
Data Hazards - userpages.uni-koblenz.deunikorn/lehre/gdra/ss16/04 Prozessor (VL18).pdf ·...
23
Data‐Hazards Grundlagen der Rechnerarchitektur ‐ Prozessor 74
Transcript of Data Hazards - userpages.uni-koblenz.deunikorn/lehre/gdra/ss16/04 Prozessor (VL18).pdf ·...

Data‐Hazards
Grundlagen der Rechnerarchitektur ‐ Prozessor 74

Motivation
Grundlagen der Rechnerarchitektur ‐ Prozessor 75
Ist die Pipelined‐Ausführung immer ohne Probleme möglich?
Beispiel:sub $2, $1, $3and $12, $2, $5or $13, $6, $2add $14, $2, $2sw $15, 100($2)
Also, alle vier nachfolgenden Instruktionen hängen von der sub‐Instruktion ab.
Annahme:$2 speichert 10 vor der sub‐Instruktion.$2 speichert ‐20 nach der sub‐Instruktion.
Betrachten wir die Pipeline:
sub $2, $1, $3and $12, $2, $5or $13, $6, $2add $14, $2, $2sw $15, 100($2)
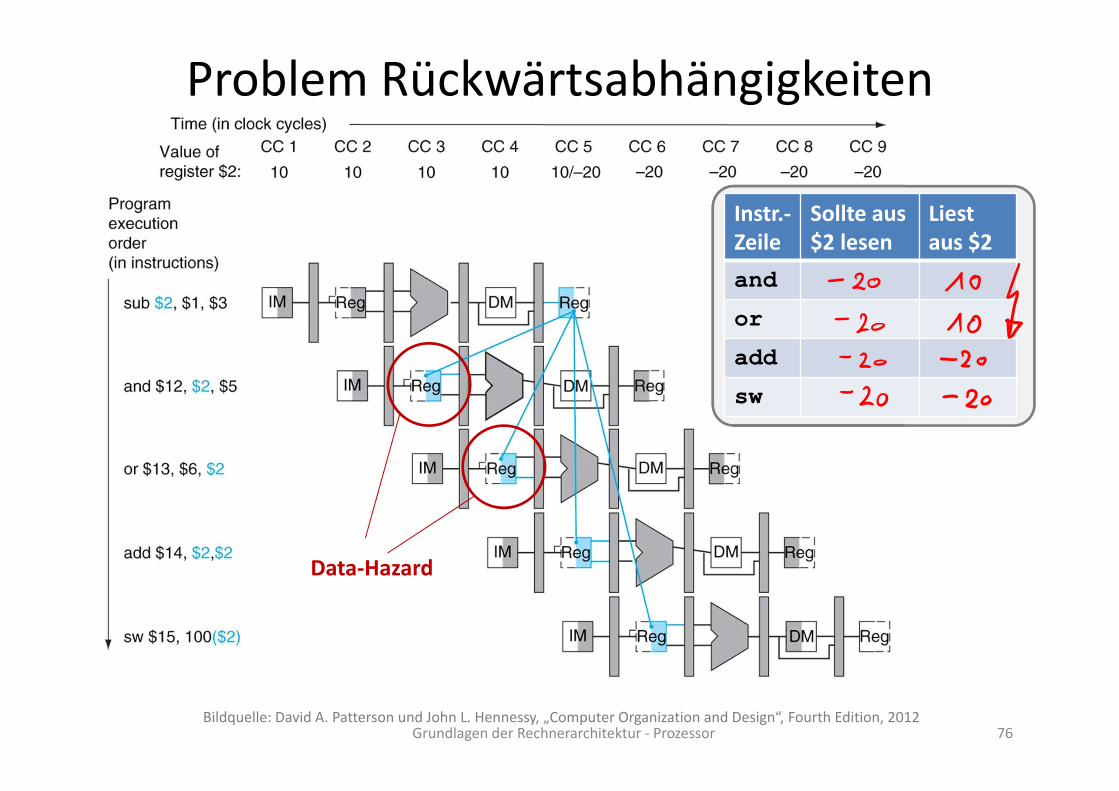
Problem Rückwärtsabhängigkeiten
