Parsing von uni kationsbasierten Grammatikformalismen · repräsentiert ganze Äquivalenzklasse von...
16
Parsing von unifikationsbasierten Grammatikformalismen Vorlesung “Grammatikformalismen” Alexander Koller 25. Juli 2016
Transcript of Parsing von uni kationsbasierten Grammatikformalismen · repräsentiert ganze Äquivalenzklasse von...

Parsing vonunifikationsbasierten
Grammatikformalismen
Vorlesung “Grammatikformalismen” Alexander Koller
25. Juli 2016
Parsing
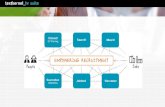
• Warum kann man kfGen in polynomieller Zeit parsen, wenn doch jeder Substring exponentiell viele Parsebäume haben kann?
A A A A A AA
AA
A
a a a a a a

Parsing
• Zwei Analysen für den gleichen Substring heißen äquivalent, wenn man die gleichen Parse-Regeln darauf anwenden kann. ‣ Es reicht grundsätzlich, von mehreren äquivalenten
Analysen nur die erste in die Chart einzutragen.
• Kontextfreies Parsing: ‣ Teilbäume sind äquivalent, wenn gleiches Wurzelsymbol.
‣ Deshalb reicht es, in Chart nur Wurzelsymbol einzutragen; repräsentiert ganze Äquivalenzklasse von Teilbäumen.
‣ Daher Parsing in Polynomzeit (vgl. aber CCG).

