
CIM Seminar - km.aifb.kit.edukm.aifb.kit.edu/ws/kmtutorial/wissensdatenbanken/... · 1. Architektur...
112
CIM Seminar Wissensdatenbanken Dr. Steffen Staab Alexander Mädche
Transcript of CIM Seminar - km.aifb.kit.edukm.aifb.kit.edu/ws/kmtutorial/wissensdatenbanken/... · 1. Architektur...

© S. Staab, A. Maedche, 2001
CIM Seminar
Wissensdatenbanken
Dr. Steffen Staab Alexander Mädche
Universität Karlsruhe (TH)
Institut AIFB
FG Wissensmanagementhttp://www.aifb.uni-karlsruhe.de/WBS
Forschungszentrum Informatik FZI
Wissensmanagement WIM,
Karlsruhehttp://www.fzi.de/wim
http://www.ontoprise.de
mailto:[email protected] mailto:[email protected]

© S. Staab, A. Maedche, 2001Folie 2
Agenda
1. Architektur einer Wissensdatenbank
– Dimensionen einer Wissensdatenbank
– Komponenten einer Wissensdatenbank
– Kernprozesse einer Wissensdatenbank
2. Aufbau und Instandhaltung einer Wissensdatenbank
– Ziele einer Wissensdatenbank
– Methodologie / Prozess der Einführung einer Wissensdatenbank
– Wiederverwendung existierender Wissensquellen
– Aufbau von Begriffsstrukturen (Terminologien, Thesauri, etc.)
– Technische Grundlagen

© S. Staab, A. Maedche, 2001Folie 3
Agenda
3. Anwendung von Wissensdatenbanken und Einbettung in Prozesse
– Generierung von Wissen
– Strukturieren von Wissen
– Wiederfinden von Wissen
– Nutzen von Wissen
4. Business Intelligence
– Der Business Intelligence Prozeß
– OLAP – Explorative Wissens- und Ideengenerierung
– Wissensvisualisierung
– Data Mining / Knowledge Discovery
Die vier Abschnitte werden mit verschiedenen IT Techniken
(Information Retrieval, Fallbasiertes Schließen, Begriffliche
Wissensmanagementsysteme) illustriert.

© S. Staab, A. Maedche, 2001Folie 4
1. Architektur einer Wissensdatenbank

© S. Staab, A. Maedche, 2001Folie 5
1. Architektur einer Wissensdatenbank
Inhalt
– Dimensionen einer Wissensdatenbank
– Komponenten einer Wissensdatenbank
– Kernprozesse einer Wissensdatenbank

© S. Staab, A. Maedche, 2001Folie 6
Datenbank versus Wissensdatenbank
Datenbank
• (typischerweise) strukturiert
• Schema anfragbar, aber
separat von den Daten
Wissensdatenbank
• Viele unstrukturierte und
semi-strukturierte Daten
• „Schema“ ist selbst Teil der
Daten
Gemeinsamkeiten
• Typische WDBs bauen auf konventionellen DBs auf
• Viele ähnliche Probleme (Konsistenz, Duplikate, Warehousing,....)
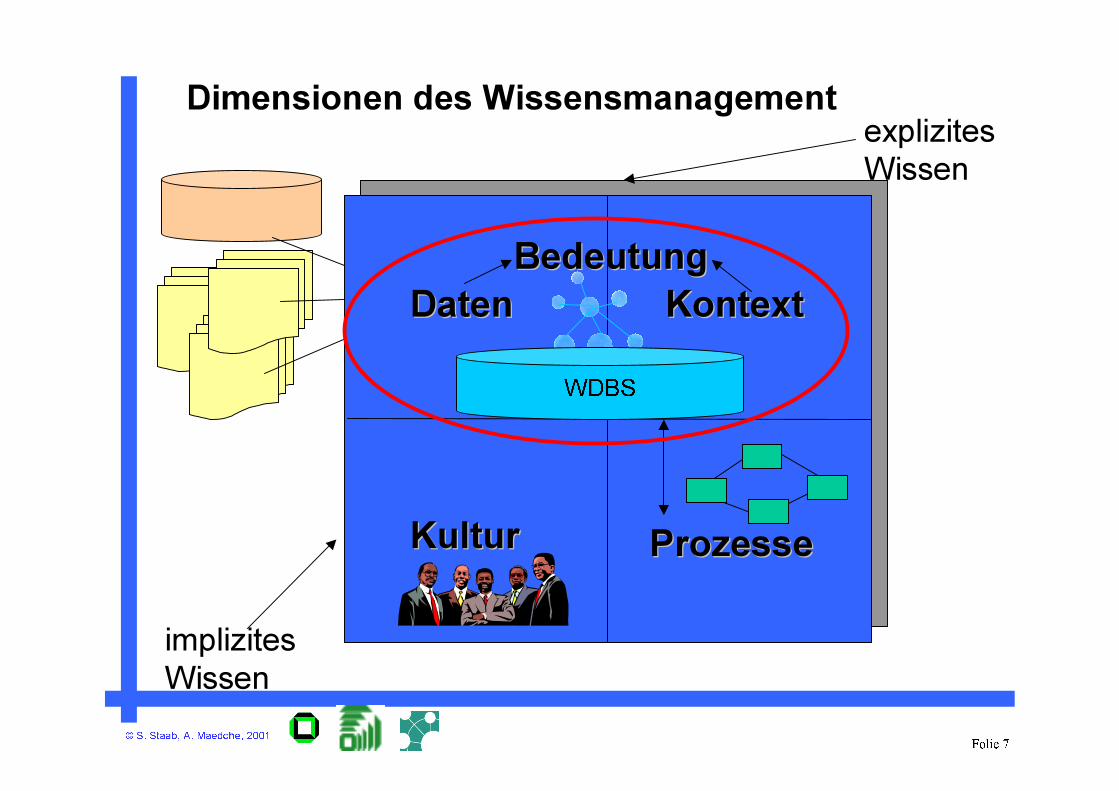
© S. Staab, A. Maedche, 2001Folie 7
Dimensionen des Wissensmanagement
DatenDaten KontextKontext
ProzesseProzesseKulturKultur
BedeutungBedeutung
WDBS
explizites
Wissen
implizites
Wissen

© S. Staab, A. Maedche, 2001Folie 8
WM & Wissensdatenbanken
• Wissensdatenbanksysteme (WDBS) stellen Mechanismen zur Speicherung von
– Daten (1. Quadrant) und
– Kontexten (2. Quadrant)
bereit. Sowohl Daten als auch Kontexte können auf unterschiedlichen Granularitätsniveaus auftreten
• Auf Wissensdatenbanksysteme greifen zu
– Wissensintensive Geschäftsprozesse
– Business Intelligence Applikationen
– ...

© S. Staab, A. Maedche, 2001Folie 9
Dimensionen einer Wissensdatenbank
• Wissensdatenbanken verwenden ein weites
Spektrum von Technologien der Informationstechnik
• Die verwendeten Technologien und die investierte
Man-Power reflektieren die Qualität der Inhalte einer
Wissensdatenbank
• Beim Aufbau einer Wissensdatenbank ist generell ein
Trade-Off zu machen zwischen
Investierter
Man-Power
Qualität der
Inhaltevs.
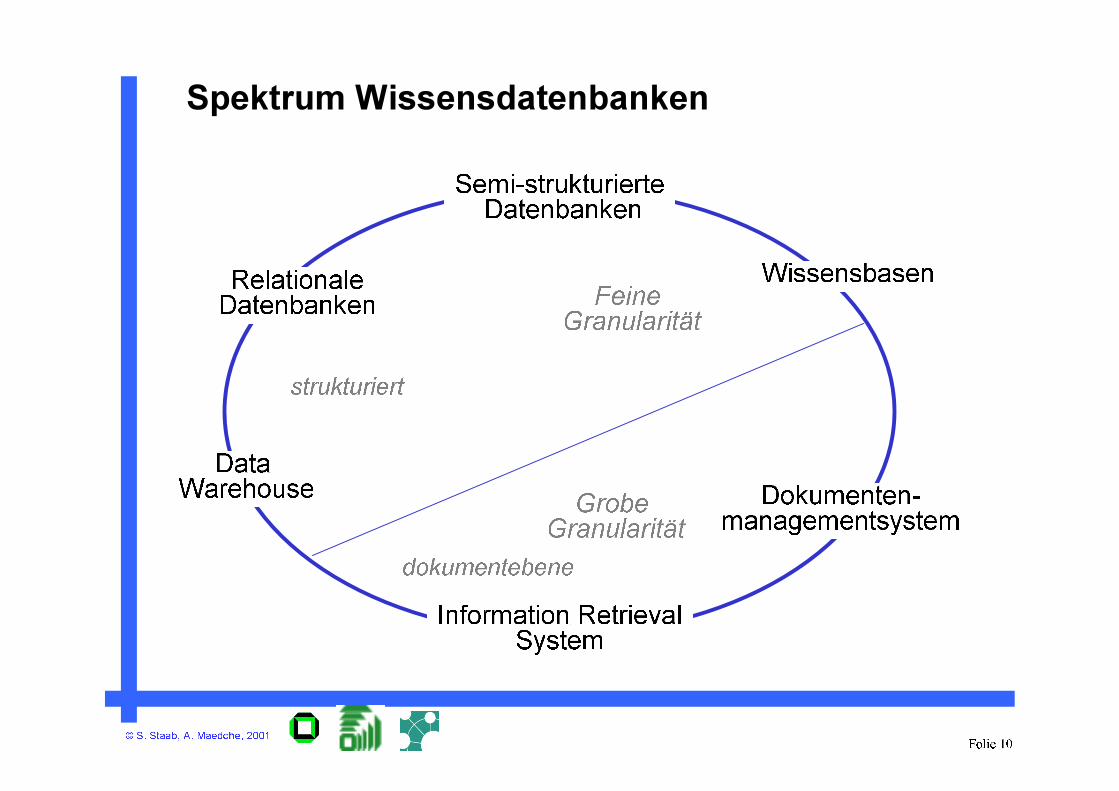
© S. Staab, A. Maedche, 2001Folie 10
Spektrum Wissensdatenbanken
Information Retrieval
System
Relationale
Datenbanken
Data
Warehouse
Semi-strukturierte
Datenbanken
Dokumenten-
managementsystem
WissensbasenFeine
Granularität
Grobe
Granularität
strukturiert
dokumentebene

© S. Staab, A. Maedche, 2001Folie 11
Schemata in Wissensdatenbanken
• Zusätzlich zur Granularität der Daten spielt das
definierte Schema (oder auch der Kontext) der
Wissensdatenbank eine wesentliche Rolle
• Unterschiedliche Typen von Schemata:
• ER-Modelle
• Thesauri
• Begriffsnetze /
Semantische Netze
• Ontologien
• Document Type Definitions
SemantikSyntax

© S. Staab, A. Maedche, 2001Folie 12
Dimensionen
‘‘Modellierung“
‘‘W-DB-Technik“
HR TopicBroker
Proper
[Ontobroker]
IR System
Dok.man.
system
Rel. DB
DWh
Inhalt
viel
Dokument
keine

© S. Staab, A. Maedche, 2001Folie 13
Szenario I: HR TopicBroker
• Unterstützung für HR Management -
7 wichtige Themen
• Lokation aktueller und neuer Schlagworte
und Themen
• Intranet/WWW-basierter Yellow Page
Mechanismus auf begrifflicher Ebene
• Aufbau einer intranetbasierten Wissensbasis

© S. Staab, A. Maedche, 2001Folie 14
Szenario II: Proper
• Basisdaten:
• Profilinformation aus relationaler Datenbank
(Mitarbeiter und Bewerber) und semantische
Annotation von Projektberichten
• Ontologie mit
• Begriffe, Relationen zwischen Begriffen und
Regeln, z.B.:
“If a programmer worked for a project, in which a specific
programming language has been used, than this programmer
has at least some experience with the programming language.”

