
Fehlende Werte in sportwissenschaftlichen Untersuchungen; Missing values in sport scientific...
11
Sportwiss 2012 · 42:126–136 DOI 10.1007/s12662-012-0249-5 © Springer-Verlag 2012 Darko Jekauc 1 · Manuel Völkle 2 · Lena Lämmle 3 · Alexander Woll 1 1 Institut für Sportwissenschaft, Universität Konstanz 2 Max Planck Institute for Human Development Berlin 3 Technische Universität München Fehlende Werte in sportwissenschaftlichen Untersuchungen Eine anwendungsorientierte Einführung in die multiple Imputation mit SPSS Fehlende Werte stellen in den empi- rischen Wissenschaften ein Problem dar, das gerade in der sportwissen- schaftlichen Literatur häufig vernach- lässigt wird. Ein nicht sachgerechter Umgang mit fehlenden Werten kann jedoch nicht nur zu schwerwiegenden Verzerrungen der Parameterschät- zungen führen, sondern auch zu einer drastisch reduzierten Stichproben- größe mit daraus resultierender redu- zierter Teststärke. Daher hat die American Psychological Association (2009) Angaben zum Um- gang mit fehlenden Daten zum interna- tionalen Publikationsstandard erklärt. Infolgedessen gab es in den letzten Jah- ren eine bemerkenswert stark ansteigen- de Anzahl von methodischen Publikatio- nen, die sich mit dem Thema beschäfti- gen (vgl. Schafer und Graham 2002), so- wie eine rasante Entwicklung neuer sta- tistischer Verfahren zum Umgang mit fehlenden Werten (Graham 2009). Die zunehmende Bedeutung dieses Themas spiegelt sich auch in der Entwicklung neuer und leistungsfähiger Software- programme zum Umgang mit fehlen- den Werten wider. Beispiele sind NORM (Schafer 1997), MICE (van Buuren und Oudshoorn 1999), oder AMELIA (King et al. 2001). Aber auch in Standardstatis- tikpaketen wie z. B. SAS SPSS, STATA oder SYSTAT werden immer mehr Ver- fahren zur Behandlung fehlender Werte angeboten. In der Sportwissenschaft ist SPSS eines der am häufigsten eingesetz- ten Statistikprogramme. Seit Version 17 (SPSS 2009) ist hier ein Modul zur mul- tiplen Imputation (MI) implementiert. Leider existieren momentan jedoch nur vereinzelte (englischsprachige) Doku- mentationen zu diesem Modul und, so- weit bekannt, keine wissenschaftlichen Anwendungen von MI mit SPSS. Ziel des vorliegenden Beitrags ist es, diese Lücke mit Hilfe einer Einführung in die Analyse von fehlenden Werten in der Sportwissenschaft zu schließen. Die Um- setzung der hier empfohlenen Methode wird im Rahmen des Statistikprogramms SPSS erläutert und die Anwendung an- hand eines empirischen Beispiels aus der Sportwissenschaft dargestellt. Im ersten Teil des Artikels werden For- men und Systematik von fehlenden Wer- ten vorgestellt. Daran anschließend wer- den im zweiten Teil Verfahren und ihre Methoden zur Schätzung fehlender Wer- te erläutert und diskutiert. Im darauf fol- genden Abschnitt wird eine praxisnahe Einführung in die Analyse von fehlenden Werten anhand des Statistikprogramms SPSS gegeben. Abschließend werden die vorgestellten Verfahren kritisch diskutiert und hinsichtlich ihrer Implikationen für die Praxis bewertet. Formen und Systematik fehlender Daten Es werden zwei verschiedene Arten von fehlenden Daten unterschieden. Beim sog. Item-Nonresponse fehlen einzelne Werte auf einer oder mehreren Variab- len. Gründe für einen solchen Daten- ausfall können z. B. die Verweigerung einer Antwort oder das zufällige Über- sehen einer Frage sein. Werden die feh- lenden Werte durch Schätzungen ersetzt, spricht man von sog. Imputationsverfah- ren bzw. Ersetzungsverfahren. Im Gegen- satz dazu ist beim Unit-Nonresponse der Datenausfall i. d. R. wesentlich umfang- reicher und entspricht dem Fehlen einer ganzen Untersuchungseinheit. In diesem Fall liegen relativ wenige Informationen über die Untersuchungseinheit vor, so dass kaum eine empirische Basis vor- handen ist, um die fehlenden Informa- tionen zu schätzen. Hier werden in der Praxis sog. Gewichtungsver- fahren ver- wendet, auf die in diesem Beitrag nicht eingegangen werden soll. Eine Über- sicht über diese Verfahren geben Schnell (1997, S. 245 ff.) sowie Groves, Fowler, Couper, Lepkowski, Singer und Touran- geau (2009, S. 347 ff.). 126 | Sportwissenschaft 2 · 2012 Hauptbeiträge
Transcript of Fehlende Werte in sportwissenschaftlichen Untersuchungen; Missing values in sport scientific...

Sportwiss 2012 · 42:126–136DOI 10.1007/s12662-012-0249-5© Springer-Verlag 2012
Darko Jekauc1 · Manuel Völkle2 · Lena Lämmle3 · Alexander Woll1
1 Institut für Sportwissenschaft, Universität Konstanz2 Max Planck Institute for Human Development Berlin3 Technische Universität München
Fehlende Werte in sportwissenschaftlichen UntersuchungenEine anwendungsorientierte Einführung in die multiple Imputation mit SPSS
Fehlende Werte stellen in den empi-rischen Wissenschaften ein Problem dar, das gerade in der sportwissen-schaftlichen Literatur häufig vernach-lässigt wird. Ein nicht sachgerechter Umgang mit fehlenden Werten kann jedoch nicht nur zu schwerwiegenden Verzerrungen der Parameterschät-zungen führen, sondern auch zu einer drastisch reduzierten Stichproben-größe mit daraus resultierender redu-zierter Teststärke.
Daher hat die American Psychological Association (2009) Angaben zum Um-gang mit fehlenden Daten zum interna-tionalen Publikationsstandard erklärt. Infolgedessen gab es in den letzten Jah-ren eine bemerkenswert stark ansteigen-de Anzahl von methodischen Publikatio-nen, die sich mit dem Thema beschäfti-gen (vgl. Schafer und Graham 2002), so-wie eine rasante Entwicklung neuer sta-tistischer Verfahren zum Umgang mit fehlenden Werten (Graham 2009). Die zunehmende Bedeutung dieses Themas spiegelt sich auch in der Entwicklung neuer und leistungsfähiger Software-programme zum Umgang mit fehlen-den Werten wider. Beispiele sind NORM (Schafer 1997), MICE (van Buuren und Oudshoorn 1999), oder AMELIA (King et al. 2001). Aber auch in Standardstatis-
tikpaketen wie z. B. SAS SPSS, STATA oder SYSTAT werden immer mehr Ver-fahren zur Behandlung fehlender Werte angeboten. In der Sportwissenschaft ist SPSS eines der am häufigsten eingesetz-ten Statistikprogramme. Seit Version 17 (SPSS 2009) ist hier ein Modul zur mul-tiplen Imputation (MI) implementiert. Leider existieren momentan jedoch nur vereinzelte (englischsprachige) Doku-mentationen zu diesem Modul und, so-weit bekannt, keine wissenschaftlichen Anwendungen von MI mit SPSS.
Ziel des vorliegenden Beitrags ist es, diese Lücke mit Hilfe einer Einführung in die Analyse von fehlenden Werten in der Sportwissenschaft zu schließen. Die Um-setzung der hier empfohlenen Methode wird im Rahmen des Statistikprogramms SPSS erläutert und die Anwendung an-hand eines empirischen Beispiels aus der Sportwissenschaft dargestellt.
Im ersten Teil des Artikels werden For-men und Systematik von fehlenden Wer-ten vorgestellt. Daran anschließend wer-den im zweiten Teil Verfahren und ihre Methoden zur Schätzung fehlender Wer-te erläutert und diskutiert. Im darauf fol-genden Abschnitt wird eine praxisnahe Einführung in die Analyse von fehlenden Werten anhand des Statistikprogramms SPSS gegeben. Abschließend werden die vorgestellten Verfahren kritisch diskutiert
und hinsichtlich ihrer Implikationen für die Praxis bewertet.
Formen und Systematik fehlender Daten
Es werden zwei verschiedene Arten von fehlenden Daten unterschieden. Beim sog. Item-Nonresponse fehlen einzelne Werte auf einer oder mehreren Variab-len. Gründe für einen solchen Daten-ausfall können z. B. die Verweigerung einer Antwort oder das zufällige Über-sehen einer Frage sein. Werden die feh-lenden Werte durch Schätzungen ersetzt, spricht man von sog. Imputationsverfah-ren bzw. Ersetzungsverfahren. Im Gegen-satz dazu ist beim Unit-Nonresponse der Datenausfall i. d. R. wesentlich umfang-reicher und entspricht dem Fehlen einer ganzen Untersuchungseinheit. In diesem Fall liegen relativ wenige Informationen über die Untersuchungseinheit vor, so dass kaum eine empirische Basis vor-handen ist, um die fehlenden Informa-tionen zu schätzen. Hier werden in der Praxis sog. Gewichtungsverfahren ver-wendet, auf die in diesem Beitrag nicht eingegangen werden soll. Eine Über-sicht über diese Verfahren geben Schnell (1997, S. 245 ff.) sowie Groves, Fowler, Couper, Lepkowski, Singer und Touran-geau (2009, S. 347 ff.).
126 | Sportwissenschaft 2 · 2012
Hauptbeiträge

Tab. 1 Übersicht über gängige Methoden zur Behandlung fehlender Werte
Methodenart Name Beschreibung Bedingung
Ausschluss Fallweiser Ausschluss
Ausschluss aller Fälle, die mindestens einen fehlenden Wert aufweisen.
MCAR
Paarweiser Ausschluss
Variablen werden paarweise analysiert, wobei alle Fälle mit fehlenden Werten auf einer oder beiden Variablen ausge-schlossen werden.
MCAR
Einfache Im-putation
Ersetzung durch Mittel-werte
Alle fehlenden Werte werden durch Mittelwerte der jeweiligen Variablen ersetzt.
MCAR
Regressions-schätzungen
Fehlende Werte werden anhand regres-sionsanalytischer Verfahren geschätzt und ersetzt.
MAR
Maximum-Likelihood-Verfahren
EM-Algorith-mus
Fehlende Werte werden anhand des EM-Algorithmus geschätzt und ersetzt.
MAR
FIML-Me-thode
Direkte ML-Schätzung der Parameter unter Berücksichtigung aller (vollstän-diger und unvollständiger) Fälle.
