition geht hervor, dass die Repräsentation des Ergebnisses (üblicherweisein tabellarischer Form mit variierenden Spalten) noch abhängig ist von der vorliegenden Imp-lementierung des Algorithmus. Um ein Ergebnis allgemein und implementierungsunabhängigzu beschreiben, wird die DM-Ergebnis-Generalisierung durchgeführt. Diese definieren wir wiefolgt:
Definition 8: DM-Ergebnis-Generalisierung. Der Prozess der DM-Ergebnis-Gene-ralisierung ist die Erzeugung eines implementierungsunabhängigen DM-Ergebnisses aus einem DM-System-Ergebnis.
Resultat der DM-Ergebnis-Generalisierung ist das DM-Ergebnis.
Definition 9: DM-Ergebnis. Ein DM-Ergebnis ist die implementierungsunabhängigeBeschreibung eines DM-System-Ergebnisses.
Um die formale Beschreibung der DM-Ergebnisse wieder in eine für den Benutzer ver-ständliche, natürlichsprachliche Form zu bringen, setzten wir die DM-KD-Transformation ein,die wir wie folgt definieren:
26 Die Stufe, auf der DM-System-Anfragen und DM-System-Ergebnisse zu finden sind, geht über die inAbbildung 9 dargestellten Ebenen hinaus, da es sich hier nicht um eine neue Sprachebene, sondern umeine Konkretisierung auf derselben Sprachebene handelt.
27 Wir verzichten im Rahmen der vorliegenden Arbeit auf eine genauere Untersuchung der Analyseal-gorithmen und betrachten diese stattdessen als „Black Box“.

46 KAPITEL 4. DER QUESTUS-KDD-ANSATZ DER WISSENSBASIERTEN BENUTZERUNTERSTÜTZUNG
Definition 10: DM-KD-Transformation. Der Prozess der DM-KD-Transformation istdie Erzeugung einer KD-Antwort aus einer nichtleeren Menge von DM-Ergebnissen.
Das Resultat der DM-KD-Transformation und das Ziel des Fragestellers ist die Formulie-rung einer KD-Antwort in der Knowledge Discovery Answer Language (KDAL), die wir inden folgenden Kapiteln im Detail beschreiben.
Definition 11: KD-Antwort. Eine KD-Antwort ist ein in KDAL formulierter Aus-druck, der einen eindeutigen Bezug zu einer KD-Frage hat und diesevollständig beantwortet.
Die Menge der KD-Antworten lässt sich zusammenfassen und verdichten, wodurch auskonkreten KD-Antworten, die einen direkten Bezug zu konkreten KD-Fragen haben, abstrak-tere KD-Antworten mit Bezug zu abstrakteren KD-Fragen werden. Hierfür führen wir die KD-Antwort-Kontraktion ein.
Definition 12: KD-Antwort-Kontraktion. Der Prozess der KD-Antwort-Kontraktionist die Verdichtung einer nichtleeren Menge von KD-Antworten zu einerabstrakteren KD-Antwort.
Diese Objekte und Teil-Prozesse bilden die Grundlage für die in dieser Arbeit beschriebe-nen Verarbeitungsschritte. Eine Einordnung der beschriebenen Objekte und Teil-Prozesse so-wie ihrer Relationen liefert Abbildung 10.
4.4 Die Modellierung der Wissensbasis
Durch die wissensintensiven Verarbeitungsschritte des QUESTUS-KDD-Ansatzes ergibt sichein hoher Bedarf an Expertenwissen unterschiedlicher Art, das in einer komplexen Wissensba-sis zur Verfügung gestellt wird. Wie in Abbildung 11 erkennbar, schlagen wir einen modularenAufbau dieser Wissensbasis vor, deren Module zum einen durch die Spezialisierung des Wis-
Abbildung 10: Das QUESTUS-KDD-Begriffsmodell.
KD-Frage
DM-Anfrage
1:nKD-DM-
Transformation
KD-Antwort
1:1
DM-Ergebnis
1:n
n:1DM-KD-
Transformation
DM-System-Anfrage
1:1DM-Anfrage-
Spezialisierung
DM-System-Ergebnis
1:n
1:1DM-Ergebnis-
Abstraktion
1:nKD-Frage-Expansion
n:1KD-Antwort-Kontraktion

474.4 DIE MODELLIERUNG DER WISSENSBASIS
sens beschrieben werden und zum anderen durch die Art der zu modellierenden Objekte. DieSpezialisierung des Wissens beschreiben wir auf den folgenden drei Ebenen:
Allgemeines WissenIn einem allgemeinen Modul stellen wir Wissen zur Verfügung, das unabhängig von den Er-fordernissen einer Domäne beschrieben werden kann. Dazu zählen die allgemeinen Elementeder Sprache für die Formulierung von Fragen (KDQL) und Antworten (KDAL) von Fachex-perten und die Beschreibungen klassischer Methoden und Algorithmen aus den Bereichen Sta-tistik und Data Mining.
Domänenspezifisches WissenDie Bereitstellung von geschlossenen Modulen mit Wissen, das typisch für eine Anwendungs-domäne, z.B. das medizinische Qualitätsmanagement, ist, stellt ein wichtiges Ziel der Modula-risierung dar. Diese Domänenmodule erlauben in Kombination mit den allgemeinen Modulendie Anwendbarkeit des QUESTUS-KDD-Ansatzes in einer Domäne. Darin sind zum einensolche Objekte enthalten, die nur in einer Domäne vorkommen, also im allgemeinen Modulnicht enthalten sind. Zum anderen finden sich hier auch Objekte, z.B. Begriffe, die zwar auchim allgemeinen Modul enthalten sind, sich aber in der gegebenen Domäne durch eine abwei-chende Interpretation auszeichnen und diese damit überschreiben. Durch den Einsatz von Do-mänenmodulen lässt sich die Übertragung des Ansatzes auf andere Domänen erleichtern, weilnur die Objekte zu modellieren sind, die von der allgemeinen Modellierung abweichen.
Anwender- und unternehmensspezifisches WissenAuf der dritten Spezialisierungsebene erlaubt der Ansatz die Formulierung von Wissen, das –in Abweichung oder Ergänzung des Domänenwissens – typisch für einen Anwender oder einUnternehmen ist, und unterstützt damit die Anpassung an anwender- oder unternehmensspezi-fische Gegebenheiten, wie beispielsweise besondere Bezeichnungen für Attribute.
Die Menge der relevanten Objekte, die für die Modulbildung entscheidend sind, besteht ausFragen, Konzepten, Methoden und Algorithmen sowie Antworten, die wir im Folgenden ge-nauer beschreiben:
Abbildung 11: Der modulare Aufbau der Wissensbasis
Unternehmens-spezifische
Fragen
Unternehmens-spezifischeKonzepte
Unternehmens-spezifische
Methoden, Algorithmen
Unternehmens-spezifischeAntworten
Allgemeine Fragen
AllgemeineKonzepte
AllgemeineMethoden, Algorithmen
AllgemeineAntworten
DomänenspezifischeFragen
DomänenspezifischeKonzepte
DomänenspezifischeMethoden, Algorithmen
DomänenspezifischeAntworten
Allgemein
Domäne
Unter-nehmen
Fragen Konzepte Methoden,Algorithmen Antworten
Objekte
Patientenfälle,Behandlungsdaten
Daten
Data Dictionary
Subo
rdin
atio
n

48 KAPITEL 4. DER QUESTUS-KDD-ANSATZ DER WISSENSBASIERTEN BENUTZERUNTERSTÜTZUNG
Wissen über FragenAls Hauptmerkmal unseres Ansatzes ist die Beschreibung der Fragen von Fachexperten wich-tiger Bestandteil der Wissensbasis. Auf den drei Spezialisierungsebenen werden deshalb dieSyntax sowie die allgemeinen, domänenspezifischen und etwaige unternehmens- oder anwen-derspezifische Ausprägungen für die einzelnen Elemente von KDQL, die wir im folgendenKapitel 5 detailliert beschreiben, verwaltet. Auch die Regeln für die Verfeinerung von KD-Fragen (KD-Frage-Expansion, siehe dazu auch Abschnitt 7.2), soweit sie die KDQL-Elementebetreffen, sind hier abgelegt. Auf der Domänenebene lassen sich darüber hinaus vollständigeFragen bereitstellen, die typisch für eine Domäne sind und deshalb im Sinne von Standardfra-gen in der Explorationsphase einer Datenanalyse verwendet werden können.
Wissen über KonzepteDie Wissensbasis für Konzepte enthält Wissen über wichtige Begriffe der Sprache von Fach-experten. Auf den verschiedenen Spezialisierungsebenen enthält sie:
• Räumliches Wissen, z.B. die Zuordnung von Postleitzahlen zu Regionen und die hierar-chische Strukturierung von Regionen im allgemeinen Modul.
• Zeitliches Wissen, z.B. die Zuordnung von Daten zu Wochentagen und die Klassifikati-on von Zeitintervallen, z.B. Jahreszeiten, im allgemeinen Modul.
• Gruppierungen von Attributwerten, z.B. die Bildung aussagekräftiger Altersgruppenwie Kind, Jugendlicher, Erwachsener im allgemeinen Modul sowie Diagnose- und Leis-tungsklassen im Domänenmodul.
• Synonyme Bezeichnungen für Attribute, z.B. GESVD für Gesamtverweildauer imDomänenmodul.
• Operationalisierung von Fachbegriffen, z.B. die Umsetzung von Begriffen wie bei-spielsweise Behandlungsqualität in einzeln überprüfbare Kriterien auf der Domänen-ebene.
Auf der anwender- und unternehmensspezifischen Ebene kann der Benutzer wiederum alsrelevant beurteilte Begriffe oder Gruppierungen von Daten (z.B. individuelle Altersgruppen)zusammenstellen und pflegen.
Wissen über Methoden und AlgorithmenZur Unterstützung der Auswahl von geeigneten Methoden und Algorithmen aus den BereichenData Mining und Statistik für die Bearbeitung der KD-Fragen und die Generierung von voll-ständigen DM-Anfragen wird ebenfalls detailliertes Wissen benötigt. Dazu zählt im einzelnenWissen über:
• Methoden und Algorithmen: Sammlung der möglichen Methoden und Algorithmenmit ihren Anwendungsbedingungen, Merkmalen und Ergebniseigenschaften.
• Parametrisierungen: geeignete Initialisierungen der relevanten Parameter der Metho-den und Algorithmen und Funktionen zu ihrer inkrementellen Anpassung.
• Implementierungen: Syntax des Aufrufs konkreter Methoden und Algorithmen einerbestimmten Implementierung.
• Interpretation von Data-Mining-Ergebnissen: z.B. Wissen über statistische „Fallen“bei extensiver Suche im Aussagenraum, Wissen über Signifikanzniveaus, Wissen überScheinkorrelationen.
Dieses Wissen kann auf der anwender- und unternehmensspezifischen Ebene beispielswei-se durch Benutzerpräferenzen in Bezug auf die Auswahl von Methoden (z.B. in Bezug auf Ak-kuratheit vs. Verständlichkeit der Ergebnisse) erweitert werden.

494.5 ZUSAMMENFASSUNG
Wissen über AntwortenFür die Rückübersetzung der Analyseergebnisse in Antworten in der Sprache des Fachexper-ten wird KDAL, die wir im Detail in Abschnitt 5.3 beschreiben, in der Wissensbasis bereitge-stellt. Neben der Syntax von KDAL ist auch Wissen über die Ableitung von verbalen Be-schreibungen von Data-Mining-Ergebnissen sowie über die Zusammenfassung von Antwortenauf einer höheren Abstraktionsebene formalisiert.
Wissen über DatenFür Informationen über die Eigenschaften der zu analysierenden Daten (z.B. Daten- und Ska-lentypen sowie Einheiten), die ebenfalls für die Ableitung von DM-Anfragen benötigt werden,wird auf das Data Dictionary der zugrunde liegenden Datenbank zurückgegriffen.
Anhang C gibt einen detaillierten Überblick über die Bestandteile der einzelnen Module derWissensbasis.
4.5 Zusammenfassung
In diesem Kapitel haben wir die konzeptionellen Grundlagen für den QUESTUS-KDD-Ansatzgelegt: Als Orientierung für die Konzeption des Ansatzes haben wir Anforderungen an die Re-alisierung des Ansatzes aus der Sicht von potentiellen Nutzern formuliert. Auf der Basis einesallgemeinen Modells für das Formulieren und die Beantwortung von Fragen haben wir in ei-nem Verarbeitungs- und einem Begriffsmodell den konzeptionellen Rahmen für unseren An-satz gelegt: Ausgehend von den Fragen der Fachexperten können KD-Fragen in KDQL formu-liert werden. Mit Hilfe von umfangreichem Wissen über Fragestellungen und Beantwortungs-methoden leiten wir aus den KD-Fragen DM-Anfragen ab, die als Eingabe von statistischenoder Data-Mining-Algorithmen verwendet werden. Die Resultate der Algorithmen, die wir alsDM-Ergebnisse bezeichnen, werden wieder im Rahmen von KD-Antworten in der Sprachevon Fachexperten formuliert. Das für die Transformationsschritte benötigte Wissen wird in ei-ner modularen Wissensbasis mit drei Subordinationsebenen bereitgestellt.
Als erste Elemente des QUESTUS-KDD-Ansatzes werden wir im folgenden Kapitel dieSyntax von KDQL für die Formulierung von Fragen von Fachexperten und von KDAL für dieFormulierung von entsprechenden Antworten im Detail vorstellen.

50 KAPITEL 4. DER QUESTUS-KDD-ANSATZ DER WISSENSBASIERTEN BENUTZERUNTERSTÜTZUNG

KAPITEL 5 KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
Fundamentaler Bestandteil des QUESTUS-KDD-Ansatzes ist die Knowledge Discovery Que-stion Language (KDQL), die die formale Repräsentation der Fragen von Fachexperten auf derKnowledge-Discovery-Ebene (siehe Abbildung 2) ermöglicht. Darüber hinaus erlaubt KDQLdie Spezifikation aller notwendigen Informationen für die KD-DM-Transformation. Im Fol-genden erläutern wir die wichtigsten Anforderungen, die der Entwicklung zugrunde liegen, so-wie die Syntax von KDQL. Im Anschluss daran beschreiben wir die Syntax der KnowledgeDiscovery Answer Language (KDAL), die wir für die Formulierung von KD-Antworten ein-setzen.
5.1 Die Anforderungen an eine Sprache für Fragen von Fachexperten
Durch die in Abschnitt 1.3 beschriebene Zielgruppe des QUESTUS-KDD-Ansatzes ergebensich spezifische Anforderungen an das Design der Sprache für die Formulierung der Fragender Fachexperten. Für die Analyse dieser Anforderungen und die darauf basierende Konzepti-on der Sprache KDQL verwenden wir einen Korpus von Fragen. Diese wurden von drei Fach-experten aus dem Bereich des medizinischen Qualitätsmanagements und zwei Fachexpertenaus dem Bereich des Qualitätsmanagements in Produktionsbetrieben bei der Datenanalyse for-muliert. Das Vorgehen bei der Analyse des Korpus lässt sich mit den folgenden Schritten be-schreiben:
1. Sammlung einer Menge von ca. 300 Fragen von Fachexperten in verschiedenen Data-Mining-Studien.
2. Klassifikation synonymer Fragen.3. Extraktion der Hauptkomponenten und Strukturierung der Fragen.4. Ableitungen der Anforderungen bezüglich der Frageformulierung.5. Ableitung einer allgemeinen Fragestruktur.Ein strukturierter Überblick über die Menge der Fragen findet sich in Anhang A.2. Wir un-
terscheiden im Folgenden die Anforderungen, die sich aus diesen Schritten ergeben, nach derTerminologie, der Kontrolliertheit, der Komplexität und Adäquatheit, sowie nach linguisti-schen Anforderungen.
Terminologische AnforderungenDurch die Analyse des Korpus von Fragen werden die Anforderungen bezüglich der in Fragenvon Fachexperten verwendeten Terminologie deutlich:
• Aufgrund der Annahme, dass Fachexperten im Wesentlichen weder mit Data-Mining-noch mit Datenbank-Terminologien vertraut sind, muss eine Sprache zur Formulierung

52 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
ihrer Fragen weitgehend frei von technologiespezifischen Konzepten, wie Bezeichnun-gen von Data-Mining-Methoden, Parameterkonfigurationen und Attributbezeichnungenaus der Datenbank sein.
• Stattdessen muss die Sprache die Formulierung auch komplexerer Konzepte aus der Ob-jektwelt des Fachexperten erlauben. Dabei handelt es sich vor allem um Hierarchien undGruppierungen von Datenbankobjekten (z.B. Risikopatienten, Stammdaten von Patien-ten), komplexe Fragegegenstände (z.B. Therapiequalität) und domänenspezifische Auf-fälligkeiten und Interessen (z.B. Behandlungsstandards).
• Fachexperten stellen Ihre Fragen häufig und vor allem zu Beginn einer Analysephase aufeinem abstrakten Niveau. Dabei fassen sie konkretere Einzelfragen unter einer abstrak-ten Frage zusammen, um einen ersten Eindruck von den Daten zu erhalten.
Anforderungen bezüglich der BenutzerführungNeben diesen terminologischen Anforderungen, die vom Fachexperten bestimmt werden, er-geben sich auch Anforderungen, die vor allem den Aspekt der Benutzerunterstützung heraus-stellen. Wie schon früher betont, wird die Zielgruppe des Systems als Personenkreis angenom-men, der mit den Methoden des Data Mining und den dadurch sich ergebenden sinnvollen undweniger sinnvollen Fragestellungen an das System nicht oder nur wenig vertraut ist. Durch dieVorgabe einer kontrollierten Sprache mit eingeschränktem Vokabular und eingeschränkterSyntax und die konsequente Offenlegung ihrer Möglichkeiten soll deshalb verhindert werden,dass Benutzer Fragen stellen, die zu unsinnigen Data-Mining-Anfragen führen würden. Durchdie Vorgabe der Syntax und des Vokabulars der Sprache wird also sichergestellt, dass alle Fra-gen, die formulierbar sind, korrekt und vollständig sowie für den Benutzer adäquat beantwortetwerden können.
Anforderungen bezüglich Komplexität und AdäquatheitGleichzeitig muss die Sprache zur Formulierung von Fragen von Fachexperten aber selbstver-ständlich komplex genug sein, um einen Großteil der Fragen und Interessen der Fachexperteneiner Domäne abzudecken. Dies schließt insbesondere die Berücksichtigung domänenspezifi-scher Fragestellungen und Frageformulierungen ein, vor allem auch wenn diese über einfache,direkt aus Data-Mining-Methoden ableitbare Fragen hinausgehen.
Die Formulierung der Fragen muss in einer für den Benutzer einer bestimmten Domäne ad-äquaten Weise möglich sein: das bedeutet, dass alle Konzepte mit der vertrauten Semantik ausder Begriffswelt der Domäne direkt oder indirekt für die Formulierung von Fragen zur Verfü-gung stehen.
Linguistische Herausforderungen Wie schon oben erwähnt, liegt der Fokus dieses Systems vor allem auf der Benutzerunterstüt-zung bei der Wissensentdeckung in Daten und weniger bei der Erarbeitung eines neuen lingu-istischen Ansatzes. Dennoch sollten Ansätze für die Lösung der grundlegendsten linguisti-schen Probleme, wie sie [And95] bei der Verwendung natürlichsprachlicher Benutzerschnitt-stellen für Datenbanken beschreibt, bereitgestellt werden. Diese sind im Einzelnen:
• Verwendung von Komposita, z.B. „Verweildauerüberschreitung“. • Auslassungen unter Benutzung des Informationskontexts (Ellipsen), z.B. „Die Kli-
nik mit dem höchsten Anteil von Verweildauerüberschreitungen?“. • Verwendung von Pronomina unter Benutzung des Informationskontexts (Ana-
phern), z.B. „Gibt es einen Zusammenhang zwischen Alter und Verweildauer? - Ist erstark?“

535.2 DIE MODELLIERUNG VON KD-FRAGEN
• Negation von Fragen, z.B. „Welche Patienten zeigen keine Auffälligkeiten?“. • Grammatik- und Orthographie-Fehler, z.B. „Welchen Zusammenhänge gibt’s zwi-
schen Alderund Verweildauer?“.• Inkorrekter Gebrauch von Konjunktionen und Disjunktionen, z.B. „Welche Patien-
ten gibt es, die die Verweildauer unter- und überschritten haben?“Darüber hinaus bestehen selbstverständlich noch weitere linguistische Herausforderungen,
die aber an dieser Stelle und für diese Anwendung als weniger relevant betrachtet werden.
5.2 Die Modellierung von KD-Fragen
Die Knowledge Discovery Question Language (KDQL) stellt einen Ansatz für eine kontrol-lierte Sprache dar, die ohne großen Aufwand von Fachexperten beim Einsatz von Data-Mi-ning-Methoden benutzbar ist. Aus diesem Grund und unter Berücksichtigung der oben skiz-zierten Anforderungen wurde die Syntax von KDQL in Form einer semantischen Grammatikim Wesentlichen von natürlichsprachlichen Fragen von Fachexperten bei der Datenanalyseübernommen. Eine KD-Frage wird durch ihre drei Hauptelemente beschrieben:
• die Fragewurzel,• die Fragegruppe und• den Fragekontext.Beispiel 12 zeigt die Analyse einer einfachen Frage. Die Fragewurzel stellt dabei ein
komplexes Konstrukt der Einzelelemente Fragetyp (siehe Abschnitt 5.2.1.1), Frageobjekt(siehe Abschnitt 5.2.1.2) und Frageargumente (siehe Abschnitt 5.2.1.3) dar, die jedoch zueinem hohen Grade voneinander abhängig sind, so dass auf eine getrennte Modellierung ver-zichtet werden musste. Die Fragegruppe (siehe Abschnitt 5.2.2.1) und der Fragekontext(siehe Abschnitt 5.2.2.2) stellen optionale Elemente dar, die aus datentechnischer Sicht auf un-terschiedliche Weise der Einschränkung der Gesamtmenge der verfügbaren Daten dienen.
Beispiel 12: Analyse einer einfachen Frage. Die Frage„Welchen Zusammenhang gibt es zwischen Alter und Verweildauer beiPatienten mit derselben Hauptdiagnose in der Augenklinik?“lässt sich mit KDQL folgendermaßen analysieren.
Für die Beschreibung der Modellierung von KDQL verwenden wir im Folgenden ein W3C-Schema28, wie es üblicherweise für die Beschreibung der Struktur von XML29-Dokumenten
Frageteil KDQL-Element
Welchen... gibt es Fragetyp
Zusammenhang Frageobjekt
zwischen Alter und Verweildauer Frageargumente
Patienten mit derselben Hauptdiagnose Fragegruppe
in der Augenklinik Fragekontext
Tabelle 6: KDQL-Elemente einer einfachen Frage.
28 W3C: World Wide Web Consortium, für Details siehe [Bro01]

54 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
eingesetzt wird. Damit kann XML als interne Zwischenrepräsentation (lingua intermedia) fürKD-Fragen verwendet werden.30 Abbildung 12 zeigt die Struktur einer KD-Frage in der gra-phischen Schema-Darstellung, aus der hervorgeht, dass eine KD-Frage aus einer Fragewurzel,einer Fragegruppe und eines Fragekontexts besteht. Alle diese Teilelemente sind weiter expan-dierbar (in der Abbildung durch + gekennzeichnet), die letzteren beiden sind optional (in derAbbildung durch die durchbrochene Umrandung gekennzeichnet).
Zur Festlegung der jeweiligen Bedeutung wird jedes Element in Ergänzung zum W3C-Standard mit einer festen Menge von Attributen beschrieben, die in Tabelle 7 aufgeführt underklärt sind.
Die Elemente des XML-Schemas lassen sich dabei unterschiedlichen Elementtypen mit un-terschiedlichen Funktionen zuordnen:
• Rahmenkonzepte dienen der Strukturierung und Modularisierung der Konzepte.• *-Konzepte erlauben die explizite Nicht-Spezifikation einer Komponente und bewirken
damit die automatische Verwendung aller Möglichkeiten für die Komponente.
29 XML: Extensible Markup Language, für Details siehe [Bra98]30 Für Details zur Nutzung der Vorteile von XML verweisen wir auf die Beschreibung der Implemen-
tierung des QUESTUS-KDD-Ansatzes im Knowledge Discovery Assistant (KDA) in Abschnitt 8.3.
Abbildung 12: Die Struktur des Elements KD-Frage.a
a. Für die Erstellung der Abbildungen aus dem XML-Schema verwenden wir den XMLSpy Schema Edi-tor der Altova Inc.
Attribut Erklärung
Elementname eindeutige Bezeichnung des Elements
Elementtyp Zuordnung des Elements zu einem der vier Typen
Elementvorgängertyp erforderlicher Elementtyp des vorhergehenden Elements
Elementnachfolgertyp erforderlicher Elementtyp des nachfolgenden Elements
Spezialisierungsebene Spezialisierungsebene des Elements in der Wissensbasis (allgemein, domänenspezi-fisch, anwender- bzw. unternehmensspezifisch)
Weitere Attribute z.B. Liste von Attribut-Attributwertpaaren, die für die Übertragung der kontinuierli-chen Funktionen auf diskrete Aussagen (siehe dazu auch Abschnitt 6.1) benötigt wer-den.
Tabelle 7: Attribute für die Modellierung eines KDQL-Elements.

555.2 DIE MODELLIERUNG VON KD-FRAGEN
• Funktionszuweisungen legen die Bedeutung eines Elements in funktionaler Weise fest(siehe dazu auch Kapitel 6).
• DB-Referenzen verweisen direkt oder indirekt auf Objekte in der Datenbank.Durch die Verwendung der Elementtypen und von Constraints, die die Abfolge der Ele-
menttypen limitieren, entsteht auf übergeordneter Ebene eine Sprache zur Beschreibung gülti-ger KDQL-Strukturen. Die dafür ausgezeichneten Attribute aus der Modellierungssprache sindder Elementnachfolgertyp und der Elementvorgängertyp. Die implizite Beschreibung vonwohlgeformten Strukturen wird vor allem beim Aufbau neuer und bei der Erweiterung beste-hender KDQL-Strukturen als einfaches Validierungswerkzeug darstellen. Im Folgenden erläu-tern wir die Elemente auf den höheren Ebenen im Detail.
5.2.1 Die Fragewurzel
Das Element Fragewurzel stellt den komplexen Kern der Frage dar. Da ihre Teilelementezum größten Teil voneinander abhängig sind, musste auf eine feingranulare Modellierung aufhoher Ebene verzichtet werden. Die Fragewurzel besteht aus einer komplexen Struktur, diesich im Wesentlichen aus den voneinander abhängigen Unterelementen
• Fragetyp• Frageobjekt• Frageargumente
zusammensetzt. Die Fragewurzel enthält alle Informationen, die für die Spezifikation einervollständigen KD-Frage benötigt werden; die Modellierung erfolgt sequentiell, wie in Abbil-dung 13 dargestellt. Das Rahmenkonzept Fragewurzel zerfällt damit in die verschiedenenAusprägungen des Fragetyps.
Abbildung 13: Die Struktur des Elements Fragewurzel.

56 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
5.2.1.1 Der Fragetyp
Der Fragetyp ist ein Indikator, ob die gestellte Frage im grammatischen Sinne geschlossenoder offen ist (siehe dazu auch Abschnitt 3.1). Damit enthält der Fragetyp wichtige Hinweiseauf das Muster und die Formulierung der Antwort. Darüber hinaus entscheidet der Fragetypüber die Komplexität der Frage. Bei einer einfachen Entscheidungsfrage kann die Antwort nuraus der Menge der vorgegebenen Alternativen ausgewählt werden. Die Beantwortung kann da-mit in diesem einem Schritt erfolgen. Eine Ergänzungsfrage verlangt eine auf die W-Frage be-zogene Antwort in Form eines Wortes oder einer Wortgruppe. Die Auswahl der Antwort istnur durch die Grenzen der Sinnhaftigkeit beschränkt, besteht potentiell aber aus einer unendli-chen Menge von Alternativen. Wie wir im Abschnitt 6.2.2 zeigen, werden für die Beantwor-tung zwei Schritte benötigt. Eine weitere Stufe leistungsfähiger sind, wie in Beispiel 13 und imDetail in Abschnitt 6.2.3 gezeigt, die in diesem Zusammenhang neu eingeführten komplexenFragen, bei denen der Fokus der Frage verschoben wird: Das ursprüngliche Objekt der Frage31
in Form einer impliziten Entscheidungsfrage (konfirmativer Typ) wird ergänzt um ein weiteresObjekt, das die Grundlage für eine Charakterisierung bildet. Damit wird zunächst eine Entsc-heidung über die Existenz des ursprünglichen Frageobjekts für alle Instanzen einer Klasse (imBeispiel: Patienten) getroffen und die Menge der Instanzen, für die die Überprüfung positivwar, dann für die Beschreibung zur Verfügung gestellt. Die bei der Beantwortung solcher ko-mplexer Fragen zugrunde liegende mehrstufige Untersuchung erfordert drei Beantwortungs-schritte.
Beispiel 13: Vergleich von Fragetypen. Gegenüberstellung einer konfirmativen,einer deskriptiven und einer komplexen Frage:
Für jeden der drei verschiedenen Fragetypen stellen wir, wie in Abbildung 13 gezeigt, einentsprechendes Konzept bereit: TypKonfirmativ, TypDeskriptiv und TypKomplex. ZurUnterstützung der automatischen Expansion von Fragen wird darüber hinaus das *-KonzeptTypOffen bereitgestellt.
Fragen des konfirmativen TypsDie mit dem Element TypKonfirmativ modellierten Fragen des konfirmativen Typs sind ge-schlossene Fragen, die streng genommen nur die beiden Kurzantworten „ja“ und „nein“ oderdie entsprechenden Langantworten erlauben.32 Beispiel 14 zeigt eine einfache konfirmativeFrage und eine dazugehörige Antwort.
31 Für eine detaillierte Beschreibung des Typs Frageobjekt verweisen wir auf Abschnitt 5.2.1.2.
Fragetyp Beispiel
konfirmativ Gibt es einen Zusammenhang zwischen Alter und Verweildauer?
deskriptiv Welchen Zusammenhang zwischen Alter und Verweildauer gibt es?
komplex Bei welchen Patienten gibt es einen Zusammenhang zwischen Alter und Verweildauer?
32 An dieser Stelle sei auf die Menge der Fragen in der Umgangssprache hingewiesen, die unter der An-nahme, dass die Hypothese positiv beantwortet wird, eine weitergehende Frage enthalten, z.B. „KönnenSie mir sagen, wie spät es ist?“. Auf Fragen dieser Art wird in der vorliegenden Arbeit nicht eingegangen,da sie ein weitergehende Modellierung von Mehrfachfragen erfordern.

575.2 DIE MODELLIERUNG VON KD-FRAGEN
Beispiel 14: Konfirmative KD-Fragen. Auf die FrageGibt es einen Zusammenhang zwischen Alter und Verweildauer?lautet eine mögliche, erwartete Langantwort:Ja, es gibt einen Zusammenhang zwischen Alter und Verweildauer!
Tabelle 8 enthält die Belegung der oben angesprochenen Attribute des Elements TypKonfir-mativ; Abbildung 14 beschreibt das Element in der XML-Schema-Darstellung.33 Dieses Ele-ment stellt entsprechend seinem Typ eine Funktion für die Entscheidung bezüglich der positi-ven oder negativen Aussage bereit. Die Funktion beinhaltet den Vergleich des Wertes, der vonder Auswertung der inneren Bestandteile einer Frage zurückgeliefert wird, mit einem Grenz-wert. Daraus wird dann die Bejahung oder Verneinung des Frageobjekts abgeleitet.
Fragen des deskriptiven TypsErgänzungsfragen verwenden zur Einleitung ein Fragewort. Dieses kann entweder mit der An-gabe eines Variablenbereichs komponiert sein oder aus einem selbständigen Fragepronomenbestehen. Den ersten Typ modellieren wir im Folgenden mit dem Element TypDeskriptiv,weil Fragen dieser Art auf eine weitergehende Beschreibung der genannten Variablen abzie-len. Fragen des zweiten Typs werden unter Verwendung des Elements TypKomplex modellie-ren und im nächsten Abschnitt im Detail beschreiben. Die verschiedenen Arten von Ergän-
33 Eine Aufstellung der wichtigsten KDQL-Elemente findet sich im Anhang B.1.
Elementname TypKonfirmativ
Elementtyp Funktionszuweisung
Elementfunktion
Elementvorgängertyp FrageWurzel
Elementnachfolgertyp FrageObjekt
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 8: Formale Beschreibung des Elements TypKonfirmativ.
<xs:element name="TypKonfirmativ"><xs:annotation>
<xs:documentation>Funktionszuweisung</xs:documentation></xs:annotation><xs:complexType>
<xs:sequence><xs:element ref="FrageObjekt"/>
</xs:sequence><xs:attribute name="Elementtyp" use="required" fixed="Funkti-
onszuweisung"/><xs:attribute name="Elementfunktion" use="required"
fixed="BinaerGrenzwertabgleich"/></xs:complexType>
</xs:element>
Abbildung 14: Darstellung des Elements TypKonfirmativ im XML-Schema.
Ausgabeja, wenn F BinärGrenzwert≥
nein, wenn F BinärGrenzwert<
=

58 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
zungsfragen nach [Kri00] und ihre Zuordnungen zu den fragetypspezifischen Elementen sindin Tabelle 9 zusammengestellt.
Deskriptive Fragen suchen nach einer Beschreibung des Frageobjekts, die sich, wie in Bei-spiel 15 gezeigt, durch eine Charakterisierung des Frageobjekts ausdrückt. Da die Menge dermöglichen Charakterisierungen vom Frageobjekt abhängt, werden diese mit dem zugehörigenElement für das Frageobjekt34 verwaltet.
Beispiel 15: Deskriptive KD-Fragen. Auf die FrageWelchen Zusammenhang zwischen Alter und Verweildauer gibt es?lautet eine mögliche, erwartete Langantwort: Es gibt einen starken, positiven Zusammenhang zwischen Alter und Ver-weildauer!
Die formale Beschreibung des Elements TypDeskriptiv wie auch aller weiteren Elementefindet sich im Anhang B.1. Konfirmative und deskriptive Fragen unterscheiden sich nicht inihrer Transformation auf Data-Mining-Anfragen. Sie haben lediglich unterschiedliche Darstel-lungen der Ergebnisse zur Folge.
Fragen des komplexen TypsWie in Tabelle 9 gezeigt, lassen sich drei Arten von selbständigen Fragewörtern unterschei-den: kasusmarkierte Fragewörter, adjunkttyp-spezifische Fragewörter und komplexe Frage-wörter. Semantisch speziellere Fragen, die kasus-markierte oder adjunkttyp-spezifische Frage-wörter verwenden, können dabei durch Verwendung von Fragen mit komplexen Fragewörternund entsprechenden Spezifikation des Variablenbereichs erreicht werden. Somit entsteht einesemantische Spezialisierung von einfachen Fragen mit kasus-markierten oder adjunkttyp-spe-zifischen Fragewörtern zu komplexen Fragen, bei denen der Variablenbereich explizit genanntwird (siehe dazu auch Tabelle 10).
Unterschiedliche Elemente je nach der semantischen Klasse des Fragepronomens erlauben,wie in Tabelle 11 dargestellt, die Operationalisierung durch unterschiedliche, teilweise domä-nenspezifische Variablenbereiche für die genauere Spezifikation des Fragefokus.
Fragen des komplexen Typs erweitern die deskriptiven Fragen um einen zusätzlichen Frei-heitsgrad. Das Frageobjekt wird damit zum sekundären Gegenstand der Frage, als primärerGegenstand kommt der Fragefokus ins Spiel. Der Fragefokus spezifiziert die Datenbankobjek-
Fragewörter Beschreibung Beispiel Modellierung
Welcher/welche/welches mit Angabe des Varia-blenbereichs
Welchen Zusammenhang gibt es?
TypDeskriptiv
Wer/was, wen/was, wem, wessen
kasusmarkiertes Frage-wort
Wer überschreitet häufig die Verweildauern?
TypKomplex
Wann, wo, wie, warum adjunkttyp-spezifisches Fragewort
Wo gibt es einen Unter-schied?
Worauf, wohin, wie viel, wieso, weshalb, warum
komplexes Fragewort Weshalb gibt es eine Ver-änderung
Tabelle 9: Gegenüberstellung verschiedener Arten von Ergänzungsfragennach [Kri00] und deren Modellierung.
34 Wie in Beispiel 15 und in Abschnitt 5.3.2 genauer erläutert, erlaubt das Frageobjekt ZusammenhangBeschreibungen über die Stärke und die Richtung.

595.2 DIE MODELLIERUNG VON KD-FRAGEN
te (und damit die Relation), die die Grundlage für die Analysen sind, z.B. Behandlungsfälleoder Abteilungen. Komplexe Fragen zielen in unserem Modell nicht auf die Enumeration derMenge der Instanzen ab, die die im Frageobjekt formulierte Hypothese erfüllen, sondern viel-mehr auf eine Charakterisierung dieser Menge. Beispiel 16 zeigt eine solche Frage und einepassende Antwort, die eine Beschreibung der Menge der Patienten enthält, für die ein Zusam-menhang vorliegt.
Beispiel 16: Komplexe KD-Fragen. Auf die FrageWelche Patienten zeigen einen Zusammenhang zwischen Alter und Ver-weildauer?lautet eine mögliche, erwartete Langantwort:Patienten, die älter sind als 55 Jahre und gesetzlich versichert sind, zei-gen einen Zusammenhang zwischen Altern und Verweildauer!
Fragen des komplexen Typs werden durch das Element TypKomplex modelliert, der, wiein Abbildung 15 gezeigt, entsprechend den semantischen Klassen des Fragepronomens in eineMenge von Unterelementen zerfällt: LokalFokus, PersonalFokus, TemporalFokus undModalFokus. Stellvertretend für die Menge der Unterelemente stellt Abbildung 16 die Mo-dellierung des Elements PersonalFokus dar: Das Rahmenkonzept PersonalFokus kannentweder ohne weitere Spezifikation bleiben (Wer...?) oder durch die Zuweisung eines Per-sonalObjekt (z.B. Patient) ergänzt werden (Welcher Patient ...?). Die darauf folgende Mo-
Einfache Fragekonstruktion(Variablenbereich implizit)
Spezialisierte Fragekonstruktion(Variablenbereich explizit)
Wer zeigt einen Zusammenhang? Welche Personen zeigen einen Zusammenhang?
Welche Patienten zeigen einen Zusammenhang?
Wo gibt es einen Zusammenhang? In welchen Abteilungen gibt es einen Zusammenhang?
In welchen Kliniken gibt es einen Zusammenhang?
Wann gibt es einen Zusammenhang? An welchen Tagen gibt es einen Zusammenhang?
Zu welchen Jahreszeiten gibt es einen Zusammenhang?
Tabelle 10: Beispiele für Fragen mit implizitem Variablenbereich unddaraus abgeleiteten expliziten Fragebereichen.
Semantische Klasse Fragewort mögliche Variablenbereiche (teilweise domänenspezifisch)
Personal Wer? Personen, Patienten, Ärzte
Lokal Wo? Abteilungen, Kliniken, Wohnorte
Temporal Wann? Tage, Jahreszeiten
Modal Wie? Maßnahmen, medizinische Leistungen, Behandlungsmuster
Kausala Warum? Ursachen
Tabelle 11: Semantische Klassen und ihre Referenzen auf mögliche Variablenbereiche.
a. Kausale Fragen, also Warum-Fragen, können im Allgemeinen von Data-Mining-Me-thoden nicht beantwortet werden, weil die wahren Ursachen für Beobachtungen nicht in denDaten zu finden sind. Sie sind deshalb nur aus Gründen der Vollständigkeit aufgeführt.
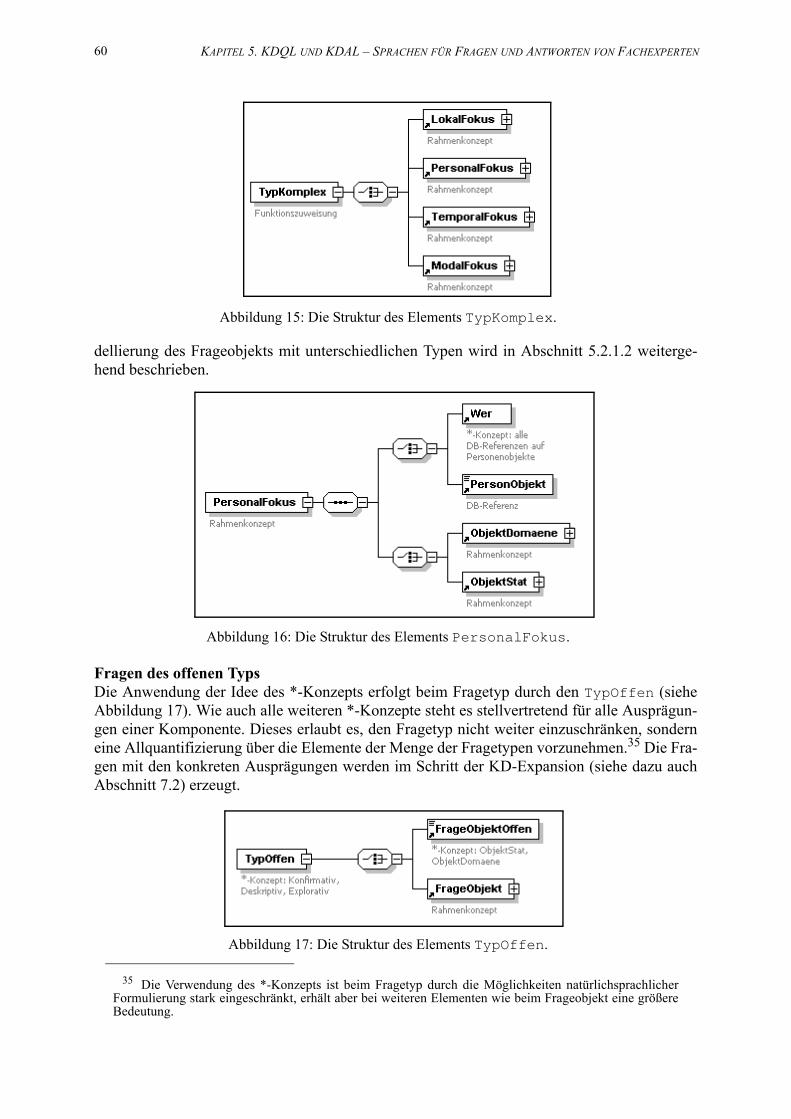
60 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
dellierung des Frageobjekts mit unterschiedlichen Typen wird in Abschnitt 5.2.1.2 weiterge-hend beschrieben.
Fragen des offenen TypsDie Anwendung der Idee des *-Konzepts erfolgt beim Fragetyp durch den TypOffen (sieheAbbildung 17). Wie auch alle weiteren *-Konzepte steht es stellvertretend für alle Ausprägun-gen einer Komponente. Dieses erlaubt es, den Fragetyp nicht weiter einzuschränken, sonderneine Allquantifizierung über die Elemente der Menge der Fragetypen vorzunehmen.35 Die Fra-gen mit den konkreten Ausprägungen werden im Schritt der KD-Expansion (siehe dazu auchAbschnitt 7.2) erzeugt.
Abbildung 15: Die Struktur des Elements TypKomplex.
Abbildung 16: Die Struktur des Elements PersonalFokus.
35 Die Verwendung des *-Konzepts ist beim Fragetyp durch die Möglichkeiten natürlichsprachlicherFormulierung stark eingeschränkt, erhält aber bei weiteren Elementen wie beim Frageobjekt eine größereBedeutung.
Abbildung 17: Die Struktur des Elements TypOffen.

615.2 DIE MODELLIERUNG VON KD-FRAGEN
Weitere FragetypenMehrfachfragen bzw. multiple Fragen, z.B. Wer zeigt welche Auffälligkeit? werden im Rah-men dieser Arbeit nicht betrachtet, weil sie durch hierarchische Dekomposition und Verfeine-rung der Fragen abgedeckt werden, z.B. Wer zeigt Zusammenhang?, Wer zeigt Unterschied?Auch Alternativfragen sind nicht Gegenstand dieser Arbeit, z.B. Welchen Gruppen zeigt Auf-fälligkeiten, die Neurologie oder die Urologie? weil sie ebenfalls durch eine Kombination an-derer Fragen ersetzt werden können.
5.2.1.2 Das Frageobjekt
Den zweiten fundamentalen Bestandteil der Fragewurzel stellt das Frageobjekt dar. Im gram-matischen Sinne bildet das Frageobjekt das direkte Objekt einer Frage. Im funktionentheoreti-schen Sinn kann es auch als Relation beschrieben werden, die durch die Menge der Frageargu-mente instantiiert wird. Den Einfluss des Frageobjekts bei der KD-DM-Transformation undvor allem bei der Auswahl der Data-Mining-Methode beschreiben wir im Abschnitt 7.3 im De-tail. In diesem Sinne stellt es eine Fokussierung des Suchraums in der Dimension der Data-Mi-ning-Methoden und -Algorithmen dar. Wir unterscheiden zwei Arten von Frageobjekten:
• Allgemeine Frageobjekte, z.B. Zusammenhang, Unterschied, und• Domänenspezifische Frageobjekte, z.B. Korrektheit der Therapeutik, Standards der
Therapeutik.Die einzelnen Frageobjekte unterscheiden sich auch durch die Anzahl und Art der mögli-
chen Frageargumente. Jedes Frageobjekt impliziert eine Hierarchie von Verfeinerungsstufen.
5.2.1.2.1 Allgemeine Frageobjekte
Entsprechend den statistischen Hypothesentypen Zusammenhang, Unterschied, Gemeinsam-keit und Veränderung führen wir die allgemeinen Frageobjekte ein.36 Diese sind für alle An-wendungsdomänen gleichermaßen relevant und stellen damit den invarianten Kern der Frage-objekte dar. Wir beschreiben im Folgenden die Modellierung der vier allgemeinen Frageobjek-te ausgehend vom Rahmenkonzept ObjektStat, wie auch in Abbildung 18 dargestellt. Fürdie Beschreibung ihrer Interpretation verweisen wir auf die Abschnitte 6.1.1 bis 6.1.4.
36 Im engeren Sinn werden in der Statistik (z.B. in [Bor93]) vor allem Zusammenhangs- und Unter-schiedhypothesen unterschieden. Die daraus abgeleiteten Gemeinsamkeits- und Veränderungshypothesenverdienen aufgrund ihrer Präsenz in den Fragen von Fachexperten aber eine eigenständige Modellierung.
Abbildung 18: Die Struktur des Elements ObjektStat.
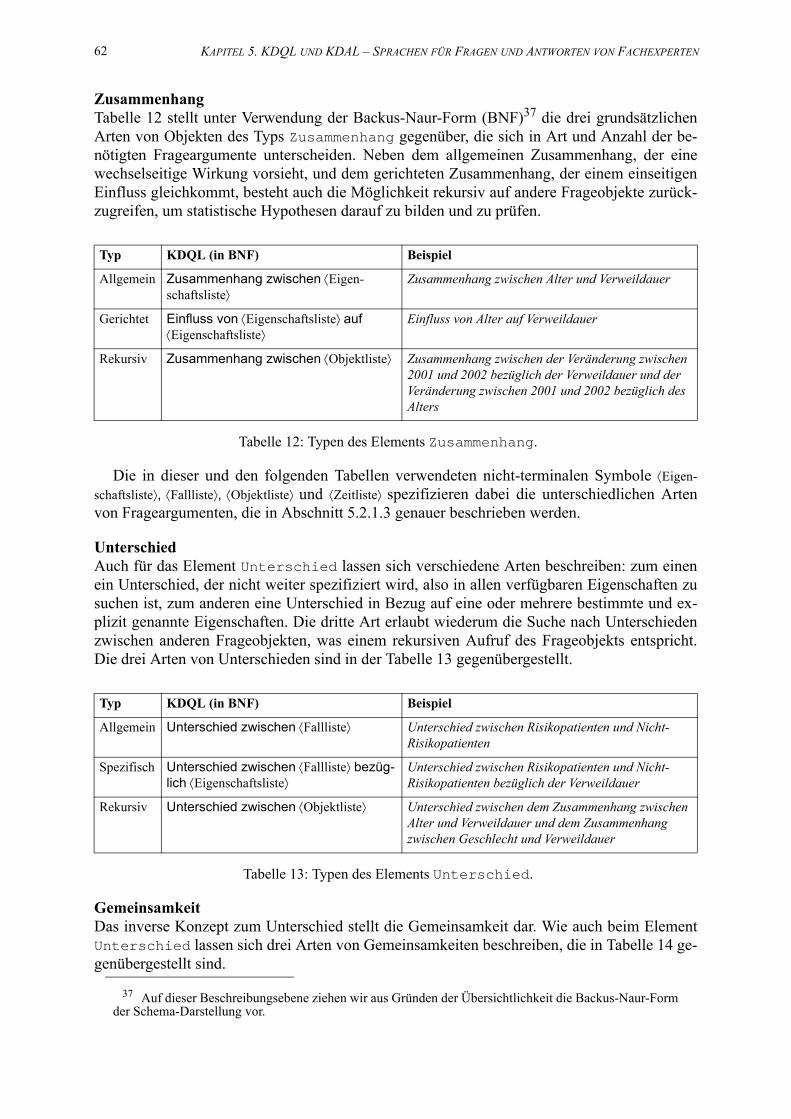
62 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
ZusammenhangTabelle 12 stellt unter Verwendung der Backus-Naur-Form (BNF)37 die drei grundsätzlichenArten von Objekten des Typs Zusammenhang gegenüber, die sich in Art und Anzahl der be-nötigten Frageargumente unterscheiden. Neben dem allgemeinen Zusammenhang, der einewechselseitige Wirkung vorsieht, und dem gerichteten Zusammenhang, der einem einseitigenEinfluss gleichkommt, besteht auch die Möglichkeit rekursiv auf andere Frageobjekte zurück-zugreifen, um statistische Hypothesen darauf zu bilden und zu prüfen.
Die in dieser und den folgenden Tabellen verwendeten nicht-terminalen Symbole ⟨Eigen-schaftsliste⟩, ⟨Fallliste⟩, ⟨Objektliste⟩ und ⟨Zeitliste⟩ spezifizieren dabei die unterschiedlichen Artenvon Frageargumenten, die in Abschnitt 5.2.1.3 genauer beschrieben werden.
UnterschiedAuch für das Element Unterschied lassen sich verschiedene Arten beschreiben: zum einenein Unterschied, der nicht weiter spezifiziert wird, also in allen verfügbaren Eigenschaften zusuchen ist, zum anderen eine Unterschied in Bezug auf eine oder mehrere bestimmte und ex-plizit genannte Eigenschaften. Die dritte Art erlaubt wiederum die Suche nach Unterschiedenzwischen anderen Frageobjekten, was einem rekursiven Aufruf des Frageobjekts entspricht.Die drei Arten von Unterschieden sind in der Tabelle 13 gegenübergestellt.
GemeinsamkeitDas inverse Konzept zum Unterschied stellt die Gemeinsamkeit dar. Wie auch beim ElementUnterschied lassen sich drei Arten von Gemeinsamkeiten beschreiben, die in Tabelle 14 ge-genübergestellt sind.
37 Auf dieser Beschreibungsebene ziehen wir aus Gründen der Übersichtlichkeit die Backus-Naur-Formder Schema-Darstellung vor.
Typ KDQL (in BNF) Beispiel
Allgemein Zusammenhang zwischen ⟨Eigen-schaftsliste⟩
Zusammenhang zwischen Alter und Verweildauer
Gerichtet Einfluss von ⟨Eigenschaftsliste⟩ auf ⟨Eigenschaftsliste⟩
Einfluss von Alter auf Verweildauer
Rekursiv Zusammenhang zwischen ⟨Objektliste⟩ Zusammenhang zwischen der Veränderung zwischen 2001 und 2002 bezüglich der Verweildauer und der Veränderung zwischen 2001 und 2002 bezüglich des Alters
Tabelle 12: Typen des Elements Zusammenhang.
Typ KDQL (in BNF) Beispiel
Allgemein Unterschied zwischen ⟨Fallliste⟩ Unterschied zwischen Risikopatienten und Nicht-Risikopatienten
Spezifisch Unterschied zwischen ⟨Fallliste⟩ bezüg-lich ⟨Eigenschaftsliste⟩
Unterschied zwischen Risikopatienten und Nicht-Risikopatienten bezüglich der Verweildauer
Rekursiv Unterschied zwischen ⟨Objektliste⟩ Unterschied zwischen dem Zusammenhang zwischen Alter und Verweildauer und dem Zusammenhang zwischen Geschlecht und Verweildauer
Tabelle 13: Typen des Elements Unterschied.
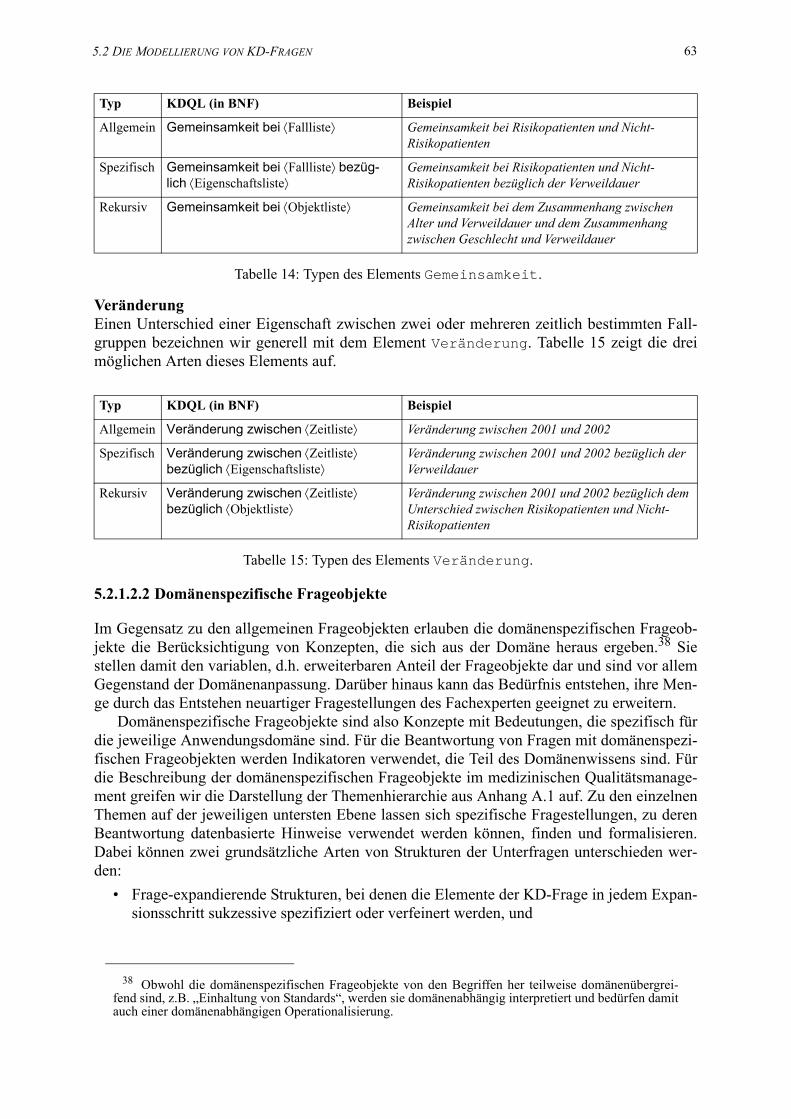
635.2 DIE MODELLIERUNG VON KD-FRAGEN
VeränderungEinen Unterschied einer Eigenschaft zwischen zwei oder mehreren zeitlich bestimmten Fall-gruppen bezeichnen wir generell mit dem Element Veränderung. Tabelle 15 zeigt die dreimöglichen Arten dieses Elements auf.
5.2.1.2.2 Domänenspezifische Frageobjekte
Im Gegensatz zu den allgemeinen Frageobjekten erlauben die domänenspezifischen Frageob-jekte die Berücksichtigung von Konzepten, die sich aus der Domäne heraus ergeben.38 Siestellen damit den variablen, d.h. erweiterbaren Anteil der Frageobjekte dar und sind vor allemGegenstand der Domänenanpassung. Darüber hinaus kann das Bedürfnis entstehen, ihre Men-ge durch das Entstehen neuartiger Fragestellungen des Fachexperten geeignet zu erweitern.
Domänenspezifische Frageobjekte sind also Konzepte mit Bedeutungen, die spezifisch fürdie jeweilige Anwendungsdomäne sind. Für die Beantwortung von Fragen mit domänenspezi-fischen Frageobjekten werden Indikatoren verwendet, die Teil des Domänenwissens sind. Fürdie Beschreibung der domänenspezifischen Frageobjekte im medizinischen Qualitätsmanage-ment greifen wir die Darstellung der Themenhierarchie aus Anhang A.1 auf. Zu den einzelnenThemen auf der jeweiligen untersten Ebene lassen sich spezifische Fragestellungen, zu derenBeantwortung datenbasierte Hinweise verwendet werden können, finden und formalisieren.Dabei können zwei grundsätzliche Arten von Strukturen der Unterfragen unterschieden wer-den:
• Frage-expandierende Strukturen, bei denen die Elemente der KD-Frage in jedem Expan-sionsschritt sukzessive spezifiziert oder verfeinert werden, und
Typ KDQL (in BNF) Beispiel
Allgemein Gemeinsamkeit bei ⟨Fallliste⟩ Gemeinsamkeit bei Risikopatienten und Nicht-Risikopatienten
Spezifisch Gemeinsamkeit bei ⟨Fallliste⟩ bezüg-lich ⟨Eigenschaftsliste⟩
Gemeinsamkeit bei Risikopatienten und Nicht-Risikopatienten bezüglich der Verweildauer
Rekursiv Gemeinsamkeit bei ⟨Objektliste⟩ Gemeinsamkeit bei dem Zusammenhang zwischen Alter und Verweildauer und dem Zusammenhang zwischen Geschlecht und Verweildauer
Tabelle 14: Typen des Elements Gemeinsamkeit.
Typ KDQL (in BNF) Beispiel
Allgemein Veränderung zwischen ⟨Zeitliste⟩ Veränderung zwischen 2001 und 2002
Spezifisch Veränderung zwischen ⟨Zeitliste⟩ bezüglich ⟨Eigenschaftsliste⟩
Veränderung zwischen 2001 und 2002 bezüglich der Verweildauer
Rekursiv Veränderung zwischen ⟨Zeitliste⟩ bezüglich ⟨Objektliste⟩
Veränderung zwischen 2001 und 2002 bezüglich dem Unterschied zwischen Risikopatienten und Nicht-Risikopatienten
Tabelle 15: Typen des Elements Veränderung.
38 Obwohl die domänenspezifischen Frageobjekte von den Begriffen her teilweise domänenübergrei-fend sind, z.B. „Einhaltung von Standards“, werden sie domänenabhängig interpretiert und bedürfen damitauch einer domänenabhängigen Operationalisierung.

