
Prozeßmodellierung und Tailoring in Prolog · 1 Einleitung Der Schwerpunkt dieser Arbeit liegt im...
35
Leibniz Universität Hannover Fakultät für Elektrotechnik und Informatik Institut für Praktische Informatik Fachgebiet Software Engineering Beschreibung und Tailoring von Softwareprozessen in Prolog Bachelorarbeit im Studiengang Informatik von Daniel Eggert Prüfer: Prof. Dr. Kurt Schneider Zweitprüfer: Prof. Dr. techn. Wolfgang Nejdl Hannover, September 2006
Transcript of Prozeßmodellierung und Tailoring in Prolog · 1 Einleitung Der Schwerpunkt dieser Arbeit liegt im...

Leibniz Universität HannoverFakultät für Elektrotechnik und Informatik
Institut für Praktische InformatikFachgebiet Software Engineering
Beschreibung und Tailoring von Softwareprozessen in Prolog
Bachelorarbeit
im Studiengang Informatik
von
Daniel Eggert
Prüfer: Prof. Dr. Kurt SchneiderZweitprüfer: Prof. Dr. techn. Wolfgang Nejdl
Hannover, September 2006

Inhaltsverzeichnis 1 Einleitung.......................................................................................................................... 1
1.1 Hintergrund............................................................................................................... 1 1.2 Aufgabe..................................................................................................................... 1 1.3 Gliederung................................................................................................................. 1
2 Beschreibung von SPEM................................................................................................. 3 3 Prozessmodelle................................................................................................................ 5
3.1 Allgemeine Prozessmodelle...................................................................................... 5 3.2 Softwareprozesse..................................................................................................... 5 3.3 Quality Gate Prozess................................................................................................ 6 3.4 Verbesserung von Prozessen................................................................................... 7
4 Prolog............................................................................................................................... 8 5 Darstellung von Prozessen in Prolog............................................................................. 11
5.1 Struktur.................................................................................................................... 11 5.2 Prozesselemente.................................................................................................... 11 5.3 Verknüpfung der Prozesselemente......................................................................... 12
5.3.1 Von Relationen zu Prädikaten......................................................................... 12 5.3.2 Kardinalitäten und Listen................................................................................. 13 5.3.3 Verknüpfungsprädikate und Ausnahmen......................................................... 16
5.4 Prozess-Tailoring.................................................................................................... 19 5.4.1 Konzepte.......................................................................................................... 19 5.4.2 Tailoring mit Fakten......................................................................................... 20 5.4.3 Tailoring mit Regeln......................................................................................... 21
5.5 Hilfsprädikate.......................................................................................................... 21 5.5.1 Manipulation von Listenelementen.................................................................. 22 5.5.2 Manipulation der Phasenabfolge..................................................................... 24 5.5.3 Tailoring Aufruf................................................................................................ 26
5.6 Lesbarkeit und Handhabbarkeit.............................................................................. 27 6 Darstellung als Prozess-Baum....................................................................................... 29 7 Technologie.................................................................................................................... 31
7.1 Prolog Interpreter.................................................................................................... 31 7.2 Java......................................................................................................................... 31 7.3 Ausblick................................................................................................................... 31
Anhang............................................................................................................................... 32Literaturverzeichnis........................................................................................................ 32Abbildungsverzeichnis................................................................................................... 32
Erklärung............................................................................................................................ 33

1 Einleitung
1 Einleitung
1.1 HintergrundDer Entwicklungsprozess eines Softwareprodukts beeinflußt dessen Qualität maß-geblich. Um Prozesse besser verstehen und analysieren zu können, werden sie durch Prozessmodelle abgebildet. Zwei bekannte Prozessmodelle sind das V-Modell XT, sowie der RUP (Rational Unified Process). Es gibt viele Formen der Prozessmodellierung. In der Regel ist der Adressat ein Mensch, weshalb meist eine Mischung aus textueller und graphischer Modellierung Verwendung findet. Maschinenlesbare Prozesse sind da formaler. Die Modellierung von Prozessen in Prädikatenlogik bildet eine Grundlage für deren Maschinenlesbarkeit. Die Pro-grammiersprache Prolog basiert auf einer solchen Prädikatenlogik. Durch das Ändern bzw. Hinzufügen von Fakten und Regeln kann eine Prozessverbesserung realisiert werden.
1.2 AufgabeIm Rahmen dieser Bachelorarbeit soll nun eine Möglichkeit erarbeitet werden, Softwareprozesse in Prolog zu modellieren. Eine solche Modellierung ist durch die verwendete Prädikatenlogik hervorragend für eine maschinelle Verarbeitung geeignet. Die Frage der Lesbarkeit und Handhabbarkeit für den Menschen ist offen und soll im Rahmen dieser Arbeit geklärt werden. Um Rollen, Aktivitäten und Dokumente als typische Prozesselemente abbilden zu können, wird in dieser Arbeit die UML-Erweiterung SPEM verwendet.
Als durchgängiges Modellierungsbeispiel wird der Quality Gate Prozess des Soft-wareprojekts Verwendung finden.
In der Arbeit wird die Prozessmodellierungssprache SPEM soweit beschreiben, wie sie von Bedeutung ist. Als wesentlicher Bestandteil gilt es, die verschiedenen Abbildungsvorschriften der wichtigsten Prozesselemente nach Prolog zu beschrei-ben.
1.3 GliederungIm folgenden Kapitel wird zunächst SPEM soweit beschrieben, wie es in dieser Arbeit von Bedeutung ist.
Das dritte Kapitel befasst sich mit Prozessmodellen. Ganz speziell natürlich mit Softwareprozessen. Es wird auf ihre Nutzung, sowie verschiedenen Ausprägungen eingegangen. Als konkretes Softwareprozess Beispiel wird der Quality Gate Pro-zess beschrieben, welcher auch das durchgängige Modellierungsbeispiel für diese Arbeit bildet.Im vierten Kapitel findet ein kleiner Prolog Exkurs statt. Es wird nur auf einige Grundlagen eingegangen, die in der weiteren Arbeit von Bedeutung sind.
-1-

1 Einleitung
Der Schwerpunkt dieser Arbeit liegt im fünften Kapitel. Es zeigt die Model-lierung der Softwareprozesse und dessen Tailoring. Dabei werden die entwi-ckelten Konzepte dargestellt und deren Vor- und Nachteile beschrieben. Die Lesbarkeit und Handhabbarkeit der einzelnen Modellierungselemente wer-den jeweils an entsprechender Stelle aufgezeigt.
Kapitel sechs zeigt die graphische Ausgabe des modellierten Prozesses mit Hilfe eines Java Applets.
Das siebte und letze Kapitel gibt einen Überblick über die verwendeten Technologien und einen kleinen Ausblick über die zukünftige Weiterent-wicklung.
-2-

2 Beschreibung von SPEM
2 Beschreibung von SPEMDieses Kapitel soll einen kleinen Überblick über das Software Process Engi-neering Meta Model (kurz SPEM) geben. Es wurde von der Object Manage-ment Group entwickelt. SPEM verfolgt einen Objekt Orientierten Ansatz, wobei UML als Notation verwendet wird. Somit ist SPEM als ein UML Pro-fil sehen, welches das Standard UML um verschiedene Stereotypen und die entsprechende Semantik erweitert.
Die Kernidee besteht darin, dass ein Softwareentwicklungsprozess als ein Zusammenspiel von aktiven und passiven Elementen definiert wird. Pro-cess Roles, als aktives Element, führen Activities an Work Products aus. Alle Prozesselemente werden zu einer abstrakten Einheit dem Model Ele-ment zusammengefasst, wobei jedes Element eine Beschreibung External Description besitzt. Jedes Model Element besitzt eine Verknüpfung zu einem anderen Model Element.
Die Hierarchien und Abhängigkeiten zwischen den einzelnen SPEM Ele-menten sind sehr komplex. Abbildung 1 zeigt eine vereinfachte Darstellung der wichtigsten Klassen.
-3-
Abbildung 1: SPEM - Hauptklassen

2 Beschreibung von SPEM
An diesem Modell orientiert sich die in dieser Arbeit entwickelte Abbildung nach Prolog. Wobei diese noch weiter vereinfacht wird und die Phase als Work Definition in den Mittelpunkt der Modellierung rück und nicht wie hier, das Element Role als Process Performer. Ein Grund für diese Maß-nahme ist, dass der modellierte Prozess in einem Prozessbaum dargestellt werden soll. Bei einem solchen Baum ist als Hierarchie der zeitliche Ablauf des Prozesses besser geeignet als die Menge der aktiven Rollen.
SPEM bringt zur Darstellung einen eigenen Symbolvorrat mit.
Diese werden später bei der Erstellung einer Prozess Ausgabe mittels eines Prozessbaums Verwendung finden. Die Beschreibung der wichtigsten Pro-zess bzw. Model Elemente soll im nächsten Kapitel folgen.
-4-
Abbildung 2: SPEM - Symbole

