
Markov Chain Monte Carlo Verfahren - Arbeitsgruppe...
58
Markov Chain Monte Carlo Verfahren Helga Wagner Bayes Statistik WS 2010/11 407
Transcript of Markov Chain Monte Carlo Verfahren - Arbeitsgruppe...

Markov Chain Monte Carlo Verfahren
Helga Wagner Bayes Statistik WS 2010/11 407

Einfuhrung
• Simulationsbasierte Bayes-Inferenz erfordert Ziehungen aus der Posteriori-Verteilung
• MCMC-Verfahren ermoglichen es, aus komplizierten, auch hochdimensionalemVerteilungen zu ziehen
• Idee: Erzeugen einer Markovkette, deren stationare Verteilung die Posteriori-Verteilung ist: Die generierten Ziehungen ϑ
(m),m = 1, . . . ,M sind dannvoneinander abhangig. Nach dem Ergodensatz konvergiert das Mittel
1
M
M∑
m=1
g(ϑ(m))
gegen den Posteriori-Erwartungswert E(g(ϑ)|y) =∫
g(ϑ)p(ϑ|y)dϑ.
Helga Wagner Bayes Statistik WS 2010/11 408

Markov Chain Monte Carlo VerfahrenWiederholung: Markov-Ketten
Helga Wagner Bayes Statistik WS 2010/11 409

Markov-Ketten
Ein zeitdiskreter stochastischer Prozess Y = Yt, t ∈ N0 mit abzahlbaremZustandsraum S heisst Markov-Kette, wenn
P (Yt = k|Y0 = j0, Y1 = j1, . . . , Yt−1 = jt−1) =
P (Yt = k|Yt−1 = jt−1).
fur alle t ≥ 0 und fur alle k, j0, . . . , jt−1 ∈ S gilt.
Helga Wagner Bayes Statistik WS 2010/11 410

Markov-Ketten
• P (Yt+1 = k|Yt = j) heisst einschrittige Ubergangswahrscheinlichkeit.
Die Markovkette ist homogen, wenn die Ubergangswahrscheinlichkeiten P (Yt+1 =k|Yt = j) nicht von t abhangen
pjk = P (Yt+1 = k|Yt = j) = P (Y1 = k|Y0 = j)
Die Matrix P = (pjk) heisst Ubergangsmatrix.
Helga Wagner Bayes Statistik WS 2010/11 411

Irreduzible Markovketten
• Eine Markov-Kette heisst irreduzibel, falls fur alle j, k ∈ S eine positive Zahl1 ≤ t < ∞ existiert, sodass
P (Yt = k|Y0 = j) > j,
d.h. Zustand k ist von Zustand j in einer endlichen Zahl von Schrittenerreichbar.
• Die Periode eines Zustands k ist der grosste gemeinsame Teiler der Zeitpunkten, zu denen eine Ruckkehr moglich ist:
d(k) = GGTt ≥ 1 : P (Yt = k|Y0 = k) > 0
• Falls alle Zustande einer Markov-Kette die Periode 1 haben, nennt man dieMarkov-Kette aperiodisch.
Helga Wagner Bayes Statistik WS 2010/11 412

Ruckkehrverhalten
• Die Wahrscheinlichkeit dafur, dass eine in k startende homogene Markov-Ketteirgendwann wieder nach k zuruckkehrt, d.h.
fkk =∞∑
t=1
P (Yt = k;Yt−1 6= k, . . . , Y1 6= k|Y0 = k)
heisst Ruckkehrwahrscheinlichkeit, und
Tkk = min(t ≥ 1 : Yt = k|Y0 = i)
Ruckkehrzeit (Rekurrenzzeit) des Zustandes k.
• Der Zustand k heisst rekurrent, falls fkk = 1
• Ein rekurrenter Zustand k ist positiv rekurrent, falls E(Tkk) < ∞ bzw. null-rekurrent, falls E(Tkk) nicht exisitiert.
Helga Wagner Bayes Statistik WS 2010/11 413

Irreduzible Markovketten
• Eine diskrete Wahrscheinlichkeitsverteilung π heisst invariante Verteilung derhomogenen Markovkette Yt bzw. ihrer Ubergangsmatrix P, wenn gilt:
π = πP.
Die invariante Verteilung einer irreduziblen Markovkette ist eindeutig, wennalle Zustande positiv rekurrent sind.
Helga Wagner Bayes Statistik WS 2010/11 414

Ergodische Markovketten
• Eine Markov-Kette heisst ergodisch, wenn die Zustandsverteilung πt von Yt fur
jede beliebige Startverteilung π0 gegen dieselbe Wahrscheinlichkeitsverteilung
π konvergiert:
limt→∞
πt = lim
t→∞π
0Pt = π.
• Die Grenzverteilung einer ergodischen Markov-Kette ist π die invariante Ver-teilung
π = limt→∞
πt = lim
t→∞
(
πtP)
=(
limt→∞
πt)
P = πP.
Helga Wagner Bayes Statistik WS 2010/11 415

Ergodische Markovketten
Eine homogene Markov-Kette mit Ubergangsmatrix P ist ergodisch, wenn sieirreduzibel und aperiodisch ist.
• Die Zustandsverteilung einer irreduziblen und aperiodischen, homogenen Mar-kovkette konvergiert daher gegen die stationare Verteilung π.
• Eine ergodische Markov-Kette wird asymptotisch stationar, d.h. der Einflussder Startverteilung geht verloren.
Helga Wagner Bayes Statistik WS 2010/11 416

Ergodische Markovketten
Sei P die Ubergangsmatrix einer irreduziblen, aperiodischen Markovkette undπ ihre stationare Verteilung.
Ist Γ die Ubergangsmatrix der Markovkette bei Zeitumkehr, d.h.
γkj = P (Yt = j|Yt+1 = k),
dann gilt
πkγkj = πjpjk, (47)
die sogenannte detailed Balance.
Umgekehrt folgt aus der detailed Balance-Bedingung (47) dass π die stationareVerteilung von P ist.
Helga Wagner Bayes Statistik WS 2010/11 417

