
2.4 Gradientenabstiegsverfahren - swl.htwsaar.de · § starte mit zufälliger Wahlder Parameter w...
42
45 2.4 Gradientenabstiegsverfahren § Optimale Parameter lassen sich bei linearer Regression analytisch bestimmen, dennoch verwendet man in der Regel das sogenannte Gradientenabstiegsverfahren, um diese (näherungsweise) zu bestimmen § Gradientenabstiegsverfahren ist meist effizienter als das Invertieren der Matrix (X T X) -1 und findet auch dann Parameter, wenn diese nicht invertierbar ist § Gradientenabstiegsverfahren auch für andere Probleme einsetzbar, deren optimale Parameter nicht analytisch bestimmt werden können Data Science / Kapitel 2: Regression
Transcript of 2.4 Gradientenabstiegsverfahren - swl.htwsaar.de · § starte mit zufälliger Wahlder Parameter w...

45
2.4 Gradientenabstiegsverfahren§ Optimale Parameter lassen sich bei linearer Regression
analytisch bestimmen, dennoch verwendet man in derRegel das sogenannte Gradientenabstiegsverfahren,um diese (näherungsweise) zu bestimmen
§ Gradientenabstiegsverfahren ist meist effizienter als das Invertieren der Matrix (XTX)-1 und findet auch dann Parameter, wenn diese nicht invertierbar ist
§ Gradientenabstiegsverfahren auch für andere Probleme einsetzbar, deren optimale Parameter nichtanalytisch bestimmt werden können
Data Science / Kapitel 2: Regression

46
Gradient§ Gradient verallgemeinert das Konzept der Ableitung
für Funktionen in mehreren Veränderlichen
§ Gradient ist eine Funktion in mehreren Veränderlichenund gibt die Richtung des steilsten Anstiegs an
rF (x) =
2
64
�F�x1
...�F�xn
3
75
Data Science / Kapitel 2: Regression
47
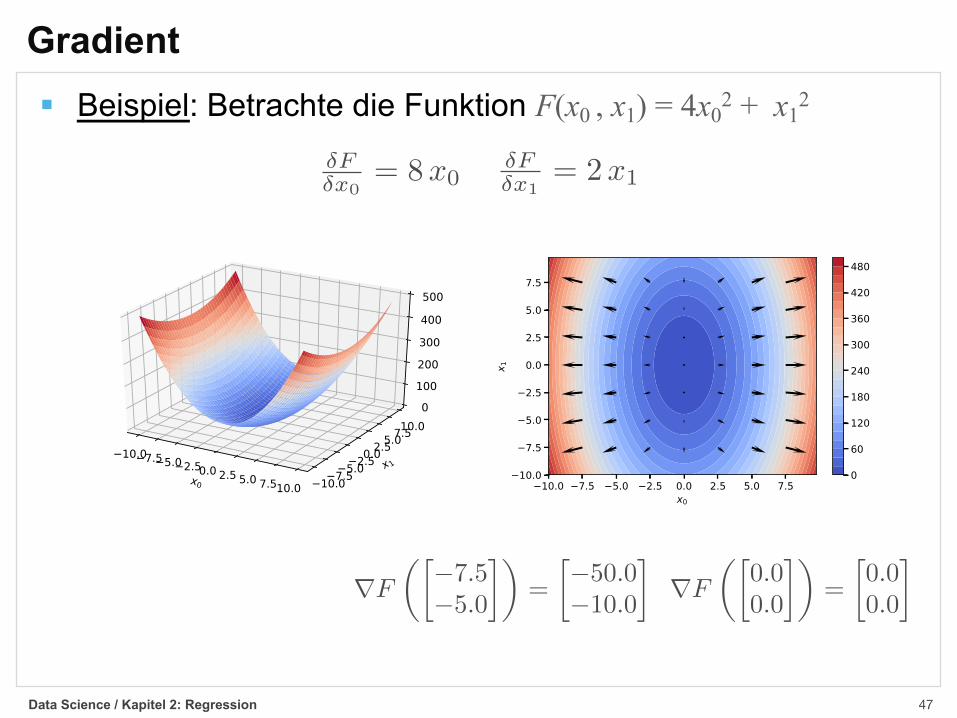
Gradient§ Beispiel: Betrachte die Funktion F(x0 , x1) = 4x0
2 + x12
�F�x0
= 8x0�F�x1
= 2x1
rF
✓0.00.0
�◆=
0.00.0
�rF
✓�7.5�5.0
�◆=
�50.0�10.0
�
Data Science / Kapitel 2: Regression

