
Hadoop in modernen BI-Infrastrukturen - inovex.de · Spielregeln im Cluster Der fleißige...
83
Hadoop in modernen BI-Infrastrukturen Dr. Stefan Igel inovex GmbH
Transcript of Hadoop in modernen BI-Infrastrukturen - inovex.de · Spielregeln im Cluster Der fleißige...

Hadoop in modernen BI-Infrastrukturen
Dr. Stefan Igel inovex GmbH

Seit 01/2005 als Projektleiter und Systemarchitekt bei inovex
Seit 08/2009 als Business Engineer bei 1&1
Erstkontakt mit Hadoop 09/2009 Mag spannende Projekte
Tischtennis-Spieler und Häuslebauer [email protected]
Stefan
2

BIG DATA und Hadoop bei 1&1 Jede Menge Blech: Die Hardware Was darf es denn sein: Das Hadoop Ecosystem Speichern, Mappen, Reduzieren Spielregeln im Cluster Der fleißige Handwerker Essenz
Agenda
3

am Beispiel eines Transport-unternehmens
Scaleout
4

am Beispiel eines Transport-unternehmens
Scaleout
5

am Beispiel eines Transport-unternehmens
Scaleout
6

am Beispiel eines Transport-unternehmens
Scaleout
7

am Beispiel eines Transport-unternehmens
Scaleout
8

am Beispiel eines Transport-unternehmens
Scaleout
$5.000.000 Anschaffung
$46.000 pro Reifen
Spezial-Know-how für Betrieb und Wartung
Hoher Schaden bei Ausfall
9

am Beispiel eines Transport-unternehmens
Scaleout
40.000€ Anschaffung pro Fahrzeug
keine Spezialkenntnisse erforderlich
Ausfall einzelner Fahrzeuge kompensierbar
skaliert in beide Richtungen
modernisierbar
10
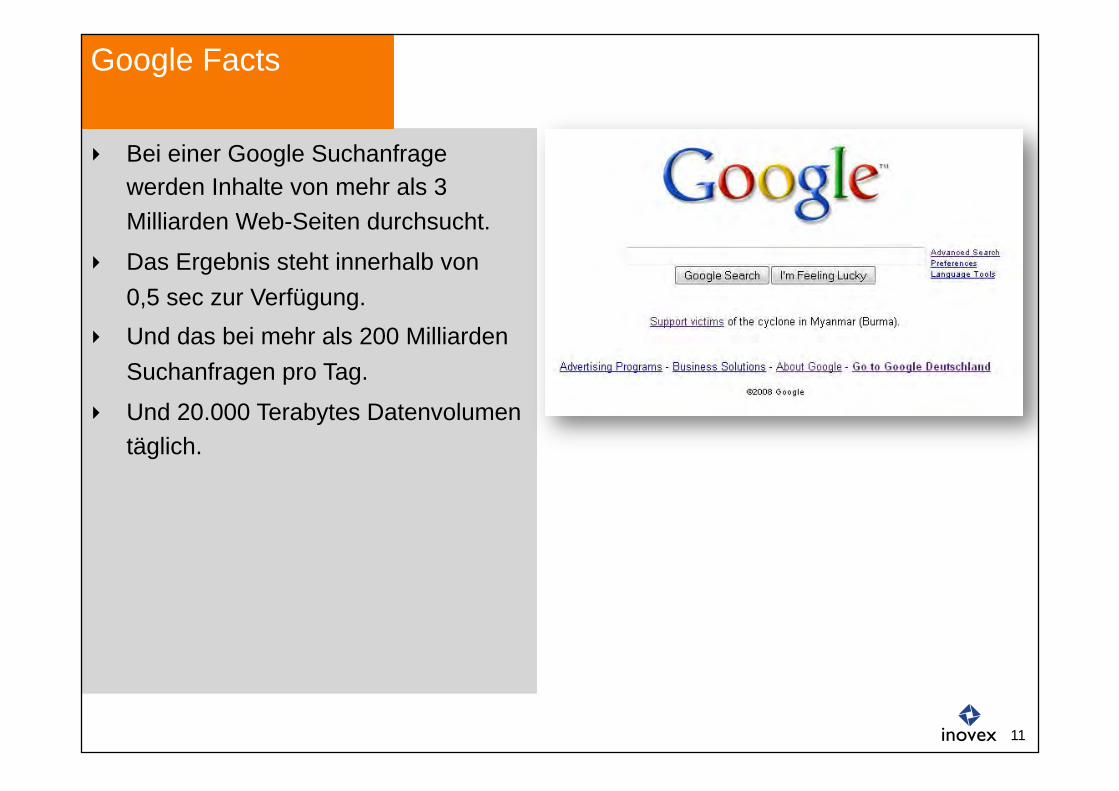
Bei einer Google Suchanfrage werden Inhalte von mehr als 3 Milliarden Web-Seiten durchsucht.
Das Ergebnis steht innerhalb von 0,5 sec zur Verfügung.
Und das bei mehr als 200 Milliarden Suchanfragen pro Tag.
Und 20.000 Terabytes Datenvolumen täglich.
Google Facts
11

à la Google Scaleout
http://en.wikipedia.org/wiki/Google_platform
Google's first production server rack, circa 1998
12

Google, Apache, Hadoop ...
Apache
Hadoop & Zusatzprojekte als Open Source http://hadoop.apache.org
lieferte Idee benutzt Hadoop
zur Weiterbildung http://code.google.com/edu/parallel/index.html
Cloudera
kommerzieller Supoort
freie Distribution Apache Committer
http://www.cloudera.com
Facebook, Amazon, LinkedIn
Apache Commiter eigene Cluster
Yahoo
Hadoop Initiator Committer freie Distribution PIG eigene Cluster
http://developer.yahoo.com/hadoop
13
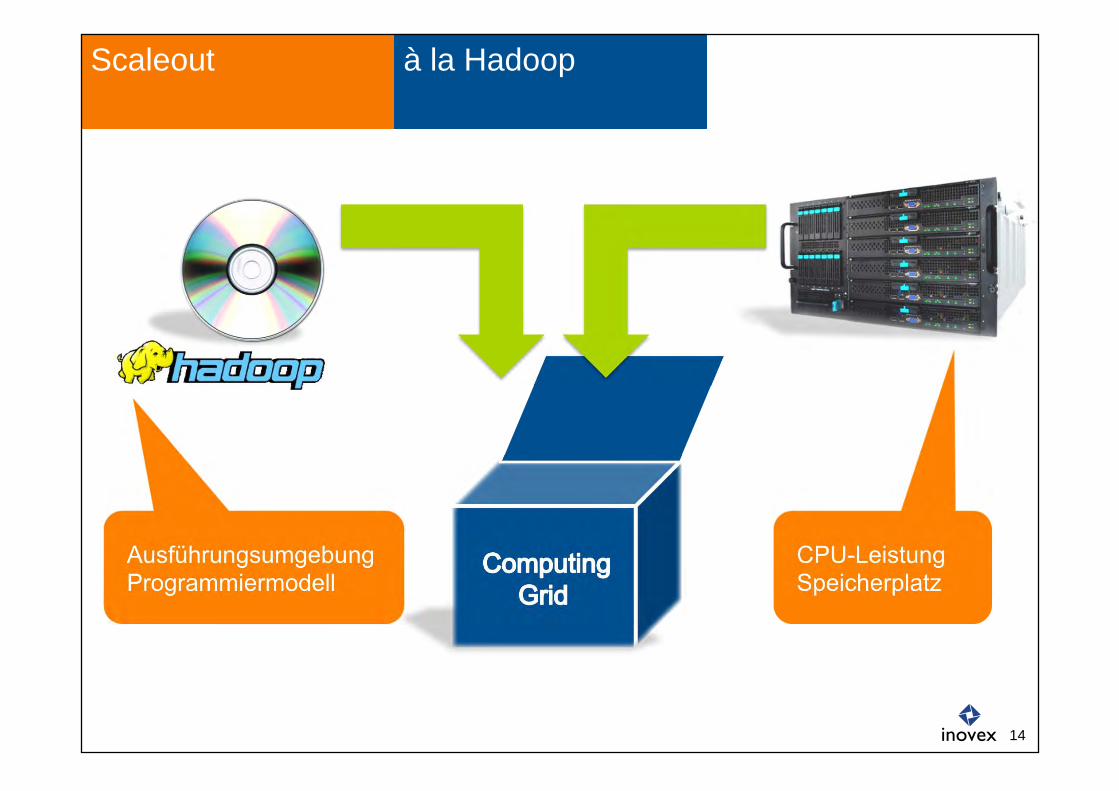
à la Hadoop Scaleout
Ausführungsumgebung Programmiermodell
CPU-Leistung Speicherplatz
14
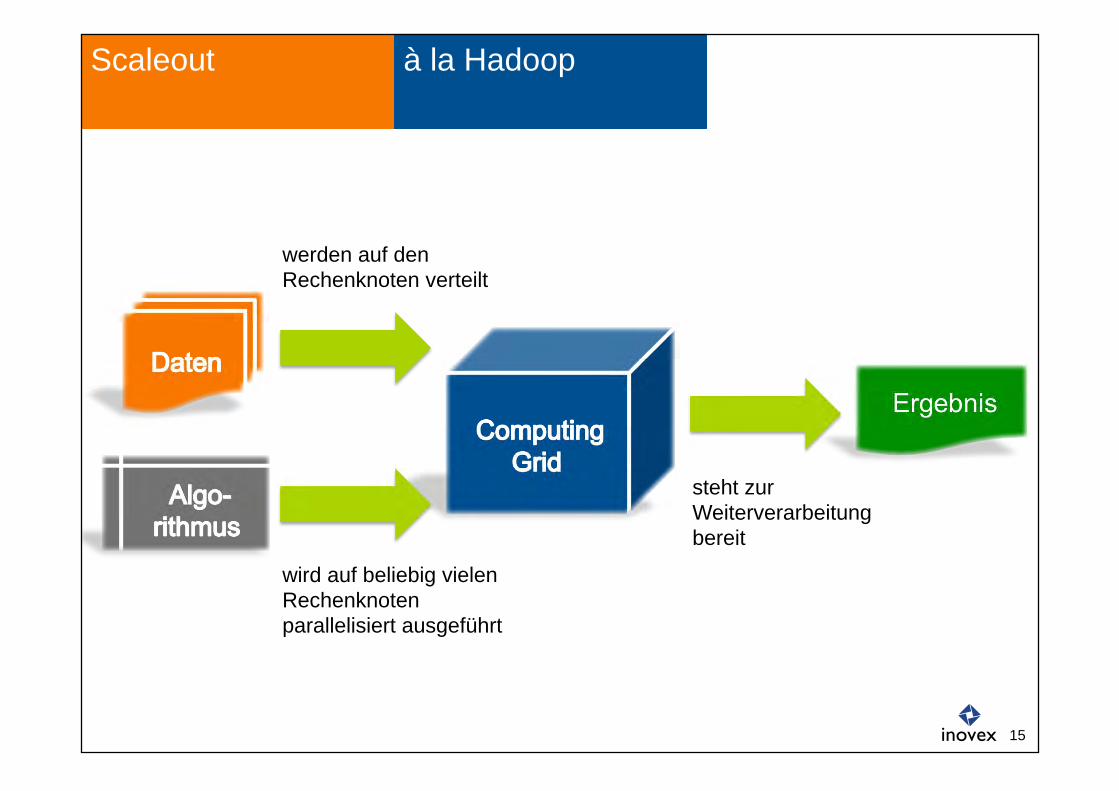
à la Hadoop Scaleout
Ergebnis
steht zur Weiterverarbeitung bereit
wird auf beliebig vielen Rechenknoten parallelisiert ausgeführt
werden auf den Rechenknoten verteilt
15

