metafinanz Business & IT Consulting · Kopieren Sie die bereitgestellten Übungsfiles nach...
95
© metafinanz Business & IT Consulting Einführung in Apache Spark 25.09.2015
Transcript of metafinanz Business & IT Consulting · Kopieren Sie die bereitgestellten Übungsfiles nach...

©
metafinanz Business & IT Consulting
Einführung in
Apache Spark
25.09.2015

©
Daten & Fakten
25 Jahre Erfahrung, Qualität & Serviceorientierung
garantieren zufriedene Kunden & konstantes Wachstum
2
220 Umsatz in Mio. EUR
25 Jahre am Markt
Referenzen (Auszug):
Allianz Group | Aioi Nissay Dowa Life Insurance Europe |
ARD.ZDF medienakademie | AXA Versicherungen |
BayWoBau | Bürklin | Commerzbank | COR & FJA | ESPRIT
Europe | Euler Hermes | Frankfurter Fondsbank | Generali |
HSH Nordbank AG | IKEA | KVB| O2 Germany | Ratioform
Verpackungen | R+V Versicherung | Sächsische Aufbaubank
| Swiss Life | Versicherungskammer Bayern u.a.
1400 Berater
1990 Gründung in St.
Georgen/Schwarzwald
1995 Management-Buy-In durch die
Allianz Group – Gründung des
Münchner Standorts
2000 München wird Headquarter
2015 metafinanz feiert
25-jähriges Jubiläum
„Je komplexer die
Prozesse werden, desto
flexibler wird metafinanz.
Die gelieferte Qualität war
hervorragend."
(Kundenstimme im Rahmen der
Zufriedenheitsumfrage 2014)

© 4
Wir fokussieren mit unseren Services die Herausforderungen
des Marktes und verbinden Mensch und IT.
Über metafinanz
metafinanz steht für branchenübergreifendes, ganzheitliches Business & IT
Consulting.
Gemeinsam mit unseren Kunden gestalten wir ihren Weg in eine digitale Welt.
Wir transformieren Geschäftsprozesse und übersetzen strategische Ziele in
effektive IT-Lösungen.
Unsere Kunden schätzen uns seit 25 Jahren als flexiblen und
lösungsorientierten Partner.
Als unabhängiges Unternehmen der Allianz Group sind wir in komplexen Abläufen
und Veränderungsprozessen in Großkonzernen zu Hause.
Insurance
reporting
Analytics
Risk
Enterprise DWH
Themenbereiche
Ihr Kontakt: Mathias Höreth
BI Consultant
• Certified Oracle Developer
• Certified Hadoop Developer
Mail: [email protected]
Phone: +49 89 360531 5416
BI & Risk
• Standard and adhoc
• Reporting
• Dashboarding
• BI office integration
• Mobile BI and in-memory
• SAS trainings for
business analysts
• Predictive models,
data mining
and statistics
• Social media analytics
• Customer intelligence
• Scorecarding
• Fraud and AML
• Data modeling and
integration and ETL
• Architecture:
DWH and data marts
• Hadoop and
Columnar DBs
• Data quality and
data masking
• Solvency II
(Standard & internal
model)
• Regulatory reporting
• Compliance
• Risk management

©
Kapitel 1 Einführung und
Organisation

©
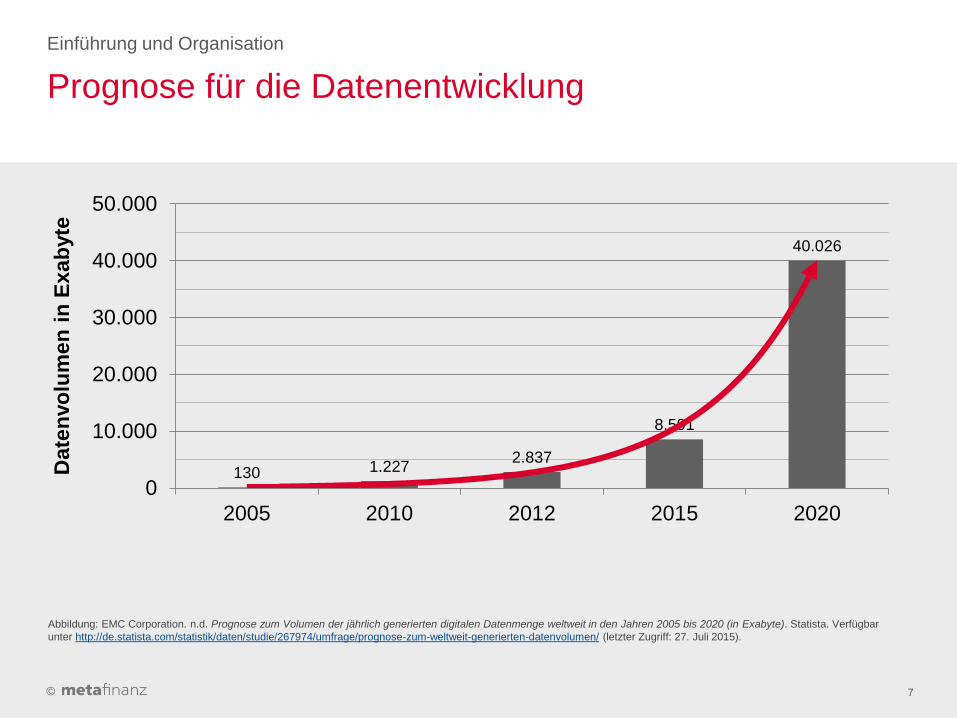
Prognose für die Datenentwicklung
IBM
Jeden Tag erzeugen wir 2,5 Trillionen Bytes an Daten.
90% der heute existierenden Daten wurde allein in den letzten
beiden Jahren erzeugt.
Quelle: http://www-01.ibm.com/software/data/bigdata/what-is-big-data.html
Gartner
Die in Unternehmen gespeicherte Datenmenge wächst innerhalb
der kommenden 5 Jahre um 800%.
80% der Steigerung entfallen auf unstrukturierte Daten. Quelle: http://www.computerwoche.de/hardware/data-center-server/2370509/index2.html
EMC Die weltweit vorhandenen Daten verdoppeln sich alle 2 Jahre
Quelle: http://www.emc.com/leadership/programs/digital-universe.htm
Einführung und Organisation
Die Analysten und großen IT-Firmen sind sich einig:
das Datenwachstum ist ungebremst.
6
©
Prognose für die Datenentwicklung
Einführung und Organisation
130 1.227 2.837
8.591
40.026
0
10.000
20.000
30.000
40.000
50.000
2005 2010 2012 2015 2020
Date
nvo
lum
en
in
Exab
yte
Abbildung: EMC Corporation. n.d. Prognose zum Volumen der jährlich generierten digitalen Datenmenge weltweit in den Jahren 2005 bis 2020 (in Exabyte). Statista. Verfügbar
unter http://de.statista.com/statistik/daten/studie/267974/umfrage/prognose-zum-weltweit-generierten-datenvolumen/ (letzter Zugriff: 27. Juli 2015).
7
©
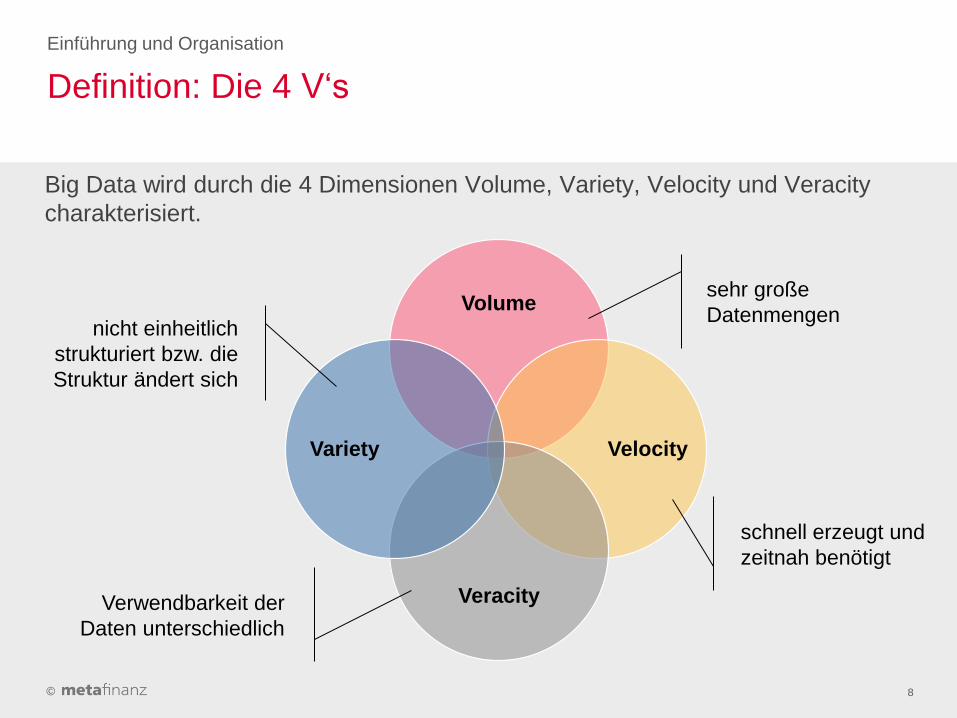
Big Data wird durch die 4 Dimensionen Volume, Variety, Velocity und Veracity
charakterisiert.
Definition: Die 4 V‘s
Einführung und Organisation
Volume
Velocity
Veracity
Variety
sehr große
Datenmengen nicht einheitlich
strukturiert bzw. die
Struktur ändert sich
schnell erzeugt und
zeitnah benötigt
Verwendbarkeit der
Daten unterschiedlich
8

©
Big Data - Anwendungsfälle
Einführung und Organisation
9
• durch Big Data - Exploration
1. Datenerweiterung
• durch die Erweiterung des DWH mit Big Data - Technologie
2. Erhöhung der Effizienz und Skalierbarkeit der IT
• durch die Auswertung von Maschinendaten
3. Betriebsoptimierung
• durch die verbesserte 360° - Sicht auf den Kunden
4. Verbesserung der Kundeninteraktion
• durch die Anwendung von Regeln
5. Betrugserkennung

©
Die Schulung soll den Teilnehmern ermöglichen, die Konzepte von Apache Spark zur Verarbeitung von BigData zu verstehen und die Möglichkeiten der Technologie einschätzen zu können.
Ziele sind:
• Apache Spark als Framework zur Lösung von BigData-Problemstellungen
kennenzulernen
• Das Spark Core-Programmiermodell zu verstehen
• Einen Einblick in die Spark Core-Programmierung zu bekommen
• Spark SQL als Alternative zur Spark Core-Programmierung für strukturierte
Daten kennenzulernen
Ziele der Schulung
Einführung und Organisation
10
©
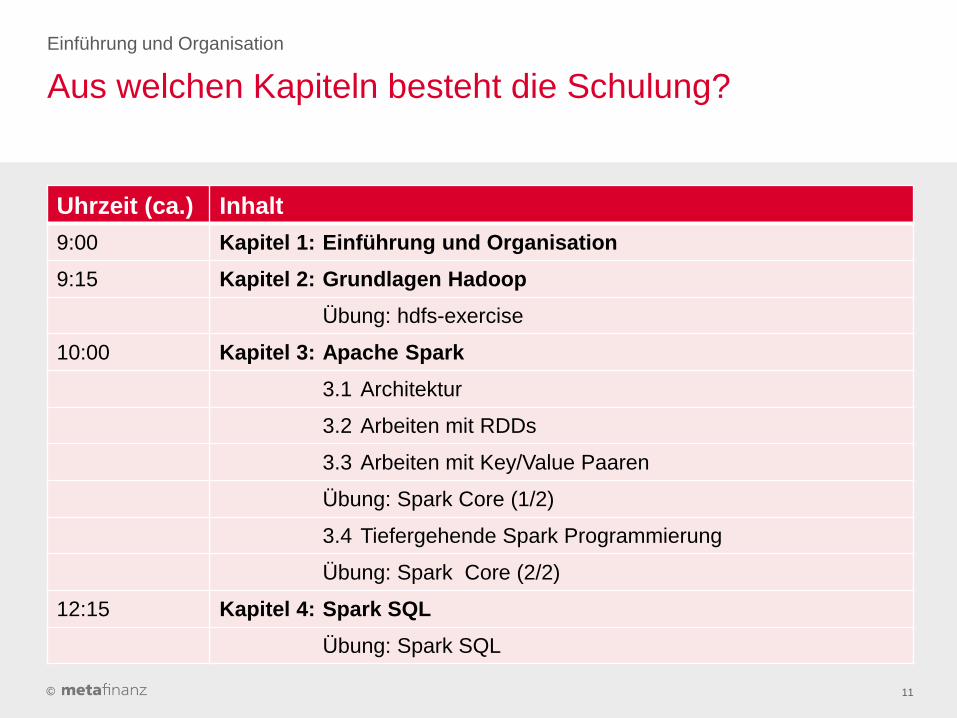
Aus welchen Kapiteln besteht die Schulung?
Uhrzeit (ca.) Inhalt
9:00 Kapitel 1: Einführung und Organisation
9:15 Kapitel 2: Grundlagen Hadoop
Übung: hdfs-exercise
10:00 Kapitel 3: Apache Spark
3.1 Architektur
3.2 Arbeiten mit RDDs
3.3 Arbeiten mit Key/Value Paaren
Übung: Spark Core (1/2)
3.4 Tiefergehende Spark Programmierung
Übung: Spark Core (2/2)
12:15 Kapitel 4: Spark SQL
Übung: Spark SQL
Einführung und Organisation
11

©
Kapitel 2 Grundlagen
Hadoop
25.09.2015
©
Hadoop
Distributed
FileSystem (HDFS)
Skalierbare
Speicherkapazität
Skalierbare Rechenkapazität
Hadoop
MapReduce
1
2
1
2
3
Hadoop Ökosystem
25.09.2
015 Se
ite
13
http://mfwiki.metafinanz.office/confluence/display/BLBIR/Hadoop+Ecosystem
HttpFS
Cascalog
FuseDFS
SequenceFiles Big Data Connectors
Big SQL
Crunch
Kafka
Oryx
ORCFiles

