
FAKULTÄT FÜR INFORMATIK - · management of operational data as well as, e.g., management of data...
88
FAKULTÄT FÜR INFORMATIK DER TECHNISCHEN UNIVERSITÄT MÜNCHEN Bachelor’s Thesis in Wirtschaftsinformatik Konzeption und prototypische Implementierung eines Überwachungscockpits für ein Data Warehouse Andreas Gerö
-
Upload
truongthuan -
Category
Documents
-
view
217 -
download
0
Transcript of FAKULTÄT FÜR INFORMATIK - · management of operational data as well as, e.g., management of data...

FAKULTÄT FÜR INFORMATIKDER TECHNISCHEN UNIVERSITÄT MÜNCHEN
Bachelor’s Thesis in Wirtschaftsinformatik
Konzeption und prototypische Implementierung einesÜberwachungscockpits für ein Data Warehouse
Andreas Gerö


FAKULTÄT FÜR INFORMATIKDER TECHNISCHEN UNIVERSITÄT MÜNCHEN
Bachelor’s Thesis in Wirtschaftsinformatik
Design and prototypical implementation of amonitoring cockpit for a data warehouse
Konzeption und prototypische Implementierung einesÜberwachungscockpits für ein Data Warehouse
Autor: Andreas GeröAufgabensteller: Prof. Dr. Florian MatthesBetreuer: Thomas ReschenhoferAbgabedatum: 15. September 2014


Ich versichere, dass ich diese Bachelor’s Thesis selbständig verfasst und nur die angege-benen Quellen und Hilfsmittel verwendet habe.
München, den 12. September 2014 Andreas Gerö


Danksagung
Zunächst möchte ich all denjenigen meinen Dank aussprechen, die diese Bachelorarbeit er-möglicht und mich während der Bearbeitung fortlaufend motiviert und unterstützt haben.
So gebührt mein Dank in erster Linie meinem Praxispartner, der ITERATEC GMBH, diemir ihre Infrastruktur zur Forschung bereitgestellt und durch die Fallstudie den Bezugzwischen Forschung und realem Projekt bei einem Unternehmen hergestellt hat. Meinenbeiden fachlichen Betreuern, JOHANNES DIETERICH und NINA PAK, gebührt mein beson-derer Dank, da sie stets ein offenes Ohr für meine Fragestellungen hatten und ihr kritischerBlick sowie ihre konstruktive Kritik wichtige Denkanstöße lieferten, um diese Arbeit so an-fertigen zu können.Selbstverständlich bin ich auch allen anderen Kollegen dankbar, die nicht namentlich ge-nannt sind und mit überragender Hilfsbereitschaft stets Zeit für mich fanden.
Weiterhin bedanke ich mich bei meinem Betreuer von Seiten der Uni, THOMAS RESCHEN-HOFER, der mich ebenfalls unterstützt hat und mir ermöglicht hat, diese Abschlussarbeitam Lehrstuhl sebis zu schreiben.
Schließlich gebührt meinen Eltern besonderer Dank. Sie sind es, die mich stets unterstützthaben und mich zu dem gemacht haben, was ich heute bin.
Danke.
vii


Zusammenfassung
Mit zunehmendem Datenvolumen, komplexen Abläufen und steigenden Anforderungenan Schnelligkeit und Stabilität entsteht der Bedarf nach einer zentralen und benutzer-freundlichen Informationsquelle zur Unterstützung des Datenmanagements im Data Ware-house (DWH). Dies umfasst sowohl die Verwaltung der operativ anfallenden Datenmen-gen als auch bspw. das Management der Datenqualität.
Die bislang bei Datenbanken mitgelieferte Funktionalität zur Überwachung der Datendeckt vor allem technische Detailaspekte, wie z.B. Speicherverbrauch oder die Anzahl neugeladener Datensätze ab. Darüber hinausgehende, auf die konkrete Architektur bezogeneFragen werden nicht in ausreichendem Maße adressiert. Für einen DWH-Administratorist beispielsweise die Nachverfolgung des Ablaufs bzw. eine eventuelle Fehleranalyse beikürzlich erfolgten Extract-Transform-Load (ETL)-Vorgängen von Interesse. So kann eineklassische Schichtenarchitektur auf die schichtenübergreifenden Anwendungsfälle hin un-tersucht werden. Durch die Identifizierung der Beziehungen und Abhängigkeiten zwi-schen einzelnen Datenbankobjekten und Anwendungsfällen können auf diese Weise dievon einem fehlerhaften Datenbankobjekt betroffenen Anwendungsfälle und damit die ent-sprechenden Anwender ermittelt werden. So entsteht der Bedarf nach einer Methodik zursystematischen Analyse und Deckung des Informationsbedarfs typischer betrieblicher Sta-keholder im Rahmen des Datenmanagements im Data Warehouse.
In dieser Bachelorarbeit wird ein Überwachungskonzept erarbeitet, welches diese Lückeschließt. Die Forschungsergebnisse umfassen eine dreiteilige Methodik:
1. Für eine Auswahl typischer betrieblicher Stakeholder aus Datenmanagement undIT-Servicemanagement wurden Ziele für das Datenmanagement ermittelt.
2. Ein Kennzahlenkatalog ermöglicht es, die Erfüllung der Ziele der Stakeholder zumessen.
3. Ein Metamodell spezifiziert die Zusammenhänge zwischen Metriken, Messobjektenund fachlichen Entitäten und erlaubt die Modellierung des Datenflusses im DWHsowie Visualisierung von Kennzahlen in einem Datenflussgraphen.
Zudem werden weitere Analysen vorgestellt, die durch den Datenflussgraphen ermöglichtwerden. Hierzu zählen Abstammungs- und Auswirkungsanalyse sowie die Berechnungvon kritischen Pfaden auf dem Graphen.
ITIL und Data Management Body of Knowledge (DMBOK) liegen als Frameworks mitempfehlendem Charakter der Analyse von Stakeholdern und Zielen zugrunde. Die Metri-ken aus dem Kennzahlenkatalog wurden mithilfe von Goal-Question-Metric (GQM) ausden zuvor ermittelten Zielen abgeleitet. Das Konzept wurde im Rahmen einer Fallstudieals Monitoring-Cockpit für ein großes Carsharing-DWH prototypisch umgesetzt. Eine ab-schließende Evaluation durch Experten aus der IT Industrie hat die Eignung des Prototypsfür die Anforderungen in der Fallstudie validiert.
ix


Abstract
With increasing amounts of data, complex processes, and rising demands regarding ve-locity and stability, the necessity for a central and user-friendly source of information insupport of data management in the data warehouse has become apparent. This comprisesmanagement of operational data as well as, e.g., management of data quality.
Currently, out-of-the-box data monitoring functionality of databases mostly covers tech-nical details, such as space usage or number of recently loaded data records. Questionsregarding the specific architecture are insufficiently dealt with. A data warehouse admi-nistrator, for instance, might be interested in tracing the course of recently finished ETLprocesses or debugging them. Thus, a conventional layer architecture may be analyzedwith respect to the use cases spanning multiple layers. By identifying the relationshipsand dependencies among database objects and use cases, use cases affected by erroneousdatabase objects and corresponding users can be determined. Hence, the need for a me-thodology to systematically analyze and cover the informational requirements of commonbusiness stakeholders in context of data management in the data warehouse has evolved.
This Bachelor’s Thesis develops a concept for monitoring data warehouses, which bridgesthis gap. The research results comprise a tripartite methodology:
1. Goals of common business stakeholders from data management and IT service ma-nagement are determined.
2. The KPI catalog facilitates measurement of the accomplishment of the stakeholders’goals.
3. A meta model defines relationships among technical components, metrics, and busi-ness entities, and enables modelling data flow in the data warehouse as well as vi-sualization of metrics in a data flow graph.
Additionally, the Thesis presents further analyses facilitated by the graph. Lineage andimpact analysis as well as computation of critical paths count among them.
ITIL and the Data Management Body of Knowledge (DMBOK) serve as the underlyingframeworks of recommendatory nature for the analysis of stakeholders and identificationof their goals. Metrics contained in the KPI catalog were deduced from those goals utili-zing the Goal-Question-Metric approach. The concept was prototypically implemented inthe scope of a case study involving a large carsharing data warehouse. A concluding eva-luation by the experts from the IT industry validated the suitability of the prototype forthe requirements of the case study.
xi

xii

Inhaltsverzeichnis
Danksagung vii
Zusammenfassung ix
Abstract xi
1 Einführung 11.1 Motivation für diese Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Zielsetzung der Forschung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Vorgehensweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Stand der Forschung 52.1 Data Warehousing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Schichtenarchitektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.1.2 Datenintegration zwischen den Schichten . . . . . . . . . . . . . . . . 7
2.2 Datenfluss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.3 Datenmanagement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3.1 Data Management Body of Knowledge . . . . . . . . . . . . . . . . . 102.3.2 Information Technology Infrastructure Library . . . . . . . . . . . . . 112.3.3 Metadaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.3.4 Datenqualität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4 Informationsaufbereitung und Cockpit-Bedienkonzept . . . . . . . . . . . . 17
3 Entwicklung des Konzepts 193.1 Identifizierung der Stakeholder . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1.1 Ausgewählte Funktionen des Datenmanagements . . . . . . . . . . . 193.1.2 Potentielle Stakeholder . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2 Ziele des Datenmanagements . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.2.1 Data Operations Management . . . . . . . . . . . . . . . . . . . . . . 203.2.2 Data Warehousing & Business Intelligence Management . . . . . . . 213.2.3 Metadatenmanagement . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2.4 Datenqualitätsmanagement . . . . . . . . . . . . . . . . . . . . . . . . 223.2.5 Ziele in der weiteren Betrachtung . . . . . . . . . . . . . . . . . . . . 22
3.3 Analyse der Stakeholder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.3.1 Zuordnung von Zielen zu DAMA-Rollen . . . . . . . . . . . . . . . . 253.3.2 Zuordnung von Zielen zu ITIL-Rollen . . . . . . . . . . . . . . . . . . 26
3.4 Informationsbedarfsanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.5 Kennzahlen und notwendige Messungen . . . . . . . . . . . . . . . . . . . . 30
3.5.1 Messpunkte für Datenqualität im Data Warehouse . . . . . . . . . . . 31
xiii

Inhaltsverzeichnis
3.5.2 Ebenen der Messung von Kennzahlen . . . . . . . . . . . . . . . . . . 313.5.3 Kennzahlenkatalog . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.6 Datenflussanalyse und Datenflussgraph . . . . . . . . . . . . . . . . . . . . . 413.6.1 Metamodell der Messobjekte . . . . . . . . . . . . . . . . . . . . . . . 413.6.2 Analysen und Messungen am Datenflussgraphen . . . . . . . . . . . 423.6.3 Darstellung des Datenflussgraphen . . . . . . . . . . . . . . . . . . . 45
4 Fallstudie 534.1 Systemkontext . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.1.1 Projekt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.1.2 Architektur und Werkzeuge . . . . . . . . . . . . . . . . . . . . . . . . 534.1.3 Spezifische Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . 54
4.2 Anwendung des Konzepts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 554.2.1 Kennzahlen und Visualisierung . . . . . . . . . . . . . . . . . . . . . . 554.2.2 Datenmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.2.3 Dashboards . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.2.4 Datenflussgraph im Projekt . . . . . . . . . . . . . . . . . . . . . . . . 59
4.3 Evaluierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5 Fazit und Ausblick 615.1 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 615.2 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
Anhang 67
Interviews 67
Abkürzungsverzeichnis 69
Literaturverzeichnis 71
xiv

1 Einführung
1.1 Motivation für diese Arbeit
Viele Unternehmen haben mittlerweile erkannt, dass Daten einen wichtigen und wertvol-len Teil ihres Kapitals darstellen. Die Berechnung von Prognosen für die zukünftige Ge-schäftsperformance gehört heutzutage ebenso zu den betrieblichen Anforderungen wieAnalysen und Auswertungen von Daten aus der Vergangenheit, sowohl auf Basis eigenerDaten als auch angereichert mit Daten aus externen Quellen.
In einer sehr schnelllebigen Welt, in der wenige Sekunden die Auswirkungen einer be-trieblichen Entscheidung erheblich verändern können, sollte ein Unternehmen zur Unter-stützung der Entscheider gemäß bestehender Anforderungen Qualitätskriterien für Datendefinieren. Zu diesen gehören aus heutiger Sicht nicht mehr nur die klassischen Kriterien,die sich auf Korrektheit [Orr98] der Daten beziehen, sondern beispielsweise auch Kriterienfür Aktualität oder Integrität.
Stetig wachsende Datenmengen und steigende Komplexität erschweren es, den Über-blick zu behalten und lassen ein effektives und möglichst automatisiertes Datenmanage-ment immer wichtiger erscheinen. Gerade der Einsatz eines Data Warehouse (DWH), derinsbesondere durch die aufwändige Integration und Konsolidierung heterogener Daten-quellen einen hohen Grad an Komplexität aufweist, profitiert stark von einer systemati-schen Überwachung.
So entsteht der Bedarf nach einer Methode zur systematischen Abdeckung des Infor-mationsbedarfs typischer betrieblicher Stakeholder im Kontext des Datenmanagements.In diesem Sinne soll festgestellt werden, welche betrieblichen Stakeholder typischerwei-se welchen Informationsbedarf zur Verfolgung ihrer Ziele im Rahmen des Datenmanage-ments haben und über welche Möglichkeiten dieser Informationsbedarf abgedeckt werdenkann.
Der Bedarf nach einer Lösung zum Monitoring im Kontext des Datenmanagements wirdteilweise von bestehenden Werkzeugen abgedeckt. Insbesondere Systemüberwachung auftechnischer Ebene ist mit vorhandenen Anwendungen möglich [Hav13, Man14]. Aberauch Werkzeuge, die eine Abstammungsanalyse im DWH durchführen können, sind ver-fügbar [Cor12]. Werkzeuge, die in der Lage sind, Metriken anhand eines Datenflussgra-phen darzustellen, sind jedoch nicht vorhanden. So könnte für den DWH-Administratorbeispielsweise die Darstellung des Durchsatzes für jeden Prozessschritt des ETL-Laufs di-rekt im Datenflussgraph (DFG) sinnvoll sein. Zudem gilt es nach [MBEH09] als Best Practi-ce, ein Dashboard für Anwender zur Verfügung zu stellen, in dem auf höherem Abstrakti-onsniveau Details zur Datenauslieferung zu sehen sind, um das Vertrauen in die Prozesseim DWH zu erhöhen. Dieses Prinzip wird in der Fallstudie prototypisch umgesetzt.
1

1 Einführung
1.2 Zielsetzung der Forschung
Folgende wissenschaftliche Fragestellungen sollen im im Kotext des Datenmanagementsim Data Warehouse beantwortet werden:
Q-1 Welchen Informationsbedarf haben typische betriebliche Stakeholder?Q-2 Welche Metriken eignen sich am besten dazu, die Ziele der Stakeholder zu überwa-
chen?Q-3 Wie kann ein Datenflussgraph bei Analyse und Überwachung eines Data Warehou-
se unterstützen?
Ziel dieser Arbeit ist die Entwicklung einer Methode zur systematischen Ermittlung undDeckung des Informationsbedarfs typischer betrieblicher Stakeholder im Rahmen des Da-tenmanagements sowie eines Konzepts für die Modellierung des Datenflusses im DataWarehouse.
1.3 Vorgehensweise
Um ein Konzept erarbeiten zu können, welches Antworten auf die im vorhergehenden Ab-schnitt formulierten Fragestellungen geben kann, werden zunächst theoretische Grund-lagen eingeführt. Der Stand der Forschung für die Themen Data Warehousing, Daten-management und Datenfluss sowie Cockpit-Bedienkonzept wird aufgezeigt. Damit dasKonzept auf etablierten Praktiken und in der Praxis verbreiteten Rahmenwerken fundie-ren kann, werden die Information Technology Infrastructure Library (ITIL) [Nis12] sowiedas DMBOK [MBEH09] der Data Management Association (DAMA) eingeführt. Auf dieseWeise können Best Practices aus dem Datenmanagement auf empfohlene Organisations-strukturen für das IT-Servicemanagement übertragen werden.
Das Konzept hat die Entwicklung einer Methode zur Überwachung eines Data Ware-house zum Ziel und erreicht dies über die Definition geeigneter Metriken. Zur Ermittlungadäquater Metriken wird der GQM Ansatz [Bas92] herangezogen, der postuliert, dass Me-triken den Grad der Erfüllung einer Zielsetzung messen. Die in dieser Arbeit verwendetenZiele sind eine Teilmenge der Gesamtanzahl von Zielen, die im DMBOK definiert sind. DieZiele sind nach Relevanz für die hier betrachtete Thematik so gewählt, dass der durch diewissenschaftlichen Fragestellungen vorgegebene Umfang eingehalten wird.
Zu Beginn wird eine Auswahl von Funktionen des Datenmanagements nach [MBEH09]getroffen, die zu einer Menge potentieller Stakeholder für die zu entwickelnde Methodeführt. Die diesen Funktionen zugeordneten Ziele werden werden daraufhin analysiert, obsie bei GQM miteinbezogen werden. Aus der Menge der verwendeten Ziele wird die Men-ge der mit dieser Arbeit tatsächlich angesprochenen Stakeholder abgeleitet. Diesen Rollendes Datenmanagements nach DAMA werden entsprechende Rollen aus der ITIL zugeord-net. Mit den nun bekannten Informationen über die betrieblichen Stakeholder wird eineInformationsbedarfsanalyse durchgeführt. Im Rahmen von GQM werden passend zu denZielen Fragestellungen aus Sicht der Stakeholder erarbeitet. Die Fragestellungen bildendie Grundlage zur Definition von Metriken, die diese Fragestellungen beantworten undden Informationsbedarf der Stakeholder decken. Der resultierende Kennzahlenkatalog ist
2

1.3 Vorgehensweise
ein zentrales Artefakt dieser Arbeit und Basis für die Überwachung von DWHs.Es wird ein Metamodell entwickelt, welches die Modellierung des Datenflusses im DWH
als gerichteten Graph ermöglicht. Das Metamodell spezifiziert die Zusammenhänge zwi-schen Messobjekten und Metriken im DWH. Hierzu werden die Metriken in verschiedeneKlassen eingeteilt und erläutert, wie die Metriken am Graphen dargestellt werden kön-nen. Es werden weitere für Graphen spezifische Analysen vorgestellt, die anhand einesDFG durchgeführt werden können. So werden Abstammungs- und Auswirkungsanalysesowie die Berechnung von kritischen Pfaden vorgestellt.
Das Konzept zur Überwachung von Data Warehouses wird mit Unterstützung des Pra-xispartners iterativ entwickelt und in einer Fallstudie prototypisch umgesetzt sowie eva-luiert. Eine mögliche Implementierung des DFG wird vorgeschlagen und anhand vonMockups aufgezeigt, wie die verschiedenen Analysen und Darstellung der Metriken kon-kret ausgestaltet werden können. Abschließend werden die Ergebnisse der Arbeit noch-mals kritisch betrachtet und diskutiert. Ein Ausblick zeigt auf, an welchen Stellen weitererBedarf zur Forschung besteht.
3

1 Einführung
4

2 Stand der Forschung
Dieses Kapitel legt den aktuellen Stand der Forschung dar und führt theoretische Grundla-gen ein, die für das spätere Konzept die Basis bilden. Zu Beginn wird der Begriff des DataWarehouse (DWH) eingeführt und typische Charakteristika der Architektur aufgezeigt.Es folgt eine kurze Einführung in das Konzept des Datenflusses, auf dem der Datenfluss-graph aufbaut. Ein Abschnitt über Datenmanagement zeigt die Struktur von DMBOK undITIL auf und gibt einen Überblick über Metadatenmanagement und Datenqualität.
2.1 Data Warehousing
Die Konsolidierung unterschiedlicher Datenquellen sowie der integrierte Zugang dazu ineiner zentralen Datenbasis stellen wichtige Fragestellungen für Industrie und Forschungdar [Wid95]. Der bei der Auswertung und Analyse von Daten aus unterschiedlichen Quel-len entstehenden Frage der Datenintegration kann man im Allgemeinen auf zweierlei Artbegegnen:
1. Auswertung der Anfrage, Auflösung in geeignete Unteranfragen für die einzelnenDatenquellen und Berechnung des Ergebnisses
2. Extraktion, Transformation und Laden relevanter Daten aus den Quellsystemen inein logisches Zielsystem und Ausführung aller Anfragen auf den so entstandenenDaten
Letzterer Ansatz wird als Data Warehouse bezeichnet und wurde unter anderem von W.H. Inmon definiert:
Definition 2.1 (Data Warehouse) Ein Data Warehouse (DWH) ist eine themenorientierte, in-tegrierte, chronologisierte und persistente Sammlung von Daten, um das Management bei seinenEntscheidungsprozessen zu unterstützen. [Inm02]
Für Inmon ist das unternehmensweite Datenmodell der zentrale Baustein des DWH. Diestrategische Ausrichtung des DWH als Teil der übergeordneten Corporate Information Fac-tory bei Inmon steht im Gegensatz zur benutzerorientierten Sicht Kimballs, der das Da-ta Warehouse als eine Kopie von Transaktionsdaten, die zum Zwecke der Abfrage und Analysestrukturiert sind, sieht [KR02]. Für Kimball beginnt der Designprozess des DWH mit derAbdeckung des Informationsbedarfs von Stakeholdern über multidimensional modellier-te Data Marts. Die Menge dieser spezifischen Sichten verkörpert für ihn das Data Ware-house. Dieses kann auch nachträglich um ein unternehmensweit integriertes Datenmodellerweitert werden.
Das DWH wird oftmals auch als Single Point of Truth (SPOT) [WS04] charakterisiert.Diese Bezeichnung resultiert aus dem Ziel, keine widersprüchlichen Analysen aus unter-
5

