
Einführung in das statistische Programmpaket - uni-trier.de · Einführung in R Melanie...
53
Wirtschafts- und Sozialstatistik Professor Dr. Ralf Münnich Dipl.-Kffr. Melanie Knobelspies Einführung in das statistische Programmpaket
Transcript of Einführung in das statistische Programmpaket - uni-trier.de · Einführung in R Melanie...

Wirtschafts- und SozialstatistikProfessor Dr. Ralf MünnichDipl.-Kffr. Melanie Knobelspies
Einführungin das statistische Programmpaket

Einführung in R Melanie Knobelspies
1 Grundlagen
1.1 Was ist R ?
• R ist GNU (Open–Source; keine Black Box ⇒ alle Algorithmen nachvollziehbar);
• Info unter: http://www.r-project.org ;
• Download unter: http://cran.r-project.org ;
• S–Plus ist kommerzielle Version (Programmiersprache fast identisch);
• Gute Programmierumgebung;
• Schnelle Entwicklung (sehr viele aktuelle Pakete);
• Interfaces zu anderen Programmen (bspw. MySQL, MS Excel, WinBUGS);
• Umfangreiche statistische Methoden;
• Flexible Graphikerstellung;
• Nachteil: Keine vollständige graphische Benutzeroberfläche.
1.2 R als Taschenrechner
− + ∗ / Grundrechenarten
ˆ bzw. ** Potenz
% / % Ganzzahlige Division
% % Modulo Division
sqrt( ) Quadratwurzel
log( ) Natürlicher Logarithmus
log10( ) Logarithmus zur Basis 10
exp( ) Exponentialfunktion
sin( ) cos( ) Trigonometrische Funktionen
round( ) rundet auf die nächste ganze Zahl auf oder ab
floor( ) rundet auf die nächste ganze Zahl ab
ceiling( ) rundet auf die nächste ganze Zahl auf
factorial( ) Fakultät
choose(n,k) Binomialkoeffizient
Wirtschafts- und Sozialstatistik, Universität Trier Seite 2

Einführung in R Melanie Knobelspies
1.3 Die wichtigsten Zeichen in R
<- Zuweisung (x <- 3 speichert beispielsweise Zahl 3unter dem Namen x).Beachte: Benutzereigene Objekte maskieren die in Rvorhandenen Befehle. Bestehende Namen wie z. B. exp, log,mean, var, c, . . . sollten daher vermieden werden.
# Kommentarzeichen
NA Fehlende Werte (Not Available)
NaN Undefinierte Werte
Inf Unendlich
NULL Leere Menge
1.4 Was es noch zu beachten gibt
• R unterscheidet zwischen Groß– und Kleinschreibung (R ist case sensitiv);
• Als Dezimaltrennzeichen wird ein Punkt verwendet (kein Komma);
• Für das Erstellen von Funktionen und längeren Aufrufen empfiehlt es sich einen Editor zu ver-wenden. Den in R implementierten Editor erhält man unter: Datei ⇒ Neues Skript (Menüleiste)Eine Liste der für R optimierten Editoren findet man unter:http://www.R-project.org/GUI/;
• R–Codes sollten stets gut kommentiert werden (Verwendung von #);
• Pakete können in R mit dem Befehl library(Paket) geladen werden (oder alternativ überdie Menüleiste Pakete→ Lade Pakete;
• Mit ls( ) oder objects( ) erhält man eine Übersicht der Objekte im Workspace;
• rm(x,y,z) entfernt einzelne Objekte;
• rm(list=ls()) entfernt alles;
• R bietet ein umfangreiches Hilfesystem. Durch Eingabe von help(Befehl) bzw. ?Befehlwird die Hilfe zu dem entsprechenden Befehl angezeigt;
• library(help="Paket") zeigt die Hilfe zu dem entspechenden Paket an;
• Auch der Befehl example(Funktion) liefert nützliche Informationen (z.B. example(plot));
• R bietet eine Reihe von Demonstrationen, die mit dem Befehl demo( ) aufgerufen werden kön-nen (z.B. demo(grahics)).
Wirtschafts- und Sozialstatistik, Universität Trier Seite 3

Einführung in R Melanie Knobelspies
2 Objekttypen in R
2.1 Datentypen
Das Programm R arbeitet mit Objekten. Die wichtigsten Objekt in R sind Vektoren, Matrizen, Listen undData.frames. Die Elemente eines Objekts können in den meisten Fällen unterschiedlichen Datentypessein. Die wichtigsten Datentypen in R sind numeric, logical und character. Mit mode(Objekt) kannder Datentyp eines Objektes abgefragt werden.
Datentyp Beschreibung Beispiel
numeric ganze und reelle Zahlen 5, 3.462
logical logische Werte FALSE, TRUE
character Buchstaben und Zeichenfolgen "Hallo"
Um zu testen, ob ein Objekt einen bestimmten Datentyp hat, gibt es folgende Befehle:
• is.numeric( )
• is.logical( )
• is.character( )
Wird das vorangestellte is durch ein as ersetzt, so kann ein anderer Datentyp erzwungen werden.(Tabelle entnommen aus PARADIS, 2002, S. 21)
Umwandlung in Funktion Resultatnumeric as.numeric FALSE → 0
TRUE → 1"1","2",... → 1,2,...
"A" → NAlogical as.logical 0 → FALSE
andere Zahlen → TRUEBuchstaben → NA
"F" → FALSE"T" → TRUE
character as.character 1,2,... → "1","2",...FALSE → "FALSE"TRUE → "TRUE"
Wirtschafts- und Sozialstatistik, Universität Trier Seite 4

Einführung in R Melanie Knobelspies
Beispiel:
> a <- 100> b <- 50
> mode(a)
[1] "numeric"
> is.numeric(a)
[1] TRUE
> is.character(a)
[1] FALSE
> a/b
[1] 2
> a <- as.character(a)
> is.character(a)
[1] TRUE
> a <- as.character(a)
> a/b
Fehler in a/b : nicht-numerisches Argument für binären Operator
2.2 numeric–Vektoren
2.2.1 Die c( ) Funktion
Vektoren enthalten mehrere Elemente des gleichen Typs (einzelne Zahlenwerte werden als Vektoren derLänge 1 behandelt).Durch die c( ) Funktion (c steht für combine) können mehrere Elemente zusammengefügt werden.
> y <- c(4,1,8,5,3)
liefert
[1] 4 1 8 5 3
Wirtschafts- und Sozialstatistik, Universität Trier Seite 5

Einführung in R Melanie Knobelspies
Die Argumente der Funktion c( ) werden zu einem Vektor zusammengefasst und durch <- als Objektunter dem Namen y abgespeichert.
2.2.2 Sequenzen
Erzeugung von regelmäßigen Zahlenfolgen anhand des Befehls seq( )
Wichtigste Argumente: from, to, by, length
Höchstens drei der Argumente dürfen spezifiziert werden.
>seq(from=-5,to=5,by=1)
liefert
[1] -5 -4 -3 -2 -1 0 1 2 3 4 5
Es geht auch die Kurzschreibweise:
> seq(-5,5) # default ist hierbei by=1
Noch kürzer geht es mit dem Doppelpunktoperator:
> -5:5
Gibt man den zusätzlichen Befehl length mit, so kann die Anzahl der Elemente eines Vektorsbestimmt werden.
Aufgabe: Erstellen Sie die folgende Sequenz. Benutzen Sie dabei verschiedene Argumente.
[1] -5.0 -4.8 -4.6 -4.4 -4.2 -4.0 -3.8 -3.6 -3.4 -3.2 -3.0 -2.8
Lösung: > seq(from=-5,length=12,by=0.2)
2.2.3 Wiederholungen
n–malige Wiederholungen eines Skalars (bzw. eines Vektors) erhält man durch den Befehl rep( ).Die Anzahl der Wiederholungen wird durch das Argument times festgelegt.
> rep(5.5,times=5)
liefert
[1] 5.5 5.5 5.5 5.5 5.5
Das ganze kann auch auch für Sequenzen angewandt werden.
> rep(1:4,times=5)
Wirtschafts- und Sozialstatistik, Universität Trier Seite 6

Einführung in R Melanie Knobelspies
liefert
[1] 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
Soll jedes Element mehrmals hintereinander wiederholt werden, so muss das Argument eachmitgegeben werden.
> rep(1:4,each=5)
liefert
[1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4>
Eine Kombination von times und each ist ebenso möglich.
> rep(1:4,each=3,times=2)
liefert
[1] 1 1 1 2 2 2 3 3 3 4 4 4 1 1 1 2 2 2 3 3 3 4 4 4
Auch eine Wiederholung von Elementen mit variabler Anzahl ist möglich.
Aufgabe: Erstellen Sie folgende Sequenz:
[1] 1 1 2 2 2 2 3 3 3 3 3 3
Lösung:
> Reihe <- seq(2,6,2)> Reihe[1] 2 4 6> rep(1:3,Reihe)
Wirtschafts- und Sozialstatistik, Universität Trier Seite 7

Einführung in R Melanie Knobelspies
2.2.4 Elementare Vektoroperationen
length(y) Länge des Vektors y (=Anzahl der Vektorelemente).
rev(y) Kehrt die Reihenfolge der Elemente eines Vektors um.
unique(y) Liefert die Elemente des Eingabevektors ohne Wiederholungen.
sort(y) Sortiert die Elemente aufsteigend.
rank(y) Bildet den zugehörigen Rangvektor.
order(y) Liefert den Vektor der Indizes der Eingabedaten für deren aufsteigende Sortierung.
Werden zwei Vektoren addiert, so geschieht dies elementweise.Beispiel:
> x <- c(10,20,30,40)> y <- 5:8> x+y[1] 15 26 37 48>
Sind die Vektoren unterschiedlicher Länge, so wird der kürzere zyklisch verlängert.
> z <- c(1,2)> z+y[1] 6 8 8 10>
Auch einzelne Funktionen können elementweise auf einen Vektor angewandt werden.
> sqrt(y) # bildet die Quadratwurzel für jedes Element in y[1] 2.236068 2.449490 2.645751 2.828427>> y^2[1] 25 36 49 64>> 2*y[1] 10 12 14 16
Beachte: Will man das Skalarprodukt aus zwei Vektoren berechnen (im Beispiel: zTz), so mussder Befehl der Matrixmultiplikation %*% verwendet werden.
> t(z)%*%z[,1]
[1,] 5
Wirtschafts- und Sozialstatistik, Universität Trier Seite 8
Einführung in R Melanie Knobelspies
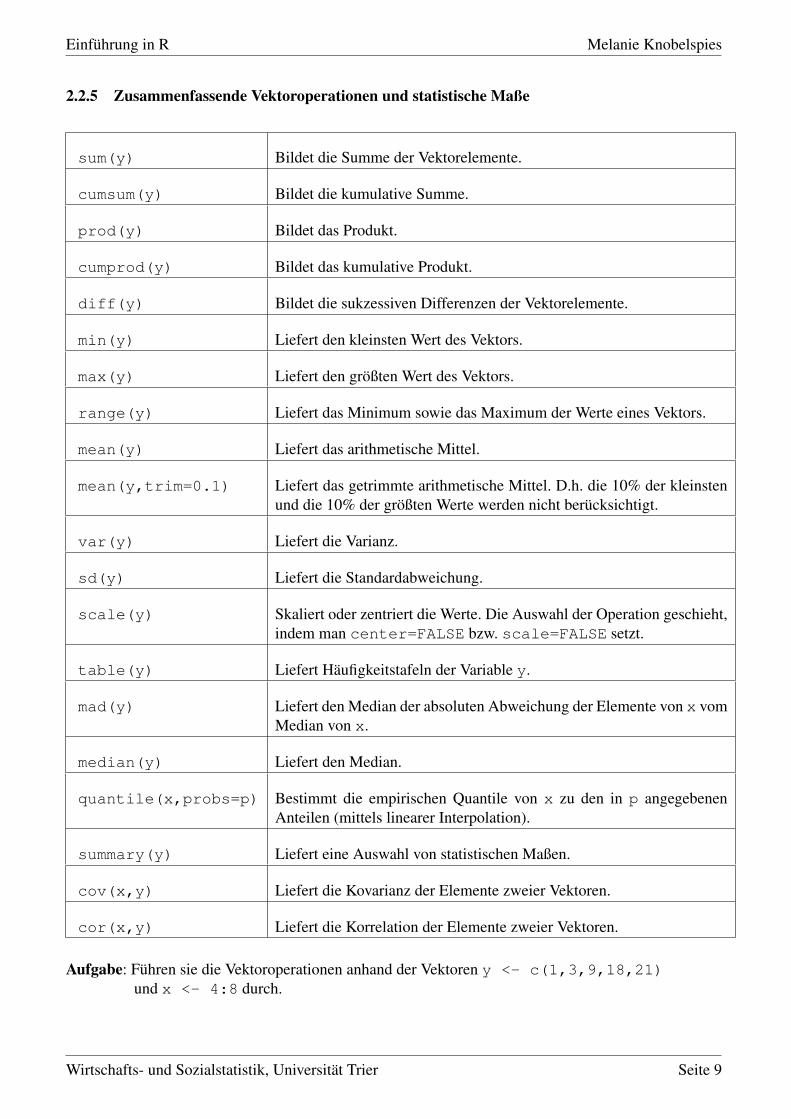
2.2.5 Zusammenfassende Vektoroperationen und statistische Maße
sum(y) Bildet die Summe der Vektorelemente.
cumsum(y) Bildet die kumulative Summe.
prod(y) Bildet das Produkt.
cumprod(y) Bildet das kumulative Produkt.
diff(y) Bildet die sukzessiven Differenzen der Vektorelemente.
min(y) Liefert den kleinsten Wert des Vektors.
max(y) Liefert den größten Wert des Vektors.
range(y) Liefert das Minimum sowie das Maximum der Werte eines Vektors.
mean(y) Liefert das arithmetische Mittel.
mean(y,trim=0.1) Liefert das getrimmte arithmetische Mittel. D.h. die 10% der kleinstenund die 10% der größten Werte werden nicht berücksichtigt.
var(y) Liefert die Varianz.
sd(y) Liefert die Standardabweichung.
scale(y) Skaliert oder zentriert die Werte. Die Auswahl der Operation geschieht,indem man center=FALSE bzw. scale=FALSE setzt.
table(y) Liefert Häufigkeitstafeln der Variable y.
mad(y) Liefert den Median der absoluten Abweichung der Elemente von x vomMedian von x.
median(y) Liefert den Median.
quantile(x,probs=p) Bestimmt die empirischen Quantile von x zu den in p angegebenenAnteilen (mittels linearer Interpolation).
summary(y) Liefert eine Auswahl von statistischen Maßen.
cov(x,y) Liefert die Kovarianz der Elemente zweier Vektoren.
cor(x,y) Liefert die Korrelation der Elemente zweier Vektoren.
Aufgabe: Führen sie die Vektoroperationen anhand der Vektoren y <- c(1,3,9,18,21)und x <- 4:8 durch.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 9

