
DLX - Technische Universität Chemnitzerma/dienst/lehre/DLX/dlx_folien.pdf · CPU von J. L....
64
DLX CPU von J. L. Hennessy und D. A. Patter son Hilf smittel zum Lehr en der Pr inzipien der Rechner ar chitektur DLX - r ömische Ziff er n, entspr icht 560 560 -> Mittelwer t aus 13 Maschinen-Kennzahlen, die der DLX- Philosophie sehr ähnlich sind: AMD 29k, DECs t ati on 3100, HP 850, IBM 801,Int el i 860, MIPS M/ 120A, MIPS M/ 1000, Mot orol a MC88k, RISC I, SGI 4D/ 60, SPARCs t ati on-1, Sun-4/ 110, Sun-4/ 260
Transcript of DLX - Technische Universität Chemnitzerma/dienst/lehre/DLX/dlx_folien.pdf · CPU von J. L....

DLX
CPU von J. L. Hennessy und D. A. PattersonHilfsmittel zum Lehren der Prinzipien der Rechnerarchitektur
DLX − römische Ziffern, entspricht 560560 −> Mittelwert aus 13 Maschinen−Kennzahlen, die der DLX−
Philosophie sehr ähnlich sind:
AMD 29k, DECstation 3100, HP 850, IBM 801,Intel i860, MIPS M/120A, MIPS M/1000, Motorola MC88k, RISC I, SGI 4D/60, SPARCstation−1,
Sun−4/110, Sun−4/260

Literatur
[1] John L. Hennessy, David A. Patterson: Rechnerarchitektur, Analyse, Entwurf, Implementierung, Bewertung;Vieweg Verlag, 1994; ISBN 3−528−05173−6
[2] Peter J. Ashenden: The Designer’s Guide to VHDL, 2nd Edition; Morgan Kaufmann Publishers, 2002; ISBN 1−55860−674−2
DLX 2/64

DLX ist eine Load/Store und RISC−Architektur
Philosophie:
Befehlssatz auf das wesentliche reduzierenMaschinenwort regulär und einfach aufgebaut, feste Befehlswortlängenalle Befehle nach einem Schema abarbeitbar
wenige/einfache Adressierungsarten, dafür in der Regel viele Register
Einfache und effiziente BefehlsverarbeitungHohe Taktraten möglich
Nachteil: Code wird in der Regel größer als bei CISC−Maschinen
DLX 3/64

Registersatz
R0
R31
R1
R2
F0F1
F2
F31031
PCS0
S1
S31031 31 0
GPR Gleitkomma Spezial
Relativ große Anzahl an Allzweck−Registern (GPR) R0...R31, 32 Bit, z.B. für Integer−Werte, R0 hat immer den Wert Null!
F0...F31 sind Gleitkomma−Register, für Single Precision IEEE−Format Gleitkomma−Zahlen oder Double Precision als Register−Paare (64 Bit) F0 & F1, F2 & F3, ..., F30 & F31
Programmcounter (PC), speichert Speicheradresse des nächsten Befehls.(muss immer ein Vielfaches von 4 sein, da ein DLX−Befehl 32 Bit lang ist,der Speicher aber byte−adressierbar ist)S0...S31 sind spezielle Register: nicht genutzt, um Operanden zu speichern,sonder haben Funktionen wie Prozessorstatuswort, Exception Control Register usw.
DLX 4/64

Befehlssatz
Umfasst Befehle für Datentransfer von und zum Speicher
Load/Storearithmetische und logische Operationen
Addition/SubtraktionMultiplikaion/DivisionAND/OR/Shift
Programmsteuerung Sprung/Verzweigung
Unterscheidung zwischen Byte, Halbwort, Wort, unsigned und signed. Bei Gleitkomma zwischen Single Precision und Double Precision.
Operanden sind entweder nur Register oder Register und Immediate.ADD R1, R2, R3 ( R1 <− R2 + R3; R−Type)ADDI R1, R2, #3 ( R1 <− R2 + 3; I −Type)
Speicher ist byte−adressierbar.LW R1, 32( 4* R2) ( R1 <− M[ 32+4* R2] ; I −Type)
Speicherzugriffe müssen ausgerichtet sein!
DLX 5/64
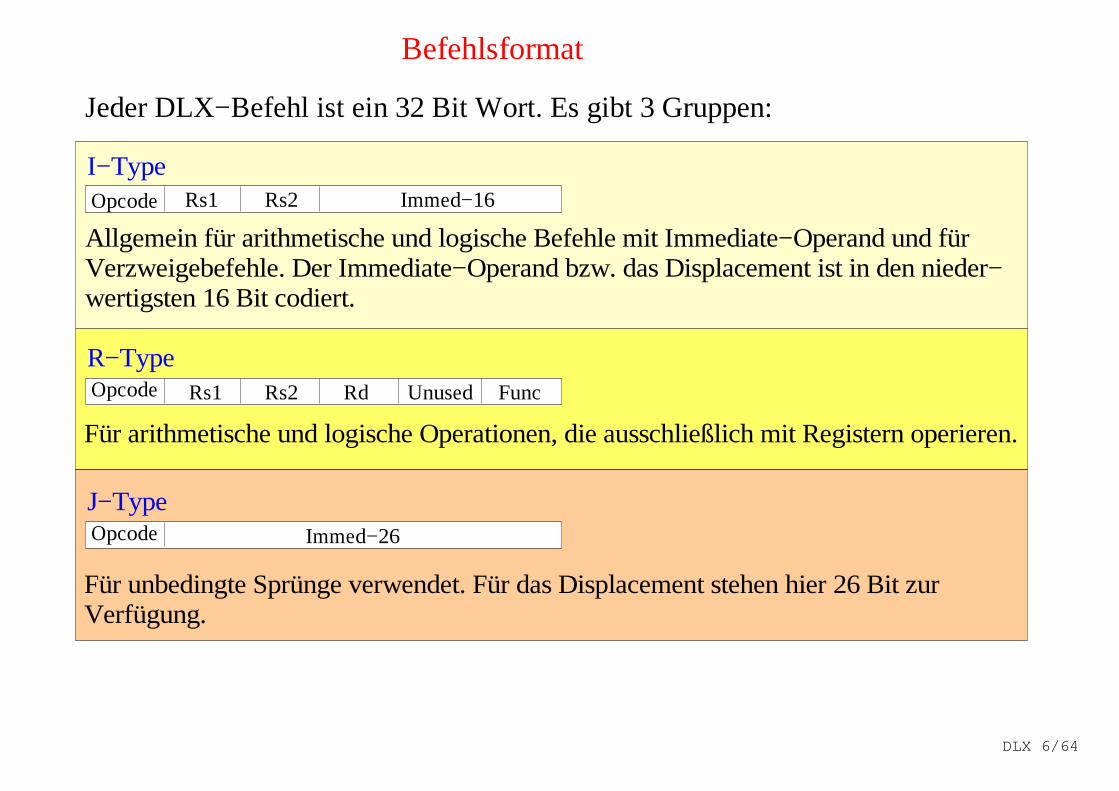
Befehlsformat
Jeder DLX−Befehl ist ein 32 Bit Wort. Es gibt 3 Gruppen:
I−TypeOpcode Rs1
Opcode
Opcode
Immed−16
Rs1 Rs2 Rd Unused Func
Rs2
Immed−26
R−Type
J−Type
Allgemein für arithmetische und logische Befehle mit Immediate−Operand und für Verzweigebefehle. Der Immediate−Operand bzw. das Displacement ist in den nieder−wertigsten 16 Bit codiert.
Für arithmetische und logische Operationen, die ausschließlich mit Registern operieren.
Für unbedingte Sprünge verwendet. Für das Displacement stehen hier 26 Bit zur Verfügung.
DLX 6/64
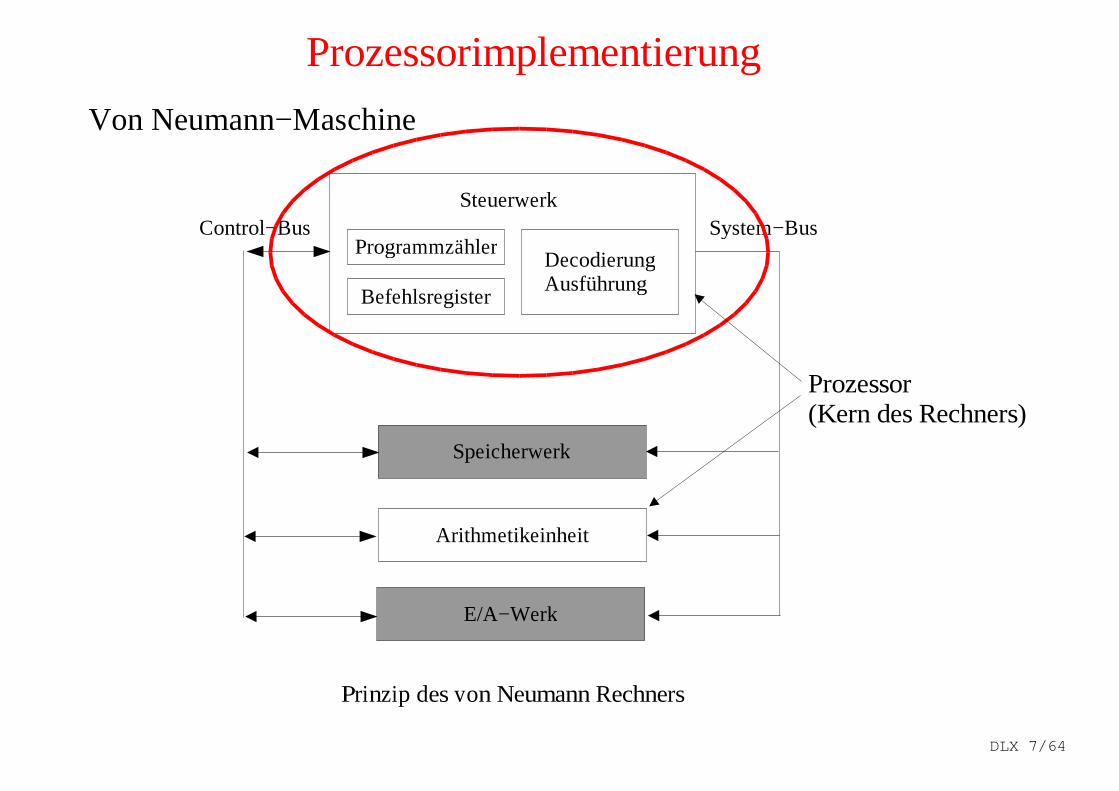
Prozessorimplementierung
Von Neumann−Maschine
Programmzähler
Befehlsregister
DecodierungAusführung
Steuerwerk
Speicherwerk
Arithmetikeinheit
E/A−Werk
Control−Bus System−Bus
Prinzip des von Neumann Rechners
Prozessor(Kern des Rechners)
DLX 7/64

Die Implementierung legt CPI−Wert und Taktzykluszeit fest.
CPI−Wert (cycles per instruction): Mittlere Anzahl interner Takt−Zyklen pro Maschinenbefehl.
Taktzykluszeit: abhängig von der Hardwaretechnologie bestimmt durch langsamste Schaltung, die während einer Taktzyklus−Periodearbeitet (oft Datenpfad)
DLX 8/64

Befehlsausführungsschritte
Die Ausführung der DLX−Befehle kann in fünf Basisschritte eingeteilt werden.
1. Befehlsholeschritt (instruction fetch)
MAR <− PC; IR <− M[MAR]
2. Befehlsdecodierung/Registerholeschritt (instruction decode/register fetch)
A <− Rs1; B <− Rs2; PC <− PC + 4
3. Ausführung/Effektivadress−Schritt (execution)
MAR <− A + (IR16
)16##IR16..31
; MDR <− Rd
Speicherzugriff:
ALU−Befehl:
ALUoutput <− A op (B or (IR16
)16##IR16..31
)
Verzweigung/Sprung:
ALUoutput <− PC + (IR16
)16##IR16..31
; cond <− (A op 0)
DLX 9/64

4. Speicherzugriff/Verzweigekomplettierungsschritt (memory access)
Nur Lade−, Speicher−, Verzweige− und Sprungbefehle sind aktiv.
Speicherzugriff:
MDR <− M[MAR] or M[MAR] <− MDR
Verzweigung:
If (cond) PC <− ALUoutput (branch)
5. Rückschreibeschritt (write back)
Rd <− ALUoutput or MDR
DLX 10/64

Prozessor−Datenpfad(von Neumannsche Arithmetikeinheit)
belegt meist rund 50% des DieBestimmt somit die Kosten des Prozessors wesentlichbestimmt die Taktzykluszeitabhängig von der Hardware−Technologiemeist einfach zu entwerfen
Umfasst die Verarbeitungseinheiten, z.B. arithmetisch−logische Einheiten, Verschieber,die Register und deren Verbindungslogik.
Aus Sicht des Programmierers meistens der Zustand des Prozessors, der bei Suspendie−rung zu retten und bei Fortsetzung der Ausführung wieder bereitzustellen ist.Der Zustand schließt die Universalregister, den Programmcounter, das Interrupt−Adreß−register und das Programmstatusregister ein.
DLX 11/64