2 Stand der Forschung
schiedlichen Datenquellen erzeugen zu können. Beispielsweise soll durch eine einheitlicheDatenbasis die Situation vermieden werden, dass Prognosen oder Statistiken von verschie-denen Abteilungen zur gleichen Fragestellung erstellt werden und widersprüchliche Er-gebnisse durch die unterschiedlichen Datenbasen folgen. Eine unternehmensweit zentraleStelle zur Pflege der Daten soll des Weiteren, durch gezielt gepflegte Datenqualität undverringerten Aufwand zur Datenpflege, den Informationsgrad der Daten im Allgemeinenund damit die Endanwenderproduktivität erhöhen.
Durch eine Historisierung der operativen Daten im Data Warehouse verspricht mansich eine langfristig aussagekräftige Datenbasis, um z.B. durch Online Analytical Proces-sing (OLAP) oder Data Mining neue Erkenntnisse aus den Daten gewinnen zu können.Operative Systeme würden nur noch für operative Zwecke genutzt und würden damitentlastet. Die geringere Last auf den operativen Systemen in Kombination mit der kon-zentrierten Last auf dem Data Warehouse bietet Potential zu finanziellen Optimierungen,wie einem effizienteren Controlling. Nicht zuletzt betrachtet man das DWH als zukunfts-sichere IT-Strategie.
Bauer und Günzel [BG04] stellen einige Anforderungen an ein Data Warehouse-System.Dazu gehört die Unabhängigkeit zwischen Datenquellen und Analysesystemen. Dies be-zieht sich auf Verfügbarkeit des DWH, unabhängige Belastung der einzelnen Systeme so-wie Unabhängigkeit des DWH von laufenden Änderungen an den Quellsystemen.
Die Daten sollen persistent gelagert sein und für verschiedene Zwecke verwertbar sein.Grundsätzlich sollen beliebige Auswertungen vorgenommen werden können und das Mo-dell so flexibel sein, dass es z.B. auch auf die Integration neuer Datenquellen erweitertwerden kann, aber gleichzeitig unterschiedliche individuelle Sichten unterstützten kann.
Die Datenstrukturen, Zugriffsberechtigungen und Prozesse sollen eindeutig sein undam Zweck des DWH, nämlich der Analyse der Daten ausgerichtet sein. Schließlich sollendie Abläufe automatisierbar sein.
2.1.1 Schichtenarchitektur
Im klassischen Sinne wird das Data Warehouse als dreischichtiges Informationssystemmodelliert (vgl. Abbildung 2.1). Daten aus operativen Quellsystemen werden in die Sta-ging Area, welche die Integrationsebene repräsentiert, geladen. Diese Ebene entkoppelt dieExtraktion aus den Quellsystemen und die tatsächliche Datenintegration, die auf dem Wegzur Ebene der Datenhaltung durchgeführt wird. Anschließend werden die Daten in denData Store geladen, wo sie meist in denormalisierter, multidimensionaler Form vorliegen.Oftmals werden bedarfsspezifische Data Marts modelliert, die auf spezielle Sichten maß-geschneidert und für voluminöse Lesezugriffe optimiert sind. Diese Daten werden zurAnalyse eingesetzt und die Ergebnisse werden schließlich in einer Clientanwendung aufder Präsentationsebene dargestellt. Die Darstellung kann aber auch beispielsweise in Formeines Berichts auf Papier erfolgen.
6

2.1 Data Warehousing
Abbildung 2.1: Typische Schichtenarchitektur eines DWH
2.1.2 Datenintegration zwischen den Schichten
Die Integration heterogener Datenquellen gehört zu den zentralen Aufgaben eines Da-ta Warehouse. Dies geschieht im Rahmen des ETL-Prozesses. Der ETL-Prozess beschreibtden Vorgang, Daten aus bestehenden Datenquellen zu extrahieren, mittels geeigneter Trans-formationsregeln zu homogenisieren, nach bestimmten Vorschriften zu bereinigen und ggf.anzureichern und in ein separates Ziel zu laden. [Ros13]
Bei der Extraktion werden für relevant befundene Daten aus den Quellen gelesen undin den Arbeitsbereich übertragen. Ein inkrementelles Laden überträgt nur die Änderungenseit der letzten Extraktion und kann somit ggf. hohe Datenvolumina bei der Extraktionminimieren (nach einem initialen Extraktionsvorgang).
Die Transformationsschritte im Arbeitsbereich dienen der Konsolidierung der extrahier-ten Daten. Datenintegration [BG04] beinhaltet bspw. Konsolidierung von Datentypen, Ein-heiten und eindeutigen globalen Schlüsseln (globale Surrogatschlüssel). Die Datenberei-nigung bzw. Data Cleaning soll einerseits fehlerhafte Werte herausfiltern und andererseitsäquivalente Objekte auf Instanzebene ermitteln und Redundanzfreiheit gewährleisten. Bau-er und Günzel [BG04] empfehlen zugunsten der Nachhaltigkeit eine in das Datenquali-tätsmanagement eingebettete Datenbereinigung, da diese ansonsten eher symptomorien-tiert eingesetzt wird. Nach weiteren syntaktischen und semantischen Transformationen[Ros13] werden die Daten verdichtet und mit Informationen aus externen Quellen ange-reichert, um bspw. Plausibilitätskontrollen durchführen zu können. Bereits in der Extrak-
7

2 Stand der Forschung
tionsphase können zahlreiche Transformationen unter Zuhilfenahme von SQL oder da-tenbankeigenen Mitteln durchgeführt werden [Ros13]. Andererseits kann die Extraktionauch ohne jegliche Transformation erfolgen und eine Kopie der Daten aus den operati-ven Systemen erzeugen. Dieses historisierte Abbild der operativen Daten kann bspw. zurWiederherstellung nach einem Datenverlust herangezogen werden.
Beim Laden in den Bereich für die Datenhaltung werden die Daten den Anforderungenentsprechend aggregiert und historisiert. An dieser Stelle kann der Einsatz eines Bulk Loa-ders [BG04] zum initialen Laden großer Datenmengen sinnvoll sein; danach können Dateninkrementell geladen werden.
2.2 Datenfluss
Data Provenance – auch bekannt als Data Lineage oder Data Pedigree [BKT01] – ist ein Pro-blem, das die Analyse der Herkunft und des Entstehungsprozesses von Daten in einembestimmten Datenbankobjekt beschreibt. Derartige Analysen spielen eine wichtige Rolle,um beispielsweise Authentizität (bzw. Glaubwürdigkeit [PM08]) von Daten nachzuwei-sen, also Vertrauen in Daten zu schaffen. Gerade im Umfeld wissenschaftlicher Berechnun-gen ist das Wissen um den Entstehungsprozess von Daten essentiell, um Wiederholbarkeitzu gewährleisten, das Ergebnis einordnen zu können, Wiederholung der Bemühungen zurBerechnung zu vermeiden und Quelldaten aus Ausgabedaten wiederherstellen zu können[BT07]. [RL09] beschreibt die Herkunft von Daten als 7-Tupel (vgl. Abbildung 2.2).
Zur Feststellung der Herkunft kann der Ansatz der verzögerten Auswertung1 oder dersofortigen Auswertung2 herangezogen werden [Tan04]. Die verzögerte Auswertung gehtdavon aus, dass Auswertungen erst vorgenommen werden, wenn man sie benötigt undgeht auf Basis einer Abfrage Q vor, die invertiert wird, um die Daten d zu rekonstruieren.Die Variante der sofortigen Auswertung verwendet Metadaten über die Datenherkunft,die bei der Berechnung neuer Daten generiert und mitgeführt werden. Bezeichnungen fürverschiedene Vorgehensweisen sind metadata-approach, source tagging, attribution approachoder annotations; vgl. [BB99, BCTV05, LBM98].
Abstammungs- und Auswirkungsanalysen
Aufgrund verschiedener Fragestellungen interessiert also die Verfolgung und Auswer-tung des Datenflusses [ABEM09] innerhalb eines Data Warehouse. Bei [VSB09] wird eineeinheitliche Taxonomie zur Diskussion über Operationen beim ETL-Vorgang erarbeitet.
Eine Auswirkungsanalyse3 betrachtet die Nachfolgerknoten eines Datenbankobjekts ineinem Datenflussgraphen. Damit sollen die bei einer Änderung des betrachteten Daten-bankobjekts betroffenen Objekte bzw. Use Cases ermittelt werden.
Die Abstammungsanalyse4 betrachtet die Vorgängerknoten eines Datenbankobjekts in ei-nem Datenflussgraphen. So kann ein Endanwender beispielsweise bei einer ihm vorlie-
1engl. lazy approach2engl. eager approach3engl. impact analysis4engl. provenance analysis
8

2.2 Datenfluss
Abbildung 2.2: Semantik der Datenherkunft als 7-Tupel [RL09]
genden Kennzahl oder einem aggregierten Wert erkennen, aus welchen Datenquellen dieberechneten Werte stammen, welche anderen Datenbankobjekte auf dem Weg durchlau-fen wurden und wie die Berechnungen zustande kamen. [Cui01, BT07] beschreiben dieseAnalyse auch als Data Lineage Problem (DLP) für relationale Views; in [CW03] wird dasProblem auch für allgemeine Transformationen beschrieben.
Ein Datenflussgraph kann auch dazu verwendet werden, aggregierte Kennzahlen aufihre einzelnen Bestandteile herunterzubrechen und diese in variabler Granularität an denKanten des Graphen zu visualisieren. Das Metamodell für einen entsprechenden Graphenliefert Abschnitt 3.6.1. Eine Spezifikation möglicher Analysen am DFG wird von Abschnitt3.6.2 gegeben. Zielgruppe für derartige Analysen und Messungen sind sowohl Entwicklerals auch Anwender.
Cui et al. [CWW00, Cui01] beschreiben das Data Lineage Problem als Ermittlung derQuelldatensätze in einer View und geben einen Lösungsweg dafür an. Dabei betrachtensie formalisiert nicht nur den relationalen Fall, bei dem die Basisdaten aus der invertier-ten Definition der View selbst alleinig anhand der relationalen Algebra berechnet werden.Sie analysieren auch den Fall, dass die Basisdaten allgemeine DWH-Transformationen biszum Endzustand durchlaufen haben. Hier ist nicht mehr allein die relationale Algebraanwendbar, sondern es kommen auch prozedurale Sprachelemente zum Einsatz. DieserFall ist zwar theoretisch komplexer und kostet auch mehr Rechenleistung in der Realität,kommt aber in der Praxis häufiger vor. Die Frage der Darstellung der Datenherkunft wirdnicht behandelt. [VSS02, SVTS05] zeigen jedoch eine Möglichkeit auf, Aktivitäten in denETL-Prozessen als Graph zu modellieren.
Die Forschungsgruppe Datenbanken der Universität Stanford ist im Bereich der Abstam-mungsanalysen aktiv. So wird im Projekt Trio [Agg09, Wid04] die Uncertainty Lineage Data-base (ULDB) [BSH+08, BSHW06] eingeführt, anhand derer aufgezeigt wird, wie Unsicher-heit und Abstammung in einem relationalen Datenbanksystem integriert werden können.Mit dem Projekt Panda [ICF+12] zeigen die Forscher eine mögliche Implementierung einesDatenflussgraphen bezogen auf eine Abstammungsanalyse an einem Datenbankobjekt.
9

2 Stand der Forschung
2.3 Datenmanagement
Der Begriff der Daten hat noch keine einheitliche und allgemein akzeptierte Definition. Bei[ABEM09] wird der Begriff in Zusammenhang mit Information und Wissen betrachtet undin den Kontext der Semiotik gesetzt. Diese allgemeine Lehre über Zeichenfolgen wird aufdie Informatik übertragen, um so die Konzepte zu erklären.
Daten werden hierbei auf die syntaktische Ebene gestellt, die einzelne Zeichen sowieZeichenfolgen betrachtet, diesen aber noch keinerlei Bedeutung zuordnet. Es können le-diglich Beziehungen zwischen diesen Zeichen analysiert werden, wie etwa relative Häu-figkeiten einzelner Zeichen in einer Zeichenkette. Sobald Daten in einem bestimmten Kon-text gesehen werden und dadurch eine Bedeutung erlangen, spricht man von Information.Information ist auf der semantischen Ebene angesiedelt. Die nächsthöhere Ebene wird Prag-matik genannt und setzt ein Informationen verwendendes Individuum (Interpreter) in denMittelpunkt. Damit aus Information Wissen werden kann, spielt die Wirkung der Informa-tion auf den Interpreter eine wichtige Rolle. Erst, wenn bekannt ist, welche Absichten miteiner Information verfolgt werden oder welchen Wert eine Information für den Benutzerhat, kann aus ihr Wissen werden.
In dieser Arbeit werden zugunsten der besseren Lesbarkeit die Begriffe Daten und Infor-mation synonym verwendet.
2.3.1 Data Management Body of Knowledge
Definition 2.2 (Datenmanagement) Das Datenmanagement befasst sich mit allen betrieblichenund technischen Aspekten der Datenmodellierung, Datenadministration, der Datentechnik und desdatenbezogenen Benutzerservice. [Krc00]
Die DAMA hat in ihrem Framework Data Management Body of Knowledge (DMBOK) [MBEH09]10 verschiedene Teilfunktionen beim Datenmanagement identifiziert (vgl. Abbildung 2.3).
Data Governance Planung, Überwachung und Stärkung des Datenmanagements auf ho-her Abstraktionsebene
Data Architecture Management Definition des betrieblichen Informationsbedarfs und Kon-zeption des unternehmensweiten Datenmodells im Kontext der Unternehmensarchi-tektur
Data Development Umsetzung der datenzentrischen Aktivitäten im Rahmen des Syste-mentwicklungslebenszyklus
Data Operations Management Planung, Kontrolle und Unterstützung strukturierter Da-tenbestände über ihren Lebenszyklus hinweg
Data Security Management Planung, Entwicklung und Umsetzung von geeigneten Si-cherheitsrichtlinien
Reference & Master Data Management Gewährleistung der Konsistenz mit einer „gol-denen Version” kontextueller Datenwerte
Data Warehousing & Business Intelligence Management Bereitstellung von entschei-dungsunterstützenden Daten zur Unterstützung von Wissensarbeitern bei Reportingund Analyse
10

2.3 Datenmanagement
Abbildung 2.3: Teilfunktionen des Datenmanagement [MBEH09]
Document & Content Management Haltung, Sicherung und Zugriff auf Daten in Datei-en und physischen Speichern
Meta Data Management Bereitstellung von einfachem Zugriff auf hochqualitative undintegrierte Metadaten
Data Quality Management Anwendung von Maßnahmen Messung, Beurteilung, Verbes-serung der Datenqualität im Rahmen eines Qualitätsmanagements
Abschnitt 3.2 selektiert für diese Arbeit relevante Unterfunktionen und greift deren vonder DAMA definierten Ziele für die weitere Verwendung im Konzept auf.
2.3.2 Information Technology Infrastructure Library
Die Information Technology Infrastructure Library (ITIL) ist ein prozessorientiertes BestPractice Framework zur Bereitstellung von IT Services mit dem Ziel, bei hoher Service-qualität das betriebliche Risiko und Kosten zu minimieren [Lim13]. Da die im Laufe die-ser Arbeit aus dem DMBOK entnommenen Ziele auf Rollen in der ITIL abgebildet werden,wird im Folgenden die Grundstruktur des Frameworks betrachtet. Der ITIL-Lifecycle (vgl.Abbildung 2.4) besteht aus fünf Phasen:
Service Strategy definiert Rahmenbedingungen für Service Provider und soll ein allge-meines Verständnis von Strategie vermitteln und Services sowie deren Zielgruppe undMehrwert definieren. Zur strategischen Planung gehören ebenfalls die Identifikation neu-er potentieller Services, Finanzierung und Service Asset Management.
11

2 Stand der Forschung
Abbildung 2.4: ITIL Lifecycle [iti07]
Service Design ist zuständig für das Design von IT Practices sowie IT-Governance Prac-tices, Prozesse und Richtlinien, um die Strategie des Service Providers zu realisieren. ZumZwecke der Konzeption hocheffektiver IT Services wird insbesondere auf Qualität, Kun-denzufriedenheit und kosteneffektive Servicebereitstellung geachtet.
Service Transition verantwortet Planung und Verwaltung effizienter und effektiver Ser-vicewechsel sowie Deployment von Service Releases und die Sicherstellung richtiger Er-wartungen an Performance und Nutzung neuer Services. Bei Änderungen von Serviceswird sichergestellt, dass der erwartete Mehrwert geschaffen wird und notwendiges Wis-sen über die Service Assets bereitgestellt wird.
Service Operation koordiniert und führt Aktivitäten aus, die zur Bereitstellung und Ver-waltung von Services zu vereinbarten Service Levels für Nutzer und Kunden notwendigsind. Im täglichen Geschäft wird zudem die Zufriedenheit der Nutzer in die IT durch ef-fektive und effiziente Bereitstellung der Services unter Minimierung der Auswirkungenvon Störungen auf den Betrieb gesteigert.
Continual Service Improvement ist zuständig für die Ausrichtung von IT Services ansich verändernde Geschäftsanforderungen durch Identifizierung und Implementierungvon Verbesserungen zur Unterstützung von Geschäftsprozessen.
2.3.3 Metadaten
Der Erfolgsfaktor zur Hebung der beschriebenen Nutzenpotenziale ist die übergrei-fende Verwaltung aller Metadaten – über System-, Werkzeug- und Schichtengrenzenhinweg. Aufgabe dieses Metadatenmanagements ist es, die Metadaten zu erfassen, zugenerieren, zu speichern, zu verwalten und den Benutzern zur Verfügung zu stellen.[ABEM09]
12

2.3 Datenmanagement
Definition 2.3 (Metadaten) Unter dem Begriff Metadaten versteht man gemeinhin jede Art vonInformation, die für den Entwurf, die Konstruktion und die Benutzung eines Informationssystemsbenötigt wird. [BG04]
Diese sehr umfassende Definition lässt darauf schließen, dass bspw. das Schlüssel-Manage-ment betreffende Informationen zu den Metadaten gehören. So muss auch nach der Daten-integration gewährleistet sein, dass jeder Datensatz über einen global eindeutigen Primär-schlüssel identifiziert werden kann. Die Mappings von Schlüsseln der Datensätze in denQuellen zu globalen Surrogatschlüsseln sowie Integritätsbedingungen bei Fremdschlüs-selbeziehungen gehören also ebenfalls zu den Metadaten. Semistrukturierte oder nichtstrukturierte Daten wie Dokumentation vorhandener Datenstrukturen, Datenflüsse undProzesse und anwendungsbezogene Daten, wie z.B. Geschäftsregeln zur Prüfung der Da-tenqualität, sind jedoch ebenfalls Teil der Metadaten.
Benachrichtigungsregeln nach dem Schema
(Kennzahl, Schwellwert,Kontaktperson)
können eine hohe Akzeptanz beim Nutzer erlangen, vor allem, wenn die Benachrichti-gungen proaktiv versendet werden und auch eine Zeitangabe mit der voraussichtlichenVerfügbarkeit der korrigierten Daten vorhanden ist [ABEM09].
Alle Metadaten werden in einem gemeinsamen Repository gespeichert, um den Auf-wand für den Betrieb zu minimieren und den Informationsgewinn für das Data Warehou-se zu optimieren.
2.3.4 Datenqualität
In der ISO Norm 9000:2005 wird Qualität als Grad, in dem ein Satz inhärenter MerkmaleAnforderungen erfüllt, definiert. Nachdem in Abschnitt 2.3 der Begriff der Daten eingeführtwurde und Qualität im Allgemeinen definiert ist, kann der zusammengesetzte Begriff derDatenqualität definiert werden.
Definition 2.4 (Datenqualität) Datenqualität (DQ) ist ein mehrdimensionales Maß für die Eig-nung von Daten, den an ihre Erfassung/Generierung gebundenen Zweck zu erfüllen. Diese Eig-nung kann sich über die Zeit ändern, wenn sich die Bedürfnisse ändern. [Wü03]
Für das Management der Datenqualität existieren verschiedene Geschäftstreiber [ABEM09],die oftmals den initialen Anstoß zur Verbesserung der Datenqualität liefern. Das Manage-ment muss sich bspw. bei der Entscheidungsfindung auf eine hohe Qualität der Datenverlassen können. Gerade bei strategischen Fragestellungen, wie der Entwicklung neuerProdukte, der Expansion auf neue Standorte oder der Planung von Kampagnen kann ho-he Datenqualität einen entscheidenden Wettbewerbsvorteil bedeuten. Weiterhin könnenMindestmaße für die Qualität der Daten durch Compliance gegeben sein; externe regu-latorische Vorgaben sowie eine interne Revision können minimale Standards definieren.Durch höhere Datenqualität kann das operative Risiko minimiert werden und damit Ko-sten eingespart werden.
13

