
Statistik für Journalistinnen und Journalisten Vorlesung ... · Superior Performing Software...
416
Statistik f¨ ur Journalistinnen und Journalisten Vorlesung im Sommersemester 2017 an der TU Dortmund J¨ org Rahnenf¨ uhrer SoSe 2017, Fakult¨ at Statistik, TU Dortmund
Transcript of Statistik für Journalistinnen und Journalisten Vorlesung ... · Superior Performing Software...

Statistik fur Journalistinnen und JournalistenVorlesung im Sommersemester 2017
an der TU Dortmund
Jorg Rahnenfuhrer
SoSe 2017, Fakultat Statistik, TU Dortmund

1 Einleitung 1.1 Ubersicht
1.1 Dozent
Prof. Dr. Jorg Rahnenfuhrer
Mathegeaude, Raum 720
Email: [email protected]
Wissenschaft
Studium der Mathematik mit Nebenfach Psychologie in Dusseldorf
Forschung an WU Wien, UC Berkeley, MPI Saarbrucken
Professor fur Statistische Methoden in der Genetik undChemometrie, Fakultat Statistik, Technische Universitat Dortmund
Forschungsgebiete: Statistische Methoden fur Medizin, Genetik undBioinformatik
Wissenschaftliche Kooperationen mit Prof. Henrik Muller und Prof.Holger Wormer vom Institut fur Journalistik
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 2

1 Einleitung 1.1 Ubersicht
1.1 Dozent
Wissenschaftliche Kooperationen
Julia Serong, Lars Koppers, Edith Luschmann, Alejandro MolinaRamirez, Kristian Kersting, Jorg Rahnenfuhrer, Holger Wormer(2017): Offentlichkeitsorientierung vonWissenschaftsinstitutionen und Wissenschaftsdisziplinen.Publizistik, 1-26.
Elena Erdmann, Karin Boczek, Lars Koppers, Gerret von Nordheim,Christian Politz, Alejandro Molina, Katharina Morik, Henrik Muller,Jorg Rahnenfuhrer, Kristian Kersting (2016): Machine Learningmeets Data-Driven Journalism: Boosting InternationalUnderstanding and Transparency in News Coverage.arXiv:1606.05110 [cs, stat].
Karin Boczek, Gerret von Nordheim, Lars Koppers (2016): Updateeines Klassikers: Beispiele fur die Kombination manuellerInhaltsanalysen mit Latent Dirichlet Allocation. Jahrestagungder DGPuK 2016.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 3

1 Einleitung 1.1 Ubersicht
1.1 Organisatorisches
Vorlesung Statistik fur Journalisten
Zeit: Dienstag, 10:15-11:45 Uhr
Raum: Horsaal E5 (Universitatsbibliothek)
Homepage: https://www.statistik.tu-dortmund.de/genetik-sj17.html
Hauptklausur
Zeit: Donnerstag, 03.08.2017, 12:00-14:00 Uhr
Raum: SRG I / Horsaal
Anmeldung bis spatestens Mittwoch, 26.07.2017, per Email imPrufungsamt bei Frau Kitsche ([email protected])
Nachklausur
Zeit: Montag, 18.09.2017, 10:00-12:00 Uhr
Raum: 3.406 in EF 50
Anmeldung bis spatestens Sonntag, 10.09.2017, per Email imPrufungsamt bei Frau Kitsche ([email protected])
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 4

1 Einleitung 1.1 Ubersicht
1.1 Inhalt
Themen der Vorlesung:
Merkmale und Datentypen
Univariate Daten
Statistische Kennzahlen fur die LageStatistische Kennzahlen fur die Streuung
Bivariate Daten
ZusammenhangsmaßeLineare Regression
Wahrscheinlichkeitsrechnung
ZufallsvariablenVerteilungen
Unabhangigkeit
Bedingte WahrscheinlichkeitenStochastische UnabhangigkeitKorrelation versus Kausalitat
Statistische Tests und Signifikanz
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 5

1 Einleitung 1.2 Literatur
1.2 Literaturempfehlungen
Fahrmeir, Ludwig; Kunstler, Rita; Pigeot, Iris; Tutz, Gerhard:Statistik: Der Weg zur Datenanalyse, Springer.
Kramer, Walter: Statistik verstehen: Eine Gebrauchsanweisung,Piper.
Ligges, Uwe: Programmieren mit R, Springer.
Muller, Christine; Denecke, Liesa: Stochastik in denIngenieurwissenschaften: Eine Einfuhrung mit R, Springer.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 6

1 Einleitung 1.3 Motivation
1.3 Statistik
There are three kinds of lies - lies, damned lies, andstatistics. (Leonard Henry Courtney, 1832-1918)
Raten ist billig - falsch raten ist teuer. (ChinesischesSprichwort)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 7

1 Einleitung 1.3 Motivation
1.3 Statistik
There are three kinds of lies - lies, damned lies, andstatistics. (Leonard Henry Courtney, 1832-1918)
Raten ist billig - falsch raten ist teuer. (ChinesischesSprichwort)
Statistik ist (auch) Spaß
Statistik ist (auch) Intuition
Statistik ist (auch) Uberraschung
Wie uns Statistik hilft: Der Zufall folgt kontrolliertenRegeln!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 8

1 Einleitung 1.3 Motivation
1.3 Statistik in den Medien
Die Rolle von Zahlen, Daten und Statistiken im Journalismus
Zunehmende Bedeutung und Verfugbarkeit von Daten
Beliebte Kategorie: Faktencheck
Beliebt: ”Empirische Studien belegen, dass . . . ”
(Statistische) Einordnung der Relevanz und der Generalisierbarkeitvon Studienergebnissen wichtig
Daten sind in der Regel mit Rauschen und Fehlern behaftet!
Statistische Methoden werden benotigt um Signal und Rauschen zuunterscheiden.
Heiße Themen: Datenjournalismus und Visualisierung
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 9

1 Einleitung 1.3 Motivation
1.3 Statistik in den Medien
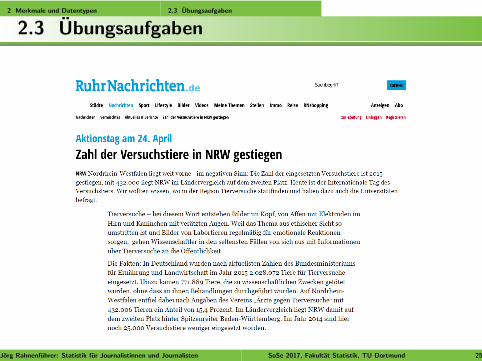
Zusammenhang von Rauchverbot und sinkender Anzahl an Herzinfarkten?Statistisch fragwurdige Aussagen in den Ruhr Nachrichten:
Abb. 1 : Artikel aus den Ruhr Nachrichten vom 15.11.2010Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 10

1 Einleitung 1.3 Motivation
1.3 Statistik in den Medien
Unstatistik des Monats (www.unstatistik.de):
”Der Berliner Psychologe Gerd Gigerenzer, der Bochumer OkonomThomas Bauer und der Dortmunder Statistiker Walter Kramer haben imJahr 2012 die Aktion
”Unstatistik des Monats“ ins Leben gerufen. Sie
hinterfragen jeden Monat sowohl jungst publizierte Zahlen als auch derenInterpretationen. Die Aktion will so dazu beitragen, mit Daten undFakten vernunftig umzugehen, in Zahlen gefasste Abbilder derWirklichkeit korrekt zu interpretieren und eine immer komplexere Weltund Umwelt sinnvoller zu beschreiben.”
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 11

1 Einleitung 1.3 Motivation
1.3 Statistik in den Medien
Aktuelle Unstatistiken:
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 12

1 Einleitung 1.4 Statistiksoftware
1.4 Statistiksoftware – Excel
Excel
keine geeignete Statistiksoftware – Beispiel Varianz
gut geeignet fur Dateneingabe und Datenansicht in der Tabelle
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 13

1 Einleitung 1.4 Statistiksoftware
1.4 Statistiksoftware – R
R
http://www.R-project.org
Entwicklung seit 1992
Inspiriert von S / S-PLUS
Einsatz an Universitaten und Forschungsinstituten sowie immer mehrin der Industrie
Lizenz: GPL 2 (freie Software, Open Source Software)
nur behelfsmaßige grafische Benutzeroberflachen
wird teilweise auch im Datenjournalismus verwendet
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 14

1 Einleitung 1.4 Statistiksoftware
1.4 Statistiksoftware – SAS
SAS
http://www.sas.com
Name:
zunachst:”Statistical Analysis Systems“
heute:”sas“
SAS Institute, gegrundet 1976, 2 Mrd. US$ Jahresumsatz.
Einsatz vor allem in Medizin, Pharmaindustrie, im CRM, beimScoring
sehr schlechte grafische Benutzeroberflachen
CRM: Customer Relationship Management
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 15

1 Einleitung 1.4 Statistiksoftware
1.4 Statistiksoftware – SPSS
SPSS
http://www.spss.com
Name:
zunachst”Statistical Package for the Social Sciences“
dann”Superior Performing Software System“
heute”SPSS“
gegrundet 1968 als eigenstandige Firma
2009 an IBM verkauft
Einsatz vor allem in den Sozial- und Geisteswissenschaften, im CRM,beim Scoring
ordentliche grafische Benutzeroberflache
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 16

1 Einleitung 1.4 Statistiksoftware
1.4 Statistiksoftware – Anforderungen
Anforderungen an Statistiksoftware:
Interaktive Arbeit mit Daten fur die Datenanalyse
Erstellung statistischer Grafik
Hohe numerische Genauigkeit
Hohe Rechengeschwindigkeit
Verarbeitung großer Datenmengen
Automatisierbarkeit von Methoden und sich wiederholender Ablaufe
Einfache Bedienbarkeit / Programmierbarkeit
Nebenbedingungen: Preis, unterstutzte Hardware, Parallelisierung, ...
Diese Anforderungen widersprechen sich teilweise. Je nach Gewichtungder Schwerpunkte erfolgt die Wahl einer entsprechenden Software.
Software kann niemals besser sein als ihr Benutzer!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 17

2 Merkmale und Datentypen 2.1 Merkmale
2.1 Merkmale
Definition 1Ein Merkmal ist eine abstrahierende Eigenschaft von einem odermehreren verschiedenen Beobachtungen (Merkmalsauspragungen =Merkmalswerten), die pro Merkmalstrager erfasst wird.Ein Merkmal
”besteht“ also aus Merkmalsauspragungen, die an
Merkmalstragern einer Gesamtheit erfasst werden.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 18

2 Merkmale und Datentypen 2.2 Merkmalstypen
2.2 Merkmalstypen
Definition 2Ein Merkmal heißt qualitativ, wenn es eine Eigenschaft,(”Qualitat“) eines Merkmalstragers bezeichnet.
Ein Merkmal heißt quantitativ, wenn seine Auspragungen”echte“
Messwerte sind. (Solche sind addier-, subtrahier- undmultiplizierbar.)
Quantitative Merkmale heißen auch metrisch oder kardinal.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 19

2 Merkmale und Datentypen 2.2 Merkmalstypen
2.2 Merkmalstypen
Definition 3Bei qualitativen Merkmalen werden zwei Arten unterschieden:
Ordinale Merkmale lassen zwar kein Addieren oder Multiplizieren zu,aber eine Anordnung ihrer Auspragungen.Nominale Merkmale erlauben auch kein Sortieren ihrerAuspragungen.
Man sagt, Merkmalsauspragungen liegen auf einer Nominalskala,Ordinalskala bzw.- Kardinalskala.
Merkmale auf der Kardinalskala werden als metrisch bezeichnet.
Bei der Kardinalskala unterscheidet man zwischen Intervallskala undVerhaltnisskala (bei dieser gibt es zusatzlich einen definiertenNullpunkt, so dass auch Verhaltnisse berechnet werden durfen).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 20

2 Merkmale und Datentypen 2.2 Merkmalstypen
2.2 Merkmalstypen
Definition 3Diskrete Merkmale haben hochstens abzahlbar unendlich vieleAuspragungen, d.h. ihre Auspragungen lassen sich mit Hilfe dernaturlichen Zahlen abzahlen.
Stetige Merkmale konnen uberabzahlbar viele Werte annehmen,z.B. jede reelle Zahl in einem Intervall.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 21

2 Merkmale und Datentypen 2.2 Merkmalstypen
2.2 Merkmalstypen
Beispiele
Metrische Merkmale: Große, Alter (beide Verhaltnisskala), Datum(Intervallskala)
Ordinale Merkmale: Frage nach Gesundheitszustand, Schulnoten
Nominale Merkmale: Geschlecht, Name, Postleitzahl
Diskrete Merkmale: Geschlecht, Einwohnerzahl
Stetige Merkmale: Temperatur, Große
Stetige Merkmale werden haufig nur diskret beobachtet wegenMessgenauigkeit (Temperatur) oder Ubereinkunft (Alter).
Merkmalstypen werden in Statistiksystemen durch enstprechendeDatenformate abgebildet.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 22

2 Merkmale und Datentypen 2.2 Merkmalstypen
2.2 Ein Datenbeispiel fur Kardinalskala
Beispiel 1
Patientendaten:a) Gewicht (in kg); NA: fehlender Wert (Not Available)
Zufallige Auswahl des Gewichts von 200 Patienten:
85 70 75 70 92 88 68 101 74 80 87 68 95 33 75 117 105 88 76
82 107 92 87 91 83 80 85 95 75 60 85 75 73 58 93 70 100 94
100 75 80 85 87 43 90 92 89 NA 100 96 58 72 77 83 48 74 90
58 78 75 56 70 75 70 67 95 74 88 70 68 66 102 72 74 113 72
81 75 55 60 75 90 71 93 NA 94 75 89 90 80 52 90 105 90 82
80 83 80 89 70 67 92 108 58 75 75 110 85 58 74 93 97 65 83
110 87 81 64 103 120 65 85 79 95 110 70 90 85 94 88 88 130 70
69 78 100 88 86 85 76 60 79 90 88 104 69 96 59 75 NA 75 66
70 86 80 65 94 72 62 75 105 91 79 88 80 85 69 87 54 96 70
82 70 95 78 95 95 84 70 90 65 67 85 NA 92 87 63 120 65 55
65 81 NA 54 81 63 64 77 70 75
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 23

2 Merkmale und Datentypen 2.3 Ubungsaufgaben
2.3 Ubungsaufgaben
Betrachten Sie journalistische Artikel, in denen Aussagen uberMerkmale (auf Zahlenbasis) gemacht werden.Bestimmen Sie die Skalenniveaus der jeweiligen Merkmale.
Gegeben sei ein Datensatz mit folgenden individuellen Angaben vonPatienten: Name, Geburtsdatum, Augenfarbe, Gewicht, Große,Bewertung des Gesundheitszustands (1-10), Korpertemperatur.Welche Skalenniveaus liegen fur diese Merkmale vor?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 24
2 Merkmale und Datentypen 2.3 Ubungsaufgaben
2.3 Ubungsaufgaben
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 25

2 Merkmale und Datentypen 2.3 Ubungsaufgaben
2.3 Ubungsaufgaben
Gegeben sei ein Datensatz mit folgenden individuellen Angaben vonPatienten: Name, Geburtsdatum, Augenfarbe, Gewicht, Große,Bewertung des Gesundheitszustands (1-10), Korpertemperatur.Welche Skalenniveaus liegen fur diese Merkmale vor?
Name: NominalskalaGeburtsdatum: Kardinalskala (Intervallskala) - metrischAugenfarbe: NominalskalaGewicht: Kardinalskala (Verhaltnisskala) - metrischGroße: Kardinalskala (Verhaltnisskala) - metrischBewertung Gesundheit: OrdinalskalaKorpertemperatur: Kardinalskala (Intervallskala) - metrisch
(fur Kelvin statt Celsius: Verhatnisskala)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 26
3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.1 Histogramm
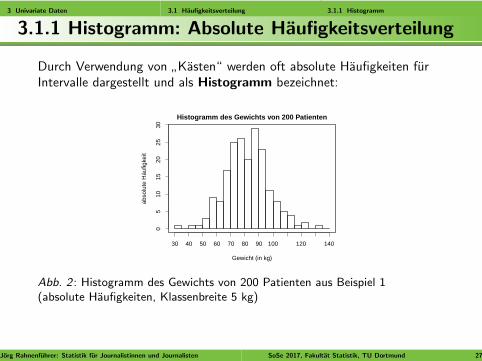
3.1.1 Histogramm: Absolute Haufigkeitsverteilung
Durch Verwendung von”Kasten“ werden oft absolute Haufigkeiten fur
Intervalle dargestellt und als Histogramm bezeichnet:
Histogramm des Gewichts von 200 Patienten
Gewicht (in kg)
abso
lute
Häu
figke
it
05
1015
2025
30
30 40 50 60 70 80 90 100 120 140
Abb. 2 : Histogramm des Gewichts von 200 Patienten aus Beispiel 1(absolute Haufigkeiten, Klassenbreite 5 kg)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 27

3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.1 Histogramm
3.1.1 Absolute Haufigkeitsverteilung
Interpretation
Jeder Kasten entspricht einer Werteklasse, hier links offene undrechts abgeschlossene Intervalle, also:A1 := (30, 35],A2 := (35, 40],A3 := (40, 45], ....
x-Achse: Merkmalsauspragungen
y -Achse: absolute Haufigkeiten H(Ak) der Klassen
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 28
3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.1 Histogramm
3.1.1 Absolute Haufigkeitsverteilung
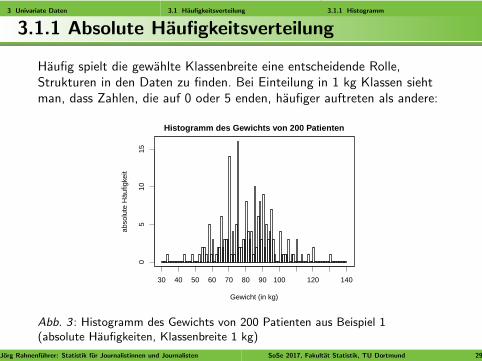
Haufig spielt die gewahlte Klassenbreite eine entscheidende Rolle,Strukturen in den Daten zu finden. Bei Einteilung in 1 kg Klassen siehtman, dass Zahlen, die auf 0 oder 5 enden, haufiger auftreten als andere:
Histogramm des Gewichts von 200 Patienten
Gewicht (in kg)
abso
lute
Häu
figke
it
05
1015
30 40 50 60 70 80 90 100 120 140
Abb. 3 : Histogramm des Gewichts von 200 Patienten aus Beispiel 1(absolute Haufigkeiten, Klassenbreite 1 kg)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 29
3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.1 Histogramm
3.1.1 Absolute Haufigkeitsverteilung
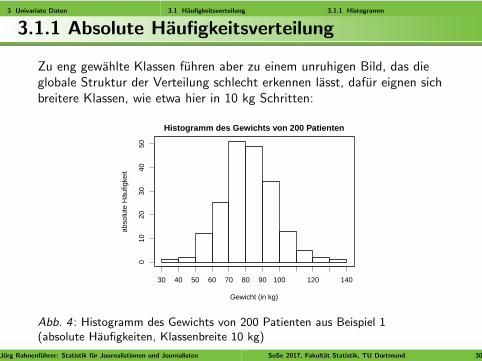
Zu eng gewahlte Klassen fuhren aber zu einem unruhigen Bild, das dieglobale Struktur der Verteilung schlecht erkennen lasst, dafur eignen sichbreitere Klassen, wie etwa hier in 10 kg Schritten:
Histogramm des Gewichts von 200 Patienten
Gewicht (in kg)
abso
lute
Häu
figke
it
010
2030
4050
30 40 50 60 70 80 90 100 120 140
Abb. 4 : Histogramm des Gewichts von 200 Patienten aus Beispiel 1(absolute Haufigkeiten, Klassenbreite 10 kg)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 30

3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.2 Relative Haufigkeitsverteilung
3.1.2 Relative Haufigkeitsverteilung
Von der Darstellung absoluter zur Darstellung relativerHaufigkeiten
Bisher wurde das Histogramm verwendet, um die absoluteHaufigkeitsverteilung darzustellen.
In der Literatur spricht man haufig nur bei der Darstellung derrelativen Haufigkeitsverteilung von einem Histogramm.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 31

3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.2 Relative Haufigkeitsverteilung
3.1.2 Relative Haufigkeitsverteilung
Definition 4Ein Histogramm ist eine grafische Darstellung der relativenHaufigkeitsverteilung der n Werte eines stetigen metrischen Merkmals Xauf einer Gesamtheit.
Dabei werden die Werte in Klassen A1,A2, . . . ,AK eingeteilt.
Die Klassengrenzen werden auf der x-Achse aufgetragen.
Fur jede Klasse wird ein Kasten gezeichnet, der auf der x-Achsedurch die Klassengrenzen begrenzt wird.
Die Flache (!) eines Kastens beschreibt die relative Haufigkeit einerKlasse.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 32

3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.2 Relative Haufigkeitsverteilung
3.1.2 Relative Haufigkeitsverteilung
Eigenschaften
Die Kastenhohe der k-ten Klasse ist rk = hk/bk , wobei hk die relativeHaufigkeit und bk die Klassenbreite sind.
Bei der Klassenbreite bk = 1 ist also die Kastenhohe rk = hk ,d.h. die relative Haufigkeit der Klasse.
Die Gesamtflache der Kasten ist gleich 1.
Mit dieser Definition lasst sich das Histogramm zurVeranschaulichung der empirischen Dichte (dazu spater mehr)verwenden.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 33
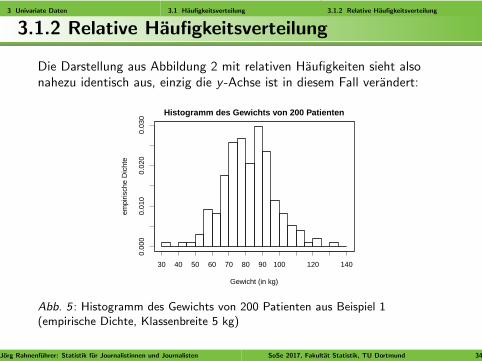
3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.2 Relative Haufigkeitsverteilung
3.1.2 Relative Haufigkeitsverteilung
Die Darstellung aus Abbildung 2 mit relativen Haufigkeiten sieht alsonahezu identisch aus, einzig die y -Achse ist in diesem Fall verandert:
Histogramm des Gewichts von 200 Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
0.00
00.
010
0.02
00.
030
30 40 50 60 70 80 90 100 120 140
Abb. 5 : Histogramm des Gewichts von 200 Patienten aus Beispiel 1(empirische Dichte, Klassenbreite 5 kg)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 34

3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.2 Relative Haufigkeitsverteilung
3.1.2 Einschub: Beschriftung einer Grafik
Die Beschriftung einer Grafik ist von zentraler Bedeutung fur guteDatenanalyse und Prasentationen.
Zu einer geeigneten Beschriftung zahlen:
Beschriftungen an den Achsen (mit Einheit!)
Titel und evtl. Untertitel
Beschriftung muss gut lesbar sein (Große und Schriftart)
Inhalt einer Grafik soll verstanden werden konnen, ohne denFließtext zu lesen
unterschiedliche Farben, Symbole und Linienarten
sollen so gewahlt werden, dass sie gut unterscheidbar sindsollen aber auch nicht von anderen Farben, Symbole und Linienartenablenkenmussen in einer Legende erklart werden
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 35

3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.3 Stabdiagramm
3.1.3 Stabdiagramm
Idee
Bei qualitativen Merkmalen hat sich eingeburgert, ein sogenanntesStabdiagramm (Balkendiagramm) zu verwenden, indem proMerkmalsauspragung ein schmaler Stab (Balken) mit der Hohe Hk oderhk (aber naturlich einheitlich) uber dem Merkmalswert gezeichnet wird.Es bezeichnen Hk die absolute und hk die relative Haufigkeit.
Bemerkungen
Bei Stabdiagrammen werden die Merkmalsauspragungen furqualitative Merkmale gleichabstandig auf der x-Achse gezeichnet.
Stabe sind immer (im Gegensatz zu Kasten beimHistogramm) voneinander separiert!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 36

3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.3 Stabdiagramm
3.1.3 Stabdiagramm
Beispiel 2
Strahlentherapie bei Patienten
keine Ja Brachytherapie k.A.
Strahlentherapie
abso
lute
Häu
figke
it
050
100
150
Abb. 6 : Strahlentherapie bei Patienten
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 37

3 Univariate Daten 3.1 Haufigkeitsverteilung 3.1.3 Stabdiagramm
3.1.3 Stabdiagramm
Stabdiagramme von ordinalen oder metrisch diskreten Merkmalen:
Da die Merkmalsauspragungen von ordinalen oder metrisch diskretenMerkmalen eine
”naturliche“ Reihenfolge haben, wird selbige
verwendet.
Stabdiagramme von nominalen Merkmalen:
Da die Merkmalsauspragungen von nominalen Merkmalen keine
”naturliche“ Reihenfolge haben, ist es erlaubt, die Merkmalswerte
beliebig anzuordnen.
Haufig ist es interessant, die Werte nach ihrer Haufigkeitanzuordnen, das haufigste zuerst, dann das zweithaufigste, usw.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 38

3 Univariate Daten 3.2 Empirische Verteilungsfunktion
3.2 Empirische Verteilungsfunktion
Idee
Die empirische Verteilungsfunktion (oder relativeSummenhaufigkeitsfunktion) F (x) = S rel(x) kann fur klassierte stetige,ordinale und metrische Merkmale durch die Folge derSummenhaufigkeiten Sk , k = 1, . . . ,K , der verwendeten Merkmalsklassenfestgelegt werden und in ein Histogramm eingezeichnet werden.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 39

3 Univariate Daten 3.2 Empirische Verteilungsfunktion
3.2 Empirische Verteilungsfunktion
Definition 5 (Empirische Verteilungsfunktion)
Sei X ein Merkmal mit reellen Zahlen als Auspragungen x1, . . . , xn. Dannheißt die Funktion
F (x) :=k∑
j=1
hj
die den Anteil der Werte xi angibt, die kleiner oder gleich x sind,empirische Verteilungsfunktion, wobei
a) x ∈ [Ende von Klasse k, Ende von Klasse k + 1) bzw.
b) x ∈ [Mitte von Klasse k, Mitte von Klasse k + 1), k < K ,
undF (x) = 0 fur alle x < Ende bzw. Mitte von Klasse 1 sowieF (x) = 1 fur alle x > Ende bzw. Mitte von Klasse K .
Typischerweise wird hier pro einzigartiger Auspragung xi eine eigeneKlasse gewahlt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 40

3 Univariate Daten 3.2 Empirische Verteilungsfunktion
3.2 Empirische Verteilungsfunktion
Verteilung des Gewichts von 200 Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
0.00
0.02
0.04
0.06
0.08
0.10
20 40 60 80 100 120 140
00.
20.
40.
60.
81
empi
risch
e V
erte
ilung
Abb. 7 : empirische Verteilungsfunktion und Histogramm zu Beispiel 1: Gewichtvon 200 Patienten, Klassenbreite 10 kg
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 41

3 Univariate Daten 3.2 Empirische Verteilungsfunktion
3.2 Empirische Verteilungsfunktion
Die empirische Verteilungsfunktion (ohne Histogramm) der nichtklassierten Daten:
40 60 80 100 120 140
0.0
0.2
0.4
0.6
0.8
1.0
Gewicht von 200 Patienten
Gewicht (in kg)
empi
risch
e V
erte
ilung
klassiertunklassiert
Abb. 8 : empirische Verteilungsfunktion zu Beispiel 1: Gewicht von 200Patienten
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 42

3 Univariate Daten 3.3 Kuchen- oder Kreis-Diagramm
3.3 Kuchen- oder Kreis-Diagramm
Idee
Zur Visualisierung von Klassenanteilen an einer Gesamtheit wirdhaufig ein Kuchen- bzw. Kreis-Diagramm verwendet.
Dabei wird ein Kreis so in Sektoren aufgeteilt, dass dieSektorflachen (!) proportional zu den absoluten (bzw. relativen)Klassenhaufigkeiten sind.
Die Kreissektoren erinnern an Kuchenstucke.
Unterschiedlich große Gesamtheiten konnen durch proportional zurGroße der Gesamtheit gewahlte Kreisflachen (!) bei mehrerenKreis-Diagrammen angedeutet werden.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 43
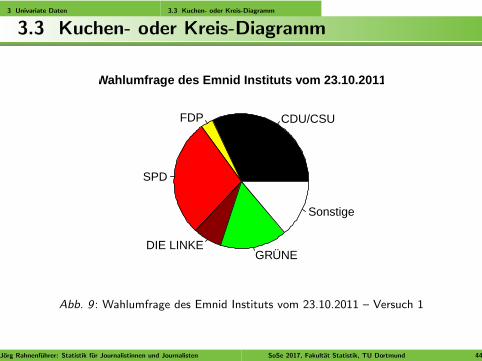
3 Univariate Daten 3.3 Kuchen- oder Kreis-Diagramm
3.3 Kuchen- oder Kreis-Diagramm
CDU/CSUFDP
SPD
DIE LINKEGRÜNE
Sonstige
Wahlumfrage des Emnid Instituts vom 23.10.2011
Abb. 9 : Wahlumfrage des Emnid Instituts vom 23.10.2011 – Versuch 1
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 44
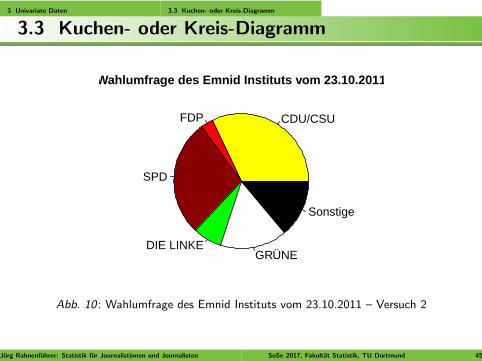
3 Univariate Daten 3.3 Kuchen- oder Kreis-Diagramm
3.3 Kuchen- oder Kreis-Diagramm
CDU/CSUFDP
SPD
DIE LINKEGRÜNE
Sonstige
Wahlumfrage des Emnid Instituts vom 23.10.2011
Abb. 10 : Wahlumfrage des Emnid Instituts vom 23.10.2011 – Versuch 2
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 45

3 Univariate Daten 3.3 Kuchen- oder Kreis-Diagramm
3.3 Kuchen- oder Kreis-Diagramm
Ganz schlimm: Niemals 3D-Kuchendiagramme!!!
CDU/CSU
Grüne
SPD
Linke
FDP
sonstige
CDU/CSU
Grüne
SPD
Linke
FDP
sonstige
Abb. 11 : Wahlumfrage des Emnid Instituts vom 23.10.2011 –Versuche 3 und 4
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 46

3 Univariate Daten 3.3 Kuchen- oder Kreis-Diagramm
3.3 Kuchen- oder Kreis-Diagramm
Was sollte verbessert werden?
3D: Flachen hinten wirken kleiner als die Flachen vorne
Farben: Dunkle Farben wirken machtiger als helle
Farben: Leuchtende Farben ziehen die Aufmerksamkeit an, graueTone werden weniger wahrgenommen.
Kreissegmente (Winkel) viel schlechter vergleichbar als Stabe /Balken
−→ Niemals 3D-Kuchendiagramme verwenden!
−→ Kreisdiagramme vermeiden!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 47

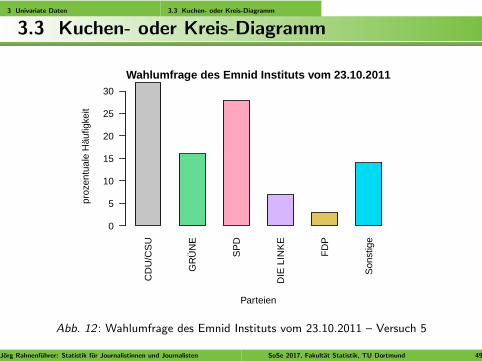
3 Univariate Daten 3.3 Kuchen- oder Kreis-Diagramm
3.3 Kuchen- oder Kreis-Diagramm
Viel besser:
Balkendiagramme verwenden!
Dabei an geeignete Farbwahl denken
Im folgenden Beispiel ist die Farbwahl entgegen der Konventiongetroffen worden, wobei aber die Farbtone zumindest ahnlichgehalten wurden und die Einfarbung letztendlich weniger ablenkendwirken sollte.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 48
3 Univariate Daten 3.3 Kuchen- oder Kreis-Diagramm
3.3 Kuchen- oder Kreis-Diagramm
CD
U/C
SU
GR
ÜN
E
SP
D
DIE
LIN
KE
FD
P
Son
stig
e
Wahlumfrage des Emnid Instituts vom 23.10.2011pr
ozen
tual
e H
äufig
keit
0
5
10
15
20
25
30
Parteien
Abb. 12 : Wahlumfrage des Emnid Instituts vom 23.10.2011 – Versuch 5
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 49

3 Univariate Daten 3.4 Lage- und Streuungs-Maße
3.4 Lage- und Streuungs-Maße
Idee
Nach”geschickten“ grafischen Darstellungen der Werte eines Merkmals
auf einer Gesamtheit interessieren jetzt”geschickte“ algebraische
Charakterisierungen der Verteilung solcher Werte.
Ziel ist es, die Verteilung durch moglichst wenige sog. Maßzahlen zubeschreiben.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 50

