
4 – Exploration en situation d’adversité · 2019-12-19 · champion humain Gary Kasparov. Deep...
48
4 – Exploration en situation d’adversité Faculté des Sciences Département d’Informatique Introduction à l’Intelligence artificielle L3 Informatique 2019/2020 http://IntroIA.wordpress.com Amine Brikci-Nigassa [email protected] Ces diapos sont librement adaptées de celles de Dan Klein et Pieter Abbeel : CS188 Intro to AI (University of California, Berkeley - ai.berkeley.edu)
Transcript of 4 – Exploration en situation d’adversité · 2019-12-19 · champion humain Gary Kasparov. Deep...

4 – Exploration en situation d’adversité
Faculté des Sciences Département d’Informatique
Introduction à l’Intelligence artificielle
L3 Informatique 2019/2020
http://IntroIA.wordpress.com Amine Brikci-Nigassa
Ces diapos sont librement adaptées de celles de Dan Klein et Pieter Abbeel : CS188 Intro to AI (University of California, Berkeley - ai.berkeley.edu)

Les diapos de ce cours sont adaptées de :CS 188: Artificial Intelligence
Adversarial Search
Instructors: Pieter Abbeel & Dan KleinUniversity of California, Berkeley
[These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley (ai.berkeley.edu).]
qui se basent sur le livre de Stuart Russell et Peter Norvig...

Programmes de Jeu : État de l’Art
Jeu de Dames (anglaises) :1950 : 1er programme joueur. 1994 : 1er programme champion : Chinook met fin aux 40 ans de reigne du champion humain Marion Tinsley. 2007 : Le jeu est résolu !
Échecs : 1997 : Deep Blue bat le champion humain Gary Kasparov. Deep Blue examinait 200M positions par seconde, avec un algorithme d’exploration alpha-beta. Les programmes actuels sont encore meilleurs...
Jeu de Go : Les champions humains commencent à êtré défiés par les machines. Dans le go, b > 300 !

Jeu de Dames (anglaises) :1950 : 1er programme joueur. 1994 : 1er programme champion : Chinook met fin aux 40 ans de reigne du champion humain Marion Tinsley. 2007 : Le jeu est résolu !
Échecs : 1997 : Deep Blue bat le champion humain Gary Kasparov. Deep Blue examinait 200M positions par seconde, avec un algorithme d’exploration alpha-beta. Les programmes actuels sont encore meilleurs...
Jeu de Go : 2016 : AlphaGo bat le champion humain Lee Sedol.2017 : Il bat le champion du monde Ke Jie.Il utilise une exploration en arbre de Monte Carlo, avec apprentissage.
Pacman
Programmes de Jeu : État de l’Art
Comportement calculé
Demo : Mystery Pacman

Jeux en situation d’adversité

De nombreux types de jeux différents !
Axes :
Déterministe ou stochastique ?
Un, deux ou plusieurs joueurs ?
Somme nulle ?
Information parfaite (peut-on voir l'état) ?
On veut des algorithmes pour calculer une stratégie (politique) qui recommande un déplacement pour chaque état.
Types de Jeux

Jeux Déterministes
Une définition formelle : États: S (départ à s0)
Joueurs: P={1...N} (chacun son tour en général) Actions: A (dépendent du joueur/de l’état) Fonction de Transition: SxA S Test Terminal: S {t,f} Utilité Terminale: SxP R
La Solution pour un joueur est une politique : S A

