
Implementação algorítmica de códigos lineares para o canal ......Implementação algorítimica...
61
1 UNIVERSIDADE FEDERAL DE PERNAMBUCO CENTRO DE TECNOLOGIA E GEOCIÊNCIAS DEPARTAMENTO DE ELETRÔNICA E SISTEMAS Implementação algorítmica de códigos lineares para o canal aditivo com dois usuários binários Por Maria de Lourdes Melo Guedes Alcoforado Recife/PE 1999
Transcript of Implementação algorítmica de códigos lineares para o canal ......Implementação algorítimica...

1
UNIVERSIDADE FEDERAL DE PERNAMBUCO CENTRO DE TECNOLOGIA E GEOCIÊNCIAS
DEPARTAMENTO DE ELETRÔNICA E SISTEMAS
Implementação algorítmica de códigos lineares para o canal aditivo com dois
usuários binários
Por
Maria de Lourdes Melo Guedes Alcoforado
Recife/PE 1999

UNIVERSIDADE FEDERAL DE PERNAMBUCO CENTRO DE TECNOLOGIA E GEOCIÊNCIAS
DEPARTAMENTO DE ELETRÔNICA E SISTEMAS
Implementação algorítmica de códigos lineares para o canal aditivo com dois usuários binários
Dissertação submetida à Coordenação do Mestrado em Engenharia Elétrica da Universidade Federal de Pernambuco, para preenchimento parcial dos pré- requisitos para obtenção do Título de Mestre em Engenharia Elétrica.
Autora: Maria de Lourdes Melo Guedes Alcoforado Orientador: Prof. Dr. Valdemar Cardoso da Rocha Jr.
Dezembro de 1999

Implementação algorítimica de códigos lineares para o 2-BAC 3
Ao meu querido Pai, que com sua grandeza me deu força e inspirou.
À minha adorável Mãe, igualmente grande, que me facilita os
caminhos percorridos na vida.

Agradecimentos Na elaboração desta dissertação, dificuldades surgiram, desânimos aconteceram e além do ego, tive as presenças marcantes do Prof. Dr. Valdemar Cardoso da Rocha Jr., de Christian Beurlem, de Francisco e dos meus irmãos e sobrinhos. O primeiro, além de orientador, abriu clarões proporcionando-me fazer reflexões judiciosas e profundas no desenvolvimento desta dissertação, mostrando seus conhecimentos com simplicidade e demonstrando a grande figura humana que é. Christian pacientemente aceitou ouvir exposições, obviamente apresentando críticas bastante construtivas na utilização da linguagem computacional Visual basic. Francisco renunciou horas de lazer que poderíamos ter desfrutado, em prol desta dissertação. Finalmente, cada um dos meus irmãos e sobrinhos, pessoas com quem pude e poderei contar em quaisquer situações.

Implementação algorítimica de códigos lineares para o 2-BAC 5
Resumo Nesta dissertação são abordados sistemas de comunicação de acesso múltiplo, isto é, sistemas consistindo de um único receptor e de mais de um transmissor. Em particular, é dada ênfase ao caso em que dois usuários binários transmitem em um canal aditivo, para um único receptor. Foram construídos vários códigos lineares para este modelo de canal a partir da implementação de um algoritmo proposto na literatura, porém até então não implementado. Este algoritmo fornece, para um dado código linear de um dos usuários, o código (não- linear) de máxima cardinalidade para o outro usuário, especificando o seu dicionário. Para a classe de códigos lineares fortemente ortogonais foi obtida uma expressão analítica para o número total de palavras-código, a partir da decomposição do código original numa seqüência equivalente finita de códigos de repetição concatenados. O conceito de códigos fortemente ortogonais balanceados foi introduzido, e foi verificado através de busca exaustiva para diversos valores dos parâmetros, que estes códigos possuem a mais alta taxa de transmissão atingível com este tipo de construção. .

Índice
1 Introdução ........................................................................................................................ 7
1.1 Canais de acesso múltiplo ......................................................................................... 8 1.2 Canal aditivo com dois usuários binários (2-BAC) .................................................. 8
2 Abordagens para canais de acesso múltiplo................................................................... 10
2.1 O modelo clássico ................................................................................................... 10 2.2 Sistemas de acesso múltiplo.................................................................................... 11 2.3 Acesso aleatório ...................................................................................................... 12
2.3.1 Sistema ALOHA .............................................................................................. 12 2.3.2 Algoritmos de resolução de colisões ................................................................ 13
2.4 Teoria da informação para canais de acesso múltiplo............................................. 15
2.5 Canal aditivo com dois usuários binários................................................................ 18
2.5.1 Decodibilidade única ........................................................................................ 20 2.5.2 Códigos lineares para o 2-BAC........................................................................ 21 2.5.3 Algumas construções de códigos para o 2-BAC .............................................. 23
3 Fundamentos teóricos para a decodibilidade única de códigos lineares no 2-BAC ...... 25
3.1 Códigos binários lineares ........................................................................................ 27 3.2 Códigos binários lineares fortemente ortogonais .................................................... 34
4 Resultados experimentais............................................................................................... 40
4.1 Análise de códigos lineares fortemente ortogonais................................................. 47 4.2 Códigos de bloco lineares repetitivos ..................................................................... 53
5 Conclusões ..................................................................................................................... 57
5.1 Sugestões................................................................................................................. 58

7
1 Introdução A origem da Teoria da Informação data de 1948 quando Claude E. Shannon publicou dois artigos no Bell System Technical Journal, que ele intitulou Teoria Matemática das Comunicações [16][17], desde então muitos outros pesquisadores dedicaram-se a estudar e expandir esta teoria. O modelo clássico de um sistema de comunicações proposto por Shannon representa sistemas de comunicação ponto-a-ponto, isto é, sistemas em que há apenas um remetente enviando informações através de um canal ruidoso para um único destinatário. Existem situações entretanto em que vários remetentes desejam se comunicar com um único destinatário, é o caso por exemplo de várias estações de rádio na Terra, figura 1.1, querendo se comunicar com um único satélite. Este sistema de comunicações é conhecido como sistema de acesso múltiplo.
Figura 1.1: Várias estações de rádio na Terra em comunicação com um único satélite. A Multiplexação no Domínio do Tempo (TDMA) e a Multiplexação no Domínio da Freqüência (FDMA) são soluções tradicionais por divisão de canal, utilizadas para resolver o problema de compartilhamento de canal, porém trazem as desvantagens de se um remetente não tem nada a transmitir os recursos alocados a ele serem desperdiçados [31]. Uma outra classe de esquemas de acesso múltiplo é o de captura de canal, cuja proposta principal é reduzir o tempo de transmissão para valores abaixo dos obtidos por divisão

8 Capítulo 1. Introdução
de canal. Nesta abordagem, o remetente pode usar o canal em sua plena capacidade no instante em que desejar, como se este fosse exclusivamente seu. É o caso do sistema ALOHA projetado por Abramson [18] na Universidade do Hawaii e do algoritmo de pilha projetado por Capetanakis [19], então estudante de doutorado juntamente com o Prof. R. Gallager e, independentemente por dois pesquisadores soviéticos B. Tsybakov e V. Mikhailov [20]. 1.1 Canais de acesso múltiplo
Em 1964 Kautz e Singleton [21] apresentaram um modelo matemático de sistema de transmissão no qual mais de um remetente pode acessá-lo simultaneamente, com a saída deste sendo a soma booleana dos sinais enviados pelos remetentes. Este conceito também é útil em comunicações sobre o canal de acesso múltiplo onde a saída é o ou-lógico dos sinais enviados pelos remetentes. Chien e Frazer [24] introduziram o conceito de superposição de códigos utilizando a adição módulo 2. Estes códigos foram posteriormente considerados por Ericson e Levenshtein [23]. O mecanismo de superposição de maior interesse ao longo desta dissertação é a adição sobre os reais. Este modelo é chamado de canal aditivo com T usuários binários (T-BAC). Será dada ênfase ao caso em que há apenas dois usuários (2-BAC).
Os modelos de transmissão citados acima são chamados, em geral, de canais de acesso mútiplo com T usuários e podemos visualizá-lo como na figura 1.2.
Figura 1.2: Canal de acesso múltiplo com T usuários.
1.2 Canal aditivo com dois usuários binários (2-BAC) No capítulo 2 ,seção 2.5.2, são analisadas as regiões de capacidade para o canal aditivo com dois usuários binários, inclusive nos casos especiais em que ambos os remetentes enviam palavras-código de códigos de blocos lineares, bem como no caso em que apenas um dos
ruído Remetente 1
Remetente 2
Remetente T
Canal de Acesso Múltiplo
X1
X2
XT
f(x)f '(x)
Implementação algorítimica de códigos lineares para o 2-BAC 9
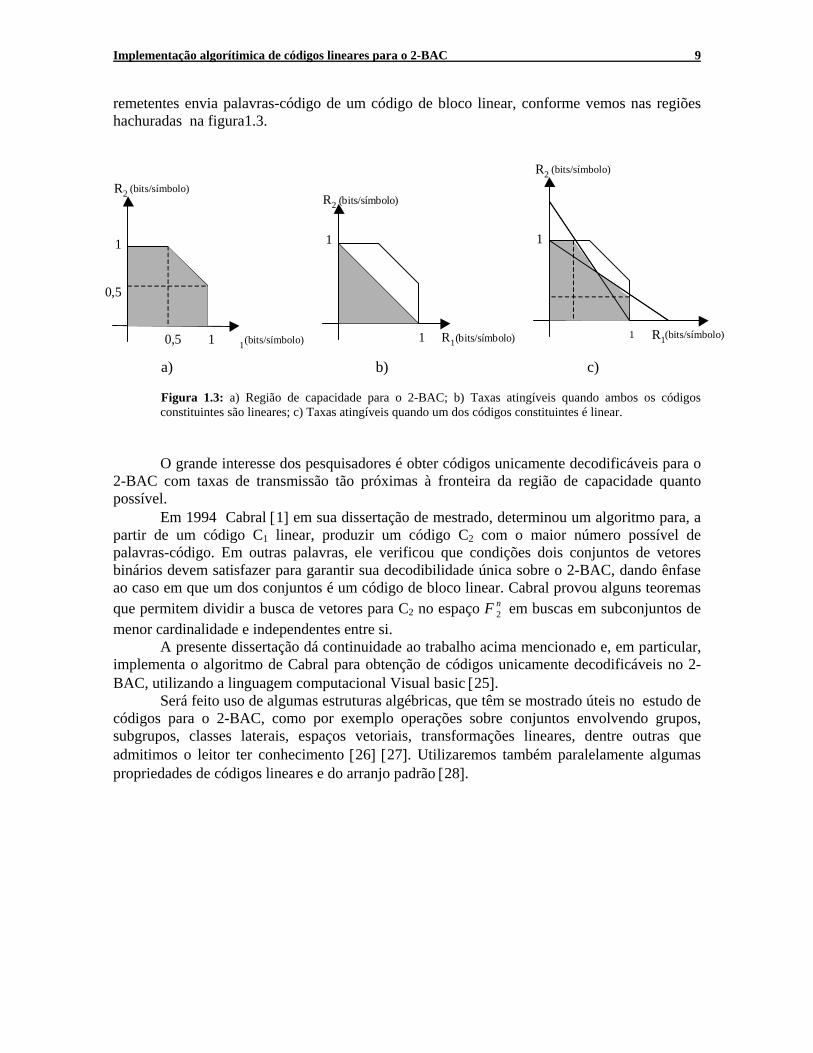
remetentes envia palavras-código de um código de bloco linear, conforme vemos nas regiões hachuradas na figura1.3.
a) b) c) Figura 1.3: a) Região de capacidade para o 2-BAC; b) Taxas atingíveis quando ambos os códigos constituintes são lineares; c) Taxas atingíveis quando um dos códigos constituintes é linear.
O grande interesse dos pesquisadores é obter códigos unicamente decodificáveis para o 2-BAC com taxas de transmissão tão próximas à fronteira da região de capacidade quanto possível. Em 1994 Cabral [1] em sua dissertação de mestrado, determinou um algoritmo para, a partir de um código C1 linear, produzir um código C2 com o maior número possível de palavras-código. Em outras palavras, ele verificou que condições dois conjuntos de vetores binários devem satisfazer para garantir sua decodibilidade única sobre o 2-BAC, dando ênfase ao caso em que um dos conjuntos é um código de bloco linear. Cabral provou alguns teoremas que permitem dividir a busca de vetores para C2 no espaço F n
2 em buscas em subconjuntos de menor cardinalidade e independentes entre si. A presente dissertação dá continuidade ao trabalho acima mencionado e, em particular, implementa o algoritmo de Cabral para obtenção de códigos unicamente decodificáveis no 2-BAC, utilizando a linguagem computacional Visual basic [25]. Será feito uso de algumas estruturas algébricas, que têm se mostrado úteis no estudo de códigos para o 2-BAC, como por exemplo operações sobre conjuntos envolvendo grupos, subgrupos, classes laterais, espaços vetoriais, transformações lineares, dentre outras que admitimos o leitor ter conhecimento [26] [27]. Utilizaremos também paralelamente algumas propriedades de códigos lineares e do arranjo padrão [28].
1
1 R1(bits/símbolo)
R2 (bits/símbolo)
1
0,5
0,5 1 1(bits/símbolo)
R2 (bits/símbolo)
1
1 R1(bits/símbolo)
R2 (bits/símbolo)

10
2 Abordagens para canais de acesso múltiplo
2.1 O modelo clássico
Os sistemas representados pelo modelo clássico [16] consideram que há apenas um remetente querendo se comunicar, através de um canal ruidoso, com apenas um receptor. Shannon mostrou que, apesar da presença de ruído, o canal permitia a transmissão das seqüências de símbolos com uma probabilidade de erro tão pequena quanto se queira, desde que se escolhesse seqüências convenientemente e que a taxa de transmissão não ultrapassasse um determinado valor dependente apenas do canal, denominado na ocasião por ele de capacidade do canal. Este modelo de sistema de comunicações constitui-se das seguintes partes principais: Fonte de informação: É a produtora de mensagens e pode ser uma pessoa ou uma máquina. Pode ser uma forma de onda contínua ou uma seqüência de símbolos discretos. Codificador de fonte: Transforma a saída da fonte em uma seqüência de símbolos usualmente binários, chamados de seqüência de informação u. Codificador de canal: Transforma a seqüência de informação u em uma seqüência codificada discreta v chamada palavra-código. Na maioria das vezes v é também uma seqüência binária. Modulador: Transforma cada símbolo de saída do codificador de canal em uma forma de onda de duração T segundos. Canal: Meio através do qual trafegam as ondas portadoras das informações geradas pela fonte para o destinatário final. Nele está incluído uma fonte de ruído aleatório que afeta o sinal durante a transmissão. Demodulador: Processa cada forma de onda recebida de duração T segundos e produz uma saída que pode ser discreta ou contínua. A saída do demodulador é a seqüência recebida r.

Implementação algorítimica de códigos lineares para o 2-BAC 11
Decodificador de canal: Transforma a seqüência recebida r em uma seqüência binária û, chamada seqüência estimada. Decodificador de fonte: Transforma a seqüência estimada û na saída estimada da fonte. Destinatário: É a quem a mensagem é enviada. Ruído: São todas as manifestações elétricas aleatórias e imprevisíveis de causas naturais, impossíveis de se eliminar de qualquer sistema de comunicações. Podemos visualizar este modelo de sistema de comunicações através da figura 2.1:
Figura 2.1: Diagrama de blocos do modelo clássico de um sistema de comunicações.
2.2 Sistemas de acesso múltiplo
Apesar do modelo clássico de um sistema de comunicações abranger um grande número de situações reais, um modelo de comunicações de interesse prático é aquele em que vários remetentes desejam se comunicar com um mesmo destinatário pelo uso simultâneo de um mesmo canal de comunicações [1][2]. Multiplexação no Domínio do Tempo (TDMA) e Multiplexação no Domínio da Frequência (FDMA) são esquemas de acesso múltiplo por divisão de canal [31]; isto é, eles dividem um único canal em muitos canais menores, um para cada remetente. Estas divisões podem ser fixas, ou elas podem ser ajustadas de acordo com as necessidades de cada remetente. É como se existissem na realidade n canais distintos, onde n é o número total de subdivisões do canal original. Cada canal neste caso pode ser estudado pelo modelo clássico ponto-a-ponto de
u
v
Fonte Codificador
de Fonte Codificador
de Canal
Modulador
Destinatário
Decodificadorde fonte
Decodificadorde Canal
Demodulador
Canal ruído
r
û

