
Funktionsweise, Eigenschaften und Anwendung der...
98
Institut für Verteilte Systeme Proseminar – Sensorik und Robotik Funktionsweise, Eigenschaften und Anwendung der Microsoft Kinect in der Robotik Sommersemester 2013 Autoren: Silyana Gerova Vasil Georgiev Fabian Göcke Lars Grotehenne Dominik Hamann Patrick Hühne Ben Rabeler Christian Schildwächter Professor: Prof. Dr. rer. nat. Kaiser Betreuer: Sebastian Zug Betreuer: Christoph Steup
Transcript of Funktionsweise, Eigenschaften und Anwendung der...

Institut für Verteilte SystemeProseminar – Sensorik und Robotik
Funktionsweise, Eigenschaften und Anwendung der MicrosoftKinect in der Robotik
Sommersemester 2013
Autoren: Silyana GerovaVasil GeorgievFabian GöckeLars GrotehenneDominik HamannPatrick HühneBen RabelerChristian Schildwächter
Professor: Prof. Dr. rer. nat. Kaiser
Betreuer: Sebastian Zug
Betreuer: Christoph Steup

2
Nachname, Vorname: Funktionsweise, Eigenschaften und Anwendung derMicrosoft Kinect in der RobotikProseminar – Sensorik und Robotik, Otto-von-Guericke-UniversitätMagdeburg, 2013.Institut, Addresse, Jahr

Inhaltsverzeichnis
Abbildungsverzeichnis vi
Tabellenverzeichnis vii
1 Einleitung 3
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Einordnung und Gliederung der Arbeit . . . . . . . . . . . . . . . . . . . . 4
2 RGB-D SLAM 5
2.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1 Definition SLAM . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2.2 Existierende Lösungsansätze . . . . . . . . . . . . . . . . . . . . . 62.2.3 Modularer Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Funktionsweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.3.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.3.2 Ablauf des ICP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.3.3 RANSAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.3.4 KD-Trees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.3.5 Spezielle Gewichtung . . . . . . . . . . . . . . . . . . . . . . . . 122.3.6 Herausforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . 132.3.7 Loop Closing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.3.8 Ablauf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.3.9 Einschränkungen der Kinect . . . . . . . . . . . . . . . . . . . . . 14
2.4 Konklusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.4.1 Rückschlüsse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.4.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 Lageregelung eines Quadcopters 19
3.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
i

ii Inhaltsverzeichnis
3.2 Funktionsweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2.1 Erkennung der Grundfläche . . . . . . . . . . . . . . . . . . . . . 19
3.2.2 Die Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.3 Der Regler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.4 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4 RoboEarth Project 25
4.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.2 Was ist RoboEarth? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.4 Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.4.1 Datenbank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.4.2 Interfaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.4.3 Generische Komponenten . . . . . . . . . . . . . . . . . . . . . . 34
4.5 Erkennung von Objekten und Positionseinschätzung . . . . . . . . . . . . . 35
4.5.1 Semantische Kartierung . . . . . . . . . . . . . . . . . . . . . . . 35
4.5.2 Schulung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.5.3 Aktions - und Situationserkennung und Etikettierung . . . . . . . . 36
4.5.4 Demonstrationen . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.6 RoboEarth und Microsoft Kinect . . . . . . . . . . . . . . . . . . . . . . . 40
4.6.1 Einführung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.6.2 Wie funktioniert die Erfassung beliebiger Objekte? . . . . . . . . . 41
4.6.3 Objekterkennung und Positionsabschätzung . . . . . . . . . . . . . 41
4.7 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5 Detektion von Personen 45
5.1 Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2 Personendetektion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.2 Related Works . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.3 Die Methode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.4 2D Kantenmatching . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.2.5 Kopferkennung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.2.6 Konturextraktion . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.2.7 Experimente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52

Inhaltsverzeichnis iii
5.3 Gestenerkennung am Beispiel des FEMD-Verfahrens . . . . . . . . . . . . 545.3.1 Motivation und Probleme in der Gestenerkennung . . . . . . . . . 545.3.2 Hand- und Fingerdetektion mit Kinect . . . . . . . . . . . . . . . . 555.3.3 Gestenerkennung mit FEMD . . . . . . . . . . . . . . . . . . . . . 565.3.4 Experimente und Einordnung . . . . . . . . . . . . . . . . . . . . 57
5.4 Anwendung entsprechender Bibliotheken . . . . . . . . . . . . . . . . . . 585.4.1 Kinect-Hacking Geschichte . . . . . . . . . . . . . . . . . . . . . 585.4.2 Vergleich verfügbarer Sensoren . . . . . . . . . . . . . . . . . . . 595.4.3 Vergleich verfügbarer Bibliotheken . . . . . . . . . . . . . . . . . 605.4.4 Frameworks zur Personen-/Gestenerkennung . . . . . . . . . . . . 63
5.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6 Alternative Sensorsysteme 656.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 656.2 Laserscanner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6.2.1 Funktionsweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . 656.2.2 Arten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 676.2.3 Anwendungsgebiete . . . . . . . . . . . . . . . . . . . . . . . . . 676.2.4 Vor- und Nachteile . . . . . . . . . . . . . . . . . . . . . . . . . . 68
6.3 PMD Kameras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 696.3.1 Funktionsweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . 696.3.2 Anwendungsgebiete . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.4 Stereoskopie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 716.4.1 Methoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 716.4.2 Anwendungsgebiete . . . . . . . . . . . . . . . . . . . . . . . . . 75
6.5 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Literaturverzeichnis 86


Abbildungsverzeichnis
1.1 Microsoft Kinect Sensor [Wikipedia] . . . . . . . . . . . . . . . . . . . . . 3
2.1 Übersicht Online Offline SLAM . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 EKF-SLAM Anwendung auf Victoria Park Toronto, E.Nebot . . . . . . . . 7
2.3 Möglicher Ablauf von SLAM . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Beispiel für einen 2-dimensionalen Baum, der Koordinaten speichert . . . . 12
2.5 Beispiel Loop-Closing in 2D, Vorher | Nachher . . . . . . . . . . . . . . . 14
2.6 An Quadrocopter montierte Kinect . . . . . . . . . . . . . . . . . . . . . . 15
2.7 Beispiel einer 3D-Karte eines Raumes . . . . . . . . . . . . . . . . . . . . 16
3.1 Gerade in Hessescher Normalform in Bild- und Hough-Raum [SHBS11b] . 20
3.2 Ebene in Hessescher Normalform[SHBS11b] . . . . . . . . . . . . . . . . 20
3.3 Quadcopter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.4 Messergebnisse [SHBS11b] für 0,5m (a) und 1m (b) . . . . . . . . . . . . 24
4.1 Datenaustausch mittel Cloud . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.2 RoboEarth Komponenten . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.3 RoboEarth Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.4 Die Drei-Schichten-Architektur von RoboEarth [www.roboearth.org] . . . . 29
4.5 Die drei Hauptteile der Datenbank von RoboEarth [www.roboearth.org] . . 30
4.6 Objektbeschreibung und Erkennung. [www.roboearth.org] . . . . . . . . . 31
4.7 Ungebungskarte [www.roboearth.org] . . . . . . . . . . . . . . . . . . . . 32
4.8 Die Handlungsanweisungen [www.roboearth.org] . . . . . . . . . . . . . . 33
4.9 RoboEarth - Demontrationsszenario A . . . . . . . . . . . . . . . . . . . . 38
4.10 RoboEarth - Demontrationsszenario B . . . . . . . . . . . . . . . . . . . . 40
5.1 Abbildung 1: Ablauf (vgl. [XCA11]) . . . . . . . . . . . . . . . . . . . . 47
5.2 Zwischenschritte des 2D chamfer match . . . . . . . . . . . . . . . . . . . 48
v

vi Abbildungsverzeichnis
5.3 Nutzen des 3D Modells . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.4 Konturextraktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.5 Pseudocode region growing (vgl. [XCA11]) . . . . . . . . . . . . . . . . . 51
5.6 Ergebnisse der Extraktion . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.7 Ergebnisse der Personenerkennung [XCA11] . . . . . . . . . . . . . . . . 53
5.8 FN Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.9 Genauigkeiten [XCA11] . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.10 Drei schwierige Fälle für die Gestenerkennung ([RMYZ11]) . . . . . . . . 55
5.11 Schritte für die Handerkennung mit Kinect ([RMYZ11]) . . . . . . . . . . 55
5.12 Beispiel für das EMD-Verfahrens . . . . . . . . . . . . . . . . . . . . . . . 56
5.13 Erkennung einer Geste mit Kinect bei vier schwierigen Fällen . . . . . . . 57
5.14 Asus Xtion (Pro) [asu] . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.15 Kinect und Xtion Live im Vergleich [kinc] . . . . . . . . . . . . . . . . . . 60
6.1 Abtastsystem eines Laserscanners [www.xdesy.de] . . . . . . . . . . . . . 66
6.2 Laserscan von Mount Rushmore [http://ncptt.nps.gov/] . . . . . . . . . . . 68
6.3 Aufbau eines PMD-Systems . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.4 Farbcodiertes Entfernungsbild (links) und Grauwertbilddarstellung (rechts)
[www.wiley-vch.de] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.5 Spiegelstereoskop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.6 3D-Anaglyphenaufnahme [Wikipedia] . . . . . . . . . . . . . . . . . . . . 73
6.7 Gegenüberstellung von Parallaxenbarrieren- und Linsenrastertechnik [Wi-
kipedia] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6.8 Prinzip eines linearen Polarisationsfilters [Wikipedia] . . . . . . . . . . . . 74
6.9 zirkulare Polarisation [Wikipedia] . . . . . . . . . . . . . . . . . . . . . . 75
6.10 Beispiele für 6D-Vision [www.6d-vision.de] . . . . . . . . . . . . . . . . . 76

Tabellenverzeichnis
2.1 Parameter des RANSAC Algorithmus . . . . . . . . . . . . . . . . . . . . 10
2.2 Vergleich zur Neuauflage . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
5.1 Sensoren im Vergleich [sen] . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.2 SDK im Vergleich . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
vii


Abkürzungen
CL Code Laboratories
EMD Earth Mover Distance
FEMD Fingers Earth Mover Distance
HCI Human Computer Interaction
MEMM hierarchical maximum entropy Markov model
SDK Software Development Kit
SLAM Simultaneous Localization and Mapping
VR Virtual Reality
TOF Time-of-flight
SLAM Simultaneous Localization And Mapping
RGB-D Red-Green-Blue-Depth
ICP Iterative-Closest-Point
GPS Global Positioning System
RANSAC RAndom SAmple Consensus
CAD Computer Aided Design
fps Frames per Second (engl. Bilder pro Sekunde; Einheit der Bildfrequenz)
SIFT Scale-Invariant Feature Transform
EKF Extended Kalman Filter
SURF Speeded Up Robust Features
IEEE Institute of Electrical and Electronics Engineers
LIDAR LIght Detection And Ranging
RGB-D Red-Green-Blue-Depth
ix

ICP Iterative-Closest-Point
GPS Global Positioning System
RANSAC RAndom SAmple Consensus
CAD Computer Aided Design
fps Frames per Second (engl. Bilder pro Sekunde; Einheit der Bildfrequenz)
SIFT Scale-Invariant Feature Transform
EKF Extended Kalman Filter
SURF Speeded Up Robust Features
IEEE Institute of Electrical and Electronics Engineers
LIDAR LIght Detection And Ranging

Todo list
1


1 Einleitung
1.1 Motivation
Verglichen mit anderen typischen Sensoren (Laserscanner, PMD-Kameras, hochwertige In-ertialsysteme), wie sie in der Robotik Einsatz finden, ist die Microsoft Kinect ein vergleichs-weise preiswertes System, dass verschiedene Möglichkeiten der Umgebungsperzeption bie-tet. Wichtigste Ausgabegröße ist dabei eine dreidimensionale Punktewolke, die Objekte ineinem Abstand von bis zu 5 Meter in einer veränderlichen Entfernungsauflösung wahr-nimmt. Die zweite Messgröße ist das Bild einer Webcam, die in die Kinect integriert ist undeine Auflösung von 960x720 Pixeln liefert. Das dritte Messystem basiert auf einem Mikro-fonarray, das über Laufzeitunterschiede eine Schallquellenlokalisation umsetzen. Der vier-te und letzte Sensor, ein Beschleunigungsmesser, mit dem die Neigung des schwenkbarenKopfes erfasst wird, ist mit den meisten Treibern nicht erfassbar.
Im Zusammenspiel dieser vier Sensorsysteme lassen sich in spezifischen Robotikanwen-dungen vielfältige Erkenntnisse über den Zustand des Roboters und Merkmale der Umge-bung gewinnen. Für fliegende Systeme kann dies beispielsweise die Höhe über dem Grundsein, die von der Kinect allerdings nur in einem schmalen Korridor bereitgestellt werdenkann. Für den Indoor-Einsatz wird mit dem Kamerabild und der Punktewolke eine drei-dimensionale Repräsentation der Umgebung berechnet. Für die Interaktion mit dem Men-schen eignet sich die Kinect wegen der Vielzahl von entsprechenden Bibliotheken zur Ges-ten und Personenerkennung.
Abbildung 1.1: Microsoft Kinect Sensor [Wikipedia]
3

4 1 Einleitung
1.2 Einordnung und Gliederung der Arbeit
Die vorliegende Arbeit versucht diese Einsatzmöglichkeiten zusammenzufassen und dieGrenzen und Möglichkeiten der Kinect in Robotikszenarien zu hinterfragen.
Die Ausarbeitung entstand dabei im Rahmen des Proseminars SSensorik und Robotik", dasvon der Arbeitsgruppe für Eingebettete Systeme und Betriebssysteme im Sommersemester2013 angeboten wurde. Neben den einzelnen Aufsätzen, die von einzelnen Studenten odervon Studentengruppen erarbeitete wurden, sind auch die entsprechenden Vorträge auf derWebseite der Arbeitsgruppe unter
http://eos.cs.ovgu.de/de/lecture/courses/ss13/
proseminar-sensorik-und-robotik/
zu finden.
Das Paper selbst gliedert sich folgendermaßen. Zunächst wird im Kapitel 1 die Funktions-weise, die Möglichkeiten und die Grenzen der Kinect als Messsystem untersucht. Im dar-auf folgenden Abschnitt werden die Grundlagen der RGB-D Slam-Techniken vorgestelltund die Anwendbarkeit dieser Methoden auf die Messdaten einer Kinect hinterfragt. Ka-pitel ?? beschäftigt sich mit dem Einsatz des Sensors in fliegenden Roboterapplikationen.Im nächsten Abschnitt wird das Cloud basierte RoboEarth-Projekt vorgestellt und die Ein-bindung von 3d-Sensoren in die Erfassung von Umgebungsobjekten untersucht. Kapitel ??fasst die Möglichkeiten zur Erfassung von Personen und Gesten zusammen. Zudem werdendie entsprechenden Bibliotheken dafür verglichen und charakterisiert. Das letzte Kapitelbeschreibt schließlich alternative Sensortechniken.

Dominik Hamann, Patrick Hühne
2 RGB-D SLAM
2.1 Einleitung
Ein Großteil der in der autonomen Robotik stattfindenden Forschung setzt sich mit fol-genden Fragestellungen auseinander. "Wo bin ich?Wie sieht die Welt um mich herumaus?"Die Lösung auf beide dieser Fragen liefern Simultaneous Localization And Map-ping (SLAM)(Simultaneous Localization And Mapping) Algorithmen. Der Grundstein fürSLAM wurde 1986 auf der Institute of Electrical and Electronics Engineers (IEEE) Ro-botics and Automation Conference in San Francisco von Peter Cheeseman, Jim Crow-ly,Hugh DurrantWhyte und einigen anderen Wissenschaftler gelegt[DWB06]. Das Akro-nym "SLAM"wurde erstmals in einem Paper präsentiert welches 1995 auf dem Ïnte-national Symposium on Robotics Research"[DWB06]vorgestellt wurde. Der essentielleTeil der Theorie, der Konvergenz und vielen weiteren initialen Ergebnissen wurden vonCsorba[DWB06] erstellt. 1999 fand die erste SLAM Sitzung statt. Auf ihr wurden dieKonvergenzen zwischen Kalman Filtern, probabilistischen Lokalisierung und Kartogra-phierungsmethoden durch Thrun [DWB06]eingeführt. Seitdem arbeiten verschiedene For-schungsgruppen an dem Thema SLAM und dessen Anwendungen. Eine dieser Anwen-dungen ist der RGB-D SLAM mithilfe eines Microsoft Kinect Systems. Dieser Artikelbeschreibt einen Einstieg in dieses Themengebiet. Dazu definieren wir zunächst wichti-ge Grundlagen und um eine bessere Einführung in RGB-D SLAM zu ermöglichen, gehenwir im Laufe des Artikels auf den Iterative-Closest-Point (ICP) und den RAndom SAmpleConsensus (RANSAC) Algorithmus ein. Ein großes Problem stellt bei der Kinect der Auf-nahmebereich dar. Der minimale Abstand zu einem Objekt beträgt 80 cm. Ist ein Objektnäher, so wird es nicht wahrgenommen und blockiert die Kamera. Der maximale Abstandhingegen liegt bei 400 cm. Dies führt gerade in der mobilen Anwendung zu Problemen,da sich die Kinect dementsprechend nur äußerst eingeschränkt für die Nutzung im Nahbe-reich, wie zum Beispiel zum Kollisionsschutz, eignet. Auch im Fernbereich, beispielsweisebei der Nutzung der Kinect zur Navigation eines Quadrocopters, ist die Reichweite einemassive Einschränkung. Im Laufe unserer Recherche sind wir auch auf Arbeiten gestoßenwelche sicherlich weiterverfolgt werden sollten. Eine dieser Arbeiten befasst sich mit dem
5

6 2 RGB-D SLAM
Rat-SLAM Verfahren. Dabei kommt statt der Kinect nur eine einzelne RGB-Kamera zumEinsatz. Mithilfe der vom Roboter genutzten Odometrie und den Informationen aus derKamera kann so eine verwertbare Karte erstellt werden
2.2 Grundlagen
2.2.1 Definition SLAM
SLAM bezeichnet Verfahren aus der Robotik, die es einem Roboter ermöglichen die ei-gene Position zu bestimmen und gleichzeitig eine Karte der Umgebung zu erstellen. Diesermöglicht die autonome Fortbewegung des Roboters. Bei SLAM spricht man von einemrelativen Navigationsverfahren, da nur im Verhältnis zu der (Ausgangs-)Position des Ro-boters gearbeitet wird. Den Gegensatz dazu stellen die absoluten Navigationsverfahren diezum Beispiel mit Global Positioning System (GPS) zur Orientierung nutzen dar. Außerdemwird das SLAM-Verfahren genutzt, um Objekte unabhängig von der Bewegung eines Ro-boters zu kartographieren. Dadurch können schnell und simpel 3D-Modelle erstellt werden.
2.2.2 Existierende Lösungsansätze
In der mobilen Robotik existieren zwei Lösungswege zur Kartenerstellung. Bei Offline-SLAM wird die Karte vor der eigentlichen autonomen Fahrt erstellt. Dabei wird die zuerkundende Umgebung zunächst manuell, durch eine oder mehrere Testfahrten/-Scans, kar-tographiert und evtl. durch Zusatzinformationen ergänzt oder berichtigt. Somit ist das er-stellen der Karte von der Verwendung getrennt. Bei dem sogenannten Online-SLAM wirddie Karte zeitgleich zu der Lokalisierung erstellt. Diese Verfahren ist wesentlich komple-xer und erfordert Anwendungen, welche mit Sprüngen und Korrekturen umgehen können.Aber dieses Verfahren ermöglicht dynamische Modifikationen und Verbesserung der Karte,was bei dem Offline-SLAM nur während der Kartographierungsphase möglich ist. FolgendeAbbildung verdeutlicht nochmal beide Verfahren und stellt sie nebeneinander.
Alle existierenden SLAM Algorithmen können diesen beiden Verfahren zugeordnet werden.Im folgenden werden wir auf einige der existierenden Verfahren eingehen und kurz ihreGrundideen erläutern. SLAM Algorithmen können 3 verschiedenen Paradigmen zugeordnetwerden.[Wie12] Diese sind:
Extended Kalman Filter
Einer der ersten SLAM Algorithmen ist der Extended Kalman Filter (EKF)-SLAM. DieserAlgorithmus ist ein reines Online-SLAM Verfahren, welcher sogenannte Landmarken nutzt.

2.2 Grundlagen 7
Abbildung 2.1: Übersicht Online Offline SLAM
Abbildung 2.2: EKF-SLAM Anwendung auf Victoria Park Toronto, E.Nebot
Landmarken sind dabei meist auffällige, permanent wahrnehmbare und damit identifizier-bare Merkmale der Umgebung, wie zum Beispiel Bäume. Allgemein wird bei EKF-SLAMnoch unterschieden ob die Landmarkenzuordnung bekannt ist oder unbekannt. Ein Nach-teil des Algorithmus ist das die Komplexität quadratisch mit der Anzahl der Landmarkenwächst. [SK08]Ein Beispiel für die Anwendung des EKF SLAMs ist die Kartierung desVictoria-Parks in Toronto von E.Nebot, welche in Abb. 2 dargestellt ist [O.B13]
Partikelfilter
Partikelfilter beruhen auf Schätzungen, dabei repräsentiert jeder Partikel eine konkrete Ver-mutung was der wahre Wert des Zustandes sein kann. Aus einer Sammlung vieler solcherPartikeln, wählt der Partikelfilter eine repräsentative Stichprobe aus dem letzteren Vorkom-men und führt damit seine Neuberechnung durch. Das Hauptproblem bei Partikelfiltern ist,dass diese ein exponentielles Wachstum für jede hinzukommende Dimension besitzen. EinTrick dieses Problem zu lösen ist FastSLAM[SK08]

8 2 RGB-D SLAM
Abbildung 2.3: Möglicher Ablauf von SLAM
Bei FastSLAM wird die Rao-Blackwellized Partikel Filterung genutzt. Diese beruht aufLandmarken welche eine 2x2 EKF repräsentieren. Jedes Partikel wiederum besitzt eineendliche Anzahl dieser EKFs[TM05]. Mit FastSLAM wird nun die aktuelle Position undder komplette Pfad konkret geschätzt. Bei jeder Bewegungsänderung erfolgt die Schätzunganhand der Odometrie und einem "Rauschen"welches hinzugefügt wird. Danach werdendie Landmarken gewichtet und das Partikelset neu berechne[MTKW02]. FastSLAM besitztdabei eine logarithmische Komplexität .
Graph-basierende Techniken
Bei den Graph-basierten Techniken werden die Odometriedaten und die Daten der Land-marken mithilfe von RGB-D Informationen verknüpft. Bei RGB-D wird das durch eine Ka-mera aufgenommene Bild (RGB) um die Entfernungsinformation (D) eines jeden einzelnenPixels ergänzt. Der genaue Ablauf von RGB-D SLAM mithilfe einer Kinect-Kamera wirdim Kapitel "3D RGB-D SLAM"behandelt.
2.2.3 Modularer Aufbau
SLAM-Algorithmen folgen in der Regel einem modularem Aufbau, wobei als Herzstückder Teil angesehen werden kann, der die vorhandenen Daten mit den neuen Daten ergänzt.In diesem Fall handelt es sich um den ICP. Diesem sind in der Regel allerdings Algorith-men vorgeschaltet, um die Qualität der Aufnahmen zu verbessern. Die folgende Grafik sollden Ablauf eines RGB-D SLAM noch einmal in seine Bestandteile zerlegen. Anschließendwerden die einzelnen Module erläutert.

