
Mathematik f¨ur Okonomen¨ Wintersemester 2005/06 · 2 A May, D. Pfeifer: Mathematik f¨ur...
109
Mathematik f¨ ur ¨ Okonomen Wintersemester 2005/06 Angelika May Dietmar Pfeifer
Transcript of Mathematik f¨ur Okonomen¨ Wintersemester 2005/06 · 2 A May, D. Pfeifer: Mathematik f¨ur...

Mathematik fur OkonomenWintersemester 2005/06
Angelika MayDietmar Pfeifer

Dietmar Pfeifer
Carl-von-Ossietzky-Universitat Oldenburg([email protected])
c© Angelika May, Dietmar Pfeifer
Dieses Skript ist zur freien Verwendung fur Studenten der Veranstaltung
”Mathematik fur Okonomen“ als Begleitmaterial zum personlichen Gebrauch
gedacht. Jede andere Verwendung, Vervielfaltigung oder anderweitigeVerwertung bedarf der ausdrucklichen Zustimmung der Autoren.

Inhaltsverzeichnis
1 Einfache Verzinsung 1
1.1 Jahrliche Zinszahlung . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Einfache unterjahrige Verzinsung . . . . . . . . . . . . . . . . . . . . 3
2 Zinseszinsrechnung 3
3 Zeitrenten 5
3.1 Formeln fur endliche Summen . . . . . . . . . . . . . . . . . . . . . . 6
3.2 Begriffe zur Rentenrechnung . . . . . . . . . . . . . . . . . . . . . . . 9
3.3 Vorschussige Zeitrente . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.4 Nachschussige Zeitrente . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.5 Aufgeschobene Rente . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4 Einfache Gleichungen 12
4.1 Lineare Gleichungen in einer Variablen . . . . . . . . . . . . . . . . . 13
4.2 Einfache Gleichungen mit Wurzeln . . . . . . . . . . . . . . . . . . . 16
4.3 Einfache Gleichungen mit Potenzen . . . . . . . . . . . . . . . . . . . 16
4.4 Auflosen nach dem Exponenten (der Hochzahl) . . . . . . . . . . . . 17
5 Konvergenz von Folgen und Reihen und die Ewige Rente 18
5.1 Arithmetische und Geometrische Folgen, Konvergenz . . . . . . . . . 19
5.2 Die unendliche Geometrische Reihe . . . . . . . . . . . . . . . . . . . 21
6 Lineare Funktionen 22
6.1 Intervalle und etwas Mengenlehre . . . . . . . . . . . . . . . . . . . . 22
6.2 Allgemeines uber Funktionen . . . . . . . . . . . . . . . . . . . . . . 24
6.3 Graphen von Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . 24
6.4 Lineare Ungleichungen . . . . . . . . . . . . . . . . . . . . . . . . . . 25
6.5 Systeme von 2 linearen (Un-)Gleichungen . . . . . . . . . . . . . . . . 25
7 Lineare Gleichungssysteme, ein systemat. Losungsverfahren 25
7.1 Der Gauß-Jordan-Algorithmus . . . . . . . . . . . . . . . . . . . . . . 25
7.2 Rechnen mit Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . 31

ii A May, D. Pfeifer: Mathematik fur Okonomen
7.3 Gaußscher Algorithmus zur Inversenberechnung . . . . . . . . . . . . 34
8 Der Simplex-Algorithmus 36
8.1 Problemstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
8.2 Das Simplex-Tableau . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
8.3 Das Aufnahmekriterium . . . . . . . . . . . . . . . . . . . . . . . . . 37
8.4 Das Eliminationskriterium . . . . . . . . . . . . . . . . . . . . . . . . 38
8.5 Dualitatsaussagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
9 Funktionen einer Variablen 41
9.1 Quadratische Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . 42
9.2 Die Exponentialfunktion . . . . . . . . . . . . . . . . . . . . . . . . . 45
9.3 Die naturliche Logarithmusfunktion . . . . . . . . . . . . . . . . . . . 47
9.4 Verschiebung von Funktionsgraphen . . . . . . . . . . . . . . . . . . . 47
10 Differentiation von Funktionen einer Variablen 49
10.1 Anderungsraten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
10.2 Rechenregeln fur Grenzwerte . . . . . . . . . . . . . . . . . . . . . . . 50
10.3 Steigung von Kurven . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
10.4 Berechnung von Ableitungen . . . . . . . . . . . . . . . . . . . . . . . 53
10.5 Ableitung von Summen, Produkten und Quotienten . . . . . . . . . . 55
10.6 Die Kettenregel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
10.7 Die Regel von L’Hospital . . . . . . . . . . . . . . . . . . . . . . . . . 57
10.8 Exponentialfunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
10.9 Logarithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
10.10Differentiation der inversen Funktion . . . . . . . . . . . . . . . . . . 59
10.11Ableitungen hoherer Ordnung . . . . . . . . . . . . . . . . . . . . . . 59
10.12Polynomiale Approximation . . . . . . . . . . . . . . . . . . . . . . . 61
10.13Die Taylor-Formel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
10.14Das Newton-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . 64
11 Extrem- und Wendepunkte fur Funktionen einer reellen Variablen 66
11.1 Notwendige Bedingungen fur Extrempunkte . . . . . . . . . . . . . . 66

Wintersemester 2005/06 iii
11.2 Der Satz vom Extrempunkt . . . . . . . . . . . . . . . . . . . . . . . 70
11.3 Hinreichende Bedingung fur Extrempunkte . . . . . . . . . . . . . . . 71
11.4 Wendepunkte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
12 Funktionen von 2 Variablen 73
12.1 Hohenlinien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
12.2 Partielle Ableitungen . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
13 Extrem- und Sattelpunkte fur Funktionen mit 2 Variablen 77
14 Anwendung der Optimierung fur Probleme mit 2 Variablen 81
14.1 Globale Maxima und Minima . . . . . . . . . . . . . . . . . . . . . . 81
14.2 Lineare Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
14.3 Die Kettenregel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
14.4 Lineare Approximationen . . . . . . . . . . . . . . . . . . . . . . . . . 85
15 Homogene und Homothetische Funktionen 86
15.1 Funktionen mit mehr als 2 Variablen . . . . . . . . . . . . . . . . . . 86
16 Die Lagrange Multiplikatoren fur Optimierung unter Nebenbedin-gungen 87
17 Integration fur Funktionen einer Variablen 94
17.1 Unbestimmte Integrale . . . . . . . . . . . . . . . . . . . . . . . . . . 94
17.2 Flachenberechnung mit dem bestimmten Integral . . . . . . . . . . . 96
17.3 Ableiten nach den Integrationsgrenzen . . . . . . . . . . . . . . . . . 98
17.4 Partielle Integration . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
17.5 Integration durch Substitution . . . . . . . . . . . . . . . . . . . . . . 99
17.6 Integration uber unendliche Intervalle . . . . . . . . . . . . . . . . . . 101

iv A May, D. Pfeifer: Mathematik fur Okonomen

Wintersemester 2005/06 1
1 Einfache Verzinsung
Beispiel 1.1. Sie besitzen zum 01.01.2004 ein Bankkonto mit einer Einlage von10.000 E. Die Bank garantiert Ihnen einen Jahreszinssatz von 4%, wobei Sie Ihnendie Zinsen am Jahresende gutschreibt.
1. Wieviel Zinsertrag haben Sie am Jahresende?
Losung: Wir schreiben i = 4% = 4100
= 0.04 und berechnen 10.000 · 0, 04 =400 E. Am Jahresende ist Ihr Guthaben also um 400 E auf 10.400 E angewach-sen.
2. Nehmen wir nun an, dass Sie Ihr Konto bis zum 31.12.2010, also 7 Jahre behal-ten. Wenn Sie den Zinsertrag am Ende jeden Jahres abheben und in den Spar-strumpf (oder unter die Matratze) legen, ohne davon Geld wegzunehmen, habenSie Ende 2010 dann insgesamt einen Zinsbetrag von 7·400 = 2.800 E eingenom-men, verfugen also insgesamt uber ein Guthaben von 10.000+2.800 = 12.800 E.
3. Naturlich wurden Sie so nicht vorgehen, sondern Ihre jahrlichen Zinsertrageauf dem Konto liegen lassen, damit Sie nicht nur auf Ihr Startguthaben von10.000 E, sondern auch auf die Zinsertrage selbst Zinsen kassieren. WievielGeld haben Sie in diesem Fall am 31.12.2010 zur Verfugung?
Losung:
Die Situation ist so:
K = 10.000, Z = 10.000 · i = K · i,
K + Ki= K(1 + i)
K = K1 K2 K3 K4 K5 K6 K7
| | | | | | | |1.1.2004 1.1.05 1.1.06 1.1.07 1.1.08 1.1.09 1.1.2010 31.12.2010
K1 = K + Z = K(1 + i)K2 = K1 + K1 · i = K1 · (1 + i) = K · (1 + i) · (1 + i)K3 = K2 + K2 · i = K2 · (1 + i) = K · (1 + i) · (1 + i) · (1 + i)
...K7 = K(1 + i)(1 + i)(1 + i)(1 + i)(1 + i)(1 + i)(1 + i)
= 10.000 · 1, 04 · 1, 04 · 1, 04 · 1, 04 · 1, 04 · 1, 04 · 1, 04= 13.159, 32
Wenn Sie Ihre Zinsen also jeweils wieder anlegen (man sagt: mit”Zinseszins“ rech-
nen), haben Sie also knapp 13.160− 12.800 = 360 E mehr zur Verfugung als bei derSparstrumpfmethode.

2 A May, D. Pfeifer: Mathematik fur Okonomen
Bevor wir uns den Feinheiten der Zinseszinsrechnung zuwenden, wollen wir ein wenigdie dahinter steckende Mathematik wiederholen. Wir haben gesehen, dass es Rech-nungen ubersichtlicher machen kann, wenn man zunachst mit Buchstaben (Varia-blen) rechnet und erst am Ende die konkreten Zahlen (hier: Euro-Betrage) einsetzt.Daher werden wir im Folgenden alle Rechenregeln stets mit Variablen formulierenund danach ein oder zwei Zahlenbeispiele zusammen rechnen. Es wird sich als nutz-lich erweisen,
”ganz unten“ bei den verschiedenen Zahlen anzufangen; dies wollen
wir tun.
Hierzu lesen Sie bitte in [Sydsaeter], Kap. 1, 1.1 nach.
Als nachstes wurden wir gerne den Ausdruck K7 = (1 + i) · (1 + i) · (1 + i) · (1 + i) ·(1 + i) · (1 + i) · (1 + i) einfacher schreiben (Denken Sie an die Lange des Ausdrucks,wenn Sie Ihr Geld 25 Jahre lang anlegen wollten!) und damit auch die Eingabe in denTaschenrechner erleichtern. Hier hilft das Rechnen mit Potenzen, die wir zunachsteinfuhren wollen, um dann daran zu erinnern, wie mit ihnen zu rechnen ist.
Alle wichtigen Grundlagen stehen in [Sydsaeter], Kap. 1, 1.2–1.5, Seiten 22–46.
1.1 Jahrliche Zinszahlung
Wir bezeichnen mit K0 das Anfangsguthaben, mit Kn das Endguthaben nach n Jah-ren. Unter der Voraussetzung, dass einfache Zinszahlung vereinbart ist, gilt fur dasEndguthaben nach 1 Jahr
K1 = K0 + K0 · i = K0 · (1 + i),
und fur das Endguthaben (den Endwert) nach n Jahren
Kn = K0 + (K0i + · · ·K0i)︸ ︷︷ ︸n Summanden
= K0 + n ·K0 · i = K0 · (1 + n · i) .
Der Vorgang, zu einem gegebenen K0 den Endwert zu bestimmen, heißt Aufzinsung .
Gelegentlich lautet die Aufgabe umgekehrt zu einem gegebenen Endkapital das heu-tige Anfangskapital (den Barwert) zu berechnen. Diesen Vorgang bezeichnet manauch als Diskontierung (Abzinsung). Wir berechnen K0 zu einem gegebenen Kn
nach folgender Formel:
K0 =Kn
1 + n · i.

Wintersemester 2005/06 3
1.2 Einfache unterjahrige Verzinsung
Fur die Zinsperiode 1 Jahr wird im (deutschen) Finanzwesen haufig der Monat mit30 Tagen und das Jahr mit 360 Tagen angenommen. Damit folgt fur den Zins z beiλ Tagen Verzinsung (wobei λ zwischen 1 und 360 Tagen variiert):
z =λ
360·K0 · i
bzw. fur das Endkapital innerhalb eines Jahres
Kλ = K0 + z = K0 +λ
360K0 · i = K0 ·
(1 +
λ
360· i)
nach der Methode”pro rata temporis“ oder 30/360-Methode.
Die Auflosung dieser Formel nach K0 beschreibt den Vorgang der Diskontierung(Abzinsung)
K0 =Kλ
1 + λ360· i
Fur ein ganzes Jahr (λ = 360 Tage) erhalten wir so unsere schon bekannte Formelaus Abschnitt 1.1 fur n = 1.
λ = 360 =⇒ K0 =K1
1 + i=
1
1 + i·K1.
2 Zinseszinsrechnung
Die Zinsen werden hierbei zu den Zinsterminen berechnet und anschließend demvorhandenen Kapital zugeschlagen, d. h. bei der nachstfolgenden Verzinsung mit ver-zinst. Ist die Laufzeit einer Kapitalbewegung mit Zinseszins ein ganzzahliges Vielfa-ches n der Zinsperiode (haufig 1 Jahr), dann gilt fur die Aufzinsung eines gegebenenKapitals K0:
K0
K1 = K0 · (1 + i)
K2 = K1 · (1 + i) = K0 · (1 + i)2
...
Kn−1 = . . . = K0(1 + i)n−1
Kn = Kn−1 · (1 + i) = K0(1 + i)n
⇒ Kn = K0 · (1 + i)n

4 A May, D. Pfeifer: Mathematik fur Okonomen
Diskontierung: Bestimme den Barwert K0 aus gegebenem Kn
K0 =Kn
(1 + i)n
Beispiel 2.1. ZinseszinsrechnungFur das Kapital nach n Jahren gilt Kn = K0 · (1 + i)n, wobei i den Jahreszinssatzund K0 das (heutige) Anfangskapital bezeichnet.
1. (Berechnung des Endwertes)Auf wie viel wachst ein Guthaben von 1.000 E bei einem Zinssatz von 5%nach 10 Jahren an? (Schatzen Sie zunachst: Ist es mehr oder weniger als dasDoppelte?)
Losung: K10 = 1000 · (1, 05)10 = 1628, 89 E.
2. (Berechnung des Barwertes: Auflosen nach K0)Wie viel ist ein Guthaben von 2.000 E, das Sie in 10 Jahren auf Ihrem Kontofinden, heute wert? Sie wissen bereits aus Teil 1., ob Sie einen Betrag großeroder kleiner 1.000 E erwarten durfen. Wieso?
Losung: Wir losen die obige Zinseszinsgleichung nach K0 auf, das entsprichtdem Vorgang des Diskontierens. (Blick von der Zukunft zuruck auf heute).Wir kennen K10 = 2000. Der zugehorige Barwert bei 5% Verzinsung ist K0 =K10(1 + i)−10 = 2000(1, 05)−10 = 2000
(1,05)10= 1227, 83 E.
3. (Berechnung des Zinssatzes: Auflosen nach i)Welchen Zinssatz mussen Sie bei der Bank heraushandeln, damit sich ihr Gut-haben von 1.000 E nach 10 Jahren (mindestens) verdoppelt hat? (Wir wissenbereits, dass es mehr als 5% sein mussen! Wieso?)
Losung: Wir kennen wie in 1. unser Startkapital K0 = 1000. Das Endkapitalsoll doppelt so groß sein, also ist K10 = 2K0 = 2000. Nun losen Sie die Glei-chung nach (1 + i)10 auf: (1 + i)10 = K10
K0= 2000
1000= 2. Bemerken Sie bitte, dass
der Zinssatz somit von der Hohe des Anfangskapitals nicht abhangt, sondernes bei der Rechnung nur auf die Verdopplung des Anfangskapitals ankommt!
Wie werde ich den Exponenten los? Indem ich auf beiden Seiten die 10-teWurzel ziehe, also auf beiden Seiten den Exponenten 1
10dazuschreibe.
Dann ist 1 + i = ((1 + i)10)1/10
= 21/10 = 1, 0718.
Indem wir noch auf beiden Seiten 1 abziehen (subtrahieren), erhalten wir einenZinssatz von (circa) i = 7, 2%, der notwendig fur eine Verdopplung des An-fangskapitals innerhalb von 10 Jahren ist.

Wintersemester 2005/06 5
3 Zeitrenten
Bei der Rentenrechnung geht es um die Zusammenfassung von Zahlungen, die zuunterschiedlichen Zeitpunkten auftreten.
Beispiel 3.1. Einfache Zinsrechnung, ohne Zinseszins.
1. Ein Angestellter erhalt am 15.03. sein Gehalt von G = 3.100 E auf ein Kon-to eingezahlt. Wie groß ist der Zinsertrag am Jahresende nach der Methode30/360, wenn ein jahrlicher Zinssatz von 4% vereinbart wurde?
Losung: Das Marzgehalt wird uber einen Zeitraum von 15 Tagen (bis 31.03.)plus 9 Monaten (April bis Dezember) verzinst, also gesamt 15 + 9 · 30 = 285Tage. Damit folgt fur den Zinsertrag Z = G·i· 285
360= 3.100·0, 04· 285
360= 98, 17 E.
2. Ein Angestellter erhalt ab dem 15.03. bis zum Jahresende sein Gehalt von 3.100E monatlich (stets in der Monatsmitte) auf ein Konto eingezahlt. Wie groß istder Zinsertrag am Jahresende bei einem jahrlichen Zinssatz von 4%, wenn ersein Geld nicht abhebt?
Losung: Wir bezeichnen sein Gehalt mit G = 3.100 E und zeichnen uns einenZeitstrahl auf:
· · ·
G G G
| | | | | | | | |1.3. 15.3. 1.4. 15.4. 1.5. . . . 1.12. 15.12. 31.12
| {z }
15 Tage| {z }
30 Tage
Wir zahlen die Anzahl der Tage bis zum Jahresende:Marzgehalt: 15 Tage (bis Ende Marz) plus 9 Mon. a 30 Tage =
15 + 9 · 30 = 285 Tage,Aprilgehalt: 15 + 8 · 30 = 255 Tage,Maigehalt: 15 + 7 · 30 = 225 Tage,...Dezembergehalt: 15 + 0 · 30 = 15 Tage.
Durch Summenbildung kommen wir zum Gesamtzins:
Z = (285+255+225+195+···+15)360
· 0, 04 · 3.100 = 1500360· 0, 04 · 3.100 = 516, 67 E.
Uns fallt auf, dass die Summanden im Zahler sich immer um 30 Tage verringern.Dies ist ein Beispiel fur eine sogenannte arithmetische Summe, bei der die Differenzvon zwei aufeinander folgenden Summanden immer konstant (hier: gleich 30) ist. MitHilfe eines Summenzeichens und Rechenregeln fur Summen konnen wir den Ausdrucksowohl ubersichtlicher schreiben als auch die Summe mit Hilfe einer Formel leichterausrechnen. Im Folgenden sind einige Grundlagen uber Summen zusammengestellt.
Wir wollen außerdem gleich noch einen weiteren Summentyp kennen lernen, diegeometrische Summe, bevor wir uns wieder der Anwendung zuwenden.

6 A May, D. Pfeifer: Mathematik fur Okonomen
3.1 Formeln fur endliche Summen
Definition 3.2. Wir schreiben abkurzend
n∑λ=1
aλ = a1 + a2 + a3 + . . . an .
Damit konnen wir Beispiel 3.1, Teil 2 eleganter schreiben als
9∑λ=1
(15 + 30λ) + 15 =9∑
λ=0
(15 + 30λ),
der Summationsindex muss also nicht immer ab 1 laufen! (Passen Sie auf, dass dieAnzahl der Summanden um 1 großer ist, wenn λ ab 0 lauft, als wenn λ erst ab 1lauft, im obigen Beispiel stehen also insgesamt 10 Summanden. Im allgemeinen Fall
steht die Summen∑
λ=0
fur eine Summe mit n + 1 Summanden.)
Damit wir die obige Summe ausrechnen konnen, benotigen wir zwei Aussagen:
Rechenregel 3.3. Es giltn∑
λ=1
1 = n (Wieso?), also fur eine allgemeine reelle Zahl
a analogn∑
λ=1
a = a ·n∑
λ=1
1 = n · a
Rechenregel 3.4. Es giltn∑
λ=1
λ =n(n + 1)
2.
Beweis. Diese Beziehung kann man verstehen, wenn man sich die Summanden einmalvon vorne und einmal von hinten nebeneinander aufschreibt. Die folgende Ubersichtmacht klar, was gemeint ist: Wir nehmen dazu (zunachst) an, dass wir eine geradeAnzahl von Summanden haben und nutzen aus, dass wir die Summanden in einerbeliebigen Reihenfolge aufaddieren durfen, ohne dass der Wert der Summe (das Er-gebnis) sich andert.
1 + 2 + · · ·+ n = 1 + n2 + (n− 1)3 + (n− 2)4 + (n− 3)...n2
+(n + 1− n
2
)

Wintersemester 2005/06 7
Damit ist die Summe in jeder waagerechten Zeile gleich mit Wert n+1 und wir habeninsgesamt n
2Zeilen. Also ergibt sich die Summe als Anzahl der Zeilen mal konstante
Zeilensumme zu n2· (n + 1), und das hatten wir oben auch behauptet.
Fur eine ungerade Anzahl von Summanden kommt man mit einer ahnlichen Uberle-gung ebenfalls zu diesem Ergebnis.
Definition 3.5. Eine Summe der Formn∑
λ=0
qn heißt geometrische Summe. Der Quo-
tient (Bruch) aus je 2 aufeinander folgenden Summanden ist dabei konstant q, dascharakterisiert eine geometrische Summe.
Rechenregel 3.6. Es gilt fur alle reellen q 6= 1
n∑λ=0
qλ =qn+1 − 1
q − 1.
Wir werden uns etwas spater in der Vorlesung uberzeugen, dass diese Formel stimmt.Im Moment wollen wir sie verwenden, um Barwert und Endwert von Renten explizitauszurechnen.
Beispiel 3.7. In Beispiel 1.1 hatten Sie ein Bankkonto mit 10.000 E, das uber 7 Jahrelang mit i = 4 % verzinst wurde. Mit Zinseszins wuchs Ihr Anfangskapital bis zumEnde des 7-ten Jahres auf etwa 13.160 E an. Wie andert sich die Situation, wennSie auf ein bis dahin leeres Konto beginnend mit dem 01.01.2004 jedes Jahr amJahresanfang (01.01., insgesamt 7 mal) einen Betrag von x = 1.430 E einzahlen? Dawir stets am Jahresanfang einzahlen, bezeichnet man diese Zahlungsweise auch alsvorschussig.
Uberschlagen Sie zunachst: Haben Sie dann am 31.12.2004 mehr oder weniger Geldauf dem Konto als bei einem Startguthaben von 10.000 E? Richtig, weniger, obwohl7 · 1430 = 10.010. Aber wieviel?
Das wollen wir im Folgenden ausrechnen. Wir machen uns die Situation wieder aneinem Schaubild klar:
x x x x| | | | | | | |
1.1.2004 1.1.05 1.1.06 1.1.07 1.1.08 1.1.09 1.1.2010 31.12.2010
Wir nahern uns der Aufgabe, indem wir sie auf die bekannte Formel fur den Endwertmit Zinseszins zuruck fuhren. Auf jede einzelne Zahlung x angewandt, ergibt sich furdas Kapital am 31.12.2010:
K7 = x(1 + i)7 + x(1 + i)6 + x(1 + i)5 + · · ·x(1 + i) .
Nun wollen wir sehen, ob die Summenformel fur die geometrische Reihe uns hilft, die-sen Ausdruck schnell zu berechnen. (Mit einem Programm wie Excel geht es naturlich

8 A May, D. Pfeifer: Mathematik fur Okonomen
auch direkt, ohne Formel! Aber wie viele von Ihnen haben immer ein Notebook mitExcel dabei?)
Wir verwenden zunachst die Summenschreibweise:
K7 =1∑
λ=7
x(1 + i)λ =7∑
λ=1
x(1 + i)λ ,
wobei wir zunachst den Laufindex so umsortiert haben, dass er statt von 7 bis 1wie ublich aufsteigend von 1 bis 7 verlauft. (Das geht wegen der Kommutativitatder Addition.). Um nun unsere Summenformel anwenden zu konnen, stellen wir fest,dass sicher q = 1 + i fur alle denkbaren echten Zinssatze großer ist als 1 (Das istgut!) und dass die Formel statt ab λ = 0 erst ab λ = 1 lauft. (Das ist nicht so gut!)Wir helfen uns, indem wir einen Faktor (1+ i) aus jedem Summanden ausklammern.Das geht, indem wir unsere Potenzregeln anwenden, mit λ = 1 + (λ− 1) so:
K7 =7∑
λ=1
x(1 + i)λ =7∑
λ=1
x(1 + i)(1 + i)(λ−1) .
Nun sind x und 1 + i unabhangig von λ, also bei jedem Summanden gleich, und wirkonnen beide ausklammern, was wir im nachsten Schritt tun:
K7 =7∑
λ=1
x(1 + i)(1 + i)(λ−1) = (1 + i)x7∑
λ=1
(1 + i)(λ−1) .
Wir stellen nun folgende Uberlegung an: Der kleinste Wert fur λ ist 1, das ergibt imExponenten λ− 1 = 1− 1 = 0. Der großte Wert fur λ in der Summe ist 7, das ergibtim Exponenten λ − 1 = 7 − 1 = 6. Also steht schon das Richtige da, man sieht esnur noch nicht gleich. Aber jetzt:
K7 = (1 + i)x7∑
λ=1
(1 + i)(λ−1) = (1 + i)x6∑
λ=0
(1 + i)λ .
Sie mussten dazu sowohl den Laufbereich von λ als auch den Exponenten andern,damit alles stimmt. Nun wenden wir die Summenformel aus Rechenregel 3.6 an undsind am Ziel:
K7 = (1 + i)x6∑
λ=0
(1 + i)λ = 1, 04 · 1430 · (1 + i)6+1 − 1
(1 + i)− 1= 1487, 20 · 1, 047 − 1
1, 04− 1.
Das ergibt K7 = 11.746, 34 E, das sind also etwa 1.413 E weniger als in Beispiel 1.1,wo Sie gleich mit einem Guthaben von 10.000 E starteten, statt jahrliche Rateneinzuzahlen.

Wintersemester 2005/06 9
3.2 Begriffe zur Rentenrechnung
Wir wenden uns nun systematisch verschiedenen Kenngroßen der Rentenberechnungzu.
Definition 3.8. Eine Rente ist eine Folge von konstanten (oder nach einem festge-legten Schema sich verandernden) Zahlungen in festen Zeitabstanden. Fur die Her-leitung von Rentenformeln wird immer vorausgesetzt, dass die konstanten Zahlungenden (normierten) Wert 1 haben. Aussagen fur Renten der Hohe x erhalt man durchMultiplikation der (normierten) Formeln mit x.
Kenngroßen
1, x Rente (regelmaßiger Zahlungsbetrag)n Anzahl der Zahlungeni Zinssatzan Rentenbarwert vorschussigan Rentenbarwert nachschussigsn Rentenendwert vorschussigsn Rentenendwert nachschussig
Der folgende Zeitstrahl verdeutlicht die Zahlungszeitpunkte fur n-jahrige Rentenmit der Nummerierung Jahresanfang des Jahres λ ist λ − 1 und λ bezeichnet dasJahresende (fur λ = 1, . . . n). Die Barwerte an und an werden demnach im Zeitpunkt 0ermittelt, die Rentenendwerte sn und sn im Zeitpunkt n.
an sn
an sn
Jahr 1 Jahr 2 Jahr n| | | | | | | |0 1 2 n− 1 n
3.3 Vorschussige Zeitrente
Es handelt sich um eine Rente mit n Zahlungen der Hohe 1 in den Zeitpunkten0, . . . , n− 1.
Barwert (heutiger Wert der Rente):
an = 1 + 1 · 1
(1 + i)+ 1 · 1
(1 + i)2+ · · ·+ 1
(1 + i)n−1=
1− 1
(1 + i)n
1− 1
(1 + i)

10 A May, D. Pfeifer: Mathematik fur Okonomen
Fur Renten der Hohe x gilt an(x) = x · an.
Rentenendwert (nach n Jahren):
sn = 1 · (1 + i)n + 1 · (1 + i)n−1 + · · ·+ 1 · (1 + i)
= (1 + i) ·[(1 + i)n−1 + · · ·+ 1
]= (1 + i)
n−1∑λ=0
(1 + i)λ = (1 + i) · (1 + i)n − 1
1 + i− 1
Alternativ konnen wir auch den vorschussigen Barwert uber n Jahre mit Zinssatz iaufzinsen (vgl. am Zahlenstrahl auf S. 9):
sn = an · (1 + i)n = (1 + i)n ·1− 1
(1+i)n
1− 11+i
=(1 + i)n − 1
1− 11+i
= (1 + i) · (1 + i)n − 1
(1 + i)− 1= (1 + i) ·
(n−1∑λ=0
(1 + i)λ
)= (1 + i) + (1 + i)2 + · · ·+ (1 + i)n
was in der Tat zum gleichen Ergebnis wie oben fuhrt.
3.4 Nachschussige Zeitrente
Es handelt sich um eine Rente mit n Zahlungen der Hohe 1 in den Zeitpunkten1, 2, . . . , n.
Nachschussiger Barwert
an = 1 · 1
(1 + i)+ 1 · 1
(1 + i)2+ · · · 1 · 1
(1 + i)n=
n∑λ=1
1
(1 + i)λ
=n∑
λ=1
1
1 + i· 1
(1 + i)λ−1=
1
1 + i
n−1∑λ=0
1
(1 + i)λ=
1
1 + i·1− 1
(1+i)n
1− 11+i
an =1− 1
(1+i)n
1 + i− 1=
1− 1(1+i)n
i
Anders ausgedruckt besteht folgender Zusammenhang zum vorschussigen Barwert:
an =1
(1 + i)· an

Wintersemester 2005/06 11
Nachschussiger Endwert
sn = 1 · (1 + i)n−1 + 1 · (1 + i)n−2 + · · ·+ 1 =n−1∑λ=0
(1 + i)λ = (1+i)n−1(1+i)−1
= (1+i)n−1i
.
Zusammenhang zum vorschussigen Endwert:
(1 + i) · sn = sn ,
da jede Zahlung um ein Jahr weiter nach hinten verschoben werden muss, damit dieZahlung der vorschussigen Rente in den gleichen Zeitpunkten stattfindet wie die dernachschussigen.
3.5 Aufgeschobene Rente
Gelegentlich legt man heute einen Betrag fest und wunscht sich die ratenweise Zah-lung nicht ab sofort, sondern ab einem in der Zukunft liegenden Zeitpunkt. Dies istz.B. bei allen Sparvertragen der Fall, die eine Versorgung im Alter versprechen.
Beispiel 3.9. Frau Mustermann legt zu Ihrem 45. Geburtstag 100.000 E auf ein Kontound wunscht sich, dass sie ab ihrem 60. Geburtstag jeweils am Jahresanfang 25 Jahrelang eine (also vorschussige) Rente von jahrlich x bezieht. Mit der Bank wurde einlangjahriger Zinssatz von 5,8% vereinbart. Wie groß ist der jahrliche Rentenbetragx?
Unsere Situation weicht von der bisherigen insofern ab, als die Rentenzahlung nichtmehr sofort beginnt. Wie bisher konnen wir ablesen:Laufzeit der Rentenzahlung n = 25,Zinssatz i = 0, 058Barwert der Rente (in t = 0) ist m|a25 = 100.000 E.
Abweichend sind die Zahlungszeitpunkte, die nicht mehr in t = 0, sondern in einemzukunftigen Zeitpunkt t = m = 15 beginnen.Man nennt die Zeit zwischen 0 und mauch Aufschubzeit .Wir starten wieder mit dem auf x = 1 vereinfachten Fall:
Situation: n Zahlungen von 1 in t = m, m+1, ...,m+n− 1 (hier: vorschussig) undin t = m + 1, ...,m + n (falls nachschussig).
D.h. die Zahlungen beginnen erst nach m Jahren, aber sie werden bereits in t = 0(”heute“) vereinbart. Fur den Rentenbarwert im vorschussigen Fall fuhren 2 Uberle-
gungen zum Ziel:1. Der Rentenbarwert der um m Jahre aufgeschobenen Rente entspricht in t = mdem einer
”normalen“ sofort beginnenden n-jahrigen Rente. Um zum Wert im Zeit-
punkt t = 0 (Barwert) zu gelangen, muss ich m Zeitintervalle (Jahre) zuruck gehen,

12 A May, D. Pfeifer: Mathematik fur Okonomen
also diskontieren. Damit kommt man zu
m|an =1
(1 + i)m· an .
2. Wie bei der sofort beginnenden n-jahrigen Rente diskontiere ich alle n Zahlungen int = m,m+1, . . . ,m+n−1 auf den Zeitpunkt t = 0, indem ich mit den entsprechendenPotenzen von 1
1+imultipliziere, also
m|an = 1· 1(1+i)m +1· 1
(1+i)m+1 +· · ·+1· 1(1+i)m+n−1
Klammert man bei jedem Summanden 1(1+i)m aus, so erhalt man in der Tat das
Ergebnis aus 1., mit dem wir gestartet waren:
m|an = 1(1+i)m
(1 · 1
(1+i)0+ 1 · 1
(1+i)1+ · · ·+ 1 · 1
(1+i)n−1
)= 1
(1+i)m · an .
Fur den Fall nachschussiger Zahlungen erhalt man ganz genauso
m|an = 1 · 1(1+i)m+1 + 1 · 1
(1+i)m+2 + · · ·+ 1 · 1(1+i)m+n = 1
(1+i)m · an .
Mit diesem Ergebnis konnen wir die jahrliche Rente aus dem obigen Beispiel 3.9berechnen:
15|a25 = 100.000 =1
1, 05815· x ·
1− 11,05825
1− 11,058
= x · 5, 9176 .
Also ist x = 16.899 E; hatten Sie das vor dem Rechnen in der richtigen Großenord-nung geschatzt?
4 Einfache Gleichungen
Wir erinnern uns an Beispiel 2.1. Dort haben wir die Zinseszinsformel Kn = (1 +i)n ·K0 nach den Variablen K0, Kn und i aufgelost. Eine noch nicht mathematischbehandelte Frage wirft das folgende Problem auf:
Beispiel 4.1. (Berechnung der Laufzeit: Auflosen nach n)Dieses Beispiel erganzt Beispiel 2.1 um einen Teil 4.
Wie viele Jahre mussen Sie warten, damit ein Guthaben von 1.000 E bei einemZinssatz von 5% auf das Doppelte (also 2.000 E) anwachst?
Losung: Lose Kn = (1 + i)n ·K0, also (1 + i)n = Kn
K0nach n auf.
Bevor wir die Antwort auf diese Frage geben konnen, geben wir systematisch an,wie Gleichungen nach einer Variablen aufgelost werden. Lesen Sie hierzu bitte in[Sydsæter], Kap. 2, 2.1, S. 61–64 nach.

