
Einfuhrung in STATA¨ - uibk.ac.at · Bevor Daten in STATA eingelesen werden k¨onnen, muss...
32
Einf ¨ uhrung in STATA Stefan Lang Universit¨ at Innsbruck Institut f¨ ur Statistik Universit¨ atsstraße 15, A-6020 Innsbruck E-mail: [email protected] Internet: http://www.uibk.ac.at/statistics/personal/lang/index.html 3. Oktober 2007
Transcript of Einfuhrung in STATA¨ - uibk.ac.at · Bevor Daten in STATA eingelesen werden k¨onnen, muss...

Einfuhrung in STATA
Stefan Lang
Universitat Innsbruck
Institut fur Statistik
Universitatsstraße 15, A-6020 Innsbruck
E-mail: [email protected]
Internet: http://www.uibk.ac.at/statistics/personal/lang/index.html
3. Oktober 2007

Ich bedanke mich bei
Jana Lehmann
fur die Unterstutzung bei der Erstellung des Skripts.

INHALTSVERZEICHNIS i
Inhaltsverzeichnis
1 Hinweise zur Verwendung dieser Einfuhrung 1
2 Illustrierender Beispieldatensatz 1
3 Struktur von STATA 3
3.1 Die Fenster von STATA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
3.2 Die Speicherverwaltung von STATA . . . . . . . . . . . . . . . . . . . . . . 3
4 Einlesen und Ausgeben von Datensatzen 3
4.1 Einlesen von ASCII Datensatzen . . . . . . . . . . . . . . . . . . . . . . . . 3
4.2 Einlesen von Daten im STATA-Format . . . . . . . . . . . . . . . . . . . . . 5
4.3 Abspeichern von Daten im ASCII-Format . . . . . . . . . . . . . . . . . . . 5
4.4 Abspeichern von Daten im STATA-Format . . . . . . . . . . . . . . . . . . 6
5 Datenhandling 6
5.1 Erzeugen und Verandern von Variablen . . . . . . . . . . . . . . . . . . . . 6
5.2 Labeln von Werten und Variablen . . . . . . . . . . . . . . . . . . . . . . . 7
6 Deskriptive Statistiken 9
7 Grafik mit STATA 13
7.1 Grafische Veranschaulichung univariater Verteilungen . . . . . . . . . . . . . 13
7.2 Grafische Veranschaulichung von Funktionen . . . . . . . . . . . . . . . . . 15
7.3 Scatterplotmatrix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
7.4 Kombination mehrerer Grafiken . . . . . . . . . . . . . . . . . . . . . . . . . 18
7.5 Mehrere Grafiktypen in einer Grafik . . . . . . . . . . . . . . . . . . . . . . 19
7.6 Allgemeine Grafikoptionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
7.7 Abspeichern von Grafiken als eps-Files . . . . . . . . . . . . . . . . . . . . . 20

INHALTSVERZEICHNIS ii
8 Regression in STATA 21
9 Programmieren in STATA 23
9.1 Batch-files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
9.2 Macros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
9.3 Schleifenprogrammierung und if-Abfragen . . . . . . . . . . . . . . . . . . . 24
9.3.1 While-Schleifen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
9.3.2 forvalues-Schleifen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
9.3.3 if-Abfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Index 27

1 HINWEISE ZUR VERWENDUNG DIESER EINFUHRUNG 1
1 Hinweise zur Verwendung dieser Einfuhrung
Dieses Skript gibt eine kurze Einfuhrung in die Benutzung des Statistik Programms STA-
TA. Die Einfuhrung ist an die Inhalte des Moduls Statistische Datenanalyse fur Studieren-
de des Bachelorstudiengangs Wirtschaftswissenschaften in Innsbruck ausgelegt. Sie erhebt
daher keinerlei Anspruch auf Vollstandigkeit. Eine vollstandige Ubersicht uber die Moglich-
keiten von STATA findet man in den STATA Handbuchern. Diese konnen im Institut fur
Statistik fur kurze Zeit zum Kopieren ausgeliehen werden (wahrend der Sekretariatsoff-
nungszeiten). Weitere Literaturhinweise findet man auf den Internetseiten www.stata.com
des Herstellers.
2 Illustrierender Beispieldatensatz
Die meisten Befehle in diesem Skript werden Anhand eines Beispieldatensatzes zur Un-
terernahrung in Zambia erlautert. Ziel der Untersuchung ist die Bestimmung von Deter-
minanten der Unterernahrung von neugeborenen Kindern im Alter von 0 bis 5 Jahren
in Zambia. In Abstimmung mit der WHO werden in Entwicklungslandern regelmaßig
DHS (Demographic and Health Surveys)–Erhebungen mittels reprasentativer Stichproben
durchgefuhrt. Sie enthalten insbesondere Informationen zu Unterernahrung, Sterblichkeit
und Krankheitsrisiken fur Kinder. Unter mehreren moglichen anthropometrischen Indi-
katoren zur Messung von Unterernahrung wird im vorliegenden Datensatz die Maßzahl
,,Z–Score” fur chronische Unterernahrung (,,Stunting”) verwendet. Sie ist fur ein Kind i
definiert durch
ZScorei =AIi − MAI
σ
Dabei wird als anthropometrischer Indikator AI die altersstandardisierte Große des Kindes
verwendet, MAI ist der Median dieses Indikators fur eine internationale Referenzpopu-
lation, und σ die entsprechende Standardabweichung in dieser Referenzpopulation. Als
erklarende Variablen kommen in der DHS-Erhebung enthaltene Merkmale zum sozio–oko-
nomischen Status der Mutter bzw. des Haushalts sowie zur hygienischen und gesundheitli-
chen Situation in Frage. Tabelle 1 beschreibt die im Datensatz enthaltenen Variablen bzw.
Merkmale.
Der Datensatz ist uber den e-campus als zambia.raw erhaltlich.
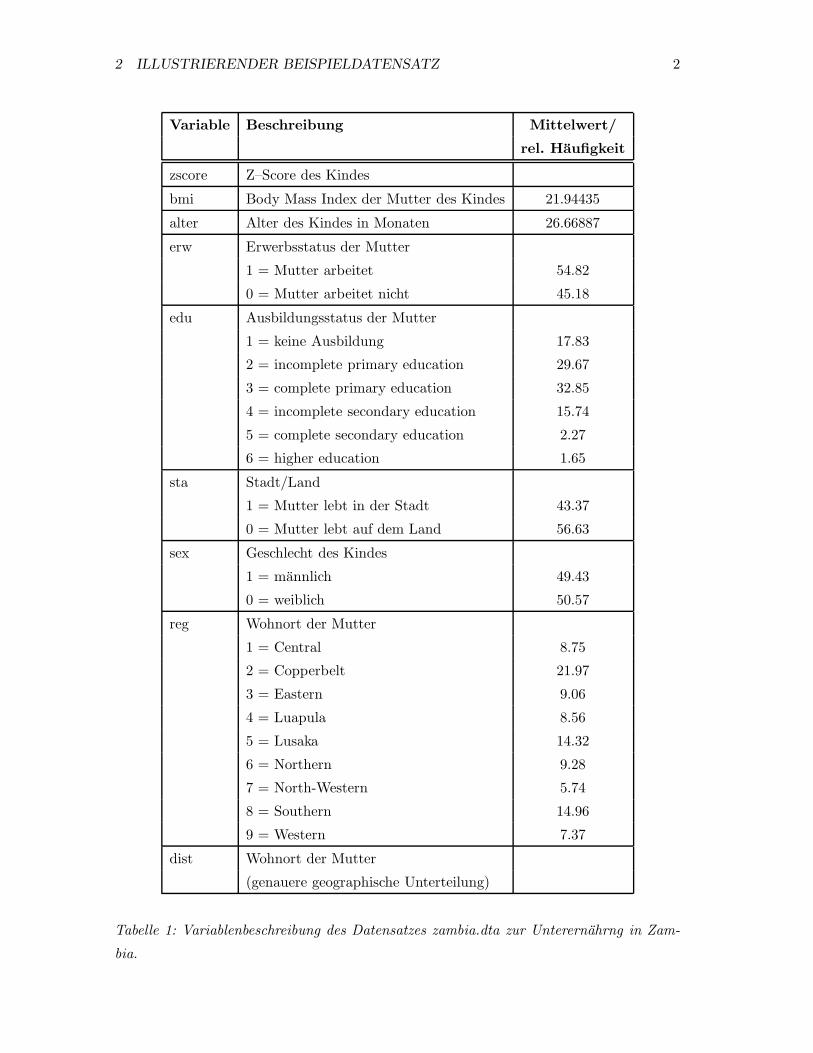
2 ILLUSTRIERENDER BEISPIELDATENSATZ 2
Variable Beschreibung Mittelwert/
rel. Haufigkeit
zscore Z–Score des Kindes
bmi Body Mass Index der Mutter des Kindes 21.94435
alter Alter des Kindes in Monaten 26.66887
erw Erwerbsstatus der Mutter
1 = Mutter arbeitet 54.82
0 = Mutter arbeitet nicht 45.18
edu Ausbildungsstatus der Mutter
1 = keine Ausbildung 17.83
2 = incomplete primary education 29.67
3 = complete primary education 32.85
4 = incomplete secondary education 15.74
5 = complete secondary education 2.27
6 = higher education 1.65
sta Stadt/Land
1 = Mutter lebt in der Stadt 43.37
0 = Mutter lebt auf dem Land 56.63
sex Geschlecht des Kindes
1 = mannlich 49.43
0 = weiblich 50.57
reg Wohnort der Mutter
1 = Central 8.75
2 = Copperbelt 21.97
3 = Eastern 9.06
4 = Luapula 8.56
5 = Lusaka 14.32
6 = Northern 9.28
7 = North-Western 5.74
8 = Southern 14.96
9 = Western 7.37
dist Wohnort der Mutter
(genauere geographische Unterteilung)
Tabelle 1: Variablenbeschreibung des Datensatzes zambia.dta zur Unterernahrng in Zam-
bia.