Jeux à Somme Nulle
Jeux à Somme Nulle
Les agents ont des utilités (valeurs des gains) opposées.
Fait penser à une valeur unique que l'un maximise et l'autre minimise.
Pure competition, en adversité
Jeux Généraux Les agents ont des utilités (valeurs
des gains) indépendantes. Coopération, indifférence,
compétition, etc. sont toutes possibles
Nous reviendrons plus tard sur les jeux à somme non nulle.
Exploration en Situation d’Adversité
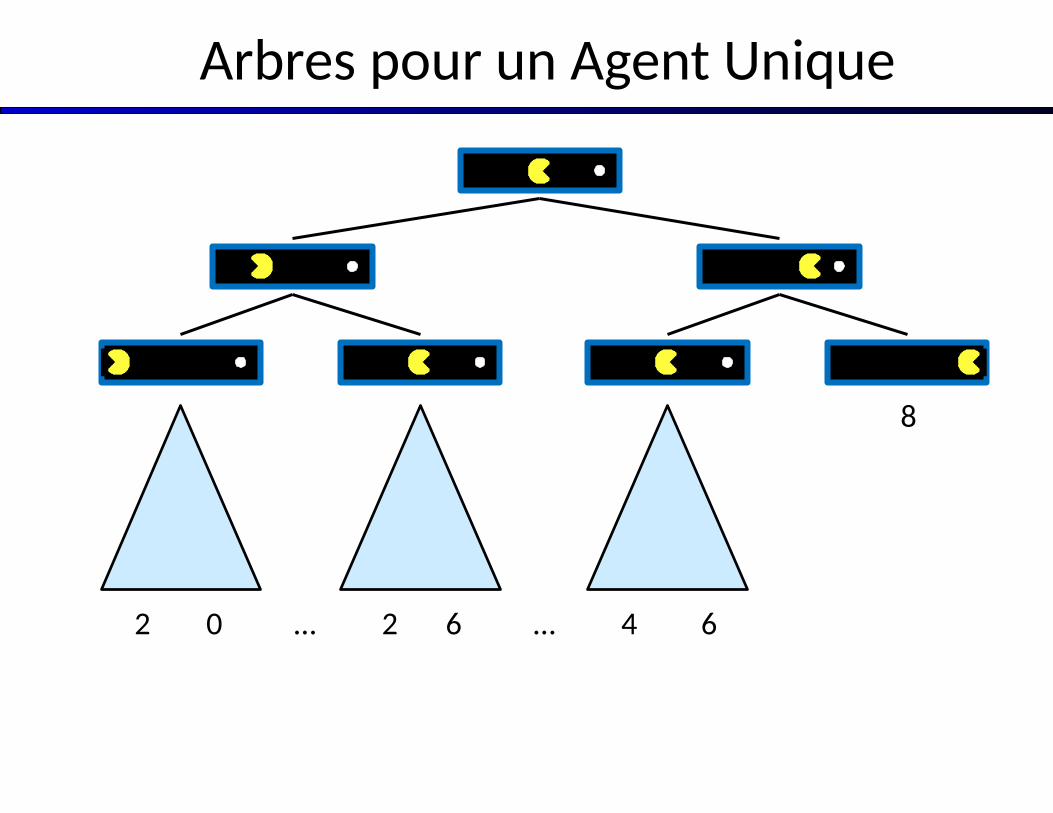
Arbres pour un Agent Unique
8
2 0 2 6 4 6… …
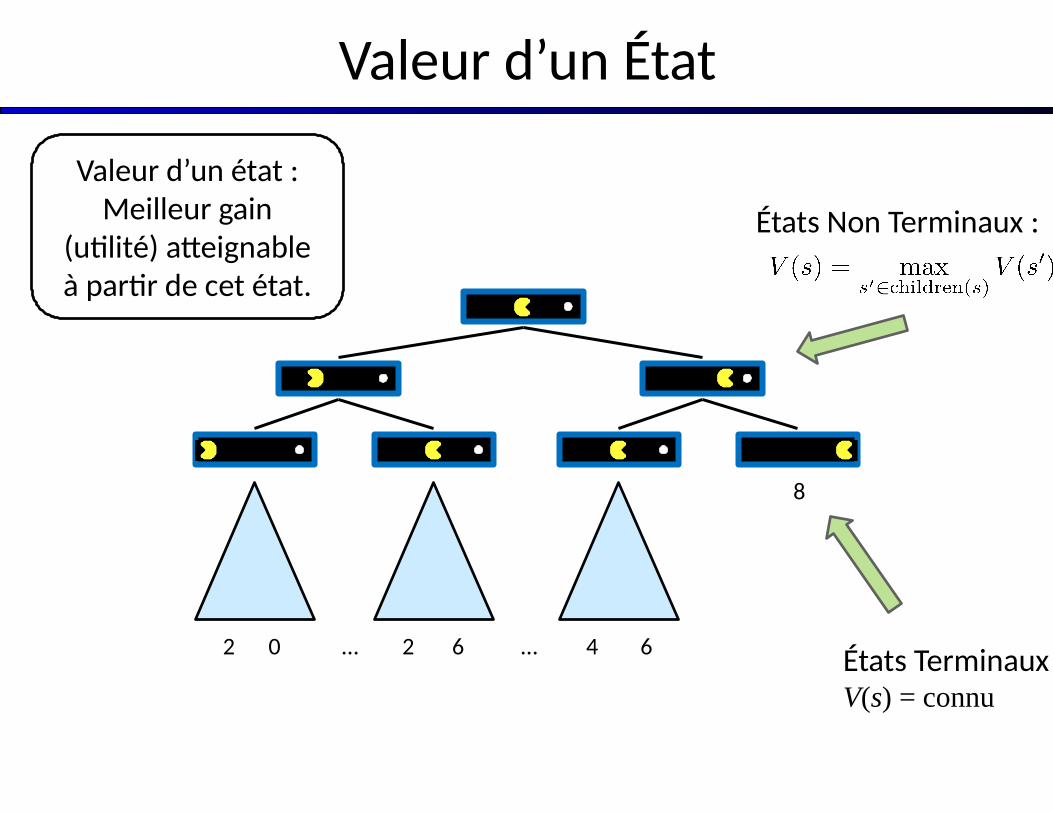
Valeur d’un État
États Non Terminaux :
8
2 0 2 6 4 6… …États Terminaux :V(s) = connu
Valeur d’un état : Meilleur gain
(utilité) atteignable à partir de cet état.
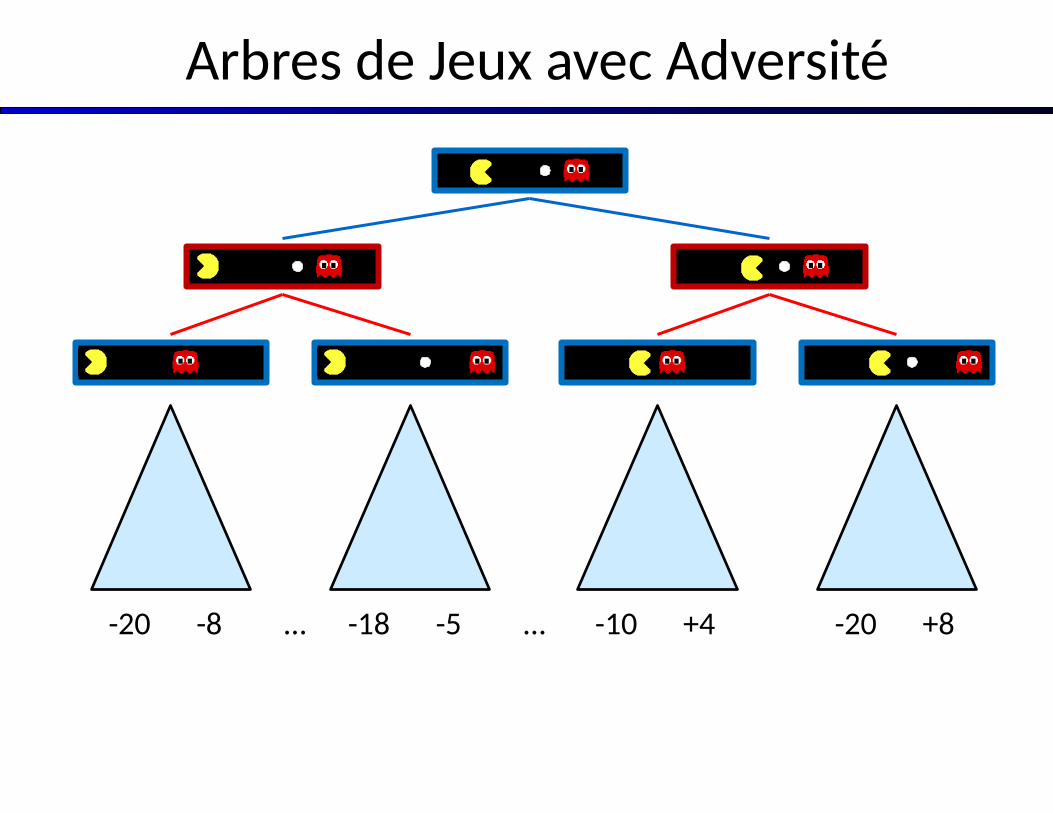
Arbres de Jeux avec Adversité
-20 -8 -18 -5 -10 +4… … -20 +8