MAR
Multiple Im-putation
Multiple Im-putation
Fehlende Werte werden durch mehrere Schätzungen ersetzt.
MAR
MAR „missing at random“, MCAR „missing completely at random“.
Die Frage, wodurch fehlende Werte verursacht wurden, lässt sich in der For-schungspraxis häufig nicht beantworten. Anstatt den Item-Nonresponse nach der Ursache zu klassifizieren, wird daher die Systematik des Ausfalls betrachtet. Eine solche Klassifizierung geht auf die Arbeit von Rubin (1976) zurück, der den Ausfall-prozess als probabilistisches Phänomen beschreibt. Neben den in einem hypo-thetischen Datensatz enthaltenen Variab-len Y werden auch sog. Ausfallindikato-ren M der Variablen betrachtet. Im Fall von nur einer einzigen Variable Y1 han-delt es sich lediglich um eine Dummy-Va-riable, die den Wert M=1 annimmt, wenn der zugehörige Wert auf Y1 vorhanden ist und den Wert M=0 annimmt, wenn der entsprechende Wert auf Y1 fehlt. Für den Fall eines beliebig großen Datensat-zes ist M eine Matrix der gleichen Ord-nung wie der Datensatz mit Nullen und Einsen an den Stellen mit fehlenden, res-pektive vorhandenen Werten (d. h. M ist eine N×J-Matrix, bei der Nder Anzahl der Personen und J der Anzahl der Va-riablen entspricht). Genau wie in einem vollständigen Datensatz handelt es sich al-so auch bei den J Dummy-Variablen in M um Zufallsvariablen mit einer bestimm-ten Wahrscheinlichkeitsfunktion P(M).
Rubin (1976) geht in seinem Ansatz da-von aus, dass sich der vollständige Daten-satz (Yges) aus den tatsächlich beobachte-ten Daten (Ybeo) und den fehlenden Daten (Ymis) zusammensetzt, also Yges=(Ybeo,Ymis). Für den Fall, dass der Ausfallpro-zess vollkommen unsystematisch ist, d. h. die fehlenden Werte ausschließlich durch Zufall entstanden sind, spricht man von „missing completely at random“ (MCAR). Dies ist der Fall wenn:
P (M|Yges) = P (M)
Ob ein Wert fehlt oder nicht (M), ist also unabhängig von Yges. Beispielsweise kann ein Proband beim Ausfüllen des Fragebo-gens eine Frage unabsichtlich übersehen haben. Die Bedingung vollständiger Zu-fälligkeit von fehlenden Daten ist in sport-wissenschaftlichen Studien leider nur sel-ten gegeben. So stehen fehlende Werte in einem sportmotorischen Test häufig in Verbindung mit bestimmten motori-schen Einschränkungen und gesundheit-lichen Auffälligkeiten.
In sportwissenschaftlichen Studien ist die Bedingung des bedingtzufälligenAus-falls (MAR) realistischer. Ist der Ausfall-mechanismus abhängig von Variablen, die im beobachteten Datensatz vorhan-
den sind, spricht man von „missing at random“ (MAR).
P (M|Yges) = P (M|Ybeo)
Leider ist die Begriffswahl etwas un-glücklich, da sie suggeriert, dass der Aus-fallprozess wie bei MCAR rein zufällig (d. h. „at random“) ist. Der Ausfall ist in diesem Fall jedoch nur bedingt zufällig, da er von anderen in der Untersuchung erhobenen Variablen abhängt. Gleichzei-tig liefern diese Variablen aber auch die ausfallrelevanten Informationen, so dass der Ausfallprozess durch Kontrolle die-ser Variablen rekonstruiert werden kann. Fehlen beispielsweise Informationen zu einem bestimmten Item einer Skala, kön-nen diese fehlenden Informationen unter Umständen aus anderen Items der Skala geschätzt werden. Im Fall der Bedingun-gen MCAR und MAR spricht man auch von ignorierbaremNonresponse (Schafer und Graham 2002).
Ist der Ausfallprozess von Faktoren abhängig, die nicht erhoben wurden, spricht man von „missing not at ran-dom“ (MNAR). Auch nach Kontrolle der vorhandenen Variablen ist das Auftre-ten von fehlenden Werten von der (feh-lenden) Ausprägung der Variable selbst abhängig. Dies ist immer dann der Fall, wenn
P (M|Yges) �= P (M|Ybeo).
Soll beispielsweise die Gesundheit einer Person erfasst werden, so kann es passie-ren, dass gerade weniger gesunde Perso-nen (z. B. aus Angst vor Stigmatisierung) die Teilnahme an der Untersuchung ver-weigern. In diesem Fall hängt der fehlen-de Wert der Gesundheit vom eigentlichen Gesundheitszustand ab, das heißt die Mis-sings wären MNAR. Auch unter Berück-sichtigung aller anderen Variablen wären die fehlenden Werte nicht rekonstruier-bar. Aus diesem Grund stellt MNAR die schwierigste Bedingung beim Umgang mit fehlenden Daten dar. Man spricht in einem solchen Fall auch von nichtigno-rierbaremNonresponse.
Leider lässt sich nur bedingt empi-risch prüfen, welche Art von Mecha-nismus vorliegt. Allein die MCAR-An-nahme ist empirisch falsifizierbar, in-dem Dummy-Variablen, die den Aus-
127Sportwissenschaft 2 · 2012 |

fall repräsentieren, mit anderen Variab-len im Datensatz korreliert werden. Sind die Korrelationen signifikant, lässt sich die Annahme von MCAR nicht län-ger aufrechterhalten. Ein Test, der die-se Überprüfung in einer einzigen Sta-tistik zusammenfasst, wurde von Litt-le (1988) entwickelt. Sollte sich bei die-sem Test herausstellen, dass die MCAR-Bedingung nicht zutrifft, muss man ent-weder von MAR oder MNAR ausgehen. Eine Klärung der Frage, welche der bei-den Annahmen zutrifft, ist jedoch ohne weitere Information – wie z. B. einer ex-pliziten Nachbefragung aller Nonrespon-der – nicht möglich (Allison 2002; Wirtz 2004). Eine solche unabhängige Unter-suchung wird aufgrund des hohen Auf-wands jedoch nur in den seltensten Fäl-len durchgeführt.
Methoden zur Behandlung von Item-Nonresponse
Im Allgemeinen unterscheidet man 4 gän-gige Verfahrensklassen zum Umgang mit fehlenden Werten, auf die im Folgenden genauer eingegangen werden soll: Aus-schluss, einfache Imputation, Maximum-Likelihood-Verfahren und multiple Im-putation (. Tab. 1).
Ausschlussverfahren
Fallweiser AusschlussDie am häufigsten eingesetzte Methode für den Umgang mit fehlenden Werten ist der fallweise Ausschluss („listwise de-letion“). Alle Personen, die mindestens einen fehlenden Wert aufweisen, werden hier von der Analyse ausgeschlossen. Als Konsequenz können Stichprobengrö-ße und Teststärke drastisch sinken. Da-rüber hinaus geht diese Methode davon aus, dass der Ausfallprozess vollkommen zufallsbedingt ist (MCAR). Ist MCAR nicht gegeben, kann der fallweise Aus-schluss zu schwerwiegenden Verzerrun-gen der Parameterschätzungen führen (Graham und Hofer 2000). Verweigern beispielsweise sportlich inaktive Per-sonen die Teilnahme an einer Untersu-chung besonders häufig, wird durch den fallweisen Ausschluss das durchschnittli-che Aktivitätsniveau der Untersuchungs-population überschätzt. Dieses Vorgehen
empfiehlt sich daher allenfalls bei einem sehr geringen Ausmaß fehlender Werte (<5% der Fälle) und bei Vorliegen eines MCAR-Ausfallprozesses, der vorher zu überprüfen ist (vgl. Allison 2002). Auf-grund der erwähnten Mängel sollte von dem fallweisen Ausschluss grundsätzlich abgesehen werden.
Paarweiser AusschlussEbenfalls häufig wird das Verfahren des paarweisen Ausschlusses („pairwise de-
letion“) angewendet. Hier werden bei je-der Analyse alle Fälle ohne fehlende Wer-te auf den zu analysierenden Variablen he-rangezogen. Dabei ist es unerheblich, ob diese Fälle auf anderen Variablen fehlende Werte aufweisen oder nicht. Dieses Ver-fahren setzt wie der fallweise Ausschluss die restriktive MCAR-Bedingung voraus. Der Verlust der Teststärke ist beim paar-weisen Ausschluss im Allgemeinen gerin-ger als beim fallweisen Ausschluss, da die Anzahl der insgesamt berücksichtigten
Zusammenfassung · Abstract
Sportwiss 2012 · 42:126–136 DOI 10.1007/s12662-012-0249-5© Springer-Verlag 2012
Darko Jekauc · Manuel Völkle · Lena Lämmle · Alexander Woll
Fehlende Werte in sportwissenschaftlichen Untersuchungen. Eine anwendungsorientierte Einführung in die multiple Imputation mit SPSS
ZusammenfassungFehlende Werte sind in der empirischen For-schung ein ernstzunehmendes Problem, das gerade in sportwissenschaftlichen Studien oft vernachlässigt wird. Häufig eingesetzte Verfahren wie Regressionsmethode, fallwei-ser und paarweiser Ausschluss und Mittel-wertsersetzungen stellen aus methodischer Sicht keine befriedigende Lösung dar. Neue-re Verfahren wie Maximum-Likelihood-Schät-zungen (ML) und multiple Imputation (MI) finden nach wie vor zu selten Anwendung. Ziel des vorliegenden Artikels ist es, dem ent-gegenzuwirken. Basierend auf der statisti-schen Theorie fehlender Werte nach Rubin (1976) werden verschiedene Verfahren zum Umgang mit fehlenden Werten vorgestellt und kritisch diskutiert. Im Fokus steht dabei
das Verfahren der multiplen Imputation (MI). Seit der Implementierung von MI in SPSS Ver-sion 17 (SPSS 2009) steht dem routinemä-ßigen Einsatz durch eine breite Anwender-schaft nichts mehr im Wege. Illustriert wird der Einsatz von MI im letzten Teil des Artikels anhand einer empirischen Studie mit einem für sportwissenschaftliche Untersuchun-gen typischen Ausfallprozess. Vorteile des MI, aber auch Grenzen und Schwierigkeiten bei der Umsetzung werden anhand dieses Bei-spiels diskutiert.
