
02 biologische grundlagen - · PDF fileFunktion der DNA n DNA: Träger von...
40
Molekularbiologische Grundlagen Ulf Leser, Sommersemester 2008 Silke Trißl
Transcript of 02 biologische grundlagen - · PDF fileFunktion der DNA n DNA: Träger von...

MolekularbiologischeGrundlagen
Ulf Leser, Sommersemester 2008
Silke Trißl

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 2
Überblick – Biologie
n Organismenn Aufbau von Zellen
– Prokaryoten und Eukaryoten
n Genom und DNAn Transkription
– DNA → RNA → Protein
n Proteinen Regulatorische und metabolische Netzwerken Human Genome Project
n 2. Teil: Überblick – Techniken
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 3
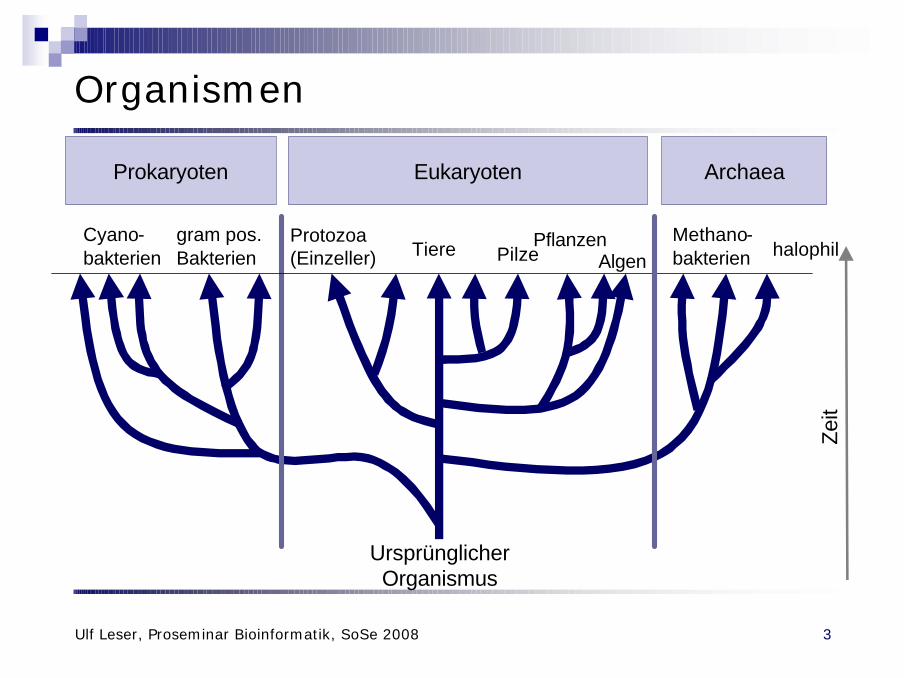
Organismen
Ursprünglicher Organismus
Protozoa(Einzeller) Tiere
Algen
EukaryotenProkaryoten
gram pos.Bakterien
Cyano-bakterien
Archaea
halophilMethano-bakterien
PflanzenPilze
Zeit
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 4
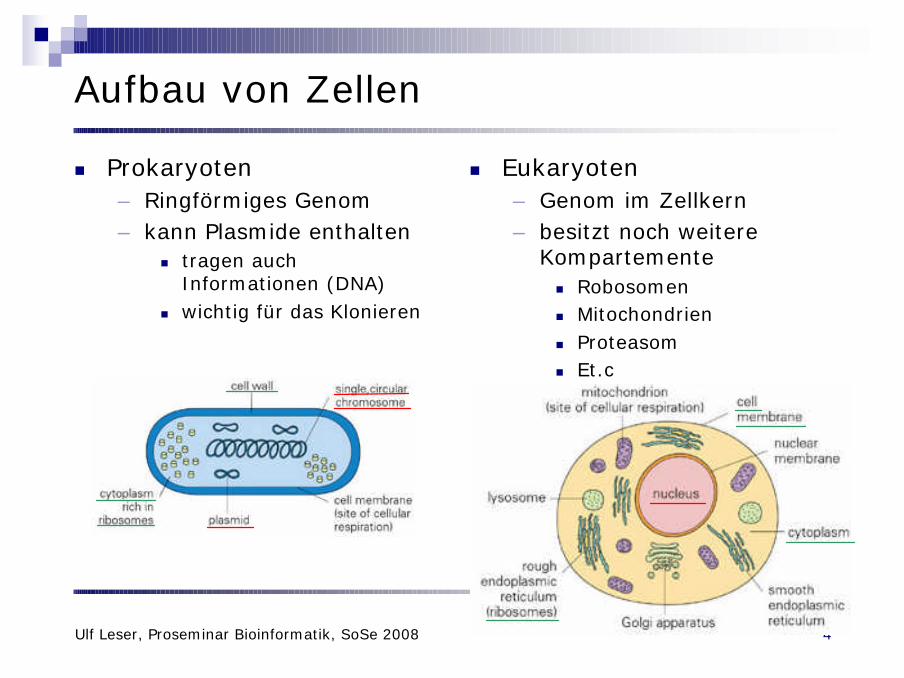
Aufbau von Zellen
n Prokaryoten– Ringförmiges Genom– kann Plasmide enthalten
n tragen auch Informationen (DNA)
n wichtig für das Klonieren
n Eukaryoten– Genom im Zellkern– besitzt noch weitere
Kompartementen Robosomenn Mitochondrienn Proteasomn Et.c