2.3 Funktionsweise 9
2.3 Funktionsweise
2.3.1 Definition
Der ICP-Algorithmus ist eine bereits etablierte Methode, um Gemeinsamkeiten in ver-schiedenen Datensätzen zu finden und diese Datensätze anhand dieser Gemeinsamkeitenzu verbinden[EEH+11]. Im Fall des Red-Green-Blue-Depth (RGB-D) SLAM erhält der Al-gorithmus zwei Punktwolken, die sich überlappende Abbildungen realer Objekte darstellen.ICP kann nun entscheiden, welche Punkte in den beiden Punktwolken identisch sind undsie zu einer konsistenten Wolke zusammenführen. Dadurch entsteht aus mehreren Aufnah-men des gleichen Objekts aus verschiedenen Perspektiven ein Modell. Bei der Aufnahmevon Objekten mit einer Kamera wird es immer das Verdeckungsproblem geben. Durch dasZusammenfügen der einzelnen Aufnahmen werden auch die Teile zum Modell hinzugefügt,die bei der ersten Aufnahme verdeckt waren.
2.3.2 Ablauf des ICP
Mittlerweile gibt es verschiedene Algorithmen, mit denen das finden von Paaren durch ICPermöglicht wird. Aber alle lassen sich nach Rusinkiewicz et al. [RL01] auf die 6 folgendenSchritte reduzieren.
1. Selektion von Punkten aus einer oder beiden Punktwolken
2. Matching/Paarung dieser Punkte zu Stichproben in der anderen Punktwolke
3. Gewichtung der zusammengehörenden Paaren
4. Verwerfung einiger dieser Paare
5. Zuweisung einer Fehlermetrik zu den einzelnen Punktpaaren
6. Minimierung dieser Fehlermetrik
Eine mögliche Anwendung des ICP zeigt folgender Pseudocode: Beschreibung des ICP inPseudocode[Nel11]: Bei diesem wird zunächst eine grundlegende Translation berechnet.Dafür wird mithilfe der beiden Punktwolken eine initiale Bewegungsschätzung durchge-führt. Da es sich dabei nur um eine grobe Schätzung handelt, ist auch der initiale Fehler sehrgroß. Um diesen zu verringern wird nun in K-Schritten zunächst die berechnete Translationauf die scan-Punktwolke angewendet und in der daraus entstandenen neuen Szene mithilfeder bereits existierenden model-Punktwolke nach Punktpaaren gesucht. Mit den nun be-rechneten Paaren, der Translation und den beiden Punktwolken (model,newscene) wird derFehler berechnet und die gegebene Translation upgedatet. Durch das mehrfache iterierenüber diese 3 Unterfunktionen kann die zunächst grobe Schätzung konkretisiert werden.

10 2 RGB-D SLAM
Input: Point[] model, Point[] scantrans := InitialTransformationEstimate (model, scan);for k FROM 1 TO K do
newscene := ApplyTranslation(scan, trans);pointpairs := GetCorrespondingPoints(model, newscene);R, t, error := UpdateTranslationEstimate(model, newscene, pointpairs, trans);
endreturn trans
Algorithm 1: ICP in Pseudocode
2.3.3 RANSAC
RANSAC ist ein etablierter, stabiler Algorithmus, um bei automatischen Messungen Feh-ler in Form von Ausreißern, also unnatürlich stark abweichenden Werten, zu entfernen.RANSAC erhält bei der Verwendung mit ICP folglich eine Punktwolke von dem Aufnah-megerät, begradigt sie und gibt sie an den ICP weiter. RANSAC verbessert also die Qualitätdes Modells, erhöht aber die Laufzeit und folglich die Latenz. Die Funktionsweise wirdanalog zum Pseudocode aus [Zha11] grob umrissen. Die Parameter der Funktion sind in derfolgenden Tabelle zusammengefasst:
Tabelle 2.1: Parameter des RANSAC AlgorithmusInput data Datensatz von Messungen
model Ein Modell, das diese Daten darstellen solln Mindestanzahl an Daten um ein Modell zu er-
stellenk Anzahl der Iterationen des Algorithmust Schwellenwert, der die Fehlertoleranz angibtd Weiterer Schwellenwert
Output bestModel Modell, das den Datensatz am besten darstellt(oder nil, wenn kein Modell zu den gegebenKriterien gefunden wurde)
bestConsensusSet Datensatz, aus dem dieses Modell entstandenist
bestError Der Fehler des Modells
RANSAC wählt zunächst zufällig Werte aus den übergebenen Daten und behandelt diese alsFixpunkte. Alle anderen Punkte werden daraufhin mit diesen Punkten verglichen und wer-den verworfen, falls der berechnete Fehler den festgelegten Schwellenwert übersteigt. Ausden verbliebenen Punkten wird ein Modell erstellt, welches zusammen mit dem Datensatzund dem dazugehörigen Fehler zwischengespeichert wird.

2.3 Funktionsweise 11
Dieser Vorgang wird k mal durchgeführt, wobei die zwischengespeicherten Werte über-schrieben werden, wenn das neue Modell einen geringeren Fehler aufweist. Nach Ausfüh-rung aller Wiederholungen wird dementsprechend das beste der erstellten Modelle ausge-geben.
Der nachfolgende Pseudocodeausschnitt 2 zeigt die Basisfunktionalität des Algorithmus:
begin initializationiterations := 0;bestModel := nil;bestConsensusSet := nil;bestError := infinity;
endwhile iterations < k do
maybeInliers := n randomly selected values from data;maybeModel := model parameters fitted to maybeInliers;consensusSet := maybeInliers;for every point in data not in maybeInliers do
if point fits maybeModel with an error smaller than t thenadd point to consensusSet;
endendif the number of elements in consensusS etis > d then/* this implies that we may have found a good model, now test
how good it is */
thisModel := model parameters fitted to all points in consensusSet;thisError := a measure of how well thisModel fits these points;if thisError < bestError then/* we have found a model which is better than any of the
previous ones, keep it until a better one is found */
bestModel := thisModel;bestConsensusSet := consensusSet;bestError := thisError;
endendincrement iterations;
endreturn bestModel, bestConsensusSet, bestError
Algorithm 2: RANSAC-Algorithmus in Pseudocode

12 2 RGB-D SLAM
Bei der Verwendung des RANSAC-Algorithmus ist zu beachten, dass die Güte und Perfor-mance stark von der Wahl der Parameter abhängt. Die Anzahl der Iterationen und die Werteder verwendeten Grenzwerte sollten dementsprechend an den Anwendungsfall angepasstwerden.
2.3.4 KD-Trees
Bei den k-d-Bäumen handelt es sich um eine mehrdimensionale Datenstruktur bei welcherungeordnete Sets von Punkten strukturiert werden und so eine effektive Suche ermöglichen.Dabei stellt die Wurzel den kompletten Suchraum dar. Die Blätter bilden die Subsets inwelchen nur eine bestimmte Anzahl an Punkten drin ist und die Zwischenknoten unter-teilen den Suchraum in k-Dimensionen. Aufgrund der Struktur des k-d-Baums ist es demICP-Algorithmus möglich effektiv (Normalfall: O(log(n))) zwei gegebene Punktsets zu ver-gleichen. Mittlerweile existieren auch für die Verwendung von k-d-Bäumen Verbesserun-gen, welche eine bis zu 50% Steigerung bei der Anwendung des ICP-Verfahrens darauferreichen[NLH07].
Abbildung 2.4: Beispiel für einen 2-dimensionalen Baum, der Koordinaten speichert
2.3.5 Spezielle Gewichtung
Mithilfe von bestimmten Algorithmen können Bilder auf besondere Merkmale untersuchtwerden. Punkte, die diese Merkmale aufweisen sind folglich robust gegen Rauschen und an-dere Fehler, da sie nicht bloß anhand des reinen Tiefen-Bildes festgelegt wurden. BekannteVertreter dieser Verfahren sind der Scale-Invariant Feature Transform (SIFT)[Low04]- undder Speeded Up Robust Features (SURF)-Algorithmus.

2.3 Funktionsweise 13
2.3.6 Herausforderungen
Die Herausforderung liegt letztendlich darin, ein auf den spezifischen Anwendungsfall zu-rechtgeschnittenes Kompromiss aus Qualität und Geschwindigkeit zu finden. Um die Pro-blematik an zwei extremen Beispielen zu erläutern:
Ein Roboter, der RGB-D SLAM zur autonomen Navigation nutzt muss in Echtzeit ein Mo-dell seiner Umgebung erstellen können. Erschwerend kommt hinzu, dass die Rechenleis-tung bereits durch das Gewicht und den Stromverbrauch der Komponenten stark begrenztsein kann. Daher muss in diesem Fall auf einen qualitativ niederwertigen, aber schnellerenAlgorithmus gesetzt werden.
Soll hingegen aus Aufnahmen von einem Objekt ein Computer Aided Design (CAD)-Modell erstellt werden, das womöglich als Bauteil produziert werden soll, muss der ver-wendete Algorithmus ein möglichst fehlerfreies Modell erstellen können. In diesem An-wendungsfall wird die Ausführung des ICP nicht so stark durch die einschränkendenFaktoren(Gewicht,Rechenleistung, Strom und Zeit) des ersten Beispiels beeinflusst, da manvon einer stationären Anwendung ausgehen kann.
2.3.7 Loop Closing
Erreicht ein Roboter eine Position, die er bereits kennt, so müsste er sich auf seiner Kartean demselben Ort wiederfinden. Durch den Fehler bei der Erstellung der Karte kann die-se Position auf der internen Karte allerdings weit von der tatsächlichen Position entferntsein. Anhand der Merkmale der bereits bekannten Umgebung muss der Roboter dement-sprechend seine Position erkennen und seine Karte korrigieren, indem er die Schleife (engl.loop) schließt. Dieses Unterproblem des SLAM ist als Loop-Closing-Problem[Wie12] be-kannt.
2.3.8 Ablauf
Der Ablauf jedes offline-SLAM-Algorithmus folgt ungefähr diesem Muster[Neu11]:
Schrittweises Abgleichen Jede neue Aufnahme wird in das bereits bestehende Modelleingegliedert.
Loop Detection Bei jedem Scan wird überprüft, ob eine Schleife geschlossen wurde, in-dem zum Beispiel eine 360◦ Drehung vollzogen wurde. Ist dies der Fall, wird dieeigentliche Schließung dieser Schleife initiiert.
Loop Closure Wurde eine geschlossene Schleife erkannt, versucht ein Algorithmus dieeigentliche Positionen der Punkte wiederherzustellen.

14 2 RGB-D SLAM
Abbildung 2.5: Beispiel Loop-Closing in 2D, Vorher | Nachher
Überwachung Die vorhergegangenen Schritte sind fehleranfällig und können daher dasModell verschlechtern. Durch bestimmte Mechanismen können aufgetretene Fehlererkannt und rückwirkend beseitigt werden.
2.3.9 Einschränkungen der Kinect
Allgemein gelten als einschränkende Faktoren der Kinect die Auflösung, der Aufnahme-winkel, die Bildrate, die Latenz, die Datenübertragungsgeschwindigkeit an andere Geräteund die Reichweite.
In der Praxis sollten jedoch hauptsächlich der Aufnahmewinkel und die Reichweite ent-scheidend sein. Mit einem horizontalen Winkel von nicht einmal 60◦ hat die Kinect ins-besondere im Vergleich zu einem LIght Detection And Ranging (LIDAR) ein stark einge-schränktes Blickfeld.
Die Kinect wurde dafür konzipiert als Teil einer Spielekonsole in einem Wohnzimmer ge-nutzt zu werden. Daher können Objekte nur in einem Abstand zwischen ungefähr 80 cmund 400 cm erfasst werden. Während diese Einschränkung im Wohnzimmer wohl kaumauffällt, stellt dies für die autonome Navigation von Robotern die größte Schranke dar. Sollein Quadrokopter beispielsweise einen großen Raum kartographieren, so muss er sich ent-sprechend der Position der einzelnen Objekte ausrichten. Je eingeschränkter der Aufnahme-bereich, desto mehr Flugoperationen benötigt der Quadrokopter und desto kleiner ist auchdie aufgenommene Fläche. Dadurch erhöht sich enorm das Fehlerpotenzial.
Ein Quadrokopters, der im freien agiert und zum Beispiel ein Haus kartographieren soll,hätte durch den knapp bemessenen Aufnahmebereich zudem ein besonders hohes Risikoabzudriften, da der Roboter sich nur anhand seiner eigenen Position und seinen bisherigenAufnahmen orientieren kann.
Auf der anderen Seite kann die Kinect kein Objekt erfassen, dass sich näher als 80 cmam Sensor befindet. In unserem Beispiel könnte das in bestimmten Situationen bereits zumTotalausfall führen. Gerade zur Kollisionsvermeidung ist die Kinect daher nicht tauglich.

2.4 Konklusion 15
Abbildung 2.6: An Quadrocopter montierte Kinect
Ein Roboter sollte daher zu diesem Zweck wenn möglich noch ein redundantes System zurAbstandsmessung nutzen.
2.4 Konklusion
2.4.1 Rückschlüsse
Grundlegend ist die Güte einer SLAM basierten Karte abhängig von einigen Faktoren. Dar-unter fallen der verwendete Algorithmus und die Hardware, welche verwendet wurde umdie grundlegenden Daten zu sammeln. Wir kommen aufgrund unserer Recherchen zu demSchluss, dass eine mit Hilfe einer Kinect erstellten Karte zwar eine hohe Güte aufweist,aber nicht an die teurerer Sensoren heranreicht. Insbesondere LIDARs sind um ein Vielfa-ches präziser. Dabei wirken sich, nach [WWN11] et al.besonders negativ das stark steigendeMessrauschen bei zunehmenden Objektabstand und die Auswertecharakteristik des Sensorsaus. Dadurch ist die Gesamtgenauigkeit limitiert. Aber aufgrund des preislichen Vorteils istdie Kinect eine gute Alternative zu teureren Sensorsystemen und mithilfe angepasster Kali-brierungsmöglichkeiten sollte es möglich sein die Güte der berechneten Karte zu erhöhen.In einigen Versuchen zeigte es sich zum Beispiel als praktikabel Innenräume mit einer Ki-nect zu kartographieren, wie im folgenden Bild.
Letztlich wird sich die Kinect wohl nicht gegen bereits etablierte Systeme durchsetzen undvermutlich höchstens für Nischenanwendungen durchsetzen. Die Vorteile für Forschungund Lehre ein so günstiges Produkt zur Erstellung von 3D-Karten und Modellen zur Verfü-gung zu haben sind jedoch enorm.

16 2 RGB-D SLAM
Abbildung 2.7: Beispiel einer 3D-Karte eines Raumes
2.4.2 Future Work
Die Forschung im Bereich des Maschinellen Sehens ist noch sehr jung und steckt vollerPotenzial. Auch die Möglichkeiten der erst 3 Jahre alte Kinect wurden noch nicht völligausgeschöpft. Im Folgenden wollen wir daher auf interessante Themen eingehen, die zumjetzigen Zeitpunkt noch unausgereift sind.
Verwendung synchronisierter Kinects
Die Möglichkeit mehrere Kinects gleichzeitig zu benutzen, um das mit ca. 4m2 relativ kleineAufnahmefeld zu vergrößern, ist Gegenstand aktueller Forschung. Durch die Verwendungeines Kinect-Arrays kann der Blickwinkel eines Roboters vergrößert werden, wodurch ernicht nur mit weniger Navigationsaufwand einen Bereich kartographieren könnte, sondernauch auf bewegliche Hindernisse reagieren könnte, die nicht direkt vor ihm liegen. Denkbarwäre sogar ein Kinect-Array, das eine 360◦ -Ansicht liefert. Ein Roboter mit solch einerAusstattung hätte in der Ebene praktisch keinen toten Winkel.
Die synchrone Nutzung von zwei Kinect-Sensoren hat sich bei Versuchen im Bereich der3D-Rekonstruktion von Objekten bereits als möglich erwiesen. Obwohl das strukturierteLicht der beiden Sensoren teils überlappte gab es keine gravierenden Interferenzen. Größ-tenteils kann das System erkennen, welche Punkte welcher Kamera zuzuordnen sind. Umdiese Technik zu nutzen, müssen jedoch bestimmte Frameworks und Treiber genutzt wer-den. Außerdem vergrößert sich der Berechnungsaufwand stark, was besonders bei autonomnavigierenden Robotern ins Gewicht fallen sollte. Trotz der theoretischen Möglichkeit istuns für die Verwendung von mehr als zwei Kinect-Sensoren zu diesem Zeitpunkt allerdingskeine Implementierung bekannt.

2.4 Konklusion 17
Rat-SLAM
RatSLAM[PMW05] ist ein SLAM-Algorithmus, der in Anlehnung an ein Computermo-dell des Hippocampus von Nagetieren entstanden ist. Der Hippocampus ist der Teil desGehirns, der für den Orientierungssinn zuständig ist. RatSLAM wurde bereits indoor undoutdoor[PMW05] getestet und nutzt im Gegensatz zum RGB-D SLAM als Datenquelle eineeinfache Ein-Linsen-Kamera. Bei der Implementierung von Prasser et al.[PMW05] wurdezum Beispiel eine Kamera mit 4 Frames per Second (fps) und einer Auflösung von 1024 x768 Pixeln in Kombination mit einem elektronischen Kompass und einem Odometer ver-wendet.
Die Ergebnisse von RatSLAM sind gerade in Anbetracht des Inputs beeindruckend. Zumjetzigen Zeitpunkt sind uns jedoch keine bionisch-orientierten Implementierungen desRGB-D SLAM bekannt. Obwohl RatSLAM einen grundlegend verschiedenen Ansatz hat,vermuten wir, dass bionische Ansätze des RGB-D SLAM ein großes Potenzial haben.
Kinect 2.0
Inoffizielle Quellen wie beispielsweise ’vgleaks.com’ berichten über die angeblichen tech-nischen Daten der neuen Version der Kinect, die noch dieses Jahr zusammen mit der Video-spielekonsole ’Xbox One’ erscheinen wird. Diese verbesserte Version liefert einige Neue-rungen, die der Nutzung für RGB-D SLAM zugute kommen.
Zur Übersicht dient diese Tabelle:
Feature Kinect(Xbox 360) Kinect(Xbox One)Field of View (FOV) 57.5◦ horizontal by 43.5◦ vertical 70◦ horizontal by 60◦ verticalResolvable Depth 0.8 m - 4.0 m 0.8 m - 4.0 mColor Stream 640x480x24 bpp 4:3 RGB @ 30fps 1920x1080x16 bpp 16:9 RGB
640x480x16 bpp 4:3 YUV @ 15fps @ 30 fpsDepth Stream 320x240 16 bpp, 13-bit depth 512x424x16 bpp, 13-bit depthInfrared (IR) Stream No IR stream 512x424, 11-bit dynamic rangeRegistration Color < − > depth Color < − > depth & active IRAudio Capture 4-mic array 48 Hz audio 4-mic array 48K Hz audioData Path USB 2.0 USB 3.0Latency 90 ms with processing 60 ms with processingTilt Motor Vertical only No tilt motor
Tabelle 2.2: Vergleich zur Neuauflage
Bei der Präsentation der Xbox One am 21.05.2013 zeigte Microsoft bereits Bilder der neuenKinect und bestätigte die Full-HD-Auflösung von 1080p mit 30 fps und eine Datenübertra-gungsrate von 2 GB/s. Alle weiteren Daten sind bis jetzt reine Spekulation. Als wichtig zu

18 2 RGB-D SLAM
erachtende Änderungen sind die von 90 ms auf 60 ms gesunkene Latenz und das Upgra-de von USB 2.0 auf USB 3.0. Das ermöglicht eine potenziell schnellere Auswertung derDaten. Außerdem ist der Blickwinkel in der Horizontalen von 57, 5◦ auf 70◦ und in derVertikalen von 43, 5◦ auf 60◦ angestiegen. Die Auflösung von sowohl der RGB-Kamera, alsauch der IR-Kamera ist ebenfalls größer. Dadurch lassen wesentlich präzisere Aufnahmenerstellen. Im Gegensatz zu ihrem Vorgänger enthält die neue Kinect keinen Motor mehr, umzu schwenken. Das könnte einen kleinen Kostenvorteil bedeuten und schränkt die Nutzungfür SLAM-Algorithmen nicht ein. Leider ist aber der Aufnahmebereich bei 80-400 cm ge-blieben und schränkt somit die Nutzung der Kinect für SLAM-Algorithmen immer nochstark ein.
Abschließend lässt sich sagen, dass die neue Version der Kinect qualitativ hochwertigereModelle erstellen können wird. Das wird wiederum auch mehr Rechenleistung am nutzen-den Gerät voraussetzen.Außerdem wird man auch von einem etwas höheren Preis ausgehenmüssen. Trotzdem wird die Kinect wohl auch in Zukunft für den professionellen Einsatzkeine zufriedenstellenden Ergebnisse liefern und daher weiter im Fokus der Forschung undBastlern sein.