SchlüsselwörterFehlende Daten · SPSS · Multiple Imputation · Maximum Likelihood · Predictive Mean Matching
Missing values in sport scientific studies. A practical guide to multiple imputation with SPSS
AbstractMissing values are a serious statistical prob-lem in empirical studies which tends not to be considered in sport scientific studies. The methods usually applied such as listwise and pairwise deletion, mean and regression im-putation do not constitute satisfactory solu-tions. New methods such as Maximum Like-lihood Estimation (ML) and Multiple Impu-tation (MI) have not yet been widely imple-mented. The aim of this article is to change this situation. For this purpose, this article provides an overview of the missing data the-ory stated by Rubin (1976). Based on this ap-proach, different methods for dealing with the problem of missing data will be present-ed and discussed. Special emphasis is put on
new methods, in particular MI. In the past, the application of MI required special soft-ware. Since the implementation of MI in SPSS 17 (SPSS 2009) there is no obstacle for a rou-tine usage of this method to handle missing data problems. The implementation of MI will be illustrated with an empirical study with a missing data mechanism typical for sport sci-entific studies. Using this example, advan-tages of MI as well as current limitations and practical difficulties will be discussed.
KeywordsMissing data · SPSS · Multiple imputation · Maximum likelihood · Predictive mean matching
128 | Sportwissenschaft 2 · 2012

Fälle gleich oder höher ist (Wirtz 2004). Jedoch kann bei multivariaten Analysen dieses Verfahren zu inkonsistenten und sogar per Definition unmöglichen Para-meterschätzungen (z. B. R2>1) führen, da die Parameter auf Grundlage unter-schiedlicher Fälle geschätzt werden (Gra-ham 2009). Das trifft beispielsweise dann zu, wenn die Korrelation von X1 und Y an-hand anderer Fälle bestimmt wird als die Korrelation von X2 und Y. Dabei bleibt die Frage nach der totalen Stichprobengröße und der Vergleichbarkeit der beiden Ef-fekte ungeklärt. Entsprechend schließen wir uns der Empfehlung von Graham und Hofer (2000) an: „pairwise deletion should never be used, not even for ‚quick and dirty‘ analyses“ (S. 205).
Zusammenfassend lässt sich also fest-halten, dass Ausschlussverfahren fast im-mer zu einer übermäßigen Reduktion der Stichprobe führen. Die Vorausset-zung von MCAR schränkt die Anwend-barkeit dieser Verfahren darüber hinaus enorm ein, da MCAR in der Forschungs-praxis als eher unwahrscheinlich angese-hen werden muss. Imputationsverfahren versuchen diesen Problemen besser ge-recht zu werden.
Einfache Imputationsverfahren
Grundlegendes Merkmal der Imputa-tionsverfahren ist die Ersetzung der feh-lenden Werte durch geschätzte Werte, bis ein vollständiger Datensatz resultiert. Im Folgenden sollen die beiden bekanntes-ten einfachen Imputationsverfahren vor-gestellt werden.
MittelwertsersetzungenBei Mittelwertsersetzungen werden feh-lende Werte durch den Mittelwert der jeweiligen Variablen ersetzt. Somit ent-steht ein kompletter Datensatz, in dem al-le Fälle in die Analysen einbezogen wer-den können. Bei dieser Methode wird je-doch ebenfalls die restriktive MCAR-Be-dingung vorausgesetzt. Sind die fehlenden Werte nicht vollkommen zufällig entstan-den, ist der Stichprobenmittelwert der vorhandenen Werte nicht nur eine syste-matisch verzerrte Schätzung jedes einzel-nen nicht vorhandenen Messwerts, son-dern auch ein verzerrter Schätzer des Mit-telwerts der Grundgesamtheit. Darüber
hinaus führt diese Methode selbst beim Vorliegen von MCAR zur Unterschät-zung der Populationsvarianz, da die feh-lenden Werte durch eine konstante Zahl (den Mittelwert) in jeder Variablen ersetzt werden und somit die Variabilität redu-zieren. Auf Mittelwertsersetzungen soll-te daher nach Möglichkeit verzichtet wer-den (vgl. Allison 2002; Graham und Hofer 2000; Wirtz 2004).
Regressionsbasierte VerfahrenBei den regressionsbasierten Verfahren („conditional mean imputation“) werden fehlende Werte durch Schätzungen an-hand einer Regression ersetzt. Wenn eine Variable Yfehlende Werte aufweist und die Variablen X1 bis Xn vollständig sind, dann können anhand der vollständigen Variablen X1 bis Xn mit Hilfe der mul-tiplen Regression die fehlenden Werte in Y geschätzt werden. Dieses Verfahren ist insofern angemessener als die Erset-zung fehlender Werte durch Mittelwer-te, da alle im Datensatz vorhandenen In-formationen genutzt werden. Die Schät-zungen der Mittelwerte und Standardab-weichungen sind geringer verzerrt und es wird lediglich die weniger restrikti-ve MAR-Bedingung vorausgesetzt (Gra-ham 2009). Dennoch weist auch die-se Methode ähnliche Schwachstellen auf wie die Mittelwertsersetzungen: Die Populationsvarianz wird ebenfalls syste-matisch unterschätzt, da sich alle Schät-zungen auf der gleichen Regressionsge-raden befinden und somit weniger stark streuen. Ein weiterer Nachteil besteht da-rin, dass die Populationskorrelation sys-tematisch überschätzt wird, da für die ersetzten Werte der multiple Determi-nationskoeffizient R2=1 beträgt. Um die-sem Problem entgegenzuwirken, schla-gen Schafer und Graham (2002, S. 159) die Addition eines zufällig aus der Feh-lerverteilung des Regressionsmodells ge-zogenen Residualwertes zu dem ermittel-ten Schätzwert vor. Diese Methode wird als „Stochastic Regression Imputation“ bezeichnet (Schafer und Graham 2002). Eine verwandte Methode ist das Predicti-ve Mean Matching. Hierbei wird der feh-lende Wert durch den Wert einer ande-ren Geberperson ersetzt. Das Kriterium zur Bestimmung der Geberperson ist die Nähe des durch die Regression geschätz-
ten Wertes der Geber-Person mit dem geschätzten fehlenden Wert.1
Ein zentrales Problem der einfachen Imputationsverfahren ist jedoch die kor-rekte Bestimmung des Standardfehlers. Die geschätzten Werte werden als echte Werte behandelt, womit fälschlicherweise eine zu große Stichprobe suggeriert wird. Aus diesem Grund wird auch von diesen Methoden weitgehend abgeraten (vgl. dazu Graham und Hofer 2000; Schafer und Graham 2002; Allison 2002; Wirtz 2004, Graham 2009).
Maximum-Likelihood-Verfahren
Maximum-Likelihood-Verfahren (ML-Verfahren) wurden in den letzten Jah-ren intensiv in der statistischen Fachlite-ratur diskutiert. Grundidee des ML-Ver-fahrens ist es, die Populationsparameter so zu schätzen, dass die Wahrscheinlich-keit für die Realisation der vorliegenden Daten maximiert wird. Dazu ist es erfor-derlich, dass die MAR- oder MCAR-Be-dingung erfüllt ist. Im Wesentlichen wer-den 2 ML-Ansätze zum Umgang mit feh-lenden Daten unterschieden: der Erwar-tungs-Maximierungs(EM)-Algorithmus und das Full-Information-Maximum-Likelihood (FIML).
EM-AlgorithmusBeim EM-Algorithmus handelt es sich um einen iterativen, 2-stufigen Prozess (Dempster et al. 1977). In einem ersten Schritt (Expectation) werden die fehlen-den Werte ersetzt und in einem zwei-ten Schritt (Maximization) die Mittel-werte und (Ko-)Varianzen des vollstän-digen Datensatzes bestimmt. Auf Ba-sis der so berechneten Parameter (Mit-telwerte, Varianzen und Kovarianzen) wird eine neue Schätzung der fehlen-den Werte vorgenommen. Diese bei-
1 Predictive Mean Matching ähnelt dabei stark einer anderen Klasse an Imputationsverfahren, der sog. Hot-Deck-Imputation (Ford, 1983). Hie-runter versteht man ganz allgemein eine Ver-fahrensklasse, die darauf abzielt, fehlende Wer-te einer Person durch die Werte einer möglichst ähnlichen anderen (Geber-)Person zu ersetzen. Die einzelnen Ansätze unterscheiden sich da-rin, wie genau diese Ähnlichkeit quantifiziert wird. Gerade in der Umfrageforschung haben Hot-Deck-Imputationen einige Aufmerksamkeit erhalten (Scheuren, 2005).
129Sportwissenschaft 2 · 2012 |

den Schritte werden so lange wiederholt, bis sich die Parameterschätzungen (al-so die Mittelwerte, Varianzen und Kova-rianzen) von einem Schritt zum nächs-ten nicht mehr verändern und somit der Algorithmus konvergiert. Der Algorith-mus beginnt mit einer ersten Schätzung der Mittelwerte, Varianzen und Kova-rianzen, z. B. auf Basis des weiter oben beschriebenen fallweisen Ausschlusses. Anhand der Mittelwerte, Varianzen und Kovarianzen wird dann für jede Variab-le eine Regressionsgleichung aufgestellt, mit der die fehlenden Werte in Analogie zur Stochastic Regression Imputation geschätzt werden. Basierend auf dem so resultierenden vollständigen Datensatz werden nun erneut die Mittelwerte, Va-rianzen und Kovarianzen berechnet. Ziel des iterativen Prozesses ist es, die Para-meter so zu bestimmen, dass die (Log-)Likelihood maximal ist. Dies impliziert die Identifikation des Mittelwertsvektors und der Kovarianzmatrix, die mit höchs-ter Wahrscheinlichkeit den beobachte-ten Datensatz generiert haben. Eine aus-führliche Beschreibung des EM-Algo-rithmus findet sich bei Little und Rubin (2002, S. 168 ff.) sowie bei Enders (2010, S. 103 ff.).
Der EM-Algorithmus wurde mittler-weile in vielen Statistikprogrammen im-plementiert. Unter der Annahme von MAR liefert er erwartungstreue und ef-fiziente Parameterschätzungen (Schafer 2000), wobei die Schätzungen in aller Re-gel immer genauer werden, je mehr Va-riablen in die Schätzung einbezogen wer-den.
Erzeugt man anhand des EM-Algo-rithmus nur einen Datensatz, wird der Standardfehler bei nachfolgenden Ana-lysen jedoch unterschätzt. Bislang wur-de zwar eine Vielzahl von Methoden zur Wahl der korrekten Stichprobengröße vorgeschlagen, doch bleibt das Problem einer korrekten Bestimmung der Stan-dardfehler im EM-Algorithmus prinzi-piell bestehen (Enders und Peugh 2004). Vorteil des EM-Algorithmus ist also eine optimale Parameterschätzung unter Be-rücksichtigung aller verfügbaren Infor-mationen im Datensatz. Nachteil hin-gegen ist die unklare Berechnung der Standardfehler.