One of the features of MapReduce is
that one can move the computation close to the data because
"Moving Computation is Cheaper than Moving Data”
à la Hadoop Scaleout
16
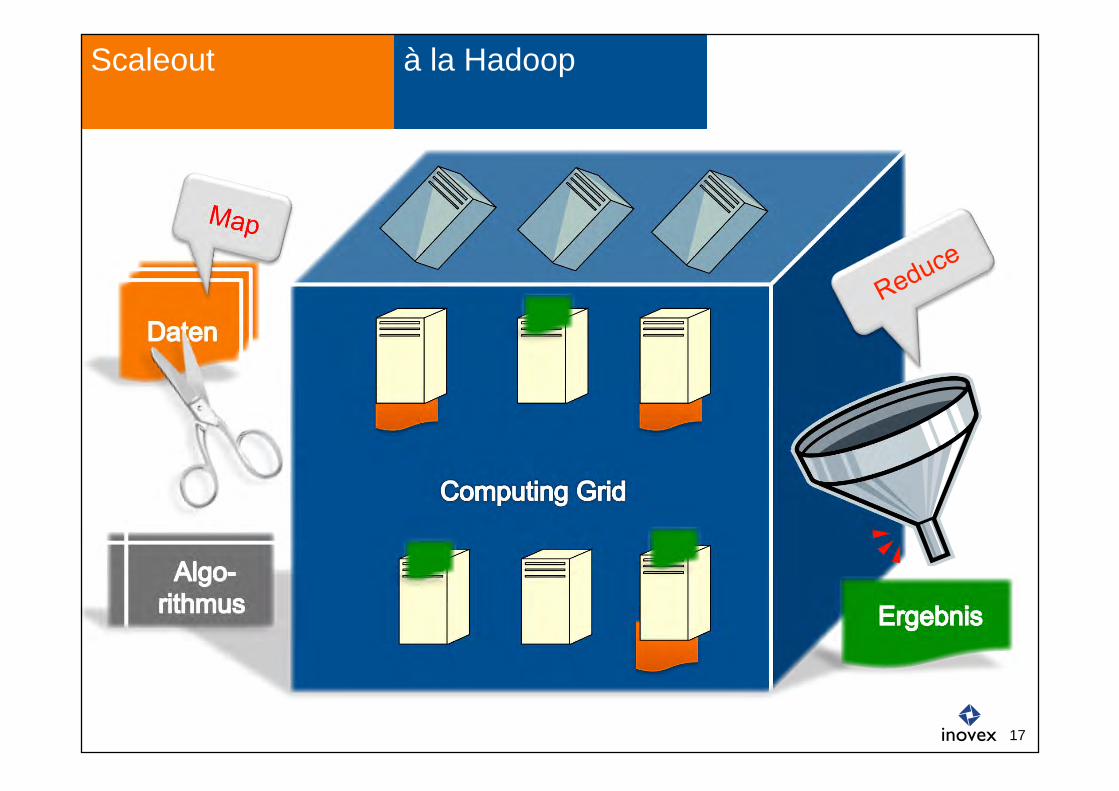
Map
à la Hadoop Scaleout
17

QUESTION “What advice would you give to enterprises considering Hadoop?”
DOUG CUTTING “I think they should identify a problem that, for whatever reason, they are not able to address currently, and do a sort of pilot. Build a cluster, evaluate that particular application and then see how much more affordable, how much better it is [on Hadoop].”
Dougs Ratschlag
http://www.computerworld.com/s/article/9222758/The_Grill_Doug_Cutting 18
http
://a.
imag
es.b
lip.tv
/Stra
taco
nf-
STR
ATA
2012
Dou
gCut
tingT
heA
pach
eHad
oopE
cosy
stem
410-
224.
jpg

BIG DATA und Hadoop bei 1&1 Jede Menge Blech: Die Hardware Was darf es denn sein: Das Hadoop Ecosystem Speichern, Mappen, Reduzieren Spielregeln im Cluster Der fleißige Handwerker Essenz
Agenda
19

1995 gestartet als Internet-Katalog Eines der größten deutschen
Internet-Portale mit 16,44 Mio. Nutzern/Monat*
WEB.DE FreeMail – beliebtester deutscher Mail-Dienst mit zahlreichen Sicherheitsfeatures
WEB.DE Beispiel 1
*Unique User / AGOF internet facts 2011-12 20

FreeMail Pionier mit leistungsstarken Mail- und Messaging-Lösungen
12,75 Mio. Nutzer/ Monat*
Umfangreiche Portalangebote, Dienste und Online-Services in Deutschland, Österreich und der Schweiz
Internationale Mail-Angebote in sechs Ländern (A, CH, F, E, UK, USA), auch unter mail.com
GMX Beispiel 2
*Unique User / AGOF internet facts 2011-12 21

70.000 Server
10,67 Mio. Kundenverträge 30,8 Mio. Free-Accounts
Hosting von 18 Millionen Domains Rund 9 Milliarden Seitenabrufe im Monat
Mehr als 5 Milliarden E-Mails pro Monat 9.000 TByte monatliches Transfervolumen
Doppelt sicher durch redundante Rechenzentren (Dual Hosting)
Nahezu 100%ige Verfügbarkeit
Mehrfach redundante Glasfaser-Anbindung
Unterbrechungsfreie Stromversorgung (USV) Vollklimatisierte Sicherheitsräume bieten
Schutz vor Gas, Wasser und Feuer
Betreuung rund um die Uhr durch hochqualifizierte Spezialisten
Betrieb mit grünem Strom
auf 2 Kontinenten 5 Hochleistungs-Rechenzentren
22

Development Romania
Team Big Data Solutions Development Romania:
Email Search mit Solr und Hadoop
Email Organizer
Development UIM
Abteilung Target Group Planning:
Mehrere produktive Hadoop-Cluster
Schwerpunkt Data Mining und Machine Learning
Abteilung Web.Intelligence:
Produktives Hadoop-Cluster SYNAPSE
Web-Analytics, Logfile-Processing und Datawarehousing
bei 1&1 Hadoop
23
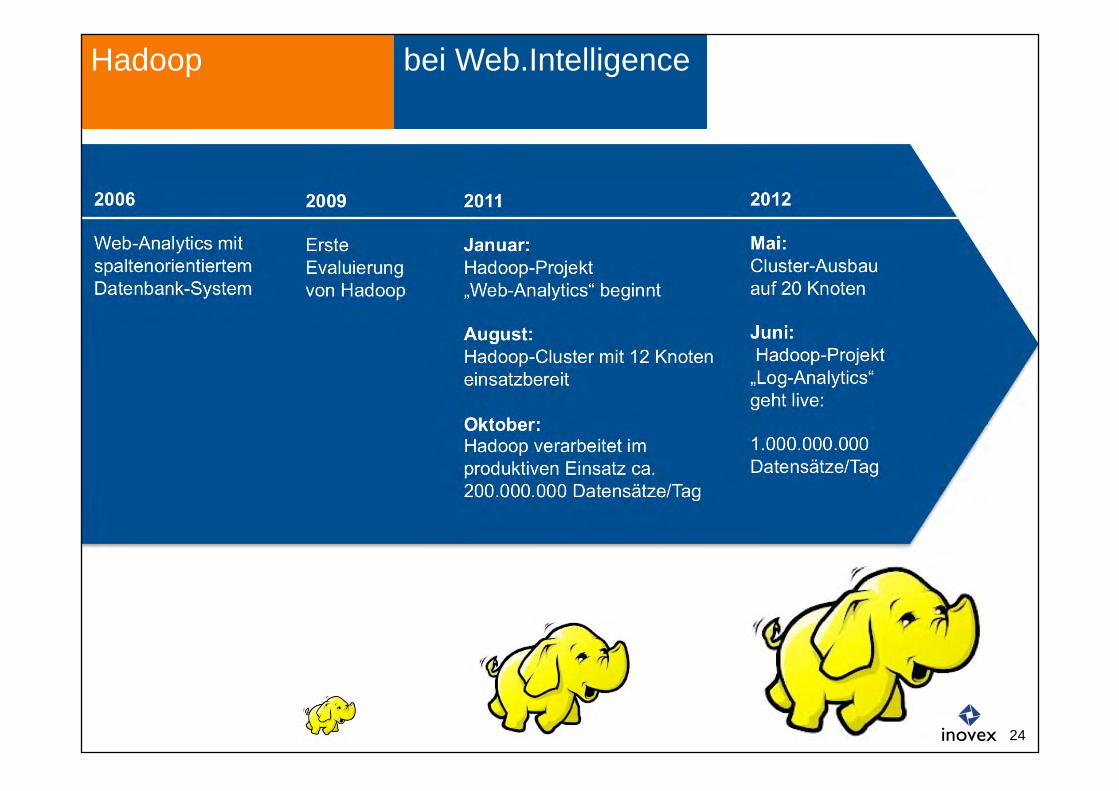
2006 Web-Analytics mit spaltenorientiertem Datenbank-System
2011 Januar: Hadoop-Projekt „Web-Analytics“ beginnt August: Hadoop-Cluster mit 12 Knoten einsatzbereit Oktober: Hadoop verarbeitet im produktiven Einsatz ca. 200.000.000 Datensätze/Tag
2012 Mai: Cluster-Ausbau auf 20 Knoten Juni: Hadoop-Projekt „Log-Analytics“ geht live: 1.000.000.000 Datensätze/Tag
24
2009 Erste Evaluierung von Hadoop
bei Web.Intelligence Hadoop
24
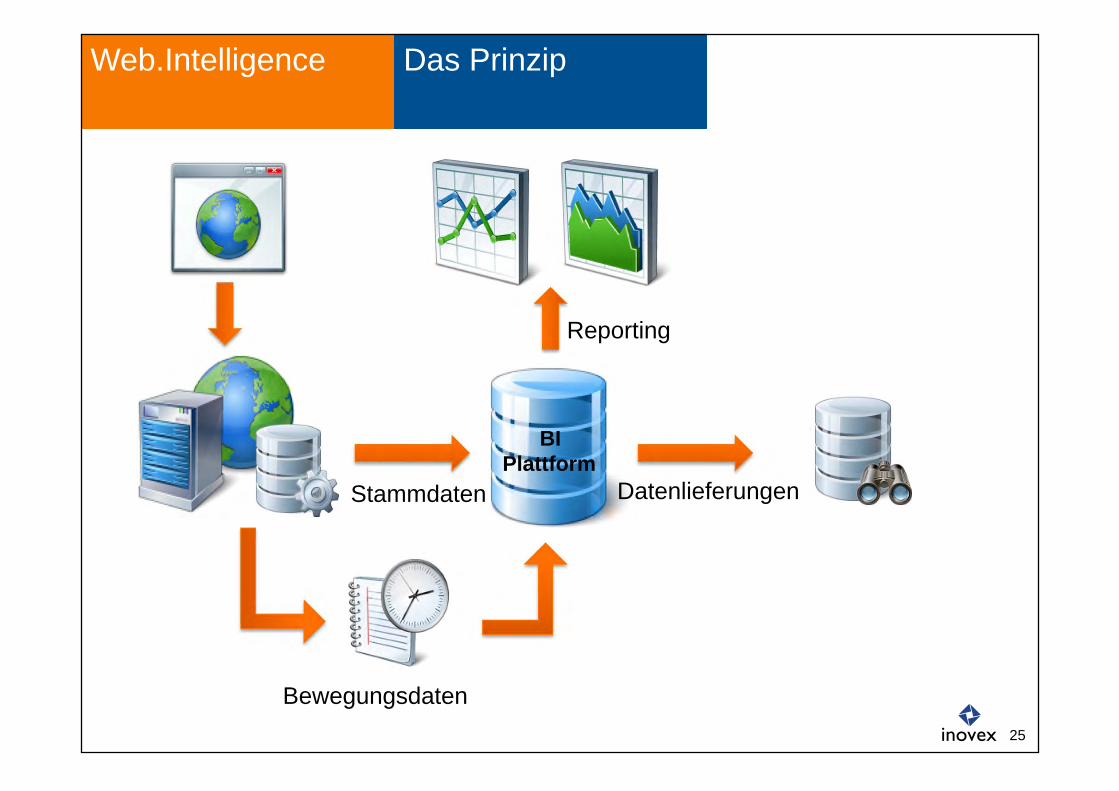
Das Prinzip Web.Intelligence
BI Plattform
Stammdaten
Bewegungsdaten
Reporting
Datenlieferungen
25
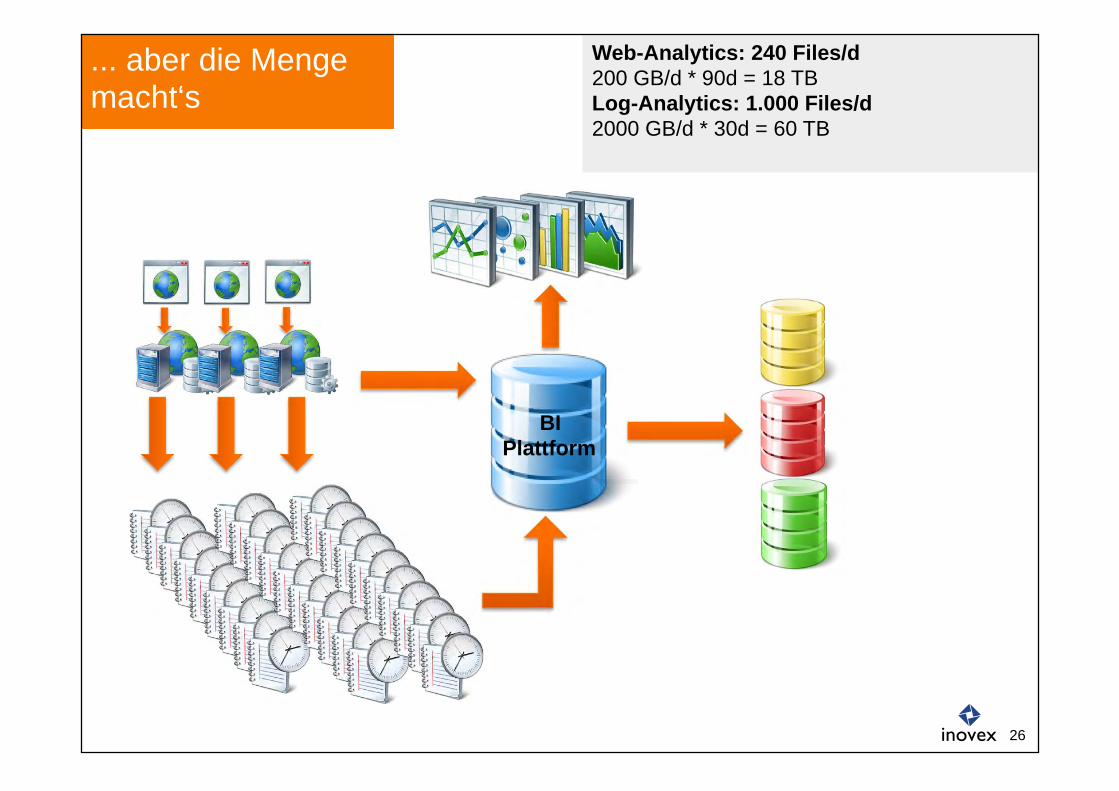
... aber die Menge macht‘s
BI Plattform
Web-Analytics: 240 Files/d 200 GB/d * 90d = 18 TB Log-Analytics: 1.000 Files/d 2000 GB/d * 30d = 60 TB
26