3 STRUKTUR VON STATA 3
3 Struktur von STATA
3.1 Die Fenster von STATA
Nach dem Start von STATA erscheint ein Hauptfenster mit vier Unterfenstern. Es handelt
sich um ein STATA Results Fenster, ein STATA Command Fenster, ein Review Fenster
und ein Variables Fenster. Im STATA Results Fenster werden Resultate von Berechnungen,
aufgerufene Befehle und Fehlermeldungen dargestellt. Das STATA Command Fenster dient
zur Eingabe von Befehlen. Im Review Fenster findet man die letzten 100 eingegebenen
Befehle. Durch Anklicken einer der Befehle erscheint dieser wieder im STATA Command
Fenster und kann (in eventuell modifizierter Form) wieder aufgerufen werden. Schließlich
gibt das Variables Fenster einen Uberblick uber alle Variablen eines Datensatzes. Man
beachte, dass jeweils nur ein Datensatz gleichzeitig in STATA bearbeitet werden kann.
3.2 Die Speicherverwaltung von STATA
Nach dem Start von STATA sind standardmaßig 10 MB fur die Speicherung von Daten
reserviert. Fur Datensatze mit großerem Speicherplatzbedarf kann man mit Hilfe des me-
mory Befehls mehr Speicherplatz zuweisen. Die Hohe des Speicherplatzes ist dabei nur
durch den Hauptspeicher des Computers limitiert, auf dem STATA ausgefuhrt wird. Bei-
spielsweise wird durch Eingabe des Befehls
set memory 20m
der zur Verfugung stehende Speicherplatz auf 20 MB erhoht. Die Erhohung des Spei-
chers ist dabei auf die aktuelle Sitzung beschrankt. Eine permanente Veranderung des
zur Verfugung gestellten Speichers erhalt man durch die zusatzliche Angabe der Option
permanently:
set memory 20, permanently
4 Einlesen und Ausgeben von Datensatzen
4.1 Einlesen von ASCII Datensatzen
Zum Einlesen von ASCII Datensatzen kommen zwei Befehle in Frage: der infile Befehl und
der insheet Befehl. Beim infile Befehl wird immer dann verwendet, wenn der einzulesende

4 EINLESEN UND AUSGEBEN VON DATENSATZEN 4
Datensatz in der ersten Zeile keine Variablennamen enthalt. Beim insheet Befehl geht das
Programm davon aus, dass in der ersten Zeile des ASCII Files die Variablennamen stehen.
Bevor Daten in STATA eingelesen werden konnen, muss allerdings sichergestellt werden,
dass nicht bereits ein anderer Datensatz in STATA eingelesen wurde. STATA kann namlich
nur mit jeweils einem Datensatz gleichzeitig arbeiten. Befinden sich also noch Daten im
Speicher, mussen diese (gegebenenfalls nach Sicherung auf Festplatte) zuerst geloscht wer-
den. Dies geschieht mit dem einfachen Befehl
clear
Infile-Befehl
Der infile Befehl besitzt folgende allgemeine Struktur:
infile varlist using myfile
Dabei wird von STATA angenommen, dass die Variablen (in varlist) in der ASCII-Datei
spaltenweise angeordnet sind. Die Spezifizierung einer Variable in varlist hat folgende
allgemeine Syntax:
newvarname
Als Variablentypen sind ganze Zahlen (byte, int und long), reelle Zahlen (float und double)
und Strings (str1 - str80) zugelassen.
Beispielsweise werden mit dem folgenden Befehl die Variablen X, Y und Z in STATA
eingelesen:
infile X Y Z using myfile
Der folgende Befehl liest die Variablen X1 – X200 in STATA ein:
infile X1-X200 using myfile
Nach dem Einlesen der Daten konnen die Variablen im STATA-Format (Dateiendung
dta) durch Anklicken des Menupunktes File–SaveAs abgespeichert werden. Durch Offnen
des Datenbrowsers oder des Dateneditors (Window–Data Editor) konnen die Daten
visualisiert werden. Der Editor erlaubt auch das Editieren (Verandern) der Daten.

4 EINLESEN UND AUSGEBEN VON DATENSATZEN 5
Insheet-Befehl
Der insheet-Befehl wird ahnlich benutzt wie der infile-Befehl, jedoch mussen die Variablen-
namen nicht angegeben werden, da STATA davon ausgeht, dass in der ersten Zeile des
Files die Variablennamen (durch Leerzeichen getrennt) stehen. Die Zambia-Daten werden
beispielsweise mit dem Befehl
insheet using d:\daten\zambia.raw
eingelesen. Der nach using angegebene Pfad muss gegebenenfalls angepasst werden.
4.2 Einlesen von Daten im STATA-Format
Befinden sich Daten bereits im STATA-Format (Dateiendungen dta) konnen diese mit
Hilfe des Befehls use eingelesen werden. Die Zambia-Daten werden beispielsweise durch
Angabe des Befehls
use d:\daten\zambia.dta
eingelesen. Der angegebene Pfad muss gegebenenfalls angepasst werden. Befindet sich
bereits ein Datensatz im Speicher von STATA, so muss dieser durch vorherige Angabe des
Befehls
clear
zunachst geloscht werden.
4.3 Abspeichern von Daten im ASCII-Format
Daten im STATA-Format lassen sich mit Hilfe des outfile Befehls als ASCII Datensatz
abspeichern. Der Befehl hat folgende allgemeine Struktur:
outfile [varlist] using filename [if exp] [in range] [, replace]
Die Option replace gibt an, dass eine bereits existierende Datei uberschrieben werden darf.
Neben der replace Option sind noch einige weitere Optionen zugelassen, vergleiche hierzu
die Handbucher bzw. die STATA Hilfe. Der folgende Befehl speichert die Variablen X, Y
und Z im ASCII-Format:
outfile X Y Z using myfile

5 DATENHANDLING 6
4.4 Abspeichern von Daten im STATA-Format
In STATA eingelesene Daten werden im STATA-Format fur die spatere Weiterverwendung
mit dem Befehl save gespeichert. Die Zambia Daten werden beispielsweise durch
save d:\daten\zambia.dta
gespeichert. Falls der angegebene Datensatz bereits existiert, muss zusatzlich die Option
replace spezifiziert werden, um dem Programm das Uberschreiben der existierenden Datei
zu ermoglichen. Der Befehl lautet dann
save d:\daten\zambia.dta , replace
Sind haufig Daten einzulesen und abzuspeichern, kann es muhsam werden, immer den
gesamten Pfad anzugeben. Es empfiehlt sich dann, ein Standardverzeichnis anzulegen, das
zum Speichern und Einlesen verwendet wird. Dies geschieht mit dem Befehl cd.
Die Befehle
cd d:\dateninsheet using zambia.raw
save zambia.dta, replace
bewirken, dass der Datensatz zambia.raw im Verzeichnis d:\daten eingelesen und anschlie-
ßend im Stata-Format im selben Verzeichnis abgespeichert wird.
5 Datenhandling
5.1 Erzeugen und Verandern von Variablen
Neue Variablen werden mit Hilfe des Befehls
generate newvar = exp [if exp]
wobei type der Variablentyp ist. Beispielsweise wird mit
generate Y = X2
die bereits existierende Variable X quadriert und das Resultat der neuen Variable Y zu-
gewiesen. Auf dem Einheitsintervall gleichverteilte Zufallsvariablen werden durch

