
Skriptum ADAT Datenmodellierung - sabin.at¼ler.pdf · Datenmodellierung Haas, Resch - 3 - 1....
43
Datenmodellierung Haas, Resch - 1 - Skriptum ADAT Datenmodellierung August 2003 Resch Andreas 1. EINLEITUNG ............................................................................................................................ 3 2. DREI SCHICHTENMODELL EINES DATENBANKS YSTEMS ..................................................... 5 2.1. LOGISCHE S CHICHT ( EXTERNES S CHEMA ) .................................................................................. 5 2.2. KONZEPTIONELLE S CHICHT (KONZEPTIONELLES SCHEMA ) ............................................................ 6 2.3. PHYSISCHE SCHICHT ( INTERNES S CHEMA ) ................................................................................. 7 3. HISTORISCHER ÜBERBLICK DATENBANKSYSTEME............................................................. 8 3.1. DATEIEN .............................................................................................................................. 8 3.1.a. sequentielle Datenträger ................................................................................................ 9 3.1.a. Datenträger mit direktem Zugriff (ab 1958) ...................................................................... 9 3.1.c. VSAM (erweitertes Dateisystem) .................................................................................... 9 3.2. DATENBANKSYSTEME............................................................................................................. 9 3.2.a. hierarchische Datenbanken (1960) ................................................................................ 10 3.2.b. Netzwerkdatenbank ...................................................................................................... 11 3.2.c. relationale Datenbanken ............................................................................................... 11 3.2.d. objektorientierte Datenbanken (OODB).......................................................................... 11 3.2.e. Textdatenbanken ......................................................................................................... 12 3.2.f. XML / XSLT .................................................................................................................. 12 4. EINFÜHRUNG IN DIE DATENMODELLIERUNG ....................................................................... 13 4.1. GRUNDLEGENDE B EGRIFFE.................................................................................................... 13 4.2. BEZIEHUNGEN (RELATIONEN) ................................................................................................. 14 4.3. PRIMARY KEY (PRIMÄRSCHLÜSSEL) ......................................................................................... 14 4.4. SECONDARY KEY (F REMDSCHLÜSSEL) ..................................................................................... 15 4.5. GRAD (KARDINALITÄT ) EINER B EZIEHUNG ................................................................................. 17 4.5.1. Kardinalität 1:1 ............................................................................................................. 17 4.5.2. Kardinalität 1:N ............................................................................................................ 17 4.5.3. Kardinalität M:N ........................................................................................................... 18 5. NOTATIONSFORMEN EINES DATENMODELLS ...................................................................... 18 5.1. CHEN DIAGRAMME................................................................................................................ 18 6. VORGEHENSWEISEN BEI DER DATENMODELLIERUNG ....................................................... 20 6.1. DISZIPLINIERTES T OP / DOWN................................................................................................. 20 6.2. "JOJO TECHNIK" ................................................................................................................... 20 7. NORMALFORMEN .................................................................................................................. 21 7.1. I NTEGRITÄTSBEDINGUNGEN.................................................................................................... 21 7.1.1. Semantische Integrität .................................................................................................. 22
Transcript of Skriptum ADAT Datenmodellierung - sabin.at¼ler.pdf · Datenmodellierung Haas, Resch - 3 - 1....

Datenmodellierung Haas, Resch
- 1 -
Skriptum ADAT Datenmodellierung
August 2003 Resch Andreas
1. EINLEITUNG ............................................................................................................................ 3
2. DREI SCHICHTENMODELL EINES DATENBANKS YSTEMS ..................................................... 5 2.1. LOGISCHE SCHICHT (EXTERNES SCHEMA).................................................................................. 5 2.2. KONZEPTIONELLE SCHICHT (KONZEPTIONELLES SCHEMA ) ............................................................ 6 2.3. PHYSISCHE SCHICHT (INTERNES SCHEMA) ................................................................................. 7
3. HISTORISCHER ÜBERBLICK DATENBANKSYSTEME............................................................. 8 3.1. DATEIEN .............................................................................................................................. 8
3.1.a. sequentielle Datenträger ................................................................................................ 9 3.1.a. Datenträger mit direktem Zugriff (ab 1958) ...................................................................... 9 3.1.c. VSAM (erweitertes Dateisystem) .................................................................................... 9
3.2. DATENBANKSYSTEME............................................................................................................. 9 3.2.a. hierarchische Datenbanken (1960)................................................................................10 3.2.b. Netzwerkdatenbank ......................................................................................................11 3.2.c. relationale Datenbanken ...............................................................................................11 3.2.d. objektorientierte Datenbanken (OODB)..........................................................................11 3.2.e. Textdatenbanken .........................................................................................................12 3.2.f. XML / XSLT ..................................................................................................................12
4. EINFÜHRUNG IN DIE DATENMODELLIERUNG.......................................................................13 4.1. GRUNDLEGENDE BEGRIFFE....................................................................................................13 4.2. BEZIEHUNGEN (RELATIONEN) .................................................................................................14 4.3. PRIMARY KEY (PRIMÄRSCHLÜSSEL).........................................................................................14 4.4. SECONDARY KEY (FREMDSCHLÜSSEL) .....................................................................................15 4.5. GRAD (KARDINALITÄT) EINER BEZIEHUNG .................................................................................17
4.5.1. Kardinalität 1:1.............................................................................................................17 4.5.2. Kardinalität 1:N ............................................................................................................17 4.5.3. Kardinalität M:N ...........................................................................................................18
5. NOTATIONSFORMEN EINES DATENMODELLS ......................................................................18 5.1. CHEN DIAGRAMME................................................................................................................18
6. VORGEHENSWEISEN BEI DER DATENMODELLIERUNG .......................................................20 6.1. DISZIPLINIERTES TOP / DOWN.................................................................................................20 6.2. "JOJO TECHNIK" ...................................................................................................................20
7. NORMALFORMEN ..................................................................................................................21 7.1. INTEGRITÄTSBEDINGUNGEN....................................................................................................21
7.1.1. Semantische Integrität ..................................................................................................22

Datenmodellierung Haas, Resch
- 2 -
7.1.2. referentielle Integrität ....................................................................................................22 7.1.3. operationale Integrität ...................................................................................................23
7.2. UNNORMALISIERT (NULLTE NORMALFORM) ...............................................................................23 7.3. DIE 1. NORMALFORM ............................................................................................................24 7.4. DIE 2. NORMALFORM ............................................................................................................25
7.4.1. Funktionale Abhängigkeit (ein Attribut)...........................................................................25 7.4.2. Funktionale Abhängigkeit (mehrere Attribute).................................................................26 7.4.3. Vorgehensweise:..........................................................................................................26
7.5. DIE 3. NORMALFORM ............................................................................................................27 7.5.1. transitive Abhängigkeit..................................................................................................27
8. UMSETZUNG VON ER MODELLEN IN RELATIONALE MODELLE (NACH DER KARDINALITÄT) 29
8.1. 1:N BEZIEHUNG ...................................................................................................................29 8.2. 1:1 BEZIEHUNG ....................................................................................................................29 8.3. M:N BEZIEHUNG...................................................................................................................30
9. NULL / FAKTUM "LEER".........................................................................................................31
10. GENERALISIERUNG (SUPER / SUBTYP)..............................................................................32
11. TEXTANALYSE.....................................................................................................................32
11. TEXTANALYSE.....................................................................................................................33 11.1. DAS REGELWERK DER TEXTANALYSE.....................................................................................33 11.2. EIN EINFACHES BEISPIEL ......................................................................................................39
12. DATENMODELLIERUNG MIT ERWIN ....................................................................................41
13. BÄUME IN TABELLEN ..........................................................................................................42

Datenmodellierung Haas, Resch
- 3 -
1. Einleitung Überall dort, wo es um die Aufbewahrung oder Verarbeitung von großen Datenmengen geht, sind Datenbanksysteme im Spiel. Diese "Informations - Lager" sind darauf spezialisiert, den Umgang mit großen Datenmengen zu vereinfachen. Dazu wird meist eine standardisierte Schnittstelle (SQL, ...) zur Verfügung gestellt.
Folie: (Datenmodellierung) Datenbanksystem
Was versteht man eigentlich unter einem Datenbanksystem ? Es gibt keine klare Definition - Es ist ein System zur Beschreibung, Speicherung und Wiedergewinnung von Daten. Ein Beispiel für ein solches Datenbanksystem ist etwa Microsoft Access. Ein Datenbanksystem besteht also aus zwei Komponenten: Der Datenbasis und dem Datenbankmanagementsystem. Ein Datenbankmanagementsystem ist für die Verarbeitung der Daten und die Wartung der Datenstrukturen zuständig. Was ist eine Datenbasis bzw. Datenbank ? Eine Datenbank ist eine Ansammlung von Daten, zum Beispiel im betrieblichem Umfeld. Die zu Grunde liegende Datenstruktur muss ausreichend gut an das Problem (Aufgabenstellung) des Benutzers angepasst sein.
Beispiel: Die Bibliothekarin verwaltet die Aus - und Rückgabe von Büchern in der Schul-Bibliothek. Die tägliche Arbeit (Anforderung) und Realisierung (Abbildung) in der Datenbank müssen übereinstimmen! - Wer darf Bücher entlehnen? - gibt es eine maximale Bücheranzahl? - darf ein Buch entliehen werden, wenn noch viele ausständig sind? - werden Gebühren verrechnet? - werden die Adressen und Telefonnummern erfasst? - darf ein Entlehner mehr als eine Adresse oder Telefonnummer haben? ....
Der Prozeß, indem diese ausreichend passende Datenstruktur entworfen wird nennt man Datenmodellierung - oder etwas theoretischer: Das Abbilden eines relevanten Ausschnitts der Umwelt in einem technischen System.

Datenmodellierung Haas, Resch
- 4 -
Um eine benutzbare Anwendung zu realisieren sind aber folgende Schritte notwendig:
Folie: (Datenmodellierung) Schritte zur Realisierung
N Analyse: - Anforderungsanalyse (-> Projektentwicklung) Die Anforderungsanalyse ist eine Art Brainstorming, indem wir den gesamten für uns relevanten Wirklichkeitsausschnitt genau ansehen.
• Dazu holen wir alle nötigen Informationen über die Anforderungen ein • informieren uns über Randbedingungen auf deren Gestaltung wir keinen Einfluß haben
(langsames Netzwerk, Technik der PC`s, Firmen Logos, ...) • bestimmen die Grenzen des Systems und • seine geplante Funktionalität.
Die Anforderungsanalyse ist in der Regel durch die Angabe des Übungsbeispiels vorweg genommen. - ER - Modelle Die Anforderungsanalyse wird zumeist in (technischer) Umgangssprache niedergeschrieben. In dieser Form können wir aber keine exakten Aussagen über den Umfang und die Leistungsfähigkeit treffen. Wir benötigen eine exakte Notationsform, die zum einen für die Kunden und Entwickler verständlich ist und auf der anderen Seite so genau ist, dass wir daraus ein konkretes Syste, implementieren können. Mit diesen beiden Schritten werden wir uns zu Beginn beschäftigen!
N Design - Umsetzung des ER Modells in Relationen. Diese kann man sofort als Tabelle realisieren, wenn da nicht noch eine Kleinigkeit wäre: - Normalisierung Die Normalisierung ist eine Optimierung und ein entfernen von Anomalien.
N Implementierung Nun bewegen wir uns in einem konkreten Datenbanksystem und erstellen dort Tabellen bzw. ändern den Inhalt der Tabellen.