2 Stand der Forschung
Das Verständnis des einzelnen Benutzers von der Semantik der Daten ist oftmals nichtstark ausgeprägt. Insbesondere, wenn der Datennutzer nicht für die Datenintegrität bzw.Datenpflege im Allgemeinen zuständig ist, kann ein fehlendes Interesse an der Semantikder Daten zu einer niedrigen Priorisierung der Datenqualität und zu Fehlinterpretationenführen. [TB98]
Zur Messung – und damit zur Überwachung – der Datenqualität sind objektiv messbareMerkmale, Qualitätskriterien, erforderlich. So kann der jeweilige Erfüllungsgrad der An-forderungen durch den Datennutzer ermittelt werden [ABEM09]. Abbildung 2.5 zeigt eineTaxonomie von Kriterien für die Datenqualität in Anlehnung an [Hin02], deren einzelneKriterien von Bauer und Günzel [BG04] beschrieben worden sind. Obwohl Integritätskri-terien oftmals zu den Datenqualitätskriterien gezählt werden (vgl. Abbildung 2.5), zähltdie Sicherung der Integrität bei der DAMA zum Data Operations Management (vgl. Ab-schnitt 3.2.1, DOM-1).
Metadaten spielen eine wichtige Rolle für die Messung der Datenqualität [Hel02] undkönnen selbst nach den Datenqualitätskriterien bewertet werden. Hinrichs definiert dieEindeutigkeit von Daten über die Auswertung bestimmter Datenqualitätskriterien auf diezugehörigen Metadaten:
Definition 2.5 (Eindeutigkeit) Die Eigenschaft, dass ein Datenprodukt eindeutig interpretiertwerden kann, d. h. zum Datenprodukt Metadaten hoher Qualität vorliegen, die dessen Semantikfestschreiben. Metadatenqualität ist wiederum im Hinblick auf die genannten Datenqualitätsmerk-male zu bewerten [Hin02].
Hinrichs selektiert die Datenqualitätskriterien anhand dieser Definition und kommt zudem Ergebnis, dass Konsistenz, Vollständigkeit und Genauigkeit der Metadaten die Ein-deutigkeit bestimmen.
Methoden zur Verbesserung der Datenqualität
Vorgehensweisen zur Verbesserung der Datenqualität können in zwei Kategorien unter-teilt werden [BCFM09].
Datengetriebene Strategien zielen auf eine Veränderung der Daten ab. Dies kann bspw.bedeuten, neue, aktuelle Daten bei mangelhafter Datenqualität zu akquirieren und diealten Daten zu ersetzen. Standardisierung (z.B. Erweiterung von Abkürzungen: Bob →Robert) und probabilistische Record Linkage Algorithmen sind Möglichkeiten, Datensätzezu finden, die dasselbe Realweltobjekt unterschiedlich beschreiben.
Prozessgetriebene Strategien verfolgen Änderungen an denjenigen Prozessen, welche Da-ten erzeugen. Auf diese Weise sollen durch process control Prozeduren zur Erstellung, Ak-tualisierung und Zugriff auf Daten überprüft und kontrolliert werden. Process redesign solldie Ursachen für schlechte Datenqualität beseitigen und Aktivitäten zur Erzeugung hoherQualität definieren. Dies kann im Rahmen von Business Process Reengineering durchge-führt werden.
Orr postuliert mit seiner Theorie über das Feedback-Control System (FCS) [Orr98], dassDatenqualität nicht von der Sammlung der Daten selbst, sondern deren Nutzung abhängt.Durch geringe Nutzung von Daten, beispielsweise aufgrund von niedriger Relevanz, Glaub-
14

2.3 Datenmanagement
Abbildung 2.5: Datenqualitätskriterien - Taxonomie und Beschreibung [Hin02]
15

2 Stand der Forschung
würdigkeit oder sonstigen Qualitätskriterien, entsteht eine Spirale von sinkendem Interes-se an den Daten (bedingt durch eben beschriebene schwache Qualitätserfüllung) und kon-sekutiv einer noch geringeren Nutzung.5 Die so entstehende Menge an Daten von minder-wertiger Qualität bläht das DWH auf und dient nicht mehr den vorgesehenen Zwecken.Damit es nicht erst zu sinkender Datenqualität kommt, empfiehlt Orr mit seinem Motto„use it or lose it!” das Entfernen von länger nicht genutzten Daten. Falls seine Hypotheseder Wahrheit entspricht, sind ernsthafte Probleme mit der Qualität von vertraulichen Da-ten aufgrund des beschränkten Nutzerkreises eine mögliche Folge. Orr [Orr98] begründetmit seiner These einen erhöhten Nutzen von der Durchführung von Nutzungsanalysen.
Datenqualitätsmonitoring
Im Mittelpunkt von Datenqualitätsmonitoring steht die laufende Überwachung derDatenqualität im Data Warehouse. Dies kann einerseits mittels definierter Kennzahlenund Berichte durchgeführt werden, andererseits lässt sich die Wirksamkeit von Maß-nahmen zur Verbesserung der Datenqualität auch durch regelmäßiges Data Profilingverifizieren. [ABEM09]
Das Datenqualitätsmonitoring ist ein Instrument zur Feststellung der Dynamik der Da-tenqualität, also der Entwicklung im Laufe der Zeit. Bei in ausreichendem Maße vorhan-dener Datenbasis können Prognosen für die zukünftige Datenqualität erstellt werden undfrühzeitig korrektive Maßnahmen bei negativen Abweichungen von Sollwerten veranlasstwerden. Es ermöglicht die Quantifizierung von Verbesserungen in der Datenqualität underleichtert die Argumentation für das Kosten-Nutzen Verhältnis im DWH. RegelmäßigesDatenqualitätsmonitoring erhöht das Vertrauen in die vorhandenen Daten [ABEM09], wasVoraussetzung für fundierte Entscheidungen und unter Umständen auch die Erfüllungvon Compliancekriterien ist.
Der Data Quality Monitoring Cycle [ABEM09] besteht aus drei Phasen und beginnt mitder Erkennung von Problemen im Rahmen des Monitoring. Relevante Informationen wer-den an die Stakeholder kommuniziert und die erkannten Probleme gelöst. Der Zyklus be-ginnt wieder bei der Erkennung neuer Probleme.
Abbildung 2.6: Data Quality Monitoring Cycle [ABEM09]
Es gibt zahlreiche weitere Ansätze zum Datenqualitätsmanagement, wie z.B. Use-Based5[SLW97] beschreibt eine abnehmende Nutzung bei niedriger Glaubwürdigkeit und somit Datenqualität.
16

2.4 Informationsaufbereitung und Cockpit-Bedienkonzept
Data Quality [Orr98] oder Total Data Quality Management [PLW02]. Viele davon basierenauf dem Plan-Do-Check-Act (PDCA)-Zyklus von Deming.
Im Wesentlichen setzt sich das Datenqualitätsmonitoring zum Ziel [ABEM09], eine pe-riodische, allgemeine Überwachung der Datenqualität im Rahmen des laufenden Bericht-wesens zu etablieren und die Nachvollziehbarkeit der Wirksamkeit von Datenqualitäts-maßnahmen zu gewährleisten. Trendanalyse und frühzeitige Identifikation von Risiken inBezug auf Datenqualität sowie Initiierung von steuernden Maßnahmen gehören ebenfallszu den Zielen. Diese versucht man im Rahmen der betrieblichen Berichterstattung durchData Profiling zu erreichen.
2.4 Informationsaufbereitung und Cockpit-Bedienkonzept
Ein Cockpit wird im Rahmen dieser Arbeit als Zusammenfassung mehrerer Dashboards mitggf. zusätzlicher Funktionalität, wie z.B. ausführlicher Analysefunktionen zur Identifika-tion von Fehlern und Ursachen, verstanden. Stephen Few definiert den Begriff des Dash-boards und legt damit einige zentrale Eigenschaften fest.
Definition 2.6 (Dashboard) Ein Dashboard ist eine Anzeige der wichtigsten Informationen zumErreichen einer oder mehrerer Zielvorgaben. Diese Informationen sind derartig auf einer einzigenBildschirmgröße konsolidiert und angeordnet, dass sie auf einen Blick überwacht werden können.[Few06]
Zur Erstellung eines Dashboards sind nach Few definierte Zielsetzungen notwendig, de-ren Erreichung durch geeignete Kennzahlen überwacht werden sollen. Im Zuge dieser Ar-beit wurden bereits Stakeholder und ihre Zielvorstellungen identifiziert. Ein Monitoring-Cockpit bildet über mehrere Dashboards die Sichten der verschiedenen Stakeholder ab.Jedes einzelne Dashboard beinhaltet Metriken und Visualisierungen zur Unterstützungder Tätigkeiten und Interessen bestimmter Stakeholder. Dabei müssen die kommunizier-ten Informationen anhand ihrer Relevanz für den jeweiligen Stakeholder gefiltert wer-den. Letztendlich darf das Informationsangebot eines einzelnen Monitoring-Dashboardsnach Few nicht den Platz überschreiten, den eine Bildschirmgröße liefert. Edward Tuftedefiniert den Begriff Data-Ink als den „nicht löschbaren Kern einer Grafik bzw. die nichtredundante Tinte, die zur Darstellung der Variation in den repräsentierten Zahlenwertenverwendet wird” [Tuf83]. Auf dieser Grundlage definiert er die Data-Ink Ratio als Kenn-zahl zur Messung der Effizienz bzw. der Informationsdichte einer Grafik. Diese setzt diezur Darstellung von Daten verwendete Tinte ins Verhältnis zur insgesamt verwendetenMenge an Tinte.
Data-Ink Ratio =data-ink
total ink used to print the graphic
Das Bedienkonzept kann zur Optimierung der Informationsversorgung die Prinzipien desinformation push6 und information pull7 miteinander kombinieren.
6etwa automatische Informationsversorgung7etwa selbstständige Informationsbeschaffung
17

2 Stand der Forschung
Reporting und Benachrichtigungen
Die erste Komponente in der Informationsversorgung von Stakeholdern durch eine Über-wachungslösung besteht in einem Reporting-System. Dieses System implementiert das in-formation push-Prinzip durch den Versand von vorab konstruierten Berichten in regelmä-ßigen Intervallen, die jeweils nur noch mit zwischenzeitlich geänderten Daten aktualisiertwerden. Neben derartigen Standardberichten leisten insbesondere Abweichungsberich-te eine Hilfestellung zur effektiven Benachrichtigung und Ermöglichung schneller Reak-tionen auf Geschäftsvorfälle. Hierbei werden für bestimmte Kennzahlen und MessungenGrenzwerte definiert. Falls diese oder andere Geschäftsregeln bei einer Messung nicht ein-gehalten werden, wird der Versand eines Abweichungsberichts ausgelöst, der eine Ursa-chenanalyse durch eine definierte Person oder Rolle initiieren soll.
Zur strukturierten Spezifikation aller zu benachrichtigender Stakeholder kann eine Be-troffenheitsmatrix [ABEM09] verwendet werden. Benachrichtigungen können über ver-schiedene Kanäle versendet werden, so zum Beispiel per E-Mail oder SMS oder aber alsBenachrichtigung in einem zentralen Informationsportal. Der Eingriff in einen Prozessab-lauf erst bei Fehlern wird auch als Management by Exception [DW99] bezeichnet.
Interaktive Analyse
Der zweite und für diese Arbeit namensgebende Teil des Bedienkonzepts ist das Monito-ring-Cockpit, welches dem information pull-Prinzip entspricht. Diese Sammlung verschie-dener Dashboards mit Analysefunktionalität dient als zentrale Anlaufstelle zur individu-ellen Informationsbeschaffung über den Zustand des zu überwachenden Objekts.
Zur Unterstützung der analytischen Funktionalität sind insbesondere Werkzeuge ge-eignet, die die interaktive und explorative Navigation durch Daten und somit Gewinnungvon Erkenntnissen erlauben. Datenhaltung im Hauptspeicher unterstützt Operationen wieinteraktive Filterung oder drill-down großer Datenmengen mit ausreichend geringen Reak-tionszeiten, um nicht auf die Verwendung statischer Berichte oder langwieriger Auswer-tungen per OLAP angewiesen zu sein. Dashboards können nach Few [Few06] strategisch,analytisch oder operativ sein. Derartige Eigenschaften sind insbesondere für analytischeDashboards, die beispielsweise zur Fehlerdiagnose eingesetzt werden, von Bedeutung.
18

3 Entwicklung des Konzepts
Zunächst wird eine Auswahl von relevanten Funktionen des Datenmanagements aus demDMBOK getroffen. Domänenspezifischen Rollen des Datenmanagements, die für die Er-füllung von Zielen verantwortlich sind, werden Rollen der ITIL zugeordnet, um auf dieseWeise nicht nur für das Datenmanagement spezifische Stakeholder im Konzept einordnenzu können, sondern auch Stakeholder aus dem IT-Servicemanagement. So profitiert dasKonzept von der weitläufigen Implementierung des ITIL-Standards in Unternehmen undstärkt seinen empfehlenden Charakter.
Die den bereits gewählten Funktionen zugeordneten Ziele bilden die Grundlage für dieEntwicklung von Metriken gemäß Goal-Question-Metric (GQM) Ansatz [Bas92]. GQM istals Top-Down Ansatz zur Ableitung von Metriken über Fragestellungen zu Zielen für dasVorgehen in dieser Arbeit geeignet. Zur Ermittlung des Informationsbedarfs der Stake-holder werden Fragestellungen zu ihren Zielen erarbeitet, die später durch Kennzahlenund andere Analysen beantwortet werden sollen. Die so entwickelten Metriken werdenKomponenten und Abläufen im Data Warehouse zugeordnet und bilden einen Kennzah-lenkatalog. Ein Metamodell für einen Datenflussgraphen beschreibt die Zusammenhängezwischen einzelnen Elementen des Graphen und darzustellenden Kennzahlen.
So entsteht eine Methode, mit deren Hilfe für bestimmte Rollen aus dem Datenmanage-ment oder aus der IT-Organisation über die entsprechenden Ziele Metriken zur Überwa-chung dieser Ziele sowie Visualisierungen dafür empfohlen werden können.
3.1 Identifizierung der Stakeholder
3.1.1 Ausgewählte Funktionen des Datenmanagements
Im Kontext des in dieser Arbeit zu konzipierenden Monitoring-Cockpits für Data Ware-houses werden im Folgenden vier Funktionen des DMBOK näher betrachtet. Die vierFunktionen setzen sich zusammen aus:
• Data Operations Management (DOM)• Data Warehousing & Business Intelligence Management (DW-BIM)• Metadatenmanagement (MDM)• Datenqualitätsmanagement (DQM)
DOM sichert den operativen Betrieb und hat die Überwachung der Datenbankperforman-ce zur Aufgabe. Metriken bezüglich Verfügbarkeit und Performance der Datenbank er-möglichen dem DOM die effektive Durchführung der zugewiesenen Tätigkeiten. DW-BIMkonzipiert und setzt eine Umgebung zur Unterstützung von Business Intelligence (BI)-Aktivitäten um und soll dabei Prozesse im DWH sowie BI-Aktivität überwachen und ver-
19

3 Entwicklung des Konzepts
bessern. Hierbei werden insbesondere Messungen zur Analyse von Nutzung, Antwort-performance und Benutzerzufriedenheit angewandt. Die Datenqualität als kritischen Er-folgsfaktor des DWH verwaltet das DQM. Dieses definiert Metriken zur Beurteilung derDatenqualität und nimmt kontinuierliche Messungen zur Erkennung von Änderungenvor. Statistiken zu den Datenwerten und Geschäftsregeln für gültige Daten helfen bei derErkennung von Daten minderer Qualität. Das MDM als Funktionseinheit zur Verwaltungvon zur Konstruktion und Benutzung des DWH benötigten Daten spielt eine zentrale Rol-le für Monitoring-Aktivitäten jeder Art, da beispielsweise Vergleichswerte für Kennzahlenoder Geschäftsregeln für gültige Wertebereiche zu den Metadaten gezählt werden. DieDAMA spezifiziert im DMBOK zu jeder Funktion Ziele, Aktivitäten und Rollen, die dieseAktivitäten durchführen.
3.1.2 Potentielle Stakeholder
Aus dem DMBOK [MBEH09] werden grundsätzlich alle mit den ausgewählten Funktio-nen in Verbindung stehende Rollen als potentielle Zielgruppe für die in dieser Arbeit ent-wickelte Methode identifiziert. Der folgende Abschnitt analysiert die Ziele der Funktionenund wählt geeignete Ziele aus, sodass anhand dieser Auswahl die Menge der potentiellenStakeholder auf die Menge der tatsächlich zu adressierenden Stakeholder eingeschränktwerden kann. So wird gewährleistet, dass nur diejenigen Stakeholder berücksichtigt wer-den, die mindestens eines der Ziele verfolgen, die in dieser Arbeit analysiert werden.
3.2 Ziele des Datenmanagements
Im Folgenden werden die ausgewählten Funktionen des Datenmanagements mit ihrenZielen kurz vorgestellt sowie in diesem Kontext interessante Aktivitäten und verantwort-liche Rollen genannt. Die Ziele der Funktionen sind von der DAMA [MBEH09] spezifi-ziert und werden dahingehend ausgewählt, ob sie im Zusammenhang mit einem operativ-analytischen Monitoring-Cockpit stehen und im Umfang der wissenschaftlichen Fragestel-lungen dieser Arbeit enthalten sind.
3.2.1 Data Operations Management
Definition 3.1 (Data Operations Management) Data Operations Management beschreibt Ent-wicklung, Wartung und Unterstützung strukturierter Daten, um den Wert von Datenressourcenfür das Unternehmen zu erhöhen [MBEH09].
Aktivitäten und verantwortliche Rollen
Die Schlüsselrolle nimmt hier der Datenbankadministrator (DBA) ein [MBEH09]. Dieserist insbesondere für die Einhaltung der Datenbankperformance Service Levels und dieÜberwachung und Verbesserung der Datenbankperformance verantwortlich. Zu denAufgaben des DBA gehört auch jede Tätigkeit zur Gewährleistung der Verfügbarkeit undFunktionstüchtigkeit der Datenbank.
20

3.2 Ziele des Datenmanagements
Ziele des Data Operations Management
DOM-1 Schutz und Gewährleistung der Integrität strukturierter Daten.DOM-2 Verwaltung der Verfügbarkeit von Daten über ihren Lebenszyklus.DOM-3 Optimierung der Performance von Datenbanktransaktionen.
3.2.2 Data Warehousing & Business Intelligence Management
Definition 3.2 (DW-BIM) Data Warehousing & Business Intelligence Management (DW-BIM)ist die Sammlung, Integration und Präsentation von Daten für Wissensarbeiter zum Zwecke derGeschäftsanalyse und Entscheidungsfindung. DW-BIM besteht aus Aktivitäten, die alle Phasendes Lebenszyklus der Entscheidungsfindung unterstützen. In diesem Lebenszyklus werden die Da-ten im Kontext betrachtet, von Quellen an ein zentral bekanntes Ziel verschoben und transformiertund anschließend den Wissensarbeitern zur Einsicht, Veränderung und Berichterstattung zur Ver-fügung gestellt [MBEH09].
Aktivitäten und verantwortliche Rollen
Für Monitoring und Verbesserung der Prozesse im DWH sind DBA und Data Integra-tion Specialist (DIS) zuständig. Monitoring und Verbesserung der BI-Aktivitäten ver-antworten DBA, Business Intelligence Specialist (BIS) und Business Intelligence Analyst(BIA). Dazu gehören beispielsweise die Feststellung der Nutzerzufriedenheit mit den BI-Lösungen sowie die Erhebung von Benutzungsstatistiken.
Ziele des Data Warehousing & Business Intelligence Management
DW-BIM-1 Unterstützung und Ermöglichung effektiver Geschäftsanalysen und Entschei-dungsfindung durch Wissensarbeiter.
DW-BIM-2 Konstruktion und Instandhaltung der Umgebung bzw. Infrastruktur zurUnterstützung von BI-Aktivität, insbesondere durch den wirksamen Ein-satz aller anderen Datenmanagement (DM)-Funktionen zur kosteneffekti-ven Lieferung konsistenter und integrierter Daten für alle BI-Aktivitäten.
3.2.3 Metadatenmanagement
Definition 3.3 (Metadatenmanagement) Metadatenmanagement ist die Menge der Prozesse,die eine geeignete Erstellung, Lagerung, Integration und Kontrolle zur Unterstützung der ver-knüpften Nutzung von Metadaten gewährleisten [MBEH09].
Aktivitäten und verantwortliche Rollen
Metadatenmanagement stellt eine wichtige Funktion für das Datenmanagement dar, lie-fert aber aufgrund der strategischen Natur der zugehörigen Ziele keine Aspekte, die der
21

3 Entwicklung des Konzepts
Überwachung im Rahmen eines operativ-analytischen Monitoring-Cockpits bedürfen. Ab-schnitt 3.2.5 liefert eine weitergehende Ausführung dazu, weshalb die Ziele des Metada-tenmanagements in dieser Arbeit nicht weiter betrachtet werden.
Ziele des Metadatenmanagement
MDM-1 Gewährung von Verständnis für Begriffe des Metadatenmanagements und de-ren Verwendung im Unternehmen.
MDM-2 Integration von Metadaten aus verschiedenen Quellen.MDM-3 Gewährleistung eines einfachen und integrierten Zugangs zu Metadaten.MDM-4 Sicherstellung der Qualität und Sicherheit von Metadaten.
3.2.4 Datenqualitätsmanagement
Definition 3.4 (Datenqualitätsmanagement) Datenqualitätsmanagement besteht aus aufein-ander abgestimmten Tätigkeiten zur Leitung und Lenkung einer Organisation bezüglich Daten-qualität [Hin02].
Aktivitäten und verantwortliche Rollen
Beim Datenqualitätsmanagement finden sich insbesondere die Rollen des Data QualityAnalyst (DQA) und Data Quality Manager (DQMan). Unter die Zuständigkeit des DQAfällt die Analyse und Beurteilung der Datenqualität. Für Management und Monitoringder Datenqualität ist der DQMan verantwortlich. Beide Rollen übernehmen gemeinsamdie Überwachung der Prozeduren und Performance des operativen Datenqualitätsma-nagements.
Ziele des Datenqualitätsmanagements
DQM-1 Messbare Verbesserung der Datenqualität in Bezug auf definierte Geschäftser-wartungen.
DQM-2 Definition von Anforderungen und Spezifikationen zur Integration von Daten-qualitätsmanagement in den Systementwicklungslebenszyklus.
DQM-3 Bereitstellung definierter Prozesse zur Messung, Überwachung und Meldungvon Konformität zu angemessenen Levels von Datenqualität.
3.2.5 Ziele in der weiteren Betrachtung
Im weiteren Verlauf dieser Arbeit werden nicht alle vorgestellten Ziele des Datenmana-gements als Grundlage für Metriken verwendet. Da nicht alle Ziele in gleicher Weise ge-eignet sind, den Grad ihrer Erfüllung im Rahmen eines operativ-analytischen Überwa-chungscockpits festzustellen, folgt eine Auswahl von relevanten Zielen, auf der der Fokusin dieser Arbeit liegt.
22