Full-Infomation-Maxi-mum-LikelihoodIm Gegensatz zum EM-Algorithmus er-folgt die Schätzung der Modellparameter bei der Full-Infomation-Maximum-Like-lihood(FIML)-Methode in einem einzigen Schritt. Die Parameterschätzung geschieht dabei durch Maximierung der Likelihood-Funktion. Im Gegensatz zur Analyse eines vollständigen Datensatzes basiert FIML jedoch auf der Maximierung des Produkts der individuellen Likelihood-Funktionen aller N Personen. Somit wird für jede ein-zelne Person eine Wahrscheinlichkeits-funktion (Likelihood-Funktion) definiert, bei der sich der Mittelwertsvektor sowie die Varianz-Kovarianz-Matrix in Abhän-gigkeit der für diese Person fehlenden Va-riablen unterscheiden. Auf diese Weise werden die fehlenden Werte aus der Like-lihood-Funktion ausintegriert (Lüdtke et al. 2007, S. 112), so dass die Standardfeh-ler korrekt bestimmt werden können. Im Gegensatz zum EM-Algorithmus bleibt jedoch die zur Parameterschätzung zur Verfügung stehende Information auf die im jeweiligen Analysemodell befindlichen Variablen beschränkt. Unter der Annah-me einer multivariaten Normalverteilung und MAR oder MCAR liefert die FIML-Methode erwartungstreue Parameter-schätzungen. Doch selbst bei moderaten Verletzungen der Normalverteilungsan-nahme schneidet FIML noch verhältnis-mäßig gut gegenüber den weiter oben be-schriebenen einfachen Verfahren ab (vgl. z. B. Enders und Bandalos 2001).
Aufgrund der modellbasierten Schät-zung wird FIML v. a. im Rahmen von Strukturgleichungsmodellen eingesetzt und stellt damit auch einen nicht zu ver-achtenden Vorteil von diesem Verfah-ren dar (Arbuckle 1996). In den gängigs-ten Programmen zur Analyse von Struk-turgleichungsmodellen (z. B. AMOS, LIS-REL, Mplus, Mx) ist FIML bereits als Stan-dardoption implementiert. Eine ebenso anschauliche wie ausführliche Einführung in die Maximum-Likelihood-Verfahren (insb. FIML) zum Umgang mit fehlenden Werten findet sich in Enders (2010).
Multiple Imputation
Ein weiteres Verfahren, das in den letz-ten Jahren stark an Bedeutung gewonnen
hat, ist die multiple Imputation (MI). Bei diesem Verfahren wird der fehlende Wert nicht nur einmal, sondern mehrmals ge-schätzt. Jeder fehlende Wert wird durch mehrere (m>1) simulierte, nicht identi-sche Werte ersetzt. Durch die m-fache Ersetzung fehlender Werte entstehen m plausible alternative Versionen des kom-pletten Datensatzes. Jeder dieser neu er-zeugten m Datensätze wird auf die glei-che Weise separat analysiert. Die Ergeb-nisse der einzelnen Analysen werden dann unter Berücksichtigung der durch die fehlenden Werte erzeugten Unsicher-heit zu einer Gesamtstatistik zusammen-gefasst. Man unterscheidet entsprechend zwischen der Imputationsphase, der Ana-lysephase und der Integration der Analy-sen in der sog. Poolingphase.
Bei der Anwendung der MI sieht man sich mit der Grundfrage konfrontiert, wie viele Datensätze generiert werden sol-len. Je mehr Datensätze generiert werden, desto weniger hängt das Gesamtergebnis von einem einzigen Imputationsschritt ab. Zudem verlängert sich auch die Be-rechnungsdauer entsprechend. In der Forschungspraxis werden in der Regel 10 bis 20 Datensätze empfohlen, wobei die-se Empfehlung von der jeweiligen Situa-tion abhängt. Daher kann diese Empfeh-lung nicht als allgemein gültig betrachtet werden (Schafer 1999).
Inzwischen existiert eine ganze Rei-he an verschiedenen Verfahren zur mul-tiplen Imputation. Für normalverteilte Daten dürfte jedoch der Data-Augmen-tation(DA)-Algorithmus (Tanner und Wong 1987) eines der am häufigsten ver-wendeten Verfahren sein. Hierbei han-delt es sich wie beim EM-Algorithmus um einen 2-stufigen Prozess. Der erste Schritt („imputation step“) ist dabei ver-gleichbar mit den weiter oben beschriebe-nen regressionsbasierten Verfahren (v. a. Stochastic Regression oder Predictive Mean Matching, vgl. Allison 2002). Hier werden aufgrund des vorhandenen Mit-telwertsvektors und der Kovarianzmatrix die fehlenden Werte mittels linearer Re-gression vorhergesagt und wie bei der Sto-chastic Regression ein Fehlerterm hinzu-addiert. Basierend auf dem so vervollstän-digten Datensatz werden in einem zwei-ten Schritt („posterior step“) Mittelwerts-vektor und Kovarianzmatrix neu berech-
130 | Sportwissenschaft 2 · 2012
Hauptbeiträge

net. Im Gegensatz zum EM-Algorithmus werden beim DA-Algorithmus nun je-doch der neu berechnete Mittelwertsvek-tor und die Kovarianzmatrix durch Ad-dition eines zufälligen Fehlerterms leicht verändert. Bei genauer Betrachtung zeigt sich, dass es sich bei dieser leichtenVer-änderung um eine Zufallsziehung aus der Posterior-Verteilung der Kovarianzmatrix handelt, gegeben den vervollständigten Datensatz und den beobachteten Mittel-wertsvektor (bzw. aus der Posterior-Ver-teilung des Mittelwertsvektors, gegeben den vervollständigten Datensatz und die beobachtete Kovarianzmatrix).2
Im Gegensatz zu den bisher behan-delten Verfahren versucht die multiple Imputation auf diese Weise zwei unter-schiedliche Arten von (durch fehlende Werte verursachte) mangelnder Variabi-lität zu korrigieren: einerseits die man-gelnde Variabilität, da alle geschätzten Werte auf der gleichen Regressionsgera-den liegen. Dieser versucht man durch Addition eines Fehlerterms zu begeg-nen. Andererseits die mangelnde Varia-bilität, da der zur Schätzung der fehlen-den Werte herangezogene Mittelwerts-vektor und die Kovarianzmatrix selbst nur eine Schätzung der wahren Popu-lationsmittelwerte und der wahren Po-pulations(ko-)varianzen darstellen. Wä-re es möglich mehrere Zufallsziehungen aus der Population vorzunehmen, wür-de man jedes Mal einen anderen Mittel-wertsvektor/Kovarianzmatrix erhalten. Da die Populationsverteilung jedoch un-bekannt ist, versucht man diesem Vorge-hen durch die leichteVeränderung (d. h. die Zufallsziehung des Mittelwertsvek-tors/Kovarianzmatrix aus der Poste rior-Verteilung) möglichst nahezukommen. Aus diesem Grund unterscheiden sich auch die Konvergenzkriterien von EM- und DA-Algorithmus. Während der EM-
2 Bei der Posteriorverteilung der Kovarianzma-trix handelt es sich um eine inverse Wishart-Ver-teilung, während es sich bei der Posteriorver-teilung des Mittelwertvektors um eine multi-variate Normalverteilung handelt. Das Konzept der Posteriorverteilung (sowie die Methode der multiplen Imputation an sich) ist eng mit dem bayesianischen Wahrscheinlichkeitsbegriff ver-bunden, auf welchen im Rahmen dieses Artikels jedoch nicht näher eingegangen werden kann. Für ein tiefergehendes Verständnis empfehlen wir die Lektüre von Enders (2010).
Algorithmus konvergiert, wenn sich die Elemente des Mittelwertvektors/Kova-rianzmatrix nicht mehr bedeutsam än-dern (was bei DA nie der Fall wäre), kon-vergiert der DA-Algorithmus, wenn sich die Verteilung aus der Kovarianzmatrix nicht mehr bedeutend ändert (vgl. En-ders 2010; Graham und Hofer 2000).
Der DA-Algorithmus gehört zur Fa-milie der Markov-Chain-Monte-Car-lo(MCMC)-Algorithmen. Das typische an MCMC-Algorithmen ist, dass die gesam-te Information eines Schritts der DA im vorangehenden Schritt enthalten ist. Des-halb sind die Schätzungen der Parame-ter und der fehlenden Werte von zwei un-mittelbar aufeinander folgenden Iteratio-nen ähnlicher als bei unabhängigen Zu-fallsziehungen aus der Population. Dies ist natürlich eine unerwünschte Situation, da die Veränderung des Mittelwertsvektors/Kovarianzmatrix möglichst unabhängig sein sollten. Glücklicherweise sinkt die Abhängigkeit mit zunehmender Distanz zwischen den einzelnen Schritten kon-tinuierlich, bis die geschätzten Parame-ter von hinreichend weit auseinander lie-genden Schritten derart voneinander un-abhängig sind, dass sie als Zufallsziehun-gen aus der gleichen Population betrach-tet werden können. Wie viele Schritte da-zu notwendig sind, ist eine der zentralen Fragen bei der Verwendung der MI. Für eine umfassende Beschreibung der tech-nischen Grundlagen der MI sei auf Little und Rubin (2002), Schafer und Graham (2002) sowie Rubin (1987, 1996) verwie-sen.
Ähnlich wie bei der EM- und Regres-sionsmethode wird auch bei der multip-len Imputation die MAR-Bedingung vo-rausgesetzt. Schafer und Graham (2002) gehen davon aus, dass die MI bei mittel-großen und großen Stichproben auch robust gegenüber Abweichungen der zu-grundeliegenden Annahme der multi-variaten Normalverteilung reagiert (vgl. auch Glynn et al. 1993). Wie bei den ML-Verfahren werden mit dieser Methode die Parameter asymptotisch unverzerrt geschätzt. Dabei ist ein einziger Impu-tationsschritt in der MI mit den Ergeb-nissen des EM-Algorithmus vergleichbar (Schafer 1999). Im Gegensatz zu den ein-fachen Imputationsmethoden bietet die MI jedoch die Möglichkeit, den Stan-
dardfehler korrekt zu bestimmen. Dies stellt einen der Hauptvorteile gegenüber dem EM-Algorithmus dar. Im Vergleich zu den einfachen Imputationsmethoden ist jedoch der Rechenaufwand mit meh-reren Datensätzen deutlich größer.