48
Gradientenabstiegsverfahren§ Gradientenabstiegsverfahren (gradient descent)
beruht auf folgender Idee:
§ starte mit zufälliger Wahl der Parameter w
§ wiederhole für bestimmte Rundenzahl oder bis Konvergenz§ berechne den Gradienten ∇L(w) an dieser Stelle,
als die Richtung des steilsten Aufstiegs
§ aktualisiere die Parameter als w = w – η ∇L(w),mit Lernrate η > 0.0, d.h. laufe ein Stückentgegen der Richtung des steilsten Aufstiegs
Data Science / Kapitel 2: Regression
49
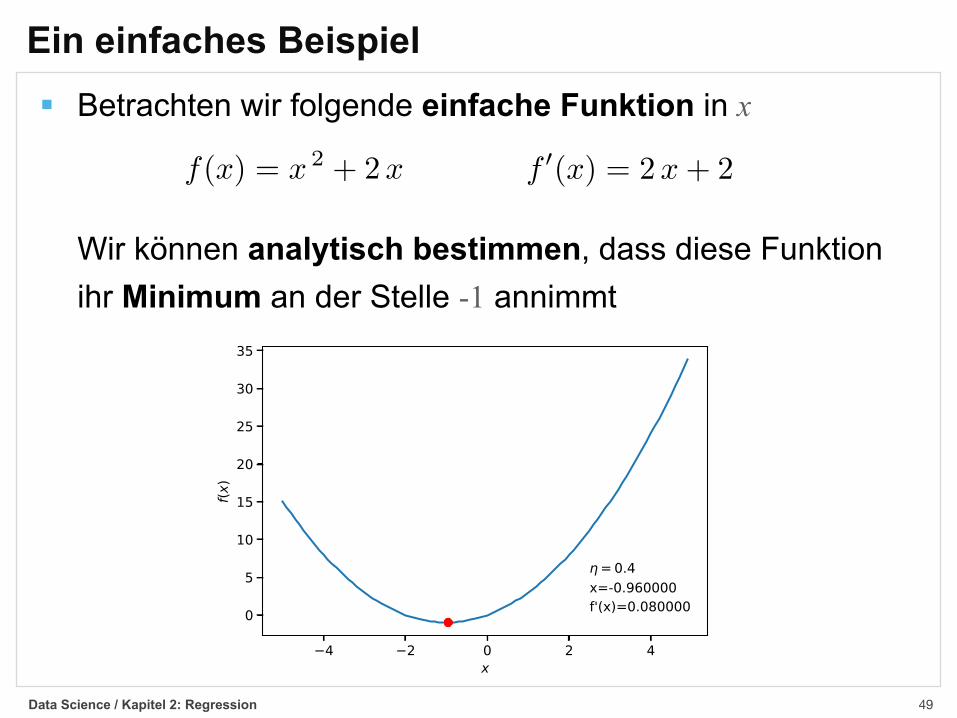
Ein einfaches Beispiel§ Betrachten wir folgende einfache Funktion in x
Wir können analytisch bestimmen, dass diese Funktionihr Minimum an der Stelle -1 annimmt
f(x) = x 2 + 2x f 0(x) = 2x+ 2
Data Science / Kapitel 2: Regression
50
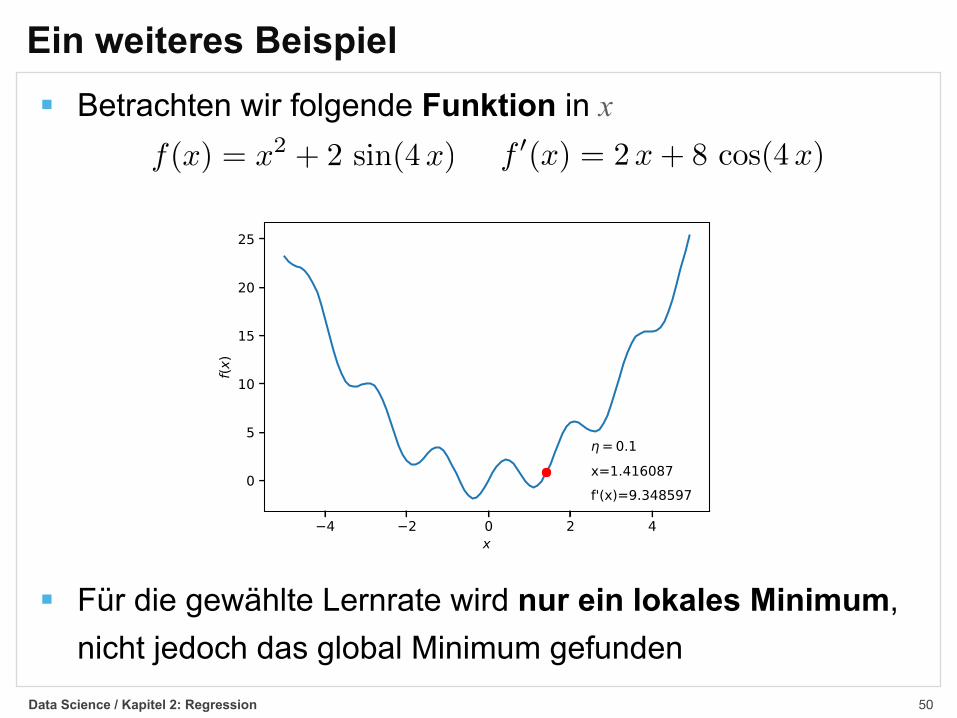
§ Betrachten wir folgende Funktion in x
§ Für die gewählte Lernrate wird nur ein lokales Minimum,nicht jedoch das global Minimum gefunden
Ein weiteres Beispiel
f(x) = x2 + 2 sin(4x) f 0(x) = 2x+ 8 cos(4x)
Data Science / Kapitel 2: Regression

51
Multiple Lineare Regression§ Gradient für multiple lineare Regression ist definiert als
Data Science / Kapitel 2: Regression
ÒL(w) = ≠ 2XT y + 2 XT X w= ≠ 2XT (y ≠ X w)
=
S
WWWU
≠2qn
i=1 xi,01
yi ≠qm
j=0 xi,j wj
2
...≠2
qni=1 xi,m
1yi ≠
qmj=0 xi,j wj
2
T
XXXV

52
Stochastisches Gradientenabstiegsverfahren§ Berechnung des Gradienten über alle Datenpunkte
ist zu teuer bei sehr großen Datenmengen
§ Stochastisches Gradientenabstiegsverfahren(stochastic gradient descent, SGD) betrachtet injedem Schritt nur einen einzelnen zufälliggewählten Datenpunkt, um denGradienten anzunähern
§ Als Mittelweg kann eine kleine Anzahl zufälliggewählter Datenpunkte betrachtet werden
Data Science / Kapitel 2: Regression

53
Adaptive Lernrate§ Zudem wird häufig eine adaptive Lernrate verwendet,
welche vom Fortschritt des Verfahrens abhängt, z.B.
in Runde r ∊ {1, 2, …} mit Konstanten c1 ≤ c2
§ Die Idee hierbei ist, dass das Verfahren zunehmend vorsichtig wird und kleinere Schritte macht und soz.B. ein gefundenes (lokales) Minimum in späteren Iterationen nicht mehr verlässt
÷(r) = c1r + c2
Data Science / Kapitel 2: Regression