Steuerung − Grundlagen
Meist schwer zu entwerfender Teil des ProzessorsKann durch Reduzierung des Befehlssatzes vereinfacht werden
Die Steuerung sagt dem Datenpfad, was in jedem Taktzyklus während der Ausführungeines Befehls zu tun ist.
Typisch mit einem Zustandsdiagramm spezifiziert:
IR <− M[PC]
PC <− PC + 4A <− Rs1B <− Rs2
Bsp. Obere Ebene desDLX−Zustandsdiagramms(vereinfacht) Speicherzugriff beendet
Speicherzugriff nichtbeendet
DLX 12/64

Es gibt zwei Haupttechniken der Steuerungs−Implementierung:Festverdrahtet
Festverdrahtete Steuerung
−> Umwandlung des Zustandsdiagramms in Hardware.Entspricht Steuerung über Finite State Machine
DLX:DLX−Zustandsdiagramm enthält 50 Zustände −> 6 Bit (26 = 64) zur Repräsentation des Zustandes erforderlich.
Werte der Steuerungsein− und −ausgängeKennung des Zustands Kennung des nächsten Zustandes
Darstellung der Steuerung in einer Tabelle
... ...
...
...
... ...
Es müssen die Kennung des Zustandes, die Werte der Steuerleitungen und die Kennung des nächstenZustandes enthalten sein.
Implementierung der Tabelle:( Read Only Memory (ROM) )Programmed Logic Array (PLA)
Microprogramm−gesteuert
DLX 13/64

Mikroprogrammierte Steuerung
Steuereinheit ist ein ’Miniaturcomputer’
Mikrobefehle auf der Steuerungsebene steuern DatenpfadMikrobefehle spezifizieren alle Steuersignale des Datenpfades, erweitert um dieFähigkeit bedingter Entscheidungen, welcher Mikrobefehl als nächstes auszuführen ist.
Vorteil:Befehlssatzänderung durch Austausch des Steuerspeicherinhalts möglich, ohne die Hardware zu berühren.Komplexer Befehlssatz möglich.
Nachteil:Abhängigkeit von Speichertechnologie
DLX 14/64
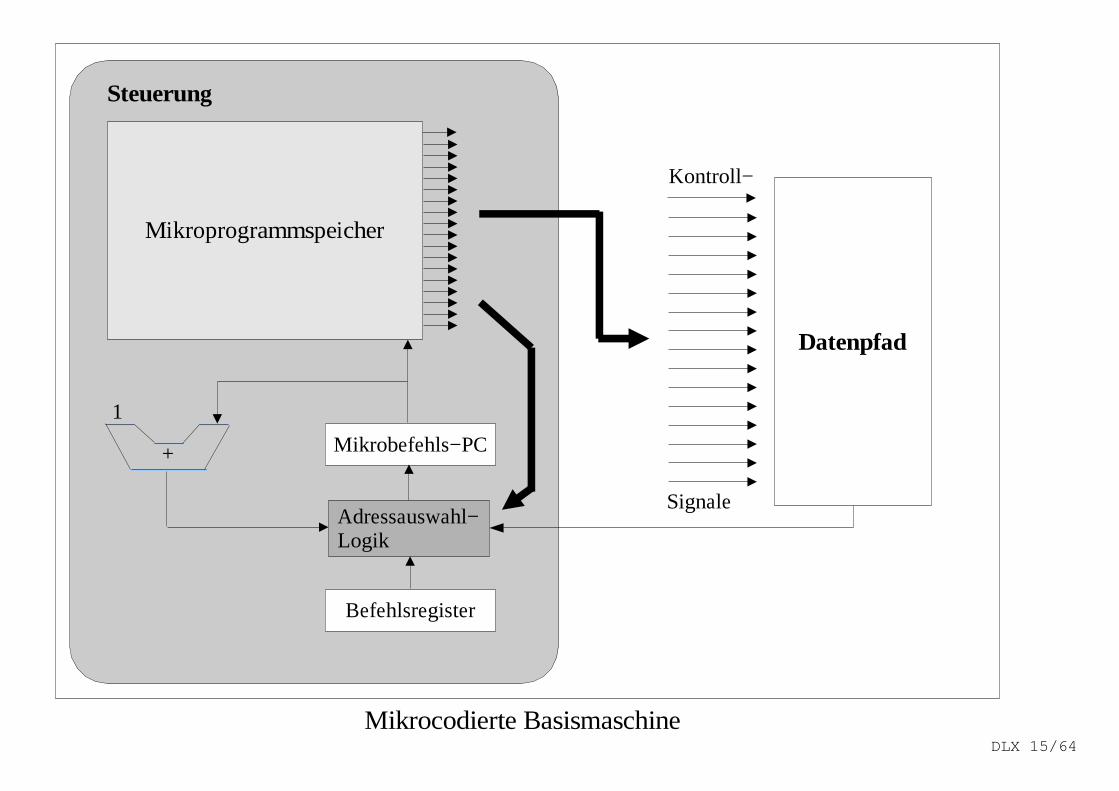
Steuerung
Datenpfad
Mikroprogrammspeicher
Mikrobefehls−PC
Adressauswahl−Logik
Befehlsregister
+
1
Kontroll−
Signale
Mikrocodierte BasismaschineDLX 15/64

Mikroprogramm: ähnlich einem Zustandsdiagramm, indem ein Befehl einem Zustandim Diagramm entspricht
Bsp. eines Mikrobefehlsformats:
Destination ALU Operation Source 1 Source 2 Constant Misc Cond Jump Address
Vorstellbar als Bereitstellung geeigneter Bitmuster in jedem Feld
DLX 16/64

Schwierigkeiten der Steuerung
Die Steuerung ist der schwierigste Teil des Prozessorentwurfs.Die wesentliche Schwierigkeit der Steuerung sind Interrupts (Unterbrechungen).
Beispiele für Interrupts:E/A−GeräteanforderungAufruf eines Betriebssystemdienstes in einem NutzerprogrammProtokollierung der BefehlsausführungUnterbrechungspunkt (vom Programmierer gesetzter Interrupt)Arithmetiküber− oder −unterlaufSeitenfehler (nicht im Hauptspeicher)nichtausgerichteter Speicherzugriff, wenn Ausrichtung erforderlichSpeicherschutzverletzungNutzung eines nicht definierten BefehlsHardware−FunktionsstörungStromversorgungsfehler
Ereignis Zeit zwischen EreignissenE/A−Interrupt 2,7 msZeitintervall−Interrupt 10,0 msSoftware−Interrupt 1,5 msJeder Interrupt 0,9 msJeder Hardware−Interrupt 2,1 ms
Häufigkeit einiger Interrupts am Beispiel einer VAX 8800 (1986) mit Mehrnutzer−Arbeitslast:
DLX 17/64

Pipelining
Heute eine Schlüsselimplementierungsmethode, um schnelle Prozessoren zu realisieren.
Implementierungsmethode, bei der mehrere Befehle zeitlich überlappt ausgeführt werden.
Vergleichbar mit Fließband: Die bei einem Befehl auszuführende Arbeit ist in kleine Abschnitte zerlegt.Jeder Schritt in der Pipeline (Pipeline−Stufe, pipeline stage) vollendet einen Teil
des Befehls.Verschiedene Pipeline−Stufen sind gleichzeitig aktiv.Befehle treten am Anfang ein, werden entlang der Stufen verarbeitet und treten am
Ende wieder aus.
Durchsatz der Pipeline: Wie oft treten Befehle aus der Pipeline aus?
Die erforderliche Zeit für den Transport eines Befehls um eine Stufe nennt man Maschinenzyklus. Die Länge des Maschinenzyklus wird bestimmt durch die Zeit für dielangsamste Stufe in der Pipeline, da alle Stufen gleichzeitig fortgesetzt werden müssen.
DLX 18/64

Ziel des Entwerfers:Günstige Balance der Länge von Pipeline−Stufen erreichen.
Zeit pro Befehl unter idealen Bedingungen = Befehlsausführungszeit der ohne Pipeline implementierten Maschine
Zahl der Pipeline−Stufen
D.h., die Leistungssteigerung gegenüber der ohne Pipeline implementierten Maschine istgleich der Anzahl der Pipeline−Stufen. −> möglichst viele, kurze Pipeline−Stufen?
Ja, in der Regel ermöglichen kleinere Stufen auch eine Erhöhung der Taktfrequenz, aber:
Mindestlänge der Stufen gegeben durch minimal mögliche Zerlegung in Ausführungsschritte und durch Overhead, welches Pipelining mit sich bringt (imwesentlichen Latches − Earle Latches − und Taktverschiebung zwischen den Stufen).
Pipelining erzielt eine Reduzierung der mittleren Ausführungszeit pro Befehl unterNutzung der Parallelität zwischen Befehlen in einem sequentiellen Befehlsstrom.Pipelining ist für den Anwender nicht sichtbar.
!
DLX 19/64

Die Basis−Pipeline für die DLX
Ausführung der DLX−Befehle in fünf Grundschritten bereits bekannt:1. IF − Instruction Fetch (Befehl holen)2. ID − Instruction Decode and register fetch (Befehl dekodieren und Register holen)3. EX − EXecution and effective address calculation (Ausführung und Adressberechnung)4. MEM − MEMory access (Speicherzugrif f)5. WB − Write Back (Rückschreiben zum Zielregister)
Realisierung der Pipeline −> einfach in jedem Taktzyklus einen neuen Befehl holen.
TaktnummerBefehls 1 2 3 4 5 6 7 8 9
Befehl i IF ID EX MEM WBBefehl i + 1 IF ID EX MEM WBBefehl i + 2 IF ID EX MEM WBBefehl i + 3 IF ID EX MEM WBBefehl i + 4 IF ID EX MEM WB
Nummer des
DLX 20/64

Jeder Befehl erfordert immernoch 5 Taktzyklen. Die Hardware führt in jedem Taktzykluseinen Teil von 5 unterschiedlichen Befehlen aus.
Pipelining erhöht den Durchsatz der Prozessorbefehle − die pro Zeiteinheit beendete Befehlsanzahl. Aber es reduziert nicht die Ausführungszeit eines einzelnen Befehls.
Grenzen der DLX−Pipeline:Ausführungszeit jedes Befehls bleibt unverändert (praktisch sogar durch Latches und Taktverzögerung vergrößert)geringe Pipeline−Tiefe
Charakteristik:
DLX 21/64
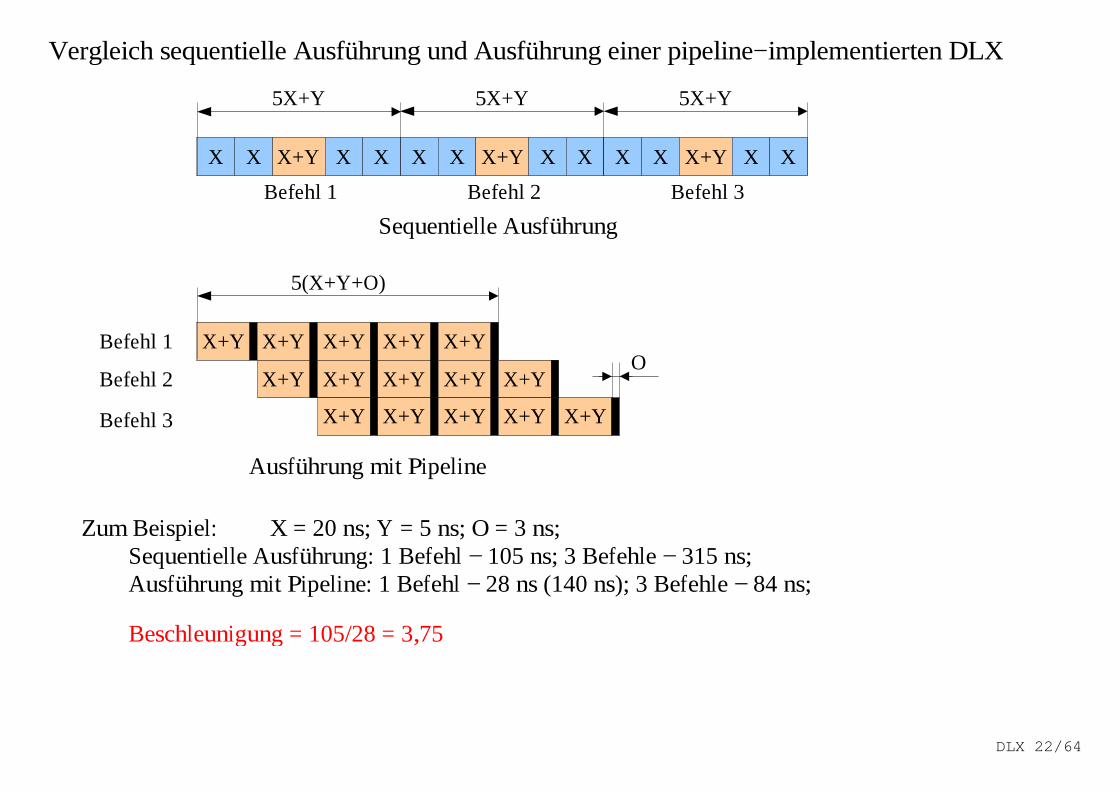
Vergleich sequentielle Ausführung und Ausführung einer pipeline−implementierten DLX
X+YX X X X X X X+Y X X X X X+Y X X
5X+Y 5X+Y 5X+Y
Befehl 1 Befehl 2 Befehl 3
Sequentiel le Ausführung
X+Y X+Y X+Y X+Y X+Y
X+Y X+Y X+Y X+Y X+Y
X+Y X+Y X+Y X+Y X+Y
5(X+Y+O)
OBefehl 1
Befehl 2
Befehl 3
Ausführung mit Pipeline
Zum Beispiel: X = 20 ns; Y = 5 ns; O = 3 ns;Sequentiel le Ausführung: 1 Befehl − 105 ns; 3 Befehle − 315 ns;Ausführung mit Pipeline: 1 Befehl − 28 ns (140 ns); 3 Befehle − 84 ns;
Beschleunigung = 105/28 = 3,75
DLX 22/64

