Beispiel für eine R Typ Instruktion - userpagesunikorn/lehre/gdra/ss12/05 Prozessor (VL12).pdf ·...
41
Beispiel für eine R‐Typ‐Instruktion add $t1, $t2, $t3 • Instruktion wird gefetched und PC um 4 erhöht • Instruktion wird gefetched und PC um 4 erhöht. • Die Register $t2 (Instruction [25‐21]) und $t3 (I t ti [20 16]) d d R it Fil (Instruction [20‐16]) wer den aus dem R egister‐File geladen. fh d d ld ( • Die ALU führt die in dem Function‐Field (Instruction [5‐0]) codierte Operation auf den gelesenen Register‐ Dt Daten aus. • Das Ergebnis der ALU wird in Register $t (Instruction [15‐11]) zurück geschrieben. Grundlagen der Rechnerarchitektur ‐ Prozessor 36
Transcript of Beispiel für eine R Typ Instruktion - userpagesunikorn/lehre/gdra/ss12/05 Prozessor (VL12).pdf ·...

Beispiel für eine R‐Typ‐Instruktion
add $t1, $t2, $t3
• Instruktion wird gefetched und PC um 4 erhöht• Instruktion wird gefetched und PC um 4 erhöht.• Die Register $t2 (Instruction [25‐21]) und $t3 (I t ti [20 16]) d d R i t Fil(Instruction [20‐16]) werden aus dem Register‐File geladen.
f h d d ld (• Die ALU führt die in dem Function‐Field (Instruction[5‐0]) codierte Operation auf den gelesenen Register‐D tDaten aus.
• Das Ergebnis der ALU wird in Register $t (Instruction[15‐11]) zurück geschrieben.
Grundlagen der Rechnerarchitektur ‐ Prozessor 36

Beispiel für eine Load/Save‐Instruktion
lw $t1, 8($t2)
• Instruktion wird gefetched und PC um 4 erhöht• Instruktion wird gefetched und PC um 4 erhöht.• Das Register $t2 (Instruction [25‐21]) wird aus dem Register‐File geladenRegister‐File geladen.
• Die ALU addiert das Register‐Datum und den 32‐Bit Sign‐exteded 16‐Bit‐Immediate‐Wert 8 (Instruction [15‐0])exteded 16 Bit Immediate Wert 8 (Instruction [15 0]).
• Die Summe aus der ALU wird als Adresse für den Datenspeicher verwendet.Datenspeicher verwendet.
• Das Datum aus dem Datenspeicher wird in das Register‐File geschrieben. Das Register in das geschrieben wird ist $t1 g g g $(Instruction [20‐16]).
Grundlagen der Rechnerarchitektur ‐ Prozessor 37

Beispiel für eine Branch‐Instruktion
beq $t1, $t2, 42
• Instruktion wird gefetched und PC um 4 erhöht• Instruktion wird gefetched und PC um 4 erhöht.• Die Register $t1 (Instruction [25‐21]) und $t2 (Instruction[20‐16]) werden aus dem Register‐File geladen.[ ]) g g
• Die Haupt‐ALU subtrahiert die ausgelesenen Register‐Daten voneinander.Di ät li h ALU ddi t PC+4 f d 32 Bit SiDie zusätzliche ALU addiert PC+4 auf den 32‐Bit Sign‐exteded und um 2 nach links geshiftete 16‐Bit‐Immediate‐Wert 42 (Instruction [15‐0]).( [ ])
• Das Zero‐Ergebins der Haupt‐ALU entschiedet ob der PC auf PC+4 oder auf das Ergebnis der zusätzliche ALU gesetzt i dwird.
Grundlagen der Rechnerarchitektur ‐ Prozessor 38

Eine Übung zum AbschlussIn der vorigen „Übung zum Abschluss“ wurde das Blockschaltbild des Datenpfads so erweitert, sodass auch die MIPS‐Instruktion junterstützt wird.
Wie müssen Control und Alu Control modifiziert werden (wennWie müssen Control und Alu‐Control modifiziert werden (wenn überhaupt), damit die MIPS‐Instruktion j auch von Seiten des Control unterstützt wird?Control unterstützt wird?
Erinnerung:j addr # Springe nach Adresse addr
000010 address
OpcodeBits 31‐26
AdresseBits 25‐0
J‐Typ
Grundlagen der Rechnerarchitektur ‐ Prozessor 39

Pipelining
Grundlagen der Rechnerarchitektur ‐ Prozessor 40

Pipeliningk klInstruktionszyklen
Grundlagen der Rechnerarchitektur ‐ Prozessor 41