Grundlagen der Rechnerarchitektur ‐ Prozessor 76
Instr.‐Zeile
Sollte aus $2 lesen
Liest aus $2
and
or
add
sw
Data‐Hazard
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
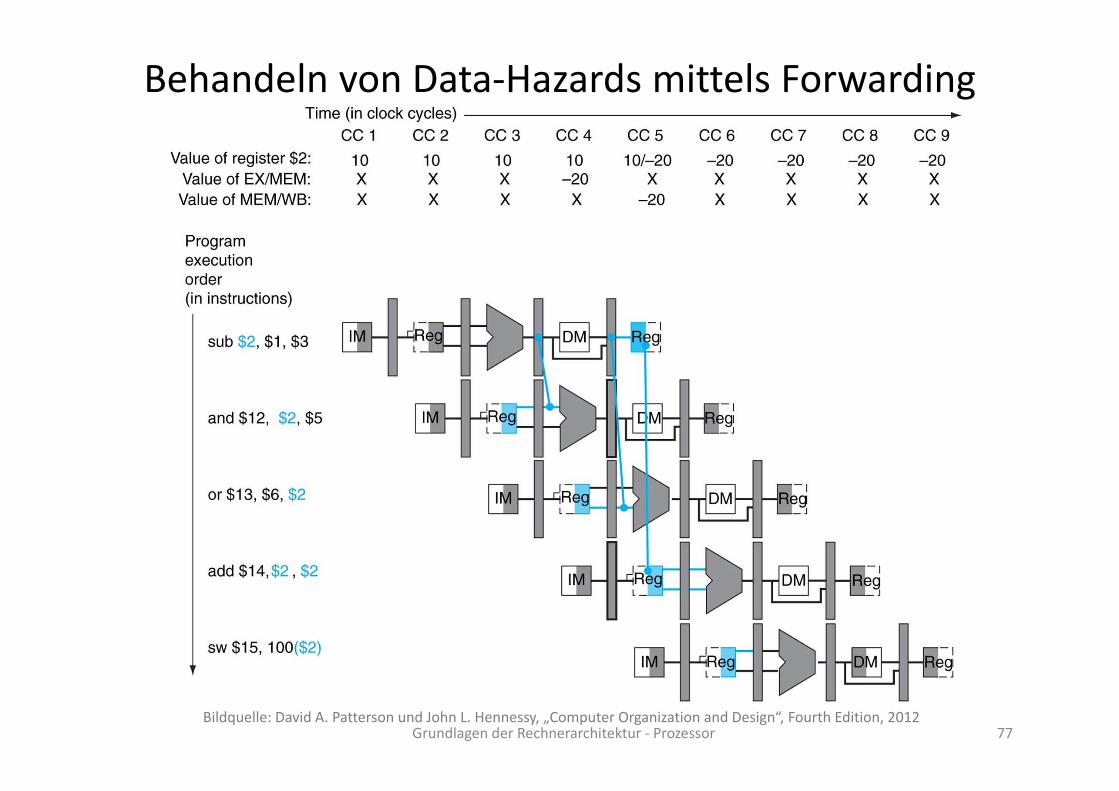
Behandeln von Data‐Hazards mittels Forwarding
Grundlagen der Rechnerarchitektur ‐ Prozessor 77Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
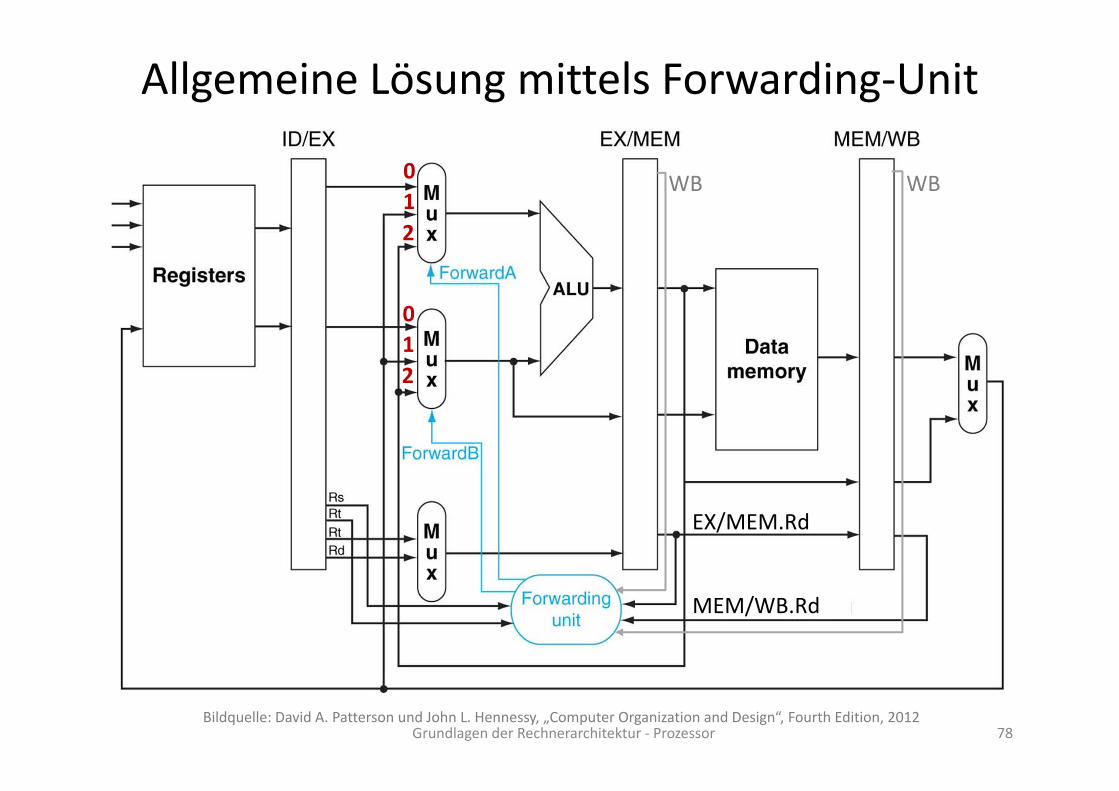
Allgemeine Lösung mittels Forwarding‐Unit
Grundlagen der Rechnerarchitektur ‐ Prozessor 78Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
012
012
WB WB
EX/MEM.Rd
MEM/WB.Rd

Implementation der Forwarding‐Unit
Grundlagen der Rechnerarchitektur ‐ Prozessor 79

Bemerkungen
Grundlagen der Rechnerarchitektur ‐ Prozessor 80
Die Bestimmung von ForwardB erfolgt analog. (Übung)
Das Ganze muss noch als Wahrheitstabelle aufgeschrieben und dann als kombinatorische Schaltung realisiert werden.