Markov Chain Monte-Carlo Methoden
Mit der Ubergangsmatrix P einer irreduziblen, aperiodischen Markovkette, derenstationare Verteilung π ist, konnen Zufallszahlen Y ∼ π folgendermaßen erzeugtwerden:
• Wahl eines beliebigen Startwertes y(0)
• Simulation der Realisierungen einer Markovkette der Lange M mit Ubergangs-matrix P, d.h. (y(1), . . . , y(M))
Ab einem gewissen Index t geht der Einfluß der Startverteilung verloren und dahergilt approximativ
y(m) ∼ π, fur m = t, . . . ,M
Diese Ziehungen sind zwar identisch, aber nicht unabhangig verteilt.
(y(1), . . . y(t)) ist der sogenannte Burn-In.
Helga Wagner Bayes Statistik WS 2010/11 418

Allgemeine Markovkette
Erweiterung auf Markovketten mit stetigem Zustandsraum:
Allgemeine MarkovketteEin zeitdiskreter stochastischer Prozess Y = Yt, t ∈ N0 mit ZustandsraumS heisst (allgemeine) Markov-Kette, wenn die Markov-Eigenschaft
P(Yt ∈ A|Y0 ∈ A0, Y1 ∈ A1, . . . , Yt−2 ∈ At−2, Yt−1 = x) =
P(Yt ∈ A|Yt−1 = x)
fur beliebige y ∈ S und beliebige A0, A1, . . . , At−2, A ⊂ S gilt
Die Markovkette heisst homogen, falls die Wahrscheinlichkeiten
P(Yt ∈ A|Yt−1 = x)
nicht vom Zeitpunkt t abhangen.
Helga Wagner Bayes Statistik WS 2010/11 419

Ubergangskern
Ist Y eine homogene Markovkette, so ist
P(x,A) = P(Yt ∈ A|Yt−1 = x) = P(Y1 ∈ A|Y0 = x)
ihr Ubergangskern.
• Fur eine Markovkette mit endlichem Zustandsaum ist P (x,A) durch dieUbergangswahrscheinlichkeiten pj,k, d.h. durch die Ubergangsmatrix bestimmt.
• Ist S = R, so ist der Ubergangskern durch die Ubergangsdichte p(x, y) mit
P (x,A) =
∫
A
p(x, y)dy
bestimmt.
Helga Wagner Bayes Statistik WS 2010/11 420

Grenzverteilung
• Eine Verteilung Π auf S mit Dichte π(x) heisst invariant fur den UbergangskernP (x,A) genau dann wenn fur alle A ∈ S gilt
Π(A) =
∫
P (x,A)π(x)dx.
• Eine allgemeinen Markovkette ist irreduzibel, wenn von beliebigen Startwertx0 aus jede Menge A mit Π(A) > 0 mit positiver Wahrscheinlichkeit in einerendlichen Zahl von Schritten erreicht werden kann.
• E1, . . . , Em−1 bilden einen m-Zyklus, wenn P (x,Ei+1 mod m) = 1 fur allex ∈ Ei ⊂ S und alle i.
Die Periode d der Markovkette ist der großte Wert m, fur den ein m-Zyklusexistiert und die Kette ist aperiodisch, wenn d = 1.
Helga Wagner Bayes Statistik WS 2010/11 421

Grenzverteilung
• Ist Y eine irreduzible, aperiodische Markovkette mit Ubergangskern P undinvarianter Verteilung π, so ist π eindeutig und es gilt
||P t(x, .)− π(.)|| → 0
mit t → ∞ wobei
||P t(x, .)− π(.)|| = 2 supA
|P t(x,A)− π(A)|
Helga Wagner Bayes Statistik WS 2010/11 422

Wahl des Ubergangskernes
Die Anwendung der MCMC Methoden basiert darauf, zur vorgegebenen Ver-teilung π(ϑ) = p(ϑ|y) eine Markovkette mit Ubergangskern P und invarianterVerteilung π zu finden.
Fur eine irreduzible Markovkette mit gegebenem Ubergangskern P ist die invari-ante Verteilung π eindeutig, nicht aber umgekehrt: Zu einer gegebenen Verteilungπ gibt es nicht nur einen Ubergangskern mit π als invarianter Verteilung
Beispiel:
Fur eine homogene Markov-Kette mit zwei Zustanden sei die Ubergangsmatrix
P =
(
1− p p
q 1− q
)
mit 0 < p < 1 und 0 < q < 1 und π = (π, 1 − π) die
stationare Verteilung.
Das Gleichungssystem fur p und q ist unterbestimmt und hat daher unendlichviele Losungen.
Helga Wagner Bayes Statistik WS 2010/11 423

Wahl des Ubergangskernes
Es gibt daher viele Moglichkeiten einen Ubergangskern P (ϑold, A) zu konstruie-ren, der die notwendige Bedingung
Π(A) =
∫
P (ϑold, A)π(ϑold)dϑold. (48)
mitπ(ϑ) = p(ϑ|y)
erfullt. Ublicherweise benutzt werden
• Metropolis-Hastings-Algorithmus (Hastings, 1970; Chib and Greenberg, 1995)
• Gibbs Sampling (Geman and Geman, 1984; Casella and George, 1992)
Helga Wagner Bayes Statistik WS 2010/11 424

MCMC zur Bayes-Inferenz
Mit Ziehungen ϑ(1), . . . ,ϑ(M) aus einer allgemeinen Markovkette mit stationarer
Verteilung
π(ϑ) = p(ϑ|y) = p(y|ϑ)p(ϑ)p(y)
kann der Posteriori-Erwartungswert
E(g(ϑ)|y) =∫
g(ϑ)p(ϑ|y)dϑ
durch den Mittelwert
g(ϑ) = ϑ1
M
M∑
m=1
g(ϑ(m))
approximiert werden.
Helga Wagner Bayes Statistik WS 2010/11 425