Julian Scholle
3 Lageregelung einesQuadcopters
3.1 Einleitung
In diesem Kapitel wird die Höhenregelung eines Quadcopters mit Hilfe der Kinect undder Hough-Transformation beschrieben. Das Vorgehen wurde dabei analog zu [SHBS11b]beschrieben. Die Microsoft Kinect ist ein kostengünstiges Peripheriegerät, das eine Tie-fenkarte mit hoher Genauigkeit und Geschwindigkeit berechnet. Durch die randomisierteHough-Transformation[XOK90] ist es möglich auf effiziente Art und Weise die Grundplat-te in dieser Karte zu erkennen. So kann die Kinect als Höhensensor eines Quadcoptersverwendet werden.
3.2 Funktionsweise
3.2.1 Erkennung der Grundfläche
Erkennung von Flächen
Das Problem besteht darin, in einer Punktwolke eine planare Fläche zu erkennen. In diesemFall ist das Erkennen der Grundplatte der Schlüssel zum Erfolg. Um Probleme mit unendli-chen Steigungen zu vermeiden, nutzen wir die Hessesche Normalform, gegeben durch einenPunkt (p) auf der Ebene und einen Normalenvektor n0 der senkrecht auf der Ebene steht.
Hough-Transformation
Die Hough-Transformation [Hou62] ist eine robuste Methode zum Erkennen von para-metresierbaren geometrischen Figuren wie Geraden im 2D-Fall oder Ebenen im 3D-Fall.
19

20 3 Lageregelung eines Quadcopters
Jeder Punkt im Hough-Raum entspricht einem geometrischen Objekt im ursprünglichenBildraum. Bei einer Geraden ist das z.B. der Winkel des Nomalenvektors im Bezug zur x-Achse und der Abstand zum Nullpunkt. Bei einer Ebene können dies, wie in unserem Fall,zwei Winkel und der Abstand zum Nullpunkt sein.
Abbildung 3.1: Gerade in Hessescher Normalform in Bild- und Hough-Raum [SHBS11b]
Für eine Gerade in Normalform gilt:
ρ = x cos θ + y sin θ
wobei θ und ρ die Parameter des Hough-Raumes sind. Im R2 wird meist vor der eigentli-chen Transformation eine Kantendetektion durchgeführt, z.B. “Canny Filter” um die Mengeder Daten zu reduzieren [Jäh05]. Für die Erkennung einer Geraden wird der Hough-Raumdiskretisiert und eine oft “Voting-Matrix”[Jäh05] genannte Datenstruktur angelegt. Dannwerden für jeden Punkt einer möglichen Gerade alle ρ und θ berechnet und in der Voting-Matrix der entsprechende Eintrag inkrementiert, weshalb die Komplexität des Algorithmu-ses direkt von der Größe der Voting-Matrix abhängt, also der Diskretisierung von ρ und θ.Wobei eine zu grobe Einteilung dazu führen kann, dass Geraden “übersehen“ werden, einezu feine Einteilung führt jedoch zu einer hohen Laufzeit. Wenn alle Punkte im Bildraumabgearbeitet sind, stehen die größten Werte in der Voting-Matrix für die wahrscheinlichstenGeraden.
Analog lässt sich das in den R3 übertragen [AAAA04, VDR+01].
Abbildung 3.2: Ebene in Hessescher Normalform[SHBS11b]

3.2 Funktionsweise 21
Eine Ebene lässt sich darstellen als:
ρ = p · ~n0
ρ = pxnx + pyny + pznz
ρ = px cos θ sin φ + py sin θ sin φ + pz cos φ (3.1)
Die Parameter im Hough-Raum sind dann θ,φ und ρ. Für die Erkennung werden dann dieWerte θ,φ und ρ diskretisiert. Die Voting-Matrix speichert dann wieder einen Score für jedender Tripel (θ,φ,ρ). Die höchsten Werte der Voting-Matrix stellen dann analog zum R3 diewahrscheinlichsten Ebenen dar. Wie am Algorithmus leicht zu erkennen ist, ist die StandardHough-Transformation auf Grund der hohen Komplexität nicht für Echtzeitanwendungengeeignet. Weshalb nun eine Abwandlung der Standard Hough-Transformation betrachtetwird.
Randomisierte Hough-Transformation
Die randomisierte Hough-Transformation [XOK90] basiert darauf, dass sich eine Ebenedurch drei auf ihr liegende Punkte eindeutig definieren lässt. Diese drei Punkte werdenzufällig aus dem diskretisierten Bildraum genommen. Der zugehörige Normalenvektor derEbene, welche diese drei Punkte aufspannen, lässt sich durch das Kreuzprodukt berechnen.
n = (p3 − p2) × (p1 − p2) (3.2)
Der Normaleneinheitsvektor ist:
n =n||n||
(3.3)
Mit Hilfe von (3.2) und (3.3) ergibt sich ρ durch:
ρ = n · p1 (3.4)
Da n der Normaleneinheitsvektor ist, lässt er sich darstellen als:cos θ sin φsin θ sin φ
cos φ
.Durch Umstellen der Gleichung kommen wir auf folgende Parameter:
φ = arccos nz (3.5)
θ = arcsinny
sin φ(3.6)

22 3 Lageregelung eines Quadcopters
Mit Hilfe von (3.5),(3.6) und (3.4) lassen sich die Einträge für θ,φ und ρ in der Voting-Matrix inkrementieren. Eine Ebene gilt als erkannt, wenn ein vorher festgelegter GrenzwertTA überschritten wird. Wenn nicht, fährt der Algorithmus fort bis alle Punkte berechnet sindoder eine obere Schranke TI an Iterationen erreicht ist. Die Komplexität die größte Ebeneder Größe m zu finden ist ungefähr O(min(m3TA,TI)), was unabhängig von der Größe desBildraumes[XO93, DPHW05] ist.
Erkennung der Grundfläche
Die größte Ebene hat die höchste Wahrscheinlichkeit erkannt zu werden, da auf ihr diemeisten Punkte liegen. Da die Kinect im 90◦ Winkel nach unten montiert ist, ist die größteEbene auch die Grundfläche. Angenommen 1
mth aller Punkte liegen auf der größten Ebene,dann ist die Wahrscheinlichkeit, dass die drei zufällig gewählten Punkte auf der größtenEbene liegen, 1
m3 .
Der Algorithmus ist implementiert wie im vorherigen Abschnitt beschrieben, aber mit fol-genden Erweiterungen:
• Da wir nur die größte Ebene erkennen wollen, wird der Algorithmus nach dem erst-maligen erreichen von TA beendet.
• Ein Distanzkriterium nach [N10] wurde eingeführt distmax(p1, p2, p3) ≤ distmax.Durch die maximale Distanz von 7 Meter der Kinect, beträgt distmax genau diese 7m.Nur Werte die kleiner sind als distmax gehen in die Berechnungen mit ein. Dadurchkann der Rechenaufwand weiter reduziert werden.
• Zusätzlich zu diesem Kriterien wählen wir nur unseren ersten Punkt p1 zufällig ausunserem gesamten Raum. Die Punkte p2 und p3 werden zufällig aus der näheren Um-gebung von p1 gewählt. Dies führt dazu, dass weniger Punkte unser Distanzkriteriumverletzten.
3.2.2 Die Hardware
Der Quadcopter ist ein Eigenbau. Er verfügt über einen eingebetteten Echtzeit Lageregler,implementiert auf einem 32 Bit ARM 7 Microprozessor [SHBS11a] und einen Trägheits-messsystem, welches einen Bescheunigungssensor, ein Gyroskop und ein Magnetometerenthält. Die Kinect ist unter dem Schwerpunkt in richtung Boden montiert. Die Kinekt istmit einem Laptop verbunden auf dem die Regellung läuft, deshalb ist die Reichweite desQuadcopters durch die Länge des USB Kabels eingeschränkt.

3.3 Ergebnisse 23
Abbildung 3.3: Quadcopter
3.2.3 Der Regler
Leider ist dieser Teil des Ausgangsmaterials[SHBS11b] nur sehr rudimentär beschrieben.Die Höhe wird von einem Proportional-Integral (PI) Regler, der auf dem Laptop imlemen-tiert ist geregelt. Davon ausgehend dass die richtige Grundplatte erkannt wurde ist ρ = Pv.Die Stellgröße c ist gegeben duch:
c = KP∆ + KI
∫∆dt
Wobei Kp = 5 und KI = 1 und ∆ die Regelabweichung ist. Es wird ein Runge-KuttaIntegrator 4. Ordnung benutzt. Der Regler läuft mit einer Frequenz von 20Hz.
Die Lageregleung läuft auf der eingebetteten Hardware des Quadcopters. In einer anderenQuelle[GBK11] wird hier ein LQ-Regler genutzt welcher den Vorteil mit sich bringt, dassGewichte auf einzelne Regelgrößen gelegt werden können und die Stellgrößen beschränktwerden können. Das aktuelle Lage (Roll, Nick und Gier) wird über eine Funkverbindungübertragen, über welche auch Steuersignale zurück an den Quadcopter übertragen werden.
3.3 Ergebnisse
Die randomisierte Hough-Transformation wurde in Matlab entwickelt und dann in C++ im-plementiert. Dem Quadcopter wurde eine feste Flughöhe vorgegeben. Schwankungen derHöhe, wie in Abbildung 3.4 zu sehen, zeigten jedoch, dass der PI-Regler für diese Aufgabenicht optimal war. Für die Dauer des Teste von 40 Sekunden war dieser allerdings ausrei-chend. Die Performance der randomisierten Hough-Transformation war hingegen sehr gut.Mit einem guten Wert für distmax betrug die Ausführungszeit des Algorithmuses rund 10ms. Dabei wurden im Mittel weniger als 2% aller Bildpunkte getestet.

24 3 Lageregelung eines Quadcopters
(a) (b)
Abbildung 3.4: Messergebnisse [SHBS11b] für 0,5m (a) und 1m (b)
3.4 Fazit
Es wurde erfolgreich gezeigt das es auch mit Hilfe der Kinect und der randomisiertenHough-Transformation möglich ist eine Höhenregelung umzusetzen. Doch diese Lösunghat einige Einschränkungen. Zum einen ist die maximale Höhe durch die Kinect auf 7Meter begrenzt. Zum anderen ist die Erkennung der Grundfläche stark vom UntergrundAbhängig. Nicht zu verachten ist auch das hohe Gewicht der Kinect und die erforderlicheRechenleistung um die Menge an Daten zu verarbeiten.

Silyana Gerova, Vasil Georgiev
4 RoboEarth Project
4.1 Einleitung
Roboter werden zu einem immer größeren Bestandteil des menschlichen Lebens. Sie ver-fügen über Präzision und eine angemessene Freiheitsgrade für Tätigkeiten in unterschied-lichen Umgebungen, sogar in solchen, die gefährlich für den Mensch sein können. Zu-dem haben sie die Möglichkeit Rezeptoren zu benutzen, über die Menschen nicht verfügen.So können die Roboter in nahe Zukunft zu unentbehrlichen Helfer der Menschen werden.Für die Umsetzung von Routinearbeiten können die Roboter genutzt werden, so dass dieMenschen die Möglichkeit haben würden, ihr volles Potential auszunutzen und sich aufKreativtätigkeiten zu konzentrieren. Bei der Umsetzung dieses Ansatzes gibt es eine großeHerausforderung mit dem Roboter: sie werden modelliert, hergestellt und programmiert umspezifische Aufgaben auszufüllen und zwar nur solche, die von den Konstrukteuren vorge-sehen waren. Diese Besonderheit begrenzt das Spektrum der Tätigkeiten, die die Roboterausführen können und auch die Sitationen, in denen sie beteiligt werden können. Die Ursa-che dafür ist, dass das Leben meistens komplizierter und vielfältiger als das Modell, auchwenn gut geplant ist. Das größte Teil von den bis jetzt existierenden Robotern benutzt manin der Industrie oder für sehr einfache Arbeiten im Haushalt, wie das Rasenmähen. Ein ak-tiver Einsatz im Alltag ist noch nicht möglich. Der Mensch als separates Individuum, dassich nur auf seine eigene Instinkten, Wissen und Erfahrung verlässt, könnte nie ohne dieKommunikation zwischen den einzelnen Individuen zur dominanten Spezies werden. Dieverstärkte Kommunikation, der Informations-, Erfahrungs- und Gedankenaustausch ist derentscheidende Vorteil, den der Mensch im Vergleich zu den anderen biologischen Speziesbesitzt. Wenn es gelingt, eine effektive Kommunikation zwischen den Roboter zu orga-nisieren, würden sich die Effektivität und das Anwendungsfeld der Helfer der Menschenerheblich vergrößern. Daher würde auch die Integration der Roboter in der zukünftigen Ge-sellschaft erfolgreicher. Um das zu ermöglichen, soll zuverlässiges, einheitliches Systemzum Wissensaustausch zwischen den Roboter erschafft werden, wobei dieses Kodierung,Austausch, Verwendung, Aktualisierung und Wiederverwendung von Daten einschließt.
25

26 4 RoboEarth Project
4.2 Was ist RoboEarth?
Die Basis des RoboEarths ist eigentlich World Wide Web für Roboter – ein große Netzwerkund Datenbankarchiv, in dem Roboter Informationen über ihr Verhalten und ihre Umgebungaustauschen können und gemeinsames Wissen teilen. Damit gibt es eine neue Bedeutungfür das Sprichwortes „Erfahrung ist der beste Lehrer“. Das Ziel des RoboEarth Projektes ises, den Roboten die Möglichkeit zu geben, von den Erfahrung anderer Roboten zu lernen,was den Weg für schnelle Fortschritt in maschinelles Erkennen und Verhalten und sogar fürdie schlauere und komplexere Mensch-Maschine Interaktion bahnen würde.
Abbildung 4.1: RoboEarth ermöglicht Austausch und Wiederverwendung von Wissen zwi-schen unterschiedlichen Arten von Roboten [www.roboearth.org]
RoboEarth bietet mit Cloud-Robotik eine Infrastruktur, welche alles umfasst, was manbraucht, um den Kreis vom Roboter zur Cloud und zurück zum Robot zu schließen. Ro-boEarth’s World-Wide-Web Datenbank speichert Wissen, gesammelt von Menschen undRoboten, in Maschinen-lesbaren Format. Die in RoboEarth gespeicherten Informationenumfassen Softwarekomponenten, Karten für Navigation (z.B. Positionen von Objekten,Welt-Modelle), Wissen über Tätigkeiten (z.B. Aktionshinweise, Betätigungsstrategien) undModelle zur Objekterkennung (z.B. Bilder, Objektmodelle).
Das RoboEarth Cloud Engine bietet den Roboten mächtige Berechnungsmethoden. Sie er-laubt es, den Roboter zu entlasten und die Computing Umgebung in der Cloud mit mini-maler Konfiguration zu sichern. Das Cloud Engine’s Computing Umgebung bietet großeErreichbarkeit auf das RoboEarth-Wissensarchiv, wobei es ermöglicht, dass die Robotendie Erfahrung von anderen Roboten nutzen.

4.3 Motivation 27
Abbildung 4.2: RoboEarth bietet Komponenten für ein ROS kompatibles, Operationssys-tem auf höhere Ebene, sowie für roboterspezifische Komponenten auf unte-rer Ebene [www.roboearth.org]
4.3 Motivation
In der Regel sind die Roboter geplant und programmiert, um bestimmte spezifische Aufga-ben zu erfüllen. Bei der ursprünglichen Programmierung sind alle bekannten Situationen,Modellen und Aufgaben im Bezug auf die Funktion, die der Roboter ausfüllen soll, in An-spruch genommen. Aber das Leben ist dynamisch und alles –langsamer oder schneller –verändert sich mit der Zeit. Manchmal passiert diese Veränderung so schnell, dass bis einRoboter produziert und in Betrieb gesetzt wurde, dieser nicht mehr aktuell ist. Zum Beispiel,wenn die Elemente, die er verarbeiten sollte, ihre Form, Größe und Gewicht verändert habenoder wenn die Lieferroute schon unterschiedlich ist oder die ganze Situation ist schon völ-lig anders geworden. Es gibt Anwendungsbereiche, wie zum Beispiel die 3D-Visualisierungvon unbekannten Objekten, bei denen der Informationsaustausch in reeller Zeit von großerBedeutung für die Projektdurchführung ist. Es gibt Projekte, bei denen die Roboter selbstso programmiert sind, dass sie bei derselben Situation unterschiedlich reagieren – „neugie-riger“ werden, mit dem Ziel, eine maximale Menge an Informationen zu bekommen undoptimale Lösungen zu finden, oder „konservativer“ mit dem Ziel den Roboter als solcherzu bewahren und nur die Information für das Objekt, die von allen Interessanten (Perso-nen und Maschinen) gebraucht wurde hochzuladen. Auf diese Weise ist zum Beispiel dastheoretische Programm zur Untersuchung von Jupiter organisiert. Das Internet für Roboterbietet sich als ausgezeichnetes Mittel, über das die gebrauchte Information in reelle Zeitausgetauscht werden kann. Es ist genug, dass ein Roboter tausende Versuche macht, bis erzu der optimalsten Lösung einer Aufgabe kommt. Dann kann er das neue Wissen in demNetz „mitteilen“, so dass jeder folgender Roboter nicht wieder alle Versuche macht, son-

28 4 RoboEarth Project
Abbildung 4.3: RoboEarth Architektur: RoboEarth’s WWW Datenbank bietet leichte Ver-bindungen in dem Cloud Computing Umgebung des Robotes in dem Ro-boEarth Cloud Engine [www.roboearth.org]
dern sich von der Erfahrung des vorherigen lernt. Auf diese Weise würde Zeit gespart unddie Aufgaben mit optimalster Methode gelöst.
So ist es genug, dass ein Roboter einmal eine Lösung schwieriger Situation findet, um dieanderen Roboter von seinem Wissen profitieren zu können und für diese Situation und Um-gebung vorbereitet zu werden. Das Mitteilen von Informationen erlaubt der Roboter, diefür bestimmte Anwendung aufgebaut sind, auch für andere vorher nicht geplante Ziele ver-wendet zu werden, ohne zusätzliche Arbeit. Außerdem würde das Nutzen von Internet fürKommunikation zwischen den Roboter zu einer Art Standardisierung von Basiskomponen-ten und Systemen, Integrierung von Interfaces und Plattformen führen.
4.4 Architektur
Die Basis dieser Architektur ist die Server-Ebene, wo sich die Datenbank von RoboEarthbefindet - Abbildung 4.4(a). Dort wurde das globale Weltmodell gespeichert, einschließ-lich Informationen zur gemeinsamen Nutzung für Objekte wie Gestalten, Punktwolken und–modellen, Umgebungen (wie zum Beispiel Karten und Lage der Objekte). Außerdem wur-den in dieser Ebene noch Handlungen (wie Fähigkeits- und Handlungsvorschriften), die mitder semantischen Information (wie Eigenschaften und Klassen) verbunden sind, sowie auchbasische logische Web-basierte Dienste gespeichert. Der Zugriff zu der Datenbank wurdedurch die üblichen Internet-Interfaces ermöglicht.
RoboEarth nutzt generische, Hardware-unabhängige mittlere Ebene, die sich für die Funk-tionalitäten und Korrespondenz mit den spezifischen für jede Art von Roboter Fähigkeitensorgt, was Teil des Universellkonzeptes dieser Ebene ist. Die generischen Komponenten,

4.4 Architektur 29
Abbildung 4.4: Die Drei-Schichten-Architektur von RoboEarth [www.roboearth.org]
die hier benutzt werden, sind Teil der lokalen, Steuersoftware des Roboters. Ihren Grund-zweck ist den Roboter die Möglichkeit zu geben, die von RoboEarth heruntergeladenenHandlungsvorschriften zu interpretieren. Es gibt auch zusätzliche Komponenten, die dieFähigkeit des Roboters zur Empfindung, logischer Motivierung, Modellierung und Schu-lung entwickeln und damit auch die Beziehung zwischen dem Roboter und der Datenbankim Internet beiderseits befestigen.
Die dritte Ebene dient zur Ausprägung der Fähigkeiten und sichert das generische Interfacefür die Roboter-spezifischen, Hardware-abhängigen Funktionalitäten.
4.4.1 Datenbank
RoboEarth speichert in der Datenbank Informationen für CAD Modelle, Punktwolken undDaten für Bilder von Objekten. Die Bilder werden als komprimierten Archiven, die auchKarten und zusätzliche Informationen, wie zum Beispiel Koordinatensystemen, beinhalten.Die Bewertungen der Aufgaben der Roboter werden als Handlungsanweisung gespeichert,die auch von Menschen gelesen werden können, indem man höhere Programmiersprachen

30 4 RoboEarth Project
Abbildung 4.5: Die drei Hauptteile der Datenbank von RoboEarth [www.roboearth.org]
verwendet, die die Wiederverwendung auf verschiedene Hardwareplattformen ermöglichen.Die Handlungsanweisungen bestehen aus semantischen Darstellungen von Fähigkeiten, diespezifische Funktionalitätenen für ihre Ausführung beschreiben. Um einen Roboter eine ge-gebene Handlungsanweisung ausführen zu lassen, muss er die entsprechenden Fähigkeitender Anwendungsanforderung besitzen, die mit der Hardware des Roboters verbunden ist.Die Anweisungen werden hierarchisch angeordnet, um die unnötige Informationsüberlas-tung zu verringern, so dass eine gegebene Aufgabe, die durch eine „Rezeptur“ beschriebenist, ein Teil von einer anderen, komplexeren Anweisung sein kann. Außerdem, entwickeltdie Wartung der Datenbank einige grundlegende schulende und logische Fähigkeiten, waszum Beispiel dem Roboter hilft, die richtige Anweisungen auf höheren Niveau zu finden,die an der technische Spezifikation entspricht, oder zu bestimmen, welche Information vonwelchen Robotertyp verwendet werden kann.
Die Datenbank von RoboEarth besteht aus drei Hauptteilen:
Strukturelle Datenbank , die alle Daten enthält, die in hierarchische Tabellen organi-siert sind, vgl. Abbildung 4.5(a). Die komplexen semantischen Verbindungen zwischen denDaten werden in eine separate grafische Datenbank gespeichert – 4.5(b). Die eingehendensyntaktischen Anfragen werden direkt nach der Datenbank für Bearbeitung hergeleitet. Diesemantischen Anfragen werden zuerst von einem logischen Server bearbeitet. Basiert aufApache Hadoop werden die Daten gespeichert und verteilt. Dieses Programm ermöglichteine hierarchische Organisation in Tabellen, und effektive, skalierbare und zuverlässige Be-arbeitung von großer Menge von Daten. Zentrale grafische Datenbank, in der semantische

4.4 Architektur 31
Information gespeichert wurde, die mittels W3C-standartized OWL kodiert wurde. In dieserDatenbank werden Daten und Relationen wie folgt bewährt:
Abbildung 4.6: Objektbeschreibung und Erkennung. [www.roboearth.org]
Objekte - Typen von Objekten, Größen, Zustände, anderen Eigenschaften, sowie Lage vonspezifischen Objekten, die relevant sind, auch Modelle, die für die Erkennung be-nutzt werden können - Abbildung 4.6. Abbildung 4.6(a) beschreibt ein Modell fürErkennung eines bestimmten Objekttyps (definiert durch providesModelFor). Eswurde auch zusätzliche Information für das Modell und den angewendeten Algo-rithmus gegeben. Das konkrete Modell wird als binärer Datei gespeichert. Abbil-dung 4.6(b) beschreibt die Erkennung von einem gegebenen Objekt. Es wurde eineAufnahme auf RoboEarthObjRec-Perception hergestellt, in der beschrieben wur-de, dass Objekt Bottle2342 (gegeben durch ObjectActedOn) auf eine bestimmtePosition (gegeben durch die Eigenschaft eventOccursAt) um eine bestimmte Zeitunter Verwendung von diesen Erkennungsmuster (gegeben durch die EigenschaftrecognizedUsingmodell) erkennt wurde.
Umgebungen - in der Datenbank werden Karten sowohl für eigene Lokalisation, als auchfür die Lage von Objekten, wie zum Beispiel Teile von der Einrichtung, gespeichert.– Abbildung 4.7. Die semantische Karte kombiniert das binäre Bild, das durch dieVerwendung von linkToMapFile verbunden mit einem Objekt wurde, der in der ge-gebenen Umgebung erkannt war. Die Darstellung des Objektes ist identisch mit dieserauf Abbildung 4.6. Von diesem Beispiel lässt sich sehen, dass binäre und semantischeKarten leicht kombiniert und ausgetauscht werden können. Das gegebene Beispiel fürErfassung definiert nicht nur die Position des Objektes, sondern auch gibt Informati-on über die Zeit, um die das Objekt zuletzt beobachtet war. Das kann zur Berechnungdes Koeffizienten von Ungenauigkeit der Position dienen, wobei der Koeffizient im-mer größer mit Laufe der Zeit würde.