Datenmodellierung Haas, Resch
- 5 -
2. Drei Schichtenmodell eines Datenbanksystems Sehen wir uns nun den Aufbau bzw. die Vorgehensweise zum Arbeiten mit Datenbanksystemen vo n einer anderen Seite an. Wir gehen nun auf eine Sichtweise die auf unterschiedliche Abstraktionsebenen bzw. Anwendungsschichten zielt. Das drei Schichtenmodell (oder auch oft Drei-Schema-Konzept) wurde 1975 vom Standard Planing and Requirements Comitee (SPARC) und dem American Standards Comite on Computers and Information Processing (ANSI/X3) als Vorschlag für die Standardisierung von Datenbankarchitekturen entwickelt.
Folie: (Datenmodellierung) Drei Schichtenmodell
Die Beschreibung der Daten erfolgt auf drei verschiedenen Ebenen, die unterschiedliche Sichtweisen auf die Daten ermöglichen und gleichzeitig für Datenunabhängigkeit sorgen.
2.1. logische Schicht (externes Schema) Das externe Schema ist die Sicht des Benutzers auf die Daten. Unter einem externen Schema versteht man anwendungsbezogene Sichten auf Teilbereiche des konzeptionellen Schemas. Dem Benutzer werden dabei die Daten in einer für ihn geeigneten Form zur Verfügung gestellt.
Beispiel: In einer Datenbank sind Personaldaten gespeichert. Bestimmten Mitarbeitern darf man nur den Name und die Anschrift der Personaldaten zugänglich machen, während anderen Mitarbeitern der Zugriff auf die gesamten Personaldaten möglich sein muss.
Das externe Schema wird unter Zuhilfenahme von einer Datenmanipulationssprache (DML), die vom Datenbanksystem zur Verfügung gestellt wird, aus dem konzeptionellen Schema abgeleitet. Dem Benutzer werden mittels DML Sprachelemente zur Kommunikation mit dem Datenbanksystem zur Verfügung gestellt, die ihm das Wiederauffinden und Ändern von Daten, d.h. die Datenmanipulation, ermöglichen. Der Benutzer muss keine Kenntnisse über den internen Aufbau einer Datenbank besitzen. Für ihn ist es unerheblich, welche Daten in welchen Tabellen abgespeichert werden.
Beispiel: Wenn man eine Reise - über das Internet - buchen will, können wir, in diesem Beispiel, über die Eingabefelder: Erwachsene, Abreise ab, Reisedauer, Reiseart, Nur Schnäppchen und Preis in DM unseren Reisewunsch spezifizieren. Das Buchungssystem listet eine Auswahl aller möglichen Reiseangebote auf.

Datenmodellierung Haas, Resch
- 6 -
Um eine Reise zu buchen müssen wir nicht wissen wie die Datenbank intern aufgebaut ist, sondern nur das Buchungssystem bedienen können.
Folie: (Datenmodellierung) logische Schicht
2.2. konzeptionelle Schicht (konzeptionelles Schema) Die konzeptionelle Schicht nimmt im 3-Schichtenmodell eine zentrale Stellung ein. Es wird jener Teil der realen Welt, der für eine Anwendung relevant ist, abgebildet. Das konzeptionelle Schicht stellt eine Gesamtsicht auf die Daten eines Unternehmens auf logischer Ebene dar, ohne darauf Rücksicht zu nehmen, wie die Anwendung später realisiert wird und welches Datenbankmanagementsystem zum Einsatz kommt. Auf konzeptioneller Ebene wird festgelegt, was in der Datenbank gespeichert werden soll, d.h. welche Daten gespeichert werden sollen, wie diese genau aussehen und wie die Daten untereinander in Beziehung stehen.
Folie: (Datenmodellierung) konzeptionelle Schicht
Beispiel: Beim Entwurf des konzeptionellen Schemas eines Flugbuchungssystems wird festgelegt, dass es einen Entitätstypen KUNDE mit den Attributen "Kundennummer", "Name", "Vorname" gibt. Außerdem besteht zwischen den Entitätstypen KUNDE und FLUGBUCHUNG eine Beziehung. Die Attribute "Haarfarbe" oder "Körpergewicht" des Entitätstypen KUNDE sind hingegen für die Erstellung eines Flugbuchungssystems nicht relevant und werden daher auch nicht beim Entwurf des konzeptionellen Schemas berücksichtigt.

Datenmodellierung Haas, Resch
- 7 -
Charakteristisch für das konzeptionelle Schema ist, dass es einen relativ stabilen Bezugspunkt im gesamten Unternehmensmodell darstellt. Änderungen der externen Sicht wie beispielsweise die Entwicklung neuer Anwendungsprogramme, berühren das konzeptionelle Schema nicht. Das ist also unser das Hauptthema für die nächste Zeit!
2.3. physische Schicht (internes Schema) Das interne Schema ist die physikalische Speicherung der Daten auf den Datenträgern. Es wird der mögliche Zugriff auf die Daten, d.h. wie und wo die Daten gespeichert werden, definiert. Neben der Speicherung der Daten in einer zentralen Datenbank ist auch der Einsatz verteilter Datenbanken möglich. Vom internen Schema ist die Performance einer Datenbank sehr stark abhängig.
Beispiel: Auf dieser Ebene wird festgelegt, in welcher Reihenfolge die Felder "Kundennummer", "Vorname", "Name" und "Ort" gespeichert werden und wie die Dateiorganisation aussieht.
• Wie ist die Datenbank (Dateiorganisationsformen, ...) realisiert? • Wie werden die Daten auf einem Datenträger gespeichert? • Welches Betriebssystem wird verwendet? • Wie kann eine Abfrage möglichst schnell bearbeitet werden?
Ein wichtiger Aspekt der Relationalen Datenbanken ist, daß die physische und die konzeptionelle Schicht NICHT von einander abhängen dürfen: Der Zugriff auf die Daten erfolgt nur mit Bordmitteln des Datenbanksystems, ein direkter Zugriff (von aussen ist NICHT möglich!). Wenn die physische Schicht ausgewechselt wird (SAP: unterschiedliche Datenbanksysteme erlaubt), dann funktioneren alle Abfragen etc. ohne Änderung - die konzeptionelle und externe Schicht sind davon NICHT betroffen! Mit diesen Aufgabenstellungen werden wir uns bei den Datenträgern und der Datenspeicherung beschäftigen!

Datenmodellierung Haas, Resch
- 8 -
3. Historischer Überblick Datenbanksysteme
3.1. Dateien
Bis Ende der 70iger Jahre war die klassische, dateiorientierte Datenhaltung vorherrschend. Charakteristisches Merkmal der Dateiorientierung ist, dass für jede Anwendung die Daten in separaten Dateien gespeichert werden (siehe Abb. 1). Dies führt dazu, dass eine erhebliche Anzahl von Insellösungen entsteht und viele Daten redundant gespeichert werden. Beispiel: In Unternehmen A sind 200 Mitarbeiter beschäftigt. Personaldatei Jeder Mitarbeiter erhält monatlich ein bestimmtes Gehalt. Die monatliche Gehaltsabrechnung erfolgt über ein Lohnverrechnungsprogramm, welches als Datenbasis eine Personaldatei verwendet. In dieser sind neben der Mitarbeiternummer der Name des Mitarbeiters, die Abteilungsnummer, die Bezeichnung der Abteilung und Angaben zum Gehalt des Mitarbeiters gespeichert. Mitarbeiternummer
Name Vorname Abteilungsnummer
Abteilungsname Gehalt
1 MUELLER HANS IV MARKETING 23990 2 MAIER PETER IV MARKETING 23990 3 MUELLER FRANZ V VERKAUF 25987
Projektdatei Das Unternehmen ist in mehrere Abteilungen gegliedert, wobei jede dieser Abteilungen ein oder mehrere Projekte bearbeitet. Jeder Mitarbeiter ist an ein oder mehreren Projekten im Unternehmen beteiligt. In einer Projektdatei sind sämtliche relevanten Informationen zur Projektverwaltung gespeichert. Zu jedem Mitarbeiter gibt es neben den Mitarbeiterdaten, Informationen zur Abteilung sowie zu sämtlichen Projekten, an denen ein Mitarbeiter beteiligt ist. Mitarbeiternummer
Name Vorname Abteilungsnummer
Abteilungsname Projekt-nummer
Projektname
1 MUELLER HANS IV MARKETING A E-COMMERCE 2 MAIER PETER IV MARKETING A E-COMMERCE 3 MUELLER FRANZ V VERKAUF B INTERNET

Datenmodellierung Haas, Resch
- 9 -
Nehmen wir an, Herr Müller Hans wird befördert und wechselt in die Finanzabteilung. Dies erfordert von der Personalabteilung eine Aktualisierung der Daten. Aufgrund der redundanten Datenhaltung, muss die Projektdatei ebenfalls verändert werden, da sonst inkonsistente Daten die Folge sind. 3.1.a. sequentielle Datenträger Zunächst gab es nur Magnetbänder (sequentielle Organisation der Daten - Satz für Satz in vorgegebener Reihenfolge verarbeitbar). Ändern der Reihenfolge (sortieren) erfordert ein Umschreiben / Neuschreiben der Daten! z.B.: Daten nach Sozialversicherungsnummer sortiert - Daten nach Postleitzahlen sortieren erfordert das Umschreiben der Daten. -> Nun haben wir aber den gleichen Datenbestand gleich zweimal - der Unterschied ist nur die Sortierung! Um Probleme bei der Bearbeitung zu vermeiden dürfen aber keine Redundanzen vorhanden sein. Dann ist nämlich die Datenintegrität gewährleistet. z.B.: Mitarbeiter Zwei Personen heiraten -> ein Familienname muß geändert werden! Wenn wir aber auf eine Kopie vergessen, dann hat eine Person zwei unterschiedliche Namen. Analog beim Löschen - in einem Datenbestand Datenbestand gelöscht, in einem anderen aber nicht. 3.1.a. Datenträger mit direktem Zugriff (ab 1958) Daten nach einem Kriterium sortiert speichern, aber wahlfrei auf diese Daten zugreifen. Sozialversicherungsnummer ist Schlüssel - direkt über diesen Begriff auf die Daten zugreifen! (indexsequentielle Organisation). -> ohne Duplizieren von Daten Zugriff möglich, aber der direkte Zugriff ist nur über einen Schlüssel möglich 3.1.c. VSAM (erweitertes Dateisystem) Wie Datenträger mit direktem Zugriff, aber Zugriff über mehrere Schlüsselbegriffe. Teil des Betriebssystems. -> Eine Datenbasis, aber Zugriff über mehrere Schlüsselbegriff
3.2. Datenbanksysteme Erst durch die Entwicklung von Datenbanksystemen wurde die anwendungsübergreifende Nutzung von Daten ermöglicht. Es kam zu einer Datenintegration. Allmählich erkannte man die Notwendigkeit der zentralen Sicht auf die Unternehmensdaten.