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 5
Funktion der DNA
n DNA: Träger von Erbinformationen– Codiert für funktionelle Produkte wie Proteine oder RNA
n Genom: Gesamtheit der DNA in einer Zelle– Sprich: alle Gene in einer Zelle
n Millionenfach kopiert – Ohne wesentliche Veränderung– Wird an Tochterzellen weitergegeben
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 6
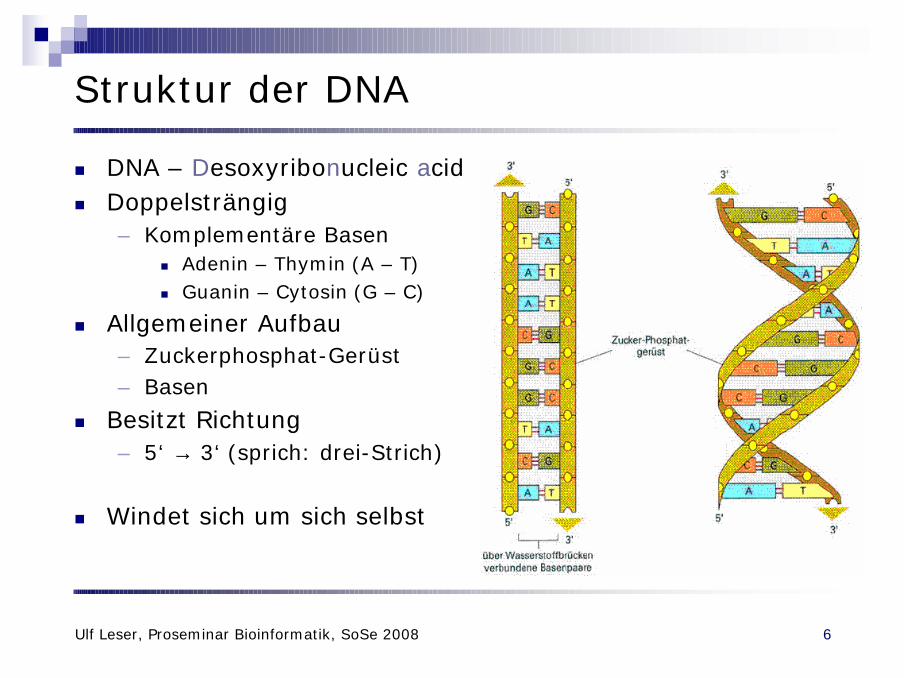
Struktur der DNA
n DNA – Desoxyribonucleic acidn Doppelsträngig
– Komplementäre Basenn Adenin – Thymin (A – T)n Guanin – Cytosin (G – C)
n Allgemeiner Aufbau– Zuckerphosphat-Gerüst– Basen
n Besitzt Richtung– 5‘ → 3‘ (sprich: drei-Strich)
n Windet sich um sich selbst