©
Das HDFS ist ein verteiltes Dateisystem und
bildet die Basis für die BigData-Verarbeitung
mit Hadoop.
Definition
• Zuständig für die redundante Speicherung großer
Datenmengen in einem Cluster unter Nutzung von Commodity-
Hardware
• Implementiert in Java auf Grundlage von Google‘s GFS.
• Liegt über einem nativen Dateisystem (wie ext3, ext4 oder xfs)
Hadoop Distributed File System (HDFS)
Grundlagen Hadoop
14

©
HDFS ist für die redundante Speicherung von großen Dateien ausgelegt,
die write-once-read-many Daten enthalten.
• Beste Performance bei der Speicherung von großen Dateien: Besser
weniger große Dateien als viele kleine Dateien!
• Dateien in HDFS sind nicht änderbar (write-once-read-many), d. h. es sind
keine wahlfreien Schreibzugriffe erlaubt.
• Seit Hadoop 2.0 ist es möglich, Daten an Dateien anzuhängen (append).
• HDFS ist optimiert für das sequenzielle Lesen großer Dateien.
• Dateien werden im HDFS in Blöcke aufgeteilt (Default-Blockgröße: 128MB).
• Jeder Block wird redundant im Cluster gespeichert (Default: dreifache
Speicherung).
• Unterschiedliche Blöcke der gleichen Datei werden auf unterschiedlichen
Knoten (und ggf. Racks) gespeichert.
HDFS - Eigenschaften
Grundlagen Hadoop
15
©
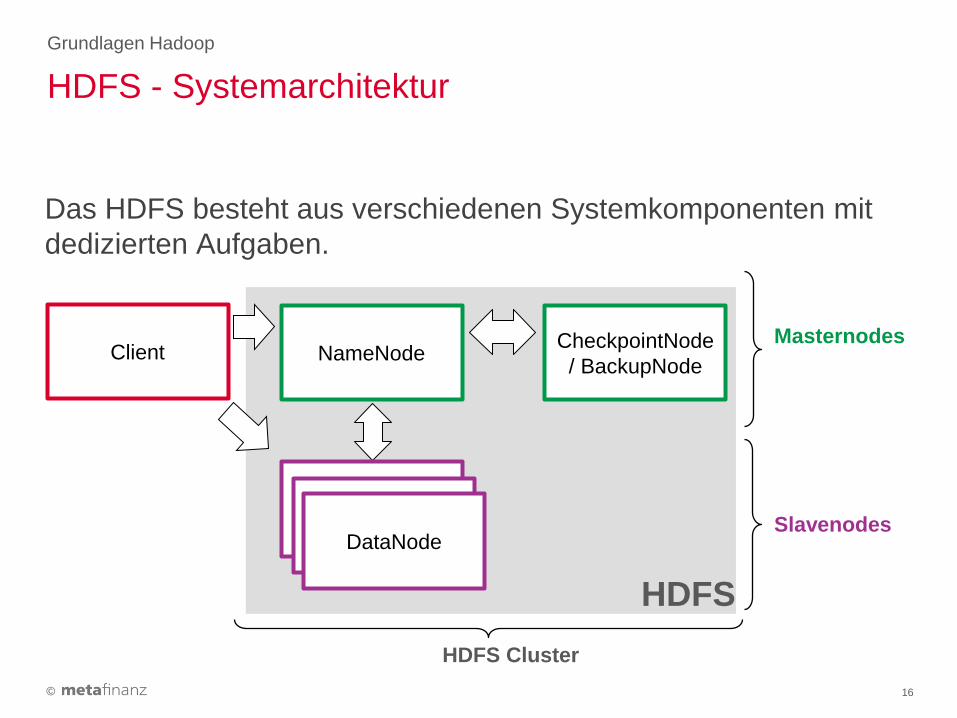
Das HDFS besteht aus verschiedenen Systemkomponenten mit
dedizierten Aufgaben.
HDFS - Systemarchitektur
Grundlagen Hadoop
16
HDFS
Client CheckpointNode
/ BackupNode
DataNode DataNode DataNode
Masternodes
Slavenodes
HDFS Cluster
NameNode

©
Alle Metainformationen über die Daten werden im Speicher der
NameNodes verwaltet.
Die NameNode hält die Metadaten (Namespaces) für das HDFS:
• Welche Datei besteht aus welchen Blöcken?
• Auf welchem Knoten liegt welcher Block?
Der NameNode Daemon muss jederzeit laufen, da sonst nicht auf die Daten im
Cluster zugegriffen werden kann.
Um schnelleren Zugriff auf diese Daten zu haben, werden alle Daten im
NameNode im Arbeitsspeicher vorgehalten.
Die NameNode persistiert ihre Daten, in zwei Dateien:
• fsimage: Stand des Namespaces beim letzten Checkpoint
• edits: Journal aller Änderungen seit dem letzten Checkpoint
HDFS - NameNodes
Grundlagen Hadoop
17

©
Die CheckpointNode unterstützt die NameNode dabei, die Metadaten zu
persistieren, damit sie bei einem Ausfall der NameNode schnell
wiederhergestellt werden können.
• Die CheckpointNode erzeugt regelmäßige Checkpoint-Stände des
Namespaces im NameNode.
• Dazu holt sie sich die aktuellen fsimage- und edits-Stände der NameNodes,
führt diese lokal zusammen und spielt den neuen Stand an die NameNode
zurück.
• Die CheckpointNode läuft in der Regel auf einem anderen Rechner als die
NameNode, da die Speicheranforderungen ähnlich groß sind wie die von der
NameNode.
HDFS - CheckpointNode
Grundlagen Hadoop
18

©
Auf den DataNodes werden die Daten in Form von Blöcken gespeichert.
• In einem typischen Hadoop-Cluster gibt es sehr viele DataNodes.
• Ein Block wird bei Verwendung der Standardkonfiguration auf drei Knoten
redundant abgelegt.
• Die DataNodes laufen typischerweise auf Commodity-Hardware.
• Um ein Rebalancing zu ermöglichen (z. B. bei Ausfall eines DataNodes),
sollte die Gesamtgröße des HDFS 80% des insgesamt vorhandenen
Speicherplatzes nicht überschreiten.
HDFS - DataNode
Grundlagen Hadoop
19
©
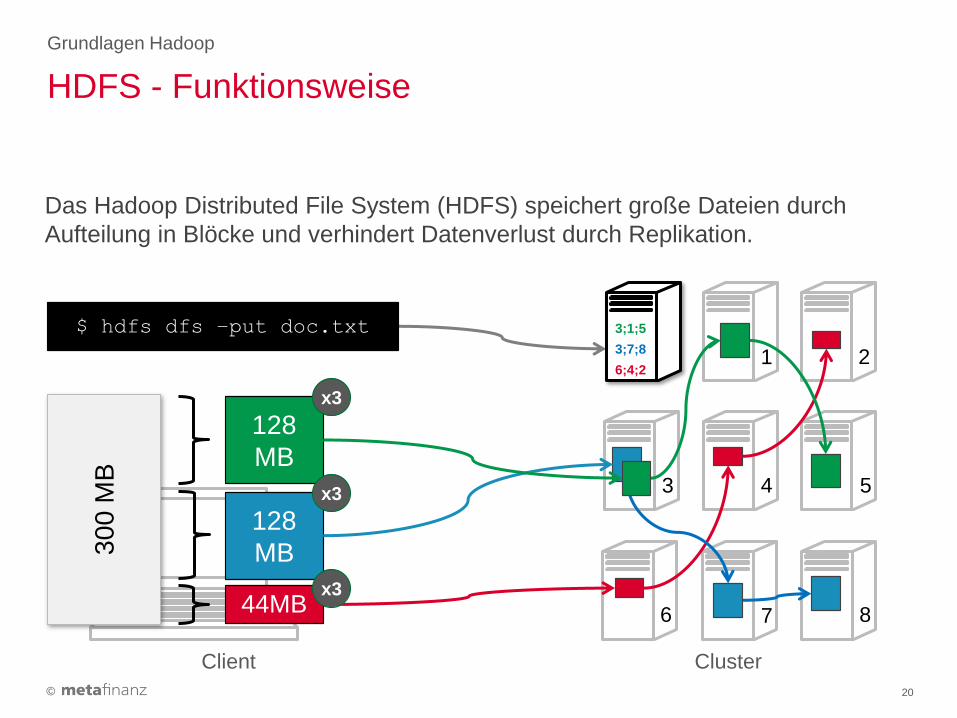
Das Hadoop Distributed File System (HDFS) speichert große Dateien durch
Aufteilung in Blöcke und verhindert Datenverlust durch Replikation.
Cluster
HDFS - Funktionsweise
Grundlagen Hadoop
20
30
0 M
B
128
MB
128
MB
44MB
$ hdfs dfs –put doc.txt
1 2
3 4 5
6 7 8
3;1;5
3;7;8
6;4;2
Client
x3
x3
x3

©
Über die Kommandozeile kann einfach und schnell auf die HDFS-Daten
zugegriffen werden.
Auf das HDFS kann über die Kommandozeile mit folgendem Befehl
zugegriffen werden:
z. B. Verzeichnislisting des HDFS-User-Home-Verzeichnisses:
z. B. Verzeichnislisting des HDFS-Root-Verzeichnisses:
HDFS - Zugriffe über die Kommandozeile
Grundlagen Hadoop
22
$ hdfs dfs <Kommando> [Optionen] [Parameter]
$ hdfs dfs -ls
$ hadoop fs –ls /

©
HDFS - Zugriff über die Kommandozeile (1/3)
Kommando Option Parameter Bedeutung
-help <Kommando> Hilfe zu einem Kommando anzeigen; ohne Angabe
eines Kommandos werden alle verfügbaren
Kommandos aufgelistet.
-ls [-d] [-h] [-R] <Pfad> Anzeige des Verzeichnisinhalts des angegebenen
Pfads.
• -d: Ordner als Dateien anzeigen
• -h: Dateigröße lesbar formatieren
• -R: rekursive Auflistung aller enthaltenen Ordner
und Dateien
-tail [-f] <Datei> Letztes 1KB der Datei anzeigen:
• -f: hinzugefügte Daten anzeigen, wenn die Datei
wächst.
Grundlagen Hadoop
23
Mit dem Help-Kommando wird die Befehlsreferenz mit allen gültigen
Befehlen und Optionen angezeigt.
$ hdfs dfs <Kommando> [Optionen] [Parameter]

©
HDFS - Zugriff über die Kommandozeile (2/3)
Kommando Optionen Parameter Bedeutung
-mkdir [-p] <path> ... Verzeichnis anlegen.
• -p: Gibt keinen Fehler aus,
wenn das Verzeichnis bereits
existiert.
-get
-copyToLocal
[-ignoreCrc] [-crc] <Quelle> … <lokales Ziel> Datei aus dem HDFS ins lokale
Dateisystem kopieren.
-put
-copyFromLocal
<lokale Quelle> … <Ziel> Lokale Datei ins HDFS kopieren.
Grundlagen Hadoop
24
Die Kommandozeile bietet auch Befehle, um Dateien vom lokalen
Dateisystem nach HDFS zu spielen (und umgekehrt).
$ hdfs dfs <Kommando> [Optionen] [Parameter]
©
HDFS - Zugriff über die Kommandozeile (3/3)
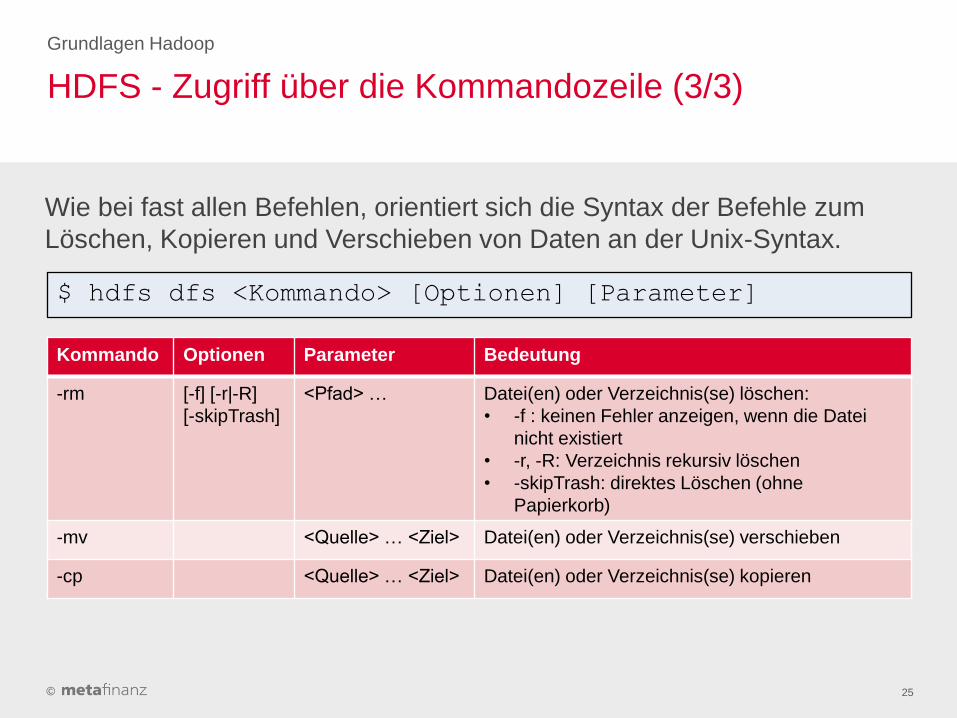
Kommando Optionen Parameter Bedeutung
-rm [-f] [-r|-R]
[-skipTrash]
<Pfad> … Datei(en) oder Verzeichnis(se) löschen:
• -f : keinen Fehler anzeigen, wenn die Datei
nicht existiert
• -r, -R: Verzeichnis rekursiv löschen
• -skipTrash: direktes Löschen (ohne
Papierkorb)
-mv <Quelle> … <Ziel> Datei(en) oder Verzeichnis(se) verschieben
-cp <Quelle> … <Ziel> Datei(en) oder Verzeichnis(se) kopieren
Grundlagen Hadoop
25
Wie bei fast allen Befehlen, orientiert sich die Syntax der Befehle zum
Löschen, Kopieren und Verschieben von Daten an der Unix-Syntax.
$ hdfs dfs <Kommando> [Optionen] [Parameter]