5 DATENHANDLING 7
generate Y = uniform()
erzeugt, standardnormalverteilte Zufallsvariablen werden durch
generate Y = invnorm(uniform())
erzeugt.
Beispiel: Zambia Daten
Der Befehl
generate alter2 = alterˆ2
erzeugt die neue Variable alter2, indem die bereits existierende Variable alter quadriert
wird.�
Sind in einem Datensatz noch keine Variablen vorhanden, so muss zunachst durch
set obs nrobs
die Anzahl der Beobachtungen nrobs festgelegt werden.
Bereits bestehende Variablen werden mit dem replace Befehl verandert. Der Befehl besitzt
folgende Syntax:
replace oldvar = exp [if exp]
Beispiel: Zambia Daten
Der Befehl
replace alter = alter/12
verandert nun die Variable alter so, dass das Alter jetzt in Jahren und nicht wie vorher in
Monaten gespeichert ist.�
5.2 Labeln von Werten und Variablen
Die Werte kategorialer Variablen wie beim Geschlecht (Variable sex) oder dem Bildungs-
stand der Mutter (Variable edu) im Zambia Datensatz werden haufig durch Zahlen kodiert.
Beim Geschlecht beispielsweise werden Jungen mit 1 und Madchen mit 0 kodiert. Bei Aus-
wertungen, die auf diesen Variablen basieren, erscheinen die Kodierungen wieder auf, so

5 DATENHANDLING 8
dass dem mit den Kodierungen nicht vertrauten Betrachter unklar ist, was sich dahinter
verbirgt. Beispielsweise wird durch Angabe des Befehls
tabulate sex
die folgende Haufigkeitstabelle erzeugt (zum tabulate Befehl vergleiche Abschnitt 6):
sex | Freq. Percent Cum.
------------+-----------------------------------
0 | 2,451 50.57 50.57
1 | 2,396 49.43 100.00
------------+-----------------------------------
Total | 4,847 100.00
Die Tabelle ware deutlich besser lesbar, wenn die Kodierung 0 und 1 durch die Bezeich-
nungen (labels) ”Madchen“ und ”Jungen“ ersetzt wurden. Das geschieht in STATA, indem
die Werte einer kategorialen Variable mit sogenannten Labels versehen werden. Fur die
Variable sex geschieht das durch die beiden folgenden Befehle:
label define sexlabel 0 “Madchen“ 1 “Jungen“
label values sex sexlabel
Der erste Befehl definiert ein Label mit dem Namen sexlabel und weist den Werten 0 und 1
die Bezeichnungen ”Madchen“und ”Jungen“ zu. Mit dem zweiten Befehl wird das soeben
definierte Label den Werten der Variable sex zugewiesen. Man beachte, dass ein definiertes
Label den Werten mehrerer Variablen zugewiesen werden kann. Wenn wir jetzt den Befehl
tabulate sex
eingeben erhalten wir den gewunschten Output:
sex | Freq. Percent Cum.
------------+-----------------------------------
Madchen | 2,451 50.57 50.57
Jungen | 2,396 49.43 100.00
------------+-----------------------------------
Total | 4,847 100.00

6 DESKRIPTIVE STATISTIKEN 9
In vielen Fallen kann es auch ubersichtlich sein, den Namen einer Variable zu labeln. Das
geschieht fur die Variable sex durch
label variable sex “Geschlecht“
Das Ergebnis des tabulate Befehls lautet dann
Geschlecht | Freq. Percent Cum.
------------+-----------------------------------
Madchen | 2,451 50.57 50.57
Jungen | 2,396 49.43 100.00
------------+-----------------------------------
Total | 4,847 100.00
6 Deskriptive Statistiken
Mit Hilfe des summarize Befehls werden deskriptive Maßzahlen (arithmetische Mittel,
Standardabweichungen, etc.) berechnet und ausgegeben. Der Befehl besitzt folgende all-
gemeine Syntax:
summarize [varlist] [if exp] [, detail ]
Die Angabe der Option detail bewirkt, dass zusatzliche Maßzahlen (etwa Quantile) be-
rechnet werden.
Beispiel: Zambia Daten
Mit dem Befehl
summarize zscore, detail
erhalt man folgenden STATA Output:
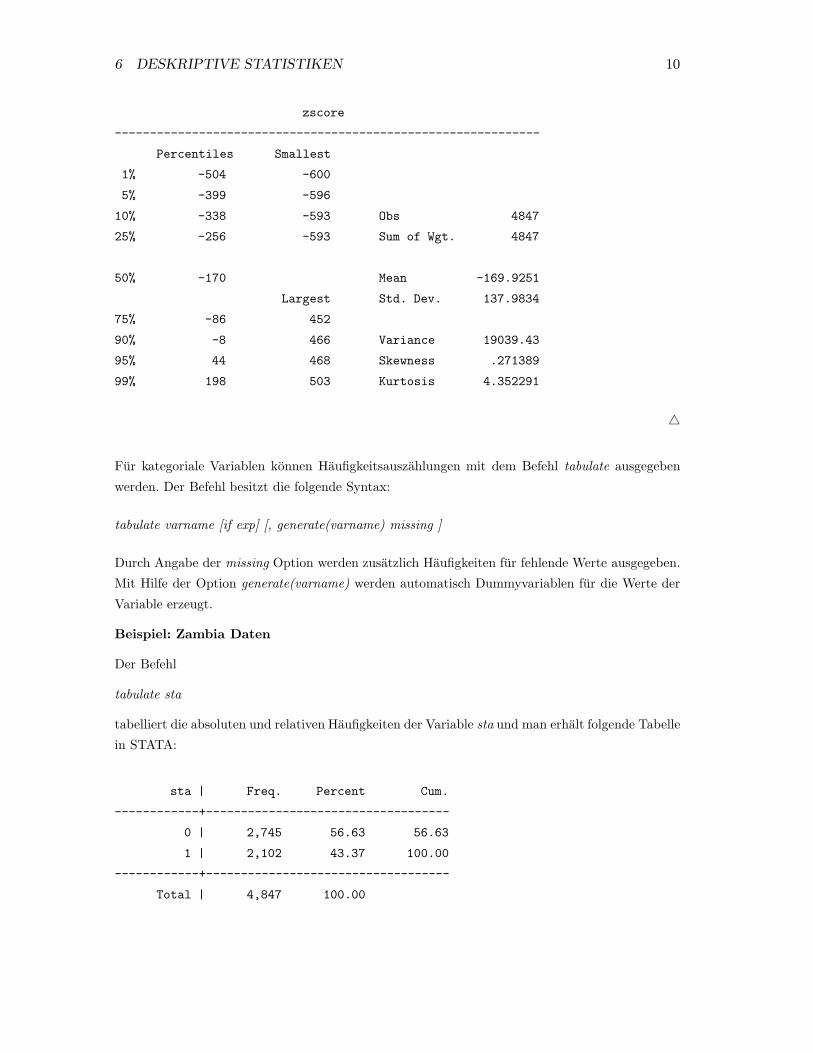
6 DESKRIPTIVE STATISTIKEN 10
zscore
-------------------------------------------------------------
Percentiles Smallest
1% -504 -600
5% -399 -596
10% -338 -593 Obs 4847
25% -256 -593 Sum of Wgt. 4847
50% -170 Mean -169.9251
Largest Std. Dev. 137.9834
75% -86 452
90% -8 466 Variance 19039.43
95% 44 468 Skewness .271389
99% 198 503 Kurtosis 4.352291
�
Fur kategoriale Variablen konnen Haufigkeitsauszahlungen mit dem Befehl tabulate ausgegeben
werden. Der Befehl besitzt die folgende Syntax:
tabulate varname [if exp] [, generate(varname) missing ]
Durch Angabe der missing Option werden zusatzlich Haufigkeiten fur fehlende Werte ausgegeben.
Mit Hilfe der Option generate(varname) werden automatisch Dummyvariablen fur die Werte der
Variable erzeugt.
Beispiel: Zambia Daten
Der Befehl
tabulate sta
tabelliert die absoluten und relativen Haufigkeiten der Variable sta und man erhalt folgende Tabelle
in STATA:
sta | Freq. Percent Cum.
------------+-----------------------------------
0 | 2,745 56.63 56.63
1 | 2,102 43.37 100.00
------------+-----------------------------------
Total | 4,847 100.00