12 Capítulo 2. Abordagens para canais de acesso múltiplo
Shannon, descrito acima. A desvantagem destes esquemas é que se um usuário não tem nada a transmitir, os recursos alocados a ele são desperdiçados. Uma segunda classe de esquemas de acesso múltiplo é a chamada captura de canal, na qual o remetente pode usar o canal em sua plena capacidade no instante em que desejar, como se este fosse exclusivamente seu. 2.3 Acesso aleatório
A técnica de acesso aleatório [2] pode ser definida como um esquema de acesso múltiplo do tipo captura de canal, no qual pode acontecer de dois ou mais remetentes tentarem utilizar o canal ao mesmo tempo. A proposta do acesso aleatório é reduzir o tempo entre o momento em que o remetente envia a informação e o momento em que ele consegue transmitir esta informação com sucesso através do canal. 2.3.1 Sistema ALOHA
Este sistema [2][3], projetado por Abramson e alguns colegas da Universidade do Hawaii, foi o primeiro sistema de acesso aleatório que se tem conhecimento. No sistema ALOHA os dados a serem transmitidos são agrupados em forma de pacotes de mesmo comprimento. Podemos ter um grande número de fontes de informação idênticas, cada uma com um remetente associado, gerando novas mensagens durante determinados intervalos de tempo, através de uma variável de Poisson com média λ (pacotes/ intervalo de tempo). Abramsom assumiu que um pacote é transmitido com sucesso se ele não se superpõe (parcialmente ou completamente) a nenhum outro pacote. Além disto, imediatamente após a transmissão do pacote o remetente é informado através de um canal de realimentação se houve ou não sucesso na transmissão. Havendo superposição estes pacotes são retransmitidos também seguindo uma variável aleatória de Poisson com média λr (pacotes/ intervalo de tempo). Portanto, o número total de pacotes transmitidos por intervalo de tempo é λt = λr + λ .
A probabilidade de um pacote ser recebido com sucesso é a probabilidade deste não ser transmitido em dois intervalos de tempo: o intervalo em que foi iniciada a transmissão de um outro pacote e o intervalo em que houve fim na transmissão de algum outro pacote. Desta forma, os pacotes recebidos com sucesso têm uma taxa de saída de τ = λt exp(-2λt) (pacotes/ intervalo de tempo). Podemos verificar que este valor é máximo quando λt = ½ (pacote/ intervalo de tempo) e portanto τ ≈ 0,184 (pacotes/intervalo de tempo).
Roberts [29] verificou que esta taxa de transmissão poderia ser dobrada se o tempo de transmissão de cada pacote fosse um múltiplo inteiro de um intervalo de tempo. Surgiu então o sistema ALOHA particionado no tempo. Desta forma temos que a taxa de saída com sucesso no receptor é a fração do intervalo de tempo no qual exatamente um pacote é transmitido, τ = λtexp(-λt) (pacotes/ intervalo de tempo). O máximo valor desta taxa de saída “τ” ocorrerá
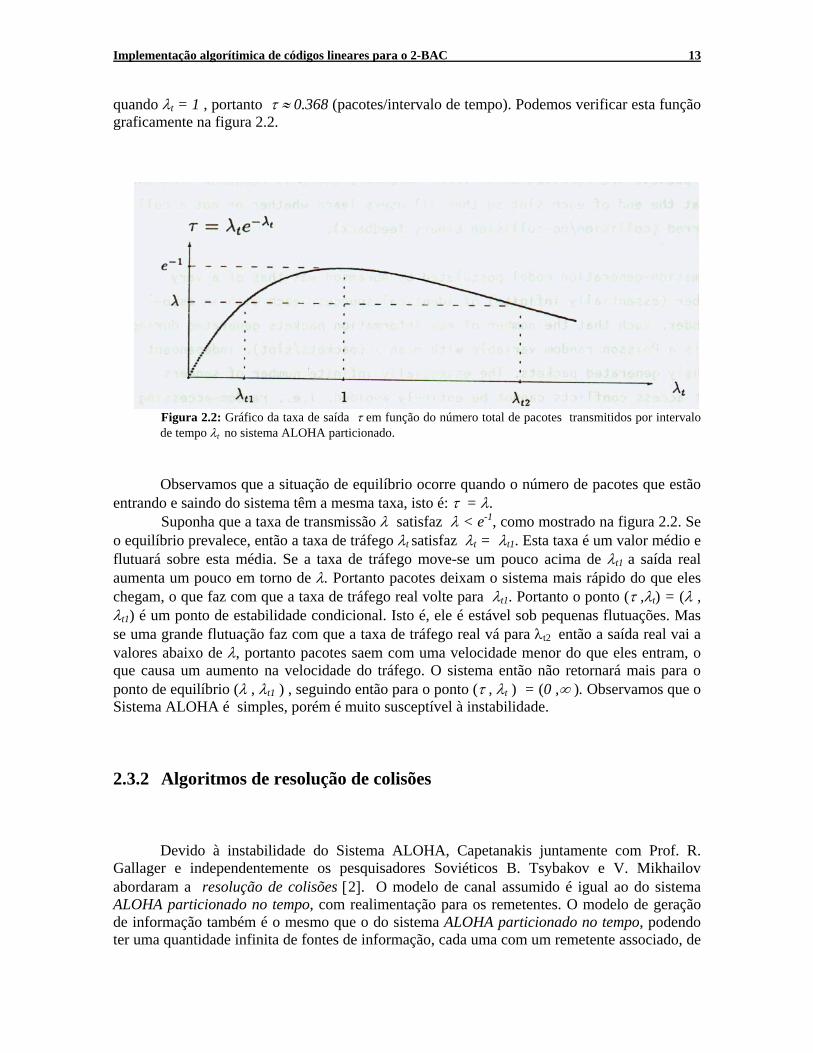
Implementação algorítimica de códigos lineares para o 2-BAC 13
quando λt = 1 , portanto τ ≈ 0.368 (pacotes/intervalo de tempo). Podemos verificar esta função graficamente na figura 2.2.
Figura 2.2: Gráfico da taxa de saída τ em função do número total de pacotes transmitidos por intervalo de tempo λt no sistema ALOHA particionado.
Observamos que a situação de equilíbrio ocorre quando o número de pacotes que estão entrando e saindo do sistema têm a mesma taxa, isto é: τ = λ.
Suponha que a taxa de transmissão λ satisfaz λ < e-1, como mostrado na figura 2.2. Se o equilíbrio prevalece, então a taxa de tráfego λt satisfaz λt = λt1. Esta taxa é um valor médio e flutuará sobre esta média. Se a taxa de tráfego move-se um pouco acima de λt1 a saída real aumenta um pouco em torno de λ. Portanto pacotes deixam o sistema mais rápido do que eles chegam, o que faz com que a taxa de tráfego real volte para λt1. Portanto o ponto (τ ,λt) = (λ , λt1) é um ponto de estabilidade condicional. Isto é, ele é estável sob pequenas flutuações. Mas se uma grande flutuação faz com que a taxa de tráfego real vá para λt2 então a saída real vai a valores abaixo de λ, portanto pacotes saem com uma velocidade menor do que eles entram, o que causa um aumento na velocidade do tráfego. O sistema então não retornará mais para o ponto de equilíbrio (λ , λt1 ) , seguindo então para o ponto (τ , λt ) = (0 ,∞ ). Observamos que o Sistema ALOHA é simples, porém é muito susceptível à instabilidade. 2.3.2 Algoritmos de resolução de colisões Devido à instabilidade do Sistema ALOHA, Capetanakis juntamente com Prof. R. Gallager e independentemente os pesquisadores Soviéticos B. Tsybakov e V. Mikhailov abordaram a resolução de colisões [2]. O modelo de canal assumido é igual ao do sistema ALOHA particionado no tempo, com realimentação para os remetentes. O modelo de geração de informação também é o mesmo que o do sistema ALOHA particionado no tempo, podendo ter uma quantidade infinita de fontes de informação, cada uma com um remetente associado, de

14 Capítulo 2. Abordagens para canais de acesso múltiplo
modo que o número de pacotes gerados em cada intervalo de tempo é uma variável aleatória de Poisson com média λ. Neste protocolo, algum tempo depois de enviados os pacotes, todos os remententes simultaneamente saberão se o seu pacote envolvido na colisão foi recebido com sucesso. Citamos como exemplo o algoritmo de pilha, Figura 2.3, que é simples de implementar. Quando envolvido em uma colisão, um remetente necessita apenas gerar uma variável aleatória binária (“0”ou “1”). Suponha que a saída da pilha está vazia (S = 0), que a porta de acesso está aberta e que um número “X” de remetentes enviam pacotes num determinado intervalo de tempo. Assumimos então que houve colisão (“C”) no intervalo de tempo considerado. Se o valor gerado pelo remetente é “0” então ele permanece na caixa de envio ; Isto significa que ele novamente vai transmitir no próximo intervalo de tempo; Caso contrário o pacote vai para o nível “1”da pilha. Agora S = 1. A regra geral é: Se “C”, então S ← S + 1, vemos portanto que cerca de X/2 dos remetentes colididos retornarão para a caixa de envio enquanto o restante irá para a pilha. Nós assumimos que a porta de acesso permanece fechada no momento da colisão inicial até que os remetentes tenham a informação de que todos os pacotes foram transmitidos com sucesso. Este processo ocorre até que nenhuma colisão mais ocorra (“NC”), o que significa que apenas “1” ou nenhum remetente está na caixa de envio. O remetente que estava no nível “1” da pilha então volta para a caixa de envio e a pilha é reduzida de 1. A regra geral é: Se “NC” e S > 0, então S ← S - 1, o processo então continua até que S = 0. Neste momento a colisão está resolvida.
Figura 2.3 : Algoritmo de pilha.
Seja Y o número de intervalos de tempo necessários para resolver a colisão inicial de X
remetentes. Uma grandeza de grande interesse é LN = E [ Y / X = N ], o número médio de intervalos de tempo necessários para resolver a colisão de “N” transmissores. Verificamos que L0 = L1 = 1, pois não existe colisão inicial. Podemos verificar também que:
L2 = 1 + ½ (L0 + L2) + ½ (L1 + L1 ) A probabilidade dos dois usuários permanecerem na caixa de envio é considerada ½ e a
probabilidade de um permanecer na caixa de envio e um ir para nível 1 da pilha também é ½. Resolvendo para L2 temos L2 = 5.
Caixa de envio Porta de
acesso
Nível 1
Nível 2
Nível S
S
“C” e “0”
“C” e “1” “NC”
“C”
“NC”
Remetente
Pilha
Contador dos níveis da pilha

Implementação algorítimica de códigos lineares para o 2-BAC 15
De uma maneira geral a solução satisfaz :
2,8810 < LN/ N + 1/N < 2,8867, N ≥ 4 Isto significa que cerca de 2,89 intervalos de tempo serão requeridos para “servir” a
cada um dos pacotes envolvidos em uma colisão. Isto significa que o algoritmo será estável apenas se:
λ ≤ 1 / 2.8867 ≈ 0.346 ( pacotes/ intervalo de tempo) Podemos também citar o caso em que ao invés de apenas dois valores aleatórios
“0”ou “1” o remetente possa gerar três valores aleatórios. A máxima saída estável neste caso terá valor λ = 0.401 ( pacotes/ intervalo de tempo). 2.4 Teoria da informação para canais de acesso múltiplo
Podemos definir formalmente canal de acesso múltiplo [1][9][13] como um modelo matemático de transmissão no qual mais de um remetente pode acessá-lo simultaneamente, com a saída deste canal sendo uma combinação dos sinais enviados pelos remetentes como mostrado na figura 2.4. Figura 2.4: Sistema de comunicação de acesso múltiplo.
Exemplos de situações deste tipo são a transmissão de vários canais de voz através de um único cabo coaxial em uma rede telefônica, a transmissão de vários programas de televisão via satélite e a troca de mensagens e informações entre um computador central e seus vários terminais em uma rede de computadores. Diversas funções de combinação f(x) já foram estudadas para este modelo de canal, sendo a mais comum a que considera o canal real aditivo, no qual as entradas são números reais e a saída é a soma real destes números, isto é f(x) = Σi xi . O canal XOR ( adição mod 2)
utiliza a função f(x) =Σi xi na qual as entradas são símbolos binários e a saída é a soma (mod2)
ruído Remetente 1
Remetente 2
Remetente N
Canal de Acesso Múltiplo
X1
X2
XN
f(x) f '(x)

16 Capítulo 2. Abordagens para canais de acesso múltiplo
destes símbolos. O canal AND utiliza a função f(x) = Πi xi com as entradas como símbolos binários e a saída como produto sobre F2. Podemos visualizar algumas funções de combinação na figura 2.5.
Figura 2.5: Algumas funções de combinação utilizadas em sistemas de acesso múltiplo. Um determinado tipo de canal que será de grande interesse nosso é o canal de acesso múltiplo com dois usuários [2][5][6][8][13][14], ilustrado na figura 2.6. Figura 2.6: Canal de acesso múltiplo com dois usuários.
Em cada unidade de tempo, a fonte 1 envia símbolos xi pertencentes a um determinado alfabeto X e a fonte 2 envia símbolos wi pertencentes a um determinado alfabeto W. A saída do canal, dada através de uma determinada função de combinação dos símbolos de entrada, é representada pelos símbolos yi pertencentes a um determinado alfabeto de saída Y .
Definimos os vetores x = (x1, .........., xn) e w = (w1, .........., wn) como as entradas dos remetentes 1 e 2 respectivamente e y = (y1, .........., yn) como a saída do canal. Como o canal é de tempo discreto e sem memória, com entradas e saídas pertencentes a alfabetos também discretos, temos que a probabilidade condicional P(y|xw) representando a matriz de transição do canal é:
P(y|xw) = Πi P(yi|xiwi)
Canal de colisão
f(x) = xi, se só 1 usuário transmitir f(x) =c(colisão) se 2 ou mais transmitirem
Canais de acesso múltiplo com Entrada- Saída Discretas
Canal Real Aditivo
f(x) = xii∑
soma sobre os reais
Canal XOR (adição mod2)
f(x) = xii∑
com soma sobre F2
Canal AND (multiplicativo)
f(x)= xii∏
com produto sobre os reais
Canal OR pulso on-off
f(x) = ∨ xi onde ∨ é a operação ou-lógico
codificador 1
codificador 2
Canal P(y|xw) decodificador
fonte 1
fonte 2
(x1,...........xn)
(w1,...........wn)
(y1,...........yn)
Implementação algorítimica de códigos lineares para o 2-BAC 17
Representamos por (C1,C2) um código de comprimento n para dois remetentes, onde o código constituinte C1 tem M palavras { x1, x2 .........., xM } e o código constituinte C2 tem L palavras {w1, w2 .........., wL }.
A taxa conjunta R do código (C1,C2) é dada por:
R = R1 + R2 = nM )(ln
+ nL)(ln
Um importante resultado acerca destes canais é o teorema provado por Ahlswede e
Liao[13], enunciado a seguir. Teorema 2.1: As taxas de transmissão possíveis R para o tipo de canal representado acima é a região convexa sobre o conjunto dos pares das taxas de transmissão (R1 ,R2) satisfazendo as seguintes desigualdades :
R1 + R2 ≤ I( XW ;Y ) 0 ≤ R1 ≤ I (X ; Y|W) 0≤ R2 ≤ I (W; Y|X)
onde I(A;B) denota a informação mútua e I(A;B|C) denota a informação mútua condicionada entre as variáveis A, B e C.
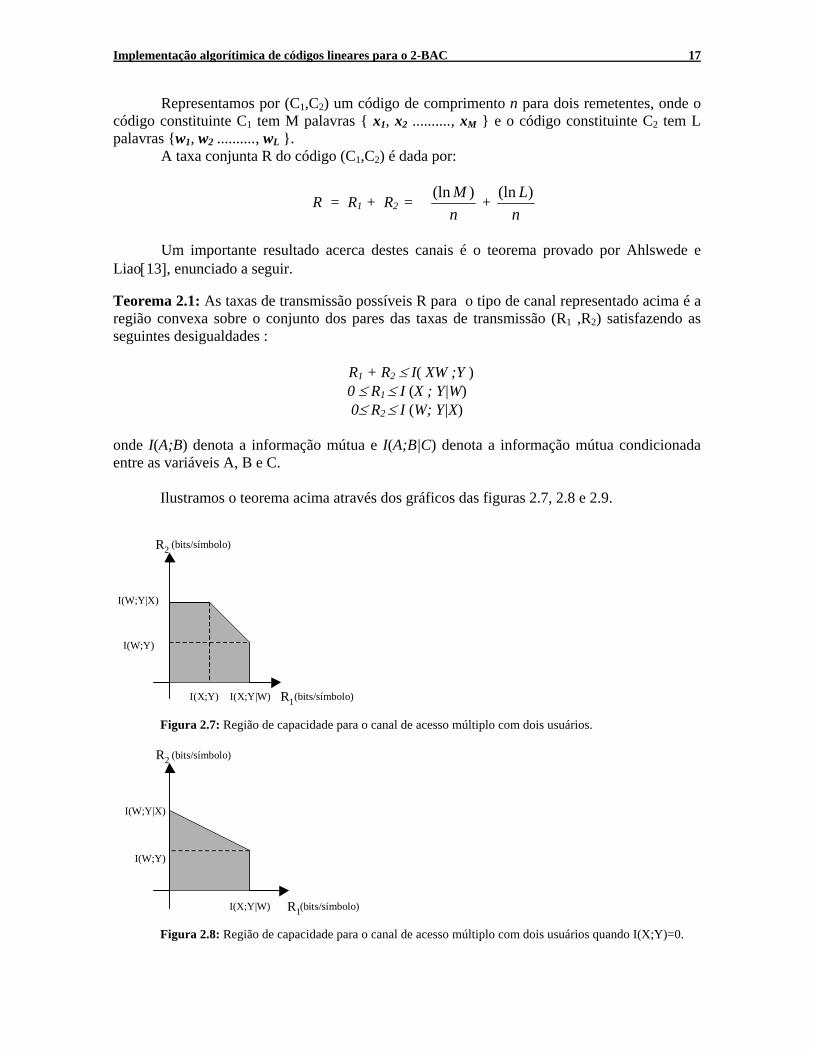
Ilustramos o teorema acima através dos gráficos das figuras 2.7, 2.8 e 2.9.
Figura 2.7: Região de capacidade para o canal de acesso múltiplo com dois usuários.
Figura 2.8: Região de capacidade para o canal de acesso múltiplo com dois usuários quando I(X;Y)=0.
I(W;Y|X)
I(W;Y)
I(X;Y|W) R1(bits/símbolo)
R2 (bits/símbolo)
I(W;Y|X)
I(W;Y)
I(X;Y) I(X;Y|W) R1(bits/símbolo)
R2 (bits/símbolo)

