
Paralleles Rechnen Konzepte und Anwendungen im Data...
96
Paralleles Rechnen Konzepte und Anwendungen im Data Mining Stefan Wissuwa 1. Dezember 2008 Thesis zur Erreichung des Grades Master of Science (M.Sc.) in Wirtschaftsinformatik Hochschule Wismar - Fakultät für Wirtschaftswissenschaften Eingereicht von: Stefan Wissuwa, Dipl. Wirt.-Inf. (FH) Erstbetreuer: Jürgen Cleve, Prof. Dr. rer. nat. Zweitbetreuer: Uwe Lämmel, Prof. Dr.-Ing.
Transcript of Paralleles Rechnen Konzepte und Anwendungen im Data...

Paralleles RechnenKonzepte und Anwendungen im Data
Mining
Stefan Wissuwa
1. Dezember 2008
Thesis zur Erreichung des GradesMaster of Science (M.Sc.) in Wirtschaftsinformatik
Hochschule Wismar - Fakultät für Wirtschaftswissenschaften
Eingereicht von: Stefan Wissuwa, Dipl. Wirt.-Inf. (FH)
Erstbetreuer: Jürgen Cleve, Prof. Dr. rer. nat.
Zweitbetreuer: Uwe Lämmel, Prof. Dr.-Ing.

Inhaltsverzeichnis1 Einleitung 1
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Anwendungsgebiete . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Inhalt der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Begriffsklärung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
I Grundlagen der parallelen Datenverarbeitung 5
2 Stufen der Parallelisierung 6
3 Parallele Architekturen 73.1 Flynnsche Klassifizierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.2 Speichermodelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.2.1 Rechner mit gemeinsamem Speicher . . . . . . . . . . . . . . . . . . . 83.2.2 Rechner mit verteiltem Speicher . . . . . . . . . . . . . . . . . . . . . 9
3.3 Prozesse / Threads . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.4 Client-Server-Architekturen . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.5 Cluster-Computing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.6 Grid-Computing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4 Parallelisierungsebenen 134.1 Parallelität auf Instruktionsebene . . . . . . . . . . . . . . . . . . . . . . . . . 134.2 Parallelität auf Datenebene . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134.3 Parallelität in Schleifen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.4 Parallelität auf Funktionsebene . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5 Parallele Programmiermodelle 165.1 Darstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165.2 Strukturierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175.3 Datenverteilung und Kommunikation . . . . . . . . . . . . . . . . . . . . . . . 17
5.3.1 Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175.3.2 Scatter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185.3.3 Gather . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185.3.4 Reduktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.4 Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195.4.1 Kritische Abschnitte . . . . . . . . . . . . . . . . . . . . . . . . . . . 205.4.2 Barrieren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205.4.3 Locks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
6 Einflussfaktoren Paralleler Programme 216.1 Parallele Skalierbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
6.1.1 Speedup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 216.1.2 Amdahl’sches Gesetz . . . . . . . . . . . . . . . . . . . . . . . . . . . 216.1.3 Gustafson-Gesetz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226.1.4 Karp-Flatt-Metrik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24

6.2 Load Balancing und Scheduling . . . . . . . . . . . . . . . . . . . . . . . . . 256.3 Lokalität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256.4 Speichersynchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
II Bibliotheken und Systeme 28
7 Unified Parallel C 297.1 Verfügbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297.2 Parallelisierungskonzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297.3 Speichermodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 307.4 Synchonisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 327.5 Globale Operatoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
8 Message Passing Interface 338.1 Verfügbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348.2 Parallelisierungskonzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348.3 Speichermodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348.4 Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348.5 Globale Operatoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
9 OpenMP 359.1 Verfügbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 359.2 Parallelisierungskonzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 359.3 Speichermodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 359.4 Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 369.5 Globale Operatoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
10 Andere 3810.1 BOINC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3810.2 BLAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3810.3 PThreads . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3810.4 Parallel Virtual Machine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
11 Vergleichende Betrachtung 4011.1 Implementierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
11.1.1 Matrizenmultiplikation Seriell . . . . . . . . . . . . . . . . . . . . . . 4011.1.2 Matrizenmultiplikation UPC . . . . . . . . . . . . . . . . . . . . . . . 4011.1.3 Matrizenmultiplikation MPI . . . . . . . . . . . . . . . . . . . . . . . 4211.1.4 Matrizenmultiplikation OpenMP . . . . . . . . . . . . . . . . . . . . . 42
11.2 Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4311.3 Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
11.3.1 UPC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4511.3.2 MPI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4611.3.3 OpenMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
III Parallelisierung im Data Mining 49

12 Data Mining Grundlagen 5012.1 Ablaufmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5012.2 Klassifikation der Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 5112.3 Künstliche Neuronale Netze . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
12.3.1 Feed-Forward-Netze . . . . . . . . . . . . . . . . . . . . . . . . . . . 5312.3.2 Selbstorganisierende Karten . . . . . . . . . . . . . . . . . . . . . . . 54
13 Parallele Algorithmen 5613.1 Serielle Selbstorganisierende Karte . . . . . . . . . . . . . . . . . . . . . . . . 5613.2 Parallele Selbstorganisierende Karte . . . . . . . . . . . . . . . . . . . . . . . 5713.3 Performance Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
14 Parallele Modelle 6114.1 Hierarchische Kohonen-Karten . . . . . . . . . . . . . . . . . . . . . . . . . . 61
14.1.1 Konzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6114.1.2 Umsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6414.1.3 Testaufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6714.1.4 Vergleich der Modellqualität . . . . . . . . . . . . . . . . . . . . . . . 7014.1.5 Vergleich der Rechengeschwindigkeit . . . . . . . . . . . . . . . . . . 72
14.2 Feed-Forward-Netze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7314.2.1 Konzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7314.2.2 Umsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7314.2.3 Vergleich der Modellqualität . . . . . . . . . . . . . . . . . . . . . . . 7414.2.4 Vergleich der Rechengeschwindigkeit . . . . . . . . . . . . . . . . . . 75
IV Zusammenfassung und Ausblick 76
V Ehrenwörtliche Erklärung 79
VI Anhang 80
A Schnittstellen und Bibliotheken 81A.1 UPC Konsortium . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81A.2 Compilerübersicht . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
B Messwerte 84B.1 Messwerte Matrizenmultiplikation . . . . . . . . . . . . . . . . . . . . . . . . 84B.2 Messwerte SOM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86B.3 Messwerte Feed-Forward-Netz . . . . . . . . . . . . . . . . . . . . . . . . . . 88B.4 Inhalt der CD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89

Algorithmenverzeichnis1 Matrizenmultiplikation Seriell . . . . . . . . . . . . . . . . . . . . . . . . . . 412 Matrizenmultiplikation MPI Global . . . . . . . . . . . . . . . . . . . . . . . 433 SOM Seriell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574 Parallele SOM mit OpenMP . . . . . . . . . . . . . . . . . . . . . . . . . . . 595 Hierarchische SOM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68

Abbildungsverzeichnis1 Gemeinsames Speichermodell UMA . . . . . . . . . . . . . . . . . . . . . . . 82 Gemeinsames Speichermodell NUMA . . . . . . . . . . . . . . . . . . . . . . 83 Verbindungsnetzwerke . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94 Effiziente Broadcast-Operation . . . . . . . . . . . . . . . . . . . . . . . . . . 185 Effiziente Akkumulations-Operation . . . . . . . . . . . . . . . . . . . . . . . 196 Parallele Skalierbarkeit nach Amdahl . . . . . . . . . . . . . . . . . . . . . . . 227 Parallele Skalierbarkeit nach Amdahl . . . . . . . . . . . . . . . . . . . . . . . 238 Speedup Amdahl vs. Gustafson . . . . . . . . . . . . . . . . . . . . . . . . . . 249 Row- vs. Column-first Ordering . . . . . . . . . . . . . . . . . . . . . . . . . 2610 Message-Passing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3311 OpenMP Fork-Join-Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3612 Performance UPC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4413 Performance OpenMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4514 Performance MPI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4515 Performance MPI vs. MPI Global . . . . . . . . . . . . . . . . . . . . . . . . 4616 Performance OpenMP vs. MPI Global . . . . . . . . . . . . . . . . . . . . . . 4717 Performance OpenMP vs. MPI Global . . . . . . . . . . . . . . . . . . . . . . 4718 CRISP-DM Phasenmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5119 Rechenzeit SOM OpenMP für kleine Karten . . . . . . . . . . . . . . . . . . . 6020 SOM OpenMP Rechenzeiten und Speedup nach Kartengröße . . . . . . . . . . 6021 U-Matrix einer Kohonen-Karte . . . . . . . . . . . . . . . . . . . . . . . . . . 6222 Aufteilung einer SOM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6323 Interpolation der Gewichte . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6324 Clusterqualität vs. Lernrate / Kartengröße . . . . . . . . . . . . . . . . . . . . 6925 U-Matrix Seriell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7126 U-Matrix Hierarchisch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7127 Clusterqualität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7128 Speedup SOM Parallel / Seriell . . . . . . . . . . . . . . . . . . . . . . . . . . 72

Tabellenverzeichnis1 Linpack Top-5 Supercomputer Stand 06/2008 . . . . . . . . . . . . . . . . . . 122 Übersicht UPC-Compiler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 823 OpenMP-fähige Compiler . . . . . . . . . . . . . . . . . . . . . . . . . . . . 834 Matrizenmultiplikation Seriell . . . . . . . . . . . . . . . . . . . . . . . . . . 845 Matrizenmultiplikation UPC . . . . . . . . . . . . . . . . . . . . . . . . . . . 846 Matrizenmultiplikation OpenMP . . . . . . . . . . . . . . . . . . . . . . . . . 857 Matrizenmultiplikation MPI Master-Worker . . . . . . . . . . . . . . . . . . . 858 Matrizenmultiplikation MPI Global . . . . . . . . . . . . . . . . . . . . . . . 869 Clusterqualität (seriell) in Abhängigkeit von Lernrate und Kartengröße . . . . . 8610 Clusterqualität (parallel) in Abhängigkeit von Lernrate und Kartengröße . . . . 8711 Rechenzeit in Abhängigkeit von Kartengröße und Parallelisierungsgrad . . . . 8712 Berechnungszeiten Parallele SOM mit OpenMP . . . . . . . . . . . . . . . . . 8813 Erkennungsrate Teilklassifikatoren . . . . . . . . . . . . . . . . . . . . . . . . 8814 Rechenzeiten und Erkennungsrate n-Fach vs. binär nach Netzgröße . . . . . . . 89

1 Einleitung
1.1 Motivation
Parallelrechner, Mehrkernprozessoren, Grid-Computing und seit geraumer Zeit Cloud-Com-puting sind Schlagworte, die immer dann genannt werden, wenn es um enorme Rechenleistungvon Computern geht. Doch um was handelt es sich dabei genau?
Die Entwicklung schnellerer Prozessoren erfolgte bisher zu einem signifikanten Anteil durchimmer stärkere Miniaturisierung der Schaltkreise, was eine höhere Zahl an Transistoren proChip und höhere Taktraten erlaubte. Die Anzahl der Transistoren verdoppelt sich etwa alle 18Monate. Dieser Zusammenhang wurde 1965 empirisch durch Gordon Moore festgestellt undwird daher auch als Moore’sches Gesetz bezeichnet1. Obwohl der dafür notwendige technolo-gische Aufwand mit der Zeit immer größer wurde, wird diese Steigerungsrate auch in näch-ster Zukunft beibehalten werden können, bis die physikalische Grenze erreicht ist. Eine stetigeSteigerung der Taktraten stellt sich bereits als sehr viel schwieriger heraus, da die damit ver-bundene Abwärme des Prozessors nur sehr schwer zu handhaben ist und bereits Werte erreichthat, die - relativ zur Oberfläche - etwa der Heizleistung einer Herdplatte gleichkommen. Stattdie Geschwindigkeit nur durch höhere Taktraten zu steigern, wurde die Komplexität der Pro-zessoren so weit erhöht, dass bereits mehrere Prozessorkerne auf einem Chip zusammengefasstwerden und somit das, was man unter einem Prozessor-Chip versteht, selbst einen kleinen Par-allelrechner bildet.2 Doch auch eine stetige Erhöhung der Anzahl der Prozessorkerne ist nichtunbedingt sinnvoll. Da Prozessoren heute um ein Vielfaches schneller Arbeiten als Daten vomHauptspeicher zum Prozessor übertragen werden können, sind schnelle, teure und damit kleineZwischenspeicher - Caches - notwendig. Da jeder Prozessorkern einen eigenen Cache besitzt,aber für alle Prozessorkerne ein konsistenter Speicherinhalt sichergestellt sein muss, sind Syn-chronisationsmechanismen notwendig, deren Komplexität mit der Zahl der Prozessoren steigt.Da eine Synchronisation zudem Zeit kosten, schmälert dies den Geschwindigkeitsgewinn durchzusätzliche Prozessorkerne. In bestimmten Fällen können zusätzliche Prozessoren sogar dazuführen, dass ein Programm langsamer wird3. Diese vielfältigen Abhängigkeiten, die so auch ingrößerem Maßstab für Rechennetze gelten, führen dazu, dass Parallelisierung auf technischerwie auch auf softwaretechnischer Seite keine triviale Aufgabe ist.
Parallelrechner waren bis vor wenigen Jahren hauptsächlich in der wissenschaftlichen Simula-tion im Einsatz. Sie erlaubten es erstmals, komplexe Phänomene, deren physische Analyse zuaufwändig, teuer oder gefährlich ist, am Computer zu simulieren. Rund um diese Simulations-technik hat sich ein eigener Wissenschaftszweig etabliert, der unter dem Begriff ComputationalScience bekannt ist.
Beginnend mit der Einführung der ersten Pentium Dual-Core Prozessoren für den Consumer-Markt durch die Firma Intel Corp., sind heute kaum noch aktuelle PCs auf dem Markt zu finden,die nicht mindestens einen Doppelkern-Prozessor enthalten. Obwohl die jeweiligen Ziele, fürdie diese Technologien entwickelt werden, höchst unterschiedlich sind, gleichen sie sich jedochin einem Punkt: die Steigerung der Leistungsfähigkeit von Computersystemen erfolgt nichthauptsächlich durch höhere Taktrate, sondern durch Parallelisierung. Dies wird dazu führen,
1 Vgl.: [RAUBER 2007] S.1002 Vgl.: [RAUBER 2008] S.6ff.3 Vgl.: Linux-Magazin, Ausgabe 11/2008, MySQL
- 1 -

dass verstärkt parallele Programmiertechniken in der Softwareentwicklung eingesetzt werdenmüssen, um die Leistung auch nutzen zu können.
Doch auch durch Parallelisierung können nicht unbegrenzt nutzbar höhere Rechengeschwin-digkeiten erzielt werden. Die Leistungsangaben für Supercomputer mögen einen in Erstaunenversetzen, jedoch ist dabei zu beachten, dass diese Leistung nur für sehr spezielle Program-me auch wirklich genutzt werden kann - nämlich für Programme oder Algorithmen, die sichüberhaupt parallelisieren lassen. Die 1,026 Peta-Flop/s des derzeit weltweit schnellsten Super-computers4 werden nur durch Kombination von über hunderttausend Mehrkern-Prozessorenerreicht. Diese Leistung zur Lösung einer Aufgabe bündeln zu wollen bedeutet, die Aufgabe inüber hunderttausend separate Teilaufgaben zu zerlegen, was weder immer möglich noch stetssinnvoll ist5.
Eine Bürosoftware wird auf einem Parallelrechner nicht unbedingt schneller ausgeführt wer-den, da sie meist nur einen einzigen der vorhandenen Prozessoren nutzen kann. Eine komplexephysikalische Simulation hingegen kann enorm von der Verteilung auf mehrere Prozessorenprofitieren, sofern der Algorithmus diese Aufteilung zulässt. Data-Mining ist ein weiteres An-wendungsgebiet, für das Parallelisierung vorteilhaft sein kann, da sehr große Datenmengen zuverarbeiten sind und dafür komplexe Algorithmen eingesetzt werden.
Die langen Rechenzeiten, die für das Erstellen eines Data-Mining-Modells notwendig sind,behindern eine interaktive und intuitive Arbeitsweise bei der Exploration von Datenmengen.Um Zeit zu sparen, können mehrere unterschiedliche Modelle nach dem Versuch-und-Irrtum-Prinzip parallel berechnet werden. Dies erfordert jedoch große Planungssorgfalt und führt inder Regel zu vielen überflüssigen Berechnungen und damit zur Vergeudung von Rechenzeit.Ein Ansatz ist, die Gesamtrechenzeit eines Experiments zu verringern, in dem sowohl der Data-Mining-Prozess als auch einzelne Algorithmen parallel ausgeführt werden. Vor dem Hinter-grund, dass selbst aktuelle, kostengünstige PCs häufig Mehrkern-Prozessoren enthalten, ist eineParallelisierung umso interessanter.
1.2 Anwendungsgebiete
Für parallele Rechnerarchitekturen lassen sich prinzipiell zwei Anwendungsgebiete unterschei-den:6
Das High-Availability-Computing dient der Zurverfügungstellung ausfallsicherer Dienste, bei-spielsweise für Datenbanken oder Web-Server, indem alle anfallenden Aufgaben nach Bedarfauf einzelne Knoten verteilt werden und dadurch auch der Ausfall einzelner Knoten kompen-siert werden kann.
Das High-Performance-Computing dient vor allem der Bündelung von Rechenleistung, um ei-ne einzelne Aufgabe entweder schneller oder sehr viel genauer zu lösen7. Dies ist auch dasAnwendungsgebiet paralleler Algorithmen und Inhalt dieser Arbeit.
Es existieren eine Reihe von wissenschaftlichen Anwendungen, die in großem Maßstab aufParallelisierung setzen und die durch die Art, diese zu realisieren, in der Öffentlichkeit große
4 Siehe Tabelle 1 auf Seite 12.5 Siehe Kapitel 6 auf Seite 21.6 Vgl.:[BAUKE 2006] S. 31ff.7 Zur Unterscheidung siehe Kapitel 6.
- 2 -

Popularität erlangt haben. Die wohl bekanntesten Vertreter gehören zur Gruppe der auf demBOINC-Framework8 basierenden at-Home-Projekte, bei denen durch ans Internet angeschlos-senen PCs ein Parallelrechner nach dem Master-Worker-Prinzip aufgebaut wird. Da hierbeiauch sehr viele Privat- und Bürorechner zum Einsatz kommen, werden diese Verfahren auch alsDesktop-Grid-Computing bezeichnet. Die bekanntesten Projekte sind Seti@Home9 und Fol-ding@Home10.
Seti@Home dient der Analyse von Radiosignalen auf Muster, die von einer extraterrestrischenIntelligenz stammen könnten. Obwohl bisher erfolglos, ist das Projekt wohl unbestritten derpopulärste Vertreter seiner Art, vor allem unter Privatpersonen. Diese stellen Rechenzeit zurVerfügung, die sie selbst nicht nutzen, indem sie eine spezielle Software - in der ursprünglichenVersion ein Windows-Bildschirmschoner - installieren, der Datenpakete von einem Server lädtund das Ergebnis der Berechnung zurückschickt.
Folding@Home funktioniert auf die gleiche Weise, nur ist das Ziel die Bestimmung der Ter-tiärstruktur11 von Proteinen. Da die Funktion eines Proteins nicht nur von dessen chemischerZusammensetzung - die durch die DNA codierte Aminsosäuresequenz - abhängt, sondern auchvon dessen räumlicher Struktur. Die Ausbildung der dreidimensionalen Struktur aus einer lan-gen Kette von Aminosäuren wird als Faltung bezeichnet, wobei es mehrere Varianten gibt. Nurdie physiologisch korrekte Form kann die ihr zugedachte Funktion erfüllen, falsch gefalteteProteine haben eine reduzierte, keine oder im schlimmsten Fall pathogene Funktion. Es wirdvermutet, dass Krankheiten wie BSE oder die Kreutzfeldt-Jakob-Krankheit durch falsch gefal-tete Proteine (Prionen) hervorgerufen werden. Neben der Erforschung, wie und unter welchenBedingungen der Faltungsprozess genau funktioniert, ist die Bestimmung der Tertiärstruktur einwichtiger Schritt, wenn es gilt, die Funktion eines neu entdeckten Gens des dadurch kodiertenProteins herauszufinden.
Weitere, jedoch weniger populäre Projekte sind zum Beispiel Docking@Home12 zur Unter-suchung der Molekülbindungen zwischen Liganden und Proteinen in der Biochemie sowieNQueens@Home13 zur Lösung des N-Damen-Problems auf Feldern größer als 26x26 Einhei-ten.
1.3 Inhalt der Arbeit
Diese Arbeit befasst sich mit den Anwendung von Parallelisierungstechniken auf dem Gebietdes Data-Mining. Da das Thema dieser Arbeit viele Teilbereiche der Informatik berührt, dieselbst wiederum sehr Umfangreich sind, gliedert sich diese Arbeit in drei Teile, die jedes fürsich eine eigenständige thematische Einheit bilden.
Der Erste Teil stellt eine hauptsächlich konzeptionelle Einführung in die Thematik des par-allelen Rechnens dar. Es werden Begriffe und die theoretischen Grundlagen erläutert sowiegrundlegende Modelle und Konzepte vorgestellt.
Der Zweite Teil widmet sich konkreten Implementationen der im ersten Teil vorgestellten Kon-zepte. Der Schwerpunkt liegt auf Sprachen, Schnittstellen und Bibliotheken für die parallele8 Siehe dazu Kapitel 10.1.9http://setiathome.berkeley.edu/
10http://folding.stanford.edu/11 Vgl.: [KNIPPERS 2001] S. 37ff.12http://docking.cis.udel.edu/13http://nqueens.ing.udec.cl/
- 3 -

Programmierung, die relativ verbreitet und frei verfügbar sind. Es werden ausgewählte Schnitt-stellen vorgestellt, deren Arbeitsweise anhand von Beispielen erläutert und eine erste verglei-chende Bewertung vorgenommen.
Der Dritte Teil behandelt das Thema Data Mining und ausgewählte Algorithmen. Es wird un-tersucht, inwiefern sich Verfahren parallelisieren lassen, welcher Aufwand hierfür notwendigist und welche Resultate erzielt werden können. Insbesondere die Parallelisierung von Data-Mining-Modellen unter Verwendung vorhandener, rein sequentieller Data-Mining-Algorithmenwird untersucht.
1.4 Begriffsklärung
Da aufgrund der Komplexität des Themas und der Vielzahl der angeschnittenen Themen zwangs-läufig Überschneidungen von Begriffen auftreten, werden der Einfachheit halber folgende Be-griffe verwendet:
Als „Prozessor” wird in dieser Arbeit nicht der physikalische Chip, sondern die tatsächlichausführende Recheneinheit bezeichnet. Demzufolge besitzt ein Computer mit einem Mehrkern-Prozessor-Chip eine entsprechende Anzahl an Prozessoren. Diese Sichtweise ist aus dem Grundgünstig, da es sich hier hauptsächlich um die Software-Sicht der parallelen Programmierunggeht, und weniger um die Hardware. Zudem stellt sich ein Mehrkern-Prozessor aus Sicht einesProgramms ebenfalls als eine Anzahl von Einzelprozessoren dar14.
In der Literatur wird zwischen Prozessen und Threads unterschieden, in dieser Arbeit wird nurder Begriff Prozesse verwendet. Der Grund dafür ist, dass sich Prozesse und Threads hauptsäch-lich durch die Art der Ressourcenteilung der Kindprozesse mit dem Elternprozess unterschei-den. Da die hier vorgestellten Programme und Bibliotheken unter Linux eingesetzt werden undLinux nur Prozesse unterstützt, ist die Nutzung von Threads zwangsläufig mit einer Emulationdurch Prozesse verbunden.
14 Vgl.:[RAUBER 2007] S.101
- 4 -

Teil IGrundlagen der parallelenDatenverarbeitung
In diesem Kapitel werden die theoretischen Grundlagen verschiedener Ansätze zur Paralleli-sierung von Algorithmen vorgestellt. Dabei werden konkrete Methoden, Konzepte und Umset-zungsmöglichkeiten gezeigt.
This chapter provides an introduction to the theory of parallel programming, concepts andtechniques. It shows the most popular approaches, methods and concepts for parallelization ofalgorithms.
- 5 -

2 Stufen der Parallelisierung
Unter Parallelisierung wird die Zerlegung eines Problems in Teilprobleme verstanden, die gleich-zeitig von mehreren Prozessoren verarbeitet werden können, so dass die Berechnung wenigerZeit benötigt, als würde sie auf einem einzelnen Prozessor erfolgen. Auf diese Weise lässt sichein gegebenes Problem in kürzerer Zeit oder aber ein größeres Problem in der selben Zeit lösen.
Es lassen sich vier Stufen der Parallelisierung unterschieden15, wobei sich die ersten drei Stu-fen Wortbreite, Pipelining und Superskalare Prozessoren direkt auf die verwendete Technik imProzessorkern beziehen. Die letzte Stufe, Parallelisierung auf Prozessebene, ist eher ein pro-grammtechnisches Konstrukt, das nicht mehr direkt vom Prozessor abhängt16, sondern vomBetriebssystem übernommen wird.
Die Wortbreite ist der Anzahl der Bits, die in einer Operation vom Prozessor gleichzeitig ver-arbeitet werden können und entspricht somit der internen Busbreite und der Registergrösse.Die Wortbreite bestimmt maßgeblich, wie viele Bytes bei einem Speicherzugriff gleichzeitigübertragen werden können. Aktuelle Prozessoren haben eine Wortbreite von 32 oder 64 Bit.
Eine Instruktion besteht aus mehreren atomaren Operationen, die in der Regel mindestens diefolgenden Schritte umfasst:
1. fetch: Laden der nächsten Instruktion aus dem Speicher,
2. decode: Dekodieren der Instruktion,
3. execute: Bestimmung von Quell- und Zieladressen der Operanden und Ausführen der In-struktion,
4. write back: Zurückschreiben des Ergebnisses.
Unter Pipelining versteht man die Ausführung solcher atomaren Operationen durch separa-te Hardwareeinheiten, wodurch eine zeitlich überlappende Ausführung mehrerer Instruktionenmöglich wird. Die Verarbeitung der nachfolgenden Instruktion kann im günstigsten Fall bereitsmit der fetch-Operation beginnen, sobald die vorhergehende Instruktion die decode-Operationdurchläuft. Dies funktioniert jedoch nur dann, wenn keine Abhängigkeiten zwischen den In-struktionen bestehen17.
Superskalare Prozessoren18 erweitern das im Pipelining eingesetzte Konzept separater Hardwa-reeinheiten für atomare Operationen auf Instruktionsebene. Dazu verfügt der Prozessor über se-parate Funktionseinheiten für bestimmte Aufgaben, zum Beispiel für Ganzzahlarithmetik (ALU- arithmetic logical unit), Fließkommaarithmetik (FPU - floatin point unit) und Speicherzugriffe(MMU - memory management unit). Die Beschränkung der parallelen Ausführung hinsichtlichder Abhängigkeiten nachfolgender Instruktionen gelten auch hier.
Moderne Prozessoren enthalten darüber hinaus auch spezielle erweiterte Befehlssätze wie MMX(Multi-Media-Extension) oder SSE (Streaming SIMD Extension)19, die für die parallele Verar-
15 Vgl.: [RAUBER 2007] S.1116 Eine Abhängigkeit besteht insofern, dass der verwendete Prozessor eine virtuelle Speicheradressierung unter-
stützt, was bereits mit der IA-32-Architektur eingeführt wurde. Dies schließt natürlich nicht aus, dass die Prozes-sortechnik Funktionen speziell für die Parallelisierung enthalten kann, wie z.B. Multi- und Hyperthreading.
17 Siehe auch Abschnitt 4.1 auf Seite 13.18 Vgl.: [RAUBER 2007] S.14ff.19 Intel: MMX ab Pentium, SSE ab Pentium III
AMD: 3D-Now! ab K-6, SSE ab Athlon XPIBM/Motorola: VMX/AltiVec ab PowerPC 7400/G4
- 6 -

beitung größerer Datenmengen nach dem SIMD-Prinzip vorgesehen sind. Diese werden in derRegel als Technologie zur Beschleunigung von Multimedia-Applikationen angepriesen, lassensich aber ebenso gut für sinnvolle Rechenaufgaben nutzen.
Die letzte Stufe der Parallelisierung auf Prozessebene ermögliche die parallele Ausführungmehrere Programme. Diese auch als Multitasking bezeichnete Konzept wird in erster Liniedurch das Betriebssystem realisiert. Wenn man vom Parallelcomputing spricht, ist in der Regeleine solche Form der Parallelisierung von Algorithmen gemeint, wobei die Berechnung durchmehrere, parallel ausgeführte Prozesse erfolgt. Dies resultiert nur dann in einer kürzeren Be-rechnungszeit, wenn für jedes Programm auch ein eigener Prozessor zur Verfügung steht.
3 Parallele Architekturen
3.1 Flynnsche Klassifizierung
Die Flynnsche Klassifizierung beschreibt vier idealisierte Klassen von Parallelrechnern basie-rend auf der Anzahl separater Programmspeicher, Datenspeicher und Recheneinheiten sowiederen Abhängigkeiten untereinander. Flynn unterscheidet dabei:20
SISD Single Instruction - Single Data beschreibt einen sequentiellen Rechner, der jeweils ge-nau eine Anweisung auf genau einem Datenelement ausführt. Es existiert keine Parallelität.
MISD Multiple Instruction - Single Data ist ein Konzept, bei dem ein Datenelement nacheinan-der durch verschiedene Anweisungen verarbeitet wird. Dieses Konzept ist eher theoretisch,jedoch kann Pipelining als eine einfache Form von MISD interpretiert werden.
SIMD Single Instruction - Multiple Data entspricht der Verarbeitung mehrerer Datenelementedurch genau eine Anweisung. Dies ist bei Vektorrechnern der Fall, aber auch bei vielenBefehlssatzerweiterungen wie MMX oder SIMD.
MIMD Multiple Instruction - Multiple Data ist die Verarbeitung unterschiedlicher Datenele-mente durch jeweils unterschiedliche Anweisungen. Dies ist bei Superskalaren Prozessorensowie Parallelrechnern der Fall, wobei verschiedene Funktionseinheiten oder Prozessorenparallel verschiedene Aufgaben ausführen.
Diese Klassifizierung lässt sich auch auf die Parallelisierung von Algorithmen anwenden, wobeijeder der als „Multiple” aufgeführten Aspekte einen potenziellen Kandidaten für eine Paralleli-sierung darstellt.
3.2 Speichermodelle
Aus logischer und physischer Sicht lassen sich Modelle mit gemeinsamem und verteiltem Spei-cher unterscheiden. Das physische Speichermodell hat großen Einfluss auf die Ausführungsge-schwindigkeit paralleler Programme, da es Latenz und Bandbreite bei Speicherzugriffen undKommunikationsoperationen bestimmt.
20 Vgl.: [HOFFMANN 2008] S.11f., [RAUBER 2007] S.17ff., [RAUBER 2008] S.27f.
- 7 -

3.2.1 Rechner mit gemeinsamem Speicher
Bei gemeinsamem Speicher existiert ein für alle Prozessoren einheitlicher Adressraum. Ge-meinsamer Speicher stellt hohe Anforderungen an Synchronisations- und Konsistenzmechanis-men, um einen einheitlichen Speicherinhalt zu gewährleisten, was insbesondere zur Vermeidungvon Race-Conditions bei konkurrierendem Schreib-Lese-Zugriffen notwendig ist.
Bei gemeinsamem Speicher kann der Speicherzugriff auf unterschiedliche Weise realisiert wer-den, abhängig davon, wie die Speicherbänke physisch organisiert sind. Der Datenaustauschzwischen Prozessoren und Speicherbänken erfolgt über einen sogenannten Interconnect. Dieserkann z.B. als Bus ausgelegt sein, so dass abwechselnd immer nur ein Prozessor exklusiven Zu-griff auf alle Speichermodule hat. Diese Architektur ist in der Regel bei Mehrkern-Prozessorenanzutreffen, die über einem gemeinsamen Adressbus mit dem Speicher-Controller kommunizie-ren. In diesem Fall ist die Zugriffsgeschwindigkeit stets gleich, daher spricht man von UMA-Architektur (Uniform Memory Access). Das Gegenstück hierzu bildet die NUMA-Architektur(Non-Uniform Memory Access), bei der jedem Prozessor ein eigenes Speichermodul zugeord-net ist, auf das demzufolge schneller zugegriffen werden kann als auf Module anderer Prozes-soren.21
Die physische Verteilung des Speichers muss nicht zwingend mit dem logischen Speichermo-dell übereinstimmen. So kann z.B. ein gemeinsamer Speicher auch über einen Netzwerkver-bund von Rechnern mit jeweils eigenem Speicher realisiert werden, wobei Adressumsetzungund Datenaustausch durch die jeweilige Programmierschnittstelle vorgenommen werden.
Abbildung 1: Gemeinsames Speichermodell UMA
Quelle: [BAUKE 2006] S. 11
Abbildung 2: Gemeinsames Speichermodell NUMA
Quelle: [BAUKE 2006] S. 12.21 Vgl.: [RAUBER 2007] S. 25ff.
- 8 -