54
2.5 Polynomiale Regression§ Polynomiale Regression nimmt an, dass das abhängige
Merkmal sich als Polynom vom Grad d in denabhängigen Merkmalen beschreiben lässt, z.B.bei einem abhängigen Merkmal als
§ Die Werte x2, …, xd werden vorberechnet und wie zusätzliche unabhängige Merkmale bei einermultiplen linearen Regression behandelt
§ Grad des Polynoms d ist ein sog. Hyperparameter,der die Gestalt des Modells beeinflusst
y = w0 + w1 x+ w2 x 2 + . . .+ wd x d
Data Science / Kapitel 2: Regression

55
Polynomiale Regression§ Auch bei mehreren ursprünglichen unabhängigen
Merkmalen können wir ein Polynom vom Grad danpassen, um das abhängige Merkmalvorherzusagen, z.B.
§ Bei m ursprünglichen unabhängigen Merkmal und einem Polynom vom Grad d erhalten wir somit
unabhängige Merkmale insgesamt
y = w0,0+w1,0 x0+w0,1 x1+w1,1 x0 x1+w2,0 x 20 +w0,2 x 2
1 + . . .+wd,d xd0 x
d1
(d+ 1)m
Data Science / Kapitel 2: Regression

56
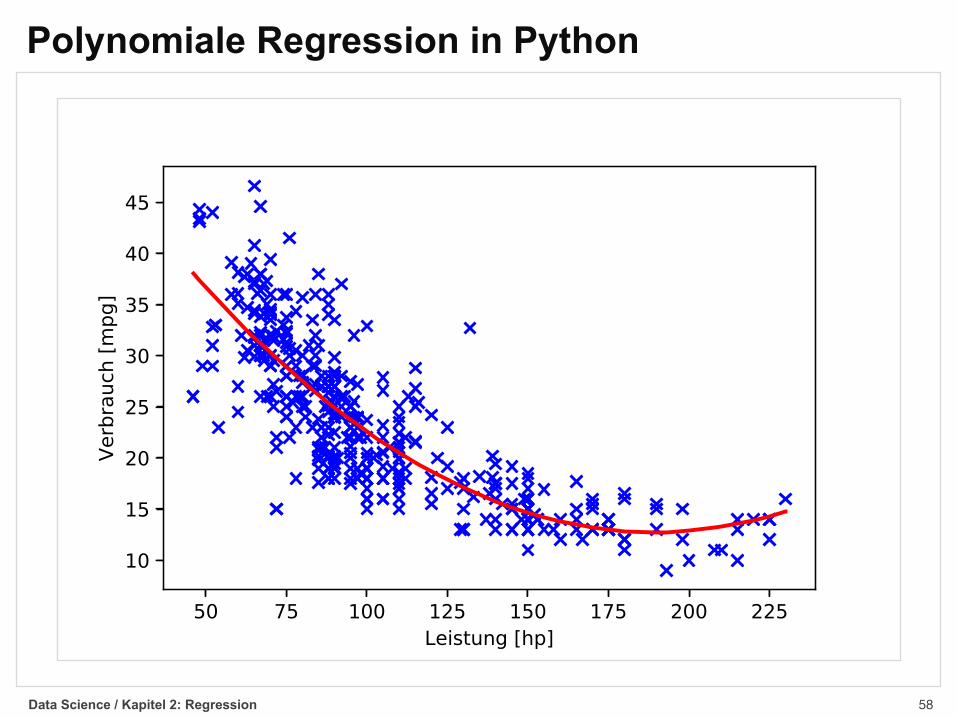
Polynomiale Regression in Pythonimport pandas as pdimport numpy as npfrom sklearn import linear_model, preprocessing, metricsimport matplotlib.pyplot as plt
# Autodaten lesencars = pd.read_csv('../data/auto-mpg/auto-mpg.data', header=None, sep='\s+')
# Verbrauchswerte extrahiereny = cars.iloc[:,0].values
# Leistungswerte extrahierenX = cars.iloc[:,[3]].valuesX = X.reshape(X.size, 1)
# Polynomiale Merkmale (d.h. Leistung^2) berechnenpoly = preprocessing.PolynomialFeatures(2)Xp = poly.fit_transform(X)
# Lineare Regressionreg = linear_model.LinearRegression()reg.fit(Xp,y)
Data Science / Kapitel 2: Regression

57
Polynomiale Regression in Python
§ Vollständiges Jupyter-Notebook unter:[HTML][IPYNB]
# Polynom plottenXs = np.array(sorted(X))Xs = Xs.reshape(Xs.size,1)Xsp = poly.fit_transform(Xs)plt.scatter(X, y, color='blue', marker='x')plt.plot(Xs, reg.predict(Xsp), color='red', lw=2)plt.xlabel('Leistung [hp]')plt.ylabel('Verbrauch [mpg]')plt.show()
# Parameter ausgebenprint('Parameter:')print('w0: %f'%reg.intercept_)print('w1: %f'%reg.coef_[0])print('w2: %f'%reg.coef_[1])print('Bestimmtheitsmaß')print('R2: %f'%metrics.r2_score(y,reg.predict(Xp)))
Data Science / Kapitel 2: Regression
58
Polynomiale Regression in Python
Data Science / Kapitel 2: Regression

59
2.6 Merkmalstransformation§ Besteht zwischen dem zu erklärenden abhängigen
Merkmal und den unabhängigen Merkmalen einnicht-linearer Zusammenhang, so lässt sichdieser häufig durch eine Transformationder Merkmale auf einen linearenZusammenhang zurückführen
Data Science / Kapitel 2: Regression