18 Capítulo 2. Abordagens para canais de acesso múltiplo
Figura 2.9: Região de Capacidade para o canal de acesso múltiplo com dois usuários quando I(X;Y) = I(X;Y|W).
2.5 Canal aditivo com dois usuários binários
O mais simples canal de acesso múltiplo é o canal aditivo com dois usuários binários (2-BAC) [1][2][5][6][7][8] mostrado na figura 2.10. Figura 2.10: Canal aditivo com dois usuários binários. Neste sistema dois remetentes geograficamente separados tentam enviar dados binários através de um mesmo canal de comunicações. A função de combinação utilizada neste canal é a soma sobre os reais. Desta forma cada remetente tem como alfabeto de entrada o conjunto F2 = {0,1}. A entrada do canal consiste de duplas binárias xi , wi e a saída yi = xi +wi , será símbolos do alfabeto {0, 1, 2}. O remetente 1 envia palavras-código de um código de bloco C1; o remetente 2 envia palavras-código de um código de bloco C2. Consideramos que: • Os dois remetentes estão na mesma freqüência. • Os dois remetentes transmitem ao mesmo tempo. • Os dois remetentes utilizam códigos binários de mesmo comprimento n. • É mantido sincronismo na transmissão dos símbolos das palavras. • Existe um único decodificador. • Os dois usuários escolhem independentemente as respectivas palavras-código a serem
transmitidas.
codificador 1
codificador 2
Canal aditivo com dois
usuários bináriosdecodificador
fonte 1
fonte 2
(x1,...........xn)
(w1,...........wn)
(y1,...........yn)
I(W;Y)
I(X;Y) R1(bits/símbolo)
R2 (bits/símbolo)
Implementação algorítimica de códigos lineares para o 2-BAC 19
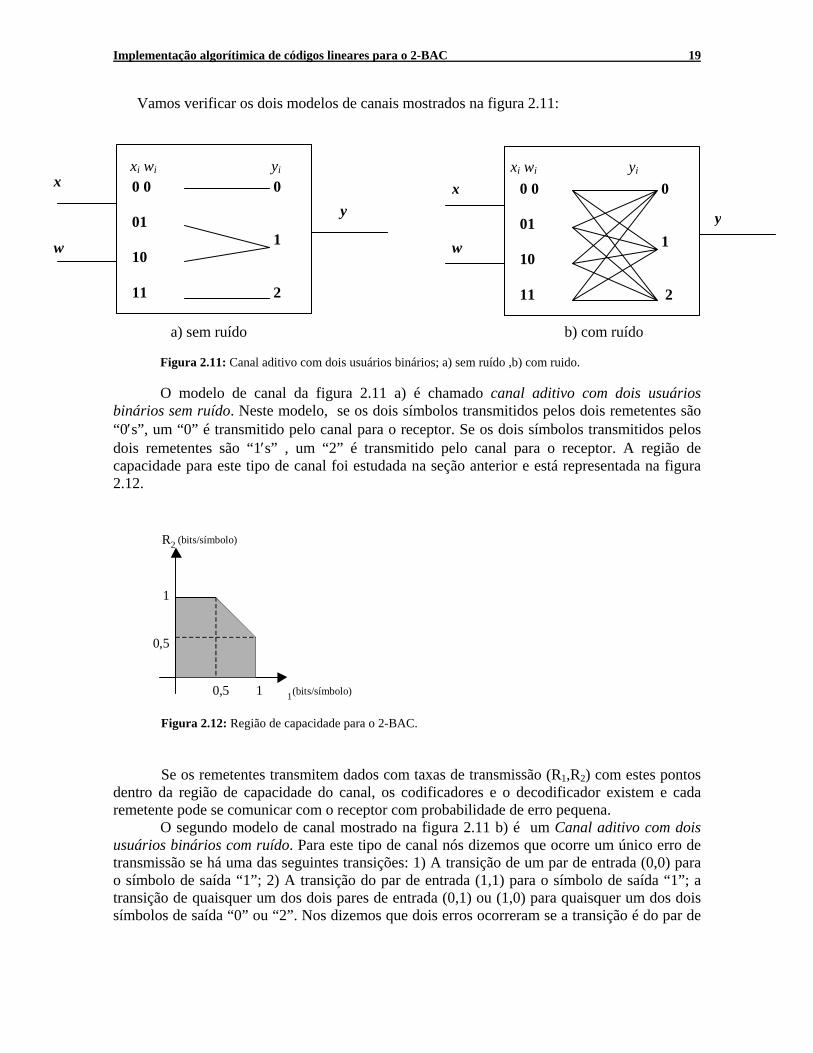
Vamos verificar os dois modelos de canais mostrados na figura 2.11:
a) sem ruído b) com ruído
Figura 2.11: Canal aditivo com dois usuários binários; a) sem ruído ,b) com ruido.
O modelo de canal da figura 2.11 a) é chamado canal aditivo com dois usuários
binários sem ruído. Neste modelo, se os dois símbolos transmitidos pelos dois remetentes são “0′s”, um “0” é transmitido pelo canal para o receptor. Se os dois símbolos transmitidos pelos dois remetentes são “1′s” , um “2” é transmitido pelo canal para o receptor. A região de capacidade para este tipo de canal foi estudada na seção anterior e está representada na figura 2.12.
Figura 2.12: Região de capacidade para o 2-BAC. Se os remetentes transmitem dados com taxas de transmissão (R1,R2) com estes pontos
dentro da região de capacidade do canal, os codificadores e o decodificador existem e cada remetente pode se comunicar com o receptor com probabilidade de erro pequena.
O segundo modelo de canal mostrado na figura 2.11 b) é um Canal aditivo com dois usuários binários com ruído. Para este tipo de canal nós dizemos que ocorre um único erro de transmissão se há uma das seguintes transições: 1) A transição de um par de entrada (0,0) para o símbolo de saída “1”; 2) A transição do par de entrada (1,1) para o símbolo de saída “1”; a transição de quaisquer um dos dois pares de entrada (0,1) ou (1,0) para quaisquer um dos dois símbolos de saída “0” ou “2”. Nos dizemos que dois erros ocorreram se a transição é do par de
0 0 0 01 1 10 11 2
0 0 0 01 1 10 11 2
x
w
yx
w
y
xi wi yi xi wi yi
1
0,5
0,5 1 1(bits/símbolo)
R2 (bits/símbolo)

20 Capítulo 2. Abordagens para canais de acesso múltiplo
entrada (0,0) para o símbolo de saída “2” ou do par de entrada (1,1) para o símbolo de saída “0”. Para ambos os modelos de canal considerados acima, as duas palavras-código transmitidas pelos dois codificadores são combinadas em um único vetor y com símbolos do alfabeto {0,1,2}. Ao término da recepção o vetor y recebido será decodificado em duas palavras-código C1 e C2.
Sejam M e L o número de palavras-código no código C1 e o número de palavras-código no código C2, respectivamente.Seja n o comprimento de ambos os códigos. Então as taxas de transmissão para C1 e C2 são respectivamente:
R1 = nM )(ln
R2 = nL)(ln
2.5.1 Decodibilidade única Nosso interesse no canal aditivo com dois usuários binários é construir um par de códigos C1 e C2 de modo que: 1) O decodificador seja capaz de decodificar o vetor y recebido, sem ambigüidade nas duas palavras-código que foram transmitidas pelos remetentes “1” e “2”. Isto é, se para quaisquer x1 , x2 ∈ C1 e w1 , w2 ∈ C2 tais que x1 ≠ x2 e w1 ≠ w2 então x1 + w1 ≠ x2 + w2. 2) As taxas de transmissão (R1,R2) de C1 e C2 respectivamente estejam em um ponto dentro da região de capacidade e tão próximas à fronteira quanto possível.
Um par de códigos (C1,C2) que possui a propriedade 1) acima é dito ser unicamente decodificável.
Exemplo2.1 Para n = 2, é possível construir um par unicamente decodificável com C1 = {00,11 } e C2 =
{00, 01, 10 }. A taxa de transmissão para C1 e C2 é ( 2
2log,
23log
), que é um ponto dentro da
região de capacidade (figura 2.12). As possíveis saídas para o 2-BAC sem ruído são:
C1 00 11 00 00 11 C2 01 01 02 10 10 21
Figura 2.13: Saídas possíveis do 2-BAC quando C1= {00,11} e C2 = {00, 01, 10}.
Onde a primeira linha representa as palavras-código de C1 , a primeira coluna
representa as palavras-código de C2 e as saídas são as somas símbolo a símbolo nos reais das linhas com as colunas.

Implementação algorítimica de códigos lineares para o 2-BAC 21
Observando a tabela da figura 2.13 verificamos que o vetor y pode ser decodificado sem ambigüidade em duas palavras-código, uma em C1 e a outra em C2 .
Este código, que será de grande interesse no capítulo 4, pode ser generalizado para n>2, simplesmente tomando C1 como {0n1n } onde 0n(1n) representa a n-upla binária com todos os elementos 0(1) e C2 como o conjunto de todas as n-uplas binárias com exceção de 1n. As taxas de transmissão de C1 e C2 são respectivamente,
R1 = n
2log e R2 =
log( )2 1n
n−
portanto a taxa conjunta para este código será:
R = R1 + R2 = n
n 1)12log( +− que tende para 1, quando n → ∞
2.5.2 Códigos lineares para o 2-BAC
Vamos analisar o comportamento das taxas de transmissão quando ambos os códigos constituintes C1 e C2 são lineares e quando apenas um dos dois códigos constituintes é linear. Quando C1 e C2 forem códigos binários lineares com parâmetros (n,k1) e (n,k2) respectivamente, para que (C1,C2) seja unicamente decodificável é preciso que eles não tenham mais de uma palavra-código em comum. Para que isto ocorra temos que: k1+ k2 ≤ n [1] e portanto,
R = R1 + R2 = n
MM 21 loglog +=
nkk 21 + ≤ 1
onde, Mi é o número de palavras-código de Ci . Desta forma vemos que a taxa de transmissão conjunta R não poderá ultrapassar 1 . Como mostra o gráfico da figura 2.14
Figura 2.14: Taxas atingíveis quando ambos os códigos constituintes são lineares. Outro caso de interesse é o que apenas um dos códigos constituintes é linear.
1
1 R1(bits/símbolo)
R2 (bits/símbolo)
22 Capítulo 2. Abordagens para canais de acesso múltiplo
Definição 2.1: Um código (C1,C2) de comprimento n para o 2-BAC é dito ser um código linear se um dos códigos constituintes for um código linear de parâmetros (n,k). Códigos lineares para o 2-BAC possuem a desvantagem de não atingirem a capacidade
quando o código constituinte linear tiver taxa menor que 3log
)13(log −, como decorre do teorema
abaixo provado por Weldon Jr [1][14]. Teorema 2.2: Seja C1 um código constituinte linear com parâmetros (n,k1) então a região de capacidade para um par (C1,C2) unicamente decodificável é limitada superiormente por: (R1,R2) ≤ ( k1/n , ( 1-k1/n )log3 ). Demonstração: Como o código C1 é linear podemos listar todas as suas palavras-código uma abaixo da outra e formarmos uma matriz com a propriedade que as k1 primeiras colunas listem todas as 2k1 k1-uplas possíveis. Para cada palavra-código enviada por C2 teremos portanto uma em C1 de modo que os k1 primeiros símbolos sejam complemento das palavras de C2 e portanto teremos M2 palavras-código de saída com os k1 primeiros símbolos todos 1. As outras ( n- k1) posições poderão ter os símbolos {0, 1, 2}. Portanto C2 poderá Ter no máximo 3n-k1 palavras-código, ou seja
M2 ≤ 3n-k1 e R2 ≤ log3 1n k
n
−
= (1- kn
1 )log3
concluindo a prova do teorema.
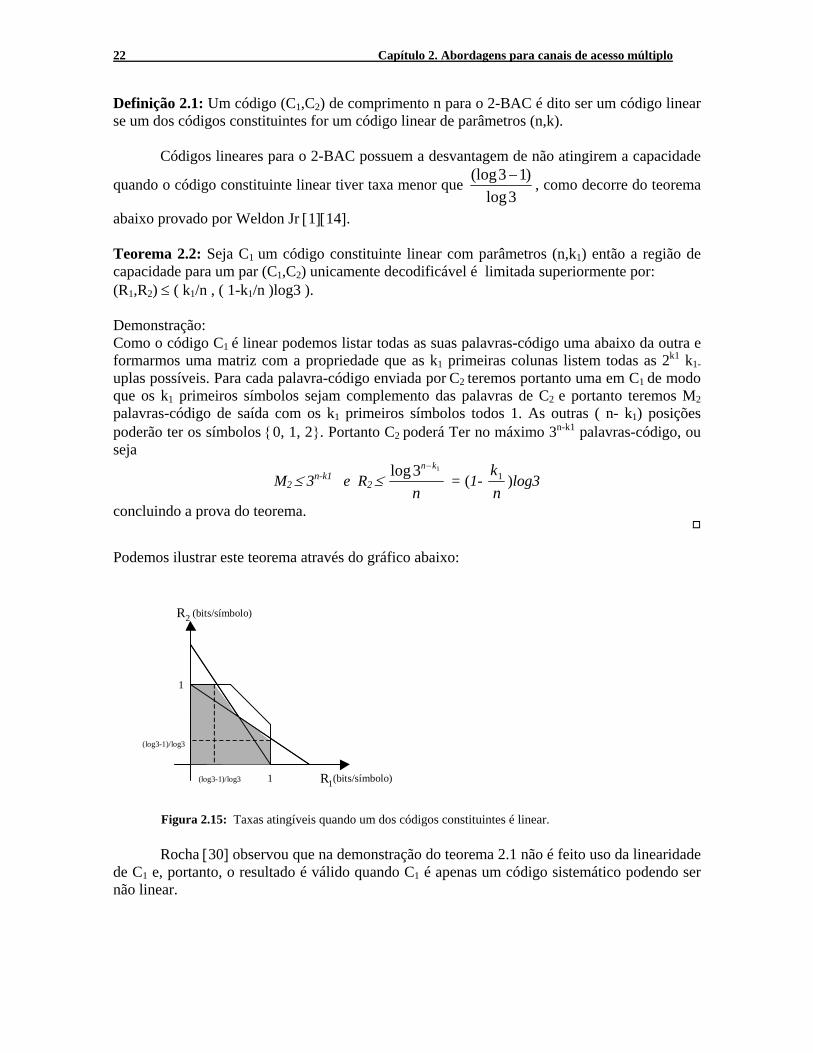
Podemos ilustrar este teorema através do gráfico abaixo:
Figura 2.15: Taxas atingíveis quando um dos códigos constituintes é linear.
Rocha [30] observou que na demonstração do teorema 2.1 não é feito uso da linearidade de C1 e, portanto, o resultado é válido quando C1 é apenas um código sistemático podendo ser não linear.
1
(log3-1)/log3
(log3-1)/log3 1 R1(bits/símbolo)
R2 (bits/símbolo)

Implementação algorítimica de códigos lineares para o 2-BAC 23
2.5.3 Algumas construções de códigos para o 2-BAC
Podemos citar uma série de trabalhos cuja finalidade é a construção de códigos para o 2-BAC, por exemplo [4][6][10]. Kasami e Lin [6] apresentaram um método para construção de pares de códigos δ-decodificáveis. Dois códigos binários C1 e C2 são δ-decodificáveis (δ > 0) se e somente se, para quaisquer dois pares distintos de n-uplas (x,w) e (x’,w’) em C1 x C2, dL(x + w, x’ + w’) ≥ δ . Um par C1 e C2 é unicamente decodificável quando ele é 1-decodificável. Em publicação posterior Kasami e Lin [7] apresentaram um esquema para decodificação de códigos δ-decodificáveis para o 2-BAC com ruído, levando em conta a linearidade e corrigindo no máximo ⎣(δ-1)/2⎦ erros de transmissão, onde ⎣(δ-1)/2 ⎦ denota o maior inteiro igual ou menor que (δ-1)/2. Ahswede e Balakirsky [10] em recente publicação , apresentaram um método de construção de códigos binários unicamente decodificáveis (C1,C2) para o 2-BAC, de comprimento tn, onde t e n são inteiros fixos , onde nem C1 nem C2 é linear. Rocha e Massey [4] estabeleceram condições suficientes para determinação de códigos binários unicamente decodificáveis (C1,C2) de peso constante para o 2-BAC, com ruído e sem ruído , obtendo a decodibilidade única como veremos através do teorema 2.3 abaixo. Teorema 2.3: Sejam C1 e C2 códigos de blocos binários com comprimento n, com distâncias mínimas de Hamming d1 e d2, respectivamente. Sejam
Dmin= min {dH(x,y): x ∈ C1, y ∈ C2}
Dmáx= máx {dH(x,y): x ∈ C1, y ∈ C2}
então máx{d1,d2} + Dmin > Dmáx é uma condição suficiente para o par (C1,C2) ser unicamente decodificável no 2-BAC. Demonstração: Suponha, contrariando a hipótese, que x + y = x’ + y’ , onde x ∈ C1, x’∈ C1, y ∈ C2 , y’∈ C2; e x≠ x’ . Segue que,
dH(x’,y’) = WH(x’⊕ y’) ≤ Dmáx
mas também,
dH(x,x’) + dH(x,y’) = WH(x’⊕ y’) ≤ Dmáx
porque x difere de x’ou y’ (mas não de ambos) apenas nos componentes onde x’⊕y’ contém um “1”. Como dH(x,x’) ≥ d1 e dH(x,y’) ≥ Dmin, nós temos
d1 + Dmin ≤ Dmáx
Similarmente temos,

24 Capítulo 2. Abordagens para canais de acesso múltiplo
D2 + Dmin ≤ Dmáx
Portanto, máx{d1,d2} + Dmin > Dmáx
A construção acima pode ser aplicada a todos os códigos binários de peso constante como os códigos obtidos das matrizes de Hadamard, Steiner Systems, códigos derivados dos códigos Berlekamp-Justesen generalizados e códigos de Reed-Solomon [4]. Nosso interesse principal está no método de construção de códigos unicamente decodificáveis para o 2-BAC, onde um dos códigos constituintes é linear, conforme veremos no capítulo seguinte.