3.2.2 Rechner mit verteiltem Speicher
Verteilter Speicher bedeutet, dass alle Prozessoren einen eigenen, privaten Adressraum besit-zen. Für den Datenaustausch muss ein Verbindungsnetzwerk existieren, und er findet nur dannstatt, wenn er explizit ausgelöst wird. Durch die entfallenden Synchronisationsmechanismenbeim Speicherzugriff ermöglicht es diese Architektur, wesentlich mehr Rechner miteinanderzu verbinden. Dies erfolgt allerdings auf Kosten der Übertragungsgeschwindigkeit von Datenzwischen den beteiligten Rechnern, was derartige Rechner für feingranulare Probleme weniggeeignet macht.22
Das Verbindungsnetzwerk hat erheblichen Einfluss auf die Geschwindigkeit. Die bestimmendenFaktoren sind Bandbreite und Latenz. Es kann davon ausgegangen werden, dass mit zunehmen-der physikalischer Entfernung zwischen den Rechnern die Latenz steigt und die Bandbreitesinkt.23
Weiterhin kann durch geschicktes Ausnutzen der Netzarchitektur die Geschwindigkeit vonDatenverteilungs-Operationen wie Broadcast erhöht werden, wenn Nachbarschaftsbeziehungenausgenutzt werden.24
Abbildung 3: Verbindungsnetzwerke
Quelle: [BAUKE 2006] S.26
Durch die Verwendung von lokal zugeordneten Cache-Speichern25 entsteht das Problem derCache-Kohärenz26, da hier lokale Kopien gemeinsamer Variablen vorgehalten werden. Die Än-derung einer Kopie muss nicht nur eine Aktualisierung des gemeinsamen Speichers, sondern
22 Vgl.: [RAUBER 2007] S.21ff.23 Vgl.: [RAUBER 2007] Kapitel 2.5 Verbindungsnetzwerke, S. 32ff.24 Vgl.: [SANTORO 2007] S. 32ff.25 Vgl.: [RAUBER 2007] S.73ff.26 Vgl.: [RAUBER 2007] S.31., S. 84ff.
- 9 -

auch eine Aktualisierung aller anderen Kopien zur Folge haben. Die Steuerung des Cachingerfolgt durch einen eigenen Cache-Controller und ist sowohl für den Prozessor als auch ausProgrammsicht transparent.27 Die Probleme des Cachings lassen sich auf höhere Ebene über-tragen, wenn es um die Entwicklung paralleler Programme und insbesondere von Bibliothekenfür das verteilte Rechnen geht, da hier ebenfalls lokale und entfernte Daten synchronisiert wer-den müssen.
3.3 Prozesse / Threads
Als Prozesse werden Programme bezeichnet, die zu einem gegebenen Zeitpunkt ausgeführtwerden. Ein Prozess besitzt dabei eine Prozessumgebung, die durch eine Datenstruktur im Be-triebssystem realisiert wird und zur Verwaltung des Zustandes sowie der Ressourcen eines Pro-zesses dient. Dazu gehören z.B. die Inhalte der Prozessorregister, verwendete Speicherbereiche,Umgebungsvariablen und geöffnete Dateien. Threads sind ebenfalls eine Form von Prozessen.Sie unterscheiden sich von ’richtigen’ Prozessen nur dadurch, dass sie keinen exklusiven Zugriffauf ihre Ressourcen haben, sondern diese mit anderen Prozessen, insbesondere mit dem Eltern-Prozess, teilen. Prozesse werden unter Unix erzeugt, indem der laufende Prozess durch Aufrufeines fork()-Kommandos in seinem aktuellen Zustand dupliziert wird. Der so entstandene Kind-Prozess kann nun einen anderen Programmzweig ausführen als der Elternprozess, andere Datenberechnen oder seine Prozessumgebung durch die eines anderen Programms ersetzen.
Die Unterscheidung zwischen Prozessen und Threads dient hauptsächlich dazu, den physischenRessourcenbedarf zu reduzieren, da beim Erzeugen eines Prozesses (theoretisch) dessen ge-samte Prozessumgebung (inklusive Speicherbereiche) dupliziert werden muss, was beim Erzeu-gen von Threads nicht der Fall ist. Threads besitzen somit per Definition einen gemeinsamenAdressraum mit dem Elternprozess, währen Prozesse eigene Adressräume besitzen. Allerdingsgibt es Methoden, wie z.B. Shared Memory, durch die auch Prozesse auf gemeinsame Speicher-bereiche zugreifen können.
Letztendlich bilden Prozesse die Grundlage für parallele Programme. Ein paralleler Algorith-mus kann also bereits durch die Methoden, die für die Verwaltung von Prozessen sowie fürdie Interprozesskommunikation vom Betriebssystem bereitgestellt werden, realisiert werden.Allerdings ist die komplette Logik zur Steuerung der einzelnen Prozesse explizit zu implemen-tieren, was zwar sehr viele Möglichkeiten zur Optimierung der Rechengeschwindigkeit, aberauch sehr viel Aufwand und hohe Fehleranfälligkeit bedeutet. Die Verwendung von speziell fürdiesen Zweck optimierten Bibliotheken ist häufig einfacher und auch effizienter.
3.4 Client-Server-Architekturen
Client-Server-Architekturen verwenden als logische Struktur ein Stern-Modell, wobei der Ser-ver im Zentrum steht und direkte Verbindungen mit allen Clients unterhält. Parallelisierungdurch Client-Server-Architekturen werden durch das Master-Worker-Konzept umgesetzt, beidem der Server (Master) Rechenaufgaben oder Daten an die verbundenen Clients (Worker) sen-det und diese das Resultat zurücksenden. Eine derartige Architektur lässt sich durch viele paral-lele Schnittstellen abbilden. Da die Abhängigkeiten zwischen den verbundenen Rechnern wenig
27 Die Existenz eines Caches macht sich durch Unterschiede in der Geschwindigkeit von Speicherzugriffen bemerk-bar. Siehe dazu Kapitel 6.3.
- 10 -

komplex sind, ist diese Architektur relativ einfach zu implementieren und - sofern die physi-schen Ressourcen entsprechend dimensioniert sind - auch für sehr große Rechennetze höchsteffektiv, wie z.B. das Seti@Home-Projekt zeigt.
3.5 Cluster-Computing
Die Idee des Cluster-Computings besteht darin, durch Verwendung handelsüblicher Kompo-nenten und freier Cluster-Software einen Parallelrechner mit verteiltem Speicher zu realisieren.Durch die günstigen Kosten werden derartige Cluster häufig von Universitäten und Forschungs-einrichtungen eingesetzt.
Diese auch als Beowulf-Cluster28 bezeichneten Computer gehen auf das Beowulf-Projekt derNASA von 1994 zurück, bei dem 16 Linux-PCs mittels PVM29 zu einem Parallelrechner ver-bunden wurden.30
Jeder Rechner in einem Cluster wird als Knoten bezeichnet und kann wiederum selbst eine eige-ne parallele Architektur aufweisen. Beowulf-Cluster lassen sich sehr leicht skalieren, da hierfürlediglich weitere Knoten an das Netzwerk angeschlossen und mit der Cluster-Software verse-hen werden müssen. Auf diese Weise lassen sich sogar ältere Rechner noch sinnvoll verwenden.Das Potential dieser Architektur zeigt sich darin, dass sich in Verbindung mit Hochleistungs-Netzwerken und moderner Rechentechnik Cluster bauen lassen, die zu den weltweit schnellstenRechnern zählen. Die Tabelle 1 zeigt die weltweit fünf schnellsten Parallelrechner nach demLinpack-Benchmark. Diese sind natürlich nicht mehr aus einzelnen PCs zusammengesetzt, son-dern bestehen aus Racks mit einer entsprechenden Anzahl von Einschüben, verwenden jedochhandelsübliche Großserientechnik.
Die Bedeutung freier Software für das Cluster-Computing zeigt sich daran, dass viele Herstellerauf eine Linux-Distribution zurückgreifen und diese nach Bedarf anpassen. Da der Quelltext derProgramme frei verfügbar und veränderbar ist, können so zum Beispiel optimierte Kernel (z.B.von Cray und IBM) zum Einsatz kommen.
3.6 Grid-Computing
Als Grid-Computing31 wird eine Form des Cluster-Computings bezeichnet, bei der eine we-sentlich losere Koppelung der Knoten zum Einsatz kommt. Ein derartiges Computing-Grid isthäufig geographisch weit verteilt.
Im deutschen Sprachraum wird häufig mit dem Begriff „Grid” ein regelmäßiges Gitter assoziiertund damit dem Grid-Computing seine Besonderheit durch Verwendung einer speziellen Topo-logie unterstellt. Tatsächlich weisen regelmäßige - und damit auch gitterförmige - Topologienmanche Vorteile für Routingverfahren auf, in Wirklichkeit aber stammt die Bezeichnung „Grid”vom Englischen Begriff für „Stromnetz” (power grid) ab und weist eine beliebige Netzstrukturim Allgemeinen - und auf das Internet im Speziellen - hin. Die Analogie zum Stromnetz ist,dass Ressourcen im Grid transparent zur Verfügung gestellt und durch einfachen Anschluss andas Grid abgerufen werden können.
28http://www.beowulf.org29 Siehe dazu Kapitel 10.4.30 Vgl.: [BAUKE 2006] S.27f.31 Vgl.:[BARTH 2006]
- 11 -
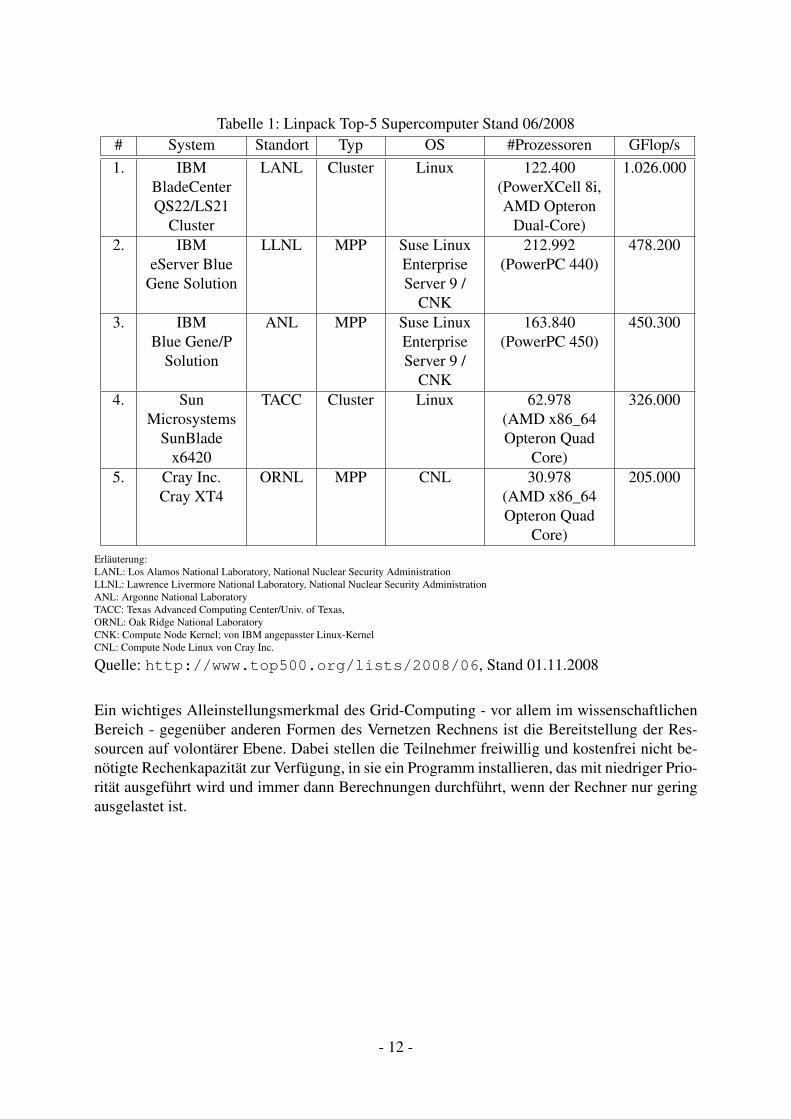
Tabelle 1: Linpack Top-5 Supercomputer Stand 06/2008# System Standort Typ OS #Prozessoren GFlop/s1. IBM
BladeCenterQS22/LS21
Cluster
LANL Cluster Linux 122.400(PowerXCell 8i,AMD Opteron
Dual-Core)
1.026.000
2. IBMeServer Blue
Gene Solution
LLNL MPP Suse LinuxEnterpriseServer 9 /
CNK
212.992(PowerPC 440)
478.200
3. IBMBlue Gene/P
Solution
ANL MPP Suse LinuxEnterpriseServer 9 /
CNK
163.840(PowerPC 450)
450.300
4. SunMicrosystems
SunBladex6420
TACC Cluster Linux 62.978(AMD x86_64Opteron Quad
Core)
326.000
5. Cray Inc.Cray XT4
ORNL MPP CNL 30.978(AMD x86_64Opteron Quad
Core)
205.000
Erläuterung:LANL: Los Alamos National Laboratory, National Nuclear Security AdministrationLLNL: Lawrence Livermore National Laboratory, National Nuclear Security AdministrationANL: Argonne National LaboratoryTACC: Texas Advanced Computing Center/Univ. of Texas,ORNL: Oak Ridge National LaboratoryCNK: Compute Node Kernel; von IBM angepasster Linux-KernelCNL: Compute Node Linux von Cray Inc.
Quelle: http://www.top500.org/lists/2008/06, Stand 01.11.2008
Ein wichtiges Alleinstellungsmerkmal des Grid-Computing - vor allem im wissenschaftlichenBereich - gegenüber anderen Formen des Vernetzen Rechnens ist die Bereitstellung der Res-sourcen auf volontärer Ebene. Dabei stellen die Teilnehmer freiwillig und kostenfrei nicht be-nötigte Rechenkapazität zur Verfügung, in sie ein Programm installieren, das mit niedriger Prio-rität ausgeführt wird und immer dann Berechnungen durchführt, wenn der Rechner nur geringausgelastet ist.
- 12 -

4 Parallelisierungsebenen
Parallelisierung von Programmen kann auf verschiedenen konzeptionellen Ebenen erfolgen, fürdie es verschiedene Ansätze und Nebenbedingungen gibt.
4.1 Parallelität auf Instruktionsebene
Die am dichtesten an der Hardware angesiedelte Ebene, in der eine Parallelisierung möglich ist,ist die Instruktionsparallelität. Unter bestimmten Voraussetzungen kann die Ausführung von In-struktionen eines an sich sequentiellen Programms von einer dafür ausgelegten CPU optimiertund parallel durchgeführt werden. Dabei legt der Scheduler die Reihenfolge der auszuführendenInstruktionen fest. Die zu parallelisierenden Instruktionen dabei lediglich auf folgende Abhän-gigkeiten zu prüfen:32
1. Fluss-Abhängigkeit
2. Anti-Abhängigkeit
3. Ausgabe-Abhängigkeit
Die Prüfung der Abhängigkeiten beschränkt sich jeweils auf die Verwendung der CPU-Registerdurch die einzelnen Instruktionen. Besteht zwischen zwei Instruktionen keine dieser Abhängig-keiten, so können sie parallel ausgeführt werden.
Eine Fluss-Abhängigkeit besteht immer dann, wenn eine Instruktion A einen Wert in ein Re-gister lädt, das anschließend durch Instruktion B als Operand verwendet wird. In diesem Fallmuss Instruktion A zwingend vor Instuktion B ausgeführt werden. Umgekehrt besteht eine Anti-Abhängigkeit, wenn Instruktion B einen Wert in ein Register lädt, dass Instruktion A als Ope-rand verwendet. Eine parallele oder umgekehrte Ausführungsreihenfolge führt in beiden Fällendazu, dass falsche Operanden verwendet werden. Wenn beide Instruktionen das selbe Registerzur Speicherung eines Ergebnisses verwenden, spricht man von Ausgabe-Abhängigkeit. Hierkann eine Parallelisierung dazu führen, dass eine nachfolgende Operation das falsche Ergebnisaus dem Register liest. Es tritt eine sogenannte Race-Condition ein, bei der das Ergebnis davonabhängt, welche Instruktion schneller ausgeführt wurde.
4.2 Parallelität auf Datenebene
Datenparallelität33 liegt immer dann vor, wenn eine Operation auf mehrere, voneinander un-abhängige Elemente oder Datenblöcke angewandt wird. Ein einfaches Beispiel hierfür ist eineSchleife, die ein Array mit Werten initialisiert:
for(int i=0; i<size; i++){array[i]=0;
}
32 Vgl.: [RAUBER 2007] S.120f.33 Vgl.: [RAUBER 2007] S.122f
- 13 -

Es ist in diesem Fall völlig unerheblich, in welcher Reihenfolge auf die einzelnen Array-Elemente zugegriffen wird, das Resultat ist stets dasselbe. Daher ließe sich die Berechnungin 1...size Teilschritte zerlegen, die parallel ausgeführt werden können. Ein anderes Beispiel istdie Matrizenmultiplikation A=B*C. Hier können alle Elemente der Ergebnismatrix A unabhän-gig voneinander berechnet werden. Tatsächlich stellt die Implementierung von Berechnungenals eine Reihe von Matrixoperationen eine der leichtesten Parallelisierungsmöglichkeiten dar,da für diese Operationen bereits parallele Verfahren existieren.34
4.3 Parallelität in Schleifen
Schleifen lassen sich parallelisieren, wenn zwischen einzelnen Iterationen keine Datenabhän-gigkeiten bestehen. Da dadurch die Reihenfolge der Iterationen unwichtig wird, kann jede Ite-ration unabhängig von den anderen ausgeführt werden.35 Dieser Ansatz wird beispielsweisedurch OpenMP verfolgt.
Unter bestimmten Umständen lassen sich auch Schleifen parallelisieren, die Datenabhängigkei-ten enthalten. Voraussetzung hierfür ist, dass sich die einzelnen Iterationen in Gruppen aufteilenlassen, deren Resultate sich zu einem Gesamtergebnis zusammenfassen lassen. So kann z.B. diefolgende Schleife:
for(int i=0; i<100; i++){summe+=array[i];
}
in Teilschleifen aufgeteilt werden, deren Einzelresultate sich durch Addition zu einem Gesamt-ergebnis zusammenfassen lassen:
for(int i=0; i<50; i++){summe1+=array[i];
}for(int i=50; i<100; i++){
summe2+=array[i];}summe=summe1+summe2;
Ist eine derartige Aufteilung möglich, kann die ursprüngliche Schleife ebenfalls parallel aus-geführt werden. Derartige Konstrukte werden von verschiedenen parallelen Schnittstellen un-terstützt, wobei die lokalen Ergebnisvariablen (hier summe) nach Beendigung aller Schleifen-durchläufe unter Verwendung eines sogenannten Reduktionsoperators zusammengefasst wer-den.
4.4 Parallelität auf Funktionsebene
Bei der Verwendung rein funktionaler Programmiersprachen wie z.B. Haskell lassen sich alleFunktionsläufe parallel ausführen, da durch die Konzeption der Sprache Seiteneffekte ausge-schlossen sind. Funktionen bestehen dabei nur aus elementaren Operationen oder aus anderen
34 Siehe Kapitel 10.2.35 Vgl.: [RAUBER 2007]S.123ff.
- 14 -

Funktionen, besitzen Eingabe- und Rückgabewerte, lösen aber keine Aktionen aus. Somit istausgeschlossen, dass eine Funktion die Eingabedaten einer anderen Funktion manipuliert.
Dieses Konzept lässt sich auch auf nicht rein funktionale Programmiersprachen anwenden, so-fern für den parallelisierenden Teil ausschließlich Funktionen verwendet werden, die nur lokaleVariablen verwenden. Dies entspricht der Zerlegung eines Programms sind unabhängige Tei-laufgaben, sogenannte Tasks. 36
36 Vgl.: [RAUBER 2007]S.127ff.
- 15 -

5 Parallele Programmiermodelle
5.1 Darstellung
Die Darstellung der Parallelität innerhalb eines Programms kann an unterschiedlichen Stellenerfolgen. Es lässt sich hier grob zwischen impliziter und expliziter Darstellung unterscheiden,wobei sich jeweils weitere Detaillierungsgrade ableiten lassen.37
Implizite Darstellung
Die implizite Darstellung stellt sich aus Sicht eines Programmierers als einfachere Variante dar.Die Programmierung erfolgt gewohnt in sequentieller Weise, die Parallelisierung wird durchden Compiler oder durch die Eigenschaften der verwendeten Programmiersprache selbst reali-siert.
Die Parallelisierung durch einen Compiler erfordert, dass der Programmablauf und die Verbin-dungen zwischen Variablen analysiert und auf Parallelisierbarkeit hin untersucht werden. Diesist ein sehr komplexer Vorgang und die erzielbaren Resultate sind in der Regel nicht sehr gut.Daher gibt es den Ansatz, im Quellcode Hinweise für den Compiler einzubetten, die Paralleli-sierbare Abschnitte anzeigen. Ein derartiger Ansatz - OpenMP - ist im Kapitel 9 beschrieben.
Eine weitere Möglichkeit der impliziten Darstellung kann zum Beispiel durch die Verwendungrein funktionaler Programmiersprachen wie Haskell geschehen. Eine Parallelisierung kann Er-folgen, indem Funktionen, die als Argumente in anderen Funktionen auftreten, parallel ausge-führt werden, da in rein funktionalen Programmiersprachen Seiteneffekte ausgeschlossen sind.
Explizite Darstellung
Die Varianten der expliziten Darstellung sind zahlreicher als die der impliziten, da es mehr Ein-flussmöglichkeiten auf die konkrete Umsetzung der Parallelisierung gibt, während sich die im-plizite Darstellung letztendlich auf eine sehr formale Beschreibung der Parallelität beschränkt.Es lassen sich die folgenden vier Klassen unterscheiden:
1. Die Parallelität wird durch Konstrukte einer parallelen Programmiersprache (z.B. High Per-formance FORTRAN) oder durch Erweiterungen sequenzieller Programmiersprachen (z.B.OpenMP) explizit dargestellt. Die konkrete Umsetzung der Parallelität erfolgt jedoch durchden Compiler.
2. Die Zerlegung eines Algorithmus in parallele Abschnitte wird ebenfalls explizit vorgenom-men, zum Beispiel durch Verwendung von mehreren Prozessen oder Threads. Die Aufteilungauf einzelne CPUs sowie die Kommunikation zwischen den Prozessen/Threads erfolgt durchden Compiler oder das Betriebssystem.
3. Die Zuordnung einzelner Prozesse/Threads zu den CPUs kann ebenfalls explizit vorgenom-men werden. Dies ist jedoch nur in Ausnahmefällen notwendig, da die Verteilung von Pro-zessen auf CPUs durch das Betriebssystem vorgenommen werden sollte.
4. Die Synchronisation zwischen Prozessen sowie die Kommunikation und der Datenaustauschkönnen ebenfalls explizit dargestellt werden. Als Vorteil wird angesehen, dass diese Methodedie Verwendung eines Standard-Compilers erlaubt und eine sehr effiziente, auf den Anwen-dungsfall abgestimmte Implementierung zulässt, die dafür jedoch einen gewissen Aufwand
37 Vgl.: [RAUBER 2007]S.128ff.
- 16 -

erfordert. Als Beispiel sind Message-Passing-Konzepte wie PVM und MPI zu nennen, aufdie im Abschnitt 10.4 bzw. im Kapitel 8 genauer eingegangen wird.
5.2 Strukturierung
Die Aufgabenverteilung zwischen den Prozessen kann auf verschiedene Weise erfolgen.38 Häu-fig eingesetzte Modelle sind:
Master-Worker: Hier wird die Arbeit durch ein oder mehrere Kindprozesse (Slaves) ausge-führt, die von einem Hauptprozess (Master) gestartet, kontrolliert und koordiniert werden.
Pipelining: Beim Pipelining werden einzelne Prozesse so miteinander verbunden, dass dieAusgabe eines Prozesses direkt als Eingabe des nachfolgenden Prozesses dient, wobei alleProzesse gleichzeitig aktiv sind.
Client-Server: Dieses Modell entspricht in seiner Funktionsweise dem umgekehrten Master-Worker-Modell, mit dem zusätzlichen Unterschied, das es sich auf einen Netzwerkverbundbezieht und es mehrere Server geben kann. Die Rechenleistung wird durch den/die Servererbracht und von den Clients angefordert.
5.3 Datenverteilung und Kommunikation
Die verschiedenen Arten, wie Daten zwischen Tasks ausgetauscht werden, können unter einerMenge von Operationen zusammengefasst werden. Diese werden so oder in ähnlicher Formdurch die meisten parallelen Sprachen und Bibliotheken implementiert. Dabei lassen sich prin-zipiell Einzel- und kollektive (globale) Operationen unterscheiden. Während erstere die asyn-chrone Kommunikation zwischen genau zwei Kommunikationspartnern beschreiben, werdenletztere von alle beteiligten Einheiten gleichzeitig ausgeführt. 39
5.3.1 Broadcast
Eine Broadcast-Operation verteilt Daten X, die einem Task P zugeordnet sind, auf alle anderenTasks, so dass jeder Task nach der Operation exakt die gleichen Daten besitzt.
P1 : XP2 : []...
Pn : []
Broadcast=⇒
P1 : XP2 : X...
Pn : X
Eine Broadcast-Operation ließe sich auch mit n nachrichtenbasierten Einzeloperationen erzie-len. Das Zusammenfassen der Einzeloperationen in eine einzige Broadcast-Anweisung erlaubtes, dem zugrundeliegenden System eine effizientere Reihenfolge für das Verteilen der Daten zuorganisieren, indem die zugrundeliegende Topologie das Verteilungsschema bestimmt. Kriteri-en sind die notwendige Anzahl von Schritten, bis die Daten komplett verteilt sind, und die dafürnotwendige Anzahl von Nachrichten.
38 Vgl.: [RAUBER 2007] S.133f.39 Vgl.: [RAUBER 2007] S.142ff.
- 17 -

Eine als Flooding bezeichnete Methode besteht darin, dass ausgehend von initiierenden Kno-ten, jeder Knoten die Daten genau einmal an alle benachbarten Knoten schickt, sobald er sieempfangen hat. Die maximale nötige Anzahl von Schritten entspricht hier dem Durchmesserdes Graphen.40 Die Anzahl der Nachrichten hängt von der Topologie ab. Ist die Topologie bei-spielsweise ein kompletter Graph, genügt genau ein Schritt, da jeder Empfänger direkt erreichtwerden kann.
Abbildung 4: Effiziente Broadcast-Operation
Quelle: [BAUKE 2006] S.174
5.3.2 Scatter
Eine Scatter-Operation verteilt Daten X, die einem Prozess P zugeordnet sind, in Blöcken x :x ∈ X gleichmäßig auf alle Prozesse, so dass jeder Prozess eine eindeutige Teilmenge derursprünglichen Daten hält. In der Regel wird eine direkte Zuordnung Prozess-Nummer = Block-Nummer vorgenommen, aber auch anderer Verteilungsmuster sind möglich.
P1 : XP2 : []...
Pn : []
Scatter=⇒
P1 : x1
P2 : x2
...Pn : xn
5.3.3 Gather
Die Gather-Operation entspricht einer umgekehrten Scatter-Operation. Dabei werden die Blöckex1...xn aller Prozesse im Datenbereich eines einzelnen Prozesses zusammengefasst. Sie wirdals Gather-all-Operation bezeichnet, wenn das Zusammenfassen der Blöcke für jeden Prozessgeschieht, die Prozesse also nach der Operation jeweils über alle Datenblöcke verfügen.
P1 : x1
P2 : x2
...Pn : xn
Gather=⇒
P1 : [x1, ..., xn]
P2 : x2
...Pn : xn
40 Vgl.: [SANTORO 2007] S.13f.
- 18 -

P1 : x1
P2 : x2
...Pn : xn
Gather−All=⇒
P1 : [x1, ..., xn]P2 : [x1, ..., xn]
...Pn : [x1, ..., xn]
5.3.4 Reduktion
Eine Reduktions- oder Akkumulations-Operation führt eine Funktion f() über den Daten allerProzesse aus und stellt das Ergebnis in einem Prozess zur Verfügung. Typischerweise werdenfür f() arithmetische Funktionen (Summe, Produkt, Durchschnitt) oder Vergleichoperationen(größtes Element, kleinstes Element) implementiert.
P1 : x1
P2 : x2
...Pn : xn
Akkumulation=⇒
P1 : f(x1, ..., xn)
P2 : x2
...Pn : xn
Der Sinn kollektiver Reduktionsfunktionen liegt ebenfalls in der Erzielung einer höheren Ge-schwindigkeit durch Verringerung der Anzahl notwendiger Kommunikationsschritte gegenüberder entsprechenden Anzahl von Einzeloperationen oder Synchronisierungsoperationen. EineAkkumulationsfunktion muss sowohl kommutativ als auch assoziativ sein, da die Reihenfolgeder Einzeloperationen nicht vorhergesagt werden kann.
Abbildung 5: Effiziente Akkumulations-Operation
Quelle: [BAUKE 2006] S.185
5.4 Synchronisation
Eine parallele Ausführung bedeutet nicht, dass Programme auch synchron ausgeführt werden.Neben unterschiedlichen Prozessorgeschwindigkeiten und der jeweiligen Prozessorauslastunggibt es eine Reihe von Störfaktoren, die Einfluss auf die tatsächliche Ausführungsgeschwindig-keit haben. Daher kann man nicht davon ausgehen, dass sich eine gemeinsame Ressource - wiezum Beispiel ein Speicherinhalt - in einem stets definierten Zustand befindet. Wenn ein Prozesseinen Abschnitt erreicht, der einen definierten Zustand voraussetzt, muss dieser zunächst her-gestellt werden. Dies wird durch Synchronisationsmechanismen erreicht, die dafür sorgen, dasssich die zu synchronisierende Ressource zu einem bestimmten Zeitpunkt für jeden beteiligten
- 19 -

Prozess in einem definierten Zustand befindet. Beispielsweise stellt die Speichersynchronisati-on identische Speicherinhalte für alle Prozesse sicher, eine Ablaufsynchronisation sorgt dafür,dass alle parallelen Prozesse die exakt gleiche Stelle im Programmtext erreicht haben.
5.4.1 Kritische Abschnitte
Bei Race-Conditions ist der Zustand einer Ressource davon abhängig, welche Prozesse in wel-cher Reihenfolge darauf zugreifen. Insbesondere nicht-atomare Anweisungen, die während derAusführung unterbrochen werden können, sind dafür anfällig. Solche Programmabschnitte wer-den als „Kritische Abschnitte” bezeichnet. Für die Koordinierung der Prozesse sind eine Reihevon Verfahren bekannt.41 Parallele Sprachen und Bibliotheken stellen in der Regel Möglich-keiten zum Kennzeichnen kritischer Abschnitte bereit, so dass der Programmierer keine eigeneZugriffssteuerung implementieren muss. Probleme bereiten nur solche kritischen Abschnitte,die vom Programmierer nicht als kritisch erkannt werden, da die dadurch resultierenden Pro-grammfehler sporadisch, an verschiedenen Programmstellen und schlecht reproduzierbar auf-treten können, was den Anschein zufälliger Fehler erzeugt. Weiterhin kann es vorkommen, dassoptimierende Compiler Code erzeugen, der nicht der Ausführungsreihenfolge der Anweisungenim Quelltext entspricht.
5.4.2 Barrieren
Barrieren sind eine Methode der Ablaufsynchronisation. Sie stellen sicher, dass sich alle Pro-zesse zu einem bestimmten Zeitpunkt an der selben Stelle im Programmtext - der Barriere - be-finden. Nachdem alle Prozesse die blockierende Barriere erreicht haben, werden sie synchronfortgesetzt. Dabei kann es vorkommen, dass einzelne Prozesse sehr lange auf andere wartenmüssen. Nicht-blockierende Barrieren dagegen erlauben es einem Prozess, mit der Ausführungvon Programmcode fortzufahren, der nicht von anderen Prozessen abhängig ist, sofern diesemindestens eine bestimmte Stelle im Programmcode erreicht haben. Auf diese Weise kann einPerformancegewinn erzielt werden, da die Wartezeiten verkürzt werden können.
5.4.3 Locks
Der konkurrierende Zugriff auf Ressourcen kann durch Locking-Mechanismen gesteuert wer-den. Locks stellen eine Möglichkeit dar, Race-Conditions zu vermeiden, da der Zugriff aufgemeinsame Ressourcen exklusiv erfolgt. Anders als kritische Abschnitte können Locks überverschiedene Programmteile hinweg aufrecht erhalten werden. So kann an einer Stelle ein Lockerzeugt und später an einer anderen Stelle wieder freigegeben werden. Die Verantwortung fürdie Freigabe eines Locks liegt allein beim Programmierer, daher ist die Verwendung potentiellAnfällig für Deadlock-Situationen.
41 Vgl. hierzu: [CARVER 2006] S. 46ff.
- 20 -