MIPS‐InstruktionszyklusEin MIPS‐Instruktionszklus besteht aus:
1 I t kti d S i h h l1. Instruktion aus dem Speicher holen(IF: Instruction‐Fetch)
2 Instruktion decodieren und Operanden aus Register lesen2. Instruktion decodieren und Operanden aus Register lesen(ID: Instruction‐Decode/Register‐File‐Read)
3. Ausführen der Instruktion oder Adresse berechnen(EX: Execute/Address‐Calculation)
4. Datenspeicherzugriff(MEM M A )(MEM: Memory‐Access)
5. Resultat in Register abspeichern(WB: Write‐Back)(WB: Write Back)
Grundlagen der Rechnerarchitektur ‐ Prozessor 42
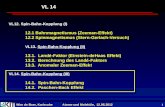
Instruktionszyklen in unserem Blockschaltbild
Grundlagen der Rechnerarchitektur ‐ Prozessor 43

Instruktionszyklen generell• Instruktionszyklen anderer moderner CPUs haben diese oder eine sehr ähnliche Form von Instruktionszyklen.
U t hi d i d B• Unterschiede sind z.B.:– Instruktion decodieren und Operanden lesen sind zwei getrennte Schritte. Dies ist z.B. notwendig,
• wenn Instruktionen sehr komplex codiert sind (z.B. x86 Instruktionen der Länge 1 bis 17 Byte)
• wenn Instruktionen Operanden im Speicher anstatt Register h b ( k b )haben (z.B. einige Instruktionen bei x86)
Grundlagen der Rechnerarchitektur ‐ Prozessor 44

Pipeliningl dDie Pipelining‐Idee
Grundlagen der Rechnerarchitektur ‐ Prozessor 45

Single‐Cycle‐PerformanceAnnahme die einzelnen Abschnitte des MIPS‐Instruktionszyklus benötigen folgende Ausführungszeiten:
h dInstruction‐Fetch 200ps, Register‐Read 100ps, ALU‐Operation 200ps, Data‐Access 200ps, Register‐Write 100ps.
Wie hoch dürfen wir unseren Prozessor (ungefähr) Takten?
Die längste Instruktion benötigt 800ps. Also gilt für den Clock‐Cycle c:
Grundlagen der Rechnerarchitektur ‐ Prozessor 46Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
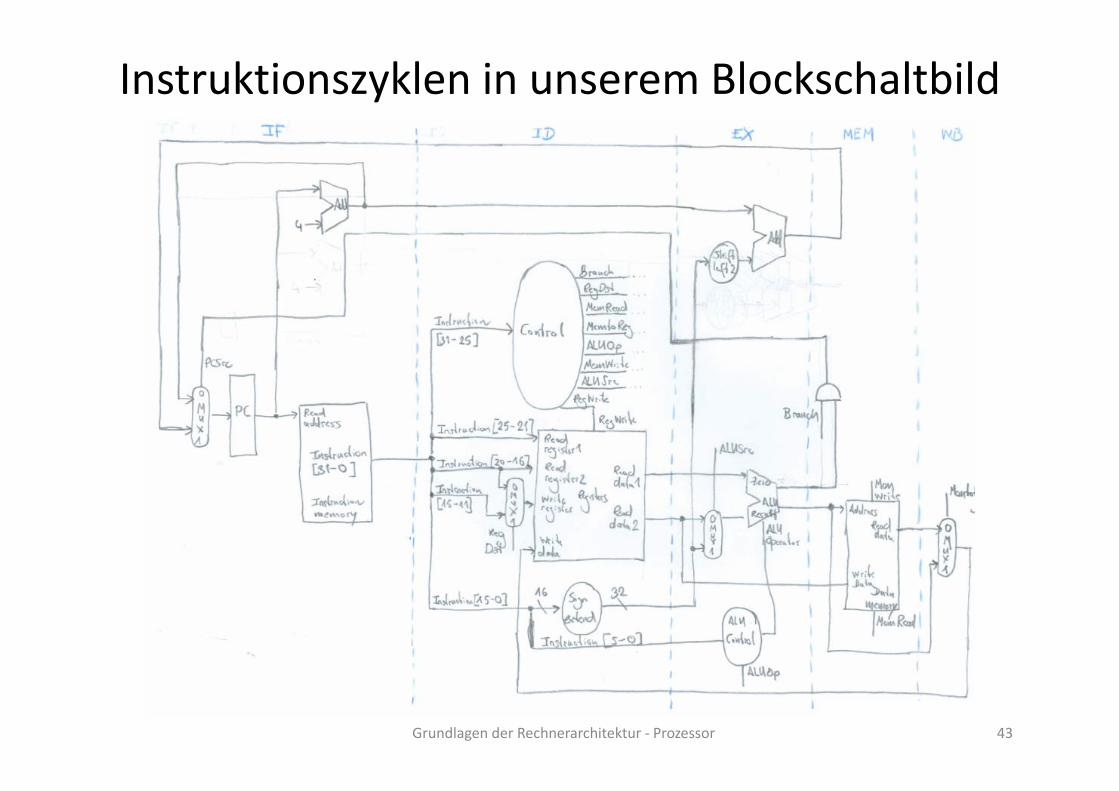
Die Pipelining‐Idee am Beispiel Wäsche waschen
Waschen
TrocknenBearbeitungszeit pro Wäscheladung bleibt
Falten
Einräumen
dieselbe (Delay).Gesamtzeit für alle Wäscheladungen sinkt
Grundlagen der Rechnerarchitektur ‐ Prozessor 47Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
Einräumen(Throughput).