© S. Staab, A. Maedche, 2001Folie 15
1. Architektur einer Wissensdatenbank
Inhalt
– Dimensionen einer Wissensdatenbank
– Komponenten einer Wissensdatenbank
– Kernprozesse einer Wissensdatenbank

© S. Staab, A. Maedche, 2001Folie 16
Komponenten einer Wissensdatenbank
• Grobe Zerlegung in Analogie zu klassischen
Datenbanken:
– WDBS = WDB + WDMS
• Ein Wissensdatenbanksystem setzt sich aus der
Wissensdatenbank und dem Wissensdatenbank-
management zusammen.

© S. Staab, A. Maedche, 2001Folie 17
Komponenten: Grobaufbau eines Datenbank-
systems
• Analogie zu Datenbanksystemen:
© S. Staab, A. Maedche, 2001Folie 18
Komponenten: Grobaufbau eines Data
Warehouse
Legacy Data
DWh - Kern
Klienten

© S. Staab, A. Maedche, 2001Folie 19
Komponenten: Grobaufbau eines WDB
Architektur
Legacy Data
WDBS
Klienten
L1
L2
Repository
1
Repository
2
Konnektoren/
Migratoren
AnfragebearbeitungWDBMS
WDB
Verwaltung
Entwicklung / Anwendung

© S. Staab, A. Maedche, 2001Folie 20
Komponenten: Grobaufbau eines WDBS
=> Keine Trennung von Schema & Daten!
Repository
1
Repository
2
Konnektoren/
Migratoren
Anfragebearbeitung
WDBMS
WDB
Verwaltung

© S. Staab, A. Maedche, 2001Folie 21
1. Architektur einer Wissensdatenbank
Inhalt
– Dimensionen einer Wissensdatenbank
– Komponenten einer Wissensdatenbank
– Kernprozesse einer Wissensdatenbank
© S. Staab, A. Maedche, 2001Folie 22
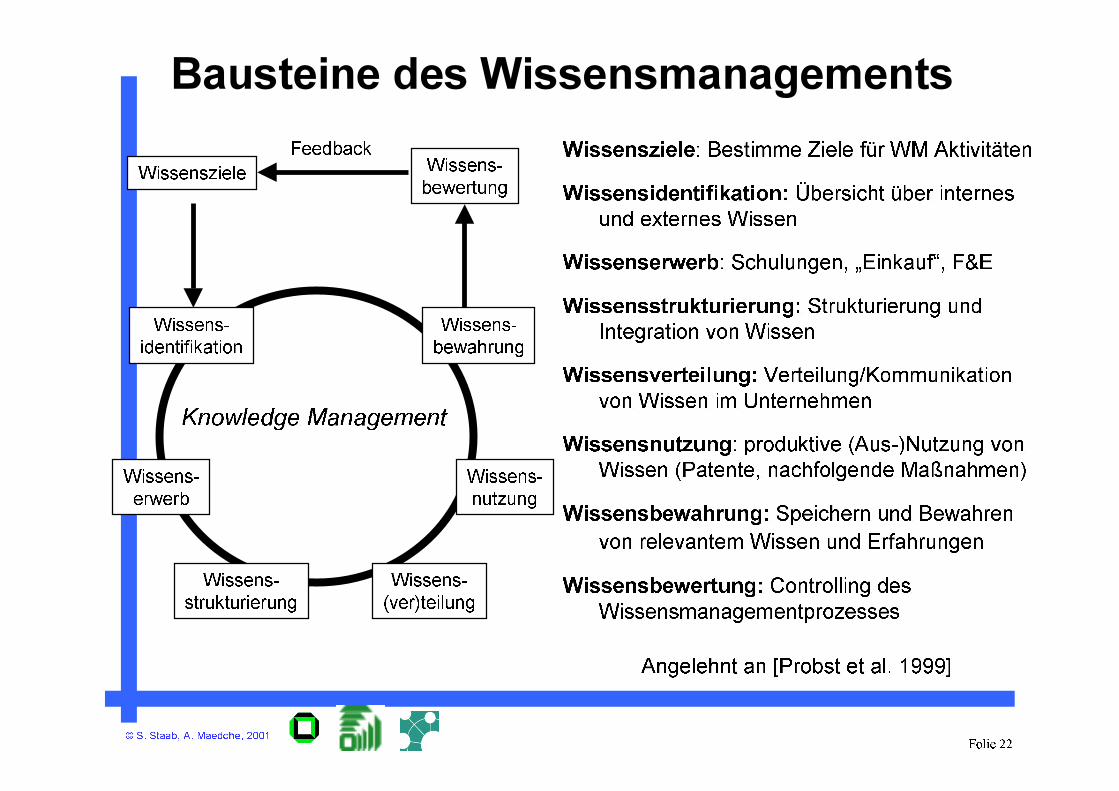
Knowledge Management
Wissens-
identifikation
Wissens-
erwerb
Wissens-
strukturierung
Wissens-
nutzung
Wissens-
bewahrung
Wissens-
(ver)teilung
Feedback Wissensziele: Bestimme Ziele für WM Aktivitäten
Wissensidentifikation: Übersicht über internes
und externes Wissen
Wissenserwerb: Schulungen, „Einkauf“, F&E
Wissensstrukturierung: Strukturierung und
Integration von Wissen
Wissensverteilung: Verteilung/Kommunikation
von Wissen im Unternehmen
Wissensnutzung: produktive (Aus-)Nutzung von
Wissen (Patente, nachfolgende Maßnahmen)
Wissensbewahrung: Speichern und Bewahren
von relevantem Wissen und Erfahrungen
Wissensbewertung: Controlling des
Wissensmanagementprozesses
Angelehnt an [Probst et al. 1999]
WissenszieleWissens-
bewertung
Bausteine des Wissensmanagements

© S. Staab, A. Maedche, 2001Folie 23
Wissensprozesse & Wissensmetaprozesse
Knowledge Meta Process
Knowledge Process
Konzeption, Realisierung und Wartung der WDB
Arbeiten mit der WDB

© S. Staab, A. Maedche, 2001Folie 24
Kernprozessschritte beim Aufbau einer
Wissensdatenbank
• Modellierung
• Installation der Wissens-DB Kernkomponenten
• Integration Legacy Daten
• Initiales Starten der WissensDB
• Maintenance
=> Abschnitt 2

© S. Staab, A. Maedche, 2001Folie 25
Kernprozessschritte beim Betreiben einer WDB
• Wissen erzeugen
• Erfassen
• Organisieren
• Finden
• Nutzen
=> Abschnitt 3 und Abschnitt 4

© S. Staab, A. Maedche, 2001Folie 26
2. Aufbau und Instandhaltung einer
Wissensdatenbank

© S. Staab, A. Maedche, 2001Folie 27
Inhalte
– Ziele einer Wissensdatenbank
– Methodologie / Prozeß der Einführung einer
Wissensdatenbank
– Wiederverwendung existierender
Wissensquellen
– Aufbau von Begriffsstrukturen
(Terminologien, Thesauri, etc.)

© S. Staab, A. Maedche, 2001Folie 28
Richtlinien für Management und Methodik
•Identifikation: Wissensbedarf,
Möglichkeiten, Engstellen,
Einsatzgebiete
•Zielgeleitete Konstruktion und
Validierung von semantischen
Modellen (Ontologien...)
• Benutzerzentrierte Einführung von
WDBMS und Werkzeugen
•Wartung und CPI (Continuous
Process Improvement)
•Kontextorientierte
Anforderungen an WDBMS
•Zielorientierung innerhalb
Organisation
•Wissensbereitstellung und
–abfrage statt
Informationoverload
•WDBMS bleibt erfolgreich
im Einsatz

© S. Staab, A. Maedche, 2001Folie 29
Kontextmodellierung durch Machbarkeitsstudie
Machbarkeitsstudie
Identifikation von Problemen und
günstigen Gelegenheiten und
Lösungsmöglichkeiten innerhalb
einer übergeordneten
organisatorischen Perspektive.
Entscheidung über
wirtschaftliche, soziologische und
technische Projektdurchführbar-
keit –
Auswahl der vielver-
sprechendsten Zielgebiete und –
lösungen (Quick Win!)
Betroffene
Personen
Entscheidung
für Anwendung
Kerngebiet der
Ontologie-
entwicklung
Quelle für WM
Prozesse
Personen
Wissens-
repoirtoire
Prozesse