Massendaten durch Aggregation, Selektion und Verknüpfung in wertvolle Informationen zu wandeln.
Horizontale und damit kostengünstige Skalierbarkeit bezüglich Verarbeitungs- und Speicherkapazität, um auf wachsende Anforderungen reagieren zu können.
Multi-Projekt-Fähigkeit, d.h. Speichern und Verarbeiten von Datenbeständen unterschiedlicher Bedeutung und Herkunft.
Einsatz einer Standard-Technologie mit breiter Know-how-Basis unter den Mitarbeitern und in der Open Source-Community.
Sämtliche granulare Daten des operativen Geschäfts eines Monats vorhalten.
Die Aufgabenstellung
27
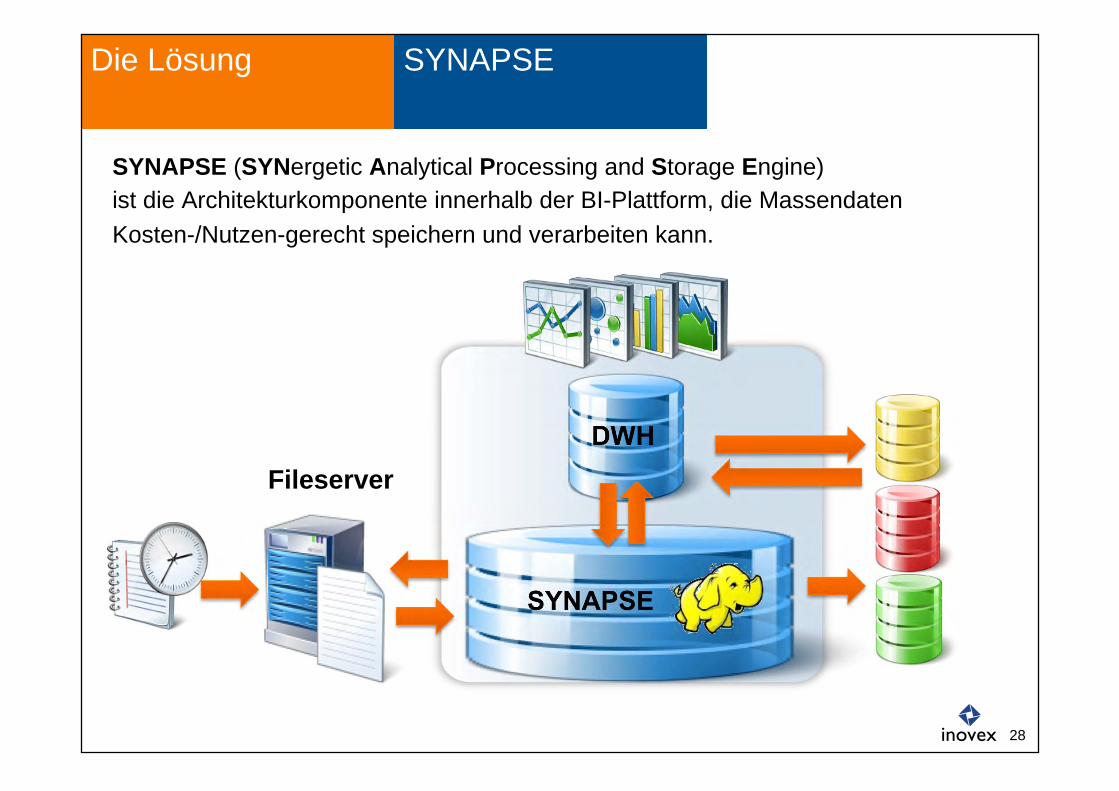
SYNAPSE Die Lösung
DWH
SYNAPSE
Fileserver
SYNAPSE (SYNergetic Analytical Processing and Storage Engine) ist die Architekturkomponente innerhalb der BI-Plattform, die Massendaten Kosten-/Nutzen-gerecht speichern und verarbeiten kann.
28

Geeignete Hardware finden und betreiben Geeignete Hadoop-Frameworks identifizieren
MapReduce Algorithmen entwickeln und testen
Verschiedene Daten-Eingangs- und Ausgangskanäle
Unterschiedliche Dateiformate
Mehrere konkurrierende Prozesse
Mehrere Benutzer
Konsistentes Verarbeiten vieler Eingangs-Files
Prozess-Steuerung über einen heterogenen System-Stack
Einige Herausfor-derungen bleiben ...
29

Identifiziere dein BIG DATA Problem
1&1 Best Practice
30

BIG DATA und Hadoop bei 1&1 Jede Menge Blech: Die Hardware Was darf es denn sein: Das Hadoop Ecosystem Speichern, Mappen, Reduzieren Spielregeln im Cluster Der fleißige Handwerker Essenz
Agenda
31
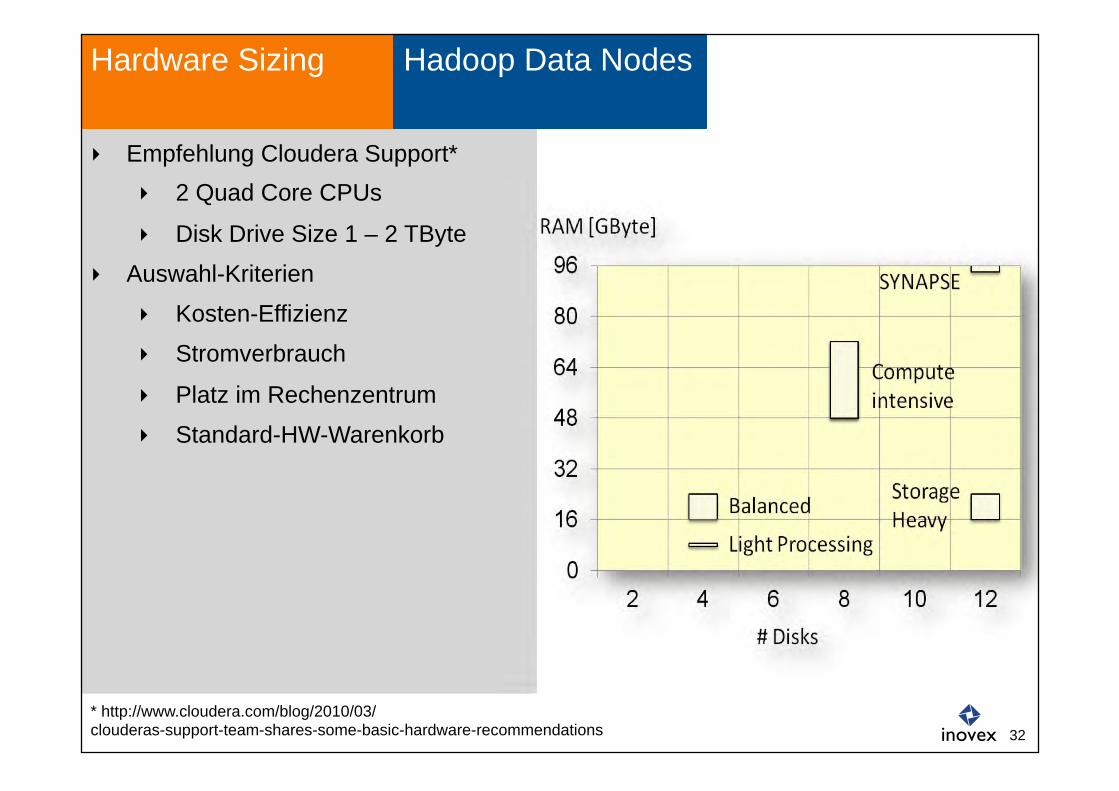
Empfehlung Cloudera Support* 2 Quad Core CPUs
Disk Drive Size 1 – 2 TByte
Auswahl-Kriterien
Kosten-Effizienz
Stromverbrauch
Platz im Rechenzentrum
Standard-HW-Warenkorb
Hardware Sizing
* http://www.cloudera.com/blog/2010/03/ clouderas-support-team-shares-some-basic-hardware-recommendations
Hadoop Data Nodes
32