32 4 RoboEarth Project
Abbildung 4.7: Ungebungskarte [www.roboearth.org]
Handlungsanweisungen - beinhalten eine Liste mit Rezepturen für Teilhandlungen und Fä-higkeiten gemeinsam mit ihren Beschränkungen, die für die Ausführung der Aufgabebenötigt werden, sowie auch die Handlungsparameter, wie Objekte, Lage und Griff-typen – Abbildung 4.8. Die Handlungsklassen werden als Blöcke visualisiert, indemdie Eigenschaften dieser Klassen in den Blöcken eingetragen werden. Die Einschrän-kungen werden als Pfeile zwischen den Blöcken dargestellt. Auf diese Weise wird dieRezeptur als eine Folge von Handlungen, die allein Handlungsanweisungen sein kön-nen, wie zum Beispiel GraspBottle, modelliert. Jede Rezeptur entspricht einer Hand-lung. Atomare(primäre) Handlungen (solche die sich nicht in kleinere Handlungenzerlegen lassen), stellen Fähigkeiten dar, die die Befehle in Bewegungen umwandeln.
Dienstleistungen bieten die Möglichkeit die logischen Fähigkeiten auf Datenbank-Ebene zu sichern. Der erste Typ von Dienstleistungen ist von dem logischen Server vonRoboEarth illustriert. Er basiert auf KnowRob und verwendet semantische Information, diesich in der Datenbank befindet, wodurch er logische Schlussfolgerungen ermöglicht. Mitseiner Hilfe wurde festgestellt, ob der Roboter B von dem Beispiel den Anforderungen, dieHandlungsvorschriften von Roboter A auszuführen, entspricht, ob er die Sensoren hat, diebenötigt werden, um dasselbe Modell zur Objektuntersuchung nutzen zu können. Außer-dem können die Dienste selbständig auf die Datenbank arbeiten. Auf diese Weise ermög-licht der Dienst zu logischen Fähigkeiten auf dem Basis von in RoboEarth-gespeichertemWissen die automatische Generierung neuer Handlungsanweisungen und Aktualisierungennoch vor dem Eintritt neuer Informationen. So kann das System vorher berechnen, wie großdie Wahrscheinlichkeit ist, dass es Tassen auf dem Tisch gibt. Solche Korrelationen könnenals effizientes Mittel zur Bestimmung von Erwartungen dienen und unterstützen die Steue-rung der Aktivitäten des Roboters. Falls es mehrere Handlungsmöglichkeiten gibt, die zurunterschiedlichen Ausführung der Aufgabe führen, kommt ein Dienst zur logischen Analy-se zum Einsatz. Dieser Dienst bildet die Menge der möglichen Handlungen ab. Falls zum

4.4 Architektur 33
Abbildung 4.8: Die Handlungsanweisungen [www.roboearth.org]
Beispiel Roboter A einen komplexen Griffmanipulator besitzt, und Roboter B nur ein Ta-blett hat, so kann mit dieser Komponente eine neue Rezeptur mit einer Handlung „Servieredem Patienten ein Getränk“ mit zwei Verzweigungen, in Abhängigkeit von der Fähigkei-ten der Roboter, die verschiedene Anforderungen haben, gebildet werden. Die Erste hat dieFlasche zu fassen, sofern der zweite die Hilfe von einem Menschen oder von einem Roboterbraucht, der die Flasche auf das Tablett stellen soll.
4.4.2 Interfaces
Die Schnittstellen, die die Datenbank von RoboEarth unterstützt, sind folgende:
• Die weit verbreitete Schnittstelle HTML (hypertext mark-up language). DieseSchnittstelle kann für Zugriff auf die Datenbank von RoboEarth von den Menschenverwendet werden, indem man Tabellen für die Erkennung der Objekte erstellen kann.
• Die zweite Schnittstelle, die von den Robotern benutzt werden kann, basiert sich aufdie REST- Architektur (Representational state transfer). Diese Schnittstelle leitet dieganze notwendige Information direkt, ohne Zwischenspeicherung an einem Server.Auf diese Weise werden die Antwortgeschwindigkeit und die Skalierung verbessert,indem man den Server optimiert. Es ist erwähnungswert, dass die REST-Schnittstelle

34 4 RoboEarth Project
direkte Kodierung in JSON (JavaScript object notation) ermöglicht und so die Kom-munikation zwischen Roboter und Datenbank problemlos wird. Durch Verwendungvon Anfragen, wie HTTP(Hypertext transfer protocol) in Kombination mit dieserSchnittstelle gibt die Möglichkeit, die meisten Plattformen unterstützt zu werden.Zum Beispiel durch diese Schnittstelle würde sowohl die Anfrage des Roboters Büber die Information für die Krankenzimmer, als auch die Antwort des RoboEartherfolgen.
• Die dritte Schnittstelle wird auf der Basis vom Modell zur Veröffentlichung vonNachrichten gebaut, die sich bei Änderungen in der Datenbank aktivieren. DieseVorgehensweise unterscheidet sich von den anderen zwei Schnittstellen, die auf dasPrinzip der Frage-Antwort basieren, was in den gegebenen Beispiel den Roboter er-möglicht, sich für Informationen über die Bewegung der Patienten zu abonnieren. Sowurde verhindert, dass sie sich ständig über die Lage der Patienten von der Datenbankinformieren sollen.
4.4.3 Generische Komponenten
Aktionserfüllung
Abbildung 4.8 zeigt das Folgen von Handlungsanweisung und schließt folgendes ein:
• Überprüfung und Bestimmung, ob der Roboter die Fähigkeiten besitzt, die er bei derErfüllung der Aufgabe braucht
• Feststellen der Reihenfolge der Fähigkeiten, die der Rahmenbedingungen der Aufga-benstellung entsprechen
• Aufbau der Beziehung zwischen der Wahrnehmung des Roboters und der abstraktenBeschreibung der Aufgabe von der Handlungsanweisung
• Ausführen der zuverlässigen Aktionen
Schritte 1 und 3 können mithilfe der RoboEarth-Server ausgeführt werden. Im Unterschieddazu verlangen die Schritte 2 und 4 die ständige Mitwirkung zwischen RoboEarth und demSystem zur Ausführung der Handlungen des Roboters.
Um zuverlässige und korrekte Erfüllung der Aufgabe erwartet zu können, ist es nötig, dassdie Komponenten zur Ausführung der Aktion des Roboters mit der Datenbank von Ro-boEarth koordiniert wurde. So kann die Beziehung zwischen der Wahrnehmung und derHandlung des Roboters betrachtet werden und solche Kombinationen gefunden werden,mit denen der Roboter die erfolglosen Versuche bekämpfen kann. Falls es zu Problemengekommen ist, die nicht gelöst werden können, sendet das System Anfragen zur Informati-on, die von dem Anwender einzuweisen ist. Zum Beispiel trifft der Roboter B ein Hindernis

4.5 Erkennung von Objekten und Positionseinschätzung 35
auf seinem Weg zu der Flasche und die Komponente zur Findung der Handlungsanweisun-gen kann keine passende in der Datenbank finden, so dass die Aufgabe korrekt ausgeführtwurde. Dann sucht der Roboter Hilfsinformation. Wenn das Problem erfolgreich gelöst wur-de, gibt die Komponente die Möglichkeit, dass die Handlungsvorschriften in der Zukunftproblemlos eingehalten werden.
Modellierung der Umgebung
Die Komponente für das Weltmodell kombiniert die vorher definierten Informationen, dievon der RoboEarth-Datenbank heruntergeladen wurden, mit den Information, die von denSensoren des Roboters generiert wurden . Diese Komponente nutzt zweistufiges Vorgehenzur Garantierung von schnelle und sichere Ausführung, sogar im Fall von potentiell unsi-cherer Internetverbindung mit der RoboEarth-Datenbank. Der Roboter ist weiter nach demlokalen Weltmodell tätig, wobei dieses meistens zehnten Mal pro Sekunde aktualisiert wur-de. Bei dieser Komponente werden die Daten von den Sensoren des Roboters, die seine3D-Weltvorstellung bilden, mit den Daten von dem System verbunden und gemischt. Ihrer-seits unterstützt die Datenbank vom RoboEarth die Komponente globales Weltmodell. Daslokale Weltmodell wurde mit vorher in der Datenbank gespeicherter Information über dasObjekt aktualisiert. Hier ist auch Platz zur Veränderungen gelassen, wenn sich das Objektänderte. Zum Beispiel würde die Flasche wahrscheinlich zwei Sekunden später nicht andersals vorher sein. Aber wenn der Roboter die Flasche am nächsten Tag suchen würde, wäre essehr wahrscheinlich, dass sie sich nicht dort befindet, wo er sie gelassen hat. Unter Beach-tung der größeren Menge von gespeicherte und zu bearbeitende Information, ist die üblicheAktualisierungsfrequenz der Information viel kleiner, bis zu einem Versuch in Sekunde.
4.5 Erkennung von Objekten und Positionseinschätzung
4.5.1 Semantische Kartierung
In der Datenbank von RoboEarth, werden allgemeine Handlungsanweisungen gespeichert.Sie unterscheiden sich in ihre Arbeitsparameter und -umgebung und in den Objekten, mitdenen sie wirken. Auf diese Weise werden verschiedene Gruppen von Szenarien gebildet,zu denen ständig in reelle Zeit neue oder detailiertere Informationen hinzugefügt werden.RoboEarth verwendet monocular visual SLAM, um die von der reellen Umgebung erfassteObjekte zu kombinieren, vergleichen und ein vollständiges Bild von den Datenbank herzu-leiten. Es ist zu erwähnen, dass SLAM Methoden ein geometrisch korrektes, aber in denmeisten Fällen semantisch sinnloses Bild erfassen. Mit semantisch bereicherte Modelle vonbekanten Objekte, die in RoboEarth hochgeladen sind, werden semantische Karten verfasst,

36 4 RoboEarth Project
die für die Lokalizierung von dem bereits zu bearbeitenden Modell dienen. Dies in Kombi-nation mit einigen Grundfähigkeiten, wie zum Beispiel „Move to“, ermöglicht, dass dieseModelle räumlich verstellt werden können oder eine vorher bestimmte Bewegungsbahn inder gegebenen Umgebung folgen können.
4.5.2 Schulung
Die wiederholende Anwendung von Handlungsanweisungen und unterschiedliche Fähig-keiten ermöglicht es, die Zuverlässigkeit und die Arbeitsleistung bei Ausführung verschie-dener Befehle zu optimieren. Die lehrende Komponente erlaubt den Benutzern die Rück-verbindung im Zusammenhang mit der aktuellen Aufgabe herzustellen. Zum Beispiel, fallsder Roboter die Flasche nicht richtig hält, die lehrende Komponente erlaubt den Operatorbesseren Griff zu sichern.
Die Leistungsverbesserung kann sowohl auf die Erfahrung anderer Roboter, die in RoboE-arth gespeichert wird, als auch auf eigene Erfahrung, die durch die Ausführung anderenAufgaben gesammelt wird, stützen. Auf diese Weise, mit Hilfe der lehrenden Komponen-ten, können die Strategien und die verwendeten Methoden verbessert werden.
4.5.3 Aktions - und Situationserkennung und Etikettierung
Es ist nicht leicht, nutzvollen Handlungsanweisungen zu generieren, die leicht zwischenRoboter wandern und sich wiederverwenden lassen. Der Grund dafür liegt daran, dass die-se Anweisungen für alle Handlungsebenen der Roboter gelten müssen, von Grundlegen-den bis streng spezialisierten Fähigkeiten. Das Hauptziel der Komponente für Handlungenund Etikettierung ist die Erleichterung von neuen Handlungsanweisungen, indem anhandvon Schritten, die spezifisch für einen bestimmten Roboter sind, eine abstrakte Aufgaben-beschreibung erstellt wird. Das ist besonders wichtig bei der Festlegung von neuen „Re-zepturen“ mittels Demonstrationen oder mittels der Aktionen von anderen Robotern oderSteuerung des Roboters von Menschen. Die Komponente für Erfassung und Etikettierungbetrachtet die Probleme aus zwei verschiedenen Sichten. Auf niedrige Ebene werden Fä-higkeiten betrachtet, die ohne zeitliche oder örtliche Verbindungen verfügen und von denSensoren ermittelt werden. Auf höhere Ebene wird das Hidden Markov Modell (HMMs)für das Erlernen von räumlichen und zeitlichen Zusammenhängen von Zuständen und Ak-tionen, die schon von der niedrigen Ebene erfassen werden, verwendet.
Zum Beispiel Roboter A kann Probleme mit dem Erreichen des Krankenzimmers haben,falls einen Tür geschlossen ist. Bei Feststellung von Problemsituationen und Not von Au-ßensteuerung von dem Anwender, kann mit Hilfe eines Steuerknüppels Instruktionen, wie

4.5 Erkennung von Objekten und Positionseinschätzung 37
sich der Tür öffnen lässt, an der Roboter hergeleitet werden. Demnächst wird eine Anwei-sung hergestellt, wie man die Tür eines Krankenzimmers öffnet. Bei ähnlicher Situation,geschlossener Tür, findet Roboter B mittels der Komponente für Handlungen und Etikettie-rung, dass diese Situation mit der vorige übereinstimmt und, nachdem er die Tür dank derAnweisungen von Roboter A erfolgreich öffnet, die Handlungsanweisung aktualisiert. Sospiegelt sich das neu erfundene Wissen wider.
Ebene für Teilung von Fähigkeiten und spezifische Arbeitskomponente. Die Ebene für Tren-nung von Fähigkeiten - Abbildung 4.4 stellt eine gemeinsame Schnittstelle zu den spezifi-schen für den Roboter Funktionalitäten bereit, die von dem Hardware abhängen. Das wirddurch Extraktion von Fähigkeiten, die für die bestimmte Hardware standardisiert sind, er-möglicht (wie z.B. MoveTo, MoveCloseToObject, Grasp Detect). Manchmal werdendiese standardisierte Fähigkeiten Primitive für Bewegung, Primitive für Erkennung, Ba-sisverhalten oder Microhandlungen benannt. Für die Ausführung von diesen Fähigkeitenwerden Anfangsparameter benötigt, wie zum Beispiel Definition der Lage, die erreicht wer-den soll oder ein bestimmter Punkt, in dem ein bestimmtes Objekt gegriffen werden muss.Eine wichtige Rolle für die erfolgreiche Mitteilung und die Wiederverwendung von Hand-lungsanweisungen spielt die Bereitstellung von einer allgemeingültigen Schnittstelle für dieBefehle und die Fähigkeiten auf eine höhere Ebene. Seinerseits, einen wichtigen Faktor beider Wahl einer Handlungsanweisung ist der spezifische Fähigkeitssatz, der einen Roboterbesitzt. Zum Beispiel, falls Roboter A und B verschiedenen Anrieb haben, der unterschied-liche Bewegungsfreiheit erlaubt, können beiden Roboter, dank der Fähigkeit MoveTo, trotzihrer technischen Unterschiede, durch die selbe Handlungsanweisung die Aufgabe erfolg-reich erledigen.
4.5.4 Demonstrationen
Für Veranschaulichung und Beweis der Hauptidee und der Vorteilen der Nutzung von ge-meinsamer Datenbank für Mitteilung von Informationen mittels RoboEarth stellen wir dreiDemonstrationen von Prototypen dar. Bei diesen Demonstrationen wird der Wissenstand,basiert auf Know-Rob, für Kommunikation zwischen generische Komponente ROS, sowieviele Funktionalitäten, die spezifisch für die Roboter sind, verwendet.
Demonstration A
Bei dieser Demonstration werden zwei verschiedene Arten von Roboter mit unterschied-lichen Hardware und Software Konfigurationen getestet, indem sie die Aufgabe haben, ineinen Labyrinth zu navigieren – Abbildung 4.9. Die Basisfähigkeiten von den beiden Ro-botern werden durch Verwendung von Code aus RoboCup programmiert. Diese Fähigkeitensind: Bewege dich 1 Meter nach vorne (erste Fähigkeit), Bewege dich 1 Meter nach hinten

38 4 RoboEarth Project
Abbildung 4.9: (A) Das Labyrinth - 6 Meter x 8 Meter bestand aus 48 quadratischen Fel-dern, die durch rote Linien begrenzt waren. Roboter versuchten, den kür-zesten Weg von einem vorgegebenen Startfeld (markiert mit einem rotenKreuz) nach einem vorgegebenen Zielbereich (gekennzeichnet durch eingrünes Kreuz) zu finden. (B) Es werden zwei Roboter mit verschiedenenPlattformen mit unterschiedlichen Freiheitsgraden verwendet. Beide Typenvon Roboter verwenden in seiner Arbeit verschiedene Arten von Software,wodurch man die direkte Übertragung und Wiederverwendung von Wissenverhindert [www.roboearth.org]
(2. Fähigkeit), Bewege dich 1 Meter nach rechts (3.Fähigkeit) Bewege dich 1 Meter nachlinks (4. Fähigkeit). Jeder von diesen Robotern kann autonom Felder in dem Labyrinth fin-den, die mit schwarzen Hindernissen belegt wird (5.Fähigkeit) und kann durch Verwendungseines Codes ohne rote Linien und Merker zu navigieren. Seinerseits würde jeder Roboterdurch eine Komponente für die Ausführung von Operationen kontrolliert, die auch die Zu-sammenhänge zwischen den anderen nicht arbeitsspezifischen Komponenten und die Infor-mationsaustausch zwischen dem Roboter und RoboEarth-Datenbank steuert. Jeder Roboterhat auch die Komponente von RoboEarth für Umgebungsmodellierung und Erfassung.JederRoboter hat ein Anfangsfeld und kann sich bewegen, bis er das Zielfeld erreicht. Die Ro-boter haben Q-learning und die vier Bewegungsfähigkeiten verwendet, um gemeinsam den

4.5 Erkennung von Objekten und Positionseinschätzung 39
optimalen Pfad durch den Labyrinth zu finden. Der erste Roboter bewegt sich, indem er dieStrategie der zufälligen Bewegung benutzt. Mit jedem weiteren Schritt hat der Roboter dievier danebenstehenden Felder untersucht und sie in einen Q-Matrix hinzugefügt. Falls derRoboter nicht das Zielfeld erreicht hat, erneut er die Information für das vorherige Feld.Wenn der Roboter das Zielfeld erreicht hat, hat er die ganze Matrix aktualisiert und sie aufder Datenbank von RoboEarth hochgeladen. Die nächsten Roboter, die über das Labyrinthgehen müssen, haben die neuste Version der Matrix heruntergeladen. Auch bei ihnen, fallssie das Ziel erreichen, wird die Matrix aktuallisirt und verbessert und wieder auf RoboEarthhochgeladen. Nach mehrmaliger Wiederholung, werden die Matrizen verschmolzen unddas ermöglicht es, am Ende der Demonstration den optimalen Weg durch das Labyrinth zufinden.
Demonstration B
Bei der zweiten Demonstration war die Aufgabe des Roboters, ein Getränk einem Patientenin einem simulierten Krankenzimmer zu servieren. Vorinstallierte Fähigkeiten des Roboterswaren mit Bewegung, Erkennung und Kartierung verbunden, aber er hatte keine Kenntnisseüber die Umgebung, die relevanten Objekte und Aufgaben.
Der erste schriftliche Befehl, der zu dem Roboter geschickt wurde, war “Serviere Getränk“(ServeADrink).Seinerseits, das Bauteil des Roboters für Aktionenausführung erhielt undverwendete eine Kommunikationsschnittstelle von RoboEarth, mit der der Roboter fernge-steuerten Zugang zu der Datenbank erhielt. Auf diese Weise hatte den Roboter die relevan-ten Informationen heruntergeladen, einschließlich der Handlungsanweisung für den BefehlServeADrink. Es wurden Details durch die Verwendung von logischem Denken identifi-ziert und erweitert, basierend auf lokales Wissensbasis unterstützt durch die Installationvon KnowRob.
Anschließend hatte der Roboter eine Karte der Krankenzimmer, die annähernde Lage desObjektes, die durch vorige Erfahrung erhalten geworden ist, sowie auch Modelle für Erfas-sung und Manipulation der Tasse, des Bettes und der Flasche bekommen. Diese waren andie semantische Komponente der Roboter, die für die Kartierung zuständig war, gesendet.Als Ergebnis begann der Roboter nach einem bestimmten Objekt zu suchen. Alle Aufträgefür die Erfassung waren auf die Weltkomponente der Modellierung, die für die Bestimmungdes globalen Zustandes der lokalen Wissensbasis verantwortlich ist, gerichtet. Die resultie-rende Karte wurde von den Komponenten des Roboters zur Lokalisierung benutzt, um ersich sicher in den Raum bewegen zu können. Die Komponente, die für die Ausführung derBefehle zuständig ist, hatte einen Befehlssatz von der Handlungsanweisung hergestellt, mitdem sie die Basisbefehle initialisierte und überwachte.
Trotz der Unterschieden in den empfangenen Informationen, die Weltmodellierungskom-ponente von RoboEarth stellte dem Roboter vorrangig geladenen Informationen zur Verfü-

40 4 RoboEarth Project
gung. So könnte die lokale Wissensbasis vielversprechende Zonen an der Karte übergeben.Andererseits das Herunterladen von genauen Daten über die Größe des Bettes hat erlaubt,nur durch die Messung einer der Seiten zu bestimmen, von welcher Seite des Bettes sich derRoboter befand. Das war möglich auch für Zonen, die nicht von der ersten Karte bedecktund noch nicht von dem Roboter besucht waren. Auf dieselbe Weise kann das Modell derFlasche den Roboter erlauben, die Flasche zuverlässig zu identifizieren und zu finden, sowiesie richtig zu fangen und mit der entsprechenden Spannkraft zu tragen - Abbildung 4.10.
Abbildung 4.10: Der Roboter serviert ein Getränk einem Patienten in einem simuliertenKrankenzimmer. Durch Verwendung von Vorkenntnissen, die in RoboEarth gespeichert sind, kann der Roboter seine Bewegung, Erfassung undManipulation von Objekten verbessern und könnte effektiv ein Getränkservieren. [www.roboearth.org]
4.6 RoboEarth und Microsoft Kinect
4.6.1 Einführung
Die Kombination zwischen der Datenbank von RoboEarth und den Möglichkeiten, die Mi-crosoft Kinect anbietet, ermöglicht es, ein Datenbank mit großem Umfang auf einen ver-nünftigen Preis und mit ziemlich guter Leistung, unabhängig von den Sensoren des Robo-ters aufgebaut zu werden. Der erste Schritt ist die Erstellung von farbigen Punkt-Wolken-Modelle der am häufigsten zu treffende Objekte in dem Haushalt mithilfe der Microsoft-Kinect-Kamera.
Der zweite Schritt ist das Speichern der neuen Information in der Datenbank von RoboE-arth, die von der ganzen Welt zugegriffen werden kann. Der dritte Schritt ist, dass Model-len zur Erkennung der entsprechenden Objekte benutzt werden, wobei die Objektaufnahmedurch normale Kamera erfolgt. Die Objekterfassung in der 3D-Datenbank ist neues Verfah-ren und als solches wurde von den verschiedenen Firmen unterschiedlich realisiert. Einigeder berühmtesten Beispiele sind die Datenbanken von KIT, Google 3D warehouse, SQLdatabase of Willow Garage’s household objects. Kennzeichnend für diese Datenbanken ist,dass die Modelle in der Form von Dreiecknetze aufgebaut und gespeichert werden. Dabei

4.6 RoboEarth und Microsoft Kinect 41
ist nachteilig, dass für ihren Aufbau sehr teure Ausstattung zum Scannen oder viel manu-elle Arbeit gebraucht wurde. Im Unterschied dazu, bietet die Verwendung von MicrosoftKinect einfache und billige Weise zur Erschaffung von Modelle von Objekte, wobei stattDreiecknetzte dreidimensionale farbige Punktwolken benutzt werden.
4.6.2 Wie funktioniert die Erfassung beliebiger Objekte?
Die Microsoft Kinect Kamera wird gemeinsam mit einer Schablone mit Markierung fürdie Erfassung von Objekte verwendet. Zuerst wird das zu erfassende Objekt in den Mittel-punkt der schon definierten Schablone mit Markierung gelegt. Danach wird das Objekt vonverschiedenen Seiten gescannt, indem er langsam gedreht wird.
Um die genaue Lage der Markierung in dem Bild in die drei Hauptfarben RGB zu erfin-den, wird die Bibliothek von ARToolkit verwendet. Damit die Genauigkeit verbessert wür-de, werden zwei Linien gewählt, die sich in dem Mittelpunkt der Marker kreuzen. Danachwerden mindestens sechs 3D Punkte aus jeder Linie durch Verwendung der von MicrosoftKinect erfassten Information gewählt und wird die Methode der kleinsten Quadrate verwen-det, um die Parameter der Linien und die Position der Marker zu ermitteln. Die Kreuzpunktoder die kleinste Distanz zwischen den beiden Linien(falls es unter eine bestimmte Grenzeliegt) stellt eine bessere Schätzung für den zugehörigen Mittelpunkt der Marker fest. Mitdem Ziel nicht korrekte Position der Marker auszuschließen, erfolgt ein Vergleich zwischenden ermittelte Ergebnis und vorher bekannten Entfernungen zwischen den Marker an derSchablone. Falls mindestens drei der Markierungspunkte auf diese Weise als zuverlässigidentifiziert werden, dann wird ein Koordinatensystem mit Mittelpunkt der Marker als An-fangspunkt gebildet, indem der Gramm-SchmidtVerfahren verwendet wird. Schließend, dieverschiedenen Bilder können in eine Koordinatensystem, mit Mittelpunkt die Schablone mitMarkierung, übertragen und gemischt werden, damit man ein vollständiges Modell erhaltenkann.
Der nächste Schritt ist die Erstellung von der Datenbank, bei der die Bilder komprimiertund in der Datenbank von RoboEarth hochgeladen werden. In diesem Fall, kann der Benut-zer dem Bild eine Objektklasse, Name und für die Menschen verständliche Beschreibungzuweisen. Dazu wird auch OWL Beschreibung gegeben, was die Weiterverarbeitung derInformation ermöglicht. In den gegebenen Fall wird KnowRob für Verarbeitung des Wis-senstands verwendet.
4.6.3 Objekterkennung und Positionsabschätzung
Der Anwender kann ein oder mehrere Dateien verwenden, die die Information über das Ob-jekt enthalten, die sich in der Datenbank von RoboEarth befinden. Nachdem diese Dateien