Beispiel Pentium 4:
Sog. NetBurst−Architektur: Hyper−Pipeline mit 20 Stufenermöglicht hohe Taktfrequenzenkann bis zu 128 Mikro−Operationen gleichzeitig bearbeiten(Mikro−Op: x86−Befehle werden in kleinere RISC−Befehle aufgeteilt)Implementiert Rapid Execution Engine, d.h. ALUs mit doppelter CPU−Frequenz getaktet (z.B. Integer−Befehle bei P4 1,6 GHz mit 3,2 GHz) kann 4 Datenworte mit 64 Bit Breite pro Takt übertragen
DLX 23/64

Durch Pipelining verursachte Probleme
Es ist abzusichern, dass die Überlappung der Befehle die Ressourcen nicht überfordert!Bsp.: einfache ALU kann nicht gleichzeitig eine effektive Adresse berechnen und Operanden
subtrahieren
Da jede Stufe zu jedem Taktzyklus aktiv ist, müssen alle Operationen einer Stufe in jedem Takt−zyklus abschließen und jede Kombination von Operationen muss gleichzeitig ausführbar sein.
Anforderungen an den Datenpfad der DLX:1. PC muss in jedem Takt inkrementiert werden, anstelle von ID in IF; da ALU stets belegt, ist
ein extra Inkrementer erforderlich2. in jedem Taktzyklus neuen Befehl holen − in der IF−Stufe3. in jedem Taktzyklus kann ein neues Datenwort erforderlich sein − in MEM4. getrenntes MDR für Laden und Speichern erforderlich (LMDR und SMDR), da sich beide
Befehle zeitlich überlappen können5. drei zusätzliche Latches nötig, um Befehl, ALU−Ausgangswert und PC zwischenzuspeichern
Stufe PC−Einheit Speicher DatenpfadIF PC <− PC+4; IR <− Mem[PC];ID PC1 <− PC; IR1 <− IR; A <− Rs1; B <− Rs2;
EX
MEM If (cond) PC <− ALUoutput; LMDR <− Mem[DMAR]; oder ALUoutput1 <− ALUoutput;Mem[DMAR] <− SMDR;
WB Rd <− ALUoutput1; oder Rd <− LMDR;
DMAR <− A+(IR16)16##IR116...31; SMDR <− B; oder
ALUoutput <− A op (B or (IR116)16##IR116..31); oder
ALUoutput <−PC1 + (IR116)16##IR116..31); cond <− (A op 0);
DLX 24/64
Die Ressource Speicher
hat den wahrscheinlich größten Einfluss auf das Pipelining
Die Speicherzugriffszeit ist gleich!Aber: Die Spitzenspeicherbandbreite muss fünffach größer sein als bei der Maschine ohne Pipeline (zwei Speicherzugriffe in jedem Takt gegenüber zwei Zugriffen in fünf Takten).
Die meisten Maschinen nutzen daher getrennte Befehls− und Datencaches (Harvard−Architektur...).
DLX 25/64

Die Pipeline würde nun gut funktionieren, wenn jeder Befehl von jedem anderen Befehl in derPipeline unabhängig wäre. Befehle können aber voneinander abhängen!
Pipeline−Hazards
Hazards sind Situationen, die die Ausführung des nächsten Befehls aus demBefehlsstrom im zugeordneten Taktzyklus verhindern.
reduzieren die mittels Pipelining gewinnbare ideale Leistungssteigerung
Hazard−Klassen:
Struktur−Hazard (structural hazard): resultiert aus einem RessourcenkonfliktDaten−Hazard (data hazard): verursacht ein Befehl, der vom Ergebnis des voran−
gegangenen Befehls in einer Weise abhängt, die sichdurch die überlappte Abarbeitung herausstellt
Steuer−Hazard (control hazard): ergibt sich durch Pipelining von Verzweigungen und anderen Befehlen, die den PC ändern
Die Steuerung muss Hazard−Situationen erkennen!Hazards können Wartezyklen (stalls) erforderlich machen!
DLX 26/64

Struktur−Hazards
TaktnummerBefehl 1 2 3 4 5 6 7 8 9Ladebefehl IF ID EX MEM WBBefehl i + 1 IF ID EX MEM WBBefehl i + 2 IF ID EX MEM WBBefehl i + 3 Stall IF ID EX MEM WBBefehl i + 4 IF ID EX MEM
Beispiel Ladebefehl (gemeinsamer Speicher für Befehle und Daten):
Eine Befehlsfolge kann in Folge von Ressourcenkonfl ikten nicht untergebracht werden.(z.B. weil eine Funktionseinheit nicht vollständig pipeline−implementiert ist, FEs nicht ausreichend dupliziert sind, usw.)
Daten−Hazards
Die Reihefolge des Operandenzugrif fs durch die Pipeline ist gegenüber der normalenReihenfolge bei sequentiel ler Ausführung geändert.
Bsp.: ADD R1, R2, R3SUB R4, R1, R5
ADD schreibt R1 in WB, SUB liest R1 in ID −> wenn Abhängigkeit nicht erkannt, wird SUB einen falschen Wert lesen.
DLX 27/64
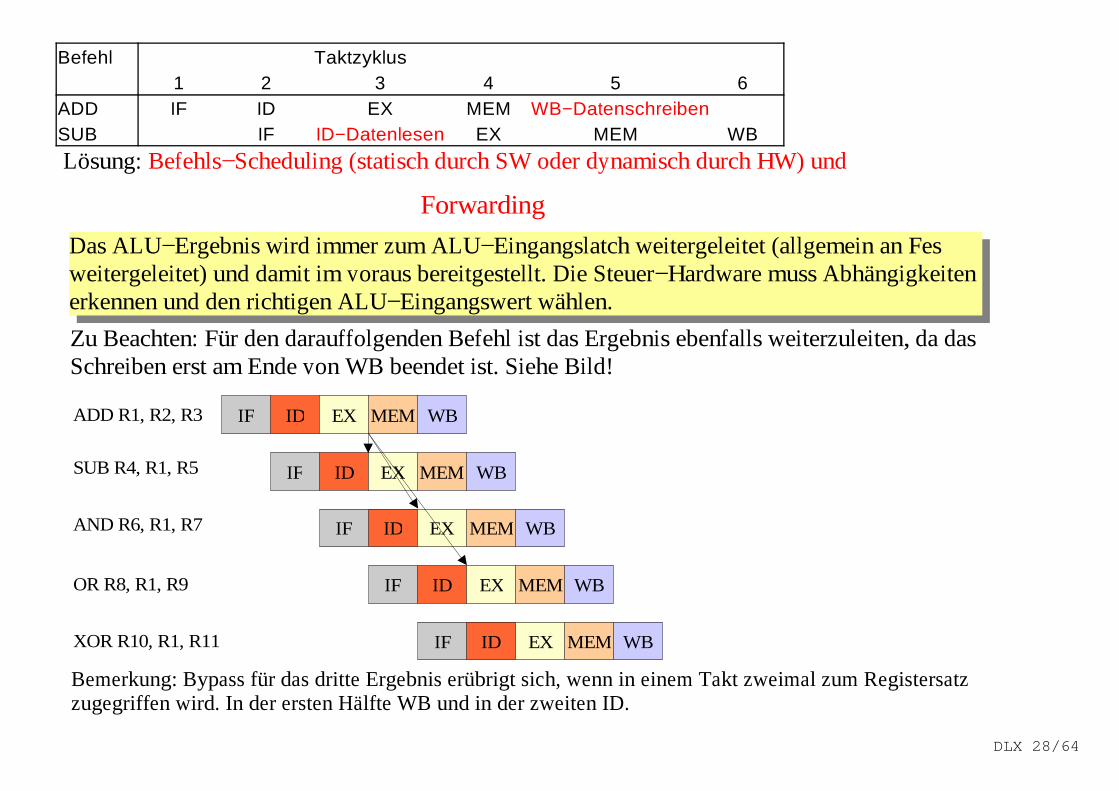
Befehl Taktzyklus1 2 3 4 5 6
ADD IF ID EX MEM WB−DatenschreibenSUB IF ID−Datenlesen EX MEM WB
Lösung: Befehls−Scheduling (statisch durch SW oder dynamisch durch HW) und
Das ALU−Ergebnis wird immer zum ALU−Eingangslatch weitergeleitet (allgemein an Fes weitergeleitet) und damit im voraus bereitgestellt. Die Steuer−Hardware muss Abhängigkeiten erkennen und den richtigen ALU−Eingangswert wählen.
Zu Beachten: Für den darauffolgenden Befehl ist das Ergebnis ebenfalls weiterzuleiten, da das Schreiben erst am Ende von WB beendet ist. Siehe Bild!
IFADD R1, R2, R3 ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
SUB R4, R1, R5
AND R6, R1, R7
OR R8, R1, R9
XOR R10, R1, R11
Bemerkung: Bypass für das dritte Ergebnis erübrigt sich, wenn in einem Takt zweimal zum Registersatzzugegriffen wird. In der ersten Hälfte WB und in der zweiten ID.
Forwarding
DLX 28/64

Typen von Daten−AbhängigkeitenRAW (read after write)WAR (write after read)WAW (write after write)
Steuer−Hazards
Können einen größeren Leistungsverlust als Daten−Hazards in der Pipeline verursachen!
Verzweigebefehl i IF ID EX MEM WBBefehl i + 1 IF Stall Stall IF ID EX MEM WBBefehl i + 2 Stall Stall Stall IF ID EX MEM WBBefehl i + 3 Stall Stall Stall IF ID EX MEMBefehl i + 4 Stall Stall Stall IF ID EXBefehl i + 5 Stall Stall Stall IF IDBefehl i + 6 Stall Stall Stall IF
Reduzierung der Anzahl von Wartezyklen:1. Frühes Herausfinden des ausgeführten und nichtausgeführten Verzweigefalles in der
Pipeline.2. Frühes Berechnen der Zieladresse für den PC bei auszuführender Verzweigung.
3 Wartezyklen!
DLX 29/64
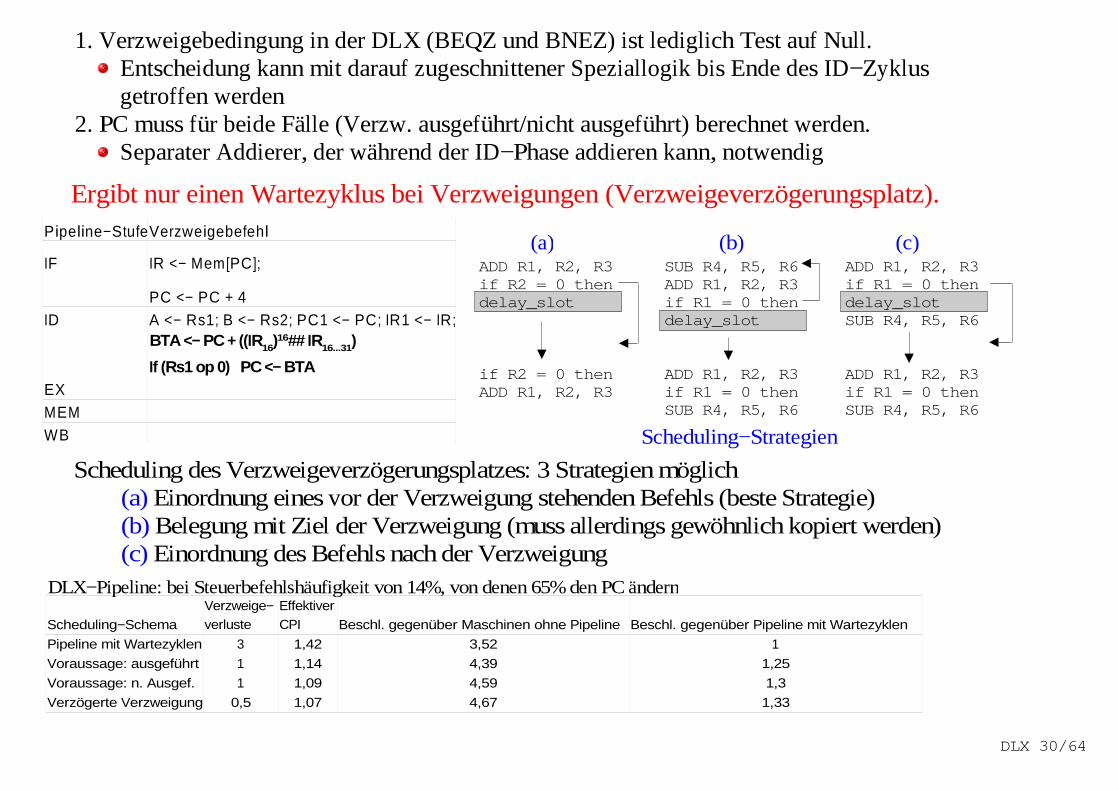
1. Verzweigebedingung in der DLX (BEQZ und BNEZ) ist lediglich Test auf Null.Entscheidung kann mit darauf zugeschnittener Speziallogik bis Ende des ID−Zyklus getroffen werden
2. PC muss für beide Fälle (Verzw. ausgeführt/nicht ausgeführt) berechnet werden.Separater Addierer, der während der ID−Phase addieren kann, notwendig
Ergibt nur einen Wartezyklus bei Verzweigungen (Verzweigeverzögerungsplatz).Pipeline−StufeVerzweigebefehl
IF IR <− Mem[PC];
PC <− PC + 4ID A <− Rs1; B <− Rs2; PC1 <− PC; IR1 <− IR;
EXMEMWB
BTA <− PC + ((IR16)16## IR16...31)
If (Rs1 op 0) PC <− BTA
Scheduling des Verzweigeverzögerungsplatzes: 3 Strategien möglich(a) Einordnung eines vor der Verzweigung stehenden Befehls (beste Strategie)(b) Belegung mit Ziel der Verzweigung (muss allerdings gewöhnlich kopiert werden)(c) Einordnung des Befehls nach der Verzweigung
Scheduling−Schema Beschl. gegenüber Maschinen ohne Pipeline Beschl. gegenüber Pipeline mit Wartezyklen
Pipeline mit Wartezyklen 3 1,42 3,52 1
Voraussage: ausgeführt 1 1,14 4,39 1,25
Voraussage: n. Ausgef. 1 1,09 4,59 1,3
Verzögerte Verzweigung 0,5 1,07 4,67 1,33
Verzweige−verluste
Effektiver CPI
DLX−Pipeline: bei Steuerbefehlshäufigkeit von 14%, von denen 65% den PC ändern
ADD R1, R2, R3if R2 = 0 thendelay_slot
if R2 = 0 thenADD R1, R2, R3
SUB R4, R5, R6ADD R1, R2, R3if R1 = 0 thendelay_slot
ADD R1, R2, R3if R1 = 0 thenSUB R4, R5, R6
ADD R1, R2, R3if R1 = 0 thendelay_slotSUB R4, R5, R6
ADD R1, R2, R3if R1 = 0 thenSUB R4, R5, R6
(a) (b) (c)
Scheduling−Strategien
DLX 30/64