6 DESKRIPTIVE STATISTIKEN 11
Der Befehl
tabulate edu, generate(edu)
erzeugt fur die kategoriale Variable edu Dummyvariablen, die dann im Variables Fenster erscheinen.
Als Output erhalt man eine Haufigkeitstabelle fur die Variable edu:
edu | Freq. Percent Cum.
------------+-----------------------------------
0 | 864 17.83 17.83
1 | 1,438 29.67 47.49
2 | 1,592 32.85 80.34
3 | 763 15.74 96.08
4 | 110 2.27 98.35
5 | 80 1.65 100.00
------------+-----------------------------------
Tabelliert man nun z.B. edu1, so erhalt man folgenden Output(edu1 entspricht edu=0):
tabulate edu1
edu== |
0.0000 | Freq. Percent Cum.
------------+-----------------------------------
0 | 3,983 82.17 82.17
1 | 864 17.83 100.00
------------+-----------------------------------
Total | 4,847 100.00
�
Kreuztabellen fur zwei Variablen konnen ebenfalls mit dem tabulate Befehl berechnet werden. Fur
zwei Merkmale besitzt der Befehl die folgende Struktur:
tabulate varname1 varname2 [if exp] [, cell chi2 column exact lrchi2 missing row ]
Mit Hilfe der Option cell werden zuatzlich die relativen Haufigkeiten (neben den absoluten) darge-
stellt. Durch Angabe der Option column bzw. row werden spaltenweise bzw. zeilenweise relative
Haufigkeiten ausgegeben. Die Optionen chi2 und lrchi2 berechnen Pearson’s χ2 Statistik und die
LQ-χ2 Statistik. Die Option exact fuhrt Fisher’s exakten Assoziationstest durch.

6 DESKRIPTIVE STATISTIKEN 12
Beispiel: Zambia Daten
Der Befehl
tabulate erw sta , cell
tabelliert den Zusammenhang der beiden kategorialen Variablen erw und sta. In STATA erhalt
man nun folgende Tabelle:
| sta
erw | 0 1 | Total
-----------+----------------------+----------
0 | 1,243 947 | 2,190
| 25.64 19.54 | 45.18
-----------+----------------------+----------
1 | 1,502 1,155 | 2,657
| 30.99 23.83 | 54.82
-----------+----------------------+----------
Total | 2,745 2,102 | 4,847
| 56.63 43.37 | 100.00
�
Mit dem Befehl
correlate [varlist] [if exp] [, options]
werden die Korrelationskoeffizienten nach Bravais-Pearson zwischen den in varlist angegebenen
Variablen berechnet. Spezifiziert man die Option covariance, werden die Kovarianzen ausgegeben.
Beispiel: Zambia Daten
Der Befehl
correlate zscore bmi
liefert den Output:
| zscore bmi
-------------+------------------
zscore | 1.0000
bmi | 0.1111 1.0000
Der Korrelationskoeffizient zwischen diesen beiden Variablen betragt 0.11.

7 GRAFIK MIT STATA 13
7 Grafik mit STATA
7.1 Grafische Veranschaulichung univariater Verteilungen
• Boxplot:
Einen Boxplot erhalt man durch folgenden Befehl:
graph box varname [if exp], [graph options]
Zu allgemeinen Grafikoptionen (z.B. Achsenbeschriftungen) siehe Abschnitt 7.6.
Beispiel: Zambia Daten
Mit dem Befehl
graph box zscore
erhalt man den in Abbildung 1 erscheinenden Boxplot.
−50
00
500
Abbildung 1: Boxplot der Variable zscore
Mit dem Befehl
graph box zscore, over (edu)
erhalt man Boxplots der Variable zscore stratifiziert nach den Kategorien der Variable edu.
Als Ergebnis erhalt man die Grafik in Abbildung 2.�
• Histogramm
Die Syntax zur Veranschaulichung einer stetigen Verteilung durch ein Histogramm ist
histogram varname [if exp], [bin(#)] [graph options]