6 Einflussfaktoren Paralleler Programme
6.1 Parallele Skalierbarkeit
Durch Parallelisierung soll in der Regel ein Geschwindigkeitszuwachs in der Form erzielt wer-den, dass pro Zeiteinheit mehr Rechenoperationen durchgeführt werden. Ähnlich der Fragenach den Grenzkosten oder dem Grenznutzen in der BWL und VWL stellt sich auch hier dieFrage, welcher Aufwand - vor allem in Form zusätzlicher Rechner oder Prozessoren - für eineParallelisierung notwendig ist und in welchem Verhältnis dieser zum erzielten Geschwindig-keitsgewinn steht.
6.1.1 Speedup
Geht man davon aus, dass ein parallelisierbares Programm auf einem Prozessor die RechenzeitT1 benötigt, so ist die Rechenzeit auf p Prozessoren im optimalen Fall T1/p. ParallelisierbareAbschnitte machen in der Regel nur einen Teil des gesamten Programms aus, so dass ein be-stimmter Anteil der Rechenzeit immer für einen sequentiellen Teil verbraucht wird, der konstantist. Durch Erhöhung der Parallelität nimmt im parallelen Teil die Rechenzeit pro Prozessor ab,was beabsichtigt ist, wodurch der relative Anteil der sequentiellen Abschnitte größer wird. Dasführt dazu, dass eine obere Grenze für den erzielbaren Geschwindigkeitszuwachs durch Hin-zunahme eines weiteren Prozessor existiert. Dieser Effekt wird nach seinem Entdecker GeneAmdahl als Amdahl’sches Gesetz42 bezeichnet.
Ist für Eingaben der Größe n die Rechenzeit auf einem Prozessor T1(n) und die Rechenzeitauf p Prozessoren Tp(n), so ergibt sich der theoretisch erzielbare Geschwindigkeitszuwachs(Speedup) aus:43
Sp(n) =T1(n)
Tp(n)(1)
Der höchste theoretisch erzielbare Speedup ist Sp(n) = p, was einem linear skalierendenProgramm entspricht. In der Praxis kann jedoch ein Speedup Sp(n) > p auftreten, was alssuperlinearer Speedup bezeichnet wird. Dies kann dadurch eintreten, dass die Problemgrößebzw. Datenmenge pro Prozessor so klein wird, dass geschwindigkeitssteigernde Effekte durchCaching-Mechanismen eintreten 44. Es ließe sich auch umgekehrt argumentieren, nämlich dassim Regelfall geschwindigkeitssenkende Effekte durch Verwendung langsamerer Komponentenaußerhalb des schnellen Cache bei zu großen Datenmengen die Ursache sind.
6.1.2 Amdahl’sches Gesetz
Amdahl nimmt einen Faktors f für den seriellen Anteil45 eines Programmlaufs an, so dass sichdie parallele Rechenzeit aus der Summe des nicht parallelisierbaren Anteils und des paralleli-
42 Vgl.: [CHAPMAN 2008] S. 33f., [CHANDRA] S. 173f., [BAUKE 2006] S.10ff., [RAUBER 2008] S. 170ff.,[RAUBER 2007] S.37f., [HOFFMANN 2008] S.13ff., [EM KARNIADAKIS 2000] S.39f.
43 Vgl.: [RAUBER 2007] S.16844 Vgl.: [RAUBER 2008] S.37, [RAUBER 2007] S.16945 In der Literatur wird auch statt des seriellen Anteils f der parallele Anteil verwendet. Der Teiler ist dann entspre-
chend umzustellen.
- 21 -
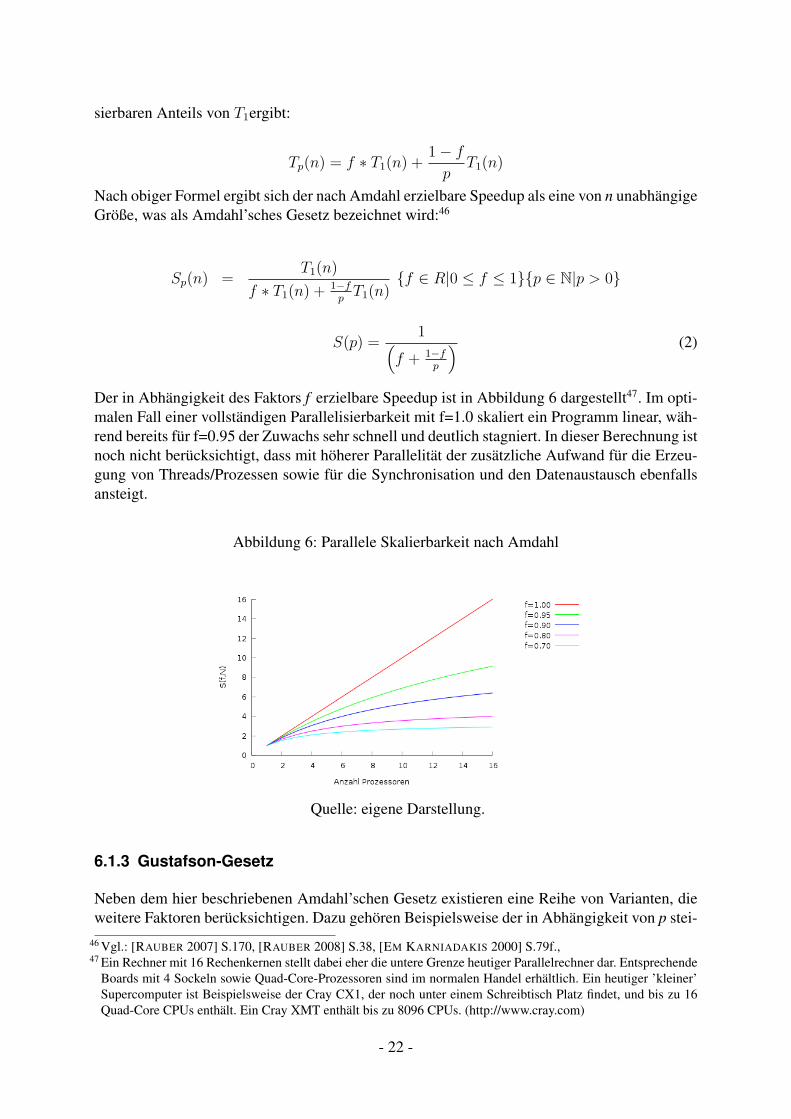
sierbaren Anteils von T1ergibt:
Tp(n) = f ∗ T1(n) +1− fp
T1(n)
Nach obiger Formel ergibt sich der nach Amdahl erzielbare Speedup als eine von n unabhängigeGröße, was als Amdahl’sches Gesetz bezeichnet wird:46
Sp(n) =T1(n)
f ∗ T1(n) + 1−fpT1(n)
{f ∈ R|0 ≤ f ≤ 1}{p ∈ N|p > 0}
S(p) =1(
f + 1−fp
) (2)
Der in Abhängigkeit des Faktors f erzielbare Speedup ist in Abbildung 6 dargestellt47. Im opti-malen Fall einer vollständigen Parallelisierbarkeit mit f=1.0 skaliert ein Programm linear, wäh-rend bereits für f=0.95 der Zuwachs sehr schnell und deutlich stagniert. In dieser Berechnung istnoch nicht berücksichtigt, dass mit höherer Parallelität der zusätzliche Aufwand für die Erzeu-gung von Threads/Prozessen sowie für die Synchronisation und den Datenaustausch ebenfallsansteigt.
Abbildung 6: Parallele Skalierbarkeit nach Amdahl
Quelle: eigene Darstellung.
6.1.3 Gustafson-Gesetz
Neben dem hier beschriebenen Amdahl’schen Gesetz existieren eine Reihe von Varianten, dieweitere Faktoren berücksichtigen. Dazu gehören Beispielsweise der in Abhängigkeit von p stei-
46 Vgl.: [RAUBER 2007] S.170, [RAUBER 2008] S.38, [EM KARNIADAKIS 2000] S.79f.,47 Ein Rechner mit 16 Rechenkernen stellt dabei eher die untere Grenze heutiger Parallelrechner dar. Entsprechende
Boards mit 4 Sockeln sowie Quad-Core-Prozessoren sind im normalen Handel erhältlich. Ein heutiger ’kleiner’Supercomputer ist Beispielsweise der Cray CX1, der noch unter einem Schreibtisch Platz findet, und bis zu 16Quad-Core CPUs enthält. Ein Cray XMT enthält bis zu 8096 CPUs. (http://www.cray.com)
- 22 -
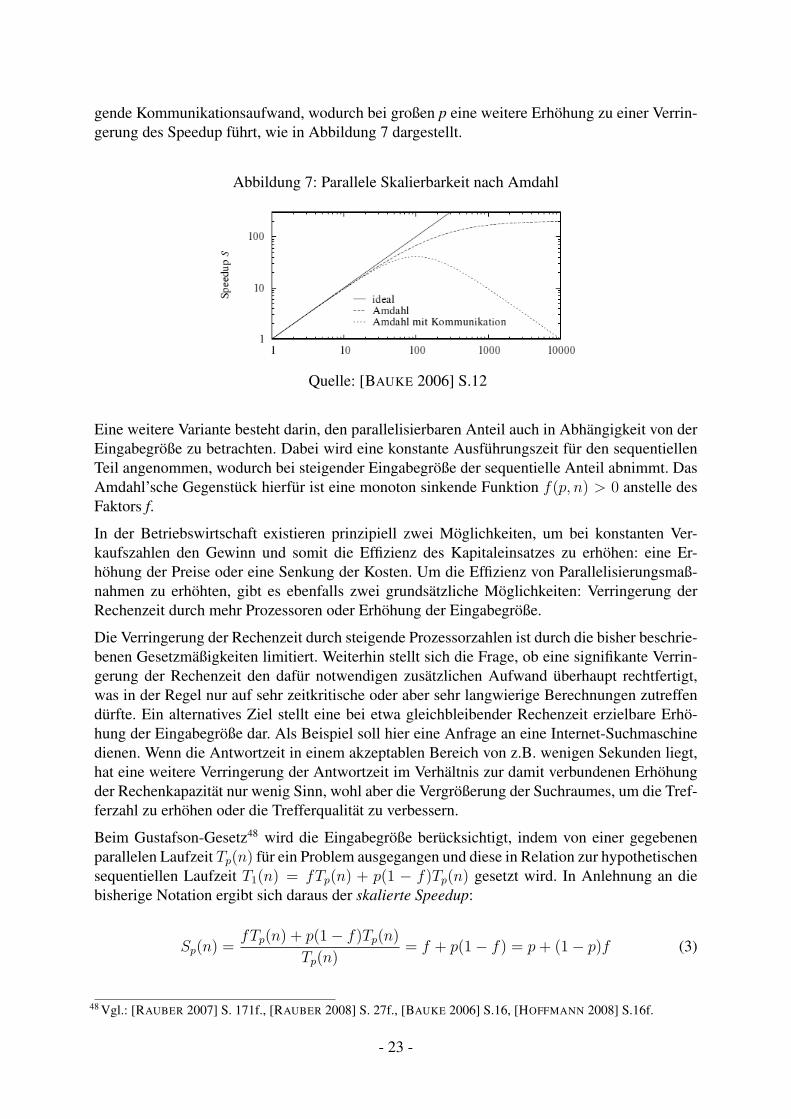
gende Kommunikationsaufwand, wodurch bei großen p eine weitere Erhöhung zu einer Verrin-gerung des Speedup führt, wie in Abbildung 7 dargestellt.
Abbildung 7: Parallele Skalierbarkeit nach Amdahl
Quelle: [BAUKE 2006] S.12
Eine weitere Variante besteht darin, den parallelisierbaren Anteil auch in Abhängigkeit von derEingabegröße zu betrachten. Dabei wird eine konstante Ausführungszeit für den sequentiellenTeil angenommen, wodurch bei steigender Eingabegröße der sequentielle Anteil abnimmt. DasAmdahl’sche Gegenstück hierfür ist eine monoton sinkende Funktion f(p, n) > 0 anstelle desFaktors f.
In der Betriebswirtschaft existieren prinzipiell zwei Möglichkeiten, um bei konstanten Ver-kaufszahlen den Gewinn und somit die Effizienz des Kapitaleinsatzes zu erhöhen: eine Er-höhung der Preise oder eine Senkung der Kosten. Um die Effizienz von Parallelisierungsmaß-nahmen zu erhöhten, gibt es ebenfalls zwei grundsätzliche Möglichkeiten: Verringerung derRechenzeit durch mehr Prozessoren oder Erhöhung der Eingabegröße.
Die Verringerung der Rechenzeit durch steigende Prozessorzahlen ist durch die bisher beschrie-benen Gesetzmäßigkeiten limitiert. Weiterhin stellt sich die Frage, ob eine signifikante Verrin-gerung der Rechenzeit den dafür notwendigen zusätzlichen Aufwand überhaupt rechtfertigt,was in der Regel nur auf sehr zeitkritische oder aber sehr langwierige Berechnungen zutreffendürfte. Ein alternatives Ziel stellt eine bei etwa gleichbleibender Rechenzeit erzielbare Erhö-hung der Eingabegröße dar. Als Beispiel soll hier eine Anfrage an eine Internet-Suchmaschinedienen. Wenn die Antwortzeit in einem akzeptablen Bereich von z.B. wenigen Sekunden liegt,hat eine weitere Verringerung der Antwortzeit im Verhältnis zur damit verbundenen Erhöhungder Rechenkapazität nur wenig Sinn, wohl aber die Vergrößerung der Suchraumes, um die Tref-ferzahl zu erhöhen oder die Trefferqualität zu verbessern.
Beim Gustafson-Gesetz48 wird die Eingabegröße berücksichtigt, indem von einer gegebenenparallelen Laufzeit Tp(n) für ein Problem ausgegangen und diese in Relation zur hypothetischensequentiellen Laufzeit T1(n) = fTp(n) + p(1 − f)Tp(n) gesetzt wird. In Anlehnung an diebisherige Notation ergibt sich daraus der skalierte Speedup:
Sp(n) =fTp(n) + p(1− f)Tp(n)
Tp(n)= f + p(1− f) = p+ (1− p)f (3)
48 Vgl.: [RAUBER 2007] S. 171f., [RAUBER 2008] S. 27f., [BAUKE 2006] S.16, [HOFFMANN 2008] S.16f.
- 23 -
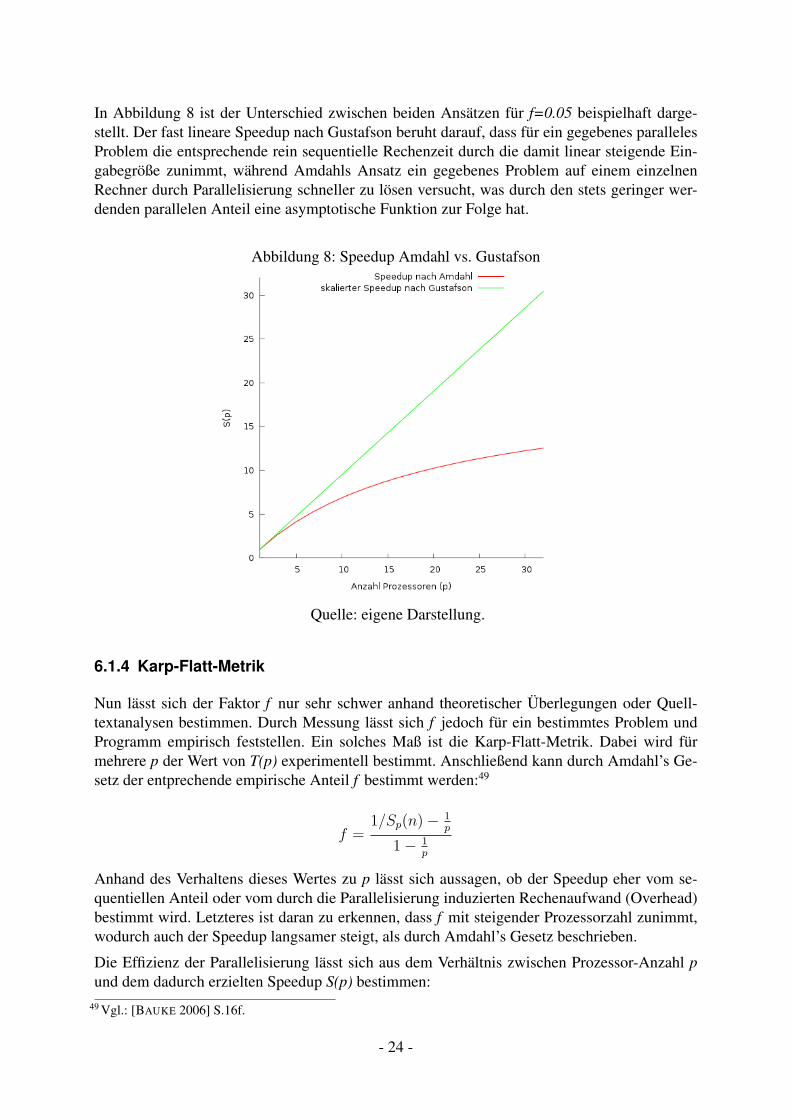
In Abbildung 8 ist der Unterschied zwischen beiden Ansätzen für f=0.05 beispielhaft darge-stellt. Der fast lineare Speedup nach Gustafson beruht darauf, dass für ein gegebenes parallelesProblem die entsprechende rein sequentielle Rechenzeit durch die damit linear steigende Ein-gabegröße zunimmt, während Amdahls Ansatz ein gegebenes Problem auf einem einzelnenRechner durch Parallelisierung schneller zu lösen versucht, was durch den stets geringer wer-denden parallelen Anteil eine asymptotische Funktion zur Folge hat.
Abbildung 8: Speedup Amdahl vs. Gustafson
Quelle: eigene Darstellung.
6.1.4 Karp-Flatt-Metrik
Nun lässt sich der Faktor f nur sehr schwer anhand theoretischer Überlegungen oder Quell-textanalysen bestimmen. Durch Messung lässt sich f jedoch für ein bestimmtes Problem undProgramm empirisch feststellen. Ein solches Maß ist die Karp-Flatt-Metrik. Dabei wird fürmehrere p der Wert von T(p) experimentell bestimmt. Anschließend kann durch Amdahl’s Ge-setz der entprechende empirische Anteil f bestimmt werden:49
f =1/Sp(n)− 1
p
1− 1p
Anhand des Verhaltens dieses Wertes zu p lässt sich aussagen, ob der Speedup eher vom se-quentiellen Anteil oder vom durch die Parallelisierung induzierten Rechenaufwand (Overhead)bestimmt wird. Letzteres ist daran zu erkennen, dass f mit steigender Prozessorzahl zunimmt,wodurch auch der Speedup langsamer steigt, als durch Amdahl’s Gesetz beschrieben.
Die Effizienz der Parallelisierung lässt sich aus dem Verhältnis zwischen Prozessor-Anzahl pund dem dadurch erzielten Speedup S(p) bestimmen:
49 Vgl.: [BAUKE 2006] S.16f.
- 24 -

E(p) =T (1)
pT (p)=S(p)
p
6.2 Load Balancing und Scheduling
Die Aufteilung einer Rechenaufgabe in Teilaufgaben und deren Zuordnung zu Prozessen kannauf verschieden Weise erfolgen. Dies wird als Scheduling bezeichnet. Die Aufteilung erfolgtanhand einer Strategie mit dem Ziel, für eine Aufgabe eine möglichst effiziente Ressourcennut-zung zu erzielen. Es lassen sich statische und dynamische Scheduling-Strategien unterscheiden.Die Verwendung einer bestimmten Strategie kann Auswirkungen auf die Gestaltung des Pro-gramms haben.
Die verwendete Scheduling-Strategie hat Auswirkungen auf die Ausführungsgeschwindigkeitparalleler Programme. Insbesondere statische Strategien sind anfällig für Verzögerungen beieinzelnen Prozessen. Die gesamte Abarbeitungszeit ist dabei vom langsamsten Prozess abhän-gig. Dies führt dazu, dass eine sehr starke Parallelisierung oft nicht den erwarteten Effekt hat.Besonders wenn die Anzahl der Prozesse sich der Zahl verfügbarer Prozessoren annähert, steigtdie Wahrscheinlichkeit, dass einzelne Prozesse sich Ressourcen mit anderen Prozessen teilenmüssen, wodurch diese eine längere Zeit zur Beendigung ihrer Aufgabe benötigen.
Dynamische Strategien oder das Master-Worker-Modell haben den Vorteil, dass Rechenaufga-ben an die gerade verfügbaren Prozesse / Prozessoren verteilt werden. Verzögerungen einzel-ner Prozesse können leicht kompensiert werden, indem schnellere Prozesse zusätzliche Anteileübernehmen.50
6.3 Lokalität
Unter Lokalität versteht man, dass die zu verarbeitenden Daten sich im direkten Zugriff desVerarbeiters befinden. Tun sie es nicht, müssen sie erst dorthin übertragen werden, was Zeitauf-wändig ist. Diese Beschreibung ist sehr allgemein und kann sich auf unterschiedliche Bereichebzw. Ebenen beziehen. Je höher diese Ebene angesiedelt ist, desto größer ist der Einfluss derLokalität auf die Rechengeschwindigkeit, da der Aufwand zur Datenübertragung steigt und dieÜbertragungsgeschwindigkeit in der Regel sinkt.
In einem Computercluster aus mehreren Knoten und einem Verbindungsnetzwerk sind Datenlokal, wenn sie im Speicher des Knoten verfügbar sind, der sie Verarbeitet. Auf der Ebene ei-nes Parallelrechners mit mehreren Prozessoren sind Daten lokal, wenn sie sich im durch denProzessor adressierbaren physikalischen Speicher befinden, auf Ebene eines Prozessors oderProzessorkernes dann, wenn sie sich in dessen Cache oder gar in den Prozessorregistern befin-den.
Der Einfluss der Lokalität lässt sich bereits in seriellen Programmen feststellen. Die Geschwin-digkeit, mit der auf Daten zugegriffen werden kann, hängt sehr stark davon ab, ob der Prozessordiese erst aus dem relativ langsamen Hauptspeicher lesen muss, oder ob die Daten bereits imdeutlich schnelleren 2nd-Level oder gar 1st-Level Cache zur Verfügung stehen. Caching erfolgtin der Regel blockweise, so dass beim erstmaligen Zugriff auf eine Speicherzelle im RAM auch
50 Zum Vergleich der Strategien siehe Kapitel 11.2.
- 25 -
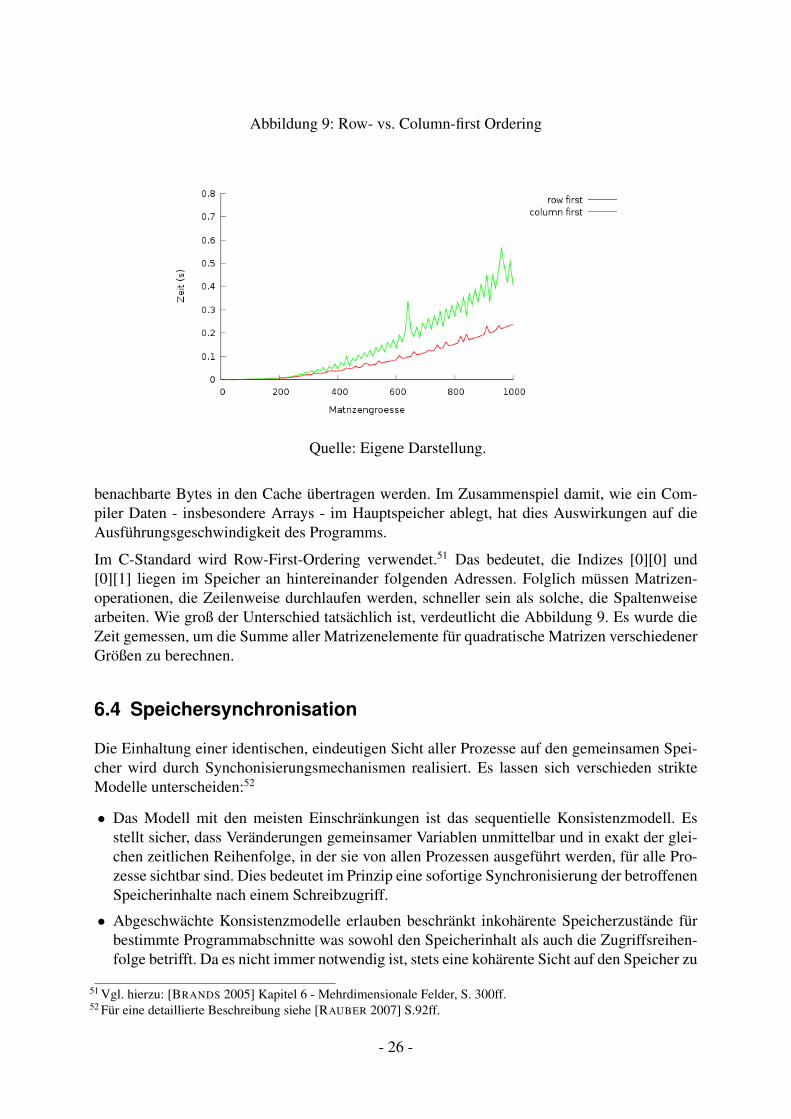
Abbildung 9: Row- vs. Column-first Ordering
Quelle: Eigene Darstellung.
benachbarte Bytes in den Cache übertragen werden. Im Zusammenspiel damit, wie ein Com-piler Daten - insbesondere Arrays - im Hauptspeicher ablegt, hat dies Auswirkungen auf dieAusführungsgeschwindigkeit des Programms.
Im C-Standard wird Row-First-Ordering verwendet.51 Das bedeutet, die Indizes [0][0] und[0][1] liegen im Speicher an hintereinander folgenden Adressen. Folglich müssen Matrizen-operationen, die Zeilenweise durchlaufen werden, schneller sein als solche, die Spaltenweisearbeiten. Wie groß der Unterschied tatsächlich ist, verdeutlicht die Abbildung 9. Es wurde dieZeit gemessen, um die Summe aller Matrizenelemente für quadratische Matrizen verschiedenerGrößen zu berechnen.
6.4 Speichersynchronisation
Die Einhaltung einer identischen, eindeutigen Sicht aller Prozesse auf den gemeinsamen Spei-cher wird durch Synchonisierungsmechanismen realisiert. Es lassen sich verschieden strikteModelle unterscheiden:52
• Das Modell mit den meisten Einschränkungen ist das sequentielle Konsistenzmodell. Esstellt sicher, dass Veränderungen gemeinsamer Variablen unmittelbar und in exakt der glei-chen zeitlichen Reihenfolge, in der sie von allen Prozessen ausgeführt werden, für alle Pro-zesse sichtbar sind. Dies bedeutet im Prinzip eine sofortige Synchronisierung der betroffenenSpeicherinhalte nach einem Schreibzugriff.
• Abgeschwächte Konsistenzmodelle erlauben beschränkt inkohärente Speicherzustände fürbestimmte Programmabschnitte was sowohl den Speicherinhalt als auch die Zugriffsreihen-folge betrifft. Da es nicht immer notwendig ist, stets eine kohärente Sicht auf den Speicher zu
51 Vgl. hierzu: [BRANDS 2005] Kapitel 6 - Mehrdimensionale Felder, S. 300ff.52 Für eine detaillierte Beschreibung siehe [RAUBER 2007] S.92ff.
- 26 -

gewährleisten, z.B. wenn nacheinander mehrere Schreibzugriffe erfolgen und nur der letzteZugriff das endgültige Resultat darstellt, kann so die Ausführungsgeschwindigkeit von Pro-grammen deutlich erhöht werden. Die Synchronisierung erfolgt in solchen Fällen explizitnach Beendigung des jeweiligen Programmabschnitts.
Parallele Bibliotheken und Programmiersprachen unterstützen in der Regel verschiedene Kon-sistenzmodelle. Da diese direkte Auswirkungen auf die Funktionsweise und Ausführungsge-schwindigkeit eines parallelen Programms haben, ist dieses Thema auch aus Sicht eines Pro-grammierers relevant.
- 27 -

Teil IIBibliotheken und Systeme
Es existieren eine Reihe von Programmbibliotheken und Compilern, die das entwickeln Paral-leler Programme unterstützen sollen. Viele davon sind GPL-Lizensiert und frei verfügbar. Indiesem Teil wird auf konkrete Implementierungen und Schnittstellen für das entwickeln paralle-ler Algorithmen unter C/C++ eingegangen.
Development of parallel programs is supported by various programming libraries, interfacesand compilers. Many of them are license under the GPL Public License, which makes themfreely available. This chapter provides an introduction to interfaces and programming librariesfor the C/C++ programming language.
- 28 -

7 Unified Parallel C
Unified Parallel C (UPC)53 erweitert ANSI C um Konstrukte, die einen Einsatz auf Hochleistungs-Parallelrechnern ermöglichen54. Dafür wurden der Sprache C folgende Erweiterungen hinzuge-fügt:
• Ein explizites paralleles Ausführungsmodell
• Ein gemeinsamer Adressraum
• Synchronisationsmechanismen
• Speicherkonsistenzmodelle
• Eine angepasste Speicherverwaltung
Die Spezifikation von UPC wurde von einem Konsortium aus Unternehmen, Bildungsträgernund Regierungsorganisationen der USA entwickelt. Die Zusammensetzung des Konsortiums istder Übersicht im Anhang A.2 zu entnehmen.
Um UPC nutzen zu können, sind spezielle Compiler erforderlich. Diese basieren häufig aufquelloffenen C/C++ Compilern, die um UPC-Konstrukte erweitert wurden. In Tabelle 2 aufSeite 82 sind einige aktuell verfügbare Compiler und die jeweils unterstützten Betriebssystemeund Rechnerarchitekturen aufgeführt. Der in dieser Arbeit verwendete Compiler ist der GCCUPC in der Version 4.0.3.
7.1 Verfügbarkeit
Ein UPC-Compiler für Linux-Systeme basierend auf dem GCC ist im Internet verfügbar undkann kostenfrei heruntergeladen werden. Neben bereits übersetzten Paketen für verschiedeneProzessoren und Distributionen ist auch ein Quellpaket vorhanden.55
Nach dem Entpacken der Quellen ist ein separates Verzeichnis anzulegen, in dem die Überset-zung erfolgt, typischerweise “build” genannt. Die Konfiguration der Make-Umgebung erfolgtmittels des mitgelieferten configure-Skriptes. Um nicht in Konflikt mit existierenden GCC-Compilern zu kommen, ist es empfehlenswert, den UPC in einem separaten Verzeichnis zuinstallieren, z.B. /usr/local/upc. Die Befehle zum Übersetzen der Quellen und anschließendemInstallieren sind:
$ t a r −x z f upc − 4 . 0 . 3 . 5 . s r c . t a r . gz && cd upc −4 . 0 . 3 . 5 && mkdirb u i l d && cd b u i l d
$ . . / c o n f i g u r e −−p r e f i x = / u s r / l o c a l /$ make && make i n s t a l l
7.2 Parallelisierungskonzept
Die Parallelisierung mittels UPC erfolgt durch Threads. Sie unterscheidet sich jedoch von her-kömmlicher Thread-Programmierung dadurch, dass der Code für die Erzeugung der Threadsdurch den UPC-Compiler in das Programm integriert wird und nicht durch den Programmierer.
53 Vgl.: [CHAUVIN 2008], [RAUBER 2007] S.371ff.,54 UPC Homepage: http://upc.gwu.edu, Stand 01.12.200855 http://www.intrepid.com/upc/downloads.html
- 29 -

Die Anzahl zu verwendender Threads kann sowohl zur Übersetzungszeit als auch zur Laufzeitfestgelegt werden.
Um Berechnungen parallel durchzuführen, wird ein Schleifenkonstrukt upc_forall verwendet:
upc_forall ( expr1; expr2; expr3; affinity)
Die Syntax entspricht exakt der C-Syntax für for-Schleifen, mit dem Unterschied, dass einvierter Parameter “affinity” existiert, der angibt, durch welchen Thread die aktuelle Iterationdurchgeführt wird. Dies kann entweder durch die Angabe der Thread-Nummer oder einer Spei-cheradresse geschehen. In letzterem Fall wird die Iteration durch den Thread durchgeführt, indessen Adressraum die Speicheradresse liegt. Dies ist insbesondere dann nützlich, wenn überein verteiltes Array iteriert wird und die Lokalität verschiedener Array-Elemente ausgenutztwerden soll.
7.3 Speichermodell
UPC implementiert ein Modell mit verteiltem Speicher, wobei dieser sowohl gemeinsam (sha-red) als auch einzeln (private) genutzt werden kann. Der private Speicher eines Threads liegtausschließlich in seinem eigenen Adressraum und ist nur für ihn selbst sichtbar. Privater Spei-cher liegt immer dann vor, wenn Speicher in herkömmlicher C-Notation alloziert wird, so dases hier keinen Unterschied zur nicht-parallelen Programmierung gibt.
Gemeinsam genutzter Speicher wird durch Verwenden des neuen Schlüsselwortes shared er-zeugt. Auf eine als shared deklarierte Variable kann von allen Threads aus zugegriffen werden.Folgendes Listing zeigt einige Möglichkeiten, private und gemeinsame Variablen zu definieren:
int local_i; // private Variableshared int global_i; // gemeinsame Variableshared int * ptr1; // privater Zeiger auf gemeinsame
Variableshared int * shared ptr2; // gemeinsamer Zeiger auf gemeinsame
Variable
Eine interessante Variante bilden verteilte Arrays. Die Deklaration erfolgt folgendermaßen:
shared [block_size] typ name[size];
Ein derart erzeugtes Array wird in Blöcken der Größe block_size komplett auf den gemeinsamenSpeicher verteilt. Wird das Array anschließend durch eine upc_forall-Schleife verarbeitet, kannauf diese Weise bereits eine Zuordnung des verwendeten Speichers zu den einzelnen Threadsvorgenommen werden, so dass Zugriffe auf die Array-Elemente lokal erfolgen können. An-derenfalls würden Zugriffe auf Elemente, die sich im Speicherbereich eines anderen Threadsbefinden, in entfernte Zugriffe umgewandelt werden müssen, was einen gewissen Kommunika-tionsaufwand erfordert und daher langsamer ist.
Standardmäßig wird eine Blockgröße von 1 angenommen. Eine Blockgröße von 0 würde dazuführen, dass alle Elemente im Speicherbereich des ersten Threads abgelegt werden. Im Fol-genden sind zwei Beispiele für die Verteilung von Elementen bei verschiedenen Blockgrößendargestellt:
- 30 -

shared int a[10];
Thread 1 Thread 2 Thread 3 Thread 4a[0]a[4]a[8]
a[1]a[5]a[9]
a[2]a[6]
a[3]a[7]
shared [2] int a[10];
Thread 1 Thread 2 Thread 3 Thread 4a[0]a[1]a[8]a[9]
a[2]a[3]
a[4]a[5]
a[6]a[7]
Verteilte Arrays müssen global und dürfen nicht dynamisch sein. Daher ist das Anwendungs-feld dieser einfachen Notation von vornherein beschränkt. Weiterhin ist die Verwendung loka-ler Variablen, z.B. in Funktionsrümpfen, für die Parallelisierung ausgeschlossen. Es kann zwarverteilter, dynamisch allozierter Speicher erzeugt werden, jedoch muss dieser dann durch ent-sprechende Speichermanipulationsroutinen explizit gefüllt werden.
Diese Beschränkung lässt sich durch Verwendung dynamisch allozierten verteilten Speichersumgehen. UPC bietet dazu verschiedene malloc-ähnliche Funktionen.
UPC stellt zwei Konsistenzmodelle bereit: strict und relaxed. Das strict-Modell stellt sicher,dass vor Speicherzugriffen eine Synchronisation stattfindet. Ebenso werden Optimierungen sei-tens des Compilers unterbunden, welche die Reihenfolge von Zugriffsoperationen auf unabhän-gige Speicherbereiche verändern.
Das relaxed-Modell dagegen erlaubt den jederzeitigen Speicherzugriff. Synchonisierung undLocking-Mechanismen müssen dabei explizit im Programmtext implementiert werden.
Das verwendete Konsistenzmodell kann entweder global durch das Einbinden der Header-Dateien upc_strict.h oder upc_relaxed.h erfolgen, durch #pragma-Direktiven für einzelne Pro-grammabschnitte festgelegt, oder direkt bei der Variablendeklaration bestimmt werden.
#include <upc_strict.h>#include <upc_relaxed.h>
strict shared int i;strict relaxed int j;
{#pragma upc strict// code-block
- 31 -