3 Univariate Daten 3.4 Lage- und Streuungs-Maße
3.4 Lage- und Streuungs-Maße
Dabei stehen zwei Fragen im Vordergrund:
1 Wo liegt die”Mitte“ der Werte?
2 Wie streuen die Werte um die Mitte?
Die erste Frage basiert auf der Hoffnung, dass sich die Verteilungeinigermaßen reprasentativ durch eine einzige Zahl, ein sogenanntesLagemaß, charakterisieren lasst (
”Einer fur Alle“).
Durch Hinzunahme eines sogenannten Streuungsmaßes soll dieGroße der Unsicherheit (= Streuung) der Merkmalswertecharakterisiert werden.
Bemerkung
Maßzahlen werden z.B. dazu verwendet, um verschiedene Gesamtheitenmiteinander zu vergleichen. Dabei hangt ihre Interpretationtypischerweise von der Problemstellung ab.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 51

3 Univariate Daten 3.4 Lage- und Streuungs-Maße
3.4 Lage- und Streuungs-Maße
Beispiel: Welcher Schutze schießt besser?
Schütze 1
Schütze 2
Abb. 13 : Welcher Schutze schießt besser?
Schutze 1: Lage gut, Streuung schlechtSchutze 2: Lage schlecht, Streuung gut
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 52

3 Univariate Daten 3.4 Lage- und Streuungs-Maße
3.4 Lage- und Streuungs-Maße
Beispiel: Schokoriegelproduktion
In einer Fabrik werden Schokoriegel produziert.
Verpackungsangabe: Ein Schokoriegel wiegt 60 g.
Es gibt regelmaßig Kontrollen, dass Verpackungsangabeneingehalten werden. Auch muss sich der Hersteller beiUnterschreitung der Verpackungsangabe schlechter Presse stellen.
Der Hersteller will also keinesfalls viele zu leichte Schokoriegelproduzieren. Andererseits kosten zu schwere Schokoriegel mehrMaterial und schmalern den Gewinn.
Idee: Erlauben, ganz wenige (< 1%) zu leichte Schokoriegel zuproduzieren.
Iteratives Vorgehen:
1 Einstellung der Lage auf Basis der Streuung.
2 Reduzieren der Streuung.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 53

3 Univariate Daten 3.4 Lage- und Streuungs-Maße
3.4 Lage- und Streuungs-Maße
Gewicht von 100 Schokoriegeln − vorher
Gewicht (in g)
empi
risch
e D
icht
e
0.0
0.1
0.2
0.3
0.4
55 60 65 70 75
Verpackungsangabe /Spezifikationsgrenze
Gewicht von 100 Schokoriegeln − nachher
Gewicht (in g)
empi
risch
e D
icht
e
0.0
0.1
0.2
0.3
0.4
55 60 65 70 75
Abb. 14 : Ersparnis bei Schokoriegelproduktion
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 54

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.1 Lagemaße
3.4.1 Lagemaße
Idee
Zur Charakterisierung der Merkmalswerte auf einer Gesamtheit durcheine einzige Zahl werden sog. Lagemaße verwendet:
Lagemaß =”Mitte“ der Merkmalswerte x1, . . . , xn.
Die wichtigsten Beispiele sind:
Lagemaße 1
Arithmetisches Mittel = Mittelwert (mean)
x :=1
n
n∑i=1
xi (1)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 55

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.1 Lagemaße
3.4.1 Lagemaße
Lagemaße 2
Median =”Zentralwert“ = 50%-Wert: medx
Der Median ist derjenige Wert, fur den 50% der Merkmalswertegroßer oder gleich und 50% kleiner oder gleich sind.Der Median ist der mittlere Wert der Rangliste:
medx :=
x( n+1
2 ) n ungerade
x( n2 ) + x( n
2 +1)
2n gerade
(2)
Modalwert / Modus = haufigster Wert: modx
Der Modalwert ist derjenige Merkmalswert, der am haufigstenvorkommt.Er liegt zwar nicht unbedingt in der Mitte der Merkmalswerte, bietetsich aber naturlich trotzdem als Reprasentant der Merkmalswerte an.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 56

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.1 Lagemaße
3.4.1 Lagemaße
Bemerkungen
Je unterschiedlicher diese Werte, desto weniger lasst sich dieVerteilung durch einen einzigen Wert charakterisieren.
Das arithmetische Mittel reagiert am empfindlichsten auf
”Ausreißer“, d.h. auf (fur die Verteilung) ungewohnlich große oder
kleine Werte, und auf”Schiefe der Verteilung“.
Der Modalwert ist u.U. nicht eindeutig.
Bei wirklich stetigen Merkmalen eignet sich der Modalwert erst nacheiner Klassierung, da evtl. gar keine Merkmalsauspragungenmehrfach beobachtet werden.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 57

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.2 Das”
richtige“ Lagemaß
3.4.2 Das”
richtige“ Lagemaß
$45000
$15000
$10000
$5700
$5000
$3700
$3000
$2000
arithmetisches Mittel
Median (12 mit mehr, 12 mit weniger)
Modalwert
Abb. 15 : Beispiel: Mittleres Einkommen von 25 Personen
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 58

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.2 Das”
richtige“ Lagemaß
3.4.2 Das”
richtige“ Lagemaß
Bemerkung
Die Wahl des Lagemaßes kann die Aussage entscheidendbeeinflussen.
Aus einem Beispiel mit Anmeldezeiten von Studierenden(Histogramm siehe nachste Folie), folgt:
Arithmetisches Mittel bei schiefer Verteilung – wieder nicht gutgeeignet.Modus bei stetigen Merkmalen: Macht erst Sinn nach Klassierung.Aber welche Klassierung verwenden?Median reprasentiert die Anmeldezeiten noch am besten, sofern dasmit einer einzigen Zahl uberhaupt moglich ist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 59

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.2 Das”
richtige“ Lagemaß
3.4.2 Das”
richtige“ Lagemaß
Histogramm der Anmeldezeiten
Zeit (in Minuten)
empi
risch
e D
icht
e
0 500 1000 1500 2000 2500 3000 3500
0.00
000.
0010
0.00
20 579.9 − Arithm. Mittel250.9 − Median200.0 − Modus (100er Klaasen)330.0 − Modus (10er Klassen)
3 Modi für 1er Klassen:139, 233, 253
Abb. 16 : Beispiel: Arithmetisches Mittel, Median und Modalwerte derAnmeldezeiten von Studierenden
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 60

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.2 Das”
richtige“ Lagemaß
3.4.2 Das”
richtige“ Lagemaß
Fortsetzung von Beispiel 1, hier sind sich die Lagemaße recht einig:
Histogramm des Gewichts von 200 Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
0.00
0.01
0.02
0.03
0.04
30 40 50 60 70 80 90 100 110 120 130 140
80.8 − Arithm. Mittel80.0 − Median75.0 − Modus (1er)80.0 − Modus (10er)
Abb. 17 : Beispiel: Arithmetisches Mittel, Median und Modalwerte des Gewichtsvon 200 Patienten
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 61

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.3 Weitere Lagemaße / Mittel
3.4.3 Weitere Lagemaße / Mittel
Idee
Neben den 3 bisher vorgestellten Lagemaßen gibt es noch viele weitereLagemaße, die fur spezielle Problemstellungen entwickelt wurden. Esfolgen einige wichtige Beispiele.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 62

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.3 Weitere Lagemaße / Mittel
3.4.3 Weitere Lagemaße / Mittel
Lagemaße 3
Gewichtetes (bzw. gewogenes) arithmetisches Mittel
xw :=n∑
i=1
wixi , mit wi ≥ 0,n∑
i=1
wi = 1 (3)
Geometrisches Mittel
xg := n
√√√√ n∏i=1
xi , mit xi ≥ 0 (4)
Gewichtetes geometrisches Mittel
xgw :=n∏
i=1
xwi
i , mit xi ,wi ≥ 0,n∑
i=1
wi = 1 (5)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 63

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.3 Weitere Lagemaße / Mittel
3.4.3 Weitere Lagemaße / Mittel
Beispiele:
Ausgaben fur Benzin und MotorolDer fur einen Autofahrer relevante mittlere Preisanstieg von Benzinund Motorol hangt naturlich davon ab, wieviel Benzin und Motorolein Auto verbraucht. Es gelte:
Preisanstieg: Benzin um 50%, Motorol um 10%.Ausgabenanteil: Benzin 90%, Motorol 10%.
Dann ist xw := 0.9 · 50 + 0.1 · 10 = 46% der mittlere Preisanstieg.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 64

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.3 Weitere Lagemaße / Mittel
3.4.3 Weitere Lagemaße / Mittel
Mittlere Wachstumsrate
Der Kurs einer Aktie habe sich uber 4 Zeitpunkte wie folgtentwickelt:1000 EUR → 1200 EUR → 1500 EUR → 1000 EUR.Sie interessieren sich fur die mittlere Rendite, wobei Zinsen undDividenden vernachlassigt werden sollen.Was fur ein Mittel wurden Sie verwenden?
a) Das arithmetische Mittel r der Wachstumsraten ri :
r = 1/3∑n
i=1 ri =(20% + 25%− 33.33%)
3= 3.89%,
b) den Median der Wachstumsraten: rmed = 20% oderc) die Differenz des geometrischen Mittels der Wachstumsfaktoren
1 + ri und 1, alsorg − 1 = 3
√1.2 · 1.25 · 0.66− 1 = 0?
Naturlich muss die mittlere Rendite = 0 sein, da der Kurs wieder zuseinem Ausgangswert zuruckgekehrt ist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 65

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.3 Weitere Lagemaße / Mittel
3.4.3 Weitere Lagemaße / Mittel
Ganz allgemein verwendet man als Durchschnitt von Wachstumsraten:
r := n
√√√√ n∏i=1
(1 + ri )− 1. (6)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 66

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.3 Weitere Lagemaße / Mittel
3.4.3 Weitere Lagemaße / Mittel
Lagemaße 4
Harmonisches Mittel
xh :=n
n∑i=1
1xi
, falls alle xi < 0 oder alle xi > 0 (7)
Gewichtetes harmonisches Mittel
xhw :=1
n∑i=1
wi
xi
, (8)
mit xi < 0 oder xi > 0 fur alle i ,wi ≥ 0,n∑
i=1
wi = 1.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 67

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.4 Rangmaßzahlen
3.4.4 Rangmaßzahlen
Idee
Die Idee, eine Verteilung durch den Zentralwert (= 50%-Wert, Median)zu beschreiben, lasst sich einfach auf beliebige 100 · p%-Werteverallgemeinern.
Solche sogenannten p-Quantile sind ebenfalls nutzliche Hilfsmittel zurBeschreibung einer Rangliste
x(1) ≤ x(2) ≤ . . . ≤ x(n).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 68

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.4 Rangmaßzahlen
3.4.4 Rangmaßzahlen
Definition 6
Ein p-Quantil Qp, p ∈ [0, 1], ist eine Zahl, fur die 100 · p% derMerkmalswerte einer Gesamtheit kleiner oder gleich sind und100 · (1− p)% großer oder gleich.
Genauer konnte man fur Qp z.B. Folgendes fordern:
Qp ≥ großtem Merkmalswert einer Gesamtheit, der ≤ 100 · p% derMerkmalswerte ist undQp ≤ nachstgroßerem Merkmalswert der Gesamtheit, also
x(bnpc) ≤ Qp ≤ x(bnpc+1). (9)
Wenn eine von beiden Forderungen nicht erfullbar ist, wird nur die andereverwendet.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 69

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.4 Rangmaßzahlen
3.4.4 Rangmaßzahlen
Die folgende Berechnungsmethode fur Quantile entspricht der obigenBerechnung des Medians.
p-Quantil Berechnung:”Standard“ (Nicht in R, dort type = 2 wahlen.)
Qp :=
x(j), j := dnpe, np nicht ganzzahlig
x(j) + x(j+1)
2, j := np, np ganzzahlig
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 70

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.4 Rangmaßzahlen
3.4.4 Rangmaßzahlen
Diese Art der Berechnung wird im Folgenden immer verwendet, wennnichts anderes vermerkt ist.
Bezeichnung
Anstelle von p-Quantil sagt man auch 100 · p(%)-Perzentil oder(1-p)-Fraktil.
0.25- bzw. 0.75-Quantile heißen auch unteres bzw. oberes Quartil:unteres Quartil q4 = 0.25-Quantil; oberes Quartil q4 = 0.75-Quantil.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 71

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.4 Rangmaßzahlen
3.4.4 Rangmaßzahlen
Beispiel 1, Gewicht von 200 Patienten, Erinnerung:
40 60 80 100 120 140
0.0
0.2
0.4
0.6
0.8
1.0
Gewicht von 200 Patienten
Gewicht (in kg)
empi
risch
e V
erte
ilung
klassiertunklassiert
Abb. 18 : Empirische Verteilungsfunktion zu Beispiel 1: Gewicht von 200Patienten
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 72
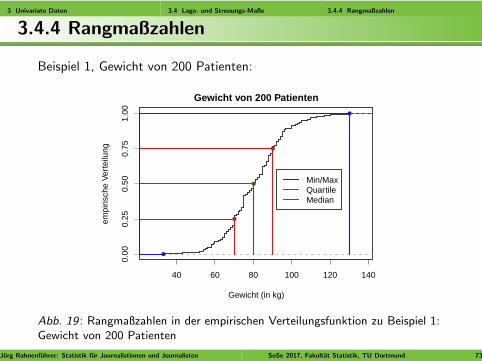
3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.4 Rangmaßzahlen
3.4.4 Rangmaßzahlen
Beispiel 1, Gewicht von 200 Patienten:
40 60 80 100 120 140
Gewicht von 200 Patienten
Gewicht (in kg)
empi
risch
e V
erte
ilung
Min/MaxQuartileMedian
0.00
0.25
0.50
0.75
1.00
Abb. 19 : Rangmaßzahlen in der empirischen Verteilungsfunktion zu Beispiel 1:Gewicht von 200 Patienten
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 73

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.5 Streuungsmaße
3.4.5 Streuungsmaße
Streuungsmaße 1
empirische Varianz:”Durchschnitt“ der quadrierten Abweichungen
vom arithmetischen Mittel
varx = s2x :=
n∑i=1
(xi − x)2
(n − 1)=
(x1 − x)2 + . . .+ (xn − x)2
(n − 1)(10)
Standardabweichung: Wurzel aus der Varianz
sx :=√
varx (11)
Quartilsdifferenz (interquartile range)
qdx := q4 − q4 (12)
Spannweite (range)
Rx := max(x)−min(x) = x(n) − x(1) (13)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 74

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.5 Streuungsmaße
3.4.5 Streuungsmaße
Beispiel:
geordnete Liste: -15, 1, 3, 4, 4, 6, 6, 7
varx = 50.86, sx = 7.13, qdx = 4,Rx = 22
Bemerkungen
Die Spannweite ist am empfindlichsten gegen”Ausreißer“, die
Quartilsdifferenz am wenigsten.
Bei”normalverteilten“ Merkmalen gilt die folgende Beziehung
zwischen den Streuungsmaßzahlen: qd ≈ 1.35sx und R ≈ 6sx .
Wiederum stellt sich die Frage nach der”richtigen“ Streuung.
Wiederum hangt die Interpretation einer Verteilung haufigentscheidend von der Wahl der Streuungsmaßzahl ab.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 75

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.5 Streuungsmaße
3.4.5 Streuungsmaße
Beispiel 1, Gewicht von 200 Patientensx = 15.14 kg, qdx = 20 kg, Rx = 97 kg
Histogramm des Gewichts von 200 Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
0.00
0.01
0.02
0.03
0.04
30 40 50 60 70 80 90 100 110 120 130 140
Quartilsdifferenzarithm. Mittel +/− Std.abw.Spannweite
Abb. 20 : Beispiel: Streuungsmaße des Gewichts von 200 PatientenJorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 76

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.5 Streuungsmaße
3.4.5 Streuungsmaße
Streuungsmaße 2
Variationskoeffizient (relative Standardabweichung)
vx :=sxx
(14)
Mittlere absolute Medianabweichung,MD (von
”Mean Deviation from the median“)
mdx :=1
n
n∑i=1
|xi −medx | (15)
Mediane absolute Medianabweichung,MAD (von
”Median Absolute Deviation“)
madx := med(|xi −medx |) (16)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 77

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.5 Streuungsmaße
3.4.5 Streuungsmaße
Bemerkungen
Die Streuung der Verteilungen (mit positiven Werten)unterschiedlicher Merkmale wird haufig durch denVariationskoeffizienten verglichen, weil er
”dimensionslos“ ist,
d.h. nicht von den Einheiten der verglichenen Merkmale abhangt.
Ein wesentlicher Vorteil des Medians gegenuber dem arithmetischenMittel ist die Robustheit gegenuber Ausreißern. Siehe auch
”robuste Statistik“.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 78

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.6 Eigenschaften der Lagemaße
3.4.6 Eigenschaften der Lagemaße
Satz 1 (Minimaleigenschaft des arithmetischen Mittels)
Das arithmetische Mittel minimiert die mittlere quadratische Abweichungvon einer Konstanten c:
n∑i=1
(xi − x)2 ≤n∑
i=1
(xi − c)2 fur alle c ∈ R (17)
Beweis.
d
dc
n∑i=1
(xi − c)2 = −2n∑
i=1
(xi − copt) = 0 ⇒ copt =1
n
n∑i=1
xi
Der Mittelwert ist damit derjenige Wert, der minimalen summiertenquadratischen Abstand zu allen anderen Werten xi hat.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 79

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.6 Eigenschaften der Lagemaße
3.4.6 Eigenschaften der Lagemaße
Satz 2 (Minimaleigenschaft des Medians)
Der Median minimiert die mittlere absolute Abweichung von einerKonstanten c:
n∑i=1
|xi −medx | ≤n∑
i=1
|xi − c | fur alle c ∈ R. (18)
Motivation (!)
n∑i=1
|xi − c | =∑xi>c
(xi − c) +∑xi<c
(c − xi ) +∑xi=c
(c − xi )
d
dc
n∑i=1
|xi − c | =d
dc
(∑xi>c
(xi − c) +∑xi<c
(c − xi )
)=
∑xi>c
(−1) +∑xi<c
(+1) = 0 ⇔ copt = medx
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 80

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.7 Eigenschaften der Varianz
3.4.7 Eigenschaften der Varianz
Satz 3 (Steiner’scher Verschiebungssatz)
Es seien x1, . . . , xn ∈ R, a ∈ R. Dann gilt:
n∑i=1
(xi − a)2 =n∑
i=1
(xi − x)2 + n(x − a)2. (19)
Beweis.siehe Literatur; nicht Teil der Vorlesung
Bemerkungen zu Steiner’schem Verschiebungssatz:
Wichtiger Satz zur Zerlegung von Quadratsummen
Anwendung im folgenden Satz
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 81

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.7 Eigenschaften der Varianz
3.4.7 Eigenschaften der Varianz
Satz 4 (Spezieller Steiner’scher Verschiebungssatz)
Die empirische Varianz lasst sich berechnen als:
varx = s2x =
1
n − 1
n∑i=1
x2i −
n
n − 1x2. (20)
Beweis.Anwendung von Satz 3 mit a = 0 und Division durch n − 1.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 82

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.8 Lage- und Streuungsmaße: Skalentypen
3.4.8 Lage- und Streuungsmaße: Skalentypen
Idee
Bisher wurde stillschweigend angenommen, dass das untersuchteMerkmal metrisch ist.
Nur dann ist es moglich, mit den Merkmalswerten zu rechnen undalso arithmetisches Mittel und Standardabweichung zu berechnen.Diese beiden Maßzahlen sind tatsachlich bei ordinalen undnominalen Merkmalen nicht verwendbar.
Anders sieht es aus bei Quantilen, wie z.B. dem Median.
Die obige Standard-Berechnung der Quantile ist sozusagenreparierbar, so dass diese Maßzahlen auch bei ordinalen Merkmalenverwendbar sind, wenn auch nicht bei nominalen Merkmalen, derenWerte ja gar nicht anzuordnen sind.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 83

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.8 Lage- und Streuungsmaße: Skalentypen
3.4.8 Lage- und Streuungsmaße: Skalentypen
Zur Reparatur der p-Quantile wird folgende Berechnung verwendet, diedas arithmetische Mittel vermeidet.
p-Quantile fur ordinale Merkmale:
Qp := x(j), j := dnpe.
Mit dem”reparierten“ Median haben wir ein angemessenes Lagemaß
fur ordinale Merkmale.
Schwieriger sieht es mit Streuungsmaßen aus, denn sowohl bei derQuartilsdifferenz als auch bei der Spannweite muss mit denMerkmalswerten gerechnet werden.Streuungsaussagen bei ordinalen Merkmalen sind deshalb vonfolgendem Typ:
50% der Werte liegen zwischen q4 und q4 oder100% der Werte liegen zwischen min und max.Fur nominale Merkmale steht mit dem Modalwert bisher lediglich einLagemaß zur Verfugung. Ein Streuungsmaß wird ab Seite 86vorgestellt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 84

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.8 Lage- und Streuungsmaße: Skalentypen
3.4.8 Lage- und Streuungsmaße: Skalentypen
Tab. 1 : Lagemaße bei den verschiedenen Skalentypen
Skalentyp: Mittelwert Median Modalwert
metrisch ja ja (ja)ordinal - ja ja
nominal - - ja
Tab. 2 : Streuungsmaße bei den verschiedenen Skalentypen
Skalentyp: Std.Abw., Quartile, Min., Max.Varianz Quartilsdiff. Spannweite
metrisch ja ja jaordinal - ja ja
nominal - - -
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 85

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.9 Empirische Entropie
3.4.9 Empirische Entropie
Idee
Ausgehend von der Idee, dass seltene Ereignisse mehr”Information“
beinhalten als haufige, schlug der osterreichische Physiker Boltzmann(1844 - 1906) vor, den Informationsgehalt eines Ereignisses durch ln(1/p)zu bestimmen, wobei p die Wahrscheinlichkeit des Ereignisses ist.
Die”mittlere“ Information von K moglichen Ereignissen heißt dann die
EntropieK∑
k=1
pk ln(1/pk), d.h. die mit den Wahrscheinlichkeiten pk
gewichteten Informationsgehalte ln(1/pk) der moglichen Ereignisse.
Diese Idee wird nun zur Definition eines Streuungsmaßes furnominale Merkmale verwendet.
Dabei werden die Ereignisse betrachtet, dass bei einemMerkmalstrager ein bestimmter Merkmalswert angenommen wird.
Die Wahrscheinlichkeiten werden durch die relativen Haufigkeitenangenahert.
Man spricht deshalb auch von empirischer Entropie.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 86

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.9 Empirische Entropie
3.4.9 Empirische Entropie
Definition 7 (Empirische Entropie als Streuungsmaß)
Gegeben seien n Merkmalstrager in K Klassen mit absolutenHaufigkeiten Hk und relativen Haufigkeiten hk , k = 1, . . . ,K .Dann ist die (normierte) empirische Entropie B (nach Boltzmann)definiert durch:
B :=1
ln(K )
K∑k=1,hk 6=0
hk · ln(
1
hk
)(21)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 87

3 Univariate Daten 3.4 Lage- und Streuungs-Maße 3.4.9 Empirische Entropie
3.4.9 Empirische Entropie
Bemerkung
Das Teilen durch ln(K ) bewirkt eine”Normierung“:
B ist maximal = 1, namlich wenn hk = 1/K, k = 1, . . . ,K ,
B ist minimal = 0, namlich wenn hj = 1 und hk = 0 fur alle k 6= j .
Diese Eigenschaften qualifizieren die empirische Entropie B zu einemStreuungsmaß, denn B ist maximal, wenn die Merkmalswerte maximalstreuen, und minimal bei uberhaupt keiner Streuung.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 88

3 Univariate Daten 3.5 Weitere Verteilungscharakterisierungen
Idee
Naturlich hat man bei den meisten Verteilungen noch keine Vorstellunguber die Form eines dazugehorigen Histogramms, wenn man nur Lage-und Streuungsmaße kennt.
Hier werden deshalb noch 3 weitere Charakteristiken von Verteilungenangesprochen, namlich Anzahl Gipfel, Schiefe und Wolbung.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 89

3 Univariate Daten 3.5 Weitere Verteilungscharakterisierungen 3.5.1 Gipfel
3.5.1 Verteilungscharakterisierungen: Gipfel
Gipfel
Bei mehrgipfligen Haufigkeitsverteilungen, insbesondere bei U-formigen,sind, im Gegensatz zu eingipfligen Verteilungen, die Lagemaße oft nichtcharakteristisch fur die Verteilung.
Man spricht von ein-, zwei- und mehrgipfligen Verteilungen.
Eingipflige Verteilung(Gewicht von 200 Patienten)
Gewicht (in kg)
empi
risch
e D
icht
e0.
000
0.00
50.
010
0.01
50.
020
0.02
5
40 60 80 100 120 140
Zweigipflige Verteilung
Ein Merkmal
empi
risch
e D
icht
e
0 2 4 6 8 10
0.00
0.05
0.10
0.15
0.20
Mehrgipflige Verteilung
Ein Merkmal
empi
risch
e D
icht
e0 5 10 15 20
0.00
0.02
0.04
0.06
0.08
0.10
0.12
Abb. 21 : a) ein-, b) zwei-, c) mehrgipflige VerteilungJorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 90

3 Univariate Daten 3.5 Weitere Verteilungscharakterisierungen 3.5.2 Schiefe
3.5.2 Verteilungscharakterisierungen: Schiefe
Schiefe (skewness)
Eingipflige Verteilungen konnen auf 2 Arten schief sein:
Linksschiefe Verteilung
Ein Merkmal
empi
risch
e D
icht
e
5 6 7 8 9 10
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Rechtsschiefe Verteilung
Ein Merkmal
empi
risch
e D
icht
e
0 1 2 3 4 5
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Abb. 22 : a) link-, b) rechtsschiefe Verteilung
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 91

3 Univariate Daten 3.5 Weitere Verteilungscharakterisierungen 3.5.2 Schiefe
3.5.2 Verteilungscharakterisierungen: Schiefe
Bei eingipfligen symmetrischen Verteilungen stimmen Modalwert, Medianund Mittelwert uberein.
Linksschiefe und Rechtsschiefe lassen sich als systematische Verschiebungdes Mittelwerts gegenuber Median und Modalwert nach links bzw. rechtscharakterisieren.
Definition 8 (Schiefe, Mittelwert-Variante)
Eine eingipflige Verteilung heißt
rechtsschief oder linkssteil, falls modx < medx < x
linksschief oder rechtssteil, falls modx > medx > x
symmetrisch, falls modx = medx = x
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 92

3 Univariate Daten 3.5 Weitere Verteilungscharakterisierungen 3.5.2 Schiefe
3.5.2 Verteilungscharakterisierungen: Schiefe
Beispiel 1: Gewicht von 200 Patienten.
Diese Verteilung ist eingipflig und symmetrisch, dennmodx = 80 = medx = 80 ≈ x = 80.8.
Histogramm des Gewichts von 200 Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
0.00
0.01
0.02
0.03
0.04
30 40 50 60 70 80 90 100 110 120 130 140
80.8 − Arithm. Mittel80.0 − Median80.0 − Modus (10er)
Abb. 23 : Lagemaße des Gewichts von 200 Patienten
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 93

3 Univariate Daten 3.5 Weitere Verteilungscharakterisierungen 3.5.3 Wolbung
3.5.3 Verteilungscharakterisierungen: Wolbung
Wolbung (Kurtosis, Exzess)
Idee
Verteilungen konnen also mehrgipflig sein oder eingipflig undsymmetrisch oder schief.
Bei symmetrischen eingipfligen Verteilungen ist außerdem von Interesse,ob die Verteilung spitz oder flach ist.
Maße dafur sind die sogenannten Wolbungskoeffizienten.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 94

3 Univariate Daten 3.5 Weitere Verteilungscharakterisierungen 3.5.3 Wolbung
3.5.3 Verteilungscharakterisierungen: Wolbung
Formen der Wolbung bei symmetrischen Verteilungen
Die Merkmalsauspragungen sind bei
i) abgeplatteten (platykurtischen) Verteilungengleichmaßig verteilt uber begrenzten Bereich;
ii) spitzen (leptokurtischen) Verteilungenstark um Mittelwert konzentriert mit wenigen weit abseits liegendenWerten;
iii) mesokurtischen Verteilungen
”ausgewogen“ um den Mittelwert verteilt.
Um die Starke der Wolbung zu bestimmen, werden unterschiedliche sog.Wolbungskoeffizienten vorgeschlagen (hier nicht diskutiert).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 95

3 Univariate Daten 3.5 Weitere Verteilungscharakterisierungen 3.5.4 Zusammenfassung
3.5.4 Verteilungscharakterisierungen: Fazit
Fazit: Verteilungscharakterisierungen
Lagemaße charakterisieren die Mitte der Verteilung.
Streuungsmaße charakterisieren die Streuung um die Mitte.
Schiefekoeffizienten charakterisieren die Unsymmetrie.
Wolbungskoeffizienten charakterisieren die Steilheit.
Unnotige Gruppierung der Daten fuhrt zu Informationsverlust.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 96

3 Univariate Daten 3.6 Box-Plots
3.6 Box-Plots
Idee
Grafische Darstellungen sind viel anschaulicher als algebraischeCharakteristiken.
Deshalb erfreut sich eine grafische Darstellung von 5 Kennzahlen derHaufigkeitsverteilung von Merkmalswerten großer Beliebtheit.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 97

3 Univariate Daten 3.6 Box-Plots
3.6 Box-Plots
Idee
Grafische Darstellungen sind viel anschaulicher als algebraischeCharakteristiken.Deshalb erfreut sich eine grafische Darstellung von 5 Kennzahlen derHaufigkeitsverteilung von Merkmalswerten großer Beliebtheit.Dargestellt wird das Pentagramm, bestehend aus den 5 KennzahlenMinimum, Maximum, unteres und oberes Quartil und Median.Die Bezeichnung Pentagramm basiert auf der angedeuteten5-eckigen Darstellung dieser Charakteristiken.
min
q4
med
q4
max
Abb. 24 : Pentagramm
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 98

3 Univariate Daten 3.6 Box-Plots
3.6 Box-Plots
Definition 9 (Box-Plot)
Der Box- (und whisker-) Plot besteht aus einem Kasten (Box), mit
unterem Quartil q4 und oberem Quartil q4 als Begrenzungslinien,
Median medx als innere Linie,
Verbindungslinien (whiskers, Schnurrbarthaare), die bis zumaußersten Wert gezogen, der
nicht großer ist als q4 + 1.5 · (q4 − q4) bzw.nicht kleiner ist als q4 − 1.5 · (q4 − q4).
Die Grenzen q4 + 1.5 · (q4 − q4) und q4 − 1.5 · (q4 − q4) heißeninnere Zaune des Box-Plots, die Punkte zwischen Box und innerenZaunen Anrainer.
Alle Punkte, die jenseits der Verbindungslinien liegen, heißenAußenpunkte und werden mit gekennzeichnet.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 99

3 Univariate Daten 3.6 Box-Plots
3.6 Box-Plots
Bemerkungen
In dem Kasten liegen die mittleren 50% der Rangliste.
Der Box-Plot kann sowohl vertikal als auch horizontal gezeichnetwerden.
Bei Normalverteilung sind nur 0.7% der Werte Außenpunkte.
Das bedeutet, man muss je nach Anzahl an Beobachtungen eineentsprechende Anzahl an Außenpunkten erwarten.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 100

3 Univariate Daten 3.6 Box-Plots
3.6 Box-Plots
Beispiel: geordnete Liste: -15, 1, 3, 4, 4, 6, 6, 7
ein Merkmal
min
=−
15 −4 1
q 4=
2
med
x=
4
q4=
6m
ax=
7
1.5(q4 − q4)
Außenpunkt
Abb. 25 : Boxplot
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 101
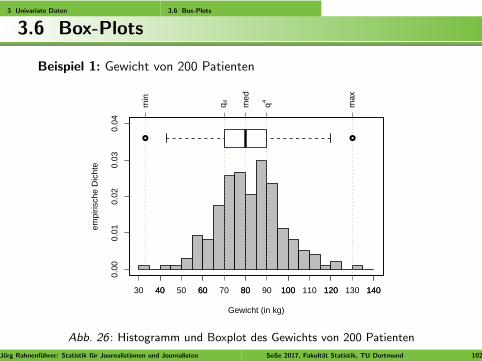
3 Univariate Daten 3.6 Box-Plots
3.6 Box-Plots
Beispiel 1: Gewicht von 200 Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
0.00
0.01
0.02
0.03
0.04
30 40 50 60 70 80 90 100 110 120 130 140
40 60 80 100 120 140
min
q 4 med
q4 max
Abb. 26 : Histogramm und Boxplot des Gewichts von 200 Patienten
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 102