Valeurs Minimax
+8-10-5-8
États sous Contrôle de l’Agent :
États terminaux :
États sous Contrôle de l’Adversaire
V(s) = connu
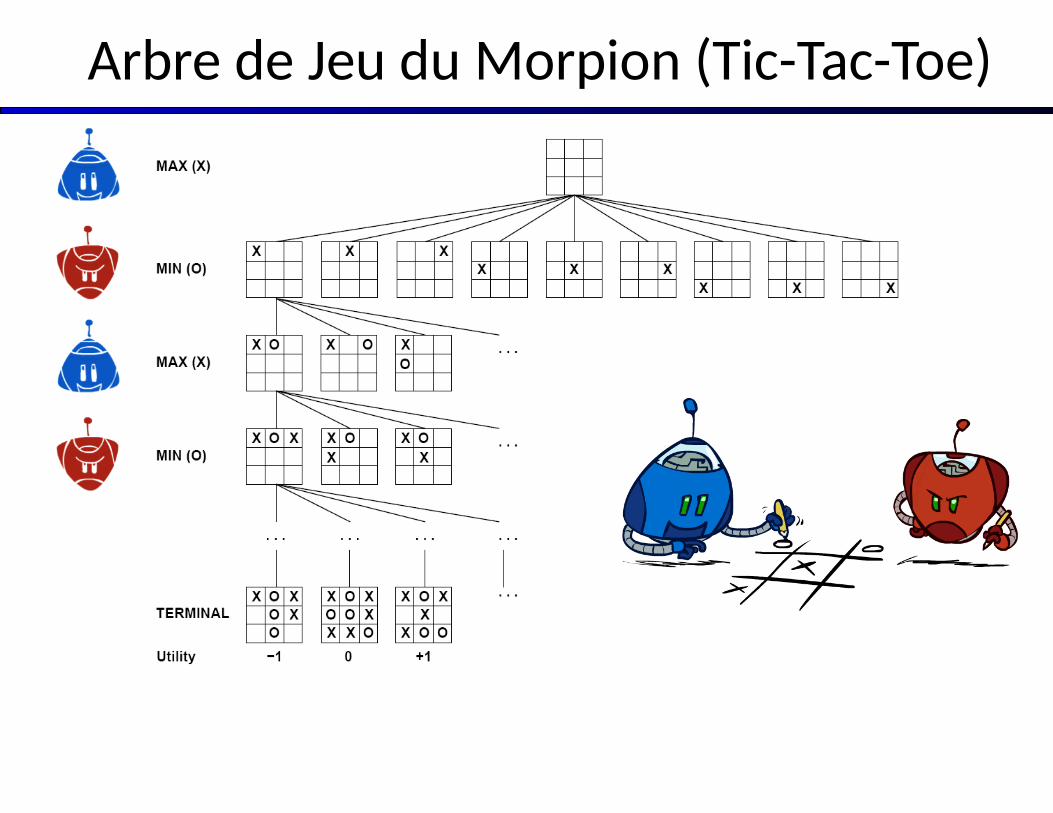
Arbre de Jeu du Morpion (Tic-Tac-Toe)
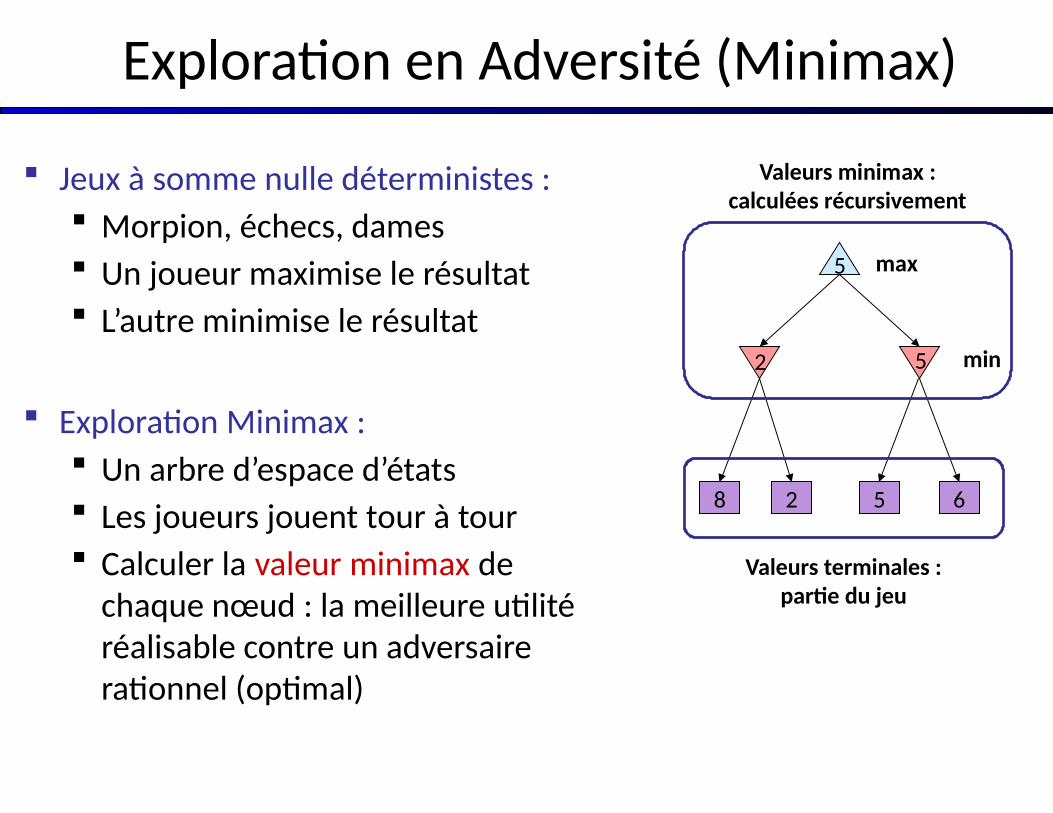
Exploration en Adversité (Minimax)
Jeux à somme nulle déterministes : Morpion, échecs, dames Un joueur maximise le résultat L’autre minimise le résultat
Exploration Minimax : Un arbre d’espace d’états Les joueurs jouent tour à tour Calculer la valeur minimax de