Einführung in R Melanie Knobelspies
2.2.6 Indizierung von Vektoren
Um Teile oder einzelne Elemente eines Vektors auszuwählen bzw. zu eliminieren, werden eckige Klam-mern benötigt. Die Indizierung eines Vektors x erfolgt gemäß x[a]. a kann hierbei eine positive odernegative Zahl, ein Vektor oder ein logischer Ausdruck (siehe Abschnitt 2.3) sein. Bei logischen Aus-drücken werden dabei nur die Elemente ausgewertet, die TRUE sind.
x <- c(5,6,7,8,9,3,2,1)
x[4] Auf das 4. Element in x zugreifen.
x[9] Beachte: Ist der angegebene Index größer als die Länge des Vek-tors, so erhält man als Ergebnis NA
x[ ] Bleibt die Klammer leer, so werden alle Vektorelementegleichzeitig indiziert.
x[2:5] Auf das 2. - 5. Element in x zugreifen.
x[4] <- NA Der vierte Wert des Vektors x soll fehlen.
x[c(2,4,5)] Auf das 2., 4. und 5. Element von x zugreifen.
x[-5] Liefert alle Elemente des Vektors x mit Ausnahme des 5. Ele-ments.
x[-c(2:4)] Liefert alle Elemente des Vektors x mit Ausnahme des 2. bis 4.Elements.
x[x<=4] Liefert alle Werte von x, die kleiner oder gleich 4 sind.
which(x<=4) Liefert den Index der Werte die kleiner oder gleich 4 sind.
sum(x<=4) Bestimmt die Anzahl der Werte von x, die kleiner oder gleich 4sind
sum(x[x<=4]) Gibt die Summe der Werte derjenigen Elemente an, die kleineroder gleich 4 sind.
Möchte man nur auf die ersten oder letzten k Elemente eines Vektors zugreifen, so können dieFunktionen head( ) und tail( ) verwendet werden.Beispiel:
> head(x,n=3) # entspricht x[1:3][1] 5 6 7> tail(x,n=2) # entspricht x[length(x)-2+1:length(x)][1] 2 1>
Aufgabe: Überprüfen Sie was passiert, wenn für den oben genannten Vektor x der Befehlx[x>8] <- c(-1,-2,-3) eingegeben wird.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 10

Einführung in R Melanie Knobelspies
2.2.7 Fehlende Werte
Enthält ein Vektor fehlende Werte, so lassen sich nicht mehr alle Vektoroperationen ohne weiteresausführen. Bei den meisten Operationen genügt es das logische Argument na.rm=TRUE zu setzen.Beispiel:
> y <- c(2,4,8,10,NA)
> sum(y) # Berechnung nicht möglich
[1] NA
> mean(y)
[1] NA
> sum(y,na.rm=TRUE) # die Summe lässt sich nun berechnen
[1] 24
> mean(y,na.rm=TRUE)
[1] 6>
Für die Berechnung der Kovarianz bzw. der Korrelation zweier Vektoren erfolgt die Berücksichtigungfehlender Werte mit dem Argument use="complete.obs".Dies sorgt dafür, dass alle Fälle eliminiert werden, von denen mindestens ein Element des Paares nichtvorhanden ist.
Mit is.na() kann auf fehlende Werte getestet werden. Weiterhin sollte is.na() auch für das Setzenfehlender Werte verwendet werden. Siehe hierzu folgendes Beispiel (entnommen aus LIGGES, 2006,S. 30).
> x <- c(5,7,NA,22)
> is.na(x)
[1] FALSE FALSE TRUE FALSE
> is.na(x[1])<- TRUE
> x
[1] NA 7 NA 22>
Wirtschafts- und Sozialstatistik, Universität Trier Seite 11

Einführung in R Melanie Knobelspies
2.2.8 Übungsaufgaben zu numeric-Vektoren
1. Generieren Sie anhand des seq Befehls den Vektor:
(−2.0 , −0.5 , 1.0 , 2.5 , 4.0 , 5.5 , 7.0)T
2. Generieren Sie einen Vektor mit 12 Elementen, wobei das kleinste Element 3 und das größteElement 12 ist. Benennen Sie den Vektor a.
3. Generieren Sie einen Vektor mit 12 Elementen, wobei das größte Element 5 und der Abstandzwischen den Elementen jeweils 0.2 beträgt. Benennen Sie den Vektor b.
4. Generieren Sie einen Vektor mit den Einträgen 1 bis 10 und benennen Sie ihn d. Probieren Siedabei verschiedene Möglichkeiten aus.
5. Erstellen Sie folgenden Vektor anhand des rep–Befehls und nutzen sie einmal das Argumentlength und einmal das Argument times.
(1 , 3 , 5 , 1 , 3 , 5 , 1 , 3 , 5)T
6. Lassen Sie sich eine Übersicht über die Objekte im Workspace geben.
7. Löschen Sie die 2 Objekte a und b.
8. Erstellen Sie folgenden Vektor anhand des rep Befehls:
(1 , 1 , 2 , 2 , 2 , 3 , 3 , 3 , 3 , 4 , 4 , 4 , 4 , 4)T
9. Erstellen Sie folgenden zwei Vektoren:
(22 , 33 , 41 , 50)T
(22 , 32 , 42 , 52)T
10. Berechnen Sie den Mittelwert, sowie die Varianz des Vektors d.
11. Modifizieren Sie den Vektor d, indem Sie dem 4. und dem 5. Element den Wert NA zuweisen undberechnen Sie daraufhin erneut den Mittelwert und die Varianz.
12. Erstellen Sie zwei Vektoren, die eine exakte negative lineare Abhängigkeit aufweisen und berech-nen Sie den Korrelationskoeffizienten. Benennen Sie die Vektoren x und y.
13. Setzten Sie das zweite Element des Vektotrs x auf NA und berechnen Sie die Korrelation erneut.
Hinweis: Die Lösung finden Sie in der Datei Vektor.r
Wirtschafts- und Sozialstatistik, Universität Trier Seite 12

Einführung in R Melanie Knobelspies
2.3 logical–Vektoren
In logischen Vektoren werden Wahrheitswerte gespeichert. Die Wahrheitswerte kennen lediglich dieZustände wshr (TRUE) und falsch (FALSE). Intern werden die logischen Werte von R in numerischeWerte (TRUE=1, FALSE=0) umgewandelt.
> x <- c(150,170,190,210,220)>> x>200>[1] FALSE FALSE FALSE TRUE TRUE>> (x>200)*2>[1] 0 0 0 2 2>
Elementweise logische Operationen
Operator Operation> größer als< kleiner als== genau gleich!= ungleich (Negation)>= größer gleich<= kleiner gleich& und| oder! Negationxor entweder oder
Bei der Kombination von Minus und „kleiner als“ bzw. „größer als“ Zeichen ist ein Leerzeichen er-forderlich.< − wird ansonsten als Zuweisung verstanden.
Zusammenfassende logische Operationen
Neben den elementweise logischen Operationen gibt es noch eine Reihe zusammenfassende logischeOperationen. Diese arbeiten nicht vektorwertig, sondern liefern immer einen einzelnen Wahrheitswert.
Operator Operation&& sequentielles und|| sequentielles oderall sind alle Elemente TRUE?any ist mindestens ein Element TRUE?which Welche Elemente sind TRUE?
Wirtschafts- und Sozialstatistik, Universität Trier Seite 13

Einführung in R Melanie Knobelspies
2.4 character–Vektoren
character–Vektoren bestehen aus Elementen, die Zeichenketten sind. In R müssen Zeichenketten inHochkommatas stehen. Auch hier werden die einzelnen Elemente wieder mir c( ) zu einem Vektorverbunden.
> Fächer <- c("BWL","VWL","Soziologie")> Fächer[1] "BWL" "VWL" "Soziologie"> Weitere.Fächer <- c("Mathematik","Informatik")> FB4 <- c(Fächer,Weitere.Fächer)> FB4[1] "BWL" "VWL" "Soziologie" "Mathematik" "Informatik">
Eine nützliche Funktion bei character–Vektoren ist die Funktion paste( ). Mit paste( ) könneneinzelne Argumente zusammengehängt werden.
>> paste("Statistik","macht","Spaß")[1] "Statistik macht Spaß">
Mit dem Argument sep kann bestimmt werden, welches Zeichen zwischen den einzelnen Argumentensteht (Voreinstellung ist das Leerzeichen).
> paste("Statistik","macht","Spaß",sep=":")[1] "Statistik:macht:Spaß">
2.5 Faktoren
Faktoren dienen zur Abbildung von kategorialen Variablen mit mehreren Ausprägungen. Die k möglichenAusprägungen (in R: levels) eines Faktors werden in R durch die natürlichen Zahlen 1 bis k codiert. Siesind aber mit Zeichenketten assoziierbar, so dass die Bedeutung der Ausprägungen erkennbar bleibt(vgl. EICHNER, 2005, S. 26).
> Tiere <-c("Hund","Pferd","Katze","Pferd","Pferd","Hund","Katze")> Tiere
[1] "Hund" "Pferd" "Katze" "Pferd" "Pferd" "Hund" "Katze"
Wirtschafts- und Sozialstatistik, Universität Trier Seite 14

Einführung in R Melanie Knobelspies
> Tiere <- factor(Tiere)> Tiere>[1] Hund Pferd Katze Pferd Pferd Hund Katze
Levels: Hund Katze Pferd>>> attributes(Tiere)$levels[1] "Hund" "Katze" "Pferd"
$class[1] "factor"
>
Die einzelnen Stufen werden dabei gemäß der lexographischen Ordnung angelegt. Für eine andereAnordnung sorgt der Parameter levels.
> Tiere2 <-factor(c("Hund","Pferd","Katze","Pferd","Pferd","Hund"),levels=c("Pferd","Katze", "Hund"))
>> Tiere2
[1] Hund Pferd Katze Pferd Pferd HundLevels: Pferd Katze Hund
Eine Umbenennung der Argumente kann mit der Funktion labels() erzielt werden.
> factor(Tiere2,labels=c("Haflinger","Perserkatze","Schäferhund"))
[1] Schäferhund Haflinger Perserkatze Haflinger Haflinger Schäferhund
Levels: Haflinger Perserkatze Schäferhund
Mit dem Befehl ordered() können geordnete Faktoren erzeugt werden. Für die Levelordnung wirdhierbei die lexographische Levelsortierung verwendet.
> Tierpreis <- ordered(Tiere, levels=c("Katze","Hund","Pferd"))>> Tierpreis[1]>Tierpreis[3][1] TRUE> Tierpreis[1]>Tierpreis[2][1] FALSE>> levels(Tiere)[1] "Katze" "Hund" "Pferd"
Wirtschafts- und Sozialstatistik, Universität Trier Seite 15

Einführung in R Melanie Knobelspies
Sollen den einzelnen Stufen Zahlenwerte zugeordnet werden, so benötigt man den Befehl unclass.
> unclass(Tiere)>[1] 1 3 2 3 3 1 2attr(,"levels")[1] "Hund" "Katze" "Pferd">
Die Funktion table( ) liefert eine Häufigkeitsauszählung von nominal skalierten Variablen. Hier-aus lässt sich dann die relative Häufigkeit berechnen.
> table(Tiere)
TiereHund Katze Pferd
2 2 3>> rel.Hfkt <- table(Tiere)/length(Tiere)> rel.HfktTiere
Hund Katze Pferd0.2857143 0.2857143 0.4285714>
Mit dem Befehl cut() kann eine numeric–Variable in eine factor–Variable umgewandelt werden. Mitbreaks() können die Klassengrenzen bestimmt werden.
> Alter <- rnorm(100,30,5)> Alter<-round(Alter,digits=0)> Alter
[1] 35 23 30 38 23 34 25 27 33 34 36 27 ...[25] 31 37 29 26 20 34 25 29 26 23 27 37 ...
...Alterklass<- cut(Alter,breaks=c(0,25,30,40),
labels=c("-25","25-30","30+"))Alterklass
[1] 30+ -25 25-30 30+ -25 30+ -25 ...[25] 30+ 30+ 25-30 25-30 -25 30+ -25 ...
...
Levels: -25 25-30 30+
> table(Alterklass)Alterklass
-25 25-30 30+28 32 39
Wirtschafts- und Sozialstatistik, Universität Trier Seite 16

Einführung in R Melanie Knobelspies
2.6 Listen
Eine Liste ist eine geordnete Sammlung von Objekten in R. Im Gegensatz zu Vektoren können in einerListe auch Objekte unterschiedlichen Typs geführt werden. Listen werden mit der Funktion list( )erzeugt (vgl. SACHS und HEDDERICH, 2006, S. 636).
> Liste1 <- list("Zahlen"=1:5,"Buchstaben"=c("A","B","C"),"Logik"=c(T,T,F,F))
> Liste1$Zahlen[1] 1 2 3 4 5
$Buchstaben[1] "A" "B" "C"
$Logik[1] TRUE TRUE FALSE FALSE
>
Auf die einzelnen Listenelemente kann mittels $ bzw. [[ ]] zugegriffen werden.
> names(Liste1)[1] "Zahlen" "Buchstaben" "Matrix"
> length(Liste1)[1] 3
> Liste1$Zahlen[1] 1 2 3 4 5
> Liste1$Buchstaben[1] "A" "B" "C"
> Liste1[[3]]> Liste1[[3]][1] TRUE TRUE FALSE FALSE
> Liste1$Buchstaben[2][1] "B">> Liste1[[3]][1][1] TRUE
Aufgabe: Erzeugen Sie eine Liste mit 3 Variablen und jeweils 4 Beobachtungen: Geschlecht= m, w, w,m; Einkommen=2599,2200,3000,4000; verheiratet= T, F, F, T
Wirtschafts- und Sozialstatistik, Universität Trier Seite 17