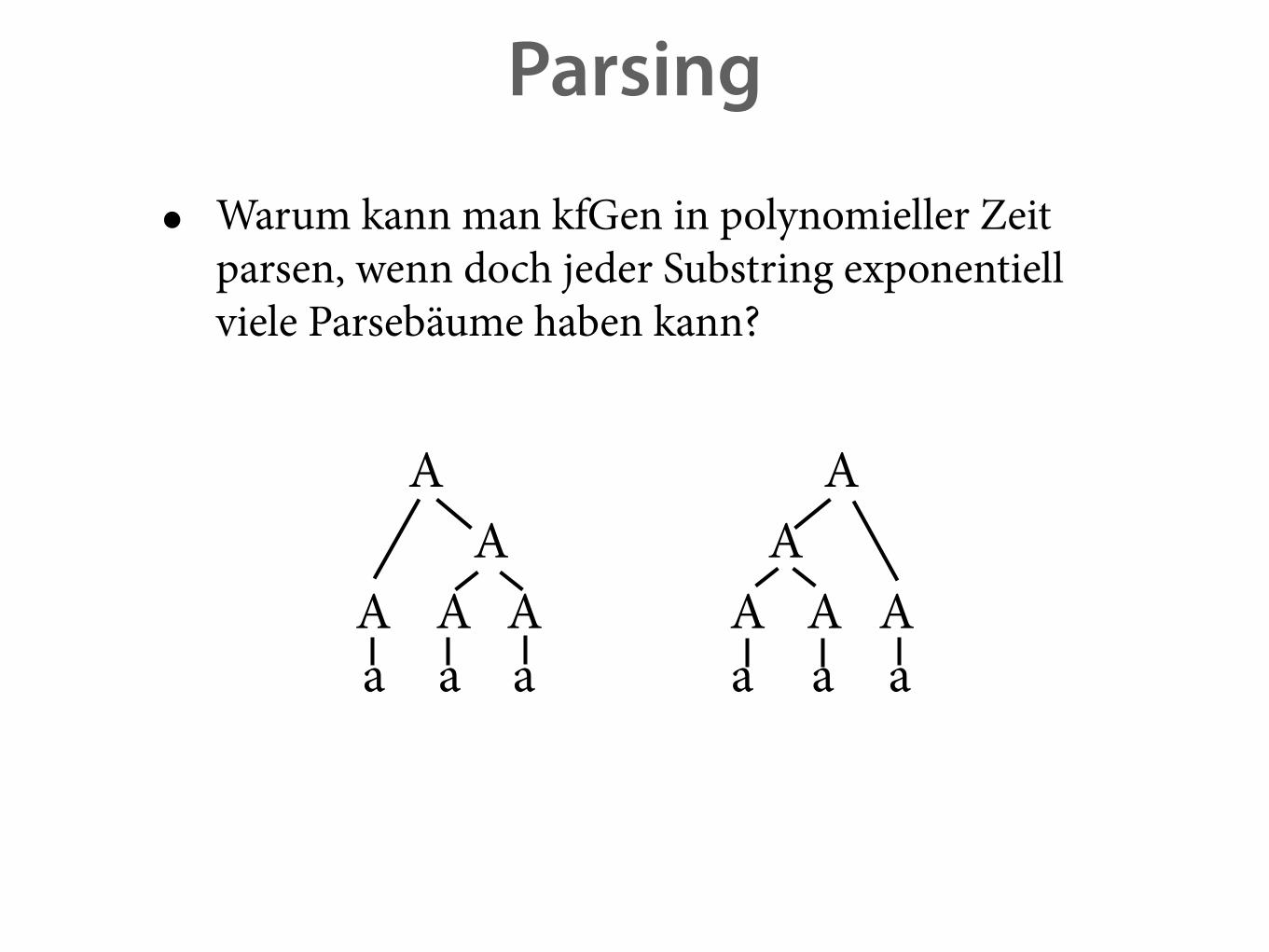
Chartparsing in HPSG
isst ein Käsebrot
isst
ein
Käse
brot
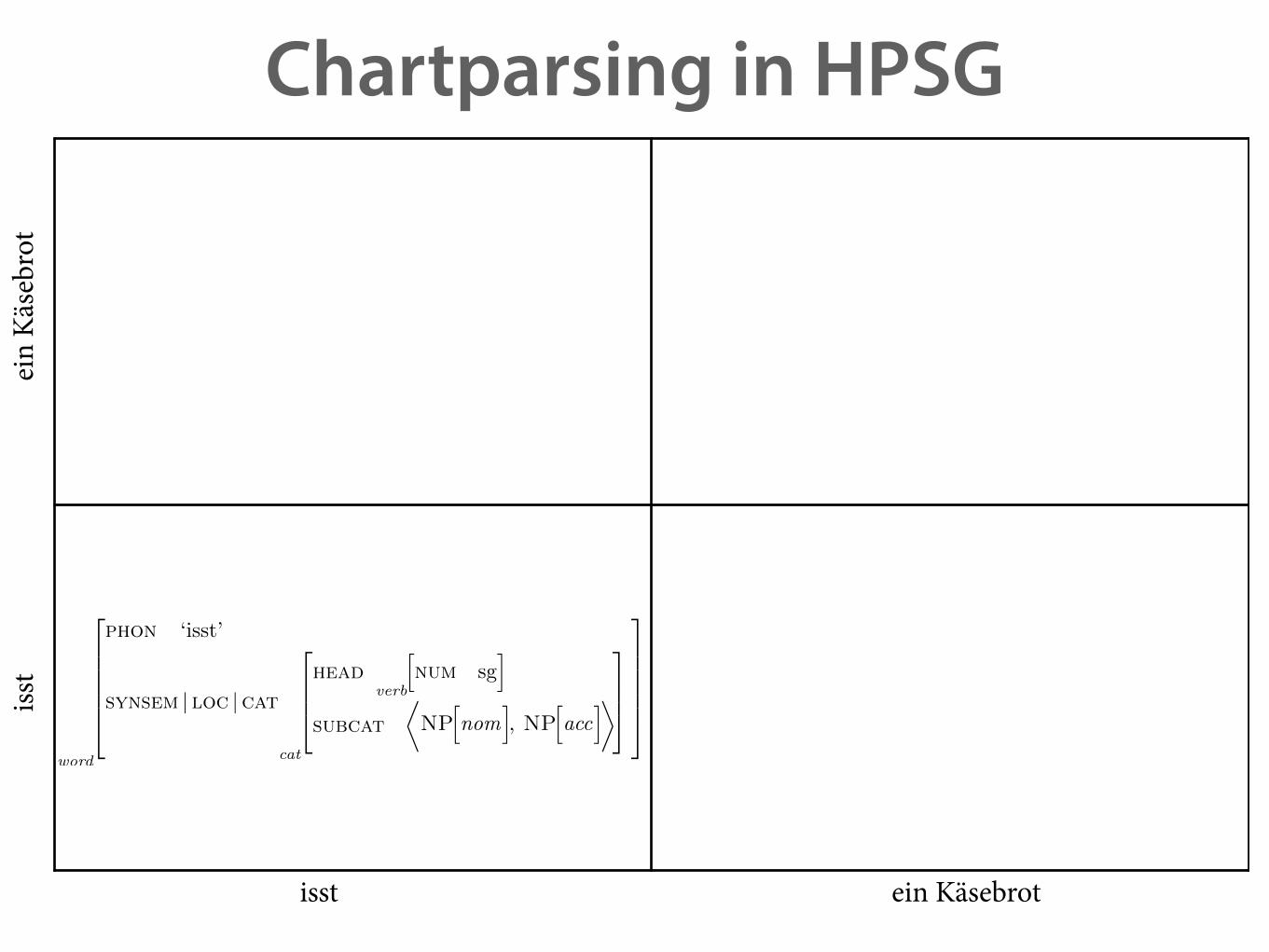
Chartparsing in HPSG
word
2
666664
phon ‘isst’
synsem | loc |cat
cat
2
664
head
verb
hnum sg
i
subcat
⌧NP
hnom
i, NP
hacc
i�
3
775
3
777775
isst ein Käsebrot
isst
ein
Käse
brot
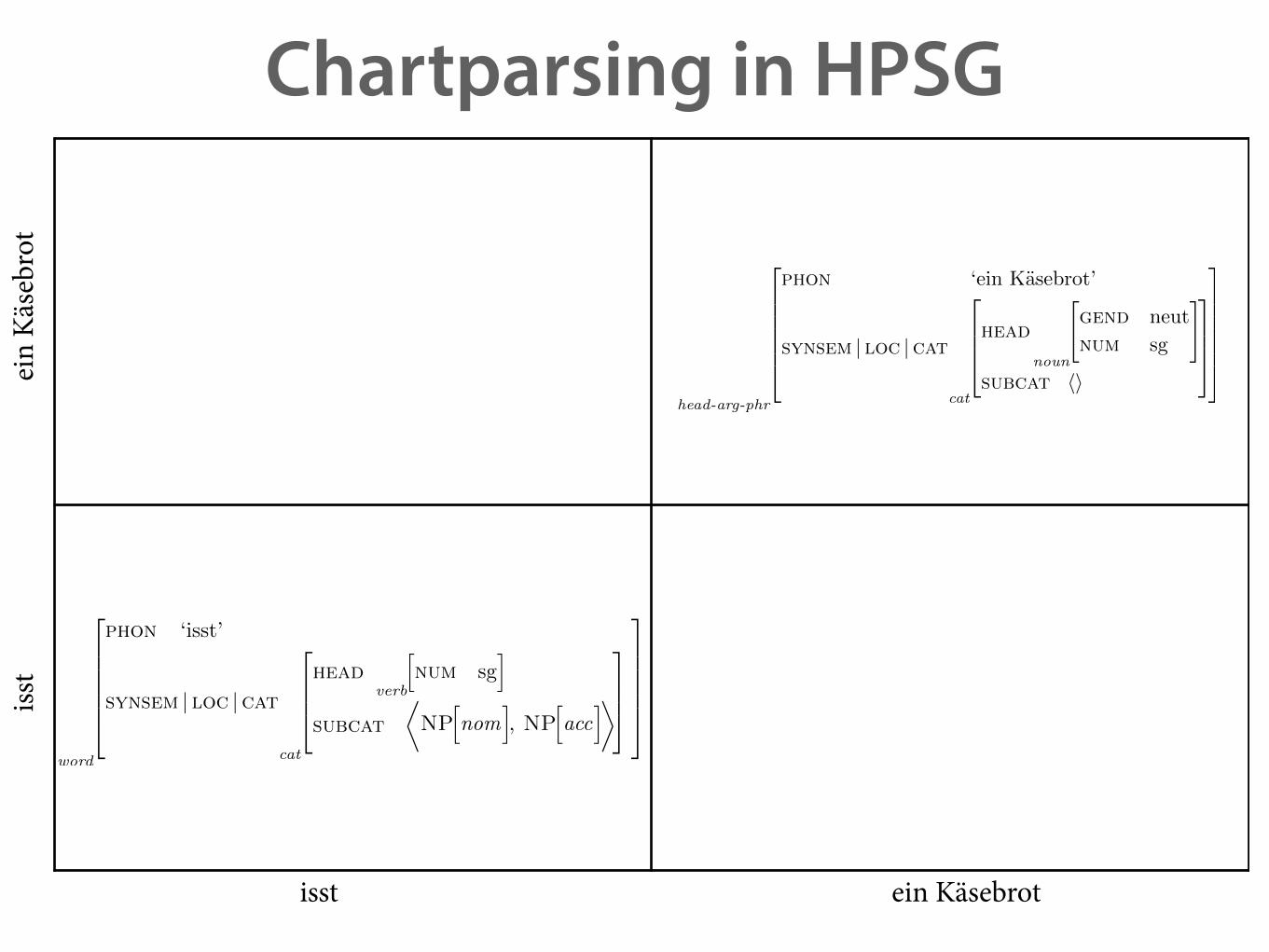
Chartparsing in HPSG
word
2
666664
phon ‘isst’
synsem | loc |cat
cat
2
664
head
verb
hnum sg
i
subcat
⌧NP
hnom
i, NP
hacc
i�
3
775
3
777775
head-arg-phr
2
666664
phon ‘ein Kasebrot’
synsem | loc |cat