Zu erwähnen bleibt, dass das oben ausführlich beschriebene MI-Verfahren zwar eine gängige, aber nicht die ein-zige Variante von MI darstellt. Besteht Grund zur Annahme, dass eine gemein-same Verteilung (z. B. Normalverteilung) nicht vorliegt, kann der Ansatz der Swit-ching-Regression angewendet werden. Bei diesem Ansatz werden fehlende Wer-te für jede Variable mit frei zu wählenden Schätzmodellen einzeln ersetzt. Für eine dichotome Variable kann beispielswei-se die logistische Regression angewandt werden, bei einer kontinuierlichen Va-riable hingegen kommt die lineare Re-gression zum Einsatz. Switching-Re-gression ist momentan im Rahmen von MICE implementiert. Mittlerweile exis-tiert eine Fülle von Statistikprogram-men, welche die Umsetzung der MI er-möglichen. Bei parametrischen Variab-len wird häufig das kostenlose Software-programm NORM von Schafer (1997) verwendet. In Verbindung mit dem Sta-tistikprogramm SAS wird auch SAS Proc MI angeboten. Darüber hinaus sind auch die Programme Amelia II, Solas und MI-CE zu erwähnen (van Buuren und Ouds-hoorn 1999). Neuerdings wird die MI-Komponente auch in SPSS (ab Version 17) angeboten. Zur Illustration der Me-thode und deren Umsetzung in SPSS, soll im folgenden Abschnitt ein konkre-tes Anwendungsbeispiel der MI im Rah-men einer sportwissenschaftlichen Stu-die genauer vorgestellt werden.
Sportwissenschaftliches Anwendungsbeispiel
SPSS3 als Statistikpaket gilt in den Sozial-wissenschaften als eines der am häufigs-ten eingesetzten Statistikpakete (O’Con-ner 1999), das in den letzten Jahren im-mer mehr Optionen zur Analyse und
3 Seit 2009 wird das Statistikprogramm SPSS (Statistical Package for the Social Sciences) unter dem Namen PASW (Predictive Analysis SoftWare) vermarktet.
131Sportwissenschaft 2 · 2012 |

zum Umgang mit fehlenden Daten inte-griert hat. Das Programm liefert ab Ver-sion 10 einen Modus zur Analyse fehlen-der Werte, der die Beschreibung des Aus-maßes der fehlenden Daten, die Suche nach hauptverantwortlichen Variablen für niedrige Fallzahlen, den MCAR-Test nach Little (1988) und die Identifikation von Variablen mit extremen Werten um-fasst (SPSS 2009). Vor allem aber beinhal-tet das Modul die Ausschluss- und die ein-fachen Imputationsverfahren, wie Regres-sionsmethode und EM-Algorithmus. Ab Version 17 hat SPSS auch die Option der multiplen Imputation integriert, was nach Kenntnis der Autoren bisher jedoch noch keinen Eingang in die sportwissenschaft-liche Forschungspraxis gefunden hat. In diesem Abschnitt soll deshalb die Anwen-dung von MI mit Hilfe von SPSS anhand eines sportwissenschaftlichen Beispiels il-lustriert werden.
Im Rahmen einer groß angelegten Studie (Woll et al. 2004) sollte unter-sucht werden, wie fit die Einwohner einer baden-württembergischen Ge-meinde im mittleren Erwachsenenalter sind. Um die körperliche Leistungsfä-higkeit zu erfassen, wurde ein sportmo-torischer Test durchgeführt, der aus einer Vielzahl einzelner Übungen bestand. Aus Gründen einer übersichtlichen Darstel-lung des Verfahrens wird exemplarisch eine Beschränkung auf die Variable Lie-gestütze vorgenommen. Bei dieser Auf-gabe sollten die Probanden in 40 Sekun-
den möglichst viele Liegestütze absolvie-ren (vgl. Woll et al. 2004, S. 99). Die Prü-fung der Tauglichkeit der Teilnehmer für die jeweiligen Aufgaben im sportmotori-schen Test erfolgte im Vorfeld anhand einer ärztlichen Untersuchung. Dabei stellt sich die Frage, inwieweit der Drop-out einen Einfluss auf die Schätzung des Populationsmittelwerts hat. Wird bei-spielsweise besonders den Personen mit schwach ausgeprägter körperlicher Leis-tungsfähigkeit von der Teilnahme am sportmotorischen Test ärztlich abgera-ten, so wird die durchschnittliche Test-leistung in der Population überschätzt. Im Anschluss soll darüber hinaus auch anhand eines regressionsanalytischen Beispiels mit Alter und Geschlecht als Prädiktoren der motorischen Leistungs-fähigkeit die Methode der MI illustriert und diskutiert werden.
Untersuchung des Ausfallmechanismus
Insgesamt haben an dieser Untersu-chungswelle 227 Männer und 228 Frau-en im Alter zwischen 33 und 63 Jahren (M=45,8; SD=9,4) teilgenommen. Um einen möglichen selektiven Stichpro-benausfall identifizieren und kontrollie-ren zu können, wurde zusätzlich zu den eigentlichen Untersuchungsinstrumen-ten auch der Funktionsfragebogen Moto-rik (FFB-Mot; Bös, Abel, Woll, Niemann, Tittlbach & Schott 2002) erhoben. In die-
sem Fragebogen haben die Teilnehmer die Möglichkeit, ihren eigenen motori-schen Funktionsstatus bezüglich Aus-dauer, Kraft, Koordination und Beweg-lichkeit einzuschätzen. Dieser Fragebo-gen wurde von 436 Teilnehmern voll-ständig ausgefüllt. Neben dem FFB-Mot wurden auch die subjektive und ärztli-che Einschätzung der Gesundheit sowie eine Variable zum ärztlichen Ausschluss von der Motorikaufgabe zur Analyse der fehlenden Daten herangezogen. Es wird angenommen, dass diese Variablen aus-fallrelevante Informationen beinhalten und dass durch deren Aufnahme in das Imputationsmodell die Genauigkeit der geschätzten Werte erhöht wird. Wie in . Tab. 2 dargestellt, gibt es außer Alter und Geschlecht auch bei diesen Variab-len fehlende Werte.
Die meisten fehlenden Werte weist die Motorikaufgabe Liegestütze auf. Von den 455 rekrutierten Teilnehmern im Jahr 1997 liegen von 392 Personen gültige Werte für diese Aufgabe vor. Bei 63 Per-sonen fehlt diese Information, was einem Prozentsatz von 13,85% entspricht. Der in . Tab. 2 abgebildete SPSS-Output liefert neben den nach der Ausschlussmetho-de berechneten Mittelwerten und Stan-dardabweichungen auch die nach dem Tukey’s-Box-Kriterium ermittelten Ext-remwerte. Nach Tukey (1977) sind Wer-te immer dann extrem, wenn sie außer-halb des 1,5-fachen Interquartilabstands liegen. Bei der Variable Liegestütze ha-ben 18 Personen extrem niedrige Wer-te und eine Person einen extrem hohen Wert. Ein extrem niedriger Wert bedeu-tet in diesem Datenbeispiel, dass 18 Per-sonen nicht in der Lage sind, einen ein-zigen Liegestütz durchzuführen. In der nächsthöheren Kategorie erreichen die Testpersonen 3 Liegestütze. Nach dem Tukey’s-Box-Kriterium bedeutet ein ext-rem hoher Wert, dass eine Person 26 Lie-gestütze in 40 Sekunden absolviert hat. Diese Person erreicht damit 3 Liegestüt-ze mehr als die zweitbeste Person.
Nachdem das Ausmaß und die Ver-teilung der beobachteten und fehlenden Daten untersucht wurden, stellt sich die Frage, ob ein auffälliges Muster der feh-lenden Daten vorliegt, das möglicherwei-se Hinweise auf die Ursache des Ausfalls liefern könnte. Die Ergebnisse der Mus-
Tab. 2 Deskriptive Statistiken und Ausmaß der fehlenden Werte
Fehlend Anzahl der Ext-remwerte
Variable N M SD Anzahl Prozent Niedrig Hoch
Geschlecht 455 0,50 0,50 0 0,00 0 0
Alter 455 45,85 9,42 0 0,00 0 0
Ärztliche Einschätzung 430 1,72 0,61 25 5,49 0 0
Ausschluss Liegestütze 424 0,04 0,20 31 6,81 0 0
Subjektive Gesundheit 437 17,15 2,85 18 3,96 24 1
FFB-Mot Ausdauer 436 17,63 4,65 19 4,18 0 0
FFB-Mot Beweglichkeit 436 19,77 4,29 19 4,18 18 0
FFB-Mot Kraft 437 20,38 4,79 18 3,96 19 0
FFB-Mot Koordination 436 19,47 4,80 19 4,18 12 0
Liegestütze 392 11,92 4,61 63 13,85 18 1
N Anzahl der Fälle ohne fehlende Werte, M Mittelwert, SD Standardabweichung.
132 | Sportwissenschaft 2 · 2012
Hauptbeiträge
teranalysen im Rahmen des MI-SPSS-Moduls zeigen, dass 377 Personen bei al-len untersuchten Variablen vollständige Daten aufweisen. Das häufigste Ausfall-muster in unserem Datenbeispiel ist, dass 30 Personen nur in der Variablen Liege-stütze fehlende Werte aufweisen, wäh-rend in allen anderen Variablen voll-ständige Daten vorliegen. Das zweithäu-figste Muster bezieht sich auf 21 Perso-nen, bei denen weder bei der Motorik-aufgabe noch bei der ärztlichen Untersu-chung Daten vorliegen. Das dritthäufigs-te Muster besteht aus 7 Personen mit un-vollständigen Daten lediglich im Frage-bogen, d. h. bei FFB-Mot und Selbstein-schätzung der Gesundheit. Die restlichen 20 Personen verteilen sich auf viele klei-ne Muster. Dieses Ergebnis impliziert, dass kein monotones Muster4 vorliegt.
In einem nächsten Schritt stellt sich nun die Frage, ob die fehlenden Wer-te vollständig zufällig entstanden sind (MCAR). Inwieweit dies zutrifft, kann in SPSS ab Version 10 anhand des MCAR-Tests nach Little (1988) getestet werden.
4 Von einem monotonen Muster spricht man, wenn der Ausfall betrachtet über einzelne Items oder Personen aufeinander aufbauend verläuft. In der Praxis kommt das monotone Ausfallmus-ter selten vor. Beispielsweise in Längsschnitt-studien, in denen Testpersonen von Messzeit-punkt zu Messzeitpunkt sukzessive ausfallen, kann dieses Muster auftreten. Das monotone Muster vereinfacht den Schätzprozess, da itera-tive Algorithmen nicht mehr gebraucht werden, weder bei ML- noch bei Bayes-Schätzungen. Im Fall eines nicht monotonen Musters empfiehlt SPSS (2009), den oben beschriebenen MCMC-Algorithmus anzuwenden. SPSS bietet auch die Möglichkeit des Einsatzes des weniger rechen-aufwendigen Verfahrens für monotone Ausfall-muster.