}
#pragma upc relaxed{#pragma upc relaxed// code-block}
7.4 Synchonisation
Neben den beschriebenen Konsistenzmodellen stellt UPC für die Synchronisation weitere Me-chanismen bereit.
Locks Locking-Mechanismen lassen sich auf Daten-Ebene verwenden. Dabei können gemein-same Variablen durch den Aufruf von upc_lock() für den Zugriff durch andere Threads ge-sperrt und später durch upc_unlock() wieder freigegeben werden.
Barrieren UPC stellt Barrier-Konstrukte bereit, mit denen sichergestellt werden kann, dass zueinem Zeitpunkt alle Threads eine bestimmte Stelle im Programmcode erreicht haben. Eswerden blockierende und nicht-blockierende Barrieren unterschieden.Blockierende Barrieren werden über das upc_barrier-Kommando in den Programmcode ein-gefügt. Der Programmablauf wird an dieser Stelle unterbrochen, bis alle anderen Threads dieselbe Stelle erreicht haben.
7.5 Globale Operatoren
UPC unterstützt Datenverteilungs- und Sammeloperationen, Reduktionsoperationen sowie Ein-und Ausgabeoperationen. Diese werden als Funktionsaufruf an entsprechender Stelle im Pro-grammtext eingefügt.
Zur Datenverteilung sind Scatter-, Gather- sowie Permutationsverfahren implementiert. Als Re-duktionsoperationen stehen arithmetische binäre Operatoren sowie Sortieroperationen zur Ver-fügung. Der koordinierte Zugriff auf Dateien und das Lesen und Schreiben aus bzw. in gemein-same Speicherbereiche wird unterstützt.
- 32 -

8 Message Passing Interface
Message-Passing ist ein Konzept für Parallelrechner mit verteiltem Speicher. Die logische Sichtist, dass Prozesse nur Zugriff auf ihren lokalen Speicher haben, aber miteinander durch das Ver-senden von Nachrichten kommunizieren können, unabhängig davon, auf welchem Prozessoroder Rechner sie gerade ausgeführt werden. Ein derartiges Modell wird beispielsweise durchMPI oder PVM dargestellt und lässt sich auf verschiedene physische Rechnerarchitekturen ab-bilden.
Abbildung 10: Message-Passing
Quelle: [BAUKE 2006] S.45
MPI ist eine Spezifikation für die Abbildung eines Modells nach dem Message-Passing-Prinzip.Es ist ein Standard, der Schnittstellen für die Sprachen C und Fortran definiert. Die ErweiterungMPI-2 stellt Schnittstellen auch für C++ bereit.
Auf MPI-Standards wird hauptsächlich durch die Bezeichnungen MPI-1 und MPI-2 verwiesen.MPI-I entspricht dabei der Version MPI 1.2 von 1995. MPI-2 ist eine spätere abwärtskompatibleEntwicklung, die MPI-1 um neue Funktionen erweitert. Dieser Standard wird nur von sehrwenigen MPI-Implementierungen vollständig unterstützt.
MPI ist extrem umfangreich und es existieren von vielen Funktionen mehrere Varianten, diesich nur in Details voneinander unterscheiden. Daher kann MPI hier nur ansatzweise dargestelltwerden. Für Details sei auf die Literatur verwiesen.56
56 Vgl. hierzu: [EM KARNIADAKIS 2000]S.80ff., [RAUBER 2007] S.207ff, [BAUKE 2006] S.167ff., [GROPP 2007]
- 33 -

8.1 Verfügbarkeit
Da MPI keine spezifische Implementation beinhaltet, existieren verschiedene MPI-Bibliothe-ken, die meist auf eine spezielle Rechnerarchitektur angepasst sind. Frei verfügbare Implemen-tierungen sind z.B. Open-MPI, LAM-MPI und das vom Argonne National Laboratory stam-mende MPICH/MPICH2. Daneben existieren noch weitere proprietäre und teils optimierte Lö-sungen wie z.B. die Intel MPI Library.
8.2 Parallelisierungskonzept
Eine MPI-Anwendung besteht stets aus einer konstanten Anzahl von Prozessen. Diese kannbeim Programmstart variabel festgelegt werden, lässt sich jedoch zur Laufzeit nicht mehr verän-dern. Häufig geschieht das Aufrufen eines MPI-Programms durch ein separates Startprogramm,dass von der verwendeten Implementierung zur Verfügung gestellt wird und das entsprechendviele Instanzen des eigentlichen MPI-Programms aufruft.
Da MPI auch in heterogenen Rechnerumgebungen ausgeführt werden kann, müssen alle Nach-richten auf MPI-Datentypen abgebildet werden, die von MPI bei Bedarf in die entsprechendeDarstellung konvertiert werden. Um komplexere Datenstrukturen nicht Wert für Wert übertra-gen zu müssen, können eigene MPI-Datentypen und Strukturen definiert werden.
8.3 Speichermodell
Einem MPI-Programm sind dabei lokal Daten zugeordnet, auf die frei zugegriffen werdenkann. Durch das Verschicken von Nachrichten kann ein MPI-Programm mit anderen MPI-Programmen kommunizieren und so Daten austauschen. MPI definiert verschiedene Funktio-nen, die Verteil- und Sammeloperationen durchführen. Dabei ist es nicht möglich, dass ein Pro-zess unbemerkt die Daten eines anderen Prozesses verändern kann, da alle Kommunikations-operationen stets, jedoch nicht zwingend synchron, durch alle beteiligten Prozesse aufgerufenwerden müssen.
8.4 Synchronisation
Barrieren und Kritische Abschnitte werden von MPI nicht unterstützt. Dies ist auch nicht not-wendig, da jeder Prozess nur Zugriff auf lokalen Speicher hat. Eine Koordinierung des Pro-grammablaufs erfolgt ausschließlich durch das Versenden von Nachrichten mit blockierendenFunktionen. MPI unterstützt bei vielen Kommunikationsfunktionen sowohl synchrone als auchasynchrone Varianten.
8.5 Globale Operatoren
MPI unterstützt eine Vielzahl von Datenverteilungs- und Aggregierungsfunktionen. Scatter-,Gather und Reduktionsoperationen sind als globale blockierende Operationen implementiert,die von alle beteiligten Prozessen gleichzeitig ausgeführt werden müssen.
- 34 -

9 OpenMP
OpenMP57 ist eine Programmierschnittstelle (API) für Fortran und C/C++, um parallele Pro-gramme mit gemeinsamem Speicher zu realisieren. Es wurde mit der Maßgabe entworfen,vorhandenen, sequentiellen Code auf einfache Weise zu parallelisieren und dabei schrittwei-se vorgehen zu können.
Ein Ziel von OpenMP ist, dass der vorhandene sequentielle Programmcode nicht oder nur mini-mal verändert und statt dessen durch Compilerdirektiven ergänzt wird. Ein OpenMP-Programmkann daher auch von einem nicht-OpenMP-fähigen Compiler übersetzt werden58, da unbekann-te Direktiven grundsätzlich ignoriert werden. Die Aufgabe des Programmierers ist es dahernicht, Algorithmen in eine parallele Version zu ändern, sondern parallelisierbare Abschnittezu identifizieren, zu kennzeichnen und zu spezifizieren. Dazu stellt OpenMP eine Reihe vonDirektiven, Bibliotheksfunktionen und Variablen bereit.
9.1 Verfügbarkeit
Um OpenMP nutzen zu können, ist ein entsprechender Compiler erforderlich. In Tabelle 2 imAnhang A.2 ist eine Übersicht verschiedener Produkte aufgeführt, die OpenMP unterstützen.
9.2 Parallelisierungskonzept
Grundsätzlich arbeitet OpenMP nach dem Thread-Konzept. Im Gegensatz zu den meisten ande-ren Konzepten, bei denen ein Programm von Anfang parallel ausgeführt wird, benutzt OpenMPdas Fork-Join-Modell zur Parallelisierung, wie in Abbildung 11 dargestellt. Das bedeutet, dasszunächst nur ein einzelner Thread aktiv ist. Erst, wenn ein parallelisierbarer Programmabschnitterreicht wird, erzeugt OpenMP neue Threads und beendet diese, sobald der Abschnitt wiederverlassen wird.
Der notwendige Programmcode für die Erzeugung Synchronisierung der OpenMP-Threadswird durch den Compiler erzeugt. Wie dies konkret vonstatten geht und ob Threads oder Prozes-se zum Einsatz kommen, hängt von dessen Implementierung ab und ist aus Sicht des Program-mierers irrelevant. Vom Programmierer ist lediglich eine Kennzeichnung und Spezifikation derzu parallelisierenden Programmabschnitte notwendig. Hierfür stellt OpenMP eine Anzahl vonCompilerdirektiven, Routinen und Variablen für die Sprachen C/C++ und Fortran bereit.
9.3 Speichermodell
OpenMP implementiert ein Modell mit verteiltem Speicher, wobei dieser sowohl gemeinsam(shared) als auch einzeln (private) genutzt werden kann. Der private Speicher eines Threads liegtausschließlich in seinem eigenen Adressraum und ist nur für ihn selbst sichtbar. Standardmäßig
57 Vgl. hierzu: [CHAPMAN 2008],[HOFFMANN 2008],[CHANDRA],[RAUBER 2008] S.127ff., [RAUBER 2007] S.207ff., 354ff.
58 Mit Einschränkungen bei der Verwendung von OpenMP Bibliotheksfunktionen, die dann natürlich nicht Verfüg-bar sind, was beim Linken zu einem Fehler führt. Durch die Verwendung eines #ifdef _OPENMP-Blocks kanndies verhindert werden.
- 35 -

Abbildung 11: OpenMP Fork-Join-Modell
Quelle: [CHAPMAN 2008] S. 24
sind alle Variablen als privat deklariert. Gemeinsame Variablen müssen in der #pragma ompparallel Direktive angegeben werden.
9.4 Synchronisation
Für die Synchronisation stellt OpenMP je nach Anforderung verschiedene Mechanismen bereit.
Kritische Abschnitte Abschnitte innerhalb eines Parallelen Anweisungsblocks, die Anfälligfür eine Race-Condition sind, können durch Markierung mit #pragma omp critical gekenn-zeichnet werden. OpenMP stellt dadurch sicher, dass der Programmabschnitt nur von einemThread zur selben Zeit ausgeführt wird. Betrifft dies nur eine kleine Anweisung, beispiels-weise eine Operation auf eine gemeinsame Variable wie a=a+b, kann diese als Atomare Ope-ration durch #pragma omp atomic gekennzeichnet werden, die für OpenMP mit geringeremVerwaltungsaufwand zur Synchronisation der beteiligten Prozesse verbunden ist. Durch dieAtomare Anweisung wird sichergestellt, dass zwischen den einzelnen dafür notwendigenProzessoranweisungen kein Prozesswechsel stattfindet.
Locks Der konkurrierende Zugriff auf Ressourcen kann durch Locking-Mechanismen gesteu-ert werden. Im Gegensatz zur Verwendung von critical, das automatisch Locks erzeugt, istes hier die Aufgabe des Programmierers, Locks zu erzeugen und wieder freizugeben. Diesist notwendig, wenn auf die zu schützende Ressource nicht nur in einem einzelnen Program-mabschnitt zugegriffen wird und somit nicht durch einen critical-Block geschützt werdenkann.OpenMP stellt keine Funktionen zur Behandlung von Deadlock-Situationen bereit.
Barrieren Barrieren lassen sich einfach durch Einfügen von #pragma omp barrier hinter ei-nem Parallelen Abschnitt realisieren.
Geordnete Ausführung In OpenMP kann die Ausführungsreihenfolge paralleler Abschnit-te durch den Programmierer gesteuert werden. Dies kann z.B. Notwendig sein, wenn Aus-gaben realisiert werden müssen. Ein mit #pragma omp ordered gekennzeichneter Bereichinnerhalb eines Parallelen Abschnitts wird exakt so ausgeführt, als würde er seriell durchlau-fen werden.
- 36 -

9.5 Globale Operatoren
OpenMP unterstützt keine expliziten Kommunikationsanweisungen. Globale Operatoren kön-nen daher nur indirekt durch entsprechende Spezifikation der parallelen Abschnitte genutzt wer-den. Hierfür wird das reduction - Konstrukt bereitgestellt:
reduction ( operator : Variable [,Variable] ...)
Wird beispielsweise eine Schleife, innerhalb der auf eine gemeinsame Variable schreibend zu-gegriffen wird, parallel ausgeführt, sind zeitaufwändige Synchronisierungsmaßnahmen erfor-derlich, um den Speicherinhalt für alle Threads konsistent zu halten. Dies muss jedoch nichtimmer notwendig sein. Durch das reduction-Konstrukt wird die Synchronisierung erst nach Be-endigung aller Iterationen unter Verwendung des angegebenen Operators durchgeführt, zumBeispiel für die Summenfunktion:
int sum(int * v, int size){result=0;#pragma omp parallel for reduction (+:result)for(i=0, i<size, i++){ result+=v[i]; }return result;
}
- 37 -

10 Andere
10.1 BOINC
BOINC - Berkeley Open Infrastructure for Network Computing59 ist eine an der UniversitätBerkeley, Californien entwickelte Umgebung für das Grid-Computing. BOINC funktioniertnach dem Client-Server-Prinzip. Ein BOINC-Client wird auf einer Anzahl von Rechnern in-stalliert und meldet sich bei einem Server an, von dem er Rechenaufgaben zugeteilt bekommtund die Resultate zurücksendet. Die BOINC-API ist sehr umfangreich und speziell für das Ver-teilte Rechnen mit sehr hoher Anzahl an Clients in heterogener Rechnerumgebung entwickelt.Basierend auf BOINC wurde weltweit Rechenleistung für verschiedene wissenschaftliche Pro-jekte wie z.B. Seti@Home gebündelt.
10.2 BLAS
BLAS ist eine Abkürzung für Basic Linear Algebra Subroutines und bezeichnet Bibliotheken,die lineare algebraischen Funktionen bereitstellen. Es existiert kein formaler Standard, dennochhat sich ein konkreter Satz an Funktionen als de-facto Standard etabliert, der mit dem BegriffBLAS bezeichnet wird. Je nach Umfang werden diese in Levels 1-3 eingeordnet, wobei Le-vel 1 Vektor-Operationen, Level 2 Vektor-Matrix-Operationen und Level 3 Matrix-Operationenunterstützt.
BLAS ist keine Parallele Programmierbibliothek, jedoch existieren auch Implementierungen,die PVM, MPICH oder LAM nutzen. Eine Parallelisierung mittels BLAS gestaltet sich so, dassdas zu lösende Problem in eine Reihe von Matrizenoperationen überführt wird, die dann durchBLAS-Funktionen ausgeführt werden.
Für BLAS gibt es eine Reihe verschiedener, zum Teil hoch optimierter Implementierungen, diehäufig von Hardware-Herstellern stammen und speziell an deren Produkte angepasst sind. Wei-terhin sind z.B. auch parallel arbeitende Versionen für verschiedene MPI-Implementierungenverfügbar.
Unix-Distributionen enthalten in der Regel mehrere BLAS-Implementierungen. Einige davonsind Beispielsweise „refblas3”, „scalapack” und „lapack3”.
10.3 PThreads
PThreads ist eine Interface-Spezifikation zur Programmierung von Threads entsprechend demPOSIX.1-Standard für Unix-Basierte Systeme. Aktuelle Implementierungen sind LinuxThreads60
und die Native POSIX Threads Library (NPTL).
10.4 Parallel Virtual Machine
PVM bildet einen virtuellen Parallelrechner mit nicht zwingend homogener Rechnerstrukturund lokal zugeordnetem Speicher ab. Die Kommunikation der beteiligten Knoten erfolgt durch
59 Homepage: http://boinc.berkeley.edu60 Wird ab glibc 2.4 nicht mehr unterstützt, stattdessen wird seit glibc 2.3.2 NPTL verwendet.
- 38 -

Message-Passing. PVM kann als Vorgänger von MPI betrachtet werden.
PVM wird durch einen Dienst (pvmd) realisiert, der auf den beteiligten Rechnern gestartetwird und als Schnittstelle zu allen Rechnern fungiert. Die Parallelisierung erfolgt durch einenElternprozess, der den Dienst dazu veranlasst, weitere Instanzen des Programms auf den an-deren Rechnern zu starten und die Kommunikation zwischen den Instanzen zu steuern. PVM-Programme müssen daher auf allen Rechnern in ausführbarer Form vorliegen und der Nutzermuß Zugriffsrechte auf alle Rechner haben, da sowohl der Dienst als auch die Programme unterseiner Nutzerkennung laufen.
- 39 -

11 Vergleichende Betrachtung
Um den Programmieraufwand sowie die Rechengeschwindigkeit der vorgestellten Bibliothekenim Ansatz vergleichen zu können, wurde ein Algorithmus zur parallelen Matrizenmultiplikati-on in serieller Form implementiert und anschließend für die Verwendung mit den parallelenBibliotheken angepasst.
11.1 Implementierung
Im Folgenden wird die serielle Version des Algorithmus vorgestellt und auf die speziellen Merk-male der Versionen für jede der untersuchten parallelen Ansätze eingegangen. Der vollständigeQuellcode ist, sofern nicht aufgeführt, auf der beiliegenden CD zu finden. Da es um den Ver-gleich der Techniken geht, wurde auf Optimierungen seitens des Compilers verzichtet.
11.1.1 Matrizenmultiplikation Seriell
Die Serielle Version ist im Algorithmus 1 dargestellt. Das Programm besteht aus zwei Teilen,einer Funktion zur Matrizenmultiplikation und dem Hauptprogramm, dass diese aufruft und dieZeitmessung durchführt.
Die Compilierung erfolgt mittels:
$gcc -std=C99 standard.c -o standard
11.1.2 Matrizenmultiplikation UPC
Für UPC sind nur wenige Änderungen erforderlich. Vor allem muss in der Funktion mult_matrix()die Hauptschleife durch das UPC-Pendant ersetzt werden.
[...]upc_forall(int ay=0;ay<y1;ay++;ay){[...]
Weiterhin ist die Ergebnismatrix R als shared zu deklarieren. Hierbei wird eine Blockgrößeentsprechend der Zeilengröße gewählt, so dass die Matrix zeilenweise auf die Threads verteiltwird:
shared double * R=upc_all_alloc(dim,dim*sizeof(double));
Bei der Zeitmessung und der Ausgabe ist zu beachten, dass diese nur von einem einzigen Pro-zess durchgeführt wird, da es sonst zu mehrfachen Ausgaben kommt. Für die Compilierungmuss ein UPC-Compiler eingesetzt werden, in diesem Fall der GCC-UPC 4.0.3.5.
Die Compilierung erfolgt mittels:
$upc-gcc -std=C99 -lupc -static upc.upc -o upc
- 40 -

Algorithm 1 Matrizenmultiplikation Seriell
1 # i n c l u d e < s t d l i b . h>2 # i n c l u d e < s t d i o . h>3 # i n c l u d e <math . h>4 # i n c l u d e < s t r i n g . h>5 # i n c l u d e < s y s / t ime . h>6 # i n c l u d e < t ime . h>78 i n t m a t r i x _ m u l t ( i n t x1 , i n t y1 , double ∗ A, i n t x2 , i n t y2 , double ∗ B , double ∗ R) {9 i f (A!=NULL && B!=NULL && R!=NULL) {
10 i n t o f s _ a =0 , o f s _ b =0 , o f s _ r =0 ;11 f o r ( i n t ay =0; ay <y1 ; ay ++) {12 f o r ( i n t bx =0; bx<x2 ; bx ++) {13 o f s _ r = ay∗x2 +bx ; R[ o f s _ r ] = 0 . 0 ;14 f o r ( i n t ax =0; ax <x1 ; ax ++) {15 o f s _ a = ay∗x1 +ax ; o f s _ b = ax∗x2 +bx ;16 R[ o f s _ r ]+=A[ o f s _ a ]∗B[ o f s _ b ] ;17 }18 }19 }20 }21 re turn 1 ;22 }2324 i n t main ( i n t argc , char∗ a rgv [ ] ) {25 i f ( a rgc <1) re turn −1;2627 / / m a t r i x e r z e u g e n und i n i t i a l i s i e r e n28 i n t dim= a t o i ( a rgv [ 1 ] ) ;29 double ∗ A=( double ∗ ) m a l loc ( dim∗dim∗ s i z e o f ( double ) ) ;30 double ∗ B=( double ∗ ) m a l loc ( dim∗dim∗ s i z e o f ( double ) ) ;31 double ∗ R=( double ∗ ) m a l loc ( dim∗dim∗ s i z e o f ( double ) ) ;32 f o r ( i n t i =0 ; i <dim∗dim ; i ++) {33 A[ i ] = 1 ; B[ i ] = 1 ; R[ i ] = 0 ;34 }35 s t r u c t t i m e v a l t ime1 , t ime2 ;36 i n t ms1 , ms2 ;3738 / / z e i t m e s s u n g und berechnung39 g e t t i m e o f d a y (& time1 ,NULL) ;40 m a t r i x _ m u l t ( dim , dim , A, dim , dim , B , R) ;41 g e t t i m e o f d a y (& time2 ,NULL) ;4243 ms1= t ime1 . t v _ s e c ∗1000000+ t ime1 . t v _ u s e c ;44 ms2= t ime2 . t v _ s e c ∗1000000+ t ime2 . t v _ u s e c ;45 i n t d e l t a =ms2−ms1 ;46 double d e l t a _ s e c =( double ) d e l t a / 1 0 0 0 0 0 0 ;47 p r i n t f ( "%i %f \ n " , dim , d e l t a _ s e c ) ;48 re turn 0 ;49 }
- 41 -

11.1.3 Matrizenmultiplikation MPI
Für MPI gibt es prinzipiell zwei Möglichkeiten der Implementierung, die jede ihre Vor- undNachteile hat: Implementation mit Globalen Operationen oder ein Master-Worker-Modell.
Die Verwendung globaler Operationen zur Verteilung der Daten erfordert weniger Aufwandals das Master-Worker-Modell, ist jedoch weniger flexibel in der optimalen Ausnutzung derRechenkapazität.
Im Gegensatz zu UPC oder OpenMP kann sich bei MPI die Parallelisierung nicht nur auf dieAnpassung der Funktion matrix_mult beschränken. So muss beispielsweise beim Programm-start eine Initialisierung von MPI erfolgen. Daher wurde der Ansatz gewählt, die originaleFunktion matrix_mult zu verwenden, deren Aufruf jedoch mit einem MPI-Konstrukt zu um-geben, so dass jeder Prozess nur Teile der Matrizen berechnen muss.
MPI verteilt Daten stets in zusammenhängenden Blöcken. Für die Verteilung der Matrix A be-deutet dies, dass jeder Prozess mehrere aufeinanderfolgende Zeilen erhält. Da die Gesamtzahlder Zeilen nicht notwendigerweise ein Vielfaches der Prozessanzahl darstellt, ist eine ungleicheVerteilung notwendig.
Die Anzahl und Größe der Pakete, die jeder Prozess empfängt, muss allen Teilnehmern beimAufruf der Funktionen bekannt sein, d.h. der Empfänger muss wissen, wieviel Daten er be-kommt, da er einen entsprechend dimensionierten Empfangspuffer bereitstellen muss.
Globale Operationen
Bei der Verwendung globaler Operationen erfolgt das Scheduling der Daten statisch. Dazu be-rechnet der Root-Prozess anhand der Prozessanzahl und der Datenmenge, wie die Aufteilungerfolgt. Der Algorithmus 2 stellt einen Auszug aus dem entsprechenden Testprogramm dar.
Master-Worker-Modell
Die Implementierung des Master-Worker-Modells erfolgt in der Form, dass Worker-ProzesseNachrichten an den Master-Prozess schicken, um diesen zu veranlassen, entweder einen neu-en Datenblock zu senden oder ein Ergebnis entgegenzunehmen. Das Master-Programm wirdbeendet, sobald alle Datenblöcke versendet und alle Ergebnisse empfangen wurden. Da der Al-gorithmus deutlich umfangreicher ist als bei Verwendung globaler Operatoren wird auf eineDarstellung verzichtet.
11.1.4 Matrizenmultiplikation OpenMP
Der Aufwand für OpenMP ist ähnlich dessen für UPC. In der Funktion mult_matrix() werdenPragmas gesetzt, um dem Compiler mitzuteilen, dass die Indexvariablen ofs_a, ofs_b und ofs_rprivat und die Matrizen A,B und R verteilt sind. Weiterhin wird eine statische Aufteilung derfor-Schleife auf die einzelnen Threads festgelegt, wodurch jeder Thread die selbe Anzahl vonSchleifen durchläuft.
#pragma omp parallel for schedule(static) \private(ofs_a,ofs_b,ofs_r) shared (A,B,R)for(int ay=0;ay<y1;ay++){...}
- 42 -