chaque nœud : la meilleure utilité réalisable contre un adversaire rationnel (optimal)
8 2 5 6
max
min2 5
5
Valeurs terminales :partie du jeu
Valeurs minimax :calculées récursivement
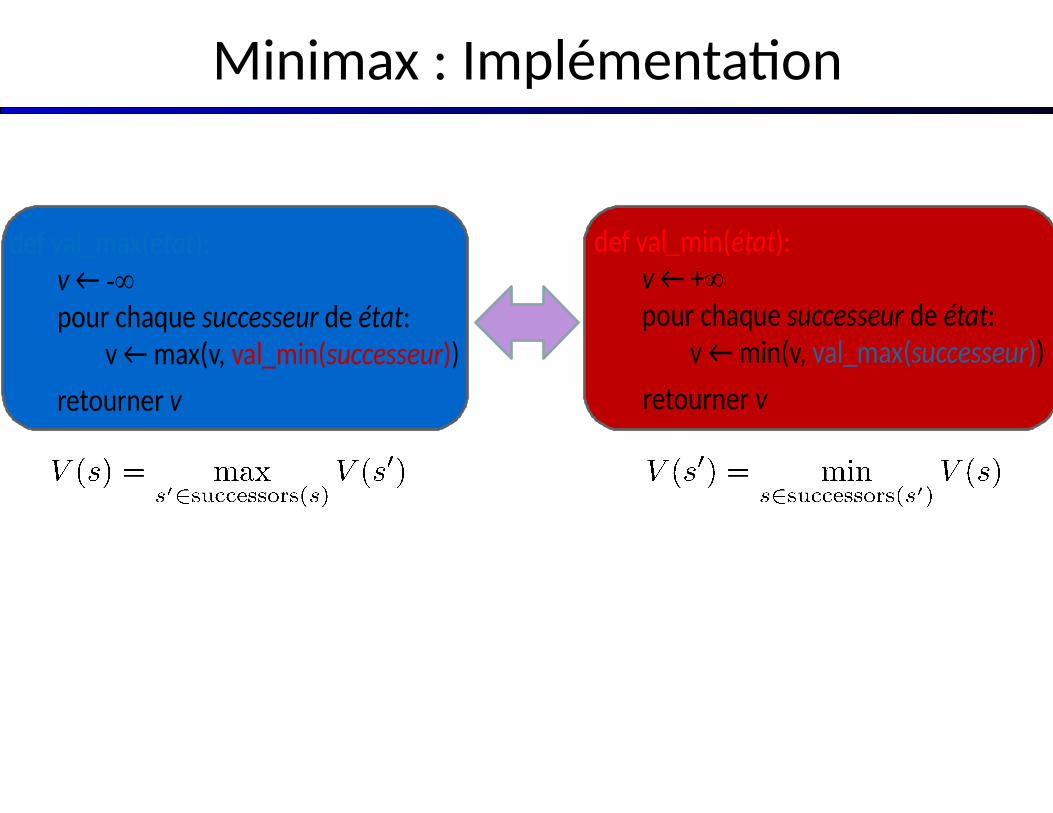
Minimax : Implémentation
def val_min(état):v ← +∞pour chaque successeur de état:
v ← min(v, val_max(successeur))
retourner v
def val_max(état):v ← -∞pour chaque successeur de état:
v ← max(v, val_min(successeur))
retourner v
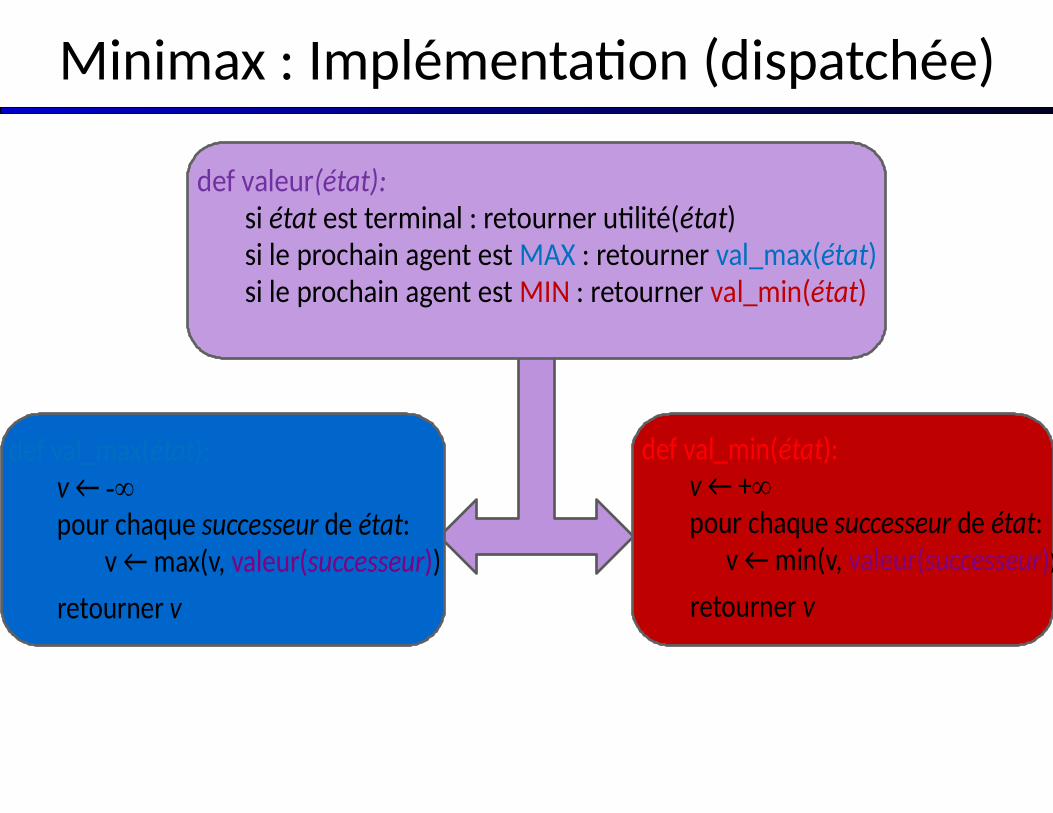