60
Potenzgesetze (power laws)§ Zahlreiche Phänomene in der Natur folgen einem
sogenannten Potenzgesetz (power law), d.h.die Größe y verhält sich zur Größe x als
§ Skaleninvarianz (scale invariance) ist eine Eigenschaft solcher Phänomene, d.h. multiplizieren wir den Wert von xmit einem Faktor c, ändert sich der Wert von y immerum einen Faktor cβ1
y = f(x) = —0 x —1
f(cx) = —0(cx) —1 = —0c —1x —1 = c —1f(x)
Data Science / Kapitel 2: Regression

61
Zipf‘sches Gesetz (Zipf‘s law)§ George K. Zipf (1902–1950) beobachtete,
dass für natürlichsprachliche Text gilt,dass die Häufigkeit eines Wortes f(w)umgekehrt proportional zu seinemHäufigkeitsrang r(w) ist, d.h.:
§ Das häufigste Wort kommt somit
§ doppelt so oft vor wie das zweithäufigste Wort§ zehnmal so oft vor wie das Wort auf Rang 10§ hundertmal so oft vor wie das Wort auf Rang 100
Quelle: http://en.wikipedia.org
Data Science / Kapitel 2: Regression
f(w) Ã 1r(w) –
mit – ¥ 1

62
Lotka‘sches Gesetz (Lotka‘s law)§ Alfred J. Lotka (1880–1949) beobachtete, dass sich die
Anzahl f(n) der Autoren mit n Veröffentlichungenbeschreiben lässt als
mit Parametern C und a, die von der Gesamtzahl derAutoren und dem Fachgebiet abhängen
f(n) = C
na
Data Science / Kapitel 2: Regression

63
Wachstumsmodelle§ Wachstumsmodelle beschreiben Populationsgröße, z.B.
einer Bakterienkultur, nach Ablauf von t Zeiteinheiten
§ Einfaches Modell unter der Annahme geometrischen Wachstums mit Wachstumsrate r und Anfangsgröße der Population P(0) als Parameter
§ Komplexere Modelle berücksichtigen zeitabhängige Wachstumsraten und Kapazitätsbeschränkungen
P (t) = P (0) · rt mit r Ø 1
Data Science / Kapitel 2: Regression

64
Merkmalstransformation§ Gesetze von Zipf und Lotka und das einfache
Wachstumsmodell beschreiben nicht-lineare Zusammenhänge zwischen Merkmalen
§ Wie können wir ihre Parameter (z.B. Wachstumsrate r)anhand von beobachteten Daten schätzen?
§ Idee: Transformiere das abhängige und die unabhängigen
Merkmale so, dass ein linearer Zusammenhangzwischen ihnen entsteht; dann können wir
lineare Regression verwenden
Data Science / Kapitel 2: Regression

65
Merkmalstransformation für Zipf‘sches Gesetz§ Worthäufigkeit f(w) verhält sich zum Häufigkeitsrang r als
§ Logarithmische Transformation der Merkmale
§ Parameter α kann also anhand der logarithmisch transformierten Merkmale geschätzt werden
Data Science / Kapitel 2: Regression
f(w) Ã 1r(w) –
mit – ¥ 1
log f(w) Ã log 1r(w) –
… log f(w) Ã ≠– log r(w)
66
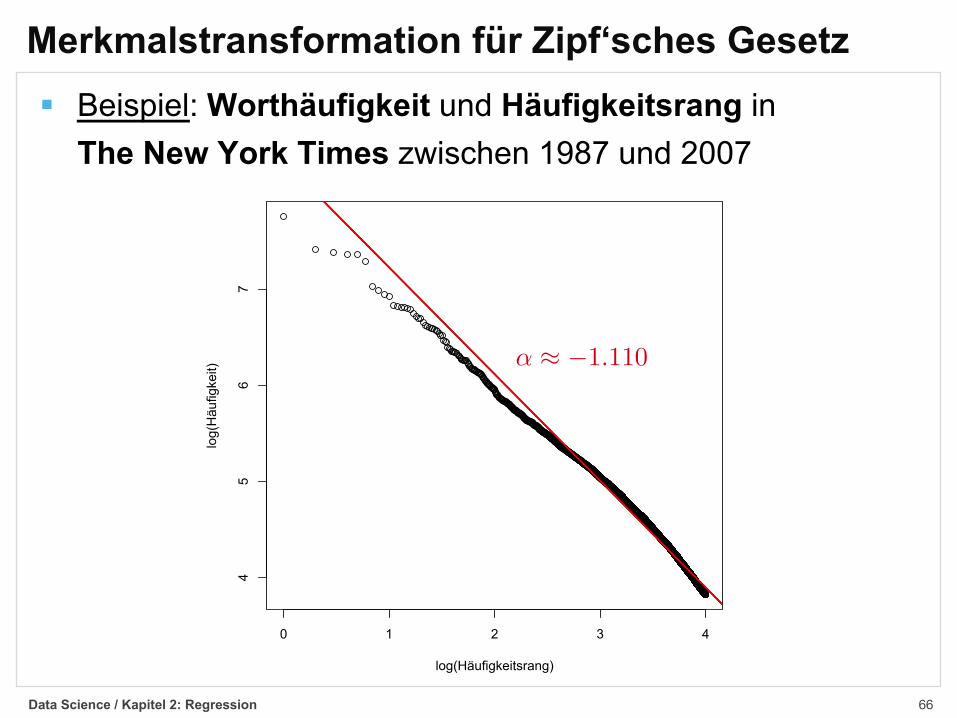
Merkmalstransformation für Zipf‘sches Gesetz§ Beispiel: Worthäufigkeit und Häufigkeitsrang in
The New York Times zwischen 1987 und 2007
0 1 2 3 4
45
67
log(Häufigkeitsrang)
log(Häufigkeit)
– ¥ ≠1.110
Data Science / Kapitel 2: Regression