cat
2
664head
noun
"gend neut
num sg
#
subcat hi
3
775
3
777775
isst ein Käsebrot
isst
ein
Käse
brot
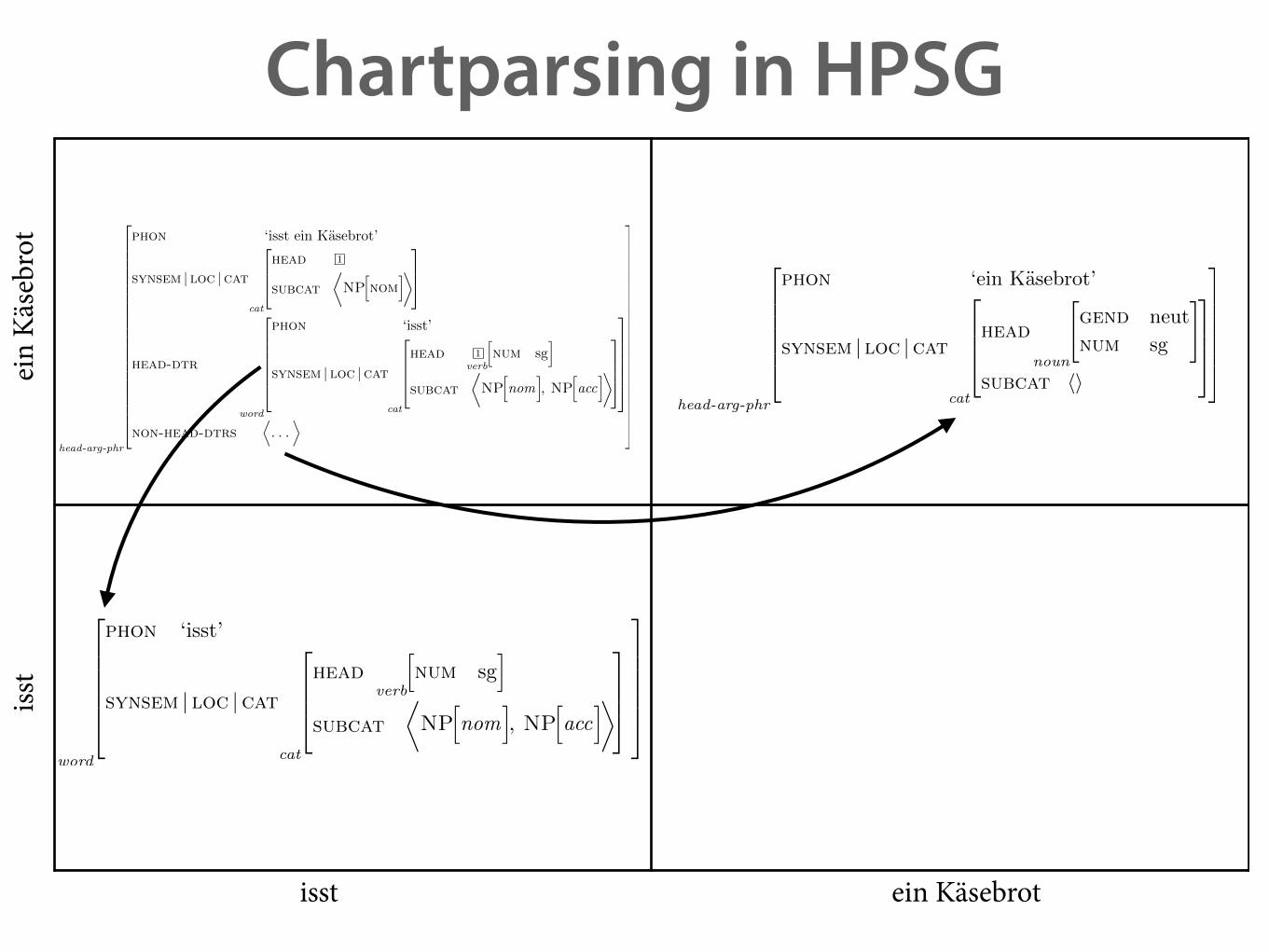
Chartparsing in HPSG
word
2
666664
phon ‘isst’
synsem | loc |cat
cat
2
664
head
verb
hnum sg
i
subcat
⌧NP
hnom
i, NP
hacc
i�
3
775
3
777775
head-arg-phr
2
666664
phon ‘ein Kasebrot’
synsem | loc |cat
cat
2
664head
noun
"gend neut
num sg
#
subcat hi
3
775
3
777775
head-arg-phr
2
666666666666666666664
phon ‘isst ein Kasebrot’
synsem | loc |cat
cat
2
64head
1
subcat
⌧NP
hnom
i�3
75
head-dtr
word
2
666664
phon ‘isst’
