
Von Mark Lutter - mpifg.de · • Nach dem Bernoulli Theorem lassen sich Wahrscheinlichkeiten für...
52
Sozialwissenschaftliche Methoden und Statistik I Universität Duisburg – Essen Standort Duisburg Integrierter Diplomstudiengang Sozialwissenschaften Skript zum SMS I Tutorium Von Mark Lutter Stand: April 2004 Teil II „Wahrscheinlichkeitsrechnung und Inferenzstatistik“
Transcript of Von Mark Lutter - mpifg.de · • Nach dem Bernoulli Theorem lassen sich Wahrscheinlichkeiten für...

Sozialwissenschaftliche Methoden und Statistik I
Universität Duisburg – Essen Standort Duisburg
Integrierter Diplomstudiengang Sozialwissenschaften
Skript zum SMS I Tutorium
Von Mark Lutter
Stand: April 2004
Teil II „Wahrscheinlichkeitsrechnung und Inferenzstatistik“

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 2 von 52
Inhaltsverzeichnis Seite
1. Wahrscheinlichkeitstheorie .............................................................. 04 1.1 Grundbegriffe ..................................................................................................... 04
• Zufallsexperiment • Wahrscheinlichkeit • Stichprobenraum Ω • Elementarereignis ω • Ereignis • Spezielle Ereignisse: das leere & das sichere Ereignis • Komplementäres Ereignis
1.2 Verknüpfung von Ereignissen ........................................................................... 06 • Durchschnittsbildung (A ∩ B) • Vereinigung (A ∪ B) • Unvereinbarkeit von Ereignissen • Differenz von Ereignissen
1.3 Empirischer Wahrscheinlichkeitsbegriff: Bernoulli Theorem ....................... 07 1.4 Theoretischer Wahrscheinlichkeitsbegriff: Laplace Experiment ................... 08 1.5 Axiome der Wahrscheinlichkeitstheorie ......................................................... 09 1.6 Wahrscheinlichkeitsrechnung: .......................................................................... 10 1.6.1 Additionssatz: ................................................................................................ 10
• Additionstheorem A • Additionstheorem B
1.6.2 Bedingte Wahrscheinlichkeit ........................................................................ 11
• Stochastische Unabhängigkeit • Multiplikationstheorem für abhängige Ereignisse • Multiplikationstheorem für unabhängige Ereignisse
1.6.3 Satz von der totalen Wahrscheinlichkeit ..................................................... 13 1.6.4 Theorem von Bayes ....................................................................................... 15
2. Kombinatorik .................................................................................... 16 2.1 Permutationen ..................................................................................................... 16 2.2 Kombinationen .................................................................................................... 17 2.3 Das Urnenmodell ................................................................................................. 20
3. Zufallsvariablen & Wahrscheinlichkeitsverteilungen ................... 21 • Definition Zufallsvariable • Diskrete vs. Stetige Zufallsvariablen • Wahrscheinlichkeitsfunktion • Verteilungsfunktion

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 3 von 52
3.1 diskrete vs. stetige Wahrscheinlichkeitsverteilungen ...................................... 24 3.1.1 diskrete Verteilungsformen ........................................................................... 24
• diskrete Gleichverteilung • Binomialverteilung • Hypergeometrische Verteilung • Poissonverteilung
3.1.2 stetige Verteilungsformen ............................................................................. 27 • Normalverteilung • Standardnormalverteilung
4. Stichprobe & Grundgesamtheit ....................................................... 32 • Die Stichprobenkennwerteverteilung • Zentraler Grenzwertsatz Wichtige Begriffe • Statistik • Schätzer • Erwartungswert • Erwartungstreue • Standardfehler (des Mittelwertes)
4.1 Bestimmung von Konfidenzintervallen .............................................................. 35
5. Die Überprüfung statistischer Hypothesen / Testverfahren ......... 37 • Hypothesenarten • Fehlerarten • Signifikanz • z-Test • t-Test • F-Test • Chi-Quadrat-Test • Interpretation der SPSS-Outputs
6. Literaturverzeichnis .......................................................................... 52

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 4 von 52
1. Wahrscheinlichkeitstheorie
1.1 Grundbegriffe Zufallsexperiment (auch: zufälliger Versuch)
• Ist ein beliebig oft wiederholbarer Vorgang • Wird nach einer genau festgelegten Vorschrift durchgeführt • Führt zu genau einem Ergebnis aus einer Menge möglicher Ergebnisse • die Menge aller möglichen Ergebnisse lässt sich genau angeben • Welches Ergebnis aber eintritt, hängt vom Zufall ab • Daher: Das Ergebnis eines Zufallsexperiments lässt sich nicht mit
Sicherheit vorherbestimmen, stattdessen lässt sich angeben, mit welcher Wahrscheinlichkeit jedes mögliche Ergebnis eintreten wird
Beispiele für Zufallsexperimente sind
• Das Werfen einer Münze • Das Werfen eines Würfels • Das Roulettespiel • Die zufällige Entnahme eines Produkts aus einer laufenden Produktion und die
Kontrolle auf Fehlerhaftigkeit
Ebenso sind die folgenden Vorgänge Beispiele für Zufallsexperimente (und hier findet sich der Knüpfpunkt zur empirischen Sozialforschung):
• Die Befragung einer zufällig ausgewählten Person nach dem Lebensalter, nach dem Geschlecht, nach dem Einkommen usw.
Wahrscheinlichkeit (engl.: probability)
• Eine Wahrscheinlichkeit gibt die Chance des Auftretens eines zufälligen Ereignisses (oder: Ergebnis eines Zufallsexperiment) an
• Eine Wahrscheinlichkeitsangabe wird immer mit einem Zahlenwert zwischen 0 und 1 (bzw. als Prozentangabe zwischen 0% und 100%) angegeben
Stichprobenraum Ω [lies: „Omega“] (auch: Ergebnismenge, Ereignisraum)
• Die Menge aller möglichen Ergebnisse eines Zufallsexperiments heißt Stichprobenraum und wird mit Ω bezeichnet Bsp.: Werfen eines Würfels: Ω = 1,2,3,4,5,6
Werfen einer Münze: Ω = Wappen, Zahl Werfen zweier Münzen: Ω = WW, ZZ, WZ, ZW

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 5 von 52
Elementarereignisse ω [lies: „klein Omega“] • Die einzelnen Elemente ω aus Ω werden Elementarereignisse genannt
Bsp.: Zufallsexperiment: „Werfen eines Würfels“
Mögliche Elementarereignisse: 1, 2, 3, 4, 5, 6
Zufallsexperiment: „Werfen einer Münze“ Mögliche Elementarereignisse: „Wappen“, „Zahl“
(zufälliges) Ereignis
• Eine Teilmenge A des Stichprobenraumes Ω heißt (zufälliges) Ereignis • Ist das Ergebnis eines Zufallsexperiments ein Element von A, dann sagt
man: „das (zufällige) Ereignis A ist eingetreten.“ • Ein Ereignis A tritt also genau dann ein, wenn ein Element ω aus Ω zur
Teilmenge A gehört • Ereignisse werden mit Großbuchstaben bezeichnet
Bsp.: Beim Zufallsexperiment „Werfen mit einem Würfel“ ist die Teilmenge 2,4,6 das Ereignis A „gerade Augenzahl“ und die Teilmenge 1,3,5 das Ereignis B „ungerade Augenzahl“
Spezielle Ereignisse
• Besondere Teilmengen von Ω sind a) das sichere Ereignis und b) das unmögliche Ereignis:
Das sichere Ereignis E = Ω enthält die Menge aller Elementarereignisse (= Ω) und tritt daher immer ein Das unmögliche Ereignis E = φ enthält die leere Menge (= φ)
und tritt daher niemals ein Komplementäres Ereignis
• Ein Ereignis A, welches aus nicht zu A gehörenden Elementarereignissen besteht, sondern aus allen anderen Elementen ω aus Ω, heißt das zu A komplementäre Ereignis A .
• Im obigem Beispiel ist Ereignis A „gerade Augenzahl“ das komplementäre Ereignis zu B „ungerade Augenzahl“ (und umgekehrt)
• Oder: das zum leeren Ereignis komplementäre Ereignis ist das sichere Ereignis
• Die Menge A ist also das Genaue Gegenteil von A

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 6 von 52
1.2 Verknüpfung von Ereignissen
1. Durchschnittsbildung • A ∩ B („A und / geschnitten B“) • A und B treten gleichzeitig ein, d.h. das nach Durchführung eines
Zufallsexperiment eingetretene Ergebnis ω aus Ω gehört gleich-zeitig sowohl in die Teilmenge A als auch in die Teilmenge B
2. Vereinigung • A ∪ B („A oder / vereinigt B“) • A oder B tritt ein, d.h. das Element ω kann zur Teilmenge A oder
zur Teilmenge B gehören
Bsp.: Zwei Ereignisse A und B haben die folgenden Teilmengen:
A = 1,2,3,6 B = 1,4,5,6
Dann ist: A ∩ B = 1,6
A ∪ B = 1,2,3,4,5,6 Unvereinbarkeit (auch: Unverträglichkeit) von Ereignissen
• Zwei Ereignisse heißen unvereinbar, wenn gilt: A ∩ B = φ • D.h. die Mengen A und B enthalten keine gleichen Elemente • Bsp.: Die Ereignisse A: „gerade Augenzahl“ und B: „ungerade Augen-
zahl“ sind unvereinbar • Bei Unvereinbarkeit kann immer nur ein Ereignis auftreten, niemals beide
gleichzeitig! Differenz von Ereignissen
• Die Differenz A \ B („A ohne B“; auch: „A minus B“) tritt dann ein, wenn A, aber nicht B eintritt

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 7 von 52
Graphisch dargestellt (die schraffierte Fläche zeigt jeweils den Bereich, in dem das Element ω liegt):
1.3 Empirische Wahrscheinlichkeit: Bernoulli Theorem (auch: Gesetz der
großen Zahl)
• Nach dem Bernoulli Theorem lassen sich Wahrscheinlichkeiten für zufällige Ereignisse empirisch anhand ihrer Auftretenshäufigkeit (bei hinreichend großer Anzahl von Wiederholungen des Zufallsexperiments) ermitteln
• Merke: die relative Häufigkeit eines Ereignisses stellt (für eine hinreichend große Anzahl von Versuchen) einen Schätzwert für die Wahrscheinlichkeit des Ereignisses dar.1
• Die Wahrscheinlichkeit für das Auftreten eines Ereignisses A wird mit
P(A) bezeichnet. P steht für das englische Wort probability = Wahrscheinlichkeit
1 vgl. dazu die Ausführungen in Dürr/Mayer, a.a.O., Kap.: 2.5 (S.26ff.) oder die entsprechenden Ausführungen im Faulbaum-Skript

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 8 von 52
1.4 Theoretische (klassische) Wahrscheinlichkeit: Laplace – Experiment
• Nach Laplace kann die Wahrscheinlichkeit für ein Ereignis a priori bestimmt werden, d.h. ohne empirische Überprüfung der relativen Häufigkeit eines Ereignis (Bernoulli-Theorem), sondern auf theoretischem Weg!
Def.: Laplace Experiment:
• Ein Zufallsexperiment mit endlich vielen, gleichwahrscheinlichen Ergebnissen heißt Laplace – Experiment
Beispiele für Laplace – Experimente sind:
• Das Werfen eines (idealen) Würfels • Das Werfen einer (idealen) Münze • Das Ziehen von Kugeln aus einer (idealen) Urne
Die Wahrscheinlichkeit eines Ereignisses A lässt sich nach Laplace mit folgender Formel bestimmen:
Anzahl günstiger Fälle Anzahl der Elemente von A
P(A) = = Anzahl möglicher Fälle Anzahl der Elemente von Ω Bsp.:
1. Werfen einer Münze. Wie groß ist die Wahrscheinlichkeit für das Eintreten des Ereignisses E = „Wappen“ ?
Da: E = „Wappen“ => 1 Element
Ω = W,Z => 2 Elemente P(„Wappen“) = ½
2. Werfen eines Würfels. Wie groß ist die Wahrscheinlichkeit für das
Auftreten des Ereignisses E = 6?
Da: E = 6 => 1 Element Ω = 1,2,3,4,5,6 => 6 Elemente P(Augenzahl = 6) =
61

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 9 von 52
3. Werfen zweier Würfel. Wie groß ist die Wahrscheinlichkeit für das Auftreten des Ereignisses E = Augensumme ≥ 10?
Da: E = (4,6); (5,5); (5,6); (6,5); (6,4); (6,6) => 6 Elemente
Ω = (1,1);(1,2);(1,3);(1,4);(1,5);(1,6); (2,1);(2,2);(2,3);(2,4);(2,5);(2,6); (3,1);(3,2);(3,3);(3,4);(3,5);(3,6);
(4,1);(4,2);(4,3);(4,4);(4,5);(4,6); (5,1);(5,2);(5,3);(5,4);(5,5);(5,6);
(6,1);(6,2);(6,3);(6,4);(6,5);(6,6) => 36 Elemente
P(Augensumme ≥ 10) = 366
Anmerkung: Bei den obigen Beispielen können die entsprechenden Anzahlen aufgrund der (Noch-)
Überschaubarkeit durch Abzählen leicht bestimmt werden – bei komplexeren Mengen ist dies nicht mehr möglich. Dann bedient man sich der Kombinatorik (näheres dazu in Kapitel 2)
1.5 Axiome (=Grundsätze) der Wahrscheinlichkeitstheorie
• P(Ω) = 1 • P(φ) = 0 • P( A ) = 1 – P(A) • P(A \ B) = P(A) – P(A ∩ B)
vgl. hierzu Beispiel 2.8 in Dürr/Mayer, S. 31