64 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
• Konzept-expandierende Strukturen, bei denen ein Konzept schrittweise verfeinert undschließlich auf domänenspezifisch operationalisierbare Teilkonzepte abgebildet wird.
Im Folgenden sei dies für einen Ausschnitt der Themen stellvertretend für die Gesamtmen-ge gezeigt:
Frage-expandierende UnterfragestrukturenDas Thema „Standards der Therapeutik“ (1.2.2 in Anhang A.1) lässt sich folgendermaßen ex-pandieren:
Standards der TherapeutikStandards der Therapeutik bezüglich VerweildauernStandards der Therapeutik bezüglich LeistungenStandards der Therapeutik bezüglich der Verteilung von LeistungenStandards der Therapeutik bezüglich der Abfolgen von Leistungen
Dabei stellt das Konzept Standards der Therapeutik das eigentliche Frageobjekt dar, dasdurch das Frageargument (bezüglich Verweildauern usw.) als weitere Beschränkung des Fra-geraums sukzessive erweitert wird. Der Fragetyp (siehe Abschnitt 5.2.1.1) sowie weitereKDQL-Elemente (siehe Abschnitt 5.2.2 und Abschnitt 5.2.2.2) können wie beschrieben ver-wendet werden.
Konzept-expandierende UnterfragestrukturenDas Thema „Korrektheit der Therapeutik“ (1.2.1.1 in Anhang A.1) dient vor allem der Unter-scheidung von erfolgreichen und weniger erfolgreichen therapeutischen Aufenthalten. Für dieUntersuchung des Themas ist es deshalb wichtig, Komplikationen im klinischen Ablauf zu er-kennen. Dies erfolgt durch die Verwendung von Heuristiken, die auf das Auftreten oder dasNicht-Auftreten von Komplikationen hinweisen. Abbildung 19 zeigt die Operationalisierungdes Begriffs der Korrektheit der Therapeutik.
Bei dem ebenfalls in Anhang A.1 dargestellten Thema „Technische Differenziertheit derDokumentation“ (1.3.1.2.1.1.3 in Anhang A.1) handelt es sich um ein allgemeines Konzept,
Abbildung 19: Ausschnitt aus der Operationalisierung des Themas „Korrektheit der Therapeutik“.
Korrektheit derTherapeutik
Geringes Maß anKorrektheit der
Therapeutik
Hohes Maß anKorrektheit der
Therapeutik
Aufenthalt in derIntenivstation
BaldigeWiederaufnahme
Zwei Operationen in Folge
Überschreiten derVerweildauer-
obergrenzeNur eine Operation
Keine baldigeWiederaufnahme
Einhalten derVerweildauer-
obergrenze

655.2 DIE MODELLIERUNG VON KD-FRAGEN
das sich jedoch durch stark domänenspezifische Indikatoren auszeichnet. Im Kontext der me-dizinischen Dokumentation lässt sich das Thema, wie in Abbildung 20 gezeigt, operationali-sieren.
Beide Arten, die Strukturen der Unterfragen aufzubauen, werden verwendet, um domänen-spezifische Frageobjekte zu verfeinern.
Zusammen mit den allgemeinen Frageobjekten unterstützen die domänenspezifischen Fra-geobjekte die Auswahl einer für die Beantwortung der Frage geeigneten Methode. Für die wei-tergehende Einschränkung des Suchraums werden die Frageargumente benötigt.
5.2.1.3 Die Frageargumente
Frageargumente spezifizieren die Menge der Argumente, die die Grundlage für das Frageob-jekt bilden, und stellen damit die Beziehung zur Datenbasis her. Darüber hinaus erlauben dieFrageargumente die Beschränkung des Suchraums in der Dimension der Daten im Sinne einerProjektion und Selektion. Betrachtet man das Frageobjekt aus der relationalen Sicht, so werdendie Variablen der Relation durch die Frageargumente belegt.
Die Frageargumente sind Konzepte aus dem Datenmodell, das den Analysen zugrundeliegt, also Attribute, Attributwerte und Fälle sowie deren Abstraktionen zu Attributgruppen,Attributwertgruppen und Fallgruppen. Abbildung 21 zeigt das Modell der Frageargumente undAbbildung 22 stellt zur Illustration einen Teil des Domänenmodells für das medizinische Qua-litätsmanagement dar. Die einzelnen Frageargumente können durch die booleschen Operato-ren und, oder und entweder...oder verknüpft werden. Die Frageargumente können unterschied-liche Funktionen innerhalb einer Frage annehmen. Im Folgenden unterscheiden wir nach derArt der Argumente:
• Eigenschaftsargumente,• Gruppenargumente und• Objektargumente.Tabelle 16 enthält eine Übersicht über die verfügbaren Frageargumente und entsprechende
Beispiele.
5.2.1.3.1 Eigenschaftsargumente
Eigenschaftsargumente spezifizieren Referenzen39 auf die Datenbankattribute, die im funktio-nalen Sinne das Frageobjekt instantiieren. Sie werden aus der Menge der verfügbaren Attributerekrutiert und treffen in diesem Sinne eine vertikale Auswahl (Datenprojektion). Die Eigen-schaftsargumente werden über das in Tabelle 16 definierte Element Eigenschaftslistespezifiziert.
Abbildung 20: Ausschnitt aus der Operationalisierung des Themas“Technische Differenziertheit der Dokumentation“.
TechnischeDifferenziertheit der
Dokumentation
Anteil unspezifischdokumentierter
Med. Leistungen
Anteil unspezifischdokumentierter
Diagnosen
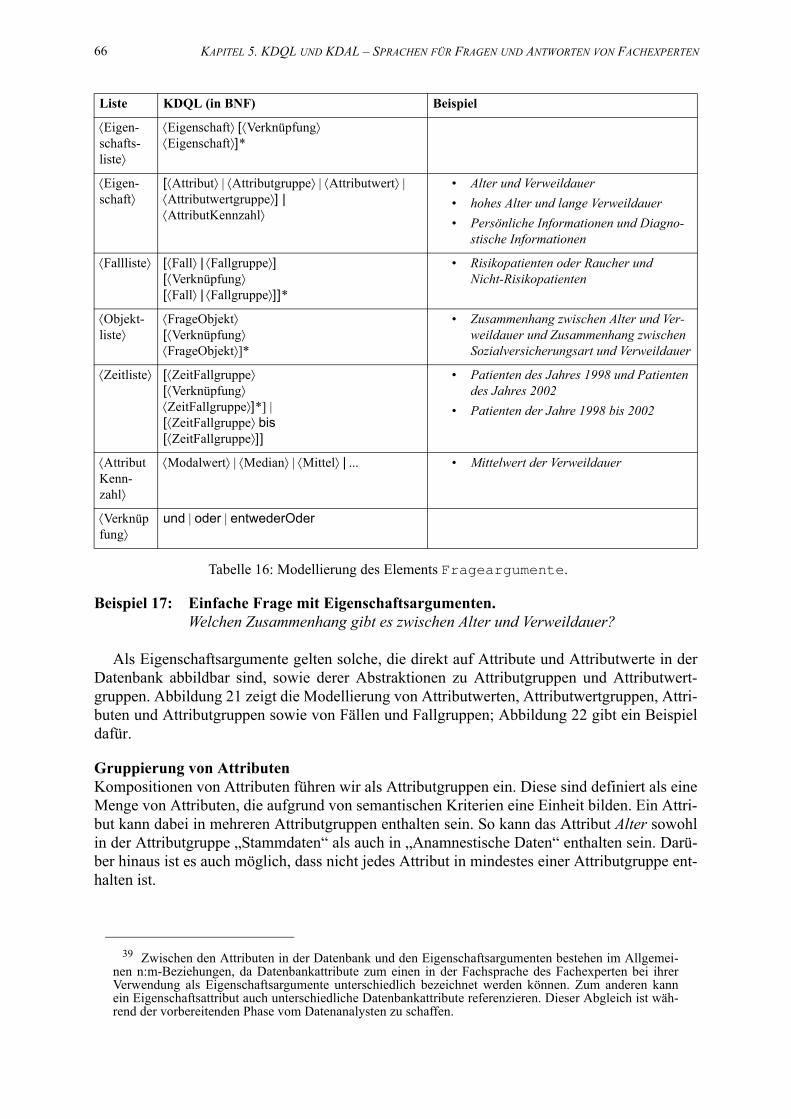
66 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
Beispiel 17: Einfache Frage mit Eigenschaftsargumenten.Welchen Zusammenhang gibt es zwischen Alter und Verweildauer?
Als Eigenschaftsargumente gelten solche, die direkt auf Attribute und Attributwerte in derDatenbank abbildbar sind, sowie derer Abstraktionen zu Attributgruppen und Attributwert-gruppen. Abbildung 21 zeigt die Modellierung von Attributwerten, Attributwertgruppen, Attri-buten und Attributgruppen sowie von Fällen und Fallgruppen; Abbildung 22 gibt ein Beispieldafür.
Gruppierung von AttributenKompositionen von Attributen führen wir als Attributgruppen ein. Diese sind definiert als eineMenge von Attributen, die aufgrund von semantischen Kriterien eine Einheit bilden. Ein Attri-but kann dabei in mehreren Attributgruppen enthalten sein. So kann das Attribut Alter sowohlin der Attributgruppe „Stammdaten“ als auch in „Anamnestische Daten“ enthalten sein. Darü-ber hinaus ist es auch möglich, dass nicht jedes Attribut in mindestes einer Attributgruppe ent-halten ist.
39 Zwischen den Attributen in der Datenbank und den Eigenschaftsargumenten bestehen im Allgemei-nen n:m-Beziehungen, da Datenbankattribute zum einen in der Fachsprache des Fachexperten bei ihrerVerwendung als Eigenschaftsargumente unterschiedlich bezeichnet werden können. Zum anderen kannein Eigenschaftsattribut auch unterschiedliche Datenbankattribute referenzieren. Dieser Abgleich ist wäh-rend der vorbereitenden Phase vom Datenanalysten zu schaffen.
Liste KDQL (in BNF) Beispiel
⟨Eigen-schafts-liste⟩
⟨Eigenschaft⟩ [⟨Verknüpfung⟩ ⟨Eigenschaft⟩]*
⟨Eigen-schaft⟩
[⟨Attribut⟩ | ⟨Attributgruppe⟩ | ⟨Attributwert⟩ | ⟨Attributwertgruppe⟩] | ⟨AttributKennzahl⟩
• Alter und Verweildauer• hohes Alter und lange Verweildauer• Persönliche Informationen und Diagno-
stische Informationen
⟨Fallliste⟩ [⟨Fall⟩ | ⟨Fallgruppe⟩] [⟨Verknüpfung⟩[⟨Fall⟩ | ⟨Fallgruppe⟩]]*
• Risikopatienten oder Raucher und Nicht-Risikopatienten
⟨Objekt-liste⟩
⟨FrageObjekt⟩[⟨Verknüpfung⟩ ⟨FrageObjekt⟩]*
• Zusammenhang zwischen Alter und Ver-weildauer und Zusammenhang zwischen Sozialversicherungsart und Verweildauer
⟨Zeitliste⟩ [⟨ZeitFallgruppe⟩ [⟨Verknüpfung⟩⟨ZeitFallgruppe⟩]*] |[⟨ZeitFallgruppe⟩ bis [⟨ZeitFallgruppe⟩]]
• Patienten des Jahres 1998 und Patienten des Jahres 2002
• Patienten der Jahre 1998 bis 2002
⟨AttributKenn-zahl⟩
⟨Modalwert⟩ | ⟨Median⟩ | ⟨Mittel⟩ | ... • Mittelwert der Verweildauer
⟨Verknüpfung⟩
und | oder | entwederOder
Tabelle 16: Modellierung des Elements Frageargumente.

675.2 DIE MODELLIERUNG VON KD-FRAGEN
Gruppierung von AttributwertenAttributwerte können zu Attributwertgruppen zusammengefasst werden. Eine Attributwert-gruppe stellt also eine Menge von n Attributen dar. Im Falle von Attributen mit einem metri-schen oder ordinalen Skalentyp kann die Attributwertgruppe als Intervall, das durch den maxi-malen und den minimalen Attributwert definiert wird, beschrieben werden. Zwischen benach-barten Intervallen darf es keine Überschneidungen geben. Für Attribute mit nominalen Skalen,die also keine implizite Ordnung tragen, kann die Attributwertgruppe nur durch die Aufzäh-lung der Attributwerte beschrieben werden. Dabei ist aber wiederum auf die Disjunktheit derAttributwertgruppen zu achten. Wenn für ein Attribut Attributwertgruppen eingeführt wurden,muss jeder einzelne Attributwert in genau einer Attributwertgruppe enthalten sein.
Kennzahlen auf AttributwertenEine weitere Form der Abstraktion erlaubt die Verwendung von Kennzahlen zur Beschreibungunivariater Häufigkeitsverteilungen der Menge der Attributwerte zu einem Attribut, wie z.B.die Bildung des Mittelwerts oder der Standardabweichung. Da die Verwendbarkeit einerKennzahl für die Attributwerte vom Skalentyp des Attributs abhängig ist, müssen minimaleSkalentypen definiert sein, die die Anwendung einer Kennzahl für ein Attribut erlauben.40 Fürdiesen Zweck wird das Element AttributKennzahl eingeführt, das in Tabelle 17 im Detailbeschrieben ist.
Abbildung 21: Das Modell der Eigenschaftsargumente und der Grup-penargumente.
Abbildung 22: Ausschnitt aus dem Domänenmodell.
Attribut
Attributwert
Attributwert-gruppe
Attributgruppe
Fall
Fallgruppe
1 : n
1 : n
n : 1
n : mn : m
Datenbankobjekte
Kompositionen derDatenbankobjekte
Persönliche Daten
Alter
Jung(0 - 45 Jahre ) Alt
(46 - 95 Jahre)
Geschlecht
0 45 46 95 MW... ...
...
Attributgruppen
Attribut
Attributwertegruppen
Attributwerte
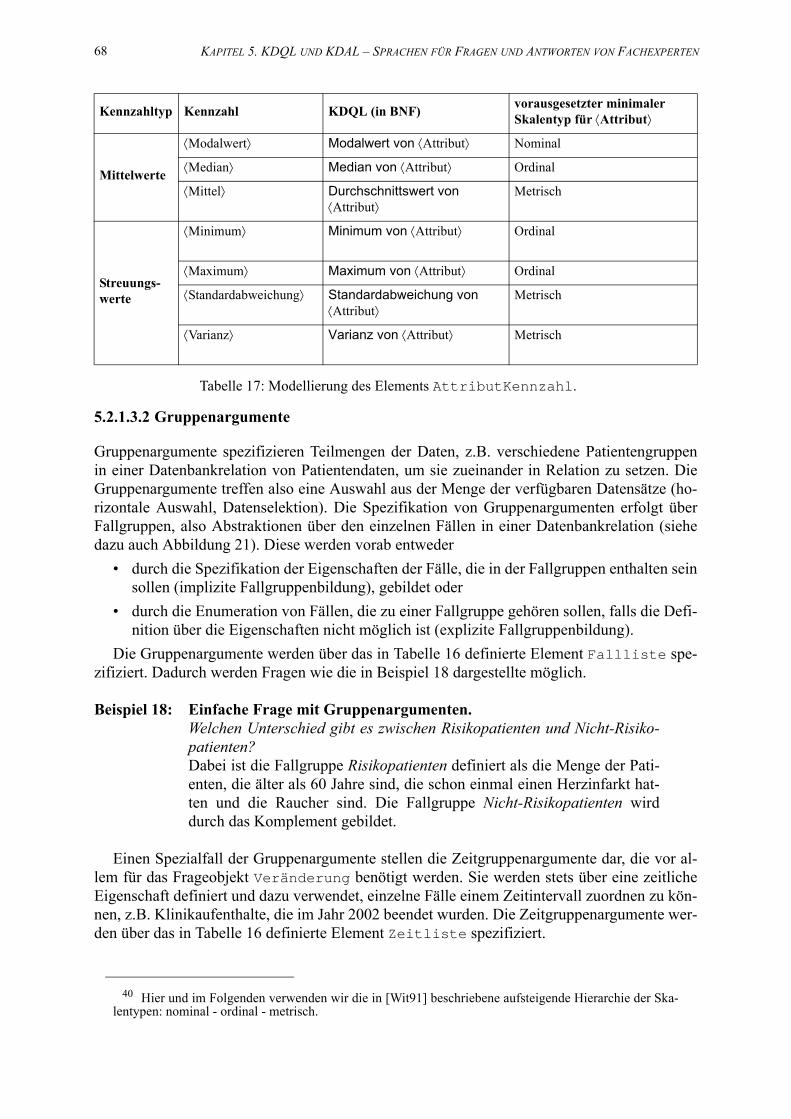
68 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
5.2.1.3.2 Gruppenargumente
Gruppenargumente spezifizieren Teilmengen der Daten, z.B. verschiedene Patientengruppenin einer Datenbankrelation von Patientendaten, um sie zueinander in Relation zu setzen. DieGruppenargumente treffen also eine Auswahl aus der Menge der verfügbaren Datensätze (ho-rizontale Auswahl, Datenselektion). Die Spezifikation von Gruppenargumenten erfolgt überFallgruppen, also Abstraktionen über den einzelnen Fällen in einer Datenbankrelation (siehedazu auch Abbildung 21). Diese werden vorab entweder
• durch die Spezifikation der Eigenschaften der Fälle, die in der Fallgruppen enthalten seinsollen (implizite Fallgruppenbildung), gebildet oder
• durch die Enumeration von Fällen, die zu einer Fallgruppe gehören sollen, falls die Defi-nition über die Eigenschaften nicht möglich ist (explizite Fallgruppenbildung).
Die Gruppenargumente werden über das in Tabelle 16 definierte Element Fallliste spe-zifiziert. Dadurch werden Fragen wie die in Beispiel 18 dargestellte möglich.
Beispiel 18: Einfache Frage mit Gruppenargumenten.Welchen Unterschied gibt es zwischen Risikopatienten und Nicht-Risiko-patienten?Dabei ist die Fallgruppe Risikopatienten definiert als die Menge der Pati-enten, die älter als 60 Jahre sind, die schon einmal einen Herzinfarkt hat-ten und die Raucher sind. Die Fallgruppe Nicht-Risikopatienten wirddurch das Komplement gebildet.
Einen Spezialfall der Gruppenargumente stellen die Zeitgruppenargumente dar, die vor al-lem für das Frageobjekt Veränderung benötigt werden. Sie werden stets über eine zeitlicheEigenschaft definiert und dazu verwendet, einzelne Fälle einem Zeitintervall zuordnen zu kön-nen, z.B. Klinikaufenthalte, die im Jahr 2002 beendet wurden. Die Zeitgruppenargumente wer-den über das in Tabelle 16 definierte Element Zeitliste spezifiziert.
40 Hier und im Folgenden verwenden wir die in [Wit91] beschriebene aufsteigende Hierarchie der Ska-lentypen: nominal - ordinal - metrisch.
Kennzahltyp Kennzahl KDQL (in BNF) vorausgesetzter minimaler Skalentyp für ⟨Attribut⟩
Mittelwerte
⟨Modalwert⟩ Modalwert von ⟨Attribut⟩ Nominal
⟨Median⟩ Median von ⟨Attribut⟩ Ordinal
⟨Mittel⟩ Durchschnittswert von ⟨Attribut⟩
Metrisch
Streuungs-werte
⟨Minimum⟩ Minimum von ⟨Attribut⟩ Ordinal
⟨Maximum⟩ Maximum von ⟨Attribut⟩ Ordinal
⟨Standardabweichung⟩ Standardabweichung von ⟨Attribut⟩
Metrisch
⟨Varianz⟩ Varianz von ⟨Attribut⟩ Metrisch
Tabelle 17: Modellierung des Elements AttributKennzahl.

695.2 DIE MODELLIERUNG VON KD-FRAGEN
5.2.1.3.3 Objektargumente
In Ergänzung zu den beiden datenorientierten Frageargumenten Eigenschaftsargumenteund Gruppenargumente führen wir den dritten Typ von Frageargumenten Objektargu-mente ein. Dieser erlaubt einen rekursiven Aufruf von Frageobjekten. Damit werden sowohlstatistische Frageobjekte, wie z.B. Zusammenhang, als auch domänenspezifische Frageobjek-te, wie z.B. Korrektheit der Therapeutik, mit ihren jeweiligen Argumenten als Frageargumentemöglich. Beispiel 19 zeigt eine solche Frage mit einer rekursiven Verwendung von Frageob-jekten.
Beispiel 19: Einfache Frage mit Objektargumenten.Welchen Zusammenhang gibt es zwischen der Veränderung der Verweil-dauer zwischen 1998 und 2002 und der Veränderung des Privatversicher-ten-Anteils zwischen 1998 und 2002?
Die Verwendung von Objektargumenten ist jedoch nur für statistische Frageobjekte not-wendig und sinnvoll. Zudem soll nicht mehr als eine Rekursionsstufe erlaubt werden, um dieKomplexität der Fragen zu begrenzen und ihre Verständlichkeit sicherzustellen.
5.2.2 Die optionalen Frageelemente
Die im vorhergehenden Abschnitt beschriebene Fragewurzel bestehend aus Fragetyp, Frage-objekt und Frageargumenten kann durch zwei optionale Elemente ergänzt werden, die vor al-lem eine Datenvorverarbeitung durch Gruppierung und Selektion realisieren: die Fragegruppeund der Fragekontext.
5.2.2.1 Die Fragegruppe
Das Element Fragegruppe realisiert eine Abstraktion über die einzelnen Datenobjekte underlaubt die implizite Gruppierung von Datenobjekten durch Spezifikation des Attributs überdessen Attributwerte die Gruppen gebildet werden. Damit wird es möglich, nur Datenobjektemiteinander in Beziehung zu setzen, d.h. als eine Grundgesamtheit für Data-Mining-Analysenzu betrachten, die in Bezug auf ein oder mehrere Attribute eine homogene Gruppe bilden.Beim medizinischen Qualitätsmanagement beispielsweise ist die Hauptdiagnose, die für jedenPatienten gestellt wurde, ein solches Kriterium. Nur innerhalb von Patientengruppen, die auf-grund derselben Hauptdiagnose behandelt werden, sind Vergleiche sinnvoll möglich.
Wie auch der im folgenden Abschnitt beschriebene Fragekontext, definiert die Frage-gruppe eine Menge von Fällen innerhalb derer die Antworten gesucht werden. Fachexpertenbezeichnen diese Gruppen üblicherweise über das Gruppierungskriterium, also z.B. die Haupt-diagnose. Die einzelnen Gruppen, die aus der Gruppierung entstehen, sind dann aber durch be-stimmte Ausprägungen zu dieser Eigenschaft charakterisiert. Die folgenden drei in Tabelle 18beschriebenen Typen von Fragegruppen lassen sich unterscheiden:
• Allgemeine Fragegruppe: Es wird keine einschränkende Gruppierung vorgenommen;alle verfügbaren Fälle werden zusammen zur Beantwortung herangezogen.
• Explizit definierte Fragegruppe: Der Fachexperte benennt die Gruppierungskriterienexplizit in der Frage.
• Implizit definierte Fragegruppe: Standardkriterien für die Gruppierungen, die Teil desDomänenwissens sind und vorab vom Fachexperten erhoben wurden, werden ange-wandt. Dies reduziert den Aufwand für den Fachexperten, bei jeder Frageformulierung

70 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
die Gruppen zu spezifizieren, die innerhalb einer Domäne als statisch angesehen werdenkönnen.
5.2.2.2 Der Fragekontext
Da in vielen Fällen nicht die vollständige Menge der Daten, die für die Beantwortung einerFrage zur Verfügung stehen, für den Fachexperten von Interesse ist, sondern nur unterschiedli-che Ausschnitte daraus, führen wir den Fragekontext ein. Dieser erlaubt die explizite Spezi-fikation eines Ausschnitts aus der Gesamtmenge der Daten durch die Angabe eines Selektions-kriteriums und eines zugehörigen Ausprägung. Im datentechnischen Sinne erfolgt damit eineSelektion der Fälle, die die in die Beantwortung der Fragestellung einbezogen werden sollen.Auch für den Fragekontext erlauben wir drei Arten der Spezifikation, die in Tabelle 19 be-schrieben sind:
• Allgemeiner Fragekontext: Es wird kein einschränkender Kontext gewählt und damitkeine Datenselektion vorgenommen; alle verfügbaren Fälle werden für die Beantwor-tung der Frage verwendet.
• Explizit definierter Kontext: Der Fachexperte benennt die kritischen Ausprägungen zuden interessanten Eigenschaften.
• Implizit definierter Kontext: Standardkriterien für die Kontextbildung, die wiederumTeil des Domänenwissens sind und vorab vom Fachexperten erhoben wurden, werdenangewandt. Damit ist auch hier eine Reduktion des Formulierungsaufwands bei Stan-dardfragen möglich.
Mit den beiden optionalen Elementen Fragegruppe und Fragekontext beschließen wir dieDarstellung der Knowledge Discovery Question Language für die Beschreibung der Syntaxvon KD-Fragen. Die aus Beispiel 12 bekannte Frage lässt sich unter Verwendung des beschrie-benen XML-Schemas mit KDQL wie in Abbildung 23 gezeigt darstellen
Bevor wir uns im Kapitel 6 der Beschreibung der Operationalisierung von KD-Fragen zu-wenden, wollen wir noch einen kurzen Blick auf das Pedant zu den KD-Fragen, also auf dieKD-Antworten und ihre Syntax werfen.
Typ KDQL (in BNF) Beispiel
Allgemein - innerhalb aller Fälle
Explizit definiert in Gruppen mit derselben ⟨Eigenschaft⟩
in Gruppen mit derselben Hauptdiagnose
Implizit definiert in interessanten Gruppen in interessanten Gruppen
Tabelle 18: Modellierung des Elements Fragegruppe.
Typ KDQL (in BNF) Beispiel
Allgemein - in den Gesamtdaten
Explizit definiert in einer Datenmenge bestimmt durch ⟨Eigenschaft⟩ ⟨Ausprägung⟩
in einer Datenmenge bestimmt durch das Jahr 2001
Implizit definiert in interessante Datenmengen in interessanten Datenmengen
Tabelle 19: Modellierung des Elements Fragekontext.

715.3 DIE MODELLIERUNG VON KD-ANTWORTEN
5.3 Die Modellierung von KD-Antworten
Der Begriff der Antwort erfährt im Vergleich zur Frage in der einschlägigen Literatur eine we-sentlich geringere Aufmerksamkeit. Dies ist sicherlich dem Umstand zuzuschreiben, dass eineAntwort nur Teil des Sprechakts Frage im linguistischen Sinne bzw. das Komplement zumSatztyp Frage im normalen Sprachgebrauch ist. Antworten werden also als spezielle Propositi-onen mit einem Bezug zu einer Frage verstanden. Durch diese nicht zu unterschätzende Ab-hängigkeit von der zu beantwortenden Frage wird nicht nur der Typ, sondern auch die Struktureiner Antwort bereits zu einem hohen Grad durch die Formulierung der Frage vorgegeben.Beispiel 20 erläutert dies anhand von zwei verschiedenen Arten von Fragen.
<KD-Frage><FrageWurzel>
<TypDeskriptiv><ObjektStat>
<Zusammenhang><ZusammenhangGerichtet>
<AbhängigArgument><EigenschaftArgument ArgumentTyp="Attribut">
Alter</EigenschaftArgument>
</AbhängigArgument><UnabhängigArgument>
<EigenschaftArgument ArgumentTyp="Attribut">Verweildauer
</EigenschaftArgument></UnabhängigArgument>
</ZusammenhangGerichtet></Zusammenhang>
</ObjektStat></TypDeskriptiv>
</FrageWurzel><FrageGruppe>
<GruppeArgument><Attribut>Hauptdiagnose</Attribut>
</GruppeArgument></FrageGruppe><FrageKontext>
<Attributwertpaar><Attribut>Klinik</Attribut><Attributwert>Augenklinik</Attributwert>
</Attributwertpaar></FrageKontext>
</KD-Frage>
Abbildung 23: XML-Darstellung der Frage aus Beispiel 12.

72 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
Beispiel 20: Antworten. Auf Entscheidungs- oder Satzfragen wie Gibt es einen Zusammenhang zwischen Alter und Verweildauer? muss notwendigerweise die minimale41 Antwort Ja, es gibt einen Zusammenhang zwischen Alter und Verweildauer! heißen, während ein Beispiel für eine angemessene Antwort auf dieErgänzungs- oder Wortfrage Welchen Zusammenhang gibt es zwischen Alter und Verweildauer bei denPatienten mit derselben Hauptdiagnose der Augenklinik?nur Es gibt einen starken, positiven Zusammenhang zwischen Alter und Ver-weildauer bei den Patienten mit derselben Hauptdiagnose in der Augen-klinik!lauten kann.
Analog zum Aufbau von KD-Fragen stellen wir die folgenden vier Hauptelemente von KD-Antworten fest:
• das Antwortobjekt, • die Antwortargumente, • die Antwortgruppe und• den Antwortkontext.Die Antwortgruppe und der Antwortkontext entsprechen der Fragegruppe (siehe Abschnitt
5.2.2.1) und dem Fragekontext (siehe Abschnitt 5.2.2.2) und werden deshalb im Folgendennicht weiter betrachtet. Für die Beschreibung von KD-Antworten führen wir die KnowledgeDiscovery Answer Language (KDAL) ein, die eine ähnliche Syntax wie KDQL aufweist. Auchin diesem Fall lässt sich die komplexe Antwortwurzel, wie in Beispiel 20 dargestellt, zerlegenin den Antworttyp, das Antwortobjekt und die zusätzliche Antwortobjektbeschreibung sowiedie Antwortargumente.
Beispiel 21: Analyse einer Antwort. Die in Beispiel 20 beschriebene Antwort lässtsich mit den folgenden Elementen von KDAL beschreiben:
Da die Formulierung von Antworten im Generellen und KD-Antworten im Speziellen, wie
41 Das Phänomen, dass mit der Frage „Gibt es einen Zusammenhang?“ eigentlich die Frage „WelchenZusammenhang gibt es?“ impliziert wird, dass also die Existenz eines Zusammenhangs bereits unterstelltwird – in der Linguistik als Präsupposition bezeichnet – soll hier nicht weiter berücksichtigt werden. Dieminimale Antwort wird dann also auch die maximale sein.
Antwortteil KDAL-Element
Es gibt Antworttyp
einen starken, positiven Antwortobjektbeschreibung
Zusammenhang Antwortobjekt
zwischen Alter und Verweildauer Antwortargumente
bei den Patienten mit derselben Hauptdiagnose Antwortgruppe
in der Augenklinik. Antwortkontext
Tabelle 20: KDAL-Elemente einer einfachen Antwort.

735.3 DIE MODELLIERUNG VON KD-ANTWORTEN
schon früher erwähnt, einen hohen Grad an Abhängigkeit von den entsprechenden Fragen bzw.KD-Fragen haben, können die Elemente Antwortobjekt, Antwortargumente, Antwort-gruppe und Antwortkontext direkt von der KD-Frage übernommen werden.42 Die zusätz-lichen Informationen, die durch die KD-Antwort geliefert werden, sind:
• bei konfirmativen KD-Fragen im Antworttyp (z.B. Ja, es gibt...!),• bei deskriptiven KD-Fragen in der Antwortobjektbeschreibung (z.B. einen star-
ken, positiven Zusammenhang) und • bei komplexen KD-Fragen in der Antwortfokusbeschreibung (z.B. Patienten, die
älter sind als 55 Jahre...) enthalten.Im Folgenden soll die Formulierung von KD-Antworten zu den unterschiedlichen Typen
von KD-Fragen detaillierter untersucht werden.
5.3.1 KD-Antworten zu konfirmativen KD-Fragen
Wie in Abschnitt 5.2.1.1 angedeutet, stellt der konfirmative Typ von Fragen ein booleschesPrädikat dar, das entscheidet, ob die Hypothese, die in der KD-Frage formuliert ist, in den Da-ten bestätigt oder widerlegt werden kann. Die dazugehörigen KD-Antworten, die wir in positivund negativ konfirmativ unterscheiden, sehen daher, wie in Tabelle 21 gezeigt, sehr einfachaus. Diese erste Möglichkeit der Formulierung von KD-Antworten wurde bereits früher in Bei-spiel 14 gezeigt.
5.3.2 KD-Antworten zu deskriptiven KD-Fragen
Die wichtigste zusätzliche Information, die von KD-Antworten zu deskriptiven Fragen gelie-fert werden, ist die Beschreibung des Frageobjekts, die wir als Antwortobjektbeschrei-bung bezeichnen. Diese stammt von der Beschreibung des Ergebnisses der Hypothesenüber-prüfung und ist damit vom Typ der Hypothese abhängig. Dabei ergeben sich unterschiedlicheBeschreibungsmaße. Im Falle einer Zusammenhangshypothese sind dies beispielsweise
• die Stärke, zum Beispiel der Betrag eines Korrelationskoeffizienten, und• die Richtung, das heißt die Art und Weise, wie sich Veränderungen der Größen der Fak-
toren zueinander verhalten.Die numerischen Beschreibungen für die einzelnen Beschreibungsmaße können nach
[Wit91] und [Käp02] gruppiert und versprachlicht werden. Eine vollständige Übersicht über
42 Obwohl beispielsweise Antwortargumente identisch mit Frageargumenten sind, verwenden wir fürsie eigenständige Bezeichnungen, da sie im Rahmen einer Antwort Teile einer vollständigen Aussage sind.
Antworttyp KDAL (in BNF)
positiv konfirmativ Ja, es gibt ⟨Antwortobjekt⟩ ⟨Antwortargumente⟩ ⟨Antwortgruppe⟩ ⟨Antwortkontext⟩.
negativ konfirmativ Nein, es gibt kein ⟨Antwortobjekt⟩ ⟨Antwortargumente⟩ ⟨Antwortgruppe⟩ ⟨Antwort-kontext⟩.
deskriptiv Es gibt ⟨Antwortobjektbeschreibung⟩ ⟨Antwortobjekt⟩ ⟨Antwortargumente⟩ ⟨Ant-wortgruppe⟩ ⟨Antwortkontext⟩.
komplexBei ⟨Antwortfokus⟩ ⟨Antwortgruppe⟩ ⟨Antwortkontext⟩, bei denen ⟨Antwortfokusbe-schreibung⟩ ist, gibt es ⟨Antwortobjektbeschreibung⟩ ⟨Antwortobjekt⟩ ⟨Ant-wortargumente⟩.
Tabelle 21: Arten von KD-Antworten.

74 KAPITEL 5. KDQL UND KDAL – SPRACHEN FÜR FRAGEN UND ANTWORTEN VON FACHEXPERTEN
die Beschreibungsmaße für alle Elemente und die Möglichkeiten der Gruppierung und Ver-sprachlichung liefert Anhang D. Die Formulierung von KD-Antworten zu deskriptiven KD-Fragen wurde bereits in Beispiel 15 dargestellt.
5.3.3 KD-Antworten zu komplexen KD-Fragen
Bei komplexen Fragen wird neben dem Frageobjekt auch der Fragefokus untersucht. Die Be-antwortung der Frage muss dementsprechend, wie in Abschnitt 6.2.3 detailliert beschrieben, inmehreren Schritten durchgeführt werden. Als Ergebnis einer solchen Beantwortungsfolge er-gibt sich damit zum einen die Beschreibung des Antwortobjekt, die Antwortobjektbe-schreibung, und zum anderen die Charakterisierung der Menge der Elemente aus dem Ant-wortfokus, für die die Hypothese bestätigt werden konnte. Diese bezeichnen wir als Antwort-fokusbeschreibung. Beispiel 16 illustriert die Formulierung von KD-Antworten zu kom-plexen Fragen.
5.4 Zusammenfassung
In diesem Kapitel haben wir die syntaktischen Aspekte der Knowledge Discovery QuestionLanguage (KDQL) für die Formulierung von Fragen von Fachexperten und der KnowledgeDiscovery Answer Language (KDAL) für die Formulierung der entsprechenden Antworten be-schrieben. Damit sind der Ausgangspunkt und das Ziel eines Analyseschrittes definiert. BeideSprachen spiegeln die Anforderungen von Fachexperten bei der Datenanalyse wider und ab-strahieren beispielsweise weitestgehend von Data-Mining- und Datenbankterminologie. Auf-grund des Abgleich mit der Grammatik der natürlicher Sprache bei der Konzeption von KDQLkann von einem hohen Grad von Vollständigkeit der Abdeckung mit den tatsächlichen Fragenvon Experten ausgegangen werden. Die beiden Sprachen bestehen aus allgemeinen und domä-nenspezifischen Teilen und sind aufgrund ihrer deklarativen Beschreibung als XML-Sprachenleicht wart- und erweiterbar. KDQL und KDAL stehen damit für den Einsatz in der prototypi-schen Realisierung unseres Ansatzes im Knowledge Discovery Assistant (KDA) zur Verfü-gung (siehe dazu auch Kapitel 8). Im nun folgenden Kapitel werden wir uns detailliert mit derOperationalisierung von KD-Fragen auseinandersetzen, um Ihre Bedeutung zu beschreiben.

KAPITEL 6 DIE OPERATIONALISIERUNG VON KD-FRAGEN
Für die Beschreibung der Semantik von Fragen existieren, wie in Abschnitt 3.2 dargestellt,zwei verschiedene Ansätze: die funktionale Theorie beschreibt die Semantik von Fragen alseine Funktion auf der Menge der Kurzantworten, während die propositionale Theorie Fragenals Mengen von kongruenten Propositionen beschreibt. Unter Verwendung der propositionalenoder Antwortmengen-Theorie und des in Abschnitt 3.2.3 erwähnten Kompositionalitätsprin-zips von Frege ließe sich postulieren:
Die Bedeutung einer KD-Frage ist die Menge ihrer KD-Antworten.
Da sich KD-Antworten, wie in Abschnitt 5.2 dargestellt, ähnlich wie KD-Fragen über eineMenge von Elementen beschreiben lassen, die für jede Instanz einer KD-Antwort durch be-stimmte Ausprägungen befüllt sind, lässt sich weitergehend fordern:
Die Menge der KD-Antworten zu einer KD-Frage ist das kartesische Kreuzproduktder Mengen aller Möglichkeiten, die einzelnen Elemente einer KD-Antwort zu fül-len.
Die propositionale Theorie lässt sich jedoch nur als Grundidee auf den hier vorliegendenFall anwenden: Bei den Frage-Antwort-Kombinationen, für die die semantischen Theorienentwickelt wurden, lässt sich davon ausgehen, dass der Gefragte die Antwort zum Zeitpunktder Fragestellung weiß und nur formulieren muss. Diese Annahme ist sicherlich bei Fragen imalltäglichen Gebrauch43 gültig, trifft hier jedoch nicht zu. Um Antworten auf die vom Fachex-perten gestellten Fragen zu liefern, werden im Kontext unserer Ansatzes verschiedene Metho-den und Algorithmen angewendet, deren Ergebnisse als Bestandteile von Antworten gesehenwerden. KD-Fragen spezifizieren also indirekt und aufgrund der flexiblen Abbildungsmecha-nismen (siehe Kapitel 7) mit einer gewissen Dynamik Experimente, die auf den Daten ausge-führt werden sollen. Damit kann KDQL als Kommandosprache auf hoher Ebene verstandenwerden. Die Bedeutung eines Ausdrucks in KDQL und damit einer KD-Frage stellt sich alsoals ihre Operationalisierung dar.
Im Folgenden gilt es zu untersuchen, wie sich die Operationalisierung einer KD-Frage imDetail beschreiben lässt, um die Bedeutung der KD-Frage verstehen zu können. Dabei gehenwir von der grundsätzlichen Annahme aus, dass die Bedeutung von Attributen, Attributwertenund Fällen, die als Frageargumente für KD-Fragen verwendet werden können, der Semantikihrer Datenbankeinträge entspricht.44
43 Dies gilt auch für fragegesteuerte Information-Retrieval-Systeme und Suchmaschinen.44 Daraus ergibt sich die Anforderung an den Benutzer, dass er mit der Bedeutung der in der Datenbank
enthaltenen Attribute usw. vertraut ist, die wir im Abschnitt 9.3 im Rahmen der Evaluierung des Ansatzesnoch detaillierter beschreiben werden.

76 KAPITEL 6. DIE OPERATIONALISIERUNG VON KD-FRAGEN
Wie wir in Kapitel 7 zeigen werden, hängt die Art der Beantwortung einer KD-Frage davonab, welche statistischen oder Data-Mining-Methoden zur Verfügung stehen und ausgewähltwerden. Aus diesem Grund lässt sich die Semantik der KD-Fragen nicht unabhängig davon be-schreiben. Wir werden deshalb im Folgenden von einem Grundvorrat an Methoden ausgehen,den wir als Standard definieren und für die Beschreibung der Semantik verwenden.
Ausschlaggebend für die Auswahl der Methode ist das Frageobjekt.45 Aus diesem Grundwerden wir die Darstellung der KD-Antwortmengen zu KD-Fragen zunächst an den Frageob-jekten orientieren.
6.1 Die Operationalisierung des Frageobjekts
Das Frageobjekt ist das primäre Auswahlkriterium für die Methode aus dem Bereich Statistikoder Data-Mining, die zur Beantwortung der KD-Frage verwendet wird. Im Folgenden gehenwir zunächst auf die Bedeutung der allgemeinen Frageobjekte (siehe auch Abschnitt 5.2.1.2.1)und der domänenspezifischen Frageobjekte (siehe auch Abschnitt 5.2.1.2.2) ein. Dabei formu-lieren wir zunächst eine Hypothese, die wir als theoretische Grundlage für die Frage betrach-ten, und wählen eine Methode aus dem Standardvorrat, die für die Überprüfung der Hypothesegeeignet ist. Da die einzelnen Methoden unterschiedliche Bewertungsmaße liefern, müssen mitden Methoden Beschreibungen dieser Maße und Kriterien, z.B. Grenzwerte, für die Entschei-dungsfunktionen geliefert werden. Eine detaillierte Beschreibung der Methoden zur Hypothe-senverifikation liefert Wittenberg in [Wit91].
Die allgemeinen Typen der Frageobjekte enthalten keine expliziten Eigenschaften, dieüberprüft werden sollen. Stattdessen werden Hypothesen für alle relevanten Eigenschaftenmithilfe der entsprechenden statistischen Tests generiert und überprüft. Die Spezialisierung ei-nes statistischen Elements durch eine Eigenschaft bewirkt eine Eingrenzung auf eine Hypothe-se und damit einen statistischen Test. In Ergänzung zu den statistischen Tests lassen sich fürden Nachweis der statistischen Elemente auch andere, „klassischere“ Data-Mining-Methoden,also beispielsweise Verfahren der Regelinduktion (z.B. diskriminierende Regeln für den Nach-weis von Unterschieden, Assoziationsregeln für Zusammenhänge) anwenden.46
6.1.1 KD-Fragen nach einem Zusammenhang
Basierend auf statistischen Zusammenhangshypothesen (z.B. „zwischen Fehlzeiten und Stressam Arbeitsplatz besteht ein positiver Zusammenhang“), löst dieses Frageobjekt die Suche nachzwei oder mehr Variablen aus, zwischen denen ein statistischer Zusammenhang besteht, wie esz.B. in der folgenden Frage ausgedrückt wird:
Gibt es einen Zusammenhang zwischen Alter und Verweildauer?
Abbildung 24a illustriert die Idee eines Zusammenhangs, bei der eine Ausprägung einer Ei-genschaft in verschiedenen, nicht vorab definierten Fallgruppen, eine bestimmte Ausprägungeiner anderen Eigenschaft bewirkt.
Dieses Verständnis geht auf die Hypothese zurück, dass sich die beiden Variablen annä-hernd über die in Gleichung 4 gezeigte Regressionsgerade beschreiben lassen.47
45 Die Frageargumente können beispielsweise aufgrund ihres Skalentyps die Verwendung bestimmterMethoden verbieten. Ihr Einfluss ist damit aber nur sekundär.
46 Eine Übersicht über die Analysemethoden liefert Anhang D.1.47 Für die Untersuchung von Zusammenhängen, die sich nicht linear beschreiben lassen, werden kom-
plexere Hypothesen mit komplexeren Überprüfungsmethoden benötigt.