Sizing ist bestimmt durch
erforderliche Speicherkapazität:
480 TB
78 TB Nutzdaten (Web- + Log-
Analytics)
Faktor 2 für Zwischenergebnisse
Replikationsfaktor 3 zur
Datensicherung
480TB / 2TB / 12 = 20 Rechner
x 8 Cores = 160 CPUs!
Die Szenarien sind „Storage Heavy“
Sizing der SYNAPSE
33

von „Commodity Hardware“
Unsere Definition
12 x 2TB as JBOD direct attached
8 Cores @2,4GHz 96 GB RAM
4x 1GB Network
20 x Worker-Node (Datanode, Tasktracker)
4 Cores @2,4GHz 12 GB RAM
50GB local Storage
2 x Namenode Server (Namenode, Sec.-Namenode, Jobtracker)
34
Hauptspeicher
Im Grenzbereich schafft es die Hadoop interne Speicherverwaltung oft nicht mehr den „spill to disk“ durchzuführen => Out Of Memory Exception
Plattenplatz Achtung: auch Zwischenergebnisse mit einrechnen Die Tasktracker schreiben lokale Temp-Files => auch dafür muss Platz
vorgesehen werden!
Laste deine Systeme ...
... nur zu 75 % aus! Best Practice
35
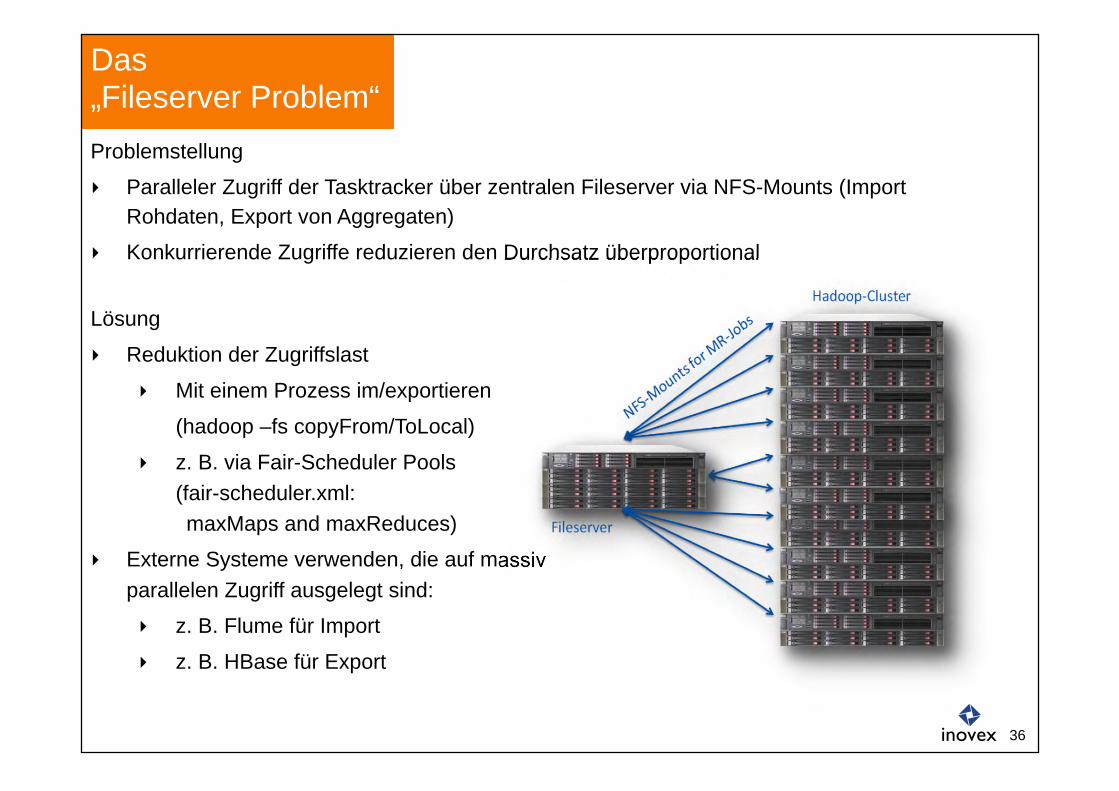
Problemstellung
Paralleler Zugriff der Tasktracker über zentralen Fileserver via NFS-Mounts (Import Rohdaten, Export von Aggregaten)
Konkurrierende Zugriffe reduzieren den Durchsatz überproportional
Lösung
Reduktion der Zugriffslast
Mit einem Prozess im/exportieren
(hadoop –fs copyFrom/ToLocal)
z. B. via Fair-Scheduler Pools (fair-scheduler.xml: maxMaps and maxReduces)
Externe Systeme verwenden, die auf massiv parallelen Zugriff ausgelegt sind:
z. B. Flume für Import
z. B. HBase für Export
Das „Fileserver Problem“
36
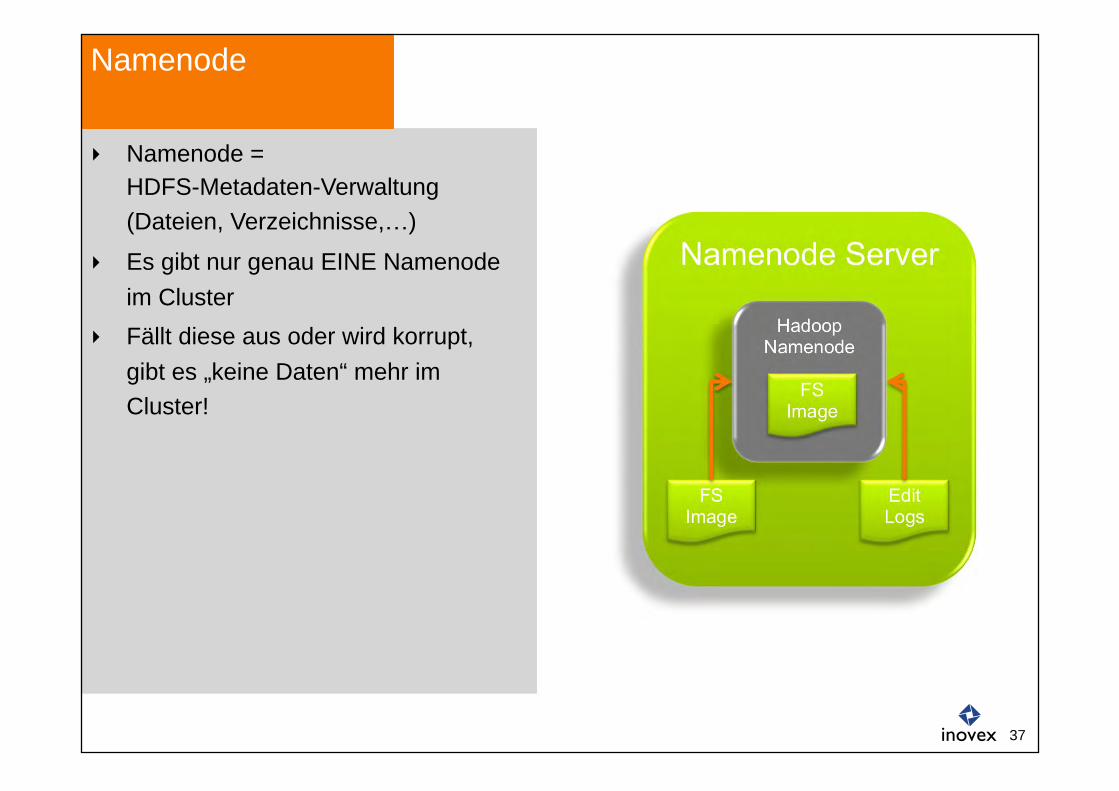
Namenode Server
Namenode = HDFS-Metadaten-Verwaltung (Dateien, Verzeichnisse, )
Es gibt nur genau EINE Namenode im Cluster
Fällt diese aus oder wird korrupt, gibt es „keine Daten“ mehr im Cluster!
Namenode
Hadoop Namenode
FS Image
FS Image
Edit Logs
37
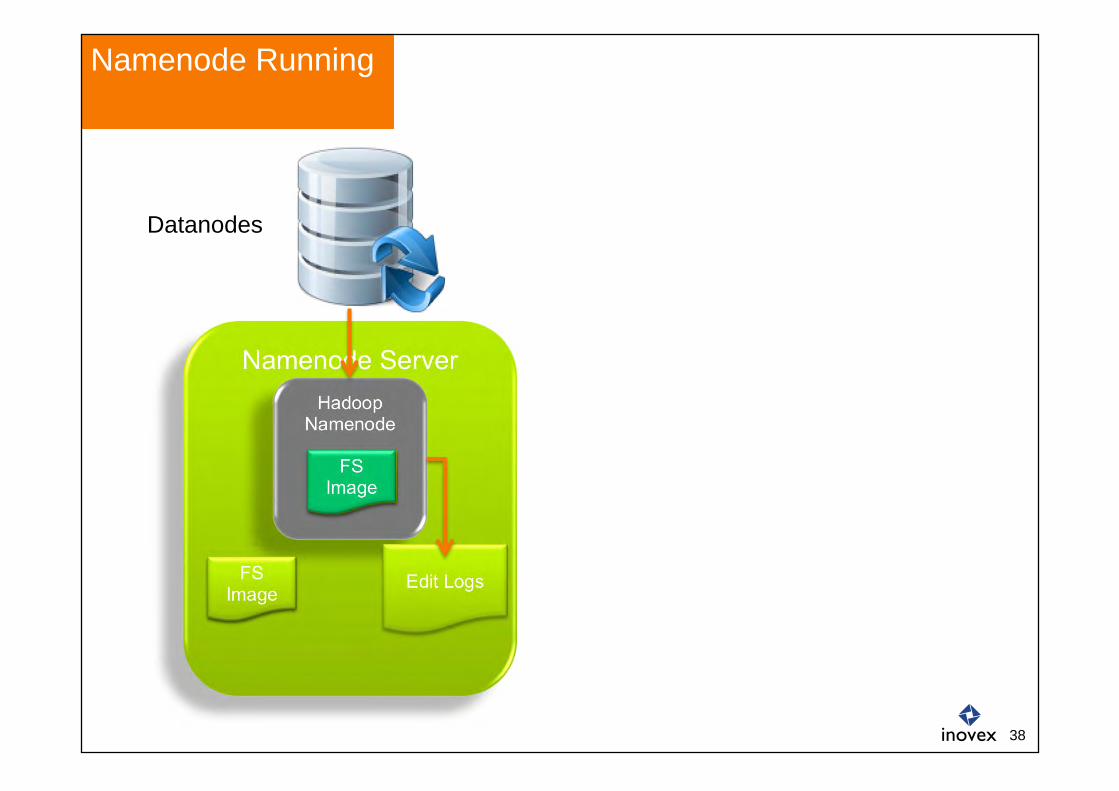
Namenode Server
Namenode Running
Hadoop Namenode
FS Image
FS Image
Edit Logs
FS Image
Edit Logs
FS Image
Datanodes
38
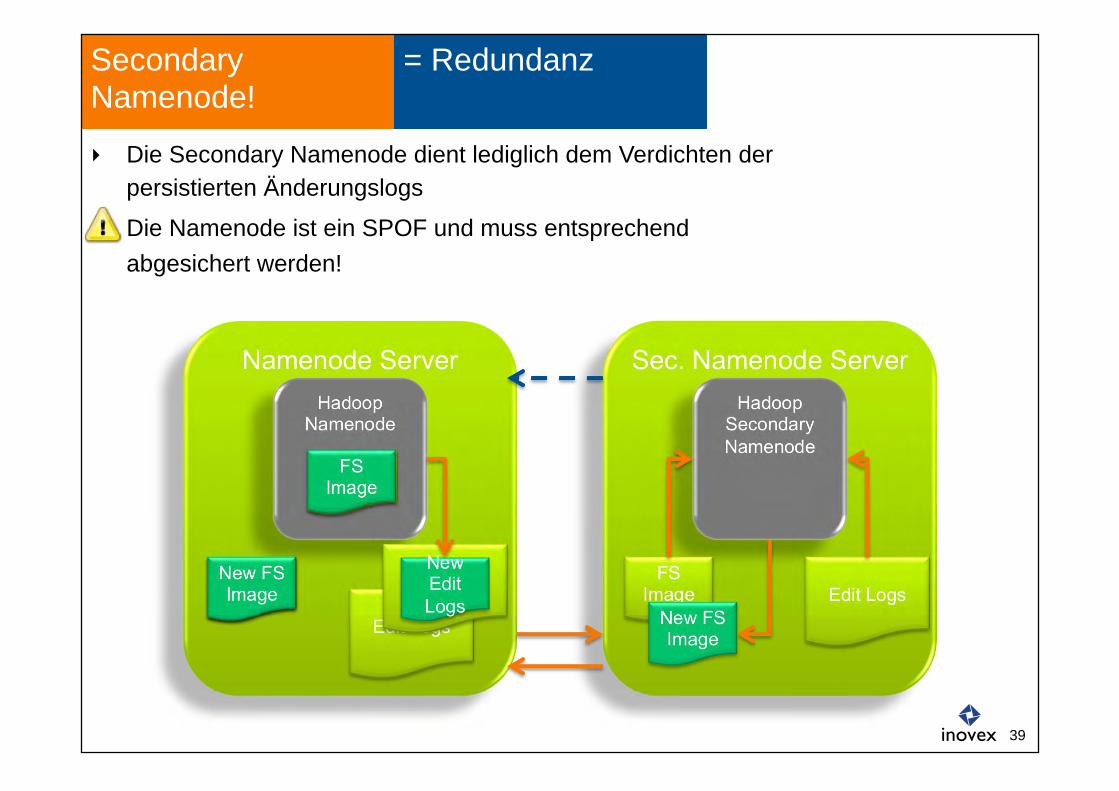
Namenode Server
Edit Logs
= Redundanz Secondary Namenode!
Hadoop Namenode
Sec. Namenode Server Hadoop
Secondary Namenode
FS Image
FS Image
Edit Logs
FS Image
Edit Logs Edit Logs
FS Image
New FS Image
New FS Image
New Edit Logs
FS Image
Die Secondary Namenode dient lediglich dem Verdichten der persistierten Änderungslogs
Die Namenode ist ein SPOF und muss entsprechend abgesichert werden!
39
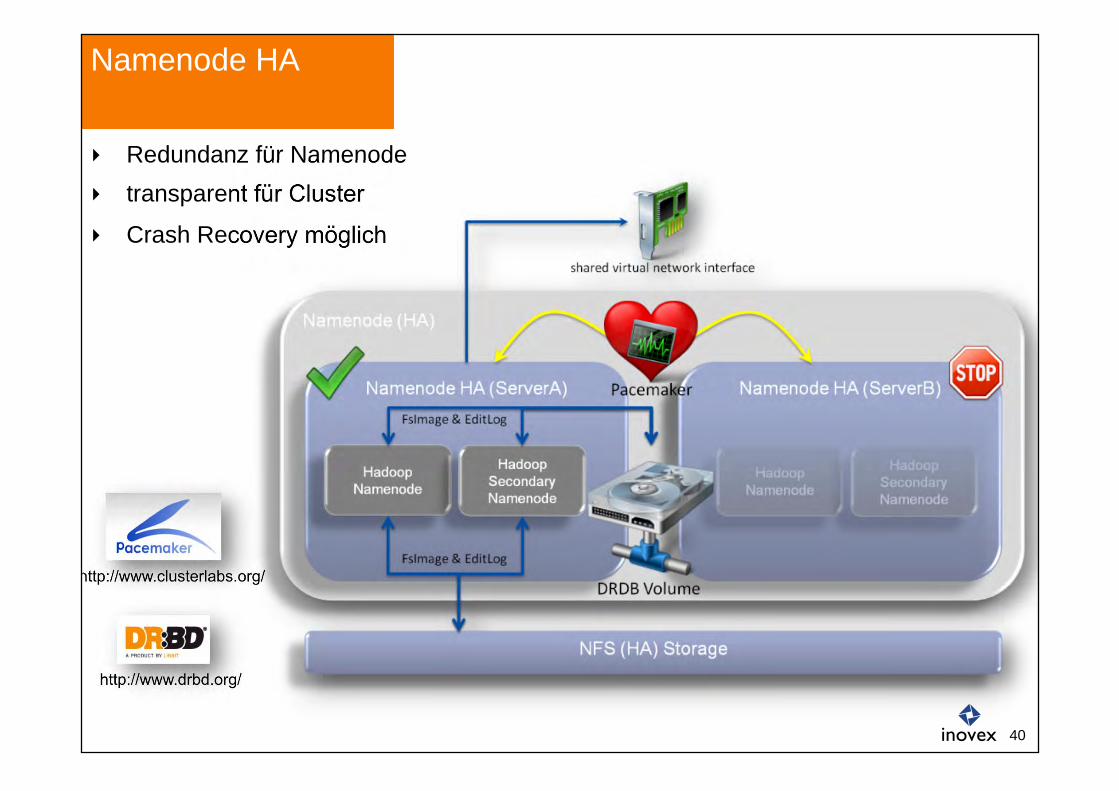
Namenode HA
http://www.drbd.org/
http://www.clusterlabs.org/
Redundanz für Namenode transparent für Cluster
Crash Recovery möglich
40
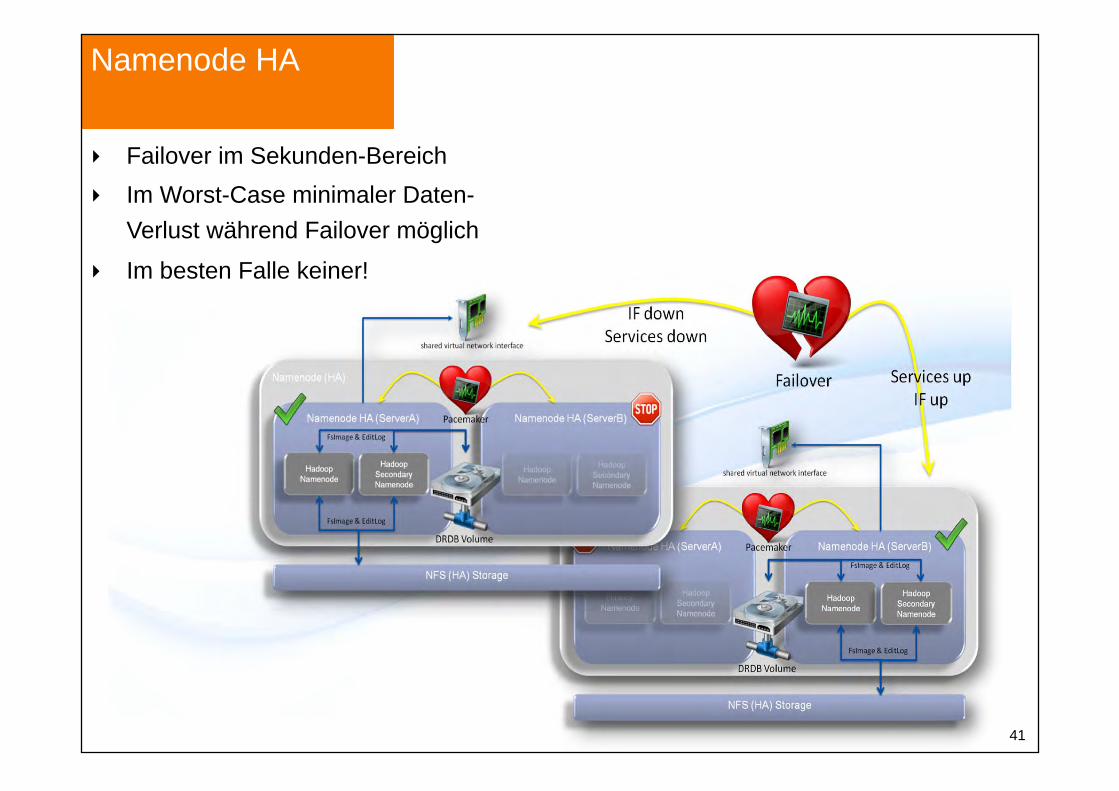
Namenode HA
Failover im Sekunden-Bereich Im Worst-Case minimaler Daten-
Verlust während Failover möglich
Im besten Falle keiner!
41