3.2 Ziele des Datenmanagements
Die Ziele des Data Operations Management betreffen den operativen Betrieb der Daten-bank und der Grad ihrer Erfüllung ist im Hinblick auf bestehende Service Level Agree-ments zu überwachen. Metriken zur Überprüfung von Datenintegrität, Verfügbarkeit undPerformance unterstützen bei der Fehleranalyse und können Hinweise auf Störungen zu-grunde liegenden Ursachen liefern. Überwachung und optimale Ausrichtung der Infra-struktur an die geschäftlichen Bedürfnisse im Sinne des Data Warehousing & BusinessIntelligence Management sowie Datenintegration gehören ebenfalls zu den operativen Tä-tigkeiten und bedürfen einer kontinuierlichen Überwachung und Beseitigung von Feh-lern.
BI Applikationen gehören zur Anwendungsschicht, unter der das DWH die Ebene derDatenhaltung darstellt. Die BI-Schicht als zentrale Schnittstelle zum Benutzer dient alswichtiger Punkt zur Messung des Erfolgs des Gesamtsystems und damit als Ausgangs-punkt für Argumentationen in Bezug auf das Aufwand-Nutzen-Verhältnis. An dieser Stel-le sind Messungen zur Nutzerzufriedenheit und zu den Nutzerzahlen von besondererBedeutung. Die Datenqualität kann großen Einfluss auf den Erfolg eines solchen Gesamt-systems haben. Aus diesem Grunde sollte die Entwicklung der Datenqualität über die Zeitüberwacht werden. Die so entstehenden Messdaten können einen Beitrag zur Ermittlungder Ursachen für eine geringe Nutzerzufriedenheit mit dem System leisten. Ein effizien-tes operatives Datenqualitätsmanagement soll die effektive Aufnahme, Bearbeitung undNachverfolgung von Problemen mit der Datenqualität gewährleisten und passt ebenfallsin das Konzept des operativ-analytischen Monitoring-Cockpits.
Von der weiteren Betrachtung ausgeschlossene Ziele
Von der weiteren Betrachtung im Zuge dieser Arbeit sind sämtliche Ziele des Metadaten-managements ausgeschlossen. Einer Überwachung der Erreichung der Ziele des MDMstehen verschiedene Schwierigkeiten entgegen, deren Überwindung den Rahmen dieserArbeit sprengen würde. Des Weiteren übersteigen nicht-operative Ziele dem Umfang derForschungsfragen bzw. der Ziele dieser Arbeit.
Zunächst stellt ein weit verbreitetes Verständnis von Begrifflichkeiten, Abläufen und Be-deutung des Metadatenmanagements im Unternehmen das Fundament für die erfolgrei-che Verwaltung von Metadaten. Die Erhebung der Informationen hierzu hat jedoch einenstrategischen Charakter für das Unternehmen und ist nicht im Rahmen eines operativenCockpits zu überwachen. Ebenso gehören integrierte, gut zugängliche und hochqualita-tive Metadaten zu strategisch wertvollen Zielen, da insbesondere die Datenqualität vonhoher Metadatenqualität profitiert (vgl. Abschnitt 2.3.3). Der Grad der Erreichung dieserZiele soll jedoch ebenfalls nicht in einem operativen Cockpit überwacht werden. Einer-seits erfordern diese Ziele aufgrund ihrer strategischen Natur eine geringere Periodizitätbei der Erhebung zugehöriger Kennzahlen. So scheint es sinnfrei, auf einer täglichen Basiszu analysieren, welche neuen Quellen zur Integration von Metadaten verwendet werdenkönnen. Es existieren aber auch ganz praktische Probleme, wie zum Beispiel in dem Fal-le, dass Metadaten in nicht oder nur semistrukturierter Form vorliegen. Diese können,im Gegensatz zu strukturierten Metadaten, nur mit erheblichem Aufwand oder gar nichtautomatisiert analysiert werden.
Ferner wird die Überwachung der Integration des Datenqualitätsmanagements in den
23

3 Entwicklung des Konzepts
DM-Ziel Kurze Erläuterung der Wahl
DOM-1 Datenintegrität als operatives Ziel soll in einem operativen Cockpit über-wacht werden.
DOM-2 Daten- und Systemverfügbarkeit als operative Ziele sollen in einem ope-rativen Cockpit überwacht werden.
DOM-3 Datenbankperformance als operatives Ziel soll in einem operativen Cock-pit überwacht werden.
DW-BIM-1 Hohe Akzeptanz eines BI-Systems bei Wissensarbeitern deutet auf dieMöglichkeit zur Durchführung effektiver Geschäftsanalysen hin. Diesesoll im Cockpit gemessen und überwacht werden.
DW-BIM-2 Die Überwachung und optimale Ausrichtung der Infrastruktur an die ge-schäftlichen Bedürfnisse sollen in einem Cockpit überwacht werden.
DQM-1 Der Zustand und die Dynamik der Datenqualität als frühzeitige Indika-toren für Störungen und Probleme im BI-Gesamtsystem sollen in einemoperativen Cockpit überwacht werden.
DQM-3 Die Überwachung des operativen Datenqualitätsmanagements soll in ei-nem operativen Cockpit überwacht werden.
Tabelle 3.1: Kurzdarstellung der Wahl der Datenmanagement-Ziele
Systementwicklungslebenszyklus von der weiteren Betrachtung ausgeschlossen. Dies istebenfalls ein strategisches Ziel und soll nicht Teil einer operativen Überwachungslösungwerden.
Zusammenfassung
Tabelle 3.1 zeigt eine zusammenfassende Übersicht über die aus der ursprünglichen Li-ste der Ziele des Datenmanagements gewählten Ziele. So verbleiben nach der Auswahllediglich sieben Ziele für die weitere Behandlung in dieser Arbeit.
3.3 Analyse der Stakeholder
In diesem Abschnitt werden Ziele und Rollen [MBEH09] des Datenmanagements in Zu-sammenhang gesetzt. Verantwortliche Rollen nach Modell der DAMA werden Rollen ausder ITIL zugeordnet, um später eine Anforderungsanalyse aus Sicht des IT Service Ma-nagements betreiben zu können. Die Analyse der Stakeholder ist ein notwendiger Schrittzur Entwicklung von Metriken gemäß GQM, da der zweite Schritt bei GQM die Ableitungvon Fragestellungen aus der Sicht von bestimmten Stakeholdern vorsieht [Bas92]. Rollen,die in Abschnitt 3.1 eingeführt wurden und keinem Ziel zugeordnet werden, werden indieser Arbeit nicht weiter berücksichtigt. In Abschnitt 3.4 werden die Ziele aufgegriffenund Fragestellungen dazu entwickelt. Die Beantwortung dieser Fragen soll Erkenntnisseüber den Grad der jeweiligen Zielerreichung liefern.
24

3.3 Analyse der Stakeholder
3.3.1 Zuordnung von Zielen zu DAMA-Rollen
Abbildung 3.1 veranschaulicht die Zuordnung von DM-Zielen zu Rollen der DAMA nach[MBEH09]. Die vertikale Achse ist dabei den drei betrachteten Funktionen entsprechendunterteilt. Im Folgenden wird erläutert wie die Zuordnung von Zielen zu Aktivitäten undanschließend von Aktivitäten zu Rollen begründet ist.
Abbildung 3.1: Zuordnung von DM-Zielen zu DM-Rollen
Data Operations Management
Datenbankperformance besteht aus den beiden grundlegenden Komponenten Verfügbar-keit und Performance [MBEH09]. Für die Einhaltung der Service Levels in Bezug auf Da-tenbankperformance sind DBAs zuständig. Durch diese Tätigkeit unterstützt der DBA dieUmsetzung der Ziele Integrität (DOM-1) und Verfügbarkeit (DOM-2). Eine Optimierungder Performance (DOM-3) erreicht der DBA durch Überwachung und Ermittlung von Ver-besserungspotential.
25

3 Entwicklung des Konzepts
Data Warehousing & Business Intelligence Management
Das DMBOK empfiehlt die Überwachung und Verbesserung von DWH-Prozessen. Da-durch unterstützen DBA und Data Integration Specialist Konstruktion und Instandhal-tung der BI-Infrastruktur und tragen zum Erreichen des Ziels DWH (DW-BIM-2) bei.
Zudem sollen BI-Aktivitäten überwacht und verbessert werden. Dies kann durch eini-ge nutzerorientierte Metriken erfolgen und trägt zum Erreichen des Ziels Analyse (DW-BIM-1) bei. Beispiele hierfür sind die durchschnittliche Antwortzeit für Anfragen oderdie Anzahl der Nutzer in einem bestimmten Zeitintervall. Zusätzlich können regelmäßigeBefragungen der Benutzer wertvolle Erkenntnisse liefern.
Datenqualitätsmanagement
Nach vorhergehender Filterung der Ziele des Datenqualitätsmanagements ist die Integra-tion des DQM in den Systementwicklungslebenszyklus (DQM-2) weggefallen. Zu den anderenbeiden Zielen empfiehlt die DAMA [MBEH09] drei für ein Monitoring-Cockpit relevanteAktivitäten. Analyse und Beurteilung der Datenqualität durch den Data Quality Analystgehören zum Ziel Datenqualität (DQM-1). In Zusammenarbeit mit dem Data Quality Ma-nager wird die Datenqualität jedoch auch über die Zeit überwacht, um so Aussagen überdie Dynamik treffen zu können. Die Überwachung der Prozesse des operativen Datenqua-litätsmanagements stellt sicher, dass die Erfüllung des Ziels operatives Datenqualitätsmana-gement (DQM-3) eingehalten und überprüft werden kann.
3.3.2 Zuordnung von Zielen zu ITIL-Rollen
Data Operations Management Die Datenbankadministration versteht sich als zentralerSammelpunkt von Fachwissen über Datenbankdesign [HJ10]. Übertragen auf ITILüberschneidet sich dies mit mehreren Rollen. Zielübergreifend wird der DBA als In-cident Manager und als Problem Manager tätig und verwaltet somit die Lebenszy-klen aller Störungen und deren zugrunde liegender Probleme in seiner fachlichenDomäne.Bezogen auf das Ziel Integrität (DOM-1) setzt der DBA seine Fachkenntnisse ein undtritt als technischer Analyst zur Wahrung der Datenintegrität auf. Dazu gehören phy-sische sowie logische Datenintegrität. Verfügbarkeit (DOM-2) zählt zu den Verant-wortlichkeiten des Availability Managers und müssen an die vereinbarten ServiceLevels angepasst, überwacht und optimiert werden. Der DBA handelt auch im In-teresse des Capacity Managers, um insbesondere die Optimierung der Performance(DOM-3) zu erreichen. Die Infrastruktur soll derartig angepasst werden, dass sievereinbarte Anforderungen an die Performance kosteneffizient und zeitnah erfüllt.Derartige Optimierungen können auch einen positiven Einfluss auf die Verfügbar-keit des Services haben [MBEH09], sodass das Capacity Management auch die Er-füllung des Ziels Verfügbarkeit (DOM-2) unterstützt.
Data Warehousing & Business Intelligence Management Beim DWH-Monitoring zumErreichen des Ziels DWH (DW-BIM-2) ist nach [MBEH09] insbesondere der DataIntegration Specialist (DIS) beteiligt. Dieser entspricht nach ITIL-Nomenklatur ver-
26

3.4 Informationsbedarfsanalyse
schiedenen Rollen. So ist dieser am Incident und Problem Management beteiligt, daer über das nötige Fachwissen verfügt, um Störungen und zugrunde liegende Ur-sachen bei der Datenintegration zu beseitigen. Ähnlich wie der DBA beim DOMtritt auch der DIS im Interesse von Availability Manager und Capacity Managerzur Überwachung und Verwaltung von Verfügbarkeit und Performance der DWHServices auf. Entwicklung der nötigen Prozesse und Konfiguration des DWH über-nimmt der DIS als technischer Analyst.BI-Spezialisten und Analysten ermöglichen durch ihre Tätigkeit effektive Analysenim Rahmen des Ziels Analyse (DW-BIM-1). Sie treten als technische Analysten auf,da sie durch ihr spezifisches Wissen bspw. die BI-Nutzerumgebung konzipieren unddie effektive Nutzung von BI Daten durch Fachanwender ermöglichen. Die Messungvon Nutzerzufriedenheit und Effektivität der Analysen liegt im Interesse des Conti-nual Service Improvement (CSI) Managers.
Datenqualitätsmanagement CSI beruht im Wesentlichen, wie viele DQM Methoden, aufdem PDCA-Zyklus von Deming [ABEM09]. Diese Verwandtschaft im Prozess unddie Forderung nach einer kontinuierlichen Überwachung und Verbesserung der Da-tenqualität (DQM-1) lassen eine Zuordnung von Data Quality Analyst und Data Qua-lity Manager zu CSI Manager zu.Zur Erfüllung des Ziels operatives Datenqualitätsmanagement (DQM-3) wirken Inci-dent und Problem Management zur Störungserkennung und Störungsbeseitigungmit. Die Rolle des technischen Analysten wirkt bei der Konzeption der Prozesse mit.
Abbildung 3.2 zeigt eine graphische Übersicht über die Zuordnungen der Ziele zu Rollen.
3.4 Informationsbedarfsanalyse
Tabelle 3.2 zeigt eine Sammlung von Fragestellungen zu den bereits definierten Zielen.Diese Sammlung wurde in Zusammenarbeit mit dem Praxispartner entwickelt und dientim Rahmen des GQM-Ansatzes als Zwischenschritt zur späteren Entwicklung von Metri-ken. Fragestellungen im Sinne von GQM verstehen sich als konkreter Informationswunscheines Stakeholders, um den Grad der Erreichung einer Zielvorgabe bestimmen zu können.
Die Fragestellungen zu den Zielen des Bereichs DOM beziehen sich insbesondere auf dietechnischen Gegebenheiten in der Datenbankumgebung. Zur Überprüfung der Integrität(DOM-1) gehören Fragestellungen zu logischen Integritätsbedingungen und Integritäts-verletzungen. Zur Messung der Verfügbarkeit (DOM-2) muss sowohl die Daten- als auchdie Systemverfügbarkeit erhoben und ausgewertet werden. Die dritte Komponente desoperativen Datenmanagements beinhaltet die Optimierung der Performance (DOM-3) derDatenbank und fragt einerseits nach von außen messbaren Daten, wie Antwortzeiten aufeine Anfrage. Aber auch interne Daten wie die Auslastung des Database Management Sy-stem (DBMS) spielen eine Rolle.
DW-BIM setzt sich aus der Anwendungsschicht und der zugrunde liegenden Infrastruk-tur zusammen. Zur Ermittlung der Erfüllung von Analyse (DW-BIM-1) dienen insbeson-dere Fragestellungen nach der Nutzerzufriedenheit sowie nach den Nutzerzahlen. Infor-mationen über die angeforderten Berichte können bei unerwartet niedriger oder sinkender
27

3 Entwicklung des Konzepts
Abbildung 3.2: Zuordnung von DM-Zielen zu ITIL-Rollen
28

3.4 Informationsbedarfsanalyse
Ziel Nr. FragestellungDOM-1 Q-1 Zu welchem Grad ist Integrität der Primärschlüssel gegeben?(Integrität) Q-2 Zu welchem Grad ist referenzielle Integrität gegeben?
Q-3 Wie oft werden Integritätsbedingungen bei Schreibvorgängenverletzt?
DOM-2 Q-4 Zu welchen Betriebszeiten ist die Datenbank verfügbar?(Verfügbarkeit) Q-5 Zu welchen Antwortzeiten sind die Daten verfügbar?
Q-6 Sind die Daten zu den vereinbarten Betriebszeiten verfügbar?DOM-3 Q-7 Wie viele Anfragen werden verarbeitet?(Performance) Q-8 Wie lange dauert die Verarbeitung einer Anfrage im Schnitt?
Q-9 Wie stark ist das System (in Phasen niedriger und hoher Ausla-stung) ausgelastet?
DW-BIM-1 Q-10 Wie zufrieden sind die Nutzer mit dem Data Warehouse?(BI) Q-11 Wie entwickeln sich die Nutzerzahlen des Data Warehouse?
Q-12 Wie viele der geplanten Anwender nutzen die DWH-Services?Q-13 Sind die Berichte (Daten) fehlerfrei?Q-14 Liegen die Antwortzeiten innerhalb eines vereinbarten Rah-
mens?Q-15 Welche Daten werden nicht (mehr) verwendet?
DW-BIM-2 Q-16 In welchem Zeitrahmen laufen die ETL-Prozesse ab?(DWH) Q-17 Laufen die ETL-Prozesse im vereinbarten Zeitrahmen ab?
Q-18 Sind die DWH Services gemäß Service Levels verfügbar?Q-19 Wie lange dauert die Wiederherstellung des DWH-Betriebs
nach einem Fehler durchschnittlich?Q-20 Ist die Hardware für die heutige und zukünftige Verwendung
optimal dimensioniert?Q-21 Besteht Handlungsbedarf beim ETL-Prozess?
DQM-1 Q-22 Sind die betrachteten Daten plausibel?(Datenqualität) Q-23 Sind die betrachteten Daten glaubwürdig?
Q-24 Sind die betrachteten Daten vollständig?Q-25 Sind die betrachteten Daten redundanzfrei?Q-26 Wie genau sind die betrachteten Daten?Q-27 Wie aktuell sind die betrachteten Daten?Q-28 Entsprechen die Daten den Kriterien für Schlüsselintegrität?Q-29 Sind die betrachteten Daten eindeutig interpretierbar?Q-30 Findet eine kontinuierliche Verbesserung der Datenqualität
statt?DQM-3 Q-31 Besteht Handlungsbedarf beim DQM-Prozess?(Datenqualitäts- Q-32 Wie viele Fälle ungenügender Datenqualität sind festzustellen?management) Q-33 Wie viele Fälle ungenügender Datenqualität wurden behoben?
Q-34 Wie lange dauert die Behebung von im DWH gemeldeten Da-tenqualitätsmängeln durchschnittlich?
Q-35 Wie lange dauert die Behebung von bekannten Datenqualitäts-fehlern im DWH durchschnittlich?
Tabelle 3.2: Fragen zu Zielen des Datenmanagements
29

3 Entwicklung des Konzepts
Nachfrage nach BI-Services Hinweise darauf liefern, ob eine ausreichende Servicequali-tät geliefert wurde. Seit längerer Zeit nicht mehr verwendete Daten, die auch keine zu-künftige Nutzung mehr erwarten lassen, sollten zugunsten eines effizienten Umgangs mitden vorhandenen Ressourcen aus der Ebene der Datenhaltung gelöscht werden. Das ZielDWH (DW-BIM-2) erfordert eine Überwachung ebendieser Ressourcen und eine optima-le Anpassung der verfügbaren Kapazitäten an die benötigten. Messungen in Bezug aufKapazität von Speichermedien, Rechenleistung und Netzwerkanbindung können bei derBeantwortung dieser Frage helfen. Die Analyse der ETL-Prozesse trägt zur Sicherstellungdes korrekten Betriebs des DWH bei und sichert die gewünschten Funktionalitäten auf derAnwendungsebene.
Das Datenqualitätsmanagement interessiert sich in erster Linie für die Messung der Da-tenqualität (DQM-1) und die Entwicklung dieser über die Zeit. Eine Taxonomie für Daten-qualitätskriterien wurde bereits mit Abbildung 2.5 eingeführt und liefert die Grundlagefür Fragestellungen. Diese Messungen müssen über die Zeitdimension analysiert werden,um feststellen zu können, ob die gewünschte Verbesserung in der Datenqualität erreichtworden ist. Durch die exakte Definition der Verantwortlichkeiten soll mithilfe von Syste-men zur Verfolgung von Incidents sichergestellt werden, dass das operative Datenquali-tätsmanagement (DQM-3) schnell handeln kann und auf Dauer alle erkannten Fehler ab-gearbeitet werden können [MBEH09]. Hier sind beispielsweise Fragestellungen in Bezugauf noch nicht behobene Fehler oder durchschnittliche Reparaturzeiten von Interesse.
3.5 Kennzahlen und notwendige Messungen
Zur Vervollständigung der Vorgehensweise im Rahmen des GQM-Ansatzes müssen nunzu den entwickelten Fragestellungen passende Metriken entwickelt werden. Gerade fürden Bereich der Datenqualität veranschaulichen Apel et al. [ABEM09] einige mit Kennzah-len verbundene Problemstellungen. So sind nicht alle Datenqualitätskriterien messbar, ei-nige sind nur zu einem bestimmten Grad messbar. Kennzahlen sollen Indikatoren für Pro-bleme bzw. Problembereiche sein und der Erstanalyse dienen, nicht jedoch einer Fehler-analyse. Dies kann beispielsweise durch Betrachtung von historischen Änderungen oderWarnungen bei Abweichung von Planwerten erfolgen.
Sie führen ebenfalls Argumente an, um die Nutzung von Kennzahlen zu begründen:Kennzahlen werden zu Beginn ihres Einsatzes grundsätzlich als geeignet zur Messung ei-nes bestimmten Sachverhalts eingestuft und eignen sich somit im späteren Verlauf zurArgumentation auf Basis von anerkannten Fakten. Sie können Abweichungen des Ist-zustands von Planwerten veranschaulichen und die Veränderung von Kriterien über dieZeit aufzeigen. Im betrieblichen Kontext können Metriken ein Bewusstsein für die Daten-qualität schaffen und Mitarbeiter zur Optimierung animieren. Definition und Erhebungvon Kennzahlen sollte kein Selbstzweck, sondern Ausgangspunkt für Verbesserungen sein[ABEM09] und stets der Erfüllung von übergeordneten Zielen dienen. Diesem Anspruchwird im Rahmen dieser Arbeit durch den Goal-Question-Metric-Ansatz Genüge getan.
Im Folgenden werden Messpunkte sowie Messebenen für Kennzahlen im DWH-Kontextdefiniert, um eine Möglichkeit zur Klassifikation der Kennzahlen zu schaffen. Diese wirdim Metamodell des Datenflussgraphen (vgl. Abschnitt 3.6) wieder aufgegriffen. Abschnitt
30