©
Übung hdfs-exercise
25.09.2015

©
1. Kopieren Sie die bereitgestellten Übungsfiles nach /home/cloudera/ebooks
2. Legen Sie im HDFS folgende Ordnerstruktur an (das Verzeichnis
/user/cloudera/ existiert bereits), verwenden Sie hierfür den Befehl „hadoop fs -mkdir <Pfad>“ :
/user/cloudera/ebooks/Kafka
/user/cloudera/ebooks/Schiller
/user/cloudera/ebooks/Goethe
3. Vergewissern Sie sich, dass alle Ordner nun in HDFS vorhanden sind
(HDFS-Verzeichnislisting von /user/cloudera/examples/hdfs), verwenden Sie hierfür den Befehl „hadoop fs -ls <Pfad>“ .
4. Wechseln Sie im lokalen Dateisystem in das Verzeichnis
/home/cloudera/ebooks/ (Shell-Befehl „cd <Pfad>“).
Importieren von Dateien ins HDFS (1)
Übung: hdfs-exercise
27

©
4. Importieren Sie die Datei Kafka_Das_Schloss.txt in das HDFS-
Verzeichnis /user/cloudera/ebooks/Kafka/.
Verwenden Sie hierfür den Befehl „hadoop fs -put <lokaler Pfad> <Zielpfad in HDFS>“.
5. Schauen Sie nach, welche Dateien im HDFS im Verzeichnis
/user/cloudera/ebooks/ vorhanden sind.
6. Wiederholen Sie die Schritte 4 + 5 unter Verwendung der Wildcard * für
folgende Daten:
Importieren von Dateien ins HDFS (2)
Übung: hdfs-exercise
28
Lokale Dateien Zielverzeichnis im HDFS
Goethe* /user/cloudera/ebooks/Goethe
Schiller* /user/cloudera/ebooks/Schiller
©
Shuffle &
Sort Reducer
0 das ist ein beispiel text mit
240 scheinbar unsinnigem inhalt
488 der sich über mehrere zeilen
736 erstreckt und so groß ist
… …
das 1
ist 1
ein 1
beispiel 1
… 1
for (word : line.split("\\s+")) {
write(word, 1);
}
sum = 0;
for (value : values) {
sum = sum + value;
}
write(key, sum);
das [1,1,1,1,1,1,1,1]
ist [1,1,1,1]
ein [1,1,1,1,1,1,1,1,1,1,1,1]
beispiel [1,1]
… […]
das 8
ist 4
ein 12
beispiel 2
… […]
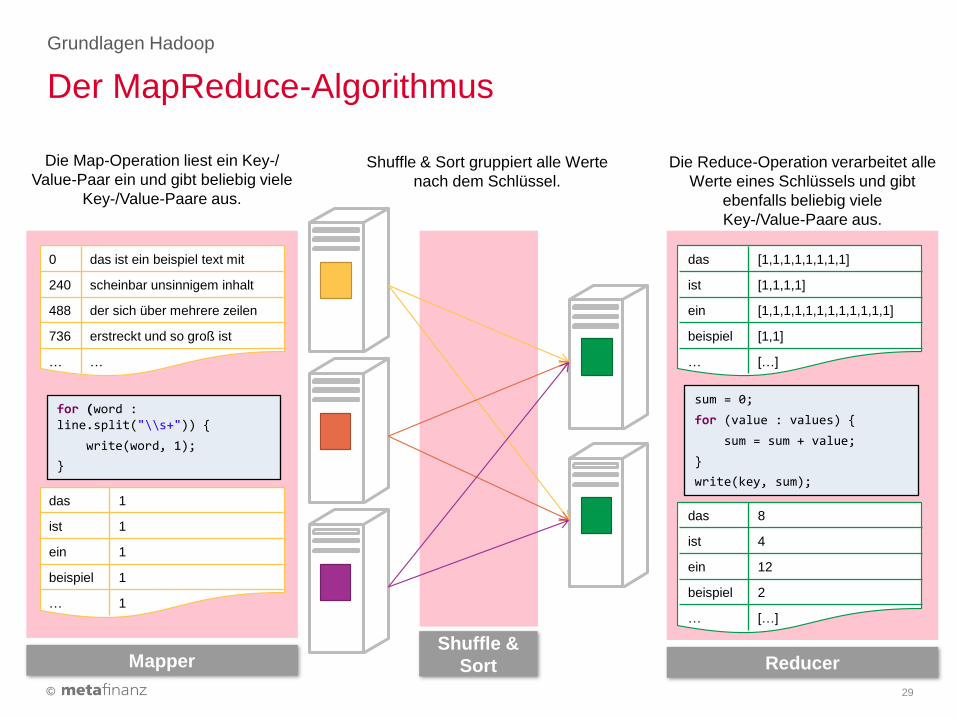
Die Map-Operation liest ein Key-/
Value-Paar ein und gibt beliebig viele
Key-/Value-Paare aus.
Die Reduce-Operation verarbeitet alle
Werte eines Schlüssels und gibt
ebenfalls beliebig viele
Key-/Value-Paare aus.
Mapper
Shuffle & Sort gruppiert alle Werte
nach dem Schlüssel.
Der MapReduce-Algorithmus
Grundlagen Hadoop
29

©
Mapper-Code WordCount
Grundlagen Hadoop
package de.metafinanz.hadoop.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
30

©
package de.metafinanz.hadoop.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
Reducer-Code WordCount
Grundlagen Hadoop
31

©
package de.metafinanz.hadoop.wordcount;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
Driver-Code WordCount
Grundlagen Hadoop
32

©
Kapitel 3 Apache Spark
©
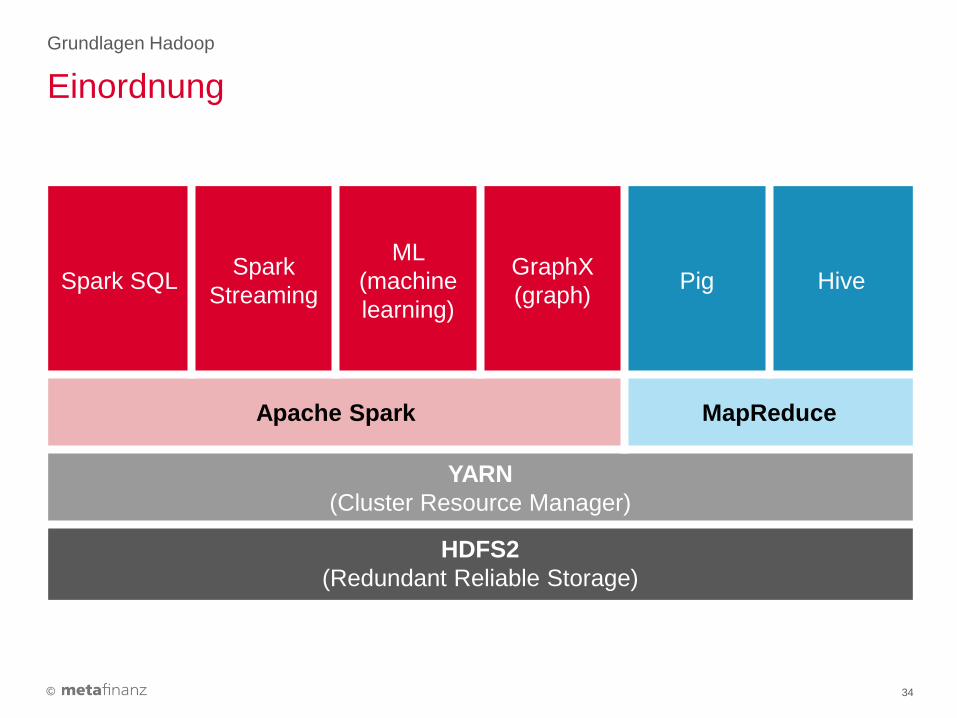
Einordnung
Grundlagen Hadoop
34
Spark SQL Spark
Streaming
ML
(machine
learning)
GraphX
(graph) Pig Hive
Apache Spark MapReduce
YARN
(Cluster Resource Manager)
HDFS2
(Redundant Reliable Storage)

©
Grundlegende Unterschiede
Apache Spark
• Viel in-memory Verarbeitung (aber
nicht nur!)
• Reduziertes I/O
• Interaktives Arbeiten
• Entwicklung „in einem Fluss“
• Kompakter Code
Apache Spark
35
Hadoop Map Reduce
• Batch-orientiert (lange
Intitierungsphase)
• MapReduce-Job-Ketten mit viel I/O
• Trennung von Logik in Mapper und
Reducer (und mehrere Jobs)
• Viel „Boilerplate“-Code
©
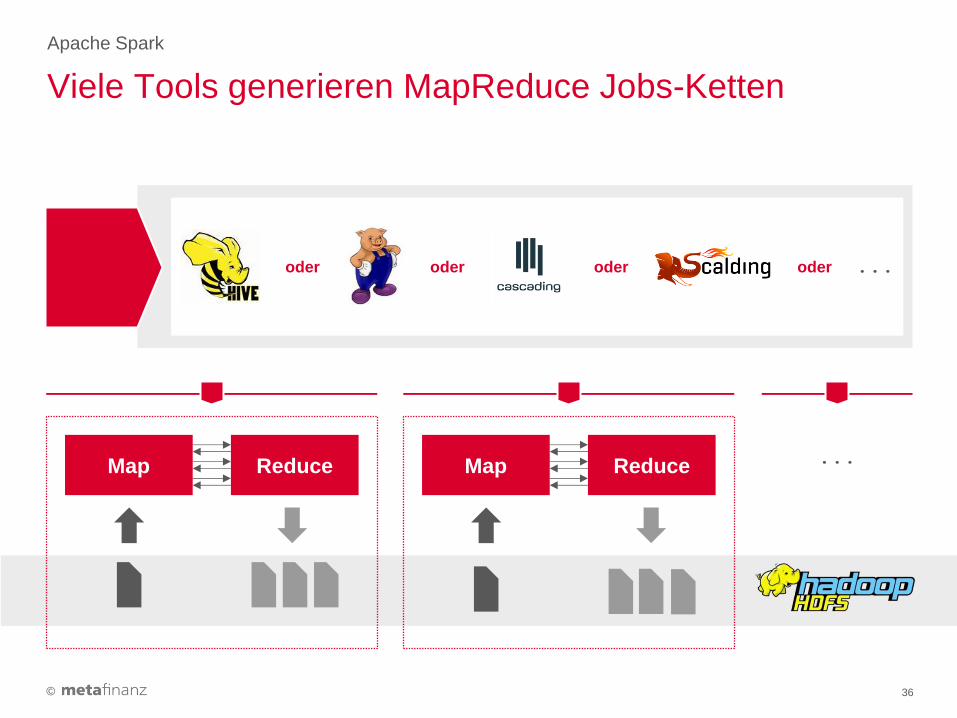
Viele Tools generieren MapReduce Jobs-Ketten
Apache Spark
36
Map Reduce Map Reduce ...
... oder oder oder oder
©
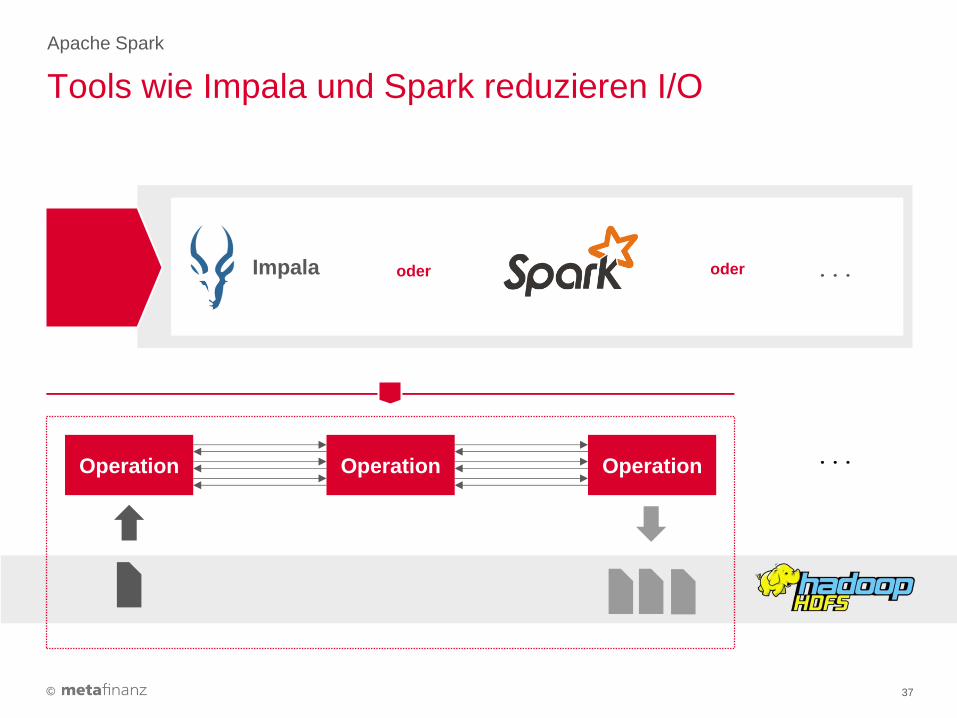
Tools wie Impala und Spark reduzieren I/O
Apache Spark
37
Impala
Operation Operation Operation ...
... oder oder