Was ist die Performance‐Ratio?Annahme jeder Arbeitsgang beansprucht dieselbe Zeit. Was ist die Performance‐Ratio für n Wäscheladungen?
Generell für k „Pipeline‐Stufen“, d.h. k Arbeitsgänge und gleiche Anzahl Zeiteinheiten t pro Arbeitsgang?
Grundlagen der Rechnerarchitektur ‐ Prozessor 48

Pipelining für unseren MIPS‐ProzessorIm Folgenden betrachten wir zunächst ein ganz einfaches Programm:l $1 100($0)lw $1, 100($0)lw $2, 200($0)lw $3, 300($0)lw $3, 300($0)lw $4, 400($0)lw $5, 500($0)
Bemerkung: Da die MIPS‐Registernamen im Folgenden nicht von B d t i d b i i d P b i i l hä fiBedeutung sind, geben wir in den Programmbeispielen häufig nur noch die Registernummern (z.B. wie oben $0 und $1) an. Außerdem betrachten wir das spezielle Zero‐Register momentan nichtbetrachten wir das spezielle Zero Register momentan nicht.
Wie kann man die Pipelining‐Idee im Falle unseres MIPS‐Prozessors anwenden?
Grundlagen der Rechnerarchitektur ‐ Prozessor 49

Die Pipeline nach den ersten drei Instruktionen
Annahme:IF = 200psID = 100pspEX = 200psMEM = 200psWB = 100ps
Grundlagen der Rechnerarchitektur ‐ Prozessor 50Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
WB 100ps

Was ist die Performance‐Ratio?Wie eben gezeigt wäre für k Pipeline‐Stufen und eine große Zahl an ausgeführten Instruktionen die Performance‐Ratio gleich k, wenn jede Pipeline Stufe dieselbe Zeit beanspruchen würdejede Pipeline‐Stufe dieselbe Zeit beanspruchen würde.
Allerdings brauchen die einzelnen Stufen s1,...,sk unterschiedliche Z it i h it t t S it i t di P f R ti füZeiteinheiten: t1,..., tk. Somit ist die Performance‐Ratio für n Instruktionen:
Mit den Zeiten aus dem vorigen Beispiel für n →∞ also:
Grundlagen der Rechnerarchitektur ‐ Prozessor 51
Die Performance‐Ratio wird durch die langsamste Stufe bestimmt.

TaktungAnnahme die einzelnen Abschnitte des MIPS‐Instruktionszyklus benötigen bisher betrachteten Ausführungszeiten:Instruction Fetch 200ps Register Read 100ps ALU Operation 200psInstruction‐Fetch 200ps, Register‐Read 100ps, ALU‐Operation 200ps, Data‐Access 200ps, Register‐Write 100ps.
Wi h h dü f i P ( fäh ) T kt ? DiWie hoch dürfen wir unseren Prozessor (ungefähr) Takten? Die längste Stufe benötigt 200ps. Also gilt für den Clock‐Cycle c:
Achtung: Maximal mögliche Taktung hängt aber auch von anderen
Grundlagen der Rechnerarchitektur ‐ Prozessor 52
Faktoren ab. (Erinnerung: Power‐Wall).