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 10 von 52
1.6 Wahrscheinlichkeitsrechnung: 1.6.1 Additionssatz:
Variante 1: Falls zwei voneinander unabhängige Ereignisse vereinbar sind, d.h. falls gilt P(A ∩ B) ≠ φ dann gilt Additionstheorem A:
P(A ∪ B) = P(A) + P(B) – P(A ∩ B)
Variante 2: Falls jedoch zwei voneinander unabhängige Ereignisse unvereinbar sind, d.h. falls gilt: P(A ∩ B) = φ dann gilt Additionstheorem B:
P(A ∪ B) = P(A) + P(B) Bsp.: Wie hoch ist die Wahrscheinlichkeit, aus einem Skatspiel (32 Karten) eine schwarze Karte oder einen König zu ziehen?
Diese Frage bezieht sich auf Additionstheorem A Es gibt insgesamt 32 Karten (16 rote, 16 schwarze) mit 4 Königen (2 sind rot, 2 sind schwarz). Auftreten kann eine schwarze Karte (Ereignis A) oder ein König (Ereignis B). Formal haben wir hier zwei voneinander unabhängige Ereignisse, die sich nicht gegenseitig voneinander ausschließen (eine schwarze Karte kann gleichzeitig auch ein König sein und umgekehrt) Daher: P(A ∪ B) = P(A) + P(B) – P(A ∩ B) Die Wahrscheinlichkeiten können wir mit Laplace ermitteln:
P(A ∪ B) 169
322
324
3216
=−+= Anmerkung: Durch die Addition von P(A)+P(B) werden zunächst 2 schwarze Könige doppelt gezählt, anschließend werden sie mit P(A ∩ B) wieder subtrahiert.
Wie hoch ist die Wahrscheinlichkeit, beim Würfeln mit einem idealen Würfel eine 2 oder eine 4 zu würfeln?
Diese Frage bezieht sich auf Additionstheorem B Hier haben wir zwei voneinander unabhängige Ereignisse, die sich gegenseitig ausschließen (es gilt: P(A ∩ B ) = φ).
Daher: P(A ∪ B) = P(A) + P(B) = 31
61
61
=+

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 11 von 52
1.6.2 Bedingte Wahrscheinlichkeit / stochastische Unabhängigkeit / Multiplikationstheorem
• Die Wahrscheinlichkeit für das Ereignis A unter der Bedingung, dass
Ereignis B bereits eingetreten ist, heißt bedingte Wahrscheinlichkeit • Man schreibt: P(AB)
Hierbei geht es um die Frage, ob das Eintreten von B die Wahrscheinlichkeit für das Auftreten von A (1) verändert oder
(2) nicht verändert (1) Hat das Eintreten von B einen Einfluss auf die Wahrscheinlichkeit für das
Auftreten von A, dann sind beide Ereignisse voneinander abhängig.
In diesem Falle gilt die Formel für die bedingte Wahrscheinlichkeit:
P(AB) = )(
)(BP
BAP ∩
Aus dieser Formel lässt sich das Multiplikationstheorem für abhängige Ereignisse ableiten:
P(A ∩ B) = P(AB) ⋅ P(B) bzw. P(A ∩ B) = P(BA) ⋅ P(A)
(2) Hat das Eintreten von B keinen Einfluss auf die Wahrscheinlichkeit für
das Auftreten von A, dann sind A und B voneinander unabhängig. Zwei Ereignisse sind insbesondere dann unabhängig voneinander, wenn das Multiplikationstheorem für unabhängige Ereignisse gilt:
P(A ∩ B) = P(A) ⋅ P(B)
bzw. P(A ∩ B ∩ C) = P(A) ⋅ P(B) ⋅ P(C)
Für die bedingte Wahrscheinlichkeit bedeutet dies, dass es keine bedingte Wahrscheinlichkeit gibt, d.h. es gilt:
P(AB) = P(A) bzw. P(BA) = P(B)

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 12 von 52
Beispielaufgaben: (weitere Aufgaben: Dürr/Mayer, a.a.O., S. 38/39) - bedingte Wahrscheinlichkeit: Für eine Untersuchung der Rauchgewohnheiten bei Männern und Frauen hat eine Zufallsstichprobe von 300 Personen folgende (absolute) Häufigkeiten ergeben:
Mann Frau ∑ Raucher 40 60 100Nicht- Raucher
100 100 200∑ 140 160 300
Wie groß ist die Wahrscheinlichkeit, dass eine aus der gleichen Population zufällig ausgewählte Person männlich ist, unter der Bedingung, dass sie zur rauchenden Bevölkerung gehört?
Die relativen Häufigkeiten können nach dem Bernoulli-Theorem als Schätzwerte für die Wahrscheinlichkeiten genommen werden. Wir definieren folgende Ereignisse: A: Person ist männlich;
B: Person ist Raucher
Gesucht ist: P(AB) =)(
)(BP
BAP ∩
Es ergeben sich folgende Wahrscheinlichkeiten:
P(A ∩ B) (=„Person ist männlich und Raucher“) = 40/300 P(B) (=„Person ist Raucher“) = 100/300
Dann ist: P(AB) = 10040
300100/
30040
= = 0,4
- Multiplikationstheorem für unabhängige Ereignisse:
Wie hoch ist die Wahrscheinlichkeit, beim 3maligen Würfeln mit einem idealen Würfel beim ersten Wurf eine 6, beim zweiten Wurf eine gerade Augenzahl und beim dritten Wurf eine ungerade Augenzahl zu würfeln?
Da die Ereignisse voneinander unabhängig sind gilt:
P(A ∩ B ∩ C) = P(A) ⋅ P(B) ⋅ P(C) 241
63
63
61
=⋅⋅=

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 13 von 52
- Multiplikationstheorem für abhängige Ereignisse Eine gutdurchgemischte Urne enthalte 20 rote und 25 weiße Kugeln. Es wird zweimal jeweils eine Kugel ohne Zurücklegen gezogen. Wie groß ist die Wahrscheinlichkeit, erst eine rote und dann eine weiße Kugel zu ziehen? Wir definieren folgende Ereignisse: A: die erste Kugel ist rot B: die zweite Kugel ist weiß Gesucht ist: P(A ∩ B). Da wir „ohne Zurücklegen“ ziehen, sind beide Ereignisse
voneinander abhängig, deswegen gilt: P(A ∩ B) = P(A) ⋅ P(BA) Die Wahrscheinlichkeiten ermitteln wir nach Laplace:
P(A) = 20/45 (20 rote Kugeln von insgesamt 45 beim ersten Zug) P(BA) = 25/44 (25 weiße Kugeln von nur noch 44 Kugeln beim zweiten Zug)
Demnach: P(A ∩ B) = 20/45 • 25/44 = 25/99 Dieser Fall kann beliebig erweitert werden: Wie groß ist die Wahrscheinlichkeit, dass die erste Kugel rot, die zweite weiß, die dritte rot und die vierte wieder weiß ist (jeweils ohne Zurücklegen)? Wir definieren folgende 4 Ereignisse:
A: erste Kugel rot B: zweite Kugel weiß C: dritte Kugel rot D: vierte Kugel weiß
Gesucht ist: P(A ∩ B ∩ C ∩ D) = P(A) · P(B A) · P(C A ∩ B) ⋅ P(D A ∩ B ∩ C)
= 4224
4319
4445⋅⋅
2520⋅ = 0,063760528
1.6.3 Satz von der totalen Wahrscheinlichkeit
• Der Satz von der totalen Wahrscheinlichkeit stellt im Prinzip nichts anderes dar als eine Erweiterung des Multiplikationssatzes für abhängige Ereignisse.
• Genauer: Es können beliebig viele Multiplikationssätze (für abhängige Ereignisse) additiv (d.h. nach Additionstheorem B) miteinander verknüpft werden.
Er ist definiert als:
P(B) = P(B ∩ A1) + P(B ∩ A2) + … + P(B ∩ Ai) = P(A1) · P(B A1) + P(A2) · P(B A2) + … + P(Ai) · P(B Ai)
oder vereinfacht geschrieben: P(B) = A∑=
⋅n
ii BPAP
1()( i)

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 14 von 52
Ein Anwendungsbeispiel bietet die Erweiterung obiger Beispielaufgabe (vgl. S.13):
Wie groß ist die Wahrscheinlichkeit, beim zweimaligen Ziehen ohne Zurücklegen erst eine rote, (und) dann eine weiße Kugel oder erst eine weiße, (und) dann eine rote Kugel zu ziehen?
Nach dem Satz der totalen Wahrscheinlichkeit ergibt sich: 4420
4525
4425
4520
⋅+⋅ = 0,5050505
Den Unterschied zwischen Satz der totalen Wahrscheinlichkeit und Multi-plikationstheorem für abhängige Ereignisse verdeutlicht auch folgende Aufgabe: Ein Unternehmen hat insgesamt 3 Produktionsstandorte mit unterschiedlich großer Anzahl an Arbeitern. An jedem der 3 Standorte müssen Arbeiter entlassen werden.
Standort: S1 S2 S3
Anteil der Arbeiter an
der Gesamtzahl
50%
25%
25%
Anteil der Arbeiter, die am Standort
entlassen werden
10%
15%
2%
Aus der Gesamtarbeiterschaft wird ein Arbeiter zufällig ausgewählt. a) Wie groß ist die Wahrscheinlichkeit, dass dieser Arbeiter zu S1 gehört und
nicht entlassen wird? b) Wie groß ist die Wahrscheinlichkeit, dass dieser Arbeiter nicht entlassen
wird, wobei er zu allen 3 Standorten gehören kann? Wir definieren zunächst folgende Ereignisse:
A: Arbeiter wird nicht entlassen A : Arbeiter wird entlassen Si: Arbeiter stammt aus Standort Si , wobei i = 1, 2, 3.
Aufgabe a) bezieht sich aufs Multiplikationstheorem für abhängige Ereignisse: Gesucht ist: P(S1 ∩ A) = P(A S1) · P(S1) = 0,9 · 0,5 = 0,45 Antwort: Mit einer Wahrscheinlichkeit von 45% gehört er zu S1 und wird nicht entlassen. Aufgabe b) bezieht sich auf den Satz der totalen Wahrscheinlichkeit: Gesucht ist P(B), wobei B das Ereignis: „Ein Arbeiter, ausgewählt aus der Gesamt-arbeiterschaft, wird nicht entlassen“ ist. Dann ergibt sich nach dem Satz der totalen Wahrscheinlichkeit: P(B) = 0,9 · 0,5 + 0,85 · 0,25 + 0,98 · 0,25 = 0,9075. Antwort: Ein (zufällig ausgewählter) Arbeiter dieser Firma hat eine 91%tige Chance, nicht entlassen zu werden.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 15 von 52
1.6.4 Theorem von Bayes2
• Das Bayes-Theorem ist nun eine Verknüpfung der bedingten Wahr-scheinlichkeit mit dem Multiplikationstheorem für abhängige Ereignisse und der totalen Wahrscheinlichkeit:
Die Formel für die bedingte Wahrscheinlichkeit lautet:
P(AB) = )(
)(BP
BAP ∩ P(AiB) = )(
)(BP
BAP i ∩
Für wird die Formel für das Multiplikationstheorem eingesetzt; )( BAP i ∩
für P(B) wird die Formel für die totale Wahrscheinlichkeit eingesetzt; daraus ergibt sich das Bayes – Theorem:
P(AiB) = ∑
=
⋅
⋅n
iii
ii
ABPAP
ABPAP
1
)()(
)()(
• Mit dem Bayes - Theorem lässt sich nun die bedingte Wahrscheinlichkeit
ermitteln, wie groß der Wahrscheinlichkeitsanteil der Schnittmenge an P(B) ist - wobei P(B) die Gesamt-(totale)-Wahrscheinlichkeit
ist )( BAP i ∩
Bezogen auf obige Beispielaufgabe („Arbeiter“, vgl. S. 14) ist man mit dem Bayes - Theorem in der Lage, folgende Frage zu klären: c) Angenommen, der ausgewählte Arbeiter gehört zu denen, die nicht
entlassen werden. Mit welcher Wahrscheinlichkeit stammt er aus Standort S1?
Gesucht ist also die Wahrscheinlichkeit, mit der ein Arbeiter aus S1 stammt, unter der Bedingung, dass er zu denen gehört, die nicht entlassen werden.
Dann gilt: P(S1 A) = )(
)()( 11
BPSPSAP ⋅
= ).).
beTeilaufgabvglaeTeilaufgabvgl
= 496,09075,0
45,≈
0
2 Das Theorem von Bayes und der Satz von der totalen Wahrscheinlichkeit wird im Dürr/Mayer nicht behandelt. Neben den entsprechenden Ausführungen im Faulbaum Skript sind sie sehr gut erklärt in: Clauß, G. et al., a.a.O., Kap.3; insbes. Kap.: 3.1.5 sowie Kap.: 3.1.7. Auch sehr gut: Bamberg/Baur, a.a.O., Kap.: 7.3.5ff. Hinweis: Das gesamte Kapitel 3 des Buches von Clauß et. al. ist meiner Meinung nach mit die beste, weil verständlichste Darstellung der Wahrscheinlichkeitstheorie; daher absolut empfehlenswert!