67
2.7 Evaluation§ Bisher haben wir die Güte unserer Modelle immer auf
den gleichen Daten gemessen, auf denen auchdas Modell selbst trainiert wurde
§ Dies ist eine sehr schlechte Idee (und verpönt), da
§ wir nicht wissen, wie gut unser Modell auf zuvorunbekannten Daten Vorhersagen treffen kann(z.B. neue Autos in unseren Autodaten)
§ eine Überanpassung des Modells an unsere Datenstattfinden kann, wenn es sehr viele Merkmale,aber nur vergleichsweise wenige Datenpunkte gibt
Data Science / Kapitel 2: Regression

68
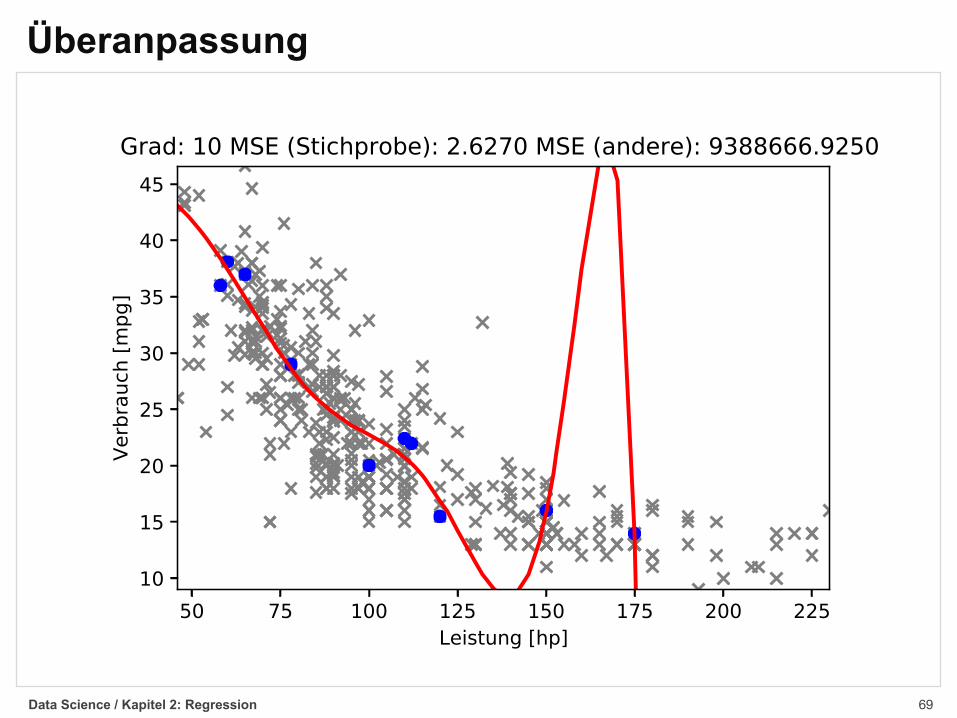
Überanpassung§ Verwendet man sehr viele unabhängige Merkmale
(z.B. bei polynomialer Regression mit hohem Grad d)kann es zu einer Überanpassung (overfitting)des Modells an die Daten kommen
§ Das gelernte Modell beschreibt dann die vorhandenenDaten nahezu perfekt, kann aber auf bisherunbekannten Daten keine verlässlichenVorhersagen treffen
Data Science / Kapitel 2: Regression
69
Überanpassung
Data Science / Kapitel 2: Regression

70
Modellauswahl§ Um eine Überanpassung zu vermeiden, müssen wir
zuerst ein Modell geeigneter Komplexität auswählen, indem wir seine Hyperparameter abstimmen
§ Hyperparameter sind solche Parameter, welche dieGestalt des Modells beeinflussen, also z.B. der Graddes Polynoms d oder die berücksichtigten Merkmale
§ Dies bezeichnet man als Modellauswahl (model selection)
Data Science / Kapitel 2: Regression

71
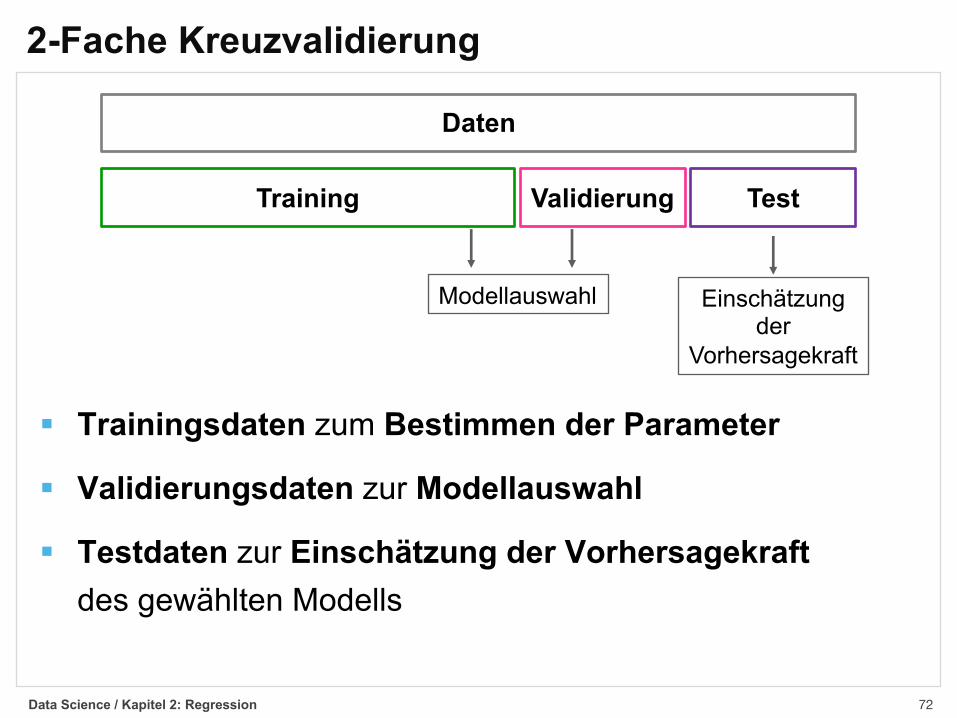
2-Fache Kreuzvalidierung§ Eine einfache Möglichkeit zur Modellauswahl und
zur Einschätzung der Vorhersagekraft bietet die2-fache Kreuzvalidierung (2-fold cross validation)
§ Die vorhandenen Daten werden zufällig aufgeteilt in
§ Trainingsdaten (z.B. 60%)
§ Validierungsdaten (z.B. 20%)
§ Testdaten (z.B. 20%)
Data Science / Kapitel 2: Regression
72
2-Fache Kreuzvalidierung
§ Trainingsdaten zum Bestimmen der Parameter
§ Validierungsdaten zur Modellauswahl
§ Testdaten zur Einschätzung der Vorhersagekraftdes gewählten Modells
Data Science / Kapitel 2: Regression
Daten
Training Validierung Test
Modellauswahl Einschätzungder
Vorhersagekraft