Quiz
Welchen CPI‐Wert suggeriert das MIPS‐Pipelining‐Beispiel?
Grundlagen der Rechnerarchitektur ‐ Prozessor 53
Achtung: der CPI‐Wert ist in der Regel höher, wie wir noch sehen.
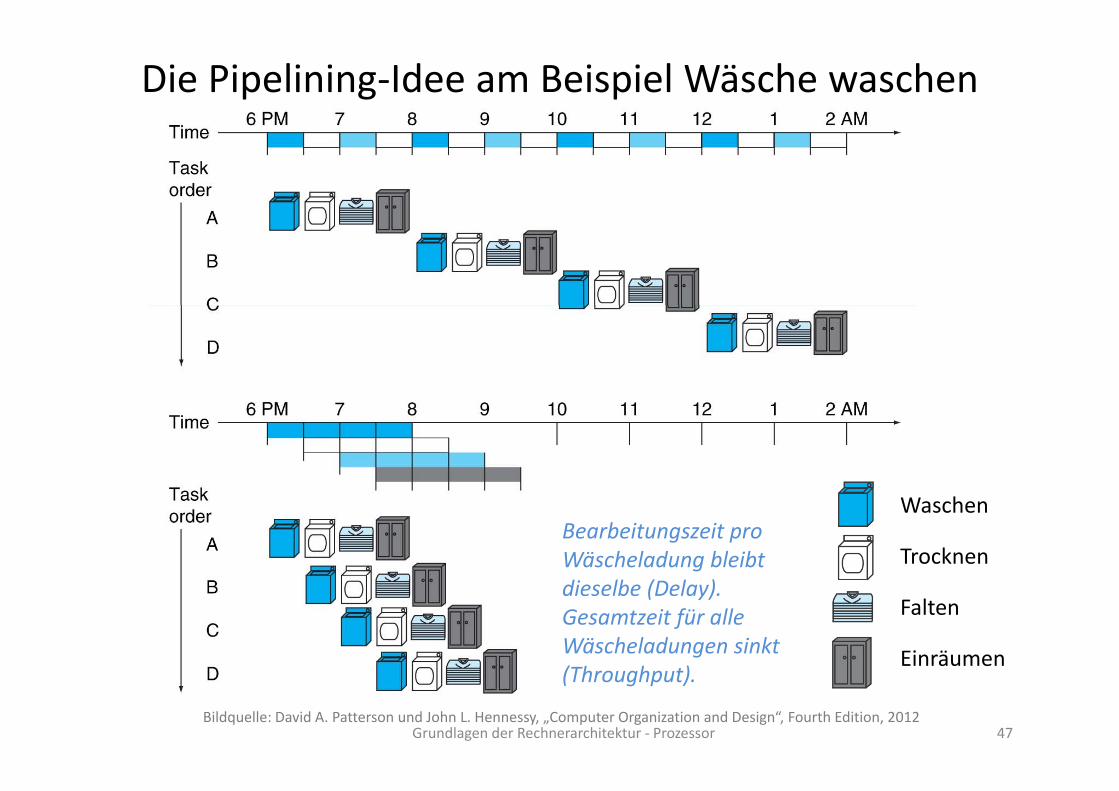
Der Ansatz ist noch zu naivlw $1 100($0)lw $2 200($0)lw $3 300($0)lw $4 400($0)l $5 500($0)B i i l lw $1, 100($0)lw $2, 200($0)lw $3, 300($0)lw $4, 400($0)lw $5, 500($0)Beispiel:
IF ID EX MEM WB
Grundlagen der Rechnerarchitektur ‐ Prozessor 54Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

PipelininglPipeline‐Register
Grundlagen der Rechnerarchitektur ‐ Prozessor 55
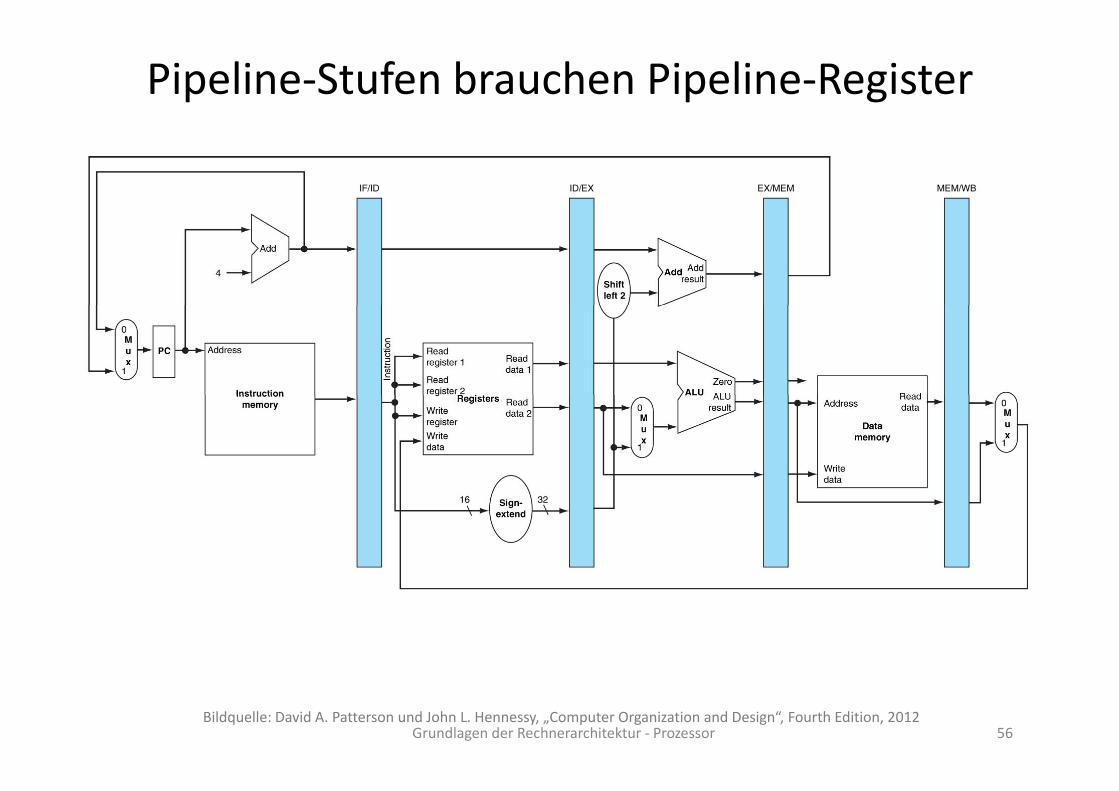
Pipeline‐Stufen brauchen Pipeline‐Register
Grundlagen der Rechnerarchitektur ‐ Prozessor 56Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Pipeline‐Stufen brauchen Pipeline‐Register
Control
…
Write‐Register darf erst in der WB‐Stufe gesetzt werden.
ÄnderungRegDst steht mit der Entscheid ng on
Wird durchgereicht
Grundlagen der Rechnerarchitektur ‐ Prozessor 57Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
im Tafelbild RegDst steht mit der Entscheidung von Control erst in der EX‐Stufe fest.