Einführung in R Melanie Knobelspies
2.7 Matrizen
2.7.1 Generierung von Matrizen
Eine Matrix besteht aus einer beliebigen Anzahl von Vektoren gleichen Typs (numeric !) und gleicherLänge. Die Anzahl der Zeilen und der Spalten legt die Dimension der Matrix (Zeile × Spalte) fest.
X =
a11 a12 . . . aik
a21 a22 . . . a2k...
...an1 a12 . . . ank
Am einfachsten können Matrizen in R durch Zusammenfügung von Vektoren erzeugt werden. Mit derFunktion rbind( ) gechieht dies zeilenweise (r steht für row) und mit der Funktion cbind( )spaltenweise (c steht für column).
>> a <- c(1,2,3,4,5,6)> b <- rep(1,6)> X <- cbind(a,b)> Y <- rbind(a,b)> X
a b[1,] 1 1[2,] 2 1[3,] 3 1[4,] 4 1[5,] 5 1[6,] 6 1> Y
[,1] [,2] [,3] [,4] [,5] [,6]a 1 2 3 4 5 6b 1 1 1 1 1 1
Matrizen können auch direkt über den matrix( ) Befehl erzeugt werden.
> X <- matrix(data=1:12,nrow=4,ncol=3) # Achtung die alte X Matrix# wird jetzt überschrieben
> X[,1] [,2] [,3]
[1,] 1 5 9[2,] 2 6 10[3,] 3 7 11[4,] 4 8 12
Wirtschafts- und Sozialstatistik, Universität Trier Seite 18

Einführung in R Melanie Knobelspies
• Der Parameter data legt die Elemente der Matrix fest.
• Der Parameter ncol legt die Spalten der Matrix fest.
• Der Parameter nrow legt die Zeilen der Matrix fest.
Mit dem Argument byrow=T wird eine zeilenweise Belegung der Matrix mit den Daten erreicht (de-fault ist byrow=F, also eine spaltenweise Belegung).
> Z <- matrix(data=1:12,nrow=4,ncol=3,byrow=T)> Z
[,1] [,2] [,3][1,] 1 2 3[2,] 4 5 6[3,] 7 8 9[4,] 10 11 12
Eine dritte Möglichkeit Matrizen in R zu generieren, ergibt sich durch die Verwendung des dim( )Befehls.
> A <-1:15> dim(A)<-c(5,3)> A
[,1] [,2] [,3][1,] 1 6 11[2,] 2 7 12[3,] 3 8 13[4,] 4 9 14[5,] 5 10 15
2.7.2 Arbeiten mit Matrizen
Addition und Subtraktion zweier Matrizen X und ZBeachte: gleiche Dimension!
X - Z
Multiplikation einer Matrix X mit einer Konstanten a a * X
Transponierte Matrix XT t(X)
Matrixmultiplikation: XT Z mit dem Operator % ∗% t(X) %*% Z
Berechnung des Kreuzprodukts XT X crossprod(X)
Matrixinversion: X−1 solve(X)
Wirtschafts- und Sozialstatistik, Universität Trier Seite 19

Einführung in R Melanie Knobelspies
Weiterhin erlaubt R die Abfrage bestimmter Matrixeigenschaften:
• dim(X) : Dimension der Matrix
• nrow(X) : Anzahl der Spalten
• ncol(X) : Anzahl der Zeilen
• mode(X) : Typ der Elemente
Zugriff auf einzelne Elemente einer Matrix, auf komplette Spalten oder auf komplette Zeilen geschieht(wie bei Vektoren) mittels eckigen Klammern.
Für die Matrix X
X =
1 2 34 5 67 8 9
liefert X[1,] die erste Zeile der Matrix (1,2,3), während X[,2] die zweite Spalte der Matrix angibt(2,5,8).Einen einzelnen Wert erhält man über X[Zeile,Spalte]. So liefert beispielsweise X[2,3] denWert 6.
2.7.3 Zuweisung von Variablennamen
Sollen den einzelnen Zeilen und Spalten einer Matrix Namen zugewiesen werden, so geschieht dies mitder Funktion dimnames( ).
>> dimnames(Z)NULL>>> Spalten <- c("Variable 1","Variable 2","Variable 3")>> Zeilen <- c("Beobachtung 1","Beobachtung 2","Beobachtung 3",
"Beobachtung 4")> dimnames(Z) <- list(Zeilen,Spalten)> Z
Variable 1 Variable 2 Variable 3Beobachtung 1 1 2 3Beobachtung 2 4 5 6Beobachtung 3 7 8 9Beobachtung 4 10 11 12>
Wirtschafts- und Sozialstatistik, Universität Trier Seite 20

Einführung in R Melanie Knobelspies
>> dimnames(Z)[[1]][1] "Beobachtung 1" "Beobachtung 2" "Beobachtung 3" "Beobachtung 4"
[[2]][1] "Variable 1" "Variable 2" "Variable 3"
>
Nun kann auf die Zeilen und Spalten der Matrix X auch mit ihrem Namen zugegriffen werden (beachtehierbei die Hochkommatas).
>> X[,Variable 2]Fehler: Syntaxfehler in Zeile "X[,Variable 2"> X[,"Variable 2"]Beobachtung 1 Beobachtung 2 Beobachtung 3 Beobachtung 4
13 17 5 3> X["Beobachtung 2","Variable 2"][1] 17>> X["Beobachtung 1",c("Variable 1","Variable 3")]Variable 1 Variable 3
9 1>
Wirtschafts- und Sozialstatistik, Universität Trier Seite 21

Einführung in R Melanie Knobelspies
2.8 Data.frames
Ein Data. frame ist eine Kombination aus Liste und Matrix. Er enthält Vektoren unterschiedlichen Typs(Merkmale, Variablen) gleicher Länge, wie sie im Rahmen von Erhebungen und Experimenten häufigauftreten. Diese Datenrahmen können durch die Funktion data.frame( ) aus Vektoren erzeugt oderaus externen Dateien mit der Funktion read.table( ) in R eingelesen werden (vgl. SACHS undHEDDERICH, 2006, S. 636).
> Gehalt <- data.frame(Alter=c(23,25,30,45,35),Einkommen=c(1000,3000,3500,4000,2500),Geschlecht=c("m","w","w","m","m"))
> GehaltAlter Einkommen Geschlecht
1 23 1000 m2 25 3000 w3 30 3500 w4 45 4000 m5 35 2500 m
In Analogie zu Matrizen besitzt ein data.frame auch eine Dimension, die über dim( ) abgefragt wer-den kann.Die Länge hingegen entspricht nicht der Anzahl der Elemente, sondern der Anzahl der Spalten einesdata.frames.
> is.data.frame(Gehalt)[1] TRUE
> length(Gehalt)[1] 3 # vgl. mit length(as.matrix(Gehalt))
> dim(Gehalt)[1] 5 3
Um eine Variable anzusprechen, vewendet man das $-Zeichen .
> Gehalt$Alter # oder Gehalt[1][1] 23 25 30 45 35
Alternativ kann mittels attach(Datensatz) der Datensatz an zweiter Stelle des Objektsuchpfadesangebracht werden. Somit können einzelne Variablen direkt angesprochen werden.Mit detach( ) wird der Datensatz wieder aus dem Objektsuchpfad entfernt.
> attach(Gehalt)> Einkommen[1] 1000 3000 3500 4000 2500> detach(Gehalt)> EinkommenFehler: objekt "Einkommen" nicht gefunden
Wirtschafts- und Sozialstatistik, Universität Trier Seite 22

Einführung in R Melanie Knobelspies
2.9 Aufgaben zu Matrizen und Data.frames
1. Erzeugen Sie folgende Matrix X1 und transponieren Sie diese.
X1 =
9 13 15 17 58 5 71 3 4
2. Greifen Sie die entsprechenden Zeilen und Spalten der Matrix X ab, so dass sie die reduzierte
Matrix X2 erhalten.
X2 =
(5 17 58 5 7
)3. Erweitern Sie die Matrix X2 um die Zeile (10, 10, 10) und benennen Sie Ihre neue Matrix X3.
4. Berechnen Sie das Kreuzprodukt von X3 und bilden Sie die Inverse davon. Was fällt Ihnen auf?
5. Benennen Sie die einzelnen Zeilen und Spalten der Matrix X3 mit frei gewählten Namen.
6. Berechnen Sie die Kovarianz sowie die Korrelation zwischen den Elementen der Matrix X3.
7. Setzen Sie alle Elemente der Matrix X3, die größer als 8 sind, auf NA.
8. Erstellen Sie folgenden data.frame:
Semesterzahl Alter Studiengang Geschlecht4 22 VWL m7 25 BWL w5 24 VWL m4 21 Soz m9 25 VWL w8 26 VWL m2 23 BWL w3 21 Soz m
• Berechnen Sie das mittlere Alter.
• Wandeln Sie die Variable Geschlecht in einen Faktor um.
• Teilen Sie den Datensatz anhand des Geschlechts in zwei getrennte Datensätze.
• Stellen Sie die Häufigkeitsverteilung des Studienfachs graphisch dar (Hinweis: BenutzenSie den barplot( ) Befehl).
• Wandeln Sie den Datensatz in eine Matrix um. Verwenden Sie einmal den Befehl as.matrix( )und einmal den Befehl data.matrix( ). Worin liegt der Unterschied zwischen diesenbeiden Befehlen?
• Betrachten Sie nur den reduzierten data.frame der VWL– und BWL–Studenten. BenutzenSie hierbei den subset() Befehl.
Hinweis: Die Lösung finden sie in der Datei Matrizen.r
Wirtschafts- und Sozialstatistik, Universität Trier Seite 23

Einführung in R Melanie Knobelspies
3 Zufallsvariablen in R
In R existieren Funktionen, um Werte von Dichte– und Verteilungsfunktionen sowie Quantile von Zu-fallsvariablen mit vorgegebener Verteilung zu berechnen. Den gewünschten Verteilungen wird jeweilsnach Fragestellung der Buchstabe d, p, oder q vorangestellt. Weiterhin besteht die Möglichkeit sich inR (Pseudo–) Zufallszahlen gemäß der gewünschten Verteilung erzeugen zu lassen.
Anfangsbuchstabe Art der Funktion
d (density) Dichte– bzw. Wahrscheinlichkeitsfunktion
p (probability) Verteilungsfunktion
q (quantiles) Berechnung von Quantilen
r (random) Erzeugung von Pseudo–Zufallszahlen
Die nachfolgende Tabelle enthält eine Übersicht über die gebräuchlichsten Verteilungen. Es wird jeweilsx durch d, p, q oder r ersetzt.
Verteilung Funktion
Normalverteilung xnorm( )
Binomialverteilung xbinom( )
χ2-Verteilung xchisq( )
Logistische Verteilung xlogis( )
Exponentialverteilung xexp( )
F–verteilung xf( )
t–verteilung xt( )
Gleichverteilung xunif( )
Hypergeometrische Verteilung xhyper( )
Poisson Verteilung xpois( )
Betrachtet man beispielsweise eine binomialverteilte Zufallsvariable mit den Parametern n = 10 undθ = 0,6
b(x|10, 0,6) =
(
10
x
)· 0,6x · (1− 0,6)10−x für x = 0, 1, 2, . . . , 10
0 sonst
so ergeben sich die Wahrscheinlichkeiten W (X = 0), W (X = 1), W (X = 2), W (X = 3), W (X = 4)über den Befehl:
dbinom(0:4,size=10,prob=0.6)
Die entsprechenden Wahrscheinlichkeiten der Verteilungsfunktion, also W (X ≤ 0), W (X ≤ 1),W (X ≤ 2), W (X ≤ 3), W (X ≤ 4) dieser Zufallsvariable erhält man über:
pbinom(0:4,size=10,prob=0.6)
Wirtschafts- und Sozialstatistik, Universität Trier Seite 24

Einführung in R Melanie Knobelspies
Gibt man zusätzlich noch das Argument lower.tail=FALSEmit, so lässt sich die Gegenwahrschein-lichkeit W (X > . . .) berechnen.
Ist man hingegen an den Quantilen interessiert, so liefert die Funktion
qbinom(c(0.1,0.9),size=10,prob=0.6)
die Werte, an welchen die Verteilungsfunktion die Wahrscheinlichkeit 0,1 bzw. 0,9 besitzt (qbinom istalso die Umkehrfunktion von pbinom).
Mit rbinom(20,10,0.6) erhält man hingegen 20 binomialverteilte Zufallszahlen, die einer Bino-mialverteilung mit den Parametern n = 10 und θ = 0,6 folgen.
Durch die Verwendung des Befehls set.seed( ) kann eine Reproduzierbarkeit der Zufallsvariablenerzeugt werden.
>set.seed(123)>rbinom(20,10,0.6)[1] 7 5 6 4 4 9 6 4 6 6 3 6 5 6 8 4 7 9 7 3>rbinom(20,10,0.6)[1] 4 5 5 2 5 5 6 6 7 8 3 4 5 5 9 6 5 7 7 7>set.seed(123)>rbinom(20,10,0.6)[1] 7 5 6 4 4 9 6 4 6 6 3 6 5 6 8 4 7 9 7 3
Beispiel:
Die nachfolgende Graphik lässt sich mit folgendem R–Code erzeugen:
x <- seq(-5,5,by=0.1)ZV1 <-dnorm(x,0,1)ZV2 <-dnorm(x,0,2)plot(x,ZV1,type="l",main="Dichtefunktionen")lines(x,ZV2,type="l",col="red")text(1.3,0.36,"ZV1")text(3,0.1,"ZV2",col="red")
Alternativ geht auch:
Vtlg1 <-pnorm(x,0,1)Vtlg2 <-pnorm(x,0,2)plot(x,Vtlg1,type="l",main="Verteilungsfunktionen")lines(x,Vtlg2,type="l",col="red")
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
Dichtefunktionen
x
ZV
1
ZV1
ZV2
Wirtschafts- und Sozialstatistik, Universität Trier Seite 25