Datenmodellierung Haas, Resch
- 10 -
Vorteile der zentralen Datenhaltung:
• Verringerung von Datenredundanzen Der Einsatz eines Datenbankmanagementsystems ermöglicht die Haltung integrierter Datenbestände, d.h. das Zusammenfassen aller in einem Unternehmen relevanten Daten. Durch die zentrale Datenhaltung kann die Mehrfachspeicherung von Daten weitgehend verhindert werden.
• Datenintegrität
Der Begriff "Datenintegrität" ist eine zusammenfassende Bezeichnung für Datenkonsistenz, Datensicherheit und Datenschutz. Datenintegrität ist dann gegeben, wenn die Daten in einer Datenbank korrekt und vollständig sind. Dazu werden wir noch einiges mehr höhren! Mögliche Gründe für Verletzungen der Datenintegrität können fehlerhafte Benutzereingaben, aber auch Hard- beziehungsweise Softwarefehler sein. Beispielsweise kann in einer Datenbank einer Abteilung kein Mitarbeiter zugeordnet sein oder es ist für einen bestimmten Mitarbeiter eine wöchentliche Arbeitszeit von 400 Stunden anstelle von 40 Stunden gespeichert. Durch eine zentrale Datenhaltung wird die Überprüfung des Datenbestandes erheblich erleichtert.
• Datenunabhängigkeit
Ein entscheidender Vorteil, der durch den Einsatz von Datenbanksystemen erzielt werden kann, ist die Datenunabhängigkeit. Von Datenunabhängigkeit spricht man dann, wenn eine Trennung zwischen der logischen Datenstruktur und ihrer physischen Realisierung erfolgt.
• Flexibler Gebrauch der Daten
Durch die Integration sämtlicher für ein Unternehmen relevanter Daten können diese relativ einfach nach unterschiedlichen Gesichtspunkten verknüpft werden.
3.2.a. hierarchische Datenbanken (1960) Auf Großrechnern realisiert. Vertreter: DL1 (Data Language 1 - IBM), IMS (Information Management System - IBM) Sehr schnell im Zugriff (noch heute), aber ein sehr starrer Aufbau. Fixe Verweise (Adressen!) auf vordefinierte Beziehungen. Erweiterung der Beziehungen etc. sind nicht einfach realisierbar. Noch Verbreitung in Banken und Versicherungen - keine Neuentwicklungen, aber Bedarf an Wartung!

Datenmodellierung Haas, Resch
- 11 -
3.2.b. Netzwerkdatenbank Vertreter: Codasyl, IDS, UDS Bei den hierarchischen Datenbanken kann es zu Duplikaten kommen, wenn die Daten nicht hierarchisch organisiert sind! In Netzwerkdatenbanken sind auch solche Daten darstellbar geworden, aber unübersichtlich und schwierig. 3.2.c. relationale Datenbanken Edgar F. Codd (70-er Jahre - IBM) erkannte die Limitationen bestehender Datenbanksysteme. 1975 Formulierung der 12 Codd`schen Regeln (und 3 Integritätsregeln) und Entwicklung eines Prototypen "System R" (Daraus hat sich später ORACLE entwickelt). Die Abfragesprache hieß Sequel (Vorläufer von SQL) und eine Abfrage Oberfläche QBE (Query by Example). Diese Gruppe hat sich getrennt in Oracle und IBM (DB2). DB2 erste SQL Datenbank (speichert Daten in VSAM Dateien - Filehandlingsystem) Es wesentlicher Unterschied zu den beiden vorigen Datenbanksystemen ist, daß bei den Relationalen Datenbanken Beziehungen durch den Wert einen Attributes, und nicht durch eine fixe, physische Adresse dargestellt werden. Als Beispiel wird noch später das Konzept des Fremdschlüssels erläutert. Weitere Vertreter: ACCESS (entspricht nicht allen Codd' schen Regeln), SQL Server, Informix, Ingres, Progres, dBase, mySQL, Gupta C.J.Date: 12 Regeln für verteilte Datenbanksysteme Hinweis: SQL (Structered Query Language) ist eine genormte Zugriffssprache, allerdings versteht jedes Datenbanksystem einen eigenen Dialekt! Eigenschaften einer relationalen Datenbank sind:
• kompakte Speicherung (kein unnützes Belegen von Speicherplatz) • keine Redundanz (ein und das selbe Faktum sind mehr als einmal gespeichert) und damit
garantierte Integrität der Daten
Beispiel: Mitarbeiterdaten, Abteilungsnummer und -Bezeichnung kommt bei jedem Mitarbeiter vor. Wenn die Bezeichnung der Abteilung geändert wird, dann müssen alle Datensätze durchsucht und die Abteilung geändert werden
• Ein und die selbe Entität darf nicht zweimal gespeichert werden (laufende Nummer beim
Schlüssel!) • Alle Teilschritte einer Änderungen müssen zu einem Zeitpunkt vollständig oder überhaupt
nicht durchgeführt werden (Transaktion) - Beispiel Abbuchung von einem Konto auf ein anderes: TAN (Transaktionsnummer beim TeleBanking)
• Kein Zugriff auf Daten außer durch "Bordmittel" des Datenbanksystems • Integrität:
3.2.d. objektorientierte Datenbanken (OODB) Derzeit noch keine etablierte Systeme im betrieblichem Umfeld. Zumeist findet man hybride Datenbanksysteme (Beispiel Caché).

Datenmodellierung Haas, Resch
- 12 -
3.2.e. Textdatenbanken Unterschied Text / strukturierte (formatierte) Daten: Bei strukturierten Daten ist der Aufbau ganz exakt definiert. Für jeden Datensatz ist genau bekannt welche Felder mit welchem Typ zu welcher Länge und welchem Namen vorhanden sind. Die kleinste Einheit, auf die zugegriffen werden kann heißt Feld. Eine Textdatenbank hat keine definierte Struktur, der ganze Text muß jedes mal wieder analysiert werden (Wort für Wort). Die kleinsten ansprechbare Einheit ist ein Dokument! Innerhalb eines Dokumentes kann man sequentiell nach Zeichenfolgen suchen.
Beispiel: Internet Suchmaschinen, Juridische Datenbank, Krankengeschichten.
Dabei treten verschiedenste Probleme (außer der Laufzeit auf):
• man sucht nach "ien" und bekommt Treffer mit "Wien" und "Yugoslavien" • Thesaurus:
Schlüsselworte werden aus dem Text herausgehoben und getrennt gespeichert. Typische Anwendung ist die Verschlagwortung - händischer Vorgang!
• Homonyme (ein Wort mehrere Bedeutungen): Leiter: Steighilfe, Vorgesetzter, ...
• Synonyme (mehrere Worte für ein Ding): Rechner, Computer, ...
• Vermeiden von Mehrzahlen, Fällen, usw. Beschlagwortung: KWIC (Keyword in Context) Beschlagwortung von Wörtern (manuell gekennzeichnete Wörter in einem Dokument) KWOC (Keyword out of Context) fertige Liste von Schlüsselwörtern wird dem Textteil zugeordnet Vertreter: Golem, Stairs, F&A, Lotus Notes 3.2.f. XML / XSLT Wir werden uns später mit XML und XSLT beschäftigen. Eine XML Datei ist eigentlich eine Textdatei, nur enthält diese Datei Informationen, welche Daten in der Datei zu finden sind.

Datenmodellierung Haas, Resch
- 13 -
4. Einführung in die Datenmodellierung Bis jetzt haben wir und auf einer sehr informellen, nicht exakten Ebene bei der Beschreibung eines Systems bewegt. Jetzt ist es Zeit uns mit einer formalen Methode zur Beschreibung unserer Sachverhalte zu beschäftigen: mit dem Entity - Relationship Modell. Eigentlich müssten wir vom EER - dem "Erweiterten ER" Modell sprechen, da wir uns auch das Konzept der Generalisierung ansehen werden.
4.1. Grundlegende Begriffe Folie: (Datenmodellierung) Begriffe zur Datenmodellierung
Die Datenmodellierung beschäftigt sich mit "Entitäten". Eine Entität ist ein individuelles, wohl unterscheidbares "Irgendwas" (Objekte, Individuen, Sachen, Begriffe, Ereignisse, ...) aus der realen Welt, das für eine konkrete Problemstellung relevant ist. Entitäten werden durch Attribute (Eigenschaften) beschrieben und in Tabellenform notiert. Jede solche Tabelle hat einen Namen, der links oben bei der Tabelle steht. Eine der möglichen Notation (Schreibweisen) ist das Relationenmodell: Beispiel: Personen SozVersNr Name GebDat Geschlecht L01 Eva 1.1.82 f L02 Peter 13.5.85 m L03 Susan 8.9.91 f …
• In den Zeilen stehen die einzelnen, genau unterscheidbaren Entitäten • Die Spalten führen die Eigenschaften (Attribute) auf • Die konkreten Werte eines Attributes zu einer Entität werden Attributswert genannt • Faktum: Zuordnung eines Attributswertes zu einem Attribut einer ganz bestimmten Entität • Die Menge aller Spalten (Attribute) einer Entität wird Relationenschema genannt und mit
einem Namen versehen • Die Tabelle mit allen Zeilen (und Spalten) wird Entitätsmenge genannt.