© S. Staab, A. Maedche, 2001Folie 30
OM-1
Checklist:
Probleme,
Lösungen,
Kontext
OM-2
Checklist:
Beschrei-bung
Organisat.
Fokus
Ver-
feinern
OM-5
Checklist:
Beurteile
Mach-
barkeit
(Entscheid
ungsdok.)
OM-4
Checklist:
Wissens-
reportoire
(assets)
OM-3
Checklist:
Prozess-
beschrei-
bung Inte-
griere
TM-1
Checklist:
Aufgaben
analyse
[wenn
unmöglich]
Stop
TM-2
Checklist:
Analyse
Wissens-
objekte
AM-1
Checklist:
Modell
der
Akteure
Fertige Kontextanalyse
[wenn
realisierbar]
TM-2
worksheet
knowledge item
analysis
TM-2
worksheet
knowledge item
analysis
TM-2
worksheet
knowledge item
analysis
Fokus für
Entwicklung
von
Ontologie
GUI
Auswahl von
Werkzeugen
CommonKADS – Roadmap für die Einführung
eines WDBMS
Entscheidungsdokum
ent
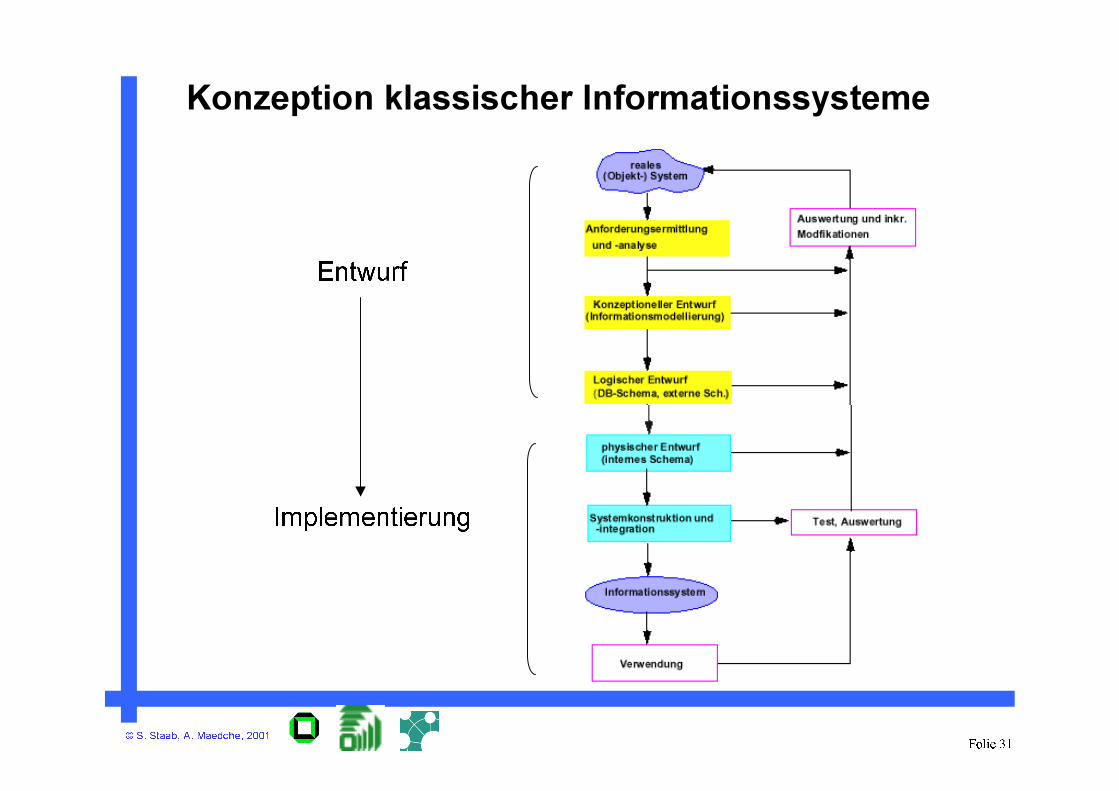
© S. Staab, A. Maedche, 2001Folie 31
Konzeption klassischer Informationssysteme
Entwurf
Implementierung

© S. Staab, A. Maedche, 2001Folie 32
Konzeption von WM-Systemen
Entwurf
Implementierung
WM
SzenarioEx. Daten
Kontext-Modellierung
Formale Repräsentation des
Kontextes
Initialisierung der Wissensdatenbank
mit Kontext & Ex. Daten
Anbindung der Wissensdatenbank
an WM Szenario
Anwendung

© S. Staab, A. Maedche, 2001Folie 33
Ontologieentwicklung für eine WDB
Kickoff Verfeinerung
Ontologie
Evaluation Wartung
•Anforderungs-
spezifikation
(ORS)
•Analysiere
Quellen
•Baue Lexikon /
Glossar
•Erhebung von
Begriffen mit
Experten
•Begriffsbildung
und -
formalisierung
•Konkretisiere
Relationen und
Regeln
•Revidiere und
erweitere
nach
Feedback
•Analysiere
Benutzung
•Analysiere
Kompetenz-
fragen
•Verwalte
organisa-
torischen
Wartungs-
prozess
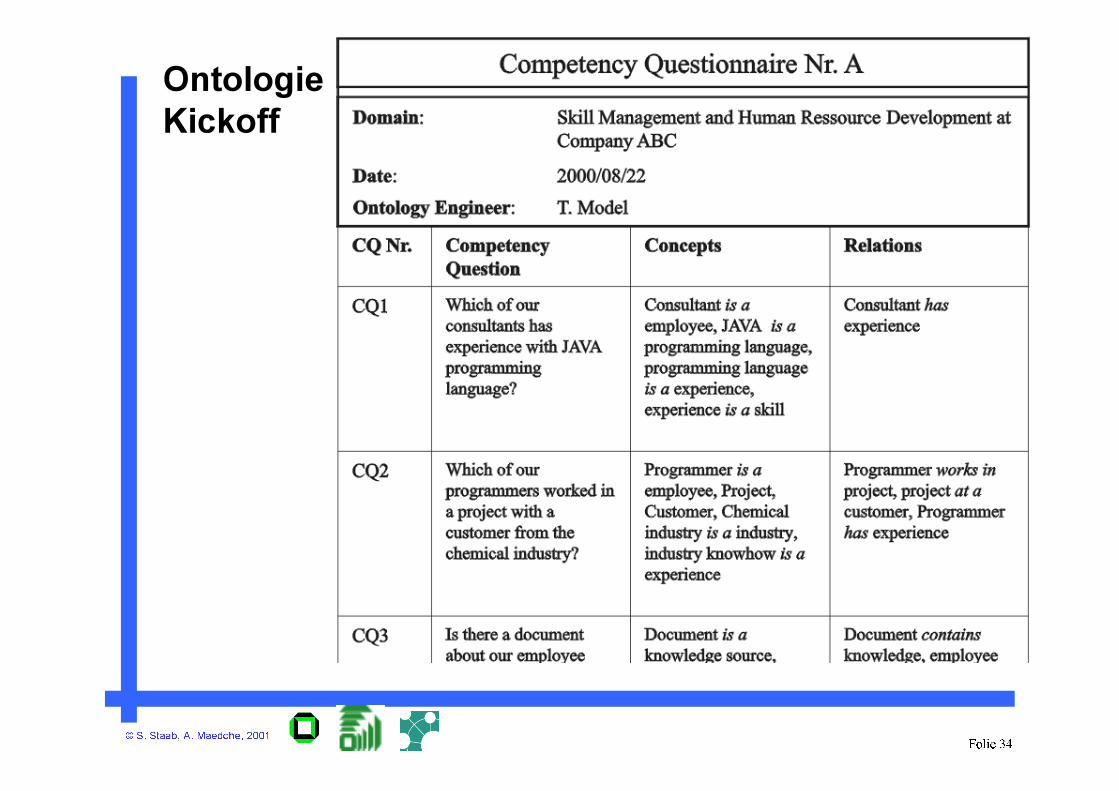
© S. Staab, A. Maedche, 2001Folie 34
Ontologie
Kickoff

© S. Staab, A. Maedche, 2001Folie 35
Ontologie
Kickoff

© S. Staab, A. Maedche, 2001Folie 36
Top-Down vs. Bottom-Up
• Das Schema für die Wissensdatenbank kann top-
down oder bottom-up erstellt werden:
• Top-down: von der Anwendung & Experten
• Bottom-up: von den existierenden Daten und
Systemen
• In realen Anwendungen hat sich eine gemischte
Strategie als erfolgreich erwiesen.

© S. Staab, A. Maedche, 2001Folie 37
Ontologieentwicklung für eine WDB
Kickoff Verfeinerung
Ontologie
Evaluation Wartung
•Anforderungs-
spezifikation
(ORS)
•Analysiere
Quellen
•Entwickle
grundlegende
Taxonomie
•Erhebung von
Begriffen mit
Experten
•Begriffsbildung
und -
formalisierung
•Konkretisiere
Relationen und
Regeln
•Revidiere und
erweitere
nach
Feedback
•Analysiere
Benutzung
•Analysiere
Kompetenz-
fragen
•Verwalte
organisa-
torischen
Wartungs-
prozess
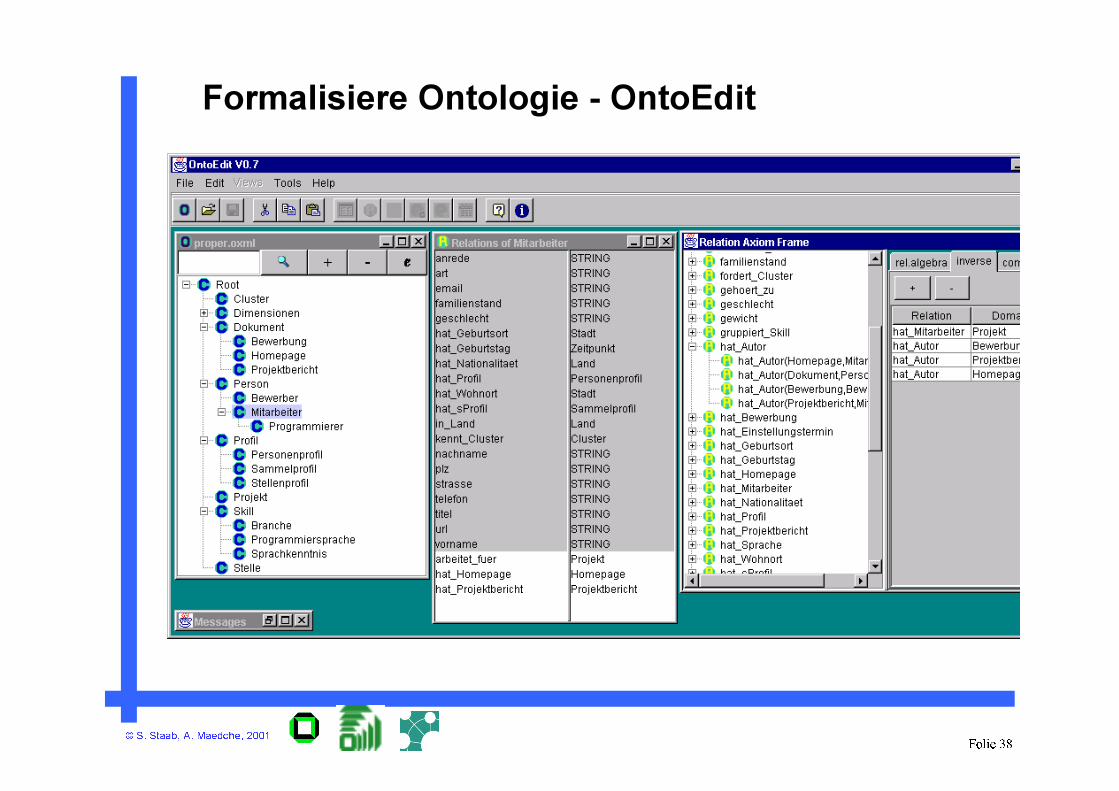
© S. Staab, A. Maedche, 2001Folie 38
Formalisiere Ontologie - OntoEdit