synsem | loc |cat
cat
2
664
head
1verb
hnum sg
i
subcat
⌧NP
hnom
i, NP
hacc
i�
3
775
3
777775
non-head-dtrs
D. . .
E
3
777777777777777777775
isst ein Käsebrot
isst
ein
Käse
brot

Äquivalenz in HPSG
• Eintrag in Chart = FS + Span. ‣ Schema-Anwendung: muss Schema mit Töchtern unifizieren
• Was für FSen zählen in HPSG als äquivalent? ‣ Je mehr FSen als äquivalent gelten, desto schneller das Parsing.
‣ Wenn Unterscheidung zwischen zwei FSen wichtig für Weiterverarbeitung ist, dürfen sie nicht äquivalent sein.
• Grundsätzlich erlaubt jede FS andere Kombinationen als jede andere. Zunächst also keine FS mit einer anderen äquivalent. ‣ … weil Schemata in beliebig tiefe Pfade schauen können.

Ansatz 1: Effizientere Unifikation
• HPSG-Parser verbringt allergrößten Teil der Zeit mit Unifizieren von FSen. Schneller Unif.algorithmus = schneller Parser.
• Bestimmte Unifikationen vorkompilieren. ‣ insbesondere Konjunktion von Typen: z.B.
Kopfmerkmalsprinzip mit Head-Arg-Schema.
• Nicht-Unifizierbarkeit früh erkennen; Kopieren vermeiden.
(Karttunen & Kay 85; Pereira 85; Wroblewski 87; Tomabechi 95; etc. etc)
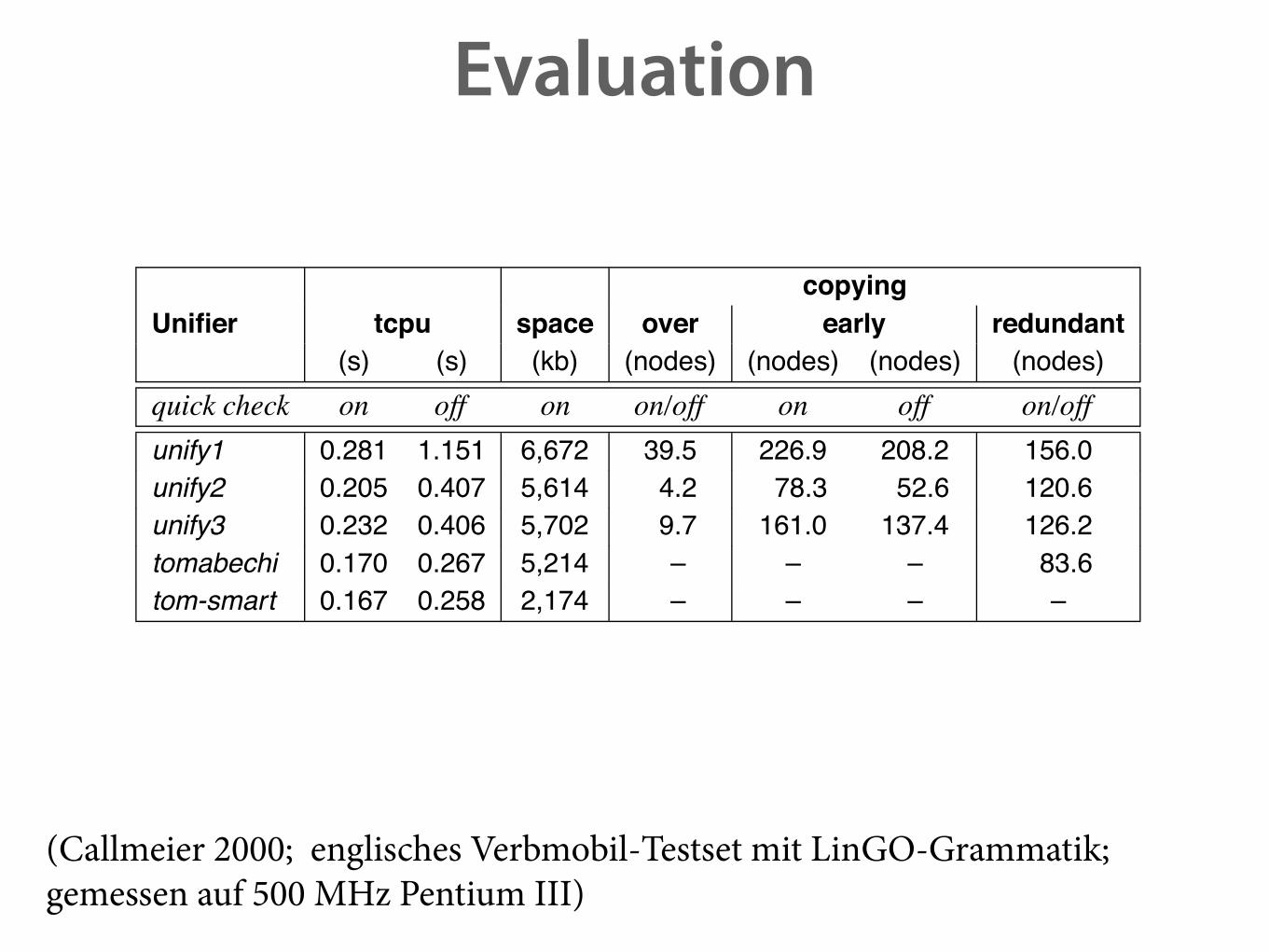
Evaluation4. Empirical Results
copyingUnifier tcpu space over early redundant
(s) (s) (kb) (nodes) (nodes) (nodes) (nodes)quick check on off on on/off on off on/offunify1 0.281 1.151 6,672 39.5 226.9 208.2 156.0unify2 0.205 0.407 5,614 4.2 78.3 52.6 120.6unify3 0.232 0.406 5,702 9.7 161.0 137.4 126.2tomabechi 0.170 0.267 5,214 – – – 83.6tom-smart 0.167 0.258 2,174 – – – –
Table 4.3.: Performance and copying behavior of selected unification algorithms on LinGOwhen parsing the aged test set. unify1 and unify2 are the functions of the same namefrom Wroblewski (1987), unify3 is the function from Section 2.4.2, tomabechi is thealgorithm from Tomabechi (1991), and tom-smart adds non-redundant copying fromMalouf et al. (2000). The row labelled quick check indicates if quick check filteringwas enabled or disabled for a column. Where the quick check makes no difference, thecolumn is labelled on/off. The static rule filter was enabled in all cases. A plain activechart parser was used.
