
Entscheidungsbaumgenerierung als eLearning-Modulcleve/vorl/projects/da/11-Ma-Rothenberg.pdf · 2.5....
115
Transcript of Entscheidungsbaumgenerierung als eLearning-Modulcleve/vorl/projects/da/11-Ma-Rothenberg.pdf · 2.5....

Hochschule Wismar
Fakultät für Wirtschaftswissenschaften
Masterthesis
Entscheidungsbaumgenerierung als eLearning-Modul
Masterthesis zur Erlangung des Grades
Master of Science in Wirtschaftsinformatik
der Hochschule Wismar
eingereicht von: Nina Rothenberggeboren am 29. August 1985 in GifhornStudiengang Master WirtschaftsinformatikMatrikel Nr. : 112616
Betreuer: Prof. Dr. J. CleveProf. Dr. J. Frahm
Hannover, den 8. März 2011


Inhaltsverzeichnis
Inhaltsverzeichnis
Abbildungsverzeichnis V
Tabellenverzeichnis VII
1. Einleitung 11.1. Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2. Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3. Einordnung in die Wirtschaftsinformatik . . . . . . . . . . . . . . . . . . . . . 21.4. Begriffsdefinition eLearning-Modul . . . . . . . . . . . . . . . . . . . . . . . . 3
2. Entscheidungsbaumgenerierung 52.1. Entscheidungsbäume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2. Prozess . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.3. Trainings- und Testdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.1. Auswahl der Trainings- und Testmenge . . . . . . . . . . . . . . . . . . 92.3.2. Attribute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4. Generierung von Entscheidungsbäumen . . . . . . . . . . . . . . . . . . . . . . 102.4.1. Split-Kriterien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.4.2. Stop-Kriterien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4.3. Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4.4. Pruning-Methoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.5. Software zur Entscheidungsbaumgenerierung . . . . . . . . . . . . . . . . . . . 19
3. eLearning-Software 233.1. Varianten des eLearning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.2. Simulationen im eLearning . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.3. Vorgehensmodelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.3.1. Vorgehensmodell nach Hambach und Urban . . . . . . . . . . . . . . . 253.3.2. Vorgehensmodell nach Wendt . . . . . . . . . . . . . . . . . . . . . . . 273.3.3. Bewertung der Vorgehensmodelle . . . . . . . . . . . . . . . . . . . . . 273.3.4. Verwendetes Vorgehensmodell in dieser Arbeit . . . . . . . . . . . . . . 28
4. Software-Analyse 314.1. Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.2. Zielgruppe analysieren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324.3. Anwendungsfall . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.4. Lerninhalte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.5. Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.5.1. Anforderungen zur Entscheidungsbaumgenerierung . . . . . . . . . . . . 354.5.2. Nichtfunktionale Anforderungen . . . . . . . . . . . . . . . . . . . . . . 38
5. Software-Entwurf 415.1. Visualisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.1.1. Entscheidungsbaum . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.1.2. Informationen aus der Entscheidungsbaumgenerierung . . . . . . . . . . 425.1.3. Benutzungsoberfläche . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
Nina Rothenberg Masterthesis III

Inhaltsverzeichnis
5.1.4. Exportierbarer Bericht . . . . . . . . . . . . . . . . . . . . . . . . . . . 455.1.5. Parametereingabe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2. Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 465.3. Erweiterbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 475.4. Komponentenschnitt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.4.1. Basis-Komponente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495.4.2. Benutzungsoberfläche . . . . . . . . . . . . . . . . . . . . . . . . . . . 505.4.3. Standard-Komponente . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.5. Sonstiges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
6. Implementierung 556.1. Visualisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 556.2. Umsetzung der Erweiterbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . 576.3. Beispiel zur Erstellung und Verwendung von Erweiterungen . . . . . . . . . . . 586.4. Umsetzung der Erklärungskomponente . . . . . . . . . . . . . . . . . . . . . . 606.5. Funktionalitäten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 606.6. Export . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
7. Fazit 65
A. Beispiel des Klassifizierungs-Outputs von Weka 67
B. Anforderungen 75B.1. Datenvorbereitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75B.2. Entscheidungsbaumgenerierung . . . . . . . . . . . . . . . . . . . . . . . . . . 78B.3. Erklärungskomponente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82B.4. Nichtfunktionale Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . 84
C. Tutorial 89C.1. Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89C.2. Quick-Start . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
D. Beispiel eines HTML-Berichts 93
E. Prototyp 99
Literaturverzeichnis 101
Abkürzungsverzeichnis 105
Ehrenwörtliche Erklärung 107
IV Masterthesis Nina Rothenberg

Abbildungsverzeichnis
Abbildungsverzeichnis
1.1. Die Taxonomie des Data Minings nach [MR05a, Seite 7]. . . . . . . . . . . . . 3
2.1. Export eines Entscheidungsbaumes aus KNIME . . . . . . . . . . . . . . . . . 192.2. Einstellungen zur Entscheidungsbaumgenerierung in KNIME . . . . . . . . . . . 202.3. Screenshot der Anwendung Weka . . . . . . . . . . . . . . . . . . . . . . . . . 212.4. Visualisierung von Entscheidungsbäumen in Weka . . . . . . . . . . . . . . . . 222.5. Visualisierung von Entscheidungsbäumen in RapidMiner . . . . . . . . . . . . . 22
3.1. eLearning-Varianten Quelle: [RR03, Seite 33] . . . . . . . . . . . . . . . . . . . 243.2. Vorgehensmodell zur systematischen Entwicklung von eLearning-Angeboten . . 263.3. Schritte der OOA und des OOD . . . . . . . . . . . . . . . . . . . . . . . . . 283.4. Erweitertes Vorgehensmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.1. Anwendungsfalldiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.2. Inhalte des eLearning-Moduls . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.3. Entscheidungsbaum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.1. Informationsblock . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435.2. Layout der Benutzungsoberfläche . . . . . . . . . . . . . . . . . . . . . . . . . 455.3. Layout eines Berichts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 455.4. Komponentendiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495.5. Modell des Entscheidungsbaums . . . . . . . . . . . . . . . . . . . . . . . . . 505.6. Bereitgestellte Schnittstellen . . . . . . . . . . . . . . . . . . . . . . . . . . . 515.7. Schnittstelle der Kern-Komponente . . . . . . . . . . . . . . . . . . . . . . . . 515.8. Die Klassen der Standard-Komponente . . . . . . . . . . . . . . . . . . . . . . 52
6.1. Baum dargestellt mittels JUNG . . . . . . . . . . . . . . . . . . . . . . . . . . 576.2. Klasse des Plugin-ClassLoaders . . . . . . . . . . . . . . . . . . . . . . . . . . 576.3. Architektur der Erweiterung ”detrin-pruningmethods” . . . . . . . . . . . . . . 596.4. Anzeige der neuen Pruning-Methoden . . . . . . . . . . . . . . . . . . . . . . 596.5. Anzeige der neuen Erklärungen . . . . . . . . . . . . . . . . . . . . . . . . . . 596.6. DeTrIn Screenshot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 616.7. Anzeige der Instanzen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 616.8. Anzeige der Attribute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 626.9. Details für Attribute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
C.1. Bereiche in der Benutzungsoberfläche von DeTrIn . . . . . . . . . . . . . . . . 90C.2. Auswahl eines FileHandlers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91C.3. Button zur manuellen Gruppierung . . . . . . . . . . . . . . . . . . . . . . . . 92
Nina Rothenberg Masterthesis V


Tabellenverzeichnis
Tabellenverzeichnis
4.1. Bildungsziel 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.2. Bildungsziel 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324.3. Zielgruppenanalyse der Zielgruppe ”Studenten” . . . . . . . . . . . . . . . . . . 33
5.1. Die Konfiguration für den ID3-Algorithmus . . . . . . . . . . . . . . . . . . . . 47
Nina Rothenberg Masterthesis VII


1. Einleitung
1. Einleitung
Die vorliegende Arbeit befasst sich mit dem Thema Entscheidungsbaumgenerierung als eLearning-
Modul. Es werden die Fragen behandelt, wie ein electronic learning (eLearning)-Modul zur Ent-
scheidungsbaumgenerierung aussehen kann und welche Inhalte dort behandelt werden. Neben
der Funktionalität wird auch die Präsentation der Inhalte in eLearning-Modulen beleuchtet.
Zu dieser Arbeit wird ein Prototyp für eine Implementierung eines solchen Moduls entwickelt.
Der Schwerpunkt bei der Implementierung liegt auf der Erweiterbarkeit, nicht auf der Voll-
ständigkeit. Durch die Erweiterbarkeit bleibt die Anwendung flexibel und kann auch für später
entwickelte Algorithmen zur Entscheidungsbaumgenerierung genutzt werden.
1.1. Motivation
Es gibt eine Vielzahl an Anwendungen, die die Entscheidungsbaumgenerierung unterstützen.
Keine von diesen erklärt allerdings im Detail, wie genau der Entscheidungsbaum zu einem gege-
benem Datensatz generiert wurde. Für Anwender in der Praxis mag dies auch irrelevant sein, da
diese nur am Ergebnis interessiert sind und der Funktionalität der Anwendungen vertrauen. Für
Menschen, die den Prozess verstehen wollen, ist dies allerdings nicht genug. Sie müssen sich in
die theoretischen Grundlagen der Algorithmen einlesen und die Beispiele dann selbst ermitteln.
Anwendungen können nur dafür genutzt werden das eigene Ergebnis zu kontrollieren. In solchen
Fällen ist eine Anwendung mit einer integrierten Erklärungskomponente nützlich. Mittels einer
solchen Anwendung kann aus einer Datenmenge ein Entscheidungsbaum generiert werden und
zusätzlich eine Dokumentation ausgegeben werden, wie das Ergebnis berechnet wurde. Eine Er-
klärungskomponente hat die Aufgabe den verwendeten Lösungsweg der Komponente zu erklären
und somit die Vorgehensweise des Systems transparent zu machen und die Problemlösung zu
begründen. [BHS07, Seite 7] Da die Anwendung zum Verstehen und Erlernen von Methodiken
der Entscheidungsbaumgenerierung optimiert ist, kann von einem eLearning-Modul gesprochen
werden.
Nina Rothenberg Masterthesis 1

1. Einleitung
1.2. Zielsetzung
In dieser Arbeit wird ein Modul zur Entscheidungsbaumgenerierung inklusive einer detaillierten
Erklärungskomponente konzipiert und prototypisch implementiert. Diese Erklärungskomponente
macht aus dem Modul ein eLearning-Modul, denn sie ist dazu gedacht, neben dem generierten
Entscheidungsbaum auch den Berechnungsweg anzuzeigen. Um den Nutzen für den Anwender
zu maximieren, soll die Anwendung an allen sinnvollen Stellen parametrisierbar sein, sodass
der Anwender experimentieren kann und so das Verständnis für das Ergebnis wächst. Hierbei
werden Benutzerfreundlichkeit und Didaktikelemente nicht außer acht gelassen.
1.3. Einordnung in die Wirtschaftsinformatik
Die Entscheidungsbaumgenerierung ist eine Methodik aus dem Data Mining. Das Data Mining
gehört zum Themengebiet der künstlichen Intelligenz und dient der Mustererkennung in einer
oder mehrerer Datenmengen, indem die einzelnen Datensätze automatisiert analysiert werden.
Erkannte Muster werden auch Hypothesen genannt.
Das Data Mining teilt sich, wie in Abbildung 1.1 zu sehen, in mehrere Themengebiete auf.
Die beiden Hauptgebiete sind das Auffinden (Discovery) und die Verifikation (Verification) von
Hypothesen. Hypothesen können durch unüberwachtes (Description) und überwachtes (Predic-
tion) Lernen gefunden werden. Zum unüberwachtem Lernen gehört zum Beispiel das Clustering.
Beim überwachtem Lernen unterscheidet man Klassifikation, das Lernen einer diskretwertigen
Funktion, und Regression, das Lernen einer stetigen Funktion. [RN04, Seite 798]
Induktive Lernalgorithmen gehören in das Themengebiet des überwachten Lernens. Sie suchen
aus einer gegebenen Datenmenge Regeln und Muster aus, indem sie die Attribute der Instan-
zen eines Datensatzes mit der Ausprägung des Zielwertes in Beziehung setzen. Diese Muster
können später verwendet werden, um die Ausprägung des Zielattributs bei neuen Instanzen zu
bestimmen.[MR05a, Seite 7 ff.] Eine der einfachsten und erfolgreichsten Formen eines indukti-
ven Lernalgorithmus ist die Entscheidungsbauminduktion.[RN04, Seite 798]
Die Grundlagen zur Entscheidungsbaumgenerierung werden detailliert in Kapitel 2 behandelt.
2 Masterthesis Nina Rothenberg

1. Einleitung
Abbildung 1.1.: Die Taxonomie des Data Minings nach [MR05a, Seite 7].
1.4. Begriffsdefinition eLearning-Modul
Die Abkürzung eLearning steht für Electronic Learning (zu deutsch: elektronisches Lernen). Im
Allgemeinen wird eLearning als ”Unterstützung und Begleitung von Lehr-Lernprozessen durch
Computertechnologie” [E-L10] definiert.1 Ein eLearning-Modul ist demnach jegliche Art von
Modul auf oder in einem digitalen Medium, welches in Lehr- und Lernaktivitäten eingebunden
ist. Somit ist auch ein Textverarbeitungsprogramm ein eLearning-Modul. In dieser Arbeit wird
der Begriff des eLearning-Moduls spezieller verwendet. Gemeint ist hier eine Fachanwendung
zur Unterstützung des Lernprozesses.
Das in dieser Arbeit beschriebene eLearning-Modul beinhaltet eine Simulation. Eine Simulation
wird hier, wie in [Rey09, Seite 21], als Computerprogramm definiert, in dem virtuell Experimente
durchgeführt werden können, um dadurch ein zugrundeliegendes mathematisches Modell besser
verstehen zu können.
Theoretische Grundlagen zum Thema eLearning werden in Kapitel 3 behandelt.
1Vgl. zum Beispiel auch [Rey09, Seite 15], [HN09, Seite 7], [Der07, Seite 10], [Hes10], [7r.10] und [Rot09,
Seite 32].
Nina Rothenberg Masterthesis 3


2. Entscheidungsbaumgenerierung
2. Entscheidungsbaumgenerierung
”The whole story is in finding good splits and knowing
when to stop splitting.” Quelle: [Bre83, Seite 23]
Die Generierung von Entscheidungsbäumen ist eine wichtige Methode im Data Mining. Aus
großen Datensätzen werden leicht verständliche Entscheidungsbäume berechnet. Ein Datensatz
besteht aus mehreren Instanzen und einen Mengen von Attributen. Eine Instanz besteht aus
jeweils einem konkreten bzw. einem explizit fehlenden Wert je Attribut. Bevor aber in diesem
Kapitel die Entscheidungsbaumgenerierung im Detail vorgestellt wird, wird auf die Entschei-
dungsbäume selbst eingegangen.
2.1. Entscheidungsbäume
Maimon und Rokach definieren Entscheidungsbäume als ”classifier expressed as a recursive par-
tition of the instance space”. [MR05a, Seite 165] Die Verwendung von Entscheidungsbäumen
ist eine sehr populäre Technik im Data Mining zum Vorhersagen und Erklären von Zusammen-
hängen zwischen Messungen eines Elements und seinem Zielwert, indem sie einen Datensatz
in Untergruppen (Klassen) segmentieren. [Leb08, Seite 106] Dies liegt an ihrer Einfachheit
und Transparenz. Durch ihre Baumdarstellung sind sie selbsterklärend und auch jemand, der
kein Data-Mining-Experte ist, kann sie richtig interpretieren. Zusätzlich zu ihrem Einsatz im
Data Mining, werden sie auch im Text Mining, Informationsextraktion, Maschinenlernen und
Mustererkennung eingesetzt. [RM08, Seite vii]
In der Wirtschaft, werden Entscheidungsbäume oft als erste Methode angewandt um eine Klas-
sifizierungsmenge aus einem Datensatz zu ermitteln. [RN04, Seite 811] Begründet wird dies vor
allem in der Einfachheit der Entscheidungsbäume, denn jeder kann sie richtig interpretieren und
verstehen und dies ist eine gesetzliche Forderung für finanzielle Entscheidungen.
Man bezeichnet einen Entscheidungsbaum als Klassifizierungsbaum, wenn für Klassifizierungs-
aufgaben verwendet wird. Wird er für Regressionsaufgaben verwendet, wird er Regressionsbaum
genannt. Klassifizierung bezeichnet hierbei das Lernen einer diskretwertigen Funktion, die Re-
gression ist das Lernen einer stetigen Funktion. [RN04, Seite 798] Klassifikationsbäume werden
verwendet, um ein Objekt oder eine Instanz gemäß ihrer Attribute einer vordefinierten Klasse
Nina Rothenberg Masterthesis 5

2. Entscheidungsbaumgenerierung
zuzuordnen. Sie werden in verschiedensten Praxisfeldern, wie z. B. dem Finanzwesen, Marketing,
Ingenieurwesen und Medizin, verwendet. [RM08, Seite 5 ff.] Eine gute Klassifizierungsmethodik
muss nicht nur akkurat klassifizieren sondern nach [Bre83, Seite 7] auch einen Einblick in und
Verständnis für die Muster innerhalb der Datenstruktur vermitteln.
Ein Entscheidungsbaum besteht aus inneren Knoten, Blättern und Kanten. Wenn von Knoten
gesprochen wird, sind in der Regel innere Knoten und Blätter (äußere Knoten) gemeint. Ein
innerer Knoten repräsentiert eine Entscheidung. Eine solche Entscheidung ist in den der Regel
genau ein Attribut. Dies muss aber nicht der Fall sein, denn eine Entscheidung kann auch
aus einer Kombination von Attributen bestehen. Ein Blatt repräsentiert ein konkreten Wert
des Zielattributs, also das Ergebnis einer Entscheidungsbaum-Kante. Dieser Wert kann der
wahrscheinlichste sein oder aber ein Vektor von Werten, die jeweils mit einer Wahrscheinlichkeit
belegt sind. [RM08, Seite 8 ff.] Eine Kante repräsentiert den Übergang von einem inneren Knoten
zu einem weiteren Knoten. Er ist beschriftet mit einem konkreten Wert des Attributs seines
Eltern-Knotens (oder entsprechend mehreren).
Gemäß [RM08, Seite 9] wird die Komplexitität eines Entscheidungsbaumes explizit durch Stop-
Kriterien und Pruning-Methoden gesteuert und kann mit einer der folgenden Metriken gemes-
sen:
∙ Anzahl der inneren Knoten
∙ Anzahl der Blätter
∙ Baumtiefe
∙ Anzahl der Attribute
Algorithmen wie ID3 oder C4.5 generieren Klassifikatoren in Form von Entscheidungsbäumen.
[QQ92, Seite 5]
Vor- und Nachteile von Entscheidungsbäumen
Entscheidungsbäume bieten viele Vor- aber auch Nachteile. Folgende Vor- und Nachteile werden
in [RM08, Seite 73 ff.] zusammengefasst:
Entscheidungsbäume sind selbsterklärend und auch von nicht-professionellen Anwendern
leicht zu verstehen.
Sie können nominale und nummerische Attribute verarbeiten.
Entscheidungsbäume können jeden Klassifikator für diskrete Werte repräsentieren.
6 Masterthesis Nina Rothenberg

2. Entscheidungsbaumgenerierung
Sie können mit Datensätzen umgehen, die Fehler oder fehlende Werte enthalten.
Sie sind eine nichtparametrische Methode. Sie inkludieren z. B. keine Annahmen über die
Klassifizierungsstruktur.
Entscheidungsbäume benötigen nur die Werte der Attribute, die entlang des Pfades ab-
gefragt werden. Bei vielen Attributen pro Datensatz ist das von Vorteil und ermöglicht
eine schnelle Klassifizierung.
Durch die ”divide and conquer”2-Methode sind Entscheidungsbäume gut bei wenigen und
gleichzeitig relevanten Attributen.
Allerdings ist die Methode weniger gut geeignet, wenn viele komplexe Zusammenhänge
zwischen den Attributen bestehen.
Die meisten Algorithmen (z. B. ID3 und C4.5) setzen ein diskretes Zielattribut voraus.
Übersensibilität zur Trainingsmenge, zu irrelevanten Attributen und zum Rauschen ma-
chen Entscheidungsbäume instabil. Eine kleine Änderung in einem Split nahe der Wurzel
führt zu einer Änderung des kompletten Baumes darunter.
Hoher Aufwand zur Behandlung von fehlenden Werten.
Entscheidungsbaumalgorithmen sind kurzsichtig: Sie beziehen nur eine Ebene weiter mit
ein. Ein solches Vorgehen übersieht Kombinationen von Attributen und bevorzugt Isolier-
te.
2.2. Prozess
Der Prozess zur Entscheidungsbaumgenerierung setzt sich aus drei Teilschritten zusammen:
1. Datenaufbereitung
2. Generierung des Entscheidungsbaums
3. Pruning
In der Datenaufbereitung werden die Beispieldaten in Trainings- und Testmengen aufgeteilt.
Die Attribute werden ausgewählt, vorbereitet und gegebenenfalls gruppiert. Sobald die Vorbe-
reitungen abgeschlossen sind, wird für die Trainingsmenge ein Entscheidungsbaum generiert.
Dabei wird die Trainingsmenge auf 4 Fälle untersucht:
2”Divide and conquer” heißt zu deutsch ”teilen und beherrschen”. Eine ”divide and conquer”-Methode teilt ein
Problem solange in kleinere Teilprobleme auf, bis diese beherrschbar sind.
Nina Rothenberg Masterthesis 7

2. Entscheidungsbaumgenerierung
∙ Die Trainingsmenge ist leer
Der Baum schließt mit einem Blatt ab. In den meisten Fällen wird die Zielattributausprä-
gung genommen, die in der Trainingsmenge des Elternknotens am häufigsten vorkommt.
Die Entscheidungsbaumgenerierung ist hiermit beendet.
∙ Die Elemente der Trainingsmenge entsprechen dem Stop-Kriterium
Die wahrscheinlichste Zielattributausprägung wird als Blatt erzeugt. Auch in diesem Fall
endet die Generierung.
∙ Es existiert kein zu untersuchendes Attribut mehr
Die wahrscheinlichste Zielattributausprägung wird als Blatt erzeugt. Auch in diesem Fall
endet die Generierung.
∙ Die Elemente entsprechen nicht dem Stop-Kriterium und es existieren noch zu
untersuchende Attribute
Mittels des Splitting-Kriteriums wird das beste Attribut zur Teilung der Trainingsmenge
ermittelt. Für jede mögliche Attributausprägung des gewählten Attributs wird eine Kante
erstellt. Alle Elemente der Trainingsmenge, die dieser Kante entsprechen, werden in die
Trainingsmenge des Teilbaumes genommen. Die Teilbäume werden rekursiv nach der
gleichen Fallunterscheidung erstellt. Dabei wird das Teilungsattribut aus der Menge der
zu untersuchenden Attribute herausgenommen.
Wenn es der verwendete Algorithmus vorsieht, wird der entstandene Entscheidungsbaum nach
der Generierung mittels einer Pruning-Methode gekürzt.
Nach Abschluss dieses Vorgangs wird die Fehlerrate des Entscheidungsbaumes ermittelt, indem
die Testmenge mit Hilfe des Entscheidungsbaumes klassifiziert wird und der Anteil der nicht
korrekt klassifizierten Instanzen berechnet wird. [RN04, Seite 807] Je nach vorgehen kann dieses
rekursiv für verschiedene Trainings- und Testmengen erfolgen.
2.3. Trainings- und Testdaten
Bei der Generierung von Entscheidungsbäumen sind zwei Datenmengen wichtig: Die Trainings-
und die Testdaten. Die Trainingsdaten sind Datenreihen, die korrekt klassifiziert sind, also
mit korrekt ausgefülltem Zielattribut. Auch Testdaten müssen einen Wert des Zielattributes
haben, damit geprüft werden kann, ob sie richtig klassifiziert worden ist. Auf Grundlage der
Trainingsdaten wird der Entscheidungsbaum generiert und anschließend mittels der Testdaten
8 Masterthesis Nina Rothenberg