©
Kapitel 3.1 Architektur
25.09.2015
©
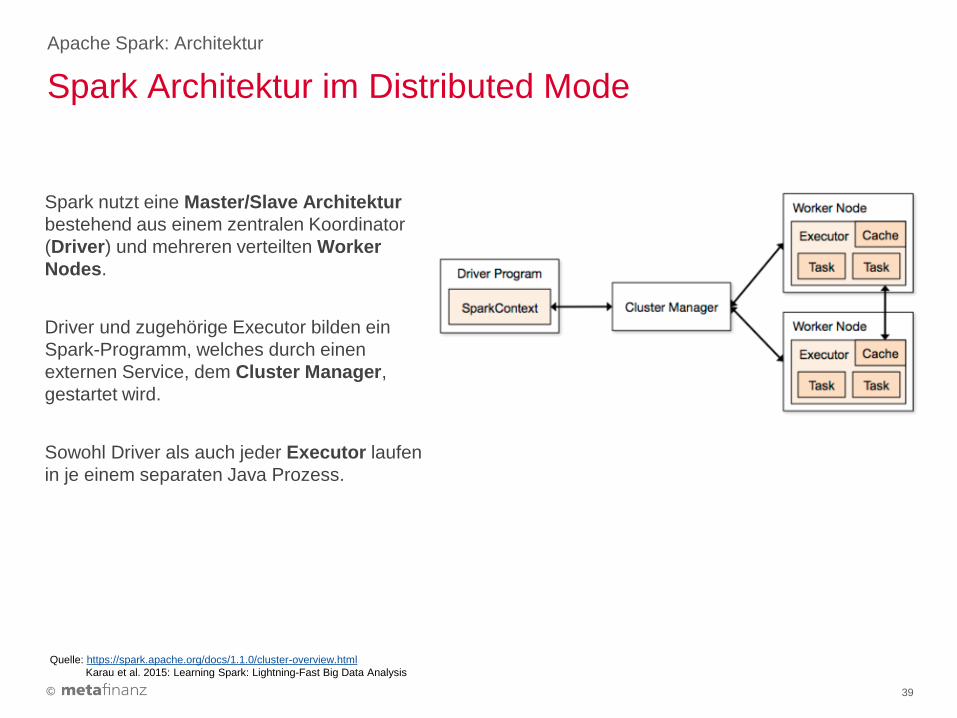
Spark nutzt eine Master/Slave Architektur
bestehend aus einem zentralen Koordinator
(Driver) und mehreren verteilten Worker
Nodes.
Driver und zugehörige Executor bilden ein
Spark-Programm, welches durch einen
externen Service, dem Cluster Manager,
gestartet wird.
Sowohl Driver als auch jeder Executor laufen
in je einem separaten Java Prozess.
Spark Architektur im Distributed Mode
Apache Spark: Architektur
39
Quelle: https://spark.apache.org/docs/1.1.0/cluster-overview.html
Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
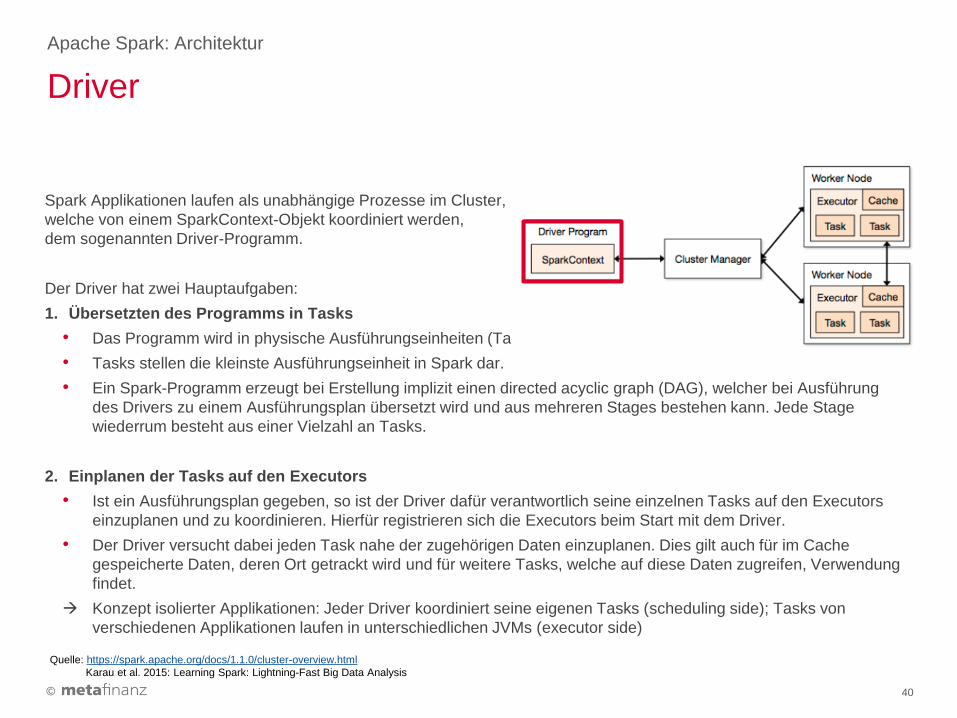
Spark Applikationen laufen als unabhängige Prozesse im Cluster,
welche von einem SparkContext-Objekt koordiniert werden,
dem sogenannten Driver-Programm.
Der Driver hat zwei Hauptaufgaben:
1. Übersetzten des Programms in Tasks
• Das Programm wird in physische Ausführungseinheiten (Tasks) übersetzt.
• Tasks stellen die kleinste Ausführungseinheit in Spark dar.
• Ein Spark-Programm erzeugt bei Erstellung implizit einen directed acyclic graph (DAG), welcher bei Ausführung
des Drivers zu einem Ausführungsplan übersetzt wird und aus mehreren Stages bestehen kann. Jede Stage
wiederrum besteht aus einer Vielzahl an Tasks.
2. Einplanen der Tasks auf den Executors
• Ist ein Ausführungsplan gegeben, so ist der Driver dafür verantwortlich seine einzelnen Tasks auf den Executors
einzuplanen und zu koordinieren. Hierfür registrieren sich die Executors beim Start mit dem Driver.
• Der Driver versucht dabei jeden Task nahe der zugehörigen Daten einzuplanen. Dies gilt auch für im Cache
gespeicherte Daten, deren Ort getrackt wird und für weitere Tasks, welche auf diese Daten zugreifen, Verwendung
findet.
Konzept isolierter Applikationen: Jeder Driver koordiniert seine eigenen Tasks (scheduling side); Tasks von
verschiedenen Applikationen laufen in unterschiedlichen JVMs (executor side)
Driver
Apache Spark: Architektur
40
Quelle: https://spark.apache.org/docs/1.1.0/cluster-overview.html
Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
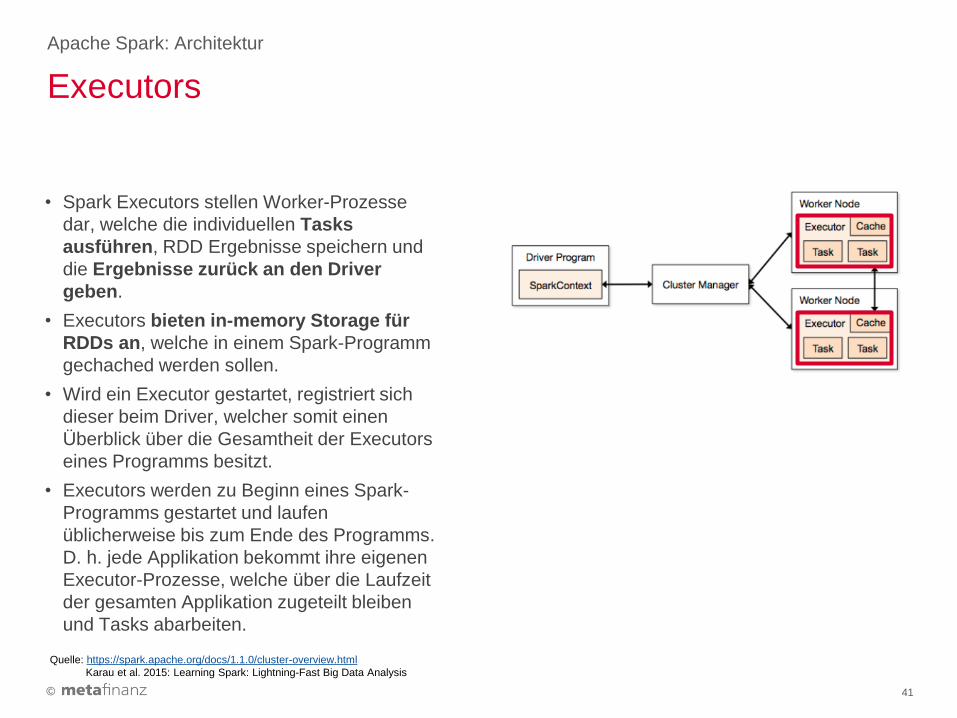
• Spark Executors stellen Worker-Prozesse
dar, welche die individuellen Tasks
ausführen, RDD Ergebnisse speichern und
die Ergebnisse zurück an den Driver
geben.
• Executors bieten in-memory Storage für
RDDs an, welche in einem Spark-Programm
gechached werden sollen.
• Wird ein Executor gestartet, registriert sich
dieser beim Driver, welcher somit einen
Überblick über die Gesamtheit der Executors
eines Programms besitzt.
• Executors werden zu Beginn eines Spark-
Programms gestartet und laufen
üblicherweise bis zum Ende des Programms.
D. h. jede Applikation bekommt ihre eigenen
Executor-Prozesse, welche über die Laufzeit
der gesamten Applikation zugeteilt bleiben
und Tasks abarbeiten.
Executors
Apache Spark: Architektur
41
Quelle: https://spark.apache.org/docs/1.1.0/cluster-overview.html
Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
• Spark hängt von einem Cluster Manager ab
(z.B. YARN), um Executors zu starten,
sowie auch in bestimmten Fällen, um den
Driver zu starten.
• Der Cluster Manager stellt dabei eine
austauschbare Komponente in Spark dar.
• Der Cluster Manager verteilt die zur
Verfügung stehenden Ressourcen des
Clusters an die einzelnen Applikationen.
Cluster Manager
Apache Spark: Architektur
42
Quelle: https://spark.apache.org/docs/1.1.0/cluster-overview.html
Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Schritte, welche ausgeführt werden, wenn ein Spark-Programm auf dem Cluster ausgeführt wird.
1. Der User übergibt ein Spark-Programm durch spark-submit
2. Spark-submit startet den Driver und ruft die main()-Methode auf
3. Der Driver kontaktiert den Cluster-Manager und frägt nach Ressourcen, um die Executors zu
starten
4. Der Cluster Manager startet die Executors im Auftrag des Drivers
5. Der Driver lässt das User-Programm laufen. Basierend auf den RDD Actions und
Transformations im Programm, sendet der Driver die auszuführende Arbeit zu den Executors
in Form von Tasks
6. Die Tasks werden auf den Executors ausgeführt, um Ergebnisse zu berechnen und zu
speichern
7. Sobald die main()-Methode beendet ist oder SparkContext.stop() aufgerufen wird, werden die
Executors beendet und die angeforderten Ressourcen vom Cluster Manager wieder freigegeben
Ausführung eines Spark Programms
Apache Spark: Architektur
43
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Kapitel 3.2 Arbeiten mit
RDDs

©
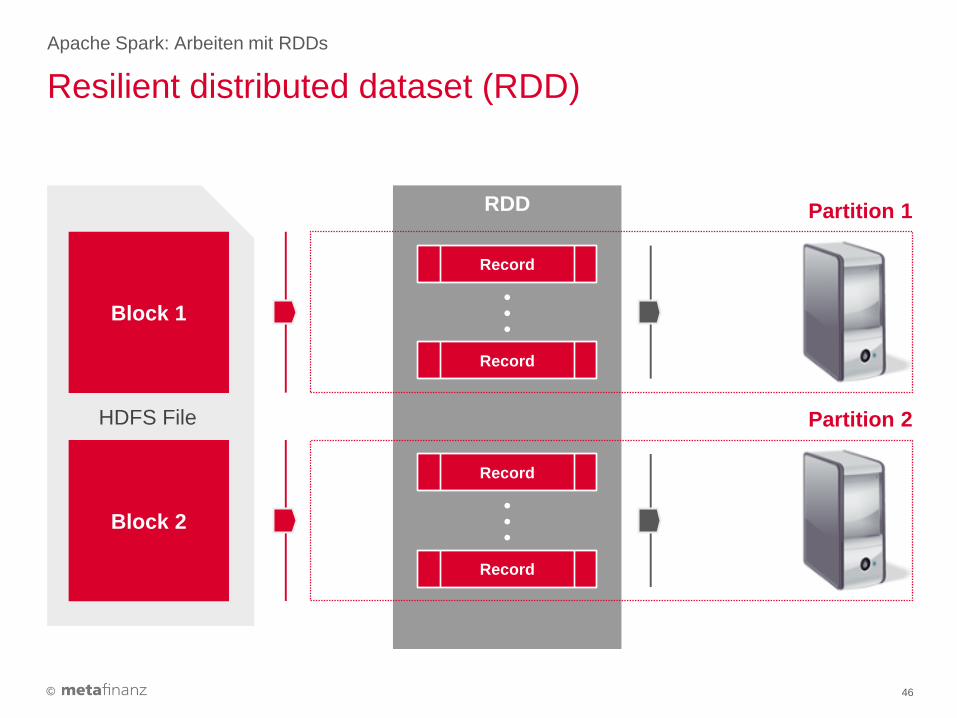
• Sparks Abstraktion zur Verarbeitung von Daten sind sogenannte RDDs (resilient distributed
datasets), welche eine verteilte Sammlung von Elementen darstellen.
• Es gibt zwei Arten von Operationen: Transformations und Actions.
• Die im RDD enthaltenen Daten werden in eine Anzahl an Partitions gesplittet, im Cluster verteilt
und parallele Operationen auf diesem ausgeführt.
• Spark berechnet RDDs in einer lazy evaluation, d. h. das RDD wird zum ersten mal berechnet, wenn
es in einer Action benutzt wird.
• Sparks RDDs werden jedes Mal neu berechnet, wenn eine Action auf diesen aufgerufen wird. Soll ein
RDD wiederverwendet werden in mehreren Actions, sollte dieses persistiert werden.
Jedes Spark Programm läuft dabei nach demselben Muster ab:
1. Erzeugen von Input RDDs aus externen Daten
2. Transformieren des erzeugten RDDs zu einem neuen RDD
3. Falls Spark intermediate RDDs wiederverwendet werden können, sollten diese persistiert werden
4. Aufrufen von Actions, um die parallele Verarbeitung zu starten, welche von Spark optimiert und
ausgeführt wird
Grundlagen zu RDDs
Apache Spark: Arbeiten mit RDDs
45
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
Resilient distributed dataset (RDD)
Apache Spark: Arbeiten mit RDDs
46
RDD
Record
Record
●
●
●
Partition 1
HDFS File
Block 1
Block 2
Record
Record
●
●
●
Partition 2