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 7
Gen
n Abschnitt auf dem Genom– Vorlage zur Herstellung eines funktionellen Produkts
n Nur RNA oder weiter zum Protein
– Alle direkt daran beteiligten Sequenzenn 5‘ UTR, 3‘ UTR (Untranslatierte Region)
n Aber: Nur der Abschnitt zwischen Start- und Stopcodonwird in mRNA übersetzt
5‘
5‘
3‘
3‘
Enhancer Promotor
Startcodon Stopcodon
Vorlage für Primärtranskript
5‘ UTR 3‘ UTR
TATA
Intron Exon
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 8
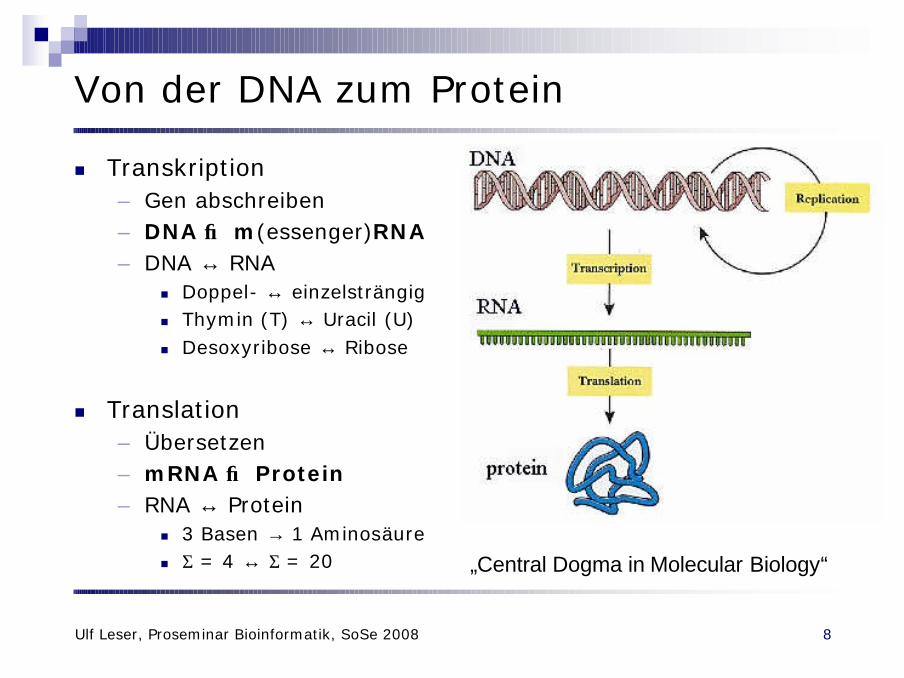
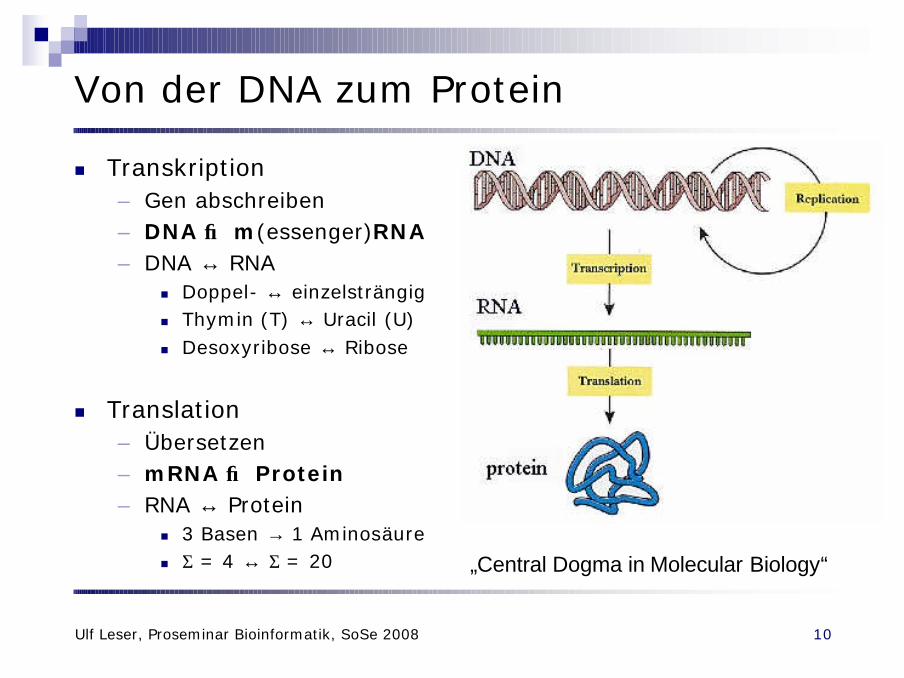
Von der DNA zum Protein
n Transkription– Gen abschreiben– DNA → m(essenger)RNA– DNA ↔ RNA
n Doppel- ↔ einzelsträngign Thymin (T) ↔ Uracil (U)n Desoxyribose ↔ Ribose
n Translation– Übersetzen– mRNA → Protein– RNA ↔ Protein
n 3 Basen → 1 Aminosäuren Σ = 4 ↔ Σ = 20 „Central Dogma in Molecular Biology“
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 9
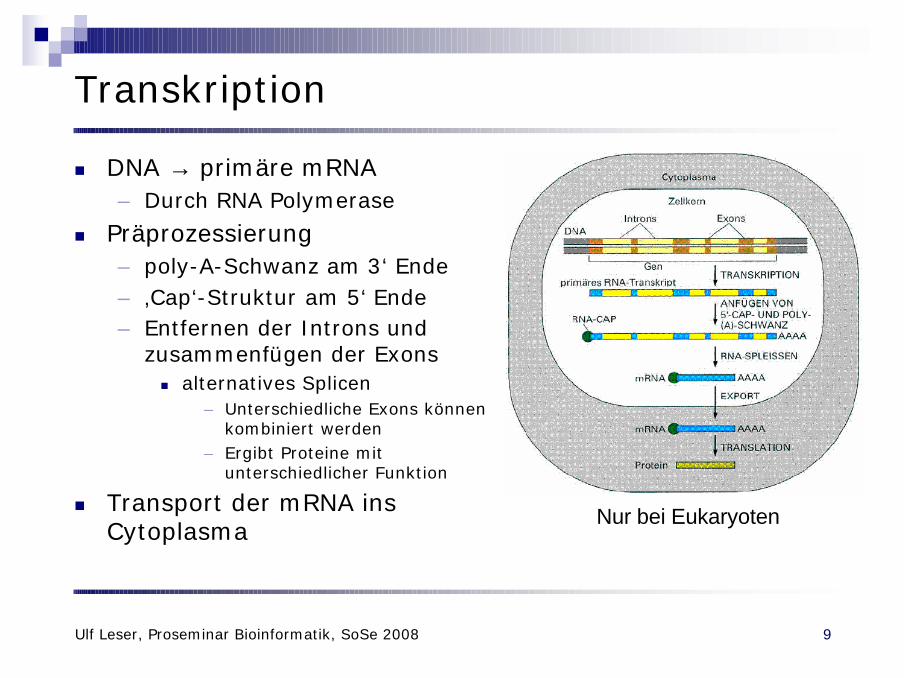
Transkription
n DNA → primäre mRNA– Durch RNA Polymerase
n Präprozessierung– poly-A-Schwanz am 3‘ Ende– ‚Cap‘-Struktur am 5‘ Ende– Entfernen der Introns und
zusammenfügen der Exonsn alternatives Splicen
– Unterschiedliche Exons können kombiniert werden
– Ergibt Proteine mit unterschiedlicher Funktion
n Transport der mRNA ins Cytoplasma
Nur bei Eukaryoten
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 10
Von der DNA zum Protein
n Transkription– Gen abschreiben– DNA → m(essenger)RNA– DNA ↔ RNA
n Doppel- ↔ einzelsträngign Thymin (T) ↔ Uracil (U)n Desoxyribose ↔ Ribose
n Translation– Übersetzen– mRNA → Protein– RNA ↔ Protein
n 3 Basen → 1 Aminosäuren Σ = 4 ↔ Σ = 20 „Central Dogma in Molecular Biology“