allocate enough memory for the resulting dag. (Wroblewski, 1987)
Early Copying Copies are created prior to the failure of unification so that copies cre-ated since the beginning of the unification up to the point of failure are wasted.
(Tomabechi, 1991)
Redundant Copying [...] a unification result graph consists only of newly createdstructures. This is unnecessary because there are often input subgraphs that canbe used as part of the result graph [...] Copying sharable parts is called redundantcopying. (Kogure, 1990)
Early copying is concerned with unnecessary copying in case of a unification failure only,while over and early copying applies in the case of a successful unification.
I used an instrumented version of the cheap parser to quantify the amounts of the threekinds of copying. The amount of early copying is simply the number of nodes that wereallocated prior to a failure in unification. The amount of over copying is determined bycomputing the difference between the number of nodes of the result dag and the number ofnodes allocated during unification. Determining the amount of redundant copying is not asstraightforward, because there is no tractable way to determine the maximum permissibleamount of sharing. A second problem is the overlap in definition between redundant andover copying; the notion of redundant copying subsumes that of over copying. My solution
40
(Callmeier 2000; englisches Verbmobil-Testset mit LinGO-Grammatik;gemessen auf 500 MHz Pentium III)

Ansatz 2: Ambiguitäten packen
• Unter bestimmten Umständen kann man zwei FSen als äquivalent gelten lassen. ‣ wenn Parser (i,k,σ) kannte und (i,k,τ) findet und τ ⊑ σ (d.h. ist allgemeiner), dann darf er (i,k,σ) löschen.
‣ Neuer Äquivalenzbegriff ⇒ Chart bleibt kleiner ⇒ Parsing wird schneller.
• Löschen von Einträgen, die aus (i,k,σ) abgeleitet wurden, ist nicht trivial.
(Oepen & Carroll 00 etc.)