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 16 von 52
2. Kombinatorik
• Mithilfe der Kombinatorik ist es möglich, die Menge der möglichen Ergebnisse eines Zufallsexperiments, also Ω, zu bestimmen
• genauer formuliert: Es kann die Menge verschiedener Anordnungs-möglichkeiten von Elementen bestimmt werden
Unterschieden wird zwischen Permutationen und Kombinationen: 2.1 Permutation von n Elementen
• Jede Zusammenstellung / Anordnung, die dadurch entsteht, dass man n gegebene Elemente in irgendeiner Reihenfolge nebeneinander setzt, heißt Permutation der gegebenen Elemente
• Dabei unterscheidet man (a) ob alle Elemente verschieden sind, oder (b) ob es Elemente gibt, die in Klassen gleicher Elemente zerfallen
(a) Alle n Elemente sind verschieden
Dann gilt: Die Anzahl der Permutation von n verschiedenen Elementen wird berechnet mit n! (lies: n Fakultät)3
Bsp.: Wie viele verschiedene `Worte´ lassen sich unter Verwendung des Wortes
MAYER bilden?
• Jeder Buchstabe - also jedes Element - des Wortes MAYER ist verschieden
• Daher: n! • Hier: 5 Elemente, also 5! = 5⋅4⋅3⋅2⋅1 = 120 verschiedene Anordnungs-
möglichkeiten (b) Es gibt n Elemente, die in k Klassen von einander gleichen Elementen
zerfallen
Dann gilt: Die Permutation wird berechnet mit !!...!!
21 knnnn
3 Unter n! versteht man das Produkt der ersten n natürlichen Zahlen. Bsp.: 4! = 1⋅2⋅3⋅4 = 24 oder 8! = 1⋅2⋅3⋅4⋅5⋅6⋅7⋅8 = 40320. Ferner wird definiert: 0! = 1

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 17 von 52
Bsp.: Wie viele verschiedene `Worte´ lassen sich unter Verwendung des Wortes MUELLER bilden?
• Insgesamt gibt es 7 Elemente, davon sind 2 Elemente gleich
12604
5040!2!2!1!1!1
!7!!...!
!
21
===knnn
n
• Erläuterung: Im Zähler steht 7! , da es insgesamt 7 Buchstaben gibt. Im Nenner stehen die Klassen von Elementen: Es gibt drei Klassen von Buchstaben (M,U,R) mit jeweils einem Element (deswegen dreimal 1!) Des weiteren gibt es zwei Klassen von Buchstaben (E,L) mit jeweils zwei Elementen (deswegen zweimal 2!)
2.2 Kombinationen k-ter Ordnung von n Elementen
• Bildet man nun aus einer Menge von n verschiedenen Elementen eine Zusammenstellung, die aus k Elementen besteht, so nennt man dies Kombination k-ter Ordnung von n Elementen
• Dabei unterscheidet man 4 Möglichkeiten: mit / ohne Berücksichtigung der Reihenfolge und mit / ohne Zurücklegen
Die Anzahl der Kombinationen k-ter Ordnung von n Elementen berechet man mit folgenden vier Formeln:
Ohne Zurücklegen Mit Zurücklegen
Mit Berücksichtigung der
Reihenfolge )!(
!kn
n−
kn
Ohne Berücksichtigung der
Reihenfolge
kn
−+k
kn 1
EXKURS:
ist der sog. Binomialkoeffizient (lies: „n über k“).
kn
Es gilt: )!(!
!knk
nkn
−=
(für k ≤ n) Wobei: (für n ≥ 0)
(für n ≥ 0) (für k > n)
nn
=
1
10
=
n
1=
nn
=
kn
0

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 18 von 52
Beispiel für die vier Kombinationsregeln: Aus 3 Elementen (a, b, c) sollen Kombinationen 2-ter Ordnung erstellt werden: Ohne Zurücklegen4 Mit Zurücklegen5
Mit Berücksichtigung der
Reihenfolge (d.h.: es können Dopplungen
auftreten, also ab ≠ ba)6
ab ac bc ba ca cb
6)!23(
!3=
−
ab ac bc ba ca cb aa bb cc
932 =
Ohne Berücksichtigung der Reihenfolge
(d.h.: es treten keine Dopplungen auf, also ab =
ba )7
ab ac bc
323
=
ab ac bc aa bb cc
624
=
Beispielaufgaben (vgl. Dürr/Mayer, a.a.O., S.47f.)
1. Beim Pferderennen sollen jeweils die 3 schnellsten Pferde eines bestimmten Rennens mit ihrer Reihenfolge des Eintreffens ins Ziel vorhergesagt werden. Insgesamt gehen 20 Pferde an den Start. Wie viel verschiedene Tipplisten gibt es?
Kombination 3-ter Ordnung von 20 Elementen
Mit Berücksichtigung der Reihenfolge / Ohne Zurücklegen
Daher: 6840)!320(
!20)!(
!=
−− knn verschiedene Tipplisten.
2. Wie viel verschiedene Tippreihen gibt es beim Lotto (6 aus 49)?
Kombination 6-ter Ordnung von 49 Elementen
Ohne Berücksichtigung der Reihenfolge / Ohne Zurücklegen
Daher:
=
verschiedene Tippreihen 13983816649
=
kn
4 „Ohne Zurücklegen“ bedeutet, dass ein einmal gezogenes Element nicht nocheinmal gezogen werden kann. Deswegen sind die drei Kombinationen aa, bb, cc nicht möglich 5 „Mit Zurücklegen“ bedeutet, dass ein einmal gezogenes Element wieder gezogen werden kann, deswegen sind die Kombinationen aa, bb und cc möglich 6 „Mit Berücksichtigung der Reihenfolge“ bedeutet, das die unterschiedliche Anordnung von Elementen eine Rolle spielt. Deswegen werden Kombinationen wie ab und ba als ungleich aufgefasst und mitgezählt. 7 Hier spielt die Anordnung der Elemente keine Rolle. Solange also zwei Kombinationen die gleichen Elemente besitzen, werden sie nur 1mal gezählt.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 19 von 52
3. Ein Zigarettenautomat hat 6 Fächer. Insgesamt hat der Händler 10 Sorten zur Verfügung. Es können mehrere Fächer mit der gleichen Sorte belegt werden. Die Reihenfolge der Belegung der 6 Fächer soll keine Bedeutung haben. Wie viel verschiedene Möglichkeiten gibt es, den Automaten zu füllen?
Kombination 6-ter Ordnung von 10 Elementen
Ohne Berücksichtigung der Reihenfolge / Mit Zurücklegen
Daher:
=
verschiedene Anordnungsmöglichkeiten
−+k
kn 15005
615
=
4. Wie viel verschiedene dreistellige Zahlen kann man aus den Ziffern 1,2,3,4,5,6,7,8,9 bilden?
Kombination 3-ter Ordnung von 9 Elementen
Mit Berücksichtigung der Reihenfolge / Mit Zurücklegen Daher: n = 9k 3 =729 verschiedene Ziffern Mithilfe der Kombinatorik können auch Wahrscheinlichkeiten ermittelt werden: Bsp.: Wie groß ist die Wahrscheinlichkeit 6 Richtige beim Lotto (6 aus 49) zu
erhalten, wenn man eine Tippreihe abgibt?
Mit Laplace können wir die Wahrscheinlichkeit bestimmen: Das Ereignis „Eine richtige Tippreihe (6 Richtige)“ hat 1 Element. Der Stichprobenraum Ω (alle möglichen Tippkombinationen) hat – wie oben bereits ermittelt – 13983816 Elemente. Damit beträgt nach Laplace die Wahrscheinlichkeit für eine richtige Tippreihe aus 13983816 möglichen Tippreihen: P(„6 Richtige“) = 120000000751,0
139838161
=

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 20 von 52
2.3 Das Urnenmodell
• Das Urnenmodell stellt eine Verallgemeinerung der Kombinationen k-ter Ordnung von n Elementen ohne Berücksichtigung der Reihenfolge und ohne Zurücklegen dar.
• Dieses Modell gestattet es, Wahrscheinlichkeiten direkt zu berechnen
Eine Urne enthalte N Kugeln, davon W weiße und S schwarze (W + S = N). Es werden n Kugeln nacheinander ohne Zurücklegen gezogen. Dann lässt sich die Wahrscheinlichkeit, dass sich unter den n Kugeln w weiße und s schwarze Kugeln befinden (Ereignis A), folgendermaßen berechnen:
=
nN
sS
wW
AP )(
Bsp.: Eine Urne (N = 10) enthalte 4 weiße und 6 schwarze Kugeln. 3 Kugeln werden nacheinander (ohne Zurücklegen; ohne Berücksichtigung der Reihenfolge) gezogen. Dann ergeben sich für die Ereignisse A = „3 weiße Kugeln werden gezogen“ und B = „2 weiße und 1 schwarze werden gezogen“ folgende Wahrscheinlichkeiten:
301
310
06
34
)( =
=
=
nN
sS
wW
AP 103
310
16
24
)( =
=
=
nN
sS
wW
BP
Das Urnenmodell lässt sich auf viele Anwendungsbereiche übertragen.8 Beispielsweise kann die Wahrscheinlichkeit für 6 Richtige im Lotto auch mit dem Urnenmodell ermittelt werden:
P(„6 Richtige“) = 120000000751,013983816
1
649
11
649
043
66
==
⋅
=
=
nN
sS
wW
8 Vgl. dazu Beispiel 3.15 in Dürr/Mayer, a.a.O., S.50.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 21 von 52
Erläuterung: Im Nenner steht , da es insgesamt in der „Urne“ 49 Kugeln gibt,
von denen 6 gezogen werden. Das macht = 13983816
verschiedene Möglichkeiten, 6 Zahlen aus 49 ohne Zurücklegen und ohne Berücksichtigung der Reihenfolge anzuordnen. Im Zähler steht , da von den 6 Richtigen genau diese 6 und von den 43
Falschen genau 0 gezogen werden sollen.
649
649
043
66
Wie groß ist demnach die Wahrscheinlichkeit für 4 Richtige im Lotto?
P(„4 Richtige“) = 00096862,013983816
90315
649
243
46
=⋅
=
Weitere Übungsaufgaben: Dürr/Mayer, a.a.O., S. 51. 3. Zufallsvariablen und Wahrscheinlichkeitsverteilungen Zufallsvariable (auch: Zufallsgröße)
• Eine Variable, deren Merkmalsausprägungen durch Ergebnisse eines Zufallsexperiments realisiert werden, heißt Zufallsvariable
• eine Zufallsvariable ist also eine Variable, deren Werte vom Zufall abhängen
• Eine Zufallsvariable ist dabei eine eindeutige Abbildung (Funktion), die jedem Ergebnis der Ergebnismenge Ω eines Zufallsexperiments Werte aus einem Wertebereich, z.B. reelle Zahlen, zuordnet
Eine mögliche diskrete Zufallsvariable, abgeleitet aus dem Zufallsexperiment „Werfen mit zwei Würfeln“, wäre die Zufallsvariable „Augensumme“; ihre Werte sind diskret, weil sie abzählbar und diskontinuierlich sind Wenn wir Personen aus einer Population zufällig auswählen und
jede ausgewählte Person nach ihrem Geschlecht zuordnen, dann ist die Variable „Geschlecht“ ebenfalls eine diskrete Zufallsvariable stetige Zufallsvariablen ergeben sich aus Zufallsexperimenten, in
denen kontinuierliche Größen erfasst werden, wie z.B. Zeit- Längen- oder Gewichtsmessungen. Der Ereignisraum besteht hier aus unendlich vielen möglichen Elementarereignissen.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 22 von 52
Wahrscheinlichkeitsfunktion • Die Wahrscheinlichkeitsverteilung einer Zufallsvariablen ist durch ihre
Wahrscheinlichkeitsfunktion f(a) definiert. Sie gibt an, wie wahrscheinlich die einzelnen Ergebnisse eines Zufallsexperiments sind
• Eine eindeutige Zuordnung (Funktion), welche jedem Wert einer Zufallsvariablen die Wahrscheinlichkeit des Auftretens jeden Wertes zuordnet, heißt Wahrscheinlichkeitsfunktion: f(ai) = pi
Bsp.: • Aus dem Zufallsexperiment „Werfen mit zwei Würfeln“ betrachten wir die
diskrete Zufallsvariable „Augensumme“. Der Wertebereich, d.h. die Werte, die die Variable annehmen kann, liegt zwischen 2 und 12.
• Jetzt ordnen wir jedem Wert – nach Laplace – seine Auftretens-wahrscheinlichkeit zu:
Wahrscheinlichkeitsverteilung der Zufallsvariable „Augensumme“ f(ai) = pi Augensumme (ai) 2 3 4 5 6 7 8 9 10 11 12
Wahrscheinlichkeit (pi) 36
1
362
363
364
365
366
365
364
363
362
361
• Die Augensumme 2 und 12 hat jeweils die geringste Auftretenswahrscheinlichkeit, da
jeweils nur 1 Ereignis [(1,1) bzw. (6,6)] aus 36 möglichen Ereignissen zutreffen kann. • Mit 6/36 hat Augensumme 7 die höchste Wahrscheinlichkeit, weil genau 6 günstige
Ereignisse aus 36 möglichen zutreffen [(6,1); (1,6); (4,3); (3,4); (5,2); (2,5)]
Graphisch dargestellt:
Verteilungsfunktion
• Aus einer Wahrscheinlichkeitsfunktion f(a) lässt sich durch Summation der einzelnen Wahrscheinlichkeiten ihre Verteilungsfunktion F(a) = Σf(pi) bilden: (man beachte: Die Summe aller Wahrscheinlichkeiten ist immer 1)
Verteilungsfunktion von „Augensumme“ Augensumme (ai) 2 3 4 5 6 7 8 9 10 11 12 Wahrscheinlichkeit (pi) 36
1
363
366
3610
3615
3621
3626
3630
3633
3635
13636
=