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 11
Translation
n Übersetzung – Nukleotidsequenz der mRNA – zu Aminosäuresequenz der Proteine
n Je 3 Basen (Codon) codieren für 1 Aminosäure
n Wie viele mögliche Kombinationen?– Triplett → 3 Stellen– 4 mögliche Buchstaben (A, T (U), G, C)– 43 = 64 mögliche Kombinationen– Aber nur 20 Aminosäuren
n Redundanz im genetischen Code

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 12
Aminosäuren
n 20 verschiedene Aminosäuren– Hydrophil (wasserliebend)– Hydrophob (wasserabstoßend)– Sauer (geladen, hydrophil)– Basisch (geladen, hydrophil)
n Redundanz im Genetischen Code
n Base Nr. 3: wobble– Kann häufig ausgetauscht
werden ohne Konsequenzen
hydrophil hydrophob sauer basisch

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 13
Redundanz im Code
Org1: AUU AGU UGG GAU AAA UUA GCUOrg2: AUA UCU UGG GAC AAG CUG GCCOrg3: AUC UCU UGG GAU AAG CUU GCGOrg4: AUU AGC UGG GAC AAA CUC GCAOrg5: AUC UCC UGG GAU AAG UUG GCU
Protein: Ile Ser Trp Asp Lys Leu Ala

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 14
Proteine Grundgerüst
n Synthese erfolgt am Ribosom– tRNA
n Besitzt Anticodonn Hat Aminosäure
n Einzelne Aminosäuren durch Peptidbindung verbunden– kovalente Verbindung
n Abfolge an Aminosäuren= Primärstruktur
mRNA
Ribosom
Anti-codon
Amino-säure
tRNA
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 15
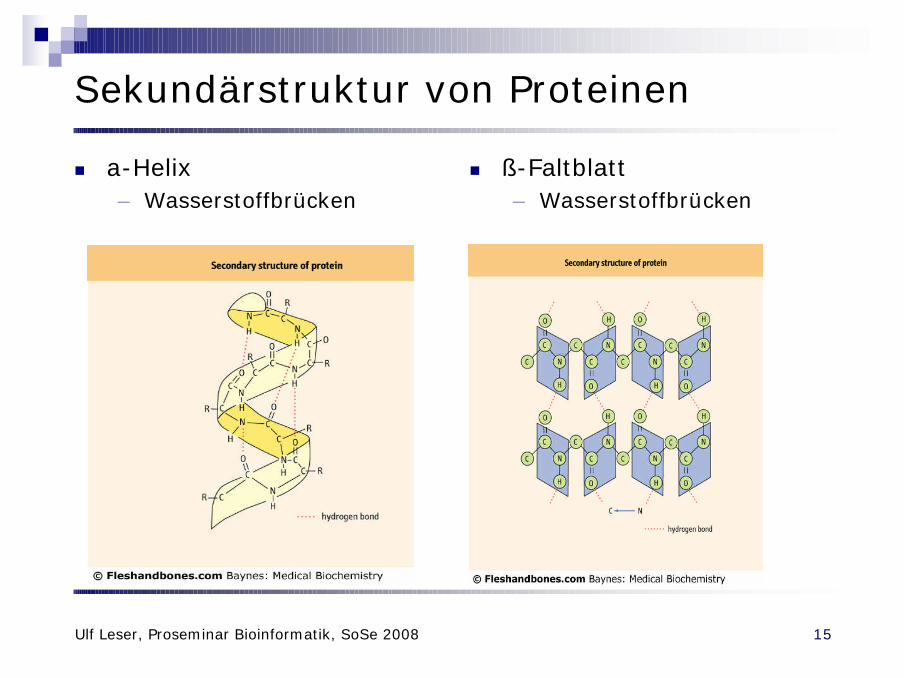
Sekundärstruktur von Proteinen
n a-Helix– Wasserstoffbrücken
n ß-Faltblatt– Wasserstoffbrücken

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 16
Tertiärstruktur
n Tertiärstruktur: Räumliche Anordnung der Sekundärstrukturelemente
1b71 aus Protein Data Bank

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 17
Mutationen in DNA – Auswirkungen
n Stille Mutation – keine Auswirkung auf Protein
n Echte Mutation– Ersetzen von Aminosäuren
n durch Ähnliche– keine Auswirkung auf Struktur– keine Auswirkung auf Funktion
n durch ‚Unähnliche‘– Auswirkung auf Struktur– Verlust / Verbesserung der Funktion