42 4 RoboEarth Project
geladen werden, können sie für Objekterkennung und Positionsabschätzung verwendet wer-den. Jedes Modell eines Objektes besteht aus viele Bilder aus verschiedenen Sichten. Fürjedes Objekt werden die 3D Punktwolke mit den SURF Eigenschaften, die mit einigen vondiesen Punkten verbunden sind, gespeichert. Heutzutage werden zwei Algorithmen für dieVerwendung der Objekte genutzt, die in der Datenbank gespeichert werden- das erste istmittels Microsoft Kinect und das zweite ist mittels RGB Kamera. Egal ob die Erfassungvon Objekte auf den RoboEarth Server oder direkt bei dem Anwender erfolgt, können dieModelle mit jeder Art Kameras benutzt werden.
Wenn die Bilder durch RGB Kamera erfasst wurden, werden die SURF Eigenschaften her-geleitet. In diesem Fall werden die Übereinstimmungen zwischen jeder Sicht des Modellsund dem Bild von der Kamera berechnet. Es wird das RANSAC Algorithmus verwendet,indem mindestens fünf Übereinstimmungen gesucht werden, die die Transformation vondem Modell zu dem Bild von der Kamera beschreibt. So wird die Positionierung des Ob-jekts eingeschätzt. In dem Fall mit der Kinect Kamera ist die Methode sehr ähnlich zu derschon beschriebenen, aber in diesem Fall wird die Position durch feste Transformation zwi-schen den Wolken von dem schon existierenden Modell und diesen von der Kamera. Dazuwird auch die Information über die Tiefe der Punkte verwendet, die in dem Bild der Kame-ra eingeschätzt sind, um die Distanz zwischen den Punkten von dem gegebenen Modell zuberechnen. Auf diese Weise werden unrealistische Übereinstimmungen weggeworfen.
4.7 Fazit
Die Verwendung von Microsoft Kinect – Verfahren zur Erschaffung von 3D Objektmodelleist billigere Alternative der bisherigen Verfahren. Mit dem Nutzen von RoboEarth-Systemhaben die Roboter von der ganzen Welt Möglichkeit zum Zugriff zu den Daten, die mit Mi-crosoft Kinect generiert worden sind, und können das Modell gleich nachdem es erschaffenund im System hochgeladen würde nutzen. Dieses Verfahren ermöglicht die Verwendungvon unterschiedlichen Arten von Kameras.
Die Objekte können richtig klassifiziert werden, wenn die in RoboEarth gespeicherte In-formation kombiniert wurde. Außerdem ist der Software schon fertig und kann sofort be-nutzt werden. Alle Vorteile von der Erschöpfung von Objekte mit Microsoft Kinect undihre weitere Speicherung, Verbreitung und Verwendung durch RoboEarth sind schwer vor-herzusagen. Sicher ist, dass die leichtere Informationsaustausch und Objekterfassung zureffektiveren Anwendung der Roboter und zur Erweiterung ihres Anwendungsfeldes führenwürde.
Ihrerseits, würden die Roboter mit ihren Sensoren – „Augen“ und „Ohren“ neue Heraus-forderungen von gesetzlicher, persönlicher und moralischer Art setzen. Eine unberechtigteNutzung der gesammelten Information kann zu schwierigen Problemen führen, wobei die

4.7 Fazit 43
Frage zur Sicherheit der Information und zu den Zielen, für die sie genutzt wurde, wahr-scheinlich in der Zukunft immer häufiger erhoben würde.
Für weitere Informationen über das Thema siehe auch: [WBC+11], [DMKZ+12], [N-213],[rob], [NS95]


Fabian Göcke, Ben Rabeler,Christian Schildwächter
5 Detektion von Personen
5.1 Abstract
Mit der Kinect hat Microsoft ein erschwingliches System zur Personendetektion für dieXbox 360 auf den Markt gebracht. Dieses bietet zahlreiche Möglichkeiten zur Erkennungvon Menschen. Es ist, unter anderem, möglich den ganzen Körper einer Person, unter Ver-wendung von Tiefeninformationen, zu identifizieren. In diesem Abschnitt werden wir hier-bei die gesamte Kontur des Menschen extrahieren, um diesen von seinem Hintergrund zusegmentieren.
Es ist nicht nur möglich eine ganze Person für die Erkennung in Betracht zu ziehen, denndurch die Kinect ist es möglich einzelne Teile separat zu betrachten, wie z.B. die Handeiner Person. In diesem Zusammenhang ist die Gestenerkennung ein wichtiger Bestandteilder Human Computer Interaction (HCI). In diesem Artikel werden zur Veranschaulichunganhand eines ausgewählten Verfahrens die Möglichkeiten der Gestenerkennung mit Kinectaufgezeigt.
Da die Kinect ursprünglich für die Xbox 360 entwickelt wurde, musste diese gehackt wer-den, um sie an einen PC anschließen zu können. Es wurde aber aufgerüstet, sodass es nunauch ein Modell für den Computer gibt. Zudem hat Asus einen Klon, die Xtion, herausge-bracht. Wie zu erwarten unterscheiden sich diese Systeme. In diesem Abschnitt verdeutli-chen wir die Unterschiede der einzelnen Modelle. Zusätzlich werden wir die dafür verfügba-ren Software Development Kit (SDK) aufzeigen, vergleichen und verfügbare Frameworks,welche die Personen- und Gestenerkennung erleichtern, vorstellen.
45

46 5 Detektion von Personen
5.2 Personendetektion
5.2.1 Einleitung
Die Erkennung von Menschen kommt heutzutage in vielen Bereichen zum Einsatz. Dafürwerden häufig Kamerasysteme eingesetzt, um Menschen beispielsweise an Tankstellen zuüberwachen, in der Kriminalistik zu identifizieren oder bei Videospielen zu erfassen. DasErkennen von Menschen in Videos oder Bildern birgt einige Schwierigkeiten in sich. Esmüssen z.B. die Körperhaltung, die Kleidung, das Licht und der Hintergrund berücksichtigtwerden.
Um Bilder zu verarbeiten, ist es möglich, sich auf RGB Images zu stützen oder die enthal-tenen Tiefeninformationen zu nutzen. Da Personen keine feste Form, in Bezug auf unter-schiedlichste Haltungen, besitzen, Licht und Farbe kaum Einfluss auf Tiefenbilder nehmenund zusätzlich 3D Informationen enthalten, werden diese hier in Kombination mit einemGradienten basierten Ansatz für die Detektion verwendet.
Viele Sensorsysteme (z.B. TOF, Kameras, Stereokameras) sind sehr kostspielig, um 3D-Informationen zu gewinnen. Seit Microsoft die Kinect für die Xbox 360 veröffentlicht hat,steht eine günstige und relativ einfach zu handhabende Alternative zur Verfügung. Die indiesem Paper betrachtete Methode nutzt die Kinect für die Menschenerkennung.
5.2.2 Related Works
Es ist nicht nur möglich, einen Menschen an sich durch die Kinect zu erkennen; Sung etal. [SPSS11] haben sich damit beschäftigt, Aktivitäten von Personen zu erkennen. Dafürwurde ein modifiziertes Markov Modell (MEMM) verwendet, welches eine Aktivität, z.B.das Zähneputzen, in Unteraktivitäten (Zahnbürste aufnehmen, Zahnpasta auf die Zahnbürs-te tun, Zahnbürste zum Mund führen etc.) einteilt. Dies soll in diesem Kontext dem Zweckdienen, einen Hilfsroboter beispielsweise für ältere Menschen zu entwickeln. Es ist auchmöglich, wie Shotton et al. [SSK+13] zeigen, 3D-Positionen des menschlichen Körpersmittels Decision Forests (eine Menge aus Entscheidungsbäumen) zu klassifizieren. Die Po-senerkennung wird vereinfacht, indem der Körper in Regionen unterteilt wird.
Die Kinect bietet somit eine Vielfalt von Anwendungsmöglichkeiten.
5.2.3 Die Methode
Als Input für das Verfahren der Menschenerkennung dient ein Tiefenarray, das aus einemBild des Videostreams der Kinect stammt. Dieses wird zu allererst vom Rauschen befreit,

5.2 Personendetektion 47
um später bessere Ergebnisse erzielen zu können. Um Personen zu detektieren, wird dasBild mittels 2D Kantenmatching auf potentiell relevante Regionen abgesucht. Im Anschlusswerden die gefundenen Regionen mit einem 3D Kopf Modell unter der Benutzung der re-lationalen Tiefeninformationen des Arrays geprüft. Die Parameter des Kopfes werden ausdem Tiefenarray extrahiert, um ein Modell des 3D Kopfes zu erstellen. Danach wird das 3DModell auf alle potentiell interessanten Regionen gematcht, um eine endgültige Schätzungzu erhalten. Zum Schluss wird ein region growing Algorithmus verwendet, um die gesamteKörperkontur zu extrahieren.
Die ganze Prozesskette ist in Abbildung 5.1 visualisiert.
Abbildung 5.1: Abbildung 1: Ablauf (vgl. [XCA11])
5.2.4 2D Kantenmatching
Vorberechnungen
Bevor das Kantenmatching beginnen kann, sind einige Vorberechnungen nötig, um besserauf den Bildern (des Videostreams) arbeiten zu können. Sensorsysteme sind in der Regelnicht fehlerfrei, dies trifft auch auf die Kinect zu. Punkte, die nicht gemessen werden kön-nen, oder auch geworfene Artefakte (z.B. kann das durch Oberflächen, die Infrarotstrahlennicht reflektieren, auftreten), werden als Rauschen angesehen und bekommen im Tiefen-array den Wert Null. Unter der Annahme, dass ein solcher Punkt einen ähnlichen Wert zuseinem Nachbarn hat, wird die nächste Nachbar (nearest neighbour) Interpolation verwen-det, um die fehlenden „Null-Pixel“ zu füllen. Zusätzlich wird ein Median-Filter mit derFenstergröße 4 x 4 eingesetzt, wodurch die Daten geglättet werden.
Ein vorberechnetes Bild ist in Abbildung 5.2(a) zu sehen.
Das Matching
Nach den Vorberechnungen werden die Kanteninformationen, die sich in dem Tiefenarraybefinden, genutzt, um solche Regionen zu entdecken, in denen das Auftreten von Personenwahrscheinlich ist. Hierbei ist es sehr wichtig, dass die false negative Rate gegen Null geht;aus dem einfachen Grund, dass sonst Menschen nicht erkannt werden, obwohl diese sich

48 5 Detektion von Personen
Abbildung 5.2: Zwischenschritte des 2D chamfer match
(a) zeigt Tiefenarray nach den Vorberechnungen. In (b) ist das binäre Kantenbild, unter Verwendung des
Canny Edge Filters und der Beseitigung kurzer Kanten, zu sehen. (c) zeigt die Distanzkarte, welche aus dem
Kantenbild berechnet wurde. Das Matching des binären Kopftemplates (d) mit (c) ergibt (e), wobei die gelben
Bereiche die möglichen Regionen für einen Menschen darstellen. [XCA11]
im Bild befinden. Im Gegensatz dazu ist es weniger nachteilig, wenn die false positive Ratesteigt, da diese Regionen in den späteren Schritten herausgefiltert werden können.
Um relevante Regionen für die Methode zu finden, wird 2D chamfer distance matchingverwendet. Kurz gesagt wird ein Template über das Bild geschoben und die Entfernungenvon den Kanten des Templates zu denen des Bildes bestimmt. Der Vorteil dieses Matchingsliegt in der Invarianz gegenüber Skalierung. Um die Kanten des Tiefenbildes zu ermitteln,wird der Canny Edge Filter benutzt, wodurch ein binäres Bild entsteht, bei dem die Kantendie Farbe Weiß und der Rest die Farbe Schwarz annehmen(Abb. 5.2(b)). Aus Gründen derBerechnungskosten und Störungen von Objekten im Raum, werden alle Kanten, die kürzerals ein festgelegter Schwellenwert sind (Pixelanzahl einer Kante), verworfen.
Als Template wird ein Binärbild eines Kopfes verwendet (Abb. 5.2(d)). Bevor das Matchingbeginnen kann, wird eine Distanz-Transformation des Bildes berechnet, was eine Distanz-karte des Kantenbildes erzeugt, in dem jeder Pixel die Distanz zu dem nächsten Datenpunkt(Kantenpunkt zu Kantenpunkt) enthält (Abb. 5.2(c)). Das hat den Effekt, dass eine Tole-ranz für das Matching geschaffen wird, sodass die Kanten des Templates nicht genau aufden Kanten des zu untersuchenden Bildes passen müssen, was wiederum die Effizienz desMatchings erhöht.
Im Anschluss werden mögliche Positionen des Kopftemplates im Distanzkartenbild ge-sucht. Das Template wird auf verschiedene Positionen des Bildes gelegt und der Abstand derPixelwerte wird berechnet. Je niedriger die Werte sind, desto höher ist die Wahrscheinlich-keit auf einen Treffer. Ein festgelegter Schwellenwert bestimmt, ob die Region als relevantangenommen wird oder nicht. Der Schwellenwert wurde in diesem Fall verhältnismäßighoch angesetzt, um eine sehr geringe false negative Rate zu garantieren, was dazu führt,dass auch Objekte im Raum als Kopf eines Menschen markiert werden. Ob dies wirklichder Fall ist, wird später festgestellt.

5.2 Personendetektion 49
Da es möglich ist, dass Personen in unterschiedlicher Distanz zur Kinect auftauchen, mussdas Template angepasst werden, um invariant gegenüber Skalierung zu sein. In diesem Fallwird das Template immer um den Faktor 3/4 verkleinert. Die Anzahl der Verkleinerungenist abhängig von der Tiefe der Szene. Sollte eine Person horizontal oder über Kopf im Bilderscheinen, muss das binäre Referenzbild nur rotiert und der gleiche Prozess wiederholtwerden.
In Abbildung 5.2 werden die durchgeführten Schritte deutlich.
5.2.5 Kopferkennung
Bestimmung der Kopfparameter
Im folgenden Abschnitt werden alle Regionen überprüft, die durch das 2D chamfer distancematching erkannt wurden. Es ist erforderlich, die genauen Parameter (Tiefe und Höhe) derKöpfe zu bestimmen, um das 3D Modell auf das Tiefenarray anzupassen. Ist die Höhe einesKopfes ermittelt so, wird in einem kreisförmigen Bereich im Kantenbild nach dem Kopfgesucht.
R = 1.33h/2 (5.1)
In (5.1) entspricht h der Höhe des Kopfes und R ist der Suchradius. Wird in dem entspre-chenden Suchareal eine kreisförmige Kante gefunden, welche alle Bedingungen erfüllt (wieetwa das Überschreiten eines Schwellenwertes), dann gilt der Kopf als gefunden. Sobalddieser als solcher erkannt wurde, muss dessen Radius Rt bestimmt werden. Allerdings ge-schieht dies nur approximativ, da das entsprechende Objekt nur eine annähernd runde Formbesitzt. Es bietet sich an, in dem Distanzkarten-Bild den Radius zu ermitteln, da ein Pixeldort die Entfernung zum nächsten Datenpixel kennt.
Nutzen des 3D Modells
Um ein möglichst allgemeines Modell zu erhalten, welches invariant gegenüber der Grö-ße einer Person oder dessen Ausrichtung zu Kinect ist, wird nur eine Halbkugel als 3DKopfmodell genutzt. Nun werden die Regionen, welche aus den vorherigen Schritten re-sultieren, durch das 3D Modell auf das tatsächliche Vorhandensein eines Kopfes überprüft.Dazu wird ein runder Bereich (RB) mit dem Radius Rt um das Zentrum der interessantenRegionen gelegt und eine Normalisierung der Tiefe durchgeführt, wodurch der RB gut mitdem 3D Kopfmodell verglichen werden kann.

50 5 Detektion von Personen
depthn(i, j) = depth(i, j) − mini, j∈RB
(depth(i, j)) (5.2)
In (5.2) entspricht depth(i, j) dem Tiefenwert eines Pixels mit den Koordinaten (i, j) ausdem Tiefenarray und depthn(i, j) ist die normalisierte Tiefe des Pixels (i, j). Zusätzlich wirdder quadratische Fehler
Er =∑
i, j∈RB
|depthn(i, j) − template(i, j)|2
aus dem RB und dem 3D Modell ermittelt, um eine gewisse Abweichung zu tolerieren (un-terschiedliche Kopfformen und –größen etc.). Durch einen Schwellenwert wird entschieden,ob in der vorliegenden Region ein Kopf vorhanden ist. Ist dem so, wird das Zentrum desKopfes gelb markiert (Abb. 5.3).
Abbildung 5.3: Nutzen des 3D Modells
(a) veranschaulicht die Berechnung für die Parameter des Kopfes aus der Distanzkarte. Nach der Überprüfung
auf Köpfe mittels des 3D Modells, sind in (b) die Kopfzentren durch gelbe Punkte markiert. [XCA11]
5.2.6 Konturextraktion
Ausgegangen von gefunden Köpfen in den einzelnen Szenarien sollen nun die Konturendieser Personen extrahiert werden. Es besteht allerdings das Problem, dass die Grenze zwi-schen den Füßen der Personen und dem Boden nicht erkannt wird. Im Tiefenarray besitzendaher Füße und Boden die gleichen Werte. Dies ist ein schwerwiegendes Problem für denregion growing Algorithmus, welcher die Konturen extrahieren soll. Das gleiche Problemtritt auf, wenn eine Person ein Objekt berührt, das sich in der gleichen Tiefe befindet. Umdies zu beheben, wird eine Filterantwort genutzt, welche die ebenen Bereiche skizziert, diesich parallel zum Boden befinden. Durch F Filterantworten werden die Füße vom Bodengetrennt (Abb. 5.4), sodass der region growing Algorithmus auf dem umgewandelten Bilderfolgreich arbeiten kann.

5.2 Personendetektion 51
Abbildung 5.4: KonturextraktionAbbildung 4: (a) ist das originale Tiefenarray. Einige Teile des Körpers sind mit dem Boden und der Wand
verschmolzen. (b) ist das Tiefenarray, welches als Input für den region growing Algorithmus genutzt wird. Es
ist zu erkennen, dass Kanten die Füße und den Boden voneinander trennen. [XCA11]
Abbildung 5.5: Pseudocode region growing (vgl. [XCA11])
Für die Extraktion wird angenommen, dass die Werte der Pixel innerhalb der Körperkonturnur in geringem Maße voneinander abweichen. Der Algorithmus startet vom Zentrum desKopfes, welches durch das 3D Modell gefunden wurde. Damit die Region vom Ausgangs-punkt wachsen kann, wird die Ähnlichkeit eines Pixels zu den Benachbarten überprüft. DasÄhnlichkeitsmaß zwischen zwei Pixeln x und y ist wie folgt definiert:
S (x, y) = |depth(x) − depth(y)| (5.3)
Hierbei ist S die Ähnlichkeit und depth() gibt den Tiefenwert des Pixels an. Die Tiefe einerRegion wird definiert über die Durchschnittstiefe aller Pixel in dieser Region:
depth(R) =1N
∑i∈R
(depth(i)) (5.4)

52 5 Detektion von Personen
Abbildung 5.6: Ergebnisse der Extraktion(a) Ergebnis des region growing Algorithmus. (b) Extrahierte Körperkontur. [XCA11]
Der ähnlichste Pixel, der zudem unter einem bestimmten Schwellenwert liegt, wird nun demKörperkonturbereich hinzugefügt. Der Pseudocode des Algorithmus‘ ist in Abbildung 5.5beschrieben. Die daraus resultierenden Ergebnisse der Extraktion zeigt Abbildung 5.6.
5.2.7 Experimente
Evaluierungsdaten
Zur Evaluierung der Methode wurde eine Sequenz von Tiefenarrays, aufgenommen durchdie Kinect, in einer Zimmerumgebung verwendet. In einer Szene befanden sich bis zu zweiPersonen, welche in unterschiedlichen Haltungen aufgenommen wurden oder mit der ande-ren Person bzw. Objekten im Raum interagierten. Im Raum befanden sich alltägliche Dinge,wie Regale, Stühle, Tische, Computer, Lampen etc.
Ein Testset umfasst 98 Frames mit einer Framerate von 0,4 s/Frame. Die Größe eines Tie-fenarrays besaß 1200 x 900 mit einer Auflösung von 10 mm. Messfehler wurden im Arraymit dem Wert Null belegt und die Tiefe im Bild wurde in Millimeter gemessen.
Ergebnisse
Die Methode der Personendetektion funktioniert gut auf dem gewählten Datenset, wie Ab-bildung 5.7 zeigt. Es treten keine false positive Instanzen auf, allerdings sind false negativeInstanzen zu vermerken. Dies geschieht, wenn eine Person durch eine andere verdeckt wirdoder die entsprechende Person nur zu Hälfte im Bild zu sehen ist. Einige dieser Fehlklassi-fikationen sind in Abbildung 5.8 zu erkennen.
Für die Evaluierung wurden drei verschiedene Genauigkeitsmetriken verwendet (precision,recall und accuracy), die wie folgt definiert sind:
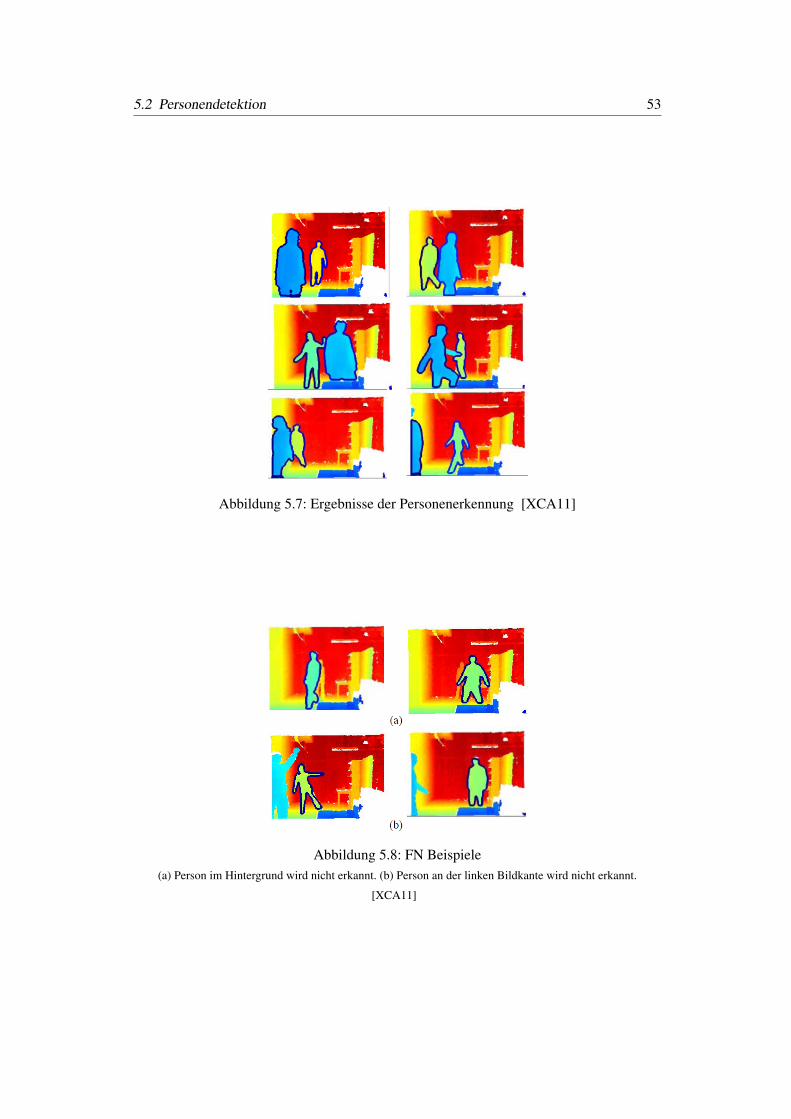
5.2 Personendetektion 53
Abbildung 5.7: Ergebnisse der Personenerkennung [XCA11]
Abbildung 5.8: FN Beispiele(a) Person im Hintergrund wird nicht erkannt. (b) Person an der linken Bildkante wird nicht erkannt.
[XCA11]