Wie sieht die Wahrheitstabelle von ForwardA nach voriger hergeleiteter Vorschrift aus? (Übung) [Tipp: um Platz zu sparen sollte man möglichst viele „don‘t cares“ verwenden.]
Auch mit der Erweiterung auf ForwardB ist die Implementation der Forwarding‐Unit noch unvollständig. Was passiert z.B. für:lw $2, 0($1)sw $2, 4($1)
Erweiterung: Forwarding muss z.B. auch in die MEM‐Stufe eingebaut werden. (Übung)
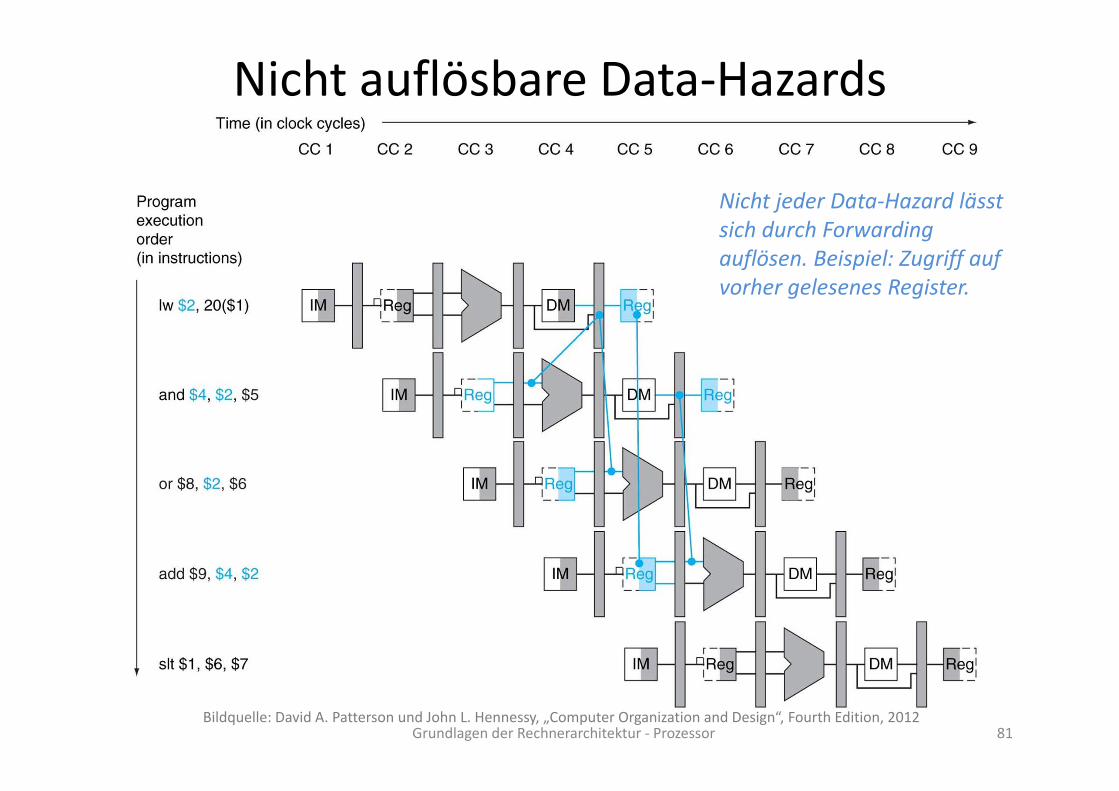
Nicht auflösbare Data‐Hazards
Grundlagen der Rechnerarchitektur ‐ Prozessor 81
Nicht jeder Data‐Hazard lässt sich durch Forwardingauflösen. Beispiel: Zugriff auf vorher gelesenes Register.