3 Univariate Daten 3.6 Box-Plots 3.6.1 Parallele Boxplots
3.6.1 Parallele Box-Plots
Idee: Parallele Box-Plots
Oft ist es wichtig, verschiedene Verteilungen zu vergleichen, z.B. beider Unterteilung der Merkmalstrager in logische Gruppen (etwaManner und Frauen).
In solchen Fallen wird ein Box-Plot pro Gruppe gezeichnet, und zwarparallel bzgl. derselben Skala (parallele Box-Plots).
Dann werden Lage und Streuung der Gruppen miteinanderverglichen.
Anstatt mehrere Histogramme zu vergleichen, kann man schnellerund auf weniger Platz mehrere Box-Plots vergleichen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 103
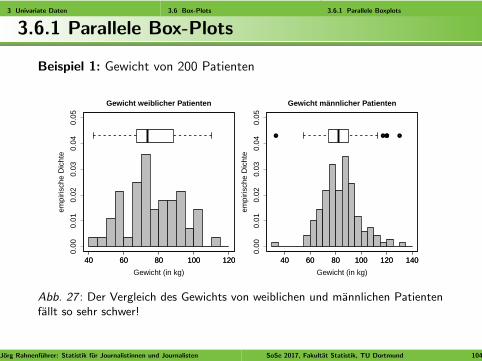
3 Univariate Daten 3.6 Box-Plots 3.6.1 Parallele Boxplots
3.6.1 Parallele Box-Plots
Beispiel 1: Gewicht von 200 Patienten
Gewicht weiblicher Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
40 60 80 100 120
0.00
0.01
0.02
0.03
0.04
0.05
40 60 80 100 120
Gewicht männlicher Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
40 60 80 100 120 1400.
000.
010.
020.
030.
040.
05
40 60 80 100 120 140
Abb. 27 : Der Vergleich des Gewichts von weiblichen und mannlichen Patientenfallt so sehr schwer!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 104

3 Univariate Daten 3.6 Box-Plots 3.6.1 Parallele Boxplots
3.6.1 Parallele Box-Plots
Beispiel 1: Gewicht von 200 Patienten
Gewicht weiblicher Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
40 60 80 100 120 140
0.00
0.02
0.04
40 60 80 100 120 140
Gewicht männlicher Patienten
Gewicht (in kg)
empi
risch
e D
icht
e
40 60 80 100 120 140
0.00
0.02
0.04
40 60 80 100 120 140
Abb. 28 : Der Vergleich des Gewichts von weiblichen und mannlichen Patientenfallt so schon leichter.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 105
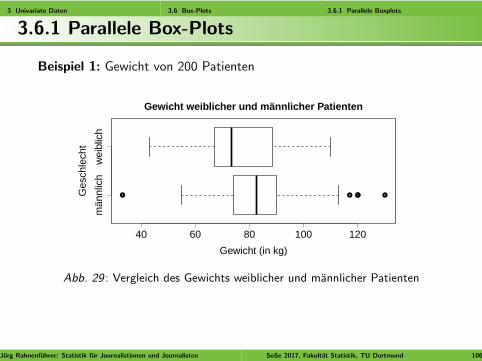
3 Univariate Daten 3.6 Box-Plots 3.6.1 Parallele Boxplots
3.6.1 Parallele Box-Plots
Beispiel 1: Gewicht von 200 Patienten
40 60 80 100 120
Gewicht weiblicher und männlicher Patienten
Gewicht (in kg)
Ges
chle
cht
män
nlic
hw
eibl
ich
Abb. 29 : Vergleich des Gewichts weiblicher und mannlicher Patienten
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 106

3 Univariate Daten 3.6 Box-Plots 3.6.1 Parallele Boxplots
3.6.1 Parallele Box-Plots
Fragen:
Wo ist das Zentrum der Daten?
Wie streuen die Daten?
Wie ist die Schiefe ist die Verteilung?
Antworten:
Frauen wiegen weniger als Manner (alle Maße der Frauen im Boxplotkleiner als entsprechende Maße fur die Manner).
Die mittleren 50% streuen bei den Frauen starker als bei denMannern.
Beide Verteilungen sind recht symmetrisch.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 107

3 Univariate Daten 3.7 Ubungsaufgaben
3.7 Ubungsaufgaben
Gegeben seien die folgenden Daten: -2, 0, 0, 2, 5.
Berechnen Sie alle Maßzahlen zur Lage und Streuung, die auf Folie84 angegeben sind. Nehmen Sie nacheinander an, dass die Daten aufKardinalskalen-, Ordinalskalen- und Nominalskalen-Niveau vorliegenund geben Sie jeweils eine geeignete Maßzahl fur die Lage und furdie Streuung an.
Gegeben sei ein Datensatz (x1, x2, x3) mit den Werten x1 = 1 undx2 = 2 und x3 ∈ R.
Fur welche Werte von x3 stimmen jeweils zwei der MaßzahlenModus, Median und Mittelwert uberein? Fur welche Werte von x3
stimmen Standardabweichung und Varianz uberein?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 108

3 Univariate Daten 3.7 Ubungsaufgaben
3.7 Ubungsaufgaben
Gegeben seien die folgenden Daten: -2, 0, 0, 2, 5.
Mittelwert: −2+0+0+2+55 = 1,
Median: x(3) = 0,Modalwert: 0.Varianz: (−2−1)2+(0−1)2+(0−1)2+(2−1)2+(5−1)2
5−1 = 9+1+1+1+164 = 7,
Standardabweichung:√
7,Quartilsdifferenz: 2-0=2, da Q0.25 = x(2) = 0 und Q0.75 = x(4) = 2,Spannweite: 5− (−2) = 7.
Gegeben sei ein Datensatz mit den Werten x1 = 1, x2 = 2, x3 ∈ R.
Modus=Median: alle x3 ∈ R (aber Modus nicht eindeutig)Median=Mittelwert: x3 = 0 oder x3 = 1.5 x3 = 3.Modus=Mittelwert: x3 = 0 oder x3 = 1.5 x3 = 3 (aber Modus nichteindeutig)Standardabweichung=Varianz ⇒ Varianz=1 ⇒ x3 = 0 oder x3 = 3(Fur Varianz=0 gilt auch Stand.abw.=Varianz, aber wegen x1 6= x2
nicht moglich)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 109

4 Bivariate Merkmale 4.1 Idee
4.1 Bivariate Merkmale
Idee
Bei der Untersuchung eines bivariaten Merkmals geht es um dieDarstellung von bivariaten Haufigkeitsverteilungen.
Wir beschaftigen uns dabei mit Situationen, in denen 2 Merkmale andemselben Merkmalstrager gleichzeitig auftreten.
Wir untersuchen also Paare von Beobachtungen.
Dabei interessiert insbesondere die Art des Zusammenhangs derbeiden Merkmale.
Bei der Zusammenhangsanalyse von 2 Merkmalen werden einerseitsgrafische Darstellungen verwendet, andererseits aber auchstatistische Maßzahlen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 110

4 Bivariate Merkmale 4.2 Kontingenztafeln
4.2 Kontingenztafeln
Bivariate Merkmale
4 Bivariate Merkmale4.2 Kontingenztafeln
Definition 10 (Kontingenztafel)
Die Merkmalsauspragungen x des univariaten Merkmals X seien inKlassen A1, . . . ,AK eingeteilt, die Merkmalsauspragungen y desunivariaten Merkmals Y in Klassen B1, . . . ,BL.Eine Kontingenztafel ist ein 2-dimensionales Schema, in dem fur jedeKombination einer der Klassen A1, . . . ,AK mit einer der KlassenB1, . . . ,BL die absolute Haufigkeit eingetragen wird, dass ein Paar(x , y) diese Klassenkombination aufweist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 111

4 Bivariate Merkmale 4.2 Kontingenztafeln
4.2 Kontingenztafeln
Tab. 3 : Kontingenztafel
Klassen von YZeilen
B1 B2 BL -summen
Kla
ssen
von
X A1 H11 H12 . . . H1L Z1
A2 H21 H22 . . . H2L Z2
A3 H31 H32 . . . H3L Z3
. . . . . . . . .AK HK1 HK2 . . . HKL ZK
Spalten- S1 S2 . . . SL nsummen
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 112

4 Bivariate Merkmale 4.2 Kontingenztafeln
4.2 Kontingenztafeln
Definition 11
Hkl ist die gemeinsame (absolute) Haufigkeit der Klassen Ak und Bl
bzw. die (absolute) Haufigkeit der Zelle k , l .
Die Zk := Hk1 + Hk2 + . . .+ HkL , k = 1, . . . ,K heißenZeilensummen und die Sl := H1l + H2l + . . .+ HKl , l = 1, . . . , Lheißen Spaltensummen.
Die Spalten- bzw. Zeilensummen reprasentieren dieHaufigkeitsverteilung von X bzw. Y . Diese heißen auchRandverteilungen.
Bemerkung
Bei nominalen, ordinalen oder diskreten metrischen Daten werden dieKlassen haufig nur mit einer Merkmalsauspragung besetzt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 113

4 Bivariate Merkmale 4.2 Kontingenztafeln
4.2 Kontingenztafeln
Erweiterung von Beispiel 1:
Patientendaten erhoben bei Untersuchungen und Behandlung nachkardiologischem Notfall; NA: fehlender Wert (Not Available)
a) Gewicht (in kg)
b) Große (in cm)
c) Herzfrequenz (in Hertz)
d) systolischer Blutdruck (in mmHg)
e) Geburtsdatum
f) Untersuchungsdatum
g) Geschlecht (m / w)
h) Diagnose (ACS = Akutes Koronarsyndrom, av = AV-Knoten-Storung,chf = Chronischer Herzfehler)
i) Rhythmus (KF = Kammerflimmern, SM = Schrittmacher,SR = Sinusrhythmus, VHF = Vorhofflimmern)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 114

4 Bivariate Merkmale 4.2 Kontingenztafeln
4.2 Kontingenztafeln
Tab. 4 : Kontingenztafeln zu je zwei Merkmalen von 200 Patienten
DiagnoseGeschl. ACS av chf
∑m 92 19 29 140w 42 5 12 59∑
134 24 41 199
RhythmusGeschl. KF SM SR VHF
∑m 0 1 115 20 136w 0 0 56 3 59∑
0 1 171 23 195
RhythmusDiagnose KF SM SR VHF
∑ACS 0 0 123 8 131
av 0 1 22 2 25chf 0 0 27 13 40∑
0 1 172 23 196
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 115

4 Bivariate Merkmale 4.2 Kontingenztafeln
4.2 Kontingenztafeln
Interpretation
Der Anteil von Mannern mit Rhythmus”VHF“ ist hoher als der der
Frauen.
Der Anteil von Mannern mit Diagnose”av“ ist hoher als der der
Frauen.
Besonders bei Diagnose”chf“ konnte als Rhythmus
”VHF“
beobachtet werden.
Bemerkungen
Es ist schwierig, schon bei halbwegs großen Zahlen alleZusammenhange zu finden.
Das fuhrt zur Suche nach geeigneten Visualisierungsmoglichkeiten.
Beispielsweise konnte man fur Tabelle 4.4 (a) versuchen, einStabdiagramm zu zeichnen, das fur jede Diagnose einen nachGeschlecht eingefarbten Anteil enthalt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 116

4 Bivariate Merkmale 4.2 Kontingenztafeln
4.2 Kontingenztafeln
ACS av chf
Diagnose bei 200 Patienten
Diagnose
Anz
ahl
0
20
40
60
80
100
120
140
FrauenMänner
Abb. 30 : Visualisierungsversuch des Zusammenhangs von Diagnose undGeschlecht
Die Anteile von Mannern und Frauen pro Diagnose sind nur schwervergleichbar.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 117

4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.1 Mosaikplots
4.2.1 Mosaikplots
Definition 12 (Mosaikplot)
Ein Mosaikplot ist ein Verfahren zur Visualisierung zweier oder mehrerer(aber weniger) qualitativer (nominalen, ordinalen oder seltener klassiertmetrischen) Merkmale mit folgenden Eigenschaften:
Die Flache der einzelnen Zellen ist proportional zur Anzahl der Fallein dieser Zelle (analog zum Stabdiagramm und zum Histogramm)
Die Gesamtflache ist 1 und wird vollstandig ausgenutzt.
Zwischenraume dienen der Ubersichtlichkeit und tragen nicht zu denAnteilen bei.
Bei Visualisierung von mehr als 2 Merkmalen wird rekursivvorgegangen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 118

4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.1 Mosaikplots
4.2.1 Mosaikplots
Mosaikplot Diagnose / Geschlecht
Diagnose
Ges
chle
cht
ACS av chf
m
w
Abb. 31 : Mosaikplot des Zusammenhangs von Diagnose und Geschlecht
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 119

4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.1 Mosaikplots
4.2.1 Mosaikplots
Bemerkungen:
Durch die pro Faktorstufe des einen Merkmals gleich großen Flachenlassen sich Unterschiede der Verhaltnisse der Faktorstufen desanderen Merkmals sehr gut vergleichen.
Das Umsortieren von Merkmalen und Faktorstufen kann wichtigsein, da es die Darstellung verandert und zu anderer Einsicht fuhrenkann (siehe folgende Abbildung).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 120

4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.1 Mosaikplots
4.2.1 Mosaikplots
Mosaikplot Diagnose / Geschlecht
Geschlecht
Dia
gnos
e
m w
ACS
av
chf
Abb. 32 : Mosaikplot des Zusammenhangs von Diagnose und Geschlecht
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 121

4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.1 Mosaikplots
4.2.1 Mosaikplots
Mosaikplot Diagnose / Rhythmus
Diagnose
Rhy
thm
us
ACS av chfKFSM
SR
VHF
Mosaikplot Geschlecht / Rhythmus
Geschlecht
Rhy
thm
us
m wKFSM
SR
VHF
Abb. 33 : Mosaikplots der weiteren Zusammenhange der Kontingenztafeln ausTabelle 4.4
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 122
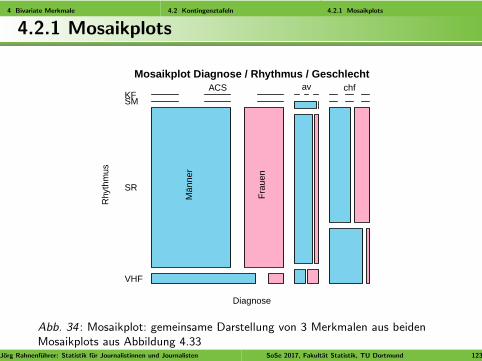
4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.1 Mosaikplots
4.2.1 Mosaikplots
Mosaikplot Diagnose / Rhythmus / Geschlecht
Diagnose
Rhy
thm
us
ACS av chfKFSM
SR
VHF
Män
ner
Fra
uen
Abb. 34 : Mosaikplot: gemeinsame Darstellung von 3 Merkmalen aus beidenMosaikplots aus Abbildung 4.33
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 123

4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.2 Streudiagramme
4.2.2 Streudiagramme
Idee
Bei metrischen bivariaten Merkmalen bilden die Merkmalswertepaareder verschiedenen Merkmalstrager eine Punktwolke in der Ebene.
Diese lasst sich anschaulich in einem x-y -Koordinatensystemdarstellen.
Definition 13 (Streudiagramm)
Ein Streudiagramm (scatterplot) ist eine grafische Darstellung von2 Merkmalen, wobei das eine Merkmal auf der x-Achse, das andere aufder y-Achse eines x-y-Koordinatensystems abgetragen wird.
Jedem Merkmalstrager i = 1, . . . , n entspricht dabei ein Symbolan der Stelle (xi , yi ), wobei xi bzw. yi der Wert des Merkmals X bzw. Yist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 124

4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.2 Streudiagramme
4.2.2 Streudiagramme
140 150 160 170 180 190
4060
8010
012
0
Streudiagramm
Größe (in cm)
Gew
icht
(in
kg)
Abb. 35 : Streudiagramm (Scatterplot) von Große und Gewicht von 200Patienten aus Beispiel 1
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 125

4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.2 Streudiagramme
4.2.2 Streudiagramme
Interpretation / Idee:
Offensichtlich steigt”im Mittel“ das Gewicht mit der Korpergroße.
Sind Sie auch auf die Idee gekommen, dass man zusatzlich dasGeschlecht mit einbeziehen sollte?
Um das zu uberprufen, bietet sich die sogenannte Stratifikation an.
Definition 14 (Stratifikation)
In einem Streudiagramm wird Stratifikation durch Verwendungverschiedener Symbole fur die Punkte unterschiedlicher Strata(= Gruppen) realisiert.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 126
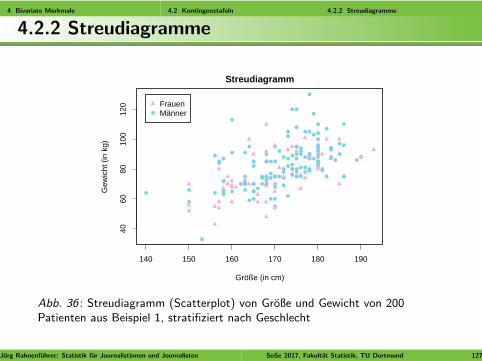
4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.2 Streudiagramme
4.2.2 Streudiagramme
140 150 160 170 180 190
4060
8010
012
0
Streudiagramm
Größe (in cm)
Gew
icht
(in
kg)
FrauenMänner
Abb. 36 : Streudiagramm (Scatterplot) von Große und Gewicht von 200Patienten aus Beispiel 1, stratifiziert nach Geschlecht
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 127

4 Bivariate Merkmale 4.2 Kontingenztafeln 4.2.2 Streudiagramme
4.2.2 Streudiagramme
Interpretation
Ganz so einfach ist es also doch nicht:Zwar liegen Frauen tendenziell etwas unterhalb der Manner, eswurde aber wohl niemand ein Vermogen darauf verwetten wollen,dass von den nachsten jeweils 5 Frauen und Mannern die Mannergroßer und schwerer als die Frauen sind.
Bemerkung
Nachdem wir grafische Darstellungen fur bivariate Zusammenhangekennengelernt haben, wird es im Folgenden darum gehen, die Starkedes Zusammenhangs mit Hilfe von statistischen Maßzahlen zucharakterisieren.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 128

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten
4.3 Kontingenzkoeffizienten – Geschichte
Geschichte
An einem Nachmittag im Jahr 1920 in der RothamstedVersuchsstation machte der beruhmte Statistiker Ronald A.Fisher (1890 – 1962) eine Tasse Tee fur Muriel Bristol.Sie protestierte, als er den Tee in die Tasse goss, bevor er dieMilch dazu gab und behauptete, dass sie unterscheiden konnte,ob die Milch zuerst oder als zweites dazu gegeben worden sei,und sie wurde ersteres vorziehen, ...
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 129

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten
4.3 Kontingenzkoeffizienten – Geschichte
Fisher entwirft Experiment, um Behauptung zu uberprufen
Muriel muss acht Tassen Tee beurteilen
Jeweils vier in jeder Reihenfolge (Milch – Tee, Tee – Milch)
Dargereicht in randomisierter Reihenfolge
Tab. 5 : Ergebnis des Experiments von Fisher
Tatsachlich Beurteilung MurielMilch-Tee Tee-Milch
Milch-Tee 3 1Tee-Milch 1 3
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 130

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten
4.3 Kontingenzkoeffizienten – Geschichte
Induktive Statistik: Fisher’s Exakter Test
Hypothese H0: Muriel kann Reihenfolge nicht unterscheiden
Teststatistik: Haufigkeit in der ersten Zelle der Tafel
Testentscheidung: Lehne H0 ab, falls Teststatistikwert großer alskritischer Wert c . Wahle c so, dass Wahrscheinlichkeit fur denFehler 1. Art (H0 ablehnen, obwohl wahr) kleiner ist als dasvorgegebene Signifikanzniveau α.
Doch bevor Sie in einem spateren Beispiel das Testen erlernen, wollen wirzunachst versuchen, den Zusammenhang zu beschreiben.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 131

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Unabhangigkeit
Idee
Bei nominalen Merkmalen soll ein Zusammenhangsmaß daruberAuskunft geben, in welchem Maße die Kenntnis des Werts einesMerkmals Information uber den Wert des anderen Merkmalsbeinhaltet.Als Grundlage fur solche Zusammenhangsmaße bieten sichKontingenztafeln an.
Tab. 6 : Kontingenztafel
Klassen von YZeilen
y1 y2 yL -summen
Kla
ssen
von
X x1 H11 H12 . . . H1L Z1
x2 H21 H22 . . . H2L Z2
x3 H31 H32 . . . H3L Z3
. . . . . . . . .xK HK1 HK2 . . . HKL ZK
Spalten- S1 S2 . . . SL nsummen
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 132

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Unabhangigkeit
Definition 15 (Kontingenzkoeffizient)
Ein Zusammenhangsmaß fur 2 nominale Merkmale heißtKontingenzkoeffizient, wenn es auf einer Kontingenztafel der beidenMerkmale beruht.Im Allg. werden dabei die Klassen nur mit einer Merkmalsauspragungbesetzt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 133

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Unabhangigkeit
Beispiel 3 (Abiturart und Bewerbungsergebnis)
Besteht ein Zusammenhang zwischen der Art des Abiturs und derChance, einen Lehrvertrag als Bankkauffrau/-mann in einem speziellenUnternehmen zu bekommen?Die Ergebnisse einer Umfrage sind in der folgenden Kontingenztafelzusammengefasst:
Tab. 7 : Ergebnisse
Bewerbungsergebnisangenommen warten abgelehnt Summe
Abiturnaturwiss. 2 6 4 12sprachlich 4 12 8 24anderes 1 3 2 6Summe 7 21 14 42
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 134

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Unabhangigkeit
In Beispiel 3 gibt es keinen Zusammenhang zwischen Abiturart undBewerbungsergebnis, denn relativ zur Zeilensumme (Anzahl Abschlusseeiner Art) sind alle Zeilen gleich.
Diese Beobachtung fuhrt zu:
Definition 16 ((empirische) Unabhangigkeit)
Zwei Merkmale heißen (empirisch) unabhangig, wenn alle beobachtetenHaufigkeiten mit den dazugehorigen Erwartungshaufigkeitenubereinstimmen, d.h. Hij = Eij fur alle i = 1, . . . ,K , j = 1, . . . , L, wobeigilt:
Erwartungshaufigkeit in Zelle (i , j) := Eij := nSj
n
Zi
n.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 135

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Unabhangigkeit
Bemerkungen
Wenn 2 Merkmale empirisch unabhangig sind, dann liefert dieKenntnis eines Merkmals keine Information uber dasHaufigkeitsverhalten des anderen Merkmals, denn
Hij = Eij = nsjzi = sjZi = Sjzi , wobei
sj :=Sj
n= Anteil der Werte in Klasse j des Merkmals Y
zi :=Zi
n= Anteil der Werte in Klasse i des Merkmals X ,
d.h. (z.B.) die Information, dass der Wert von Merkmal X in Klassei fallt, liefert insofern keine Information uber den Wert von MerkmalY , dass Klasse j von Merkmal Y genau so haufig vorkommen wird,wie diese Klasse insgesamt, d.h. summiert uber alle Klassen vonMerkmal X .
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 136

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Unabhangigkeit
Bei empirischer Unabhangigkeit
sind samtliche Zeilen gleich, wenn man pro Zeile durch die jeweiligeZeilensumme Zi teilt, denn es gilt:
Eij
Zi= sj .
Analoges gilt fur Spalten:
Eij
Sj= zi .
hangen die Werte in den Zellen der Kontingenztafel nur von denRandern der Tafel ab, werden also allein durch die Randverteilungenfestgelegt.
ist die relative Haufigkeit eines Paares (xi , yj) gleich dem Produktder relativen Haufigkeiten der Komponenten:
hij =Hij
n= zi sj .
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 137

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Unabhangigkeit
Beispiel 3: Abiturart und Bewerbungsergebnis
Nach Division durch die jeweiligen Zeilensummen sind alle Zeilen gleichund haben die Werte:
s1 =7
42=
1
6, s2 =
21
42=
1
2, s3 =
14
42=
1
3.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 138

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Unabhangigkeit
Idee
Die Summe der Abweichungen der Zellenhaufigkeiten von denErwartungshaufigkeiten kann als Maß fur Abhangigkeit und damitfur Zusammenhang verwendet werden.
Alle folgenden Kontingenzkoeffizienten beruhen auf dieser Idee.
Man verwendet allerdings nicht die Summe der Abweichungen,sondern die Summe der quadrierten Abweichungen derZellenhaufigkeiten von den Erwartungshaufigkeiten relativ zu denErwartungshaufigkeiten.
Wegen der Quadrierung werden Abweichungen unterschiedlichenVorzeichens gleich behandelt.
Wegen der Division durch die Erwartungshaufigkeit werdenAbweichungen bei kleinen Erwartungshaufigkeiten starker gewichtet.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 139

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – χ2-Koeffizient
Definition 17 (χ2-Koeffizient)
χ2–Koeffizient := χ2 :=K∑i=1
L∑j=1
(Hij − Eij)2
Eij(22)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 140

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – χ2-Koeffizient
Bemerkung
Obige Formel fur den χ2-Koeffizienten ist anschaulich, aber unhandlich,da zunachst die Erwartungshaufigkeiten berechnet werden mussen,danach quadrierte Differenzen zu den beobachteten Haufigkeiten, dienoch durch die Erwartungshaufigkeiten geteilt werden mussen.
Zur Berechnung verwendet man deshalb die folgende Beziehung:
χ2 =K∑i=1
L∑j=1
(Hij − ZiSj
n )2
ZiSj
n
= nK∑i=1
L∑j=1
(H2
ij
ZiSj− 2Hij
n+
ZiSj
n2
)
= n
K∑i=1
L∑j=1
H2ij
ZiSj− 1
, denn:
K∑i=1
L∑j=1
Hij =K∑i=1
L∑j=1
Eij = n.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 141

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – χ2-Koeffizient
Idee: Anforderungen an einen Kontingenzindex
Um den χ2-Koeffizienten als Kontingenzkoeffizienten verwenden zukonnen, normiert man ihn so, dass er nicht nur nach unten durch 0,sondern auch nach oben durch 1 beschrankt ist.
Kontingenzkoeffizienten sollten
bei empirischer Unabhangigkeit = 0 sein,bei vollstandiger Abhangigkeit = 1.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 142

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Phi-Koeffizient
Definition 18 (dichotom)
Ein Merkmal, das nur 2 Merkmalsauspragungen annehmen kann, heißtdichotom (zweiwertig).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 143

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Phi-Koeffizient
Idee
Wenn die beiden Merkmale X und Y dichotom sind (alternative Daten),wird die Kontingenztafel zu einer sogenannten Vierfeldertafel:
Tab. 8 : Vierfeldertafel
y1 y2 Zeilensummex1 a b a + bx2 c d c + dSpaltensumme a + c b + d n = a + b + c + d
Fur solche Vierfeldertafeln lasst sich der χ2-Koeffizient relativ einfachnach oben abschatzen. Daraus ergibt sich dann der einfachsteKontingenzkoeffizient.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 144

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Phi-Koeffizient
Lemma 1Es gilt:
χ2 = n(ad − bc)2
(a + b)(c + d)(a + c)(b + d). (23)
Beweis.
χ2 = n
(a2
Z1S1+
b2
Z1S2+
c2
Z2S1+
d2
Z2S2− 1
)=
n(a2Z2S2 + b2Z2S1 + c2Z1S2 + d2Z1S1 − Z1Z2S1S2)
Z1Z2S1S2
=n(ad − bc)2
(a + b)(c + d)(a + c)(b + d), wegen
Z1 = a + b, Z2 = c + d , S1 = a + c , S2 = b + d .
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 145

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Phi-Koeffizient
Satz 5Es gilt:
0 ≤ χ2 ≤ n. (24)
Beweis.
χ2 = n(ad − bc)2
(a + b)(c + d)(a + c)(b + d)= max! = n, wenn
b = c = 0 (und a, d 6= 0) oder a = d = 0 (und b, c 6= 0).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 146

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Phi-Koeffizient
Motiviert durch die Idee, das ein geeigneter Koeffizient die Form
φ = ±√χ2
n
haben konnte, kommen wir zu folgender Definition, die auch demVorzeichen noch eine Bedeutung beimisst:
Definition 19 (Phi-Koeffizient)
Der Phi-Koeffizient ist definiert durch:
φ :=ad − bc√
(a + b)(c + d)(a + c)(b + d). (25)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 147

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Phi-Koeffizient
Bemerkungen
Offensichtlich wird in der Definition das negative Vorzeichenverwendet, wenn ad < bc ist, und sonst das positive.
|φ| ist in obigem Sinne ein Kontingenzkoeffizient.
Im Fall |φ| = 1 wird ein Merkmal vollstandig durch das anderebestimmt.
Fur φ selber gilt: −1 ≤ φ ≤ 1, wobei
φ = +1⇔ b = c = 0 (und a, d 6= 0) undφ = −1⇔ a = d = 0 (und b, c 6= 0).
Generell teht ein negatives Vorzeichen von φ fur einen negativenZusammenhang, d.h. fur die Tendenz, dass Merkmal Y den 2. Wertannimmt, wenn Merkmal X den 1. Wert annimmt.
Da die Merkmalswerte bei nominalen Merkmalen keine naturlicheReihenfolge haben, macht eine solche Aussage aber wenig Sinn.
Bei nominalen Merkmalen wird deshalb im Allg. |φ| alsKontingenzkoeffizient verwendet.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 148
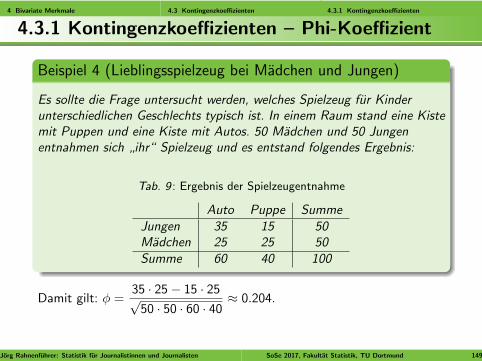
4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Phi-Koeffizient
Beispiel 4 (Lieblingsspielzeug bei Madchen und Jungen)
Es sollte die Frage untersucht werden, welches Spielzeug fur Kinderunterschiedlichen Geschlechts typisch ist. In einem Raum stand eine Kistemit Puppen und eine Kiste mit Autos. 50 Madchen und 50 Jungenentnahmen sich
”ihr“ Spielzeug und es entstand folgendes Ergebnis:
Tab. 9 : Ergebnis der Spielzeugentnahme
Auto Puppe SummeJungen 35 15 50Madchen 25 25 50Summe 60 40 100
Damit gilt: φ =35 · 25− 15 · 25√
50 · 50 · 60 · 40≈ 0.204.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 149

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Kontingenzkoeffizienten – Phi-Koeffizient
Der Phi-Koeffizient deutet also auf eine”schwache“ Abhangigkeit von
Geschlecht und Lieblingsspielzeug hin, was mit der Anschauung derZahlen ubereinstimmt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 150

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Ubungsaufgaben
Gegeben sei die folgende Kontigenztafel:
Erkrankt Nicht erkrankt Summemit Impfung 6 54 60ohne Impfung 12 18 30Summe 18 72 90
Berechnen Sie den Phi-Koeffizienten und interpretieren Sie das Ergebnis.
Welchen Wert erhalt man, wenn alle Eintrage in der Tabelle mit 10multipliziert werden?
Welchen Wert erhalt man annahernd, wenn auf alle Werte dieselbe sehrgroße Zahl addiert wird und wie sieht dann der Mosaikplot aus?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 151

4 Bivariate Merkmale 4.3 Kontingenzkoeffizienten 4.3.1 Kontingenzkoeffizienten
4.3.1 Ubungsaufgaben
Fur den Phi-Koeffizienten erhalt man: φ =6 · 18− 12 · 54√60 · 30 · 18 · 72
≈ −0.354.
Es besteht somit ein schwacher (negativer) Zusammenhang zwischenErkrankt und mit Impfung oder gleichwertig dazu ein schwacher(positiver) Zusammenhang zwischen Erkrankt und ohne Impfung.
Man kann also sagen, dass der Anteil der Erkrankten ohne Impfunggroßer ist, bei der Interpretation der Kausalitat muss man aber vorsichtigsein, hierzu fehlen Hintergrundinformationen.
Wenn man alle Eintrage mit einer Konstanten multipliziert, andert sichder Wert des Phi-Koeffizienten nicht.
Wenn man auf alle Werte dieselbe große Zahl addiert, sind alle vierEintrage annahernd gleich, der Phi-Koeffizient ist nahe bei 0 und derMosaikplot besteht aus vier etwa gleich großen Quadraten.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 152

4 Bivariate Merkmale 4.4 Korrelation
4.4 Maßkorrelationskoeffizienten
Idee
Bei metrischen Merkmalen soll ein Zusammenhangsmaß daruberAuskunft geben, auf welche Weise die Große des Werts des einenMerkmals die Große des Werts des anderen Merkmals beeinflusst.
Als Grundlage fur solche Zusammenhangsmaße bieten sichStreudiagramme an.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 153

4 Bivariate Merkmale 4.4 Korrelation
4.4 Regression – Korrelation
Wie groß ist der Korrelationskoeffizient bei folgenden Streudiagrammen?
−0.5 0.5 1.5
16
18
20
22
1) rx1y1= ?
x1
y1
−1.0 0.0 1.0
0
2
4
6
2) rx2y2= ?
x2y2
−3 −1 1 2 3
468
1012141618
3) rx3y3= ?
x3
y3
−4 −2 0 2 4
−4
−2
0
2
4
4) rx4y4= ?
x4
y4
−3 −1 0 1 2 3
2.0
2.5
3.0
3.5
4.0
5) rx5y5= ?
x5
y5
−2 −1 0 1 2
0
1
2
3
4
6) rx6y6= ?
x6y6
Abb. 37 : Quiz: Wie groß ist die jeweilige Korrelation?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 154