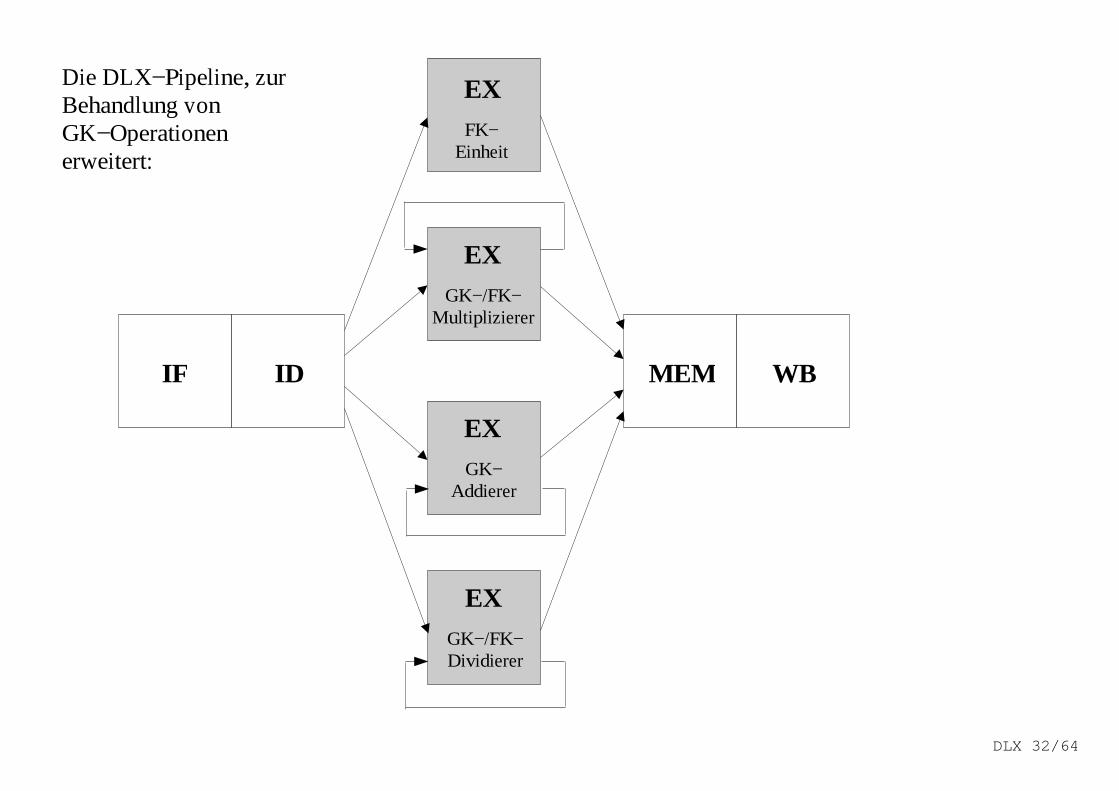
Erweiterung der DLX−Pipeline zur Behandlung vonGK−Operationen
Ausführung von DLX−GK−Operationen in einem oder zwei Taktzyklen würde entweder einenlangsamen Takt oder die Nutzung eines enormen Logikumfangs in der GK−Einheit erfordernoder beides!
Änderungen gegenüber FK−Pipeline:EX−Zyklus kann so oft wie notwendig wiederholt werden, um die Operation zu beenden.Es kann mehrere GK−Funktionseinheiten geben.
Ein Wartezyklus wird auftreten, wenn der auszuführende Befehl einen Struktur−Hazard für die Nutzung der funktionellen Einheiteinen Daten−Hazard
verursacht.
Struktur der DLX: 4 getrennte Funktionseinheiten1. Haupt−FK−Einheit2. GK− und FK−Multipl izierer3. GK− Addierer4. GK− und FK−Dividierer
DLX 31/64
EX
EX
EX
EX
FK−Einheit
GK−/FK−Multiplizierer
GK−Addierer
GK−/FK−Dividierer
IF ID MEM WB
Die DLX−Pipeline, zurBehandlung vonGK−Operationenerweitert:
DLX 32/64

Dynamisches Scheduling
Bisher: Pipeline holt Befehl und übergibt ihn, es sei denn, es gibt eine Datenabhängigkeitzwischen einem Befehl, der sich bereits in der Pipeline bef indet und dem zu holendenBefehl. Wenn Datenabhängigkeit −> Wartezyklen!Für das Scheduling von Befehlen zur Minimierung dieser Wartezeit ist Software ver−antwortl ich (Compiler), sog. Statisches Scheduling.
−> Dynamisches Scheduling: Hardware reduziert Wartezyklen durch Umordnen derBefehlsausführung
Vorteile dyn. Scheduling:Behandlung von Fällen, in denen Abhängigkeiten zur Compilezeit unbekannt sinderlaubt effektive Abarbeitung von Code auf einer anderen Pipeline als der, für die derCode übersetzt wurde
Nachteil:Signif ikante Erhöhung der Hardware−Komplexität!
Scoreboarding Tomasulo−Algorithmus Hardware−Verzweigevoraussage
Aufwandsreduzierung von Datenabhängigkeiten
Verlustreduzierung von Steuer−Hazards
}}
Drei Methoden:
DLX 33/64

Übergabe der Befehle in normaler Reihenfolge.Wenn ein Befehl die Pipeline anhält, kann kein anderer fortsetzen und FEs könnenungenutzt sein!
Code−Segment: DIVF F0, F2, F4ADDF F10, F0, F8SUBF F6, F6, F14
SUBF kann wegen der Abhängigkeit von ADDF zu
DIVF nicht ausgeführt werden (Wartezyklen).
SUBF ist aber unabhängig von den beiden Befehlen!
−> Durch Außer−Reihe−Ausführung von Befehlen kann diese Leistungsbegrenzungvermieden werden.
Notwendig: Test auf Struktur−Hazards und Abwesenheit von Daten−Hazards.
Die Ausführung eines Befehls kann beginnen, sobald die Operanden verfügbar sindund keine Daten−Hazards vorliegen. Auf Struktur−Hazards kann noch getestet werden,während der Befehl seine Ausführung beginnt.
Problem:
DLX 34/64

Außer−Reihe−Ausführung in der DLXAufteilung der Stufen:
1. ID − Befehlsdecodierung und Test auf alle Hazards (wenn nötig warten) und Operandenholen2. EX − Befehlsausführung
in drei Stufen:1. Übergabe − Befehl decodieren und Test auf Struktur−Hazards2. Operanden lesen − warten bis keine Hazards auftreten und dann Operanden lesen3. Ausführung
Die Übergabe−Stufe wird von allen Befehlen noch in Reihe durchlaufen.In der 2. Stufe (Operanden lesen) können sich Befehle gegenseitig anhalten oder über einenBypass Ergebnisse bereitstellen und so in eine Außer−Reihe−Ausführung eintreten, die eineAußer−Reihe−Beendigung nach sich zieht (−> WAW−, WAR−Hazards?).
Scoreboarding − Methode, die eine Außer−Reihe−Ausführung erlaubt, wenn esausreichende Ressourcen und keine Datenabhängigkeiten gibt.(benannt nach dem CDC 6600−Scoreboard, Control Data Corporation 1964)
Vermeiden von WAR−Hazards! Zwei Regeln:(1) Lies Register nur in der Stufe Registerlesen!(2) Speichere sowohl Operationen als auch Operanden in einer Queue ab!WAW−Hazards:
Müssen getestet werden! Wenn nötig Einfügen von Wartezyklen.
Scoreboard
DLX 35/64

Scoreboard
GK−Multiplik.GK−Multiplik.
GK−Division
GK−Addition
FK−Einheit
RegisterDatenbusse
Steuerung/StatusSteuerung/Status
Basisstruktur einer DLX−Maschine mit Scoreboard
Mehrere Befehle müssen sich in der EX−Stufe befinden können!Mehrere Funktionseinheiten, oder in Pipelining realisierte Funktionseinheiten notwendig.
Funktion: Steuerung der Befehlsausführung. Jedes Register besitzt Valid−BitJeder Befehl geht durch Scoreboard, Datenabhängigkeiten u. Zielregister werden aufgezeichnet;Aufzeichnungen bestimmen, wann Befehl seine Operanden lesen und Ausführung beginnen kannZukünftiges Resultatregister wird nach ID invalid gesetzt, da Inhalt sich ändert, wenn Befehl fertigNach WB−Phase wird Register auf valid gesetztEntscheidet Scoreboard, dass Befehl nicht sofort ausgeführt werden kann (Befehl versucht invalid−Register zu lesen oder Ressourcen belegt), überwacht es jede Änderung der HW + entscheidet, wann Befehl auszuführen ist. Scoreboard überwacht auch, wann Befehl sein Ergebnis in Zielregister schreiben kann.
Gesamte Hazarderkennung und −Auflösung im Scoreboard zentralisiert.
DLX 36/64

Ausführungsschritte des DLX−Scoreboard
1. Übergabe: Wenn eine FE für den Befehl frei ist und kein anderer aktiver Befehl das selbe Zielregister hat (WAW−Hazard), übergibt das Scoreboard den Befehl der FE und aktualisiert seine interne Datenstruktur.
2. Operanden lesen: Das Scoreboard überwacht die Verfügbarkeit der Quelloperanden. Ein Quelloperand ist verfügbar, wennkein aktiver Befehl beabsichtigt, zu diesem zu schreiben oder wenn das den Operanden enthaltende Re−gister durch eine gerade aktive FE geschrieben wird. Sind die Operanden verfügbar, teilt das Scoreboardder FE mit, dass das Lesen der Operanden von den Registern fortgesetzt und mit der Ausführung begonnenwerden kann. (dynamisches Auflösen von RAW−Hazards)
3. Ausführung: Die FEs beginnen die Ausführung nach Erhalt der Operanden. Wenn das Ergebnis vorliegt, registriert dasScoreboard, dass die Ausführung beendet ist.
4. Ergebnis schreiben: Wenn das Scoreboard wahrnimmt, dass die FE die Ausführung beendet hat, testet es auf WAR−Hazards.Einem in der Endphase befindlichen Befehl kann nicht erlaubt werden, sein Ergebnis zu schreiben, wenn:
es einen Befehl gibt, der noch nicht seine Operanden gelesen hateiner der Operanden im selben Register wie das Ergebnis des endenden Befehls ist undder andere Operand das Ergebnis eines früheren Befehls ist
Wenn kein WAR−Hazard vorliegt oder wenn er behoben ist, signalisiert das Scoreboard den Funktions−einheiten, ihr Ergebnis im Zielregister zu speichern.
DLX 37/64