Algorithm 2 Matrizenmultiplikation MPI Global
1 # i n c l u d e <mpi . h>23 / / . . .45 i n t main ( i n t argc , char∗ a rgv [ ] ) {67 / / . . .8 i n t rank , np roc ;9 M P I _ In i t (& argc ,& argv ) ;
10 MPI_Comm_rank (MPI_COMM_WORLD,& rank ) ;11 MPI_Comm_size (MPI_COMM_WORLD,& nproc ) ;1213 i n t s s i z e s [ np roc ] , s o f s [ np roc ] ;14 i f ( r ank ==0) {15 f o r ( i n t i =0 ; i < nproc ; i ++) {16 i n t rows=dim / nproc ; i f ( rows ==0) rows =1;17 s s i z e s [ i ]= dim∗ rows ; s o f s [ i ]= dim∗ rows∗ i ;18 i f ( i == nproc−1){ s s i z e s [ i ]+=( dim%rows ) ∗dim ; }19 }20 }2122 MPI_Bcast (&dim , 1 , MPI_INT , 0 ,MPI_COMM_WORLD) ;23 MPI_Bcast (B , dim∗dim , MPI_DOUBLE, 0 ,MPI_COMM_WORLD) ;24 MPI_Bcast ( s s i z e s , nproc , MPI_INT , 0 ,MPI_COMM_WORLD) ;25 M P I _ S c a t t e r v (A, s s i z e s , s o f s , MPI_DOUBLE, A, s s i z e s [ r ank ] , MPI_DOUBLE, 0 ,MPI_COMM_WORLD) ;2627 m a t r i x _ m u l t ( dim , s s i z e s [ r ank ] / dim , A, dim , dim , B , R) ;2829 MPI_Gatherv (A, s s i z e s [ r ank ] , MPI_DOUBLE, A, s s i z e s , s o f s , MPI_DOUBLE, 0 ,MPI_COMM_WORLD3031 re turn 0 ;32 }
Das Hauptprogramm wird lediglich zu Beginn um Anweisungen zur Festlegung der Anzahl zuverwendender Prozesse ergänzt:
int procs=atoi(argv[1]);omp_set_dynamic(0);omp_set_num_threads(procs);
Die Compilierung erfolgt mittels des GCC-4.2:
$gcc-4.2 -fopenmp -std=C99 openmp.c -o openmp
11.2 Performance
Um den Einfluss des Betriebssystems beim Programmstart sowie eventuelle Initialisierungs-phasen der Bibliotheken zu minimieren, wurde nur die Berechnungszeit für die eigentlicheMultiplikation ermittelt. Die Berechnungszeit wurde in Abhängigkeit von Matrizengröße undProzessanzahl gemessen. Jede Messung wurde drei mal Durchgeführt und das beste Resultatausgewertet.
Die Tests wurden auf einem Parallelrechner mit 8 Dual Core AMD Opteron(tm) Prozessorenmit 1 GHz Taktfrequenz und 32GB RAM durchgeführt. Als Betriebssystem diente Ubuntu 2.6.Außer für UPC wurde als Compiler der GCC 4.1.2 verwendet. Alle Messergebnisse sind inTabellenform im Anhang B.2 aufgeführt.
- 43 -
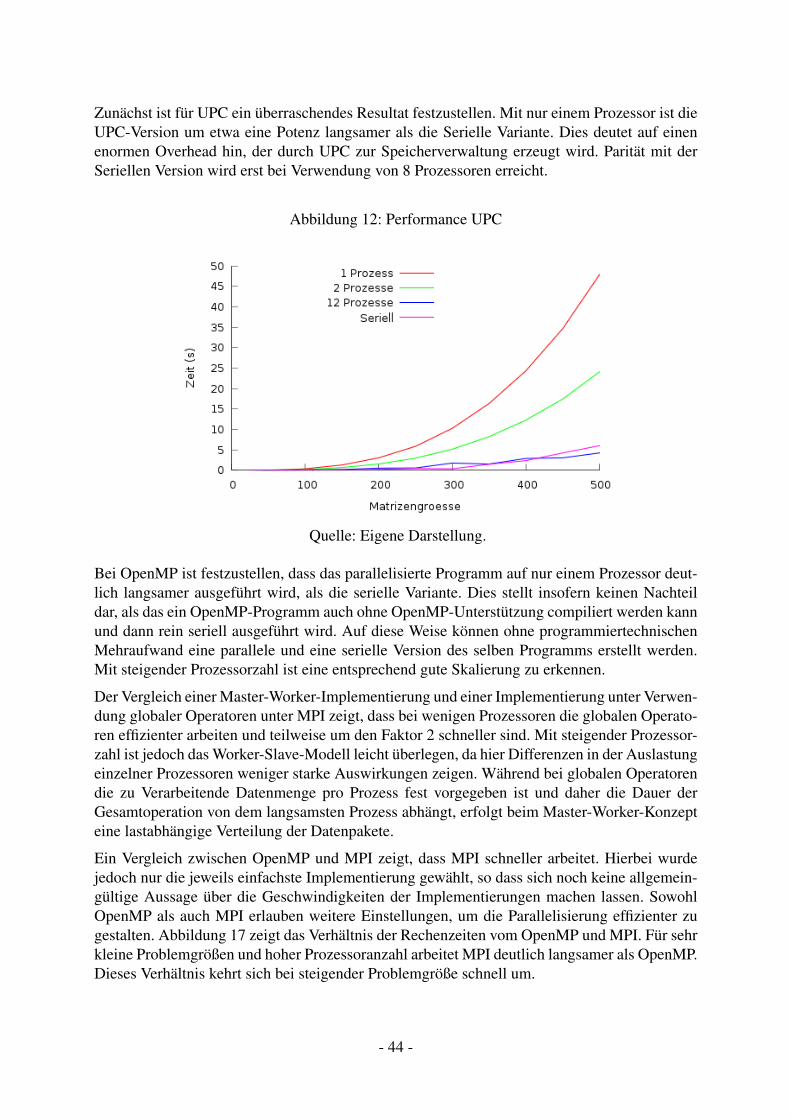
Zunächst ist für UPC ein überraschendes Resultat festzustellen. Mit nur einem Prozessor ist dieUPC-Version um etwa eine Potenz langsamer als die Serielle Variante. Dies deutet auf einenenormen Overhead hin, der durch UPC zur Speicherverwaltung erzeugt wird. Parität mit derSeriellen Version wird erst bei Verwendung von 8 Prozessoren erreicht.
Abbildung 12: Performance UPC
Quelle: Eigene Darstellung.
Bei OpenMP ist festzustellen, dass das parallelisierte Programm auf nur einem Prozessor deut-lich langsamer ausgeführt wird, als die serielle Variante. Dies stellt insofern keinen Nachteildar, als das ein OpenMP-Programm auch ohne OpenMP-Unterstützung compiliert werden kannund dann rein seriell ausgeführt wird. Auf diese Weise können ohne programmiertechnischenMehraufwand eine parallele und eine serielle Version des selben Programms erstellt werden.Mit steigender Prozessorzahl ist eine entsprechend gute Skalierung zu erkennen.
Der Vergleich einer Master-Worker-Implementierung und einer Implementierung unter Verwen-dung globaler Operatoren unter MPI zeigt, dass bei wenigen Prozessoren die globalen Operato-ren effizienter arbeiten und teilweise um den Faktor 2 schneller sind. Mit steigender Prozessor-zahl ist jedoch das Worker-Slave-Modell leicht überlegen, da hier Differenzen in der Auslastungeinzelner Prozessoren weniger starke Auswirkungen zeigen. Während bei globalen Operatorendie zu Verarbeitende Datenmenge pro Prozess fest vorgegeben ist und daher die Dauer derGesamtoperation von dem langsamsten Prozess abhängt, erfolgt beim Master-Worker-Konzepteine lastabhängige Verteilung der Datenpakete.
Ein Vergleich zwischen OpenMP und MPI zeigt, dass MPI schneller arbeitet. Hierbei wurdejedoch nur die jeweils einfachste Implementierung gewählt, so dass sich noch keine allgemein-gültige Aussage über die Geschwindigkeiten der Implementierungen machen lassen. SowohlOpenMP als auch MPI erlauben weitere Einstellungen, um die Parallelisierung effizienter zugestalten. Abbildung 17 zeigt das Verhältnis der Rechenzeiten vom OpenMP und MPI. Für sehrkleine Problemgrößen und hoher Prozessoranzahl arbeitet MPI deutlich langsamer als OpenMP.Dieses Verhältnis kehrt sich bei steigender Problemgröße schnell um.
- 44 -
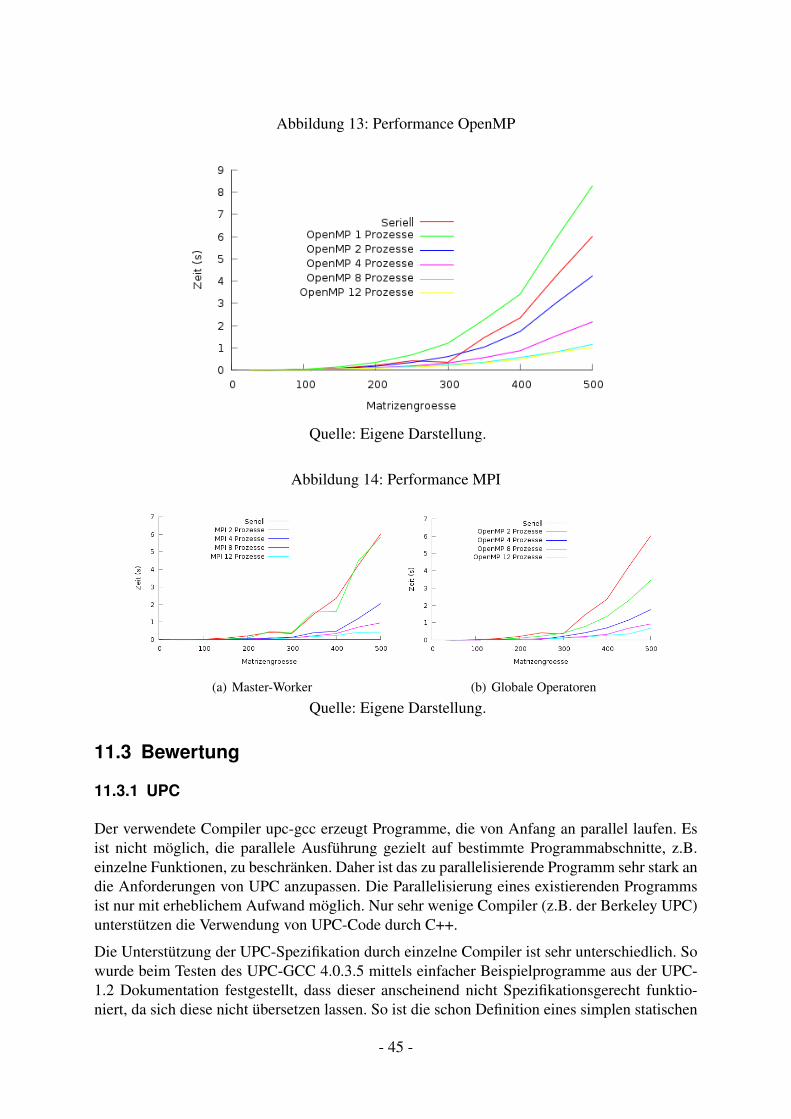
Abbildung 13: Performance OpenMP
Quelle: Eigene Darstellung.
Abbildung 14: Performance MPI
(a) Master-Worker (b) Globale Operatoren
Quelle: Eigene Darstellung.
11.3 Bewertung
11.3.1 UPC
Der verwendete Compiler upc-gcc erzeugt Programme, die von Anfang an parallel laufen. Esist nicht möglich, die parallele Ausführung gezielt auf bestimmte Programmabschnitte, z.B.einzelne Funktionen, zu beschränken. Daher ist das zu parallelisierende Programm sehr stark andie Anforderungen von UPC anzupassen. Die Parallelisierung eines existierenden Programmsist nur mit erheblichem Aufwand möglich. Nur sehr wenige Compiler (z.B. der Berkeley UPC)unterstützen die Verwendung von UPC-Code durch C++.
Die Unterstützung der UPC-Spezifikation durch einzelne Compiler ist sehr unterschiedlich. Sowurde beim Testen des UPC-GCC 4.0.3.5 mittels einfacher Beispielprogramme aus der UPC-1.2 Dokumentation festgestellt, dass dieser anscheinend nicht Spezifikationsgerecht funktio-niert, da sich diese nicht übersetzen lassen. So ist die schon Definition eines simplen statischen
- 45 -
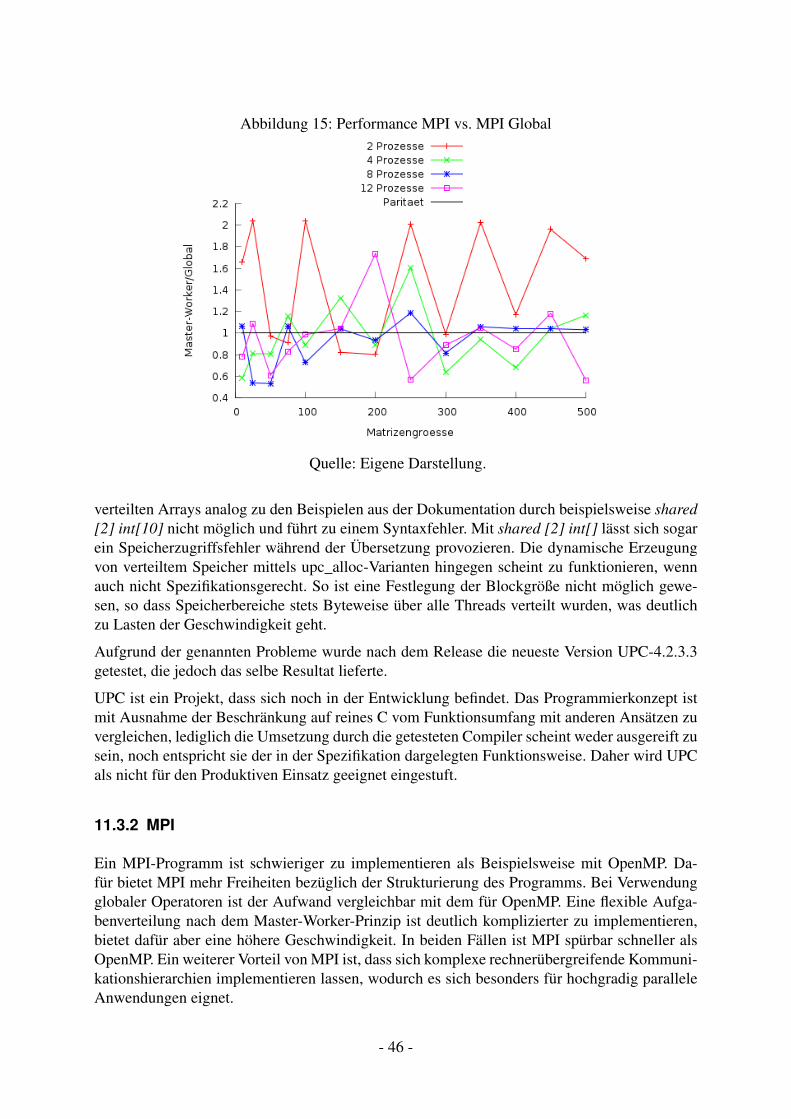
Abbildung 15: Performance MPI vs. MPI Global
Quelle: Eigene Darstellung.
verteilten Arrays analog zu den Beispielen aus der Dokumentation durch beispielsweise shared[2] int[10] nicht möglich und führt zu einem Syntaxfehler. Mit shared [2] int[] lässt sich sogarein Speicherzugriffsfehler während der Übersetzung provozieren. Die dynamische Erzeugungvon verteiltem Speicher mittels upc_alloc-Varianten hingegen scheint zu funktionieren, wennauch nicht Spezifikationsgerecht. So ist eine Festlegung der Blockgröße nicht möglich gewe-sen, so dass Speicherbereiche stets Byteweise über alle Threads verteilt wurden, was deutlichzu Lasten der Geschwindigkeit geht.
Aufgrund der genannten Probleme wurde nach dem Release die neueste Version UPC-4.2.3.3getestet, die jedoch das selbe Resultat lieferte.
UPC ist ein Projekt, dass sich noch in der Entwicklung befindet. Das Programmierkonzept istmit Ausnahme der Beschränkung auf reines C vom Funktionsumfang mit anderen Ansätzen zuvergleichen, lediglich die Umsetzung durch die getesteten Compiler scheint weder ausgereift zusein, noch entspricht sie der in der Spezifikation dargelegten Funktionsweise. Daher wird UPCals nicht für den Produktiven Einsatz geeignet eingestuft.
11.3.2 MPI
Ein MPI-Programm ist schwieriger zu implementieren als Beispielsweise mit OpenMP. Da-für bietet MPI mehr Freiheiten bezüglich der Strukturierung des Programms. Bei Verwendungglobaler Operatoren ist der Aufwand vergleichbar mit dem für OpenMP. Eine flexible Aufga-benverteilung nach dem Master-Worker-Prinzip ist deutlich komplizierter zu implementieren,bietet dafür aber eine höhere Geschwindigkeit. In beiden Fällen ist MPI spürbar schneller alsOpenMP. Ein weiterer Vorteil von MPI ist, dass sich komplexe rechnerübergreifende Kommuni-kationshierarchien implementieren lassen, wodurch es sich besonders für hochgradig paralleleAnwendungen eignet.
- 46 -
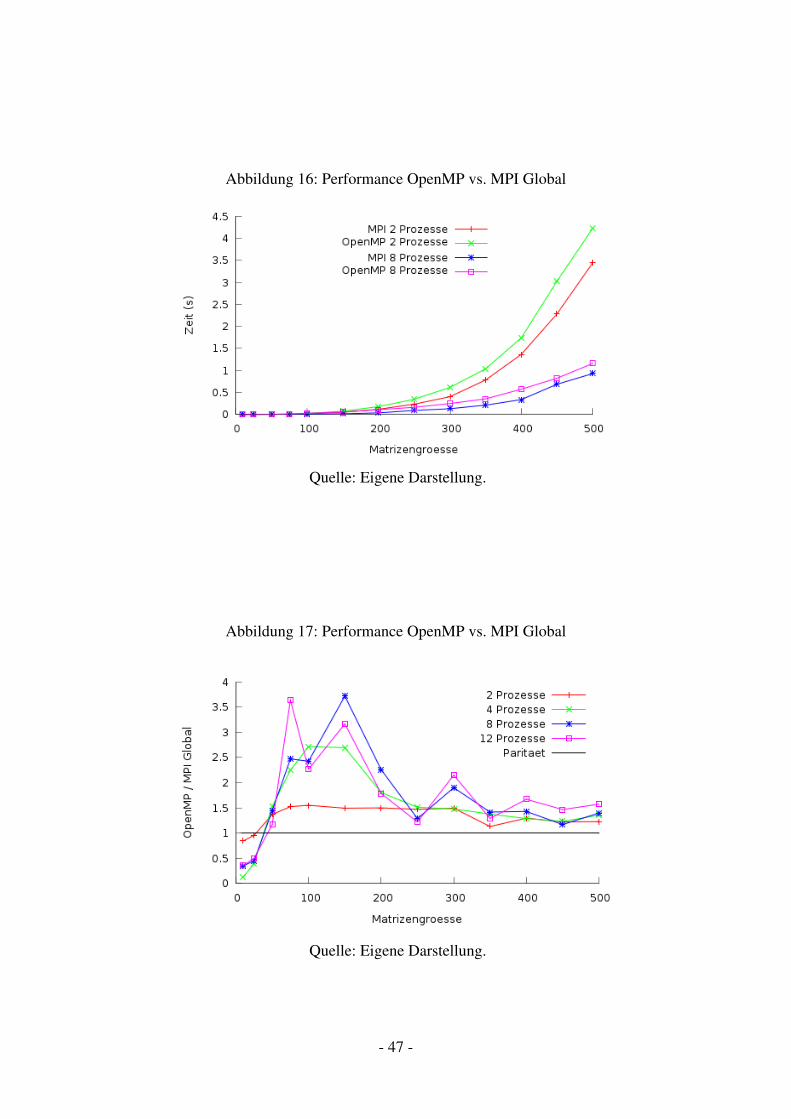
Abbildung 16: Performance OpenMP vs. MPI Global
Quelle: Eigene Darstellung.
Abbildung 17: Performance OpenMP vs. MPI Global
Quelle: Eigene Darstellung.
- 47 -

11.3.3 OpenMP
Eine Parallelisierung sowohl vorhandenen Codes als auch als Neuentwicklung stellt sich mitOpenMP außerordentlich einfach dar. Das Konzept der Schrittweisen Parallelisierung lässt sichgut umsetzen und es werden schnell erste Resultate erzielt. Dennoch muss der korrekten Spezi-fikation der parallelen Abschnitte und insbesondere der Unterscheidung zwischen privaten undnicht-privaten Variablen viel Aufmerksamkeit gewidmet werden.
Im Gegensatz zu MPI kann ein OpenMP-Programm nur auf einem einzigen Rechner ausgeführtwerden. Die maximale sinnvolle Parallelisierbarkeit ist dadurch entsprechend der Anzahl vor-handener Prozessoren eingeschränkt. Der Geschwindigkeitsgewinn durch Parallelisierung istdeutlich messbar, wenn auch nicht so groß wie bei MPI.
- 48 -

Teil IIIParallelisierung im Data Mining
Da sich diese Arbeit mit der Anwendung des verteilten Rechnens speziell im Data Mining be-fasst, gibt dieser Teil eine Einführung in das Data-Mining und die in dieser Arbeit verwendetenVerfahren. Es werden mögliche Umsetzungen für ein verteiltes Rechen im Data-Mining und ex-emplarisch die konkrete Implementierung zweier Ansätzes vorgestellt. Dabei wird gezeigt, dasseine Parallelisierung nicht in jedem Fall eine große Hürde darstellt, die komplizierte Program-me erfordert, sondern dass Bereits mit einfachen Mitteln ein signifikanter Geschwindigkeitszu-wachs erzielt werden kann.
This chapter deals with the parallization of Data Mining algorithms. It provides a brief in-troduction into Data Mining and the methods to be parallelized. This chapter also shows thatparallization does not necessarily mean complicated algorithms, but that the performance ofData Mining algorithms can be significantly improved using standard tools.
- 49 -

12 Data Mining Grundlagen
Data Mining ist Bestandteil einer Disziplin, die als Wissensextraktion aus Datenbanken - Know-ledge Discovery in Databases (KDD) - bekannt ist. Es befasst sich mit der Gewinnung von neu-em Wissen aus vorhandenen Daten. Dabei werden die Informationen, die in den Daten implizitenthalten sind, durch verschiedene Data-Mining-Verfahren extrahiert und in geeigneter Formdargestellt. Das auf diese Weise explizierte Wissen kann beispielsweise durch Modelle, Regelnoder Diagramme ausgedrückt und somit nutzbar gemacht werden.61
12.1 Ablaufmodell
Als „Data Mining” bezeichnet man sowohl die Anwendung der Methoden als auch das For-schungsgebiet selbst. Da es ein relativ neues und stark experimentelles Forschungsgebiet ist,sind sowohl die Methoden als auch deren Anwendung Forschungsgegenstand. Besonders letz-teres ist für den erfolgreichen Einsatz des Data Mining von Bedeutung, da hier stets auf die kon-krete Zielstellung und die verfügbaren Daten eingegangen werden muss. Daher existiert kein füralle Fälle geeignetes Verfahren. Es lässt sich lediglich ein allgemeines Vorgehensmodell ablei-ten, das den Data-Mining-Vorgang als iteratives Phasenmodell beschreibt. Jedoch berücksich-tigt dies weder konkrete Methoden noch lassen sich die einzelnen Phasen exakt gegeneinanderabgrenzen, da sie sich in der Praxis teilweise überschneiden und stark aufeinander aufbauen. Eslassen sich folgende Phasen definieren:
• Datenvorverarbeitung (Aufbereitung, Kodierung)
• Analyse
• Datennachbearbeitung (Auswertung, Visualisierung)
• Interpretation
Vor der eigentlichen Analyse der Daten ist eine Datenvorverarbeitung notwendig. Neben derinhaltlichen Bereinigung (Eliminieren von Fehlern, fehlenden Werten oder Ausreißern; Aus-wählen von Untermengen, Test- und Trainingsdaten) müssen die Daten in eine Form gebrachtwerden, die durch die gewählte Data-Mining-Methode verarbeitet werden kann, zum Beispieldurch Normalisierung, Skalierung, Intervallbildung oder Transformation.
Die Datenerhebung als Teil der Datenvorverarbeitung hat dafür Sorge zu tragen, dass die einenSachverhalt beschreibenden Informationen auch in der Datenmenge enthalten sind und ande-rerseits irrelevante, aber signifikante Informationen die Datenmenge nicht verfälschen. Ebensokönnen ungenaue, fehlende oder falsche Werte das Ergebnis beeinträchtigen oder unbrauchbarmachen. Die Datenvorverarbeitung hat entscheidenden Einfluss auf das Ergebnis der eingesetz-ten Methoden, da durch die Wahl ungeeigneter Vorverarbeitungsverfahren die Daten verfälschtwerden können. Es ist notwendig, bei der Kodierung die Daten korrekt und reproduzierbar ab-zubilden und dabei deren implizite Eigenschaften und Beziehungen zu berücksichtigen.
Die Datenanalyse bezieht sich auf die eigentliche Anwendung der Data-Mining-Methoden. Jenach Zielstellung finden Methoden aus den Bereichen Klassifikation, Clustering, Prognose oderAssoziation Anwendung. Um die für die zu analysierenden Daten optimale Methode aus dem
61 Dieses Kapitel wurde in ähnlicher Form vom Autor in [WISSUWA 2003] und [CLEVE 2005] aufgeführt.
- 50 -

jeweiligen Bereich zu ermitteln, sind umfangreiche Experimente mit verschiedenen Methodenund Parametern notwendig.
Die Validierung dient der Überprüfung des Data-Mining-Ergebnis auf tatsächliche Korrektheit.Dies geschieht meist durch Anwenden des erstellten Modells auf ausgewählte Testdaten.
Datenvorverarbeitung (inkl. Datenerhebung) sowie die Validierung sind dem Data-Mining-Prozessvor- bzw. nachgelagert. Beide sind stark anwendungsbezogen und daher nur bedingt dem DataMining selbst zuzuordnen. Jedoch haben sie großen Einfluss auf den Erfolg des Data Mining.
Ein ähnliches Modell wurde durch das CRISP-DM Konsortium erstellt, das mit dem Ziel ent-wickelt wurde, ein generelles Vorgehensmodell für den praktischen Einsatz von Data Mining inUnternehmen zu bieten.
Abbildung 18: CRISP-DM Phasenmodell
Quelle: http://www.crisp-dm.org
12.2 Klassifikation der Verfahren
In der Literatur ist eine Vielzahl von Data-Mining-Algorithmen beschrieben, von denen vielein der Praxis mit Erfolg eingesetzt werden.62 Die Anwendungsmöglichkeiten des Data Miningsind außerordentlich vielfältig. Es lassen sich drei grundlegende Formen der Anwendung unter-scheiden:
1. Klassifikation,
2. Assoziation,
3. Clustering,
4. Vorhersage.
Bei der Klassifikation werden überwachte Lernverfahren eingesetzt. Es wird anhand der At-tribute von bereits klassifizierten Objekten ein Klassifikator erzeugt, der in der Lage ist, un-bekannte Objekte ebenfalls korrekt zu klassifizieren. Als Klassifikatoren können zum Beispiel
62 Vgl.: [WITTEN 2001],[WITTEN 2005],[LÄMMEL 2004],[LÄMMEL 2003],[ALPAR 2000],[NAKHAEIZADEH 1998]
- 51 -

Entscheidungsbäume, k-Nearest-Neighbour oder Neuronale Netze zum Einsatz kommen. Typi-sche Anwendungen sind z. B. Klassifikation von Kunden oder die Schrifterkennung.
Die Assoziation unterscheidet sich von der Klassifikation dadurch, dass nicht nur die Klasse,sondern die Ausprägungen beliebiger Attribute und Attributkombinationen eines Objektes pro-gnostiziert werden können. Als Methoden kommen hier der a-priori-Algorithmus oder wieder-um Neuronale Netze in Betracht. Beispielanwendungen findet man in der Warenkorbanalyseoder beim Wiederherstellen eines verrauschten oder fehlerhaften Pixelmusters anhand einesvorher trainierten Beispiels.
Das Clustering, ein unüberwachtes Verfahren, wird zur Bildung von Gruppen (Cluster) einanderähnlicher Objekte aus einer Grundmenge eingesetzt. Dabei kommen verschiedene multivaria-te Verfahren zum Einsatz. Es kann verwendet werden, um die Attribute herauszufinden, diewesentliche Merkmale einer Gruppe darstellen oder durch die sie sich von anderen Gruppenunterscheiden. Bekannte Clustering-Verfahren sind das K-Means-Verfahren und die von Teu-vo Kohonen entwickelten Selbstorganisierenden Karten. Die mathematisch motivierten SupportVector Machines stellen ebenfalls einen erfolgversprechenden Clustering-Ansatz dar.
Die Vorhersage ähnelt der Klassifikation. Sie dient der Bestimmung von Zielgrößen anhandgegebener Attributausprägungen. Im Gegensatz zur Klassifikation liefert die Vorhersage jedochquantitative Werte.
- 52 -

12.3 Künstliche Neuronale Netze
Als Ansatz zur Parallelisierung im Data Mining sollen zwei Vertreter der Künstlichen Neuro-nalen Netze dienen: Feed-Forward-Netze und Selbstorganisierende Karten. Dieses Kapitel gibteine grobe Einführung in die zugrundeliegenden Konzepte beider Verfahren. Für eine Detail-lierte Darstellung sei auf die Literatur verwiesen.63
Künstliche neuronale Netze sind eine stark idealisierte Nachbildung der Funktionsweise vonbiologischen Neuronalen Netzen, wie beispielsweise Gehirne oder Nervensysteme. Die Verar-beitung von Informationen erfolgt nicht durch komplexe Algorithmen, sondern vielmehr durchsehr einfache Einheiten, die allerdings in großer Zahl vorhanden sind und untereinander Infor-mationen austauschen.
Analog zu ihren biologischen Vorbildern bestehen künstliche neuronale Netze aus Neuronenund einem Verbindungsnetzwerk. Die Informationsverarbeitung erfolgt mit Hilfe der Propa-gierungsfunktion, die für jedes Neuron den Aktivierungszustand anhand der von anderen Neu-ronen eingehenden Signale und der Verbindungsgewichte errechnet. Ein daraus abgeleitetesAusgabesignal wird dann an andere Neuronen über das Verbindungsnetzwerk weitergeleitet.Ein künstliches neuronales Netz kann als gerichteter Graph mit gewichteten Kanten angesehenwerden, durch den definiert wird, welche Neuronen miteinander kommunizieren. Die Gewichtedienen der Hemmung oder Verstärkung von Signalen. Zusammen mit dem Schwellwert (Bias)der Neuronen, der bestimmt, ab welchem Aktivierungsgrad ein Neuron aktiv wird und Signaleaussendet, sind es die Gewichte, in denen das “Wissen” des Netzes gespeichert wird. Durch die-se verteilte Repräsentation des Wissen sind neuronale Netze relativ unempfindlich gegenüberunvollständigen und verrauschten Eingabemustern.
Die Anordnung der Neuronen erfolgt typischerweise in Schichten von Neuronen gleichen Typs.Die zu verarbeitenden Daten werden über Neuronen der Eingabeschicht an das Netz trans-feriert, indem diesen eine initiale Aktivierung entsprechend dem jeweiligen Trainingsmusterzugewiesen wird. Diese Aktivierungen werden entsprechend der Propagierungsfunktion durchdas Netz verarbeitet. Nach vollständiger Propagierung kann die sogenannte „Netzantwort” alsAktivierungswerte der Neuronen der Ausgabeschicht abgelesen und interpretiert werden. Zwi-schen Eingabe- und Ausgabeschicht können sich weitere Schichten befinden, die als VersteckteSchichten bezeichnet werden.
Der Einsatz Neuronaler Netze sind immer dann sinnvoll, wenn sich andere Lösungsansätze wiezum Beispiel algorithmische Lösungen oder eine regelbasierte Wissensdarstelllung als nicht ge-eignet herausgestellt haben. Natürlich funktionieren Künstliche Neuronale Netze ebenfalls nacheinem Algorithmus, doch dient dieser nicht der Lösung eines Problems, sondern der Anpassungdes Netzes an das Problem.
12.3.1 Feed-Forward-Netze
Feed-Forward-Netze gehören zu den Klassifikatoren. Sie sind sind dadurch gekennzeichnet,dass die Propagierung nur in eine Richtung von der Eingabeschicht hin zur Ausgabeschichterfolgt. Es existiert keine Rückkopplung, das Netz ist ein zyklenfreier Graph.64
63 Siehe dazu: [ZELL 2000],[LÄMMEL 2004]64 Vgl.: [ZELL 2000] S.78
- 53 -

Bei Feed-Forward-Netzen werden überwachte Lernverfahren eingesetzt. Dabei wird dem Netzein Eingabemuster präsentiert, das nach der Propagierung ein Ausgabemuster erzeugt. Durchden Vergleich der Ausgabe mit der gewünschten Ausgabe (teaching input) kann für jedes Aus-gabeneuron ein Fehlerwert entsprechend der Abweichung zur gewünschten Ausgabe errechnetwerden. Basierend auf diesem Fehlersignal, den Verbindungsgewichten und der Aktivierungder Neuronen kann berechnet werden, wie die Verbindungsgewichte im Netz verändert werdenmüssen, damit der Fehler minimiert wird. Dieser Vorgang wird iterativ für alle Trainingsmusterdurchlaufen bis der Fehler hinreichend klein ist.
Ein trainiertes Feed-Forward-Netz ist in der Lage, neue Eingabemuster entsprechend ihrer Ähn-lichkeit zu gelernten Mustern zu klassifizieren.
12.3.2 Selbstorganisierende Karten
Unüberwachte Lernverfahren finden überall dort Anwendung, wo Datenmengen nach unbe-kannten Regeln zu klassifizieren sind, was beim Data Mining meist der Fall ist. Ein gutes Bei-spiel für die Anwendung unüberwachten Lernens sind die von Teuvo Kohonen entwickeltenSelbstorganisierenden Karten, auch Feature Maps genannt.65
Eine SOM ist ein Neuronales Netz dessen Neuronen typischerweise als zweidimensionale Git-terstruktur angeordnet sind. Die Anzahl der Neuronen beeinflusst die Genauigkeit und die Fä-higkeit zur Generalisierung der SOM. Jedes Neuron besitzt einen gewichteten Vektor W alsVerbindung mit den Neuronen der Eingabeschicht, deren Anzahl n der Variablen im Eingabe-raum entspricht:
Wi = [wi,1, ..., wi,n]
Das Trainieren der SOM beginnt mit der Initialisierung der Gewichtsvektoren durch Zufallszah-len im Intervall [-1,1]. Während des Trainings wird ein zufällig gewählter Eingabevektor I mitdem Gewichtsvektor W jedes Neurons der Kartenschicht verglichen. Das Neuron, dessen Ge-wichtsvektor der Eingabe am ähnlichsten ist, wird das Gewinnerneuron (BMU, Best MatchingUnit). Als Abstandsmaß wird in der Regel die Euklidische Distanz verwendet.
d(I,W ) =
√√√√ n∑i=0
(Ii −Wi)2
Der Gewichtsvektor W des Gewinnerneurons wird anschließend so verändert, dass er dem Ein-gabevektor I ähnlicher wird. Das gleiche gilt für die Neuronen innerhalb eines Radius um dasGewinnerneuron. Der Grad der Beeinflussung wird durch den Lernfaktor η und die Distanz-funktion h (meist Gauss-Funktion) bestimmt, die normalerweise nach jedem Trainingsschrittreduziert werden:
Wj(t+ 1) = Wj(t) + η(t)hcj(t)[X(t)−Wj(t)]
65 Vgl.:[KOHONEN 2001], [ZELL 2000] S179ff.
- 54 -

Eine SOM hat die Eigenschaft einer topologieerhaltende Transformation eines hochdimensio-nalen Eingaberaumes auf eine niedrigere Dimension. Ähnliche Eingabevektoren werden dabeiauf benachbarte Neuronen projeziert. Da meist zweidimensionale SOMs zum Einsatz kommen,ist eine Visualisierung der Ergebnisse relativ einfach.
- 55 -

13 Parallele Algorithmen
Die augenscheinlichste Möglichkeit zur Parallelisierung im Data-Mining stellt der verwendeteAlgorithmus selbst dar. Abhängig davon, wie der Zugriff auf die Daten erfolgt, kann dies sogarsehr einfach geschehen, wie im Folgenden anhand künstlicher Neuronaler Netze skizziert wird.
13.1 Serielle Selbstorganisierende Karte
Als Ausgangspunkt soll eine Kohonen-Karte dienen, die auf herkömmliche, serielle Weise im-plementiert ist. Ausgehend davon werden parallele Varianten implementiert, um verschiedeneAnsätze miteinander vergleichen zu können.
Das Netz wird in Form von Schichten von Neuronen abgebildet. Eine Schicht repräsentiert dabeieine Anzahl von Neuronen gleichen Typs. Schichten können miteinander vernetzt werden. Diesentspricht der vollständigen Vernetzung der Neuronen untereinander.
Die Struktur einer Schicht kann wie folgt implementiert werden:typedef struct {
char type; // Neuronen-Typint size; // Anzahl Neuronenint wsize; // Anzahl Gewichte pro Neuronvoid * source; // Vorhergehende Schichtdouble * act; // Aktivierungs-Vektordouble * bias; // BiasVektordouble * error; // Fehler-Vektordouble * weights; // Gewichts-Matrix
} t_layer;
Die Gewichtsmatrix W einer Schicht, wobei i die Anzahl der Quell-Neuronen und j die Anzahlder Ziel-Neuronen ist, stellt sich wie folgt dar:
Wij =
w0;0 w1;0 ... wi;0
w0;1 ... ... ...... ... ... ...w0;j ... ... wij
Neuronen als Arrays ihrer Eigenschaftswerte zu speichern, anstelle eine eigene Neuronen-Struktur zu verwenden, hat den Vorteil, dass die Propagierungsfunktionen als Matrix-Opera-tionen dargestellt werden können, die direkt auf den entsprechenden Schichten operieren. Dasist zum einen sehr schnell, zum anderen lassen sich Matrix-Operationen sehr leicht parallelisie-ren.
Eine Propagierungsfunktion, die Aktivierungen einer Schicht mit den entsprechenden Gewich-ten auf die Aktivierung der nachfolgenden Schicht abbildet, hat somit die Form:
Ai+1 = Ai ∗Wi
Analog dazu lässt sich auch die Rückwärtspropagierung des Fehlersignals z.B. beim Backpropa-gation-Lernverfahren als Matrizenoperationen darstellen:
- 56 -