In unserem Datenbeispiel liefert der MCAR-Test einen χ2-Wert von 369,4, der bei 88 Freiheitsgraden signifikant ist (p<0,001). Damit kann die MCAR-An-nahme als unzutreffend abgelehnt wer-den. Ob es sich jedoch um eine MAR- oder MNAR-Bedingung handelt, lässt sich nicht unmittelbar überprüfen, son-dern hängt nicht zuletzt davon ab, ob alle ausfallrelevanten Informationen berück-sichtigt wurden.
Imputationsphase
Die multiple Schätzung der fehlenden Werte wird, wie oben beschrieben, an-hand des Programms SPSS 18 durchge-führt. Zu Zwecken einer übersichtlichen Darstellung wird in unserem Datenbei-spiel eine MI mit 5 Imputationsschrit-ten durchgeführt. Der oben erwähnte MCMC-Algorithmus wird mit 1000 Ite-rationen angewendet, wobei nach jeweils 200 Iterationen die Imputationen gespei-chert werden. In unserem Datenbeispiel wird die lineare Regression als Schätzme-thode angewendet, wobei SPSS 18 auch Predictive Mean Matching anbietet. Im Rahmen dieses Regressionsmodells bie-tet SPSS 18 die Möglichkeit, die Rolle der Variablen weiter zu spezifizieren. Da bei vorliegender Fragestellung nur die Va-riable Liegestütze geschätzt werden soll, werden die restlichen Variablen als Ein-flussvariablen spezifiziert. Bei diesen Va-riablen werden fehlende Werte nicht ge-schätzt, sondern ihre vorhandenen Wer-te zur Schätzung der fehlenden Daten in der Variable Liegestütze verwendet. Bei der Variable Liegestütze wird die Null als Minimum festgelegt. Ein maximaler
Wert wird hingegen nicht spezifiziert.5 Darüber hinaus wird bei der Schätzung eine Rundung auf ganze Zahlen vorge-nommen, da auch Liegestütze nur ganz-zahlig gezählt werden. Die so spezifizier-te MI wird in einer neuen Datei gespei-chert, in der die Originaldaten zusam-men mit den 5 imputierten Datensätzen untereinander angeordnet sind.
Analysephase
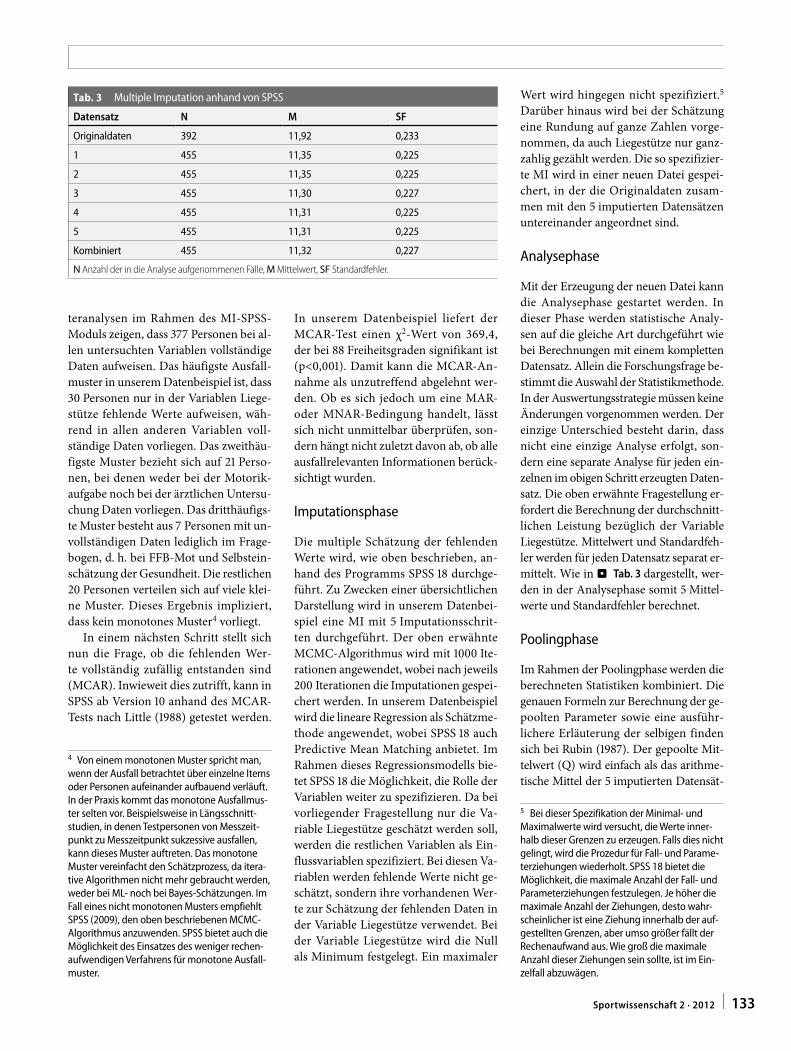
Mit der Erzeugung der neuen Datei kann die Analysephase gestartet werden. In dieser Phase werden statistische Analy-sen auf die gleiche Art durchgeführt wie bei Berechnungen mit einem kompletten Datensatz. Allein die Forschungsfrage be-stimmt die Auswahl der Statistikmethode. In der Auswertungsstrategie müssen keine Änderungen vorgenommen werden. Der einzige Unterschied besteht darin, dass nicht eine einzige Analyse erfolgt, son-dern eine separate Analyse für jeden ein-zelnen im obigen Schritt erzeugten Daten-satz. Die oben erwähnte Fragestellung er-fordert die Berechnung der durchschnitt-lichen Leistung bezüglich der Variable Liegestütze. Mittelwert und Standardfeh-ler werden für jeden Datensatz separat er-mittelt. Wie in . Tab. 3 dargestellt, wer-den in der Analysephase somit 5 Mittel-werte und Standardfehler berechnet.
Poolingphase
Im Rahmen der Poolingphase werden die berechneten Statistiken kombiniert. Die genauen Formeln zur Berechnung der ge-poolten Parameter sowie eine ausführ-lichere Erläuterung der selbigen finden sich bei Rubin (1987). Der gepoolte Mit-telwert (Q) wird einfach als das arithme-tische Mittel der 5 imputierten Datensät-
5 Bei dieser Spezifikation der Minimal- und Maximalwerte wird versucht, die Werte inner-halb dieser Grenzen zu erzeugen. Falls dies nicht gelingt, wird die Prozedur für Fall- und Parame-terziehungen wiederholt. SPSS 18 bietet die Möglichkeit, die maximale Anzahl der Fall- und Parameterziehungen festzulegen. Je höher die maximale Anzahl der Ziehungen, desto wahr-scheinlicher ist eine Ziehung innerhalb der auf-gestellten Grenzen, aber umso größer fällt der Rechenaufwand aus. Wie groß die maximale Anzahl dieser Ziehungen sein sollte, ist im Ein-zelfall abzuwägen.
Tab. 3 Multiple Imputation anhand von SPSS
Datensatz N M SF
Originaldaten 392 11,92 0,233
1 455 11,35 0,225
2 455 11,35 0,225
3 455 11,30 0,227
4 455 11,31 0,225
5 455 11,31 0,225
Kombiniert 455 11,32 0,227
N Anzahl der in die Analyse aufgenommenen Fälle, M Mittelwert, SF Standardfehler.
133Sportwissenschaft 2 · 2012 |
ze berechnet. Die Poolingprozedur wird vom Programm SPSS 18 unterstützt und die Ergebnisse automatisch ausgegeben, so dass keine Berechnung von Hand er-forderlich ist. Der gepoolte Mittelwert (Q) beträgt in unserem Beispiel Q=11,32 und liegt damit deutlich unter dem anhand des Ausschlussverfahrens berechneten Mittelwerts von M=11,92. Damit bestätigt sich die eingangs formulierte Vermutung, dass in unserem Beispiel der systemati-sche Ausfall der Daten bei konventionel-len Ausschlussmethoden zur Überschät-zung des Populationsmittelwerts führt.
Zur Bestimmung des Standardfeh-lers ist es erforderlich, 2 Variationskom-ponenten zu unterscheiden (Rubin 1987): die Varianz innerhalb der Datensätze (U) und die Varianz zwischen den Datensät-zen (B). Die Varianz innerhalb der impu-tierten Datensätze ist das arithmetische Mittel der quadrierten geschätzten Stan-dardfehler (U) aus den einzelnen Daten-sätzen i=1, …, m.
In unserem Datenbeispiel ist das arithme-tische Mittel der 5 quadrierten Standard-fehler 0,051. Die Varianz zwischen den Datensätzen B repräsentiert hingegen die Variation zwischen den Imputationen. Sie entspricht der mittleren quadrierten Ab-weichung des jeweiligen Mittelwerts vom gepoolten Mittelwert.
In diesem Datenbeispiel ist B=0,001. In einem weiteren Schritt werden die beiden
Varianzquellen zur Berechnung des Stan-dardfehlers (SF) verknüpft.
Im Rahmen unseres Beispiels beträgt der MI-geschätzte Standardfehler 0,227 (vgl. auch . Tab. 3). Betrachtet man die For-mel zur Berechnung des Standardfehlers, so wird ersichtlich, dass der Anteil der Va-rianz zwischen den imputierten Datensät-zen immer kleiner wird, je größer die An-zahl der Imputationen ist. Im Gegensatz dazu hat die Anzahl der Imputationen keinen Einfluss auf die Varianz innerhalb der Datensätze. Anhand des Standardfeh-lers lassen sich dann in weiteren Schritten (z. B. mit Hilfe der t-Verteilung) wie üb-lich Konfidenzintervalle bzw. Signifikanz-tests für den Mittelwert ermitteln.
