
Masterarbeit - Institut Prof. Berekovic · Den Komplex aus Zellen, Kanten und Punkten der Polyeder...
101
Technische Universität Braunschweig Direkte Volumenvisualisierung auf unstrukturierten Gittern mit OpenSG in AVS/Express Masterarbeit vorgelegt von cand. inform. Hagen Gädke Institut für Computergrafik Prof. Dr. D. W. Fellner Betreuer: Christoph Fünfzig September 2004
Transcript of Masterarbeit - Institut Prof. Berekovic · Den Komplex aus Zellen, Kanten und Punkten der Polyeder...

1
Technische Universität Braunschweig
Direkte Volumenvisualisierungauf unstrukturierten Gittern
mit OpenSG in AVS/Express
Masterarbeitvorgelegt von cand. inform. Hagen Gädke
Institut für ComputergrafikProf. Dr. D. W. Fellner
Betreuer: Christoph Fünfzig
September 2004

2

3
ErklärungIch versichere, die vorliegende Arbeit selbständig und nur unter Benutzung der angegebenen Quel-len und Hilfsmittel angefertigt zu haben.
Braunschweig, den 30.09.2004

4
Widmung und Dank
Ich widme diese Arbeit meinen Eltern Jürgen Gädke und Edith Gädke-Döblitz und bedanke michfür die finanzielle Unterstützung meines Studiums.
Vielen Dank an Alexander Böswetter, Torsten Bagdonat und Prof. Dr. rer. nat. Uwe Motschmann(Institut für Theoretische Physik, TU Braunschweig) für den Mars-Datensatz.
Mein besonderer Dank geht an meinen Betreuer Christoph Fünfzig für seine Unterstützung, vorallem im Bereich OpenSG.

5
Abstract
Several techniques for Direct Volume Rendering (DVR) have been proposedduring the past 15 years. The fastest techniques allow realtime rendering of largedatasets, but only for regular or rectilinear grids, respectively. In this work, twotechniques for DVR on unstructured grids (Shirley-Tuchman and Hierarchical3D-Textures) are implemented and examined for realtime rendering capabilities.The implementation uses the scene graph library OpenSG. In addition, theimplemented functionality has been integrated into the commercial visualizingsoftware AVS/Express.

6
Inhaltsverzeichnis
1 Einleitung 8
2 Gittertypen und Beleuchtungsmodelle 92.1 Reguläre Gitter 92.2 Rektilineare Gitter 92.3 Irreguläre Gitter 102.4 Unstrukturierte Gitter 102.5 Beleuchtungsmodelle 11
3 Techniken zur direkten Volumenvisualisierung 143.1 Raytracing 143.2 Splatting 153.3 Überblendung texturierter Ebenen 153.3.1 2D-Texturen 163.3.2 3D-Texturen 183.4 Shear-Warp-Faktorisierung 203.5 Shirley-Tuchman-Verfahren 213.6 Hierarchische Verfahren 22
4 Anforderungen und Ziele 23
5 Implementierung des Shirley-Tuchman-Verfahrens 255.1 Klassifizierung 255.2 Dickpunktbestimmung und Farbzuweisung 265.3 Alpha-Korrektur 295.4 Tetraeder-Sortierung 315.5 Ablaufdiagramm 325.6 Ergebnisse 345.7 Klassenbeschreibungen 385.7.1 ProjectedTetrahedraBase 385.7.2 ProjectedTetrahedra 405.7.3 Tetrahedron 415.7.4 NormalTetrahedron 415.7.5 ClassifiedTetrahedron 425.7.6 ColorManager 425.7.7 ParametricIntersections 42
6 Implementierung des hierarchischen 3D-Textur-Verfahrens 446.1 Aufbau und Implementierung des Octrees 446.2 Octree-Verfeinerung und -Vergröberung 456.2.1 Orakel 466.2.2 Octree-Verfeinerung 486.2.3 Octree-Vergröberung 486.3 Separating Axis Theorem für Quader / Tetraeder 486.4 Resampling auf ein reguläres Gitter 506.4.1 Intuitiver Algorithmus 506.4.2 3D-Rasterisierung 50

7
6.5 Alpha-Korrektur 536.5.1 Notwendigkeit der Alpha-Korrektur 536.5.2 Herleitung der Alpha-Korrektur-Formel 546.5.3 Numerische Probleme bei der Alpha-Korrektur 556.6 Octree-Anzeige 576.7 Artefakte 596.8 Ergebnisse 616.9 Klassenbeschreibungen 676.9.1 HierarchicalTextures3DBase 676.9.2 HierarchicalTextures3D 696.9.3 OctreeTGBase 696.9.4 OctreeTG 706.9.5 OctreeTGNodeBase 716.9.6 OctreeTGNode 726.9.7 PositionedSlicesBase 726.9.8 PositionedSlices 736.9.9 SystemInformation 73
7 Das AVS-Modul 747.1 Modul-Überblick 747.2 AVS-Modul-Schnittstelle 757.3 Einbindung OpenSG-basierter Funktionalität 767.4 Datenimport 777.4.1 AVS-Datenformate für Volumendaten 777.4.2 Die Field-Datenstruktur in AVS 787.4.3 C++ Klassen zur Verwaltung der Field-Daten 787.5 Rendersystem 807.6 Visualisierungssystem 817.7 Tetraederzerlegung 827.7.1 Pyramiden 837.7.2 Prismen 837.7.3 Hexaeder 837.8 Die grafische Benutzeroberfläche 877.9 Methoden des VolumeRender_UCD-Moduls 907.10 Klassenbeschreibungen 91
8 Zusammenfassung und Ausblick 95
9 Abkürzungsverzeichnis und Begriffserklärungen 97
10 Literaturverzeichnis 99
Anhänge auf CD:A1 OpenSG-Testprogramm zum Shirley-Tuchman-VerfahrenA2 OpenSG-Testprogramm zum hierarchischen 3D-Textur-VerfahrenA3 Quellcode der OpenSG-Erweiterungsbibliothek UnstructuredVolRenLibA4 Makro VolumeRender_UCD_GUI für AVS/Express 6A5 Quellcode des Makros VolumeRender_UCD_GUI

8
1 EinleitungIn vielen Gebieten der Wissenschaft und Industrie werden Volumendaten eingesetzt. Sie entstehenentweder in Rechner-Simulationen oder sind das Ergebnis von Messungen. In der Medizin werdenVolumendaten bei der Magnet-Resonanz-Tomographie (MRT) und der Computer-Tomographie(CT) aus einzelnen Schichten rekonstruiert. Die Computer-Tomographie wird auch im industriel-len Bereich zur Materialprüfung eingesetzt. Bei Rechner-Simulationen wendet man Finite-Ele-ment-Methoden (FEM) und Modelle aus dem CFD-Bereich (Computational Fluid Dynamics) an.Eine häufige Anwendung ist hier die Untersuchung des Strömungsverhaltens von Flüssigkeiten,Gasen oder Plasmen. Druck-, Temperatur- und Dichte-Daten sind typische Resultate solcher Simu-lationen. Auch für fotorealistische Visualisierungen in der Computergrafik sind Volumendaten wich-tig, wenn Oberflächenbeschreibungen nicht ausreichen; z. B. bei der Darstellung von Wolken oderFeuer.
Je nach Anwendungsbereich verwendet man unterschiedliche Gitter (siehe Kapitel 2) zur Definiti-on von Abtastpunkten für die Daten. Im medizinischen Bereich werden hauptsächlich reguläre undrektilineare Gitter eingesetzt. Für Simulationen ist es jedoch häufig sinnvoll, zur Darstellung be-stimmter Details an einigen Stellen das Gitter zu verfeinern. Zu diesem Zweck setzt man irreguläreund unstrukturierte Gitter ein.
Standardmethoden zur Visualisierung von Volumendaten sind die Darstellung von 2D-Schnittensowie die Extraktion von Isoflächen. Beide Methoden beruhen auf dem Prinzip, einen festgelegtenAusschnitt des Datensatzes darzustellen. Im Gegensatz dazu steht die direkte Volumenvisualisierung(Direct Volume Rendering, DVR), in der stets der gesamte Datensatz angezeigt wird. Über eineTransferfunktion wird jedem Volumenwert eine Farbe und Opazität zugeordnet; so kann man be-stimmte Werte durch eine hohe Opazität hervorheben und andere durch eine niedrige Opazitätverbergen. DVR ist nicht für eine exakte Analyse geeignet; das Ziel ist vielmehr, einen visuellenGesamtüberblick über einen Datensatz zu erhalten.
Es gibt unterschiedliche Methoden für das Direct Volume Rendering (siehe Kapitel 3). Bei derWahl eines bestimmten Verfahrens sind drei Aspekte zu beachten: die gewünschte Ausgabequalitätsowie Berechnungszeit für ein Frame und der Gittertyp des Datensatzes. Ausgehend vom Raytracing,das eine sehr hohe Qualität bei sehr langer Berechnungszeit liefert und auf jedem Gittertyp an-wendbar ist, wurden in den letzten 15 Jahren unterschiedliche Alternativen entwickelt. Viele sol-cher Visualisierungsmethoden sind an Gittertypen gebunden. Das Shear-Warp-Verfahren etwa kannnur auf rektilinearen Gittern angewendet werden. Sehr schnelle Verfahren verringern häufig durchArtefakte die Ausgabequalität. So lässt sich mit der Überblendung texturierter Ebenen zwar auchfür große Datensätze eine Echtzeitdarstellung (d. h. die benötigte Zeit für ein Bild liegt unter 0,04Sekunden) erreichen, die Übergänge zwischen den Ebenen sind jedoch im Allgemeinen unstetig.Zudem sind die schnellsten bekannten Verfahren nur auf regulären bzw. rektilinearen Gittern mög-lich.
Diese Arbeit untersucht DVR-Methoden für unstrukturierte Gitter, die sich für eine Echtzeit-darstellung eignen. Nach einem Vergleich basierend auf bestehender Literatur (Kapitel 4) wurdedas Shirley-Tuchman-Verfahren (Kapitel 5) und die Visualisierung mit hierarchischen 3D-Textu-ren (Kapitel 6) für eine Implementierung ausgewählt. Diese Visualisierungsmethoden wurden zu-nächst in den Szenengraph OpenSG eingebettet. Darauf aufsetzend wurde ein Modul für die kom-merzielle Visualisierungssoftware AVS/Express entworfen (Kapitel 7), das die in OpenSG imple-mentierten Methoden für dieses Softwarepaket nutzbar macht. AVS/Express bietet bislang mit deraktuellen Version 6.3 keine Möglichkeit zum Direct Volume Rendering auf unstrukturierten Git-tern.

9
2 Gittertypen und BeleuchtungsmodelleZur Definition von Volumendaten ordnet man jedem Punkt innerhalb des Volumens einen skalarenWert zu. Um eine Verarbeitung mit dem Rechner zu ermöglichen, ist eine Diskretisierung nötig.Die Elemente der zugrundeliegenden endlichen Punktmenge des Volumens heißen Abtastpunkte(Samplepunkte). Diese Punkte sind Eckpunkte von Volumenzellen. Weil es nur endlich vieleSamplepunkte gibt, sind diese Zellen dreidimensionale Polyeder. Die Volumenwerte innerhalb derZellen erhält man durch Interpolation; typischerweise benutzt man hier eine lineare Interpolationüber die Eckpunkte. Den Komplex aus Zellen, Kanten und Punkten der Polyeder nennt man Gitter.Da es für den Umgang mit den Daten wesentlich ist, auf welchem Gittertyp sie definiert sind,werden die Gitter in den Abschnitten 2.1 bis 2.4 in unterschiedliche Typen klassifiziert.
Für die Darstellung von Volumendaten benötigt man ein Beleuchtungsmodell, auf das wir in 2.5eingehen.
2.1 Reguläre GitterEin reguläres Gitter ist ein quaderförmiger Ausschnitt eines kartesischen Gitters, wobei dieserQuader hauptachsenausgerichtet ist. An jedem Gitterlinienschnittpunkt befindet sich genau einSamplepunkt. Abb. 2.1 zeigt ein zwei- und ein dreidimensionales Beispiel eines regulären Gitters.
Zur Definition eines solchen dreidimensionalen Gitters gibt man die Anzahl Samplepunkte in jededer drei Raumrichtungen und die Endpunkte der Raumdiagonalen an. Falls der Abstand zwischenbenachbarten Samplepunkten für jede Raumrichtung gleich ist, kann die Angabe der Diagonalenentfallen. Die Zellen eines dreidimensionalen regulären Gitters sind Quader.
2.2 Rektilineare GitterRektilineare Gitter sind eine Verallgemeinerung regulärer Gitter. Hier können die Abstände zwi-schen den Samplepunkten entlang einer Achse variieren. Allerdings müssen die Samplepunkte, diedie gleiche x-Koordinate haben, auf einer Ebene liegen. Analog gilt diese Vorraussetzung auch fürdie y- und z-Koordinaten. Diese Einschränkung bewirkt, dass die Zellen auch hier quaderförmigsind. Zur Definition wird neben der Anzahl der Samplepunkte pro Achse noch jeweils der Achsen-abschnitt für die Samplepunkt-Ebenen angegeben. Abb. 2.2 zeigt Beispiele für rektilineare Gitter.
����
��������
����
Abb. 2.1:Zweidimensionales (links) und dreidimensionales (rechts) reguläres Gitter. Die explizitdefinierten Punkte sind jeweils markiert.

10
2.3 Irreguläre GitterEine weitere Verallgemeinerung wird durch irreguläre Gitter gegeben. Ein Gitter ist irregulär,wenn es eine Abbildung auf ein reguläres Gitter gibt, die nur die Position der Samplepunkte ändert.Die Quaderform der Zellen geht dadurch gegenüber rektilinearen Gittern verloren, die Anzahl be-nachbarter Zellen jedoch bleibt konstant. Diese Verallgemeinerung der Quader-Zellen bezeichnenwir als Hexaeder. Beispiele für irreguläre Gitter sind in Abb. 2.3 zu sehen.
Bei irregulären Gittern muss für jeden Samplepunkt eine Position im Raum angegeben werden.Obwohl die Definition Zelldurchdringungen zulässt, legt man irreguläre Gitter für reale Anwen-dungen so an, dass sich die Zellen nicht durchdringen.
2.4 Unstrukturierte GitterDie bis hierher vorgestellten Gittertypen fasst man auch unter dem Sammelbegriff strukturierteGitter zusammen. Unstrukturierte Gitter bilden den allgemeinsten Gittertyp. Nicht nur die
Abb. 2.3:Zweidimensionales (links) bzw. dreidimensionales (rechts) irreguläres Gitter.
Abb. 2.4:Zweidimensionales (links) bzw. dreidimensionales (rechts) unstrukturiertes Gitter.
Abb. 2.2:Zweidimensionales (links) und dreidimensionales (rechts) rektilineares Gitter.

11
2.5 BeleuchtungsmodelleWir stellen uns das zu visualisierende Volumen vor wie eine leuchtende Gaswolke. Für die Visua-lisierung dieser Wolke sind vier physikalische Vorgänge von Bedeutung: Licht-Emission, Absorp-tion, Reflexion und Brechung. Durch die vielen kleinen Partikel in der Wolke treten Reflexion undBrechung innerhalb des Mediums sehr häufig auf, und eine korrekte Simulation wird sehr kompli-ziert. Heutige Visualisierungsmethoden, besonders diejenigen, deren Ziel eine möglichst schnelleAnzeige ist, beschränken sich deswegen auf Emission und Absorption. Eine sehr verständlicheHerleitung der Intensitätsberechnungsformel für dieses Emissions- und Absorptionsmodell findetsich in [2], Abschnitt 3 (Continuous Model). Weil jenes Modell eine theoretische Basis für dieseArbeit darstellt, soll es hier vorgestellt werden.
Die Licht-Emission der Gaswolke wird als Intensitätsfunktion abhängig von der Wellenlänge füreinen Punkt (x, y, z) gegeben durch die Funktion
κ(x, y, z, λ)
Die Absorption ist zurückzuführen auf die optische Dichte der Wolke, die ebenfalls abhängig vonder Wellenlänge und durch
ρ(x, y, z, λ)
definiert ist.
Sei P(t) ein Sichtstrahl durch das Medium zum Auge (siehe Abb. 2.1), und sei ρ(t, λ) = ρ(P(t), λ)sowie κ(t, λ) = κ(P(t), λ). Ist die optische Dichte an einer Stelle höher, so wird dort einerseits mehrLicht absorbiert, andererseits aber auch mehr Licht emittiert.
Sei I(t, λ) die Intensität der Wellenlänge λ an der Stelle t des Sichtstrahls.
Für ∆t gegen 0 ist ρ(t, λ)∆t der Bruchteil der Intensität des einfallenden Lichts der Wellenlänge λ,der beim Überstreichen von ∆t absorbiert wird. κ(t, λ)ρ(t, λ)∆t hingegen ist die über ∆t emittierteIntensität der Wellenlänge λ. Unser Ziel ist es, für jeden Sichtstrahl den Wert I(tn, λ) zu berechnen,da dies genau die Intensität der Wellenlänge λ ist, die ins Auge fällt. Der Weg zu diesem Ziel führt
���
�
��
�
��� ��
��� ��
Abb. 2.1:2D-Schema einer Gaswolke. P(t) ist ein von t0 bis tn parametrisierter Sichtstrahl, der durchdie Wolke ins Auge fällt. Entnommen aus [2].
Samplepunkte können beliebig im Raum positioniert sein; auch der Zelltyp kann variieren. NebenHexaedern werden häufig Tetraeder, Pyramiden und Prismen verwendet. Formal zugelassen sindaber alle Polyeder. Abb. 2.4 zeigt Beispiele.
Im praktischen Gebrauch werden unstrukturierte Gitter so angelegt, dass sich Zellen nicht durch-dringen und das Gitter aus genau einer Zusammenhangskomponente besteht.

12
uns von einem aus Bild 2.1 abgeleiteten Ansatz über die Herleitung einer Differenzialgleichung biszu einem Ausdruck für I(tn, λ).
Die Lichtintensität, die auf dem Sichtstrahl die Stelle t + ∆t2
erreicht, ist
I(t +∆t
2, λ) = I(t − ∆t
2, λ)(1 − ρ(t, λ)∆t) + κ(t, λ)ρ(t, λ)∆t
Dies lässt sich umformen in
I(t + ∆t2
, λ) − I(t − ∆t2
, λ)
∆t= −ρ(t, λ)I(t − ∆t
2, λ) + κ(t, λ)ρ(t, λ)
Für ∆t gegen 0 ergibt sich die Differenzialgleichung
dI(t, λ)
dt= −ρ(t, λ)I(t, λ) + κ(t, λ)ρ(t, λ) (1)
Wir stellen die Gleichung nun um und multiplizieren auf beiden Seiten mit dem Term e� tt0
ρ(u,λ)du.Es ergibt sich
e� tt0
ρ(u,λ)du dI(t, λ)
dt+ ρ(t, λ)e
� tt0
ρ(u,λ)duI(t, λ) = e
� tt0
ρ(u,λ)duκ(t, λ)ρ(t, λ)
Durch Anwenden der Produktregel erhalten wir
d
dt[e
� tt0
ρ(u,λ)duI(t, λ)] = e
� tt0
ρ(u,λ)duκ(t, λ)ρ(t, λ)
Nun integrieren wir beide Seiten von t0 bis tn
[e� t
t0ρ(u,λ)du
I(t, λ)]tnt0 =
∫ tn
t0
e� tt0
ρ(u,λ)duκ(t, λ)ρ(t, λ)dt
und erhalten
e� tn
t0ρ(u,λ)du
I(tn, λ) − e� t0t0
ρ(u,λ)duI(t0, λ) =
∫ tn
t0
e� tt0
ρ(u,λ)duκ(t, λ)ρ(t, λ)dt
Unter der Berücksichtigung, dass auf der linken Seite das Integral im rechten Term 0 ist, machenwir eine einfache Umformung
I(tn, λ) = e− � tn
t0ρ(t,λ)dt
∫ tn
t0
e� tt0
ρ(u,λ)duκ(t, λ)ρ(t, λ)dt + I(t0, λ)e
− � tnt0
ρ(t,λ)dt
und vereinigen die beiden Exponenten im ersten Summanden:
I(tn, λ) =
∫ tn
t0
e−� tnt
ρ(u,λ)duκ(t, λ)ρ(t, λ)dt + I(t0, λ)e− � tn
t0ρ(t,λ)dt
(2)
Für I(tn, λ) ist keine geschlossene Formel bekannt. Zur tatsächlichen Berechnung dieses Wertes hatman daher nur folgende drei Möglichkeiten:
• numerische Berechnung von (1)• numerische Berechnung von (2)• Approximieren von ρ(t, λ) und κ(t, λ) durch einfachere Funktionen, sodass sich Formel (2) zu
einem geschlossenen Ausdruck vereinfachen lässt.

13
Da die zuletzt genannte Möglichkeit brauchbare Ansätze für viele Visualisierungstechniken liefert,wird sie hier etwas weiter ausgeführt. Wir nehmen zunächst an, κ(t, λ) und ρ(t, λ) seien entlangeines Sehstrahls unabhängig von t, bevor wir diesen Ansatz anschließend auf stückweise Unabhän-gigkeit von t erweitern.
Wegen der Unabhängigkeit der Funktion κ(t, λ) von t lässt sich (2) vereinfachen zu
I(tn, λ) = κ(λ)(1 − e− � tn
t0ρ(u,λ)du
) + I(t0, λ)e− � tn
t0ρ(t,λ)dt
Da auch ρ(t, λ) unabhängig von t ist, erhalten wir
I(tn, λ) = κ(λ)(1 − e−ρ(λ)(tn−t0)) + I(t0, λ)e−ρ(λ)(tn−t0) (3)
Gleichung (3) lässt sich identifizieren mit der aus dem Alpha-Blending bekannten Formel für dasBack-to-Front-Compositing,
Cout = Cnew ∗ α + Cin ∗ (1 − α)
wobei gilt
α = 1 − e−ρ(λ)(tn−t0)
Cnew = κ(λ)
Cin = I(t0, λ)
Cout = I(tn, λ)
Es ist somit möglich, eine stückweise Integration entlang des Sehstrahls durchzuführen, wobei κund ρ für jeden Abschnitt variieren können. Dies entspricht dem Ansatz, dass κ und ρ für festes λentlang des Sichtstrahls stückweise konstant sind. Einerseits bietet sich also durch ein detaillierte-res Sampling des Sichtstrahls die Möglichkeit zur exakteren Berechnung der Gesamtintensität, undandererseits ist die Identifizierung mit dem Alpha-Blending ein wichtiger Schritt in RichtungHardwarebeschleunigung.
Häufig wird die Funktion ρ(t, λ) als unabhängig von λ betrachtet. κ(x, y, z, λ) = Iλ und ρ(x, y, z)werden dann in der Regel kompakt als Transferfunktion f(v) = (Ir(v), Ig(v), Ib(v), ρ(v)) definiert,wobei v(x, y, z) der Skalarwert unserer Gaswolke an der Position (x, y, z) ist (dies kann z. B. eineDichte oder ein Druck sein).

14
3 Techniken zur direkten VolumenvisualisierungIn den vergangenen Jahren wurden viele unterschiedliche Techniken zur direkten Volumen-visualisierung vorgeschlagen. Das Raytracing (z. B. [3]) ist der älteste Ansatz; er ist sehr flexibelund erlaubt die Verwendung verschiedener physikalischer Modelle, ist aber sehrberechnungsaufwändig. Um die Rechenzeiten zu verkürzen hat man nach schnelleren Darstellungs-methoden gesucht, die die qualitativ hochwertigen Ergebnisse aus dem Raytracing möglichst gutapproximieren sollten. Durch vereinfachende Annahmen über Lichtverhalten und Variation derVolumendaten zwischen den Sample-Punkten des Gitters wurden sowohl schnelle Software-Ver-fahren als auch die Ausnutzung von Hardwarebeschleunigungen möglich. Reguläre Gitter habensich für Hardwarebeschleunigungen als sehr hilfreich erwiesen (z. B. 3D-Texturierung [29]), er-möglichen aber auch Softwaretechniken, die erhebliche Geschwindigkeitsvorteile bieten können(z. B. Shear-Warp-Transformation [15]).
Um diese schnellen Verfahren auch für nicht-reguläre Gitter verwenden zu können, wurden Versu-che unternommen, diese auf reguläre Gitter abzubilden. Dieser Ansatz ist zunächst widersinnig, dadas Gitter in der Regel genau für solche Daten nicht-regulär ist, die an bestimmten Regionen be-sonders detailreich sind. Durch ein Resampling würden genau diese Details wieder verlorengehen,oder man müsste das reguläre Zielgitter sehr fein auslegen, was jedoch wegen des kubischenSpeicherzuwachses einen immensen Speicheraufwand bedeuten würde. Eine Lösung für diesesProblem sind hierarchische Verfahren.
Daneben gibt es jedoch auch Verfahren, die ohne ein Resampling auskommen und direkt auf nicht-regulären Gittern arbeiten können. Beispielsweise haben Shirley und Tuchman [4] eine Methodefür Tetraedernetze vorgeschlagen, für die es mittlerweile sogar Ansätze zur Hardwarebeschleunigungmit Consumer-Hardware gibt [5] [6].
Man kann die bestehenden Techniken klassifizieren in Objektraum-Verfahren (Object-Order) undBildraum-Verfahren (Image-Order).Object-Order bedeutet, dass pro Frame für jede Gitterzelle ein bestimmter Algorithmus durchlau-fen wird, der diese Zelle visualisiert. Die Gesamtheit der visualisierten Zellen ergibt das gewünschteResultat.Bei Image-Order-Techniken wird stattdessen ein Algorithmus für jedes Pixel der Sichtebene durch-laufen, um für dieses Pixel den passenden Farbwert zu erhalten.
Eine andere wichtige Einteilung der Visualisierungsverfahren ergibt sich aus den Gittern, auf de-nen die Verfahren arbeiten können. Während Raytracing auf allen Gittertypen funktioniert, benö-tigt beispielsweise ein 3D-Textur-Ansatz reguläre Gitter. Bevor wir jedoch eine Klassifizierungder Techniken vornehmen (Kapitel 4), werden sie zunächst etwas näher erläutert.
3.1 RaytracingBeim Raytracing von Volumendaten wird durch jedes Pixel der Sichtebene ein Sehstrahl gesendet,der das Volumen durchquert, ähnlich dem Strahl P(t) aus Abb. 2.1. Zur Intensitätsberechnung I(tn,λ)kann eines der in Abschnitt 2.5 angegeben Verfahren verwendet werden.
Zum Entwurf eines effizienten Raytracers ist es nötig, die Berechnung möglichst effizient zu ge-stalten. Für jedes Bildpixel über den gesamten Sehstrahl zu integrieren würde sehr lange dauern.Zur Beschleunigung der Berechnung gibt es zwei grundlegende Vorschläge. Erstens kann manvollständig transparente Bereiche im Volumen einfach überspringen, zweitens kann die Integrationentlang des Sehstrahls abgebrochen werden, sobald die Opazität des aktuellen Pixels ohnehin schonnahe 1 ist. Die zweite Technik wird in der Literatur auch Early Ray Termination genannt. Dafür

15
muss die Integration allerdings von vorne nach hinten anstatt von hinten nach vorne (wie in Ab-schnitt 2.5 angegeben) durchgeführt werden. Beide Optimierungen werden z. B. in [3] beschrie-ben. Trotz Optimierungen bleibt das Raytracing aber eins der langsamsten bekannten Verfahren.
In Abb. 3.1 sehen wir ein Beispiel für eine per Raytracing erzeugte direkte Volumenvisualisierung.
3.2 SplattingSplatting wurde ursprünglich von Westover [28] vorgeschlagen. Die Idee dabei ist, für jedes Voxeleine zweidimensionale Abbildung (Splat) zu berechnen. Die Überlagerung der Splats auf der Bild-ebene ergibt das finale Bild. Die Berechnung der Splats besteht aus zwei Schritten. In einem Vor-verarbeitungsschritt wird aus einem gewählten Filterkern durch Integration ein generischer Ab-druck erzeugt und in einer Lookup-Tabelle gespeichert (generic footprint table). Je nach Kamera-position wird dieser dann pro Frame in einen blickpunktabhängigen Abdruck transformiert (view-dependent footprint table). Ein solcher Abdruck definiert die Verteilung des dem Voxel zugeordne-ten RGBA-Farbwertes im beeinflussten Bildbereich. Um nun den eigentlichen Splat zu berechnen,muss der Abdruck mit dem Wert des Voxels multipliziert und auf der Bildebene an die entsprechen-de Stelle verschoben werden. Dort kann dann ein Resampling auf die Bildpixel stattfinden. Falls inder Betrachtungstransformation eine nicht-uniforme Skalierung auftritt, haben die Splats die Formeiner Ellipse; bei nur uniformen Skalierungen ergibt sich der Spezialfall eines Kreises.
Splatting wurde ursprünglich für reguläre Gitter konzipiert, später aber auch auf rektilineare Gittererweitert. Falls ein reguläres Gitter zugrunde liegt und die Betrachtungstransformation eine ortho-gonale Projektion ist, sind die Abdrücke für alle Voxel identisch. Daher muss dann pro Frame nurein blickpunktabhängiger Abdruck berechnet werden.
3.3 Überblendung texturierter EbenenDiese Visualisierungstechnik ist eng verbunden mit der Vorstellung, die Volumendaten seien ausvielen übereinanderliegenden Schichten zusammengesetzt. Für jede dieser Schichten wird reprä-sentativ eine RGBA-texturierte Ebene (Slice) gezeichnet. Durch die Transparenz (Alpha-Kanal)
Abb. 3.1:Direkte Visualisierung des Datensatzes „Lobster“ (Computertomographie eines Hummers)per Raytracing mit der Software AVS/Express 6.1.