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
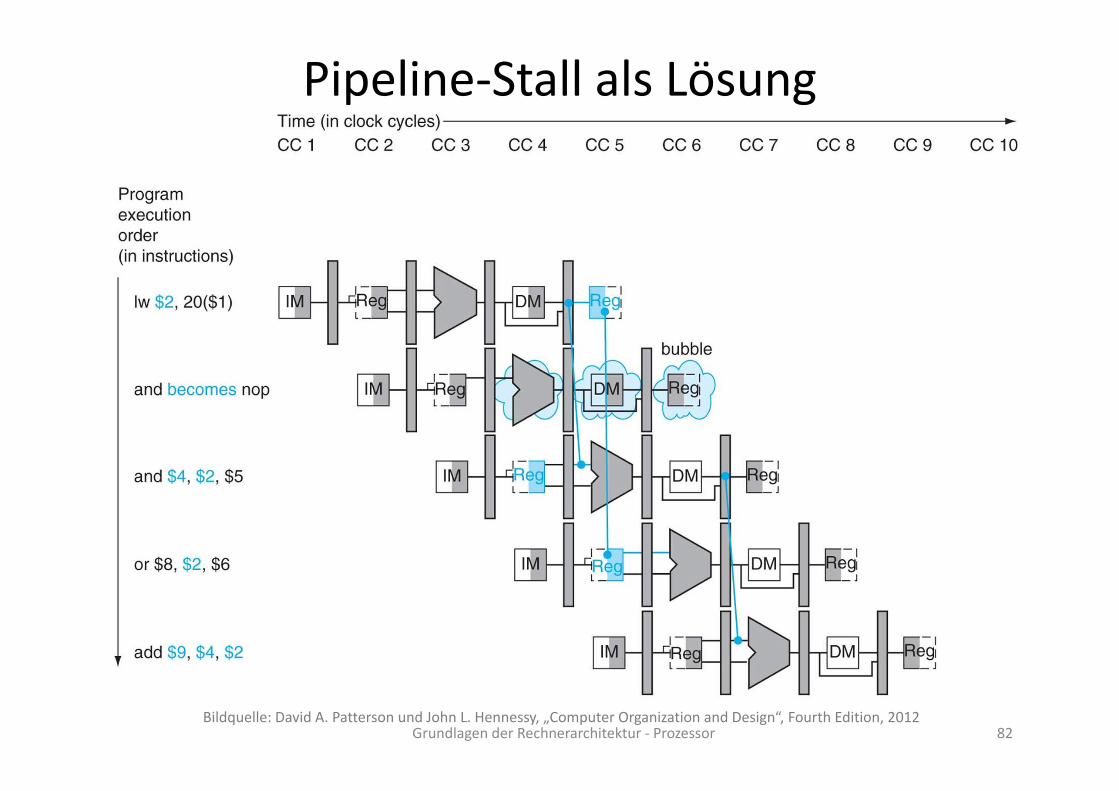
Pipeline‐Stall als Lösung
Grundlagen der Rechnerarchitektur ‐ Prozessor 82Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
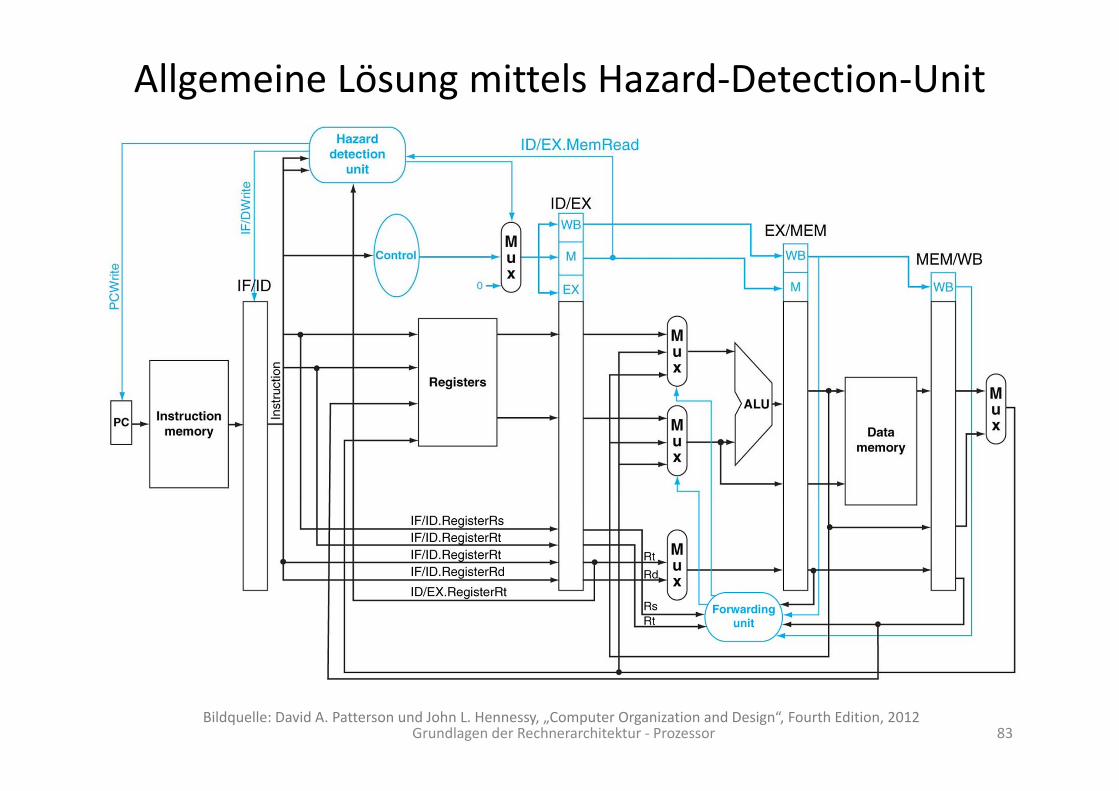
Allgemeine Lösung mittels Hazard‐Detection‐Unit
Grundlagen der Rechnerarchitektur ‐ Prozessor 83Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Implementation der Hazard‐Detection‐Unit
Grundlagen der Rechnerarchitektur ‐ Prozessor 84

Quiz: Vermeiden von Pipeline‐Stalls
Grundlagen der Rechnerarchitektur ‐ Prozessor 85
lw $t1, 0($t0)
lw $t2, 4($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)
lw $t4, 8($t0)
add $t5, $t1, $t4
sw $t5, 16($t0)
Wo findet ein Pipe‐line‐Stall statt? Bitte ankreuzen.