Datenmodellierung Haas, Resch
- 14 -
Achtung: Das Relationenmodell ist ein mengentheoretisches Konstrukt - die Reihenfolge der Attribute ist irrelevant. Es ist natürlich übersichtlicher, wenn die Schlüsselfelder zu Beginn aufgeführt werden. Typische Operationen (Damit werden wir uns bei SQL beschäftigen!) Selektion: Aus einer beliebigen Anzahl von Tupeln (Entitäten, Zeilen) werden ganz bestimmte Tupel selektiert. Die Anzahl der Treffer ist nicht vorhersehbar - die Anzahl ändert sich durch neue Daten auch dauernd. Projektion: Auswahl der Attribute (nicht alle Attribute als Ergebnis ausgeben!) Bemerkung: Modellieren ist wie Aufsatzschreiben, es gibt unterschiedlichste Ansätze keiner ist ganz richtig oder falsch - alles hängt vom persönlichen Blickwinkel, was einem wichtig ist, ab.
4.2. Beziehungen (Relationen) Mit einer Entitätsmenge kann man sicherlich keinen brauchbaren Ausschnitt aus dem Realen Leben beschreiben. Im wirklichen Leben gibt es immer Abhängigkeiten und Zusammenhänge. Eine Entitätsmengen kann einen Zusammenhang zu einer oder mehreren Entitätsmengen haben. Wir sprechen von einer Beziehung oder Relation. Sehen wir uns ein Beispiel an:
• Ein Arzt behandelt einen Patienten. • Ein Gärtner besitzt mehrere Gewächshäuser. In jedem Gewächshaus werden
unterschiedliche Pflanzen kultiviert.
4.3. Primary Key (Primärschlüssel) Folie: (Datenmodellierung) Begriffe zur Datenmodellierung 2
Die Entitäten einer Entitätsmenge müssen eindeutig unterscheidbar sein. Zu diesem Zweck ist in jedem Relationenschema ein eindeutiger Schlüssel (Primary Key) zu definieren. Dieser Schlüssel wird in der Tabelle unterstrichen dargestellt. Ein Schlüssel kann auch aus mehreren Attributen bestehen. Eigenschaften eines Schlüssels:

Datenmodellierung Haas, Resch
- 15 -
• obligatorisch (muß immer einen Wert haben - nicht NULL) • prägnant (so kurz wie möglich um dennoch aussagekräftig zu sein) • unveränderbar • umkehrbar eineindeutig • In einer Entitätsmenge sind genau solche Entitäten enthalten, die von ihrem Schlüssel
funktional abhängig sind (dazu noch mehr bei den Normalformen) • ein Schlüssel sollte sprechend sein (vorhanden Attribute verwenden, wenn möglich ->
"natürlicher Schlüssel") - bei laufenden Nummern besteht Gefahr ein und die selbe Entität mehrfach zu speichern!
Überlegungen zu Primärschlüsseln: A. Ein Buch wird genau ein einziges mal ausgeborgt. Bibliothek ISBN Leser# 3-783499-600630 220 3-783499-212212 341 Es ist also nicht möglich, dass das gleiche Buch von einem andern Leser entlehnt wird. Wenn das dennoch gehen soll, dann muß die Leser# geändert werden - die vorherige Entlehnung ist dann aber verschwunden! Bibliothek ISBN Leser# 3-783499-600630 43 3-783499-212212 341 B. Ein Buch kann an unterschiedliche Leser verborgt werden Bibliothek ISBN Leser# 3-783499-600630 220 3-783499-212212 341 3-783499-600630 341 Jetzt haben wir aber das Problem, das eine Person ein Buch nur genau einmal entlehnen kann! C. Ein Bucht an unterschiedliche Leser, mehrmals Bibliothek ISBN Leser# Entlehndatum 3-783499-600630 220 1.1.2001 3-783499-212212 341 3.1.2001 3-783499-600630 341 3.1.2001 3-783499-600630 220 2.6.2002
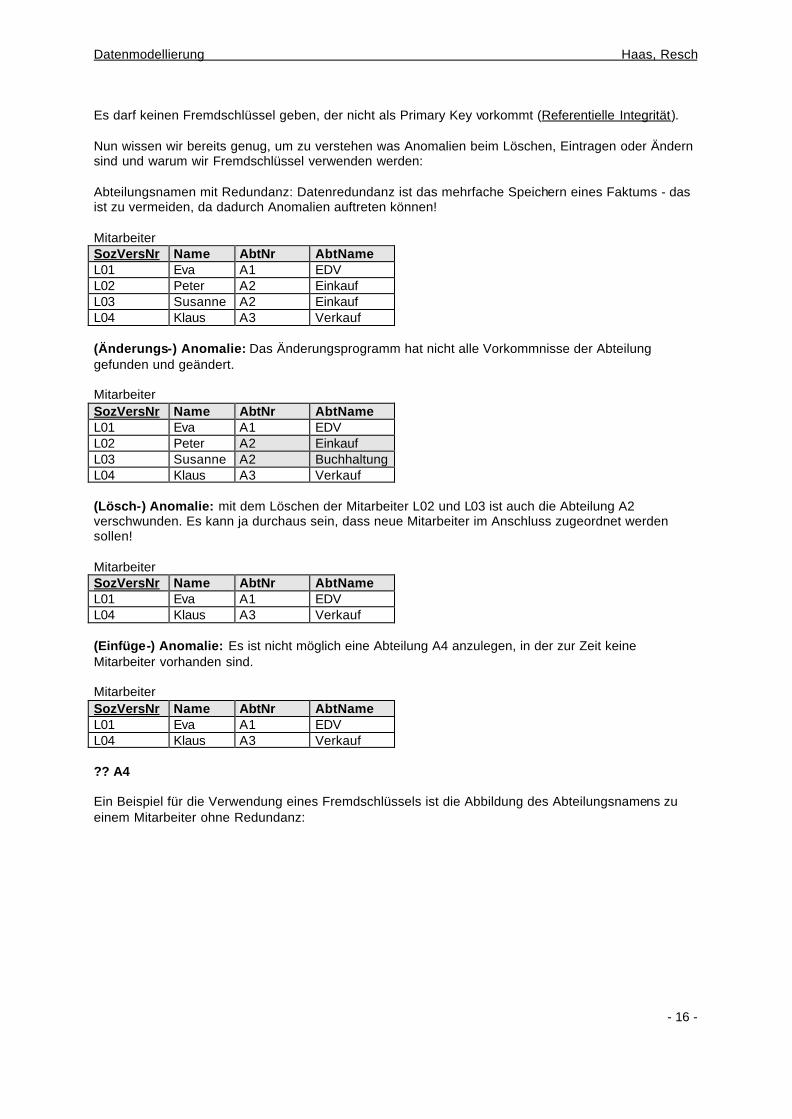
4.4. Secondary Key (Fremdschlüssel) Ein Secondary Key (Fremdschlüssel) ist eine Beziehung von einem Attribut zu einem Primary Key einer anderen Entitätsmenge. Alle Beziehungen in einer relationalen Datenbank werden über solche Fremdschlüssel realisiert. Es handelt sich also nicht um Pointer, denen gefolgt wird, sondern Beziehungen werden immer über Suchprozesse realisiert. Achtung:
Datenmodellierung Haas, Resch
- 16 -
Es darf keinen Fremdschlüssel geben, der nicht als Primary Key vorkommt (Referentielle Integrität). Nun wissen wir bereits genug, um zu verstehen was Anomalien beim Löschen, Eintragen oder Ändern sind und warum wir Fremdschlüssel verwenden werden: Abteilungsnamen mit Redundanz: Datenredundanz ist das mehrfache Speichern eines Faktums - das ist zu vermeiden, da dadurch Anomalien auftreten können! Mitarbeiter SozVersNr Name AbtNr AbtName L01 Eva A1 EDV L02 Peter A2 Einkauf L03 Susanne A2 Einkauf L04 Klaus A3 Verkauf (Änderungs-) Anomalie: Das Änderungsprogramm hat nicht alle Vorkommnisse der Abteilung gefunden und geändert. Mitarbeiter SozVersNr Name AbtNr AbtName L01 Eva A1 EDV L02 Peter A2 Einkauf L03 Susanne A2 Buchhaltung L04 Klaus A3 Verkauf (Lösch-) Anomalie: mit dem Löschen der Mitarbeiter L02 und L03 ist auch die Abteilung A2 verschwunden. Es kann ja durchaus sein, dass neue Mitarbeiter im Anschluss zugeordnet werden sollen! Mitarbeiter SozVersNr Name AbtNr AbtName L01 Eva A1 EDV L04 Klaus A3 Verkauf (Einfüge-) Anomalie: Es ist nicht möglich eine Abteilung A4 anzulegen, in der zur Zeit keine Mitarbeiter vorhanden sind. Mitarbeiter SozVersNr Name AbtNr AbtName L01 Eva A1 EDV L04 Klaus A3 Verkauf ?? A4 Ein Beispiel für die Verwendung eines Fremdschlüssels ist die Abbildung des Abteilungsnamens zu einem Mitarbeiter ohne Redundanz:

Datenmodellierung Haas, Resch
- 17 -
Mitarbeiter SozVersNr Name AbtNr L01 Eva A1 L02 Peter A2 L03 Susanne A2 L04 Klaus A3 Abteilungen AbtNr AbtName A1 EDV A2 Einkauf A3 Verkauf Den Pfeil nennen wir Beziehung oder Relation. Den Beziehungen geben wir sprechende Namen. Beispiel zu obiger Beziehung: "gehört zu"
4.5. Grad (Kardinalität) einer Beziehung 4.5.1. Kardinalität 1:1 Eine Entität der einen Seite wird genau einer Entität der anderen Seite zugeordnet und umgekehrt. Beispiel: Standort eines Buchexemplares (In Regalen gibt es Fächer für genau ein Buch) Ein Exemplar eines Buches (auf die Entiät Standort schauen) steht genau an einem bestimmten Standort, Standort ist "1" Seite An einem bestimmten Standort (auf die Entität Bücher schauen) steht genau ein Exemplar eines Buches Bücher ist "1" Seite Bücher Standorte ISBN Exemplar Zimmer Regal Fach Platz 3-783499-600630 1 B404 1 B 21 3-783499-600630 2 B405 4 12 5 4.5.2. Kardinalität 1:N Einer Entität der einen Seite können mehrere Entitäten der anderen Seite zugeordnet werden, umgekehrt aber höchstens eine Entität. Beispiel: Mitarbeiter einer Abteilung Ein Mitarbeiter (auf die Entität Abteilung schauen) gehört zu genau einer Abteilung, Abteilung ist"1" Seite In einer Abteilung (auf die Entität Mitarbeiter schauen) sind mehrere Mitarbeiter " Mitarbeiter ist N" Seite Abteilung Mitarbeiter Abteilungs# AbtName SozVers# MitName Abteilungs# EINK Einkauf 2111230765 Resch EINK BUCHH Buchhaltung 1231010182 Meier EINK 4321230376 Müller BUCHH