3.5 Kennzahlen und notwendige Messungen
3.5.3 beinhaltet den Kennzahlenkatalog, der die Grundlage für das zu entwickelnde Moni-toring-Cockpit liefert. Eine Metrik-Ziel-Matrix stellt Kennzahlen und die Ziele, deren Gradder Erreichung diese messen, übersichtlich dar und geht dem detaillierten Katalog voraus.
3.5.1 Messpunkte für Datenqualität im Data Warehouse
An den fünf verschiedenen Ebenen der klassischen DWH-Architektur können Messungenbezüglich der Datenqualität [ABEM09] vorgenommen werden:
Quellsysteme — Messung ist abhängig von der Machbarkeit und der Kosten im Ein-zelfall und kann zu einem operationalen Risiko (Performanceeinbußen) führen. Einsinnvoller Messpunkt, um bereits bei Erfassung der Daten z.B. auf einheitliche For-mate oder Wertebereiche zu achten.
Staging Area — Ein geeigneter Messpunkt für einfache Messungen im Rahmen von ETL-Läufen, z.B. Anzahl an NULL-Werten oder erste Integritätsprüfungen. Es besteht dieMöglichkeit zum Vergleich mit Sollwerten aus dem Metadaten-Repository oder zumautomatisierten Vergleich der aktuellen Fehlerliste mit der vom letzten ETL-Lauf.
DWH — Im Datenhaltungsbereich können automatisierte Berechnungen durch Prozedu-ren implementiert werden. Die Kennzahlen auf dieser Ebene bauen auf der unter-nehmensweiten Geschäftslogik und sind insbesondere für Datenbereichs- und Quell-systemübergreifende Messungen geeignet, wie z.B. Konsistenzprüfungen.
Data Marts — Auf dieser Ebene sind meist aggregierte Daten bzw. fachbereichspezifischeLogik und Kennzahlen angesiedelt. Die Kennzahlen auf dieser Ebene beantwortenprimär fachliche Fragestellungen, wie z.B. den Umsatz einer Vertriebsabteilung.
DWH-Anwendung — In der einfachsten Form sind Berechnungen in den Berichten auf-zufinden. Definierte Summengrößen können automatisiert an Verantwortliche derQuellsysteme rückgemeldet werden und mit den Daten in den operativen Systemenabgeglichen werden. Diese Schicht wird in [ABEM09] ursprünglich als Schicht der BIAnwendungen benannt. Da die Daten im DWH aber auch von anderen Applikationenverwendet werden können, wurde die Schicht in dieser Arbeit umbenannt.
Letztendlich muss der Ort der Implementierung der Kennzahlen nach technischen Kriteri-en, Kosten und Verfügbarkeit der Daten abgewogen und entschieden werden [ABEM09].
Die Angaben im Kennzahlenkatalog (vgl. Abschnitt 3.5.3) zum Messpunkt einer Kenn-zahl verstehen sich als eine Empfehlung für einen möglichst frühen Messpunkt in derDatenverarbeitungskette, um Fehler möglichst früh aufzudecken und eine mögliche Ver-breitung in nachfolgende Systeme zu vermeiden [ABEM09].
3.5.2 Ebenen der Messung von Kennzahlen
Kennzahlen können auf verschiedenen Aggregationsebenen in der Datenbank erhobenwerden [Hin02]. Die folgende Liste beschreibt diese Ebenen, aufsteigend geordnet nachdem Grad der Aggregation.
Attributebene Metriken, denen der Wert eines einzelnen Attributs zur Berechnung zu-grunde liegt.
31

3 Entwicklung des Konzepts
Tupelebene Metriken, denen ein einzelner Datensatz mit den Ausprägungen mehrererAttribute zur Berechnung zugrunde liegt.
Relationenebene Metriken, denen eine Relation mit den enthaltenen Datensätzen zurBerechnung zugrunde liegt.
Datenbankebene Metriken, denen eine Datenbank mit den enthaltenen Relationen zurBerechnung zugrunde liegt.
Grundsätzlich können Metriken, die auf einer Ebene geringer Aggregation erhoben wer-den, auch auf eine höhere Ebene aggregiert werden. Umgekehrt ist dies im Allgemeinennicht möglich. Die Angaben im Kennzahlenkatalog (vgl. Abschnitt 3.5.3) zur Ebene einerKennzahl verstehen sich somit als Hinweis auf die minimale Aggregationsebene, auf derdie entsprechende Kennzahl dargestellt werden kann.
Da jedoch im weiteren Verlauf auch Metriken definiert werden, die nicht innerhalb derDatenbank bzw. innerhalb des Data Warehouse, sondern in der äußeren Anwendungs-schicht gemessen werden, wird noch eine zusätzliche Messebene eingeführt:
Systemebene Metriken, denen ein DBMS als Gesamtsystem aus Sicht der DWH-Anwen-dungsschicht zugrunde liegt.
Die Erhebung von prozessbezogenen Kennzahlen erfordert die Erfassung entsprechenderMetadaten über den Prozess selbst sowie über seine Performance während der Ausfüh-rung, da eine Prozessinstanz, im Gegensatz zu herkömmlichen Daten, selbst nicht persi-stent ist. Prozessmetadaten sind keine Informationen, die in den Daten intrinsisch vorlie-gen, sondern liefern Informationen über den Kontext von Daten [SEW06]. Die Zuordnungvon Prozessmetriken zu einer der bereits eingeführten Ebenen ist aufgrund ebendieser Ei-genschaften nicht sinnvoll. Es wird eine neue Messebene speziell für Prozesse im DWHeingeführt:
Prozessebene Metriken, denen explizite prozessbezogene Metadaten zugrunde liegen.
3.5.3 Kennzahlenkatalog
Tabelle 3.3 liefert eine Übersicht darüber, welche Kennzahlen es ermöglichen, den Grad derErfüllung bestimmter Ziele zu messen. So kann bei bereits gewählten Zielen (vgl. Abbil-dung 3.2 zur Wahl von Zielen bei bekannten Rollen) eine schnelle Auswahl der passendenMetriken zur Deckung des Informationsbedarfs vorgenommen werden. Im Anschluss zurÜbersicht folgt der Kennzahlenkatalog, dem Detailinformationen zu jeder Metrik entnom-men werden können.
32
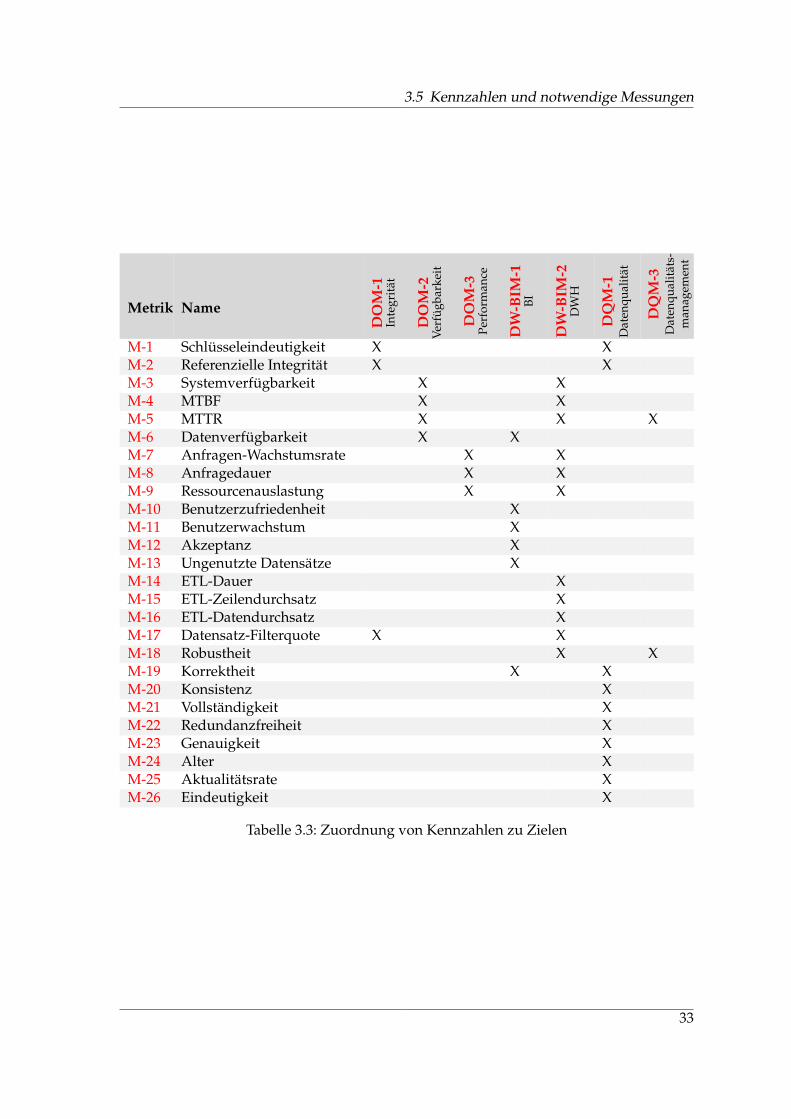
3.5 Kennzahlen und notwendige Messungen
Metrik Name
DO
M-1
Inte
grit
ät
DO
M-2
Verf
ügba
rkei
t
DO
M-3
Perf
orm
ance
DW
-BIM
-1BI
DW
-BIM
-2D
WH
DQ
M-1
Dat
enqu
alit
ät
DQ
M-3
Dat
enqu
alit
äts-
man
agem
ent
M-1 Schlüsseleindeutigkeit X XM-2 Referenzielle Integrität X XM-3 Systemverfügbarkeit X XM-4 MTBF X XM-5 MTTR X X XM-6 Datenverfügbarkeit X XM-7 Anfragen-Wachstumsrate X XM-8 Anfragedauer X XM-9 Ressourcenauslastung X XM-10 Benutzerzufriedenheit XM-11 Benutzerwachstum XM-12 Akzeptanz XM-13 Ungenutzte Datensätze XM-14 ETL-Dauer XM-15 ETL-Zeilendurchsatz XM-16 ETL-Datendurchsatz XM-17 Datensatz-Filterquote X XM-18 Robustheit X XM-19 Korrektheit X XM-20 Konsistenz XM-21 Vollständigkeit XM-22 Redundanzfreiheit XM-23 Genauigkeit XM-24 Alter XM-25 Aktualitätsrate XM-26 Eindeutigkeit X
Tabelle 3.3: Zuordnung von Kennzahlen zu Zielen
33

3 Entwicklung des Konzepts
M-1 Schlüsseleindeutigkeit [Hin02]
Erläuterung Anzahl eindeutiger Primärschlüssel im Verhältnis zur Anzahl Datensät-ze.
DM-Ziel(e) DOM-1: IntegritätDQM-1: Datenqualität
Frage(n) Q-1: Zu welchem Grad ist Integrität der Primärschlüssel gegeben?Q-28: Entsprechen die Daten den Kriterien für Schlüsselintegrität?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?
Messpunkt Staging AreaEbene Relationenebene
M-2 Referenzielle Integrität [Hin02]
Erläuterung Anzahl der Verstöße gegen definierte Multiplizitäten in Fremdschlüs-selbeziehungen im Verhältnis zur Anzahl der insgesamt referenziertenFremdschlüssel.
DM-Ziel(e) DOM-1: IntegritätDQM-1: Datenqualität
Frage(n) Q-2: Zu welchem Grad ist referenzielle Integrität gegeben?Q-28: Entsprechen die Daten den Kriterien für Schlüsselintegrität?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?
Messpunkt DWHEbene Relationenebene
M-3 Systemverfügbarkeit [Leu01]
Erläuterung Zeit, in der das System verfügbar ist, im Verhältnis zur Zeit, in der dasSystem verfügbar sein soll.
DM-Ziel(e) DOM-2: VerfügbarkeitDW-BIM-2: DWH
Frage(n) Q-4: Zu welchen Betriebszeiten ist die Datenbank verfügbar?Q-18: Sind die DWH Services gemäß Service Levels verfügbar?
Messpunkt DWH-AnwendungEbene Systemebene
M-4 MTBF [SVD+09]
Erläuterung Durchschnittliche zwischen Fehlern verstreichende Zeit.DM-Ziel(e) DOM-2: Verfügbarkeit
DW-BIM-2: DWHFrage(n) Q-4: Zu welchen Betriebszeiten ist die Datenbank verfügbar?
Q-18: Sind die DWH Services gemäß Service Levels verfügbar?
Messpunkt Staging AreaEbene Relationenebene
34

3.5 Kennzahlen und notwendige Messungen
M-5 MTTR [SVD+09]
Erläuterung Durchschnittliche Zeit zur Fehlerbehebung. Unterscheidung nach Fehler-typ.
DM-Ziel(e) DOM-2: VerfügbarkeitDW-BIM-2: DWHDQM-3: Datenqualitätsmanagement
Frage(n) Q-4: Zu welchen Betriebszeiten ist die Datenbank verfügbar?Q-18: Sind die DWH Services gemäß Service Levels verfügbar?Q-19: Wie lange dauert die Wiederherstellung des DWH-Betriebs nacheinem Fehler durchschnittlich?Q-31: Besteht Handlungsbedarf beim DQM-Prozess?Q-34: Wie lange dauert die Behebung von im DWH gemeldeten Daten-qualitätsmängeln durchschnittlich?Q-35: Wie lange dauert die Behebung von bekannten Datenqualitätsfeh-lern im DWH durchschnittlich?
Messpunkt Staging AreaEbene Relationenebene
M-6 Datenverfügbarkeit [BCFM09]
Erläuterung Tatsächliche Antwortzeit auf eine Anfrage im Verhältnis zu einer festge-legten maximalen Antwortzeit.
DM-Ziel(e) DOM-2: VerfügbarkeitDW-BIM-1: Analyse
Frage(n) Q-5: Zu welchen Antwortzeiten sind die Daten verfügbar?Q-6: Sind die Daten zu den vereinbarten Betriebszeiten verfügbar?Q-14: Liegen die Antwortzeiten innerhalb eines vereinbarten Rahmens?
Messpunkt DWH-AnwendungEbene Systemebene
M-7 Anfragen-Wachstumsrate
Erläuterung Anzahl der Anfragen in der aktuellen Periode im Verhältnis zur Anzahlder Anfrage in der vorhergehenden Periode.
DM-Ziel(e) DOM-3: PerformanceDW-BIM-2: DWH
Frage(n) Q-7: Wie viele Anfragen werden verarbeitet?Q-20: Ist die Hardware für die heutige und zukünftige Verwendung op-timal dimensioniert?
Messpunkt Staging AreaEbene Relationenebene
35

3 Entwicklung des Konzepts
M-8 Anfragedauer
Erläuterung Durchschnittliche Dauer zur Verarbeitung einer Anfrage in der Daten-bank aus einer Referenzmenge von Anfragen.
DM-Ziel(e) DOM-3: PerformanceDW-BIM-2: DWH
Frage(n) Q-8: Wie lange dauert die Verarbeitung einer Anfrage im Schnitt?Q-20: Ist die Hardware für die heutige und zukünftige Verwendung op-timal dimensioniert?
Messpunkt Staging AreaEbene Relationenebene
M-9 Ressourcenauslastung
Erläuterung Auslastung einzelner Hardware-Ressourcen. Unterscheidung nach CPU,Arbeitsspeicher und persistentem Speicher.
DM-Ziel(e) DOM-3: PerformanceDW-BIM-2: DWH
Frage(n) Q-9: Wie stark ist das System (in Phasen niedriger und hoher Auslastung)ausgelastet?Q-20: Ist die Hardware für die heutige und zukünftige Verwendung op-timal dimensioniert?
Messpunkt Staging AreaEbene Relationenebene
M-10 Benutzerzufriedenheit [Küt11]
Erläuterung Zufriedenheit der Benutzer mit den DWH-Services. Erhebung über Um-fragen und Interviews, z.B. im Rahmen von Mitarbeitergesprächen.[Küt11].
DM-Ziel(e) DW-BIM-1: Analyse
Frage(n) Q-10: Wie zufrieden sind die Nutzer mit dem Data Warehouse?
Messpunkt DWH-AnwendungEbene Systemebene
M-11 Benutzerwachstum [Küt11]
Erläuterung Anzahl der Nutzer in der betrachteten Periode im Verhältnis zur Anzahlder Nutzer in der vorhergehenden Periode.
DM-Ziel(e) DW-BIM-1: Analyse
Frage(n) Q-11: Wie entwickeln sich die Nutzerzahlen des Data Warehouse?
Messpunkt DWH-AnwendungEbene Systemebene
36

3.5 Kennzahlen und notwendige Messungen
M-12 Akzeptanz
Erläuterung Anzahl der tatsächlichen Nutzer der DWH-Services im Verhältnis zurAnzahl der geplanten Nutzer.
DM-Ziel(e) DW-BIM-1: Analyse
Frage(n) Q-12: Wie viele der geplanten Anwender nutzen die DWH-Services?
Messpunkt DWH-AnwendungEbene Systemebene
M-13 Ungenutzte Datensätze [Orr98, KC04]
Erläuterung Anteil ungenutzter Datensätze. Bemessungsgrundlage ist der Zeitpunktdes letzten Zugriffs verglichen mit einem festgelegten Schwellwert fürveraltete Daten.
DM-Ziel(e) DW-BIM-1: Analyse
Frage(n) Q-15: Welche Daten werden nicht (mehr) verwendet?
Messpunkt DWHEbene Relationenebene
M-14 ETL-Dauer [SVD+09, SWCD09, KC04]
Erläuterung Durchschnittliche Dauer eines ETL-Laufs. Unterscheidung nach ETL-Schritten.
DM-Ziel(e) DW-BIM-2: DWHFrage(n) Q-16: In welchem Zeitrahmen laufen die ETL-Prozesse ab?
Q-17: Laufen die ETL-Prozesse im vereinbarten Zeitrahmen ab?Q-21: Besteht Handlungsbedarf beim ETL-Prozess?
Messpunkt Staging AreaEbene Prozessebene
M-15 ETL-Zeilendurchsatz [SVD+09, SWCD09, KC04]
Erläuterung Anzahl verarbeiteter Datensätze pro Zeiteinheit.DM-Ziel(e) DW-BIM-2: DWHFrage(n) Q-16: In welchem Zeitrahmen laufen die ETL-Prozesse ab?
Q-20: Ist die Hardware für die heutige und zukünftige Verwendung op-timal dimensioniert?Q-21: Besteht Handlungsbedarf beim ETL-Prozess?
Messpunkt Staging AreaEbene Prozessebene
37

3 Entwicklung des Konzepts
M-16 ETL-Datendurchsatz [KC04]
Erläuterung ETL-Zeilendurchsatz multipliziert mit der Größe einer Zeile.DM-Ziel(e) DW-BIM-2: DWHFrage(n) Q-16: In welchem Zeitrahmen laufen die ETL-Prozesse ab?
Q-20: Ist die Hardware für die heutige und zukünftige Verwendung op-timal dimensioniert?Q-21: Besteht Handlungsbedarf beim ETL-Prozess?
Messpunkt Staging AreaEbene Prozessebene
M-17 Datensatz-Filterquote [ABEM09]
Erläuterung Anteil der angelieferten und nicht übernommenen Datensätze. Unter-scheidung nach ETL-Job und Fehlercode.
DM-Ziel(e) DOM-1: IntegritätDW-BIM-2: DWH
Frage(n) Q-3: Wie oft werden Integritätsbedingungen bei Schreibvorgängen ver-letzt?Q-21: Besteht Handlungsbedarf beim ETL-Prozess?
Messpunkt Staging AreaEbene Prozessebene
M-18 Robustheit [SVD+09]
Erläuterung Anteil der nach einem Fehler erfolgreich wieder aufgenommenen ETLSteps. Unterscheidung nach Fehlercode.
DM-Ziel(e) DW-BIM-2: DWHDQM-3: Datenqualitätsmanagement
Frage(n) Q-31: Besteht Handlungsbedarf beim DQM-Prozess?Q-33: Wie viele Fälle ungenügender Datenqualität wurden behoben?Q-21: Besteht Handlungsbedarf beim ETL-Prozess?
Messpunkt Staging AreaEbene Prozessebene
38
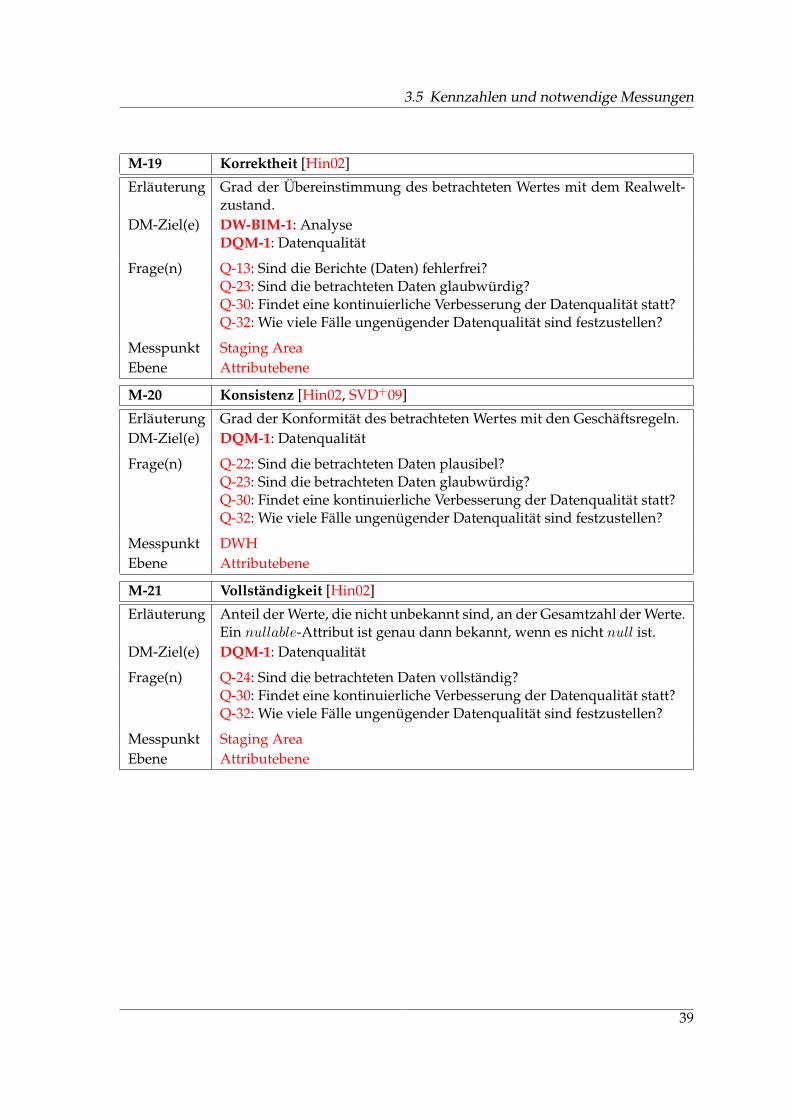
3.5 Kennzahlen und notwendige Messungen
M-19 Korrektheit [Hin02]
Erläuterung Grad der Übereinstimmung des betrachteten Wertes mit dem Realwelt-zustand.
DM-Ziel(e) DW-BIM-1: AnalyseDQM-1: Datenqualität
Frage(n) Q-13: Sind die Berichte (Daten) fehlerfrei?Q-23: Sind die betrachteten Daten glaubwürdig?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?Q-32: Wie viele Fälle ungenügender Datenqualität sind festzustellen?
Messpunkt Staging AreaEbene Attributebene
M-20 Konsistenz [Hin02, SVD+09]
Erläuterung Grad der Konformität des betrachteten Wertes mit den Geschäftsregeln.DM-Ziel(e) DQM-1: Datenqualität
Frage(n) Q-22: Sind die betrachteten Daten plausibel?Q-23: Sind die betrachteten Daten glaubwürdig?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?Q-32: Wie viele Fälle ungenügender Datenqualität sind festzustellen?
Messpunkt DWHEbene Attributebene
M-21 Vollständigkeit [Hin02]
Erläuterung Anteil der Werte, die nicht unbekannt sind, an der Gesamtzahl der Werte.Ein nullable-Attribut ist genau dann bekannt, wenn es nicht null ist.
DM-Ziel(e) DQM-1: Datenqualität
Frage(n) Q-24: Sind die betrachteten Daten vollständig?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?Q-32: Wie viele Fälle ungenügender Datenqualität sind festzustellen?
Messpunkt Staging AreaEbene Attributebene
39