Die Knoten eines Hadoop-Clusters sollten möglichst „nahe“ beieinander stehen und auch bei den Datenquellen
dafür muss Platz im Rechenzentrum verfügbar sein
Je besser die Netzwerk-Anbindung des Clusters desto besser seine Performance
Netzwerk
2GB
it each 4GBit
1GBit
42

Identifiziere dein BIG DATA Problem Etwas mehr schadet nicht: Alle Systeme müssen
skalieren und benötigen Reserven, Namenode HA!
1&1 Best Practice
43

BIG DATA und Hadoop bei 1&1 Jede Menge Blech: Die Hardware Was darf es denn sein: Das Hadoop Ecosystem Speichern, Mappen, Reduzieren Spielregeln im Cluster Der fleißige Handwerker Essenz
Agenda
44

und schauen mal, was wir darin finden ...
Wir machen unsere Werkzeugkiste auf
45

Aufgabenverteilung
Transport kontinuierlich entstehender Massendaten
Aggregation Speicherung Suche AdHoc Anfragen ILM
Vorgänge koordinieren
Integration mit DWH Nachvollziehbarkeit Wiederaufsetzbarkeit
>1000 Files/Tag ~ 3TB
Aggregationen alle 3 Stunden
46

(Reduced to the Max)
Unser Technologie-Stack
Que
lle: h
ttp://
ww
w.fl
ickr
.com
/pho
tos/
_mrs
_b/4
7174
2742
9/
47

Entwicklung ist immer noch im Fluss
Hadoop- Kern ist bereits sehr stabil - aber kein Vergleich bspw. mit einer DB-Lösung
Flankierende Projekte haben gefühlt oft noch Beta-Status – im Handumdrehen ist man Committer eines OS-Projektes ;-)
Lessons learned Stabilität
48

Ähnliche Toolsets unterscheiden sich meist nur in Details Pig, Hive, Cascading
HBase und Casandra
Askaban vs. Oozie
Aber gerade die – können manchmal entscheidend sein!
Lessons learned Feature-Set
49

Hadoop-Solution-Provider ...
geben Sicherheit Schön, dass es Distributionen gibt!
Hadoop-Solution-Partner geben Sicherheit
Beispiel: Cloudera Eigenes Hadoop-Release basierend auf den Apache Repositories bietet konsistente, „in sich schlüssige Release-Stände“ und Bugfixes Möglichkeit des kommerziellen Supports
Beispiel: Cloudera Eigenes Hadoop-Release basierend auf den Apache
Repositories
bietet konsistente, „in sich schlüssige Release-Stände“ und Bugfixes
Möglichkeit des kommerziellen Supports
50

Identifiziere dein BIG DATA Problem Etwas mehr schadet nicht: Alle Systeme müssen skalieren
und benötigen Reserven, Namenode HA!
Keep Your Ecosystem Simple, wähle sorgfältig aus!
1&1 Best Practice
51