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 23 von 52
Beispielaufgaben zur diskreten Wahrscheinlichkeitsverteilung Wie hoch ist die Wahrscheinlichkeit beim Werfen zweier Würfel...
1. ...Augensumme 2 oder 12 zu würfeln? 2. ...höchstens Augensumme 4 zu würfeln? 3. ...eine Augensumme kleiner als 5 zu würfeln? 4. ...mindestens Augensumme 4 zu würfeln? 5. ...eine Augensumme größer als 3 zu würfeln? 6. ...eine Augensumme zwischen 4 und 8 zu würfeln? 7. ...eine Augensumme größer als 12 zu würfeln? 8. ...eine Augensumme kleiner als 2 zu würfeln?
Lösung:
1. P(AS = 2 ∪ 12) = 1/36 + 1/36 = 1/18 2. P(AS ≤ 4) = 6/36 3. P(AS < 5) = P(AS ≤ 4) = 6/36 4. P(AS ≥ 4) = 1 – P(AS ≤ 3) = 1 – 3/36 = 11/12 5. P(AS > 3) = 1 – P(AS ≤ 3) = 11/12 6. P(4 ≤ AS ≤ 8) = P(AS ≤ 8) – P(AS ≤ 3) = 26/36 – 3/36 = 23/36 7. P(AS > 12) = 0 8. P(AS < 2) = 0
Unterschied zur stetigen Zufallsvariablen:
• Bei stetigen Zufallsvariablen heißt die Wahrscheinlichkeitsfunktion auch Dichtefunktion
• Dadurch, dass die stetige Zufallsvariable einen kontinuierlichen Wertebereich hat, entsteht durch die Dichtefunktion eine Kurve
• Betrachtet werden nicht einzelne Ereignisse, sondern Ereignisintervalle , da der Wertebereich stetig ist (also z.B. Körpergröße zwischen 170cm und 180cm). Der Flächenanteil unter der Kurve eines Intervalls ist dann die Wahrscheinlichkeit für das Eintreten eines Wertes aus diesem Intervall.
• Auch die stetige Verteilungsfunktion hat die Eigenschaft, dass die Summe aller Wahrscheinlichkeiten immer 1 ergibt.
• Demnach ist die Gesamtfläche unter der Kurve der Dichtefunktion 1
Die wichtigste stetige Wahrscheinlichkeitsdichteverteilung ist die Normalverteilung (s.u.)

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 24 von 52
3.1 Diskrete vs. stetige Wahrscheinlichkeitsverteilungen 3.1.1 Diskrete Wahrscheinlichkeitsverteilungen
• Basieren auf diskreten Zufallsvariablen (d.h. ihr Wertebereich ist endlich oder abzählbar unendlich)
• Beispiele für diskrete Zufallsvariablen sind: Augensumme (s.o.) Anzahl Wappen Anzahl der Personen in einem Haushalt
Wichtige diskrete Verteilungsformen: Diskrete Gleichverteilung
• Alle Werte der Zufallsvariablen treten mit gleicher Wahrscheinlichkeit auf
Beispiel Münzwurf: Die möglichen Ereignisse „Wappen“ u. „Zahl“ treten beide mit gleicher Wahrscheinlichkeit von ½ auf
Binomialverteilung
• Es liegt ein Zufallsexperiment vor, bei dem immer nur zwischen zwei Ergebnissen unterschieden wird:
Ereignis A, sowie das zu A komplementäre Ereignis A
Bsp.:
bei einer Qualitätskontrolle von Waren wird unterschieden zwischen „fehlerhaft“ und „fehlerfrei“ beim Werfen eines Würfels interessiert man sich für die Ereignisse
„Sechs“ und „Nicht-Sechs“ Allgemein formuliert:
• Man interessiert sich für die Wahrscheinlichkeit, dass bei n-maliger Durchführung eines Zufallsexperiments das Ereignis A genau / höchstens / mindestens k-mal auftritt
• Die Wahrscheinlichkeit von A ist p • Die Wahrscheinlichkeit von A ist 1 – p • Die Formel für die Wahrscheinlichkeitsfunktion der Binomialverteilung,
kurz B(n;p) – Verteilung, lautet: knk ppkn
kXPkf −−⋅⋅
=== )1()()(

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 25 von 52
Bsp.: 1. Wie hoch ist die Wahrscheinlichkeit, dass bei einem 5-maligen Münzwurf
genau 3-mal Wappen eintritt?
Dann ist die Zufallsvariable X „Anzahl Ereignis Wappen“ binomialverteilt mit n = 5 p = 0,5 k = 3
Daraus folgt: P(X =„3mal Wappen“ = k = 3) = 3125,0)5,01(5,035 353 =−⋅⋅
−
2. Wie hoch ist die Wahrscheinlichkeit, dass bei einem 5-maligen Münzwurf
höchstens 3-mal Wappen eintritt?
P(„höchstens 3mal Wappen“ = k ≤ 3)
= P(0mal Wappen) + P(1mal Wappen) + P(2mal Wappen) + P(3malWappen) = P(k = 0) + P(k = 1) + P(k = 2) + P(k = 3)
= 353252151050 )5,01(5,0
35
)5,01(5,025
)5,01(5,015
)5,01(5,005 −−−− −⋅⋅
+−⋅⋅
+−⋅⋅
+−⋅⋅
= 0,8125
3. Wie hoch ist die Wahrscheinlichkeit, dass bei einem 5-maligen Münzwurf mindestens 3-mal Wappen eintritt?
P(„mindestens 3mal Wappen“ = k ≥ 3) = 1 – P(„höchstens 2mal Wappen“) = 1 – P(k ≤ 2)
= 1 – ( ) = 0,5 252151050 )5,01(5,0
25
)5,01(5,015
)5,01(5,005 −−− −⋅⋅
+−⋅⋅
+−⋅⋅
Erwartungswert (Mittelwert) und Varianz der Binomialverteilung:
E(X) = µx = n⋅p Var(X) = σ2 = n⋅p⋅(1-p) Dies bedeutet, dass z.B. bei einem 5maligem Münzwurf durchschnittlich mit einem Erwartungswert von E(X = Anzahl Wappen) = µx = n⋅p = 5 ⋅ 0,5 = 2,5 mal Wappen gerechnet werden kann.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 26 von 52
Hypergeometrische Verteilung
• Knüpft unmittelbar an das Urnenmodell an (s.o.) – bzw.: es ist nichts anderes als das Urnenmodell
• Wie bei der Binomialverteilung werden nur die Ereignisse A und A unterschieden
• Vergleicht man beide Verteilungen mit dem Urnenmodell wäre die Binomialverteilung das Ziehen mit Zurücklegen und die Hypergeometrische Verteilung das Ziehen ohne Zurücklegen
• Für die Wahrscheinlichkeitsfunktion f(k) einer H(N;K;n) – verteilten Zufallsvariablen X gilt:
−−
====
nN
knKN
kK
nKNHkXPkf );;()()(
• Die Übereinstimmung mit dem Urnenmodell wird deutlich, wenn wir uns
obiges Lottobeispiel noch einmal verdeutlichen:9 Wie hoch ist die Wahrscheinlichkeit für 4 Richtige im Lotto? Lösung: Von den N = 49 Zahlen werden n = 6 gezogen. Gleichzeitig haben
von allen 49 Zahlen K = 6 die Eigenschaft „richtig“ und N – K = 43 die Eigenschaft „falsch“ zu sein. Von den n = 6 gezogenen Zahlen sollen k = 4 die Eigenschaft „richtig“ , sowie n – k = 2 die Eigenschaft „falsch“ besitzen.
Demnach ergibt sich die Wahrscheinlichkeit für das Ereignis k = 4 richtige Zahlen der H(49;6;6)-verteilten Zufallsvariablen X = Anzahl der richtigen Zahlen folgendermaßen:
00096862,013983816
90315
649
46649
46
)4( =⋅
=
−
−
==XP
9 Vgl. S. 17 hier im Skript

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 27 von 52
Poissonverteilung
• Allgemein: Ein Ereignis A tritt in einem gegebenen Zeitraum durchschnittlich µ - mal ein. Man interessiert sich dann für die Wahrscheinlichkeit, dass das Ereignis E in einem Zeitraum genau / höchstens / mindestens k – mal eintritt. Die Zufallsvariable X „Anzahl der pro Zeiteinheit eintretenden Ereignisse A“ ist dann poissonverteilt. Die Wahrscheinlichkeitsfunktion ist definiert mit:
µµ −=== e
kkXPkf
k
!)()(
Man kann zeigen, dass bei seltenen Ereignissen (p → 0; n → ∞)
die Binomialverteilung in eine Poissonverteilung übergeht
Erwartungswert und Varianz der Poissonverteilung sind beide gleich µ E(X) = Var(X) = µ
Die Poissonverteilung findet Anwendung bei Problemen der folgenden Art:
• In einem Callcenter kommen im Durchschnitt 5 Anrufe pro Minute an. Interessiert ist man an der Wahrscheinlichkeit, dass pro Minute genau / höchstens / mindestens 7 Anrufe eingehen
• Im Durchschnitt gibt es bundesweit jährlich 10 Neuinfektionen an einer seltenen Krankheit. Wie hoch ist dann die Wahrscheinlichkeit, dass sich in einem Monat genau / höchstens / mindestens eine Person ansteckt?
Aufgabe: Versucht an die Lösung eigenständig zu gelangen,
und/oder: vgl. Beispiel 5.8 in Dürr/Mayer, a.a.O., S.77 sowie: Übungsaufgaben in Dürr/Mayer, S.78
3.1.2 Stetige Wahrscheinlichkeitsverteilungen
• Die wichtigste stetige Wahrscheinlichkeitsverteilung ist die Normalverteilung10
• Weitere wichtige stetige Verteilungen sind aus der Normalverteilung abgeleitet: die Chi-Quadrat-Verteilung, die t-Verteilung, die F-Verteilung
10 Vgl. hierzu die Abhandlung in Bortz, a.a.O., S.72ff. über die Bedeutsamkeit der Normalverteilung (insbes. S. 75f.)