def valeur(état):si état est terminal : retourner utilité(état)si le prochain agent est MAX : retourner val_max(état)si le prochain agent est MIN : retourner val_min(état)
def val_min(état):v ← +∞pour chaque successeur de état: v ← min(v, valeur(successeur))
retourner v
def val_max(état):v ← -∞pour chaque successeur de état:
v ← max(v, valeur(successeur))
retourner v
Minimax : Implémentation (dispatchée)
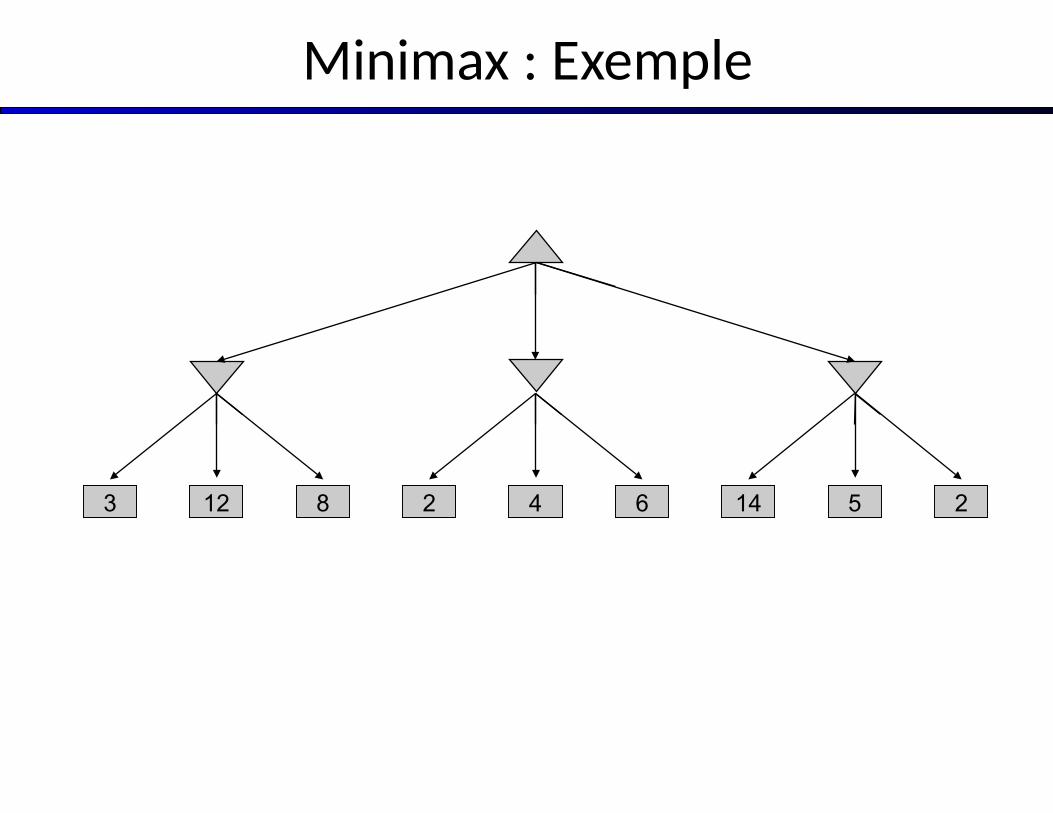
Minimax : Exemple
12 8 5 23 2 144 6