25
3 Fundamentos teóricos para a decodibilidade única de
códigos lineares no 2-BAC
Cabral [1], em sua dissertação de mestrado, estabeleceu que condições dois conjuntos de vetores binários devem satisfazer para garantir sua decodibilidade única sobre o 2-BAC. Ele deu ênfase ao caso em que um dos conjuntos é um código de bloco linear de comprimento n , tentando determinar qual o maior conjunto de palavras-código para o segundo código, de modo a ainda haver a decodibilidade única. Em outras palavras, Cabral determinou as condições para que um código (C1,C2) seja unicamente decodificável considerando C1 um código linear. Ele utilizou o conceito de classes laterais, e a partir disto criou um algoritmo para busca de palavras-código pertencentes a C2 em cada classe lateral. Estas buscas são feitas de forma independente, isto é, classe lateral a classe lateral. Ele provou alguns teoremas que permitem dividir a busca de vetores para C2 no espaço F n
2 em buscas através de subconjuntos menores e independentes entre si. No 2-BAC cada remetente tem como alfabeto de entrada o conjunto F2 = {0,1}, de forma que a entrada do canal consiste de duplas binárias (x, w), com x e w pertencentes a F2. A saída y do canal sem ruído é a soma real entre os elementos do par (x, w) portanto, y = (x+w). Consideremos uma extensão para o modelo 2-BAC. Neste caso cada entrada é uma n-upla binária, que nesta dissertação será representada em negrito, onde a coordenada i, i = 1, ..., n, representa a i-ésima entrada do usuário correspondente, isto é, x = ( x1, x2, x3, ... xn ) w = ( w1, w2, w3, ... wn ) a saída para o 2-BAC será então, y = ( x1 + w1, x2 + w2, x3 + w3 ... , xn + wn ) Definindo as operações de adição e multiplicação binários sobre n-uplas binárias como as respectivas operações sobre F2, aplicadas componente a componente temos que,

26 Capítulo 3. Fundamentos teóricos para a decodibilidade única de códigos lineares no 2-BAC
x ⊕ w = ( x1⊕ w1, x2⊕ w2, x3 ⊕ w3, ... xn⊕ wn ) x . w = ( x1. w1, x2. w2, x3 . w3, ... xn. wn )
Podemos representar a saída do 2-BAC da seguinte forma, utilizando apenas operações sobre o espaço vetorial das n-uplas sobre o Campo de Galois de ordem 2, isto é,
xi + wi = xi ⊕ wi + 2.xi.wi
onde, + , ⊕ , . , denotam respectivamente as operações de adição real, adição e multiplicação binários. Verificamos facilmente este fato a partir das tabelas abaixo. a) b) c)
Figura 3.1: a) Possíveis saídas para o 2-BAC; b) Tabela para operação de adição em F2; c) Tabela para operação de multiplicação em F2.
Representaremos a saída do 2-BAC como um par de elementos binários, ou seja:
x + w ≈ ( x ⊕w , x.w )
A partir da expressão acima, juntamente com as tabelas anteriores, construímos uma nova tabela representada na figura 3.2.
Figura 3.2: Representação de saída do 2-BAC, como um par de elementos binários. Esta tabela só tem significado prático porque para cada valor resultante do 2- BAC, temos um par distinto para as operações de adição e multiplicação sobre F n
2 . Esta forma de representação nos é útil pois assim conseguimos representar as entradas e saídas do 2-BAC como elementos de F n
2 . Chamaremos as n-uplas binárias de vetores, enquanto as respectivas coordenadas serão
denominadas escalares.
+ 0 1 0 0 1 1 1 2
⊕ 0 1 0 0 1 1 1 0
. 0 1 0 0 0 1 0 1
x + w (x ⊕w , x . w ) 0 ( 0 , 0 ) 1 ( 1 , 0 ) 2 ( 0 , 1 )

Implementação algorítimica de códigos lineares para o 2-BAC 27
Podemos relembrar do capítulo 2, seção 2.5.1, que para haver decodibilidade única temos que para quaisquer vetores x1, x2 ∈ C1 e w1, w2 ∈ C2 tais que x1 ≠ x2 e w1 ≠ w2, x1 + w1 ≠ x2 + w2 portanto, para que não ocorra a decodibilidade única teremos que ter x1 + w1 = x2 + w2 , ou de forma análoga: x1 ⊕ w1 = x2 ⊕ w2 x1 . w1 = x2 . w2 rearrumando os termos encontramos: w1 = (x1 ⊕ x2 ) ⊕ w2
x1 . (x1 ⊕ x2 ⊕ w2) = x2 . w2 w1 = (x1 ⊕ x2 ) ⊕ w2
x1 . x1 ⊕ x1 . x2 ⊕ x1 . w2 = x2 . w2 w1 = (x1 ⊕ x2 ) ⊕ w2
0 = x1 . x1 ⊕ x1 . x2 ⊕ x1 . w2 ⊕ x2 . w2 w1 = (x1 ⊕ x2 ) ⊕ w2
0 = x1 . (x1 ⊕ x2 ) ⊕ w2 ( x1 ⊕ x2 )
w1 = (x1 ⊕ x2 ) ⊕ w2 0 = (x1 ⊕ x2 ) . ( x1 ⊕ w2 ) Resumindo o exposto acima, podemos enunciar o lema seguinte: Lema 3.1: Um código (C1,C2) para o 2-BAC é unicamente decodificável se, e somente se, não existirem dois pares de vetores (x1,w1 ) e (x2 ,w2 ) ∈ C1 x C2 satisfazendo ambas as equações: w1 = (x1 ⊕ x2 ) ⊕ w2 0 = (x1 ⊕ x2 ) . ( x1 ⊕ w2 ) 3.1 Códigos binários lineares Se considerarmos C1 um código linear binário temos que, a soma de duas palavras-código de C1 é uma terceira palavra-código em C1, portanto, x1⊕ x2 = x3 , onde x3 é um terceiro elemento de C1. Assim, reescrevemos as equações acima da seguinte forma:

28 Capítulo 3. Fundamentos teóricos para a decodibilidade única de códigos lineares no 2-BAC
w1 = (x1 ⊕ x2 ) ⊕ w2 (3.1) 0 = x3 . ( x1 ⊕ w2 ) (3.2) Podemos particionar o conjunto das n-uplas binárias em classes laterais de C1, isto é, arranjamos todos os 2k vetores de C1 em linha, um ao lado do outro, iniciando com o vetor nulo, 0 =(000 ... 0 ). Abaixo do vetor nulo colocamos qualquer uma das 2n – 2k n-uplas que não esteja representada na primeira linha, somamos módulo 2 esta n-upla com cada palavra-código de C1 e colocamos o resultado na segunda linha. A terceira linha inicia com uma n-upla que não esteja representada nas duas linhas anteriores e de forma análoga ao que fizemos na segunda linha, somamos módulo 2 este vetor com cada palavra-código de C1 e colocamos os resultados na terceira linha. Este raciocínio é mantido até que tenhamos representado todas as 2n n-uplas. Considerando que C1 possui 2k palavras-código, o arranjo padrão terá um total de 2k colunas e 2n-k linhas. Ilustramos o arranjo padrão na figura 3.3.
0 x1 x2 x3 ... 12 −kx
v1 x1 ⊕ v1 x2 ⊕ v1 x3 ⊕ v1 ... 12 −kx ⊕ v1
v2 x1 ⊕ v2 x2 ⊕ v2 x3 ⊕ v2 ... 12 −kx ⊕ v2
v3 x1 ⊕ v3 x2 ⊕ v3 x3 ⊕ v3 ... 12 −kx ⊕ v3
.
.
.
.
.
.
.
.
.
.
.
.
. . .
12 −−knv x1 ⊕ 12 −−knv x2 ⊕
12 −−knv x3 ⊕ 12 −−knv ...
12 −kx ⊕ 12 −−knv
Figura 3.3: Representação esquemática do arranjo padrão. Exemplo 3.1: Se considerarmos que os vetores (0000000, 1010101, 0110011, 1100110, 0001111, 1011010, 0111100, 1101001) são palavras-código de C1, então podemos ter o seguinte arranjo padrão: 0000000 1010101 0110011 1100110 0001111 1011010 0111100 1101001 0000001 1010100 0110010 1100111 0001110 1011011 0111101 1101000 0000010 1010111 0110001 1100100 0001101 1011000 0111110 1101011 0000011 1010110 0110000 1100101 0001100 1011001 0111111 1101010 0000100 1010001 0110111 1100010 0001011 1011110 0111000 1101101 0000101 1010000 0110110 1100011 0001010 1011111 0111001 1101100 0000110 1010011 0110101 1100000 0001001 1011100 0111010 1101111 0000111 1010010 0110100 1100001 0001000 1011101 0111011 1101110 0010000 1000101 0100011 1110110 0011111 1001010 0101100 1111001 0010001 1000100 0100010 1110111 0011110 1001011 0101101 1111000 0010010 1000111 0100001 1110100 0011101 1001000 0101110 1111011 0010011 1000110 0100000 1110101 0011100 1001001 0101111 1111010 0010100 1000001 0100111 1110010 0011011 1001110 0101000 1111101 0010101 1000000 0100110 1110011 0011010 1001111 0101001 1111100 0010110 1000011 0100101 1110000 0011001 1001100 0101010 1111111 0010111 1000010 0100100 1110001 0011000 1001101 0101011 1111110 Figura 3.4: Arranjo padrão esquemático.

Implementação algorítimica de códigos lineares para o 2-BAC 29
Se definirmos para o vetor w2 pertencente a F n2 o conjunto exclusão
2wZ consistindo dos vetores w1 dados pela equação (3.1), onde tomamos o vetor x3 ∈ C1 não nulo e satisfazendo a equação (3.2) para algum (x1 ⊕ w2) ∈ v ⊕C1 teremos o seguinte teorema. Teorema 3.1: Seja (C1,C2) um código linear para o 2-BAC. (C1,C2) será unicamente decodificável se, e somente se, o código C2 não tiver nenhum elemento em comum com o conjunto
2wZ , para qualquer vetor w2 ∈ C2 . Além disto, para um vetor w2 fixo, 2wZ é o
conjunto com o maior número de vetores com esta propriedade, e se w2 pertence à classe lateral v⊕C1 então
2wZ ⊂ v⊕C1. Definição 3.1:
1CvA ⊕ é o conjunto associado à classe lateral v⊕C1 consistindo dos vetores desta classe lateral pertencentes ao código constituinte C2 do par (C1,C2), unicamente decodificável para o 2-BAC.
O código C2 pode ser escrito como a união dos conjuntos disjuntos 1CvA ⊕ para todas as
classes laterais v⊕C1 que compõem a partição de F n2 em relação a C1.
Corolário 3.1: Seja (C1,C2) um código linear unicamente decodificável para o 2-BAC e seja
1CvA ⊕ o conjunto de vetores de C2 pertencentes à classe lateral v⊕C1 . Então 2wZ ⊆ v ⊕ C1 e
2wZ ∩ C2 = 2wZ ∩
1CvA ⊕ = ∅, para cada w2 ∈ 1CvA ⊕ .
Demonstração: Como (C1,C2) é unicamente decodificável e cada w2 ∈ v⊕C1, então pelo teorema 3.1
2wZ ⊆ v ⊕ C1 e 2wZ ∩ C2 = ∅ . Como
1CvA ⊕ ⊆ C2 então 2wZ ∩
1CvA ⊕ ⊆ 2wZ ∩ C2 e
portanto, 2wZ ∩
1CvA ⊕ = ∅.
Vemos pelo que foi exposto anteriormente que podemos escolher os vetores w2 ∈ v⊕C1 para o conjunto
1CvA ⊕ sem nos preocuparmos com um possível comprometimento na
construção dos conjuntos 1CvA ⊕ para outra classe lateral qualquer. A busca de palavras-código
para C2 será feita portanto de modo independente para cada classe lateral. Definição 3.2: Consideremos
2wS = {x3 ∈ C1; x3 . (x1 ⊕w2) = 0, para algum x1 ∈ C1} ⊆ C1,
onde w2 = v ⊕ xi ∈ v⊕C1. Este conjunto não depende do vetor w2, pois ele é invariante para cada classe lateral como demostraremos abaixo. Lema 3.2: Para quaisquer vetores w2 e w2’ ∈ v⊕C1 temos que '
2wS =
2wS .
Demonstração: Para cada w2 e w2′ ∈ C2 em v⊕C1 existem xi e xi′ ∈ C1 tais que w2 = xi ⊕ v e w2′ = xi′ ⊕ v, então: x3 . ( x1 ⊕ w2 ) = x3 . ( x1 ⊕ (xi ⊕ v ))

30 Capítulo 3. Fundamentos teóricos para a decodibilidade única de códigos lineares no 2-BAC
= x3 . ( (x1 ⊕ xi ⊕ xi′ ) ⊕ xi′ ⊕ v ) = x3 . (x1′ ⊕ w2′ ) onde, x1′ e x1 ∈ C1. Logo se x3 ∈
2wS significa que existe (x1 ⊕w2) ∈ v ⊕ C1 tal que
x3 . (x1 ⊕ w2) = x3 . (x1′ ⊕ w2′ ) = 0 e portanto, como x1′∈ C1 , x3 ∈ '2w
S , ou seja, 2wS ⊆ '
2wS .
Trocando os papéis de w2 e w2′ e repetindo o raciocínio acima encontramos que '2w
S ⊆ 2wS onde
concluímos que '2w
S = 2wS .
Chamaremos o conjunto '
2wS =
2wS = 1CvS ⊕ pois ele é invariante para cada classe lateral
v⊕C1. Exemplo 3.2: Vamos encontrar o conjunto
1CvS ⊕ , da classe lateral cujo líder de classe é o vetor (0000001) do arranjo padrão apresentado na figura 3.4. Vamos considerar w2 = 0000001
x1 x1 ⊕ w2 x3
0000000 0000001 1100110 /1011010 / 0111100 0110011 1010100 - 1010101 0110010 - 1100110 1100111 - 0001111 0001110 - 1011010 1011011 - 0111100 0111101 - 1101001 1101000 -
Figura 3.5: Tabela com valores de x3. Assim
1CvS ⊕ = {1100110, 1011010, 0111100}
Agora que já conhecemos o conjunto 1CvS ⊕ podemos expressar
2wZ da seguinte forma:
2wZ = { w2 ⊕ x3 ∈ v ⊕ C1, ∀ x3 ∈ 1CvS ⊕ , x3 ≠ 0 }
Considerando x3 ∈
1CvS ⊕ o conjunto de todos os vetores x3 ∈ C1 tal que x3 . (x1 ⊕ w2) = 0 para algum x1 ∈ C1. Assim, se w2 ∈ C2 então pelo teorema 3.1 e corolário 3.1 devemos ter
2wZ ∩ C2 = 2wZ ∩
1CvA ⊕ = ∅. Além disto, se 1CvA ⊕ = {
02w ,12w ,
22w , ..., 12 −m
w } então o conjunto:
1CvAZ⊕
= Υ1
02
−
=
m
iw i
Z ⊆ v⊕C1

Implementação algorítimica de códigos lineares para o 2-BAC 31
será composto de todos os vetores w1 que devem ser excluídos de C2. Lema 3.3: Sejam w2 e '2
w dois vetores pertencentes à classe lateral v⊕C1. Então '2w ∈
2wZ ,
se, e somente se, w2 ∈ '2w
Z .
Demonstração: Vamos supor que '2
w ∈ 2wZ . Existe x3 ∈
1CvS ⊕ tal que '2w = w2 ⊕ x3, daí w2 = '2
w ⊕ x3 e
portanto , w2 ∈ '2w
Z . Invertendo os papéis de w2 e '2w encontraremos que se w2 ∈ '
2wZ
então '2w ∈
2wZ .
Corolário 3.2: Seja w2 um vetor de uma classe lateral v⊕C1. Então dizer que w2 ∉ 1CvAZ
⊕é
equivalente a dizer que 1CvAZ
⊕não contém nenhum elemento de
1CvA ⊕ , ou seja, 2wZ ∩
1CvA ⊕ =
∅. Demonstração: Temos que w2 ∉
1CvAZ⊕
se, e somente se, que w2 ∉ iwZ
2, para 0 ≤ i ≤ m-1. Mas, pelo lema
3.3 , w2 ∉ iwZ
2, se, e somente se,
iw2 ∉ 2WZ , ou seja, se, e somente se,
2WZ ∩ 1CvA ⊕ = ∅.
Portanto w2 ∉ 1CvAZ
⊕se, e somente se,
2wZ ∩ 1CvA ⊕ = ∅.
O corolário 3.2 facilita a busca de vetores para C2, pois vemos que não é possível um vetor w2 ∈ v⊕C1 , que ainda não tenha sido escolhido para C2 nem excluído pelos que já foram escolhidos anteriormente. Lema 3.4: Seja C1 um código de bloco binário linear e M = {
02w ,12w ,
22w , ..., 12 −m
w } um subconjunto da classe lateral v⊕C1 . Então existirá um código C2 tal que M ⊆ C2 e (C1, C2) é unicamente decodificável se, e somente se,
iw2 ∉
jwZ2
, ∀i, j = 0, 1, ..., m-1.
Demonstração: Vamos supor que (C1, C2) é um código binário linear unicamente decodificável para o 2-BAC tal que M ⊆ C2 . Então
iw2 ∈ C2 e pelo teorema 3.1 temos que
iw2 ∉
jwZ2
, quaisquer que
sejam 0≤ i, j ≤ m-1. Considerando que o conjunto M tem a propriedade que i
w2 ∉ jwZ
2, para
quaisquer 0≤ i, j ≤ m-1, se tomarmos um código C2 tal que C2 = '2C ∪ M, onde (C1 ,
'2C ) é
unicamente decodificável e '2C ∩ (v⊕C1) = ∅ então, '
2C ∩ M = ∅ e (C1,C2) é unicamente decodificável.
Exemplo3.3: Vamos encontrar o conjunto
1CvAZ⊕
e 1CvA ⊕ pertencente a classe lateral (v⊕C1), onde v =
0000001 no arranjo padrão da figura 3.4.