73
2-Fache Kreuzvalidierung§ Beispiel: Polynomiale Regression mit Grad d
§ bestimme den Grad d, so dass ein auf den entsprechendesauf den Trainingsdaten trainiertes Modell die besteVorhersagekraft auf den Validierungsdaten erreicht
§ schätze die Vorhersagekraft des gewählten Modellsdurch Anwendung auf die Testdaten
Data Science / Kapitel 2: Regression

74
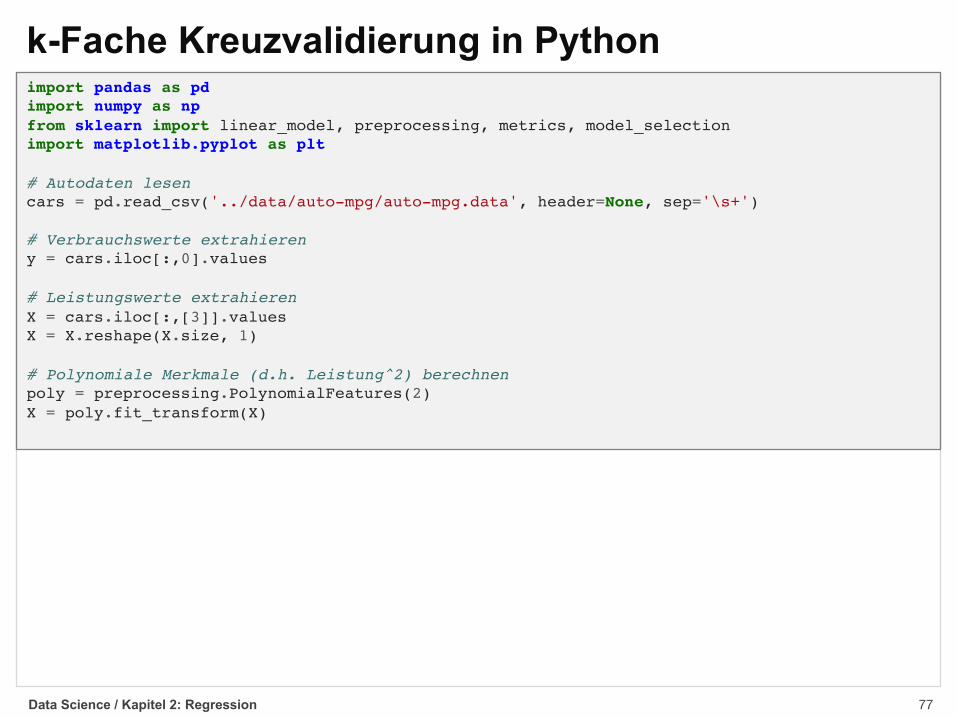
k-Fache Kreuzvalidierung§ Bei der k-fachen Kreuzvalidierung (k-fold crossvalidation) werden die Daten zufällig ink gleich große Teilmengen aufgeteilt
§ Es werden k Iterationen durchgeführt, wobei jede Teilmenge einmal zum Testen verwendet wird
§ Dies führt zu einer robusteren Einschätzung der Vorhersagekraft, insbesondere wenn dieursprüngliche Datenmenge klein ist
Data Science / Kapitel 2: Regression

75
k-Fache Kreuzvalidierung
Data Science / Kapitel 2: Regression
1 2 3 4 5
1 2 3 4 5 M1 (e.g., MSE1)
1 2 3 4 5 M2 (e.g., MSE2)
1 2 3 4 5 M3 (e.g., MSE3)
1 2 3 4 5 M4 (e.g., MSE4)
1 2 3 4 5 M5 (e.g., MSE5)