16
wird vermieden, dass darunterliegende Slices verdeckt werden. Um die darzustellenden Slices kor-rekt texturieren zu können, müssen die Volumendaten auf einem regulären Gitter definiert sein.Das Beleuchtungsmodell entspricht dem in Abschnitt 2.5 vorgestellten Modell, wobei κ und ρ fürden von einer Slice repräsentierten Volumenbereich als konstant vorausgesetzt werden. Häufigwerden über die Anwendung der Transferfunktion nicht κ und ρ, sondern κ und direkt α ermittelt(α ist die vierte Komponente der RGBA-Textur). Ermöglicht wird dies durch das reguläre Gitter:der Abstand ∆t zwischen zwei Slices ist konstant, daher hängt α nur noch von ρ ab (siehe EndeAbschnitt 2.5) und kann so auch direkt angegeben werden.
Man unterscheidet zwischen Verfahren, die zur Hardwarebeschleunigung lediglich 2D-Textureneinsetzen und solchen, die 3D-Texturen verwenden.
3.3.1 2D-TexturenBei 2D-Textur-Verfahren sind die Lage der einzelnen Slices und die Texturen auf den Slices kon-stant. Deswegen werden hier die Slices komplett vorberechnet. Um zu vermeiden, dass dieBetrachtungsrichtung um mehr als 45° von der Flächennormale der Slices abweicht, werden insge-samt drei Textur-Stapel benötigt. Jeder Stapel enthält die entsprechenden texturierten Slices ortho-gonal zu einer der drei Hauptachsen. Pro Frame kann dann der Stapel für die Anzeige ausgewähltwerden, der für die aktuelle Kameraposition am besten geeignet ist (d. h. geringste Abweichungder Sichtebenennormale von den Slicenormalen).
Abb. 3.2:2D-Textur-Darstellung des Lobster-Datensatzes, erzeugt mit AVS/Express 6.1.
17
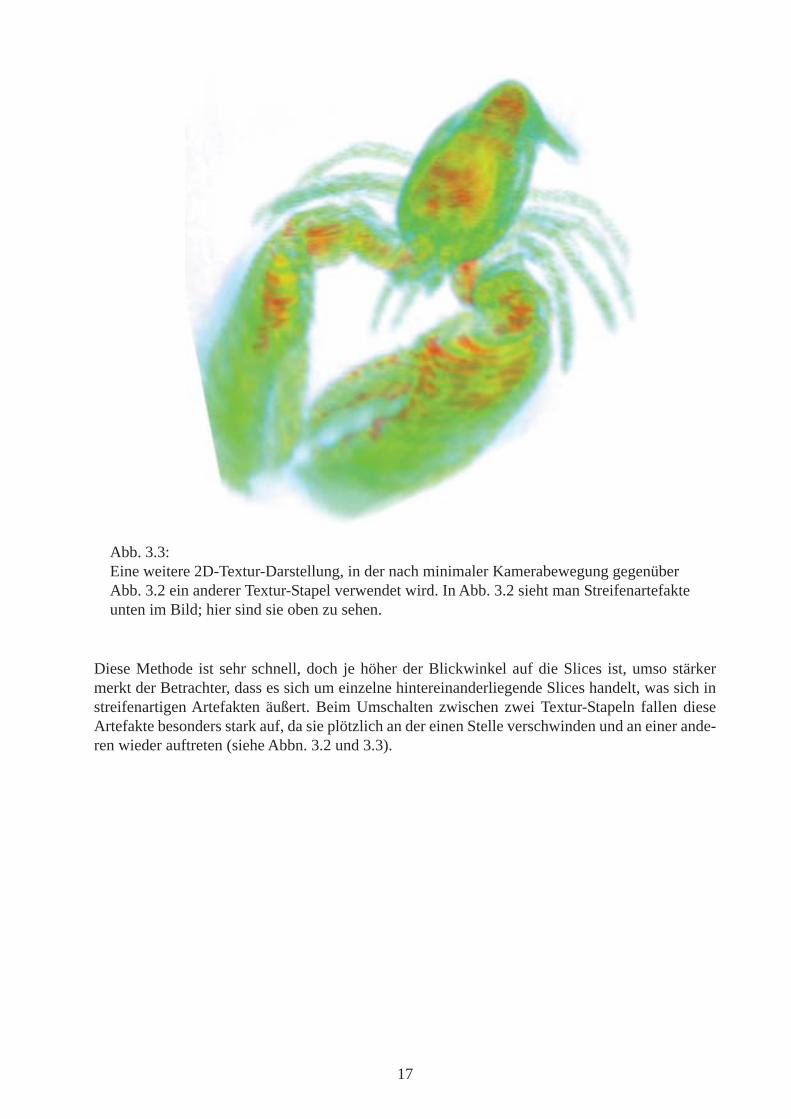
Diese Methode ist sehr schnell, doch je höher der Blickwinkel auf die Slices ist, umso stärkermerkt der Betrachter, dass es sich um einzelne hintereinanderliegende Slices handelt, was sich instreifenartigen Artefakten äußert. Beim Umschalten zwischen zwei Textur-Stapeln fallen dieseArtefakte besonders stark auf, da sie plötzlich an der einen Stelle verschwinden und an einer ande-ren wieder auftreten (siehe Abbn. 3.2 und 3.3).
Abb. 3.3:Eine weitere 2D-Textur-Darstellung, in der nach minimaler Kamerabewegung gegenüberAbb. 3.2 ein anderer Textur-Stapel verwendet wird. In Abb. 3.2 sieht man Streifenartefakteunten im Bild; hier sind sie oben zu sehen.

18
3.3.2 3D-TexturenBei der 3D-Texturierung wird versucht, das Umschalten zwischen verschiedenen Textur-Stapelnzu vermeiden, indem die Slices in jedem Fall parallel zur Bildebene ausgerichtet werden (sieheAbb. 3.4). Eine Slice-Vorberechnung ist dann natürlich nicht mehr möglich. Die Ebenen müssenalso pro Frame neu berechnet und texturiert werden. Da außerdem die Ausrichtung der Ebenen nunnicht mehr mit der der einzelnen Volumenschichten übereinstimmt, ist keine 2D-Texturierungmöglich. Stattdessen legt man den Volumendatensatz als 3D-Textur ab und ordnet den Eckpunktender Slices 3D-Texturkoordinaten zu. Durch eine hardwareunterstützte, trilineare Interpolation bleibtdas Verfahren echtzeittauglich. In Abb. 3.5 sehen wir eine 3D-Textur-Darstellung.
Bei zu wenigen Slices sieht man einerseits am Rand des Volumens Artefakte (siehe Abb. 3.4);andererseits kommen im gesamten Bildbereich Streifenartefakte vor, die durch den Abstand derÜberblendungsebenen zueinander in Verbindung mit deren unterschiedlicher Größe entstehen. Rand-artefakte treten beim 3D-Textur-Verfahren an allen Rändern auf, beim 2D-Textur-Verfahren hinge-gen nicht an allen Rändern (vgl. Abb. 3.4). Komplett beseitigen lassen sich die Artefakte nicht;man kann jedoch die Anzahl der Slices erhöhen bzw. den Slice-Abstand verkleinern, um die visu-ellen Auswirkungen zu verringern.
Abb. 3.4:Links: 2D-Textur-Stapel, Randartefakte fett gezeichnet.Rechts: orthogonale Ausrichtung der Slices bei der Verwendung von 3D-Texturen;Artefakte an allen Rändern möglich; Streifenartefakte immer noch vorhanden.

19
Abb. 3.5:3D-Textur-Darstellung, erzeugt mit einer erweiterten Version des OpenSG VolumeViewers[33]. Die Streifenartefakte, die hier ansatzweise im Übergang von roten zu grünenFarbtönen zu sehen sind, werden bei einer interaktiven Betrachtung noch deutlicher.

20
Abb. 3.6:Shear-Warp-Faktorisierung der orthogonalen (oben) bzw. perspektivischen (unten)Betrachtungstransformation.
3.4 Shear-Warp-FaktorisierungDie Basis für diese Technik ähnelt der des 2D-Textur-Verfahrens. Man betrachtet hauptachsen-orthogonale Schnitte durch einen rektilinearen Volumendatensatz. Anstatt nun texturierte Schnitt-ebenen im Raum zu platzieren und von der Grafikhardware rendern zu lassen, wird die Betrachtungs-transformation in die drei Komponenten Scherung (im perspektivischen Fall mit Skalierung), achsen-parallele Projektion und 2D-Bildtransformation (Warp) faktorisiert (siehe Abb. 3.6).
Lacroute und Levoy haben dieses reine Software-Verfahren von der ursprünglichen orthogonalenauf eine perspektivische Projektion erweitert und stellen Möglichkeiten zur Beschleunigung derachsenorthogonalen Projektion vor [15]. Diese Beschleunigungen werden durch eine scanline-basierte Traversierung von Volumenvoxeln und Bildpixeln und die Verwendung von speziellen,
�������������
��������������
���������
��������
����������
�� ��!
�����������������������
����������
�� ��!
�������������
��������������
���������

21
Abb. 3.7:Tetraeder-Projektion auf die Sichtebene.
Lauflängencodierungen verwendenden Datenstrukturen möglich. So können transparente und ver-deckte Voxel übersprungen werden.
Die Shear-Warp-Faktorisierung ist ein effizientes Software-Verfahren für rektilineare Gitter, je-doch treten Qualitätsverluste durch das zweimalige Resampling (Überblendung der geschertenEbenen sowie 2D-Warp) auf, die je nach Kameraposition und Transferfunktion unterschiedlichstark ausfallen.
3.5 Shirley-Tuchman-VerfahrenDas direkte Volumenrendering einer einzelnen Volumenzelle erzeugt auf der Sichtebene einen zwei-dimensionalen Bereich, dessen Rand identisch ist mit dem Rand der 2D-Projektion der Volumen-zelle auf die Sichtebene. Diese Tatsache ist es, die dem Verfahren von Shirley und Tuchman [4]zugrunde liegt. Hier wird die Projektion einer Volumenzelle auf die Sichtebene berechnet unddirekt mit 2D-Primitiven hardwarebeschleunigt gezeichnet, anstatt wie beim Raytracing über Inte-gration Pixel für Pixel zu berechnen. Dabei ist es wichtig, die Farben und Opazitäten der 2D-Primitive so zu wählen, dass das Ergebnis aussieht wie ein aus dem Raytracing entstandenes Bild.
Um nicht nur reguläre, sondern auch unstrukturierte Gittertypen mit abzudecken, wird bei diesemVerfahren für die Projektion auf die Sichtebene das Tetraeder als Grund-Volumenzelle gewählt.(Jedes Polyeder und damit jedes unstrukturierte Gitter kann in eine Menge von sich nicht durch-dringenden Tetraedern zerlegt werden.) Deswegen heißt diese Technik auch Verfahren der proji-zierten Tetraeder (Projected Tetrahedra Algorithm).
Den Rand dieser Projektion zu bestimmen ist einfach (siehe auch Abb. 3.7).
Schwieriger ist es jedoch, die Farben und Opazitäten für die Dreiecke zu berechnen, die die Projek-tion darstellen und dem Betrachter ein gerendertes Tetraeder vortäuschen sollen. Hier lässt sichFormel (3) aus Abschnitt 2.5 anwenden. Der Sehstrahl wird dabei so gesampelt, dass die ti mit 0 <i < n die Grenzen zwischen je zwei benachbarten Tetraedern entlang des Sichtstrahls markieren.
Werden nun mehrere Tetraeder nacheinander gerendert, ist für das Compositing auf eine korrekteReihenfolge von hinten nach vorne zu achten. Das bedeutet aber, dass die zu zeichnende Tetraeder-menge neu sortiert werden muss, sobald sich die Kameraposition ändert. Eine einfach zu ermitteln-de Sortierung ergibt sich aus den Abständen zwischen Kamera und Tetraederzentren. Obwohl die-se Sortierung nicht korrekt ist, wie Abb. 3.8 verdeutlicht, ermöglicht sie doch annähernd korrekteErgebnisse und wird wegen ihrer schnellen Berechenbarkeit häufig in Echtzeitanwendungen ein-gesetzt.

22
In den vergangenen Jahren wurde viel Arbeit in die Erforschung korrekter, aber möglichst schnel-ler Sortierverfahren für diese Anwendung gesteckt. Die derzeit schnellsten Methoden [17] [18]beruhen auf der Speicherung eines Graphen, dessen Knoten die Volumenzellen darstellen. EineKante existiert zwischen zwei Knoten genau dann, wenn die entsprechenden Zellen benachbartsind. Die Richtung einer Kante gibt an, welche der beiden Zellen die vordere und welche diehintere ist. Bei einer Änderung der Kameraposition wird nur die Richtung der Kanten aktualisiert.Die Kanten induzieren eine partielle Ordnung auf der Menge aller Zellen, die benutzt werden kannum eine korrekte Sortierung aller Zellen zu erhalten.
3.6 Hierarchische VerfahrenFür die derzeit schnellsten Techniken der direkten Volumenvisualisierung sind reguläre Gitter not-wendig. Über Resampling lassen sich zwar alle Gittertypen auf reguläre Gitter abbilden, dies bringtaber - wie am Anfang von Kapitel 3 beschrieben - Detailverluste oder einen immensen Speicher-aufwand mit sich. Hierarchische Verfahren bieten hier einen Ausweg. Sie arbeiten mit einer Kom-position unterschiedlich hoch aufgelöster regulärer Gitter. Dort, wo das Ursprungsgitter sehr hochaufgelöst ist, werden die Daten auf ein sehr feines reguläres Gitter abgebildet; für gröbere Regio-nen sieht man ebenfalls ein gröberes reguläres Zielgitter vor. Angewendet wurde diese Idee bereitsauf 3D-Textur-Verfahren [7] [11].
Hierarchische Verfahren bringen jedoch auch zwei Probleme mit sich. Zum einen können je nachVerfahren an den Übergängen zwischen je zwei regulären Gittern unterschiedlich hoher AuflösungDarstellungsartefakte entstehen. Für hierarchische 3D-Texturen ist die Beseitigung dieser Artefak-te ein aktueller Forschungsgegenstand. Zum anderen ist darauf zu achten, dass je nach Feinheit desregulären Zielgitters evtl. einige Parameter der verwendeten Visualisierungstechnik angepasst werdenmüssen. Bei hierarchischen 3D-Texturen ist eine Alpha-Korrektur nötig, um die höher aufgelöstenBereiche nicht durch eine zu hohe Opazität hervorstechen zu lassen.
Abb. 3.8:In diesem Beispiel liegt das Zentrum CB von B näher an der Kamera als das Zentrum CAvon A. Bei einer Sortierung nach Zentrumsabständen zur Kamera wird daher zuerst A undanschließend B gezeichnet. Der durch A überdeckte Teil von B wird inkorrekt dargestellt.
"�����
#$#�
��
$
�
������������%�����&���$�&��������'���
23
4 Anforderungen und ZieleIn dieser Masterarbeit soll ein Modul für AVS/Express entwickelt werden, das direkte Volumen-visualisierung auf unstrukturierten Daten möglich macht. Für die Visualisierung soll der SzenengraphOpenSG verwendet werden.
AVS/Express bietet bislang kein solches Visualisierungsverfahren auf unstrukturierten Gittern an.Man kann zwar ein Resampling auf ein reguläres Gitter durchführen, jedoch verliert man dadurchentweder Detailinformationen oder benötigt unverhältnismäßig viel Speicher und, damit verbun-den, auch sehr hohe Rechenzeiten. Die Verwendung von AVS als eine Basis für diese Arbeit istsinnvoll, weil dadurch bereits unterschiedliche Datenimport- und Vorverarbeitungsmöglichkeitenexistieren. Außerdem bietet AVS eine sehr effiziente Erstellung von grafischen Benutzeroberflä-chen.
Die Programmierung dieses Moduls unter Verwendung der OpenSG-Bibliothek hat eine gute Er-weiterbarkeit und Wartbarkeit zur Folge. Die Erweiterbarkeit bezieht sich z. B. auf das Einbindenweiterer Rendertechniken oder das Unterstützen unterschiedlicher Ausgabegeräte (wie etwa dieVisualisierung in einem Rechner-Cluster).
Als Rendertechnik soll hier nicht das Resampling auf ein einziges reguläres Gitter angewendetwerden. Die Nachteile dieser Methode wurden oben bereits erwähnt, außerdem wird dieses Fea-ture bereits von AVS unterstützt.
Ein Ziel ist die möglichst echtzeitnahe Darstellung, d. h. dass ein Benutzer im Idealfall denunstrukturierten Datensatz ohne merkbare Verzögerungen von allen Seiten interaktiv betrachtenkann.
Wir wollen nun die in Kapitel 3 vorgestellten Methoden zur direkten Volumenvisualisierung be-züglich dieser Bedürfnisse untersuchen. Die wesentlichen Aspekte sind der erlaubte Gittertyp unddie Renderzeit für ein Frame. Der Vergleich von Renderzeiten für unterschiedliche Verfahren istproblematisch, da diese Zeiten nicht nur vom Verfahren selbst, sondern auch von der Beschaffen-heit des dargestellten Datensatzes und der gewählten Transferfunktion abhängen. Außerdem hängtdie Schnelligkeit einer Implementierung natürlich davon ab, welche Optimierungen eingesetztwerden. Es sei zudem darauf hingewiesen, dass die Änderung gewisser Parameter sich für unter-schiedliche Verfahren unterschiedlich stark in der Rechenzeit auswirkt. Wenn man z. B. die Auflö-sung des Viewports erhöht, steigt die Rechenzeit beim Raytracing wesentlich stärker an als bei
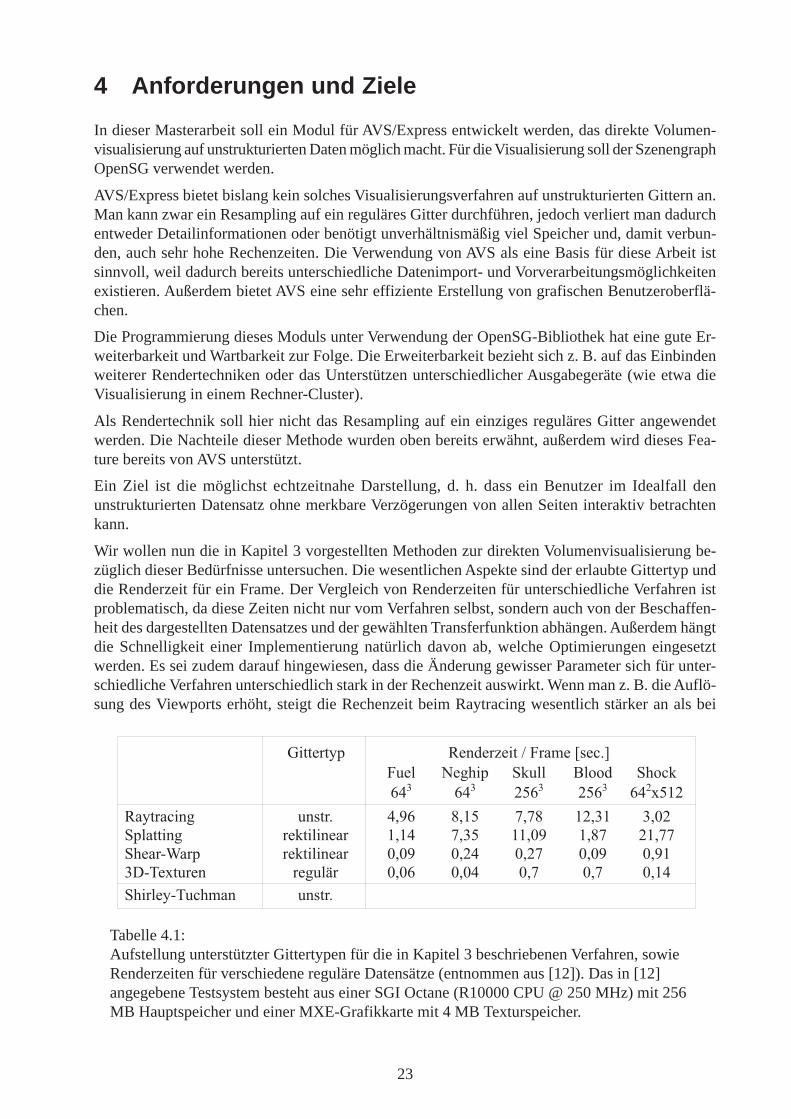
Tabelle 4.1:Aufstellung unterstützter Gittertypen für die in Kapitel 3 beschriebenen Verfahren, sowieRenderzeiten für verschiedene reguläre Datensätze (entnommen aus [12]). Das in [12]angegebene Testsystem besteht aus einer SGI Octane (R10000 CPU @ 250 MHz) mit 256MB Hauptspeicher und einer MXE-Grafikkarte mit 4 MB Texturspeicher.
��������� ��������� ����������������� ������ ����� ���� ������ ! � ! "#�! "#�! � "$#%"
��������� ����� &'� (&%# )&)( %"&!% !&*"�������� ���������� %&% )&!# %%&*' %&() "%&))�����+,��� ���������� *&*' *&" *&") *&*' *&'%!-+.�$���� �����/� *&*� *&* *&) *&) *&% �������+.����� �����

24
einer 3D-Textur-Darstellung. In [12] wird ein Vergleich vier verschiedener Renderverfahren ver-sucht. Die dort für unterschiedliche Datensätze gemessenen Renderzeiten sind in Tabelle 4.1 zu-sammengestellt.
Wie wir der Tabelle entnehmen, sind Raytracing und Splatting in jedem Fall deutlich langsamer alsdas Shear-Warp-Verfahren und die 3D-Textur-Darstellung. Leider ist davon das Raytracing dieeinzige Methode für unstrukturierte Gitter.
Mit der Shirley-Tuchman-Methode wurden unter Verwendung von Vertex-Shadern bereits Render-zeiten erzielt, die für Gittergrößen bis zu 40.000 Tetraedern im Echtzeitbereich liegen [5], wobeiallerdings die Zeit zum Sortieren der Tetraeder nicht berücksichtigt wurde. Einen Teil der Ergeb-nisse aus [5] sehen wir in Tabelle 4.2.
Das direkte Rendern von unstrukturierten Daten (Tetraedern) ist nur per Raytracing oder mit demShirley-Tuchman-Verfahren möglich. Raytracing scheidet wegen seiner Langsamkeit für Echtzeit-anwendungen aus. Daher wurde für diese Arbeit die Entscheidung getroffen, die Shirley-Tuchman-Methode zu benutzen.
Über hierarchisches Resampling auf reguläre Gitter ist auch jedes andere Verfahren aus Kapitel 3auf unstrukturierten Daten verwendbar. Über Verfeinerungen an detaillierteren Gitterbereichen kanngerade dort eine genauere Visualisierung erfolgen. Die Verfeinerungen können zudem adaptiv denMöglichkeiten des eingesetzten Rechners angepasst werden. Diese Technik eignet sich hervorra-gend für Echtzeitanwendungen und wurde daher in dieser Arbeit ebenfalls am Beispiel von hierar-chischen 3D-Texturen implementiert.
Programmiert wurde auf der Windows-Plattform; als Compiler wurde der Intel Compiler 7.1 be-nutzt. Die Entwicklungsumgebung zum Compilieren der OpenSG-Erweiterungen war Cygwin 1.5;für die Entwicklung des AVS-Moduls wurde Microsoft Visual Studio 6.0 eingesetzt; zum Testendiente AVS/Express 6.1 [34].
-������� 0�.������� �12+3����4����5 �12+3���� � *�***�.�������������� %()�!'# *&"* *&* !6$����1��� #%!�!)# *&## *&* !-�����,�� %�**#��)# %&*) *&* !
Tabelle 4.2:GPU-Renderzeiten des mit Vertex-Shadern implementierten Shirley-Tuchman-Verfahrensaus [5] für drei verschiedene Datensätze. Die Zeiten beinhalten nicht die nötigeTetraedersortierung (Daten hierüber gibt das Paper nicht her). Es wird von einemkonstanten Volumenwert innerhalb der Tetraeder ausgegangen.

25
5 Implementierung des Shirley-Tuchman-VerfahrensDas Shirley-Tuchmann-Verfahren ist ein Object-Order-Verfahren. Pro Frame wird jedes Tetraedergenau einmal gezeichnet. In den Abschnitten 5.1 und 5.2 schauen wir uns zunächst an, welcheSchritte pro Frame durchgeführt werden. Implementiert man diese Visualisierungstechnik genauso, wie sie im Paper [4] von Shirley und Tuchman beschrieben wird, so erhält man deutliche Arte-fakte. 5.3 zeigt ein Beispiel solcher Artefakte und beschreibt, wie man sie vermeiden kann. Dawegen der Transparenz die Tetraeder von hinten nach vorne gerendert werden müssen, muss vorjedem Frame eine Sortierung der Tetraeder stattfinden. 5.4 beschäftigt sich mit dieser Thematikund gibt eine sehr einfache und schnelle Art der Sortierung an. Abschnitt 5.5 beschreibt den Gesamt-ablauf für das Rendern eines Frames. 5.6 präsentiert visuelle Ergebnisse und Zeitmessungen, bevor5.7 das Kapitel mit Beschreibungen der entworfenen C++ Klassen abschließt.
Das OpenSG-Paket wurde im Zuge dieser Arbeit um die neue Library UnstructuredVolRenLiberweitert, die nun unter anderem einen OpenSG-Knoten ProjectedTetrahedra zur Benutzung desShirley-Tuchman-Verfahrens anbietet. In den folgenden Abschnitten wird neben den detailliertenVerfahrensbeschreibungen auch auf diese Erweiterung eingegangen.
5.1 KlassifizierungStellen wir uns das zu projizierende Tetraeder als Drahtmodell vor, so besteht die 2D-Projektionauf der Sichtebene je nach Lage dieser Ebene aus einem, zwei, drei oder vier Dreiecken. Da esspäter genau diese Dreiecke sind, die wir zeichnen möchten, ist es sinnvoll zunächst festzuhaltenum welchen Fall es sich handelt. Für die spätere Farbgebung ist aber nicht nur die Anzahl der zuzeichnenden Dreiecke wichtig, sondern auch die Information, welche Seite des Tetraeders der Ka-
"�������������
"������(�������
"������ �������
"������)������
"������*������
"������+�����
Abb. 5.1:Klassifizierung projizierter Tetraeder.

26
mera zu- und welche ihr abgewandt ist. Analog zu Shirley und Tuchman definieren wir hier sechsTetraeder-Klassen über die Anzahl der zur Kamera gerichteten („+“), abgewandten („-“) und or-thogonal zur Blickrichtung orientierten („0“) Seitenflächen (siehe Abb. 5.1).
Da die Normalen der Seitenflächen für die Klassifizierung eine entscheidende Rolle spielen undsomit in jedem Frame benötigt werden, sind sie Member-Variablen der TetraederklasseClassifiedTetrahedron und werden direkt beim Erzeugen eines Tetraeders berechnet.
Der Klassifizierungs-Funktion classify in der Klasse ProjectedTetrahedra wird ein Tetraederund die Kamera-Position übergeben. Während der Klassifizierung wird für jede der vier Seitenflä-chen das Skalarprodukt zwischen der Flächennormale und dem Vektor von einem Flächenpunktzur Kamera berechnet. Je nach Ergebnis (nahe 0, größer als 0, kleiner als 0) liegt die Fläche ortho-gonal zur Blickrichtung, der Kamera zu- oder abgewandt.
In der Klasse ClassifiedTetrahedron gibt es eine 16-bittige Variable classification, die in denBits 0 bis 5 die Anzahl der „+“-, „0“- und „-“-Flächen speichert und in den Bits 6 bis 13 denZustand (+, 0 oder -) für jede Fläche einzeln festhält (siehe Abb. 5.2). So wird viel Information mitgeringem Platzbedarf übersichtlich und schnell abfragbar bereit gehalten.
5.2 Dickpunktbestimmung und FarbzuweisungDa wir die Dreiecke mit Hardwareunterstützung zeichnen möchten, genügt es, die Farben undOpazitäten für die Eckpunkte der Dreiecke zu bestimmen. Die Grafikhardware führt dann einebilineare Interpolation für die Punkte innerhalb des Dreiecks durch.
Für die folgenden Beschreibungen benötigen wir zunächst einige Definitionen. Wir stellen unsStrahlen vor, die ausgehend von der Kameraposition das Tetraeder durchdringen oder berühren.Jeder dieser Strahlen markiert auf der Sichtebene einen Punkt auf der 2D-Projektion des Tetra-eders. Sei der Punkt SR ein solcher Punkt für den Strahl R. Dann definieren wir den Schnitt von Rmit dem Tetraeder als Schnittstrecke DR. Die Länge von DR nennen wir Dicke dR des Strahls R oderauch Dicke von SR. Von allen Strahlen gibt es genau einen Strahl M mit maximaler Dicke. SMbezeichnen wir mit Dickpunkt, DM mit Dickstrecke, dM mit Tetraederdicke (siehe Abb. 5.3).
Wir entnehmen Abb. 5.4, welche Dreiecke man je nach Tetraederklasse sinnvollerweise zeichnet,um eine Tetraederprojektion zu approximieren. Es fällt sofort auf, dass bei jedem Dreieck genau
Abb. 5.2:Codierung der Klassifizierungsdaten in der Variablen classification der KlasseClassifiedTetrahedron. Für die Flächenzustände steht der Bitcode „00“ für eine„-“-Fläche, „01“ für eine „0“-Fläche und „10“ für eine „+“-Fläche.
�� �� �� �� �� �� �� ��
$�,����-�.�/�0����
1�������/�0����$�#
$�,����-.�/�0����1�������/�0����$#�
1�������/�0����$��
�������,�
��������(+
$�,����-�.�/�0����1�������/�0�����#�

27
Abb. 5.3:Definition von Dickpunkt SM, Dickstrecke DM und Tetraederdicke dM.
ein Eckpunkt ein Dickpunkt ist. Die übrigen beiden Eckpunkte sind jeweils Punkte mit einer Dickevon 0.
Farbe und Opazität für Punkte mit einer Dicke von 0 zu ermitteln ist einfach: man wendet lediglichdie Transferfunktion auf den Skalarwert an einem solchen Punkt an und erhält die gewünschteFarbe. Die Opazität wird für diesen Punkt zu 0 gesetzt, da bei einem durch den Punkt fallendenLichtstrahl weder Absorption noch Emission auftreten.
Handelt es sich um einen Dickpunkt, wird zwar die Farbe wieder direkt über die Transferfunktionermittelt, die Opazität ist jedoch ungleich 0 und muss aus Tetraeder-Dicke und optischer Dichteberechnet werden. Die optische Dichte wird abhängig vom Skalarwert am Dickpunkt über dieTransferfunktion definiert (vierte Komponente nach RGB). Um Verwechslungen zu vermeidenbeachte man, dass der durch die Transferfunktion gelieferte Alpha-Wert der optischen Dichte ρ(v)entspricht und sich unterscheidet von der Opazität α des Dickpunktes. Diese Dickpunkt-Opazität
2
�2
�2
�2
"�������%�( "������ "�������)%�* "������+
)��������� *��������� ��������� (��������
Abb. 5.4:Zerlegung der Tetraederprojektionen in Dreiecke. Die Dickpunkte sind durch Kreisemarkiert.
28
wird berechnet nach der Formel
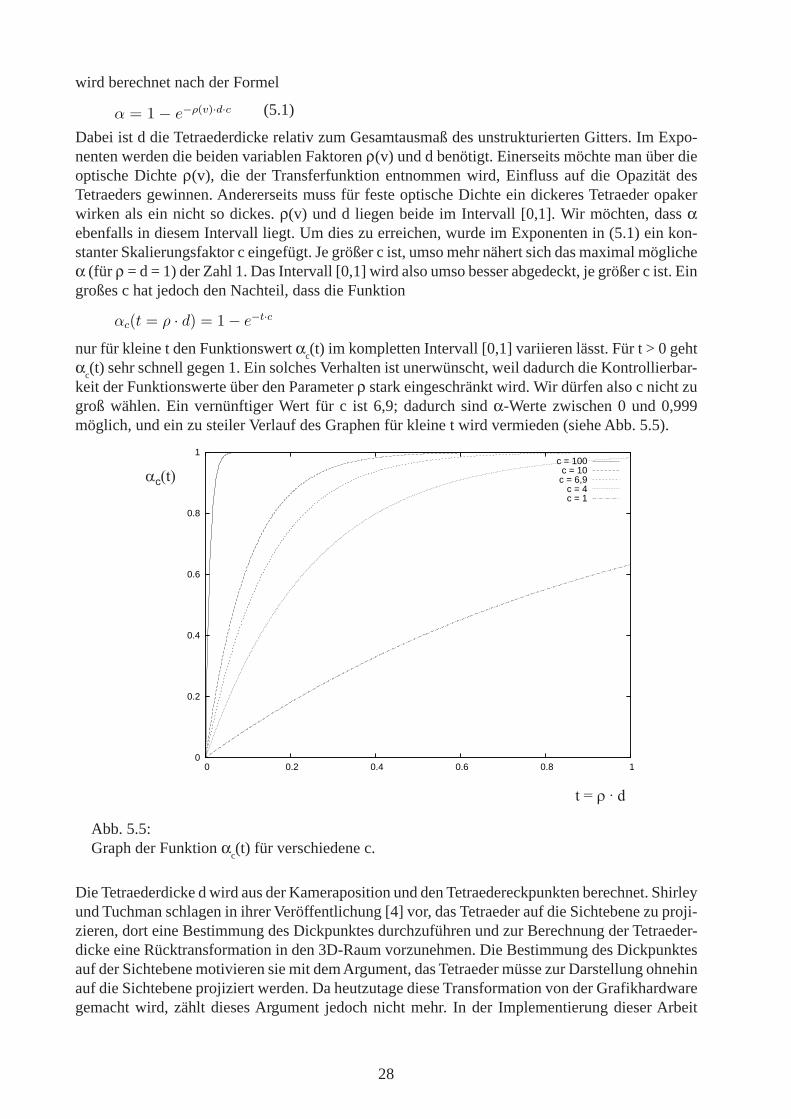
α = 1 − e−ρ(v)·d·c (5.1)
Dabei ist d die Tetraederdicke relativ zum Gesamtausmaß des unstrukturierten Gitters. Im Expo-nenten werden die beiden variablen Faktoren ρ(v) und d benötigt. Einerseits möchte man über dieoptische Dichte ρ(v), die der Transferfunktion entnommen wird, Einfluss auf die Opazität desTetraeders gewinnen. Andererseits muss für feste optische Dichte ein dickeres Tetraeder opakerwirken als ein nicht so dickes. ρ(v) und d liegen beide im Intervall [0,1]. Wir möchten, dass αebenfalls in diesem Intervall liegt. Um dies zu erreichen, wurde im Exponenten in (5.1) ein kon-stanter Skalierungsfaktor c eingefügt. Je größer c ist, umso mehr nähert sich das maximal möglicheα (für ρ = d = 1) der Zahl 1. Das Intervall [0,1] wird also umso besser abgedeckt, je größer c ist. Eingroßes c hat jedoch den Nachteil, dass die Funktion
αc(t = ρ · d) = 1 − e−t·c
nur für kleine t den Funktionswert αc(t) im kompletten Intervall [0,1] variieren lässt. Für t > 0 gehtαc(t) sehr schnell gegen 1. Ein solches Verhalten ist unerwünscht, weil dadurch die Kontrollierbar-keit der Funktionswerte über den Parameter ρ stark eingeschränkt wird. Wir dürfen also c nicht zugroß wählen. Ein vernünftiger Wert für c ist 6,9; dadurch sind α-Werte zwischen 0 und 0,999möglich, und ein zu steiler Verlauf des Graphen für kleine t wird vermieden (siehe Abb. 5.5).
Die Tetraederdicke d wird aus der Kameraposition und den Tetraedereckpunkten berechnet. Shirleyund Tuchman schlagen in ihrer Veröffentlichung [4] vor, das Tetraeder auf die Sichtebene zu proji-zieren, dort eine Bestimmung des Dickpunktes durchzuführen und zur Berechnung der Tetraeder-dicke eine Rücktransformation in den 3D-Raum vorzunehmen. Die Bestimmung des Dickpunktesauf der Sichtebene motivieren sie mit dem Argument, das Tetraeder müsse zur Darstellung ohnehinauf die Sichtebene projiziert werden. Da heutzutage diese Transformation von der Grafikhardwaregemacht wird, zählt dieses Argument jedoch nicht mehr. In der Implementierung dieser Arbeit
��7���8�
��4�5
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
c = 100c = 10
c = 6,9c = 4c = 1
Abb. 5.5:Graph der Funktion αc(t) für verschiedene c.