32 Capítulo 3. Fundamentos teóricos para a decodibilidade única de códigos lineares no 2-BAC
Sabemos do exemplo anterior que
1CvS ⊕ = {1100110, 1011010, 0111100} Escolhendo w2 = 0000001 então, w1 = w2 ⊕ x3 ⇒
2wZ = {1100111, 1011011, 0111101} Escolhendo w2 = 1010100 então, w1 = w2 ⊕ x3 ⇒
2wZ = {0110010, 0001110, 1101000} Desta forma ,
1CvAZ⊕
= {1100111, 1011011, 0111101, 0110010, 0001110, 1101000}
1CvA ⊕ = {0000001, 1010100}
É possível gerar um espaço linear a partir de 1CvS ⊕ consistindo no conjunto de todas as
possíveis combinações lineares de vetores de 1CvS ⊕ , que denotaremos por
1Cv⊕ε . Como
1CvS ⊕ ⊆ C1 e C1 é um espaço linear temos que 1Cv⊕ε é um subespaço de C1. Portanto
1Cv⊕ε é
subespaço de C1 gerado por 1CvS ⊕ .
Exemplo 3.4: Considerando
1CvS ⊕ = {1100110, 1011010, 0111100} fazendo as combinações lineares temos que:
1Cv⊕ε = {0000000, 1100110, 1011010, 0111100} Vamos dividir uma classe lateral v⊕C1 em subconjuntos disjuntos entre si. Podemos observar que
1Cv⊕ε é subespaço de C1 e por conseguinte de F n2 definindo uma partição deste
último. Teorema 3.2: Seja v⊕C1 uma classe lateral de C1 em relação a F n
2 e seja 1Cv⊕ε ⊆ C1 o
subespaço de dimensão l ≤ k , onde k é a dimensão de C1, gerado pelo conjunto 1CvS ⊕ associado
a esta classe. 1Cv⊕ε define uma partição de F n
2 tal que para w2 ∈ v⊕C1 a classe lateral
w2 ⊕ 1Cv⊕ε =
2wW está contida em v⊕C1. Além disso, temos:
Υ1
02
−
=
L
iw i
W = v⊕C1,
onde L = 2k-l é o número de classes distintas iwW
2, com
iwW2∩
jwW2
= ∅ para i ≠ j.
Demonstração: Vamos ver primeiramente que o conjunto
2wW está contido inteiramente em v⊕C1. Para isso,
suponha um vetor w ∈ 2wW e um vetor e ∈
1Cv⊕ε . Por definição podemos escrever w = w2 ⊕ e . Como w2 é um vetor de v⊕C1 podemos escrevê-lo como w2 = v ⊕ xi , onde xi ∈ C1 daí, w = w2 ⊕ e = (v ⊕ xi ) ⊕ e = v ⊕ (xi ⊕ e) ∈ v ⊕ C1 pois C1 é linear. Portanto,
2wW ⊆ v⊕C1 ,

Implementação algorítimica de códigos lineares para o 2-BAC 33
∀ w2 ∈ v⊕C1 , o que implica que Υ12 2Cvw wW
⊕∈⊆ v⊕C1 . Por outro lado, como
1Cv⊕ε é
subespaço de C1 , então 0 ∈ 1Cv⊕ε e portanto w2 ∈
2wW . Logo, v ⊕ C1 ⊆ Υ12 2Cvw wW
⊕∈, donde
concluímos que Υ2 2w wW = v⊕C1.
iwW2
e jwW
2são duas classes laterais de
1Cv⊕ε em relação a F n2 e portanto são disjuntas,
completando assim a prova do teorema.
Teorema 3.3: Seja v⊕C1 uma classe lateral de C1 em relação a F n2 e seja
2wW uma classe lateral
de 1Cv⊕ε em relação a F n
2 . Então se w ∈ 2wW temos wZ ⊆
2wW . Além disto , se '2
wW ≠ 2wW ,
wZ ∩ '2
wW = ∅.
Demonstração: Como
2wW é uma classe lateral de 1Cv⊕ε em relação a F n
2 existe um vetor u ∈ 1Cv⊕ε tal que w
= w2 ⊕ u . Pela definição 3.2 qualquer vetor z ∈ wZ pode ser escrito como z = w ⊕ xi = w2 ⊕ (u ⊕ xi) para algum xi ∈
1CvS ⊕ ⊆ 1Cv⊕ε . Como
1Cv⊕ε é um subespaço, u ⊕ xi ∈ 1Cv⊕ε e
portanto z ∈ 2wW . Além disso como
2wW ∩ '2
wW ≠ ∅, e como wZ ⊆ 2wW , então wZ ∩
'2wW =
∅.
Lema 3.5: Sejam iwW
2, 0 ≤ i ≤ L-1, as L classe laterais distintas de
1Cv⊕ε com relação a F n2
contidas na classe lateral v ⊕C1 de C1 com relação a F n2 . Se
mwWA2
for um conjunto de vetores w
∈ mwW
2 pertencentes a C2 tal que (C1,C2) é um código linear unicamente decodificável para o
2-BAC, então o conjunto
1CvA ⊕ = Υ1
022 )(
−
=
⊕L
imi
ww ⊕mwWA
2 = Υ
1
022 )(
−
=
⊕L
imi
ww ⊕ w ∈ v⊕C1 ; w ∈ jwW
2 ⊆ v⊕C1
está incluído em um código '2C tal que (C1, '
2C ) também é um código linear unicamente decodificável. Esta demonstração pode ser vista em [1].
A partir dos resultados anteriores, Cabral [1] construiu um algoritmo em que, para cada classe lateral, é encontrado o conjunto
1CvS ⊕ e a partir de uma combinação linear destes é
encontrado o subespaço 1Cv⊕ε .Particionamos então v⊕C1 em classes laterais
2wW , em cada
classe lateral encontramos o conjunto 2w
WA de vetores pertencentes ao código C2. Uma vez
encontrado todos os 2w
WA teremos o conjunto 1CvA ⊕ . Fazendo o mesmo para cada classe lateral
v⊕C1 teremos encontrado todas as palavras-código de C2. A partir da construção acima é possível atingir o máximo número de vetores pertencentes a
1CvA ⊕ , podemos ver a razão desta afirmação se supormos que M = {02w ,
12w ,

34 Capítulo 3. Fundamentos teóricos para a decodibilidade única de códigos lineares no 2-BAC
22w , ..., 12 −m
w } é o conjunto 1CvA ⊕ com o maior número de vetores em uma classe lateral
v⊕C1, que podem pertencer a C2. Deve-se portanto escolher o elemento j
w2 para pertencer ao
conjunto 1CvA ⊕ .O teorema abaixo utiliza o máximo conjunto
1CvA ⊕ . Teorema 3.4: A cardinalidade máxima do conjunto
1CvA ⊕ é dada pelo produto entre o índice
[C1: 1Cv⊕ε ] de C1 em relação ao seu subespaço vetorial ( portanto subgrupo) 1Cv⊕ε e a
cardinalidade do maior conjunto vWA determinado no algoritmo citado acima.
3.2 Códigos binários lineares fortemente ortogonais
Cabral [1] lançou o conceito de códigos fortemente ortogonais. Iremos apresentar os resultados matemáticos abaixo por questão de completude, pois os princípio a serem usados no capítulo 4, seção 4.1,dependem desta teoria. Definição 3.3: Um código C1 linear binário, tendo sua matriz geradora G na forma sistemática é definido como fortemente ortogonal se para a i-ésima linha de G, denominada ci, e considerando-a como vetor em nF2 tivermos:
ci . cj = 0 ∀i, j = 1, 2, ..., k. Da definição acima verificamos facilmente que as colunas da matriz geradora podem ter apenas um componente não nulo, isto é, cada coluna contém k símbolos com no máximo um símbolo tendo o valor 1. Vamos considerar a matriz geradora de um código fortemente ortogonal na forma sistemática tendo a seguinte representação: Ik Akx(n-k)
Figura 3.6: Representação de matriz geradora de um código fortemente ortogonal.
onde, Ik é a matriz identidade e Akx( n-k) é a matriz formada por n-k colunas, onde cada coluna contém apenas um elemento não nulo. O número máximo de colunas distintas é k +1. Podemos agrupar as n-k colunas de Akx(n-k) em conjuntos de colunas idênticas para simplificar o entendimento conforme figura 3.7.
k l1 l2 lk lk+1
10...0 1...1 0...0 ... 0...0 0...0 01...0 0...0 1...1 ... 0...0 0...0
00...1 0...0 0...0 ... 1...1 0...0
Figura 3.7: Representação na forma sistemática de matriz geradora de código linear fortemente ortogonal.

Implementação algorítimica de códigos lineares para o 2-BAC 35
O código (C1,C2) para o 2-BAC será considerado um código linear fortemente ortogonal se C1 além de linear for fortemente ortogonal.
Sabemos também que para cada vetor xi ∈ C1, existe uma combinação linear única dos vetores ci’s resultando em xi . Se cm estiver nesta combinação linear então xi terá valores não nulos nas mesmas coordenadas de cm , independente de quais outros vetores ci’s, com 1 ≤ i ≤ k, i ≠ m, estejam na combinação.
Sabemos que para um código (C1,C2) linear ser unicamente decodificável não podem existir dois pares de vetores (x1,w1), (x3, w2) ∈ C1 X C2 satisfazendo ambas as equações:
w1 = (x1 ⊕ x2 ) ⊕ w2 (3.1) 0 = x3 . ( x1 ⊕ w2 ) (3.2)
Como x1 e x3 ∈ C1 , eles são combinações lineares dos vetores formados pelas linhas da Matriz G, isto é:
x3 = a1.c1 + a2.c2 + a3.c3 + .... + ak.ck = ∑=
k
iii ca
1
.
x1 = b1.c1 + b2.c2 + b3.c3 + .... + bk.ck = ∑=
k
jjj cb
1.
Escrevendo a equação (3.2) de outra forma temos:
0 = x3 . x1 ⊕ x3 . y2
0 = ∑=
k
iii ca
1. . ∑
=
k
jjj cb
1. ⊕ x3 . y2
0 = ∑∑= =
k
j
k
ijiji ccba
1 1
.. ⊕ x3. y2
Mas pela definição de códigos fortemente ortogonais, verificamos facilmente que ci.cj =
0 se i ≠ j, assim a equação torna-se:
0 = ∑=
k
iiii cba
1
.. ⊕ x3. y2
Vamos considerar y2 = v, onde v é o líder de classe de uma classe lateral e vamos
encontrar todos estes líderes utilizando a matriz da figura 3.8 como matriz geradora.
0 (n-k)xk In-k Figura 3.8: Matriz geradora dos líderes de classe.
Esta matriz gera um espaço complementar de C1. Sabemos que todos os xi’s que
pertencem a C1 , possuem as k coordenadas mais à esquerda diferentes de 0 com exceção do

36 Capítulo 3. Fundamentos teóricos para a decodibilidade única de códigos lineares no 2-BAC
vetor nulo. Os líderes de classe por sua vez gerados pela matriz acima terão todas as k coordenadas mais à esquerda iguais a 0, portanto podemos defini-los desta forma pois o único vetor com as k primeiras coordenadas nulas numa classe lateral será o líder de classe.
0 = ∑=
k
iiii cba
1
.. ⊕ x3. v
sabemos que,
∑=
k
iiii cba
1
.. (3.3)
tem as “k” coordenadas mais à esquerda nulas, assim x3. v (3.4) também deverá ter, porém isto só acontecerá se ai ou bi = 0, então teremos:
∑=
k
iiii cba
1
.. = 0 e assim segue que,
x3. v = 0 Teremos então que
1CvS ⊕ será formado por todas as palavras-código de C1 que satisfazem a equação acima. Vamos considerar x3’, x3” ∈ C1 e satisfazendo a equação (3.4), vemos que: x3’ . v = 0 x3” . v = 0 Se somarmos as equações acima teremos: x3’ .v ⊕ x3” . v = 0 (x3’ ⊕ x3”) . v = 0 x3’’’ . v = 0 , onde x3”’ ∈ C1 Assim concluímos que
1CvS ⊕ é subespaço de C1, desta forma ele é o próprio 1Cv⊕ε .
Portanto, provamos o seguinte teorema. Teorema 3.5: Seja C1 um código linear fortemente ortogonal sobre F2. Então o conjunto
1CvS ⊕
definido anteriormente é o subespaço vetorial igual a 1Cv⊕ε .
Corolário 3.3: Nas condições do teorema acima temos que
1CvS ⊕ = 1Cv⊕ε e portanto a máxima
cardinalidade para o conjunto 1CvA ⊕ é dada pelo índice [ C1 : 1CvS ⊕ ] de C1 em relação a
1CvS ⊕ Demonstração:

Implementação algorítimica de códigos lineares para o 2-BAC 37
Segue do teorema 3.4 e do fato que a cardinalidade do maior conjunto vWA é “1”, pois o único
vetor que não poderá ser usado para eliminar palavras-código para C2 é o vetor nulo, assim particionando v⊕C1 em classes laterais de
1Cv⊕ε teremos apenas o líder de classe pertencente a
vWA .
Sabe-se da álgebra [26][27]que se V e W são dois espaços vetoriais de dimensões n e
m, respectivamente e F: V → W uma transformação linear de V em W, então
dim Ker( F ) + dim F( V) = n, onde n é a dimensão de V e Ker(F), denominado núcleo da transformação F, é o conjunto de vetores v ∈ V tais que F(v) = 0 Vamos a partir de agora verificar qual a cardinalidade máxima do conjunto
1CvA ⊕ . Primeiramente é necessário descobrirmos qual a dimensão do Ker ( Tv ). Teorema 3.6: Seja C1 um código linear fortemente ortogonal de parâmetros (n,k) com matriz geradora G e sejam c1, c2, ..., ck as k linhas desta matriz. Denotando por m o número de linhas ci’s para as quais ci . v ≠ 0 e considerando Tv : C1 → nF2 ci → ci . v então dim Ker (Tv) é o conjunto de vetores ci para os quais ci → Tv (ci ) = 0 dim Ker (Tv) + dimTv(C1) = dim C1
dim Ker (Tv) + dimTv(C1) = k Como m é o número de linhas ci’s para as quais ci . v ≠ 0 e como Tv(C1) ≠ 0, são linearmente independentes e portanto formam uma base para Tv(C1), temos que a dimTv(C1) = m, assim: dim Ker (Tv) + m = k
dim Ker (Tv) = k - m
Teorema 3.7: A cardinalidade máxima do conjunto
1CvA ⊕ é 2m. Demonstração: A demonstração é imediata, visto que: ⎪ C1⎪= [ C1 : 1CvS ⊕ ] . ⎢
1CvS ⊕ ⎢ como, ⎢
1CvS ⊕ ⎢= ⎢Ker (Tv) ⎢ = 2k-m

38 Capítulo 3. Fundamentos teóricos para a decodibilidade única de códigos lineares no 2-BAC
então [ C1 : 1CvS ⊕ ] = 2m
Como a máxima cardinalidade para o conjunto
1CvA ⊕ é dada por [ C1 : 1CvS ⊕ ] temos que a
máxima cardinalidade de 1CvA ⊕ é 2m.
A partir do resultado anterior encontraremos a máxima cardinalidade para C2 de modo que (C1,C2) seja unicamente decodificável e fortemente ortogonal. Para facilitar o entendimento vamos representar um vetor x3 ∈ C1 como mostrado abaixo.
x3 = ( a1a2 ... ak a1a1 ... a1 a2a2 ... a2 ... akak ... ak 00... 0)
onde os k símbolos mais à esquerda representam a mensagem, e cada conjunto de ai’s, 1 ≤ i ≤ k, é um vetor de comprimento li formado por vetores nulos ou com todos os símbolos 1’s. Para obtermos semelhança com as palavras-código de C1 podemos dividir os líderes de classe v em blocos vi, 1 ≤ i ≤ k+1, com os mesmos comprimentos li’s, isto é v = ( 00 ... 0 v1 v2 ... vk vk+1 ) (3.5)
onde os k símbolos mais à esquerda do vetor v são nulos. Analogamente podemos escrever ci da seguinte forma: ci = ( 0...010...0 0l1 0l2 ... 1li ... 0lk 0lk+1 ) onde 0li e 1li representam as l-uplas com todas as coordenadas 0 ou 1 respectivamente e a k-upla inicial tem o 1 na i-ésima posição. Vemos que,
ci . v = ( 0k 0l1 0l2 ... vi ... 0lk0lk+1 ) (3.6)
Lema 3.6: Seja C1 um código fortemente ortogonal e seja v um líder de classe como representado em (3.5) com apenas m blocos vi , 1 ≤ i ≤ k não nulos. A máxima cardinalidade do conjunto
1CvA ⊕ é 2m . Demonstração: Para Tv(ci) ≠ 0 , o bloco vi não pode ser nulo, pode-se observar este fato em (3.6). Portanto, se o líder de classe v tiver apenas os m blocos
1iv ,
2iv , ...
miv , 1 ≤ ij ≤ k, 1 ≤ j ≤ m, não nulos, então
Tv(ci) ≠ 0 , se i = l1,l2,... lm
Tv(ci) = 0 , caso contrário Então o máximo número de vetores que podem pertencer a C2 é 2m.
Teorema 3.8: Seja C1 um código fortemente ortogonal. A máxima cardinalidade para o código C2 de modo que (C1,C2) seja unicamente decodificável é