Wintersemester 2005/06 13
4.1 Lineare Gleichungen in einer Variablen
Beispiel 4.2. Lose 3x + 10 = x + 4 nach x auf.
Ziel: Alle Ausdrucke mit x auf die linke Seite, alle Ausdrucke ohne x auf die rechteSeite.
Losung:3x + 10 = x + 4 | −x
3x + 10− x = 4 | −103x− x = 4− 10
2x = −6 |: 2
x = −3
Etwas komplizierter wird der Fall, wenn Bruche auftreten. Dann lautet der 1. Schritt,alle Nenner durch Multiplizieren der gesamten Gleichung mit dem Nenner wegzubrin-gen.
Beispiel 4.3. 1. Lose nach x auf:
32x + 5 = 1
2x + 2 | ·2
3x + 10 = x + 4 , weiter wie oben
2. Wir gehen genauso vor, falls der Nenner die Variable x enthalt.
3x + 10
x + 4= 1 | ·(x + 4)
3x + 10 = x + 4 , weiter wie oben
Test:Wird der Nenner 0? Mit x = −3 folgt x + 4 = −3 + 4 = 1 6= 0. Das ist gut,denn erst damit ist x = −3 wirklich Losung dieser Gleichung.
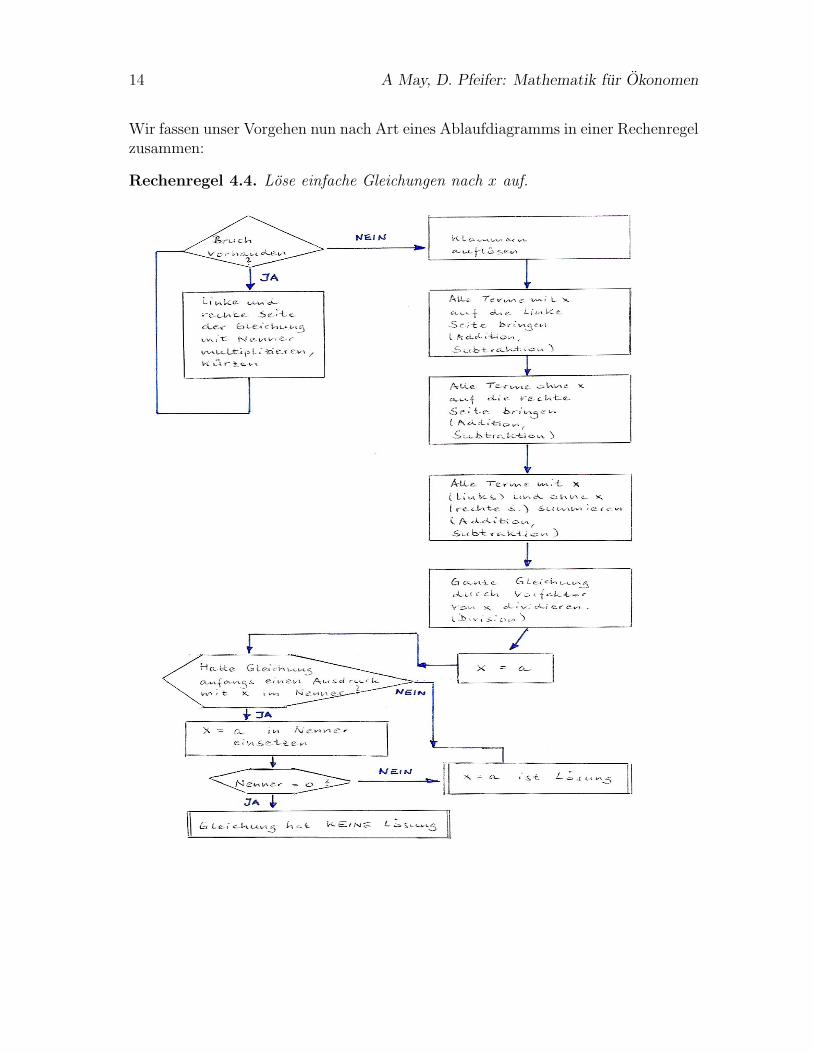
14 A May, D. Pfeifer: Mathematik fur Okonomen
Wir fassen unser Vorgehen nun nach Art eines Ablaufdiagramms in einer Rechenregelzusammen:
Rechenregel 4.4. Lose einfache Gleichungen nach x auf.

Wintersemester 2005/06 15
Beispiel 4.5. Eine Firma stellt ein Konsumgut her, dessen Produktion 20 E pro Stuckkostet. Die Wartung der Maschine verursacht zusatzlich monatliche Fixkosten von2.000 E. Wie viele Stuck des Konsumgutes mussen bei einem Stuckpreis von 75 E proMonat verkauft werden, damit die Firma einen monatlichen Gewinn von 14.500 E
erzielt?
Losung: Setzen wir x als die Anzahl produzierter und verkaufter Stucke des Kon-
sumgutes.Einnahmen der Firma: 75xGesamtkosten der Firma: 20x + 2000
Der Gewinn ergibt sich als Differenz aus Einnahmen minus Kosten und soll 14.500 Eergeben. Daraus ergibt sich folgende Gleichung:
75x− (20x + 2.000) = 14.50075x− 20x− 2.000 = 14.500 | +2000
75x− 20x = 14.500 + 2.00055x = 16.500 |: 55x = 16.500
55= 300
Also mussen 300 Stuck pro Monat verkauft werden.
Zusammenfassung
• Eine Gleichung aufzustellen heißt, eine Beziehung zwischen gegebenen undeiner gesuchten Große herzustellen.
• Der Wert einer Gleichung andert sich nicht, wenn auf beiden Seiten die gleichenRechenoperationen mit den gleichen Werten angewendet werden.
• Wir durfen auf beiden Seiten der Gleichung
– dieselbe Zahl addieren oder subtrahieren
– mit derselben Zahl multiplizieren(Beachte: Vorzeichen
”minus mal plus ist minus“ etc. und Klammern
”je-
der mit jedem“, Regeln auf dem Merkzettel)
– durch dieselbe Zahl (nicht 0) dividieren
– mit derselben Hochzahl potenzieren
– dieselbe Wurzel ziehen
– den Logarithmus ln anwenden
• Die letzten drei Spiegelstriche sind neu und werden im Folgenden behandelt.

16 A May, D. Pfeifer: Mathematik fur Okonomen
4.2 Einfache Gleichungen mit Wurzeln
Lose p√
x + 7 = 16 nach x auf.
Mit anderen Worten besteht die Aufgabe darin, den Ausdruck mit x ohne Wurzel-zeichen zu schreiben, also den Exponenten
”wegzubekommen“. Dazu schreiben wir
p√
x + 7 = (x + 7)1p nach unserer Potenzregel. Nun nutzen wir die Regel (ar)s = ar·s
aus und fragen uns, mit welcher Zahl wir 1p
multiplizieren mussen, damit im Expo-nenten eine 1 steht.[
(x + 7)1p
]p= (x + 7)
1p·p = (x + 7)1 = x + 7 .
Also mussen wir beide Seiten”hoch p“ rechnen:(p√
x + 7)p
= 16p
x + 7 = 16p
x = 16p − 7 ,
z. B. fur p = 2 folgt x = 162 − 7 = 256− 7 = 249.
4.3 Einfache Gleichungen mit Potenzen
Diesem Typ Gleichung begegnen wir, wenn wir unsere Zinseszinsformel nach demZinssatz i auslosen wollen (vgl. Beispiel 2.1, Teil 3.).
Beispiel 4.6. Ein Guthaben von 5.000 E wachst in 15 Jahren auf 10.000 E an. WelcherZinssatz wurde angewendet?
Losung: Mit K0 = 5000, n = 15 und Kn = K15 = 10.000 folgt die Zinseszinsformel
10.000 = 5.000 · (1 + i)15 |: 5.000
2 = (1 + i)15 oder (1 + i)15 = 2. Die Aufgabe besteht nun darin, den Exponenten15 weg zu bekommen, damit (1 + i)1 = 1 + i auf der linken Seite stehen bleibt. Wirbenutzen wieder die Potenzregel (ar)s = ar·s und fragen wie eben:
Mit welcher Zahl muss der Exponent (15) multipliziert werden, damit danach eine 1
im Exponenten stehen bleibt? Es ist [(1 + i)15]1/15 = (1 + i)15· 115 = (1 + i)1 = 1 + i.
Also mussen wir beide Seiten der Gleichung hoch 1/15 rechnen (mit 1/15 potenzie-ren), also die 15-te Wurzel ziehen:
(1 + i)15 = 2
[(1 + i)15]1/15 = 21/15
1 + i = 20,06667 = 1, 0473 | −1
i = 0, 0473 = 4, 73% .

Wintersemester 2005/06 17
4.4 Auflosen nach dem Exponenten (der Hochzahl)
Wir kehren nun zu unserer Aufgabe zuruck, die Zinseszinsformel nach der Laufzeitn aufzulosen. Dazu benotigen wir die Logarithmenrechnung . Ausgangspunkt ist dieGleichung an = b, wobei wir die Grundzahl a und den Potenzwert b kennen und denExponenten n suchen.
Definition 4.7. Die Losung von an = b ist der Logarithmus von b zur Basis a,schreibe n = loga b.
Da wir mit dem Taschenrechner arbeiten, wollen wir uns auf eine einzige Basisa = e = 2, 71828, die sogenannte Eulersche Zahl, beschranken. Wir schreiben imFolgenden loge = ln. Suchen Sie diese Taste auf Ihrem Taschenrechner. Nun formu-lieren wir Rechenregeln, die wir zum Auflosen der Gleichung nach dem Exponentenbenotigen.
Spezialfalle 4.8. Es gilt stets:
1. ln e = 1, denn e1 = e;
2. ln 1 = 0, denn e0 = 1;
3. ln 0 ist keine reelle Zahl, sondern eine sehr, sehr kleine negative Große, die dieMathematiker
”minus unendlich“, in Zeichen −∞ nennen.
Rechenregeln 4.9. 1. Der Logarithmus eines Produkts ist gleich der Summe derLogarithmen der einzelnen Faktoren:
ln(b · c) = (ln b) + (ln c) ,
denn ist n = ln b die Losung von en = b und m = ln c die Losung von em = c,so folgt mit den bekannten Potenzregeln b · c = en · em = en+m, also ist n+m =ln b + ln c die Losung von b · c = en+m.
2. Der Logarithmus eines Quotienten (Bruches) ist gleich der Differenz aus demLogarithmus des Zahlers und dem Logarithmus des Nenners:
ln
(b
c
)= (ln b)− (ln c) mit c 6= 0 .
3. Der Logarithmus einer Potenz ist gleich dem Produkt aus dem Exponenten (derHochzahl) und dem Logarithmus der Grundzahl:
ln(bs) = s · (ln b) ,
denn ist n = ln b die Losung von en = b, so folgt mit dem Potenzgesetz (en)s =en·s, dass s · n = s · ln b die Losung von bs = en·s ist.

18 A May, D. Pfeifer: Mathematik fur Okonomen
4. Der Logarithmus einer Wurzel ist gleich dem Produkt aus 1 durch den Wurzel-exponenten und dem Logarithmus des Ausdrucks unter der Wurzel (des Radi-kanden):
lnp√
b =1
p· ln b .
Derart ausgerustet konnen wir nun unsere Zinseszinsformel nach der Laufzeit nauflosen und erhalten, indem wir auf beiden Seiten logarithmieren:
(1 + i)n =Kn
K0
ln((1 + i)n) = lnKn
K0
n · ln(1 + i) = lnKn
K0
mit Rechenregel 3. aus 4.9
n · ln(1 + i) = ln Kn − ln K0 mit Rechenregel 2. aus 4.9
n =ln Kn − ln K0
ln(1 + i).
Mit den Zahlenwerten aus Beispiel 4.1 folgt dann n =ln 2000− ln 1000
ln 1, 05=
ln 2
ln 1, 05=
14, 2,also muss man 15 Jahre (14,2 ist mehr als 14) warten, bis eine Verdopplung desKapitals bei einem Zinssatz von 5% erreicht ist.
5 Konvergenz von Folgen und Reihen und die Ewi-
ge Rente
Gelegentlich soll eine Rente nicht nur n mal, sondern – theoretisch – unendlich oftausgezahlt werden.
Beispiel 5.1. Frau Dr. Edel stiftet einen Wissenschaftspreis. Ihr Vermogen von 1Mio. E soll dazu verwendet werden, jahrlich einer Forschergruppe einen Preis furihre Arbeiten auszuzahlen. Als Stiftungskapital dient ihr Vermogen von 1 Mio. E,dieses wird langjahrig sicher mit 4% verzinst. Wie hoch ist das jahrliche Preisgeld,uber das sich die Preistrager freuen konnen?
Im Gegensatz zu unseren bisherigen Beispielen fehlt uns hier ein n, so dass diebisherigen Formeln nicht ausreichen. Wir wissen aber, dass n beliebig groß werdenkann. Wir werden nach einem mathematischen Ausflug auf die Losung der obigenFrage zuruck kommen.
Definition 5.2. Eine (Zahlen-)Folge ist eine Auflistung von (reellen) Zahlen, dieich mit einer Zahlgroße λ ∈ N abzahlen kann. Wir schreiben allgemein aλ fur dieeinzelnen Glieder einer solchen Folge und a1, a2, a3, . . . fur die gesamte Folge.

Wintersemester 2005/06 19
Eine endliche Folge hat nur endlich viele (von 0 verschiedene) Glieder, hort alsoz.B. bei n = 6 auf, etwa die Folge 1, 2, 3, 4, 5, 6 oder 1, 1, 11, 111, 27, 18.
Eine unendliche Folge liegt vor, wenn die Anzahl der (von 0 verschiedenen Glieder)unbegrenzt ist, z.B. die Menge aller naturlichen Zahlen 1, 2, 3, 4, . . ..
Besonders beliebt sind Folgen, deren Bildungsgesetz man in Abhangigkeit von λbeschreiben kann. Aus dem Abschnitt uber Formeln fur endliche Summen 3.1 kennenwir bereits die Begriffe Arithmetisch und Geometrisch. Diese werden uns jetzt hierwieder begegnen.
5.1 Arithmetische und Geometrische Folgen, Konvergenz
Definition 5.3. Bei einer arithmetischen Folge ist die Differenz zweier aufeinanderfolgender Folgenglieder stets gleich groß.
Wir konstruieren eine arithmetische Folge aus einem Anfangsglied a und der kon-stanten Differenz d, alle weiteren Glieder kommen aus der Formel aλ = a+(λ−1) ·d.Das ist das sogenannte Bildungsgesetz einer arithmetischen Folge.
Beispiel 5.4. 1. Wie lautet die arithm. Folge mit a = 2 und d = 0, 5?Losung: a1 = 2, a2 = 2 + (2 − 1) · 0, 5 = 2, 5, a3 = 2 + (3 − 1) · 0, 5 = 3, a4 =2 + (4− 1) · 0, 5 = 3, 5, . . ..
2. Betrachten Sie die Folge −8, 0, 8, 16, 24, 32, . . .. Wie lauten a und d? BerechnenSie a15.Losung: Die Differenz von je zwei aufeinander folgenden Gliedern ist 8, alsoist d = 8. Fur a1 gilt −8 = a1 = a+0 ·d = a, woraus wir direkt a = −8 ablesen.Also ist das Bildungsgesetz aλ = −8 + (λ− 1) · 8. Das ergibt fur λ = 15 danna15 = −8 + 14 · 8 = 104.
3. Auch die Kapitalentwicklung bei einfacher Verzinsung (ohne Zinseszins) ist einearithmetische Folge mit dem Bildungsgesetz Kλ = (K0 +K0i)+ (λ− 1) ·K0i =K0 + λK0i, das das Kapital mit Zinsen am Ende des Jahres λ beschreibt. Alsoist a = K0 + K0 · i und d = K0i.
4. Auf wie viel wachst ein Kapital von 10.000 E nach 7 Jahren bei einfacherVerzinsung mit i = 4% an?Losung: K7 = 10.000 + 7 · 10.000 · 0, 04 = 12.800 E, in Ubereinstimmung mitdem Ergebnis aus Beispiel 1.1.
Wir stellen fest, dass die Glieder einer arithmetischen Folge vom Zahlenwert herimmer großer werden (in positiver Richtung auf dem Zahlenstrahl, falls d positiv,und in negativer Richtung, falls d negativ ist.)

20 A May, D. Pfeifer: Mathematik fur Okonomen
Bitte wiederholen Sie hierzu [Sydsæter], Abschnitt 1.7, Seiten 54–57.
Wir erinnern an folgenden Sachverhalt: Jede reelle Zahl hat einen eindeutigen Ab-stand vom Nullpunkt (kann man mit dem Lineal ausmessen).
Definition 5.5. Ist a eine relle Zahl und |a| der Abstand von a zu 0, so heißt |a|der Absolutbetrag von a. Konkret ist
|a| ={
a falls a ≥ 0−a falls a < 0 .
Dabei heißt a < b, dass”a (echt) links von b“ auf dem Zahlenstrahl liegt und a ≥ b,
dass”a rechts von b“ auf dem Zahlenstrahl liegt und auch a = b eintreten kann.
Beachten Sie, dass also a negativ (a < 0) und positiv (a > 0) sein kann, im Gegensatzdazu aber stets |a| ≥ 0 gilt.
Es gibt keine großte reelle (oder naturliche, ganze, rationale) Zahl. Das Objekt, dasgroßer ist als jede beliebig große reelle Zahl, nennen wir unendlich oder∞. BeachtenSie, dass also fur alle reellen a die Ungleichung a <∞ gilt.
Wir konnen nun (mathematisch prazise) formulieren, dass der Absolutbetrag derFolgenglieder einer unendlichen arithmetischen Folge unendlich groß ist, also keinensogenannten reellen Grenzwert besitzt.
Definition 5.6. Bei der Grenzwertbetrachtung einer Folge ist der Wert des”letzten“
Folgengliedes gesucht.Bei einer endlichen Folge a1, a2, . . . , aN ist das offenbar gerade das Folgenglied aN .Bei einer unendlichen Folge ist das gerade das Folgenglied
”a∞“, in der Mathematik
schreibt man dafur limλ→∞ aλ (Lies: limes aλ fur lambda gegen unendlich).Man sagt, der Grenzwert existiert, wenn limλ→∞ aλ eine reelle Zahl ist. Ist limλ→∞ aλ
keine reelle Zahl, so existiert der Grenzwert nicht, dies ist insbesondere der Fall, wennlimλ→∞ aλ = ±∞, also unendlich groß oder unendlich klein wird.
Wir sehen relativ schnell, dass limn→∞1n
= 0, denn die Glieder der Folge 1, 12, 1
3, . . . ,
1100
,. . . , 1100.000
, . . . werden (sogar ziemlich schnell) winzig klein, bleiben aber immerpositiv (und werden auch selber nie Null).
Wie sieht nun die Situation bei einer geometrischen Folge aus?
Definition 5.7. Ist der Quotient zweier aufeinander folgenden Folgenglieder stetskonstant (und gleich q 6= 0), so nennen wir die Folge geometrische Folge. Das Bil-dungsgesetz einer geometrischen Folge ist aλ = a · qλ, dabei durchlauft λ = 0, 1, 2, . . .und a 6= 0 ist eine reelle Konstante.
Wir machen uns klar, dass fur alle q > 1 die Folgenglieder immer großer werden,die Folge also keinen Grenzwert besitzt. Fur q = 1 erhalten wir die Folge mit nurEinsen 1, 1, . . . , und fur q = −1 eine sogenannte alternierende Folge, bei der sich

Wintersemester 2005/06 21
+1 und −1 abwechseln. 1,−1, 1,−1, 1,−1, . . .. Liegt hingegen 0 < q < 1, so werdendie Folgenglieder immer kleiner, blieben aber positiv und nahern sich von rechts der0 an. Fur −1 < q < 0 werden die Folgenglieder betragsmaßig immer kleiner undnahern sich alternierend (abwechselnd von links und rechts) der 0 an.
Beispiele: q = 2 liefert die geometrische Folge 1, 2, 4, 8, 16, . . .q = 1 liefert die geometrische Folge 1, 1, 1, 1, 1, 1, . . .q = −1 liefert die geometrische Folge 1,−1, 1,−1, 1,−1, 1,−1, . . .q = 1
10liefert die geometrische Folge 1, 1/10, 1/100, 1/1000, 1/10.000, . . .
q = − 110
liefert die geometrische Folge 1,−1/10, 1/100,−1/1000, 1/10.000, . . ..
Beispiel 5.8. (Zinseszinsrechnung)
1. Die Ermittlung des Endwertes Kn = (1 + i)n ·K0 entspricht der Bildung einer(aufsteigenden) geometrischen Folge mit a = K0 und q = r = 1 + i > 1.Den Quotienten r nennt man dann auch Aufzinsungsfaktor . Dabei werden dieFolgenglieder (das Endkapital) mit wachsendem n immer großer, ein Grenzwertexistiert nicht.
2. Die Ermittlung des Barwertes K0 = (1 + i)−n ·Kn entspricht der Bildung einer
(absteigenden) geometr. Folge mit a = Kn und q = v =1
1 + i< 1. Die Große v
heißt auch Diskontfaktor , und es gilt r · v = 1. Dabei werden die Folgengliederbetragsmaßig immer kleiner, der Grenzwert fur n→∞ ist daher Null.
5.2 Die unendliche Geometrische Reihe
Wir haben bereits festgestellt, dass sich die Folge qλ unterschiedlich verhalt, wennwir 2 und 1
2einsetzen. Im ersten Fall werden die Folgenglieder immer großer, im
zweiten Fall kommen die Folgenglieder immer naher an die 0 heran. Mit dem neuenKonvergenzbegriff konnen wir auch sagen limλ→∞ qλ = 0. Wir haben bereits die Fragebeantwortet, fur welche q diese Beziehung insgesamt gilt, das waren alle reellen q mit0 < |q| < 1.
Nun betrachten wir die Summe Sn =n−1∑λ=0
qλ. Dann ist auch Sn eine Folge. Existiert
der Grenzwert limn→∞ Sn und ist eine reelle Zahl, so sagen wir”die unendliche Reihe
konvergiert“.
Satz 5.9. (Grenzwert der geometrischen Reihe)Ist 0 < |q| < 1, so gilt limλ→∞ qλ = 0, und es folgt
limn→∞
Sn = limn→∞
n−1∑λ=0
qλ = limn→∞
1− qn
1− q=
1
1− q.

22 A May, D. Pfeifer: Mathematik fur Okonomen
Mit dieser Formel konnen wir nun die Hohe x unseres jahrlichen Wissenschaftspreisesaus Beispiel 5.1 ausrechnen. Wir haben
1.000.000 = a =∞∑
λ=0
x · 1
(1 + i)λ= x · 1
1− 1, 04−1.
Mit Hilfe des Taschenrechners erhalten wir x = 38.461, 50 E.
6 Lineare Funktionen
Unter einer Funktion wollen wir im folgenden eine Zuordnungsvorschrift verstehen,die jeder reellen Zahl x aus einer bestimmten Menge einen Wert zuordnet. Wenn esum endlich viele x geht, konnen wir die Sache mit einer Aufzahlung erledigen, beiunendlich vielen x erfolgt die Zuordnung uber eine Gleichung (Formel), in die wir xeinsetzen.
6.1 Intervalle und etwas Mengenlehre
Wir haben bereits festgestellt, dass man zu je zwei beliebigen reellen Zahlen stetssagen kann, welche die kleinere von beiden ist (evtl. sind beide gleich groß). Wirschreiben a < b, wenn die Gleichheit der beiden Zahlen ausgeschlossen ist.
Definition 6.1. Ist a < b, so heißt die Menge aller reeller Zahlen, die zwischen a undb liegen, ein Intervall. Je nachdem, ob die Randpunkte a, b zum Intervall gehoren odernicht unterscheiden wir die folgenden Falle, je nachdem aus welchen x das Intervallbesteht:
• (a, b) heißt offenes Intervall, wenn a < x < b gilt;
• [a, b] heißt abgeschlossenes Intervall, wenn a ≤ x ≤ b gilt;
• (a, b] heißt (links) halboffenes Intervall, wenn a < x ≤ b gilt;
• [a, b) heißt (rechts) halboffenes Intervall, wenn a ≤ x < b gilt.
Ein offenes Intervall enthalt also keinen seiner Endpunkte, ein abgeschlossenes Inter-vall beide Endpunkte. Alle vier Intervalle haben dieselbe Lange |b− a| = b− a.
Unter einer Menge wollen wir eine Ansammlung von Objekten (haufig: reellen Zah-len) verstehen. Liegt x in einer Menge A, so schreiben wir kurz x ∈ A und sagen
”x
ist Element von A“. Wenn x nicht in A liegt, so schreiben wir x 6∈ A. Fur unsereGrundmenge der reellen Zahlen schreiben wir kurz R.

Wintersemester 2005/06 23
Beispiel 6.2. Ist die Menge A ein Intervall mit Endpunkten a ∈ R und b ∈ R, sokonnen wir A uber Ungleichungen beschreiben:
1. (a, b) = {x ∈ R | a < x und x < b} = {x ∈ R | a < x < b};
2. [a, b] = {x ∈ R | a ≤ x und x ≤ b} = {x ∈ R | a ≤ x ≤ b};
3. (a, b] = {x ∈ R | a < x und x ≤ b} = {x ∈ R | a < x ≤ b};
4. [a, b) = {x ∈ R | a ≤ x und x < b} = {x ∈ R | a ≤ x < b}.
Manchmal betrachtet man Mengen, die durch Kombination bereits bekannter Men-gen entstehen. Die prominentesten Beispiele sind Vereinigung, (Durch-) Schnitt undKomplement.
Definition 6.3. Seien A, B Mengen.
1. Die Vereinigung von A und B besteht aus den Elementen, die mindestens zueiner der beiden Mengen gehoren, also in A oder B liegen. Wir schreiben kurz
A ∪B = {x | x ∈ A oder x ∈ B}.
2. Der Schnitt von A und B besteht aus den Elementen, die zu beiden Mengengehoren, also in A und B liegen. Wir schreiben kurz
A ∩B = {x | x ∈ A und x ∈ B}.
3. Das Komplement von B in A besteht aus den Elementen, die zu A, nicht aberzu B gehoren, also in A minus B liegen. Wir schreiben kurz
A \B = {x | x ∈ A und x 6∈ B}.
Hat eine Menge kein einziges Element, so sagen wir die Menge ist leer und schreibendafur ∅. Liegt eine Menge B vollstandig in einer anderen Menge A, so sagen wir
”B
ist Teilmenge von A und schreiben B ⊆ A.
Beispiel 6.4. Es gilt (a, b) ⊆ (a, b] ⊆ [a, b]. Außerdem ist [a, b]\ [a, b) = {b}; beachtenSie bitte, dass auch rechts eine Menge stehen muss, nicht nur ein Element, daher dieMengenklammern um das b.

24 A May, D. Pfeifer: Mathematik fur Okonomen
6.2 Allgemeines uber Funktionen
Definition 6.5. Eine Funktion f wird beschrieben durch ihren DefinitionsbereichD und eine Zuordnungsvorschrift x 7→ f(x) fur alle x ∈ D. D.h. es kann jede Zahlx ∈ D auch wirklich in die Formel fur f eingesetzt werden. Damit f eine Funktionist, muss die Zuordnung x 7→ f(x) in eindeutiger Weise erfolgen (
”nur ein f(x) pro
x“), wenn dies nicht der Fall ist, sprechen wir von einer Relation.
Der Wertebereich W von f ist die Menge aller moglichen Funktionswerte f(x), alsodie Menge aller Werte die ich erhalte, wenn ich alle x ∈ D in die Zuordnungsvorschriftvon f einsetze,
W = {f(x) ∈ R | x ∈ D} .
Beachte, dass f die ganze Funktion (Zuordnungsvorschrift) bezeichnet, hingegen f(x)fur den Wert von f an der Stelle x steht.
Beispiele 6.6. f : x 7→ f(x) = a · x, a ∈ R \ {0} mit Df = R,g : x 7→ g(x) = ln x mit Dg = {x ∈ R | x > 0},K : i 7→ K(i) = K0 · (1 + i)15 mit DK = {i ∈ R | 0 < i < 0, 25}.
Definition 6.7. Eine lineare Funktion ist von der Form f : x 7→ f(x) = m · x +b, m, b ∈ R mit D = R.
6.3 Graphen von Funktionen
Ein Koordinatensystem besteht aus 2 aufeinander senkrecht stehenden Achsen, vondenen wir die waagerechte die x-Achse und die senkrechte die y-Achse nennen wollen.Sie schneiden sich im Nullpunkt, das ist der Punkt mit den Koordinaten (0, 0). EinPunkt mit den Koordinaten (p, q) hat den Abstand |p| vom Nullpunkt auf der x-Achse und den Abstand |q| vom Nullpunkt auf der y-Achse. Die Vorzeichen von p, qbestimmen dabei, auf welcher Seite des Nullpunktes der Punkt liegt (rechts/links,oben/unten). Zu einer gegebenen Funktion f konnen wir immer den Graphen von fzeichnen, der uns die Eigenschaften von f gut veranschaulicht. Wir schreiben
Gf = {(x, y) | x ∈ D und y = f(x)} .
Der Graph jeder linearen Funktion der Form f : x 7→ f(x) = mx + b ist eine Ge-rade ` mit der Gleichung y = mx + b. Wir nennen m die Steigung und b den y-Achsenabschnitt.
Wir halten folgende Ergebnisse fur Geraden fest:
Satz 6.8. 1. SteigungsberechnungSind (x1, y1), (x2, y2) zwei Punkte auf einer Geraden ` mit x1 6= x2, so ist dieSteigung der Geraden
m =y2 − y1
x2 − x1
.