29
findet deswegen keine softwareseitige 2D-Projektion statt. Die Berechnung des Dickpunktes er-folgt im 3D-Raum über Geraden- und Ebenenschnitte, und für Positionen der einzelnen Dreieckewerden direkt die Koordinaten der Tetraedereckpunkte verwendet.
5.3 Alpha-KorrekturDie in 5.2 beschriebene Farbgebung ist zwar für die Eckpunkte korrekt, aber die bilineare Interpo-lation liefert für die übrigen Dreieckspunkte falsche Opazitäts-Werte. Dies soll anhand Abb. 5.6verdeutlicht werden.
Der Wert α4 auf halber Strecke zwischen α0 und α3 ist bei einer bilinearen Interpolation genau derMittelwert, also
α4,bilinear =1
2− 1
2e−ρ·d·c
Der korrekte Wert für α4 ist jedoch
α4 = 1 − e−ρ· d2·c
α4 und α4, bilinear sind nur für ρ = 0 oder d = 0 identisch, allgemein liefert die bilineare Interpolationhier demnach falsche Ergebnisse. Dies äußert sich in der Darstellung durch Artefakte, wie sie inAbb. 5.7 zu sehen sind.
Dieser Fehler lässt sich durch Texturierung des Dreiecks korrigieren. Die Farben werden weiterhindurch bilineare Interpolation aus den drei Eckpunkten ermittelt, und der Alpha-Wert wird zunächstzu 1 gesetzt. Anschließend modulieren wir eine Luminanz-Alpha-Textur über die bisherige Dreiecks-einfärbung, wobei die Farben unverändert bleiben (Textur-Luminanz = 1) und der Alpha-Wert ausder Textur übernommen wird. So kann für jedes Dreieck ein und dieselbe Textur verwendet wer-den. Mit den Texturkoordinaten ρ und d (optische Dichte und Tetraederdicke) wird in einem Vor-verarbeitungsschritt diese Alpha-Korrektur-Textur analog zu Gleichung (5.1) wie folgt initialisiert:
tex(ρ, d) = 1 − e−ρ·d·c
Der Alpha-Kanal ist in Abb. 5.8 illustriert.
Für das Setzen der Texturkoordinaten für jeden Dreiecks-Eckpunkt benötigt man die optische Dichte(wird wie in Abschnitt 5.2 ermittelt) sowie die Tetraederdicke.
Abb. 5.6:Bilineare Interpolation liefert inkorrekte Opazitätswerte.
�(�3� � �3�
�)�3�(��������
�*

30
Abb. 5.8:Links: Alpha-Kanal der Alpha-Korrektions-Textur. Auf der x-Achse ist die Tetraederdickeaufgetragen, auf der y-Achse die optische Dichte. Rechts: beispielhafte Positionierung eineszu zeichnenden Dreiecks im Textur-Koordinatenraum.
�
�
(
( �
�
(
(
Abb. 5.7:Oben: Artefaktbildung ohne Alphakorrektur; unten: mit Alphakorrektur.

31
5.4 Tetraeder-SortierungIn einer nicht gut durchdachten Implementierung des Shirley-Tuchman-Verfahrens kann die Echtzeit-darstellung schon an einer zu zeitaufwändigen Tetraedersortierung scheitern. Daher ist es beson-ders wichtig, hier so viel Rechenzeit einzusparen wie möglich. Um dies zu erreichen, kann mansehr schnelle Sortieralgorithmen einsetzen, die speziell auf dieses Problem zugeschnitten sind [17][18]. Eine andere Möglichkeit ist, lediglich eine approximative Sortierung vorzunehmen, d. h.potenziell in nicht jedem Fall eine korrekte Sortierung zu erhalten, dafür aber Rechenzeit zu spa-ren. Da sich beim Testen der zuletzt genannten Möglichkeit gute visuelle Ergebnisse zeigten, wirdhier ein einfaches, approximatives Sortierverfahren eingesetzt.
Die gewählte Methode ist eine Kombination aus drei Approximationen. Als erste Approximationwerden lediglich die Tetraederzentren betrachtet anstatt Tetraederverdeckungen zu untersuchen.So werden keine Zusammenhangsinformationen für die einzelnen Tetraeder benötigt. Zum Sortie-ren der Tetraeder nach dem Abstand ihrer Zentren zur Kamera kommt ein Bucketsort-Algorithmuszum Einsatz, der in nur einem Durchlauf durch die Tetraederliste die Tetraeder grob in je einen von100 Abstandsbereichen einsortiert. Diese zweite Approximation ist sinnvoll, da sich viele der Te-traeder mit annähernd gleichem Abstand zur Kamera ohnehin nicht überdecken. Mit diesen beidenApproximationen hat man bereits sehr viel Rechenzeit gegenüber einer exakten Sortierung mitQuicksort eingespart (siehe Abb. 5.9).
Ohne viel Mehraufwand kann die Framerate aber noch weiter gesteigert werden. Wir machen eineVorsortierung der Tetraeder für 13 unterschiedliche Blickrichtungen. Für diesen Vorverarbeitungs-schritt könnte man zwar anstatt des schnellen Bucketsort-Algorithmus auf einen langsameren, ex-akten Algorithmus umsteigen, aber da Bucketsort in hier vorgenommenen Tests sehr gute Resulta-te geliefert hat, wird dieser Algorithmus auch zur Vorsortierung eingesetzt. Eine schnelle Vor-verarbeitung ist für eine Applikation, die das Shirley-Tuchman-Verfahren benutzt, angenehm.
Zur Bestimmung der Sortierungs-Richtungen stellen wir uns eine Einheitskugel um das Zentrumder globalen Boundingbox vor (siehe Abb. 5.10). Die Oberfläche der Einheitskugel istparametrisierbar über Längengrad λ und Breitengrad β, mit 0° <= λ < 360° und -90° <= β <= 90°.Mit den 13 in Abb. 5.8 über Längen- und Breitengrad angegebenen Richtungen wird die gesamteKugel abgedeckt, wenn man berücksichtigt, dass sich durch Spiegelung am Kugelzentrum 13 wei-tere Positionen ergeben. Im Programm entspricht eine Spiegelung am Kugelzentrum dem Rückwärts-ablaufen der sortierten Tetraederliste.
Pro Frame muss nun nur noch eine der vorsortierten Tetraederlisten ausgewählt werden. Dazu wirddie aktuelle Kameraposition auf die Einheitskugel abgebildet, und Längen- und Breitengrad (λp,βp) dieser Projektion werden berechnet. (λp, βp) wird dann durch separate Rundung der beidenKomponenten einer der 26 Vorsortierungs-Richtungen zugewiesen.
Abb. 5.9:Sortierzeit verschiedener Algorithmen für 74884 Tetraeder (AMD Athlon XP CPU @ 1666MHz). PreSort: nur Auswahl der vorsortierten Liste. Init. PreSort: Anwendung von approx.BucketSort für 13 verschiedene Richtungen.
����������������9�������� !!*�����$������������ ! &'1������ *&*�)):����1������ #

32
5.5 AblaufdiagrammAbb. 5.11 zeigt die wesentlichen Vorgänge beim Rendern des OpenSG-KnotensProjectedTetraehedra.
Mit den vorangegangenen Erläuterungen in diesem Kapitel sollten die einzelnen Schritte leicht zuverstehen sein. Die Normalisierung der Tetraederdaten wird vor dem ersten Rendern einmal durch-geführt, um in den folgenden Renderdurchläufen je eine Subtraktion und eine Division pro Anwen-dung der Transferfunktion auf einen Volumenwert zu sparen.
Abb. 5.10:Die 13 Pfeile geben die Richtungen für die Vorsortierung an: 3 · 4 Richtungen für λ = 0°,45°, 90°, 135°; β = 45°, 0°, -45°; sowie eine Richtung für den Nordpol (β = 90°).λ = Längengrad, β = Breitengrad; die dargestellten Kurven auf der Einheitskugel sindGroßkreishälften.
λ = 0°β = 45° λ = 45° λ = 90°
λ = 135°
β = 0°
β = -45°
β = 90°

33
���'�������&��
��,�����$�!���"���������4�����%5�����������$�5�6�������0������'����
���������4��������������1���������������,���"�����
�������������4�������������%�5�������������������������
������������������"�����!����������� ��������������
5�������3�4���������(��������
'�����4����5��5����������5�4�����������!��������75�������!���58�������*�������������9�5�����5���������0�������4��������
������5�,��������
&��,'�������������"������&������%���������:��������/���!��������)����'���4�������������
���������8����4����5��5������������/������������������!��������������!���������������������!����
,�������4��������/��9
��#����*59�;%�<%��%�(4�����������������58��$�!�����������9���3��!�������������%�&�3�������=�4�������������
Abb. 5.11:Ablaufdiagramm für das Rendern des OpenSG-Knotens ProjectedTetrahedra.

34
5.6 ErgebnisseIn diesem Abschnitt werden Resultate bezüglich Darstellungsqualität und Renderzeit präsentiert.Alle Frameratenmessungen wurden auf einem Rechner mit AMD Athlon XP 2000 CPU (1666MHz) und 512 MB RAM durchgeführt; die Grafikkarte ist eine GeForce4 Ti 4600 (128 MB RAM,AGP 4x). Dieses System wird im folgenden als Testsystem 1 referenziert.Die Abbildung 5.12 zeigt zwei Ausgabebilder für den AVS-Datensatz unter Verwendung unter-schiedlicher Transferfunktionen sowie das Drahtmodell der zugrundeliegenden Tetraeder.
Abb. 5.12:AVS-Datensatz (3390 Tetraeder @ 46 FPS auf Testsystem 1), gerendert nach dem Shirley-Tuchman-Verfahren (oben und Mitte), bzw. Tetraeder-Wireframe (unten); unterschiedlicheTransferfunktionen.

35
Abb. 5.13:Bluntfin-Datensatz (2205 Tetraeder @ 40 FPS auf Testsystem 1, Fenstergröße 1600x1153),gerendert nach dem Shirley-Tuchman-Verfahren; verschiedene Auflösungen der Alpha-Korrektur-Textur.Links: Auflösung für optische Dichte konstant 64, Auflösungen für Tetraederdicke von obennach unten: 32, 64, 128, 256, 512.Rechts: Auflösung für Tetraederdicke konstant 512, Auflösungen für optische Dichte vonoben nach unten: 4, 8, 16, 32, 64.
36
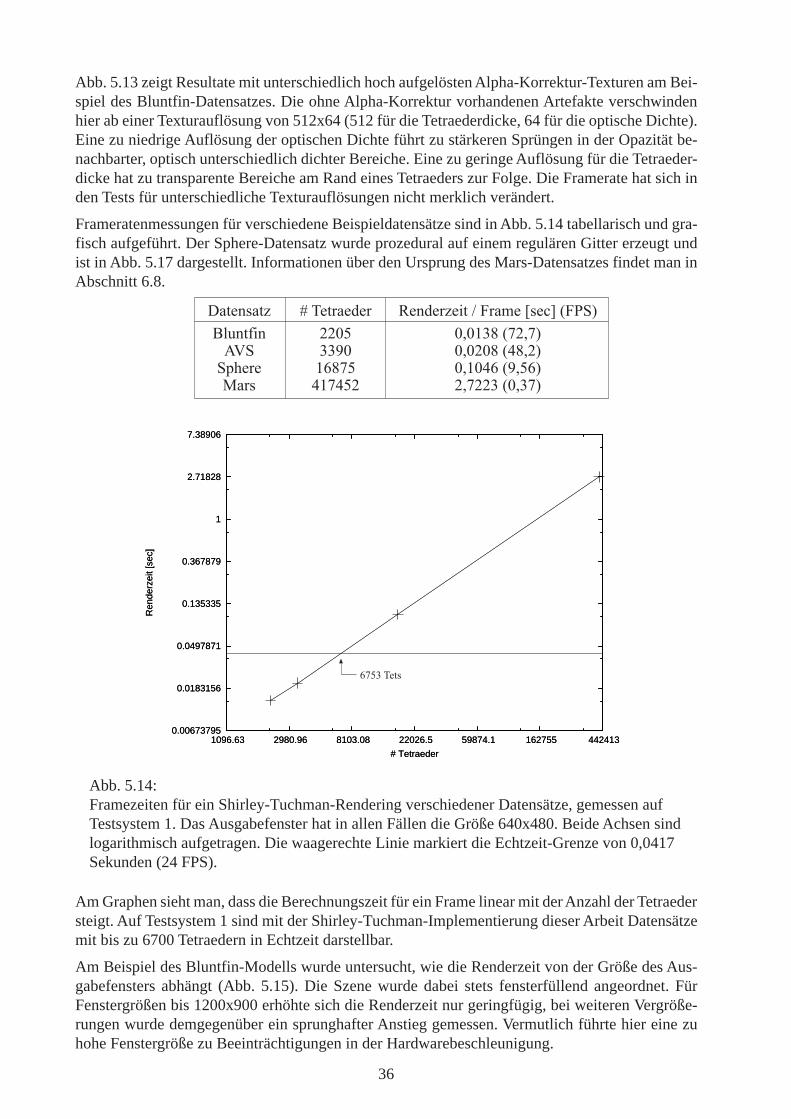
Abb. 5.13 zeigt Resultate mit unterschiedlich hoch aufgelösten Alpha-Korrektur-Texturen am Bei-spiel des Bluntfin-Datensatzes. Die ohne Alpha-Korrektur vorhandenen Artefakte verschwindenhier ab einer Texturauflösung von 512x64 (512 für die Tetraederdicke, 64 für die optische Dichte).Eine zu niedrige Auflösung der optischen Dichte führt zu stärkeren Sprüngen in der Opazität be-nachbarter, optisch unterschiedlich dichter Bereiche. Eine zu geringe Auflösung für die Tetraeder-dicke hat zu transparente Bereiche am Rand eines Tetraeders zur Folge. Die Framerate hat sich inden Tests für unterschiedliche Texturauflösungen nicht merklich verändert.
Frameratenmessungen für verschiedene Beispieldatensätze sind in Abb. 5.14 tabellarisch und gra-fisch aufgeführt. Der Sphere-Datensatz wurde prozedural auf einem regulären Gitter erzeugt undist in Abb. 5.17 dargestellt. Informationen über den Ursprung des Mars-Datensatzes findet man inAbschnitt 6.8.
Am Graphen sieht man, dass die Berechnungszeit für ein Frame linear mit der Anzahl der Tetraedersteigt. Auf Testsystem 1 sind mit der Shirley-Tuchman-Implementierung dieser Arbeit Datensätzemit bis zu 6700 Tetraedern in Echtzeit darstellbar.
Am Beispiel des Bluntfin-Modells wurde untersucht, wie die Renderzeit von der Größe des Aus-gabefensters abhängt (Abb. 5.15). Die Szene wurde dabei stets fensterfüllend angeordnet. FürFenstergrößen bis 1200x900 erhöhte sich die Renderzeit nur geringfügig, bei weiteren Vergröße-rungen wurde demgegenüber ein sprunghafter Anstieg gemessen. Vermutlich führte hier eine zuhohe Fenstergröße zu Beeinträchtigungen in der Hardwarebeschleunigung.
Abb. 5.14:Framezeiten für ein Shirley-Tuchman-Rendering verschiedener Datensätze, gemessen aufTestsystem 1. Das Ausgabefenster hat in allen Fällen die Größe 640x480. Beide Achsen sindlogarithmisch aufgetragen. Die waagerechte Linie markiert die Echtzeit-Grenze von 0,0417Sekunden (24 FPS).
-������� 0�.������� ��������� �������������4�1�5����;� ""*# *&*%!(�4)"&)5<=� !!'* *&*"*(�4 (&"5������ %�()# *&%* ��4'&#�5>��� %) #" "&)""!�4*&!)5
0.00673795
0.0183156
0.0497871
0.135335
0.367879
1
2.71828
7.38906
1096.63 2980.96 8103.08 22026.5 59874.1 162755 442413
Ren
derz
eit [
sec]
# Tetraeder
0.00673795
0.0183156
0.0497871
0.135335
0.367879
1
2.71828
7.38906
1096.63 2980.96 8103.08 22026.5 59874.1 162755 442413
Ren
derz
eit [
sec]
# Tetraeder
�)#!�.���

37
Dieser Effekt würde sich noch extremer bemerkbar machen, wenn der Berechnungsanteil der Grafik-hardware höher wäre. Beim Shirley-Tuchman-Verfahren muss jedoch pro Frame für jedes Tetra-eder vor dem Senden der darzustellenden Dreiecke an die Grafikkarte noch eine Klassifizierung,Dickpunktberechnung und Farbzuweisung durchgeführt werden. Eine Verteilung der Frame-Re-chenzeit zeigt die Tabelle in Abb. 5.16.
Abb. 5.17:Sphere-Datensatz, erzeugt auf einem regulären Gitter der Größe 153, danach zerlegt in16875 Tetraeder.Links: Shirley-Tuchman-Rendering; rechts: Wireframe-Ansicht der Tetraeder.
Abb. 5.15:Framezeiten für den Bluntfin-Datensatz bei unterschiedlichen Fenstergrößen, gemessen aufTestsystem 1.
Abb. 5.16:Prozentuale Verteilung der Framezeit auf Klassifizierung, Dickpunktberechnung undFarbzuweisung sowie Verarbeitung der Dreiecke in der Grafikpipeline.
��������?@� ��������������� ������� �������4�1�5!"*$" * *&*% " )*� *$ (* *&*% " )*(**$�** *&*% �'& %*" $)�( *&*% # �'&*%"**$'** *&*% ( �)&�% *$%*(* *&*%� #'&*%�**$%%#! *&*" ) *&#
A�����;������� -�������B��������������B��C����� ���;���������%�&(�D "&)�D *&#�D

38
5.7 KlassenbeschreibungenVon den in der Bibliothek UnstructuredVolRenLib enthaltenen Klassen werden folgende zumRendern nach dem Shirley-Tuchman-Verfahren benötigt:
• ProjectedTetrahedraBase• ProjectedTetrahedra• Tetrahedron• NormalTetrahedron• ClassifiedTetrahedron• ColorManager• ParametricIntersectionsFür jede dieser Klassen folgt eine kurze Beschreibung, und es werden die wichtigsten Variablenund Methoden sowie ggf. OpenSG-FieldMasks erklärt. Abb. 5.17 gibt einen Überblick über dieKlassenbeziehungen.
5.7.1 ProjectedTetrahedraBaseBeschreibung:
Dies ist die Basisklasse des OpenSG-Knotens zur Darstellung nach dem Shirley-Tuchman-Verfah-ren. Sie ist abgeleitet von MaterialDrawable. Als Datenstruktur zum Speichern der Tetraeder wirdein Multifield (eine Array-Datenstruktur in OpenSG) der Klasse ClassifiedTetrahedron benutzt.In jedem Tetraeder werden zusätzlich zu den essenziellen Informationen (Eckpunkt-Koordinaten,zugeordnete Volumenwerte und Klassifizierungscode) noch die Flächennormalen gespeichert. Für
Abb. 5.17:Klassendiagramm mit den Klassen der Bibliothek UnstructuredVolRenLib, die zurDarstellung nach dem Shirley-Tuchman-Verfahren verwendet werden. Die hier nichtdargestellten Hilfsklassen ColorManager und ParametricIntersections enthaltenlediglich statische Methoden und werden nur innerhalb ProjectedTetrahedra benutzt.
���������4���������
���������4������������� #�����5���4����������( >
4����������
:�����4����������

39
ein Tetraeder werden dadurch 114 Bytes anstatt nur 66 Bytes benötigt. Dieser Mehraufwand imSpeicherverbrauch wird in Kauf genommen, um die Renderzeit pro Frame zu minimieren (dieFlächennormalen werden für die Klassifizierung benötigt). Der zeitliche Gewinn ist nur gering(siehe Abb. 5.18) wenn man betrachtet, dass dafür der Speicherbedarf um knapp 73 % steigt. Aller-dings ist das Shirley-Tuchman-Verfahren in der vorliegenden Implementierung ohnehin nicht ge-eignet, wenn man sehr große Datensätze (> 100.000 Tetraeder) in Echtzeit oder annähernd in Echt-zeit betrachten möchte. Hierfür ist das in Kapitel 6 beschriebene Verfahren besser geeignet. EinDatensatz bestehend aus 100.000 Tetraedern benötigt ohne Normalen-Speicherung 6,29 MB, mitNormalenspeicherung 10,87 MB. Für reale Datensätze 4,58 MB mehr zu belegen ist ein sinnvollesVorgehen, wenn sich dadurch die Darstellungsgeschwindigkeit geringfügig erhöht.
Variablen:
MFClassifiedTetrahedron _mfTetrahedraMultiField, in dem alle Tetraeder gespeichert sind.
std::list<ClassifiedTetrahedron*> sortedTetrahedraListe von Tetraederpointern, sortiert für die Back-to-Front-Anzeige, falls QuickSort oderBucketSort verwendet wird. Wird bei PreSort nicht verwendet.
std::list<ClassifiedTetrahedron*> preSortedLists[4][4]Die 13 vorsortierten Tetraederpointerlisten, aus Konsistenzgründen (Kugelparametrisierung)in einem 4*4-Array abgelegt.
std::list<ClassifiedTetrahedron*>* sortedTetrahedraPZeiger auf die für das aktuelle Frame zu verwendende vorsortierte Tetraederpointerliste.
ImagePtr textureLuminanz-Alpha-Textur, die für jedes Dreieck benutzt wird.
FieldMasks:TetrahedraFieldMask
Hinzufügen eines weiteren Tetraeders(Methode void addTetrahedron(const ClassifiedTetrahedron& value)).
TransferFuncFieldMaskÄndern der Transferfunktion (Methode void setTransferFunc(const Color4ub value[])).
ScalarMinFieldMask, ScalarMaxFieldMaskWerden intern verwendet betreffend Änderungen des aktuellen minimalen und maximalenVolumenwertes.
SortFieldMaskÄndern des Sortieralgorithmus (möglich: PreSort, BucketSort, QuickSort).
Abb. 5.18:Renderzeit pro Frame für den Sphere-Datensatz (16875 Tetraeder), gemessen aufTestsystem 1. Durch das Speichern der Flächennormalen erhöht sich die Framerate zwar nurgeringfügig, aber merkbar.
A�����;���������%*+������ ��������������;E��%�������������������B������� "& (* %"%�4(&!��1�5������������������� %&((" %*(�4'&!��1�5

40
TetValuesNormalizedFieldMaskWird intern verwendet zur Feststellung, ob die Volumenwerte bereits normalisiert sind odernicht.
RecomputeTextureFieldMaskWird intern verwendet zur Feststellung, ob die Alpha-Korrektur-Textur neu berechnet wer-den muss.
WireframeFieldMaskWireframe-Darstellung an- / ausschalten.
ThicknessResolutionFieldMaskÄnderung der Auflösung der Alpha-Korrektur-Textur bezüglich der Tetraederdicke.
ExtinctionResolutionFieldMaskÄnderung der Auflösung der Alpha-Korrektur-Textur bezüglich der optischen Dichte.
TetrahedraCompleteFieldMaskDie Variable _sfTetrahedraComplete muss vom Benutzer gesetzt werden, nachdem dasletzte Tetraeder zum OpenSG-Knoten hinzugefügt wurde und bevor die erste Darstellungerfolgt.Hierdurch soll dem Benutzer bewusst gemacht werden, dass er nach dem ersten Zeichnenkeine weiteren Tetraeder mehr hinzufügen kann. Grund für diese Einschränkung: vor derersten Anzeige findet die Normalisierung der Volumenwerte statt (siehe auch 5.5). Würdenun ein weiteres Tetraeder eingefügt werden, könnten seine Volumenwerte außerhalb desbisherigen Min-/Max-Bereiches liegen. Man müsste dann entweder die Normalisierungender zuvor hinzugefügten Tetraeder rückgängig machen (großer Rechenaufwand) oder dieWerte des neuen Tetraeders beschneiden (Clamping, würde hier zu falschen normalisiertenWerten und daher einer falschen Darstellung führen).
5.7.2 ProjectedTetrahedraBeschreibung:
OpenSG-Knoten zur Darstellung nach dem Shirley-Tuchman-Verfahren, abgeleitet vonProjectedTetrahedraBase. Es gibt zwei innere Klassen: PntQuantity und PntQuantityP. Diessind Templates, die eine Punkt-Klasse (z. B. Pnt3f) und einen skalaren Wert (z. B. Real32) zureinfacheren Übergabe an Methoden zusammenfassen. PntQuantityP speichert im Gegensatz zuPntQuantity nicht einen Punkt selbst, sondern nur einen Pointer auf einen Punkt.
Methoden:
Action::ResultE ProjectedTetrahedra::drawPrimitives(DrawActionBase* action)Einsprungspunkt bei der Szenengraphtraversierung.
bool refineTetrahedra()Kann benutzt werden, um Tetraeder automatisch weiter zu unterteilen, wenn die Skalarwertein ihren Eckpunkten zu unterschiedlich von einander sind. Zur Zeit wird dieses Feature nichtverwendet, da durch Tetraederunterteilungen die Anzahl der Tetraeder steigt, was wiederumlängere Framezeiten bedeutet.
void classifyTetrahedronPersp(const Pnt3f& camPos, ClassifiedTetrahedron& tet)Einordnung des Tetraeders tet in eine der sechs Klassen. Zusatz „Persp“, weil hier mitperspektivischer Projektion gearbeitet wird. Bei orthogonaler Projektion würde ein

41
Tetraeder potentiell in eine andere Klasse eingeteilt werden als bei perspektivischerProjektion.
void processTetrahedron( const Pnt3f& camPos, ClassifiedTetrahedron& tet,UInt32& vertexCount, UInt32& triCount)
Berechnet für ein klassifiziertes Tetraeder die Tetraederdicke, ordnet den Eckpunkten sowiedem Dickpunkt (siehe computeColorAtThickestPoint()) Farbwerte zu, erstellt eine Punkteliste zum Zeichnen eines Triangle-Fans und zeichnet diesen Triangle-Fan (Aufruf der Me-thode drawTriangleFan()).
void computeColorAtThickestPoint( Real32 nearPointValue, Real32 farPointValue,Real32 dist, Color4f& color)
Berechnet die Farbe und optische Dichte des Tetraeder-Dickpunktes. Die optische Dichtewird im Alpha-Kanal von color abgelegt.
void drawTriangleFan(const std::list<std::pair< Pnt3fQuantityP*, Color4f*> >& triangle,Real32 tetNormThickness, UInt32& vertexCount, UInt32& triCount)
Zeichnet eine Punkteliste (hier aus Effizienzgründen kombiniert mit Volumenwert und Far-be) als Triangle-Fan. Die optische Dichte (erster Parameter für die Alpha-Korrektur-Textur)ist im Alpha-Kanal von Color4f abgelegt, die normalisierte Tetraederdicke (zweiter Parame-ter für die Alpha-Korrektur-Textur) wird der Methode als tetNormThickness übergeben.
5.7.3 TetrahedronBeschreibung:
Tetraeder-Klasse zur Speicherung der vier Eckpunkte und der zugeordneten Volumenwerte. Benö-tigt werden hier 64 Byte pro Tetraeder.
Variablen:
Pnt3f a, b, c, dDies sind die vier Eckpunkte des Tetraeders.
Real32 valueA, valueB, valueC, valueDVolumenwerte für die Eckpunkte.
5.7.4 NormalTetrahedronBeschreibung:Abgeleitet von Tetrahedron, erweitert um die Speicherung der 4 Flächennormalen. Ein Tetraederbelegt hier 112 Bytes (Eckpunkte und Volumenwerte 64 Bytes, Normalen 48 Bytes).
Variablen:
Vec3f n_bcd, n_acd, n_abd, n_abcDie Variablen für die vier Normalen sind jeweils nach den Definitionspunkten des zugehöri-gen Tetraederoberflächendreiecks benannt.

