
INDEXED FILES ISAM (Indexed Sequential Access Method) · i m i ªn f v,v 1,v 2 º. Indexdateien 19...
49
Indexdateien 1 Grundlagen der Datenbanksysteme II INDEXDATEIEN ( INDEXED FILES ) ISAM (Indexed Sequential Access Method) Sätze werden nach ihren Schlüsselwerten sortiert. Schlüsselwerte sind immer vergleichbar und daher auch sortierbar. (Speicherung als Bit-Strings)
Transcript of INDEXED FILES ISAM (Indexed Sequential Access Method) · i m i ªn f v,v 1,v 2 º. Indexdateien 19...

Indexdateien 1
Grundlagen der Datenbanksysteme II
INDEXDATEIEN
( INDEXED FILES )
ISAM (Indexed Sequential Access Method)
Sätze werden nach ihren Schlüsselwerten sortiert.
Schlüsselwerte sind immer vergleichbar und daher auch
sortierbar. (Speicherung als Bit-Strings)

Indexdateien 2
Grundlagen der Datenbanksysteme II
Ordnungen der Standard-Datentypen
Ganzzahlen, reelle Zahlen (Integer, Real):
numerische Ordnung.
Zeichenketten (Character Strings):
lexikographische (alphabetische) Ordnung.
Die lexikographische Ordnung wird definiert durch die
Ordnung: X X X YY Yk m1 2 1 2
wobei X und Y jeweils Zeichen sind, wenn
1. k m und X X X YY Yk k1 2 1 2 , oder wenn
2. Für ein i k m min( , ) gilt, daß X Y X Y X Yi i1 1 2 2 1 1 , , ,
und der numerische Code für X i ist numerisch kleiner als
der für Yi .

Indexdateien 3
Grundlagen der Datenbanksysteme II
Beispiele:
‘UN’ < ‘UND’
(Regel 1)
‘BETRAG’ < ‘BETRUG’
(Regel 2 mit i=5)
B = B
E = E
T = T
R = R
A < U

Indexdateien 4
Grundlagen der Datenbanksysteme II
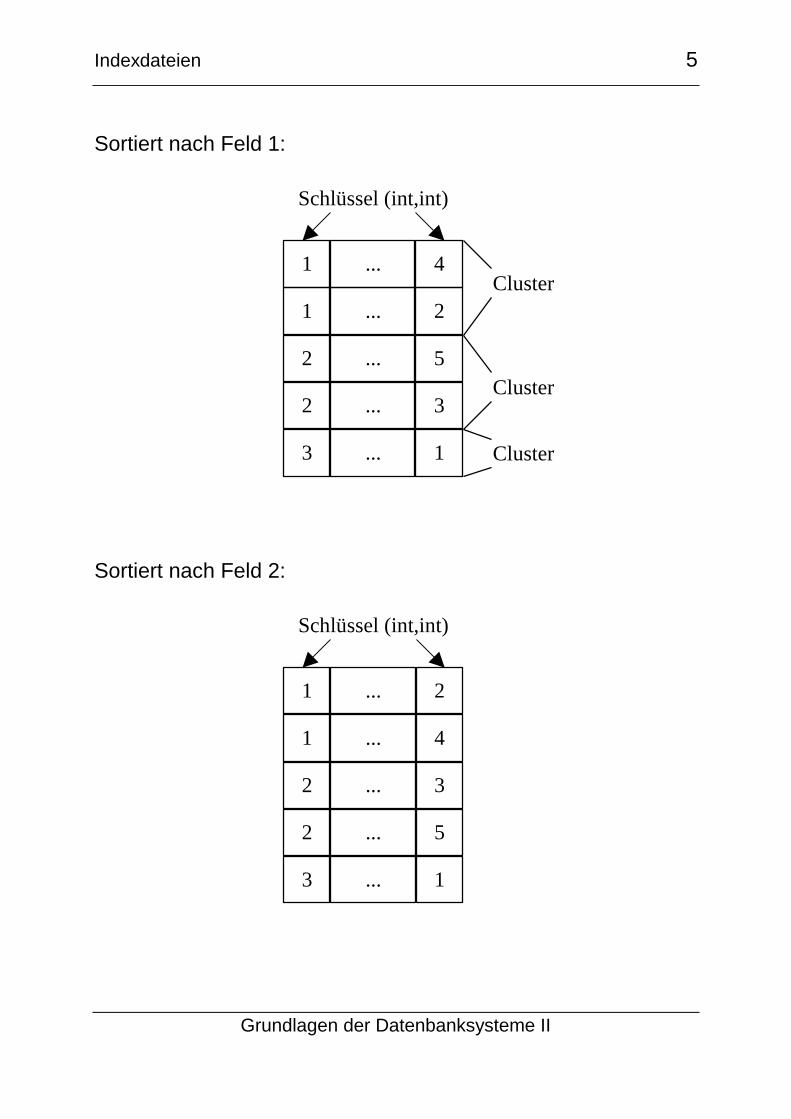
Schlüssel aus mehreren Feldern
Wenn ein Schlüssel aus mehr als einem Feld besteht, werden
die Sätze nach dem ersten Feld sortiert, wobei Cluster
entstehen, in denen der Wert im ersten Feld gleich ist. Diese
Cluster werden nach dem zweiten Feld sortiert ...
Dies stellt nur eine Generalisierung der lexikographischen
Ordnung dar.
Beispiel:
2
1
2
1
3
...
...
...
...
...
5
4
3
2
1
Schlüssel (int,int)
Indexdateien 5
Grundlagen der Datenbanksysteme II
Sortiert nach Feld 1:
1
1
2
2
3
...
...
...
...
...
4
2
5
3
1
Schlüssel (int,int)
Cluster
Cluster
Cluster
Sortiert nach Feld 2:
1
1
2
2
3
...
...
...
...
...
2
4
3
5
1
Schlüssel (int,int)