MCMC zur Bayes-Inferenz
Aufgrund der Abhangigkeit der Ziehungen ist die Varianz dieses Schatzers nichtwie bei unabhangigen Ziehungen Var(g)/M sondern
E((g(ϑ)− E(g(ϑ)))2) =1
MΩ0 (g) . (49)
Ω0 (g) ist die Spektraldichte des Prozesses g(ϑ(m)) und es gilt (Geweke, 1992):
τ =Ω0 (g)
Var(g)= 1 + 2
∞∑
s=1
ρs.
Dabei ist ρs die Autokorrelation des Prozesses g(ϑ(m)) zum Lag s.
Helga Wagner Bayes Statistik WS 2010/11 426

MCMC zur Bayes-Inferenz
• τ heisst Ineffizienzfaktor. Je grosser der Ineffizienzfaktor τ , desto ineffizienterist das Verfahren. Da die Ziehungen ublicherweise positiv korreliert sind, istτ > 1, d.h. MCMC Ziehungen sind weniger effizient als i.i.d. Ziehungen.
• Die effektive Stichprobengroße M/τ gibt an, wievielen ua. Ziehungen die MZiehungen aus der Markov-Kette entsprechen.
• Annahernd ua. Ziehungen erhalt man, wenn nur jeder k − te Wert derStichprobe, also ϑ
(1),ϑ(k+1), . . . zur Inferenz benutzt wird (Verdunnung,thinning).
Helga Wagner Bayes Statistik WS 2010/11 427

Markov Chain Monte Carlo VerfahrenMetropolis-Hastings-Algorithmus
Helga Wagner Bayes Statistik WS 2010/11 428

Metropolis-Hastings-Algorithmus
Im Metropolis-Hastings-Algorithmus wird der Ubergangskern der Markovketteerzeugt, indem ausgehend von ϑ
(m−1) = ϑold eine Ziehung aus einer Vorschlags-
dichte q(ϑold,ϑnew) = q(ϑnew|ϑold) erfolgt.
Der Wert ϑnew wird mit Wahrscheinlichkeit
α(ϑnew|ϑold) = α(ϑold,ϑnew) = min(
1,p(ϑnew|y)q(ϑold|ϑnew)
p(ϑold|y) q(ϑnew|ϑold)
)
akzeptiert, d.h.ϑ(m) = ϑ
new
sonst wird ϑold beibehalten, dh.
ϑ(m) = ϑ
old.
Dieser Algorithmus erzeugt eine homogene Markovkette.
Helga Wagner Bayes Statistik WS 2010/11 429

Metropolis-Hastings-Algorithmus
• Ein Ubergang von x = ϑold nach z = ϑ
new 6= ϑold findet statt, wenn ϑ
new
ausgehend von ϑold vorgeschlagen wird und ϑ
new akzeptiert wird, sonst bleibtdie Kette in x = ϑ
old.
• Der Ubergangskern der Markovkette ist also
P (x,A) =
∫
A
p(x, z)dz + r(x)δx(A)
mit
p(x, z) =
q(x, z)α(x, z) x 6= z
0 sonst
und
r(x) = 1−∫
p(x, z)dz.
Helga Wagner Bayes Statistik WS 2010/11 430

Die invariante Verteilung
Die Posteriori-Verteilung p(ϑ|y) ist die invariante Verteilung der Markovkette.
Wir zeigen zunachst, dass die detailed balance Bedingung
p(x|y)p(x, z) = p(z|y)p(z, x)
gilt:
p(x|y)p(x, z) = p(x|y)q(x, z)α(x, z) = p(x|y)q(x, z)min(
1,p(z|y)q(z, x)
p(x|y)q(x, z)
)
=
= min(
p(x|y)q(x, z), p(z|y)q(z, x))
=
= p(z|y)q(z, x)min(p(x|y)q(x, z)
p(z|y)q(z, x), 1
)
=
= p(z|y)p(z, x)
Helga Wagner Bayes Statistik WS 2010/11 431

Die invariante Verteilung
p(x|y) ist die invariante Verteilung:
∫
P (x,A)p(x|y)dx =
∫
(
∫
A
p(x, z)dz)
p(x|y)dx +
∫
r(x)δx(A)p(x|y)dx =
=
∫
A
(
∫
p(x, z)p(x|y)dx)
dz +
∫
A
r(x)p(x|y)dx =
=
∫
A
(
∫
p(z, x)p(z|y)dx)
dz +
∫
A
r(x)p(x|y)dx =
∫
A
(1 − r(z))p(z|y)dz +
∫
A
r(x)p(x|y)dx =
=
∫
A
p(z|y)dz = P (A|y)
Helga Wagner Bayes Statistik WS 2010/11 432

Anwendung des MH-Algorithmus
• Die Akzeptanzwahrscheinlichkeit kann berechnet werden als
α(ϑnew|ϑold) = min(
1,p(ϑnew|y)q(ϑold|ϑnew)
p(ϑold|y) q(ϑnew|ϑold)=
= min(
1,p(y|ϑnew)p(ϑnew)q(ϑold|ϑnew)
p(y|ϑold)p(ϑold)q(ϑnew|ϑold)=)
Die Normierungskonstante p(y) muss also zur Anwendung des MH-Algortihmus nicht bekannt sein.
• Fur die Konvergenz des Algorithmus ist Irreduzibilitat und Aperiodizitat derMarkov-Kette erforderlich. Diese Eigenschaften sind theoretisch schwer zuuberprufen =⇒ Analyse der Ziehungen
Helga Wagner Bayes Statistik WS 2010/11 433