©
Spark bietet zwei Arten an um RDDs zu erstellen:
• Laden von externen Daten (filesystem, HDFS, HBase)
• Verteilen (parallelizing) einer Collection im Driver
Erstellen von RDDs
Apache Spark: Arbeiten mit RDDs
47
val lines = sc.textFile("/user/cloudera/ebooks/Kafka/Kafka_Das_Schloss.txt")
val lines = sc.parallelize(List(“metafinanz“,“Spark“,“Einführung“))

©
RDDs bieten zwei Arten von Operationen an:
Transformations sind Operationen auf RDDs, welche erneut ein
RDD erzeugen.
Beispiel: map(), filter()
Actions sind Operationen, welche Ergebnisse zum Driver
zurückliefern bzw. diese auf ein Storage System schreiben. Sie
stoßen damit die Berechnung an.
Beispiel: count(), first()
RDD Operationen
Apache Spark: Arbeiten mit RDDs
48
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Die => Syntax ist eine Kurzschreibweise, um Funktionen
innerhalb von Scala zu definieren.
Beispiel:
Passing Functions to Spark (Scala)
Apache Spark: Arbeiten mit RDDs
49
// Erzeugen eines RDDs
val input = sc.parallelize(List(1,2,3,4))
// Erzeugen eines neuen RDDs mit Hilfe der map-Funktion
val square_result = input.map(x => x*x)
©
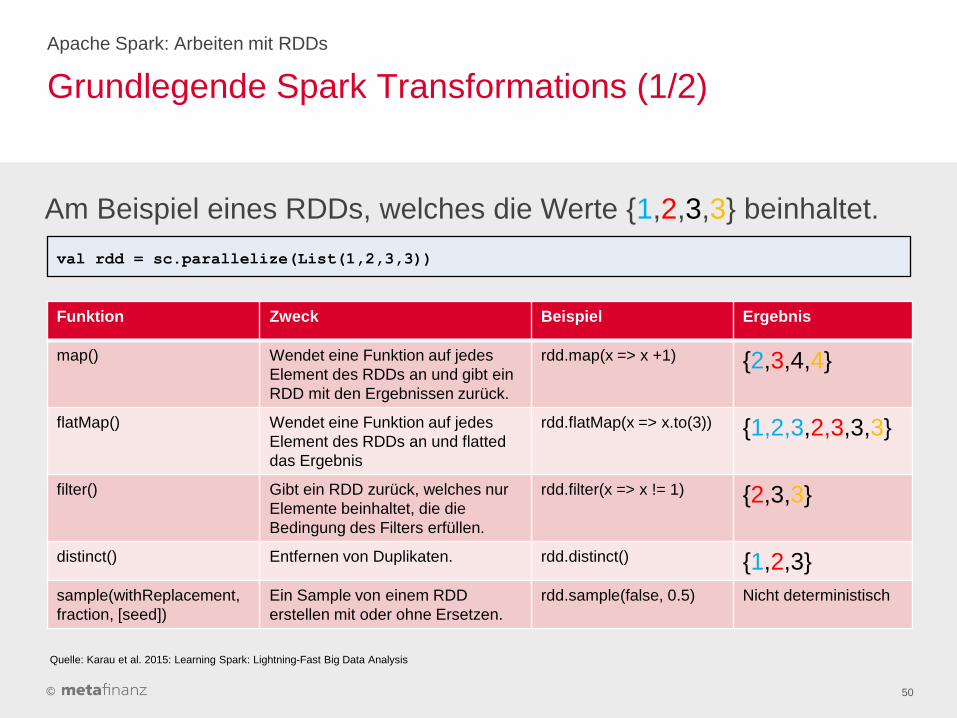
Grundlegende Spark Transformations (1/2)
rdd input containing {1,2,3,3}
Apache Spark: Arbeiten mit RDDs
50
Funktion Zweck Beispiel Ergebnis
map() Wendet eine Funktion auf jedes
Element des RDDs an und gibt ein
RDD mit den Ergebnissen zurück.
rdd.map(x => x +1) {2,3,4,4}
flatMap() Wendet eine Funktion auf jedes
Element des RDDs an und flatted
das Ergebnis
rdd.flatMap(x => x.to(3)) {1,2,3,2,3,3,3}
filter() Gibt ein RDD zurück, welches nur
Elemente beinhaltet, die die
Bedingung des Filters erfüllen.
rdd.filter(x => x != 1) {2,3,3}
distinct() Entfernen von Duplikaten. rdd.distinct() {1,2,3}
sample(withReplacement,
fraction, [seed])
Ein Sample von einem RDD
erstellen mit oder ohne Ersetzen.
rdd.sample(false, 0.5) Nicht deterministisch
Am Beispiel eines RDDs, welches die Werte {1,2,3,3} beinhaltet.
val rdd = sc.parallelize(List(1,2,3,3))
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Grundlegende Spark Transformations (2/2)
Apache Spark: Arbeiten mit RDDs
51
Funktion Zweck Beispiel Ergebnis
union() Erzeugt ein RDD, welches die Elemente aus
beiden RDDs beinhaltet.
rdd.union(other) {1, 2, 3, 3, 4, 5}
intersect() Erzeugt ein RDDs, welches nur diejenigen
Elemente beinhaltet, die in beiden RDDs
vorhanden sind.
rdd.intersection(other) {3}
subtract() Entfernt die Inhalte aus einem RDD. rdd.subtract(other) {1, 2}
cartesian(num) Bildet ein kartesisches Produkt von einem
RDD mit einem anderen.
rdd.cartesian(other) {(1, 3), (1, 4), …
(3, 5)}
Am Beispiel von RDDs, welche die Werte {1,2,3} und {3,4,5}
beinhalten.
val rdd = sc.parallelize(List(1,2,3))
val other = sc.parallelize(List(3,4,5))
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
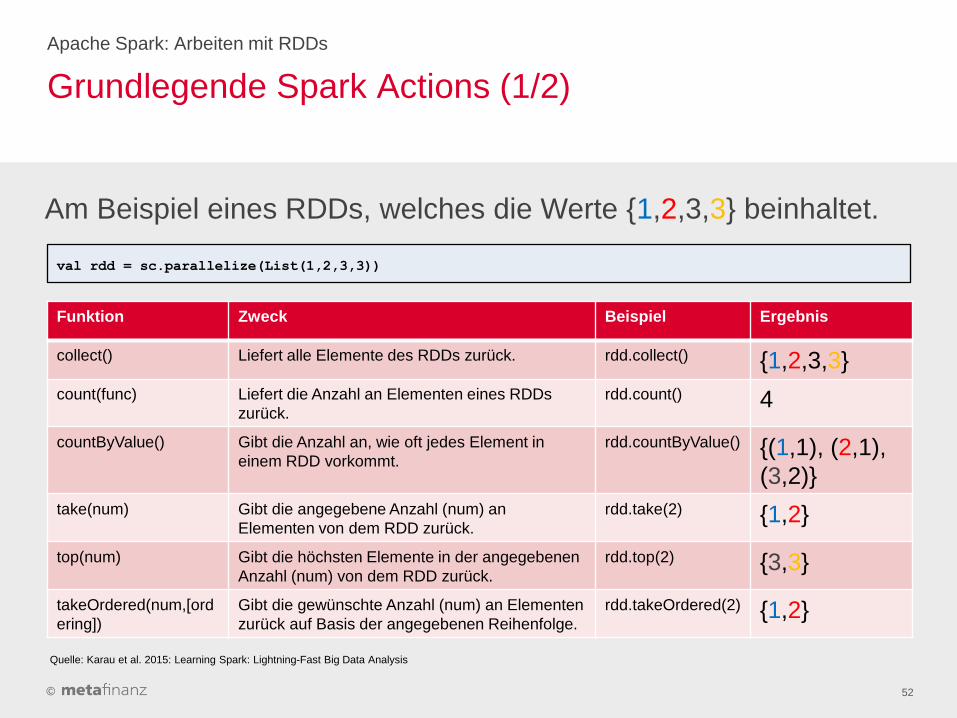
Grundlegende Spark Actions (1/2)
Apache Spark: Arbeiten mit RDDs
52
Funktion Zweck Beispiel Ergebnis
collect() Liefert alle Elemente des RDDs zurück. rdd.collect() {1,2,3,3}
count(func) Liefert die Anzahl an Elementen eines RDDs
zurück.
rdd.count() 4
countByValue() Gibt die Anzahl an, wie oft jedes Element in
einem RDD vorkommt.
rdd.countByValue() {(1,1), (2,1),
(3,2)}
take(num) Gibt die angegebene Anzahl (num) an
Elementen von dem RDD zurück.
rdd.take(2) {1,2}
top(num) Gibt die höchsten Elemente in der angegebenen
Anzahl (num) von dem RDD zurück.
rdd.top(2) {3,3}
takeOrdered(num,[ord
ering])
Gibt die gewünschte Anzahl (num) an Elementen
zurück auf Basis der angegebenen Reihenfolge.
rdd.takeOrdered(2) {1,2}
Am Beispiel eines RDDs, welches die Werte {1,2,3,3} beinhaltet.
val rdd = sc.parallelize(List(1,2,3,3))
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
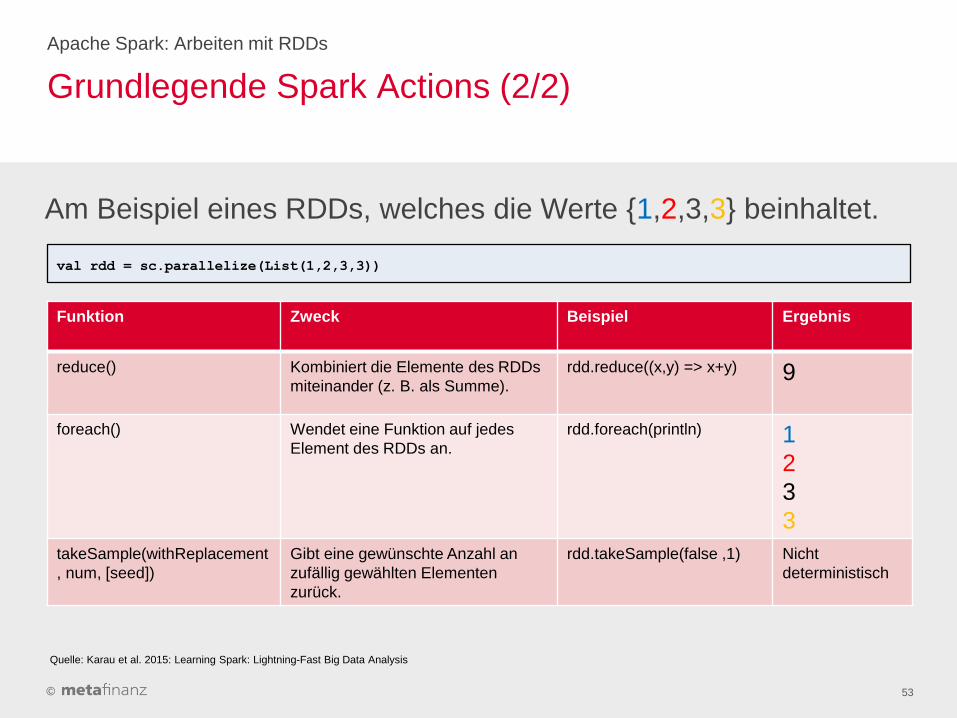
Grundlegende Spark Actions (2/2)
Apache Spark: Arbeiten mit RDDs
53
Funktion Zweck Beispiel Ergebnis
reduce() Kombiniert die Elemente des RDDs
miteinander (z. B. als Summe).
rdd.reduce((x,y) => x+y) 9
foreach() Wendet eine Funktion auf jedes
Element des RDDs an.
rdd.foreach(println) 1
2
3
3
takeSample(withReplacement
, num, [seed])
Gibt eine gewünschte Anzahl an
zufällig gewählten Elementen
zurück.
rdd.takeSample(false ,1) Nicht
deterministisch
Am Beispiel eines RDDs, welches die Werte {1,2,3,3} beinhaltet.
val rdd = sc.parallelize(List(1,2,3,3))
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
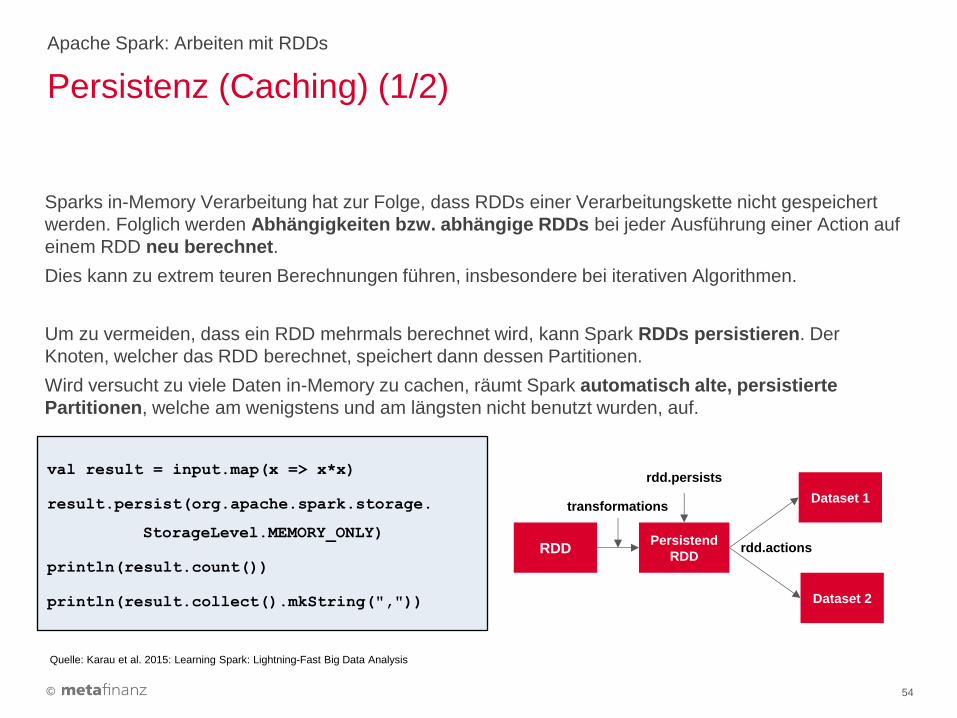
Sparks in-Memory Verarbeitung hat zur Folge, dass RDDs einer Verarbeitungskette nicht gespeichert
werden. Folglich werden Abhängigkeiten bzw. abhängige RDDs bei jeder Ausführung einer Action auf
einem RDD neu berechnet.
Dies kann zu extrem teuren Berechnungen führen, insbesondere bei iterativen Algorithmen.
Um zu vermeiden, dass ein RDD mehrmals berechnet wird, kann Spark RDDs persistieren. Der
Knoten, welcher das RDD berechnet, speichert dann dessen Partitionen.
Wird versucht zu viele Daten in-Memory zu cachen, räumt Spark automatisch alte, persistierte
Partitionen, welche am wenigstens und am längsten nicht benutzt wurden, auf.
Persistenz (Caching) (1/2)
Apache Spark: Arbeiten mit RDDs
54
val result = input.map(x => x*x)
result.persist(org.apache.spark.storage.
StorageLevel.MEMORY_ONLY)
println(result.count())
println(result.collect().mkString(","))
RDD Persistend
RDD
Dataset 1
Dataset 2
rdd.persists
transformations
rdd.actions
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
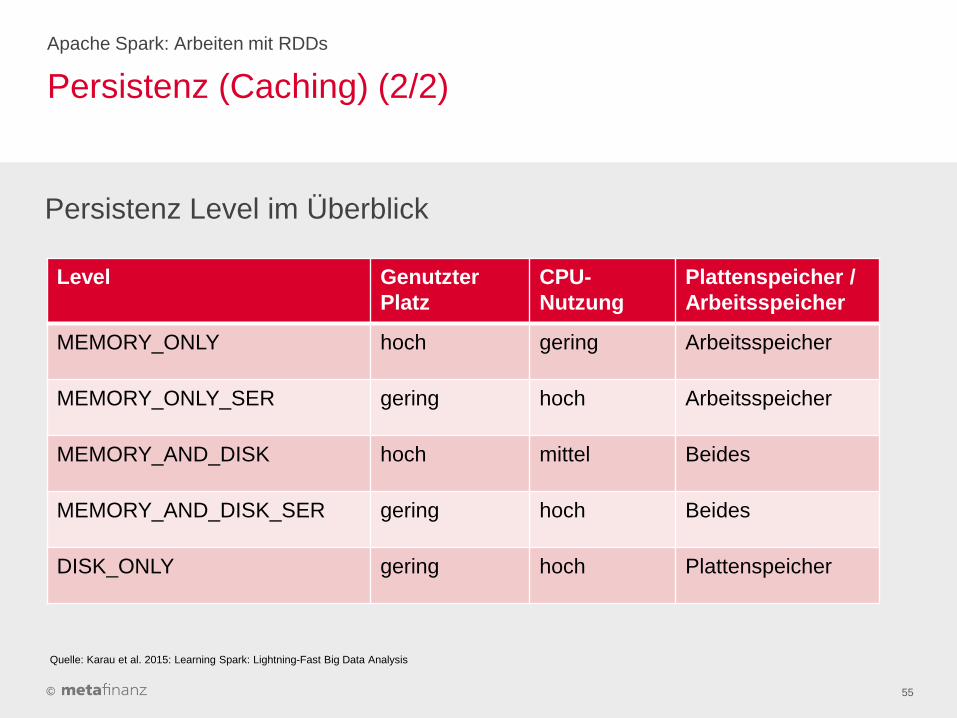
Persistenz (Caching) (2/2)
Level Genutzter
Platz
CPU-
Nutzung
Plattenspeicher /
Arbeitsspeicher
MEMORY_ONLY hoch gering Arbeitsspeicher
MEMORY_ONLY_SER gering hoch Arbeitsspeicher
MEMORY_AND_DISK hoch mittel Beides
MEMORY_AND_DISK_SER gering hoch Beides
DISK_ONLY gering hoch Plattenspeicher
Apache Spark: Arbeiten mit RDDs
55
Persistenz Level im Überblick
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Kapitel 3.3 Arbeiten mit
Key/Value
Paaren