76
k-Fache Kreuzvalidierung§ Jede Iteration liefert eine Schätzung der Vorhersagekraft,
aus denen wir Mittelwert und Varianz bestimmen können
§ Da die Vorhersagekraft auf den Testdaten, die in anderen Iterationen Trainingsdaten sind, geschätzt wird, kann es zu einer Überanpassung kommen
§ Bei der geschachtelten k-fachen Kreuzvalidierung wird dieses Problem durch eine Aufteilung der Trainingsdatenin Trainingsdaten und Testdaten vermieden
Data Science / Kapitel 2: Regression
77
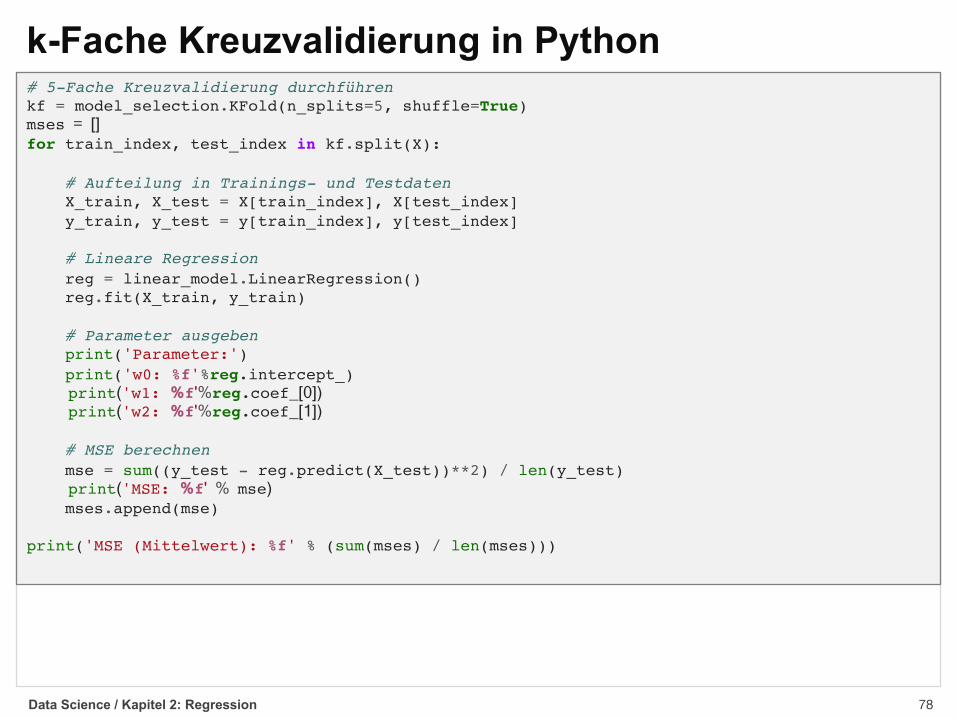
k-Fache Kreuzvalidierung in Python
Data Science / Kapitel 2: Regression
import pandas as pdimport numpy as npfrom sklearn import linear_model, preprocessing, metrics, model_selectionimport matplotlib.pyplot as plt
# Autodaten lesencars = pd.read_csv('../data/auto-mpg/auto-mpg.data', header=None, sep='\s+')
# Verbrauchswerte extrahiereny = cars.iloc[:,0].values
# Leistungswerte extrahierenX = cars.iloc[:,[3]].valuesX = X.reshape(X.size, 1)
# Polynomiale Merkmale (d.h. Leistung^2) berechnenpoly = preprocessing.PolynomialFeatures(2)X = poly.fit_transform(X)
78
k-Fache Kreuzvalidierung in Python
Data Science / Kapitel 2: Regression
# 5-Fache Kreuzvalidierung durchführenkf = model_selection.KFold(n_splits=5, shuffle=True)mses = []for train_index, test_index in kf.split(X):
# Aufteilung in Trainings- und TestdatenX_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]
# Lineare Regressionreg = linear_model.LinearRegression()reg.fit(X_train, y_train)
# Parameter ausgebenprint('Parameter:')print('w0: %f'%reg.intercept_)print('w1: %f'%reg.coef_[0])print('w2: %f'%reg.coef_[1])
# MSE berechnenmse = sum((y_test - reg.predict(X_test))**2) / len(y_test)print('MSE: %f' % mse)mses.append(mse)
print('MSE (Mittelwert): %f' % (sum(mses) / len(mses)))

79
2.8 Regularisierung§ Regularisierung (regularization oder shrinkage) bietet
eine Möglichkeit, die Komplexität des Modellsin der Straffunktion zu berücksichtigen
§ Beim Trainieren, d.h. Bestimmen der Parameter, könnendann bessere Vorhersagekraft und Modellkomplexitätgegeneinander abgewogen werden
§ Ridge Regression und LASSO sind gängige regularisierte Varianten der linearen Regression
Data Science / Kapitel 2: Regression

80
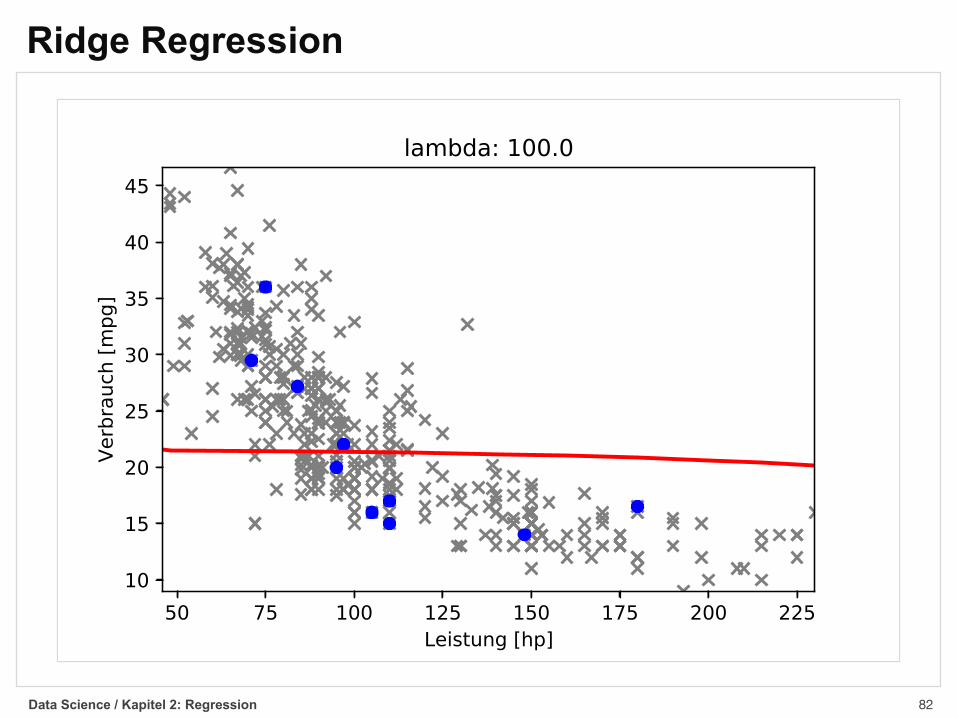
Ridge Regression§ Ridge Regression verwendet folgende Straffunktion
mit
und λ > 0 als Hyperparameter
§ Komplexe Modelle, die viele Parameter verwenden,werden damit durch die Straffunktion benachteiligt
Data Science / Kapitel 2: Regression
L(w) = (y ≠ Xw)T (y ≠ Xw) + ⁄wTw
wTw =mÿ
i=1w2
i