Implementação algorítimica de códigos lineares para o 2-BAC 39
12 +kl . ( ∑=
k
mm
m N0
.2 ) (3.7)
onde Nm é o número de classes laterais distintas cujos líderes v têm exatamente m dos k blocos vi’s não nulos.
Nm = ∑ ∑ ∑= += += −
−−−k
i
k
ii
k
ii
lll
mm
miii
1 1 11 12 1
21 )12)...(12).(12(... (3.8)
onde li é o comprimento do bloco vi. A demonstração do teorema 3.8 poderá ser encontrada em [1], porém no capítulo 4, seção 4.1 é dada uma nova abordagem aos códigos lineares fortemente ortogonais, onde demonstramos de forma bastante concisa e simples o resultado deste teorema.
Corolário 3.4: A taxa de transmissão do código C2 é dada por
11
0 12
)).2(log(
+=
= +
++
+=
∑∑
kk
i m
k
m kmm
llk
lNR (3.9)
Um caso especial de códigos fortemente ortogonais é obtido fazendo lk+1 = 0 e li = l, 1 ≤ i ≤ k. Neste caso a expressão (3.8) torna-se
)()12( km
mlmN −= (3.10)
e a taxa de transmissão será
1)12log( 1
2 +−
=+
lR
l
(3.11)
A taxa do 2-BAC , R = R1 + R2 será
1)12log(1 1
+−+
=+
lR
l
(3.12)

40
4 Resultados Experimentais
A partir dos resultados obtidos no capítulo 3 implementamos o algoritmo de Cabral [1] em Visual basic (anexo A), o qual permite encontrar o conjunto de maior cardinalidade de palavras-código para um código C2 a partir de um código linear C1 dado, de modo a garantir a decodibilidade única. Temos a ressalva de que na nossa implementação não é encontrado o subespaço
1Cv⊕ε , assim não particionamos v⊕C1 em classes laterais 2wW , por
não acharmos que desta forma há maior rapidez nos cálculos. De uma maneira geral podemos resumir esta implementação da seguinte forma:
1) É solicitada a matriz geradora de C1, com k linhas e n colunas, e a partir desta são obtidas
todas as palavras-código de C1. 2) Particionamos o conjunto das n-uplas binárias em classes laterais de C1, isto é, construímos
o arranjo padrão segundo C1 . 3) Para cada classe lateral obtemos o conjunto
1CvS ⊕ = {x3 ∈ C1; x3 .(x1 ⊕ w2 ) = 0, para x1 ∈ C1} ⊆ C1.
4) Tendo o conjunto 1CvS ⊕ estamos em condições de encontrar o conjunto
1CvZ ⊕ =Υ1
02
−
=
m
iw i
Z ⊆
v⊕C1, para cada classe lateral, onde iwZ
2= {w2 ⊕ x3 ∈ v⊕C1, ∀x3 ∈
1CvS ⊕ , x3 ≠0 }.
5) Podemos então obter o conjunto
1CvA ⊕ , formado por todas as palavras-código pertencentes
a C2 em uma determinada classe lateral. O conjunto formado pelos 1CvA ⊕ ’s de todas as
classes laterais e uma palavra-código em comum com C1 será o próprio C2. Denotaremos por M o número de palavras-código de C2.
6) Encontramos então as taxas de transmissão dos códigos C1 , C2 e do 2-BAC
respectivamente,
R kn1 = (4.1)

Implementação algorítimica de códigos lineares para o 2-BAC 41
R Mn2 =
log (4.2)
R R R k Mn
= + =+
1 2log
(4.3)
Podemos ilustrar os passos acima através do fluxograma seguinte:
Figura 4.1: Fluxograma simplificado, no qual são encontradas as palavras-código de C2 contidas nas classe laterais.
Unindo-se um vetor pertencente a C1 com o conjunto Av Ci
i
n k
⊕=
−−
11
2 1
Υ teremos encontrado
todas as palavras-código pertencentes a C2. É oportuno ilustrarmos as telas que são apresentadas no software implementado:
Início
Matriz Geradorade C1
Classe laterali← 0
Arranjo padrão
i = 2n-k-1?
i ← i +1
Sim
Não
Fim
S v Ci⊕ 1
Z v Ci⊕ 1
A v Ci⊕ 1 A vi
i C
n k
0
2 1
1
⊕
−
=
−
Υ

42 Capítulo 4. Resultados Experimentais
Figura 4.2: Nesta tela o usuário do software modifica o número de linhas (k) e o número de colunas (n) da matriz geradora do código C1, bem como insere a própria matriz.
Figura 4.3: Tela em que é mostrado o arranjo padrão calculado. Nesta tela temos a opção de ao invés de utilizarmos os dados da matriz geradora inserida na tela da figura 4.2, modificarmos o número de linhas e colunas do arranjo padrão e inserirmos as palavras-código de C1 diretamente, recalculando então o arranjo padrão.
Ícone utilizado para cálculo do arranjo padrão
Ícone utilizado para alterar númerode linhas e colunas na matriz G
Leva às palavras-código de C2
Permite alterar o número de linhas ecolunas do arranjo padrão
Desfaz o arranjo padrão existente a partirda matriz geradora da tela origem
Recalcula o arranjo padrão a partir depalavras-código de C1 inseridas na primeira linha
Implementação algorítimica de códigos lineares para o 2-BAC 43
Figura 4.4: A tela acima mostra as palavras-código calculadas para C2, bem como o número de palavras do dicionário e as taxas de transmissão R1 , R2 , R1+R2, além do número de palavras-código resultantes por coluna. Ilustramos esta tela com um exemplo para visualização dos dados. É importante observar que na primeira linha o único vetor que pertence ao código C2 é o vetor nulo.
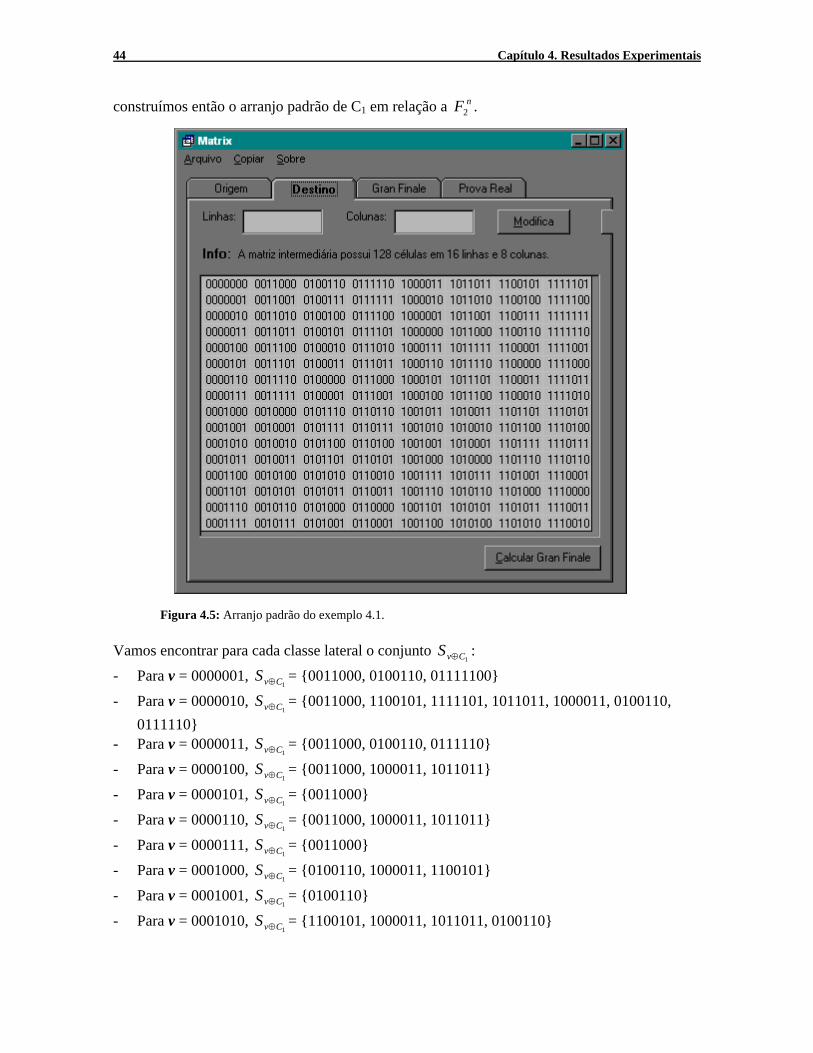
Figura 4.4: Tela que ilustra todas as palavras código possíveis para o 2-BAC. Exemplo 4.1: A partir da matriz geradora:
1 0 0 0 0 1 1 G= 0 1 0 0 1 1 0
0 0 1 1 0 0 0 encontramos o conjunto de palavras-código de C1, isto é, C1= {0000000, 0011000, 0111110, 1000011, 1011011, 1100101, 1111101}
44 Capítulo 4. Resultados Experimentais
construímos então o arranjo padrão de C1 em relação a nF2 .
Figura 4.5: Arranjo padrão do exemplo 4.1. Vamos encontrar para cada classe lateral o conjunto
1CvS ⊕ :
- Para v = 0000001, 1CvS ⊕ = {0011000, 0100110, 01111100}
- Para v = 0000010, 1CvS ⊕ = {0011000, 1100101, 1111101, 1011011, 1000011, 0100110,
0111110} - Para v = 0000011,
1CvS ⊕ = {0011000, 0100110, 0111110}
- Para v = 0000100, 1CvS ⊕ = {0011000, 1000011, 1011011}
- Para v = 0000101, 1CvS ⊕ = {0011000}
- Para v = 0000110, 1CvS ⊕ = {0011000, 1000011, 1011011}
- Para v = 0000111, 1CvS ⊕ = {0011000}
- Para v = 0001000, 1CvS ⊕ = {0100110, 1000011, 1100101}
- Para v = 0001001, 1CvS ⊕ = {0100110}
- Para v = 0001010, 1CvS ⊕ = {1100101, 1000011, 1011011, 0100110}

Implementação algorítimica de códigos lineares para o 2-BAC 45
- Para v = 0001011, 1CvS ⊕ = {0100110}
- Para v = 0001100, 1CvS ⊕ = {1000011}
- Para v = 0001101, 1CvS ⊕ = ∅
- Para v = 0001110, 1CvS ⊕ ={1000011}
- Para v = 0001111, 1CvS ⊕ = ∅
Em seguida obtemos o conjunto 1CvZ ⊕ :
- Para v = 0000001, 1CvZ ⊕ = {0011001, 0100111, 0111111, 1000010, 11001000, 1111100}
- Para v = 0000010, 1CvZ ⊕ = {0011010, 0100100, 0111100, 1000001, 1011001, 1100111,
1111111} - Para v = 0000011,
1CvZ ⊕ = {0011011, 0100101, 0111101, 1011000, 1100110, 1111110}
- Para v = 0000100, 1CvZ ⊕ = {0011100, 0111010, 1000111, 1011111, 1100001, 1111001}
- Para v = 0000101, 1CvZ ⊕ = {0011101, 0111011, 1011110, 1111000}
- Para v = 0000110, 1CvZ ⊕ = {0011110, 0111000, 1000101, 1011101, 1100011, 1111011}
- Para v = 0000111, 1CvZ ⊕ = {0011111, 0111001, 1011100, 1111010}
- Para v = 0001000, 1CvZ ⊕ = {0101110, 0110110, 1001011, 1010011, 1101101, 1110101}
- Para v = 0001001, 1CvZ ⊕ = {0101111, 0110111, 1101100, 1110100}
- Para v = 0001010, 1CvZ ⊕ = {0101100, 0110100, 1001001, 1010001, 1101111, 1110111}
- Para v = 0001011, 1CvZ ⊕ = {0101101, 0110101, 1101110, 1110110}
- Para v = 0001100, 1CvZ ⊕ = {1001111, 1010111, 1101001, 1110001}
- Para v = 0001101, 1CvZ ⊕ = ∅
- Para v = 0001110, 1CvZ ⊕ = {1001101, 1010101, 1101011, 1110011}
- Para v = 0001111, 1CvZ ⊕ = ∅
Calculamos agora os conjuntos 1CvA ⊕ para cada classe lateral:
-Para v = 0000001, 1CvA ⊕ = {0000001, 1000010}
-Para v = 0000010, 1CvA ⊕ = {0000010}
-Para v = 0000011, 1CvA ⊕ = {0000011, 1000000}
-Para v = 0000100, 1CvA ⊕ = {0000100, 0100010}
-Para v = 0000101, 1CvA ⊕ = {0000101, 0100011, 1000110, 1100000}
-Para v = 0000110, 1CvA ⊕ = {0000110, 0100000}
-Para v = 0000111, 1CvA ⊕ = {0000111, 0100001, 1000100, 1100010}
-Para v = 0001000, 1CvA ⊕ = {0001000, 0010000}
-Para v = 0001001, 1CvA ⊕ = {0001001, 0010001, 1001010, 1010010}
-Para v = 0001010, 1CvA ⊕ = {0001010, 0010010}
-Para v = 0001011, 1CvA ⊕ = {0001011, 0010011, 1001000, 1010000}
46 Capítulo 4. Resultados Experimentais
-Para v = 0001100, 1CvA ⊕ = {0001100, 0010100, 0101010, 0110010}
-Para v = 0001101, 1CvA ⊕ = {0001101, 0010101, 0101011, 0110011, 1001110, 1010110,
1101000, 1110000} -Para v = 0001110,
1CvA ⊕ = {0001110, 0010110, 0101000, 0110000}
-Para v = 0001111, 1CvA ⊕ = {0001111, 0010111, 0101001, 0110001, 1001100, 1010100,
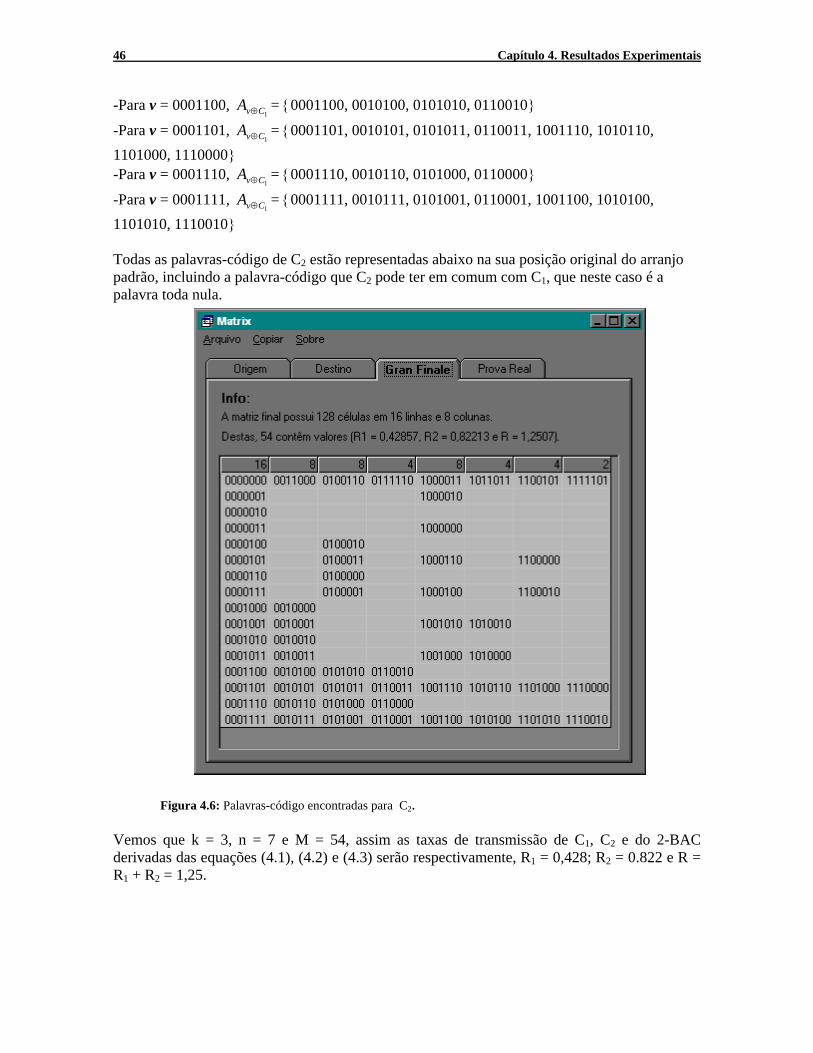
1101010, 1110010} Todas as palavras-código de C2 estão representadas abaixo na sua posição original do arranjo padrão, incluindo a palavra-código que C2 pode ter em comum com C1, que neste caso é a palavra toda nula.
Figura 4.6: Palavras-código encontradas para C2. Vemos que k = 3, n = 7 e M = 54, assim as taxas de transmissão de C1, C2 e do 2-BAC derivadas das equações (4.1), (4.2) e (4.3) serão respectivamente, R1 = 0,428; R2 = 0.822 e R = R1 + R2 = 1,25.