776.1 DIE OPERATIONALISIERUNG DES FRAGEOBJEKTS
, mit a und b sind metrische Variablen (4)
Um diese Hypothese zu überprüfen, lässt sich unter der Annahme zweier metrischer Attri-bute Pearson’s r als Maß verwenden, „das Enge und Richtung eines bivariaten Zusammen-hangs auch im Vergleich mit anderen bivariaten Korrelationen in einem einzigen Kennwert zucharakterisieren erlaubt“ ([Wit91:132]).48 Dieser Wert wird im Falle eines konfirmativen Fra-getyps für die Entscheidung verwendet, ob ein Zusammenhang zwischen zwei Variablen at1und at2 gegeben ist, und im Falle eines deskriptiven Fragentyps, wie der Zusammenhang be-schrieben werden kann.
|| Zusammenhang || (at1, at2) = Pearson_R (at1, at2) (5)
Die Bedeutung des Frageobjekts Zusammenhang und damit des Antwortobjekts lässt sichdann als das Ausmaß der Korrelation oder konkret als der Wert von Pearson’s r zwischen denbeiden Variablen beschreiben.
6.1.2 KD-Fragen nach einem Unterschied
Basierend auf statistischen Unterschiedshypothesen, nach denen sich zwei oder mehrere Popu-lationen bezüglich einer oder mehrerer abhängiger Variablen unterscheiden (z.B. „Studierendeder Sozialwissenschaften und der Naturwissenschaften unterscheiden sich in ihrem politischenEngagement“), erlaubt dieses Frageobjekt die Suche nach diskriminierenden Merkmalen zwi-schen zwei oder mehr Fallgruppen. Wie in Abbildung 24b gezeigt, wird bei einem spezifischen
Abbildung 24: Visualisierung der allgemeinen Frageobjekte.
48 Für ordinalskalierte Variablen lässt sich Spearman’s Rangkorrelationskoeffizient Rho analog ver-wenden. Für eine detaillierte Beschreibung der beiden Tests verweisen wir auf [Wit91] und [Bor93].
c) Gemeinsamkeit
b) Unterschieda) Zusammenhang
Alle Patienten
Verw
eild
auer
Verw
eild
auer
Alte
r
Alte
rPatient A
Patient B
Alle Patienten
Verw
eild
auer
1999 2000 2001
Verw
eild
auer
Verw
eild
auer
<
<
d) Veränderung
Risikopatienten
Verw
eild
auer
Risikopatienten
Verw
eild
auer
Nicht-Risikopatienten
<
Alle Patienten
RisikopatientenRisikopatientenNicht-
Risikopatienten
=
Alle Patienten
Verw
eild
auer
Verw
eild
auer
a x1b x2+=

78 KAPITEL 6. DIE OPERATIONALISIERUNG VON KD-FRAGEN
Unterschied davon ausgegangen, dass sich eine Eigenschaft unterschiedlich in verschiedenen,aber vorab (explizit) definierten Fallgruppen verhält.
Als Beispiel für eine KD-Frage nach einem Unterschied verwenden wir im Folgenden:
Gibt es einen Unterschied bezüglich der Verweildauer zwischen Risikopatientenund Nicht-Risikopatienten?
Damit formuliert die Frage die in Gleichung 6 gezeigte Hypothese, die davon ausgeht, dasssich der Mittelwert der Verweildauer in den beiden Populationen Risikopatienten und Nicht-Risikopatienten unterscheidet:
, (6)
mit sind Wertemengen einer Variablen a aus zwei Populationen p1, p2 mit .
Auch im Falle des Unterschieds legen wir ein Standardverfahren zur Auswertung zugrunde:wir verwenden Student’s t-Test49 für metrische Variablen, wie beispielsweise die Verweildau-er, der die Existenz von signifikanten Mittelwertunterschieden einer Variablen at in zwei Po-pulationen DT1 und DT2 überprüft. Als zusätzlichen Parameter nehmen wir ein mittleres Signi-fikanzniveau von 95% an, das im Laufe der Analyse angepasst werden kann.50 Mit dem t-Testwird getestet, ob der errechnete d.h. empirische t-Wert bei der zuvor festgelegten Irrtumswahr-scheinlichkeit51 α größer als der theoretische t-Wert ausfällt. In diesem Fall ist davon auszuge-hen, dass der Unterschied der Mittelwerte signifikant ist. Damit lässt sich die Bedeutung desFrageobjekts Unterschied mit Gleichung 7 darstellen:
|| Unterschied || (at, DT1, DT2) = α | T-Testemp(at, DT1, DT2) > T-Testthe(α) und α ist min. (7)
Die Bedeutung des Frageobjekts Unterschied und damit auch wiederum des Antwortobjektsentspricht also der minimalen Irrtumswahrscheinlichkeit α, mit der ein statistischer Unter-schied nachgewiesen werden kann, oder dem maximalen Signifikanzniveau.
6.1.3 KD-Fragen nach einer Gemeinsamkeit
Als Inversion von statistischen Unterschiedhypothesen in dem Sinne, dass zwei oder mehrerePopulationen Gemeinsamkeiten bezüglich einer oder mehrerer abhängiger Variablen aufwei-sen (z.B. „Studierende der Informatik und der Elektrotechnik zeigen ein gleich stark ausge-prägtes politisches Engagement“), macht diese Frageobjekt die Suche nach gemeinsamen cha-rakterisierenden Merkmalen von zwei oder mehr Fallgruppen möglich. Bei diesem Frageob-jekt steht also die Hypothese zur Untersuchung an, ob sich eine Eigenschaft (Attribut) in ver-schiedenen, aber vorab (explizit) definierten Fallgruppen gleich verhält (siehe auch Abbildung24c). Gemeinsamkeiten werden also als das Fehlen eines Unterschieds interpretiert. Ein Bei-spiel für eine KD-Frage nach einer Gemeinsamkeit stellt sich dann als Inversion der KD-Frageaus Abschnitt 6.1.2 dar:
Gibt es eine Gemeinsamkeit bezüglich der Verweildauer zwischen Risikopatienten
49 Für eine detaillierte Beschreibung verweisen wir auch hier auf [Wit91] und [Bor93].50 Für nominal- und ordinalskalierte Variablen verwenden wir analog den Chi²-Test.51 Die Irrtumswahrscheinlichkeit, fälschlicherweise die Nullhypothese zu verwerfen, stellt das Komple-
ment zum Signifikanzniveau dar. Eine Irrtumswahrscheinlichkeit von 1 % entspricht also einem Signifi-kanzniveau von 99%.
µp1a( ) µp2
a( )– 0>
ap1ap2
, p1 p2≠

796.1 DIE OPERATIONALISIERUNG DES FRAGEOBJEKTS
und Nicht-Risikopatienten?
Damit ist auch die dieser KD-Frage zugrunde liegende Hypothese invers zur oben beschrie-benen Unterschiedshypothese und ergibt sich, wie in Gleichung 8 gezeigt, als Gleichheit derMittelwerte der zu untersuchenden Variablen in zwei verschiedenen Populationen.
, (8)
mit sind Wertemengen einer Variablen a aus zwei Populationen p1, p2 mit .
Damit lässt sich wieder Student’s t-Test anwenden. Die Bedeutung einer KD-Frage nach ei-ner Gemeinsamkeit wird damit wie in Gleichung 9 dargestellt beschrieben. In diesem Fall giltjedoch in Abweichung zur Unterschiedshypothese: Die Hypothese wird angenommen, wennder empirische t-Wert kleiner oder gleich dem theoretischen t-Wert ist.
|| Gemeinsamkeit || (at, DT1, DT2) = α | T-Testemp(at, DT1, DT2) ≤ T-Testthe(α) und α ist min. (9)
Die Bedeutung des Frageobjekts Gemeinsamkeit entspricht also der minimalen Irrtums-wahrscheinlichkeit α, mit der ein statistischer Unterschied nicht mehr nachgewiesen werdenkann.
6.1.4 KD-Fragen nach einer Veränderung
Basierend auf statistischen Veränderungshypothesen, dass sich Ausprägungen einer abhängi-gen Variablen im Verlauf der Zeit verändern, löst das Frageobjekt die Suche nach unterschied-lichen Werten eines Attributs zu unterschiedlichen Zeiten aus, also z.B. „Wiederholte Wer-bung für ein Produkt erhöht die Bereitschaft, das Produkt zu kaufen“. Abbildung 24d illustriertdie Annahme, dass in verschiedenen Fallgruppen, die (explizit) durch eine zeitliche Eigen-schaft charakterisiert sind, die Ausprägungen einer anderen Eigenschaft mit zunehmender oderabnehmender zeitlicher Eigenschaft zu- oder abnehmen oder sich andere zeitliche Muster bil-den. Als Beispiel für eine KD-Frage nach einer Veränderung verwenden wir im Folgenden dieFrage:
Gibt es eine Veränderung bezüglich der Verweildauer zwischen 2001 und 2002?
Im Falle von einfachen Hypothesen zu Veränderungen einer Variablen zwischen zwei odermehr Zeitpunkten lassen sich statistischen Hypothesen gemeinhin genauso formulieren wie fürUnterschiedhypothesen. Die Veränderung kann damit als eine gleichgerichtete, auf- oder ab-steigende Folge von Unterschieden einer Variablen interpretiert werden. Dies lässt sich mit derin Gleichung 10 formulierten Hypothese darstellen.
oder
(10)
mit sind Wertemengen der Variablen a zu Zeitpunkten
Für den Fall von zwei Vergleichszeitpunkten t1 und t2 lässt sich mit Hilfe dieser Hypotheseund Student’s t-Test zu ihrer Überprüfung die Bedeutung der Frage wie in Gleichung 11 darge-stellt beschreiben.52
µ ap1( ) µ ap2
( )– 0=
ap1ap2
, p1 p2≠
µ at1( ) µ at2
( ) 0 ... , , µ atn 1–( ) µ atn
( ) 0<–<–
µ at1( ) µ at2
( ) 0 ... , , µ atn 1–( ) µ atn
( ) 0>–>–
at1at2
, ..., atn, t1 t2 ... tn< <

80 KAPITEL 6. DIE OPERATIONALISIERUNG VON KD-FRAGEN
|| Veränderung || (at, t1, t2) =α | T-Testemp(at, t1, t2) > T-Testthe(α) und α ist min. (11)
Die Bedeutung des Frageobjekts Veränderung und des korrespondierenden Antwortobjektsentspricht also der minimalen Irrtumswahrscheinlichkeit α, mit der ein statistischer Unter-schied zwischen den beiden Zeitpunkten nachgewiesen werden kann, oder dem maximalen Si-gnifikanzniveau.
6.1.5 KD-Fragen mit domänenspezifischen Frageobjekten
Die Bedeutung der domänenspezifischen Frageobjekte lässt sich nicht allgemein beschreibensondern muss im Kontext der Domäne betrachtet werden. Darüber hinaus ist sie stark abhängigvon den jeweils gewählten Operationalisierungen, wie sie beispielsweise Abbildung 19 in Ab-schnitt 5.2.1.2.2 zeigt. In diesem Fall lässt sich die Semantik des Frageobjekts „Korrektheit derTherapeutik“ auf einer Menge von Datensätzen DT durch eine gewichtete Summe der Ergeb-nisse aus den i einzelnen Operationalisierungsmöglichkeiten Opi darstellen. Da die einzelnenOperationalisierungen jeweils prozentuale Anteile liefern, mit denen die Merkmale erfüllt wer-den, lässt sich daraus leicht ein Ergebniswert für die Bewertung der Korrektheit der Therapeu-tik ermitteln. Dies wird in Gleichung 12 dargestellt.
|| Korrektheit der Therapeutik || (DT) = (12)
Für weitere domänenspezifische Frageobjekte bietet sich ein analoges Vorgehen an.
6.2 Die Operationalisierung des Fragetyps
Wie oben beschrieben, wird also vor allem durch das Frageobjekt ein Algorithmus zur Beant-wortung der Frage ausgewählt. Je nach Art des Algorithmus werden verschiedene Werte gelie-fert, die für die Beschreibung des Ergebnisses und damit für die genaue Formulierung der Ant-wort verwendet werden können. Die Art der Formulierung der Antwort wird durch den Frage-typ festgelegt, dessen Bedeutung im Folgenden näher untersucht werden soll.
6.2.1 Konfirmative KD-Fragen
Konfirmative KD-Fragen erwarten als Entscheidungsfragen eine Ja/Nein-Antwort. Sie stellendamit ein boolesches Prädikat dar, das beschreibt, ob die Hypothese, die in der Frage formu-liert ist, im statistischen Sinne in den Daten bestätigt oder widerlegt werden kann. Wie in Al-gorithmus 1 skizziert, stellen konfirmative Fragen den einfachsten Typ von Fragen dar undkönnen im Unterschied zu den folgenden Typen in einem Schritt beantwortet werden, da dieEntscheidung über Annahme oder Ablehnung der Hypothese gemeinhin noch als Bestandteildes Hypothesentests gesehen wird:.
Die Ergebnisbewertung, die von der Analysemethode geliefert wird, muss also in eine dis-krete Entscheidung umgesetzt werden. Dies geschieht durch den Vergleich der Ergebnisbe-wertung mit einem methodenspezifischen Grenzwert, der als Metadatum zu jeder Methodemodelliert wird. Der dafür benötigte Grenzwert kann an dieser Stelle nicht global spezifiziertwerden, sondern muss von der Realisierung des jeweiligen Frageobjekts bereitgestellt werden.Im Falle von Pearson’s r, das für die Analyse von Zusammenhängen zwischen metrischen At-
52 Im Falle von mehr als zwei Vergleichszeitpunkten ist der t-Test wiederholt anzuwenden.
αi
∑iOpi

816.2 DIE OPERATIONALISIERUNG DES FRAGETYPS
tributen eingesetzt wird, wurde dieser Grenzwert empirisch auf 0,20 festgelegt, im Falle des t-Tests muss das Signifikanzniveau, auf dem die Hypothese verifiziert werden konnte, bei 5%oder darunter liegen. Die Bedeutung des konfirmativen Fragetyps stellt sich damit als die inGleichung 13 dargestellte Funktion der Analysemethode M und des von ihr zurückgeliefertenErgebniswertes R dar. Die Menge der möglichen Welten wird dabei, wie in Abschnitt 3.2 be-schrieben, in die geteilt, in denen der Ergebniswert den von der Analysemethode abhängigenGrenzwert θkonfirmativ erfüllt oder überschreitet, und in die, in denen der Ergebniswert denGrenzwert θkonfirmativ unterschreitet. Im ersten Fall kann die Hypothese bestätigt und die KD-Frage positiv beantwortet werden, im zweiten Fall wird die Hypothese widerlegt und die KD-Frage negativ beantwortet.
|| Gibt es ... || (R,M) = {λi[R ≥ θkonfirmativ(M) in i],
λi[R < θkonfirmativ(M) in i]} (13)
6.2.2 Deskriptive KD-Fragen
Deskriptive KD-Fragen leisten im Sinne von Ergänzungsfragen mit ihren KD-Antworten mehrals nur die Dichotomisierung des Ergebniswertes. Sie liefern eine genauere Beschreibung desFrageobjekts mit den Mitteln, die die jeweilige Analysemethode, die für die Beantwortung ver-wendet wird, zur Verfügung stellt. Wie in Algorithmus 2 gezeigt, werden für die Beantwor-tung von deskriptiven KD-Fragen zwei Verarbeitungsschritte benötigt.
Um die Bewertung der Aussage durch eine verbale Beschreibung und damit die Entschei-dung zwischen verschiedenen Charakterisierungen leisten zu können, ist die Diskretisierungeines kontinuierlichen Wertes im Sinne einer sprachlichen Beschreibung notwendig. Durch dieAbhängigkeit der Beschreibungsmöglichkeiten von der Analysemethode M müssen diese wie-derum zusammen mit der Methode modelliert werden. Durch Gleichung 14 lässt sich die Parti-tionierung des Raums der Antworten in Abhängigkeit vom Ergebniswert R, der Methode Mund einer Menge von n Intervallgrenzwerten θdeskriptiv,j für die Auswahl von n+1 geeignetenAntwortbeschreibungen darstellen.
Ausgangsbasis: Konkrete Hypothese im Frageobjekt (z.B. Zusammenhang)
Schritte: 1. Überprüfung der Hypothese
Ergebnis: Bestätigung oder Widerlegung der Hypothese
Algorithmus 1: Vorgehen bei der Beantwortung einer konfirmativen Frage
Ausgangsbasis: Konkrete Hypothese im Frageobjekt (z.B. Zusammenhang)
Schritte: 1. Überprüfung der Hypothese
2. Bewertung der Aussage
Ergebnis: Deskription des Ergebnisses der Überprüfung
Algorithmus 2: Vorgehen bei der Beantwortung einer deskriptiven Frage

82 KAPITEL 6. DIE OPERATIONALISIERUNG VON KD-FRAGEN
|| Welchen ... gibt es || (R,M) = {λi[R < θdeskriptiv,0 (M) in i],{λi[R ≥ θdeskriptiv,1 (M) in i],λi[R ≥ θdeskriptiv,2 (M) in i],
...,λi[R ≥ θdeskriptiv,n (M) in i]} (14)
Entsprechend der Entscheidung für eine Beschreibungskategorie können die entsprechen-den verbalen Beschreibungen ausgewählt werden. Im Falle von Zusammenhangshypothesen,die mit Pearson’s r überprüft wurden, stehen die in Tabelle 22 aufgeführten Intervalle mit ih-ren verbalen Beschreibungen zur Verfügung.53
Für die anderen statistischen Hypothesen, bei denen das Ziel der Untersuchung das Signifi-kanzniveau bzw. die Irrtumswahrscheinlichkeit ist, mit der die Hypothese nachgewiesen wer-den kann, verwenden wir die in Tabelle 23 aufgeführte Klassifikation der Irrtumswahrschein-lichkeit α.
Wertebereich Beschreibung
-1.00 ≤ |Pearson_R(x,y)| < -0.90 sehr stark, negativ
-0.90 ≤ |Pearson_R(x,y)| < -0.70 stark, negativ
-0.70 ≤ |Pearson_R(x,y)| < -0.50 mittel, negativ
-0.50 ≤ |Pearson_R(x,y)| < -0.20 gering, negativ
-0.20 ≤ |Pearson_R(x,y)| < 0.00 sehr gering, negativ
0.00 < |Pearson_R(x,y)| ≤ 0.20 sehr gering, positiv
0.20 < |Pearson_R(x,y)| ≤ 0.50 gering, positiv
0.50 < |Pearson_R(x,y)| ≤ 0.70 mittel, positiv
0.70 < |Pearson_R(x,y)| ≤ 0.90 stark, positiv
0.90 < |Pearson_R(x,y)| ≤ 1.00 sehr stark, positiv
Tabelle 22: Gruppierung und Übersetzung von Korrelationskoeffizienten wie beispielsweise Pearson’s r in verbale Beschreibungen (nach
[Wit91]).
53 Die beiden Bewertungsmaße Stärke (ausgedrückt durch den Betrag von R) und Richtung (ausge-drückt durch das Vorzeichen von R), die hier aus Gründen der Übersichtlichkeit kombiniert dargestelltwerden, ließen sich auch durch getrennte Beschreibungen formulieren.
Wertebereich Beschreibung
5% < α ≤ 100% nicht signifikant
1% < α ≤ 5% signifikant
0,1% < α ≤ 1% sehr signifikant
0% < α ≤ 0,1% höchst signifikant
Tabelle 23: Gruppierung und Übersetzung der Irrtumswahrscheinlichkeit α (nach [Wit91]).

836.3 DIE KONSTRUKTION KOMPLEXER BEDEUTUNGEN VON KD-FRAGEN
6.2.3 Komplexe KD-Fragen
In einer weiteren Komplexitätsstufe erlauben komplexe KD-Fragen zunächst die Überprüfungin einer von den konfirmativen KD-Fragen bekannten Form und im Erfolgsfall die Charakteri-sierung der überprüften Gesamtheit. Dafür benötigt der komplexe Fragetyp ein mehrstufigesVorgehen. Dieses basiert auf der im Frageobjekt formulierten allgemeinen Hypothese und demTyp der Objekte, für die die Hypothese zu überprüfen ist. Algorithmus 3 stellt dieses Vorgehenim Detail dar.
Dabei ist wieder von der ausgewählten Methode M und dem von ihr gelieferten ErgebniswertRDT auszugehen, der mit einem Schwellwert θkonfirmativ verglichen wird. Die Bedeutung derFrage lässt sich dann mit Hilfe einer Konjunktion der Attribut-Attributwertpaare beschreiben,die für alle Datensätze dt aus der Gesamtheit der untersuchten Datensätze DT erfüllt ist. Glei-chung 15 illustriert diesen Sachverhalt. Dabei extrahiert die Funktion val(at(dt)) den Attribut-wert im Datensatz dt zum Attribut at.
|| Bei welchen ... gibt es ...|| (RDT,M) = (15)
Durch eine Verbalisierung der Konjunktion der Attribut-Attributwertpaare lassen sich Ant-worten auf komplexe KD-Fragen formulieren.
6.3 Die Konstruktion komplexer Bedeutungen von KD-Fragen
Durch die oben durchgeführte Analyse der Semantik von Fragetyp und Frageobjekt könnenwir jetzt die Konstruktion komplexer Bedeutungen von vollständigen KD-Fragen untersuchen.Dabei verwenden wir das Prinzip der semantischen Kompositionalität in dem Sinne, dass dieBedeutung eines komplexen Ausdrucks eine Funktion der Bedeutungen seiner Teilausdrückeist. Zur Ermittlung der Bedeutung einer vollständigen KD-Frage werden also die oben darge-stellten Bedeutungen der einzelnen KD-Elemente zu einer Funktion zusammengesetzt. Deneinzelnen Elementen kommen dabei die in Tabelle 24 dargestellten unterschiedlichen Rollenzu.
Dem Grundsatz der Komposition folgend stellen die Beispiele 22 und 23 die Bedeutung ei-ner konfirmativen Frage nach einem Zusammenhang und einer deskriptiven Frage nach einemUnterschied dar.
Ausgangsbasis: Konkrete Hypothese im Frageobjekt (z.B. Zusammenhang), Objekttyp für Hypothe-senüberprüfung (z.B. Patient)
Schritte: 1. Bildung von Clustern des Objekttyps
2. Überprüfung der Hypothese innerhalb der Cluster
3. Auswahl der Cluster, in denen die Hypothese bestätigt wurde
Ergebnis: Beschreibung der Cluster, für die die Hypothese bestätigt wurde
Algorithmus 3: Vorgehen bei der Beantwortung einer komplexen Frage
atn awn;{ } d∀ t DT val atn dt( )( ),∈n∪ awn λ i RDT θkonfirmativ M( ) in i≥[ ]∧=

84 KAPITEL 6. DIE OPERATIONALISIERUNG VON KD-FRAGEN
Beispiel 22: Die Bedeutung einer konfirmativen KD-Frage nach einem Zusam-menhang. Für die Beschreibung der Bedeutung einer solchen KD-Frageverwenden wir die Frage:
Gibt es einen Zusammenhang zwischen Alter und Verweildauer?
Durch Einsetzen der Gleichung 5 für die Formalisierung der Bedeutungdes Frageobjekts Zusammenhang in die Gleichung 13 für die Formalisie-rung der Bedeutung des konfirmativen Fragetyps lässt sich die folgendeGleichung 16 aufstellen. Dafür werden die beiden Attribute Alter undVerweildauer als Eingabewerte verwendet.54
|| Gibt es einen Zusammenhang || (Alter, VD) = (16)
{λi[|Pearson_R(Alter, VD)| ≥ θkonfirmativ(Pearson_R) in i],λi[|Pearson_R(Alter, VD)| < θkonfirmativ(Pearson_R) in i]} =
{λi[|Pearson_R(Alter, VD)| ≥ 0,20 in i],λi[|Pearson_R(Alter, VD)| < 0,20 in i]} =
{λi[Ja, es gibt einen Zusammenhang zwischen Alter und Verweildauer in i],λi[Nein, es gibt keinen Zusammenhang zwischen Alter und Verweildauer in i]}
Durch Einsetzen des konfirmativen Grenzwerts für Pearson’s r, der bei0,20 festgelegt wurde, lässt sich die Bedeutung der Frage über die Mengeder Antwort beschreiben. Diese besteht in den beiden Möglichkeiten, dassder Grenzwert von Pearson’s r überschritten wird, dass also mindestensein geringer Zusammenhang nachgewiesen werden konnte, oder dass derGrenzwert nicht überschritten wird. In diesem Fall liegt kein Zusammen-hang vor und die Frage würde negativ beantwortet werden.
Beispiel 23: Die Bedeutung einer deskriptiven KD-Frage nach einem Unterschied.Hierfür verwenden wir die Frage
KDQL-Element Verwendung
Fragetyp Entscheidungsfunktion
Frageobjekt Evaluierungsfunktion
Frageargumente Eingabewerte für Evaluierungsfunktion,Projektion der Datensätze
Fragegruppe Selektion der Datensätze
Fragekontext Selektion der Datensätze
Tabelle 24: Verwendung der KDQL-Elemente bei der Ermittlung der Semantik.
54 Zusätzlich angegebene Fragegruppen oder Fragekontexte würden eine Selektion der zur Verfügungstehenden Datensätze bewirken.

856.4 ZUSAMMENFASSUNG
Welchen Unterschied gibt es bezüglich der Verweildauer zwischenGruppe 1 und Gruppe 2?
Wiederum setzen wir die Beschreibung des Frageobjekts aus Gleichung 7in die Beschreibung des Fragetyps aus Gleichung 14 ein und erhalten da-mit die folgende Gleichung 17.
|| Welchen Unterschied gibt es || (VD, Gruppe1, Gruppe2) = (17)
{λi[ 0% ≤ α < 0,1% in i],λi[ 0,1% ≤ α < 1% in i],λi[ 1% ≤ α < 5% in i],
λi[ 5% ≤ α < 100% in i]} =
{λi[Es gibt einen höchst signifikanten Unterschied bezüglich der Ver-weildauer zwischen Gruppe 1 und Gruppe 2 in i],λi[Es gibt einen sehr signifikanten Unterschied bezüglich der Verweil-dauer zwischen Gruppe 1 und Gruppe 2 in i],λi[Es gibt einen signifikanten Unterschied bezüglich der Verweildauerzwischen Gruppe 1 und Gruppe 2 in i],λi[Es gibt keinen signifikanten Unterschied bezüglich der Verweildauerzwischen Gruppe 1 und Gruppe 2 in i]}
Durch Einsetzen der Grenzwerte für die Beschreibung der Signifikanzbzw. der Irrtumswahrscheinlichkeit des Ergebnisses aus Tabelle 23 erhal-ten wir die Menge der vier möglichen Antworten und damit im Sinne derAntwortmengentheorie die Bedeutung der Frage.
6.4 Zusammenfassung
Nach der Beschreibung der Syntax von KD-Fragen im vorhergehenden Kapitel haben wir indiesem Kapitel ein Vorgehen für die Beschreibung der Semantik von KD-Fragen entworfen:Unter Verwendung der Antwortmengentheorie gehen wir davon aus, dass die Bedeutung einerFrage allgemein durch die Menge der Antworten darauf beschrieben werden kann. Dieser Ideefolgend, haben wir für die Ermittlung der möglichen Antworten zunächst das Frageobjekt ausund anschließend den Fragetyp von KD-Fragen zusammen mit ihren Einflüssen auf die Mengeder Antworten analysiert. Durch die Kombination der Einflüsse nach dem Frege’schen Kom-positionalitätsprinzip können daraus dann Beschreibungen der Antwortmengen von vollständi-gen KD-Fragen abgeleitet werden.
Die Sprache für KD-Fragen mit ihrer Syntax und ihre Semantik ist damit als Ausgangs-punkt des Analyseprozesses umfassend beschrieben. Wir wenden uns jetzt dem Einsatz derKD-Fragen und ihre pragmatischen Verarbeitung zu. Im folgenden Kapitel werden wir deshalbim Detail die Expansion und die schrittweise Transformation von KD-Fragen bis hin zur Gene-rierung von vollständigen Aufrufen von Analysealgorithmen in der Form von DM-Anfragenbeschreiben.

86 KAPITEL 6. DIE OPERATIONALISIERUNG VON KD-FRAGEN

KAPITEL 7 DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
Die Abbildung der Fragen von Fachexperten auf Data-Mining-Anfragen zu unterstützen, istein wichtiger Bestandteil des QUESTUS-KDD-Ansatzes. Dies bedeutet, dass KD-Fragen inder KD-Expansion zunächst verfeinert und die verfeinerten KD-Fragen in der KD-DM-Trans-formation dann auf DM-Anfragen abgebildet werden müssen. Dafür wird umfangreiches Ex-pertenwissen benötigt und in der bereits in Abschnitt 4.4 beschriebenen Wissensbasis überMethoden und Algorithmen aus den Bereichen Data Mining und Statistik bereitgestellt. Dieseumfasst unter anderem Wissen darüber, welche Fragestellungen mit welcher Methode beant-wortbar sind, unter welchen Voraussetzungen welche Methoden anwendbar sind und wie Wer-te für die Parametrisierung der Algorithmen zu bestimmen sind.
Diese Abbildung von KD-Fragen auf DM-Anfragen besteht aus zwei Teilabbildungen: diebereits in Abschnitt 4.3 erwähnte KD-Frage-Expansion, die die KD-Fragen in verfeinerte KD-Fragen auflöst, und anschließend die ebenfalls in Abschnitt 4.3 definierte KD-DM-Transfor-mation, die als eigentlicher Kernprozess der Abbildung betrachtet werden kann. Letztere stelltdamit den Übergang zwischen der Sprache auf der Benutzerebene, die wir auch als KD-Ebenebezeichnen, und der Sprache auf der DM-Ebene dar. Die KD-DM-Transformation wählt wie-derum in mehreren Schritten für die konkret formulierte KD-Frage zunächst geeignete Data-Mining-Methoden, dann Konfigurationen von Data-Mining-Methoden und zuletzt Data-Mi-ning-Algorithmen mit geeigneten Konfiguration aus. Dabei werden neben den in der Frageformulierten Interessen auch generellen Präferenzen des Benutzers in Form von globalen Para-metereinstellungen sowie datenbankbezogene Parameter berücksichtigt. Das Ergebnis der KD-DM-Transformation stellt dann eine implementierungsunabhängige DM-Anfrage sein, die ineinem weiteren Schritt in eine implementierungsabhängige DM-System-Anfrage transformiertwerden kann. Für Details zur Beschreibung der beiden Abbildungsschritte verweisen wir auf[Kok00].
Bevor wir jedoch in den Abschnitten 7.2 und 7.3 zu einer genaueren Beschreibung der ein-zelnen Abbildungsschritte kommen, ist es notwendig, einen Blick auf die Objekte zu werfen,die während der Abbildung oder als ihr Ziel relevant sind.
7.1 Die Modellierung relevanter Objekte für die Abbildung
Im Folgenden beschreiben wir die für die Abbildungen benötigte Modellierung von DM-An-fragen, von Data-Mining-Methoden und von Data-Mining-Algorithmen. Dabei unterscheidenwir zwischen dynamischen Objekten, die im Rahmen der Transformation einer KD-Frage ent-stehen (DM-Anfrage), und statischen Objekten, die für die Realisierung der Transformationbenötigt werden und bereits vor dem Beginn der Abbildung in der Wissensbasis enthalten sind(Data-Mining-Methode, Data-Mining-Algorithmus).

88 KAPITEL 7. DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
7.1.1 Die Modellierung von DM-Anfragen
Alle Informationen, die zum Aufruf eines Data-Mining-Laufs benötigt werden, sind entwederexplizit oder als Referenzen im Objekttyp DM-Anfrage zusammengefasst. Eine DM-Anfrageist dabei im Gegensatz zur DM-System-Anfrage unabhängig von konkreten Implementierun-gen von Data-Mining-Algorithmen. Die DM-Anfragen werden als persistente Objekte in einerDatenbank gehalten, so dass jederzeitiger ein späterer Zugriff möglich ist.
Zur formalen Beschreibung der Objekte vom Typ DM-Anfrage entwickeln wir die DataMining Algorithm Query Language (DMAQL). Eine DM-Anfrage in DMAQL besteht aus denfolgenden Elementen:
• Anfrage-Algorithmus-Konfiguration (AAKonf): Konfiguration des Data-Mining-Al-gorithmus, der für die Anfrage verwendet wird.
• Anfrage-Algorithmus-Konfiguration Argumente (AAKonfArgs): Argumente, diedie ausgewählte Konfiguration instantiieren.
• Anfrage globale Parameter (AGP): globale Parameter für die Anfrage.• Anfrage-Daten (AD): Daten, die die Basis für die Anfrage bilden.AAKonf spezifiziert eine bestimmte Art und Weise, wie ein Data-Mining-Algorithmus zu
verwenden ist. Diese Konfiguration stellt allerdings nicht nur eine Parametrisierung dar, son-dern entspricht stets auch einer bestimmten Klasse von Fragestellungen, die damit bearbeitetwerden können, und damit einer Art gedanklichem Lösungsplan. Zu beachten ist, dass mit derAngabe der AAKonf auch implizit ein zugeordneter Data-Mining-Algorithmus und eine zuge-ordnete Data-Mining-Methode angegeben sind.
Im zweiten Element AAKonfArgs werden die benötigten Argumente für die Konfigurationdes Data-Mining-Algorithmus (AAKonf) angegeben. Die Werte werden dabei aus den in deraktuellen KD-Frage enthaltenen Frageargumenten abgeleitet.
Im Element AGP werden die globalen Parametersätze angegeben. Sie enthalten Präferenzendes Benutzers, wie beispielsweise die minimal geforderte Konfidenz von Regeln. Die Parame-tersätze sind global in dem Sinne, dass sie nicht nur auf die aktuelle KD-Frage bezogen sind,sondern fragenunabhängig sind und damit eine Art globalen Kontext darstellen. Die Parameterdienen als eine Art Einstellungsparameter des Data-Mining-Algorithmus, beeinflussen und pa-rametrisieren also dessen Verhalten und Ergebnisse. Im Gegensatz zu den in den Argumentenzur Algorithmus-Konfiguration (AAKonfArgs) enthaltenen Parametern können sie eher alseine Art Feineinstellung des Ablaufs angesehen werden.
Das Element AD dient der Angabe bzw. Eingrenzung der Datensätze, die die Basis für dieDatenanalyse darstellen. Dabei werden drei Informationen bereitgestellt: die Angabe der Rela-tion, die die Daten enthält, die Angabe der darin relevanten Attribute und die Angabe der inte-ressierenden Datensätze. Die Relation kann dabei auch implizit gegeben sein. Die Attributaus-wahl stellt im datenbanktechnischen Sinne eine Projektion, die Datensatzauswahl eine Selekti-on dar.
Damit lässt sich folgende Grammatik für die Sprache DMAQL in Backus-Naur-Form(BNF) angeben:
⟨DM-Anfrage⟩ ::==
(⟨AAKonf⟩, ⟨AAKonfArgs⟩, ⟨AGP⟩, ⟨AD⟩)
⟨AAKonfArgs⟩ ::==
((⟨AAKonfArg⟩)*)

897.1 DIE MODELLIERUNG RELEVANTER OBJEKTE FÜR DIE ABBILDUNG
⟨AAKonfArg⟩ ::==
([⟨AList⟩ | ⟨Attribut⟩])
⟨AGP⟩ ::==
((⟨Parameter⟩ = ⟨Wert⟩)*)
⟨AD⟩ ::==
(⟨ADRelation⟩,
⟨ADProjektion⟩,
⟨ADSelektion⟩)
Beispiel 24 zeigt eine DM-Anfrage in natürlichsprachlicher und formaler DMAQL-Darstel-lung.
Beispiel 24: DM-Anfrage. In formaler DMAQL-Darstellung lässt sich eine DM-Anfrage wie folgt darstellen:
AAKonf: Apriori_2aAAKonfArgs: ((Alter),
(Verweildauer))AGP: (MinSupp=0.02)AD: (Patienten_Relation, (),
(Klinik=Augenklinik, Jahr=2002))
In natürlichsprachlicher Formulierung liest sich diese DM-Anfrage wiefolgt:
Ausführung der Data-Mining-Methode „Induktion von Regeln“ über den Algorithmus „Apriori“ in der Konfiguration „Apriori_2a“mit den weiteren Bedingungen „Alter im WENN-Teil und Verweildauerim DANN-Teil“,einem „Mindestsupport von 2 %“ und Beschränkung der Suche auf „Datensätze zur Augenklinik 2002“in der Relation „Patienten_Relation“.
7.1.2 Die Modellierung von Data-Mining-Methoden
Bei der stufenweisen Abbildung von KD-Fragen auf DM-Anfragen stellen Data-Mining-Me-thoden die erste wichtige Zwischenstufe dar. Wir unterscheiden dabei im Folgenden Data-Mi-ning-Methoden von Data-Mining-Algorithmen: Der Begriff der Data-Mining-Methode wird inder Literatur uneinheitlich gebraucht, teilweise mit dem Analysemodell ([Fay96b]) oder Data-Mining-Algorithmus ([Klo00]) gleichgesetzt und teilweise auch als Data-Mining-Operationen(data mining operations, [Agr96]) bezeichnet. Im Kontext der vorliegenden Arbeit bezeichnenwir mit Data-Mining-Methoden Verfahren zur Erstellung von Modellen, deren Instantiierun-gen mit Hilfe des Data Mining gesucht werden, also z.B. die Induktion von Regeln. Eine Über-sicht über die Menge der verfügbaren Data-Mining-Methoden bietet beispielsweise [Fay96b].
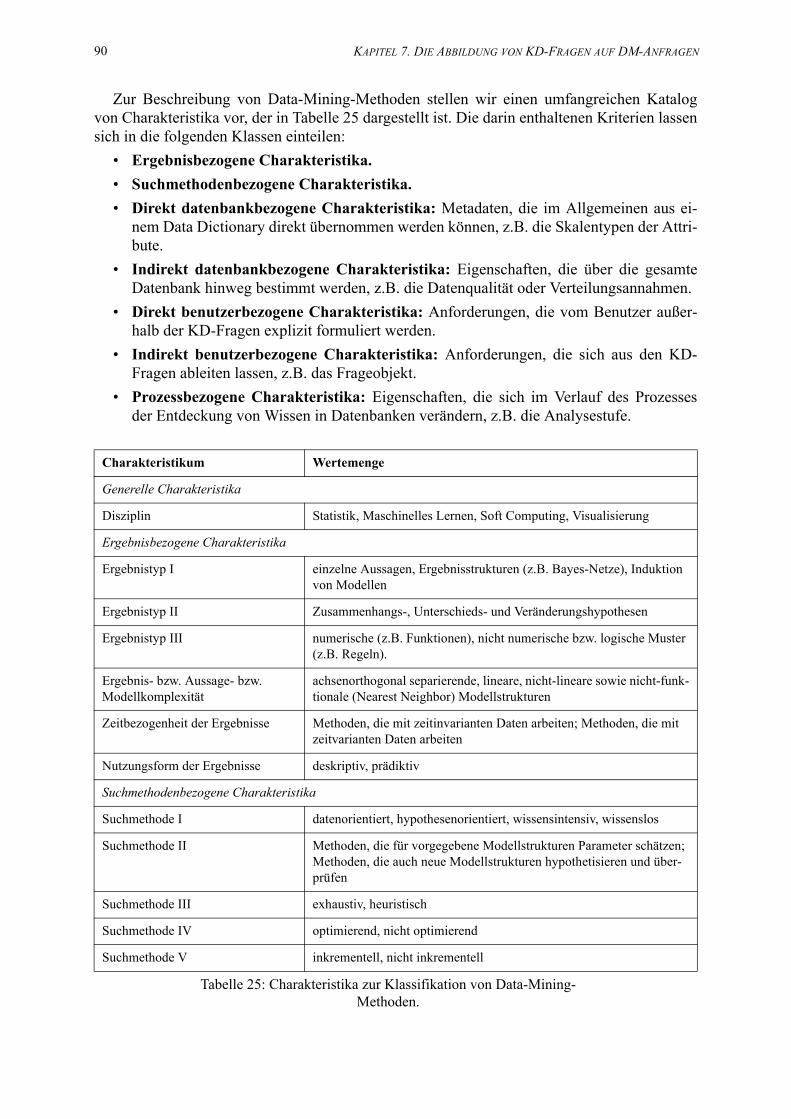
90 KAPITEL 7. DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
Zur Beschreibung von Data-Mining-Methoden stellen wir einen umfangreichen Katalogvon Charakteristika vor, der in Tabelle 25 dargestellt ist. Die darin enthaltenen Kriterien lassensich in die folgenden Klassen einteilen:
• Ergebnisbezogene Charakteristika. • Suchmethodenbezogene Charakteristika. • Direkt datenbankbezogene Charakteristika: Metadaten, die im Allgemeinen aus ei-
nem Data Dictionary direkt übernommen werden können, z.B. die Skalentypen der Attri-bute.
• Indirekt datenbankbezogene Charakteristika: Eigenschaften, die über die gesamteDatenbank hinweg bestimmt werden, z.B. die Datenqualität oder Verteilungsannahmen.
• Direkt benutzerbezogene Charakteristika: Anforderungen, die vom Benutzer außer-halb der KD-Fragen explizit formuliert werden.
• Indirekt benutzerbezogene Charakteristika: Anforderungen, die sich aus den KD-Fragen ableiten lassen, z.B. das Frageobjekt.
• Prozessbezogene Charakteristika: Eigenschaften, die sich im Verlauf des Prozessesder Entdeckung von Wissen in Datenbanken verändern, z.B. die Analysestufe.
Charakteristikum Wertemenge
Generelle Charakteristika
Disziplin Statistik, Maschinelles Lernen, Soft Computing, Visualisierung
Ergebnisbezogene Charakteristika
Ergebnistyp I einzelne Aussagen, Ergebnisstrukturen (z.B. Bayes-Netze), Induktion von Modellen
Ergebnistyp II Zusammenhangs-, Unterschieds- und Veränderungshypothesen
Ergebnistyp III numerische (z.B. Funktionen), nicht numerische bzw. logische Muster (z.B. Regeln).
Ergebnis- bzw. Aussage- bzw. Modellkomplexität
achsenorthogonal separierende, lineare, nicht-lineare sowie nicht-funk-tionale (Nearest Neighbor) Modellstrukturen
Zeitbezogenheit der Ergebnisse Methoden, die mit zeitinvarianten Daten arbeiten; Methoden, die mit zeitvarianten Daten arbeiten
Nutzungsform der Ergebnisse deskriptiv, prädiktiv
Suchmethodenbezogene Charakteristika
Suchmethode I datenorientiert, hypothesenorientiert, wissensintensiv, wissenslos
Suchmethode II Methoden, die für vorgegebene Modellstrukturen Parameter schätzen; Methoden, die auch neue Modellstrukturen hypothetisieren und über-prüfen
Suchmethode III exhaustiv, heuristisch
Suchmethode IV optimierend, nicht optimierend
Suchmethode V inkrementell, nicht inkrementell
Tabelle 25: Charakteristika zur Klassifikation von Data-Mining-Methoden.

917.1 DIE MODELLIERUNG RELEVANTER OBJEKTE FÜR DIE ABBILDUNG
Überwachtheit überwachtes, unüberwachtes Lernen
Größe des Suchraumes selektiv, konstruktiv
Art der Voraussetzungen parametrische, nicht-parametrische Verfahren
Direkt datenbankbezogene Charakteristika
Datenvolumen gering, mittel, hoch
Anzahl der involvierten Variablen univariate, bivariate, multivariate Analysen
Skalentyp der abhängigen Attribute nominal, ordinal, metrisch
Skalentyp der unabhängigen Attri-bute
nominal, ordinal, metrisch
Anzahl der Werte der abhängigen Attribute
wenige, mittel, viele
Anzahl der Werte der unabhängigen Attribute
wenige, mittel, viele
Indirekt datenbankbezogene Charakteristika
Datenqualität gering, mittel, hoch
Datendynamik gering, mittel, hoch
Verteilungsannahmen erfüllt, nicht erfüllt
Direkt benutzerbezogene Charakteristika
Suchstrategie datengetrieben, hypothesengetrieben, fragengetrieben
Konstruktivität selektiv, konstruktiv
Genauigkeit gering, mittel, hoch
Verständlichkeit des Ergebnisses gering, mittel, hoch
Explizitheit des Ergebnisses gering, mittel, hoch
Antwortzeit kurz, mittel, lang
Indirekt benutzerbezogene Charakteristika.
Frageobjekt Zusammenhang, Einfluss, Gemeinsamkeit, Unterschied, Veränderung
Autonomie gering, mittel, hoch
Aufgabenart deskriptiv, prädiktiv
Anzahl der abhängigen Attribute 0, 1, n
Anzahl der unabhängigen Attribute 0, 1, n
Prozessbezogene Charakteristika
Analysestufe deskriptiv, explorierend, konfirmativ
Unterstützter Iterationsschritt 1, 2, …
Tabelle 25: Charakteristika zur Klassifikation von Data-Mining-Methoden.

92 KAPITEL 7. DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
Die Modellierung von Data-Mining-Methoden erfolgt anhand einer Teilmenge der darge-stellten Charakteristika, die für die Auswahl relevant ist (siehe auch Anhang D.1). Die in derBeschreibung der Data-Mining-Methoden enthaltenen Informationen werden im zweitenSchritt der KD-DM-Transformation (siehe Abschnitt 7.3.2) zur Einschränkung einer Mengevon Kandidaten für die Auswahl der geeigneten Data-Mining-Methode verwendet. Die jewei-ligen Ausprägungen der einzelnen Data-Mining-Methoden werden dabei als Auswahlkriterienangesehen und entsprechend benutzt. Die Kriterien sind eingeteilt in harte Kriterien, die alsFilterbedingung benutzt werden, und weiche Kriterien, die eine Priorisierung der gefundenenKandidaten bewirken.
7.1.3 Die Modellierung von Data-Mining-Algorithmen
Neben den Data-Mining-Methoden sind Data-Mining-Algorithmen wichtige Objekte bei derAbbildung der KD-Fragen auf DM-Anfragen. Wir verstehen Data-Mining-Algorithmen dabeiim Gegensatz zu Data-Mining-Methoden als konkrete Berechnungsvorschriften, die die Erstel-lung von Modellen, wie sie durch die zugeordnete Data-Mining-Methode vorgeben sind, erlau-ben. Im Kontext der vorliegenden Arbeit werden Data-Mining-Algorithmen damit als die Rea-lisierungen von Data-Mining-Methoden gesehen: beispielsweise realisiert der AlgorithmusC4.5 in diesem Sinne die Methode Entscheidungsbauminduktion. Data-Mining-Algorithmenhaben oft spezielle Anwendungsbedingungen, wie beispielsweise die Erfordernis numerischerAttributtypen, und oft bestimmte Parametrisierungsmöglichkeiten zur Beeinflussung des Al-gorithmenablaufs oder der Art der Ergebnisse. Da sich diese Anforderungen auch bei verschie-denen Data-Mining-Algorithmen zur selben Data-Mining-Methode unterscheiden können, isteine Modellierung der Data-Mining-Algorithmen als eigenständiger Objekttyp und die Be-rücksichtigung bei der Transformation von KD-Fragen in DM-Anfragen angebracht und not-wendig.
Wie die Data-Mining-Methoden sind auch die Data-Mining-Algorithmen mit einer Mengevon Kriterien modelliert, die die Grundlage für die Auswahl darstellen. Dabei werden die fol-genden Kategorien von Kriterien, die eine Teilmenge der Kategorien aus Abschnitt 7.1.2 bil-den, verwendet:
• Ergebnisbezogene Charakteristika, z.B. Robustheit gegen Verunreinigungen, Genau-igkeit.
• Suchmethodenbezogene Charakteristika, z.B. Parametrisierbarkeit, Skalierbarkeit,Effizienz.
• Indirekt datenbankbezogene Charakteristika, z.B. Inkrementalität.• Indirekt benutzerbezogene Charakteristika, z.B. Antwortzeit.Die Kriterien werden wieder in harte Kriterien und weiche Kriterien unterteilt. Erstere müs-
sen mit den Wertebelegungen bei der aktuellen Transformation unbedingt übereinstimmen, da-mit der Algorithmus überhaupt zur Auswahl in Betracht gezogen wird; es sind also KO-Krite-rien bzw. Filterbedingungen. Die weichen Kriterien dagegen dienen zur Priorisierung der sichbei der Berücksichtigung der harten Kriterien ergebenden Kandidaten. Zusätzlich werden fürjeden Algorithmus eine Menge von Parametern verwaltet, die vom Algorithmus als Einschrän-kung auf der Menge der Ergebnisse verstanden werden können (z.B. minimaler Support), so-wie Funktionen zur ergebnisgesteuerten Anpassung der Parameter.

937.2 DIE VERFEINERUNG VON KD-FRAGEN
7.2 Die Verfeinerung von KD-Fragen
Aus den in KDQL repräsentierten KD-Fragen auf der KD-Ebene entsteht mittels der KD-Fra-ge-Expansion eine Formulierung von verfeinerten KD-Fragen mit dem Ziel, dass diese direktals Eingabe für die eigentliche Transformation in DM-Anfragen, die KD-DM-Transformation,verwendet werden können.
Bei der KD-Frage-Expansion werden die den Objekten vom Typ KD-Frage zugeordneten,notwendigen Objekte der Type Frageargumente und Fragegruppe, die in Form von elementa-ren oder komplexen (hierarchisch zusammengesetzten) Domänenbegriffen vorliegen, in Listenvon Attributen oder Bedingungen auf den Werten von Attributen übersetzt. Die entstehendenAttributlisten oder Attributwertbedingungen enthalten dabei stets ein oder mehrere Elemente,dürfen also nicht leer sein.
Für die KD-Frage-Expansion wird umfangreiches domänenspezifisches Wissen benötigt,das zur Vereinfachung der Wartbarkeit und zur Schaffung von Transparenz in deklarativenDatenstrukturen verwaltet wird. Dazu zählen:
• Begriffstaxonomien der Domäne: Typischerweise Bestandteilhierarchien (part-of)oder Ober-/Unterbegriffshierarchien (is-a).
• Domänenbegriffe als Attributgruppen: Definitionen von Domänenbegriffen über At-tributgruppen, z.B. Persönliche Informationen durch die Attributgruppe {Alter, Wohn-staat, Geburtsstaat}.
• Domänenbegriffe als Attributwertgruppen: Definitionen von Domänenbegriffen überAttributwertgruppen, z.B. jung über die Attributwertgruppe {10,11,12,13,14,15,16,17}oder [10-17] mit dem zugehörigen Attribut Alter.
• Domänenbegriffe als Fallgruppen: Definitionen von Domänenbegriffen über Fallgrup-pen, z.B. Risikopatient über die Liste von Attribut-Attributwertpaaren {{Raucher, ja},{Alter,[55-999]}}.55
• Domänenbegriffe als Attribute: Abbildung von Domänenbegriffen auf zugehörige At-tribute.
• Domänenbegriffe als Attribut-Attributwertpaare: Abbildung von Domänenbegriffenauf zugehörige Attribut-Attributwertpaare.
Diese Domänenbegriffe werden auf die folgenden zwei Arten als Parameter eingesetzt:• Projektionsparameter schränken die Relation der zu analysierenden Daten vertikal ein,
indem eine bestimmte Teilmenge aus den Attributen der ausgewählten Datenbankrelati-on und damit eine Teilmenge der Datenbankspalten ausgewählt werden. Hierfür werdendie aus Abschnitt 5.2.1.3.1 bekannten Frageargumente vom Typ Eigenschaftsargumenteverwendet. Bei der KD-Frage-Expansion entsteht eine Liste von ein oder mehreren Attri-buten. Diese sind ein wichtiger Bestandteil bei der KD-DM-Transformation und dienenzur Befüllung der notwendigen Argumente der Data-Mining-Methoden-Konfigurationenund Data-Mining-Algorithmus-Konfigurationen. Nur solche Konfigurationen, bei denenalle notwendigen Argumente belegt werden können, werden in den Auswahlprozessender einzelnen Schritte der KD-DM-Transformation weiter verwendet.
• Selektionsparameter schränken die Relation der zu analysierenden Daten horizontalein, indem eine bestimmte Teilmenge der Datensätze ausgewählt wird. Dies geschieht
55 In gewissem Sinne können Fallgruppen als Verallgemeinerung von Attributwertgruppen verstandenwerden: Attributwertgruppen lassen sich wie Fallgruppen repräsentieren, nämlich als Liste von Attribut-Attributwertpaaren oder Attribut-Attributwertintervallpaaren; beide werden zur Selektion einer Teilmengeder Datensätze der zu analysierenden Daten verwendet.