Wintersemester 2005/06 25
2. Punkt-Steigungsformel einer GeradenDie Gleichung einer Geraden mit der Steigung m durch den Punkt (x1, y1) ist
y − y1 = m(x− x1) .
3. Zweipunkte-Formel fur GeradenGegeben seien 2 Punkte (x1, y1) und (x2, y2) mit x1 6= x2. Die Gleichung derGerade ` durch die beiden Punkte erhalt man, indem man zunachst die Steigungausrechnet gemaß
m =y2 − y1
x2 − x1
.
Wenn man dann im 2. Schritt diese Steigung in die Punkt-Steigungsformeleinsetzt, erhalt man
y − y1 =y2 − y1
x2 − x1
· (x− x1) .
6.4 Lineare Ungleichungen
Lineare Ungleichungen ax + b ≤ c kann man graphisch losen, indem man beachtet,dass ≤ bedeutet, dass Werte gemeint sind, die unterhalb der Geraden liegen (≥ be-deutet entsprechend: oberhalb). Rechnerisch kann man lineare Ungleichungen nachdem gleichen Algorithmus nach einer Variable (x) nach dem Algorithmus fur Glei-chungen auflosen, allerdings muss man beachten, dass das Ungleichheitszeichen sichbei Multiplikation mit (Division durch) eine negative Zahl umdreht.
6.5 Systeme von 2 linearen (Un-)Gleichungen
Die rechnerische Losung erfolgt nach unserem Algorithmus, nach dem wir zunachstbeide Gleichungen nach derselben Variablen (x) auflosen und dann gleichsetzen. Da-mit erhalten wir die andere Variable (y) und konnen dann x herausbekommen, indemwir das gefundene y in eine der beiden nach x aufgelosten Gleichungen einsetzen.
Graphisch lost man 2 lineare Gleichungen mit 2 Unbekannten, indem man denSchnittpunkt der zugehorigen Geraden bestimmt.
7 Lineare Gleichungssysteme und ein systemati-
sches Losungsverfahren
7.1 Der Gauß-Jordan-Algorithmus
Wir haben bereits in 6.5 ein Verfahren kennengelernt, um zwei Gleichungen mit 2 Un-bekannten zu losen. Bei mehr als 2 Gleichungen (was in wirtschaftswissenschaftlichen

26 A May, D. Pfeifer: Mathematik fur Okonomen
Modellen durchaus haufiger vorkommt) funktioniert das Verfahren zwar immer noch,wird aber schnell unubersichtlich und damit fehleranfallig. Das folgende Beispiel il-lustriert eine Aufgabe, die bereits im Chinesischen Reich (vor uber 2.000 Jahren)bekannt war und dort benutzt wurde, um das mathematische Wissen von Bewerbernum die begehrten Beamtenstellungen zu uberprufen.
Beispiel 7.1. Ein Bauer verkauft 2 Pferde (Stuckpreis p) und 8 Schafe (Stuckpreiss) und erholt dafur 18 Ziegen (Stuckpreis z) und 500 Munzen. Ein zweiter Bauerverkauft ebenfalls 2 Pferde und dazu 9 Schafe, er erhalt dafur 16 Ziegen und 900Munzen. Ein dritter Bauer verkauft 12 Ziegen und erhalt dafur ein Pferd, 3 Schafeund 300 Munzen.
Die Munzen haben einen festen Wert. Wie viele Munzen kostet ein Tier jeder Art?
Losung: Wir setzen p fur den Preis eines Pferdes,s fur den Preis eines Schafes und z fur den Preis einer Ziege.Da alle Munzen gleich viel wert sind, nehmen wir fur die Rechnung an, dass jedeMunze den Wert 1 besitzt. (Wir konnten auch x fur den Munzwert schreiben, dannbekamen wir am Ende statt der Anzahl der Munzen (z.B. 100) den Preis des Tieres(z.B. 100x heraus. Wir rechnen mit x = 1, da das den Rechenweg erleichtert und wirso nicht auf das x aufpassen mussen.)
Damit sieht das Gleichungssystem, das wir aus der Aufgabenstellung ablesen, in-dem wir links die Verkaufe von Bauer 1,2,3 und rechts die jeweiligen Verkaufserloseangeben, wie folgt aus:
2p + 8s = 18z + 500 · 12p + 9s = 16z + 900
12z = 1p + 3s + 300
Wenn wir unserem Flussdiagramm aus 4.1 folgen und es auf die Situation mit 3 Va-riablen anpassen, wurden wir wahrscheinlich zunachst Gleichung (3) nach z auflosenund diesen Ausdruck in (1) und (2) einsetzen. Damit hatten wir ein Gleichungs-system mit 2 Variablen und 2 Gleichungen gewonnen, das wir wiederum nach derMethode aus dem Flussdiagramm auflosen wurden.
Ein alternatives Vorgehen sieht so aus:
1. 2p + 8s− 18z = 5002p + 9s− 16z = 900−p− 3s + 12z = 300
Hier stehen die Variablen in allen 3 Gleichungen in derselben Reihenfolge aufder linken Seite, der konstante Term steht jeweils auf der rechten Seite.
2. Wir tragen nun die Vorfaktoren der Variablen (ohne p, s, z) in eine Art Ar-beitsblatt ein und schreiben in der Spalte dahinter auf, in welcher Reihenfolgewir die Variablen aufgeschrieben hatten. Das ergibt:

Wintersemester 2005/06 27
2 8 −182 9 −16−1 −3 12
· p
sz
=
500900300
3. Wir rechnen nun nur mit den Zahlen weiter, Grundlage ist das Arbeitsblatt 2 8 −18 500
2 9 −16 900−1 −3 12 300
4. Unser Ziel besteht darin, auf der Diagonale nur 1 zu erzeugen. Dazu dividieren
wir zunachst die 1. Zeile durch die erste darin befindliche Zahl (6= 0): 2 8 −18 5002 9 −16 900−1 −3 12 300
|: 2∼
1 4 −9 2502 9 −16 900−1 −3 12 300
Damit steht in der ersten Zeile eine 1 auf der Diagonalen.
5. Nun kommt die zweite Zeile dran. Zu diesem Zweck durfen wir Vielfache derersten Zeile von der zweiten (und danach der dritten Zeile) abziehen: 1 4 −9 250
2 9 −16 900−1 −3 12 300
= Z1
|←↩ −2Z1
|←↩ +Z1
∼
1 4 −9 2502− 2 9− 2 · 4 −16− 2 · (−9) 900− 2 · 250−1 + 1 −3 + 4 12− 9 300 + 250
∼
1 4 −9 2500 1 2 4000 1 3 550
Damit steht in der zweiten Zeile eine 1 auf der Diagonalen.
6. Nun kommt die dritte Zeile dran. Zu diesem Zweck durfen wir Vielfache derzweiten Zeile von der dritten abziehen: 1 4 −9 250
0 1 2 4000 1 3 550
|= Z2
|←↩ −Z2
∼
1 4 −9 2500 1 2 4000 0 1 150
Damit steht in der dritten Zeile eine 1 auf der Diagonalen.
7. Wir ubersetzen das Arbeitsblatt zuruck in unser Gleichungssystem: 1 4 −90 1 20 0 1
· p
sz
=
250400150

28 A May, D. Pfeifer: Mathematik fur Okonomen
oder anders aufgeschrieben:
p + 4s− 9z = 250
s + 2z = 400
z = 150
Wir lesen sofort den Preis einer Ziege zu z = 150 Munzen ab und setzen vonunten nach oben ein: (2. Zeile) s + 2 · 150 = 400 ergibt s = 400 − 300 = 100und (1. Zeile) p + 4 · 100− 9 · 150 = 250 ergibt p = 250− (−950) = 1200. Alsokostet ein Schaf 100 Munzen und ein Pferd 1200 Munzen.
Wir wollen das Verfahren noch an einem weiteren Beispiel – diesmal mit 4 Variablenin 4 Gleichungen – testen, bevor wir das Verfahren als Rechenregel (Algorithmus)formulieren und auch auf die dahinter liegende Mathematik eingehen.
Beispiel 7.2. In einem Unternehmen mit 4 Produktionsstatten in Deutschland (Opel. . . ) soll aus Kostendampfungsgrunden die Gehaltsstruktur fur folgende Gruppenvon Arbeitnehmern ermittelt werden: A Arbeiter, V Vorarbeiter, M Meister und LGruppenleiter. Wir kennen nur die Anzahl der Arbeitskrafte pro ProduktionsstatteP1, P2, P3, P4 und das monatliche Gesamteinkommen G in E. Die Betriebsrate in denvier Produktionsstatten haben folgende Zahlen ubermittelt:
P1 P2 P3 P4
A 12 6 30 10V 8 4 15 5M 4 2 5 5L 0 1 2 0G 82.400 46.400 178.900 69.500
Ihre Aufgabe besteht nun darin, aus dieser Tabelle das monatliche Einkommen derGruppen A, V, M, L zu ermitteln. Dazu stellen Sie 4 Gleichungssysteme auf, indemSie die 4 Spalten, also die Angaben pro Produktionsstatte, von oben nach unten inGleichungen umsetzen:
Losung: Wir setzen A fur das monatliche Einkommen eines Arbeiters,V fur das monatliche Einkommen eines Vorarbeiters,M fur das monatliche Einkommen eines Meisters undL fur das monatliche Einkommen eines Gruppenleiters.Damit sieht das Gleichungssystem wie folgt aus:
12A + 8V + 4M + 0 · L = 82.400
6A + 4V + 2M + 1 · L = 46.400
30A + 15V + 5M + 2L = 178.900
10A + 5V + 5M + 0 · L = 69.500

Wintersemester 2005/06 29
Nun arbeiten wir die Methode aus dem vorangegangenen Beispiel ab.
1. Wir sortieren die Variablen nach aufsteigender Hierarchie im Unternehmen,und sie stehen bereits in allen Gleichungen in der gleichen Reihenfolge, derkonstante Term steht jeweils auf der rechten Seite.
2. Wir tragen nun die Vorfaktoren der Variablen (ohne A, V, M, L) ein Arbeits-blatt ein (wie in der Tabelle, nur mit den Spalten waagerecht geschrieben!) undschreiben in der Spalte dahinter auf, in welcher Reihenfolge wir die Variablenaufgeschrieben hatten. Das ergibt:
12 8 4 06 4 2 1
30 15 5 210 5 5 0
·
AVML
=
82.40046.400178.90069.500
3. Wir rechnen nun nur mit den Zahlen weiter, Grundlage ist das Arbeitsblatt
12 8 4 0 82.4006 4 2 1 46.400
30 15 5 2 178.90010 5 5 0 69.500
4. Unser Ziel besteht darin, auf der Diagonale nur 1 zu erzeugen. Dazu dividieren
wir zunachst die 1. Zeile durch die erste darin befindliche Zahl (12 6= 0):12 8 4 0 82.4006 4 2 1 46.400
30 15 5 2 178.90010 5 5 0 69.500
|: 12
∼
1 2/3 1/3 0 20.600/36 4 2 1 46.400
30 15 5 2 178.90010 5 5 0 69.500
Damit steht in der ersten Zeile eine 1 auf der Diagonalen.
5. Nun kommt die zweite Zeile dran. Zu diesem Zweck durfen wir Vielfache der er-sten Zeile von der zweiten (und danach der dritten Zeile, und dann der vierten)abziehen:
1 2/3 1/3 0 20.600/36 4 2 1 46.400
30 15 5 2 178.90010 5 5 0 69.500
= P1
|←↩ −6P1
|←↩ −30P1
|←↩ −10P1
∼
1 2/3 1/3 0 20.600/3
6− 6 4− 4 2− 2 1 46.400− 41.20030− 30 15− 20 5− 10 2 178.900− 206.00010− 10 5− 20/3 5− 10/3 0 69.500− 206.000/3
∼
1 2/3 1/3 0 20.600/30 0 0 1 5.2000 −5 −5 2 −27.1000 −5/3 5/3 0 2.500/3

30 A May, D. Pfeifer: Mathematik fur Okonomen
Damit steht in der zweiten Zeile eine 0 auf der Diagonalen. Aber:
6. Die zweite Zeile hat bereits eine 1 auf Platz 4, wir schreiben sie daher nachganz unten, dann steht die 1 bereits auf der Diagonalen der 4. Zeile; und wirmussen uns nur noch um die Zeilen 2 und 3 kummern.
1 2/3 1/3 0 20.600/30 −5 −5 2 −27.1000 −5/3 5/3 0 2.500/30 0 0 1 5.200
7. Nun kommt die (neue) zweite Zeile dran, die wir durch (−5) dividieren:
1 2/3 1/3 0 20.600/30 −5 −5 2 −27.1000 −5/3 5/3 0 2.500/30 0 0 1 5.200
|: (−5) ∼
1 2/3 1/3 0 20.600/30 1 1 −2/5 5.4200 −5/3 5/3 0 2.500/30 0 0 1 5.200
Damit steht in der zweiten Zeile eine 1 auf der Diagonalen.
8. Nun kommt die dritte Zeile dran. Dazu muss zunachst der zweite Platz in der3. Zeile zu Null werden (jetzt: −5/3).
1 2/3 1/3 0 20.600/30 1 1 −2/5 5.4200 −5/3 5/3 0 2.500/30 0 0 1 5.200
| +5/3 · Z2)
∼
1 2/3 1/3 0 20.600/30 1 1 −2/5 5.4200 0 10/3 −2/3 29.600/30 0 0 1 5.200
9. Nun muss noch das Diagonalelement in der 3. Zeile zu 1 werden (durch Division
durch 10/3):1 2/3 1/3 0 20.600/30 1 1 −2/5 5.4200 0 10/3 −2/3 29.600/30 0 0 1 5.200
|: (10/3)∼
1 2/3 1/3 0 20.600/30 1 1 −2/5 5.4200 0 1 −1/5 2.9600 0 0 1 5.200
10. Wir ubersetzen das Arbeitsblatt zuruck in unser Gleichungssystem:
1 2/3 1/3 00 1 1 −2/50 0 1 −1/50 0 0 1
·
AVML
=
20.600/3
5.4202.9605.200

Wintersemester 2005/06 31
oder anders aufgeschrieben:
A +2
3V +
1
3M = 20.600/3
V + M − 2
5L = 5.420
M − 1
5L = 2.960
L = 5.200
Wir lesen sofort das Monatsgehalt eines Gruppenleiters ab L = 5.200 E. Nunsetzen wir wieder von unten nach oben ein: (3. Zeile) M − 1
5· 5.200 = 2.960
ergibt M = 2.960 + 1.040 = 4.000 und (2. Zeile) V + M − 25L = 5.420 ergibt
V = 5.420 − 4.000 + 2.080 = 3.500 und schließlich (1. Zeile) A + 23V + 1
3M =
20.600 ergibt A = 20.600/3− 7.000/3− 4.000/3 = 3.200.
7.2 Rechnen mit Matrizen
Wir haben in den vorangegangenen Einfuhrungsbeispielen lineare Gleichungssyste-me mit mehr als 2 Gleichungen bereits recht elegant unter Verwendung der Matrix-schreibweise gelost. Das folgende Kapitel stellt die dazu benotigte Mathematik zurVerfugung.
Definition 7.3. Eine Matrix ist eine rechteckige Anordnung von Zahlen. Wir konnensie uns als Inhalt einer Zahlentabelle oder Arbeitsblatt vorstellen.
Wenn unsere Tabelle m Zeilen und n Spalten besitzt, haben wir eine m-Kreuz-nMatrix und schreiben dafur auch m× n.
In der aller allgemeinsten Form sieht eine Matrix damit so aus
A =
a11 a12 a13 · · · a1n
a21 a22 a23 · · · a2n...
......
...am1 am2 am3 · · · amn
mit reellen Zahlen aij, die wir Matrixelemente (Eintrage) nennen wollen. Davon gibtes insgesamt m · n Stuck. (Wieso?)
Matrizen bezeichnen wir mit Großbuchstaben, also A, B, C usw.
Hat eine Matrix nur eine Spalte, so nennen wir sie (Spalten-)Vektor.
Schreiben Sie zur Ubung eine 3× 2 Matrix mit allen Elementen gleich 1 auf.
Zwei Matrizen A und B heißen gleich, wenn alle ihre Elemente gleich sind. GleicheMatrizen haben demnach dieselbe Zeilen- und Spaltenanzahl, wir schreiben dannA = B, wenn aij = bij fur alle Positionen ij in der Matrix.

32 A May, D. Pfeifer: Mathematik fur Okonomen
Beispiel 7.4. Wann ist
(3 x− 12x y
)=
(x 2z
y + 1 x + 2
)?
Losung: Wir stellen zunachst fest, dass beide Matrizen 2 × 2 Matrizen sind. Diebeiden Matrizen sind gleich, wenn alle ihre Elemente gleich sind. Also uberprufenwir nacheinander die Elemente auf den Positionen 11: 3 = x und 12: x− 1 = 2z und
21: 2x = y + 1 und y = x + 2 auf Position 22. Das ergibt x = 3, y = 3 + 2 = 5, z =0.5 · (x− 1) = 1 und 2x = 6 = 5 + 1 ist damit automatisch erfullt.
Rechenregeln 7.5. Addition von MatrizenVoraussetzung fur die Addition von Matrizen ist wieder, dass die Anzahl von Zeilenund Spalten bei beiden Matrizen ubereinstimmt. Sind also A, B Matrizen vom Typm× n mit Elementen aij und bij, so gilt:
1. Die Matrix A + B hat die Elemente aij + bij.
2. Die Nullmatrix 0 besteht nur aus Nullen, d.h. A = 0 heißt aij = 0 fur allePositionen i, j.
3. A + 0 = A.
4. Die Matrix −A hat die Eintrage −aij fur alle Positionen ij.
5. Ist α eine relle Zahl, so multipliziert man eine Matrix mit einer Zahl, indemman alle ihre Eintrage mit dieser Zahl (dem Vorfaktor) multipliziert. Die Ma-trix α · A hat also die Elemente α · aij.
6. Es ist A + (−A) = A− A = 0.
Etwas komplizierter ist das Produkt zweier Matrizen. Wir erinnern uns zunachst dar-an, wie wir beim Gauß-Jordan Verfahren die Koeffizientenmatrix mit einem Vektorbestehend aus den Variablen multipliziert haben: Dazu hatten wir die erste Zeile derKoeffizientenmatrix mit dem Variablenvektor multipliziert, indem wir die
”zueinan-
der passenden“ Elemente multipliziert hatten und diese Produkte alle aufaddierten: 1 2 3∗ ∗ ∗∗ ∗ ∗
· x
yz
=
x + 2y + 3z∗∗
Nun verfahren wir in gleicher Weise mit den beiden anderen Zeilen und erhalten so 1 2 3
4 5 67 8 9
· x
yz
=
x + 2y + 3z4x + 5y + 6z7x + 8y + 9z

Wintersemester 2005/06 33
Wenn wir nun eine Matrix statt mit einem Vektor mit einer weiteren Matrix multi-plizieren, so gehen wir genauso vor, indem wir die zweite Matrix nacheinander furdie erste Spalte, die zweite Spalte und so weiter behandeln.
Beispiel 7.6. Berechnen Sie nun:
A ·B =
0 1 22 3 14 −1 6
· 3 2
1 0−1 1
Losung: 1. Schritt: Alle Zeilen von A mit der ersten Spalte von B (das kann mansich als Spaltenvektor vorstellen!) multiplizieren.
A ·B =
0 1 22 3 14 −1 6
· 3 ∗
1 ∗−1 ∗
=
−185
2. Schritt: Alle Zeilen von A mit der zweiten Spalte von B multiplizieren (das ist fursich genommen wieder ein Spaltenvektor!).
A ·B =
0 1 22 3 14 −1 6
· 3 2
1 0−1 1
=
−1 28 55 14
Damit haben wir bereits das Matrixprodukt A · B ausgerechnet. Nebenbei habenwir gelernt, dass die Anzahl der Spalten von A mit der Anzahl der Zeilen von Bubereinstimmen muss, damit unsere Multiplikationsvorschrift funktioniert.
Rechenregeln 7.7. MatrixmultiplikationSei A eine m× n Matrix und B und C n× p Matrizen und D eine p× q Matrix, sogilt:
1. A ·B ist eine m× p Matrix.
2. Ist I =
1 0 0 · · · 00 1 0 · · · 00 0 1 · · · 0...
......
...0 0 0 · · · 1
, so heißt I die Einheitsmatrix, und es gilt A ·I =
A und I ·B = B fur beliebige Matrizen A und B.
3. Achtung, es gilt im allgemeinen A ·B 6= B · A.
4. A(B + C) = AB + AC
5. (B + C)D = BD + CD

34 A May, D. Pfeifer: Mathematik fur Okonomen
6. (B + C)(B + C) = BB + BC + CB + CC, die binomische Formel gilt hiernicht, da BC + CB 6= 2BC gilt.
Bei der Ubertragung der Tabelle aus Beispiel 7.2 in die Matrixschreibweise haben wirdie Rolle von Spalten und Zeilen vertauscht. Dieser Vorgang heißt in der Mathematiktransponieren“.
Definition 7.8. Ist A eine m × n Matrix, so bezeichnet die Transponierte von A,die wir mit AT bezeichnen wollen, diejenige n × n Matrix, deren ersten Spalte dieerste Zeile von A ist, die zweite Spalte entspricht der zweiten Zeile usw.
Beispiel 7.9.
Die Transponierte zu A =
−1 02 35 −1
ist AT =
(−1 2 50 3 −1
).
Rechenregeln 7.10. Transponieren einer Matrix
1. (AT )T = A
2. (A + B)T = AT + BT
3. (αA)T = α · AT fur reelle Zahlen α.
7.3 Gaußscher Algorithmus zur Inversenberechnung
Sei A n×n-Matrix mit Inverser A−1. Dann existieren endlich viele Matrizen B1, . . . , Bs
von Elementar-Operationen derart, daß
Bs Bs−1 · · ·B1 A = I (n× n−Einheitsmatrix),
d.h. es istA−1 = Bs Bs−1 · · ·B1.
Schema:
(A|I)→ (B1 A|B1)→ (B2 B1 A|B2 B1)→ . . .→ (Bs · · ·B1 A|Bs · · ·B1) = (I|A−1)
Naturlich konnen statt Matrizen von Elementar-Operationen (durch Zusammenfas-sung) auch die kombinierten Matrizen SM(zi ⊕ a � zj) und V (zi, zj) verwendetwerden.

Wintersemester 2005/06 35
Beispiel: A =
1 2 34 3 2−1 −2 1
Die Umformungen konnen in 7 (z.T. kombinierten) Schritten z.B. wie folgt vorge-nommen werden:
B1 = SM(z2 ⊕ (−4)� z1) B2 = S(z3 ⊕ z1) B3 = M(−15� z2) B4 = M(1
4� z3)
B5 = SM(z1 ⊕ (−3)� z3) B6 = SM(z2 ⊕ (−2)� z3) B7 = SM(z1 ⊕ (−2)� z2)
1 2 3 1 0 04 3 2 0 1 0−1 −2 1 0 0 1
z2 ⊕ (−4)� z1
z3 ⊕ z1−−−−−−−−−−−→
1 2 3 1 0 00 −5 −10 −4 1 00 0 4 1 0 1
−15� z2
14� z3
−−−−−−−→
1 2 3 1 0 00 1 2 4
5−1
50
0 0 1 14
0 14
z1 ⊕ (−3)� z3
z2 ⊕ (−2)� z3−−−−−−−−−−−→
1 2 0 14
0 −34
0 1 0 310−1
5−1
2
0 0 1 14
0 14
z1 ⊕ (−2)� z2−−−−−−−−−−−→
1 0 0 − 720
25
14
0 1 0 310−1
5−1
2
0 0 1 14
0 14
Es ist also
A−1 =
− 720
25
14
310−1
5−1
214
0 14
Mit dem oben beschriebenen Verfahren laßt sich auch feststellen, ob eine n × n–Matrix A uberhaupt eine Inverse besitzt. Dies ist namlich nur dann der Fall, wennmit endlich vielen Elementar–Operationen im linken Teil des Schemas tatsachlicheine Einheitsmatrix erreichbar ist. Anderenfalls ergibt sich namlich in diesem Teildes Schemas nach endlich vielen Umformungen (mindestens) eine Zeile oder Spalteaus lauter Nullen. Das Erreichen einer Einheitsmatrix ist dann nicht mehr moglich,d.h. eine Inverse zu der gegebenen Matrix existiert nicht.

36 A May, D. Pfeifer: Mathematik fur Okonomen
8 Der Simplex-Algorithmus
8.1 Problemstellung
Primales (Standard-)Problem:
max! ax
unter Ax ≤ b, x ≥ 0,
wobei a ein gegebener 1×n-Vektor, A eine gegebene m×n-Matrix und b ein gegebenerm× 1-Vektor mit b ≥ 0 ist.
Durch Einfuhrung sogenannter Schlupfvariablen s1, . . . , sm mit s =
s1...
sm
laßt
sich das gegebene Ungleichungssystem in ein Gleichungssystem uberfuhren. Das ge-stellte Problem geht dann uber in das Problem
max! cz
unter (I, A)z = b, z ≥ 0,
wobei jetzt c = (0, a) und z =(
sx
)zu setzen ist und I die m × m-Einheitsmatrix
bezeichnet.
Das ursprungliche Problem ist also genau dann losbar, wenn das modifizierte Problemlosbar ist mit s ≥ 0.
Im Falle der Losbarkeit handelt es sich bei dem modifizierten Gleichungssystem umein System vom Typ II, welches bereits in der Endform vorliegt. Dabei sind gera-de x1, . . . , xn die frei wahlbaren Parameter. Eine triviale Losung des modifiziertenGleichungssystems erhalt man durch die Wahl von x = 0 und damit auch s = 0bzw. z = 0. Diese Losungerfullt zwar die gestellten Nebenbedingungen, liefert aberin der Regel nicht das Maximum der Zielfunktion ax bzw. cz. Die Idee des Simplex-Algorithmus besteht nun darin, das (modifizierte) Gleichungssystem schrittweise –unter Beibehaltung der Form – so zu transformieren, daß sich jeweils zulassigeLosungen (d.h. solche, welche die Nebenbedingungen erfullen) ergeben, der ent-sprechende Zielfunktionswert aber jeweils verbessert wird, bis die ggf. existierendeoptimale Losung erreicht wird.
8.2 Das Simplex-Tableau
Das aktuelle Tableau wird standardmaßig in der folgenden Form notiert:
c∗I c∗Nc∗I I N b∗
0 −(c∗N − c∗IN) c∗Ib∗
lies: z∗I + Nz∗N = b∗

Wintersemester 2005/06 37
Fur das Anfangstableau gilt dabei: N = A, c∗ = (c∗I , c∗N), b∗ = b, z∗I = s, z∗N = x.
Hier stimmt also die unterste Zeile des Tableaus mit der negativen obersten uberein.Die jeweils in dem m×1-Vektor z∗I zusammengefaßten Variablen heißen Basisvaria-blen, die ubrigen, in dem n×1-Vektor z∗N zusammengefaßten Variablen entsprechendNichtbasisvariablen. Die Komponenten von z∗ und z unterscheiden sich dabei nurdurch ihre Anordnung (im Sinne der Ausfuhrungen auf Seite 6 bzw. Seite 10), umformal die ubersichtlichere Blockschreibweise beibehalten zu konnen. Entsprechendesgilt fur die Vektoren c∗ und c, x∗ und x, s∗ und s. Die Indizierung mit I bzw. N solldabei zum Ausdruck bringen, daß sich die Komponenten der Vektoren c∗I bzw. c∗Nim Tableau gerade uber der Matrix I bzw. der Matrix N befinden. Der Ubersicht-lichkeit halber wird die Bezeichnungsweise mit einem ∗ fur alle Tableaus einheitlichbeibehalten, wenn auch tatsachlich fur verschiedene Tableaus die Anordnung der inz∗ usw. zusammengefaßten Variablen i.a. verschieden ist.
Die aktuelle Losung ergibt sich jeweils durch Nullsetzen der Nichtbasisvariablen(d.h. z∗N = 0) zu
z∗I = b∗ −Nz∗N = b∗,
der aktuelle Zielfunktionswert entsprechend zu
c∗z∗ = c∗Iz∗I + c∗Nz∗N = c∗I(b
∗ −Nz∗N) + c∗Nz∗N = c∗Ib∗ + (c∗N − c∗IN)z∗N = c∗Ib
∗.
Die aktuelle Losung ist also jeweils in der rechten Spalte in der Mitte abzulesen, deraktuelle Zielfunktionswert in der rechten Spalte unten.
8.3 Das Aufnahmekriterium
Aus der zuletzt angegebenen allgemeinen Form des aktuellen Zielfunktionswerts er-gibt sich, daß eine Verbesserung dieses Werts dann moglich ist, wenn in dem Zeilen-vektor −(c∗N − c∗IN) (mindestens) ein negatives Element −(c∗N − c∗IN)j vorhandenist, und man der entsprechenden Variablen (z∗N)j einen positiven Wert zuweist, wo-durch (z∗N)j zu einer Basisvariablen wird. In der Praxis hat es sich bewahrt, dabeidenjenigen Index j auszuwahlen, fur den der Ausdruck −(c∗N − c∗IN)j minimal ist,da dann der relative Zuwachs in der Zielfunktion am großten ist. Hieraus resultiertdas folgende
Aufnahmekriterium: Wahle in der unteren Tableauzeile Index j mit mini-malem negativem Wert −(c∗N − c∗IN)j. Gibt es keinensolchen Index (d.h. sind alle −(c∗N − c∗IN)j ≥ 0), ist dieoptimale Losung erreicht, und der Algorithmus brichtab.
Bemerkung 8.1. Es kann vorkommen, daß in der unteren Tableauzeile noch Nul-len unter Nichtbasisvariablen stehen. Dies bedeutet nach dem Aufnahmekriterium,

38 A May, D. Pfeifer: Mathematik fur Okonomen
daß noch weitere Nichtbasisvariablen zu Basisvariablen gemacht werden konnten, al-lerdings ohne den Wert der Zielfunktion zu erhohen. In diesem Fall existieren alsomehrere verschiedene optimale Losungen.
8.4 Das Eliminationskriterium
Um die Form des Tableaus beizubehalten, muß fur die im vorigen Schritt aufgenom-mene Nichtbasisvariable (z∗N)j eine geeignete Basisvariable (z∗I )i eliminiert, d.h. Nullgesetzt werden. Dies geschieht dadurch, daß man den Wert der aufzunehmenden Va-riablen (z∗N)j soweit erhoht, bis erstmalig eine Basisvariable (z∗I )i den Wert 0 erreicht.Damit wird gewahrleistet, daß die Kapazitatsrestriktion Ax ≤ b erfullt bleibt.
An der Form der aktuellen Losung z∗I = b∗ − Nz∗N sieht man, daß wegen (z∗N)k = 0fur k 6= j diese auch geschrieben werden kann als
(z∗I )i = b∗i − nij(z∗N)j, 1 ≤ i ≤ m,
so daß eine Basisvariable (z∗I )i erstmalig dann den Wert 0 annimmt, wenn
b∗inij
= min
{b∗rnrj
∣∣∣ 1 ≤ r ≤ m,nrj > 0
}gilt. Hieraus resultiert das folgende
Eliminationskriterium: Wahle unter den Quotientenb∗rnrj
, 1 ≤ r ≤ m, fur die
nrj positiv ist, den kleinsten, etwa fur r = i. Die Ba-sisvariable (z∗I )i wird eliminiert, d.h. Null gesetzt. Sindalle Elemente nrj, 1 ≤ r ≤ m nicht-positiv, existiertkeine endliche optimale Losung, d.h. die Zielfunktionkann in diesem Fall uber dem durch Ax ≤ b gegebenenzulassigen Bereich beliebig große Werte annehmen.
Die neue aktuelle Losung erhalt damit die Gestalt
z∗I (neu)r = b∗r(alt)− nrj(alt)
nij(alt)b∗i (alt) = z∗I (alt)r −
nrj(alt)
nij(alt)b∗i (alt) (r 6= i)
z∗I (neu)i =b∗i (alt)
nij(alt),
wobei b∗(alt) und N(alt) die rechte Seite bzw. Nichtbasis-Matrix des vorigen Tableausbezeichnen. Zweckmaßigerweise erganzt man das Tableau dabei um eine Spalte mit
den (positiven) Quotientenbr(alt)
∗
nrj(alt), um die Uberprufung des Eliminationskriteriums
zu erleichtern.

Wintersemester 2005/06 39
Der Ubergang vom alten zum neuen Tableau geschieht also praktisch durch Anwen-dung des Gaußschen Algorithmus derart, daß die i-te Zeile des alten Tableaus mit
dem Faktor1
nij(alt)multipliziert und anschließend das nrj(alt)-fache der i-ten Zeile
von der r-ten Zeile subtrahiert wird fur alle r 6= i. Die unterste Zeile des Tableauskann entsprechend mittransformiert werden; daher braucht die linke Seite c∗I des Ta-bleaus i.a. nicht notiert zu werden. (Formal muß abschließend durch Vertauschungvon Komponenten noch die Standard-Form des Tableaus hergestellt werden; in praxiverzichtet man aber in der Regel hierauf, da die aktuellen Basisvariablen anhand derEinheitsvektoren eindeutig identifiziert werden konnen.)
Beispiel 8.2.max! 3x1 + 2x2 + 4x3
unter den Nebenbedingungen
x1 + x2 + 2x3 ≤ 42x1 + 3x2 + x3 ≤ 6x1 + 2x2 + x3 ≤ 4
Losung:0 0 0 3 2 41 0 0 1 1 2 4 2 ←0 1 0 2 3 1 6 60 0 1 1 2 1 4 40 0 0 −3 −2 −4 0
↑12
0 0 12
12
1 2 4
−12
1 0 32
52
0 4 83←
−12
0 1 12
32
0 2 42 0 0 −1 0 0 8
↑23−1
30 0 −1
31 2
3
−13
23
0 1 53
0 83
−13−1
31 0 2
30 2
353
23
0 0 53
0 323
d.h. die optimale Losung ist
x1 =8
3, x2 = 0, x3 =
2
3,
der optimale Zielfunktionswert betragt 323.
Basisvariablen sind hier also x1 und x3 (sowie s3 mit Wert 23).

40 A May, D. Pfeifer: Mathematik fur Okonomen
8.5 Dualitatsaussagen
Primales Problem (P ) :
max! ax
unter Ax ≤ bx ≥ 0
Duales Problem (D) :
min! yb
unter yA ≥ ay ≥ 0
(mit einem 1×m-Vektor y). Es gilt stets (Dualitatssatz):
Sind x und y primal bzw. dual zulassig (d.h. erfullen die jeweiligen Nebenbedingun-gen), so ist
ax ≤ yAx ≤ yb.
Sind x∗ und y∗ sogar optimale Losungen von (P) bzw. (D), so ist
ax∗ = y∗Ax∗ = y∗b.
Erfullen umgekehrt eine primal zulassige Losung x∗ und eine dual zulassige Losungy∗ obige Gleichung, so sind x∗ bzw. y∗ auch optimale Losungen.
Bestimmung der optimalen dualen Losung: Bei der Bestimmung der optimalenprimalen Losung wird mit Hilfe des Gaußschen Algorithmus das Ausgangstableau
0 a0 I A b
0 −a 0
umgeformt in ein Endtableau (ohne Spaltenvertauschung)
0 ac∗I B BA b∗ = Bb
c∗IB −(a− c∗IBA) c∗Ib∗ = c∗IBb
wobei B das Produkt der im Gaußschen Algorithmus verwendeten Matrizen fur dieElementarOperationen und c∗I wieder den aus den Basisindices gebildeten Teilvektorvon c∗ bezeichne. Dann ist
y∗ = c∗IB
die gesuchte optimale duale Losung, denn es gilt:
y∗b = c∗IBb = c∗Ib∗ = c∗Iz
∗I = c∗z∗ = ax∗
und
y∗A = c∗IBA = −(a− c∗IBA) + a ≥ a
wegen der erreichten Nicht-Negativitat der unteren Tableauzeile; d.h. y∗ = c∗IB istdual zulassig und erfullt die Optimalitats-Gleichung y∗b = ax∗, ist also dual optimal.

Wintersemester 2005/06 41
Bemerkung 8.3. Es ist yb = y(I, A)(
sx
)= ys + yAx, d.h. bei Optimalitat der
Losungen muß gelten:y∗b = y∗s∗ + y∗Ax∗ = y∗Ax∗,
also y∗s∗ = 0 (sog. komplementare Schlupf-Eigenschaft). Dies bedeutet, daßsich im Endtableau die positiven Komponenten der optimalen dualen Losung nurunterhalb derjenigen Komponenten primaler Schlupfvariablen befinden, die Nichtba-sisvariable sind.
Fur das oben angegebene Beispiel erhalt man somit als optimale duale Losung
y1 =5
3, y2 =
2
3und y3 = 0.
Die duale Losung y∗ = c∗IB kann auch zu einer ersten Probe fur die richtige Berech-nung der optimalen primalen Losung verwendet werden; dazu muß man lediglich dasProdukt der dualen Losung (linker Teil der unteren Zeile) mit der rechten Spalte bdes Ausgangstableaus bilden. Bei richtiger Rechnung stimmt dieser Wert mit demoptimalen Zielfunktionswert uberein (rechtes unteres Element des Endtableaus).
9 Funktionen einer Variablen
Wir werden uns im Folgenden mit dem Teilgebiet der Mathematik beschaftigen, dassich mit der Beschreibung von Funktionen beschaftigt, der sogenannten Analysis.Zunachst interessieren uns Funktionen, die von einer Variablen abhangen. Wir habenbereits in 6.2 eine Definition dafur angegeben und auch den Graph einer Funktionals gute Moglichkeit der Veranschaulichung kennen gelernt.
Mathematisch gesehen interessieren in der Analysis die Probleme der Nullstellenbe-stimmung, Schnittpunktberechnung, Asymptotik (Verhalten fur große Werte), Dif-ferentiation (Berechnung der Steigung, d.h. Zu- oder Abnahme in einem Punkt) undder Integration (Flachenbestimmung unter einem Teil des Graphen). In der Schulewird der eine oder die andere bereits Kurvendiskussionen ausgefuhrt haben, was einegute Vorarbeit fur dieses Kapitel darstellt.
Aus Sicht der Anwendung ist klar, dass wir bei dem bisher Behandelten nicht ste-hen bleiben konnen. Sie kennen jede Menge Beispiele nicht linearer Zusammenhange,die Laffer-Kurve, die die Steuereinnahmen einer Volkswirtschaft beschreibt, war einerstes Beispiel dazu, das bereits in der Vorlesung vorkam. Zusammengefasst ist dieAnalysis also das Gebiet, das dazu dient, allgemeine Abhangigkeiten zwischen gege-benen und gesuchten Variablen uber quantitative Zusammenhange (Funktionen) zubeschreiben oder eine konkrete Situation an eine als richtig erkannte Modellklasseanzupassen. Sie wissen beispielsweise, dass Angebots- und Nachfragekurven in derRegel keinen linearen, sondern einen
”irgendwie gebogenen“ Verlauf zeigen.