42
5.7.5 ClassifiedTetrahedronBeschreibung:Abgeleitet von NormalTetrahedron, erweitert um die Speicherung eines Klassifikations-Codes.Ein Tetraeder belegt hier 114 Bytes (Eckpunkte und Volumenwerte 64 Bytes, Normalen 48 Bytes,Klassifikationscode 2 Bytes).
Variablen:
UInt16 classificationCodierte Speicherung der Ausrichtung der vier Tetraederflächen zur Kamera, zur Codierungsiehe Abb. 5.2 in Abschnitt 5.1.
5.7.6 ColorManagerBeschreibung:Enthält statische Funktionen zur Zuordnung von Farben und Opazitäten zu Volumenwerten übereine Transferfunktionstabelle.
Methoden:
static void getInterpolatedValueByTransferFuncColor4f(const Color4ub* transferFunc,Real32 normValue,Color4f& tmpColor4f)
Dem Volumenwert normValue wird mittels der Tabelle transferFunc eine Farbe und ein Al-pha-Wert tmpColor4f zugewiesen.
5.7.7 ParametricIntersectionsBeschreibung:Diese Klasse bietet statische Methoden zur Berechnung des Schnitts zwischen einer Gerade undeiner Ebene. Die Schnitte werden über das Lösen linearer Gleichungssysteme von drei Variablenmittels Determinantenberechnung gefunden. Die Implementierung dieser Methoden war nötig, weildie hierfür vorgesehenen Funktionen aus der OpenSG-Bibliothek zwar den Schnittpunkt, nichtaber die Position des Schnittpunktes auf der Geraden bzw. der Ebene ausgeben. Diese Schnitt-punkt-Lage (in parametrischer Form) wird zur Interpolation der Volumenwerte an den Eckpunktenauf den Nah- bzw. Fernpunkt benötigt.
Methoden:
static void intersectStraightLineWithPlane( const Pnt3f& l1, const Pnt3f& l2,const Pnt3f& p1, const Pnt3f& p2, const Pnt3f& p3,Pnt3f& x,Real32& lambda, Real32& u, Real32& v)
Berechnet den Schnittpunkt x zwischen der Gerade (l1, l2) und der Ebene (p1, p2, p3). Es giltx = l1 + lambda · (l2 - l1)
sowiex = p1 + u · (p2 - p1) + v · (p3 - p1).

43
static void intersectStraightLineWithPlane( const Pnt3f& l1, const Pnt3f& l2,const Pnt3f& p1, const Pnt3f& p2, const Pnt3f& p3,Pnt3f& x,Real32& u, Real32& v)
Berechnet x, u und v wie die erste Methode, jedoch ohne Berechnung von lambda.
static void intersectStraightLineWithPlane( const Pnt3f& l1, const Pnt3f& l2,const Pnt3f& p1, const Pnt3f& p2, const Pnt3f& p3,Pnt3f& x,Real32& lambda)
Berechnet x und lambda wie die erste Methode, jedoch ohne Berechnung von u und v.
static Real32 det3(const Vec3f& a, const Vec3f& b, const Vec3f& c)Berechnet die Determinante der drei dreidimensionalen Spaltenvektoren a, b, c.
static Real32 det2(const Vec2f& v1, const Vec2f& v2)Berechnet die Determinante der beiden zweidimensionalen Spaltenvektoren v1, v2.

44
6 Implementierung des hierarchischen 3D-Textur-Verfahrens
Um das Verfahren der 3D-Texturen hierarchisch anwenden zu können, benötigen wir eine hierar-chische Datenstruktur. In dieser Implementierung wird ein Octree verwendet. Der Octree wird anfeineren Stellen im unstrukturierten Gitter tiefer unterteilt, um dort einen höheren Detailgrad beimResampling zu erreichen. Da Gitter-Verfeinerungen so bereits durch Verfeinerungen des Octreesabgedeckt sind, muss die Auflösung der regulären Zielgitter selbst nicht mehr geändert werden undwird deswegen konstant gehalten. Die Darstellung der hierarchischen 3D-Texturen ist in Echtzeitmöglich, für Verfeinerungen und Vergröberungen am Octree gilt dies aber nicht (siehe Abschnitt6.2).
Aufbau und Implementierung des Octrees werden in Abschnitt 6.1 beschrieben. 6.2 behandelt da-nach das Verfeinern und Vergröbern. Während diesen Vorgängen finden Schnitttests zwischen Te-traedern und Quadern und außerdem 3D-Rasterisierungen statt, die in den Abschnitten 6.3 bzw. 6.4erläutert werden. 6.5 beschäftigt sich mit der Alpha-Korrektur auf den verfeinerten Regionen imOctree, bevor in 6.6 auf die eigentliche Anzeige der im Octree gespeicherten Daten eingegangenwird. Die bei der Visualisierung auftretenden Artefakte werden in Abschnitt 6.7 angegeben. Schließ-lich folgen noch visuelle Ergebnisse sowie Zeitmessungen in Abschnitt 6.8 und eine Beschreibungder C++ Klassen in 6.9.
6.1 Aufbau und Implementierung des OctreesZum Octree gehören zwei Klassen, nämlich OctreeTG und OctreeTGNode (der Zusatz „TG“bedeutet „Tetrahedra“ und „Grid“, abgeleitet von den beiden Datenstrukturen, die in dem Octreegespeichert werden). Für den Benutzer dieser Datenstruktur ist jedoch nur OctreeTG sichtbar.
OctreeTG fungiert als globaler Manager. Von dieser Klasse existiert nur eine einzige Instanz, diefür die Verwaltung aller Informationen zuständig ist, die nicht spezifisch für einen Octree-Knotensind. So speichert eine Instanz der Klasse OctreeTG (im folgenden auch „Octree-Manager“ ge-nannt) die zum unstrukturierten Gitter gehörenden Tetraeder, die Transferfunktion in Form einerLookup-Tabelle, sowie globale Visualisierungs-Parameter (Anzahl Slices, Auflösung der regulä-ren Gitter) und Anweisungen für das Verfeinerungsorakel. Der Octree-Manager hat über einenPointer außerdem Zugriff auf den Wurzelknoten des Octrees, der wie alle anderen Octree-Knotenauch eine Instanz der Klasse OctreeTGNode ist.
Jeder Octree-Knoten OctreeTGNode hat natürlich Pointer auf seinen übergeordneten (Parent)und seine untergeordneten (Children) Knoten, hat aber auch Zugriff auf den Octree-Manager, umoben genannte globale Daten abfragen zu können. Desweiteren speichert ein Octree-Knoten auchseine räumliche Ausdehnung. Diese wird für die Zuordnung von Tetraedern zu Octree-Knotenwährend der Octree-Verfeinerung benötigt. Wegen der Quaderform der Knoten genügt hier dieAngabe von zwei Punkten im 3D-Raum. Die eigentlichen „Nutzdaten“, die ein Octree-Knotenhält, bestehen aus Tetraederindizes, dem regulären Gitter und den anzuzeigenden texturierten Slices.Tetraederindizes werden anstatt Tetraederpointern verwendet, weil gespeicherte Pointer auf einemanderen Rechner in einem Cluster keine Gültigkeit mehr hätten. Die Verwendung von Indizes lässtalso die Möglichkeit bestehen, den OpenSG-Knoten HierarchicalTextures3D in einem OpenSG-Cluster zu verwenden. Mittels eines Tetraederindex kann über den Octree-Manager auf das spezi-fizierte Tetraeder zugegriffen werden. Zur Speicherung der Tetraeder wird die BasisklasseTetrahedron verwendet; ein Speichern der Normalen (sie werden für den Schnitttest in Abschnitt6.3 benötigt) bewirkte in durchgeführten Tests nur sehr geringfügige Geschwindigkeitsvorteile.

45
Für die Speicherung des regulären Gitters reicht ein Array von Typ Real32, zusammen mit denbereits im Octree-Manager vorliegenden Angaben zur Gitter-Auflösung. Die Berechnung, Spei-cherung und Anzeige der texturierten Slices übernimmt die Klasse PositionedSlices, von derOctreeTGNode eine Instanz hält.
Abb. 6.1 veranschaulicht grob die Verbindungen in der verwendeten Octree-Datenstruktur. Umeinen besseren Überblick über die Member der Klassen zu erhalten, sei auf Abschnitt 6.8 verwie-sen.
Da dieser OpenSG-Knoten clusterfähig sein soll, können zur Verlinkung innerhalb der Octree-Datenstruktur keine bloßen C-Pointer verwendet werden. Stattdessen mussten OctreeTG undOctreeTGNode von der Basisklasse FieldContainer abgeleitet werden (direkt abgeleitet sind diebeiden Klassen jedoch von AttachmentContainer).
6.2 Octree-Verfeinerung und -VergröberungEine größere Detaillierung des Zielgitters wird durch Octree-Verfeinerung erreicht. Verfeinerun-gen bzw. Vergröberungen geschehen schrittweise, d. h. pro Schritt wird maximal ein Knoten ver-feinert oder vergröbert. Ein Schritt entspricht einem Funktionsaufruf renderStep() in der KlasseHierarchicalTextures3D. Wieviele Schritte pro Zeiteinheit durchgeführt werden, definiert einBenutzer selbst. Wie in der Einleitung zu Kapitel 6 bereits angedeutet, geschieht die Verfeinerungoder Vergröberung eines Octree-Knotens in der Implementierung dieser Arbeit nicht in Echtzeit.Wie in 6.2.2 beschrieben wird, muss bei einer Verfeinerung für jedes Tetraeder geprüft werden, mitwelchen Octree-Knoten eine Überschneidung stattfindet. Danach erfolgt die 3D-Rasterisierungmit anschließender Anwendung der Transferfunktion, d. h. es gibt zwei Operationen, für die Spei-cher reserviert werden muss. Die Rechenzeit für die 3D-Rasterisierung hängt von der Anzahl derTetraeder und der Auflösung des Zielgitters ab, während die Anwendung der Transferfunktion nurvon der Zielgitterauflösung abhängt. Unabhängig von der Implementierung der 3D-Rasterisierungund der Transferfunktionsanwendung gibt es daher immer eine Tetraederanzahl oder Gitterauf-lösung, für die eine Verfeinerung nicht in Echtzeit berechenbar ist. Man könnte hier Vorberechnungeneinsetzen und über Out-of-Core-Methoden das Umschalten zu einem verfeinerten Octree in Echt-zeit ermöglichen [7]. Diese Vorberechnungen könnten schon vor dem ersten Anzeigen des Octreesdurchgeführt werden, was aber sehr speicheraufwändig wäre. Alternativ kann man diese Berech-nungen in einem parallel zur Anzeige laufenden Thread machen, so dass nicht alle 3D-Texturen im
Abb. 6.1:Verlinkungen innerhalb der Octree-Datenstruktur.
?�����4< ?�����4<:���
!�����
����
������2������
��������
(
@(
(

46
vorhinein berechnet werden müssen. Ein weiterer Thread in diesem OpenSG-Knoten würde je-doch zu Synchronisationsschwierigkeiten beim Clustering führen. Typischerweise werden Ände-rungen am Szenengraph in der OpenSG-Client-Applikation (die auf dem Server läuft) durchge-führt und auf die OpenSG-Server übertragen. Durch den Einsatz eines weiteren Threads im OpenSG-Knoten würde jeder Server seinen Szenengraph zusätzlich selbst ändern, was ohne weitereSynchronisationsmechanismen Kollisionen zur Folge hätte. Um die Synchronisation möglichsteinfach zu halten und so viel Speicher wie möglich zu sparen, werden in dieser Implementierungkeine Vorberechnungen verwendet, jedenfalls nicht auf dieser OpenSG-Knoten-Ebene. Stattdes-sen wird empfohlen, für die eigene Applikation, die diesen OpenSG-Knoten verwendet, zwei Threadszu verwenden. Einer ist für die Anzeige und die Ausführung eventueller Callback-Funktionen zu-ständig, der andere hingegen ruft stets und parallel dazu die Methode renderStep() auf dem Kno-ten auf, wodurch die nächste Verfeinerung bzw. Vergröberung erfolgt. Durch diese Technik machtes Sinn, bei der Verfeinerung eines Knotens seine 3D-Textur zu löschen, anstatt sie für eine spätereWiederverwendung im Speicher zu halten. Bei einer späteren Vergröberung muss dann zwar erneuteine 3D-Textur erstellt werden, dies erledigt dann aber ein separater Thread. So wird die Echtzeit-anzeige kaum gestört. Bei diesem Ansatz werden also immer genau die Blätter des Octrees ange-zeigt, anstatt eine Front aus inneren Knoten und Blattknoten zu benutzen.
Um automatisch entscheiden zu können, welcher Octree-Knoten sinnvollerweise als nächster ver-feinert / vergröbert wird, wurde ein Orakel in den Octree-Manager integriert. Dieses wählt anhandvon verschiedenen Kriterien den nächsten Octree-Knoten aus (siehe Abschnitt 6.2.1), der verfei-nert bzw. vergröbert werden soll. Was genau bei einer Verfeinerung geschieht, steht in 6.2.2;Vergröberungen werden in 6.2.3 behandelt.
6.2.1 OrakelIm Octree-Manager kann der Benutzer über das Setzen von Constraints die Entscheidungen desOrakels beeinflussen. Diese Constraints beziehen sich auf:
• Octree-Tiefe,
• freien Arbeitsspeicher,
• Framerate und
• Tetraederanzahl pro Octree-Knoten.
Falls eine Verfeinerung stattfindet, wird dafür der Knoten ausgewählt, der die meisten Tetraederbeinhaltet. Die Anwesenheit vieler Tetraeder in einer bestimmten Region des Gitters deutet daraufhin, dass dort die Tetraeder kleiner sind als in anderen Gitterregionen. Kleinere Tetraeder wieder-um sind verknüpft mit einer größeren Detailliertheit. Es macht also Sinn, gerade dort den Octree zuverfeinern, da ein feinerer Octree ebenfalls mit einer höheren Auflösung verbunden ist. Zum Auf-finden von Octree-Knoten, die viele kleine Tetraeder beinhalten, kann man auch andere heuristi-sche Methoden anwenden, z. B. könnte man die kleinste in einem Octree-Knoten vorkommendeTetraederkantenlänge vergleichen mit der räumlichen Ausdehnung des Knotens und den Knotenweiter verfeinern, wenn die Kantenlänge um mehr als einen bestimmten Faktor kleiner ist als derKnoten selbst. Dieses Verfahren ist jedoch nicht sehr robust gegen Tetraeder-Datensätze, in denenentartete Tetraeder mit sehr kleinen Kantenlängen vorkommen. Man kann sich ein Beispiel vor-stellen, bei dem ein Tetraeder mit fünf sehr langen Kanten und einer sehr kurzen Kante den zuverfeinernden Knoten angibt, obwohl in anderen Regionen viel mehr Tetraeder liegen. Hier ist eineKnotenauswahl aufgrund der Tetraederanzahl pro Knoten sinnvoller. Auch ist sie mit viel wenigerRechenaufwand verbunden, da die Tetraederanzahl pro Knoten bereits der Länge der Tetraeder-indexliste dieses Knotens entspricht. Der benötigte Wert kann daher einfach abgelesen werden.Abb. 6.2 zeigt ein Beispiel für die Auswahl des nächsten zu verfeinernden Knotens. Derjenige mit

47
der 20 darin würde als nächstes verfeinert werden, da in keinem anderen Blatt-Knoten mehr als 20Tetraeder enthalten sind.
Analog wird für eine Vergröberung der Knoten gewählt, der die wenigsten Tetraeder beinhaltet(siehe Abb. 6.3) und vergröberbar ist, d. h. die Kinder dieses Knotens müssen Blätter sein.
Die Frage ist nun, ob einerseits der Octree im nächsten Schritt verfeinert oder vergröbert wird, undan welchem Knoten eine solche Operation stattfinden soll. Das oberste Ziel bei diesen Auswahl-möglichkeiten ist, die gesetzten Constraints einzuhalten. D. h. die Tiefe des Octrees darf nichttiefer werden als vom Benutzer verlangt, es muss eine Mindestmenge an Arbeitsspeicher frei sein,die Framerate darf das gesetzte Minimum nicht unterschreiten und ein Knoten darf nur dann ver-feinert werden, wenn er eine Mindestmenge an Tetraedern enthält. Das Orakel überprüft zunächst,ob momentan die Kriterien bezüglich des freien Arbeitsspeichers (Festplattenauslagerungsdateienwerden nicht als Arbeitsspeicher angesehen) oder der Framerate verletzt sind. Falls dies der Fallist, erfolgt ein Vergröberungsschritt.
( +
A @ +* ( *( (*
( ) ( * ) BB ) *( )(
Abb. 6.3:Schema eines Octrees. Die Zahlen geben die Anzahl der in den Knoten liegenden oder dieKnoten schneidenden Tetraeder an. Der markierte Knoten mit 54 Tetraedern wäre derjenige,der für eine Vergröberung als nächstes ausgewählt werden würde. Auch hier ist die Wahlstets deterministisch.
( +
A @ ( *( (*
( ) ( * ) BB ) *( )(
+*
Abb. 6.2:Schema eines Octrees. Die Zahlen geben die Anzahl der in den Knoten liegenden oder dieKnoten schneidenden Tetraeder an. Der markierte Knoten mit 20 Tetraedern wäre derjenige,der für eine Verfeinerung als nächstes ausgewählt werden würde. Bei gleicherTetraederanzahl mehrerer Knoten wird deterministisch einer dieser Knoten gewählt.

48
Falls aufgrund der Constraints keine Vergröberung stattfindet, ist das Ziel, den Octree stets weiterzu verfeinern, da dann die 3D-Textur-Darstellung an Qualität gewinnt. Bei einer Verfeinerung darfdie maximale Octree-Tiefe nicht überschritten werden, und eine minimale Anzahl Tetraeder mussin dem zu verfeinernden Knoten vorhanden sein. Das letzte Kriterium dient dazu, das Zielgitternicht unnötig fein auszulegen. Um ein Oszillieren eines Knotens (d. h. ständiger Wechsel zwischenVergröberung und Verfeinerung) zu vermeiden, werden für Framerate und freien Arbeitsspeicher jezwei Werte festgelegt. Unterschreitet die Framerate den unteren Wert, wird vergröbert. Verfeinertwerden darf nur, falls der obere Wert momentan nicht unterschritten ist. Analog gilt dies für denfreien Arbeitsspeicher. Der Benutzer muss diese oberen und unteren Werte sinnvoll wählen.
Jedes der vier Constraints kann über entsprechende Schalter auf Wunsch deaktiviert werden. Mög-lich ist auch ein globales Deaktivieren von Verfeinerungen und / oder Vergröberungen. Darüberhinaus wurde die Möglichkeit eingebaut, unter Nichtbeachtung sämtlicher vorher genannter Ein-stellungen den Octree um einen Schritt zu verfeinern oder auch zu vergröbern.
Um nicht für jeden Schritt den kompletten Octree auf der Suche nach zu verfeinernden bzw. zuvergröbernden Knoten durchlaufen zu müssen, gibt es zwei Listen, die Pointer auf die sogenanntenverfeinerbaren Knoten (refinable nodes) bzw. vergröberbaren Knoten (unrefinable nodes) spei-chern. Die verfeinerbaren Knoten sind genau die Blätter des Octrees. Die vergröberbaren sind dieKnoten, deren acht Kinder Octree-Blätter sind. Die beiden Knoten-Listen werden während Verfei-nerungen und Vergröberungen entsprechend aktualisiert.
6.2.2 Octree-VerfeinerungZur Verfeinerung (refine) eines Octree-Knotens wird zunächst seine zugehörige 3D-Textur ge-löscht, um nicht benötigten Speicher freizugeben. Anschließend müssen seine acht Kind-Knotenerzeugt und jedem dieser Kinder die enthaltenen Tetraeder zugeordnet werden (die für die Zuord-nung benötigten Schnitttests werden in 6.3 beschrieben). Danach erfolgt das Resampling derVolumendaten auf ein reguläres Gitter (siehe 6.4); diese Daten werden als Float-Array gespeichert.
Nun wird jeder dieser im regulären Gitter gespeicherten Volumenwerte mit Hilfe der Transfer-funktion in einen RGBA-Farbwert umgewandelt. Das Ergebnis ist ein Array aus RGBA-Farben.Dieses Farb-Array wird der PositionedSlices-Instanz des Octree-Knotens übergeben und dort als3D-Textur für die Anzeige verwendet.
Man sollte darauf achten, dass das reguläre Gitter entlang jeder der drei Definitionsachsen eineAuflösung hat, die einer Zweierpotenz entspricht. Ist dies nicht der Fall, wird nämlich nach demResampling noch eine Skalierung auf Zweierpotenzgröße durchgeführt, die zusätzliche Rechen-zeit kostet.
6.2.3 Octree-VergröberungBei der Vergröberung (unrefine) eines Octree-Knotens werden alle Kind-Knoten mit sämtlichenAttributen gelöscht. Anschließend wird über ein Resampling und über Anwendung der Transfer-funktion wie in 6.2.2 eine 3D-Textur erzeugt.
6.3 Separating Axis Theorem für Quader / TetraederUm bei einer Verfeinerung eines Octree-Knotens festzustellen, welche Tetraeder welchem Kindzugeordnet werden müssen, benötigen wir einen Schnitttest zwischen Quader (Octree-Knoten)und Tetraeder. Dieser Test sollte so schnell wie möglich sein, da er bei jeder Knotenverfeinerungfür jedes einzelne Tetraeder angewendet wird.
Der heutzutage schnellste Schnitttest für zwei beliebig zueinander orientierte Quader basiert auf

49
dem Finden von separierenden Achsen (Separating Axis Theorem, [25]). Zunächst wird definiert,was eine Separationsachse für zwei Quader A und B ist (siehe Abb. 6.4). Ihre Zentren sind durchdie Linie T verbunden. L ist ein beliebiger Vektor. a ist ein Vektor, der vom Quaderzentrum AZ aufeinen Eckpunkt von A zeigt, oder in die umgekehrte Richtung, so dass die Projektion aL von a aufL maximal wird. b ist analog definiert. Falls nun aL + bL kleiner ist als die Projektion TL von T aufL, so ist L eine Separationsachse. Dies ist gleichbedeutend damit, dass eine Ebene orthogonal zu Lexistiert, so dass A vollständig in einem Halbraum und B im anderen Halbraum liegt. Offensicht-lich schneiden sich A und B nicht, wenn es eine Separationsachse zwischen ihnen gibt.
Sobald mindestens eine Separationsachse gefunden wurde, steht fest, dass sich A und B nicht schnei-den. Das Theorem besagt nun, dass man maximal 15 potentielle Separationsachsen untersuchenmuss. Ist keine dieser 15 Achsen eine Separationsachse, so schneiden sich die beiden Quader. Die15 zu testenden Achsen setzen sich zusammen aus den 2 · 3 = 6 Face-Normalen der beiden Quaderund 3 · 3 = 9 Kreuzprodukten aus den Kantenrichtungen der Quader.
In [7] wird vorgeschlagen, diesen Schnitttest etwas abzuwandeln und auf die Kombination ausQuader und Tetraeder anzuwenden. Dieser Ansatz wird auch hier verfolgt. An den Definitionen derin Abb. 6.4 dargestellten Größen ändert sich dadurch nichts, wie wir in Abb. 6.5 sehen.
$
�
4�
�
�C
C
�C$1
�1
Abb. 6.4:Zur Definition einer Separationsachse L für den Schnitt zweier Quader.
$1
$
�
4�
�
�C
C
�C
�1
Abb. 6.5:Zur Definition einer Separationsachse L für den Schnitt zwischen Quader und Tetraeder.

50
Nun muss jedoch nicht auf nur 15, sondern sogar 25 potentielle Separationsachsen geprüft werden:3 + 4 = 7 Face-Normalen und 6 · 3 = 18 Kreuzprodukte von Kantenrichtungen (3 Kanten beimQuader, 6 beim Tetraeder).
6.4 Resampling auf ein reguläres GitterZum Resampling der in einem Octree-Knoten enthaltenen Tetraeder auf das reguläre Gitter jenesKnotens gibt es grundsätzlich zwei mögliche Vorgehensweisen: den in 6.4.1 beschriebenen intuiti-ven Algorithmus oder die 3D-Rasterisierung (6.4.2).
6.4.1 Intuitiver AlgorithmusBeim intuitiven Algorithmus traversiert man die regulären Gitterzellen und sucht für jedes Zellen-zentrum ein Tetraeder, welches dieses Zentrum umhüllt. Dann ermittelt man die baryzentrischenKoordinaten des Zentrums bezüglich der Tetraedereckpunkte. Die baryzentrischen Koordinatenlassen sich direkt zur linearen Interpolation der Eckpunkt-Volumendaten auf den Zentrumspunktverwenden. Ohne Tetraeder-Zusammenhangsinformationen ist es nicht leicht, die Suche einesumhüllenden Tetraeders für ein Zellenzentrum effizient zu implementieren. Für die Messungen inAbb. 6.6 wurde der intuitive Algorithmus so programmiert, dass zunächst das für die vorhergehen-de Zelle gefundene Tetraeder auf Umhüllung des aktuellen Zellzentrums überprüft wird. Falls die-ses Tetraeder den aktuellen Zentrumspunkt nicht umhüllt, wird über ein Durchlaufen der Tetraeder-liste nach einem passenden Tetraeder gesucht.
Der intuitive Algorithmus wird zwar im Paper [7] für das Resampling angewendet, dort findet dasResampling jedoch in einem Vorverarbeitungsschritt statt. Ein Ziel dieser Arbeit ist es, eine spei-cheraufwändige Vorverarbeitung zu vermeiden, trotzdem aber den Octree möglichst schnell ver-feinern und vergröbern zu können. Da der intuitive Algorithmus für praktische Gittergrößen (43, 83,163) wesentlich langsamer ist als die 3D-Rasterisierung (Laufzeitvergleiche siehe Abb. 6.6), wirdin dieser Arbeit die 3D-Rasterisierung eingesetzt.
6.4.2 3D-RasterisierungAnstatt die regulären Gitterzellen zu traversieren, wird bei dieser Methode die Tetraederliste durch-laufen. Für jedes Tetraeder wird eine 3D-Rasterisierung durchgeführt [8]. Zur Berechnung derWerte an den Zentrumspunkten der Gitterzellen stellen wir uns die z-achsen-orthogonalen Ebenen
Abb. 6.6:Laufzeitvergleich zwischen intuitivem Resampling und 3D-Rasterisierung für verschiedeneZielgittergrößen. Je größer das Zielgitter ist, umso schneller ist die 3D-Rasterisierunggegenüber dem intuitiven Algorithmus (siehe 4. Zeile).Für die Messung wurde die Datei „avs.inp“ benutzt; sie ist Bestandteil des SoftwarepaketsAVS/Express 6 und beschreibt nach einer Zerlegung in Tetraeder ein unstrukturiertes Gitteraus 3390 Tetraedern.Testplattform: Testsystem 1 (AMD Athlon XP @ 1666 MHz, 512 MB RAM).
��?@�����3���������� "F F (F %�F !"F��������������������G���<���������������� *&*#(# *&%)'* %&%)!� (& '*# � &*#��������������!-+������������������� *&* (# *&*�%" *&*()# *&*('" *&"%#*3�����������<���� �3����!-+����� %&" "&' %!& '#&" "')&'

51
Abb. 6.8:Beim Resampling auftretende Fälle von Tetraederkonfigurationen. Punkte, die beimÜbergang von einer Scanplane zur nächsten gleichzeitig überstrichen werden, sind mithervorgehobenen Kanten verbunden.
$
�
#
�
$
�
#�
$
�
#
�
$
� #
�
/����(
$
� #
�
$
� #
�
/����
/����* /����+ /����D
/����)
$
�
#
�
$
�
#
�
$
�
#
�
Abb. 6.7:Scanplane-basierte 3D-Rasterisierung eines Tetraeders. Als Schnittflächen können Dreieckeund Vierecke vorkommen.

52
durch die Zentrumspunkte vor und berechnen nun für jede die Bounding-Box des Tetraeders schnei-dende Ebene den Schnitt mit dem Tetraeder. Dies entspricht einer Verallgemeinerung der bekann-ten Rasterisierung mit Scanlines. Die Schnittflächen auf den hier verwendeten Scan-Ebenen kön-nen Dreiecke oder Vierecke sein, wie Abb. 6.7 veranschaulicht.
Wir teilen die Vierecke in je zwei Dreiecke und wenden für jedes Dreieck eine schnelle 2D-Rasterisierung an.
Die vorgestellte Technik erlaubt eine sehr effiziente Implementierung, in der die 2D-Schnittflä-chen inkrementell berechnet und für jede Schnittfläche ebenfalls eine schnelle, inkrementelle 2D-Rasterisierung benutzt werden kann. Die Schnelligkeit des Verfahrens beruht somit auf der Aus-nutzung von Kohärenzen im 2D- und 3D-Raum.
Eine entscheidende Schwierigkeit bei der inkrementellen Berechnung der Schnittflächen ist, dassdie vier Eckpunkte des Tetraeders im allgemeinen nicht direkt auf den Scan-Ebenen liegen. Zu-sammen mit den unterschiedlichen Tetraeder-Konfigurationen (siehe Abb. 6.8) ergeben sich eineReihe von Fallunterscheidungen, die man in der Implementierung der 3D-Rasterisierung beachtenmuss. Die Fallunterscheidungen basieren auf der Startkonfiguration und der Anzahl der Tetraeder-eckpunkte, die beim Übergang von einer Scanplane zur nächsten überschritten werden. SolchePunkte wurden in Abb. 6.8 mit einer hervorgehobenen Kante verbunden. Es kann wie in Fall 1, 2und 3 die Startkonfiguration vorliegen, in der ausgehend von einem oberen Punkt zunächst dreiek-kige Scanplanes vorliegen. In Fall 6 sind die obersten Scanplanes zwar auch dreieckig, jedochstartet das Verfahren hier mit drei Punkten (A, B, C) anstatt mit einem (A) wie in den ersten dreiFällen. Bei Fall 4 und 5 hingegen liegen genau zwei Eckpunkte über der ersten Scanplane, wo-durch zunächst viereckige Scanplanes entstehen. In Fall 5 wird gegenüber Fall 4 vor dem Errei-chen der untersten Scanplane noch der Punkt C überschritten, was einen Übergang auf dreieckigeScanplanes unterhalb von C bedeutet. In Fall 1 liegt zwischen B und C noch mindestens eineviereckige Scanplane, bevor unterhalb von C wieder dreieckige Scanplanes auftreten. In den Fäl-len 2 und 3 dagegen kommen nur dreieckige Scanplanes vor, wobei in Fall 3 jedoch noch zweiPunkte (B, C) über der untersten Scanplane liegen und gleichzeitig überstrichen werden.