81
LASSO§ LASSO verwendet folgende Straffunktion
mit
und λ > 0 als Hyperparameter
§ LASSO weist, im Vergleich zu Ridge Regression, vielen Parametern den Wert 0 zu und verwendet damitnur eine Teilmenge der Merkmale
Data Science / Kapitel 2: Regression
L(w) = (y ≠ Xw)T (y ≠ Xw) + ⁄ÎwÎ1
ÎwÎ1 =mÿ
i=1|wi|
82
Ridge Regression
Data Science / Kapitel 2: Regression

83
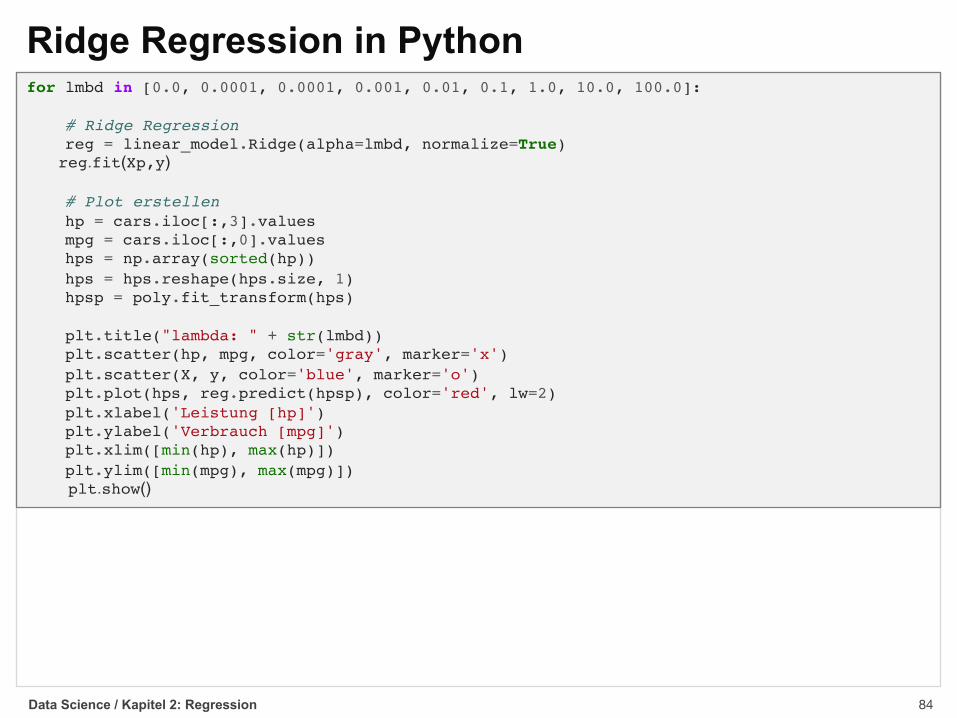
Ridge Regression in Python
Data Science / Kapitel 2: Regression
import pandas as pdimport numpy as npfrom sklearn import linear_model, preprocessingimport matplotlib.pyplot as plt
# Autodaten lesencars = pd.read_csv('../data/auto-mpg/auto-mpg.data', header=None, sep='\s+')
# Stichprobe von 10 Autossample = random.sample(range(0,len(cars)), 10)out_of_sample = list(set(range(0,len(cars))) - set(sample))
# Leistungs- und Verbrauchswerte extrahiereny = cars.iloc[sample, 0].valuesy_oos = cars.iloc[out_of_sample, 0].values
# Leistungswerte für Stichprobe auswählenX = cars.iloc[sample, [3]].valuesX.reshape(X.size, 1)
# Polynomiale Merkmale berechnenpoly = preprocessing.PolynomialFeatures(5)Xp = poly.fit_transform(X)
84
Ridge Regression in Python
Data Science / Kapitel 2: Regression
for lmbd in [0.0, 0.0001, 0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0]:
# Ridge Regressionreg = linear_model.Ridge(alpha=lmbd, normalize=True)reg.fit(Xp,y)
# Plot erstellenhp = cars.iloc[:,3].valuesmpg = cars.iloc[:,0].valueshps = np.array(sorted(hp))hps = hps.reshape(hps.size, 1)hpsp = poly.fit_transform(hps)
plt.title("lambda: " + str(lmbd))plt.scatter(hp, mpg, color='gray', marker='x')plt.scatter(X, y, color='blue', marker='o')plt.plot(hps, reg.predict(hpsp), color='red', lw=2)plt.xlabel('Leistung [hp]')plt.ylabel('Verbrauch [mpg]')plt.xlim([min(hp), max(hp)])plt.ylim([min(mpg), max(mpg)])plt.show()

85
Zusammenfassung§ Gradientenabstiegsverfahren zum Bestimmen (nahezu)
optimaler Parameter für multiple lineare Regression
§ Polynomiale Regression und Merkmalstransformationzum Anpassen polynomialer bzw. nicht-linearer Modelle
§ Kreuzvalidierung zum Vermeiden von einer Überanpassung des Modells an die Daten
§ Regularisierung zum Abwägen zwischenModellkomplexität und Vorhersagekraft
Data Science / Kapitel 2: Regression

86
Literatur[1] L. Fahrmeir, R. Künstler, I. Pigeot und G. Tutz:
Statistik – Der Weg zur Datenanalyse,Springer, 2017 (Kapitel 12)
[2] S. Raschka: Machine Learning in Python,mitp, 2017 (Kapitel 6 und 10)
Data Science / Kapitel 2: Regression


