Wahl der Vorschlagsdichte
Grundsatzlich liefert praktisch jede Vorschlagsdichte Ziehungen aus der gewunsch-ten Verteilung (Tierney, 1994), allerdings hangt die Effizienz von der gewahltenVorschlagsdichte ab.
Die Vorschlagsdichte soll so gewahlt werden, dass
• daraus leicht Zufallszahlen erzeugt werden konnen
• die Akzeptanzraten nicht zu klein sind
Helga Wagner Bayes Statistik WS 2010/11 434

Wahl der Vorschlagsdichte
• Independence ProposalDie Vorschlagsdichte ist u.a. vom aktuellen Wert, d.h. q(ϑnew|ϑold) =q(ϑnew).
Die Akzeptanzwahrscheinlichkeit betragt
α(ϑnew|ϑold) = min(
1,p(ϑnew|y)q(ϑold)
p(ϑold|y) q(ϑnew)
)
Ein einfacher Spezialfall ergibt sich, wenn die Vorschlagsdichte die Zielvertei-lung p(ϑ|y) ist. Dann wird jeder Vorschlag akzeptiert.
Helga Wagner Bayes Statistik WS 2010/11 435

Wahl der Vorschlagsdichte
• Random Walk ProposalDie Vorschlagsdichte ist ein Random Walk d.h.
ϑnew = ϑ
old + ε, ε ∼ f,
d.h. q(ϑnew|ϑold) = f(ϑnew − ϑold).
Fur einen symmetrischen Random Walk ist die Akzeptanzwahrscheinlichkeit
α(ϑnew|ϑold) = min(
1,p(ϑnew|y)p(ϑold|y)
)
= min(
1,p(y|ϑnew)p(ϑnew)
p(y|ϑold)p(ϑold)
)
Ein Vorschlag ϑnew mit p(ϑnew|y) > p(ϑold|y) wird immer akzeptiert.
Helga Wagner Bayes Statistik WS 2010/11 436

Normal Random Walk
Eine ubliche Wahl ist die Vorschlagsdichte
ϑnew ∼ N
(
ϑold, C
)
,
mit fester Varianz-Kovarianzmatrix C.
• kleine Skala =⇒ kleine Schritte ϑnew − ϑ
old mit i.A. hohen Akzeptanzraten,aber hohen Autokorrelationen.
Extremfall C → 0: Akzeptanzrate von 1, τ → ∞
• große Skala =⇒ große Schritte ϑnew−ϑold mit Vorschlagen oft in den Enden
der Verteilung und daher kleinen Akzeptanzraten
Helga Wagner Bayes Statistik WS 2010/11 437

Multivariate Zielverteilung
Anwendung des MH-Algorithmus zum Ziehen eines multivariate Parametern ϑ istineffizient, wenn Vorschlage fur den gesamten Parameter niedrige Akzeptanzratenhaben.
Eine Alternative besteht darin, Metropolis-Hastings-Schritte fur die einzelnenKomponenten durchzufuhren, d.h. einen Vorschlag jeweils nur fur eine Kompo-nente ϑj zu machen.
Die Komponenten konnen in einer festen oder in einer zufalligen Reihenfolgeaufdatiert werden.
Helga Wagner Bayes Statistik WS 2010/11 438

Eye Tracking: MH-Algorithmus
• Modell: yi ∼ NegBin (θ, β), d.h.
p(yi; θ, β) =
(
θ + yi − 1
θ − 1
)
( β
β + 1
)θ( 1
β + 1
)yi
• Ua. Priori-Verteilungen: θ ∼ G (1, 1), β ∼ G (1, 0)
• Algorithmus: 2- Block Sampler
Wahle einen Startwerte fur θ(0) und ziehe(a) β(m) aus p(β|θ(m−1),y)(b) θ(m) aus p(θ|β(m),y).
Helga Wagner Bayes Statistik WS 2010/11 439

Eye Tracking: MH-Algorithmus
Die bedingten Dichten sind gegeben als
p(β|θ,y) ∝ p(y|θ, β)p(θ, β) ∝( β
β + 1
)nθ( 1
β + 1
)
∑
yi
p(θ|β,y) ∝ p(y|θ, β)p(θ, β) ∝∏
i
(
θ + yi − 1
θ − 1
)
( β
β + 1
)nθ
exp(−θ)
Fur den transformierten Parameter π = β/(1 + β) hat die bedingte Dichtep(π|θ,y) den Kern einer Beta-Verteilung:
p(π|θ,y) ∝ πnθ(1− π)∑
yi1
(1− π)2
⇒ Vorschlag π ∼ B (nθ + 1,∑
yi − 1) mit Akzeptanzrate 1 moglich
Helga Wagner Bayes Statistik WS 2010/11 440

Eye Tracking: MH-Algorithmus
Log-Normal Random walk Proposal fur θ, d.h. log θnew ∼ N(
log θold, C)
:
• Erzeuge θnew = exp(log θold +√Cε) ε ∼ N (0, 1).
Damit ist q(θnew|θold) = 1/θnew.
• Akzeptiere θnew wenn fur u ∼ U [0, 1] gilt
log(u) ≤ log(α(θnew|θold) = min(0, h(θnew|π,y)− h(θold|π,y)
mit
h(θ|π,y) = log(p(θ|β,y)θ) + c∗ =
=∑
i
log(Γ(θ + yi))− n log(Γ(θ)) + nθ log(π)− θ + log(θ)
Helga Wagner Bayes Statistik WS 2010/11 441

Eye Tracking: MH-Algorithmus
Abhangigkeit der Akzeptanzrate von der Varianz der Vorschlagsdichte
C Akzeptanzrate
2.0 0.06
0.3 0.35
0.02 0.92
Helga Wagner Bayes Statistik WS 2010/11 442

Eye Tracking: MH-Algorithmus
0 500 1000 1500 2000 2500 3000 3500 4000 4500 50000.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2Posterior Draws for α
0 500 1000 1500 2000 2500 3000 3500 4000 4500 50000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2Posterior Draws for α
0 500 1000 1500 2000 2500 3000 3500 4000 4500 50000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2Posterior Draws for α
Abbildung 45: Posteriori-Ziehungen von α fur verschiedene Vorschlagsdich-ten (links C = 2, Mitte: C = 0.02, rechts: C = 0.3)
Helga Wagner Bayes Statistik WS 2010/11 443