3 Prozessmodelle
3 ProzessmodelleDieses Kapitel befasst sich mit Prozessmodellen im allgemeinen und mit Softwareprozessen im speziellen. Als konkretes Softwareprozess Beispiel wird der Quality Gate Prozess des Fachgebiets Software Engineering heran-gezogen.
3.1 Allgemeine ProzessmodelleProzessmodelle bilden die entscheidende Grundlage für die Analyse von Prozessen. Obwohl der eigentlich ausgeführte Prozess oft signifikant vom formalen Modell abweicht, helfen Prozessmodelle Zusammenhänge und Abhängigkeiten zwischen einzelnen Prozessteilen zu identifizieren und damit zu verstehen. Modelle existieren in unterschiedlichen Granularitäts-stufen, von einfach, abstrakt bis komplex, speziell. In den meisten Bereichen der Wirtschaft werden Prozessmodelle zur Analyse und Verbesserung der mit ihnen modellierten Prozesse verwendet. Die Bandbreite reicht von Geschäftsprozessen aus der Betriebswirtschaftslehre bis hin zu Softwarepro-zessen in der Informatik.
3.2 SoftwareprozesseSoftwareprozesse beschreiben den Ablauf, sowie die Verbindung zwischen den einzelnen Prozessteilen, während der Entwicklung eines Softwarepro-dukts. Um ein Modell für Softwareprozesse zu realisieren, müssen zunächst einmal die wesentlichen Prozesselemente identifiziert werden.
Das erste offensichtlichste Prozesselement ist ein Prozess, welcher auch ein Teilprozess eines größeren Prozesses sein kann. Er ist aus aufeinander fol-gende Phasen aufgebaut. Womit schon das nächste Element benannt wäre, eine Phase. Die Phasen eines Prozesses definieren im groben dessen zeitlichen Verlauf.
Eine Phase besitzt gewisse Vor- und Nachbedingungen.
Ein weiteres wichtiges Element sind Rollen. Eine Rolle repräsentiert einen begrenzten Zuständigkeitsbereich mit gewissen Aktivitäten. Rollen sind an verschiedenen Phasen beteiligt. Wobei eine Rolle mit mehreren Personen verbunden sein könnte, oder auch eine Person verschiedene Rollen inneha-ben kann.Während eines Prozess werden unterschiedliche Produkte erschaffen oder weiterverarbeitet. Sie werden als Artefakte bezeichnet. Sie repräsentieren die In- und Outputs der verschiedenen Phasen.
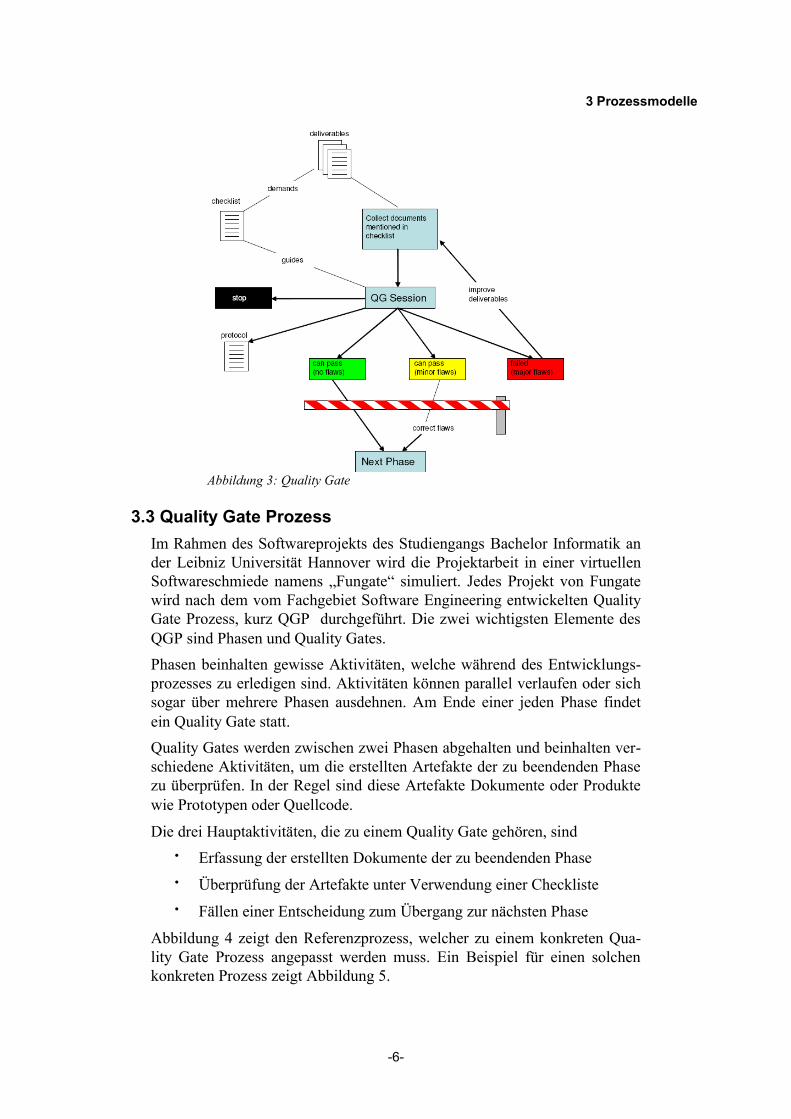
Zur Qualitätssicherung können unterschiedlichste Kontrollelemente dienen. Sie sollen die minimale Qualität der erstellten Artefakte während des gesam-ten Prozesses sicherstellen. Eine solche Qualitätssicherungsmaßnahme ist das Abhalten von Quality Gates, in denen anhand einer Checkliste die erstellten Artefakte, jeweils am Ende einer Phase, überprüft werden.
-5-
3 Prozessmodelle
3.3 Quality Gate ProzessIm Rahmen des Softwareprojekts des Studiengangs Bachelor Informatik an der Leibniz Universität Hannover wird die Projektarbeit in einer virtuellen Softwareschmiede namens „Fungate“ simuliert. Jedes Projekt von Fungate wird nach dem vom Fachgebiet Software Engineering entwickelten Quality Gate Prozess, kurz QGP durchgeführt. Die zwei wichtigsten Elemente des QGP sind Phasen und Quality Gates.Phasen beinhalten gewisse Aktivitäten, welche während des Entwicklungs-prozesses zu erledigen sind. Aktivitäten können parallel verlaufen oder sich sogar über mehrere Phasen ausdehnen. Am Ende einer jeden Phase findet ein Quality Gate statt.Quality Gates werden zwischen zwei Phasen abgehalten und beinhalten ver-schiedene Aktivitäten, um die erstellten Artefakte der zu beendenden Phase zu überprüfen. In der Regel sind diese Artefakte Dokumente oder Produkte wie Prototypen oder Quellcode.
Die drei Hauptaktivitäten, die zu einem Quality Gate gehören, sind• Erfassung der erstellten Dokumente der zu beendenden Phase• Überprüfung der Artefakte unter Verwendung einer Checkliste• Fällen einer Entscheidung zum Übergang zur nächsten Phase
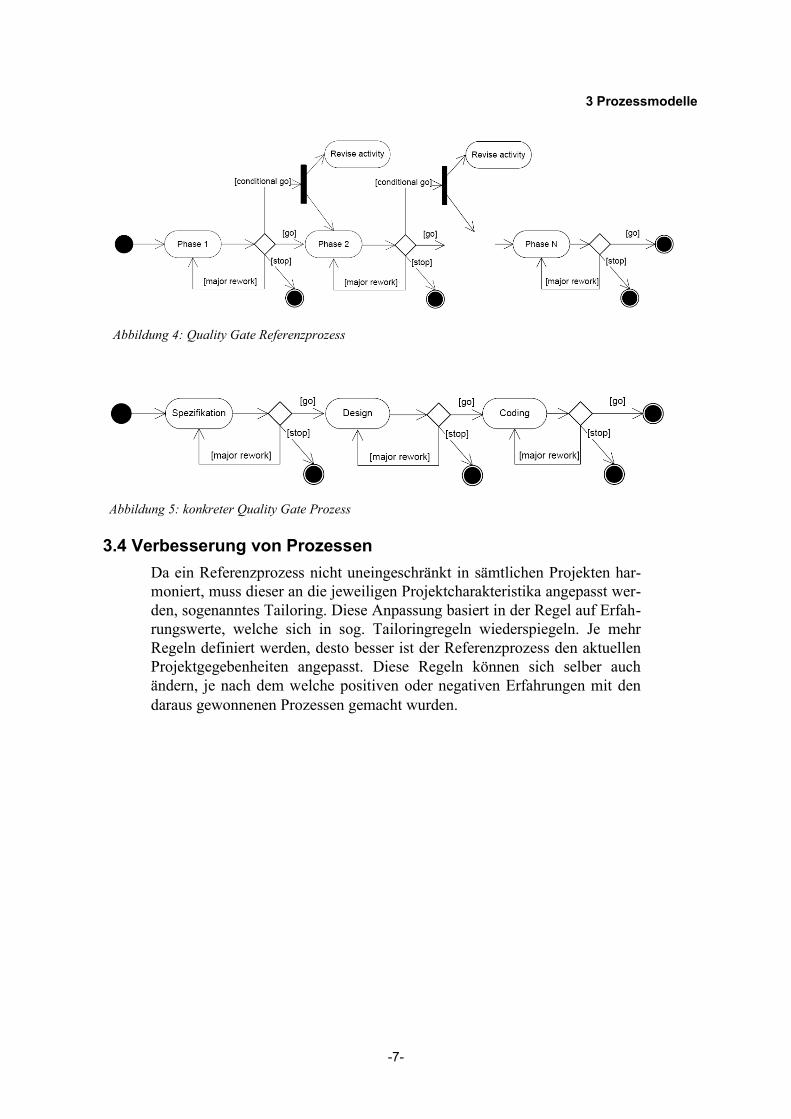
Abbildung 4 zeigt den Referenzprozess, welcher zu einem konkreten Qua-lity Gate Prozess angepasst werden muss. Ein Beispiel für einen solchen konkreten Prozess zeigt Abbildung 5.
-6-
Abbildung 3: Quality Gate
3 Prozessmodelle
3.4 Verbesserung von ProzessenDa ein Referenzprozess nicht uneingeschränkt in sämtlichen Projekten har-moniert, muss dieser an die jeweiligen Projektcharakteristika angepasst wer-den, sogenanntes Tailoring. Diese Anpassung basiert in der Regel auf Erfah-rungswerte, welche sich in sog. Tailoringregeln wiederspiegeln. Je mehr Regeln definiert werden, desto besser ist der Referenzprozess den aktuellen Projektgegebenheiten angepasst. Diese Regeln können sich selber auch ändern, je nach dem welche positiven oder negativen Erfahrungen mit den daraus gewonnenen Prozessen gemacht wurden.
-7-
Abbildung 4: Quality Gate Referenzprozess
Abbildung 5: konkreter Quality Gate Prozess