Einführung in R Melanie Knobelspies
Aufgaben zu Zufallsvariablen
1. Was liefert pnorm(c(-2,3))?
2. Was liefert qnorm(0.2,2,3)?
3. Berechnen Sie die Wahrscheinlichkeiten für X = 0, 2, . . . , 10 von 20 poissonverteilten Zufallsvari-ablen mit Parameter λ = 2,5 und zeichnen Sie die Wahrscheinlichkeitsfunktion.Hinweis: Benutzen Sie den plot( ) Befehl mit dem Argument type="h".
4. Berechnen Sie die entsprechenden Werte der Verteilungsfunktion der Zufallsvariablen aus 3.
5. Wie groß ist die Wahrscheinlichkeit in 10 Münzwürfen vier mal Kopf zu erzielen?
6. Wie groß ist die Wahrscheinlichkeit in 10 Münzwürfen mehr als vier mal Kopf zu erzielen?
7. Angenommen 1% aller Schulkinder können vor ihrer Einschulung schon lesen und schreiben.Wie groß ist die Wahrscheinlichkeit, dass in einer 1. Klasse von 30 Schülern keines, 1 Kind bzw.2 Kinder schon lesen und schreiben können?
8. Generieren Sie 50 standardnormalverteilte Zufallszahlen und stellen Sie diese anhand eines (rel-ativen) Histogramms graphisch dar. Schätzen Sie µ und σ2 ihrer Stichprobe und zeichnen Sie dieDichtefunktion der Normalverteilung mit den geschätzten Parametern µ und σ2 in die bestehendeGraphik ein.
9. Generieren Sie 50 binomialverteilte Zufallszahlen mit Parameter θ = 0,25. Zeigen Sie anhandeiner geeigneten Graphik, inwieweit die Binomialverteilung durch die Normalverteilung approx-imiert werden kann.Hinweis: µ = n · θ , σ2 = n · θ · (1− θ)
10. In einer Population von jungen Frauen sei die Körpergröße normalverteilt mit µ = 166,5 cm undσ = 6,5 cm.
(a) Bestimmen Sie ein 95% Konfidenzintervall.
(b) Simulieren Sie das Ziehen einer Stichprobe vom Umfang n = 9 aus dieser Population. Wiegroß ist der Mittelwert und die Standardabweichung Ihrer Stichprobe? Was für einen Werterwarten Sie?
(c) Berechnen Sie aus Ihrer Stichprobe ein 95%–Konfidenzintervall für µ. Liegt µ, das Sie ausder Aufgabenstallung kennen innerhalb dieses Intervalls?
11. Bei einem Klassentreffen des Abiturjahrgangs 2003 unterhalten sich die N = 400 Teilnehmerüber ihren beruflichen Werdegang. Aus den Gesprächen wird ersichtlich, dass sich 270 Teilnehmeran einer Universität eingeschrieben haben. Bei einer zufälligen Stichprobe (Modell ohne Zurück-legen) vom Umfang n = 18 wurde die Anzahl der Studenten in der Stichprobe ermittelt.
(a) Bestimmen Sie die Wahrscheinlichkeit, dass genau 12 Studenten in der Stichprobe enthaltensind (Hinweis: Verwenden Sie die Hypergeometrische Verteilung).
(b) Bestimmen Sie die Wahrscheinlichkeit, dass höchstens 15 Studenten in der Stichprobe en-thalten sind. Benutzen Sie hierbei die Approximation durch die Standardnormalverteilungmit den Parametern µ = n · M
Nund σ2 = n · M
N· (1− M
N) · N−n
N−1.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 26

Einführung in R Melanie Knobelspies
12. In einer Schokoladenfabrik werden täglich 500 000 Schokoladentafeln XXL produziert. Bei ein-er Zufallsstichprobe von n = 41 Tafeln wurde ein durchschnittliches Gewicht einer Tafel von202 Gramm ermittelt. Der Mittelwert des Gewichts aller produzierten Tafeln ist unbekannt. Ausvorangegangenen Untersuchungen ist jedoch bekannt, dass die Standardabweichung 10g beträgt.Ferner darf von einer normalverteilten Grundgesamtheit ausgegangen werden.
(a) Ermitteln Sie ein 90% Konfidenzintervall für das durchschnittliche Gewicht einer Schoko-ladentafel und begründen Sie, warum von einem Modell mit Zurücklegen ausgegangen wer-den darf.Hinweis: KI für µ bei normalverteilter GG und bekanntem σ2:[
x− z(1− α/2) · σ√n
; x + z(1− α/2) · σ√n
](b) Angenommen die Varianz σ2 sei unbekannt. Aus der Stichprobe sei jedoch die Varianz
s2 = 90 g2 bekannt. Bestimmen Sie ein 95% Konfidenzintervall für die Varianz σ2 desdurchschnittlichen Gewichts.Hinweis: KI für σ2 bei normalverteilter GG:[
(n− 1) · s2
χ2(1− α2
; n− 1);
(n− 1) · s2
χ2(α2
; n− 1)
]
Hinweis: Die Lösung befindet sich in der Datei Zufallsvariable.r
Wirtschafts- und Sozialstatistik, Universität Trier Seite 27

Einführung in R Melanie Knobelspies
4 Stichproben in R
Für das Ziehen von Stichproben gibt es in R die Funktion sample(). Hierbei wird aus dem Vektor xeine Stichprobe der Größe n gezogen. Mit replace kann bestimmt werden, ob das Modell mit oderohne Zurücklegen zugrunde liegt.
sample(x, size, replace = FALSE, prob = NULL)
> #Simulation von 50 Würfelwürfen>> x <- 1:6>> stichprobe <- sample(x,size=50,replace=T) #Modell mit ZL>> table(stichprobe)stichprobe1 2 3 4 5 69 9 6 7 9 10>
Mit der Option prob können den einzelnen Elemeneten von x unterschiedliche Wahrscheinlichkeitenzugeordnet werden. Wird hier nichts angegeben, hat jedes Element von x dieselbe Wahrscheinlichkeit.
Beispiel
Eine Urne enthält 4 Kugeln die 50g wiegen und 6 Kugeln, die 100g wiegen. Aus dieser Urne soll nuneine Stichprobe (Modell mit Zurücklegen) des Umfangs n = 3 gezogen werden.
sample(x=c(50,100),size=3,replace=TRUE,prob=c(0.4,0.6))[1] 100 50 50
Natürlich geht auch hier wieder die Kurzschreibweise.
sample(c(50,100),3,TRUE,c(0.4,0.6))
Beachte: Mit Hilfe der probOption können Sie keine validen Ziehungen mit unterschiedlichen Auswahl-wahrscheinlichkeiten erzeugen. Dazu dient das Paket sampling.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 28

Einführung in R Melanie Knobelspies
5 Kontroll–Strukturen
Kontroll–Strukturen werden benötigt, wenn man häufiger die gleiche Anweisungsfolge bei eventuellunterschiedlichen Parameterkonstellationen ausführen will (vgl. SCHLITTGEN, 2004, S. 307). In R sinddas bedingte Anweisungen und Schleifen.
5.1 Bedingte Anweisungen
if (Bedingung){Ausführen falls Bedingung wahr}
else{Ausführen falls Bedingung falsch}
• Beachte: Die Bedingung in dieser Form darf nicht vektorwertig sein, bzw. wird dann nur das ersteElement des Vektors ausgewertet.
• Die Bedingung kann ein komplexer logischer Ausdruck sein, der entsprechend auch und und oderVerknüpfungen enthält.
• Daneben existiert noch eine Kurzform für die vektorwertige Auswertung von Bedingungen.
ifelse(Bedingung, Ja, Nein)
• Dieser Befehl hilft insbesondere bei Kodierung von Variablen.
5.2 Schleifen
for(i in M) {Ausdruck} Wiederholung des Ausdrucks für jedes i ∈ M
while (Bedingung) Wiederholung so lange ein bestimmtes Kriterium erfüllt ist
repeat{Ausdruck} Im Gegensatz zur while–Schleife, kennt die repeat–Schleifekein Abbruchkriterium, sondern kann nur mit break beendetwerden.
break Sofortiges Verlassen der Schleife
next Sprung in den nächsten Iterationsschritt
Wirtschafts- und Sozialstatistik, Universität Trier Seite 29
Einführung in R Melanie Knobelspies
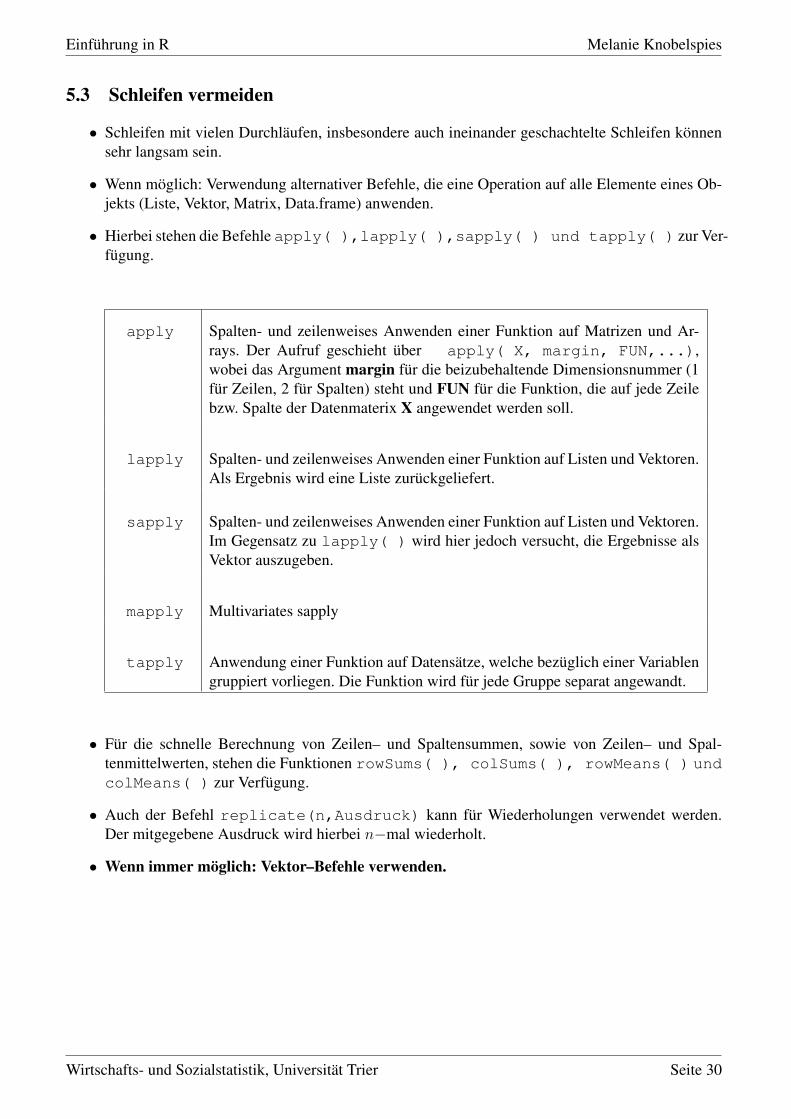
5.3 Schleifen vermeiden
• Schleifen mit vielen Durchläufen, insbesondere auch ineinander geschachtelte Schleifen könnensehr langsam sein.
• Wenn möglich: Verwendung alternativer Befehle, die eine Operation auf alle Elemente eines Ob-jekts (Liste, Vektor, Matrix, Data.frame) anwenden.
• Hierbei stehen die Befehle apply( ),lapply( ),sapply( ) und tapply( ) zur Ver-fügung.
apply Spalten- und zeilenweises Anwenden einer Funktion auf Matrizen und Ar-rays. Der Aufruf geschieht über apply( X, margin, FUN,...),wobei das Argument margin für die beizubehaltende Dimensionsnummer (1für Zeilen, 2 für Spalten) steht und FUN für die Funktion, die auf jede Zeilebzw. Spalte der Datenmaterix X angewendet werden soll.
lapply Spalten- und zeilenweises Anwenden einer Funktion auf Listen und Vektoren.Als Ergebnis wird eine Liste zurückgeliefert.
sapply Spalten- und zeilenweises Anwenden einer Funktion auf Listen und Vektoren.Im Gegensatz zu lapply( ) wird hier jedoch versucht, die Ergebnisse alsVektor auszugeben.
mapply Multivariates sapply
tapply Anwendung einer Funktion auf Datensätze, welche bezüglich einer Variablengruppiert vorliegen. Die Funktion wird für jede Gruppe separat angewandt.
• Für die schnelle Berechnung von Zeilen– und Spaltensummen, sowie von Zeilen– und Spal-tenmittelwerten, stehen die Funktionen rowSums( ), colSums( ), rowMeans( ) undcolMeans( ) zur Verfügung.
• Auch der Befehl replicate(n,Ausdruck) kann für Wiederholungen verwendet werden.Der mitgegebene Ausdruck wird hierbei n−mal wiederholt.
• Wenn immer möglich: Vektor–Befehle verwenden.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 30

Einführung in R Melanie Knobelspies
Beispiele:
> A <- matrix(c(1:10,rep(5,10)),ncol=2)> A
[,1] [,2][1,] 1 5[2,] 2 5[3,] 3 5[4,] 4 5[5,] 5 5[6,] 6 5[7,] 7 5[8,] 8 5[9,] 9 5[10,] 10 5
> apply(A,1,sum)[1] 6 7 8 9 10 11 12 13 14 15
> apply(A,2,sum)[1] 55 50>
> lapply(1:3,sqrt)[[1]][1] 1
[[2]][1] 1.414214
[[3]][1] 1.732051
> sapply(1:3,sqrt)[1] 1.000000 1.414214 1.732051>
> a <- 1:10> Index <- c(1,1,1,1,1,2,2,2,2,3)> tapply(a,Index,sum)1 2 315 30 10
Wirtschafts- und Sozialstatistik, Universität Trier Seite 31

Einführung in R Melanie Knobelspies
5.4 Exkurs: Eigene Funktionen schreiben
Eine Funktionsdefinition geschieht mittels function( ) und hat die Form
Funktionsname <- function(Argumente){Befehlsfolge
}
• Beim Aufruf der Funktion werden die Argumente als Objekte an die Befehlsfolge der Funktionweitergereicht.
• Alles in den geschweiften Klammern wird beim Aufruf der Funktion ausgeführt.
• Das in der letzten Zeile erzeugte Objekt wird nach dem Aufruf zurück gegeben.
• Mit return( ) kann der Wert an einer anderen Stelle zurück gegeben werden.
• Beispiel: Funktion für die Standardabweichung:
> stdabw <- function(x){+ anzahl <- length(x)+ summe <- sum(x)+ mittel <- summe/anzahl+ saq <- sum((x-mittel)^2)+ abw <- (sqrt(saq/anzahl-1))+ return(abw)+ }>> a <- c(3,6,7,10,13,14,18)>> stdabw(a)[1] 4.718613>
• Mehrere Ergebnisse können in einer Liste mit list( ) zusammengefasst werden.
• print( ) bzw. cat( ) eignen sich zur Ausgabe von Informationen oder Objekten in Textformauf die Konsole oder in Textdateien.
• Es besteht auch die Möglichkeit die Argumente einer Funktion mit einer Standardbelegung zuversehen.
• Vorzeitiges Beenden einer Funktion geschieht mit dem Befehl stop("Fehlermeldung").
• Mit der Funktion missing( ) lässt sich überprüfen, ob alle benötigten Argumente einer Funk-tion angegeben sind.
• Eine Abfrage der Zeit (d.h. wie lang die Funktion für die Berechnung braucht) erhält man überden Befehl system.time(Funktion)[3].
Wirtschafts- und Sozialstatistik, Universität Trier Seite 32