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
(Bravais-Pearson) Korrelationskoeffizient
Idee (W. Kramer (1994): Statistik verstehen, Campus)
Das verbreitetste Zusammenhangsmaß fur metrische Merkmale istder Korrelationskoeffizient.
Die zugrundeliegenden Ideen stammen von Galton (1888).
Heute ist der Koeffizient nach seinem Schuler Pearson benannt.Galton argumentierte, dass wir einen Merkmalswert als großempfinden, wenn er deutlich großer als der Durchschnitt ist, undeine Abweichung vom Mittelwert als umso großer, je weniger dieDaten streuen.
Die Große eines Merkmalswerts wird also auf den Durchschnittswertbezogen, Abweichungen vom Durchschnitt werden in AnzahlStandardabweichungen gemessen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 155
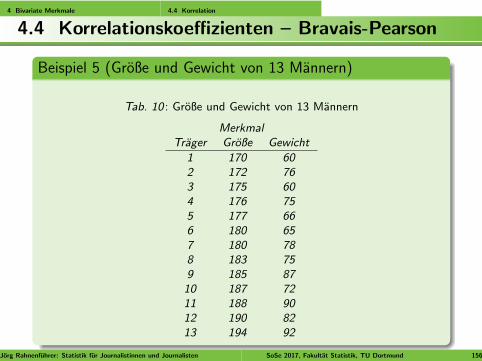
4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
Beispiel 5 (Große und Gewicht von 13 Mannern)
Tab. 10 : Große und Gewicht von 13 Mannern
MerkmalTrager Große Gewicht
1 170 602 172 763 175 604 176 755 177 666 180 657 180 788 183 759 185 87
10 187 7211 188 9012 190 8213 194 92
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 156

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
170 175 180 185 190
6065
7075
8085
90
Größe und Gewicht von 13 Männern
Größe (in cm)
Gew
icht
(in
kg)
Abb. 38 : Große und Gewicht von 13 Mannern
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 157

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
Interpretation
Wir interessieren uns fur den Zusammenhang von Große undGewicht von Mannern.
Dazu werden bei 13 Mannern mittleren Alters Große und Gewichtgemessen.
Nach Galton sprechen wir von einem”großen“ Mann, wenn er
”groß
in Bezug auf den Durchschnitt (181.3 cm)“ ist, und ein Mann ist
”schwer“, wenn er
”schwer in Bezug auf den Durchschnitt (75.2
kg)“ ist.
Abweichungen vom Mittelwert werden gemessen in AnzahlStandardabweichungen, also in den Einheiten SGroße = 7.3 cm undSGewicht = 10.6 kg.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 158

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
−1.5
−1.0
−0.5
0.0
0.5
1.0
1.5
Größe und Gewicht von 13 Männern
Größenabw. vom Mittel (in Anz. Standardabw.)
Gew
icht
sabw
. vom
Mitt
el (
in A
nz. S
tand
arda
bw.)
III
III IV
Abb. 39 : Große und Gewicht von 13 Mannern – transformiert
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 159

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
Idee
Wenn die Große eines Merkmalswerts auf den Durchschnittswertbezogen wird, entspricht das einer Nullpunktverschiebung in dasarithmetische Mittel der Punkte, wie in Abb. 38 angedeutet.
Wenn Abweichungen vom Durchschnitt in”Anzahl
Standardabweichungen“ gemessen werden, entspricht das derVerwendung neuer Einheiten, wie in Abb. 39 angedeutet.
Beide Transformationen zusammen entsprechen dem Ubergang zustandardisierten Abweichungen vom Mittelwert:
xi :=xi − x
sx, i = 1, . . . , n.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 160

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
Nummeriert man die Quadranten in dem neuen Koordinatenkreuzwie in Abb. 39, so spricht man von positiver Korrelation, wenn sichdie Punkte in den Quadranten I und III haufen, und von negativerKorrelation, wenn die Punkte sich in den Quadranten II und IVhaufen.
Abweichungen vom Durchschnitt werden proportional zur Flache desRechtecks vom Mittelwert zum Streudigramm-Punkt gerechnet.
Dabei werden die Vorzeichen der beiden Koordinaten eines Punktesinsofern berucksichtigt, dass Punkte in den Quadranten I und III alspositive Abweichungen gezahlt werden (grun in der Skizze) undPunkte in Quadranten II und IV als negative Abweichungen (rot inde Skizze).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 161

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
Definition 20 ((empirischer) Korrelationskoeffizient)
Der (empirische) Korrelationskoeffizient rxy der Merkmale X und Yist definiert als die
”mittlere Flache mit dem Achsenschnittpunkt“:
rxy :=1
n − 1
n∑i=1
xi yi =
n∑i=1
(xi − x)(yi − y)
(n − 1)sxsy(26)
Bemerkung
Wie bei der Berechnung der Standardabweichungen teilt man nicht durchn, sondern durch n − 1.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 162

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
Berechnung des Korrelationskoeffizienten
rxy =
n∑i=1
(xi − x)(yi − y)√n∑
i=1
(xi − x)2n∑
i=1
(yi − y)2
=
n∑i=1
xiyi − nx y√(n∑
i=1
x2i − nx2
)(n∑
i=1
y 2i − ny 2
)
Beispiel 5: Große und Gewicht von 13 Mannern
rxy =178026− 13 · 75.2308 · 181.3077√
(427977− 13 · 181.30772)(74932− 13 · 75.23082)=
707.0
927.8= 0.76
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 163

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Bravais-Pearson
Bemerkung
Der Korrelationskoeffizient standardisiert eine Große mit Hilfe derStandardabweichungen der beiden beteiligten Merkmale, die ganzahnlich wie die Varianzen der Merkmale aufgebaut ist.
Anstelle der quadrierten Abweichungen (xi − x)2 bzw. (yi − y)2
werden sogenannte”Kreuzprodukte“ (xi − x)(yi − y) aufsummiert.
Der Korrelationskoeffizient rxy liegt zwischen -1 und +1 (Bew.folgt).
Z.B. ist rxy = +1, wenn y = +x und rxy = −1, wenn y = −x .
Allerdings ist rxy undefiniert, falls X oder Y nicht variiert (sx odersy = 0).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 164

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Kovarianz
Die statistische Maßzahl im Zahler des Korrelationskoeffizienten hateinen eigenen Namen:
Definition 21 (Kovarianz)
Die (empirische) Kovarianz covxy der Merkmale X und Y ist definiertals:
covxy :=1
n − 1
n∑i=1
(xi − x)(yi − y) (27)
Beispiel 5: Große und Gewicht von 13 Mannern
covxy =(178026− 13 · 75.2308 · 181.3077)
12=
707.0
12= 58.9
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 165

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten – Kovarianz
Bemerkungen
Die Kovarianz ist im Gegensatz zum Korrelationskoeffizienten nichtdimensionslos.
Die Großenordnung der Kovarianz hangt von den Messeinheiten ab.
Insofern ist die Kovarianz als Zusammenhangsmaß nicht besondersgut geeignet.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 166

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelation und Unabhangigkeit
Definition 22 ((Empirische) Unkorreliertheit)
Merkmale, deren Korrelationskoeffizient gleich Null ist, heißen(empirisch) unkorreliert.
Bemerkung
Aus Unabhangigkeit folgt also Unkorreliertheit, aber nicht umgekehrt!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 167

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten fur ordinale Daten
Rangkorrelationskoeffizienten
Idee
Korrelationskoeffizienten fur 2 ordinale Merkmale beruhen aufRangzahlen.
Anforderungen an Rangkorrelationskoeffizienten r :
i) r ist normiert, d.h. −1 ≤ r ≤ 1ii) r = 1 bei gleicher Rangordnung, d.h. falls rxi = ryi , i = 1, . . . , niii) r = −1 bei inverser Rangordnung, d.h. falls rxi = n + 1− ryi ,
i = 1, . . . , niv) r = 0 bei empirischer Unabhangigkeit.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 168

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten fur ordinale Daten
Spearman’scher Rangkorrelationskoeffizient
Idee
Der Bravais-Pearson-Maßkorrelationskoeffizient hat eine direkteEntsprechung fur ordinale Merkmale.
Dabei wird statt mit den Merkmalswerten mit den Rangzahlengerechnet.
Wir verwenden bei der Definition gleich die Berechnungsformel.
Definition 23 (Spearman’scher Rangkorrelationskoeffizient)
Der Spearman’sche Rangkorrelationskoeffizient ist definiert durch:
rs :=
n∑i=1
rxi ryi − nrx ry√(n∑
i=1
r 2xi − nr 2
x
)(n∑
i=1
r 2yi − nr 2
y
) (28)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 169

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten fur ordinale Daten
Satz 6 (Spearman Korrelation ohne Bindungen)
Falls keine Rangzahl mehrfach auftritt, gilt fur denSpearman-Korrelationskoeffizienten:
rs = 1−6
n∑i=1
d2i
n(n2 − 1), (29)
wobei di := rxi − ryi , i = 1, . . . , n.
Beweis.ohne Beweis, siehe Literatur
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 170

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten fur ordinale Daten
Bemerkung
Obige Anforderungen an Rangkorrelationskoeffizienten sind zumindest imdem Fall, dass keine Rangzahl mehrfach auftritt, bei Spearman erfullt:
i) Normierung: −1 ≤ rS ≤ 1 ist klar wegen Maßkorrelation.
ii) rS = 1 bei gleicher Rangordnung, d.h. falls rxi = ryi , i = 1, . . . , n;klar, da alle di = 0
iii) rS = −1 bei inverser Rangordnung, d.h. falls rxi = n + 1− ryi ,i = 1, . . . , n; (hier ohne Beweis, siehe Literatur).
iv) rS = 0 bei empirischer UnabhangigkeitFalls keine Rangzahl mehrfach auftritt, sind die Merkmale X und Yniemals (empirisch) unabhangig (ohne Bew.), sie konnen aberempirisch unkorreliert sein (vgl. Abschnitt 4).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 171

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten fur ordinale Daten
Bemerkung
Der Spearman’sche Rangkorrelationskoeffizient nimmt immer dann denWert 1 an, wenn zwischen den Merkmalen X und Y eine monotonwachsende Beziehung besteht, d.h. wenn fur alle (xi , yi ), (xj , yj) gilt:wenn xi < xj ist, dann ist auch yi < yj .
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 172

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten fur ordinale Daten
Beispiel 6 (Leistung und soziale Position in der Gruppe)
Es soll untersucht werden, ob ein Zusammenhang zwischen derschulischen Leistung und der Position in einer Gruppe besteht.
Dazu wurden die 6 Mitglieder der Gruppe sowohl bzgl. ihrerLeistung, als auch bzgl. ihrer Stellung in der Gruppe rangiert:
Tab. 11 : Leistung und soziale Position in der Gruppe
Name rLeistung rSympathie |d | d2
Rainer 1 2 1 1Horst 2 3 1 1Klaus 3 1 2 4Mario 4 4 0 0Peter 5 6 1 1Tilo 6 5 1 1
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 173

4 Bivariate Merkmale 4.4 Korrelation
4.4 Korrelationskoeffizienten fur ordinale Daten
Daraus ergibt sich der Spearman’sche Rangkorrelationskoeffizient als
rS = 1− 6 · 86 · 35
= 0.77.
Der interessierende Zusammenhang ist also nicht abzustreiten.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 174

4 Bivariate Merkmale 4.5 Regression
4.5 Regression
Korrelation und Linearitat
Idee
Der Korrelationskoeffizient ist auch deshalb so beliebt, weil er einMaß fur die Linearitat eines Zusammenhangs darstellt.
Es gilt rxy = ±1, genau wenn die Punkte (xi , yi ) auf einer Geradenliegen, und es gilt rxy = 0, wenn keine lineare Beziehung besteht.
Um den Grad der Linearitat eines Zusammenhangs quantifizieren zukonnen, ist es zunachst notwendig, sich auf einOptimalitatskriterium zu einigen, nach dem man eine
”optimal an
die Punkte angepasste Gerade“ bestimmt.
Das beliebteste Kriterium ist das Prinzip der Kleinsten Quadrate,nach dem die Gerade so bestimmt wird, dass die Quadratsummederjenigen Abstande der Punkte von der Geraden minimal werden,die senkrecht zu der x-Achse gemessen werden.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 175

4 Bivariate Merkmale 4.5 Regression
4.5 Regression
Beispiel 5: Große und Gewicht von 13 Mannern
Tab. 12 : Große und Gewicht von 13 Mannern
Merkmal GeradeTrager x=Große y=Gewicht ya1 170 60 62.72 172 76 64.93 175 60 68.24 176 75 69.35 177 66 70.46 180 65 73.77 180 78 73.78 183 75 77.09 185 87 79.210 187 72 81.411 188 90 82.612 190 82 84.813 194 92 89.2
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 176

4 Bivariate Merkmale 4.5 Regression
4.5 Regression
170 175 180 185 190
6065
7075
8085
90
Größe und Gewicht von 13 Männern
Größe (in cm)
Gew
icht
(in
kg)
ei
ya
Abb. 40 : Große und Gewicht von 13 Mannern
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 177

4 Bivariate Merkmale 4.5 Regression
4.5 Regression
Interpretation
Zu jedem Punkt (xi , yi ) und jeder Gerade mit Achsenabschnitt b0
und Steigung b1 wird der Abstand ei := yi − b0 − b1xi senkrecht zurx-Achse berechnet (e = error).
Bei der optimalen Gerade ist S = e21 + . . .+ e2
n minimal.
Die Kleinste-Quadrate-Gerade hat hier die Form:ya = −126.73 + 1.114 · x (ya steht fur
”angepasster“ y -Wert).
Wie wird eine solche Gerade konstruiert?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 178

4 Bivariate Merkmale 4.5 Regression
4.5 Regression
Definition 24 (Definitionen zur Regression)
Die Bestimmung einer optimal angepassten Gerade nach demPrinzip der Kleinsten Quadrate heißt Regression oder Methodeder kleinsten Quadrate.
Dabei werden Achsenabschnitt b0 und Steigung b1 berechnet, sodass die Fehlerquadratsumme
S(b0, b1) =n∑
i=1
e2i (b0, b1) :=
n∑i=1
(yi − b0 − b1xi )2 (30)
minimal wird.
Die so bestimmte Gerade heißt Regressionsgerade.
yai := b0 + b1xi heißt Anpassung (Fit) von yi
ei := yi − yai heißt Residuum, jeweils fur die Beobachtungi = 1, . . . , n.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 179

4 Bivariate Merkmale 4.5 Regression
4.5 Regression
Satz 7
Fur Achsenabschnitt b0, Steigung b1 und minimale FehlerquadratsummeSmin der Regressionsgerade gilt:
b1 =covxy
s2x
= rxy ·sysx,
b0 = y − b1x ,
Smin := (n − 1)(1− r 2xy )s2
y .
Beweis zu Satz 7
Wir bestimmen b0 und b1 durch Nullsetzen der 1. Ableitungen
∂S(b0,b1)∂b0
= −2n∑
i=1
(yi − b0 − b1xi ) = 0
Daraus folgt:n∑
i=1
yi − nb0 − b1
n∑i=1
xi = 0 , also: b0 = y − b1x .
∂S(b0,b1)∂b1
= −2n∑
i=1
(yi − b0 − b1xi )xi = 0Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 180

4 Bivariate Merkmale 4.5 Regression
4.5 Regression
Daher:n∑
i=1
yixi − n(y − b1x)x − b1
n∑i=1
x2i = 0, also:
b1 =
(n∑
i=1
yixi − nxy
)(
n∑i=1
x2i − nx2
) =
n∑i=1
(yi − y)(xi − x)
n∑i=1
(xi − x)2
=covxy
s2x
=rxy sxsy
s2x
= rxysysx.
Fur die minimale Fehlerquadratsumme gilt:
Smin =n∑
i=1
(yi − b0 − b1xi )2 =
n∑i=1
((yi − y)− b1(xi − x))2
= (n − 1)(s2y − 2b1 covxy +b2
1s2x ) = (n − 1)(s2
y − b21s2
x ), denn covxy = b1s2x
= (n − 1)(1− r 2xy )s2
y
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 181

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Idee
Als Nachstes ist eine statistische Maßzahl gesucht, die die Gute derAnpassung der optimalen Gerade an die Daten beschreibt.
Tatsachlich kennen wir mit dem Korrelationskoeffizienten schon einesolche Maßzahl.
Es ist jedoch Konvention, die Anpassungsgute mit dem Quadrat desKorrelationskoeffizienten zu messen.
Definition 25 (Bestimmtheitsmaß)
Das Bestimmtheitsmaß (der Daten durch die Regressionsgerade) istdefiniert durch R2 := r 2
xy
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 182

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Beispiel 5: Große und Gewicht von 13 Mannern
b1 =covxy
s2x
= rxysysx
= 0.7610.6
7.4= 1.104,
b0 = y − b1x = 75.2− 1.104 · 181.3 = −125.0,
ya = −125.0 + 1.104 · x ,R2 = r 2
xy = 0.762 = 0.58.
ya wurde in der letzten Tabelle mit aufgefuhrt und in der dazugehorigenSkizze eingezeichnet.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 183

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Folgerung
Der Korrelationskoeffizient ist genau dann +1 bzw. -1, wenn die Merk-malsauspragungen auf einer Gerade mit positiver bzw. negativer Steigungliegen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 184

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Wie groß ist der Korrelationskoeffizient bei folgenden Streudiagrammen?
−0.5 0.5 1.5
16
18
20
22
1) rx1y1= ?
x1
y1
−1.0 0.0 1.0
0
2
4
6
2) rx2y2= ?
x2y2
−3 −1 1 2 3
468
1012141618
3) rx3y3= ?
x3
y3
−4 −2 0 2 4
−4
−2
0
2
4
4) rx4y4= ?
x4
y4
−3 −1 0 1 2 3
2.0
2.5
3.0
3.5
4.0
5) rx5y5= ?
x5
y5
−2 −1 0 1 2
0
1
2
3
4
6) rx6y6= ?
x6y6
Abb. 41 : Quiz: Wie groß ist die jeweilige Korrelation?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 185

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Bemerkungen
Die”wahren“ Korrelationskoeffizienten werden in der Vorlesung
angegeben.
Der Korrelationskoeffizient gibt den Grad des linearenZusammenhangs an.
Ganz und gar nicht-lineare Zusammenhange konnen denselbenKorrelationskoeffizienten haben wie ein nahezu linearer.
Die folgenden 4 Streudiagramme haben denselbenKorrelationskoeffizienten von rxy = 0.82.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 186

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
5 10 15
4
6
8
10
12
x1
y1
5 10 15
4
6
8
10
12
x2
y2
5 10 15
4
6
8
10
12
x3
y3
5 10 15
4
6
8
10
12
x4
y4
4 Datensätze zur Regression von Anscombe
Abb. 42 : Beispiel: 4 Mal rxy = 0.82; aus: Anscombe (1973):”Graphs in
statistical analysis“, American Statistician, 27, p. 17–21Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 187

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Vorteile von Streudiagrammen
Bei der Darstellung des Zusammenhangs zwischen 2 Merkmalendurch ein Streudiagramm gibt es, im Gegensatz zur Verwendung desKorrelationskoeffizienten, keinen Informationsverlust – im Prinzip(s.u.)!
Samtliche Information ist ablesbar, die Art des Zusammenhangs,Ausreißer, auch nicht-lineare Zusammenhange.
Dagegen misst der Korrelationskoeffizient nur den Grad des linearenZusammenhangs!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 188

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Probleme von Streudiagrammen
Mehrere Punkte konnen an derselben Stelle liegen und verdeckensich gegenseitig.
Extrem viele Punkte verursachen einen schwarzen Punktehaufen, indem man wichtige zugrundeliegende Strukturen nicht mehr sieht.
Als Losung empfiehlt sich in beiden Fallen der Einsatz von
Transparenz (jeder Punkt mit einigen Prozent Deckung:”je mehr
Punkte desto schwarzer“),
zufallige Auswahl und Darstellung einer kleineren Stichprobe,
Jitter (absichtliches Hinzufugen einer kleinen Streuung oder damitnicht alle Datenpunkte an exakt einer Stelle liegen)
Dichteschatzung und zeichnen der Hohenlinien.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 189

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Wir stellen diastolischen und systolischen gemessenen Blutdruck dar:
Abb. 43 : Diastolischer und systolischer Blutdruck
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 190

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
... und jetzt nochmal mit Transparenz::
Abb. 44 : Diastolischer und systolischer Blutdruck
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 191

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Ein weiteres Extrembeispiel zur Transparenz mit simulierten Daten (esversteckt sich eine Gruppe von Beobachtungen mit perfektemZusammenhang in allgemeinen Chaos):
Abb. 45 : Vergleich der Darstellungen ohne und mit Einsatz von Transparenz
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 192

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
In diesem Beispiel zu Motorendaten (Ethanolgemisch und Kompression)sieht man die Nutzlichkeit von zusatzlicher Streuung:
8 10 12 14 16 18
0.6
0.7
0.8
0.9
1.0
1.1
1.2
ohne Jitter
Kompression
Eth
anol
gem
isch
8 10 12 14 16 18
0.6
0.7
0.8
0.9
1.0
1.1
1.2
mit Jitter
Kompression
Eth
anol
gem
isch
Ethanolgemisch und Kompression bei verschiedenen Motoren
Abb. 46 : Vergleich der Darstellungen ohne und mit Einsatz von Jitter
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 193

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Bemerkungen
Einsatz von Jitter macht Sinn, wenn es nicht allzuvieleBeobachtungen gibt, die allerdings gehauft in einzelnen Punktenauftreten.Man beachte, dass kunstlich eine Streuung hinzugefugt wird, dieeigentlich nicht vorhanden ist. So wird leicht der Eindruck inRichtung der Jitterstreuung verfalscht.
Transparenz empfiehlt sich bei sehr vielen Beobachtungen, umStrukturen aufzudecken.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 194

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Achtung: Interpretation von Streudiagrammen
Ein Streudiagramm oder eine Korrelation sagt nichts uber dieInterpretation des Zusammenhangs!
Nicht selten sind sogenannte Scheinkorrelationen.
Das sind Korrelationen, die entweder durch Zufall oder deswegenzustande kommen, weil eine sogenannte Hintergrundvariable furbeide beobachteten Merkmale verantwortlich ist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 195

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Beispiele fur zufallige Korrelationen:
in den 60er/70er Jahren die negative Korrelation zwischenRocklange und Dow-Jones Index,
nach dem 1. Weltkrieg die positive Korrelation zwischen der AnzahlStorche und der Anzahl Geburten.
Beispiele fur das Wirken einer Hintergrundvariable:
Große von Geschwistern (gleiche Eltern!),
Wasserstand von Rhein und Donau (Regen, Schneeschmelze !) undevtl. auch
die gleichzeitige Abnahme der Anzahl Storche und der AnzahlGeburten (Industrialisierung nach dem 1. Weltkrieg).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 196

4 Bivariate Merkmale 4.5 Regression
4.5 Regression – Korrelation
Achtung: Kausalitatsrichtung
Der Korrelationskoeffizient sagt uber Kausalitat oder Kausalitatsrichtungnichts aus! Insbesondere bei der Kausalitatsrichtung neigt man haufig zuTrugschlussen.
Beispiel:
Bei einem Naturvolk wurde eine negative Korrelation zwischenKopflausen und Fieber festgestellt.
Naturlich ware es falsch, daraus abzuleiten, dass Lause gut sind furdie Gesundheit sind. Tatsachlich vertreibt Fieber die Lause!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 197
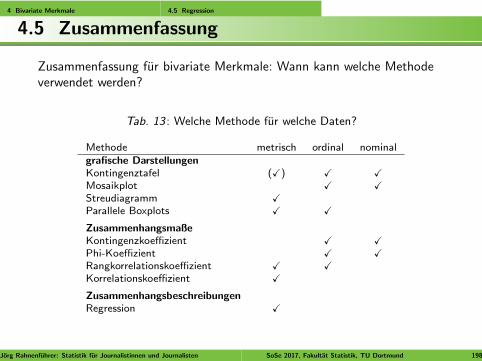
4 Bivariate Merkmale 4.5 Regression
4.5 Zusammenfassung
Zusammenfassung fur bivariate Merkmale: Wann kann welche Methodeverwendet werden?
Tab. 13 : Welche Methode fur welche Daten?
Methode metrisch ordinal nominalgrafische DarstellungenKontingenztafel (X) X XMosaikplot X XStreudiagramm XParallele Boxplots X X
ZusammenhangsmaßeKontingenzkoeffizient X XPhi-Koeffizient X XRangkorrelationskoeffizient X XKorrelationskoeffizient X
ZusammenhangsbeschreibungenRegression X
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 198

4 Bivariate Merkmale 4.6 Ubungsaufgaben
4.6 Ubungsaufgaben
Gegeben seien drei Beobachtungen eines Datensatzes mit zwei VariablenX und Y:
x1 = 4, x2 = 1, x3 = 1, y1 = −1, y2 = 0, y3 = 1.
Berechnen Sie fur die beiden Variablen die Varianz und dieStandardabweichung.
Berechnen Sie fur die beiden Variablen den Korrelationskoeffizientennach Bravais-Pearson.
Berechnen Sie die Regressionsparameter des linearen Modellsy = c + d x , bei dem also Y durch X vorhergesagt wird.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 199

4 Bivariate Merkmale 4.6 Ubungsaufgaben
4.6 Ubungsaufgaben
x1 = 4, x2 = 1, x3 = 1 ⇒ x = 2
y1 = −1, y2 = 0, y3 = 1 ⇒ y = 0
s2x =
(4− 2)2 + (1− 2)2 + (1− 2)2
2=
4 + 1 + 1
2= 3 ⇒ sx =
√3
s2y =
(−1− 0)2 + (0− 0)2 + (1− 0)2
2=
1 + 1
2= 1 ⇒ sy = 1
sxy =(4− 2)(−1− 0) + (1− 2)(0− 0) + (1− 2)(1− 0)
2= −3
2
rxy =sxy
sx sy=−3
2√
3= −√
3
2≈ −0.866
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 200

4 Bivariate Merkmale 4.6 Ubungsaufgaben
4.6 Ubungsaufgaben
x1 = 4, x2 = 1, x3 = 1 ⇒ x = 2
y1 = −1, y2 = 0, y3 = 1 ⇒ y = 0
s2x = 3, s2
y = 1, sxy = −3
2
d =sxys2x
= − 3
2 · 3= −1
2
c = y − d x = 0−(−1
2
)· 2 = 1
⇒ y = c + d x = 1− 1
2x
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 201

5 Wahrscheinlichkeitstheorie 5.1 Mengenlehre
5.1 Wahrscheinlichkeitstheorie
Nach der deskriptiven Statistik werden wir uns nun der induktivenStatistik zuwenden, um mit Hilfe von Wahrscheinlichkeiten und derenVerteilungen Schlussfolgerungen ziehen zu konnen.
Beim Aufbau des Modells fur die Wahrscheinlichkeitsrechnung wird dieMengenlehre verwendet. Die folgenden Folien dienen der Erinnerung anSchulmathematik!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 202

5 Wahrscheinlichkeitstheorie 5.1 Mengenlehre
5.1 Exkurs: Mengenlehre
Gegeben 2 Ereignisse A, B, dann werden die folgendenMengenoperationen benotigt:
Abb. 47 : Venn-Diagramme der Mengenoperationen
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 203

5 Wahrscheinlichkeitstheorie 5.1 Mengenlehre
5.1 Exkurs: Mengenlehre
Beispiel: Werfen von 2 verschiedenfarbigen Wurfeln
A: Die Augenzahlen beider Wurfel sind gleich (Pasch)
B: Die Augensumme beider Wurfel ist gleich 6.
Abb. 48 : Mogliche Operationen bei Wurfelbeispiel
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 204

5 Wahrscheinlichkeitstheorie 5.1 Mengenlehre
5.1 Exkurs: Mengenlehre
Satz 8 (Eigenschaften von Mengensystemen)
(i) Kommutativgesetze:A ∪ B = B ∪ A und A ∩ B = B ∩ A
(ii) Assoziativgesetze:A ∪ (B ∪ C ) = (A ∪ B) ∪ C und (A ∩ B) ∩ C = A ∩ (B ∩ C )
(iii) Distributivgesetze:A ∩ (B ∪ C ) = (A ∩ B) ∪ (A ∩ C ) undA ∪ (B ∩ C ) = (A ∪ B) ∩ (A ∪ C )
(iv) Doppeltes Komplement:¯(A) = A
(v) Sonderstellung von ∅, Ω:A ∩ Ω = A, A ∪ Ω = Ω, A ∩ ∅ = ∅, A ∪ ∅ = A
(vi) Mengen und ihr Komplement:A ∩ A = ∅, A ∪ A = Ω, A ∩ A = A, A ∪ A = A
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 205

5 Wahrscheinlichkeitstheorie 5.1 Mengenlehre
5.1 Exkurs: Mengenlehre
Satz 8 (Eigenschaften von Mengensystemen)
(vii) De Morgan’s Gesetze:(A ∪ B) = A ∩ B und (A ∩ B) = A ∪ B
(viii) Mengendifferenz:A− B = A ∩ B
(ix) Mengendiskrepanz:A ∆ B = (A− B) ∪ (B − A)
(x) Komplementaritat:A = (A ∩ B) ∪
(A ∩ B
)und (A ∩ B) ∩
(A ∩ B
)= ∅
(xi) Teilmengen:Sei A ⊂ B, dann gilt: A ∩ B = A und A ∪ B = B
Beweis: Illustration mit Venn Diagrammen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 206

5 Wahrscheinlichkeitstheorie 5.1 Mengenlehre
5.1 Exkurs: Mengenlehre
Beispiele fur formale Beweise.
(vii) zz. (A ∪ B) = A ∩ B, d.h.zz. a) (A ∪ B) ⊂ A ∪ B und b) (A ∪ B) ⊃ A ∩ B
a) ω ∈ (A ∪ B)⇒ ω /∈ (A ∪ B)⇒ ω /∈ A ∧ ω /∈ B ⇒ ω ∈ A ∧ ω ∈ B
⇒ ω ∈ (A ∩ B)
b) ω ∈ (A ∩ B)⇒ ω /∈ A ∧ ω /∈ B ⇒ ω /∈ (A ∪ B)
(ix) A = A ∩ Ω = A ∩ (B ∪ B) = (A ∩ B) ∪ (A ∩ B)(A ∩ B) ∩ (A ∩ B) = (A ∩ A) ∩ (B ∩ B) = A ∩ ∅ = ∅
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 207

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Definition 26 (Grundgesamtheit)
Eine Grundgesamtheit ( Stichprobenraum) Ω ist die Menge aller(prinzipiell) denkbaren Versuchsergebnisse ω.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 208

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Beispiele
Werfen einer Munze: Ω = ω1, ω2 = Kopf, ZahlWerfen eines Wurfels:Ω = ω1, ω2, ω3, ω4, ω5, ω6 = 1, 2, 3, 4, 5, 6Werfen von 3 verschiedenen Munzen: pro Munze 2 Moglichkeiten,insgesamt 2 · 2 · 2 = 8 Versuchsergebnisse,Ω =(Z,Z,Z), (Z,Z,W), (Z,W,Z), (W,Z,Z), (Z,W,W), (W,Z,W),
(W,W,Z), (W,W,W)Werfen von 2 verschiedenfarbigen Wurfeln: pro Wurfel 6Moglichkeiten, insgesamt 6 · 6 = 36 Versuchsergebnisse,Ω = (1, 1), (1, 2), . . . , (1, 6), (2, 1), . . . , (2, 6), . . . , (6, 6)Korpergroße und Gewicht: Ω = ω = (ωK , ωG ) |ωK , ωG > 0
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 209

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Definition 27 (Ereignis)
Ein ( zufalliges) Ereignis A ist eine Teilmenge des Stichprobenraums Ω.
Beispiele
Werfen eines Wurfels: Ereignis A = 2, 4, 6:Wurfeln einer geraden Zahl
Werfen von 3 verschiedenen Munzen:A =(Z,W,W), (W,Z,W), (W,W,Z): genau 1mal Zahl
Werfen von 2 verschiedenfarbigen Wurfeln:A = (1, 4), (2, 3), (3, 2), (4, 1): Wurfelsumme = 5
Korpergroße und Gewicht:A = ω = (ωK , ωG ) |ωK > 1.70, ωG < 68.5
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 210

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Definition 28Ein Ereignis A tritt ein, wenn ein Versuchsergebnis in A liegt. Die leereMenge ∅ heißt unmogliches Ereignis, die Gesamtmenge Ω heißtsicheres Ereignis, die einzelnen Versuchsergebnisse ω heißenElementarereignisse.
Definition 29 (Axiomatische Definition des Ereignisraums)
Eine Menge A von Teilmengen eines Stichprobenraums Ω heißtEreignisalgebra, wenn gilt:
(i) Ω ∈ A,
(ii) Falls A ∈ A, dann A ∈ A.
(iii) Falls A1,A2 ∈ A, dann A1 ∪ A2 ∈ A.
Andere Bezeichnungen sind: Boole’sche (Mengen-)Algebra oder(Mengen-)Korper bzw. Ereignisraum oder Ereigniskorper.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 211