© S. Staab, A. Maedche, 2001Folie 39
Ontologieentwicklung für eine WDB
Kickoff Verfeinerung
Ontologie
Evaluation Wartung
•Anforderungs-
spezifikation
(ORS)
•Analysiere
Quellen
•Entwickle
grundlegende
Taxonomie
•Erhebung von
Begriffen mit
Experten
•Begriffsbildung
und -
formalisierung
•Konkretisiere
Relationen und
Regeln
•Revidiere und
erweitere
nach
Feedback
•Analysiere
Benutzung
•Analysiere
Kompetenz-
fragen
•Verwalte
organisa-
torischen
Wartungs-
prozess
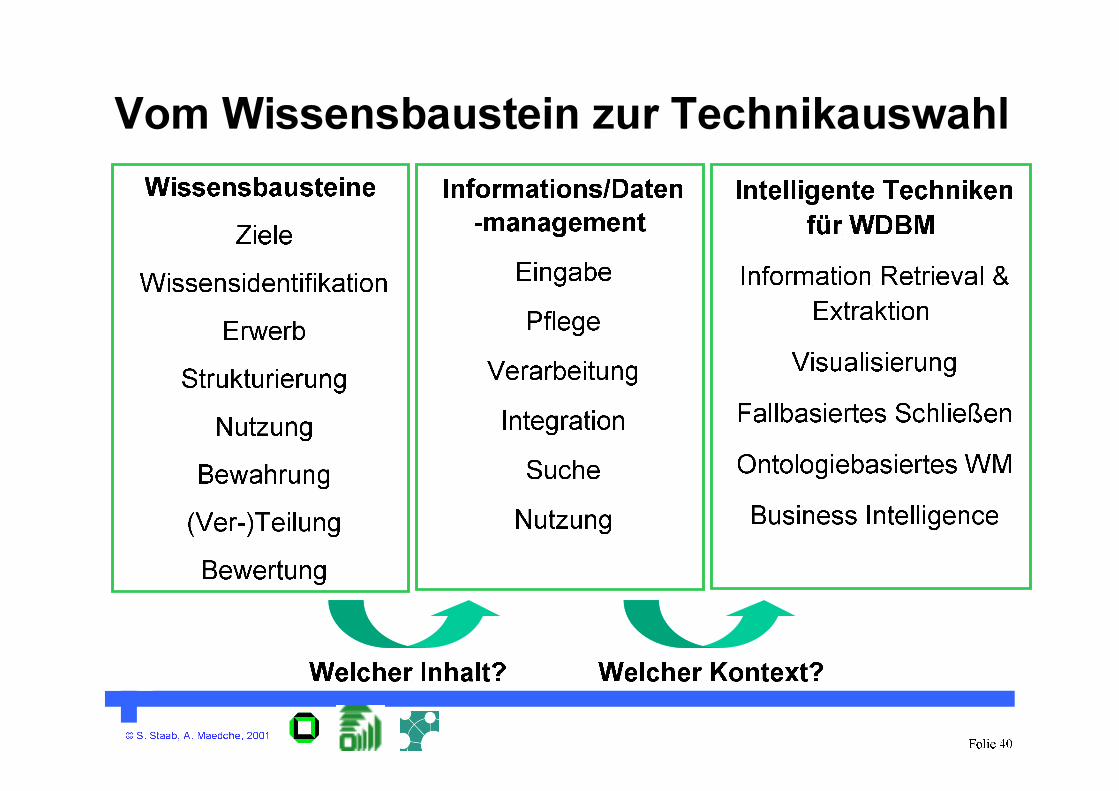
© S. Staab, A. Maedche, 2001Folie 40
Vom Wissensbaustein zur Technikauswahl
Wissensbausteine
Ziele
Wissensidentifikation
Erwerb
Strukturierung
Nutzung
Bewahrung
(Ver-)Teilung
Bewertung
Informations/Daten
-management
Eingabe
Pflege
Verarbeitung
Integration
Suche
Nutzung
Welcher Inhalt?
Intelligente Techniken
für WDBM
Information Retrieval &
Extraktion
Visualisierung
Fallbasiertes Schließen
Ontologiebasiertes WM
Business Intelligence
Welcher Kontext?

© S. Staab, A. Maedche, 2001Folie 41
Entwickle möglichst frühzeitig Prototyp!!
Traue niemandem außer den Nutzern Deines
Systems!!

© S. Staab, A. Maedche, 2001Folie 42
Ontologieentwicklung für eine WDB
Kickoff Verfeinerung
Ontologie
Evaluation Wartung
•Anforderungs-
spezifikation
(ORS)
•Analysiere
Quellen
•Entwickle
grundlegende
Taxonomie
•Erhebung von
Begriffen mit
Experten
•Begriffsbildung
und -
formalisierung
•Konkretisiere
Relationen und
Regeln
•Revidiere und
erweitere
nach
Feedback
•Analysiere
Benutzung
•Analysiere
Kompetenz-
fragen
•Verwalte
organisa-
torischen
Wartungs-
prozess

© S. Staab, A. Maedche, 2001Folie 43
Beispiel: Customer Care – Siemens Automation
and Drive
http://www4.ad.siemens.de/support/index.asp (nach Lenz 1998)
Wartung der Ontologie:
• Ca. ein halber Manntag pro Monat
• Kundenvorschläge werden berücksichtigt
• Gestellte Fragen werden berücksichtigt
Z.B. Kunde fragt „Wieso klemmt der Schekel?“
System: „Bitte beschreiben Sie das Wort Schekel.“
-> Feedback an Wissensmanager

© S. Staab, A. Maedche, 2001Folie 44
Das Bootstrapping - Problem
WDBS
L1

© S. Staab, A. Maedche, 2001Folie 45
Füllen einer Wissensdatenbank
• Der Aufbau einer Wissensdatenbank geschieht
typischerweise nicht „from scratch“.=> Einbeziehung von Legacy Systemen!
• Die Konzeption einer Wissensdatenbank wird durch
Anwendungsgebiete ‘‘getriggert‘‘.
• Wissensdatenbanken wachsen idealerweise durch
ihre Anwendung (siehe TopicBroker)

© S. Staab, A. Maedche, 2001Folie 46
Initialisierung der Wissens-DB
• Im schlechtesten Fall kann auf keine existierende Daten zurückgegriffen werden
• Typischerweise existieren relevante Daten (z.B. Profilinformationen bei Proper Anwendung)
• Im einfachsten Fall startet die Wissensdatenbank mit einem Dokumentenindex (vgl. Topicbroker)
• Wichtig: Eine Initialisierung der Wissens-DB erhöht die Gesamtqualität und schafft Anreize zur Erweiterung

© S. Staab, A. Maedche, 2001Folie 47
Lessons Learned
1. Vermittle dem Benutzer die Bedeutung von
Wissensstrukturierung (Ontologie, Thesaurus,...)!
2. Zeige den Nutzen konkret an einem (eventuell rein
graphischen) Prototypen auf!
3. Modelliere genau – aber gebe dem Benutzer auch ungenaue
Sichten in die Hand!
4. Plane einen Instandhaltungsprozess unter Beteiligung eines
„Wissensmanagers“!
5. Plane die „Befüllung“, die die WDB interessant macht!
6. Suche nach dem Quick Win!

© S. Staab, A. Maedche, 2001Folie 48
3. Anwendung von Wissensdatenbanken
und Einbettung in Prozesse

© S. Staab, A. Maedche, 2001Folie 49
Inhalte
– Generierung von Wissen
– Strukturieren von Wissen
– Wiederfinden von Wissen
– Nutzen von Wissen

© S. Staab, A. Maedche, 2001Folie 50
Benutze
Organisiere
Finde
Erfasse
Wissensprozess
KreiereImportiere /
LinkeFact B
Fact C
Fact E
Fact A
Fact D

© S. Staab, A. Maedche, 2001Folie 51
Abfragen von Wissen
• Kontext über die Ontologie
• Generalisiere / verfeinere via Ontologie
• Matching von Abfragen mit Begriffen aus
der Ontologie
• Vordefinierte Abfragen an die WDB
?
? ??
?
?