ZielErreichen einer Ausführungsrate von einem Befehl pro Taktzyklus (wenn es keineStruktur−Hazards gibt), indem ein Befehl so früh wie möglich ausgeführt wird.
Das Scoreboard trägt die volle Verantwortung für die Befehlsübergabe und −ausführung,einschließlich der Hazard−Erkennung. Es steuert die Befehlsabarbeitung von einem Schrittzum nächsten beruhend auf seinen eigenen Datenstrukturen durch Kommunikation mit denFunktionseinheiten.
Probleme des Scoreboard:Alle Ergebnisse durch Registerf i le geschrieben und niemals durch Forwarding bereitgestellt!
Wenn Befehl sein Ergebnis schreibt, muss ein abhängiger Befehl auf Zugrif f zum Registerf i le warten. Das erhöht die Latenzzeit und begrenzt die Möglichkeit, mehrere Befehle zu initi ieren, die auf ein Ergebnis warten.WAR− und WAW−Hazards möglich!
DLX 38/64
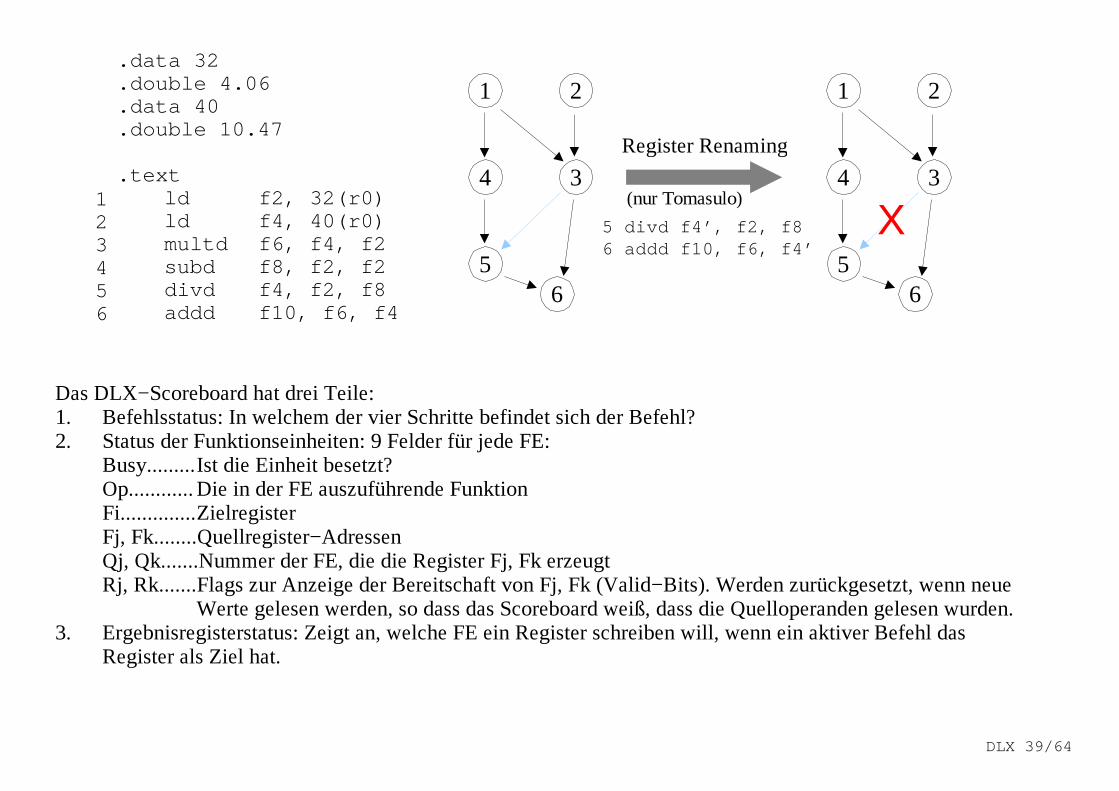
.data 32
.double 4.06
.data 40
.double 10.47
.textld f2, 32(r0)ld f4, 40(r0)multd f6, f4, f2subd f8, f2, f2divd f4, f2, f8addd f10, f6, f4
Das DLX−Scoreboard hat drei Teile:1. Befehlsstatus: In welchem der vier Schritte befindet sich der Befehl?2. Status der Funktionseinheiten: 9 Felder für jede FE:
Busy.........Ist die Einheit besetzt?Op............ Die in der FE auszuführende FunktionFi..............ZielregisterFj, Fk........Quellregister−AdressenQj, Qk.......Nummer der FE, die die Register Fj, Fk erzeugtRj, Rk.......Flags zur Anzeige der Bereitschaft von Fj, Fk (Valid−Bits). Werden zurückgesetzt, wenn neue
Werte gelesen werden, so dass das Scoreboard weiß, dass die Quelloperanden gelesen wurden.3. Ergebnisregisterstatus: Zeigt an, welche FE ein Register schreiben will, wenn ein aktiver Befehl das
Register als Ziel hat.
123456
1 2
34
56
1 2
34
56
X
Register Renaming
5 divd f4’, f2, f86 addd f10, f6, f4’
DLX 39/64
(nur Tomasulo)

Der Tomasulo−Algorithmus
Erstmals bei der IBM 360/91−GK−Einheit etwa 3 Jahre nach der CDC 6600 angewendet, von R. Tomasulo geschaffen.− Konzentriert sich auf die GK−Einheit− ähnlich Scoreboard
VorteileVerteilung der Hazard−ErkennungslogikEliminieren von Wartezyklen für WAW− und WAR−Hazards (treten bei Wiederver−wendung von Registern auf) durch Register Renaming
Nachteilegroßer Hardwareaufwandeinzelner Bus (Common Data Bus, CDB) begrenzt den LeistungsgewinnLade− und Speicherbefehle können in unterschiedlicher Reihenfolge ausgeführt werden(Es muss sichergestellt sein, dass sie auf verschiedene Adressen zugreifen−> Test in Speicherpuffer)
DLX 40/64

Zwei wesentliche Unterschiede zum Scoreboard der CDC 6600:
1. Hazard−Erkennung und Ausführungssteuerung sind verteilt − Reservierungstabellen(reservation stations) an jeder FE informieren die Steuerung, wenn ein Befehl mit derAusführung an dieser Einheit beginnen kann.
2. Ergebnisse werden den FE direkt übermittelt (CDB), anstatt durch Register zu gehen.
Reservierungstabellen der DLX − jeweils sechs Felder :Op − Die auf die Quelloperanden S1 und S2 auszuführende OperationQj, Qk − Die Reservierungstabellen, die den zugeordneten Quelloperanden bereitstellen. Null zeigt an,
dass der Quelloperand bereits in Vi oder Vj verfügbar oder nicht erforderlich ist.Vj, Vk − Die Werte der Quelloperanden. Sie werden SINK und SOURCE bei der IBM 360/91 genannt.
Beachten Sie, dass nur eines des V− oder Q−Feldes fuer jeden Operanden vorhanden ist.Busy − Anzeige des Besetzt−Zustandes der Reservierungstabelle und der verbundenen FE
Das Registerfile und der Speicherpuffer haben ein Feld Qi:Qi − Adresse der FE, die einen in das Register oder den Speicher zu schreibenden Wert erzeugen will.
Wenn der Wert von Qi Null ist, berechnet keiner der gegenwärtig aktiven Befehle ein Ergebnis,das für dieses Register oder den Puffer bestimmt ist.
DLX 41/64
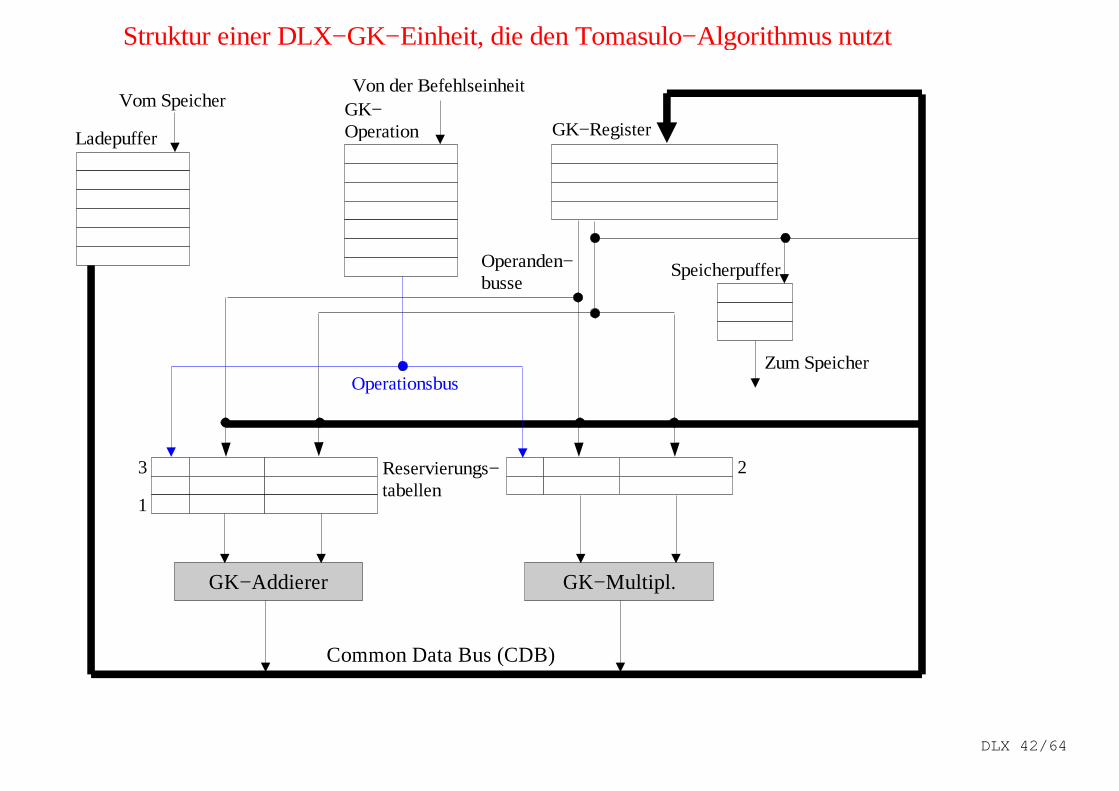
Struktur einer DLX−GK−Einheit, die den Tomasulo−Algorithmus nutzt
GK−Addierer GK−Multipl.
Ladepuffer
GK−Operation
Vom SpeicherVon der Befehlseinheit
GK−Register
Common Data Bus (CDB)
Reservierungs−tabellen
Zum Speicher
SpeicherpufferOperanden−busse
Operationsbus
321
21
DLX 42/64

Funktionsweise
1. Übergabe: Ein Befehl wird von der GK−Operations−Queue bereitgestellt. Die GK−Operation ist zu übergeben, wennes eine leere Reservierungstabelle gibt, und es sind die Operanden zur Reservierungstabelle zu senden,wenn sie in den Registern sind. Wenn es eine Lade− oder Speicheroperation ist, kann sie übergeben werden, wenn es einen freien Puffer gibt. Wenn es keine leere Reservierungstabelle oder einen leerenPuffer gibt, dann liegt ein Struktur−Hazard vor, und der Befehl hält an, bis eine Station oder ein Pufferfrei geworden ist.
2. Ausführung: Wenn einer oder mehrere der Operanden noch nicht verfügbar sind, ist der CDB zu überwachen, währendauf die zu berechnenden Register gewartet wird. Dieser Schritt testet auf RAW−Hazards. Wenn beideOperanden verfügbar sind, ist die Operation auszuführen.
3. Ergebnis schreiben: Ist das Ergebnis verfügbar, wird es zum CDB geschrieben und von dort in die Register, sowie in jedeFunktionseinheit, die auf dieses Ergebnis wartet.
Es gibt keinen Test auf WAW− und WAR−Hazards! −> wurden als Begleiterscheinung des Algorithmus entfernt.Der CDB wird zur Übermittlung von Ergebnissen genutzt, anstatt auf Register zu warten.Lade− und Speichereinheiten werden wie Basisfunktionseinheiten behandelt.
DLX 43/64
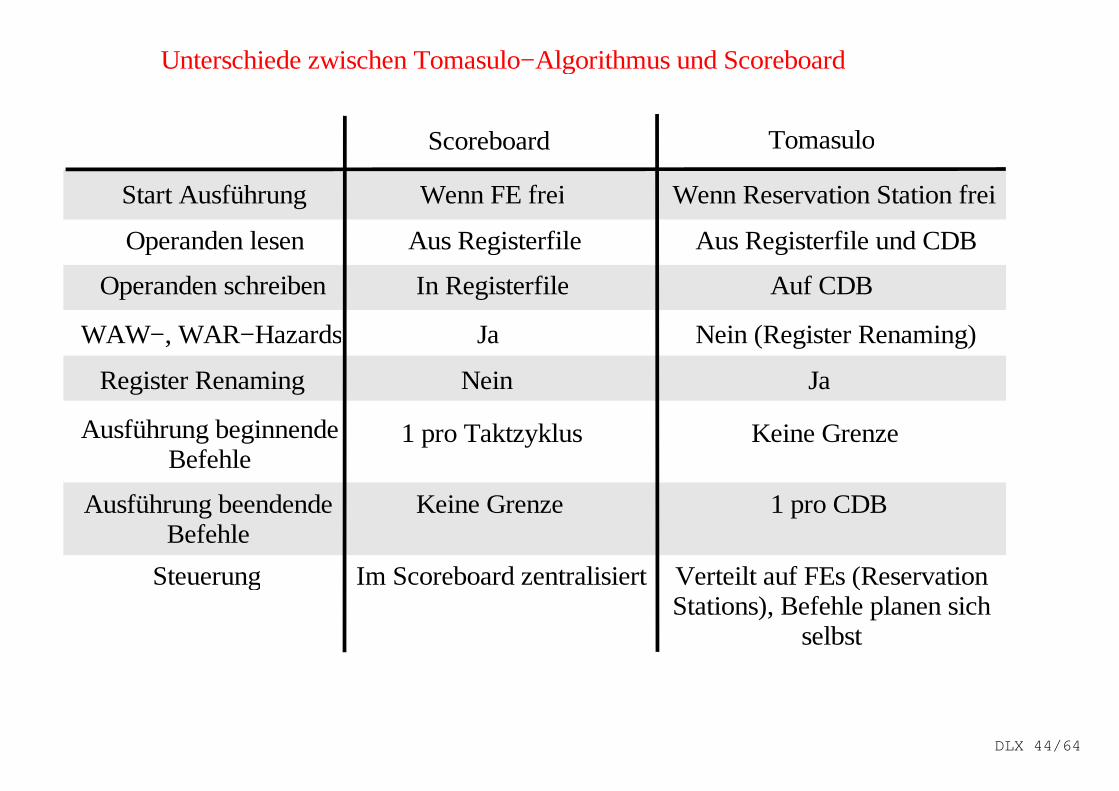
Unterschiede zwischen Tomasulo−Algorithmus und Scoreboard
Scoreboard Tomasulo
Start Ausführung Wenn FE frei Wenn Reservation Station frei
Operanden lesen Aus Registerfile Aus Registerfile und CDB
Operanden schreiben In Registerfile Auf CDB
WAW−, WAR−Hazards Ja Nein (Register Renaming)
Register Renaming Nein Ja
Ausführung beginnendeBefehle
1 pro Taktzyklus Keine Grenze
Ausführung beendendeBefehle
Keine Grenze 1 pro CDB
Steuerung Im Scoreboard zentralisiert Verteilt auf FEs (ReservationStations), Befehle planen sich
selbst
DLX 44/64