Bitte Befehle umorganisie‐ren, sodass alle Stalls vermieden werden.
Anzahl Taktzyklen mit Stalls?Anzahl Taktzyklen ohne Stalls?

Control‐Hazards
Grundlagen der Rechnerarchitektur ‐ Prozessor 86
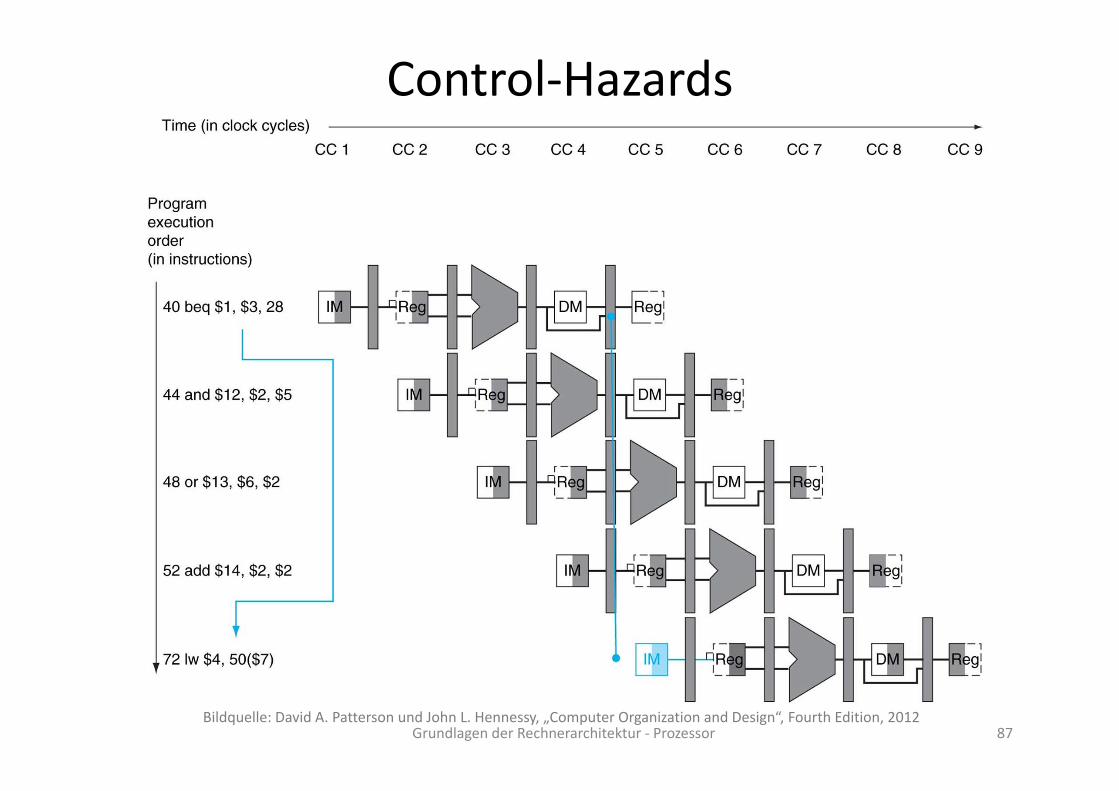
Control‐Hazards
Grundlagen der Rechnerarchitektur ‐ Prozessor 87Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
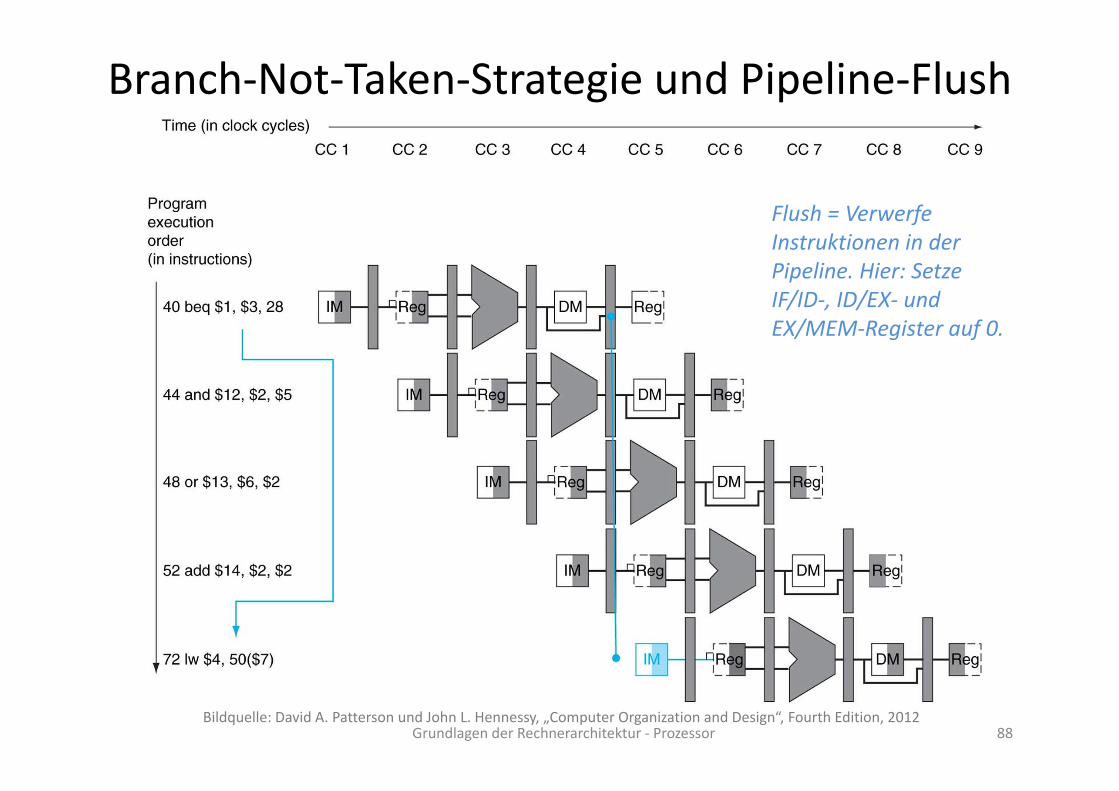
Branch‐Not‐Taken‐Strategie und Pipeline‐Flush
Grundlagen der Rechnerarchitektur ‐ Prozessor 88
Flush = Verwerfe Instruktionen in der Pipeline. Hier: Setze IF/ID‐, ID/EX‐ und EX/MEM‐Register auf 0.