53
6.5 Alpha-KorrekturDa der Octree unbalanciert ist, liegen die Blatt-Knoten auf unterschiedlichen Tiefen. Bei der 3D-Textur-Darstellung ergeben sich für unterschiedliche Blatt-Knoten trotz gleicher Anzahl Slices proKnoten unterschiedliche Slice-Abstände. Die daraus entstehenden Probleme werden in Abschnitt6.5.1 gezeigt. Zur Beseitigung dieser Probleme muss eine Alpha-Korrektur durchgeführt werden,die in Abschnitt 6.5.2 vorgestellt wird. Wendet man die Alpha-Korrektur auf gängigen Grafik-karten an, treten jedoch numerische Probleme auf, welche in 6.5.3 erläutert werden.
6.5.1 Notwendigkeit der Alpha-KorrekturAbb. 6.9 zeigt ein mögliches Szenario, bei dem ein Knoten der Tiefe 1 neben vier Knoten der Tiefe2 liegt (hier als Teil eines Quadtrees dargestellt).
Im linken Knoten werden zur Darstellung 8 Slices überblendet, im rechten werden über die gleicheStrecke 16 Slices überblendet. Angenommen, das betrachtete Volumen hat überall die gleichenWerte. Nach Anwendung der Transferfunktion sind dann auch alle Slices mit den gleichen Farb-und Opazitätswerten texturiert. Die nach dem Überblenden für die Pixel A und B im Framebufferstehenden Farbwerte C8 und C16 müssten bei einer korrekten Darstellung identisch sein.
Wir sehen am folgenden Beispiel, dass für C8 und C16 jedoch unterschiedliche Farbwerte berechnetwerden. Nehmen wir an, alle Slices wären mit einem transparenten Weiß texturiert: RGBA = (1, 1,1, 0.1); der Hintergrund sei schwarz. Um C8 zu berechnen, wendet die Grafikhardware dieCompositing-Formel
Cout = Cnew · αnew + Cin · (1 − αnew)
achtmal an, zur Berechnung von C16 16 mal. Es ergeben sich die Farben C8 = (0.570, 0.570, 0.570)und C16 = (0.815, 0.815, 0.815).
Der Unterschied zwischen C8 und C16 äußert sich in der Darstellung der Anordnung aus Abb. 6.9dadurch, dass die rechte Seite heller dargestellt wird als die linke. Am Übergang zeigt sich eine
#@ #(D�
/������55��
����
5����
���!�������
$
Abb. 6.9:Unterschiedliche Ergebnisse beim Back-to-Front-Compositing für unterschiedlicheAnzahlen Slices, obwohl alle Slices identisch texturiert sind.Links: 1 Octree-Knoten der Tiefe 1; rechts: 4 Knoten der Tiefe 2. Anzahl Slices pro Knoten:8. Für Pixel A des Framebuffers ergibt sich die Farbe C8, für Pixel B die Farbe C16.

54
Unstetigkeit in der Helligkeit. Bei der Verwendung einer höheren Anzahl Slices sind die einzelnenSlices also nicht mehr transparent genug.
Für eine korrekte Darstellung müssen daher die Alpha-Werte der Slice-Texturen in Abhängigkeitvon der Anzahl Slices pro zurückgelegter Sichtstrahlstrecke angepasst werden (Alpha-Korrektur).
6.5.2 Herleitung der Alpha-Korrektur-FormelUm zu ermitteln, nach welchem Mechanismus diese Korrekturen durchgeführt werden müssen,wollen wir wie oben im Beispiel vereinfachend annehmen, dass alle Slices die gleiche Farbe undOpazität haben. Außerdem betrachten wir in den folgenden Überlegungen nur einen Farbkanal Ranstatt aller drei Kanäle RGB. Sei R0 durch die Hintergrundfarbe definiert; Rnew und αnew stellenFarbwert und Opazität der aktuellen Slice dar. Rout(n) ist der Farbwert nach der Überblendung vonn Slices, mit Rout(0) = R0. Wir setzen c:= αnewRnew sowie d:= 1 - αnew und erhalten
Rnew(n) = c + dRnew(n − 1)
Nach einem Blick auf die Werte von Rout für n = 0, ..., 3
Rout(0) = R0
Rout(1) = c + dR0
Rout(2) = c + dc + d2R0
Rout(3) = c + dc + d2c + d3R0
wird klar, dass gilt
Rout(n) = R0dn + c(d0 + d1 + . . . + dn−1)
was sich mit Hilfe der geometrischen Summenformel umformen lässt zu
Rout(n) = R0dn + c
1 − dn
1 − d
Einsetzen von c und d liefert
Rout(n) = R0(1 − αnew)n + Rnew(1 − (1 − αnew)n) (1)
Das Ziel ist nun, durch Änderung von αnew zu erreichen, dass Rout unabhängig von n wird. Über eineeinfache Umformung auf der rechten Seite von (1) gelangen wir zu
Rout(n) = (R0 − Rnew)(1 − αnew)n + Rnew
Bei der Wahl von
αnew := 1 − (1 − α1)1n (2)
gilt dann das gewünschte. α1 ist dabei der Alpha-Wert des betrachteten Pixels für n = 1, der direktder Transferfunktion entnommen werden kann. Bewiesen wurde nun, dass diese Alpha-Korrekturfür gleiche Farb- und Opazitätswerte der einzelnen Slices funktioniert. Für den allgemeinen Fallwird hier kein Beweis geführt, jedoch wurden mit dem Rechner Beispiele durchgerechnet, die dieKorrektheit von (2) auch für den allgemeinen Fall bestätigen.
Zur Anwendung von (2) muss für einen Octree-Knoten zusätzlich n berechnet werden, was abereinfach dem Produkt aus der Anzahl Slices pro Knoten (wird vom Benutzer zur Laufzeit festgelegt)mit 2d entspricht, wobei d die Tiefe des Octree-Knotens ist (die Wurzel hat die Tiefe 0).
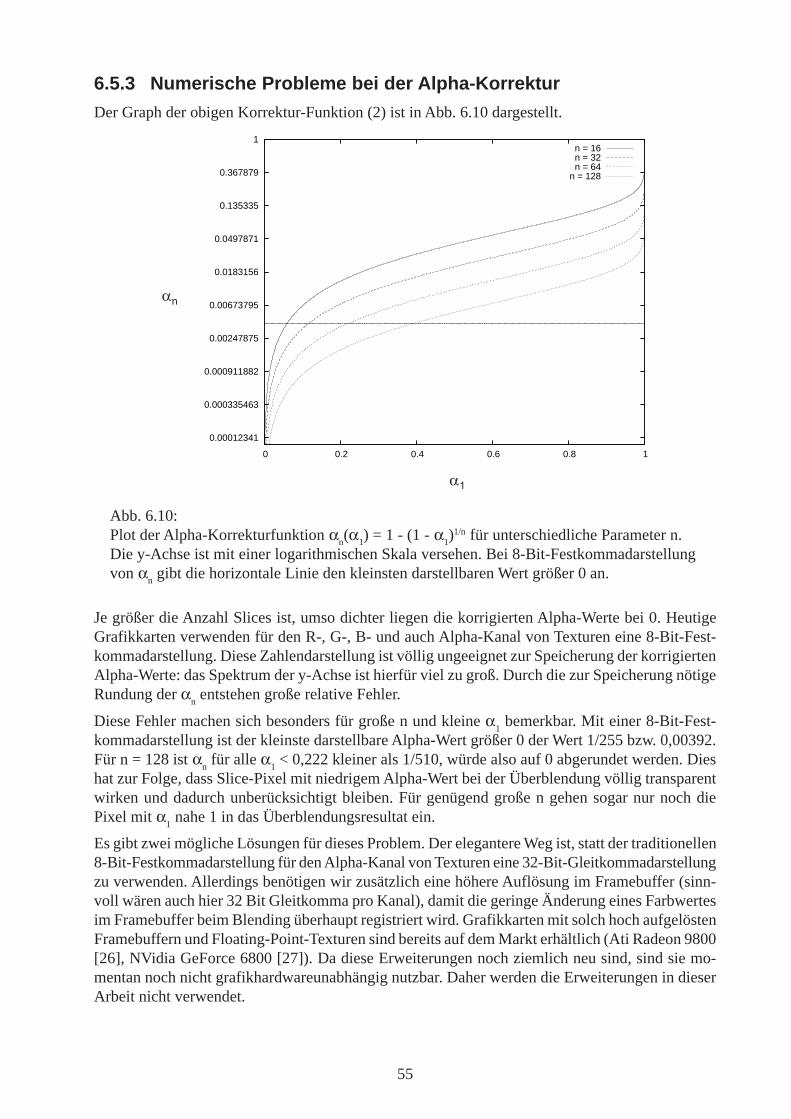
55
6.5.3 Numerische Probleme bei der Alpha-KorrekturDer Graph der obigen Korrektur-Funktion (2) ist in Abb. 6.10 dargestellt.
Je größer die Anzahl Slices ist, umso dichter liegen die korrigierten Alpha-Werte bei 0. HeutigeGrafikkarten verwenden für den R-, G-, B- und auch Alpha-Kanal von Texturen eine 8-Bit-Fest-kommadarstellung. Diese Zahlendarstellung ist völlig ungeeignet zur Speicherung der korrigiertenAlpha-Werte: das Spektrum der y-Achse ist hierfür viel zu groß. Durch die zur Speicherung nötigeRundung der αn entstehen große relative Fehler.
Diese Fehler machen sich besonders für große n und kleine α1 bemerkbar. Mit einer 8-Bit-Fest-kommadarstellung ist der kleinste darstellbare Alpha-Wert größer 0 der Wert 1/255 bzw. 0,00392.Für n = 128 ist αn für alle α1 < 0,222 kleiner als 1/510, würde also auf 0 abgerundet werden. Dieshat zur Folge, dass Slice-Pixel mit niedrigem Alpha-Wert bei der Überblendung völlig transparentwirken und dadurch unberücksichtigt bleiben. Für genügend große n gehen sogar nur noch diePixel mit α1 nahe 1 in das Überblendungsresultat ein.
Es gibt zwei mögliche Lösungen für dieses Problem. Der elegantere Weg ist, statt der traditionellen8-Bit-Festkommadarstellung für den Alpha-Kanal von Texturen eine 32-Bit-Gleitkommadarstellungzu verwenden. Allerdings benötigen wir zusätzlich eine höhere Auflösung im Framebuffer (sinn-voll wären auch hier 32 Bit Gleitkomma pro Kanal), damit die geringe Änderung eines Farbwertesim Framebuffer beim Blending überhaupt registriert wird. Grafikkarten mit solch hoch aufgelöstenFramebuffern und Floating-Point-Texturen sind bereits auf dem Markt erhältlich (Ati Radeon 9800[26], NVidia GeForce 6800 [27]). Da diese Erweiterungen noch ziemlich neu sind, sind sie mo-mentan noch nicht grafikhardwareunabhängig nutzbar. Daher werden die Erweiterungen in dieserArbeit nicht verwendet.
0.00012341
0.000335463
0.000911882
0.00247875
0.00673795
0.0183156
0.0497871
0.135335
0.367879
1
0 0.2 0.4 0.6 0.8 1
n = 16n = 32n = 64
n = 128
�(
��
Abb. 6.10:Plot der Alpha-Korrekturfunktion αn(α1) = 1 - (1 - α1)
1/n für unterschiedliche Parameter n.Die y-Achse ist mit einer logarithmischen Skala versehen. Bei 8-Bit-Festkommadarstellungvon αn gibt die horizontale Linie den kleinsten darstellbaren Wert größer 0 an.
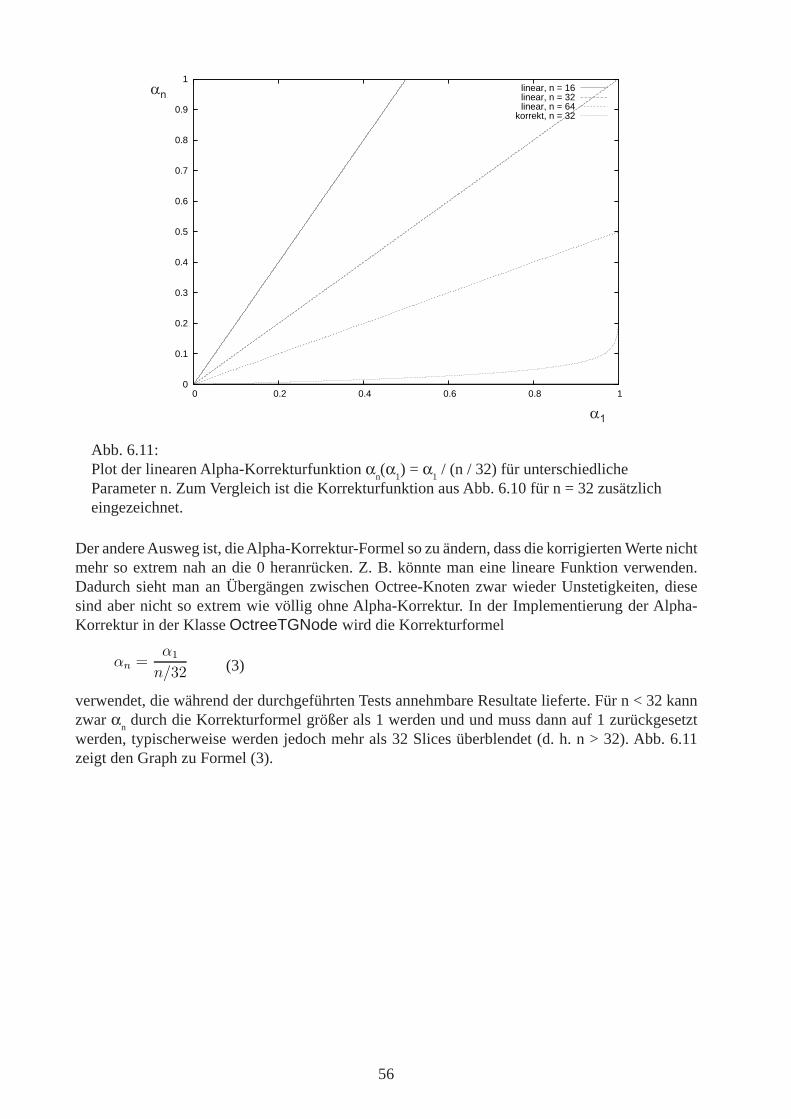
56
Der andere Ausweg ist, die Alpha-Korrektur-Formel so zu ändern, dass die korrigierten Werte nichtmehr so extrem nah an die 0 heranrücken. Z. B. könnte man eine lineare Funktion verwenden.Dadurch sieht man an Übergängen zwischen Octree-Knoten zwar wieder Unstetigkeiten, diesesind aber nicht so extrem wie völlig ohne Alpha-Korrektur. In der Implementierung der Alpha-Korrektur in der Klasse OctreeTGNode wird die Korrekturformel
αn =α1
n/32 (3)
verwendet, die während der durchgeführten Tests annehmbare Resultate lieferte. Für n < 32 kannzwar αn durch die Korrekturformel größer als 1 werden und und muss dann auf 1 zurückgesetztwerden, typischerweise werden jedoch mehr als 32 Slices überblendet (d. h. n > 32). Abb. 6.11zeigt den Graph zu Formel (3).
Abb. 6.11:Plot der linearen Alpha-Korrekturfunktion αn(α1) = α1 / (n / 32) für unterschiedlicheParameter n. Zum Vergleich ist die Korrekturfunktion aus Abb. 6.10 für n = 32 zusätzlicheingezeichnet.
�(
��
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.2 0.4 0.6 0.8 1
linear, n = 16linear, n = 32linear, n = 64
korrekt, n = 32

57
6.6 Octree-AnzeigeBei der Anzeige des Octrees muss nicht nur für jeden Knoten die Zeichenreihenfolge der Slicesvon hinten nach vorne eingehalten werden, auch auf eine Back-to-Front-Ordnung der Knoten selbstmuss geachtet werden. Würde man eine Liste aller Octree-Blätter bilden und diese Liste anhanddes Abstands der Blattzentren zur Kamera sortieren (globaler Ansatz), so erhielte man eine inkor-rekte Zeichenreihenfolge, wie wir in Abb. 6.12 sehen.
Eine korrekte Sortierung erhalten wir, indem wir - angefangen bei der Wurzel und dann per Tiefen-suche traversierend - für jeden Knoten die acht Kindknoten anhand ihres Zentrumsabstandes zurKamera ordnen. In Abb. 6.13 wird dies an einem Beispiel erläutert. Die vier Knoten A bis D aufLevel 1 im Baum werden zunächst nach Zentrumsabstand zur Kamera sortiert, woraus die Reihen-folge A, B, C, D hervorgeht. Nun werden für jeden der vier Knoten die Kinder sortiert. Im Beispielhat nur der Knoten C Kinder. Wir wenden auf C1 bis C4 das gleiche Verfahren an wie auf A bis D,wodurch wir die Sortierung C1, C2, C3, C4 erhalten. Nun ersetzen wir C in der vorherigen Sortie-rung durch seine sortierten Kinder und erhalten dadurch eine korrekte Sortierung der Octree-Blät-ter: A, B, C1, C2, C3, C4, D. Die Sortierung des Unterbaums C ist unabhängig von seinen übergeord-neten Knoten sowie seinen Nachbarknoten (lokaler Ansatz).
Pro Octree-Knoten (innere Knoten und Blätter) wird hier der quadratische Abstand zwischen zweiPunkten (Kamera und Knotenzentrum) berechnet, was drei Multiplikationen und fünf Additionenentspricht.
Die Sortierung der Kindknoten kann jedoch noch etwas effizienter ausgeführt werden (siehe Abb.6.14). Der Vaterknoten wird nacheinander orthogonal zu jeder der Hauptachsen mittig in zweiHälften geteilt. Die Reihenfolge der Achsen ist dabei gleichgültig. Mit zwei Additionen und zweiVergleichen pro Achse wird ermittelt, welche Kindknoten-Zentren in der kameraabgewandten Re-gion des Knotens liegen; diesen Zentren wird ein 0-Bit zugeordnet, den anderen ein 1-Bit. Vor demTest für die nächste Achse wird der bisherige Bitcode einfach um eine Stelle nach links geschoben.So ergeben sich für die Kind-Knoten dreistellige (im 2D zweistellige) Binärcodes, die - als Binär-zahlen interpretiert - die Sortierung der Kinder angeben. Das Kind mit der kleinsten Zahl (0) wirdzuerst gezeichnet.
"�����
�
$
��
Abb. 6.12:Inkorrekte Zeichenreihenfolge bei Ordnung nach Octree-Blattzentren: Knoten A wird vonKnoten B verdeckt, trotzdem liegt das Zentrum von A näher an der Kamera als das Zentrumvon B. Demnach würde fälschlicherweise zuerst B und danach A gezeichnet werden.

58
Die Korrektheit dieses Verfahrens wird per Widerspruchsbeweis gezeigt. Angenommen, der Bit-code für Kindknoten M sei kleiner als der Code für Knoten N, und das Zentrum von M liege näheran der Kamera als das Zentrum von N. Da sich die Bitcodes unterscheiden, gibt es mindestens einBit, das in beiden Codes unterschiedlich ist. Wir vergleichen die beiden Bitcodes bitweise, ange-fangen beim höchstwertigen Bit. Das k-te Bit sei das höchstwertige Bit, welches sich in beidenCodes unterscheidet. Da der Code für M kleiner ist, hat dieses k-te Bit für M den Wert 0 und für Nden Wert 1. Wegen der oben definierten Konstruktion der Bitcodes liegt daher das Zentrum von N
"�����
����
����(
(
( ((
Abb. 6.14:Sortierung der Kindknoten über Zuweisung von Bitcodes je nach Lage einesKindknotenzentrums relativ zu Schnittebenen (hier durch die gestrichelten Linien
Abb. 6.13:Korrekte abstandsbasierte Sortierung durch levelweise Vorgehensweise. Berechne zuerstSortierung A, B, C, D auf Level 1, verfeinere dann das Ergebnis auf Level 2 usw.(Erläuterungen siehe Text). Aus den levelweisen Sortierungen A, B, C, D und C1, C2, C3, C4geht durch Einsetzen die Blattsortierung A, B, C1, C2, C3, C4, D hervor.
"�����
#*
#( #)
#)
"�����
�$
# �

59
näher an der Kamera als das Zentrum von M, was einen Widerspruch zur Annahme liefert.
Diese Sortiertechnik per Bitzuweisung wurde in der Klasse OctreeTGNode implementiert.
6.7 ArtefakteBei der Darstellung hierarchischer 3D-Texturen treten mindestens die Artefakte auf, die sich be-reits beim 3D-Textur-Verfahren (siehe Kapitel 3) zeigen. Hinzu kommen nun noch Probleme beimÜbergang zwischen zwei Octreeknoten unterschiedlicher Tiefe. Selbst mit Verwendung der in 6.5.2beschriebenen Alpha-Korrektur würde der Betrachter Unstetigkeiten im Übergang sehen; der Grundhierfür soll im folgenden erklärt werden. Abb. 6.15 zeigt benachbarte Octreeknoten mit einemTiefenunterschied von eins, d. h. im linken Knoten werden doppelt so viele Slices angezeigt wie imrechten.
Zur Vereinfachung nehmen wir an, der zugrundeliegende Volumendatensatz habe überall densel-ben Wert. Die Slices sind dann alle einfarbig. Durch die Alpha-Korrektur haben sie im linkenKnoten den Alpha-Wert α4, im rechten Knoten den Wert α2. In dem Bereich links des Sehstrahls RLwerden vier Slices überlagert, die den Alpha-Wert α4 besitzen. Im Bereich zwischen RL und RRliegen dagegen drei α4-Slices und eine α2-Slice. Wegen α2 > α4 unterscheiden sich die resultieren-den Farbwerte dieser beiden Bereiche im Framebuffer; dem Betrachter fällt dies als Unstetigkeitauf.
Zur Korrektur dieser fehlerhaften Darstellung muss der zu opake Bereich zwischen RL und RRkorrigiert werden. Hierfür gibt es zwei Möglichkeiten (siehe Abb. 6.16): Polygonclipping im höheraufgelösten Knoten oder eine weitere Alpha-Korrektur in den gröberen Knoten.
�*
�*
�*
�*
�
�
;C ;;
Abb. 6.15:Artefakte im Übergang zwischen Octreeknoten unterschiedlicher Tiefe trotz Alpha-Korrektur: links von RL werden trotz identischer Volumendaten Slices überlagert, die sich inihrer Opazitätskombination von denen zwischen RL und RR unterscheiden.(Die linke Hälfte besteht aus vier kleineren Knoten, deren Umrisse der Übersicht halbernicht dargestellt sind.)

60
Abb. 6.16:Zwei Möglichkeiten zur Vermeidung von Übergangsartefakten: Polygonclipping (links)oder eine weitere Alpha-Korrektur (rechts). Beide Möglichkeiten sindkamerapositionsabhängig.
�*
�*
�*
�*
�
�
;C ;;
#��!!���
�*
�*
�*
�*
�
�
;C ;;
$�!���"���������� �*
Diese Korrekturen hängen von der Position der Kamera ab und lassen sich deswegen nicht ohneEinbußen bezüglich der Framerate verwenden. Sie werden in dieser Arbeit nicht angewendet.

61
Abb. 6.17:3D-Textur-Rendering des AVS-Datensatzes; die Octree-Tiefe beträgt 1, d. h. es gibt 8Blätter.Oben: das reguläre Zielgitter hat für jeden Knoten die Größe 83.
Abb. 6.18:3D-Textur-Rendering des Bluntfin-Datensatzes; Gitterauflösung: 163; Anzahl Blätter imOctree: 78.
6.8 ErgebnisseAbb. 6.17 zeigt den mit 3D-Texturen dargestellten AVS-Datensatz. Durch das Resampling tretenstarke Treppen-Artefakte auf (oberer Teil von Abb. 6.17), die man mit einer höheren Zielgitterauf-lösung verringern kann, wie im unteren Teil der Abbildung zu sehen ist.

62
Abb. 6.19:Rendering mit hierarchischen 3D-Texturen (oben) und Tetraeder-Wireframe-Darstellung (unten)des Mars-Datensatzes.Der Datensatz beschreibt die Dichte der Ionen um den Mars und entstammt einerRechnersimulation, die am Institut für Theoretische Physik der TU Braunschweig durchgeführtwurde. Die Transferfunktion ist dieselbe wie in Abb. 6.17; niedrige Dichten erscheinen bläulich,mittlere Dichten grün und hohe Dichten rot.Die Simulation wurde auf einem irregulären Gitter durchgeführt, das jedoch nur leicht vonder regulären Struktur abweicht. Die Irregularität ist in der Wireframe-Darstellung deswegennicht zu erkennen.Vor der Darstellung der Daten wurde aus dem irregulären 923-Hexaedergitter durch Zerlegung(5 Tetraeder pro Hexaeder) ein Tetraedergitter aus 3.893.440 Tetraedern gewonnen. DurchEntfernen der Tetraeder, die an allen Eckpunkten normalisierte Werte < 0,0001 haben, ist derdargestellte Datensatz (417.452 Tetraeder) entstanden.
In Abb. 6.18 sieht man links deutliche Streifenartefakte, die bei einer Erhöhung der Anzahl Slices(rechte Abbildung) erheblich verringert werden.
Das Verfahren der hierarchischen 3D-Texturen macht es möglich, sehr große Datensätze in Echt-zeit zu betrachten. Ein Beispiel dafür ist der Datensatz in Abb. 6.19; er umfasst über 400.000Tetraeder.

63
Stufe 1
Stufe 2
Stufe 3
Stufe 4
Stufe 5
Der Mars-Datensatz aus Abb. 6.19 ist in Abb. 6.20 für neun verschiedene Octree-Verfeinerungs-stufen dargestellt.
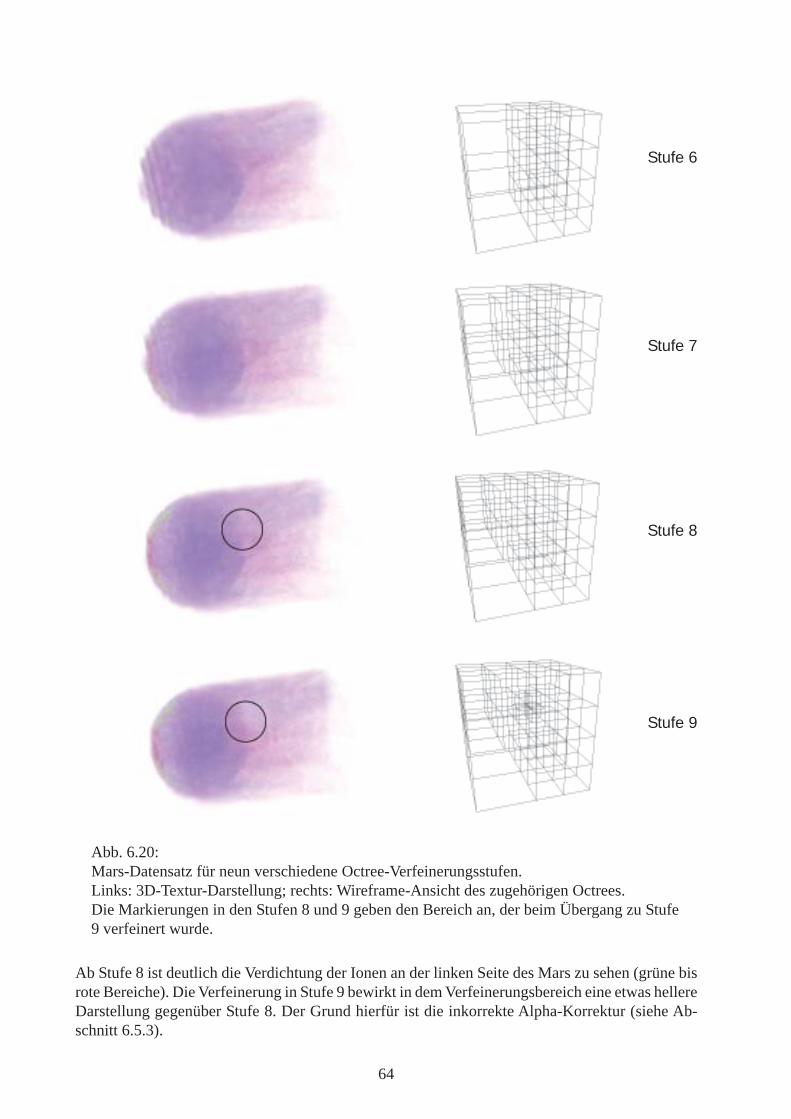
64
Abb. 6.20:Mars-Datensatz für neun verschiedene Octree-Verfeinerungsstufen.Links: 3D-Textur-Darstellung; rechts: Wireframe-Ansicht des zugehörigen Octrees.Die Markierungen in den Stufen 8 und 9 geben den Bereich an, der beim Übergang zu Stufe9 verfeinert wurde.
Stufe 6
Stufe 7
Stufe 8
Stufe 9
Ab Stufe 8 ist deutlich die Verdichtung der Ionen an der linken Seite des Mars zu sehen (grüne bisrote Bereiche). Die Verfeinerung in Stufe 9 bewirkt in dem Verfeinerungsbereich eine etwas hellereDarstellung gegenüber Stufe 8. Der Grund hierfür ist die inkorrekte Alpha-Korrektur (siehe Ab-schnitt 6.5.3).