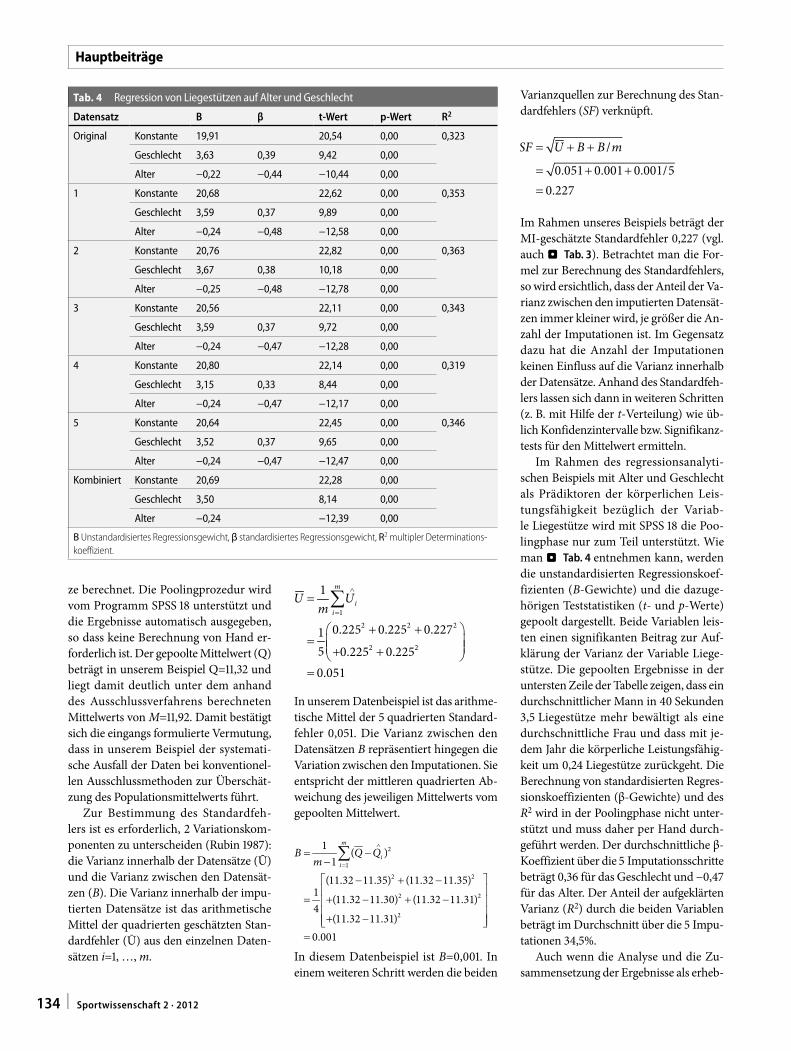
Im Rahmen des regressionsanalyti-schen Beispiels mit Alter und Geschlecht als Prädiktoren der körperlichen Leis-tungsfähigkeit bezüglich der Variab-le Liegestütze wird mit SPSS 18 die Poo-lingphase nur zum Teil unterstützt. Wie man . Tab. 4 entnehmen kann, werden die unstandardisierten Regressionskoef-fizienten (B-Gewichte) und die dazuge-hörigen Teststatistiken (t- und p-Werte) gepoolt dargestellt. Beide Variablen leis-ten einen signifikanten Beitrag zur Auf-klärung der Varianz der Variable Liege-stütze. Die gepoolten Ergebnisse in der untersten Zeile der Tabelle zeigen, dass ein durchschnittlicher Mann in 40 Sekunden 3,5 Liegestütze mehr bewältigt als eine durchschnittliche Frau und dass mit je-dem Jahr die körperliche Leistungsfähig-keit um 0,24 Liegestütze zurückgeht. Die Berechnung von standardisierten Regres-sionskoeffizienten (β-Gewichte) und des R2 wird in der Poolingphase nicht unter-stützt und muss daher per Hand durch-geführt werden. Der durchschnittliche β-Koeffizient über die 5 Imputationsschritte beträgt 0,36 für das Geschlecht und −0,47 für das Alter. Der Anteil der aufgeklärten Varianz (R2) durch die beiden Variablen beträgt im Durchschnitt über die 5 Impu-tationen 34,5%.
Auch wenn die Analyse und die Zu-sammensetzung der Ergebnisse als erheb-
Tab. 4 Regression von Liegestützen auf Alter und Geschlecht
Datensatz B β t-Wert p-Wert R2
Original Konstante 19,91 20,54 0,00 0,323
Geschlecht 3,63 0,39 9,42 0,00
Alter −0,22 −0,44 −10,44 0,00
1 Konstante 20,68 22,62 0,00 0,353
Geschlecht 3,59 0,37 9,89 0,00
Alter −0,24 −0,48 −12,58 0,00
2 Konstante 20,76 22,82 0,00 0,363
Geschlecht 3,67 0,38 10,18 0,00
Alter −0,25 −0,48 −12,78 0,00
3 Konstante 20,56 22,11 0,00 0,343
Geschlecht 3,59 0,37 9,72 0,00
Alter −0,24 −0,47 −12,28 0,00
4 Konstante 20,80 22,14 0,00 0,319
Geschlecht 3,15 0,33 8,44 0,00
Alter −0,24 −0,47 −12,17 0,00
5 Konstante 20,64 22,45 0,00 0,346
Geschlecht 3,52 0,37 9,65 0,00
Alter −0,24 −0,47 −12,47 0,00
Kombiniert Konstante 20,69 22,28 0,00
Geschlecht 3,50 8,14 0,00
Alter −0,24 −12,39 0,00
B Unstandardisiertes Regressionsgewicht, β standardisiertes Regressionsgewicht, R2 multipler Determinations-koeffizient.
12 2 2
2 2
1
0.225 0.225 0.22715 0.225 0.2250.051
m
ii
U Um
∧
=
=
+ + = + + =
∑
2
1
2 2
2 2
2
1 ( )1(11.32 11.35) (11.32 11.35)
1 (11.32 11.30) (11.32 11.31)4
(11.32 11.31)0.001
m
ii
B Q Qm
∧
=
= −−
− + −
= + − + − + −
=
∑
/
0.051 0.001 0.001/50.227
SF U B B m= + +
= + +=
134 | Sportwissenschaft 2 · 2012
Hauptbeiträge

licher Aufwand erscheinen, werden diese Schritte mit Hilfe von SPSS weitgehend automatisiert durchgeführt. Für die meis-ten Anwendungen wie t-Tests, ANOVA, lineare, logistische, ordinale, Cox-Regres-sionen, Korrelationen, Diskriminanzana-lysen, χ2-Test usw. wird die Poolingpha-se unterstützt. Es ist jedoch kritisch an-zumerken, dass SPSS 18 noch nicht al-le Statistiken ausgibt. Beispielsweise wer-den bei deskriptiven Analysen die gepool-ten Standardabweichungen oder bei linea-ren Regressionen die gepoolten R2 und β-Gewich te von SPSS nicht automatisch berechnet. In diesen Fällen sind Rechen-schritte per Hand nicht zu vermeiden.
Zusammenfassende Diskussion
Fehlende Daten kommen in der empi-rischen Forschung häufig vor, was eine Reihe von Problemen nach sich zieht. Im Rahmen dieser Arbeit wurden gängi-ge Verfahren zum Umgang mit fehlenden Daten vorgestellt und kritisch diskutiert. Hierbei wurde zwischen Ausschluss- , einfachen Imputationsverfahren, Maxi-mum-Likelihood-Verfahren und multip-len Imputationsverfahren unterschieden. Die beiden Ausschlussverfahren (fallwei-ser und paarweiser Ausschluss), bei denen Fälle mit fehlenden Daten von den Ana-lysen ausgeschlossen werden, haben zur Folge, dass sie mit einem Verlust an Test-stärke einhergehen und bei nicht rein zu-fälligem Ausfallmechanismus (MCAR) zu verzerrten Parameterschätzungen füh-ren können. Bei den Imputationsverfah-ren wurden neben den Mittelwertserset-zungen auch Regressions-, ML- und MI-Verfahren vorgestellt. Sind die weiter oben diskutierten Annahmen erfüllt (primär MAR und ggf. multivariate Normalvertei-lung), führen sowohl ML-Schätzungen als auch MI-Verfahren zu erwartungstreuen Parameterschätzungen. Obwohl viele der neueren Methoden bereits in den 1980er Jahren entwickelt wurden und seit den 90er Jahren spezielle Software dafür exis-tiert, haben sie bisher nur selten Eingang in die Forschungspraxis gefunden (Peugh & Enders 2004). Vor allem ökonomische Aspekte wie spezielle Software und zu-sätzlicher Rechenaufwand haben eine breite Anwendung bislang erschwert. Mit der Implementierung von MI in das Stan-
dardstatistikpaket SPSS ergeben sich neue Möglichkeiten für dessen routinemäßigen Einsatz in der Forschungspraxis.
Im Rahmen dieses Beitrags wurde da-her der Einsatz von MI am Beispiel einer empirischen Studie mit einem für sport-wissenschaftliche Untersuchungen typi-schen systematischen Ausfall unter An-wendung von SPSS dargestellt. Das Pro-gramm bietet eine differenzierte Anwen-dung von MI und unterstützt für viele sta-tistische Verfahren die Poolingphase. Lei-der gilt dies bisher nicht für alle Statisti-ken (z. B. SD, R2 oder β-Gewichte). Ein zusätzlicher Rechenaufwand per Hand bleibt dadurch unumgänglich.
Im Allgemeinen sind unter der MCAR- und MAR-Annahme MI oder FIML die Methoden der Wahl (Schafer & Graham 2002). Besteht jedoch Grund zur Annahme, dass MNAR vorliegt, stellt sich die Frage, welche Methode dafür geeignet ist. Im Wesentlichen gibt es zwei Möglich-keiten mit diesem Problem umzugehen (Graham 2009). Einerseits stellen sog. Se-lektionsmodelle eine Möglichkeit dar, dem MNAR-Mechanismus zu begegnen. Diese Modelle setzen sehr detaillierte A-priori-Annahmen (z. B. über die Vertei-lung der zu untersuchenden Variablen in den jeweiligen Populationen) voraus, die sich i. d. R. nicht prüfen lassen. In seltenen Fällen liegen externe Informationen (z. B. über die Verteilung der jeweiligen Popula-tion) vor, die den Ausfallprozess beschrei-ben können. Dies schränkt die Anwend-barkeit dieser Modelle in der empirischen Forschungspraxis jedoch stark ein und bei einer Verletzung der A-priori-Annah-men können die Parameterschätzungen schlechter ausfallen als bei ML und MI (Demirtas & Schafer 2003).
Andererseits empfiehlt Graham (2009) auch dann die ML und MI-Methoden an-zuwenden, wenn die MAR oder MCAR-Bedingungen nicht erfüllt sind. Grund-lage dieser Empfehlung ist, dass MCAR, MAR und MNAR niemals in Reinform auftreten. In jeder Untersuchung besteht der Ausfallmechanismus aus allen 3 Kom-ponenten. Ein Teil des Ausfalls besteht aus rein zufälligen Prozessen (MCAR). Ein zweiter Teil setzt sich aus den Prozes-sen zusammen, die anhand der vorhan-denen Daten beschrieben werden können (MAR). Schließlich sind im Ausfallpro-
zess auch systematische Effekte vorhan-den, die nicht anhand der Daten rekons-truierbar sind (MNAR). Aus dieser Pers-pektive stellt sich nicht länger die Frage, ob man es mit MNAR zu tun hat, sondern ob der Anteil von MNAR im Ausfallpro-zess so groß ist, dass der Einsatz von ML und MI nicht mehr sinnvoll ist.