Einführung in R Melanie Knobelspies
Aufgaben
1. Gummibärchen gibt es in 5 verschiedenen Farben mit folgenden Wahrscheinlichkeiten:
Farbe rot gelb grün orange weißWahrscheinlichkeit 0,3 0,3 0,15 0,15 0,1
Eine kleine 100g Tüte enthält ca. 60 Gummibärchen. Simulieren Sie eine solche Gummibärchen-tüte und zählen Sie die Anzahl Gummibärchen pro Farbe.
2. Laden Sie aus der library car den Datensatz Prestige. Untersuchen Sie die Verteilung der Vari-ablen income.Nehmen Sie an, dass es sich bei diesem Datensatz um eine Grundgesamtheit handelt. Ziehen Sieeine Zufallsstichprobe des Umfangs n = 50 der Variablen income, und schauen Sie sich dieVerteilung des Einkommens dieser Stichprobe an.Wiederholen Sie den Vorgang r-mal (variieren Sie r mit 50, 100, 200, 500) und ermitteln Siejeweils die Mittelwerte dieser r Stichproben. Schauen Sie sich die Verteilung der Mittelwerte an.Welche Verteilung vermuten Sie?
3. Schreiben Sie eine Funktion für das geometrische Mittel.Hinweis:
g =n∏
i=1
(xi)1n = exp
(1
n
n∑i=1
log(xi)
)
4. Schreiben Sie eine Funktion zur Berechnung der Dichte einer Normalverteilung an einer be-liebigen Stelle x. Bauen Sie in die Funktion anhand einer if–else–Bedingung eine Kontrolle ein,welche darauf achtet, dass der Wert x in der Funktion angegeben wird.Hinweis: Die Dichte der Normalverteilung an der Stelle x ∈ R ist gegeben durch:
f(x) =1√
2πσ2exp
(−(x− µ)2
2σ2
)5. Schreiben Sie eine Funktion zur Berechnung eines t−Tests für zwei unverbundene Stichproben
(Annahme: NV, Varianz unbekannt aber identisch).
Testwert =X1 −X2√
S2 · ( 1n1
+ 1n2
)mit S2 =
(n1 − 1)S21 + (n2 − 1)S2
2
n1 + n2 − 2
6. Schreiben Sie eine Funktion für ein Würfelexperiment. Ein Würfel soll n = 10-mal geworfenwerden und die Funktion soll folgendes in Form einer Liste ausgeben:
• Die geworfenen Zahlen.
• Eine Häufigkeitstabelle der geworfenen Zahlen.
• Wie oft die Augenzahl 5 geworfen wurde.
Hinweis: Die Lösung befindet sich in der Datei Funktionen.r
Wirtschafts- und Sozialstatistik, Universität Trier Seite 33

Einführung in R Melanie Knobelspies
6 Graphiken in R
R unterscheidet zwischen sogenannten High Level Graphiken und Low Level Graphiken. High Lev-el Graphiken öffnen ein eigenes Graphikausgabefenster und erlauben eine vollständige Graphik mitAchsen und Beschriftungen. Mit Low Level Graphiken hingegen können zusätzliche Punkte, Linien,Beschriftungen oder ähnliches zu einer schon bestehenden Graphik hinzugefügt werden. Low LevelGraphiken dienen somit zur Modifizierung und Erweiterung von High Level Graphiken (siehe hierzuauch Kapitel 8 in LIGGES, 2006).
6.1 High Level Graphiken
Der plot Befehl
Die wichtigste High Level Graphik ist die plot( ) Funktion. Je nach mitgegebenen Argumentenliefert diese Funktion andere Graphikausgaben. In der einfachsten Form plot(x) wird ein Indexplotdes Vektors x erstellt. Mit dem Befehl plot(x,y) werden die Werte von x gegen die Werte vony abgetragen. Hierbei erfolgt eine automatische Achsenskalierung, so dass der gesamte Wertebereichbeider Variablen abgedeckt ist.
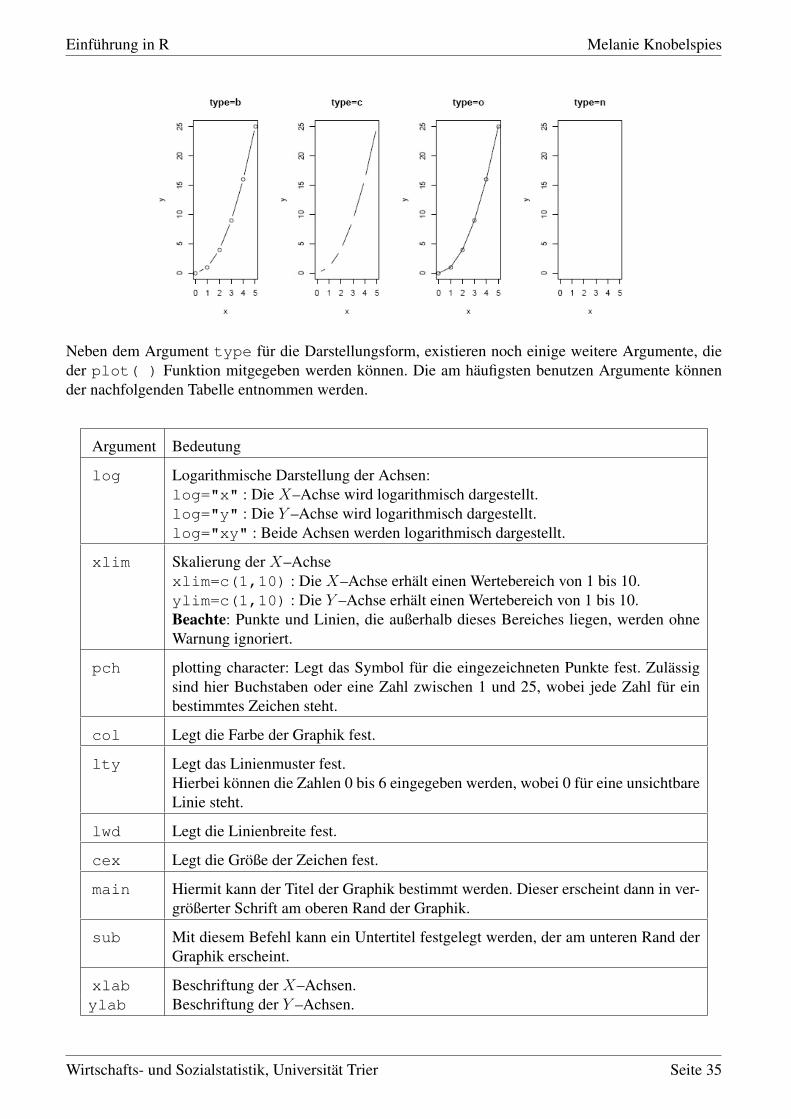
Durch das Argument type kann die Darstellungsform festgelegt werden (vgl. DOLIC, 2004, S. 78).
• type="p" erzeugt Punkte (Voreinstellung);
• type="l" erzeugt eine durchgezogene Linie;
• type="h" erzeugt vertikale Linien;
• type="s" erzeugt eine Treppenfunktion;
• type="b" erzeugt eine Linie mit Punkten bei den Werten;
• type="c" erzeugt eine Linie mit Lücken bei den Werten;
• type="o" erzeugt eine durchgezogene Linie mit Punkten bei den Werten;
• type="n" erzeugt lediglich ein leeres Koordinatensystem.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 34
Einführung in R Melanie Knobelspies
Neben dem Argument type für die Darstellungsform, existieren noch einige weitere Argumente, dieder plot( ) Funktion mitgegeben werden können. Die am häufigsten benutzen Argumente könnender nachfolgenden Tabelle entnommen werden.
Argument Bedeutung
log Logarithmische Darstellung der Achsen:log="x" : Die X–Achse wird logarithmisch dargestellt.log="y" : Die Y –Achse wird logarithmisch dargestellt.log="xy" : Beide Achsen werden logarithmisch dargestellt.
xlim Skalierung der X–Achsexlim=c(1,10) : Die X–Achse erhält einen Wertebereich von 1 bis 10.ylim=c(1,10) : Die Y –Achse erhält einen Wertebereich von 1 bis 10.Beachte: Punkte und Linien, die außerhalb dieses Bereiches liegen, werden ohneWarnung ignoriert.
pch plotting character: Legt das Symbol für die eingezeichneten Punkte fest. Zulässigsind hier Buchstaben oder eine Zahl zwischen 1 und 25, wobei jede Zahl für einbestimmtes Zeichen steht.
col Legt die Farbe der Graphik fest.
lty Legt das Linienmuster fest.Hierbei können die Zahlen 0 bis 6 eingegeben werden, wobei 0 für eine unsichtbareLinie steht.
lwd Legt die Linienbreite fest.
cex Legt die Größe der Zeichen fest.
main Hiermit kann der Titel der Graphik bestimmt werden. Dieser erscheint dann in ver-größerter Schrift am oberen Rand der Graphik.
sub Mit diesem Befehl kann ein Untertitel festgelegt werden, der am unteren Rand derGraphik erscheint.
xlab Beschriftung der X–Achsen.ylab Beschriftung der Y –Achsen.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 35

Einführung in R Melanie Knobelspies
Argument Bedeutung
axes Der Befehl axes=FALSE unterdrückt das Zeichnen der Achsen.
las Ausrichtung der Achsenskalenbeschriftung.las=0 : Text steht waagrecht zur jeweiligen Achse.las=1 : Text steht waagrecht.las=2 : Text steht senkrecht zur jeweiligen Achse.las=3 : Text steht senkrecht.
tcl Länge der Tickmarks.
adj Ausrichtung von geplottetem Text.
pch–Symbole
Linientypen
Wirtschafts- und Sozialstatistik, Universität Trier Seite 36

Einführung in R Melanie Knobelspies
Möchte man für mehrere Graphiken dieselben Argumente verwenden, so empfiehlt es sich über dieFunktion par( ) die Voreinstellung in den einzelnen Graphikfunktionen zu überschreiben. Diese Ein-stellungen werden für alle nachfolgenden Graphiken beibehalten bis sie explizit mit par( ) wiedergeändert werden, oder ein neues Graphikfenster aufgerufen wird.Hierbei können sämtliche Argumente verwendet werden, die im Kontext der plot Funktion eingeführtwurden. Darüber hinaus existieren noch einige weitere Argumente. Einen Überblick hierzu findet manin der R–Hilfe unter ?par bzw. par().
Seiten–Layout Funktionen
Möchte man das Seitenlayout ändern (z.B. breitere Ränder, oder mehrere Graphiken in einem Fenster)so wird hierfür auch die Funktion par verwendet.
Argument Bedeutung
mgp=c(x1,x2,x3) Legt den Abstand der Achsenbeschriftung (x1), derAchsenskalenbeschriftung (x2) und der Achsenlinie (x3)in relativen Einheiten der Schriftgröße im Plotrand fest.
mfrow=c(z,s) Teilt das Graphikfenster in z × s einzelne Graphikbe-reiche. Somit erhält man einen Mehrfach–Plotrahmen. DasGraphikfenster wird dann zeilenweise mit den Graphikengefüllt.
mfcol=c(z,s) Analog zu mfrow=c(z,s), mit dem Unterschied, dassdie Seite spaltenweise mit Graphiken gefüllt wird.
oma=c(u,l,o,r) Spezifiziert die maximale Textzeilenzahl für den unteren(u), linken (l), oberen (o) und rechten (r) äußeren Seiten-rand eines Mehrfach–Plotrahmens. Diese können dann mitmtext (siehe Low–Level Graphiken) beschriftet werden.
mar=c(u,l,o,r) Bestimmt die Breite der Seitenränder (unten, links, obenrechts) eines einzelnen Plotrahmens.
pty Setzt den aktuell gültigen Plotrahmen fest. pty=m erzeugteinen maximalen (meist rechteckigen) Plotrahmen (Vorein-stellung) und pty=s einen quadratischen.
Neben par(mfrow=c(z,s)) existieren noch 2 weitere Funktionen, die es ermöglichen mehrerePlots in einem Fenster zu platzieren.
1. layout(matrix, width, heights)Diese Funktion arbeitet so ähnlich wie mfrow, ist aber flexibler in der Einteilung. matrix gibtdie Einteilung des Fensters an. widths und heights stehen für die Teilungsverhältnisse derSpalten bzw. Zeilen.
2. split.screen( )Diese Funktion ist am einfachsten zu bedienen. Der Bildschirm wird hier in zwei Unterfensteraufgeteilt. Mit screen(i) kann gezielt ein Unterfenster aktiviert werden und erase.screen()macht die zuletzt gezeichnete Graphik wieder rückgängig.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 37
Einführung in R Melanie Knobelspies
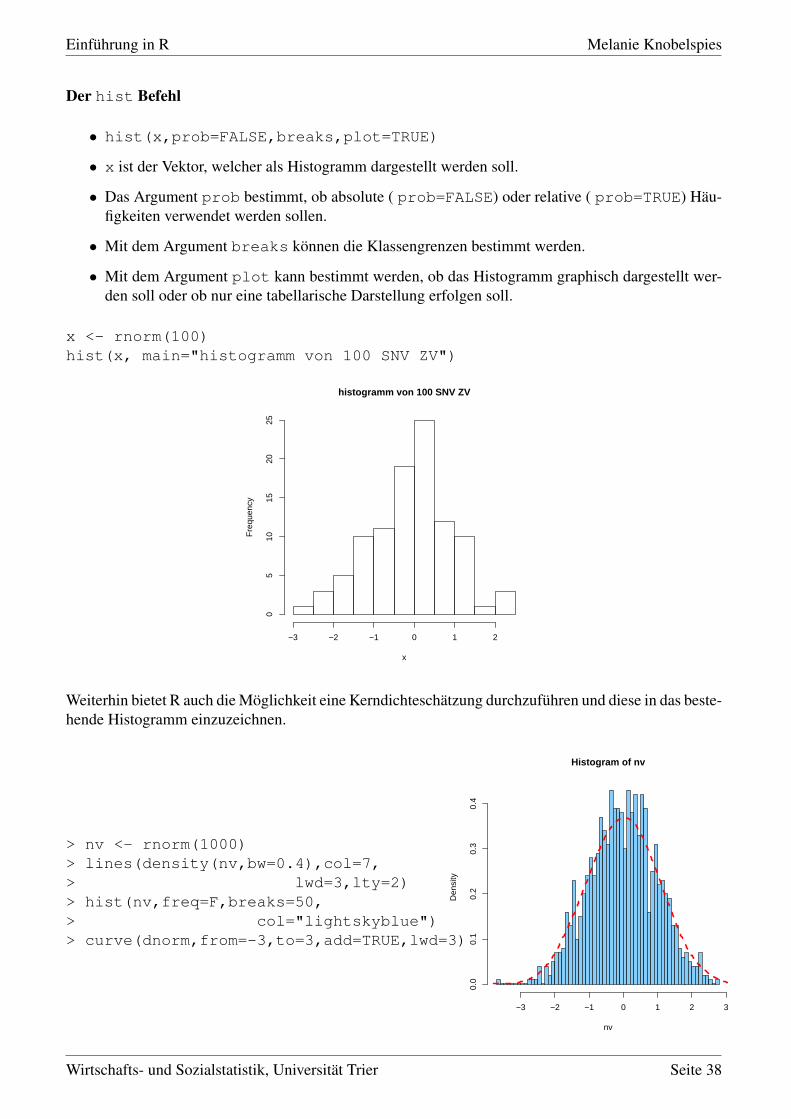
Der hist Befehl
• hist(x,prob=FALSE,breaks,plot=TRUE)
• x ist der Vektor, welcher als Histogramm dargestellt werden soll.
• Das Argument prob bestimmt, ob absolute ( prob=FALSE) oder relative ( prob=TRUE) Häu-figkeiten verwendet werden sollen.
• Mit dem Argument breaks können die Klassengrenzen bestimmt werden.
• Mit dem Argument plot kann bestimmt werden, ob das Histogramm graphisch dargestellt wer-den soll oder ob nur eine tabellarische Darstellung erfolgen soll.
x <- rnorm(100)hist(x, main="histogramm von 100 SNV ZV")
histogramm von 100 SNV ZV
x
Fre
quen
cy
−3 −2 −1 0 1 2
05
1015
2025
Weiterhin bietet R auch die Möglichkeit eine Kerndichteschätzung durchzuführen und diese in das beste-hende Histogramm einzuzeichnen.
> nv <- rnorm(1000)> lines(density(nv,bw=0.4),col=7,> lwd=3,lty=2)> hist(nv,freq=F,breaks=50,> col="lightskyblue")> curve(dnorm,from=-3,to=3,add=TRUE,lwd=3)
Histogram of nv
nv
Den
sity
−3 −2 −1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
Wirtschafts- und Sozialstatistik, Universität Trier Seite 38