2. Entscheidungsbaumgenerierung
getestet. In einigen Methoden wird dieses Vorgehen mehrmals mit verschiedenen Trainings- und
Testmengen durchgeführt.
2.3.1. Auswahl der Trainings- und Testmenge
Ein Datensatz kann manuell in eine Trainings- und eine Testmenge aufgeteilt werden. In der
Entscheidungsbaumgenerierung wird dies allerdings in der Regel automatisch vorgenommen.
Hierzu gibt es verschiedene Methoden einen Datensatz aufzuteilen.
∙ manuelle Auswahl
Ein Datensatz wird manuell in Test- und Trainingsmenge geteilt.
∙ zufällige automatisierte Auswahl
Ein Datensatz mit 𝑁 Instanzen wird in 𝑘 Teilmengen aufgeteilt, wobei 𝑘 ≤ 𝑁 ist. Nun
werden 𝑘 − 1 Teilmengen als Trainingsmenge und die übrige als Testmenge verwendet.
∙ berechnete automatisierte Auswahl
Die Teilmengen werden so gewählt, dass alle Teilmengen eine möglichst gleiche Verteilung
haben.
Die Aufteilung eines Datensatzes in mehr als zwei Teilmengen dient der Kreuz-Validierung.
Um einen möglichst idealen Entscheidungsbaum zu generieren, wird der Algorithmus in der
Regel mehrmals mit verschiedenen Trainings- und Testmengen durchlaufen und der beste der
entstandenen Bäume wird gewählt.
2.3.2. Attribute
Es gibt drei wichtige Attributtypen:
∙ nominal
Die verschiedenen Ausprägungen von nominale Daten haben keine natürliche Ordnung.
Man kann sie nur über das Kriterium ”Gleichheit” vergleichen.
Beispiel: Geschlecht, Beruf
∙ ordinal
Ordinale Daten können in eine Reihenfolge gebracht werden. Man kann sie daher mit ≥und ≤ vergleichen.
Beispiel: Schulnote, Schuhgröße
Nina Rothenberg Masterthesis 9

2. Entscheidungsbaumgenerierung
∙ metrisch
Mit Metrische Daten lassen sich Rechenoperationen, wie Addition, Mittelwertbildung u.ä.
durchführen.
Beispiel: Länge, Temperatur
In der Regel unterscheidet man im Fall der Entscheidungsbaumgenerierung allerdings nur zwi-
schen nominalen und nummerischen Attributen, wobei bei nummerischen Attributen auch im-
mer von einem unbeschränkten Zahlenraum ausgegangen wird. Falls die Anzahl der möglichen
Ausprägungen zu hoch wird, wie es zum Beispiel bei den unendlich vielen Möglichkeiten der
nummerischen Attributen der Fall ist, können mehrere Ausprägungen gruppiert werden. Bei
nummerischen Attributen geschieht dies in Form von Intervallen. Quinlan schlägt in [QQ92,
Seite 64] vor, bereits bekannte Gruppen über zusätzlich Attribute von vorne herein bekannt zu
geben. Für nicht von vorn herein bekannt Gruppen bietet sein C4.5-Algorithmus eine Methodik
zur idealen Gruppierung an, welche die einzelnen Gruppen solange paarweise zusammengeführt,
bis nur noch zwei Teilmengen bestehen oder bis sich die Aufteilung der Trainingsmenge im
Vergleich zum aktuellen Stand nicht mehr verbessert. Die initialen Gruppen bilden hierbei die
einzelnen Ausprägungen. [QQ92, Seite 65]
2.4. Generierung von Entscheidungsbäumen
Aus dem Trainingsdatensatz wird mittels eines Entscheidungsbaum-Algorithmus ein Entschei-
dungsbaum generiert. Das Ziel ist in der Regel einen möglichst optimalen Entscheidungsbaum
zu finden, der die geringste Fehlerrate ermöglicht.[RM08, Seite 18] Das Problem am Finden
des idealen Entscheidungsbaumes für eine Datenmenge ist nichtdeterministisch polynomiell voll-
ständig (NP-vollständig). [QQ92, Seite 20] NP-vollständig bedeutet, dass für ein Problem kein
Algorithmus existiert, der es in polynomieller Zeit lösen kann. [RN04, Seite 1187] Eine Lösung
kann erst dann gefunden werden, wenn alle Möglichkeiten ausprobiert und miteinander verglei-
chen wurden, um die ideale Lösung ermitteln. Da dies allerdings sehr zeitintensiv ist, wurden
Algorithmen entwickelt, die einen möglichst idealen Entscheidungsbaum finden. Tests zeigen,
dass die Ergebnisse gut genug sind, um die Algorithmen den Überprüfen aller Möglichkeiten
vorzuziehen.
Der Algorithmus generalisiert den Zusammenhang der Attribute und dem Zielattribut anhand
der Instanzen der Trainingsmenge in Form eines Modells. [RM08, Seite 16] Für die vorgestellten
induktiven Entscheidungsbaumalgorithmen eignen sich nicht alle Datensätze. Die Anforderun-
gen, die ein Datensatz erfüllen muss, werden in [QQ92, Seite 2 ff.] wie Folgt zusammengefasst:
10 Masterthesis Nina Rothenberg

2. Entscheidungsbaumgenerierung
∙ Mögliche Attributausprägung
Alle Informationen einer Instanz aus dem Datensatz müssen in einer festen Liste von
Attributen ausdrückbar sein. Attribute haben eine für alle Fälle gleichbleibend Menge von
diskrete bzw. numerische Ausprägungen.
∙ Vordefinierte Klassen
Da es sich bei der Entscheidungsbaumgenerierung um überwachtes Lernen handelt, müs-
sen die Klassen, in die verschiedene Datensätze klassifiziert werden sollen, im Vorfeld
festgelegt und bekannt sein.
∙ Diskrete Klassen
Die einzelnen Klassen sind disjunkt. Eine Instanz muss eindeutig klassifiziert werden kön-
nen. Zusätzlich muss es deutlich mehr Fälle als Klassen geben. Kontinuierliche Klassen
können nicht verwendet werden. Wenn man sie in Gruppen aufteilt, sollte darauf geachtet
werden, dass diese scharf abgegrenzt und nicht zu vage sind, wie z.B. jung und alt.
∙ Ausreichend viele Daten
Die Entscheidungsbaumgenerierung ist eine induktive Methode. Induktive Methoden ver-
suchen Muster in den Daten zu identifizieren. Es werden statistische Methoden verwendet,
um valide, robuste Muster von invaliden Mustern zu unterscheiden. Um diese sinnvoll an-
wenden zu können, müssen allerdings genügend Datensätze vorhanden sein. Die Anzahl
der benötigten Datensätze ist abhängig von der Anzahl der Attribute und Klassen, sowie
der Komplexität des Klassifizierungsmodels.
∙ ”Logische” Klassifizierungsmodelle
Da Entscheidungsbäume oder Klassifizierungsregeln erstellt werden, müssen die möglichen
Klassen logischen Ausdrücke sein (z. B. ein bestimmter Wert eines bestimmten Attributs).
Die generierten Entscheidungsbäume können zur Klassifizierung von neuen Instanzen verwendet
werden. Hierbei unterscheidet man die sogenannten ”crisp classifier”, die eine Klasse identifizie-
ren und zurückgeben, und die ”probability classifier”, die einen Vektor von Wahrscheinlichkeiten
zurückgeben, mit denen die Instanz zu einer bestimmten Klasse gehört. [RM08, Seite 16]
2.4.1. Split-Kriterien
Das Split-Kriterium legt fest, aufgrund welcher Regel sich der Knoten eines Entscheidungs-
baumes weiter aufteilt. In den meisten Algorithmen sind die Split-Funktionen univariat und ein
Knoten wird nur aufgrund der Ausprägung eines Wertes definiert. [RM08, Seite 53] Im folgenden
Abschnitt werden die gängisten Split-Kriterien vorgestellt.
Nina Rothenberg Masterthesis 11

2. Entscheidungsbaumgenerierung
Information Gain
Der Information Gain3 ermittelt das Attribut, welches den meisten Informationsgehalt bringt.
Es hat das Ziel, die Tiefe des Entscheidungsbaumes zu minimieren. [RN04, Seite 804]
Er berechnet sich wie folgt: Für jede mögliche Ausprägung 𝑖 des Zielattributes 𝑍 innerhalb der
betrachteten Trainingsmenge 𝑇 wird die Häufigkeit ermittelt, wie oft es in 𝑇 vorkommt. Diese
Häufigkeit wird definiert als |𝑇𝑖|. Die Wahrscheinlichkeit dieser Ausprägung ergibt sich dann im
Verhältnis der Häufigkeit zur Gesamtgröße der Trainingsmenge |𝑇 |:
|𝑇𝑖||𝑇 |
Die Entropie, der Erwartungswert des Informationsgehalts, wird dann durch die Informationsge-
halte der 𝑛 einzelnen Ziel-Ausprägungen im Verhältnis zu ihrer Häufigkeit in der Trainingsmenge
𝑇 berechnet.
𝑒𝑛𝑡𝑟𝑜𝑝𝑦(𝑇 ) = −𝑛∑
𝑖=1
|𝑇𝑖||𝑇 |· log2(
|𝑇𝑖||𝑇 |
)
Die Trainingsmenge 𝑇 wird auf ein Attribut 𝑋 getestet. Das Attribut 𝑋 hat 𝑛 mögliche Ausprä-
gungen. Für jede Ausprägung von𝑋 wird die Entropie der sicher ergebenen Teilmenge berechnet
und im Verhältnis zum Wahrscheinlichkeit der Ausprägung aufsummiert. Somit ergibt sich die
bedingte mittlere Information:
𝑒𝑛𝑡𝑟𝑜𝑝𝑦𝑋(𝑇 ) =𝑛∑
𝑖=1
|𝑇𝑖||𝑇 |· 𝑒𝑛𝑡𝑟𝑜𝑝𝑦(𝑇𝑖)
Der Information Gain4 eines Attributs 𝑋 berechnet sich aus der ”Differenz zwischen der ur-
sprünglichen Information und der Restinformation” [BKI06, Seite 116].
𝑔𝑎𝑖𝑛(𝑋) = 𝑒𝑛𝑡𝑟𝑜𝑝𝑦(𝑇 )− 𝑒𝑛𝑡𝑟𝑜𝑝𝑦𝑋(𝑇 )
Die Entropie der gesamten Trainingsmenge ist nach [RN04, Seite 805] ”[e]ine Schätzung der
in einer korrekten Antwort enthaltenen Information”. Wenn der Information Gain aller Attri-
bute berechnet wurde, wird das Attribut 𝑋 für den Split ausgewählt, welches den maximalen
Information Gain hat.
Dieses einfache Split-Kriterium liefert gute Ergebnisse. Dennoch hat es einen schwerwiegenden
Nachteil, denn es bevorzugt Attribute mit vielen möglichen Werten. [QQ92, Seite 22]
3Zu deutsch: Informationsgewinn.4Der mittlere Informationsgehalt zwischen Attribut 𝑋 und der Ziel-Ausprägung. [QQ92, Seite 22]
12 Masterthesis Nina Rothenberg

2. Entscheidungsbaumgenerierung
Gain ratio criterion
Der angesprochene Mangel des Information Gains, wonach dieser Attribute mit vielen möglichen
Ausprägungen bevorzugt, kann mit einer Art Normalisierung behoben werden. [QQ92, Seite 23]
Der Information Gain wird wie gewohnt ermittelt. Er wird allerdings am Ende durch einen
Normalisierungsfaktor geteilt.
gain ratio(𝑋) =𝑔𝑎𝑖𝑛(𝑋)
split entropy(𝑋)
Der Normalisierungsfaktor entspricht der Entropie des Attributs 𝑋:
split entropy(𝑋) = −𝑛∑
𝑖=1
|𝑇𝑖||𝑇 |· log2
(|𝑇𝑖||𝑇 |
)Der Gain Ratio repräsentiert die potenzielle Information, die erzeugt wird, wenn die Trainings-
menge 𝑇 in 𝑛 Teilmengen aufgeteilt wird. Der Gain Ratio drückt den Anteil der durch den Split
erzeugten Information aus, der für die Klassifikation nützlich ist. [QQ92, Seite 23]
Quinlan bewertet das Gain Ratio Kriterium als robust und bewertet die Ergebnisse im Vergleich
zum Information Gain als besser. [QQ92, Seite 24]
Gini Index
Der Gini Index misst die Divergenz zwischen den Wahrscheinlichkeitsverteilungen der möglichen
Ausprägungen des Ziel-Attributs.[RM08, Seite 55] Er berechnet sich mit Hilfe der Wahrschein-
lichkeit der Ausprägungen des betrachteten Attributs 𝑋.
𝐺𝑖𝑛𝑖(𝑋,𝑇 ) = 1−𝑛∑
𝑖=1
(|𝑇𝑖||𝑇 |
)2
Das Auswahlkriterium für das Attribut 𝑋 bei einem Zielattribut 𝑍 berechnet sich wie folgt:
𝐺𝑖𝑛𝑖𝐺𝑎𝑖𝑛(𝑋,𝑇 ) = 𝐺𝑖𝑛𝑖(𝑍, 𝑇 )−𝑛∑
𝑖=1
|𝑇𝑖||𝑇 |·𝐺𝑖𝑛𝑖(𝑍, 𝑇𝑖)
Der Gini Index kann einfach und schnell berechnet werden. [Bre83, Seite 104]
Twoing Criterion
Das binäre Twoing Criterion wird in [Bre83, Seite 104 ff.] als Vorgehen beschrieben, welches
alle Objekte eines Knotens in zwei disjunkte Teilmengen teilt. Alle möglichen Klassen werden
gebildet und die Einteilung, bei der der Informationsgewinn am größten ist, wird gewählt.
Nina Rothenberg Masterthesis 13

2. Entscheidungsbaumgenerierung
Das Twoing Criterion berechnet sich wie folgt:
𝑡𝑤𝑜𝑖𝑛𝑔(𝑎𝑖, 𝑑𝑜𝑚1(𝑎𝑖), 𝑑𝑜𝑚2(𝑎𝑖), 𝑆) = 0, 25 ·|𝜎𝑎𝑖∈𝑑𝑜𝑚1(𝑎𝑖)𝑆|
|𝑆|·|𝜎𝑎𝑖∈𝑑𝑜𝑚2(𝑎𝑖)𝑆|
|𝑆|·
⎛⎝ ∑𝑐𝑖∈𝑑𝑜𝑚(𝑦)
|𝜎𝑎𝑖∈𝑑𝑜𝑚1(𝑎𝑖)∧𝑦=𝑐𝑖𝑆||𝜎𝑎𝑖∈𝑑𝑜𝑚1(𝑎𝑖)𝑆|
−|𝜎𝑎𝑖∈𝑑𝑜𝑚2(𝑎𝑖)∧𝑦=𝑐𝑖𝑆||𝜎𝑎𝑖∈𝑑𝑜𝑚2(𝑎𝑖)𝑆|
⎞⎠2
Hierbei teilen sich alle möglichen Werte des Attributs 𝑎𝑖 in zwei Gruppen 𝑑𝑜𝑚1(𝑎𝑖) und
𝑑𝑜𝑚2(𝑎𝑖) auf. |𝜎𝑎𝑖∈𝑑𝑜𝑚1(𝑎𝑖)𝑆| definiert die Häufigkeit des Auftretens von Werten aus 𝑑𝑜𝑚1(𝑎𝑖)
in der Menge 𝑆. Die Häufigkeit der Werte aus 𝑑𝑜𝑚1(𝑎𝑖) in Kombination mit der Ausprägung
𝑐𝑖 des Zielattributs 𝑦 drückt sich in |𝜎𝑎𝑖∈𝑑𝑜𝑚1(𝑎𝑖)∧𝑦=𝑐𝑖𝑆| aus.
Wenn es sich beim betrachteten Attribut um ein binäres Attribut handelt, sind der Gini Index und
das Twoing Cirterion äquivalent. [RM08, Seite 57] Das Twoing Criterion hat den entscheidenden
Vorteil, dass es strategische Splits erstellt und Klassengemeinsamkeiten aufdeckt. [Bre83, Seite
105]
2.4.2. Stop-Kriterien
Die Generierung eines Entscheidungsbaums endet, wenn ein Stop-Kriterium erreicht wird. In
[RM08, Seite 19] sind folgende Beispiele für Stop-Kriterien zusammengefasst:
∙ Alle Instanzen der Trainingsmenge haben den selben Wert des Zielattributs.
∙ Die maximale Baumtiefe ist erreicht.
∙ Die Anzahl der Fälle in der ermittelten Teilmenge ist kleiner als der festgelegte Minimal-
wert für Elternknoten.
∙ Der bestmögliche Split-Wert unterschreitet den festgelegten Grenzwert.
Wenn ein Stop-Kriterium erreicht wurde, wird der Teilbaum mit einem Blatt abgeschlossen.
2.4.3. Algorithmen
Beispielhaft werden die drei gängigen Algorithmen zur Entscheidungsbaumgenerierung näher
beschrieben.
14 Masterthesis Nina Rothenberg

2. Entscheidungsbaumgenerierung
CART
Der Classification and Regression Trees (CART)-Algorithmus generiert binäre Entscheidungs-
bäume, durch wiederholtes Aufteilen der Datenmenge in zwei disjunkte Teilmengen. Er unter-
scheidet zwei Arten von Attributtypen: nummerische und nominale. [Bre83, Seite 5]
Als Split-Kriterium ist neben dem Gini Index auch das Twoing Criterion implementiert. [Bre83,
Seite 109] Die Wahl des Kriteriums hängt hierbei von der Problemstellung ab. Da der Gini
index in der Regel bessere Ergebnisse liefert, wird von Breiman vorgeschlagen den Gini Index
zu verwenden. [Bre83, Seite 111]
Der Baum wird anschließend nach der Methode des Cost-Complexity-Pruning optimiert. [RM08,
Seite 71 ff.]
ID3
Der ID3-Algorithmus wurde 1986 von Quinlan entwickelt. Er benutzt als Split-Kriterium den
Information Gain5. Der Algorithmus stoppt, wenn alle Datenreihen den gleichen Wert des Ziel-
Attributes haben oder aber der maximal zu erreichende Information Gain kleiner als 0 ist.
[RM08, Seite 71] Der Algorithmus nimmt kein Pruning des Entscheidungsbaumes vor.
ID3 ist ein einfacher Algorithmus, der gute Ergebnisse liefert, allerdings auch starke Schwächen
aufweist. So werden durch die Verwendung des Information Gains Attribute mit viele möglichen
Ausprägungen bevorzugt [QQ92, Seite 23], außerdem behandelt er weder nummerische Attribute
noch fehlende Werte [RM08, Seite 71].
C4.5
Der C4.5-Algorithmus verwendet als Split-Kriterium den Gain Ratio und behebt damit den
Kritikpunkt am ID3-Algorithmus.
Der C4.5-Algorithmus unterstützt drei Arten von Tests [QQ92, Seite 24]:
∙ Diskrete Attribute, bei denen für jede mögliche Ausprägung eine Kante erzeugt wird.
∙ Diskrete Attribute, bei denen die möglichen Ausprägungen in einer beliebigen Menge von
Gruppen zusammengefasst werden.
5Vergleiche Abschnitt 2.4.1 auf Seite 12.
Nina Rothenberg Masterthesis 15

2. Entscheidungsbaumgenerierung
∙ Nummerische Attribute, für die ein Grenzwert ermittelt mittels dem zwei Intervalle 𝑎𝑖 ≤ 𝑋
und 𝑎𝑖 > 𝑋 gebildet werden.
Zur Ermittlung der Grenze der Intervalle bei nummerischen Attributen werden alle existierenden
Werte aus dem Datensatz gesammelt und der Größe nach sortiert. Nun wird jeweils zwischen
zwei nebeneinander liegenden Werten die Intervallgrenze gesetzt. Es entstehen zwei Intervalle:
𝑥 ≤ Grenze und 𝑥 > Grenze, wobei die Grenze der Mittelwert der zwei betrachteten Werte
ist. Für jede mögliche Grenze wird das Split-Kriterium berechnet. Die Grenze, die den besten
Gain Ratio ergibt, wird gewählt. [QQ92, Seite 25 ff.]
Es wird empfohlen als Stop-Kriterium eine Mindestanzahl6 an erforderlichen Instanzen zu de-
finieren, die mindestens zwei Teilmengen nach einem Split haben müssen. [QQ92, Seite 24]
Durch diese Maßnahme werden triviale Splits bei kleinen Trainingsmengen vermieden.
Am Ende wird der Baum mittels Error-based Pruning gekürzt. C4.5 kann auch mit fehlenden
Werten umgehen, indem der korrigierte Gain Ratio verwendet wird. [RM08, Seite 71] Der
Information Gain wird dazu mit einem Faktor 𝐹 multipliziert, der den Anteil der nicht leeren
Instanzen repräsentiert. Ähnlich wird auch die Split Entropie der Gain Ratio angepasst. Hier
werden, die fehlenden Werte einfach als zusätzliche Gruppe behandelt werden. [QQ92, Seite 28
ff.]
Wenn der Datensatz in Teilmengen aufgeteilt wird, werden unbekannte Werte in alle Teilmen-
gen aufgenommen. Datenreihen werden in diesem Fall allerdings gewichtet. Datenreihen mit
einem Wert bekommen die Gewichtung 1, Datenreihen mit unbekannten Wert bekommen die
Gewichtung:
Gewichtung =Ausprägung𝑋
Anzahl Datenreihen mit gültigem Wert
Also die Wahrscheinlichkeit, dass der Wert der untersuchten Ausprägung 𝑋 entspricht. An den
Blättern stehen Werte der Form (𝑁) oder (𝑁 |𝐸), wobei 𝑁 der aufsummierten Gewichtungen
aller Trainingsfälle der Teilmenge entspricht, die der Klasse angehören und 𝐸 die entsprechende
aufsummierte Gewichtung der Trainingsfälle der Teilmenge, die nicht der Klasse angehören.
[QQ92, Seite 32]
Wenn die Stop-Kriterien zu strikt gewählt werden, werden kleine ”under-fitted” Entscheidungs-
bäume generiert. Bei nicht so strikten Stop-Kriterien wird der Entscheidungsbaum sehr groß
und ist in Bezug auf die Trainingsmenge überangepasst. [MR05a, Seite 175] Diese Überanpas-
sung kann man im nachhinein durch Pruning korrigieren. Eine Pruning-Methode gibt vor, wie
man die nicht relevanten Teilbäume erkennen kann. Laut [Bre83, Seite 39] ist die Wahl der
Pruning-Methode sogar wichtiger für das endgültige Ergebnis als das Split-Kriterium.
6Standardmäßig ist dieser Wert 2. [QQ92, Seite 24]
16 Masterthesis Nina Rothenberg

2. Entscheidungsbaumgenerierung
Im folgenden werden zwei der bekanntesten Pruning-Methoden vorgestellt. Das Cost-Complexity
Pruning und das Error-based Pruning.
2.4.4. Pruning-Methoden
Als Beispiel für Pruning-Methoden werden die Methoden näher beschrieben, die in den in Kapitel
2.4.3 beschriebenen Algorithmen Anwendung finden.
Cost Complexity Pruning
Das Cost Complexity Pruning besteht aus zwei Schritten. Im ersten Schritt werden aus dem
Baum alle möglichen gekürzten Bäume erstellt. Hierbei beginnt man beim generierten Entschei-
dungsbaum und endet bei dem Baum, der nur noch aus dem Wurzelknoten besteht. Um die
Bäume zu erzeugen, werden bei dem Ausgangsbaum nach und nach Teilbäume innerhalb des
Baumes durch Blätter ersetzt. Hierbei werden die Teilbäume gekürzt, die die Fehlerrate pro
gekürztem Blatt am wenigsten erhöhen. Diese Erhöhung der Fehlerrate pro Blatt wird nach
[RM08, Seite 64] wie folgt definiert:
𝛼 =𝜀(𝑝𝑟𝑢𝑛𝑒𝑑(𝑇, 𝑡), 𝑆)− 𝜀(𝑇, 𝑆)
|𝑙𝑒𝑎𝑣𝑒𝑠(𝑇 )| − |𝑙𝑒𝑎𝑣𝑒𝑠(𝑝𝑟𝑢𝑛𝑒𝑑(𝑇, 𝑡))|
Hier ist 𝜀(𝑇, 𝑆) die Fehlerrate des Entscheidungsbaumes 𝑇 des Datensatzes 𝑆. Die Anzahl der
Blätter in 𝑇 wird ausgedrückt durch |𝑙𝑒𝑎𝑣𝑒𝑠(𝑇 )|. Der Baum, der entsteht, wenn man in 𝑇 den
Knoten 𝑡 durch ein Blatt ersetzt, wird ausgedrückt durch 𝑝𝑟𝑢𝑛𝑒𝑑(𝑇, 𝑡). Die Fehlerrate ist die
Anzahl der falsch klassifizierten Instanzen der Testmenge.
Große Datensätze werden in Trainings- und Pruningmenge geteilt. Wenn der Datensatz nicht
groß genug ist, wird die Kreuz-Validierung angewandt. [RM08, Seite 64]
Error-based Pruning
Error-based Pruning ist eine Entwicklung aus dem pessimistischen Pruning und wird vom C4.5-
Algorithmus verwendet. [RM08, Seite 66] Pessimistisches Pruning ist ein Oberbegriff für alle
Pruning-Methoden, die die Fehlerrate eines Teilbaumes mit Hilfe einer Testmenge anpassen
und kann somit die Kreuz-Validierung ersparen. [Man97, Seite 2] Der Top-Down-Ansatz kürzt
direkt einen ganzen Teilbaum und ist daher eine relativ schnelle Pruning-Methode. [MR05b,
Seite 48]
Nina Rothenberg Masterthesis 17