Minimax : Propriétés
Optimal contre un joueur parfait. Sinon ?
10 10 9 100
max
min
Video of Demo Min vs. Exp (Min)
Chaque déplacement : -1 pointChaque bille mangée : +10 pointsFin du jeu : Toutes les billes mangées : +500 Collision avec fantôme : -500
Video of Demo Min vs. Exp (Exp)
Chaque déplacement : -1 pointChaque bille mangée : +10 pointsFin du jeu : Toutes les billes mangées : +500 Collision avec fantôme : -500

Minimax : Efficacité
Quelle est l’efficacité de minimax ? Tout comme DFS (exhaustive) Temps : O(bm) Espace : O(bm)
Exemple : Jeu d’échecs, b 35, m 100 La solution exacte est totalement irréalisable. Mais, a-t-on besoin d’explorer tout l’arbre ?

Ressources Limitées
Élagage de l’Arbre de Jeu

Minimax : Exemple
12 8 5 23 2 144 6

Minimax : Élagage
12 8 5 23 2 14

Élagage Alpha-Bêta
Configuration générale (version MIN) On veut calculer la VALEUR MIN à un nœud n
On fait une itération sur les nœuds fils de n
La valeur estimée pour n diminue pendant
l’itération
Qui a besoin de la valeur de n ? MAX
Soit a la meilleure valeur que MAX peut obtenir à
n'importe quel nœud de choix le long du chemin
courant depuis la racine
Si n devient pire que a, MAX l’évitera, donc on peut
arrêter d’examiner les autres fils de n (c’est déjà
assez mauvais pour ne pas être joué)
La version MAX est la symétrique
MAX
MIN
MAX
MIN
a
n

Alpha-Bêta : Implémentation
def valeur_min(état , α, β):
v ← +∞ Pour chaque successeur s de état : v ← min(v, valeur(s, α, β)) si v ≤ α retourner v β ← min(β, v) retourner v
def valeur_max(état, α, β): v ← –∞ Pour chaque successeur s de état : v ← max(v, valeur(s, α, β)) si v ≥ β retourner v α ← max(α, v) retourner v
α : le meilleur choix pour MAX sur le chemin vers la racineβ : le meilleur choix pour MIN sur le chemin vers la racine

Propriétés de l’élagage Alpha-Bêta
Cet élagage n’a pas d’effet sur la valeur minimax calculée pour la racine !
Les valeurs des nœuds intermédiaires peuvent être fausses Important : les nœuds fils de la racine peuvent avoir la mauvaise valeur Ainsi la version la plus naïve ne vous laissera pas sélectionner l’action
Bien ordonner les nœuds fils améliore l’efficacité de l’élagage
Avec l’ordre « parfait » : La complexité temporelle tombe à O(bm/2) La profondeur résoluble est doublée ! L’exploration complète dans le jeu d’échecs (par ex.) reste sans espoir…
Ceci est un exemple de métaraisonnement (raisonnement sur le raisonnement: calcul de ce qu’il faut calculer)
10 10 0
max
min
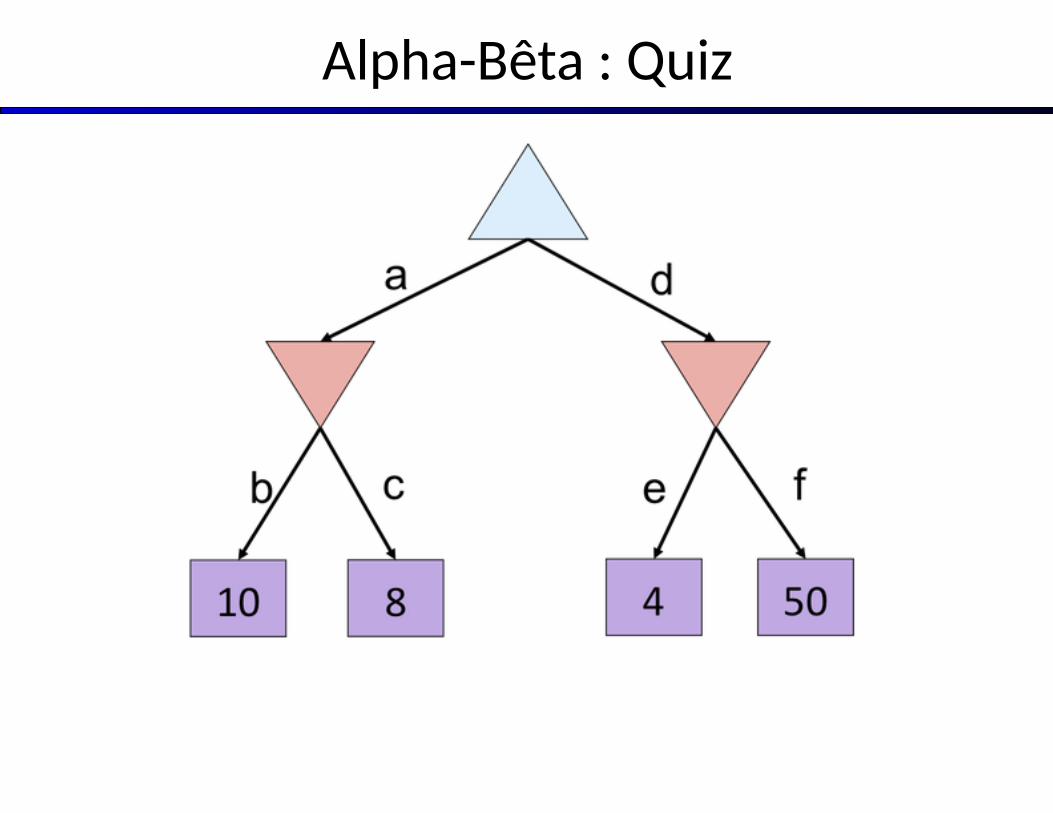
Alpha-Bêta : Quiz
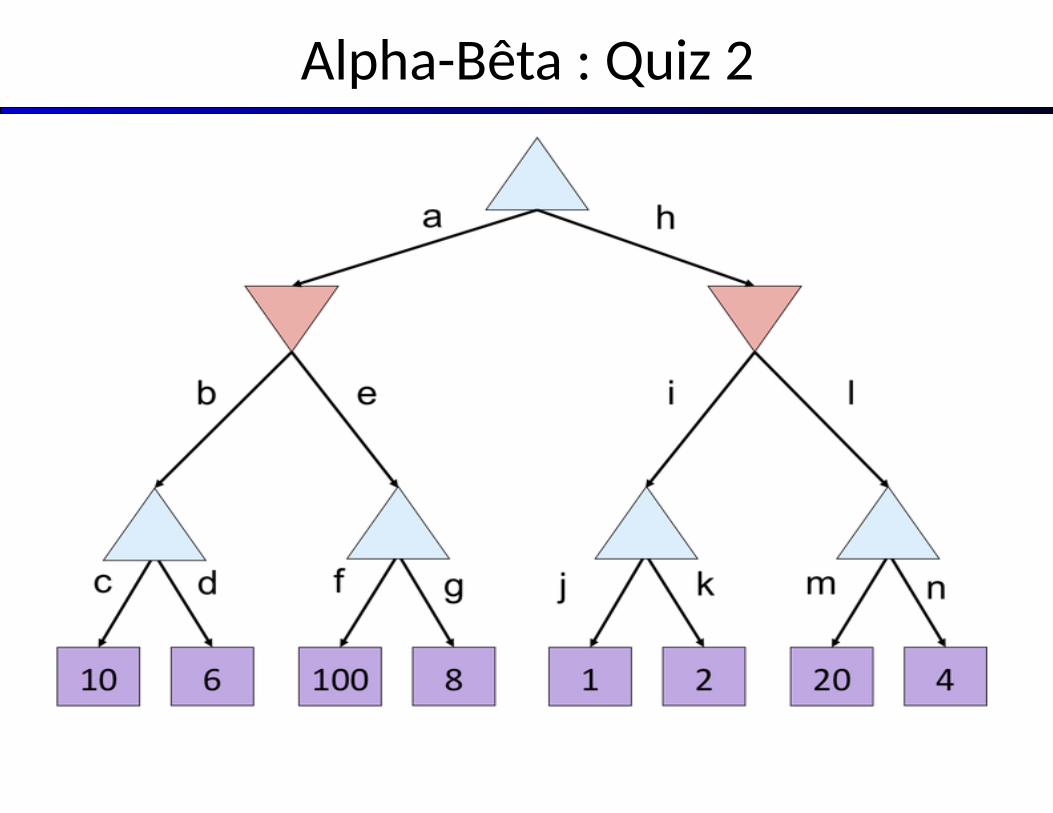
Alpha-Bêta : Quiz 2