Implementação algorítimica de códigos lineares para o 2-BAC 47
4.1 Análise de códigos lineares fortemente ortogonais
É conveniente representarmos a matriz geradora do código linear fortemente ortogonal C1 na forma sistemática conforme é mostrado na figura 4.1.
K l1-1 l2 -1 lk-1 lk+1 10...0 1...1 0...0 ... 0...0 0...0 01...0 0...0 1...1 ... 0...0 0...0
0...01 0...0 0...0 ... 1...1 0...0
Figura 4.7: Matriz geradora de código linear fortemente ortogonal.
Outra forma de representação da matriz mostrada acima é obtida quando a retiramos da forma sistemática agrupando todas as lj , 1≤ j ≤ k+1 colunas idênticas, inclusive as k colunas mais à esquerda. Podemos visualizar esta representação através da figura 4.8.
l1 l2 lk lk+1 1...1 0...0 ... 0...0 0...0 0...0 1...1 ... 0...0 0...0
0...0 0...0 ... 1...1 0...0
Figura 4.8: Matriz geradora de código fortemente ortogonal com todas as lj colunas idênticas agrupadas. Neste momento faz-se necessário apresentarmos uma construção já citada no capítulo 2,
para códigos unicamente decodificáveis. Construção 4.1: Seja C1 = {0n,1n} e seja C2 constituído por todas as n-uplas exceto 1n. Podemos verificar que este código é unicamente decodificável pois todos os elementos de C2 são distintos e todos os elementos para o 2-BAC serão da seguinte forma {0n + c2j} ou {1n + c2j}, onde c2j são os elementos do código C2, donde podemos ver que {0n + c2j}∩ {1n + c2j } = ∅. Exemplo 4.2: a) Considerando n=1 temos: C1= {0, 1} C2= {0}, |C2|= 1 b) Considerando n=2 podemos ver no capítulo 2 que: C1= {00, 11} C2= {00, 01,10}, |C2|= 3 c) Considerando n=3 temos: C1= {000, 111} C2= {000, 001, 010, 011, 100, 101, 110}, |C2|= 7

48 Capítulo 4. Resultados Experimentais
d) Considerando n= 4 temos: C1= {0000, 1111} C2= {0000, 0001, 0010, 0011, 0100, 0101, 0110, 0111, 1000, 1001, 1010, 1011, 1100, 1101, 1110, }, |C2|= 15 Vemos que para este tipo de código o número total de palavras-código obtida para C2 é |C2| = (2n – 1) e o número de palavras-código de C1 é |C1| = 2. Analisando a matriz da figura 4.8 vemos que podemos representá-la como sendo formada por k+1 matrizes geradoras, que a partir de agora serão chamadas de submatrizes, isto é,
l1 l2 lk+1
G = G1 G2 ... Gk+1
a) Onde,
l1
l2 lk+1
1 ... 1 0 ... 0 0 ... 0 G1 = 0 ... 0 G2 = 1 ... 1 ...... Gk+1= 0 ... 0
... ... ... 0 ... 0 0 ... 0 0 ... 0
b) Figura 4.9 : a)Representação da matriz fortemente ortogonal sendo formada por k+1 submatrizes G1 ,G2 ,..., Gk+1, b) Representação das submatrizes G1 ,G2 ,..., Gk+1.
Vemos que as submatrizes geradoras Gi’s , 1≤ i ≤ k, são de um código de bloco linear com parâmetros (1,lj) e cada uma delas gera duas palavras-código {0lj, 1lj}. Vamos chamar de C1j, o código gerado pela matriz geradora Gj e C2j, o código encontrado com o máximo número de palavras-código possível de modo a obtermos a decodibilidade única para o 2-BAC (C1j,C2j). Queremos mostrar que o C2j encontrado através do algoritmo implementado é o mesmo mostrado na construção 4.1 anterior. Este fato verifica-se porque, após obtermos as duas palavras-código de C1j de comprimento lj, particionamos o conjunto das lj -uplas binárias em classes laterais de C1j e verificamos que
jCvS1⊕ = {x3j ∈ C1j; x3j . ( x1j ⊕ w2j ) = 0, para algum x1j ∈ C1j}= ∅
para cada classe lateral. Onde os vetores que possuem os índices j são lj-uplas formadas a partir do arranjo padrão de C1j em relação a F l j
2 . Assim,
jwZ2
= { w2j ⊕ x3j ∈ v ⊕ C1j, ∀ x3j ∈ jCvS
1⊕ , x3j ≠ 0 } = ∅ pois não teremos o elemento x3j.
Desta forma não eliminaremos nenhum vetor das classes laterais e o código C2j será formado por todas as lj -uplas contidas nas classes laterais juntamente com uma lj -upla que C2j

Implementação algorítimica de códigos lineares para o 2-BAC 49
poderá ter em comum com o código C1j .Assim o código C2j será formado por todas as lj -uplas com exceção de uma que pertença a C1j . Isto quer dizer que o número de palavras-código para o código C2j será exatamente | C2j | = 2lj –1, 1≤ j ≤ k. Vamos a partir de agora analisar a submatriz geradora Gk+1. Vemos que ela gera um código cujo vetor nulo é sua única palavra-código, o código C2,k+1 portanto pode ter qualquer uma das lk+1-uplas como palavras-código, incluindo o vetor nulo. Portanto o máximo ⎜C2,k+1⎜é 2 lk +1 . Como temos as k+1 submatrizes lado a lado, formando a matriz geradora G, as palavras-código de C2 resultam da concatenação das palavras-código de C2j e portanto o máximo número de palavras-código pertencentes ao código C2 será:
)12(1
2 −=∏=
k
lj
ljC .2 lk +1 (4.1)
Podemos sintetizar os resultados obtidos acima no seguinte teorema.
Teorema 4.1: A partir do código binário linear fortemente ortogonal C1, encontramos um
código C2, de máxima cardinalidade, contendo )12(1
2 −=∏=
k
lj
ljC . 2 lk +1 palavras- código, de
modo a obtermos o par (C1,C2) unicamente decodificável no 2-BAC. Exemplo 4.2: Consideremos a matriz geradora fortemente ortogonal para C1 abaixo, com l1 = 3, l2 = 2 e l3 = 1. Interessa-nos saber qual o número máximo de palavras-código que podemos obter para C2 de modo a garantir a decodibilidade única de (C1,C2) no 2-BAC.
1 0 0 1 1 0 1 1 1 0 0 0
G = 0 1 0 0 0 1 ou de forma equivalente G’ = 0 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0 0 1
Utilizando a equação (4.1) temos que:
∏=
−=3
12 )12(
lj
ljC = (2l1-1).(2l2-1).(2l3-1) = (23-1).(22-1).(21-1) = 21
Assim C2 terá um total de 21 palavras-código, que podem ser vistas na tela da figura 4.10 construída a partir do algoritmo implementado.

50 Capítulo 4. Resultados Experimentais
Figura 4.10: Palavras-código obtidas para C2. Definição 4.1: Seja C1 um código de bloco linear sobre F2 de parâmetros (n,k), com matriz geradora G na forma sistemática. Denominando a i-ésima linha da matriz G por ci e considerando-as como vetores em nF2 , dizemos que C1 é um código fortemente ortogonal balanceado se ci . cj = 0, ∀i,j=1,2,...k, com i≠j; e cuja matriz geradora tem a seguinte representação:
k l1-1 l2 -1 lk-1 10...0 1...1 0...0 ... 0...0 01...0 0...0 1...1 ... 0...0
0...01 0...0 0...0 ... 1...1
com lj = l, 1≤ j ≤ k. Uma propriedade interessante de códigos fortemente ortogonais balanceados é que suas matrizes geradoras podem ser representadas de forma equivalente por matrizes identidade dispostas lado a lado, conforme figura 4.11 , onde Ik é a matriz identidade de dimensão k.

Implementação algorítimica de códigos lineares para o 2-BAC 51
Ik Ik ... Ik
a)
k k k k 10...0 10...0 10...0 ... 10...0 01...0 01...0 01...0 ... 01...0
0...01 0...01 0...01... 0...01
b) Figura 4.11: a) e b) Representação de matrizes fortemente ortogonais balanceadas.
Este fato ocorre pois, supondo a matriz geradora como na figura 4.7, podemos construir uma nova matriz geradora equivalente G’ agrupando k colunas distintas, formando matrizes identidade, conforme mostrado na fig 4.11 a) e b). A matriz G’ gera um código C1’ equivalente a C1 no sentido de que um é obtido do outro através de uma permutação de coordenadas. A outra forma de construção para estes códigos é obtida quando o retiramos da forma sistemática agrupando todas as colunas idênticas, inclusive as que fazem parte da primeira matriz identidade. Podemos visualizar esta representação através da figura 4.12.
k k k 11...1 00...0 ... 00...0 00...0 11...1 ... 00...0
00...0 00...0 ... 11...1
Figura 4.12: Representação de matriz geradora fortemente ortogonal balanceada agrupando-se todas as colunas idênticas.
Aplicando o teorema 4.1 para matrizes fortemente ortogonais balanceadas, encontramos que,
klk
jCC )12(22 −== (4.2)
pois cada palavra-código de C2 será formada pela combinação das (2l –1) palavras-código de todos os C2j’s, 1≤ j ≤ k. Neste caso temos que,
)12log()12log(2 −=
−= l
kl
nk
nR (4.3)
)12log(21 −+=+= l
nk
nkRRR (4.4)
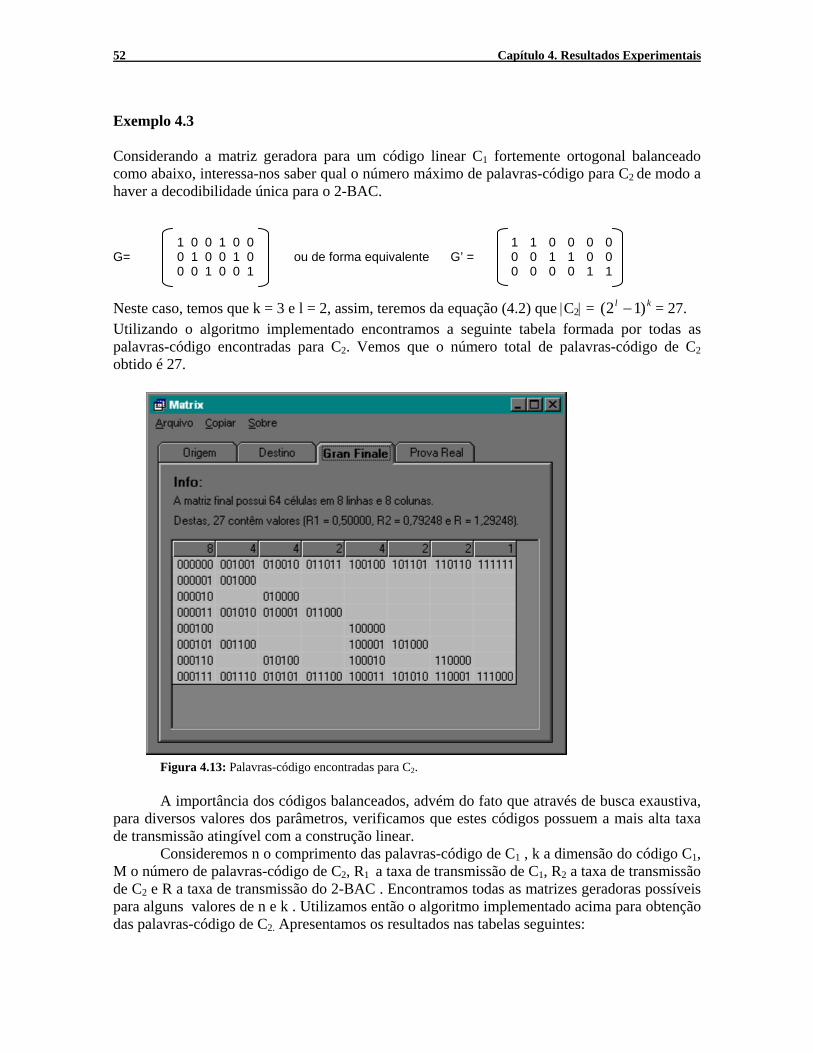
52 Capítulo 4. Resultados Experimentais
Exemplo 4.3 Considerando a matriz geradora para um código linear C1 fortemente ortogonal balanceado como abaixo, interessa-nos saber qual o número máximo de palavras-código para C2 de modo a haver a decodibilidade única para o 2-BAC.
1 0 0 1 0 0 1 1 0 0 0 0 G= 0 1 0 0 1 0 ou de forma equivalente G’ = 0 0 1 1 0 0
0 0 1 0 0 1 0 0 0 0 1 1 Neste caso, temos que k = 3 e l = 2, assim, teremos da equação (4.2) que |C2| = kl )12( − = 27. Utilizando o algoritmo implementado encontramos a seguinte tabela formada por todas as palavras-código encontradas para C2. Vemos que o número total de palavras-código de C2 obtido é 27. Figura 4.13: Palavras-código encontradas para C2. A importância dos códigos balanceados, advém do fato que através de busca exaustiva, para diversos valores dos parâmetros, verificamos que estes códigos possuem a mais alta taxa de transmissão atingível com a construção linear. Consideremos n o comprimento das palavras-código de C1 , k a dimensão do código C1, M o número de palavras-código de C2, R1 a taxa de transmissão de C1, R2 a taxa de transmissão de C2 e R a taxa de transmissão do 2-BAC . Encontramos todas as matrizes geradoras possíveis para alguns valores de n e k . Utilizamos então o algoritmo implementado acima para obtenção das palavras-código de C2. Apresentamos os resultados nas tabelas seguintes:
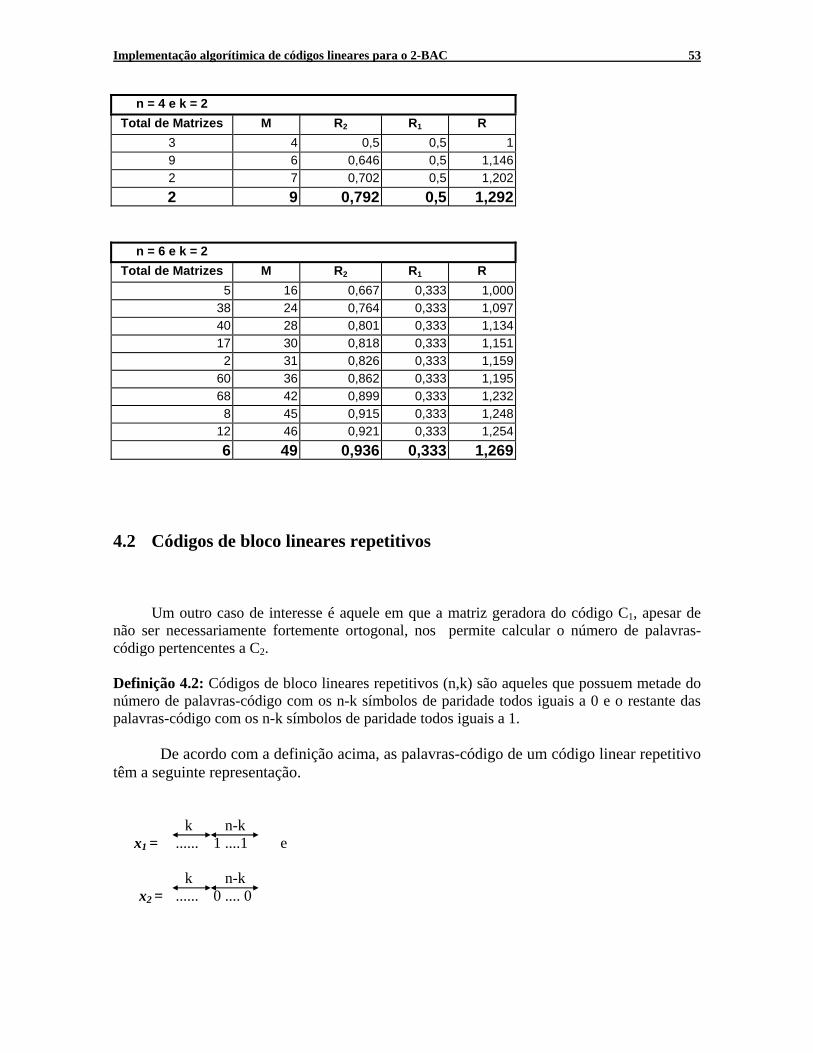
Implementação algorítimica de códigos lineares para o 2-BAC 53
n = 4 e k = 2 Total de Matrizes M R2 R1 R
3 4 0,5 0,5 19 6 0,646 0,5 1,1462 7 0,702 0,5 1,2022 9 0,792 0,5 1,292
n = 6 e k = 2 Total de Matrizes M R2 R1 R
5 16 0,667 0,333 1,00038 24 0,764 0,333 1,09740 28 0,801 0,333 1,13417 30 0,818 0,333 1,151
2 31 0,826 0,333 1,15960 36 0,862 0,333 1,19568 42 0,899 0,333 1,232
8 45 0,915 0,333 1,24812 46 0,921 0,333 1,2546 49 0,936 0,333 1,269
4.2 Códigos de bloco lineares repetitivos
Um outro caso de interesse é aquele em que a matriz geradora do código C1, apesar de não ser necessariamente fortemente ortogonal, nos permite calcular o número de palavras-código pertencentes a C2.
Definição 4.2: Códigos de bloco lineares repetitivos (n,k) são aqueles que possuem metade do número de palavras-código com os n-k símbolos de paridade todos iguais a 0 e o restante das palavras-código com os n-k símbolos de paridade todos iguais a 1. De acordo com a definição acima, as palavras-código de um código linear repetitivo têm a seguinte representação.
k
n-k
x1 = ...... 1 ....1 e
k
n-k
x2 = ...... 0 .... 0