42 A May, D. Pfeifer: Mathematik fur Okonomen
9.1 Quadratische Funktionen
Definition 9.1. Eine quadratische Funktion ist von der Form f : R → R, x 7→ax2 + bx + c mit reellen Zahlen a, b, c ∈ R und a 6= 0. Der Definitionsbereich einerquadratischen Funktion besteht aus allen rellen Zahlen, Df = R.
Ist a = 0, so erhalten wir eine lineare Funktion, sind a = b = 0, so ist die Funktionkonstant.
Der Graph einer quadratischen Funktion ist eine sogenannte Parabel, die man sich alsSchattenriss (ebene Projektion) eines Sektkelches gut vorstellen kann. Das Vorzeichenvon a bestimmt dabei die Richtung, in der die Parabel geoffnet ist. Ist namlicha > 0, so haben wir die Sektkelchsituation vorliegen, die Parabel ist also nach obengeoffnet:
⋃. Fur negative a, also a < 0, erhalten wir hingegen eine nach unten
geoffnete Parabel:⋂
. In beiden Fallen gibt es einen tiefsten (bzw. hochsten) Punkt,den Scheitelpunkt (an dem sozusagen
”der Stiel ansetzt“), und die Parabel ist ein
idealer Sektkelch in dem Sinne, dass die rechte und linke Halfte relativ zu einergedachten Mittelsenkrechte durch diesen Punkt identisch aussehen.
Wir merken uns: Der Graph einer quadratischen Funktion ist also symmetrisch zurSymmetrieachse, die senkrecht durch den Scheitelpunkt verlauft.
Problem 1:Nullstellenbestimmung bei quadratischen Funktionen
Satz 9.2. Die Gleichung ax2 + bx + c = 0 hat fur a 6= 0 die Losungen
x1 =−b +
√b2 − 4ac
2aund x2 =
−b−√
b2 − 4ac
2a.
Wir wollen die Aussage dieses Satzes etwas diskutieren. Zunachst sei darauf hin-gewiesen, dass diese Losungsformel fur quadratische Gleichungen gilt, deren rechteSeite gleich Null ist. Der erste Schritt sollte also immer darin bestehen, durch ent-sprechende Addition/Subtraktion die rechte Seite zu Null zu machen, da erst danachdie Formel angewandt werden darf. Einige von Ihnen werden sich aus der Schule andie p, q-Formel erinnern und daran, dass man dazu den Faktor vor dem x2 wegdivi-dieren musste. Selbstverstandlich konnen Sie auch diese Formel verwenden, ich werdeim Rahmen der Vorlesung aber nur die allgemeinere o.g. Formel verwenden, da ichsie fur weniger fehleranfallig halte.
Bei fluchtiger Betrachtung des obigen Satzes konnte man – vorschnell – zu der An-nahme verleitet werden, jede quadratische Gleichung habe 2 Losungen. Dies ist inzweierlei Hinsicht nicht die volle Wahrheit. Zum einen konnen beide Nullstellen zu-sammenfallen (also auf ein und denselben Punkt fallen). Zum anderen muss es nichtunbedingt zwei reelle Nullstellen geben. Wir fassen diese Erkenntnis systematischzusammen:

Wintersemester 2005/06 43
Folgerung 9.3. Nullstellenanzahl bei quadratischen Gleichungen Gegebensei die quadratische Gleichung ax2 + bx + c = 0 mit a 6= 0.
1. Ist b2 − 4ac = 0, so hat die Gleichung nur eine reelle Nullstelle bei x0 = − b2a
.
Graphisch entspricht das der Situation, dass der Scheitelpunkt der Parabel aufder x-Achse liegt.
2. Ist b2 − 4ac > 0, so hat die Gleichung 2 verschiedene reelle Nullstellen beix1 6= x2 wie in Satz 9.2 angegeben.
Graphisch entspricht das der Situation, dass der Scheitelpunkt der nach obengeoffneten Parabel (bei a > 0) unterhalb der x-Achse liegt bzw. fur a < 0 derScheitelpunkt der nach unten geoffneten Parabel oberhalb der x-Achse liegt.
3. Ist b2 − 4ac < 0, so hat die Gleichung gar keine reelle Nullstelle, weil nurWurzeln aus positiven Zahlen reelle Ergebnisse liefern.
Graphisch entspricht das der Situation, dass der Scheitelpunkt der nach obengeoffneten Parabel (bei a > 0) oberhalb der x-Achse liegt bzw. fur a < 0 derScheitelpunkt der nach unten geoffneten Parabel unterhalb der x-Achse liegt.
Beispiel 9.4. Nullstellenbestimmung mit der abc-FormelWir fragen nach den Losungen der quadratischen Gleichung−2x2 + 40x− 150 = 0.
Um die abc-Formel korrekt anzuwenden, schreiben wir zunachst die Koeffizientenauf: a = −2, b = 40 und c = −150. Nun uberprufen wir den Ausdruck b2 − 4ac =402−4·(−2)·(−150) = 1600−1200 = 400. Wir verwenden die Aussage aus Folgerung9.3 und schließen aus b2 − 4ac = 400 > 0, dass die Gleichung zwei Nullstellen hat.Diese berechnen wir mit der Formel aus Satz 9.2 und erhalten
x1 =−40 +
√400
−4= 5 und x2 =
−40−√
400
−4= 15 .
Problem 2:Scheitelpunktbestimmung bei quadratischen FunktionenOffensichtlich ist der Scheitelpunkt fur a > 0 der tiefste Punkt des Graphen, also einMinimum der Funktion, fur a < 0 hat die Funktion im Scheitelpunkt ein Maximum.
Definition 9.5. Ein Punkt xE ∈ Df heißt Maximumpunkt fur f : Df → R, fallsf(xE) ≥ f(x) fur alle x ∈ Df . Der Maximalwert (das Maximum) der Funktion istdann f(xE).
Analog heißt xE ∈ Df ein Minimumpunkt fur f : Df → R, falls f(xE) ≤ f(x) fur allex ∈ Df . Der Minimalwert (das Minimum) der Funktion ist dann ebenso f(XE).

44 A May, D. Pfeifer: Mathematik fur Okonomen
Um die Koordinaten des Scheitelpunktes zu bestimmen, rechnen wir aus, dass
a
(x +
b
2a
)2
− b2 − 4ac
4a= a
(x2 + 2 · x b
2a+
b2
4a2
)− b2 − 4ac
4a
= ax2 + bx + c. Wir wissen bereits, dass Quadrate reeller Zahlen stets nichtnegativ
sind. Ist also (Fall 1) a > 0, so ist der erste Summand”a mal
(. . .)2
“ stets positiv,
und daher gilt fur alle x ∈ Df stets f(x) ≥ − b2−4ac4a
, also ist c− b2
4aein Minimum fur
xE = − b2a
, weil diese Einsetzung den quadratischen Ausdruck, der von x abhangt,zu Null macht, was der kleinstmogliche Wert fur ein Quadrat einer reellen Zahl ist.
Ist (Fall 2) a < 0, so gilt umgekehrt f(x) ≤ − b2−4ac4a
fur alle x ∈ Df , weil das Produktaus (negativem) a und (positivem) Quadrat reeller Zahlen stets negativ ist (
”minus
mal plus“). Also ist c− b2
4aein Maximum fur xE = − b
2a.
Beispiel 9.6. Der maximale GewinnEin Unternehmen stellt ein Gut her, dessen Herstellung und Verkauf pro Q EinheitenKosten in Hohe von
C = 2Q +1
2Q2
verursachen. Beim Verkauf von Q Einheiten dieses Gutes erzielt das Unternehmenden folgenden Preis pro Einheit in E
P = 102− 2Q .
Der Gewinn, den das Unternehmen beim Verkauf von Q Einheiten macht, berechnetsich nun aus dem Preis pro verkaufter Einheit mal Anzahl Einheiten abzuglich derKosten, also
Π(Q) = PQ− C = (102− 2Q) ·Q−(
2Q +1
2Q2
)= −5
2Q2 + 100Q .
Als Unternehmer fragen wir uns, bei welcher Anzahl von Einheiten unser Gewinnmaximal wird. Dazu stellen wir zunachst fest, dass unsere Gewinnfunktion als Grapheine nach unten geoffnete Parabel hat (wegen a = −5
2< 0). Damit liefert der Schei-
telpunkt einen Maximumpunkt fur die Funktion Π. Wir berechnen zunachst diex-Koordinate (die hier Q heißt) uber QE = − b
2a= −100
−5= 20. D.h. bei 20 Ein-
heiten des Gutes ist der Gewinn maximal. Der maximale Gewinn liegt bei Π(20) =−(5/2) · 400 + 100 · 20 = 1000 E.
Ist der hochste Exponent von x nicht 2 wie bei den quadratischen Funktionen, son-dern eine großere naturliche Zahl, so haben wir es mit einem Polynom zu tun.
Definition 9.7. Eine Funktion p : R → R mit p(x) = anxn + an−1x
n−1 + · · · + a0
heißt Polynom vom Grad n, falls n wirklich der hochste Exponent ist, falls also

Wintersemester 2005/06 45
an 6= 0. Die reellen Zahlen an, an−1, . . . , a0 heißen Koeffizienten des Polynoms, an
heißt Leitkoeffizient (oder: fuhrender Koeefizient) und a0 ist das konstante Glied.
Beachten Sie, dass alle Polynome als Definitionsbereich die gesamten reellen Zahlenhaben, Dp = R, dass aber nicht jedes Polynom eine Nullstelle haben muss.
Wenn wir im Exponenten auch rationale Zahlen (also Bruche) zulassen, sind wirbei der wichtigen Klasse der Potenzfunktionen, zu denen auch die Wurzelfunktionengehoren wegen
√x = x1/2.
Definition 9.8. Die allgemeine Potenzfunktion f : Df → R ist definiert durch dieFunktionsvorschrift
f(x) = A · xr .
Hierbei konnen A, r sogar beliebige reelle Zahlen sein. Wie das Beispiel der Qua-dratwurzel zeigt, ist es fur nicht ganzzahlige r > 0 vernunftig, fur den Definitionsbe-reich Df anzunehmen, dass er nur nichtnegative Zahlen mit x ≥ 0 enthalt, denn ausnegativen Zahlen kann man keine Wurzel ziehen.
Lassen wir im Exponenten auch negative r zu, so sollte der Definitionsbereich dieNull nicht enthalten (also Df ⊆ {x ∈ R : x 6= 0}, da z.B. x−1 = 1/x (fur r = −1)und wir durch Null nicht dividieren durfen. Fur nicht ganzzahlige r < 0 folgt alsoinsgesamt Df ⊆ {x ∈ R : x > 0}.
Beachten Sie, dass alle Potenzfunktionen durch den Punkt (1, 1) laufen. Die Formdes Graphen hangt entscheidend von dem Exponenten r ab. (Fur den Einfluss dermultiplikativen Konstante A verweisen wir auf die Uberlegungen in Satz 9.14.) Istr > 1, so haben wir es mit Graphen zu tun, die der Normalparabel ahneln. Liegt rzwischen 0 und 1, so bekommen wir Graphen, die denen der Wurzelfunktion ahneln.Wie bekannt, erhalten wir den Graphen der Quadratwurzel, indem wir den rechtenTeil der Normalparabel an der Geraden y = x (Das ist die Winkelhalbierende imersten Quadrant des Koordinatensystems.) spiegeln. Der Graph verlauft also nuroberhalb der x-Achse, der Wertebereich ist fur 0 < r < 1 eine Teilmenge der positivenreellen Zahlen, W ⊆ {y ∈ R : y ≥ 0}. Fur r < 0 erhalten wir als Graph sogenannteHyperbeln, die dem Seitenprofil eines Sessels ahneln und sich fur große Werte fur xund y an die Achsen anschmiegen, ohne diese jedoch je zu schneiden oder zu beruhren(asymptotisches Verhalten).
Bitte beachten Sie, dass es keine einfache Form gibt, Wurzeln aus Summen zu ziehen,also√
x + y als Summe von zwei einzelnen Wurzeln zu schreiben.
9.2 Die Exponentialfunktion
Aus der Rechnung mit Zinseszinsen kennen wir bereits Formeln, bei denen die un-abhangige Variable im Exponenten stand. So wurde das Wachstum eines Kapitals

46 A May, D. Pfeifer: Mathematik fur Okonomen
bei einem Zinssatz von i durch die Formel Kn = K0(1 + i)n beschrieben, die denEndwert nach n Jahren angibt. Ist nun i = p/100, so wird das Kapital K0 jahrlichum p% anwachsen. Der Barwert eines Kapitals Kn, das in n Jahren zur Verfugungsteht, berechnete sich hingegen aus K0 = Kn(1 + i)−n. In beiden Fallen steht dieVeranderliche n im Exponenten.
Allgemein nennt man eine Große, die pro Zeiteinheit um einen festen Faktor falltoder steigt, exponentiell wachsend oder fallend. Viele Großen in unserer Umwelt,die mit Wachstum und Zerfall zu tun haben, zeigen ein exponentielles Verhalten.Neben dem Kapital mit Zinseszinsen gehoren hierzu das Bevolkerungwachstum, derradioaktive Zerfall sowie auch der Wertverlust eines Wirtschaftsgutes. Im Folgendendefinieren wir die dazu gehorige Funktion.
Definition 9.9. Unter einer allgemeinen Exponentialfunktion mit der Basis a > 0verstehen wir die Funktion
f : R→ R, x 7→ f(x) = A · ax .
Hierbei ist f(0) = A und a ist der Faktor, mit dem die wachsende oder fallendeGroße f(x) sich andert, wenn x um 1 anwachst.
Beispiel 9.10. Stetige AbschreibungWirtschaftsguter nehmen jedes Jahr im Wert ab. Der Fall einer stetigen Abschreibungliegt vor, wenn die Wertabnahme jedes Jahr mit einem festen Prozentsatz erfolgt.Die Wertabnahme kann dabei recht schnell vor sich gehen, das ist die Eigenschaftdes exponentiellen Verhaltens.
Wir betrachten ein Auto mit dem Anschaffungswert P0 = 25.000 E, das jedes Jahruber einen Zeitraum von 5 Jahren 20% an Wert verliert. Den (Rest-)Wert nacht Jahren konnen wir allgemein beschreiben duch die Formel W (t) = P0 · (0, 8)t, da100%−20% Abschreibung gleich 80% = 0, 8. Also erhalten wir W (1) = 25.000·0, 81 =20.000 fur den Zeitwert nach einem Jahr. Nach t = 5 Jahren ist der Wert unseresAutos bereits auf W (5) = 25.000 · 0, 85 = 8.192 Egesunken, das sind nur noch knapp33% des Anschaffungswertes.
Viele Wachstums- und Zerfallprozesse in der Natur gehorchen einem besonderenWachstumsgesetz, das auf der Basis a = e = 2, 7182818284590..... beruht, der Euler-schen Zahl.
Definition 9.11. Die naturliche Exponentialfunktion f : R → R ist definiert durchdie Funktionsvorschrift f(x) = ex. Ihr Definitionsbereich sind die gesamten reellenZahlen, Df = R, ihr Wertebereich sind die positiven reellen Zahlen, Wf = {y ∈R : y > 0}, (d.h. der Graph verlauft echt oberhalb der x-Achse), und es gilt f(0) =e0 = 1.
Wir erinnern an die folgenden allgemeinen Rechenregeln:
es · et = es+t undes
et= es−t und (es)t = est .

Wintersemester 2005/06 47
9.3 Die naturliche Logarithmusfunktion
Wollten wir unsere Kapitalformel nach dem Exponenten, also der Anzahl der Jah-re n, auflosen, so mussten wir den Logarithmus anwenden, um den Exponenten
”nach
unten“ zu bekommen. Ein typisches Beispiel, bei dem die zugehorige Logarithmus-funktion eine Rolle spielt, ist die Frage nach der Verdopplungzeit, das ist diejenigeZeit, die eine Exponentialfunktion benotigt, um eine gegebene Ausgangsgroße zuverdoppeln.
Beispiel 9.12. Nach wie vielen Jahren verdoppelt sich ein Kapital von 1 Ebei einemZinssatz von 8% ? Hier ist die gesuchte Große also die Anzahl von Jahren n. und wirmussen 2 = Kn = (1+ i)n = 1, 08n nach dem Exponenten n auflosen. Dazu benutzenwir die e-Funktion. Dann ist namlich ln 2 = ln (1, 08n) = n ln 1, 08, woraus wir sofortn = ln 2/ ln 1, 08 = 9 Jahre ablesen.
Definition 9.13. Der naturliche Logarithmus ist die”Umkehrung“ der naturlichen
Exponentialfunktion in dem Sinne, dass
eln x = x fur alle x > 0 und ln ex = x fur alle x .
Die naturliche Logarithmusfunktion ln : Dln = {x ∈ R : x > 0} → R, x 7→ ln x hat alsDefinitionsbereich die positiven reellen Zahlen (Der Logarithmus ist nicht definiertin 0 oder fur negative Zahlen.), ihr Wertebereich sind die gesamten reellen Zahlen,und es gilt ln 1 = 0 und ln e = 1.
Wir erinnern an folgende nutzliche Rechenregeln fur positive reelle Zahlen x, y:
ln(xy) = ln x + ln y und lnx
y= ln x− ln y und ln(xr) = r · ln x .
Bitte beachten Sie, wo die Summe und wo das Produkt steht! Es gibt keine einfachenFormeln fur ln(x + y) oder fur ln(x− y).
9.4 Verschiebung von Funktionsgraphen
Haufig trifft man auf Funktionsvorschriften, die fast so aussehen wie Funktionen,die man bereits anderswo ausfuhrlich studiert hat. Statt ganz von Neuem zu uberle-gen, wie der Funktionsgraph der gegebenen Funktion aussieht, hilft es, sich folgendeRegeln zu merken, wie man den neuen Graphen aus dem bereits bekannten erhalt.
Satz 9.14. Sei f : Df → R, x 7→ f(x) eine Funktion, deren Graph wir bereits kennen,und sei a ∈ R eine reelle Zahl, die wir als positiv voraussetzen wollen (a > 0). Danngilt:
1. Die Funktion Vf+ : x 7→ Vf
+(x) = f(x) + a hat als Graph die gleiche Form wieder Graph von f , der ganze Graph ist aber um a Einheiten in y-Richtung nachoben oben verschoben.

48 A May, D. Pfeifer: Mathematik fur Okonomen
2. Die Funktion Vf− : x 7→ Vf
−(x) = f(x)− a hat als Graph die gleiche Form wieder Graph von f , der ganze Graph ist aber um a Einheiten in y-Richtung nachunten verschoben.
3. Die Funktion Mfx : x 7→ Vf (x) = −f(x) hat als Graph die gleiche Form wie der
Graph von f , der ganze Graph ist aber an der x-Achse gespiegelt (was vorheroberhalb der x-Achse verlief, liegt nun unterhalb und umgekehrt).
4. Die Funktion Hf` : x 7→ Hf
`(x) = f(x + a) hat als Graph die gleiche Form wieder Graph von f , der ganze Graph ist aber um a Einheiten auf der x-Achsenach links verschoben.
5. Die Funktion Hfr : x 7→ Hf
r(x) = f(x− a) hat als Graph die gleiche Form wieder Graph von f , der ganze Graph ist aber um a Einheiten auf der x-Achsenach rechts verschoben.
6. Die Funktion Mfy : x 7→ Vf (x) = f(−x) hat als Graph die gleiche Form wie der
Graph von f , der ganze Graph ist aber an der y-Achse gespiegelt (was vorherrechts der y-Achse verlief, liegt nun links davon und umgekehrt).
7. Die Funktion Sf+ : x 7→ Sf
+f (x) = af(x) hat als Graph eine um den Faktor
a > 1 gestreckten Verlauf gegenuber dem Graph von f , fur 0 < a < 1 ist derGraph um den Faktor a gestaucht.
Wir wollen dieses Ergebnis nun konkret auf Parabeln anwenden.
Beispiel 9.15. 1. Der Graph der Funktion x 7→ x2 + 1 ist gegenuber der Normal-parabel f : x 7→ x2 um 1 nach oben in y-Richtung verschoben.
2. Der Graph der Funktion g : x 7→ (x − 2)2 ist gegenuber der Normalparabelum 2 Einheiten nach rechts verschoben. Der neue Scheitelpunkt, der bei derNormalparabel im Punkt (0, 0) liegt, liegt demnach im Punkt (2, 0).
3. Der Graph der Funktion x 7→ (x−2)2−7 ist gegenuber der Normalparabel um2 Einheiten nach rechts und um 7 Einheiten nach unten verschoben. Der neueScheitelpunkt, der bei der Normalparabel im Punkt (0, 0) liegt, liegt demnachim Punkt (2,−7).
4. Der Graph der Funktion M : x 7→ −(x − 2)2 ist gegenuber dem Graph derFunktion g : x 7→ (x − 2)2 an der x-Achse gespiegelt. Er hat seinen Scheitel-punkt wie der Graph von g im Punkt (2, 0). Wahrend der Scheitelpunkt fur gaber ein Minimumpunkt war (Parabel nach oben geoffnet:
⋃), ist es nun ein
Maximumpunkt, weil durch das Spiegeln an der x-Achse die neue Parabel nachunten geoffnet ist (
⋂).

Wintersemester 2005/06 49
5. Der Graph der Funktion x 7→ 4x2 ist gegenuber der Normalparabel um denFaktor 4 gestreckt, ist also ein
”schlankerer Sektkelch“. Betrachten wir hingegen
den Graph zu x 7→ 18x2, so ist dieser gegenuber der Normalparabel um den
Faktor 1/8 gestaucht, ist also ein”flacherer Sektkelch“ und ahnelt je kleiner
der Betrag von a > 0 wird, eher einer Sektschale.
10 Differentiation von Funktionen einer Variablen
In den Wirtschaftswissenschaften wie auch bei anderen Anwendungen interessiertman sich gerne fur Anderungsraten (eines funktionalen Zusammenhangs, eines Kur-venverlaufs in einem Punkt). Der Bereich der Analysis, der sich mit derartigen Ande-rungsraten beschaftigt, ist die so genannte Differentialrechnung. Man kann sich demDifferenzieren (der Ableitung einer Funktion) auf verschieden Arten annahern: Geo-metrisch bemuhen wir uns darum, in einem Punkt die Steilheit einer Kurve (einesGraphen einer Funktion) zu ermitteln bzw. eine Kurve (einen Graphen) in einemPunkt linear zu approximieren. Rechnerisch kann man sich die Ableitung einer Funk-tion f in einem Wert x0 als momentane Anderungsrate von f in x0 vorstellen. Dabeiverweist das Wort
”momentan“ darauf, dass wir hier dem Grenzwertbegriff wieder
begegnen werden, der uns schon einmal bei den Folgen und Reihen begegnete. Einweiterer Begriff, mit dem wir hier zentral arbeiten werden, ist der der Geraden,beschrieben durch ihre Geradengleichung, und der Steigung einer Geraden.
10.1 Anderungsraten
Wir nehmen an, dass wir aus einer Anwendungssituation wissen, dass eine Große yuber eine Funktion f in Beziehung zu einer (variablen) Große x steht, dass wir alsoden Zusammenhang y = f(x) kennen. Wenn wir mit einem (bekannten) Anfangswertx = a starten, dann ist der Wert der Funktion (und damit der abhangigen Großey) offenbar gleich f(a). Nun variieren wir den Anfangswert, gehen also mit x von aetwa auf a + h. Die Anderung im Funktionswert ist damit gegeben durch f(a + h)−f(a). (Diese Große kann – je nach Funktion f – positiv oder negativ sein.) Um zurdurchschnittlichen Anderungsrate von f uber dem Intervall [a, a + h] zu kommen,muss man diese Differenz noch durch die Lange des Intervalls (a + h − a = h)dividieren, so dass man erhalt:
f(a + h)− f(a)
h.
Wird nun h immer kleiner (infinitesimal klein), so bilden wir am Ende den Grenzwertfur h → 0, und erhalten so die momentane Anderungsrate von f in a. Diese Großebezeichnen wir mit f ′(a), lies: f Strich von a.

50 A May, D. Pfeifer: Mathematik fur Okonomen
Beispiel 10.1. Wir betrachten die zeitliche Veranderung der Große einer Population(Menschen, Tiere, Pflanzen). Sei also N(t) die Zahl der Individuen in der betrachtetenPopulation zur Zeit t. Wenn wir in der Zeit um h Zeitschritte in die Zukunft gehen, soandert sich die Zahl der Individuen um N(t+h)−N(t) Individuen. Damit bestimmenwir die durchschnittliche Anderungsrate zu:
N(t + h)−N(t)
h.
Lassen wir h gegen 0 gehen, so erhalten wir die momentane Anderungsrate zur Zeit t
als N ′(t) = N(t) =dN
dt. Wenn man nach der Zeit ableitet, schreiben manche Autoren
gerne statt des Strichs ′ einen Punkt uber die Funktion. Die Notation”dN nach dt“
wird uns erst spater in der Vorlesung wieder begegnen, wenn wir Funktionen mitmehreren Variablen diskutieren.
Beispiel 10.2. Ein Unternehmen produziere ein bestimmtes Gut; die dabei entstehen-den Kosten fur die Produktion von x Einheiten des Gutes seien gegeben durch C(x).Die Grenzkosten bei x seien C ′(x). Dann konnen wir die Grenzkosten berechnendurch
C ′(x) = limh→0
C(x + h)− C(x)
h.
Ist h eine im Absolutbetrag kleine Große (”h nahe bei 0“), so konnen wir approxi-
mativ schreiben
C ′(x) ≈ C(x + h)− C(x)
h.
Daran lesen wir ab, dass fur kleines h der Zuwachs C(x + h) linear (in h) durchC ′(x) · h + C(x) approximiert werden kann. (Beachten Sie: Das ist die Gleichungeiner Geraden (in h) mit Steigung C ′(x) und y-Achsenabschnitt C(x).)
Setzen wir speziell h = 1, so erhalten wir C ′(x) ≈ C(x+1)−C(x) . Die Grenzkostensind daher annahernd gleich den Mehrkosten C(x + 1)−C(x), d.h. den zusatzlichenKosten fur die Herstellung einer weiteren Einheit von x.
Beispiel 10.3. C(x) seien die Kosten in Millionen Euro fur die Beseitigung von x%der Verschmutzung durch eine Chemikalie in einem See. Was bedeutet es, wenn wirwissen C ′(50) = 3?
Wie im vorangegangenen Beispiel approximieren wir 3 = C ′(50) ≈ C(50+1)−C(50).Mussen wir also (durch einen zusatzlichen Eintrag der Chemikalie in den See) statt50% nur 1% mehr, also 51%, beseitigen, so verursacht das Mehrkosten von 3 MillionenEuro.
10.2 Rechenregeln fur Grenzwerte
Nehmen wir an, dass der Definitionsbereich einer Funktion f ein”Loch“ bei x = a
hat, aber ein ganzes Intervall um a herum in Df liegt, der Definitionsbereich von f

Wintersemester 2005/06 51
also in a punktiert ist. Auch wenn f in x = a nicht definiert ist, macht es Sinn, nachdem Verhalten von f in der Nahe von a zu fragen. Der Grenzwert von f in a sagtetwas daruber aus, wie sich die Funktion f verhalt, wenn sich x an a annahert, ohnedass jedoch x = a angenommen wird.
Definition 10.4. Sei f eine Funktion, die in einer ganzen Umgebung von x = adefiniert ist, aber nicht notwendig in x = a. Wir sagen, dass f in a einen GrenzwertA hat und schreiben dafur
limx→a
f(x) = A ,
falls f(x) gegen A strebt (sich A annahert), wenn x gegen a geht (aber nicht gleich aist). Falls ein solcher Grenzwert nicht exisitiert, sagen wir, dass f keinen Grenzwertin x = a hat oder dass der Grenzwert nicht existiert.
Satz 10.5. RechenregelnSeien f, g Funktionen, die in einer ganzen Umgebung von x = a definiert sind, abernicht notwendig in a selbst.Gilt lim
x→af(x) = A und lim
x→ag(x) = B, so gilt:
1. limx→a
(f(x)± g(x)) = A±B,
2. limx→a
(f(x) · g(x)) = A ·B,
3. limx→a
f(x)
g(x)=
A
B, falls B 6= 0,
4. limx→a
(f(x))r = Ar, falls Ar definiert ist.
Manchmal hat man Gluck und die Funktion f ist so beschaffen, dass die Punktierungin a nur kunstlich ist, also die Herausnahme von x = a aus dem Definitionsbereicheinfach ein Loch im Graphen der Funktion produziert. Solche Funktionen heißenstetig in a.
Satz 10.6. Stetige FunktionenEine Funktion f heißt stetig in x = a, wenn lim
x→af(x) = f(a).
Beachten Sie, dass folgende Bedingungen erfullt sein mussen, damit eine Funktionstetig in einer Stelle x = a sein kann:
1. Die Funktion muss an der Stelle x = a definiert sein.
2. Der Grenzwert von f fur x→ a muss existieren.
3. Dieser Grenzwert muss den Wert f(a) haben.

52 A May, D. Pfeifer: Mathematik fur Okonomen
Aus den Rechenregeln fur Grenzwerte lesen wir sofort die folgenden Regeln ab:
Satz 10.7. Regeln fur stetige FunktionenSind f und g stetig in x = a, so gilt:
1. f + g und f − g sind stetig in a.
2. f · g und f/g (falls g(a) 6= 0) sind stetig in a.
3. x 7→ (f(x))r ist stetig in a, falls (f(a))r definiert ist.
Alle linearen und quadratischen Funktionen (sowie auch alle Polynome hoheren Gra-des) sind stetig in jedem Punkt ihres Definitionsbereichs. Auch die Exponentialfunk-tion x 7→ ex ist stetig auf ganz R, ebenso die Logaritmusfunktion x 7→ ln x fur allex > 0.
10.3 Steigung von Kurven
Sei f : x 7→ f(x) eine Funktion mit Definitionsbereich Df . Ist x0 ∈ Df , so liegtdemnach der Punkt (x0, f(x0)) auf dem Graphen der Funktion. Eine Tangente anden Graphen von f in (x0, f(x0)) schneidet die Kurve (den Graphen) in genau einemPunkt und zwar in (x0, f(x0)).
Betrachten wir hingegen 2 Punkte auf dem Funktionsgraphen, sagen wir P = (x0, f(x0))und Q = (x0 + h, f(x0 + h)), so konnen wir auch durch diese beiden Punkte eine(dann eindeutig bestimmte) Gerade legen. Diese schneidet den Graphen nun nichtmehr nur in einem Punkt, sondern (mindestens) in den Punkten P und Q. Einederartige Gerade wollen wir Sekante nennen. Offenbar ist die Tangente ein Grenzfallder Sekante, wenn namlich h→ 0 strebt. (Dann rucken P und Q aufeinander zu, imGrenzfall ist dann Q = P .)
Definition 10.8. Die Ableitung der Funktion f in x = x0, die wir mit f ′(x0) be-zeichnen, ist gegeben durch den Ausdruck
f ′(x0) = limh→0
f(x0 + h)− f(x0)
h.
Die Zahl f ′(x0) gibt dabei die Steigung der Tangente an die Kurve y = f(x) imPunkt (x0, f(x0)) an.
Satz 10.9. Tangentengleichung an den FunktionsgraphenDie Gleichung der Tangente an den Graphen der Funktion y = f(x) im Punkt(x0, f(x0)) ist gegeben durch
y − f(x0) = f ′(x0)(x− x0) .

Wintersemester 2005/06 53
10.4 Berechnung von Ableitungen
Satz 10.10. Rezept zur Berechnung von f ′(a)Gehen Sie zur Berechnung von f ′(a) in folgenden Schritten vor:
1. Setzen Sie voraus, dass h 6= 0, und berechnen Sie f(a + h).
2. Berechnen Sie die Anderung im Funktionswert f(a + h)− f(a).
3. Bilden Sie den Quotienten fur die relative Anderungf(a + h)− f(a)
h.
4. Vereinfachen Sie diesen Bruch durch Kurzen so weit wie moglich. Kurzen Sieinsbesondere h in Zahler und Nenner, so weit es geht.
5. Berechnen Sie nun limh→0
f(a + h)− f(a)
hnach den Rechenregeln. (Beachten Sie,
dass weiterhin h 6= 0 vorausgesetzt ist!)
Satz 10.11. Ist f : x 7→ xr mit x 6= 0 falls r < 0, so ist f ′(a) = r · ar−1.
Wir haben bereits eingangs darauf verwiesen, dass man aus der Ableitung von fin einem Punkt etwas uber das Verhalten des Funktionsgraphen in der Umgebungdes Punktes aussagen kann. Da f ′(a) die Steigung der Tangente angibt, konnen wirzunachst einmal entscheiden, ob diese positiv oder negativ ist (die Tangente alsosteigenden oder fallenden Verlauf aufweist).
Definition 10.12. Sei f : D → R, x 7→ f(x) eine Funktion. Wir wahlen ein IntervallI ⊆ D und Werte x1, x2 ∈ I. Wir sagen,
1. f ist monoton wachsend in I, falls f(x2) ≥ f(x1) fur alle x1, x2 ∈ I mit x2 > x1;
2. f ist streng monoton wachsend in I, falls f(x2) > f(x1) fur alle x1, x2 ∈ I mitx2 > x1;
3. f ist monoton fallend in I, falls f(x2) ≤ f(x1) fur alle x1, x2 ∈ I mit x2 > x1;
4. f ist streng monoton fallend in I, falls f(x2) < f(x1) fur alle x1, x2 ∈ I mitx2 > x1.
Nehmen wir nun an, dass f ′(a) fur alle a ∈ I existiert. Wir sagen dann, f ist differen-zierbar in I. Eine differenzierbare Funktion ist also so beschaffen, dass man in jedemPunkt des Graphen eine Tangente an die Kurve (den Funktionsgraphen) legen kann.Als wir in 10.6 einfuhrten, wann wir eine Funktion stetig nennen wollen, haben wiruns klar gemacht, dass man den Graph einer stetigen Funktion als Kurve in einemZug durchzeichnen kann (der Graph also keine
”Locher“ und
”Sprunge“) aufweist.