Einführung in R Melanie Knobelspies
Der barplot Befehl
Die Funktion barplot erlaubt das Zeichnen von Balkendiagrammen.
> barplot(1:6)
Möchte man die Häufigkeiten von verschiedenen Kategorien darstellen, so müssen die Daten erst ineiner Häufigkeitstabelle tabelliert werden.
> y <-c(1,2,4,5,4,6,3,4,5,6,2,3,1,2,4,5,6,4,3,2,1,6,5,3,2,3,4,2,5)>> barplot(table(y)) # barplot(y) liefert kein sinnvolles Ergebnis
Der boxplot Befehl
Ein Box–and–Whisker–Plot erhält man mit dem Befehl boxplot. Wird bei dieser Funktion das Ar-gument plot auf FALSE gesetzt, so erhält man (wie bei der hist Funktion) anstelle der Graphikeine Übersicht der wichtigsten Statistiken (Quartilswerte, Median, Minima und Maxima, Anzahl derBeobachtungen, . . . )
> set.seed(1)> h <-c(rnorm(100,50,10),> rnorm(10,40,5),100)> boxplot(h,col="lightblue")> text(1.3,28,"Unterer Whisker")> text(1.3,44,"1.Quartil")> text(1.3,56,"3.Quartil")> text(1.3,74,"Oberer Whisker")> text(1.3,50,"Median")> text(1.3,100,"Ausreißer")
●
4060
8010
0
Unterer Whisker
1.Quartil
3.Quartil
Oberer Whisker
Median
Ausreißer
Wirtschafts- und Sozialstatistik, Universität Trier Seite 39

Einführung in R Melanie Knobelspies
Werden mehrere Vektoren der boxplot Funktion mitgegeben, so werden die Boxplots parallel ge-zeichnet. Die verschiedenen Daten in den Vektoren können somit gut miteinander verglichen werden.
>boxplot(rnorm(100),rnorm(100),rnorm(100),rnorm(100))
●
●
●
1 2 3 4
−2
−1
01
23
Der qqnorm Befehl
Mit der Funktion qqnorm werden die Quantile der empirischen Verteilung gegen die die Quantile dertheoretischen Normalverteilung geplottet. Anhand der Abweichungen von der 1. Winkelhalbierenden,die mit dem Befehl qqline nachträglich eingezeichnet werden kann, erkennt man die Abweichungender empirischen Verteilungen. Möchte man beispielsweise 50 exponentialverteilte Zufallsvariablen aufNormalverteiltheit prüfen, so lautet der Befehl:
> y<-rexp(100,0.1)> qqnorm(y,main="Exp.verteilte ZV")> qqline(y,col="red",lwd=2)
●
●
●
●
● ●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
−2 −1 0 1 2
010
2030
40
Exp.verteilte ZV
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Wirtschafts- und Sozialstatistik, Universität Trier Seite 40
Einführung in R Melanie Knobelspies
Weitere High Level Graphiken
Funktion Beschreibung
contour Höhenlinien–Plot
coplot Conditioning–Plot
curve Funktionen zeichnen
dotchart Dotplots
image 3 dimensionale Bilder
mosaicplot Mosaikplots
pairs Streudiagramm Matrix
persp perspektivische Fläche
pie Kreisdiagramm
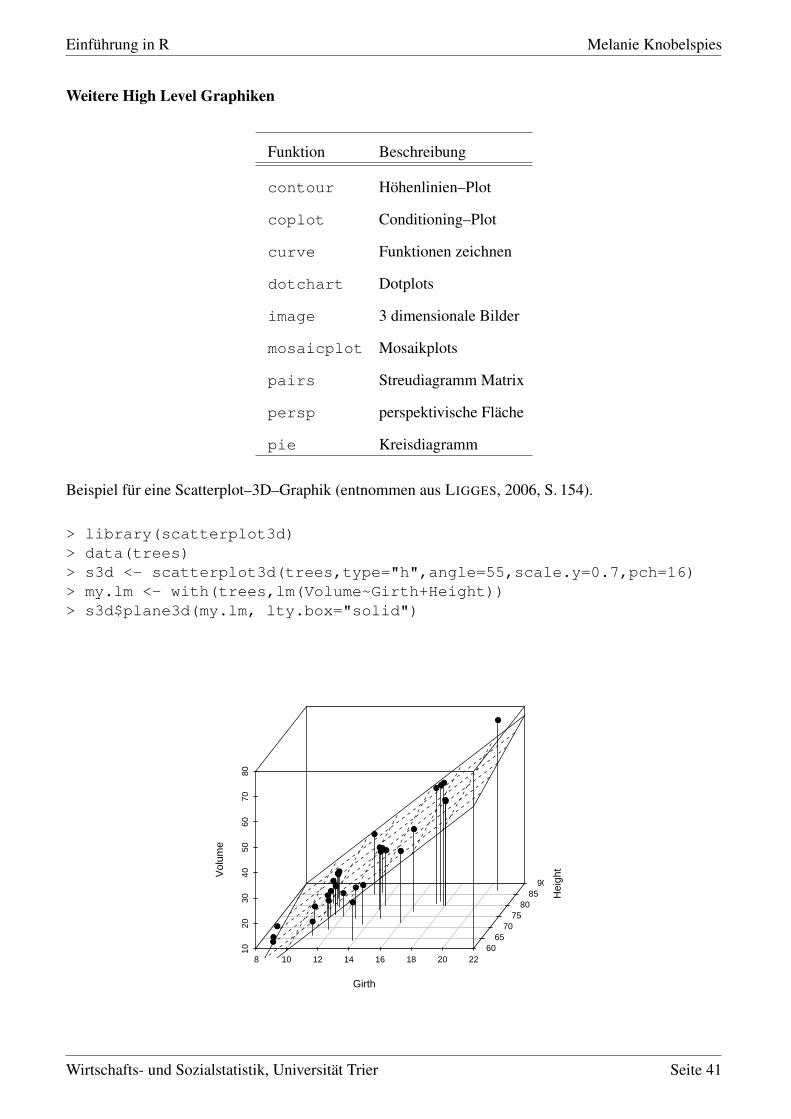
Beispiel für eine Scatterplot–3D–Graphik (entnommen aus LIGGES, 2006, S. 154).
> library(scatterplot3d)> data(trees)> s3d <- scatterplot3d(trees,type="h",angle=55,scale.y=0.7,pch=16)> my.lm <- with(trees,lm(Volume~Girth+Height))> s3d$plane3d(my.lm, lty.box="solid")
8 10 12 14 16 18 20 22
1020
3040
5060
7080
6065
7075
8085
90
Girth
Hei
ghtVol
ume
●
●
●
●
●●
●
●●
●
●
●●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●
Wirtschafts- und Sozialstatistik, Universität Trier Seite 41

Einführung in R Melanie Knobelspies
6.2 Low Level Graphiken
Die nachfolgende Tabelle enthält die wichtigsten Funktionen, die zu einer bestehenden Graphik nachträg-lich hinzugefügt werden können. Die einzelnen Funktionen können hierbei wieder durch zahlreicheArgumente erweitert werden. Nähere Informationen findet man in der R–Hilfe.
Funktion Beschreibung
grid() Fügt ein Gitternetz hinzu.
points(x,y) Zeichnet die Punkte (X,Y ) in ein bestehendes Koordi-natensystem ein.
text(x,y,text) Schreibt einen Text in ein bestehendes Koordinatensystemhinein.
lines(x,y) Zeichnet einen Polygonzug durch die Punkte der Vektorenx und y.
ploygon(x,y,col) Zeichnet ebenfalls einen Polygonzug durch die Punkte derVektoren x und y. Zusätzlich wird die umschlossene Flächemit der gewünschten Farbe oder einer Schraffur (siehe?polygon) ausgefüllt.
abline(a,b) Zeichnet eine Gerade mit Y -Abschnitt a und Steigung b inein bestehendes Koordinatensystem ein.
abline(h=a) Zeichnet eine horizontale Linie auf der Höhe von a in einbestehendes Koordinatensystem ein. abline(v=a) einevertikale Linie.
segments(x1,y1,x2,y2) Zieht eine Linie von den Punkten mit den Koordinaten(X1, Y 1) zu (X2, Y 2).
arrows(x1,y1,x2,y2) Dieser Befehl hat die gleiche Wirkung wie segment, nurwird an jedem Endpunkt X2, Y 2 eine Pfeilspitze gezeich-net.
axis(side,at,labels) Zeichnet Achsen und markiert sie bei at mit den labels.
mtext(text,side) Schreibt einen Text an den Rand (side=1:unten,side=2:links, side=3:oben, side=4:rechts)derGraphik.
title(main,sub,... ) Fügt nachträglich einen Titel (in größeren Buchstaben) derGraphik hinzu.
box( ) Umrahmt den Plotbereich.
legend(x,y,text) Fügt der bestehenden Graphik eine Legende hinzu.
rug( ) Fügt ein ergänzendes Stabdiagramm der Graphik hinzu.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 42

Einführung in R Melanie Knobelspies
6.3 Mathematische Beschriftung
Mathematische Symbole und mathematische Beschriftungen können in R mit dem Befehl expressionerzeugt werden.Die Eingabe einer Formel erfolgt hierbei in LATEX ähnlicher Notation. Die Formel derDichtefunktion einer standardnormalverteilten Zufallsvariablen
f(X) =1
σ√
2π· e−
√(x−µ)22σ2
erzeugt man mit:
> plot(1:10,typ="n",axes=F,ylab="",xlab="")> text(3,5,adj=0,cex=2,+ expression(f(X) == frac(1,sigma * sqrt(2*pi)) ~~+ e^{frac(-(X-mu)^2,2*sigma^2)})+ )>
6.4 Interaktion mit Plots
Mit dem Befehl identify() können durch ein Klick mit der linken Maustaste Beobachtungen iden-tifiziert werden. Vor allem bei Vorhandensein von Ausreißern in einem Datensatz kann diese Funktionsehr nützlich sein. Im Graphikfenster erscheint dann die Indexnummer des betrachteten Objektes. Miteinem Klick der mittleren Maustaste wird die Funktion identify() beendet.
> X <- c(2,5,8,10,13,16,30)> plot(X)> identify(X)
●
●
●
●
●
●
●
1 2 3 4 5 6 7
510
1520
2530
Index
X
1
23
4
5
6
7
Wirtschafts- und Sozialstatistik, Universität Trier Seite 43

Einführung in R Melanie Knobelspies
6.5 Trellis–Graphiken
Trellis Graphiken sind eine Verallgemeinerung der Idee von Co–Plots, welche durch das Laden desPaketes lattice zur Verfügung stehen. Lattice basiert auf dem Graphiksystem Grid (siehe Murrell 2001),kann jedoch als eigenständiges Paket behandelt werden. Eine umfangreiche Dokumentation findet manauch unter http://cm.bell-labs.com/cm/ms/departments/sia/project/trellis/index.html.
Gegenüber den konventionellen Graphiken, bei denen Element für Element nacheinander gezeichnetwird, wird ein Trellis Objekt erst generiert und bearbeitet, bevor es gezeichnet wird (vgl. LIGGES,2006, S. 166). Häufig benutzte Elemente stehen als panel-Funktion (siehe Abschnitt ....) zur Verfügungund können miteinander kombiniert werden. Darüber hinaus weisen Lattice Graphiken gegenüber denkonventionellen Graphiken noch weitere Vorteile auf:
• Mehrere Graphiken gleichen Typs können in einem Raster direkt nebeneinander dargestellt wer-den, wobei in jedem Raster nur eine Teilmenge der Daten zu sehen ist⇒ Die Daten werden dabeiz. Bsp. über kategoriale Variablen aufgeteilt.
• Die Unterscheidung von Variablen nach Gruppen erfolgt standardmäßig durch unterschiedlicheFarben oder Symbole.
• Funktionen von Grid können auf Lattice Outputs angewendet werden (bei den traditionellenGraphiken fehlt diese Schnittstelle).
• Trellis Graphiken bieten weit umfangreichere Möglichkeiten als traditionelle Graphiken und sindoptisch eher an Präsentationsgraphiken orientiert.
>library(lattice)>data(Titanic)>> barplot(apply(Titanic,1,sum)) # Konventionelle Graphik> barchart(apply(Titanic,1,sum)) # Lattice Graphik>> barplot(Titanic)Fehler in barplot.default(Titanic) : ’height’ must be a vector or a matrix>> barchart(Titanic) #Der barchart Befehl kann sowohl auf Rohdaten,> # als auch auf Tabellen angewandt werden.
1st 2nd 3rd Crew
020
040
060
080
0
apply(Titanic, 1, sum)
1st
2nd
3rd
Crew
300 400 500 600 700 800 900
Freq
1st
2nd
3rd
Crew
0 200 400 600 800
MaleChild
FemaleChild
1st
2nd
3rd
Crew
MaleAdult
0 200 400 600 800
FemaleAdult
Wirtschafts- und Sozialstatistik, Universität Trier Seite 44