Ei = Ei+1 ∗Wi ∗Oi
Algorithmus 3 zeigt eine Implementierung für das Trainingsverfahren einer Kohonen-Karte. ZurBestimmung des Gewinnerneurons wurde nicht der Euklidische Abstand, sondern das maxima-le Skalarprodukt verwendet, weshalb Eingabe- und Gewichtsvektoren in normalisierter Formvorliegen müssen.
Algorithm 3 SOM Seriell
1 do{2 for(int i=0;i<nPatterns;i++){34 // propagation5 for(int j=0;j<I->size;j++) { I->act[j]=pattern[i][j]; }6 matrix_mult(O->wsize,O->size,O->weights, 1,I->size,I->act, O->act);78 // find winner9 id_max=0;
10 for(int j=0;j<nOutput;j++){if(O->act[j] > O->act[id_max]) id_max=j;}1112 maxx=id_max % sx;13 maxy=id_max / sx;1415 // adjust weights16 for(int j=0;j<nOutput;j++){17 dx=maxx - (j%sx); dy=maxy - (j/sx);1819 rate=sqrt( (double)(dx*dx + dy*dy));20 rate=factor * exp (- ((rate*rate) / (radius*radius)) );21 len=0.0;22 for(int k=0;k<nInput;k++){23 O->weights[j*nInput+k]+=rate*(I->act[k]-O->weights[j*nInput+k]);24 len+=O->weights[j*nInput+k]*O->weights[j*nInput+k];25 }2627 len=1.0/sqrt(len);28 for(int k=0;k<nInput;k++){29 O->weights[j*nInput+k]*=len;30 }31 }32 radius*=radius_factor;33 }34 }while(++cycle < cycles);
13.2 Parallele Selbstorganisierende Karte
Die Berechnungszeit für einen Trainingszyklus einer selbstorganisierenden Karte hängt haupt-sächlich von der Anzahl der Trainingsmuster sowie der Größe der Kartenschicht ab. Ein Trai-ningsschritt läuft dabei in 3 Stufen mit unterschiedlichem Rechenaufwand ab:
1. Propagierung des Eingabemusters: O(n2)
- 57 -

2. Bestimmung des Gewinnerneurons: O(n)
3. Anpassung der Gewichte: O(n2)
Die einzelnen Stufen sind nicht unabhängig voneinander, so dass eine Paralleliserung nichtdurch Aufteilung der Trainingsmuster erfolgen kann. Stattdessen kann versucht werden, denTrainingsschritt zu parallelisieren. Die besten Kandidaten stellen die Stufen 1 und 3 dar. ImFolgenden wird die Parallelisierung unter Verwendung von OpenMP dargestellt. Der Bezugzum jeweils Abgebildeten Quelltext findet durch Angabe der Zeilennummer in Klammern statt.
Ausgehend von Algorithmus 3 kann die Parallelisierung der einzelnen Stufen durch OpenMPmit wenig Aufwand durch das Hinzufügen von Compilerdirektiven erfolgen. Die parallelisierteVariante ist in Algorithmus 4 dargestellt.
Da sich innerhalb der äußersten Schleife parallelisierbare (z.B. Schleifen) und nicht-paralleli-sierbare Abschnitte (z.B. Anpassung des Trainingsradius) abwechseln, ist es wenig sinnvoll,die Abschnitte einzeln zu parallelisieren, da so der zusätzliche Aufwand für die Erzeugung ein-zelner Prozesse den Geschwindigkeitsgewinn durch die parallele Berechnung schnell zunichtemachen würde. Die Aufteilung in einzelne Prozesse sollte stets so weit außen wie möglicherfolgen (1).
Die Initialisierung der Eingabeschicht muss für alle Prozesse zum selben Zeitpunkt stattfinden,da ansonsten die anschließende Propagierung unterschiedliche Resultate liefern würde. Dieswird durch den Prozess vorgenommen, der die Schleife zur Initialisierung als erstes Erreicht.Gleichzeitig wird implizit eine Barriere errichtet (7).
Die Propagierung mittels Matrizenmultiplikation kann durch Verwendung des parallelen Mul-tiplikationsalgorithmus wie in Abschnitt 11.1.4 dargestellt erfolgen (10). Dieser muss jedochleicht modifiziert werden, da zum Zeitpunkt des Funktionsaufrufs das Programm bereits paral-lel ausgeführt wird. Somit ist dort die Zeile
#pragma omp parallel for schedule(static) ...
durch
#pragma omp for schedule(static) ...
zu ersetzen.
Nach der Bestimmung des Gewinnerneurons durch genau einen Prozess (12) erfolgt die Anpas-sung der Gewichte. Dies kann parallel für jedes Neuron der Kartenschicht erfolgen. Die jewei-ligen Abstände zum Gewinnerneuron, der Lernradius sowie die Länge des Gewichtsvektors fürdie Normalisierung müssen als privat deklariert werden (18).
Abschließend wird nach jeder Iteration über die Trainingsmuster der Lernradius angepasst, waswiederum nur einmal pro Iteration geschehen darf und daher nur von einem Prozess durchge-führt wird (24).
- 58 -

Algorithm 4 Parallele SOM mit OpenMP
1 #pragma omp parallel2 {3 do{4 for(int i=0;i<nPatterns;i++)5 {6 // propagation7 #pragma omp single8 for(int j=0;j<I->size;j++){ I->act[j]=pattern[i][j]; }9
10 matrix_mult(O->wsize,O->size,O->weights, 1,I->size,I->act, O->act);1112 #pragma omp single13 {14 // find winner15 ...16 }1718 #pragma omp for schedule(static) private(dx,dy,len,rate)19 // adjust weights20 for(int j=0;j<O->size;j++){21 ...22 }23 }24 #pragma omp single25 radius*=radius_factor;26 }27 } while(++cycle < cycles);
13.3 Performance Test
In Abbildung 19 ist dargestellt, wie sich für verschiedene Problemgrößen die Steigerung derParallelität auf die Rechenzeit auswirkt. Es ist sehr gut zu erkennen, dass eine zu starke, nichtan die Problemgröße angepasste Parallelisierung zu steigenden Rechenzeiten führt.
Für größere Kohonen-Karten ist die Rechenzeit und der Speedup in Abhängigkeit von der Kar-tengröße in Abbildung 20 dargestellt. Es ist zu sehen, dass für p=12 der Speedup im Vergleichzu p=4 im Verhältnis nur gering ist.
- 59 -
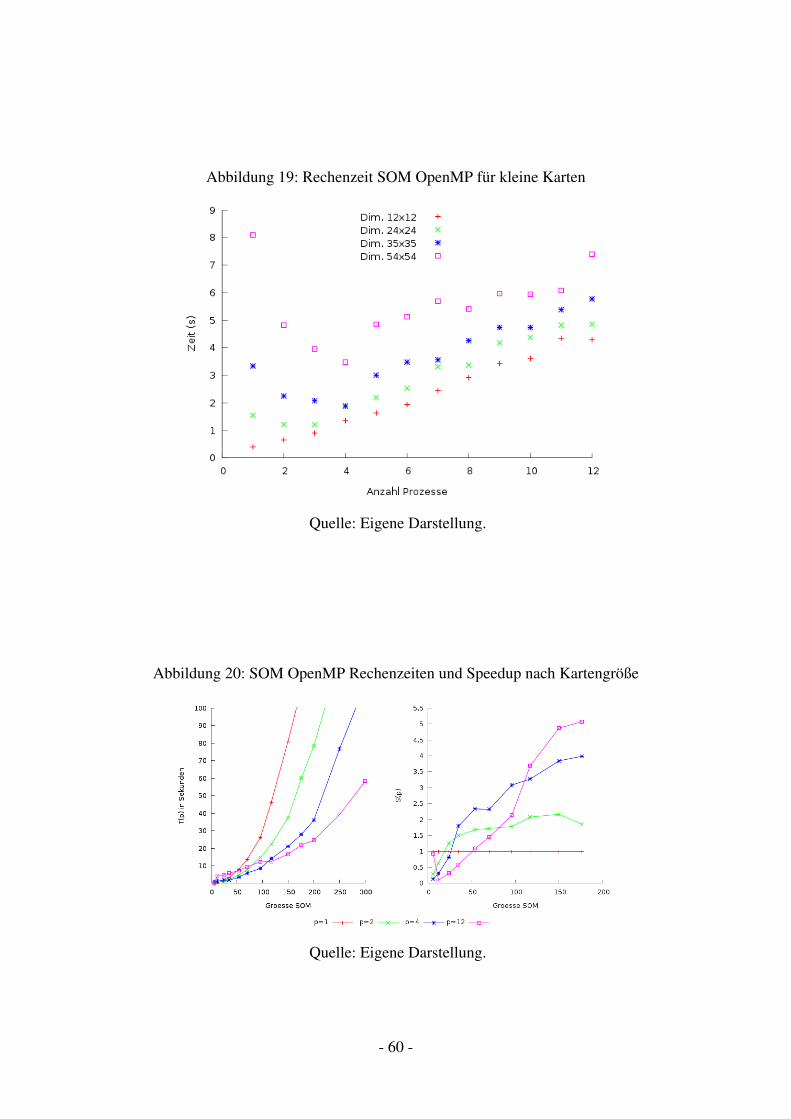
Abbildung 19: Rechenzeit SOM OpenMP für kleine Karten
Quelle: Eigene Darstellung.
Abbildung 20: SOM OpenMP Rechenzeiten und Speedup nach Kartengröße
Quelle: Eigene Darstellung.
- 60 -

14 Parallele Modelle
Verschiedene Gründe können gegen den Einsatz eines parallelen Algorithmus sprechen. Diesist beispielsweise der Fall, wenn keine passende parallele Implementierung existiert und auchkeine Anpassung des Quellcodes möglich ist, weil dieser zu komplex, nicht verfügbar oder derEinsatz ein einmaliges Projekt ist, dass den Aufwand nicht rechtfertigt.
Wenn es nicht möglich ist, den Algorithmus zur Erzeugung eines Modells parallel auszuführen,kann stattdessen versucht werden, das Modell selbst zu Parallelisieren. Man kann ein Modellals Klassifikator betrachtet, der eine nichtsymmetrische Abbildung des Merkmalsraumes Rd aufKlassen realisiert:
f : Rd → C, x 7→ f(x) :=
{y dist(x, y) ≤ δ, y ∈ C∅ sonst
Anstelle eines einzelnen Klassifikators können auch mehrere Klassifikatoren verwendet werden,die jeweils eine Abbildung auf Teilmengen vornehmen. Die letztendliche Abbildung wird durcheinen zusammengesetzten Klassifikator vorgenommen, der die entgültige Abbildung durch dieKombinationsfunktion σ()bestimmt:
fn : Rd → Cn, x 7→ fn(x) :=
{y dist(x, y) ≤ δ, y ∈ C∅ sonst
fN : Rd → C, x 7→ fN(x) := σ(f1(x), ..., fn(x))
Diese Vorgehensweise ist dann interessant, wenn dadurch die Komplexität der Berechnung je-des einzelnen Klassifikators gesenkt werden kann.
14.1 Hierarchische Kohonen-Karten
Das Trainieren von Kohonen-Karten mit großer Eingabeschicht, großer Kohonen-Schicht undvielen Trainingsmustern ist sehr Rechen- und damit Zeitaufwändig. Eine Parallelisierung kanndurch Zerlegung der Karte in kleinere Karten erfolgen, die unabhängig voneinander berechnetwerden können, so dass ein paralleler Algorithmus nicht notwendig ist. Gleichzeitig sinkt derRechenaufwand pro Karte, da weniger Neuronen und damit weniger Gewichtsvektoren vorhan-den sind.
14.1.1 Konzept
Diese Herangehensweise wird dadurch motiviert, dass während des Trainings einer Kohonen-Karte tatsächlich zu Beginn eine derartige grobe Aufteilung stattfindet, wie in Abbildung 21 zusehen ist. Die Abbildung zeigt eine U-Matrix-Darstellung einer Karte in verschiedenen Stadiendes Trainings. Neuronen, deren Gewichtsvektoren sich stark von denen benachbarter Neuronenunterscheiden, sind dunkel dargestellt, Cluster sind als helle Gebiete zu erkennen. Es ist deutlichzu sehen, dass sich zu Beginn mehrere sehr großflächige Bereiche herausgebildet haben.
Bei diesem Ansatz sind jedoch folgende Faktoren zu berücksichtigen:
- 61 -

Abbildung 21: U-Matrix einer Kohonen-Karte
(a) Initiale Karte (b) 2 Trainingszyklen
(c) 5 Trainingszyklen (d) 10 Trainingszyklen
Quelle: Eigene Darstellung.
1. Das Aufteilen der Trainingsmuster muss so erfolgen, dass die Teilkarten nur mit den Musterntrainiert werden, die für sie relevant sind. Es ist also eine Vorauswahl zu treffen.
2. Durch die Aufteilung der Karte könnten Nachbarschaftsbeziehungen zwischen Clustern ge-stört werden. Läge ein Gewinnerneuron am Rand einer Teilkarte, würde es bei entsprechendGroßem Trainingsradius auch Neuronen benachbarter Karten beeinflussen müssen.
Laut Punkt 1. stellt sich zunächst die Frage, wie die Datensätze auf die einzelnen Teil-Kartenzu verteilen sind, da genau dies - die Gruppierung ähnlicher Datensätze - ja eigentlich durch dieKarte selbst erfolgen soll. Hierfür bietet sich ein mehrstufiges Clustern an, bei dem zunächsteine grobe Aufteilung der Datensätze P durch eine sehr kleine Kohonen-Karte mit wenigenNeuronen vorgenommen wird. Anschließend werden für jeden Cluster bzw. jedes Neuron neine neue Karte erzeugt und mit den diesem Cluster zugeordneten Trainingsmustern Pn ⊂P, dist(P,Wn)→ min trainiert.
Punkt 2. ist schwieriger zu Lösen. Ein Ansatz wäre, die Teilkarten erst dann zu erzeugen, wennder Trainingsradius klein genug ist, dass die Distanzfunktion hcj(t) Werte nahe Null liefert undsomit der zweite Summand der Lernfunktion ebenfalls gegen Null geht:
Wj(t+ 1) = Wj(t) + η(t)hcj(t)[X(t)−Wj(t)]
Um beim späteren Zusammenfügen der Karten ein konsistentes Kartenbild zu erhalten, müssendie Teilkarten eine Gewichtung der Neuronen aufweisen, die die Nachbarschaftsbeziehung soabbildet, dass Neuronen an den Rändern benachbarter Karten ähnlich sind. Dies kann durch
- 62 -
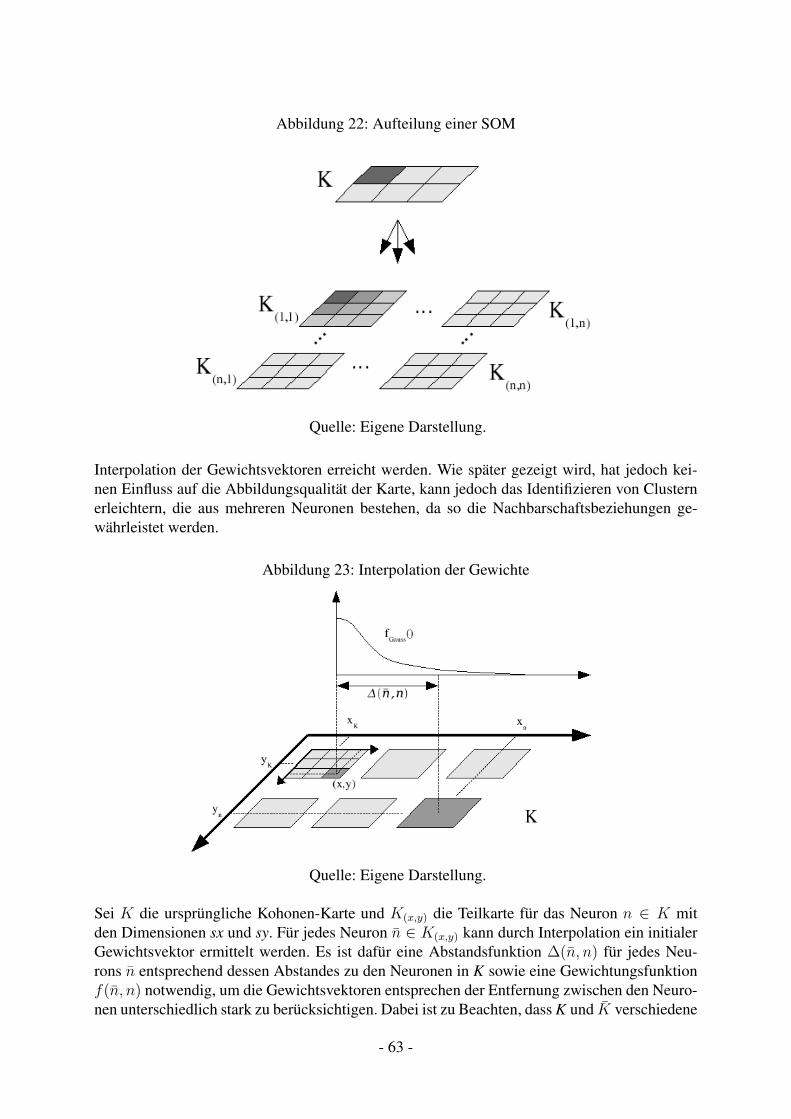
Abbildung 22: Aufteilung einer SOM
Quelle: Eigene Darstellung.
Interpolation der Gewichtsvektoren erreicht werden. Wie später gezeigt wird, hat jedoch kei-nen Einfluss auf die Abbildungsqualität der Karte, kann jedoch das Identifizieren von Clusternerleichtern, die aus mehreren Neuronen bestehen, da so die Nachbarschaftsbeziehungen ge-währleistet werden.
Abbildung 23: Interpolation der Gewichte
Quelle: Eigene Darstellung.
Sei K die ursprüngliche Kohonen-Karte und K(x,y) die Teilkarte für das Neuron n ∈ K mitden Dimensionen sx und sy. Für jedes Neuron n̄ ∈ K(x,y) kann durch Interpolation ein initialerGewichtsvektor ermittelt werden. Es ist dafür eine Abstandsfunktion ∆(n̄, n) für jedes Neu-rons n̄ entsprechend dessen Abstandes zu den Neuronen in K sowie eine Gewichtungsfunktionf(n̄, n) notwendig, um die Gewichtsvektoren entsprechen der Entfernung zwischen den Neuro-nen unterschiedlich stark zu berücksichtigen. Dabei ist zu Beachten, dass K und K̄ verschiedene
- 63 -

Koordinatensysteme verwenden. Die entsprechende Abstandsfunktion ∆(n̄, n) für den Euklidi-schen Abstand lautet:
∆(n̄, n) =
√(1
2+ xK +
xn̄
sx− xn
)2
+
(1
2+ yK +
12yn̄
sy− yn
)2
Als Gewichtungsfunktion kann eine beliebige stetige, monoton fallende Funktion verwendetwerden, zum Beispiel eine quadratisch fallende Funktion der Form
f(n̄, n) =1
∆(n̄, n)
oder die Gauss’sche Distanzfunktion, die häufig zur Bestimmung des Nachbarschaftsradius ver-wendet wird:
f(n̄, n) = e−(∆(n̄,n)d )
2
Der interpolierte Gewichtsvektor ergibt sich somit aus:
W̄n̄ =1
N
i<N∑i=0
Wi ∗ f(n̄, ni)
Eine andere Möglichkeit ist die von Kohonen vorgeschlagene lokale Interpolation für wachsen-de SOMs, die jeweils nur die direkt benachbarten Neuronen von K(x,y)in K berücksichtigt.66
14.1.2 Umsetzung
Ist eine geeignete nicht-interaktive Umgebung zur Simulation Neuronaler Netze vorhanden,lässt sich dieses Konzept vollständig mit Hilfe der Verfügbaren Tools sowie der Shell-Skript-Programmierung lösen. Hier wird das Konzept anhand des SNNS und der mitgelieferten Toolsgezeigt. Hierfür sind folgende Komponenten notwendig:
1. Erzeugen der Kohonen-Karten
2. Trainieren der Kohonen-Karte
3. Bestimmung der Gewinnerneuronen für jedes Trainingsmuster
4. Aufteilung der Trainingsmuster
Der SNNS arbeitet mit Dateien für die Ein- und Ausgabe sowie Konfiguration. Wenn im Fol-genden von der Erzeugung von Mustern oder Netzen die Rede ist, so ist damit das Generiereneiner entsprechenden Datei gemeint. Relevant sind hier die folgenden Dateiformate:
• .pat : Pattern-Dateien enthalten Trainings- und Testmuster.
• .net : Netz-Datei enthalten eine Beschreibung eines Neuronalen Netzes inklusive Topologie,Verbindungen, Aktivierungs- und Lernfunktionen.
66 Siehe [KOHONEN 2001] S. 172f.
- 64 -

• .res : Result-Dateien sind ähnlich wie Pattern-Dateien aufgebaut und können Muster fürInput, Teaching-Output sowie Output enthalten.
• .batchman : Skript-Dateien stellen die Eingabe für den SNNS-Batch-Prozessor dar, mit demsich der SNNS per Kommandozeile bedienen lässt.
Erzeugen von Kohonen-Karten
Eine Kohonen-Karte lässt sich leicht mit dem Tool ff_bignet erzeugen. Der Aufruf zum Erzeu-gen einer Karte mit einer Eingabeschicht der Dimension [X1,Y1] sowie einer Kohonen-Schichtder Dimension [X2,Y2] lautet:
$ff_bignet -p X1 Y1 Act_Identity Out_Identity input \-p X2 Y2 Act_Identity Out_Identity hidden \-l 1 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 DATEINAME.net
Das Kommando wurde zur besseren Benutzbarkeit durch ein Shell-Skript create_kohonen.shgekapselt. Die Syntax für den Aufruf lautet:
$create_kohonen.sh #Inputs X-Groesse Y-Groesse Dateiname
Als Aktivierungsfunktion der Kartenschicht wurde die Identität (Act_Identity) gewählt. Die Eu-klidische Distanz (Act_Euclid) als Aktivierungsfunktion ist sowohl ungeeignet als auch nutzlos.Dies hat folgende Gründe:
1. Der SNNS bestimmt während des Trainings das Gewinnerneuron der Kartenschicht anhanddes maximalen Skalarproduktes aus Eingabevektor und Gewichtsvektor, die Aktivierungs-funktion wird dabei ignoriert. Dieses Verhalten entspricht der Verwendung von Act_Identity.Die Funktion Act_Euclid existiert lediglich zum Zweck der Visualisierung durch die Grafi-sche Oberfläche XGUI.
2. Um die SOM in ein Feed-Forward-Netz umzuwandeln, wird eine Aktivierungsfunktion be-nötigt, die dem Neuron mit dem geringsten Euklidischen Abstand zum Eingabevektor diehöchste Aktivierung zuweist. Act_Euclid würde hier stattdessen die geringste Aktivierungliefern und ist somit ungeeignet.
3. Es wurde festgestellt, dass der Bias-Wert während des Trainings extrem hohe Werte errei-chen kann, obwohl eine Anpassung des Bias in der Theorie der Kohonen-Karten nicht vorge-sehen ist. Der SNNS-Quellcode zeigt, dass der Bias-Wert als Zähler dafür genutzt wird, wiehäufig ein Neuron Gewinnerneuron war. Daher müssen entweder alle Bias-Werte nach demTraining explizit auf 0,0 gesetzt werden, oder es wird eine Aktivierungsfunktion verwendet,die den Bias-Wert nicht benutzt, was bei Act_Identity der Fall ist.
Trainieren der Kohonen-Karte
Für das Trainieren einer Karte ist ein entsprechendes Batchman-Skript notwendig, dass die not-wendigen Dateien lädt, die Trainingsfunktion konfiguriert und die Trainingszyklen durchführt(Auszug):
loadNet(infile)loadPattern(patfile)setInitFunc("Randomize_Weights",-1.0,1.0)initNet()
- 65 -

setLearnFunc("Kohonen",0.8 ,radius, factor ,factor, width)setUpdateFunc("Kohonen_Order")setShuffle(TRUE)while radius>0.7 do
trainNet()radius=radius*(factor^PAT)
endwhilesaveNet(outfile)
Dieses Skript verwendet Variablen, deren Werte jedoch im Skript fest definiert sein müssen, weilBatchman keine Möglichkeit bietet, diese zur Laufzeit festzulegen und z.B. durch Kommando-zeilen-Parameter zu übergeben. Da verschiedene Kohonen-Karten verwendet werden und daherverschiedene Werte für die Trainingsfunktion notwendig sind, ist es ratsam, das Skript dyna-misch zu generieren. Dies wurde durch das Skript train_kohonen.sh realisiert. Die Syntax fürden Aufruf lautet:
$train_kohonen.sh Netz-Datei Ausgabe-Datei Pattern-Datei \Kartenbreite Zyklen Faktor
Bestimmung der Gewinnerneuronen
Nachdem eine Karte trainiert wurde, müssen für jedes Trainingsmuster das Gewinnerneuron er-mittelt werden, dass den Cluster repräsentiert, dem das Trainingsmuster zugeordnet wurde. DerSNNS ist in der Lage, eine Result-Datei zu generieren, die für jedes Trainingsmuster die Ak-tivierungswerte aller Ausgabeneuronen enthält. Das Problem ist, dass eine Kohonen-Karte imSNNS keine Ausgabeneuronen besitzt, sondern die Karten-Schicht aus Versteckten Neuronen(Hidden Layer) besteht.
Wenn man jedoch alle Versteckten-Neuronen in Ausgabe-Neuronen umwandelt, erhält manein einschichtiges Feed-Forward-Netz, womit sich dann problemlos die besagte Result-Dateierzeugen lässt. Hierfür ist es lediglich Notwendig, die Definition des Neuronen-Typs in derNetzwerk-Datei zu verändern, was sich mit einem einfachen Kommando bewerkstelligen lässt:
$sed ’s/| h/| o/g’ < infile.net > outfile.net
Anschließend kann wie schon beim Training der Kohonen-Karte ein Batchman-Skript erstelltwerden, welches Netz- und Patterndatei lädt und die Erzeugung der Result-Datei veranlasst.Auch hier ist es ratsam, das Skript dynamisch zu erzeugen.
loadNet(netfile)loadPattern(patfile)setUpdateFunc("Topological_Order")setShuffle(FALSE)saveResult(resfile, 1, PAT, TRUE, FALSE, "create")
Das hier beschriebene Vorgehen wird durch das Shell-Skript apply_kohonen.sh realisiert. DieSyntax für den Aufruf lautet:
$apply_kohonen.sh network.net pattern.net result.res
Anschließend müssen aus den Ausgabemustern in der Result-Datei die entsprechenden Gewin-nerneuronen bestimmt werden. Das fehlerfreie Parsen einer beliebigen Result-Datei erfordert
- 66 -

jedoch ein komplizierteres Skript, so dass hier auf das Tool cnv_res2sxml aus dem SXML-SNNS-Interface67 zurückgegriffen wird. Da dieses XML-Dateien erzeugt, müssen diese nochin CSV-Dateien umgewandelt werden.
$cnv_res2sxml mod=number input=false teaching=false \output=false file=pattern0.res -nostdin | mod_process -f \xml2csv.sxml 2>/dev/null | grep -v winner > pattern.csv
Die so erzeugte Datei pattern.csv enthält für jedes Muster eine Zeile mit der Nummer des Ge-winnerneurons. Mittels
$grep -n $a < pattern.csv | cut -f1 -d":" > subset0_$a.sub
kann daraus eine Datei mit der Nummer aller Trainingsmuster erzeugt werden, die als Gewin-nerneuron den Wert von $a haben. Diese Datei kann als Eingabe für das Tool pat_sel_simpleverwendet werden, um aus der ursprünglichen Pattern-Datei eine Untermenge von Mustern zubilden. Damit ist die Aufteilung der Trainingsmuster abgeschlossen.
Erzeugen von Teilkarten
Für jede Untermenge an Trainingsmustern kann nun erneut eine Kohonen-Karte erstellt undtrainiert werden. Dies kann durch das oben genannte Skript create_kohonen.sh erfolgen oderaber es wird das Tool net_subdiv aus dem SXML-SNNS-Interface zurückgegriffen, welches fürein gewähltes Neuron eine interpolierte Karte erzeugt:
$net_subdiv som.net #neuron X-Groesse Y-Groesse > subnet.net
14.1.3 Testaufbau
Für eine Beurteilung des Verfahrens ist ein Vergleich der hierarchischen Kohonen-Karte gegen-über einer normalen Kohonen-Karte unter kontrollierten Bedingungen Voraussetzung. FolgendeParameter (SNNS-Pendant in Klammern) können dabei variiert werden:
• die verwendete Kartengröße und initiale Gewichtung
• Eigenschaften und Umfang der Trainingsdaten
• der Lernfaktor η (Adption height h(0))
• die Distanzfunktion h (Adaption radius r(0))
• die Anzahl der Lernzyklen
Die Qualität einer SOM bezüglich einer Menge an Eingabevektoren lässt sich anhand der Zu-ordungsgenauigkeit der Eingabevektoren zu Clustern bestimmen. Dazu kann der gemittelte Eu-klidische Abstand aller Eingabevektoren I zu den jeweiligen Gewichtsvektoren W der Gewin-nerneuronen ermittelt werden:
∆(I,W ) =
√∑ni=0(Ii −Wi)2
n
Das Resultat allein stellt noch keine absolute Aussage über die Qualität dar, kann jedoch alsVergleichswert dienen.
67 Siehe dazu [WISSUWA], [WISSUWA 2003]; Die Bibliothek ist im Quellcode auf der beiliegenden CD enthalten.
- 67 -