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 28 von 52
Normalverteilung (auch: „Gauß´sche Glockenkurve“) Die Normalverteilung hat folgende Eigenschaften:
• Die Verteilung ist symmetrisch und glockenförmig • Modalwert, Median und Mittelwert (=µ) fallen zusammen • Die Verteilung nähert sich asymptotisch der x-Achse • Das Maximum liegt bei µ • Die Wendepunkte liegen bei µ ± 1⋅σ • Die Fläche, die von der Dichtefunktion der Normalverteilung zwischen
x1 = µ + z⋅σ und x1 = µ - z⋅σ eingeschlossen wird ist immer gleich groß: • Eine Normalverteilung hat einzig und allein die Parameter µ und σ • Kurzschreibweise: N(µ;σ)
z Intervallgrenzen Anteil der Teilfläche
1 µ ± 1⋅σ 68,27 % 2 µ ± 2⋅σ 95,44 % 3 µ ± 3⋅σ 99,73 % 4 µ ± 4⋅σ 99,99 % 1,64 µ ± 1,64⋅σ 90 % 1,96 µ ± 1,96⋅σ 95 % 2,58 µ ± 2,58⋅σ 99 % 2,81 µ ± 2,81⋅σ 99,5 %
Bsp.:
Gegeben sei eine N(100;25) – verteile Zufallsvariable (d.h. sie sei normalverteilt mit µ = 100 und σ = 25). In welchem Intervall liegen 95% der Fälle?
µ ± 1,96⋅σ = 0,95 ⇔ 100 ± 1,96⋅25 = 0,95 ⇔ 100 ± 49= 0,95 Demnach: Untere Intervallsgrenze = 51 Obere Intervallsgrenze = 149
95% der Fälle liegen in dem Intervall zwischen 51 und 149.
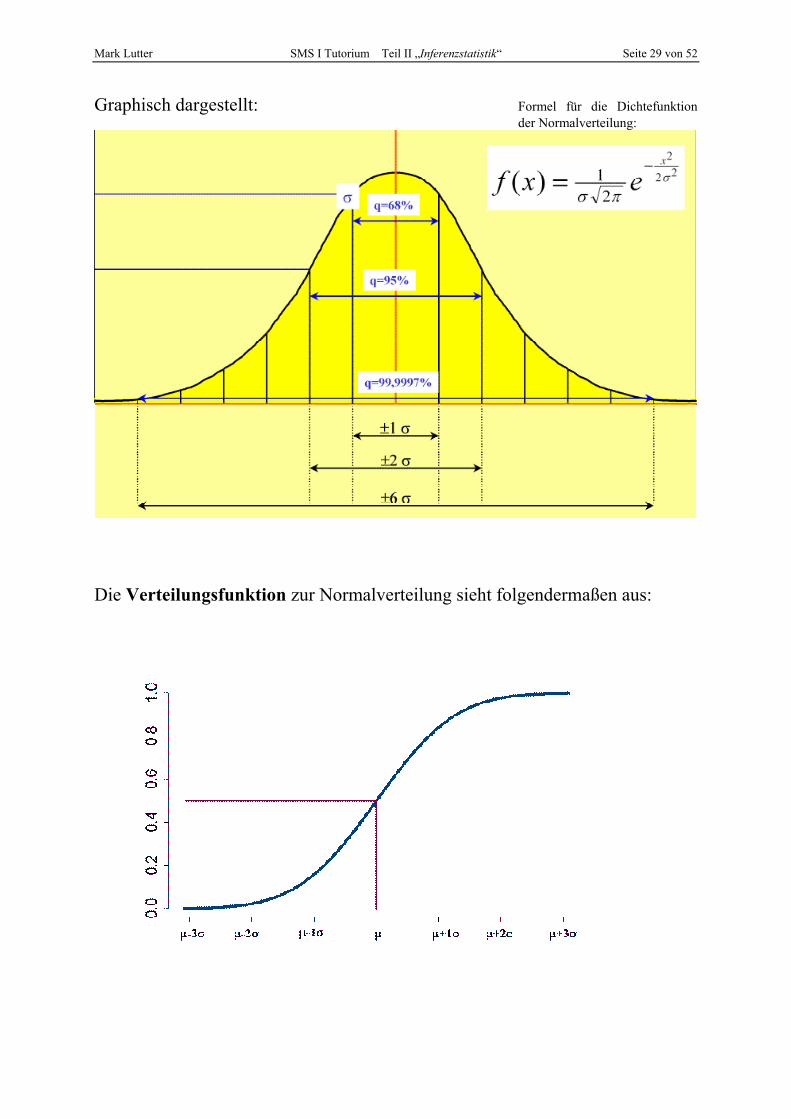
Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 29 von 52
Graphisch dargestellt: Formel für die Dichtefunktion der Normalverteilung:
Die Verteilungsfunktion zur Normalverteilung sieht folgendermaßen aus:

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 30 von 52
Standardnormalverteilung
• Unter den theoretisch unendlich vielen Normalverteilungen ist die Standardnormalverteilung diejenige, bei der gilt:
µ = 0 σ = 1
• Die Standardnormalverteilung ist also eine N(0;1) – Verteilung • Mittels Z-Transformation einzelner Messwerte
σµ−
=→ iii
xzx lässt sich
jede Normalverteilung in eine Standardnormalverteilung überführen Tabelle zur Standardnormalverteilung
• Die Verteilungsfunktion zur Standardnormalverteilung liegt in tabellierter Form vor11
• Es reicht aus, nur die Verteilungsfunktion F0(x) zur Standardnormalverteilung zu tabellieren, da man Werte der Verteilungsfunktion F(x) einer beliebigen Normalverteilung durch folgende Transformationsregel durch Werte der Verteilungsfunktion der Standardnormalverteilung ersetzen kann:
−
=σ
µxFxF 0)(
• Damit lassen sich Wahrscheinlichkeiten dafür ermitteln, dass ein Wert
einer normalverteilten Zufallsvariablen in einem bestimmten Intervall liegt bzw. dass ein Wert höchstens / mindestens eine bestimmte Größe annimmt.
Vgl. hierzu die Beispiel 6.1, 6.2 und 6.3 in Dürr/Mayer, a.a.O.,
S.83f.
• Auch können die anhand der Tabelle abgelesenen z-Werte mit der Formel für die Z-Transformation wieder in ihre ursprünglichen xi – Werte umgerechnet werden:
µσσ
µ+⋅=⇔
−= ii
ii zx
xz
Damit können Aufgaben der folgenden Art gelöst werden: 11 vgl. Bortz, a.a.O., Tabelle B, S.694ff.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 31 von 52
1. Die Zeit, die Studierende pro Semesterwoche in der Vorlesungszeit für die Vorbereitung von Seminaren aufwenden sei normalverteilt mit µ = 10 und σ = 6. Bestimmen Sie, wie viele Stunden sich ein Studierender mindestens vorbereiten muss, um zu den 5% der Studierenden zu gehören, die sich am längsten vorbereiten.
Lösung: Lt. Tabelle zur Verteilungsfunktion der Standardnormalverteilung
ermitteln wir für eine Anteilsfläche von 95% einen z-Wert von 1,65 (genauer: 0,9505 = 1,65). Über diesem z-Wert liegen die eifrigsten 5% der Studenten. Da wir nun aber einen z-Wert aus der Verteilungs-funktion der Standardnormalverteilung erhalten haben, müssen wir diesen z-Wert wieder in den ursprünglichen xi - Wert umwandeln:
µσσ
µ+⋅=⇔
−= ii
ii zx
xz
9,1910665,1 =+⋅=ix
Ein Studierender muss sich also mindestens 19,9 Stunden pro Woche vorbereiten, um zu den eifrigsten 5% zu gehören.
2. Es sei unterstellt, der Intelligenzquotient sei normalverteilt mit µ = 100; σ = 10.
Wenn man insgesamt 10% der Population mit den extremsten Werten (jeweils 5% an beiden Enden) nicht berücksichtigt, in welchem Bereich wird der IQ dann noch variieren?
Lösung: Gesucht sind also zwei xi – Werte, deren Intervall die mittleren 90%
Anteilsfläche markieren. Da wir wiederum nur die Möglichkeit haben, in der Tabelle zur Verteilungsfunktion der Standardnormalverteilung nachzusehen, ermitteln wir statt unserer gesuchten xi -Werte zunächst z-transformierte xi – Werte, nämlich z-Werte:
Lt. Tabelle ermitteln wir: Untere Grenze z = -1,65 (für Fläche 0,0495 ≈ 5%) Obere Grenze z = + 1,65 (für Fläche 0,9505 ≈ 95%) Wiederum müssen unsere z-Werte in ihre ursprünglichen xi – Werte
umgewandelt werden mit: 5,831001065,11 =+⋅−=x 5,1161001065,12 =+⋅+=x
Demnach variiert der IQ, wenn man nur die mittleren 90% der Population berücksichtigt, zwischen 83,5 und 116,5.
Zusatzfrage: Wie wahrscheinlich ist das Auftreten eines IQs zwischen 100 und
108? Lösung: Zu berechnen ist demnach die Fläche zwischen 100 und 108. Damit der Flächenanteil und somit die Wahrscheinlichkeit zu ermitteln
ist, müssen die xi – Werte 100 bzw. 108 zunächst in ihre z-Werte transformiert werden: 0
10100100
1 =−
=z 8,010
1001082 =
−=z
Lt. Tabelle ergibt sich bis z = 0,8 ein Flächenanteil von 0,7881. Davon wird die Fläche bis z = 0 (Fläche= 0,5) abgezogen, um den Flächen- anteil für das relevante Intervall zu erhalten: 0,7881 – 0,5 = 0,2881. Mit einer Wahrscheinlichkeit von ca. 28% wird der IQ in diesem Intervall liegen.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 32 von 52
4. Stichprobe und Grundgesamtheit12 (a) Die Stichprobenkennwerteverteilung (engl.: „sampling distribution“)
Die Logik der Stichprobenkennwerteverteilung ist für das Verständnis der gesamten schließenden Statistik von zentraler Bedeutung.
Diese Logik wird deutlich anhand folgendem Gedankenexperiment: 1. Gegeben sei eine bestimmte Grundgesamtheit 2. Wir ziehen aus dieser Grundgesamtheit eine genügend große Stichprobe
(n>30) und berechnen einen statistischen Kennwert, z.B. den Mittelwert13 eines Merkmals. Anschließend legen wir die für die Stichprobe ausgewählten Elemente wieder zurück in die Grundgesamtheit.
3. Dann wiederholen wir Schritt 2 sehr oft (z.B. unendlich oft). Jedesmal notieren wir uns den berechneten (Stichproben-) Mittelwert.
4. aus allen berechneten Mittelwerten erstellen wir eine Häufigkeits-verteilung – dies ist dann die Stichprobenkennwerteverteilung (des Mittelwertes, in diesem Fall)14
5. berechnen wir dann aus allen einzelnen Stichprobenkennwerten den Durchschnitt – quasi den Mittelwert aller Mittelwerte – dann ergibt sich der Erwartungswert (s.u.)
6. berechnen wir nach gleicher Logik aus allen Stichprobenkennwerten die Standardabweichung, dann ergibt sich der Standardfehler (s.u.)
Eigenschaften der Stichprobenkennwerteverteilung:15 • Diese „Häufigkeitsverteilung der Stichprobenkennwerte“ (hier:
Mittelwerte) wird immer die Form einer Normalverteilung annehmen, • Denn: nach dem Zentralen Grenzwertsatz (s.u.) konvergiert diese
Verteilung mit wachsender Wiederholung der Ziehung bei genügend großer Stichprobe (z.B. n>30 für die Mittelwerteverteilung) gegen eine Normalverteilung – und zwar unabhängig davon, wie das Merkmal sonst in der Population verteilt ist Die Stichprobenkennwerteverteilung ist also N( µ ;σ )-verteilt!
12 zum tieferen Verständnis der folgenden Thematik empfehle ich die Lektüre des 3. Kapitels „Stichprobe
und Grundgesamtheit“ in Bortz, a.a.O., S.83ff sowie Dürr/Mayer, a.a.O., Kapitel 9.4, S.109ff. 13 Prinzipiell sind auch andere Kennwerte denkbar, z.B. der Median, die Varianz, die Standardabweichung, etc. 14 Je nachdem, welcher Kennwert zugrundegelegt wird, sind Stichprobenkennwerteverteilungen verschiedener Kennwerte denkbar, so z.B. die des Medians, der Varianzen, etc. Vgl. dazu näheres z.B. im Faulbaum-Skript. Generell folgen alle Stichprobenkennwerteverteilungen der gleichen Logik & haben die gleichen Eigenschaften (wobei die eine schneller, die andere langsamer gegen eine Normalverteilung konvergiert). 15 Die Logik der Stichprobenkennwerteverteilung, sowie die von Konfidenzintervallen wird sehr gut deutlich mit dem Programm „Sampling-Sim“, einer Simulations-Software, die o. g. „Gedankenexperiment“ anschaulich simuliert und damit sehr gut zum Verständnis der gesamten schließenden Statistik beiträgt. Kostenloser Download unter: http://www.gen.umn.edu/research/stat_tools/stat_tools_software.htm