54 5 Detektion von Personen
Pr =T P
T P + FP(5.5)
Re =T P
T P + FN(5.6)
Acc =T P + T N
T P + T N + FP + FN(5.7)
Abbildung 5.9 zeigt die Werte dieser Genauigkeiten auf Basis der durchgeführten Tests.
Abbildung 5.9: Genauigkeiten [XCA11]
5.3 Gestenerkennung am Beispiel des FEMD-Verfahrens
5.3.1 Motivation und Probleme in der Gestenerkennung
Neben der Erkennung von Körpern ist Handgestenerkennung von großer Wichtigkeit fürdie HCI. Wichtige Einsatzfelder der Gestenerkennung sind z.B. Anwendungen der VirtualReality (VR), Computerspiele oder Zeichensprachenerkennung. Ein gutes Beispiel für dieAnwendung von Gestenerkennung ist die Roboter-Mensch-Interaktion (näheres dazu in:[VdBCDN+11]).
Für die Handerkennung gibt es verschiedene Ansätze. In diesem Artikel wird näher auf dieErkennung mit bildliche Erkennung der Hand mit Kinect eingegangen. Weitere Möglich-keiten beruhen darauf, dass der Anwender Zusatzmaterial benötigt (z.B. einen Datenhand-schuh) benötigt, der ihn in der Benutzung einschränkt und wofür häufig eine Kalibrierungnotwendig ist. Mit der optischen Handerkennung durch Kinect werden diese Probleme zwarumgangen, es entstehen aber neue Probleme. Wie bereits vorgestellt, lassen sich größereTeile des menschlichen Körpers erkennen. Die Hand ist aber ein kleineres Körperteil, dasviele verschiedene Formen annehmen kann [EBN+07].
Abbildung 5.10 verdeutlicht dieses Problem mit drei aufgenommen Gesten und zugehöri-gen Aufnahmeresultaten. Die ersten beiden Gesten haben dieselbe Bedeutung, während diedritte Geste die beiden anderen stört. Aufgrund der geringen Aufnahmequalität der Kinect
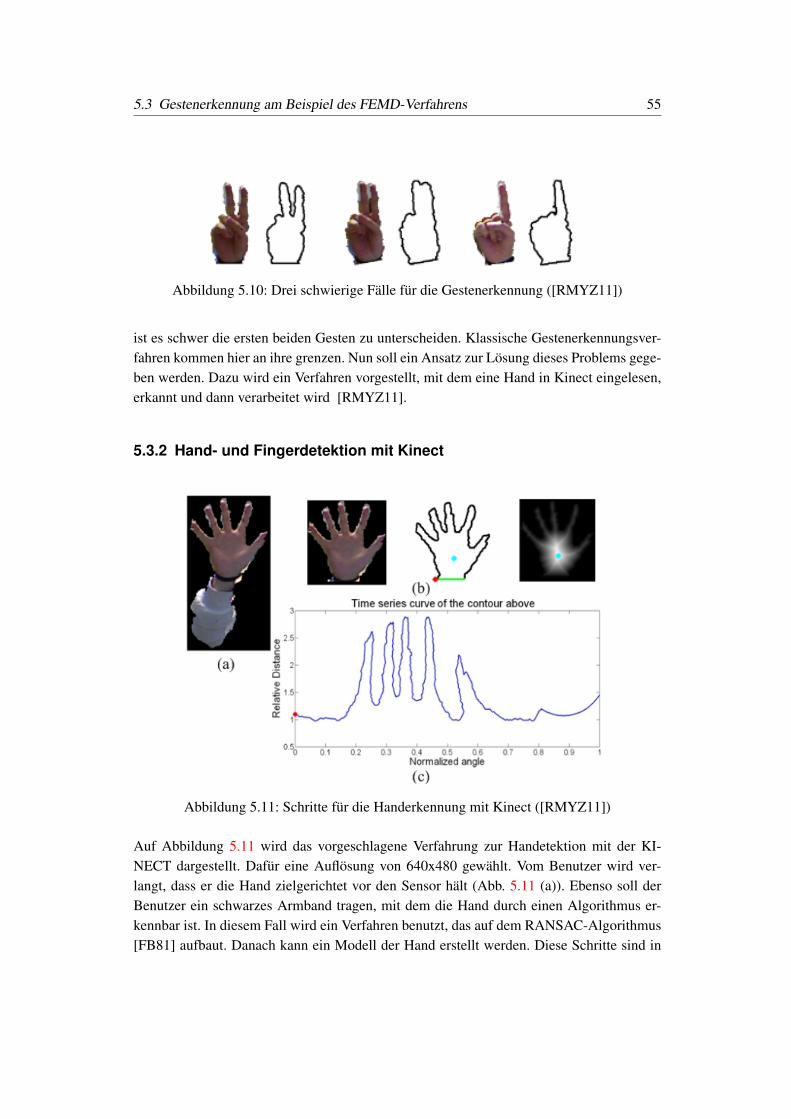
5.3 Gestenerkennung am Beispiel des FEMD-Verfahrens 55
Abbildung 5.10: Drei schwierige Fälle für die Gestenerkennung ([RMYZ11])
ist es schwer die ersten beiden Gesten zu unterscheiden. Klassische Gestenerkennungsver-fahren kommen hier an ihre grenzen. Nun soll ein Ansatz zur Lösung dieses Problems gege-ben werden. Dazu wird ein Verfahren vorgestellt, mit dem eine Hand in Kinect eingelesen,erkannt und dann verarbeitet wird [RMYZ11].
5.3.2 Hand- und Fingerdetektion mit Kinect
Abbildung 5.11: Schritte für die Handerkennung mit Kinect ([RMYZ11])
Auf Abbildung 5.11 wird das vorgeschlagene Verfahrung zur Handetektion mit der KI-NECT dargestellt. Dafür eine Auflösung von 640x480 gewählt. Vom Benutzer wird ver-langt, dass er die Hand zielgerichtet vor den Sensor hält (Abb. 5.11 (a)). Ebenso soll derBenutzer ein schwarzes Armband tragen, mit dem die Hand durch einen Algorithmus er-kennbar ist. In diesem Fall wird ein Verfahren benutzt, das auf dem RANSAC-Algorithmus[FB81] aufbaut. Danach kann ein Modell der Hand erstellt werden. Diese Schritte sind in

56 5 Detektion von Personen
Abbildung 5.11 (b) dargestellt. Aus dieser Vorarbeit entsteht die time-series-curve, die dieHand auf anhand des Handmittelpunkts normalisierten Achsen darstellt.
Für weitere zielführende Untersuchungen ist eine möglichst genaue Fingerdetektion hilf-reich. Der generelle Ansatz darin besteht einen Finger als Peak der time-series-curve aufzu-fassen. Für die Wahl zur Erfassung eines Peaks gibt es zwei Ansätze. Im ersten Ansatz wirdein Referenzwert h f gewählt, mit dem ein Finger zugeordnet wird sobald ein Vergleichs-wert größer als h f ist. Hierfür ist die Wahl von h f entscheidend, um eine geeignete Effizienzzu erhalten. Dieser Ansatz könnte zu Problemen führen (z.B. bei einem kleinen Finger wiedem Daumen). Ein genauerer aber komplexerer Ansatz ist near-convex hand decompositi-on. In diesem Verfahren wird eine Gerade zwischen zwei geeignete Punkte eines Fingersgelegt. Das bringt den Vorteil mit sich, dass die Erkennung eines einzelnen Fingers nichtmehr abhängig ist von den Eigenschaften der anderen Finger und einem h f [RYLL11].
Als Resultat der Hand-und Fingerdetektion erhält man nun eine Hand R =
{(~r1,w~r1), . . . , ( ~rm,w ~rm)}, die als eine Menge von Tupeln beschrieben werden kann. Dabeiist m die Anzahl der erkannten Finger ("Cluster"). ~ri = [ria, rib] beschreibt in einem In-tervall die Länge eines Fingers. Dabei muss 0 < ria < rib < 1 gelten, um eine gültigeFingerlänge in dem normierten Raum zu erhalten. w~ri beschreibt für einen Finger dessenFlächeninhalt.
5.3.3 Gestenerkennung mit FEMD
Abbildung 5.12: Beispiel für das EMD-Verfahrens
Fingers Earth Mover Distance (FEMD) ist ein Verfahren, das zwei Hände miteinandervergleicht. Es basiert auf dem Verfahren Earth Mover Distance (EMD), das ein Ähnlich-keitsproblem zwischen zwei Signaturen mit einem linearem Optimierungsproblem angeht.Abbildung 5.12 zeigt zwei Graphen. Wendet man das EMD-Verfahren an, erhält man alsResultat einen Wert ungefähr 0, da der rechte Graph ein Teil des linken Graphs ist. Die-ses Verfahren lässt sich jetzt auf eine Hand übertragen, in der die Finger einem Peak einesGraphs entsprechen.
Neben R wird eine weitere Signatur T = {(~t1,w~t1), . . . , (~tn,w~tn)} zum Vergleich eingeführt.Weiterhin ist F = [ fi j] die Flußmatrix (ergibt sich aus dem EMD-Verfahren) und D = [di j]

5.3 Gestenerkennung am Beispiel des FEMD-Verfahrens 57
Distanzmatrix, in der di j = min(|ria − t ja|, |rib − t jb|) die minimale Differenz zwischen denFingern ri und t j ist. Für F und R ist die FEMD-Distanz definiert durch:
FEMD(R,T ) =β∑m
i=1∑n
j=1 di j fi j + (1 − β)|∑m
i=1 w~ri −∑n
j=1 w~t j∑mi=1∑n
j=1 fi j| (5.8)
β ist eine Konstante, mit der zwischen beiden Summentermen moduliert werden kann.Tiefergehendes zum EMD-Verfahren kann [Bov03], zum FEMD-Verfahren [RMYZ11]entnommen werden.
5.3.4 Experimente und Einordnung
Abbildung 5.13: Erkennung einer Geste mit Kinect bei vier schwierigen Fällen
Abbildung 5.13 zeigt die Erfassung der Hand für vier verschiedene Fälle, die für eineeinzige Geste (Victory-Zeichen) aufgenommen ist. Die Finger wurden über near con-vex hand decomposition erfasst (blaue Geraden). In den Fällen (a) und (b) wurden vomAlgorithmus zwei Finger erkannt. Die zugehörige Hand lässt sich also darstellen durch{(~t1,w~t1), (~t2,w~t2)}. Für die Fälle (c) und (d) wurden die zwei Finger als ein Finger vom Al-gorithmus erkannt. Diese Hand lässt sich darstellen durch {(~r1,w~r1)}. Es ist anzunehmen,dass w~t1 + w~t2 ≈ w~r1 . Ebenso sind d11, d21 ≈ 0. Folglich ist auch die FEMD-Distanz zwi-schen allen Gesten ≈ 0. Somit kann mit dem Verfahren erreicht werden, dass eine Gestetrotz vier irritierender Darstellungen erkannt wird.
Dieses dargestellte Verfahren kann für die Erkennung von Gesten eingesetzt werden. Da-für werden z.B. in einer Referenzgesten hinterlegt, für die dann eine aufgenommene Gestemit dem FEMD-Verfahren verglichen wird. Für Gestensteuerung eignet sich das Verfah-ren aufgrund von Performance-Schwierigkeiten (Erkennung der Finger, Abgleich mit derDatenbank) nicht. Hier werden in der Praxis vor allem Skelettmodelle verwendet.

58 5 Detektion von Personen
5.4 Anwendung entsprechender Bibliotheken
5.4.1 Kinect-Hacking Geschichte
Am Tag der Veröffentlichung der Kinect versprach Adafruit Industries, ein OpenSourceElektronikversand und Unterstützer, demjenigen 3000$, der als erster OpenSource-Treiberfür die Kinect zur Verfügung stellt, und dies mit einem einfachen Demoprogramm beweist,in dem der Video- und Depthstream der Kinect gezeigt werden [Ind] [boua].
Nur zwei Tage nach der Veröffentlichung, am 6. November 2010, hatte der Hacker AlexPvon Code Laboratories (CL) die Kinect schon teilweise gehacked und am 9. November, fünfTage nach der Veröffentlichung, vollen Zugriff auf alle Sensoren außer Audio [cl]. Da CLaber 10000$ haben wollte, um das Projekt als OpenSource zu veröffentlichen:
We are not looking for money but believe a properly funded project will bringus great results [...] [firb]
und nur 457$ plus der Belohnung von 3000$ zusammenkamen, gewann CL den Adafruit-Wettbewerb nicht. Am 8. Dezember veröffentlichte CL das erste offizielle SDK - CL NUIPlatform - kostenlos für Windows, jedoch weiterhin nicht OpenSource [cln].
Am 10. November veröffentlichte der Spanier Héctor Martin Cantero alias „marcan“OpenSource-Treiber für die Kinect (libfreenect), nur ein paar Stunden, nachdem diese inEuropa erschienen war [mar]. Damit gewann er die 3000$ von Adafruit und CL spende-te ihm die 457$, die aus der Community zusammenkamen. Adafruit spendete außerdem2000$ an die Electronic Frontier Foundation - EFF, die sich für die Bürgerrechte in derdigitalen Welt einsetzt [eff] [boub]. Aus dem Hack von Cantero entstand das OpenKinect-Projekt [oped].
Ende November wurde die Non-Profit-Organisation OpenNI gegründet. Eines der Haupt-mitglieder ist PrimeSense, das Unternehmen, dass das Referenzdesign der Kinect entwickelthat [opef] [Pri]. Am 8. Dezember wurde die erste Version des OpenNI Frameworks ver-öffentlicht, inklusive OpenSource-Treiber für die PrimeSense Sensoren und BodytrackingMiddleware NiTE [fira] [nit].
Ein halbes Jahr später, am 16. Juni 2011, veröffentlichte Microsoft, aufgrund der schnellwachsenden Kinect Community, das erste offizielle Kinect for Windows SDK, welches an-fangs nur für nichtkommerzielle Zwecke eingesetzt werden durfte [Mic].
Ungefähr zur gleichen Zeit erschien die Asus Xtion (Pro), eine „abgespeckte Kinect“, wel-che in Zusammenarbeit mit PrimeSense entstand. Die Xtion wird offiziell vom OpenNIFramework unterstützt und funktioniert deshalb unter Windows, Linux und Mac OS. ImSeptember erschien dann die Weiterentwicklung Xtion (Pro) Live [xtia] [xtib].

5.4 Anwendung entsprechender Bibliotheken 59
Am 1. Februar 2012 erschien die Kinect for Windows zusammen mit dem Kinect for Win-dows SDK Version 1.0, welches nun auch für kommerzielle Zwecke genutzt werden durfte.Die Xbox-Version der Kinect ist mit diesem jedoch nur zu Entwicklungs- und Testzweckenutzbar [kind] [kinb] [kos].
5.4.2 Vergleich verfügbarer Sensoren
Zum Erscheinen dieses Reports waren folgende Kinect- und Kinectähnliche Sensoren ver-fügbar:
• Microsoft Kinect for XBOX
• Microsoft Kinect for Windows
• Asus Xtion (Pro)
• Asus Xtion (Pro) Live
Die ursprüngliche Variante der Kinect, die Kinect for XBOX, unterscheidet sich von derneueren Kinect for Windows äußerlich lediglich durch die Aufschrift. Bei der Kinect forXBOX steht rechts neben den Kameras „XBOX 360“ und auf dem Sockel „Kinect“, wiein Abb. 5.15 zu sehen, bei der Kinect for Windows steht neben den Kameras „Kinect“ undauf dem Sockel „Microsoft“. Hardwareseitig sind die beiden Versionen identisch, Softwa-reseitig gibt Microsoft jedoch an, dass die Kinect for Windows für eine Bedienung vomSchreibtisch aus optimiert wurde, dies äußert sich in einer veränderten Firmwareversion,die einen sogenannten „Near-Mode“ aufweist. In diesem kann die Kinect, laut Microsoft,Objekte schon ab knapp 40cm wahrnehmen und nicht erst ab 80cm wie im Default-Mode.Dafür verschiebt sich die maximale Reichweite von 4m auf 3m [nea].
Abbildung 5.14: Asus Xtion (Pro) [asu]
Die Asus Xtion (Pro), Abb. 5.14, war der erste Versuch von Asus in Zusammenarbeit mitPrimeSense, Microsofts Kinect Konkurrenz zu machen. Die Pro-Version der Xtion unter-

60 5 Detektion von Personen
scheidet sich von der normalen lediglich in der beigelegten Software, bei ihr ist das OpenNI-Framework auf CD mit dabei. Die Xtion hat im Gegensatz zur Kinect keine RGB-Kamera,keine Mikrofone und keinen Motor zum Kippen, dafür ist keine zusätzliche Stromquellenotwendig.
Abbildung 5.15: Kinect und Xtion Live im Vergleich [kinc]
Die Xtion (Pro) Live hat zusätzlich eine RGB-Kamera und zwei Mikrofone, jedoch weiter-hin keinen Motor. Beide Xtion Varianten sind wie in Abb. 5.15 zu sehen deutlich kleiner alsdie Kinect und darum auch deutlich leichter.
Eigenschaft Kinect (for Windows) Xtion (Live)
max. Video Auflösung 1280x1024 @ ca.10Hz 1280x1024 @ ca.10Hzmax. IR Auflösung 1280x1024 @ ca.10Hz 1280x1024 @ ca.10Hzmax. Depth Auflösung 640x480 @ 30Hz 640x480 @ 30HzMaße in cm 30,5x7,6x6,4 17,8x5,1x3,8Gewicht in kg 1,36 0,23Preis in Euro ca. 90 (180) ca. 120 (145)
Tabelle 5.1: Sensoren im Vergleich [sen]
5.4.3 Vergleich verfügbarer Bibliotheken
CL NUI Platform
Die aktuelle Version von CL NUI Platform ist v1.0.1210 vom 12. Oktober 2010 und wirdscheinbar nicht weiterentwickelt. Das SDK ist kostenlos nur für Windows und nur für dieKinect verfügbar, es ist nicht OpenSource und besteht lediglich aus dem Treiber, der C API

5.4 Anwendung entsprechender Bibliotheken 61
und zwei Beispielen in C# und bietet daher nur einen low level Zugriff auf die Kinect. Eswerden alle Funktionen der Kinect außer die Mikrofone unterstützt [cln].
OpenNI-Framework
Das OpenNI-Framework entstand in Zusammenarbeit von u.a. PrimeSense und Willow Ga-rage (Robotikexperte und Mitentwickler von ROS, OpenCV und PCL) [opeh]. Die aktuellestabile Version ist 2.1 vom 24. Januar 2013 und ist sowohl für Windows, als auch für Li-nux und Mac verfügbar. Der Develop-Branch wird täglich weiterentwickelt [opea]. Mit der2.x Version hat OpenNI sein OpenSource Framework neu designt, die wichtigsten Verän-derungen sind sehr gut im „OpenNI Migration Guide“ beschrieben [mig]. Allgemein istdie Dokumentation sehr gut und es gibt viele Beispiele, auch die Community ist sehr groß,laut eigenen Angaben wird das OpenNI SDK monatlich 85000 mal runtergeladen. OpenNIunterstützt offiziell nur die Sensoren von PrimeSense, bzw. die von anderen Partnern, sowie die Asus Xtion. Um die Kinect mit OpenNI zu nutzen, gab es für die 1.x Versioneneinen inoffiziellen Treiber namens avin2 [avi]. Für die 2.x Versionen muss man nun dasoffizielle Kinect for Windows SDK installiert haben, dies ist natürlich nur für Windows ver-fügbar [opeg]. Alternativ kann man den OpenNI2-FreenectDriver benutzen, um die Kinectmit dem OpenNI-Framework auch unter Linux oder Mac nutzbar zu machen [ni2]. Für dasFramework gibt es sehr viel Middleware z.B. für Skelett-Tracking oder Gestenerkennung,diese ist jedoch meist nicht OpenSource.
OpenKinect (libfreenect)
Das OpenKinect-Projekt brachte den ersten OpenSource-Treiber hervor, libfreenect. Wieauch die CL NUI Platform besteht libfreenect lediglich aus dem Treiber, der API und einpaar Beispielen und bietet nur Funktionen zur Kommunikation mit der Hardware. Im Ver-lauf des Projekts soll sich jedoch der Schwerpunkt ändern und die Entwicklung in Richtung„OpenKinect Analysis Library“ gehen, mit der z.B. Hand- und Skelett-Tracking möglichsein soll [opee]. Leider ist es seit über einem Jahr sehr ruhig um OpenKinect geworden,was vermutlich an OpenNI und dem offiziellen Kinect SDK liegt. Es ist zu bezweifeln, dasssich das Projekt über libfreenect hinausentwickelt [lib] [opec].
Kinect for Windows SDK
Die offizielle Entwicklerlösung für die Kinect ist seit dem 18. März 2013 in der Version1.7 erhältlich, für Windows 7 oder neuer [lat]. Das SDK ist nicht OpenSource und nur mitder Kinect benutzbar, kommerzielle Anwendungen dürfen nur für die Windows-Version derKinect entwickelt werden und funktionieren nicht mit der XBOX-Version. Mit jeder neuen
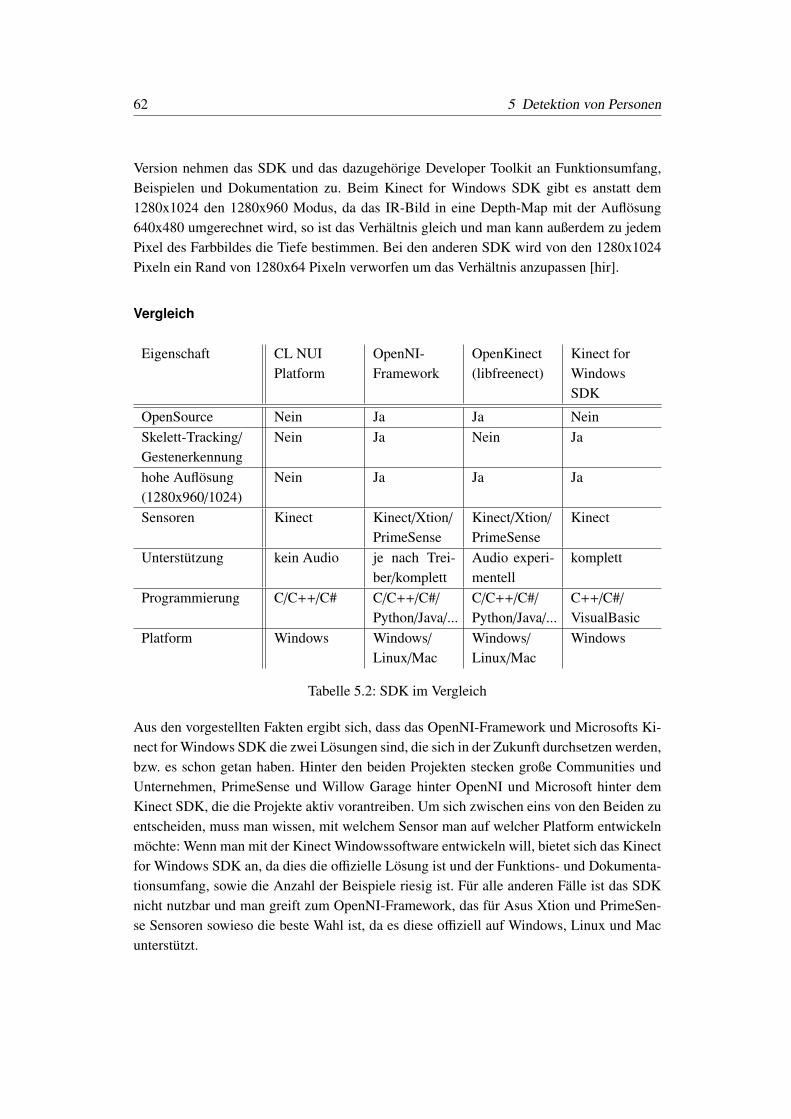
62 5 Detektion von Personen
Version nehmen das SDK und das dazugehörige Developer Toolkit an Funktionsumfang,Beispielen und Dokumentation zu. Beim Kinect for Windows SDK gibt es anstatt dem1280x1024 den 1280x960 Modus, da das IR-Bild in eine Depth-Map mit der Auflösung640x480 umgerechnet wird, so ist das Verhältnis gleich und man kann außerdem zu jedemPixel des Farbbildes die Tiefe bestimmen. Bei den anderen SDK wird von den 1280x1024Pixeln ein Rand von 1280x64 Pixeln verworfen um das Verhältnis anzupassen [hir].
Vergleich
Eigenschaft CL NUIPlatform
OpenNI-Framework
OpenKinect(libfreenect)
Kinect forWindowsSDK
OpenSource Nein Ja Ja NeinSkelett-Tracking/
GestenerkennungNein Ja Nein Ja
hohe Auflösung(1280x960/1024)
Nein Ja Ja Ja
Sensoren Kinect Kinect/Xtion/
PrimeSenseKinect/Xtion/
PrimeSenseKinect
Unterstützung kein Audio je nach Trei-ber/komplett
Audio experi-mentell
komplett
Programmierung C/C++/C# C/C++/C#/
Python/Java/...C/C++/C#/
Python/Java/...C++/C#/
VisualBasicPlatform Windows Windows/
Linux/MacWindows/Linux/Mac
Windows
Tabelle 5.2: SDK im Vergleich
Aus den vorgestellten Fakten ergibt sich, dass das OpenNI-Framework und Microsofts Ki-nect for Windows SDK die zwei Lösungen sind, die sich in der Zukunft durchsetzen werden,bzw. es schon getan haben. Hinter den beiden Projekten stecken große Communities undUnternehmen, PrimeSense und Willow Garage hinter OpenNI und Microsoft hinter demKinect SDK, die die Projekte aktiv vorantreiben. Um sich zwischen eins von den Beiden zuentscheiden, muss man wissen, mit welchem Sensor man auf welcher Platform entwickelnmöchte: Wenn man mit der Kinect Windowssoftware entwickeln will, bietet sich das Kinectfor Windows SDK an, da dies die offizielle Lösung ist und der Funktions- und Dokumenta-tionsumfang, sowie die Anzahl der Beispiele riesig ist. Für alle anderen Fälle ist das SDKnicht nutzbar und man greift zum OpenNI-Framework, das für Asus Xtion und PrimeSen-se Sensoren sowieso die beste Wahl ist, da es diese offiziell auf Windows, Linux und Macunterstützt.