© S. Staab, A. Maedche, 2001Folie 52
Beispiel: Vordefinierte Abfragen

© S. Staab, A. Maedche, 2001Folie 53
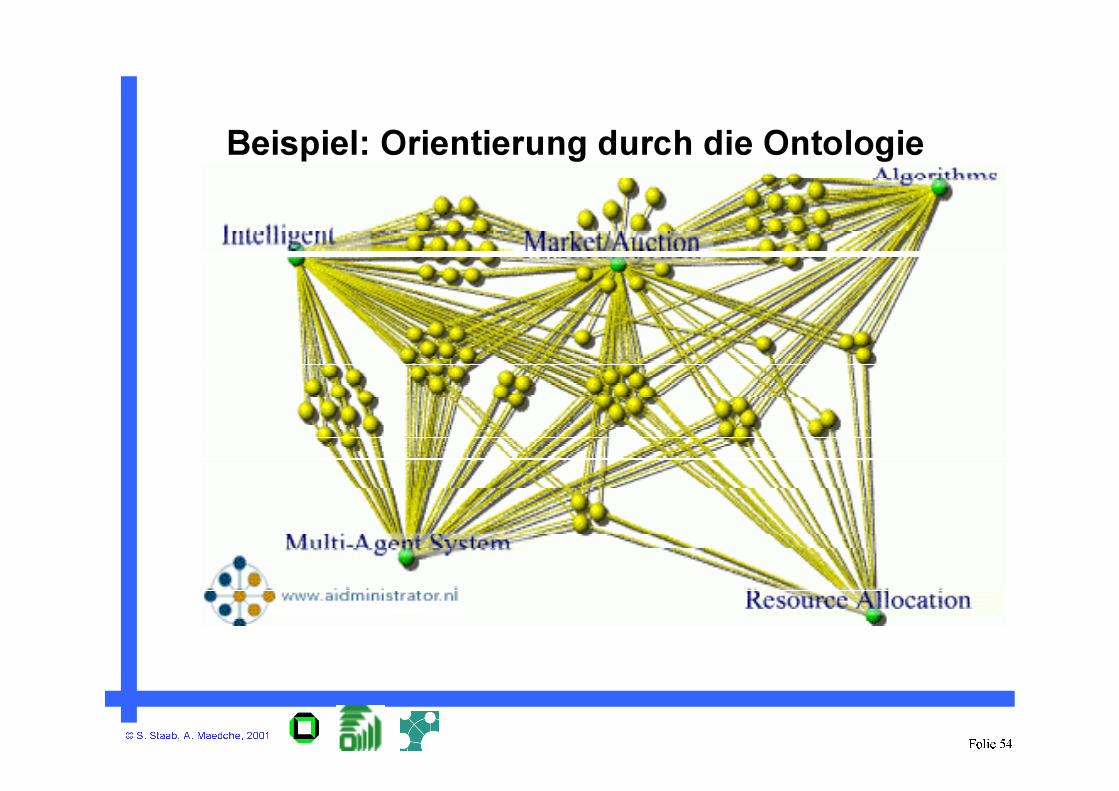
Ontologie als Landkarte
• Navigation via Ontologie
• Individuelle Sichten auf Wissen
• Dynamische Sichten auf Wissen
• Vordefinierte Abfragen
© S. Staab, A. Maedche, 2001Folie 54
Beispiel: Orientierung durch die Ontologie

© S. Staab, A. Maedche, 2001Folie 55
Beispiel: Dynamische Sichten auf Wissen

© S. Staab, A. Maedche, 2001Folie 56
Community zum Teilen von Wissen
• Organisatorische Maßnahmen
• Die Entwicklungsmethodik erfaßt
die Bedürfnisse der Benutzer und
berücksichtigt sie bei der
Erstellung der Anwendung
• Eingebettet in tägliche
Arbeitsumgebung

© S. Staab, A. Maedche, 2001Folie 57
Einbettung in Arbeitsumgebung –
Beispielarchitektur
Annotated Document
Templates
MS ppt
Adobe
Frame-
maker
MS
Word
Lotus
Notes
Work Document
XML
Structure
partially
filled
Smart Task Control
Views
ONTOLOGY
Archive
of Annotated
Documents
MS ppt
Adobe
Frame-
maker
MS
Word
Lotus
NotesOntobroker
CrawlerFacts in
Database
Inference
Engine

© S. Staab, A. Maedche, 2001Folie 58
Einbettung in Arbeitsumgebung –
Praktisches Beispiel
Großer Mehrwert
durch einfache
Dinge:
Gemeinsame
Adressverwaltung
!!!!!

© S. Staab, A. Maedche, 2001Folie 59
Case Study I: HR TopicBroker
• Unterstützung zur HR Strategieentwicklung -
7 Challenges
• Lokation aktueller und neuer Schlagworte
und Themen
• Intranet/WWW-basierter Yellow Page
Mechanismus auf begrifflicher Ebene
• Aufbau einer intranetbasierten Wissensbasis

© S. Staab, A. Maedche, 2001Folie 60
HR TopicBroker – Verwendete Techniken
• Ontologie mit Begriffe und Relationen zwischen
Begriffen; Zusätzlich Auflösung von Synonymen
• Information Retrieval + Ontologie-fokussiertes
Crawling
• “Gemischte” Techniken für Wissensdatenbank:
• Begriffs-Dokumentindex
• Wissensbasis für manuelle Einträge

© S. Staab, A. Maedche, 2001Folie 61
HR TopicBroker Ontologie
© S. Staab, A. Maedche, 2001Folie 62
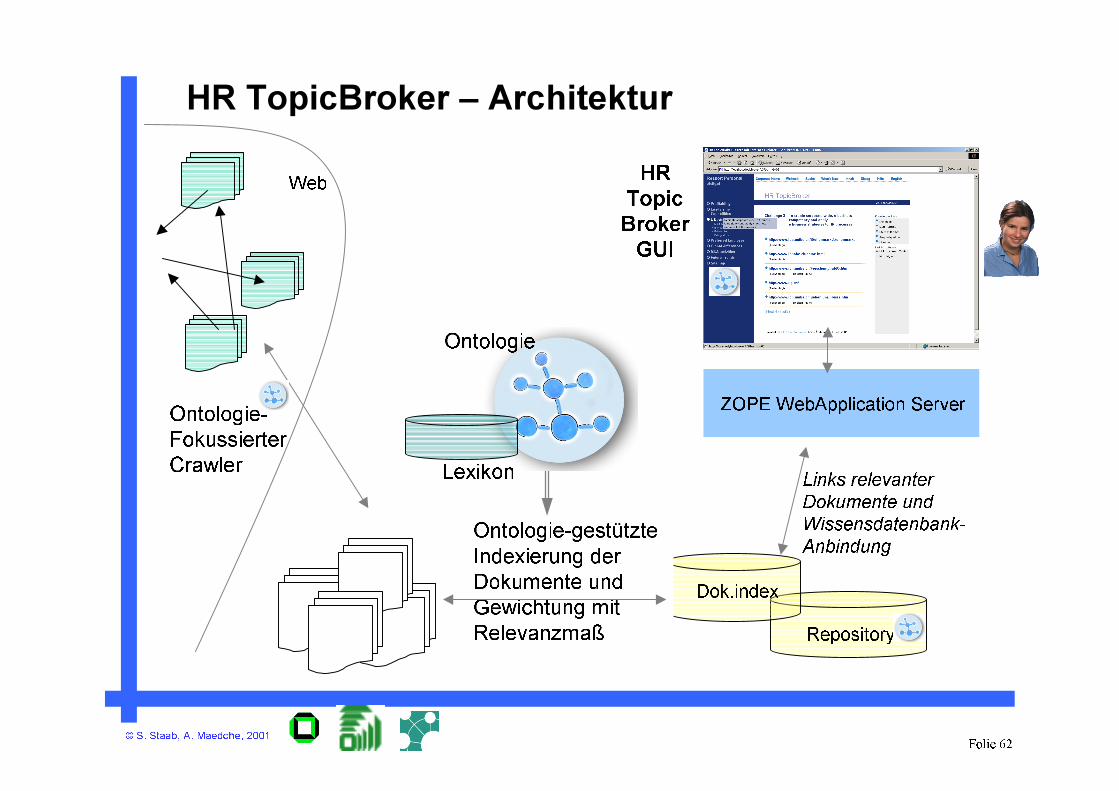
HR TopicBroker – Architektur
Ontologie-
Fokussierter
Crawler
HR
Topic
Broker
GUI
Links relevanter
Dokumente und
Wissensdatenbank-
Anbindung
Web
Ontologie-gestützte
Indexierung der
Dokumente und
Gewichtung mit
Relevanzmaß
Dok.index
Repository
ZOPE WebApplication Server
Ontologie
Lexikon
© S. Staab, A. Maedche, 2001Folie 63
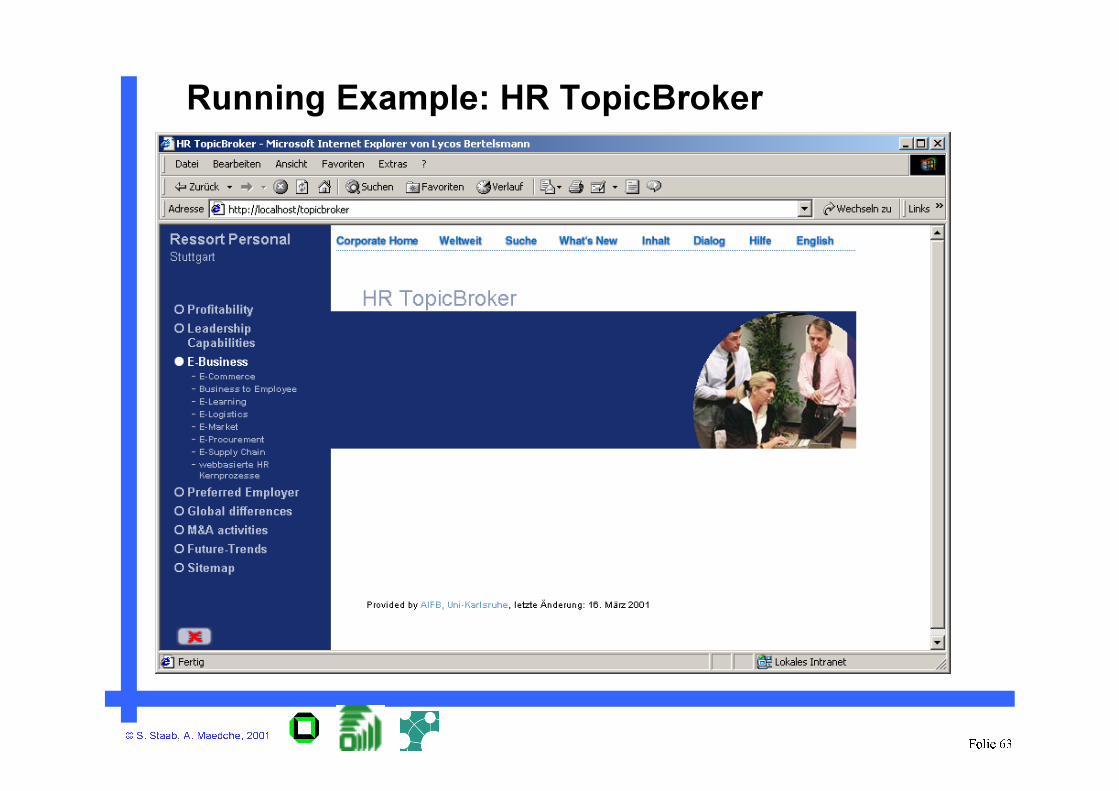
Running Example: HR TopicBroker