©
Key/Value Verarbeitung in Spark
Apache Spark: Arbeiten mit Key/Value Paaren
57
• RDDs, welche Key/Value Paare enthalten werden pair RDDs genannt. Spark bietet
spezielle Operationen für pair RDDs an.
• Pair RDDs stellen ebenfalls RDDs dar, jedoch als Tuple2 Objekte (Scala/Java) und
unterstützen damit die gleichen Funktionen wie herkömmliche RDDs.
• Pair RDDs Funktionen können in die Gruppen Aggregations, Grouping, Joins und
Sorting unterteilt werden.
Durch das Konzept der implicit conversion werden automatische die pair-RDD Funktionen verfügbar.
// Erzeugung durch die map-Funktion
val pairs = lines.map(x => (x.split(" ")(0), x))
(Das,Das ist eine Zeile)
// Erzeugung durch die keyBy-Funktion
val pairs2 = lines.keyBy(_.length)
(19,Das ist eine Zeile)
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Transformationen auf pair-RDDs (1/3)
Apache Spark: Arbeiten mit Key/Value Paaren
58
Funktion Zweck Beispiel Ergebnis
reduceByKey(func) Kombiniert Values, die den gleichen Key
haben.
rdd.reduceByKey((x,y)
=> x + y) {(1, 2), (3, 10)}
groupByKey() Gruppiert Values, die den gleichen Key
haben.
rdd.groupByKey() {(1, [2]), (3, [4,
6])}
mapValues(func) Wendet eine Funktion auf jeden Value eines
pair RDDs an, ohne den Key zu ändern.
rdd.mapValues(x => x+1) {(1, 3), (3, 5),
(3, 7)}
flatmapValues(func) Wendet eine Funktion an, die einen Iterator
zu jedem Value eines pair RDDs zurückgibt
und für jedes zurückgegebene Element einen
Key/Value Eintrag mit dem alten Key erstellt.
rdd.flatMapValues(x =>
(x.to(5))) {(1, 2), (1, 3),
(1, 4), (1, 5),
(3, 4), (3, 5)}
Am Beispiel eines RDDs, welches die Werte {(1,2),(3,4),(3,6)} beinhaltet.
val rdd = sc.parallelize(List((1,2),(3,4),(3,6)))
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
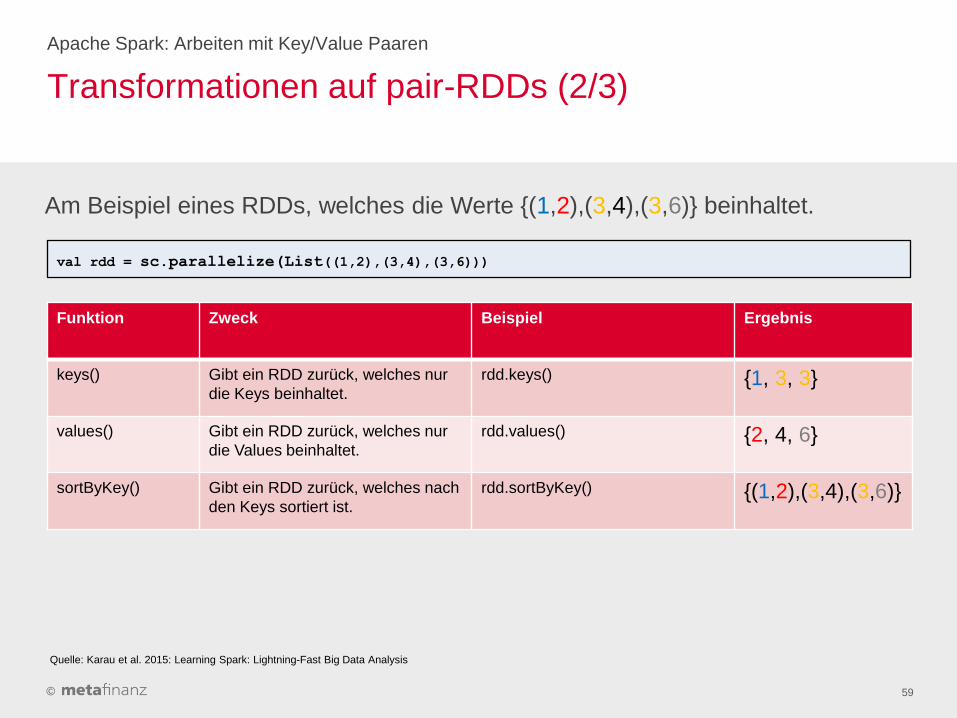
Transformationen auf pair-RDDs (2/3)
Apache Spark: Arbeiten mit Key/Value Paaren
59
Funktion Zweck Beispiel Ergebnis
keys() Gibt ein RDD zurück, welches nur
die Keys beinhaltet.
rdd.keys() {1, 3, 3}
values() Gibt ein RDD zurück, welches nur
die Values beinhaltet.
rdd.values() {2, 4, 6}
sortByKey() Gibt ein RDD zurück, welches nach
den Keys sortiert ist.
rdd.sortByKey() {(1,2),(3,4),(3,6)}
Am Beispiel eines RDDs, welches die Werte {(1,2),(3,4),(3,6)} beinhaltet.
val rdd = sc.parallelize(List((1,2),(3,4),(3,6)))
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Transformationen auf pair-RDDs (3/3)
Apache Spark: Arbeiten mit Key/Value Paaren
60
Funktion Zweck Beispiel Ergebnis
subtractByKey Entfernt Elemente aus dem RDD, deren Key
in dem anderen RDD enthalten ist.
rdd.subtractByKey(other) {(1, 2)}
join Führt einen Inner Join von zwei RDDs aus. rdd.join(other) {(3, (4, 9)), (3, (6, 9))}
rightOuterJoin Führt einen Right Outer Join von zwei RDDs
aus.
rdd.rightOuterJoin(other) {(3, (Some(4),9)),
(3, (Some(6),9))}
leftOuterJoin Führt einen Left Outer Join von zwei RDDs
aus.
rdd.leftOuterJoin(other)
{(1,(2,None)), (3
(4,Some(9))), (3,
(6,Some(9)))}
cogroup Gruppiert die Values von zwei RDDs, die
den gleichen Key haben.
rdd.cogroup(other) {(1,([2],[])), (3
([4, 6], [9]))}
Am Beispiel von RDDs, welche die Werte {(1, 2), (3, 4) ,(3, 6)} und {(3, 9)}
beinhalten.
val rdd = sc.parallelize(List((1,2),(3,4),(3,6)))
val other = sc.parallelize(List((3,9)))
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
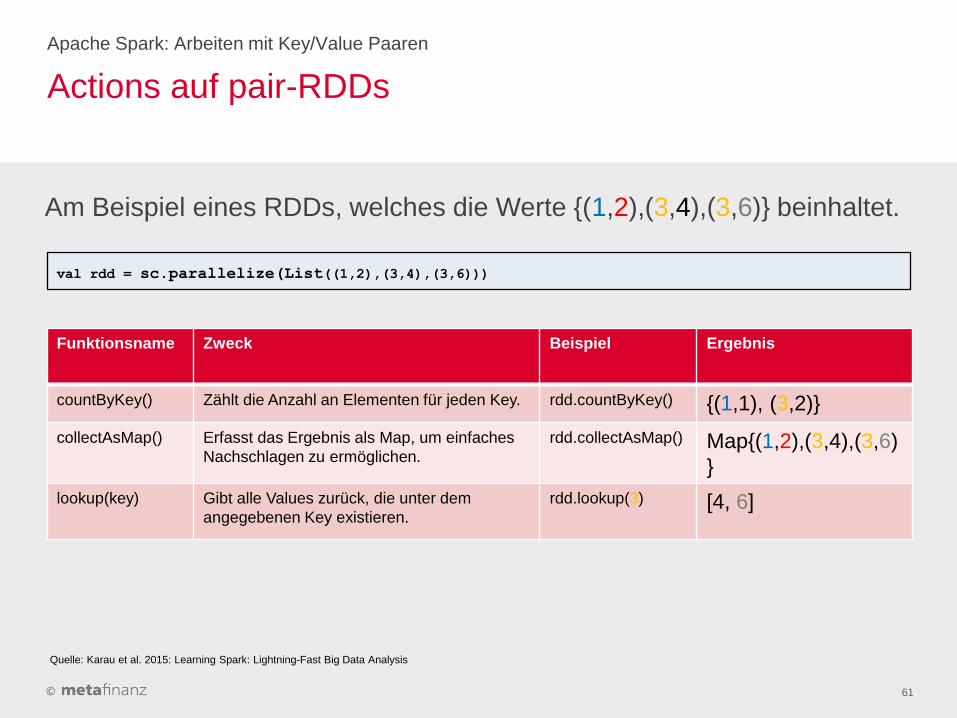
©
Actions auf pair-RDDs
Apache Spark: Arbeiten mit Key/Value Paaren
61
Funktionsname Zweck Beispiel Ergebnis
countByKey() Zählt die Anzahl an Elementen für jeden Key. rdd.countByKey() {(1,1), (3,2)}
collectAsMap() Erfasst das Ergebnis als Map, um einfaches
Nachschlagen zu ermöglichen.
rdd.collectAsMap() Map{(1,2),(3,4),(3,6)
}
lookup(key) Gibt alle Values zurück, die unter dem
angegebenen Key existieren.
rdd.lookup(3) [4, 6]
Am Beispiel eines RDDs, welches die Werte {(1,2),(3,4),(3,6)} beinhaltet.
val rdd = sc.parallelize(List((1,2),(3,4),(3,6)))
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
1. Laden der externen Daten in das RDD input
2. Aufteilen der Zeilen zu einzelnen Wörtern [split()] und
schreiben der Wörter in je eine einzelne Zeile [flatMap()]
3. Erzeugen von Key/Value Paaren (word,1) und summieren der values pro
Key (word,value)
4. Ausgabe auf der Console
5. Abspeichern als TextFile
HandsOn Example: WordCount
Apache Spark: Arbeiten mit Key/Value Paaren
62
val input = sc.textFile("/user/cloudera/ebooks/Kafka/Kafka_Das_Schloss.txt") #1
val words = input.flatMap(line => line.split(“ “)) #2
val result = words.map(word => (word,1)).reduceByKey((value1,value2) => value1+value2) #3
result.collect().foreach(println) #4
result.saveAsTextFile("/user/cloudera/WordCount") #5
(word.toUpperCase.replaceAll("[^a-zA-z0-9\\s ]", ""),1))
©
Übung Spark Core (1/2)