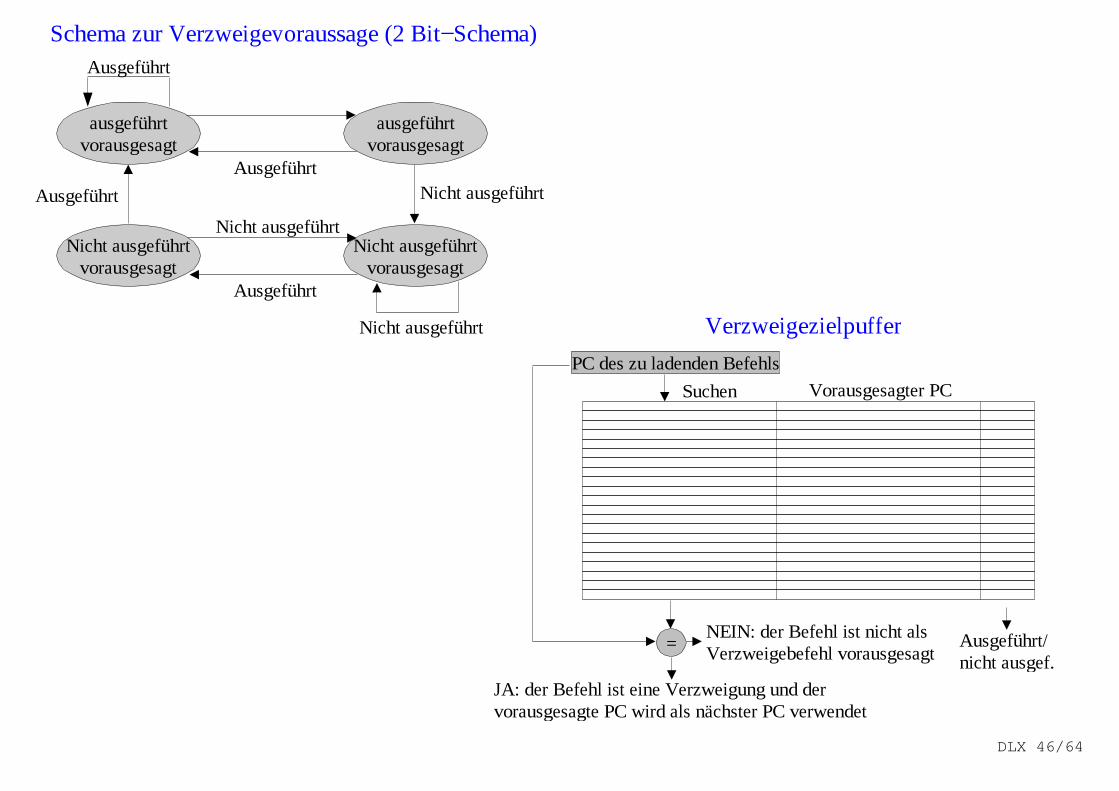
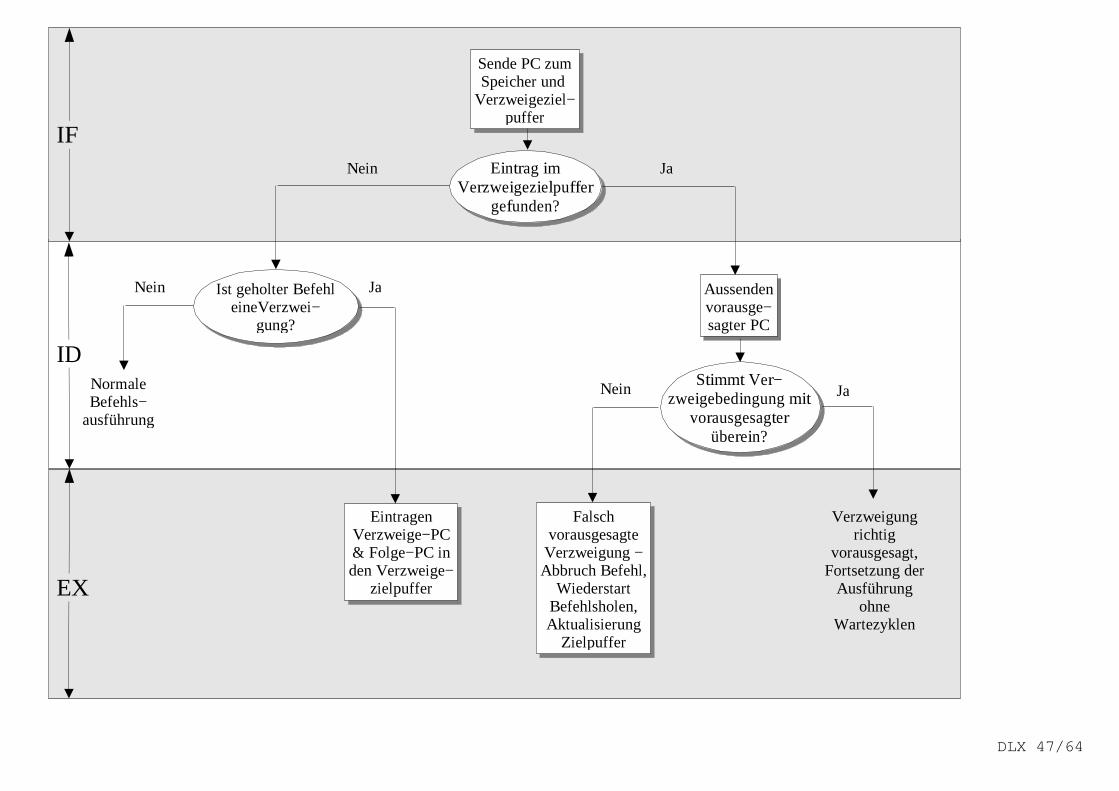
Dynamische Hardware−Verzweigevoraussage
Nutzung von Hardware zur dynamischen Voraussage des Ergebnisses einer Verzweigungzur Reduzierung der Verzweigeverzögerung.
Verzweigung ausgeführt/nicht ausgeführt? nächster PC?
Dynamisches Verzweigevoraussageschema :VerzweigevoraussagepufferVoraussage des ausgeführten/nicht ausgeführten Falls.Enthält statistische Aussage über den ausgeführtenbzw. nicht ausgeführten Fall von Verzweigungen.Keine Voraussage des nächsten PC!Indexierung mit dem niederen Teil der Verzweige−befehlsadresse (schnell).Ob die Voraussage richtig ist, ist unbekannt!Befehlsholen beginnt erst, wenn PC berechnet ist!−> nur sinnvoll, wenn Verzweigeverzögerung grösserals die Zeit zur Berechnung des möglichen Ziel−PC ist.
VerzweigezielpufferVoraussage der Adresse des nächsten Befehls.Enthält neben der Adresse des nächsten BefehlsInformationen, ob der geholte Befehl als eineausgeführte Verzweigung vorausgesagt ist und ob die Adresse im Zielpuffer als eine ausgeführte oder nichtausgeführte Voraussage gilt.Indexierung des Befehls mit gesamten PC notwendig,da der nächste PC vorausgesagt wird (muss korrekt sein!).Holen des nächsten Befehls beginnt vor Decodieren(wenn auszuführende Verzweigung vorausgesagt).
Problem: Steuer−Hazards begrenzen Pipeline−Ausführungsleistung wesentl ich.
Die Voraussage ändert sich, wenn das Verzweigeverhalten sich während der Programmabarbei−tung ändert.
DLX 45/64
ausgeführtvorausgesagt
Nicht ausgeführtvorausgesagt
ausgeführtvorausgesagt
Nicht ausgeführtvorausgesagt
Ausgeführt
Ausgeführt
Ausgeführt
Ausgeführt
Nicht ausgeführt
Nicht ausgeführt
Nicht ausgeführt
Schema zur Verzweigevoraussage (2 Bit−Schema)
Verzweigezielpuffer
PC des zu ladenden Befehls
Suchen Vorausgesagter PC
Ausgeführt/nicht ausgef.
=
JA: der Befehl ist eine Verzweigung und dervorausgesagte PC wird als nächster PC verwendet
NEIN: der Befehl ist nicht alsVerzweigebefehl vorausgesagt
DLX 46/64
Sende PC zumSpeicher und
Verzweigeziel−puffer
Eintrag imVerzweigezielpuffer
gefunden?
Ist geholter BefehleineVerzwei−
gung?
Aussendenvorausge−sagter PC
Stimmt Ver−zweigebedingung mit
vorausgesagterüberein?
EintragenVerzweige−PC& Folge−PC inden Verzweige−
zielpuffer
FalschvorausgesagteVerzweigung −Abbruch Befehl,
WiederstartBefehlsholen,Aktualisierung
Zielpuffer
Verzweigungrichtig
vorausgesagt,Fortsetzung der
Ausführungohne
Wartezyklen
NormaleBefehls−
ausführung
Nein Ja
Nein Ja
Nein Ja
EX
ID
IF
DLX 47/64

Erweiterte Befehlsebenenparallelität
Ziel: Weitere Leistungsverbesserung durch CPI−Wert von weniger als eins.mehrfache Befehlsübergabe in einem Taktzyklus
Ausnutzung der Pipeline erfordert Ausnutzung der Parallelität zwischen Befehlen:Ermittlung von Folgen unabhängiger Befehle
Mehr Befehle zu überlappen und pro Takt auszuführen, erfordert mehr Befehlsebenen−parallelität. Es existieren einfache Compilertechniken, die helfen, zusätzliche Paralle−lität zu erzeugen.
Software−Pipeliningzeitl iche Überlappung verschiedener Iterationen eines Schleifenkörpers
Trace−SchedulingScheduling über mehrere Verzweigungen, optimiert den am wahrscheinlichsten ausge−führten Pfad
Loop Unroll ingErzeugen langer Geradeausfolgen
Code−Inlininganstatt z.B. dem Aufruf eines Unterprogramms wird direkt der UP−Code eingefügt
...
DLX 48/64

Bsp.: Aufrollen von Schleifen
Loop Unrolling − Erhöhung der Befehlsanzahl in einer Schleifeniteration.D.h. Mehrfache Wiederholung des Schleifenkörpers, Korrektur des Schleifenkörpersund Scheduling der aufgerollten Schleife.
Bsp.:for (i=1; i<n+1; i++) y[i] = y[i] + a*x[i];
wird dreifach aufgerollt:
nrest = mod(n, 4);//Vorschleife für die ersten 4 Elementen1 = nrest + 1;
... //Elemente 0...(n1−1)for (i=n1; i<n+1; i+=4){//3−fach aufgerollte Schleife −> Aufrolltiefe 4
y[i] = y[i] + a*x[i];y[i+1] = y[i+1] + a*x[i+1];y[i+2] = y[i+2] + a*x[i+2];y[i+3] = y[i+3] + a*x[i+3];
}
Ziel:Weniger Rechenschritte bei Abarbeitung der Schleife (weniger Iterationen −> wenigerSchleifenoverhead)Erzeugen von mehr Befehlsebenenparallel ität durch längere Geradeausfolge vonBefehlen pro Iteration
DLX 49/64