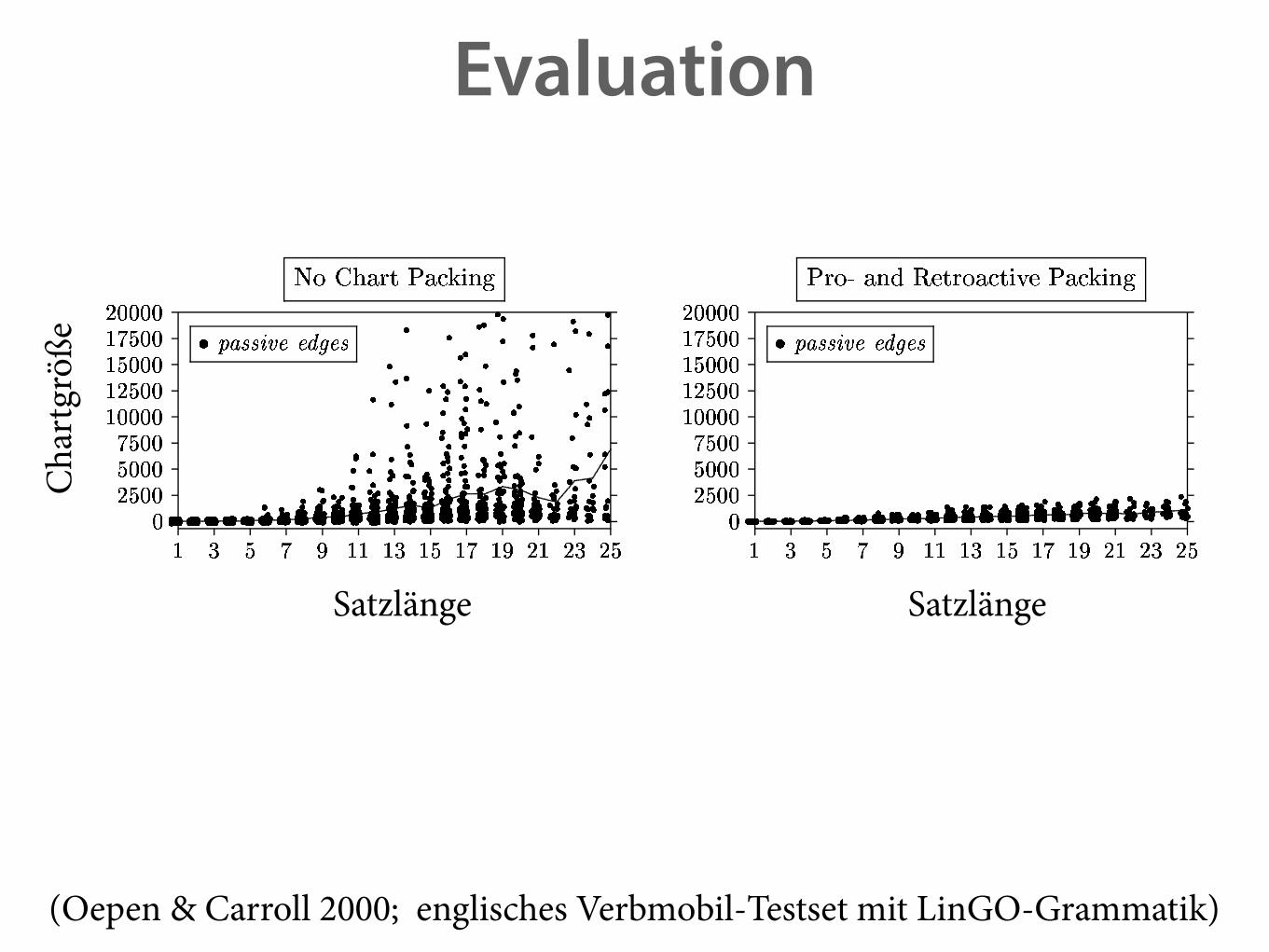
EvaluationC
hart
größ
e
Satzlänge Satzlänge
(Oepen & Carroll 2000; englisches Verbmobil-Testset mit LinGO-Grammatik)

Ansatz 3: Approximation
• HPSG-Schemata definieren Phrasenstruktur. Kann man mit kfG approximieren. ‣ [cat=V, subcat=<NPnom>] →
[cat=V, subcat=<NPnom, NPacc>] [cat=N, subcat=<>]
• Mit (statistischer) kfG parsen; dann versuchen, beste Parsebäume in HPSG-Parses zu expandieren. (Kann fehlschlagen!)
• Unifikationen nur für Strukturen ausführen, die überhaupt eine Chance haben.
(Kiefer & Krieger 00; Zhang & Krieger 11; etc.)