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
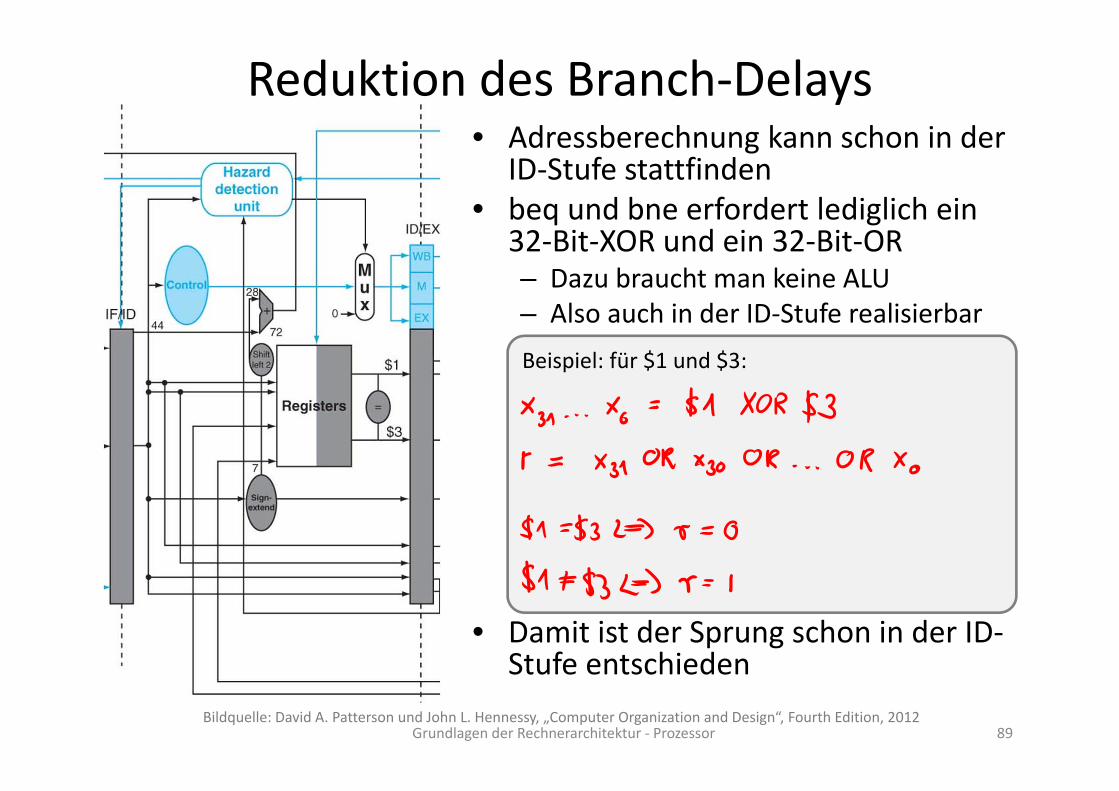
Reduktion des Branch‐Delays• Adressberechnung kann schon in der
ID‐Stufe stattfinden• beq und bne erfordert lediglich ein
32‐Bit‐XOR und ein 32‐Bit‐OR– Dazu braucht man keine ALU– Also auch in der ID‐Stufe realisierbar
• Damit ist der Sprung schon in der ID‐Stufe entschieden
Grundlagen der Rechnerarchitektur ‐ Prozessor 89Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
Beispiel: für $1 und $3:

Reduktion des Branch‐Delays