2. Entscheidungsbaumgenerierung
Die Fehlerrate wird mit Hilfe der oberen Grenze des Konfidenzintervalls abgeschätzt. Diese
berechnet sich nach [MR05a, Seite 177] wie folgt:
𝜀obere Grenze(𝑇, 𝑆) = 𝜀(𝑇, 𝑆) + 𝑍𝛼 ·
√𝜀(𝑇, 𝑆) · (1− 𝜀(𝑇, 𝑆))
|𝑆|
Wobei 𝜀(𝑇, 𝑆) die Rate der falschen Klassifizeriungen der Menge 𝑆 durch den Entscheidungs-
baum 𝑇 ist. 𝑍 definiert die inverse Verteilungsfunktion der Standardnormalverteilung mit dem
gewünschten Signifikanzniveau 𝛼.
Der Teilbaum 𝑠𝑢𝑏𝑡𝑟𝑒𝑒(𝑇, 𝑡) mit der Wurzel 𝑡 wird von den Instanzen der Teilmenge 𝑆𝑡 erreicht.
Der Kindknoten, dem die meisten Instanzen von 𝑆𝑡 zugeordnet sind, wird als 𝑚𝑎𝑥𝑐ℎ𝑖𝑙𝑑(𝑇, 𝑡)
bezeichnet.
Das error-based Pruning durchläuft nun von oben aus alle Knoten und vergleicht folgende
Werte:
1. 𝜀obere Grenze(𝑠𝑢𝑏𝑡𝑟𝑒𝑒(𝑇, 𝑡), 𝑆𝑡)
2. 𝜀obere Grenze(𝑝𝑟𝑢𝑛𝑒𝑑(𝑠𝑢𝑏𝑡𝑟𝑒𝑒(𝑇, 𝑡), 𝑡), 𝑆𝑡)
3. 𝜀obere Grenze(𝑠𝑢𝑏𝑡𝑟𝑒𝑒(𝑇,𝑚𝑎𝑥𝑐ℎ𝑖𝑙𝑑(𝑇, 𝑡)), 𝑆𝑚𝑎𝑥𝑐ℎ𝑖𝑙𝑑(𝑇,𝑡))
Je nachdem, welcher Wert am niedrigsten ist, bleibt der Baum, wie er ist, kürzt den Knoten
𝑡 oder ersetzt den Knoten 𝑡 mit dem Teilbaum 𝑠𝑢𝑏𝑡𝑟𝑒𝑒(𝑇,𝑚𝑎𝑥𝑐ℎ𝑖𝑙𝑑(𝑇, 𝑡). [RM08, Seite 66
ff.]
Bewertung von Methoden
Studienergebnisse haben ergeben, dass Pruning-Methoden entweder zum Über- oder zum Unter-
Pruning neigen. [RM08, Seite 68] Somit wird der Entscheidungsbaum entweder zu stark gekürzt,
sodass nur noch ein kleiner, ungenauer Baum zurückbleibt, oder aber er wird zu wenig gekürzt.
Das Cost-Complexity-Pruning neigt eher zum Über-Pruning. Im Gegensatz dazu neigt das Error-
based Pruning eher zu Unter-Pruning. Die meisten Studien kommen zu dem Schluss, dass es
keine die anderen überragende Pruning-Methode gibt. [MR05a, Seite 179] Derjenige der einen
Entscheidungsbaum verkürzen möchte, muss sich also vorher entscheiden, ob er sich eher für
eine Methode entscheidet, die zum Über-Pruning neigt, oder für eine, die zum Unter-Pruning
neigt.
18 Masterthesis Nina Rothenberg

2. Entscheidungsbaumgenerierung
2.5. Software zur Entscheidungsbaumgenerierung
Es gibt viele Anwendungen die zur Entscheidungsbaumgenerierung eingesetzt werden. Men-
schen, die sich nur zeitweise mit dem Thema Entscheidungsbaumgenerierung beschäftigen,
bevorzugen kostenlose Anwendungen. Zu den bekanntesten Anwendungen zählen Konstanz In-
formation Miner (KNIME)7, Weka8 und RapidMiner9. Alle drei erzeugen mit verschiedenen
Algorithmen und manipulierbaren Eingabeparameter Entscheidungsbäume. Leider wird aber in
keiner der Anwendungen das Vorgehen noch einmal ausgegeben.
KNIME gibt dem Anwender nur den Entscheidungsbaum zurück. Wie in Abbildung 2.1 ist dieser
zwar detaillierter als es in anderen Anwendungen der Fall ist, jedoch reicht die Information nicht
aus um den Generierungsprozess nachvollziehen zu können.
Abbildung 2.1.: Export eines Entscheidungsbaumes aus KNIME
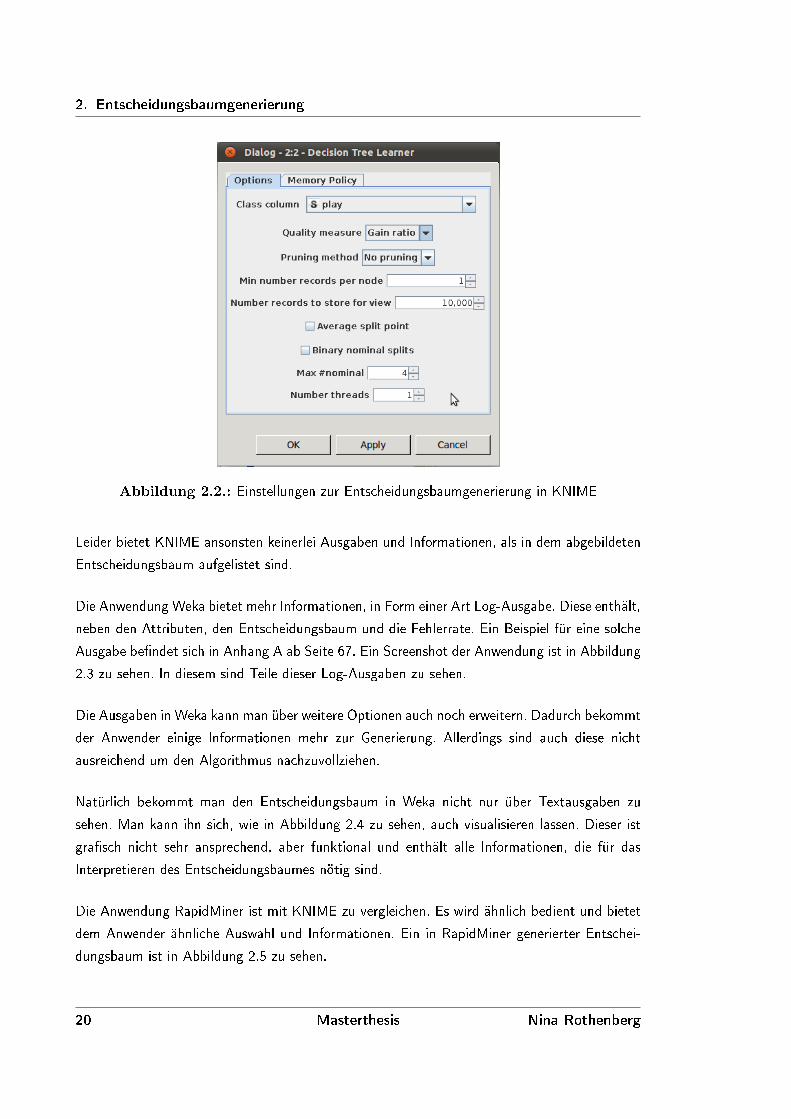
KNIME bietet einige Einstellungsmöglichkeiten. Split-Kriterium und Pruning-Methode kann
gewählt werden. Auch weitere Konfiguration der Stop-Kriterien sind möglich. Die möglichen
Einstellungen sind in der Abbildung 2.2 zu sehen. Allerdings sind die jeweiligen Auswahlmög-
lichkeiten sehr begrenzt. So kann unter dem Punkt ”Quality Measure” nur zwischen Gain ratio
und Gini index entschieden werden. Bei der Wahl der Pruning-Methode gibt es die Auswahl
zwischen keinem Pruning und Minimal Description Length (MDL).
7Projekthomepage: http://www.knime.org.8Projekthomepage: http://sourceforge.net/projects/weka.9Projekthomepage: http://www.rapid-i.com.
Nina Rothenberg Masterthesis 19
2. Entscheidungsbaumgenerierung
Abbildung 2.2.: Einstellungen zur Entscheidungsbaumgenerierung in KNIME
Leider bietet KNIME ansonsten keinerlei Ausgaben und Informationen, als in dem abgebildeten
Entscheidungsbaum aufgelistet sind.
Die Anwendung Weka bietet mehr Informationen, in Form einer Art Log-Ausgabe. Diese enthält,
neben den Attributen, den Entscheidungsbaum und die Fehlerrate. Ein Beispiel für eine solche
Ausgabe befindet sich in Anhang A ab Seite 67. Ein Screenshot der Anwendung ist in Abbildung
2.3 zu sehen. In diesem sind Teile dieser Log-Ausgaben zu sehen.
Die Ausgaben in Weka kann man über weitere Optionen auch noch erweitern. Dadurch bekommt
der Anwender einige Informationen mehr zur Generierung. Allerdings sind auch diese nicht
ausreichend um den Algorithmus nachzuvollziehen.
Natürlich bekommt man den Entscheidungsbaum in Weka nicht nur über Textausgaben zu
sehen. Man kann ihn sich, wie in Abbildung 2.4 zu sehen, auch visualisieren lassen. Dieser ist
grafisch nicht sehr ansprechend, aber funktional und enthält alle Informationen, die für das
Interpretieren des Entscheidungsbaumes nötig sind.
Die Anwendung RapidMiner ist mit KNIME zu vergleichen. Es wird ähnlich bedient und bietet
dem Anwender ähnliche Auswahl und Informationen. Ein in RapidMiner generierter Entschei-
dungsbaum ist in Abbildung 2.5 zu sehen.
20 Masterthesis Nina Rothenberg
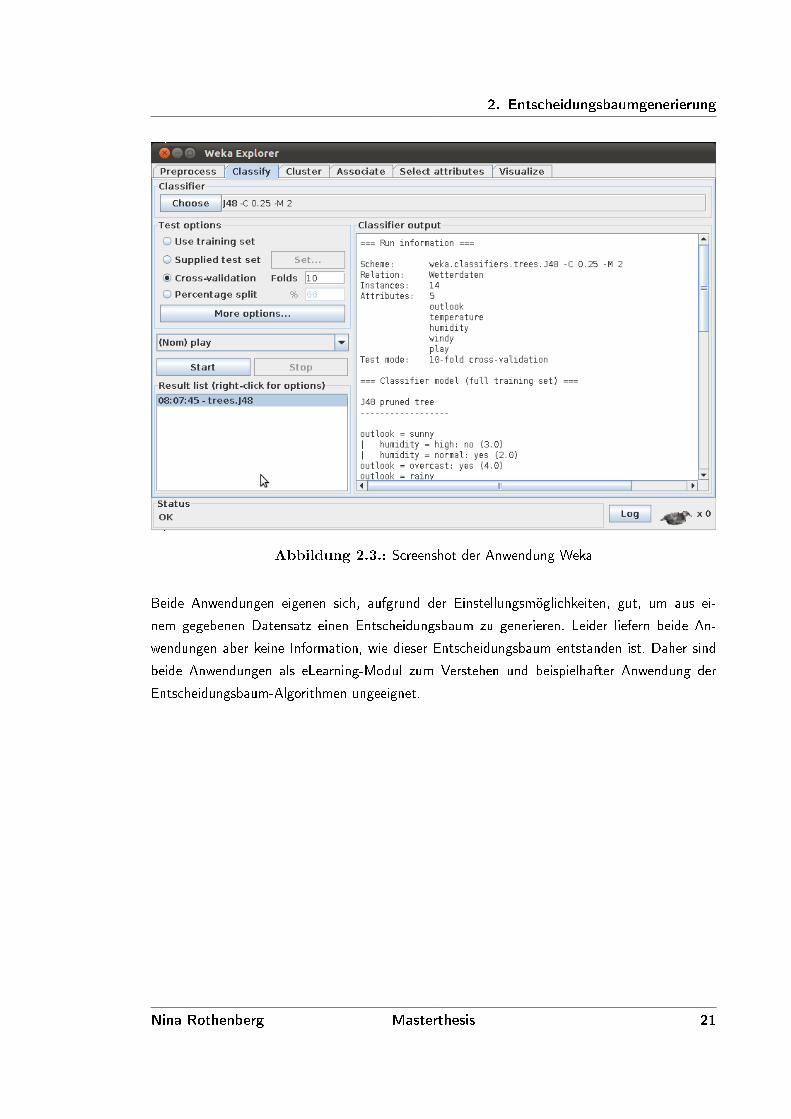
2. Entscheidungsbaumgenerierung
Abbildung 2.3.: Screenshot der Anwendung Weka
Beide Anwendungen eigenen sich, aufgrund der Einstellungsmöglichkeiten, gut, um aus ei-
nem gegebenen Datensatz einen Entscheidungsbaum zu generieren. Leider liefern beide An-
wendungen aber keine Information, wie dieser Entscheidungsbaum entstanden ist. Daher sind
beide Anwendungen als eLearning-Modul zum Verstehen und beispielhafter Anwendung der
Entscheidungsbaum-Algorithmen ungeeignet.
Nina Rothenberg Masterthesis 21
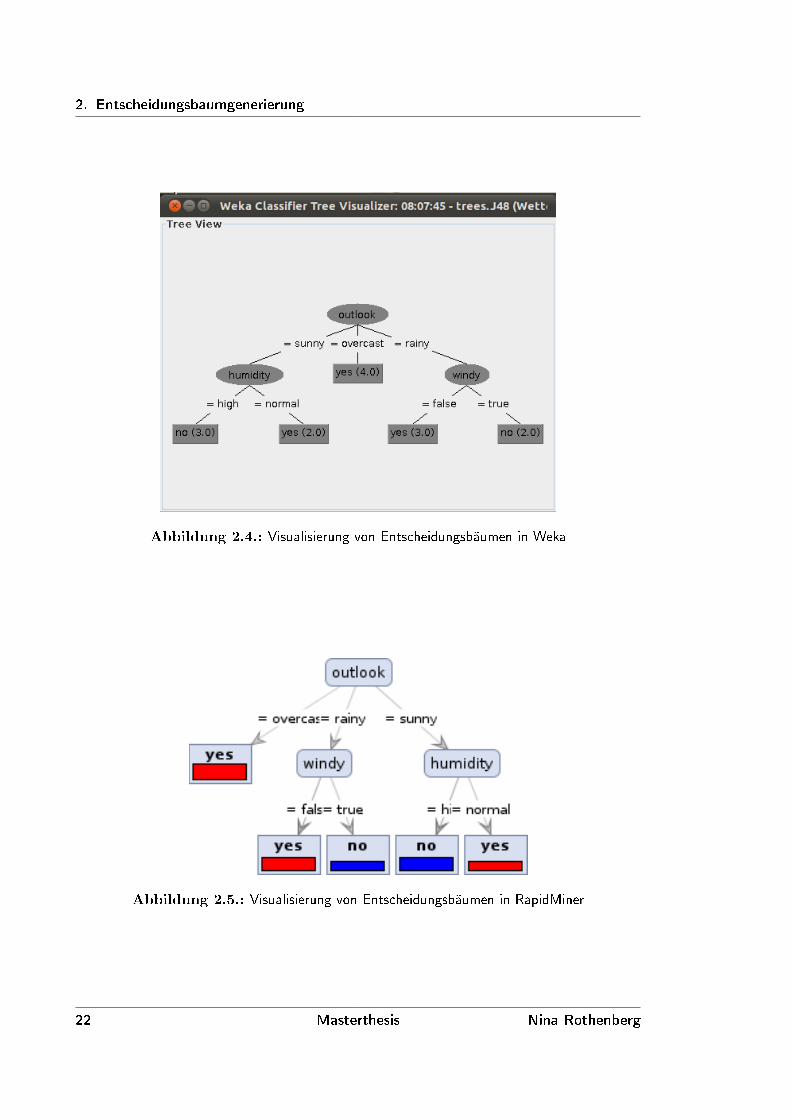
2. Entscheidungsbaumgenerierung
Abbildung 2.4.: Visualisierung von Entscheidungsbäumen in Weka
Abbildung 2.5.: Visualisierung von Entscheidungsbäumen in RapidMiner
22 Masterthesis Nina Rothenberg

3. eLearning-Software
3. eLearning-Software
Wie bereits in Kapitel 1.4 beschrieben versteht man unter eLearning computergestütztes Lehren
und Lernen. Ein eLearning-Modul ist demnach ein Computer-Programm, welches Lehren und
Lernen unterstützt. In diesem Kapitel werden die theoretischen Grundlagen zur Erstellung eines
eLearning-Moduls erläutert.
3.1. Varianten des eLearning
Es gibt verschiedene Varianten des eLearning. Reinmann-Rothmeier unterscheidet in [RR03,
Seite 32] drei Formen:
∙ eLearning by distributing
∙ eLearning by interacting
∙ eLearning by collaborating
Beim eLearning by distribution werden Informationen und Inhalte über elektronische Medien
bereitgestellt, die dann von den Lernenden selbst erarbeitet werden. Im Gegensatz dazu werden
die Inhalte beim eLearning by interacting von den elektronischen Medien so angeboten, dass
die Lernenden sie durch die Interaktion mit einem technischen System eigenständig erarbei-
tet können. Das eLearning by collaboration beschreibt eine Variante des eLearnings, bei dem
mehrere Lernende zusammen Aufgaben lösen. In der Regel werden sie von Tutoren unterstützt.
Abbildung 3.1 fasst die Varianten noch einmal zusammen.
Das zu entwickelnde eLearning-Modul ist im Bereich eLearning by interaction anzusiedeln. Der
Anwender erarbeitet sich selbstständig Wissen und Verständnis mittels Interaktion mit dem
eLearning-Modul.
Als Anforderungen an ein solches eLearning-Modul ist vor allem die lernfreundliche Informati-
onsgestaltung, wobei vom Lernenden ein außreichendes Maß an Motivation sowie die Fähigkeit
zur Selbstorganisation gefordert wird. [RR03, Seite 34]
Nina Rothenberg Masterthesis 23

3. eLearning-Software
Abbildung 3.1.: eLearning-Varianten Quelle: [RR03, Seite 33]
3.2. Simulationen im eLearning
Ein solches technisches System kann folgende Elemente beinhalten:
∙ (Hyper-)Texte,
∙ Bilder,
∙ Animationen und
∙ Simulationen.
Um den Unterschied zwischen Animationen und Simulationen noch einmal zu verdeutlichen
werden beide Begriffe in den folgenden Abschnitten noch einmal definiert.
Roth fasst in [Rot09, Seite 37] Animationen und Simulationen als einen Anwendungstyp zusam-
men, bei dem komplexe, dynamische Zusammenhänge in einem Modell abgebildet werden und
ggf. die Möglichkeit besteht ”die Auswirkung von Parameter- und Variablenmanipulation zu be-
obachten”. Dieser Anwendungstyp findet hauptsächlich im explorativem Lernen anwendung.
Animationen10 sind bewegte Darstellungen aus Einzelbildern. Sie werden einmal erstellt oder
generiert und danach ein oder mehrmals abgespielt. Einige Anomationen können vom Nutzer
10Anomation kommt vom lateinischen Wort animare, welches übersetzt ”Leben einhauchen” oder ”zum Leben
erwecken” bedeutet.
24 Masterthesis Nina Rothenberg

3. eLearning-Software
gesteuert werden, indem diese die Geschwindigkeit verändern bzw. ”blättern” können. Andere
Manipulationsmöglichkeiten hat der Anwender allerdings nicht.
Simulationen sind Umgebungen in denen der Anwender ”in kontrollierten Umgebungen virtuell
Experimente durchführen kann, um das zugrundeliegende mathematische Modell der Simulation
besser verstehen zu können” [Rey09, Seite 21].
Das eLearning-Modul, welches im Rahmen dieser Arbeit beschrieben wird, ist eine Simulation.
Der Anwender wählt Werte für Parameter aus und kann sich auf Grundlage dieser Eingaben
den resultierenden Entscheidungsbaum anzeigen und ggf. weiter manipulieren.
De Jong beschreibt in seinem Artikel [dJ06, Seite 532] Probleme, die es beim Umgang der
Lernenden mit Simulationen gibt. Dazu gehören unter Anderem, dass es Probleme bei der Wahl
der Eingabevariablen und Hypothesenformulierung gibt oder aber Probleme bei dem Ziehen
von Schlussfolgerungen. Um diese Probleme zu reduzieren, fasst [Rey09, Seite 106] folgende
Maßnahmen zusammen:
∙ Übungsaufgaben implementieren
∙ Erläuterungen und Hintergrundinformationen hinzufügen
∙ Überwachungs- und Planungswerkzeuge bereitstellen
∙ Instruktionshinweise oder ähnliche Unterstützungsmaßnahmen anbieten
∙ Lernumgebung strukturieren
∙ (Komplexe) Computersimulationen allmählich aufbauen
3.3. Vorgehensmodelle
Im Folgenden werden bereits vorhandene Vorgehensmodelle beschrieben und bewertet. Im An-
schluss wird das Vorgehensmodell beschrieben, nach welchem in dieser Arbeit vorgegangen
wird.
3.3.1. Vorgehensmodell nach Hambach und Urban
Im Rahmen des Projektes E-Learning Qualität (ELQ) ist ein Vorgehensmodell zur systemati-
schen Entwicklung von eLearning-Angeboten entwickelt worden. Dieses wird in [HU06] vorge-
stellt. Diese Vorgehnsmodell besteht aus sechs Phasen, die in Abbildung 3.2 zu sehen sind.
Nina Rothenberg Masterthesis 25

3. eLearning-Software
Abbildung 3.2.: Vorgehensmodell zur systematischen Entwicklung von eLearning-Angeboten
In der Analyse-Phase werden der Bildungsbedarf, die Zielgruppe und der Kontext analysiert. Der
Bildungsbedarf wird in einer Bedarfsbeschreibung dokumentiert. Der Kontext beinhaltet orga-
nisatorische und institutionelle Rahmenbedingungen, Interessenhalter sowie externe Einflüsse.
Auf Basis dieser Ergebnisse werden dann in der Phase des Rahmenkonzepts die Ziele festge-
legt, der didaktische Ansatz und das Rahmenkonzept entwickelt. Das Ziel des Schrittes ”Ziele
festlegen” ist die Festlegung ”was das E-Learning-Angebot leisten muss, um den Bildungsbe-
darf zu befriedigen und um weiteren Rahmenbedingungen zu genügen.” [HU06, Seite 33]. Dazu
werden Bildungsziele, allgemeine Ziele und Projektmanagementziele definiert. Um den didak-
tischen Ansatz zu ermitteln, werden verschiedene mögliche Ansätze verglichen und bewertet.
Der geeignetste Ansatz wird dann ausgewählt. Auf Grundlage der Ziele und des didaktischen
Ansatzes wird das Rahmenkonzept erarbeitet.
Das Detailkonzept konkretisiert das Rahmenkonzept. [HU06, Seite 56] Hierzu werden Detail-
konzepte zur Lehr-/Lernzielen, -inhalten, -formen und -material erstellt. Diese Detailkonzepte
beenden die Konzeption und geben detaillierte Vorgaben zur Umsetzung. [HU06, Seite 56]
In der Umsetzung werden Lehr- und Lernmedien erstellt, die Materialien zusammengestellt und
zu einem eLearning-Angebot zusammengefasst. [HU06, Seite 81] Danach folgen Einführung und
Durchführung. In der Durchführung wird das eLearning-Angebot geprüft und Rückmeldungen
von Anwendern ausgewertet um Verbesserungspotentiale zu ermitteln.
26 Masterthesis Nina Rothenberg