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Satz 9 (Eigenschaften von Boole’schen Algebren)
Sei A eine Ereignisalgebra. Dann gilt:
(a) ∅ ∈ A(b) Falls A1,A2 ∈ A, dann A1 ∩ A2 ∈ A.
(c) Falls A1,A2, . . . ,An ∈ A, dannn⋂
i=1
Ai ∈ A,n⋃
i=1
Ai ∈ A.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 212

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Definition 30
Ereignisse A1,A2 ∈ A heißen unvereinbar ( disjunkt), wennA1 ∩ A2 = ∅. Ereignisse A1,A2, . . . ,An ∈ A heißen ein vollstandigesEreignissystem ( Partition), wenn sie paarweise unvereinbar sind unddurch sie eine Zerlegung der Grundgesamtheit Ω gegeben ist, d.h. wenn
Ai ∩ Aj = ∅, i 6= j undn⋃
i=1
Ai = Ω.
Abb. 49 : Skizze (vollstandiges Ereignissystem)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 213

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Konstruktion einer Ereignisalgebra
Man geht von allen interessierenden Ereignissen (= Teilmengen) einerGrundgesamtheit aus. Wenn notwendig, nimmt man dann
(i) das sichere Ereignis,
(ii) samtliche Komplementarereignisse und
(iii) alle endlichen Vereinigungen und Durchschnitte von Ereignissen mithinzu.
Beispiel: Lebensdauer x ≥ 0 einer Gluhbirne
Ω = [0,∞), interessante Ereignisse Aa = x |x ≥ a, a > 0:Lebensdauer großer oder gleich a (Tage).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 214

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Definition 31
Sei E := Aii=1,...,n eine Menge von Teilmengen eines StichprobenraumsΩ. Dann heißt die Ereignisalgebra A(E ), die wie oben aus E konstruiertwird, die von den Ai , i = 1, . . . , n, erzeugte Ereignisalgebra.
Bemerkung
Bei einem endlichen Stichprobenraum Ω = ω1, ω2, . . . , ωn (= endlichviele Elementarereignisse) ist jede Teilmenge ein Ereignis in der von denElementarereignissen ωi , i = 1, . . . , n, erzeugten EreignisalgebraA(ω1, ω2, . . . , ωn) = P(Ω) = Potenzmenge von Ω.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 215

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Bemerkung
Unendliche Stichprobenraume sind u.a. deswegen problematisch, weilu.U. bei obiger Konstruktion einer Ereignisalgebra, die vorgegebeneTeilmengen enthalt,
”wichtige“ andere Teilmengen nicht erzeugt werden.
Beispiel: Lebensdauer x ≥ 0 einer Gluhbirne
Ω = [0,∞), vorgegebene Ereignisse Aa = x |x ≥ a, a > 0.Es gilt: [0, a) ∩ [b,∞) = ∅ oder [b, a). Also sind die Elementarereignisseb nicht in der erzeugten Ereignisalgebra, aber
”wichtig“!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 216

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Definition 32 (σ-Algebra, σ-Korper)
Eine Mengenalgebra (oder Mengenkorper) A heißt σ-Algebra (oderσ-Korper), wenn gilt:
∞⋂i=1
Ai ∈ A,∞⋃i=1
Ai ∈ A fur alle Folgen A1,A2, . . . ∈ A.
”Konstruktion“ einer σ-Algebra
Ausgehend von allen interessierenden Ereignissen einer Grundgesamtheitnimmt man (wenn notwendig) (i) das sichere Ereignis, (ii) samtlicheKomplementarereignisse und (iii) alle abzahlbaren Vereinigungen undDurchschnitte von Ereignissen mit hinzu.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 217

5 Wahrscheinlichkeitstheorie 5.2 Grundgesamtheit: Ereignisse
5.2 Grundgesamtheit: Ereignisse
Definition 33
Sei E := Aii∈I , I beliebige Indexmenge, eine Menge von Teilmengeneines Stichprobenraums Ω. Dann heißt die σ-Algebra A(E ), die wie obenaus E
”konstruiert“ wird, die von den Aii∈I erzeugte σ-Algebra.
Beispiele
Lebensdauer x ≥ 0 einer Gluhbirne:[0, ai ) ∩ [b,∞) = [b, ai )→ b fur b < ai → b⇒ Elementarereignisse b sind in der erzeugten σ-Algebra !
Korpergroße und Gewicht:Ω = ω = (ωK , ωG ) |ωK , ωG > 0, interessante Ereignisse:Amk := ω = (ωK , ωG ) |ωK > m, 0 < ωG < k, m, k > 0.Interessant sind also insbesondere schlanke (große und leichte)Menschen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 218

5 Wahrscheinlichkeitstheorie 5.3 Relative Haufigkeit
5.3 Relative Haufigkeit
Ziel:
Bewertung eines jeden Ereignisses A aus einer σ-Algebra A mit derChance seines Auftretens, also einer Zahl zwischen 0 und 1.
Wir betrachten die Grundgesamtheit Ω, die alle moglichenVersuchsergebnisse ωi , i ∈ I , eines Versuchs enthalt, und die von den ωi ,i ∈ I , erzeugte σ-Algebra A. Wir wiederholen diesen Versuch n Mal.Dabei interessieren wir uns dafur, welches Ereignis jeweils eintritt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 219

5 Wahrscheinlichkeitstheorie 5.3 Relative Haufigkeit
5.3 Relative Haufigkeit
Definition 34 (Erinnerung: Haufigkeit)
Die absolute Haufigkeit Hn(A) des Eintretens von A in den erstenn > 0 Versuchen ist definiert als die Anzahl des Auftretens von A indiesen n Versuchen.Die relative Haufigkeit hn(A) ist die absolute Haufigkeit geteilt durchdie Anzahl Versuche: hn(A) := Hn(A)/n.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 220

5 Wahrscheinlichkeitstheorie 5.3 Relative Haufigkeit
5.3 Relative Haufigkeit
Satz 10 (Eigenschaften der relativen Haufigkeit)
(i) hn(A) kann nur die Werte 0, 1/n, 2/n, . . . , n/n = 1 annehmen.
(ii) 0 ≤ hn(A) ≤ 1 fur alle A ∈ A.
(iii) hn(∅) = 0/n = 0, hn(Ω) = n/n = 1.
(iv) relative Haufigkeiten sind (sub-)additiv (!):hn(A ∪ B) = hn(A) + hn(B)− hn(A ∩ B)
(v) hn(A ∪ B) = hn(A) + hn(B), falls A ∩ B = ∅(vi) hn(A) = 1− hn(A)
Beweis.
(iv) Venn-Diagramm
(vi) 1 = hn(A ∪ A) = hn(A) + hn(A) wegen (v).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 221

5 Wahrscheinlichkeitstheorie 5.4 Wahrscheinlichkeit
5.4 Wahrscheinlichkeit
Ziel:
Wir betrachten wieder die Grundgesamtheit Ω und eine dazugehorigeσ-Algebra A. Jedem Ereignis A ∈ A soll die (theoretische)Wahrscheinlichkeit seines Eintretens zugeordnet werden. Jeder TeilmengeA von Ω, die zu der σ-Algebra gehort, soll also eine reelle Zahl ∈ [0, 1]zugeordnet werden.
Man benotigt also eine Funktion, die einer Menge eine Zahl zuordnet(Mengenfunktion) und die mit den Eigenschaften von Haufigkeit
”vertraglich“ ist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 222

5 Wahrscheinlichkeitstheorie 5.4 Wahrscheinlichkeit
5.4 Wahrscheinlichkeit
Definition 35Eine Mengenfunktion M auf einer σ-Algebra A von Ω ordnet jedemEreignis A ∈ A eine reelle Zahl zu (−∞ und ∞ evtl. eingeschlossen).
Definition 36 (Wahrscheinlichkeitsfunktion)
Eine Wahrscheinlichkeitsfunktion P ist eine Mengenfunktion auf einerσ-Algebra A von Ω mit Wertebereich [0, 1] und folgenden Eigenschaften:
(i) P(A) ≥ 0 fur alle A ∈ A(ii) P(Ω) = 1
(iii) Fur alle Folgen von paarweise unvereinbaren EreignissenA1, A2, . . . (Ai ∩ Aj = ∅, i 6= j) gilt:
P
(∞⋃i=1
Ai
)=∞∑i=1
P(Ai ).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 223

5 Wahrscheinlichkeitstheorie 5.4 Wahrscheinlichkeit
5.4 Wahrscheinlichkeit
Sprechweise
P(A) heißt auch”Wahrscheinlichkeit des Ereignisses A“ oder
”Wahrscheinlichkeit, dass das Ereignis A eintritt“, d.h. die
Wahrscheinlichkeit, dass ein Versuchsergebnis in A liegt.
Beispiele
Werfen einer Munze: Ω = ω1, ω2 = Kopf, Zahl:P(K ) = P(Z ) = 0.5 erfullt offenbar die Axiome.
Werfen eines Wurfels: P(1) = P(2) = . . . = P(6) = 1/6
Werfen von 3 verschiedenen Munzen:P(Z,Z,Z) = P(Z,Z,W) = P(Z,W,Z) = P(W,Z,Z) = P(Z,W,W) =P(W,Z,W) = P(W,W,Z) = P(W,W,W) = 1/8
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 224

5 Wahrscheinlichkeitstheorie 5.4 Wahrscheinlichkeit
5.4 Wahrscheinlichkeit
Satz 11 (Rechnen mit Wahrscheinlichkeiten)
(i) P(∅) = 0
(ii) P(n⋃
i=1
Ai ) =n∑
i=1
P(Ai ) fur paarweise unvereinbare A1,A2, . . . ,An
(iii) P(A) = 1− P(A)
(iv) P(A) = P(A ∩ B) + P(A ∩ B)
(v) P(A− B) = P(A)− P(A ∩ B)
(vi) P(A ∪ B) = P(A) + P(B)− P(A ∩ B)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 225

5 Wahrscheinlichkeitstheorie 5.4 Wahrscheinlichkeit
5.4 Wahrscheinlichkeit
Satz 11 (Rechnen mit Wahrscheinlichkeiten)
(vii) Einschluss- / Ausschluss-Formel:
P(A1 ∪ A2 ∪ . . . ∪ An) =n∑
i=1
P(Ai )−∑∑
i<j
P(Ai ∩ Aj)
+∑∑∑
i<j<k
P(Ai ∩ Aj ∩ Ak)− . . .+ (−1)n+1P(A1 ∩ A2 ∩ . . . ∩ An)
Siehe Skizze an Tafel...
(viii) Sei A ⊂ B, dann gilt: P(A) ≤ P(B)
(ix) Boole’s Ungleichung: P(n⋃
i=1
Ai ) ≤n∑
i=1
P(Ai )
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 226

5 Wahrscheinlichkeitstheorie 5.4 Wahrscheinlichkeit
5.4 Wahrscheinlichkeit
Beweis.
(i) A1 = A2 = . . . = ∅ in Axiom (iii)
(ii) A ∪ A = Ω, A ∩ A = ∅ in Eigenschaft (ii)
(viii) B = (B ∩ A) ∪ (B ∩ A) = A ∪ (B ∩ A), A ∩ (B ∩ A) = ∅also: P(B) = P(A) + P(B ∩ A) ≥ P(A)
Definition 37 (Wahrscheinlichkeitsraum)
Ein Wahrscheinlichkeitsraum ist ein Tripel (Ω,A,P), wobei Ω eineGrundgesamtheit, A eine σ-Algebra auf Ω und P eineWahrscheinlichkeitsfunktion auf A ist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 227

5 Wahrscheinlichkeitstheorie 5.5 Ubungsaufgaben
5.5 Ubungsaufgaben
Gegeben sei ein Wahrscheinlichkeitsraum (Ω,A,P).
Wann gilt P(A ∪ B) = P(A) + P(B) und wann giltP(A ∪ B) > P(A) + P(B)?
Welche Wahrscheinlichkeit ist großer, P(A ∩ B) oder P(A) · P(B)?
Warum gilt fur Wahrscheinlichkeiten stets P(A) ≥ 0 und P(A) ≤ 1?
Folgt aus P(A− B) ≤ P(B − A) stets P(A) ≤ p(B)?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 228

5 Wahrscheinlichkeitstheorie 5.5 Ubungsaufgaben
5.5 Ubungsaufgaben
Gegeben sei ein Wahrscheinlichkeitsraum (Ω,A,P).
Wann gilt P(A ∪ B) = P(A) + P(B) und wann giltP(A ∪ B) > P(A) + P(B)?
Wegen Satz 10 (vi) ist der erste Ausdruck gleichbedeutend mitP(A ∩ B) = 0, d.h. A und B sind unvereinbar. Der zweite Ausdruckist gleichbedeutend mit P(A ∩ B) < 0, was nie gilt.
Welche Wahrscheinlichkeit ist großer, P(A ∩ B) oder P(A) · P(B)?
Beides ist moglich, siehe Kapitel zur Unabhangigkeit.
Warum gilt fur Wahrscheinlichkeiten stets P(A) ≥ 0 und P(A) ≤ 1?
Das erste folgt aus Definition 36 (i), das zweite aus Definition 36 (ii)und Satz 11 (viii) mit B = Ω.
Folgt aus P(A− B) ≤ P(B − A) stets P(A) ≤ P(B)?
Ja, direkt aus dem zweimaligen Anwenden von Satz 11 (v).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 229

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten
5.6 Endliche Grundgesamtheiten
Ziel:
Formeln zur Berechnung von Wahrscheinlichkeiten
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 230

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.1 Gleichwahrscheinliche Elementarereignisse
5.6.1 Klassische Wahrscheinlichkeit
Definition 38
Eine Mengenfunktion P mit den Eigenschaften (i), (ii) heißtWahrscheinlichkeitsfunktion mit gleichwahrscheinlichenElementarereignissen:Seien ω1, ω2, . . . , ωN die N Elementarereignisse der endlichenGrundgesamtheit Ω, dann gilt:
(i) P(ω1) = P(ω2) = . . . = P(ωN) = 1/N
(ii) P(A) = N(A)/N, wobei N(A) := Anzahl Elementarereignisse inEreignis A ∈ A.
Bemerkung:
P = Zahl der gunstigen Ereignisse / Zahl der moglichen Ereignisse
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 231

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.1 Gleichwahrscheinliche Elementarereignisse
5.6.1 Klassische Wahrscheinlichkeit
Beispiele
Werfen eines Wurfels:A = 2, 4, 6: Wurfeln einer geraden Zahl: P(A) = 3/6
Werfen von 3 verschiedenen Munzen: A = (Z,W,W), (W,Z,W),(W,W,Z): genau 1mal Zahl: P(A) = 3/8
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 232

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik
Annahme
Jedes Ergebnis eines Experiments ist ein n-Tupel.
Beispiele sind 3,4,6,7, aber auch Experimente, deren Ergebnisse auseiner Stichprobe der Große n einer Grundgesamtheit bestehen.
Typisch sind sogenannte Urnenexperimente, bei denen aus einer Urnemit M Kugeln eine Stichprobe der Große n gezogen wird. Dabei soll jedeKugel in der Urne (!) die gleiche Chance haben, gezogen zu werden(Zufallsauswahl). Man unterscheidet 2 Arten des Stichprobenziehens:
Ziehen ohne Zurucklegen bzw. Ziehen mit Zurucklegen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 233

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik
Wahrscheinlichkeit einer Menge von n-Tupeln
Sei A eine Menge von n-Tupeln, die auf eine spezielle Weise auseiner Urne mit M Kugeln konstruiert wird.
Bestimme N(A) auf die folgende Weise:
Bestimme die Anzahl N1 der Objekte, die als erstes Element einesn-Tupels in A gewahlt werden konnen.Bestimme die Anzahl N2 der Objekte, die als zweites Elementgewahlt werden konnen, unter der Annahme, dass die Anzahl N2
nicht von der Wahl des ersten Elements abhangt.. . .Bestimme die Anzahl Nn der Objekte, die als n-tes Element gewahltwerden konnen, unter der Annahme, dass die Anzahl Nn nicht vonder Wahl der ersten (n − 1) Elemente abhangt.
Dann gilt: N(A) = N1 ·N2 · . . . ·Nn.
Sei nun A ⊂ Ω := alle relevanten n-Tupel aus M Objekten. Danngilt: P(A) = N(A)/N(Ω) ist die Wahrscheinlichkeit von A in derGrundgesamtheit Ω.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 234

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Permutationen ohneWiederholungen
Definition 39Sei eine Gruppe von n Objekten fest vorgegeben. Eine Permutationdieser Objekte ist eine Umordnung der Objekte.Sind alle gegebenen Objekte voneinander verschieden, so spricht man vonPermutationen ohne Wiederholungen. Treten gewisse Objektemehrfach auf, so spricht man von Permutationen mit Wiederholungen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 235

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Permutationen ohneWiederholungen
Satz 12Sei A := Permutationen von n Objekten ohne Wiederholung(n-maliges Ziehen aus n Objekten ohne Zurucklegen)Dann gilt: N(A) = n!.
Beweis.
Anwendung des allgemeinen Prinzips in diesem Abschnitt (Kombinatorik):Um eine Permutation eines n-Tupels zu erhalten, kann man an der erstenStelle zwischen N1 = n Objekten wahlen, an der zweiten zwischenN2 = n − 1, . . ., und an der letzten zwischen Nn = n − (n − 1) = 1Objekten.Also: N(A) = n · (n − 1) · . . . · 1 = n!.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 236

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Permutationen ohneWiederholungen
Beispiele
12 Personen in Kinoreihe mit 12 PlatzenWieviele Sitzanordnungen gibt es?N(A) = 12! = 479 001 600
10 Paare aus 10 Herren und 10 DamenWieviele Konstellationen gibt es?Damen nehmen feste Platze 1− 10 ein. Herren werden auf diesePlatze
”permutiert“.
N(A) = 10! = 3 628 800
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 237

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Permutationen mitWiederholungen
Sei A := Permutationen von n nicht unbedingt unterschiedlichenObjekten (n-maliges Ziehen aus n Objekten ohne Zurucklegen!)
Beispiel: 4-stellige Zahlen aus den 4 Ziffern 1,1,3,3
Wieviele verschiedene Zahlen gibt es?
1133, 1313, 3113, 1331, 3131, 3311: N(A) = 6
Zuruckfuhrung auf Permutationen ohne Wiederholung”Farbtrick“:
Farbe identische Elemente verschieden ein.Permutiere ohne Wiederholungen.Entfarbe! Dabei fallen jeweils (!) soviele Moglichkeiten zusammen, wiesich durch Permutation innerhalb der Gruppen gleicher Elemente ergeben.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 238

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Permutationen mitWiederholungen
Gegebene Hilfskonstruktion Permutationen AnzahlElemente mittels Fettdruck mit Wiederholung
1,1,3 113 113 113131 131 131 3!/2! = 3311 311 311
a,a,b,b aabb aabb aabbaabb aabbabab abab abababab abab 4!/(2! · 2!) = 6abba abba abbaabba abba
... baab, baba, bbaa
Tab. 14 : Beispiele fur Permutationen mit Wiederholungen
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 239

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Permutationen mitWiederholungen
Satz 13Die n Objekte zerfallen in k Gruppen identischer Objekte mit denAnzahlen n1, n2, . . . , nk , so dass n1 + n2 + . . .+ nk = n.Dann gilt: N(A) = n!/(n1! · n2! · . . . · nk !)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 240

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Variationen / Kombinationen
Bei Permutationen sind samtliche Elemente der n-Tupel vorher bekannt,nur die Reihenfolge ist variabel.
Bei Variationen und Kombinationen werden die Elemente der n-Tupel inA aus einem Grundvorrat von Elementen ausgewahlt. Falls dieReihenfolge des Ziehens wesentlich ist, spricht man von Variationen,sonst von Kombinationen. Man unterscheidet Variationen undKombinationen mit und ohne Zurucklegen.
Sprechweise
Anstelle von Variationen und Kombinationen mit und ohne Zurucklegenspricht man auch von mit und ohne Wiederholungen (s. Beispiel).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 241

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Variationen / Kombinationen
Beispiel: Eisdiele
Aus 3 Eissorten sollen Portionen mit 2 Kugeln zusammengestellt werden.Spielt die Reihenfolge eine Rolle (spitze Eisbecher), so erhalt manVariationen. Kommt es nur auf die Kombination an, so erhalt manKombinationen (runde Eisschalen).
Abb. 50 : Veranschaulichung des Beispiels
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 242

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Variationen ohne Zurucklegen
Definition 40n-Variationen ohne Zurucklegen sind n-Tupel aus M unterschiedlichenObjekten (n ≤ M) unter Beachtung der Reihenfolge, wobei kein Objektmehr als einmal ausgewahlt werden darf.
Bemerkung
Fur das erste Element des n-Tupels stehen also M Elemente zur Auswahl,fur das zweite Element nur noch (M − 1), . . . ,fur das n-te Element nur noch (M − (n − 1)).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 243

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Variationen ohne Zurucklegen
Satz 14Sei A := n-Variationen von M Objekten ohne Zurucklegen
(n-maliges Ziehen aus M Objekten ohne Zurucklegen)Dann gilt: N(A) = M · (M − 1) · . . . · (M − n + 1).
Beispiele
Eisdiele2 Kugeln aus 3 Eissorten ohne Wiederholungen unter Beachtung derReihenfolge: N(A) = 3 · 2 = 6
MedaillenWieviele Moglichkeiten der Medaillenverteilung Gold/Silber/Bronzegibt es bei einem Wettkampf von 10 Teilnehmern?N(A) = 10 · 9 · 8 = 720
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 244

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Variationen mit Zurucklegen
Definition 41n-Variationen mit Zurucklegen sind n-Tupel aus M unterschiedlichenObjekten unter Beachtung der Reihenfolge, wobei die Objekte mehr alseinmal ausgewahlt werden durfen.
Satz 15Sei A := n-Variationen von M Objekten mit Zurucklegen
(n-maliges Ziehen aus M Objekten mit Zurucklegen).Dann gilt: N(A) = Mn.
Bemerkung
Offenbar muss hier nicht mehr n ≤ M gelten!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 245

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Variationen mit Zurucklegen
Beispiele
Werfen von 3 verschiedenen MunzenN(Ω) = 23 = 8 mogliche Versuchsergebnisse
Eisdiele2 Kugeln aus 3 Eissorten mit Wiederholungen unter Beachtung derReihenfolge: N(A) = 32 = 9
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 246

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen ohneZurucklegen
Definition 42n-Kombinationen ohne Zurucklegen sind n-Tupel aus Munterschiedlichen Objekten (n ≤ M) ohne Beachtung der Reihenfolge,wobei kein Objekt mehr als einmal ausgewahlt werden darf.
Bemerkung
Zwei n-Tupel, die sich nur durch die Reihenfolge ihrer Elementeunterscheiden, entsprechen also derselben Kombination.
Ziel
Auswahl einer n-elementigen Teilmenge aus einer M-elementigen Menge.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 247

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen ohneZurucklegen
Zuruckfuhrung auf Variationen ohne Zurucklegen
Ziehe zunachst unter Beachtung der Reihenfolge:
”N(A) = M · (M − 1) · . . . · (M − n + 1)“.
Danach eliminiere alle n-Tupel, die in anderer Reihenfolge schon einmalvorkamen. Von jedem n-Tupel kommen alle Permutationen vor!
N(A) = M · (M − 1) · . . . · (M − n + 1)/n!
Beachte: Anzahl Terme im Zahler und Nenner gleich!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 248

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen ohneZurucklegen
Satz 16Sei A := n-Kombinationen von M Objekten ohne Zurucklegen
(n-maliges Ziehen aus M Objekten ohne Zurucklegen).Dann gilt:
N(A) =
(M
n
):=
M!
n!(M − n)!: Binomialkoeffizienten
Beweis.
N(A) =M · (M − 1) · . . . · (M − n + 1)
n!=
M!
n!(M − n)!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 249

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen ohneZurucklegen
Satz 17 (Eigenschaften von Binomialkoeffizienten)
(i)(M0
)=(MM
)(ii)
(Mn
)=(
MM−n
): Symmetrie
(iii)(Mn
)+(
Mn+1
)=(M+1n+1
)Es gilt (ohne Beweis):
(a + b)M =
(M
0
)a0bM +
(M
1
)a1bM−1 + . . .+
+
(M
M − 1
)aM−1b1 +
(M
M
)aMb0
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 250

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen ohneZurucklegen
Beispiele
Eisdiele2 Kugeln aus 3 Eissorten ohne Wiederholungen ohne Beachtung derReihenfolge:
N(A) =
(3
2
)=
3!
2! · 1!= 3
PotenzmengeWieviele verschiedene Teilmengen einer Menge Ω mit M Elementengibt es?
N(Ω) =
(M
0
)+
(M
1
)+ . . .+
(M
M − 1
)+
(M
M
)= (1 + 1)M = 2M
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 251

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen ohneZurucklegen
Beispiele (Fortsetzung)
LottoWieviele verschiedene mogliche Tippscheine gibt es?
N(A) =
(49
6
)=
49 · 48 · 47 · 46 · 45 · 44
6!= 13 983 816
Wie groß ist die Wahrscheinlichkeit, 6 Richtige zu haben?A = gezogene Zahlenkombination
⇒ P(A) =1
13 983 816.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 252

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen ohneZurucklegen
Beispiele (Fortsetzung)
Urne mit K roten und (M − K ) weißen KugelnWie groß ist die Chance, beim n-fachen Ziehen ohne Zurucklegengenau k rote Kugeln zu bekommen?
A := k rote Kugeln und (n − k) weiße Kugeln gezogenΩ := alle n-elementigen Teilmengen aus M Kugeln
P(A) =
(Kk
)(M−Kn−k
)(Mn
)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 253

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen ohneZurucklegen
Beispiele (Fortsetzung)
KartenspielWie groß ist die Chance bei einem Kartenspiel 6 Herz auf der Handzu haben?Es gibt K = 13 Herz-Karten und M − K = 52− 13 andere! JederSpieler bekommt n = 13 Karten. Also:
P(A) =
(136
)(52−1313−6
)(5213
) =?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 254

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen mitZurucklegen
Definition 43 (Kombinationen mit Zurucklegen)
n-Kombinationen mit Zurucklegen sind n-Tupel aus Munterschiedlichen Objekten ohne Beachtung der Reihenfolge, wobei dieObjekte mehrmals ausgewahlt werden durfen.
Satz 18
Sei A := n-Kombinationen von M Objekten mit Zurucklegen (n-maligesZiehen aus M Objekten mit Zurucklegen).Dann gilt:
N(A) =
(M + n − 1
n
)=
(M + n − 1) · (M + n − 2) · . . . ·Mn!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 255

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen mitZurucklegen
Beweis (wird nicht in der Vorlesung behandelt).
Sei (o.B.d.A.) X := 1, 2, . . . ,M die Menge der Objekte, aus der nElemente mit Zurucklegen gezogen werden. Es genugt, eine bijektiveAbbildung von A auf die Menge der n-elementigen Teilmengen von1, 2, . . . ,M + n − 1 anzugeben.Seien a1 ≤ a2 ≤ . . . ≤ an die Elemente eines n-Tupels in A. Dann ordnejedem ai+1 mit ai = ai+1 den Wert M + i zu und allen anderen ai denWert i . Diese Abbildung ist offenbar injektiv.Bsp. M = 8, n = 6 : 1, 2, 2, 2, 5, 5→ 1, 2, 10, 11, 5, 13Sei umgekehrt b1 < b2 < . . . < bn eine n-elementige Teilmenge aus1, 2, . . . ,M + n − 1. Dann lasst sich ein Urbild in A wie folgtkonstruieren:Fur alle bi > M wiederhole die Zahl an der Stelle bi −M, ansonstenubernehme bi . Damit ist die Abbildung auch surjektiv.Bsp. 1, 2, 2, 2, 5, 5← 1, 2, 10, 11, 5, 13.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 256

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten 5.6.2 Berechnung von Wahrscheinlichkeiten
5.6.2 Kombinatorik: Kombinationen mitZurucklegen
Beispiele
Eisdiele2 Kugeln aus 3 Eissorten mit Wiederholungen ohne Beachtung derReihenfolge:
N(A) =
(4
2
)=
4 · 32
= 6
WurfelbilderWieviele Wurfelbilder gibt es bei 2 gleichfarbigen Wurfeln?
N(A) =
(6 + 2− 1
2
)=
7 · 62
= 21
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 257

5 Wahrscheinlichkeitstheorie 5.6 Endliche Grundgesamtheiten5.6.3 Elementarereignisse mit ungleichen Wahr-scheinlichkeiten
5.6.3 Elementarereignisse mit ungleichenWahrscheinlichkeiten
Konstruktion einer Wahrscheinlichkeitsfunktion
Falls die Elementarereignisse nicht alle die gleiche Wahrscheinlichkeithaben, kann man zur Definition einer Wahrscheinlichkeitsfunktion auf denTeilmengen einer endlichen Grundgesamtheit Ω folgendermaßen vorgehen:
Sei Ω = ω1, ω2, . . . , ωN und A eine σ-Algebra auf Ω, dann wahle
pj := P(ωj) mitN∑j=1
pj = 1
und setze
P(A) :=∑ωj∈A
pj
fur ein beliebiges Ereignis A ∈ A.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 258

5 Wahrscheinlichkeitstheorie5.7 Wahrscheinlichkeit in unendlichen Grundge-samtheiten
5.7 Wahrscheinlichkeit in unendlichenGrundgesamtheiten
Bei der klassischen Wahrscheinlichkeit wird vorausgesetzt, dass dieAnzahl der Elementarereignisse endlich ist. Der Wahrscheinlichkeitsbegriffsoll jetzt auf den Fall von
”unendlich vielen gleichwahrscheinlichen
Elementarereignissen“ verallgemeinert werden.
Annahme:
Die Grundgesamtheit Ω aller moglichen Versuchsergebnisse fallt einendlich begrenztes
”Gebiet“ vollstandig und gleichmaßig aus.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 259

5 Wahrscheinlichkeitstheorie5.7 Wahrscheinlichkeit in unendlichen Grundge-samtheiten
5.7 Wahrscheinlichkeit in unendlichenGrundgesamtheiten
Definition 44Die geometrische Wahrscheinlichkeit eines Ereignisses A aus einerσ-Algebra A auf Ω ist definiert durch:P(A) :=
”Ausdehnung“ von A /
”Ausdehnung“ von Ω.
Beispiele fur”Ausdehnung“ sind Lange (1D), Flache (2D), Volumen
(3D) usw.
Bemerkung
Die Gleichwahrscheinlichkeit des Eintretens aller Versuchsergebnisse wirddadurch zum Ausdruck gebracht, dass die Wahrscheinlichkeit einesEreignisses A nicht von seiner Lage in Ω abhangt, sondern nur von seiner
”Ausdehnung“.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 260

5 Wahrscheinlichkeitstheorie5.7 Wahrscheinlichkeit in unendlichen Grundge-samtheiten
5.7 Wahrscheinlichkeit in unendlichenGrundgesamtheiten
Beispiel: Verabredung
2 Personen wollen garantiert zwischen 8.00 Uhr und 9.00 Uhr an einemvereinbarten Ort sein. Jeder Zeitpunkt innerhalb dieser Grenzen wird als
”gleichwahrscheinlich“ angesehen. Jede Person wartet maximal 15
Minuten, dann geht sie wieder.
Mit welcher Wahrscheinlichkeit treffen sich beide (Ereignis A)?
P(A) =Flache von A
Flache von Ω=
602 − 452
602= 0.4375
(siehe Skizze)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 261

5 Wahrscheinlichkeitstheorie5.7 Wahrscheinlichkeit in unendlichen Grundge-samtheiten
5.7 Wahrscheinlichkeit in unendlichenGrundgesamtheiten
ACHTUNG
So wie die”klassische“ Wahrscheinlichkeit einer speziellen
Wahrscheinlichkeitsfunktion auf einer endlichen Grundgesamtheitentspricht (vgl. 5.6.3), so entspricht die
”geometrische“
Wahrscheinlichkeit einer speziellen Wahrscheinlichkeitsfunktion aufunendlichen Grundgesamtheiten, namlich einer
”Gleichverteilung“ uber
das gesamte”Gebiet“ von Ω.
Naturlich hangt im allgemeinen Fall die Wahrscheinlichkeit einesEreignisses nicht nur von seiner Ausdehnung, sondern auch von seinerLage ab. Die
”Verteilung“ der
”Wahrscheinlichkeitsmasse“ ist also
ungleichmaßig (vgl. folgende Skizze). Lediglich die”Gesamtmasse“ ist
immer gleich 1!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 262

5 Wahrscheinlichkeitstheorie5.7 Wahrscheinlichkeit in unendlichen Grundge-samtheiten
5.7 Wahrscheinlichkeit in unendlichenGrundgesamtheiten
Massenverteilung: Beispiel in zwei Dimensionen
Abb. 51 : Massenverteilung
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 263

5 Wahrscheinlichkeitstheorie 5.8 Ubungsaufgaben
5.8 Ubungsaufgaben
An einem Fußballturnier nehmen 8 Mannschaften teil.
Es sollen alle Mannschaften gegeneinander spielen. Wieviele Spielegibt es?
Es werden zwei Gruppen zu je vier Mannschaften gebildet. Innerhalbeiner Gruppe sollen alle Mannschaften gegeneinander spielen. Dannspielen die Gruppenersten, Gruppenzweiten usw. gegeneinander.Wieviele Spiele gibt es insgesamt?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 264