4 Prolog
4 PrologProlog (Programming in Logic) bildet die Grundlage dieser Arbeit. Prolog gehört, wie der Name schon vermuten lässt, zu den logischen Programmier-sprachen und unterliegt somit dem Paradigma der deklarativen Programmie-rung. Grundlage für Prolog bildet die Prädikatenlogik, somit könnte man ein Prologprogramm als Sammlung von Hornklauseln bezeichnen. Würde es einen auf Logik basierenden Computerprozessor geben, wäre Prolog die ent-sprechende Maschinensprache dazu.Die Verwendung von Prädikatenlogik bietet zwei Möglichkeiten Dinge in Prolog zu definieren, Fakten und Regeln. Fakten sind ein oder mehrstellige Prädikate, die einem Sachverhalt eine bestimmte Eigenschaft zuordnen.
zufrieden(hans).Der obige Fakt sagt aus, dass hans zufrieden ist, d.h. es wird dem Objekt hans die Eigenschaft zufrieden zugeordnet. Fakten müssen nicht zwangsläu-fig einstellige Prädikate sein.
liebt(hans, lisa).Dieses zweistellige Prädikat sagt aus, dass hans lisa liebt, verknüpft also zwei Objekte miteinander. Angenommen die Wissensbasis würde aus den zwei obengenannten Fakten bestehen. Anfragen an Wissensbasen werden durch Auswertung der bekannten Fakten abgearbeitet. Dabei liefert der Pro-log Interpreter je nach Anfrage ein ja oder nein, oder den Wert einer Varia-blen. Die Anfrage ?-zufrieden(hans). liefert ja, da die Wissenbasis weiß, dass hans zufrieden ist. Hingegen liefert ?-zufrieden(lisa). ein nein, da ein solcher Fakt nicht bekannt ist. Dies illustriert, dass Prolog nach der Closed World Assumption arbeitet. Das hat zur Folge, dass Prolog auf alle Anfra-gen, deren Antwort nicht aus der Wissenbasis ableitbar ist, nein antwortet. Um nun zum Beispiel alle zufriedenen Personen zu ermitteln, muss das Prä-dikat mit einer Variablen aufgerufen werden. Variablen beginnen in Prolog immer mit einem Großbuchstaben.
?-zufrieden(Person).Eine solche Anfrage liefert alle möglichen Zuweisungen der Variablen Person in Verbindung mit dem Prädikat zufrieden. In unserem Fall ist die Antwort des Interpreters Person = hans. Äquivalent verhält es sich zu mehr-stelligen Prädikaten. Die Frage nach wen liebt hans würde in Prolog folglich
?-liebt(hans, Person).lauten und mit der Zuweisung Person = lisa beantwortet werden.
Jedoch unterscheidet Prolog strikt die Reihenfolge der Argumente in den Prädikaten. Die Anfrage ?-liebt(lisa, hans). ergibt ein nein. Was auch intui-tiv richtig ist, da hans liebt lisa sicherlich nicht lisa liebt hans impliziert.
Das zweite bedeutende Prologelement sind Regeln. Dabei ist der Regelope-rator :- wie ein umgekehrter Implikationspfeil zu sehen, als Wort triff es „falls“ wohl am besten.
-8-

4 Prolog
großvater(X, Y) :- vater(X,Z), vater(Z,Y).Diese Regel besagt, X ist großvater von Y, falls es ein Z gibt, so dass X vater von Z und Z vater von Y ist. Das Komma zwischen den beiden vater-Prädikaten bildet eine UND-Verknüpfung. Eine ODER-Verknüpfung wird durch eine zweite Regel mit identischem Kopf erzielt.
Die Verwendung von Listen bildet neben der Rekursion eine entscheidende Programmiertechnik in Prolog. Listen werden durch eckige Klammern defi-niert, in denen die einzelnen Elemente durch Kommata getrennt werden.
liebt(hans, [lisa, julia]).Nun liebt hans nicht nur lisa, sondern auch julia. Zwei der wichtigsten Funktionen zur Manipulation und Auswertung von Listen bilden append, welches zwei Listen zusammenfügt und member, welches überprüft, ob etwas Element der Liste ist. Sie gehören zu den vordefinierten Prädikaten eines Prolog Interpreters und müssen nicht selber definiert werden. Weitere für diese Arbeit wichtige vordefinierte Prädikate sind assert, retract und dynamic. assert fügt der Wissensbasis zur Laufzeit neue Fakten hinzu. Um auf diese Weise vorhandene Prädikate zu erweitern müssen diese als dyna-mic deklariert werden. Retract bildet das Gegenstück zu assert und entfernt einen Fakt zur Laufzeit aus der Wissensbasis. Diese Manipulation der Wis-senbasis ist nur temporär und ändert keinesfalls die der Wissensbasis zugrundeliegende Prologdatei.
Wenn man über Prädikate, Terme, Fakten und Regeln spricht, kann es oft zu Missverständnissen kommen. Manche werden auch fälschlicherweise als Synonyme verwandt. Um dessen vorzubeugen, sollen die in dieser Arbeit benutzten Prologelemente hier definiert werden. Diese Definitionen bilden dann die Grundlage für ihre anschließende Verwendung.
Prädikate sind mit Funktionen bzw. Prozeduren gleichzusetzen. Sie besitz-ten einen Bezeichner (functor) und eine Arität (arity). Die Arität gibt die Anzahl der Argumente mit deren das Prädikat verwendet wird an. Functor und Arität bestimmen ein Prädikat eindeutig und dienen ihrer eindeutigen Identifizierung. Daher werden Prädikate mit functor/arity dargestellt.
liebt/2Terme sind Ausdrücke, die Konstanten sehr nahe kommen und können als Argumente in Prädikate eingesetzt werden. Sie beginnen immer mit einem Kleinbuchstaben.
hans
-9-

4 Prolog
Fakten werden aus Prädikaten und Termen gebildet, nämlich indem man Terme als Argumente in ein Prädikat einsetzt. Fakten werden mit einem Punkt abgeschlossen.
liebt(hans, lisa).Regeln werden durch die Verknüpfung von Fakten mit dem Regeloperator :- erstellt, wobei die Fakten wiederum durch Kommata als Konjunktions-operator verbunden werden können. Die Prädikate vor dem Regeloperator bilden den Kopf der Regel, die Prädikate dahinter den Rumpf.liebt(peter, Person) :- blond(Person),
weiblich(Person).
-10-

5 Darstellung von Prozessen in Prolog
5 Darstellung von Prozessen in PrologIm Folgenden werden die entwickelten Konzepte bzw. Konzeptelemente für die Abbildung der Prozesse und deren Elemente nach Prolog beschrieben.
5.1 StrukturDie Modellierung ist in drei Bereiche strukturiert. Jeder Bereich stellt eine separate Prolog-Wissensbasis dar und wird somit jeweils in einer eigenen Datei gespeichert. Zunächst müssen alle Prozesselemente abgebildet wer-den, dies geschieht in der „Entity-Wissensbasis“. Hier werden alle Elemente mit einstelligen Prädikaten definiert. Zwischen den einzelnen Elementen bestehen in dieser Wissensbasis noch keinerlei Zusammenhänge. In einer „Assignment-Wissensbasis“ werden alle Zusammenhänge und Abhängig-keiten zwischen den Elementen definiert. Dies geschieht durch zweistellige Prädikate. Um die Modellierung anpassbar (tailorbar) zu machen, wird eine dritte Wissensbasis erstellt. Diese „Tailoring-Wissensbasis“ enthält je nach „Tailoring-Konzept“ die entsprechenden Prädikate, um den Prozess nach eigenen, in der Regel empirischen Daten anzupassen.Diese Strukturierung bietet eine optimale Handhabbarkeit der Modellierung. Die Kapselung ermöglicht es zum Einen die Wissensbasen verhältnismäßig klein zu halten, zum Anderen können Änderungen an einer Basis durchge-führt werden, ohne den genauen Aufbau der Anderen zu kennen.
5.2 ProzesselementeIm Folgenden wird die Abbildung der einzelnen Elemente beschrieben. Ein Prozesselement (Entität) wird durch ein Prologprädikat mit entsprechender Bezeichnung abgebildet. Um die erfolgte Transformation von einer Entität zu einem Prologprädikat zu verdeutlichen, werden Abbildungen wie folgt dargestellt.
entity → predicate/1Beginnen wir mit der Abbildung des Prozesses an sich. Ein Prozess als Enti-tät wird zu einem Prologprädikat transformiert.
process → process/1Um den Prozess eindeutig zuordnen zu können benötigt er natürlich noch eine Bezeichnung. Will man z.B. einen Quality Gate Prozess instantiieren, so geschieht dies wie folgt.process(qualityGateProcess).Dieser Fakt definiert einen Prozess mit der Bezeichnung qualityGatePro-cess. Wobei darauf zu achten ist, dass die Bezeichnung mit einem kleinen Buchstaben beginnt, da Werte mit großem Anfangsbuchstaben Variablen darstellen.
-11-