Einführung in R Melanie Knobelspies
Die folgende Tabelle enthält die wichtigsten Trellis High-Level und Low-Level Graphikfunktionen,sowie Funktionen zur Kontrolle des Trellis Device:
Funktion Beschreibungbarchart Balkendiagrammbwplot Boxplotcloud 3D Punktewolkecontourplot Contourplotdensityplot Dichteplotdotplot Punkteplothistogramm Histogrammlevelplot Levelplotpiechart Kuchendiagrammqq QQ–Plotsplom Scatterplot Matrixwireframe 3D Oberflächexyplot Scatterplotlarrows Pfeilellines Linienlpoints Punktelsegments mehrere Linien gleichzeitigltext Textpanel... bereits vordefinierte Funktion zum
Hinzufügen komplexerer Elementelset Parameter des Device einstellenprint Trellis Objekt zeichnentrelis.device Trellis Devicetrellis.par.get Parameter des Device abfragentrellis.par.set Parameter des Device einstellen
Exkurs: RGL–Graphiken
Das rgl Paket bietet die Möglichkeit Graphiken im 3 dimensionalen Raum darzustellen, wobei eineinteraktive Navigation vom Benutzer möglich ist. Die Graphik kann im 3 dimensionalen Raum beliebiggedreht und gezoomt werden. Verschiedene Lichtquellen und (Teil–)Transparenz sorgen dafür, dass beivielen Datenpunkten die Graphik übersichtlich bleibt und die Strukturen im Raum noch erkannt werdenkönnen.
Ein Beispiel hierzu findet man in der Datei RGL.r
Wirtschafts- und Sozialstatistik, Universität Trier Seite 45

Einführung in R Melanie Knobelspies
Statistische Analyse eines Datensatzes
R stellt eine Menge von Datensätzen in den Paketen zur Verfügung. Eine Liste aller Datensätze, die inden geladenen Libraries vorhanden sind, erhält man durch data( ). Im folgenden wird das Paket carverwendet.
• Laden Sie das Paket car.
• Lassen Sie sich mit help(car) einen Überblick über die Daten und Funktionen in diesem Paketgeben.
• Nehmen Sie den Datensatz in den Suchpfad und lassen Sie sich die Namen der darin enthaltenenVariablen ausgeben. Schauen Sie sich daraufhin die Attribute der Variablen an und lassen sie sichdann eine allgemeine Übersicht über den Datensatz geben.
• Schauen Sie sich nun die Zusammenfassung der Variablen gesondert für jede Ausprägung derVariablen type an (benutzen Sie hierfür den by Befehl).
• Stellen Sie die Variable income graphisch anhand eines Histogramms dar und zeichnen Sie in diebestehende Graphik eine Kerndichteschätzung ein.
• Überprüfen Sie die Variable type auf fehlende Werte. Eliminieren Sie daraufhin alle Beobachtun-gen mit fehlenden Werten in der Variable type.
• Überlegen Sie sich weitere graphische Methoden (univariat sowie bivatiat), die für diesen Daten-satz geeignet sind.
• Berechnen Sie die Korrelationsmatrix.
• Führen Sie eine lineare Einfachregression durch. Verwenden Sie dabei Prestige als abhängige undeducation als unabhängige Variable. Hinweis: lm(y~x).
• Bilden Sie für die Variable education die folgenden vier verschiedene Einkommensgruppen:(−∞; 8] (8; 10] (10; 12] (12;∞].Benutzen Sie hierbei den cut( ) Befehl.
• Lassen Sie sich anhand des Befehls subset(Prestige,type=="wc") die Teilmenge desDatensatzes ausgeben.
• Verwenden Sie den Befehl subset(Prestige,education %in% c(1,4)).Erläutern Sie kurz, welche Funktion der %in% Befehl hat.
• Eine Aufteilung des Datensatzes gemäß der Ausprägung einer Variablen erreicht man mit demsplit( ) Befehl. Als Ergebnis erhält man eine Liste, wobei die einzelnen Teile wieder durchdas $–Zeichen angesprochen werden können.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 46

Einführung in R Melanie Knobelspies
Lösungsvorschlag
Hinweis: Der gesamte R–Code befindet sich auch in der Datei data.frame.r
data()
library(car)help(car)attach(Prestige)Prestige[1:5,]attach(Prestige)
Die ersten 5 Zeilen können mit eckigen Klammern abgegriffen werden.
> Prestige[1:5,]education income women prestige census type
GOV.ADMINISTRATORS 13.11 12351 11.16 68.8 1113 profGENERAL.MANAGERS 12.26 25879 4.02 69.1 1130 profACCOUNTANTS 12.77 9271 15.70 63.4 1171 profPURCHASING.OFFICERS 11.42 8865 9.11 56.8 1175 profCHEMISTS 14.62 8403 11.68 73.5 2111 prof>
Die Namen und Attribute erhält man mit names(Prestige) und attributes(Prestige)
> names(Prestige)[1] "education" "income" "women" "prestige" "census" "type">> attributes(Prestige)$names[1] "education" "income" "women" "prestige" "census" "type"
$class[1] "data.frame"
$row.names[1] "GOV.ADMINISTRATORS" "GENERAL.MANAGERS" "ACCOUNTANTS"
[4] "PURCHASING.OFFICERS" "CHEMISTS" "PHYSICISTS" ...
...
Wirtschafts- und Sozialstatistik, Universität Trier Seite 47

Einführung in R Melanie Knobelspies
Eine Zusammenfassung aller Variablen im data.frame erhält man durch summary(Prestige).
summary(Prestige)#> summary(Prestige)
education income women prestige census typeMin. : 6.380 Min. : 611 Min. : 0.000 Min. :14.80 Min. :1113 bc :441st Qu.: 8.445 1st Qu.: 4106 1st Qu.: 3.592 1st Qu.:35.23 1st Qu.:3120 prof:31Median :10.540 Median : 5930 Median :13.600 Median :43.60 Median :5135 wc :23Mean :10.738 Mean : 6798 Mean :28.979 Mean :46.83 Mean :5402 NA’s: 43rd Qu.:12.648 3rd Qu.: 8187 3rd Qu.:52.203 3rd Qu.:59.27 3rd Qu.:8312Max. :15.970 Max. :25879 Max. :97.510 Max. :87.20 Max. :9517
Um eine Zusammenfassung der Variablen getrennt für jede Kategorie der Variable type zu erhalten,benötigt man den Befehl: by(Prestige,type,summary)
> by(Prestige,type,summary)type: bc
education income women prestige census typeMin. : 6.380 Min. :1656 Min. : 0.000 Min. :17.30 Min. :3135 bc :441st Qu.: 7.570 1st Qu.:3837 1st Qu.: 0.945 1st Qu.:27.10 1st Qu.:7579 prof: 0Median : 8.350 Median :5216 Median : 4.725 Median :35.90 Median :8424 wc : 0Mean : 8.359 Mean :5374 Mean :18.971 Mean :35.53 Mean :79453rd Qu.: 8.922 3rd Qu.:6730 3rd Qu.:30.400 3rd Qu.:42.60 3rd Qu.:8780Max. :10.930 Max. :8895 Max. :90.670 Max. :54.90 Max. :9517
---------------------------------------------------------------------------------------------type: prof
education income women prestige census typeMin. :11.09 Min. : 4614 Min. : 0.580 Min. :53.80 Min. :1113 bc : 01st Qu.:12.94 1st Qu.: 6698 1st Qu.: 4.725 1st Qu.:61.00 1st Qu.:2142 prof:31Median :14.44 Median : 8865 Median :11.680 Median :68.40 Median :2331 wc : 0Mean :14.08 Mean :10559 Mean :25.512 Mean :67.85 Mean :25743rd Qu.:15.15 3rd Qu.:12416 3rd Qu.:40.845 3rd Qu.:72.95 3rd Qu.:2922Max. :15.97 Max. :25879 Max. :96.120 Max. :87.20 Max. :9111
---------------------------------------------------------------------------------------------type: wc
education income women prestige census typeMin. : 9.17 Min. :2448 Min. : 3.16 Min. :26.50 Min. :3156 bc : 01st Qu.:10.57 1st Qu.:3450 1st Qu.:20.46 1st Qu.:35.90 1st Qu.:4138 prof: 0Median :11.13 Median :4741 Median :56.10 Median :41.50 Median :4173 wc :23Mean :11.02 Mean :5052 Mean :52.83 Mean :42.24 Mean :43413rd Qu.:11.46 3rd Qu.:6626 3rd Qu.:79.61 3rd Qu.:47.50 3rd Qu.:4664Max. :12.79 Max. :8780 Max. :97.51 Max. :67.50 Max. :5191
Wirtschafts- und Sozialstatistik, Universität Trier Seite 48

Einführung in R Melanie Knobelspies
Histogramme erhält man mit dem hist Befehl.
par(mfrow=c(1,2))hist(income)hist(income,col="red",prob=TRUE,breaks=10,main="Histogramm des Einkommens")lines(density(income),lwd=2,col="green")
Histogram of income
income
Fre
quen
cy
0 5000 10000 15000 20000 25000 30000
010
2030
4050
Histogramm des Einkommens
income
Den
sity
0 5000 10000 15000 20000 25000
0.00
000
0.00
004
0.00
008
0.00
012
Abfrage auf fehlende Werte:
is.na(Prestige)Prestige <- Prestige[!is.na(type),]
Weitere Graphiken:
par(mfrow=c(2,2))boxplot(income,ylab="Einkommen",
col="lightblue")qq.plot(income)qq.plot(income,
labels=row.names(Prestige))plot(income,prestige)
Wirtschafts- und Sozialstatistik, Universität Trier Seite 49
Einführung in R Melanie Knobelspies
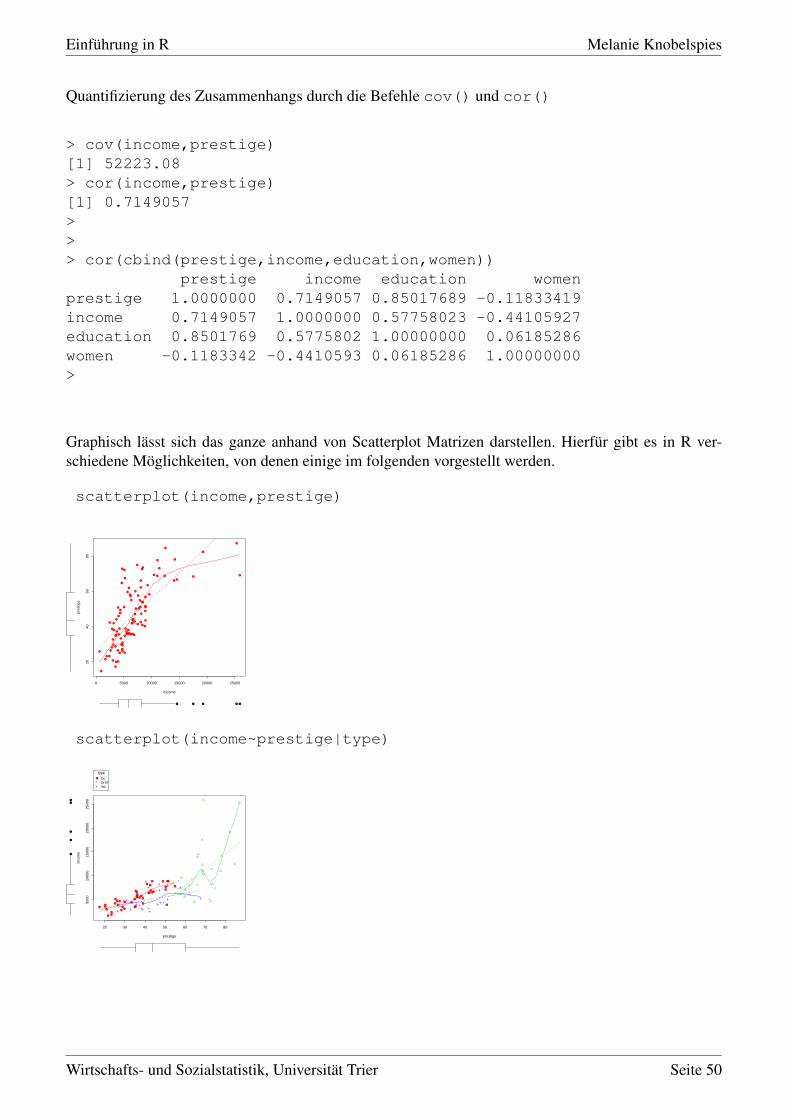
Quantifizierung des Zusammenhangs durch die Befehle cov() und cor()
> cov(income,prestige)[1] 52223.08> cor(income,prestige)[1] 0.7149057>>> cor(cbind(prestige,income,education,women))
prestige income education womenprestige 1.0000000 0.7149057 0.85017689 -0.11833419income 0.7149057 1.0000000 0.57758023 -0.44105927education 0.8501769 0.5775802 1.00000000 0.06185286women -0.1183342 -0.4410593 0.06185286 1.00000000>
Graphisch lässt sich das ganze anhand von Scatterplot Matrizen darstellen. Hierfür gibt es in R ver-schiedene Möglichkeiten, von denen einige im folgenden vorgestellt werden.
scatterplot(income,prestige)
●● ●● ●
0 5000 10000 15000 20000 25000
2040
6080
income
pres
tige
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
scatterplot(income~prestige|type)
●
●
●
●
●
20 30 40 50 60 70 80
5000
1000
015
000
2000
025
000
prestige
inco
me
●
●
● ●
●
●
●
●● ●
●
●
●
● ●
●
●
●
●
●● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
type
bcprofwc
Wirtschafts- und Sozialstatistik, Universität Trier Seite 50