3. eLearning-Software
3.3.2. Vorgehensmodell nach Wendt
Wendt benutzt in [Wen03] sein eigenes Vorgehensmodell zur Erstellung eines eLearning-Angebots.
Er beschreibt dort viele Einzelschritte und verdeutlicht diese an einem Beispielprojekt. Diese
Einzelschritte kann man grob in folgende Prozessschritte zusammenfassen:
∙ Zielgruppenanalyse
∙ Sichtung, Auswahl und Strukturierung der Lerninhalte
∙ Formulierung von Lernzielen
∙ Entwicklung einer Lehrstrategie
∙ Aufbau der Programmstruktur
∙ Visuelles Konzept ausarbeiten
Die Zielgruppenanalyse ist der erste Schritt bei der Planung eines eLearning-Systems. Es ent-
steht ein Bedarfsprofil [Wen03, Seite 93], indem auch die technischen Voraussetzungen berück-
sichtigt werden. Anschließend werden die Lerninhalte lernthemenorientiert gesichtet, ausgewählt
und strukturiert und auf ihrer Grundlage werden Lernziele formuliert. Mit Hilfe der gesammel-
ten Informationen wird nun die Lehrstrategie entwickelt. Mittels Lernzielen und Lehrstrategie
werden Aufgaben und Elemente zur Lernerfolgskontrolle konstruiert. [Wen03, Seite 93] An-
schließend wird die Programmstruktur aufgebaut, die unter anderem das Lernmanagement und
den Medieneinsatz (also den Programmtyp) beinhaltet. Abschließend wird das visuelle Konzept
ausgearbeitet und die Umsetzung kann beginnen.
In seinem Beispiel zeigt sich Wendt pragmatisch und macht deutlich, dass je nach eLearning-
Modul entsprechende Analyse-Schritte gewählt werden müssen. Das von ihm verwendete Bei-
spiel ist ein Plan- und Lernspiel, zudem auch ein Spielplan erstellt. Das ist bei anderen Pro-
grammtypen selbstverständlich nicht notwendig.
3.3.3. Bewertung der Vorgehensmodelle
In dieser Arbeit wird ein eLearning-Modul entwickelt, welches nicht an zentraler Stelle zum
erlernen der Inhalte steht. Es dient lediglich zur Unterstützung des Lernprozesses an einer
spezifischen Stelle. Das eLearning-Modul wird nicht in einer konkreten Vorlesung verwendet und
an deren konkreten Unterichtsstoff angepasst bzw. in diese integriert. Sie ist ein eigenständiges
Modul, welches von jedem Anwender benutzt werden kann. Da das Thema und die Inhalte
Nina Rothenberg Masterthesis 27

3. eLearning-Software
fest sind und keinen Spielraum für Interpretationen liefern, ist es auch nicht nötig die Inhalte
anzupassen.
Diesen Rahmenbedingungen zu folge, ist das Modell nach Hambach und Urban für die Zwecke
dieser Arbeit überdimensioniert. Es eignet sich vor allem dafür, eine komplette Vorlesung als
eLearning-Angebot zu gestalten. Für ein einzelnes Modul enthält es viele überflüssige Schritte.
Das Modell nach Wendt eignet sich im Vergleich besser. Dennoch ist es noch immer nicht
ideal. Denn auch hier ist der Schritt zur Entwicklung der Lernstrategie ein wenig zu intensiv.
Mit einer Mind-Map schlägt Wendt in [Wen03, Seite 101] eine interessante Vorgehensweise zur
Identifizierung der Lerninhalte vor, die im späteren Vorgehen wieder aufgegriffen wird.
3.3.4. Verwendetes Vorgehensmodell in dieser Arbeit
Das Vorgehen in dieser Arbeit richtet sich nach der Objektorientierten Analyse (OOA) und
dem Objektorientierten Design (OOD). Diese werden um die speziellen Anforderungen für eine
eLearning-Komponente, auf Grundlage der vorgestellten Vorgehensmodelle, erweitert.
Die OOA umfasst alle Vorgehensschritte die der Ermittlung, Klärung und Beschreibung von
Anforderungen dienen. [Oes04, Seite 351] Das OOD beschreibt, wie diese Anforderungen erfüllt
werden. [Oes04, Seite 353] Die einzelnen Schritte sind in Abbildung 3.3 visualisiert. Auf die
einzelnen Schritte des Modells wird nicht weiter eingegangen. Detaillierte Beschreibungen sind
z. B. in [Oes04, Seite 89 ff.] zu finden.
Abbildung 3.3.: Schritte der OOA und des OOD
Als wichtige Schritte für eLearning-Komponenten werden folgende Prozessschritte in Anlehnung
an die Vorgehensmodelle von Wendt und Hambach und Urban aufgenommen:
28 Masterthesis Nina Rothenberg

3. eLearning-Software
∙ Zielgruppenanalyse
∙ technische Rahmenbedingungen
∙ Lerninhalte identifizieren
Hierbei wird der Schwerpunkt vor allem auf die Zielgruppenanalyse gelegt. In der OOA ist von
der Identifizierung der Interessenhalter die Rede. In diesem Fall ist dieser Schritt zu Wage, denn
die wichtigste Interessengruppe ist die Zielgruppe, die aus diesem Grund besondere Gewichtung
erhält und als extra Schritt aufgenommen wird.
Auch für die technischen Rahmenbedingungen wird ein extra Schritt aufgenommen. Die Zie-
larchitektur ist immer zu berücksichtigen. Ein expliziter Vorgehensschritt scheint sinnvoll und
wird dem Vorgehensmodell aus diesem Grund hinzugefügt.
Statt der einfachen Identifizierung und Beschreibung von Anwendungsfällen, wie es in der OOA
vorgeschlagen wird, werden zuerst Lerninhalte identifiziert, auf deren Grundlage dann die An-
wendungsfälle und Anforderungen ermittelt werden.
In den beiden vorgestellten Modellen kommen, aus Sicht des Autors, zu wenige nichtfunktiona-
le Anforderungen vor. Diese sind gerade für die Ergonomie und die Wartung einer Anwendung
wichtig. Außerdem sollte gerade bei eLearning-Komponenten umso größerer Wert auf die An-
wenderfreundlichkeit und Barrierefreiheit gelegt werden.
Abbildung 3.4.: Erweitertes Vorgehensmodell
Nina Rothenberg Masterthesis 29

3. eLearning-Software
Das um die vorher beschriebenen zusätzlichen Schritte erweiterte Vorgehensmodell ist in Ab-
bildung 3.4 zu sehen. Zusätzlich wurde der Schritt ”Verteilungsmodell definieren” entfernt, da
dieser nur für verteilte Systeme interessant ist. Die folgenden Kapitel gliedern sich in die ein-
zelnen Prozessschritte.
30 Masterthesis Nina Rothenberg

4. Software-Analyse
4. Software-Analyse
In der Analyse-Phase werden die Anforderungen gesammelt und beschrieben. Die Anforderungen
definieren den Soll-Zustand der Anwendung und legen somit fest, was umgesetzt werden soll.
4.1. Zielsetzung
Ziel ist es aus Datensätzen Entscheidungsbäume zu generieren und dem Anwender hierzu detail-
liert zu erklären, wie die Anwendung den Entscheidungsbaum aus dem Datensatz ermittelt hat
(Vgl. Tabelle 4.1). Somit soll es dem Anwender möglich sein die Entscheidungsbaumalgorithmen
an einem praktischen Beispiel nachzuvollziehen und auch Sonderfälle erklärt zu bekommen.
Bildungsziel 1 BZ-1
Beschreibung Mit der Anwendung ist der Lernende in der Lage die
Entscheidungsbaumgenerierung nachzuvollziehen.
Kriterien zur Zielerreichung Nach der Generierung eines Entscheidungsbaum kön-
nen alle Rechenschritte nachvollzogen werden.
Tabelle 4.1.: Bildungsziel 1
Aktuell ist so etwas nur über Umwege möglich, denn die aktuell verfügbare Software11 bietet den
Anwendern zwar die Generierung von Entscheidungsbäumen an, aber eine Erklärungskompo-
nente fehlt diesen Anwendungen. Somit muss ein Anwender die Algorithmen selbst durchführen
und somit einen Entscheidungsbaum ermitteln und kann diesen mit dem generierten Baum ver-
gleichen. Allerdings ist auch die Gleichheit der Bäume keine Garantie für ihn den Algorithmus
richtig angewandt zu haben. Aus diesem Grund kann bei der Verwendung von Software zur Ent-
scheidungsbaumgenerierung nur bedingt von einer Unterstützung beim Lernen und Verstehen
der Algorithmen gesprochen werden.
Ein begleitendes Skript und eine detaillierte Beispielrechnung können den Anwender unterstüt-
zen. Diese statischen Beispielrechnungen können nur sehr schwer alle Eventualitäten abdecken.
Ein eLearning-Modul mit Erklärungskomponente bietet den Vorteil, dass der Anwender flexibel
11Vgl. Kapitel 2.5 ”Software zur Entscheidungsbaumgenerierung” ab Seite 19.
Nina Rothenberg Masterthesis 31

4. Software-Analyse
ist und auch frei erfundene Datensätze testen kann. Die Flexibilität ist das zweite Kernziel,
welches in Tabelle 4.2 zusammengefasst ist.
Bildungsziel 2
Beschreibung Lernende sollen in der Lage sein eigene Datensätze
zu importieren um evtl. nicht beschriebene Sonderfälle
nachvollziehen zu können oder aber eigene Übungsauf-
gaben zu kontrollieren.
Kriterien zur Zielerreichung Ein Datensatz kann importiert werden und als Grund-
lage für eine Entscheidungsbaumgenerierung verwen-
det werden.
Tabelle 4.2.: Bildungsziel 2
4.2. Zielgruppe analysieren
Die Zielgruppe des eLearning-Moduls sind Studenten, die sich innerhalb ihres Studiums mit
Entscheidungsbaumgenerierung beschäftigen. Dies ist z. B. im Masterstudiengang Wirtschafts-
informatik der Hochschule Wismar der Fall.
Die Zielgruppe des eLearning-Moduls sind die Studenten, denen schriftliche Erklärungen zum
Thema Entscheidungsbaumgenerierung nicht genug sind. Selbstverständlich kann das Modul
auch von Nicht-Studenten verwendet werden, wenn diese an dem Thema interessiert sind. Die
Voraussetzungen gleichen denen der Studenten. Aus diesem Grund wird auch nur ein einziges
Zielgruppenprofil für die Zielgruppe ”Studenten” angelegt (Vgl. Tabelle 4.3).
Das Thema Entscheidungsbaumgenerierung ist ein Spezialthema aus dem Fachbereich der Wirt-
schaftsinformatik. Es kommt in der Regel in Spezialisierungsstudiengängen vor, wie einem wei-
terführenden Masterstudiengang. Die Studenten haben also in der Regel schon ein Studium
abgeschlossen oder aber zumindest ein Grundstudium hinter sich. Studieren kann man bis ins
hohe Alter. Es wird allerdings davon ausgegangen, dass der Großteil der Studenten unter 35
Jahre alt ist.
Studenten haben in der Regel viel Erfahrungen mit der Nutzung von Computern und entspre-
chenden Anwendungen. Gerade Studenten, die sich mit dem Thema Entscheidungsbaumgene-
rierung beschäftigen, tun dies meistens in Vorlesungen zum Thema Data Mining. In Studien-
32 Masterthesis Nina Rothenberg

4. Software-Analyse
Zielgruppe Studenten
Altersgruppe 20-45 (Schwerpunkt bei 25-35)
Erwartungen, Interessen Algorithmen an Beispielen verdeutlichen. Dabei alle
nötigen Informationen angezeigt bekommen.
Motivationen zur Teilnahme Persönliches Interesse am Verstehen der Entschei-
dungsbaumalgorithmen. Aber auch Notwendigkeit um
z.B. eine Klausur zu bestehen. Hohe Eigenmotivati-
on entweder aus explizitem Interesse am Thema oder
dadurch, dass das Studium gut abgeschlossen wird.
thematisches Vorwissen und
fachliche Voraussetzungen
Theoretisches Grundwissen zur Entscheidungsbaum-
generierung durch eine entsprechende Hochschulvorle-
sung.
Medienkompetenz hohe Medienkompetenz
bisherige Lernerfahrungen und
bevorzugte Lernstile
Viel Lernerfahrung durch das Studium. Vor allem
selbstbestimmtes Lernen und exploratives Lernen.
individueller Kontext mit
Bezug zum zu entwickelnden
eLearning-Angebot
Die Anwendung sollte kostenfrei sein, da die Studenten
für eine derartige Lernanwendung, die so sehr auf ein
bestimmtes Thema spezialisiert sind, kein Geld ausge-
ben wollen.
Tabelle 4.3.: Zielgruppenanalyse der Zielgruppe ”Studenten”
gängen in denen dieses Thema behandelt wird, kann man davon ausgehen, dass ihnen eine hohe
Medienkompetenz zuzusprechen ist.
4.3. Anwendungsfall
Die Anwendungsfälle werden gemäß der Ziele identifiziert. Hierbei werden vier Anwendungsfäl-
le identifiziert, die im Anwendungsfalldiagramm in Abbildung 4.1 inklusive ihrer Beziehungen
zueinander dargestellt sind.
Für jeden Anwendungsfall müssen als erstes Daten importiert werden. Diese können dann, wenn
gewünscht, manipuliert werden. Nach diesen Schritten kann ein Entscheidungsbaum generiert
Nina Rothenberg Masterthesis 33

4. Software-Analyse
Abbildung 4.1.: Anwendungsfalldiagramm
werden, welches der Hauptanwendungsfall des eLearning-Moduls ist. Im Anschluss kann das
Ergebnis exportiert werden.
4.4. Lerninhalte
Die Lerninhalte gehen detaillierter auf die Ziele der Anwendung ein. Sie fassen zusammen, was
genau in der Anwendung geboten werden soll.
Für die Identifizierung der Inhalte schlägt [Wen03, Seite 101] den Einsatz von Mindmaps vor.
Dieser Ansatz wird hier aufgenommen, weil er die Lerninhalte auf übersichtliche Art und Weise
darstellt. In Abbildung 4.2 ist die Mindmap der Inhalte für die fachlichen Inhalte des eLearning-
Moduls zu sehen.
Abbildung 4.2.: Inhalte des eLearning-Moduls
34 Masterthesis Nina Rothenberg

4. Software-Analyse
Im Folgenden werden aus diesen Inhalten die Anforderungen identifiziert und zusammengefasst.
Eine komplette Liste der Anforderungen ist in Anhang B ab Seite 75 zu finden.
4.5. Anforderungen
Die Anforderungen teilen sich in funktionale und nicht-funktionale Anforderungen auf. Einige
Anforderungen sind abhängig von anderen Anforderungen. Das bedeutet, dass diese nur dann
umgesetzt werden, wenn eine oder mehrere andere Anforderungen umgesetzt sind. Die Priorität
einer solchen Anforderung kommt erst dann zum tragen, wenn die abhängigen Anforderungen
bereits umgesetzt worden sind.
4.5.1. Anforderungen zur Entscheidungsbaumgenerierung
Das eLearning-Modul soll aus einer gegebenen Datenmenge einen Entscheidungsbaum generie-
ren und die dazu notwendigen Schritte in einer Erklärungskomponente beschreiben. Die funk-
tionalen Anforderungen werden grob nach Prozessschritten12 unterteilt.
Datenvorbereitung
Damit das eLearning-Modul die Studenten wirklich unterstützen kann, muss es dem Anwender
möglich sein, eigene Beispiele einzulesen. Dadurch ist er in der Lage bestimmt Fälle nachvoll-
ziehen zu können, die ihm nicht klar sind. können Datensätze in Form von Dateien manuell
importiert werden. Um dies für den Anwender so angenehm wie möglich zu gestalten, kann er
verschiedene Dateiformate nutzen. Der Vorteil hier ergibt sich durch die bessere Austauschbar-
keit von Datensätzen unter den Studenten und der Möglichkeit, dass auch Dozenten Datensätze
zur Verfügung stellen können.
Die Benutzerfreundlichkeit wird durch die Möglichkeit manuelle Datenreihen einzugeben bzw.
erstellte oder importierten Daten zu manipulieren weiter erhöht. Diese Anforderung ist allerdings
mit einer niedrigeren Priorität zu versehen, da man die Daten auch über weitere Dateien einlesen
kann. Viel höher ist der Aufwand für einen Anwender nicht, wenn er die Datei selbst manipu-
liert und diese erneut einliest. Wenn es möglich ist Datensätze zu manipulieren bzw. manuell
einzugeben, ist eine Exportfunktion sinnvoll. So kann der Anwender interessante Datensätze
speichern und sogar weitergeben.
12Vgl. Kapitel 2.2 auf Seite 7.
Nina Rothenberg Masterthesis 35

4. Software-Analyse
Ein Datensatz besteht nicht nur aus den Datenreihen sondern auch aus Attributen. Bei den
Attributen wird dem Anwender die Möglichkeit gegeben sie an- und abzuwählen. Angewählte
Attribute werden bei der Entscheidungsbaumgenerierung berücksichtigt. Auch das Zielattribut,
zu dem ein Entscheidungsbaum generiert werden soll, muss ausgewählt werden.
Nummerische Attribute können manuell gruppiert werden. Hierzu werden verschiedene Gruppen,
bestehend aus einem oder mehreren Intervallen, erstellt und, wenn gewünscht, mit einem Namen
versehen. Auch nominale Attribute können gruppiert werden. Hierzu werden eine oder mehrere
Ausprägungen zu einer Gruppe zusammengefasst.
Entscheidungsbaumgenerierung
Die Anwendung soll an allen sinnvollen Stellen parametrisierbar sein. Ein Entscheidungsbaum
soll nicht anhand eines festen Musters generiert werden, sondern so, wie es der Anwender
wünscht. Hierbei sollte er nicht zwischen einigen wenigen Algorithmen entscheiden können,
sondern jedes mögliche Kriterium selbst wählen können. Ein Anwender kann folgende Parameter
selbst beeinflussen:
∙ Split-Kriterium
∙ Stop-Kriterium
∙ Pruning-Methode
∙ Umgang mit fehlenden Werten
∙ Anzahl der Gruppen bei der automatischen Gruppierung von Attributen
Natürlich muss nach einer Auswahl auch angezeigt werden, ob es sich bei der gewählten Konfi-
guration um einen bestimmten Algorithmus handelt. Zusätzlich sollte die Möglichkeit geboten
werden eine vorkonfigurierte Einstellungsmenge als Algorithmus zu speichern. Schließlich möch-
te ein Anwender vielleicht einen bestimmten Algorithmus näher verstehen. Dann sollte man ihm
die Parametrisierung abnehmen, indem er einfach den Algorithmus auswählt und dann gegebe-
nenfalls variable Werte verändert. Die Auswahl des Anwenders muss zu jeder Zeit sichtbar sein,
damit es nicht zu Unklarheiten kommt.
Falls die Einstellungen verändert werden und ein neuer Baum generiert wird, ist es sinnvoll,
mehrere Ergebnisse gegenüberzustellen. Diese Anforderung ist weniger hoch priorisiert, weil
man denselben Effekt haben kann, wenn man zwei Ergebnisse exportiert. Die Exportergebnisse
kann der Anwender dann in Ruhe vergleichen.
36 Masterthesis Nina Rothenberg

4. Software-Analyse
Eine nützliche Funktion ist ein Debug-Modus, indem der Anwender die Generierung Schritt für
Schritt nachvollziehen kann und manuell zum nächsten Schritt wechseln kann. Allerdings kann
auch dieses durch einen Export im Nachhinein erreicht werden, sodass eine derart aufwändige
Anforderung mit der niedrigsten Priorität zu versehen ist.
Wenn die Entscheidungsbaumgenerierung beendet ist, wird der Entscheidungsbaum grafisch
angezeigt. Hierzu wird die bekannte Baumdarstellung gewählt. Ein Beispiel für eine solche
Anzeige ist in Abbildung 4.3 zu sehen.
Abbildung 4.3.: Entscheidungsbaum
Die einzelnen Elemente werden wie folgt beschriftet: Name des aktuell betrachteten Attributs
bei inneren Knoten, der betrachtete Wert bzw. des aktuellen Attributs bei Kanten und den
Namen und ggf. die Wahrscheinlichkeit einer Ausprägung des Zielattributs an einem Blatt.
Erklärungskomponente
Die Erklärungen sollen nahe dem Element angezeigt werden, zu welchem sie gehört. Hier ist es
wichtig, nicht alle Informationen auf einmal anzuzeigen sondern dem Anwender die Möglichkeit
zu geben, sich gezielt die Informationen anzeigen zu lassen, die ihn interessieren.
Die anzuzeigenden Informationen sind folgende:
∙ inneren Knoten
An einem inneren Knoten wird das ausgewählte Attribut und der Grund, warum es aus-
gewählt worden ist, angezeigt. Zusätzlich sind die anderen Attribute anzuzeigen und der
Grund, warum diese nicht ausgewählt worden sind. Falls eine automatische Gruppierung
vorgenommen worden ist, muss auch diese hier erläutert werden.
Nina Rothenberg Masterthesis 37

4. Software-Analyse
∙ Kante
An einer Kante werden die Werte13 angezeigt, mit denen dieser Kante gefolgt wird, sowie
die Gründe zur Auswahl der Werte.
∙ Blatt
An einem Blatt wird der Wert des Zielattributs und dessen Wahrscheinlichkeit an dieser
Stelle anzeigt. Auch die restlichen möglichen Zielattribut-Werte werden mit Wahrschein-
lichkeit angezeigt. Zusätzlich werden Informationen zum Pruning angezeigt, falls das Blatt
durch eine Pruning-Methode entstanden ist.
Für die Erklärungskomponente ist es aber auch wichtig, einen Export der Informationen aus-
geben zu können, damit sich die Studierenden die Informationen gebündelt anschauen können.
In einem Modul experimentieren zu können ist praktisch für den Anwender. Es ersetzt aber
keinen Ausdruck einer detaillierten Vorgehensbeschreibung, welche für Übungen sehr hilfreich
ist. Die Ausgabe ist so detailliert wie möglich zu gestalten, wobei die Übersichtlichkeit nicht zu
kurz kommen darf. Ein Anwender kann die Ausgabe immer noch manuell kürzen, sich weitere
Informationen selbst zu erarbeiten ist deutlich aufwändiger.
Sehr wichtig ist auch, dass der Anwender immer die Eingabeparameter vor Augen hat. Diese
müssen zu jedem Zeitpunkt anzeigbar sein.
4.5.2. Nichtfunktionale Anforderungen
Neben den funktionalen Anforderungen gibt es auch nichtfunktionale Anforderungen. Oestereich
unterteilt diese nichtfunktionale Anforderungen in [Oes04, Seite 233] in folgende Gruppen:
∙ Benutzbarkeit,
∙ Performance,
∙ Zuverlässigkeit,
∙ Wartbarkeit,
∙ Administrierbarkeit und
∙ Rahmenbedingungen.
Diese Unterteilung wird hier übernommen, um die nichtfunktionalen Anforderungen thematisch
zu gruppieren.
13Bei nummerischen Werten in Form von Intervallen.
38 Masterthesis Nina Rothenberg

4. Software-Analyse
Benutzbarkeit
Die Benutzbarkeit ist gerade bei eLearning-Modulen sehr wichtig. Die funktionalste Anwendung
ist sinnlos, wenn sie nicht ohne langes Studium der Beschreibung benutzt werden kann. In einem
solchen Fall verlieren die Anwender schnell die Lust und suchen sich eine benutzerfreundlichere
Anwendung.
In einem eLearning-Modul sollten Abbildungen jeglicher Art (auch Graphen u.ä.) immer einen
Alternativ-Text haben, der dann angezeigt wird, wenn das Bild, aus welchem Grund auch immer,
nicht geladen werden kann. [FMC02, Seite 52 ff.] Bei Farben muss auf Anforderungen von
Farbenblinden und auch auf Rot-Grün-Blindheit geachtet werden. Dies ist auch für den Ausdruck
auf einem schwarz-weiß-Drucker wichtig. Auch auf verstellbare Schriftgröße soll Wert gelegt
werden.
Allerdings ist vollständige Barrierefreiheit für solch eine fachliche Anwendung nur schwer rea-
lisierbar. Die Simulation des Entscheidungsbaumes ist das zentrale Element. Diesen kann man
nur sehr schwer auf eine verständliche Art und Weise als Alternativtext anzeigen. Es könnte
höchstens über Sprachausgaben erklärt werden. Allerdings eignen sich für blinde Anwender eher
andere didaktische Ansätze als ein solches eLearning-Modul. Aus diesem Grund sollte der Auf-
wand für eine Sprachausgabe eingespart werden und ein anderer didaktischer Ansatz gewählt
werden.
Performance
Die Performance ist ”die Leistung und Geschwindigkeit eines Systems oder Systemteils zu ei-
nem bestimmten Zeitpunkt bei der Erfüllung einer definierten Aufgabe” [Wun05, Seite 484].
Die Anwendung soll angemessen performant sein. Im Detail bedeutet dies, dass die Anwendung
innerhalb weniger Sekunden die Aktivitäten durchführt. Aktivitäten, die länger als eine Sekun-
de dauern, sollen zudem durch eine Ladeanzeige angezeigt werden, damit der Anwender ein
Feedback auf seine Eingabe erhält.
Zuverlässigkeit
Eine Anwendung ist dann zuverlässig, wenn sie eine geringe Ausfallrate hat. [McC05, Seite 477]
Bei einem unerwarteten Fehler, soll die Anwendung diesen in einer Log-Dateien loggen, um
ihn später von Entwicklern beheben zu können. Gleichzeitig soll dem Anwender eine möglichst
sprechende Fehlermeldung angezeigt werden. Der Anwender soll danach die Möglichkeit haben
Nina Rothenberg Masterthesis 39