5.5 Zusammenfassung 63
5.4.4 Frameworks zur Personen-/Gestenerkennung
• Kinect Developer Toolkit: Nur mit Kinect SDK nutzbar, bietet Skelett- und Ge-sichtstracking, Gesten- und Spracherkennung, 3D Scanning, viele Open Source Bei-spiele u.a. mit OpenCV und Matlab [kina]. Microsoft verrät in dem Paper „Real-TimeHuman Pose Recognition in Parts from Single Depth Images“ seinen Body-TrackingAlgorithmus [bta] [SSK+13].
OpenNI Middleware:
Für das OpenNI Framework gibt es eine Vielzahl von Middleware, dies ist nur eine kleineAuswahl aus dem Bereich Bodytracking, wobei NiTE und Grab Detector von PrimeSenseselbst entwickelt wurden.
• NiTE: Enthält zwei Hauptkomponenten: Hand Based Control und Full Body Control,bietet u.a. Skelett- und Benutzererkennung und -Tracking, Algorithmen wurden nichtveröffentlicht [nit].
• Grab Detector: Erlaubt die Erkennung von „Greif- und Loslassgesten“ [gra].
• TipTep Skeletonizer: Erstellt ein Skelett der Hand aus dem Tiefenbild [tts].
• iGesture: Bietet Erkennung von Handgesten, z.B. wieviele Finger man zeigt [ige].
• 3D Hand Tracking Library: Erlaubt 3D Handgestenerfassung, entwickelt vomFORTH, nur mit CUDA-fähiger GPU nutzbar [han].
• GST API: Erkennt Ganzkörperposen, z.B. Stehen, Hocken [gst].
Allgemein:
• OpenCV: OpenSource, quasi Standard in der Computer Vision, bietet u.a. Gesichts-und Gestenerkennung [opeb].
• PCL - Point Cloud Library: OpenSource-Projekt zur Verarbeitung von 3D-Punktwolken z.B. zur Objekterkennung [pcl].
5.5 Zusammenfassung
Die durchgeführten Versuche haben gezeigt, dass Personen effektiv mit der Kinect erkanntund die Körperkonturen vom Hintergrund sauber getrennt werden können. Erweiterungs-möglichkeiten für die Zukunft wären das Verfolgen (Tracking) und, daraus resultierend,

64 5 Detektion von Personen
die Erkennung von Aktivitäten einer Person. Zusätzlich könnte die Methode dahingehenderweitert werden, dass nicht nur die Körperkontur, sondern auch einzelne Regionen desKörpers detektiert werden können. Zur Personendetektion hat sich besonders die Handges-tenerkennung als wichtiges Feld der HCI herausgestellt, diese ist mit dem FEMD-Verfahrenzuverlässig möglich. Dieses basiert auf dem Vergleich zweier Hände, wofür erst die Handund dann die Finger erkannt werden, daraus ergibt sich ein Diagramm, auf das das Ver-fahren angewendet wird. Ein Anwendungsfall ist der Einsatz in einem Abgleichsverfahren,bei dem eine Menge gespeicherter Gesten benutzt wird. Für die Kinect und ihre verwandtenSensoren gibt es schon eine Vielzahl von Lösungen im Bereich der Personenerkennung, vie-le sind gut Dokumentiert und laden zum ausprobieren ein. In Zukunft wird die Genauigkeitder Erkennung, mit verbesserten Algorithmen und besseren Sensoren erhöht. Die nächsteGeneration der Kinect wird noch dieses Jahr kommen, mit einer Full HD Auflösung bei 30Bildern pro Sekunde, damit sollte sich besonders die fingergenaue Erkennung von Gestenverbessern.

Lars Grotehenne
6 Alternative Sensorsysteme
6.1 Einleitung
In diesem Kapitel werde ich mich mit unterschiedlichen alternativen Sensorsystemen zurKinect beschäftigen. Dabei betrachte ich sowohl die Funktionsweise, als auch unterschied-liche Arten und Systeme. Des Weiteren möchte ich die Anwendungsgebiete aufzeigen undjeweilige Vor- und Nachteile nennen.Anschließend werde ich diesen Abschnitt mit einer kurzen Zusammenfassung der kennen-gelernten Systeme und deren Unterschiede beenden.
6.2 Laserscanner
Es gibt viele verschiedene Funktionsweisen und Anwendungsgebiete von Laserscannern.Da wäre zum einen das so genannten Airborne-Laserscanning, welches wie der Nameschon sagt, hauptsächlich für Aufnahmen aus der Luft gedacht ist. Des Weiteren exis-tiert das konfokales Laserscanning, dass in der Mikroskopie eingesetzt wird. Auch bei derMaterialbearbeitung- und fertig spricht man von Laserscannern, wenn du Laserleistung aus-reichend groß ist, um Gegenstände zu Gravieren, Schweißen oder Härten. Ich werde michhier mit dem terrestrischen Laserscanning befassen, bei der es um die digitale Oberflächen-erfassung in vielen unterschiedlichen Bereichen geht.
6.2.1 Funktionsweise
Ein terrestrischer Laserscanner besteht aus drei wesentlichen Komponenten:
• Zum einen einer Entfernungsmesseinheit, die reflektorlos durch elektrooptischeEntfernungsmessung oder durch das Triangulationsverfahren die Schrägstrecken zu
65

66 6 Alternative Sensorsysteme
den Messepunkten auf der Oberfläche des abzutastenden Objektes bestimmt.
• Als nächstes kommt eine Einheit zur Ablenkung des Laserstrahls zur Verwendung,dabei wir der Laserstrahl entweder durch Schrittmotoren oder durch drehbare Spiegelin horizontaler und vertikaler Richtung abgelenkt, um so das gesamte Messobjektabtasten zu können.
• Letztendlich errechnet die Steuer- und Aufzeichnungseinheit zu jedem Messpunktdie Entfernung und kann mit diesem Wissen und den beiden Ablenkungswinkeln diedreidimensionalen Koordinaten des Messpunktes berechnen.
Der Anwender erhält nun sogenannte Punktwolken, die aus vielen 3D-Messpunkten mit ih-ren x-, y- und z-Koordinaten bestehen. Dieses Punktwolke kann nun noch weiter verarbeitetwerden um Computermodelle des aufgezeichneten Objektes zu erstellen.[Gor08]
Abbildung 6.1: Abtastsystem eines Laserscanners [www.xdesy.de]

6.2 Laserscanner 67
6.2.2 Arten
Bei der Entfernungsmessung des Laserscanners kommen unterschiedliche Verfahren zumEinsatz, sie besitzen Vor- und Nachteile, die hauptsächlich davon abhängen, ob man liebergrößere Reichweiten messen möchte oder sehr viel Wert auf die exakte Genauigkeit derMessungen legt.
Triangulationsverfahren
Beim Triangulationsverfahren wird ein Punkt oder eine Linie von einer Laserdiode auf daszu messende Objekte gerichtet. Das von dort reflektierte Licht wird über eine lichtemp-findliche Empfangseinheit (CMOS, CCD, PCD) aufgenommen. Wenn sich das Objekt nunnähert oder entfernt, ändert sich die beleuchtete Stelle und man kann den Abstand präzi-se berechnen. Vorteil des Verfahrens ist die hohe Genauigkeit, die unter einem Millimeterliegt, allerdings ist die Reichweite mit bis zu 10 Metern sehr begrenzt.
Phasenlaufzeitverfahren
Beim Phasenvergleichsverfahren werden Wellen mit unterschiedlicher Wellenlänge vomLaserscanner ausgesandt und anschließend wird über die Phasenverschiebung die Wegstre-cke ermittelt. Die Messgeschwindigkeit ist so sehr hoch und es kann eine hohe Auflösungerzielt werden, die Genauigkeit ist immer noch kleiner als 10 Millimeter, dafür ist die Reich-weite auch hier begrenzt, sie liegt bei bis zu 100 Metern.
Impulslaufzeitverfahren
Beim Impulslaufzeitverfahren werden kurze Laserimpulse gesendet und anschließend wirddie Zeit gemessen, bis der Laserscanner diese Impulse wieder empfängt. aus der Laufzeitlässt sich nun die Strecke ableiten. Vorteile des Impulslaufzeitverfahrens ist die große Reich-weite, sie beträgt ungefähr 1000 Meter, dafür ist die Genauigkeit mehr als 10 Millimeternnicht mehr so gut.[lasa][lasb][Ajl08]
6.2.3 Anwendungsgebiete
Das größte Einsatzgebiet von Laserscannern ist in bautechnischen Bereichen, zum Vermes-sen von bereits bestehender Architektur, Denkmalvermessung, beim Bergbau, sowie Tun-nelbau. Des Weiteren zur Gebäudedokumentation und für Schadensaufnahmen.

68 6 Alternative Sensorsysteme
Außerdem kann er in der Archäologie und in Museen zur Aufnahme von Skulpturen benutztwerden.Des Weiteren dient er der Forensik und Unfallforschung.[uVDIUHW]
Abbildung 6.2: Laserscan von Mount Rushmore [http://ncptt.nps.gov/]
6.2.4 Vor- und Nachteile
Durch Laserscanning erhält man eine 1:1 Abbildung des Objektes, durch die Liste vonmehreren Millionen 3D-Punkten, eine objektive Dokumentation eines Objektzustandes istgegeben. Ebenfalls spricht die Schnelligkeit von weit über 1000 Messpunkten pro Sekundefür den Laserscanner, dabei wird die Genauigkeit trotzdem extrem hoch gehalten. DesWeiteren ist der Laserscanner unabhängig von Umweltbedingungen, da es sich um einaktives Messverfahren handelt, sind Messung sowohl bei schwierigen Lichtverhältnissenals auch bei absoluter Dunkelheit problemlos möglich. Auch große Reichweiten von 1000Metern sind hierbei kein Problem. Die erhaltenen Messpunkte lassen sich problemlos inAuswertungsprozesse integrieren.
Nachteile des Laserscanners liegen darin, dass sich der Standpunkt während des Scanvor-gangs nicht bewegen darf, außerdem hängt die Qualität des Scans stark von den Reflexions-eigenschaften des Objektes ab. Des Weiteren sind Laserscanner nicht farbfähig, nur über dieStärke des reflektierten Laserlichtes kann eine geringe Farbinformation getroffen werden.An dieser Stelle wird der Laserscanner in einigen Einsatzgebieten oft mit einer Digitalka-mera ergänzt und so kann man den Scan nachträglich einfärben. Auch die unstrukturiertePunktwolke, kann zu aufwendigen Nacharbeiten führen, um markante Punkte oder Struktu-ren abzuleiten.[Ker07]

6.3 PMD Kameras 69
6.3 PMD Kameras
6.3.1 Funktionsweise
PMD-Kameras (Photomischdetektoren, engl. Photonic Mixer Device) basieren auf demLichlaufzeitprinzip. Es handelt sich dabei um einen recht simplen Aufbau, der durchHalbleitersensoren, ohne rechenintensive Algorithmen, direkt zu jedem Bildpunkt Hel-ligkeiten und Entfernungen erfasst. Dazu wird ein Lichtimpuls ausgesendet, dabei nutztman typischerweise infrarotes Licht, aber auch sichtbare Beleuchtungen sind möglich.Der ausgesendete Lichtimpuls wird vom Objekt reflektiert und von der Empfangseinheitwieder aufgenommen. Über die Laufzeit des Lichtimpulses kann die Messstrecke bestimmtwerden.
Abbildung 6.3: Aufbau eines PMD-Systems
Um eine Auflösung von bis zu einem Millimeter zu erreichen, muss die Laufzeit mit einerGenauigkeit von ungefähr 6,6 ps gemessen werden, was bei herkömmlichen Systemennur durch sehr hohen Aufwand möglich war, der dazu führte, dass diese Systeme sehrunflexibel, teuer und nicht echtzeitfähig sind. Bei neuartigen PMD-Kameras wird die bisdahin aufwändige Empfangskette durch in einem Element integriert, dem sogenanntenPMD-Pixel. Diese Pixel werden in einem Array angeordnet, nun wird jedem Pixel auch derEntfernungswert zugeordnet und es entsteht eine digitalisierte 3D-Punktewolke.
PMD-Pixel können in einfachen CMOS-Herstellungsprozessen gefertigt werden und sosind die Herstellungskosten ebenfalls vergleichbar günstig. Neben der reinen Tiefeninfor-mation wird auch der Grauwert des reflektierten Lichtes und der des ausgesendeten Signalesaufgezeichnet. So kann die Qualität der Messung für jedes einzelne Pixel im Nachhinein be-urteilt werden.Je nach Art und Bauweise sind bei PMD-Kameras Reichweite von bis zu 40 Metern möglichund Bildwiederholungsfrequenzen von bis zu 100 fps.[RH06][PH]

70 6 Alternative Sensorsysteme
Abbildung 6.4: Farbcodiertes Entfernungsbild (links) und Grauwertbilddarstellung (rechts)[www.wiley-vch.de]
SBI-Schaltung
Probleme bei Aufnahmen dieser Art sind oft Störungen durch Fremdlichteinfluss und son-dern auch thermische Effekte. Diese werden durch die sogenannte SBI-Schaltung (Hinter-grundlichtunterdrückung, engl. Suppression of Background Illumination) gelöst. Dabei istes möglich direkt im Empfänger die aktive, modulierte Beleuchtung vom übrigens Um-gebungslicht (Fremdlicht, Sonnenlicht) zu unterscheiden. Des Weiteren unterdrückt dieseSchaltung auch durch thermische Effekte generierte Ladungsträger und so kann die 3D-PMD-Kamera nicht nur unter schwierigen Lichtverhältnissen, sondern auch unter schwie-rigen Temperaturbedingungen eingesetzt werden.[RH06]
6.3.2 Anwendungsgebiete
Die PMD-Kamera ist für vielfältige Anwendungsgebiete geeignet:
• Bereichsüberwachung
• Robotersteuerung
• Mensch-Maschine Interaktion
• Multimedia/Gaming
• Automobilindustrie
• Medizintechnik
[RPS09]

6.4 Stereoskopie 71
6.4 Stereoskopie
Bei der Stereoskopie gibt es eine hohe Anzahl an verschiedenen Methoden, im allgemeinengeht es darum, 3-Dimensionale Bilder zu erzeugen, indem man paarweise Bilder getrenntfür jedes Auge erzeugt. Denn unsere Augen haben einen gewissen Abstand zueinander undsehen die "Weltäus einem geringfügig anderem Winkel. Erst im Gehirn werden die beidenEinzelbilder zu eine dreidimensionalen Bild zusammengefügt. So ist auf den paarweisenBildern das gleiche Motiv abgebildet, allerdings sind sie zueinander gering verschoben.Es gibt viele verschiedene Aufnahme und Betrachtungsverfahren in der Stereoskopie, vondenen ich im Folgenden die wichtigsten vorstellen möchte.[But]
6.4.1 Methoden
Shutterverfahren
Bei der Shuttertechnik werden die aufgenommen Halbbilder nacheinander projiziert. Da-bei muss das benutzte Darstellungsgerät, doppelt soviel leisten, zum Beispiel 60 Fps, damitder Nutzer die Szene mit 30 Fps wahrnimmt. Zusätzlich muss der Nutzer eine Shutter-bzw. Blendebrille tragen, diese ist mit LCD-Gläsern bestückt, die durch einen Infrarot-Signalgeber immer abwechselnd abgedunkelt werden, dies passiert in Synchronisation mitdem Projektionssystem. Dadurch sieht das jeweilige Auge immer das richtige Bild. Vorteiledieses Systems sind die hohe Farbtreue, die Bewegungsfreiheit des Kopfes, da man keinegenau Position halten muss, und das keine spezielle Leinwand oder ähnliches nötig sind,sondern ein normaler Computer-Monitor oder ein Fernsehgerät benutzt werden kann. EinNachteil ist der hohe Preis der Brillen.[HD]
Stereobildpaar
Bei Stereobildpaaren werden einfach die beiden Aufnahmen aus den leicht unterschiedli-chen Betrachtungswinkeln gemacht, und anschließend gibt es verschiedene Betrachtungs-arten.Entweder man legt die beiden Bilder direkt nebeneinander und wendet den Kreuzblick bzw.den Parallelblick an.Beim Kreuzblick wird das Bild für das linke Auge auf die rechte Seite gelegt und umge-kehrt, nun konzentriert man sich stark auf die Mitte zwischen den Bilder, bis sich ein drittelBild dazwischen verschärft, auf dem eine Mischung aus beiden zu erkennen ist. Beim Par-allelblick sind die beiden Bilder in der richtigen Reihenfolge und man verschmilzt sie zueinem durch ein entspanntes hindurchschauen.Eine weitere Möglichkeit ist es, eine Prismenbrille zu nutzen (auch KMQ-Technik), die es

72 6 Alternative Sensorsysteme
ermöglicht nebeneinander oder untereinander liegende Bilder zu einem zu verschmelzen,allerdings muss man dabei seinen Kopf dauerhaft waagerecht halte und den richtigen Ab-stand zum Bild nicht verändern.Die einfachste Möglichkeit die beiden Bilder mit dem jeweils richtigen Auge anzuschauen,ist ein sogenannter Stereoskop, bei denen sichergestellt wird, dass man mit dem richtigenAuge auf das richtige Bild schaut (siehe Abbildung 6.5).[HD][Hin]
Abbildung 6.5: Spiegelstereoskop
Anaglyphenverfahren
Beim Anaglyphenverfahren wird das linke und das rechte Bild unterschiedlich eingefärbt.Anschließende werden die beiden Bilder übereinander gedruckt und können durch Brillenmit unterschiedlichen Farbfiltern wieder getrennt werden. So sieht das linke Auge ein Bildund das rechte Auge das andere, das Gehirn vereinigt beide Bilder wieder zu eine räumlichwirkenden Gesamtbild.Nun gibt es verschiedene Varianten wie man die Bilder darstellen kann. Zum Beispiel er-scheinen rote Elemente durch einen grünen Filter betrachtet schwarz und die grünen Ele-mente werden kaum wahrgenommen. Mit grünen Bildelementen durch eine roten Filterpassiert das gleiche nur umgekehrt. Weiße Elemente werden in der jeweiligen Farbe gese-hen und verschmelzen zu weiß bzw. hellgrau.Da das Gehirn nicht nur das Bild sondern auch die Farben fusionieren muss, ist dieses Ver-fahren sehr anstrengend und führte bei den ersten 3D-Filmen in den 50er Jahren oft zuKopfschmerzen.Der Vorteil dieses Verfahrens ist, dass es sehr einfach funktioniert und die Herstellung derBilder und der Filterbrillen sehr kostengünstig ist. Oft entstehen allerdings Schatteneffekteund Geisterbilder, da die Trennung der Teilbilder nicht immer perfekt funktioniert.Bei farbigen Anaglyphenbildern, wirken die Farben oft etwas blasser und die Motivfarbespielt eine große Rolle. Je nach Anwendung gibt es unterschiedliche Filterkombinationen,

6.4 Stereoskopie 73
meistens wird Rot/cyan verwendet.In Abildung 6.6 sehen sie eine typische Anaglyphenaufnahme.[ana]
Abbildung 6.6: 3D-Anaglyphenaufnahme [Wikipedia]
Parallaxbarrieren-/Linsenraster-Technik
Ein Linsenraster-Bild kann ohne optische Hilfsmittel betrachtet werden, statt eines räumli-chen Eindrucks entstehen dadurch auch die sogenannten Wechsel- oder Wackelbilder.Für die Herstellung von solchen Bildern werden mindestens zwei Bilder, im Augenabstandaufgenommen, benötigt. Oft werden aber auch vier oder noch mehr Bilder verwendet, dabeidarf die horizontale Achse von der Kamera nicht verlassen werden und der Kamera-Abstandmuss genau berechnet, aus der Objektentfernung und -größe, der Tiefe des Objektes, derBrennweite des Kameraobjektives, sowie der Linsenrastergröße und dem Abbildungsmaß-stab.Anschließend werden die Fotos in schmalen Streifen auf einen Papierträger gebracht unddarüber wird ein durchsichtiges Raster durch vertikal verlaufende Zylinderlinsen oder -prismen angebracht, sodass sich das Bild je nach Blickwinkel verändert, bzw. ein räumlicherEffekt durch den Abstand zwischen den Augen und dem damit einhergehenden unterschied-lichen Blickwinkel entsteht.Hier besteht auch der Unterschied zur Parallaxbarrieren-Technik, bei dem statt Linsen Sicht-barrieren angebracht werden.Bei Displays werden heutzutage beide Methoden verwendet, so arbeiten 3D-Computermonitore oft mit dem Linsenrasterprinzip. Die Nintendo 3DS dagegen beruht aufdem Parallaxbarrierenprinzip.In der Abbildung 6.7 erkennt man den Unterschied zwischen beiden Verfahren.[Wik13]