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 18
Überblick – Biologie
n Organismenn Aufbau von Zellen
– Prokaryoten und Eukaryoten
n Genom und DNAn Transkription
– DNA → RNA → Protein
n Proteinen Regulatorische und metabolische Netzwerken Human Genome Project
n 2. Teil: Überblick – Techniken
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 19
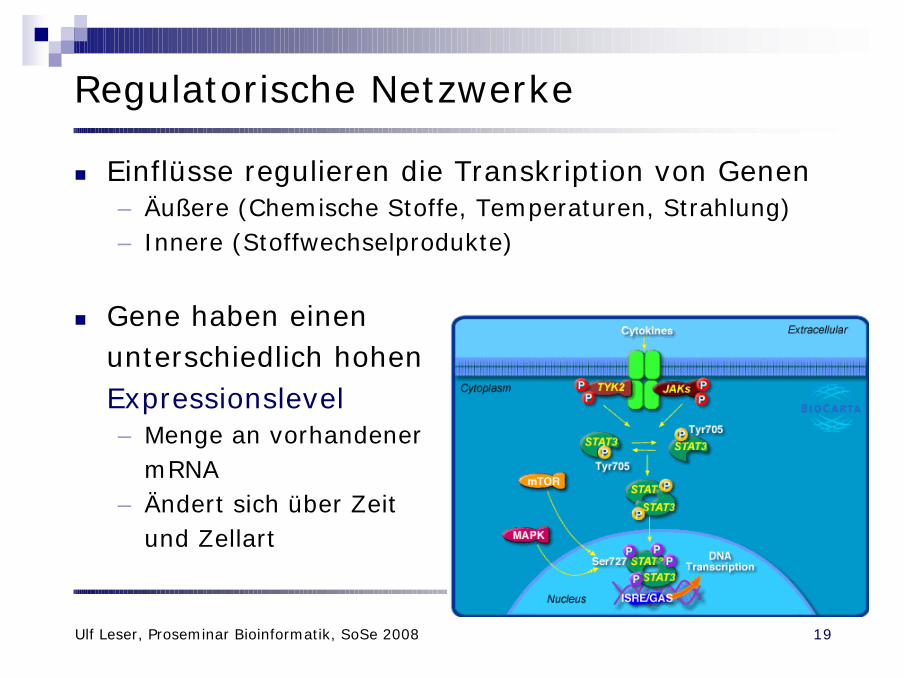
Regulatorische Netzwerke
n Einflüsse regulieren die Transkription von Genen– Äußere (Chemische Stoffe, Temperaturen, Strahlung)– Innere (Stoffwechselprodukte)
n Gene haben einen unterschiedlich hohenExpressionslevel– Menge an vorhandener
mRNA– Ändert sich über Zeit
und Zellart

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 20
Metabolische Netzwerke
n Glykolyse– Umwandlung von Glukose
zu Pyruvat unter Engergiegewinnung
n Start-, Zwischen- und Endprodukte regulieren auch die Transkription
n Enzyme katalysieren die Reaktionen– Enzyme ⊆ Protein

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 21
Überblick – Biologie
n Organismenn Aufbau von Zellen
– Prokaryoten und Eukaryoten
n Genom und DNAn Transkription
– DNA → RNA → Protein
n Proteinen Regulatorische und metabolische Netzwerken Human Genome Project
n 2. Teil: Überblick – Techniken

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 22
Human Genome Project
n Begonnen 1986– Geplante Fertigstellung 2005 – Ziel: Finden aller Gene des Menschen
n Weltweite Kollaboration– 20 große Institutionen– In Deutschland: seit 1996 etwas 60 Mbp
n Fertiggestellt– Draft im Jahr 2000: (90% draft, 30% finished, 99.99%
accuracy)– Beinahe fertig 2001 (analyzed draft)– Wirklich fertig 2003

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 23
Menschliche Genom
n Menschen – Homo sapiens– ~ 3.100.000.000 bp (Basenpaare)
n Entspricht ~ 2 m DNA
– Verteilt auf n 22 Chromosomenn + 2 Geschlechtschromosomenn Länge: 50–250 Mbp
– ~ 25.000 Genen (war mal bei ~100.000)
– ~ 150.000 Proteine– ~ 500.000 Proteinformen

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 24
Menschliche Gene
n ~ 25.000 Gene– Niemand weis wirklich wie viele
n Länge zwischen 100bp und 2Mbp (Introns+Exons)n Durchschnittliche Länge der codierenden Region: 1400 bps
– Durchschnittliche Proteinlänge 447 Aminosäurenn Durchschnittliches Gen hat 9 Exonsn Nur wenige Prozent des menschlichen Genoms ist
kodierend– Rest: „junk“?– Viele Repeats, Transposons– Regulatorische Elemente– Pseudogene– Chromosomale Struktur: Zentromere und Telomere

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 25
gatcaattatagttgacttcagtcctgcctgattcatctccaaaaatgtagtctgcctgattcatctcccaaaaatgtagctccgcttaaaggagctttcaagttgggggtggtgggccattcagtgttgtcactaacagatgcatcttgtgggggtaaaatgtcccaaagtatcttttcttgcttatgttcataagggcgctggtctggaatgtgccacatctgttctcactctgccatggactcctggaccctctgtgtgtccctttgtatcctggtagcgagtgagtcctcatgatttatcatcctcatgctgggcctctgtatagatga
Genomsequenzierung
n Jedes Chromosom isolierenn Chromosom in kleine Stücke brechenn Jedes Stück DNA sequenzierenn Die einzelnen Stücke zu einem zum Chromosom
zusammenfügen (Assembly)