BIG DATA und Hadoop bei 1&1 Jede Menge Blech: Die Hardware Was darf es denn sein: Das Hadoop Ecosystem Speichern, Mappen, Reduzieren Spielregeln im Cluster Der fleißige Handwerker Essenz
Agenda
52
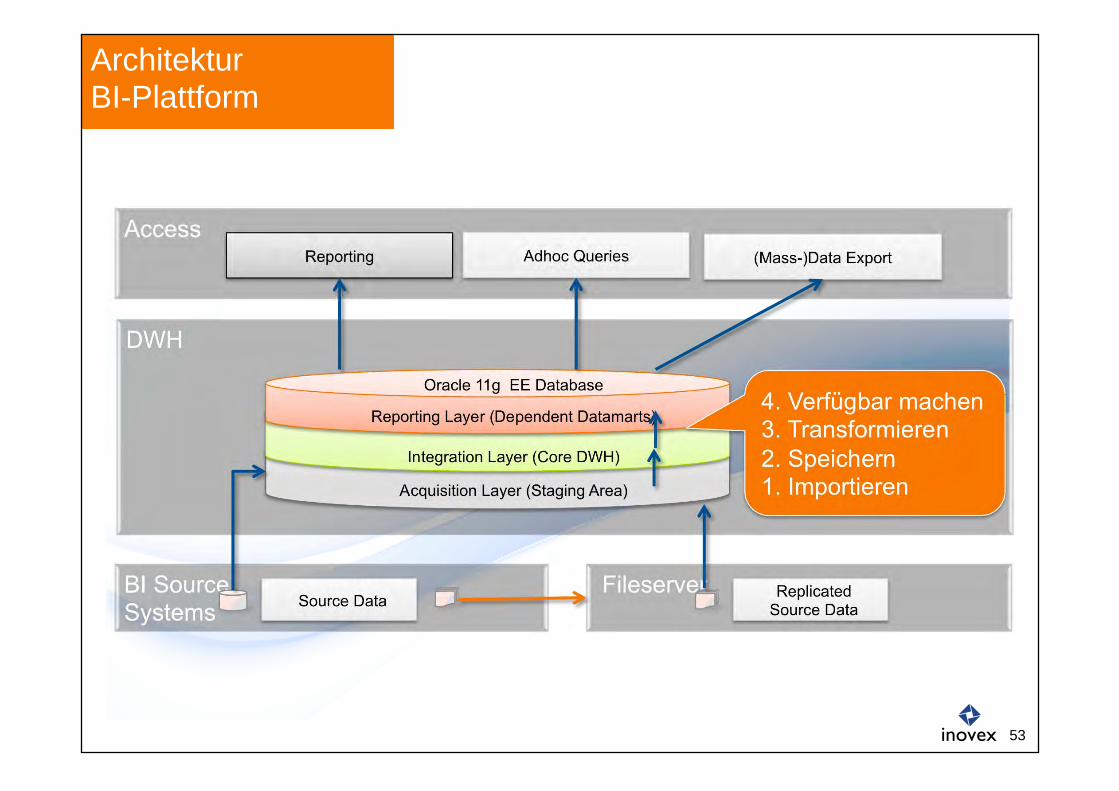
BI Source Systems Source Data
Fileserver Replicated Source Data
DWH
Architektur BI-Plattform
Access Reporting
Oracle 11g EE Database
Reporting Layer (Dependent Datamarts)
Integration Layer (Core DWH)
Acquisition Layer (Staging Area)
Adhoc Queries (Mass-)Data Export
4. Verfügbar machen 3. Transformieren 2. Speichern 1. Importieren
53
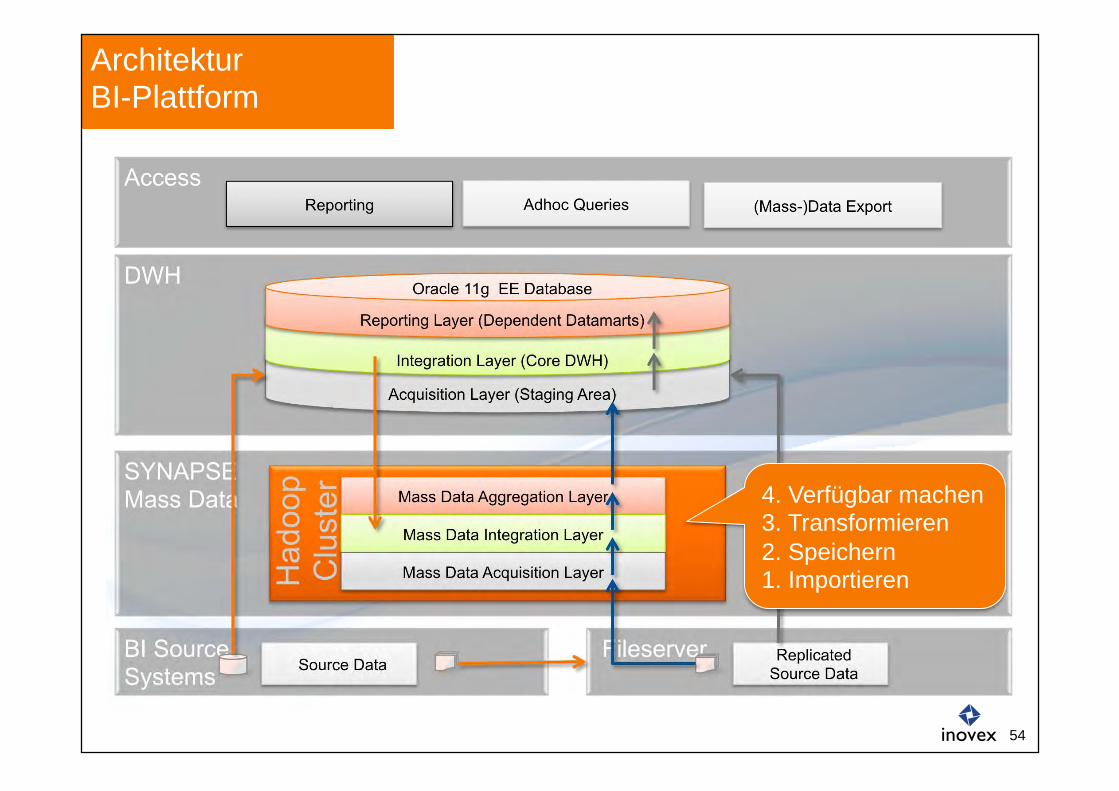
BI Source Systems Source Data
Fileserver Replicated Source Data
DWH
Architektur BI-Plattform
Access Reporting
Oracle 11g EE Database
Reporting Layer (Dependent Datamarts)
Integration Layer (Core DWH)
Acquisition Layer (Staging Area)
Adhoc Queries (Mass-)Data Export
SYNAPSE Mass Data
Had
oop
Clu
ster
Mass Data Aggregation Layer
Mass Data Integration Layer
Mass Data Acquisition Layer
4. Verfügbar machen 3. Transformieren 2. Speichern 1. Importieren
54

Unterstützt die Verarbeitung durch Header-Zeile pro File mit
Typ-Information (JSON-Format)
Versionsprüfung möglich
IDL optional
Effiziente Verarbeitung durch
Speicher-effizientes Binärformat
(De-)Serialisierung ok
Zukunftssicher da
Künftiger Hadoop-Standard
Aktive Weiterentwicklung
Sukzessive Integration in die Hadoop-Teilprojekte
Das Serialisierungs-Framework
Importieren und Speichern
# avro textual representation {"type": "record", "name": "Point", "fields": [ {"name": "x", "type": "int"}, {"name": "y", "type": "int"} ] } 5 8 -3 4 2 -7
55

FLIS - Flexibilität gefragt
Importieren und Speichern
Plain csv
thrift
Flexible Input Selector
56

Map Side Join Eingangsfiles müssen nach gleichem
Schlüssel sortiert und partitioniert sein
Sorted-Merged-Join noch vor dem Mapper
Sehr effizient, da Shuffle/Sort-Phase nichts mehr zu tun hat
Reduce Side Join
Klassischer MR-Join
Hauptlast wird in der Shuffle/Sort-Phase getragen
Join in MapReduce Transformieren
57

Join-Operationen können in MR als Hash Join implementiert werden Lookup wird als Hashmap über den Distributed Cache an Mapper verteilt
Kleine CPU, keine Netzwerk-Last während der Verarbeitung
Die Grenze bildet das Volumen der Lookup-Daten
MR-Join
Lookup-Data
Result Data Data
MR-Join
Result Data Data
Lookup-Data Lookup-
Data Lookup-Data Lookup-
Data
Join in MapReduce Transformieren
58
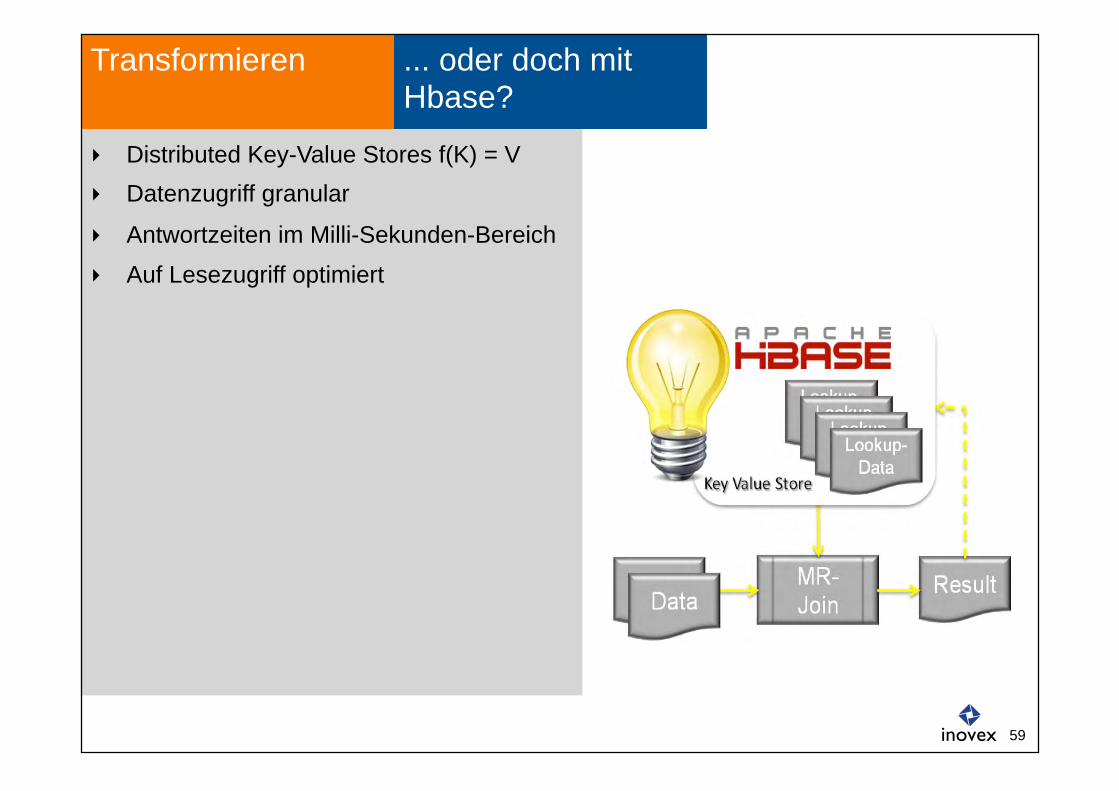
Distributed Key-Value Stores f(K) = V Datenzugriff granular
Antwortzeiten im Milli-Sekunden-Bereich
Auf Lesezugriff optimiert
... oder doch mit Hbase?
Transformieren
59