Ressources Limitées
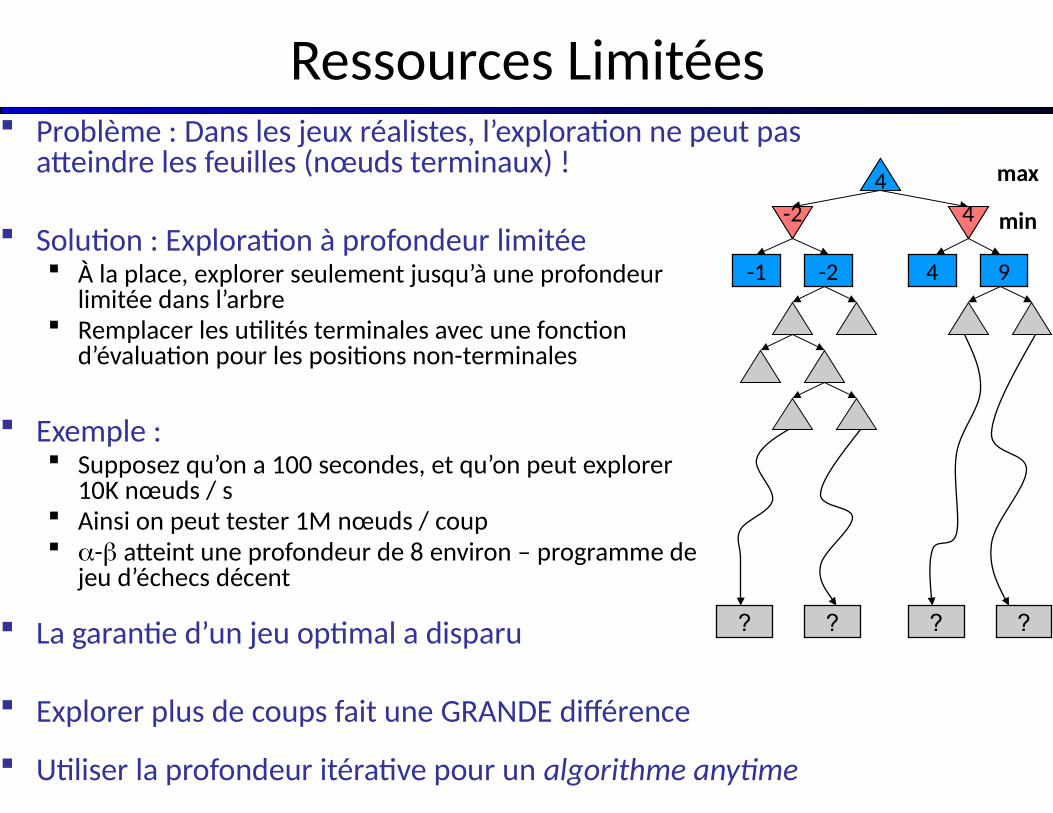
Ressources Limitées Problème : Dans les jeux réalistes, l’exploration ne peut pas
atteindre les feuilles (nœuds terminaux) !
Solution : Exploration à profondeur limitée À la place, explorer seulement jusqu’à une profondeur
limitée dans l’arbre Remplacer les utilités terminales avec une fonction
d’évaluation pour les positions non-terminales
Exemple : Supposez qu’on a 100 secondes, et qu’on peut explorer
10K nœuds / s Ainsi on peut tester 1M nœuds / coup - atteint une profondeur de 8 environ – programme de
jeu d’échecs décent
La garantie d’un jeu optimal a disparu
Explorer plus de coups fait une GRANDE différence
Utiliser la profondeur itérative pour un algorithme anytime
? ? ? ?
-1 -2 4 9
4
min
max
-2 4
Démo : Thrashing (d=2)
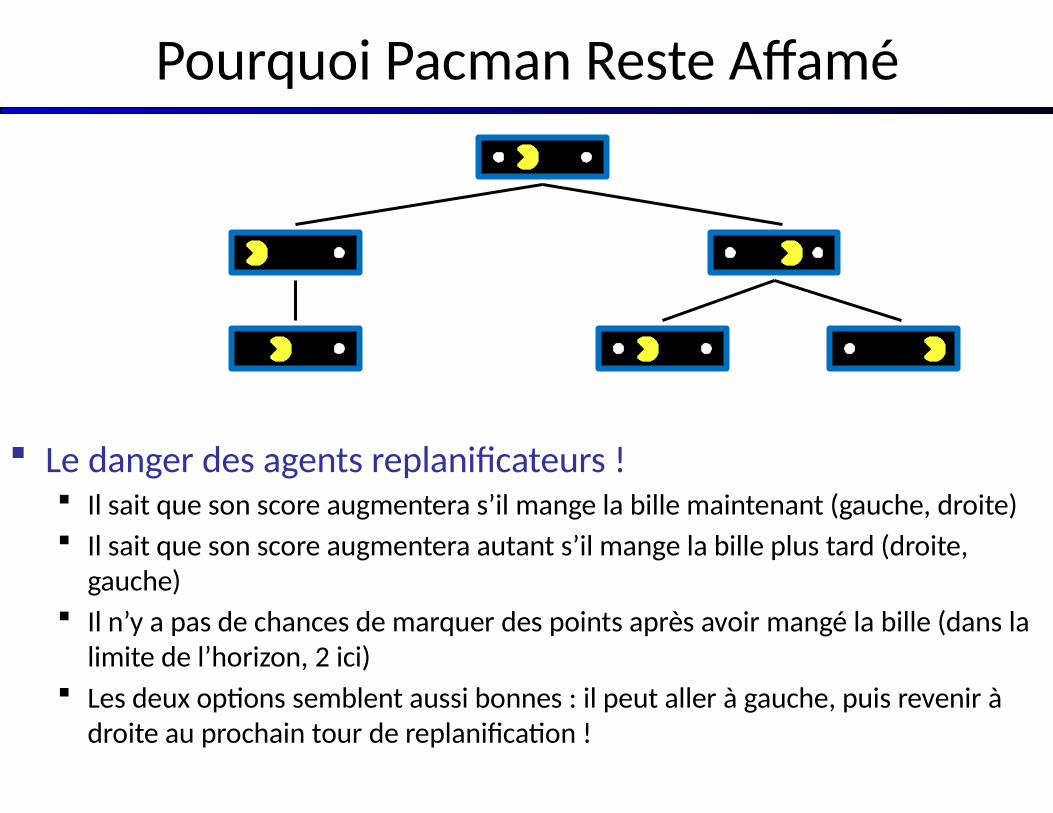
Pourquoi Pacman Reste Affamé
Le danger des agents replanificateurs ! Il sait que son score augmentera s’il mange la bille maintenant (gauche, droite) Il sait que son score augmentera autant s’il mange la bille plus tard (droite,
gauche) Il n’y a pas de chances de marquer des points après avoir mangé la bille (dans la
limite de l’horizon, 2 ici) Les deux options semblent aussi bonnes : il peut aller à gauche, puis revenir à
droite au prochain tour de replanification !
Démo : Thrashing -- Réparé (d=2)