Schleife:Loop: ld f0, 0(r1) ;Lade Vektorelement
addd f4, f0, f2 ;Addiere Skalar in f2sd 0(r1), f4 ;Speichere Vektorelementsub r1, r1, #8 ;Dekrementieren des Zeigers um 8 Bytebnez r1, Loop ;Verzweige wenn r1=0
−> Benötigt 9 Taktzyklen pro Iteration.
Scheduling der Schleife:Loop: ld f0, 0(r1)
addd f4, f0, f2sub r1, r1, #8bnez r1, Loopsd 8(r1), f4
;Verzögerte Verzweigung;Geändert durch Austausch mit sub
Befehl, der das Ergebnis erzeugt Auf das Ergebnis zugreifender BefehlLatenzzeit in TaktzyklenGK−ALU−Operation Weitere GK−ALU−Operation 3GK−ALU−Operation Speichern doppelt 2Laden DP−GK GK−ALU−Operation 1Laden DP−GK Speichern doppelt 0Sonstige Kombinationen 0
Operationslatenzzeiten
−> Benötigt 6 Taktzyklen pro Iteration.
Verzweigungen erzeugen einen Verzögerungsplatz. Verzweigung wird als nicht ausgeführt angenommen.
Die Schleife bringt Overhead mit sich (SUB, BNEZ und Verzweigeverzögerungsplatz).
DLX 50/64
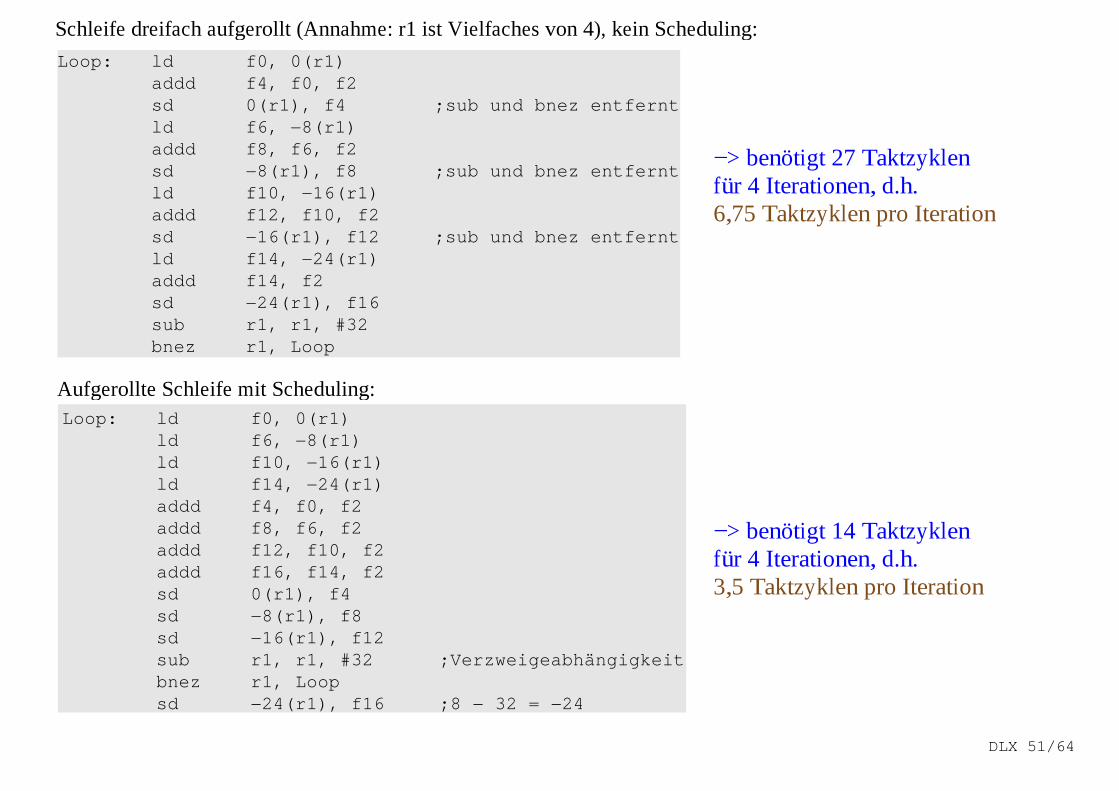
Aufgerollte Schleife mit Scheduling:Loop: l d f 0, 0( r 1)
l d f 6, −8( r 1)l d f 10, −16( r 1)l d f 14, −24( r 1)addd f 4, f 0, f 2addd f 8, f 6, f 2addd f 12, f 10, f 2addd f 16, f 14, f 2sd 0( r 1) , f 4sd −8( r 1) , f 8sd −16( r 1) , f 12sub r 1, r 1, #32 ; Ver zwei geabhängi gkei tbnez r 1, Loopsd −24( r 1) , f 16 ; 8 − 32 = −24
Schleife dreifach aufgerollt (Annahme: r1 ist Vielfaches von 4), kein Scheduling:
Loop: l d f 0, 0( r 1)addd f 4, f 0, f 2sd 0( r 1) , f 4 ; sub und bnez ent f er ntl d f 6, −8( r 1)addd f 8, f 6, f 2sd −8( r 1) , f 8 ; sub und bnez ent f er ntl d f 10, −16( r 1)addd f 12, f 10, f 2sd −16( r 1) , f 12 ; sub und bnez ent f er ntl d f 14, −24( r 1)addd f 14, f 2sd −24( r 1) , f 16sub r 1, r 1, #32bnez r 1, Loop
−> benötigt 27 Taktzyklenfür 4 Iterationen, d.h.6,75 Taktzyklen pro Iteration
−> benötigt 14 Taktzyklenfür 4 Iterationen, d.h.3,5 Taktzyklen pro Iteration
DLX 51/64

Bsp.: Software−Pipelining
Umorganisieren von Schleifen, so dass jede Iteration im Software−Pipeline−Code aus Befehlsfolgenentsteht, die aus mehreren Iterationen des ursprünglichen Codesegmentes ausgewählt werden.
D.h., der Scheduler verschachtelt Befehle unterschiedlicher Schleifeniterationen, ohne die Schleifeaufzurollen.
Vorteil gegenüber Aufrollen von Schleifen:geringerer Speicherverbrauch (Register)
Loop: ld f0, 0(r1)addd f4, f0, f2sd 0(r1), f4sub r1, r1, #8bnez r1, Loop
ld f0, 0(r1) ; Lade M[n]addd f4, f0, f2 ; Addiere zu M[n]sd 0(r1), f4 ; Speichere M[n]subi r1, r1, #16 ; Setze Loop−Counter
; M[n] ist das erste in der Schleife gespeicherte Element
; M[3] ist das letzte in der Schleife gespeicherte Element
Loop:sd 16(r1), f4 ; Speichere M[i]addd f4, f0, f2 ; Addiere zu M[i−1]ld f0, 0(r1) ; Lade M[i−2]subi r1, r1, #8bnez r1, Loop
out_of_loop:sd 16(r1), f4 ; Speichere M[2]addd f4, f0, f2 ; Addiere zu M[1]sd 8(r1), f4 ; Speichere M[1]
Software−
Pipelining
DLX 52/64

Eine superskalare Version der DLX
Maschinen, die mehrere unabhängige Befehle pro Taktzyklus übergeben, wenn siegeeignet durch den Compiler zugeordnet sind, nennt man superskalare Maschinen.
Maschine prüft Abhängigkeiten: Sind Befehle im Befehlsstrom abhängig oder erfül len be−stimmte Kriterien nicht, wird nur der erste Befehl der Folge übergeben.
Bsp. Superskalare DLX; 2 Befehle pro Taktzyklus − FK/Lade/Speicher/Verzweige− und GK−Operation als Paar; erfordert 64 Bit für das Holen und Decodieren von Befehlen
Befehlstyp Pipeline−StufenFK−Befehl IF ID EX MEM WBGK−Befehl IF ID EX MEM WBFK−Befehl IF ID EX MEM WBGK−Befehl IF ID EX MEM WBFK−Befehl IF ID EX MEM WBGK−Befehl IF ID EX MEM WBFK−Befehl IF ID EX MEM WBGK−Befehl IF ID EX MEM WB
Erhöht im wesentl ichen die Übergaberate der GK−Befehle.Es sind entweder Pipeline−GK−Einheiten oder mehrfache unabhängige Einheiten notwendig!
HW kann kleine Zahl (2 bis 4) unabhängiger Befehle in einem einzigen Takt übergeben.
DLX 53/64

Ausführung der aufgerollten Schleife mit der superskalaren DLX:
Um ein Scheduling ohne jede Verzögerung zu ermöglichen, müssen hier fünf Kopien desSchleife aufgerollt werden.
Loop: l d f 0, 0( r 1) 1l d f 6, −8( r 1) 2l d f 10, −16( r 1) addd f 4, f 0, f 2 3l d f 14, −24( r 1) addd f 8, f 6, f 2 4l d f 18, −32( r 1) addd f 12, f 10, f 2 5sd 0( r 1) , f 4 addd f 16, f 14, f 2 6sd −8( r 1) , f 8 addd f 20, f 18, f 2 7sd −16( r 1) , f 12 8sd −24( r 1) , f 16 9sub r 1, r 1, #40 10bnez r 1, Loop 11sd 8( r 1) , f 20 12
FK−Befehl GK−Befehl Taktzyklus
Wichtig für das Ausnutzen der verfügbaren effektiven Parallelität einer superskalaren Pipeline sind Compiler−Scheduling−Methoden.
−> 2,4 Taktzyklen pro Iteration
Bsp. Aufrollen von Schleifen:
DLX 54/64

Die VLIW−Methode
Superskalar: 2 Befehle pro Taktzyklus übergeben, viel leicht 3, 4 oder 5.Schwierigkeit: Erkennen, wie viele Befehle und in welcher Reihenfolge Befehle gleichzeitig über−geben werden können, wie sie geladen werden können und welche Abhängigkeiten bestehen.
Alternative: LIW− bzw. VLIW (Very Long Instruction Word)−Architektur
VLIWs nutzen mehrfache unabhängige Funktionseinheiten. Anstatt zu versuchen, denEinheiten mehrere unabhängige Befehle zu übergeben, packt eine VLIW−Architekturmehrere Operationen in einen sehr langen Befehl (daher der Name).
Erkennung und Erzeugung von Parallelität zur Ausnutzung der verfügbaren Funktions−einheiten muss vom Compiler vorgenommen werden!
Grenzen/Kosten (Warum übergeben wir nicht 50 Operationen pro Taktzyklus)?begrenzte Parallelitätbegrenzte Hardware−Ressourcen (Speicher− und Registerfilebandbreite −> vieleLese− und Schreibports, erheblicher Schaltungsaufwand vs. Taktgeschwindigkeit!)Nutzung von Daten−Caches schwierigbegrenzte Codelängenausdehnung
DLX 55/64

Zuordnung der aufgerollten Schleife zu VLIW−Befehlen einer VLIW−DLX, die zwei Speicher−zugrif fsbefehle, zwei GK− und ein FK−Befehl in einem Befehlswort enthalten kann. (um jeden Wartezyklus zu vermeiden, muss die Schleife hier 6fach aufgerollt werden.)Speicherzugriff 1 Speicherzugriff 2 GK−Operation 1 GK−Operation 2 FK−Operation/Verzweigungld f0, 0(r1) ld f6, −8(r1)ld f10, −16(r1) ld f14, −24(r1)ld f18, −32(r1) ld f22, −40(r1) addd f4, f0, f2 addd f8, f6, f2ld f26, −48(r1) addd f12, f10, f2 addd f16, f14, f2
addd f20, f18, f2 addd f24, f22, f2sd 0(r1), f4 sd −8(r1), f8 addd f28, f26, f2sd −16(r1), f12 sd −24(r1), f16sd −32(r1), f20 sd −40(r1), f24 sub r1, r1, #48sd −0(r1), f28 bnez r1, Loop
Die Effektivität, bestimmt durch die Anzahl belegter Operationsplätze, beträgt etwa
60 %
−> 1,29 Taktzyklen pro Iteration
Übergaberate: 23 Operationen in 9 Taktzyklen bzw. 2,5 Operationen pro Zyklus.Um diese Übergaberate zu erreichen, ist eine viel größere Registerzahl erforderl ich, als sie die DLX normalerweise in dieser Schleife nutzen würde!
DLX 56/64