Ursprünglich von Yahoo entwickelt File basiertes High Level Daten-Manipulations-Framework
SQL-artige Sprache welche durch das Framework in Map/Reduce Jobs übersetzt und ausgeführt wird
http://hadoop.apache.org/pig/
mit PIG Transformieren
60
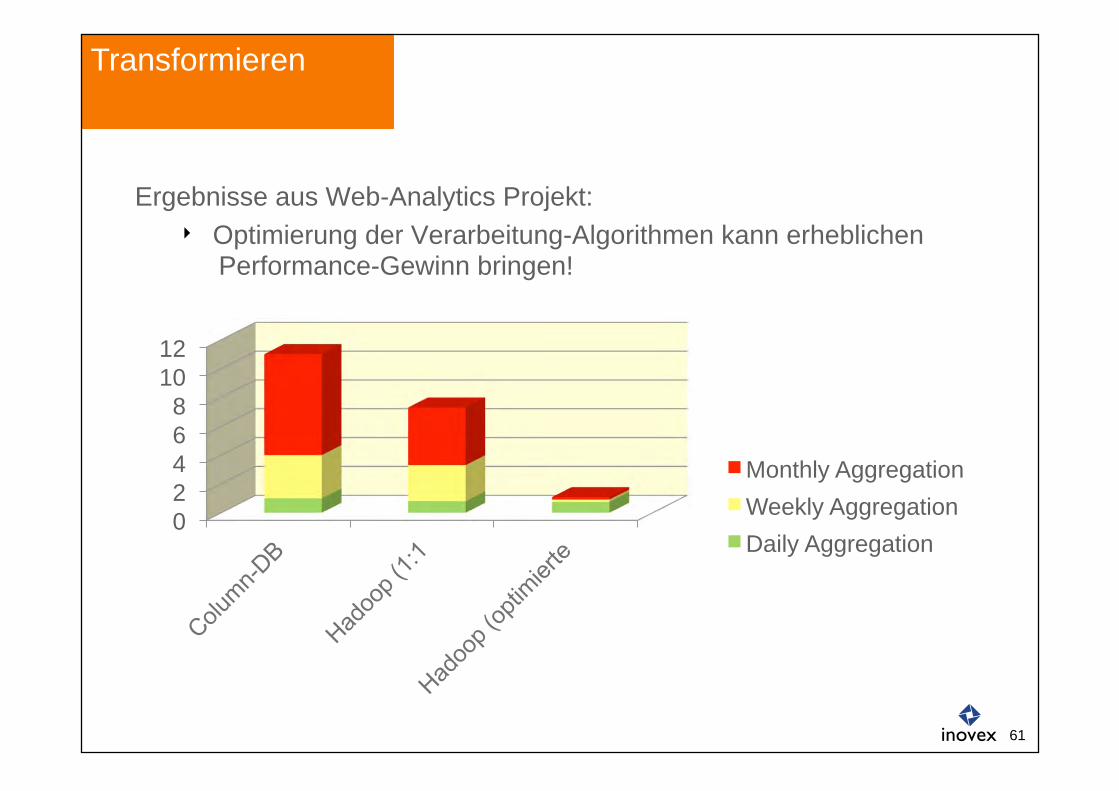
Transformieren
0 2 4 6 8
10 12
Monthly Aggregation Weekly Aggregation Daily Aggregation
Ergebnisse aus Web-Analytics Projekt: Optimierung der Verarbeitung-Algorithmen kann erheblichen
Performance-Gewinn bringen!
61

Muss oft erst aufgebaut werden. Hierfür passende Projekte einplanen.
Am Anfang fehlt das Know-how an allen Fronten
DEV: Best Practices sind nicht vorhanden. Oft funktionieren die Dinge in Dev und brechen dann im Live-Einsatz.
QS: Herausforderung: verteiltes Testen - möglichst mit Echt-Daten (bzgl. Qualität und Quantität)
LIVE: Lastverhalten ist nur bedingt vorhersehbar. Tuning-Möglichkeiten mannigfaltig und oft nur mit DEV-Unterstützung durchführbar.
Lessons learned Know-how ...
62

Identifiziere dein BIG DATA Problem Etwas mehr schadet nicht: Alle Systeme müssen skalieren
und benötigen Reserven, Namenode HA!
Keep Your Ecosystem Simple, wähle sorgfältig aus!
Die Algorithmen bestimmen die Effizienz!
1&1 Best Practice
63

BIG DATA und Hadoop bei 1&1 Jede Menge Blech: Die Hardware Was darf es denn sein: Das Hadoop Ecosystem Speichern, Mappen, Reduzieren Spielregeln im Cluster Der fleißige Handwerker Essenz
Agenda
64

BI Source Systems Source Data
WI Gateway Fileserver
Replicated Source Data
DWH
Information Lifecycle Management
BI-Plattform
Access Standard Reporting
Oracle 11g EE Database
Reporting Layer (Dependent Datamarts)
Integration Layer (Core DWH)
Acquisition Layer (Staging Area)
Adhoc Queries (Mass) Data Export
Had
oop
Clu
ster
Mass Data Aggregation Layer
Mass Data Integration Layer
Mass Data Acquisition Layer
Hadoop als Kurzzeit-Archiv Kosten: 0,0005 €/MB
DWH als Langzeit-Archiv Kosten: 0,15 €/MB
65
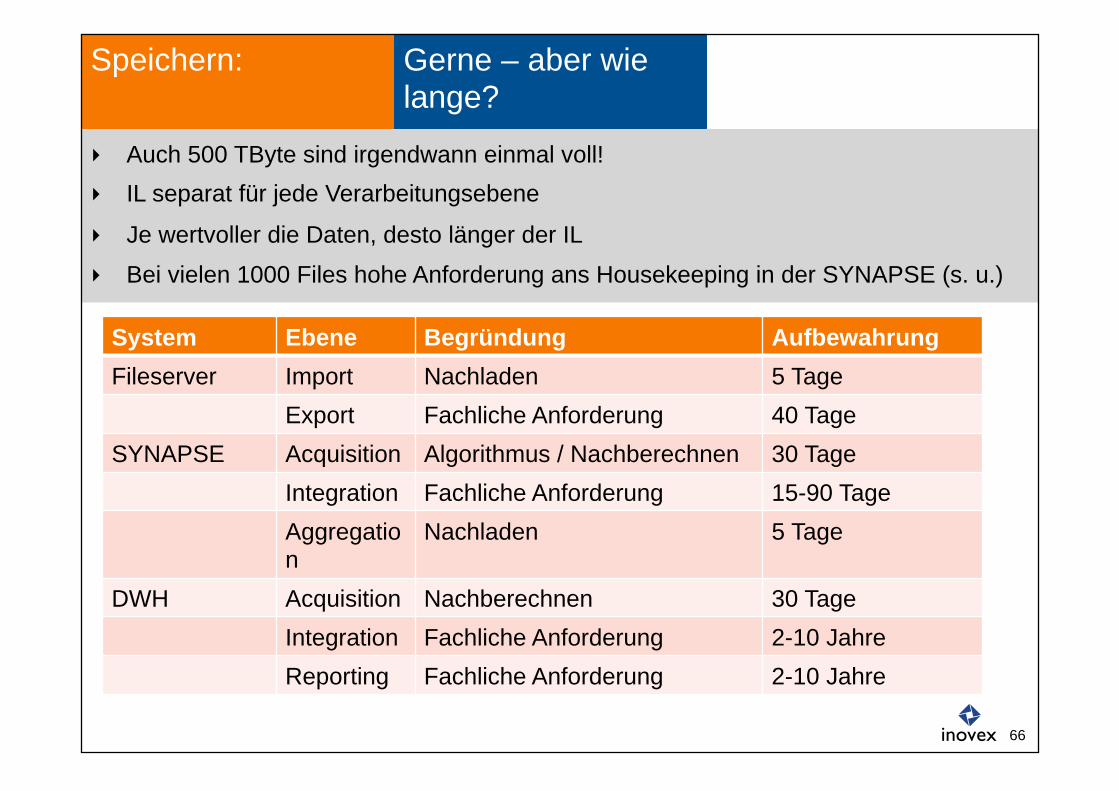
Gerne – aber wie lange?
Speichern:
System Ebene Begründung Aufbewahrung Fileserver Import Nachladen 5 Tage
Export Fachliche Anforderung 40 Tage SYNAPSE Acquisition Algorithmus / Nachberechnen 30 Tage
Integration Fachliche Anforderung 15-90 Tage Aggregation
Nachladen 5 Tage
DWH Acquisition Nachberechnen 30 Tage Integration Fachliche Anforderung 2-10 Jahre Reporting Fachliche Anforderung 2-10 Jahre
Auch 500 TByte sind irgendwann einmal voll! IL separat für jede Verarbeitungsebene
Je wertvoller die Daten, desto länger der IL
Bei vielen 1000 Files hohe Anforderung ans Housekeeping in der SYNAPSE (s. u.)
66

Wer darf wann? Mehrparteien-Betrieb
Default Capacity Fair Mechanismus Vergeben von
Prioritäten pro Job Job-Queues mit festgelegten Prioritäten
Job-Queues und Pools mit Gewichten
Funktionsfähig Ja Ja Ja Clusterauslastung Ja Nein Ja Gefahr von Starvation
Ja Nein Nein
Hadoop Job Scheduler Gleichmäßige Lastverteilung über die Zeit nach Prioritäten
Verschiedene Anwendungen können konkurrierend betrieben werden
67

Wer darf überhaupt? Mehrparteien-Betrieb
“ This user identity mechanism combined with the permissions model allows a cooperative community to share file system resources in an organized fashion.”
Hadoop hat ein Zugriffsberechtigungskonzept angelehnt an POSIX (ohne sticky, setuid or setgid bits) für Files und Directories
Hadoop hat keine eigene Benutzer-Authentifizierung
Hadoop übernimmt user name (whoami) und group name (bash -c groups) vom aufrufenden Client-Prozess
Authorisierung ist damit (nur) auf File- und Verzeichnisebene möglich
Das schützt im Mehrparteienbetrieb vor versehentlichem Löschen oder Überschreiben fremder Dateien.
Authorisierung muss auf Betriebssystem-Ebene konsequent umgesetzt sein
Geeignetes Konzept für „Tool“-User oder Application Manager
http://hadoop.apache.org/common/docs/r0.20.2/hdfs_permissions_guide.html 68

Identifiziere dein BIG DATA Problem Etwas mehr schadet nicht: Alle Systeme müssen skalieren
und benötigen Reserven, Namenode HA!
Keep Your Ecosystem Simple, wähle sorgfältig aus!
Die Algorithmen bestimmen die Effizienz!
Sorge für geordnete Verhältnisse im Cluster!
1&1 Best Practice
69

BIG DATA und Hadoop bei 1&1 Jede Menge Blech: Die Hardware Was darf es denn sein: Das Hadoop Ecosystem Speichern, Mappen, Reduzieren Spielregeln im Cluster Der fleißige Handwerker Essenz
Agenda
70

PRO Workflows können graphisch
dargestellt und gedrilled werden
Einfache Handhabung (Komplexes wird in Scripts ausgelagert)
Startet Hadoop-Jobs und “Anderes” einfach als Unix-Prozesse
Ressoucen (.jar files, pig scripts) werden durch Azkaban verwaltet und deployed
Azkaban (LinkedIn)
CONTRA Minimaler Funktionsumfang
Keine Rechte und Zugriffs-Verwaltung
Jobausführung nur Zeit-basiert
Keine Redundanz (Azkaban-Server wird zum SPOF)
71