94 KAPITEL 7. DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
typischerweise über die Festlegungen eines Kriteriums in Form von einem oder mehre-ren Attribut-Attributwertpaaren. Hierfür werden die aus Abschnitt 5.2.1.3.2 bekanntenFrageargumente vom Typ Gruppenargumente verwendet. Bei der KD-Frage-Expansionentsteht eine Liste von ein oder mehreren Attribut-Attributwertpaaren.56 Diese Listespielt bei der KD-DM-Transformation eine analoge Rolle wie die Projektionsparameter:Sie dienen als Befüllung der notwendigen Argumente der Data-Mining-Methoden- undData-Mining-Algorithmus-Konfigurationen.
Als Ergebnis der KD-Frage-Expansion entstehen aus einer KD-Frage eine oder mehrereverfeinerte KD-Fragen, in denen alle Frageargumente direkt auf Datenbankattribute abbildbarsind. Diese KD-Fragen dienen als Eingaben für die weitere Transformation in DM-Anfragen.Diese wird als KD-DM-Transformation bezeichnet und im folgenden Abschnitt beschrieben.Davor illustriert Beispiel 25 die KD-Expansion für eine abstrakte KD-Frage.
Beispiel 25: Expansion einer KD-Frage. Abbildung 25 (mit verkürzt formuliertenFragen) veranschaulicht die Entstehung einer Menge von konkreten KD-Frage aus der abstrakten KD-Frage
Welchen Einfluss der Stammdaten auf die Verweildauer gibt es in Grup-pen mit demselben Geschlecht?
(Die Frageargumente, die im jeweils nächsten Schritt expandiert werden,sind dabei kursiv dargestellt.)
56 Im datenbanktechnischen Sinne und unter Verwendung von SQL kann dies als Selektion mittels ei-ner Konjunktion von WHERE-Statements betrachtet werden.
Abbildung 25: Ausschnitt aus einem bei der KD-Frage-Expansion entste-henden Fragebaum.
KD-Frage:Einfluss
der Stammdaten auf die Verweildauernach Geschlecht
KD-Frage:Einfluss
von Alter und Geburtsland auf die Verweildauernach Geschlecht
KD-Frage:Einfluss
von Alter auf die Verweildauernach Geschlecht
KD-Frage:Einfluss
von Alter auf die Verweildauerbei Männern
KD-Frage:Einfluss
von Alter auf die Verweildauerbei Frauen
KD-Frage:Einfluss
von Geburtsland auf die Verweildauernach Geschlecht

957.3 DIE ÜBERSETZUNG VON KD-FRAGEN IN DM-ANFRAGEN
7.3 Die Übersetzung von KD-Fragen in DM-Anfragen
In der KD-DM-Transformation findet die Abbildung der KD-Fragen auf DM-Anfragen statt.Als Vorbedingung dafür nehmen wir an, dass bereits eine vollständige KD-Frage-Expansionfür die betreffende Frage stattgefunden hat, dass also bereits alle Frageargumente und Frage-gruppen direkt auf Datenbankattribute und -attributwerte abbildbar sind.
Die KD-DM-Transformation erfolgt dann in mehreren aufeinander folgenden Schritten.Aus der vollständig expandierten KD-Frage, globalen Parametereinstellungen sowie daten-bankbezogenen Parametern werden mit Hilfe des Abbildungswissens stufenweise die Bestand-teile einer vollständigen, autonomen DM-Anfrage abgeleitet:
1. Ermittlung von Kandidaten für die Bestimmung der Data-Mining-Methode aus dem Fra-geobjekt.
2. Einschränkung der Menge der Kandidaten von Data-Mining-Methoden unter Verwen-dung der globalen und datenbankbezogenen Parametersätze.
3. Auswahl von möglichen Konfigurationen der gewählten Data-Mining-Methoden anhandder Frageargumente.
4. Auswahl der Menge der Kandidaten von Data-Mining-Algorithmen anhand der gewähl-ten Konfiguration der Data-Mining-Methoden und unter Verwendung der globalen unddatenbankbezogenen Parameter.
5. Spezifikation der Datenbasis anhand von Fragegruppe und Fragekontext.6. Formulierung der DM-Anfrage unter Verwendung der Datenbasis und der gewählten
Konfiguration des Data-Mining-Algorithmus.7. Ermittlung der implementierungsabhängigen DM-System-Anfrage unter Verwendung
der DM-Anfrage und einer gegebenen Algorithmenimplementierung.Die folgenden Abschnitte stellen die einzelnen Prozessschritte im Detail dar. Der Gesamt-
prozess der KD-DM-Transformation ist in Abbildung 26 dargestellt.
7.3.1 Die Ermittlung von Kandidaten von Data-Mining-Methoden
Grundlage der Ermittlung von Kandidaten für die Bestimmung der Data-Mining-Methode istzum einen das in der zu bearbeitenden KD-Frage formulierte Frageobjekt und zum anderen diein Tabelle 25 dargestellte Beschreibung der bekannten Data-Mining-Methoden. Durch einenAbgleich lässt sich eine Menge von Kandidaten ermitteln, die in der Beschreibung als geeignetfür die Beantwortung einer Frage mit dem gegebenen Frageobjekt gekennzeichnet sind. Abbil-dung 27 gibt einen Überblick über die Zuordnung von Methoden zu den vier allgemeinen Fra-geobjekten. Beispiel 26 illustriert diesen Auswahlprozess und ist Grundlage für die Beispiele27 bis 30 zur Verdeutlichung der weiteren Schritte im Prozess der KD-DM-Transformation.
Beispiel 26: Ermittlung von Kandidaten von Data-Mining-Methoden. Die fol-gende KD-Frage wurde zur Beantwortung ausgewählt, nachdem sie imProzess der KD-Expansion vollständig expandiert wurde (das Beispielaus Abbildung 25 wurde hierfür um den Fragekontext „in der Augenkli-nik 2002“ angereichert).
Welchen Einfluss von Alter auf die Verweildauer gibt es bei männlichenPatienten in der Augenklinik 2002?
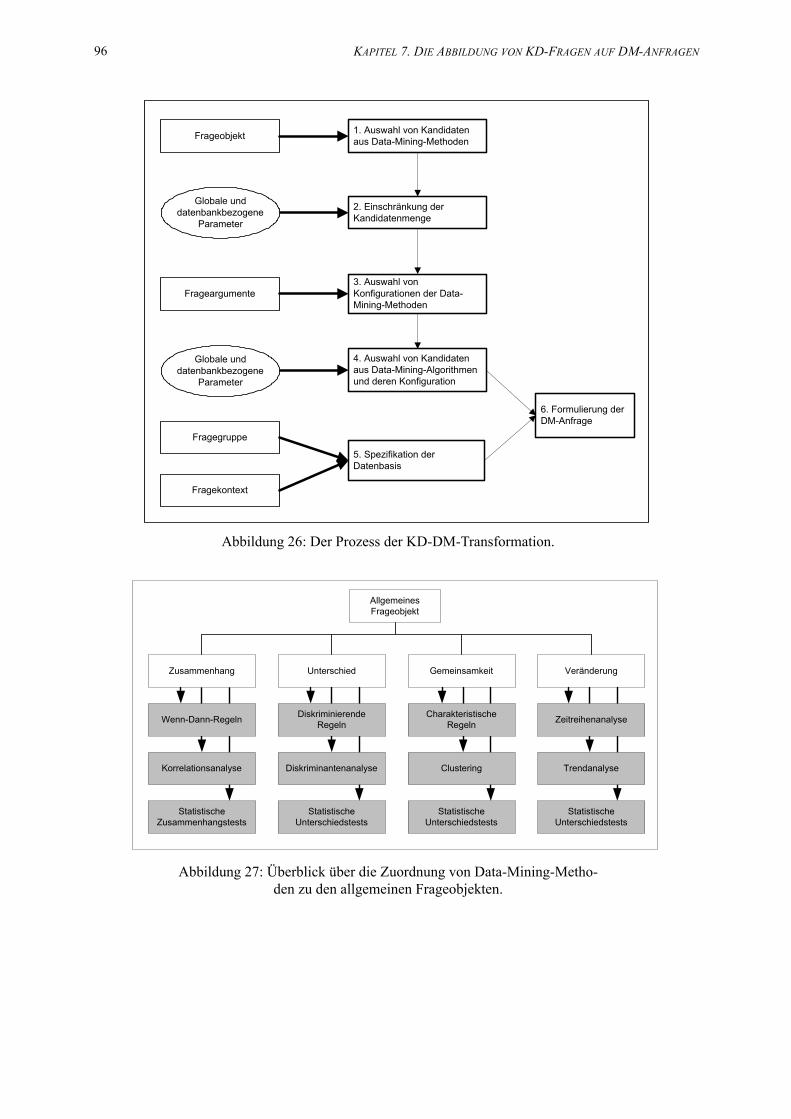
96 KAPITEL 7. DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
Abbildung 26: Der Prozess der KD-DM-Transformation.
Abbildung 27: Überblick über die Zuordnung von Data-Mining-Metho-den zu den allgemeinen Frageobjekten.
Frageobjekt 1. Auswahl von Kandidatenaus Data-Mining-Methoden
2. Einschränkung derKandidatenmenge
Frageargumente3. Auswahl vonKonfigurationen der Data-Mining-Methoden
6. Formulierung derDM-Anfrage
Fragegruppe
Fragekontext
5. Spezifikation derDatenbasis
Globale unddatenbankbezogene
Parameter
Globale unddatenbankbezogene
Parameter
4. Auswahl von Kandidatenaus Data-Mining-Algorithmenund deren Konfiguration
AllgemeinesFrageobjekt
Zusammenhang Unterschied Gemeinsamkeit
Wenn-Dann-Regeln
Korrelationsanalyse
StatistischeZusammenhangstests
Veränderung
DiskriminierendeRegeln
Diskriminantenanalyse
StatistischeUnterschiedstests
Clustering
Zeitreihenanalyse
Trendanalyse
StatistischeUnterschiedstests
StatistischeUnterschiedstests
CharakteristischeRegeln

977.3 DIE ÜBERSETZUNG VON KD-FRAGEN IN DM-ANFRAGEN
Die Frage stellt damit den Ausgangspunkt für die KD-DM-Transformati-on dar. Zu dem in der Frage formulierten Frageobjekt Einfluss (entsprichteinem gerichteten Zusammenhang) möge sich die folgende Menge57 vonData-Mining-Methoden ergeben, die als Kandidaten für die Beantwortungweiter bearbeitet werden:
Lkand = {Assoziationsregeln, statistische Abhängigkeitstests,Neuronale Netze, Wenn-Dann-Regeln}.
7.3.2 Die Einschränkung der Kandidaten von Data-Mining-Methoden
In der Liste möglicher Data-Mining-Methoden zur aktuellen Frage aus dem vorhergehendenProzessschritt spiegelt sich lediglich die grundsätzliche Eignung wider. Weitere Eigenschaftender Methoden sind aber noch nicht berücksichtigt worden. Dies geschieht nun über einen Ab-gleich mit dem Parameterkontext, d.h. der Sätze von Parametereinstellungen, die einerseitsvom Benutzer stammen und sich andererseits aus den Eigenschaften der Daten ergeben. Hier-zu verwenden wir wieder die aus dem Abschnitt 7.1.2 bekannte, detaillierte Beschreibung derData-Mining-Methoden. Wie schon erwähnt, verwenden wir einen Teil der Kriterien als harteKriterien, die in jedem Fall erfüllt sein müssen, damit die zugehörige Methode in die weitereAuswahl kommt.58 Der andere Teil der Kriterien wird als weiche Kriterien betrachtet: er dientzum Vergleich, welche Methoden besser oder schlechter geeignet sind, also einer Priorisie-rung.
Die Ermittlung der momentanen Vergleichswerte zu den einzelnen Kriterien kann auf diefolgenden zwei Arten erfolgen. Bei direkten Kriterien existiert ein dem Kriterium genau ent-sprechender Benutzerparameter oder Datenbankparameter; dieser wird dann zum Abgleich be-nutzt. Im Fall von indirekten Kriterien wird eine dem Kriterium fest zugeordnete Funktion auf-gerufen, die den Vergleichswert in geeigneter Weise aus den Parametersätzen von Benutzerund Datenbank ermittelt (z.B. die Überprüfung von Verteilungsannahmen).59
Die Einschränkung der Kandidatenmenge erfolgt in zwei Schritten:
1. Zunächst wird für alle Kandidaten von Data-Mining-Methoden überprüft, ob die hartenKriterien erfüllt sind. Durch diese Filtermenge entsteht eine reduzierte oder gleich großeKandidatenmenge.
2. Mittels der Werte für die weichen Kriterien und deren Gewichtung lässt sich dann jedemKandidaten ein Prioritätswert zuordnen. Damit erhalten wir aus der ursprünglichen,keine inhaltliche Ordnung enthaltenden Menge von Kandidaten, eine geordnete Listevon Kandidaten.
Beispiel 27 beschreibt die Einschränkung der Kandidatenmenge ausgehend von der in Bei-spiel 26 formulierten KD-Frage.
57 Als Symbol für die ungeordnete Menge verwenden wir „{}“.58 Die harten Kriterien lassen sich auch als inverse KO-Kriterien verstehen.59 Die Informationen, ob zu einem Kriterium ein fest zugeordneter Parameter oder eine Berechnungs-
vorschrift existiert, werden als Metadaten zu den Kriterien aus Tabelle 25 verwaltet.

98 KAPITEL 7. DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
Beispiel 27: Einschränkung der Kandidatenmenge. Wir nehmen an, dass der Benut-zer dem System eine Präferenz für Ergebnisse bekannt gegeben hat, beidenen das Wissen explizit dargestellt wird (hartes, direktes KriteriumExplizitheit des Ergebnisses = hoch). Weiterhin nehmen wir an, dass dieVerteilung der Attributwerte des Attributs Verweildauer nicht der Nor-malverteilung entspricht (hartes, indirektes Kriterium Verteilungsan-nahme = nicht erfüllt), was durch eine entsprechende Funktion aus denDaten ermittelt wurde. In diesem Fall lässt sich die Menge der Kandidaten
Lkand = {Assoziationsregeln, statistische Abhängigkeitstests,Neuronale Netze, Wenn-Dann-Regeln}.
auf die eingeschränkte Menge
Lkand,2 = {Assoziationsregeln, Wenn-Dann-Regeln}
reduzieren, weil statistische Abhängigkeitstests nur unter der Annahmevon normalverteilten Variablen sinnvoll anwendbar sind und neuronaleNetze das ermittelte Wissen in den Gewichten verbergen und nicht expli-zit machen.
Im zweiten Schritt werden die weichen Kriterien überprüft. Da der Benut-zer eine Präferenz für leicht verständliche Ergebnisse hat, werden Wenn-Dann-Regeln (weiches, direktes Kriterium Verständlichkeit = hoch) höherbewertet als Assoziationsregeln (Verständlichkeit = mittel). Damit ergibtsich die geordnete Liste60 der Kandidaten mit
Lkand,3 = (Wenn-Dann-Regeln, Assoziationsregeln).
7.3.3 Die Auswahl von Konfigurationen der Data-Mining-Methoden
Die Data-Mining-Methoden und die später noch zu bestimmenden Data-Mining-Algorithmenkönnen im Allgemeinen in vielfacher Weise parametrisiert werden. Dabei nehmen wir an, dasssich zwei verschiedene Arten von Parametrisierung unterscheiden lassen, die wir Makropara-metrisierung und Mikroparametrisierung bezeichnen wollen.
• Mikroparametrisierung: In diesem einfacheren Fall werden lediglich Feineinstellun-gen vorgenommen, die aber das Verhalten der Methode nicht grundlegend beeinflussen,wie zum Beispiel die Angabe eines minimalen Konfidenzwertes bei der Regelinduktion
• Makroparametrisierung: In diesem Fall kann sich durch die Wahl der Parameter derAblauf und das Ergebnis der Anwendung von Data-Mining-Methoden und -Algorithmenstark unterscheiden. Dadurch können grundlegend verschiedene Konfigurationen vonData-Mining-Methoden entstehen. Dabei kann jede solche Konfiguration als eine be-stimmte eigenständige Art von Problembearbeitung oder Lösungsidee verstanden wer-den. Umgekehrt betrachtet kann über die dahinter stehende Lösungsidee erst eine Konfi-guration definiert werden. In formaler Form lässt sich eine Konfiguration über das Para-digma eines programmiersprachlichen Prozeduraufrufs beschreiben, wobei der Typ der
60 Als Symbol für die geordnete Liste verwenden wir „()“.

997.3 DIE ÜBERSETZUNG VON KD-FRAGEN IN DM-ANFRAGEN
jeweiligen Parameter über Rollen angegeben wird. Beispiele für Konfigurationen in die-sem Sinne sind:
• Wenn-Dann-Regelinduktion(): Ein zur Data-Mining-Methode Regelinduktiongehöriger Algorithmus, der später im Prozess zu bestimmen ist, wird ohne weitereArgumente aufgerufen. Damit werden alle Regeln, die gewissen Auffälligkeitskri-terien61 entsprechen, auf den Daten gesucht. Alle Attribute auf der gegebenen Da-tenrelation werden dabei gleichberechtigt behandelt.
• Wenn-Dann-Regelinduktion(abhängige_Attribute, unabhängige_Attribute):Ein zu derselben Data-Mining-Methode gehöriger Algorithmus wird aufgerufen,und es werden zwei Sätze von Attributen benannt, die die Rollen abhängiges undunabhängiges Attribut einnehmen sollen. Dies hat zur Folge, dass nur solche Re-geln generiert werden, die im WENN-Teil eines der Attribute aus der Liste abhän-gige_Attribute und im DANN-Teil eines aus der Liste unabhängige_Attribute ent-halten.62
Für die Auswahl einer bestimmten Konfiguration der Data-Mining-Methoden, die im vor-hergehenden Prozessschritt ausgewählt wurden, werden nun die Frageargumente als weitereBestandteile der in der KD-Frage formulierten Interessen des Benutzers verwendet. Dabeiwerden den einzelnen Frageargumenten Rollen zugeordnet, die sie innerhalb der Frage einneh-men und die für die Auswahl der geeigneten Konfiguration verwendet werden. Zusätzlich wirdunterschieden, wie viele Argumente derselben Rolle zugeordnet werden können, beispielswei-se zwei abhängige Argumente, und ob es sich bei den Argumenten um Eigenschaftsargumenteoder Gruppenargumente handelt. Die Konfigurationen von Data-Mining-Methoden lassen sichin BNF wie folgt beschreiben:
⟨DM-Methode_Konfiguration⟩ ::== ⟨DM-Methode⟩ (⟨Argumentrolle⟩∗ )
Jede Konfiguration einer Data-Mining-Methode wird also durch die Methode selbst undeine Aufzählung der Rollen der möglichen Argumente definiert, z.B.
Wenn-Dann-Regelinduktion(abhängige_Argumente)
Wenn-Dann-Regelinduktion(unabhängige_Argumente abhängige_Argumente)
wobei im ersten Fall nur der DANN-Teil der gesuchten Regeln mit der Liste der abhängi-gen Attribute und im zweiten Fall sowohl der WENN- als auch der DANN-Teil spezifiziertwird.
Durch einen Abgleich der in der KD-Frage gegebenen Argumente und ihrer Rollen mit denverfügbaren Konfigurationen der Data-Mining-Methoden wird zu jedem Kandidaten aus derListe der Data-Mining-Methoden aus dem vorgehenden Prozessschritt die passende Konfigu-ration gesucht. Hieraus ergibt sich nun die gewünschte Liste der Methoden-Konfigurationen.Sie ist entsprechend der Priorisierung der Liste der Data-Mining-Methoden geordnet. Beispiel28 führt die Auswahl der Konfigurationen der Data-Mining-Methoden auf der Basis der vor-hergehenden Beispiele fort.
61 z.B. Support und Konfidenz62 Wie sich diese Rollenzuordnung in den Aufrufen weiterhin auswirkt, wird stets über die weitere Kon-
figuration der zugehörigen Data-Mining-Algorithmen und die Realisierung mittels der einzelnen Imple-mentierungen der Algorithmen, die am Ende des Transformationsprozesses in den DM-System-Anfragenausgewählt werden, bestimmt.

100 KAPITEL 7. DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
Beispiel 28: Auswahl einer Konfiguration der Data-Mining-Methode. Wiederumausgehend von der KD-Frage aus Beispiel 26 und der aus dem Beispiel 27bekannten, geordneten Liste von Data-Mining-Methoden lassen sich diefolgenden Konfigurationen zu den Data-Mining-Methoden Wenn-Dann-Regelinduktion und Assoziationsregeln finden:
1. Wenn-Dann-Regelinduktion(unabhängige_Argumente abhängige_Argumente),
bei der die Verweildauer als abhängiges und Alter als unabhängiges Argu-ment eingeordnet werden, und
2. Assoziationsregeln(Fokus_Argumente),
bei der beide Argumente gleichwertig für die Fokussierung der Assoziati-onsregeln mit Hilfe der Liste Fokus_Argumente verwendet werden.63
7.3.4 Die Ermittlung von Kandidaten von Data-Mining-Algorithmen
Nachdem die möglichen Lösungspläne zur gegebenen Fragestellung in Form von abstraktenAufrufen der Konfigurationen von Data-Mining-Methoden identifiziert wurden, sind imnächsten Schritt ein geeigneter Data-Mining-Algorithmus und eine oder mehrere Konfigurati-onen davon auszuwählen. Das Vorgehen hierbei kann mit der Auswahl einer Menge von Data-Mining-Methoden als Kandidaten für die Beantwortung einer KD-Frage (siehe Abschnitt7.3.1) verglichen werden. Die Auswahl von geeigneten Data-Mining-Algorithmen erfolgt wiedie oben beschriebene Auswahl der Data-Mining-Methoden. Die Kriterien sind dabei zu den inAbschnitt 7.3.1 formulierten Kriterien für die Beschreibung der Data-Mining-Methoden nichtvollständig disjunkt, weil sich die Menge der weichen Kriterien für die Data-Mining-Metho-den in einigen Fällen auch als Priorisierung für die Data-Mining-Algorithmen verwenden las-sen.
Wurden in Abhängigkeit von den Data-Mining-Methoden sowie globalen und datenbankbe-zogenen Parametern geeignete Algorithmen gewählt und entsprechend ihrer Eignung priori-siert, werden noch in demselben Schritt Konfigurationen dazu bestimmt. Die Parameter, dieeine Konfiguration beschreiben, werden dabei direkt von der Konfiguration der Data-Mining-Methode übernommen. Damit entsteht eine geordnete Liste von Konfigurationen von Data-Mining-Algorithmen, für die jetzt eine Entscheidung bezüglich ihrer Bearbeitung zu treffen ist.Dabei sind die folgenden Alternativen denkbar:
• Vollständige Ausführung: Alle Konfigurationen zu allen gewählten Data-Mining-Al-gorithmen werden ausgeführt. Da die Ergebnisse zum Vergleich durch den Benutzer ne-beneinander gestellt werden, erhöht sich der Aufwand bei der Analyse und Interpretationder Ergebnisse.
• Vollständige Ausführung und anschließende Auswahl: Das System führt alle Algo-rithmen aus und entscheidet sich dann a posteriori anhand des Ergebnisses (Performanz,Fehlermaße) für einen Algorithmus, dessen Ergebnisse präsentiert werden. Durch dieseVerlagerung der Auswahl auf die Nachbereitung der Ergebnisse entsteht neuer Berech-nungsaufwand und die Transparenz für den Benutzer reduziert sich.
63 Hierbei liegt die Annahme zugrunde, dass der Algorithmus zur Generierung von Assoziationsregelnnur auf den Attributen der gewählten Datenbankrelation arbeitet, die im Argument Fokus_Attribute ange-geben sind. Dies entspricht im datenbanktechnischen Sinne einer Projektion auf die Datenrelation.

1017.3 DIE ÜBERSETZUNG VON KD-FRAGEN IN DM-ANFRAGEN
• Auswahl durch den Benutzer: Der Benutzer entscheidet durch direkte Interaktion, wel-cher Algorithmus ausgeführt werden. Damit wird vom Benutzer wieder methodischesWissen über Data-Mining-Algorithmen gefordert, was mit der Zielsetzung des InvisibleData Mining konfligiert.
• Auswahl durch das System: Aufgrund der Priorisierungen entscheidet sich das Systemführt den am besten bewerteten Algorithmus und führt ihn aus.
Im Rahmen der vorliegenden Arbeit werden die Informationen über die Priorisierung derData-Mining-Algorithmen als ausreichend betrachtet, um die Auswahl zu steuern. Es wird alsogenau ein Element aus der Liste der Konfigurationen von Data-Mining-Algorithmen verwen-det, nämlich das höchst priore. Beispiel 29 stellt die Auswahl der Konfigurationen der Data-Mining-Algorithmen auf der Basis der vorgehenden Beispiele dar.
Beispiel 29: Auswahl des Data-Mining-Algorithmus. Wir verwenden im Folgendendie im Beispiel 28 ermittelten Konfigurationen von Data-Mining-Metho-den als Ausgangspunkt:
Wenn-Dann-Regelinduktion(unabhängige_Argumenteabhängige_Argumente) und
Assoziationsregeln(Fokus_Argumente).
Zur Methode Wenn-Dann-Regelinduktion stehen die folgendenMengen von Data-Mining-Algorithmen zur Verfügung:
1. {AIS, SETM, Apriori, AprioriTid}
und zur Methode Assoziationsregeln:
2. {PART, PRISM}64.
Aufgrund der oben erwähnten Kriterien und der globalen und datenbezo-genen Anforderungen, die Antwortzeiten bei hoher Skalierbarkeit mög-lichst gering ausfallen sollen (Kriterien Antwortzeit=gering, Skalierbar-keit=hoch), wird die folgende Ordnung der Algorithmen berechnet:
(Apriori, AprioriTid, PRISM, AIS, SETM, PART)
Aufgrund der Annahme, dass nur der am besten bewertete Algorithmusausgeführt werden soll, fällt die Wahl auf den Apriori-Algorithmus([Agr94]). Dieser Algorithmus erlaubt die Spezifikation einer Mindestan-forderung bezüglich des Supports (z.B. 2%), der für die gefundenen Re-geln gelten soll. Damit ist das Ergebnis dieses Prozessschrittes:
Apriori ((Alter), (Verweildauer), (MinSupp=0,02)).
64 Für Details zu den Algorithmen verweisen wir auf die Literatur: Apriori ([Agr94]), AprioriTid([Agr94]), AIS ([AIS93b]), PART ([Wit99]), PRISM ([Cen87]) und SETM ([Hou93]).

102 KAPITEL 7. DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
7.3.5 Die Spezifikation der Datenbasis
Die Daten, die als Grundlage für das Data Mining verwendet werden soll, lassen sich über dreiAngaben spezifizieren:
• Datenrelation, • Informationen zur Auswahl von Attributen (Projektion) und • Information zur Auswahl von Datensätzen (Selektion).Die Datenrelation wird als implizit gegebenes Argument betrachtet, das bei der Erstellung
der DM-Anfrage nicht extra ermittelt zu werden braucht. Die Projektionsinformationen wer-den mit der Auswahl der Argumentlisten zu den Data-Mining-Methoden und -Algorithmenspezifiziert. Die Selektionsinformationen können aus der bislang noch nicht berücksichtigten,verfeinerten Fragegruppe und dem Fragekontext der KD-Frage übernommen werden: Beideenthalten Attribut-Attributwertpaare, die als Selektionskriterien für die Datensätze verwendetwerden. Die Konjunktion dieser einzelnen Bedingungen ergibt insgesamt die gewünschte Se-lektionsinformation zu den zu analysierenden Daten. Beispiel 30 illustriert die Spezifikationder Datenbasis.
Beispiel 30: Spezifikation der Datenbasis. Aus der aus Beispiel 26 bekannten KD-Frage lässt sich die Datenbasis wie folgt spezifizieren:
(Patienten_Relation, (), (Klinik=Augenklinik, Jahr=2002)).
7.3.6 Die Formulierung der DM-Anfrage
Mit Hilfe der vorhergehenden Prozessschritte lässt sich jetzt die vollständige DM-Anfrage zu-sammensetzen. Dafür werden die in Abschnitt 7.1.1 vorgestellte Syntax und die bislang ermit-telten Elemente verwendet. Beispiel 24 stellt die vollständige DM-Anfrage dar, die sich ausden Beispielen 26 bis 30 ergibt.
7.3.7 Die Ermittlung der implementierungsabhängigen DM-System-Anfrage
Mit der entstandenen DM-Anfrage sind alle Informationen zur Durchführung von Data-Mi-ning-Läufen in einer implementierungsunabhängigen Form gegeben. Welche Implementie-rungsfunktion zu welcher Algorithmenkonfiguration genau aufzurufen ist, ist in der Wissens-basis niedergelegt, in der zu jeder Data-Mining-Algorithmus-Konfiguration eine bestimmteZeichenkette angegeben ist. Diese beschreibt den konkreten Aufruf in der Form des Namensder aufzurufenden Prozedur und der Angabe der Namen der zu übergebenden Parameter.Durch die Implementierungsunabhängigkeit der in der DM-Anfrage enthaltenen Informatio-nen und den Zwischenschritt der DM-Anfrage-Spezialisierung wird eine Modularisierung indem Sinne erreicht, dass verhältnismäßig leicht neue Bibliotheken zur Realisierung von Data-Mining-Algorithmen als Implementierungsmodule eingebracht werden können.
7.4 Der Prozess der Beantwortung von KD-Fragen
Nachdem wir in den vorhergehenden Abschnitten die Transformation einer KD-Frage in eineDM-Anfrage aus der lokalen Sicht betrachtet haben, schlagen wir nun einen globalen Prozessfür die Beantwortung von KD-Fragen vor. Dieser Prozess ist auf der Basis des allgemeinen

1037.4 DER PROZESS DER BEANTWORTUNG VON KD-FRAGEN
Prozesses für die Formulierung und Beantwortung von Fragen aus Abschnitt 4.2 entstandenund in Abbildung 28 vollständig dargestellt.
Der Prozess, den wir im Folgenden nur skizzieren wollen, beginnt aus der Sicht des QUES-TUS-KDD-Ansatzes mit der Eingabe einer Frage in natürlicher Sprache durch den Benutzerund der Übersetzung der Frage in die formale KDQL-Repräsentation mit den im Abschnitt8.3.1.2 beschriebenen Methoden. Diese neue KD-Frage wird in den Kontext der bestehendenFragen durch Überprüfung der Subsumtionsbeziehungen, die wir an dieser Stelle jedoch nichtweiter vertiefen wollen, eingebettet: Ziel dieser Überprüfung ist die Feststellung, ob die neueFrage eine oder mehrere bestehende Fragen umfasst, also allgemeiner ist als diese (Überord-nung), oder ob sie in einer oder mehreren bestehenden Fragen bereits enthalten ist, also spezi-eller ist als diese (Unterordnung). Auch die Möglichkeiten, dass die neue Frage mit den beste-hen Fragen disjunkt ist (Beiordnung) oder aber dass sie zu einer bestehenden Frage äquivalentist (Gleichordnung), sind hier zu überprüfen. Mit diesen Informationen kann die neue Frage aneine geeignete Stelle im Fragenbaum eingeordnet werden.
Durch direkte Interaktion oder Automatismen, die z.B. für jede neu eingegebene Frage ak-tiv werden, kann eine Frage zur Beantwortung ausgewählt werden. Um die Effizienz der Fra-gebeantwortung zu gewährleisten, wird dabei zunächst überprüft, ob die gewählte KD-Frageoder eine oder mehrere ihrer Unterfragen bereits früher beantwortet wurden. Für diese Ent-
Abbildung 28: Der Prozess der Beantwortung von KD-Fragen.
Eingabe einerFrage und
Formalisierung
Überprüfung vonSubsumptions-beziehungen
Auswahl von"Beantworten"
Überprüfungfrüherer
KD-Antworten
KD-DM-Transformation
KD-Fragetransformierbar?
Ja
NeinBedingte oder
vollständige KD-Expansion
Historie vonBeantwort-
ungen
VorhandeneKD-Fragen
In Abhängigkeit von derÜberprüfung früherer
Beantwortung und derAktualität der Daten
DM-Anfrage-Spezialisierung
Zuanalysierende
Daten
In Abhängigkeitvon der gewählten
Implementierungder Algorithmen
Ausführung derDM-System-
Anfrage
Präsentation derKD-Antwort
Ergebnisseanforderungs-
gemäß?
Anpassung derKonfigurations-
parameter
Ja
Nein
DM-Ergebnis-Generalisierung
Analyse derDM-Ergebnisse
DM-KD-Transformation
In Abhängigkeitvon der gewähltenImplementierungder Algorithmen
In Abhängigkeit vonden Anforderungendes Benutzers

104 KAPITEL 7. DIE ABBILDUNG VON KD-FRAGEN AUF DM-ANFRAGEN
scheidung wird eine Historie der Beantwortungsschritte verwendet. Zudem muss entschiedenwerden, ob die KD-Frage in der gegebenen Form transformierbar ist (siehe Abschnitt 7.3),oder ob zunächst eine KD-Frage-Expansion (siehe Abschnitt 7.2) stattfinden muss. Dies ge-schieht wieder unter Verwendung von historischen Informationen über bereits beantworteteund damit expandierte KD-Fragen, die über den benötigten Umfang der Expansion entschei-den. Sobald die Frage ausreichend expandiert wurde, kann die in Abschnitt 7.3 ausführlich be-schriebene KD-DM-Transformation beginnen. In Abhängigkeit von der verfügbaren Imple-mentierung wird das Ergebnis der Transformation, die DM-Anfrage, in eine DM-System-An-frage übersetzt und diese auf den zu analysierenden Daten ausgeführt.
Da die Repräsentation der Menge der DM-System-Ergebnisse noch in einem implementie-rungsabhängigen Format vorliegt, muss im nächsten Schritt eine Transformation der Ergebnis-se in eine implementierungsunabhängige Repräsentation vorgenommen werden. Dies ermög-licht dann die Formulierung von DM-Ergebnissen. Sollten die gefundenen Ergebnisse nichtden Erwartungen des Benutzers entsprechen, weil entweder zu viele Ergebnisse oder solchemit geringer Aussagekraft gefunden wurde, müssen die Konfigurationsparameter der Data-Mi-ning-Algorithmen angepasst (d.h. relaxiert oder verschärft) und die Transformation zusammenmit den nachfolgenden Prozessschritten wiederholt werden. Andernfalls können die DM-Er-gebnisse mittels einer DM-KD-Transformation in KD-Antworten in der Knowledge DiscoveryAnswer Language (siehe Abschnitt 5.3) formuliert werden.
7.5 Zusammenfassung
In diesem Kapitel haben wir die verschiedenen Prozesse für die Abbildung von KD-Fragen aufDM-Anfragen und DM-System-Anfragen untersucht. Der Fokus lag dabei auf den beidenKernprozessen: der KD-Frage-Expansion für die Verfeinerung von abstrakten KD-Fragen undder KD-DM-Transformation für die eigentliche Abbildung. Die DM-Anfragen als das Ziel derAbbildung wurden syntaktisch beschrieben. Data-Mining-Methoden und -Algorithmen wur-den mit ihren charakteristischen Anwendungsbedingungen, Merkmalen und Ergebniseigen-schaften, die als wichtige Entscheidungskriterien in den Abbildungsprozess einfließen, model-liert. Als Ausblick haben wir den gesamten Prozess der Beantwortung von KD-Fragen skiz-ziert und damit die Betrachtung des QUESTUS-KDD-Ansatzes aus der prozesstechnischenSicht vervollständigt.
Um die in diesem und den vorhergehenden Kapiteln beschriebenen Elemente unseres An-satzes von ihrer theoretischen Beschreibung in eine praktische Umsetzung zu überführen, wur-de der QUESTUS-KDD-Ansatz zu großen Teilen als Komponenten des Knowledge DiscoveryAssistant (KDA) implementiert. Im nun folgenden Kapitel werden wir einige Details dieserImplementierung beschreiben.

KAPITEL 8 DER KNOWLEDGE DISCOVERY ASSISTANT
Ausgehend von dem in den vorhergehenden Kapiteln beschriebenen Ansatz und auf der Basisfrüherer Arbeiten von Timm ([Tim97]), Müller ([Mül98]), Hausdorf ([Hau98]), Hogl([Hog98]) und Kokowski ([Kok00]) wurde der Knowledge Discovery Assistant (KDA) konzi-piert und weitestgehend implementiert. Eine umfassende und detaillierte Beschreibung des ak-tuellen Standes der Implementierung des KDA liefert Käppel in [Käp02].
Der KDA stellt ein wissensbasiertes Assistenzsystem für die Entdeckung von Wissen inDatenbanken dar, das von seinem Benutzer nur ein geringes Maß an Vorwissen über Datena-nalyse und Data Mining erfordert. Zudem bietet der KDA die Möglichkeit, durch Methodender Fokussierung, der Abstraktion und der Bewertung die Menge der Ergebnisse auf ein für dieBenutzer überschaubares Maß zu reduzieren. Damit lässt sich zum einen vermeiden, dass rele-vantes Wissen aufgrund der Überhäufung mit Ergebnissen übersehen wird. Zum anderen kanndie Umsetzung der Ergebnisse gefördert werden, weil nur wirklich relevante weil umsetzbareErkenntnisse präsentiert werden. Ein weiteres Designziel für den KDA ist die einfache Erwei-terbarkeit, zum Beispiel um neue Data-Mining-Methoden, Data-Mining-Algorithmen und de-ren Implementierungen, und die einfache Übertragbarkeit, z.B. auf neue Domänen.
In diesem Kapitel beschreiben wir zunächst die Gesamtarchitektur des KDA und die Kon-zeption der graphischen Benutzerschnittstelle. Im dritten Teil des Kapitels gehen wir dann aufdie Realisierung der Konzepte aus dem QUESTUS-KDD-Ansatz für den Umgang mit Fragenund Antworten ein und beschreiben in diesem Zusammenhang die wichtigsten Methoden.
8.1 Die Gesamtarchitektur des Knowledge Discovery Assistant
Die Grobstruktur des KDA leitet sich im Wesentlichen aus dem in Abbildung 2 dargestelltenSprachebenenmodell, auf dem wir, wie in Abschnitt 1.3 beschrieben, die Knowledge-Discove-ry-Ebene, die Data-Mining- und die Datenbank-Ebene unterscheiden. Diesen Ebenen entspre-chen die in Abbildung 29 dargestellten Module, die wir als Knowledge-Discovery-Agent (KD-Agent), Data-Mining-Agent (DM-Agent) und Datenbank-Agent (DB-Agent) bezeichnen undim Folgenden kurz erläutern:
8.1.1 Der Knowledge-Discovery-Agent
Der Knowledge-Discovery-Agent als zentrales Modul realisiert im Wesentlichen die imQUESTUS-KDD-Ansatz konzipierten Methoden. Er lässt sich weiter in drei Komponentenzerlegen:
• KD-Frage-Manager: Er beinhaltet die Methoden für die Eingabe von natürlichsprachli-chen Fragen, für deren Formalisierung und die Verwaltung der KD-Fragen (siehe dazuauch Abschnitt 8.3.1), für die Verfeinerung von KD-Fragen (KD-Expansion, siehe Ab-schnitt 7.2) und die Übersetzung in DM-Anfragen und DM-System-Anfragen (KD-DM-

106 KAPITEL 8. DER KNOWLEDGE DISCOVERY ASSISTANT
Transformation, siehe Abschnitt 7.3). Letztere werden an den Data-Mining-Agenten zurAusführung übergeben.
• KD-Antwort-Manager: Er leistet die Verarbeitung von DM-System-Ergebnissen, dievom Data-Mining-Agenten geliefert werden. Dazu zählen die Übertragung in DM-Er-gebnisse (DM-Ergebnis-Generalisierung), die Rückübersetzung zu KD-Antworten (DM-KD-Transformation) und die Verdichtung von KD-Antworten (KD-Antwort-Kontrakti-on, siehe Abschnitt 7.4).
• Komponente zur Interessantheitsbewertung65: Sie unterstützt die Bearbeitung derDM-Ergebnisse durch strukturierte Bewertungen ihrer Interessantheit anhand von hierar-chisch geordneten Facetten wie z.B. Validität, Neuheit, Nützlichkeit und Verständlich-keit. Für genauere Information zur Bewertung der Interessantheit verweisen wir auf[Mül98].
8.1.2 Der Data-Mining-Agent
Der Data-Mining-Agent leistet die effiziente Verarbeitung von DM-System-Anfragen, dievom Knowledge-Discovery-Agenten geliefert werden, durch geeignete Implementierungenvon Data-Mining-Algorithmen. Diese werden als eigenständige Module in den KDA integriert(siehe dazu Abbildung 30) und zur Laufzeit des KDA geladen werden. Ziel bei der bisherigenRealisierung war es jedoch, die Implementierung eigener Algorithmen nur auf die grundle-gendsten zur beschränken und stattdessen Schnittstellen zu Tools und Bibliotheken von ande-ren Anbietern66 zu schaffen.67 Die Ergebnisse der Data-Mining-Algorithmen werden als DM-System-Ergebnisse an den Knowledge-Discovery-Agenten zurückgeliefert.
Abbildung 29: Die Gesamtarchitektur des Knowledge Discovery Assis-tant.
65 Diese Komponente wird von Müller in [Mül98] als Interestingness Engine bezeichnet.66 Eine solche frei verfügbare Bibilothek von Data-Mining-Algorithmen ist beispielsweise das WEKA
Toolkit zum Maschinellen Lernen der Universität Waikato, Neuseeland ([Wit99]).

1078.1 DIE GESAMTARCHITEKTUR DES KNOWLEDGE DISCOVERY ASSISTANT
8.1.3 Der Datenbank-Agent
Der Datenbank-Agent stellt eine einheitliche Schnittstelle für verschiedene Datenbanksystemeals Quellen für die zu analysierenden Daten und als Senken für die Ergebnisse zur Verfügung.Dies wird durch eine ODBC-Konfigurationsschnittstelle realisiert, die Möglichkeiten zur An-passung an verschiedene Datenquellen bzw. Datensenken bietet. Damit lassen sich Datenban-ken wie Microsoft Access, Microsoft SQL Server, Oracle Server, MySQL oder Postgress ein-fach anbinden. Abbildung 31 zeigt die Konfigurationsfenster des KDA für die Wahl der rele-vanten Datenquellen aus einer Datenbank.
67 Über eine COM-Schnittstelle können entsprechende Module in den Sprachen C++, Visual Basic, Ja-va, Lisp usw. integriert werden. Bedingung ist dabei die Unterstützung von COM, d.h. die von der verwen-deten Sprache erzeugten Klassenbibliotheken müssen durch die standardisierte Interface DescriptionLanguage (IDL) beschrieben werden.
Abbildung 30: Die modulare Integration von Algorithmen in den Data-Mining-Agenten.
Abbildung 31: Die Konfiguration der Datenquellen im Datenbank-Agen-ten.

108 KAPITEL 8. DER KNOWLEDGE DISCOVERY ASSISTANT
8.1.4 Die Berichtsgeneratoren
Um eine schnelle und verteilte Nutzung der Ergebnisse des Data Mining zu ermöglichen, wer-den die Ergebnisse in einer für die Einbindung in das Intranet des Kunden geeigneten Darstel-lung abgelegt. Abbildung 32 zeigt eine solche Darstellung aus einem beispielhaften KDD-Pro-jekt. Darüber hinaus lassen sich Berichte im Rich Text Format (RTF) generieren. Weitere Ge-neratoren für spezifische Darstellungsformate (Latex, PDF usw.) lassen sich modular integrie-ren.
8.2 Die graphische Benutzeroberfläche
Die graphische Benutzeroberfläche wurde mit Hilfe von Microsoft Visual Basic für Windows-Systeme entwickelt. Sie besteht, wie im Screenshot in Abbildung 33 und in der Darstellung derFensterstruktur in Abbildung 34 gezeigt, aus dem KDA-Hauptfenster, das sich aus der Menü-leiste sowie den folgenden drei Unterkomponenten zusammensetzt:
• Struktur der Fragen in der linken Hälfte,• Detailansicht der KD-Fragen im rechten oberen Bereich und• Detailansicht der KD-Antworten im rechten unteren Bereich.Die Strukturansicht wird durch einen interaktiven Strukturbrowser (wie z.B. aus dem Mic-
rosoft Windows-Explorer bekannt) realisiert, der den Zugriff auf die in einem KDD-Projektenthaltenen KD-Fragen erlaubt. In diese Struktur können die KD-Fragen ausgewählt, verscho-ben und über Kontextmenüs bzw. die Menüleiste zur Expansion oder zur Beantwortung ausge-wählt werden. Auf die gleiche Weise lässt sich die Eingabe neuer Fragen in die Struktur auslö-sen, die in einem eigenen Fenster (siehe Abbildung 37) durchgeführt und in Abschnitt 8.3.1.1genauer beschrieben wird.
Abbildung 32: Die Darstellung der Ergebnisse in einem Bericht im HTML-Format.
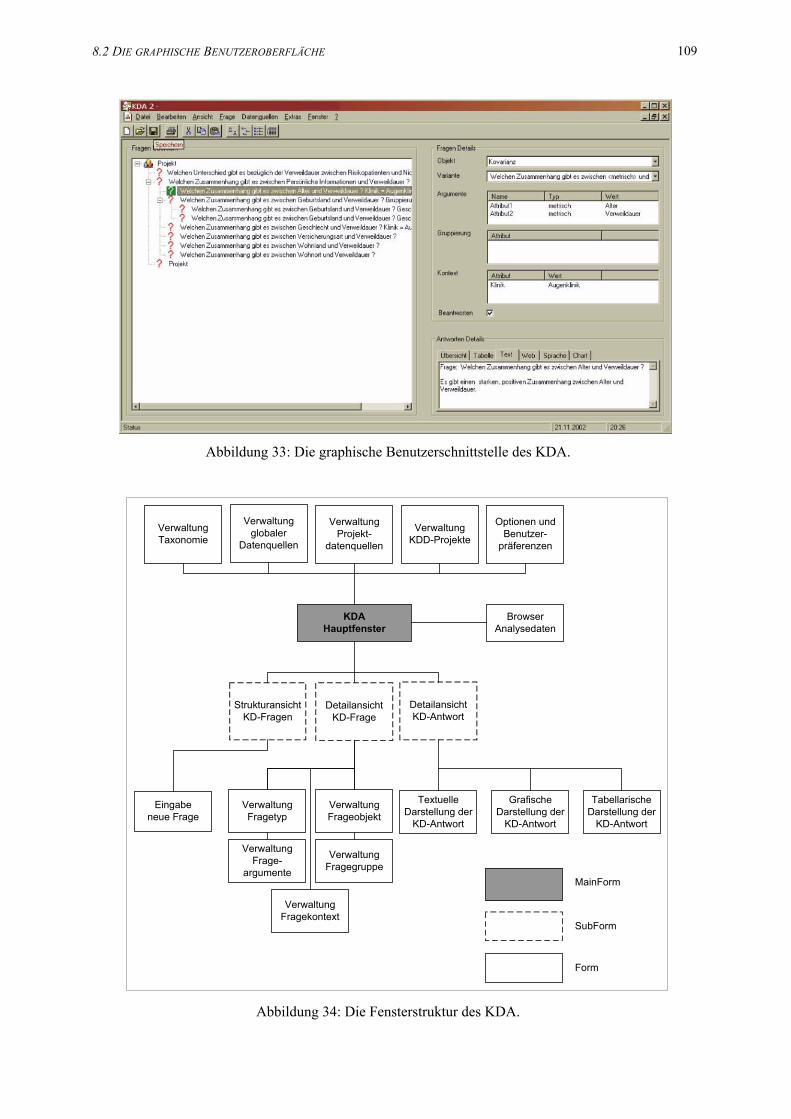
1098.2 DIE GRAPHISCHE BENUTZEROBERFLÄCHE
Abbildung 33: Die graphische Benutzerschnittstelle des KDA.
Abbildung 34: Die Fensterstruktur des KDA.
KDAHauptfenster
StrukturansichtKD-Fragen
DetailansichtKD-Frage
DetailansichtKD-Antwort
TextuelleDarstellung der
KD-Antwort
GrafischeDarstellung der
KD-Antwort
TabellarischeDarstellung der
KD-Antwort
VerwaltungTaxonomie
Verwaltungglobaler
Datenquellen
VerwaltungProjekt-
datenquellen
Eingabeneue Frage
Optionen undBenutzer-
präferenzen
VerwaltungKDD-Projekte
VerwaltungFrageobjekt
VerwaltungFragetyp
VerwaltungFrage-
argumente
VerwaltungFragegruppe
VerwaltungFragekontext
BrowserAnalysedaten
MainForm
SubForm
Form

110 KAPITEL 8. DER KNOWLEDGE DISCOVERY ASSISTANT
Die Detailansicht der KD-Fragen dient zum einen dazu, dem Benutzer ein Feedback unddamit Transparenz über die vom System vorgenommene Formalisierung der von ihm eingege-benen Frage zu geben. Zum anderen bietet sie für Benutzer, die bereits eine gewisse Vertraut-heit mit dem System besitzen, einen schnellen Überblick über die Details der Frage zusammenmit einer direkten Möglichkeit, die einzelnen Elemente der KD-Frage zu manipulieren.
Das Unterfenster für die KD-Antworten erlaubt dem Benutzer verschiedene Sichten auf dievom System ermittelte Antwort. Dabei sind in der aktuellen Realisierung die in Abbildung 33gezeigte Textansicht, mit der natürlichsprachlichen Formulierung, sowie eine tabellarische undeine graphische Darstellung, in der die Antworten als Business Charts visualisiert werden, ver-fügbar.
Über die Menüstruktur des KDA sind verschiedene Hilfsfenster aufrufbar:• Verwaltung der Taxonomie: In diesem Fenster lassen sich verschiedene Begriffe aus
der Anwendungsdomäne, die durch die Attribute der Datenbank oder abstrakte Konzeptevorgegeben werden, ergänzen, hierarchisch anordnen und durch Synonyme beschreiben(siehe Abbildung 35). Damit wird eine direkte Manipulation der Wissensbasis unter-stützt.
• Verwaltung der Datenquellen: Die Anbindung der Datenbanken, die die zu analysie-renden Daten enthalten (Projektdatenquellen) und weiterer strukturierter Informations-quellen als Bestandteile der Wissensbasis (globale Datenquellen, z.B. Kataloge für dieÜbersetzung medizinischer Leistungscodes), wird in zwei weiteren Fenstern unterstützt(siehe Abbildung 31).
• Verwaltung der KDD-Projekte: Hiermit lassen sich ein Überblick über die existieren-den KDD-Projekte gewinnen, neue Projekte anlegen sowie existierende verändern oderlöschen.
• Optionen und Benutzerpräferenzen: Über dieses Fenster können die in den Abschnit-ten 7.3.1 bis 7.3.4 beschriebenen Benutzerpräferenzen eingeben und verwaltet werden.Darüber hinaus können vom Benutzer verschiedene Optionen, beispielsweise für dieKonfiguration der Benutzeroberfläche, gewählt werden.
8.3 Die Realisierung des QUESTUS-KDD-Ansatzes
Die in dieser Arbeit beschriebenen Ansätze stellen den Kern des in Abschnitt 8.1.1 beschriebe-nen Knowledge-Discovery-Agenten dar. Ihre Realisierung ist Gegenstand des folgenden Ab-schnitts, in dem wir zunächst die Eingabe und Verwaltung von Fragen untersuchen und dannauf ihre Verarbeitung zum Zwecke der Beantwortung eingehen.
8.3.1 Die Eingabe und Verwaltung der KD-Fragen
Für jede KD-Frage, die ein Element im Fragebaum darstellt, wird die Klasse KDQuestion-Item instantiiert. Das KDQuestionItem enthält dabei im Attribut SourceData eine Refe-renz auf die Teilmenge der Daten, die für die Beantwortung der Frage relevant sind. Wenn dieKD-DM-Transformation abgeschlossen ist, werden die Daten dynamisch erzeugt, um die Spei-cheranforderung des Gesamtsystems gering zu halten. Weiterhin können durch die dynami-sche Erzeugung andere Daten zur Verfügung gestellt werden, z.B. DM-Ergebnisse zu anderenKD-Fragen als Quelldaten für Meta-Mining-Methoden. Neben der Filterung durch die im Rah-mensystem implementierten Methoden der Interessantheit ist es zusätzlich möglich, Sortierun-gen von KD-Fragen innerhalb eines Teilbaums entsprechend ihrer Interessantheit erzeugen.

1118.3 DIE REALISIERUNG DES QUESTUS-KDD-ANSATZES
8.3.1.1 Die Abbildung von natürlichsprachlichen Fragen auf KD-Fragen
Die Eingabe einer natürlichsprachlichen Frage und ihre Formalisierung mit KDQL erfolgt ineinem aus mehreren Schritten bestehenden, interaktiven Prozess, der darauf ausgerichtet ist,einen möglichst hohen Grad an Transparenz der Verarbeitungsschritte für den Benutzer herzu-stellen. Dieser Prozess ist in Abbildung 36 dargstellt und wird im Folgenden beschrieben:
1. Im ersten Schritt gibt der Benutzer seine natürlichsprachliche Frage in ein dafür vorgese-henes Textfeld ein (siehe Abbildung 37).
2. Anschließend wird die eingegebene Frage auf der Basis von KDQL analysiert. Dafürwird in der aktuellen Realisierung ein einfacher, XML-basierter Parsing-Algorithmus inKombination mit einem in [Käp02] beschriebenen Algorithmus zur fehlertolerantenErkennung von Schlüsselwörtern (z.B. die aus der Begriffstaxonomie bekannten Domä-nenkonzepte) eingesetzt. Ergebnis dieses Schritts ist dann eine Liste der KDQL-Sätze,die die höchste Übereinstimmung mit der eingegeben Frage aufweisen.
3. Aus dieser Kandidatenliste von KDQL-Sätzen werden unter Verwendung der XML-Beschreibung von KDQL wieder natürlichsprachliche Fragen generiert und dem Benut-zer mit einer Bewertung ihres Überstimmungsgrades mit der eingegebenen Frage prä-sentiert (siehe Abbildung 37).
4. Der Benutzer hat jetzt die Möglichkeit, die am besten bewertete Frage direkt zu überneh-men oder eine der übrigen Fragen aus der Liste auszuwählen. Für den Fall, dass die vomBenutzer intendierte Frage nicht richtig erkannt wurde und damit keine Frage aus derAuswahlliste passend ist, kann der Benutzer entweder versuchen, die Frage neu einzuge-
Abbildung 35: Die Verwaltung taxonomischer Informationen im KDA.

112 KAPITEL 8. DER KNOWLEDGE DISCOVERY ASSISTANT
ben und dabei zu modifizieren, oder er kann die Frage über ihre einzelnen KDQL-Ele-mente bestimmen.
5. Im Erfolgsfall wird die vom Benutzer gewählte Frage als KD-Frage instantiiert(KDQuestionItem), in den Fragebaum übernommen und steht zur Beantwortungbereit.
8.3.1.2 Die Methoden für die Konfiguration von KD-Fragen
Methoden und Attribute für den einfacheren Umgang mit Benutzerfragen werden in den fol-genden Unterpunkten erläutert. Dabei sind insbesondere die Methoden zur Initiierung der na-türlichsprachlichen Verarbeitung dokumentiert:
Abbildung 36: Die Eingabe von Fragen und Generierung von Feedback an den Benutzer.
Abbildung 37: Die Eingabe einer neuen natürlichsprachlichen Frage in den KDA.
KDQL-Modelle dernatürlichsprach-
lichen Frage
KD-FrageKDQuestionItem
KD-ExpansionKD-DM-TransformationKDExpandKDDMTransform
SynthesePräsentationGenUserText
AnalyseParseUserQuestion
NatürlichsprachlicheFrage
BestätigungAuswahlInitKDQuestionItem
Natürlichsprach-liche Fragen
EingabeEnterUserQuestion
DM-AnfrageDMQueryItem
Externe PräsentationInterne Repräsentation

1138.3 DIE REALISIERUNG DES QUESTUS-KDD-ANSATZES
• EnterUserQuestion initialisiert die interaktive Frageneingabe, wie in Abschnitt8.3.1.1 beschrieben, und fordert den Benutzer auf, eine natürlichsprachliche Eingabevorzunehmen. Anschließend wird die Frage weiterverarbeitet.
• ParseUserQuestion nimmt als Parameter einen Text als Benutzereingabe in natürli-cher Sprache, um mit diesem das aktuelle KDQuestionItem zu konfigurieren. NachAblauf des Vorgangs – eine gültige und bestätigte Benutzereingabe vorausgesetzt – sinddie einzelnen KDQL-Elemente konfiguriert, sodass die Beantwortung der Frage durchKD-Expansion und KD-DM-Transformation stattfinden kann.
• GenUserText erzeugt einen für den Benutzer lesbare Formulierung der aktuellen Frage.Im Fall, dass noch kein Frageobjekt ausgewählt wurde, wird dies angezeigt. Ansonstenwird eine Frage, die zum Frageobjekt passt mit den bisher eingegebenen Argumenten be-setzt. So kann während der Konfiguration einer Frage der aktuelle Zustand leichter vomBenutzer beobachtet werden.
• InitKDQuestionItem instantiiert eine neue KD-Frage als KDQuestionItem.
8.3.2 Die Verarbeitung von KD-Fragen
Nachdem eine neue KD-Frage instantiiert wurde, steht sie für die Expansion und Beantwor-tung zur Verfügung. Für die Realisierung der KD-Expansion (wie in Abschnitt 7.2 beschrie-ben) und der KD-DM-Transformation (wie in Abschnitt 7.3 beschrieben), sowie der Generie-rung von KD-Antworten stellen wir die folgende Menge von Methoden bereit.
8.3.2.1 Die Methoden zur KD-Expansion und KD-DM-Transformation
Die Struktur der im KDA gespeicherten Fragen ist eine Hierarchie. Diese Methoden, derenZiel die direkte oder indirekte Veränderung der Fragehierarchie ist, werden im Folgenden vor-gestellt:
• KDExpand erzeugt die Expansion eines Frageknotens um eine Ebene. Dabei werden diein XML spezifizierten Elemente automatisch in den Unterfragen übernommen und ent-sprechend konfiguriert. Im Gegensatz dazu erzeugt AnswerAll die Expansion und Be-antwortung aller untergeordneten Fragen.
• GenChildKDQuestionItem erzeugt eine neue Unterfrage zur aktuellen KD-Frage, diejedoch noch nicht spezifiziert ist. Die Methode hat das optionale Attribut ArgumentMo-de, welches festlegt, ob die Gruppierung oder die Argumente von der aktuellen Frageübernommen werden sollen. Diese Angabe erleichtert die KD-Expansion von abstraktenFragen. Je nachdem, ob ein Frageargument oder ein Gruppierungsargument expandiertwerden soll, kann mit ArgumentMode das andere Element übernommen werden.
• CollapseKDQuestionItem bewirkt, dass alle Unterfragen der aktuellen KD-Fragegelöscht werden. Diese Methode wird zum einen bei erneuter Beantwortung, zum ande-ren beim impliziten Löschen durch Manipulation der Fragen sowie bei explizitem Lö-schen von Unterfragen aufgerufen.
• RemoveKDQuestionItem entfernt ein KDQuestionItem wieder aus der Fragestruk-tur. Diese Methode wird implizit bei einer Neubeantwortung von expandierenden Fragenverwendet, aber auch explizit durch Löschen einer Frage seitens des Benutzers. Schließ-lich wird die Methode noch bei der Terminierung des darüber liegenden KDQuestionI-tem benötigt, welche durch Terminierung des QuestionTree rekursiv ausgelöst wur-de.