Was speichern die Pipeline‐Register?Wir schauen uns den Weg einer einzigen Instruktion durch die Pipeline an; und zwar der Load‐Word‐Instruktion lw.
Auf dem Weg durch die Pipeline überlegen was alles in den Pipeline‐Registern IF/ID, ID/EX, EX/MEM und MEM/WB stehen muss.Registern IF/ID, ID/EX, EX/MEM und MEM/WB stehen muss.
In der Darstellung verwenden wir folgende Konvention.
Grundlagen der Rechnerarchitektur ‐ Prozessor 58
Bedeutet: Register/Speicher wird gelesen Bedeutet: Register/Speicher wird beschrieben

Was speichern die Pipeline‐Register?
IF/ID:• Instruktion• PC+4 (z B für beq)• PC+4 (z.B. für beq)
Grundlagen der Rechnerarchitektur ‐ Prozessor 59Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Was speichern die Pipeline‐Register?
ID/EX:• PC+4 (z.B. für beq)• Inhalt Register 1• Inhalt Register 1• Inhalt Register 2• Sign‐ext. Immediate (z.B. für beq)• Das Write‐Register
Generell: Alles was in einem späteren Clock‐Cycle noch verwendet werden könnte muss
Grundlagen der Rechnerarchitektur ‐ Prozessor 60
• Das Write‐Register(wird im Letzten Zyklus von lw gebraucht)
noch verwendet werden könnte muss durchgereicht werden.
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Was speichern die Pipeline‐Register?
EX/MEM:• Ergebnis von PC+4+Offset (z B für beq)Offset (z.B. für beq)
• Zero der ALU(z.B. für beq)
• Result der ALU• Register 2 Daten (z.B. für sw)D W i R i ( i d i L Z kl l b h )
Grundlagen der Rechnerarchitektur ‐ Prozessor 61
• Result der ALU
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
• Das Write‐Register (wird im Letzten Zyklus von lw gebraucht)
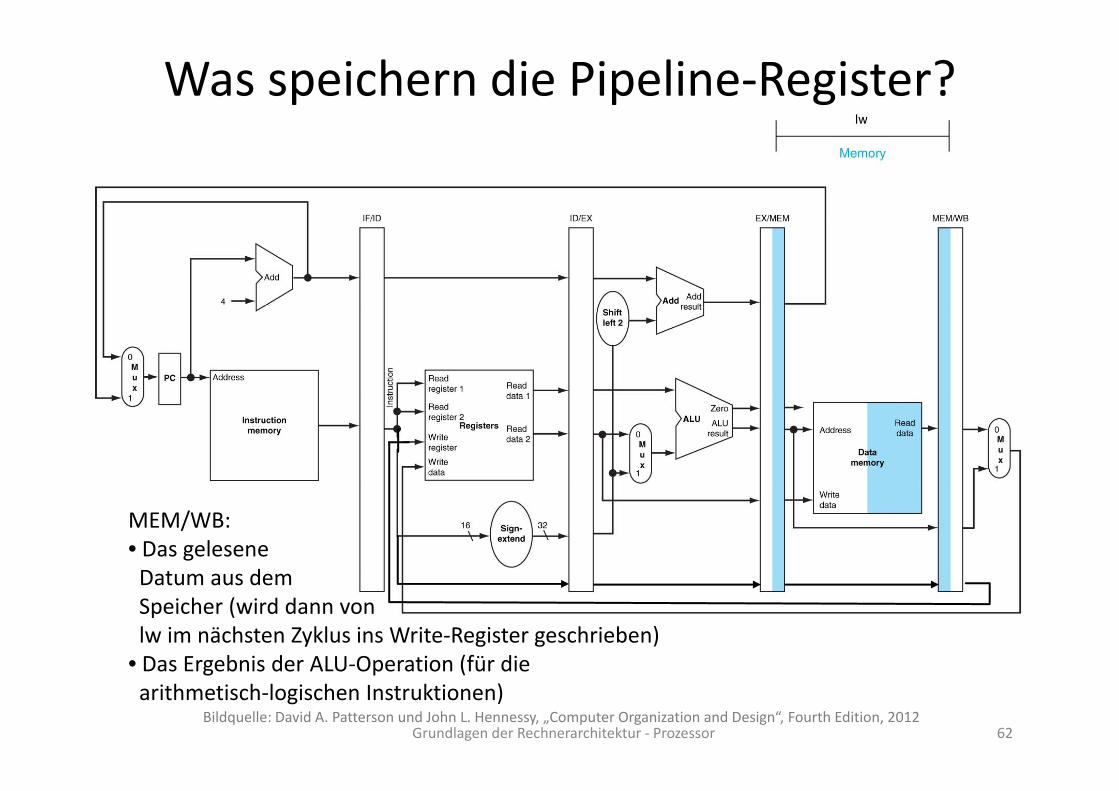
Was speichern die Pipeline‐Register?
MEM/WB:• Das geleseneDatum aus demDatum aus demSpeicher (wird dann vonlw im nächsten Zyklus ins Write‐Register geschrieben)
• Das Ergebnis der ALU‐Operation (für die
Grundlagen der Rechnerarchitektur ‐ Prozessor 62
• Das Ergebnis der ALU‐Operation (für diearithmetisch‐logischen Instruktionen)
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Was speichern die Pipeline‐Register?