Eye Tracking: MH-Algorithmus
Einfluß des Startwertes
0 50 100 150 200 250 300 350 4000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2Posterior Draws for α
0 50 100 150 200 250 300 350 4000
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5Posterior Draws for β
Abbildung 46: Posteriori-Ziehungen von α (links) und β (rechts) fur ver-schiedene Startwerte α(0) and β(0)
Helga Wagner Bayes Statistik WS 2010/11 444

SFr Wechselkurs-Daten: MH-Algorithmus
• Modell: yi ∼ tν(
µ, σ2)
mit bekanntem ν = 4
• Priori-Verteilung: p(µ, σ2|ν).
• Algorithmus: Single Move Sampler
Wahle einen Startwert fur σ2,(0) und ziehe fur m = 1, . . . ,M
(a) µ(m) aus p(µ|σ2,(m−1),y): Normal Random Walk Vorschlag
(b) σ2,(m) aus p(σ2|µ(m),y): Log-Normal Random Walk Vorschlag
Die ersten M0 Ziehungen (Burn-In) werden zur Schatzung nicht verwendet.
Helga Wagner Bayes Statistik WS 2010/11 445

SFr Wechselkurs-Daten: MH-Algorithmus
Die bedingten Dichten sind gegeben als
p(µ|σ2,y) ∝ p(y|µ, σ2)p(µ, σ2)
p(α|β,y) ∝ p(y|µ, σ2)p(µ, σ2)
p(y|µ, σ2, ν) ist die Likelihood des Student t-Modells.
Helga Wagner Bayes Statistik WS 2010/11 446

SFr Wechselkurs-Daten: MH-Algorithmus
Sampling-Schritte:
(a) Der Vorschlag µnew ∼ N(
µ(m−1), c2µ)
wird akzeptiert, wenn
u1 ≤p(y|µnew, σ2,(m−1), ν)p(µnew, σ2,(m−1)|ν)
p(y|µ(m−1), σ2,(m−1), ν)p(µ(m−1), σ2,(m−1)|ν),
wobei u1 ∼ U [0, 1]
(b) Vorgeschlagen wird log σ(2,new) ∼ N(
log σ2,(m−1), c2s)
. Der Vorschlag
σ(2,new) wird akzeptiert, wenn
u2 ≤p(y|µ(m), σ(2,new), ν)p(µ(m), σ(2,new)|ν)σ(2,new)
p(y|µ(m), σ2,(m−1), ν)p(µ(m), σ2,(m−1)|ν)σ2,(m−1),
wobei u2 ∼ U [0, 1]
Helga Wagner Bayes Statistik WS 2010/11 447

SFr Wechselkurs-Daten: MH-Algorithmus
Tuning: Wahl der Standardabweichungen cµ and cs der Vorschlagsdichten
• Ziehen
– mit verschiedenen Werten der Standardabweichung– von verschiedenen Startwerten
• Bestimmen von
– Akzeptanzrate (acc)– Ineffizienzfaktor (ineff)
Helga Wagner Bayes Statistik WS 2010/11 448
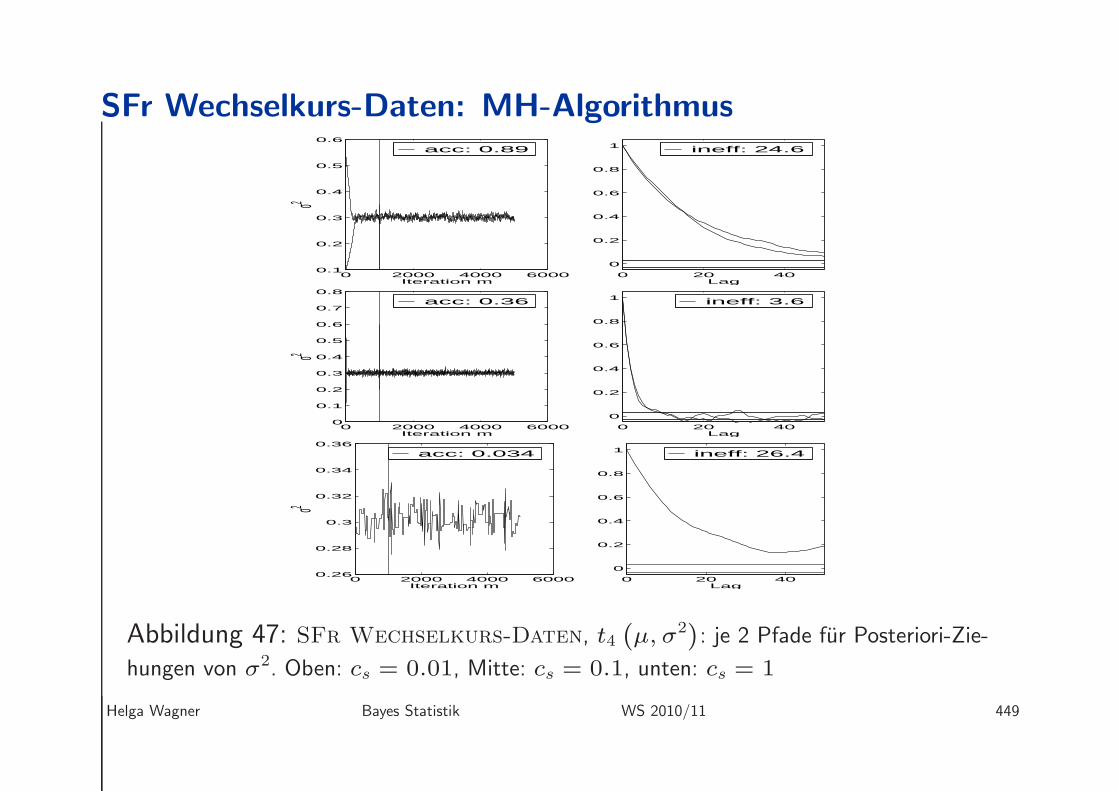
SFr Wechselkurs-Daten: MH-Algorithmus
0 2000 4000 60000.1
0.2
0.3
0.4
0.5
0.6
σ2Iteration m
0 20 40
0
0.2
0.4
0.6
0.8
1
Lag
ineff: 24.6acc: 0.89
0 2000 4000 60000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
σ2
Iteration m0 20 40
0
0.2
0.4
0.6
0.8
1
Lag
ineff: 3.6acc: 0.36
0 2000 4000 60000.26
0.28
0.3
0.32
0.34
0.36
σ2
Iteration m0 20 40
0
0.2
0.4
0.6
0.8
1
Lag
ineff: 26.4acc: 0.034
Abbildung 47: SFr Wechselkurs-Daten, t4(
µ, σ2)
: je 2 Pfade fur Posteriori-Zie-
hungen von σ2. Oben: cs = 0.01, Mitte: cs = 0.1, unten: cs = 1
Helga Wagner Bayes Statistik WS 2010/11 449