3 Entwicklung des Konzepts
M-22 Redundanzfreiheit [Hin02]
Erläuterung Anzahl in der Datenbank repräsentierter Entitäten im Verhältnis zur An-zahl tatsächlich existierender Entitäten in der Realwelt.
DM-Ziel(e) DQM-1: Datenqualität
Frage(n) Q-24: Sind die betrachteten Daten vollständig?Q-25: Sind die betrachteten Daten redundanzfrei?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?Q-32: Wie viele Fälle ungenügender Datenqualität sind festzustellen?
Messpunkt DWHEbene Relationenebene
M-23 Genauigkeit [Hin02]
Erläuterung Tatsächliche Stelligkeit eines Wertes im Verhältnis zur optimalen Stellig-keit. Bei Dezimalzahlen kann die Stelligkeit (Genauigkeit) aus der An-zahl der geltenden Ziffern gebildet werden. Bei einer mehrstufigen Klas-sifikationshierarchie [Hin02] ist die optimale Stelligkeit die spezifischsteBezeichnung für eine Entität. 1
DM-Ziel(e) DQM-1: Datenqualität
Frage(n) Q-26: Wie genau sind die betrachteten Daten?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?Q-32: Wie viele Fälle ungenügender Datenqualität sind festzustellen?
Messpunkt Staging AreaEbene Attributebene
M-24 Alter
Erläuterung Zeit, die seit der letzten Änderung eines Datums vor der letzten Extrak-tion in das DWH bis hin zum Zeitpunkt der Abfrage abgelaufen ist.
DM-Ziel(e) DQM-1: Datenqualität
Frage(n) Q-27: Wie aktuell sind die betrachteten Daten?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?Q-32: Wie viele Fälle ungenügender Datenqualität sind festzustellen?
Messpunkt Staging AreaEbene Attributebene
1Beispiel: „Automobil” und „Motorrad” hätten beide in einer Vererbungshierarchie mit „Fahrzeug” und„Kraftfahrzeug” als Vorgänger die Stelligkeit 3. „Fahrzeug” als Wurzel der Vererbung hätte die Stelligkeit1. Eine Entität, die als „Kraftfahrzeug” beschrieben wurde hätte somit nicht die optimale Stelligkeit, da siegenauer hätte beschrieben werden können.
40

3.6 Datenflussanalyse und Datenflussgraph
M-25 Aktualitätsrate [BP04]
Erläuterung Anteil der aktuellen Werte an der Gesamtanzahl der Werte. Ein Wert istaktuell, wenn er im Quellsystem seit der Extraktion noch nicht aktuali-siert worden ist.
DM-Ziel(e) DQM-1: Datenqualität
Frage(n) Q-27: Wie aktuell sind die betrachteten Daten?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?Q-32: Wie viele Fälle ungenügender Datenqualität sind festzustellen?
Messpunkt Staging AreaEbene Relationenebene
M-26 Eindeutigkeit [Hin02]
Erläuterung Eindeutigkeit von Daten wird bestimmt über Konsistenz, Vollständigkeitund Genauigkeit (M-20, M-21, M-23) der zugehörigen Metadaten (vgl.Abschnitt 2.3.4).
DM-Ziel(e) DQM-1: Datenqualität
Frage(n) Q-29: Sind die betrachteten Daten eindeutig interpretierbar?Q-30: Findet eine kontinuierliche Verbesserung der Datenqualität statt?Q-32: Wie viele Fälle ungenügender Datenqualität sind festzustellen?
Messpunkt DWHEbene Attributebene
3.6 Datenflussanalyse und Datenflussgraph
Auf dem in Abschnitt 2.2 eingeführten Konzept des Datenflusses bzw. der Data Prove-nance aufbauend wird im Folgenden das Konzept des Datenflussgraphen erläutert. Eswird ein Metamodell für den Graphen entwickelt, das alle für den weiteren Verlauf re-levanten Komponenten enthält. Eine mögliche Darstellungsform für einen DFG führt Ab-schnitt 3.6.3 ein.
3.6.1 Metamodell der Messobjekte
Abbildung 3.3 zeigt ein auf die wesentlichen Elemente eines DFG abstrahiertes Metamo-dell. Ein DataObject ist diejenige Entität, welche die zu messenden Datensätze enthält – dieDataRows. Ein Process ist eine geordnete Menge einzelner Ausführungsschritte (Steps) undmuss über mindestens ein DataObject als Ein- oder Ausgabe verfügen. Diese Eigenschaftwird über die Assoziationsklasse DataFlow spezifiziert, jedoch im den folgenden Metamo-dellen aufgrund des hohen Detailgrades ausgeblendet. Dasselbe DataObject kann sowohlEingabe als auch Ausgabe für einen Prozess sein.
41

3 Entwicklung des Konzepts
Abbildung 3.3: Grundlegendes Metamodell für den Datenflussgraphen
Erweiterung des grundlegenden Metamodells
Zur Modellierung des Datenflusses wird das grundlegende Metamodell um einige techni-sche und fachliche Elemente erweitert. So müssen für die Betrachtung der Auswirkungenvon Änderungen oder Beschädigungen an bestimmen Datenbankobjekten sowie zur Er-mittlung derjenigen Datenbankobjekte, aus denen Daten für eine bestimmte Endansichtbzw. einen bestimmten Anwendungsfall gesammelt wurden beispielsweise interessierteRollen hinzugefügt werden (vgl. Abbildung 3.4).
Jedes Datenbankobjekt (DataObject) kann nun beliebig vielen Anwendungsfällen (Use-Case) als Datenquelle zugeordnet sein und jeder Anwendungsfall kann aus beliebig vielenQuelle Daten beziehen. An einem Anwendungsfall ist mindestens eine Rolle (Role) interes-siert und jede Rolle ist an mindestens einem Anwendungsfall interessiert. Jedes DataObjectgehört zu genau einer Schicht (DWHLayer) in der Architektur des Data Warehouse. Die Da-tenbank (Database) besteht aus einer Aggregation von Datenbankobjekten (DataObject), dieihrerseits wiederum Datensätze (DataRow) aggregieren. Datensätze bestehen jeweils ausmindestens einem Attribut (DataAttribute). Ein Datenbankobjekt ist in genau einer Daten-bank enthalten, die von mindestens einem DBMS (DBMSystem) verwaltet wird. Ein DBMSkann mehrere Datenbanken verwalten.
3.6.2 Analysen und Messungen am Datenflussgraphen
Anhand des Datenflussgraphen lassen sich verschiedene Messungen und Analysen durch-führen. Dazu gehören nicht quantifizierbare Erkenntnisse, wie z.B. die bereits eingeführtenKonzepte der Abstammungs- und Auswirkungsanalyse sowie quantifizierbare Messun-gen, wie Metriken. Zur Vorbereitung der Visualisierung von Kennzahlen am DFG musszunächst ermittelt werden, welche Arten von Metriken anhand der verschiedenen Mes-sobjekte unterschieden werden können und wie diese den Elementen des DFG zugeordnetwerden können. Es können drei verschiedene Typen von Metriken unterschieden werden:
• Metriken, die Eigenschaften von Daten messen• Metriken, die Eigenschaften des DBMS messen
42

3.6 Datenflussanalyse und Datenflussgraph
Abbildung 3.4: Erweiterung des grundlegenden Metamodells
• Metriken, die Eigenschaften von Prozessen messen
Die Basis für alle Messungen bilden diese drei Messobjekte, wobei die Daten unterschied-lich granular dargestellt werden können. Den Ebenen der Granularität entsprechen die inAbschnitt 3.5.2 definierten Messebenen. Diese Einteilung wird als Grundlage für die fol-gende Modellierung verwendet. Abbildung 3.5 zeigt ein integriertes Metamodell der Zu-sammenhänge zwischen Kennzahlen und deren Messobjekten im Metamodell des DFG.Es ergeben sich gemäß Abschnitt 3.5.2 sechs Messebenen zur Modellierung:
• Attribute werden durch das DataAttribute repräsentiert und von der DataAttribute-Metric gemessen.
• Datensätze werden durch die DataRow repräsentiert und von der DataRowMetric ge-messen.
• Relationen werden durch das DataObject repräsentiert und von einer DataObjectMe-tric gemessen.
• Datenbanken werden durch die Database repräsentiert und von einer DatabaseMetricgemessen.
• DBMSs werden durch das DBMSystem repräsentiert und von einer SystemMetric ge-messen.
• Prozesse werden durch den Process repräsentiert und von der ProcessMetric gemes-sen.
43

3 Entwicklung des Konzepts
Abbildung 3.5: Erweitertes Datenflussgraph-Metamodell
44

3.6 Datenflussanalyse und Datenflussgraph
Entsprechend den verschiedenen Ebenen der Datenaggregation lassen sich Metriken aufverschiedenen Ebenen definieren. Unter der Bedingung, dass aus jeder Metrik auf einerniedrigen Aggregationsstufe eine entsprechende Metrik höherer Aggregationsstufe defi-niert werden kann (z.B. über ein gewichtetes Mittel [Hin02]), ist jede Metrik auf Attribu-tebene (DataAttributeMetric) zugleich Basis für eine Metrik auf Tupelebene (DataRowMe-tric) sowie transitiv für eine Metrik auf Relationenebene (DataObjectMetric) und Daten-bankebene (DatabaseMetric). Diese Beziehungen werden im Metamodell durch die Asso-ziationen zum Ausdruck gebracht, die den Attribut-, Tupel-, Relationen- und Datenbank-metriken zugrunde liegen. Prozessmetriken messen einen Aspekt der Gesamtperformanceeines Prozesses und erfordern Erhebung und persistente Speicherung von entsprechendenMetadaten (vgl. Abschnitt 3.5.2).
3.6.3 Darstellung des Datenflussgraphen
Die Struktur des DFG ist durch das Metamodell (vgl. Abbildung 3.5) spezifiziert. Im Fol-genden wird ein Konzept erarbeitet, auf welche Weise Messungen am DFG dargestelltwerden können und wie verschiedene Aggregationsstufen berücksichtigt werden können.Es werden verschiedene durch den DFG ermöglichte Analysen vorgestellt und Vorschlägezur Visualisierung gegeben.
Grundstruktur
Abbildung 3.6 zeigt die vorgeschlagene Grundstruktur für einen Datenflussgraphen aufder Stufe höchster Granularität. Datenbankobjekte werden durch rechteckige Knoten re-präsentiert (z.B. DataObject3), die auch enthaltene Datensätze darstellen können (z.B. Da-taObject1). Falls Metriken auf Tupelebene dargestellt werden sollen, muss die Anzeigevon Datensätzen an einer Relation aktiviert sein. Dann können TupleMetrics an jedem Da-tensatz angezeigt werden, wie ein zusätzliches berechnetes Attribut. Bei Auswahl einesbestimmten Datensatzes können auch auf die einzelnen Attribute bezogenen Metrikendargestellt werden (Attribute Metrics). Metriken auf Relationenebene können unter demNamen des entsprechenden Datenbankobjekts jeweils in einer eigenen Zeile dargestelltwerden. Metriken auf Datenbankebene sowie Metriken auf Systemebene sind im KnotenGlobal Metrics, der mit den restlichen Knoten durch keine Kante verbunden ist, zu finden.Die Darstellung von Datenbank- und Systemmetriken verläuft analog zur Darstellung vonMetriken auf der Relationenebene jeweils in einer eigenen Zeile des Knotens.
Die Zugehörigkeit der Datenbankobjekte zu einer Schicht des DWH wird im DFG durcheine Gruppierung zum Ausdruck gebracht. Metriken auf Relationenebene können analogzur Aggregation auf die Datenbankebene unter dem Aspekt aggregiert werden, dass nurDatenbankobjekte einer bestimmten Schicht zur Berechnung herangezogen werden. Dieresultierenden Kennzahlen können im DWHLayer dargestellt werden (vgl. Abbildung 3.7).Falls der Vergleich mehrerer Kennzahlen gewünscht ist, können die Metriken auch in einerTabelle aufgeführt werden.
Die Kanten im DFG stellen die Input- / Output-Beziehung zwischen Datenbankobjektenund Prozessen dar und verlaufen in Richtung des Datenflusses. Prozesse werden durchdreieckige Knoten repräsentiert (z.B. P2) und zeigen mit ihrer Dreiecksspitze in Richtung
45
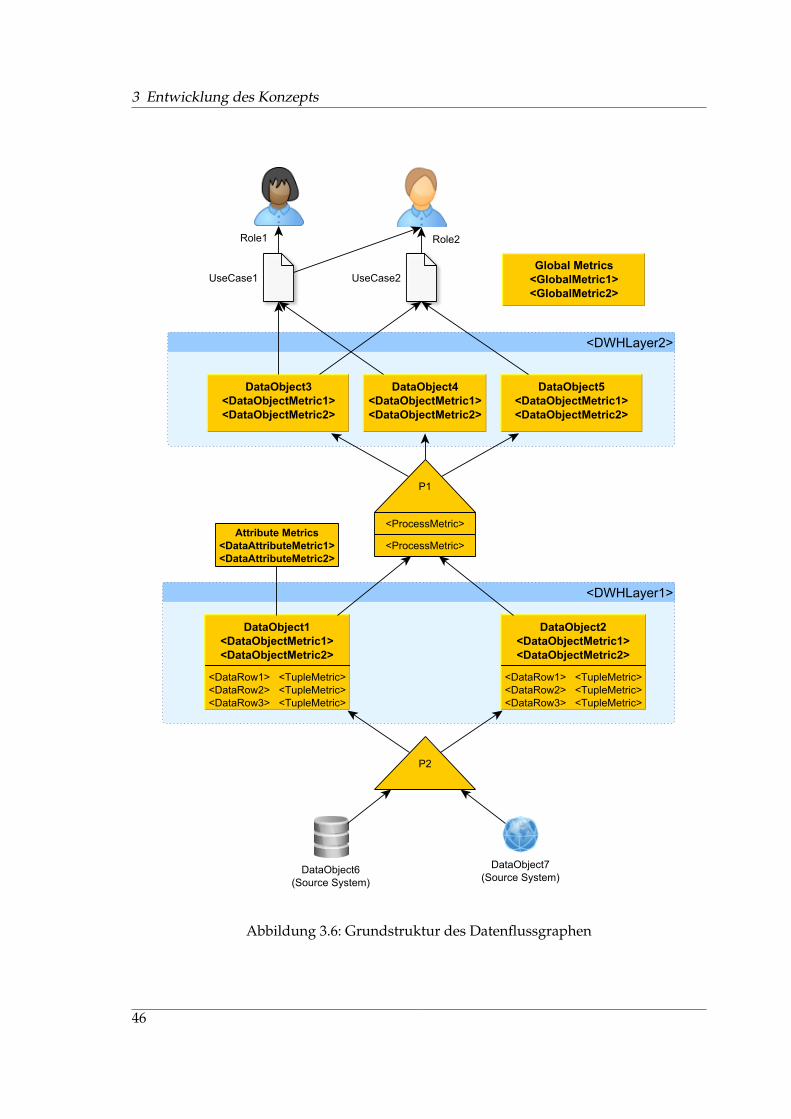
3 Entwicklung des Konzepts
Abbildung 3.6: Grundstruktur des Datenflussgraphen
46

3.6 Datenflussanalyse und Datenflussgraph
Abbildung 3.7: Aggregierte DWH-Schicht
47

3 Entwicklung des Konzepts
des Outputs. Prozessmetriken können an der Inputkante des Prozessdreiecks dargestelltwerden. Jede Metrik wird in einer eigenen Zeile gelistet.
Use Cases und Rollen sind Knoten außerhalb einer Schicht. Use Cases werden durchBlätter repräsentiert, die über eingehende Kanten mit den Prozessen verbunden sind, dieihnen die nötigen Daten liefern und über ausgehende Kanten mit den interessierten Rol-len verbunden sind. Rollen stellen den Endpunkt des Datenflusses im Graphen dar undverfügen nur über eingehende Kanten aus den relevanten Use Cases.
Quellsysteme können grundsätzlich wie Datenbankobjekte behandelt werden und wer-den deshalb durch eigene Knoten repräsentiert. Diese Knoten können beispielsweise jenach Art der Quelle in ihrer symbolischen Darstellung variieren. Der Übergang von Quell-system zum Datenbankobjekt geschieht über einen Prozess.
Benutzerinteraktion
Die Anzahl darzustellender DFG-Elemente kann insbesondere bei großen DWHs derartigeGrößenordnungen erreichen, dass eine Darstellung des vollständigen DFG in seiner fein-granularen Grundstruktur auf einer Bildschirmgröße nur unter extremer Verkleinerungder grafischen Elemente möglich wäre. So besteht der Bedarf nach Darstellungsformen,die die angezeigte Menge an Informationen reduzieren.
Eine Möglichkeit besteht darin, die minimal angezeigte Aggregationsebene im Vergleichzur Grundform zu erhöhen (bzw. die Granularität zu verringern). Dieser Vorgang, bei demnicht durch Verkleinerung der grafischen Bildelemente, sondern vielmehr durch Aggrega-tion einfacher Elemente in zusammengesetzte Elemente aus einem Bild „herausgezoomt”wird, wird als semantischer Zoom bezeichnet. Weaver beschreibt den semantischen Zoomals eine „Form von details on demand2, bei der der Benutzer durch Herein- und Heraus-zoomen unterschiedliche Detailmengen sehen kann [Wea04].” [SVTS05] zeigt eine mögli-che Darstellungsform für ETL-Graphen auf verschiedenen Ebenen. Die hier vorgestellteGrundstruktur entspricht der Schemaebene in [SVTS05].
Ein weiteres Instrument zur Beherrschung der Informationsflut besteht in der Nutzungvon Filtern [YaKSJ07]. So sollte es möglich sein, bestimmte Elemente des DFG anhand vonFilterkriterien hervorzuheben bzw. auszublenden. Denkbare Szenarien bestehen bspw. inder Filterung der angezeigten Objekte nach denjenigen Objekten, die bestimmten Qua-litätskriterien nicht genügen oder in der Markierung des kritischen Pfades im Sinne derProzessdauer.
Auswirkungsanalyse
Abbildung 3.8 zeigt eine mögliche Darstellung für eine Auswirkungsanalyse am DFG.Ausgangspunkt für die Analyse ist DataObject8, welches durch eine grüne Umrandungmarkiert ist. Alle Knoten und Kanten, die keine Nachfolger von DataObject8 sind, sindkontrastarm eingefärbt, um eine schnelle Unterscheidung von den relevanten Elementendes Graphen zu gewährleisten. So kann bspw. aus dieser Ansicht abgelesen werden, dass
2etwa Details auf Abruf, also die aktive Anforderung eines höheren Detailgrades durch den Nutzer
48