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 33 von 52
In diesem Zusammenhang wichtige Begriffe:
Stichprobenkennwert (auch: „Statistik“) • Ein Stichprobenkennwert ist ein aus einer Stichprobe berechneter
statistischer Kennwert, wie z.B. der Mittelwert, Median, Modus, Varianz, Standardabweichung, die Differenz zweier Mittelwerte, etc.
Schätzer • Ein Schätzer ist ein Stichprobenkennwert, der als Schätzer für den
dahinterstehenden, wahren Populationsparameter fungiert. • In diesem Sinne ist z.B. der Stichprobenmittelwert ein Schätzer für den
tatsächlichen, wahren Populationsmittelwert
Erwartungswert • Das arithmetische Mittel der Stichprobenkennwerteverteilung heißt
Erwartungswert. Der Erwartungswert des Mittelwertes ist also nichts anderes als der „Mittelwert aller (Stichproben-)Mittelwerte“
Erwartungstreue (auch: Unverzerrtheit) • entspricht der Erwartungswert genau dem tatsächlichen, wahren
Populationswert, dann ist der verwendete statistische Kennwert „erwartungstreu“ bzw. „unverzerrt“ (engl.: unbiased)
• „Erwartungstreue“ heißt also: der statistische Kennwert trifft im Mittel den tatsächlichen Populationswert
• der verwendete Kennwert ist dann also ein „erwartungstreuer Schätzer“ des wahren Wertes16
Standardfehler • Die Standardabweichung der Stichprobenkennwerteverteilung heißt
Standardfehler. So ist z.B. der Standardfehler des Mittelwertes nichts anderes als die „Standardabweichung aller (Stichproben-)Mittelwerte“
• Der Standardfehler gibt somit Auskunft über die durchschnittliche Abweichung der Stichprobenkennwerte vom Erwartungswert
• Liegt genau eine Stichprobe und ein Schätzer vor, dann ist er ein Kriterium für die Güte einer Schätzung, denn er sagt etwas aus über die (wahrscheinliche) Streuung eines Kennwertes von Stichprobe zu Stichprobe: Denn ist der Standardfehler eines Schätzers gering, so ist es wahrscheinlich, dass der Schätzer nur gering vom Erwartungswert abweicht. Ist er dagegen hoch, so wird ein Schätzer aller Vorrausicht nach sehr ungenau sein, da eben die „sample-to-sample-variation“ groß ist, und es somit sein kann, dass eine einzelne Schätzung stark vom tatsächlichen Wert abweicht.
16 In der Statistik sind alle uns bekannten Kennwerte erwartungstreu oder zumindest: annähernd erwartungstreu.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 34 von 52
Der Standardfehler des Mittelwertes (= xσ ) berechnet sich mit:
nxσσ =
wobei: σ ist die Standardabweichung des Merkmals in der
Population; dieser Wert ist oft oder fast immer unbekannt. In diesem Fall gilt: σ wird durch die Standardabweichung des Merkmals in der Stichprobe (s) geschätzt:
saσ n
xxs i∑ −
=2)(
Daraus ergibt sich der geschätzte Standardfehler des Mittelwertes (deswegen mit ^ versehen):
ns
x =σ
(b) Der Zentrale Grenzwertsatz Der Zentrale Grenzwertsatz besagt, wann eine Zufallsvariable normalverteilt ist! Definition:
Eine Zufallsvariable X, die sich als Summe von n Zufallsvariablen X1, X2, ... Xn ergibt, ist näherungsweise normalverteilt, wenn
• die Anzahl n der Zufallsvariablen X1, X2, ... Xn hinreichend groß ist (n>30) • die Zufallsvariablen X1, X2, ... Xn unabhängig voneinander sind • nicht eine bzw. einige wenige Zufallsvariablen gegenüber den übrigen
Zufallsvariablen stark dominieren Der Zentrale Grenzwertsatz besagt im wesentlichen Folgendes:
• eine Normalverteilung liegt genau dann vor, wenn viele einzelne Zufallseinflüsse additiv und unabhängig voneinander auf eine Variable einwirken
• Für die Stichprobenkennwerteverteilung bedeutet dies: egal wie eine Variable in der Population verteilt ist, die Verteilung des Stichprobenkennwertes wird die Form einer Normalverteilung haben (unter den entsprechenden Vorraussetzungen, die im Zentralen Grenzwertsatz formuliert sind, wie z.B. n>30)

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 35 von 52
4.1 Bestimmung von Konfidenzintervallen (auch: Vertrauensintervall) Zunächst die Unterscheidung zweier Begriffe:
Punktschätzung • es handelt sich um eine Punktschätzung, wenn ein Stichprobenkennwert
als Schätzer (s.o.) für den dahinterstehenden, wahren Populationswert fungiert
Intervallschätzung • Eine Schätzung durch Angabe von zwei Zahlen, von denen angenommen
wird, dass der Populationsparameter zwischen ihnen liegt, heißt Intervall-schätzung.
• Hierfür konstruiert man Konfidenzintervalle, in die der unbekannte Parameter mit einer bestimmten Überdeckungs- oder Sicherheits-wahrscheinlichkeit (1 - α) fällt. Während 1 - α die Wahrscheinlichkeit (z.B.: 0,95, also 95%) angibt, mit der der gesuchte Populationsparameter in dem Intervall liegt, ist α die Irrtumswahrscheinlichkeit (z.B. 0,05, also 5%), die angibt, mit welcher Wahrscheinlichkeit die Intervallschätzung fehlerbehaftet ist.
Bestimmung von Konfidenzintervallen für den Mittelwert
• Für die Bestimmung von Konfidenzintervallen macht man sich die Tatsache zunutze, dass die Stichprobenkennwerteverteilung nach dem Zentralen Grenzwertsatz normalverteilt ist. D.h., wir kennen die Verteilung aller möglichen Stichproben-Mittelwerte und können deswegen die Grenzen berechnen, die einen beliebig vorgebbaren (meist 90, 95 oder 99%) Flächenanteil (= 1 - α) unter der Normalverteilungs-kurve der Stichprobenkennwerteverteilung des Mittelwertes markieren:
Obere Grenze: xzx σ+ Untere Grenze: xzx σ−
Setzten wir für z = 1,96 ein, dann markieren die Grenzen ein 95% Konfidenzintervall; für z = 1,64 ein 90% Intervall, etc.17
Da 1 - α der entsprechende Flächenanteil ist und xσ der Standardfehler des Mittelwertes, ergibt sich als Berechnungsformel:
17 Vgl. dazu noch einmal die Ausführungen über die Eigenschaften der Normalverteilung, S. 28 hier im Skript.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 36 von 52
ασµσ−=+≤≤− 1)(
nzx
nzxP
Bzw. falls σ unbekannt, wird σ durch s geschätzt:
αµ −=+≤≤− 1)(nszx
nszxP
• Haben wir aufgrund einer konkreten Stichprobe einen Stichproben-
mittelwert berechnet und möchten ein Konfidenzintervall berechnen, gilt es zunächst die Fläche festzulegen, die das Intervall einschließen soll. Legen wir z.B. 95% als Flächenanteil fest, dann entspricht dies jenem Anteil aller Mittelwerte, die innerhalb dieser Intervallgrenzen liegen
• Ein 95% Konfidenzintervall bedeutet also, dass das Intervall in 95% aller gezogenen Stichproben zur Überdeckung des wahren Parameters führt.
• Der durch die Intervallgrenzen markierte Flächenanteil stellt somit die Überdeckungswahrscheinlichkeit (engl.: „coverage probability“) dar, mit der das berechnete Intervall den wahren Parameter trifft
Bsp.: (vgl. Dürr/Mayer, a.a.O., Beispiel 10.5, S.129)
Eine Untersuchung von n = 50 Hähnchen auf ihren Kaloriengehalt ergab einen Stichproben-Mittelwert von x = 215,48, sowie eine Standardabweichung von s = 33,14. Wie lauten die Intervallgrenzen bei 95% Überdeckungswahrscheinlichkeit?
Für ein 95% - Vertrauensintervall erhalten wir z = 1,96:
5014,3396,148,215
5014,3396,148,215 +≤≤− µ
⇔ 67,22429,206 ≤≤ µ
Mit 95%tiger Überdeckungswahrscheinlichkeit wird der wahre Populationswert µ innerhalb der Grenzen von 206,29 und 224,67 liegen.
Achtung: Bei kleinen Stichproben (n ≤ 30) sind die Stichprobenmittelwerte nicht mehr normalverteilt, sodass dann die z-Werte (als t-Werte) in der Tabelle für die t-Verteilung für n – 1 Freiheitsgrade (df) ermittelt werden müssen.18 18 Vgl. Tabelle D in Bortz, a.a.O., S.701

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 37 von 52
Wichtig: Konfidenzintervalle können z.B.: auch für Anteilswerte (Prozentwerte) gebildet werden. Die Vorgehensweise ist dabei ähnlich, vgl. dazu die Ausführungen in Dürr/Mayer, a.a.O., S.131ff. oder Bortz, a.a.O., S.99f.
Generell gilt:
• Die Länge des Konfidenzintervalls hängt ab von σ, n und 1 - α • Hat also das untersuchte Merkmal eine große Streuung, so erhält man ein
entsprechend großes Intervall. Wird die Sicherheitswahrscheinlichkeit erhöht, so verlängert sich auch das Vertrauensintervall. Das bedeutet, es verringert sich damit die Genauigkeit der Intervallschätzung. Umgekehrt gilt: je geringer die Sicherheitswahrscheinlichkeit gewählt wird, desto kleiner wird das Vertrauensintervall und desto größer wird die Genauigkeit. Jedoch: Durch Verkleinerung der Sicherheitswahr-scheinlichkeit 1 - α erhöht sich die Irrtumswahrscheinlichkeit α.
• Soll die Länge des Intervalls verkürzt werden und damit die Genauigkeit der Intervallschätzung erhöht werden, so muss der Stichprobenumfang n vergrößert werden. Dabei gilt:
Eine Halbierung der Intervalllänge erfordert eine Vervierfachung des Stichprobenumfangs
weitere Übungsaufgaben: Dürr/Mayer, a.a.O., S.140f. Bortz, a.a.O., S.102f. 5. Die Überprüfung statistischer Hypothesen / Testverfahren19 Mithilfe von statistischen Testverfahren lassen sich (sozial-)wissenschaftliche Hypothesen überprüfen. Beispiele für Hypothesen
• H1: Männer haben eine geringere Lebenserwartung als Frauen • H2: Je länger die Arbeitslosigkeit einer Person andauert, desto geringer ist
ihre Bereitschaft zur politischen Partizipation Hypothesen solcher Art lassen sich zunächst auf deskriptiver Basis mit den bekannten Verfahren überprüfen.20 19 Vgl. zum tieferen Verständnis die Ausführungen in Bortz, a.a.O., Kap. 4, S.104ff., sowie Kap. 5, S. 128ff. 20 z.B.: H1 durch einen Vergleich der durchschnittlichen Lebenserwartung bei Männern und Frauen, H2 durch eine Korrelationsrechnung zwischen den Variablen „Dauer der Arbeitslosigkeit“ und „Bereitschaft zur polit. Partizipation“

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 38 von 52
(Sozial-)Wissenschaftliche Hypothesen werden zwecks Überprüfung umformuliert in statistische Hypothesen. Statistische Hypothesen sind Aussagen über Parameter in der Population. Die Hypothesenformulierung kann unterschieden werden zwischen
• Zusammenhangshypothesen (z.B.: Chi-Quadrat-Test) hier wird überprüft, ob ein Zusammenhang zwischen zwei Variablen
signifikant ist
• Unterschiedshypothesen (z.B.: z-Test; t-Test, F-Test) hier wird überprüft, ob sich Parameter (z.B. Mittelwerte) signifikant
unterscheiden
Statistische Hypothesen: Alternativhypothese (H1): • Die Alternativhypothese ist die präzise Formulierung der Vermutung des
Forschers über einen bestimmten Sachverhalt • Deshalb wird H1 gelegentlich auch wissenschaftliche Hypothese genannt Nullhypothese (H0): • Die Nullhypothese ist die Verneinung der Alternativhypothese. • Damit ist sie die genaue Verneinung der Vermutung des Forschers
Fehlermöglichkeiten:
Fehler 1. Art (auch: α - Fehler) • Angenommen, die H0 ist in Wirklichkeit wahr, wir lehnen sie dennoch
ab. Dies ist der Fehler 1. Art: Das Ablehnen einer (eigentlich richtigen) Nullhypothese. Das Signifikanzniveau α ist die Wahrscheinlichkeit für den Fehler 1. Art (Irrtumswahrscheinlichkeit oder α- Risiko genannt)
Fehler 2. Art (auch β - Fehler) • Angenommen, die H0 ist in Wirklichkeit nicht wahr, wir nehmen sie
dennoch an. Dies ist der Fehler 2. Art: Das Ablehnen einer (eigentlich richtigen) Alternativhypothese. Die Wahrscheinlichkeit einen Fehler 2. Art zu begehen, wird β - Risiko genannt

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 39 von 52
Überblick über klausurrelevante Testverfahren z-Test (auch: „Gauß-Test“ oder bei SPSS: „t-test bei einer Stichprobe“)
• Überprüft, ob sich ein Stichprobenmittelwert signifikant von einem vorgegebenen (z.B. bekannt aus einer früheren Erhebung) „Populations-“ Mittelwert unterscheidet
t-Test (für abhängige oder unabhängige Stichproben)
• Überprüft, ob sich zwei Stichprobenmittelwerte signifikant unterscheiden F-Test (wird hier im Einzelnen nicht behandelt, vgl. Bortz, a.a.O., Kap. 5.1.5)
• Überprüft, ob sich zwei Stichprobenvarianzen signifikant unterscheiden Chi-Quadrat-Test
• Überprüft, ob der Zusammenhang zwischen zwei nominalskalierten variablen signifikant ist (also ob Chi-Quadrat signifikant von Null verschieden ist)
Zum Begriff der Signifikanz (= Überzufälligkeit o. Bedeutsamkeit)
• Erweist sich ein Unterschied oder Zusammenhang als signifikant, bedeutet dies, der Zusammenhang ist so stark oder der Unterschied so groß, dass er nicht aufgrund von Zufallseinflüssen entstanden sein kann.
Zur Durchführung der Tests z-Test (bei SPSS: t-test bei einer Stichprobe; sonst auch: Gauss-Test)21
• der z-Test vergleicht einen Stichprobenmittelwert (mit µ bezeichnet) mit einem (bekannten oder erwarteten) Populationsmittelwert (mit µ0 bezeichnet)
• hierbei wird die Hypothese überprüft, ob sich ein Stichprobenmittelwert signifikant von einem Populationsmittelwert unterscheidet
Folgende Parameter müssen also gegeben sein: µ ( x ), µ0, xσ ( xσ )
21 Beispielaufgaben zu den Testverfahren finden sich in den Übungsklausuren