SFr Wechselkurs-Daten: MH-Algorithmus
• Sowohl zu hohe als auch zu niedrige Akzeptanzraten fuhren zu einem ineffizi-enten Sampler: =⇒ Wahl cs = 0.1
• Fur cµ = 0.05 ist die Akzeptanzrate ca. 25% , der Ineffizienzfaktor 6 (geringeAbhangigkeit von der Vorschlagsdichte fur σ2.
• Burn-In: erste 1000 Werte
• Aus den letzten 4000 Ziehungen werden Posteriori-Erwartungswert und HPD-Intervalle (approximativ) bestimmt
Parameter Posteriori-Erwartungswert 95%-HPD-Intervall
µ 0.0052; [-0.017, 0.026]
σ2ν/(ν − 2) 0.6 [ 0.56, 0.64]
Helga Wagner Bayes Statistik WS 2010/11 450
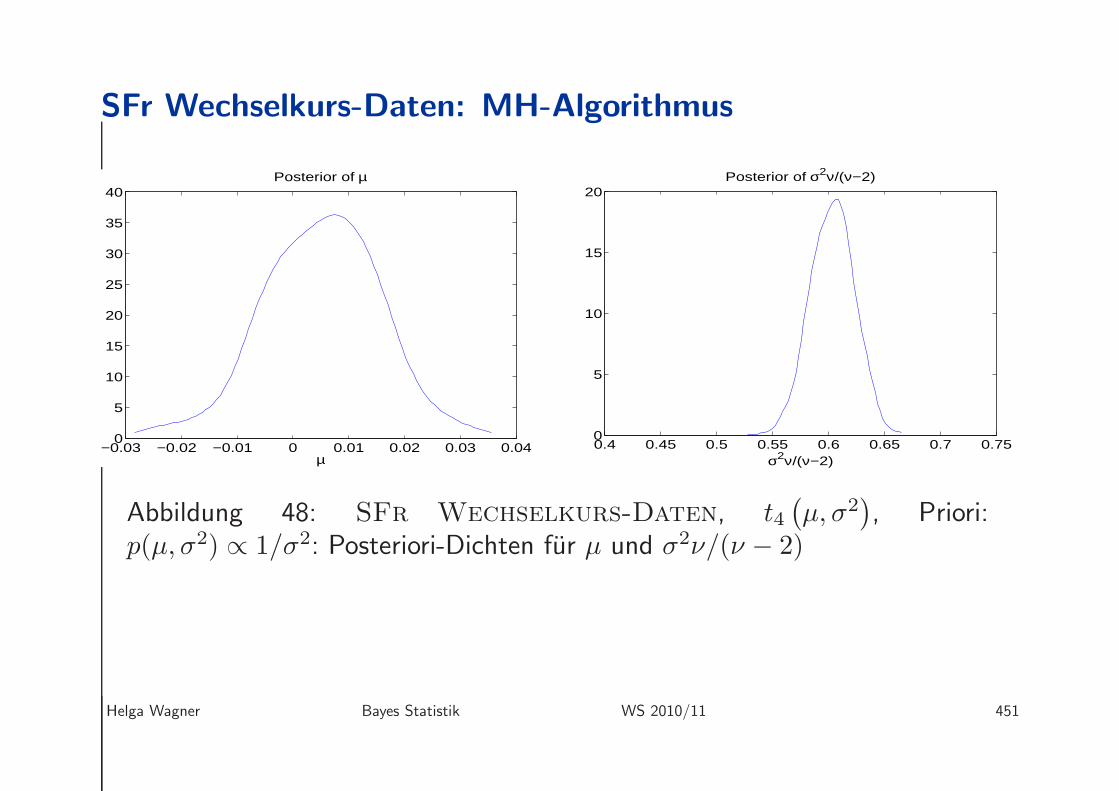
SFr Wechselkurs-Daten: MH-Algorithmus
−0.03 −0.02 −0.01 0 0.01 0.02 0.03 0.040
5
10
15
20
25
30
35
40Posterior of µ
µ0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.750
5
10
15
20Posterior of σ2ν/(ν−2)
σ2ν/(ν−2)
Abbildung 48: SFr Wechselkurs-Daten, t4(
µ, σ2)
, Priori:p(µ, σ2) ∝ 1/σ2: Posteriori-Dichten fur µ und σ2ν/(ν − 2)
Helga Wagner Bayes Statistik WS 2010/11 451