© S. Staab, A. Maedche, 2001Folie 64
Running Example: HR TopicBroker

© S. Staab, A. Maedche, 2001Folie 65
Running Example: HR TopicBroker

© S. Staab, A. Maedche, 2001Folie 66
Case Study II: Proper
• Ontologie mit
• Begriffe, Relationen zwischen Begriffen und
Regeln, z.B.:
“If a programmer worked for a project, in which a specific
programming language has been used, than this programmer
has at least some experience with the programming language.”
• Basisdaten:
• Profilinformation aus relationaler Datenbanken
und semantische Annotation von
Projektberichten
© S. Staab, A. Maedche, 2001Folie 67
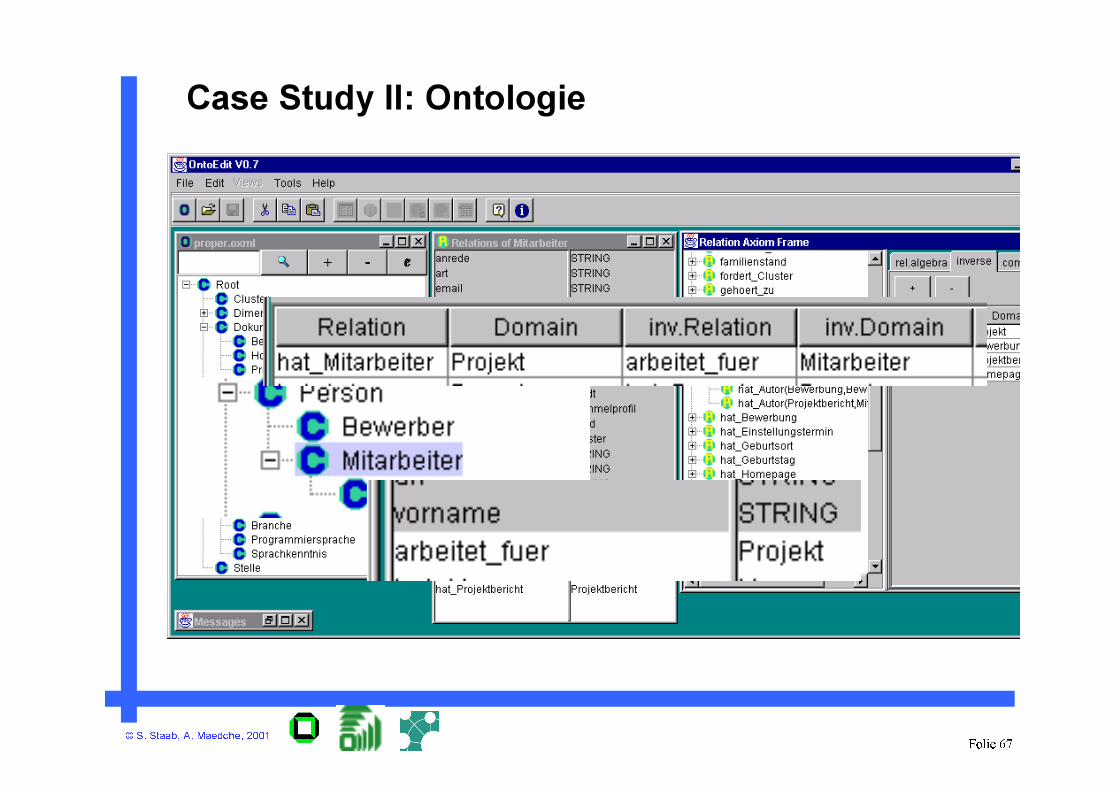
Case Study II: Ontologie
• …
• Screenshot of OntoEdit

© S. Staab, A. Maedche, 2001Folie 68
Case Study II: Architecture
Annotation
& Crawling
Inference
Engine
Ontology
Profile
DB
Web
Server
Browser
Browser
Matching
Internet:
Applicant sends application.
Intranet:
Employee gives annotated
entries (project reports ..)
Employee provides profile.
Employee searches for
experts.
HR Manager wants to fill
vacant positions.
Employee gives annotated
entries (project reports ..)
Templates &
Documents
Templates &
Documents

© S. Staab, A. Maedche, 2001Folie 69
Case Study II: Screenshot

© S. Staab, A. Maedche, 2001Folie 70
4. Business Intelligence

© S. Staab, A. Maedche, 2001Folie 71
Inhalte
– Der Business Intelligence Prozeß
– OLAP – Explorative Wissens- und
Ideengenerierung
– Wissensvisualisierung
– Data Mining / Knowledge Discovery

© S. Staab, A. Maedche, 2001Folie 72
Business Intelligence Prozeß
• Der BI Prozeß setzt sich aus mehreren Schritten
zusammen:
• Business & Data Understanding
• Data Preparation
• Modeling
• Evaluation
• Deployment
• Der BI Prozeß ist interaktiv und iterativ
• Anwendung von BI benötigt Kenntnisse im Bereich
Datenanalyse, Datenbanken und der
Anwendungsdomäne

© S. Staab, A. Maedche, 2001Folie 73
Business Intelligence Prozeß

© S. Staab, A. Maedche, 2001Folie 74
Architektur
© S. Staab, A. Maedche, 2001Folie 75
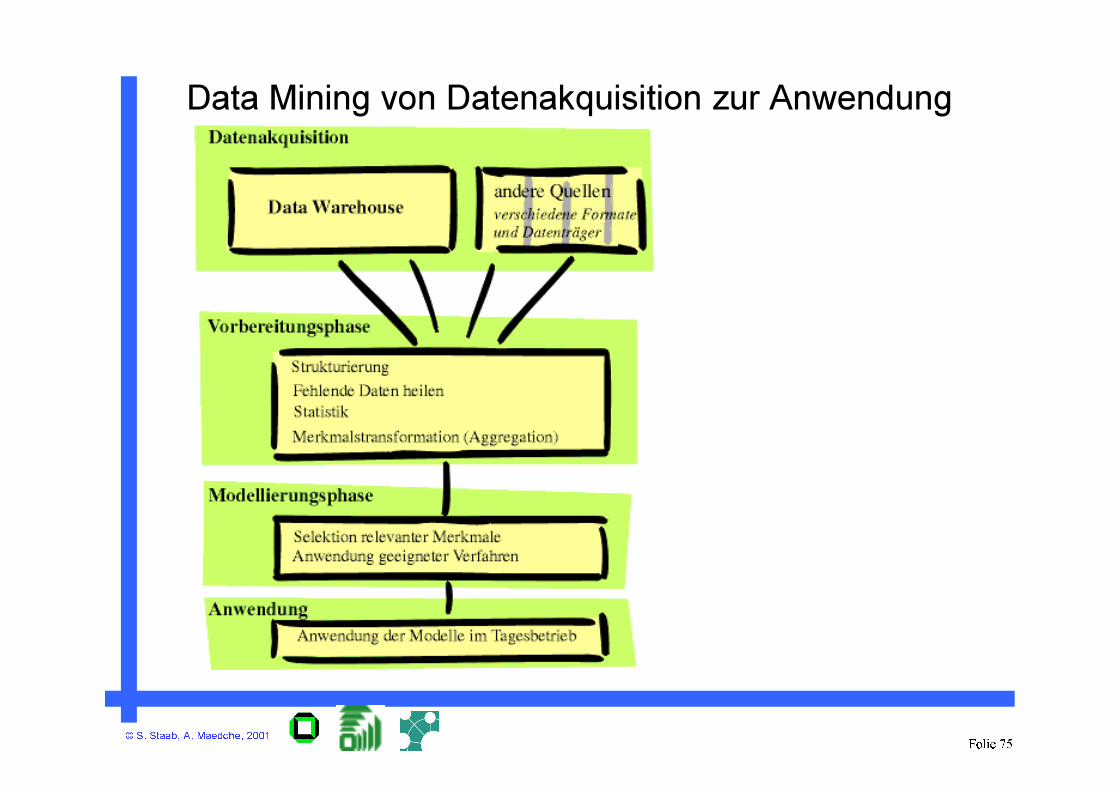
Data Mining von Datenakquisition zur Anwendung

© S. Staab, A. Maedche, 2001Folie 76
BI – Erkenntnisse haben ihren Preis

© S. Staab, A. Maedche, 2001Folie 77
Inhalte
– Der Business Intelligence Prozeß
– OLAP – Explorative Wissens- und
Ideengenerierung
– Wissensvisualisierung
– Data Mining / Knowledge Discovery

© S. Staab, A. Maedche, 2001Folie 78
Einführung in OLAP
Wie gesehen, gibt es große Unterschiede zwischen
operativen Systemen und dem DWh
Entsprechend gibt es fundamentale Unterschiede auch
zwischen den jeweiligen Zugriffsarten auf diese
Datenquellen:
• OLAP = On-Line Analytical Processing benutzt DWh
• OLTP = On-Line Transaction Processing benutzt
operative Systeme

© S. Staab, A. Maedche, 2001Folie 79
• den schnellen, interaktiven Zugriff auf Unternehmens-
daten
• unter „beliebigen“ unternehmensrelevanten Blickwinkeln
(Dimensionen)
• auf verschiedenen Aggregationsstufen
• mit verschiedenen Techniken der Visualisierung
• Hauptmerkmal ist die multi-dimensionale Sichtweise
auf Daten mit flexiblen interaktiven Aggregations-
bzw. Verfeinerungsfunktionen entlang einer oder
mehrerer Dimensionen.
Einführung in OLAP

© S. Staab, A. Maedche, 2001Folie 80
• Mehrdimensionale Sichtweise auf Daten ist
sehr natürlich: Sichtweise der Analysten auf
Unternehmen ist mehrdimensional.
� Konzeptuelles Datenmodell sollte mehr-
dimensional sein, damit Analysten leicht
und intuitiv Zugang finden.
Multi-Dimensionalität