7 GRAFIK MIT STATA 14
−50
00
500
0 1 2 3 4 5
Abbildung 2: Boxplot der Variable zscore stratifiziert nach den Kategorien der Variable edu
wobei bin(#) die Anzahl k der Intervalle angibt. Wird die Option bin nicht angegeben, so
wird die Anzahl der Intervalle automatisch unter Zuhilfenahme der Faustregel
k = min{√
(n), 10 · log10(n)}
gewahlt.
Beispiel: Zambia Daten
Mit dem Befehl
histogram zscore
wird ein Histogramm fur die Variable zscore in STATA erzeugt, vgl. Abbildung 3. �
• Saulendiagramm
Ein Saulendiagramm fur kategoriale Variablen erhalt man in STATA mit Hilfe des Befehls
histogram variable, discrete gap(20).
Durch Angabe der Option discrete geht das Programm von einer diskreten Variable aus,
so dass letztendlich ein Saulendiagramm gezeichnet wird. Die Option gap(20) bewirkt, dass
zwischen den einzelnen Saulen ein kleiner Abstand eingehalten wird. Durch Variation der
Zahl innerhalb der Klammer kann der Abstand variiert werden (zugelassene Werte liegen im
Bereich 0-100).
Beispiel: Zambia Daten
Mit dem Befehl
histogram reg, discrete gap(20)
erhalt man die Grafik in Abbildung 4. �
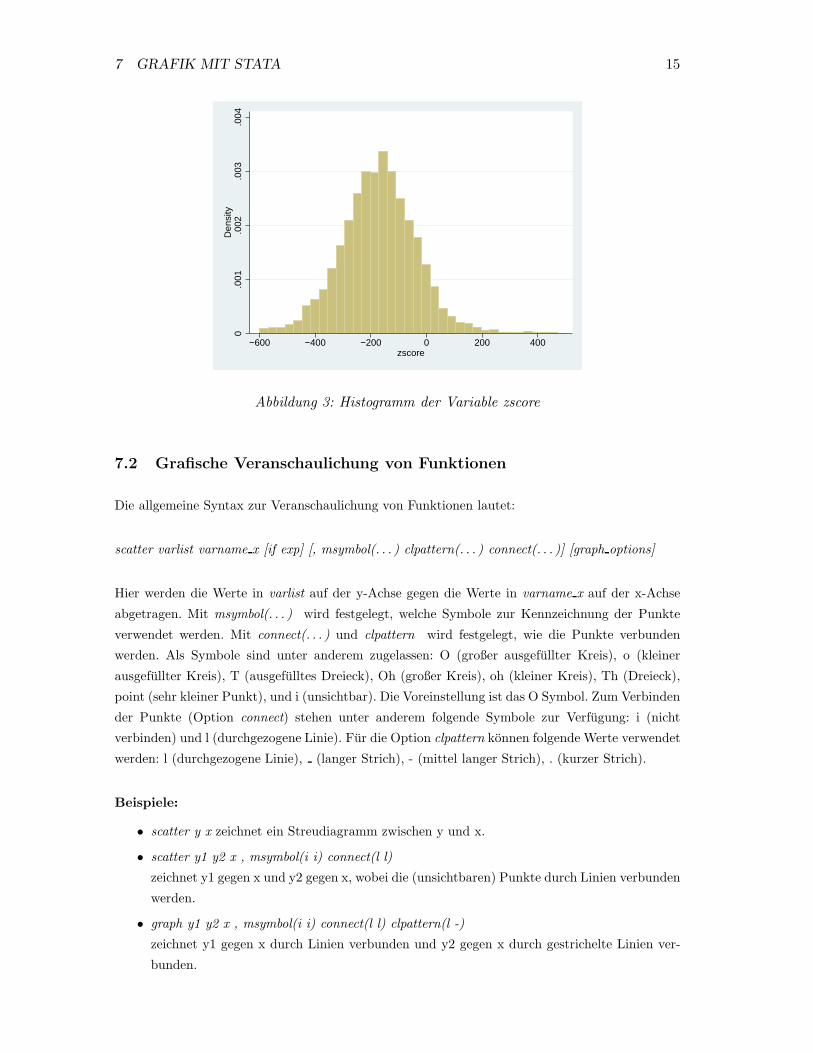
7 GRAFIK MIT STATA 15
0.0
01.0
02.0
03.0
04D
ensi
ty
−600 −400 −200 0 200 400zscore
Abbildung 3: Histogramm der Variable zscore
7.2 Grafische Veranschaulichung von Funktionen
Die allgemeine Syntax zur Veranschaulichung von Funktionen lautet:
scatter varlist varname x [if exp] [, msymbol(. . . ) clpattern(. . . ) connect(. . . )] [graph options]
Hier werden die Werte in varlist auf der y-Achse gegen die Werte in varname x auf der x-Achse
abgetragen. Mit msymbol(. . . ) wird festgelegt, welche Symbole zur Kennzeichnung der Punkte
verwendet werden. Mit connect(. . . ) und clpattern wird festgelegt, wie die Punkte verbunden
werden. Als Symbole sind unter anderem zugelassen: O (großer ausgefullter Kreis), o (kleiner
ausgefullter Kreis), T (ausgefulltes Dreieck), Oh (großer Kreis), oh (kleiner Kreis), Th (Dreieck),
point (sehr kleiner Punkt), und i (unsichtbar). Die Voreinstellung ist das O Symbol. Zum Verbinden
der Punkte (Option connect) stehen unter anderem folgende Symbole zur Verfugung: i (nicht
verbinden) und l (durchgezogene Linie). Fur die Option clpattern konnen folgende Werte verwendet
werden: l (durchgezogene Linie), (langer Strich), - (mittel langer Strich), . (kurzer Strich).
Beispiele:
• scatter y x zeichnet ein Streudiagramm zwischen y und x.
• scatter y1 y2 x , msymbol(i i) connect(l l)
zeichnet y1 gegen x und y2 gegen x, wobei die (unsichtbaren) Punkte durch Linien verbunden
werden.
• graph y1 y2 x , msymbol(i i) connect(l l) clpattern(l -)
zeichnet y1 gegen x durch Linien verbunden und y2 gegen x durch gestrichelte Linien ver-
bunden.
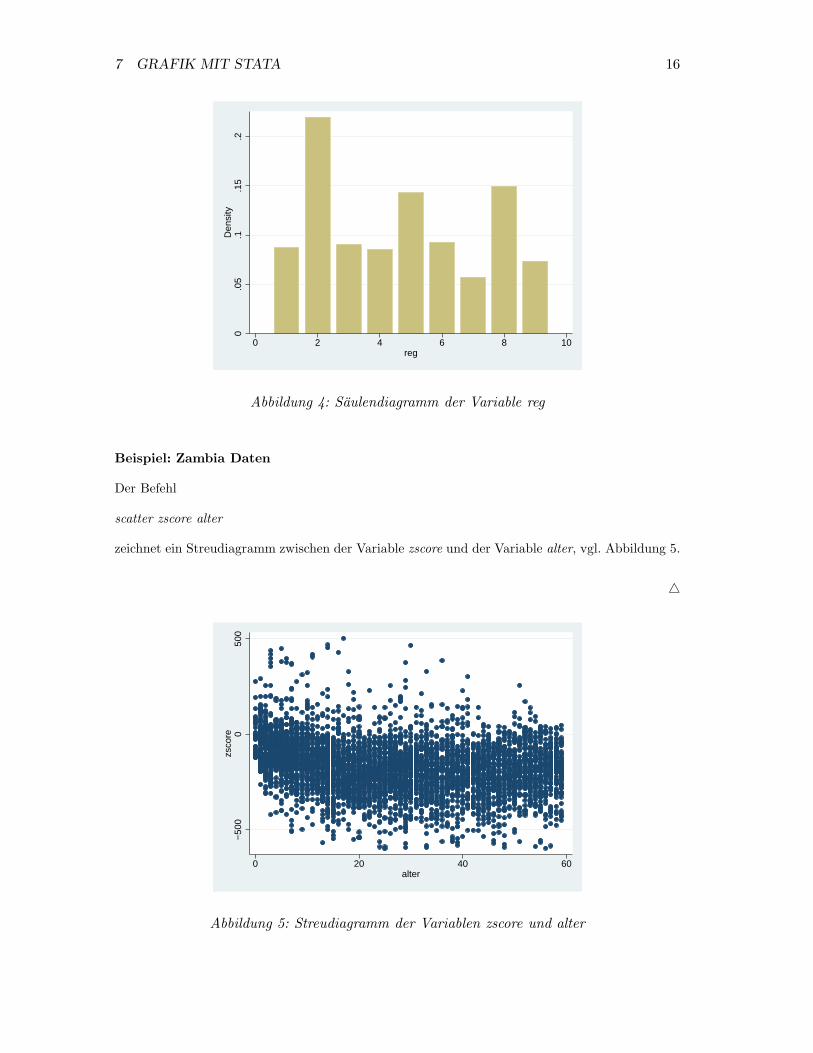
7 GRAFIK MIT STATA 16
0.0
5.1
.15
.2D
ensi
ty
0 2 4 6 8 10reg
Abbildung 4: Saulendiagramm der Variable reg
Beispiel: Zambia Daten
Der Befehl
scatter zscore alter
zeichnet ein Streudiagramm zwischen der Variable zscore und der Variable alter, vgl. Abbildung 5.
�
−50
00
500
zsco
re
0 20 40 60alter
Abbildung 5: Streudiagramm der Variablen zscore und alter
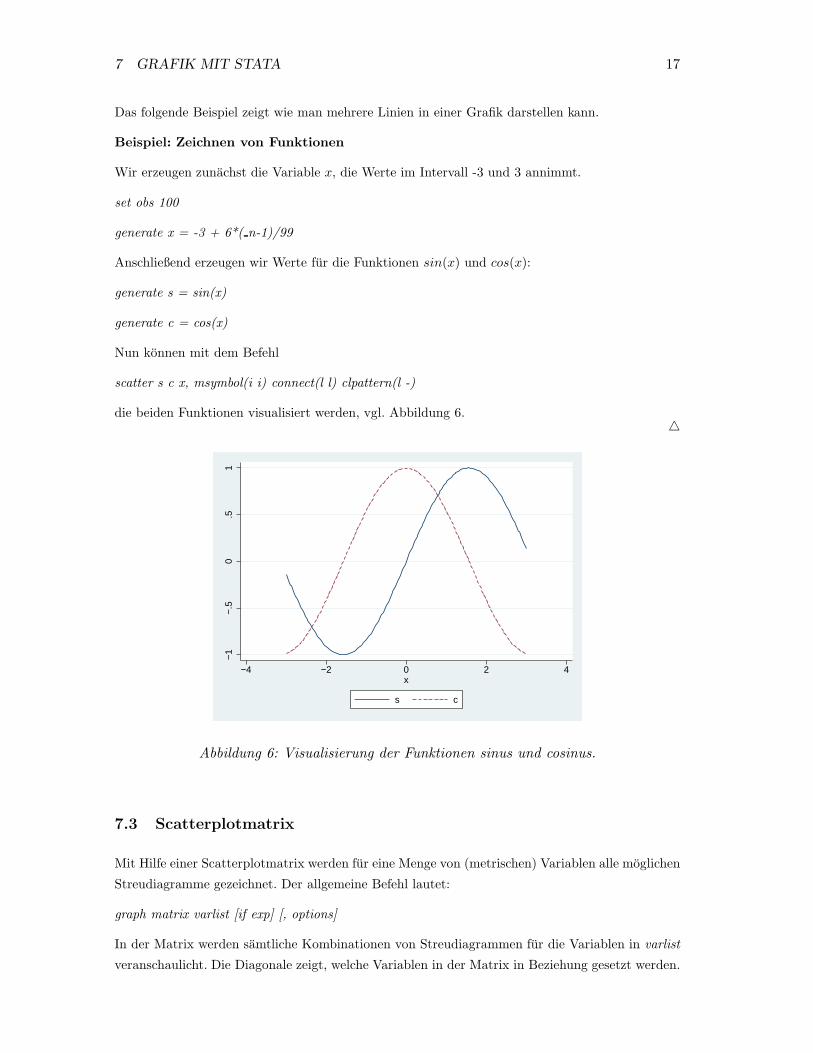
7 GRAFIK MIT STATA 17
Das folgende Beispiel zeigt wie man mehrere Linien in einer Grafik darstellen kann.
Beispiel: Zeichnen von Funktionen
Wir erzeugen zunachst die Variable x, die Werte im Intervall -3 und 3 annimmt.
set obs 100
generate x = -3 + 6*( n-1)/99
Anschließend erzeugen wir Werte fur die Funktionen sin(x) und cos(x):
generate s = sin(x)
generate c = cos(x)
Nun konnen mit dem Befehl
scatter s c x, msymbol(i i) connect(l l) clpattern(l -)
die beiden Funktionen visualisiert werden, vgl. Abbildung 6.�
−1
−.5
0.5
1
−4 −2 0 2 4x
s c
Abbildung 6: Visualisierung der Funktionen sinus und cosinus.
7.3 Scatterplotmatrix
Mit Hilfe einer Scatterplotmatrix werden fur eine Menge von (metrischen) Variablen alle moglichen
Streudiagramme gezeichnet. Der allgemeine Befehl lautet:
graph matrix varlist [if exp] [, options]
In der Matrix werden samtliche Kombinationen von Streudiagrammen fur die Variablen in varlist
veranschaulicht. Die Diagonale zeigt, welche Variablen in der Matrix in Beziehung gesetzt werden.