54 A May, D. Pfeifer: Mathematik fur Okonomen
Anschaulich ist klar, dass Differenzierbarkeit eine starkere Voraussetzung als Stetig-keit ist, denn ein Funktionsgraph mit Knicken kann zwar zu einer stetigen Funktiongehoren, ist aber in der Stelle des Knicks ganz sicher nicht differenzierbar. In der Tatkann man das auch mathematisch beweisen. Es gilt also: Ist f eine differenzierbareFunktion, so ist f auch stetig.
Satz 10.13. Sei f differenzierbar in I ⊆ Df . Dann gelten die folgenden Aquivalenz-aussagen:
1. f ist monoton wachsend in I ⇐⇒ f ′(x) ≥ 0 fur alle x ∈ I.
2. f ist streng monoton wachsend in I ⇐⇒ f ′(x) > 0 fur alle x ∈ I.
3. f ist monoton fallend in I ⇐⇒ f ′(x) ≤ 0 fur alle x ∈ I.
4. f ist streng monoton fallend in I ⇐⇒ f ′(x) < 0 fur alle x ∈ I.
5. f ist eine konstante Funktion auf dem Intervall I ⇐⇒ f ′(x) = 0 fur alle x ∈ I.
Wir bemerken, dass eine auf einem Intervall I streng monotone Funktion dort niemalsdenselben Funktionswert in 2 verschiedenen x-Werten annimmt (anders als z.B. dieNormalparabel oder jede andere zur y-Achse symmetrische Funktion). Eine derartigeFunktion heißt umkehrbar eindeutig auf I.
Definition 10.14. Sei f : D → W eine Funktion mit der Eigenschaft, dass furbeliebige x1, x2 ∈ D mit x1 6= x2 stets folgt f(x1) 6= f(x2). Dann heißt f umkehrbareindeutig in D.
Mit anderen Worten: Fur jedes y ∈ W gibt es genau ein x ∈ D, so dass y = f(x).
Umkehrbar eindeutige Funktionen haben die (gelegentlich nutzliche) Eigenschaft,dass man die Rolle der unabhangigen (x) und der abhangigen (y) Variable vertau-schen kann und weiterhin eine Funktion erhalt. Geometrisch gesprochen dreht mandas Koordinatenkreuz um 90◦ (Das entspricht einer Vertauschung der x und dery-Achse.) und erhalt weiterhin den Graphen einer Funktion, d.h. zu jedem y-Wert(neue unabhangige Variable) findet man genau einen Funktionswert (neu) x. DieserVorgang entspricht der Bildung der inversen Funktion.
Definition 10.15. Sei f : D → W eine Funktion mit Wertebereich W . Genau dann,wenn f umkehrbar eindeutig ist, besitzt f eine inverse Funktion g = f−1 mitDefinitionsbereich W und Wertebereich D.
Die Funktionsvorschrift fur g ist durch die folgende Regel gegeben: Fur jedes y ∈ Wist g(y) die eindeutig bestimmte Zahl x ∈ D mit f(x) = y. Dann gilt:
g(y) = x⇐⇒ y = f(x) fur alle x ∈ D, y ∈ W .
Folgerung 10.16. Wenn zwei Funktionen f und g invers zueinander sind, dann sinddie Graphen von f : x 7→ f(x) und g : x 7→ g(x) symmetrisch zur Geraden y = x,wenn auf beiden Koordinatenachsen dieselben Einheiten gewahlt wurden.

Wintersemester 2005/06 55
10.5 Ableitung von Summen, Produkten und Quotienten
Satz 10.17. Seien f, g : D → W Funktionen mit dem gleichen Definitionsbereich D.Dann gilt:
1. Sind f und g in x ∈ D differenzierbar, so sind auch die Summe und die Dif-ferenz in x differenzierbar, und die Ableitung ist gleich der Summe (Differenz)der Ableitungen:
(f(x)± g(x))′ = f ′(x)± g′(x) .
2. Produktregel: Sind f und g in x ∈ D differenzierbar, so ist auch das Produktin x differenzierbar, und die Ableitung ist gleich
(f(x) · g(x))′ = f ′(x) · g(x) + f(x) · g′(x) .
3. Quotientenregel: Wenn f und g differenzierbar in x sind und g(x) 6= 0 gilt,dann ist f/g auch differenzierbar in x, und es gilt(
f(x)
g(x)
)′
=f ′(x)g(x)− f(x)g′(x)
(g(x))2.
Beispiele 10.18. 1. Produktregel Wir betrachten die Fordermenge, die aus einerOlquelle gefordert wird. Wir nehmen an, dass sich sowohl die pro Zeiteinheitgeforderte Olmenge als auch der Preis pro Einheit mit der Zeit andern. Wirhaben also 2 zeitabhangige Funktionen zu betrachten: m(t) sei die Fordermengein Barrel pro Tag zur Zeit t und p(t) sei der Preis in Dollar pro Barrel zur Zeitt.
Die Einnahmen sind dann das Produkt aus Menge mal Preis, also gibt R(t) =m(t) · p(t) die Einnahmen in Dollar pro Tag an. Nach der Produktregel ergibtsich R′(t) = m′(t)p(t) + m(t)p′(t). Wir versuchen, die rechte Seite aus der ge-gebenen Anwendung heraus zu interpretieren: Nehmen wir an, dass Preis undMenge beide in der Zeit wachsende Großen sind. Der Preis wachst inflations-bedingt und die Fordermenge ebenso, weil die Olgesellschaft, die die Quellebetreibt, ihre Fordereinrichtungen stetig ausbaut und erweitert. Dann wachstR gleich aus 2 Grunden. Zum einen wachst R(t), weil der Preis steigt. DiesesWachstum ist proportional zum Betrag der Fordermenge m(t) und ist gleichm(t)p′(t). Aber R(t) wachst auch, weil die Forderung zunimmt. Diese Ande-rung von R(t) muss proportional zum Preis sein und ist gleich m′(t)p(t). DieGesamtanderung der Einnahmen ist nun die Summe der beiden Anderungsra-ten, wie es auch die Formel besagt.
Die relative Wachstumsrate der Einnahmen erhalt man, indem man den Quo-tienten R′/R berechnet:
R′(t)
R(t)=
m′(t)p(t) + m(t)p′(t)
m(t)p(t)=
m′(t)
m(t)+
p′(t)
p(t).

56 A May, D. Pfeifer: Mathematik fur Okonomen
Die relative Wachstumsrate der Einnahmen ist also die Summe der relativenAnderungsraten von Menge und Preis.
2. QuotientenregelSeien C(x) die Gesamtkosten fur die Herstellung von x Einheiten eines Gutes.Dann sind C(x)/x die Durchschnittskosten pro Einheit bei der Produktion vonx Einheiten. Die Ableitung der Durchschnittskosten ist dann(
C(x)
x
)′
=C ′(x)x− C(x)
x2=
1
x
(C ′(x)− C(x)
x
).
10.6 Die Kettenregel
Hier betrachten wir Funktionen, die eine Funktion von y sind, wobei y selbst eineFunktion von x ist. Wir haben also eine außere Funktion y 7→ f(y) und eine innereFunktion x 7→ g(x) = y. Wenn wir diese beiden Funktionen hintereinander ausfuhren,erhalten wir eine Funktion F : x 7→ f(g(x)).
Beispiel 10.19. Wir studieren die Nachfrage d nach einem Gut als Funktion desPreises p. Wenn der Preis sich mit der Zeit verandert, ist p selber eine Funktionder Zeit t. Dann ist die Nachfrage d zum einen eine Funktion des Preises, d(p), zumanderen aber auch selber eine Funktion der Zeit, D(t) = d(p(t)). Ich erhalte also dieZeitabhangigkeit der Nachfrage, indem ich zunachst die Zeitabhangigkeit des Preisesauswerte und dann den zeitabhangigen Preis in die Nachfragefunktion d einsetze.Daher heißt dieses Vorgehen auch Hintereinanderausfuhrung von Funktionen.
Die Kettenregel sagt etwas daruber aus, wie man die Ableitung von F erhalt, wennman die Ableitungen von f und g kennt.
Satz 10.20. KettenregelIst g differenzierbar in a und f differenzierbar in g(a), dann ist F (x) = f(g(x))differenzierbar in a, und es gilt
F ′(a) = f ′(g(a)) · g′(a) .
Beispiel 10.21. Die Nachfrage d nach einem bestimmten Gut hangt vom Preis p ab.Also ist die beschreibende Funktion von der Form d : p 7→ d(p). Der Preis seiner-seits hange zusatzlich von der Zeit t ab, d. h. p : t 7→ p(t). Damit hangt auch dieNachfragefunktion d (uber die Zeitabhangigkeit von p) von der Zeit t ab, und es gilt:
D′(t) = (d(p(t)))′ = d′(p(t)) · p′(t) .
Nehmen wir nun an, dass die Nachfrage nach Butter um 5.000 kg abnimmt, wenn derPreis um 1 E pro Kilogramm steigt. Das bedeutet, dass d′(p) · 1 = d(p)− d(p− 1) =−5.000. Nehmen wir weiter an, dass der Preis um 0.05 E pro Kilogramm steigt, so

Wintersemester 2005/06 57
dass p′(t) = 0.05. Die zusammengesetzte Funktion beschreibt nun den Ruckgang derNachfrage in Kilogramm pro Monat: D(t) = d(p(t)). Da der Preis um 0.05 E proMonat steigt und die Nachfrage um 5.000 kg je 1 E Preissteigerung zuruckgeht, falltdie Nachfrage um 5.000 · 0.05 ≈ 250 kg pro Monat. Das heißt D′(t) ≈ −250. Wirsetzen zur Kontrolle in die Kettenregel ein und erhalten: (d(p(t)))′ = d′(p(t)) ·p′(t) =−5000 · 0.05 = −250.
10.7 Die Regel von L’Hospital
Wir haben schon bisher immer genauestens darauf geachtet, dass bei Bruchen derNenner nicht 0 wird, und gegebenfalls bei Funktionen diejenigen Werte, die denNenner zu Null machen, aus dem Definitionsbereich ausgenommen. Eine besondereSituation liegt aber vor, wenn wir bei der Division von 2 Funktionen auf die Situation
”Null durch Null“ stoßen. In diesem Fall kann der Grenzwert alle moglichen Werte
annehmen, kann insbesondere auch definiert sein, also eine reelle Zahl liefern.
Satz 10.22. Ist f(a) = g(a) = 0 und g′(a) 6= 0, dann gilt
limx→a
f(x)
g(x)=
f ′(a)
g′(a).
Die Regel gilt auch, wenn a keine reelle Zahl ist, sondern ±∞.
Die Regel ist auch auf andere unbestimmte Ausdrucke anwendbar, wie etwa”±∞
durch ±∞“.
Beispiel 10.23. L’Hospital erweitert
limx→∞
1− 3x2
5x2 + x− 1= lim
x→∞
−6x
10x + 1= lim
x→∞
−6
10= −3
5.
10.8 Exponentialfunktion
Die Exponentialfunktion ist die Funktion, mit der man Wachstums- und Zerfallspro-zesse beschreibt. Auch vom Rechnen mit Zinseszinsen kennen wir die e-Funktion.Wie gewohnt bezeichen wir die Funktion exp: R → {y ∈ R : y > 0}, x 7→ ex alsnaturliche Exponentialfunktion mit der Eulerschen Zahl e = 2, 7182818 als Basis.
Satz 10.24. Ableitung der ExponentialfunktionDie Ableitung der naturlichen Exponentialfunktion ist gleich der Exponentialfunktionselbst:
f(x) = ex =⇒ f ′(x) = ex .
Beweis. Wir berechnen
limh→0
f(x + h)− f(x)
h= lim
h→0
ex+h − ex
h= lim
h→0ex eh − 1
h= ex · lim
h→0
eh − 1
h.

58 A May, D. Pfeifer: Mathematik fur Okonomen
Indem man mit dem Taschenrechner den Wert des Bruchs (eh−1)/h fur verschiedeneWerte von h ausrechnet, die nahe bei 0 liegen, aber nicht gleich 0 sind (Nenner = 0),
kommt man auf die Vermutung, dass der Grenzwert limh→0
eh−1h
= 1. Wir wollen diese
Vermutung hier nicht streng mathematisch beweisen (was wir aber mussten, umsicherzugehen, dass die Aussage stimmt. Einige Werte einsetzen reicht nicht!), uns
aber den Fakt als solchen einpragen. Damit erhalt man dann (ex)′ = limh→0
ex+h−ex
h=
ex · 1 = ex.
Wie wir bereits wissen, gilt fur alle x ∈ R immer ex > 0. Damit wissen wir nunsofort, dass (ex)′ = ex > 0. Also ist f auf dem ganzen Definitionsbereich (also R)streng monoton wachsend.
Satz 10.25. Ableitungen der Form”e hoch Funktion“
Sei g : x 7→ g(x) = y eine Funktion.Dann gilt fur die Ableitung von ey = eg(x):
(ey)′ = ey · y′ = eg(x) · g′(x) .
10.9 Logarithmus
Wir haben den Logarithmus als inverse Funktion zur Exponentialfunktion kennen-gelernt. Wir wissen also bereits, dass eln x = x fur alle x ∈ Dln = {x ∈ R : x > 0}.Nun differenzieren wir diese Gleichung auf beiden Seiten (linke Seite: Kettenregel)und erhalten:
eln x · (ln x)′ = 1⇔ (ln x)′ = 1/eln x = 1/x .
Satz 10.26. Ableitungen der Form”Logarithmus von Funktion“
Sei x 7→ f(x) eine Funktion mit einem Wertebereich in den positiven reellen Zahlen.Dann kann man F : x 7→ ln f(x) stets bilden, da die Logarithmusfunktion fur allepositiven reellen Zahlen definiert ist (bzw. ihr Definitionsbereich die positiven reellenZahlen sind). Fur die Ableitung dieser zusammengesetzten Funktion gilt:
(ln f(x))′ = (ln)′(f(x)) · f ′(x) =f ′(x)
f(x).
Beispiele 10.27. 1. (ln(1− x))′ =(1− x)′
1− x=−1
1− x,
2. (ln(4− x2))′=
(4− x2)′
(4− x2)=−2x
4− x2.

Wintersemester 2005/06 59
10.10 Differentiation der inversen Funktion
Wir haben am Beispiel von Logarithmus und Exponentialfunktion gesehen, dass esnutzlich sein kann, die Ableitung einer Funktion (hier: des Logarithmus) aus derKenntnis der Ableitung ihrer inversen Funktion zu folgern. Wir formulieren nunnoch allgemein, was wir uns anhand von ln und exp bereits uberlegt hatten, als wirln′(x) = 1/x ausrechneten.
Satz 10.28. Sind f und g inverse Funktionen zueinander, dann gilt f(g(x)) = x.Durch Ableiten dieser Beziehung erhalt man nach der Kettenregel f ′(g(x))·g′(x) = 1,also falls f ′(g(x)) 6= 0
g′(x) =1
f ′(g(x)).
Ist f eine streng monoton wachsende (oder fallende) Funktion, so gilt f ′(x) > 0 (bzw.f ′(x) < 0) fur alle x und f hat dann sicher eine inverse Funktion g (da es wegen derstrengen Monotonie keine 2 verschiedenen x-Werte geben kann, die denselben y-Wertliefen). Außerdem ist dann nach der obigen Formel auch g′(x) > 0 (bzw. g′(x) < 0), sodass eine streng monoton wachsende Funktion auch eine streng monoton wachsendeinverse Funktion hat. (Fur streng monoton fallende Funktionen geht es genauso.)
10.11 Ableitungen hoherer Ordnung
Haben wir eine Funktion f differenziert, so erhalten wir durch f ′ : x 7→ f ′(x) wie-derum eine Funktion in x, von der wir – falls sie existiert – in der gleichen Weise(uber Rechenregeln oder Grenzwert des Differenzenquotienten) die Ableitung be-rechnen konnen. Wir erhalten so die sogenannte zweite Ableitung von f , geschrieben
f ′′def= (f ′)′.
Definition 10.29. Sei f : x 7→ f(x) eine n-mal nach x differenzierbare Funktion.Durch Ableitung von f erhalten wir die erste Ableitung f ′. Durch nochmaliges Ab-leiten (der Funktion f ′) erhalten wir die zweite Ableitung f ′′. Leiten wir f ′′ nocheinmal ab, so erhalten wir die dritte Ableitung f ′′′. Hohere Ableitungen entstehen,wenn man diesen Prozess immer weiterfuhrt. Wir schreiben dann f (4), f (5) oder all-gemein f (n), wenn n fur eine naturliche Zahl steht. Diese Zahl n heißt die Ordnungder Ableitung.
Beispiele 10.30. 1. Zweite Ableitung an einer Stelle
Welchen Wert hat g′′(2) fur die Funktion g : x 7→ g(x) =x2
1− x?
Wir berechnen zuerst die 1. Ableitung als Funktion von x nach der Quotien-
tenregel als g′(x) =2x(1− x) + x2
(1− x)2=
x(2− x)
(1− x)2.
Durch nochmaliges Ableiten erhalten wir aus g′ die 2. Ableitung

60 A May, D. Pfeifer: Mathematik fur Okonomen
g′′(x) =(2− 2x)(1− x)2 − x(2− x)2(1− x)(−1)
(1− x)4
=(2− 2x)(1− x) + 2x(2− x)
(1− x)3
=2(1− 2x + x2) + 4x− 2x2
(1− x)3=
2
(1− x)3.
Da der Nenner dieses Bruchs fur x = 2 nicht verschwindet, kann man einsetzeng′′(2) = 2/(−1) = −2.
2. Zweite Ableitung als FunktionSei L : t 7→ L(t) = 1/
√2t− 1 eine von t abhangige Funktion. Zu berechnen ist
die 2. Ableitung von L (als Funktion von t). Die Funktion L ist fur alle t ∈ Rdefiniert, fur die der Ausdruck unter der Wurzel nicht negativ ist, also furt ≥ 1/2. (Dies ist der Definitionsbereich von L.) Nun differenzieren wir L nachder Kettenregel nach t und erhalten L′(t) = −0, 5·(2t−1)−3/2·2 = −(2t−1)−3/2.Leiten wir L′ noch einmal nach t ab, so sind wir bei L′′(t) = 1, 5·(2t−1)−5/2 ·2 =3 ·(2t−1)−5/2. Dies ist die (von t abhangige) 2. Ableitung von L (als Funktion).
Mit Hilfe der 2. Ableitung einer Funktion f konnen wir eine Aussage uber dieKrummung des zugehorigen Funktionsgraphen machen. Ist namlich f ′′(x) ≥ 0 aufeinem Intervall im Definitionsbereich von f ′′, so entspricht das einer Linskurve, wennman den Funktionsgraphen von links nach rechts abfahrt (d.h. das Steuer ist nachlinks eingeschlagen). Umgekehrt ist der Graph mit einer Rechtskurve vergleichbar,wenn f ′′(x) ≤ 0 fur alle x in einem Intervall in Df ′′ .
Definition 10.31. Sei f eine Funktion und I ⊆ Df ein offenes Intervall, auf dem fzweimal differenzierbar ist. Dann gelten die folgenden Aquivalenzen:
1. f ist konvex auf I ⇐⇒ f ′′(x) ≥ 0 fur alle x ∈ I,
2. f ist konkav auf I ⇐⇒ f ′′(x) ≤ 0 fur alle x ∈ I.
Beachten Sie, dass bei konvexen Funktionen die 1. Ableitung also monoton wachsendist, bei konkaven Funktionen fallt die 1. Ableitung hingegen monoton.
Beispiel 10.32. Eine Produktionsfunktion habe die allgemeine Form Y : K 7→ A ·Ka
mit Parametern A, a > 0. Als Ableitungen von Y nach K berechnen wir: Y ′(K) =A · aKa−1 und Y ′′(K) = Aa(a − 1)Ka−2. Also ist Y ′′(K) ≥ 0, wenn a − 1 > 0(da A, a > 0 nach Voraussetzung an die Parameter sowieso gilt). Somit ist Y einekonvexe Produktionsfunktion, wenn a > 1. Fur 0 < a < 1 ist hingegen a − 1 < 0,also auch Aa(a − 1) < 0, also folgt Y ′′(K) ≤ 0, und wir haben in diesem Fall einekonkave Produktionsfunktion.

Wintersemester 2005/06 61
10.12 Polynomiale Approximation
Wir haben bereits mehrfach die Gleichung einer Tangente an einen gegebenen Punkteines Funktionsgraphen bestimmt. Dies hat den Vorteil, dass wir das Verhalten desFunktionsgraphen in einem hinreichend kleinen Intervall um diesen Punkt durch dieGerade annahern konnen. Wichtig ist dies besonders bei komplizierten Funktionen.Rechnerisch bedeutet das, dass wir eine beliebige Funktion in der Nahe eines gegebe-nen Punktes a durch eine lineare Funktion (die Gleichung der Tangente) annahern.
Satz 10.33. Lineare ApproximationSei f : Df → Wf eine Funktion und a ∈ Df . Dann ist die lineare Approximation vonf um a gegeben durch die Gleichung der Tangente an den Graphen von f in a, also:
f(x) ≈ f(a) + f ′(a)(x− a) .
Diese Gleichung gilt fur alle x, die hinreichend nahe bei a liegen. Mathematischbeschreibt man diesen Sachverhalt gerne mit einem kleinen Intervall um a herum.Man schreibt dann, es existiere ein δ > 0, so dass die Approximation fur alle x gilt(also gut ist), fur die x ∈ (−δ + a, a + δ).
Beweis. Wir wollen uns auf 2 Arten klar machen, dass die obige Gleichung korrektist. Die Steigung der Tangente in a ist – wie wir bereits wissen – f ′(a). Nun verlaufensowohl die Tangente als auch der Funktionsgraph durch den Punkt (a, f(a)). D.h.die Funktionswerte der Funktion f und der linearen Funktion mussen in a uberein-stimmen. Wir haben das schon fruher ausgenutzt und die Gleichung der Tangentegeschrieben als y = f ′(a)x + b und dann uber Einsetzen von x = a, y = f(a) deny-Achsenabschnitt berechnet zu b = y − f ′(a)x = f(a) − f ′(a)a. Damit ergibt sichfur die Gleichung der Tangente y = f ′(a)x + (f(a)− f ′(a)a) = f(a) + f ′(a)(x− a),wie behauptet.
Man kann auch direkt einsehen, dass die obige Formel richtig ist. Dazu uberlegt manwieder, dass f an der Stelle a den Funktionswert f(a) hat. Damit ist die linke Seiteder Formel aus dem Satz gleich f(a). Nun ist die Approximation in a aber exakt(nicht nur angenahert), da die lineare Funktion ja durch den Punkt (a, f(a)) geht.Also muss auch der Funktionswert der Funktion auf der rechten Seite gleich f(a)sein. Da x − a = 0 fur x = a, muss also noch f(a) dazu addiert werden, damit derFunktionswert auf der rechten Seite auch f(a) ist. Damit muss die rechte Seite gleichf(a) + f ′(a)(x− a) sein.
Beispiele 10.34. 1. Wir approximieren f : x 7→ 3√
x um den Punkt x = 1. DerPunkt auf dem Funktionsgraphen, durch den auch die lineare Approximationgeht, ist demnach (1, f(1)) = (1, 1).
Die Steigung der linearen Funktion erhalten wir durch f ′(x) = 13x−2/3. Nun
wenden wir die Formel aus dem Satz an und erhalten:
f(x) = 3√
x ≈ f(1) + f ′(1)(x− 1) = 1 +1
3(x− 1) fur alle |x− 1| < δ .

62 A May, D. Pfeifer: Mathematik fur Okonomen
2. Die Okonomen Samuelson und Swamy interessieren sich in einer Publikation fur
das Verhalten der Funktion h : x 7→√
1 +3
2x +
1
2x2 in der Nahe von 0. (Haufig
tauchen solche Terme auf, wenn man den Fehlerterm einer Naherungsformelbetrachtet und nachpruft, ob er fur kleine x auch klein wird, also gegen 0 geht.)Wir nahern die Funktion in (0, 1) linear an, berechnen mit der Kettenregel
h′(x) =1
2
(1 +
3
2x +
1
2x2
)−0,5
· (1, 5 + x) und erhalten:
h(x) ≈ 1 +1
2· 1 · 3
2x = 1 +
3
4x fur alle |x| < δ .
Haufig ist die Approximation durch eine lineare Funktion nicht gut genug. Dies trifftvor allem fur stark gekrummte Funktionsgraphen zu, bei denen der Graph und dieTangente sich nach dem Beruhrpunkt x = a schnell voneinander entfernen. Dannmuss man statt mit einer linearen Funktion mit einem Polynom hoheren Gradesapproximieren. Dabei verstehen wir unter einem Polynom vom Grad n eine Funktionder Form p : R → W ⊆ R, x 7→ p(x) = anx
n + an−1xn−1 + · · · a1x + a0 mit reellen
Koeffizienten ak ∈ R (vgl. Definition 9.7. Insbesondere ist eine lineare Funktion alsoein Polynom vom Grad 1. Wir nahern nun eine gegebene Funktion in einem Punktx = a durch eine quadratische Funktion (ein Polynom vom Grad 2) an.
Satz 10.35. Quadratische ApproximationSei f : Df → Wf eine Funktion und a ∈ Df . Dann ist die quadratische Approxima-tion von f um a allgemein gegeben durch
(∗) f(x) ≈ C + B(x− a) + A(x− a)2 .
Die Koeffizienten A, B, C konnen abhangig von a und f ausgerechnet werden, so dassdie Formel dann lautet:
f(x) ≈ f(a) + f ′(a)(x− a) +f ′′(a)
2(x− a)2 fur alle |x− a| < δ .
Beweis. Wir uberlegen uns, wie man auf die zweite Formel im Satz kommt. Wirwaren von der linearen zur quadratischen Approximation ubergegangen, weil unsdie Prazision der linearen Funktion fur stark gekrummte Funktionsgraphen nichtausreichte. Diese wird großer, wenn wir nicht nur fordern, dass Funktion und Appro-ximation in x = a den gleichen Funktionswert haben sollen, sondern auch die gleiche1. und 2. Ableitung. Wenn wir diese Forderung auf beide Seiten der Gleichung (∗)anwenden, ergeben sich 3 Gleichungen mit 3 Unbekannten:gleicher Funktionswert: f(a) = C + 0 + 0 =⇒ C = f(a),gleiche 1. Ableitung: f ′(a) = B + 2A(a− a) = B =⇒ B = f ′(a),gleiche 2. Ableitung: f ′′(a) = 2A =⇒ A = 1
2f ′′(a). Damit ist die zweite Gleichung
aus dem Satz hergeleitet, indem wir in (∗) fur A, B, C die ausgerechneten Ausdruckeeinsetzen.

Wintersemester 2005/06 63
Beispiel 10.36. Wir approximieren f : x 7→ 3√
x quadratisch um den Punkt x = 1. DerPunkt auf dem Funktionsgraphen, durch den auch die quadratische Approximationgeht, ist demnach (1, f(1)) = (1, 1).
Die Ableitungen sind f ′(1) = 13x−2/3 und f ′′(1) = 1
3·(−2
3
)x−5/3. Nun wenden wir
die Formel aus dem Satz an und erhalten:
f(x) = 3√
x ≈ f(1) + f ′(1)(x− 1) +f ′′(1)
2(x− 1)2 = 1 +
1
3(x− 1)− 1
9(x− 1)2
fur alle x mit |x− 1| < δ. Wir vergleichen die Gute unserer beiden Approximationenan der Stelle a = 1, 03. Zunachst berechnen wir den exakten Funktionswert (TR)zu 3√
1, 03 = 1, 009902. Mit der linearen Approximation aus Beispiel 10.34 erhaltenwir die Naherung 1 + 1
3(1, 03− 1) = 1, 01 und mit der quadratischen Approximation
von eben 1 + 13(1, 03 − 1) − 1
9(1, 03 − 1)2 = 1 + 0, 01 − 0, 0001 = 1, 0099 eine auf 4
Nachkommastellen genaue Naherung.
10.13 Die Taylor-Formel
Wir haben gesehen, dass der Ubergang von der linearen zur quadratischen Appro-ximation die Genauigkeit verbessern kann. Noch besser konnen wir eine gegebeneFunktion annahern, wenn wir hohere Ableitungen verwenden.
Satz 10.37. Ist f eine Funktion mit a ∈ Df , so gilt in x = a die Approximationdurch ein Taylor-Polynom n-ter Ordnung Tf,n,a(x)
f(x) ≈ f(a) +f ′(a)
1!(x− a) +
f ′′(a)
2!(x− a)2 + ·+ f (n)(a)
n!(x− a)n ,
hierbei steht n! = n(n − 1)(n − 2) · · · 3 · 2 · 1 fur ein Produkt mit n Faktoren, diesogenannte Fakultat.
Als Anwender interessiert man sich mindestens ebenso sehr wie fur die Approxima-tion selber fur die Approximationsgute, also die Genauigkeit, mit der das Taylor-Polynom die gegebene Funktion annahert. Hierzu mochte man gerne eine Formel(oder jedenfalls eine Abschatzung) fur den Ausdruck f(x)− Tf,n,a(x) angeben.
Wir betrachten a = 0 und erhalten eine Approximation fur f in x ∈ R mit kleinem|x| < δ durch Tf,n,0(x) der folgenden Form:
f(x) ≈ f(0) +f ′(0)
1!x +
f ′′(0)
2!x2 + ·+ f (n)(0)
n!xn .
Nun nennen wir die Abweichung zwischen Funktion und Taylorpolynom RestgliedRn+1(x) und schreiben
Rn+1(x) = f(x)− Tf,n,0(x) ,

64 A May, D. Pfeifer: Mathematik fur Okonomen
oder anders geschrieben
f(x) = f(0) +f ′(0)
1!x +
f ′′(0)
2!x2 + ·+ f (n)(0)
n!xn + Rn+1(x) .
Fur dieses Restglied gibt es verschiedene Ausdrucke. Eine besonders nutzliche Formist die folgende:
Satz 10.38. Lagrangesches Restglied fur die Taylor-FormelWir nehmen an, dass f auf einem Intervall I mit 0, x ∈ I nicht nur n-, sondern sogar(n + 1)-mal differenzierbar ist. Dann konnen wir eine Zahl c angeben mit 0 < c < x(oder x < c < 0 bei negativen x), so dass wir das Restglied als (n + 1)-te Ableitungausrechnen konnen:
Rn+1(x) =1
(n + 1)!f (n+1)(c)xn+1 .
Bei der Formel fur das Restglied scheint die Stelle c zu storen, da wir ja nicht genauwissen, wo sie liegt. Da wir aber haufig (fast immer) nur an einer Großenordnung furden Fehler interessiert sind, hilft uns die Formel, den Fehler mit einer Abschatzungnach oben großenmaßig zu beziffern. Das geht so:
Nehmen wir an, dass wir ausrechnen konnen, dass∣∣f (n+1)(x)
∣∣ ≤ S fur alle x ∈ I.Dann rechnen wir aus
|Rn+1(x)| =∣∣∣∣ 1
(n + 1)!
∣∣∣∣ · ∣∣f (n+1)(c)∣∣ · ∣∣xn+1
∣∣ ≤ 1
(n + 1)!· S |x|n+1 .
10.14 Das Newton-Verfahren
Die Taylor-Formel liefert ein Verfahren, eine nicht gut berechenbare (oder unbekann-te) Funktion in der Nahe eines bekannten Funktionswertes linear zu approximieren.In diesem Abschnitt lernen wir ein Verfahren kennen, approximativ eine Nullstelleder Gleichung f(x) = 0 zu bestimmen, wenn wir wissen, wo diese Nullstelle ungefahrliegt. Bei der Aufgabe, einen ungefahren Bereich (ein Intervall) anzugeben, in demdie Nullstelle liegt, hilft der folgende theoretische Satz.
Satz 10.39. ZwischenwertsatzSei f : D → R eine stetige Funktion, sei [a, b] ⊆ D mit f(a) ·f(b) < 0. (Das bedeutet,dass f(a) und f(b) verschiedene Vorzeichen haben, also entweder f(a) > 0, f(b) < 0oder f(a) < 0, f(b) > 0.) Dann gibt es (mindestens) eine Nullstelle a < xN < bzwischen a und b mit f(xN) = 0.
Dieser Satz ist vom Typ her das, was die Mathematik eine Existenzaussage nennt,das heißt wir wissen nur, dass es eine Nullstelle zwischen a und b gibt, wo diesegenau liegt, daruber sagt der Satz nichts aus. Um nun xN wenigstens naherungsweiseangeben zu konnen, benutzen wir das Newton-Verfahren.