Prinzipiell wäre es natürlich wün-schenswert, fehlende Werte im Vorfeld auszuschließen. Ein erster Schritt in die-se Richtung ist sicherlich eine gründliche Planung der Untersuchung und vor allem eine sorgfältige Feldarbeit auf dem derzei-tigen Stand der empirischen Forschung (vgl. Groves et al., 2009; Dillman, 2000). Es gilt dabei eine maximale Ausschöp-fungsquote zu erreichen. Die Maßnah-men zur Steigerung der Ausschöpfungs-quote beziehen sich z. B. auf eine profes-sionelle Kommunikation der Forschungs-vorhaben, Schulung des Untersuchungs-teams, Optimierung der Erhebungsfor-men und der Itemkonstruktion. Im Rah-men von Felduntersuchungen sollte die Kontaktaufnahme sorgfältig vorbereitet werden und eventuelle Maßnahmen zur Konvertierung von Verweigerern geplant werden (vgl. Schnell, 1997, S. 251 ff.).
Jedoch sind auch bei einer optimal vor-bereiteten Feldarbeit fehlende Daten nicht zu vermeiden. Deshalb sollte in einem zweiten Schritt schon bei der Planung einer Studie berücksichtigt werden, dass auch solche Variablen erhoben werden, die möglicherweise mit Nonresponse zu-sammenhängen könnten. Im Rahmen der oben beschriebenen Studie wurde z. B. neben dem sportmotorischen Test auch der FFB-Mot erhoben, der durch eine an-dere Methode das gleiche Merkmal er-fasst. Von Vorteil war vor allem, dass die vom sportmotorischen Test ausgeschlos-senen Personen den Fragebogen ausfüllt haben. Nur durch Erhebung von ausfallre-levanten Daten kann die Gefahr des nicht zufälligen Fehlens (MNAR) reduziert und so die erwähnten Methoden effizient ein-gesetzt werden (Wirtz, 2004).
Sind die Daten erhoben, geht es in einem dritten Schritt um die Beschrei-bung des Ausfallmechanismus. Hier gilt es zu erkennen, wie groß das Ausmaß der fehlenden Werte ist und ob der Aus-fall systematisch entstanden ist. Häufig kommt es dabei vor, dass bei bestimm-
135Sportwissenschaft 2 · 2012 |

ten Variablen der Ausfall wesentlich hö-her ist als bei anderen Variablen. Darüber hinaus ist zu untersuchen, ob es Gruppen von Personen mit ähnlichem Ausfallmus-ter gibt. In diesem Fall sollte untersucht werden, ob sich diese Gruppe von ande-ren Personen bezüglich eines oder meh-rerer Merkmale unterscheidet. Aus sol-chen Analysen kann man häufig ableiten, um was für einen Ausfallmechanismus es sich handelt.
Schließlich gilt es, sich mit den Metho-den zum Umgang mit fehlenden Daten auseinanderzusetzen, eine begründete Auswahl des Verfahrens zu treffen und die Sensitivität der Ergebnisse zu überprüfen. Insgesamt ist in der methodischen Litera-tur ein Konsens hinsichtlich der Überle-genheit von ML- und MI-basierten Me-thoden zu finden (vgl. z. B. Allison, 2002; Graham, 2009; Lüdtke et al., 2007; Schafer & Graham, 2002; Wirtz, 2004). Trotzdem werden diese Methoden noch relativ sel-ten eingesetzt (vgl. z. B. Peugh & Enders, 2004). Jedoch kann davon ausgegangen werden, dass sich dieser Trend in den nächsten Jahren ändern wird. Mit Einbin-dung neuer Verfahren in Standardstatis-tikpakete wie SPSS wird die Zugänglich-keit deutlich erleichtert. Darüber hinaus wird bei wissenschaftlichen Zeitschriften immer häufiger die Thematisierung des Umgangs mit fehlenden Daten gefordert. Der vorliegende Beitrag ist ein Versuch, diesen positiven Prozess – gerade in der angewandten Sportwissenschaft – weiter voranzutreiben.
Korrespondenzadresse
Dr. Darko JekaucInstitut für Sportwissenschaft, Universität KonstanzUniversitätsstr. 10, 78457 [email protected]
Interessenkonflikt. Der korrespondierende Autor gibt für sich und seine Koautoren an, dass kein Interes-senkonflikt besteht.
Literatur
1. Allison, P.D. (2002). Missing Data. Thousand Oaks: Sage.
2. American Psychological Association (2009). Pu-blication manual of the American Psychological Association. Washington D.C.: American Psycholo-gical Association.
3. Arbuckle, J.L. (1996). Full information estimation in the presence of incomplete data. In G.A. Marcouli-des & R.E. Schumacker (Eds.), Advanced structural equation modeling (pp. 243–277). Mahwah, NJ: Lawrence Erlbaum.
4. Bös, K., Abel, T., Woll, A., Niemann, S., Tittlbach, S. & Schott, N. (2002). Der Fragebogen zur Erfassung des motorischen Funktionsstatus (FFB-Mot): Be-richt über die Entwicklung und Überprüfung. Dia-gnostica, 48, 101–111.
5. Demirtas, H. and Schafer, J.L. (2003). On the perfor-mance of random-coefficient pattern-mixture mo-dels for non-ignorable dropout. Statistics in Medi-cine, 22, 2553–2575.
6. Dempster, A.P., Laird, N & Rubin, D.B. (1977). Maxi-mum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, B39, 1–38.
7. Dillman, D.A. (2000). Mail and internet surveys. The tailored design method. New York: Wiley.
8. Enders, C.K. (2010). Applied missing data analy-sis. New York: Guilford Press.
9. Enders, C.K., & Bandalos, D.L. (2001). The relati-ve performance of full information maximum li-kelihood estimation for missing data in structural equation models. Structural Equation Modeling, 8, 430–457.
10. Enders, C.K., & Peugh, J.L. (2004). Using an EM co-variance matrix to estimate structural equation models with missing data: Choosing an adjusted sample size to improve the accuracy of inferences. Structural Equation Modeling, 11, 1–19.
11. Ford, B.L. (1983). An overview of hot-deck proce-dures. In W.G. Madow, I. Olkin & D.B. Rubin (Eds.), Incomplete data in sample surveys (pp. 185–207). New York: Academic Press.
12. Glynn, R.J., Laird, N.M. & Rubin, D.B. (1993). Multip-le imputation in mixture models for nonignorable nonresponse with followups. Journal of American Statistical Association, 88, 984–93.
13. Graham, J.W. (2009). Missing data analysis: making it work in the real world. Annual Review of Psy-chology, 60, 549–576.
14. Graham, J.W. & Hofer, S.M. (2000). Multiple Impu-tation in Multivariate Research. In T.D. Little, K.U. Schnabel & J. Baumert (Hrsg). Modeling longitu-dinal and multilevel data. Mahwah: Erlbaum.
15. Groves, R.M., Fowler, F.J., Couper, M.P., Lepkowski, J.M., Singer, E. & Tourangeau, R. (2009). Survey Me-thodology. Hoboken: Wiley
16. King, K., Honaker, J., Joseph, A. & Scheve, K. (2001). Analyzing incomplete political science data: an al-ternative algorithm for multiple imputation. Ame-rican Political Science Review, 95, 49–69.
17. Little, R.J.A. (1988). A test of missing completely at random for multivariate data with missing values. Journal of the American Statistical Association, 83, 1198–1202.
18. Little, R.J.A. & Rubin, D.B. (2002). Statistical analy-sis with missing data. New Jersey: Wiley.
19. Lüdtke, O., Robitzsch, A., Trautwein, U. & Köller, O. (2007). Umgang mit fehlenden Daten in der psy-chologischen Forschung. Probleme und Lösungen. Psychologische Rundschau, 58, 103–117.
20. O’Conner, B.P. (1999). Simple and flexible SAS and SPSS programs for analysing lag-sequential cate-gorical data. Behavior Research Methods, Instru-ments and Computers, 31, 718–726.
21. Peugh, J.L. & Enders, C.K. (2004). Missing data in educational research: A review of reporting prac-tices and suggestions for improvement. Review of Educational Research, 74, 525–556.
22. Rubin, D.B. (1976). Inference and missing data. Biometrika, 63, 581–592.
23. Rubin, D.B. (1987). Multiple imputation for nonre-sponse in surveys. New York: Wiley.
24. Rubin, D.B. (1996). Multiple imputation after 18+ years. Journal of American Statistical Associati-on, 91, 473–489.
25. Schafer, J.L. (1997). NORM: multiple imputation of incomplete multivariate data under a normal model, version 2.03. Online: http://www.stat.psu.edu/~jls/misoftwa.html (24.09.2010).
26. Schafer, J.L. (1999). Multiple imputation: a primer. Statistical Methods in Medical Research, 8, 3–15.
27. Schafer, J.L. (2000). Analysis of incomplete multi-variate data. Boca Raton: Chapman & Hall.
28. Schafer, J.L. & Graham, J.W. (2002). Missing data: our view of the state of the art. Psychological Met-hods, 7, 147–177.
29. Scheuren, F. (2005). Multiple imputation: How it began and continues. The American Statistician, 59, 315–319.
30. Schnell, R. (1997). Nonresponse in Bevölkerungs-umfragen. Ausmaß, Entwicklungen und Ursachen. Opladen: Leske & Budrich.
31. SPSS (2009). SPSS Missing Values 17.0. Chicago, IL: SPSS.
32. Tanner, M.A. & Wong, W.H. (1987). The calculation of posterior distributions by data augmentation. Journal of American Statistical Association, 82, 528–50.
33. Tukey, J.W. (1977). Exploratory data analysis. Rea-ding, MA: Addison-Wesley Publishing.
34. Van Buuren, S. & Oudshoorn, C.G.M. (1999) Flexib-le multivariate imputation by MICE. TNO-rapport PG 99.054. TNO Prevention and Health. Leiden: TNO.
35. Wirtz, M. (2004). Über das Problem fehlender Wer-te: Wie der Einfluss fehlender Informationen auf Analyseergebnisse entdeckt und reduziert werden kann. Rehabilitation, 43, 109–115.
36. Woll, A., Tittlbach, S. & Schott, N. (2004). Diagnose körperlich-sportlicher Aktivität, Fitness und Ge-sundheit – Methodenband II. Berlin: Dissertation.de.
136 | Sportwissenschaft 2 · 2012
Hauptbeiträge


