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 26
DNA schneiden
n Restriktionsenzyme– Erkennen Sequenzabschnitte
auf der DNA– Schneiden an der Stelle
n Blunt (gerader Schnitt)n Sticky (überhängende Enden)
n Länge der Erkennungssequenz steuert die DNA Fragmentgröße– 4 Basen → 256 bp Fragmente– 6 Basen → 4,000 bp Fragmente– 8 Basen → 65,000 bp Fragmente
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 27
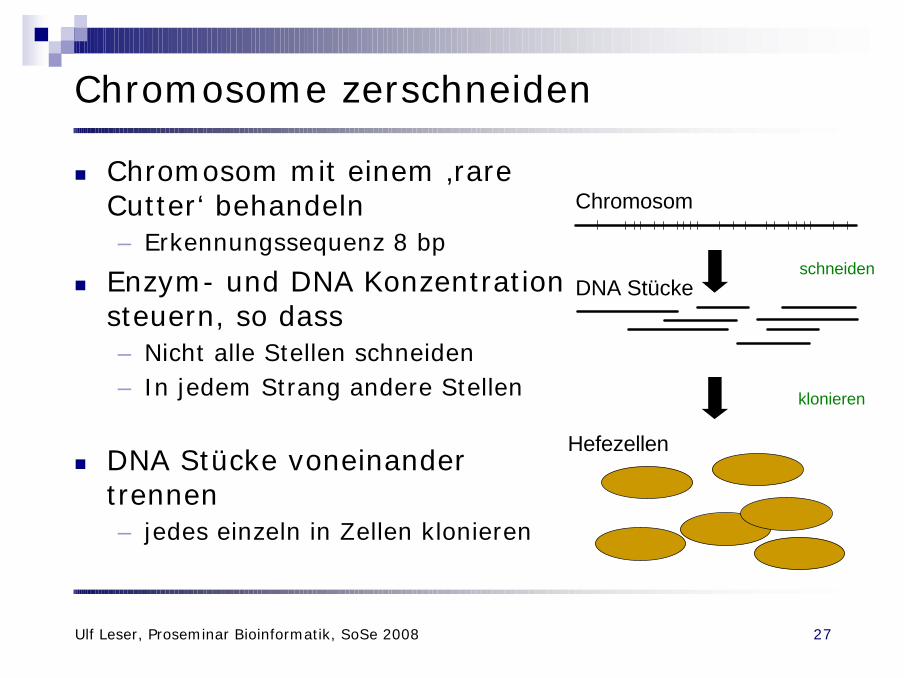
Chromosome zerschneiden
n Chromosom mit einem ‚rare Cutter‘ behandeln– Erkennungssequenz 8 bp
n Enzym- und DNA Konzentration steuern, so dass– Nicht alle Stellen schneiden– In jedem Strang andere Stellen
n DNA Stücke voneinander trennen– jedes einzeln in Zellen klonieren
schneiden
klonieren
Chromosom
DNA Stücke
Hefezellen

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 28
Chromosomen zerkleinern
n YAC – Yeast ArtificialChromosome– Enthält < 1.000.000 bp
chromosomale DNA– Je YAC nur einen Abschnitt
n BAC – Bacterial ArtificialChromosome– < 250.000 bp erneut
geschnittene DNA
n Plasmid– < 4.000 bp– Wird in Bakterien eingebracht

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 29
Klonieren – cont. –
n Jedes Bakterium nimmt nur ein Plasmid aufn Ausplattieren der Bakterien
– Auf Nährbodenn Agarn Nährstoffen Antibiotikum
n Inkubieren (wachsen lassen)– E. coli: 37 °C, über Nacht
n Jede einzelne Bakterie wächstzu einer sichtbaren Kolonie (Klon)– Nur Bakterien mit Plasmid können wachsen

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 30
DNA Sequenzierung (nach Sanger)
n Abfolge von Basen in DNA Sequenz lesenn Sequenzierreaktion (basiert auf PCR) mit
– DNA Template (doppelsträngig)– 1 Primer– DNA Polymerase– dNTP‘s– ddNTP‘s (Didesoxynukleotide)
n Brechen Kettenverlängerung abn Sind markiert
– Früher: radioaktiv– Heute: fluoreszent (1 Farbstoff je Base)
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 31
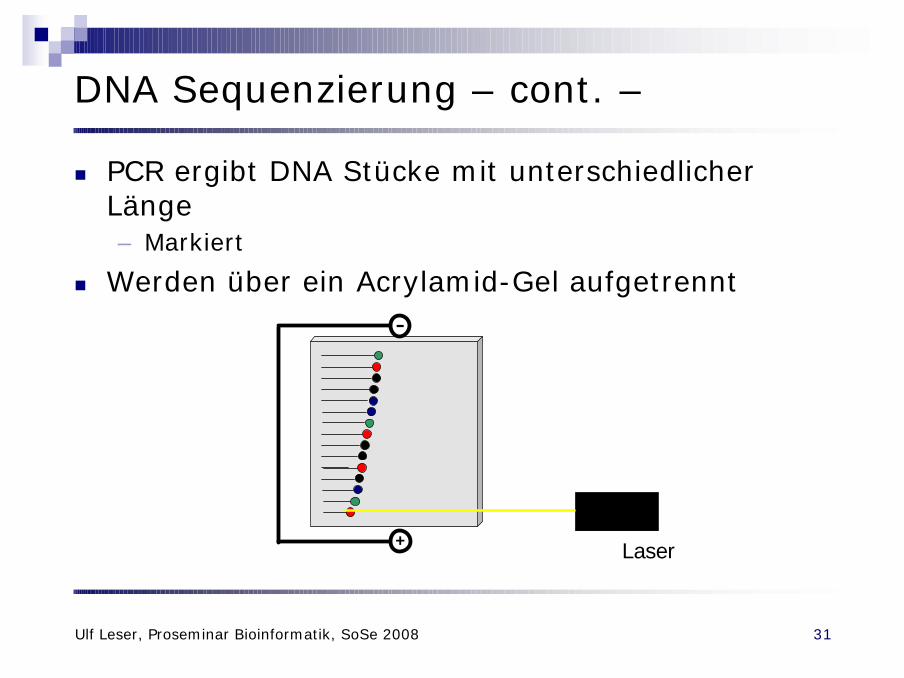
DNA Sequenzierung – cont. –
n PCR ergibt DNA Stücke mit unterschiedlicher Länge– Markiert
n Werden über ein Acrylamid-Gel aufgetrennt-
+ Laser
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 32
DNA Sequenzierung – cont –
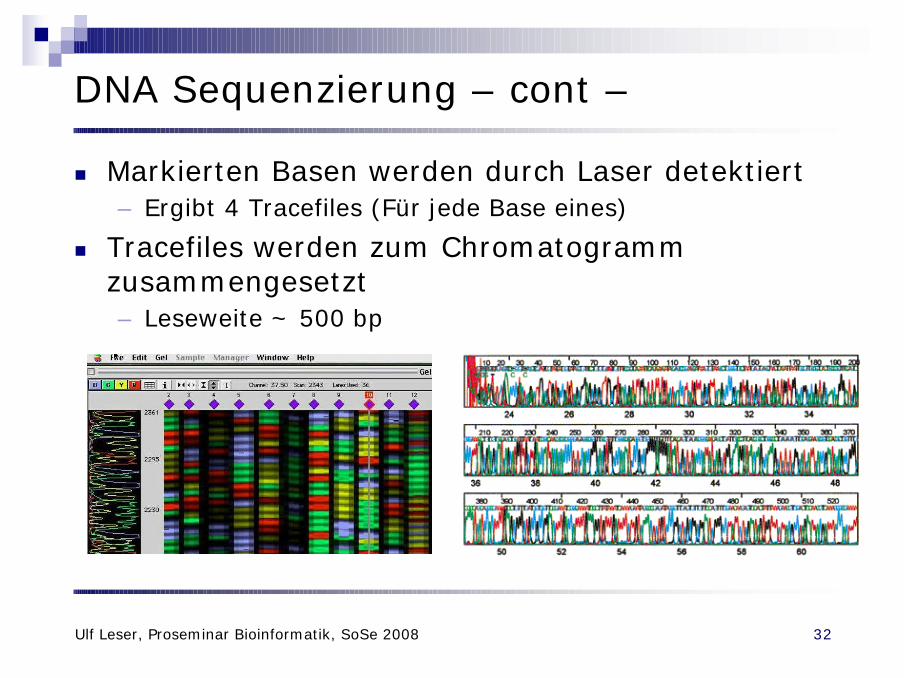
n Markierten Basen werden durch Laser detektiert– Ergibt 4 Tracefiles (Für jede Base eines)
n Tracefiles werden zum Chromatogrammzusammengesetzt– Leseweite ~ 500 bp