4. Software-Analyse
die Anwendung weiter zu verwenden oder zumindest kontrolliert zu beenden. Sie soll nicht
unkontrolliert abstürzen.
Wartbarkeit
Die Anwendung soll an allen nötigen Stellen unkompliziert erweiterbar sein. Es soll die Mög-
lichkeit vorgesehen werden, dass ein Anwender alternative Komponenten, die er selbst oder
ein Dritter implementiert hat, benutzen kann. Folgende Komponenten der Anwendung sollen
hierbei erweiterbar sein:
∙ Dateiformat für den Import
∙ Dateiformat für den Export von Datensätzen
∙ Algorithmus
∙ Split-Kriterium
∙ Stop-Kriterium
∙ Pruning-Methode
∙ Methoden zur Bestimmung von Test- und Trainingsmengen
∙ Dateiformat für den Export der Erklärungen
Unkompliziert erweiterbar heißt in diesem Fall, dass ein Programmierer ohne viel Aufwand
weitere Elemente implementieren und einbinden kann.
Administrierbarkeit
Das eLearning-Modul soll einfach installierbar sein. Weitere Plugin-Ordner sollen einfach hin-
zugefügt werden.
Rahmenbedingungen
Die Anwendung soll Plattform unabhängig sein. Gerade bei Studenten im Bereich der Informa-
tik sind verschiedene Betriebssysteme verbreitet. Die Anwendung soll daher so implementiert
werden, dass sie auf den verschiedenen Betriebssystemen (z. B. Windows, Linux und Solaris)
lauffähig ist.
40 Masterthesis Nina Rothenberg

5. Software-Entwurf
5. Software-Entwurf
Um die im vorherigen Kapitel beschriebenen Anforderungen umzusetzen, werden an dieser Stelle
Konzepte zur Umsetzung vorgestellt. Hierbei wird der Schwerpunkt auf die zentralen Konzepte
zur Visualisierung und zur Erweiterung gelegt.
5.1. Visualisierung
Die Visualisierung der Elemente spielt eine tragende Rolle bei der Entwicklung des eLearning-
Moduls. Wenn die Elemente übersichtlich und verständlich angezeigt werden, kann der Anwen-
der die Informationen aufnehmen. Bei der Visualisierung ist vor allem darauf zu achten, dass
die Herkunft verschiedener Informationen nachvollziehbar ist.
5.1.1. Entscheidungsbaum
Ein Entscheidungsbaum wird so platzsparend wie möglich dargestellt. Kaufmann und Wagner
beschreiben in [KW09, Seite 47] fünf typische Anforderungen für die ideale Darstellung von
Bäumen mit Wurzelelemente:
1. Planarität: Keine Überschneidungen von Kanten.
2. Netzartig: Knoten haben ganzzahlige Koordinaten.
3. Gradlinigkeit: Jede Kante ist ein geradliniges Segment, wobei in mehrlinigen Graphen jede
Kante eine mehrkantige Kette ist.
4. (Strikt) aufsteigend: Ein Kind wird (strikt) unter seinen Eltern angezeigt.
5. Starke Ordnungserhaltung: Die Kindelemente eines Knotens stehen im gleichmäßigem
Abstand zueinander.
Zur Darstellung wird ein Algorithmus verwendet, der diese Anforderungen erfüllt. Ein solcher
Algorithmus ist z. B. in [Ski08, Seite 518] beschrieben. In Anlehnung an diese Beschreibung,
wurde der Algorithmus in Algorithmus 5.1 formalisiert.
Nina Rothenberg Masterthesis 41

5. Software-Entwurf
Algorithmus 5.1 Darstellung eines Baumes
Input: startArea ← 0, y ← 0, verticalDistance > 0, nodeWidth > 0, area.width ≥tree.width
function createTree(tree, area)
tree.root.position ← (𝑎𝑟𝑒𝑎.𝑤𝑖𝑑𝑡ℎ2 − 𝑛𝑜𝑑𝑒𝑊𝑖𝑑𝑡ℎ
2 , y)
y ← y + verticalDistance
for all subtree : tree.childNodes do
createTree(subtree, area[startArea, startArea + subtree.width])
startArea ← startArea + subtree.width
end for
y ← y - verticalDistance
end function
Hierbei ist die Breite des Baumes interessant. Diese lässt sich berechnen durch die Addition der
Breite aller Teilbäume. Die Breite eines Blattes ist die Standardbreite eines Knotens14 addiert
mit dem horizontalen Abstand15. Verkürzt kann man die Breite also durch folgende Formel
berechnen:
Breite des Baums =Anzahl aller Blätter des Baumes ·
(horizontaler Abstand+ Breite eines Knotens)
Skiena kritisiert zu recht, dass hierdurch viele schmale Bereiche entstehen können. Er schlägt
vor, dass Bereiche von breiteren Knoten, in die benachbarten ragen können, solange der jeweils
benachbarte Teilbaum eine geringere Tiefe haben, als der überschneidende Bereich.
Ein Beispiel für die Anzeige eines Entscheidungsbaums ist in Abbildung 4.3 zu sehen. Wie in
Anforderung EBG-12 bis EBG-14 gefordert, sind die Knoten und Kanten entsprechend beschrif-
tet.
5.1.2. Informationen aus der Entscheidungsbaumgenerierung
Zu allen Kanten und Knoten des Entscheidungsbaums sollen gemäß Anforderungen EK-2 bis
EK-2 die entsprechenden Informationen angezeigt werden können. Die Anforderungen fordern
zusätzlich, dass der Anwender die Möglichkeit hat, die Informationen beliebig ein- und auszu-
blenden. Hierdurch ist implizit gefordert, dass die Anzeige der Informationen über ”Zeige alle
14Diese ergibt sich aus der breite des Anzeigeelementes.15Der horizontale Abstand berechnet sich aus der Summe des rechten und linken Abstands, wobei immer rechter
Abstand = linker Abstand gilt.
42 Masterthesis Nina Rothenberg

5. Software-Entwurf
Informationen” und ”Zeige keine Informationen” hinausgeht. Es reicht allerdings auch nicht, die
Information des aktuell ausgewählten Baumelementes anzuzeigen. Aus diesem Grund, sollte es
mehrere Informationsblöcke geben. Für jedes Element kann ein Informationsblock einzeln ein-
und ausgeblendet werden. Abbildung 5.1 skizziert beispielhaft einen solchen Informationsblock
je nach Baumelement.
Abbildung 5.1.: Informationsblock
Ein Informationsblock kann direkt am dazugehörigen Baumelement angezeigt werden oder aber
an zentraler Stelle. Für die direkte Anzeige am Baumelement spricht, dass die Information dort
angezeigt wird, wo sie hingehört. Andererseits machen diese Informationsblöcke die Baumanzei-
ge unübersichtlich, denn entweder überlappen sie andere Elemente oder die anderen Elemente
müssen so verschoben werden, dass es keine Überlappungen gibt. Eine zentrale Anzeige ist
aufgeräumter. Diese muss aber das zum aktuell markierten Informationsblock gehörende Bau-
melement optisch hervorheben, damit unmissverständlich klar wird, wo diese Information zuge-
hört. Die zu den weiteren angezeigten Informationsblöcken gehörenden Baumelemente müssen
ebenfalls hervorgehoben werden, allerdings nicht so stark wie das Aktive.
Für die Umsetzung wird aus Gründen der Übersichtlichkeit die zentrale Anzeige der Erklärungen
gewählt. Wenn mehrere Informationsblöcke angezeigt werden können, ist es wichtig, dass diese
auch positioniert werden können. Eine Mindestanforderung ist hierbei das Maximieren eines
Nina Rothenberg Masterthesis 43

5. Software-Entwurf
einzelnen Blocks und die Möglichkeit mehrere Informationsblöcke nebeneinander anzeigen zu
können.
5.1.3. Benutzungsoberfläche
Die Funktionalitäten der Benutzungsoberfläche werden hier, in der Reihenfolge in der sie im An-
wendungsfall aufgerufen werden, näher beschreiben. Hierbei steht die Visualisierung der Funk-
tionalität im Vordergrund.
Der Anwender kann Daten über einen Dateiimport importieren (vgl. Anforderung DV-1). Da-
nach werden die Instanzen und die Attribute angezeigt und können vom Anwender angepasst
werden.
Ein Attribut kann deaktiviert und aktiviert werden (vgl. Anforderung DV-3). Wenn es deakti-
viert ist, wird es bei der Generierung ignoriert. Attribute können manuell gruppiert werden(vgl.
Anforderung DV-9). Hierzu können Gruppen erstellt und gelöscht16 werden und Werte den
Gruppen zugeordnet werden können.
Alle wichtigen Informationen für Attribute (Name, mögliche Werte) sowie Funktionalitäten
(Aktivierung, Art der Gruppierung, Gruppierung) sollen, wenn möglich, direkt sichtbar bzw.
erreichbar sein. Alle Elemente direkt sichtbar zu machen nimmt allerdings viel Platz weg. Aus
diesem Grund sollte z. B. die Gruppierung der Attribute in ein separates Fenster ausgelagert
werden. Zu diesem muss man allerdings intuitiv gelangen können. Man kann hierzu ein Symbol
anzeigen, welches zu dem entsprechenden Fenster führt.
Nach vollständiger Datenvorbereitung wählt der Anwender nun die Einstellungen für die Kon-
figuration der Entscheidungsbaumgenerierung aus und startet diese. Die Parameterauswahl ist
in Kapitel 5.1.5 näher erläutert. Nach der Generierung können die Erklärungen zu einzelnen
Baumelementen angezeigt und exportiert werden.
Damit der Anwender zu jeder Zeit alles im Blick hat (vgl. Anforderung EBG-10) werden alle
Oberflächenbereiche in einem Fenster angezeigt. Ein Layout für eine Anordnung der einzelnen
Bereiche ist in Abbildung 5.2 zu sehen. Die einzelnen Bereiche der Oberfläche können in der
Größe verändert werden oder auch ganz ausgeblendet werden. Dies ist gerade bei einer geringen
Bildschirmauflösung wichtig.
16Die Löschfunktion ist dann wichtig, wenn man bereits definierte Gruppen löschen möchte, um die Attribute
einer neuen Gruppe zuzuordnen.
44 Masterthesis Nina Rothenberg

5. Software-Entwurf
Abbildung 5.2.: Layout der Benutzungsoberfläche
5.1.4. Exportierbarer Bericht
Die Anwendung ermöglicht es dem Anwender Berichte zu exportieren (vgl. Anforderung EK-5.).
Diese Berichte enthalten, neben den Eingabeparametern und der Abbildung des Entscheidungs-
baums, die Erklärungen zur Generierung. Der initiale Bericht ist grob in diese drei Teile gegliedert
(vgl. Abbildung 5.3).
Abbildung 5.3.: Layout eines Berichts
Nina Rothenberg Masterthesis 45

5. Software-Entwurf
Der Bericht zeigt grundsätzlich erst einmal alle Informationen an. Allerdings wird die Anwendung
so implementiert, dass ein späteres Hinzufügen einer Komponentenauswahl ohne viel Aufwand
hinzugefügt werden kann (vgl. Anforderung EK-6.).
5.1.5. Parametereingabe
Der Bereich zur Parametereingabe werden alle dem Programm bekannten Einstellungsoptionen
eines Parameters angezeigt. Die Einstellungen sind in Kapitel 4.5.1 aufgelistet. Zu jeder Einstel-
lung können beliebig viele Optionen implementiert werden. Beim Laden der Anwendung werden
alle verfügbaren Einstellungen geladen und zur Auswahl angeboten.
Da durch die geforderte Erweiterbarkeit erst beim Programmstart bekannt ist, wie viele Optio-
nen es pro Einstellung gibt, ist es sinnvoll die verschiedenen Optionen in einem Drop-Down-Feld
zur Auswahl zu stellen. Alternativ ist eine Darstellung als Radio-Buttons denkbar, dies bietet
sich allerdings eher in dem Fall an, dass die Anzahl der Optionen bekannt ist. Bei vielen Op-
tionen werden die Radio-Buttons ansonsten auf mehrere Zeilen verteilt und die Auswahl wird
unübersichtlich.
5.2. Algorithmen
Algorithmen sind bereits implementiert und stehen in verschiedenen Bibliotheken zur Verfügung.
Ein Nachprogrammieren vorhandener Algorithmen sollte vermieden werden, da spezialisierte Bi-
bliotheken die Algorithmen performanceoptimiert umgesetzt haben. Allerdings kann man diese
im nachhinein leider sehr schlecht um die Erklärungen erweitern. Natürlich kann man mit Hilfe
eines Proxys die einzelnen Methoden kapseln und entsprechende Ausgaben zurückgeben, aller-
dings ist dieses Vorgehen sehr unflexibel und garantiert nicht, dass alle wichtigen Informationen
bereitgestellt werden können. Um die Algorithmen erweiterbar zu machen, dem Anwender die
nötige Flexibilität zu garantieren und sämtliche Erklärungsinformationen sammeln zu können,
kommt man um eine eigene Implementierung nicht herum. Allerdings können natürlich Teile
einer Open-Source-Implementierung als Grundlage genommen werden und verwendet werden.
So muss man nur die nötigen Stellen um die Erklärungen erweitern.
Ein Algorithmus zur Entscheidungsbaumgenerierung ist eine Menge von Konfigurationen. Eine
solche Konfiguration besteht aus Split- und Stopkriterium, Attributeigenschaften17 sowie einer
Pruning-Methode. Als Beispiel ist der ID3-Algorithmus in Tabelle 5.1 konfiguriert.
17Beispielsweise dass jedes Attribut als nominales Attribut behandelt wird.
46 Masterthesis Nina Rothenberg

5. Software-Entwurf
ID3
Attribute Es werden nur nominale Attribute verwendet.
Splitkriterium Information Gain
Stopkriterium Alle Einträge der Datenmenge haben den gleichen Wert für das
Zielattribut.
Pruning-Methode -
Tabelle 5.1.: Die Konfiguration für den ID3-Algorithmus
Wichtig ist bei einer solchen Konfiguration die Unterscheidung zwischen ”darf nicht benutzt
werden” und ”beliebige Auswahl”.
5.3. Erweiterbarkeit
Die Erweiterbarkeit der Anwendung ist eine zentrale Anforderung, die an verschiedenen Stellen
gefordert ist. Diese Stellen sollen möglichst gleich behandelt werden, um einem Entwickler,
der Erweiterungen implementieren möchte, nicht mit verschiedenem Vorgehen zu irritieren.
Außerdem verbessert ein einheitliches Vorgehen die Übersichtlichkeit des Quellcodes, da die
verschiedenen Stellen auf gleiche Art implementiert sind und auch die Implementierung zum
Laden der Erweiterungen getreu dem Motto ”Code once - use many” wiederverwendet werden
kann.
Die Erweiterbarkeit wird durch ein Plugin-Konzept gelöst. Hierzu werden bestimmte Interfaces
und Modellklassen in einer Java Archive (jar)-Datei bereitgestellt, die von den Entwicklern einer
Erweiterung eingebunden werden können. Die Entwickler lassen ihre Klassen das entsprechende
Interface implementieren, erstellen eine jar-Datei und legen diese in einen Plugin-Ordner. Die
jar-Dateien dieses Ordners werden zur Laufzeit nach Klassen die ein gesuchtes Interface imple-
mentieren geladen und können somit verwendet werden. Somit kann das eLearning-Grundmodul
unverändert bestehen bleiben.
Bei diesem Konzept existieren zwei Möglichkeiten der Umsetzung:
1. Die Verwendung eines existierenden Plugin-Framework wie z. B. dem Java-Plugin Frame-
work (JPF).
Nina Rothenberg Masterthesis 47

5. Software-Entwurf
2. Eigene Implementierung eines entsprechenden ClassLoaders18.
Generell ist es von Vorteil vorhandene Bibliotheken zu nutzen, um sich unnötigen Implementie-
rungsaufwand zu sparen. Bibliotheken sind ohne viel Aufwand einzubinden und zu verwenden.
Allerdings müssen dann natürlich die Anforderungen der Bibliothek erfüllt werden. Im Fall von
JPF ist eine solche Anforderung zum Beispiel das Vorhandensein einer Manifest-Datei19. Diese
muss von jedem zu erstellenden Plugin entsprechend gepflegt werden, was Aufwand für den
Entwickler bedeutet und fehleranfällig ist.
Um die Schnittstellen so erweiterbar wie möglich zu halten, werden ihnen bestimmte Eingabe-
objekte übergeben. Diese Eingabeobjekte können dann von Entwicklern, denen zu ihrer Erwei-
terung noch Informationen fehlen, erweitert werden, indem ein Objekt mit der Oberklasse des
Eingabeobjektes definiert wird. Hierbei ist allerdings darauf zu achten, dass die neu hinzugefüg-
ten Parameter auch befüllt werden müssen. Hierzu ist mindestens eine neue Implementierung
eines Datei-Importes nötig. Somit wird eine erweiterte Behandlung von bisher unbekannten
Informationen möglich.
Der Anwender hat die Möglichkeit der Anwendung weiter Plugin-Ordner anzugeben.
Bei einem solchen Plugin-Konzept ist natürlich nicht ausgeschlossen, dass es zwei Implemen-
tierungen zu einem Thema gibt. Da allerdings jede Implementierung eine Bezeichnung hat,
mit der sie an der Oberfläche wählbar ist, kann der Anwender so zwischen den verschiedenen
Implementierungen wählen. Falls es z. B. mehrere Implementierungen des Importes für ein be-
stimmtes Datei-Format gibt, werden dem Anwender die verschiedenen Alternativen angezeigt
und er wählt, welche er verwenden möchte.
5.4. Komponentenschnitt
Um die Anwendung möglichst schlank und variable zu gestalten, wird sie in mehrere Komponen-
ten aufgeteilt. Die Komponenten sind so konzipiert, dass sie, soweit möglich, möglichst einfach
ausgetauscht werden können.
Folgende vier Komponenten werden identifiziert:
∙ Basis-Komponente
∙ Kern-Komponente
18ClassLoader sind Klassenlader, die ”Gruppen von Klassen, oft in Form von jar-Dateien” [Ess08, Seite 280]
laden.19Eine Manifest-Datei beinhaltet Metadaten zu einer Anwendung.
48 Masterthesis Nina Rothenberg

5. Software-Entwurf
∙ Benutzungsoberfläche
∙ Standard-Implementierungen
Im folgenden werden diese näher beschrieben. Die Beziehung der vier Komponenten ist in
Abbildung 5.4 zu sehen.
Abbildung 5.4.: Komponentendiagramm
5.4.1. Basis-Komponente
Diese Basis-Komponente ist Grundlage aller weiteren Komponenten. Hier sind die grundlegenden
Datenmodelle und Schnittstellen implementiert. Dies sind, neben dem Entscheidungsbaum und
dem Modell der Datenmenge, die Schnittstellen für die erweiterbaren Elemente wie Split- und
Stop-Kriterien.
In Abbildung 5.5 ist das Modell des Entscheidungsbaums zu sehen.
Abbildung 5.6 zeigt die Schnittstellen, die angeboten werden. Diese Schnittstellen sind die
Grundlage der Erweiterbarkeit der Anwendung. Sie müssen so modelliert sein, das möglichst
alle wünschenswerten Erweiterungen umgesetzt werden können.
Diese Kern-Komponente enthält die Logik, die die einzelnen Komponenten zusammenbringt.
Sie lädt die Erweiterungen nach und stellt diese zur Verfügung. Außerdem enthält sie die Logik
mit der Split- und Stop-Kriterium aufgerufen werden und erstellt mittels der Ergebnisse den
Entscheidungsbaum. Diese Komponente enthält die Teile, die bei jeder Entscheidungsbaumge-
nerierung gleich sind. Sie ist die konstante Komponente der Anwendung und wird sich nur in
großen Ausnahmefällen ändern.
Nina Rothenberg Masterthesis 49

5. Software-Entwurf
Abbildung 5.5.: Modell des Entscheidungsbaums
Neben dem Laden der einzelnen Erweiterungen, wird die Schnittstelle zur Entscheidungsbaum-
generierung bereitgestellt. Diese bekommt ein Objekt übergeben, welches alle Einstellungen und
Eingabe-Objekte für diese Generierung beinhaltet. Hierzu gehören auch die Trainings- und die
Testmenge.
5.4.2. Benutzungsoberfläche
In dieser Komponente ist die Benutzungsoberfläche implementiert. Die Oberfläche ist somit
losgelöst von der Logik und damit austauschbar.
Wenn in Zukunft zum Beispiel eine barrierefreie Oberfläche mit Sprachausgabe erstellt werden
soll, kann die gleiche Logik aus der Kern-Komponente genutzt werden und es muss wirklich nur
die reine Oberfläche neu entwickelt werden. Dies macht die Anwendung zukunftssicher.
50 Masterthesis Nina Rothenberg
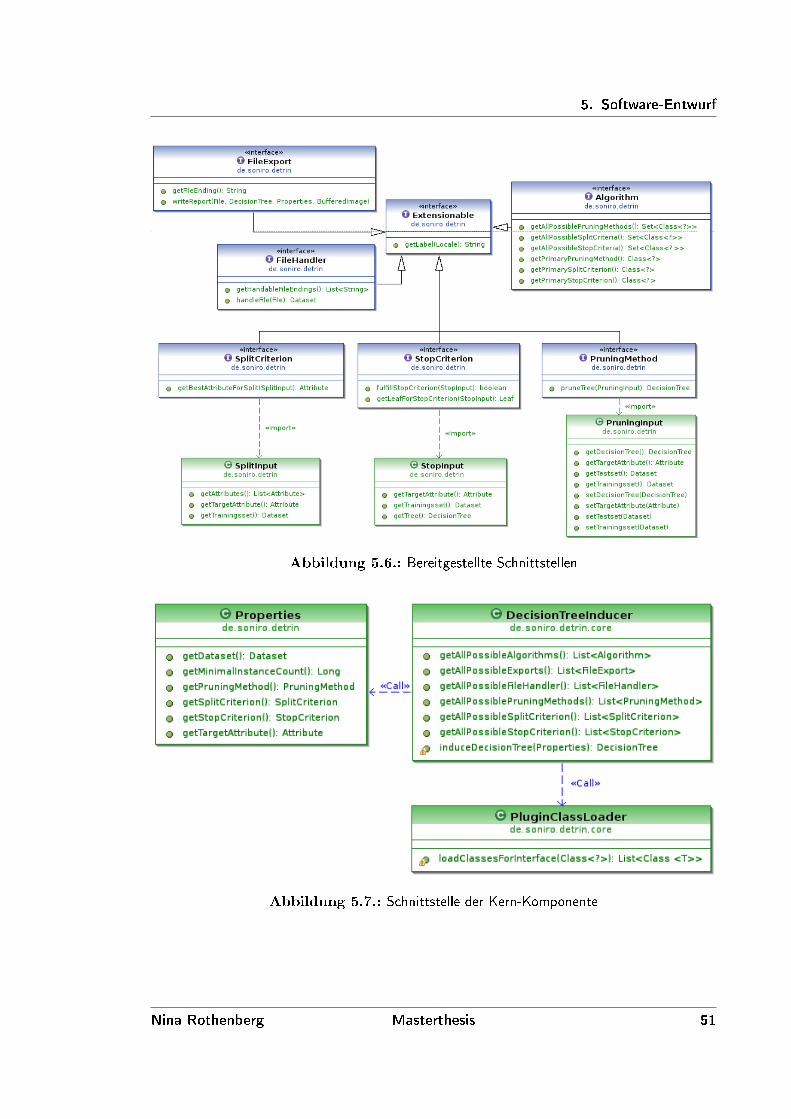
5. Software-Entwurf
Abbildung 5.6.: Bereitgestellte Schnittstellen
Abbildung 5.7.: Schnittstelle der Kern-Komponente
Nina Rothenberg Masterthesis 51