Datenmodellierung Haas, Resch
- 18 -
4.5.3. Kardinalität M:N Einer Entität der einen Seite können mehrere Entitäten der anderen Seite zugeordnet werden und umgekehrt. Wenn M:N Beziehungen auftreten, dann müssen im Datenmodell in eine 1:N und eine 1:M Beziehung aufgelöst werden. Aber dazu noch später - Stichwort "Assoziationstabelle". Ein Buch (auf die Entität Autor schauen) kann mehrere Autoren haben, Autor ist "M" Seite Ein Autor (auf die Entität Bücher schauen) kann mehrere Bücher schreiben Buch ist "N" Seite Bücher Authoren ISBN Author Author Name 3-783499-600630 4 4 Resch 3-783499-600630 5 5 Müller 3-783499-212121 4 Die Modellierung der Bücher wird in Wirklichkeit NICHT so vorgenommen - wir werden diesen Sachverhalt mit einer zusätzlichen Tabelle abbilden! (Assoziationstabelle) Wir sehen, dass wir im Relationenmodell KEINE Kardinalitäten hinterlegen können. Wir benötigen daher eine bessere Notationsform!
5. Notationsformen eines Datenmodells Die Datenmodellierung liefert als Ergebnis folgendes:
• Welche Entitäten sind relevant? • Welche Attribute beschreiben die Entitäten? • Welche Beziehungen herrschen unter den Entitäten?
Diese Informationen müssen nicht nur aus der Wirklichkeit abgeleitet werden, sondern zur Dokumentation und Transport an andere niedergeschrieben werden. Zu diesem Zweck gibt es unterschiedliche Methoden und Werkzeuge:
• Relationenmodell (schon behandelt) • Chen Diagramme • Entity - Relation Diagramme (Werkzeug: ERWIN - Entity Relation Diagrams for Windows) • XML • UML • ...
Die Modellierungswerkzeuge sind in der Regel auch fähig die Tabellen in einem Datenbanksystem, laut Datenmodellierung, anzulegen.
5.1. Chen Diagramme Entitätsmenge:
Bücher

Datenmodellierung Haas, Resch
- 19 -
Attribute: p_name an eine Entität oder Beziehung gebunden

Datenmodellierung Haas, Resch
- 20 -
6. Vorgehensweisen bei der Datenmodellierung
6.1. diszipliniertes Top / Down a. alle Entitäten b. alle Attribute zu den Entitäten c. alle Beziehungen Dieses Vorgehen ist in der Praxis schwer einzuhalten, obwohl es sicherlich sehr gut wäre. Wir werden diesen Ansatz bei der Textanalyse verwenden.
6.2. "Jojo Technik" Je nach Bedarf werden die hierarchischen Ebenen gewechselt. Das Vorgehen ist situationsabhängig.

Datenmodellierung Haas, Resch
- 21 -
7. Normalformen Folie: (Datenmodellierung) Kriterien eines optimalen Datenmodells
Ziel der Anwendung der Normalformen: Datenmodell ist kompakt, integer und redundanzfrei. Kompakt Nicht mehr Speicherplatz / Tabellen / Felder als unbedingt nötig (Name1, Name2, Name3, usw.) integer einhalten der Integritätsbedingungen Redundanzfrei Ein und dasselbe Faktum darf nur einmal gespeichert werden Um dieses Ziel zu erreichen gibt es ein Verfahren, das von Codd erfunden wurde: die Normalisierung bzw. die Normalformen. Diese hat die Zerlegung von Datenstrukturen ohne Informationsverluste in mehrere einfachere und redundanzärmere Strukturen zum Inhalt. Durch den Prozess der Normalisierung können Datenredundanzen vermieden und die daraus resultierenden Speicheranomalien verhindert werden. Folgende Arten von Speicheranomalien lassen sich unterscheiden, wie wir ja schon gesehen haben.
• Einfügeanomalien • Löschanomalien • Änderungsanomalien
7.1. Integritätsbedingungen Folie: (Datenmodellierung) Kriterien eines optimalen Datenmodells
Datenmodellierung Haas, Resch
- 22 -
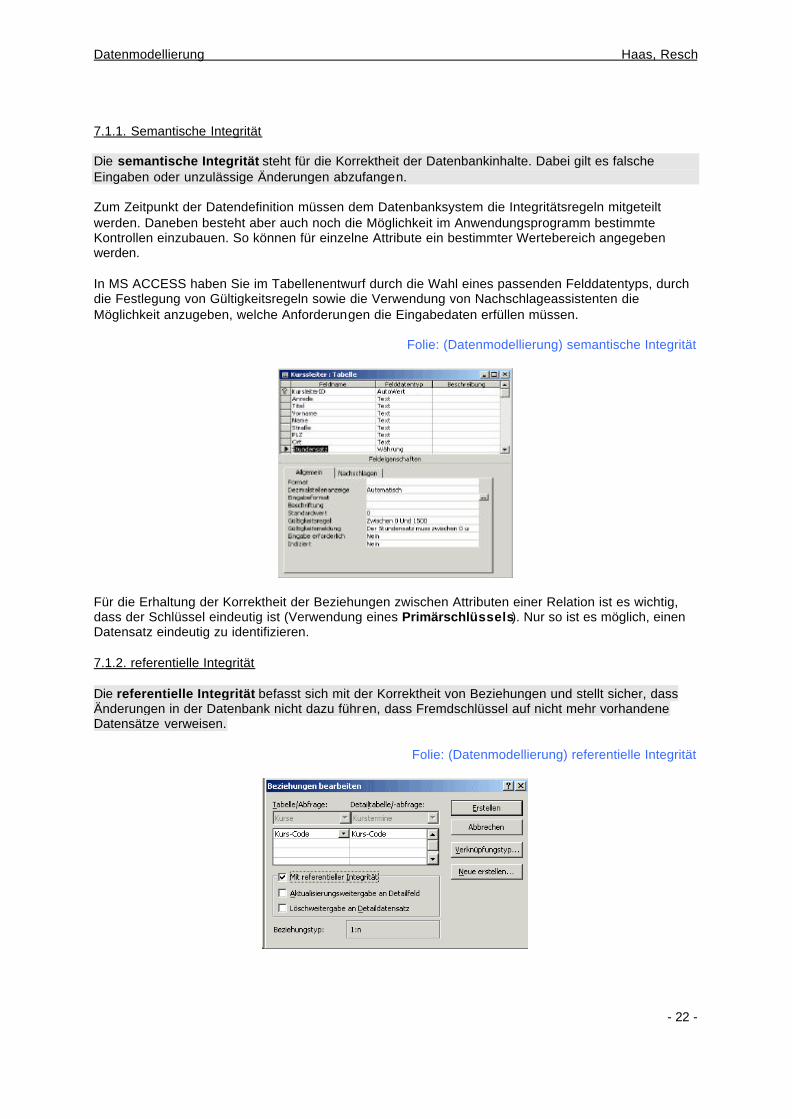
7.1.1. Semantische Integrität Die semantische Integrität steht für die Korrektheit der Datenbankinhalte. Dabei gilt es falsche Eingaben oder unzulässige Änderungen abzufangen. Zum Zeitpunkt der Datendefinition müssen dem Datenbanksystem die Integritätsregeln mitgeteilt werden. Daneben besteht aber auch noch die Möglichkeit im Anwendungsprogramm bestimmte Kontrollen einzubauen. So können für einzelne Attribute ein bestimmter Wertebereich angegeben werden. In MS ACCESS haben Sie im Tabellenentwurf durch die Wahl eines passenden Felddatentyps, durch die Festlegung von Gültigkeitsregeln sowie die Verwendung von Nachschlageassistenten die Möglichkeit anzugeben, welche Anforderungen die Eingabedaten erfüllen müssen.
Folie: (Datenmodellierung) semantische Integrität
Für die Erhaltung der Korrektheit der Beziehungen zwischen Attributen einer Relation ist es wichtig, dass der Schlüssel eindeutig ist (Verwendung eines Primärschlüssels). Nur so ist es möglich, einen Datensatz eindeutig zu identifizieren. 7.1.2. referentielle Integrität Die referentielle Integrität befasst sich mit der Korrektheit von Beziehungen und stellt sicher, dass Änderungen in der Datenbank nicht dazu führen, dass Fremdschlüssel auf nicht mehr vorhandene Datensätze verweisen.
Folie: (Datenmodellierung) referentielle Integrität

Datenmodellierung Haas, Resch
- 23 -
7.1.3. operationale Integrität
Folie: (Datenmodellierung) operationale Integrität
Die operationale Integrität bezieht sich auf das korrekte Verhalten der Anwendung. Um zu verhindern, dass Datenbankinhalte durch systembedingte Fehler verfälscht werden, wurden sogenannte Transaktionen eingeführt. Benutzerzugriffe auf die Datenbank erfolgen über Transaktionen, die einerseits nur Daten abfragen, andererseits aber auch Daten ändern beziehungsweise löschen können. Transaktionen sind eine logische Folge von Datenbankoperationen, die in Gesamtheit die gültigen Konsistenzbedingungen erfüllen. Transaktionen, die Änderungen in der Datenbank bewirken dürfen nur in Gesamtheit durchgeführt werden oder gar nicht. Daher werden diese auch als atomar bezeichnet. Kommt es während der Durchführung einer Transaktion zu einem Systemfehler, muss der Zustand der Transaktion auf den Beginn zurückgesetzt werden. Die Transaktionsverarbeitung ist heute bereits fester Bestandteil von Datenbanksystemen. Greifen mehrere Benutzer zugleich auf eine Datenbank zu ist die Konsistenzsicherung jedoch wesentlich komplexer als oben beschrieben. Sperrmechanismen sind eine Möglichkeit Zugriffskonflikte zu vermeiden. Beispiel: Überweisung auf ein Konto.
7.2. Unnormalisiert (Nullte Normalform) Die Abbildung zeigt ein Formular, welches Daten zur Projektabrechnung enthält. Aus dem Formular geht hervor, welcher Mitarbeiter an einem bestimmten Projekt mitgewirkt hat.