Indexdateien 6
Grundlagen der Datenbanksysteme II
Kosten: Die Datei muß über den Schlüsselwerten sortiert
sein und bleiben (Insert).
Vorteil: Die Operation Lookup wird sehr schnell ausgeführt
(wenn der Schlüsselwert bekannt ist).
Beispiele:
Wörterbuch
Telefonbuch

Indexdateien 7
Grundlagen der Datenbanksysteme II
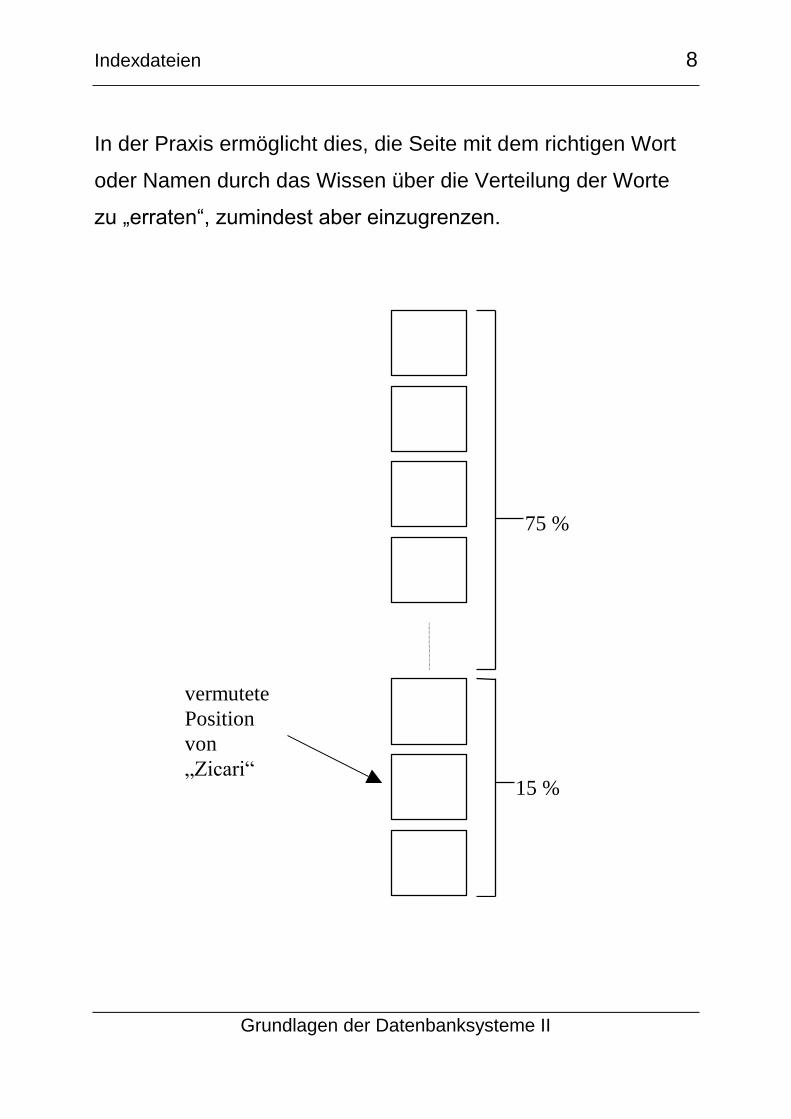
Sowohl bei Telefonbüchern als auch bei Wörterbüchern findet
sich in der oberen Ecke das erste Wort (oder der erste Name)
auf der Seite:
Schmidt
Schmidt A.
Schmidt B.
Schmidt X.
Talbot
Talbot A.
Wagner C.
Indexdateien 8
Grundlagen der Datenbanksysteme II
In der Praxis ermöglicht dies, die Seite mit dem richtigen Wort
oder Namen durch das Wissen über die Verteilung der Worte
zu „erraten“, zumindest aber einzugrenzen.
15 %
75 %
vermutete
Position
von
„Zicari“