• Konsequenz– Branch‐Delay ist damit ein Instruktions‐Zyklus– Wir brauchen lediglich ein Flush‐IF/ID‐Register
Grundlagen der Rechnerarchitektur ‐ Prozessor 90
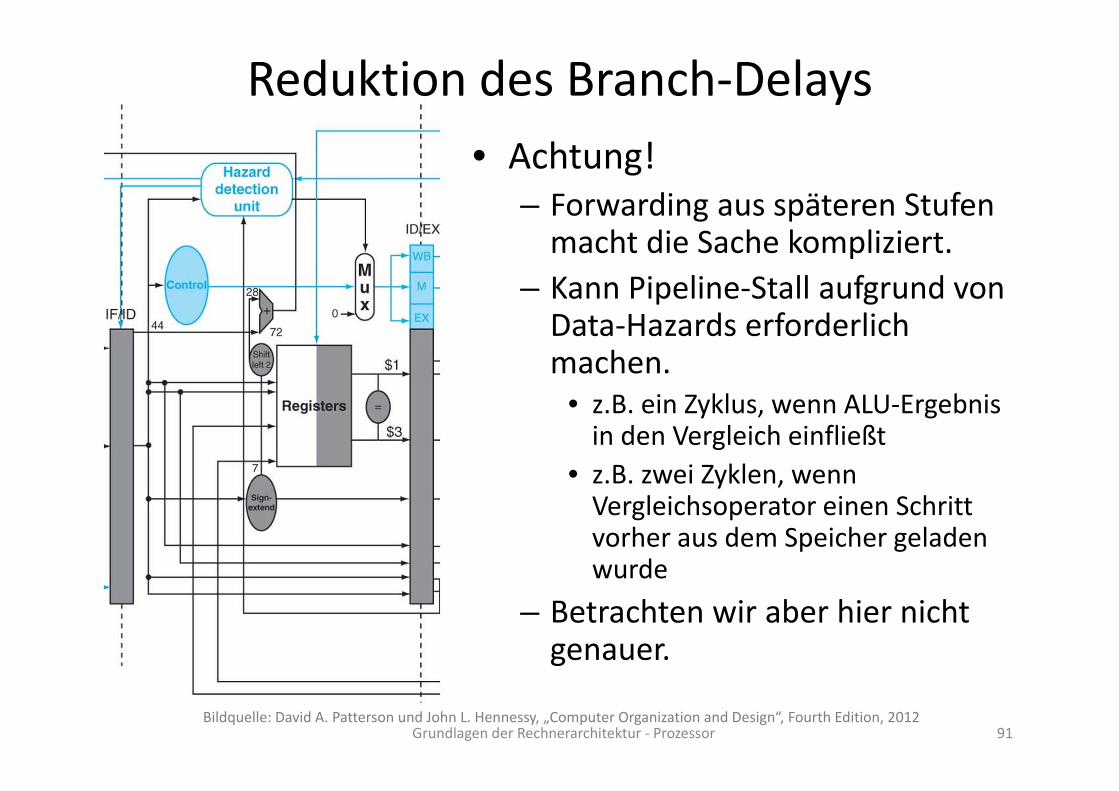
Reduktion des Branch‐Delays• Achtung!
– Forwarding aus späteren Stufen macht die Sache kompliziert.
– Kann Pipeline‐Stall aufgrund von Data‐Hazards erforderlich machen.
• z.B. ein Zyklus, wenn ALU‐Ergebnis in den Vergleich einfließt
• z.B. zwei Zyklen, wenn Vergleichsoperator einen Schritt vorher aus dem Speicher geladen wurde
– Betrachten wir aber hier nicht genauer.