74 6 Alternative Sensorsysteme
Abbildung 6.7: Gegenüberstellung von Parallaxenbarrieren- und Linsenrastertechnik [Wi-kipedia]
3D-Polarisationssystem
Beim Polarisationsverfahren werden die Bilder für das linke und das rechte Auge unter-schiedlich polarisiert, was heißt, dass die Lichtwellen-Schwingungen in eine bestimmteRichtung gebracht werden (siehe Abbildung 6.8. Die Richtung der Schwingungen sindanschließend für beide Augen unterschiedlich.
Abbildung 6.8: Prinzip eines linearen Polarisationsfilters [Wikipedia]
Zur Darstellung werden zwei Beamer benutzt, vor deren Linsen werden Polarisationsfiltergesetzt oder aber man nutzt 3D-Geräte, die bereits intern für eine Polarisierung sorgen. Dieentstehenden Bilder werden möglichst exakt übereinander projiziert.Die nötige Leinwand muss metallisch beschichtet sein, damit die zurückgestrahltenSchwingungen ihre Richtung beibehalten, dies würde mit einer normalen weißen Leinwandnicht funktionieren.Die Betrachter tragen Polarisationsfilter-Brillen, die dafür sorgen, dass die beiden Bilder

6.4 Stereoskopie 75
wieder getrennt werden und bei jedem Auge das richtige Bild ankommt, dazu werden diefalsch polarisierten Bilder wieder herausgefiltert.Unterschiede gibt es in der Art der Polarisation, die erste einfachere Variante ist dielineare Polarisation, dabei stehen die unterschiedlichen Schwingungen der Bilder senkrechtzueinander. Nachteil dieser Variante ist, dass sich beim Neigen des Kopfes die Winkel-Ausrichtung ändert, so wird der 3D-Effekt schnell zerstört.Die etwas kompliziertere Variante ist die zirkulare Polarisation, bei der die Lichtwellenzuerst linear polarisiert werden und anschließend durch einen Verzögerungsfilter noch ineine Links- bzw. Rechts-Drehung versetzt werden (siehe Abbildung zirkulare Polarisation[Wikipedia]). Die Trennung der beiden Bilder erfolgt wieder durch die Brille, bei der dieSchwingungen die Filter in umgekehrter Reihenfolge wieder durchlaufen. Vorteil diesesVerfahrens ist, dass man den Kopf beliebig neigen kann.[pol]
Abbildung 6.9: zirkulare Polarisation [Wikipedia]
6.4.2 Anwendungsgebiete
Anwendung findet die Stereoskopie vor allem in der Unterhaltung, so nutzen 3D-Kinosmeistens das Polarisationssystem und 3D-Fernseher das Linsenraster-Prinzip, früherdas Shutterverfahren. Des weiteren können moderne Computerspiele heutzutage auf3D-Monitoren dargestellt werden.Stereoskopische Bilder werden überall verwendet, wo eine 3D-Wirkung erzielt werdensoll, vor allem in der Biologie und Chemie.In der Fahrzeug- und Robotertechnik dienen Stereovideosensoren zur Entfernungsschät-zung und Abstandsmessung.
Stereoskopische Bewegungsmessung (6D-Vision)
Die 6D-Vision wurde von Daimler Forschern entwickelt und dient der Kollisionsvorbeu-gung. Dabei werden mit einem Stereosystem Bilder aufgenommen, anschließend werden

76 6 Alternative Sensorsysteme
die Bildfolgen zeitlich analysiert und man kann prognostizieren wo sich zum Beispiel ge-fährdete Personen in 0,5 Sekunden befinden. Dadurch ist es möglich, Gefahren schneller alsein Mensch zu erkennen und Unfälle zu vermeiden.[6Dv]
Abbildung 6.10: Beispiele für 6D-Vision [www.6d-vision.de]
6.5 Fazit
Die drei vorgestellten Sensorsysteme haben recht unterschiedliche Einsatzzwecke unddamit verbundene Stärken und Schwächen.Der Laserscanner wird hauptsächlich in bautechnischen Bereichen verwendet und zur Auf-nahme von Bilder von statischen Objekten, seine Vorteile liegen in der hohen Genauigkeitund seiner Unabhängigkeit von Umweltbedingungen, auch schlechte Lichtverhältnissebzw. Dunkelheit sind Dank der Lasertechnik kein Problem. Die Entfernungen könnensehr genau bestimmt werden und das bei sehr großen Reichweiten von über 1000 Metern.Allerdings darf sich der Standpunkt des Scanners sowie das Objekt während des Scanvor-gangs nicht bewegen. Für bewegte Bilder ist diese Methode damit absolut ungeeignet. DesWeiteren ist der Laserscanner an sich nicht farbfähig, dies kann nur durch Nacharbeitenmit Bildern einer Digitalkamera geschehen. Die Qualität des Scans hängt stark von denReflexionseigenschaften des Objektes ab.PMD-Kameras funktionieren normalerweise mit infraroten Licht, dabei sind Auflösungenvon bis zu einem Millimeter möglich, die nach dem Lichtlaufzeitsystem berechnet werden.Die früher sehr teure Technik ist inzwischen durch das Integrieren von PMD-Pixeln,die in günstigen CMOS-Herstellungsprozessen gefertigt werden können, sehr günstiggeworden. Neben der Tiefeninformation wird auch der Grauwert des reflektierten Lichtesaufgezeichnet, so kann die Qualität der Pixel im Nachhinein beurteilt werden. Es sindEntfernungen von bis zu 40 Metern und Bildwiederholungsfrequenzen von bis zu 100 fpsmöglich. Durch die SBI-Schaltung werden Störlichter sowie thermische Effekte unterdrücktund die Kamera funktioniert auch unter schwierigen Verhältnissen. Die PMD-Kamerawird vor allem in Gebieten verwendet, in denen bewegte Bilder notwendig sind, sowie zur

6.5 Fazit 77
Bewegungserkennung.Bei der Stereoskopie ist vor allem das Polarisationssystem und das Linsenraster-Prinzip vongroßer Bedeutung, bei 3D-Kinos, 3D-Fernsehern sowie 3D-Monitoren für Computerspiele.Durch hohe Bildwiederholungsfrequenzen und das unterschiedliche Aufnehmen für dieeinzelnen Augen ist ein starker und unterhaltsamer 3D-Effekt möglich. StereoskopischeBilder stellen noch eine Bedeutung in der Biologie und Chemie dar. Stereoskopische Be-wegungsmessung stellt des Weiteren einen wichtigen Punkt in der Kollisionsvorbeugung da.


Literaturverzeichnis
[6Dv] 6D-Vision. http://www.6d-vision.de/home. [Online; accessed29.05.2013].
[AAAA04] A, Jens Overby, Lars Bodum A, Erik Kjems A und Peer M. Ilsøe A: Au-tomatic 3D Building Reconstruction from Airborn Laser Scanning and ca-dastral data using Hough Transform, 2004.
[Ajl08] Ajlani, Ayman: Dreidimensionale Erfassung der beiden Hallen der Fahr-zeugswerk FWW GmBH in Neubrandenburg mit einem 3DLaserscanner-system HDS6000. Doktorarbeit, Hochschule Neubrandenburg, 2008.
[ana] Anaglyphen Verfahren. http://www.perspektrum.de/knowhow/
anaglyphen.htm. [Online; accessed 29.05.2013].
[asu] Asus Xtion. http://images.gizmag.com/hero/wavi-xtion-6.png.
[avi] Github: avin2. https://github.com/avin2/SensorKinect.
[boua] Adafruit-Wettbewerb. http://www.adafruit.com/blog/2010/11/
04/the-open-kinect-project-the-ok-prize-get-1000-bounty-for-kinect-for-xbox-360-open-source-drivers/.
[boub] Adafruit-Wettbewerb Gewinner. http:
//www.adafruit.com/blog/2010/11/10/
we-have-a-winner-open-kinect-drivers-released-winner-will-use-3k-for-more-hacking-plus-an-additional-2k-goes-to-the-eff/.
[Bov03] Bovermann: The Earth Mover’s Distance, 2003.
[bta] Microsoft paper reveals Kinect body tracking algo-rithm. http://www.developerfusion.com/news/116479/
microsoft-paper-reveals-kinect-body-tracking-algorithm/.
[But] Butz, Prof.: Vortragsthema Stereoskopie. http://www.medien.ifi.lmu.de/lehre/ws0809/akf/Stereoskopie.pdf. [Online; accessed29.05.2013].
[cl] Code Laboratories. http://www.codelaboratories.com/.
[cln] CL NUI Platform. http://codelaboratories.com/kb/nui.
79

80 Literaturverzeichnis
[DMKZ+12] Di Marco, Daniel, Andreas Koch, Oliver Zweigle, Kai Haussermann,Bjorn Schiessle, Paul Levi, Dorian Galvez-Lopez, Luis Riazuelo, Javier
Civera, J.M.M. Montiel, Moritz Tenorth, Alexander Perzylo, Markus
Waibel, Rene van de Molengraft et al.: 2012 IEEE International Confe-rence on Robotics and Automation. In: Creating and using RoboEarthobject models, Band 2, Seiten 3549–3550. IEEE, May 2012.
[DPHW05] Ding, Yihong, Xijian Ping, Min Hu und Dan Wang: Range image seg-mentation based on randomized Hough transform. Pattern Recogn. Lett.,26(13):2033–2041, Oktober 2005.
[DWB06] Durrant-Whyte, Hugh und Tim Bailey: Simultaneous Localisation andMapping (SLAM): Part I The Essential Algorithms. IEEE ROBOTICSAND AUTOMATION MAGAZINE, 2:2006, 2006.
[EBN+07] Erol, Ali, George Bebis, Mircea Nicolescu, Richard D Boyle und Xander
Twombly: Vision-based hand pose estimation: A review. Computer Visionand Image Understanding, 108(1):52–73, 2007.
[EEH+11] Engelhard, N., F. Endres, J. Hess, J. Sturm und W. Burgard: Real-time 3Dvisual SLAM with a hand-held camera. In: Proc. of the RGB-D Workshopon 3D Perception in Robotics at the European Robotics Forum, Vasteras,Sweden, April 2011.
[eff] Electronic Frontier Foundation - EFF. http://www.eff.org.
[FB81] Fischler, Martin A und Robert C Bolles: Random sample consensus: aparadigm for model fitting with applications to image analysis and auto-mated cartography. Communications of the ACM, 24(6):381–395, 1981.
[fira] Erste Version von OpenNI. https://github.com/OpenNI/OpenNI/commit/43c256b554dcbe478644be73e29af16b3470f1c1.
[firb] Erster Kinect Hack. http://nuigroup.com/forums/viewthread/
11154/.
[GBK11] Gyou Beom Kim, Trung Kien Nguyen: Design and Development of a Classof Rotorcraft-based UAV. International Journal of Advanced Robotic Sys-tems, 2011.
[Gor08] Gordon, Bianca: Zur Bestimmung von Messunsicherheiten terrestrischerLaserscanner. Doktorarbeit, TU Darmstadt, 2008.
[gra] Grab Detector. http://www.openni.org/files/grab-detector/.
[gst] GST API. http://www.openni.org/files/gst-api/.

Literaturverzeichnis 81
[han] Kinect 3D Hand Tracking. http://cvrlcode.ics.forth.gr/
handtracking/.
[HD] Hochschule Darmstadt, Fachbereich Informatik: Grundlagen der Ste-reoskopie. http://www.fbi.h-da.de/labore/virtual-reality/
basiswissen/stereoskopie.html. [Online; accessed 29.05.2013].
[Hin] Hinrichs, C.F. http://stereoauge.de/. [Online; accessed 29.05.2013].
[hir] RGB Sensor VGA vs. SVGA. https://groups.google.com/forum/?fromgroups#!topic/openkinect/cUfnBNMRAfU.
[Hou62] Hough, Paul: Method and Means for Recognizing Complex Patterns. U.S.Patent 3.069.654, Dezember 1962.
[ige] iGesture3D. http://www.openni.org/files/igesture3d/.
[Ind] Industries, Adafruit: Firmenwebseite. http://www.adafruit.com.
[Jäh05] Jahne, B.: Digitale Bildverarbeitung. Springer, 2005.
[Ker07] Kern, Prof. Dr.-Ing. Fredie: Terrestrisches Laserscanning kurz & bün-dig. http://www.architekturvermessung.de/05-Literatur/doc/laserscanning_fkern.pdf, 2007.
[kina] Kinect for Windows Developer Toolkit. http://www.microsoft.com/en-us/kinectforwindows/develop/developer-downloads.aspx.
[kinb] Kinect SDK EULA. http://www.microsoft.com/en-us/
kinectforwindows/develop/sdk-eula.aspx.
[kinc] Kinect und Xtion. http://3.bp.blogspot.com/-Q-pB7CzbBgQ/
Tm23QaqSryI/AAAAAAAACfA/_UwxBXGkhiw/s1600/xtion-open-03.
jpg.
[kind] Starting February 1, 2012: Use the Power of Kinectfor Windows to Change the World. http://blogs.
msdn.com/b/kinectforwindows/archive/2012/01/09/
kinect-for-windows-commercial-program-announced.aspx.
[kos] Why the Kinect for Windows Sensor Costs $ 249.99. http:
//www.imaginativeuniversal.com/blog/post/2012/02/14/
Why-the-Kinect-for-Windows-Sensor-Costs-2424999.aspx.
[lasa] http://blog.micro-epsilon.de/methoden-der-wegmessung/
laser-scanner/. [Online; accessed 21.05.2013].
[lasb] http://www.laserscanning-europe.com/de/laserscanning/
laserscanner-hardware. [Online; accessed 21.05.2013].

82 Literaturverzeichnis
[lat] The latest Kinect for Windows SDK is here. http://blogs.
msdn.com/b/kinectforwindows/archive/2013/03/18/
the-latest-kinect-for-windows-sdk-is-here.aspx.
[lib] Github: libfreenect/Commit History. https://github.com/
OpenKinect/libfreenect/commits/master.
[Low04] Lowe, David G.: Distinctive Image Features from Scale-Invariant Keypo-ints. Int. J. Comput. Vision, 60(2):91–110, November 2004.
[mar] Marcansoft. http://marcansoft.com/blog/.
[Mic] Microsoft: Microsoft Releases Kinect for Windows SDK Beta for Aca-demics and Enthusiasts. http://www.microsoft.com/en-us/news/press/2011/jun11/06-16MSKinectSDKPR.aspx.
[Mic13a] Microsoft: Accelerometer. Online documentation: http://msdn.microsoft.com/en-us/library/jj663790.aspx, 2013. Stand:20.05.2013.
[Mic13b] Microsoft: Kinect for Microsoft Sensor. Online specifications: http://msdn.microsoft.com/en-us/library/jj131033.aspx, 2013. Stand:20.05.2013.
[mig] OpenNI Migration Guide. http://www.openni.org/
openni-migration-guide/#.Uan6xZy8_IU.
[MTKW02] Montemerlo, M., S. Thrun, D. Koller und B. Wegbreit: FastSLAM: AFactored Solution to the Simultaneous Localization and Mapping Problem.In: Proceedings of the 18th National Conference on Artificial Intelligence(AAAI), Seiten 593–598, July 2002.
[N-213] N-24: Mars-Roboter "Curiosity"bohrt wieder. http://
www.n24.de/n24/Nachrichten/Wissenschaft/d/2879200/
-curiosity--bohrt-wieder.html, 2013.
[N10] 2041, 2005. K. L. Dorit Borrmann, Jan Elseberg und A. Nuchter: A DataStructure for the 3D Hough Transform for Plane Detection. 20110.
[nea] Near Mode: What it is (and isn’t). http://blogs.
msdn.com/b/kinectforwindows/archive/2012/01/20/
near-mode-what-it-is-and-isn-t.aspx.
[Nel11] Nelson, Peter: 3D-Mapping for Robotic Search and Rescue. Seiten 13–14,May 2011.

Literaturverzeichnis 83
[Neu11] Neuhaus, Frank: A Full 2D/3D GraphSLAM System for Globally Consis-tent Mapping based on Manifolds. Diplomarbeit, Universität Koblenz-Landau, September 2011.
[ni2] Github: OpenNI2-FreenectDriver. https://github.com/piedar/
OpenNI2-FreenectDriver.
[nit] Prime Sense. http://www.primesense.com/solutions/
nite-middleware/.
[NLH07] Nuchter, Andreas, Kai Lingemann und Joachim Hertzberg: Cached kdtree search for ICP algorithms. In: 3-D Digital Imaging and Modeling,2007. 3DIM’07. Sixth International Conference on, Seiten 419–426. IEEE,2007.
[NS95] Nischeva, Maria und Dimitar Schischkov: Artificial Intelligence. Integral,1995.
[O.B13] O.Bittel: EKF-SLAM: Synchrone Lokalisierung und Kartenerstellung miteinem erweiterten Kalman-Filter, 2013.
[opea] Github: OpenNI2. https://github.com/OpenNI/OpenNI2.
[opeb] Open Computer Vision - OpenCV. http://opencv.org/.
[opec] OpenKinect History. http://openkinect.org/wiki/History.
[oped] OpenKinect Projekt. http://www.openkinect.org.
[opee] OpenKinect Roadmap. http://openkinect.org/wiki/Roadmap.
[opef] OpenNI. http://www.openni.org/about/.
[opeg] OpenNI 2 is available, uses MS Kinect SDK (drivers) when using Ki-nect sensor. http://social.msdn.microsoft.com/Forums/en-US/kinectsdk/thread/a11ff6d9-7fbe-4636-8ff0-92d6220ac3f8/.
[opeh] Organization. http://www.openni.org/organization/.
[pcl] Point Cloud Library - PCL. http://pointclouds.org/.
[PH] Paintner, Michael und Volker Hauser: 2D/3D - Kamerasys-teme für Fahrerassistenz- und Sicherheitsfunktionen. http:
//spectronet.de/portals/visqua/story_docs/vortraege_
2008/081118_pmd_visionday/081118_03_paintner_ifm.pdf.[Online; accessed 22.05.2013].
[PMW05] Prasser, David, Michael Milford und Gordon Wyeth: Outdoor Simulta-neous Localisation and Mapping using RatSLAM. In: International Con-ference on Field and Service Robots, 2005.
http://social.msdn.microsoft.com/Forums/en-US/kinectsdk/thread/a11ff6d9-7fbe-4636-8ff0-92d6220ac3f8/

84 Literaturverzeichnis
[pol] Polarisations-Verfahren. http://www.3d.de/wiki/
Polarisations-Verfahren. [Online; accessed 29.05.2013].
[Pri] PrimeSense: Firmenwebseite. http://www.primesense.com/.
[RH06] Ringbeck, Dr. Thorsten und Bianca Hagebeuker: Mehrdimensionale Ob-jekterfassung mittels PMD-Sensorik. Sensormagazing, 2006. [Online; ac-cessed 22.05.2013].
[RL01] Rusinkiewicz, Szymon und Marc Levoy: Efficient Variants of the ICP Al-gorithm. 2001.
[RMYZ11] Ren, Zhou, Jingjing Meng, Junsong Yuan und Zhengyou Zhang: Robusthand gesture recognition with kinect sensor. In: Proceedings of the 19thACM international conference on Multimedia, Seiten 759–760. ACM,2011.
[rob] RoboEarth [A Worldwide Web for Robots]. http://www.roboearth.org/.
[RPS09] Ringbeck, Thorsten, Martin Profittlich und Christian Schaller: Kame-ras für die dritte Dimension. Optik & Photonik, 2009.
[RYLL11] Ren, Zhou, Junsong Yuan, Chunyuan Li und Wenyu Liu: Minimum near-convex decomposition for robust shape representation. In: Computer Visi-on (ICCV), 2011 IEEE International Conference on, Seiten 303–310. IE-EE, 2011.
[sen] Depth Sensors Comparison. http://wiki.ipisoft.com/Depth_
Sensors_Comparison.
[SHBS11a] Stowers, J., M. Hayes und A. Bainbridge-Smith: Altitude control of a qua-drotor helicopter using depth map from Microsoft Kinect sensor. In: Me-chatronics (ICM), 2011 IEEE International Conference on, Seiten 358–362, 2011.
[SHBS11b] Stowers, John, Michael Hayes und Andrew Bainbridge-Smith: QuadrotorHelicopter Flight Control Using Hough Transform and Depth Map froma Microsoft Kinect Sensor. In: Proceedings of the IAPR Conference onMachine Vision Applications, Nara, Japan, Seiten 352–356, 2011.
[SK08] Siciliano, B. und O. Khatib (Herausgeber): The Handbook of Robotics.Springer, Berlin, Heidelberg, Germany, 2008.
[SPSS11] Sung, Jaeyong, Colin Ponce, Bart Selman und Ashutosh Saxena: Humanactivity detection from rgbd images. In: AAAI workshop on Pattern, Activityand Intent Recognition (PAIR), Band 2, Seite 7, 2011.

Literaturverzeichnis 85
[SSK+13] Shotton, Jamie, Toby Sharp, Alex Kipman, Andrew Fitzgibbon, Mark Fi-nocchio, Andrew Blake, Mat Cook und Richard Moore: Real-time humanpose recognition in parts from single depth images. Communications of theACM, 56(1):116–124, 2013.
[TM05] Thrun, S. und M. Montemerlo: The GraphSLAM Algorithm With Applica-tions to Large-Scale Mapping of Urban Structures. International Journalon Robotics Research, 25(5/6):403–430, 2005.
[tts] TipTep Skeletonizer. http://tiptep.com/index.php/skeletonizer.
[uVDIUHW] Vermessungsburo Dipl.-Ing. Udo-Heinrich Wenck, Ingenieur und:Laserscanning -Anwendungsgebiete. http://www.ing-wenck.
de/laserscanning/anwendungsgebiete.php. [Online; accessed21.05.2013].
[VdBCDN+11] Bergh, Michael Van den, Daniel Carton, Roderick De Nijs, Nikos
Mitsou, Christian Landsiedel, Kolja Kuehnlenz, Dirk Wollherr, Luc
Van Gool und Martin Buss: Real-time 3D hand gesture interaction with arobot for understanding directions from humans. In: RO-MAN, 2011 IEEE,Seiten 357–362. IEEE, 2011.
[VDR+01] Vosselman, George, Er Dijkman, Key Words Building Reconstruction,Laser Altimetry und Hough Transform: 3D building model reconstructi-on from point clouds and ground plans. Int. Arch. of Photogrammetry andRemote Sensing, Seiten 37–43, 2001.
[WBC+11] Waibel, Markus, Michael Beetz, Javier Civera, Raffaello D’Andrea,Jos Elfring, Dorian Galvez-Lopez, Kai Haussermann, Rob Janssen, JMMMontiel, Alexander Perzylo et al.: Roboearth. Robotics & AutomationMagazine, IEEE, 18(2):69–82, 2011.
[Wie12] Wiese, Tim: Kognitive Perzeption und RGBD. Seminararbeit an der TUMünchen, July 2012.
[Wik13] Wikipedia: Linsenraster-Bild — Wikipedia, Die freie Enzyklopädie, 2013.[Online; Stand 29. Mai 2013].
[WWN11] Wujanz, Daniel, Sven Weisbrich und Frank Neitzel: 3D-Mapping mitdem Microsoft R© Kinect Sensor - erste Untersuchungsergebnisse. 2011.
[XCA11] Xia, Lu, Chia-Chih Chen und JK Aggarwal: Human detection using depthinformation by Kinect. In: Computer Vision and Pattern Recognition Work-shops (CVPRW), 2011 IEEE Computer Society Conference on, Seiten 15–22. IEEE, 2011.

86 Literaturverzeichnis
[XO93] Xu, Lei und Erkki Oja: Randomized Hough transform (RHT): basic me-chanisms, algorithms, and computational complexities. CVGIP: ImageUnderst., 57(2):131–154, März 1993.
[XOK90] Xu, L., E. Oja und P. Kultanen: A new curve detection method: randomizedHough transform (RHT). Pattern Recogn. Lett., 11(5):331–338, Mai 1990.
[xtia] ASUS wird neuen Kinect-Konkurrenten veröf-fentlichen. http://www.pcmasters.de/news/
13373993-asus-wird-neuen-kinect-konkurrenten-veroeffentlichen.
html.
[xtib] ASUS Xtion PRO LIVE Unboxing. http://www.iheartrobotics.com/2011/09/asus-xtion-pro-live-unboxing.html.
[Zha11] Zhang, Ning: Plane Fitting on Airborne Laser Scanning Data Using RAN-SAC. Seite 13, 2011.


