Für die letzte Pipeline‐Stufe braucht man keinbraucht man kein Pipeline‐Register.
Grundlagen der Rechnerarchitektur ‐ Prozessor 63Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Zusätzlich wird noch Control‐Info gespeichert
Control
…
Grundlagen der Rechnerarchitektur ‐ Prozessor 64Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Zusätzlich wird noch Control‐Info gespeichertWerden durchWerden durch‐gereicht.
Control hängt Das ID/EX‐ Das EX/MEM‐ Das MEM/WB‐Control hängt von der Instruktion ab. Damit muss
Das ID/EXRegister muss bereitstellen:• RegDst
Das EX/MEMRegister muss bereit stellen:• Branch
Das MEM/WBRegister muss bereit stellen:• MemtoRegDamit muss
Control‐Info erst ab ID/EX‐Register
RegDst• ALUOp (2)• ALUSrc
Branch•MemRead•MemWrite
MemtoReg• RegWrite
ggespeichert werden.
Grundlagen der Rechnerarchitektur ‐ Prozessor 65Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Pipeliningl lPipelining‐Visualisierung
Grundlagen der Rechnerarchitektur ‐ Prozessor 66

Pipelining‐VisualisierungZusammenfassung der vorhin implizit eingeführten Visualisierungen und Einführung einer neuen Visualisierung.
Wir betrachten folgenden Beispiel‐Code:
lw $10, 20($1)sub $11, $2, $3$ , $ , $add $12, $3, $4lw $13, 24($1)add $14, $5, $6
Wir unterscheiden generell zwischen zwei Visualisierungs Arten:Wir unterscheiden generell zwischen zwei Visualisierungs‐Arten:Single‐Clock‐Cylce‐Pipeline‐Diagramm undMultiple‐Clock‐Cycle‐Pipeline‐Diagramm
Grundlagen der Rechnerarchitektur ‐ Prozessor 67
p y p g

Single‐Clock‐Cycle‐Pipeline‐Diagramm
Grundlagen der Rechnerarchitektur ‐ Prozessor 68Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Einfaches Multiple‐Clock‐Cycle‐Pipeline‐Diagramm
Grundlagen der Rechnerarchitektur ‐ Prozessor 69Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Detaillierteres Multiple‐Clock‐Cycle‐Pipeline‐Diagramm
IF ID EX MEM WBIF ID EX MEM WB
Grundlagen der Rechnerarchitektur ‐ Prozessor 70Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Pipeliningl lKomplexere Pipelines
Grundlagen der Rechnerarchitektur ‐ Prozessor 71