5 Wahrscheinlichkeitstheorie 5.8 Ubungsaufgaben
5.8 Ubungsaufgaben
An einem Fußballturnier nehmen 8 Mannschaften teil.
Es sollen alle Mannschaften gegeneinander spielen. Wieviele Spielegibt es?
Man bestimmt die Anzahl an Moglichkeiten, von 8 Mannschaften 2auszuwahlen (Kombination ohne Zurucklegen). Es gibt(
82
)= 8·7
2·1 = 28 Spiele.
Es werden zwei Gruppen zu je vier Mannschaften gebildet. Innerhalbeiner Gruppe sollen alle Mannschaften gegeneinander spielen. Dannspielen die Gruppenersten, Gruppenzweiten usw. gegeneinander.Wieviele Spiele gibt es insgesamt?
In jeder der beiden Gruppen gibt es zunachst(
42
)= 4·3
2·1 = 6 Spiele.Mit den 4 Platzierungsspielen gibt es insgesamt 6 + 6 + 4 = 16Spiele.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 265

5 Wahrscheinlichkeitstheorie 5.8 Ubungsaufgaben
5.8 Ubungsaufgaben
Ein Lampengeschaft mochte sein Schaufenster mit 4 roten, 3 blauen und2 gelben Gluhlampen dekorieren. Wieviele Moglichkeiten gibt es, wenn
es keine weiteren Einschrankungen gibt?
die Gluhlampen gleicher Farbe jeweils nebeneinander angeordnetwerden sollen?
die Reihe mit einer blauen Gluhlampe beginnen und aufhoren soll?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 266

5 Wahrscheinlichkeitstheorie 5.8 Ubungsaufgaben
5.8 Ubungsaufgaben
Ein Lampengeschaft mochte sein Schaufenster mit 4 roten, 3 blauen und2 gelben Gluhlampen dekorieren. Wieviele Moglichkeiten gibt es, wenn
es keine weiteren Einschrankungen gibt?
Es gibt 9!4!3!2! = 1260 Moglichkeiten.
die Gluhlampen gleicher Farbe jeweils nebeneinander angeordnetwerden sollen?
Es muss nur die Reihenfolge der Farben festgelegt werden, also3! = 6 Moglichkeiten.
die Reihe mit einer blauen Gluhlampe beginnen und aufhoren soll?
Es mussen nur noch 7 Gluhlampen verteilt werden, davon eine blaue.Es gibt 7!
4!1!2! = 7·6·52 = 105 Moglichkeiten.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 267

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Bedingte Wahrscheinlichkeit
Zusatzinformation
Nicht selten soll die Wahrscheinlichkeit eines Ereignisses A berechnetwerden unter der Voraussetzung, dass ein Ereignis B schon eingetretenist (Zusatzinformation). Dadurch wird die Menge der moglichenVersuchsergebnisse
”a-priori“ auf die Menge B eingeschrankt. Das
Eintreten von B ist nicht mehr zufallig, es ist sicher. Man spricht von
”bedingter Wahrscheinlichkeit“ des Ereignisses A, gegeben das Ereignis
B.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 268

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Bedingte Wahrscheinlichkeit
Definition 45
Sei (Ω,A,P) ein Wahrscheinlichkeitsraum, wobei Ω eineGrundgesamtheit, A eine σ-Algebra auf Ω und P eineWahrscheinlichkeitsfunktion auf A ist. Seien A,B zwei Ereignisse in A.Dann ist die bedingte Wahrscheinlichkeit von A unter derBedingung B definiert durch
PB(A) = P(A|B) := P(A ∩ B)/P(B), falls P(B) > 0.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 269

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Bedingte Wahrscheinlichkeit
Satz 19 (Eigenschaften der bedingten Wahrscheinlichkeit)
(i) P(∅|B) = 0
(ii) P(n⋃
i=1
Ai |B) =n∑
i=1
P(Ai |B) fur paarweise unvereinbare Ai
(iii) P(A|B) = 1− P(A|B)
(iv) P(A1|B) = P(A1 ∩ A2|B) + P(A1 ∩ A2|B)
(v) P(A1 − A2|B) = P(A1|B)− P(A1 ∩ A2|B)
(vi) P(A1 ∪ A2|B) = P(A1|B) + P(A2|B)− P(A1 ∩ A2|B)
(vii) P(n⋃
i=1
Ai |B) ≤n∑
i=1
P(Ai |B)
(viii) Sei A1 ⊂ A2, dann gilt: P(A1|B) ≤ P(A2|B)
Beweis.Literatur.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 270

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Bedingte Wahrscheinlichkeit
Bemerkung
Bedingte Wahrscheinlichkeit bei endlichen Grundgesamtheiten mitgleichwahrscheinlichen Elementarereignissen:P(A|B) = N(A ∩ B)/N(B), denn P(A) = N(A)/N(Ω).
Beispiele
Werfen von 3 verschiedenen Munzen:A = (Z,W,W), (W,Z,W), (W,W,Z): genau 1mal ZahlB = (W,Z,Z), (W,Z,W), (W,W,Z), (W,W,W):Wappen auf erster MunzeP(A|B) = P(A ∩ B)/P(B) = N(A ∩ B)/N(B) = 2/4 = 0.5
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 271

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Bedingte Wahrscheinlichkeit
Satz 20 (Multiplikationsregel)
Sei (Ω,A,P) ein Wahrscheinlichkeitsraum. Seien Ai , i = 1, 2, . . . , n, nEreignisse in A mit P(A1 ∩ . . . ∩ An−1) > 0, dann gilt:
P
(n⋂
i=1
Ai
)= P(A1)P(A2|A1)P(A3|(A1 ∩ A2) · · ·P(An|(A1 ∩ . . . ∩ An−1))
Beweis.Nach der Definition der bedingten Wahrscheinlichkeit gilt:P(A ∩ B) = P(A)P(B|A), falls P(A) > 0. Genauso gilt:P(A ∩ B ∩ C ) = P(A ∩ B)P(C |A ∩ B) = P(A)P(B|A)P(C |A ∩ B),falls P(A ∩ B) > 0.Die Behauptung folgt durch Induktion.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 272

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Bedingte Wahrscheinlichkeit
Beispiele
Urne mit 10 roten und 15 weißen KugelnWie groß ist die Wahrscheinlichkeit, dass bei 3 Ziehungen ohneZurucklegen zuerst eine rote, dann eine weiße und dann wieder einerote Kugel gewahlt wird?P(A ∩ B ∩ C ) = P(A)P(B|A)P(C |A ∩ B) = (10/25)(15/24)(9/23)
Urne mit 3 roten und 7 weißen KugelnBetrachte folgendes Spiel: Bei jeder Ziehung wird eine Kugel zufalliggezogen, die Farbe wird notiert, und die Kugel wird zuruckgelegtzusammen mit 2 zusatzlichen Kugeln derselben Farbe. Wie groß istdie Wahrscheinlichkeit, dass bei den ersten 3 Ziehungen immer einerote Kugel gewahlt wird?P(A ∩ B ∩ C ) = P(A)P(B|A)P(C |A ∩ B) = (3/10)(5/12)(7/14) =1/16
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 273

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Unabhangigkeit
Definition 46
Sei (Ω,A,P) ein Wahrscheinlichkeitsraum. Seien A,B zwei Ereignisse inA. Dann heißen A und B ( statistisch bzw. stochastisch) unabhangigeEreignisse, wenn eine der folgenden Bedingungen gilt:
(i) P(A ∩ B) = P(A)P(B),
(ii) P(A|B) = P(A), falls P(B) > 0,
(iii) P(B|A) = P(B), falls P(A) > 0.
Aquivalenz der Bedingungen
(i) ⇒ (ii): P(A|B) = P(A ∩ B)/P(B) = P(A)P(B)/P(B) = P(A),falls P(B) > 0
(ii) ⇒ (iii): P(B|A) = P(A ∩ B)/P(A) = P(A|B)P(B)/P(A) =P(A)P(B)/P(A) = P(B), falls P(A),P(B) > 0
(iii) ⇒ (i): P(A ∩ B) = P(B|A)P(A) = P(B)P(A), falls P(A) > 0P(A ∩ B) = P(B)P(A), falls P(A) = 0 oder P(B) = 0
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 274

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Unabhangigkeit
Beispiel: Werfen von 2 verschiedenen Wurfeln
Sei A das Ereignis einer ungeraden Augensumme,B das Ereignis einer 1 auf dem ersten Wurfel,C das Ereignis
”Augensumme = 7“.
Sind A und B,A und C bzw. B und C unabhangig?
P(A|B) = N(A ∩ B)/N(B) = 3/6 = 0.5 = P(A),
P(A|C ) = 1 6= 0.5 = P(A)⇒ A und C sind nicht unabhangig
P(C |B) = N(C ∩ B)/N(B) = 1/6 = 6/36 = P(C )
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 275

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Unabhangigkeit
Satz 21 (Eigenschaften von unabhangigen Ereignissen)
(i) Seien P(A) 6= 0 und P(B) 6= 0. Dann gilt:A und B unabhangig ⇒ A ∩ B 6= ∅
(ii) A und B unabhangig ⇒ A und B unabhangig, A und B unabhangig,A und B unabhangig
Beweis.
(i) A und B unabhangig ⇒ P(A ∩ B) = P(A)P(B) 6= 0 = P(∅)(ii) P(A ∩ B) = P(A)− P(A ∩ B) = P(A)− P(A)P(B) =
P(A)(1− P(B)) = P(A)P(B) (z. B.)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 276

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Unabhangigkeit
Definition 47
Sei (Ω,A,P) ein Wahrscheinlichkeitsraum. Seien Ai , i = 1, . . . , n, nEreignisse in A. Dann heißen die Ai ( statistisch bzw. stochastisch)unabhangige Ereignisse, wenn samtliche (!) der folgenden Bedingungengelten:
P(Ai ∩ Aj) = P(Ai )P(Aj) fur i 6= j ,
P(Ai ∩ Aj ∩ Ak) = P(Ai )P(Aj)P(Ak) fur i 6= j , j 6= k, i 6= k,
. . . ,
P(n⋂
i=1
Ai ) =n∏
i=1
P(Ai )
ACHTUNG
Es werden alle Bedingungen benotigt! Z. B. impliziert paarweiseUnabhangigkeit NICHT
”globale“ Unabhangigkeit!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 277

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Unabhangigkeit
Beispiel: Werfen von 2 verschiedenen Wurfeln
A1 := ungerade Zahl auf dem ersten WurfelA2 := ungerade Zahl auf dem zweiten WurfelA3 := ungerade Augensumme
P(A1)P(A2) = 0.5 · 0.5 = P(A1 ∩ A2),
P(A1)P(A3) = 0.5 · 0.5 = P(A3|A1)P(A1) = P(A1 ∩ A3),
P(A2)P(A3) = 0.5 · 0.5 = P(A3|A2)P(A2) = P(A2 ∩ A3), aber
P(A1 ∩ A2 ∩ A3) = 0 6= 1/8 = P(A1)P(A2)P(A3)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 278

6 Bedingte Wkt. und Unabhangigkeit 6.1 Bedingte Wahrscheinlichkeit
6.1 Unabhangigkeit
Intuition
Beim Ziehen ohne Zurucklegen liegt sicher eine Abhangigkeit zwischenden Ergebnissen von zwei Ziehungen vor!
Bei Stichprobennahme mit Zurucklegen sind die einzelnen Ziehungenvoneinander (stochastisch) unabhangig!
Bei Versuchen mit denselben Testpersonen (Langsschnittansatz) liegti.a. eine Abhangigkeit der Versuchsergebnisse vor, bei einem Wechselder Versuchspersonen (Querschnittsansatz) kann hingegenUnabhangigkeit erreicht werden!
Bemerkung
Ziel von Unabhangigkeitsuntersuchungen ist (haufig) Bestimmung vonP(A ∩ B)! Es gilt immer:
P(A ∩ B) = P(A|B)P(B), falls P(B) > 0
P(A ∩ B) = P(B|A)P(A), falls P(A) > 0
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 279

6 Bedingte Wkt. und Unabhangigkeit 6.2 Totale Wahrscheinlichkeit
6.2 Totale Wahrscheinlichkeit
Ziel:
Bei einem Versuch, bei dem das Versuchsergebnis durch verschiedeneQuellen gleichzeitig beeinflusst wird, soll die Wahrscheinlichkeit einesEreignisses B bestimmt werden. Durch
”Fallunterscheidung“ bei einem
der Einflussfaktoren sei es moglich, die Gesamt- (totale)Wahrscheinlichkeit von B in leicht berechenbare Teile aufzuspalten.Genauer hat man ein vollstandiges System (Partition) von EreignissenA1,A2, . . . ,An, fur das die WahrscheinlichkeitenP(B|A1),P(B|A2), . . . ,P(B|An) bekannt sind. Daraus lasst sich dannP(B) zusammensetzen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 280

6 Bedingte Wkt. und Unabhangigkeit 6.2 Totale Wahrscheinlichkeit
6.2 Totale Wahrscheinlichkeit
Ziel (Fortsetzung):
Diese Vorgehensweise ist besonders nutzlich fur Experimente mitmehreren Stufen. Dabei stehen die Partitionsindizes fur dieverschiedenen Stufen. Z. B. Stufe 1: Auswahl einer Urne, Stufe 2:Auswahl einer Kugel aus der gewahlten Urne (vgl. folgendesUrnen-Beispiel).
Skizze (Ereignis B und vollstandiges Ereignissystem):
Abb. 52 : Ereignis B und vollstandiges Ereignissystem
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 281

6 Bedingte Wkt. und Unabhangigkeit 6.2 Totale Wahrscheinlichkeit
6.2 Totale Wahrscheinlichkeit
Satz 22 (von der totalen Wahrscheinlichkeit)
Sei (Ω,A,P) ein Wahrscheinlichkeitsraum. Seien Ai , i = 1, 2, . . . , n, eine
Partition von Ω, d.h. Ai ∩ Aj = ∅, i 6= j , undn⋃
i=1
Ai = Ω, mit P(Ai ) > 0.
Dann gilt fur jedes B ∈ A:
P(B) =n∑
i=1
P(B|Ai )P(Ai )
Beweis.
B =n⋃
i=1
(B ∩ Ai ) und die B ∩ Ai sind alle disjunkt. Also:
P(B) = P(n⋃
i=1
(B ∩ Ai )) =n∑
i=1
P(B ∩ Ai ) =n∑
i=1
P(B|Ai )P(Ai )
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 282

6 Bedingte Wkt. und Unabhangigkeit 6.2 Totale Wahrscheinlichkeit
6.2 Totale Wahrscheinlichkeit
Spezialfall
P(B) = P(B|A)P(A) + P(B|A)P(A), falls 0 < P(A) < 1
Bemerkung
Der Satz bleibt richtig fur n =∞.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 283

6 Bedingte Wkt. und Unabhangigkeit 6.2 Totale Wahrscheinlichkeit
6.2 Totale Wahrscheinlichkeit
Beispiele
Urnen i = 1, . . . , 5 mit i roten und 10− i weißen KugelnWahle zunachst zufallig eine Urne und dann zufallig eine Kugel ausder gewahlten Urne. Wie groß ist die Wahrscheinlichkeit, dass einerote Kugel gewahlt wird?
P(B) =5∑
i=1
P(B|Ai )P(Ai ) =5∑
i=1
i
10· 1
5=
1
50
5∑i=1
i =1
50· 5 · 6
2=
3
10
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 284

6 Bedingte Wkt. und Unabhangigkeit 6.2 Totale Wahrscheinlichkeit
6.2 Totale Wahrscheinlichkeit
Beispiele (Fortsetzung)
GesamtproduktionsausschussIn einem Betrieb werde die Gesamtproduktion eines bestimmtenTeiles zu 20 % durch Maschine 1, zu 55 % durch Maschine 2 und zu25 % durch Maschine 3 hergestellt. Die gefertigten Teile liegenwillkurlich gemischt in einem Behalter. Sei B das Ereignis, dass einzufallig entnommenes Teil Ausschuss ist. Sei Ai das Ereignis, dassdieses Teil von Maschine i stammt. Die Qualitat der einzelnenMaschinen sei bekannt: Maschine 1, 2, 3 produziert 2 %, 1 %, 4 %Ausschuss.Wie groß ist die Wahrscheinlichkeit von B?P(B) = 0.02 · 0.20 + 0.01 · 0.55 + 0.04 · 0.25 = 0.0195
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 285

6 Bedingte Wkt. und Unabhangigkeit 6.3 Bayes’sche Formel
6.3 Bayes’sche Formel
Ziel:
Im Zusammenhang mit der totalen Wahrscheinlichkeit ist die folgendeFrage von Interesse: Wie groß ist der Anteil der einzelnen EreignisseA1,A2, . . . ,An an der Gesamtwahrscheinlichkeit P(B)? Es interessierenalso fur die bedingten Wahrscheinlichkeiten P(Ai |B) := P(Ai ∩B)/P(B).
Idee:
Schließen von den bekannten bedingten Wahrscheinlichkeiten P(B|Ai )mit Hilfe des Satzes von der totalen Wahrscheinlichkeit auf dieunbekannten (in gewisser Weise
”umgekehrten“) bedingten
Wahrscheinlichkeiten P(Ai |B)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 286

6 Bedingte Wkt. und Unabhangigkeit 6.3 Bayes’sche Formel
6.3 Bayes’sche Formel
Definition 48 (Formel von Bayes (1702-1761))
Sei (Ω,A,P) ein Wahrscheinlichkeitsraum. Seien Ai , i = 1, 2, . . . , n, einePartition von Ω mit P(Ai ) > 0. Dann gilt fur jedes B ∈ A mit P(B) > 0:
P(Ai |B) =P(B|Ai )P(Ai )n∑
i=1
P(B|Ai )P(Ai )
Beweis.
P(Ai |B) := P(Ai ∩ B)/P(B) = P(B|Ai )P(Ai )/P(B)
Bemerkung
Der Satz bleibt richtig fur n =∞.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 287

6 Bedingte Wkt. und Unabhangigkeit 6.3 Bayes’sche Formel
6.3 Bayes’sche Formel
Beispiel
GesamtproduktionsausschussAus welcher Maschine stammt das defekte Teil?P(A1|B) = 0.02 · 0.20/0.0195 = 0.2051P(A2|B) = 0.01 · 0.55/0.0195 = 0.2821P(A3|B) = 0.04 · 0.25/0.0195 = 0.5128
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 288

6 Bedingte Wkt. und Unabhangigkeit 6.3 Bayes’sche Formel
6.3 Bayes’sche Formel
Maximale Mutmaßlichkeit (maximum-likelihood)
Bei einem Zufallsexperiment kann genau eines der n EreignisseA1,A2, . . . ,An eintreten. Die direkte Beobachtung, welches Ereigniswirklich eingetreten ist, sei aber unmoglich!Es wird angenommen, dass die Eintrittswahrscheinlichkeiten der Ai gleichP(Ai ) sind (a-priori-Verteilung).Bei der Versuchsdurchfuhrung beobachtet man das Eintreten desEreignisses B (Versuchsergebnis).Daraus berechnet man neue Wahrscheinlichkeiten der Ereignisse Ai
(a-posteriori-Verteilung), namlich die bedingten WahrscheinlichkeitenP(A1|B),P(A2|B), . . . ,P(An|B) (mit Hilfe der bedingtenWahrscheinlichkeiten P(B|A1),P(B|A2), . . . ,P(B|An)).Es soll nun eine Vermutung daruber abgegeben werden, welches derEreignisse wirklich eingetreten ist. Nach dem Prinzip der maximalenMutmaßlichkeit ist das wahrscheinlichste Ereignis das plausibelste. Manentscheidet sich deshalb fur das Ereignis mit der maximalen a-posterioriWahrscheinlichkeit P(Ai |B)!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 289

6 Bedingte Wkt. und Unabhangigkeit 6.3 Bayes’sche Formel
6.3 Bayes’sche Formel
Beispiel
GesamtproduktionsausschussVon welcher Maschine stammt ein Ausschussteil?Von Maschine 3 (P(A3|B) = 0.5128)! Diese wurde man also(zunachst) fur jeglichen Ausschuss verantwortlich machen!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 290

6 Bedingte Wkt. und Unabhangigkeit 6.3 Bayes’sche Formel
6.3 Zusammenfassung
Satze (Fortsetzung)
Totale WahrscheinlichkeitSeien Ai , i = 1, 2, . . . , n, eine Partition von Ω mit P(Ai ) > 0. Dann giltfur jedes B ∈ A:
P(B) =n∑
i=1
P(B|Ai )P(Ai )
Formel von BayesFur jedes B ∈ A mit P(B) > 0 gilt:
P(Ai |B) =P(B|Ai )P(Ai )n∑
i=1
P(B|Ai )P(Ai )
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 291

6 Bedingte Wkt. und Unabhangigkeit 6.4 Ubungsaufgaben
6.4 Ubungsaufgaben
Nehmen Sie an, dass zwei Personen viele Twitter-Nachrichten schreiben.Person T1 schreibt 5 Nachrichten pro Tag und Person T2 schreibt 45Nachrichten pro Tag. Dabei sei die Wahrscheinlichkeit, dass es sich beieiner Nachricht um Fake-News F handelt, bei T1 80% und bei T2 nur20%.
Wie hoch ist die Wahrscheinlichkeit, dass es sich bei einer zufalligausgewahlten Bachricht um Fake-News handelt?
Wie groß ist die Wahrscheinlichkeit, dass eine zufallig ausgewahlteFake-News von Person T1 stammt?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 292

6 Bedingte Wkt. und Unabhangigkeit 6.4 Ubungsaufgaben
6.4 Ubungsaufgaben
Wie hoch ist die Wahrscheinlichkeit, dass es sich bei einer zufalligausgewahlten Bachricht um Fake-News handelt?
Wie groß ist die Wahrscheinlichkeit, dass eine zufallig ausgewahlteFake-News von Person T1 stammt?
Berechnung mit Formel von der totalen Wahrscheinlichkeit und Formelvon Bayes. Sei Ti , i = 1, 2 das Ereignis Die Nachricht stammt vonPerson Ti und F das Ereignis Es handelt sich um Fake-News. Dann gilt:
P(F ) = P(F |T1) · P(T1) + P(F |T2) · P(T2) = 0.8 · 0.1 + 0.2 · 0.9= 0.26
P(T1|F ) =P(F |T1) · P(T1F )
P(F )=
0.8 · 0.10.26
=0.08
0.26=
4
13≈ 0.31
Das heißt, dass T1 nur 10% der Nachrichten schreibt, aber viele falsche,und wenn eine falsche Nachricht aufkommt, steigt die Wahrscheinlichkeit,dass die Nachricht von T1 kommt, von 10% auf 31%.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 293

6 Bedingte Wkt. und Unabhangigkeit 6.4 Ubungsaufgaben
6.4 Ubungsaufgaben
Zwei Taxigesellschaften sind in einer Stadt tatig. Die Taxis derGesellschaft A sind grun, die der Gesellschaft B blau. Die Gesellschaft Astellt 15% der Taxis, die Gesellschaft B die verbleibenden 85%. EinesNachts kommt es zu einem Unfall mit Fahrerflucht. Das fliehende Autowar ein Taxi. Ein Zeuge sagt aus, es habe sich um ein grunes Taxigehandelt.
Das Gericht lasst den Zeugen auf seine Fahigkeit untersuchen, grune undblaue Taxis unter nachtlichen Sichtbedingungen zu unterscheiden. DasUntersuchungsergebnis ist: In 80% der Falle identifiziert der Zeuge dieFarbe zutreffend, in 20% der Falle irrt er sich.
Wie hoch ist die Wahrscheinlichkeit, dass es sich bei dem fliehenden Taxium ein Taxi der Gesellschaft A gehandelt hat?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 294

6 Bedingte Wkt. und Unabhangigkeit 6.4 Ubungsaufgaben
6.4 Ubungsaufgaben
Erste Moglichkeit:
Berechnung von Anzahlen uber Baum, dann Wahrscheinlichkeitberechnen als Anzahl gunstiger Falle geteilt durch Anzahl moglicherFalle. Der Baum ist unten abgebildet.
Die Wahrscheinlichkeit ergibt sich zu 120120+170 ≈ 0.41, also etwa 41%.
file:///C|/Joerg/teaching/Statistik_für_Journalistik/Bilder/schweizer_statistik_abb_1.gif[12.06.2017 22:28:08]
Abb. 53 : Taxibeispiel
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 295

6 Bedingte Wkt. und Unabhangigkeit 6.4 Ubungsaufgaben
6.4 Ubungsaufgaben
Zweite Moglichkeit:
Berechnung mit Hilfe der Formel von Bayes. Sei dazu A das Ereignis Dasfliehende Taxi ist ein Taxi der Gesellschaft A und Z das Ereignis DerZeuge sagt aus, dass es sich um ein Taxi der Gesellschaft A handelt.Dann gilt:
P(A|Z ) =P(Z |A) · P(A)
P(Z )=
P(Z |A) · P(A)
P(Z |A) · P(A) + P(Z |A) · P(A)
=0.8 · 0.15
0.8 · 0.15 + 0.2 · 0.85=
0.12
0.12 + 0.17=
12
29≈ 0.41
Bemerkung: Ohne Zeugenaussage betragt die WahrscheinlichkeitP(A) = 0.15.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 296

7 Zufallsvariablen 7.1 Begriffsbildung
7.1 Begriffsbildung
Idee:
Als Ergebnis von Zufallsexperimenten treten i.a. Zahlen auf, die bei derWiederholung des Versuchs nicht gleich bleiben, sondern aufgrund derWirkung des Zufalls
”streuen“.
Diese sogenannten Zufallsgroßen kommen entweder direkt alsMessergebnis des Zufallsexperiments vor (metrische Daten) oder ergebensich indirekt, indem aus dem Ergebnis des Experiments eininteressierender Wert mittels einer genau definierten Bildungsvorschriftbestimmt wird.
Eine Zufallsvariable ist also eine Funktion, die einem Ergebnis einesZufallsexperiments eine (reelle) Zahl zuordnet.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 297

7 Zufallsvariablen 7.1 Begriffsbildung
7.1 Begriffsbildung
Idee (Fortsetzung):
Anstatt mit den Wahrscheinlichkeiten selber wird i.a. mit Zufallsvariablenund deren
”Verteilung“ gearbeitet. Verteilungsfunktionen beschreiben
die Wahrscheinlichkeiten von gewissen Ereignissen, die mit Hilfe derWerte von Zufallsvariablen definiert wurden.
Sie haben den großen Vorteil, dass sie Funktionen von den reellen Zahlen(dem Wertebereich von Zufallsvariablen) in das Intervall [0, 1] sind.Solche Funktionen kann man mit den Methoden der Analysis bearbeiten,man kann sie grafisch darstellen und mit ihnen rechnen.
Deshalb werden Zufallsexperimente i.a. durch Annahmen uber dieVerteilung einer passenden Zufallsvariablen modelliert, und dieBeschreibung des Wahrscheinlichkeitsraums wird vollstandig umgangen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 298

7 Zufallsvariablen 7.1 Begriffsbildung
7.1 Begriffsbildung
Definition 49 (Zufallsvariable)
Sei (Ω,A,P) ein Wahrscheinlichkeitsraum. Eine Zufallsvariable ist eineFunktion von der Grundgesamtheit Ω in R, die dieMessbarkeitseigenschaft besitzt, dass namlich jedesAr := ω |X (ω) ≤ r fur jedes r ∈ R in der σ-Algebra A liegt.
Die Messbarkeitseigenschaft wird zur Definition der Verteilungsfunktionbenotigt. Sie stellt selten eine Einschrankung dar, muss aber naturlichuberpruft werden, wenn man sich fur die Zufallsvariable selber interessiertund nicht nur fur eine bestimmte Verteilung.
Zufallsvariablen werden im folgenden mit großen Buchstaben bezeichnet,ihre Werte, die sogenannten Realisierungen, mit entsprechenden kleinenBuchstaben: x = X (ω).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 299

7 Zufallsvariablen 7.1 Begriffsbildung
7.1 Begriffsbildung
Beispiele
Werfen einer Munze: Ω = ω1, ω2 = Kopf, Zahl,X (ω) := 1, wenn ω = KopfX (ω) := 0, wenn ω = Zahl.
Werfen eines Wurfels:Ω = ω1, ω2, ω3, ω4, ω5, ω6 = 1, 2, 3, 4, 5, 6, X (ω) := ω
Werfen von 2 verschiedenfarbigen Wurfeln:Ω = (1, 1), (1, 2), . . . , (1, 6), (2, 1), . . . , (2, 6), . . . , (6, 6)X (ω1, ω2) := ω1 + ω2, Y (ω1, ω2) := |ω1 − ω2|Korpergroße und Gewicht:Ω = ω = (ωK , ωG ) |ωK , ωG > 0, X (ωK , ωG ) := ωG
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 300

7 Zufallsvariablen 7.1 Begriffsbildung
7.1 Verteilungsfunktion
Definition 50
Die ( kumulative) Verteilungsfunktion FX einer Zufallsvariable X istdefiniert als:FX (x) := P(X ≤ x) := P(ω |X (ω) ≤ x) = P(Ax) fur jedes x ∈ R.
Bemerkungen
Die Verteilungsfunktion einer Zufallsvariablen beschreibt dieWahrscheinlichkeiten spezieller Mengen einer
”zu der Variable
gehorenden σ-Algebra“, die die Mengen ω |X (ω) ≤ x enthalt(Messbarkeitseigenschaft!).
Offenbar werden mit wachsendem x die”Wahrscheinlichkeiten der
darunter liegenden Werte kumuliert“.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 301

7 Zufallsvariablen 7.1 Begriffsbildung
7.1 Verteilungsfunktion
Achtung:
Verschiedene Zufallsvariablen konnen dieselbe Verteilungsfunktion haben(vgl. Beispiel mit 2 verschiedenfarbigen Wurfeln auf folgender Folie).
Beispiele
Werfen einer Munze:Ω = ω1, ω2 = Kopf, Zahl,Sei X (ω) := Anzahl Kopfe (0 oder 1), dann gilt:
FX (x) =
0 fur x < 0,
0.5 fur 0 ≤ x < 1,
1 fur 1 ≤ x
Werfen eines Wurfels:Ω = ω1, ω2, ω3, ω4, ω5, ω6 = 1, 2, 3, 4, 5, 6, X (ω) := ωWie sieht die Verteilungsfunktion aus? Ubung!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 302

7 Zufallsvariablen 7.1 Begriffsbildung
7.1 Verteilungsfunktion
Beispiele (Fortsetzung)
Werfen von 2 verschiedenfarbigen Wurfeln:Ω = (1, 1), (1, 2), . . . , (1, 6), (2, 1), . . . , (2, 6), . . . , (6, 6)Die zu Y (ω1, ω2) := |ω1 − ω2| gehorende Verteilungsfunktion hateine Form wie in der folgenden Skizze; denn es gibt6
”Wurfelbilder“ mit absoluter Differenz = 0,
10 mit abs. Diff. = 1 ((1, 2), (2, 3), (3, 4), (4, 5), (5, 6) +Umkehrungen), ...,4
”Wurfelbilder“ mit abs. Diff. = 4 ((1, 5), (2, 6) + Umkehr.)
und 2”Wurfelbilder“ mit abs. Differenz = 5 ((1, 6), (6, 1)).
Außerdem gilt: Sei Xk := Wert auf dem k-ten Wurfel, k = 1, 2.Dann haben die Xk offenbar dieselbe Verteilungsfunktion.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 303

7 Zufallsvariablen 7.1 Begriffsbildung
7.1 Verteilungsfunktion
0 1 2 3 4 5
Verteilungsfunktion F(x)
x
F(x
)
0/36
6/36
16/36
24/36
30/36
34/3636/36
Abb. 54 : Verteilungsfunktion
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 304

7 Zufallsvariablen 7.1 Begriffsbildung
7.1 Verteilungsfunktion
Satz 23 (Eigenschaften der Verteilungsfunktion)
Sei FX die Verteilungsfunktion einer Zufallsvariablen X . Dann gilt:
(i) FX (−∞) := limx→−∞
FX (x) = 0 und FX (+∞) := limx→+∞
FX (x) = 1
(ii) FX ist monoton wachsend: FX (a) ≤ FX (b) fur a < b
(iii) FX ist rechtsstetig: lim0<h→0
FX (x + h) = FX (x)
Definition 51
Jede Funktion von R in das Intervall [0, 1] mit den Eigenschaften (i), (ii),(iii) aus obigem Satz definiert eine ( kumulative) Verteilungsfunktion.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 305

7 Zufallsvariablen 7.2 Dichtefunktionen
7.2 Dichtefunktionen
Es gibt zwei Klassen von Zufallsvariablen, deren Verteilung sich besonderseinfach durch sogenannte Dichtefunktionen beschreiben lasst:Diskrete und stetige Zufallsvariablen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 306