Datenmodellierung Haas, Resch
- 24 -
Folie: (Datenmodellierung) Projektabrechnung
Die Informationen aus dem Formular können in Form einer unnormalisierten Relationmodell dargestellt werden (Wir haben diese bis jetzt Realitätsbeobachtungen genannt). Personal# Name Vorname Abteilungs# Abteilung Projekt# Projektname Stunden
1 Winkler Ursula 1 Marketing A E-Commerce 60 2 Maier Peter 1 Marketing A, B E-Commerce,
Internet 100, 75
Eine unnormalisierte Relation ist dadurch gekennzeichnet, dass sie Attribute mit Attributwerten aufweist, welche sich aus mehreren Elementen (einer Liste - nicht ein einzelner Wert!) zusammensetzen. Beispielsweise sind in der Tabelle zu Mitarbeiter 2 (Herr Maier) zwei Projekte gespeichert. Aufgrund der redundanten Datenhaltung können mehrere Speicheranomalien beobachtet werden:
• Beispielsweise kann eine neue Abteilung nur dann hinzugefügt werden, wenn diese einem Mitarbeiter zugeordnet wird (Einfügeanomalie).
• Werden alle Mitarbeiterinformationen gelöscht, gehen auch die Informationen über die Projekte und über die Abteilungen verloren (Löschanomalie).
• Wird beispielsweise bei Mitarbeiter 1 der Name der Abteilung von Marketing in Finanzierung umgeändert, dann muss diese Änderung bei allen Mitarbeitern, die ebenfalls in dieser Abteilung arbeiten, gemacht werden. Ansonsten führt dies zu inkonsistenten Daten (Änderungsanomalie).
7.3. Die 1. Normalform Durch den Normalisierungsprozess kann eine unnormalisierte Relation in die erste Normalform überführt werden. Eine Relation befindet sich in der ersten Normalform, wenn sie nur einfache Attribute enthält . Man sagt auch, dass die Attribute nur atomare Werte (Keine Listen) annehmen dürfen. Unser Beispieldatenmodell hat aber genau so ein Attribut, das nicht atomar ist: Der Mitarbeiter 2 (Herr Maier) hat eine Liste von Projekten im Attribut Projekt# und Projekt eingetragen. Wir müssen unser Datenmodell daher ändern, um die erste Normalform nicht zu verletzten! Die einfachste Methode ist einen zusätzliches Attribut (Projekt#) in den Primärschlüssel aufzunehmen. Wir

Datenmodellierung Haas, Resch
- 25 -
können dann die beiden Projekte von Herrn Maier (Mitarbeiter 2) in zwei Entitäten (Datensätzen) abspeichern.
Folie: (Datenmodellierung) 1. Normalform Personal# Name Vorname Abteilungs# Abteilung Projekt# Projektname Stunden 1 Winkler Ursula 1 Marketing A E-Commerce 60 2 Maier Peter 1 Marketing A E-Commerce 100 2 Maier Peter 1 Marketing B Internet 75 Weil wir sofort sehen, dass das Datenmodell noch nicht ideal ist (Redundanz, ...) gibt es natürlich noch weitere Normalformen:
7.4. Die 2. Normalform Eine Relation ist in der 2. Normalform, wenn sie • in der 1. Normalform ist und • wenn jedes Attribut, das zu keiner Schlüsselkombination gehört, nur von der gesamten
Schlüsselkombination, nicht aber von einem Teil, funktional abhängig ist. Die 2. Normalform richtet sich an zusammengesetzte Schlüssel:
• Wenn also nur ein Attribut zum Primärschlüssel gehört, dann ist die 2. Normalform erfüllt • Wenn es zusammengesetzte Schlüssel gibt, dann dürfen alle Attribute nur vom gesamten
Schlüssel funktional abhängig sein - nicht nur von einem Teil des Schlüssels 7.4.1. Funktionale Abhängigkeit (ein Attribut) Um diese Definition etwas genauer analysieren zu können, müssen wir uns mit dem Begriff der funktionalen Abhängigkeit beschäftigen! Beispiel: r3
R Entität a1 a2 a3 ... amax r s s2 Ein Attribut ai eines Relationenschemas R heißt funktional abhängig von einem Attribut ak , falls für alle Entitäten r,s aus der Entitätsmenge R (Entitätsmenge und Relationenschema mit dem gleichen Namen bezeichnet) und 0 <= i,k <= maximale Anzahl der Entitäten in R, gilt: rk = sk => ri = s i
Wir schreiben kurz: ak -> ai Anders formuliert:
• Jedes Auftreten eines Attributwertes im Attribut ak zeigt an, dass es sich um eine unterscheidbare Entität handelt.
• Alle anderen Attributwerte können nur dann andere Werte annehmen, wenn sich auch das Attribut ak ändert.

Datenmodellierung Haas, Resch
- 26 -
Beispiel: Personal# Name 1 Resch 2 Meier Also: Personalnummer 1 bedeutet immer Resch, 2 immer Meier! Hinweis: Das kennen wir doch schon, das war die Geschichte mit dem Primärschlüssel! 7.4.2. Funktionale Abhängigkeit (mehrere Attribute) Der Primärschlüssel ist aber schon längst für uns erledigt, die Definition der 2. Normalform bezieht sicht auf zusammengesetzte Primärschlüssel! Das Attribut ai heißt funktional abhängig von ak und am (akam -> ai), wenn gilt: rk = sk und rm = sm => ri = s i Wieder in anderen Worten: Das Attribut ai darf sich also nur dann ändern, wenn sich auch die Attribute ak und/oder am ändern! 7.4.3. Vorgehensweise: Alle Attribute, die zum Schlüssel gehören werden - einzeln - untersucht, ob es funktionale Abhängigkeiten gibt! Genau das ist aber unser Problem: Personal# Name Vorname Abteilungs# Abteilung Projekt# Projektname Stunden 1 Winkler Ursula 1 Marketing A E-Commerce 60 2 Maier Peter 1 Marketing A E-Commerce 100 2 Maier Peter 1 Marketing B Internet 75 Die Schlüsselattribute sind Personal# und Projekt#. Folgende Verletzungen der 2. Normalform sind festzustellen:
• Personal# Name, Vorname, Abteilungsnummer und Abteilung sind vom Schlüsselteil Personal# funktional abhängig
• Projekt# Das Attribut Projektname ist vom Schlüsselteil Projekt# funktional abhängig
Hinweis: Wir sehen, dass es noch weitere funktionale Abhängigkeiten gibt (Abteilungs# -> Abteilung). Das ist aber jetzt noch nicht interessant, wir sehen uns nur die Attribute im Schlüssel, mit deren Abhängigkeiten an! Wie gehen wir nun vor, um das Datenmodell in 2. Normalform zu erreichen? Wir müssen das bestehende Relationsschema aufspalten. Die Attribute mit den kritischen Abhängigkeiten werden dabei als neuer Schlüssel verwendet.

Datenmodellierung Haas, Resch
- 27 -
Folie: (Datenmodellierung) 2. Normalform
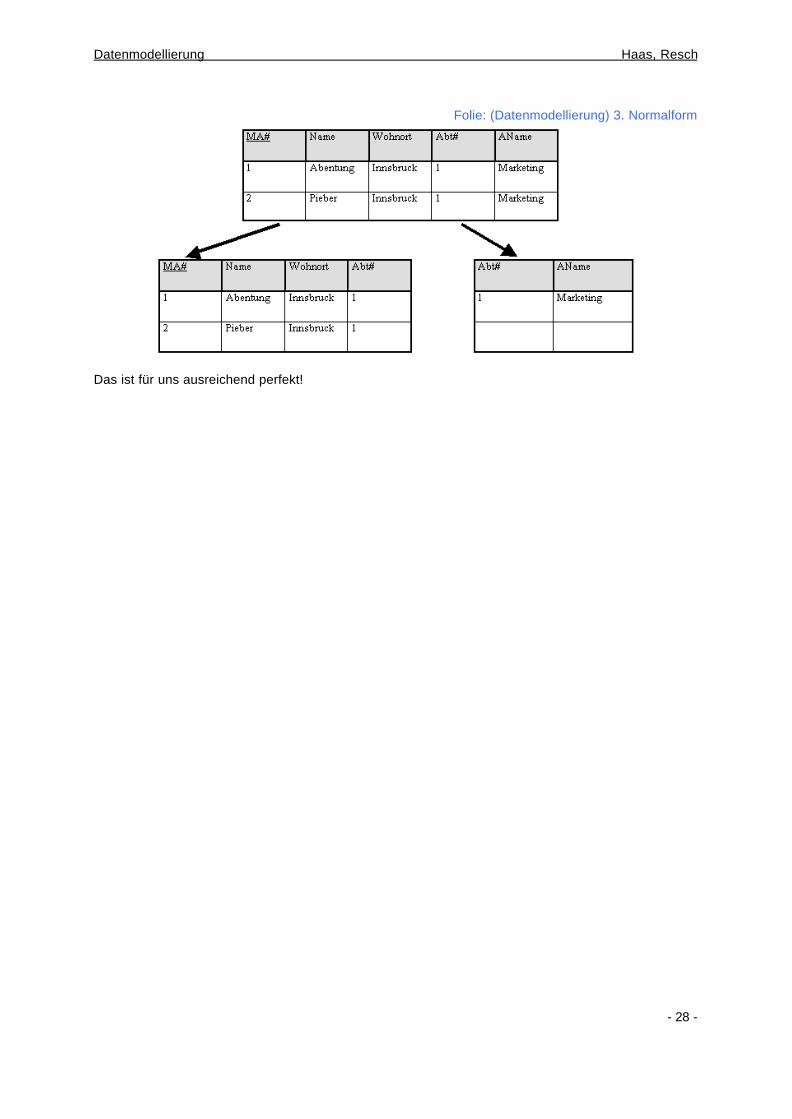
7.5. Die 3. Normalform Das sieht schon sehr gut, aus. Es gibt aber noch einen Schönheitsfehler: Eine Relation ist in der 3. Normalform, wenn die zweite Normalform erfüllt ist und kein Attribut, das nicht zum Identifikationsschlüssel gehört, transitiv von diesem abhängig ist. 7.5.1. transitive Abhängigkeit Das Attribut "Abteilung" wird vom Nicht-Schlüsselattribut "Abteilungs#" identifiziert. Andererseits aber auch vom Attribut "Mitarbeiter#". Aus der Sicht der funktionalen Abhängigkeit gilt hier also:
Mitarbeiter# -> Abteilungs# -> Abteilung Die Eigenschaft der Transitivität bedeutet dann:
Mitarbeiter# -> Abteilungs# -> Abteilung => Mitarbeiter# -> Abteilung
Also: • Abteilungs# -> Abteilung und • Mitarbeiter# -> Abteilung
Diese mehrfachen Abhängigkeiten, die einen Verstoß gegen die 3. Normalform darstellen, müssen durch das Aufsplitten der Relation beseitigt werden. Die neu entstandenen Relationen werden durch einen Fremdschlüssel in Beziehung gebracht.
Datenmodellierung Haas, Resch
- 28 -
Folie: (Datenmodellierung) 3. Normalform
Das ist für uns ausreichend perfekt!

Datenmodellierung Haas, Resch
- 29 -
8. Umsetzung von ER Modellen in relationale Modelle (nach der Kardinalität) Zusammenfassung Vorgehensweise: 1:1 gleiche Tabelle 1:N Fremdschlüssel mitnehmen N:M Assoziationstabelle (Primärschlüssel der beteiligten Entitäten sind Fremdschlüssel)
Folie: (Datenmodellierung) ER - Diagramm nach relationales Modell
8.1. 1:N Beziehung Der Primärschlüssel der Prüftabelle (Fremdschlüsselbeziehung) wird als Attribut in die Tabelle aufgenommen:
Tabelle Mitarbeiter Personal# ... Raum# ...
Tabelle Räume Raum# Standort# ...
8.2. 1:1 Beziehung 1:1 Bezieungen sind nur Sonderfälle der 1:N Beziehung. Diese sind auch in einer Tabelle abbildbar: Wir erinnern uns an das Beispiel mit der Firma eConsult - In einem Raum sitzt genau ein Mitarbeiter. Ein Mitarbeiter sitzt in genau einem Raum.
Tabelle Mitarbeiter Personal# ... Raum# Standort#
Wir werden also nur dann auf die Methode der Attribute zurückgreifen, wenn wir ganz sicher sind, dass wir niemals eine 1:N Beziehung abbilden werden müssen. Wenn diese Annahme nicht hält werden wir unsere Datenmodell, unsere Datenbank und die Daten in der Datenbank ändern müssen!