Algorithm 5 Hierarchische SOM
1 INPUTS=102 SX=43 SY=14 SX2=305 SY2=256 CYCLES1=500007 CYCLES2=10000089 SUBS=""; for (( a=0; a<SX*SY; a++ )); do SUBS=$SUBS"$a "; done
1011 ./create_kohonen.sh $INPUTS $SX $SY som_untrained.net12 ./train_kohonen.sh som_untrained.net som_trained.net pattern0.pat $SX
$CYCLES113 ./apply_kohonen.sh som_trained.net pattern0.pat pattern0.res1415 /usr/local/sxml/bin/cnv_res2sxml mod=number input=false teaching=false
output=false file=pattern0.res -nostdin | /usr/local/sxml/bin/mod_process -f xml2csv.sxml 2>/dev/null | grep -v winner > pattern0.csv
1617 for a in $SUBS ; do18 grep -n $a < pattern0.csv | cut -f1 -d":" > subset0_$a.sub19 if test -e pattern1_$a.pat; then rm pattern1_$a.pat; fi20 /usr/local/SNNS/bin/pat_sel_simple subset0_$a.sub pattern0.pat
pattern1_$a.pat21 done2223 for a in $SUBS ; do24 ./create_kohonen.sh 10 $SX2 $SY2 subnet0_$a.net25 done2627 for a in $SUBS ; do28 if test -s subset0_$a.sub ; then29 ./train_kohonen.sh subnet0_$a.net subnet_trained_0_$a.net pattern1_$a.
pat $SX2 $CYCLES2 &30 else31 cp subnet0_$a.net subnet_trained_0_$a.net32 echo "no patterns for subnet $a."33 fi34 done3536 wait3738 Nets="";39 for a in $SUBS ; do40 Nets=$Nets"subnet_trained_0_$a.net "41 done4243 /usr/local/sxml/bin/net_merge $SX $Nets > som_trained_1.net
- 68 -
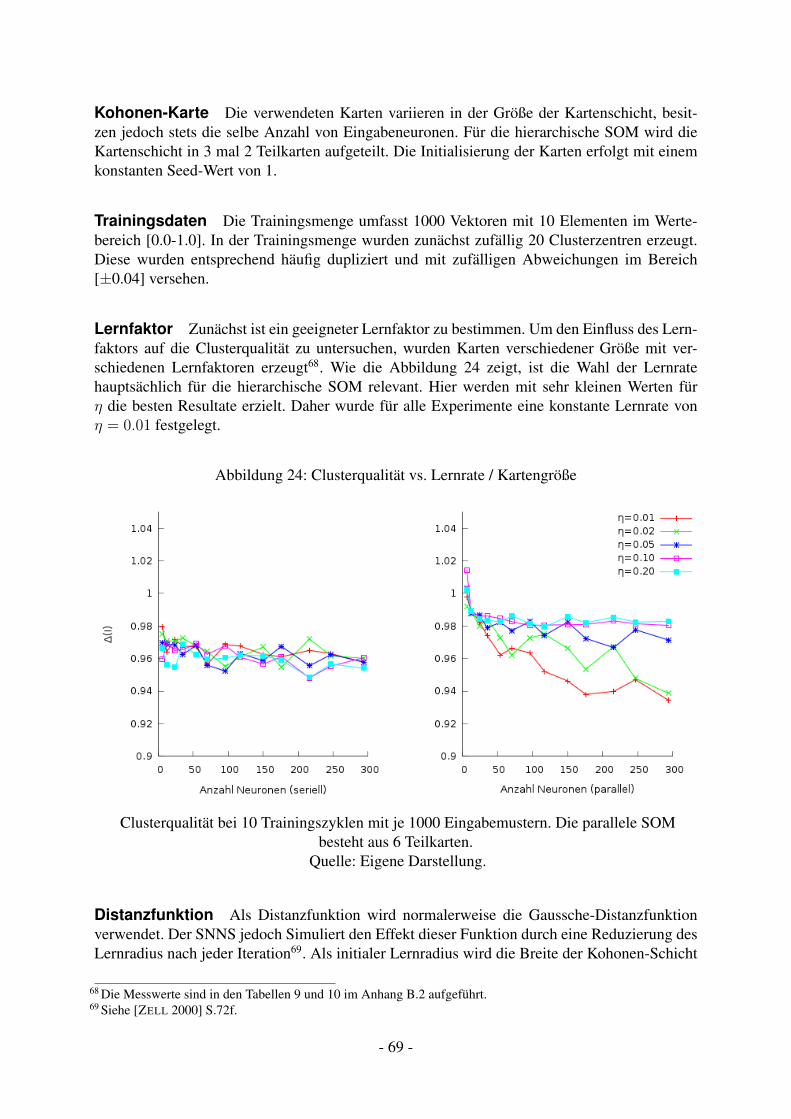
Kohonen-Karte Die verwendeten Karten variieren in der Größe der Kartenschicht, besit-zen jedoch stets die selbe Anzahl von Eingabeneuronen. Für die hierarchische SOM wird dieKartenschicht in 3 mal 2 Teilkarten aufgeteilt. Die Initialisierung der Karten erfolgt mit einemkonstanten Seed-Wert von 1.
Trainingsdaten Die Trainingsmenge umfasst 1000 Vektoren mit 10 Elementen im Werte-bereich [0.0-1.0]. In der Trainingsmenge wurden zunächst zufällig 20 Clusterzentren erzeugt.Diese wurden entsprechend häufig dupliziert und mit zufälligen Abweichungen im Bereich[±0.04] versehen.
Lernfaktor Zunächst ist ein geeigneter Lernfaktor zu bestimmen. Um den Einfluss des Lern-faktors auf die Clusterqualität zu untersuchen, wurden Karten verschiedener Größe mit ver-schiedenen Lernfaktoren erzeugt68. Wie die Abbildung 24 zeigt, ist die Wahl der Lernratehauptsächlich für die hierarchische SOM relevant. Hier werden mit sehr kleinen Werten fürη die besten Resultate erzielt. Daher wurde für alle Experimente eine konstante Lernrate vonη = 0.01 festgelegt.
Abbildung 24: Clusterqualität vs. Lernrate / Kartengröße
Clusterqualität bei 10 Trainingszyklen mit je 1000 Eingabemustern. Die parallele SOMbesteht aus 6 Teilkarten.
Quelle: Eigene Darstellung.
Distanzfunktion Als Distanzfunktion wird normalerweise die Gaussche-Distanzfunktionverwendet. Der SNNS jedoch Simuliert den Effekt dieser Funktion durch eine Reduzierung desLernradius nach jeder Iteration69. Als initialer Lernradius wird die Breite der Kohonen-Schicht
68 Die Messwerte sind in den Tabellen 9 und 10 im Anhang B.2 aufgeführt.69 Siehe [ZELL 2000] S.72f.
- 69 -

verwendet. Der Faktor zur Anpassung des Lernradius nach der Präsentation jedes einzelnenEingabevektors wird in Abhängigkeit von der Anzahl der Eingabemuster nI und der Trainings-zyklen nT so berechnet, dass der Lernradius nach Ablauf aller Iterationen n = nI ∗nT den Wert1.0 erreicht:
1.0 = r ∗multRn
multR =n
√1
r= e
ln( 1r )
n
Anzahl der Lernzyklen Es werden, sofern nicht anders angegeben, stets 50000 Lernschrittedurchlaufen.
14.1.4 Vergleich der Modellqualität
Durch eine visuelle Auswertung lassen sich erste Schlüsse auf die Eigenschaften einer Kohonen-Karte ziehen. Abbildung 25 und 26 zeigen jeweils eine U-Matrix-Darstellung von Kohonen-Karten identischer Dimension nach jeweils 50000 Lernschritten. Die Hierarchische Karte be-steht aus vier Teilkarten. Die unterschiedliche Anzahl von erkennbaren Cluster-Bereichen proTeilkarte ist darauf zurückzuführen, dass die Aufteilung der Trainingsdaten nicht gleichmäßigerfolgte.
Es ist zu erkennen, dass beide Karten entsprechend der Clusteranzahl in den Trainingsmustern(mindestens) 20 Cluster-Bereiche enthalten. Während die normale Karte exakt die in den Datenenthaltenen 20 Cluster darstellt, ist die Anzahl bei der Hierarchischen Karte etwas höher. Esist zu vermuten, dass einige Cluster-Bereiche den selben Cluster repräsentieren. Die U-Matrixder normalen Karte zeigt, dass einige Cluster-Bereiche sehr ähnlich sind, da die Clustergrenzenrelativ schwach ausgeprägt sind. Die zugehörigen Trainingsmuster können bei der Aufteilungbenachbarten Teilkarten der hierarchischen SOM zugewiesen werden, wo sie eigene Clusterbilden und so die Gesamtzahl von Cluster-Bereichen erhöhen. Dies ist jedoch eher ein optischesProblem, denn die Zugehörigkeit von Kartenneuronen zu Clustern wird letztendlich durch dieÄhnlichkeit der Gewichtsvektoren und nicht durch die Position auf der Karte bestimmt.
Da die Clusterqualität von der Größe der Karte abhängt, wurden Versuche mit unterschiedli-chen Kartengrößen durchgeführt. Das Resultat ist in Abbildung 27 dargestellt. Wie zu erwartenliefern beide Karten relativ schlechte Ergebnisse, wenn die Anzahl der Neuronen nicht für dieabzubildenden Cluster ausreicht. Die Hierarchische Karte ist sogar noch etwas schlechter, wasdadurch bedingt ist, dass durch die Aufteilung der Karte die Neuronenzahl weiter abnimmt. Beigrößeren Karten jedoch liefert die Hierarchische Version deutlich bessere Ergebnisse.
- 70 -
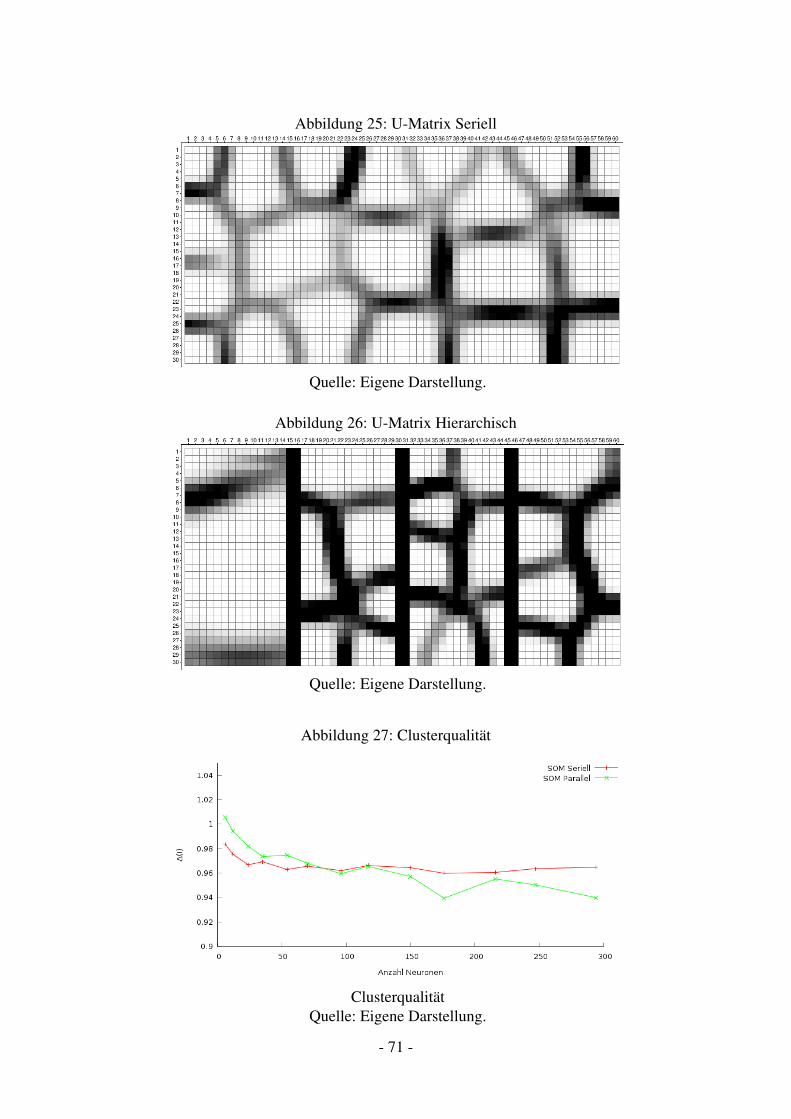
Abbildung 25: U-Matrix Seriell
Quelle: Eigene Darstellung.
Abbildung 26: U-Matrix Hierarchisch
Quelle: Eigene Darstellung.
Abbildung 27: Clusterqualität
ClusterqualitätQuelle: Eigene Darstellung.
- 71 -
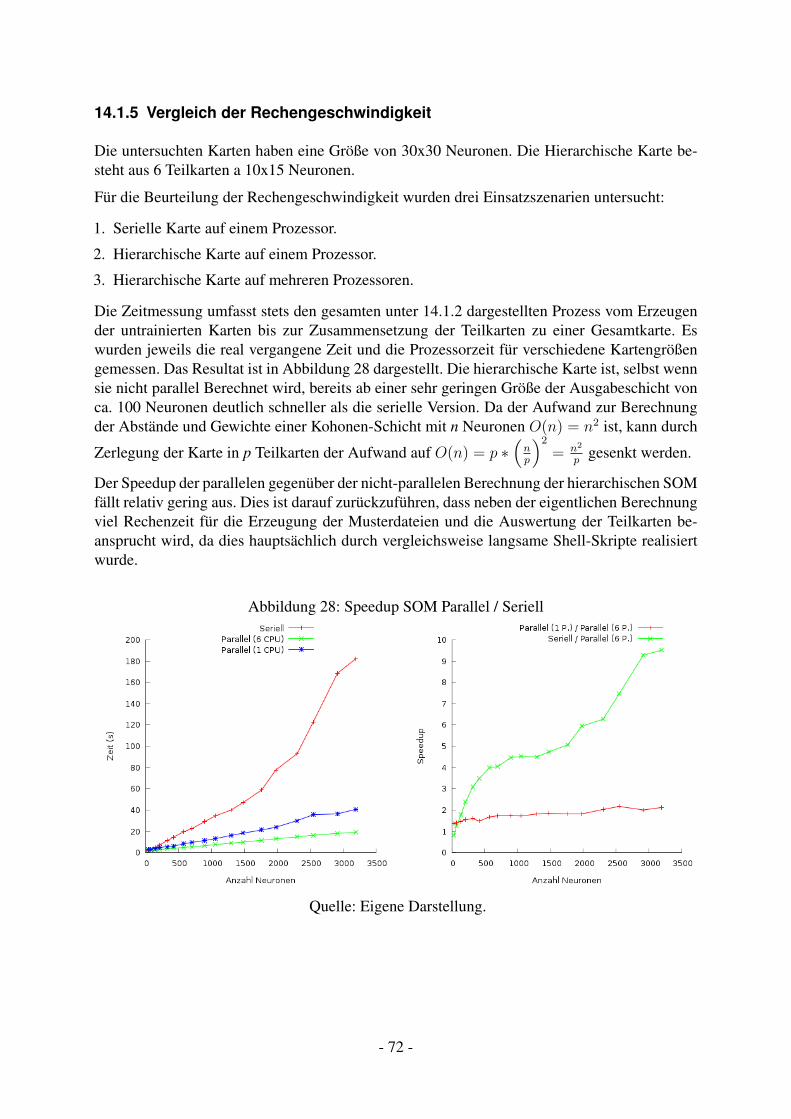
14.1.5 Vergleich der Rechengeschwindigkeit
Die untersuchten Karten haben eine Größe von 30x30 Neuronen. Die Hierarchische Karte be-steht aus 6 Teilkarten a 10x15 Neuronen.
Für die Beurteilung der Rechengeschwindigkeit wurden drei Einsatzszenarien untersucht:
1. Serielle Karte auf einem Prozessor.
2. Hierarchische Karte auf einem Prozessor.
3. Hierarchische Karte auf mehreren Prozessoren.
Die Zeitmessung umfasst stets den gesamten unter 14.1.2 dargestellten Prozess vom Erzeugender untrainierten Karten bis zur Zusammensetzung der Teilkarten zu einer Gesamtkarte. Eswurden jeweils die real vergangene Zeit und die Prozessorzeit für verschiedene Kartengrößengemessen. Das Resultat ist in Abbildung 28 dargestellt. Die hierarchische Karte ist, selbst wennsie nicht parallel Berechnet wird, bereits ab einer sehr geringen Größe der Ausgabeschicht vonca. 100 Neuronen deutlich schneller als die serielle Version. Da der Aufwand zur Berechnungder Abstände und Gewichte einer Kohonen-Schicht mit n Neuronen O(n) = n2 ist, kann durch
Zerlegung der Karte in p Teilkarten der Aufwand auf O(n) = p ∗(
np
)2
= n2
pgesenkt werden.
Der Speedup der parallelen gegenüber der nicht-parallelen Berechnung der hierarchischen SOMfällt relativ gering aus. Dies ist darauf zurückzuführen, dass neben der eigentlichen Berechnungviel Rechenzeit für die Erzeugung der Musterdateien und die Auswertung der Teilkarten be-ansprucht wird, da dies hauptsächlich durch vergleichsweise langsame Shell-Skripte realisiertwurde.
Abbildung 28: Speedup SOM Parallel / Seriell
Quelle: Eigene Darstellung.
- 72 -

14.2 Feed-Forward-Netze
14.2.1 Konzept
Analog zur hierarchischen SOM kann auch bei Feed-Forward-Netzen eine Parallelisierungdurch Anpassung der Netztopologie erfolgen. Dies ist jedoch Abhängig von der Codierungund der Anzahl der Ausgabemuster. Für den Fall, dass ein n-fach-Klassifikator erzeugt werdensoll, kann dies durch Verwendung von n binären Klassifikatoren erreicht werden, die jeweilsseparat berechnet werden können. Der Rechenaufwand reduziert sich jedoch entsprechend derAnzahl der Verbindungen maximal um den Faktor n. Eine Aufteilung der Trainingsmuster unddamit eine Reduzierung der Trainingszyklen ist nicht möglich.
Die Zahl der Rechenschritte p für einen Propagierungsschritt in einem mehrschichtigen Netzmit n voll vernetzten Schichten L ist:
p =n−1∑i=0
Li ∗ Li+1
Durch Bildung separater Netze für jedes Ausgabeneuron in Ln reduziert sich die Anzahl derzu berechnenden Verbindungen in der letzten Schicht, gleichzeitig steigt die Anzahl der zuberechnenden Netze, so dass für p in diesem Fall gilt:
p = Ln ∗ (Ln−2 +n−2∑i=0
Li ∗ Li+1)
Für ein 10x10x20-Netz ist die Anzahl der zu Berechnenden Verbindungsgewichte 300, nachReduktion auf ein 10x10x1-Netz nur noch 110. Da jedoch 20 solcher Netze trainiert werdenmüssen, steigt die Gesamtzahl auf 2200 Rechenschritte. Dieses Verfahren ist also nur dannsinnvoll, wenn die Berechnung wirklich parallel erfolgen kann. In diesem Fall ist eine Ge-schwindigkeitssteigerung um den Faktor
S =
∑n−1i=0 Li ∗ Li+1
Ln−2 +∑n−2
i=0 Li ∗ Li+1
zu erwarten.
14.2.2 Umsetzung
Die Trainingsmenge umfasst 1000 Vektoren mit 10 Elementen im Wertebereich [0.0-1.0]. DieVektoren sind jeweils einer von 20 Klassen zugeordnet, die erkannt werden sollen. Dazu wurdein der Trainingsmenge wurden zufällig 20 Referenzvektoren erzeugt, die entsprechend häufigdupliziert und mit zufälligen Abweichungen im Bereich±0.2 versehen wurden. Die Codierungdes Teaching-Output erfolgte so, dass für jede Klasse C das n-te Element aktiviert und dierestlichen Elemente deaktiviert wurden:
tn =
{1, 0 n = C
0, 0 sonst
- 73 -

Für die binären Klassifikatoren wurde eine ähnliche Kodierung verwendet. Da jeder Klassifika-tor für die Unterscheidung zwischen C und ¬C trainiert wird, lautet die Kodierung:
t =
{[1, 0; 0, 0] C
[0, 0; 1, 0] ¬C
14.2.3 Vergleich der Modellqualität
Zunächst ist die Topologie des zu verwendenden Netzes, insbesondere die Größe der versteck-ten Schicht zu ermitteln. Hierzu wurden Netze mit versteckten Schichten unterschiedlicher Grö-ße jeweils so lange trainiert, bis der Fehlerwert klein genug war. Als Basis für den Fehlerwertdient der Summierte Quadratische Fehler (SSE70). Für eine Trainingsmenge P und die Ausgabe-Neuronen O ist dieser definiert als
SSE =∑i∈P
∑j∈O
(tij − oj)2
Basierend darauf lassen sich der mittlere Fehler über alle Ausgabeneuronen SSE/O und dermittlere Fehler über alle Trainingsmuster MSE=SSE/P ableiten. Als genereller Indikator fürden Trainingsfortschritt ist der MSE am besten geeignet, da er die Anzahl der Trainingsmusterberücksichtigt.
Da das parallele Modell eine andere Topologie und eine andere Kodierung des Teaching-Outputaufweist, sind geeignete Kriterien notwendig, um sowohl die Erkennungsqualität als auch diebenötigte Rechenzeit vergleichbar zu machen. Da es das Ziel ist, eine möglichst hohe Erken-nungsrate der Trainingsmuster zu erzielen, ist es sinnvoll, den jeweiligen Netzfehler als Indika-tor heranzuziehen und das Training zu beenden, sobald z.B. der MSE < 0.008 ist. Um diesenWert zu erreichen, benötigt der n-fach-Klassifikator eine bestimmte Anzahl von Trainingszy-klen c und eine bestimmte Rechenzeit t. Die Verwendung binärer Klassifikatoren ist sinnvoll,sobald t und im optimalen Fall auch c unterschritten werden.
Die Bewertung der erstellten Netze wurde mittels des SNNS-Tools analyze durchgeführt. AlsAnalysefunktion wurde „WTA” gewählt, da die Klassenzugehörigkeit durch genau ein aktivesNeuron repräsentiert wird.
In Tabelle 14 sind die Erkennungsraten, Rechenzeiten und Trainingszyklen für einen n-Fach-Klassifikator und einen Binären Klassifikator für verschiedene große Zwischenschichten gegen-übergestellt. Beim Binären Klassifikator wurde die Erkennungsgenauigkeit des jeweils schlech-testen Teilklassifikators zugrundegelegt. Als Vergleich sind die Erkennungsraten und Trainings-zyklen aller Teilklassifikatoren für eine Zwischenschicht mit einem Neuron in Tabelle 13 auf-geführt.
Der n-Fach-Klassifikator liefert erst ab einer Zwischenschicht mit 5 Neuronen akzeptable Wer-te, wogegen der Binäre Klassifikator bereits mit nur einem Zwischenneuron eine hohe Erken-nungsrate erzielt. Eine Steigerung der Neuronenzahl bewirkt hier nur marginale Veränderungen.
70 Der SNNS und das Tool analyze geben für das selbe Netz und die selben Muster für den SSE leicht abweichendeWerte an.
- 74 -

14.2.4 Vergleich der Rechengeschwindigkeit
Die Rechenzeiten sind Tabelle 14 zu entnehmen. Es wurden jeweils 3 Messungen durchgeführtund die kürzeste Rechenzeit gewertet.
Die Rechenzeiten des n-Fach-Klassifikators und des binären Klassifikators lassen sich hinsicht-lich zweier Kriterien miteinander verleichen: ähnliche Topologie und ähnliche Resultate.
Beim Vergleich der Klassifikatoren mit ähnlicher Topologie bzw. gleicher Größe der Zwischen-schicht reduziert sich der Speedup von ≈ 6, 8 bei 5 Zwischenneuronen auf ≈ 1, 25 ab 7 Zwi-schenneuronen.
Werden die jeweils kleinsten Klassifikatoren verglichen, die vergleichbare Resultaten liefern,so kann ein deutlich höherer Geschwindigkeitszuwachs festgestellt werden. So erreicht der bi-näre Klassifikator bereits mit nur zwei Zwischenneuronen eine Erkennungsrate von 99,00 %.Der n-Fach-Klassifikator benötigt hierfür mindestens fünf Zwischenneuronen und eine deutlichhöhere Berechnungszeit. Der Speedup beträgt in diesem Fall ≈ 7, 4.
- 75 -

Teil IVZusammenfassung und Ausblick
In dieser Arbeit wurden verschiedene Ansätze zur Parallelisierung von Algorithmen vorgestellt.Diese bezogen sich sowohl auf die Anpassung des Algorithmus selbst durch Verwendung par-alleler Programmierkonzepte, als auch auf die Parallelisierung durch Aufteilung der Rechen-aufgaben unter Verwendung serieller Programme. Es wurde gezeigt, dass Parallele Program-mierung ein sehr komplexes Thema ist, das eine enge Verzahnung von Hardware, Software undAnwendungsgebiet auf verschiedenen Ebenen aufweist.
Der aktuelle Stand der Technik wird durch MPI/MPI2 und OpenMP festgelegt. Beide Ansätzesind ausgereift, flexibel, relativ einfach zu handhaben und liefern sehr gute Resultate. MPI hatsich dabei als besonders performant erwiesen, während OpenMP sehr leicht auf bestehendeProgramme anzuwenden ist. UPC hingegen muss anhand der gemachten Erfahrungen als reinExperimentell angesehen werden.
Die Entscheidung, ob MPI oder OpenMP das Mittel der Wahl sind, hängt im wesentlichen vonden Faktoren Wiederverwendung und Skalierbarkeit ab. MPI erfordert einen höheren Program-mieraufwand, ist dafür jedoch auch in sehr großen, netzwerkbasierten und heterogenen Rech-nerumgebungen einsetzbar, während OpenMP-basierte Programme naturgemäß nur auf einemeinzigen System ausführbar sind, sofern das Betriebssystem nicht die Migration von Prozessenüber Rechenknoten hinweg unterstützt. Da MPI und OpenMP miteinander Kombiniert werdenkönnen und beispielsweise MPI für die Kommunikation zwischen Rechenknoten und OpenMPfür die parallele Ausführung auf einem Knoten eingesetzt wird, lassen sich hochgradig paralleleAnwendungen bei gleichzeitig überschaubarer Komplexität des Programmcodes implementie-ren.
Anhand der Parallelisierung von Data-Mining-Modellen mittels Basistechnologien von Linux-Systemen wurde gezeigt, dass ein signifikanter Geschwindigkeitsgewinn erzielt werden kann,ohne den Algorithmus verändern zu müssen. Die vorgestellte Hierarchische Kohonen-Kartesowie der auf mehreren Feed-Forward-Netzen basierende n-Fach-binäre Klassifikator erzielenResultate, die qualitativ mit der herkömmlichen Vorgehensweise der Erstellung eines Einzelm-odells vergleichbar sind, jedoch deutlich schneller berechnet werden. Besonders die Hierarch-ische-Kohonen-Karte ist ein vielversprechender Ansatz, da auch bei nicht-paralleler Berech-nung ein signifikanter Geschwindigkeitsgewinn erzielt wurde.
Diese Arbeit zeigt, dass Parallelisierung von Data-Mining-Verfahren selbst in geringem Maßdeutliche Geschwindigkeitsvorteile bringt. Die vorgestellten Ansätze bezogen sich dabei nurauf einen Teilaspekt des Data Mining - der Erstellung von Modellen. Der gesamte Data-Mining-Prozess besteht jedoch aus mehreren Stufen, die jede für sich auf Parallelisierbarkeit untersuchtwerden sollte. Insbesondere die zeitaufwändige Vorverarbeitung stellt ein geeignetes Ziel fürweiterführende Arbeiten dar.
- 76 -

Literatur
[UPC 2005] (2005). UPC Language Specification V1.2. The UPC Consortium.
[ALPAR 2000] ALPAR, PAUL (2000). Data Mining im praktischen Einsatz. Vieweg, München.
[BARTH 2006] BARTH, THOMAS UND SCHÜLL, ANKE (2006). Grid Computing - Konzepte,Technologien, Anwendungen. Vieweg, Wiesbaden.
[BAUKE 2006] BAUKE, HEIKE UND MERTENS, STEFAN (2006). Cluster Computing - Prak-tische Einführung in der Hochleistungsrechnen auf Linux-Clustern. Springer, Heidelberg.
[BRANDS 2005] BRANDS, GILBERT (2005). Das C++ Kompendium. Springer.
[CARVER 2006] CARVER, RICHARD H. UND TAI, KUO-CHUNG (2006). Modern Multithrea-ding. Wiley.
[CHANDRA] CHANDRA, ROHIT UND DAGUM, LEONARDO UND KOHR DAVE UND MAY-DAN DROR UND MCDONALD JEFF UND MENON RAMESH. Parallel Programming inOpenMP. Morgan Kaufmann Publishers.
[CHAPMAN 2008] CHAPMAN, BARBARA UND JOST, GABRIELE UND VAN DER PAS RUUD
(2008). Using OpenMP - Portable Shared Memory Parallel Programming. The MIT Press.
[CHAUVIN 2008] CHAUVIN, SÈBASTIEN (2008). UPC Manual v1.2.
[CLEVE 2005] CLEVE, JÜRGEN UND LÄMMEL, UWE UND WISSUWA STEFAN (2005). DataMining auf zeitabhängigen Daten – Kundenanalyse im Bankbereich. Hochschule Wismar,Wismar.
[EM KARNIADAKIS 2000] EM KARNIADAKIS, GEORGE UND KIRBY, ROBERT M. II (2000).Parallel Scientific Computing in C++ and MPI. Cambridge University Press.
[ENGELN-MÜLLGES 2005] ENGELN-MÜLLGES, GISELA UND NIEDERDRENK, KLAUS
UND WODICKA REINHARD (2005). Numerik-Algorithmen - Verfahren, Beispiele, Anwen-dungen.
[UND GORDON S. LINOFF 2000] GORDON S. LINOFF, MICHAEL J. A. BERRY UND (2000).Mastering Data Mining. John Wiley and Sons, New York.
[GROPP 2007] GROPP, WILLIAM UND LUSK, EWING UND SKJELLUM ANTHONY (2007).MPI - Eine Einführung. Oldenbourg, München Wien.
[HAN 2001] HAN, JIAWEI UND KAMBER, MICHELINE (2001). Data Mining - Concepts andTechniques. Morgan Kaufmann Publishers, San Francisco.
[HOFFMANN 2008] HOFFMANN, SIMON UND LIENHART, RAINER (2008). OpenMP - EineEinführung in die parallele Programmierung mit C/C++. Springer, Berlin Heidelberg.
[KNIPPERS 2001] KNIPPERS, ROLF (2001). Molekulare Genetik. Georg Thieme Verlag, Stutt-gart.
[KOHONEN 2001] KOHONEN, TEUVO (2001). Self-Organizing Maps. Springer.
[LÄMMEL 2007] LÄMMEL, UWE UND BEIFERT, ANATOLI UND WISSUWA STEFAN (2007).Business Rules - Die Wissensverarbeitung erreicht die Betriebswirtschaft. Wismarer Diskus-sionspapiere Heft 05/2007, Wismar.
[LÄMMEL 2004] LÄMMEL, UWE UND CLEVE, JÜRGEN (2004). Künstliche Intelligenz. Fach-buchverlag Leipzig, Leipzig.
- 77 -

[LÄMMEL 2004] LÄMMEL, UWE UND CLEVE, JÜRGEN (2004). Lehr- und ÜbungsbuchKünstliche Intelligenz. Fachbuchverlag Leipzig, Leipzig.
[LÄMMEL 2003] LÄMMEL, UWE (2003). Data Mining mittels künstlicher neuronaler Netze,WDP No. 7. Hochschule Wismar, Wismar.
[MAHLMANN 2007] MAHLMANN, PETER UND SCHINDELHAUER, CHRISTIAN (2007). Peer-to-Peer Netzwerke - Algorithmen und Methoden. Springer, Berlin Heidelberg.
[NAKHAEIZADEH 1998] NAKHAEIZADEH, G. (1998). Data Mining - Theoretische Aspekteund Anwendungen. Physica-Verlag, Heidelberg.
[PETERSEN 2004] PETERSEN, W. P. UND ARBENZ, P. (2004). Introduction to Parallel Com-puting. Oxford University Press.
[RAUBER 2007] RAUBER, THOMAS UND RÜNGER, GUDULA (2007). Parallele Programmie-rung. Springer, Heidelberg.
[RAUBER 2008] RAUBER, THOMAS UND RÜNGER, GUDULA (2008). Multicore: ParalleleProgrammierung. Springer, Heidelberg.
[SANTORO 2007] SANTORO, NICOLA (2007). Design and Analysis of Distributed Algorithms.Wiley.
[SCHILL 2007] SCHILL, ALEXANDER UND SPRINGER, THOMAS (2007). Verteilte Systeme -Grundlagen und Basistechnologien. Springer, Berlin Heidelberg.
[WISSUWA 2003] WISSUWA, STEFAN (2003). Data Mining und XML - Modularisierung undAutomatisierung von Verarbeitungsschritten, WDP No. 12. Hochschule Wismar, Wismar.
[WISSUWA] WISSUWA, STEFAN UND LÄMMEL, UWE UND CLEVE J.
[WITTEN 2001] WITTEN, I.H. UND FRANK, E. (2001). Data Mining. Hanser, München.
[WITTEN 2005] WITTEN, I.H. UND FRANK, E. (2005). Data Mining: Practical MachineLearning Tools and Techniques. Morgen Kaufmann, San Francisco.
[ZELL 2000] ZELL, ANDREAS (2000). Simulation Neuronaler Netze. Oldenbourg, München.
[ZELL] ZELL, ANDREAS ET. AL. SNNS User Manual, Version 4.2. University of Stuttgart,University of Tübingen.
- 78 -

Teil VEhrenwörtliche Erklärung
Ich erkläre hiermit ehrenwörtlich, dass ich die vorliegende Arbeit ohne unzulässige Hilfe Drit-ter und ohne Benutzung anderer als den angegebenen Hilfsmitteln angefertigt habe. Die ausanderen Quellen direkt oder indirekt übernommenen Daten und Konzepte sind unter Angabeder Quelle als solche gekennzeichnet.
Die Arbeit wurde bisher weder im In- noch im Ausland in gleicher oder ähnlicher Form eineranderen Prüfungsbehörde vorgelegt.
Wismar, 01.12.2008.
- 79 -