7 GRAFIK MIT STATA 18
Mit der Option half erscheint nur der untere Teil der Matrixdarstellung. Weiterhin sind die Op-
tionen msymbol(), mcolor() und msize() ahnlich wie bei einfachen Streudiagrammen anwendbar.
Weitere Optionen findet man in der STATA Hilfe.
Beispiel: Zambia Daten
Mit dem Befehl
graph matrix zscore alter bmi
wird in STATA die in Abbildung 7 abgedruckte Matrix erzeugt.�
zscore
alter
bmi
−500
0
500
−500 0 500
0
20
40
60
0 20 40 60
10
20
30
40
10 20 30 40
Abbildung 7: Scatterplotmatrix fur die Variablen zscore, alter und bmi.
7.4 Kombination mehrerer Grafiken
Es besteht die Moglichkeit sich mehrere Grafiken in einem Fenster anzeigen zu lassen. Dafur muss
zunachst jede Grafik mit dem Befehl
graph save “filename.gph“
abspeichert werden. Anschließend werden dann die Grafiken durch den Befehl
graph combine “filename1.gph“ “filename2.gph“ ...
in einem gemeinsamen Grafikfenster angezeigt.
Beispiel: Zambia Daten
Mit den Befehlen
histogram zscore
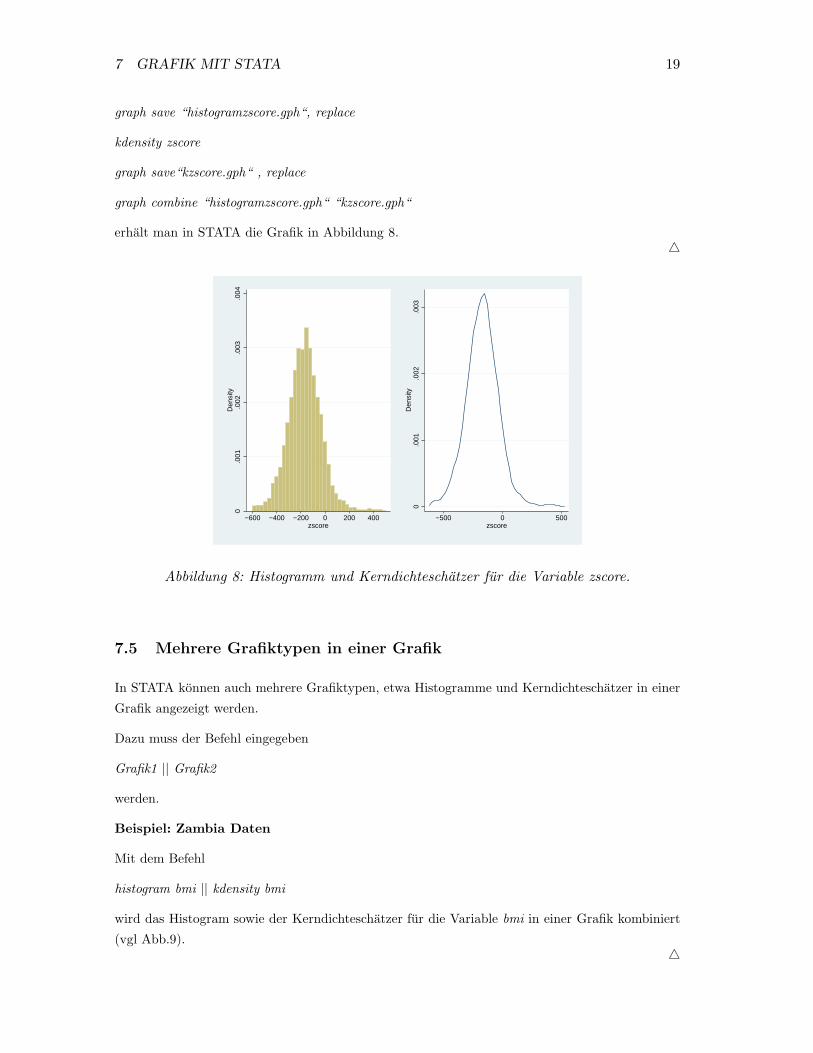
7 GRAFIK MIT STATA 19
graph save “histogramzscore.gph“, replace
kdensity zscore
graph save“kzscore.gph“ , replace
graph combine “histogramzscore.gph“ “kzscore.gph“
erhalt man in STATA die Grafik in Abbildung 8.�
0.0
01.0
02.0
03.0
04D
ensi
ty
−600 −400 −200 0 200 400zscore
0.0
01.0
02.0
03D
ensi
ty
−500 0 500zscore
Abbildung 8: Histogramm und Kerndichteschatzer fur die Variable zscore.
7.5 Mehrere Grafiktypen in einer Grafik
In STATA konnen auch mehrere Grafiktypen, etwa Histogramme und Kerndichteschatzer in einer
Grafik angezeigt werden.
Dazu muss der Befehl eingegeben
Grafik1 || Grafik2
werden.
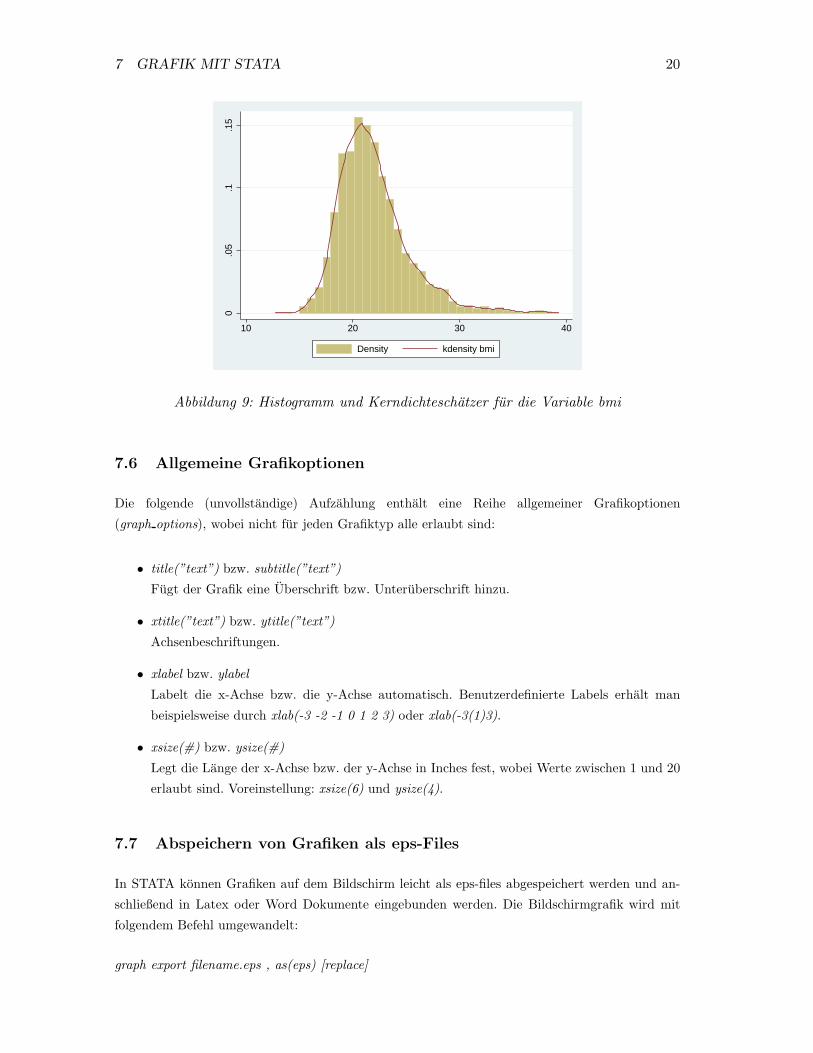
Beispiel: Zambia Daten
Mit dem Befehl
histogram bmi || kdensity bmi
wird das Histogram sowie der Kerndichteschatzer fur die Variable bmi in einer Grafik kombiniert
(vgl Abb.9).�
7 GRAFIK MIT STATA 20
0.0
5.1
.15
10 20 30 40
Density kdensity bmi
Abbildung 9: Histogramm und Kerndichteschatzer fur die Variable bmi
7.6 Allgemeine Grafikoptionen
Die folgende (unvollstandige) Aufzahlung enthalt eine Reihe allgemeiner Grafikoptionen
(graph options), wobei nicht fur jeden Grafiktyp alle erlaubt sind:
• title(”text”) bzw. subtitle(”text”)
Fugt der Grafik eine Uberschrift bzw. Unteruberschrift hinzu.
• xtitle(”text”) bzw. ytitle(”text”)
Achsenbeschriftungen.
• xlabel bzw. ylabel
Labelt die x-Achse bzw. die y-Achse automatisch. Benutzerdefinierte Labels erhalt man
beispielsweise durch xlab(-3 -2 -1 0 1 2 3) oder xlab(-3(1)3).
• xsize(#) bzw. ysize(#)
Legt die Lange der x-Achse bzw. der y-Achse in Inches fest, wobei Werte zwischen 1 und 20
erlaubt sind. Voreinstellung: xsize(6) und ysize(4).
7.7 Abspeichern von Grafiken als eps-Files
In STATA konnen Grafiken auf dem Bildschirm leicht als eps-files abgespeichert werden und an-
schließend in Latex oder Word Dokumente eingebunden werden. Die Bildschirmgrafik wird mit
folgendem Befehl umgewandelt:
graph export filename.eps , as(eps) [replace]