Indexdateien 9
Grundlagen der Datenbanksysteme II
Indexdateien:
Definition: Ein Index I zu einer Datei D ist eine Datei, deren
Sätze Paare der Form (vi, bi) darstellen, wobei vi der
Schlüsselwert eines Satzes in D ist und bi die
Adresse dieses Satzes. D wird als Hauptdatei (main
file) bezeichnet.
Annahme:
Die Schlüsselwerte einer Datei sind geordnet.
Der Index ist nach den Schlüsselwerten sortiert.
Die Index Records sind unpinned.

Indexdateien 10
Grundlagen der Datenbanksysteme II
Sparse Index
Hauptdatei sortiert gespeichert. Nur ein Indexeintrag pro Block
der Hauptdatei; dieser Eintrag enthält den niedrigsten im Block
gespeicherten Schlüssel.
Beispiel: (vi,bi) : bi ist die Adresse des Blockes Bi, dessen erster
Schlüsselwert vi ist.
v b
v’ b’
v
vn
v’
Indexdatei
sortierte Hauptdatei
Block
Block

Indexdateien 11
Grundlagen der Datenbanksysteme II
Suche nach einem Schlüssel v :
Durchsuche den Index sequentiell, bis ein Satz (v1,b) gefunden
ist, für den gilt:
1. v1 v und
2. (v1,b) ist der letzte Satz, oder für den Schlüssel v2 des
nächsten Satzes im Index gilt v < v2.
Man sagt: „v1 überdeckt (covers) v“.
Durchsuche den gefundenen Block nach dem gesuchten Satz.
Die Sortierreihenfolge der Hauptdatei muß innerhalb der Blöcke
nicht eingehalten werden.

Indexdateien 12
Grundlagen der Datenbanksysteme II
Suchen in einem Index
Die Aufgabe ist, zu einem gegebenen v einen Satz (v1,b) im
Index zu finden, so daß v von v1 überdeckt wird.
1. lineare Suche:
Für einen Index mit n Blöcken müssen im Schnitt
n2 Blockzugriffe
erfolgen.
Nur für sehr kleine Indizes ausreichend schnell, aber immer
noch besser als das Durchsuchen der ganzen Hauptdatei. Für
eine Hauptdatei mit c Sätzen pro Block hat der Index nur
1/c-tel soviel Einträge wie die Hauptdatei. Außerdem passen
mehr Index-Sätze in einen Block als Hauptdatei-Sätze.