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 40 von 52
I. Schritt: Hypothesenformulierung Die Hypothesen werden je nach Fragestellung unterschiedlich formuliert:
1. zweiseitige Fragestellung (d.h. es wird danach gefragt, ob die
Mittelwerte gleich oder ungleich sind)
H0: µ = µ0 Die Mittelwerte sind gleich H1: µ ≠ µ0 Die Mittelwerte sind nicht gleich
2. einseitige Fragestellung (d.h. es wird danach gefragt, ob der
Stichprobenmittelwert kleiner oder größer geworden ist)
Variante 1: Postuliert wird, dass der Stichprobenmittelwert kleiner geworden ist:
H0: µ ≥ µ0 µ ist nicht kleiner geworden H1: µ < µ0 µ ist kleiner geworden
Variante 2: Postuliert wird, dass der Stichprobenmittelwert größer geworden ist:
H0: µ ≤ µ0 µ ist nicht größer geworden H1: µ > µ0 µ ist größer geworden
II. Schritt: Berechnung des empirischen z-Wertes:
• Ist die Standardabweichung der Population σ bekannt, dann gilt:
nx
n
xxz
xemp ⋅
−=
−=
−=
σµ
σµ
σµ 000
• Ist die Standardabweichung der Population σ unbekannt, dann wird sie
durch die der Stichprobe (s) geschätzt. In diesem Fall gilt:
ns
x
ns
xxz
xemp ⋅
−=
−=
−= 000
ˆµµ
σµ

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 41 von 52
III. Schritt: Ermitteln des theoretischen z-Wertes anhand der Tabelle:
• Der theoretische z-Wert wird anhand der Tabelle „Verteilungsfunktion der Standardnormalverteilung“ (Tabelle B in Bortz, a.a.O.) nachgesehen und ist abhängig vom festgelegtem Signifikanzniveau. Er markiert das Intervall des Annahmebereichs der Nullhypothese. Berücksichtigt werden muss hier die zugrundegelegte Fragestellung:
1. bei zweiseitiger Fragestellung nachsehen bei
21 α
− sowie 2α
2. bei einseitiger Fragestellung nachsehen bei α−1 für H0: µ ≤ µ0 oder bei α für H0: µ ≥ µ0
Merke:
Für kleine Stichproben (n ≤ 30) sind die Stichprobenmittelwerte nicht mehr normalverteilt. In diesem Falle muss das Merkmal selber normalverteilt sein. Dann muss der theoretische z-Wert (als t-Wert) in der t-Tabelle (Tabelle D in Bortz, a.a.O.) für n-1 Freiheitsgrade abgelesen werden.
IV. Schritt: Ergebnisinterpretation
1. bei zweiseitiger Fragestellung
• die Nullhypothese wird angenommen, wenn zemp im Intervall [±ztheoret.] liegt
• die Nullhypothese wird abgelehnt zugunsten der Alternativhypothese, wenn zemp außerhalb dieses Intervalls liegt
2. bei einseitiger Fragestellung
• die Nullhypothese wird angenommen, wenn der Betrag von zemp kleiner ist als der Betrag von ztheoret., wenn also gilt: theoretemp zz ≤
• die Nullhypothese wird abgelehnt, wenn gilt: theoretemp zz >

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 42 von 52
Z- Test mit SPSS
• der z-Test findet sich unter der Prozedur „t-Test für eine Stichprobe“ • dort muss manuell ein Testwert vorgegeben werden, der dem erwarteten
Populationsmittelwert µ0 entspricht. Dieser wird dann mit einem Stichprobenmittelwert verglichen.
Bsp.: Man geht davon aus, dass sich bei der ALLBUS - Variable „Politische Selbsteinstufung /Links; Rechts“ der Populationsmittelwert µ0 genau in der Mitte befinden wird. Auf einer Skala von 0 = ganz links bis 10 = ganz rechts erwarten wir also ein µ0 von 5.5. Dies ist der Testwert, der nun mit dem tatsächlichen Mittelwert der Stichprobe (= 5,02) verglichen werden soll:
Statistik bei einer Stichprobe
3056 5,02 1,63 2,95E-02LINKS-RECHTS-SELBSTEINSTUFUNG, BEFR.
N MittelwertStandardabweichung
Standardfehler des
Mittelwertes
Der Stichprobenumfang beträgt N = 3056 Befragte, der Mittelwert der Variable „Politische Selbsteinstufung“ liegt bei 5,02 mit einer Standardabweichung von 1,63 und einem (geschätzten) Standardfehler des Mittelwertes von
0295,20295,03056
63,1ˆ −==== Ens
xσ
Nun wird geprüft, ob sich dieser Stichprobenmittelwert von 5,02 signifikant von dem erwarteten Populationsmittelwert (Testwert = 5,5) unterscheidet. Wie müssten dazu die Hypothesen formuliert werden?
Test bei einer Sichprobe
-16,213 3055 ,000 -,48 -,54 -,42LINKS-RECHTS-SELBSTEINSTUFUNG, BEFR.
T df Sig. (2-seitig)Mittlere
Differenz Untere Obere
95% Konfidenzintervallder Differenz
Testwert = 5.5
Sichtbar ist hier zunächst der empirische T-Wert von -16,213, die Freiheitsgrade df = n - 1 = 3055. Daneben steht die Signifikanzzahl von 0,000 (Sig. 2-seitig). Dies bedeutet, der Unterschied zwischen den Mittelwerten ist hochsignifikant.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 43 von 52
D.h. wir können mit fast 100%tiger Sicherheit davon ausgehen, dass die Mittelwerte in der Grundgesamtheit nicht gleich sind. Die Nullhypothese: „Die Mittelwerte sind gleich“ kann abgelehnt werden. Das Ergebnis ist signifikant, solange die Signifikanzzahl das
zulässige (vorgegebene) Signifikanzniveau (von meist 5%) nicht überschreitet
Achtung:
• Bei einseitiger Fragestellung muss der Wert der Signifikanz (Sig. 2-seitig) halbiert werden.
t-Test: Vergleich zweier Stichprobenmittelwerte
• t-Test für unabhängige Stichproben • t-Test für abhängige Stichproben
Unterschied zwischen abhängigen und unabhängigen Stichproben Abhängige Stichproben (auch: verbundene o. gepaarte Stichprobe)
• Abhängige Stichproben liegen vor, wenn jedem Wert der einen Stichprobe auf sinnvolle und eindeutige Weise genau ein Wert der anderen Stichprobe zugeordnet werden kann
Bsp.: Alkoholtest Die Reaktionszeit einer Person wird gemessen vor und nach dem Konsum von Alkohol Gesundheitstest Der Gesundheitszustand wird vor und nach einer Behandlung untersucht
• Hier liegen jeweils zwei Messungen vor, die anhand der gleichen Stichprobe durchgeführt werden, wobei die Elemente beider Messzeitpunkte jeweils paarweise zugeordnet werden können
Unabhängige Stichproben
• Unabhängige Stichproben liegen vor, wenn zwischen beiden Stichproben keine eindeutige Wertezuordnung möglich ist
Bsp.: In einer Umfrage sind Personen aus Ost- und Westdeutschland befragt
worden. Dann stellen die Personen aus Ost- sowie Westdeutschland jeweils zwei unabhängige Stichproben dar.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 44 von 52
t-Test für unabhängige Stichproben
Gegeben sind 2 unabhängige Stichproben des Umfangs n1 und n2; sowie deren Stichprobenmittelwerte 1x und 2x eines erhobenen Merkmals X
Der t-Test für unabhängige Stichproben prüft nun die Nullhypothese, dass beide Stichproben aus Populationen stammen, deren Populationsmittelwerte identisch sind.
I. Schritt: Formulierung der Hypothesen Auch hier wird wieder nach Fragestellung unterschieden:
1. zweiseitige Fragestellung (Es wird danach gefragt, ob die Mittelwerte gleich sind)
H0: µ1 = µ2 H1: µ1 ≠ µ2
2. einseitige Fragestellung
Variante 1: Es wird danach gefragt, ob µ1 größer ist
H0: µ1 ≤ µ2 H1: µ1 > µ2
Variante 2: Es wird danach gefragt, ob µ1 kleiner ist
H0: µ1 ≥ µ2 H1: µ1 < µ2
II. Schritt: Berechnung des empirischen t-Wertes Der empirische t-Wert wird mit folgender Formel berechnet:
21
21
xxemp
xxt
−
−=
σ
wobei
21 xx −σ der Standardfehler der Mittelwertsdifferenzen ist und mit folgender Formel berechnet wird, sofern er nicht vorgegeben ist:

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 45 von 52
2121
222
211 11
)1()1()()(
21 nnnnxxxx ii
xx +⋅−+−
−+−= ∑ ∑
−σ
III. Schritt: Ablesen des theoretischen t-Wertes in der t-Tabelle
Der theoretische t-Wert wird in der t-Tabelle22 anhand der Freiheitsgrade und des zulässigen Signifikanzniveaus abgelesen.
Das zulässige Signifikanzniveau α wird meistens in der
Aufgabenstellung vorgeben. Falls nicht, muss es selbst festgelegt werden (z.B. α = 0,05)
Je nach Fragestellung variiert die Vorgehensweise: 1. bei zweiseitiger Fragestellung nachsehen bei:
• )1()1( 21 −+−= nndf (Freiheitsgrade)
• 2α sowie
21 α
−
2. bei einseitiger Fragestellung nachsehen bei:
• )1()1( 21 −+−= nndf (Freiheitsgrade) • α (für H0: µ1 ≥ µ2) bzw. 1- α (für H0: µ1 ≤ µ2)
Achtung:
• Für größere Stichproben (n1 + n2 ≥ 50) ist t normalverteilt, sodass dann der theoretische t-Wert (als z-Wert) in der Tabelle zur Verteilungsfunktion der Standardnormalverteilung (Tabelle B) nachgeschlagen werden muss
IV. Schritt: Ergebnisinterpretation
1. bei zweiseitiger Fragestellung • die Nullhypothese wird angenommen, wenn temp im Intervall von
–ttheoretisch bis +ttheoretisch (Nullhypothesen-Annahmebereich) liegt • Andernfalls ist sie zugunsten der Alternativhypothese abzulehnen
22 Vgl. Tabelle D in Bortz, a.a.O., S. 701

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 46 von 52
2. bei einseitiger Fragestellung • die Nullhypothese wird angenommen, wenn gilt: theoretemp tt ≤
• die Nullhypothese wird abgelehnt, wenn gilt: theoretemp tt >
wird die Nullhypothese verworfen, dann sind die Populationsmittelwerte signifikant auf dem vorgegebenen Niveau voneinander verschieden
Statistische Vorraussetzungen für die Durchführung des t-Tests:
• Für kleine Stichproben muss gelten, dass sie aus normalverteilten Grundgesamtheiten stammen. Falls nicht, findet der Mann-Whitney- U-Test Anwendung
• Die Varianzen beider Grundgesamtheiten sollten in etwa gleich sein (Varianzhomogenität). Falls nicht, werden für temp entsprechende Korrekturformeln benutzt (SPSS berücksichtigt diese – s.u.: Test auf Varianzhomogenität)
t-Test für unabhängige Stichproben mit SPSS Es soll auf dem 5% - Signifikanzniveau (also mit 95%tiger Sicherheit) überprüft werden, ob sich die Mittelwerte der Variable „Wichtigkeit: eigene Familie und Kinder“23 in Ost- und Westdeutschland signifikant voneinander unterscheiden. Vorliegen haben wir also zwei unabhängige Stichproben: n1 = 2208 Befragte aus West-, sowie n2 = 1021 Befragte aus Ostdeutschland.
Gruppenstatistiken
2208 6,00 1,69 3,59E-02
1021 6,30 1,45 4,55E-02
ERHEBUNGSGEBIET:WEST - OSTALTE BUNDESLAENDERNEUEBUNDESLAENDER
WICHTIGKEIT: EIGENEFAMILIE UND KINDER
N MittelwertStandardabweichung
Standardfehler des
Mittelwertes
Wie anhand der beiden Stichprobenmittelwerte ( 1x = 6,00; 2x = 6,30) erkennbar, halten scheinbar ostdeutsche Bundesbürger ihre eigene Familie für wichtiger als Westdeutsche. Dadurch gelangen wir zu der Vermutung, dass sich die
23 Diese Variable wurde gemessen auf einer Skala von 1 = sehr unwichtig bis 7 = sehr wichtig