5 Darstellung von Prozessen in Prolog
Auf die gleiche Art und Weise werden alle weiteren Prozesselemente abge-bildet. Um ein aussagekräftiges Prozessmodell zu erhalten, werden folgende Entitäten aus der SPEM Spezifikation abgebildet.
process → process/1process_attribute → process_attribute/1workdefinition → workdefinition/1
phase → phase/1activity → activity/1
workProductKind → workProductKind/1workProduct → workProduct/1
processPerformer → processPerformer/1role → role/1team → team/1
Für die Verarbeitung von Checklisten, die z.B. in Quality Gates benötigt werden, stehen weitere Prädikate zur Verfügung. Da die entsprechenden Instanzen in der Regel längere Texte sind, werden in diesen Fakten nur Referenzen zu diesen definiert.
qualitygate → qualitygate/1checklistCategory → checklistCategory/1
checklistEntry → checklistEntry/1Dies sind jedoch alles nur einzelne Entitäten, ohne jeglichen Zusammen-hang. Wie oben beschrieben, füllen diese Fakten die erste Wissensbasis. Für ein komplettes Beispiel einer „Entity-Wissensbasis“ mit dem Quality Gate Prozess siehe Quelltext Datei [qgp_entityKB.pl]
5.3 Verknüpfung der ProzesselementeNachdem alle Elemente definiert sind, kann nun ein Zusammenhang zwi-schen ihnen hergestellt werden.
5.3.1 Von Relationen zu PrädikatenEine Relation wird mit einem zweistelligen Prädikat hergestellt.
↓predicate/2
-12-
entity2entity1connected to n
connected ton

5 Darstellung von Prozessen in Prolog
Dabei ist der Prädikatenname (functor) der Name der Relation und die bei-den Argumente bilden die beiden Entitäten. Die Definition einer Phasen-folge würde beispielsweise wie folgt gebildet.
↓following_phase/2
Eine konkrete Instanz dieses Prädikats würde folgendermaßen aussehen.following_phase(design, implementation).Dieser Fakt heißt, dass der Phase design die Phase implementation folgt. Ein weiteres Beispiel wäre die Zuordnung von einzelnen Rollen zu Teams. Ana-log dazu können weitere Relationen realisiert werden.
5.3.2 Kardinalitäten und ListenUm auch die Kardinalitäten der Entitäten zu berücksichtigen,
könnte man das Prädikat einfach mehrmals mit den entsprechenden Elemen-ten definieren, beispielsweisephase_output(implementation, quellcode).phase_output(implementation, application).phase_output(implementation, api).Diese Fakten ordnen der Phase implementation die Outputs quellcode, app-lication und api zu. Diese Art der Zuweisung ist allerdings sehr redundant und kann selbstverständlich verkürzt werden. Um eine unnötige Faktenfülle zu vermeiden, werden, wie in Prolog üblich, Listen genutzt. Sie machen die Zuweisungen erheblich kürzer und übersichtlicher.
↓predicate(arg1, [list]).
Also konkret zum oberen Beispiel.phase_outputs(implementation, [quellcode,
application, api]).
-13-
phase2phase1follow 1
follow1
outputphasebuild >0
build by1
entity2entity1connected to >0
connected to1

5 Darstellung von Prozessen in Prolog
Um zu verdeutlichen, wie das angegebene Prädikat aufgebaut ist, wird an dieser Stelle von der Standard Prolog Notation Prädikat/Arität abgewichen. Hinter jedem Prädikat steht in Klammern welchen Typ die Argumente des Prädikats besitzen. • E für ein Element, z.B. eine Phase (design)• L für eine Liste von Elementen, z.B. Attributwerte ([small, huge])• T für einen Textstring, z.B. eine Elementbeschreibung („abc“)
Folgende Verknüpfungsprädikate können in der Modellierung eines Prozes-ses genutzt werden, um ...
● ... einem Prozess-Attribut Werte zuzuweisenattribute_values/2(E,L)
● ... einem Artefakttyp (workProductKind) Artefakte(workProducts) zuzuweisenworkProductKindAssign/2(E,L)
● ... einem Team Rollen zuzuweisenteam_roles/2(E,L)
● ... einer Rolle Aktivitäten zuzuweisenrole_activity/2(E,L)
● ... einem Prozess Element eine Beschreibung zuzuweisenelement_description/2(E, T)
● ... einer Phase ...• ... eine Folgephase zuzuweisen
following_phase/2(E,E)• ... Inputs zuzuweisen
phase_inputs/2(E,L)• ... Outputs zuzuweisen
phase_outputs/2(E,L)• ... Rollen zuzuweisen
phase_responsibility/2(E,L)• ... Start-Bedingungen zuzuweisen
phase_startconstraints/2(E,L)• ... End-Bedingungen zuzuweisen
phase_endconstraints/2(E,L)
-14-

5 Darstellung von Prozessen in Prolog
Abbildung 6 zeigt die Abhängigkeiten von Artefakten und ihren Typen. Ein Beispiel für einen Artefakttyp sind Checklisten.
Werden in einem Prozess Checklisten verwendet, z.B. in Quality Gate Pro-zessen, so stehen weitere Prädikate zur Verfügung.
Folgendes Prädikat kann genutzt werden, um ...● ... einer Phase Quality Gates zuzuweisen
phase_qualitygates/2(E,L)● ... einem Quality Gate Rollen zuzuweisen
qualitygate_responsibility/2(E,L)● ... einem Quality Gate Checklisten zuzuweisen
qualitygate_checklists/2(E,L)● ... Einträge einer Kategorie zuzuweisen
category_entry_assignment/2(E,L)● ... Kategorien einer Checkliste zuzuweisen
checklist_category_assignment/2(E,L)
Abbildung 7: Checklist Meta Model
Abbildung 7 zeigt das Checklist Meta Model. Eine Checkliste ist dabei eine konkrete Instanz eines workProducts vom Typ (workProductKind) checklist. Da die Kategorien und Einträge der Checklisten in den Wissensbasen nur durch Referenzen dargestellt werden, benötigt man noch eine Zuweisung eines Textes zu diesen Referenzen. Dies geschieht mit Hilfe des element_desciption/2 Prädikats. Anstatt unnötig zusätzliche Textzuwei-sungsprädikate zu nutzen, wird einfach die Beschreibung der Referenzen als textueller Inhalt der Kategorien und Einträge verwendet.
-15-
checklist>0
checklistCategoryhas >0
belongs to
checklistEntry
has1
belongs to >0
Abbildung 6: workProduct Meta Model
workProductKindworkProductdefined by 1
defines>0
outputinput

5 Darstellung von Prozessen in Prolog
5.3.3 Verknüpfungsprädikate und AusnahmenAuffällig an der Modellierung ist der Aufbau der einzelnen Prädikate. Bis auf die Text Zuweisungen und die Phasenfolge ist jedes „Verknüpfungsprä-dikat“ nach dem Schema functor(Element, [Liste]). aufgebaut. Dieser immer gleiche Aufbau ermöglicht eine effiziente Weiterverarbeitung der Daten, da die Abfrage der Verknüpfungen immer nur eine „Frage“ nach der Liste zu einem bestimmten Element bei einem bestimmten Prädikat ist. Dies macht das Bilden der Anfragen in Prolog, oder darüber, sehr einfach und effizient, da immer die gleiche Anfrage mit verschiedenen Elementen und Prädikaten verwandt werden kann. Alle Antworten auf diese Anfragen bilden immer Listen mit äquivalentem Aufbau, was wiederum das Parsen des Antwort-strings erleichtert. Daher benötigt man auch lediglich einen vereinheitlichten „Prologlistenparser“ in einem externen Programm, der alle Prolog-Antwor-ten, also die Prolog Listen, in verarbeitbare Arrays umwandelt. Das für das Tailoring wichtige Hinzufügen und Entfernen von Listenelementen kann durch die vordefinierten Prädikate append und delete bewerkstelligt werden (vgl. Hilfsprädikate).
Das erste Beispiel einer Verknüpfung zu Beginn des Kapitels war die Pha-senfolge Relation. Da jede Phase natürlich nur genau eine nachfolgende Phase(die letzte Phase selbstverständlich keine) besitzt, macht der Einsatz von Listen hier nicht viel Sinn. Daher fällt das following_phase/2 Prädikat aus dem oben genannten Schema heraus. Es besitzt als zweites Argument anstelle der Liste lediglich ein Element. Ein weiterer Grund für die Verwen-dung eines (Element, Element)-Prädikats ist, dass es das Tailoring der Pha-senfolge vereinfacht. Um Phasen hinzuzufügen, bzw. zu entfernen wäre eine Listenmanipulation aufwendiger als das Erstellen der Liste nach dem Tailor-ing.
Ein typische Phasenabfolge wärefollow_phase(start, analysis).follow_phase(analysis, design).follow_phase(design, implementation).Um nun zur weiteren Verarbeitung eine Liste mit den Phasen in der beab-sichtigten Reihenfolge zu erhalten, wird durch Aufruf des Hilfsprädikats fin-dall_phases/2 eine solche Liste erstellt.findall_phases(Phase, PhaseList) :-
following_phase(Phase, Follow_Phase),append([Follow_Phase], [], PhaseList),not(following_phase(Follow_Phase, _)).
-16-