Wintersemester 2005/06 65
Satz 10.40. Newton-VerfahrenGesucht ist eine Approximation (Naherung) fur die unbekannte Nullstelle xN derGleichung f(x) = 0. Beginnend mit einem Startwert x0 sind die durch das Newton-Verfahren erzeugten Punkte, die Schritt fur Schritt die Nullstelle von f annahern,rekursiv durch die folgende Formel gegeben:
xn+1 = xn −f(xn)
f ′(xn), n = 0, 1, 2, . . .
Damit das Verfahren anwendbar ist, muss die Funktion f so sein, dass f ′(xn) 6= 0.
Nun konnen wir eine Nullstelle von f wie folgt bestimmen:
Satz 10.41. Algorithmus zur NullstellenbestimmungWir suchen eine Nullstelle xN von f : D → R, x 7→ f(x), also xN ∈ D mit f(xN) =0.
Wir brauchen einen Startwert x0, von dem wir wissen, dass er in der Nahe der Null-stelle liegt. Entweder wir wenden den Zwischenwertsatz 10.39 an, um ein Intervall zufinden, in dem die Nullstelle liegen muss – dann konnen wir einen der Randpunktedes Intervalls als x0 nehmen – oder eine erste Naherung ist uns aus der Problem-stellung gegeben.
Mit diesem Startwert berechnen wir zunachst x1 mit der Formel aus Satz 10.40, dannmit Hilfe von x1 die nachste Naherung x2 usw. Da das Verfahren gewohnlich schnellkonvergiert, kann man aufhoren, wenn sich die neue und die vorherige Naherung nurnoch
”wenig“ unterscheiden, oder man uberpruft, wie weit der Funktionswert f(xn)
noch von der Null entfernt ist und nimmt diese Abweichung |f(xn)− 0| = |f(xn)|als Maß fur die Genauigkeit der Aproximation.
Beispiel 10.42. Wir wollen eine Nullstelle von f(x) = x6+3x2−2x−1 naherungsweisebestimmen.
Als erstes stellen wir fest, dass f(0) = −1 < 0 und f(1) = 1 + 3− 2− 1 = 1 > 0, sodass wir nach dem Zwischenwertsatz sofort sagen konnen, dass f zwischen 0 und 1(mindestens) eine Nullstelle haben muss.
Diese berechnen wir nun nach dem Newton-Verfahren. Wir werden die erste Ablei-tung benotigen, diese ist f ′(x) = 6x5 + 6x − 2. Wir nehmen zunachst als Startwertx0 = 1 und berechnen
x1 = 1− f(1)
f ′(1)= 1− 1/10 = 0, 9000
x2 = 0, 9− f(0, 9)
f ′(0, 9)= 0, 8930
x3 = 0, 8762

66 A May, D. Pfeifer: Mathematik fur Okonomen
Wir vergleichen die Funktionswerte f(x1) = 0, f(x2) = 0, 1134 und f(x3) = 0, 0034,diese nahern sich wie erwartet recht schnell der Null an.
Wir konnten alternativ auch mit dem linken Randpunkt des Intervalls x0 = 0 starten.
x1 = 0− f(0)
f ′(0)= 1− 1/2 = 0, 5
x2 = 0, 5− f(0, 5)
f ′(0, 5)= 1, 5395
Bereits im zweiten Schritt erhalten wir hier eine Naherung, die außerhalb des Inter-valls [0, 1] liegt. Der Startwert x0 = 0 erweist sich also als ungeeignet, weswegen manhier aufhoren sollte und mit einem anderen Startwert (hier: x0 = 1, dem rechtenRandpunkt) rechnen sollte.
Wir wollen noch eine Aufgabe betrachten, die wir in ahnlicher Form auch mit derTaylor-Formel losen konnten. Ein grundlegender Unterschied besteht darin, dass dieTaylor-Formel einen Funktionswert annahert, das Newton-Verfahren hingegen eineNullstelle naherungsweise bestimmt.
Beispiel 10.43. Gesucht ist eine Naherung fur 15√
2.
Zunachst suchen wir eine Gleichung, deren Nullstelle 15√
2 ist. Diese finden wir mitf(x) = x15 − 2 = 0, denn ( 15
√2)15 − 2 = 2 − 2 = 0. Wegen 1 − 2 = −1 < 0 und
215−2 > 0 liegt unsere Nullstelle zwischen 1 und 2. Wir wahlen als Startwert x0 = 1,weil der Funktionswert f(1) viel naher an Null liegt als f(2).
Wir benotigen f ′(x) = 15x14 und berechnen nach dem Newton-Verfahren
x1 = 1− f(1)
f ′(1)= 1− −1
15=
16
15≈ 1, 0667
x2 = 1, 0667− f(16/15)
f ′(16/15)≈ 1, 0473
Wir uberprufen f(1, 0473) = −8 · 10−8 und bestatigen eine recht gute Naherung derNullstelle bereits nach 2 Schritten, da |f(x2)| = 8 · 10−8 ≤ 10 · 10−8 = 10−7.
11 Extrem- und Wendepunkte fur Funktionen ei-
ner reellen Variablen
11.1 Notwendige Bedingungen fur Extrempunkte
Besonders haufig wird bei wirtschaftswissenschaftlichen Anwendungen nach dem op-timalen Wert (eines Preises, einer Strategie, einer Gewinnfunktion) gefragt. Die Be-stimmung von maximalen oder minimalen Funktionswerten hat daher mit Recht

Wintersemester 2005/06 67
eine zentrale Stellung in den mathematischen Methoden. Wir haben bereits bei denquadratischen Funktionen Maximum- und Minimumpunkte bestimmt, indem wir dieKoordinaten des Scheitelpunktes ausrechneten. Der Gang der Dinge war dabei im-mer so, dass wir zunachst den x-Wert xE (das sogenannten Argument) ausrechnetenund dann in die (quadratische) Funktionsgleichung einsetzten. Der Extrempunkt, wiewir zusammenfassend fur Maximum- und Minimumpunkt sagen wollen, ist also der-jenige x-Wert, der eine gegebene Funktion (auf einer bestimmten Menge) maximaloder minimal werden lasst. Dieser maximale (minimale) Wert errechnet sich danndurch Einsetzen von xE in die Funktionsvorschrift und Ausrechnen von f(xE).
Definition 11.1. Sei f : D → W ⊆ R eine Funktion. Dann heißt– c ∈ D ein Maximumpunkt fur f immer dann, wenn fur alle x ∈ D gilt f(x) ≤ f(c).Der Funktionswert f(c) ist dann also der großte Wert im Wertebereich W und heißtMaximalwert.– d ∈ D ein Minimumpunkt fur f immer dann, wenn fur alle x ∈ D gilt f(x) ≥ f(d).Der Funktionswert f(d) ist dann also der kleinste Wert im Wertebereich W und heißtMinimalwert.
Gilt fur alle x ∈ D sogar f(x) < f(c), so nennen wir c einen strikten Maximumpunkt.Umgekehrt heißt d ∈ D strikter Minimumpunkt, falls fur alle x ∈ D gilt f(x) > f(d).
Beispiel 11.2. Ein Unternehmen, das ein einzelnes Gut herstellt, mochte seinen Ge-winn maximieren. Der Gesamterlos, der durch die Produktion und den Verkauf vonQ Einheiten erzielt wird, sei R(Q) E, die zugehorigen Gesamtkosten belaufen sich aufC(Q). Der durch die Produktion und den Verkauf von Q Einheiten erzielte Gewinnist dann die Differenz aus dem Gesamterlos minus den eingesetzten Kosten, also
Π(Q) = R(Q)− C(Q) .
Auf Grund technischer Einschrankungen gibt es eine Maximalzahl Q von Einheiten,die von dem Unternehmen in einer vorgegebenen Periode produziert werden kann.Betrachten wir nun die Funktionen R und C und stellen uns die Frage, ob der GewinnΠ in dem technisch moglichen Intervall [0, Q] einen Maximumpunkt hat. Wenn wirwissen, dass die Funktion streng monoton wachsend ist, muss dieser Maximumpunktam rechten Intervallende liegen (also xE = Q). Ist die Funktion hingegen monotonfallend, so liegt der Maximumpunkt auf dem linken Intervallende (also xE = 0,eine okonomisch nicht sehr sinnvolle Aussage, die besagt, dass der Gewinn maximalist, wenn gar nichts produziert wird). Wenn wir eine quadratische Funktion Π voruns haben, konnen wir noch die x-Koordinate des Scheitelpunktes berechnen (alsoxE = −b/2a) und uberpufen, ob a < 0 (garantiert Maximum, nicht Minimum) und−b/2a ∈ [0, Q] (garantiert, dass Maximumpunkt auch technisch erreichbar wegen derobigen Produktionsbeschrankung).
Die folgenden Uberlegungen dienen dazu, unser Repertoire auf allgemeine (nichtquadratische, nicht monotone) Funktionen zu erweitern.

68 A May, D. Pfeifer: Mathematik fur Okonomen
Definition 11.3. Sei f : I → W eine Funktion, die auf einem Intervall I differenzier-bar ist, und sei c ∈ I nicht einer der beiden Endpunkte des Intervalls (mathematischgesprochen: c liegt im Inneren von I).Ist (c, f(c)) ein Punkt auf dem Funktionsgraphen von f mit einer horizontalen Tan-gente, gilt also f ′(c) = 0, so nennen wir c einen stationaren Punkt fur f .
Veranschaulichen wir uns die Situation: Wenn wir eine Funktion vorfinden, die nichtmonoton ist, aber dennoch im Innern des Intervalls einen Minimumpunkt hat unddort differenzierbar ist, dann muss der Funktionsgraph also gekrummt sein und zwarderart, dass die Steigung in c ihr Vorzeichen wechselt, also vorher (links davon) ne-gativ war und danach (rechts davon) positiv ist (oder naturlich auch umgekehrt furMaximumpunkte). Im Extrempunkt selber findet der Wechsel statt, d.h. ein Ex-trempunkt im Innern eines Intervalls ist immer ein stationarer Punkt. Diese wichtigeErkenntnis fassen wir in einem Satz zusammen.
Satz 11.4. Notwendige Bedingung fur ExtrempunkteSei f : I → W eine Funktion, die auf einem Intervall I differenzierbar ist, und sei c ∈I ein Punkt im Inneren von I. Dann erfullen alle Maximum- oder Minimumpunktedie Bedingung f ′(c) = 0, sind also stationare Punkte.
Da alle Extrempunkte auch stationar sind (das Umgekehrte aber nicht gelten muss,d.h. nicht alle stationaren Punkte sind Extrempunkte oder anders: Es kann stati-onare Punkte geben, die kein Maximum- oder Minimumpunkt sind.), sprechen wirvon f ′(c) = 0 als einer notwendigen Bedingung fur Extrempunkte.
Die Erkenntnis, die uns zu diesem Satz fuhrte, war, dass in der Umgebung eines Ex-trempunktes ein Wechsel im Vorzeichen der Ableitung stattfindet. Dieses Resultatfuhrt uns zur Formulierung einer Bedingung, die wir testen konnen um herauszube-kommen, ob ein Extrempunkt vorliegt.
Satz 11.5. Sei f : I → W eine Funktion, die auf einem Intervall differenzierbar istund sei c ∈ I ein Punkt im Inneren von I.
Gilt f ′(x) ≥ 0 fur x ≤ c (links von c) und f ′(x) ≤ 0 fur x ≥ c (rechts von c), dannist xE = c ein Maximumpunkt fur f .
Falls f ′(x) ≤ 0 fur x ≤ c (links von c) und f ′(x) ≥ 0 fur x ≥ c (rechts von c), dannist xE = c ein Minimumpunkt fur f .
Wir verknupfen diesen Satz mit der Eigenschaft einer Funktion, konkav zu sein.Zur Erinnerung: Eine zweimal differenzierbare Funktion nannten wir konkav, fallsf ′′(x) ≤ 0 fur alle x aus einem Intervall I. Ist f ′′, also die Ableitung von f ′, kleineroder gleich Null, so konnen wir daraus folgern, dass f ′ monoton fallend in demIntervall ist. Ist nun c ein innerer Punkt des Intervalls und f ′(c) = 0, so folgt daraus,dass f ′(x) ≥ 0 links von c, also fur alle x ≤ c und f ′(x) ≤ 0 rechts von c, alsofur alle x ≥ c. Nun sagen diese Bedingungen wiederum etwas uber die Monotonie,

Wintersemester 2005/06 69
diesmal fur die Funktion f selber aus. Und zwar heißt das, dass die Funktion f furalle x ≤ c monoton wachsend und fur x ≥ c monoton fallend sein muss. Damit liegtin xE = c ein Maximumpunkt fur f im Intervall vor. Ganz analog schließt man aufeinen Minimumpunkt in einem Intervall fur konvexe Funktionen f . Also haben wir –fur konkave oder konvexe Funktionen – damit ein weiteres Kriterium, wie wir einenExtrempunkt fur die Funktion finden konnen.
Satz 11.6. Sei f : I → W eine konkave Funktion mit einem stationaren Punkt c imInnern von I. Dann ist c auch ein Maximumpunkt von f in I.
Ist f eine konvexe Funktion mit f ′(c) = 0 und c liegt im Innern von I, dann ist cein Minimumpunkt von f in I.
Beispiele 11.7. 1. Sei f : R→ {y ∈ R : y ≥ 0}, x 7→ ex−1 − x.Hat f einen Extrempunkt in I = R?
Wir bilden die erste f ′(x) = ex−1 − 1 und zweite Ableitung f ′′(x) = ex−1
und stellen fest, dass f ′′(x) > 0 fur alle x ∈ R, da der Wertebereich derExponentialfunktion oberhalb der x-Achse liegt. Damit ist also f eine konvexeFunktion. Wir finden einen stationaren Punkt fur f durch f ′(x) = ex−1−1 = 0,also x − 1 = 0 (damit ex−1 = 1 gilt), d.h. x = 1. Dann muss nach demvorangegangenen Satz aber x = 1 ein Minimumpunkt fur die konvexe Funktionf sein.
2. Im Botanischen Garten in Bonn steht eine exotische Blutenstaude, deren Hoheuber dem Beet nach t Monaten sich nach der folgenden Formel berechnet:
h(t) =√
t− 1
2t, t ∈ [0, 3] .
Der Gartner mochte gerne wissen, wie hoch die Pflanze maximal werden kann,da er sie zum Schutz vor saurem Regen mit einem Schutzdach versehen mochte.
Wir berechnen wieder die Ableitungen
h′(t) =1
2· 1√
t− 1
2und h′′(t) = −1
4· 1
t3/2.
Fur das Intervall I = (0, 3] ist stets t3/2 > 0, also gilt h′′(t) < 0 auf I, undh ist folglich konkav auf I. Ein stationarer Punkt fur h liegt fur c = 1 vor,denn
√1 = 1, folglich ist h′(t) = 1
2· 1 − 1
2= 0. Der stationare Punkt einer
konkaven Funktion ist aber ein Maximumpunkt, also hat die Funktion h intE = 1 einen Maximumpunkt. Die maximale Hohe der Pflanze erhalten wir nundurch Einsetzen von 1 in die Funktion h als Funktionswert h(1) =
√1− 1
2= 1/2.
Nach einem Monat ist die Pflanze 0,5 m hoch und der Garnter muss sein Dachalso in mehr als 50 cm uber dem Boden anbringen, damit die Pflanze sichungehindert entwickeln kann.

70 A May, D. Pfeifer: Mathematik fur Okonomen
11.2 Der Satz vom Extrempunkt
Wir stellen uns zunachst die Frage, wann uberhaupt eine Funktion auf einem Inter-vall einen Extrempunkt hat. In voller Allgemeinheit ist das schwierig. Wir wissenbereits, dass es durchaus einfache Funktionen gibt, die weder Maximum- noch Mi-nimumpunkt haben, z.B. die lineare Geradengleichung, die fur alle x ∈ R definiertist. Schranken wir aber den Definitionsbereich auf ein endliches Intervall ein, des-sen Endpunkte zum Intervall gehoren, so ist die Situation verandert. Dadurch, dasswir nur noch ein endlich langes Stuck der gesamten Geraden betrachten, liegt dannein Minimumpunkt im linken Randpunkt und ein Maximumpunkt im rechten Rand-punkt, falls wir eine Gerade mit positiver Steigung betrachten. Diese Aussage kannman verallgemeinern auf stetige Funktionen, das waren solche, deren Graph keineSprunge aufweist. Voraussetzung ist dass wir ein 1) abgeschlossenes und 2) endlichlanges reelles Intervall betrachten. Fehlen 1) oder 2), so ist die Aussage nicht korrekt.
Satz 11.8. Satz vom ExtrempunktSei f : I 7→ W eine stetige Funktion auf einem Intervall I = [A, B], das abgeschlossenund beschrankt ist. Dann existiert ein Mimimumpunkt x = d ∈ [A, B] und auchein Maximumpunkt c ∈ [A, B], so dass zusammen fur alle x ∈ I = [A, B] gilt:f(d) ≤ f(x) ≤ f(c).
Wir haben nun also 2 Sorten von Extrempunkten kennen gelernt, solche die imInnern eines Intervalls liegen und stationare Punkte sind, und solche, die am Randeeines Intervalls liegen. Wenn man fur eine Funktion also den maximalen und denminimalen Wert auf einem Intervall bestimmen soll, muss man beide Moglichkeitenaustesten.
Satz 11.9. Algorithmus ExtrempunktsucheAufgabe: Bestimmen Sie den maximalen und den minimalen Wert einer Funktionf : [A, B]→ W . Wir setzen voraus, dass wir die Funktion f differenzieren konnen.
Losung: Erste Feststellung: Das Intervall I = [A, B] ist abgeschlossen und vonendlicher Lange, zweite Feststellung: die Funktion ist dort differenzierbar, also auchstetig. Damit mussen nach Satz 11.8 ein Maximumpunkt und ein Minimumpunkt imIntervall I existieren. Nun geht man wie folgt vor:
1. Mit der Gleichung f ′(x) = 0 bestimmen wir alle stationaren Punkte x = c, dieim Innern von I liegen, also c ∈ (A, B).
2. Wir setzen x = A, c, B ein und berechnen die drei Funktionswerte f(A), f(c),f(B). Falls es mehr als einen stationaren Punkt c gibt, muss man naturlichalle c’s einsetzen, dann stehen hier entsprechend mehr Funktionswerte.
3. Der großte der in 2. gefundenen Funktionswerte ist der maximale, der klein-ste der gefundenen Funktionswerte ist der minimale Wert der Funktion f imIntervall [A, B].

Wintersemester 2005/06 71
Beispiele 11.10. 1. Nun konnen wir zuruckkommen auf das Beispiel 11.2 und unsfragen, unter welchen Bedingungen ein Maximum vorliegt. Die GewinnfunktionΠ: [0, Q] → {y ∈ R : y ≥ 0} sei differenzierbar (also auch stetig) auf demIntervall [0, Q]. Damit muss Π nach dem Satz vom Extrempunkt 11.8 dort einenMaximumpunkt haben. In einigen Fallen konnte das Maximum Π(Q∗) an denEndpunkten des Intervalls angenommen werden, also fur Q∗ = 0 oder Q∗ = Q.Falls der Maximumpunkt Q∗ im Innern des Intervalls liegt, ist er ein stationarerPunkt fur Π, muss also die Gleichung Π′(Q∗) = 0 erfullen. Da Π(Q) = R(Q)−C(Q) gilt, ist dann wegen der Ableitungsregel fur Summen R′(Q∗)−C ′(Q∗) = 0.Dies ist der Fall, wenn die Produktion so eingestellt ist, dass der Grenzerlosgleich den Grenzkosten ist. Falls es mehrere stationare Punkte fur Π gibt,muss unter allen diesen fur die Suche nach dem Gewinnmaximum derjenigeausgewahlt werden, der den großten Funktionswert Π(Q∗) liefert.
2. Wir bleiben im Kontext von Beispiel 11.2 und nehmen nun an, dass das Un-ternehmen einen festen Preis P pro verkaufter Einheit erhalt. Dann ist alsoR(Q) = P ·Q, und wir erhalten fur den Maximumpunkt Q∗ im Innern des In-tervalls (falls das Maximum also nicht in den Endpunkten des Intervalls 0 oderQ angenommen wird) die Gleichung C ′(Q∗) = R′(Q∗) = (PQ)′ = P . Wennalso der Preis der Einflußnahme des Unternehmens entzogen ist, sollte die Pro-duktion auf ein Niveau eingestellt werden, bei dem die Grenzkosten gleich demPreis pro Einheit des Gutes sind.
11.3 Hinreichende Bedingung fur Extrempunkte
Wir haben uns im letzten Abschnitt mit dem Finden sogenannter globaler Extrem-punkte einer Funktion in einem Intervall beschaftigt, indem wir den großten oderkleinsten Funktionswert fur alle x in diesem Intervall bestimmt haben. Haufig istman auch daran interessiert, lokale Extrempunkte ausfindig zu machen, deren Funk-tionswerte maximal (oder minimal) sind, wenn man sie mit Punkten in der Nahevergleicht. Diese definiert man am eingangigsten, indem man sie in Bezug auf einkleines Intervall um den Extrempunkt herum definiert.
Definition 11.11. Sei f : D → W eine Funktion, sei c ∈ D ein Punkt im Innern vonD, so dass eine Zahl h > 0 existiert mit (c−h, c+h) ⊆ D. Man kann also ein kleinesIntervall um den Punkt c der Lange 2h so legen, dass das ganze kleine Intervall nochim Definitionsbereich liegt.Wir sagen, c ist ein lokaler Maximumpunkt fur f , falls f(x) ≤ f(c) fur alle x ∈(c − h, c + h). (Analog nimmt f in c ein lokales Minimum an, falls f(x) ≥ f(c) furalle x ∈ (c− h, c + h).)
Auch in einem lokalen Extrempunkt muss ein stationarer Punkt vorliegen, also dieAbleitung Null sein. Wenn man alle moglichen lokalen Extrempunkte einer Funktion

72 A May, D. Pfeifer: Mathematik fur Okonomen
f : D → W bestimmen soll, muss man demnach folgende Typen von Punkten unter-suchen:– Innere Punkte x von I mit f ′(x) = 0;– Endpunkte von I, falls sie zu I dazugehoren (Symbol [ oder ]);– innere Punkte c von I, in denen die Funktion f nicht differenzierbar ist, so dassf ′(c) = 0 nicht uberpruft werden kann, weil f ′(c) nicht existiert.
Wir beantworten nun die Frage, welche Bedingung man an einen stationaren Punktstellen muss, damit man sicher sagen kann, dass er auch ein Extrempunkt ist.
Satz 11.12. Hinreichende Bedingung fur lokale ExtrempunkteSei f : I → W eine zweimal differenzierbare Funktion, sei c ∈ I ein Punkt aus demInneren des Intervalls I. Dann gilt:
1. Ist f ′(c) = 0 und f ′′(c) < 0, so ist x = c ein lokaler Maximumpunkt, und esgilt sogar f(c) > f(x) fur alle x in der Umgebung von c. Solche Punkte wollenwir strikt nennen.
2. Ist f ′(c) = 0 und f ′′(c) > 0, so ist x = c ein strikter lokaler Minimumpunkt,d.h. es gilt sogar f(c) < f(x) fur alle x in der Umgebung von c.
3. Ist f ′(c) = 0 und f ′′(c) = 0, so kann man nichts aussagen.
Beispiel 11.13. Kehren wir noch einmal zu Beispiel 11.2 zuruck. Wir nehmen zusatz-lich an, dass dem Unternehmen eine Verkaufssteuer von t Euro pro Einheit auferlegtwird. Der Gewinn des Unternehmens aus der Produktion und dem Verkauf von QEinheiten des Gutes ist dann nur noch
Π(Q) = R(Q)− C(Q)− tQ .
Um den Gewinn fur eine Produktionsmenge Q∗ ∈ (0, Q) zu maximieren, muss manΠ′(Q∗) = 0 haben, also R′(Q∗)− C ′(Q∗)− t = 0. Wir nehmen an, dass R′′(Q∗) < 0und C ′′(Q∗) > 0. Wir wollen nun Q∗ als von t abhangige Große betrachten und mitder Kettenregel ausrechnen, was das fur die Ableitung Q∗(t) qualitativ bedeutet.Q∗ ist also in der Terminologie der Kettenregel als innere Funktion anzusehen. Wirdifferenzieren beide Seiten und erhalten
R′′(Q∗(t)) · (Q∗)′(t)− C ′′(Q∗(t)) · (Q∗)′(t)− 1 = 0 .
Losen wir nach (Q∗)′(t) auf, so folgt
(Q∗)′(t) =1
R′′(Q∗(t))− C ′′(Q∗(t)).
Wenn wir nun, wie oben geschehen, R′′(Q∗) < 0 und C ′′(Q∗) > 0 annehmen, so folgt(Q∗)′(t) < 0. Daher wird die optimale Anzahl der produzierten Einheiten abnehmen,wenn der Steuersatz t steigt.

Wintersemester 2005/06 73
11.4 Wendepunkte
Der Wendepunkt hat einen sprechenden Namen, der sich uns erschließt, wenn wir unsden Funktionsgraphen als Straße vorstellen, auf der wir mit einem Auto unterwegssind. In naheliegender Weise werden wir erwarten, dass wir in einem Wendepunktunser Steuer andersherum einschlagen mussen, also von links nach rechts oder um-gekehrt. Diese Vorstellung ist die richtige.
Mathematisch ausgedruckt, andert an der Stelle eines Wendepunktes die Funktion ihrVerhalten von konvex zu konkav (oder gerade umgekehrt, von konkav zu konvex).Noch anders ausgedruckt, andert also die zweite Ableitung von f an der Stelle cgerade ihr Vorzeichen. Diese Erkenntnis verwenden wir, um zu definieren, was wirunter einem Wendepunkt verstehen wollen.
Definition 11.14. Sei f : D → W eine Funktion, die zweimal differenzierbar ist.Wir nennen einen inneren Punkt c ∈ D einen Wendepunkt von f , falls ein Intervall(A, B) um c herum existiert (genauer c ∈ (A, B) ⊆ D) mitentweder f ′′(x) ≥ 0 fur alle x ∈ (A, c) und f ′′(x) ≤ 0 fur alle x ∈ (c, B),oder f ′′(x) ≤ 0 fur alle x ∈ (A, c) und f ′′(x) ≥ 0 fur alle x ∈ (c, B).
Satz 11.15. Untersuchung auf WendepunkteFalls f ′′(c) = 0 und f ′′ an der Stelle c das Vorzeichen wechselt, dann ist c einWendepunkt von f .
Beispiel 11.16. Die Funktion g : x 7→ g(x) = 19x3− 1
6x2− 2
3x+1 soll auf Wendepunkte
untersucht werden. Wir bilden die erste g′(x) = 13x2 − 1
3x− 2
3und zweite Ableitung
g′′(x) = 23x − 1
3. Fur einen moglichen Wendepunkt losen wir 0 = g′′(x) = 2
3x − 1
3,
also x = 1/2. Nun uberprufen wir g′′(x) ≤ 0 fur x ≤ 1/2 und g′′(x) ≥ 0 fur x ≥ 1/2.Damit hat f in x = 1/2 einen Wendepunkt.
12 Funktionen von 2 Variablen
Viele Zusammenhange in den Wirtschafts- wie auch den Naturwissenschaften zeich-nen sich dadurch aus, dass die interessierende Output-Große nicht nur von einer,sondern von mehreren unabhangigen Variablen abhangt. So ist etwa die Nachfrageeines Konsumenten nach einem Gut nicht nur vom Preis, sondern auch von seinemverfugbaren Einkommen oder den Preisen des gleichen Gutes von einem anderenProduzenten oder auch den Preisen anderer (konkurrierender) Guter abhangig. Dasliefert die Motivation, unsere Diskussion von Funktionen auszuweiten auf Funktio-nen, die von mehreren Variablen abhangen. Wir wollen uns hier in der Regel aufFunktionen von 2 Variablen beschranken, um das Prinzip besser zu verstehen. BeiFunktionen mehrerer Variabler wird die raumliche Vorstellung schwieriger und wirhaben es statt mit Ableitungen nach 2 Variablen mit Ableitungen nach allen Varia-

74 A May, D. Pfeifer: Mathematik fur Okonomen
blen zu tun. Die prinzipiellen Uberlegungen unterscheiden sich aber – insbesonderewas die mehrdimensionale Differentialrechnung angeht – nicht.
Wir starten mit der grundlegenden Definition.
Definition 12.1. Eine Funktion f von zwei Variablen ist eine Vorschrift, die jedemPaar (x, y) eine eindeutig bestimmte reelle Zahl zuordnet. Wir schreiben fur diesenVorgang wieder (x, y) 7→ f(x, y). Der Definitionsbereich ist nun fur die erste Zahl imPaar (x, y) die Menge aller reellen Zahlen, die fur x eingesetzt werden durfen, analogfur die zweite Zahl im Paar (x, y) die Menge aller reellen Zahlen, die fur y eingesetztwerden durfen.
Wir merken schon hier, dass uns unsere Erkenntnis uber die Funktionen einer Varia-blen helfen wird, denn haufig konnen wir x und y separat betrachten, d.h. wir tunso, als ob die andere Variable eine Konstante sei (wie 7 oder A).
Wir wissen bereits vom Graph einer Funktion von einer Variablen, dass Punktepaarein der Ebene liegen (im Koordinatenkreuz). Dieser Ebene aller reellen Zahlen (demKoordinatensystem als Ganzes) wollen wir nun einen Namen geben. Die reelle Ebenebezeichnen wir mit R×R = R2 und schreiben (x, y) ∈ R×R. Damit ist der Definiti-onsbereich einer Funktion von zwei reellen Variablen also eine Teilmenge der reellenEbene: Df ⊆ R×R. Das ist das Neue, wenn wir von einer auf zwei Variablen gehen,der Wertebereich bleibt wie zuvor, als es nur eine Variable gab, eine Teilmenge derreellen Zahlen.
Also gilt f : Df → R, (x, y) 7→ f(x, y) mit Df ⊆ R× R.
Zum Berechnen von Funktionswerten setzen wir die angegebenen Werte fur x und yein.
Beispiel 12.2. Sei f eine Funktion mit f(x, y) = 2x+x2y3. Dann wird der Funktions-wert an der Stelle (−2, 3) dadurch berechnet, dass wir x = −2 und y = 3 einsetzen.Damit folgt f(−2, 3) = 2 · (−2) + (−2)2 · 33 = −4 + 4 · 27 = 104.
12.1 Hohenlinien
Der Graph einer Funktion von zwei Variablen ist nun keine Kurve mehr, die ubereinem Intervall (oder der reellen Achse) liegt, sondern eine Flache, die uber derreellen Ebene liegt oder einem Teilgebiet davon. Wir stellen uns anschaulich denGraph als Gebirge vor. Dies fuhrt uns zu einem wichtigen Begriff, den alle diejenigengut kennen, die gelegentlich im Gebirge wandern. Dort gibt ein Blick auf die Karteuns uber Hohenlinien (deren Gestalt, und Hohe uber dem Meer) einen Eindruck, wieviel Anstrengung es uns kosten wird, einen Gipfel zu erklimmen.
Eine gute Vorstellung von Hohenlinien liefert wieder unser Sektkelch, den wir er-halten, indem wir eine Parabel um ihre Mittelachse rotieren lassen. (Der korrektemathematische Ausdruck dafur ist Paraboloid.) Dies ist der Graph einer Funktion

Wintersemester 2005/06 75
von zwei Variablen. Wenn wir nun in einer beliebigen Hohe z = c den Sektkelch miteiner Ebene schneiden, die parallel zur Grundebene liegt (also waagerecht), erhal-ten wir als Schnittbild auf dieser Ebene die Menge aller Punkte, die auf der Hohec (
”uber dem Meer“) liegen, auf der die waagerechte Ebene auch liegt. Bei unserem
Sektkelch ergeben sich Kreise, was aus der Rotation der Parabel um die Achse folgt.
Definition 12.3. Eine Hohenlinie oder Niveaulinie von f zur Hohe c ist die Mengealler Punkte (x, y) ∈ Df , fur die der Funktionswert auf Hohe c liegt, also Hc(f) ={(x, y) ∈ Df : f(x, y) = c}.
Hier sind wir davon ausgegangen, dass wir wie bei der Gebirgskarte die Punkte aufdie Grundebene herunter geholt (projiziert) haben. Wenn wir die Hohenlinie auf derHohe belassen wollen, auf der wir mit der waagerechten Ebene geschnitten haben, somussen wir schreiben Hc(f) = {(x, y, z) ∈ Df × R : z = f(x, y) = c}. Beachten Sie,dass die Hohenlinie bei dieser zweiten Betrachtung nun auf der Hohe z = c im Raumliegt. Wenn Sie sich aus Hohenlinien eine Vorstellung des dreidimensionalen Graphender Funktion verschaffen wollen, hilft haufig diese Definition schneller weiter.
12.2 Partielle Ableitungen
Wir erinnern uns, was wir uber Ableitungen von Funktionen einer Variablen wissen.Auf den ersten Blick macht die Ubertragung der Begriffe Schwierigkeiten, weil wirja nicht wissen, wie wir damit umgehen sollen, dass wir nun 2 Richtungen im Raumhaben, die x- und die y-Richtung. Wir stellen uns den Graphen einer Funktion vonzwei Variablen wieder als krumme Flache (Gebirge) im Raum vor. Offensichtlich istalles wie fruher, wenn ich nur in eine Richtung (z.B. x) ableite und die andere Rich-tung als nicht veranderlich betrachte. Das entspricht dem Bilden einer Tangente nurin x-Richtung. Ich laufe also genau in Richtung der x-Achse das Gebirge hinunter,und gehe nicht irgendwie quer. Diese Vorstellung fuhrt zu dem Begriff der Richtungs-ableitung, zunachst in x und dann mit vertauschten Rollen auch in y-Richtung.
Definition 12.4. Sei f : Df → R, (x, y) 7→ f(x, y) mit Df ⊆ R×R eine Funktion vonzwei Variablen. Dann sind die ersten partiellen Ableitungen (
”nach x“ bzw.
”nach
y“) definiert als
∂f(x, y)
∂x= f ′x(x, y) = lim
h→0
f(x + h, y)− f(x, y)
h
und∂f(x, y)
∂y= f ′y(x, y) = lim
k→0
f(x, y + k)− f(x, y)
k.
Man berechnet die partielle Ableitung nach x, indem man die Funktion wie gewohntnach x ableitet und y als Konstante betrachtet.

76 A May, D. Pfeifer: Mathematik fur Okonomen
Aus der linearen Approximation einer Funktion von einer Variablen durch ihre ersteAbleitung folgern wir: Die partielle Ableitung ∂f(x,y)
∂xist ungefahr gleich der Anderung
im Funktionswert f(x, y), die aus einer Erhohung von x um 1 resultiert, wenn wir ygleichzeitig konstant halten.
Fur die partielle Ableitung nach y gilt analog, dass wir nur nach y ableiten und xdabei als konstant betrachten.
Beispiel 12.5. Man berechne die beiden ersten partiellen Ableitungen zu f(x, y) =x3ey2
.
Bei der partiellen Ableitung nach x mussen wir also (x3)′ = 3x2 ausrechnen, undey2
ist eine multiplikative Konstante. Umgekehrt verhalt es sich bei der partiellenAbleitung nach y. Hier mussen wir (ey2
)′ = (y2)′ ·ey2= 2y ·ey2
(nach der Kettenregel)ausrechnen, und x3 wird als konstant betrachtet. Damit folgt
∂f(x, y)
∂x= 3x2 · ey2
und∂f(x, y)
∂y= x3 · 2y · ey2
= 2x3yey2
.
Leiten wir die partiellen Ableitungen noch einmal ab, so sind wir bei den zweitenpartiellen Ableitungen. Die Berechnung erfolgt wieder wie bei den ersten partiellenAbleitungen. Man leitet nur nach der einen Variable ab, nach der die partielle Ab-leitung gebildet wird (Welche das ist, sieht man im Nenner hinter dem ∂-Symbol.)und betrachtet die andere Variable in diesem Schritt als Konstante.
Wie viele zweite partielle Ableitungen erwarten wir? Wir haben zwei erste partielleAbleitungen (nach x und nach y) und konnen diese beiden Ableitungen noch ein-mal jeweils nach x oder y ableiten. D.h. es gibt pro erster partieller Ableitung zweiMoglichkeiten, die zweite Ableitung zu bilden, also erwarten wir insgesamt 2 · 2 = 4zweite partielle Ableitungen.
Definition 12.6. Zweite partielle AbleitungenWir bezeichnen die Ableitungen, die man erhalt, wenn man die ersten partiellenAbleitungen noch einmal ableitet, wie folgt
∂2f(x, y)
∂x2= f ′′xx(x, y) (zweimal nach x ableiten),
und∂2f(x, y)
∂y2= f ′′yy(x, y) (zweimal nach y ableiten),
und∂2f(x, y)
∂y∂x= f ′′xy(x, y) (erst nach x, dann nach y ableiten),

Wintersemester 2005/06 77
und∂2f(x, y)
∂x∂y= f ′′yx(x, y) (erst nach y, dann nach x ableiten).
Man beachte, dass in der Notation∂2
∂y∂xf(x, y) zunachst nach der Variablen abge-
leitet wird, die am nachsten zur Funktionsvorschrift f steht, also die Reihenfolge voninnen nach außen (von rechts nach links) ist.
Beispiel 12.7. Wir berechnen zur Kontrolle die beiden gemischten zweiten partiellenAbleitungen zu f(x, y) = x3ey2
aus dem Beispiel 12.5.
∂2f(x, y)
∂y∂x=
∂
∂y
(3x2 · ey2
)= 3x2 · 2yey2
= 6x2yey2
und∂2f(x, y)
∂x∂y=
∂f(x, y)
∂x
(2x3y · ·ey2
)= 6x2yey2
.
In der Tat stimmen die beiden Ableitungen uberein.
Bei den gemischten Ableitungen (nach x und nach y) ist dabei die Reihenfolge,in der nach x und y abgeleitet wird, fur die meisten
”normalen“ Funktionen egal.
Wir wollen im Folgenden stets annehmen, dass wir den nachstehenden Satz stetsannehmen durfen, ohne die Voraussetzungen, die in unseren Beispielen stets erfulltsein werden, nachzuprufen. Das gilt selbstverstandlich nur, solange die Funktionenhinreichend
”nett“ sind.
Satz 12.8. Sei f : Df → R, (x, y) 7→ f(x, y) mit Df ⊆ R×R eine Funktion von zweiVariablen. Wenn alle zweiten partiellen Ableitungen von f stetig sind, dann ist dieReihenfolge, in der abgeleitet wird, bei den gemischten Ableitungen egal (
”erst nach
x, dann nach y“ fuhrt zum gleichen Ergebnis wie”erst nach y, dann nach x“):
∂2f(x, y)
∂y∂x=
∂2f(x, y)
∂x∂y.
13 Extrem- und Sattelpunkte fur Funktionen mit
2 Variablen
Ein zentraler Begriff bei der Bestimmung von lokalen Extrempunkten fur Funktioneneiner Variablen war der des stationaren Punktes. Stationare Punkte waren immer in-nere Punkte im Definitionsbereich. Und ein innerer Punkt, so hatten wir uns uber-legt, war dabei gekennzeichnet dadurch, dass er Mittelpunkt eines kleinen offenenIntervalls war, das noch ganz im Definitionsbereich lag.