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 33
Großer Fortschritt
n Früher:– Radioaktiv– Handarbeit
n Heute:– 4 Floureszensfarbstoffe– vollautomatisch
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 34
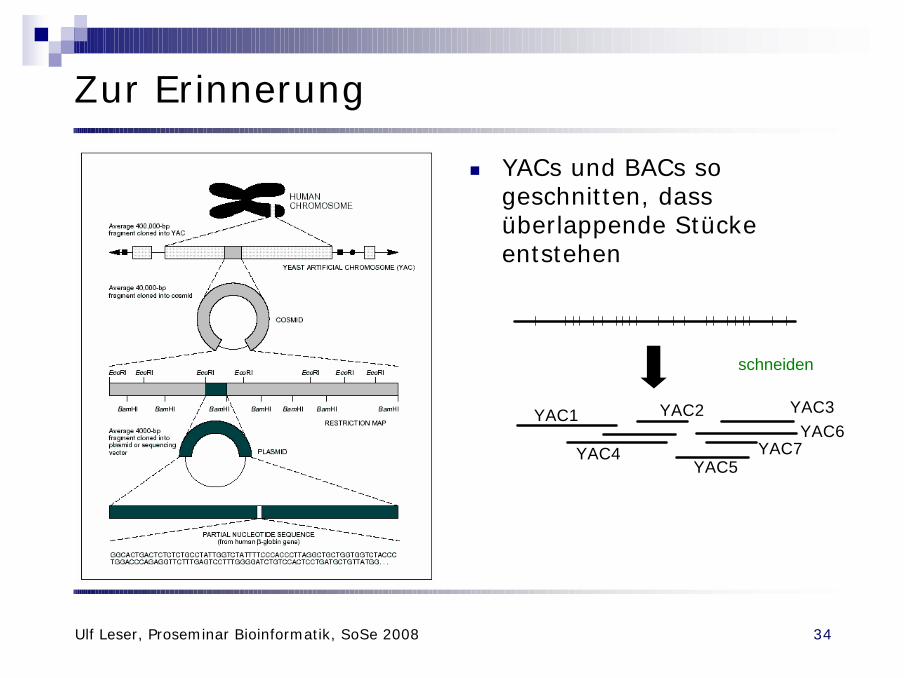
Zur Erinnerung
n YACs und BACs so geschnitten, dass überlappende Stücke entstehen
schneiden
YAC1 YAC2 YAC3
YAC4YAC5
YAC6YAC7

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 35
Assembly
n Wir haben jetzt sequenzierte Stücke DNA– ~ 500 bp groß– Überlappend
n Wir wissen, sie kommen aus einem BAC, bzw. einem YAC
n Algorithmisches Problem: Sequence assembly– setze die 500 bp großen Stücke wieder zu einem BAC
bzw. YAC zusammen
n Aber: nicht überall funktioniert diese Strategie– Chromosome walking