5 Darstellung von Prozessen in Prolog
findall_phases(Phase, PhaseList) :-following_phase(Phase, Follow_Phase), append([Follow_Phase], PhaseListA, PhaseList),findall_phases(Follow_Phase, PhaseListA).
Es sind zwei Regeln mit gleichem Kopf, die obere bildet die Abbruchbedin-gung, die untere die Rekursion. Diese Konstrukte mit Abbruchbedingung und Rekursion sind typisch für Prologprogramme.
Wie von der SPEM Modellierung vorgegeben erhalten alle Elemente der Modellierung eine Beschreibung. Diese wird mit element_description/2 fest-gelegt. Dabei kann zu jedem Element unabhängig von dessen Typ eine Beschreibung definiert werden. Beschreibungen sind optional und müssen keineswegs erstellt werden. Genau genommen ist das element_description/2 Prädikat keine richtige Abweichung vom Schema functor(Element, Liste), da Texte in Prolog als Listen von Character-Indizes dargestellt werden. Mit diesen Verknüpfungsprädikaten wird die „Assignment-Wissensbasis“ gebildet und ein Referenzprozess erschaffen. Der Übersicht halber hier noch eine komplettes Meta-Modell-Diagramm der Modellierung.
-17-
Abbildung 8: Prozess Meta Model
process
attribute
defined by
defines
1
>0
valuehas
belongs to
>0
1
has responsible
responsible in
>0
>0phase
processPerformer
workProductKind
workProduct
defined by
1defines
>0
output
inputneed by>0
constraint
build in
>0
build1
0..1
follow
role
team
belongs to
consists of
>0
0..n
beginconstraint
endconstraint
must satisfy
>0
must satisfied>0
activity
consists of
>0
compose
1
workdefinition
need1
performed by
perform>0
>0

5 Darstellung von Prozessen in Prolog
Abbildung 8 zeigt das der Prologmodellierung zugrundeliegende Meta Model. Ein process wird dabei durch seine attributes mit konkreten values definiert. Ein process besteht aus phases, welche den Mittelpunkt der Modellierung bilden. Jede phase besitzt inputs und outputs, sowie process performer und verschiedene constraints, die es zu erfüllen gilt. Eine phase kann von einer weiteren gefolgt werden. phase, als auch activity sind work-definitions. Ein process performer führt eine activity aus. Um die Übersicht-lichkeit nicht zu gefährden ist die Generalisierung von model element, sowie die Quality Gate und Checklisten Erweiterung nicht mit aufgeführt. Da alle Elemente von model element abgeleitet sind, können auch alle Elemente eine Beschreibung element description besitzen.
Abbildung 9 zeigt die Erweiterung für Quality Gate Prozesse mit Checklis-ten.
Jede phase besitzt ein oder mehrere qualitygates. Diese verwenden wie-derum checklists, welche ein spezielles workProduct sind. checklists beste-hen aus checklistCategories mit entsprechenden checklistEntries. Jedem qualitygate sind wie phase process performer zugewiesen.
Für ein komplettes Beispiel einer „Assignment-Wissensbasis“ mit dem Qua-lity Gate Prozess siehe Quelltext Datei [qgp_assignmentKB.pl].
-18-
Abbildung 9: Meta Model Erweiterung Quality Gate und Checklisten
qualitygate
has responsible
responsible in>0
>0
phase
processPerformer
workProduct
checklisthas
1belongs to
>0
used by 1
use>0
checklistCategory
has>0
belongs to >0
checklistEntryhas
1 belongs to
>0
responsible in
>0
has responsible>0

5 Darstellung von Prozessen in Prolog
5.4 Prozess-TailoringHat man in der „Assignment-Wissensbasis“ alle Prozesselemente entspre-chend verknüpft, so hat man bereits einen Referenzprozess definiert. Um gemachte Erfahrungswerte in die Prozessmodellierung mit einfließen zu las-sen, kann man in der „Tailoring-Wissensbasis“ alle dafür notwendigen Änderungen definieren. Da der bereits definierte Prozess an sich nicht ver-ändert werden soll, sondern immer nur je nach Prozessmerkmal temporär angepasst wird, verwenden die Tailoringregeln einen kleinen Trick.
Das Erstellen einer Tailoringregel geschieht vor dem Einbinden der Wis-sensbasis in den Interpreter, daher können dort nicht einfach wahllos Ele-mente und Verknüpfungen definiert oder entfernt werden, da dann der Pro-zess permanent nach allen Prozessmerkmalen angepasst ist, sobald die „Tai-loring-Wissensbasis“ durch den Interpreter eingebunden wird. Daher darf das eigentliche Ausführen der Anpassung erst zu Laufzeit passieren und zudem noch separat für jedes Merkmal. Der Trick besteht nun darin ein Pro-log-Fakt oder eine Prolog-Regel zu definieren, der bzw. die zur Laufzeit auf-gerufen wird und die bereits geladenen Wissensbasen entsprechend des gewählten Merkmals anpasst.
5.4.1 KonzepteWie werden nun Merkmale angepasst. Im Wesentlichen sind hier drei Vari-anten denkbar. Es wird ein minimaler Referenzprozess in der „Assignment-Wissensbasis“ definiert, welche alle benötigten Elementverknüpfungen ent-hält. Das Tailoring besteht nun darin, diesen Referenzprozess für jedes Pro-jektmerkmal zu erweitern, also neue Elemente hinzuzufügen. Diese im wei-teren Verlauf Essential-Konzept genannte Methode des Tailorings ist der Funktionsweise von Prolog sehr ähnlich. Wie in der Prologeinführung erwähnt, unterliegt Prolog der Closed World Assumption. Um nun die Welt zu erweitern, müssen neue Fakten hinzugefügt werden. Komplementär zu diesem Konzept kann ein maximaler Referenzprozess erschaffen werden, der alle möglichen Elementverknüpfungen enthält. Das Tailoring dieses Prozesses erfolgt nun durch das Entfernen von Elementen und Verknüpfungen, je nach Projektmerkmal. Aufgrund der Gegensätzlich-keit zum Essential-Konzept wird dieses NonEssential-Konzept heißen.
Das dritte in dieser Arbeit behandelte Konzept stellt eine Mischung der bei-den Vorangegangen dar. Initial wird ein Standard Referenzprozess definiert, welcher dann durch hinzufügen und/oder entfernen von Elementen ange-passt wird. Da es hier zu Konflikten zwischen Einfügen und Entfernen kom-men kann, ist eine Priorisierung der Regeln notwendig. Aus diesem Grund wird dieses Konzept im Folgenden auch Priority-Konzept genannt.
-19-

5 Darstellung von Prozessen in Prolog
5.4.2 Tailoring mit FaktenEin erster naiver Versuch ein Tailoring durchzuführen, besteht darin, die Tailoringregel in ein Prolog Fakt zu verpacken. Dies könnte beim Essential-Konzept z.B. so aussehen.essential(AttributWert, BetreffendesElement, Func-tor, HinzuzufügendesElement).Dabei wird die zu einer bestimmten Charkteristik AttributWert gehörende Änderung am Prädikat Functor des Prozesselements BetreffendesElement definiert. Allerdings können diese Fakten an sich nicht zum Ändern des Pro-zesses benutzt werden, da deren Aufruf keine Aktionen provoziert, sondern nur eine ja oder nein Antwort liefert. Ein Prologfakt allein kann somit noch keinen Prozess tailorn, bzw. ändern. Die eigentliche Anpassung kann letzt-lich auf verschiedene Wege geschehen. Zum einen gäbe es die Möglichkeit bei der Ausgabe des Prozesses darauf zu achten, welche Elemente zusätzlich ausgegeben bzw. welche nicht ausgege-ben werden sollen. Möchte man bspw. alle Rollen zu einer Phase ausgeben, wird die entsprechende Liste aus der „Assignment-Wissensbasis“ geholt und anschließend anhand der definierten Tailoringfakten abgeändert. Diese Art des Tailorings ist allerdings sehr ineffizient, da bei jeder Listenabfrage ein Vergleich mit fast allen vorhandenen Tailoringfakten statt findet.
Zum Anderen besteht die Möglichkeit eine Art „Tailoring-Maschine“ zur kreieren. Diese wird vor der Ausgabe des Prozesses einmal mit den gewünschten Attributwerten, nach denen getailort werden soll, aufgerufen und führt eine temporäre Anpassung auf Grundlage der Vorhandenen Tailo-ring Fakten durch. Damit wäre das Effizienzproblem gegenüber der vorheri-gen Variante gelöst, da der Prozess nicht bei jeder Listenausgabe erneut angepasst wird. Leider hat ein solche „Tailoring-Maschine“ auch gewisse Nachteile. Ist sie möglichst einfach strukturiert, macht sie das recht unflexi-bel. Soll bspw. nicht immer nach allen Prozessmerkmalen getailort werden oder ändert sich die Anzahl der Merkmale, ist das mit sehr Aufwendigen Änderungen in der Maschine verbunden. Die Flexibilität hat den Preis, dass die Maschine dadurch sehr komplex wird. Das macht sie sehr Fehleranfällig und sollten doch einmal Änderungen an ihr nötig werden, ist dies auf Grund der hohen Komplexität nur eingeschränkt möglich.
Sicherlich gibt es noch weitere Verfahren die definierten Fakten zu verarbei-ten. Diese werden alle allerdings ähnliche Probleme bzw. Nachteile aufwei-sen, da die Prädikate nicht direkt zum tailorn aufgerufen werden können. Ein weiteres Gegenargument ist die mangelnde Nähe zur Modellierungs-weise in der „Assignment-Wissensbasis“. Abhilfe schafft da nur die Ver-wendung von Prolog Regeln als Tailoringregeln.
Die aufgeführten doch teils gravierenden Nachteile machen den Vorteil der recht einfachen Erstellung einer Tailoringregel mit Prolog Fakten zunichte, da man den Preis der Komplexität nur an anderer Stelle zahlen muss.
-20-