Datenmodellierung Haas, Resch
- 30 -
Ein anderes Beispiel - Prüfungsgeschehen: Zwischen Fach und Prüfer herrscht eine 1:1 Beziehung, diese sind mit Vorsicht als Attribut (in einer Tabelle) auffassbar! Pr# Pr Name F# F_Bez BF Berger GEDV Grundlagen RI Riese PR Programmieren MU Muth MAM Mathematik GR Groß LÜK Leibesübungen Wir sprechen in diesem Fall von einer 1:1 Beziehung mit obligatorischer Teilnahme beider Entitäten: Es gibt keine Entität, die nicht an der Relation teilnimmt.
• jedes Fach wird geprüft • jeder Prüfer hat ein Fach
=> Dann können die Attribute der einen Entität als Attribute der anderen Eintität angesehen werden (Schlüssel oder Attribute gehen mit, sonst NF verletzt!) In unserm Beispiel wird das Fachkürzel mitgenommen
8.3. M:N Beziehung Eine M:N Beziehungen ist nicht direkt darstellbar - diese wird in zwei 1:N Beziehungen aufgelöst! Die Methode hierzu heißt "Assoziationstabelle". Dieses kann auch nur aus Schlüsseln (ohne Attribute) bestehen (All Key Table)! Beispiel der Bibliothek:
Notation im Relationenmodell:
Entlehner(Leser#, Adresse, ...) Buch(ISBN, Titel, ...) entleiht(Leser#, ISBN, Datum) <= Assoziationstabelle

Datenmodellierung Haas, Resch
- 31 -
9. NULL / Faktum "Leer" In einer Tabelle muß man unterscheiden zwischen:
• NULL es ist kein Datum als Attributwert vorhanden (Wert ist derzeit noch nicht bekannt) Ein Beispiel ist das Rückgabedatum bei unserer Bibliothek. Zu dem Zeitpunkt, wo ein Buch entlehnt wird, ist auch das Attribut "Rückgabedatum" vorhanden. Dieses Attribut ist aber so lange nicht gefüllt, bis das Buch zurückgebracht wird. ACHTUNG: Die Attribute, die zum Primärschlüssel gehören DÜRFEN KEINE NULL Werte enthalten!
• Leer oder Wert 0
Der Wert eines Attributes ist mit Absicht auf "Leer" oder 0 gesetzt. Ein Beispiel ist unsere Stadtbibliothek: Dort kann man auch Getränke zu sich nehmen. Die muß man natürlich auch bezahlen. Wenn man will kann man diese Beträge gemeinsam mit den Bibliotheksbeiträgen verrechnen lassen. Wenn ich aber keine Getränke konsumiert habe, dann ist der Wert - im zugehörigen Attribut - 0.
Ein Datenbanksystem geht bei dem Auftreten von NULL Werten wie folgt vor:
• Wahr und NULL => NULL • Wahr oder NULL => Wahr
Hinweis: Wenn es Attribute gibt, die fast nur NULL-Werte enthalten - dann ist das Datenmodell nicht ausreichend geplant. Hinweis: Ein Datenbanksystem unterscheidet auf Grund des Wertes zwischen NULL und Leer: Ein NULL Wert wird anders dargestellt, zum Beispiel durch einen Wert, den ein normales Datum nicht annehmen darf (-32767, ...) Hinweis: Im SQL werden wir auch nach diesen NULL Werten abfragen können!

Datenmodellierung Haas, Resch
- 32 -
10. Generalisierung (Super / Subtyp) Supertyp: alle gemeinsamen Attribute Subtyp: spezielle Attribute Diese Idee kennen wir auch aus der objektorientierten Programmierung: Hier sprechen wir von einer Basisklasse (=Supertyp) und der abgeleiteten Klasse (=Subtyp). Beispiel: "Ein Arzt ist eine Person" "Ein Patient ist eine Person"
Folie: (Datenmodellierung) Generalisierung

Datenmodellierung Haas, Resch
- 33 -
11. Textanalyse Die Zerlegung des Datenmodells über die Normalformen (Normalisierung) ist nur bei sehr einfachen Modellen möglich, wegen: - der Komplexität von großen Datenmodellen - es keine Algorithmus zur Normalisierung gibt (wir kennen zwar die Kriterien, haben aber keinen allgemeingültigen Weg zur Erreichung der Normalformen) Zum Einsatz in der Praxis kann man daher Regelwerke zur Optimierung des Datenmodells einsetzten. Ein Beispiel für ein solches Regelwerk ist die Textanalyse:
• Entitäten und die Beziehungen werden zunächst im Text der Aufgabenstellung mit unterschiedlichen Farben zu markieren
• Anschließend notiert man die Beziehungen zwischen den Entitätsmengen und deren Grade • dann ergänzt man die Attribute zu den Entitätsmengen. • mit den acht Regeln zur Textanalyse wird das Datenmodell optimiert • prüfen, ob der Primärschlüssel aus der minimalen Attributskombination besteht (unter
Einhaltung der Eindeutigkeit!). Es kann also passieren, dass Schlüsselattribute zu Attributen werden oder umgekehrt
• Zuletzt wird geprüft, ob die Tabellen der 3. Normalform genügen
11.1. Das Regelwerk der Textanalyse Das Regelwerk verwendet oft den Begriff "obligatorisch". Damit ist gemeint:
• dass der Wert eines Attributes immer gefüllt sein muß - also nicht NULL sein darf. • Im Sinne einer Beziehung muß eine Entität vorhanden sein
Regel 1) Grad 1 : 1 - Generalisierung 1: 1 Beziehungen treten meist nur in Generalisierungen auf, wobei der Supertyp mit dem Subtyp in dieser Beziehung steht; der Primärschlüssel des Supertypen wird als Primärschlüssel des Subtypen mitgenommen. Beispiel: "Ein Arzt ist eine Person" "Ein Patient ist eine Person" Notation im Relationenmodell: Ausgangsbasis: Person (Supertyp ...allgemeinerer Begriff) Pers# Name P1 Meier P2 Müller P3 Bürger Name ist ein gemeinsames Attribut!

Datenmodellierung Haas, Resch
- 34 -
Arzt (Subtyp ... speziellerer Begriff) Arzt# Fachgebiet
A Chirurgie B Unfall Patient (Subtyp ... speziellerer Begriff) Pat# Zimmer
0001 B404 Also, der Primärschlüssel des Supertypen (Pers#) wird als Primärschlüssel des Subtypen mitgenommen: Person (Supertyp ...allgemeinerer Begriff) Pers# Name P1 Meier P2 Müller P3 Bürger Arzt (Subtyp ... speziellerer Begriff) Arzt# Pers# Fachgebiet
A P2 Chirurgie
B P1 Unfall
Patient (Subtyp ... speziellerer Begriff) Pat# Pers# Zimmer
00001 P3 B404
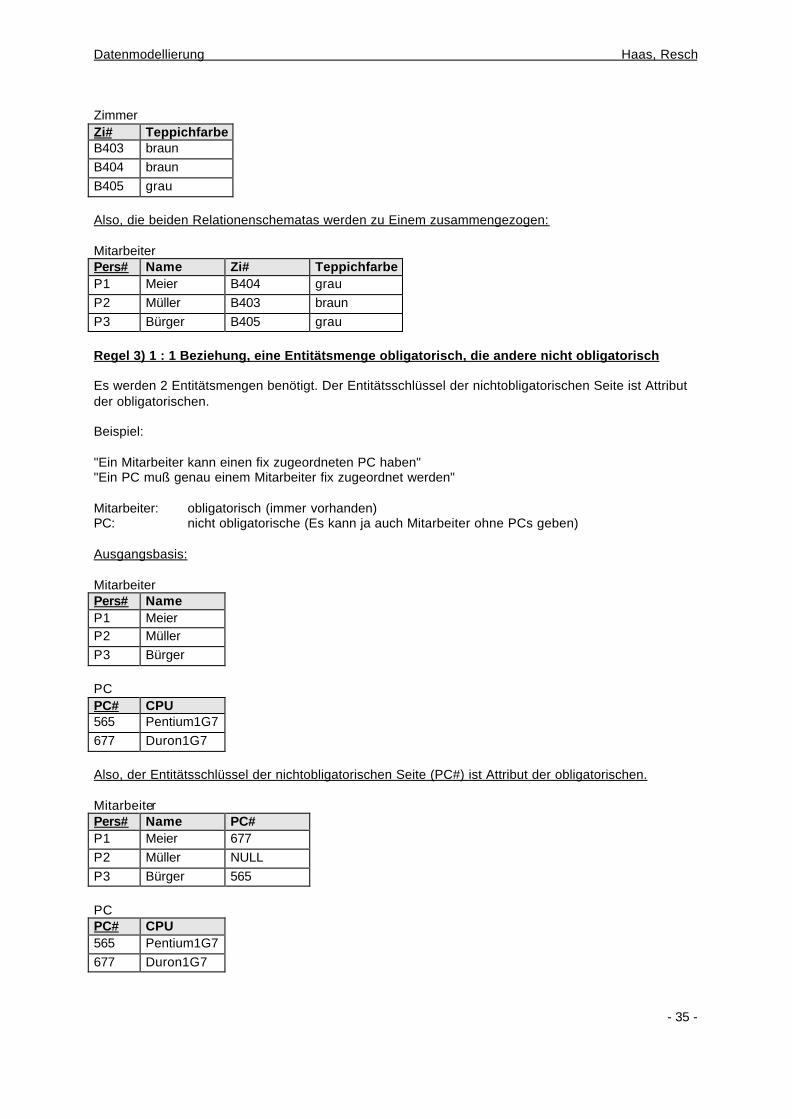
Regel 2) 1 : 1 Beziehungen, obligatorische Teilnahme beider Entitätsmengen Es wird nur eine Entitätsmenge benötigt, wobei die Attribute der einen Entitätsmenge als Attribute der anderen Entitätsmenge (ev. ohne Primärschlüssel) aufscheinen. Also aus beiden Relationenschematas (oder Entitätsmengen) muß genau ein Vertreter vorhanden sein! Beispiel: "Jeder Mitarbeiter hat ein eigenes Zimmer" "In jedem Zimmer sitzt nur ein Mitarbeiter" Ausgangsbasis: Mitarbeiter Pers# Name P1 Meier P2 Müller P3 Bürger
Datenmodellierung Haas, Resch
- 35 -
Zimmer Zi# Teppichfarbe B403 braun B404 braun B405 grau Also, die beiden Relationenschematas werden zu Einem zusammengezogen: Mitarbeiter Pers# Name Zi# Teppichfarbe P1 Meier B404 grau P2 Müller B403 braun P3 Bürger B405 grau Regel 3) 1 : 1 Beziehung, eine Entitätsmenge obligatorisch, die andere nicht obligatorisch Es werden 2 Entitätsmengen benötigt. Der Entitätsschlüssel der nichtobligatorischen Seite ist Attribut der obligatorischen. Beispiel: "Ein Mitarbeiter kann einen fix zugeordneten PC haben" "Ein PC muß genau einem Mitarbeiter fix zugeordnet werden" Mitarbeiter: obligatorisch (immer vorhanden) PC: nicht obligatorische (Es kann ja auch Mitarbeiter ohne PCs geben) Ausgangsbasis: Mitarbeiter Pers# Name P1 Meier P2 Müller P3 Bürger PC PC# CPU 565 Pentium1G7 677 Duron1G7 Also, der Entitätsschlüssel der nichtobligatorischen Seite (PC#) ist Attribut der obligatorischen. Mitarbeiter Pers# Name PC# P1 Meier 677 P2 Müller NULL P3 Bürger 565 PC PC# CPU 565 Pentium1G7 677 Duron1G7