54 Capítulo 4. Resultados Experimentais
Exemplo 4.4: O código C = {10111, 01111, 11000, 00000}, no qual n = 5 e k = 2, é um código linear repetitivo pois além de linear, temos duas palavras-codigo com os n-k símbolos de paridade “000” e duas palavras-código com os n-k símbolos de paridade “111” .
Da definição 4.2 decorre que a matriz geradora de um código de bloco linear repetitivo (n, k) na forma sistemática tem a seguinte forma:
1 0 0 ... 0 g00 g01 ...... g0,n-k-1 G = 0 1 0 ... 0 g10 g11 ...... g1,n-k-1
0 0 0 ... 1 gk-1,0 gk-1,1 ...... gk-1,n-k-1
ou
1 0 0 ... 0 g0 G = 0 1 0 ... 0 g1
0 0 0 ... 1 gk-1
onde gi , 0≤ i ≤ k-1 pode ter apenas uma das seguintes representações gi = (11... 1) ou gi = (00... 0). Representemos por u = (u0, u1,u2,... uk-1) uma mensagem a ser codificada, cuja palavra-código correspondente é v = (v0, v1, v2,... vn-1) = (u0, u1,u2,... uk-1).G. Os componentes de v são portanto, vi = uj , 0 ≤ i ≤ k-1 vk+j = u0.g0j + u1.g1j + ... uk-1.gk-1j , 0≤ j ≤ n-k-1
Podemos representar vk+j = ul0 + ul1 + ... + ul m-1 , onde uli, 0≤ i ≤ m-1, é o símbolo da mensagem que foi multiplicado por algum gi ≠ 0, 0 ≤ i ≤ k-1. Como temos, a soma dos símbolos de 2m-1-uplas distintas e como metade destas 2m-1-uplas distintas possuem peso par e o restante peso ímpar, temos que a metade das palavras-código possuem os “n-k” símbolos de paridade todos 1’s e a outra metade todos 0’s. Nosso interesse é que a partir da matriz geradora de C1 , um código linear repetitivo, possamos obter o máximo número de palavras-código de imediato para C2 de modo a termos o 2-BAC unicamente decodificável. O próximo lema estabelece que o conjunto
1CvS ⊕ é formado por todas as palavras-código pertencentes a C1, cujo produto com qualquer vetor da classe lateral cujo lider é v resulte no vetor nulo. Lema 4.1: Sejam ai , 1≤ i ≤ k , todos os vetores de uma determinada classe lateral, cujo líder de classe é v , então
1CvS ⊕ = {x3 ∈ C1; x3 . ai = 0, para ai ∈ classe lateral cujo líder de classe é v} ⊆ C1. Demonstração: Sabemos do lema 3.2 que para quaisquer vetores w2 e w2’ ∈ v⊕C1 temos que '
2wS =
2wS =
1CvS ⊕ , onde 1CvS ⊕ = {x3 ∈ C1; x3 .(x1 ⊕ w2 ) = 0, para x1 ∈ C1} ⊆ C1. Se escolhermos w2 = v,

Implementação algorítimica de códigos lineares para o 2-BAC 55
teremos que 1CvS ⊕ = {x3 ∈ C1; x3 .(x1 ⊕ v ) = 0, para x1 ∈ C1} ⊆ C1, mas (x1 ⊕ v ) para todos os
x1 ∈ C1 serão os vetores ai , 1 ≤ i ≤ k . Assim 1CvS ⊕ = {x3 ∈ C1; x3 . ai = 0, para ai ∈ classe
lateral cujo líder de classe é v} ⊆ C1.
Teorema 4.2: O número máximo possível de 2n-k+1-2 palavras-código é obtido para C2 quando C1 é um código linear repetitivo tendo sua matriz geradora (kxn) possuindo um número par de linhas em que os “n-k” últimos símbolos são 1’s. Demonstração: Vamos particionar F n
2 em classes laterais de C1, utilizando os líderes de classe como um espaço complementar a C1. Isto é, os líderes de classe devem ser formados pelas combinações lineares das linhas da matriz representada abaixo.
0 (n-k)xk In-k
Figura 4.14: Matriz geradora dos líderes de classe.
Assim os 2n-k líderes de classe terão os k primeiros símbolos nulos e os n-k símbolos restantes serão uma das 2n-k-uplas. Sabemos do lema 4.1 que o conjunto
1CvS ⊕ = {x3 ∈ C1; x3 . ai = 0,
para ai ∈ classe lateral cujo líder de classe é v} ⊆ C1, isto é, 1CvS ⊕ é formado por todos os
vetores de C1 que multiplicados com cada um dos vetores da classe lateral cujo líder é v, resulta no vetor nulo. Analisando todas as classes laterais, com exceção daquela cujo líder possui todos os n-k símbolos iguais a 1, verificamos que todos os vetores pertencentes a ela têm em todos os n-k símbolos finais pelo menos um símbolo 1.
1CvS ⊕ , portanto é formado por todos os vetores que possuam os n-k símbolos finais 0, com exceção do vetor todo nulo. Como temos 2k-1 vetores em C1 com os n-k símbolos de paridade nulos, conforme vimos no lema 4.4, nós eliminaremos a partir do v = w2 escolhido 2k-1-1 vetores de cada classe lateral. A partir de um segundo vetor escolhido para pertencer a C2, eliminaremos mais 2k-1-1 vetores de cada classe lateral. Assim nós já teremos eliminado 2k-2 vetores de cada classe, isto é, ⎢
1CvZ ⊕ ⎢= 2k-2 .
Teremos então 2 palavras-código de C2 por linha, ou ⎢1CvA ⊕ ⎢= 2, com exceção da linha cujo
líder de classe é o vetor (0...01...1), pois esta é formada por vetores que são complementares aos vetores de C1. Assim o
1CvS ⊕ neste caso, é o próprio C1 com exceção do vetor nulo e a partir do líder escolhido para fazer parte de C2 eliminamos todos os outros. Neste caso portanto C2 terá um total de 2n-k+1-2 palavras-código.
Teorema 4.3: O número máximo possível de 2n-k+1-1 palavras-código é obtido para C2 quando C1 é um código de bloco linear repetitivo tendo sua matriz geradora possuindo um número ímpar de linhas em que os n-k últimos símbolos são 1’s . Demonstração: A demonstração para este caso segue idêntica a anterior com exceção da análise feita à classe lateral cujo líder de classe é o vetor (0...01...1). Esta classe lateral, diferentemente do caso

56 Capítulo 4. Resultados Experimentais
anterior não é formada por vetores complementares aos de C1 e a análise é idêntica à feita para todas as outras classes laterais do arranjo padrão. Esta classe lateral como as outras terá um total de 2 palavras-código. Desta forma C2 terá 2n-k+1-1 palavras-código.

57
5 Conclusões
O canal aditivo com dois usuários binários vem sendo estudado há vários anos e em várias partes do mundo por pesquisadores. Neste trabalho tivemos oportunidade de fazer a implementação computacional de um algoritmo proposto na literatura, mas até então não implementado, na linguagem Visual basic para obtenção de um código C2 de máxima cardinalidade a partir de um código linear C1 e assim obtermos código linear unicamente decodificável para o 2-BAC.
A partir dos resultados experimentais encontrados nesta implementação verificamos que a matriz geradora de um código fortemente ortogonal pode ser analisada como uma série de matrizes concatenadas e assim obtivemos uma expressão bastante concisa do número de palavras-código para o 2-BAC nestes casos, conforme podemos verificar abaixo:
)12(1
2 −=∏=
k
lj
ljC . 2lk+1
O conceito de códigos fortemente ortogonais balanceados foi introduzido, e foi verificado
através de busca exaustiva para diversos valores dos parâmetros, que estes códigos possuem a mais alta taxa de transmissão atingível com a construção linear.
Também foi introduzido o conceito de códigos lineares repetitivos, para os quais foram derivadas as expressões para o número de palavras-código de C2. São elas, 2n-k+1-2 ou 2n-k+1-1, que são respectivamente os números de palavras-código de C2 quando a matriz geradora de C1 tem um número par de linhas com os n-k símbolos mais à direita todos 1’s ou um número ímpar de linhas com os n-k símbolos mais à direita todos 1’s, respectivamente.
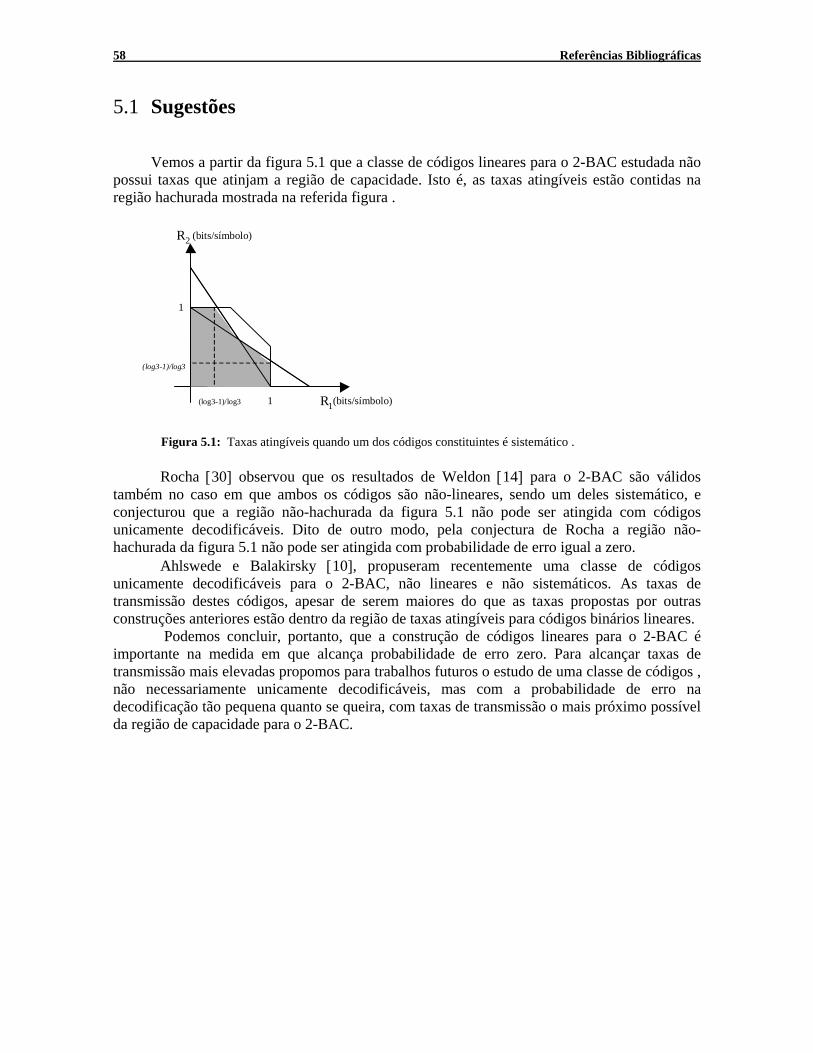
58 Referências Bibliográficas
5.1 Sugestões
Vemos a partir da figura 5.1 que a classe de códigos lineares para o 2-BAC estudada não possui taxas que atinjam a região de capacidade. Isto é, as taxas atingíveis estão contidas na região hachurada mostrada na referida figura .
Figura 5.1: Taxas atingíveis quando um dos códigos constituintes é sistemático .
Rocha [30] observou que os resultados de Weldon [14] para o 2-BAC são válidos também no caso em que ambos os códigos são não-lineares, sendo um deles sistemático, e conjecturou que a região não-hachurada da figura 5.1 não pode ser atingida com códigos unicamente decodificáveis. Dito de outro modo, pela conjectura de Rocha a região não-hachurada da figura 5.1 não pode ser atingida com probabilidade de erro igual a zero. Ahlswede e Balakirsky [10], propuseram recentemente uma classe de códigos unicamente decodificáveis para o 2-BAC, não lineares e não sistemáticos. As taxas de transmissão destes códigos, apesar de serem maiores do que as taxas propostas por outras construções anteriores estão dentro da região de taxas atingíveis para códigos binários lineares. Podemos concluir, portanto, que a construção de códigos lineares para o 2-BAC é importante na medida em que alcança probabilidade de erro zero. Para alcançar taxas de transmissão mais elevadas propomos para trabalhos futuros o estudo de uma classe de códigos , não necessariamente unicamente decodificáveis, mas com a probabilidade de erro na decodificação tão pequena quanto se queira, com taxas de transmissão o mais próximo possível da região de capacidade para o 2-BAC.
1
(log3-1)/log3
(log3-1)/log3 1 R1(bits/símbolo)
R2 (bits/símbolo)

Implementação algorítimica de códigos lineares para o 2-BAC 59
Referências Bibliográficas
[1] H. A. Cabral, Codificação para Canal de Acesso Múltiplo Síncrono, Dissertação de mestrado, Departamento de Eletrônica e Sistemas, Universidade Federal de Pernambuco, Recife, Brasil, 1994. [2] J. L. Massey, “Some new approaches to random-access communications”, in Performance’87 (Eds.P.J. Courtois and G. Latouche), Proc. 12 th IFIP WG 7.3 Int. Symp. in Computer Performance Modelling. Amsterdam and New York: North Holland 1988, pp.551-569. [3] J. L. Massey , “Channel models for random-access systems”, in Performance Limits in Communication Theory and Practice (Ed J.K. Skwirzynski), NATO Advanced Study Institute Series E142. Dordrecht, The Netherlands: Kluwer Academic, 1988, pp. 391-402. [4] V. C. da Rocha, Jr. and J. L. Massey, “A new approach to the design of codes for the binary adder channel” in Cryptography and Coding III (Ed. M.J. Ganley ), IMA Conf. Series, New Series Number 45. Oxford: Clarendon Press, 1993, pp. 179-185. [5] T. Kasami and Shu Lin, “Coding for a Multiple-access Channel”, IEEE Trans. Inform. Theory, Vol. IT-22, Number 2, march 1976, pp. 129-137. [6] T. Kasami and Shu Lin, “Bounds on the achievable rates of Block Coding for a Memoryless Multiple-access Channel” IEEE Trans. Inform. Theory , Vol. IT-24, Number 2, march 1978, pp. 187-197. [7] T. Kasami and Shu Lin, “Decoding of Linear δ-Decodable Codes for a Multiple-access Channel” IEEE Trans. Inform. Theory , Vol. IT-24, Number 5, september1978, pp. 633-635. [8] M. A. Deaett and J.K. Wolf, “Some Very Simple Codes for the Nonsynchronized Two-User Multiple-access Adder Channell with Binary inputs”, IEEE Trans. Inform. Theory , Vol. IT-24, Number 5, september1978, pp. 635-636.

60 Referências Bibliográficas
[9] P. Z. Fan, M. Darnell and B. Honary, “Superimposed Codes for the Multiacess Binary Adder Channel”, IEEE Trans. Inform. Theory , Vol. 41, Number 4, July 1995, pp. 1178-1182. [10] R. Ahlswede and V. B. Balakirsky, “Construction of Uniquely Decodable Codes for the Two-User Binary adder Channel”, IEEE Trans. Inform. Theory , Vol. 45, Number 1,January 1999, pp.326-33. [11] H.A. Cabral and V. C. da Rocha, Jr., “Linear Code Construction for the 2-User Binary Adder Channel”, IEEE Int. Symp. on Info. Theory, Whistler, Canada, 1995, pp. 497. [12]H.A. Cabral and V. C. da Rocha, Jr., “Coding for the 2-User Binary Adder Channel”, Relatório de pesquisa, Grupo de Pesquisa em Comunicações- CODEC, Universidade Federal de Pernambuco, 1995. [13] R. G. Gallager, “A Perspective on Multiaccess Channels”, IEEE Trans. Inform. Theory, Vol. IT-31, Number 2, 1985, pp.124-142. [14] E. J. Weldon, Jr., “Coding for a Multiple-access Channel”, Information and Control 36, 1978, pp. 256-274. [15] N. Abramson, Information Theory and Coding, Stanford University, McGraw-Hill Book Company, 1963. [16] Claude E. Shannon, “ A mathematical theory of communication,” Bell Syst. Tech. Journal, vol. 27, Jul 1948, pp.379-423. [17] Claude E. Shannon, “ A mathematical theory of communication,” Bell Syst. Tech. Journal, vol. 27, oct 1948, pp. 623-656,. [18] N. Abramson, “ The ALOHA system- Another alternative for computer communications”, Proc. Fall Joint Computer Conf., AFIPS Press, vol. 37, 1970, pp. 281-285,. [19] J. Capetanakis, “ A protocol for resolving conflicts on ALOHA channels”, Abstracts of Papers, IEEE Int. Symp. Info. Th., vol. IT-31, March 1985, pp. 176-184. [20] B. S. Tsybakov and V. A . Mikhailov, “ Slotted multiaccess packet broadcasting feedback channel”, Probl. Peredachi Inform., vol. 14, oct.dec.1978, pp. 32-59,. [21] W. H. Kautz and R. C. Singleton, “ Nonrandom binary superimposed codes,” IEEE Trans. Inform. Theory, vol. IT-10, N° 4, 1964, pp. 363-377. [22] P. de Laval and S. Abdul-Jabbar, “ Decoding of superimposed codes in multiaccesss communication, “ in Conf. Proc. On Area Comm, EUROCOM’88 ( Stockholm, Sweden, June 1998), pp. 154-157. [23] T. Ericson and V. Levenshtein, “Superimposed codes in Hamming space,” in IEEE Int. Symp. On Information Theory, vol. IT-12, 1966, pp. 92-96.

Implementação algorítimica de códigos lineares para o 2-BAC 61
[24] R. T. Chien and W. D. Frazer, “ No application of coding theory to document retrieval,” IEEE Trans. Inform. Theory, vol. IT-12 , N°2, pp.92-96, 1966. [25] Halvorson Michael, Microsoft Visual basic 5 passo a passo, Editora Afiliada, 1997. [26] Howard Anton and Chris Rorres, Elementary Linear Algebra with Applications. New York: John Wiley & Sons, 1987. [27] I.N. Herstein, Topics in algebra. New York: Blaisdell Publishing Company, 1964. [28] Shu Lin, Daniel costello, Error Control Coding: Fundamentals and Applications, Prentice-Hall Computer applications in electrical Engineering series, 1983. [29] L. G. Roberts, “ALOHA packet system with and whithout slots and capture”, Comp. Comm. Ver., vol 5, pp. 28-42, april 1975. [30] V. C. da Rocha, Jr., Seminário sobre codificação para o 2-BAC, Departamento de Eletrônica e Sistemas , Universidade Federal de Pernambuco, Recife, Brasil ,1995. [31] J. G. Proakis, Digital Communication, Editora Mc Graw Hill, inc., New York, 3a edição, 1995. [32] G. Kachatrian, Code construction for the two user binary adder channel. Seminário de pesquisa, Departamento de Eletrônica e Sistemas, Universidade Federal de Pernambuco, Recife, Brasil, 1992.


