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 47 von 52
Mittelwerte nicht nur in der Stichprobe, sondern auch in der Grundgesamtheit unterscheiden werden (H1).
An der Standardabweichung ist bereits erkennbar, dass die Varianzen beider Stichproben nicht gleich sind. Ob sie aber signifikant nicht gleich sind, entscheidet der „Levene-Test auf Varianzhomogenität“ (s.u.)
Zuerst aber folgt die Hypothesenformulierung: Wir formulieren unsere Vermutung in Form der Alternativhypothese, während die Verneinung dessen in der Nullhypothese benannt wird:
H0: µ1 = µ2 (Mittelwerte unterscheiden sich nicht) H1: µ1 ≠ µ2 (Mittelwerte unterscheiden sich)
Ob nun ein Mittelwertunterschied tatsächlich (d.h. in der Grundgesamtheit) existiert, oder ob nur zufällig genau diese beiden Stichproben einen Unterschied uns „vormachen“, entscheidet der t-Test:
Test bei unabhängigen Stichproben
26,255 ,000 -4,985 3227 ,000 -,30 6,12E-02
-5,261 2274,913 ,000 -,30 5,79E-02
Varianzen sind gleicVarianzen sind nichtgleich
WICHTIGKEIT: EIGENFAMILIE UND KINDER
F Signifikanz
Levene-Test derVarianzgleichheit
T df Sig. (2-seitig)Mittlere
DifferenzStandardfehler der Differenz
T-Test für die Mittelwertgleichheit
I. Schritt: Test auf Varianzhomogenität / Levene-Test
• Der „Levene – Test der Varianzgleichheit“ überprüft zunächst, ob die Varianzen beider Verteilungen signifikant gleich oder ungleich sind.
• Je nachdem ob die Varianzen gleich oder ungleich sind muss entweder die obere oder die untere Zeile betrachtet werden
• Hier sind die Varianzen signifikant nicht gleich, weil die Signifikanzzahl (0,000) neben dem F – Wert kleiner ist als 0,05. Mit fast 100%tiger Sicherheit sind demnach die Varianzen nicht gleich. Das bedeutet, es muss die untere Zeile betrachtet werden („Varianzen sind nicht gleich“). Andernfalls (also falls die Signifikanzzahl des Levene - Tests größer wäre als 0,05) müsste die obere Zeile betrachtet werden.

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 48 von 52
II. Schritt Ergebnisinterpretation
• Da wir aufgrund des Levene-Tests die untere Zeile betrachten, erhalten wir einen empirischen t-Wert von –5,261 sowie Freiheitsgrade von df = 2274,913. Daneben steht die Signifikanzzahl (Sig. 2-seitig), die uns sagt, ob wir die Nullhypothese ablehnen oder annehmen müssen.
Ist dieser Wert gleich oder kleiner als das vorgegebene
Signifikanzniveau (hier: 0,05), dann ist die Nullhypothese abzulehnen. Andernfalls ist sie anzunehmen.
• Hier ist sie kleiner (0,000 ≤ 0,05), deswegen ist die gefundene
Mittelwertsdifferenz auf dem 5%-Niveau signifikant. Die Nullhypothese wird demnach verworfen.
• Zwischen Ost- und Westdeutschen besteht also ein signifikanter Unterschied der Mittelwerte in der Variable „Wichtigkeit: eigene Familie und Kinder“
Achtung: Bei einseitiger Fragestellung muss der Wert der Signifikanz (Sig. 2-
seitig) halbiert werden. Chi – Quadrat – Unabhängigkeitstest (kurz: χ2 – Test)
• Der χ2 – Test überprüft, ob ein in der Stichprobe gefundener Zusammenhang zwischen zwei nominalskalierten Variablen signifikant ist
I. Schritt: Hypothesenformulierung
H0: χ2 Es besteht kein Zusammenhang 0= H1: χ2 Es besteht ein Zusammenhang 0≠
II. Schritt: Festlegung des Signifikanzniveaus
• Falls nicht bereits aus der Aufgabenstellung vorgegeben, wird das
Signifikanzniveau α festgelegt (meist 5%, d.h. α = 0,05)

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 49 von 52
III. Schritt: Ermittlung von χ2emp. und χ2
theor.
• Der empirische χ2 – Wert wird berechnet aus den Daten der Stichprobe bzw. aus den beobachteten und erwarteten Häufigkeiten der Kreuztabelle:24
efefbf
emp2)(2 −
= ∑χ
• Der theoretische χ2 – Wert wird abgelesen in der χ2 – Tabelle25 anhand
des vorgegebenen Signifikanzniveaus (nachsehen bei 1 - α) und der Anzahl der Freiheitsgrade df, welche ermittelt werden mit:
df = (r – 1)(c – 1)
wobei: r = Anzahl der Zeilen der Kreuztabelle („rows“)
c = Anzahl der Spalten der Kreuztabelle („columns“)
Bsp.: Für eine 3x4 Kreuztabelle würden wir Freiheitsgrade von df = (3-1)(4-1) = 6 erhalten
IV. Schritt: Ergebnisinterpretation
• Anschließend wird der theoretische χ2 – Wert mit dem empirischen χ2 – Wert verglichen:
Wenn gilt: χ2emp. ≤ χ2
theor. dann wird H0 angenommen, d.h.
zwischen beiden Variablen besteht kein signifikanter Zusammenhang
Wenn gilt: χ2
emp. > χ2theor. dann wird H0 abgelehnt, d.h.
zwischen beiden Variablen besteht ein signifikanter
Zusammenhang
24 Vgl. hierzu die Ausführungen zum Chi-Quadrat Konzept im Skript Teil I, S. 27ff. 25 Vgl. Tabelle C in Bortz, a.a.O., S. 699f.
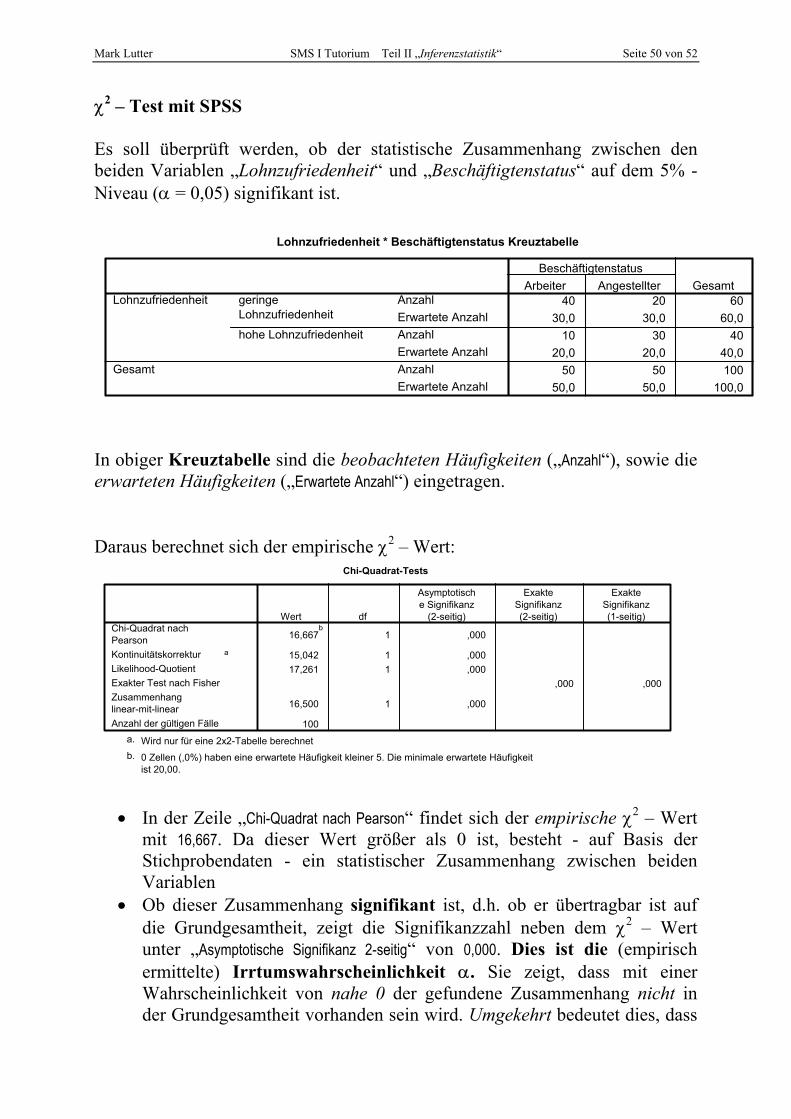
Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 50 von 52
χ2 – Test mit SPSS Es soll überprüft werden, ob der statistische Zusammenhang zwischen den beiden Variablen „Lohnzufriedenheit“ und „Beschäftigtenstatus“ auf dem 5% - Niveau (α = 0,05) signifikant ist.
Lohnzufriedenheit * Beschäftigtenstatus Kreuztabelle
40 20 6030,0 30,0 60,0
10 30 4020,0 20,0 40,0
50 50 10050,0 50,0 100,0
AnzahlErwartete AnzahlAnzahlErwartete AnzahlAnzahlErwartete Anzahl
geringeLohnzufriedenheit
hohe Lohnzufriedenheit
Lohnzufriedenheit
Gesamt
Arbeiter AngestellterBeschäftigtenstatus
Gesamt
In obiger Kreuztabelle sind die beobachteten Häufigkeiten („Anzahl“), sowie die erwarteten Häufigkeiten („Erwartete Anzahl“) eingetragen. Daraus berechnet sich der empirische χ2 – Wert:
Chi-Quadrat-Tests
16,667b
1 ,000
15,042 1 ,00017,261 1 ,000
,000 ,000
16,500 1 ,000
100
Chi-Quadrat nachPearsonKontinuitätskorrektur a
Likelihood-QuotientExakter Test nach FisherZusammenhanglinear-mit-linearAnzahl der gültigen Fälle
Wert df
Asymptotische Signifikanz
(2-seitig)
ExakteSignifikanz(2-seitig)
ExakteSignifikanz(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
0 Zellen (,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeitist 20,00.
b.
• In der Zeile „Chi-Quadrat nach Pearson“ findet sich der empirische χ2 – Wert
mit 16,667. Da dieser Wert größer als 0 ist, besteht - auf Basis der Stichprobendaten - ein statistischer Zusammenhang zwischen beiden Variablen
• Ob dieser Zusammenhang signifikant ist, d.h. ob er übertragbar ist auf die Grundgesamtheit, zeigt die Signifikanzzahl neben dem χ2 – Wert unter „Asymptotische Signifikanz 2-seitig“ von 0,000. Dies ist die (empirisch ermittelte) Irrtumswahrscheinlichkeit α. Sie zeigt, dass mit einer Wahrscheinlichkeit von nahe 0 der gefundene Zusammenhang nicht in der Grundgesamtheit vorhanden sein wird. Umgekehrt bedeutet dies, dass

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 51 von 52
wir mit fast 100%tiger Sicherheit von einem signifikanten Zusammenhang ausgehen können. Ist die Irrtumswahrscheinlichkeit so gering wie hier, spricht man auch von einem „hochsignifikanten“ Zusammenhang.
• Ein Ergebnis ist signifikant, solange die Irrtumswahrscheinlichkeit den Wert des zulässigen (vorgegebenen) Signifikanzniveaus von hier 5% nicht überschreitet. Die ermittelte Irrtumswahrscheinlichkeit dürfte also nicht größer sein als 0,05.
• Da also hier die empirisch ermittelte Signifikanzzahl von 0,000 kleiner ist als das vorgegebene Signifikanzniveau von 0,05 ist die Nullhypothese „Zwischen beiden Variablen existiert kein signifikanter Zusammenhang“ abzulehnen (zugunsten der Alternativhypothese).
demnach existiert also ein signifikanter Zusammenhang zwischen
beiden Variablen

Mark Lutter SMS I Tutorium Teil II „Inferenzstatistik“ Seite 52 von 52
6. Literaturverzeichnis
Unverzichtbare Basisliteratur & Exzellente Darstellung des Stoffs:
Bortz, Jürgen: Statistik für Sozialwissenschaftler, 4. Auflage, Berlin, 1993.
Dürr, Walter / Mayer, Horst: Wahrscheinlichkeitsrechnung und schließende Statistik, 3. Auflage, München, Wien, 1992.
Alles relevante für die Klausur steht in:
Faulbaum, Frank: Vorlesungs-Skript SMS I/A
Ebenfalls sehr wichtig für die Klausurvorbereitung: Sämtliche Musterklausuren
Sehr gut zum Selbststudium eignet sich:
Clauß, G.; Finze, F.-R. ; Partzsch, L. : Statistik für Soziologen, Pädagogen, Psychologen und Mediziner. Band I: Grundlagen, 2. Auflage, Frankfurt / Main, 1995.
Sehr formal, aber dafür sehr korrekt:
Bamberg, G.; Baur, F.: Statistik, 10. Auflage, München, Wien, 1998.
Darüber hinaus lohnt sich: Krämer, Walter: So lügt man mit Statistik, Frankfurt / Main, 1991. Krämer, Walter: Statistik verstehen, Frankfurt / Main, 1992.


