5. Software-Entwurf
5.4.3. Standard-Komponente
Die Standard-Komponente ist das erste Plugin der Anwendung. Es enthält die ersten Implemen-
tierungen der bereitgestellten Interfaces zum Datei-Import/-Export, Split- und Stop-Kriterium,
Pruning-Methoden sowie Algorithmen.
In dem entwickelten Prototyp werden hierzu erst einmal die gängigen Algorithmen ID3, C4.5
und CART implementiert. Datei-Import und -Export werden beispielhaft anhand eines Charac-
ter Separated Values (CSV)-Handler zum importieren eines Datensatzes und einem Hypertext
Markup Language (HTML)-Export realisiert.
Die sich dazu ergebenen Klassen sind in Abbildung 5.8 zu sehen.
Abbildung 5.8.: Die Klassen der Standard-Komponente
5.5. Sonstiges
Um eine Anwendung möglichst flexibel zu halten, sollte u.a. immer die Mehrsprachigkeit beach-
tet werden. Neben den flexibel austauschbaren Komponenten ist dies wichtig, um zukünftige
Anforderungen umsetzen zu können. Mehrsprachigkeit ist eine sehr wahrscheinliche Anforde-
rung an das eLearning-Modul, da Anwendungen über das Internet sehr schnell international
verbreitet werden können. Mehrsprachigkeit im Nachhinein einzubauen kann sehr aufwändig
sein und macht, von Anfang an berücksichtigt, kaum Mehraufwand. Aus diesem Grund muss
es von Anfang an bedacht werden.
Aus diesem Grund wird in der Anwendung an allen Stellen, an denen Bezeichnungen eine Rolle
spielen, immer ein Locale-Objekt mitgegeben, damit an dieser Stelle mehrsprachige Ausgaben
52 Masterthesis Nina Rothenberg

5. Software-Entwurf
ermöglicht werden. Natürlich ist ein Plugin-Entwickler nicht gezwungen diese auch zu nutzen,
sondern kann immer eine konstante Bezeichnung zurückgeben. Diejenigen, die mehrere Sprachen
unterstützen wollen, sollen aber nicht daran gehindert werden.
Auch die Fehlerbehandlung ist ein wichtiges Thema. Jeder Fehler wird in Log-Dateien geloggt,
damit er gemeldet und möglichst leicht behoben werden kann. Der Anwender muss natürlich
auch über einen Fehler informiert werden. Aus diesem Grund, werden ihm Fehlermeldungen
angezeigt. Die Anzeige kann durch Pop-Up-Fenster oder durch einen Bereich für Fehlermeldun-
gen an der Oberfläche angezeigt werden. Ein zentraler Fehlerbereich ermöglicht es, mehrere
Fehler anzuzeigen. Allerdings ist es immer schwierig den richtigen Zeitpunkt der Löschung einer
Fehlermeldung zu finden. Ein Pop-Up-Fenster zieht die Aufmerksamkeit des Anwenders auf sich
und ermöglicht es Funktionalitäten, wir z. B. ”Fehlerbericht senden”, hinzuzufügen. Ein Pop-Up
ist praktisch und umgeht die schwierige Entscheidung zur Löschung eines zentralen Fehlerspei-
chers. Aus diesem Grund werden Fehlermeldungen in der Anwendung in einem Pop-Up-Fenster
angezeigt.
Nina Rothenberg Masterthesis 53


6. Implementierung
6. Implementierung
Die Implementierung des eLearning-Moduls erfolgt, wie in Kapitel 5.4 beschrieben, in vier ver-
schiedenen Komponenten. In dieser Arbeit wird ein Prototyp implementiert. Hier ist es nicht
wichtig, dass alle Anforderungen vollständig umgesetzt sind, sondern, dass alle Konzepte erprobt
werden. Um die Anwendung demonstrieren zu können, werden die in Kapitel 5.4.3 beschriebenen
Algorithmen implementiert.
Die Anwendung wird als Java Fat Client20-Anwendung umgesetzt. Die Wahl fällt auf Java weil
diese Sprache sehr mächtig ist und hat eine große Verbreitung21 hat. Aufgrund der großen Ver-
breitung kann man davon ausgehen, dass der Anwender jede gewünschte Erweiterung schnell
und einfach umsetzen (lassen) kann. Die Oberfläche es Prototypen wird mit Swing implemen-
tiert. Dieses ist das Standard-GUI-Frontend von Java [Wun05, Seite 230] und in der Java
Runtime Environment (JRE) integriert.
6.1. Visualisierung
Die Visualisierung der Entscheidungsbäume wird das Framework Java Universal Network/Graph
Framework (JUNG)22 verwendet. Dieses erstellt die Bäume automatisch in einer möglichst
kompakten Darstellung. Zusätzlich bietet es die Möglichkeit, dass Knoten per Drag-and-Drop
verschoben werden können. So kann der Anwender den Baum nach belieben hin- und her-
ziehen. Außerdem können Knoten, wie auch Kanten ausgewählt werden und ihre Erklärungen
anzeigen.
In Kapitel 5.1.1 werden die Anforderungen für eine kompakte Baumdarstellung und die Be-
schreibung einer möglichen Umsetzung beschrieben. Bäume, die mit dem Framework JUNG
visualisiert werden, erfüllen diese Anforderungen.
20Fat Clients (oder Rich Clients) werden ”in Gänze (Präsentation, Geschäftslogik, Datenspeicherung) durch ein
einzelnes, atomares Programm repräsentiert” [Wun05, Seite 199]. Hierbei kann das Programm aus mehreren
Komponenten bestehen, diese werden jedoch nicht von anderen Anwendungen genutzt oder mit ihnen geteilt
werden.21Laut dem Tiobe Programming Community Index [TIO11] ist Java die populärste Programmiersprache.22Projekthomepage: http://jung.sourceforge.net/.
Nina Rothenberg Masterthesis 55

6. Implementierung
Das JUNG-Framework implementiert die Darstellung des Baumes fast identisch zu dem be-
schriebenen Algorithmus in Kapitel 5.1.1. Hierzu werden die Positionen der einzelnen Knoten
ermittelt, die dann mittels Kanten verbunden werden. Das Vorgehen ist hierbei wie folgt:
1. Berechnung der Breite je Teilbaum.
2. Auf Basis der Breite die Berechnung der Knoten-Position
Die Breite wird hierbei durch die konstante Breite eines Knotens, die vom Benutzer verändert
werden kann, berechnet. Hierzu wird pro Teilbaum die Breite des Teilbaums mit der Knotenbreite
addiert. Ein Blatt hat hierbei die Breite 0. Am Ende wird eine Knotenbreite abgezogen. Die
Breite pro Teilbaum wird gespeichert.
Der Wurzelknoten wird nun horizontal mittig im Bild positioniert, indem die Breite des Baumes
halbiert und um die Knotenbreite erhöht wird. Nun wird die Position jedes Teilbaums ermittelt.
Das Vorgehen ist in Algorithmus 6.1 abgebildet.
Algorithmus 6.1 Erzeugung eines Baumes
Input: currentPoint ← 𝑡𝑟𝑒𝑒.𝑤𝑖𝑑𝑡ℎ2 + horizontalDistance
1: function buildTree(tree, startXPosition)
2: currentPosition.y ← currentPosition.y + verticalDistance
3: currentPosition.x ← startXPosition
4: image.setLocation(tree) ← currentPoisition
5: lastXPosition ← startXPosition − 𝑡𝑟𝑒𝑒.𝑤𝑖𝑑𝑡ℎ2
6: for all subtree : tree.subtrees do
7: startXPositionForChild ← lastXPosition + 𝑠𝑢𝑏𝑡𝑟𝑒𝑒.𝑤𝑖𝑑𝑡ℎ2
8: buildTree(subtree, startXPositionForChild)
9: lastXPosition ← lastXPosition + subtree.width + horizontalDistance
10: end for
11: currentPosition.y ← currentPosition.y - verticalDistance
12: end function
Bei jedem Teilbaum wird damit begonnen, dass der Wurzelknoten positioniert wird. Dieses
ist in Zeile 4 des Algorithmus zu sehen. Dann werden die Teilbäume von links nach rechts23
positioniert. Auf Grundlage des horizontalen Wertes des Nachbarknotens und der Breite des
betrachteten Knotens wird die horizontale Position so ermittelt, dass ein Knoten immer mittig
über seinen Kindknoten positioniert ist.
23Die Reihenfolge der Teilbäume ist beliebig. Es ist keine Logik implementiert, die die optimale Reihenfolge von
Teilbäumen ermittelt.
56 Masterthesis Nina Rothenberg

6. Implementierung
Zusätzlich ist das JUNG-Framework sehr flexibel. Die Darstellung der Bäume, sowie die Inter-
aktionen24 sind vom Anwender beliebig veränderbar. Abbildung 6.1 zeigt beispielhaft einen mit
JUNG visualisierten Baum.
Abbildung 6.1.: Baum dargestellt mittels JUNG
6.2. Umsetzung der Erweiterbarkeit
Um die Erweiterbarkeit umzusetzen, wird ein Plugin-Konzept verwendet, welches in Kapitel 5.3
beschrieben ist. Der Anwender soll es möglichst leicht haben ein neues Plugin zu erstellen oder
einzubinden. Dafür wird ein Plugin-Ordner definiert, der bei jedem Start des Programms nach
Erweiterungen durchsucht wird. Hierzu wird ein ClassLoader implementiert, der alle jar-Dateien
dieses Ordners beim Programmstart nachlädt. Der ClassLoader bietet eine Methode an, mit der
man aus dem Pool der geladenen Klassen all diejenigen zurückgibt, die ein bestimmtes, über-
gebenes Interface implementieren (Vgl. Abbildung 6.2). So kann man z. B. alle Split-Kriterien
laden. Diese Methode wird an allen nötigen Stellen verwendet, sodass alle Erweiterungen auf
die gleiche Art geladen werden.
Abbildung 6.2.: Klasse des Plugin-ClassLoaders
Aus Performance-Gründen werden die Klassen, gruppiert nach Interfaces, einmalig geladen und
im ClassLoader gespeichert. Wenn alle Klassen, die ein bestimmtes Interface implementieren,
24Wie OnClick oder MouseOver-Ereignisse.
Nina Rothenberg Masterthesis 57

6. Implementierung
zurückgegeben werden sollen, wird die Gruppe der Klassen zu dem Interface zurückgegeben.
Das initiale Laden der Klassen ist im Algorithmus 6.2 beschrieben.
Algorithmus 6.2 Ablauf des ClassLoaders
for all class : jar.allClasses do
for all interface : class.implementedInterfaces do
interface.implementedClasses.add(class)
end for
end for
6.3. Beispiel zur Erstellung und Verwendung von
Erweiterungen
Anhand eines Beispiels wird das Plugin-Konzept veranschaulicht und die Erstellung und Ver-
wendung von Erweiterungen erläutert. Annahme für dieses Beispiel ist, dass eine Erweiterung
implementiert werden soll, die weitere Pruning-Methoden implementiert. Das Projekt bekommt
den Namen ”detrin-pruningmethods”. Dieses Projekt bindet die Bibliothek detrin-base
ein, die das Interface PruningMethod enthält. In detrin-pruningmethods werden nun zwei
Klassen erstellt: ReducedErrorPruning und PessimisticErrorPruning. Beide Klassen sind
Implementierungen des Interfaces PruningMethod. Die Methode getLabel(Locale locale)
den entsprechenden Namen zurück, also ”Reduced-Error Pruning” bzw. ”Pessimistic Error Pru-
ning”, die später verwendet werden, um sie für die Auswahl an der Oberfläche anzeigbar zu
machen. Die Klasse PessimisticErrorPruning verwendet die Bibliothek errorrate-utils,
die in detrin-pruningmethods eingebunden wird. Die vollständige Architektur der Erweite-
rung ist in Abbildung 6.3 zu sehen.
Beide Methode prüfen für alle Teilbäume, ob die Ersetzung durch ein Blatt den Baum vereinfa-
chen kann. Wenn dies zutrifft, wird der Teilbaum durch ein Blatt ersetzt. Das Blatt wird über
die Methode setExplanation(String explanation) mit den entsprechenden Erklärungen
bestückt. Aus dem Projekt wird nun die Datei detrin-pruningmethods.jar kompiliert. Die-
se wird, zusammen mit der Bibliothek errorrate-utils.jar in den Plugin-Ordner plugins
gelegt. Alternativ kann die zusätzliche Bibliothek auch direkt mit in die jar-Datei eingebunden
werden. In diesem Fall muss dann nur die Erweiterung in den Ordner kopiert werden, da diese
ihre Abhängigkeit schon enthält.
Beim Start der Anwendung wird nun die Auswahlliste für die Pruning-Methoden um die beiden
Einträge erweitert (vgl. Abbildung 6.4). Wenn eine der beiden Einträge ausgewählt wird, wird
58 Masterthesis Nina Rothenberg

6. Implementierung
Abbildung 6.3.: Architektur der Erweiterung ”detrin-pruningmethods”
Abbildung 6.4.: Anzeige der neuen Pruning-Methoden
die Pruning-Methode in der Entscheidungsbaumgenerierung ausgeführt. In den Erklärungen der
durch die Methode generierten Blätter, sind die entsprechend in den Plugin-Klassen definierten
Einträge zu finden (vgl. Abbildung 6.5).
Abbildung 6.5.: Anzeige der neuen Erklärungen
Nina Rothenberg Masterthesis 59

6. Implementierung
6.4. Umsetzung der Erklärungskomponente
Für die Erklärungskomponente werden an jedes Element des Entscheidungsbaumes Erklärungen
geknüpft. Diese können von den entsprechenden Methoden, die die Baumelemente bei der
Generierung durchlaufen, befüllt werden. Nach der Generierung sind an jeder Kante und an
jedem Knoten des Baumes Erklärungen, die mit einem Klick auf das entsprechende Element
angezeigt werden können. In Kapitel 5.1.2 wird der Ansatz zur zentralen Anzeige argumentiert,
der so umgesetzt wird. In dieser Anzeige sollen die Erklärungen zu mehreren Baumelementen
angezeigt werden können. Diese sollen auch nebeneinander anzeigbar sein.
Für die Erfüllung der Anforderungen bieten sich zwei Möglichkeiten an:
∙ Eine Fläche, auf der der Anwender pro Erklärung ein Fenster sieht, welches er frei in dieser
Fläche bewegen und in der Größe verändern kann.
∙ Pro Erklärung ein Tab in einem Tab-Panel.
Der erste Ansatz ist sehr flexibel und lässt dem Anwender viele Freiheiten sich die Fenster so
zu positionieren, wie es ihm beliebt. Der Tab-Ansatz wirkt aufgeräumter, ist aber unflexibler. In
diesem Fall ist die Ausgliederung eines Tabs in einen neuen horizontal oder vertikal parallelen
Bereich sinnvoll. Ohne eine solche Funktionalität hat der Ansatz, im Vergleich zu einem einzigen
Erklärungsbereich, der je nach Selektion eines Baumelements neu befüllt wird, kaum einen
Vorteil, da immer nur eine Erklärung sichtbar ist. Mit dieser Funktionalität bietet der Ansatz
fast alle Vorteile der freien Fläche mit mehreren Erklärungsfenstern. Die Erklärungen können
zwar in dem Tab-Ansatz nicht ganz so flexibel angeordnet werden, aber sie können geordnet
und übersichtlich nebeneinander angezeigt werden.
Aus Gründen der Übersichtlichkeit wird der Tab-Ansatz und nicht die Erklärungsfläche umge-
setzt.
6.5. Funktionalitäten
Die Benutzungsoberfläche ist, wie in Kapitel 5.2 beschrieben, in vier Bereiche aufgeteilt (Vgl.
Abbildung 6.6). Um die Größe der einzelnen Bereiche flexibel zu gestalten, werden die Berei-
che durch Teilungskomponenten (Split-Panes) voneinander getrennt. Durch die verschiebbare
Trennleiste, kann die sichtbare Größe der Bereiche verändert werden.
Die Funktionalität der Benutzungsoberfläche wird im Prototyp nicht vollständig umgesetzt.
Das Editieren von Instanzen ist für die Kern-Funktionalität nicht zwingend notwendig und auch
60 Masterthesis Nina Rothenberg

6. Implementierung
Abbildung 6.6.: DeTrIn Screenshot
technisch unproblematisch umzusetzen. Die Umsetzung muss also nicht zwangsläufig erprobt
werden. Die Anzeige von Instanzen ist also im Prototyp auf die reine Anzeige beschränkt (Vgl.
Abbildung 6.7).
Abbildung 6.7.: Anzeige der Instanzen
Die Gruppierung von Attributen hingegen sollte erprobt werden, da Gruppierungen einen we-
sentlichen Einfluss auf die Funktionalität und das Datenmodell haben. Die Anzeige der Attribute
Nina Rothenberg Masterthesis 61
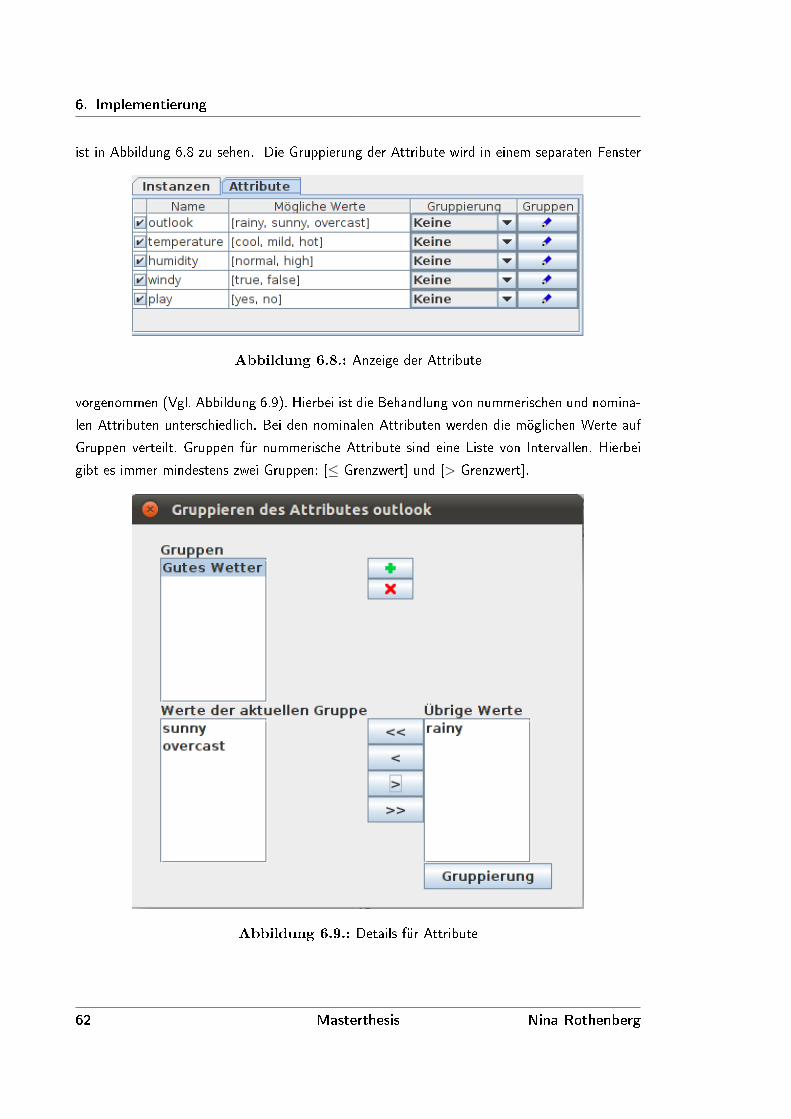
6. Implementierung
ist in Abbildung 6.8 zu sehen. Die Gruppierung der Attribute wird in einem separaten Fenster
Abbildung 6.8.: Anzeige der Attribute
vorgenommen (Vgl. Abbildung 6.9). Hierbei ist die Behandlung von nummerischen und nomina-
len Attributen unterschiedlich. Bei den nominalen Attributen werden die möglichen Werte auf
Gruppen verteilt. Gruppen für nummerische Attribute sind eine Liste von Intervallen. Hierbei
gibt es immer mindestens zwei Gruppen: [≤ Grenzwert] und [> Grenzwert].
Abbildung 6.9.: Details für Attribute
62 Masterthesis Nina Rothenberg

6. Implementierung
6.6. Export
Als Beispiel für einen Export wird ein HTML-Bericht implementiert. Dieser erstellt einen Be-
richt, der dem in Kapitel 5.1.4 vorgeschlagenen Layout entspricht. Der Bericht wird in den vom
Anwender gewählten Ordner des Dateisystems gespeichert. Das Bild des Entscheidungsbaums
wird übergeben und für die Darstellung im HTML-Bericht in eine Datei gespeichert. Hierzu wird
im Zielordner des Berichts ein neuer Ordner angelegt, der dem Bericht eindeutig zuzuordnen
ist. Damit die Zuordnung gewährleistet ist, beinhaltet der Ordnername den Namen des Berich-
tes. In diesen Ordner wird dann die Bilddatei abgelegt und kann somit in den HTML-Bericht
eingebunden werden.
Die Instanzen und Attribute werden ähnlich der Benutzungsoberfläche, in Tabellenform, dar-
gestellt. Die Ausgabe der Eingabeparameter ähnelt der Ausgabe der Anwendung Weka25. Alle
eingegebenen Werte werden in Listenform untereinander angezeigt. Es folgt die Abbildung des
Entscheidungsbaums.
Die Erklärungen des Entscheidungsbaumes folgen. Diese sind in der ersten Version des Exports
untereinander dargestellt und nur aufgrund der Dokumenten-Struktur hierarchisch angeordnet.
In einer weiteren Ausbaustufe können diese per Cascading Style Sheets (CSS) noch verschönert
werden. Somit kann die Zugehörigkeit der einzelnen Erklärungen noch besser hervorgehoben
werden. In Anhang D ist ein Beispiel eines mit dem HTML-Export erstellten Berichtes zu
finden.
Der große Vorteil einer HTML-Datei ist, dass die Schriftgröße veränderbar ist und auch das Bild
vergrößert werden kann. Die Veränderlichkeit der Schriftgröße ist ein wichtiger Punkt für die
Barrierfreiheit und Anwenderfreundlichkeit. Durch den Bericht kann die noch nicht umgesetzte
Verstellbarkeit der Schriftgröße ausgeglichen werden.
25Vgl. Kapitel 2.5.
Nina Rothenberg Masterthesis 63


7. Fazit
7. Fazit
Ziel dieser Arbeit war die Konzeption und prototypische Implementierung eines eLearning-
Moduls zur Entscheidungsbaumgenerierung. Diese soll die Kernziele erfüllen, dass ein Anwen-
der sich eigene Datensätze importieren und als Grundlage der Entscheidungsbaumgenerierung
verwenden kann und die Generierung anhand einer Erklärungskomponente näher erläutert be-
kommt. Diese Erklärungskomponente ermöglicht es dem Anwender die Entscheidungsbaumge-
nerierung nachzuvollziehen und die Auswirkungen einzelner Parameter zu erkennen. Durch den
Bericht, den die Anwendung als Export anbietet, kann das eigene Beispiel als Musterlösung
exportiert werden.
Diese Anforderungen werden bereits durch den Prototypen erfüllt. Für diesen wurden beispielhaft
Algorithmen implementiert, die einen Entscheidungsbaum generieren. Hauptziel des Prototypen
ist allerdings die technische Erprobung der Kernkonzepte.
Der Schwerpunkt liegt hierbei auf einem leicht zu verwendenden und flexiblen Erweiterungskon-
zept. Dieses wurde erfolgreich implementiert. Entwicklern wird es leicht gemacht Erweiterungen
zu schreiben und einzubinden und der Anwender ist flexibel und kann die aktuellen Erweiterun-
gen selbst beeinflussen, indem er neue Erweiterungen in den Plugin-Ordner legt bzw. nicht mehr
benötigte Erweiterungen daraus entfernt. Den Schnittstellen werden spezielle Eingabeobjekte
übergeben, die möglichst umfangreich sind, um auf alle denkbaren kommenden Erweiterungen
vorbereitet zu sein. Sobald diese aber einmal nicht mehr ausreichen, können sie erweitert werden
ohne ältere Erweiterungen negativ zu beeinflussen.
Durch die aktuell umgesetzten Funktionalitäten ist neben der technischen Erprobung aber auch
schon klar der Nutzen für den Anwender erkennbar. Wenn erst einmal die ersten Algorithmen
vollständig umgesetzt sind, kann die Anwendung bereits zum Korrigieren von Aufgaben oder
Nachvollziehen von Beispielen verwendet werden.
Im nächsten Schritt sollte auch mehr auf die Benutzungsoberfläche geachtet werden. Diese
entspricht aktuell nicht den hohen Anforderungen eines eLearning-Moduls. Auch an den Aus-
gaben der Erklärungskomponente kann es noch Verbesserungen geben. Im aktuellen Bericht ist
z. B. sehr schwierig zu erkennen, wohin eine Erklärung genau gehört. Dies kann durch optische
Aufbereitung (z. B. durch die Verwendung von Rahmen, die Teilbäume optisch zusammenfasst)
verbessert werden.
Nina Rothenberg Masterthesis 65