65
Abb. 6.21:Auflistung des Octree-Zustands (Tiefe und Anzahl Blätter), der Anzahl Tetraeder imverfeinerten Octree, der maximalen Anzahl Tetraeder der geresampelten Kindknoten, derZeit für den gesamten Verfeinerungsschritt (bestehend aus 8 Resampling-Vorgängen) sowieder Frameraten für die in Abb. 6.20 dargestellten Verfeinerungsstufen (gemessen aufTestsystem 1).
0.025
0.03
0.035
0.04
0.045
0.05
0.055
0.06
0.065
0.07
0 10 20 30 40 50 60
Ren
derz
eit [
sec]
# Octree-Blaetter
Abb. 6.22:Renderzeiten aus Abb. 6.21, aufgetragen über der Anzahl der Octree-Blätter.
Abb. 6.21 gibt einen Überblick über den Zustand des Octrees für jede der neun betrachtetenVerfeinerungsstufen. Wie in Abschnitt 6.2 beschrieben wurde, wird stets der Octree-Knoten verfei-nert, der die meisten Tetraeder hält. Das impliziert, dass mit jeder weiteren Verfeinerungsstufe diebenötigte Zeit für das Verfeinern (Schnitttests, Resampling, 3D-Texturerzeugung) abnimmt, was inder sechsten Tabellenspalte in Abb. 6.21 zu sehen ist.
In Abb. 6.22 sind die Renderzeiten aus Abb. 6.21 in Abhängigkeit von der Anzahl der Octree-Blätter (d. h. ebenfalls Anzahl unterschiedlicher 3D-Texturen) grafisch aufgetragen.
���;� 6�����+.��;� 0���/���� �����0�������������� ��$��0���������� =��;����������� ��������A�������������� ����� ������4�1�5
% * % %) #" + + *&*")* *�4!)&*5" % ( %) #" %*'#"% #&(%" *&* *#!��4" &)5! " %# %*'#"% ! #�' %&�*) *&*#%) )�4%'&!5 " "" %*( !) ! #') %&#!( *&*#"(('�4%(&'5# " "' #% �� ""!') %&%%# *&*#�*) �4%)&(5� " !� #*�)! ""%�* *&))! *&*�*""'�4%�&�5) " ! %'#* %(#*' *&�"" *&*��'%*�4% &'5( " #* *�(( %(!!% *&�*# *&*�))'��4% &(5' ! #) ! #') #�%' *&#'* *&*�)��%�4% &(5
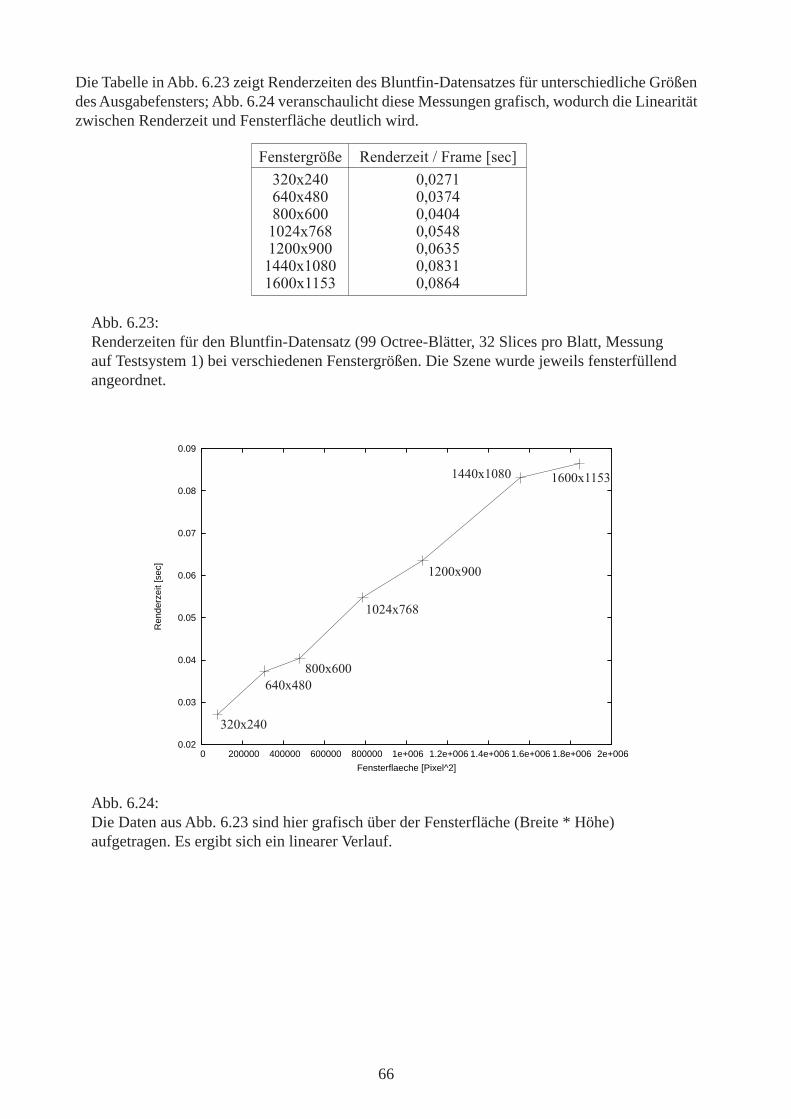
66
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0 200000 400000 600000 800000 1e+006 1.2e+006 1.4e+006 1.6e+006 1.8e+006 2e+006
Ren
derz
eit [
sec]
Fensterflaeche [Pixel^2]
!"*$" *
� *$ (*(**$�**
%*" $)�(
%"**$'**
% *$%*(* %�**$%%#!
��������?@� ��������� ������������!"*$" * *&*")%� *$ (* *&*!) (**$�** *&* * %*" $)�( *&*# (%"**$'** *&*�!#% *$%*(* *&*(!%%�**$%%#! *&*(�
Abb. 6.23:Renderzeiten für den Bluntfin-Datensatz (99 Octree-Blätter, 32 Slices pro Blatt, Messungauf Testsystem 1) bei verschiedenen Fenstergrößen. Die Szene wurde jeweils fensterfüllendangeordnet.
Abb. 6.24:Die Daten aus Abb. 6.23 sind hier grafisch über der Fensterfläche (Breite * Höhe)aufgetragen. Es ergibt sich ein linearer Verlauf.
Die Tabelle in Abb. 6.23 zeigt Renderzeiten des Bluntfin-Datensatzes für unterschiedliche Größendes Ausgabefensters; Abb. 6.24 veranschaulicht diese Messungen grafisch, wodurch die Linearitätzwischen Renderzeit und Fensterfläche deutlich wird.

67
6.9 KlassenbeschreibungenVon den in der Bibliothek UnstructuredVolRenLib enthaltenen Klassen werden folgende zumRendern mit dem Verfahren der hierarchischen 3D-Texturen benötigt:
Node-Core:
• HierarchicalTextures3DBase• HierarchicalTextures3D
Octree:
• OctreeTGBase• OctreeTG• OctreeTGNodeBase• OctreeTGNode• PositionedSlicesBase• PositionedSlices• Tetrahedron (Beschreibung siehe 5.7.3)
Anwendung der Transferfunktion:
• ColorManager (Beschreibung siehe 5.7.6)
Orakel:
• SystemInformationFür jede dieser Klassen folgt eine kurze Beschreibung, und es werden die wichtigsten Variablenund Methoden sowie ggf. OpenSG-FieldMasks erklärt. Einen Überblick über die Klassen-beziehungen gibt Abb. 6.25.
6.9.1 HierarchicalTextures3DBaseBeschreibung:Diese Klasse ist von MaterialDrawable (Teil der OpenSG-Bibliothek) abgeleitet und bildet dieBasisklasse für die Visualisierung mit hierarchischen 3D-Texturen.
Variablen:
SFOctreeTGPtr _sfOctreeManagerDies ist ein Verweis auf das Objekt der Klasse OctreeManager, welches für die Verwaltungdes Octrees zuständig ist.
SFBool _sfDrawSlicesSFBool _sfDrawTetrahedraWireframeSFBool _sfDrawOctreeWireframe
Enthält den Wert true, falls die hierarchischen 3D-Texturen, eine Wireframeansicht der Te-traeder bzw. eine Wireframeansicht der Octree-Knoten gezeichnet werden sollen. Die dreiMöglichkeiten können auch kombiniert werden.
SFBool _sfTetrahedraCompleteDer Programmierer ordnet dieser Variablen den Wert true nach dem letzten Hinzufügen ei-nes Tetraeders zu. Solange diese Variable nicht gesetzt ist, produziert der OpenSG-Knoten
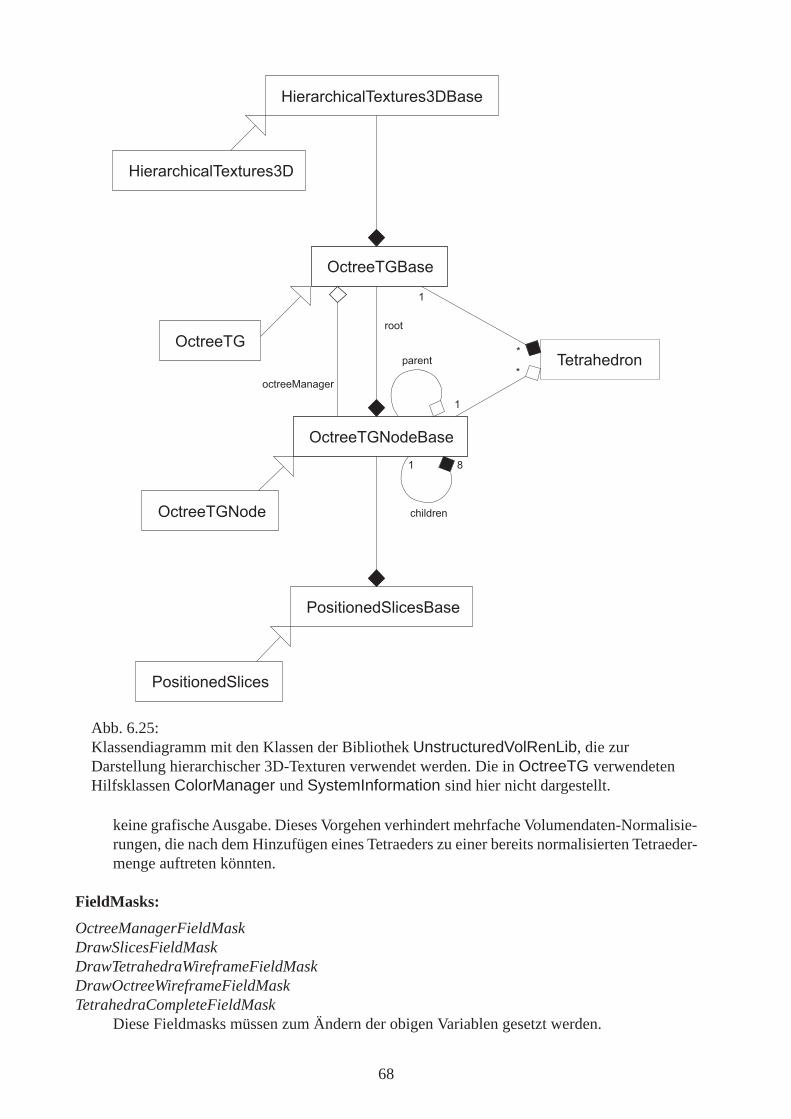
68
Abb. 6.25:Klassendiagramm mit den Klassen der Bibliothek UnstructuredVolRenLib, die zurDarstellung hierarchischer 3D-Texturen verwendet werden. Die in OctreeTG verwendetenHilfsklassen ColorManager und SystemInformation sind hier nicht dargestellt.
keine grafische Ausgabe. Dieses Vorgehen verhindert mehrfache Volumendaten-Normalisie-rungen, die nach dem Hinzufügen eines Tetraeders zu einer bereits normalisierten Tetraeder-menge auftreten könnten.
FieldMasks:OctreeManagerFieldMaskDrawSlicesFieldMaskDrawTetrahedraWireframeFieldMaskDrawOctreeWireframeFieldMaskTetrahedraCompleteFieldMask
Diese Fieldmasks müssen zum Ändern der obigen Variablen gesetzt werden.
E�����������4�������)�
?�����4<
?�����4<:���
����������������
E�����������4�������)�����
?�����4<����
?�����4<:�������
��������������������
( @
(
>
(
>
��������
!�����
����
������2������
4����������

69
6.9.2 HierarchicalTextures3DBeschreibung:Ein Objekt dieser Klasse kann als Node-Core für einen OpenSG-Knoten zur Visualisierung mithierarchischen 3D-Texturen verwendet werden.
Methoden:
Action::ResultE drawPrimitives(DrawActionBase* action)Diese Methode wird während der Szenengraphtraversierung aufgerufen und bildet den Ein-stiegspunkt für das Zeichnen des aktuellen Frames.
void initObject()Muss nach dem Erzeugen einer Instanz dieser Klasse aufgerufen werden; sorgt für die kor-rekte Initialisierung des Octree-Managers sowie der OpenSG-Pointer innerhalb dieser Klas-se.
void applyTransferFunc()Aktualisiert die 3D-Textur unter Verwendung der momentan im Octree-Manager vorliegen-den Transferfunktion.
bool renderStep(const Real32& currentFps)Führt den nächsten Verfeinerungs- bzw. Vergröberungsschritt auf dem Octree durch. Dieaktuelle Framerate currentFps wird an das Orakel weitergereicht. Falls der Szenengraphgeändert wurde, wird true zurückgeliefert.
bool bypassConstraintsRefine()bool bypassConstraintsUnrefine()
Führt einen Verfeinerungs- bzw. Vergröberungsschritt auf dem Octree ohne Rücksicht aufdie gesetzten Constraints durch.
void addTetrahedron(const NormalTetrahedron& tet)Fügt das Tetraeder tet der Menge der zu visualisierenden Tetraeder hinzu.
void balanceOctree(const bool& refine)Balanciert den Octree. Falls refine gesetzt ist, wird solange verfeinert, bis alle Blätter dieTiefe des momentan tiefsten Blattes haben. Anderenfalls wird der Octree um ein Level vergrö-bert, d. h. es werden all die Knoten vergröbert, die momentan die größte Tiefe haben.
6.9.3 OctreeTGBaseBeschreibung:
Dies ist die Octree-Manager-Basisklasse. Sie hält die zu visualisierenden Tetraeder in einer Array-Datenstruktur bereit (OpenSG-MultiField) und speichert Einstellungen zum Visualisierungsverfahren(Transferfunktion, Größe des regulären Gitters, Anzahl Slices pro Knoten, außerdem Constraintsfür das Orakel).
Variablen:
SFOctreeTGNodePtr _sfRootOpenSG-Pointer auf den Wurzelknoten des Octrees.
SFPnt3f _sfMin, _sfMaxBegrenzungspunkte für die hauptachsenausgerichtete Bounding-Box um die Tetraedermenge.Diese beiden Punkte werden beim Hinzufügen eines neuen Tetraeders jeweils aktualisiert.

70
MFTetrahedron _mfTetrahedraDiese arraybasierte, OpenSG-typische Datenstruktur speichert die zu visualisierenden Tetra-eder. Laufzeittests haben ergeben, dass eine Speicherung der Normalen im Gegensatz zumVerfahren aus Kapitel 5 keine merkbaren Geschwindigkeitsvorteile bringt.
Color4ub transferFunc[256]Tabellenbasierte Speicherung der Transferfunktion.
Int32 numberOfPositionedSlicesAnzahl Slices pro Octree-Knoten zur Anzeige der 3D-Texturen. Diese Angabe bezieht sichauf die Raumdiagonale eines Octree-Knotens. Wird der Octree-Knoten aus einer anderenRichtung betrachtet, kann die tatsächliche Anzahl der Slices variieren. Der Abstand zwi-schen zwei benachbarten Slices wird beim Betrachten aus einer anderen Richtung jedochkonstant gehalten.
Int32 gridSizeDas reguläre Gitter, auf dem das Resampling durchgeführt wird, hat die Größe gridSize3.
std::list<OctreeTGNodePtr> refinableNodesListe der Octree-Knoten, die unabhängig von jeglichen Constraints momentan verfeinert wer-den könnten. Diese Knoten sind genau die Octree-Blätter.
std::list<OctreeTGNodePtr> unrefinableNodesListe von Octree-Knoten, die unabhängig von jeglichen Constraints momentan vergröbertwerden könnten. Dies sind genau die Knoten, die keine Blätter sind und nur Blätter als Kin-der haben.
6.9.4 OctreeTGBeschreibung:
Diese Klasse ist für die Verwaltung des Octrees zuständig. Ein wesentlicher Bestandteil ist dasVerfeinerungsorakel.
Methoden:
void initObject()Muss nach dem Erzeugen einer Instanz aufgerufen werden, um einige OpenSG-Pointer kor-rekt zu setzen.
bool askRefinementOracle(const Real32& currentFps)Führt je nach Entscheidung des Orakels eine Verfeinerung, Vergröberung oder keines vonbeiden durch.
bool bypassConstraintsRefineStep()Führt unter Nichtbeachtung der Constraints einen Verfeinerungsschritt durch.
bool bypassConstraintsUnrefineStep()Führt unter Nichtbeachtung der Constraints einen Vergröberungsschritt durch.
void testTetrahedraValuesNormality()Diese Methode kann beim Debugging verwendet werden, um zu testen, ob alle Volumen-werte der Tetraeder im Bereich [0, 1] liegen.

71
6.9.5 OctreeTGNodeBaseBeschreibung:Dies ist die Basisklasse für einen Octree-Knoten. Neben Verweisen auf Vater- und Kindknotenwerden hier auch eine Tetraeder-Indexliste und die auf das reguläre Gitter rasterisierten Datengespeichert.
Variablen:
SFOctreeTGPtr _sfOctreeManagerOpenSG-Pointer auf den Octree-Manager (Instanz der Klasse OctreeTG).
SFOctreeTGNodePtr _sfParentOpenSG-Pointer auf den Vaterknoten.
MFOctreeTGNodePtr _mfChildrenArray-basierte Speicherung von OpenSG-Pointern auf die acht Kindknoten.
SFInt32 _sfLevelGibt den Level (d. h. die Tiefe) dieses Knotens im Octree an. Die Wurzel befindet sich aufLevel 0; für jede tiefere Ebene im Octree steigt die Levelzahl um eins.
SFInt32 _sfIdJeder Knoten speichert eine ID, die seine Lage im Octree eindeutig bestimmt. Sie wird nur zuDebug-Zwecken verwendet.
SFPnt3f _sfMin, _sfMaxDiese beiden Punkte begrenzen das Volumen des Octree-Knotens im 3D-Raum.
SFPositionedSlicesPtr _sfPositionedSlicesDies ist ein OpenSG-Pointer auf ein PositionedSlices-Objekt, welches für die Darstellungder 3D-Textur dieses Knotens zuständig ist.
SFBool _sfTransparentFalls diese Variable true ist, wird dieser Knoten bei der Anzeige nicht betrachtet, da ervollständig transparent erscheinen würde (Transparency Culling). _sfTransparent wird nachdem Anwenden der Transferfunktion entsprechend gesetzt.
Real32* sampledDataDieser Pointer zeigt auf ein Array, welches die auf das reguläre Gitter rasterisierten Volu-mendaten beinhaltet. Da diese Daten nur einen Zwischenschritt zur Erstellung der RGBA-3D-Texturen darstellen, müssen sie nicht mit anderen Aspekten oder Cluster-Einheiten syn-chronisiert werden. Deswegen wird hier anstatt der sonst verwendeten OpenSG-Pointer le-diglich ein C-Pointer benutzt.
std::list<UInt32> tetIndexListDie Information, welche Tetraeder zu diesem Octree-Knoten gehören, wird in Form einerIndexliste gespeichert. Ein Index k bezieht sich auf das k-te in der Tetraederliste des Octree-Managers gespeicherte Tetraeder.
FieldMasks:OctreeManagerFieldMaskParentFieldMaskChildrenFieldMaskLevelFieldMaskIdFieldMask

72
MinFieldMaskMaxFieldMaskPositionedSlicesFieldMaskTransparentFieldMask
Die Field-Masks gehören zu den zuvor beschriebenen Variablen, daher sind hier keine weite-ren Erläuterungen nötig.
6.9.6 OctreeTGNodeBeschreibung:
Dies ist die Klasse für einen Octree-Knoten. Sie implementiert die Vorgänge zur Verfeinerung undVergröberung.
Methoden:void refine()
Zur Verfeinerung dieses Knotens erfolgt zunächst ein unsample()-Aufruf (siehe unten). Dannwerden 8 Kindknoten erzeugt, auf denen nach der Zuordnung der Tetraeder jeweils die Me-thode sample() aufgerufen wird.
void unrefine()Beim Vergröbern dieses Knotens werden seine Kindknoten gelöscht, und auf dem Knotenwird die Methode sample() aufgerufen. Eine erneute Tetraederzuordnung für den Knoten istnicht nötig, da die Indexliste beim vorangegangenen Verfeinern nicht gelöscht wurde.
void sample()Hier wird die 3D-Rasterisierung durchgeführt, mit der Transferfunktion die 3D-RGBA-Tex-tur erzeugt und eine Instanz von PositionedSlices für die Darstellung der 3D-Textur initia-lisiert. Die rasterisierten Volumenwerte bleiben erhalten, um auf Änderungen der Transfer-funktion schnell reagieren zu können.
void unsample()Löscht die 3D-Textur und die auf das reguläre Gitter rasterisierten Volumendaten diesesKnotens.
void applyTransferFunc()Wendet die momentan im Octree-Manager gehaltene Transferfunktion an, d. h. die aktuelle3D-Textur wird aus den noch gespeicherten rasterisierten Volumendaten neu erzeugt.
6.9.7 PositionedSlicesBaseBeschreibung:Dies ist die Basisklasse für die Darstellung von 3D-Texturen. Sie ist von MaterialDrawable abge-leitet und kann daher auch separat verwendet werden. Als Vorlage für diese und ihre abgeleiteteKlasse dienten die in der OpenSG-Bibliothek bereits vorhandenen Klassen Slices und SlicesBase.PositionedSlices erweitert die Funktionalität von Slices um die Positionierung von 3D-Texturenan einer beliebigen Stelle im Weltkoordinatensystem, was für die Anwendung in einem hierarchi-schen Verfahren zwingend notwendig ist.
Variablen:
SFVec3f _sfSizeDiagonale Größe des mit den Slices auszufüllenden Quaders.

73
SFPnt3f _sfCenterMittelpunkt des mit den Slices auszufüllenden Quaders.
SFInt32 _sfNumberOfPositionedSlicesDiese Variable speichert die Anzahl der anzuzeigenden Slices. Sie bezieht sich auf das Slicingentlang der Raumdiagonalen _sfSize. Bei Betrachtung des Textur-Quaders aus einer ande-ren Richtung kann die tatsächliche Anzahl der Slices variieren. Der Abstand zwischen zweibenachbarten Slices bleibt stets konstant.
6.9.8 PositionedSlicesBeschreibung:Eine Instanz dieser Klasse wird von jedem Octree-Blatt verwaltet. Sie ist für die Darstellung derzugehörigen 3D-Textur zuständig.
Methoden:
Action::ResultE drawPrimitives(DrawActionBase* action)Durch die Ableitung von MaterialDrawable kann diese Klasse auch separat zur Darstellungvon 3D-Texturen verwendet werden. Diese Methode bietet den Einstiegspunkt beim Traver-sieren des Szenengraphen.
void drawPositionedSlices(const Vec3f& planeNormal, UInt32& triCount, UInt32& vertexCount)Diese Methode wird vom Octree-Knoten aufgerufen, um die Slices zur Darstellung der 3D-Textur zu zeichnen. Die Slices werden orthogonal zum Vektor planeNormal ausgerichtet. IntriCount und vertexCount wird für die Statistik die Anzahl der gezeichneten Dreiecke bzw.Punkte geschrieben.
6.9.9 SystemInformationBeschreibung:
Diese Klasse ist plattformspezifisch (Windows) und bietet statische Methoden zur Abfrage derGröße des zur Zeit freien Arbeitsspeichers sowie seiner Gesamtgröße. (Diese Daten werden vomVerfeinerungsorakel benötigt.)
Methoden:
static unsigned long getFreePhysicalMemory()Gibt die Größe des momentan freien Arbeitsspeichers (ohne Auslagerungsdatei) in Byteszurück.
static unsigned long getTotalPhysicalMemory()Gibt die Gesamtgröße des Arbeitsspeichers (ohne Auslagerungsdatei) in Bytes zurück.

74
7 Das AVS-ModulDas in dieser Arbeit entwickelte AVS-Makro ermöglicht es, die in den Kapiteln 5 und 6 vorgestell-ten OpenSG-Implementierungen in dem kommerziellen Visualisierungspaket AVS/Express [34]einzusetzen. Das Makro definiert eine grafische Benutzeroberfläche und ein Modul für die OpenSG-basierte Visualisierung. Dieses Modul besteht intern aus den drei Hauptkomponenten Datenimport,Rendersystem und Visualisierungssystem.
Abschnitt 7.1 gibt einen genaueren Überblick über das AVS-Makro. 7.2 beschreibt die AVS-Mo-dul-Schnittstelle und stellt einige wichtige Funktionen der Modulbeschreibungssprache „V“ vor.In 7.3 wird geschildert, was speziell beim Einbinden von OpenSG-Funktionalität in AVS beachtetwerden muss. Die Abschnitte 7.4 bis 7.6 erläutern die drei oben genannten Hauptkomponenten desAVS-Moduls. Abschnitt 7.7 behandelt die Tetraederzerlegung von Pyramiden, Prismen und Hexa-edern, bevor in 7.8 die grafische Benutzeroberfläche vorgestellt wird. Die letzten beiden Abschnit-te beenden das Kapitel mit einem Überblick über die Methoden des VolumeRender_UCD-Mo-duls und einer kurzen Beschreibung der entworfenen C++ Klassen.
7.1 Modul-ÜberblickAVS erlaubt die Einbindung eigener Module und die Verknüpfung von bestehenden Komponentenzu sogenannten Makros. In dieser Arbeit wurde das Makro VolumeRender_UCD_GUI entwor-fen. Es hat einen Dateneingang, der über ein data_math-Modul an das eigentliche, in C++ pro-grammierte Modul VolumeRender_UCD angeschlossen ist. Das Modul data_math dient ledig-lich dazu, eingehende Volumendaten stets in den Datentyp float umzuwandeln. So werden denDatentyp betreffende Fallunterscheidungen im VolumeRender_UCD-Modul vermieden.VolumeRender_UCD selbst ist die Hauptkomponente im Makro. Sie erzeugt aus den Volumen-daten einen OpenSG-Szenengraph, den sie in einem GLUT-Fenster rendert. Eine weitere Kompo-nente von VolumeRender_UCD_GUI ist das in V-Code geschriebene Makro SettingsUI. Esbietet dem Benutzer Einstellmöglichkeiten zu den beiden implementierten Visualisierungstechniken.Der Transferfunktionseditor ist ebenfalls Bestandteil des Makros. Er gehört zum AVS-Paket undbietet hier dem Benutzer die Definition von Transferfunktionen an. Abb. 7.1 zeigt die Komponen-ten des Makros VolumeRender_UCD_GUI und ihre Verknüpfungen.
Abb. 7.1:Komponenten des Makros VolumeRender_UCD_GUI.

75
7.2 AVS-Modul-SchnittstelleMöchte man selbstprogrammierte Abläufe in AVS verwenden, ist dies über die Modul-Schnittstel-le möglich. Einbinden lässt sich C++ oder Fortran-Code. Jedes AVS-Modul hat Datenein- undausgänge, Variablen und Funktionen. Diese Eigenschaften werden mit der AVS-eigenenBeschreibungssprache V (Dateieindung „.v“) definiert. V-Code für ein Modul befindet sich relativzum Modulverzeichnis stets in der Datei „./v/templ.v“. Um dem Leser einen Eindruck über V-Code zu geben, folgt ein kurzes Beispiel.
1 WORKSPACE_1 {2 module VolumeRender_UCD<src_file="DVR_UCD_OSG.cpp",process="DVR_UCD_OSG"> {3 cxxmethod+notify_inst runOnInstantiation();4 cxxmethod+notify_deinst runOnDeinstantiation();5 cxxmethod runOnTransferFunctionChange(6 applyButtonTransferFunction+notify+req);7 int+read+write applyButtonTransferFunction;8 };9 };
In AVS sind mehrere Workspaces zum Ablegen eigener Module vorgesehen. Durch die AngabeWORKSPACE_1 im V-Code wird das Modul VolumeRender_UCD im Workspace Nr. 1 in derWorkspaces-Library abgelegt. In der zweiten Zeile wird für das Modul angegeben, in welcherDatei relativ zum Modulverzeichnis sich der Code für seine Funktionen befindet (src_file=“...“).Die korrekte Angabe der Quellcode-Datei ist nur dann notwendig, wenn man die Compilierung desModulcodes über das Menü von AVS initiieren möchte. Stattdessen kann man jedoch auch seineeigene Entwicklungsumgebung für diesen Zweck einsetzen (unter Windows z. B. Visual Studio).Außerdem definiert die zweite Zeile, wie der Prozess heißen soll, in dem der Modulcode abläuft(process=“...“). Wird hier process=“express“ angegeben, so läuft der Modulcode nicht in einemeigenen Prozess ab, sondern im gleichen wie die AVS-Software selbst. Das verkürzt zwar dieInitialisierungszeit beim Ausführen von Modulcode; falls ein Absturz im Modul stattfindet, stürztjedoch auch AVS mit ab.
In den Zeilen 3, 4 und 5 wird mit dem Schlüsselwort cxxmethod je eine C++ Methode definiert.Variablen und Methoden werden in V C-ähnlich definiert, können aber mit zusätzlichen Schlüssel-worten versehen werden. Die Zusätze +notify_inst und +notify_deinst z. B. geben an, dass diebetreffende Methode bei der Instanzierung bzw. Deinstanzierung des Moduls aufgerufen werdensoll. Eine Modulinstanzierung findet statt, sobald ein Benutzer in AVS das Modul per „Drag andDrop“ aus dem Workspace in ein Applikations-Fenster zieht. Die Deinstanzierung entspricht demLöschen des Moduls aus dem Applikations-Fenster.
In der Definition der Methode runOnTransferFunctionChange wird durch Angabe eines Variablen-namens gefolgt von +notify festgelegt, dass diese Methode immer dann ausgeführt wird, wenn sichdie angegebene Variable ändert. Wegen dem Zusatz +req darf die Methode aber nur ausgeführtwerden, wenn diese Variable bereits einen Wert zugewiesen bekommen hat.applyButtonTransferFunction selbst wird in Zeile 7 als Integer-Variable festgelegt, auf die dasModul Lese- und Schreibzugriff hat (+read+write).
Falls man das Modul über den Object-Editor von AVS erzeugt (dieser ermöglicht die GUI-basierteDefinition von neuen Modulen), wird zusätzlich zum V-Code eine Quelltextdatei mit entsprechen-dem C++ Code (inklusive Makefile sowie Workspace für Visual Studio 6.0) angelegt. Die Klasse

76
zu obigem Modul würde WORKSPACE_1_VolumeRender_UCD heißen, d. h. der Klassen-name wird aus dem Workspace- und dem Modulnamen zusammengesetzt. Einer ähnlichen Namens-konvention sind die C++ Methodenbezeichnungen unterworfen. Die Instanzierungs- undDeinstanzierungsmethode im V-Code kann man als Konstruktor bzw. Destruktor eines Modulsverstehen, während die übrigen Methoden Callback-Funktionen sind. Sie werden ausgeführt, so-bald sich bestimmte Modul-Variablen ändern.
Der C++ Code für ein Modul muss, bevor das Modul in AVS verwendet werden kann, zunächstcompiliert werden. Dies ist entweder mit einer eigenen Entwicklungsumgebung oder über denMenübefehl Project/Compile zu erledigen. Das Executable liegt dann im Unterverzeichnis „./bin/pc/“ und muss genauso heißen wie im V-Code mit „process=...“ angegeben, im obigen Beispielalso „DVR_UCD_OSG“ bzw. „DVR_UCD_OSG.exe“ für die Windows-Plattform.
7.3 Einbindung OpenSG-basierter FunktionalitätUnser Ziel ist, die in Kapitel 5 und 6 beschriebenen und bereits mit OpenSG implementiertenVisualisierungstechniken in AVS zu nutzen. Wir wollen uns überlegen, wie ein Visualisierungs-modul VolumeRender_UCD beschaffen sein muss, um dies leisten zu können.
Das Modul benötigt als wesentlichen Bestandteil ein Renderfenster, in dem stets der momentaneOpenSG-Szenengraph angezeigt wird. Für die ständige Anzeige dieses Fensters muss das Moduleine im Hintergrund laufende Endlosschleife mit entsprechender Eventverarbeitung besitzen (ähn-lich der Funktion glutMainLoop() für GLUT-Programme). Im Widerspruch hierzu steht jedoch dieAVS-Philosophie, nach der bei einem Modulmethodenaufruf die Methode wieder beendet werdenmuss, bevor das AVS-Hauptprogramm weiterläuft. Würde man eine Endlosschleife direkt in einerModulmethode betreten, so würde die AVS-Software nicht mehr reagieren, weil sie vergeblich aufeine Beendigung der Modulmethode warten würde.
Die Lösung für dieses Problem ist, in der Modulmethode einen weiteren Thread zu erzeugen (inVolumeRender_UCD ist dies der Visualizer, siehe Abb. 7.2), der bis zur Deinstanzierung desModuls aktiv ist und die Eventverarbeitung für das Renderfenster übernimmt.
Abb. 7.2:Die Erzeugung eines zusätzlichen Threads (Visualizer) ermöglicht die Verwaltung einesmoduleigenen Renderfensters.
$�� 2�������;FG#�F?�< �������,��
2���������?�H�������������H�����,������
��,�����4�������������,��

77
7.4 DatenimportDieser Abschnitt stellt von AVS unterstützte Volumendaten-Dateiformate vor (7.4.1), erklärt dieinterne Speicherung eingelesener Daten (7.4.2) und beschreibt die C++ Klassen, die diese Arbeitzur Verwaltung der Daten einsetzt (7.4.3).
7.4.1 AVS-Datenformate für VolumendatenAVS ist in der Lage, zwei allgemeine und hauptsächlich im CFD-Umfeld verwendete Datenforma-te einzulesen: CGNS [19] und NetCDF [21] (siehe auch Kapitel 9). Ein wichtiges Feature dieserFormate ist die Möglichkeit der Speicherung mehrerer Datensätze in einer Datei. CGNS und NetCDFbieten zusätzlich die Möglichkeit der Selbst-Dokumentation, z. B. über einen einleitenden ASCII-String vor einem Datensatz. Eine solche Allgemeinheit hat aber auch zur Folge, dass ein Benutzernach dem Einlesen der Datei zunächst angeben muss, welcher der beinhalteten Datensätze für z. B.eine Visualisierung verwendet werden soll, und wie dieser Datensatz zu interpretieren ist. DieAVS-Module zum Einlesen dieser Formate heißen Read_CGNS bzw. Rd_netCDF_Fld undRd_netCDF_Obj.PLOT3D ist ein spezielleres, aber mittlerweile veraltetes Dateiformat aus dem CFD-Bereich, dasAVS einlesen kann (Modul Read_PLOT3D). Ein großer Nachteil ist, dass PLOT3D keineunstrukturierten Gitter erlaubt.
Desweiteren können Volumendaten auch schichtweise aus einzelnen 2D-Bildern eingelesen wer-den, dies macht das Modul Read_Img2Vol möglich. Als Bildformate sind u. a. BMP, GIF, JPEGund TIFF zugelassen.
AVS bietet außerdem ein proprietäres, aber sehr einfaches Volumendatenformat an, das die Be-zeichnung „AVS Volume“ trägt. Es speichert Volumendaten des Typs unsigned char auf regulärenGittern. Die Daten werden binär als ein großes Array in der Datei abgelegt und mit einem drei Bytegroßen, binären Header versehen, der die Größe des Gitters in x-, y- und z-Richtung angibt. Durchdiese Festlegung beträgt die maximale Gittergröße 2553.
Das für AVS-Anwendungen am häufigsten benutzte Format ist das AVS Field Format [22]. Esberuht auf der Definition von Gitterpunkten, die mit Volumen- oder Vektordaten versehen werdenkönnen. Über einen ASCII-Header werden AVS alle zum Einlesen der Daten notwendigen Infor-mation mitgeteilt: Gittertyp (regulär, rektilinear, irregulär) und Gittergröße, Datentyp für die Volu-men- oder Vektordaten (byte, integer, float, double) sowie Angaben von Dateien, in denen dieeigentlichen Daten (Volumen- / Vektordaten und ggf. Koordinaten der Gitterpunkte) stehen. DieDaten und Gitterpunktkoordinaten können binär oder in ASCII-Codierung eingelesen werden; dieAngabe von Offsets ist genauso möglich wie ein Stride-Mechanismus. Die Offset-Angabe erlaubtdas Überspringen eines Headers, bevor das Einlesen der Daten beginnt. Durch den Stride-Mecha-nismus ist es möglich, zwischen zwei einzulesenden Daten eine feste Anzahl von Daten zu über-springen. So wird beispielsweise mit einem Stride von 3 nur jedes dritte Datum eingelesen, zweiDaten werden jeweils übersprungen. Über das Setzen von Zeitschritten erlaubt das Field Formatauch zeitliche Veränderungen der Daten.
Das Field Datenformat ist zwar relativ allgemein gehalten, erlaubt aber keine unstrukturierten Git-ter. Zu diesem Zweck dient in AVS das UCD-Format (Unstructured Cell Data) [23]. Dies ist einASCII-Format, das aus drei Hauptblöcken besteht: Definition von Punkten im 3D-Raum, Angabevon 1D- 2D- oder 3D-Primitiven (sogenannte Zellen, deren Eckpunkte die zuvor definierten Punk-te sind) und Zuweisung von Volumen- oder Vektorwerten. Ein Wert kann einem Zellen-Eckpunkt(NodeData), der gesamten Zelle (CellData) oder einer Gruppe von mehreren Zellen (ObjectData)

78
zugewiesen werden. Für unstrukturierte Volumendaten verwendet man typischerweise Volumen-werte an den Eckpunkten der Zellen (NodeData) und interpoliert im Zelleninneren. Mögliche 3D-Zelltypen im UCD-Format sind Tetraeder, Pyramiden, Prismen und Hexaeder (siehe Abb. 7.3). DerDatentyp für Volumen- und Vektordaten ist im UCD-Format zwar nicht festgelegt, AVS speichertsolche Werte nach dem Einlesen jedoch stets im 32-Bit-Gleitkomma-Format.
7.4.2 Die Field-Datenstruktur in AVSUnabhängig vom verwendeten Dateiformat speichert AVS die eingelesenen Daten intern in einerField-Datenstruktur, die im Wesentlichen aus drei Records besteht: coordinates, node_data undcell_set (siehe Abb. 7.4).
coordinates verwaltet ein Array values von 32-Bit-Gleitkommazahlen, das die Koordinaten derGitterpunkte hält. Die Speicherung erfolgt nach dem Schema x1, y1, z1, x2, y2, z2, usw.
In node_data gibt es ebenfalls ein Array values, das jedoch die Werte enthält, die den Gitter-punkten zugeordnet sind. Das values-Array in node_data hat stets dieselbe Länge wie das values-Array in coordinates, d. h. jedem Punkt wird immer genau ein Wert zugeordnet (wobei dieserWert ein Skalar oder ein Vektor sein kann). node_data selbst ist aber auch ein Array, so dass denGitterpunkten auf mehreren Ebenen Werte zugeordnet werden können.
cell_set ist wie node_data ebenfalls ein Array, bei dem jeder Array-Eintrag wiederum ein Recordist. Ein solcher Record kann eine Menge von Zellen definieren, die alle denselben Typ (z. B. Tetra-eder) haben. In einem Index-Array node_connect_list werden für alle diese Zellen fortlaufendVertex-Indizes gespeichert (die Indizes beziehen sich auf die oben genannten coordinates), diedie Eckpunkte der Zellen angeben. Im 1D- und 2D-Fall sind beliebige Polygone erlaubt; hierfür istdas Array poly_connect_list vorgesehen. Ferner erlaubt der Record die Speicherung von den Zel-len zugeordneten Daten über ein Array cell_data.
7.4.3 C++ Klassen zur Verwaltung der Field-DatenDie in der Field-Datenstruktur gespeicherten Daten sind in AVS über die Variable ucd desVolumeRender_UCD-Moduls ansprechbar. Für den Zugriff auf diese Daten aus dem C++ Codeheraus stellt die C-Bibliothek von AVS Funktionen bereit. Werte primitiver AVS-Variablen (vomTyp int, float, usw.) werden direkt ausgelesen und in eine entsprechende C-Variable kopiert; fürden Array-Zugriff liefern die Bibliotheksfunktionen C-Pointer, mit deren Hilfe jeder einzelne Wert
(
)
(
) +
*
(
*
)
(
)
+
*
D
A
4�������� �I������ ������ E�������
Abb. 7.3:3D-Zelltypen im UCD-Format. Wenn die Zellen über Punktlisten gespeichert werden, istauf die durch die Zahlen in den Eckpunkten gegebene Reihenfolge zu achten.

79
gelesen oder auch geschrieben werden kann, je nach angeforderter Art des Zugriffsrechts.
Einerseits werden die Field-Daten sowie die GUI-Einstellungen an unterschiedlichen Stellen imSystem benötigt, andererseits sollte jedoch für eine bessere Übersichtlichkeit und Wartbarkeit dieSchnittstelle zu AVS möglichst klein gehalten werden. Um beidem gerecht zu werden, wurde eineKlasse AVSAccess angelegt, die sämtliche AVS-Datenzugriffe kapselt und die eingelesenen Da-ten und Array-Pointer in Objekten speziell dafür vorgesehener Klassen puffert. So können Infor-mationen gebündelt an verschiedene Komponenten im System weitergegeben werden.
Analog zu den drei Hauptrecords der Field-Datenstruktur gibt es drei solcher Datenpuffer-Klassen:VertexArray (Gitterpunktpositionen), NodeData (Volumenwerte) und Cell (Zelltyp und Index-liste). Primitive Datentypen werden als Kopie in diesen Klassen gehalten, im Fall von Arrays wer-den lediglich Pointer auf die von AVS verwalteten Daten gespeichert. Der Record für die Zelldatencell_data wird für dieses AVS-Modul nicht benötigt.
Da node_data und cell_set Arrays sind, wurden die Klassen NodeDataVector und CellVectordefiniert; sie speichern eine Menge von Pointern auf ein NodeData- bzw. Cell-Objekt. Zur Visua-lisierung eines Volumendatensatzes ist nur ein einziger node_data-Record nötig, daher wird hiernur der erste im NodeDataVector vorhandene Datensatz benutzt. Für eine Instanz nodeDataVectorder Klasse NodeDataVector entspricht also nodeDataVector[0] einem Pointer auf ein Objektder Klasse NodeData. Einen Pointer auf die eigentlichen Volumendaten erhält man mit
nodeDataVector[0]->getValues()Von CellVector müssen jedoch alle Komponenten beachtet werden, da in jedem seiner Recordseine weitere Menge von zu visualisierenden Zellen definiert wird. Für eine Instanz cellVector vonCellVector könnte z. B. cellVector[0] ein Pointer auf eine Cell-Instanz sein, in der eine Menge
Abb. 7.4:Schemtische Darstellung der AVS-internen Field-Datenstruktur. Daten aus allenDateiformaten werden auf diese Datenstruktur abgebildet.
�����
���������������
������� JJ�(%� %�)
5�����&������K����������>����L
��������������������������
����F����F�I!��&������K���������L�K&�����L
����������� ������������ �
����F�I!���I!�
��������F�������F�����K&�I!��>����#����L
����!��IF�������F�����K �>�������I�L
�����������F�����K���#�������L
������������M��������58�����������I���

80
von Tetraedern definiert wird, wohingegen beispielsweise cellVector[1] eine Menge von Hexa-edern beschreiben könnte.
7.5 RendersystemAus den nach dem Import in AVSAccess verfügbaren Daten wird durch das Rendersystem einSzenengraph zur Visualisierung erstellt. Das Rendersystem besteht aus verschiedenen Renderer-Klassen und einem RenderManager. Die Renderer-Klassen sind für die eigentlicheSzenengrapherstellung zuständig, während der RenderManager die Renderer verwaltet und dieSchnittstelle zum übrigen System darstellt. Der Entwickler kann beliebig viele weitere Rendererzu den schon bestehenden hinzufügen und so das Rendersystem erweitern. Jeder Renderer läuft ineinem eigenen Thread; dadurch kann der Benutzer während einer Szenengrapherstellung in AVSoder mit dem Visualisierungssystem weiterarbeiten.
Jeder Renderer wird abgeleitet von der Basisklasse Renderer. Die endlos laufende Verarbeitungs-schleife in Renderer ruft, falls neue Daten eingelesen wurden, die Methoden precompute() undcreateSceneGraph() auf. In precompute() finden Vorberechnungen statt (z. B. Zerlegen vonHexaedern in Tetraeder), während createSceneGraph() für die eigentliche Szenengrapherstellungvorgesehen ist. In einer von Renderer abgeleiteten Render-Klasse müssen nur diese beiden Me-thoden überladen werden. Eine Erweiterung der Funktionalität von Renderer bietet die abgeleite-te Klasse AdaptiveRenderer. Ihre Hauptverarbeitungsschleife enthält den Aufruf einer weiterenMethode renderStep(), die dazu dient, Änderungen auf einem bereits erstellten Szenengraph durch-zuführen.
In dieser Arbeit werden zwei Render-Klassen benutzt: ProjectedTetrahedraRenderer (direktvon Renderer abgeleitet) zur Nutzung des Shirley-Tuchman-Verfahrens undHierarchicalTextures3DRenderer (von AdaptiveRenderer abgeleitet) für die Darstellung mithierarchischen 3D-Texturen. Abb. 7.5 gibt einen Überblick über die Klassenhierarchie.
In beiden Renderer-Klassen bestehen die Vorberechnungen in precompute() aus einer Normali-sierung der Volumenwerte und der Zerlegung von Pyramiden, Prismen und Hexaedern in Tetraeder
;���������!�����!�����������������<��!��
$��!��&�;������������������!�
���������4���������;������� E�����������4�������)�;�������
Abb. 7.5:Hierarchie der Renderer-Klassen. (In den Klassendiagrammen sind nur die hier relevantenMethoden aufgeführt.)

81
(siehe Abschnitt 7.6). In createSceneGraph() wird ein OpenSG-Knoten (ProjectedTetrahedra bzw.HierarchicalTextures3D, siehe Kapitel 5 bzw. 6) erzeugt, dem dann die Tetraeder zugeordnetwerden. Für die Visualisierung der Tetraeder sind nun die OpenSG-Knoten verantwortlich.
7.6 VisualisierungssystemDas Visualisierungssystem besteht aus einer einzigen Klasse namens Visualizer. Visualizer ver-waltet ein GLUT-Fenster für die grafische Ausgabe und zeigt dort stets den aktuellen Szenengraphan. Für jedes Renderer-Objekt reserviert der Visualizer in seinem Szenengraph einen Teilbereich,für den allein dieses Renderer-Objekt zuständig ist. So werden Zugriffskonflikte im Visualizer-Szenengraph vermieden. Dieses Design erlaubt ein gleichzeitiges Anzeigen der Resultate verschie-dener Renderer. Die hierarchischen 3D-Texturen gleichzeitig mit den texturierten Dreiecken ausdem Shirley-Tuchman-Verfahren anzuzeigen macht zwar keinen Sinn, aber man könnte weitereRenderer-Klassen implementieren, die z. B. Orientierungshilfen wie etwa Koordinatenachsen an-zeigen könnten.
G�������������������������2�������������� ���?��������
#�������!�������������
���:�'����������������
G������������$��'�������������
K$���'��������5�����������&�����?��������#������L
5������������������
����������
0�������,�������!���5�$�!����
�!�����������,���$�!������������#�����C���
���:�'����������������
�!����$�!����������C���K����2������%�����N�������������,�������!�
�������58����'�����7���������������G!����L
2���� ?;"��$#MF( $��$����� ;������ ;������� �������,��������;������ F������;������ 2������
FG#� FG#�
�!����$�!���:�'�K�I��������������&���;��������4�����������������,���4�����7�������,���8������������N��������������������C���L
Abb. 7.6:Sequenzdiagramm über die beim Anlegen neuer Daten an das Modul VolumeRender_UCDausgeführten Aktionen. Die unterstrichenen Klassennamen stehen für eigenständigeThreads.

82
Während ein Szenengraph geändert wird (z. B. durch Änderung der Transferfunktion oder garEinlesen eines neuen unstrukturierten Volumendatensatzes), kann er nicht gleichzeitig dargestelltwerden. Für den Benutzer äußert sich dies je nach Dauer der Änderung in einer kurzen oder auchlängeren Wartezeit. Um dem Benutzer hier entgegenzukommen und eine möglichst ungestörte In-teraktion zu ermöglichen, arbeitet der Visualizer auf einem von den Renderern unabhängigen Spei-cherbereich. Jede von den Renderern erzeugte Szenengraphkomponente (OpenSG-Field-Contai-ner wie Knoten und Cores dieser Knoten, sowie die Member der Container) existiert zweimal. Diesist ein in OpenSG integrierter Mechanismus, der für den Programmierer transparent verwendbar ist(siehe [30]). Die unterschiedlichen Speicherbereiche werden als Aspekte bezeichnet. So kann einRenderer auf Aspekt 0 den Szenengraph ändern, während der Visualizer den in Aspekt 1 vorhande-nen Graph zur Anzeige verwendet. Sobald der Renderer seine Szenengraphänderungen abgeschlos-sen hat, können die Änderungen auf Aspekt 1 übernommen werden. Hierfür müssen Renderer undVisualizer synchronisiert werden, und der Visualizer muss während dieser Zeit die Anzeige desGraphen unterbrechen. Diese Unterbrechung ist aber kurz verglichen mit der Zeit, die der Rendererfür die Änderungen auf dem Szenengraph benötigt.
Abb. 7.6 veranschaulicht in einem Sequenzdiagramm die Reihenfolge der nach dem Anlegen neu-er Daten ausgeführten Aktionen.
7.7 TetraederzerlegungDa die beiden verwendeten Techniken zur direkten Volumenvisualisierung tetraederbasiert arbei-ten, müssen die in AVS erlaubten 3D-Primitive (Pyramiden, Prismen, Hexaeder, siehe Abb. 7.3 inAbschnitt 7.4.1) in Tetraeder zerlegt werden. Diese 3D-Primitive besitzen an ihrer Oberfläche Drei-ecke und Vierecke (Pyramide, Prisma) bzw. nur Vierecke (Hexaeder). Sobald zwei benachbartePrimitive eine gemeinsame Vierecksoberfläche besitzen, ist die Zerlegung der Primitive nicht mehrbeliebig wählbar, wie Abb. 7.7 veranschaulicht.
Für die Teilung des Vierecks in zwei Dreiecke muss in beiden Fällen dieselbe Diagonale gewähltwerden. Falls nämlich die Diagonalen nicht identisch sind und die Punkte des Vierecks keine Ebe-ne bilden, so liegen die Diagonalen windschief zueinander. Das würde entweder eine Überschnei-dung der Tetraeder oder eine Lücke zwischen ihnen zur Folge haben, was sich in der Visualisierungdurch zu opake bzw. zu transparente Übergänge zwischen benachbarten Tetraedern äußern würde.
Im Folgenden wird für Pyramiden, Prismen und Hexaeder beschrieben, wie die Tetraederzerlegungunter Beachtung der dargestellten Problematik in dieser Arbeit erfolgt.
$
�
#
�
Abb. 7.7:Eine gemeinsame Vierecksoberfläche erfordert eine zwischen den beiden angrenzendenPrimitiven (hier: Hexaedern) abgestimmte Zerlegung. Zur Zerteilung der grauen Fläche inDreiecke muss entweder in beiden Fällen die Diagonale AC oder die Diagonale DB gewähltwerden.

83
7.7.1 PyramidenEs gibt zwei verschiedene Möglichkeiten, eine Pyramide in zwei Tetraeder zu zerlegen. Entwederverläuft eine diagonale Kante zwischen den Punkten mit den Indizes i1 und i3, oder sie verläuftzwischen i2 und i4 (siehe Abb. 7.8). Wir wählen die Kante, die den kleinsten der vier Indizes be-inhaltet (im Beispiel in Abb. 7.8 ist dies entweder i1 oder i3). Dieses Verfahren liefert bei der Zerle-gung der angrenzenden Pyramide dieselbe Diagonale für das Viereck i1 i2 i3 i4 und ist daher injedem Fall korrekt.
7.7.2 PrismenDie Oberfläche eines Prismas besteht aus zwei Dreiecken und drei Vierecken. Da jedes der Vierek-ke in zwei Dreiecke geteilt werden muss und es je zwei Möglichkeiten für die Lage der Diagonalengibt, existieren insgesamt 23 = 8 unterschiedliche Anordnungen für die Diagonalen. Wie Abb. 7.9zeigt, liefern jedoch nur 6 dieser Anordnungen eine Zerlegung in drei disjunkte Tetraeder.
Da die Diagonalen also nicht frei wählbar sind, kann das indexbasierte Verfahren aus 7.6.1 hiernicht angewendet werden. Zur Ermittlung einer überschneidungs- und lückenfreien Zerlegung isteine Betrachtung der Nachbarschaft unerlässlich. Leider stellt die AVS-Field-Datenstruktur keineZusammenhangsinformationen zur Auffindung benachbarter Primitive bereit. Ein Nachbarschafts-suche in der Menge aller bereits zerlegten Prismen würde in einem O(n2)-Algorithmus resultieren,wobei n die Gesamtanzahl aller Prismen des Datensatzes ist. Um dies zu vermeiden, wird eineheuristische Herangehensweise verwendet: Die Nachbarschaftssuche findet lediglich in der Men-ge der letzten 20 zuvor bearbeiteten Prismen statt.
7.7.3 HexaederEin Hexaeder kann man auf unterschiedliche Arten und Weisen in Tetraeder zerlegen. Eine Zerle-gung, die - unabhängig von einer vorgegebenen Anordnung der Oberflächendiagonalen - immerfunktioniert, wird beispielsweise folgendermaßen erreicht: Wir fügen im Zentrum des Hexaederseinen neuen Punkt ein, der mit allen acht Hexaederpunkten verbunden wird. So ergibt sich für jedeHexaederoberfläche eine Pyramide mit dem neuen Zentrumspunkt als Spitze. Mit den Pyramiden
Abb. 7.8:Dargestellt sind zwei angrenzende Pyramiden. Bei der Zerlegung einer Pyramide inTetraeder erfolgt eine eindeutige Kantenwahl ((i1, i3) oder (i2, i4)) über die Vertex-Indizes.
�
�( �
�)�*

84
kann dann wie in 7.7.1 fortgefahren werden. Hier soll jedoch eine Methode verwendet werden, diekeine weiteren Punkte einfügt und so wenig Tetraeder wie möglich benötigt.
Effizienter ist es, das Hexaeder zunächst in zwei Prismen zu teilen und diese dann wie in 7.7.2 zuzerlegen. So bekämen wir 6 Tetraeder. Hier muss jedoch für korrekte Übergänge zwischen Primi-tiven die Nachbarschaft mit berücksichtigt werden.
Eine noch effizientere Zerlegung erzeugt lediglich 5 Tetraeder. Sie basiert auf dem Abschneidenvon 4 Ecken, sodass nur noch ein Tetraeder übrigbleibt. Abb. 7.10 gibt zwei mögliche Zerlegungenin 5 Tetraeder an. Es gibt nicht mehr als diese zwei Möglichkeiten. Bevor wir diese Behauptungbeweisen, folgt noch zwei Definitionen.
7.7.3.1 Definition (Innen- und Außendreieck)
Bei der Zerlegung eines Hexaeders in Tetraeder wollen wir ein Dreieck als Innendreieck bezeich-nen, falls nicht alle seiner Kanten Teil eines Oberflächenvierecks des Hexaeders sind.Ein Dreieck, dass kein Innendreieck ist, nennen wir Außendreieck.
1���������������6�����
( )
* +1���������������6�����
D A
Abb. 7.9:Nur 6 der 8 möglichen Anordnungen der diagonalen Kanten bei einem Prisma liefern eineZerlegung in drei disjunkte Tetraeder.

85
7.7.3.2 Definition (Innen- und Außentetraeder)
Bei der Zerlegung eines Hexaeders in Tetraeder wollen wir ein Tetraeder als Innentetraeder be-zeichnen, falls seine Oberfläche nur aus Innendreiecken besteht.Ein Tetraeder, dass kein Innentetraeder ist, nennen wir Außentetraeder.
7.7.3.3 Satz
Es gibt nicht mehr als zwei Möglichkeiten (bis auf Umbenennung der Eckpunkte), ein Hexaeder infünf disjunkte Tetraeder zu zerlegen.
Beweis:Da jedes Viereck der Oberfläche des Hexaeders in Dreiecke zerlegt werden muss, besteht dieHexaederoberfläche nach der Zerlegung aus 12 Dreiecken. Die 5 für die Zerlegung benutzten Te-traeder liefern insgesamt 4 · 5 = 20 Oberflächendreiecke. 12 davon bilden die Oberfläche deszerlegten Hexaeders, daher bleiben 8 Dreiecke übrig, die nicht auf der Hexaederoberfläche liegen.Da an jede Tetraederinnenfläche ein weiteres Tetraeder anschließt, sind je 2 Innendreiecke dek-kungsgleich. Also gibt es 4 unterschiedliche Innendreiecke. Wir überlegen uns, wie die Kanten derInnendreiecke im Hexaeder liegen können. Sie können (i) auf einer Hexaederkante, (ii) auf einerDiagonalen einer Hexaederoberfläche oder (iii) auf einer Raumdiagonalen des Hexaeders liegen.Wir zeigen, dass nur Fall (ii) auftreten kann:
(i) Hexaederkante:Sei o.B.d.A. die Kante AB in Abb. 7.11 (links) eine Kante des Innendreiecks. Als weiterer Dreiecks-punkt können nicht die Punkte C, D, E, F gewählt werden, da das Dreieck dann ein Außendreieckwäre. Wählt man G oder H, so bekommt man eine Zerlegung des Hexaeders in zwei Prismen (also6 Tetraeder), im Widerspruch zur geforderten Zerlegung in 5 Tetraeder.
(iii) Raumdiagonale:Sei o.B.d.A. die Raumdiagonale in Abb. 7.11 (rechts) eine Kante des Innendreiecks. Wie manleicht sieht, führt die Hinzunahme eines beliebigen weiteren Punktes ebenfalls zu einer Prismen-zerlegung des Hexaeders.
Die Kanten eines Innendreiecks bestehen daher nur aus Diagonalen der Hexaedervierecks-oberflächen. Es gibt genau 6 solcher Diagonalen. Die einzige Möglichkeit, die 4 Flächen so anzu-ordnen, dass sich insgesamt 6 Kanten ergeben, wird durch ein Tetraeder gegeben. D. h., die 4Innenflächen bilden ein Innentetraeder. Alle Innentetraederkanten sind Diagonalen der Hexaeder-oberflächenvierecke. Gegenüberliegende Kanten des Innentetraeders müssen wie in Abb. 7.10 zu-einander verdreht sein, damit keine Prismenzerlegung entsteht. Durch die beiden gegenüberliegen-den Kanten ist das Innentetraeder bereits vollständig festgelegt. Das Setzen einer Diagonalen aufder Oberfläche des Hexaeders bestimmt daher bereits die Lage des Innentetraeders vollständig. Da
Abb. 7.10:Zwei Möglichkeiten der optimalen Zerlegung eines Hexaeders in 5 Tetraeder.

86
es bei einem Viereck nur zwei Möglichkeiten für die Lage einer Diagonalen gibt, gibt es auch nurzwei unterschiedliche Innentetraeder. Die vier an das Innentetraeder angrenzenden Außentetraedermüssen, wie in Abb. 7.10 dargestellt, mit den restlichen vier Hexaederpunkten verbunden sein,also wird durch die Lage des Innentetraeders die gesamte Tetraederzerlegung definiert. Bei genauzwei unterschiedlichen Lagen des Innentetraeders gibt es demnach genau zwei unterschiedlicheTetraederzerlegungen, was den Beweis abschließt.
Die Verdrehung gegenüberliegender Diagonalen lässt sich für die Tetraederzerlegung eines struk-turierten Gitters nutzen: Für je zwei benachbarte Hexaeder verwendet man unterschiedliche Zerle-gungen. Hierfür müssen während des Traversierens des Gitters lediglich die beiden Zerlegungenalternierend angewendet werden.
Abb. 7.12:Projektion eines Hexaedernetzes auf eine 2D-Ebene. Auf gegenüberliegendenHexaederflächen ist die Diagonale verdreht, was durch die Ziffern 0 bzw. 1 dargestelltwerden soll. Eine Vermeidung von Tetraederüberdeckungen oder -Lücken ist für diesesHexaedernetz nicht möglich, da sich das Aufeinandertreffen von zwei Flächen mitunterschiedlicher Diagonale nicht verhindern lässt.
(( (
Abb. 7.11:Links: Ein Innentetraeder hat keine Kante mit dem Hexaeder gemein.Rechts: Eine Raumdiagonale kann ebenfalls keine Kante eines Innentetraeders sein.
$ �
# �
M /
< E
$ �
# �
M /
< E

87
Bei unstrukturierten Gittern können Fälle wie in Abb. 7.12 auftreten, die bei der Zerlegung in 5Tetraeder keine Lösung des Tetraederüberdeckungs- bzw. Lückenproblems zulassen. Die Existenzeiner Zerlegung eines Hexaedergitters, bei der 5-Tetraeder-Zerlegungen und 6-Tetraeder-Zerle-gungen kombiniert werden dürfen, ist nicht leicht zu beweisen. Dieses Thema ist ein separatesForschungsgebiet (siehe z. B. [31]; zu Problemen bei Hexaederzerlegungen im Allgemeinen siehe[32]) und nicht Gegenstand dieser Arbeit.
Wir wollen hier ähnlich der Zerlegung der Prismen (7.7.2) heuristisch vorgehen und einen Algo-rithmus benutzen, der zwar nicht immer korrekte Resultate liefert, sich aber leicht implementierenlässt und für die meisten praktischen Fälle sinnvoll ist. Wir benutzen dabei die 5-Tetraeder-Zerle-gung. Der Algorithmus funktioniert folgendermaßen:
Suche unter den 20 zuvor zerlegten Hexaedern nach Nachbarn des aktuell zu zerlegenden Tetra-eders T, und lege für den ersten gefundenen Nachbarn die Zerlegung von T passend fest. Falls keinNachbar gefunden wird, wähle beliebig eine der beiden 5-Tetraeder-Zerlegungen.
7.8 Die grafische BenutzeroberflächeDie grafische Benutzerfläche für das AVS-Modul besteht aus drei Komponenten: dem Visualizer-Fenster, dem Settings-Fenster und dem Colormap-Editor-Fenster.
Das Visualizer-Fenster (Abb. 7.13) stellt die visualisierten Daten dar und bietet dem Benutzer eineStandard-Interaktion per Maus an. Die Szene lässt sich mit gedrückter linker Maustaste drehen, mitder mittleren Taste parallel zur Bildschirmfläche verschieben, und mit der rechten Taste kann manhinein- bzw. hinauszoomen.
Abb. 7.13:Visualizer-Fenster zur Visualisierung der Daten.
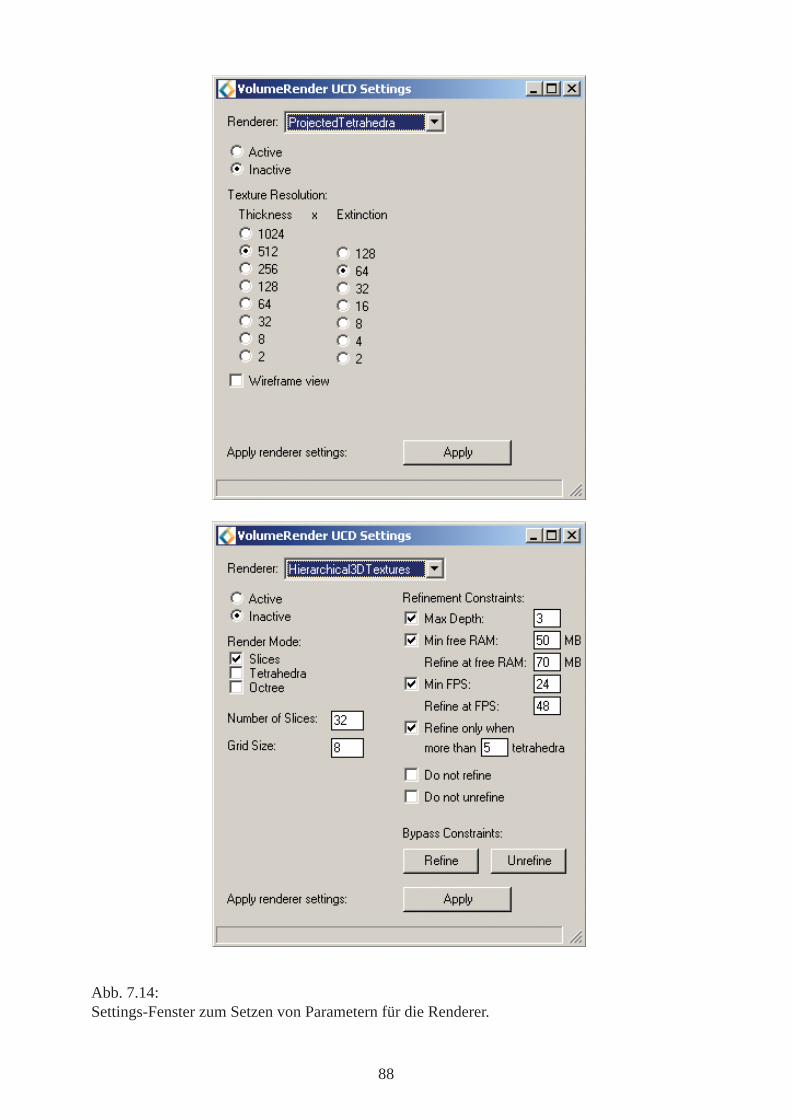
88
Abb. 7.14:Settings-Fenster zum Setzen von Parametern für die Renderer.