8 REGRESSION IN STATA 21
Beispiel: Zambia Daten
Der Befehl
graph export ”boxplotzscore.eps“ , replace
speichert die Grafik der Abbildung 1 als eps-Datei.�
Die zusatzliche Option replace gibt an, ob eine bereits existierende Grafik uberschrieben werden
darf. Es sei darauf hingewiesen, dass neben eps-Grafiken auch andere Grafiktypen (etwa wmf oder
pdf) erlaubt sind. Beispielsweise erhalt man eine Grafik im wmf (Windows Metafile) Format durch:
graph export filename.wmf , as(wmf) [replace]
8 Regression in STATA
Lineare Modelle konnen mit dem regress Befehl geschatzt werden. Der Befehl hat folgende Syntax:
regress depvar [varlist] [if exp] [, level(#) noconstant ]
Mit Hilfe der Option ’level’ kann das gewunschte Konfidenzniveau fur Konfidenzintervalle angege-
ben werden. Beispielsweise erhalt man mit ’level(80)’ 80 % Konfidenzintervalle fur die unbekannten
Parameter (Voreinstellung 95 %). Die Option ’noconst’ verhindert das Mitschatzen eines Intercepts.
Gewichtete Regressionsmodelle konnen durch zusatzliche Angabe einer Gewichtsvariable geschatzt
werden. Sei Beispielsweise w eine Gewichtsvariable. Dann wird durch
regress y x [aweight=w]
eine gewichtete Regression zwischen y und x geschatzt.
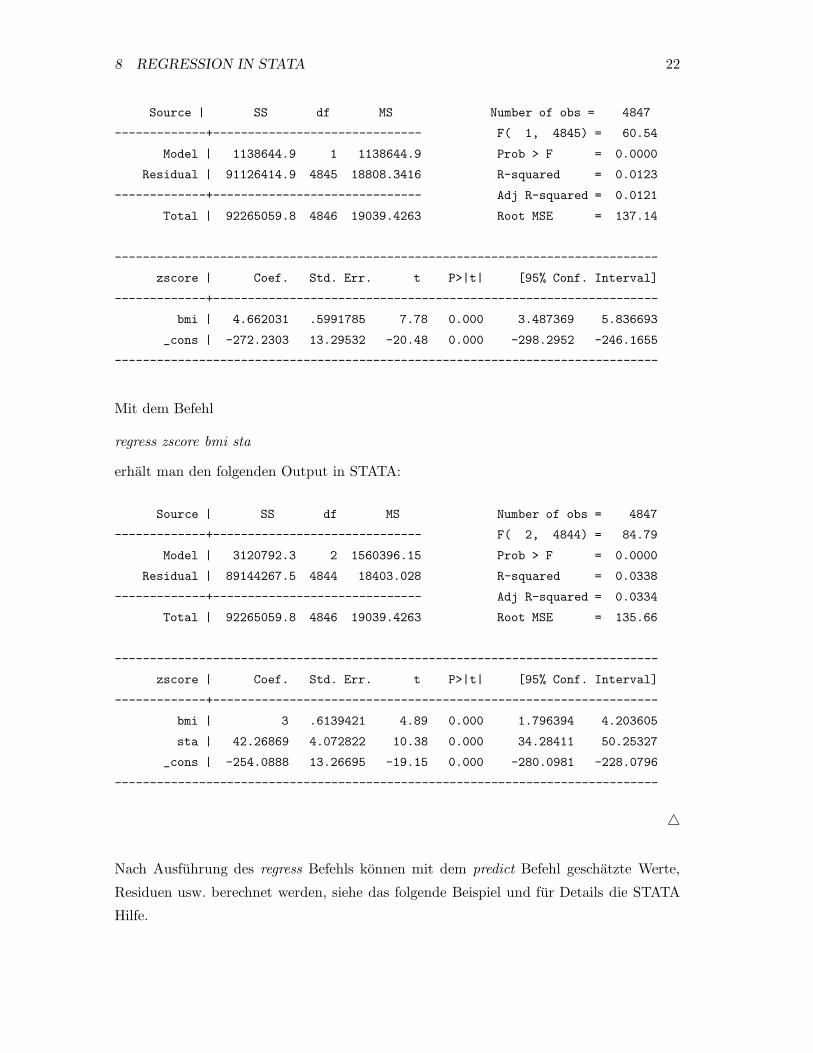
Beispiel: Zambia Daten
Mit dem Befehl
regress zscore bmi
erhalt man folgenden Output des linearen Regressionsmodells fur den zscore in Abhangigkeit von
bmi in STATA:
8 REGRESSION IN STATA 22
Source | SS df MS Number of obs = 4847
-------------+------------------------------ F( 1, 4845) = 60.54
Model | 1138644.9 1 1138644.9 Prob > F = 0.0000
Residual | 91126414.9 4845 18808.3416 R-squared = 0.0123
-------------+------------------------------ Adj R-squared = 0.0121
Total | 92265059.8 4846 19039.4263 Root MSE = 137.14
------------------------------------------------------------------------------
zscore | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
bmi | 4.662031 .5991785 7.78 0.000 3.487369 5.836693
_cons | -272.2303 13.29532 -20.48 0.000 -298.2952 -246.1655
------------------------------------------------------------------------------
Mit dem Befehl
regress zscore bmi sta
erhalt man den folgenden Output in STATA:
Source | SS df MS Number of obs = 4847
-------------+------------------------------ F( 2, 4844) = 84.79
Model | 3120792.3 2 1560396.15 Prob > F = 0.0000
Residual | 89144267.5 4844 18403.028 R-squared = 0.0338
-------------+------------------------------ Adj R-squared = 0.0334
Total | 92265059.8 4846 19039.4263 Root MSE = 135.66
------------------------------------------------------------------------------
zscore | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
bmi | 3 .6139421 4.89 0.000 1.796394 4.203605
sta | 42.26869 4.072822 10.38 0.000 34.28411 50.25327
_cons | -254.0888 13.26695 -19.15 0.000 -280.0981 -228.0796
------------------------------------------------------------------------------
�
Nach Ausfuhrung des regress Befehls konnen mit dem predict Befehl geschatzte Werte,
Residuen usw. berechnet werden, siehe das folgende Beispiel und fur Details die STATA
Hilfe.
9 PROGRAMMIEREN IN STATA 23
Beispiel: Zambia Daten
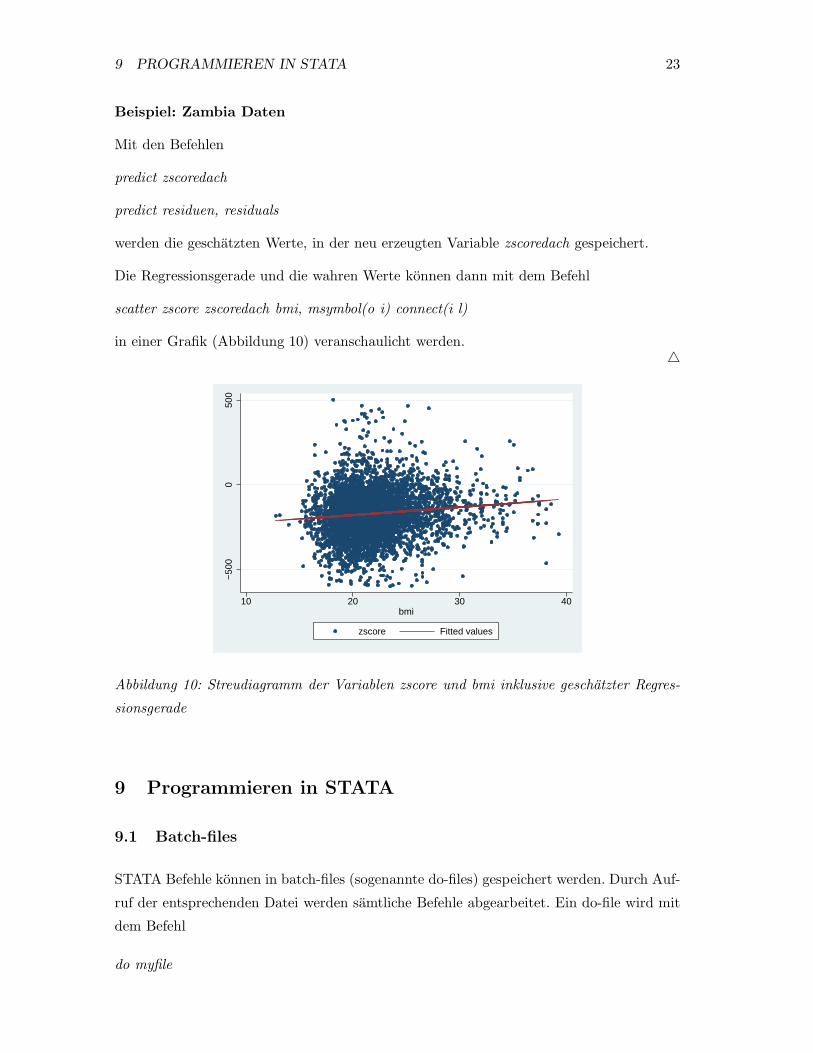
Mit den Befehlen
predict zscoredach
predict residuen, residuals
werden die geschatzten Werte, in der neu erzeugten Variable zscoredach gespeichert.
Die Regressionsgerade und die wahren Werte konnen dann mit dem Befehl
scatter zscore zscoredach bmi, msymbol(o i) connect(i l)
in einer Grafik (Abbildung 10) veranschaulicht werden.�
−50
00
500
10 20 30 40bmi
zscore Fitted values
Abbildung 10: Streudiagramm der Variablen zscore und bmi inklusive geschatzter Regres-
sionsgerade
9 Programmieren in STATA
9.1 Batch-files
STATA Befehle konnen in batch-files (sogenannte do-files) gespeichert werden. Durch Auf-
ruf der entsprechenden Datei werden samtliche Befehle abgearbeitet. Ein do-file wird mit
dem Befehl
do myfile