5 Darstellung von Prozessen in Prolog
5.4.3 Tailoring mit RegelnIm Gegensatz zum oben beschriebenen „Tailoring mit Fakten“ kann auch mit Prolog Regeln getailort werden. Dabei bildet eine Tailoringregel eine Prolog Regel, die den Prozess entsprechend verändert. Diese Vorgehens-weise ist etwas näher an der Modellierungsweise der „Assignment-Wissens-basis“ als das bei „Tailoring mit Fakten“ der Fall war, da Regeln mit Regeln umgesetzt werden und man selber Elemente hinzufügt oder entfernt.Wie weiter oben bereits beschrieben, beschränkt sich das Anpassen des Pro-zesses auf die Manipulation der mit einem Element verknüpften Listen. Jedoch soll wie im oben gezeigten Fall keine aufwendige „Tailoring-Maschine“ notwendig sein, um das Tailoring durchzuführen. Um dies zu bewerkstelligen sind Prolog Regeln die beste Wahl. Da die Prozessdaten zur Laufzeit geändert werden, müssen sie als dynamisch definiert sein. Dies geschieht am Besten bereits in der „Assignment-Wissensbasis“ mit dem Befehl:-dynamic(Prädikat/Arität).Damit sind nun alle Voraussetzungen für das erfolgreiche Tailoring mit Pro-log Regeln erfüllt. Aber wie definiert man Tailoringregeln jetzt genau? Mit den vordefinierten Prädikaten assert/1 und retract/1 lassen sich während der Laufzeit neue Definitionen, besser gesagt Fakten, zu Wissensbasis hinzufü-gen bzw. schon vorhandene entfernen. Die, mit diesen Prädikaten durchge-führten, Änderungen sind nur temporär und werden nicht in den vorhanden Prologdateien gespeichert. Eine Tailoring Prolog-Regel hätte folgende Form.regelname(Projektmerkmal) :-
assert(NeuerProzessFakt).Hier noch ein konkretes Beispiel.essential(huge) :-
assert(follow_phase(implementation, test)).Diese Regel fügt dem Referenzprozess hinter der Phase implementation die Phase test an. Der Wert huge gehört zum Prozessmerkmal size, also findet diese Anpassung nur statt, wenn ein Projekt mit der Eigenschaft size = huge erstellt werden soll.Um Änderungen an den Wissensbasen zu vereinfachen und zu vereinheitli-chen stellt die „Tailoring-Wissensbasis“ einige Hilfsprädikate bereit, mit dessen Hilfe die Tailoringregeln erstellt werden können. Der einheitliche Aufbau der „Verknüpfungsprädikate“ bringt den zusätzlichen Vorteil, dass sich alle mit nur einem Hilfsprädikat manipulieren lassen.
5.5 HilfsprädikateIm Folgenden werden die zur Verfügung gestellten Hilfsprädikate und deren Verwendung dargestellt. Zum besseren Verständnis und um spätere Verbes-serungen zu erleichtern ist deren Quelltext mit angegeben.
-21-

5 Darstellung von Prozessen in Prolog
5.5.1 Manipulation von ListenelementenNach dem Essential-Konzept werden Elemente der jeweiligen Liste hinzu-gefügt. Um dies effizient zu bewerkstelligen, wird das Prädikat add_ele-ment/2 bereitgestellt.add_element(Term, ElementToAdd) :-
apply(Term, [OldList]),(not(member(ElementToAdd, OldList)) ->
append(OldList, [ElementToAdd], NewList),sort(NewList, NewSortList),build_fact(Term, OldList, OldTerm),build_fact(Term, NewSortList, NewTerm),retract(OldTerm),assert(NewTerm)).
build_fact(Term, List, NewTerm) :-functor(Term, Functor, 1),arg(1, Term, Element),NewTerm =.. [Functor, Element, List].
Das Hilfsprädikat add_element/2 fügt das Element ElementToAdd zur Liste des Verknüpfungsprädikats Term hinzu. Dabei ist zu beachten, dass Term nicht das komplette Prädikat darstellt, sondern eine um das zweite Argument verkürzte Form, soll heißen, die zugehörige Liste wird automatisch ermittelt. Potenzielle Duplikate werden nicht eingefügt, da vor der Manipulation über-prüft wird, ob das einzufügende Element bereits Bestandteil der List ist.
add_element(qualitygate_responsibility(qualitygate_analysis), kunde).Dieser Aufruf fügt dem zweiten Argument des Fakts qualitygate_responsi-bility(qualitygate_analysis, [Liste]). also der mit qualitygate_analysis ver-knüpften Liste, das Element kunde hinzu. Wichtig ist hierbei, dass der aktu-elle Inhalt der Liste nicht bekannt sein muss, was durch mehrfache Tailo-ring-Aufrufe ohnehin kaum nachvollziehbar wäre. Sollte kunde bereits ein Bestandteil der Liste sein, wird kein weiteres Element kunde hinzugefügt.
Die Verwendung des NonEssential-Konzepts verlangt die Eliminierung von Elementen. Um dies zu unterstützen wird das Prädikat remove_element/2 durch die „Tailoring-Wissensbasis“ bereitgestellt.remove_element(Term, ElementToRemove) :-
apply(Term, [OldList]),(member(ElementToRemove, OldList) ->
delete(OldList, ElementToRemove,NewList),sort(NewList, NewSortList),build_fact(Term, OldList, OldTerm),build_fact(Term, NewSortList, NewTerm),retract(OldTerm),assert(NewTerm)).
-22-

5 Darstellung von Prozessen in Prolog
Analog zu add_element/2 entfernt remove_element/2 das Element Element-ToRemove aus der zu Term gehörigen Liste. Dabei ist Term wieder das um das zweite Argument verkürzte „Verknüpfungsprädikat“. Aufrufe von remove_element/2 mit dem Ziel, ein nicht in der entsprechenden Liste vor-handenes Element zu löschen, wird ignoriert und die Liste verbleibt im ursprünglichen Zustand.remove_element(qualitygate_responsibility(quality-gate_analysis), kunde).Dieser Aufruf entfernt, sofern vorhanden, das Element kunde aus der Liste von qualitygate_responsibility(qualitygate_analysis, [Liste]). Wie schon bei add_element/2 muss auch hier die aktuelle Liste nicht bekannt sein, da sie ebenfalls automatisch ermittelt wird.Da das Priority-Konzept das Hinzufügen, als auch das Entfernen von Ele-menten erlaubt, kann hier auf add_element/2, sowie auf remove_element/2 zurückgegriffen werden. Aufgrund dieser Tatsache kann es natürlich zu Konflikten zwischen verschiedenen Tailoringregeln kommen. Beispiels-weise bei diesen beiden Tailoringregeln.priority(small) :-
remove_element(qualitygate_responsibility(qualitygate_analysis), kunde).
priority(customer_project) :- add_element(qualitygate_responsibility(
qualitygate_analysis), kunde).Die Regel priority(small) versucht das Element kunde zu entfernen, wohin-gegen priority(customer_project) versucht das Vorhandensein von kunde sicherzustellen. Um diese Konflikte aufzulösen werden, wie der Name des Konzepts erahnen lässt Prioritäten für die einzelnen Regeln vergeben. Bes-ser gesagt, sie werden mit verschiedenen Prioritäten aufgerufen. Der einfachste Weg eine Priorisierung der Regeln zu bewerkstelligen, ist, die Reihenfolge der Regel-Aufrufe zu manipulieren. Die Ausführung einer Regel nach einer anderen kann die Änderungen der ersteren Regel über-schreiben, bzw. rückgängig machen. Für das obige Beispiel heißt das, dass die Regel, die als letztes Ausgeführt wird, die höhere Priorität besaß. Wird also priority(small) nach priority(customer_project) aufgerufen, so wird das Element kunde fehlen. Werden sie in umgekehrter Reihenfolge aufgerufen, so wird das Element kunde vorhanden sein. Um nicht immer die Reihen-folge der Aufrufe beachten zu müssen, wird eine (Schlüssel, Element) Liste mittels des vordefinierten Prädikats keysort nach dem Schlüssel sortiert und anschließend werden die Elemente der Liste ausgeführt. Für die genaue Funktionsweise siehe Hilfsprädikat tailor_priority/1.
-23-