114 KAPITEL 8. DER KNOWLEDGE DISCOVERY ASSISTANT
• IsTransformable? überprüft, ob die gegebene KD-Frage vollständig expandiert istund damit direkt beantwortet werden kann.
• KDDMTransform realisiert die Übersetzung der in einem KDQuestionItem verwalte-ten KD-Frage in eine DM-Anfrage, die als DMQueryItem verwaltet wird.
• DMQuerySpecialization schließlich übersetzt die aktuelle DM-Anfrage bei einer ge-gebenen Implementierung in eine DM-System-Anfrage.
8.3.2.2 Die Methoden zur Beantwortung von KD-Fragen
Die im folgenden Abschnitt erläuterten Methoden und Attribute befassen sich mit der Beant-wortung von Frage, die sich aus dem Finden der Antwort und der Generierung einer natürlich-sprachlichen Formulierung der Antworten zusammensetzt. Im Folgenden beschreiben wir Ele-mente, die das Verhalten bei der Beantwortung von KD-Fragen beeinflussen.
• AnswerKDQuestionItem leitet die Beantwortung der aktuellen KD-Frage ein. Dazugehören Abfragen, die sicherstellen, dass nur Fragen beantwortet werden, die auch be-antwortbar und zur Beantwortung gekennzeichnet sind. Optional kann spezifiziert wer-den, ob Warnungen, z.B. beim Überschreiben einer bereits beantworteten Frage, ausge-geben werden sollen.
• AnswerAllKDQuestionItem verwendet die Methode AnswerKDQuestionItem auf,beantwortet und expandiert jedoch rekursiv jedes neu entstehende KDQuestionItem.Dabei werden entstehende Warnungen unterdrückt, sodass eine weitgehend autonomeBeantwortung einer Menge von Fragen möglich ist. AnswerAllKDQuestionItem ar-beitet auch am Wurzelknoten des Fragebaums.
• Answered? gibt an, ob eine Frage in der gegebenen Daten- und Präferenzumgebung be-reits früher beantwortet wurde. Das Prädikat findet vorwiegend interne Verwendung, derEinsatz ist aber auch bei Data-Mining-Methoden, die auf die Antwort anderer Data-Mi-ning-Methoden aufbauen, möglich.
• DMKDTransform überführt eine Menge von DM-Ergebnissen in eine verdichtete KD-Antwort.
• GenerateKDAnswerItem generiert schließlich die natürlichsprachliche Formulierungeiner KD-Antwort, die als KDAnswerItem verwaltet wird.
• RemoveKDAnswerItem löscht alle vorhandenen KD-Antworten zur aktuellen KD-Fra-ge und löst dann das Aktualisierungsereignis des QuestionTree aus. Die Methodewird entweder manuell vom Benutzer oder durch Neubeantwortung einer Frage ausge-löst.
8.4 Zusammenfassung
In diesem Kapitel haben wir den Knowledge Discovery Assistant (KDA) als Rahmen für dieprototypische Realisierung der in dieser Arbeit beschriebenen Konzepte eingeführt. Der KDAunterstützt auf der Benutzerseite die Eingabe natürlichsprachlicher Fragen und stellt die vomSystem ermittelten Antworten in unterschiedlichen Sichten dar. Dabei wird dem Benutzerdurch verschiedene Mechanismen Transparenz über die Bearbeitungsschritte des Systems undMöglichkeiten zur Interaktion und Manipulation gegeben. Auf der datenanalytischen Seite er-laubt der KDA die flexible Anbindung von Datenbanken in verschiedenen Formaten sowie dieschnelle und modulare Integration von Data-Mining-Methoden. Durch die Realisierung übereine COM-Schnittstelle können auch Analysemethoden von Drittanbietern integriert werden.

1158.4 ZUSAMMENFASSUNG
Der KDA verwaltet eine KD-Frage mit Hilfe eines KDQuestionItem, das sich durch ver-schiedene Methoden manipulieren lässt. Dazu zählen Methoden für die Abbildung von natür-lichsprachlichen Fragen auf KD-Fragen, Methoden für die Konfiguration von KD-Fragen aufder einen Seite und Methoden zur KD-Expansion und KD-DM-Transformation sowie zur Be-antwortung von KD-Fragen auf der anderen Seite. Dadurch ist ein Großteil der in den vorher-gehenden Kapiteln beschriebenen Ansätze realisiert.
Nach dieser Überprüfung der praktischen Umsetzbarkeit des Ansatzes werden wir im fol-genden Kapitel die Möglichkeiten und Grenzen einer Evaluierung anhand von formaleren Kri-terien beschreiben.

116 KAPITEL 8. DER KNOWLEDGE DISCOVERY ASSISTANT

KAPITEL 9 DIE EVALUIERUNG DES QUESTUS-KDD-ANSATZES
Um die Güte des QUESTUS-KDD-Ansatzes beurteilen zu können, wollen wir ihn einer ge-naueren Untersuchung einiger formaler Kriterien unterwerfen. Dabei wollen wir zeigen, dassdie Arbeit mit natürlichsprachlichen Formulierungen von Fragen anstelle von formalen For-mulierungen von Data-Mining-Aufrufen nicht nur auf den ersten Blick intuitiver erscheint,sondern tatsächlich Vorteile für den Benutzer, den wir mit diesem Ansatz fokussieren, mit sichbringt. Dieser Nutzen kann sich in verschiedenen Dimensionen zeigen, z.B. der Einarbeitungs-zeit, der Benutzerakzeptanz und der Effizienz der Lösung von Analyseaufgaben.
Im Folgenden führen wir als Grundlage für die Evaluierung einen Katalog von Kriterienein. Diese werden wir anschließend, soweit es der Rahmen dieser Arbeit erlaubt, untersuchenbzw. den Weg für ihre weiterführende Untersuchung skizzieren. Der Fokus dabei liegt auf demKriterium der Vollständigkeit, das uns und anderen Interessierten gerade in Bezug auf die For-mulierungsmöglichkeiten von Fragen entscheidend erscheint. Auf diese Untersuchungen auf-bauend entwickeln wir dann ein Anforderungsprofil für die Nutzer des Ansatzes bzw. – im in-versen Sinn betrachtet – das Leistungsspektrum der Benutzerunterstützung. Zum Abschlussdes Kapitels beschreiben wir die Einbettung des Ansatzes in die Analyseprozesse der Anwen-dungsdomäne und damit die Möglichkeiten einer Optimierung des Geschäftsprozesses.
9.1 Die Kriterien für die Evaluierung
Aufgrund der Neuheit des Ansatzes und des damit verbundenen Fehlens von konkreten Evalu-ierungskriterien für die Benutzerunterstützung bei der Entdeckung von Wissen in Datenbankenist es zunächst erforderlich, den Blick auf verwandte Aufgabenfelder zu richten:
• Bewertung von intelligenten Benutzerschnittstellen ([Gra92b]).• Bewertung von natürlichsprachlichen Schnittstellen, v.a. NLIDB ([And95]).• Bewertung von kontrollierten Sprachen ([Cer94], [Rui94]).Daraus und in Kombination mit den aus [DIN91] bekannten sechs DIN-Standard-Qualitäts-
merkmalen für Software (Funktionalität, Zuverlässigkeit, Benutzbarkeit, Effizienz, Änderbar-keit und Übertragbarkeit) ergeben sich die folgenden Kriterien für die Evaluierung unseres An-satzes:
BenutzbarkeitMit diesem Kriterium wird der Aufwand beschrieben, der für die Benutzung des Systems er-forderlich ist. Dies geschieht im Allgemeinen durch eine individuelle Beurteilung der Benut-zung durch eine festgelegte oder vorausgesetzte Zielgruppe und erstreckt sich auf die Unterkri-terien Verständlichkeit, Erlernbarkeit und Bedienbarkeit ([DIN91]).

118 KAPITEL 9. DIE EVALUIERUNG DES QUESTUS-KDD-ANSATZES
Änderbarkeit und PortierbarkeitDie in der [DIN91] beschriebenen Kriterien Änderbarkeit und Übertragbarkeit bzw. Portier-barkeit werden zusammengefasst, da Portierungen im Folgenden als Spezialfall von Änderun-gen gesehen werden. Im Rahmen der Bewertung des Kriteriums ist zu überprüfen, inwieweitÄnderungen und Portierungen mit einer bestimmten Auftretenshäufigkeit lokal durchgeführtwerden können bzw. globale Anpassungen vorgenommen werden müssen. Der Aufwand fürÄnderungen und Portierungen sollte im umgekehrten Verhältnis zur Häufigkeit ihres Auftre-tens stehen.
AdäquatheitMit diesem Kriterium wird bewertet, inwieweit der Ansatz geeignet ist, Benutzer aus der gege-benen Zielgruppe geeignet zu unterstützen. Adäquatheit geht dabei über den Begriff der for-malen Adäquatheit68 hinaus und beinhaltet vor allem die terminologische und die erkenntnis-theoretische Adäquatheit. Damit soll der Grad der Abdeckung der relevanten natürlichsprach-lichen Formulierungen durch die vorgeschlagene Sprache überprüft werden.69 Weiterhin ist zuprüfen, ob das Gesamtsystem die Formulierung von Fragen in KDQL, die einer Abbildung derStruktur der Fragen beim Experten auf die Struktur von KDQL gleichkommt, expertengerechtunterstützt. Die beim QUESTUS-KDD-Ansatz verwendeten Strukturen von Fragen, die Be-zeichnung und Operationalisierung von Fachbegriffen und die natürlichsprachliche Formulie-rung der Antworten in einer bestimmten Anwendungsdomäne müssen weitgehend den tatsäch-lichen Konzepten der Domäne entsprechen. Teilaspekte der Adäquatheit sind die Ausdrucksfä-higkeit und die Effizienz der Formulierung.
KorrektheitDas Kriterium Korrektheit stellt einen Teilaspekt der formalen Adäquatheit dar, erfährt aberaufgrund seiner besonderen Bedeutung eine eigenständige Erwähnung: Die Minimalanforde-rung an informationsverarbeitende Systeme jedweder Art besteht in der Korrektheit der durch-geführten Verarbeitungsschritte. Im vorliegenden Fall wird die klassische Korrektheitsanfor-derung, wie sie beispielsweise Balzert in [Bal96] beschreibt und wie sie die durch die Konsis-tenz zwischen Spezifikation und Implementierung der im Programmcode realisierten Algorith-men definiert wird, jedoch erweitert: Korrektheit im vorliegenden Fall der Benutzerunterstüt-zung ist ein Kriterium bei der Eingabe und der Verarbeitung der Anfragen und bei der Aufbe-reitung der Ergebnisse. Dabei bildet die algorithmische Korrektheit nur einen Teilaspekt.Ebenso bedeutend für den Gesamterfolg ist die Korrektheit des in den Wissensbasen formali-sierten Wissens. Dabei handelt es sich aber im Gegensatz zu algorithmischen Korrektheitgrößtenteils nicht um ein (formal) verifizierbares Kriterien, da Wissen zumindest in einigenDefinition zwar einen Wahrheitsanspruch erhebt, für die Überprüfung bislang aber die Metho-den fehlen.
Vollständigkeit Auch die Vollständigkeit stellt einen Teilaspekt der formalen Adäquatheit dar. Abgesehen vonformaler Vollständigkeit70, die im Allgemeinen schwerer zu erreichen und nachzuweisen istals die Korrektheit, ist bei der vorliegenden Problemstellung vor allem die vollständige Abde-
68 im Sinne von Korrektheit und Vollständigkeit der Syntax und Semantik formaler Systeme69 Das Ziel einer vollständigen Abdeckung kann dabei aus plausiblen Gründen immer nur annähernd er-
reicht werden.70 Mittelstraß unterscheidet drei Arten von Vollständigkeit: semantische Vollständigkeit, wenn jede
wahre Aussage aus einem System ableitbar ist, syntaktische Vollständigkeit, wenn das System maximalwiderspruchsfrei ist, und klassische (bzw. deduktive) Vollständigkeit, wenn zu jeder nicht selbst ableitba-ren Aussage ihr Negat aus einem System ableitbar ist ([Mit96]).

1199.2 DIE ANWENDUNG DER EVALUIERUNGSKRITERIEN
ckung der Anwendungsdomäne von Bedeutung, die jedoch nur empirisch verifizierbar ist. Bal-zert beschreibt das Kriterium Vollständigkeit als den Grad, indem der Ansatz dem Benutzeralle benötigten Funktionen und Daten selbst zur Verfügung stellt, um damit die gefordertenZiele zu erreichen ([Bal96]).
RedundanzfreiheitDie Vermeidung von Redundanzen, wie sie ein wichtiges Thema bei der Gestaltung von for-malen Sprachen ist und beispielsweise in [Rui94] beschrieben wird, ist auch relevant für dieEvaluierung des vorliegenden Ansatzes. Da jedoch Redundanzen an einigen Stelle auch er-wünscht und notwendig sind, beispielsweise bei der Möglichkeit semantisch äquivalente Be-nutzerfragen unterschiedlich zu formulieren, ist die Redundanzfreiheit nur in sehr einge-schränkten Bereichen zu überprüfen. Dies ist vor allem für die in unserem Ansatz verwendetenSprachen KDQL und DMAQL der Fall.
Tabelle 26 ordnet den verschiedenen Verarbeitungsschritten im QUESTUS-KDD-Ansatzdie jeweils relevanten Evaluierungskriterien zu. Neben diesen Kriterien, die den in dieser Ar-beit konzipierten Ansatz für die Benutzerunterstützung betrachten, lassen sich bei der Betrach-tung des Gesamtansatzes, der auch die Data-Mining-Methoden und ihre Implementierungeneinschließt, weitere Kriterien (z.B. Korrektheit und Vollständigkeit der Ergebnisberechnung)finden. Diese sind jedoch aus dem Blickwinkel der Benutzerunterstützung, die mit unseremAnsatz ja vorwiegend verfolgt werden soll, nicht weiter relevant. Auch rein software-techni-sche Kriterien wie Effizienz und Zuverlässigkeit ([DIN91]) sind für die Beurteilung der Imple-mentierung wichtig, werden aber aufgrund ihres prototypischen Charakters hier nicht weiterbetrachtet.
9.2 Die Anwendung der Evaluierungskriterien
Im Folgenden wollen wir versuchen, die oben beschriebenen Evaluierungskriterien auf denQUESTUS-KDD-Ansatz anzuwenden. Da eine umfassende Untersuchung aller Kriterien, dievor allem auch einiger empirischer Studien bedarf, über den Rahmen dieser Arbeit hinausge-hen würde, zeigen wir hier an einigen Stellen nur die Wege auf, die für die weitergehende Eva-luierung zu wählen sind.
BenutzbarkeitDas Interaktionsmodell des QUESTUS-KDD-Ansatzes entspricht weitgehend einem sehr na-türlichen Vorgehen von Menschen bei der Suche nach Informationen, nämlich dem Stellenvon Fragen und dem Erhalten von Antworten. Auch die Strukturierung von Fragen über ver-schiedene Abstraktionsstufen hinweg kommt dem alltäglichen Vorgehen sehr nahe. Diese Pa-radigmen wurden im Zuge von Befragungen von ausgewählten Experten aus dem Bereich desmedizinischen Qualitätsmanagements aber auch aus dem Bereich des Qualitätsmanagementsbei Produktionsprozessen wieder erkannt und nach vorläufigen Aussagen für verständlich be-funden.
Die prinzipielle Bedienbarkeit der Benutzerschnittstelle ist stark von der Bewertung ihrerAdäquatheit abhängig, da der Großteil der Möglichkeiten von Benutzerinteraktionen über dieFormulierung von Fragen und Antworten realisiert sind. Lediglich der Zugang zur Anbindungvon neuen Objekten, wie Daten, Methoden und Algorithmen, sowie einige weitere Konfigura-tionseinstellungen, die jedoch nur in ausgezeichneten und seltenen Fällen benötigt werden, er-folgen über die üblichen Menüstrukturen. Aus diesem Grund ist eine weitergehende Untersu-chung der Implementierung des Ansatzes im Knowledge Discovery Assistant mit Usability-
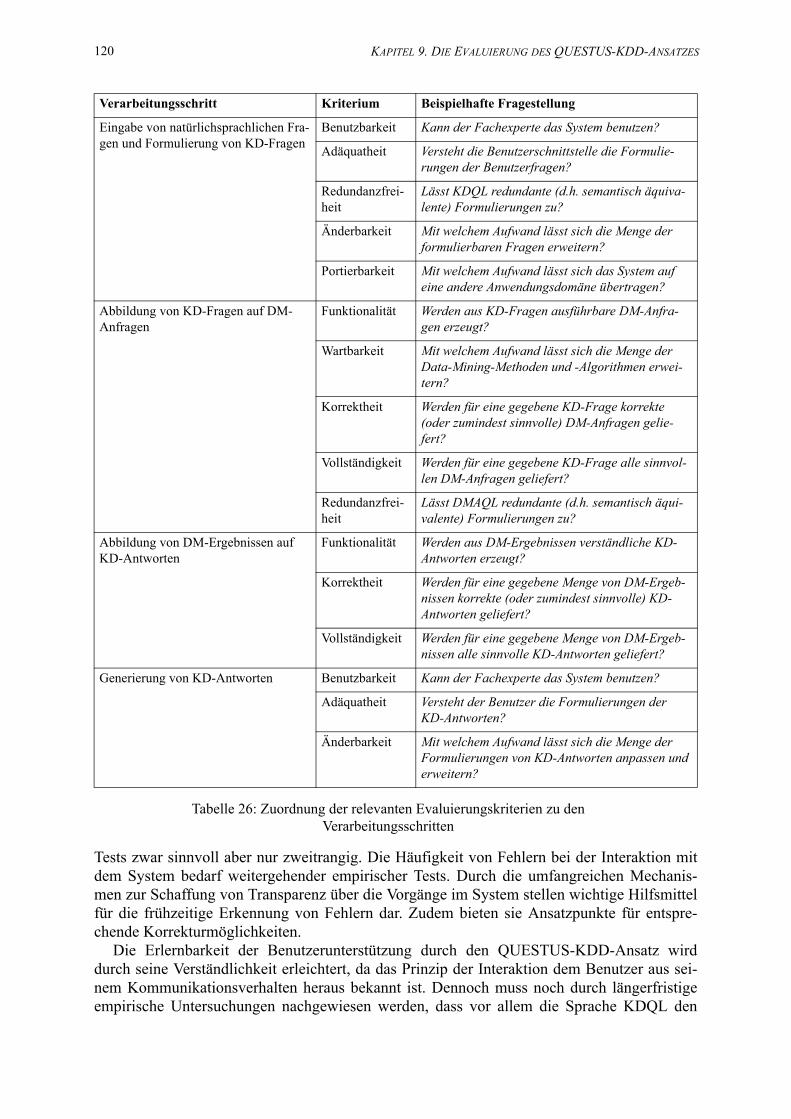
120 KAPITEL 9. DIE EVALUIERUNG DES QUESTUS-KDD-ANSATZES
Tests zwar sinnvoll aber nur zweitrangig. Die Häufigkeit von Fehlern bei der Interaktion mitdem System bedarf weitergehender empirischer Tests. Durch die umfangreichen Mechanis-men zur Schaffung von Transparenz über die Vorgänge im System stellen wichtige Hilfsmittelfür die frühzeitige Erkennung von Fehlern dar. Zudem bieten sie Ansatzpunkte für entspre-chende Korrekturmöglichkeiten.
Die Erlernbarkeit der Benutzerunterstützung durch den QUESTUS-KDD-Ansatz wirddurch seine Verständlichkeit erleichtert, da das Prinzip der Interaktion dem Benutzer aus sei-nem Kommunikationsverhalten heraus bekannt ist. Dennoch muss noch durch längerfristigeempirische Untersuchungen nachgewiesen werden, dass vor allem die Sprache KDQL den
Verarbeitungsschritt Kriterium Beispielhafte Fragestellung
Eingabe von natürlichsprachlichen Fra-gen und Formulierung von KD-Fragen
Benutzbarkeit Kann der Fachexperte das System benutzen?
Adäquatheit Versteht die Benutzerschnittstelle die Formulie-rungen der Benutzerfragen?
Redundanzfrei-heit
Lässt KDQL redundante (d.h. semantisch äquiva-lente) Formulierungen zu?
Änderbarkeit Mit welchem Aufwand lässt sich die Menge der formulierbaren Fragen erweitern?
Portierbarkeit Mit welchem Aufwand lässt sich das System auf eine andere Anwendungsdomäne übertragen?
Abbildung von KD-Fragen auf DM-Anfragen
Funktionalität Werden aus KD-Fragen ausführbare DM-Anfra-gen erzeugt?
Wartbarkeit Mit welchem Aufwand lässt sich die Menge der Data-Mining-Methoden und -Algorithmen erwei-tern?
Korrektheit Werden für eine gegebene KD-Frage korrekte (oder zumindest sinnvolle) DM-Anfragen gelie-fert?
Vollständigkeit Werden für eine gegebene KD-Frage alle sinnvol-len DM-Anfragen geliefert?
Redundanzfrei-heit
Lässt DMAQL redundante (d.h. semantisch äqui-valente) Formulierungen zu?
Abbildung von DM-Ergebnissen auf KD-Antworten
Funktionalität Werden aus DM-Ergebnissen verständliche KD-Antworten erzeugt?
Korrektheit Werden für eine gegebene Menge von DM-Ergeb-nissen korrekte (oder zumindest sinnvolle) KD-Antworten geliefert?
Vollständigkeit Werden für eine gegebene Menge von DM-Ergeb-nissen alle sinnvolle KD-Antworten geliefert?
Generierung von KD-Antworten Benutzbarkeit Kann der Fachexperte das System benutzen?
Adäquatheit Versteht der Benutzer die Formulierungen der KD-Antworten?
Änderbarkeit Mit welchem Aufwand lässt sich die Menge der Formulierungen von KD-Antworten anpassen und erweitern?
Tabelle 26: Zuordnung der relevanten Evaluierungskriterien zu den Verarbeitungsschritten

1219.2 DIE ANWENDUNG DER EVALUIERUNGSKRITERIEN
Formulierungsgewohnheiten der Experten entspricht und dass damit ohne explizite Erklärungvon Syntax und Semantik von KDQL neue Fragen formuliert werden können.
Änderbarkeit und PortierbarkeitDie Änderbarkeit und die Portierbarkeit des Ansatzes sind auf verschiedenen Stufen erfüllt.Wir unterscheiden dabei, wie in Abbildung 38 gezeigt, technologische und anwendungsorien-tierte Stufen von Änderungen und Portierungen.
Im Bereich der Technologie kann im einfachsten Fall die Menge der bestehenden Auswer-tungsalgorithmen verändert oder erweitert werden. Die zweite Stufe der technologischen Er-weiterung besteht dann in der Einführung neuer Auswertungsmethoden, die zwangsläufig auchdie Einführung neuer Algorithmen zur Implementierung der Methoden erfordert. Als weitereStufe wäre ein Wechsel der Informationsgrundlage, also beispielsweise von Datenbanken aufInformationssysteme mit weniger stark strukturierten Inhalten denkbar. Ein Wechsel der Infor-mationsgrundlage hat damit auch den Wechsel der Analysemethoden (z.B. von Data-Mining-Methoden zum Methoden des Information Retrieval) zur Folge. Dieser generelle Paradigmen-wechsel steht nicht im Fokus des in dieser Arbeit beschriebenen Ansatzes, ist aber im Rahmenkünftiger Erweiterungsschritte durchaus denkbar.
Die einfachste Stufe aus Sicht der Anwendung, die in der Praxis auch die häufigste ist, be-steht in der Verwendung neuer Daten, wobei sich hier im Detail noch einmal zwischen dembloßen Austausch der Dateninhalte innerhalb derselben Datenbankstruktur mit identischen At-tributen und dem teilweisen oder vollständigen Austausch der Datenbankstruktur unterschei-den lässt. Ein Wechsel der Anwendungsdomäne, beispielsweise vom medizinischen Qualitäts-management zur Controlling von Produktionsdaten, wird nicht nur die Einbindung neuer Da-tenbanken nach sich ziehen, sondern hat auch die Neuformulierung der domänenabhängigenBestandteile der Fragensprache zur Folge. Durch den modularen Aufbau der Wissensbasis unddie Kapselung des domänenspezifischen Wissens in einem Modul kann der Aufwand für dieIntegration des neuen Wissens aber lokal gehalten werden (siehe dazu auch Abschnitt 4.4).
AdäquatheitDie Ausdrucksfähigkeit als Teilaspekt der Adäquatheit lässt sich zum einen in Bezug auf dieFormulierbarkeit von syntaktisch und semantisch unterschiedlichen Fragen und zum anderenin Bezug auf die Formulierbarkeit von semantisch äquivalenten aber syntaktisch unterschiedli-chen Fragen untersuchen. Der erste Fall weist dabei eine starke Interdependenz zur Analyseder Vollständigkeit auf und wird dementsprechend dort behandelt. Im zweiten Fall muss dieMöglichkeit von synonymen Frageformulierungen auf Satzebene untersucht werden. Da inKDQL für semantisch äquivalente Fragen nur eine einzige Formulierung zugelassen wird,werden die synonymen Frageformulierungen bereits auf der Ebene der Frageneingabe erkanntund auf ihre eindeutigen KDQL-Formulierungen abgebildet (siehe Abschnitt 8.3.1.1). Durch
Abbildung 38: Das Stufenmodell für Änderbarkeit und Portierbarkeit.
Informationsgrundlage Anwendungsdomäne
MethodenDatenstruktur
Algorithmen Dateninhalte
Methoden
AnwendungTechnologie
Häu
figke
it
Aufw
and

122 KAPITEL 9. DIE EVALUIERUNG DES QUESTUS-KDD-ANSATZES
eine Vergrößerung der Menge von synonymen Formulierungen lässt sich die Ausdrucksfähig-keit des Ansatzes in dieser Beziehung weiter erhöhen.
Die terminologische Adäquatheit, also die möglichst hohe Übereinstimmung der Konzepteaus der Sprachwelt des Benutzers mit den im Ansatz vorgeschlagenen Konzepten, wurde beider Konzeption über den schon früher erwähnten Korpus von Fragen, die in verschiedenen Da-tenanalyse-Szenarien gesammelt wurden, weitgehend erreicht. Dasselbe Vorgehen wurde auchfür das Ziel der erkenntnistheoretischen Adäquatheit angewendet. Durch weiterführende, em-pirische Untersuchungen ließe sich aber an dieser Stelle weitere Gewissheit schaffen.
KorrektheitDie algorithmische Korrektheit, d.h. die Korrektheit der im QUESTUS-KDD-Ansatz entwi-ckelten und in den KDA integrierten Methoden und Algorithmen wurden bereits mit Verfahrendes Software Testing nach Balzert ([Bal96]) und durch die Anwendung auf ausgezeichneteTestfälle überprüft. Die Korrektheit der Wissensbasis bedarf noch einer weitergehenden Eva-luierung, in deren Verlauf neben empirischen Untersuchungen auch formale Evaluierungsme-thoden, wie sie etwa Herrmann in [Her97] und Sommer in [Som97] beschreiben, zur Anwen-dung kommen könnten. Bei der Begutachtung des Abbildungswissens ist jedoch darauf zuachten, dass Interpretationsspielräume existieren, die z.B. bei der Verwendbarkeit einer be-stimmten Data-Mining-Methode für eine gegebene Frage auftreten können. An diesen Stellenbesteht dann die Notwendigkeit einer weitergehenden Personalisierung bzw. Domänenanpas-sung.
VollständigkeitEin entscheidendes Kriterium für die Evaluierung von kontrollierten Sprachen im Allgemeinenund des QUESTUS-KDD-Ansatzes im Speziellen stellt ihre Vollständigkeit dar. Im vorliegen-den Fall lässt sich das Kriterium über die in Abbildung 39 dargestellten vier Abbildungen be-trachten und mit vier Teiluntersuchungen überprüfen:
• Formalisierung von natürlichsprachlichen Fragen durch KD-Fragen: Auf der Ebe-ne der natürlichsprachlichen Fragen ist zum einen zu untersuchen, ob jede KD-Frage
Abbildung 39: Die Abbildungen zur Überprüfung der Vollständigkeit.
F: KD-Fragen
Abbildung f1:Formalisierung
N: NatürlichsprachlicheFragen
A: DM-Anfragen
Abbildung f2:Verwendung
Abbildung f4:Muster finden
Abbildung f3:Beantwortung
M: Muster

1239.2 DIE ANWENDUNG DER EVALUIERUNGSKRITERIEN
durch eine natürlichsprachliche Frage erreicht wird. Um die Anwendbarkeit des QUES-TUS-KDD-Ansatzes nachzuweisen, ist die Untersuchung, ob für jede natürlichsprachli-che Frage71 eine entsprechende Formalisierung durch KDQL möglich ist, jedoch vongrößerer Bedeutung. Kann also durch die Abbildung f1 aus (18) für jede natürlichsprach-liche Frage aus der Menge N eine adäquate Formalisierung aus der Menge der KD-Fra-gen F gefunden werden?
(18)
Diese Frage, die genau genommen die Surjektivität der Funktion f1 untersucht, lässt sichüber eine genauere Betrachtung von KDQL beantworten: Wie in Abschnitt 5.2 beschrie-ben, setzt sich eine in KDQL formulierte KD-Frage aus bis zu fünf Elementen zusam-men. Diese Elemente lassen sich entweder durch Schlüsselelemente aus der natürlichenSprache besetzen (z.B. konfirmativer Fragetyp, Zusammenhang), stellen indirekt Ver-weise auf Objekte in der Datenbank dar (z.B. Argumente) oder sind Operationalisierun-gen von Domänenkonzepten (z.B. Korrektheit der Therapeutik). Im ersten Schritt ist zu untersuchen, ob natürlichsprachliche Fragen durch die Menge derKDQL-Elemente vollständig beschrieben werden können und ob also die möglichen Be-legungen jedes KDQL-Elements den aus der natürlichen Sprache bekannten Belegungenentsprechen. Für diese Belegung der einzelnen KDQL-Elemente muss im zweiten Schrittdurch Untersuchungen mit Hilfe der in Tabelle 27 beschriebenen Disziplinen die voll-ständige Modellierung nachgewiesen werden.
• Verwendung von DM-Anfragen durch KD-Fragen: Auf der Ebene der KD-Fragen istzu überprüfen, ob alle Interessen in Fragen formuliert werden können, die auch als DM-
71 Wir beschränken uns dabei natürlich auf solche natürlichsprachliche Fragen, die von Fachexpertenzum Zwecke der Datenanalyse gestellt werden.
Typ KDQL-Element Anzahl möglicher Belegungen
Überprüfung der Vollständigkeit durch
Schlüsselelemente der natürlichen Sprache
Fragetyp 3 Linguistik
Allgemeine Frageobjekte
4 Statistik
Objektargumente 4 Statistik
Verweise auf Objekte der Datenbank
Fragegruppe Anzahl der Datenbankattribute
Datenbanktheorie,Datenbankmodellierung
Fragekontext Anzahl der Datenbankattribute
Datenbanktheorie,Datenbankmodellierung
Eigenschafts-argumente
Anzahl der Datenbankattribute
Datenbanktheorie,Datenbankmodellierung
Gruppenargumente Anzahl der modellierten Gruppen
Datenbankmodellierung,Domänenmodellierung
Operationalisie-rungen
Domänenspezifi-sche Frageobjekte
Anzahl der operationalisierten Konzepte
Domänenmodellierung
Tabelle 27: Überprüfung der Vollständigkeit der Abbildung von natürlichsprachlichen Fragen
f1:F N→

124 KAPITEL 9. DIE EVALUIERUNG DES QUESTUS-KDD-ANSATZES
Anfrage formuliert werden können. Deckt also die Menge der mit KDQL formulierbarenKD-Fragen F die Menge der verfügbaren DM-Anfragen A vollständig ab? Oder im rela-tionentheoretischen Sinn: Ist die auch Abbildung f2 aus (19), die die Menge der Fragenauf die Menge der verwendeten Anfragen abbildet, surjektiv?
(19)
Für den Nachweis ist zu zeigen, dass alle Elemente, die bei der Formulierung von DM-Anfragen relevant sind (siehe Abschnitt 7.3), durch einzelne Elemente aus KD-Fragenangesprochen werden können. Dies zeigen wir mit Hilfe von Tabelle 28, in der wir denObjekttypen auf der DM-Ebene die KDQL-Elemente auf der KD-Ebene gegenüberstel-len. Die vollständige Abbildung im Detail ist dann noch für die Regelbasis, die bei derErmittlung eines Data-Mining-Algorithmus aus dem Frageobjekt und bei der Ermittlungvon Werten für die Parametrisierung der Algorithmen verwendet wird, zu zeigen. Da alleweiteren Objekttypen direkt oder indirekt über die Frage angesprochen werden, ist fürdiese keine weitere Untersuchung notwendig.
• Beantwortung von KD-Fragen durch DM-Anfragen: Umgekehrt ist auf der Ebeneder DM-Anfragen zu überprüfen, ob die Menge der durch DM-Anfragen formuliertenverfügbaren Konfigurationen von Data-Mining-Algorithmen A die Beantwortung dermit KDQL formulierbaren KD-Fragen F vollständig abdeckt. Oder im relationentheore-tischen Sinn: ist die Abbildung f3 aus (20), die die Menge der DM-Anfragen A auf dieMenge der KD-Fragen F, die von den Algorithmen beantwortet werden, abbildet, surjek-tiv?
(20)
Dieser Nachweis, dass also durch die Menge der erzeugbaren DM-Anfragen tatsächlichHinweise zur Beantwortung aller KD-Fragen gegeben werden können, erfordert einenRückgriff auf empirische Untersuchungen, die über den Rahmen dieser Arbeit hinausge-hen. Eine solche Studie sollte sich vor allem an Experten der Anwendungsdomäne rich-ten, die Ergebnisse aber mit den Ansichten von Experten der Datenanalyse abgleichen.
• Finden von Mustern durch DM-Anfragen: Wenn Data Mining auch als die Entde-ckung von interessanten Mustern in Daten bezeichnet wird72, stellt sich weiterhin die
DM-Objekttyp Erreichbarkeit über Überprüfung in
DM-Methode Frageobjekt, Eigenschaftsargumente,Objektargumente
Wissensbasis für die Auswahl von DM-Metho-den (siehe Abschnitte 7.3.1-7.3.3)
DM-Algorithmus DM-Methode, Eigenschaftsargumente,Objektargumente
Wissensbasis für die Auswahl von DM-Algo-rithmen (siehe Abschnitt 7.3.4)
Argumente Eigenschaftsargumente Frageformulierungen
Analysedaten FragegruppeFragekontextGruppenargumente
Parameter Regelbasis für die Instantiierung der Anfrageparameter
Regelbasis für die Instantiierung der Anfrage-parameter
Tabelle 28: Überprüfung der Vollständigkeit der Abbildung von KD-Fragen
f2:F A→
f3:A F→

1259.2 DIE ANWENDUNG DER EVALUIERUNGSKRITERIEN
Frage nach der algorithmischen Abdeckung: Werden alle interessanten Muster in Datenals Ergebnisse von DM-Anfragen gefunden? Auch für die Abbildung f4, die nach (21)für eine DM-Anfrage A eine Menge von Mustern M als Ergebnisse liefert, gilt demnachdie Forderung nach Surjektivität, d.h. jedes mögliche Muster sollte Ergebnis mindestenseiner DM-Anfrage sein.
(21)
Dies erfordert die grundlegende Annahme, dass für alle interessanten Muster in Datengeeignete Data-Mining-Algorithmen existieren und diese in das vorliegende System in-tegriert sind. Wenn nun sichergestellt ist, dass alle verfügbaren DM-Algorithmen in allenKonfigurationen erzeugt werden können, kann auch davon ausgegangen werden, dassalle interessanten Muster gefunden werden.
Im Hintergrund der oben genannten Teiluntersuchungen soll die Konzentration auf das Ar-beitsgebiet der Benutzerunterstützung stehen. Aus diesem Grund verzichten wir auf weiteregrundlegende Fragen, z.B. nach der generellen Vollständigkeit der bis heute entwickeltenData-Mining-Algorithmen in Bezug auf die Menge potentiell interessanter Muster. Diese sindzwar von großem wissenschaftlichem Interesse, können für den Zweck der Benutzerunterstüt-zung jedoch nachrangig behandelt werden.
RedundanzfreiheitFür die Überprüfung von Redundanzen – seien sie absichtlich oder unabsichtlich entstanden –greifen wir noch einmal auf die im vorhergehenden Abschnitt beschriebenen und in Abbildung39 dargestellten Abbildungen zurück. War die Surjektivität der Abbildungen das Merkmal fürdie Vollständigkeit, so verwenden wir jetzt die Injektivität der genannten Abbildungen alsMerkmal, um mögliche Redundanzen in den Abbildungen zu überprüfen.
• Formalisierung von natürlichsprachlichen Fragen durch KD-Fragen: Hier kannkeine injektive Abbildung (f1 in Abbildung 39) vorliegen, da sich eine in KDQL formali-sierte Frage auf verschiedene Arten formulieren lässt. Redundanz an dieser Stelle ist alsogegeben und notwendig.
• Verwendung von DM-Anfragen durch KD-Fragen: Bei dieser Abbildung (f2 in Ab-bildung 39) entstehen bewusst Redundanzen: Durch die in Abschnitt 7.2 beschriebenenMechanismen bei der Verfeinerung von abstrakten KD-Fragen entsteht eine Menge vonUnterfragen, die auf DM-Anfragen abgebildet werden. Die in Abschnitt 7.3 beschriebe-ne Auswahl eines geeigneten Data-Mining-Algorithmus zum Frageobjekt ist dagegendurch das gewählte Vorgehen der abschließenden Kürzung der Kandidatenliste auf dieLänge eins eindeutig.
• Beantwortung von KD-Fragen durch DM-Anfragen: Hier kann nicht von einer ein-deutigen Abbildung (f3 in Abbildung 39) ausgegangen werden, weil gleiche Muster vonverschiedenen DM-Anfragen gefunden und damit deren Ergebnisse auch verschiedenenKD-Fragen zugeordnet werden können. Diesem Phänomen lässt sich durch aufwändigeMaßnahmen zur Redundanzfilterung auf der Ebene der Ergebnisse begegnen.
• Finden von Mustern durch DM-Anfragen: Wie schon erwähnt, erlaubt diese Abbil-dung (f4 in Abbildung 39) ebenfalls Redundanzen, da ein Muster von mehreren DM-An-fragen als Ergebnis geliefert werden kann.
72 „Knowledge discovery in databases is the non-trivial process of identifying valid, novel, potentiallyuseful, and ultimately understandable patterns in data.“ [Fay96b:6]
f4:A M→

126 KAPITEL 9. DIE EVALUIERUNG DES QUESTUS-KDD-ANSATZES
Bei allen diesen Abbildungen sind also Redundanzen möglich oder gewünscht. Dies gilt je-doch nicht für die Formulierung von natürlichsprachlichen Fragen in KDQL. Hier ist zu for-dern, dass semantisch äquivalente Fragen auch auf identische KD-Fragen abgebildet werden.
Wie bereits erwähnt, können diese Ansätze für die Überprüfung der Evaluierungskriteriennur erste Schritte darstellen. Schon an dieser Stelle schlagen wir deshalb im Sinne zukünftigerArbeiten vor allem eine umfassende empirische Untersuchung der vorgestellten Konzepte vor.
9.3 Die Anforderungen an den Benutzer
Den in Abschnitt 1.3.1 beschriebenen Ziele der Arbeit und den in Abschnitt 4.1 beschriebenenAnforderungen, die an die Realisierung der Benutzerschnittstelle gestellt werden, stellen wirim Folgenden die Anforderungen gegenüber, die ein Benutzer erfüllen sollte, um mit dem Sys-tem erfolgreich arbeiten zu können.
• Verfügbare Daten: Eine grundlegende Anforderung an den Benutzer ist ein Überblicküber die verfügbaren Daten. Zwar ist es denkbar, domänenspezifische Standardfragenauf Standarddatenbeständen zu generieren und dem Benutzer vorzuschlagen. Dennocherschließt sich dem Benutzer der Umfang der möglichen Fragen und damit das Potenzialder Analysen erst, wenn er die Daten kennt. Wichtig ist dabei vor allem die Kenntnis derdurch die Daten modellierten Objekte (z.B. Patienten, Patientenaufenthalte in der Klinikusw.) und die modellierenden Attribute (z.B. Krankversicherungsart eines Patienten,Dauer des Aufenthalts in der Klinik usw.).
• Datenbankmodellierung: Die Struktur der für die Analysen bereitstehenden Daten (Da-tenbankmodell) sollte durch Vorverarbeitungsschritte bereinigt, fusioniert und homoge-nisiert sein. Damit kann der Benutzer die der ursprünglichen Modellierung zugrunde lie-genden Strukturen vernachlässigen.
• Attributbenennungen: Die Benennungen der den Analysen zugrunde liegenden Attri-bute verändern sich in der Praxis häufig mit Anpassungen der Datenbankstruktur. Zudemsind die in der Datenbankmodellierung verwendeten Benennungen häufig durch Abkür-zungen (z.B. GesVD für „Gesamtverweildauer“) oder technische Formulierungen (z.B.ObjID als allgemeine Bezeichnung des eindeutigen Identifikationsschlüssels der in einerRelation modellierten Objekte) geprägt. Durch die Verwendung von synonymen Be-zeichnungen (siehe Abschnitt 4.4), die fehlertolerante Erkennung von Benennungen undeiner optionalen listenbasierte Auswahl (siehe Abschnitt 8.3.1) werden diese Schwierig-keiten aber umgangen. Damit kann die Anforderung an den Benutzer diesbezüglich aufdie grobe Kenntnis der natürlichsprachlichen Attributbenennungen begrenzt werden.
• Daten- und Skalentypen der Attribute: Metadaten der Attribute, wie Daten- und Ska-lentypen, werden bei der Vorverarbeitung gesammelt, im QUESTUS-KDD-Ansatz ver-waltet und beispielsweise bei der Auswahl von Data-Mining-Methoden berücksichtigt.Der Benutzer wird damit nicht konfrontiert.
• Semantik der Attribute: Die Bedeutung der Datenbankattribute lässt sich nur schwerdurch Metadaten ausdrücken, ihre Modellierung liegt damit bislang nicht im Fokus desQUESTUS-KDD-Ansatzes. Stattdessen wird davon ausgegangen, dass dem Benutzerdie Semantik eines Attributs, das in Form eines KDQL-Fragearguments in einer Frageverwendet wird, bekannt ist.
• Data-Mining-Methoden: Die Auswahl von Data-Mining-Methoden, die für die gegebe-nen Mengen an Fragestellungen und Daten geeignet sind, stellt bislang eine der größten

1279.3 DIE ANFORDERUNGEN AN DEN BENUTZER
Herausforderungen für die Anwender von Data-Mining-Systemen dar. Nicht wenigeraufwändig gestaltet sich die Interpretation der Ergebnisse. Der QUESTUS-KDD-Ansatzrealisiert eine wissensbasierte Auswahl von Data-Mining-Methoden und -Algorithmen,deren Ergebnisse zusammen in der Lage sind, eine gegebene Frage auf gegebenen Datenkorrekt und vollständig zu beantworten (siehe auch Abschnitt 7.3). Zudem wird die In-terpretation der Ergebnisse durch die Rückübersetzung in natürlichsprachliche Antwor-ten unterstützt. Damit kann der Benutzer von der Last der Methodenauswahl, die norma-lerweise hohe Anforderungen bezüglich der Vertrautheit des Benutzers mit Datenbankenund Data Mining erfordert, und der Interpretation ihrer Ergebnisse weitestgehend befreitwerden.
• Frageformulierungen: Die komplexeste Aufgabe stellt die Abbildung der Fragen imKopf des Fachexperten auf Fragen im QUESTUS-KDD-Ansatz, also die Formulierungvon KD-Fragen durch den Fachexperten dar. Dies wird wiederum durch die Verwaltungsynonymer Fragenformulierungen, die fehlertolerante Eingabe von Fragen, die listenba-sierte Manipulation und die Möglichkeit der Überprüfung der Korrektheit der Formulie-rungen durch die Schaffung von Transparenz über Transformationen unterstützt. Den-noch lässt es sich an dieser Stelle nicht vermeiden, vom Benutzer Kenntnis und Ver-ständnis der Grundmuster der formulierbaren Fragen zu fordern.
• KDD-Prozess: Der QUESTUS-KDD-Ansatz konzentriert sich auf den für den Fachex-perten relevanten Teil der Analyse. Er baut darauf auf, dass die Daten in einem Vorver-arbeitungsschritt in eine adäquate Form gebracht und Metadaten über die Attribute sowierelevantes Domänenwissen erfasst und formalisiert wurden. Auf dieser Basis wird vomFachexperten keine Kenntnis des KDD-Prozesses gefordert, die Data-Mining-Analysenkönnen interaktiv und ohne weitere Kenntnis des KDD-Prozess durchgeführt werden.
Abbildung 40 klassifiziert den Umfang der oben beschriebenen Anforderungen an den Be-nutzer und stellt sie in einem Anforderungsprofil dar.
Schwierigkeiten bei der Formulierung von Fragen durch Fachexperten treten in den folgen-den Fällen auf:
• Abstraktionsniveau: Die Fragen sind zu abstrakt für die automatische Beantwortung:• Wird auf ökonomische Aspekte Rücksicht genommen? • Wird in Abteilungen bewusst nach Guidelines vorgegangen?
Abbildung 40: Die Anforderungen an die Benutzer des QUESTUS-KDD-Ansatzes.
Attributbezeichnungen
Daten- und Skalentypen
Datenbankmodellierung
Data-Mining-Methoden
Semantik der Attribute
Verfügbare Daten
Gefordertes Wissen übergering
KDD-Prozess
Frageformulierungen
hoch

128 KAPITEL 9. DIE EVALUIERUNG DES QUESTUS-KDD-ANSATZES
• Wo können Einsparungspotenziale abgeleitet werden?Dieses Problem beruht darauf, dass die Grenzen des Systems für den Benutzer nicht er-kennbar sind: Er kann nicht entscheiden, welche Fragen sich mit dem vorhandenen Hin-tergrundwissen und den Methoden und Algorithmen beantworten lassen und welchenicht. Damit kann er auch das Abstraktionsniveau seiner Fragen nicht einschätzen.
• Formulierung: Die Fragen entsprechen nicht den Formulierungsanforderungen. Um siedurch unseren Ansatz bearbeitbar zu machen, müssen sie umformuliert werden:
• Kommen in bestimmten Abteilungen häufiger Komplikationen vor? Die entsprechende beantwortbare Frage lautet: Gibt es Unterschiede bezüglich der Verteilung von Komplikationen zwischen denAbteilungen?
• Bei welchen Diagnosen gibt es Hinweise, dass sich die Verteilung der Überschrei-tungen der Verweildaueruntergrenze nach Geschlecht unterscheiden? Die entsprechende beantwortbare Frage lautet: Gibt es Unterschiede bezüglich der Verteilung der Überschreitungen der Verweil-daueruntergrenze zwischen männlichen und weiblichen Patienten?
• Ist die Behandlung davon abhängig, um welche Leistungsklasse73 es sich handelt?Die entsprechende beantwortbare Frage lautet: Gibt es eine Abhängigkeit der Behandlung von der Leistungsklasse?
• Werden Patienten mit derselben Diagnose weitgehend im selben Fachbereich be-handelt? Die entsprechende beantwortbare Frage lautet: Gibt es Unterschiede bezüglich des Fachbereichs bei Patienten mit derselben Dia-gnose?
Im Falle dieser Fragen, die nicht den Formulierungsanforderungen entsprechen, ist dieSyntax von KDQL für den Benutzer nicht erkennbar. Dieses Problem lässt sich auchdurch eine kontinuierliche Erweiterung von KDQL nicht beseitigen, weil eine vollständi-ge Abdeckung aller möglichen Formulierungen von Fragen nicht realisierbar ist. EinAusweg kann deshalb nur in der Entwicklung von Methoden zur Darstellung der Gram-matik von KDQL nach außen bestehen, um dem Benutzer die Umformulierung seinerFrage zu erleichtern.
• Zusätzliche Elemente: Die Fragen enthalten zusätzliche Elemente, z.B. Bedingungen,die nicht durch KDQL abgedeckt sind:
• Wenn Patienten mit derselben Diagnose nicht im selben klinischen Fachbereichbehandelt werden, gibt es dann Unterschiede in der Behandlungsqualität derFachbereiche?
Bei solchen Fragen besteht ein ähnliches Problem wie bei den vorhergehenden: Auchhier sind die Grenzen des Umfangs von KDQL für den Benutzer nicht erkennbar. In die-sem Fall ist eine Umformulierung durch den Benutzer aber nicht oder nur bedingt mög-lich. Nur eine strukturelle Erweiterung von KDQL kann hier Abhilfe schaffen.
73 Die Leistungsklasse im österreichischen Gesundheitssystem kann mit der Art der Krankenversiche-rung (privat oder gesetzlich) in Deutschland verglichen werden.

1299.4 DIE INTEGRATION IN DEN GESAMTPROZESS
9.4 Die Integration in den Gesamtprozess
Am Beispiel des datenbasierten medizinischen Qualitätsmanagements wollen wir im Folgen-den die Rolle und Einbettung des Data Mining in den Gesamtprozess (siehe auch Abbildung41) darstellen. In diesen Prozess, den wir zunächst ohne unseren Ansatz der Benutzerunterstüt-zung darstellen, sind innerhalb einer Klinik oder eines Klinikverbundes verschiedene Gruppeninvolviert:
• Der Datenbankadministrator entwirft, implementiert und wartet die Datenstrukturenfür die Akquisition der Daten in klinischen Prozessen. Die konkrete Form der Datenver-waltung weist zum Zeitpunkt der Erhebung starke Schwankungen zwischen Ländern undKliniken auf. Aufgrund von Standardisierungsbemühungen, die vor allem auf die Ein-führung von Fallpauschalen bei der Leistungsabrechnung zurückzuführen sind, lässt sichaber eine Tendenz zu spezialisierten Data Warehouses oder Krankenhausinformations-systemen (KIS) erkennen.
• Der medizinische Datenmanager ist auf der einen Seite im technischen Sinne für dieVerwaltung aller in einer Klinik erhobenen abrechnungs- und behandlungsrelevantenDaten zuständig. Auf der anderen Seite unterstützt er das medizinische und administrati-ve Personal der Klinik bei der Dokumentation sowie bei der zielgruppenspezifischenAufbereitung der Daten, wie sie für die Verwaltung einer Station und für die Abrech-nung von Behandlungsleistungen benötigt werden. Damit stellt der medizinische Daten-manager das Bindeglied zwischen den Management-, Controlling- und Qualitätsmanage-ment-Instanzen einer Klinik sowie dem medizinischen Personal und der technischen Da-tenbankadministration dar.74
• Der Datenanalyst nimmt in einem Prozess ohne weitgehende Benutzerunterstützung fürdas Data Mining aufgrund seiner grundlegenden Kompetenzanforderungen eine eigen-ständige Rolle ein. Zusammen mit dem Datenbankadministrator und dem medizinischenDatenmanager leistet er durch die Anwendung seines methodischen Wissens technischeUnterstützung bei der Durchführung von Analysen für das Qualitätsmanagement in derKlinik.
• Das Qualitätsmanagement gibt den Fokus dieser Analysen vor: Dieser entsteht übli-cherweise aus Aufgaben und Zielen der Klinikverwaltung (z.B. Verkürzung der mittle-ren Verweildauer unter Beibehaltung der Behandlungsqualität), die beim Qualitätsmana-ger konkretere Fragestellungen (z.B. Welche Unterschiede bezüglich der Behandlungs-qualität gibt es bei Patienten, die die Verweildauernormen überschreiten, und bei sol-chen, die diese unterschreiten?) auslösen.
Die beiden letztgenannten Gruppen, also Qualitätsmanager und Datenanalyst, führen bis-lang zusammen die Data-Mining-Analysen, vor allem die Kernprozessschritte aus demCRISP-Modell business understanding, modeling und evaluation, durch (siehe dazu auch Ab-schnitt 2.1.3).75
Ziel des QUESTUS-KDD-Ansatzes ist, wie bereits früher erwähnt, eine systemische Unter-stützung für eine Vereinfachung dieses Prozesses. Um die sprachliche Diskrepanz zwischendem Qualitätsmanager als Fragesteller und dem Datenanalysten als Methodenlieferanten zurreduzieren und vor allem auch, um den Bedarf an teuren Datenanalyse-Experten zumindest für
74 Der Ausbildungsgang zum „Medizinischen Daten-Manager“ wird derzeit bei den Tiroler Landes-krankenanstalten (TILAK) vorbereitet.
75 Neben komplexen Data-Mining-Analysen sind natürlich auch Standardberichte und OLAP-Anfragenzur Datenanalyse denkbar. Wichtige Hilfsmittel für alle genannten Verfahren sind Methoden der Statistikund der Visualisierung.