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.1 Diskrete Zufallsvariablen
7.2.1 Diskrete Zufallsvariablen
Definition 52Eine Zufallsvariable X heißt diskret, wenn sie hochstens abzahlbar vieleWerte x1, x2, x3, . . . annimmt.Wenn eine Zufallsvariable diskret ist, dann heißt auch die dazugehorigeVerteilungsfunktion diskret.
Fur eine diskrete Verteilungsfunktion gilt:
FX (x) =
0, x < xi fur alle i ,n∑
i=1
P(X = xi ), xn ≤ x < xn+1,
1, x ≥ xi fur alle i .
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 307

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.1 Diskrete Zufallsvariablen
7.2.1 Diskrete Zufallsvariablen
Definition 53Die Funktion
fX (x) := P(X = xi ), falls x = xi , fX (x) := 0, sonst,
heißt diskrete Dichtefunktion (oder Zahldichte) von X .Die Menge der xi mit f (xi ) > 0 heißt Trager von f . Diese xi heißen auchMassenpunkte der Verteilung.fur eine diskrete Verteilungsfunktion gilt offenbar:
FX (x) =∑xi≤x
fX (xi ).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 308

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.1 Diskrete Zufallsvariablen
7.2.1 Diskrete Zufallsvariablen
0 1 2 3 4 5
Verteilungsfunktion F(x) und Dichte f(x)
x
F(x
), f(
x)
0/36
6/36
16/36
24/36
30/36
34/3636/36
Verteilungsfunktion F(x)Dichtefunktion f(x)
Abb. 55 : Skizze: Diskrete Dichte
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 309

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.1 Diskrete Zufallsvariablen
7.2.1 Diskrete Zufallsvariablen
Satz 24Sei X eine diskrete Zufallsvariable, FX und fX die dazugehorigeVerteilungsfunktion bzw. Dichtefunktion. Dann kann FX aus fXberechnet werden und umgekehrt.
Beweis.Es bleibt, fX aus FX zu berechnen:fX (xi ) = FX (xi )− lim
0<h→0FX (xi − h) und
fX (x) = 0 fur x 6= Massenpunkt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 310

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.1 Diskrete Zufallsvariablen
7.2.1 Diskrete Zufallsvariablen
Definition 54
Jede Funktion von den reellen Zahlen in das Intervall [0, 1] definiert einediskrete Dichtefunktion, wenn fur eine hochstens abzahlbare Mengex1, x2, x3, . . . gilt:
(i) f (xi ) > 0 fur i = 1, 2, 3, . . .
(ii) f (x) = 0 fur x 6= xi , i = 1, 2, 3, . . .
(iii)∑i
f (xi ) = 1
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 311

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.2 Stetige Zufallsvariablen
7.2.2 Stetige Zufallsvariablen
Definition 55
Eine Zufallsvariable X , die als Wertebereich (einen Teilbereich der)reelle(n) Zahlen hat, heißt stetig, wenn sich ihre Verteilungsfunktion wiefolgt durch eine sogenannte Dichtefunktion fX (x) darstellen lasst:
FX (x) =
∫ x
−∞fX (t)dt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 312

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.2 Stetige Zufallsvariablen
7.2.2 Stetige Zufallsvariablen
Satz 25Sei X eine stetige Zufallsvariable, FX und fX die dazugehorigeVerteilungsfunktion bzw. Dichtefunktion. Dann kann FX aus fXberechnet werden und umgekehrt.
Beweis.Es bleibt, fX aus FX zu berechnen:
fX (x) =dFX (x)
dx
fur die Punkte x , wo FX differenzierbar ist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 313

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.2 Stetige Zufallsvariablen
7.2.2 Stetige Zufallsvariablen
Bemerkungen
Intervalle von reellen Zahlen haben die Wahrscheinlichkeit
P((a, b]) = F (b)− F (a) =
∫ b
a
fX (x)dx , wenn a < b.
Einzelne reelle Zahlen haben die Wahrscheinlichkeit 0:
fX (x) =dFX (x)
dx= lim
∆x→0
FX (x + ∆x)− FX (x −∆x)
2∆x, also
fX (x) 2 ∆x ≈ FX (x + ∆x)− FX (x −∆x) = P(x −∆x < X ≤ x + ∆x)
Wegen ∆x → 0 erhalt man also P(X = x) = 0 fur alle x , wo FX
differenzierbar ist.
Die Flache unterhalb der Dichtefunktion ist∫ ∞−∞
fX (x)dx = FX (∞) = 1
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 314

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.2 Stetige Zufallsvariablen
7.2.2 Stetige Zufallsvariablen
Definition 56
Jede Funktion f : R→ [0,∞) definiert eine Dichtefunktion, wenn gilt:
(i) f (x) ≥ 0 fur alle x und
(ii)∫∞−∞ f (x)dx = 1
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 315

7 Zufallsvariablen 7.2 Dichtefunktionen 7.2.3 Andere Zufallsvariablen
7.2.3 Andere Zufallsvariablen
Zufallsvariablen mussen weder diskret noch stetig sein!
Diskrete Zufallsvariablen haben stuckweise konstanteVerteilungsfunktionen,stetige Zufallsvariablen stetige Verteilungsfunktionen.
Es gibt aber auch Verteilungsfunktionen, die sowohl Sprunge aufweisen,als auch stetige Abschnitte (gemischte Verteilungen).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 316

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.1 Erwartungswert
7.3.1 Erwartungswert
Definition 57
Der Erwartungswert µX oder E[X ] einer Zufallsvariable X ist definiertdurch
E[X ] =∑i
xi P(X = xi ) =∑i
xi fX (xi )
fur diskretes X mit Massenpunkten x1, x2, . . . , (vorausgesetzt die Reiheist absolut konvergent)
E[X ] =
∫ ∞−∞
x fX (x)dx
fur stetiges X mit Dichte fX (vorausgesetzt das Integral existiert).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 317

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.1 Erwartungswert
7.3.1 Erwartungswert
Bemerkungen
Fur diskrete Zufallsvariablen mit unendlich vielen Massenpunkten ist derErwartungswert nur definiert, wenn obige Reihe absolut konvergiert.Sonst sagt man, dass der Erwartungswert nicht existiert.
Fur stetige Zufallsvariablen wird ganz analog vorgegangen. Man sagt,dass der Erwartungswert nur existiert, wenn
∫∞−∞ x fX (x)dx existiert.
Falls nichts anderes erwahnt, wird im Folgenden angenommen,dass samtliche Erwartungswerte existieren.
Fur diskrete Zufallsvariablen mit endlich vielen Massenpunkten ist derErwartungswert ein gewichtetes arithmetisches Mittel derMassenpunkte der Zufallsvariablen, wobei die Gewichte denWahrscheinlichkeiten entsprechen, mit denen die Massenpunkteangenommen werden.
Der Erwartungswert ist Schwerpunkt der Massenverteilung, die durchdie Dichtefunktion gegeben ist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 318

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.1 Erwartungswert
7.3.1 Erwartungswert
Beachte:
Bei der Definition des Erwartungswerts werden nur die Werte vonZufallsvariablen und ihre Wahrscheinlichkeit verwendet, nicht derWahrscheinlichkeitsraum oder die Zuordnungsvorschrift derZufallsvariable. Der Erwartungswert ist also eine Eigenschaft einerVerteilung, nicht einer Zufallsvariable!
Beispiel: Werfen von 2 verschiedenfarbigen Wurfeln
Ω = (1, 1), (1, 2), . . . , (1, 6), (2, 1), . . . , (2, 6), . . . , (6, 6)X (ω1, ω2) := ω1 + ω2, Y (ω1, ω2) := |ω1 − ω2|:
E[X ] =12∑i=2
i P(X = i) =
(2+12) · 136 +(3+11) · 2
36 +(4+10) · 336 +(5+9) · 4
36 +(6+8) · 536 +7· 6
36 = 7
E[Y ] =5∑
i=0
i P(Y = i) = 0 · 636 + 1 · 10
36 + 2 · 836 + 3 · 6
36 + 4 · 436 + 5 · 2
36 = 7036
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 319

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.1 Erwartungswert
7.3.1 Erwartungswert
Beachte:
Die Bezeichnung Erwartungswert ist insofern unglucklich, dass derberechnete Wert u.U. gar nicht realisiert werden kann (z.B. 70/36) unddeshalb auch nicht
”erwartet“ wird.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 320

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.1 Erwartungswert
7.3.1 Erwartungswert
Beispiele (Fortsetzung)
Lange einer TelefonverbindungZufallsvariable X := Lange einer Telefonverbindung ≥ 0,FX (x) := (1− e−λx), x ≥ 0, λ > 0⇒ fX (x) = λ e−λx , x ≥ 0.
E[X ] =
∫ +∞
−∞x fX (x)dx =
∫ +∞
−∞x λe−λx dx =
1
λ
Erwartungswert existiert nichtfX (x) := 1/x2, x ∈ [1,∞), fX (x) := 0, sonst, definiert eine Dichte
”auf [1,∞)“. Aber:
E[X ] =
∫ +∞
−∞x fX (x)dx =
∫ +∞
1
x1
x2dx = lim
b→∞logb =∞
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 321

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.1 Erwartungswert
7.3.1 Erwartungswert
Bemerkung
Der Erwartungswert einer Verteilung ist insofern ein Lagemaß derVerteilung, dass er einen
”mittleren Wert“ der Verteilung darstellt.
Streuungsmaße messen die Variabilitat einer Verteilung”um ein
Lagemaß herum“. Ein Beispiel fur ein Streuungsmaß ist die Varianz.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 322

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.2 Varianz
7.3.2 Varianz
Definition 58
Sei X eine Zufallsvariable mit Erwartungswert µX . Die Varianz σ2X oder
var(X ) von X ist definiert durch
var(X ) =∑i
(xi − µX )2 fX (xi )
fur diskretes X mit Massenpunkten x1, x2, . . . ,
var(X ) =
∫ +∞
−∞(x − µX )2 fX (x)dx
fur stetiges X mit Dichte fX .
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 323

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.2 Varianz
7.3.2 Varianz
Bemerkungen
Die Varianz einer Zufallsvariablen ist der Erwartungswert desquadrierten Abstandes von ihrem Erwartungswert.
Fur diskrete Zufallsvariablen mit endlich vielen Massenpunkten ist dieVarianz ein gewichtetes arithmetisches Mittel der quadriertenAbweichungen der Massenpunkte der Zufallsvariablen von ihremErwartungswert, wobei die Gewichte den Wahrscheinlichkeitenentsprechen, mit denen die Werte angenommen werden.
Die Varianz ist das Tragheitsmoment der Massenverteilung, die durchdie Dichtefunktion gegeben ist, bezogen auf eine Achse durch denSchwerpunkt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 324
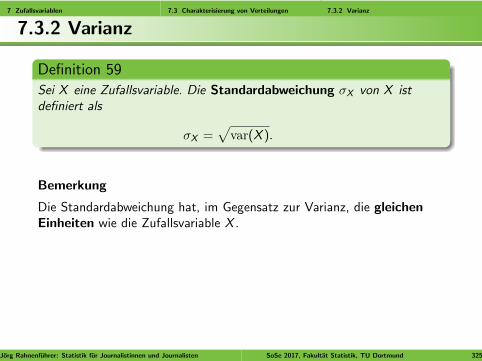
7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.2 Varianz
7.3.2 Varianz
Definition 59Sei X eine Zufallsvariable. Die Standardabweichung σX von X istdefiniert als
σX =√var(X ).
Bemerkung
Die Standardabweichung hat, im Gegensatz zur Varianz, die gleichenEinheiten wie die Zufallsvariable X .
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 325

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.2 Varianz
7.3.2 Varianz
Beispiele
Werfen von 2 verschiedenfarbigen Wurfeln:X (ω1, ω2) := ω1 + ω2:
var(X ) =12∑i=2
(i − 7)2 P(X = i) =
(25+25)· 136 +(16+16)· 2
36 +(9+9)· 336 +(4+4)· 4
36 +(1+1)· 536 = 210
36
Lange einer Telefonverbindung
var(X ) =
∫ +∞
−∞(x − µX )2 fX (x)dx =
∫ +∞
−∞
(x − 1
λ
)2
λe−λx dx =1
λ2
σX = 1/λ = E[X ]
Bemerkung
Die Varianz ist insofern ein”sinnvolles“ Streuungsmaß, dass bei
gleichem Erwartungswert diejenige Verteilung die kleinere Varianz hat,die
”enger um den Erwartungswert herum“ liegt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 326

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.2 Varianz
7.3.2 Funktionen von Zufallsvariablen
Satz 26 (Varianzen von linearen Tranformationen)
Sei X eine Zufallsvariable und a, b Konstanten, dann gilt:
var(a + bX ) = b2 var(X ).
Beweis.
var(a + bX ) = E[(a + bX − E[a− bX ])2] = E[(a + bX − a− b E(X ))2]
= b2 E[(X − E(X ))2]
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 327

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.2 Varianz
7.3.2 Funktionen von Zufallsvariablen
Bemerkung: Standardisierung
Allgemein gilt:
E[a + bX ] = a + bµX , var(a + bX ) = b2 var(X ). Also gilt:
E[X − µX ] = 0, var(X − µX ) = var(X ) : Zentrieren
E[X/σX ] = µX/σX , var(X/σX ) = 1 : Normieren
E[(X − µX )/σX ] = 0, var((X − µX )/σX ) = 1 : Standardisieren
Die Zufallsvariable (X − µX )/σX hat also immer Erwartungswert 0 undVarianz 1.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 328

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.3 Momente
7.3.3 Momente
Definition 60
Sei X eine Zufallsvariable. Das r-te Moment µ′r von X ist definiert als
µ′r = E[X r ].
Definition 61Sei X eine Zufallsvariable. Das r-te zentrale Moment µr von X istdefiniert als
µr = E[(X − µX )r ].
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 329

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.3 Momente
7.3.3 Momente
Definition 62Sei X eine Zufallsvariable. Das 3. zentrale Moment µ3 von X heißtAsymmetriemaß bzw. Schiefe von X .Der Quotient µ3/σ
3X heißt Schiefekoeffizient.
Eine Verteilung heißt linksschief (= rechtssteil) bzw. rechtsschief(=linkssteil), wenn µ3 < 0 bzw. > 0.
Definition 63Eine diskrete oder stetige Zufallsvariable X heißt symmetrisch verteiltum ihren Erwartungswert, wenn fur die dazugehorige Dichte gilt:
fX (µX − x) = fX (µX + x) fur alle x ∈ R.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 330
7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.3 Momente
7.3.3 Momente
Satz 27fur symmetrische diskrete oder stetige Zufallsvariablen gilt µ3 = 0.
Beweis.
E[(X − µX )3] =
∫ µX
−∞(x − µX )3 fX (x)dx +
∫ +∞
µX
(x − µX )3 fX (x)dx = 0
Bemerkung
Die Umkehrung gilt nicht!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 331

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.3 Momente
7.3.3 Momente
Definition 64Sei X eine Zufallsvariable. Das 4. zentrale Moment µ4 von X bzgl. µX
heißt Wolbung oder Kurtosis von X .(µ4/σ
4X − 3) heißt Wolbungskoeffizient.
Bemerkung
Der Wolbungskoeffizient ist nur interpretierbar bei symmetrischenVerteilungen. Es gilt:Symmetrische Verteilungen mit negativem Wolbungskoeffizienten sindflacher in der Nahe des Erwartungswerts als die
”Standard-Normalverteilung“, symmetrische Verteilungen mit positivem
Wolbungskoeffizienten sind spitzer.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 332

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.4 Quantile
7.3.4 Quantile
Definition 65Sei X eine Zufallsvariable. Das q-Quantil ξq von X ist definiert als diekleinste Zahl ξ mit FX (ξ) ≥ q.
Bemerkung
Falls X eine stetige Zufallsvariable ist, dann ist das q-Quantil die kleinsteZahl ξ mit FX (ξ) = q.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 333

7 Zufallsvariablen 7.3 Charakterisierung von Verteilungen 7.3.4 Quantile
7.3.4 Quantile
Definition 66
Sei X eine Zufallsvariable. Der Median medX , med(X ) oder ξ0.5 von Xist das 0.5-Quantil.
Bemerkung (Bezeichnungsweise)
Falls X eine stetige Zufallsvariable ist, dann gilt:∫ med(X )
−∞fX (x)dx =
1
2=
∫ +∞
med(X )
fX (x)dx ,
d.h. der Median (= Zentralwert) ist eine Zahl, so dass die Halfte der
”Wahrscheinlichkeitsmasse“ links und die andere Halfte rechts
davon liegt!
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 334

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.1 Diskrete Gleichverteilung
7.4.1 Diskrete Gleichverteilung
Definition 67Jede diskrete Dichtefunktion der Art
f (x) = f (x ; N) =1
N, x = 1, 2, . . . ,N und f (x) = 0, sonst,
wobei N eine naturliche Zahl ist, definiert die Dichte einer diskretenGleichverteilung. Eine Zufallsvariable mit einer solchen Dichte heißtdiskret gleichverteilt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 335

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.1 Diskrete Gleichverteilung
7.4.1 Diskrete Gleichverteilung
x
f(x)
1
N
1 2 3 4 5 N
...
Abb. 56 : Dichte einer diskreten Gleichverteilung
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 336

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.1 Diskrete Gleichverteilung
7.4.1 Diskrete Gleichverteilung
Satz 28Sei X diskret gleichverteilt, dann gilt:
E[X ] =(N + 1)
2, var(X ) =
(N2 − 1)
12
Beweis.
E[X ] =N∑i=1
i1
N=
(N + 1)
2,
var(X ) = E[X 2]− (E[X ])2 =N∑j=1
j2
N−(
N + 1
2
)2
=N(N + 1)(2N + 1)
6N− (N + 1)2
4=
(N + 1)(N − 1)
12
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 337

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.2 Bernoulli Verteilung
7.4.2 Bernoulli Verteilung
Definition 68Jede diskrete Dichtefunktion der Art
fx = f (x ; p) = px(1− p)1−x fur x = 0, 1 und f (x) = 0, sonst,
wobei 0 ≤ p ≤ 1, definiert die Dichte einer Bernoulliverteilung ( mitParameter p).Eine Zufallsvariable mit einer solcher Dichte heißt bernoulliverteilt.
Bezeichnung: q := 1− p
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 338

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.2 Bernoulli Verteilung
7.4.2 Bernoulli Verteilung
x
f(x)
0 1
q
p
Abb. 57 : Dichte einer Bernoulliverteilung (mit q := 1− p)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 339

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.2 Bernoulli Verteilung
7.4.2 Bernoulli Verteilung
Satz 29Sei X bernoulliverteilt, dann gilt:
E[X ] = p,
var(X ) = pq
Beweis.
E[X ] = 0 · q + 1 · p = p,
var(X ) = E[X 2]− (E[X ])2 = 02q + 12p − p2 = pq
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 340

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.2 Bernoulli Verteilung
7.4.2 Bernoulli Verteilung
Beispiele
BernoulliexperimentDas Versuchsergebnis kann ERFOLG oder MISSERFOLG sein. EineZufallsvariable mit dem Wert 1 bei Erfolg und dem Wert 0 beiMisserfolg hat eine Bernoulli Verteilung mit dem Parameterp = P(Erfolg).
IndikatorfunktionSei (Ω,A,P) ein Wahrscheinlichkeitsraum und A in der σ-AlgebraA. Sei die Zufallsvariable X die Indikatorfunktion fur A, d. h.X (ω) = 1, falls ω ∈ A, X (ω) = 0, sonst. X ist bernoulliverteilt mitdem Parameter p = P(X = 1) = P(A).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 341

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.3 Binomial Verteilung
7.4.3 Binomial Verteilung
Definition 69Jede diskrete Dichtefunktion der Art
f (x) = f (x ; n, p) =
(n
x
)pxqn−x fur x = 0, 1, . . . , n und f (x) = 0, sonst,
wobei n ∈ N, 0 ≤ p ≤ 1 und q := 1− p, definiert die Dichte einerBinomialverteilung ( mit Parametern n, p). Eine Zufallsvariable miteiner solchen Dichte heißt binomialverteilt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 342

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.3 Binomial Verteilung
7.4.3 Binomial Verteilung
0.0
0.1
0.2
0.3
0.4
0.5n=5, p=0.2
x
f(x)
0 1 2 3 4 5
0.0
0.1
0.2
0.3
0.4
0.5n=5, p=0.6
x
f(x)
0 1 2 3 4 5
0.0
0.1
0.2
0.3
0.4n=10, p=0.5
x
f(x)
0 1 2 3 4 5 6 7 8 9 10
0.0
0.1
0.2
0.3
0.4n=10, p=0.25
x
f(x)
0 1 2 3 4 5 6 7 8 9 10
Abb. 58 : Dichten von Binomialverteilungen
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 343

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.3 Binomial Verteilung
7.4.3 Binomial Verteilung
Satz 30Sei X binomialverteilt, dann gilt:
E[X ] = np,
var(X ) = npq
Beweis.Beweisidee:Eine binomialverteilte Zufallsvariable kann als Summe von nunabhangigen bernoulliverteilten Zufallsvariablen geschrieben werden.Wegen der Unabhangigkeit kann man sowohl fur den Erwartungswert alsauch fur die Varianz dann mit n multiplizieren.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 344

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.3 Binomial Verteilung
7.4.3 Binomial Verteilung
Beispiele
BinomialexperimentBetrachte das Zufallsexperiment, das aus n
”unabhangigen“
Wiederholungen desselben Bernoulliexperiments besteht. DerStichprobenraum hat also die Form:Ω = ω = (ω1, ω2, . . . , ωn) |ωi = Erfolg oder ωi = Misserfolg.Da die Versuche unabhangig voneinander sind, errechnet sich dieWahrscheinlichkeit eines Ergebnisses des Gesamtexperiments durchdie Multiplikation der Wahrscheinlichkeiten der Ergebnisse derEinzelexperimente.Sei die Zufallsvariable X := Anzahl Erfolge in n unabhangigenBernoulliexperimenten. Dann gilt:P(X = x) =
(nx
)pxqn−x fur x = 0, 1, . . . , n,
da die Wahrscheinlichkeit von x Erfolgen und (n − x) Misserfolgengleich pxqn−x ist und
(nx
)verschiedene Kombinationen von
Bernoulliexperimenten”erfolgreich“ sein konnen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 345

7 Zufallsvariablen 7.4 Diskrete Verteilungen 7.4.3 Binomial Verteilung
7.4.3 Binomial Verteilung
Beispiele (Fortsetzung)
Anzahl Defekte mit ZurucklegenBeim Ziehen mit Zurucklegen aus einem Behalter mit K defektenund (M − K ) nicht defekten Teilen interessiert man sich fur dieWahrscheinlichkeit von x defekten Teilen bei n Versuchen. Seip := P(Erfolg) := P(Teil defekt bei einer Ziehung) = K/M.Sei X := Anzahl defekte Teile. Dann gilt:P(X = x) =
(nx
) (KM
)x(1− K
M )n−x fur x = 0, 1, . . . , n.
Bemerkung
Bernoulliverteilung = Binomialverteilung mit n = 1
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 346

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.1 Gleichverteilung (uniform distribution)
7.5.1 Gleichverteilung (uniform distribution)
Definition 70Eine stetige Dichtefunktion der Art
f (x) = f (x ; a, b) =1
b − a, x ∈ [a, b], und f (x) = 0, sonst,
wobei a, b reelle Zahlen sind, definiert die Dichte der stetigenGleichverteilung auf dem Intervall [a, b]. Eine Zufallsvariable mit einersolcher Dichte heißt ( stetig) gleichverteilt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 347

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.1 Gleichverteilung (uniform distribution)
7.5.1 Gleichverteilung (uniform distribution)
Beispiel: Rundungsfehler
X = Fehler beim Runden von Messwerten auf 1 Stelle nach dem Komma:Wertebereich: −0.05 bis +0.05
x
f(x)
−0.05 0.00 0.05
0
10
Integral = 1
Abb. 59 : DichtefunktionJorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 348

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.1 Gleichverteilung (uniform distribution)
7.5.1 Gleichverteilung (uniform distribution)
Bemerkungen
Wegen der Form der Dichte nennt man diese Verteilung auch oftRechteckverteilung.
Die Verteilung ist wohldefiniert, da die Flache des Rechtecksoffensichtlich = 1 ist.
Verteilungsfunktion einer stetigen Gleichverteilung:
F (x) =
0, x < a,x∫a
1b−a dy = x−a
b−a , x ∈ [a, b],
1, x > b.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 349

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.1 Gleichverteilung (uniform distribution)
7.5.1 Gleichverteilung (uniform distribution)
Satz 31
Sei X (stetig) gleichverteilt, dann gilt:
E[X ] =a + b
2, var(X ) =
(b − a)2
12
Beweis.
E[X ] =
∫ b
a
x1
b − adx =
b2 − a2
2(b − a)=
a + b
2
var(X ) = E[X 2]− (E[X ])2 =
∫ b
a
x2
b − adx −
(a + b
2
)2
=b3 − a3
3(b − a)− (a + b)2
4=
(b − a)2
12
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 350

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.2 Normalverteilung
7.5.2 Normalverteilung
Definition 71Eine stetige Dichtefunktion der Art
f (x) = f (x ;µ, σ2) =1√2πσ
e−12 ( x−µ
σ )2
,
wobei σ > 0 und µ ∈ R, definiert die Dichte der Normalverteilung oderauch Gauss-Verteilung mit den Parametern µ, σ2. Eine ZufallsvariableX mit einer solchen Dichte heißt normalverteilt.
Kurzschreibweise: X ∼ N (µ, σ2)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 351

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.2 Normalverteilung
7.5.2 Normalverteilung
0.0
0.1
0.2
0.3
0.4
x
f(x)
µ − σ µ µ + σ
Abb. 60 : Dichte der Normalverteilung
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 352

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.2 Normalverteilung
7.5.2 Normalverteilung
Bemerkung
fur die Verteilungsfunktion Φµ,σ2 (x) einer Normalverteilung gilt:
Φµ,σ2 (x) : =
∫ x0
−∞f (z)dz =
∫ x0
−∞
1√2πσ
e−12 ( z−µ
σ )2
dz =
∫ µ+σy
−∞
1√2π
e−12 y
2
dy
= Φ(0,1)
(x − µσ
), y :=
z − µσ
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 353

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.2 Normalverteilung
7.5.2 Normalverteilung
x
Φ(x
)=F(x
)
0.00
0.50
0.84
1.00
µ−
3σ
µ−
2σ
µ−
σ µ
µ+
σ
µ+
2σ
µ+
3σ
Abb. 61 : Verteilungsfunktion der Normalverteilung
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 354

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.2 Normalverteilung
7.5.2 Normalverteilung
Bemerkungen
Bei der Standardnormalverteilung N (0, 1) gilt:Schiefe: µ3 = 0, Wolbung: µ4 = 3
µ ist der Erwartungswert der Normalverteilung und bestimmt dieLage der Dichte f (x).
σ ist die Standardabweichung und bestimmt die Streuung derVerteilung bzw. die Breite der Dichte f (x).
σ2 ist die Varianz der Normalverteilung.
X ∼ N (µ, σ2): normalverteilt mit Erwartungswert µ, Varianz σ2
Standard-Normalverteilung: µ = 0, σ = σ2 = 1 : N (0, 1)
Transformation auf Standard-Normalverteilung:
Sei X ∼ N (µ, σ2), dann ist Y :=(
X−µσ
)∼ N (0, 1).
Bezeichnung: Φ := Φ0,1 : N (0, 1)− Verteilungsfunktion
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 355

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.2 Normalverteilung
7.5.2 Normalverteilung
Satz 32Sei X normalverteilt, dann gilt:
E[X ] = µ, var(X ) = σ2
Satz 33
Sei X N (µ, σ2)-verteilt, dann gilt:
P(a < X < b) = Φ
(b − µσ
)− Φ
(a− µσ
)
Bemerkungen
Φ(x) = 1− Φ(−x) wegen der Symmetrie um Null
Φ(x), x ≥ 0, ist vertafelt
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 356

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.2 Normalverteilung
7.5.2 Normalverteilung
Bemerkung
fur Normalverteilungen N (µ, σ2) gilt:
Lagemaße modx = medx = µ
Streuungsmaße qd ≈ 1.35 · σx , also 1.5 · qd ≈ 2σx
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 357

7 Zufallsvariablen 7.5 Stetige Verteilungen 7.5.2 Normalverteilung
7.5.2 Normalverteilung
Bemerkung
Bei Normalverteilungen N (µ, σ2) werden haufig symmetrische Intervalleum den Erwartungswert verwendet, die den Wahrscheinlichkeiten 0.5,0.68, 0.95, 0.999 entsprechen. Die folgende Tabelle gibt die ungefahrehalbe Breite dieser Intervalle in Quartilsabstanden undStandardabweichungen an.
Wahrscheinlichkeit 50 % 68 % 95 % 99.9 %Faktor fur qd 0.5 0.75 1.5 2.25Faktor fur x 0.68 1 2 3
Das bedeutet z.B., dass gilt:P([µ− 2σ, µ+ 2σ]) ≈ P([µ− 1.5qd , µ+ 1.5qd ]) ≈ 0.95.
Diese Intervalle sind insbesondere wegen ihrer einfachen Darstellung inder Praxis sehr beliebt.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 358

7 Zufallsvariablen 7.6 Ubungsaufgaben
7.6 Ubungsaufgaben
Ein Wurfel habe vier Seiten mit den Zahlen 0, 1, 2 und 5. DieWahrscheinlichkeit, eine bestimmte Zahl zu wurfeln, sei fur alle Zahlengleich groß.
a) Bestimmen Sie die Zahldichte der Zufallsvariablen X , die dasWurfelergebnis bezeichnet.
b) Bestimmen und skizzieren Sie die Verteilungsfunktion von X .
c) Bestimmen Sie den Erwartungswert und die Varianz von X .
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 359

7 Zufallsvariablen 7.6 Ubungsaufgaben
7.6 Ubungsaufgaben
a) Bestimmen Sie die Zahldichte der Zufallsvariablen X , die dasWurfelergebnis bezeichnet.
f (x) =
1/4, x ∈ 0, 1, 2, 5,0, sonst.
b) Bestimmen und skizzieren Sie die Verteilungsfunktion von X .
F (x) =
0, x < 0,1/4, 0 ≤ x < 1,1/2, 1 ≤ x < 2,3/4, 2 ≤ x < 5,1, 5 ≤ x .
Fur die Skizze siehe Tafelbild.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 360

7 Zufallsvariablen 7.6 Ubungsaufgaben
7.6 Ubungsaufgaben
c) Bestimmen Sie den Erwartungswert und die Varianz von X .
E[X ] =4∑
i=1
xi P(X = xi ) = 0 · 1
4+ 1 · 1
4+ 2 · 1
4+ 5 · 1
4
= (0 + 1 + 2 + 5) · 1
4=
8
4= 2
var(X ) =4∑
i=1
(xi − E[X ])2 P(X = i)
= (0− 2)2 · 1
4+ (1− 2)2 · 1
4+ (2− 2)2 · 1
4+ (5− 2)2 · 1
4
= (4 + 1 + 0 + 9) · 1
4=
14
4=
7
2
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 361

7 Zufallsvariablen 7.6 Ubungsaufgaben
7.6 Ubungsaufgaben
Es sei X eine bimomialverteilte Zufallsvariable mit n = 10 und p = 0.5.
a) Bestimmen Sie den Erwartungswert von die Varianz von X und vonY = 2 · X + 3.
b) Bestimmen und skizzieren Sie die Verteilungsfunktion von Y .
c) Standardisieren Sie die Zufallsvariablen X und Y .
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 362

7 Zufallsvariablen 7.6 Ubungsaufgaben
7.6 Ubungsaufgaben
a) Bestimmen Sie den Erwartungswert von die Varianz von X und vonY = 2 · X + 3.
E(X ) = n · p = 10 · 0.5 = 5
E(Y ) = E(2 · X + 3) = 2 · E(X ) + 3 = 2 · 5 + 3 = 13
var(X ) = n · p · (1− p) = 10 · 0.5 · 0.5 = 2.5
var(Y ) = var(2 · X + 3) = 22 · var(X ) = 4 · 2.5 = 10
c) Standardisieren Sie die Zufallsvariablen X und Y .
X − E(X )√var(X )
=X − 5√
2.5
Y − E(Y )√var(Y )
=Y − 13√
10
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 363

7 Zufallsvariablen 7.6 Ubungsaufgaben
7.6 Ubungsaufgaben
b) Bestimmen und skizzieren Sie die Verteilungsfunktion von Y .
Verteilungsfunktion von X:
FX (x) = P(X ≤ x) =
bxc∑k=0
(n
k
)pk(1− p)n−k fur x ∈ R
=
bxc∑k=0
(10
k
)0.5k0.510−k =
bxc∑k=0
(10
k
)0.510
Verteilungsfunktion von Y:
FY (y) = P(Y ≤ y) = P(2 · X + 3 ≤ y) = P
(X ≤ y − 3
2
)
=
b y−32 c∑
k=0
(10
k
)0.510
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 364