78 A May, D. Pfeifer: Mathematik fur Okonomen
Wir wollen in volliger Analogie definieren, was ein innerer Punkt fur eine Funktionvon zwei Variablen sein soll. Wir betrachten also wieder eine Funktion f : D →R, (x, y) 7→ f(x, y). Ein Punkt (x0, y0) ∈ D ⊆ R × R heißt innerer Punkt, falls esein kleines Rechteck R um (x0, y0) gibt, so dass (x0, y0) ∈ R und R ⊆ D. Dabeiwollen wir vereinbaren, dass (x0, y0) in der
”Mitte“ des Rechtecks liegt, also auf
dem Schnittpunkt der Winkelhalbierenden. Wir sehen, dass Rechtecke so etwas wiedie zweidimensionale Verallgemeinerung unserer reellen Intervalle sind und in vielenSatzen fur Funktionen von zwei Variablen dort auftauchen werden, wo in Satzen furFunktionen einer Variablen von Intervallen gesprochen wurde. Wir beginnen mit derUbertragung des Begriffs lokaler Extrempunkt auf Funktionen von zwei Variablen.
Wenn wir uns den Graphen einer Funktion von 2 Variablen als Gebirge vorstellen,dann interessiert man sich in der Regel nicht nur fur den hochsten Gipfel, sondernauch fur kleinere Gipfel. Das ist der Fall lokaler Maxima. Lokale Extrempunkte sindwie bei den Funktionen von nur einer Variablen stets stationare Punkte und immerfur innere Punkte der Definitionsmenge definiert (sonst hatte man nur einen ein-seitigen Gipfel, weil man nicht weiß, ob es auf der anderen Seite auch runter geht,oder ob es auf der anderen Seite weiter ansteigt). Damit wir die Stationaritat uber-prufen konnen, mussen wir die Funktion differenzieren konnen. Wir wollen darunterverstehen, dass wir die beiden partiellen Ableitungen berechnen konnen.
Satz 13.1. Notwendige Bedingung fur lokale ExtrempunkteSei f : D → R, (x, y) 7→ f(x, y) mit D ⊆ R×R eine auf D differenzierbare Funktionund sei (x0, y0) ∈ D ein innerer Punkt von D. Der Punkt (x0, y0) kann nur dannein lokaler Minimum- oder Maximumpunkt fur f sein, wenn (x0, y0) ein stationarerPunkt ist. D.h. in dem Punkt (x0, y0) mussen (notwendig) die beiden folgenden Be-dingungen erfullt sein:
∂f(x0, y0)
∂x= 0 und
∂f(x0, y0)
∂y= 0 .
Auch fur Funktionen von mehr als 2 Variablen gilt, dass bei einer differenzierba-ren Funktion in einem lokalen Extrempunkt im Innern des Definitionsbereichs allepartiellen Ableitungen erster Ordnung (heißt: nach allen Variablen einmal partiellabgeleitet) gleich Null sind.
Aus der Diskussion von Funktionen einer Variablen wissen wir bereits, dass nichtalle stationaren Punkte lokale Extrempunkte sind. D.h. es gibt innere Punkte vonD, in denen beide partiellen Ableitungen gleich Null werden, ohne dass ein lokalerExtrempunkt in (x0, y0) vorliegt. Wir nannten solche Punkte fruher Wendepunkte,hier heißen sie Sattelpunkte.
Definition 13.2. Ein Sattelpunkt ist ein stationarer Punkt (x0, y0) von f mit derEigenschaft, dass es Punkte (x, y) ∈ D beliebig nahe an (x0, y0) gibt mit einerseitsf(x, y) < f(x0, y0), es andererseits aber auch Punkte gibt mit f(x, y) > f(x0, y0).

Wintersemester 2005/06 79
Wenn wir uberprufen wollen, ob ein gefundener stationarer Punkt ein lokaler Extrem-punkt fur die Funktion f ist, so benotigen wir wie fruher statt der in Satz 13.1 an-gegebenen notwendigen Bedingung zusatzlich hinreichende Bedingungen. D.h. wennwir diese Bedingungen uberprufen und herausfinden, dass unser stationarer Punkt(x0, y0) sie erfullt, dann durfen wir schließen, dass ein lokaler Extrempunkt vorliegt.
Satz 13.3. Hinreichende Bedingungen fur lokale ExtrempunkteSei f : D → R, (x, y) 7→ f(x, y) mit D ⊆ R × R eine auf D zweimal stetig diffe-renzierbare Funktion, und sei (x0, y0) ∈ D ein innerer Punkt von D. Ist (x0, y0) einstationarer Punkt fur f , so gilt
1. (x0, y0) ist ein lokaler Minimumpunkt fur f in D, falls die folgenden 3 Be-dingungen (alle drei zusammen) fur alle (x, y) in einem kleinen Rechteck um(x0, y0) gelten:
∂2f(x, y)
∂x2≥ 0,
∂2f(x, y)
∂y2≥ 0 und
∂2f(x, y)
∂x2· ∂
2f(x, y)
∂y2−(
∂2f(x, y)
∂y∂x
)2
≥ 0 .
2. (x0, y0) ist ein lokaler Maximumpunkt fur f in D, falls die folgenden 3 Be-dingungen (alle drei zusammen) fur alle (x, y) in einem kleinen Rechteck um(x0, y0) gelten:
∂2f(x, y)
∂x2≤ 0,
∂2f(x, y)
∂y2≤ 0 und
∂2f(x, y)
∂x2· ∂
2f(x, y)
∂y2−(
∂2f(x, y)
∂y∂x
)2
≥ 0 .
In den folgenden beiden weiteren Fallen muss man hingegen vorsichtig sein.
Satz 13.4. Sei f : D → R, (x, y) 7→ f(x, y) mit D ⊆ R×R eine auf D zweimal stetigdifferenzierbare Funktion und sei (x0, y0) ∈ D ein innerer Punkt von D. Ist (x0, y0)ein stationarer Punkt fur f , so gilt
1. (x0, y0) ist ein Sattelpunkt fur f in D, falls gilt:
∂2f(x, y)
∂x2· ∂
2f(x, y)
∂y2−(
∂2f(x, y)
∂y∂x
)2
< 0 .
In diesem Fall liegt also definitiv kein lokaler Extrempunkt vor.

80 A May, D. Pfeifer: Mathematik fur Okonomen
2. Gilt hingegen
∂2f(x, y)
∂x2· ∂
2f(x, y)
∂y2−(
∂2f(x, y)
∂y∂x
)2
= 0 ,
so kann (x0, y0) sowohl ein lokaler Minimum- als auch Maximumpunkt als auchein Sattelpunkt sein.
Ein lokaler Maximumpunkt heißt strikt, falls der zugehorige Funktionswert echtgroßer als alle anderen Funktionswerte in der naheren Umgebung ist. Analog gibtes auch strikte Minimumpunkte. In diesem Fall lassen sich die hinreichenden Bedin-gungen aus Satz 88 noch etwas bequemer uberprufen.
Satz 13.5. Sei f : D → R, (x, y) 7→ f(x, y) mit D ⊆ R × R eine auf D zweimalstetig differenzierbare Funktion, und sei (x0, y0) ∈ D ein innerer Punkt von D. Ist(x0, y0) ein stationarer Punkt fur f , so gilt:
1. Wenn ∂2f(x0,y0)∂x2 < 0 und ∂2f(x0,y0)
∂x2 · ∂2f(x0,y0)
∂y2 −(
∂2f(x0,y0)∂y∂x
)2
> 0, dann ist (x0, y0)
ein (strikter) lokaler Maximumpunkt.
2. Wenn ∂2f(x0,y0)∂x2 > 0 und ∂2f(x0,y0)
∂x2 · ∂2f(x0,y0)
∂y2 −(
∂2f(x0,y0)∂y∂x
)2
> 0, dann ist (x0, y0)
ein (strikter) lokaler Minimumpunkt.
Diese Bedingung ist sehr bequem zu uberprufen, weil man im Gegensatz zu denhinreichenden Bedingungen aus Satz 88 die partiellen Ableitungen nur in dem stati-onaren Punkt (x0, y0) auswerten muss (nicht in einem ganzen kleinen Rechteck umden stationaren Punkt herum.)

Wintersemester 2005/06 81
14 Anwendung der Optimierung fur Probleme mit
2 Variablen
14.1 Globale Maxima und Minima
Wie bei den Funktionen von einer Variablen unterscheidet man globale und lokaleExtrempunkte. Der globale Maximalwert gibt den großten Funktionswert unter allenmoglichen Funktionswerten an, der globale Minimalwert analog den kleinsten.
Definition 14.1. Gilt fur alle (x, y) ∈ D, dass f(a, b) ≤ f(x, y), so ist (a, b) ∈ D einMinimumpunkt fur die Funktion f und f hat dort ein globales Minimum f(a, b).
Gilt fur alle (x, y) ∈ D, dass f(x, y) ≤ f(c, d), so ist (c, d) ∈ D ein Maximumpunktfur die Funktion f und f hat dort ein globales Maximum f(c, d).
Ist die Funktion stetig auf einer beschrankten Menge, die zusatzlich abgeschlossen ist(sich also darstellen laßt als Rechteck mit Rand oder allgemeiner als Menge, zu der ihrRand dazu gehort), so hat sie auf einer solchen Menge stets ein globales Maximumund ein globales Minimum. Einen ahnlichen Satz haben wir in Satz 10.39 bereitsfur Funktionen von nur einer Variablen kennengelernt, die auf abgeschlossenen undbeschrankten (also endlichen) Intervallen definiert sind.
Satz 14.2. Satz vom Extrempunkt Sei f : D → R mit D ⊆ R×R und sei S ⊆ Deine Teilmenge des Definitionsbereiches D, die abgeschlossen und beschrankt ist (d.h.der Rand von S gehort ganz zu S dazu und S liegt in der xy-Ebene.) Dann gibt esPunkte (a, b) ∈ S und (c, d) ∈ S, in denen f ein globales Minimum bzw. Maximumannimmt, also
f(a, b) ≤ f(x, y) ≤ f(c, d) fur alle x, y ∈ S .
Kurz: Jede stetige Funktion auf einer abgeschlossenen und beschrankten Menge nimmtdort ihr globales Minimum und ihr globales Maximum an.
Steht man nun vor der Aufgabe, alle Maximum- und Minimumpunkte einer gege-benen Funktion zu finden, so muss man sowohl nach globalen als auch nach lokalenExtrempunkten suchen. Haufig ist in Anwendungen nach dem maximalen und demminimalen Wert einer Funktion f auf einer gegebenen Menge S gefragt. Dann mussman die minimalen bzw. maximalen Funktionswerte (also y-Werte) suchen, die dieFunktion auf dieser Menge annimmt. Der folgende Satz gibt ein Rezept dafur an:
Satz 14.3. Minima und Maxima bei Funktionen von 2 VariablenIst f : S → R, (x, y) 7→ f(x, y) differenzierbar und ist S eine abgeschlossene und be-schrankte Menge in der xy-Ebene, so hat nach dem Extrempunktsatz 14.2 die Funk-tion f einen Maximum- und einen Minimumpunkt in S.
Die (globalen) Maximum- und Minimumwerte von f bestimmt man wie folgt:

82 A May, D. Pfeifer: Mathematik fur Okonomen
1. Suche alle stationaren Punkte (x0, y0) von f im Inneren von S und berechnedie zugehorigen Funktionswerte f(x0, y0).
2. Bestimme den großten und den kleinsten Wert von f auf dem Rand von S unddie zugehorigen globalen Extrempunkte (Min. und Max.). (Manchmal muss mandazu den Rand in verschiedene Teilstucke unterteilen, z.B. in die 4 Geraden,die den Rand eines Rechtecks bilden.)
3. Der großte Funktionswert aus den beiden vorangegangenen Schritten ist nunder Maximalwert, der kleinste Funktionswert aus den beiden vorangegangenenSchritten liefert den Minimalwert von f .
14.2 Lineare Regression
Nehmen wir an, dass Sie aus einer Beobachtung (Erhebung) uber einen bestimmtenZeitraum Daten ermittelt haben, aus denen Sie nun eine Prognose fur die Zukunftableiten wollen. Mathematisch bedeutet das, dass Sie aus empirischen Daten der Ver-gangenheit eine Schatzung fur das zukunftige Verhalten der Daten (der Kurve) ablei-ten wollen. Am haufigsten geht man dabei nach der Methode der linearen Regressionvor. Diese besteht darin, dass Sie durch gegebene Punkte eine optimale Gerade legen,wobei optimal bedeutet, dass die Gerade die gegebenen Punkte optimal annahert.Wir werden im Folgenden sagen, was unter optimal annahern in diesem Kontext zuverstehen ist. Naturlich gibt es Daten, die ein eindeutig nichtlineares Verhalten zeigen(z.B. einen quadratischen Verlauf, die Punkte liegen auf einer gedachten Parable).Dann wird die Annaherung durch eine Gerade schwer gelingen bzw. sehr ungenausein. Bei vielen Phanomenen in den Wirtschaftswissenschaften ist die lineare Re-gression dennoch die Methode der Wahl. (Auch in den Naturwissenschaften arbeitetman mit der linearen Regression, wenn etwa verschiedene Meßergebnisse gemitteltwerden sollen.)
Wir nehmen an, dass wir 2 Variablen (x, y) haben und dass y (die abhangige Va-riable) von x (der unabhangigen Variable) abhangt. Wir denken etwa an Nachfra-gefunktionen, wo y die nachgefragte Menge und x den Preis oder das Einkommenbezeichnet.
Nun beobachten wir Datenpaare (x, y) innerhalb eines Zeitintervalls [0, T ] zu festenZeitpunkten t = 1, 2, . . . , T , z.B. jeweils montags um 10.00 Uhr oder jeweils amErsten eines Monats. Die Beobachtungsdaten nummerieren wir anhand der Beob-achtungszeitpunkte durch. In jedem Zeitpunkt ermitteln wir den Preis xt und dienachgefragte Menge yt. Wir erhalten also Punktepaare (xt, yt), t = 1, 2, . . . , T , diewir in ein Koordinatenkreuz einzeichnen konnen. Unsere Aufgabe besteht nun darin,durch die eingezeichneten Punkte eine Gerade so zu legen, dass die Abstande derPunkte zu der Geraden in der Summe
”moglichst klein“ sind.
Betrachten wir zunachst den – seltenen – Fall, dass die Punkte wirklich alle auf

Wintersemester 2005/06 83
einer gedachten Geraden liegen. Dann konnen wir reelle Zahlen m, b ∈ R angeben,so dass yt = m · xt + b fur alle t (und das heißt ein universelles m und ein b fur allet gleichzeitig.)
Falls – was meistens der Fall ist – die Punkte um eine gedachte Gerade streuen,so wird diese Gerade dennoch durch y = m · x + b beschrieben, aber bei jedemeinzelnen Punkt muss ich eine Abweichung berucksichtigen: et = yt − mxt − b furalle Zeitpunkte t. Diese Abweichung heißt Fehlerterm oder Storgroße. Offensichtlichgibt
∑Tt=1 et =
∑Tt=1 yt − mxt − b die Summe aller Abweichungen der Punkte von
der idealen Geraden an. Diese Form der Darstellung hat den Nachteil, dass derFehlerterm – scheinbar – Null wird, falls die Abweichung nach unten genauso großist wie die nach oben (anders ausgedruckt: falls negative und positive Fehler einanderaufheben). Daher betrachtet man lieber die Quadrate dieser Abweichungen, die damit(durch das Quadrieren) alle positiv sind.
Definition 14.4. Der mittlere quadratische Fehler ist gegeben durch die Verlust-funktion L : R × R → {` ∈ R : ` ≥ 0}, die von der Steigung und dem y-Achsenab-schnitt der sogenannten Ausgleichsgerade abhangt,
L(m, b) =1
T
T∑t=1
e2t =
1
T
T∑t=1
(yt −mxt − b)2 .
Wegen der Division durch die Anzahl der Punkte T gibt L den mittleren (durch-schnittlichen) quadratischen Fehler an.
Unser Ziel besteht nun darin, m und b nur unter Verwendung der bekannten Daten(xt, yt) zu bestimmen. Wir benotigen dazu einige nutzliche Abkurzungen, die aus derStatistik kommen und dort auch haufig verwendet werden.
Definition 14.5. Gegeben und uns bekannt seien Daten xt bzw. yt fur Zeitpunktet = 1, 2, . . . , T . Dann heißt
1. µx =x1 + · · ·+ xT
Tder (empirische) Mittelwert (oder: das arithmetische Mit-
tel) von x = (x1, x2, . . . , xT )
und analog µy =
∑Tt=1 yt
Tder (empirische) Mittelwert von y = (y1, y2, . . . , yT ).
2. σxx = 1T
T∑t=1
(xt − µx)2 die (empirische) Varianz von x
und analog σyy = 1T
T∑t=1
(yt − µy)2 die (empirische) Varianz von y.
3. σxy = 1T
T∑t=1
(xt − µx) · (yt − µy) die (empirische) Kovarianz von x und y.

84 A May, D. Pfeifer: Mathematik fur Okonomen
Nach diesen Uberlegungen nehmen wir die Aufgabe in Angriff, die Verlustfunktionzu minimieren. Dazu mussen wir zunachst stationare Punkte fur L suchen, also dieersten partiellen Ableitungen bestimmen und gleich Null setzen.
∂L(m, b)
∂b= 2
1
T
T∑t=1
(yt −mxt − b)(−1)
= 2
(1
T
T∑t=1
b− 1
T
T∑t=1
yt + m1
T
T∑t=1
xt
)= 2b− 2µy + 2mµx = 0
und
∂L(m, b)
∂m= 2mµ2
x − 2µxµy + 2bµx + 2mσxx − 2σxy = 0
Daraus erhalten wir fur den stationaren Punkt
m =σxy
σxx
und b = µy −σxy
σxx
· µx .
Damit geht die geschatzte Gerade
y =σxy
σxx
· x + µy −σxy
σxx
· µx
durch den Mittelwert (µx, µy) der beobachteten Datenpunkte (xt, yt).
Um zu ermitteln, ob der gefundene stationare Punkt ein Extrempunkt (konkret: einMinimumpunkt) ist, mussen wir noch die Bedingungen aus 88 nachprufen. Dies zeigt,dass tatsachlich (m, b) ein Minimumpunkt fur L ist.
Wir halten als wichtiges Ergebnis fest:
Die Gerade y = mx + b ist die beste lineare Anpassung an die beobachteten Da-tenpunkte (xt, yt) in dem Sinne, dass der mittlere quadratische Fehler minimiertwird.
14.3 Die Kettenregel
Satz 14.6. Hangt f von den beiden Variablen x und y ab, (x, y) 7→ f(x, y), die ih-rerseits selber von einer weiteren Variable t abhangen, haben wir also folgende Funk-tionen f(x, y) sowie x(t) und y(t), so konnen wir auch f als nur von einer Variablent abhangig betrachten. Dazu definieren wir F : R→ R, t 7→ F (t) = f(x(t), y(t)). Da-mit ist F also eine von einer Variable abhangende Funktion und wir konnen F wiegewohnt ableiten:
F ′(t) =df(x(t), y(t))
dt=
∂f(x(t), y(t))
∂x· x′(t) +
∂f(x(t), y(t))
∂y· y′(t) .

Wintersemester 2005/06 85
Die Ableitung von F bezuglich t nennt man auch totale Ableitung von f nach t undschreibt dafur gerne df(x(t),y(t))
dt.
Beispiel 14.7. Es seien f(x, y) = x + y2, x = t2 und y = t3. Wir berechnen erst die(normalen) Ableitungen von x und y als x′(t) = 2t und y′(t) = 3t2. Nun kommen die
partiellen Ableitungen von f nach x und y an die Reihe, und wir erhalten ∂f(x,y)∂x
= 1
und ∂f(x,y)∂y
= 2y. Wir wenden nun die Kettenregel an, um die totale Ableitung vonf zu berechnen.
df(x(t), y(t))
dt= 1 · 2t + 2y · 3t2 = 2t + 2t3 · 3t2 = 2t + 6t5 ,
dabei haben wir im vorletzten Schritt y = t3 eingesetzt.
14.4 Lineare Approximationen
Wir erinnern uns an die lineare Approximation im Umfeld der Taylor-Formel
f(x) ≈ f(a) + f ′(a)(x− a) .
Wir wollen eine ahnliche Approximation fur Funktionen, die von 2 Variablen abhan-gen, angeben. Klar ist, dass wir mit einer Gerade als lineare Approximation an dieFlache, die den Graphen von f beschreibt, nicht auskommen, sondern nun eine ganzeEbene als Approximation benotigen. Diese erhalten wir, indem wir einmal in x undeinmal in y-Richtung (als den beiden moglichen Richtungen in der Ebene) ableiten.
Satz 14.8. Lineare ApproximationIst f : Df → R mit (x, y) 7→ f(x, y) und Df ⊆ R×R, so ist die lineare Approximationvon f um (a, b) gegeben durch
f(x, y) ≈ f(a, b) +∂f(a, b)
∂x(x− a) +
∂f(a, b)
∂y(y − b) .
Wir beachten, was wir auch schon von fruher wissen, dass die Approximation nur furx in der Nahe von a und y in der Nahe von b gut ist und dass wir eine Aussage uberden Fehler benotigen, wenn wir etwas uber die Gute der Approximation aussagenwollen.
Wir konnen die Tangentialebene, die in einer kleinen Umgebung um (a, b) den Gra-phen der Funktion (Flache!) annahert, explizit angeben.
Satz 14.9. TangentialebeneDie Tangentialebene an den Graphen der Funktion Gf = {(x, y, z) ∈ Df × R : z =f(x, y)} im Punkt (a, b, f(a, b)) hat die Gleichung
z − f(a, b) =∂f(a, b)
∂x(x− a) +
∂f(a, b)
∂y(y − b) .

86 A May, D. Pfeifer: Mathematik fur Okonomen
15 Homogene und Homothetische Funktionen
Definition 15.1. Eine Funktion f : D ⊆ R×R→ R heißt homogen vom Grad k ∈ R,wenn fur alle (x, y) ∈ D gilt, dass auch (tx, ty) ∈ D und
f(tx, ty) = tkf(x, y) fur alle t > 0 .
Homogene Funktionen spielen eine wichtige Rolle bei vielen okonomischen Anwen-dungen, so sind etwa Produktionsfunktionen oder Cobb-Douglas Funktionen haufighomogen. In einfachen Fallen kann man durch Nachrechnen leicht uberprufen, obeine gegebene Funktion homogen ist.
Beispiel 15.2. Ist etwa f(x, y) = x4 + x2y2, so sieht man (fast ohne Nachrechnen),dass f(tx, ty) = (tx)4 + (tx)2(ty)2 = t4(x4 + x2y2) = t4 · f(x, y), dass also f homogenvom Grad 4 ist.
Bei komplizierteren Funktionsvorschriften hilft eine Uberprufung der partiellen Ab-leitungen.
Satz 15.3. Euler KriteriumDie folgenden beiden Aussagen sind aquivalent:f ist homogen vom Grad k ⇐⇒ x∂f(x,y)
∂x+ y ∂f(x,y)
∂y= kf(x, y) .
Definition 15.4. Eine Funktion f : K ⊆ R× R → R heißt homothetisch, wenn furalle (x, y) ∈ K gilt, dass auch (tx, ty) ∈ K und
f(x1, y1) = f(x2, y2)⇒ f(tx1, ty1) = f(tx2, ty2) fur alle t > 0 und (x1, y1), (x2, y2) ∈ K .
Wir bemerken folgenden Zusammenhang zwischen homogenen und homothetischenFunktionen:
Folgerung 15.5. Eine homogene Funktion eines beliebigen Grades k ist homothe-tisch, aber nicht alle homothetischen Funktionen sind homogen.
15.1 Funktionen mit mehr als 2 Variablen
Da homogene und homothetische Funktionen recht haufig in den Wirtschaftswissen-schaften vorkommen, wollen wir an dieser einen Stelle einmal eine Definition angeben,die mit mehr als 2 Variablen arbeitet.
Definition 15.6. Sei f : K → R, (x1, x2, . . . , xn) 7→ f(x1, x2, . . . , xn) eine Funktionvon n Variablen, die auf einem Bereich K ⊆ R × R definiert ist, fur den gilt, dassmit (x1, x2, . . . , xn) ∈ K fur alle t > 0 auch alle Vielfachen (tx1, tx2, . . . , txn) ∈ Kliegen. Man nennt eine solche Menge auch Konus oder verallgemeinerter Kegel.

Wintersemester 2005/06 87
Eine Funktion f heißt homogen vom Grad k, falls
f(tx1, tx2, . . . , txn) = tkf(x1, x2, . . . , xn) fur alle t > 0 .
Eine Funktion heißt homothetisch, falls
f(x1, x2, . . . , xn) = f(y1, y2, . . . , yn)⇒ f(tx1, tx2, . . . , txn) = f(ty1, ty2, . . . , tyn)
fur alle t > 0 und alle (x1, x2, . . . , xn), (y1, y2, . . . , yn) ∈ K.
Wir vermerken noch folgende nutzliche Folgerung uber partielle Ableitungen homo-gener Funktionen.
Folgerung 15.7. Wenn f eine Funktion von n Variablen ist, die homogen vom Gradk ist, dann gilt
(i)∂f(x1, x2, . . . , xn)
∂xj
ist homogen vom Grad k − 1, fur alle j = 1, . . . , n
und
(ii)n∑
j=1
n∑i=1
xjxi∂2f(x1, x2, . . . , xn)
∂xi∂xj
= k(k − 1)f(x1, x2, . . . , xn).
Dabei sind die partiellen Ableitungen nach einer Variablen xj genauso definiert wiebei Funktionen von 2 Variablen, d.h. man leitet nach xj ab und betrachtet alleanderen Variablen (ohne xj) bei diesem Ableiten als konstant.
16 Die Lagrange Multiplikatoren fur Optimierung
unter Nebenbedingungen
Wir wollen uns einer weiteren Methode zuwenden, Maxima und Minima einer Funk-tion von zwei Variablen zu bestimmen, die speziell in der Okonomie eine wichtigeBedeutung hat. Es handelt sich hierbei um Optimierungsprobleme unter Nebenbedin-gungen. Mathematisch kommt dabei nichts Neues hinzu, wir werden es – wie immerbei Optimierungsproblemen fur Funktionen zweier Variabler – wieder mit partiel-len Ableitungen zu tun haben. Allerdings muss nicht die Funktion selbst, sonderndie sogenannte Lagrange-Funktion abgeleitet werden. Wir beginnen mit einem An-wendungsbeispiel, zu dem Sie gerne noch einmal die Aufgabe G8 zur Hand nehmendurfen.
Beispiel 16.1. Mathematische WirtschaftstheorieEine Person (Anna) hat einen Betrag (Budget) von m E zur Verfugung. Annaschwarmt fur Kinobesuche; eine Kinokarte kostet p E. Wir wollen wissen, wieviel

88 A May, D. Pfeifer: Mathematik fur Okonomen
Geld von ihrem Budget ubrig bleibt, wenn sie sich entscheidet, x Kinokarten zukaufen.
Ihre Budget-Menge (vgl. Aufgabe G8 c)) ist dann
B = {(x, y) | px + y ≤ m, x ≥ 0, y ≥ 0} .
Nehmen wir nun an, dass Annas Vorlieben durch eine Nutzenfunktion u(x, y) ab-gebildet werden – schließlich muss sie trotz ihrer Kinoleidenschaft auch essen, Busfahren und ihre Versicherungsbeitrage bezahlen. Die Frage ist, wie viele KinokartenAnna kaufen kann, ohne dass sie verhungert, nur noch zu Fuss gehen kann etc. Mehrals ihr verfugbares Budget in Hohe von m E kann sie insgesamt keinesfalls ausgeben.
Damit lautet die mathematische Formulierung fur dieses Problem: Suche ein Ma-ximum fur die Nutzenfunktion u(x, y) unter der Nebenbedingung px + y = m. Wirwerden auf ein konkretes Beispiel spater eingehen, wollen aber zunachst die Methode,wie man diese Frage beantworten kann, aufschreiben.
Wichtig ist es sich klarzumachen, dass wir es mit 2 Funktionen zu tun haben, einerFunktion f , zu der wir das Maximum suchen, und einer Funktion, die die Nebenbe-dingung beschreibt und die wir im Folgenden mit g bezeichnen werden.
Definition 16.2. Sei f : D → R eine Funktion von 2 Variablen mit D ⊆ R × R.Die Nebenbedingung werde beschrieben durch eine Gleichung g(x, y) = c, wobei ceine reelle Zahl ist. Wir machen aus dieser Gleichung durch Subtraktion von c eineGleichung mit der rechten Seite Null: g(x, y)− c = 0.
Nun fuhren wir eine reelle Zahl λ ein, die allgemein Lagrange-Multiplikator genanntwird. Die Lagrange-Funktion L ist eine Funktion von zwei Variablen, die gleich f(x, y)ist, wenn die Nebenbedingung g(x, y)− c = 0 erfullt ist,
L(x, y) = f(x, y)− λ(g(x, y)− c) .
Wenn wir ein lokales Extremum fur die Funktion f suchen wurden, wurden wirzunachst die Funktion f partiell nach x und y ableiten und beide partielle Ablei-tungen gleich Null setzen, um stationare Punkte zu finden. Vom Prinzip her machenwir hier genau das Gleiche, nur leiten wir L statt f partiell nach x und y ab. Dannlautet das Rechenschema fur die Bestimmung von stationaren Punkten von f(x, y)unter der Nebenbedingung g(x, y) = c wie folgt.
Satz 16.3. Methode des Lagrange-MultiplikatorsGesucht ist ein Maximumpunkt (oder Minimumpunkt) von f(x, y) unter der Ne-benbedingung g(x, y) = c. Dazu sind zunachst die stationaren Punkte von L unterBeachtung der Nebenbedingung zu bestimmen.
Nacheinander sind folgende Schritte durchzufuhren:
1. Formen Sie die Nebenbedingung so um, dass ihre rechte Seite Null wird,g(x, y)− c = 0.

Wintersemester 2005/06 89
2. Stellen Sie die Lagrange-Funktion auf, indem Sie wie in der obigen Definitionvorgehen,
L(x, y) = f(x, y)− λ(g(x, y)− c), λ ∈ R .
3. Bilden Sie die beiden ersten partiellen Ableitungen von L,
∂L(x, y)
∂x=
∂f(x, y)
∂x− λ · ∂g(x, y)
∂x
und∂L(x, y)
∂y=
∂f(x, y)
∂y− λ · ∂g(x, y)
∂y.
4. Bestimmen Sie stationare Punkte (x, y) von L, indem Sie die beiden partiellenAbleitungen gleich Null setzen:
(1)∂f(x, y)
∂x− λ · ∂g(x, y)
∂x= 0
(2)∂f(x, y)
∂y− λ · ∂g(x, y)
∂y= 0 .
Bei der Losung werden Sie merken, dass Sie eine Variable (λ) zu viel oder eineGleichung zu wenig haben. Die dritte fehlende Gleichung erhalten Sie aus derNebenbedingung
(3) g(x, y)− c = 0 .
5. Losen Sie die ersten beiden Gleichungen (1) und (2) nach x und y auf (Beidekonnen in diesem Schritt noch von λ abhangen!) und setzen Sie das so gewon-nene Paar (x0, y0) in die Nebenbedingung g(x, y) − c = 0 ein. Daraus erhaltman λ, das man in die Ausdrucke fur x0 und y0 einsetzt, und so einen stati-onaren Punkt als Kandidaten fur den Maximum- oder Minimumpunkt von fermittelt.
Wir fuhren nun das Einstiegsbeipiel mit konkreten Zahlen fort.
Beispiel 16.4. Der Preis p fur eine Kinokarte sei 10 E. Anna hat insgesamt m = 550 Ezur Verfugung. Dann ist ihre Budget-Restriktion gegeben durch 10x+y = 550, das istwie oben eingefuhrt die Nebenbedingung g(x, y) = 10x + y = 550 = c. Wir nehmenan, dass wir Annas Praferenzen mit der Nutzenfunktion u(x, y) = xy beschreibenkonnen. Damit muss also ein Extremumpunkt fur die Funktion u(x, y) unter derNebenbedingung 10x + y − 550 = 0 gesucht werden.
Wir arbeiten die Schritte aus Satz 16.3 nacheinander ab.
1. Nebenbedingung ist 10x + y − 550 = 0.

90 A May, D. Pfeifer: Mathematik fur Okonomen
2. Lagrange-Funktion L(x, y) = xy − λ(10x + y − 550).
3. Partielle Ableitungen fur L(x, y) bilden.Es gilt ∂
∂x(xy) = y und ∂
∂x(10x + y − 550) = 10. Damit ist
∂L(x, y)
∂x= y − 10λ, und mit ∂
∂y(xy) = x und ∂
∂y(10x + y − 550) = 1 folgt
∂L(x, y)
∂y= x− λ.
4. Gleichungssystem mit 3 Gleichungen aufstelleny − 10λ = 0x− λ = 010x + y − 550 = 0
5. Die ersten beiden Gleichungen nach x und y aufgelost liefern x0 = λ undy0 = 10λ. Diese beiden Ausdrucke setzen wir in die Nebenbedingung ein 0 =10x+y−550 = λ+10λ−550. Dies nach λ aufgelost ergibt λ = 550/20 = 27, 5.Damit ergibt sich dann durch Einsetzen von λ, dass x0 = λ = 27, 5 und y0 =10λ = 275. Also hat die Funktion f (moglicherweise) einen Maximumpunktin (27, 5; 275), was bedeutet, dass Anna 27 Kinokarten kaufen durfte, um ihreNutzenfunktion zu maximieren.
Der Satz 16.3 gibt notwendige Bedingungen fur die Bestimmung von Extrempunktenunter Nebenbedingungen an. Als nachstes wenden wir uns der Frage zu, wie wir unsuberzeugen konnen, dass der ermittelte stationare Punkt fur L tatsachlich ein lokalerExtremumpunkt fur f ist. Dabei erwarten wir aus der Beschaftigung mit Funktionenvon 2 Variablen, dass wir hinreichende Bedingungen aufschreiben konnen, die wieder(wie in 13.5) etwas mit den Vorzeichen der zweiten partiellen Ableitungen zu tunhaben. Wir erinnern an die Funktionen einer Variablen, dort wurden hinreichendeBedingungen fur einen lokalen Maximumpunkt hergeleitet, die f ′′(x0) ≤ 0 abpruften.Wir werden zunachst eine – hier abgewandelte Bedingung – an das Vorzeichen derzweiten Ableitung von f nach x angeben, die wir als erstes mit der Kettenregelberechnen.
Hilfssatz 16.5. Wenn wir in Satz 16.3, 4. statt nach x und y im ersten Schrittnach y und λ auflosen, erhalten wir am Ende einen Ausdruck fur y, der noch von xabhangt. Dann konnen wir schreiben y = h(x) . Wenn wir diesen Ausdruck fur y indie Nebenbedingung g(x, y) = c einsetzen, so lautet sie G(x) = g(x, h(x)) = c. Leitenwir nun die Gleichung fur die Nebenbedingung G(x) = g(x, h(x)) = c auf beidenSeiten nach x ab, so folgt aus der Kettenregel in Satz 14.6 und weil (x)′ = 1, dass
G′(x) =dg(x, h(x))
dx=
∂g(x, y)
∂x· 1 +
∂g(x, y)
∂y· h′(x) = 0.