©
Anhand der Übung hdfs-exercise haben Sie verschiedene Bücher in das
hdfs geladen.
Führen Sie zuerst das Programm WordCount für Kafka_Das_Schloss
aus.
Schreiben Sie dann das Programm CharCount, welches äquivalent zum
Beispiel WordCount die Zeichen des Buches zurückgibt. Gehen Sie
hierfür schrittweise vor.
WordCount to CharCount
Übung: Spark Core (1/2)
64
val input = sc.textFile("/user/cloudera/ebooks/Kafka/Kafka_Das_Schloss.txt") #1
val words = input.flatMap(line => line.split(“ “)) #2
val result = words.map(word => (word,1)).reduceByKey((value1,value2) => value1+value2) #3
result.collect().foreach(println) #4
result.saveAsTextFile("/user/cloudera/WordCount") #5

©
Lösungsvorschlag CharCount
Übung: Spark Core (1/2)
65
// Einlesen der Dateien
val lines =
sc.textFile("/user/cloudera/ebooks/Kafka/Kafka_Das_Schloss.txt")
// Aufsplitten der Zeilen in Chars
val chars = lines.flatMap(line => line.split(""))
// Konvertierung der Buchstaben in Großbuchstaben
val upperchars = chars.map(c => c.toUpperCase)
// Bildung von K/V-Paaren mit Char als Key und 1 als Value
val kv_char = upperchars.map(character => (character,1))
// Reduce/Count der Values pro Key
val charcount = kv_char.reduceByKey((v1,v2) => v1 + v2)
// Ausgabe
charcount.collect().foreach(println)

©
Kapitel 3.4 Tiefergehende
Spark
Programmierung

©
Data Partitioning
Apache Spark: Fortgeschrittene Spark Programmierung
67
• Sparks Partitioning ist für alle RDDs verfügbar, welche Key/Value Paare enthalten.
• Partitioning ist besonders dann sinnvoll, wenn Datasets mehrfach in key-orientierten
Operationen wiederverwendet werden, wie z. B. Joins.
• Partitioning zwingt das System Datenelemente zu gruppieren basierend auf einer
Funktion auf jedem Key (z. B. Hash-Partitioning, Range-Partitioning).
• Partitioning garantiert, dass sich Daten mit denselben Keys auf dem selben Knoten
befinden. Damit wird das Prinzip der Datenlokalität eingehalten, da Kommunikation
zwischen Knoten in einem verteilten Programm extrem teuer ist.
Good to know
• Partitioning stellt eine Transformation dar und erstellt damit ein neues RDD. Hierfür ist
es extrem sinnvoll, dass neu erstellte RDD zu persistieren, da sonst das RDD ständig
neu partitioniert wird.
• Es kann die Anzahl der zu erstellenden Partitionen angegeben werden. Diese sollte
mindestens so groß sein wie die Anzahl der Cores im Cluster.
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
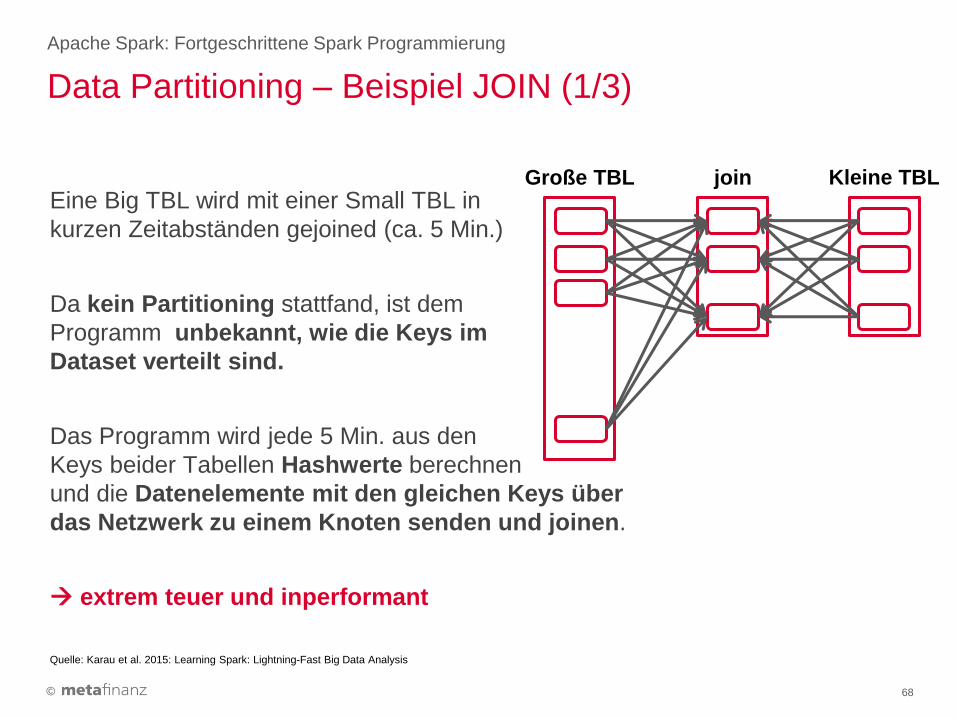
Eine Big TBL wird mit einer Small TBL in
kurzen Zeitabständen gejoined (ca. 5 Min.)
Da kein Partitioning stattfand, ist dem
Programm unbekannt, wie die Keys im
Dataset verteilt sind.
Das Programm wird jede 5 Min. aus den
Keys beider Tabellen Hashwerte berechnen
und die Datenelemente mit den gleichen Keys über
das Netzwerk zu einem Knoten senden und joinen.
extrem teuer und inperformant
Data Partitioning – Beispiel JOIN (1/3)
Apache Spark: Fortgeschrittene Spark Programmierung
68
Kleine TBL Große TBL join
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
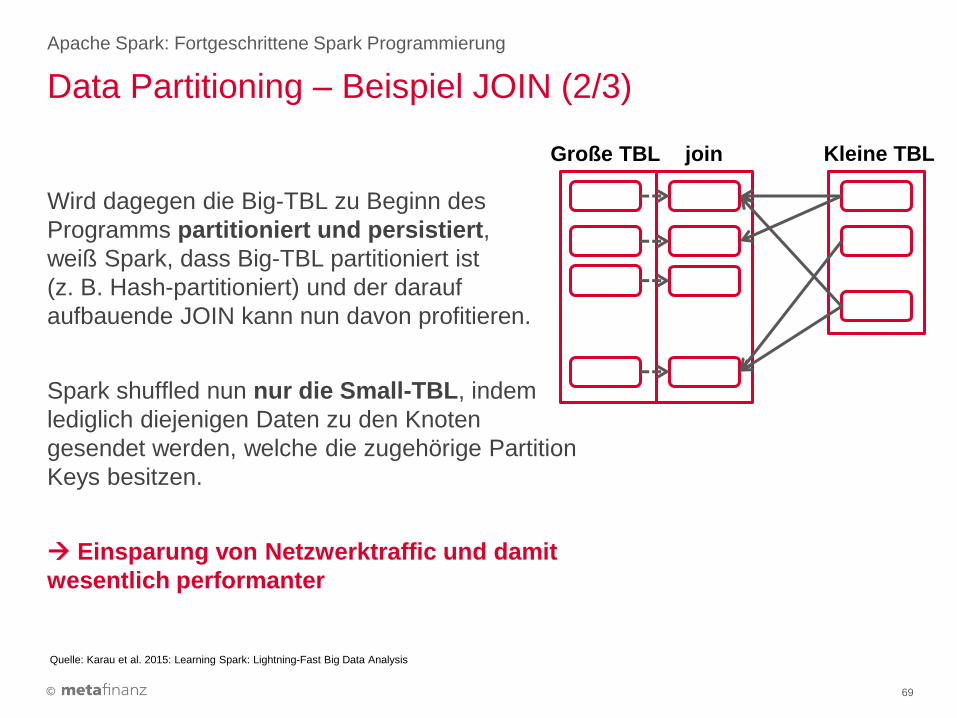
Data Partitioning – Beispiel JOIN (2/3)
Apache Spark: Fortgeschrittene Spark Programmierung
69
Wird dagegen die Big-TBL zu Beginn des
Programms partitioniert und persistiert,
weiß Spark, dass Big-TBL partitioniert ist
(z. B. Hash-partitioniert) und der darauf
aufbauende JOIN kann nun davon profitieren.
Spark shuffled nun nur die Small-TBL, indem
lediglich diejenigen Daten zu den Knoten
gesendet werden, welche die zugehörige Partition
Keys besitzen.
Einsparung von Netzwerktraffic und damit
wesentlich performanter
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
Kleine TBL Große TBL join

©
Codebeispiel
Data Partitioning – Beispiel JOIN (3/3)
Apache Spark: Fortgeschrittene Spark Programmierung
70
// Laden der externen Daten
val lines = sc.sequenceFile(“/path/to/file“)
// Erstellen von 100 Partitionen
.partitionBy(new HashPartitioner(100))
// Persistieren des RDDs
.persist()

©
Einige Spark Operationen folgern automatisch in RDDs mit bekannten
Partitionsinformationen, wovon andere Operationen wiederum profitieren.
Spark setzt hier automatisch den entsprechenden Partitioner.
Andere Operationen wie map() heben die Partition seines „Eltern“-RDDs jedoch
auf, da sich dadurch theoretisch der Key eines jeden Records verändert
haben könnte.
Hierfür kann in Spark auf zwei Operationen zugegriffen werden, mapValues()
und flatMapValues(). Beide garantieren, dass die Keys der Tuple die selben
bleiben.
Data Partitioning
Apache Spark: Fortgeschrittene Spark Programmierung
71
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Spark bietet zwei Arten von sogenannten shared variables:
• Accumulators, welche Informationen aggregieren.
• Werden häufig verwendet, um Events zu zählen.
• Broadcast variables, welche es dem Programm erlauben
große read-only Werte auf allen Worker Nodes zu verteilen.
• Werden häufig für Lookup-Tabellen verwendet.
(vgl. Hadoop-MapReduce: Counter, Distributed Cache)
Shared Variables
Apache Spark: Fortgeschrittene Spark Programmierung
72
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
• Acculumulators aggregieren Werte von den Worker Nodes und geben diese
an den Driver zurück.
• Accumulators sind write-only Variablen, d. h. Tasks auf den Worker Nodes
haben keinen Zugriff auf den Accumulatorwert.
• Der Accumulatorwert ist nur im Driver zugänglich über die Funktion value()
Hinweis:
Accumulator können in älteren Spark Versionen (Spark 1.2) falsche Werte
zurückliefern
Shared Variables: Accumulators
Apache Spark: Fortgeschrittene Spark Programmierung
73
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Im Beispiel wird ein accumulator[int] zum Zählen der Wörter einer Datei genutzt.
Accumulators – Beispiel (Total-)WordCount
Apache Spark: Fortgeschrittene Spark Programmierung
74
// Laden der externen Daten
val lines = sc.textFile("/user/cloudera/ebooks/Kafka/Kafka_Das_Schloss.txt")
// Erstellen des Accumulators
val totalwordcount = sc.accumulator(0)
// Splitten der Datei in Wörter
val words = lines.flatMap(_.split(“ “))
// Iterieren über Wörter und Hochzählen des Accumulators
words.foreach(w => totalwordcount += 1)
// Ausgabe
println(“Total Word Count : “ + totalwordcount.value)