Teil VIAnhang
- 80 -

A Schnittstellen und Bibliotheken
A.1 UPC Konsortium
Mitglieder des UPC-Konsortiums nach[CHAUVIN 2008]:
UPC-Konsortium: National Security Agency (NSA - http://www.nsa.gov)IDA Institute for Defense Analyses, Center for Computing Sciences (IDA-CCS - http://www.super.org)The George Washington Universtity, High Performance Computing Laboratory (GWU HPCL -http://upc.gwu.edu)Arctic Region Supercomputing Center (ARSC - http://www.arsc.edu); Hewlett-Packard(HP - http://h30097.ww3.hp.com/upc/)Cray Inc. (http://www.cray.com)Etnus LLC. (http://www.etnus.com)IBM (http://www.ibm.com)Intrepid Technologies (http://www.intrepid.com)Ernest Orlando Lawrence Berkley National Laboratory (LBNL - http://upc.lbl.gov)Lawrence Livermore National Laboratory (LLNL - http://www.llnl.gov)Michigan Technological University (MTU - http://upc.mtu.edu)Silicon Graphics, Inc. (SGI - http://www.sgi.com)Sun Microsystems (http://www.sun.com)University of California, Berkley (http://www.berkley.edu)US Department of Energy (DoE -http://www.energy.gov)Ohio State University (OSU - http://www.osu.edu)Argonne National Laboratory (ANL - http://www.anl.gov)Sandia National Laboratory (http://www.sandia.gov)University of North Carolina (UNC - http://www.unc.edu)
- 81 -
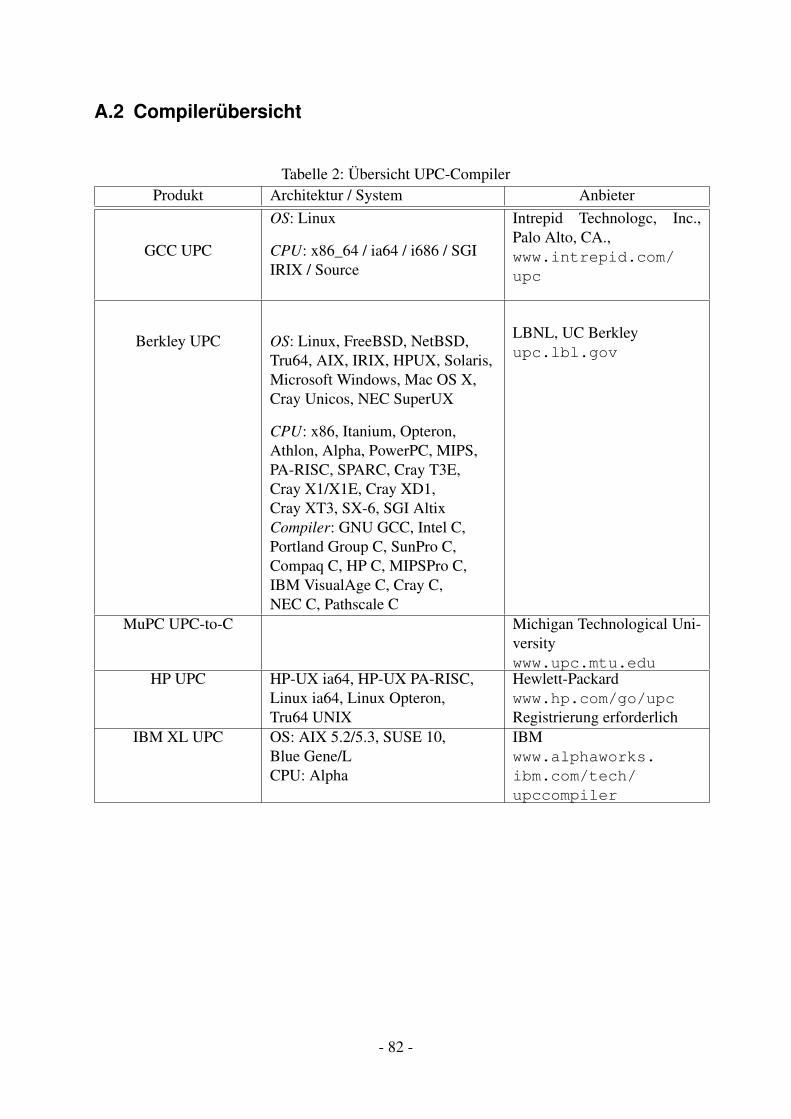
A.2 Compilerübersicht
Tabelle 2: Übersicht UPC-CompilerProdukt Architektur / System Anbieter
GCC UPC
OS: Linux
CPU: x86_64 / ia64 / i686 / SGIIRIX / Source
Intrepid Technologc, Inc.,Palo Alto, CA.,www.intrepid.com/upc
Berkley UPC OS: Linux, FreeBSD, NetBSD,Tru64, AIX, IRIX, HPUX, Solaris,Microsoft Windows, Mac OS X,Cray Unicos, NEC SuperUX
CPU: x86, Itanium, Opteron,Athlon, Alpha, PowerPC, MIPS,PA-RISC, SPARC, Cray T3E,Cray X1/X1E, Cray XD1,Cray XT3, SX-6, SGI AltixCompiler: GNU GCC, Intel C,Portland Group C, SunPro C,Compaq C, HP C, MIPSPro C,IBM VisualAge C, Cray C,NEC C, Pathscale C
LBNL, UC Berkleyupc.lbl.gov
MuPC UPC-to-C Michigan Technological Uni-versitywww.upc.mtu.edu
HP UPC HP-UX ia64, HP-UX PA-RISC,Linux ia64, Linux Opteron,Tru64 UNIX
Hewlett-Packardwww.hp.com/go/upcRegistrierung erforderlich
IBM XL UPC OS: AIX 5.2/5.3, SUSE 10,Blue Gene/LCPU: Alpha
IBMwww.alphaworks.ibm.com/tech/upccompiler
- 82 -
Tabelle 3: OpenMP-fähige CompilerProdukt Architektur / System Anbietergcc (4.2) OS: Linux, Solaris, AIX,
MacOSX, WindowsGNU
XL C/C++, Fortran OS: Windows, AIX, Linux IBMC/C++, Fortran OS: Solaris, Linux Sun MicrosystemsC/C++, Fortran OS: Windows, Linux, MacOSX IntelC/C++, Fortran Portland Goup Compilers
and ToolsFortran Absoft Pro FortranMP
C/C++, Fortran Lahey / Fujitsu Fortran 95C/C++, Fortran OS: Linux PathScaleC/C++, Fortran Hewlett-Packard
Visual Studio 2008C++
Microsoft
Quelle: http://openmp.org/wp/openmp-compilers/
- 83 -
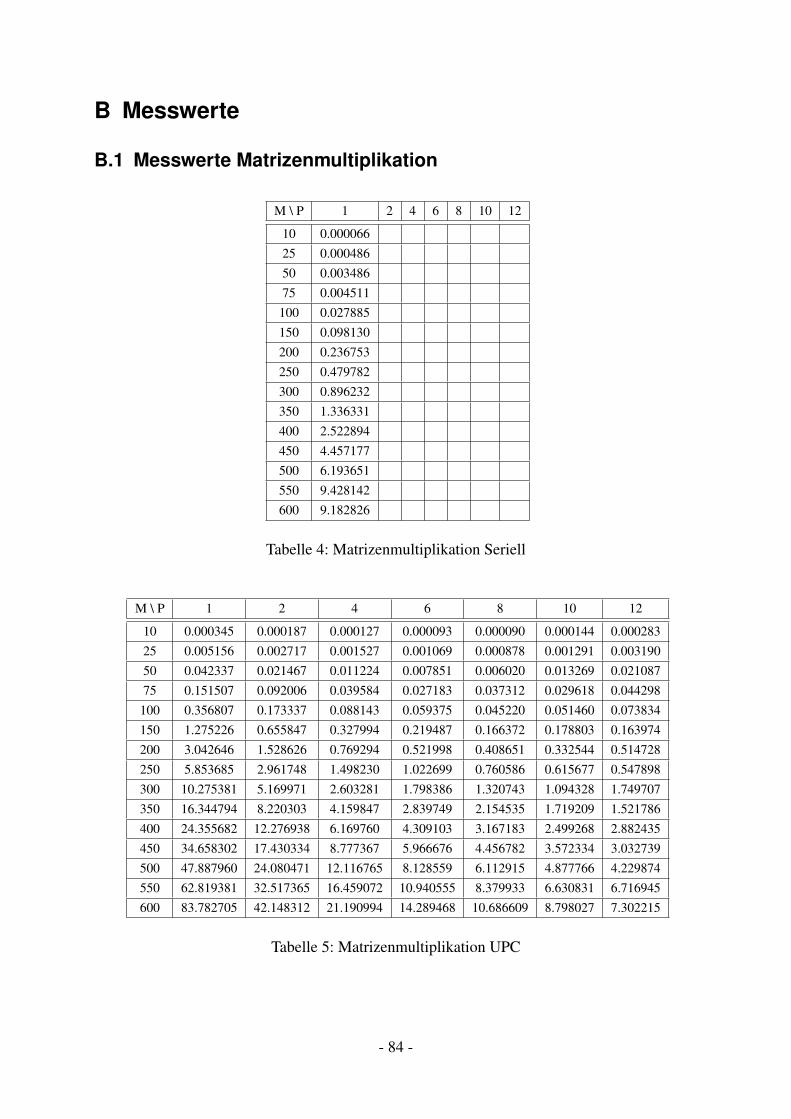
B Messwerte
B.1 Messwerte Matrizenmultiplikation
M \ P 1 2 4 6 8 10 12
10 0.00006625 0.00048650 0.00348675 0.004511
100 0.027885150 0.098130200 0.236753250 0.479782300 0.896232350 1.336331400 2.522894450 4.457177500 6.193651550 9.428142600 9.182826
Tabelle 4: Matrizenmultiplikation Seriell
M \ P 1 2 4 6 8 10 12
10 0.000345 0.000187 0.000127 0.000093 0.000090 0.000144 0.00028325 0.005156 0.002717 0.001527 0.001069 0.000878 0.001291 0.00319050 0.042337 0.021467 0.011224 0.007851 0.006020 0.013269 0.02108775 0.151507 0.092006 0.039584 0.027183 0.037312 0.029618 0.044298
100 0.356807 0.173337 0.088143 0.059375 0.045220 0.051460 0.073834150 1.275226 0.655847 0.327994 0.219487 0.166372 0.178803 0.163974200 3.042646 1.528626 0.769294 0.521998 0.408651 0.332544 0.514728250 5.853685 2.961748 1.498230 1.022699 0.760586 0.615677 0.547898300 10.275381 5.169971 2.603281 1.798386 1.320743 1.094328 1.749707350 16.344794 8.220303 4.159847 2.839749 2.154535 1.719209 1.521786400 24.355682 12.276938 6.169760 4.309103 3.167183 2.499268 2.882435450 34.658302 17.430334 8.777367 5.966676 4.456782 3.572334 3.032739500 47.887960 24.080471 12.116765 8.128559 6.112915 4.877766 4.229874550 62.819381 32.517365 16.459072 10.940555 8.379933 6.630831 6.716945600 83.782705 42.148312 21.190994 14.289468 10.686609 8.798027 7.302215
Tabelle 5: Matrizenmultiplikation UPC
- 84 -
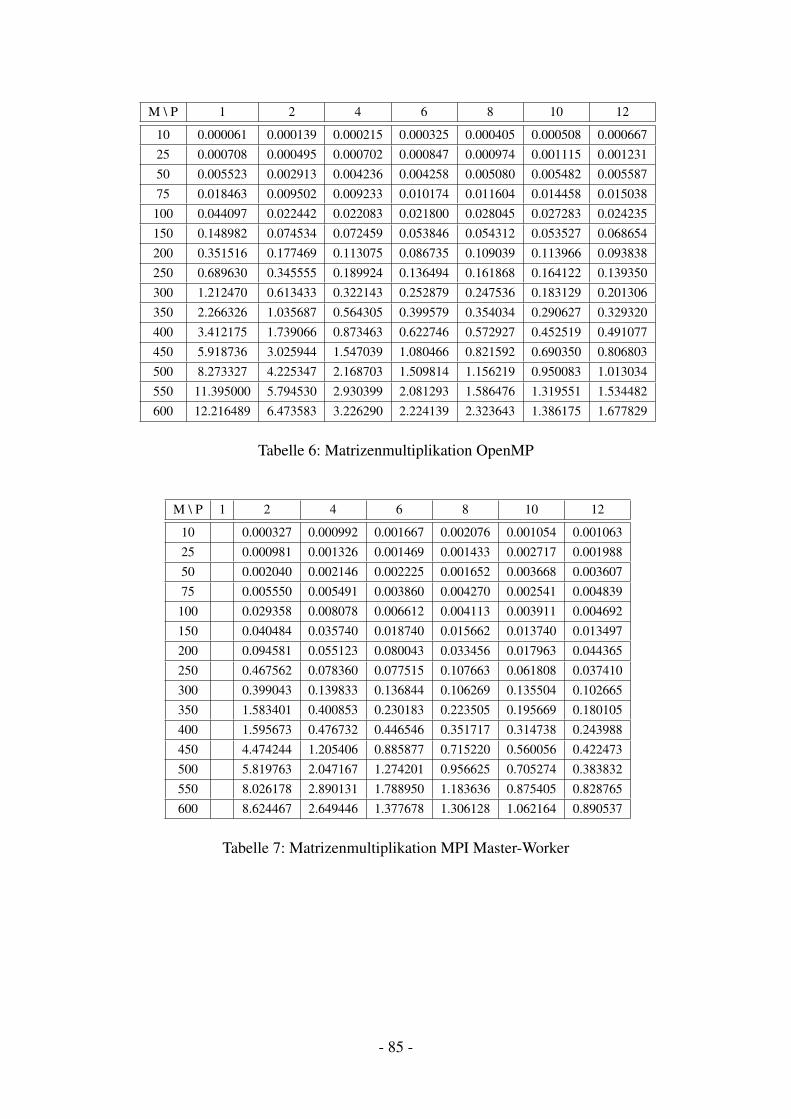
M \ P 1 2 4 6 8 10 12
10 0.000061 0.000139 0.000215 0.000325 0.000405 0.000508 0.00066725 0.000708 0.000495 0.000702 0.000847 0.000974 0.001115 0.00123150 0.005523 0.002913 0.004236 0.004258 0.005080 0.005482 0.00558775 0.018463 0.009502 0.009233 0.010174 0.011604 0.014458 0.015038
100 0.044097 0.022442 0.022083 0.021800 0.028045 0.027283 0.024235150 0.148982 0.074534 0.072459 0.053846 0.054312 0.053527 0.068654200 0.351516 0.177469 0.113075 0.086735 0.109039 0.113966 0.093838250 0.689630 0.345555 0.189924 0.136494 0.161868 0.164122 0.139350300 1.212470 0.613433 0.322143 0.252879 0.247536 0.183129 0.201306350 2.266326 1.035687 0.564305 0.399579 0.354034 0.290627 0.329320400 3.412175 1.739066 0.873463 0.622746 0.572927 0.452519 0.491077450 5.918736 3.025944 1.547039 1.080466 0.821592 0.690350 0.806803500 8.273327 4.225347 2.168703 1.509814 1.156219 0.950083 1.013034550 11.395000 5.794530 2.930399 2.081293 1.586476 1.319551 1.534482600 12.216489 6.473583 3.226290 2.224139 2.323643 1.386175 1.677829
Tabelle 6: Matrizenmultiplikation OpenMP
M \ P 1 2 4 6 8 10 12
10 0.000327 0.000992 0.001667 0.002076 0.001054 0.00106325 0.000981 0.001326 0.001469 0.001433 0.002717 0.00198850 0.002040 0.002146 0.002225 0.001652 0.003668 0.00360775 0.005550 0.005491 0.003860 0.004270 0.002541 0.004839
100 0.029358 0.008078 0.006612 0.004113 0.003911 0.004692150 0.040484 0.035740 0.018740 0.015662 0.013740 0.013497200 0.094581 0.055123 0.080043 0.033456 0.017963 0.044365250 0.467562 0.078360 0.077515 0.107663 0.061808 0.037410300 0.399043 0.139833 0.136844 0.106269 0.135504 0.102665350 1.583401 0.400853 0.230183 0.223505 0.195669 0.180105400 1.595673 0.476732 0.446546 0.351717 0.314738 0.243988450 4.474244 1.205406 0.885877 0.715220 0.560056 0.422473500 5.819763 2.047167 1.274201 0.956625 0.705274 0.383832550 8.026178 2.890131 1.788950 1.183636 0.875405 0.828765600 8.624467 2.649446 1.377678 1.306128 1.062164 0.890537
Tabelle 7: Matrizenmultiplikation MPI Master-Worker
- 85 -
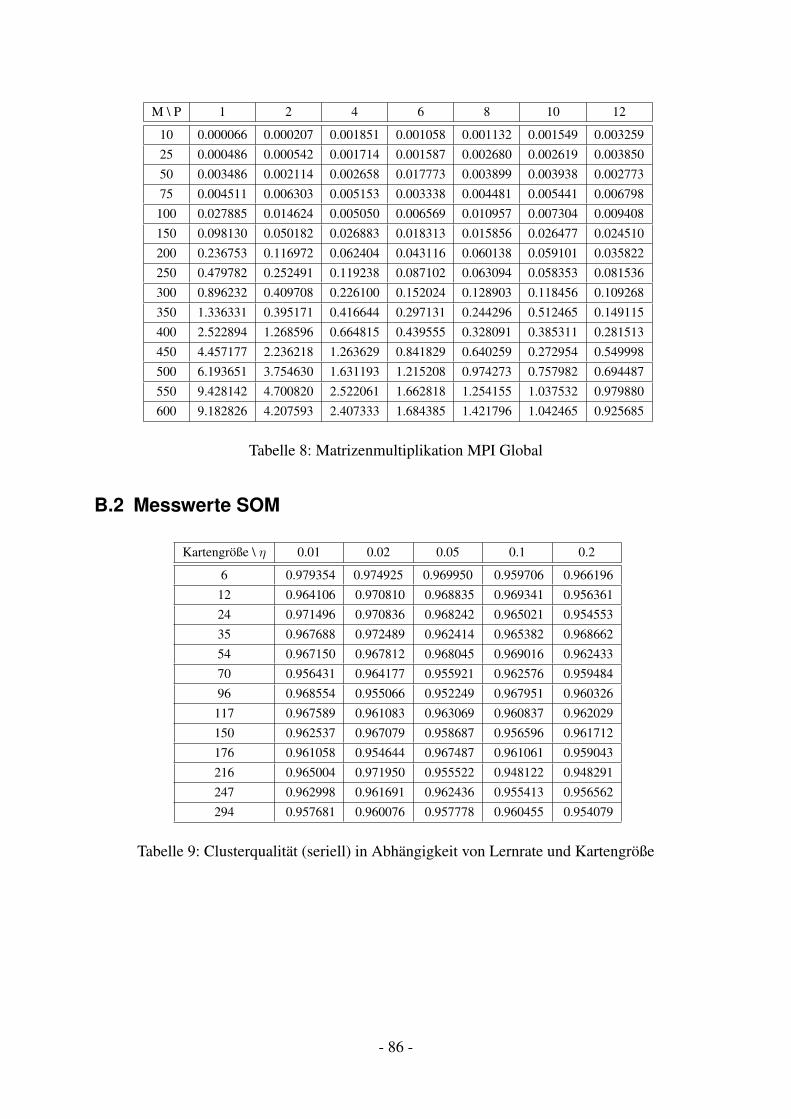
M \ P 1 2 4 6 8 10 12
10 0.000066 0.000207 0.001851 0.001058 0.001132 0.001549 0.00325925 0.000486 0.000542 0.001714 0.001587 0.002680 0.002619 0.00385050 0.003486 0.002114 0.002658 0.017773 0.003899 0.003938 0.00277375 0.004511 0.006303 0.005153 0.003338 0.004481 0.005441 0.006798100 0.027885 0.014624 0.005050 0.006569 0.010957 0.007304 0.009408150 0.098130 0.050182 0.026883 0.018313 0.015856 0.026477 0.024510200 0.236753 0.116972 0.062404 0.043116 0.060138 0.059101 0.035822250 0.479782 0.252491 0.119238 0.087102 0.063094 0.058353 0.081536300 0.896232 0.409708 0.226100 0.152024 0.128903 0.118456 0.109268350 1.336331 0.395171 0.416644 0.297131 0.244296 0.512465 0.149115400 2.522894 1.268596 0.664815 0.439555 0.328091 0.385311 0.281513450 4.457177 2.236218 1.263629 0.841829 0.640259 0.272954 0.549998500 6.193651 3.754630 1.631193 1.215208 0.974273 0.757982 0.694487550 9.428142 4.700820 2.522061 1.662818 1.254155 1.037532 0.979880600 9.182826 4.207593 2.407333 1.684385 1.421796 1.042465 0.925685
Tabelle 8: Matrizenmultiplikation MPI Global
B.2 Messwerte SOM
Kartengröße \ η 0.01 0.02 0.05 0.1 0.2
6 0.979354 0.974925 0.969950 0.959706 0.96619612 0.964106 0.970810 0.968835 0.969341 0.95636124 0.971496 0.970836 0.968242 0.965021 0.95455335 0.967688 0.972489 0.962414 0.965382 0.96866254 0.967150 0.967812 0.968045 0.969016 0.96243370 0.956431 0.964177 0.955921 0.962576 0.95948496 0.968554 0.955066 0.952249 0.967951 0.960326117 0.967589 0.961083 0.963069 0.960837 0.962029150 0.962537 0.967079 0.958687 0.956596 0.961712176 0.961058 0.954644 0.967487 0.961061 0.959043216 0.965004 0.971950 0.955522 0.948122 0.948291247 0.962998 0.961691 0.962436 0.955413 0.956562294 0.957681 0.960076 0.957778 0.960455 0.954079
Tabelle 9: Clusterqualität (seriell) in Abhängigkeit von Lernrate und Kartengröße
- 86 -
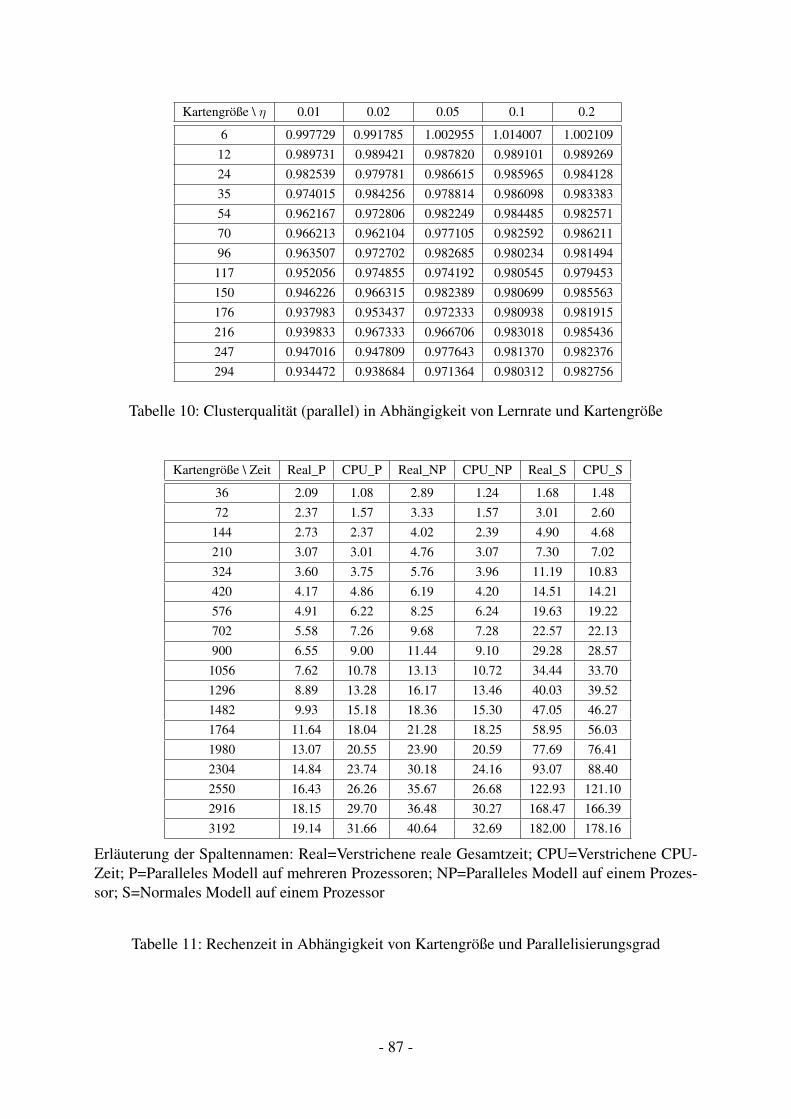
Kartengröße \ η 0.01 0.02 0.05 0.1 0.2
6 0.997729 0.991785 1.002955 1.014007 1.00210912 0.989731 0.989421 0.987820 0.989101 0.98926924 0.982539 0.979781 0.986615 0.985965 0.98412835 0.974015 0.984256 0.978814 0.986098 0.98338354 0.962167 0.972806 0.982249 0.984485 0.98257170 0.966213 0.962104 0.977105 0.982592 0.98621196 0.963507 0.972702 0.982685 0.980234 0.981494117 0.952056 0.974855 0.974192 0.980545 0.979453150 0.946226 0.966315 0.982389 0.980699 0.985563176 0.937983 0.953437 0.972333 0.980938 0.981915216 0.939833 0.967333 0.966706 0.983018 0.985436247 0.947016 0.947809 0.977643 0.981370 0.982376294 0.934472 0.938684 0.971364 0.980312 0.982756
Tabelle 10: Clusterqualität (parallel) in Abhängigkeit von Lernrate und Kartengröße
Kartengröße \ Zeit Real_P CPU_P Real_NP CPU_NP Real_S CPU_S
36 2.09 1.08 2.89 1.24 1.68 1.4872 2.37 1.57 3.33 1.57 3.01 2.60
144 2.73 2.37 4.02 2.39 4.90 4.68210 3.07 3.01 4.76 3.07 7.30 7.02324 3.60 3.75 5.76 3.96 11.19 10.83420 4.17 4.86 6.19 4.20 14.51 14.21576 4.91 6.22 8.25 6.24 19.63 19.22702 5.58 7.26 9.68 7.28 22.57 22.13900 6.55 9.00 11.44 9.10 29.28 28.571056 7.62 10.78 13.13 10.72 34.44 33.701296 8.89 13.28 16.17 13.46 40.03 39.521482 9.93 15.18 18.36 15.30 47.05 46.271764 11.64 18.04 21.28 18.25 58.95 56.031980 13.07 20.55 23.90 20.59 77.69 76.412304 14.84 23.74 30.18 24.16 93.07 88.402550 16.43 26.26 35.67 26.68 122.93 121.102916 18.15 29.70 36.48 30.27 168.47 166.393192 19.14 31.66 40.64 32.69 182.00 178.16
Erläuterung der Spaltennamen: Real=Verstrichene reale Gesamtzeit; CPU=Verstrichene CPU-Zeit; P=Paralleles Modell auf mehreren Prozessoren; NP=Paralleles Modell auf einem Prozes-sor; S=Normales Modell auf einem Prozessor
Tabelle 11: Rechenzeit in Abhängigkeit von Kartengröße und Parallelisierungsgrad
- 87 -
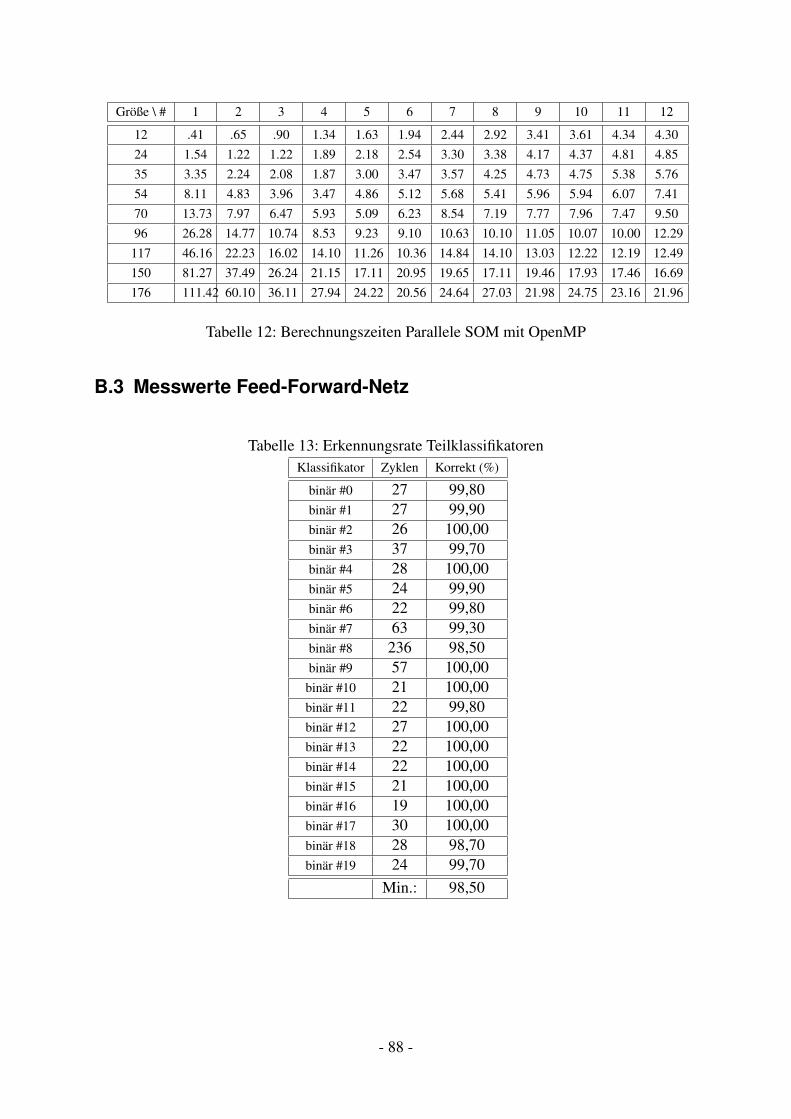
Größe \ # 1 2 3 4 5 6 7 8 9 10 11 12
12 .41 .65 .90 1.34 1.63 1.94 2.44 2.92 3.41 3.61 4.34 4.3024 1.54 1.22 1.22 1.89 2.18 2.54 3.30 3.38 4.17 4.37 4.81 4.8535 3.35 2.24 2.08 1.87 3.00 3.47 3.57 4.25 4.73 4.75 5.38 5.7654 8.11 4.83 3.96 3.47 4.86 5.12 5.68 5.41 5.96 5.94 6.07 7.4170 13.73 7.97 6.47 5.93 5.09 6.23 8.54 7.19 7.77 7.96 7.47 9.5096 26.28 14.77 10.74 8.53 9.23 9.10 10.63 10.10 11.05 10.07 10.00 12.29117 46.16 22.23 16.02 14.10 11.26 10.36 14.84 14.10 13.03 12.22 12.19 12.49150 81.27 37.49 26.24 21.15 17.11 20.95 19.65 17.11 19.46 17.93 17.46 16.69176 111.42 60.10 36.11 27.94 24.22 20.56 24.64 27.03 21.98 24.75 23.16 21.96
Tabelle 12: Berechnungszeiten Parallele SOM mit OpenMP
B.3 Messwerte Feed-Forward-Netz
Tabelle 13: Erkennungsrate TeilklassifikatorenKlassifikator Zyklen Korrekt (%)
binär #0 27 99,80binär #1 27 99,90binär #2 26 100,00binär #3 37 99,70binär #4 28 100,00binär #5 24 99,90binär #6 22 99,80binär #7 63 99,30binär #8 236 98,50binär #9 57 100,00
binär #10 21 100,00binär #11 22 99,80binär #12 27 100,00binär #13 22 100,00binär #14 22 100,00binär #15 21 100,00binär #16 19 100,00binär #17 30 100,00binär #18 28 98,70binär #19 24 99,70
Min.: 98,50
- 88 -
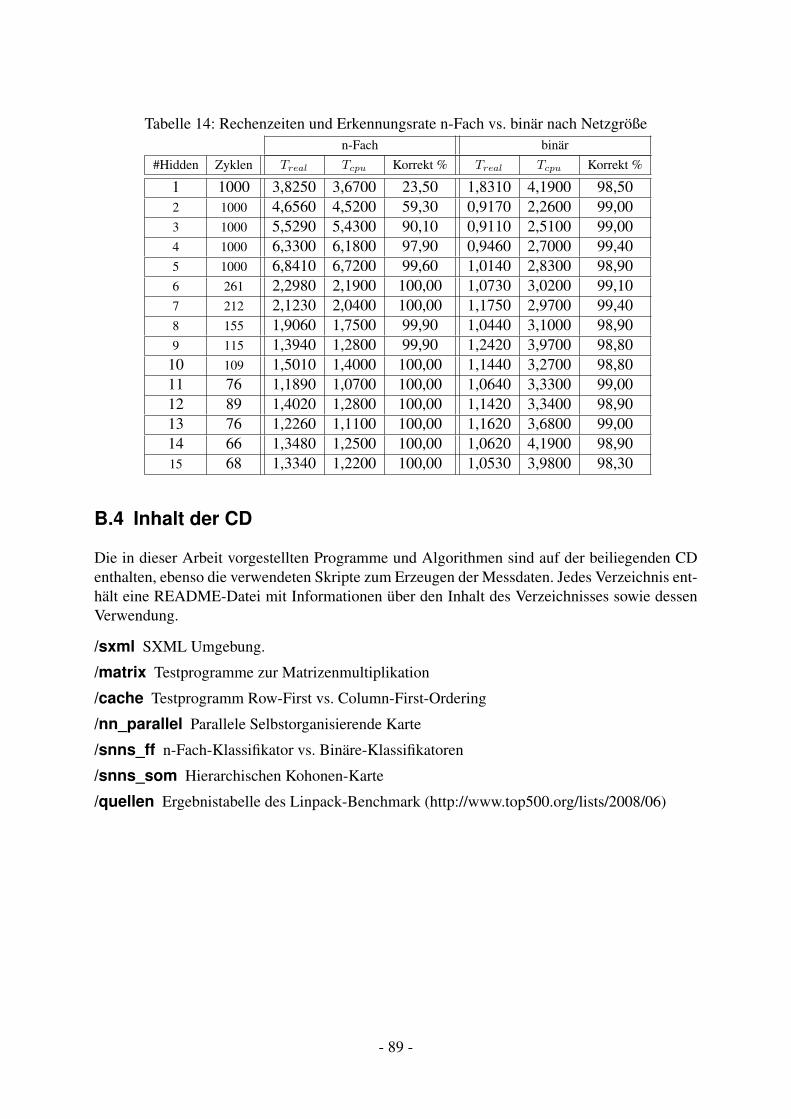
Tabelle 14: Rechenzeiten und Erkennungsrate n-Fach vs. binär nach Netzgrößen-Fach binär
#Hidden Zyklen Treal Tcpu Korrekt % Treal Tcpu Korrekt %
1 1000 3,8250 3,6700 23,50 1,8310 4,1900 98,502 1000 4,6560 4,5200 59,30 0,9170 2,2600 99,003 1000 5,5290 5,4300 90,10 0,9110 2,5100 99,004 1000 6,3300 6,1800 97,90 0,9460 2,7000 99,405 1000 6,8410 6,7200 99,60 1,0140 2,8300 98,906 261 2,2980 2,1900 100,00 1,0730 3,0200 99,107 212 2,1230 2,0400 100,00 1,1750 2,9700 99,408 155 1,9060 1,7500 99,90 1,0440 3,1000 98,909 115 1,3940 1,2800 99,90 1,2420 3,9700 98,80
10 109 1,5010 1,4000 100,00 1,1440 3,2700 98,8011 76 1,1890 1,0700 100,00 1,0640 3,3300 99,0012 89 1,4020 1,2800 100,00 1,1420 3,3400 98,9013 76 1,2260 1,1100 100,00 1,1620 3,6800 99,0014 66 1,3480 1,2500 100,00 1,0620 4,1900 98,9015 68 1,3340 1,2200 100,00 1,0530 3,9800 98,30
B.4 Inhalt der CD
Die in dieser Arbeit vorgestellten Programme und Algorithmen sind auf der beiliegenden CDenthalten, ebenso die verwendeten Skripte zum Erzeugen der Messdaten. Jedes Verzeichnis ent-hält eine README-Datei mit Informationen über den Inhalt des Verzeichnisses sowie dessenVerwendung.
/sxml SXML Umgebung.
/matrix Testprogramme zur Matrizenmultiplikation
/cache Testprogramm Row-First vs. Column-First-Ordering
/nn_parallel Parallele Selbstorganisierende Karte
/snns_ff n-Fach-Klassifikator vs. Binäre-Klassifikatoren
/snns_som Hierarchischen Kohonen-Karte
/quellen Ergebnistabelle des Linpack-Benchmark (http://www.top500.org/lists/2008/06)
- 89 -


