8 Schatzen und Testen 8.1 Schatzen
8.1 Schatzen
Definition: Sei X1, . . . ,XN eine Zufallsstichprobe mit der Dichte fX (x , θ).Sei τ(θ) eine Funktion der unbekannten Parameter θ = (θ1, . . . , θK ).
Ein Punktschatzer ist eine Statistik T (X1, . . . ,XN), derenRealisierung benutzt wird, um die Unbekannte τ(θ) moglichst gut zureprasentieren.
Ein Intervallschatzer ist ein Paar von Statistiken T1(X1, . . . ,XN)und T2(X1, . . . ,XN) mit T1(X1, . . . ,XN) < T2(X1, . . . ,XN), so dassPθ(T1(X1, . . . ,XN) < τ(θ) < T2(X1, . . . ,XN)) = γ,wobei 0 < γ < 1 eine vorgegebene Wahrscheinlichkeit ist.
γ = 1− α heißt Konfidenzniveau (Vertrauensniveau),T1 und T2 untere bzw. obere Konfidenzgrenzen(Vertrauensgrenzen) fur τ(θ).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 365

8 Schatzen und Testen 8.1 Schatzen
8.1 Schatzen
Ein Intervall (T1(x1, . . . , xN),T2(x1, . . . , xN)) von Realisierungeneines Intervallschatzers heißtzweiseitiges 100γ%-Konfidenzintervall fur τ(θ).
Ein Punktschatzer T (X1, . . . ,XN) heißt unverzerrter(erwartungstreuer) Schatzer fur τ(θ), wenn gilt:Eθ[T ] = Eθ[T (X1, . . . ,XN)] = τ(θ).
Ein unverzerrter Schatzer T (X1, . . . ,XN) fur τ(θ) heißt besterunverzerrter Schatzer, wenn fur alle θ gilt, dassvarθ(T ) = Eθ[(T − τ(θ))2] minimal ist fur alle unverzerrtenSchatzer.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 366

8 Schatzen und Testen 8.1 Schatzen
8.1 Schatzen am Beispiel
Beispiel: Schatzer fur Blutdruckwerte von Frauen und Mannern in einemMedizindatensatz
FRAUEN: Schatzer aus der Stichprobe (n=9190)
Mittel = 122.07; Standardabw. = 19.51
Quantile 0% 2.5% 25% 50% 75% 97.5% 100%
43 89 108 120 134 164 217
Quantile einer $N(122.07, 19.51^2)$ Verteilung
-Inf 84 109 122 135 160 Inf
MANNER: Schatzer aus der Stichprobe (n=7173)
Mittel = 126.68; Standardabw. = 19.57
Quantile 0% 2.5% 25% 50% 75% 97.5% 100%
46 91 113 126 139 167 213
Quantile einer $N(126.68, 19.57^2)$ Verteilung
-Inf 88 113 127 140 165 Inf
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 367
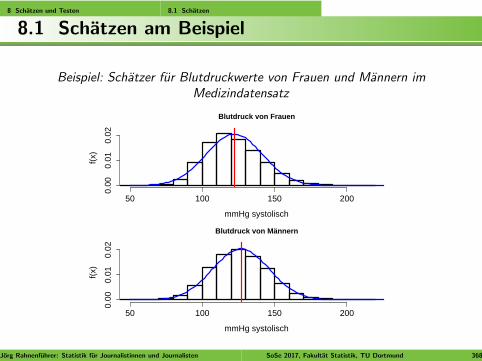
8 Schatzen und Testen 8.1 Schatzen
8.1 Schatzen am Beispiel
Beispiel: Schatzer fur Blutdruckwerte von Frauen und Mannern imMedizindatensatz
Blutdruck von Frauen
mmHg systolisch
f(x)
50 100 150 200
0.00
0.01
0.02
Blutdruck von Männern
mmHg systolisch
f(x)
50 100 150 200
0.00
0.01
0.02
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 368

8 Schatzen und Testen 8.1 Schatzen
8.1 Schatzen am Beispiel
Das 1− α Konfidenzintervall fur µ bei unbekanntem σ bei unabhangigidentisch N (µ, σ)-verteilten Zufallsvariablen Xi :[
x − tn−1;1−α/2s√n
; x + tn−1;1−α/2s√n
],
wobei s der Schatzer der Standardabweichung und tn−1;1−α/2 das1− α/2 Quantil einer t-Verteilung mit n − 1 Freiheitsgraden ist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 369

8 Schatzen und Testen 8.1 Schatzen
8.1 Schatzen am Beispiel
Das Konfidenzintervall fur den Blutdruck von Frauen bei α = 0.05 istdamit konkret:[
122.07− t9189;0.97519.51
95.864; 122.07 + t9189;0.975
19.51
95.864
]
=
[122.07− 1.96
19.51
95.864; 122.07 + 1.96
19.51
95.864
]= [121.67 ; 122.47]
Das entsprechende Konfidenzintervall fur Manner:[126.68− t7172;0.975
19.57
84.69; 126.68 + t7172;0.975
19.57
84.69
]= [126.23 ; 127.13]
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 370

8 Schatzen und Testen 8.2 Testen
8.2 Testen
Definitionen:
Eine statistische Hypothese H0 fur einen unbekannten Parameterθ = (θ1, . . . , θK ) einer Verteilung ist eine Annahme uber dieVerteilung einer Zufallsvariablen.
Ein Test einer statistischen Hypothese H0 ist eine Regel oderProzedur zur Entscheidung uber die Ablehnung (bzw.Nicht-Ablehnung) der statistischen Hypothese.
Man spricht von einem Typ I Fehler, wenn die Hypothese H0
abgelehnt wird, obwohl sie richtig ist.
Die Große des Typ I Fehlers wird Signifikanzniveau (α) des Testsgenannt.
Ist die Wahrscheinlichkeit, bei der Testentscheidung den Typ I Fehlerzu begehen, kleiner oder gleich α, so lehnt man den Test ab undspricht von einem signifikanten Ergebnis.
Man spricht von einem Typ II Fehler, wenn die Hypothese H0 nichtabgelehnt wird, obwohl sie falsch ist.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 371

8 Schatzen und Testen 8.2 Testen
8.2 t-Test
Beispiel: Unterscheiden sich die Blutdruckwerte von Frauen undMannern?
t-Test: (Ein-Stichproben-Fall)Falls die Xi unabhangig N (µ, σ2) normalverteilt sind mitunbekannter Varianz, dann gilt:
t =X − µ√
s2/n, t ∼ tn−1,
wobei s der ubliche Schatzer der Standardabw. σ ist.Man spricht: Die Teststatistik t ist t-verteilt mit n − 1Freiheitsgraden.
Dies kann zur Uberprufung von Hypothesen genutzt werden, wiez.B.: H0 : µ = µ0 vs. H1 : µ 6= µ0.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 372

8 Schatzen und Testen 8.2 Testen
8.2 t-Test
t-Test: (Zwei-Stichproben-Fall)Analog zum Ein-Stichproben-Fall kann die Teststatistik
t =(X − Y )− δ0√
s2X/n + s2
Y /m
fur den Vergleich zweier Erwartungswerte mit unbekanntenVarianzen verwendet werden, wobei sX und sY die ublichen Schatzerder Standardabweichung sind und n und m die Stichprobenumfange.Unter µX − µY = δ0 ist t wieder t-verteilt mit k Freiheitsgraden, diegegeben sind durch:
k =
(
s2X
n +s2Y
m
)2
1n−1
(s2X
n
)2
+ 1m−1
(s2Y
m
)2
.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 373

8 Schatzen und Testen 8.2 Testen
8.2 t-Test
mogliche Hypothesen, Alternativen und Ablehnungsbereich dert-Tests:
(a) H0 : µX − µY = δ0 (zweiseitig)H1 : µX − µY 6= δ0
ablehnen, wenn: |t| > t1−α/2(k)
(b) H0 : µX − µY ≥ δ0 (einseitig)H1 : µX − µY < δ0
ablehnen, wenn: t < −t1−α(k)
(c) H0 : µX − µY ≤ δ0 (einseitig)H1 : µX − µY > δ0
ablehnen, wenn: t > t1−α(k)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 374

8 Schatzen und Testen 8.2 Testen
8.2 t-Test am Beispiel
Beispiel: Unterscheiden sich die Blutdruckwerte von Frauen und Mannern?Einsetzen:
t =(X − Y )− δ0√
s2X/n + s2
Y /m
=(122.07− 126.68)− 0√
380/9190 + 383/7173=−4.61√
0.095= −14.98.
k =
(
s2Xn
+s2Ym
)2
1n−1
(s2Xn
)2
+ 1m−1
(s2Ym
)2
=
⌊ (380
9190+ 383
7173
)2
19189
(380
9190
)2+ 1
7172
(383
7173
)2
⌋= 15381
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 375

8 Schatzen und Testen 8.2 Testen
8.2 t-Test am Beispiel
H0 : µX − µY = δ0 → H0 : µX = µY
H1 : µX − µY 6= δ0 → H1 : µX 6= µY
|t| > t1−α/2(k) → 14.98 > t1−0.05/2(15381)
= t0.975(15381) = 1.96
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 376

8 Schatzen und Testen 8.2 Testen
8.2 t-Test am Beispiel
−15 −10 −5 0 5 10 15
0.0
0.2
0.4
0.6
0.8
1.0
Verteilungs− und Dichtefunktion der t(15381)−Verteilung
x
F(x
), f(
x)
Verteilung F(x)Dichte f(x)Realisierung tAblehngrenzen
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 377

8 Schatzen und Testen 8.2 Testen
8.2 t-Test am Beispiel
−4 −2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
Verteilungs− und Dichtefunktion der t(15381)−Verteilung
x
F(x
), f(
x)
Verteilung F(x)Dichte f(x)Ablehngrenzen 5%Ablehngrenzen 2.5%
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 378

8 Schatzen und Testen 8.2 Testen
8.2 Test
Offensichtlich muss man sich Gedanken machen, ob folgendeEinstellungen des Tests vernunftig sind:
gerichtete (?) Nullhypothese
Relevanz, nicht alleine Signifikanz
Stichprobengroße
Verteilungsannahme
Gibt es bereits bekannte Parameter?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 379

8 Schatzen und Testen 8.2 Testen
8.2 Wilcoxon / Mann-Whitney-Tests
Eine (zu?) oft verwendete Alternative des t-Tests auf Lageunterschiedeist der Wilcoxon-Rangsummentest oder Mann-Whitney-(U)-Test.
Die Wilcoxon-Rangsummenstatistik ist
Wm,n =m∑i=1
R(Xi )
mit R(Xi ) der Rang von Xi in der gepoolten, geordneten Stichprobe.Der Test ist verteilungsfrei und wird bei Abweichung von derNormalverteilung haufig als Alternative zum t-Test verwendet, erdarf allerdings nur bei symmetrischer Verteilung verwendet werden(Voraussetzung!), was dann meist auch nicht erfullt ist!Die exakte Verteilung von Wm,n unter der Bedingung derNullhypothese kann mittels kombinatorischer Uberlegungenmathematisch leicht gefunden werden, ist aber fur große m und nkaum beherrschbar.Fur m > 25 oder n > 25 kann die Teststatistik durch dieNormalverteilung (N
(m (n+m+1)
2 ; n m (n+m+1)12
)) approximiert werden.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 380

8 Schatzen und Testen 8.2 Testen
8.2 Fisher Test (Unabhangigkeit i.d.Kontingenztafel)
Bei dem exakten Test von Fisher werden in der Kontingenztafel Zeilen-und Spaltensummen angeschaut: Man berechnet die bedingteWahrscheinlichkeit fur die Zellhaufigkeiten, gegeben die Randsummen.
Es werden die Wahrscheinlichkeiten fur den vorgegebenen Fall undfur die extremeren Falle berechnet und addiert.
Diese Wahrscheinlichkeiten folgen, wenn die Nullhypothese stimmt,einer hypergeometrischen Verteilung:
Die berechnete Wahrscheinlichkeit ist der p-Wert.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 381

8 Schatzen und Testen 8.2 Testen
8.2 Fisher Test (Unabhangigkeit i.d.Kontingenztafel)
Erinnerung:
Tab. 15 : Ergebnis des Experiments von Fisher
Tatsachlich Beurteilung MurielMilch-Tee Tee-Milch
Milch-Tee 3 1Tee-Milch 1 3
p-Wert am Beispiel:
p =
(43
)(41
)(84
) +
(44
)(40
)(84
) ≈ 0.24
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 382

8 Schatzen und Testen 8.2 Testen
8.2 χ2 Test
In Kontingenztafeln mit mehr Spalten oder Zeilen oder sehr großenBesetzungszahlen ist es schwierig oder gar unmoglich, einen exakten Testzu verwenden.
Dann geht man uber zum χ2 Test, der
den bereits kennengelernten χ2 Kontingenzkoeffizienten alsTeststatistik verwendet,
welcher χ2-verteilt ist mit m und n Freiheitsgraden.
Es muss also nur noch mit dem entsprechenden Quantil derχ2-Verteilung verglichen werden, um zu einer Testentscheidung zukommen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 383

9 Statistische Grafik 9.1 Statistische Grafik
9.1 Statistische Grafik
Statistische Grafik dient dazu
Informationen in Daten zu finden
Zusammenhange in Daten zu erkennen
Daten schnell und ohne Worte zu beschreiben
Informationen ohne Worte schnell an andere weiterzugeben
Informationen in Grafiken sollen neutral und objektiv weitergegebenwerden. Das ist schwierig, weil
der Statistiker schon ein Vorurteil hat,
der Kunde schon einen konkreten Wunsch zum Ergebnis hat,
die Wahl von Farben, Anordnungen usw. die Wahrnehmung (z.T.unbewusst oder unterbewusst) beeinflusst.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 384

9 Statistische Grafik 9.1 Statistische Grafik
9.1 Statistische Grafik
Anforderungen an statistische Grafik sind
vollstandige, selbsterklarende Beschriftung (siehe Seite 386)
gute Lesbarkeit
Vergleichbarkeit
Objektivitat
Viele Grafiken, die man im taglichen Leben sieht, z.B. in Zeitungen,Zeitschriften, Werbematerial, sind leider oft verfalschend, weil
sie ohne besseres Wissen und Reflektion unabsichtlich so erstelltwerden,
sie absichtlich den Blick des Betrachters auf bestimmte Teilgebietelenken oder von anderen ablenken sollen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 385

9 Statistische Grafik 9.1 Statistische Grafik
9.1 Statistische Grafik
Die Beschriftung einer Grafik ist von zentraler Bedeutung fur guteDatenanalyse und Prasentationen.
Zu einer geeigneten Beschriftung zahlen:
Beschriftungen an den Achsen (mit Einheit!)
Titel und eventuell Untertitel
Beschriftung muss gut lesbar sein (Große und Schriftart)
Inhalt einer Grafik soll verstanden werden konnen, ohne denFließtext zu lesen
unterschiedliche Farben, Symbole und Linienarten
sollen so gewahlt werden, dass sie gut unterscheidbar sindsollen aber auch nicht von anderen Farben, Symbolen undLinienarten ablenkenmussen in einer Legende erklart werden
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 386

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Gute und schlechte statistische Grafik
Die folgenden Beispiele sollen dazu dienen, den Blick fur Probleme zuscharfen.
Als abschreckende Beispiele haben wir bereits die schlechteVergleichbarkeit der Kreissegmente bei Kreisdiagrammen und die wegender Perspektive stark verfalschende Darstellung bei den 3DTortendiagrammen gesehen (S. 43 ff.).
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 387

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Gute und schlechte statistische Grafik
Beispiel 7 (Umsatzentwicklung zweier Firmen)
0 1 2 3 4 5 6 7
800
900
1000
1100
1200
1300
Umsatz zweier Firmen
Quartal (= t−1)
Um
satz
in M
io E
UR
Müller
Maier
0 1 2 3 4 5 6 7
0.90
0.95
1.00
1.05
1.10
Umsatz zweier Firmen
Quartal (= t−1)
Um
satz
indi
zes
xt
x 4, y
ty 4
Müller
Maier
Abb. 62 : Umsatzverlaufe zweier Firmen, einmal in Mio EUR und einmal skaliertauf den Wert in Quartal 4
Auf der nachsten Folie werden mit zwei Grafiken die Entwicklung desUmsatzes von Firma Maier vor und nach Quartal 5 dargestellt – mitunterschiedlicher Skalierung der vertikalen (y) Achse.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 388

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Gute und schlechte statistische Grafik
0 1 2 3 4 5
020
040
060
080
010
00
Quartale 0 bis 5
Um
satz
in M
io E
UR
1080
1090
1100
1110
1120
1130
Umsatz der letzten 3 Quartale
Um
satz
in M
io E
UR
5 6 7
Umsatz der Firma Maier
Abb. 63 : Umsatzverlauf der Firma Maier – verfalscht dargestellt
Die Gefahr der verfalschenden Darstellung bei unterschiedlich gewahlterSkalierung ist direkt offensichtlich.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 389

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Gute und schlechte statistische Grafik
Bemerkungen
Immer die selbe Skalierung der entsprechenden Achsen verwenden,an denen etwas verglichen werden soll!
Man kann die Wahl der Skalierung nicht der Voreinstellung desComputerprogramms uberlassen.
Je nachdem, wie weit der Wertebereich von der Null weg liegt undvariiert, sollte man uberlegen, ob die Null inkludiert werden sollteoder nicht.
Ist die Null in der Nahe, sollte man sie aufnehmen, da sie einenaturliche Basis fur Vergleiche liefert (bzw. die 1 bei Indizes /Verhaltniszahlen).
Ist die Null weit weg vom Geschehen, sieht man nicht mehr gutUnterschiede der dargestellten Beobachtungen.
Einzelne Punkte, die weit vom Geschehen entfernt liegen, werden oftnicht dargestellt (wie Fernpunkte im Boxplot),
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 390

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Gute und schlechte statistische Grafik
Beispiel 8 (Kursverlauf der BVB Aktie)
Kursverlauf der BVB Aktie vom 17. November 2000 bis zum 24.November 2010.
Tageswerte, es liegen jeweils vor:Eroffnung, Schluss, Tageshoch, Tagestief, gehandeltes Volumen
Wir starten mit einer Grafik der letzten 2 Jahre.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 391

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Gute und schlechte statistische Grafik
2009 2010
1.0
1.5
2.0
2.5
3.0
3.5
Tagestief, −hoch und Schlusskurse der BVB Aktie
Datum
Kur
s pr
o A
ktie
in E
UR
Tageshoch, −tiefSchlusskurs
Abb. 64 : Kursverlauf der BVB Aktie der letzten 2 Jahre (25.11.2008 –24.11.2010)
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 392

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Gute und schlechte statistische Grafik
2002 2004 2006 2008 2010
24
68
Tagestief, −hoch und Schlusskurse der BVB Aktie
Datum
Kur
s pr
o A
ktie
in E
UR Tageshoch, −tief
SchlusskursVolumen
050
0000
1500
000
Vol
umen
Abb. 65 : Kursverlauf der BVB Aktie (17.11.2000 – 24.11.2010)
Hier sieht man wieder, dass die Prasentation eines Teilabschnitts derDaten immer vorsichtig interpretiert werden muss.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 393

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Gute und schlechte statistische Grafik
CD
U/C
SU
GR
ÜN
E
SP
D
DIE
LIN
KE
FD
P
Son
stig
e
proz
entu
ale
Häu
figke
it
0
5
10
25
30
ParteienC
DU
/CS
U
GR
ÜN
E
SP
D
DIE
LIN
KE
FD
P
Son
stig
e
proz
entu
ale
Häu
figke
it
0
5
10
15
20
25
30
Parteien
Wahlumfrage des Forsa Instituts vom 13.10.2010
Abb. 66 : Wahlumfrage des Forsa Instituts vom 13.10.2010 – linker Teilverfalscht dargestellt
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 394

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Gute und schlechte statistische Grafik
Bemerkungen
Lucken in einer Achse (linker Teil) werden leider immer wiederverwendet. Lucken in der Achse sind aber fast niemals sinnvoll!
Auf der vorherigen Folie sieht man einen Vergleich inklusive eineranderen Farbdarstellung.
Es bietet sich die Verwendung eines perzeptiven Farbraums ab, deralso die menschliche Farbwahrnehmung nachahmt. Ein Beispiel istder hcl (hue, chroma, luminance), bei dem Farbton, Farbintensitatund Helligkeit separat eingestellt werden konnen.
Leider wird sehr oft der rgb (red, green, blue) Farbraum verwendet(dieser wird z.B. fur die Kommunikation zwischen Rechner undMonitor verwendet). Hier ist es sehr schwierig, vergleichbare Farbendarzustellen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 395

9 Statistische Grafik 9.2 Gute und schlechte statistische Grafik
9.2 Anforderungen an”
gute“ Grafik (Tufte, 1982)
Grafik ist”anziehend“, erweckt Neugier, nicht voll von
”Chartjunk“
Beschriftung ist klar, prazise und unaufdringlich, nicht”zerronnen“,
klobig oder uberladen
Worter werden ausgeschrieben, keine mysteriose und aufwendigeKodierung
Worter werden von links nach rechts geschrieben, nicht vertikaloder in verschiedene Richtungen
Beschriftung benutzt Groß- und Kleinschreibung, nicht nurGroßschreibung
Schatten, Schraffierungen und Farbe werden minimal eingesetzt:5-10% der Betrachter sind rot-grun-blind!
Grafik ist selbsterklarend, wenig Text und wenig Legende reicht zurErklarung
Exzellente Grafik vermittelt dem Betrachter die”
Wahrheit“ uberdie Daten in kurzer Zeit, mit kleinem
”Tintenverbrauch“, auf
kleinstem Raum.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 396

9 Statistische Grafik 9.3 Weitere Bemerkungen zu Grafiken
9.3 Weitere Bemerkungen zu Grafiken
(Cleveland (1994):”The Elements of Graphing Data“)
Inhalt einer Grafik
Es sind im Wesentlichen zwei Arten von Information, die in einer Grafikkodiert sind:
tabellarische Informationuber die wahren Werte der Beobachtungen und
physische Information,d.h. das Bild, das sich durch eine Umsetzung dieser Werte (in cmund Farbe) auf dem Medium ergibt.
Eine Beurteilung einer Grafik richtet sich danach, wie gut dietabellarische Information entnommen werden kann, und inwieweit diephysische Information die wesentlichen Aspekte der Grafik transportiert.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 397

9 Statistische Grafik 9.3 Weitere Bemerkungen zu Grafiken
9.3 Weitere Bemerkungen zu Grafiken
Nachschlagen
Um die tabellarische Information zu erhalten, muss man
die Grafik abtasten, um die Skalenwerte innerhalb des Datenfensterswieder zu finden,
Werte zwischen den angegebenen Skalenwerten interpolieren konnenund
die Legende (Key) mit der Darstellung der Werte abgleichen konnen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 398

9 Statistische Grafik 9.3 Weitere Bemerkungen zu Grafiken
9.3 Weitere Bemerkungen zu Grafiken
Mustererkennung
Die physische Information liefert uns Aussagen uber die Struktur derDaten. Dafur mussen wir
Beobachtungen erkennen,
Gruppen von Beobachtungen vereinigen und
verschiedene Beobachtungen vergleichen, d.h. unterscheiden,anordnen und ins Verhaltnis setzen.
Die Qualitat einer Darstellung hangt davon ab, ob diese Operationen gutund schnell ausgefuhrt werden konnen.
Die Richtigkeit der tabellarischen Information ist eine selbstverstandlicheForderung, die Richtigkeit der physischen Information ist sowohl schwererzu definieren als auch, wenn sie definiert ist, schwerer zu erreichen.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 399

9 Statistische Grafik 9.3 Weitere Bemerkungen zu Grafiken
9.3 Weitere Bemerkungen zu Grafiken
Uberlagerte Kurven
Sowohl die Differenzen als auch das Verhaltnis zweier Großen wird durcheine Uberlagerung von Kurven schlecht dargestellt.
Zum einen werden Abstande zwischen Kurven verzerrt wahrgenommen,d.h. die Mustererkennung ist falsch, zum anderen ist das Nachschlagender Abstande eine vielschrittige Aktion.
Daher ist es besser, die Zielgroße (Abstand, Verhaltnis,. . . ) selberabzubilden, oder die Verlaufe auf parallelen Panels.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 400

9 Statistische Grafik 9.3 Weitere Bemerkungen zu Grafiken
9.3 Weitere Bemerkungen zu Grafiken
Visuelle Referenzgitter
Die Wichtigkeit von Rastern leitet Cleveland vom sogenanntenWeber’schen
”Gesetz“ uber den Vergleich der Lange zweier Linien ab.
Demnach ist die Wahrscheinlichkeit, mit der eine um w Einheiten langereLinie korrekterweise als großer erkannt wird, umgekehrt proportional zurLange der kurzeren Linie.
Wahrgenommen wird also eher der prozentuale, denn der absoluteUnterschied.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 401

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Histogramm
Es sei x1 = 1.4, x2 = 1.6, x3 = 2.0, x4 = 2.3 und x5 = 6.5.
Welches Histogramm beschreibt die Daten mathematisch korrekt?
Histogramm 1
data
Den
sity
1 2 3 4 5 6 7
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Histogramm 2
data
Den
sity
2 3 4 5 60.
00.
51.
01.
52.
0
Abb. 67 : Potentielle Histogramme
Welches Histogramm ist prinzipiell besser zur Visualisierung derDaten geeignet?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 402

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Mittelwerte
Ein Schuler wechselt von einem Gymnasium auf eine Gesamtschule.Darauf steigt an beiden Schulen der mittlere IQ. (arithmetischesMittel). Ist das moglich? Begrunden Sie die Antwort.
Wie berechnet man einen geeigneten Mittelwert vonWachstumsraten?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 403

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Unabhangigkeit
Wir nehmen an, dass zwei zufallig ausgewahlte Menschen in Deutschlandjeweils 2000 (in Deutschland zufallig ausgewahlte) Bekannte haben unddass Deutschland genau 80 Millionen Einwohner hat.
Wie groß ist die dann die Wahrscheinlichkeit, dass die beidenMenschen mindestens einen gemeinsamen Bekannten haben?
Warum ist diese Wahrscheinlichkeit in der Realitat deutlich kleiner,d.h. welche Annahme ist unrealistisch?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 404

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Bedingte Wahrscheinlichkeit
Eine Ehefrau ist ermordet worden. Es ist bekannt, dass der Ehemannseine Ehefrau geschlagen hat. Welche Wahrscheinlichkeit muss betrachtetwerden, um ohne weitere Zusatzinformationen abzuschatzen, ob derEhemann der Morder ist?
P(Ehemann ist Morder | Ehemann hat Frau geschlagen und Frau istermordet worden) = 8/9
P(Ehemann ist Morder | Ehemann hat Frau geschlagen) = 1/2500
Quelle: I. Good:”When batterer becomes murderer,“ Nature 391, 1969,
S. 481
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 405

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Verteilungen
Jeder vierte Bundesburger stirbt an Krebs. Sie lesen in der Zeitung vondrei unzusammenhangenden Todesfallen.
Mit welcher Wahrscheinlichkeit
starben alle drei an Krebs?
starb genau einer an Krebs?
starb mindestens einer an Krebs?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 406

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Lage und Streuung
Ein Wurfel habe sechs Seiten mit den Zahlen 1, 2, 3 und dreimal die 6.
a) Bestimmen Sie die Zahldichte der Zufallsvariablen X , die dasWurfelergebnis bezeichnet.
b) Bestimmen Sie den Erwartungswert und die Varianz von X .
c) Was ware das Ergebnis fur (arithmetisches) Mittel und Varianz,wenn es sich um einen Datensatz (mit den Werten 1, 2, 3, 6, 6, 6)und nicht um eine Zufallsvariable handeln wurde.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 407

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Wahrscheinlichkeit
Abb. 68 : Wo liegt der Fehler?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 408

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 t-Test
Es haben 8 Journalisten und 18 Germanisten eine Klausur geschrieben,die aus vielen kleinen Teilaufgaben bestand (das Klausurergebnis wirddamit als metrisches Maerkmal aufgefasst). Die Journalisten haben imDurchschnitt 60.5 Punkte erzielt und die Germanisten 56.5 Punkte. Die(empirische) Standardabweichung der Punktzahlen betrug jeweils 4 und6. Wir nehmen an, dass die Zufallsvariablen fur beide Punktzahlennormalverteilt sind. Die wahren Erwartungswerte seien mit µJ und µG
bezeichnet.
Es soll nun mit einem t-Test bestimmt werden, ob die Journalistensignifikant hohere Punktzahlen erzielen als die Germanisten(gerichtete Hypothese). Wie lauten H0 und H1?
Wie lauten H0 und H1, wenn untersucht werden soll, ob sich diePunktzahlen signifikant unterscheiden (ungerichtete Hypothese)?
Wie lautet der Wert der Teststatistik des t-Tests?
In welchen der beiden Falle lehnt der entsprechende Test dieNullhypothese zum Niveau α = 0.05 ab (signifkantes Ergebnis)?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 409

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 t-Test
Wie lauten H0 und H1?
H0 : µJ ≤ µG und H1 : µJ > µG .
Wie lauten H0 und H1, wenn untersucht werden soll, ob sich diePunktzahlen signifikant unterscheiden (ungerichtete Hypothese)?
H0 : µJ = µG und H1 : µJ 6= µG .
Wie lautet der Wert der Teststatistik des t-Tests?
t =(XJ − XG )− 0√
s2J/n + s2
G/m
=(60.5− 56.5)√
42/8 + 62/18=
4√2 + 2
= 2.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 410

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 t-Test
In welchen der beiden Falle lehnt der entsprechende Test dieNullhypothese ab (signifkantes Ergebnis)?
Die Anzahl der Freiheitsgrade berechnet sich zu
k =
(
s2X
n +s2Y
m
)2
1n−1
(s2X
n
)2
+ 1m−1
(s2Y
m
)2
=
⌊ (168 + 36
18
)2
17
(168
)2+ 1
17
(3618
)2
⌋= 9.
Fur den einseitigen Test ist der kritische Wert c das 95%-Quantileiner t9-Verteilung, also c = 1.833.Wegen t = 2 > c ist das Ergebnis zum Niveau 0.05 statistischsignifikant.
Fur den zweiseitigen Test ist der kritische Wert c das 97.5%-Quantileiner t9-Verteilung, also c = 2.262.Wegen |t| = 2 ≤ c ist das Ergebnis zum Niveau 0.05 nichtstatistisch signifikant.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 411

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Korrelation und Kausalitat
Zusammenhang zwischen der Anzahl in den USA verkaufter japanischerAutos und der Anzahl der Selbstmorde durch Autounfalle in den USA
SuicidesbycrashingJapa
nesecarssold
JapanesepassengercarssoldintheUScorrelateswith
Suicidesbycrashingofmotorvehicle
Suicidesbycrashing Japanesecarssold
1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009
1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009
80suicides
100suicides
120suicides
140suicides
600thousandcars
800thousandcars
1000thousandcars
1200thousandcars
tylervigen.com
Abb. 69 : Japanische Autos provozieren Selbstmorde?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 412

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Korrelation und Kausalitat
Zusammenhang zwischen den Ausgaben fur Haustiere (USA) und derAnzahl von Anwalten in Kalifornien
!
!"#! $%"& $%
Abb. 70 : Haustiere machen prozessierwutig?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 413

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Interpretation von Zahlen und Statistiken
Titelthema”Lugen nach Zahlen“ in der Zeit (
”Kann das stimmen“,
24.04.2017)
Fragwurdige Aussagen:
Eine Million Manner gehen in Deutschland zu Prostituierten – Tagfur Tag! 400 000 Prostituierte bieten auf deutschen Straßen, inPrivatwohnungen und Bordellen ihre Dienste an.
15,7 Prozent der Deutschen sind arm, ein neuer Rekord.
Nur 8,4 Prozent der Frauen, die ihren Vergewaltiger anzeigen,erleben die Verurteilung des Taters – vor 20 Jahren waren es noch21,6 Prozent.
Fast die Halfte der Arbeitsplatze konnte durch die fortschreitendeDigitalisierung aller Lebensbereiche vernichtet werden, in dennachsten 13 Jahren.
Eine große Mehrheit der Deutschen will kunftig nicht mehr vomAuto abhangig sein.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 414

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Interpretation von Zahlen und Statistiken
Titelthema”Lugen nach Zahlen“ in der Zeit (
”Kann das stimmen“,
24.04.2017)
Fragwurdige Aussagen:
300 Frauen tragen in Deutschland eine Burka.
Um mehr als ein Funftel ist der Anteil von Kindern mit derAufmerksamkeitsdefizit-Storung gestiegen, innerhalb von nur vierJahren.
21 000 Patienten konnten in Krankenhausern und Heimen getotetworden sein – in einem Jahr.
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 415

10 Ubungsaufgaben 10.1 Ubungsaufgaben
10.1 Interpretation von Zahlen und Statistiken
Titelthema”Lugen nach Zahlen“ in der Zeit (
”Kann das stimmen“,
24.04.2017)Fragen, die man sich stellen sollte:
1 Hat der Produzent der Zahl ein plausibles Interesse, will er einPhanomen groß oder klein erscheinen lassen? (Und sei es bloß, umsich mit einer
”Neuigkeit“ hervorzutun.)
2 Geht es um ein Phanomen, bei dem es schwierig ist, ehrlicheAntworten zu bekommen?
3 Ist das Ergebnis politisch opportun?
4 Wer wurde befragt? Und: Wer nicht?
5 Ist das Phanomen klar definiert?
6 Sind auch absolute Haufigkeiten angegeben oder nur relativeVeranderungen?
Jorg Rahnenfuhrer: Statistik fur Journalistinnen und Journalisten SoSe 2017, Fakultat Statistik, TU Dortmund 416


