VektorprozessorenWarum?Leistung von Pipelining durch 2 Faktoren Grenzen gesetzt:
Taktzykluszeit − kann durch tieferes Pipelining reduziert werden, tiefere Pipeline erhöhtaber Pipeline−Abhängigkeiten, daraus resultiert ein höherer CPI−Wert.Befehlshole− und Befehlsdecodierungsrate (Flynnscher Flaschenhals), verhindert das Holenund Übergeben von mehr als ein paar Befehlen pro Taktzyklus.
Vektormaschinen verfügen über Operationen höheren Niveaus, die Vektoren verarbeiten.Eigenschaften der Operationen:
Berechnung jedes Ergebnisses ist unabhängig von der Berechnung vorangegangener Ergebnisseund erlaubt sehr tiefes Pipelining, ohne Daten−Hazards zu verursachen (Compiler/Programmie−rer entscheidet, wo ein Vektorbefehl genutzt werden kann).Einzelner Vektorbefehl spezif iziert eine große Menge an Arbeit − reduziert erforderl ichenBefehlsstrom (Flynnscher Flaschenhals wirkt weniger begrenzend)Zum Speicher zugreifende Vektorbefehle haben ein bekanntes Zugrif fsmuster. Ein Zugrif f wirdfür einen gesamten Vektor initi iert, d.h. Latenzzeit des Speichers fäl lt weniger ins Gewicht.Vektorbefehle ersetzen Schleifen; das Verhalten ist vorbestimmt −> keine Schleifenverzweigung,keine Steuer−Hazards
Vektorbefehle können daher schneller gemacht werden als eine Folge von skalaren Operationenbei derselben Menge von Datenelementen.Motiviert Entwerfer, Vektoreinheiten einzubeziehen, wenn das Anwendungsgebiet diese häufigzu nutzen vermag.
DLX 57/64
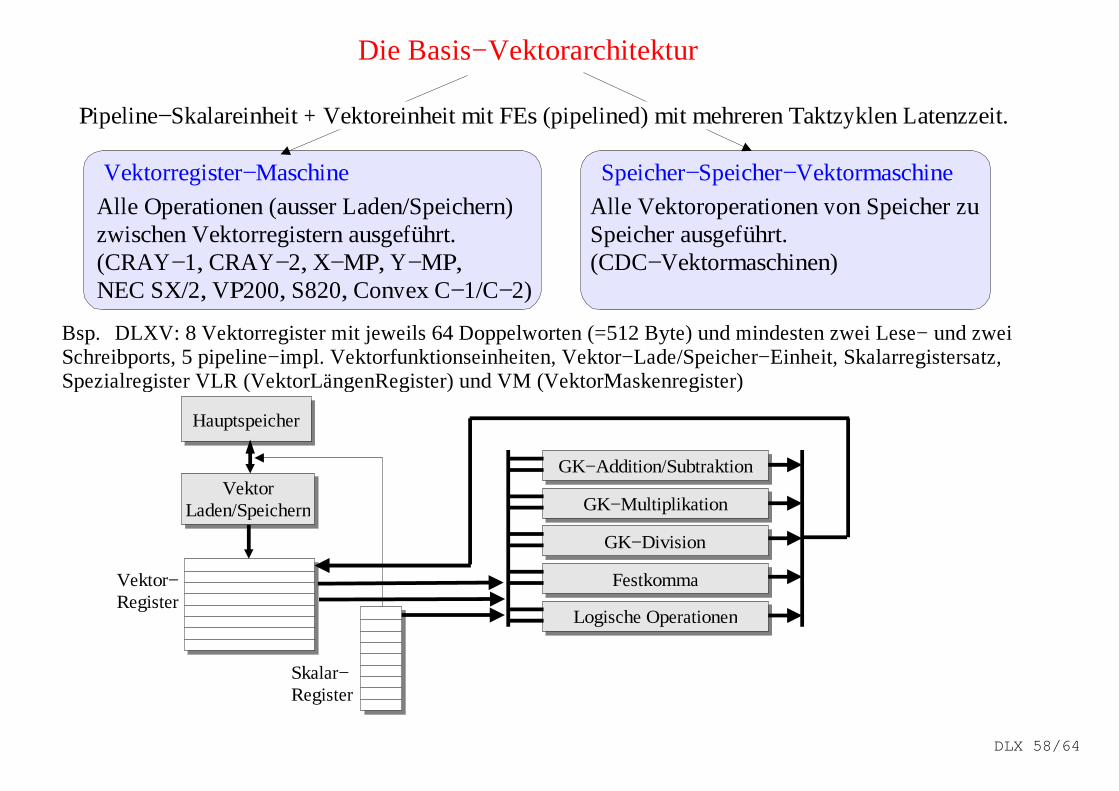
Die Basis−Vektorarchitektur
Pipeline−Skalareinheit + Vektoreinheit mit FEs (pipelined) mit mehreren Taktzyklen Latenzzeit.
Vektorregister−Maschine Speicher−Speicher−Vektormaschine
Alle Operationen (ausser Laden/Speichern)zwischen Vektorregistern ausgeführt.(CRAY−1, CRAY−2, X−MP, Y−MP, NEC SX/2, VP200, S820, Convex C−1/C−2)
Alle Vektoroperationen von Speicher zuSpeicher ausgeführt.(CDC−Vektormaschinen)
Bsp. � DLXV: 8 Vektorregister mit jeweils 64 Doppelworten (=512 Byte) und mindesten zwei Lese− und zweiSchreibports, 5 pipeline−impl. Vektorfunktionseinheiten, Vektor−Lade/Speicher−Einheit, Skalarregistersatz,Spezialregister VLR (VektorLängenRegister) und VM (VektorMaskenregister)
Hauptspeicher
VektorLaden/Speichern
Vektor−Register
GK−Addition/Subtraktion
GK−Multiplikation
GK−Division
Festkomma
Logische Operationen
Skalar−Register
DLX 58/64

Bsp. Problem Y = a*X + Y, Annahme Vektorlänge = 64
ld f0, aaddi f4, rx, #512 ; Laden ab letzer Adresse
loop:ld f2, 0(rx) ; Laden X(i)multd f2, f0, f2 ; a*X(i)ld f4, 0(ry) ; Laden Y(i)addd f4, f2, f4 ; a*X(i) + Y(i)sd f4, 0(ry) ; Speichern zu Y(i)addi rx, ry, #8 ; Inkrementieren des Indexes für Xaddi ry, ry, #8 ; Inkrementieren des Indexes für Ysub r20, r4, rx ; Dekrementieren des Schleifenindexesbnez r20, loop ; Test auf letzten Schleifendurchlauf
ld f0, a ; Laden des Skalars alv v1, rx ; Laden Vektor Xmultsv v2, f0, v1 ; Vektor−Skalar−Multiplikationlv v3, ry ; Laden Vektor Yaddv v4, v2, v3 ; Vektoradditionsv ry, v4 ; Speichern Ergebnisvektor
DLX−Befehlsfolge:
DLXV−Befehlsfolge:
Fast 600 Befehleauszuführen
6 Befehle auszuführen
Jeder Vektorbefehl arbeitet mit al len Vektorelementen unabhängig, d.h. keine Pipeline−Blockierungen.Beachten: Anlaufzeit und Initi ierungsrate der Vektoreinheit!
DLX 59/64

Vektorlaufzeiten und Initiierungsrate
Anlaufzeit einer Vektoroperation − Zeit, bis das erste Ergebnis bereit steht. Sie ist durch die Pipeline−Tiefe der sie ausführenden FE gegeben, d.h. sie entspricht der Latenzzeit der betref fenden Pipeline.
Initi ierungsrate − Zeit pro Ergebnis, wenn die Pipeline der FE läuft.
Abschlussrate − muss gleich der Initiierungsrate sein!
Für die Verarbeitung eines Vektors der Länge n gilt demnach:Vektorlaufzeit = Anlaufzeit + n * Initiierungsrate
Bsp.: Vektorlänge n = 64 ElementeAnlaufzeit 10 Taktzyklen, Initi ierungsrate 1 Taktzyklus
Wieviele Taktzyklen pro Vektorelement?
Taktzyklen VektorlaufzeitVektorelement Vektorlänge
Anlaufzeit + n * Initi ierungsrateVektorlänge
= (10 + 64*1) / 64 = 1,16 Taktzyklen pro Vektorelement
=
=
DLX 60/64

Register−Vektoroperationen:Anlaufzeit abhängig von Pipeline−TiefeBei Abhängigkeiten zwischen Operationen zusätzl iche Startverzögerung!Initi ierungsrate dadurch bestimmt, wie oft eine Einheit einen neuen Operanden aufnehmenkann. Bei vollständiger Pipeline einen pro Takt.
Lade/Speicher−Vektoroperationen:Anlaufzeit für Ladebefehl, um das erste Doppelwort vom Speicher in ein Register zu ladenKeine Anlaufzeit für Speicherbefehl zu berücksichtigen (erzeugt kein eigentl iches Ergebnis)Muss Lade− auf den Abschluss eines Speicherbefehls warten, ergibt sich für ersteren eine zusätzl iche Startverzögerung, die so groß wie die Anlaufzeit istUm Initi ierungsrate für das Laden und Speichern eines Doppelwortes pro Taktzyklus zu er−reichen, muss Speichersystem aus mehreren Speicherbanken bestehen, zu denen mit ver−schiedenen Adressen parallel zugegrif fen wird.
DLX 61/64

Vektorlänge und Schrittweite der Vektorelemente
Vektorlängensteuerung:Länge der Vektorregister bestimmt maximale in einer Vektoroperation verarbeitbare Vektor−länge ( MVL )Stimmt aber selten mit der tatsächlichen Vektorlänge überein!
−> Vektorlängenregister (VLR), Vektor beliebiger Länge muss vor seiner Verarbeitung seg−mentiert werden:Anzahl der gleichen Segmente: j = n div MVLFür die Länge des Restsegments gilt dann:
m = n modulo MVLBis auf Restsegment haben alle Segmente die maximale Vektorlänge MVL − nutzen volleLeistung der Vektormaschine
Vektorschritte:Position angrenzender Elemente eines Vektors im Speicher muss nicht sequentiel l sein.( Bsp. A(i,j+1) grenzt bei den meisten Sprachen an A(i,j), −> A(i+1,j) nicht an A(i,j) )Abstand getrennter, zu einem Vektor zusammengefasster Elemente − Schrittweite (stride)
Schrittweite wird dynamisch berechnet und in einem Universalregister gespeichert.
DLX 62/64
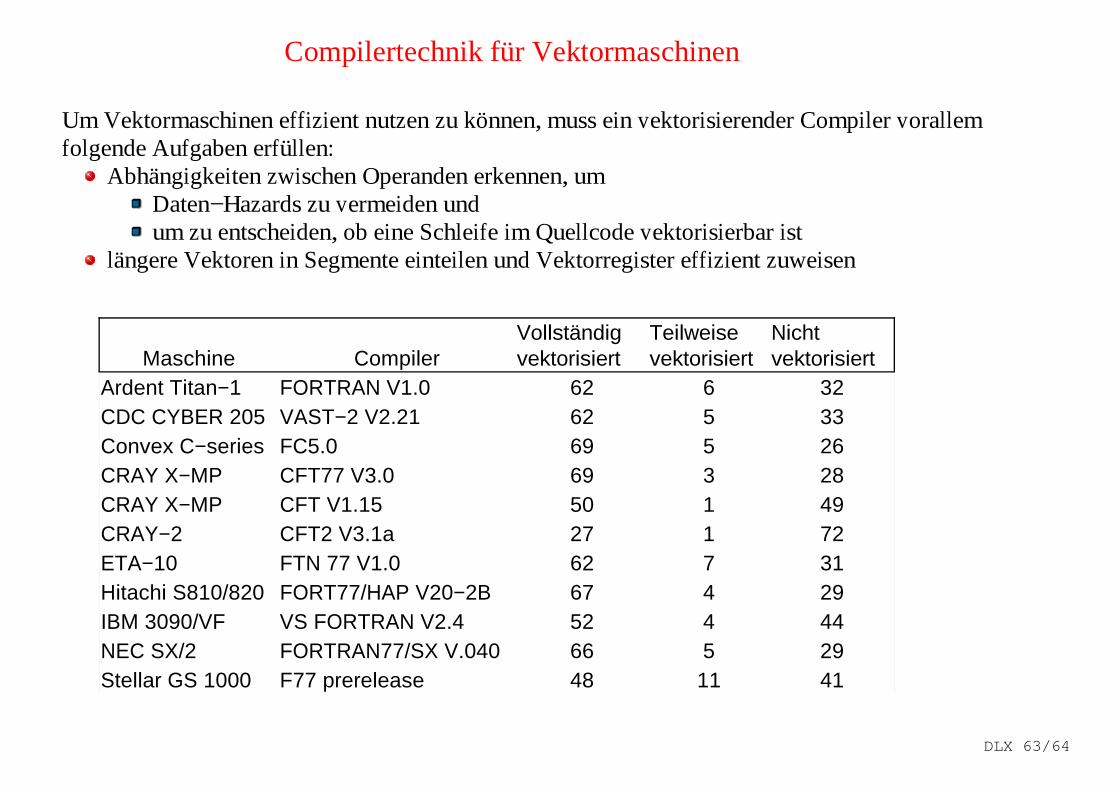
Compilertechnik für Vektormaschinen
Um Vektormaschinen eff izient nutzen zu können, muss ein vektorisierender Compiler vorallemfolgende Aufgaben erfül len:
Abhängigkeiten zwischen Operanden erkennen, um Daten−Hazards zu vermeiden undum zu entscheiden, ob eine Schleife im Quellcode vektorisierbar ist
längere Vektoren in Segmente einteilen und Vektorregister ef f izient zuweisen
Maschine CompilerArdent Titan−1 FORTRAN V1.0 62 6 32CDC CYBER 205 VAST−2 V2.21 62 5 33Convex C−series FC5.0 69 5 26CRAY X−MP CFT77 V3.0 69 3 28CRAY X−MP CFT V1.15 50 1 49CRAY−2 CFT2 V3.1a 27 1 72ETA−10 FTN 77 V1.0 62 7 31Hitachi S810/820 FORT77/HAP V20−2B 67 4 29IBM 3090/VF VS FORTRAN V2.4 52 4 44NEC SX/2 FORTRAN77/SX V.040 66 5 29Stellar GS 1000 F77 prerelease 48 11 41
Vollständig vektorisiert
Teilweise vektorisiert
Nicht vektorisiert
DLX 63/64

Höhere Taktfrequenz
GeringererCPI−Wert
Underpipline−Maschinen*
DLX−Pipeline
Superskalar−Maschinen
VLIW−Maschinen
Superpipeline−Maschinen**
Vektor−Maschinen
* Maschinen, die mehrere Pipeline−Stufen, z. B. der DLX−Pipeline, zusammenfassen, resultiert in langsamerem Takt
** Maschinen mit höherer Taktfrequenz und tieferer Pipeline, Pipelining aller Funktionseinheiten
DLX 64/64


