© S. Staab, A. Maedche, 2001Folie 81
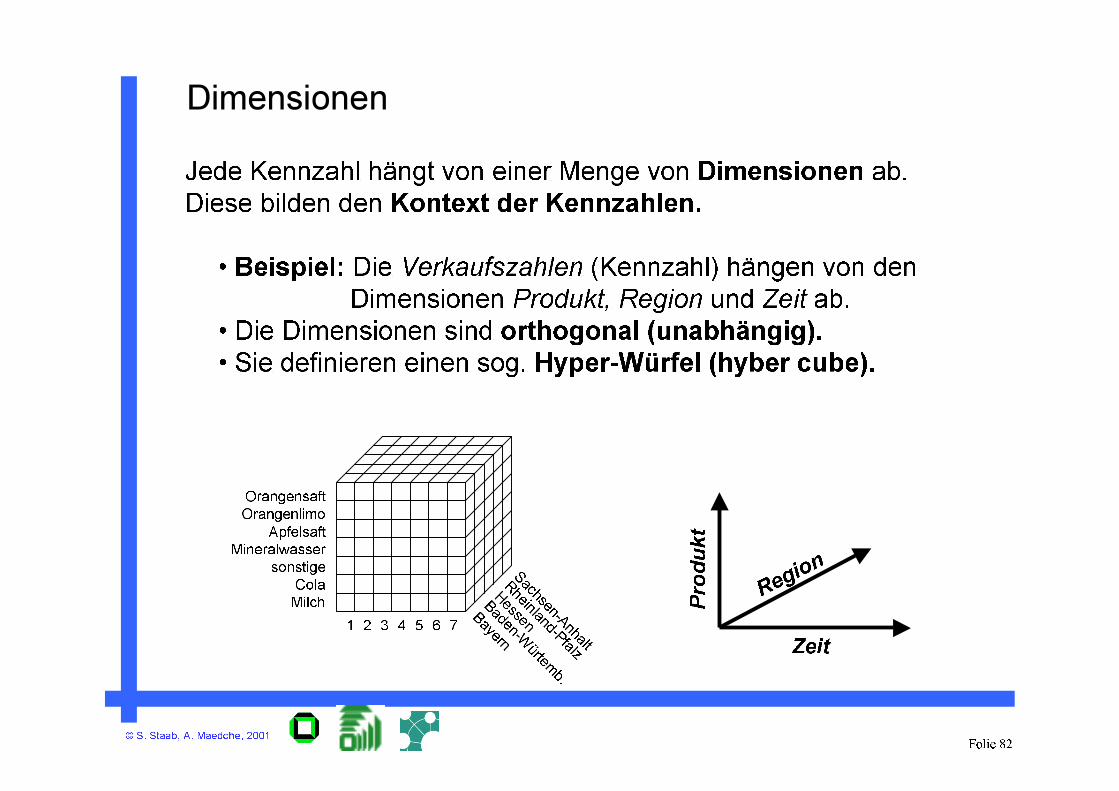
• Verkaufszahlen können nach unterschiedlichen
Kriterien / Dimensionen aggregiert und analysiert
werden:
• nach Produkt: Produkt, Produktkategorie,Industriezweig
• nach Region: Filiale, Stadt, Bundesland
• nach Zeit: Tag, Woche, Monat, Jahr
• nach verschiedenen Dimensionen des Käufers: Alter,
Geschlecht, Einkommen und nach beliebigen
Kombinationen von Dimensionen, z.B.nach
Produktkategorie, Stadt und Monat
Beispiel: Multi-Dimensionalität
© S. Staab, A. Maedche, 2001Folie 82
Jede Kennzahl hängt von einer Menge von Dimensionen ab.
Diese bilden den Kontext der Kennzahlen.
• Beispiel: Die Verkaufszahlen (Kennzahl) hängen von den
Dimensionen Produkt, Region und Zeit ab.
• Die Dimensionen sind orthogonal (unabhängig).
• Sie definieren einen sog. Hyper-Würfel (hyber cube).
Zeit
Produkt
Regio
n
1 2 3 4 5 6 7Bayern
Baden-W
ürtemb.
Hessen
Rheinland-P
falz
Sachsen-A
nhalt
Orangensaft
Orangenlimo
Apfelsaft
Mineralwasser
sonstige
Cola
Milch
Dimensionen

© S. Staab, A. Maedche, 2001Folie 83
• Bei der Analyse können beliebige Aggregationsstufen
visualisiert werden: Drill-Down bzw. Roll-Up-Operationen
• Bedingungen an Dimensionen, Attribute und Attribut-
elemente reduzierenDimensionalität der visualisierten
Daten: Slice & Dice - Operationen
• Analyse wird durch Vielzahl von Visualisierungs-
techniken unterstützt. Bedingungen werden interaktiv
gewählt (Buttons, Menüs, drag & drop).
OLAP Funktionalität

© S. Staab, A. Maedche, 2001Folie 84
• Entlang der Attribut-Hierarchien werden die Daten
verdichtet bzw. wieder detailliert und sind so auf
verschiedenen Aggregationsstufen für Analysen
zugreifbar.
roll - up
Orangensaft
Orangenlimo
Apfelsaft
Mineralwasser
sonstige
Cola
Milch
1 2 3 4 5 6 7Bayern
Baden-W
ürtemb.
Hessen
Rheinland-P
falz
Sachsen-A
nhalt
drill - down
Coca-Cola
Pepsi-Cola
Afri-Cola
Kinder-Cola
...
1
.7
2
.7
3
.7
4
.7
5
.7
6
.7
7
.7
Nürnberg
Passau
Augsburg
Fürth
München
Hier: Gleichzeitige
Detaillierung aller Dimensionen
OLAP Funktionalität: Drill-Down / Roll-Up

© S. Staab, A. Maedche, 2001Folie 85
• Bei dieser Operation wird die Dimensionalitätder visualisierten Daten reduziert.
• Zu einer Teilmenge der Dimensionen werden
Bedingungen formuliert.
• Alle Daten in der resultierenden Tabelle genügen
diesen Bedingungen.
• Slice & Dice entspricht dem Herausschneiden einer
Scheibe (slice) aus dem Hyper-Würfel. Nur diese
Scheibe wird weiterhin visualisiert.
OLAP Funktionalität: Slice & Dice

© S. Staab, A. Maedche, 2001Folie 86
Lokation bestimmter atomarer und aggregierter
Werte im Hyper-Würfel:
=> Verkaufszahlen für Orangensaft in Bayern im Mai
a)
1 2 3 4 5 6 7
Bayern
Baden-W
ürtemb.
Hessen
Rheinland-P
falz
Sachsen-A
nhalt
Orangensaft
Orangenlimo
Apfelsaft
Mineralwasser
sonstige
Cola
Milch
Beispiel I:

© S. Staab, A. Maedche, 2001Folie 87
Inhalte
– Der Business Intelligence Prozeß
– OLAP – Explorative Wissens- und
Ideengenerierung
– Wissensvisualisierung
– Data Mining / Knowledge Discovery

© S. Staab, A. Maedche, 2001Folie 88
Visualisierung
• Visualisierung im Kontext Wissensdatenbanken kann
verwendet werden für:
• Explizite Präsentation von Wissensstrukturen zur
Anfrage („Ostensive Browsing“)
• Explorative Datenanalyse
• Bestätigende Analyse (ausgehend von einer
Hypothese)

© S. Staab, A. Maedche, 2001Folie 89
Visualisierung
– Visualisierung kann interaktiv durchgeführt werden:
Kombination menschlicher Wahrnehmungsfähigkeiten
mit hoher Leistungsfähigkeit heutiger Rechner
– Visualisierungstechniken können in verschiedene
Klassen eingeteilt werden:
• Pixel-orientierte Techniken
• Geometrische Techniken
• Icon-basierte Techniken
• hierarchische Techniken
• Graph-basierte Techniken

© S. Staab, A. Maedche, 2001Folie 90
Pixel-orientierte Techniken
• jeder Attributwert eines n-stelligen Datentupels wird als
ein farbiges Pixel repräsentiert
• die m Werte eines Datentupels werden auf m separate
Windows verteilt
• in jedemWindow werden die Attributwerte eines Datentupels
an derselben Stelle angezeigt

© S. Staab, A. Maedche, 2001Folie 91
Beispiel: Pixel-orientierte Techniken

© S. Staab, A. Maedche, 2001Folie 92
Geometrische Techniken
Projektion multidimensionaler Datenbestände auf 2-dimensionale Darstellungen: es existiert eine Vielzahl von Techniken (z.B. Hauptkomponentenanalyse, Faktoranalyse), hier parallele Koordinatentechnik
Idee:
– für n-dimensionale Datentupel werden n
äquidistante Achsen verwendet (1 Achse pro
Attribut)
– jede Achse wird entsprechend dem Wertebereich
des zugehörigen Attributs skaliert
– Datentupel wird als Polygon visualisiert
(Schnittpunkt mit Achse i repräsentiert Attributwert ai)

© S. Staab, A. Maedche, 2001Folie 93
Geometrische Techniken
Abbildung 5: Parallele Koordinatentechnik (Keim/Kriegel 1996)

© S. Staab, A. Maedche, 2001Folie 94
Todo!
Visualizing Hierachies: 2D Hyperbolic Viewer
[J. Lamping 1996]
•“Focus & Context”
• Smooth Navigation

© S. Staab, A. Maedche, 2001Folie 95
Visualizing Hierachies: 3D Hyperbolic View
•Enables bigger graphs a 2D Viewer
•Suitable for Tree Structure
© S. Staab, A. Maedche, 2001Folie 96
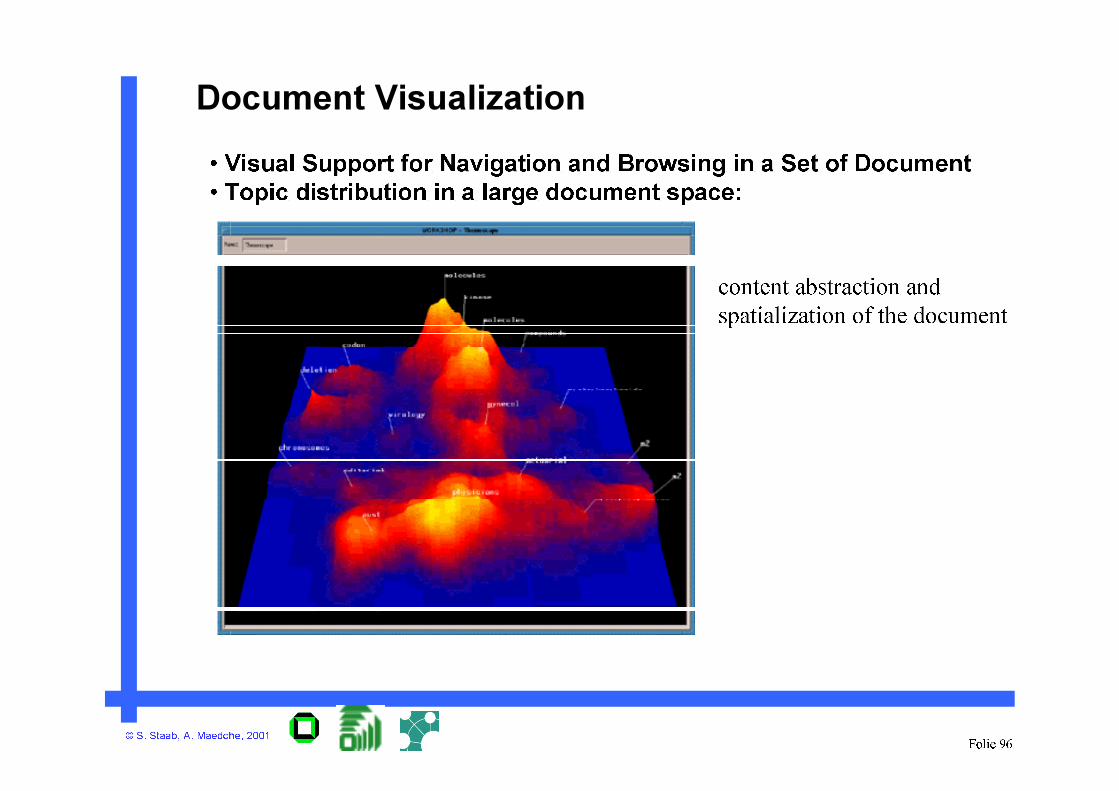
Document Visualization
• Visual Support for Navigation and Browsing in a Set of Document
• Topic distribution in a large document space:
content abstraction and
spatialization of the document