PRO Enge Integration mit Hadoop and
M/R
Kann mit unterschiedlichen Job-Typen umgehen: Java MR, PIG, Java, etc.
Webservice- und Java-API
Zeit- und Ereignis-basierte Job-Ausführung
Oozie (Yahoo!)
CONTRA WEB-Konsole ist “Read-Only”, keine
graphische Aufbereitung von Abhängigkeiten
Ressoucen (.jar files, pig scripts) müssen manuell vor der Jobausführung auf dem HDFS deployed werden
Müsste um File-Registierung erweitert werden
72
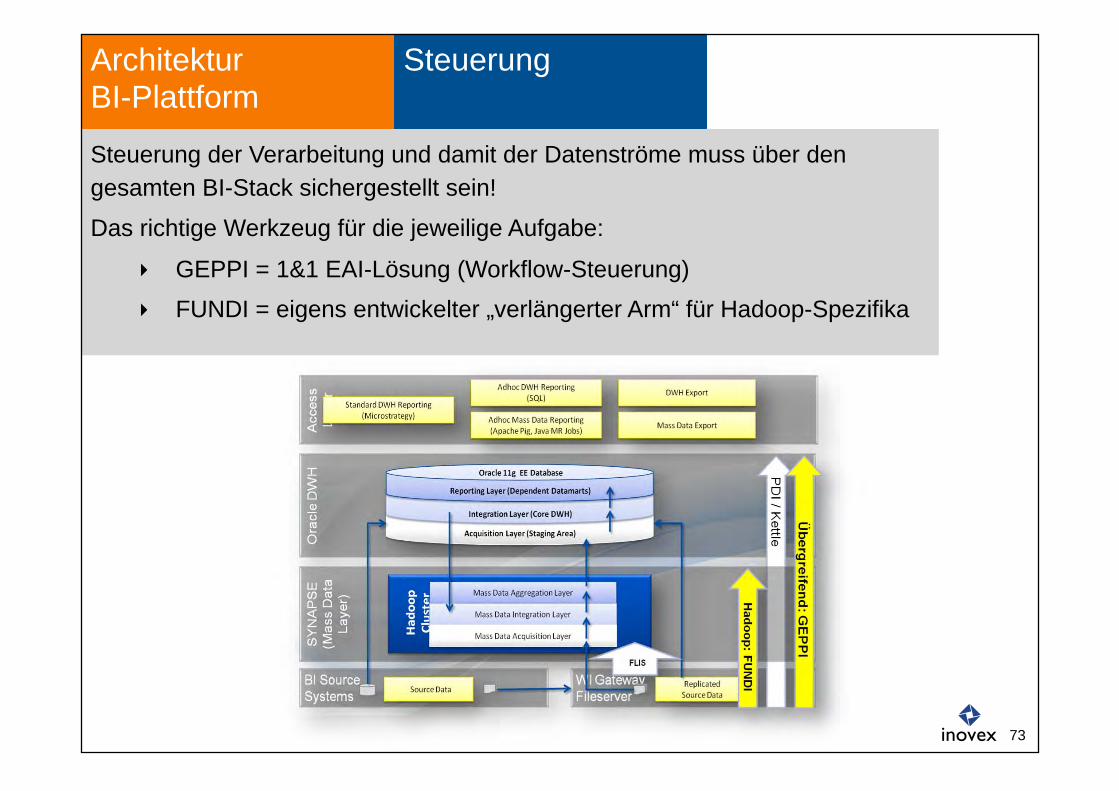
Steuerung Architektur BI-Plattform
Steuerung der Verarbeitung und damit der Datenströme muss über den gesamten BI-Stack sichergestellt sein!
Das richtige Werkzeug für die jeweilige Aufgabe:
GEPPI = 1&1 EAI-Lösung (Workflow-Steuerung)
FUNDI = eigens entwickelter „verlängerter Arm“ für Hadoop-Spezifika
73
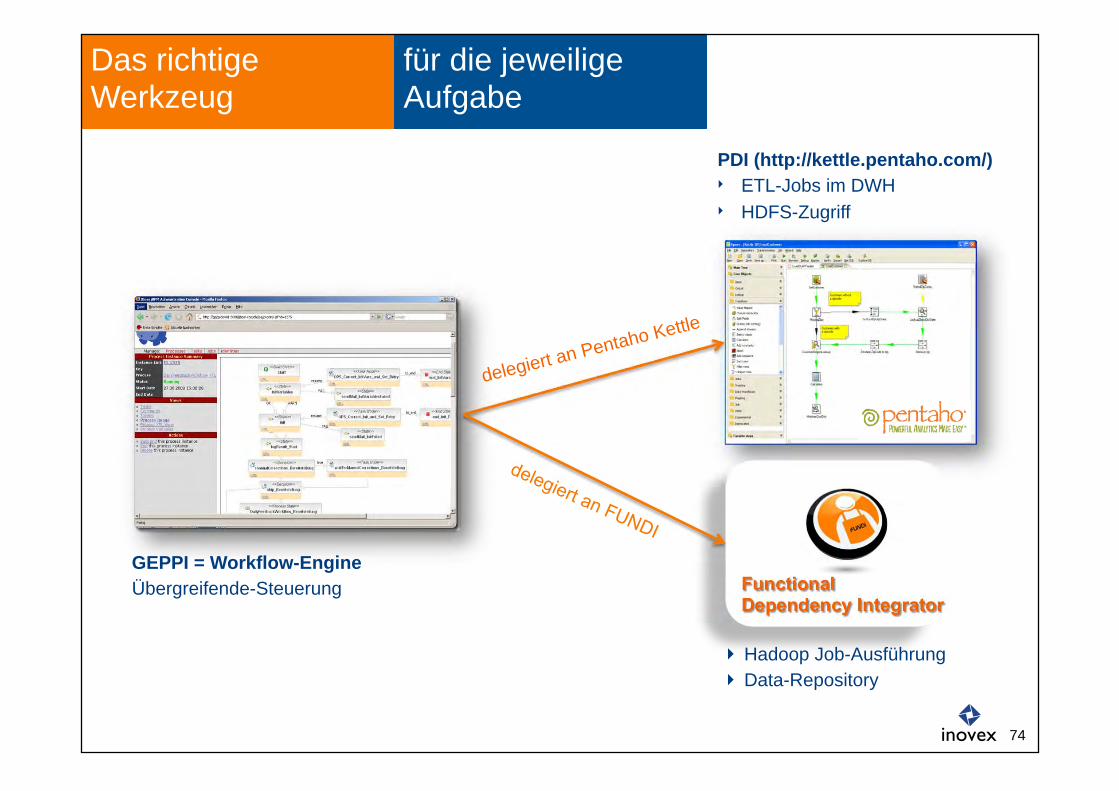
für die jeweilige Aufgabe
Das richtige Werkzeug
Functional Dependency Integrator
GEPPI = Workflow-Engine Übergreifende-Steuerung
delegiert an Pentaho Kettle
PDI (http://kettle.pentaho.com/) ETL-Jobs im DWH HDFS-Zugriff
Hadoop Job-Ausführung Data-Repository
74
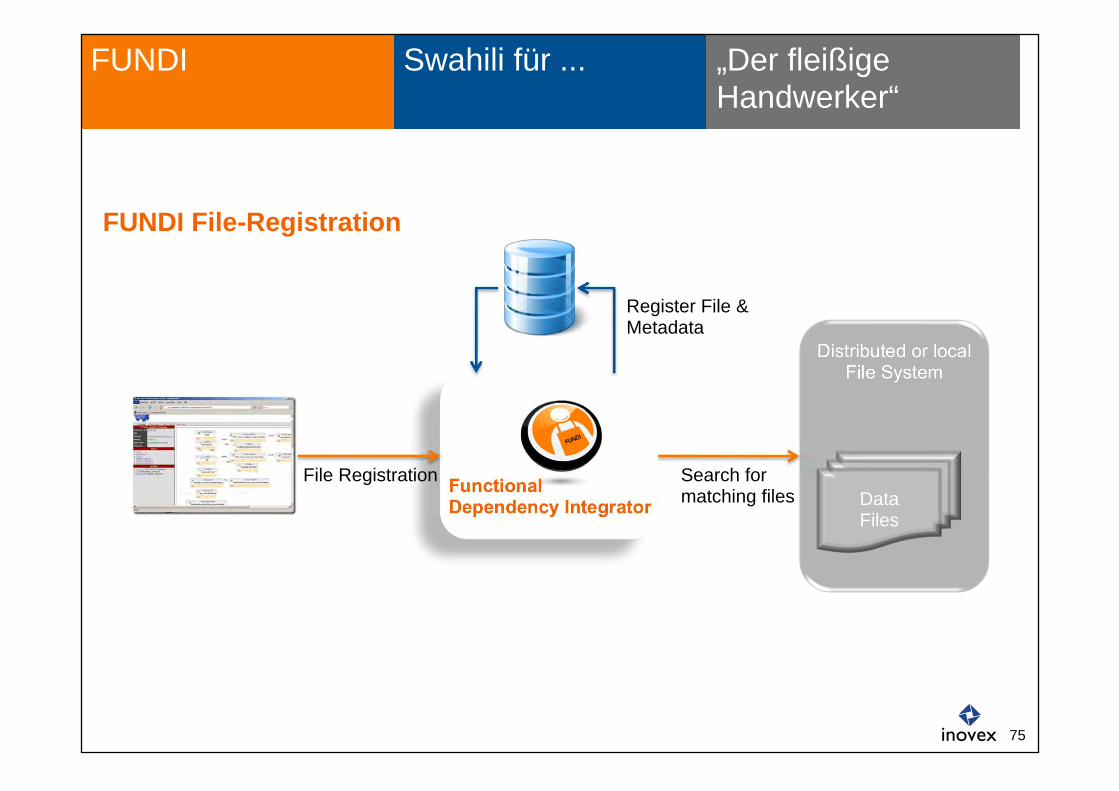
Swahili für ... „Der fleißige Handwerker“
FUNDI
FUNDI File-Registration
Distributed or local File System
Functional Dependency Integrator Data
Files
File Registration Search for matching files
Register File & Metadata
75

Run Job(name) Start
Register Output-Files & Metadata
get Jar/PIG Metadata Input-Filenames
Hadoop-Cluster
Inp. Data Files
MR Job
Outp Data Files
Fundi Job-Run
Swahili für ... „Der fleißige Handwerker“
FUNDI
Functional Dependency Integrator
76

Fundi Job-Ketten (Das EVA-Prinzip)
Fundi-JOB A
Fundi-JOB B
Named-Input
Named-Output
Configuration e.g. Path, Filenames, Jar/PIG-Script, Settings
Metadata for Job-Rung, Inp.-Files, Outp.-Files E V A
Swahili für ... „Der fleißige Handwerker“
FUNDI
77

Identifiziere dein BIG DATA Problem Etwas mehr schadet nicht: Alle Systeme müssen skalieren
und benötigen Reserven, Namenode HA!
Keep Your Ecosystem Simple, wähle sorgfältig aus!
Die Algorithmen bestimmen die Effizienz!
Sorge für geordnete Verhältnisse im Cluster!
Es geht auch ohne Skript-Wüste und cron-Jobs!
1&1 Best Practice
78

BIG DATA und Hadoop bei 1&1 Jede Menge Blech: Die Hardware Was darf es denn sein: Das Hadoop Ecosystem Speichern, Mappen, Reduzieren Spielregeln im Cluster Der fleißige Handwerker Essenz
Agenda
79

Hadoop verlangt ein neues Denken in allen IT-Bereichen: Operations, Entwicklung, QS,
Binde alle Stakeholder möglichst früh in deine Planung ein! Know-how zum Entwickeln, Testen und Betreiben einer
verteilten Umgebung muss erarbeitet werden! Identifiziere dein Pilotprojekt! Bleibe nicht zu lange im „Spielbetrieb“, evaluiere gegen
echte Anforderungen!
Die Aufgabe Lange Rede kurzer Sinn:
80

Hadoop und sein Ecosystem bieten hervorragende Lösungen für viele BIG DATA Probleme!
http://www.flickr.com/photos/xrm0/184379507/
Die Belohnung Lange Rede kurzer Sinn:
81

Massendatenverarbeitung ist bei 1&1 für Web-Analytics, Logfile-Verarbeitung und Datawarehousing mit Hadoop messbar performanter, kostengünstiger, skalierbarer, flexibler und zukunftsfähiger
geworden!
Der Beweis Lange Rede kurzer Sinn:
82

für eure Aufmerksamkeit
Vielen Dank
83


