Grundlagen der Rechnerarchitektur ‐ Prozessor 91Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Dynamic‐Branch‐Prediction‐Strategie
Grundlagen der Rechnerarchitektur ‐ Prozessor 92
Unterer Teil der Adresse
Branch hat stattgefunden
0x00 10x04 00x08 1...0xf8 00xfc 0
Branch‐Prediction‐Buffer
0x400000 : lw $1, 0($4)0x400004 : beq $1, $0, 400x400008 : add $1, $1, $10x40000c : ......
...0x40c004 : bne $3, $4, 120...

Vorhersagegenauigkeit
Grundlagen der Rechnerarchitektur ‐ Prozessor 93
Annahme unendlich langer Loop, der immer 9 mal und dann einmal nicht durchlaufen wird. Was ist die Vorhersagegenauigkeit der vorher beschriebenen Branch‐Prediction?
Lässt sich das verbessern?
loop: ......bne $1,$2,loop...j loop

N‐Bit‐Vorhersage am Beispiel 2‐Bit
Grundlagen der Rechnerarchitektur ‐ Prozessor 94Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
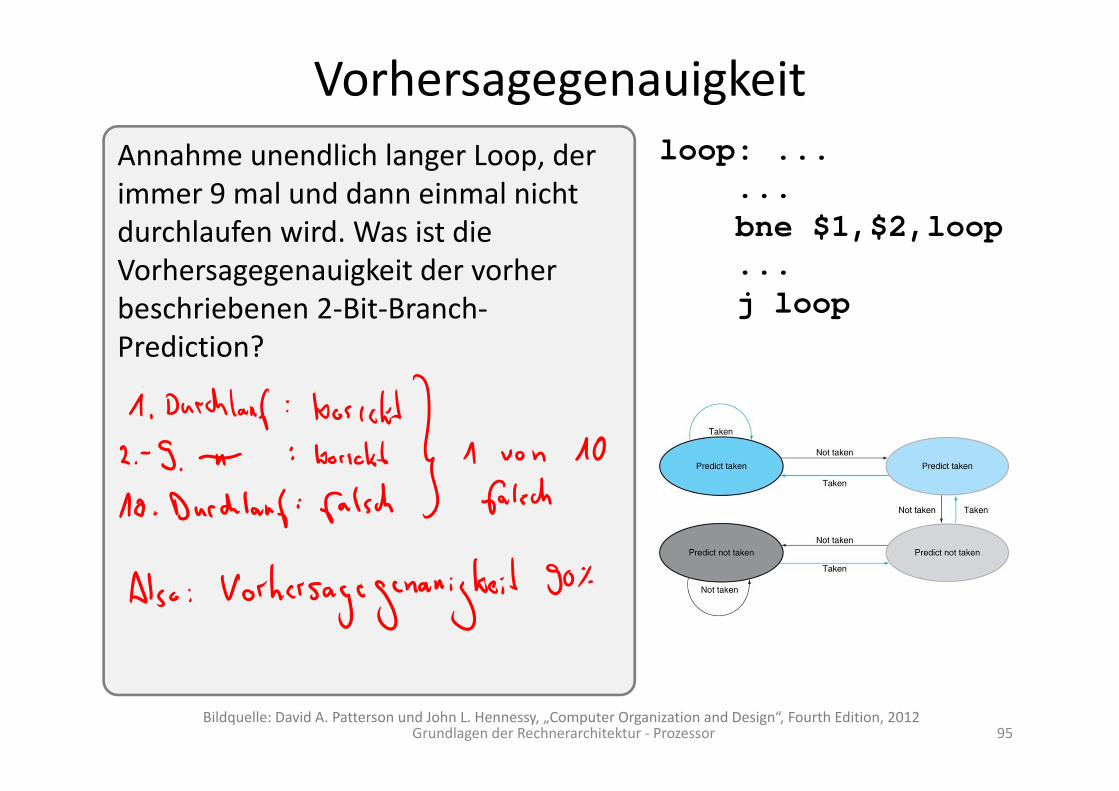
Vorhersagegenauigkeit
Grundlagen der Rechnerarchitektur ‐ Prozessor 95
Annahme unendlich langer Loop, der immer 9 mal und dann einmal nicht durchlaufen wird. Was ist die Vorhersagegenauigkeit der vorher beschriebenen 2‐Bit‐Branch‐Prediction?
loop: ......bne $1,$2,loop...j loop
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Branch‐Delay‐Slot‐Idee
Grundlagen der Rechnerarchitektur ‐ Prozessor 96
loop: ......bne $1,$2,loop<instruktion><instruktion>
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
• Wird immer ausgeführt.• Instruktion muss aber unabhängig vonder Branch‐Entscheidung sein.
• Das muss der Compiler entscheiden.• Im Zweifelsfall: nop passt immer.


