89
Das Settings-Fenster (Abb. 7.14) zeigt die Einstellungen für den ProjectedTetrahedraRendererbzw. für den HierarchicalTextures3DRenderer an. Beide Renderer können über die AuswahlActive / Inactive aktiviert oder deaktiviert werden. Ein aktivierter Renderer sorgt dafür, dass dieam Moduleingang anliegenden Daten auf eine bestimmt Art und Weise im Visualizer angezeigtwerden. Ist ein Renderer deaktiviert, so führt er keine Berechnungen durch, zeigt keine Szene imVisualizer-Fenster an und gibt ggf. zuvor reservierten Speicher frei. Der Benutzer muss bei allenRenderern nach dem Ändern von Einstellungen den Apply-Button betätigen, um die Änderungenwirksam werden zu lassen.
Für den ProjectedTetrahedraRenderer lässt sich die Auflösung der Alpha-Korrektur-Textur ändern,und eine Wireframe-Anzeige der zugrundeliegenden Tetraeder ist möglich.
Der HierarchicalTextures3DRenderer erlaubt unter Render Mode die Anzeige der 3D-Textu-ren (Slices), den ursprünglichen Tetraedern per Wireframe (Tetrahedra) sowie eine Wireframe-Darstellung der momentanen Octree-Knoten (Octree). Mit Number of Slices lässt sich die Anzahl
Abb. 7.15:Der Colormap-Editor bietet vorgegebene Transferfunktionen an und lässt dem Benutzer dieFreiheit, eigene Funktionen zu definieren oder bestehende abzuändern.

90
der zu überblendenden Ebenen pro Octree-Knoten festlegen. Grid Size definiert die Größe desregulären Gitters, auf das die Tetraeder rasterisiert werden. Wird für diese Größe der Wert n festge-legt, so wird das Gitter als reguläres Gitter der Größe n3 festgelegt. Unter Refinement Constraintslassen sich die unterschiedlichen Constraints zur Verfeinerung des Octrees einstellen bzw. an- undausschalten. Mit Max Depth kann man die Tiefe des Octrees beschränken. Falls momentan wenigerfreier Arbeitsspeicherspeicher vorhanden ist als unter Min Free RAM angegeben, so wird einVergröberungsschritt ausgeführt. Refine at Free RAM legt fest, wieviel RAM mindestens frei seinmuss, um einen Verfeinerungsschritt auszuführen. Dasselbe Schema gilt analog für die Vorgabeeiner minimalen Framerate mit Min FPS und Refine at FPS. Das Constraint Refine only when morethan ... tetrahedra bezieht sich auf die Anzahl von Tetraedern in einem Knoten, die mindestensnötig ist um einen Verfeinerungsschritt durchzuführen. Über Do not refine und Do not unrefinewird der automatische Verfeinerungs- und Vergröberungsmechanismus angehalten. Der Benutzerkann dann über die Buttons Refine und Unrefine den Octree selbst weiter verfeinern oder vergrö-bern.
Im Colormap-Editor (siehe Abb. 7.15) kann der Benutzer vordefinierte Transferfunktionen aus-wählen oder nach seinen eigenen Vorstellungen verändern. Dazu können mit der rechten Maustasteim Graphen Transfer Function Points weitere Kontrollpunkte eingefügt werden, denen mit dendarüberliegenden Reglern Farben und Opazitätswerte zugewiesen werden können. Mit gedrückterShift-Taste lassen sich Kontrollpunkte über die rechte Maustaste wieder löschen.
7.9 Methoden des VolumeRender_UCD-ModulsrunOnInstantiation():
Diese Methode wird bei der Modul-Instanzierung aufgerufen, d. h. wenn der Benutzer in AVS dasModul per Drag and Drop aus dem Workspace in ein Applikationsfenster zieht. Während derInstanzierung wird je eine Instanz von AVSAccess, ProjectedTetrahedraRenderer,HierarchicalTextures3D-Renderer, RenderManager und Visualizer erzeugt. Die Renderer-Threads werden im RenderManager registriert und gestartet. Der Visualizer-Thread wird eben-falls gestartet. Er öffnet ein GLUT-Fenster und baut einen Basis-Szenengraph auf, der noch keinerenderbaren Knoten enthält, jedoch bereit ist, Updates der Renderer entgegenzunehmen.
runOnSourceChange():Ein Aufruf dieser Methode erfolgt, wenn neue zu visualisierende Daten an den Moduleingangangelegt werden. AVSAccess liest die relevanten Daten aus AVS ein und speichert sie in dafürvorgesehenen Datenstrukturen (siehe Abschnitt 7.4.3). Dem RenderManager wird mitgeteilt, dassneue Daten vorhanden sind; er leitet diese Nachricht an alle registrierten Renderer weiter. DieMethode runOnSourceChange() wird beendet, wodurch andere Verarbeitungsschritte in AVSfortgeführt werden können. Die als eigenständige Threads laufenden Renderer lesen nun die inAVSAccess gespeicherten Daten, bauen daraus einen Szenengraphen und übertragen diesen anden Visualizer, der ihn in den Visualisierungsgraph einhängt. Eine Darstellung dieser Abläufezeigt das Sequenzdiagramm in Abb. 7.6.
runOnRendererControlAction():
Ein Aufruf erfolgt, sobald der Benutzer nach Änderung von Rendereinstellungen in der GUI (Fen-ster VolumeRender UCD Settings) den Button Apply betätigt. Über AVSAccess werden die aktu-ellen Einstellungen eingelesen und an den RenderManager übergeben, der sie wiederum an diezuständigen Renderer verteilt.

91
runOnTransferFunctionChange():
Diese Methode wird aufgerufen, wenn der Benutzer im GUI-Fenster ColormapEditor die Transfer-funktion geändert hat. AVSAccess liest dann die aktuelle Transferfunktionstabelle ein, undRenderManager verteilt sie an die einzelnen Renderer, die damit ihren Szenengraph aktualisie-ren und diese Änderungen an den Visualizer übermitteln.
runOnRefine():Diese Methode wird nach dem Betätigen des Refine-Buttons in der GUI für denHierarchicalTextures3DRenderer (Fenster VolumeRender UCD Settings) ausgeführt. Hier wirdlediglich die Methode bypassConstraintsRefine() auf dem HierarchicalTextures3DRendereraufgerufen. Der HierarchicalTextures3DRenderer führt dann den nächsten Verfeinerungsschrittunter Nichtbeachtung sämtlicher gesetzter Constraints durch. (Die Auswahl des zu verfeinerndenKnotens wird in Abschnitt 6.2.1 beschrieben.)
runOnUnrefine():
Analog zur vorhergehenden Methode wird runOnUnrefine() nach dem Betätigen des Unrefine-Buttons ausgeführt und dieses Kommando per Methodenaufruf bypassConstraintsUnrefine() anden HierarchicalTextures3DRenderer weitergeleitet.
runOnDeinstantiation():
Diese Methode wird aufgerufen, sobald der Benutzer das Modul VolumeRender_UCD aus derAVS-Applikation löscht. Die Renderer-Threads werden angehalten, reservierter Speicher wird frei-gegeben, und das OpenSG-Programm wird nach einem osgExit()-Aufruf beendet.
7.10 KlassenbeschreibungenDieser Teil des Kapitels nennt die zur Programmierung des AVS-Moduls entworfenen C++ Klas-sen und beschreibt ihre Bedeutung für das Gesamtsystem. Abb. 7.16 fasst die Beziehungen ineinem Klassendiagramm zusammen.
7.10.1 Basis-Klasse des Moduls
WORKSPACE_1_VolumeRender_UCD:WORKSPACE_1_VolumeRender_UCD ist die Modulklasse, deren in 7.9 beschriebene Metho-den von AVS aufgerufen werden. Die Methode runOnInstantiation() (siehe 7.9) bildet den Ein-stiegspunkt für die Ausführung des C++ Modulcodes.
7.10.2 Klassen für den Datenimport
AVSAccess:
Eine Instanz dieser Klasse wird in WORKSPACE_1_VolumeRender_UCD gehalten. Sie dientder Kapselung der AVS-Daten-Zugriffe.
VertexArray:
Dies ist eine weitere Klasse zum Halten von in AVS gespeicherten Daten. Sie hält als wesentlicheKomponente einen Pointer auf ein Array von Koordinaten, in dem die Positionen der Gitterpunktedefiniert werden.

92
Abb. 7.16:Klassendiagramm der für das Modul VolumeRender_UCD entworfenen C++ Klassen.Nicht aufgeführt ist die Klasse GeoUtils, die lediglich statische Methoden zurTetraederzerlegung enthält.
$��$�����
������$���I :�������������
:������� #���
#���������
#�������������
#�����������
;�����2�������������,��
;�������
$��!��&�;�������
(
>
(
>
(
>
?;"��$#MF(F������;�����FG#�
(
>
���������4���������;������� E�����������4�������)�;�������

93
Data:
Dies ist die Basisklasse von NodeData und CellData, die angelegt wurde, um die vielen Gemein-samkeiten jener beiden Klassen nicht doppelt implementieren zu müssen.
NodeData:Hier wird ein Pointer auf die den Vertices zugeordneten Daten sowie minimaler und maximalerDatenwert gespeichert.
NodeDataVector:
NodeDataVector spezialisiert die Klasse vector aus der Standard Template Library auf die Spei-cherung von NodeData-Pointern.
Cell:Diese Klasse dient zum Speichern von Zelldaten wie Zelltyp und Vertex-Index-Liste.
CellVector:
Hierdurch wird die vector-Klasse der STL auf das Halten einer Menge von Cell-Pointern speziali-siert. Werden in einem Datensatz mehrere Typen von Zellen (Tetraeder, Pyramiden, Prismen, He-xaeder) verwendet, so legt AVS für jeden Zelltyp mindestens eine AVS-Zell-Datenstruktur an. JedeAVS-Zell-Datenstruktur wird im C++ Code einer Instanz der Klasse Cell zugeordnet.
CellData:
Diese Klasse dient zum Speichern von Volumen- und Vektordaten, die einer Zelle zugeordnet wur-den. Sie wird von den in dieser Arbeit eingesetzten Visualisierungstechniken jedoch nicht verwen-det und lediglich aus Konsistenzgründen entworfen.
CellDataVector:
CellDataVector spezialisiert die Klasse vector aus der Standard Template Library auf die Spei-cherung von CellData-Pointern.
7.10.3 Klassen des Rendersystems
Renderer:Renderer ist die Basisklasse für alle Renderer. Charakteristisch für Renderer ist die Ausführungjeder Instanz in einem separaten Thread. Die Funktion des Renderers ist aufgeteilt in drei Bereiche:Vorberechnungen, Szenengrapherstellung und Übertragung des aktuellen Szenengraphs an denVisualizer.
AdaptiveRenderer:
Dies ist eine von Renderer abgeleitete Klasse, die die Renderfunktionalität um die periodischaufgerufene Methode renderStep() erweitert.
ProjectedTetrahedraRenderer:Diese Renderer-Klasse ist direkt von der Basisklasse Renderer abgeleitet. Sie ermöglicht die Ein-bindung des Shirley-Tuchman-Verfahrens.

94
HierarchicalTextures3DRenderer:
Dieser Bestandteil des Rendersystems ist von AdaptiveRenderer abgeleitet und sorgt für die Er-stellung eines OpenSG-Graphen zum Rendern mit hierarchischen 3D-Texturen.
RenderManager:Die Verwaltung der unterschiedlichen Renderer fällt in den Aufgabenbereich des RenderManagers.Dieser Manager nimmt Informationen, wie z. B. GUI-Einstellungen, entgegen und verteilt sie andie zuständigen Renderer. Er bietet ebenfalls eine zentrale Schnittstelle zum Starten oder Anhaltender Renderer-Threads.
GeoUtils:
Diese Klasse enthält statische Methoden zur in Abschnitt 7.7 beschriebenen Tetraederzerlegung.
7.10.4 Klassen des VisualisierungssystemsVisualizer:
Die Visualizer-Klasse stellt das Visualisierungssystem dar. Ihre Instanz läuft wie die Renderer ineinem eigenen Thread, jedoch arbeitet dieser Thread im Gegensatz zu den Renderern auf demOpenSG-Aspekt 1. So kann der Visualizer einen Szenengraph darstellen, dessen Kopie potenziellwährenddessen von einem Renderer geändert wird. Der Visualizer benutzt ein GLUT-Fenster fürdie grafische Ausgabe des Szenengraphen.

95
8 Zusammenfassung und AusblickIn dieser Arbeit wurden die grundlegenden Methoden für die direkte Volumenvisualisierungzusammengefasst und bezüglich Verwendbarkeit für unstrukturierte Gitter sowie Echtzeitfähigkeitverglichen. Das Shirley-Tuchman-Verfahren der projizierten Tetraeder und ein hierarchisches 3D-Textur-Verfahren wurden in C++ für die Szenengraphbibliothek OpenSG implementiert. DieseImplementierung beruht auf dem Entwurf zweier neuer OpenSG-Knoten. Durch die Zusammen-fassung aller benötigter Klassen zu der Erweiterungsbibliothek UnstructuredVolRenLib ist die In-tegration in eine bestehende OpenSG-Installation sehr einfach. Die OpenSG-Implementierung setztvoraus, dass das unstrukturierte Gitter durch eine Menge von Tetraedern gegeben wird. AnderePrimitive oder komplexere Strukturen müssen von einer Anwendung zuvor in Tetraeder zerlegtwerden. Die OpenSG-Knoten benötigen keine Zusammenhangsinformationen über die Tetraeder,und ein gegebenes Tetraedergitter darf Lücken haben und aus mehreren Zusammenhangs-komponenten bestehen. In der Implementierung wurde versucht, ein sinnvolles Gleichgewicht zwi-schen Verarbeitungsgeschwindigkeit (stets mit dem Ziel einer Echtzeitdarstellung) und Speicher-verbrauch zu finden. Ferner wurden die OpenSG-Knoten so entworfen, dass die Verwendung ineinem OpenSG-Clustersystem möglich ist. Die Implementierungen wurden bezüglich der Frame-Berechnungszeit in Abhängigkeit von verschiedenen Faktoren analysiert. Sofern Artefakte im be-rechneten Bild auftraten, wurden neben Beschreibungen und Verdeutlichungen an Beispielen Me-thoden zur Beseitigung dieser Artefakte erläutert.
Die für OpenSG programmierte Funktionalität wurde als Modul in das kommerzielle Visualisierungs-paket AVS/Express eingebunden, wobei auf eine benutzerfreundliche Bedienung und eine einfacheErweiterbarkeit geachtet wurde. Die Zerlegung der von AVS unterstützten 3D-Primitive in Tetra-eder ist ebenfalls Teil dieser Arbeit. Hierzu wurden auf Heuristiken beruhende, leicht umzusetzen-de Techniken verwendet. Das AVS-Modul wurde mit einer grafischen Benutzeroberfläche ausge-stattet, die es dem Benutzer erlaubt, verschiedene Moduleinstellungen komfortabel zu ändern. DasModul ist in ein Makro eingebettet, welches zusätzlich eine angenehme Möglichkeit zur Konfigu-ration der Transferfunktion zur Verfügung stellt. Das Visualisierungspaket AVS/Express wurde soum eine sinnvolle Funktionalität erweitert, die dieses Paket bisher nicht bietet.
Die Entwicklung erfolgte für das Windows-Betriebssystem. Da sowohl OpenSG als auch AVS/Express außerdem für viele Unix-basierte Systeme verfügbar sind, ist eine Anpassung an eins die-ser Systeme leicht durchführbar. Die OpenSG-Komponenten in der UnstructuredVolRenLib wur-den plattformunabhängig entwickelt, mit Ausnahme der Klassen Profiler (setzt einen windows-spezifischen High-Performance-Counter ein) und SystemInformation (Abfrage des momentanfreien Arbeitsspeichers). Nach einer Portierung dieser Funktionalität sind die Implementierungensofort auch auf anderen Betriebssystemen verwendbar.
Abgesehen von der Portierung auf andere Systeme gibt es weitere sinnvolle Erweiterungsmöglich-keiten der vorliegenden Implementierung. Beim Shirley-Tuchman-Verfahren könnte man durchBenutzung moderner Sortierverfahren garantieren, dass die Sichtbarkeitssortierung für alle Fällekorrekt ist. Zur Beschleunigung des Shirley-Tuchman-Verfahrens gibt es bereits Vertex-Shader-Ansätze, auf die in dieser Arbeit nicht eingegangen wurde. Mit solchen Ansätzen wurden bereitsDatensätze aus bis zu 40.000 Tetraedern in Echtzeit visualisiert [5]. Eine weitere Idee ist, die Klas-sifizierung und Dickpunktberechnung inkrementell durchzuführen. Dazu müsste man eine Metho-de finden, mit der man aus den berechneten Daten des vorhergehenden Frames und einer Änderungder Kameraposition die neuen Klassifizierungs- und Dickpunktdaten schneller finden kann, alsdies ohne Berücksichtigung der vorhergehenden Daten möglich ist. Außerdem könnte man versu-chen, analog zur Early Ray Termination des Raytracings ein Verfahren zu entwickeln, bei demverdeckte Tetraeder unberücksichtigt bleiben, wenn in diesem Bereich ohnehin schon eine Opazität

96
von nahezu eins erreicht ist. Dazu müsste man allerdings die Reihenfolge beim Compositing um-kehren.
Die Methode der hierarchischen 3D-Texturen könnte man durch Beseitigung von Artefakten beimÜbergang von Octree-Knoten unterschiedlicher Tiefe aufwerten. Methoden hierzu (kamerapositions-abhängiges Polygonclipping bzw. kamerapositionsabhängige Alpha-Korrektur) wurden in Kapitel6 vorgestellt. Sie haben jedoch den Nachteil einer höheren Rechenzeit pro Frame. Die sinnvollsteErweiterung für dieses Verfahren besteht in der Verwendung neuer Grafikhardware, die 3D-Textu-ren und Framebuffer auf Gleitkomma-Basis anbietet. Dies würde ermöglichen, die in Kapitel 6hergeleitete Alpha-Korrektur tatsächlich zu verwenden und damit die durch die momentan ange-wendete lineare Alpha-Korrektur vorhandenen Übergangsartefakte zu vermeiden.
Das AVS-Modul könnte man um die Funktionalität in einem OpenSG-Cluster erweitern sowieweitere effiziente Verfahren für reguläre und rektilineare Gitter einbauen, da AVS für die direkteVolumenvisualisierung bislang lediglich 2D-Textur-Verfahren und Raytracing beherrscht.
Ferner wäre es möglich, außer der hierarchischen Nutzung des 3D-Textur-Ansatzes auch andereschnelle Verfahren auf hierarchische Art und Weise zu verwenden. Vorstellbar wäre beispielsweiseein hierarchisches Shear-Warp-Verfahren.

97
9 Abkürzungsverzeichnis und BegriffserklärungenAVS-Makro
Ein Makro in AVS ist eine Zusammenstellung aus anderen Makros und Modulen. Ein Makrokann, ähnlich einem Modul, Datenein- und ausgänge besitzen. Makros werden auch alsNetzwerk bezeichnet.
AVS-ModulEin AVS-Modul ist ein atomares Element bei der Zusammenstellung von Makros. Es hatDatenein- und ausgänge, Variablen und Methoden. Über die Methoden kann der Benutzereigenen C++ oder Fortran-Code in das Modul integrieren.
CFDComputational Fluid Dynamics, ein wissenschaftliches Gebiet, in dem die Navier-Stokes-Gleichungen (oder Approximationen daran) zur Berechnung des zeitlichen Verhaltens vonTemperatur, Geschwindigkeit, Dichte und Druck in Flüssigkeiten oder Gasen benutzt wer-den.
CGNSCFD General Notation System [19]; hauptsächlich im CFD-Umfeld eingesetztes Dateiformat.Den Kern von CGNS bildet das nicht-proprietäre und portable ADF (Advanced Data For-mat, [20]). CFD beruht auf einer Baumstruktur, bei der jeder Knoten textuelle Beschreibun-gen und numerische Daten enthalten kann. Über Verknüpfungen zwischen Knoten sindDatenwiederverwendungen möglich.
Dickpunkt, Fernpunkt, NahpunktBei der Projektion eines Tetraeders auf die Sichtebene gibt es stets einen Sichtstrahl, der mitdem Tetraeder die größte Schnittmenge hat. Der Sichtstrahl dringt in das Tetraeder am Nah-punkt ein und verlässt es am Fernpunkt. Die Projektion von Nah- sowie Fernpunkt auf dieSichtebene heißt Dickpunkt.
FernpunktSiehe Dickpunkt.
NahpunktSiehe Dickpunkt.
NetCFDNetwork Common Data Form [21]; Format zur Speicherung von Array-basierten Daten. Selbst-dokumentation durch ASCII-Header sowie die Speicherung unterschiedlicher Datensätze ineiner Datei sind wie bei CGNS möglich. Besonderen Wert legt NetCFD auf Portabilität zwi-schen verschiedenen Rechnerplattformen.
PLOT3DEin von der NASA speziell für CFD-Daten entwickeltes Dateiformat. Es war bis Mitte der90er Jahre das Standard-Format in diesem Bereich, wurde jedoch den Weiterentwicklungenim CFD-Gebiet nicht mehr gerecht, da es z. B. keine unstrukturierten Gitter unterstützt.PLOT3D wurde durch das allgemeinere Format CGNS abgelöst.

98
Testsystem 1Die Laufzeittests in den Kapiteln 5 und 6 wurden auf einem Rechner mit einer AMD AthlonXP 2000 CPU @ 1666 MHz, 512 MB RAM und einer GeForce4 Ti 4600 GPU (128 MB,AGP 4x) unter Microsoft Windows 2000 Professional durchgeführt. Dieses System wird hierals Testsystem 1 referenziert.
VolumenwertSkalarer Wert an einem Gitterpunkt oder für eine Gitterzelle eines Volumendatensatzes. Aufunstrukturierten Gittern werden Volumenwerte an den Vertices (den Eckpunkten der Poly-eder) definiert.
ZielgitterBeim Resampling einer Tetraedermenge auf ein reguläres Gitter wird dieses Gitter als Ziel-gitter bezeichnet.

99
10 Literaturverzeichnis[1] Max, N., „Optical Models for Direct Volume Rendering“,
IEEE Transactions on Visualization and Computer Graphics, Vol. 1 no. 2, June 1995.http://www.llnl.gov/graphics/biblo.html
[2] Williams, P. L., Max, N., „A Volume Density Optical Model“, Workshop on VolumeVisualization, Boston, Massachusetts, October 1992.http://www.llnl.gov/graphics/biblo.html
[3] Levoy, M., „Efficient Ray Tracing of Volume Data“,ACM Transactions on Graphics (TOG), Vol. 9, Issue 3, pp. 245 - 261, July 1990.
[4] Shirley, P., Tuchman, A., „A Polygonal Approximation to Direct Scalar Volume Rendering“,Workshop on Volume Visualization and Computer Graphics, San Diego, December 1990.
[5] Wylie, B., Moreland, K., Fisk, L. A., Crossno, P., „Tetrahedral Projection Using VertexShaders“,Symposium on Volume Visualization and Graphics, Boston, Massachusetts, October 2002.http://www.cs.unm.edu/~kmorel/documents/volvis2002/
[6] Max, N., Williams, P., Silva, C., „Approximate Volume Rendering for Curvilinear andUnstructured Grids by Hardware-assisted Polyhedron Projection“,International Journal of Imaging Systems and Technology, Vol. 11, pp. 53 - 61, 2000.
[7] Leven, J., Corse, J., Cohen, J., Kumar, S., „Interactive Visualization of Unstructured GridsUsing Hierarchical 3D Textures“,Symposium on Volume Visualization and Graphics, Boston, Massachusetts, October 2002.http://csdl.computer.org/comp/proceedings/vv/2002/7641/00/76410037abs.htm
[8] Rueda, A. J., Segura, R. J., Feito, F. R., de Miras, J. R., Ogáyar, C., „Voxelization of solidsusing simplicial coverings“, WSCG 2004, Plzen - Bory, Czech Republic, Febuary 2004.http://wscg.zcu.cz/wscg2004/Papers_2004_Short/J53.htm
[9] Weiler, M., Ertl, T., „Hardware-Software-Balanced Resampling for the InteractiveVisualization of Unstructured Grids“,12th IEEE Visualization 2001 Conference (VIS 2001), San Diego, California, October 2001.http://csdl.computer.org/comp/proceedings/visualization/2001/7200/00/7200weilerabs.htm
[10] Xue, D., Crawfis, R., „Efficient Splatting Using Modern Graphics Hardware“, Journal ofGraphics Tools, Vol. 8 no. 3, pp. 1 - 21., 2003.http://www.cse.ohio-state.edu/~crawfis/Publications.htm
[11] Weiler, M., Westermann, R., Hansen, C., Zimmermann, K., Ertl, T., „Level-of-Detail VolumeRendering via 3D Textures“,Symposium on Volume Visualization and Graphics, Salt Lake City, Utah, October 2000.http://www.vis.uni-stuttgart.de/ger/research/fields/current/lodvolren/
[12] Meißner, M., Huang, J., Bartz, D., Mueller, K., Crawfis, R., „A Practical Evolution of PopularVolume Rendering Algorithms“,Symposium on Volume Visualization and Graphics, Salt Lake City, Utah, October 2000.http://www.gris.uni-tuebingen.de/~bartz/proj/volume/
[13] Brodlie, K., Wood, J., „Recent Advances in Volume Visualization“,Computer Graphics Forum, Vol. 20, Issue 2, June 2001.
[14] LaMar, E., Hamann, B., Joy, K. I., „Multiresolution Techniques for Interactive Texture-BasedVolume Visualization“, Conference on Visualization, San Francisco, California, October 1999.

100
[15] Lacroute, P., Levoy, M., „Fast Volume Rendering Using a Shear-Warp Factorization of theViewing Transformation“, SIGGRAPH '94, Orlando, Florida, July 1994.
[16] Yang, C., „Integration of Volume Visualization and Compression: A Survey“,Technical Report, State University of New York at Stony Brook, August 2000.http://www.ecsl.cs.sunysb.edu/~ckyang/resume.html
[17] Williams, P. L., „Visibility Ordering Meshed Polyhedra“, ACM Transactions on Graphics(TOG), Vol. 11, Issue 2, April 1992.
[18] Comba, J., Klosowski, J. T., Max, N., Mitchell, J. S. B., Silva, C., Williams, P. L., „FastPolyhedral Cell Sorting for Interactive Rendering of Unstructured Grids“,Eurographics ‘99, Milan, Italy, September 1999.http://graphics.stanford.edu/papers/fpcs/
[19] Das CGNS-Dateiformat, http://www.cgns.org
[20] ADF User’s Guide, http://www.grc.nasa.gov/WWW/cgns/adf/adf.pdf
[21] Das NetCDF-Dateiformat, http://my.unidata.ucar.edu/content/software/netcdf/index.html
[22] Das AVS Field Format, http://help.avs.com/Express/doc/help/books/dv/dvfdtype.html
[23] Das UCD-Dateiformat,http://help.avs.com/Express/doc/help/reference/dvmac/UCD_Form.htm
[24] UG-Homepage, Interdisziplinäres Zentrum für Wissenschaftliches Rechnen, Uni Heidelberg,http://cox.iwr.uni-heidelberg.de/~ug/intro.html
[25] Gottschalk, S., Lin, M. C., Manocha, D., „OBB-Tree: A Hierarchical Structure for RapidInterference Detection“, SIGGRAPH ‘96, New Orleans, Louisiana, August 1996.
[26] Ati Radeon 9800 Pro Spezifikation,http://www.ati.com/products/radeon9800/radeon9800pro/specs.html
[27] NVidia GeForce6 Spezifikation, http://www.nvidia.com/page/pg_20040406661996.html
[28] Westover, L., „Footprint Evaluation for Volume Rendering“,SIGGRAPH ‘88, Atlanta, Georgia, 1988.
[29] Cullip, T. J., Neumann, U., „Accelerating Volume Reconstruction With 3D TextureHardware“,Technical Report no. TR93-027, University of North Carolina at Chapel Hill, 1994.
[30] Voss, G., Behr, J., Reiners, D., Roth, M., „A Multi-Thread Safe Foundation for Scenegraphsand its Extension to Clusters“,Eurographics Workshop on Parallel Graphics and Visualization, Blaubeuren, Germany,September 2002.
[31] Tomei, H., Tomei, D., Tomei, C., „Tetrahedral Decompositions of Hexahedral Meshes“,European Journal on Combinatorics, Academic Press, Vol. 10, pp. 435-443, 1989.
[32] Kolcun, A., „Nonconformity Problem in 3D Grid Decompositions“,WSCG 2002, Plzen - Bory, Czech Republic, Febuary 2002.
[33] Weiler, M., Ertl, T., „Ein Volume-Rendering-Framework für OpenSG“,OpenSG Symposium 2002, Januar 2002.
[34] AVS/Express, http://www.avs.com

101


