5 Darstellung von Prozessen in Prolog
5.5.2 Manipulation der PhasenabfolgeDa das following_phase/2 Prädikat aus dem genannten Schema functor(Ele-ment, [Elementliste]). herausfällt, muss auch hier etwas anders „getailort“ werden.
Nach dem Essential-Konzept können dem Prozess Phasen hinzugefügt wer-den. Dafür muss das entsprechende following_phase Prädikat hinzugefügt werden. Dies kann manuell mit dem assert/1 Prädikat geschehen. Dabei muss allerdings beachtet werden, dass der vorherige following_phase/2 Fakt ebenfalls angepasst werden muss, um die Phasenabfolge richtig ableiten zu können. Ebenfalls ist dabei auf die Besonderheiten am Anfang und Ende der Phasenfolge zu achten. Um hier Inkonsistenzen zu vermeiden und das Ein-fügen zu vereinfachen und zu vereinheitlichen stellt die „Tailoring-Wissens-basis“ auch hierzu ein Hilfsprädikat bereit. Das Prädikat add_phase/2 fügt eine neue Phase an gewollter Stelle in die Phasenfolge ein und stellt dessen Konsistenz sicher.add_phase(PrevPhase, Phase) :-
Term =.. [following_phase, PrevPhase],NewTerm1 =.. [following_phase, PrevPhase, Phase],(apply(Term, [FollowPhase]) ->
OldTerm =.. [following_phase, PrevPhase, FollowPhase],
NewTerm2 =.. [following_phase, Phase, FollowPhase],
retract(OldTerm),assert(NewTerm2); true),
assert(NewTerm1).add_phase(PrevPhase, Phase). fügt die Phase Phase nach der Phase Prev-Phase in die Phasenabfolge ein. Um Phase als Startphase einzufügen wird PrevPhase einfach auf start gesetzt.
add_phase(implementation, test).Dieser Aufruf fügt die „neue“ Phase test hinter der Phase implementation in die Phasenabfolge ein. Wichtig hierbei ist, dass die Phase implementation schon vorhanden sein muss, da sonst ein follow_phase Fakt eingefügt wird, der nicht beim Erstellen der Phasenfolge durch findall_phases/2 berücksich-tigt wird. Nun wurde zwar die entsprechende Phase in den Prozess inte-griert, jedoch kennt die Wissensbasis noch keinerlei Phasenelemente, wie Inputs, Outputs oder Rollen der soeben hinzugefügten Phase. Diese können im Wesentlichen auf zwei Arten definiert werden. Zum Einen können die Phasenelemente der neuen Phase ebenfalls in der Tailoringregel definiert werden. Zum Anderen könnte man die Phasenelemente bereits in der „Assi-gnment-Wissensbasis“ definieren, obwohl die zugehörige Phase hier noch gar nicht existiert.
-24-

5 Darstellung von Prozessen in Prolog
Dies ist zwar ein Bruch der Vorschrift, dass nur Elemente des minimalen Referenzprozesses in der „Assignment-Wissensbasis“ verknüpft werden, bietet jedoch gegenüber dem Definieren in der Tailoringregel wesentliche Vorteile. Der offensichtlichste Vorteil ist, man vergisst es nicht in der Tailo-ringregel zu definieren. Desweiteren wird die Regel entschieden kürzer und übersichtlicher. Der wichtigste Vorteil ist jedoch die erhebliche Verringe-rung von redundanten Daten. Denn sollten mehr als eine Regel diese Phase definieren wollen, so müssten bei jeder Regel die Phasenelemente definiert werden. Auf welche Methode die Wahl fällt, hängt letztlich auch von der Art und Weise der Weiterverarbeitung der Modelldaten ab. Verlangt bzw. Erwartet zum Beispiel der weiterverarbeitende Prozess die minimal Defini-tionen in der „Assignment-Wissensbasis“, so bleibt nur die Wahl der redun-danten Definition der Elementverknüpfungen in den Tailoringregeln.
Um Phasen korrekt aus dem Prozess zu entfernen, stellt das NonEssential-Konzept das Prädikat remove_phase/1 bereit.remove_phase(Phase) :-
(following_phase(_, Phase) ->Term =.. [following_phase, Phase],apply(Term, [FollowPhase]),apply(following_phase(PrevPhase), [Phase]),NewTerm =.. [following_phase, PrevPhase,
FollowPhase],assert(NewTerm),OldTerm1 =.. [following_phase, PrevPhase,
Phase],OldTerm2 =.. [following_phase, Phase,
FollowPhase],retract(OldTerm1),retract(OldTerm2); true).
Analog zum Essential-Konzept tritt hier das Problem auf, dass die Verknüp-fungen der Phase mit Inputs, Outputs, Rollen, etc. immer noch in der „Assi-gnment-Wissensbasis“ vorhanden sind. Jedoch hat man nun den Vorteil, dass man diese Verknüpfungen identifizieren und ebenfalls entfernen kann. Das Entfernen der vorhandenen Verknüpfungen kann manuell als Teil der Tailoringregel geschehen, oder in das remove_phase/1 Prädikat integriert werden. Letzteres könnte beispielsweise so aussehen.
retract(phase_inputs(Phase, _)).Wird diese Zeile in remove_phase/1 integriert, würde automatisch die Ver-knüpfung der Phase Phase mit dessen Inputs eliminiert. Für die restlichen Verknüpfungsprädikate gelten analoge Aufrufe.Da das in dieser Arbeit entwickelte GUI für die Ausgabe des Prozesses keine solche strenge Vorschrift für die Assignment-Wissensbasis fordert, wurde diese Erweiterung nicht in den Beispieldateien implementiert.
-25-

5 Darstellung von Prozessen in Prolog
Das Priority-Konzept nutzt add_phase/2, sowie remove_phase/1 um Tailo-ringregeln betreffend der Phasen zu erstellen. Die eigentliche Priorisierung erfolgt, wie oben erwähnt mit dem Hilfsprädikat tailor_priority/1, welches im folgenden Abschnitt beschrieben wird.
5.5.3 Tailoring AufrufMit den eben aufgeführten Hilfsprädikaten lassen sich recht einfach Tailo-ringregeln erstellen, die die Grundlage für eine Anpassung des Referenzpro-zesses bilden. Um den Aufruf der Tailoringregeln zu vereinfachen und ver-einheitlichen, stellt die „Tailoring-Wissensbasis“ das Prädikat tailor_pro-cess/1 bereit.tailor_process(AttributeList) :-
(not(isEmpty(AttributeList)) ->[Attribute|RemainList] = AttributeList,essential(Attribute),tailor_process(RemainList);
true).isEmpty(List) :- (List == []).Für die Konzepte Essential und NonEssential sieht das Prädikat absolut gleich aus, mit der Ausnahme, dass einmal essential/1 und einmal nonessen-tial/1 als Tailoringregel verwendet wird. tailor_process/1 wird eine Liste mit Projektattributen übergeben, nach welchen getailort werden soll, dabei muss die Liste nicht alle vorgegebenen Attribute umfassen, sondern nur die relevanten.Das Priority-Konzept verlangt eine Priorisierung der Attribute, nach denen getailort werden soll, um Konflikte zwischen den Tailoringregeln zu kom-pensieren. Das erledigt das Prädikat tailor_priority/1.tailor_priority(AttributeKeyList) :-
keysort(AttributeKeyList, AttributeList),tailor_process(AttributeList).
tailor_process(AttributeList):- (not(isEmpty(AttributeList)) -> [PriorityAttribute|RemainList] = AttributeList, arg(2, PriorityAttribute, Attribute), priority(Attribute), tailor_process(RemainList); true).tailor_priority/1 bekommt eine Liste mit Schlüssel-Attribut Paaren überge-ben, welche dann mit keysort entsprechend der Schlüssel sortiert wird. Anschließend erfolgt der Aufruf von tailor_process/1 wie bei den anderen beiden Konzepten, mit dem Unterschied, dass hier noch die Schlüssel-Attri-but Paare getrennt werden müssen.
-26-