9 PROGRAMMIEREN IN STATA 24
aufgerufen.
9.2 Macros
Macros haben in STATA eine ahnliche Aufgabe wie Variablen in hoheren Programmier-
sprachen(z.B. C++). Ein Macro besitzt einen Macronamen und einen Macroinhalt. STATA
unterscheidet lokale Macros, die nur innerhalb eines Programms bekannt sind, und globale
Makros. Die folgenden Befehle beinhalten einige gultige Macrodefinitionen:
local a =”myvar”
local a = 2+2
local a = ‘a’+1
Auf den Inhalt lokaler Macros wird mit ‘macroname’ zugegriffen und auf den Inhalt glo-
baler Macros mit $macroname. Das folgende Code Fragment definiert mehrmals einen
lokalen Macro ‘a’ und gibt den Inhalt aus:
local a = ”myvar”
display ‘a’
local a = 2+2
display ‘a’
Im folgenden Code Fragment wird einem Macro der Name einer Variable zugewiesen und
anschließend deskriptive Kennzahlen berechnet:
local a = ”var1”
summarize ‘a’
Ein Macro kann mit Hilfe des Befehls tokenize in seine Bestandteile zerlegt werden. Die
einzelnen Token werden nacheinander in den Macros ‘1’, ‘2’, usw. gespeichert. Folgendes
Code Fragment zerlegt den Macro ‘a’ in die Token ”Dies”, ”ist”, ”ein” und ”Test”:
local a = ”Dies ist ein Test”
tokenize ‘a’

9 PROGRAMMIEREN IN STATA 25
9.3 Schleifenprogrammierung und if-Abfragen
9.3.1 While-Schleifen
While-Schleifen besitzen folgende Syntax:
while exp {STATA Befehle
}
Folgendes Code Fragment ist ein Beispiel:
local i = 1
while ‘i’ < 10 {display ‘i’
local i = ‘i’+1
end
9.3.2 forvalues-Schleifen
forvalues-Schleifen besitzen folgende Syntax
forvalues lname = range {STATA Befehle, die auf ‘lname’ zugreifen
}
wobei range die Syntax #1 (#2) #3 besitzt. Mit forvalues wird beginnend mit #1 eine
Schleife mit einer Schrittweite von #2 durchlaufen solange die Bedingung ‘lname’ <= #3
zutrifft.
Folgendes Code Fragment ist ein Beispiel:
forvalues i = 1 (2) 10 {display ‘i’
}
Mit diesem Code Fragment werden nacheinander die Zahlen 1, 3, 5, 7 und 9 am Bildschirm
ausgegeben.
Im Vergleich zu while-Schleifen sind die entsprechenden forvalues-Schleifen schneller und
sollten daher bevorzugt eingesetzt werden.

9 PROGRAMMIEREN IN STATA 26
9.3.3 if-Abfragen
if-Abfragen besitzen folgende Syntax:
if exp {STATA Befehle
}else STATA Befehle
Als ein Beispiel betrachte folgendes Code Fragment:
if ‘x’ > 0 {display ”x > 0”
}else display ”x <= 0”

Index
Abspeichern von Daten, 5
ado-file, 23
Boxplot, 9
cell Option, 9
chi2 Option, 9
Cleveland’s loess Verfahren, 22
Clevelands trikubische Gewichtsfunktion, 22
column Option, 9
Command Fenster, 3
connect Option, 13
cplattern Option, 13
deskriptive Kennzahlen, 3
deskriptive Kennzahlen(zusatzlich), 6
detail Option, 7
do-file, 23
Dummyvariablen, 7
Einlesen von Datensatzen, 4
eps Format, 19
Erzeugen von Variablen, 5
exakt Option, 9
Fenster von STATA, 3
Fisher’s exakten Assoziationstest, 9
forvalues-Schleifen, 28
generalisierte Regression, 21
generate Befehl, 5
Gewichtete Regression, 19
Glattungssplines, 22
globaler Macro, 25
Grafikoptionen, 18
Grundstruktur Befehle, 3
Histogramm, 10
if-Abfragen, 28
infile Befehl, 4
kategoriale Regression, 21
kategoriale Variablen, 7
Kerndichteschatzer, 11
Kreuztabellen, 8
Lineare Regression, 19
lokaler Macro, 25
Lokalisierung von Fehlern, 27
LQ-χ2 Statistik, 9
lrchi2 Option, 9
Macro, 24
Macrodefinitionen, 24
memory Befehl, 4
missing Option, 7
msymbol Option, 13
outfile Befehl, 5
Pearson’s χ2 Statistik, 9
predict Befehl, 20
preserve Befehl, 29
Programme, 23
regress Befehl, 19
Regression, 19
Regressionsmodelle, 21
replace Befehl, 6
replace Option, 5, 19
Results Fenster, 3
Review Fenster, 3
row Option, 9
Saulendiagramm, 12
Scatterplotsmoother, 22
27

INDEX 28
selbst definierte Programme, 23
set trace off, 27
set trace on, 27
Speicherplatzerweiterung, 4
Streudiagramm, 13
Struktur von Programmen, 24
summarize Befehl, 6
Symbole in Grafiken, 13
syntax Befehl, 25
Syntaxelemente, 25
tabulate Befehl, 7
Temporare Variablen, 29
tokensize Befehl, 25
Variablentypen, 4
Variables Fenster, 3
Verandern von Variablen, 6
While-Schleifen, 27
Zerlegung von Macros, 25


