Datenmodellierung Haas, Resch
- 36 -
Regel 4) 1 : 1 Beziehung, beide Entität nichtobligatorisch Es werden 3 Entitätsmengen benötigt: Die beiden ursächlichen Entität und eine Entitätsmenge für die Beziehung, die die Entitätsschlüssel beider Entitätsmengen enthält. Beispiel: "Ein Mitarbeiter kann einen fix zugeordneten PC haben" "Ein PC kann einem Mitarbeiter fix zugeordnet werden" Ausgangsbasis: Mitarbeiter Pers# Name P1 Meier P2 Müller P3 Bürger PC PC# CPU 412 I386 542 Celeron766 565 Pentium1G7 677 Duron1G7 Also, eine Entitätsmenge für die Beziehung, die die Entitätsschlüssel beider Entitätsmengen enthält, zusätzlich zu den beiden bestehenden Entitätsmengen. Mitarbeiter Pers# Name P1 Meier P2 Müller P3 Bürger PC PC# CPU 412 I386 542 Celeron766 565 Pentium1G7 677 Duron1G7 Zugeordneter PC Pers# PC P1 677 P2 542 P3 565 Den PC mit der Inventarnummer 412 will (aus verständlichen Gründen) niemand haben! Hinweis: Wir können uns in diesem Fall aussuchen, welches Attribut wir in der Entitätsmenge "Zugeordneter PC als Schlüsselattribut verwenden wollen!

Datenmodellierung Haas, Resch
- 37 -
Regel 5) 1 : n Beziehung, n- Seite obligatorisch (Fremdschlüssel) Es werden zwei Entitätsmengen benötigt. Der Entitätsschlüssel der 1 -Seite ist Attribut der Entitätsmenge der n -Seite. Beispiel: "Eine Person kann mehrer Bücher entlehnen" "Ein Buch kann nur von einer Personen entlehnt werden (es gibt also immer nur ein Exemplar)" Ausgangsbasis: Person ist die 1-Seite Buch ist die N-Seite (obligatorisch) Personen Pers# Name P1 Meier P2 Müller P3 Bürger Bücher ISBN# Titel 1212 SQL 1213 ACCESS 1214 ORACLE 1215 Datenmodellierung Hinweis: Was muß mit jedem Buch sein (Es muß an eine Person verliehen sein!) Also, der Entitätsschlüssel der 1 -Seite wird Attribut der Entitätsmenge der n -Seite. Personen Pers# Name P1 Meier P2 Müller P3 Bürger Bücher ISBN# Titel Pers# 1212 SQL P1 1213 ACCESS P3 1214 ORACLE P2 1215 Datenmodellierung P1 Regel 6) 1 : n Beziehung, beide Seite nichtobligatorisch Es werden drei Entitätsmengen benötigt - eine zusätzliche für die Entitätsmenge, die die Entitätsschlüssel beider Entitätsmengen enthält.

Datenmodellierung Haas, Resch
- 38 -
Beispiel: "Eine Person kann beliebig viele Bücher entlehnen (also auch gar keine)" "Ein Buch kann von höchstens einer Personen entlehnt werden" Ausgangsbasis: Person ist die 1-Seite Buch ist die N-Seite Personen Pers# Name P1 Meier P2 Müller P3 Bürger Bücher ISBN# Titel 1212 SQL 1213 ACCESS 1214 ORACLE 1215 Datenmodellierung Also, eine zusätzliche für die Entitätsmenge, die die Entitätsschlüssel beider Entitätsmengen enthält. Personen Pers# Name P1 Meier P2 Müller P3 Bürger Bücher ISBN# Titel 1212 SQL 1213 ACCESS 1214 ORACLE 1215 Datenmodellierung entlehnt ISBN# Pers# 1212 P2 1215 P1 Es gibt also Bücher, die nicht entlehnt sind und Personen, die keine Bücher ausgeborgt haben.

Datenmodellierung Haas, Resch
- 39 -
Hinweis: Wozu gibt es diese beiden Unterscheidungen? Bei der Regel 5) könnten dann Zeilen mit vielen NULL Werten entstehen: ISBN# Titel Pers# 1212 SQL P2 1213 ACCESS NULL 1214 ORACLE NULL 1215 Datenmodellierung P1 Das ist ein Zeichen von schlechtem Datenbankdesign, da Speicherplatz verschwendet wird! Regel 7) n : m Beziehung Es werden drei Entitätsmengen benötigt - eine Zusätzliche für die Beziehung, die die Entitätsschlüssel beider Entitätenmengen (meist als gemeinsamen Primärschlüssel- 'All Keyed' Relation -) enthält. Beispiel: Verkäufer (Verk#, Name) Käufer (K#, Name) Verkauf(Verk#, K#, Menge) Regel 8) m: n : o Beziehung (tenäre oder mehrwertige Beziehung) Es werden Anzahl der Entitätsmengen + eine zusätzliche Entitätsmenge benötigt, sonst wie Regel 7. Beispiel: Verkäufer (Verk#, Name) Käufer (K#, Name) Artikel (Art#, Name, Preis) Verkauf(Verk#, K#, A#, Menge)
11.2. ein einfaches Beispiel In einem Betrieb arbeiten Personen (Mitarbeiter) in Abteilungen an Produkten. Folgende Feststellungen können getroffen werden: § ein Mitarbeiter hat einen Namen sowie einen Wohnort § Er ist in einer Abteilung tätig und arbeitet an mehreren Produkten jeweils eine vorbestimmte Zeit. § Jede Abteilung weist einen Namen auf. § Desgleichen ist jedem Produkt ein Name zugeordnet § In einer Abteilung sind mehrere Personen tätig § an einem Produkt arbeiten meist mehrere Personen

Datenmodellierung Haas, Resch
- 40 -
Entitätsmengen Beziehung Grad Personen Name, arbeitet_in 1:N Wohnort Abteilungen Name arbeitet_an N:M Zeit Produkte Name Person arbeitet_in Abteilung N : 1
Regel 5) N Seite obligatorisch (muß vorhanden sein!) - OK gilt, in einer Abteilung muß also immer mindestens ein Mitarbeiter sein. Also: Zwei Relationen (eine je Entität). Der Entitätsschlüssel der 1-Seite ist Attribut der Relation der N Seite (Fremdschlüssel!) Regel 6) Beide Seiten sind Nicht - obligatorisch (beide Seiten brauchen nicht vorhanden zu sein!) - Gilt NICHT, da eine Person zu einer Abteilung gehört und eine Abteilung mindestens einen Mitarbeiter haben soll
Personen arbeiten_an Produkten M : N
Regel 7) N:M Beziehung, Produkt-Per# <-N:M-> Person_Abt-Per#. Dies kann in einem relationalen Datenbanksystem nur über eine zusätzliche Tabelle ("Produktion" - Assoziationstabelle) dargestellt werden.

Datenmodellierung Haas, Resch
- 41 -
12. Datenmodellierung mit ERWIN Wir habe bis jetzt schon sehr viele Dinge über Datenmodellierung gelernt: Wir kenne die Grundbegriffe (Entität, Attribut, Beziehung, Kardinalität, Primary Key, Sekundary Key, Normalformen, usw.) Wir kennen bereits zwei unterschiedliche Notationsformen:
• Relationenmodell • Chen Diagramme
Nun beginnen wir uns in eine andere Notationsform einzuarbeiten: ERWIN - Entity Realtion Diagrams for Windows. Bis jetzt haben wir uns nur sehr theoretisch mit unseren Datenmodellen befasst - nun werden wir am Computer unsere Datenmodelle entwickeln und Skripts zum Erzeugen der Tabellen daraus ableiten lassen.

Datenmodellierung Haas, Resch
- 42 -
13. Bäume in Tabellen Beispiel Diensthierarchie Kriterien für einen echten Baum: - ein Knoten hat beliebig viele Nachfolger - ein Knoten hat genau einen Vorgänger Figl (FI) Stappler (SP) Mitmannsgr. (MI) Behringer (BE) Preissl (PR) Krieger (KR) Hickel (HI) Berger (BF) Haas (HS) Halbritter (HA) Lederbauer (LB) Sina (SI) Wie in eine Tabelle abbilden? Zwischenschritt: Lehrer L# LName VLName HI NULL BF HI SP HI LB HI ... Vorgesetzte VL# LName HI BF SP LB ... Das ist eine 1:N Beziehung mit Auflösung als Non - Key -> "Self Join" oder laut Erwin "Fisher Hook". Hinweis: In Erwin über Rollennamen zu lösen! Also: Eine Tabelle genügt, der Vorgesetzte kommt selbst in der Tabelle vor! L# VL# LName HI NULL BF HI SP HI LB HI FI SP MI SP BE SP ...

Datenmodellierung Haas, Resch
- 43 -
Achtung, KEIN Baum ist etwa eine Stückliste: Speichen Rad Nabe Felgen Fahrrad Rahmen Muttern Lenker Muttern hat mehr wie einen Vorgänger! Weitere Beispiele für KEINE Bäume: Stammbaum (ein Kind hat zwei Eltern) ... Artikel: Ein Artikel kann aus mehreren Bestandteilen bestehen ein Artikel kann Bestandteil von mehreren Artikeln sein Artikel Stückliste Artikel oben unten Anzahl Fahrrad Fahrrad Rad 2 Rad Fahrrad Rahmen 1 Rahmen Fahrrad Lenker 1 Lenker Rad Speichen 26 Speichen Rad Nabe 1 Nabe 1:N Rad Felgen 1 Felge Rahmen Mutter 5 Lenker Nabe Muttern 2 1:N Lenker Muttern 1 N:M Es werden hier aber nur zwei Tabellen benötigt, da "oben" und "unten" gleiches "Ding", nämlich Artikel oben: besteht aus unten: enthalten in


