3.6 Datenflussanalyse und Datenflussgraph
Daten aus DataObject8 nur in UseCase2 verwendet werden und im Falle von Problemenmit der Datenqualität Role2 benachrichtigt werden muss.
Abstammungsanalyse
Abbildung 3.9 zeigt ein Szenario für eine Abstammungsanalyse am DFG. DataObject4 bil-det den Ausgangspunkt für diese Analyse und ist durch eine blaue Umrandung gekenn-zeichnet. Alle Knoten und Kanten, die keine Vorgänger von DataObejct4 sind, sind wieder Auswirkungsanalyse blass eingefärbt, um die schnelle Unterscheidung von den re-levanten Elementen des Graphen zu gewährleisten. Aus solch einer Ansicht kann bspw.abgelesen werden, dass die Daten in DataObject4 aus den Quellen DataObject6 und Data-Object7 stammen und diese Daten in DWHLayer1, respektive DataObject1 und DataObject2zwischengespeichert wurden.
Kritischer Pfad
Abbildung 3.10 zeigt eine mögliche Darstellung für die Analyse des kritischen Pfades einesAnwendungsfalls. Es wird derjenige Pfad vom Ausgangsobjekt zu den Datenquellen vi-sualisiert, bei dem die Menge von Prozessen mit maximaler Gesamtdauer traversiert wird.Das Ausgangsobjekt sowie alle auf dem Pfad befindlichen Elemente des Graphen werdenrot markiert. Nicht relevante Objekte werden auch bei dieser Analyse kontrastarm einge-färbt, um die Elemente auf dem kritischen Pfad hervorzuheben. Die Berechnung und Dar-stellung des kritischen Pfades bezüglich der Prozessdauer ist jedoch nur ein Beispiel, dagrundsätzlich auch andere Prozessmetriken mit einer geeigneten Aggregation verwendetwerden können. So ist bspw. ein kritischer Pfad im Sinne des minimalen Datendurchsatzesvorstellbar.
49
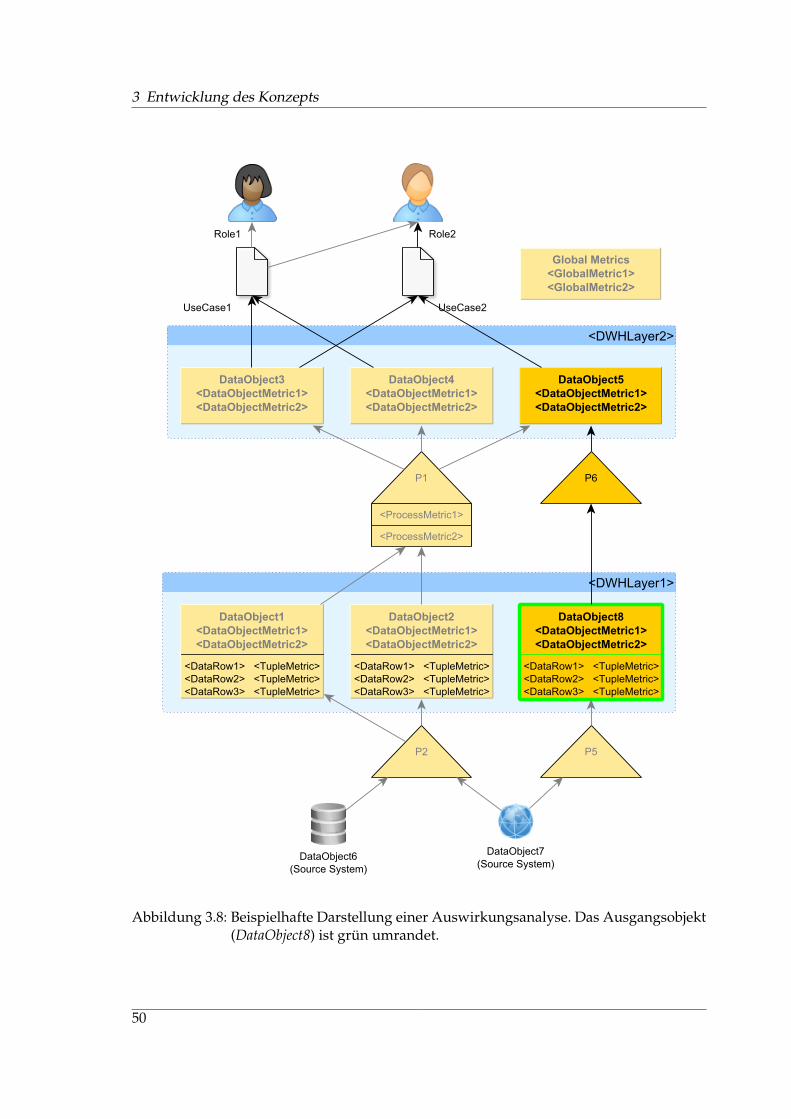
3 Entwicklung des Konzepts
Abbildung 3.8: Beispielhafte Darstellung einer Auswirkungsanalyse. Das Ausgangsobjekt(DataObject8) ist grün umrandet.
50
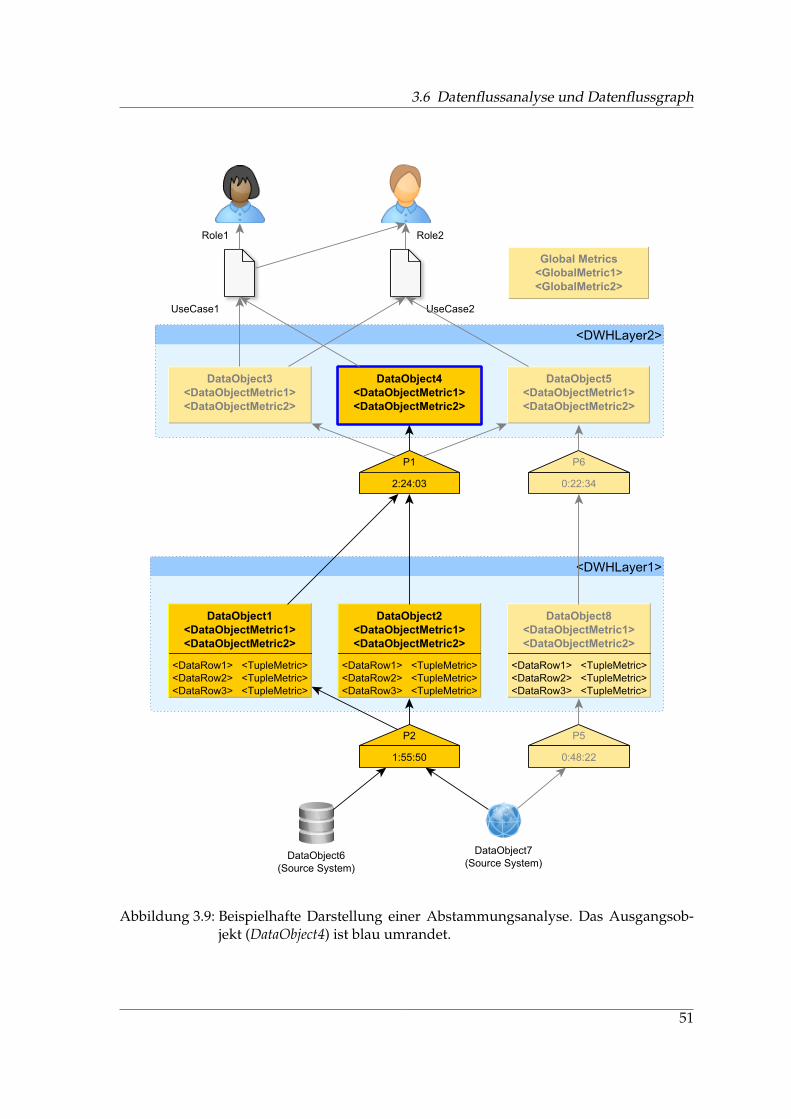
3.6 Datenflussanalyse und Datenflussgraph
Abbildung 3.9: Beispielhafte Darstellung einer Abstammungsanalyse. Das Ausgangsob-jekt (DataObject4) ist blau umrandet.
51
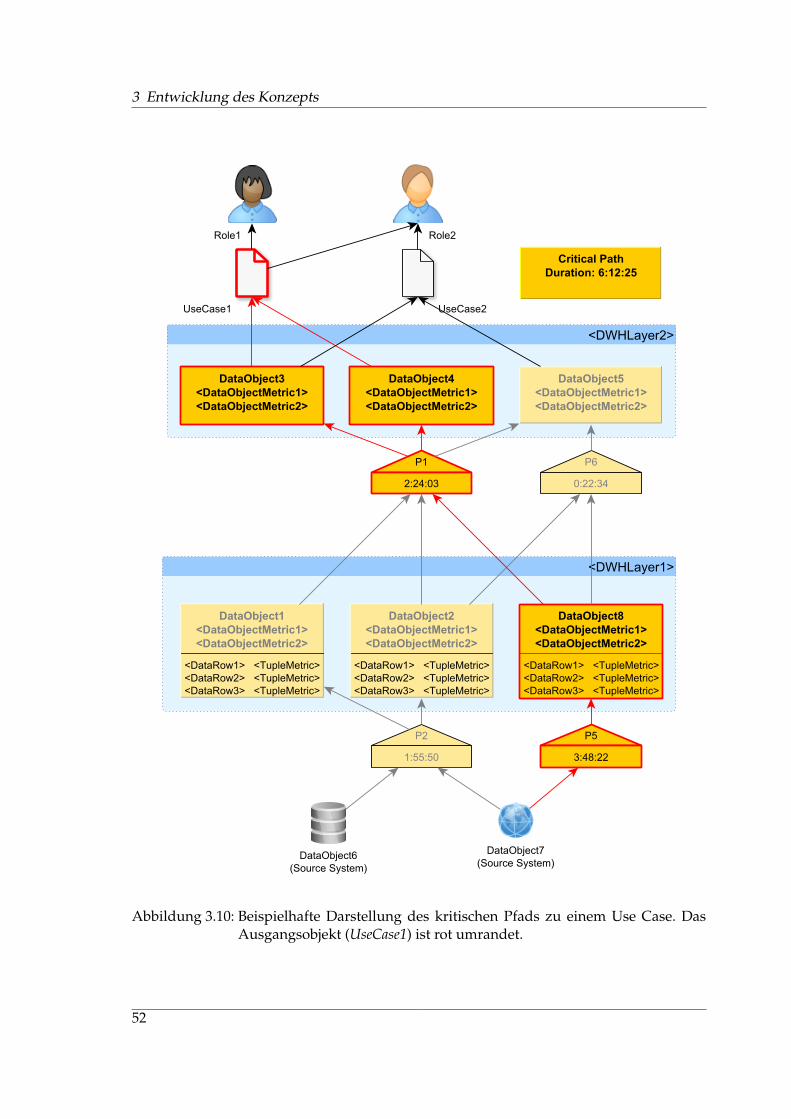
3 Entwicklung des Konzepts
Abbildung 3.10: Beispielhafte Darstellung des kritischen Pfads zu einem Use Case. DasAusgangsobjekt (UseCase1) ist rot umrandet.
52

4 Fallstudie
Der Kennzahlenkatalog sowie das Konzept zum Datenflussgraphen wurden in einer Fall-studie prototypisch implementiert. Dazu wird der Systemkontext beim Praxispartner be-schrieben, die konkreten Stakeholder ermittelt und ihre Anforderungen analysiert. DerAbschnitt Anwendung des Konzepts beschreibt, welche Maßnahmen zur Deckung des Infor-mationsbedarfs der Stakeholder umgesetzt werden und wie die Informationen dargestelltwerden. Eine Evaluation durch Experten des Praxispartners validiert den Prototyp für dieFallstudie.
4.1 Systemkontext
4.1.1 Projekt
Die Fallstudie ist in einem Projekt der iteratec GmbH einzuordnen, das die Weiterentwick-lung der Softwarelösung eines Carsharing-Dienstes für einen deutschen Automobilher-steller zum Ziel hat. Das in diesem Kontext entwickelte Data Warehouse soll um ein Mo-nitoring-Cockpit zum Zwecke des Datenmanagements ergänzt werden. Eine Datenbankmit einem momentanen Datenvolumen der Größenordnung eines Terabyte sowie die Er-wartung, dass die Datenmenge in Zukunft aufgrund von größerer Servicebeliebtheit undExpansion noch schneller wachsen wird, verpflichten zum systematischen Datenmanage-ment.
Das DWH dient der Historisierung der Daten aus den operativen Systemen und vorallem der Aufbereitung für die Analyse der technischen Fahrzeugdaten sowie der Integra-tion von Daten aus verschiedenen Quellen. So werden die aufbereiteten Daten wesentlichzur qualitativen Verbesserung der eingesetzten Soft- und Hardware und auch zur Unter-stützung und Optimierung der Supportprozesse genutzt. Durch diese konsequente Da-tenanalyse soll gerade im noch jungen Bereich des Carsharing das Gesamtangebot für denNutzer des Carsharing Systems fortlaufend verbessert werden.
4.1.2 Architektur und Werkzeuge
Das Data Warehouse ist in einer Oracle 11g Datenbank implementiert und folgt der klas-sischen Schichtenarchitektur (vgl. Abschnitt 2.1.1). Die Daten werden bei der Extraktionin den Arbeitsbereich (Staging Area) geladen, von dem aus die nötigen Transformationendurchgeführt werden. Die Spezifikation der ETL-Prozesse liegt in SQL vor und wurde oh-ne Unterstützung dedizierter Werkzeuge für die Erstellung von ETL-Workflows geschrie-ben. Die Haltung der integrierten Daten geschieht in der Catalog-Schicht. Zur Implemen-tierung des Monitoring-Cockpits wird die In-Memory-Datenbank QlikView (QV) gewählt,
53

4 Fallstudie
die auch die Aufgaben der Präsentationsschicht übernimmt und das Data Discovery Be-dienkonzept durch hohe Interaktivität unterstützt. Der QV-Entwickler stellt Dashboardszusammen, die den Anwendern über geeignete Steuerelemente und Visualisierungen dieDaten zur Verfügung stellen. Über ein Ladeskript können Datenquellen sowie Transfor-mationen definiert werden, um das QV-interne Datenmodell zu spezifizieren. Auf dieseWeise werden Data Marts modelliert und die entsprechende Schicht in den Speicher vonQlikView ausgelagert. Die Interaktivität wird bspw. durch Filter ermöglicht, die aufgrundder Datenhaltung im Arbeitsspeicher vergleichsweise kurze Reaktionszeiten gewährlei-sten sollen. Abbildung 4.1 zeigt einen Überblick über die Architektur in der Fallstudie.
Abbildung 4.1: Architekturskizze in der Fallstudie
4.1.3 Spezifische Anforderungen
Die in ITIL und DMBOK spezifizierten Rollen für Servicemanagement und Datenmanage-ment decken sich mit den im Projekt vorhandenen Rollen. Zur Erhebung der projektspezi-fischen Anforderungen werden zunächst die konkreten Stakeholder (vgl. [MBEH09]) füreine Monitoring-Anwendung identifiziert:
• Datenbankadministrator• Data Integration Specialist
54

4.2 Anwendung des Konzepts
Diese Rollen verfolgen (vgl. Abschnitt 3.3.1) die operativen Ziele zur Sicherung von Inte-grität (DOM-1), Verfügbarkeit (DOM-2) und Performance (DOM-3) sowie die Bereitstellungeiner für effektive und effiziente Geschäftsanalysen geeigneten DWH (DW-BIM-2). Damitkommen gemäß der in Kapitel 3 entwickelten Methode, insbesondere der Zuordnung vonZielen zu Metriken (vgl. Tabelle 3.3) für die Implementierung grundsätzlich die MetrikenM-1 bis M-9 sowie die Metriken M-14 bis M-18 infrage.
4.2 Anwendung des Konzepts
4.2.1 Kennzahlen und Visualisierung
Aus den Kennzahlen, die aufgrund der ermittelten Stakeholder und deren Ziele als geeig-net befunden wurden, wird eine Auswahl getroffen, die in einer ersten Iteration in einemPrototyp implementiert wird. Unter Berücksichtigung der Prioritäten der Stakeholder so-wie der momentanen Datenverfügbarkeit im DWH werden folgende Kennzahlen exem-plarisch als Proof of Concept umgesetzt (die Einheit wird in eckigen Klammern angegeben):
• M-4 Mean Time Between Failures bzw. Anzahl FehlerAuf Wunsch der Stakeholder kommt anstelle einer Darstellung der MTBF eine Dar-stellung der Fehlerhäufigkeiten pro Tag zum Einsatz. Dazu wird eine Tabelle sowieein Boxplot mit Statistiken zu den Häufigkeiten pro Tag eingesetzt. Bei den Darstel-lungen wird nach Fehlerstatus unterschieden.In einem Blasendiagramm wird zusätzlich, über die Dimensionen Fehlerstatus undObjektname die Anzahl der Fehler angezeigt, um die Fehleranalyse zu vereinfachen.
• M-9 Ressourcenauslastung: Persistenter Speicher [Prozent, GiB]Die anteilige Speicherauslastung wird als Kuchendiagramm visualisiert. Die histo-rische Speicherauslastung wird mithilfe eines Liniendiagramms dargestellt. Ein Bal-kendiagramm zeigt diejenigen zehn Datenbankobjekte geordnet an, die den meistenSpeicher belegen. Die Diagramme werden als Small Multiples realisiert, wobei eineUnterscheidung nach Tablespace stattfindet.Eine zusätzliche Tabelle, erlaubt die zügige Informationsgewinnung über die persi-stente Größe auf detaillierter Ebene.
• M-14 ETL-Dauer [Stunden:Minuten:Sekunden]Ein Liniendiagramm visualisiert die Entwicklung der Dauer von ETL-Prozessen überdie Zeit und stellt auch den Verlauf von Teilprozessen grafisch dar. Statistiken zurDauer einzelner Steps werden in einem Boxplot darstellt, wobei eine absteigendeSortierung nach nach Dauer verwendet wird.
• M-15 ETL-Zeilendurchsatz [Zeilen pro Sekunde]Ein Balkendiagramm visualisiert den Durchsatz einzelner ETL-Steps anhand des Ob-jekts, das als Output für den entsprechenden Prozessschritt diente. Die Darstellungist nach Durchsatz absteigend geordnet.
55

4 Fallstudie
4.2.2 Datenmodell
Das assoziative [qli14] Datenmodell ordnet gleichnamige Attribute einander zu und solldamit intuitive Analysen ermöglichen. QlikView bietet eine spezielle Ansicht, die das ge-ladene Datenmodell visualisiert (Data Mart Ansicht). Abbildung 4.2 zeigt das Datenmodellfür den Prototyp.
Abbildung 4.2: Datenmodell in QlikView
4.2.3 Dashboards
Die Abbildungen 4.3 und 4.4 zeigen die beiden Dashboards zu Speicherauslastung undETL-Analyse. Auf der linken Seite eines jeden Dashboards befinden sich Steuerelemente,die die Filterung der angezeigten Daten ermöglichen.
56
4.2 Anwendung des Konzepts
Abb
ildun
g4.
3:D
ashb
oard
zur
Ana
lyse
der
Nut
zung
des
pers
iste
nten
Spei
cher
s
57

4 Fallstudie
Abb
ildun
g4.
4:D
ashb
oard
zur
Ana
lyse
der
ETL-
Vorg
änge
58

4.3 Evaluierung
4.2.4 Datenflussgraph im Projekt
Abbildung 4.5 zeigt ein Mockup einer Instanz des DFG im Kontext der Fallstudie. Das Bei-spiel zeigt einen anonymisierten Teil des gesamten DFG mit einer Auswirkungsanalyse,die von der grün umrandeten Quellen als Startknoten ausgeht. Metriken zu Objekten undProzesse, die nicht auf den für die Analyse relevanten Pfaden liegen, werden grundsätz-lich ausgeblendet.
4.3 Evaluierung
Zur Evaluierung wurden Stakeholder und Anwender der Überwachungslösung im Rah-men von semistrukturierten qualitativen Interviews [RQL12] daraufhin befragt, inwieferndas Konzept ihre Problematik umfasst und wie gut die Lösung ist, die es anbietet. Zuden befragten Personen gehören ein DWH-Entwickler, der im Sinne der DAMA als Da-tenbankadministrator und Data Integration Specialist agiert sowie der Projektleiter, dernach ITIL-Nomenklatur für Capacity und Availability Management des Data Warehouseals Service zuständig ist. Den Befragten wurde eine Reihe von Aussagen vorgestellt, diesie ohne weitere Vorgaben kommentieren sollten. Mit einer größeren Teilnehmeranzahl beieiner derartigen Umfrage könnten die Aussagen auch als Grundlage für eine quantitativeAnalyse dienen, bspw. mit einer fünfstufigen Skala. Folgende Aussagen wurden von denStakeholdern kommentiert:
• Die Metriken unterstützen mich bei meiner Zielerreichung.• Die Metriken beantworten meine fachlichen Fragestellungen.• Die Metriken werden im Prototyp sinnvoll dargestellt.• Der DFG unterstützt mich beim Erreichen meiner Ziele.• Der Prototyp senkt den Aufwand zur Erreichung meiner Ziele.
Zusätzlich wurden die Stakeholder befragt, welche Erweiterungen und Verbesserungenfür sie wünschenswert wären (vgl. Interviews, S. 67).
Die Stakeholder bestätigten, dass die implementierten Kennzahlen (vgl. Abschnitt 4.2.1)ihre Fragestellungen zufriedenstellend beantworten und bei der Erreichung ihrer Ziele un-terstützen. Sie bestätigten ebenso die sinnvolle Darstellung der Kennzahlen im Prototyp.Ein Stakeholder äußerte den Wunsch, die Struktur des DFG aus dem Code in der Daten-bank generieren zu können. Der Prototyp erziele insbesondere aufgrund der übersichtli-chen Darstellung und der geringen Reaktionszeiten einen Mehrwert für die Stakeholderund optimiere ihren Aufwand im Vergleich zur manuellen Berechnung der Kennzahlen.
Als Erweiterung zum Data Discovery Bedienkonzept hielten die Stakeholder ein Benach-richtigungssystem für wünschenswert, das bei Störungen höherer Dringlichkeit zuvor de-finierte Personen über den Systemstatus in Kenntnis setzt. Eine Ampeldarstellung, anhandderer schnell erkannt werden kann, ob Metriken außerhalb eines erlaubten Wertebereichssind, sei ebenfalls interessant.
59