Komplexere PiplelinesPi li S f i d i h f 5 f l !• Pipeline‐Stufen sind nicht auf 5 festgelegt!
• z.B. weitere Unterteilung von IF, ID, EX, MEM, WB– Erlaubt höhere Taktung– Kann aufgrund der Instruktions‐Komplexität erforderlich sein– Kann aufgrund von Instruktionen mit zeitlich unbalancierten Stufen erforderlich sein
• Wie Pipelined man x86 ISA mit Instruktionslängen zwischen 1 und 17 Bytes?l k l k k– Komplexe Instruktionen der x86 ISA werden in Folge von Mikroinstruktionen
übersetzt– Mikroinstruktionssatz ist vom Typ RISC– Pipelining findet auf den Mikroinstruktionen statt– Pipelining findet auf den Mikroinstruktionen statt
• Beispiel AMD Opteron X4:
Was das ist sehen wir noch im Kapitel Multiple‐Issue
Grundlagen der Rechnerarchitektur ‐ Prozessor 72
p p
Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
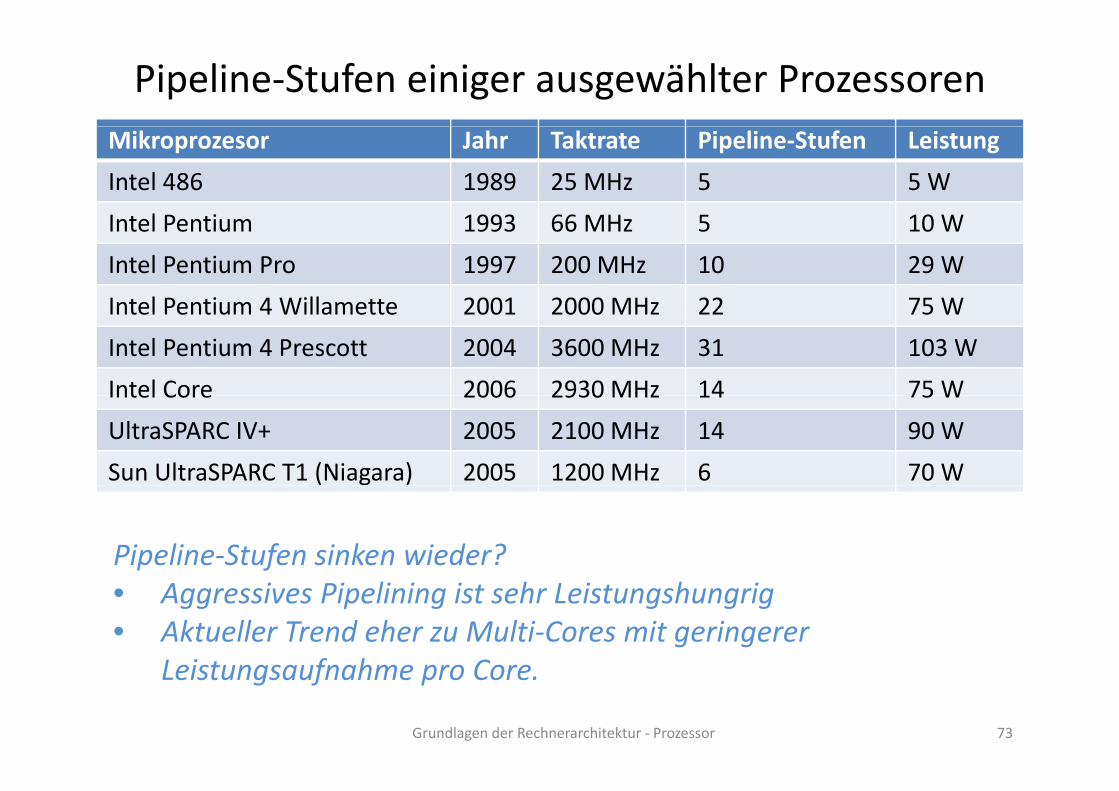
Pipeline‐Stufen einiger ausgewählter ProzessorenMikroprozesor Jahr Taktrate Pipeline‐Stufen Leistung
Intel 486 1989 25 MHz 5 5 W
I t l P ti 1993 66 MH 5 10 WIntel Pentium 1993 66 MHz 5 10 W
Intel Pentium Pro 1997 200 MHz 10 29 W
Intel Pentium 4 Willamette 2001 2000 MHz 22 75 WIntel Pentium 4 Willamette 2001 2000 MHz 22 75 W
Intel Pentium 4 Prescott 2004 3600 MHz 31 103 W
Intel Core 2006 2930 MHz 14 75 WIntel Core 2006 2930 MHz 14 75 W
UltraSPARC IV+ 2005 2100 MHz 14 90 W
Sun UltraSPARC T1 (Niagara) 2005 1200 MHz 6 70 W
Pipeline‐Stufen sinken wieder?• Aggressives Pipelining ist sehr Leistungshungrig• Aktueller Trend eher zu Multi‐Cores mit geringerer
Leist ngsa fnahme pro Core
Grundlagen der Rechnerarchitektur ‐ Prozessor 73
Leistungsaufnahme pro Core.