Fonctions d’Évaluation

Les fonctions d’évaluation estiment le score des nœuds non terminaux dans l’exploration en profondeur limitée
Fonction idéale : renvoie la valeur minimax réelle de la position En pratique : souvent une somme linéaire pondérée des attributs :
Par ex. : f1(s) = (nombre de reines blanches – nombre de reines noires), etc.
Fonctions d’Évaluation

Evaluation for Pacman

Démo Smart Ghosts (Coordination)

Démo Smart Ghosts (Coordination) – Zoomée
La Profondeur a son Importance
Les fonctions d'évaluation sont toujours imparfaites.
Plus la fonction d'évaluation est enfouie profondément dans l'arbre, moins la qualité de la fonction d'évaluation est importante.
Il s’agit d’un exemple important de compromis entre la complexité des fonctionnalités et la complexité du calcul.
Démo : Profondeur Limitée (2)

Démo : Profondeur Limitée (10)

Synergies entre Fonction d'évaluation et Alpha-bêta ?
Alpha-Bêta : la quantité d'élagage dépend de I'ordre de développement. La fonction d'évaluation peut fournir des indications pour développer
d'abord les nœuds les plus prometteurs (ce qui rend plus probable qu'il existe déjà une bonne alternative sur le chemin vers la racine). (assez similaire au rôle de l’heuristique A*)
Alpha-Bêta : (rôles similaires de min-max échangés) La valeur d’un nœud min ne fera que diminuer Quand la valeur d’un nœud min est plus basse que la meilleure option
pour max sur le chemin vers la racine, on peut élaguer Donc : SI la fonction d’évaluation fournit une limite sup. de la valeur à un
nœud min, et la limite sup. déjà plus basse que la meilleure option pour max sur le chemin vers la racine ALORS on peut élaguer

La prochaine fois : Incertitude !


