Einführung in R Melanie Knobelspies
pairs(Prestige)
education
5000 20000
●●
●
●
●
●● ●
●●
●●
●●●●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●●●
●●●●
●
●
●●
●●●
●
●
●●
●
●●●
● ●
●●●●●●
●
●●●
●●●
●
●
●
●
●
●●
●
●●
●●
●
●
●●●
●
●
●
●●
●
●
●
●●●
●●
●●
●●●●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●●
●● ●●
●
●
●
●●
●●●
●
●
●●
●
●●●
●●
●●● ●● ●
●
●●●
●● ●
●
●
●
●
●
●●
●
●●
●●●
●
●●●
●
●
●
20 40 60 80
●●
●
●
●
●●●●●
●●
●● ●●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●● ●●
●
●
●
●
●●●
● ●●●
●
●
●●
●●●
●
●
●●
●
●●●
● ●
●● ●●●●
●
●●
●● ● ●
●
●
●
●
●
●●
●
●●
●●
●
●
●●●
●
●
●
●●●
●
●
●●●●●
●●
●●●●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●●●●●
●
●
●
●●●●●●●
●
●
●●
●●●
●
●
●●
●
●●●
●●
●●●●●●
●
●●●●●●
●
●
●
●
●
●●
●
●●
●●●
●
●●●●
●
●
1.0 2.0 3.0
68
1216
●●●
●
●
●●●●●
●●
●●●●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●●●●●
●
●
●
●●●●●●●
●
●
●●
●●●
●
●
●●
●
●●●
●●
●●●●●●
●
●●●●●●
●
●
●
●
●
●●
●
●●
●●●
●
●●●●
●
●
5000
2000
0
●
●
●● ●
●
●
●
●●
●●
●●●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●●●
●●●
●●
●●●
●●●
●
●●
●●
●●●
● ●
●●
●
●●●●
●
●●●
●
●●
●●●●●●
●●
●
●●
●
●●
●
●● ●●
●
●
●
●●●
●
●
income ●
●
●●●
●
●
●
●●
●●
● ●●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●●●
●●●
● ●
●● ●
● ●●
●
●●
●●
●●●
●●
●●
●
●●●●
●
●●●
●
● ●
●●●● ●●
●●
●
●●
●
●●●
●●●●
●
●
●
●●●
●
●
●
●
●● ●
●
●
●
●●
●●
● ● ●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●●
●●●
●●●
● ●
●●●
● ●●●
●●
●●
●●●● ●
●●
●
●●●●
●
●● ●
●
●●
●●● ●● ●
●●
●
●●
●
●●●
●●●
●
●
●
●
●●●
●
●
●
●
●● ●
●
●
●
●●
●●●●●●
●
●
●
●
●
●●
●
●
●
●●●
●
●●●
●●●●●●●●
●●●●●●●
●●
●●
●●●
●●
●●
●
●●●●
●
●●●
●
●●
●●●●●●
●●
●
●●
●
●●●
●●●●
●
●
●
●●●●
●
●
●
●●●
●
●
●
●●
●●●●●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●●●●●●●●
●●●●●●●
●●
●●
●●●
●●
●●
●
●●●●
●
●●●
●
●●
●●●●●●
●●
●
●●
●
●●●
●●●●
●
●
●
●●●●
●
●●
●● ●
●
●
●●●●●
●
●●●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
● ●
●
●●
●
●● ●
●
●
●●
●
●●
●●●●●●
●
●
●
● ●● ● ●●●● ●●● ●●●●●
●
●
●●
●●● ●
●
●●●●●
●
●●
●
●
●
●
●
●
●
●
●● ●
●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
●●
●
●●
●
●●●
●
●
●●
●
●●
●●●●●●
●
●
●
●●● ●●●●●● ●● ●●●
●●
●
●
women
●●
●● ●
●
●
●●●●●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
● ●
●
●●
●
●●●
●
●
● ●
●
●●
●●● ●●
●
●
●
●
● ●● ● ●●●●● ●● ●●●
●●
●
●
●●
●● ●
●
●
●●●●●●
●●●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
●●
●
●●
●
●● ●
●
●
●●
●
●●
●●●●●●
●
●
●
●●●●●●●●●●●●●●●●
●
●
040
80
●●
●●●●
●
●●●●●●
●●●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
●●
●
●●
●
●●●
●
●
●●
●
●●
●●●●●●
●
●
●
●●●●●●●●●●● ●●●●●
●
●
2040
6080
●●●
●
●●
●●
●●
●●●
●
●
●
●
● ●
●
●
●●
●
●●●
●
● ●●
● ●
●●
●●
●
● ●●● ●●
●
●
●●● ●
●●
●●●
●
●
●
●
●
●●● ●
●●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●●
●●
● ●●●
●●
●●
●●
●●●
●
●
●
●
● ●
●
●
●●
●
● ●●
●
● ●●
●●
●●
●●
●
●●● ●●●
●
●
●●●●
●●
●●●
●
●
●
●
●
●●●
●
●●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●●
●●
●●●
●
●●
●●●●●●
●
●
●
●
●
●●
●
●
●●
●
●● ●
●
●● ●
●●
●●
●●
●
● ●●● ● ●
●
●
● ●●●
●●
● ●●
●
●
●
●
●
●●●
●
●●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●●
●●
prestige●●●●
●●●●●●●●●
●
●
●
●
●●
●
●
●●
●
●●●
●
●●●
●●
●●
●●●
●●●●●●
●
●
●●●●
●●
●●●
●
●
●
●
●
●●●
●
●●
●
●
●
●●
●●
●●●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●●
●●
●●●●
●●●●●●●●●
●
●
●
●
●●
●
●
●●
●
●●●
●
●● ●
● ●
●●
●●●
●●●●●●
●
●
●●●●
●●
●●●
●
●
●
●
●
●●●●
●●
●
●
●
●●
●●
●●●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●●
●●
●●●●
● ●●●●●●● ●●●● ●● ●● ●● ●●●●●● ● ●●● ●
●●●●●● ●●● ●●●●●●
● ●●● ●●●
● ●●● ●●●●
●●
●●●●●● ●●●●●●● ●● ● ●● ● ●●●● ●●● ●●●●● ●●
● ●●●
● ●● ●●●●●●●●● ●● ●● ●● ●●● ●●●● ●●●●
●●●●●●●● ●●●●●●●
●●●● ●●●
●●●● ●●●●
●●
●●●● ●● ●●●●●●●●● ●●● ●●●●●● ●● ●●●●●●●
●● ●●
●● ●●●●●●● ●●●● ●●● ● ●●●●● ●●●● ●●●
●●● ●●● ● ●● ● ●● ●● ●
●● ●● ● ●●
●● ●●● ●●●
●●
●●● ●● ●●●●● ●● ●● ●●●●●●●●●●●●●● ●●● ● ●
●●●●
●●●●●●●●● ● ●● ●●● ● ●● ●●●●●● ●●●●●
●● ●●●●● ●●●●● ●●●
●●●● ●●●
● ●●● ●●●●
●●
●● ●● ●● ●●● ●● ● ●●● ● ●● ● ●●●●● ●● ●●●●● ●●
census
2000
6000
●●●●
●●●●●●●●●●●●●●●●●●●●●●●● ●● ●● ●
●●●●●●●●●●●●●●●
●●●● ●●●
●●●●●●●●
●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●●●●●●●
6 8 12 16
1.0
2.0
3.0
●●●● ● ●●●●●●● ●●●● ●● ●● ●● ● ●●●●
●
● ●
●
●
●●●●●●● ●●● ●●●●●●● ●●
●
●●●
● ●●● ●●●● ●●●●●●●● ●●●●●●● ●● ● ●● ● ●●●● ●●●
●
●●●● ●●
● ●●●● ●● ●●●●●●●●● ●● ●● ●● ● ●● ●●
●
● ●
●
●
●●●●●●●●● ●●●●●●● ●●●
●
●●●
●●●● ●●●●● ●●●●● ●● ●●●●●●●●● ●●● ●●●●●● ●●
●
●●●●●●
0 40 80
●● ●●●● ●●●●●●● ●●●● ●●● ● ●●●●● ●
●
●●
●
●
● ●●● ●●● ● ●● ● ●● ●● ●●● ●
●
● ●●
●● ●●● ●●●●● ●●● ●● ●●●●● ●● ●● ●●●●●●●●●●●●
●
● ●●● ● ●
●●●● ●●●●●●●●● ● ●● ●●● ● ●● ● ●●●●
●
●●
●
●
●●● ●●●●● ●●●●● ●●● ●●●
●
●●●
● ●●● ●●●●● ●●● ●● ●● ●●● ●● ● ●●● ● ●● ● ●●●●● ●●
●
●●●● ●●
2000 6000
●●●● ●●●●●●●●●●●●●●●●●●●●●●●
●
●●
●
●
● ●●●●●●●●●●●●●●● ●●●
●
●●●
●●●●●●●● ●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●
●●●●●●
type
scatterplot.matrix(cbind(prestige,income,education,women),diagonal="boxplot")
prestige
0 10000 20000
● ●●
●
●●
●●
●●
●●
●
●
●
●
●
● ●
●
●
●
●
●
● ●●
●
●●●
●●●
●●
●
●●
●●
●●●●
●
●
●●
●●
●
●
●
●●●
●
●
●
●
●
●●●●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●
●
●●
●
●
●●●
●
●●
●●
●●
●●
●
●
●
●
●
● ●
●
●
●
●
●
●●●
●
●●●
● ●●
●●
●
●●
● ●
●● ●●
●
●
●●
● ●
●
●
●
●●●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
0 20 60 100
2040
6080
●●●
●
●●
●●●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●● ●
●
●● ●
●●●
●●
●
●●
● ●
●● ● ●
●
●
● ●
●●
●
●
●
● ●●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
010
000
2000
0
●
●
●● ●
●
●
●
●●
●●
● ● ●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●●
●●
●●
●●● ●
●●●
● ●●
●
●●
●●
●
●●
●● ●
●●
●
●
●●● ●●
●
●● ●
●
●●
●●● ●● ●
●●
●
●●
●
●●●
●●●
●
●
●
●
●●●
●
●
●
●
●
●
●
income
●
●
●● ●
●
●
●
●●
●●
● ●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●●●
●●●
●●
●●●
●●●
●
●●
●●●
●●●
● ●
●●
●
●
●●●●●
●
●●●
●
●●
●●●●●●
●●
●
●●
●
●●
●
●●●
●
●
●
●
●●●
●
●
●
●
●●●
●
●
●
●●
●●
● ●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●●
●●
●●● ●
●● ●
● ●●
●
●●
●●
●
●●●
●●
●●
●
●
●●●●●
●
●●●
●
●●
●●●● ●●
●●
●
●●
●
●●●
●●●
●
●
●
●
●●●
●
●
●
●●
●
●
●●
●
●●
●●
●● ●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●● ●●
●
●
●
●
●
●●
● ●●●
●
●
●●
●
●●●
●
●
●●
●
●
●●●
●
● ●
●● ●●●●
●
●●
●●
● ●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●●
●
●
●
●●
●
●
●●
●
●●
●●
●●●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●●●
●
●
●
●
●
●●
●●●●
●
●
●●
●
●●●
●
●
●●
●
●
●●●●
● ●
●●●●●●
●
●●●
●●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●●
●
●
education
68
1014
●
●●
●
●
●●
●
●●
●●
●●● ●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●●●●
●
●
●
●
●
●●
● ●●●
●
●
●●
●
●●●
●
●
●●
●
●
●●●
●
●●
●●● ●● ●
●
●●●
●● ●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
20 40 60 80
020
6010
0
●●
●● ●
●
●
●●●●●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
● ●
●
●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●●● ●
●
●
●
●
●
● ●● ● ●●●●● ●● ●●
●●●
●
●
●●
●●●
●
●
●●●●●
●
●
●●
●
●
●
●
●
●
●
●● ●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●●●
●
●
●
●
●
● ●● ●● ●●●● ●● ●●
●●●
●
●
6 8 10 14
●●
●● ●
●
●
●●●●●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
● ●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●●●
●
●
●
●
●
● ●● ● ●●●● ●●● ●●
●●
●
●
●
women
Lineare Einfachregression:
> Reg <- lm(prestige~education)> summary(Reg)
Call:lm(formula = prestige ~ education)
Residuals:Min 1Q Median 3Q Max
-26.0397 -6.5228 0.6611 6.7430 18.1636
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -10.732 3.677 -2.919 0.00434 **education 5.361 0.332 16.148 < 2e-16 ***---Signif. codes: 0 ’***’ 0.001 ’**’ 0.01 ’*’ 0.05 ’.’ 0.1 ’ ’ 1
Residual standard error: 9.103 on 100 degrees of freedomMultiple R-Squared: 0.7228, Adjusted R-squared: 0.72F-statistic: 260.8 on 1 and 100 DF, p-value: < 2.2e-16
Wirtschafts- und Sozialstatistik, Universität Trier Seite 51

Einführung in R Melanie Knobelspies
Graphische Darstellung der linearen Einfachregression:
plot(prestige~education,ylab="Prestige",xlab="Einkommen", main="Streudiagramm",col="blue",lwd=2)
abline(Reg,col="red",lty=2)
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●●
● ●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
6 8 10 12 14 16
2040
6080
Streudiagramm
Einkommen
Pre
stig
e
Nun werden alle Objekte gelöscht und der Datensatz Prestige neu geladen. Daraufhin wird die Variableeducation in vier Klassen eingeteilt.
#---------rm(list=ls(all=TRUE))attach(Prestige)#----------> education<- cut(education,c(-Inf,8,10,12,Inf))> education <- unclass(education)>> education
[1] 4 4 4 3 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4[25] 4 4 4 2 4 4 4 3 4 3 3 3 3 3 3 2 4 3 2 3 3 3 3 3 3[50] 2 3 3 2 2 3 3 3 2 3 1 2 3 2 1 1 1 1 2 2[70] 1 1 1 1 1 1 3 2 2 1 2 2 2 3 1 2 3 1 2 2 2 1 1 1 2[95] 1 4 2 1 1 2 2 2
attr(,"levels")[1] "(-Inf,8]" "(8,10]" "(10,12]" "(12, Inf]">> Prestige$education <- education
Aufteilung des Datensatzes mit subset und split
subset(Prestige,type=="wc")
subset(Prestige,education %in% c(1,4))
Teilung <- split(Prestige,education)Teilung$"1"Teilung$"3"mode(Teilung)
Wirtschafts- und Sozialstatistik, Universität Trier Seite 52

Einführung in R Melanie Knobelspies
LiteraturBehr, A. (2005): Einführung in die Statistik mit R. Vahlen.
Dalgaard, P. (2002): Introductory Statistics with R. Springer.
Dolic, D. (2004): Statistik mit R. Oldenbourg.
Eichner, G. (2005): Einführung in die Statistik mit R. Mathemathisches Institut der Justus-Liebig-Universität Gießen, www.uni-giessen.de/~gcb7.
Fox, J. (2002): An R and S–Plus Companion to Applied Regression. Sage Publications.
Ligges, U. (2006): Programmieren mit R. Springer, 2 Auflage.
Paradis, E. (2002): R for Beginners. Istitut des Sciences de l‘Évolution, Université Montpellier II,http://cran.r-project.org/doc/contrib/Paradis-rdebuts_en.pdf.
Sachs, L. und Hedderich, J. (2006): Angewandte Statistik, Methodensammlung mit R. Springer, 11Auflage.
Schlittgen, R. (2004): Statistische Auswertungen mit R. Oldenbourg.
Wirtschafts- und Sozialstatistik, Universität Trier Seite 53













![Numismatik - BSZ Wiki [BSZ Wiki] Das Programmpaket IMDAS-Numismatik erweitert das normale IMDAS-Pro Produkt um Erfassungsmasken, die für den speziellen Einsatz in Münzarchiven ausgelegt](https://static.fdokument.com/doc/165x107/5e20cec8c5aebb3f2f030833/numismatik-bsz-wiki-bsz-wiki-das-programmpaket-imdas-numismatik-erweitert-das.jpg)