MH-Algorithmus fur die Parameter der Student-Verteilung
• Modell: yi ∼ tν(
µ, σ2)
• Priori-Verteilung: p(µ, σ2, |ν).
• Algorithmus: Single Move Sampler
Wahle einen Startwerte fur σ2,(0) und ν(0) und und ziehe fur m = 1, . . . ,M
(a) µ(m) aus p(µ|σ2,(m−1), ν(m−1),y): Normal Random Walk Vorschlag
(b) σ2,(m) aus p(σ2|µ(m), ν(m−1),y): Log-Normal Random Walk Vorschlag
(c) ν(m) aus p(ν|µ(m), σ2,(m)y): Log-Normal Random Walk Vorschlag
Die ersten M0 Ziehungen (Burn-In) werden zur Schatzung nicht verwendet.
Helga Wagner Bayes Statistik WS 2010/11 452

MH-Algorithmus fur die Parameter der Student-Verteilung
Schritt (a) und (b) sind wie im Fall ν bekannt
(c) Vorgeschlagen wird log νnew ∼ N(
log ν(m−1), c2ν)
. Der Vorschlag νnew wirdakzeptiert, wenn
u3 ≤p(y|µ(m), σ2,(m), νnew)p(µ(m), σ2,(m), νnew)νnew
p(y|µ(m), σ2,(m), ν(m−1))p(µ(m), σ2,(m), ν(m−1))ν(m−1)
wobei u3 ∼ U [0, 1].
p(y|µ, σ2, ν) ist die Likelihood des Student-Modells.
Helga Wagner Bayes Statistik WS 2010/11 453

Ziehen aus einer uneigentlichen Posteriori-Verteilung
Was passiert bei Implementierung des MH-Algorithmus mit uneigentlicherPosteriori-Verteilung, z.B. p(ν) = 1/ν?
Fur die Priori-Verteilung p(ν) = 1/ν hangt die Akzeptenzrate nur von den Wertender Likelihood ab. Diese ist in den Enden der Verteilung jedoch praktisch konstantin ν:
• Liegen sowohl νold and der Vorschlag νnew in den Enden =⇒ Akzeptanzwahr-scheinlichkeit ≈ 1
Sampler bleibt in den Enden bis ein Wert aus dem modalen Bereich derLikelihood vorgeschlagen wird
Helga Wagner Bayes Statistik WS 2010/11 454

Ziehen aus einer uneigentlichen Posteriori-Verteilung
• Sei νold ein Wert aus dem modalen Bereich. Die Wahrscheinlichkeit dafur,dass ein Wert aus den Enden der Verteilung vorgeschlagen und akzeptiert wirdist
R(νold) ≈ cN(µ, σ2)
p(y|νold, µ, σ2),
wobei cN(µ, σ2) die Likelihood unter dem Normalmodell ist (ν → ∞) . Jekleiner R(νold) desto geringer ist das Risiko, dass der Sampler in den Endender Verteilung
’hangen‘ bleibt
Helga Wagner Bayes Statistik WS 2010/11 455

Ziehen aus einer uneigentlichen Posteriori-Verteilung
0 0.5 1 1.5 2
x 104
2
2.5
3
3.5
4
4.5
ν
Iteration m
Data Set 1 (ν0=1)
acc: 0.2
1.5 2 2.5 3 3.5 40
0.2
0.4
0.6
0.8
1
1.2
1.4Posterior of ν
ν
0 0.5 1 1.5 2
x 104
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
σ2
Iteration m
Data Set 1 (ν0=1)
acc: 0.16
0.5 0.6 0.7 0.8 0.9 1 1.1 1.2 1.30
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5Posterior of σ2
σ2
Abbildung 49: Daten 1: 1000 Werte ∼ t3 (0, 1). links: MCMC Ziehungen furν und σ2 Rechts:
”Posteriori“-Verteilungen p(ν|y) und p(σ2|y) unter den
Priori-Verteilungen p(ν) = 1/ν (strichliert) und ν ∼ U [0, 200] (voll)Die Posteriori-Verteilung ist uneigentlich fur p(ν) = 1/ν !
Helga Wagner Bayes Statistik WS 2010/11 456