130 KAPITEL 9. DIE EVALUIERUNG DES QUESTUS-KDD-ANSATZES
grundlegende Data-Mining-Analysen zu reduzieren, schlagen wir deshalb einen vereinfachtenProzess unter Verwendung des KDA als Implementierung des QUESTUS-KDD-Ansatzes vor.Dieser Prozess ist in Abbildung 42 dargestellt und zeichnet sich vor allem durch eine reduzier-te Rolle des Datenanalysten aus, die hier durch die im QUESTUS-KDD-Ansatz bereitgestellteumfangreiche Benutzerunterstützung für die Kernphasen der Entdeckung von Wissen in Da-tenbanken ersetzt wird. Hauptaufgabe des Datenanalysten ist jetzt die Konfiguration des KDA,also die Eingabe und Wartung des für die Benutzerunterstützung benötigten Wissens im Be-reich Data Mining.
Die Ergebnisse des erfolgreichen Data Mining, z.B. Hinweise für Kapazitätsplanungen,qualitätsrelevante Faktoren, Behandlungsrichtlinien (guidelines) oder sogar neues oder überar-beitetes medizinisches Wissen, lassen sich in einer Ergebnisdatenbank ablegen. Auf dieser Ba-sis können dann verschiedene zielgruppengerechte Darstellungen der Ergebnisse in unter-schiedlichen Formaten, z.B. für die Präsentation im Intranet oder für gedruckte Berichte, gene-rieren (siehe Abschnitt 8.1.4). Damit lassen sich Antworten auf die Fragen des Qualitätsmana-gers finden, die wiederum für die Lösung der von der Klinikverwaltung gestellten Aufgabenund die Erreichung ihrer Ziele umgesetzt werden können. Das medizinische Personal erhältdarüber hinaus Hinweise auf die Qualität ihrer Leistungen und Hinweise für mögliche Verbes-serungen.
Abbildung 41: Der Ausgangsprozess des datenbasierten medizinischen Qualitätsmanagements.
Statistik und Visualisierung
Modeling
MedizinischesPersonal
Qualitäts-managerDatenanalyst
Evalua-tion
Daten-sammlung
BusinessUnder-
standing
Data Mining
MedizinischerDatenmanager
OLAP
Berichts-wesen
Datenbank-administrator
Verwaltungs-direktor
Aufgaben/Ziele
Interessen
KIS
Feedbackschleife
Einfluss
Datenfluss
Datenbank
(Teil-)Prozess
Person/Rolle
Ergebnisse
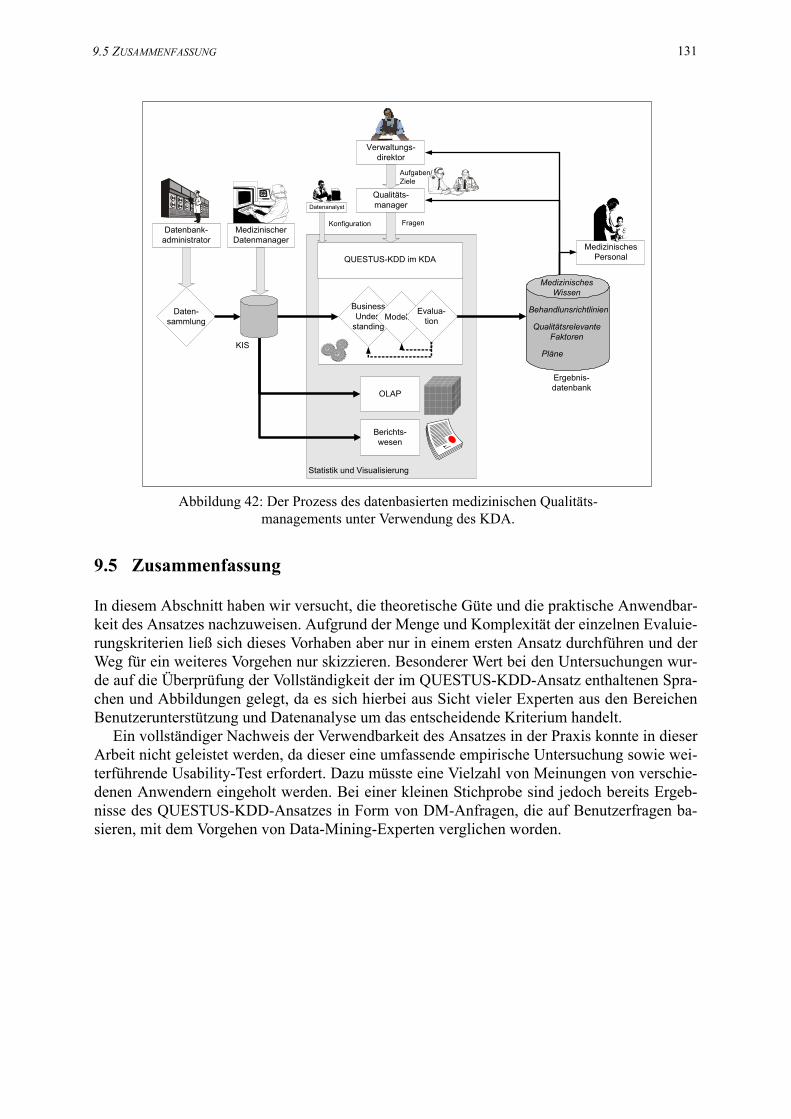
1319.5 ZUSAMMENFASSUNG
9.5 Zusammenfassung
In diesem Abschnitt haben wir versucht, die theoretische Güte und die praktische Anwendbar-keit des Ansatzes nachzuweisen. Aufgrund der Menge und Komplexität der einzelnen Evaluie-rungskriterien ließ sich dieses Vorhaben aber nur in einem ersten Ansatz durchführen und derWeg für ein weiteres Vorgehen nur skizzieren. Besonderer Wert bei den Untersuchungen wur-de auf die Überprüfung der Vollständigkeit der im QUESTUS-KDD-Ansatz enthaltenen Spra-chen und Abbildungen gelegt, da es sich hierbei aus Sicht vieler Experten aus den BereichenBenutzerunterstützung und Datenanalyse um das entscheidende Kriterium handelt.
Ein vollständiger Nachweis der Verwendbarkeit des Ansatzes in der Praxis konnte in dieserArbeit nicht geleistet werden, da dieser eine umfassende empirische Untersuchung sowie wei-terführende Usability-Test erfordert. Dazu müsste eine Vielzahl von Meinungen von verschie-denen Anwendern eingeholt werden. Bei einer kleinen Stichprobe sind jedoch bereits Ergeb-nisse des QUESTUS-KDD-Ansatzes in Form von DM-Anfragen, die auf Benutzerfragen ba-sieren, mit dem Vorgehen von Data-Mining-Experten verglichen worden.
Abbildung 42: Der Prozess des datenbasierten medizinischen Qualitäts-managements unter Verwendung des KDA.
Statistik und Visualisierung
MedizinischesPersonal
Qualitäts-manager
Daten-sammlung
BusinessUnder-
standing
MedizinischerDatenmanager
OLAP
Berichts-wesen
Datenbank-administrator
Pläne
QualitätsrelevanteFaktoren
Behandlunsrichtlinien
MedizinischesWissen
Verwaltungs-direktor
Aufgaben/Ziele
Fragen
Ergebnis-datenbank
KIS
ModelingEvalua-
tion
QUESTUS-KDD im KDA
Datenanalyst
Konfiguration

132 KAPITEL 9. DIE EVALUIERUNG DES QUESTUS-KDD-ANSATZES

KAPITEL 10 ZUSAMMENFASSUNG, DISKUSSION UND AUSBLICK
Die vorliegende Arbeit bewegt sich in einem Bereich, der von verschiedenen Disziplinen derInformatik berührt wird. Zum einen sind dies Aufgabenstellungen aus dem Bereich der Lingu-istik und der erotetischen Logik, die vor allem bei der Analyse der Fragen von Fachexpertenund der Konzeption von KDQL zu finden sind. Von höherer Relevanz, weil in beinahe allenKomponenten des Ansatzes präsent, sind die Bereiche wissensbasierte Systeme und Know-ledge Engineering: Dies betrifft vor allem den Aufbau der Wissensbasis sowie den Erwerb unddie Formalisierung des Abbildungswissens. Als Anwendungsgebiet der Benutzerunterstützungstehen Methoden und Algorithmen der Statistik und des Data Mining im Vordergrund. Und alsGrundthema des Ansatzes kommt der Bereich intelligenter Benutzerschnittstellen zum Tragen.
Im Folgenden fassen wir die wichtigsten Leistungen unseres Ansatzes noch einmal zusam-men, hinterfragen kritisch seine Vor- und Nachteile und geben einen Ausblick auf möglicheErweiterungen des Ansatzes und zukünftige Arbeiten in diesem Bereich.
10.1 Zusammenfassung
Wir haben in dieser Arbeit den QUESTUS-KDD-Ansatz für die Unterstützung von Fachexper-ten bei der Entdeckung von Wissen in Datenbanken entwickelt. Der Idee des Invisible DataMining folgend erlaubt unser Ansatz die Spezifikation von Data-Mining-Anfragen ohne ver-tiefte Kenntnis von Methoden und Algorithmen. Damit lassen sich Data-Mining-Analysendurch Fachexperten in Form von Fragen in natürlicher Sprache spezifizieren. Die Fragen wer-den über mehrere wissensbasierte Transformationsschritte in ausführbare Data-Mining-Anfra-gen überführt, deren Ergebnisse wieder in die Fachsprache des Experten zurückübersetzt wer-den können.
Im Detail lassen sich die folgenden Leistungen beschreiben:• Mit der Knowledge Discovery Questions Language (KDQL) wurde erstmals eine kon-
trollierte Sprache für Fragen von Fachexperten vorgestellt, die aufgrund ihrer Nähe zunatürlichsprachlichen Formulierungen nicht das Erlernen neuer Konzepte und Strukturenvom Benutzer fordert. Damit können abstrakte Benutzerinteressen in Form von Fragenformuliert und damit als Grundlage für die Spezifikation von Data-Mining-Analysenverwendet werden.
• Unter Einsatz von umfangreichem Wissen über Data-Mining-Methoden und -Algorith-men sowie verschiedenen Arten von taxonomischem Wissen können die Fragen in Data-Mining-Anfragen übersetzt werden. Dabei werden abstrakte Fragen zunächst mittels derTaxonomien expandiert und konkretisiert. Auf einem bestimmten Konkretisierungsni-veau können diese dann verwendet werden, um zunächst eine Data-Mining-Methode unddann einen Data-Mining-Algorithmus auszuwählen, sowie die weiteren Elemente einerData-Mining-Anfrage zu bestimmen. Im letzten Schritt kann noch die Anpassung auf

134 KAPITEL 10. ZUSAMMENFASSUNG, DISKUSSION UND AUSBLICK
verschiedene Implementierungen des Algorithmus mit entsprechend variierender Auf-rufsyntax erfolgen.
• Das für den QUESTUS-KDD-Ansatz benötigte Wissen über Fragen, Antworten, Metho-den und Konzepte wurde in einer modularen Wissensbasis beschrieben. Durch die Mo-dellierung auf verschiedenen Spezialisierungsstufen lässt sich die Portierung des Ansat-zes beispielsweise auf andere Domänen erleichtern.
Diese Ergebnisse der Arbeit wurden prototypisch als Komponenten in ein bestehendesData-Mining-Werkzeug integriert und einer ersten Evaluierung in der Praxis unterworfen.
10.2 Diskussion
Die Grundidee, zwei so komplexe wie unterschiedliche Welten wie die Gedankenwelt von Fa-chexperten mit den formalen Beschreibungen von Data-Mining-Methoden zu kombinieren,bleibt eine grundsätzliche Herausforderung. Der Ansatz unterscheidet sich von bestehendenAnsätzen zwar deutlich in Bezug auf die Komplexität der Benutzerunterstützung beim DataMining und die Sprachebene, auf der die Interaktion verläuft. Dennoch erscheint es möglich,dass sich im real-world-Einsatz weitere grundsätzliche Fragen ergeben.
Der Prozess der Formulierung von Fragen durch Fachexperten könnte in diesem Sinne einerweitergehenden Untersuchung bedürfen. Dabei ist zu klären, inwieweit sich die Fragen aus dernatürlichen Sprache tatsächlich auf die KDQL-Formulierungen abbilden lassen und ob die bis-lang vorgeschlagenen Mittel dafür ausreichen. Dabei steht auch zur Diskussion ob durch dievorgestellten Methoden zur Schaffung von Transparenz für den Benutzer genügen, um Ambi-guitäten und andere linguistischen Schwierigkeiten beim Umgang mit natürlicher Sprache zuvermeiden sowie den Umfang der linguistischen Abdeckung zu verdeutlichen. Vorwiegend isthierbei zu untersuchen, ob sich dem Benutzer die Menge der formulierbaren Fragen erschließtund ob andererseits aus dem System heraus klar wird, warum Fragen, die die Grenzen des Sys-tems überschreiten, nicht verarbeitet werden können. So ist es möglich, dass ausgehend von ei-ner Frage, die vom System nicht beantwortet werden kann, andere Fragen aber, die der Benut-zer als gleich komplex einschätzen würde, gegen die Erwartungen des Benutzers verstandenwerden können (falsch-negative Erwartungen). Das gleiche gilt im umgekehrten Fall, wennFragen, von deren Beantwortbarkeit der Benutzer durch den Vergleich mit scheinbar ähnlichenFragen ausgeht, nicht beantwortet werden können (falsch-positive Erwartungen).
Durch die umfangreichen internen Transformationsschritte ergibt sich ein weiteres Risiko,das sich auch als „Gefahr der stillen Post“ bezeichnen lässt: Bei jedem Transformationsschrittwird eine kleine syntaktische oder semantische Ungenauigkeit in der eingegebenen Frage ver-stärkt, ohne dass dies für den Benutzer transparent wird. Erst am Ende der Transformationsket-te wird ein Ergebnis präsentiert, das jedoch von dem Ergebnis, das zur Ausgangsfragestellungzu erwarten war, abweicht. Im einfacheren Fall ist diese Abweichung erkennbar, dann kannder Benutzer entsprechende Maßnahmen zur Korrektur ergreifen. Im schlimmeren Fall nimmtder Benutzer die Abweichung unbewusst hin und zieht falsche Schlüsse aus dem Ergebnis. Dadiese Effekte nur durch kontinuierlichen, expliziten Vergleich der Transformationsergebnissemit den Erwartungen des Benutzers behoben werden können, werden Feedback-Mechanismennotwendig, die der Idee des Invisible Data Mining jedoch zuwider laufen.
Der QUESTUS-KDD-Ansatz unterstützt eine stärkere Integration der Kernprozesse desCRISP-DM-Modells (Business Understanding, Modeling und Evaluation). Durch diese Kon-zentration auf die zentralen Schritte wird jedoch keine Prozessunterstützung im eigentlichenSinne geleistet. Zu prüfen ist deshalb auch, ob für die Komplexität der Analysen, die von denFachexperten in einer vorkonfigurierten Umgebung selbst durchgeführt werden sollen, eine

13510.3 AUSBLICK
Konzentration auf die eigentliche Analysephase ausreichend ist, oder ob der Ansatz durch eineweitergehende Prozessunterstützung zu erweitern ist.
Als ein grundsätzliches Problem bei der Entdeckung von Wissen in Datenbanken ist derGrad der Fokussierung auf die Interessen des Benutzers anzusehen: Einerseits bewahrt dieKonzentration auf die Benutzerinteressen, die durch unseren Ansatz unterstützt wird und sichin verschiedenen Einschränkungen des Suchraums manifestiert, vor großen Mengen von po-tentiell uninteressanten Ergebnissen. Andererseits besteht die Gefahr, dass durch eine zu fo-kussierte Suche wirklich interessante weil unerwartete Ergebnisse, die damit jedoch außerhalbdes spezifizierten Fokus liegen, nicht gefunden werden. Einen möglichen Ausweg aus diesemDilemma könnte das Zusammenspiel mit den von Müller in [Mül98] beschriebenen Methodenzur Bewertung der Interessantheit von Data-Mining-Ergebnissen bieten.
10.3 Ausblick
Zum Abschluss dieser Arbeit wollen wir den Blick auf einige Arbeitsgebiete lenken, die imSinne einer Erweiterung unseres Ansatzes ein lohnendes Ziel darstellen könnten. Als ersterAnsatzpunkt kann der Umfang der Benutzerunterstützung von der syntaktischen auf die Über-prüfung der semantischen Korrektheit bzw. Sinnhaftigkeit der Fragen ausgedehnt werden.Durch eine weitergehende Beschreibung der Semantik von Belegungen für KDQL-Elemente,z.B. von Frageargumenten kann erreicht werden, dass der Benutzer bei der Formulierung vonFragen weiter unterstützt werden kann. Durch Kennzeichnung des Attributs Verweildauer alsZeitintervall und des Attributs Aufnahmedatum als Zeitpunkt lässt sich beispielsweise sicher-stellen, dass Attribute die in diesem Sinne nicht vom gleichen Typ sind, nicht gleiche Rolleninnerhalb einer Frage einnehmen können.
Aufgrund ihrer großen Bedeutung verdient auch die Erweiterung der Wissensbasis beson-dere Aufmerksamkeit. Da die Modellierung einer Domäne durch ihre jeweilige Dynamik nieals abgeschlossen betrachtet werden können, werden Möglichkeiten benötigt, Erweiterungendurch den Fachexperten in adäquater Weise selbst vornehmen zu lassen. Vor allem beim Auf-treten von konzeptionellen Lücken z.B. bei der Formulierung einer Frage müssen die fehlen-den Begriffe dem System auf der Basis von primitiven Konzepten und schon bekannten Be-griffen „gelehrt“ werden. Die Optimierung und Erweiterung der Wissensbasis in Bezug aufneue Analysemethoden und -algorithmen wird dagegen im Aufgabenbereich eines entspre-chenden Datenanalysten bleiben. Dennoch kann auch hier über eine stärkere Unterstützung beider Formalisierung des entsprechenden Wissens nachgedacht werden. Die Erweiterung vonKDQL kann unter Einsatz der in Abschnitt 5.2 beschriebenen Knotentypen und einer Metabe-schreibungssprache auf dieser Ebene in einem entsprechenden Editor unterstützt werden.
Ein weiteres zukünftiges Arbeitsgebiet kann die Erweiterung des Interaktionszyklus darstel-len: Während der Fachexperte bislang selbst von der Ziel- über die Maßnahmen- auf die Fra-genebene absteigen muss, um die Analysen zu spezifizieren, könnte die Benutzerunterstützungkünftig höher z.B. auf der Zielebene angesiedelt werden. Aus der Basis, der vom Benutzer for-mulierten Aufgaben, z.B. Senkung der mittleren Verweildauer der Patienten, ließen sich dannvom System Fragen ableiten, z.B. Welchen Zusammenhang gibt es zwischen Therapien undder Verweildauer?, die dann als Eingaben für den QUESTUS-KDD-Ansatz verwendet werdenkönnen.
Portierungen des Ansatzes können in verschieden Dimensionen vorgenommen werden: Ab-gesehen von Domänenportierungen, die teilweise schon realisiert wurden, sind hier auch tiefergreifende Schritte möglich. So wurde der QUESTUS-KDD-Ansatz zwar mit dem Fokus derBenutzerunterstützung für das Data Mining entwickelt, könnte aber auch für andere Quellenvon Ergebnissen adaptierbar sein. Zum einen ist hier eine Integration des Zugriffs auf andere

136 KAPITEL 10. ZUSAMMENFASSUNG, DISKUSSION UND AUSBLICK
hochstrukturierte Datenquellen wie beispielsweise OLAP-Würfel denkbar. Zum anderen ließesich über die Formulierung von Fragen in einer KDQL-ähnlichen Sprache auf die Inhalte vonHypertext-basierten Informationssystemen, wie sie am Bayerischen Forschungszentrum fürWissensbasierte Systeme zum Zwecke der Wissenssicherung aufgebaut werden, zugreifen.
Die Erfahrungen, die wir bei der Analyse des Stands der Technik im Theoretischen als auchbei der Durchführung von Data-Mining-Projekten im Praktischen gemacht haben, zeigen, dasseine Benutzerunterstützung vor allem für Fachexperten als die eigentlichen Endkunden desData Mining dringend erforderlich aber bisher kaum realisiert ist. Dies ist sicherlich wenigerauf fehlendes Problembewusstsein als vielmehr auf die Komplexität der Aufgabe zurückzufüh-ren. Dennoch vertreten wir die Auffassung, dass ohne adäquate Benutzerunterstützung die Zu-gangsschwellen zum Data Mining zu hoch bleiben werden. Nur durch konsequente Bemühun-gen in diese Richtung können die Technologie des Data Mining einer weiteren Verbreitungund das in den vorhandenen Datenbeständen enthaltene Wissen einer tiefer greifenden Nut-zung zugeführt werden.

ANHANG A EMPIRISCHE GRUNDLAGEN
A.1 Die Themenhierarchie im Bereich des medizinischen Leistungscontrollings
Abbildung 43 stellt die Hierarchie der im Bereich des medizinischen Qualitätsmanagementsrelevanten Themen strukturiert da. Die Codierung der einzelnen Themen ist Grundlage für dieBeschreibung der domänenspezifischen Frageobjekte in Abschnitt 5.2.1.2.2.
A.2 Der Fragekorpus
Die folgenden Fragen wurden aus verschiedenen Data-Mining-Studien von Fachexperten ge-sammelt und strukturiert. Sie dienen als Grundlage für die Konzeption der Knowledge Disco-very Question Language (KDQL) in Kapitel 5.
A.2.1 Allgemeine Fragen
• Welche Auffälligkeiten gibt es in <Kontext>?• Welche Auffälligkeiten gibt es im <Bereich>?• Welche Auffälligkeiten gibt es in <Gruppe>?• Was kann zu <Objekten> in Zusammenhang mit <Attribut> gesagt werden?• Was kann zu <Attribut1> von <Objekten> in Zusammenhang mit <Attribut2> gesagt
werden?
A.2.2 Fragen nach Einfluss
A.2.2.1 Geschlossene bzw. konfirmative bzw. hypothesentestende Fragen
• Hat <Einflussfaktor> Einfluss auf <Ziele>?• Hat <Einflussfaktor> Einfluss auf <Ziele> im <Bereich>?• Hat <Einflussfaktor> positiven Einfluss auf <Ziele> im <Bereich>?• Hat <Einflussfaktor> negativen Einfluss auf <Ziele> im <Bereich>?
A.2.2.2 Deskriptive Fragen
• Welchen Einfluss hat <Einflussfaktor> auf <Ziele>?• Welchen Einfluss hat <Einflussfaktor> auf <Ziele> im <Bereich>?

138 ANHANG A. EMPIRISCHE GRUNDLAGEN
A.2.2.3 Offene explorative Fragen
• Welcher <Einflussfaktor> beeinflusst <Ziele> im <Bereich>?• Welcher <Einflussfaktor> beeinflusst <Ziele> im <Bereich> positiv?• Welcher <Einflussfaktor> beeinflusst <Ziele> im <Bereich> negativ?
A.2.3 Fragen nach Unterschied
A.2.3.1 Geschlossene bzw. konfirmative bzw. hypothesentestende Fragen
• Ist <Kennzahl> bei <Gruppe1> <Relation <=>> <Gruppe2>?• Liegt <Kennzahl> in <Gruppe> über <Kennzahl> in Gesamtdaten?
Abbildung 43: Die Themenhierarchie des Medizinischen Leistungscon-trollings.
1 Medizinisches Leistungscontrolling 1.1 Medizinisches Leistungscontrolling für Diagnostik 1.1.1 Adäquatheit der Diagnostik 1.1.1.1 Qualität der Diagnostik 1.1.1.1.1 Korrektheit der Diagnostik 1.1.1.1.2 Vollständigkeit der Diagnostik 1.1.1.1.3 Differenziertheit der Diagnostik 1.1.1.2 Belastung des Patienten bei der Diagnostik 1.1.1.3 Kosten der Diagnostik 1.1.2 Diagnose-Standards 1.2 Medizinisches Leistungscontrolling für Therapeutik 1.2.1 Adäquatheit der Therapeutik 1.2.1.1 Qualität der Therapeutik 1.2.1.1.1 Korrektheit der Therapeutik 1.2.1.1.2 Vollständigkeit der Therapeutik 1.2.1.1.3 Differenziertheit der Therapeutik 1.2.1.2 Belastung des Patienten bei der Therapeutik 1.2.1.3 Kosten der Therapeutik 1.2.2 Standards der Therapeutik 1.3 Medizinisches Leistungscontrolling für Verwaltung 1.3.1 Dokumentation 1.3.1.1 Medizinische Aspekte der Dokumentation 1.3.1.1.1 Medizinische Adäquatheit der Dokumentation 1.3.1.1.1.1 Medizinische Qualität der Dokumentation 1.3.1.1.1.1.1 Medizinische Korrektheit der Dokumentation 1.3.1.1.1.1.2 Medizinische Vollständigkeit der Dokumentation 1.3.1.1.1.1.3 Medizinische Differenziertheit der Dokumentation 1.3.1.1.1.2 Belastung des Patienten durch Dokumentation 1.3.1.1.1.3 Medizinische Kosten der Dokumentation 1.3.1.1.2 Medizinische Standards der Dokumentation 1.3.1.2 Technische Aspekte der Dokumentation 1.3.1.2.1 Technische Adäquatheit der Dokumentation 1.3.1.2.1.1 Technische Qualität der Dokumentation 1.3.1.2.1.1.1 Technische Korrektheit der Dokumentation 1.3.1.2.1.1.2 Technische Vollständigkeit der Dokumentation 1.3.1.2.1.1.3 Technische Differenziertheit der Dokumentation 1.3.1.2.1.2 Belastung des Patienten durch Dokumentation 1.3.1.2.1.3 Technische Kosten der Dokumentation 1.3.1.2.2 Technische Standards der Dokumentation 1.3.2 Planung 1.3.2.1 Adäquatheit der Planung 1.3.2.1.1 Qualität der Planung 1.3.2.1.1.1 Korrektheit der Planung (Planungssicherheit) 1.3.2.1.1.2 Vollständigkeit der Planung 1.3.2.1.1.3 Differenziertheit der Planung 1.3.2.1.2 Belastung des Patienten 1.3.2.1.3 Kosten der Planung 1.3.2.2 Planungsstandards

139A.2 DER FRAGEKORPUS
• Unterscheiden sich <Gruppe1> von <Gruppe2> bzgl. der Verteilung von <Kennzahl>?
A.2.3.2 DeskriptiveFragen
• Welche Patientengruppen weisen signifikante Unterschiede in der Verteilung von <At-tribut> auf?
• Welche Patientengruppen nach <Attribut1> weisen signifikante Unterschiede in der Ver-teilung von <Attribut2> auf?
A.2.3.3 Offene explorative Fragen
• Wie unterscheiden sich <Gruppe1> von <Gruppe2>?• Wie unterscheidet sich <Kennzahl> in <Gruppe> von <Kennzahl> in Gesamtdaten?• Wie unterscheiden sich <Gruppe1> von <Gruppe2> bzgl. <Kennzahl>?
A.2.4 Fragen nach Veränderung
A.2.4.1 Geschlossene bzw. konfirmative bzw. hypothesentestende Fragen
• Hat sich <Kennzahl> verändert?• Hat sich <Kennzahl> zwischen <Zeitpunkt1> und <Zeitpunkt2> verändert?
A.2.4.2 Deskriptive Fragen
• Wie hat sich <Kennzahl> verändert?• Wie hat sich <Kennzahl> zwischen <Zeitpunkt1> und <Zeitpunkt2> verändert?• Wie hat sich <Kennzahl1> im Vergleich zu <Kennzahl2> entwickelt?• Wie hat sich <Kennzahl1> im Vergleich zu <Kennzahl2> zwischen <Zeitpunkt1> und
<Zeitpunkt2> entwickelt?
A.2.4.3 Offene explorative Fragen
• Welche <Kennzahl> hat sich verändert?

140 ANHANG A. EMPIRISCHE GRUNDLAGEN

ANHANG B MODELLIERUNG RELEVANTER OBJEKTE
B.1 Modellierung relevanter KDQL-Elemente
Im Folgenden beschreiben wir die wichtigsten KDQL-Elemente mit der in Tabelle 7 (im Ab-schnitt 5.2) dargestellten Form. Darüber hinaus stellen wir jeweils die Elemente im XML-Schema dar.
TypKonfirmativ
Elementname TypKonfirmativ
Elementtyp Funktionszuweisung
Elementfunktion
Elementvorgängertyp FrageWurzel
Elementnachfolgertyp FrageObjekt
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 29: Formale Beschreibung des Elements TypKonfirmativ.
<xs:element name="TypKonfirmativ"> <xs:annotation> <xs:documentation>Funktionszuweisung</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="FrageObjekt"/> </xs:sequence>
<xs:attribute name="Elementtyp" use="required" fixed="Funktionszu-weisung"/>
<xs:attribute name="Elementfunktion" use="required" fixed="Binaer-Grenzwertabgleich"/> </xs:complexType></xs:element>
Abbildung 44: Darstellung des Elements TypKonfirmativ im XML-Schema.
Ausgabeja, wenn F BinaerGrenzwert≥
nein, wenn F B< inaerGrenzwert
=

142 ANHANG B. MODELLIERUNG RELEVANTER OBJEKTE
TypDeskriptiv
TypKomplex
Elementname TypDeskriptiv
Elementtyp Funktionszuweisung
Elementfunktion gestufte Entscheidungsfunktion anhand der Kategorien aus Anhang D.3
Elementvorgängertyp FrageWurzel
Elementnachfolgertyp FrageObjekt
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 30: Formale Beschreibung des Elements TypDeskriptiv.
<xs:element name="TypDeskriptiv"> <xs:annotation> <xs:documentation>Funktionszuweisung</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="FrageObjekt"/> </xs:sequence>
<xs:attribute name="Elementtyp" use="required" fixed="Funktionszu-weisung"/>
<xs:attribute name="Elementfunktion" use="required" fixed="Beschrei-bungsfunktion"/> </xs:complexType></xs:element>
Abbildung 45: Darstellung des Elements TypDeskriptiv im XML-Schema.
Elementname TypKomplex
Elementtyp Funktionszuweisung
Elementfunktion1. Clusterbildung2. binäre Entscheidungsfunktion wie bei
TypKonfirmativ
Elementvorgängertyp FrageWurzel
Elementnachfolgertyp *Fokus
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 31: Formale Beschreibung des Elements TypKomplex.

143B.1 MODELLIERUNG RELEVANTER KDQL-ELEMENTE
TypOffen
<xs:element name="TypKomplex"> <xs:annotation> <xs:documentation>Funktionszuweisung</xs:documentation> </xs:annotation> <xs:complexType> <xs:choice> <xs:element ref="LokalFokus"/> <xs:element ref="PersonalFokus"/> <xs:element ref="TemporalFokus"/> <xs:element ref="ModalFokus"/> </xs:choice>
<xs:attribute name="Elementtyp" use="required" fixed="Funktionszu-weisung"/>
<xs:attribute name="Elementfunktion" use="required" fixed="Cluster-funktion"/> </xs:complexType></xs:element>
Abbildung 46: Darstellung des Elements TypKomplex im XML-Schema.
Elementname TypOffen
Elementtyp
*-Konzept:TypKonfirmativ, TypDeskriptiv, TypKomplex
Elementvorgängertyp FrageWurzel
Elementnachfolgertyp FrageObjektFrageObjektOffen
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 32: Formale Beschreibung des Elements TypOffen.

144 ANHANG B. MODELLIERUNG RELEVANTER OBJEKTE
Frageobjekt
<xs:element name="TypOffen"> <xs:annotation> <xs:documentation>*-Konzept: Konfirmativ, Deskriptiv,Komplex</xs:documentation> </xs:annotation> <xs:complexType> <xs:choice> <xs:element ref="FrageObjekt"/> <xs:element ref="FrageObjektOffen"/> </xs:choice>
<xs:attribute name="Elementtyp" use="required" fixed="*-Konzept"/><xs:attribute name="*-Nachfolger1" use="optional" fixed="TypKonfir-
mativ"/><xs:attribute name="*-Nachfolger2" use="optional" fixed="TypDeskrip-
tiv"/><xs:attribute name="*-Nachfolger3" use="optional" fixed="TypKom-
plex"/></xs:complexType>
</xs:element>
Abbildung 47: Darstellung des Elements TypOffen im XML-Schema.
Elementname FrageObjekt
Elementtyp Rahmenkonzept
Elementvorgängertyp Fragetyp
Elementnachfolgertyp ObjektStatObjektDomaene
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 33: Formale Beschreibung des Elements FrageObjekt.
<xs:element name="FrageObjekt"> <xs:annotation> <xs:documentation>Rahmenkonzept</xs:documentation> </xs:annotation> <xs:complexType> <xs:choice> <xs:element ref="ObjektStat"/> <xs:element ref="ObjektDomaene"/> </xs:choice>
<xs:attribute name="Elementtyp" use="required" fixed="Rahmenkon-zept"/> </xs:complexType></xs:element>
Abbildung 48: Darstellung des Elements FrageObjekt im XML-Schema.

145B.1 MODELLIERUNG RELEVANTER KDQL-ELEMENTE
Zusammenhang
Unterschied
Elementname Zusammenhang
Elementtyp Funktionszuweisung
Elementfunktion Funktion wird über den ausge-wählten Algorithmus realisiert
Elementvorgängertyp ObjektStat
ElementnachfolgertypZusammenhangAllgemein,ZusammenhangGerichtet,ZusammenhangRekursiv
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 34: Formale Beschreibung des Elements Zusammenhang.
<xs:element name="Zusammenhang"> <xs:annotation> <xs:documentation>Funktionszuweisung</xs:documentation> </xs:annotation> <xs:complexType> <xs:choice> <xs:element ref="ZusammenhangArgumente"/> <xs:element ref="ZusammenhangGerichtet"/> <xs:element ref="ZusammenhangRekursiv"/> </xs:choice>
<xs:attribute name="Elementtyp" use="required" fixed="Funktionszu-weisung"/> </xs:complexType></xs:element>
Abbildung 49: Darstellung des Elements Zusammenhang im XML-Schema.
Elementname Unterscheid
Elementtyp Funktionszuweisung
Elementfunktion Funktion wird über den ausge-wählten Algorithmus realisiert
Elementvorgängertyp ObjektStat
ElementnachfolgertypUnterschiedAllgemein,UnterschiedSpezifisch,UnterschiedRekursiv
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 35: Formale Beschreibung des Elements Unterschied.

146 ANHANG B. MODELLIERUNG RELEVANTER OBJEKTE
Gemeinsamkeit
<xs:element name="Unterschied"> <xs:annotation> <xs:documentation>Funktionszuweisung</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="UnterschiedAllgemein"/> <xs:element ref="UnterschiedSpezifisch"/> <xs:element ref="UnterschiedRekursiv"/> </xs:sequence>
<xs:attribute name="Elementtyp" use="required" fixed="Funktionszu-weisung"/> </xs:complexType></xs:element>
Abbildung 50: Darstellung des Elements Unterschied im XML-Schema.
Elementname Gemeinsamkeit
Elementtyp Funktionszuweisung
Elementfunktion Funktion wird über den ausge- wählten Algorithmus realisiert
Elementvorgängertyp ObjektStat
ElementnachfolgertypGemeinsamkeitAllgemein,GemeinsamkeitSpezifisch,GemeinsamkeitRekursiv
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 36: Formale Beschreibung des Elements Gemeinsamkeit.
<xs:element name="Gemeinsamkeit"> <xs:annotation> <xs:documentation>Funktionszuweisung</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="GemeinsamkeitAllgemein"/> <xs:element ref="GemeinsamkeitSpezifisch"/> <xs:element ref="GemeinsamkeitRekursiv"/> </xs:sequence>
<xs:attribute name="Elementtyp" use="required" fixed="Funktionszu-weisung"/> </xs:complexType></xs:element>
Abbildung 51: Darstellung des Elements Gemeinsamkeit im XML-Schema.

147B.2 MODELLIERUNG RELEVANTER ALLGEMEINER OBJEKTE
Veränderung
B.2 Modellierung relevanter allgemeiner Objekte
Für die Verwendung im QUESTUS-KDD-Ansatz und vor allem für die Anwendung im Know-ledge Discovery Assistant (KDA) modellieren wir die folgenden Objekte, die sich auf der KD-Ebene (KD-Fragen und KD-Antworten), der DM-Ebene (DM-Anfragen und DM-Ergebnisse)sowie auf der DB-Ebene (Attribut, Attributwert, Fall, Attributgruppe, Attributwertgruppe undFallgruppe) des Ansatzes finden lassen.
Elementname Veraenderung
Elementtyp Funktionszuweisung
Elementfunktion Funktion wird über den ausge-wählten Algorithmus realisiert
Elementvorgängertyp ObjektStat
ElementnachfolgertypVeraenderungAllgemein,VeraenderungSpezifisch,VeraenderungRekursiv
Spezialisierungsebene allgemein
Weitere Attribute -
Tabelle 37: Formale Beschreibung des Elements Veraenderung.
<xs:element name="Veraenderung"> <xs:annotation> <xs:documentation>Funktionszuweisung</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="VeraenderungAllgemein"/> <xs:element ref="VeraenderungSpezifisch"/> <xs:element ref="VeraenderungRekursiv"/> </xs:sequence>
<xs:attribute name="Elementtyp" use="required" fixed="Funktionszu-weisung"/> </xs:complexType></xs:element>
Abbildung 52: Darstellung des Elements Veraenderung im XML-Schema.

148 ANHANG B. MODELLIERUNG RELEVANTER OBJEKTE
B.2.1 Attribut
B.2.2 Attributwert
B.2.3 Fall
Attribut1
1. An dieser Stelle muss zwischen dem Objekttyp Attribut und den Attributen des Objekts, also sei-nen Eigenschaften, unterschieden werden.
Beschreibung Wertebereich Beispiel
AttributNR eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 007
Attribut-Kurz-Bezeichnung
kurze, möglichst eindeu-tige Beschreibung
alphanumerisch GESVD
Attribut-Lang-Bezeichnung
ausführliche, möglichst eindeutige Beschreibung
alphanumerisch Verweildauer in Tagen
Attribut-DatenTyp
Beschreibung des Datentyps
INT, FLOAT, STRING, unbe-kannt
INT
Attribut-SkalenTyp
Beschreibung des Skalentyps
nominal, ordinal, metrisch, unbekannt
nominal
Attribut-Herkunft
Herkunft des Attributs System, Benutzer, Daten Daten
Tabelle 38: Attribute des Objekttyps Attribut.
Attribut Beschreibung Wertebereich Beispiel
Attributwert-NR
eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 008
Attributwert-Kurz-Bezeichnung
kurze, möglichst eindeu-tige Beschreibung
alphanumerisch 5
Attributwert-Lang-Bezeichnung
ausführliche, möglichst eindeutige Beschreibung
alphanumerisch 5 Tage
AttributNR Referenz auf das zugehörige Attribut
natürliche Zahlen 007
Tabelle 39: Attribute des Objekttyps Attributwert.
Attribut Beschreibung Wertebereich Beispiel
FallNR eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 009
Liste von Attribut-werten
alphanumerisch 3 16 89 46 35 23
Tabelle 40: Attribute des Objekttyps Fall.
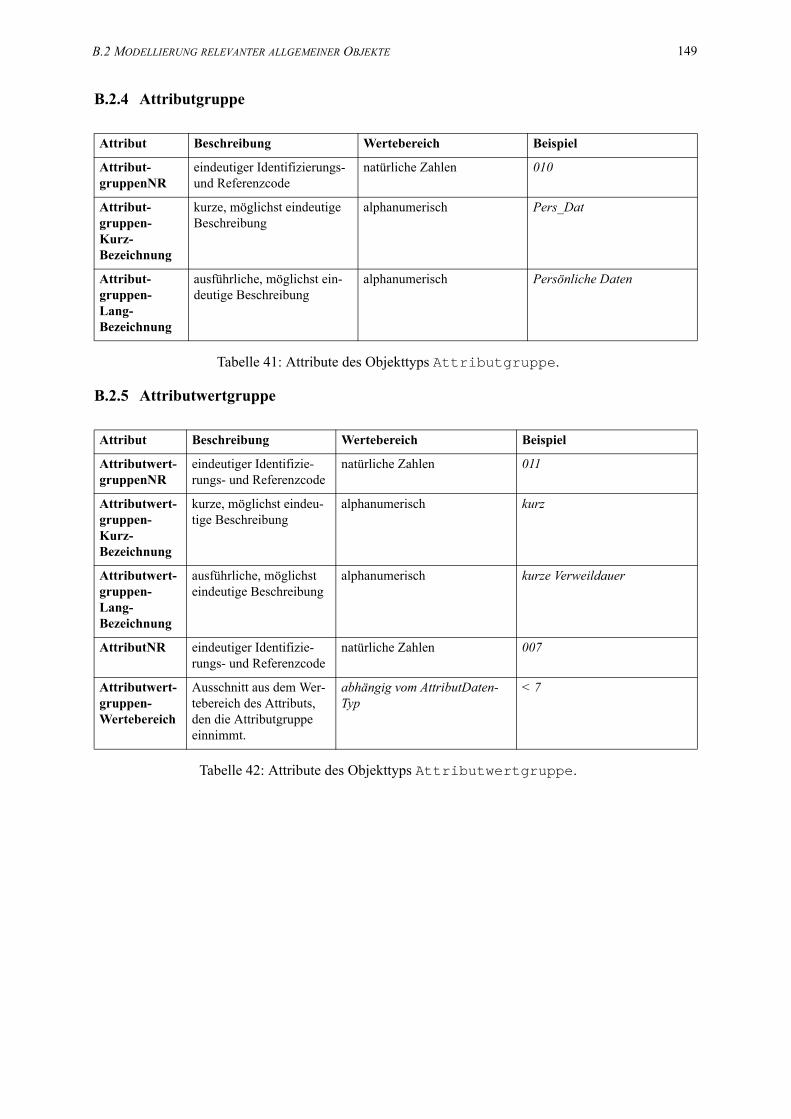
149B.2 MODELLIERUNG RELEVANTER ALLGEMEINER OBJEKTE
B.2.4 Attributgruppe
B.2.5 Attributwertgruppe
Attribut Beschreibung Wertebereich Beispiel
Attribut-gruppenNR
eindeutiger Identifizierungs- und Referenzcode
natürliche Zahlen 010
Attribut-gruppen-Kurz-Bezeichnung
kurze, möglichst eindeutige Beschreibung
alphanumerisch Pers_Dat
Attribut-gruppen-Lang-Bezeichnung
ausführliche, möglichst ein-deutige Beschreibung
alphanumerisch Persönliche Daten
Tabelle 41: Attribute des Objekttyps Attributgruppe.
Attribut Beschreibung Wertebereich Beispiel
Attributwert-gruppenNR
eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 011
Attributwert-gruppen-Kurz-Bezeichnung
kurze, möglichst eindeu-tige Beschreibung
alphanumerisch kurz
Attributwert-gruppen-Lang-Bezeichnung
ausführliche, möglichst eindeutige Beschreibung
alphanumerisch kurze Verweildauer
AttributNR eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 007
Attributwert-gruppen-Wertebereich
Ausschnitt aus dem Wer-tebereich des Attributs, den die Attributgruppe einnimmt.
abhängig vom AttributDaten-Typ
< 7
Tabelle 42: Attribute des Objekttyps Attributwertgruppe.
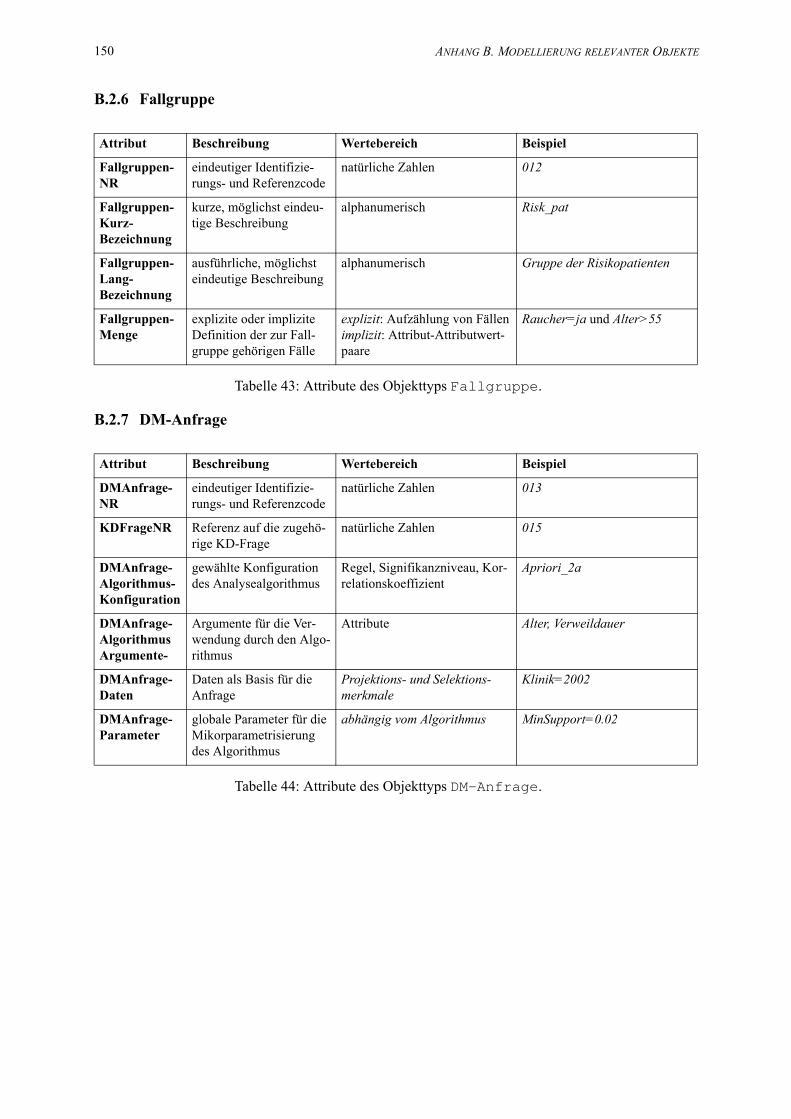
150 ANHANG B. MODELLIERUNG RELEVANTER OBJEKTE
B.2.6 Fallgruppe
B.2.7 DM-Anfrage
Attribut Beschreibung Wertebereich Beispiel
Fallgruppen-NR
eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 012
Fallgruppen-Kurz-Bezeichnung
kurze, möglichst eindeu-tige Beschreibung
alphanumerisch Risk_pat
Fallgruppen-Lang-Bezeichnung
ausführliche, möglichst eindeutige Beschreibung
alphanumerisch Gruppe der Risikopatienten
Fallgruppen-Menge
explizite oder implizite Definition der zur Fall-gruppe gehörigen Fälle
explizit: Aufzählung von Fällenimplizit: Attribut-Attributwert-paare
Raucher=ja und Alter>55
Tabelle 43: Attribute des Objekttyps Fallgruppe.
Attribut Beschreibung Wertebereich Beispiel
DMAnfrage-NR
eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 013
KDFrageNR Referenz auf die zugehö-rige KD-Frage
natürliche Zahlen 015
DMAnfrage-Algorithmus-Konfiguration
gewählte Konfiguration des Analysealgorithmus
Regel, Signifikanzniveau, Kor-relationskoeffizient
Apriori_2a
DMAnfrage-AlgorithmusArgumente-
Argumente für die Ver-wendung durch den Algo-rithmus
Attribute Alter, Verweildauer
DMAnfrage-Daten
Daten als Basis für die Anfrage
Projektions- und Selektions-merkmale
Klinik=2002
DMAnfrage-Parameter
globale Parameter für die Mikorparametrisierung des Algorithmus
abhängig vom Algorithmus MinSupport=0.02
Tabelle 44: Attribute des Objekttyps DM-Anfrage.

151B.2 MODELLIERUNG RELEVANTER ALLGEMEINER OBJEKTE
B.2.8 DM-Ergebnis
B.2.9 KD-Frage
Attribut Beschreibung Wertebereich Beispiel
DMErgebnisNR
eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 014
DMErgebnisTyp
Aussagetyp Regel, Signifikanzniveau, Kor-relationskoeffizient
Apriori_2a
DMErgebnis-Sortierung
Sortierkriterium [x], [|x|/|y|], ... [x]
DMErgebnis-Tabelle
Tabelle der Ergebnisse natürliche Zahlen
DMAnfrage-NR
Referenz auf die DM-Anfrage
Menge der DMAnfrageNRn
Tabelle 45: Attribute des Objekttyps DM-Ergebnis.
Attribut Beschreibung Wertebereich Beispiel
FrageNR eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 015
OberFrage-NRn
Menge der Vorgänger Menge der FrageNRn
UnterFrage-NRn
Menge der Nachfolger Menge der FrageNRn
FrageTyp Typ der Frage konfirmativ, deskriptiv, kom-plex
konfirmativ
FrageObjekt Frageobjekt Zusammenhang, Unterschied, ..., domänenspezifische Objekte
Zusammenhang
Frage-Argumente
Einflussfaktoren der Frage
Attribute, Attributgruppen Fälle, Fallgruppen
Alter (Eigenschaft),Verweildauer (Eigenschaft)
FrageGruppe Fragegruppe Attribut Hauptdiagnose
FrageKontext Beschreibung des Kon-texts in Form von Fall-gruppenNRn
Menge der FallgruppenNRn 012
FrageText Natürlichsprachliche Formulierung
alphanumerisch Gibt es einen Zusammenhang zwischen Verweildauer und Alter?
Tabelle 46: Attribute des Objekttyps KD-Frage.
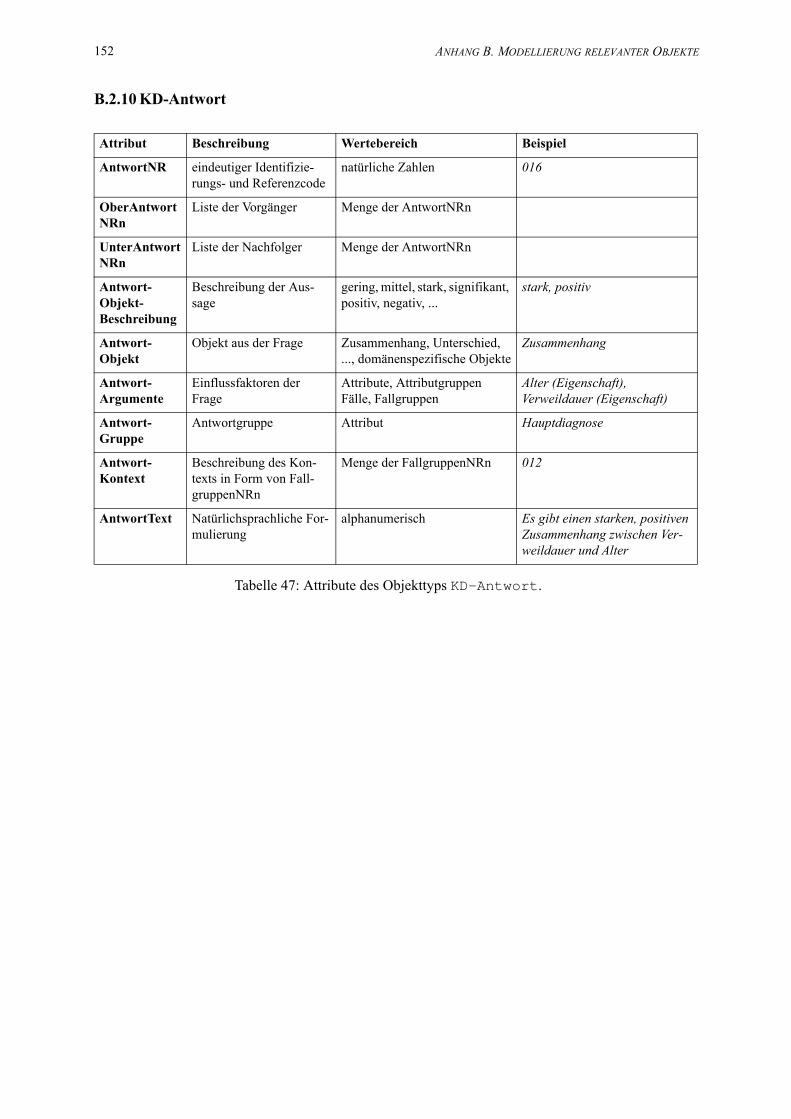
152 ANHANG B. MODELLIERUNG RELEVANTER OBJEKTE
B.2.10 KD-Antwort
Attribut Beschreibung Wertebereich Beispiel
AntwortNR eindeutiger Identifizie-rungs- und Referenzcode
natürliche Zahlen 016
OberAntwortNRn
Liste der Vorgänger Menge der AntwortNRn
UnterAntwortNRn
Liste der Nachfolger Menge der AntwortNRn
Antwort-Objekt-Beschreibung
Beschreibung der Aus-sage
gering, mittel, stark, signifikant, positiv, negativ, ...
stark, positiv
Antwort-Objekt
Objekt aus der Frage Zusammenhang, Unterschied, ..., domänenspezifische Objekte
Zusammenhang
Antwort-Argumente
Einflussfaktoren der Frage
Attribute, Attributgruppen Fälle, Fallgruppen
Alter (Eigenschaft),Verweildauer (Eigenschaft)
Antwort-Gruppe
Antwortgruppe Attribut Hauptdiagnose
Antwort-Kontext
Beschreibung des Kon-texts in Form von Fall-gruppenNRn
Menge der FallgruppenNRn 012
AntwortText Natürlichsprachliche For-mulierung
alphanumerisch Es gibt einen starken, positiven Zusammenhang zwischen Ver-weildauer und Alter
Tabelle 47: Attribute des Objekttyps KD-Antwort.