7. Fazit
Aus Sicht des Autors ist es auf jeden Fall empfehlenswert das eLearning-Modul weiterzuent-
wickeln und potenziellen Anwendern zur Verfügung zu stellen. Der Prototyp zeigt jetzt schon,
dass in naher Zukunft ein vollumfängliches eLearning-Modul entwickelt werden kann. Die Um-
setzung der noch nicht implementierten fachlichen Anforderungen, z. B. die Kreuz-Validierung,
wird schnell einen Mehrwert schaffen. Studenten, die die Anwendung nutzen, können von der Er-
klärungskomponente profitieren und somit kann das eLearning-Modul zum besseren Verständnis
der Algorithmen zur Entscheidungsbaumgenerierung beitragen.
66 Masterthesis Nina Rothenberg

A. Beispiel des Klassifizierungs-Outputs von Weka
A. Beispiel des Klassifizierungs-Outputs
von Weka
=== Run information ===
Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: Wetterdaten
Instances: 14
Attributes: 5
outlook
temperature
humidity
windy
play
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
J48 pruned tree
——————
outlook = sunny
| humidity = high: no (3.0)
| humidity = normal: yes (2.0)
outlook = overcast: yes (4.0)
outlook = rainy
| windy = false: yes (3.0)
| windy = true: no (2.0)
Nina Rothenberg Masterthesis 67
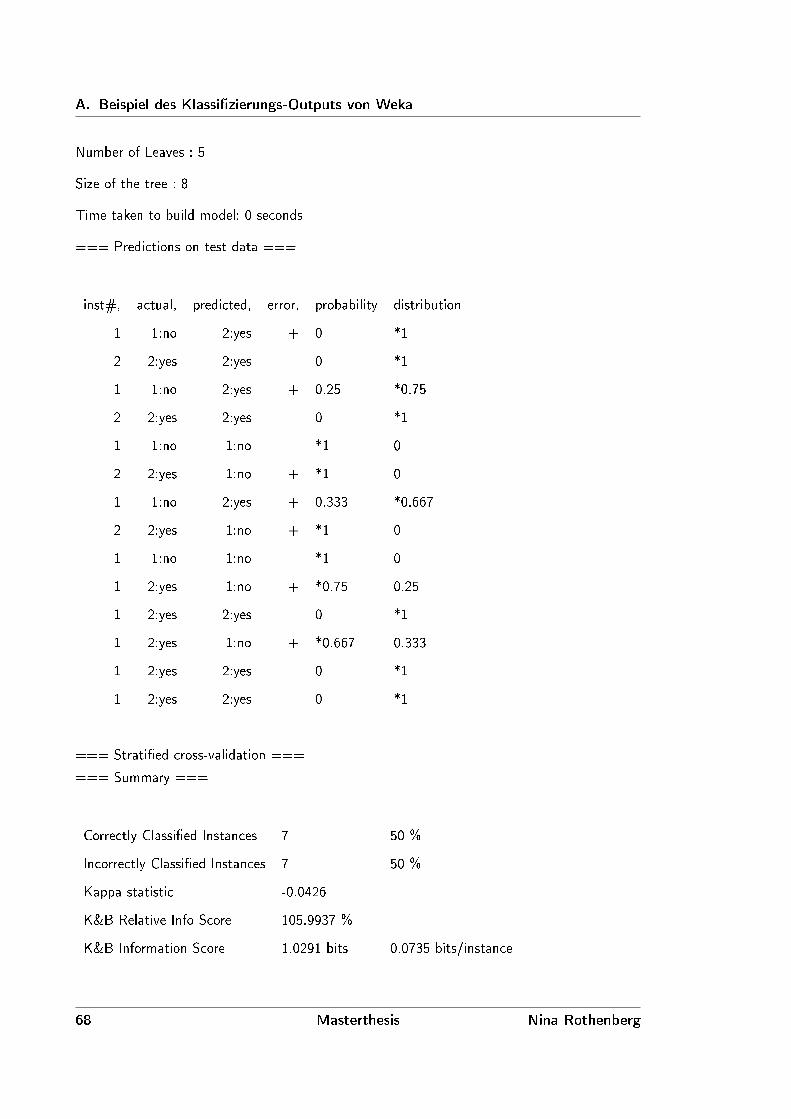
A. Beispiel des Klassifizierungs-Outputs von Weka
Number of Leaves : 5
Size of the tree : 8
Time taken to build model: 0 seconds
=== Predictions on test data ===
inst#, actual, predicted, error, probability distribution
1 1:no 2:yes + 0 *1
2 2:yes 2:yes 0 *1
1 1:no 2:yes + 0.25 *0.75
2 2:yes 2:yes 0 *1
1 1:no 1:no *1 0
2 2:yes 1:no + *1 0
1 1:no 2:yes + 0.333 *0.667
2 2:yes 1:no + *1 0
1 1:no 1:no *1 0
1 2:yes 1:no + *0.75 0.25
1 2:yes 2:yes 0 *1
1 2:yes 1:no + *0.667 0.333
1 2:yes 2:yes 0 *1
1 2:yes 2:yes 0 *1
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 7 50 %
Incorrectly Classified Instances 7 50 %
Kappa statistic -0.0426
K&B Relative Info Score 105.9937 %
K&B Information Score 1.0291 bits 0.0735 bits/instance
68 Masterthesis Nina Rothenberg

A. Beispiel des Klassifizierungs-Outputs von Weka
Class complexity | order 0 13.7612 bits 0.9829 bits/instance
Class complexity | scheme 3229.1699 bits 230.655 bits/instance
Complexity improvement (Sf) -3215.4087 bits -229.6721 bits/instance
Mean absolute error 0.4167
Root mean squared error 0.5984
Relative absolute error 87.5 %
Root relative squared error 121.2987 %
Total Number of Instances 14
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.4 0.444 0.333 0.4 0.364 0.633 no
0.556 0.6 0.625 0.556 0.588 0.633 yes
Weighted Avg. 0.5 0.544 0.521 0.5 0.508 0.633
=== Confusion Matrix ===
a b <– classified as
2 3 | a = no
4 5 | b = yes
=== Source code ===
// Generated w i th Weka 3 . 6 . 0
//
// Thi s code i s p u b l i c domain and comes w i th no war ran ty .
//
// Timestamp : Thu Feb 10 09 : 38 : 29 CET 2011
package weka . c l a s s i f i e r s ;
import weka . co r e . A t t r i b u t e ;
Nina Rothenberg Masterthesis 69

A. Beispiel des Klassifizierungs-Outputs von Weka
import weka . co r e . C a p a b i l i t i e s ;
import weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y ;
import weka . co r e . I n s t a n c e ;
import weka . co r e . I n s t a n c e s ;
import weka . c l a s s i f i e r s . C l a s s i f i e r ;
pub l i c c l a s s WekaWrapper
extends C l a s s i f i e r {
/*** Retu rns on l y the t o S t r i n g ( ) method .
** @re tu rn a s t r i n g d e s c r i b i n g the c l a s s i f i e r
*/pub l i c S t r i n g g l o b a l I n f o ( ) {
return t o S t r i n g ( ) ;
}
/*** Retu rns the c a p a b i l i t i e s o f t h i s c l a s s i f i e r .
** @re tu rn the c a p a b i l i t i e s
*/pub l i c C a p a b i l i t i e s g e t C a p a b i l i t i e s ( ) {
weka . co r e . C a p a b i l i t i e s r e s u l t = new weka . co r e . C a p a b i l i t i e s (
t h i s ) ;
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y .
NOMINAL_ATTRIBUTES) ;
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y .
BINARY_ATTRIBUTES) ;
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y .
UNARY_ATTRIBUTES) ;
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y .
EMPTY_NOMINAL_ATTRIBUTES) ;
70 Masterthesis Nina Rothenberg

A. Beispiel des Klassifizierungs-Outputs von Weka
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y .
NUMERIC_ATTRIBUTES) ;
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y .
DATE_ATTRIBUTES) ;
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y .
MISSING_VALUES) ;
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y .NOMINAL_CLASS
) ;
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y . BINARY_CLASS)
;
r e s u l t . e nab l e ( weka . co r e . C a p a b i l i t i e s . C a p a b i l i t y .
MISSING_CLASS_VALUES) ;
r e s u l t . setMin imumNumberInstances (0 ) ;
return r e s u l t ;
}
/*** on l y checks the data a g a i n s t i t s c a p a b i l i t i e s .
** @param i the t r a i n i n g data
*/pub l i c void b u i l d C l a s s i f i e r ( I n s t a n c e s i ) throws Excep t i on {
// can c l a s s i f i e r hand l e the data ?
g e t C a p a b i l i t i e s ( ) . t e s tW i t h F a i l ( i ) ;
}
/*** C l a s s i f i e s the g i v e n i n s t a n c e .
** @param i the i n s t a n c e to c l a s s i f y
* @re tu rn the c l a s s i f i c a t i o n r e s u l t
*/pub l i c double c l a s s i f y I n s t a n c e ( I n s t a n c e i ) throws Excep t i on {
Objec t [ ] s = new Object [ i . numAtt r i bu t e s ( ) ] ;
Nina Rothenberg Masterthesis 71

A. Beispiel des Klassifizierungs-Outputs von Weka
for ( i n t j = 0 ; j < s . l e n g t h ; j++) {
i f ( ! i . i sM i s s i n g ( j ) ) {
i f ( i . a t t r i b u t e ( j ) . i sNomina l ( ) )
s [ j ] = new S t r i n g ( i . s t r i n gV a l u e ( j ) ) ;
e l s e i f ( i . a t t r i b u t e ( j ) . i sNumer i c ( ) )
s [ j ] = new Double ( i . v a l u e ( j ) ) ;
}
}
// s e t c l a s s v a l u e to m i s s i n g
s [ i . c l a s s I n d e x ( ) ] = nu l l ;
return WekaC l a s s i f i e r . c l a s s i f y ( s ) ;
}
/*** Retu rns on l y the c l a s snames and what c l a s s i f i e r i t i s based
on .
** @re tu rn a s h o r t d e s c r i p t i o n
*/pub l i c S t r i n g t o S t r i n g ( ) {
return "Auto−gene r a t ed c l a s s i f i e r wrapper , based on weka .
c l a s s i f i e r s . t r e e s . J48 ( gene r a t ed w i th Weka 3 . 6 . 0 ) . \ n" +
t h i s . g e tC l a s s ( ) . getName ( ) + "/Wek aC l a s s i f i e r " ;
}
/*** Runs the c l a s s f i e r from commandl ine .
** @param a rg s the commandl ine arguments
*/pub l i c s t a t i c void main ( S t r i n g a r g s [ ] ) {
r u n C l a s s i f i e r (new WekaWrapper ( ) , a r g s ) ;
}
72 Masterthesis Nina Rothenberg

A. Beispiel des Klassifizierungs-Outputs von Weka
}
c l a s s WekaC l a s s i f i e r {
pub l i c s t a t i c double c l a s s i f y ( Object [ ] i )
throws Excep t i on {
double p = Double .NaN ;
p = Wek aC l a s s i f i e r . Na5f99b9 ( i ) ;
return p ;
}
s t a t i c double Na5f99b9 ( Objec t [ ] i ) {
double p = Double .NaN ;
i f ( i [ 0 ] == nu l l ) {
p = 0 ;
} e l s e i f ( i [ 0 ] . e q u a l s ( " sunny " ) ) {
p = Wek aC l a s s i f i e r . Na6359910 ( i ) ;
} e l s e i f ( i [ 0 ] . e q u a l s ( " o v e r c a s t " ) ) {
p = 1 ;
} e l s e i f ( i [ 0 ] . e q u a l s ( " r a i n y " ) ) {
p = Wek aC l a s s i f i e r . N9036e11 ( i ) ;
}
return p ;
}
s t a t i c double Na6359910 ( Objec t [ ] i ) {
double p = Double .NaN ;
i f ( i [ 2 ] == nu l l ) {
p = 0 ;
} e l s e i f ( i [ 2 ] . e q u a l s ( " h igh " ) ) {
p = 0 ;
} e l s e i f ( i [ 2 ] . e q u a l s ( " normal " ) ) {
p = 1 ;
}
return p ;
}
s t a t i c double N9036e11 ( Objec t [ ] i ) {
Nina Rothenberg Masterthesis 73

A. Beispiel des Klassifizierungs-Outputs von Weka
double p = Double .NaN ;
i f ( i [ 3 ] == nu l l ) {
p = 1 ;
} e l s e i f ( i [ 3 ] . e q u a l s ( " f a l s e " ) ) {
p = 1 ;
} e l s e i f ( i [ 3 ] . e q u a l s ( " t r u e " ) ) {
p = 0 ;
}
return p ;
}
}
74 Masterthesis Nina Rothenberg

B. Anforderungen
B. Anforderungen
In diesem Abschnitt werden die Anforderungen aufgelistet. Sie sind gemäß der Analyse-Kapitel26
gruppiert, um eine bessere Übersicht zu gewährleisten.
B.1. Datenvorbereitung
Anforderung DV-1 DV-1
Beschreibung Der Anwender kann eigene Datensätze importieren. Er
soll also nicht durch fest vorprogrammierte Beispiele
eingeschränkt sein.
Priorität 1
Tabelle: Anforderung DV-1
Anforderung DV-2 DV-2
Beschreibung Der Anwender kann verschiedene Dateiformate benut-
zen.
Abhängigkeit DV-1
Priorität 1
Tabelle: Anforderung DV-2
26Vgl. Kapitel 4.4 ab Seite 34.
Nina Rothenberg Masterthesis 75
B. Anforderungen
Anforderung DV-3 DV-3
Beschreibung Bei jedem Attribut kann eingestellt werden, ob es
bei der Entscheidungsbaumgenerierung berücksichtigt
werden soll oder nicht. Mindestens ein Attribut, wel-
ches nicht das Zielattribut ist, muss ausgewählt sein.
Priorität 1
Tabelle: Anforderung DV-3
Anforderung DV-4 DV-4
Beschreibung Manuelle Eingabe von Datensätze ist möglich.
Priorität 2
Tabelle: Anforderung DV-4
Anforderung DV-5 DV-5
Beschreibung Datensätze können manuell verändert werden.
Priorität 2
Tabelle: Anforderung DV-5
Anforderung DV-6 DV-6
Beschreibung Der eingegebene oder veränderte Datensatz kann ex-
portiert werden.
Priorität 3
Tabelle: Anforderung DV-6
76 Masterthesis Nina Rothenberg

B. Anforderungen
Anforderung DV-7 DV-7
Beschreibung Die Export-Datentypen entsprechen (mindestens) de-
nen, die man auch importieren kann.
Abhängigkeit DV-6
Priorität 1
Tabelle: Anforderung DV-7
Anforderung DV-8 DV-8
Beschreibung Pro Attribut kann ausgewählt werden, ob es nicht, ma-
nuell oder automatisch gruppiert werden soll.
Priorität 2
Tabelle: Anforderung DV-8
Anforderung DV-9 DV-9
Beschreibung Attribute können manuell gruppiert werden. Eine
Gruppe besteht bei nominalen Attributen aus einer
Liste von möglichen Werten. Bei nummerischen At-
tributen besteht sie aus ein oder mehreren Intervallen.
Abhängigkeit DV-8
Priorität 1
Tabelle: Anforderung DV-9
Anforderung DV-10 DV-10
Beschreibung Der Anwender kann ein Zielattribut auswählen. Es gibt
immer genau ein Zielattribut. Wenn kein Zielattribut
ausgewählt ist, kann die Entscheidungsbaumgenerie-
rung nicht beginnen.
Priorität 1
Tabelle: Anforderung DV-10
Nina Rothenberg Masterthesis 77
B. Anforderungen
B.2. Entscheidungsbaumgenerierung
Anforderung EBG-1 EBG-1
Beschreibung Die Anwendung soll aus einem bereitgestellten Daten-
satz einen Entscheidungsbaum generieren können.
Priorität 1
Tabelle: Anforderung EBG-1
Anforderung EBG-2 EBG-2
Beschreibung Ein Algorithmus kann ausgewählt werden. Nach der
Auswahl, werden automatisch die zum Algorithmus
gehörenden Attribute, wie z. B. Split-Kriterium aus,
ausgewählt.
Priorität 1
Tabelle: Anforderung EBG-2
Anforderung EBG-3 EBG-3
Beschreibung Das Split-Kriterium kann ausgewählt werden.
Priorität 1
Tabelle: Anforderung EBG-3
Anforderung EBG-4 EBG-4
Beschreibung Das Stop-Kriterium kann ausgewählt werden.
Priorität 1
Tabelle: Anforderung EBG-4
78 Masterthesis Nina Rothenberg

B. Anforderungen
Anforderung EBG-5 EBG-5
Beschreibung Die Pruning-Methode kann ausgewählt werden.
Priorität 1
Tabelle: Anforderung EBG-5
Anforderung EBG-6 EBG-6
Beschreibung Der Umgang mit fehlenden Werten kann ausgewählt
werden.
Priorität 2
Tabelle: Anforderung EBG-6
Anforderung EBG-7 EBG-7
Beschreibung Die Methode zur Bestimmung von Test- und Trai-
ningsmenge muss ausgewählt werden können.
Priorität 2
Tabelle: Anforderung EBG-7
Anforderung EBG-8 EBG-8
Beschreibung Die maximale Anzahl der automatisch zu erstellenden
Gruppen pro Attribut kann vom Anwender angegeben
werden.
Priorität 2
Tabelle: Anforderung EBG-8
Anforderung EBG-9 EBG-9
Beschreibung Die maximale Baumtiefe kann eingegeben werden.
Priorität 2
Tabelle: Anforderung EBG-9
Nina Rothenberg Masterthesis 79

B. Anforderungen
Anforderung EBG-10 EBG-10
Beschreibung Die Eingabeparameter sind jederzeit sichtbar.
Priorität 1
Tabelle: Anforderung EBG-10
Anforderung EBG-11 EBG-11
Beschreibung Der generierte Entscheidungsbaum soll auf eine intui-
tiv verständliche Weise angezeigt werden.
Priorität 1
Tabelle: Anforderung EBG-11
Anforderung EBG-12 EBG-12
Beschreibung Jeder innere Knoten wird mit dem Namen des Split-
Attributes betitelt.
Priorität 1
Tabelle: Anforderung EBG-12
Anforderung EBG-13 EBG-13
Beschreibung Jede Kante wird mit einem Wert bzw. einer Werte-
gruppe der möglichen Werte des Split-Attributes beti-
telt.
Priorität 1
Tabelle: Anforderung EBG-13
80 Masterthesis Nina Rothenberg

B. Anforderungen
Anforderung EBG-14 EBG-14
Beschreibung Jedes Blatt wird mit dem wahrscheinlichsten Wert des
Zielattributes betitelt.
Priorität 1
Tabelle: Anforderung EBG-14
Anforderung EBG-15 EBG-15
Beschreibung Mehrere Entscheidungsbäume, die aufgrund von unter-
schiedlichen Einstellungen generiert worden sind, kön-
nen gegenübergestellt werden.
Priorität 5
Tabelle: Anforderung EBG-15
Anforderung EBG-16 EBG-16
Beschreibung In einer Art Debug-Modus, kann der Anwender die
Generierung Schritt für Schritt verfolgen.
Priorität 5
Tabelle: Anforderung EBG-16
Anforderung EBG-17 EBG-17
Beschreibung Wenn sich aus dieser Umstellung eine Kombination
ergibt, die einem Algorithmus entspricht, wird dieser
ebenfalls ausgewählt. Wenn kein Algorithmus passt,
wird kein Algorithmus ausgewählt (eine eventuell vor-
herige Auswahl entfällt). Wenn mehrere Algorithmen
passen, werden mehrere Algorithmen markiert.
Priorität 5
Tabelle: Anforderung EBG-17
Nina Rothenberg Masterthesis 81

B. Anforderungen
Anforderung EBG-18 EBG-18
Beschreibung Nach der Generierung des Entscheidungsbaums wird
dieser grafisch angezeigt.
Priorität 1
Tabelle: Anforderung EBG-18
B.3. Erklärungskomponente
Anforderung EK-1 EK-1
Beschreibung Die Informationen können pro Baumelement ein- und
ausgeblendet werden.
Priorität 1
Tabelle: Anforderung EK-1
Anforderung EK-2 EK-2
Beschreibung Für jeden inneren Knoten werden auf Wunsch folgende
Informationen angezeigt:
∙ Split-Kriterium, nachdem das Attribut ausge-
wählt wurde.
∙ Ergebnisse für andere mögliche Attribute gemäß
des Split-Kriteriums.
Priorität 1
Tabelle: Anforderung EK-2
82 Masterthesis Nina Rothenberg

B. Anforderungen
Anforderung EK-3 EK-3
Beschreibung Für jede Kante werden auf Wunsch folgende Informa-
tionen angezeigt:
∙ Zur Kante gehörende Werte/Intervalle des be-
trachteten Attributs.
∙ Gründe zur Werteauswahl. (Z. B. Grenzwerte bei
Intervallen.)
Priorität 1
Tabelle: Anforderung EK-3
Anforderung EK-4 EK-4
Beschreibung Für jedes Blatt werden auf Wunsch folgende Informa-
tionen angezeigt:
∙ Welches Stop-Kriterium ist aus welchem Grund
erfüllt?
∙ Wert des Zielattributs und die Wahrscheinlich-
keit des Wertes.
∙ Wahrscheinlichkeit anderer Werte an diesem
Zielknoten.
∙ Eventuell angewandtes Pruning-Kriterium inkl.
Erklärung.
Priorität 1
Tabelle: Anforderung EK-4
Nina Rothenberg Masterthesis 83

B. Anforderungen
Anforderung EK-5 EK-5
Beschreibung Die Erklärungen sind als eine Art Musterlösung ex-
portierbar. In diesem Export sind alle Informationen
enthalten, auch die Eingabeparameter.
Priorität 2
Tabelle: Anforderung EK-5
Anforderung EK-6 EK-6
Beschreibung Der Export kann konfiguriert werden. Das bedeutet,
der Anwender kann einstellen, welche Informationen
er gern in diesem Export enthalten haben möchte und
welche nicht
Abhängigkeit EK-4
Priorität 5
Tabelle: Anforderung EK-6
B.4. Nichtfunktionale Anforderungen
Anforderung NF-1 NF-1
Beschreibung Ein neues Dateiformat für den Import eines Datensat-
zes kann unkompliziert hinzugefügt werden.
Abhängigkeit DV-1
Priorität 1
Tabelle: Anforderung NF-1
84 Masterthesis Nina Rothenberg