Wintersemester 2005/06 91
Wenn wir diesen Ausdruck nach h′(x) auflosen, so folgt
y′ = h′(x) = −∂g(x,y)
∂x∂g(x,y)
∂y
.
Wir konnen auch f(x, y) als nur von x abhangig aufschreiben. Indem wir y = h(x)einsetzen, erhalten wir F (x) = f(x, h(x)), und wir rechnen wiederum mit der Ket-tenregel aus, dass
F ′(x) =df(x, y)
dx=
∂f(x, y)
∂x+
∂f(x, y)
∂y· h′(x) =
∂f(x, y)
∂x− ∂f(x, y)
∂y·
∂g(x,y)∂x
∂g(x,y)∂y
,
wobei wir im letzten Schritt fur h′(x) den berechneten Ausdruck eingesetzt haben.Um die Gleichung ubersichtlicher zu halten, schreiben wir die partiellen Ableitungenausnahmsweise mit den Variablen, nach denen abgeleitet wurde, im Index. Dannlautet die obige Gleichung umgeschrieben wie folgt
F ′(x) =df(x, y)
dx= f ′x(x, y)− f ′y(x, y) · g
′x(x, y)
g′y(x, y).
Zur Uberprufung, ob ein Maximum vorliegt, muss nun nach Satz 13.5 das Vorzeichender 2. Ableitung uberpruft werden. Dazu berechnen wir d2f/dx2 nach der Kettenre-gel 14.6 wie folgt und beachten, dass die Schreibweise f ′′xy bedeutet
”erst nach x, dann
nach y ableiten“:
F ′′(x) =d2f(x, h(x))
dx2=
d
dxF ′(x)
= f ′′xx(x, y) · 1 + f ′′xy · h′(x)
−(f ′′yx(x, y) · 1 + f ′′yy(x, y) · h′(x))g′x(x, y)
g′y(x, y)
−f ′y(x, y)(g′′xx(x, y) + g′′xyh
′(x))g′y(x, y)− (g′′yx(x, y) + g′′yyh′(x))g′x(x, y)
(g′y(x, y))2,
wobei wir in der zweiten Zeile den Ausdruck f ′x(x, y) noch einmal nach x abgeleitethaben, in der dritten Zeile den Ausdruck −f ′y(x, y) nach der Produktregel nach x
abgeleitet haben (unter Beibehaltung von g′x(x,y)g′y(x,y)
, also u′v) und in der vierten Zeile
den Bruch g′x(x,y)g′y(x,y)
nach der Quotientenregel nach x abgeleitet haben unter Beibehaltung
von f ′y(x, y) (also uv′ als zweiter Summand in der Produktregel). Nun setzen wirnoch h′(x) = −g′x(x, y)/g′y(x, y) ein und erhalten mit f ′x = λg′x und f ′y = λg′y und derTatsache, dass es bei den gemischten zweiten Ableitungen egal ist, ob wir erst nachx oder erst nach y ableiten (fxy = fyx), dass

92 A May, D. Pfeifer: Mathematik fur Okonomen
∂2f(x, h(x))
dx2=
1
(g′y(x, y))2
[(f ′′xx(x, y)− λg′′xx(x, y))(g′y(x, y))2
−2(f ′′xy(x, y)− λg′′xy(x, y))g′x(x, y)g′y(x, y)
+(f ′′yy(x, y)− λg′′yy(x, y))(g′x(x, y))2]
.
Da Quadrate immer positiv sind, ist der Faktor vor der eckigen Klammer also immer≥ 0 und wir konnen uns bei der Betrachtung des Vorzeichens auf den Ausdruck in dereckigen Klammer beschranken. Diesen werden wir im Folgenden mit ∆ bezeichnen.
Wir verwenden dieses Ergebnis der zweimaligen Differentiation und starten mit dergleichen Aufgabe wie in Satz 16.3, um hinreichende Bedingungen dafur anzugeben,dass ein stationarer Punkt tatsachlich ein lokaler Extrempunkt ist.
Satz 16.6. Lokale Extrempunkte unter NebenbedingungenGesucht ist ein Maximumpunkt (oder Minimumpunkt) von f : D → R, (x, y) 7→f(x, y) unter der Nebenbedingung g(x, y) = c.
Wir setzen
∆(x, y) =
(∂2f(x, y)
∂x2− λ
∂2g(x, y)
∂x2
)·(
∂g(x, y)
∂y
)2
−2
(∂2f(x, y)
∂y∂x− λ
∂2g(x, y)
∂y∂x
)· ∂g(x, y)
∂x· ∂g(x, y)
∂y
+
(∂2f(x, y)
∂y2− λ
∂2g(x, y)
∂y2
)·(
∂g(x, y)
∂x
)2
.
Sei (x0, y0) ein stationarer Punkt fur L, der die beiden Gleichungen (1) und (2) ausSatz 16.3, 4. erfullt. Es gilt also
∂f(x0, y0)
∂x− λ · ∂g(x0, y0)
∂x= 0
∂f(x0, y0)
∂y− λ · ∂g(x0, y0)
∂y= 0 ,
oder anders geschrieben
∂f(x0, y0)
∂x= λ · ∂g(x0, y0)
∂x∂f(x0, y0)
∂y= λ · ∂g(x0, y0)
∂y.
Dann gilt

Wintersemester 2005/06 93
1. Wenn ∆(x0, y0) < 0, dann lost (x0, y0) das lokale Maximierungsproblem. Derstationare Punkt (x0, y0) liefert also einen lokalen Maximumpunkt.
2. Wenn ∆(x0, y0) > 0, dann lost (x0, y0) das lokale Minimierungsproblem. Derstationare Punkt (x0, y0) liefert also einen lokalen Minimumpunkt.
Wir konnen nun zu unserem Beispiel aus 16.4 zuruckkehren und bestimmen, ob derstationare Punkt (27, 5; 275) tatsachlich einen lokalen Maximumpunkt liefert.
Beispiel 16.7. Wir bilden die zweiten partiellen Ableitungen von L. Dazu stellen wirmit den Bezeichnungen von eben fest, dass f ′′xx = 0 = f ′′yy und f ′′xy = 1. Wir leitennoch die Nebenbedingung g(x, y) = 10x + y − 550 ab und erhalten g′x = 10, g′y = 1und fur die zweiten Ableitungen g′′xx = g′′xy = g′′yy = 0.
Damit berechnen wir ∆(x, y) = (−2) · 1 · 10 · 1 = −20 < 0 und bestatigen so, dass(27, 5; 275) in der Tat ein lokaler Maximumpunkt fur die Nutzenfunktion u(x, y) = xyunter der Nebenbedingung 10x + y = 550 ist.
Falls die Bedingungen aus Satz 88 fur L(x, y) erfullt sind, so erhalten wir in diesemFall sogar einen globalen Maximumpunkt (oder Minimumpunkt), weil wir dann sofortfolgern konnen, dass die Lagrange-Funktion konkav (bzw. konvex) ist.
Satz 16.8. Konkave/konvexe Lagrange-FunktionGesucht ist ein Maximumpunkt (oder Minimumpunkt) von f : D → R, (x, y) 7→f(x, y) unter der Nebenbedingung g(x, y) = c. Es sei (x0, y0) ein stationarer Punktfur die Lagrange-Funktion L(x, y).
Wir betrachten fur L(x, y) die 3 Ausdrucke aus Satz 88 in Bezug auf ihre Vorzeichenfur alle Punkte (x, y) in einem kleinen Rechteck R um (x0, y0). Zur Verkurzung derSchreibweise nummerieren wir die Ausdrucke mit A1, A2, A3 durch:
(A1)∂2L(x, y)
∂x2
(A2)∂2L(x, y)
∂y2
(A3)∂2L(x, y)
∂x2· ∂
2L(x, y)
∂y2−(
∂2L(x, y)
∂y∂x
)2
.
Dann gilt:
1. Falls die Lagrange-Funktion konvex ist (Das ist sie, falls (A1) ≥ 0, (A2) ≥ 0und (A3) ≥ 0 auf dem ganzen Rechteck R gilt.), so ist (x0, y0) ein (globaler)Minimumpunkt fur f(x, y) unter der Nebenbedingung g(x, y) = c.
2. Falls die Lagrange-Funktion konkav ist (Das ist sie, falls (A1) ≤ 0, (A2) ≤ 0und (A3) ≥ 0 auf dem ganzen Rechteck R gilt.), so ist (x0, y0) ein (globaler)Maximumpunkt fur f(x, y) unter der Nebenbedingung g(x, y) = c.

94 A May, D. Pfeifer: Mathematik fur Okonomen
17 Integration fur Funktionen einer Variablen
Wir werden im Folgenden wieder mit Funktionen arbeiten, die nur von einer Variableabhangen. Wahrend uns in den vergangenen Abschnitten die Frage beschaftigt hat,wie wir die Ableitung zu einer gegebenen Funktion bestimmen, interessiert uns hierdie umgekehrte Frage, wie namlich eine Funktion aussieht, zu der wir die Ableitungkennen. Dies fuhrt uns zur Definition der Stammfunktion.
Definition 17.1. Sei f : Df → R eine Funktion, die von einer Variablen abhangt,also f : x 7→ f(x). Dann ist F eine Stammfunktion zu f , falls F ′(x) = f(x) fur allex ∈ DF .
Wir uberlegen uns sofort, dass es nicht nur eine Stammfunktion zu f gibt, sonderneine ganze Klasse von Funktionen, die sich nur um eine Konstante unterscheiden.Ist namlich F (x) mit F ′(x) = f(x) eine Stammfunktion zu f , so gilt nach unserenRegeln fur Ableitungen fur F1(x) = F (x) + c mit c ∈ R, dass F ′
1(x) = F ′(x) = f(x),weil eine additive Konstante (c) zu 0 abgeleitet wird. Des Weiteren kann man sichfragen, ob jede beliebige Funktion denn uberhaupt eine Stammfunktion besitzt. Dajede stetige Funktion eine Stammfunktion hat und wir im Rahmen dieser Vorlesung(fast) nur stetige Funktionen betrachtet haben, konnen wir davon ausgehen, dassalle Funktionen, die uns hier begegnen, Stammfunktionen besitzen.
Bei der Frage, wie man im konkreten Beispiel zu einer gegebenen Funktion f eineStammfunktion F bestimmt, benotigen wir das Integral als Hilfsmittel.
17.1 Unbestimmte Integrale
Definition 17.2. Sei f : Df → R, f : x 7→ f(x) eine Funktion. Dann bezeichnet dasunbestimmte Integral die Klasse der Stammfunktionen von f , d.h.∫
f(x)dx = F (x) + c, wobei F ′(x) = f(x) .
Wir bezeichnen die Funktion f als Integranden und c ∈ R als Integrationskonstante.Falls mehrere Variable (oder auch Konstanten) auftreten, so kann man an
”dx“ ab-
lesen, dass x die Variable ist, nach der integriert werden soll (oder an dy, dass nachy integriert wird etc.). Wir bezeichnen x auch als Integrationsvariable.
Wir bemerken, dass wir die eingangs als Motivation benutzte Aussage, dass Integrie-ren die entgegengesetzte Operation zum Differenzieren ist, nun auch mathematischkorrekt und pragnant formulieren konnen.
Bemerkung 17.3. Die Ableitung eines unbestimmten Integrals ist gleich dem Inte-granden (
”erst integrieren, dann ableiten“),
d
dx
∫f(x)dx = f(x) .

Wintersemester 2005/06 95
Außerdem gilt, dass man die ursprungliche Funktion wieder bekommt, wenn man siezunachst differenziert und uber das Ergebnis dann integriert,∫
F ′(x)dx = F (x) + c .
Wie beim Ableiten bleibt auch beim Integrieren eine multiplikative Konstante erhal-ten, und man integriert eine Summe, indem man die einzelnen Summanden integriert.
Satz 17.4. IntegrationsregelnEs gilt: ∫
αf(x)dx = α
∫f(x)dx fur alle Konstanten α ∈ R,∫
[f(x) + g(x)]dx =
∫f(x)dx +
∫g(x)dx .
Wir merken uns die folgenden Rechenregeln, von deren Richtigkeit man sich sofortuberzeugt, indem man die rechte Seite ableitet und dann den Integranden herausbe-kommt.
Satz 17.5. Rechenregeln fur das unbestimmte Integral I: PotenzfunktionSei a ∈ R \ {−1}. Dann gilt: ∫
xadx =1
a + 1xa+1 + c .
Fur das Integral uber 1/x erinnern wir uns daran, dass die Ableitung des Logarithmusgerade 1/x ist und konnen sofort folgern:∫
1
xdx = ln |x|+ c .
Satz 17.6. Rechenregeln II: ExponentialfunktionWir wissen, dass die Ableitung der e-Funktion wieder dieselbe Funktion ergibt. Alsoist ∫
exdx = ex + c .
Falls eine multiplikative Konstante im Exponenten steht, ergibt sich nach der Ket-tenregel (auf die rechte Seite angewandt):∫
eaxdx =1
aeax + c, falls a 6= 0 .
Bei allgemeinen Wachstums- oder Abschreibungsfunktionen haben wir es gelegentlichauch mit Exponentialfunktionen zu einer allgemeinen Basis b zu tun. Falls b > 0,so konnen wir bx = e(ln b)x schreiben. Damit erhalten wir als Spezialfall der ebenaufgeschriebenen Regel (wieder mit der Kettenregel auf der rechten Seite):∫
bxdx =1
ln bbx + c, falls a > 0 und a 6= 0 .

96 A May, D. Pfeifer: Mathematik fur Okonomen
17.2 Flachenberechnung mit dem bestimmten Integral
Wir beschaftigen uns hier mit der Frage, wie man die Flache unter einer stetigen (undzunachst als nicht-negativ angenommenen) Funktion uber einem gegebenen Intervall[A, B] berechnen kann. Dies benotigt man z.B. in der Statistik, wenn man berechnenmochte, wieviel Prozent einer Grundgesamtheit unterhalb einer bestimmten Schwelle(z.B. Note) liegen.
Satz 17.7. Flache unter der KurveSei f : Df → R, f : x 7→ f(x) eine Funktion, F die Stammfunktion zu f mit c = 0.Dann berechnet man den Flacheninhalt A der Flache unter dem Funktionsgraphenvon f uber dem Intervall [A, B] ⊆ Df mit Hilfe des bestimmten Integrals
A =
∫ B
A
f(x)dx = F (x)
∣∣∣∣BA
= F (B)− F (A) .
Wir nennen A die untere Integrationsgrenze und B die obere Integrationsgrenze.
Das bestimmte Integral erhalt man also, indem man die Integrationsgrenzen (In-tervallgrenzen) in das unbestimmte Integral einsetzt. Statt der Stammfunktion mitc = 0 hatten wir auch jede andere Stammfunktion nehmen konnen, da bei der Diffe-renzbildung F (B) − F (A) die additive Konstante c ohnehin weggefallen ware. Wiebeim unbestimmten Integral erhalten wir sofort Regeln, nach denen wir Vielfacheund Summen von Funktionen integrieren konnen.
Satz 17.8. IntegrationsregelnSei f : Df → R, f : x 7→ f(x) eine Funktion, die uber [A, B] ⊆ Df integriert werdensoll. Es gilt: ∫ B
A
αf(x)dx = α
∫ B
A
f(x)dx fur alle Konstanten α ∈ R ,∫ B
A
[f(x) + g(x)]dx =
∫ B
A
f(x)dx +
∫ B
A
g(x)dx ,∫ B
A
[αf(x) + βg(x)]dx = α
∫ B
A
f(x)dx + β
∫ B
A
g(x)dx .
Falls das Intervall, uber das wir integrieren, die Lange Null hat, so hat die Flacheunter dem Funktionsgraphen von f also keine Breitenausdehnung, d.h. der Flachen-inhalt ist Null, unabhangig von der gewahlten Funktion f :∫ A
A
f(x)dx = 0 .
Falls die untere Integrationsgrenze großer als die obere sein sollte, so kann man durchMultiplikation mit −1 die Integrationsgrenzen wieder vertauschen:∫ A
B
f(x)dx = −∫ B
A
f(x)dx .

Wintersemester 2005/06 97
Diese Vertauschung wendet man haufig an, wenn B > A.
Aufpassen mussen wir bei der Flachenberechnung, falls der Funktionsgraph nichtoberhalb, sondern unterhalb der x-Achse verlauft. Da der Flacheninhalt A einerFlache immer positiv sein muss, konnen wir nicht einfach die Funktion integrieren,sondern mussen den Funktionsgraphen zunachst an der x-Achse spiegeln, so dassder Graph oberhalb der x-Achse verlauft. Der Flacheninhalt zwischen Graph undx-Achse verandert sich dadurch nicht in der Große.
Bemerkung 17.9. Flacheninhalt unterhalb der x-AchseSei f : Df → R, f : x 7→ f(x) eine Funktion mit f(x) ≤ 0 fur alle x ∈ [A, B]. Danngilt −f(x) ≥ 0 fur alle x ∈ [A, B] und der Flacheninhalt A zwischen dem Graphenvon f und der x-Achse ist gleich dem Flacheninhalt der Flache unterhalb des Graphenvon −f und oberhalb der x-Achse, also
A = −∫ B
A
f(x)dx = −(F (B)− F (A)) = F (A)− F (B), .
Falls eine Funktion f Nullstellen im Integrationsintervall besitzt, muss man denFlacheninhalt der Flache zwischen Funktionsgraph und x-Achse ausrechnen, indemman das Integrationsintervall in kleinere Teilintervalle unterteilt, je nachdem ob dieFunktion dort nichtnegativ oder negativ ist. Das nachfolgende Beispiel illustriert,was gemeint ist:
Beispiel 17.10. Bestimmen Sie den Flacheninhalt A der Flache zwischen dem Funk-tionsgraphen von f mit f(x) = ex/3 − 3 uber dem Intervall [0, 4].
Erste Uberlegung: Gibt es Nullstellen von f in [0, 4]? Dazu losen wir ex/3 − 3 =0 durch Logarithmieren nach x auf ln 3 = ln(ex/3) = x
3, also ist x = 3 ln 3 die
einzige reelle Nullstelle von f(x), und da 3 ln 3 < 4 liegt diese Nullstelle auch imIntegrationsbereich.
Zweite Uberlegung: Wo ist die Funktion positiv bzw. negativ? Hier hilft eine Mono-toniebetrachtung. Wir wissen bereits, dass die e-Funktion streng monoton wachsendist. Daran andert es nichts, dass im Exponenten x/3 steht, denn nach der Kettenre-gel ist (ex/3)′ = 1
3· ex/3 > 0 fur alle reellen x. Auch die Addition einer Konstanten
(hier: −3) andert die Monotonie nicht. Also ist unsere Funktion f streng monotonwachsend. Das bedeutet, dass sie links von der Nullstelle x = 3 ln 3 negativ sein mussund rechts von der Nullstelle positiv. Beim Integrieren mussen wir also die beidenTeilintervalle [0, 3 ln 3] und [3 ln 3, 4] gesondert (und das heißt mit unterschiedlichemVorzeichen) behandeln.
Dritter Schritt: Berechnen des gefragten Flacheninhalts. Wir schreiben die Betrags-striche |f(x)| = |f(x)− 0| fur den Abstand zwischen Funktionswert und der x-Achse(y = 0), solange wir das Vorzeichen von f(x) nicht berucksichtigen.
A =∫ 4
0|ex/3−3|dx = −
∫ 3 ln 3
0(ex/3−3)dx+
∫ 4
3 ln 3(ex/3−3)dx, wobei wir das erste Inte-
gral in der Summe mit einem Minuszeichen versehen haben, damit der Flacheninhalt

98 A May, D. Pfeifer: Mathematik fur Okonomen
zwischen Graph und x-Achse positiv wird, da wir bereits wissen, dass f(x) ≤ 0 furx ∈ [0, 3 ln 3].
Nun konnen wir mit unseren Rechenregeln ausrechnen A = −[3ex/3 − 3x]∣∣3 ln 30 +
[3ex/3 − 3x] |43 ln 3 = −(3eln 3 − 3 · 3 ln 3 − 3e0) + (3e4/3 − 12 − (3eln 3 − 3 · 3 ln 3)) =3e4/3 − 9 + 3− 12− 9 + 2 · 9 ln 3 = 3e4/3 + 18 ln 3− 27 ≈ 4, 16.
17.3 Ableiten nach den Integrationsgrenzen
Wir haben bisher die Stammfunktion nach der Integrationsvariable abgeleitet, umzu bestatigen, dass wir den Integranden erhalten. Haufig trifft man aber in realenAnwendungen auf das Problem, nach einer der Integrationsgrenzen differenzieren zumussen. Dabei hilft der folgende Satz, in dem es nutzlich ist, statt des Strichs ′, denwir sonst fur die Ableitung verwenden, auf die Schreibweise d
dtumzusteigen, damit
klar wird, nach welcher Variable (nicht der Integrationsvariable!) wir ableiten wollen.
Satz 17.11. Ableiten nach der IntegrationsgrenzeIst F eine Stammfunktion zu f , so ist die Ableitung des bestimmten Integrals nachder oberen Grenze gleich dem Integranden, berechnet an dieser Grenze,
d
dt
∫ t
a
f(x)dx =d
dt(F (t)− F (a)) = F ′(t) = f(t) .
Das Gleiche gilt sinngemaß auch fur die untere Integrationsgrenze, allerdings dannmit einem Minuszeichen:
d
dt
∫ b
t
f(x)dx =d
dt(F (b)− F (t)) = −F ′(t) = −f(t) .
Falls in den Integrationsgrenzen einmal Funktionen von t stehen sollten, so erhaltenwir mit der Kettenregel fur die Differentiation, dass
d
dt
∫ b(t)
a(t)
f(x)dx =d
dt(F (b(t))− F (a(t)))
= F ′(b(t))b′(t)− F ′(a(t))a′(t)
= f(b(t))b′(t)− f(a(t))a′(t) .
17.4 Partielle Integration
Wir wollen die Klasse der Integrale, die wir ausrechnen konnen, erweitern. Da Inte-grieren die umgekehrte Operation zum Ableiten ist, liegt es nahe, unsere Differentia-tionsregeln zu verwenden, um neue Integrationsregeln zu erhalten. Wir starten mitder Produktregel.

Wintersemester 2005/06 99
Satz 17.12. Integrationsregel: ProdukteEs gilt: ∫
u(x)v′(x) dx = u(x)v(x)−∫
u′(x)v(x) dx .
Die gleiche Regel gilt auch fur bestimmte Integrale.∫ b
a
u(x)v′(x) dx = u(x)v(x)
∣∣∣∣ba
−∫ b
a
u′(x)v(x) dx .
Beispiele 17.13. 1.∫
xex dx ‖ Faktoren: u(x) = x, u′(x) = 1v′(x) = ex, v(x) = ex
= x · ex −∫
ex · 1 dx = x · ex − ex + c.
2. Wir berechnen zunachst ein”einfaches“ unbestimmtes Integral, dessen Ergeb-
nis wir im Folgenden verwenden wollen.∫ln x dx = x ln x− x + c .
Wir bestatigen dieses Resultat, indem wir die rechte Seite nach x ableiten underhalten mit der Produktregel fur die Differentiation
d
dx(x ln x− x + c) = ln x + x · 1
x− 1 + 0 = ln x ,
so dass in der Tat auf der rechten Seite eine Stammfunktion von ln x stand.
3.∫
ln xx
dx ‖ Faktoren: u(x) = ln x, u′(x) = 1/xv′(x) = 1/x, v(x) = ln x
= ln x ln x−∫
1x
ln x dx. Auf den ersten Blick scheinen wir nichts gewonnen zuhaben. Allerdings steht nun auf der rechten Seite noch einmal das ursrpunglicheIntegral mit einem Minuszeichen, so dass wir es (mit +) auf die linke Seitebringen konnen, um dann durch 2 zu dividieren. Damit erhalten wir∫
ln x
xdx =
1
2(ln x)2 + c .
17.5 Integration durch Substitution
Die zweite Klasse von komplizierteren Integralen kann man gut berechnen, wenn mandie Kettenregel fur Ableitungen von Funktionen verwendet. Diese hilft uns, zu einerneuen Integrationsvariable zu wechseln, so dass der ursprungliche Funktionsausdrucksich vereinfacht und eine Stammfunktion besitzt, die wir angeben konnen.

100 A May, D. Pfeifer: Mathematik fur Okonomen
Satz 17.14. Integrationsregel: SubstitutionEs gilt:∫
f(g(x))g′(x) dx =
∫f(u)du ‖ Substitution u = g(x), du = g′(x)dx
Dabei haben wir du erhalten, indem wir g nach x abgeleitet haben (aus der Ket-tenregel) und die – mathematisch nicht ganz korrekte, aber hier sehr instruktive –Umformung
du
dx= g′(x) ⇔ du = g′(x)dx
verwendet haben.
Die Aufgabe besteht also darin, eine innere Funktion so geschickt zu wahlen, dass indem komplizierteren Ausdruck auf der linken Seite die Ableitung der inneren Funk-tion als Faktor mit im Integranden steht. Falls ein bestimmtes Integral zu berechnenist, so mussen Sie zunachst u = g(x) wieder in die Stammfunktion einsetzen, be-vor Sie die Stammfunktion an den Integralgrenzen auswerten durfen. Die folgendeSchreibweise soll sie daran erinnern, dass Sie nicht x fur u einsetzen durfen.
∫ b
a
f(g(x))g′(x) dx =
∫ x=b
x=a
f(u)du = F (u)
∣∣∣∣x=b
x=a
= F (g(x))
∣∣∣∣∣x=b
x=a
= F (g(b))−F (g(a)) .
Beispiele 17.15. 1.∫
(x2+10)502x dx, ‖ Substitution u = g(x) = x2 + 10 ,du = g′(x)dx = 2x dx
=∫
u50du = 151
u51 + c = 151
(x2 + 10)51 + c .
2.
e∫1
1 + ln x
xdx, ‖ Substitution u = 1 + ln x, du = (1/x)dx
=∫ x=e
x=1u du = 1
2u2∣∣x=e
x=1= 1
2(1 + ln x)2
∣∣e1
= 12(4− 1) = 3
2.
Ein nutzliches Resultat liefert der folgende Hilfssatz.
Hilfssatz 17.16. Integration: Ableitung durch FunktionFur differenzierbare Funktionen f : R → {y ∈ R : y > 0} mit positiven Funktions-werten gilt:∫
f ′(x)
f(x)= (ln f(x)) + c.
Wir berechnen dazu∫f ′(x)
f(x), ‖ Substitution u = f(x), du = f ′(x) dx
=∫
1/u du = ln u + c = (ln |f(x)|) + c, und erhalten in der Tat die behaupteteStammfunktion.

Wintersemester 2005/06 101
17.6 Integration uber unendliche Intervalle
In der Statistik interessieren uns haufig die Flacheninhalte unter Funktionsgraphen,die zu Dichtefunktionen gehoren. Wir konnen sie uns als stetige Varianten von Hi-stogrammen vorstellen. Wahrend ein Histogramm sich aber immer (bei naturgemaßendlicher Stichprobengroße, die ausgezahlt wird) uber ein Intervall endlicher Langeerstreckt, wird die Dichtefunktion zu einer stetigen Verteilung in der Regel einen De-finitionsbereich aufweisen, der jedenfalls auf einer Seite ∞ als Randpunkt hat. Wirdefinieren zunachst, um die Arbeit in der Statistik vorzubereiten:
Definition 17.17. Sei f : R → {y ∈ R : y ≥ 0} eine Funktion mit nichtnegativenFunktionswerten. Die Funktion f ist eine Wahrscheinlichkeitsdichte oder Dichtefunk-tion, wenn die Wahrscheinlichkeit, dass ein
”Ereignis“ mit dem Merkmal x (also ein
Einkommen in einer Volkswirtschaft oder eine Schadensumme in der Versicherung)zwischen reellen Zahlen a und b liegt, unter Zuhilfenahme von f wie folgt beschriebenwerden kann
Wahrscheinlichkeit [a ≤ X ≤ b] =
∫ b
a
f(x)dx .
Dabei steht das X fur eine Zufallsvariable, die als Funktionswerte alle moglichenMerkmale (Einkommen, Schadensummen) aufweist, die uberhaupt moglich sind.
Die Funktion f beschreibt dann, wie die Gesamtheit aller Merkmale verteilt ist.Wenn man nach der Wahrscheinlichkeit uberhaupt aller Merkmale, die vorkommenkonnen, insgesamt fragt, so muss die Wahrscheinlichkeit insgesamt 1 sein. Damitkonnen wir eine Dichtefunktion durch den folgenden Ausdruck charakterisieren
Wahrscheinlichkeit[−∞ < X <∞] =
∫ ∞
−∞f(x)dx = 1 .
Wir wollen versuchen, der Integration uber ein Intervall mit unendlichen Integrati-onsgrenzen eine Bedeutung zu geben. Dabei hilft uns der Begriff des Grenzwertesaus 10.2.
Definition 17.18. Sei f : R → R eine stetige Funktion. Dann ist auf alle Falle∫ b
af(x)dx = F (b) − F (a) fur alle b ≥ a definiert, wenn F die Stammfunktion zu f
bezeichnet. Falls der Grenzwert limb→∞ F (b) existiert (Solche Grenzwerte haben wirin Abschnitt 10.2 ausgerechnet.), so sagen wir, dass f integrierbar uber [a,∞) ist.Wir definieren daher∫ ∞
a
f(x)dx = limb→∞
∫ b
a
f(x)dx = limb→∞
F (b)− F (a) .
Falls der obige Grenzwert existiert, sagen wir das uneigentliche Integral∫∞
af(x)dx
konvergiert. Fur Funktionen f mit nichtnegativen Funktionswerten f(x) ≥ 0 fur x ≥

102 A May, D. Pfeifer: Mathematik fur Okonomen
a interpetieren wir das uneigentliche Integral dann in Analogie zu den bestimmtenIntegralen aus Abschnitt 17.2 als Flache unter dem Graphen von f uber dem Intervall[a,∞).
Falls die untere Integrationsgrenze minus unendlich ist, definieren wir in naheliegen-der Weise ∫ b
−∞f(x)dx = lim
a→−∞
∫ b
a
f(x)dx = F (b)− lima→−∞
F (a) .
Sind beide Integrationsgrenzen unendlich, so ist das uneigentliche Integral einer ste-tigen Funktion uber (−∞,∞) definiert durch∫ ∞
−∞f(x)dx =
∫ 0
−∞f(x)dx +
∫ ∞
0
f(x)dx .
Die Uberprufung auf Konvergenz erfolgt nun, indem man sich an die bereits ein-gefuhrten Rechenregeln fur den Umgang mit dem Limes erinnert.
Beispiele 17.19. 1. Wir behaupten, dass fur a > 1 das folgende uneigentlicheIntegral konvergiert: ∫ ∞
1
1
xadx .
Wir verwenden die Grenzwertbetrachtung aus 17.18 und berechnen zunachst∫ b
1
1
xadx =
∫ b
1
x−adx =1
1− ax−a+1
∣∣∣∣b1
=1
1− a(b1−a − 1) .
Ist nun a > 1, so gilt limb→∞ b1−a = limb→∞ 1/ba−1 = 0. Also konvergiert dasuneigentliche Integral und hat den Wert 1/(1− a).
2. Wir berechnen zunachst das unbestimmte Integral∫
xe−kx2dx fur k 6= 0 mit
der Susbstitution u = −kx2, du = −2kx dx.∫xe−kx2
dx = − 1
2k
∫(−2kx)e−kx2
dx = − 1
2k
∫eudu = − 1
2keu+c = − 1
2ke−kx2
.
Fur das bestimmte Integral von 0 bis zu einer oberen Grenze b > 0 folgt dann
durch Einsetzen der Integrationsgrenzen:
∫ b
0
xe−kx2
dx =1
2k(1− e−kb2). Damit
konvergiert das uneigentliche Integral∫ ∞
0
xe−kx2
dx = limb→∞
∫ b
0
xe−kx2
dx =1
2k.
Beispiele 17.20. Dichtefunktionen

Wintersemester 2005/06 103
1. Gegeben sei die Funktion f mit f(x) =
{0, fur x < 11x2 fur x ≥ 1 .
Dann ist f eine
Dichtefunktion, denn es gilt∫ ∞
−∞f(x) dx = lim
b→∞
∫ b
1
1
x2dx = lim
b→∞(−1)x−1
∣∣∣∣b1
= − limb→∞
1
b+ 1 = 1 .
2. Gegeben sei eine Funktion g mit r < 1 und g(x) =
{0, fur x < 1kx−r fur x ≥ 1 .
Fur welchen Wert von k ist g eine Dichtefunktion? Wir berechnen dazu:∫ ∞
−∞g(x) dx = lim
b→∞
∫ b
1
kx−r dx = limb→∞
k
−r + 1x−r+1
∣∣∣∣b1
= limb→∞
k
(1− r)b1−r− k
−r + 1=
k
r − 1.
Also ist g eine Dichtefunktion, wenn k/(r − 1) = 1, d.h. k = r − 1.
3. Um die Lebensdauer von Geraten mit Abnutzungserscheinungen zu beschrei-ben, benutzt man die sogenannte Weibull-Verteilung .
Sie hat die Dichtefunktion w mit w(x) =
{0, fur x < 0
αβxβ−1e−αxβfur x ≥ 0 .
Wir rechnen nach, dass w mit der obigen Definition tatsachlich eine Dichte-funktion ist:∫ ∞
0
αβxβ−1e−αxβ
dx = ||Subst.: u = e−αxβ
, du = −αβxβ−1e−αxβ
dx
=
∫ ∞
0
−du = −u
∣∣∣∣∞0
= −e−αxβ∣∣∣∞0
= e0 − limb→∞
1
eb= 1 .
Die Ausfallrate des Gerates ist definiert als die Große
r(t) =w(t)∫∞
tw(x) dx
.


