ANHANG C ALLGEMEINE MODELLIERUNG DER WISSENSBASIS
Die Modularisierung der Wissensbasis erfolgte in der ersten Dimension bezüglich des Gradesder Spezialisierung des Wissens. Dabei unterscheiden wir zwischen:
• Allgemeinem Wissen,• Domänenspezifischem Wissen und• Unternehmens- bzw. anwenderspezifischem Wissen.In der zweiten Dimension wurden die modellierten Objekte für die Modularisierung ver-
wendet:• Begriffswissen: Wissen über Begriffe und Gruppenbildungen.• Methoden- und Algorithmenwissen: Wissen, das benötigt wird, um Fragen auf Data-
Mining-Anfragen abzubilden.• Fragewissen: Wissen über die Formulierung von Fragen durch Endbenutzer.• Antwortwissen: Wissen über die Formulierung von Antworten auf die Fragen der End-
benutzer.• Interessantheitswissen: Wissen über die Messung einzelner Facetten der Interessantheit
(siehe [Mül98]).• Expertenwissen: Wissen, das bei den Experten bereits a priori vorhanden ist.• Datenwissen: Wissen über Charakteristika der zu analysierenden Daten.• Work-Flow-Wissen: Wissen über den Analyseprozess.• Algorithmenimplementierungswissen: Wissen, das benötigt wird, um DM-Anfragen
auf DM-System-Anfragen abzubilden.• Antwortwissen: Wissen, das benötigt wird, um DM-Anfragen in KD-Antworten zu
transformieren.

154 ANHANG C. ALLGEMEINE MODELLIERUNG DER WISSENSBASIS
Tabelle 48 beschreibt die wichtigsten Objekte der Wissensbasis und ordnet sie mit Hilfe derbeiden Modularisierungsdimensionen ein.
Allgemein Domänenspezifisch Unternehmensspezifisch
Begriffe • Postleitzahlen• Orte• Nationen• Kalender
Gruppenbildungen:• PLZ – Ort – Bezirk –
Bundesland• Nation – Nationengrup-
pe• Datum – Wochentag,
Feiertag• Datum – Zeitintervall
(Urlaubszeit, ...)
• Diagnosen• Medizinische Leistun-
gen• Funktionsleistungen• Kostensträger• Aufnahmeart• Aufnahmetyp• Entlassungsart
Gruppenbildungen:• Alter – Altersgruppe• Diagnose – Diagnose-
kategorie• Medizinische Einzel-
leistung – Gruppierung nach Unterorganen – Gruppierung nach Or-ganen – Gruppierung nach Art (therapeu-tisch, diagnostisch), Gruppierung nach OP (operativ vs. nicht ope-rativ)
• Funktionsleistungen – FL-Unterkapitel – FL-Kapitel – FL-Hauptka-pitel
• Abteilungsfunktions-codes
• Krankenanstalten
Methoden und Algorithmen
• Methoden (Assoziati-onsregeln, Entschei-dungsbäume, ...)
• Algorithmen (C4.5, ...)• Anwendbarkeitsbedingun-
gen, Ergebniseigen-schaften
• Benötigte Vorverarbei-tungsschritte
• Parametrisierung von Methoden
• Hinweise zur Ergebnis-interpretation (statisti-sche Fallen, Signifi-kanzniveaus, Schein-korrelationen)
• Syntax von DMAQL (Data Mining Query Language)
• Methoden (Episodena-nalyse, Standardberei-che, ...)
• Anwendbarkeitsbedingun-gen, Ergebniseigen-schaften
• Benötigte Vorverarbei-tungsschritte
• Parametrisierung von Methoden
• Hinweise zur Ergebnis-interpretation (statisti-sche Fallen, Signifi-kanzniveaus, Schein-korrelationen)
• Erweiterung von DMQL für domänen-spezifische Methoden
• Präferenzen von Me-thoden
Tabelle 48: Modularisierung des Wissens.

155
Fragen • KDQL Syntax• Fragetypen• Frageobjekte (Zusam-
menhang, Unterschied, Gemeinsamkeit, Verän-derung)
• Verfeinerung von Fra-gen (Konzepthierarchi-en)
• Standardfragen
• Frageobjekte, d.h. Do-mänenobjekte (Kom-plikationen, Dokumen-tationsqualität, Stan-dards)
• Verfeinerung domä-nenspezifischer Frage-objekte
• Standardfragen
• Standardfragen
Antworten • KDAL Syntax• Abstraktion von Ant-
worten (Konzepthierar-chien)
• Antwortobjekte• Abstraktion domänen-
spezifischer Antwort-objekte
Interessantheit • Validität• Neuheit• Nützlichkeit• Verständlichkeit• Filterung und Sortie-
rung von Data-Mining-Ergebnissen auf der Basis der Facettenbe-wertungen
• Validität• Neuheit• Nützlichkeit• Verständlichkeit• Filterung und Sortie-
rung von Data-Mining-Ergebnissen auf der Basis der Facettenbe-wertungen
Expertenwissen • Trivialitäten • Trivialitäten • Hypothesen über Kom-plikationen
• Hypothesen über Do-kumentationsqualität
• Hypothesen über Stan-dards
Datenwissen • Standardattribute (Wohnort, Alter)
• Standardeigenschaften der Attribute (Daten-typ, Skalentyp, ...)
• Gruppierung von Wer-tebereichen (Quantils-bildung, ...)
• Standardattribute (Hauptdiagnose, Ver-weildauer)
• Standardeigenschaften der Attribute (Daten-typ, Skalentyp, ...)
• Regeln für die Abbil-dung der Attribute auf die Standardattribute
Tabelle 48: Modularisierung des Wissens.

156 ANHANG C. ALLGEMEINE MODELLIERUNG DER WISSENSBASIS
Abbildung 53 stellt stellvertretend für die anderen Module die Modellierung der Datenbankfür die Verwaltung des allgemeinen Wissens über Data-Mining-Methoden und -Algorithmendar.
Work-Flow • lokale Strategien des Vorgehens (erst Asso-ziationsregeln mit rest-riktiven Konfidenzwer-ten dann Aufweichung)
• globale Strategien des Vorgehens (univariate vor bivariaten vor mul-tivariaten Analysen).
Algorithmen-implementierun-gen
Modular strukturiert nach Toolbox:• Methodenspektrum der Toolbox• Aufrufsyntax• Übersetzung von DMAQL in die methodenspezifischen DM-System-Anfragen• Ergebnissyntax• Übersetzung der methodenspezifischen Ergebnisrepräsentation
Abbildung 53: Die Datenbankstruktur für die Modellierung des Wissensüber Data-Mining-Methoden und -Algorithmen.
Tabelle 48: Modularisierung des Wissens.
AM_MethodenKriterienWerte
PK,FK1 KriterienName
KrtierienWert
AM_Algorithmen
PK AlgorithmenName
ToolboxNameFK1,I1 MethodenName
Erklaerung
AM_AlgoKonfigurationen
PK KonfigurationenName
FK1,I1 AlgorithmenNameFK2,I2 MethodenKonfigurationenName
Erklaerung
AM_AlgoKonfigArgumente
PK,FK1,I1 KonfigurationenNamePK ArgumentPosition
SkalenTypErklaerung
AM_MethKonfigurationen
PK KonfigurationenName
FK1,I1 MethodenNameErklaerung
AM_MethKonfigArgumente
PK,FK1,I1 KonfigurationenNamePK ArgumentPosition
RolleErklaerung
AM_AlgorithmenArgumente
PK ArgumentName
ArgumentDefaultWertFK1,I1 AlgorithmenName
Optional?Hart?Priorität
AM_MethodenKriterien
PK KriterienName
FK1,I1 KriterienKlasseErklaerungOrdnungsNRHart?Bewertung
AM_Methoden
PK MethodenName
I1 OrdnungsNRFK1,I2 MethodenKlasse
DisziplinAnzAbhAttAnzUnabhAttSkalaAbhAttSkalaUnabhAttVolumenDatenDynamikDatenQualitaetDatenParametrisch?SuchStrategieKonstruktivitaetGenauigkeitExplizitheitAntwortzeitAutonomieAufgabeAnalyseStadium
AM_MethodenKlassen
PK MethodenKlasse
Erklaerung
AM_KriterienKlassen
PK KriterienKlasse
Erklaerung
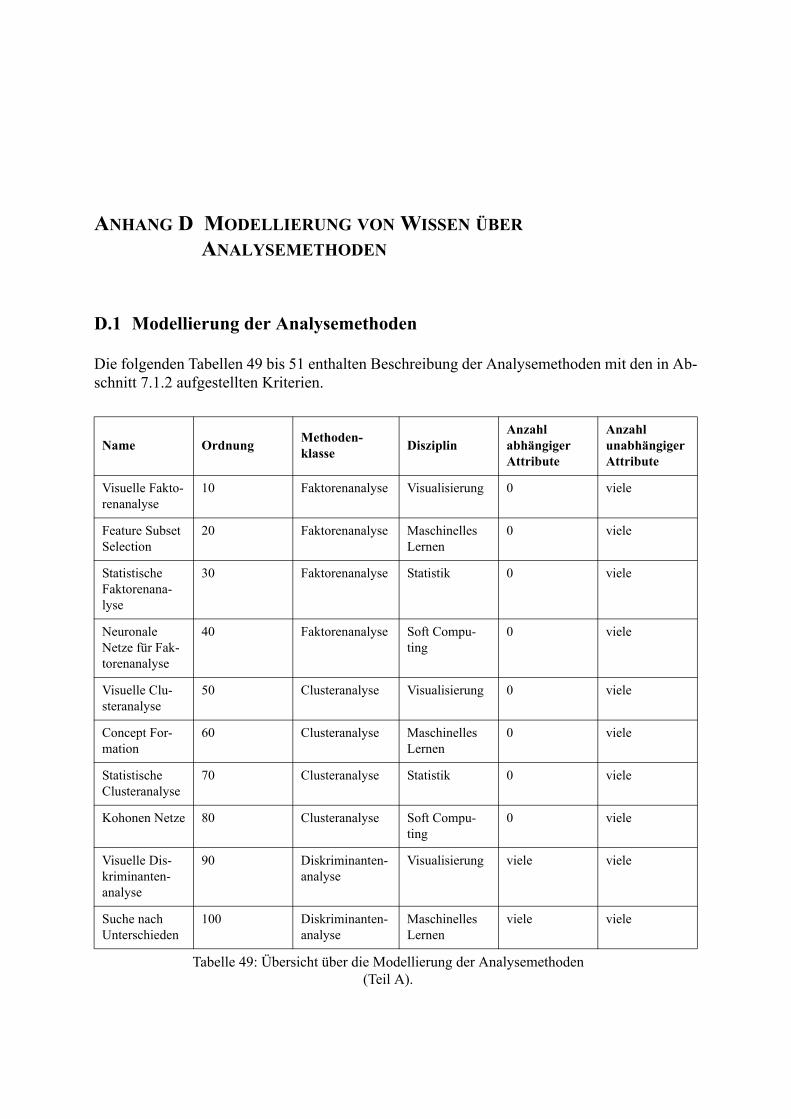
ANHANG D MODELLIERUNG VON WISSEN ÜBER ANALYSEMETHODEN
D.1 Modellierung der Analysemethoden
Die folgenden Tabellen 49 bis 51 enthalten Beschreibung der Analysemethoden mit den in Ab-schnitt 7.1.2 aufgestellten Kriterien.
Name Ordnung Methoden-klasse Disziplin
Anzahl abhängiger Attribute
Anzahl unabhängiger Attribute
Visuelle Fakto-renanalyse
10 Faktorenanalyse Visualisierung 0 viele
Feature Subset Selection
20 Faktorenanalyse Maschinelles Lernen
0 viele
Statistische Faktorenana-lyse
30 Faktorenanalyse Statistik 0 viele
Neuronale Netze für Fak-torenanalyse
40 Faktorenanalyse Soft Compu-ting
0 viele
Visuelle Clu-steranalyse
50 Clusteranalyse Visualisierung 0 viele
Concept For-mation
60 Clusteranalyse Maschinelles Lernen
0 viele
Statistische Clusteranalyse
70 Clusteranalyse Statistik 0 viele
Kohonen Netze 80 Clusteranalyse Soft Compu-ting
0 viele
Visuelle Dis-kriminanten-analyse
90 Diskriminanten-analyse
Visualisierung viele viele
Suche nach Unterschieden
100 Diskriminanten-analyse
Maschinelles Lernen
viele viele
Tabelle 49: Übersicht über die Modellierung der Analysemethoden (Teil A).
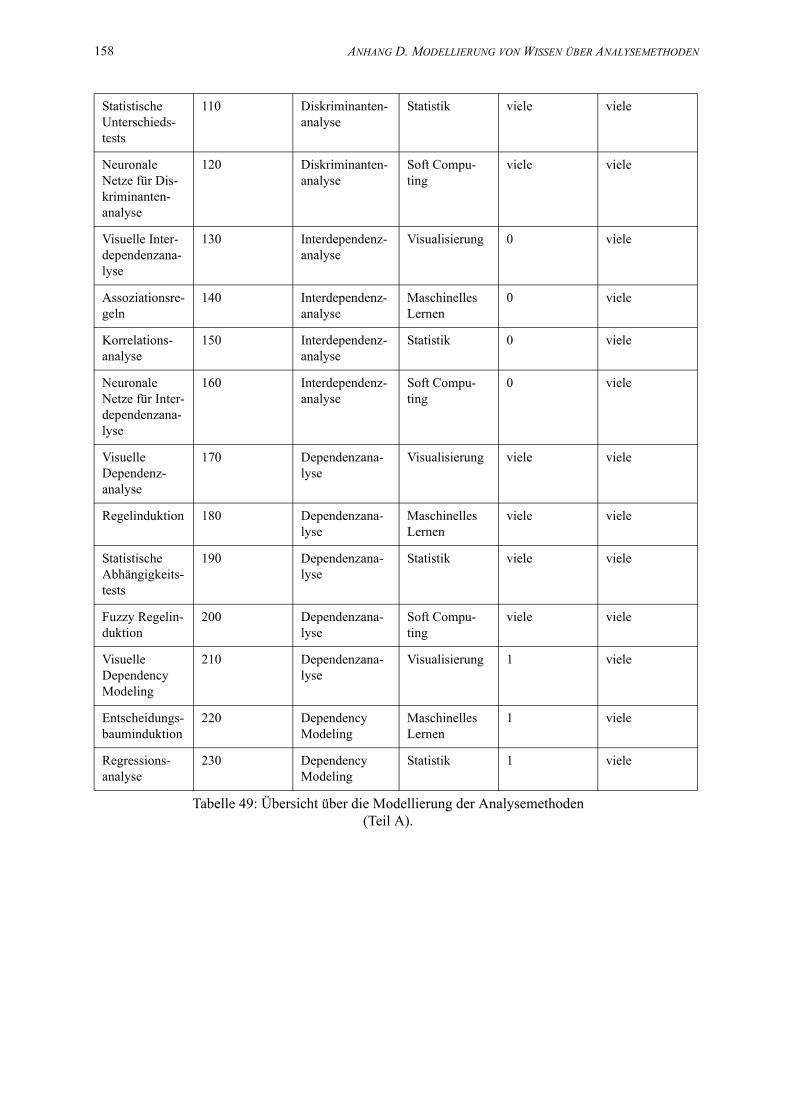
158 ANHANG D. MODELLIERUNG VON WISSEN ÜBER ANALYSEMETHODEN
Statistische Unterschieds-tests
110 Diskriminanten-analyse
Statistik viele viele
Neuronale Netze für Dis-kriminanten-analyse
120 Diskriminanten-analyse
Soft Compu-ting
viele viele
Visuelle Inter-dependenzana-lyse
130 Interdependenz-analyse
Visualisierung 0 viele
Assoziationsre-geln
140 Interdependenz-analyse
Maschinelles Lernen
0 viele
Korrelations-analyse
150 Interdependenz-analyse
Statistik 0 viele
Neuronale Netze für Inter-dependenzana-lyse
160 Interdependenz-analyse
Soft Compu-ting
0 viele
Visuelle Dependenz-analyse
170 Dependenzana-lyse
Visualisierung viele viele
Regelinduktion 180 Dependenzana-lyse
Maschinelles Lernen
viele viele
Statistische Abhängigkeits-tests
190 Dependenzana-lyse
Statistik viele viele
Fuzzy Regelin-duktion
200 Dependenzana-lyse
Soft Compu-ting
viele viele
Visuelle Dependency Modeling
210 Dependenzana-lyse
Visualisierung 1 viele
Entscheidungs-bauminduktion
220 Dependency Modeling
Maschinelles Lernen
1 viele
Regressions-analyse
230 Dependency Modeling
Statistik 1 viele
Tabelle 49: Übersicht über die Modellierung der Analysemethoden (Teil A).
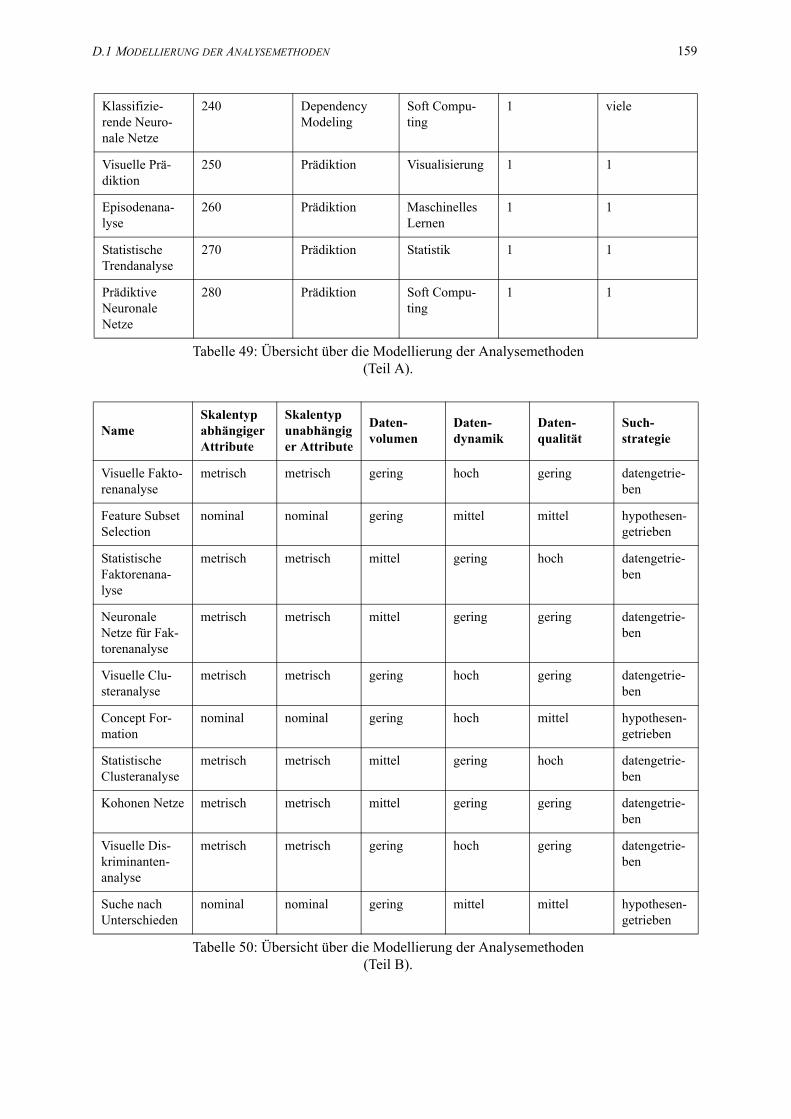
159D.1 MODELLIERUNG DER ANALYSEMETHODEN
Klassifizie-rende Neuro-nale Netze
240 Dependency Modeling
Soft Compu-ting
1 viele
Visuelle Prä-diktion
250 Prädiktion Visualisierung 1 1
Episodenana-lyse
260 Prädiktion Maschinelles Lernen
1 1
Statistische Trendanalyse
270 Prädiktion Statistik 1 1
Prädiktive Neuronale Netze
280 Prädiktion Soft Compu-ting
1 1
NameSkalentyp abhängiger Attribute
Skalentyp unabhängiger Attribute
Daten-volumen
Daten-dynamik
Daten-qualität
Such-strategie
Visuelle Fakto-renanalyse
metrisch metrisch gering hoch gering datengetrie-ben
Feature Subset Selection
nominal nominal gering mittel mittel hypothesen-getrieben
Statistische Faktorenana-lyse
metrisch metrisch mittel gering hoch datengetrie-ben
Neuronale Netze für Fak-torenanalyse
metrisch metrisch mittel gering gering datengetrie-ben
Visuelle Clu-steranalyse
metrisch metrisch gering hoch gering datengetrie-ben
Concept For-mation
nominal nominal gering hoch mittel hypothesen-getrieben
Statistische Clusteranalyse
metrisch metrisch mittel gering hoch datengetrie-ben
Kohonen Netze metrisch metrisch mittel gering gering datengetrie-ben
Visuelle Dis-kriminanten-analyse
metrisch metrisch gering hoch gering datengetrie-ben
Suche nach Unterschieden
nominal nominal gering mittel mittel hypothesen-getrieben
Tabelle 50: Übersicht über die Modellierung der Analysemethoden (Teil B).
Tabelle 49: Übersicht über die Modellierung der Analysemethoden (Teil A).
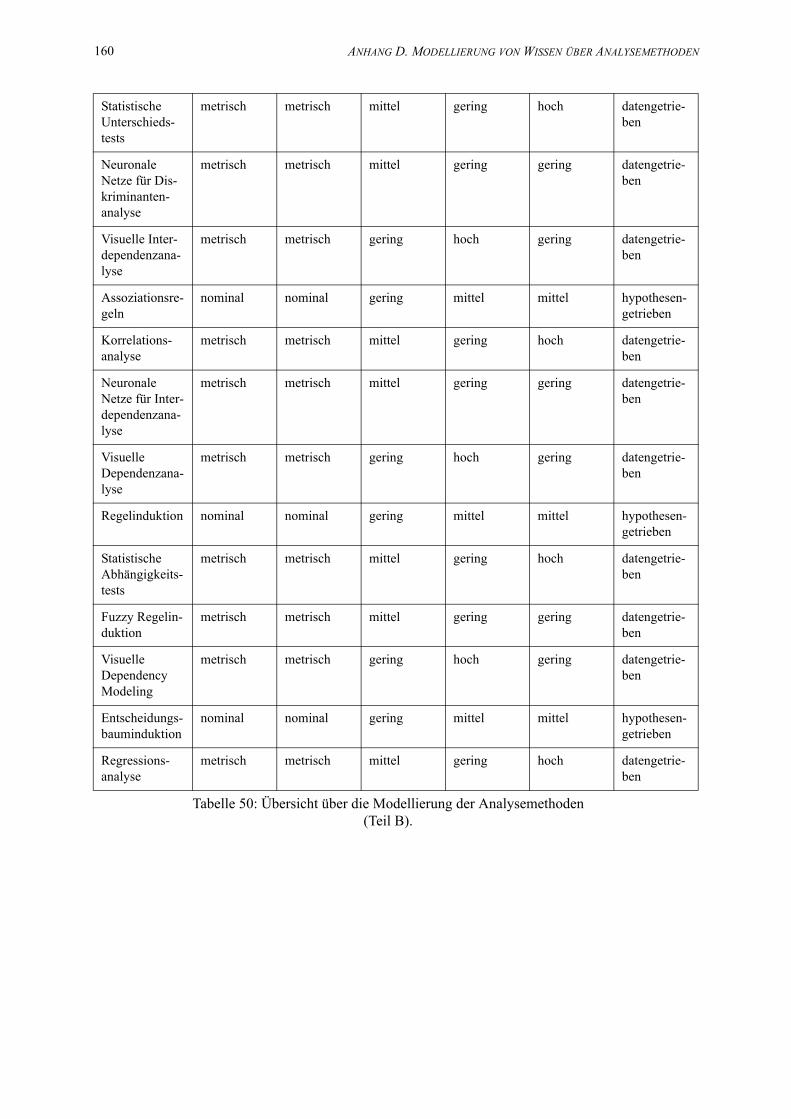
160 ANHANG D. MODELLIERUNG VON WISSEN ÜBER ANALYSEMETHODEN
Statistische Unterschieds-tests
metrisch metrisch mittel gering hoch datengetrie-ben
Neuronale Netze für Dis-kriminanten-analyse
metrisch metrisch mittel gering gering datengetrie-ben
Visuelle Inter-dependenzana-lyse
metrisch metrisch gering hoch gering datengetrie-ben
Assoziationsre-geln
nominal nominal gering mittel mittel hypothesen-getrieben
Korrelations-analyse
metrisch metrisch mittel gering hoch datengetrie-ben
Neuronale Netze für Inter-dependenzana-lyse
metrisch metrisch mittel gering gering datengetrie-ben
Visuelle Dependenzana-lyse
metrisch metrisch gering hoch gering datengetrie-ben
Regelinduktion nominal nominal gering mittel mittel hypothesen-getrieben
Statistische Abhängigkeits-tests
metrisch metrisch mittel gering hoch datengetrie-ben
Fuzzy Regelin-duktion
metrisch metrisch mittel gering gering datengetrie-ben
Visuelle Dependency Modeling
metrisch metrisch gering hoch gering datengetrie-ben
Entscheidungs-bauminduktion
nominal nominal gering mittel mittel hypothesen-getrieben
Regressions-analyse
metrisch metrisch mittel gering hoch datengetrie-ben
Tabelle 50: Übersicht über die Modellierung der Analysemethoden (Teil B).
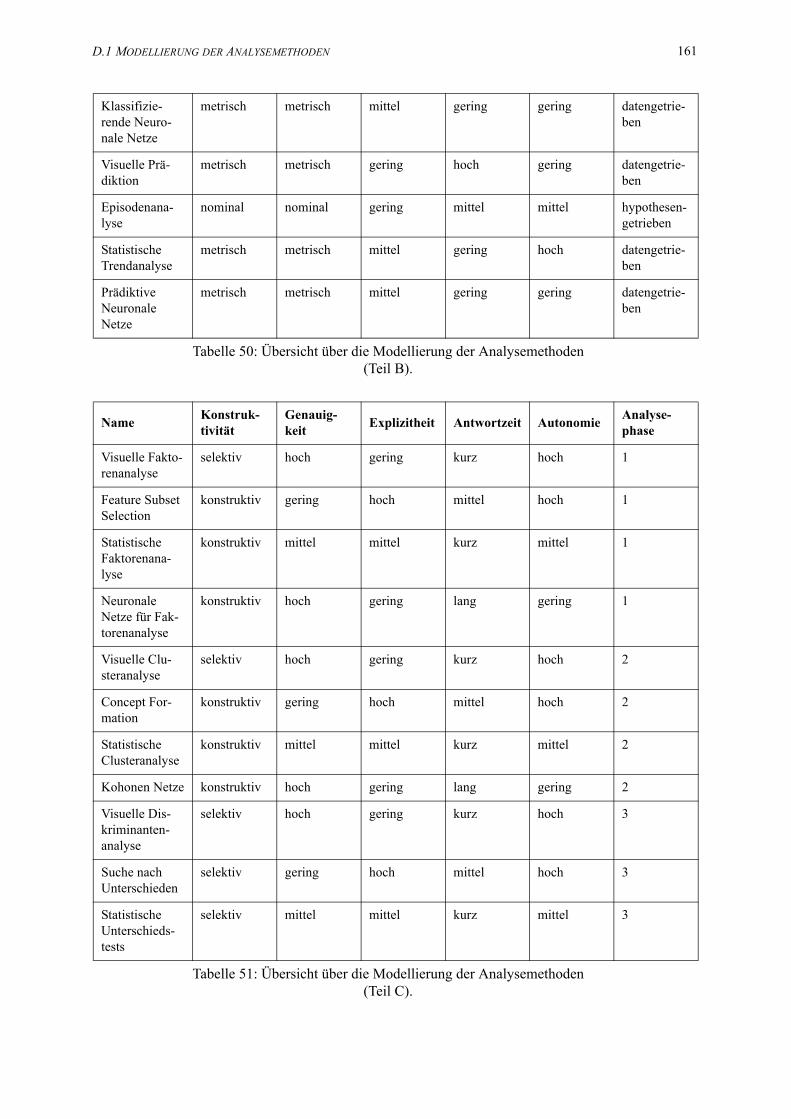
161D.1 MODELLIERUNG DER ANALYSEMETHODEN
Klassifizie-rende Neuro-nale Netze
metrisch metrisch mittel gering gering datengetrie-ben
Visuelle Prä-diktion
metrisch metrisch gering hoch gering datengetrie-ben
Episodenana-lyse
nominal nominal gering mittel mittel hypothesen-getrieben
Statistische Trendanalyse
metrisch metrisch mittel gering hoch datengetrie-ben
Prädiktive Neuronale Netze
metrisch metrisch mittel gering gering datengetrie-ben
Name Konstruk-tivität
Genauig-keit Explizitheit Antwortzeit Autonomie Analyse-
phase
Visuelle Fakto-renanalyse
selektiv hoch gering kurz hoch 1
Feature Subset Selection
konstruktiv gering hoch mittel hoch 1
Statistische Faktorenana-lyse
konstruktiv mittel mittel kurz mittel 1
Neuronale Netze für Fak-torenanalyse
konstruktiv hoch gering lang gering 1
Visuelle Clu-steranalyse
selektiv hoch gering kurz hoch 2
Concept For-mation
konstruktiv gering hoch mittel hoch 2
Statistische Clusteranalyse
konstruktiv mittel mittel kurz mittel 2
Kohonen Netze konstruktiv hoch gering lang gering 2
Visuelle Dis-kriminanten-analyse
selektiv hoch gering kurz hoch 3
Suche nach Unterschieden
selektiv gering hoch mittel hoch 3
Statistische Unterschieds-tests
selektiv mittel mittel kurz mittel 3
Tabelle 51: Übersicht über die Modellierung der Analysemethoden (Teil C).
Tabelle 50: Übersicht über die Modellierung der Analysemethoden (Teil B).
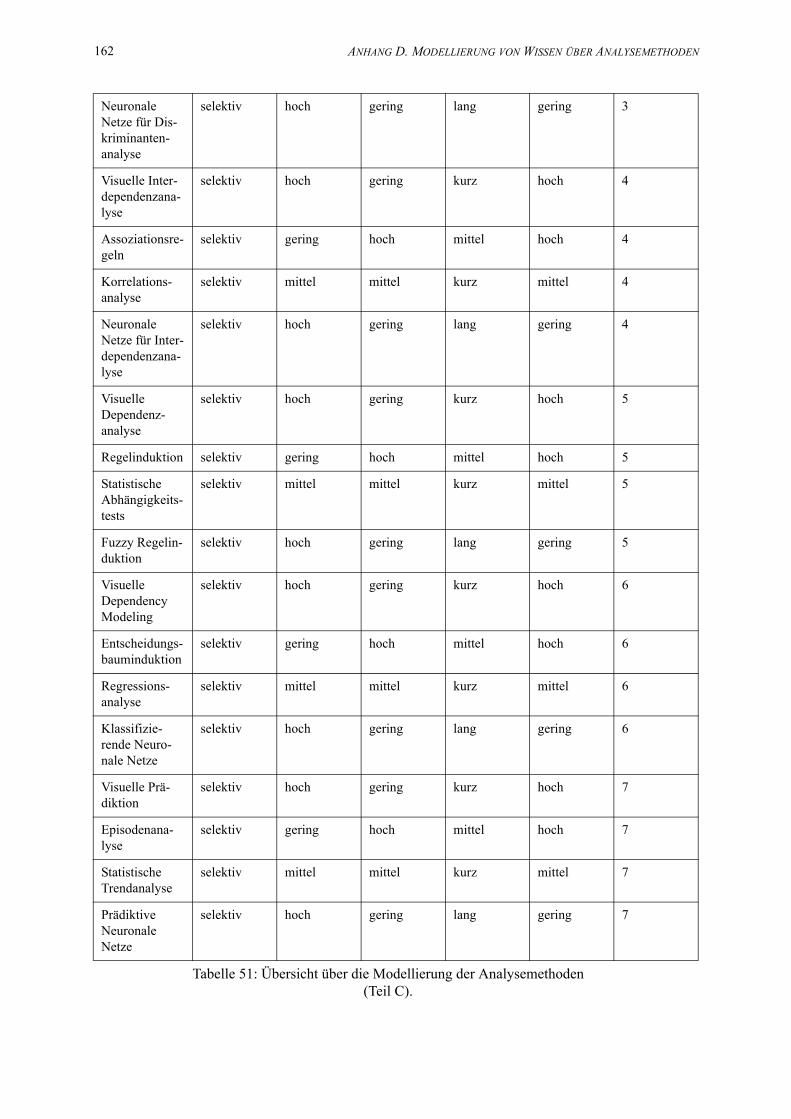
162 ANHANG D. MODELLIERUNG VON WISSEN ÜBER ANALYSEMETHODEN
Neuronale Netze für Dis-kriminanten-analyse
selektiv hoch gering lang gering 3
Visuelle Inter-dependenzana-lyse
selektiv hoch gering kurz hoch 4
Assoziationsre-geln
selektiv gering hoch mittel hoch 4
Korrelations-analyse
selektiv mittel mittel kurz mittel 4
Neuronale Netze für Inter-dependenzana-lyse
selektiv hoch gering lang gering 4
Visuelle Dependenz-analyse
selektiv hoch gering kurz hoch 5
Regelinduktion selektiv gering hoch mittel hoch 5
Statistische Abhängigkeits-tests
selektiv mittel mittel kurz mittel 5
Fuzzy Regelin-duktion
selektiv hoch gering lang gering 5
Visuelle Dependency Modeling
selektiv hoch gering kurz hoch 6
Entscheidungs-bauminduktion
selektiv gering hoch mittel hoch 6
Regressions-analyse
selektiv mittel mittel kurz mittel 6
Klassifizie-rende Neuro-nale Netze
selektiv hoch gering lang gering 6
Visuelle Prä-diktion
selektiv hoch gering kurz hoch 7
Episodenana-lyse
selektiv gering hoch mittel hoch 7
Statistische Trendanalyse
selektiv mittel mittel kurz mittel 7
Prädiktive Neuronale Netze
selektiv hoch gering lang gering 7
Tabelle 51: Übersicht über die Modellierung der Analysemethoden (Teil C).
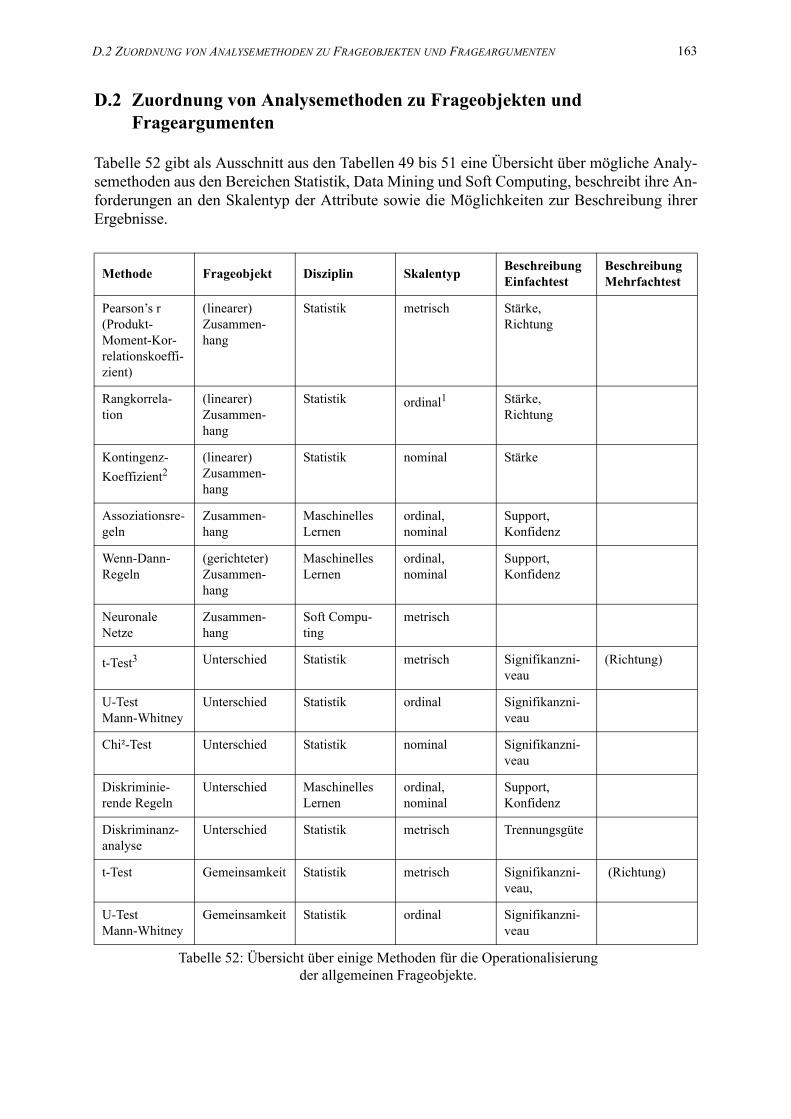
163D.2 ZUORDNUNG VON ANALYSEMETHODEN ZU FRAGEOBJEKTEN UND FRAGEARGUMENTEN
D.2 Zuordnung von Analysemethoden zu Frageobjekten und Frageargumenten
Tabelle 52 gibt als Ausschnitt aus den Tabellen 49 bis 51 eine Übersicht über mögliche Analy-semethoden aus den Bereichen Statistik, Data Mining und Soft Computing, beschreibt ihre An-forderungen an den Skalentyp der Attribute sowie die Möglichkeiten zur Beschreibung ihrerErgebnisse.
Methode Frageobjekt Disziplin Skalentyp BeschreibungEinfachtest
Beschreibung Mehrfachtest
Pearson’s r (Produkt-Moment-Kor-relationskoeffi-zient)
(linearer)Zusammen-hang
Statistik metrisch Stärke, Richtung
Rangkorrela-tion
(linearer)Zusammen-hang
Statistik ordinal1 Stärke, Richtung
Kontingenz-Koeffizient2
(linearer)Zusammen-hang
Statistik nominal Stärke
Assoziationsre-geln
Zusammen-hang
Maschinelles Lernen
ordinal, nominal
Support, Konfidenz
Wenn-Dann-Regeln
(gerichteter) Zusammen-hang
Maschinelles Lernen
ordinal,nominal
Support, Konfidenz
Neuronale Netze
Zusammen-hang
Soft Compu-ting
metrisch
t-Test3 Unterschied Statistik metrisch Signifikanzni-veau
(Richtung)
U-Test Mann-Whitney
Unterschied Statistik ordinal Signifikanzni-veau
Chi²-Test Unterschied Statistik nominal Signifikanzni-veau
Diskriminie-rende Regeln
Unterschied Maschinelles Lernen
ordinal, nominal
Support, Konfidenz
Diskriminanz-analyse
Unterschied Statistik metrisch Trennungsgüte
t-Test Gemeinsamkeit Statistik metrisch Signifikanzni-veau,
(Richtung)
U-Test Mann-Whitney
Gemeinsamkeit Statistik ordinal Signifikanzni-veau
Tabelle 52: Übersicht über einige Methoden für die Operationalisierungder allgemeinen Frageobjekte.
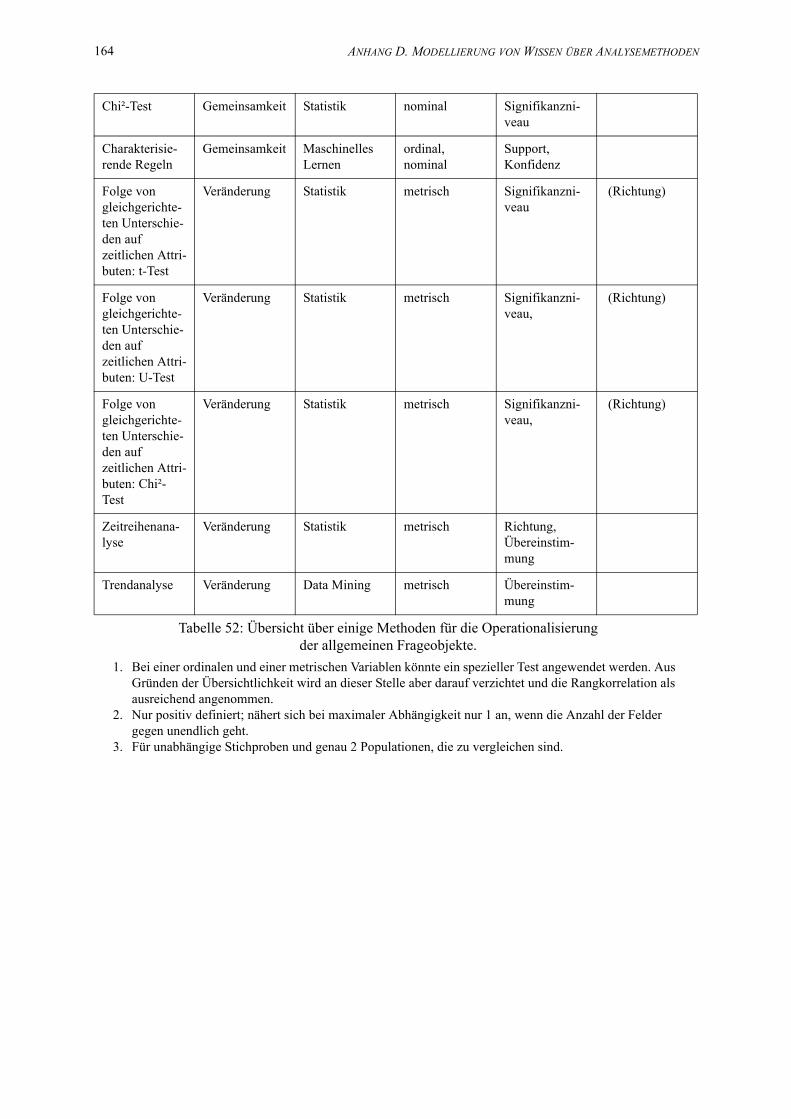
164 ANHANG D. MODELLIERUNG VON WISSEN ÜBER ANALYSEMETHODEN
Chi²-Test Gemeinsamkeit Statistik nominal Signifikanzni-veau
Charakterisie-rende Regeln
Gemeinsamkeit Maschinelles Lernen
ordinal, nominal
Support, Konfidenz
Folge von gleichgerichte-ten Unterschie-den auf zeitlichen Attri-buten: t-Test
Veränderung Statistik metrisch Signifikanzni-veau
(Richtung)
Folge von gleichgerichte-ten Unterschie-den auf zeitlichen Attri-buten: U-Test
Veränderung Statistik metrisch Signifikanzni-veau,
(Richtung)
Folge von gleichgerichte-ten Unterschie-den auf zeitlichen Attri-buten: Chi²-Test
Veränderung Statistik metrisch Signifikanzni-veau,
(Richtung)
Zeitreihenana-lyse
Veränderung Statistik metrisch Richtung, Übereinstim-mung
Trendanalyse Veränderung Data Mining metrisch Übereinstim-mung
1. Bei einer ordinalen und einer metrischen Variablen könnte ein spezieller Test angewendet werden. Aus Gründen der Übersichtlichkeit wird an dieser Stelle aber darauf verzichtet und die Rangkorrelation als ausreichend angenommen.
2. Nur positiv definiert; nähert sich bei maximaler Abhängigkeit nur 1 an, wenn die Anzahl der Felder gegen unendlich geht.
3. Für unabhängige Stichproben und genau 2 Populationen, die zu vergleichen sind.
Tabelle 52: Übersicht über einige Methoden für die Operationalisierungder allgemeinen Frageobjekte.

165D.3 VERSPRACHLICHUNG VON BESCHREIBUNGSMAßEN
D.3 Versprachlichung von Beschreibungsmaßen
WahrheitswerteWahrheitswerte sind von der Übersetzung etwas schwierig zu handhaben, insbesondere weildie diskrete Interpretation von (absolut) wahr und falsch hinzukommt. Irrtumswahrscheinlich-keiten von <1% können bei Antworten auf gewöhnliche Fragestellungen von wahr bzw. falschtoleriert werden können. Genauere Anforderungen bei bestimmten Anwendungen sind denk-bar.
Wahrheitswert Übersetzung
0,00 - 0,011
1. Zur Vereinfachung der Tabellen wird außer Acht gelassen, dass sich die infinite-simale Grenze bei reellen Zahlen über-schneidet, d.h. es können Intervalle [0;0.5] sowie [0.5;1] innerhalb der gleichen Tabelle auftreten. Da die Wahrscheinlich-keit, die Intervallgrenze zu treffen gleich Null ist, ist diese Problematik eher von theoretischem Interesse und wird hier ignoriert. Tatsächlich wird der Grenzwert bei der Implementierung zu einem angren-zenden Intervall beliebig hinzugenommen.
falsch
0,01 - 0,10 sehr unwahrscheinlich
0,10 - 0,30 unwahrscheinlich
0,30 - 0,50 wenig wahrscheinlich
0,50 - 0,70 wahrscheinlich
0,70 – 0,90 sehr wahrscheinlich
0,90 - 0,99 außerordentlich wahrscheinlich
0,99 - 1,00 wahr
Tabelle 53: Sprachliche Ausdrücke für Wahrheitswerte (nach [Käp02]).

166 ANHANG D. MODELLIERUNG VON WISSEN ÜBER ANALYSEMETHODEN
InteressantheitEinige Aspekte der Interessantheit werden im KDA durch Fließkommawerte im Intervall [0;1]repräsentiert. Tabelle 54 zeigt eine Übersetzung der Interessantheitswerte in sprachliche Aus-drücke.
HäufigkeitswerteHäufigkeitswerte befinden sich im gleichen Intervall wie Wahrheitswerte, jedoch ist die Inter-pretation zeitlicher Art. Je nach Fragestellung muss diese Ausdrucksweise in der entsprechen-den Antwort berücksichtigt werden. Tabelle 55 zeigt die Übersetzung von Häufigkeitswertenin sprachliche Ausdrücke.
KorrelationsmaßeKorrelationsmaße sind wieder ähnlich zu Wahrheitswerten, jedoch beträgt das gültige Intervallder Werte hier [-1;1]. Die Interpretation erfolgt als Zusammenhang, der die EigenschaftenStärke und Richtung besitzt. Wie in Abschnitt 6.2.2 erwähnt, erfolgt die Beschreibung vonKorrelationsmaßen, wie Pearson’s r, über die in Tabelle 56 dargestellten sprachlichen Ausdrü-cke.
SignifikanzFür statistische Hypothesen, bei denen das Ziel der Untersuchung das Signifikanzniveau bzw.die Irrtumswahrscheinlichkeit ist, mit der die Hypothese nachgewiesen werden kann, verwen-den wir die in Tabelle 57 aufgeführte Beschreibung der Irrtumswahrscheinlichkeit α.
Normierte GrößenIm Gegensatz zu der direkten Ablesbarkeit der obigen Werte, müssen normierte Größen erstvorverarbeitet werden. Bei der relativen Normierung wird davon ausgegangen, dass die betrof-fene Größe normalverteilt vorliegt. Daher werden zunächst der empirische Mittelwert und die
Interessantheit Übersetzung
0,00 - 0,10 uninteressant
0,10 - 0,30 wenig interessant
0,30 - 0,50 interessant
0,50 - 0,85 sehr interessant
0,85 - 1,00 außerordentlich interessant
Tabelle 54: Sprachliche Ausdrücke für Interessantheitswerte (nach [Käp02]).
Häufigkeit Übersetzung
0,00 - 0,10 sehr selten
0,10 - 0,30 selten
0,30 - 0,50 häufig
0,50 - 0,85 sehr häufig
0,85 - 1,00 außerordentlich häufig
Tabelle 55: Sprachliche Ausdrücke für Häufigkeitswerte (nach [Käp02]).

167D.3 VERSPRACHLICHUNG VON BESCHREIBUNGSMAßEN
empirische Standardabweichung aus der vorliegenden Gesamtheit der Daten durch Gleichung22 berechnet.
(22)
Zur Normierung wird nun vom entsprechenden Messwert x zuerst der Mittelwert subtrahiertund schließlich wird durch die Standardabweichung (siehe Gleichung 23) dividiert. Es entstehteine standardnormalverteilte Zufallsgröße.
(23)
Durch die Fehlerfunktion, also das Integral der Normalverteilung, wird die standardnormal-verteilte Zufallsgröße in eine gleichverteilte Zufallsgröße zwischen [0;1] transformiert. Für dieTransformation erhält man schließlich die in Gleichung 24 gezeigte Gleichung.
(24)
Korrelation Übersetzung
-1.00 - -0.90 sehr stark, negativ
-0.90 - -0.70 stark, negativ
-0.70 - -0.50 mittel, negativ
-0.50 - -0.20 gering, negativ
-0.20 - 0.00 sehr gering, negativ
0.00 - 0.20 sehr gering, positiv
0.20 - 0.50 gering, positiv
0.50 - 0.70 mittel, positiv
0.70 - 0.90 stark, positiv
0.90 - 1.00 sehr stark, positiv
Tabelle 56: Sprachliche Ausdrücke für Korrelationsmaße (nach [Wit91]).
Wertebereich Beschreibung
5% - 100% nicht signifikant
1% - 5% signifikant
0,1% - 1% sehr signifikant
0% - 0,1% höchst signifikant
Tabelle 57: Sprachliche Ausdrücke für Maße der Irrtumswahrscheinlichkeit (nach [Wit91]).
∑=
=n
iix
nm
1
1
( )∑=
−−
=n
ii mx
ns
1
22
11
−=′
smxx i
i erf

168 ANHANG D. MODELLIERUNG VON WISSEN ÜBER ANALYSEMETHODEN
Für diese gleichverteilte Zufallsgröße kann schließlich wieder eine Versprachlichung durcheine Tabelle vorgenommen werden.
Die in diesem Abschnitt vorgestellten Übersetzungen sind in den XML-Definitionen derzugehörigen Skalentypen eingetragen. Dadurch kann nicht nur die sprachliche Übersetzung ei-nes bestimmten Skalentyps herausgesucht werden, es können auch neue Skalentypen ohneVeränderungen am Code des KDA hinzugefügt werden. Für Details hierzu verweisen wir auf[Käp02].
Normalmaß Übersetzung
0,00 - 0,10 sehr klein
0,10 - 0,30 klein
0,30 - 0,40 etwas klein
0,40 - 0,60 normal
0,60 - 0,70 etwas groß
0,70 - 0,90 groß
0,90 - 1,00 sehr groß
Tabelle 58: Sprachliche Ausdrücke für normierte Größen (nach [Käp02]).

LITERATURVERZEICHNIS
[Ada97] Adam, N. R., Gangopadhyay, A.: A Form-Based Natural Language Front-End to aCIM Database, IEEE Transactions on Knowledge and Data Engineering, Vol. 9,Nr. 2, S. 238-250.
[Ado97] Adomavicius, G. et al.: Discovery of Actionable Patterns in Databases: The ActionHierarchy Approach, in Proceedings of the Third International Conference onKnowledge Discovery & Data Mining (KDD-97), AAAI Press, 1997.
[Agr93] Agrawal, R. et al.: Mining Association Rules between Sets of Items in Large Data-bases, in Proceedings of the 1993 ACM SIGMOD International Conference on Ma-nagement of Data, Washington D.C., 1993, S. 207-216.
[Agr94] Agrawal, R., Srikant, R.: Fast Algorithms for Mining Association Rules, in Bocca,J., Jarke, M. et al. (Hrsg.): 20th International Conference on Very Large Data Bases(VLDB), Santiago, Chile, Morgan Kaufmann, 1994, S. 487-499.
[Agr96] Agrawal, R. et al.: The Quest Data Mining System, in Proceedings of the 1996 In-ternational Conference on Data Mining and Knowledge Discovery (KDD'96), Port-land, Oregon, August 1996, AAAI Press, S. 244-249.
[AIA98] Applied Intelligence Atelier: Statex, Website: http://www.a-i-a.com/englishHome-Page/statexExample.html, 1998.
[Alb85] Albano, A. et al.: Galileo: A Strongly-Typed, Interactive Conceptual Language,ACM Transactions on Database Systems, Vol. 10 Nr. 2, 1985.
[And95] Androutsopoulos, I. et al.: Natural Language Interfaces to Databases – An Intro-duction, in Journal of Natural Language Engineering, Cambridge University Press,1995.
[ANS92] American National Standard Dictionary of Information Technology (ANSDIT),Website: http://www.ncits.org/tc_home/k5htm/Ansdit.htm
[Bae99] Baeza-Yates, R., Ribeiro-Neto, B.: Modern Information Retrieval, ACM Press, Ad-dison Wesley Publishing Company, Reading, Massachusetts, 1999.
[Bal96] Balzert, H.: Lehrbuch der Software-Technik – Software-Entwicklung (Band 1),Spektrum Akademischer Verlag, 1996.