B. Anforderungen
Anforderung NF-2 NF-2
Beschreibung Ein neues Dateiformat für den Export eines Datensat-
zes kann unkompliziert hinzugefügt werden.
Abhängigkeit DV-6
Priorität 1
Tabelle: Anforderung NF-2
Anforderung NF-3 NF-3
Beschreibung Ein neuer Algorithmus kann unkompliziert hinzuge-
fügt werden.
Abhängigkeit EBG-2
Priorität 1
Tabelle: Anforderung NF-3
Anforderung NF-4 NF-4
Beschreibung Ein neues Split-Kriterium kann unkompliziert hinzu-
gefügt werden.
Abhängigkeit EBG-3
Priorität 1
Tabelle: Anforderung NF-4
Anforderung NF-5 NF-5
Beschreibung Ein neues Stop-Kriterium kann unkompliziert hinzu-
gefügt werden.
Abhängigkeit EBG-4
Priorität 1
Tabelle: Anforderung NF-5
Nina Rothenberg Masterthesis 85
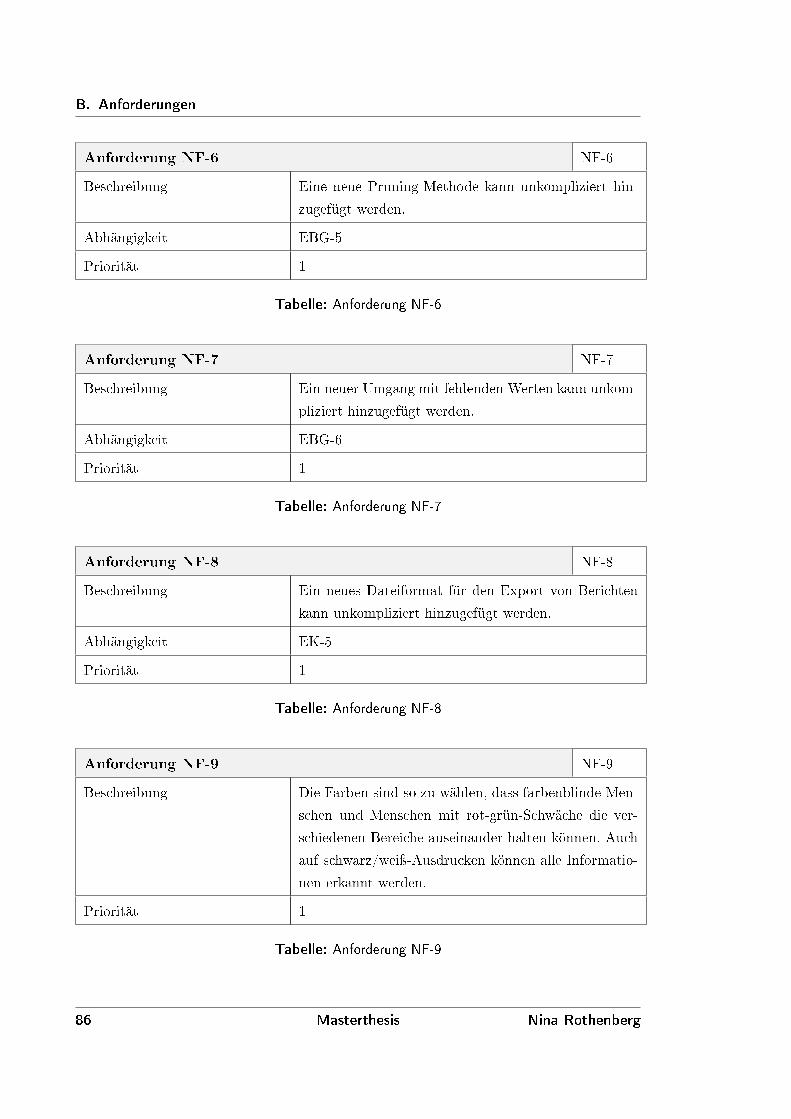
B. Anforderungen
Anforderung NF-6 NF-6
Beschreibung Eine neue Pruning-Methode kann unkompliziert hin-
zugefügt werden.
Abhängigkeit EBG-5
Priorität 1
Tabelle: Anforderung NF-6
Anforderung NF-7 NF-7
Beschreibung Ein neuer Umgang mit fehlenden Werten kann unkom-
pliziert hinzugefügt werden.
Abhängigkeit EBG-6
Priorität 1
Tabelle: Anforderung NF-7
Anforderung NF-8 NF-8
Beschreibung Ein neues Dateiformat für den Export von Berichten
kann unkompliziert hinzugefügt werden.
Abhängigkeit EK-5
Priorität 1
Tabelle: Anforderung NF-8
Anforderung NF-9 NF-9
Beschreibung Die Farben sind so zu wählen, dass farbenblinde Men-
schen und Menschen mit rot-grün-Schwäche die ver-
schiedenen Bereiche auseinander halten können. Auch
auf schwarz/weiß-Ausdrucken können alle Informatio-
nen erkannt werden.
Priorität 1
Tabelle: Anforderung NF-9
86 Masterthesis Nina Rothenberg

B. Anforderungen
Anforderung NF-10 NF-10
Beschreibung Die Schriftgröße ist verstellbar. Die Anwendung ist
auch mit vergrößerter und verkleinerter Schrift noch
lesbar.
Priorität 3
Tabelle: Anforderung NF-10
Nina Rothenberg Masterthesis 87


C. Tutorial
C. Tutorial
Dieses Tutorial beschreibt die Installation von und die ersten Schritte in DeTrIn27. Sie ist
möglichst kurz gehalten, um dem Anwender einen schnellen Einstieg zu ermöglichen.
C.1. Installation
Die Anwendung kann als zip-Datei von der Projektseite http://code.google.com/p/detrin/
heruntergeladen werden. Zusätzlich ist sie als zip-Datei auf der beiliegenden CD-ROM (vgl.
Anhang E) zu finden.
Sie kann an jeder beliebigen Stelle des Dateisystems entpackt werden. Nach dem Entpacken ist
die Installation abgeschlossen.
In der Datei config.properties können weitere Plugin-Ordner konfiguriert werden. Standard-
mäßig ist der plugin-Ordner auf gleicher Ebene konfiguriert, indem sich nach der Installation
bereits das erste Plugin detrin-standard befindet.
C.2. Quick-Start
Das Programm kann über die Datei DeTrIn.jar, mit Hilfe des folgenden Befehls, gestartet
werden:
j a v a − j a r DeTrIn . j a r
Die Benutzungsoberfläche der Anwendung ist in fünf Bereiche unterteilt (vgl. Abbildung C.1).
Im Folgenden werden die Bereiche kurz erklärt, um es dem Anwender leichter zu machen, das
Tutorial zu verstehen:
1. Menü-Leiste
Im Menü finden sich die globalen Funktionalitäten, wie z. B. Datei-Import und -Export.
27Decision Tree Inducer (DeTrIn).
Nina Rothenberg Masterthesis 89

C. Tutorial
Abbildung C.1.: Bereiche in der Benutzungsoberfläche von DeTrIn
2. Datenvorbereitung
Die Datenvorbereitung ist in zwei Bereiche gegliedert: Die Anzeige der importierten In-
stanzen eines Datensatzes sowie die Anzeige der Attribute. Hier können die Attribute u.a.
manuell gruppiert werden.
3. Einstellungen
Im Bereich Einstellungen können die Einstellungen für die Entscheidungsbaumgenerierung
vorgenommen werden. Hier befindet sich auch der Button, mit dem die Generierung
gestartet wird.
4. Entscheidungsbaum
Der Bereich Entscheidungsbaum ist standardmäßig der größte Bereich der Benutzungso-
berfläche. Hier wird der generierte Entscheidungsbaum angezeigt.
5. Erklärungen
Im Bereich der Erklärungen werden die detaillierten Erklärungen des Entscheidungsbaums
angezeigt. Informationen erhält man, indem man auf das gewünschte Baumelement im
Bereich ”Entscheidungsbaum” klickt.
Nachdem die Benutzungsoberfläche verfügbar ist, kann der Anwender einen Datensatz impor-
tieren. Er hat dazu zwei Möglichkeiten. Entweder, er nutzt einen der Buttons in der Datenvorbe-
reitung oder er verwendet den Menü-Eintrag (Datei > Import Datensatz). Standardmäßig
90 Masterthesis Nina Rothenberg

C. Tutorial
wird ein Import von CSV-Dateien unterstützt. Die Struktur der zu importierenden CSV-Datei
muss folgender beispielhaften Struktur entsprechen, wobei fehlende Werte einfach weggelassen
werden:
At t r i bu tname 1 , At t r i bu tname 2 , At t r i bu tname 3
Wert A1 . 1 , Wert A2 . 1 , Wert A3 . 1
Wert A1 . 2 , Wert A2 . 2 , Wert A3 . 2
Wert A1 . 3 , , Wert A3 . 3
. . .
Diese Struktur gleicht den exportierten weka-Datensätzen, sodass diese Beispiele aus weka in
DeTrIn ausgeführt werden können.
Es erscheint ein Datei-Auswahl-Fenster. Dieses unterstützt nur die Dateiformate, zu denen min-
destens ein FileHandler gefunden wurde. Sobald eine passende Datei ausgewählt wurde, wird
diese importiert. Hierzu wird automatisch der passende FileHandler zum Dateiformat gewählt.
Falls es auf Grund von mehrerer eingebundener FileHandler zu einem Format zu keiner eindeu-
tigen Auswahl eines FileHandlers zu einer Datei kommt, wird ein Auswahlfenster angezeigt (vgl.
Abbildung C.2).
Abbildung C.2.: Auswahl eines FileHandlers
Nach dem Import werden die Datensätze in der Datenvorbereitung angezeigt. Im zweiten Tab
des Bereichs werden die Attribute angezeigt. Die Attribute können manipuliert werden. Der An-
wender kann einzelne Attribute abwählen, die nicht in die Entscheidungsbaumgenerierung einflie-
ßen sollen. Hierzu kann er die Checkboxen in der linken Tabellenspalte nutzen. Zusätzlich kann
die Art der Gruppierung pro Attribut ausgewählt werden. Hier hat der Anwender die Wahl zwi-
schen Keine Gruppierung28, manuelle Gruppierung und automatischer Gruppierung.
Bei der automatischen Gruppierung übernimmt die Anwendung die Gruppierung und sucht die
28Bei nummerischen Attributen bedeutet dies, dass sie wie nominale Attribute behandelt werden
Nina Rothenberg Masterthesis 91

C. Tutorial
beste Gruppe heraus. Im Falle der manuellen Gruppierung muss der Anwender das Attribut
manuell Gruppieren. Hierzu geht er, durch eine Klick auf den Button (vgl. Abbildung C.3) in
die Detailsicht. In der Detailansicht kann der Anwender neue Gruppen erzeugen. Im Falle von
Abbildung C.3.: Button zur manuellen Gruppierung
nummerischen Attributen, kann er diese benennen und den Gruppen die einzelnen Werte zu-
weisen. Die Gruppen sind disjunkt, d. h. jeder Wert kann nur in einer der Gruppen vorkommen.
Für die Gruppierung sollte jeder Wert in einer Gruppe sein. Falls ein Wert nicht zugeordnet ist,
wird für ihn automatisch eine einzelne Gruppe erstellt.
Nachdem die Datenvorbereitung abgeschlossen ist, kann der Anwender die Einstellungen vor-
nehmen. Hierzu kann er einen vorkonfigurierten Algorithmus verwenden oder die Einstellungen
selbst setzen. In den Auswahlfeldern finden sich alle in den Plugins gefundenen Erweiterungen.
Wenn die Einstellungen abgeschlossen sind, kann der Anwender die Generierung starten, indem
er den Button Generiere Entscheidungsbaum klickt.
Der Entscheidungsbaum wird nun generiert und im Bereich Entscheidungsbaum angezeigt.
Mit einem Klick auf einen Knoten oder eine Kante können die Erklärungen angezeigt werden.
Mit einem erneuten Klick werden sie wieder ausgeblendet.
Der Anwender kann sich nun die Erklärungen anschauen und, wenn gewünscht, einen Report
erstellen. Hierzu geht er über das Menü Datei > Exportiere Report und wählt einen Export-
FileHandler aus. Nach Eingabe des Dateinamens, wird der Report an der gewünschten Stelle
im Dateisystem abgelegt.
92 Masterthesis Nina Rothenberg

D. Beispiel eines HTML-Berichts
D. Beispiel eines HTML-Berichts
Report zur Entscheidungsbaumgenerierung
Eingabeparameter
Verwendeter Datensatz
Aktiv outlook temperature humidity windy play
x sunny hot high false no
x sunny hot high true no
x overcast hot high false yes
x rainy mild high false yes
x rainy cool normal false yes
x rainy cool normal true no
x overcast cool normal true yes
x sunny mild high false no
x sunny cool normal false yes
x rainy mild normal false yes
x sunny mild normal true yes
x overcast mild high true yes
x overcast hot normal false yes
x rainy mild high true no
Nina Rothenberg Masterthesis 93

D. Beispiel eines HTML-Berichts
Attribute
Name Mögliche Werte Art der Gruppierung
outlook [rainy, overcast, sunny] Keine
temperature [mild, hot] Keine
humidity [normal, high] Keine
windy [false, true] Keine
play [no, yes] Keine
Einstellungen
Ziel-Attribut: play
Split-Kriterium: Information Gain
Stop-Kriterium: All Instances are in the same class
Pruning-Methode: Cost Complexity Pruning
Mindestanzahl von Instanzen: 2
94 Masterthesis Nina Rothenberg

D. Beispiel eines HTML-Berichts
Erklärung für den Knoten ’outlook’
Das beste Attribut ist ’outlook’ mit einem Information Gain von 0.2467. Diese Entropy wurde
wie Folgt berechnet:
Entropy_gesamt = - 9/14 log2(9/14)- 5/14 log2(5/14) = 0.9403
Entropy_rainy = - 3/5 log2(3/5)- 2/5 log2(2/5) = 0.9710
Entropy_overcast = - 4/4 log2(4/4) = 0.0
Entropy_sunny = - 3/5 log2(3/5)- 2/5 log2(2/5) = 0.9710
Somit ergibt sich eine Entropy für das Attribut ’outlook’ von:
Entropy_outlook = 5/14 * 0.9710 + 4/14 * 0.0 + 5/14 * 0.9710 = 0.6935
Der Information Gain berechnet sich daraus wie folgt:
Information Gain = Entropy_gesamt - Entropy_outlook = 0.9403 - 0.6935 = 0.2467
Die Werte des Information Gain für die restlichen Attribute sind folgende:
Information Gain_temperature = 0.0292
Information Gain_humidity = 0.1518
Information Gain_windy = 0.0481
Erklärung der Kante ’rainy’
Der Kante ’rainy’ folgen 5 Datensätze.
Als Split-Attribut des Zielknotens wird das Attribut ’windy’ ermittelt.
Erklärung für den Knoten ’windy’
Das beste Attribut ist ’windy’ mit einem Information Gain von 0.2467. Diese Entropy wurde
wie Folgt berechnet:
Entropy_gesamt = - 3/5 log2(3/5)- 2/5 log2(2/5) = 0.9710
Entropy_true = - 2/2 log2(2/2) = 0.0
Entropy_false = - 3/3 log2(3/3) = 0.0
Somit ergibt sich eine Entropy für das Attribut ’windy’ von:
Entropy_windy = 2/5 * 0.0 + 3/5 * 0.0 = 0.0
Der Information Gain berechnet sich daraus wie folgt:
Information Gain = Entropy_gesamt - Entropy_windy = 0.9710 - 0.0 = 0.9710
Die Werte des Information Gain für die restlichen Attribute sind folgende:
Information Gain_temperature = 0.0200
Information Gain_humidity = 0.0200
Nina Rothenberg Masterthesis 95

D. Beispiel eines HTML-Berichts
Erklärung der Kante ’false’
Der Kante ’false’ folgen 3 Datensätze.
Als Zielknotens wird das Blatt mit dem Wert ’yes’ ermittelt.
Erklärung das Blatt ’yes’
Alle Datensätze, die über die Kante kommen, haben den gleichen Wert des Zielattributs. Sie
erfüllen damit das Stop-Kriterium. Der Wert des Zielattributes ist bei allen Instanzen ’yes’.
Dieser Wert wird als Blatt verwendet.
Erklärung der Kante ’true’
Der Kante ’false’ folgen 2 Datensätze.
Als Zielknotens wird das Blatt mit dem Wert ’no’ ermittelt.
Erklärung das Blatt ’no’
Alle Datensätze, die über die Kante kommen, haben den gleichen Wert des Zielattributs. Sie
erfüllen damit das Stop-Kriterium. Der Wert des Zielattributes ist bei allen Instanzen ’no’.
Dieser Wert wird als Blatt verwendet.
Erklärung der Kante ’sunny’
Der Kante ’sunny’ folgen 5 Datensätze.
Als Split-Attribut des Zielknotens wird das Attribut ’humidity’ ermittelt.
Erklärung für den Knoten ’humidity’
Das beste Attribut ist ’humidity’ mit einem Information Gain von 0.2467. Diese Entropy wurde
wie Folgt berechnet:
Entropy_gesamt = - 3/5 log2(3/5)- 2/5 log2(2/5) = 0.9710
Entropy_normal = - 2/2 log2(2/2) = 0.0
Entropy_high = - 3/3 log2(3/3) = 0.0
Somit ergibt sich eine Entropy für das Attribut ’humidity’ von:
Entropy_humidity = 2/5 * 0.0 + 3/5 * 0.0 = 0.0
Der Information Gain berechnet sich daraus wie folgt:
Information Gain = Entropy_gesamt - Entropy_humidity = 0.9710 - 0.0 = 0.9710
96 Masterthesis Nina Rothenberg

D. Beispiel eines HTML-Berichts
Die Werte des Information Gain für die restlichen Attribute sind folgende:
Information Gain_temperature = 0.5710
Information Gain_windy = 0.0200
Erklärung der Kante ’normal’
Der Kante ’false’ folgen 2 Datensätze.
Als Zielknotens wird das Blatt mit dem Wert ’yes’ ermittelt.
Erklärung das Blatt ’yes’
Alle Datensätze, die über die Kante kommen, haben den gleichen Wert des Zielattributs. Sie
erfüllen damit das Stop-Kriterium. Der Wert des Zielattributes ist bei allen Instanzen ’yes’.
Dieser Wert wird als Blatt verwendet.
Erklärung der Kante ’high’
Der Kante ’high’ folgen 2 Datensätze.
Als Zielknotens wird das Blatt mit dem Wert ’no’ ermittelt.
Erklärung das Blatt ’no’
Alle Datensätze, die über die Kante kommen, haben den gleichen Wert des Zielattributs. Sie
erfüllen damit das Stop-Kriterium. Der Wert des Zielattributes ist bei allen Instanzen ’no’.
Dieser Wert wird als Blatt verwendet.
Erklärung der Kante ’overcast’
Der Kante ’false’ folgen 4 Datensätze.
Als Zielknotens wird das Blatt mit dem Wert ’yes’ ermittelt.
Erklärung das Blatt ’yes’
Alle Datensätze, die über die Kante kommen, haben den gleichen Wert des Zielattributs. Sie
erfüllen damit das Stop-Kriterium. Der Wert des Zielattributes ist bei allen Instanzen ’yes’.
Dieser Wert wird als Blatt verwendet.
Nina Rothenberg Masterthesis 97


E. Prototyp
E. Prototyp
Anbei ist eine CD-ROM, die die aktuelle Version des Prototypen inkl. Sourcen beinhaltet.
Nina Rothenberg Masterthesis 99


Literaturverzeichnis
Literaturverzeichnis
[7r.10] 7r. Agentur für Arbeitgebermarketing: Berufswelt LOGISTIK - Glossar
- Begriffe der beruflichen Weiterbildung. http://www.berufswelt-logistik.de/
?glossar_weiterbildung_logistik Stand: 21.08.2010, 2010.
[BHS07] Boersch, Ingo, Jochen Heinsohn und Rolf Socher: Wissensverarbeitung.
Eine Einführung in die Künstliche Intelligenz für Informatiker und Ingenieure (Sav
Informatik). Spektrum Akademischer Verlag, 2. A. Auflage, 5 2007.
[BKI06] Beierle, Christoph und Gabriele Kern-Isberner: Methoden wissensbasier-
ter Systeme. Grundlagen, Algorithmen, Anwendungen. Vieweg Friedr. + Sohn Ver, 3.,
erw. A. Auflage, 4 2006.
[Bre83] Breiman, Leo: Classification and Regression Trees. Wadsworth Co, 6 1983.
[Der07] Derntl, Michael: Patterns for Person-Centered E-Learning. Ios Pr, illustrated
edition Auflage, 3 2007.
[dJ06] Jong, Ton de: Computer simulations - Technological advances in inquiry learning.
Science, 312:532–533, 2006.
[E-L10] E-Learning-Koordination der Philosophischen Fakultät der Uni-
versität Zürich: Was ist E-Learning? http://www.phil.uzh.ch/institute/
elearning/definition.html, 2010.
[Ess08] Esser, Friedrich: Java 6 Core Techniken: Essentielle Techniken für Java-Apps.
Oldenbourg, 4 2008.
[FMC02] Frey, Barbara A., Ashli Molinero und Ellen R. Cohn: Strategies to
Increase Web Accessibility and Usability in Higher Education. In: Design and Imple-
mentation of Web-Enabled Teaching Tools, Kapitel III, Seiten 48–60. IGI Publishing,
illustrated edition Auflage, 11 2002.
[Hes10] Hesse, Prof. Dr. Dr. Friedrich W.: e-teaching.org - Glossar. http://www.
e-teaching.org/glossar?azrange=E Stand: 31.10.2010, 2010.
[HN09] Holten, Roland und Dieter Nittel (Herausgeber): E-Learning in Hochschule
und Weiterbildung: Einsatzchancen und Erfahrungen. Bertelsmann, Bielefeld, 1 Auf-
lage, 11 2009.
Nina Rothenberg Masterthesis 101

Literaturverzeichnis
[HU06] Hambach, Sybille und Bodo Urban (Herausgeber): E-Learning-Angebote sys-
tematisch entwickeln: Ein Leitfaden. IRB Verlag Stuttgart, 1. Aufl. Auflage, 10 2006.
[KW09] Kaufmann, Michael und Dorothea Wagner (Herausgeber): Drawing Graphs:
Methods and Models (Lecture Notes in Computer Science). Springer, 1 Auflage, 2
2009.
[Leb08] Lebert, Stefan: Gruppen segmentieren mit Entscheidungsbäumen: Ein praxisori-
entierter Methodenvergleich am Beispiel von PC-Nutzung. Vdm Verlag Dr. Müller, 4
2008.
[Man97] Mansour, Yishay: Pessimistic Decision Tree Pruning based on Tree size. Techni-
scher Bericht, Tel-Aviv University, 1997.
[McC05] McConnell, Steve: Code Complete - Deutsche Ausgabe der Second Edition.
Microsoft Press Deutschland, 1., Aufl. Auflage, 1 2005.
[MR05a] Maimon, Oded und Lior Rokach (Herausgeber): Data Mining and Knowledge
Discovery Handbook. Springer, Berlin, 1 Auflage, 9 2005.
[MR05b] Maimon, Oded und Lior Rokach: Decomposition Methodology for Knowled-
ge: Theory and Applications (Machine Perception and Artificial Intelligence). World
Scientific Pub Co, 7 2005.
[Oes04] Oestereich, Bernd: Objektorientierte Softwareentwicklung. Analyse und Design
mit UML 2.0. Oldenbourg, 7., aktualis. A. Auflage, 12 2004.
[QQ92] Quinlan, Ross und J. R. Quinlan: C4.5: Programs for Machine Learning. Morgan
Kaufman Publ Inc, Revised, Update. Auflage, 12 1992.
[Rey09] Rey, Günter Daniel: E-Learning. Theorien, Gestaltungsempfehlungen und For-
schung. Huber, Bern, 1., Aufl. Auflage, 8 2009.
[RM08] Rokach, Lior und Oded Maimon: Data Mining with Decision Trees: Theory and
Applications. World Scientific Pub Co., 3 2008.
[RN04] Russell, Stuart und Peter Norvig: Künstliche Intelligenz: Ein moderner An-
satz. Pearson Studium, 2., überarb. A. Auflage, 8 2004.
[Rot09] Roth, Alexander: Spezifikation und Entwicklung universitärer Lern- und Arbeit-
sumgebungen. Shaker, 1., Aufl. Auflage, 2 2009.
102 Masterthesis Nina Rothenberg

Literaturverzeichnis
[RR03] Reinmann-Rothmeier, Gabi: Didaktische Innovation durch Blended Learning:
Leitlinien anhand eines Beispiels aus der Hochschule. Huber, Bern, 1., Aufl. Auflage,
3 2003.
[Ski08] Skiena, Steven S.: The Algorithm Design Manual. Springer, Berlin, 0002 Auflage,
9 2008.
[TIO11] TIOBE Software BV: TIOBE Programming Community Index for Februa-
ry 2011. http://www.tiobe.com/index.php/content/paperinfo/tpci/index.
html Stand: 01.03.2011, 2011.
[Wen03] Wendt, Matthias: CBT und WBT konzipieren, entwickeln, gestalten. Praxisbuch.
Hanser Fachbuch, 1 2003.
[Wun05] Wunderlich, Lars: Software-Architekturen in Java - Modelle, Techniken, Praxis.
Mitp-Verlag, 1 Auflage, 2005.
Nina Rothenberg Masterthesis 103


Ehrenwörtliche Erklärung
Abkürzungsverzeichnis
CART Classification and Regression Trees.
CSS Cascading Style Sheets.
CSV Character Separated Values.
DeTrIn Decision Tree Inducer.
eLearning electronic learning.
ELQ E-Learning Qualität.
HTML Hypertext Markup Language.
jar Java Archive.
JPF Java-Plugin Framework.
JRE Java Runtime Environment.
JUNG Java Universal Network/Graph Framework.
KNIME Konstanz Information Miner.
NP-vollständig nichtdeterministisch polynomiell vollständig.
OOA Objektorientierte Analyse.
OOD Objektorientiertes Design.
Nina Rothenberg Masterthesis 105


Ehrenwörtliche Erklärung
Ehrenwörtliche Erklärung
Ich erkläre hiermit ehrenwörtlich, dass ich die vorliegende Arbeit selbständig angefertigt habe,die aus fremden Quellen direkt oder indirekt übernommenen Gedanken sind als solche kenntlichgemacht. Es wurden keine anderen als die angegebenen Quellen und Hinweise verwandt. Dievorliegende Arbeit wurde bisher noch keiner anderen Prüfungsbehörde vorgelegt und auch nochnicht veröffentlicht.
Hannover, 08. März 2011Unterschrift Nina Rothenberg
Nina Rothenberg Masterthesis 107




![Data Mining Studie 2013 | Praxistest & Benchmarking€¦ · RapidMiner fälschlicherweise als nominal er-kannt [siehe Abb.29]. Dieser Umstand lässt sich in RapidMiner ...](https://static.fdokument.com/doc/165x107/5b0139497f8b9af1148dd132/data-mining-studie-2013-praxistest-benchmarking-rapidminer-flschlicherweise.jpg)