4 Fallstudie
Abbildung 4.5: Mockup einer Instanz des DFG in der Fallstudie
60

5 Fazit und Ausblick
Dieses Kapitel fasst die wichtigsten Ergebnisse und Erkenntnisse noch einmal zusammenund diskutiert sie kritisch. Abschließend wird ein Ausblick für mögliche zukünftige For-schung gegeben.
5.1 Fazit
Es werden folgende Antworten auf die Forschungsfragen formuliert:
Q-1 Welchen Informationsbedarf haben typische betriebliche Stakeholder?Abschnitt 3.3.2 zeigt auf, dass sechs ITIL-Rollen ein besonderes Interesse an opera-tivem Datenmanagement, Infrastruktur und Datenqualität haben. Dazu zählen derCapacity Manager, Availability Manager, Incident Manager, Problem Manager undCSI Manager sowie Technische Analysten verschiedener Spezialisierungen.Mithilfe der ermittelten Stakeholder und ihren Zielen im Rahmen des betrieblichenDatenmanagements wurden Fragestellungen formuliert (vgl. Abschnitt 3.4), die ih-ren Informationsbedarf repräsentieren.
Q-2 Welche Metriken eignen sich am besten dazu, die Ziele der Stakeholder zu überwachen?Abschnitt 3.5.3 führt einen Katalog mit Kennzahlen ein, die zur Überwachung derErfüllung von Zielsetzungen des Datenmanagements dient. Diese Ziele wurdendem DMBOK entnommen und dienen als Grundlage für die Metriken. Die Metri-ken wurden mithilfe des GQM Ansatzes entwickelt und beantworten Fragestellun-gen, die aus Sicht von Stakehodern formuliert sind und den Informationsbedarfdieser widerspiegeln.Auf diese Weise wurde eine Methode zur Deckung des Informationsbedarfs derStakeholder entwickelt. Rollen aus dem Datenmanagement und dem IT-Service-management können Ziele im Kontext des Datenmanagements zugeordnet wer-den (vgl. Abbildung 3.2). Da jedem dieser Ziele mindestens je eine Metrik aus demKennzahlenkatalog zugeordnet ist (vgl. Tabelle 3.3), können für jede Rolle Emp-fehlungen zur Deckung des Informationsbedarfs anhand von Metriken abgegebenwerden.
Q-3 Wie kann ein Datenflussgraph bei Analyse und Überwachung eines Data Warehouse un-terstützen?Abschnitt 3.6.2 entwickelt inkrementell ein Metamodell, welches die verschiedenenArten von Metriken; Messobjekten und alle weiteren notwendigen Elemente für dieModellierung des Datenflusses im DWH in Verbindung setzt. Hierzu gehört auchdie Integration von Anwendungsfällen und Rollen in das Metamodell, um so dieBrücke zwischen technischen und fachlichen Aspekten im Datenfluss zu schlagen.
61

5 Fazit und Ausblick
Das Konzept zeigt auf, wie und wo Kennzahlen an einem DFG sinnvoll dargestelltwerden können und welche weiteren Analysen, die die Eigenschaften des Graphennutzen, durchgeführt werden können. So werden Abstammungsanalyse, Auswir-kungsanalyse und die Berechnung eines kritischen Pfades vorgestellt.
5.2 Ausblick
Monitoring alleine, als reaktives Instrument für das Datenmanagement, kann die Proble-matik nicht vollständig umfassen. Gerade beim Datenqualitätsmanagement sind auch pro-zessgetriebene Methoden zur Verbesserung der DQ von Interesse. So sollten bspw. direktnach der Eingabe von Daten Plausibilitätskontrollen bezüglich der Geschäftsregeln ange-stoßen werden, um Daten, die den geltenden Qualitätsstandards nicht entsprechen, in dasSystem nicht erst aufzunehmen.
Aufgrund des begrenzten Umfangs einer solchen Arbeit können nicht alle möglicher-weise interessanten Thematiken, die in Bezug mit der Forschung stehen, berücksichtigtwerden. So ist bspw. das Metadatenmanagement ebenfalls ein wichtiger Teil des Daten-managements, aber aufgrund seines strategischen Charakters in einer gesonderten Arbeitnäher zu betrachten. Auch beim Datenflussgraphen sind neben der Darstellung von Me-triken weitere Operationen vorstellbar, die zur Analyse der Daten- und Prozessstrukturenspezielle Charakteristika eines Graphen ausnutzen:
• Wenn der DFG als gerichtet azyklisch angenommen wird, könnten Analysen zur Fin-dung von Zyklen bei der Fehleranalyse unterstützen.
• Die Ermittlung von Zusammenhangskomponenten gibt Aufschluss über voneinan-der unabhängigen Bereiche im DWH bzw. im Datenfluss.
• Die Interpretation des DFG als Netzwerk könnte das Capacity Management unter-stützen. Die Kanten des Graphen können bspw. nach Datendurchsatz gewichtet wer-den, um so insbesondere bei großen, verteilten DWHs Potential zur Optimierungdurch Ermittlung von Bottlenecks und Verteilung der Last auszuschöpfen.
• Bei Prozessknoten kann ein „vorher-nachher”-Effekt veranschaulicht werden. Durchden Vergleich eines Datenqualitätskriteriums oder des Datenvolumens der verarbei-teten Daten vor und nach einem Prozess kann z.B. der Grad der Anreicherung derDaten bestimmt werden.
Zur Generierung eines DFG werden grundsätzlich Metadaten zur DFG-Struktur sowie dieeigentlichen Messwerte benötigt. Insbesondere bei großen DWHs und solchen mit einervolatilen Struktur ist die automatische Generierung des DFG durch Einlesen der entspre-chenden Metadaten aus dem DWH wünschenswert. Es besteht Bedarf zur weiteren Re-cherche, inwieweit vorhandene Systeme Schnittstellen zum automatisierten Einlesen derMetadaten liefern. Eine mögliche Lösung zur Erhebung der strukturellen Informationenbesteht darin, zu jeder Prozessausführung zusätzlich zu den Metriken auch Informatio-nen über die Ein- und Ausgabebeziehungen von Prozessen zu speichern. Auf diese Weisekann unter Zuhilfenahme von Zeitstempeln eine historisierte Dokumentation des DFG er-zeugt werden.
In dieser Arbeit wurde das Datenmanagement im Kontext von Data Warehousing nä-
62

5.2 Ausblick
her untersucht. Dies impliziert die persistente Haltung strukturierter Daten [Inm02]. DerTrend zu Big Data bringt die Haltung und Auswertung massiver Mengen von Daten mitsich und gibt Anlass zur Forschung im Bereich des Datenmanagements unstrukturierterund semistrukturierter Daten.
Im Rahmen der Fallstudie wurden nur technische Metriken und keine Metriken zurDatenqualität erhoben. Eine für das Projekt besonders relevante DQ Metrik wäre z.B. dieKonsistenz (M-20). So könnten die Zustandsübergänge beim Buchungsprozess auf Kon-formität mit den Geschäftsregeln überwacht werden.
Mit der Fallstudie wurde gezeigt, dass und wie das Konzept zumindest prototypischumgesetzt werden kann. Im Rahmen der Kooperation mit dem Praxispartner wurde derPrototyp in einem konkreten Projektumfeld eingesetzt und evaluiert. Für die konkretenAnforderungen des Praxispartners erwies sich der Prototyp als geeignet. Der allgemeineNachweis der Validität für das Konzept ist jedoch im Rahmen dieser Arbeit nicht möglich.
63

5 Fazit und Ausblick
64

Anhang
65


Interviews
Dieses Kapitel enthält die Aussagen der Stakeholder zur Evaluation des Prototyps.
Interview mit dem Datenbankadministrator / Data Integration Specialist
• Die Metriken unterstützen mich bei meiner Zielerreichung.Ja.
• Die Metriken beantworten meine fachlichen Fragestellungen.Ja.
• Die Metriken werden im Prototyp sinnvoll dargestellt.Ja.
• Der DFG unterstützt mich beim Erreichen meiner Ziele.Ja.
• Der Prototyp senkt den Aufwand zur Erreichung meiner Ziele.Ja – bisher hatte ich diverse Queries, die ich nach und nach in einem SQL-Client ausgeführthatte, mit normaler textueller Darstellung der Ergebnisse. Filter/Sortierungen u.a. erforder-te dann eine Änderung des SQLs. Jetzt ist alles grafisch aufbereitet und ein einziger Klickauf „Aktualisieren” bringt alle Auswertungen auf einmal auf den neuesten Stand und dieBedienung ist um Welten schneller und komfortabler.
• Welche Erweiterungen/Verbesserungen wären wünschenswert?Für die bestehenden Auswertungen habe ich momentan keinen Verbesserungsbedarf, die sinddank der super Zusammenarbeit in der Implementierungsphase genau nach Wunsch gewor-den. Eine weitere Idee wäre ein „Ampelcockpit” Tab, auf dem ganz knapp nur rot/grün (evtl.gelb) Ampeln dargestellt werden, um auf einen Blick zu sehen, ob es irgendwo Metriken gibt,die nicht innerhalb eines definierten Normbereichs liegen. Damit könnte man dann die Infor-mationen noch weiter verdichten, ohne über mehrere Tabs schalten zu müssen. Das ist vorallem für kurzfristige operative Fragestellungen interessant, kann aber auch für einige dereher langfristig orientierten Management-Metriken Sinn machen.
Interview mit dem Projektleiter
• Die Metriken unterstützen mich bei meiner Zielerreichung.Ja, aber eher indirekt.
• Die Metriken beantworten meine fachlichen Fragestellungen.Ja.
• Die Metriken werden im Prototyp sinnvoll dargestellt.
67

Ja – nicht nur sinnvoll, sondern aus meiner Sicht bzw. für mich auch gut verständlich undlesbar.
• Der DFG unterstützt mich beim Erreichen meiner Ziele.Ja, absolut. Interessant wäre es hier, DFG aus dem Code generieren zu können.
• Der Prototyp senkt den Aufwand zur Erreichung meiner Ziele.Ja. Und schont auch meine Nerven.
• Welche Erweiterungen/Verbesserungen wären wünschenswert?In erster Linie wären Notifications / Benachrichtigungen eine tolle Ergänzung.
68

Abkürzungsverzeichnis
BI Business IntelligenceBIA Business Intelligence AnalystBIS Business Intelligence SpecialistCSI Continual Service ImprovementDAMA Data Management AssociationDBA DatenbankadministratorDBO DatenbankobjektDBMS Database Management SystemDFG DatenflussgraphDIS Data Integration SpecialistDLP Data Lineage ProblemDM DatenmanagementDMBOK Data Management Body of Know-
ledgeDOM Data Operations ManagementDQ DatenqualitätDQA Data Quality AnalystDQM DatenqualitätsmanagementDQMan Data Quality ManagerDQMO Datenqualitätsmonitoring
DW-BIM Data Warehousing & Business In-telligence Management
DWH Data WarehouseETL Extract-Transform-LoadFCS Feedback-Control SystemGQM Goal-Question-MetricIS InformationssystemITIL Information Technology Infrastructure
LibraryKPI Key Performance IndicatorMDM MetadatenmanagementMTBF Mean Time Between FailuresMTTR Mean Time to RepairOLAP Online Analytical ProcessingPDCA Plan-Do-Check-ActQV QlikViewSL Service LevelSLA Service Level AgreementSPOT Single Point of TruthTDQM Total Data Quality ManagementULDB Uncertainty Lineage Database
69

70

Literaturverzeichnis
[ABEM09] D. Apel, W. Behme, R. Eberlein, and C. Merighi. Datenqualität Erfolgreich Steu-ern. Hanser, 2009.
[Agg09] C. C. Aggarwal. Trio: A system for data uncertainty and lineage. In Managingand Mining Uncertain Data, pages 1–35. Springer, 2009.
[Bas92] V. R. Basili. Software modeling and measurement: the goal/question/metricparadigm. 1992.
[BB99] P. A. Bernstein and T. Bergstraesser. Meta-data support for data transformationsusing microsoft repository. IEEE Data Eng. Bull., 22(1):9–14, 1999.
[BCFM09] C. Batini, C. Cappiello, C. Francalanci, and A. Maurino. Methodologies for dataquality assessment and improvement. ACM Computing Surveys, 41, July 2009.
[BCTV05] D. Bhagwat, L. Chiticariu, W.-C. Tan, and G. Vijayvargiya. An annotation mana-gement system for relational databases. The VLDB Journal, 14(4):373–396, 2005.
[BG04] A. Bauer and H. Günzel. Data-Warehouse-Systeme: Architektur, Entwicklung, An-wendung. dpunkt Verlag, 2nd edition, December 2004.
[BKT01] P. Buneman, S. Khanna, and W.-C. Tan. Why and where: A characterization ofdata provenance. In J. Bussche and V. Vianu, editors, Database Theory — ICDT2001, volume 1973 of Lecture Notes in Computer Science, pages 316–330. SpringerBerlin Heidelberg, 2001.
[BP04] M. Bouzeghoub and V. Peralta. A framework for analysis of data freshness. InProceedings of the 2004 international workshop on Information quality in informationsystems, pages 59–67. ACM, 2004.
[BSH+08] O. Benjelloun, A. D. Sarma, A. Halevy, M. Theobald, and J. Widom. Databaseswith uncertainty and lineage. The VLDB Journal, 17(2):243–264, 2008.
[BSHW06] O. Benjelloun, A. D. Sarma, A. Halevy, and J. Widom. ULDBs: Databases withuncertainty and lineage. In Proceedings of the 32nd international conference on Verylarge data bases, pages 953–964. VLDB Endowment, 2006.
[BT07] P. Buneman and W.-C. Tan. Provenance in databases. In Proceedings of the 2007ACM SIGMOD international conference on Management of data, pages 1171–1173.ACM, 2007.
[Cor12] IBM Corporation. IBM Infosphere Metadata Workbench version 9 release 1,tutorial. http://publibfp.boulder.ibm.com/epubs/pdf/c1938380.pdf, 2012. Accessed 06.06.14.
[Cui01] Y. Cui. Lineage Tracing in Data Warehouses. PhD thesis, Stanford University, 2001.[CW03] Y. Cui and J. Widom. Lineage tracing for general data warehouse transfor-
mations. The VLDB Journal—The International Journal on Very Large Data Bases,
71

Literaturverzeichnis
12(1):41–58, 2003.[CWW00] Y. Cui, J. Widom, and J. L. Wiener. Tracing the lineage of view data in a ware-
housing environment. ACM Transactions on Database Systems, 2000.[DW99] S. W. Dekker and David D. Woods. To intervene or not to intervene: the di-
lemma of management by exception. Cognition, Technology & Work, 1(2):86–96,1999.
[Few06] S. Few. Information dashboard design. O’Reilly, 2006.[Hav13] P. H. Havewala. Advanced uses of oracle enterprise manager 12c.
http://www.oracle.com/us/products/enterprise-manager/wp-advanced-uses-em12c-1982907.pdf?ssSourceSiteId=ocomde,August 2013. Accessed 06.06.14.
[Hel02] M. Helfert. Planung und Messung der Datenqualitat in Data-Warehouse-Systemen.PhD thesis, Universität St. Gallen, 2002.
[Hin02] H. Hinrichs. Datenqualitätsmanagement in Data Warehouse-Systemen. PhD thesis,Carl von Ossietzky Universität Oldenburg, 2002.
[HJ10] J. Higgins and B. Johnson. Information lifecycle support: wisdom, knowledge, infor-mation and data management (WKIDM). The Stationery Office, 2010.
[ICF+12] R. Ikeda, J. Cho, C. Fang, S. Salihoglu, S. Torikai, and J. Widom. Provenance-based debugging and drill-down in data-oriented workflows. 2012.
[Inm02] W. H. Inmon. Building the Data Warehouse. Wiley, J, 2002.[iti07] ITIL version 3 news. http://www.lucidit.com.my/itil_
version3news.php, June 2007.[KC04] R. Kimball and J. Caserta. The data warehouse ETL toolkit. John Wiley & Sons,
2004.[KR02] R. Kimball and M. Ross. The data warehouse toolkit: the complete guide to dimensio-
nal modelling. Wiley, 2002.[Krc00] H. Krcmar. Informationsmanagement. Springer, 2000.[Küt11] Martin Kütz. Kennzahlen in der IT: Werkzeuge für Controlling und Manage-
ment, 2011.[LBM98] T. Lee, S. Bressan, and S. E Madnick. Source attribution for querying against
semi-structured documents. In Workshop on Web Information and Data Manage-ment, pages 33–39, 1998.
[Leu01] H. K.N. Leung. Quality metrics for intranet applications. Information & Mana-gement, 38(3):137–152, 2001.
[Lim13] AXELOS Limited. ITIL® Glossar und Abkürzungen deutsch. http://www.itil-officialsite.com/InternationalActivities/ITILGlossaries_2.aspx, March 2013.
[Man14] Enterprise Manager Product Management. Strategies for scalable,smarter monitoring using oracle enterprise manager cloud control12c. http://www.oracle.com/technetwork/oem/sys-mgmt/wp-em12c-monitoring-strategies-1564964.pdf, June 2014. Ac-cessed 06.06.14.
72

Literaturverzeichnis
[MBEH09] M. Mosley, M. H. Brackett, S. Earley, and D. Henderson. DMBOK@ Guide.Technics Publications, 2009.
[Nis12] C. F. Nissen. Passing Your ITIL Foundation Exam. The Stationery Office Books,2012.
[Orr98] K. Orr. Data quality and systems theory. Communications of the ACM, 41:66–71,February 1998.
[PLW02] L. L. Pipino, Y. W. Lee, and R. Y. Wang. Data quality assessment. Communicati-ons of the ACM, 45:211–218, April 2002.
[PM08] N. Prat and S. Madnick. Measuring data believability: A provenance approach.In Hawaii International Conference on System Sciences, Proceedings of the 41st An-nual, pages 393–393. IEEE, 2008.
[qli14] Qlikview homepage. http://www.qlik.com/de/explore/products/qlikview, August 2014.
[RL09] S. Ram and J. Liu. A new perspective on semantics of data provenance. InSWPM. Citeseer, 2009.
[Ros13] I. Rossak. Datenintegration. Hanser, 2013.[RQL12] F. J. Riemer, M. T. Quartaroli, and S. D. Lapan. Qualitative Research: An Introduc-
tion to Methods and Designs. Jossey-Bass, 2012.[SEW06] G. Shankaranarayanan, A. Even, and S. Watts. The role of process metadata
and data quality perceptions in decision making: an empirical framework andinvestigation. Journal of Information Technology Management, 17(1):50–67, 2006.
[SLW97] D. M. Strong, Y. W. Lee, and R. Y. Wang. Data quality in context. Communicationsof the ACM, 40:103–110, May 1997.
[SVD+09] A. Simitsis, P. Vassiliadis, U. Dayal, A. Karagiannis, and V. Tziovara. Bench-marking ETL Workflows. In R. Nambiar and M. Poess, editors, PerformanceEvaluation and Benchmarking, volume 5895 of Lecture Notes in Computer Science,pages 199–220. Springer Berlin Heidelberg, 2009.
[SVTS05] A. Simitsis, P. Vassiliadis, M. Terrovitis, and S. Skiadopoulos. Graph-based mo-deling of etl activities with multi-level transformations and updates. In DataWarehousing and Knowledge Discovery, pages 43–52. Springer, 2005.
[SWCD09] A. Simitsis, K. Wilkinson, M. Castellanos, and U. Dayal. QoX-driven ETL de-sign: reducing the cost of ETL consulting engagements. In Proceedings of the2009 ACM SIGMOD International Conference on Management of data, pages 953–960. ACM, 2009.
[Tan04] W.-C. Tan. Research problems in data provenance. IEEE Data Eng. Bull.,27(4):45–52, 2004.
[TB98] G. K. Tayi and D. P. Ballou. Examining data quality. Communications of the ACM,41:54–57, February 1998.
[Tuf83] E. R. Tufte. The visual display of quantitative information, volume 2. Graphics pressCheshire, CT, 1983.
[VSB09] P. Vassiliadis, A. Simitsis, and E. Baikousi. A taxonomy of ETL activities. In Pro-ceedings of the ACM twelfth international workshop on Data warehousing and OLAP,
73

Literaturverzeichnis
pages 25–32. ACM, 2009.[VSS02] P. Vassiliadis, A. Simitsis, and S. Skiadopoulos. Modeling ETL activities as gra-
phs. In DMDW, volume 58, pages 52–61, 2002.[Wü03] V. G. Würthele. Datenqualitätsmetrik für Informationsprozesse. PhD thesis, ETH
Zürich, 2003.[Wea04] C. Weaver. Building highly-coordinated visualizations in improvise. In Infor-
mation Visualization, 2004. INFOVIS 2004. IEEE Symposium on, pages 159–166.IEEE, 2004.
[Wid95] J. Widom. Research problems in data warehousing. In Proceedings of the fourthinternational conference on Information and knowledge management, pages 25–30.ACM, 1995.
[Wid04] J. Widom. Trio: A system for integrated management of data, accuracy, andlineage. Technical Report, 2004.
[WS04] R. Winter and B. Strauch. Information requirements engineering for data ware-house systems. In Proceedings of the 2004 ACM symposium on Applied computing,pages 1359–1365. ACM, 2004.
[YaKSJ07] J. S. Yi, Y. ah Kang, J. T. Stasko, and J. A. Jacko. Toward a deeper understandingof the role of interaction in information visualization. Visualization and ComputerGraphics, IEEE Transactions on, 13(6):1224–1231, 2007.
74


![How to use opm [Kompatibilitätsmodus]€¦ · Leibniz-Institut DSMZ-Deutsche Sammlung von Mikroorganismen und Zellkulturen GmbH Batch-export of OmniLog kinetic data as CSV files](https://static.fdokument.com/doc/165x107/5ea9f76c899da410124c89e2/how-to-use-opm-kompatibilittsmodus-leibniz-institut-dsmz-deutsche-sammlung-von.jpg)