170 LITERATURVERZEICHNIS
[Bal98] Balzert, H.: Lehrbuch der Software-Technik – Software-Management, Software-Qualitätssicherung, Unternehmensmodellierung (Band 2), Spektrum Akademi-scher Verlag, 1998.
[Bar92] Barclay, P.J., Kennedy, J.B.: Semantic integrity for persistent objects, Informationand Software Technology, Vol. 34 Nr. 8, 1992.
[Bäu91] Bäuerle, R., Zimmermann, Th.: Fragesätze, in: Wunderlich, D., von Stechow, A.(Hrsg.): Semantik, de Gruyter, Berlin, 1991, S. 333-348.
[Bel76] Belnap, N., Steele, T.: The Logic of Questions and Answers, Yale University, NewHaven, 1976.
[Bel85] Belnap, N., Steele, T.: Logik von Frage und Antwort, Vieweg, Braunschweig, 1985.
[Bel92] Bell, J. E., Rowe, L. A.: An Exploratory Study of Ad Hoc Query Languages to Da-tabases, in Proceedings of the 8th International Conference on Data Engineering,IEEE Computer Society Press, 1992, S. 606-613.
[Ber97] Berson, A., Smith S.: Data Warehousing, Data Mining & OLAP, McGraw-Hill,New York, 1997.
[Bib93] Bibel, W. et al.: Wissensrepräsentation und Inferenz, Vieweg, Braunschweig, 1993.
[Bis96] Bissantz, N.: Data Mining im Controlling, Dissertation, Friedrich-Alexander-Uni-versität Erlangen-Nürnberg, Erlangen, 1996.
[Bla99] Blaschka, M. et al.: An Overview of Multidimensional Data Models for OLAP,FORWISS Technical Report 1999-01, 1999.
[Bob90] Bobrow, R. J. et al.: Multiple Underlying Systems: Translating User Requests intoPrograms to Produce Answers, in Proceeding of the 28th Annual Meeting of the As-sociation for Computational Linguistics, University of Pittsburgh, Pittsburgh, Penn-sylvania, Juni 1990.
[Bor93] Bortz, J.: Statistik für Sozialwissenschaftler, Springer Verlag, Heidelberg, 1993.
[Bor00] Borgelt, Ch. et al.: Unsicheres und vages Wissen, in: Görz et al. [Gör00], S. 291-347.
[Bra94] Brazdil, P. et al.: Characterizing the Applicability of Classification AlgorithmsUsing Meta-Level Learning in: Kodratoff, Y. (Hrsg.): Proceedings of MLNet Work-shop on Industrial Applications of Machine Learning, September 1994, Dourdan,France, S. 127-146.
[Bra96] Brachman, R., Anand, T.: The Process of Knowledge Discovery in Databases: AHuman-Centered Approach, in Fayyad, U. et al. [Fay96a], S. 37-58.
[Bra98] Bray, T. et al.: Extensible Markup Language (XML) 1.0, World Wide Web Consor-tium, 1998.

171LITERATURVERZEICHNIS
[Bro01] Brown, A. et al.: A Model for W3C XML Schema, Microsoft, Hong Kong, 2001.
[Can92] Cannan, S., Otten, G.: SQL – The Standard Handbook, McGraw-Hill, Berkshire,England, 1992.
[Car86] Carlsen, F., Heuch, I.: EXPRESS – An Expert System Utilizing Standard StatisticalPackages, in Proceedings of COMPSTAT 1986, Physika-Verlag, Heidelberg, 1986.
[Cat95] Catarci, T. et al.: Visual Query Systems for Databases: A Survey, Technical ReportSI/RR-95/17, Dipartimento di Scienze dell'Informazione, Universita' di Roma „LaSapienza“, 1995.
[Caz92] Cazalens, S. et al.: Intelligent Access to Data and Knowledge Bases via User’s To-pics of Interest, Elsevier Science Publishers B. V., Amsterdam, 1992.
[Cen87] Cendrowska, J.: PRISM: an algorithm for inducing modular rules, InternationalJournal of Man-Machine Studies, Vol. 27, 1987, S. 349-370.
[Cer94] Cercone, N. et al.: The SystemX Natural Language Interface: Design, Implementa-tion and Evaluation, Centre for Systems Science, Simon Fraser University, Burn-aby, British Columbia, 1994.
[Cha00a] Chapman, P. et al.: CRISP-DM 1.0 – Step-by-step data mining guide, CRISP-DMConsortium, August 2000.
[Cha00b] Chai, J. et al.: Comparative Evaluation of a Natural Language Dialog Based Systemand a Menu Driven System for Information Access: A Case Study, Proceedings ofthe International Conference on Multimedia Information Retrieval (RIAO 2000),April, 2000.
[Cod70] Codd, E. F.:, A relational model of data for large shared data banks, Communica-tions of the ACM, Vol. 13 Nr. 6, Juni 1970.
[Cod93] Codd, E. F. et al.: Providing OLAP to user-analysts: An IT mandate, Technical re-port, E. F. Codd & Associates, 1993.
[Cra92] Craw, S. et al.: CONSULTANT: Providing Advice for the Machine Learning Tool-box, in: Bramer, M., Milne, R. (Hrsg.): Research and Development in Expert Sy-stems, 1992, S. 5-23.
[CRC02] Communications Research Centre: CHAT (Conversational Hypertext Access Tech-nology), Ottawa, Kanada, Website: http://debra.dgbt.doc.ca/chat, 2002.
[CRI01] CRISP-DM Consortium: The CRISP-DM Process Model, Website: http://www.crisp-dm.org, 2001.
[Dat87] Date, C. J.: A Guide to the SQL Standard, Addison-Wesley Publishing Company,Reading, Massachusetts, 1987.

172 LITERATURVERZEICHNIS
[Dea89] Dearle, A. et al.: Napier88 – a database programming language, Proceedings ofDBPL, 1989.
[Dem96] Demers, N.: A Lexicalist Approach to Natural-Language Database Front-Ends, Si-mon Fraser University, April 1999.
[Den95] Dennebouy, Y. et al.: SUPER: Visual Interfaces for Object+Relationship Data Mo-dels, Journal of Visual Languages and Computing, Vol. 6, Nr. 1, 1995, S. 73-99.
[Deu98] Deutsch, A. et al.: XML-QL: A Query Language for XML – Submission to the WorldWide Web Consortium 19-August-1998, Website: http//www.w3.org/TR/NOTE-xml-ql, August 1998.
[DIN91] DIN ISO 9126 – Informationstechnik – Beurteilen von Softwareprodukten, Quali-tätsmerkmale und Leitfaden zu deren Verwendung, 1991.
[Die93] Dieterich, H. et al.:. State of the Art in Adaptive User Interfaces, in: Schneider-Huf-schmidt et al. [Sch93], S. 13-48.
[Doa95] Doan, D. et al.: A Multi-Pradigm Query Interface to an Object-Oriented Database,Interacting with Computers, Vol. 7, Nr. 1, 1995, S. 25-47.
[Don92] Donabedian, A.: The Role of Outcomes in Quality Assessment and Assurance, Qua-lity Review Bulletin, Vol. 18, Nr. 11, November 1992, S. 356-360.
Egg97] Egg, M., Feldhaus, A.: Syntax and Semantics of Complex an Ambiguous wh-Que-stions, in Proceedings of the 2nd International Workshop on Computational Seman-tics, Tilburg, 1997.
[Eic89] Eichler, W., Bünting, K.-D.: Deutsche Grammatik, athenäum, Frankfurt am Main,1989.
[Enc97] Encarnação, M.: Concept and realization of intelligent user support in interactivegraphics applications, Dissertation, Eberhard-Karls-Universität zu Tübingen, Tü-bingen, 1997.
[Eng96] Engels, R.: Planning tasks for Knowledge Discovery in Databases; PerformingTask-Oriented User-Guidance, in Proceedings of the 2nd International. ConferenceOn Knowledge Discovery in Databases, American Association for Artificial Intel-ligence, 1996.
[Eng97a] Engels, R. et al: Providing User-Support in Performing Knowledge Discovery inDatabases, in Proceedings of AAAI Spring Symposium on Artificial Intelligence inKnowledge Management (AIKM'97), 1997, S. 38-39.
[Eng97b] Engels, R. et al: Providing User Support for Developing Knowledge Discovery Ap-plications: A Midterm Report, Künstliche Intelligenz, Vol. 12, Nr. 1, 1998, S. 40-45.

173LITERATURVERZEICHNIS
[Eng97c] Engels, R. et al.: A Guided Tour through the Data Mining Jungle, in: Pregibon, D.et al. (Hrsg.): Proceedings of The Third International Conference on KnowledgeDiscovery and Data Mining (KDD-97), AAAI Press, 1997.
[Eng98] Engels, R., Theusinger, C.: Using a Data Metric for Preprocessing Advice for DataMining Applications, in Proceedings of the European Conference on Artificial In-telligence, 1998, S. 430-434.
[Eng99] Engels, R.: Component-Based User Guidance in Knowledge Discovery and DataMining, Infix, Sankt Augustin, 1999.
[Fay96a] Fayyad, U. et al. (Hrsg.): Advances in Knowledge Discovery and Data Mining,AAAI Press, Menlo Park, Kalifornien, 1996
[Fay96b] Fayyad, U. et al.: From Data Mining To Knowledge Discovery: An Overview, in:Fayyad et al. [Fay96a], S. 1-34.
[Fis94] Fischer, D.: Gestaltung wissensbasierter Systeme auf der Grundlage betrieblicherEntscheidungssituationen, Göttinger Wirtschaftsinformatik, Band 9, Unitext-Ver-lag, Göttingen, 1994.
[Fre18] Frege, G.: Der Gedanke. Eine logische Untersuchung, in Beiträge zur Philosophiedes deutschen Idealismus, Vol. 1, 1918, S. 58-77.
[Fuc96] Fuchs, N. E. et al.: Attempto Controlled English (ACE), in CLAW96: The First In-ternational Workshop on Controlled Language Applications, Katholieke Universi-teit Leuven, Belgien, März 1996.
[Fuh98] Fuhrmann, A.: Wie zusammengesetzt ist Bedeutung?, Arbeitspapier, FachgruppePhilosophie, Universität Konstanz, 1998.
[Gaa92] Gaasterland, T. et al.: An Overview of Cooperative Answering, in Journal of Intel-ligent Information Systems, Kluwer Academic Publishers, Vol. 1, Nr. 2, 1992, S.123-157.
[Gam95] Gama, J., Brazdil, P.: Characterization of Classification Algorithms, in: Pinto-Fer-reira, C., Mamede, N. (Hrsg.): Progress in Artificial Intelligence, 7th PortugueseConference on Artificial Intelligence, {EPIA-95), Springer-Verlag, 1995, S. 189-200.
[Gal86] Gale, W.: REX Review, in: Gale, W. (Hrsg.): Artificial Intelligence and Statistics,Addison-Wesley, 1986, S. 173-224.
[Gas93] Gastner, R.: Automatisches Programmieren von Wartungswerkzeugen für Wissens-basen, Bayerisches Forschungszentrum für Wissensbasierte Systeme, Report-Nr.FR-1993-003, Erlangen, 1993.
[Gin95] Ginzburg, J.: Interrogatives. Questions, Facts and Diaglogues, in: Lappin, S.(Hrsg.): Handbook of Contemporary Semantic Theory, Blackwell, 1995, S. 385-422.

174 LITERATURVERZEICHNIS
[Gör00] Görz, G. et al. (Hrsg.): Handbuch der Künstlichen Intelligenz, Oldenbourg VerlagMünchen, 3. Auflage, 2000.
[Gra92a] Graesser, A. C. et al.: Mechanisms that Generate Questions, in: Lauer, T. W. et al.:Questions and Information Systems, Lawrence Erlbaum Associates, Hillsdale, NewJersey, 1992, S. 167-187.
[Gra92b] Graesser, A. C. et al.: Answering Questions About Information in Databases in:Lauer, T. W. et al: Questions and Information Systems, Lawrence Erlbaum Asso-ciates, Hillsdale, New Jersey, 1992, S. 229-252.
[Gro84] Groenendijk, J., Stokhof, M.: Studies on the Semantics of Questions and the Prag-matics of Answers, Dissertation, University of Amsterdam, 1984.
[Gro98] Groenendijk, J., Stokhof, M.: Questions, in: Van Benthem, J., Ter Meulen, A.(Hrsg.): Handbook of Logic and Language, Elsevier Science Publishers B. V., Am-sterdam, 1998, S. 1055-1124.
[Ham58] Hamblin, C.: Questions, in Australasian Journal of Philosophy, Vol. 36, Nr. 3,1958, S. 159-168.
[Ham73] Hamblin, C.: Questions in Montague English, in Foundations of Language, Vol. 10,1973, S. 41-53.
[Ham81] Hammer, M., McLeod, D.: Database Description with SDM: A Semantic DatabaseModel, ACM Transactions on Database Systems, Vol. 6, Nr. 3, 1981.
[Han91] Han, J. et al.: Concept-Based Data Classification in Relational Databases, in Work-shop Notes of 1991 AAAI Workshop on Knowledge Discovery in Databases(KDD'91), Anaheim, Kalifornien, Juli 1991, S. 77-94.
[Han94] Hand, D.: Deconstructing Statistical Questions in Journal of the Royal StatisticalSociety, 1994, S. 317-356.
[Han96] Han, J. et al.: DMQL: A Data Mining Query Language for Relational Data Bases,in Proceedings of the SIGMOD Workshop on Research Issues on Data Mining andKnowledge Discovery (DMKD-96), Montreal, Canada, 1996.
[Han96] Hannig, U. (Hrsg.): Data Warehouse und Managementinformationssysteme, Schäf-fer-Poeschel Verlag, Stuttgart, 1996.
[Han97] Han, J.: OLAP Mining: An Integration of OLAP with Data Mining, Chapman &Hall, IFIP, 1997.
[Har84] Harrah, D.: The logic of Questions, in: Gabbay, D., Guenthner, F. (Hrsg.): Hand-book of Philosophical Logic, Vol. II, Kluwer, Dordrecht, 1984, S. 715-764.
[Hau86] Haux, R.: Expert Systems in Statistics, Fischer Stuttgart, 1986.

175LITERATURVERZEICHNIS
[Hau98] Hausdorf, C.: Konzeption und Realisierung eines gemischt daten- und hypothe-senorietiert arbeitenden, generischen Data-Mining-Agenten, Diplomarbeit, Fried-rich-Alexander-Universität Erlangen-Nürnberg, 1998.
[Hee00] Heeb, D.: StatiBot, Website: http://www.statibot.com., 2000.
[Hei92] Heinz, W. et al.: Comparison in NLIs – Habitability and Database Reality, in Pro-ceedings of the 10th European Conference on Artificial Intelligence (ECAI-92),Wiley Wien, 1992, S. 548-552.
[Hei94] Heinsohn, J.: ALCP: Ein hybrider Ansatz zur Modellierung von Unsicherheit in ter-mino-logischen Logiken, Dissertationen zur künstlichen Intelligenz, St. Augustin,1994.
[Hen78] Hendrix, G. et al.: Developing a Natural Language Interface to Complex Data,ACM Transactions on Database Systems, Vol. 3, Nr. 2, 1978, S. 105-147.
[Her97] Herrmann, J.: Maschinelles Lernen und Wissensbasierte Systeme, SytematischeEinführung mit praxisorientierten Fallstudien, Springer-Verlag, Berlin, 1997.
[Hie86] Hielata, P.: How to Assist an Inexerpereinced User in the Preliminary Analyses ofTime Series: First Version of the ESTES Expert System, in Proceedings of COMP-STAT 1986, Physika-Verlag, Heidelberg, 1986.
[Hog98] Hogl, O.: Konzeption und Realisierung eines Data-Mining-Front-Ends zur Konkre-tisierung von Benutzerinteressen und eines Data-Mining-Back-Ends zur Abstrakti-on von Data-Mining-Ergebnissen, Diplomarbeit, Friedrich-Alexander-UniversitätErlangen-Nürnberg, 1998.
[Hog00a] Hogl, O. et al.: The Knowledge Discovery Assistant: Making Data Mining Availablefor Business Users, in: Gunopulos, D. et al. (Hrsg.): Proceedings of the 2000 ACMSIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery(DMKD-2000), Dallas, Texas, Mai 2000, S. 96-105.
[Hog01a] Hogl, O. et al.: On Supporting Medical Quality with Intelligent Data Mining, in:Sprague, R. (Hrsg.): Proceedings of the Thirty-Fourth Annual Hawaii InternationalConference on System Sciences (HICSS-01), Maui, Hawaii, IEEE Press, Januar2001.
[Hog01b] Hogl, O. et al.: Using Questions and Interests to Guide Data Mining for MedicalQuality Management, in: Iz, P. et al. (Hrsg.): Topics in Health Information Mana-gement, Vol. 22, Nr. 1, August 2001, S. 36-50.
[Hop96] Hoppe, T.: Kriterien zur Auswahl maschineller Lernverfahren, Informatik Spek-trum, Springer Verlag, Vol. 19, 1996, S. 12-19.
[Hou93] Houtsma, M., Swami, A.: Set-oriented Mining of Association Rules, Research Re-port, RJ 9567, IBM Almaden Research Center, San Jose, Kalifornien, Oktober1993.

176 LITERATURVERZEICHNIS
[Hub97] Huber, P. J.: From Large to Huge: A Statistician’s Reactions to KDD & DM, in Pro-ceeding of the Third International Conference on Knowledge Discovery & Data Mi-ning (KDD-97), AAAI Press, 1997.
[Imi96] Imielinsky, T. et al.: DataMine: Application Programming Interface and QueryLanguage for Database Mining, in: Simoundis, E. et al. (Hrsg.): The Second Inter-national Conference on Knowledge Discovery and Data Mining, AAAI Press, Men-lo Park, Kalifornien, 1996, S. 256-261.
[Imi99] Imielinsky, T., Virmani, A.: MSQL: A Query Language for Database Mining, DataMining and Knowledge Discovery, Vol. 3, Nr. 4, 1999, S. 373-408.
[Jee03] Jeeves Solutions: JeevesOne Product Family Overview, Website, http://www.jee-vessolutions.com/products/index.asp, 2003.
[Jid86] Jida, J., Lemaire, J.: Expert Systems and Data Analysis Package Management, inProccedings of COMPSTAT 1986, Physika-Verlag, Heidelberg, 1986.
[Joh85] Johnson, T.: Natural Language Computing: The Commercial Applications, OvumLtd., London, 1985.
[Käp02] Käppel, D.: Konzeption und Realisierung einer natürlichsprachlichen Benutzer-schnittstelle für ein System zur Entdeckung von Wissen in Datenbanken, Diplomar-beit, Georg-Simon-Ohm-Fachholschule Nürnberg, 2002.
[Kea98] Keading, A.-K. et al.: The Elicitation of Problem-Solving Scenarios as new Metho-dical approach for the Knowledge Acquisition in: Jamshidi, M., de Silva, C. W.(Hrsg.): Intelligent Automation and Control, Proceeding of the World AutomationCongress (WAC’98), TSI Press, Albuquerque, 1998.
[Kle94] Klemettinen, M. et al.: Finding Interesting Rules from Large Sets of Discovered As-sociation Rules, Proceedings of the Third International Conference on Informationand Knowledge Management (CIKM'94), Maryland, ACM, 1994, S. 401-407.
[Klo00] Kloesgen, W., Zytkow, J.: Machine Discovery Terminology, Website: http://org-wis.gmd.de/explora/terms.html, Juni 2000.
[Koh97] Kohavi, R. et al.: Data Mining Using MLC++: A Machine Learning Library inC++, in International Journal on Artificial Intelligence Tools, Vol. 6, Nr. 4, 1997,S. 537-566.
[Kok00] Kokowski, R.: Konzeption und Realisierung einer Komponente zur Abbildung vonFragen in der Sprache des Endbenutzers auf Data-Mining-Anfragen für ein Systemzur Entdeckung von Wissen in Datenbanken, Diplomarbeit, Friedrich-Alexander-Universität Erlangen-Nürnberg, 2000.
[Kri00] Krifka, M.: Syntax und Semantik von Fragen und Antworten, Vorlesungsskript, WS2000/2001, Institut für deutsche Sprache und Linguistik, Humboldt-Universität zuBerlin.

177LITERATURVERZEICHNIS
[Lar84] Larson, J., Wallick, J. B.: An Interface for Novice and Infrequent Database Mana-gement System Users, AFIPS Conference Proceedings, National Computer Confe-rence, Vol. 53, 1984, S. 523-529.
[Lat89] Latocha, P.: Exploration von Aussagenräumen – Ein semantischer Ansatz, GMD-Studien Nr. 164, Gesellschaft für Mathematik und Datenverarbeitung mbH, 1989.
[Leh78] Lehnert, W.: The Process of Question Answering, Lawerence Eichbaum Associates,Hilsdale, New Jersey, 1978.
[Lin99] Lindner, G., Studer, R.: AST: Support for Algorithm Selection with a CBR Ap-proach, in Principles of Data Mining and Knowledge Discovery, 1999, S. 418-423
[Liu96] Liu, B. et al.: Finding Interesting Patterns Using User Expectations, Technical Re-port: TRA7/96, Department of Information Systems and Computer Science, Natio-nal University of Singapore, Singapur, 1996.
[Liu97] Liu, B. et al.: Using General Impressions to Analyze Discovered Classification Ru-les, American Association for Artificial Intelligence, 1997.
[Men99] Meng, F., Chu, W.: Database Query Formation from Natural Language using Se-mantic Modeling and Statistical Keyword Meaning Disambiguation, Technical Re-port CSD-TR 990003, Computer Science Department, University of California, LosAngeles, 1999.
[Meo96] Meo, R. et al.: A new sql-like operator for mining association rules, Proceedings ofthe 22nd International Conference on Very Large Data Bases (VLDB’96), Bombay,Indien, 1996, S. 122-133.
[Mic94] Michie, D. et al. (Hrsg.): Machine Learning, Neural and Statistical Classification,Ellis Horwood, Chicester, 1994.
[Mil91] Miller, J. et al.: Introduction, in: Sullivan [Sul91], S. 1-10.
[Mit96] Mittelstraß, J. (Hrsg.): Enzyklopädie Philosophie und Wissenschaftstheorie, Biblio-graphisches Institut, Mannheim, 1980.
[MLT93] MLT Consortium: Final public report Esprit II Project 2154, Technical Report,1993.
[Mül98] Müller, M.: Interessantheit bei der Entdeckung von Wissen in Datenbanken, Disser-tation, Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen, 1998.
[Mur98] Murray, N., et al.: A Framework for Describing Visual Interfaces to Databases,Journal of Visual Languages and Computing, Vol. 9, Nr. 4, 1998, S. 429-456.
[Nae87] Naeve, P., Steinecker, J.: SETUP – Statistisches Expertensystem mti TWAICE undP-STAT, Bericht Nr. 172 der Fakultät der Wirtschaftswissenschaften, UniversitätBielefeld, 1987.

178 LITERATURVERZEICHNIS
[NAG02] Numerical Algorithms Group: GLIM 4, The Generalised Linear Interactive Model-ling Package, Website: http://www.nag.co.uk/stats/GDGE_soft.asp.[Nak97]Nak-haeizadeh,G., Schnabl, A.: Development of Multi-Criteria Metrics for Evaluation ofData Mining Algorithms, in: Heckerman, D. et al. (Hrsg.): Proceedings of The ThirdInternational Conference on Knowledge Discovery and Data Mining (KDD-97),AAAI Press, 1997.
[Nak98] Nakhaeizadeh, G.; Schnabl, A.: Towards the Personalization of Algorithms Eva-luation in Data Mining, in: Agrawal, R. et al. (Hrsg.): Proceedings of The FourthInternational Conference on Knowledge Discovery and Data Mining, New York,1998, S. 289-293.
[Nau97] Nauer, E. et al.: Using of multiple data source for information filtering: first ap-proaches in the MedExplore project, in 5th DELOS Workshop on Filtering and Col-laborative Filtering, Budapest, Ungarn, November 1997.
[Nel87] Nelder, J.: AI and Generalized Linerar Modelling: An Expert System for GLIM, in:Phelps, B. (Hrsg.): Interactions in Artificial Intelligence and Statistical Methods,Gower, Aldershot, 1987.
[Nel00] Nelken, R., Nissim, F.: Querying Temporal Databases Using Controlled NaturalLanguage, Computer Science Department, The Technion, Haifa, Israel, 2000.
[Pap95] Papantonakis, A., King, P.: Syntax and Semantics of GQL, a Graphical Query Lan-guage, Journal of Visual Languages and Computing, Vol 6, 1995, S. 3-25.
[Pou90] Poulovassilis, A., King, P.: Extending the Funktional Data Model to ComputationalCompleteness, in Advances in Database Technology – EDBT’90, International Con-ference on Extending Database Technology, 1990, S. 75-91.
[Pre94] Preece, J. et al.: Human-Computer Interaction, Addison-Wesley Publishing Com-pany, Reading, Massachusetts, 1994.
[Pri55] Prior, A., Prior, M.: Erotetic logic, The Philosophical Review, Vol. 64 (1955), S.43-59.
[Pul96] Pulman, S. G.: Controlled Language for Knowledge Representation in CLAW96:Proceedings of the First International Workshop on Controlled Language Applica-tions, Katholieke Universiteit Leuven, Belgien, März 1996, S. 233-242.
[Ram90] Ram, A.: Knowledge Goals: A Theory of Interestingness, in Proceedings of theTwelfth Annual Conference of the Cognitive Science Society, Cambridge, MA, Au-gust 1990, S. 206-214.
[Ram91] Ram, A.: A theory of questions and question asking, The Journal of the LearningSciences, 1991, S. 273-318.
[Ram92] Ramos, H.: Design and Implementation of a Graphical SQL with Generic Capabi-lities, in: Cooper, R. (Hrsg.): Interfaces to Database Systems, (R. Cooper, Ed.),Springer-Verlag, Berlin, 1992, S. 74-91.

179LITERATURVERZEICHNIS
[Rui94] Ruiz, F. et al.: Evaluating a formal modelling language, in: Steels et al. (Hrsg.):Proceeding of the 8th European Knowledge Acquisition Workshop (EKAW’94),LNAI 867, Springer-Verlag, Berlin, 1994, S. 26-45.
[Sch79] Schank, R. C.: Interestingness: Controlling Inferences, Artificial Intelligence 12,North-Holland Publishing Company, 1979, S. 273-297.
[Sch97] Schmidhuber, J.: What’s Interesting?, Technical Report IDSIA-35-97, Version 1.0,IDSIA, Lugano, Schweiz, 14. Juli 1997.
[Sch93] Schneider-Hufschmidt, M. et al. (Hrsg.): Adaptive User Interfaces: Principles andPractice, North-Holland, 1993.
[Sen97] Sengupta, A., Dillon, A.: Query by Templates: A Generalized Approach for VisualQuery Formulation for Text Dominated Databases, Symposium on Advanced Di-gital Libraries (ADL-97), 1997, S. 36-47.
[She96] Shen, W.: Metaqueries for Data Mining, in: Fayyad, U. et al. [Fay96a], S.375-398.
[Shi81] Shipman, D. W.: The Functional Data Model and the Data Language, ACM Tran-sactions on Database Systems, Vol. 6, Nr. 1, März 1981, S. 140-173.
[Sma03] SmartKom: Dialogische Mensch-Technik-Interaktion durch koordinierte Analyseund Generierung multipler Modalitäten, Website: http://smartkom.dfki.de, 2003.
[Som97] Sommer, E.: Theory Restructuring, A Perspective on Design and Maintenance ofKnowledge Based Systems, Infix, St. Augustin, 1997.
[Sta02] Statistical Solutions, Inc.: SigmaStat, Website: http://www.statsol.ie/sigmastat/sig-mastat.htm.
[Sta94] Stathis, K.: How to give FAST advice, in Proceedings of the 7th Symposium and Ex-hibition on Industrial Applications of Prolog (INAP’94), Tokio, Japan, 1994.
[Sta97] Stathis, K., Sergot, M.: Knowledge-Based Front-Ends as Games, in: Liebowitz, J.(Hrsg.): Journal of Lessons Learned in Information Systems Management, Vol. 2,Nr. 1, S. 135-147, 1997.
[Ste67] Stenius, E.: Mood and language game, Synthese, Vol. 17, Nr. 3, S. 254-274.
[Ste91] von Stechow, A., Wunderlich, D. (Hrsg.): Semantik, de Gruyter, Berlin, 1991.
[Stü00] Stühlinger, W. et al.: Intelligent Data Mining for Medical Quality Management, in:Lavrac, N. et al. (Hrsg.): The Fifth Workshop on Intelligent Data Analysis in Medi-cine and Pharmacology (IDAMAP-2000), Workshop Notes of the 14th EuropeanConference on Artificial Intelligence (ECAI-2000), Berlin, August 2000.
[Sul91] Sullivan, J. W., Tyler, S. W. (Hrsg.): Intelligent User Interfaces, ACM Press, NewYork, 1991.

180 LITERATURVERZEICHNIS
[Ten83] Tennant, H. R. et al.: Usable Natural Language Interfaces through Menu-BasedNatural Language Understanding, in Proceedings of CHI’83, Conference on Hu-man Factors in Computer Systems, ACM, Boston, 1983.
[The98] Theusinger, C., Lindner, G.: Benutzerunterstützung eines KDD-Prozesses anhandvon Datencharakteristiken, 1998.
[Tho75] Thompson, F. B., Thompson, B. H.: Practical Natural Language Processing: TheREL System Prototype in: Rubinoff, M., Yovits, M. C. (Hrsg.): Advances in Com-puters, Academic Press, New York, 1975, S. 109-168.
[Tho94] Thonnat, M. et al.: Supervision of Perception Tasks for Autonomous Systems: TheOCAPI Approach, in Journal of Information Science and Technology, Vol. 3, 1994,S. 140-163.
[Tim97] Timm, T.: Konzeption und Realisierung einer graphischen Benutzerschnittstelle fürein System zur Entdeckung von Wissen in Datenbanken, Diplomarbeit, Friedrich-Alexander-Universität Erlangen-Nürnberg, 1997.
[Tyl91] Tyler, S. et al.: An Intelligent Interface Architecture for Adaptive Interaction, in:Sullivan [Sul91], S. 85-109.
[Utg89] Utgoff, P. E. et al.: Representation Problems in Machine Learning: A Proposal,COINS Technical Report 89-23, 15. März 1989.
[Usz92] Usznski M.: Machine learning toolbox, Technical Report, European EconomicCommunity, Esprit II, 1992.
[Van90] Vanderveken, D.: Meaning and Speech Acts, 2 Bände, Cambrigde University Press,Cambridge, 1990.
[Wal78] Waltz, D. L.: An English Language Question Answering System for a Large Rela-tional Database, Communications of the ACM, Vol. 27, Nr. 7, Juli 1978, S. 526-539.
[Wal85] Walther, J.: Logik der Fragen, de Gruyter, 1985.
[War82] Warren, D., Pereira, F.: An Efficient Easily Adaptable System for Interpreting Na-tural Language Queries, Computational Linguistics, Vol. 8, Nr. 3-4, Juli-Dezember1982, S. 110-122.
[Wed81] Wedekind, H.: Datenbanksysteme I – Eine konstruktive Einführung in die Daten-verarbeitung in Wirtschaft und Verwaltung, Bibliographisches Institut, Mannheim,1981.
[Wir97] Wirth, R. et al: Towards Process-Oriented Tool Support for Knowledge Discoveryin Databases, Principles of Data Mining and Knowledge Discovery, 1997, S. 243-253.

181LITERATURVERZEICHNIS
[Wit85] Wittkowski, K.: Ein Expertensystem zur Datenhaltung und Methodenauswahl fürstatistische Anwendungen, Dissertation, Universität Stuttgart, 1985.
[Wit91] Wittenberg, R.: Computerunterstützte Datenanalyse, Gustav Fischer Verlag, Stutt-gart, 1991.
[Wit99] Witten, I., Frank, E.: Data Mining – Practical Machine Learning Tools and Tech-niques with Java Implementations, Morgan Kaufmann, Oktober 1999.
[Woo72] Woods, W. A. et al.: The Lunar Science Natural Language Information System, Fi-nal Report, BBN Report 2378, Bolt Beranek and Newman Inc., Cambridge, Massa-chusetts, 1972.
[Zlo77] Zloof, M. M.: Query By Example: A Database Language., IBM Systems Journal,Vol. 16 Nr. 4, 1977.
[Zbi98] Zbigniew, W. R. et al.: Knowledge Discovery Objects an Queries in DistributedKnowledge Systems, in AISC’98, LNAI 1476, Springer-Verlag, Berlin, 1998, S.259-269.

182 LITERATURVERZEICHNIS

STICHWORTVERZEICHNIS
*-Konzept . . . . . . . . . . . . . . . . . . . . . .54, 56, 60
Aaction hierarchy . . . . . . . . . . . . . . . . . . . . . . .24actionability . . . . . . . . . . . . . . . . . . . . . . . . . .24Adäquatheit . . . . . . . . . . . . . . . . .118, 120–121Änderbarkeit . . . . . . . . . . . . . . . . .118, 120–121Anforderung
funktionale . . . . . . . . . . . . . . . . . . . . . . . .23nicht-funktionale . . . . . . . . . . . . . . . . . . .23
Anfragesprache, formale . . . . . . . . . .12–13, 18Anfragesystem, natürlichsprachliches . . . . . .13Antwort
-argumente . . . . . . . . . . . . . . . . . . . . . . . .72-fokusbeschreibung . . . . . . . . . . . . . .73–74-gruppe . . . . . . . . . . . . . . . . . . . . . . . . . . .72-kontext . . . . . . . . . . . . . . . . . . . . . . . . . .72Kurz- . . . . . . . . . . . . . . . . . . . . . . . . . . . .35Lang- . . . . . . . . . . . . . . . . . . . . . . . . . . . .35-objekt . . . . . . . . . . . . . . . . . . . . . . . . . . .72-objektbeschreibung . . . . . . . . . . . . .72–74-typ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .73
Antwortmengen-Methode . . . . . . . . . . . .36–37Argument . . . . . . . . . . . . . . . . . . . . . . . .88, 124
Eigenschafts- . . . . . . . . . . . . . .65, 123–124Gruppen- . . . . . . . . . . . . . . . . .68, 123–124Objekt- . . . . . . . . . . . . . . . . . . .69, 123–124
AskJeeves . . . . . . . . . . . . . . . . . . . . . . . . . . . .12Assoziationsregeln . . . . . . . . . . . . . . .19, 97–98Attribut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .93
-benennung . . . . . . . . . . . . . . . . . . . . . .126Daten- und Skalentyp . . . . . . . . . . . . . .126-gruppe . . . . . . . . . . . . . . . . . . . . . . . .66, 93Semantik . . . . . . . . . . . . . . . . . . . . .75, 126-wertgruppe . . . . . . . . . . . . . . . . . . . .67, 93
BBenutzbarkeit . . . . . . . . . . . . . . . 117, 119–120Benutzermodellierung . . . . . . . . . . . . . . . . . . 10Benutzerschnittstelle . . . . . . . . . . . . . . . . . . . 11
formularbasierte . . . . . . . . . . . . . . . . 13, 16graphische . . . . . . . . . . . . . . . . . . 13, 17, 24hybride . . . . . . . . . . . . . . . . . . . . . . . . . . 13intelligente . . . . . . . . . . . . . . . . . . 2, 9, 117listenbasierte . . . . . . . . . . . . . . . . . . . . . . 24menübasierte . . . . . . . . . . . . . . . . . . . . . . 24wissensbasierte . . . . . . . . . . . . . . . . . . 9, 41
BenutzerunterstützungParadigma der . . . . . . . . . . . . . . . . . . . . . 12
Business Understanding . . . . . . 2, 21, 129, 134
CCase-Based-Reasoning . . . . . . . . . . . . . . . . . 28Charakteristika
von Algorithmen . . . . . . . . . . . . . . . . . . . 92von Methoden . . . . . . . . . . . . . . . . . . . . . 90
CHAT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12CHAT-80 . . . . . . . . . . . . . . . . . . . . . . . . . . . 14Clementine . . . . . . . . . . . . . . . . . . . . . . . . . . 24Consultant . . . . . . . . . . . . . . . . . . . . . . . . . . . 26CRISP-DM . . . . . . . . . . . . . . . . . . 1–2, 21, 134
DDAPLEX . . . . . . . . . . . . . . . . . . . . . . . . . 13, 17Data Characterisation Tool . . . . . . . . . . . . . . 27Data Mining Algorithm Query Language 44, 88Data Mining Query Language . . . . . . . . . . . 19Data Preparation . . . . . . . . . . . . . . . . . . . . . . 22Data Understanding . . . . . . . . . . . . . . . . . . . 22Data-Mining
-Agent . . . . . . . . . . . . . . . . . . . . . . . . . . 105-Algorithmus . . . . . . . . . . . . . . . . . . . . . 92-Ebene . . . . . . . . . . . . . . . . . . . . . . . 44, 105

184 STICHWORTVERZEICHNIS
-Methode . . . . . . . . . . . . . . . . . . . . . . . . .89Daten
-analyst . . . . . . . . . . . . . . . . . . . .2, 66, 129-manager, medizinischer . . . . . . . . . . . .129-vorverarbeitung . . . . . . . . . . . . . . . . . . . . .
. . . . . . . .1, 5, 22–24, 27–28, 69, 126–127Datenbank . . . . . . . . . . . . . . .4–5, 28, 123, 129
-abfrage . . . . . . . . . . . . . . . . . . . . . . . . . .12-administrator . . . . . . . . . . . . . . . . . . . .129-Agent . . . . . . . . . . . . . . . . . . . . . .105, 107-Anfrage . . . . . . . . . . . .4, 14–15, 17, 19–20-definition . . . . . . . . . . . . . . . . . . . . . . . .12-Ebene . . . . . . . . . . . . . . . . . . . . . . . . . .105-manipulation . . . . . . . . . . . . . . . . . . . . . .12-tupel . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4
DB-Agent . . . . . . . . . . . . . . . . . . . . . . . . . . .105DB-Ebene . . . . . . . . . . . . . . . . . . . . . . . . .4, 105DB-Referenz . . . . . . . . . . . . . . . . . . . . . . . . .55Deployment . . . . . . . . . . . . . . . . . . . . . . . . . .22DM-Agent . . . . . . . . . . . . . . . . . . . . . . . . . .105DM-Algorithmus . . . . . . . . . . . . . . . . . . . . .124DM-Anfrage . . . . . . . . . . .44, 89, 102, 123–125DM-Anfrage-Spezialisierung . . . . . . . . .45, 102DMAQL . . . . . . . . . . . . . . .44, 88–89, 119–120DM-Ebene . . . . . . . . . . . . . . . . . . . . .4, 87, 124DM-Ergebnis . . . . . . . . . . . . . . . . . . . . .45, 110DM-Ergebnis-Generalisierung . . . . . . . . . . . .45DM-KD-Transformation . . . . . . . . . . . . . . . .46DM-Methode . . . . . . . . . . . . . . . . . . . . . . . .124DMQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .19DM-System-Anfrage . . . . .45, 87, 95, 102, 106DM-System-Ergebnis . . . . . . . . . . . . . . .45, 106Domänenmodul . . . . . . . . . . . . . . . . . . . . . . .47
EEbene
referentielle . . . . . . . . . . . . . . . . . . . . . . .32semantische . . . . . . . . . . . . . . . . . . . . . . .32syntaktische . . . . . . . . . . . . . . . . . . . . . . .32
Ebenen, semiotische . . . . . . . . . . . . . . . . . . . .32Editieren, syntaktisches . . . . . . . . . . . . . .13, 16Elementtyp . . . . . . . . . . . . . . . . . . . . . . . . . . .54Enterprise Miner . . . . . . . . . . . . . . . . . . . . . .24Entscheidungsbauminduktion . . . . . . . . . . . .92ESTES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .25Evaluation . . . . . . . . . . . . . . . . . . .22, 129, 134EXPRESS . . . . . . . . . . . . . . . . . . . . . . . . . . . .26
FFall . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .65
-gruppe . . . . . . . . . . . . . . . . . . . . . . . 68, 93FASMI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13FAST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26Fast Analysis of Shared Information . . . . . . 13Frage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Alternativ- . . . . . . . . . . . . . . . . . . . . . . . 33-argumente . . . . . . . . . . . . . . 53, 55, 65, 75elementare . . . . . . . . . . . . . . . . . . . . . . . 34Entscheidungs- . . . . . . . . . . . . . . . . . 33, 80Ergänzungs- . . . . . . . . . . . . . . . . . . . 33, 81-expandierende Struktur . . . . . . . . . . . . . 63-gruppe . . . . . . . . . . . . . . . 53, 69, 123–124-kontext . . . . . . . . . . . . . . . 53, 70, 123–124Ob- . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34-objekt . . . . . . . . . . . . . . 53, 55, 61, 76, 124
allgemeines . . . . . . . . . . . . 61, 76, 123domänenspezifisches . . 63, 76, 80, 123
rhetorische . . . . . . . . . . . . . . . . . . . . . . . 32-typ . . . . . . . . . . . . . . . . . . . 53, 55–56, 123
deskriptiver . . . . . . . . . . . . . . . . . . . 57komplexer . . . . . . . . . . . . . . . . . . . . 58konfirmativer . . . . . . . . . . . . . . . . . . 56offener . . . . . . . . . . . . . . . . . . . . . . . 60
Welche- . . . . . . . . . . . . . . . . . . . . . . . . . 34-wurzel . . . . . . . . . . . . . . . . . . . . . . . 53, 55
Funktionalität . . . . . . . . . . . . . . . . . . . . . . . 120
GGalileo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13Gemeinsamkeit . . . . . . . . . . . . . . . . . . . . 62, 78GLIM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26GLIMPSE . . . . . . . . . . . . . . . . . . . . . . . . . . . 26Grammatik, semantische . . . . . . . . . . . . . 15, 53
HHappyAssistant . . . . . . . . . . . . . . . . . . . . . . . 12Hybride Ansätze . . . . . . . . . . . . . . . . . . . . . . 17
IIDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16Information Retrieval . . . . . . . . . . . . . . . . . . 12Intelligent User Interface . . . . . . . . . . . . . . . . 9Interaktionszyklus . . . . . . . . . . . . . . . . . . . . . 11Interessantheit . . . . . . . . . . . . . . . . . . . . . . . 106Interface-Adaptivität . . . . . . . . . . . . . . . . . . . 10Interrogativ . . . . . . . . . . . . . . . . . . . . . . . . . . 33
-akt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31-pronomen . . . . . . . . . . . . . . . . . . . . . . . 33

185STICHWORTVERZEICHNIS
-satz . . . . . . . . . . . . . . . . . . . . . . . . . . . . .31IQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .16Irrtumswahrscheinlichkeit . . . . . . . . .78–79, 82
JJanus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .14
KKDA . . . . . . . . . . . . . .6, 74, 105–106, 109, 111KD-Agent . . . . . . . . . . . . . . . . . . . . . . . . . . .105KDAL . . . . . . . . . . . . . . . . . . . . . .46–47, 51, 72KD-Antwort . . . . . . . . . . . .46, 71, 75, 104, 114KD-Antwort-Kontraktion . . . . . . . . . . . . . . . .46KD-Antwort-Manager . . . . . . . . . . . . . . . . .106KD-DM-Transformation . . .44, 51, 87, 95, 105KDD-Prozess . . . . . . . . . . . . . . . . . . . . . . . .127KD-Ebene . . . . . . . . . . . . . . . . . .4, 87, 105, 124KD-Expansion . . . . . . . . . . . . . . . . . . . .87, 105KD-Frage .44, 48, 105, 110, 112–113, 122–125
Beantwortung . . . . . . . . . . . . . . . . . . . .102deskriptive . . . . . . . . . . . . . . . . . . . . .73, 81Gemeinsamkeit . . . . . . . . . . . . . . . . . . . .78komplexe . . . . . . . . . . . . . . . . . . . . . .74, 83konfirmative . . . . . . . . . . . . . . . . . . .73, 80Unterschied . . . . . . . . . . . . . . . . . . . . . . .77Veränderung . . . . . . . . . . . . . . . . . . . . . .79Zusammenhang . . . . . . . . . . . . . . . . . . . .76
KD-Frage-Expansion . . . . . . . . . . . . .44, 48, 93KD-Frage-Manager . . . . . . . . . . . . . . . . . . .105KDQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . .5–6, 44, 47, 51, 53, 111–112, 118–119, 123Knowledge Discovery Answer Language . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . .46, 51, 72, 104Knowledge Discovery Assistant . . . .6, 74, 105Knowledge Discovery Question Language . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . .5, 44, 51, 53Knowledge Engineering . . . . . . . . . . . . . . . . .27Knowledge-Discovery
-Agent . . . . . . . . . . . . . . . . . .105–106, 110-Ebene . . . . . . . . . . . . . . . . . . . .44, 51, 105
Kommunikation, multimodale . . . . . . . . . . . . .9Kompositionalitätsprinzip . . . . . .37, 75, 83, 85Konfidenz . . . . . . . . . . . . . . . . . . . . . .19, 88, 99Konfiguration
von Algorithmen . . . . . . . . . . . . . . . . . . .95von Methoden . . . . . . . . . . . . . .95, 98, 100
Konzept-expandierende Struktur . . . . . . . . . .64Korrektheit . . . . . . . . . . . . . . . . . .118, 120, 122
LLADDER . . . . . . . . . . . . . . . . . . . . . . . . 14–15Logik, erotetische . . . . . . . . . . . . . . . . . . . . . 32LUNAR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
MMachine Learning Toolbox Projekt . . . . . . . 26MDSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13MDX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13MINE RULE Operator . . . . . . . . . . . . . . . . . 19MLC++ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28Modeling . . . . . . . . . . . . . . . . . . . . 22, 129, 134Modularität . . . . . . . . . . . . . . . . . . . . . . . . . . 42
NNapier88 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13Natural Language Interfaces to Databases . . 14Neuronale Netze . . . . . . . . . . . . . . . . . . . 97–98NLIDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14NLMENU . . . . . . . . . . . . . . . . . . . . . . . . . . . 16NOODL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
OOLAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13On-Line Analytical Processing . . . . . . . . . . . 13
PParameter . . . . . . . . . . . . . . . . . . . . . . . . . . 124
Projektions- . . . . . . . . . . . . . . . . . . . . . . 93Selektions- . . . . . . . . . . . . . . . . . . . . . . . 93
Pearson’s r . . . . . . . . . . . . . . . . . . . . . . . . 77, 82PLANES . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15Portierbarkeit . . . . . . . . . . . . . . . . 118, 120–121Propositionen . . . . . . . . . . . . . . . . . . . . . . . . 33Prozessunterstützung, formularbasierte . . . . 21
QQBE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16QBT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16Qualitätsmanagement . . . . . . . . . . . . . . . 1, 129
medizinisches . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6, 8, 43, 47, 63, 65, 69, 119, 121, 129
Qualitätsmerkmale für Software . . . . . . . . . 117Query-by-Example . . . . . . . . . . . . . . . . . 13, 16

186 STICHWORTVERZEICHNIS
Query-by-Template . . . . . . . . . . . . . . . . .13, 16QUEST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .40QUESTUS-KDD . . . . . . . . . . . . . . . . . . . . . . .3
-Ansatz . . . . . . . . . . . . . . . . . .3, 41, 51, 103-Begriffsmodell . . . . . . . . . . . . . . . . . . . .46Realisierung . . . . . . . . . . . . . . . . . . . . . .105-Verarbeitungsmodell . . . . . . . . . . . . . . .43
RRedundanzfreiheit . . . . . . . . . . . .119–120, 125REL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .15REX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .25RISQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .13
SSatzradikalmethode . . . . . . . . . . . . . . . . . . . .33SAVVY . . . . . . . . . . . . . . . . . . . . . . . . . . . . .14Scheinfragesätze . . . . . . . . . . . . . . . . . . . . . . .32SDM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .13Semantik
funktionale Theorie . . . . . . . . . . . . . . . . .35propositionale Theorie . . . . . . . . . . . .36–37von Fragen . . . . . . . . . . . . . . . . . . . . . . . .34
exhaustive . . . . . . . . . . . . . . . . . . . . .38nicht-exhaustive . . . . . . . . . . . . . . . .38
SEMMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . .24SETUP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .26SigmaStat . . . . . . . . . . . . . . . . . . . . . . . . . . . .26Signifikanzniveau . . . . . . . . . . . . . . . . . . .78, 82Smartkom . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2SmartKom-Projekt . . . . . . . . . . . . . . . . . . . . .10Sprechakt . . . . . . . . . . . . . . . . . . . . . . . . . . . .35SQL . . . . . . . . . . . . . . . . . . . . . . . . . .13, 15–16SQL-Standard . . . . . . . . . . . . . . . . . . . . . . . . .13Statex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .26STATIBOT . . . . . . . . . . . . . . . . . . . . . . . . . .26Statistik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .25StatLog-Projekt . . . . . . . . . . . . . . . . . . . .26, 28Student’s t-Test . . . . . . . . . . . . . . . . . . . .78–79Support . . . . . . . . . . . . . . . . . . . . .19, 89, 92, 99System
Analyse- . . . . . . . . . . . . . . . . . . . . . . . . . .26Anfrage- . . . . . . . . . . . . . . . . . . . .11, 13–15Assistenz- . . . . . . . . . . . . . . . . . . . . .25, 27Beratungs- . . . . . . . . . . . . . . . . . . . . .12, 26Data-Mining- . . . . . . . . . . . . . . . . . . . . . .28Datenbank- . . . . . . . . . . . . .13–14, 28, 183Experten- . . . . . . . . . . . . . . . . . . . . . .14, 26
statistisches . . . . . . . . . . . . . . . . . . . .25Frage-und-Antwort- . . . . . . . . . . . . . . . . .12
Hilfe- . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9Information-Retrieval- . . . . . . . . . . . . . . 12Informations- . . . . . . . . . . . . . . . . 2, 10–11intelligentes . . . . . . . . . . . . . . . . . . . . . . . 9Keyword-Spotting- . . . . . . . . . . . . . . . . . 14Knowledge-Based . . . . . . . . . . . . . . . . . 10NLIDB- . . . . . . . . . . . . . . . . . . . . . . 14–15OLAP- . . . . . . . . . . . . . . . . . . . . . . . . . . 13Pattern-Matching- . . . . . . . . . . . . . . . . . . 14syntaxbasiertes . . . . . . . . . . . . . . . . . 14–15Tutor- . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9Web-Retrieval- . . . . . . . . . . . . . . . . . . . . 12wissensbasiertes . . . . . . . . . . . . . . . . . . . 10
TText Retrieval . . . . . . . . . . . . . . . . . . . . . . . . 12Textverstehen . . . . . . . . . . . . . . . . . . . . . . . . 39Transparenz . . . . . . . . . . . . . . . . . . . . . . . . . . 41t-Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78–79TypDeskriptiv . . . . . . . . . . . . . . . . . . . . . . . . 58TypKomplex . . . . . . . . . . . . . . . . . . . . . . . . . 59TypKonfirmativ . . . . . . . . . . . . . . . . . . . . . . 57
UUGM . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22–23Unterschied . . . . . . . . . . . . . . . . . . . . . . . 62, 77User Guidance Module . . . . . . . . . . . . . . . . . 22
VVariablenbereich . . . . . . . . . . . . . . . . . . . . . . 59Veränderung . . . . . . . . . . . . . . . . . . . . . . 63, 79Vollständigkeit . . . . . . . . . . . . . . 118, 120, 122
WW3C-Schema . . . . . . . . . . . . . . . . . . . . . . . . 53Wartbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . 120Welt
konversationelle . . . . . . . . . . . . . . . . . . . 11Modell- . . . . . . . . . . . . . . . . . . . . . . . . . . 11
Wenn-Dann-Regeln . . . . . . . . . . . . . . . . 97–98W-Frage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56Wissen
allgemeines . . . . . . . . . . . . . . . . . . . . . . . 47anwender-, unternehmensspezifisches . . 47domänenspezifisches . . . . . . . . . . . . 47, 93Spezialisierungsebenen . . . . . . . . . . 47, 54

187STICHWORTVERZEICHNIS
über Antworten . . . . . . . . . . . . . . . . . . . .49über Daten . . . . . . . . . . . . . . . . . . . . . . . .49über Fragen . . . . . . . . . . . . . . . . . . . . . . .48über Konzepte . . . . . . . . . . . . . . . . . . . . .48über Methoden und Algorithmen . . . . . .48
Wissens-basis . . . . . . . . . . . . . . . . . . . . . . .42, 46–49defizit . . . . . . . . . . . . . . . . . . . . . . . . . . . .40elemente . . . . . . . . . . . . . . . . . . . . . . . . . .38entdeckung . . . . . . . . . . . . . . . . . . . . . . . .31erwerb . . . . . . . . . . . . . . . . . . . . . . . .38, 43kontext . . . . . . . . . . . . . . . . . . . . . . . . . . .43lücke . . . . . . . . . . . . . . . . . . . . . . . . . . . .40ziele . . . . . . . . . . . . . . . . . . . . . . .38–39, 43
XXML . . . . . . . . . . . . . . . . . . . . . . . .53, 111, 113
ZZusammenhang . . . . . . . . . . . . . . . . . . . .62, 76

188 STICHWORTVERZEICHNIS

LEBENSLAUF
Name: Oliver Mathias Johannes HoglAdresse: Kirchenweg 47, 90419 NürnbergGeburtsdatum: 1. August 1970Geburtsort: PfaffenhofenFamilienstand: ledigStaatsangehörigkeit: deutsch
Schulbildung:1977 - 1981 Knabengrundschule Pfaffenhofen1981 - 1990 Schyrengymnasium Pfaffenhofen
Abschluss: Allgemeine Hochschulreife
Zivildienst:1990 - 1991 Sonderschule für geistig behinderte Kinder, Pfaffenhofen
Studium:1991 - 1998 Friedrich-Alexander-Universität Erlangen-Nürnberg
University of Warwick, Coventry, GroßbritannienAbschluss: Diplom-Informatiker Univ.Studienfach: InformatikVertiefungsrichtungen: Künstliche Intelligenz
MustererkennungKommunikationssysteme
Nebenfach: Medizinische Informationsverarbeitung
Berufstätigkeit:1998-2002 wissenschaftlicher Mitarbeiter in der Forschungsgruppe
Wissenserwerb am Bayerischen Forschungszentrum für Wissensbasierte Systme (FORWISS)Leiter verschiedener Projekte in den Bereichen Data Mining, Wissensbasierte Assistenzsysteme und Wissensmanagement
ab 2003 Projektconsultant bei amball business-software, Nürnberg



