©
Broadcast Variables werden verwendet, um große read-only Daten auf allen
Worker Nodes zu verteilen.
Spark sendet automatisch alle Variablen, welche im Programm referenziert sind,
zu den Worker Nodes.
• Spark ist per default auf kleine Tasks optimiert
• Variablen in parallelen Operationen werden für jede Operation separat
gesendet
Mit steigender Größe dieser Variablen (z. B. Lookup-Tables) ist dieses Vorgehen
jedoch extrem ineffizient.
Wird die Variable stattdessen als broadcast variable definiert, ist sichergestellt,
dass diese nur einmal zu jedem Knoten übertragen.
Shared Variables: Broadcast Variables
Apache Spark: Fortgeschrittene Spark Programmierung
75
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Broadcast Variables – Beispiel Array Lookup
Apache Spark: Fortgeschrittene Spark Programmierung
76
val lookup_rdd = sc.textFile("/path/to/file") // val array: Array[Int]
val fakten_rdd = sc.parallelize(List(5)) // Beliebiges RDD
// Array wird jedes Mal durchs Netzwerk geschickt
fakten_rdd.map(x => lookup_rdd.contains(x))
// Erstellung broadcast variable
val broadcasted = sc.broadcast(lookup_rdd)
// Array wird einmalig zu den Knoten geschickt extreme Performance Benefit
fakten_rdd.map (x => broadcasted.value.contains(x))
©
Übung Spark Core (2/2)

©
Blank Lines
Übung: Spark Core (2/2)
78
Anhand der Übung hdfs-exercise haben Sie verschiedene Bücher
in das hdfs geladen.
Schreiben Sie hierfür das Programm Blank Lines, welches mit
Hilfe eines Accumulators die Anzahl der leeren Zeilen mitzählt.
Die Ausgabe soll dabei keine leeren Zeilen beinhalten.
Tipps:
• val totalwordcount = sc.accumulator(0)
• foreach(println)
• split()
• if (Bedingung) { doThis }; else doThat
• filter()

©
Accumulators – Lösung „Blank Lines“
Übung: Spark Core (2/2)
79
val lines = sc.textFile(“path/o/file“) // Laden der externen Daten
val blankLines = sc.accumulator(0) // Erstellung Accumulator
val words= file.flatMap(line => {
if (lines == ““) {
blankLines += 1 // Hochzählen des Accumulators
};
lines.split(“ “);
});
words.saveAsTextFile(“/user/cloudera/Accumulator“)
println(“Leere Zeilen: “ + blankLines.value)
Wichtig: Der richtige Wert des Accumulator wird erst mit der Operation saveAsTextFile() sichtbar, da die
darüber liegende Transformation flatMap der lazy Evaluation unterliegt!

©
Kapitel 4 Spark SQL

©
Mit Spark SQL wird ein Interface zur Verfügung gestellt, um mit strukturierten, d. h.
schemagestützten Daten zu arbeiten.
Spark SQL ermöglicht es…
• Daten aus einer Vielzahl von strukturierten Quellen (JSON, Hive, Parquet) zu laden.
• Daten durch SQL abzufragen, sowohl innerhalb von Spark als auch durch externe
Tools, welche sich zu Spark SQL durch Standard Datenbankkonnektoren
(JDBC/ODBC) verbinden können.
• SQL und regulären Python/Scala/Java Code zu integrieren, einschließlich der
Möglichkeit RDDs und SQL Tabellen zu verbinden sowie Custom Functions in SQL und
vieles mehr.
Um dies zu bewerkstelligen, bietet Spark ein spezielles RDD an, das sogenannte
DataFrame, welches ein RDD von Row-Objects darstellt.
DataFrames können aus externen Datenquellen, aus dem Ergebnis einer Abfrage oder
aus regulären RDDs erzeugt werden und bieten neue Operationen an.
Grundlagen
Spark SQL
81
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Spark SQL kann mit oder auch ohne Apache Hive, der Hadoop SQL
Engine, verwendet werden. Es wird jedoch empfohlen Spark SQL mit
Hive-Support zu nutzen, um bestehende Features verwenden zu
können.
Spark SQL mit Hive erlaubt es auf Hive-Tables, UDFs, SerDes und die
Hive Query Language zurückzugreifen, wobei keine vorhandene Hive
Installation vorausgesetzt wird.
Spark mit Hive
Spark SQL
82
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
DataFrames können ähnlich zu Tabellen einer traditionellen Datenbank
verstanden werden.
Ein DataFrame ist ein RDD bestehend aus RowObjects mit
zusätzlichen Schemainformationen der Datentypen jeder Zeile.
Da DataFrames ebenfalls RDDs sind, können auf diesen auch
Transformationen wie map() und filter() angewandt werden.
DataFrames bieten zusätzlich weitere Möglichkeiten
• registerTempTable()
• sql()
• …
DataFrame
Spark SQL
83
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
©
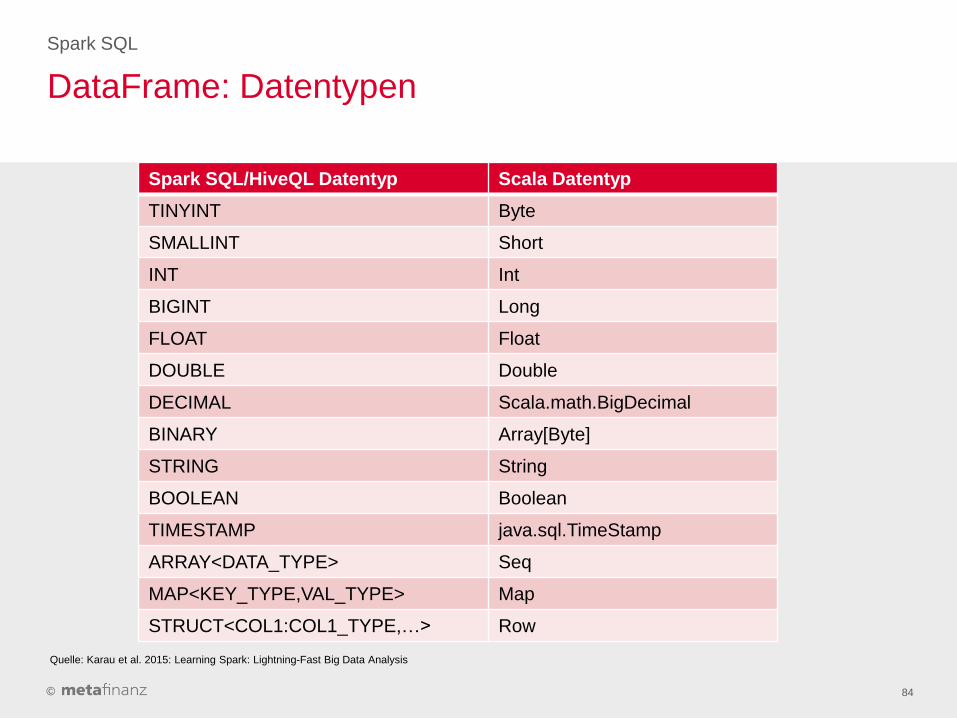
DataFrame: Datentypen
Spark SQL
84
Spark SQL/HiveQL Datentyp Scala Datentyp
TINYINT Byte
SMALLINT Short
INT Int
BIGINT Long
FLOAT Float
DOUBLE Double
DECIMAL Scala.math.BigDecimal
BINARY Array[Byte]
STRING String
BOOLEAN Boolean
TIMESTAMP java.sql.TimeStamp
ARRAY<DATA_TYPE> Seq
MAP<KEY_TYPE,VAL_TYPE> Map
STRUCT<COL1:COL1_TYPE,…> Row
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Um Hive vollständig nutzen zu können , muss sich die hive-site.xml zusätzlich in
$SPARK_HOME/conf befinden.
Initiieren von Spark SQL
Spark SQL
85
// Erzeugen eines SQL-Contexts
val sqlContext = new org.apache.spark.sql.SQLContext(sc) // SQLContext
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc) // HiveContext
// Import Spark SQL
import org.apache.spark.sql.hive.HiveContext; // mit Hive Abhängigkeiten
import org.apache.spark.sql.SQLContext; // ohne Hive Abhängigkeiten
// Import JavaSchemaRDD/DataFrame – konvertiert implizit ein RDD zu einem DataFrame
import sqlContext.implicits._
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Caching in Spark SQL kann effizienter bearbeitet werden, da die Datentypen
der Spalten bekannt sind.
Um sicherzustellen, dass die memory-effiziente Repräsentation anstatt der
ganzen Objekte gecached wird, sollte die Funktion
hiveCtx.cacheTable(“Tablename“) verwendet werden.
Spark SQL repräsentiert dabei die Daten in einem in-memory-Spaltenformat
(cached Table), welches solange wie das Driver-Programm existiert.
Genau wie bei RDDs sollte man Tabellen cachen, wenn erwartet wird, dass
diese mehrfach abgefragt werden bzw. mehrfach Tasks auf diesen laufen (vgl.
Programming with RDDs -Persistence).
Caching in Spark SQL
Spark SQL
86
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis

©
Basic Query – JSON
Spark SQL
87
// Erstellen eines SQL Context
val hiveCtx = new org.apache.spark.sql.hive.HiveContext(sc)
// Laden von Twitterdaten über JSON
val lines = hiveCtx.jsonFile(“/path/to/file“)
// Registrieren der Daten als „temporäre Tabelle“
lines.registerTempTable(“tbl_JSON“)
// Abfragen der Daten über die sql()-Funktion
hiveCtx.sql(“Select * FROM tbl_JSON“).show
{ “data“: [
{
“id“: “Y123_X123“,
“from“: {
“name“: “Bugs Bunny“, “id“; “X15“
},
“message“: “Hello World! “,
[…]

©
Basic Query – Textfile
Spark SQL
88
val sqlContext = new org.apache.spark.sql.SQLContext(sc) // Erstellen des SQL-Contexts
import sqlContext._ // Import Dataframe
case class Customer(id:Int, first_name: String, last_name: String) // Erstellen des Customer-Schemas
val dfCustomer = sc.textFile(“customers.txt“) // Laden der Datei
.map(_.split(“; “)) // Splitten auf Spalten
.map(p => Customer(p(0).trim.toInt, p(1).trim, p(2).trim)) // Mapping auf Spalten
.toDF() // Bildung Dataframe
dfCustomers.registerTempTable(“customers“) // Registrieren des DataFrame als Tabelle
sqlCtx.sql(“SELECT * FROM customers“).show // Select Statement
1;Bugs;Bunny;
2;Donald;Duck;
…

©
Auch das Erstellen und Abfragen von Hive Tables ist möglich.
Basic Query – Hive Tables
Spark SQL
89
val hiveCtx = new org.apache.spark.hive.HiveContext(sc) // Erstellen HiveContext
import org.apache.spark.sql.hive.HiveContext; // Import HiveContext
// Create Table Statement
hiveCtx.sql = (“CREATE TABLE KATALOG(ID INT, AUTOR STRING, TITEL STRING )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE“)
// Load Local Data
hiveCtx.sql = (“ LOAD DATA LOCAL INPATH ‘/home/cloudera/ebooks/Katalog.txt‘ INTO TABLE KATALOG “)
hiveCtx.sql(“SELECT * FROM KATALOG“).show // Select

©
Der Beeline Client ist eine simple SQL-Shell, welche es erlaubt HiveQL zu nutzen.
Details hierzu siehe https://hive.apache.org/
Um Hive on Spark verwenden zu können, muss die execution engine auf Spark
umgestellt werden.
Anlegen einer managed-Table
Laden lokaler Daten
Durchführen einer Abfrage
Arbeiten mit Beeline
Spark SQL
90
> CREATE TABLE EMPLOYEES(
EMPLOYEE_ID INT,
FIRST_NAME STRING,
LAST_NAME STRING )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
> LOAD DATA LOCAL INPATH 'home/cloudera/employee_data.csv' INTO TABLE EMPLOYEES;
> SELECT * FROM EMPLOYEES;
©
Übung Spark SQL
25.09.2015

©
In der Spark Core Übung (1/2) haben sie sowohl das Programm WordCount als
auch CharCount entworfen.
Laden sie die Outputdatei von WordCount von Kafka_Das_Schloss als
DataFrame und selektieren sie die Top10-Wörter.
Tipp:
Da der Output als Tupel abgespeichert wurde, sollte dieser bereinigt geladen
werden.
Die Funktion replaceAll() ist hier hilfreich.
Optional:
Führen Sie WordCount für Goethe_Wilhelm_Meisters_Lehrjahre durch und
joinen Sie die ermittelten Top10 von Kafka_Das_Schloss an
Goethe_Wilhelm_Meisters_Lehrjahre. Welches Buch hat wie viele Wörter ?
WordCount Auswertung
Übung: Spark SQL
92

©
WordCount Auswertung - Lösungsvorschlag
Übung: Spark SQL
93
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
case class KAFKA(WORD: String, ANZAHL: Int)
val input = sc.textFile("/user/cloudera/WordCount/part-00000").map(x => x.replaceAll("[()]","") )
val dfKafka = input.map(_.split(",")).map(p => KAFKA(p(0).trim, p(1).trim.toInt )).toDF()
dfKafka.registerTempTable("Kafka")
val result = sqlContext.sql("SELECT WORD, ANZAHL FROM Kafka ORDER BY ANZAHL DESC LIMIT 10")
result.collect().foreach(println)

©
Holende et al. (2015): Learning Spark: Lightning-Fast Big Data Analysis
Marko Bonaci, Petar Zecevic (MEAP): Spark IN ACTION
Tom White (2015): Hadoop: The Definitive Guide, 4th Edition
Literaturempfehlung
Übung: Spark SQL
94

©
http://www.metafinanz.de/news/schulungenl
Wir bieten offene Trainings, sowie maßgeschneiderte
Trainings für individuelle Kunden an.
Einführung Apache Spark
Datenverarbeitung in Hadoop
mit Pig und Hive
Oracle SQL Tuning
OWB Skripting mit OMB*Plus
Data Warehousing & Dimensionale Modellierung
Einführung in Oracle: Architektur, SQL und
PL/SQL
Einführung Hadoop (1 Tag)
Hadoop Intensiv-Entwickler
Training (3 Tage)
95

©
Danke! metafinanz
Informationssysteme GmbH
Leopoldstraße 146
D-80804 München
Phone: +49 89 360531 - 0
Fax: +49 89 360531 - 5015
Email: [email protected]
www.metafinanz.de

©
Backup
97