© S. Staab, A. Maedche, 2001Folie 97
Document Visualization
Visual Support for Navigation and Browsing in a Set of Document
As close as possible to
a real world-book

© S. Staab, A. Maedche, 2001Folie 98
Visualisierung von Association Rules
© S. Staab, A. Maedche, 2001Folie 99
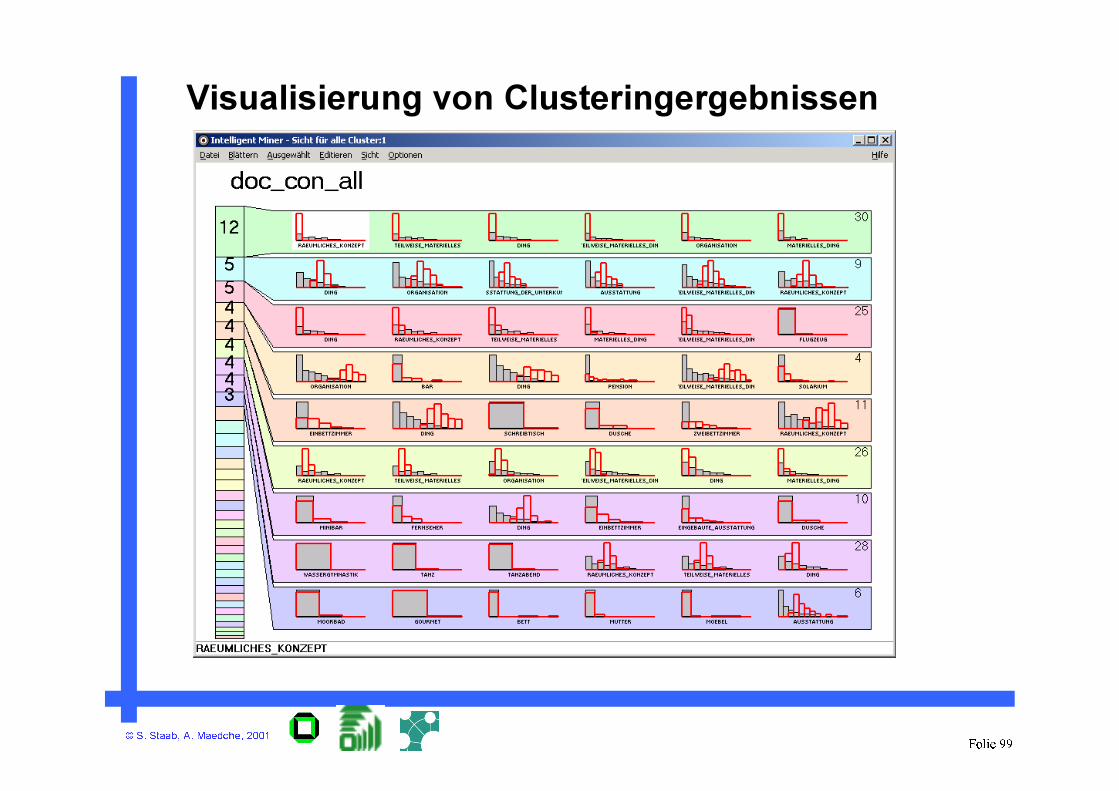
Visualisierung von Clusteringergebnissen

© S. Staab, A. Maedche, 2001Folie 100
Inhalte
– Der Business Intelligence Prozeß
– OLAP – Explorative Wissens- und
Ideengenerierung
– Wissensvisualisierung
– Data Mining / Knowledge Discovery

© S. Staab, A. Maedche, 2001Folie 101
Data Mining im Buzzword-Netz

© S. Staab, A. Maedche, 2001Folie 102
Data Mining ist interdisziplinär

© S. Staab, A. Maedche, 2001Folie 103
Data Mining Techniken
Generell unterscheidet man zwischen:
• Überwachten Verfahren:
• Entscheidungsbäume
• Neuronale Netze
• ...
• Unüberwachten Verfahren:
• Clustering
• Assoziationsregeln
• ...

© S. Staab, A. Maedche, 2001Folie 104
Example: Mining mit SAP BW

© S. Staab, A. Maedche, 2001Folie 105
Werkzeuge für Data Mining

© S. Staab, A. Maedche, 2001Folie 106
Case Study: CRM – Deutsche Telekom
• Ausgangsbasis: Panel über ca. 5000 HH
• Data Mart ‘‘Panel Analyse System‘‘ (PAS)
enthält:
• Kommunikationsdaten
• Befragungsdaten

© S. Staab, A. Maedche, 2001Folie 107
Sternschema
Kommunikationsdaten
Befragung
Haushalte
Befragung
Arbeitsstätten
Teilnehmer_ID
Kundensegment
Tarifzone
Tagart
Zeit
. . .
Kennzahlen
(Verb.minuten)
Teilnehmer_ID
Teilnehmer_ID
Branche_Code
. . .
Beruf_Code
. . .
Haushaltsgröße
Anzahl Mitarbeiter
Kundensegment
Haushalt (PK)
Arbeitsstätte (GK)
Tarifzone
Ort
Regional
Deutschland
. . .
Tagart
Mo - Fr
Sa, So, Fe
Zeit
Stunde (0 .. 23)
Tag
Monat
Jahr
Branche_Code
Branche
Branche
Wirtschaftszweig
(fein gegliedert)
Wirtschaftszweig
(fein gegliedert)Wirtschaftszweig
(grob gegliedert)
Beruf_Code
Beruf
star schema of PAS

© S. Staab, A. Maedche, 2001Folie 108
Kommunikationsdaten
customerID distance type of day date/time comm. minutes
1 Ort Mo-Fr 19.11.98/9:55 20 min
1 Ort Mo-Fr 20.11.98/10:10 18 min
2 Regional Mo-Fr 19.11.98/21:00 120 min
2 Regional Mo-Fr 20.11.98/17:00 2 min
• Verwendung der Kommunikationsdaten zur Generierung
eines Profils
• Auf Basis der Profile folgt die Definition von
Kundensegmenten
• Kundensegmente werden mittels sozio-demographischer
Merkmale aus dem Panel beschrieben

© S. Staab, A. Maedche, 2001Folie 109
Kommunikationsprofil
weekday
weekend
Zeitfenster
Ort
FernRegio
communication
feature
• hour window: 0-6
•distance: Ort
•type of day: weekday

© S. Staab, A. Maedche, 2001Folie 110
Kundensegmentierung via Clustering
Profil in einem KundenclusterDurchschnittliches Profil

© S. Staab, A. Maedche, 2001Folie 111
Beschreibung von Segmenten
• Verwendung der sozio-demographischen Daten aus
dem Panel
• Größe des Haushaltes
• Beruf
• Anzahl Kinder
• Alter
• ...
• Verwendung einer Entscheidungsbaumtechnik führt zu:
WENN HH > 4 und Beruf = „Beamter“
DANN Cluster_Nr = 1

© S. Staab, A. Maedche, 2001Folie 112
Literatur
Andreas Abecker, Ansgar Bernardi, Heiko Maus, Michael
Sintek, and Claudia Wenzel: Information Supply for
Business Processes - Coupling Workflow with
Document Analysis and Information Retrieval.
Knowledge-Based Systems 13(5):271-284, Special
Issue on AI in Knowledge Management, Elsevier,
2000.
Matthias Jarke, Roland Klemke, Achim Nick. Broker's
Lounge - an Environment for Multi-Dimensional
User-Adaptive Knowledge Management, in: HICSS-
34: 34th Hawaii International Conference on System
Siences, 3.-6. January 2001, Maui, Hawaii.
Mario Lenz. Managing the Knowledge Contained in
Technical Documents. In Ulrich Reimer (ed.).
PAKM 98 - Practical Aspects of Knowledge
Management. Proceedings of the Second
International Conference. Basel, Switzerland,
October 29-30, 1998.
Alexander Mädche, Steffen Staab: Ontology Learning for
the Semantic Web. IEEE Intelligent Systems, 16(2),
March/April 2001 (Special issue on Semantic Web).
Alexander Mädche, Steffen Staab, Nenad Stojanovic, Rudi
Studer, York Sure. SEmantic portAL - The SEAL
approach. In D. Fensel, J. Hendler, H. Lieberman, W.
Wahlster (eds.) Creating the Semantic Web. MIT
Press, Cambridge, MA, 2001 (In Druck).
Gilbert Probst, Steffen Raub, Kai Romhardt. Wissen
managen. Wie Unternehmen ihre wertvollste Ressource
optimal nutzen. Th. Gabler Verlag, 1999.
Guus Schreiber, Robert de Hoog, Hans Akkermans, Anjo
Anjewierden, Nigel Shadbolt, Walter Van de Velde.
Knowledge Engineering and Management. The MIT
Press, 2000.
Steffen Staab, Alexander Mädche: Knowledge Portals -
Ontologies at Work. AI Magazine, 21(2), Summer
2001.
Steffen Staab, Hans-Peter Schnurr, Rudi Studer, York
Sure. Knowledge Processes and Ontologies. IEEE
Intelligent Systems, 16(1), January/February 2001
(Special issue on Knowledge Management).
.


