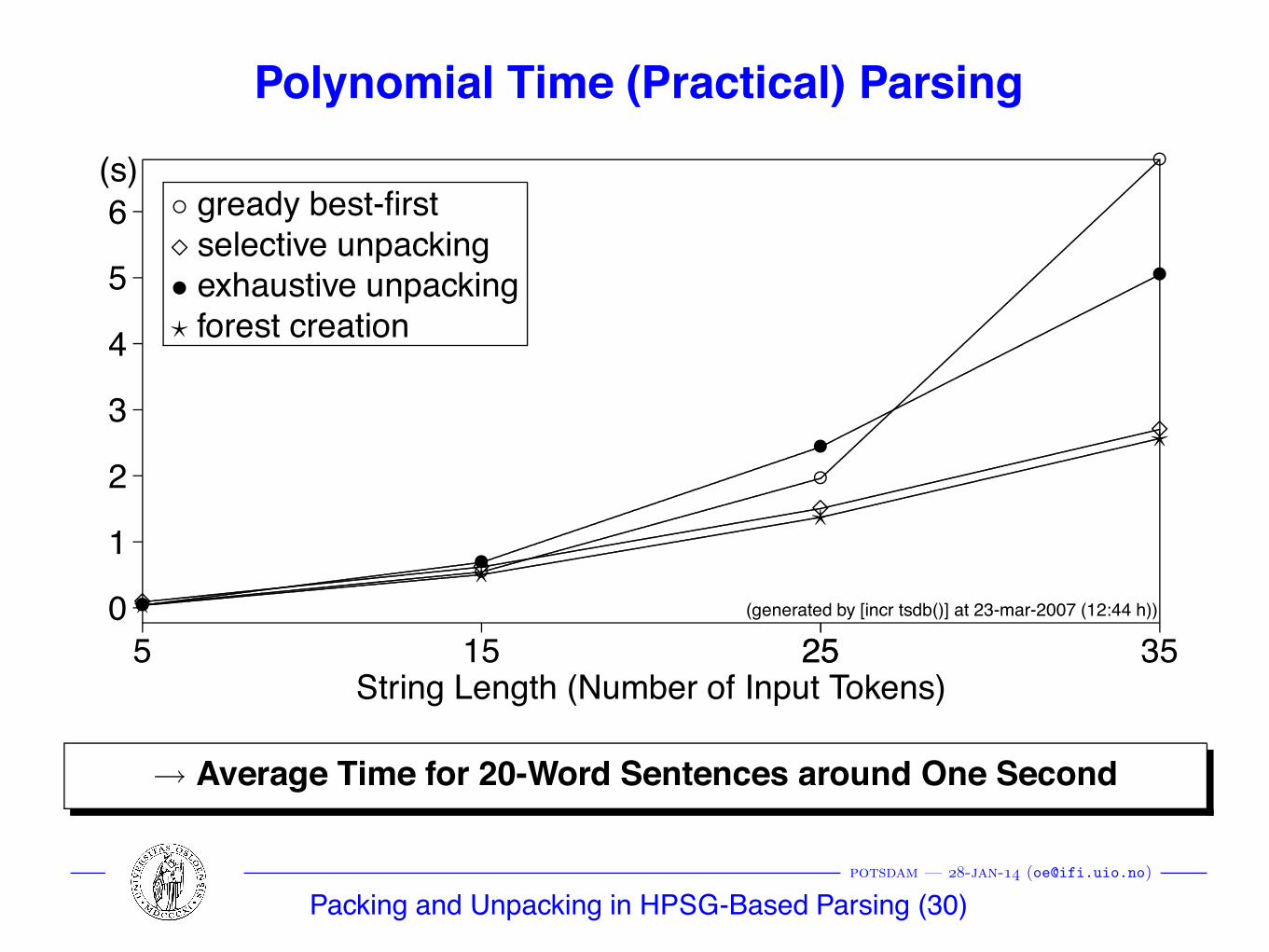
Polynomial Time (Practical) Parsing
5 15 2525 35String Length (Number of Input Tokens)
0
1
2
3
4
5
6(s)
(generated by [incr tsdb()] at 23-mar-2007 (12:44 h))◦◦
◦
◦
••
•
•
⋄⋄
⋄
⋄
⋆⋆
⋆
⋆
◦ gready best-first⋄ selective unpacking• exhaustive unpacking⋆ forest creation
→ Average Time for 20-Word Sentences around One Second
potsdam — 28-jan-14 ([email protected])
Packing and Unpacking in HPSG-Based Parsing (30)

Stand der Kunst
• LKB: Grammatikentwicklungssystem. ‣ verwendet Type Description Language (TDL), um
Grammatiken aufzuschreiben
• TDL-Grammatiken kann man effizient mit dem PET-Parser verarbeiten. ‣ LKB + PET + andere = DELPH-IN
‣ DELPH-IN ist internationales Konsortium, das zueinander kompatible Parser, Grammatiken etc. entwickelt: http://www.delph-in.net/

Zusammenfassung
• Expressivität: turing-vollständig.
• Parsing: wird durch FS schwerer. ‣ verschiedene Ansätze zur Verbesserung
‣ aktuelle Software funktioniert sehr gut