Ziehen aus einer uneigentlichen Posteriori-Verteilung
0 2000 4000 6000 8000 100000
200
400
600
800
1000
1200
1400
1600
1800
2000
ν
Iteration m
Data Set 2 (ν0=1)
acc: 0.16
0 2000 4000 6000 8000 100000
20
40
60
80
100
120
140
160
180
200
ν
Iteration m
Data Set 2 (ν0=−200)
acc: 0.18
Abbildung 50: Daten 2: 1000 Werte ∼ t10 (0, 1). MCMC Ziehungen vonν. Links: Priori p(ν) = 1/ν; rechts: U [0, 200]-Prior jeweils mit Startwertν(0) = 100, und σ2,(0) = 10)
Helga Wagner Bayes Statistik WS 2010/11 457
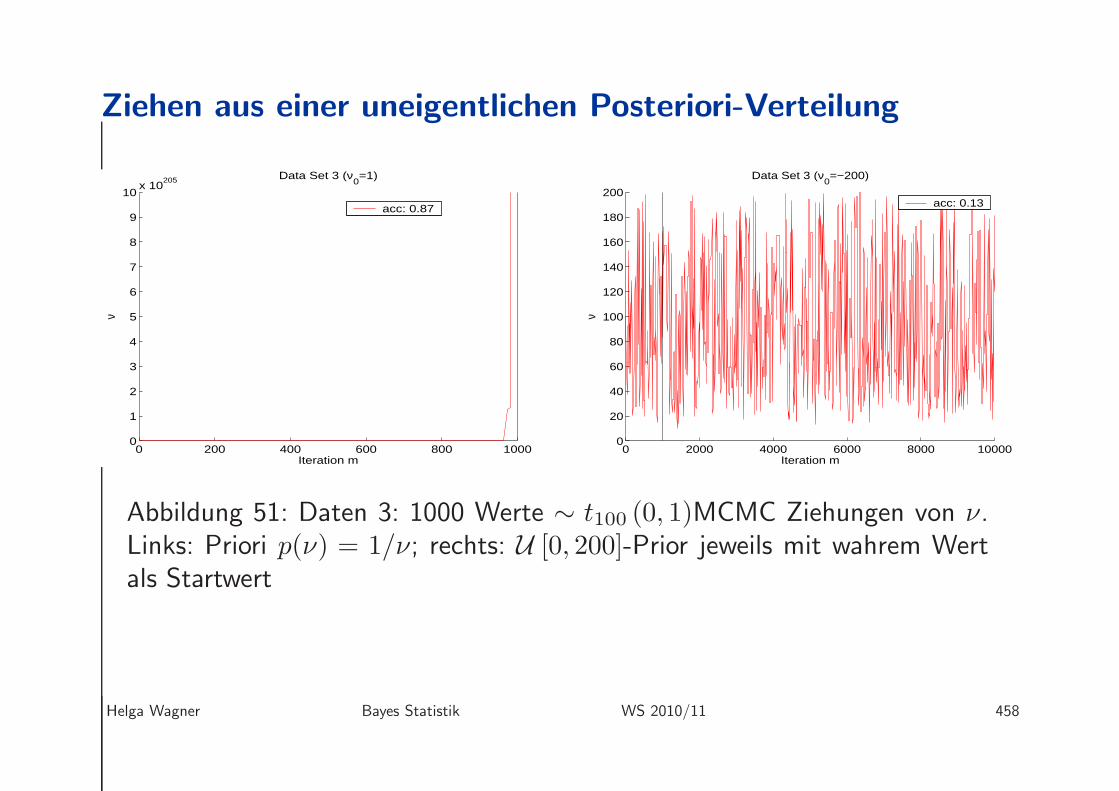
Ziehen aus einer uneigentlichen Posteriori-Verteilung
0 200 400 600 800 10000
1
2
3
4
5
6
7
8
9
10x 10
205
ν
Iteration m
Data Set 3 (ν0=1)
acc: 0.87
0 2000 4000 6000 8000 100000
20
40
60
80
100
120
140
160
180
200
ν
Iteration m
Data Set 3 (ν0=−200)
acc: 0.13
Abbildung 51: Daten 3: 1000 Werte ∼ t100 (0, 1)MCMC Ziehungen von ν.Links: Priori p(ν) = 1/ν; rechts: U [0, 200]-Prior jeweils mit wahrem Wertals Startwert
Helga Wagner Bayes Statistik WS 2010/11 458

Anwendung: SFr Wechselkurs-Daten
0.20.25
0.30.35
0.4
2
4
6
80
0.2
0.4
0.6
0.8
1
σ2ν
Likeli
hood
Abbildung 52: SFr Wechselkurs-Daten: Likelihood destν(
0, σ2)
-Modells mit ν und σ2 unbekannt
Helga Wagner Bayes Statistik WS 2010/11 459

Anwendung: SFr Wechselkurs-Daten
0.51
1.52
2040
6080
100−7000
−6500
−6000
−5500
−5000
−4500
−4000
σ2ν
Log L
ikelih
ood
Abbildung 53: SFr Wechselkurs-Daten:Log-likelihood destν(
0, σ2)
-Modells mit ν und σ2 unbekannt
Helga Wagner Bayes Statistik WS 2010/11 460

Anwendung: SFr Wechselkurs-Daten
20 40 60 80 100−5000
−4500
−4000log L(y|ν, σ2 fixed)
σ2=0.3
2 4 6 80
0.5
1L(y|ν, σ2 fixed)
σ2=0.3
20 40 60 80 100−4290
−4280
−4270
σ2=0.7
200 400 600 800 10000
0.5
1
σ2=0.7
200 400 600 800 1000−4700
−4600
−4500
ν
σ2=12000 4000 6000 800010000
0
0.5
1
ν
σ2=1
Abbildung 54: SFr Wechselkurs-Daten: Likelihood- und Log-Like-lihood-Profile fur verschiedene Werte von σ2
Helga Wagner Bayes Statistik WS 2010/11 461

Anwendung: SFr Wechselkurs-Daten
0 1000 2000 3000 4000 50000
20
40
60
80
100
ν
Iteration m
acc: 0.355
0 200 400 600 800 10000
2
4
6
8
10x 10
6
ν
Iteration m
acc: 0.248
Abbildung 55: SFr Wechselkurs-Daten: MCMC Ziehungen aus deruneigentlichen Posteriori-Verteilung. Startwerte: ν(0) = 4 , verschiedeneStartwerte fur σ(2,0). Links: σ(2,0) zwischen 1 und 10, rechts: σ(2,0) = 100
Helga Wagner Bayes Statistik WS 2010/11 462

Anwendung: SFr Wechselkurs-Daten
2 3 4 5 6 70
0.2
0.4
0.6
0.8
1Posterior of ν
ν
Abbildung 56: SFr Wechselkurs-Daten: Posteriori-Dichten von ν unterPriori p(ν) = (1/ν)n0. Voll: eigentliche Posteriori fur n0 = 2, strichliert:uneigentliche Posteriori fur n0 = 0
Helga Wagner Bayes Statistik WS 2010/11 463

Anwendung: SFr Wechselkurs-Daten
−0.03 −0.02 −0.01 0 0.01 0.02 0.03 0.040
5
10
15
20
25
30
35
40Posterior of µ
µ0.35 0.4 0.45 0.5 0.55 0.6 0.65 0.70
5
10
15
20
25Posterior of σ2ν/(ν−2)
σ2ν/(ν−2)
Abbildung 57: SFr Wechselkurs-Daten, Posteriori-Dichten von µ undσ2 unter Priori p(ν) = (1/ν)n0. Voll: eigentliche Posteriori fur n0 = 2,strichliert: uneigentliche Posteriori fur n0 = 0. Strichpunkt: ν = 4 fest
Helga Wagner Bayes Statistik WS 2010/11 464


