Data‐Hazards
Grundlagen der Rechnerarchitektur ‐ Prozessor 74

MotivationIst die Pipelined‐Ausführung immer ohne Probleme möglich?
Beispiel:psub $2, $1, $3and $12, $2, $5
$13 $6 $2
sub $2, $1, $3and $12, $2, $5or $13, $6, $2add $14, $2, $2sw $15 100($2)
or $13, $6, $2add $14, $2, $2sw $15 100($2)sw $15, 100($2)
Also, alle vier nachfolgenden Instruktionen hängen von der sub‐
sw $15, 100($2)
Instruktion ab.
Annahme:$2 speichert 10 vor der sub‐Instruktion.$2 speichert ‐20 nach der sub‐Instruktion.
Grundlagen der Rechnerarchitektur ‐ Prozessor 75
Betrachten wir die Pipeline:
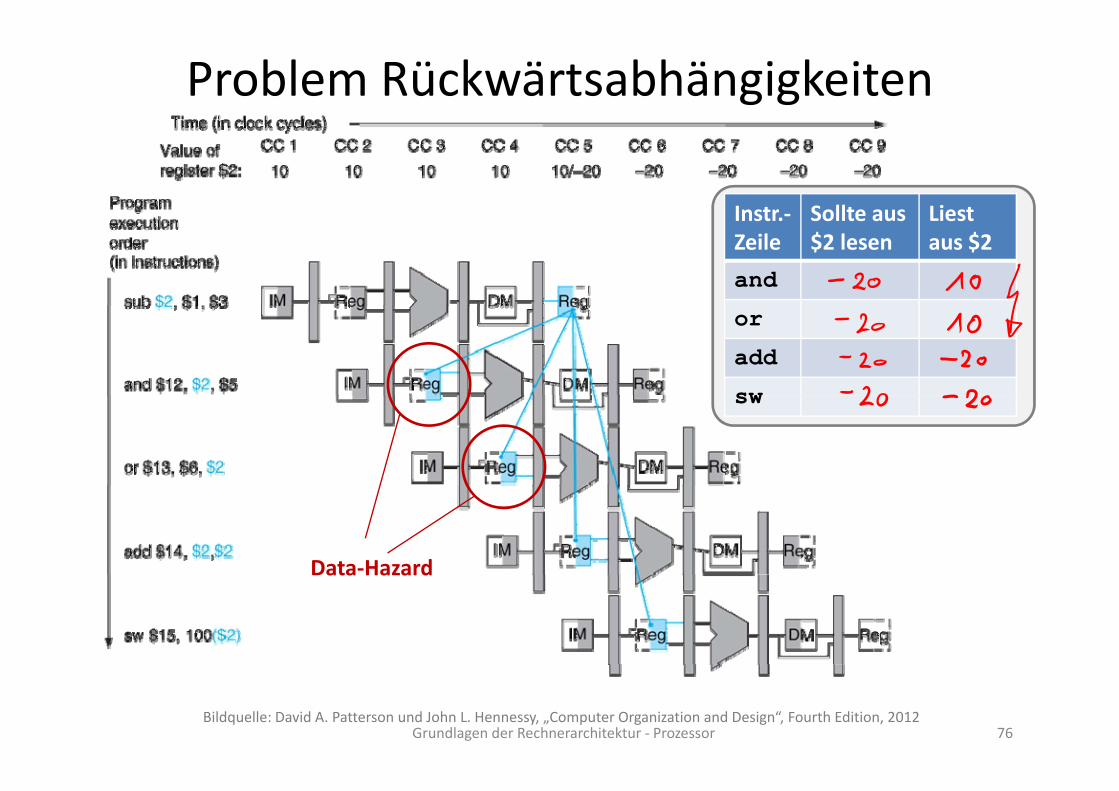
Problem Rückwärtsabhängigkeiten
Instr ‐ Sollte aus LiestInstr.‐Zeile
Sollte aus $2 lesen
Liest aus $2
and
or
add
swsw
Data‐HazardData Hazard
Grundlagen der Rechnerarchitektur ‐ Prozessor 76Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012
![VL12+13 Spin-Bahn-Magnetismus [Kompatibilitätsmodus]13_Spin-Bahn... · Vektormodell der Spin-Bahn-Kopplung Wim de Boer, Karlsruhe Atome und Moleküle, 25.05.2010 38. Wim de Boer,](https://static.fdokument.com/doc/165x107/5d49d71588c993af078bc05d/vl1213-spin-bahn-magnetismus-kompatibilitaetsmodus-13spin-bahn-vektormodell.jpg)