5 Darstellung von Prozessen in Prolog
Ein Schlüssel-Attribut Paar hat die Form
Schlüssel-AttributAls konkretes Beispiel hier ein Aufruf von tailor_priority/1 mit einer Liste von Schlüssel-Attribut Paaren.
tailor_priority([5-huge, 3-customer_project, 4-xp]).Die Schlüssel dienen der Priorisierung der größte Schlüssel, im obigen Bei-spiel 5, entspricht der höchsten Priorität, der kleinste damit der niedrigsten Priorität. Wie weiter oben bereits erwähnt, spiegelt sich die Priorisierung in der Reihenfolge der Ausführung der Tailoringregeln wieder. Im obigen Bei-spiel wird als erstes nach customer_project getailort, anschließend nach xp und zum Schluss nach huge, wobei das Tailoring nach huge die Änderungen von customer_project und xp wieder überschreiben kann, falls diese im Konflikt miteinander stehen.
Für ein komplettes Beispiel einer „Tailoring-Wissensbasis“ mit dem Quality Gate Prozess siehe Quelltext Datei [qgp_tailoringKB.pl].
5.6 Lesbarkeit und HandhabbarkeitUm die Lesbarkeit und Handhabung der Modellierung zu testen, habe ich einen Kommilitonen gebeten einen kleinen Prozess zu modellieren und mit einigen Tailoringregeln zu versehen. Obwohl er nur rudimentäre Prolog-kenntnisse besaß, gelang ihm die Erstellung der Modellierung in adäquater Zeit. Der geschilderte Fall bestätigt, dass die Lesbarkeit der Modellierung auch ohne höhere Prolog Kenntnisse gegeben ist, da die Verknüpfungsprädikate immer dem gleichen Schema folgen. Beschränkt man die Handhabbarkeit auf das Editieren der Prolog Dateien, so können sich immer schnell kleinere Tippfehler, wie das falsche Setzen von Klammen oder deren Vergessen, ein-schleichen. Dies ist allerdings bei anderen Programmiersprachen ebenso kri-tisch. Die Modellierung kann auch Problemlos um weitere Verknüpfungen erweitert werden. Solange sie dem gegebenen Schema entsprechen, können auch die bereitgestellten Hilfsprädikate weiterverwendet werden. Ein gutes Beispiel dafür sind die Erweiterungen für den Quality Gate Prozess, welcher ja als Modellierungsbeispiel genutzt wurde.
Die Lesbarkeit und Handhabbarkeit beim Tailoring ist jedoch zumindest fragwürdig. Das Tailoring mit Hilfe von Prolog-Fakten ist recht einfach und übersichtlich, jedoch sprechen die bereits gezeigten Nachteile eher gegen deren Verwendung. Die Verwendung von Prolog-Regeln liegt näher an der Art und Weise der Modellierung mit dem eigenhändigen Hinzufügen und Entfernen von Fakten aus den Wissensbasen. Jedoch wird dies bei vielen Änderungen pro Regel sehr schnell unübersichtlich.
-27-

5 Darstellung von Prozessen in Prolog
Dies zeigte sich auch beim Test mit meinem Kommilitonen. Als er komple-xere Tailoringregeln erstellte verlor er gelegentlich den Überblick über die Regelsammlung, was zu kleineren Fehlern führte. Dies sollte jedoch mit etwas Übung in der Modellierung abzustellen sein. Gute Unterstützung geben die bereitgestellten Hilfsprädikate. Sie sorgen für kürzere Regeln und die Konsistenz der durchgeführten Änderungen. Mit ihrer Hilfe ist das Tai-loring ebenfalls gut lesbar und die Handhabung sollte auch Prolog Neuligen leicht fallen. Leider schränken die Hilfsprädikate die Flexibilität der Model-lierung ein wenig ein, da sie die Verwendung des Schemas functor(Element, [Liste]) verlangen. Dieser Nachteil wird durch die gewonnene Lesbarkeit und Handhabung jedoch mehr als wett gemacht.
-28-

6 Darstellung als Prozess-Baum
6 Darstellung als Prozess-BaumDa die textuelle Ausgabe des Prolog Interpreters nicht sehr ansehnlich ist und keinen guten Überblick über den ganzen modellierten Prozess schafft, ist im Rahmen dieser Arbeit über das Entwickeln einer Modellierung hinaus ein kleines Java-GUI entstanden. Mit dessen Hilfe die Prolog-Prozess-Modellierung in einem Prozessbaum ausgegeben werden kann. Als Brücke zwischen dem Prolog Interpreter und Java dient die JPL Bibliothek, welche zum SWI-Prolog Paket gehört. Näheres dazu in Kapitel 7. Das Java GUI-Applet bietet ein Projekt-Wizard, welcher ein einfaches erstellen und tailorn von Prozessen erlaubt.
Es besteht die Auswahl zwischen dem Tailoring eines Prozesses für ein bestimmtes Projekt oder ein Checklisten Tailoring. Nach dem Treffen der Auswahl müssen die drei Wissensbasen Entity, Assignment und Tailoring gewählt werden. Anschließend gelangt man zur Auswahl der Projektparame-ter, mit denen der Prozess bzw. die Checklisten getailort werden sollen. Das GUI ermittelt die definierten Attribute, sowie deren Wertebereich direkt aus den Wissensbasen.
-29-
Abbildung 10: GUI Applet - Projekt Wizard
Abbildung 11: GUI Applet - Wählen der Projektparameter

6 Darstellung als Prozess-Baum
Sind alle Parameter spezifiziert, kann der Prozessbaum bzw. können die Checklisten erstellt werden. Ein Projektparameter kann auch mit nonrele-vant besetzt werden, dann wird nach diesem Attribut nicht getailort. Möchte man also den Referenzprozess ausgeben, wählt man bei allen Attributen nonrelevant. Durch den nun angezeigten Prozessbaum kann wie durch ein Verzeichnisbaum navigiert werden. Auf der rechten Fensterseite erscheinen dann Informationen zum gerade gewählten Element.
Um die Übersicht zu erhalten, kann das Baumfenster vertikal gescrollt und horizontal vergrößert werden. Die Ausgabe der Checklisten könnte so ausse-hen.
Zwischen den beiden Ansichten kann nach Wunsch auch hin und her gewechselt werden.
-30-
Abbildung 12: GUI Applet - Prozessbaum
Abbildung 13: GUI Applet - Ausgabe der Checklisten

7 Technologie
7 TechnologieDieses Kapitel soll einen kleinen Überblick über die Verwendeten Techno-logien geben. Des weiteren wird ein kleiner Ausblick in die Zukunft gewagt.
7.1 Prolog InterpreterDer in dieser Arbeit verwendete Prolog Interpreter ist SWI-Prolog. Er steht unter der Lesser GNU Public License(Siehe http://www.gnu.org/copyleft/lesser.html) und ist damit kostenlos ver-fügbar (Download unter http://www.swi-prolog.org/). Um eine Brücke zu Java zu schlagen, stellt SWI-Prolog die Java-Bibliothek JPL bereit. Diese kann in jedes Java Projekt als externe Bibliothek eingebunden werden. JPL bietet vielseitige Möglichkeiten Anfragen an den Prolog Interpreter aus Java heraus zu stellen. Jedoch wird nicht der komplette Umfang der Bibliothek benötigt. Daher habe ich ein Kapselung der Bibliothek durch eine eigene Knowledgebase Klasse vorgenommen, welche die Anfragen über JPL an den Prolog Interpreter vereinheitlicht und vereinfacht. Ein kleiner Nachteil, der JPL Bibliothek ist, dass sich der Prolog Interpreter nicht neu initialisie-ren lässt, ohne das GUI zu beenden. Um also einen neuen Prozess zu erstel-len und zu tailorn ist ein Neustart des GUI' notwendig.
7.2 JavaWie schon weiter oben beschrieben wurde das GUI als Java Applet erstellt. Zur Kommunikation mit dem Prolog Interpreter wird eine selbstgeschrie-bende Knowledgebase Klasse benutzt. Mit ihr kann man alle benötigten Anfragen zum Erstellen eines Prozessbaumes an den Prolog Interpreter stel-len. Die graphische Ausgabe erfolgt gänzlich mit Swing-Komponenten.
7.3 AusblickFür eine universellere Verwendung sollte ein Prolog Interpreter in der Spra-che des GUIs verwendet werden. Für eine Java Implementierung bietet sich die tuProlog Interpreter Bibliothek an. Diese ist Open Source und wird von der Università di Bologna entwickelt.(Download: http://www.alice.unibo.it:8080/tuProlog/)
Leider bin ich erst gegen Ende dieser Arbeit auf diese Prolog Bibliothek auf-merksam geworden und die Zeit reichte leider nicht mehr, um alles darauf umzustellen.
-31-

Anhang
Anhang
Literaturverzeichnis(1) Sommerville, „Software Engineering“ (2001)
(2) Acuna, Juristo, „Software Process Modeling“ (2005)
(3) Flohr, „NetQGate – Tool Support for Quality Gate Processes“ (2006)(4) Flohr, Lübke, „Experiences from the Conduction of a simulated Software Project driven by Quality Gates „
(5) Kellner, „ISPW-6 Software Process Example“ (1991)
AbbildungsverzeichnisAbbildung 1: SPEM - Hauptklassen 3
Abbildung 2: SPEM - Symbole 4
Abbildung 3: Quality Gate 6
Abbildung 4: Quality Gate Referenzprozess 7
Abbildung 5: konkreter Quality Gate Prozess 7
Abbildung 6: workProduct Meta Model 15
Abbildung 7: Checklist Meta Model 15
Abbildung 8: Prozess Meta Model 17
Abbildung 9: Meta Model Erweiterung Quality Gate und Checklisten 18
Abbildung 10: GUI Applet - Projekt Wizard 29
Abbildung 11: GUI Applet - Wählen der Projektparameter 29
Abbildung 12: GUI Applet - Prozessbaum 30
Abbildung 13: GUI Applet - Ausgabe der Checklisten 30
-32-

Erklärung
Erklärung
Hiermit versichere ich, dass die Bachelorarbeit selbständig und ohne fremde Hilfe erstellt worden ist. Alle benutzten Materialien und Quellen sind in die-ser Bachelorarbeit angegeben.
_______________________________Hannover, 14.09.2006, Daniel Eggert
-33-


