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 36
Auswirkungen vom HGP
n Datenflut– Datenbanken & Bioinformatik
n Datenbasis für Finden von Genen– Alle Gene finden– Zusammenwirken von Genen erkennen– Erkennen von Genen, die mit Erbkrankheiten in
Verbindung stehen
n Erkenntnis über ähnliche/gleiche Gene in anderen Organismen– Experimente mit Modellorganismen
n Maus, Hefe, E. coli

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 37
Expressionslevel von Genen
n Microarrays– enthält kurze Abschnitte von bekannten Genen– 30.000 – 100.000 Spots (Proben) pro Array– jeder Spot enthält mehrere Kopien
Array mit DNA Proben
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 38
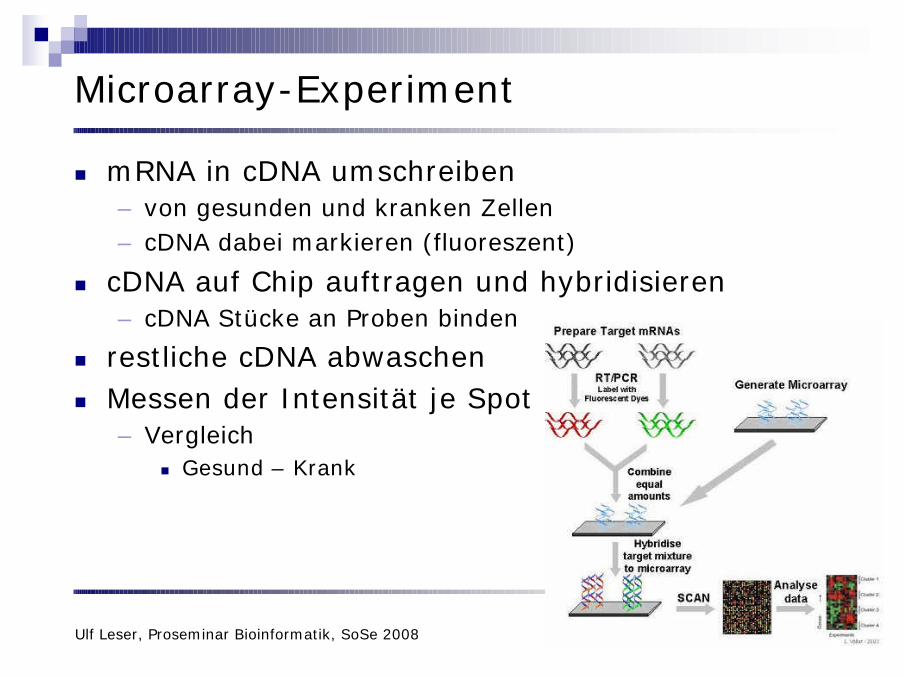
Microarray-Experiment
n mRNA in cDNA umschreiben– von gesunden und kranken Zellen– cDNA dabei markieren (fluoreszent)
n cDNA auf Chip auftragen und hybridisieren– cDNA Stücke an Proben binden
n restliche cDNA abwaschenn Messen der Intensität je Spot
– Vergleichn Gesund – Krank
Ulf Leser, Proseminar Bioinformatik, SoSe 2008 39
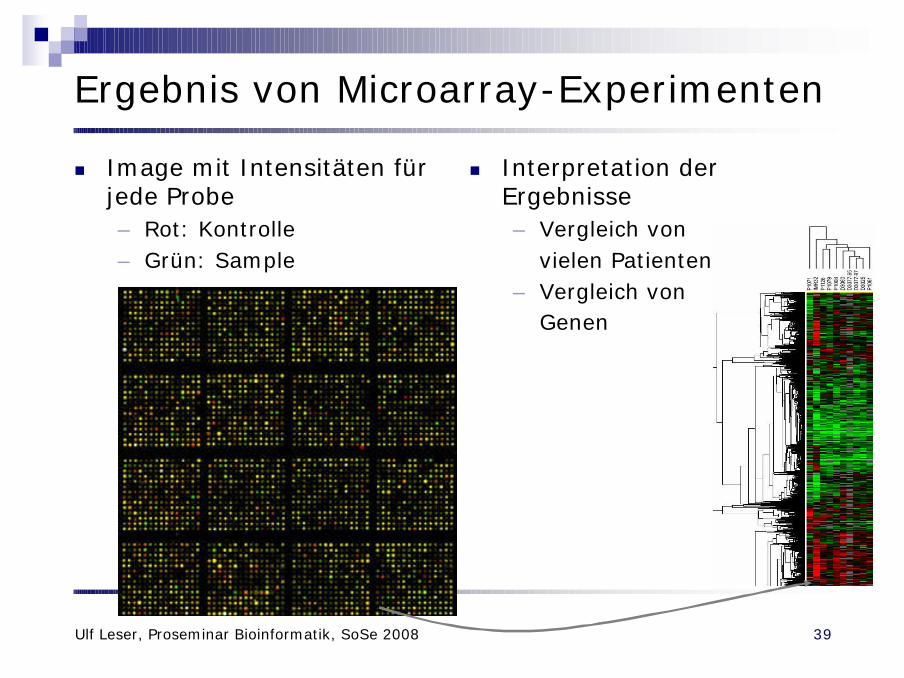
Ergebnis von Microarray-Experimenten
n Image mit Intensitäten für jede Probe– Rot: Kontrolle– Grün: Sample
n Interpretation der Ergebnisse– Vergleich von
vielen Patienten– Vergleich von
Genen

Ulf Leser, Proseminar Bioinformatik, SoSe 2008 40
Danke!
Fragen?


