Indexdateien 13
Grundlagen der Datenbanksysteme II
2. binäre Suche:
Gegeben ist der Schlüssel v und ein Index der in den Blöcken
B1, B2, ... , Bn gespeichert ist.
Betrachtet wird dann der mittlere Block
Bn
2
und der Wert v1
des ersten Satzes in diesem Block wird mit v verglichen.
Falls
v v 1 : weiter mit den Blöcken
B Bn1
21
.
v v 1 : weiter mit den Blöcken
B Bn n
2
.
Wenn nur noch ein Block übrig ist, wird dieser linear nach dem
Schlüssel v durchsucht.
Bemerkung: Für die Abbildung der (errechneten) Werte i auf die
Adresse des Blocks Bi, wird eine Tabelle benötigt.

Indexdateien 14
Grundlagen der Datenbanksysteme II
Zeitverhalten:
Da die Anzahl der Blöcke mit jedem Schritt halbiert wird, ist die
Suche nach höchstens log2 1n Schritten beendet.
Es werden also ca. log2 n Blöcke des Index in den
Hauptspeicher geladen. Dann wird der Block der Hauptdatei
geladen und evtl. Wieder geschrieben.
Insgesamt kommt die binäre Suche im Index auf
3 2 log n Blockzugriffe.

Indexdateien 15
Grundlagen der Datenbanksysteme II
Beispiel:
Hauptdatei:
1.000.000 Sätze.
10 Sätze in jedem Block.
= 100.000 Blocks.
Index:
100.000 Sätze.
100 Sätze in jedem Block.
= 1.000 Blocks
Lineare Suche:
1000
2500
. Blockzugriffe
Binäre Suche:
3 1000 132 log . Blockzugriffe

Indexdateien 16
Grundlagen der Datenbanksysteme II
Beispiel (Fortsetzung):
Hashing:
Im optimalen Fall (Gleichverteilung) benötigt Hashing zum
finden eines Satzes nur
3 Blockzugriffe!
Dazu muss jeder Block der Hauptdatei mit 10 Sätzen gefüllt
sein und die Bucketgröße auf 100.000 gesetzt sein.
Nachteile:
Es ist schwierig, Sätze sortiert aufzulisten oder zu
bearbeiten.
Keine „Range Queries“.

Indexdateien 17
Grundlagen der Datenbanksysteme II
Dense Index
Für jeden Satz der Hauptdatei ist im Index das entsprechende
Schlüssel/Zeiger-Paar gespeichert und die Hauptdatei ist
beliebig auf Blöcke verteilt (nicht sortiert!).
Vorteil: Sätze oder Index unpinned
1. Sätze unpinned: bessere Ausnutzung der Blöcke in der
Hauptdatei.
2. Hauptdatei pinned, aber Index nicht, daher effizientere
Zugriffsstruktur auf den Index möglich.

Indexdateien 18
Grundlagen der Datenbanksysteme II
3. Interpolation (address calculation search)
Das Interpolationsverfahren basiert darauf, daß die Verteilung
der Schlüsselwerte bekannt ist.
Annahme: Es gibt einen Algorithmus f(v,v1,v2) der angibt auf
welchem Bruchstück des Weges zwischen v1 und v2 der
gesuchte Wert v liegt.
V1 V2
f(v,v1,v2) = .25
Dieser Wert muß (wieder per Tabelle) in eine Blockadresse
umgewandelt werden:
B i n f v v vi , ,1 2

Indexdateien 19
Grundlagen der Datenbanksysteme II
Der Schlüssel des ersten Satzes des so ermittelten Index-
Blocks wird dann mit dem gesuchten Wert v verglichen dann
wird wie bei der binären Suche weiter verfahren:
v v 1 : weiter mit den Blöcken 1 i 1B B
.
v v 1 : weiter mit den Blöcken i nB B .
Es kann gezeigt werden, daß dieses Verfahren
3 2 2 log log n Blockzugriffe
benötigt.
Dies sind bei dem obigen Beispiel
6 Blockzugriffe statt 13
wie bei der binären Suche.

Indexdateien 20
Grundlagen der Datenbanksysteme II
INDEX MIT UNPINNED RECORDS
Suchen
Einfügen
Löschen
Modifizieren
Annahme:
Hauptdatei sortiert, Sätze sind unpinned.
(Sparse) Index sortiert, Sätze sind unpinned.

Indexdateien 21
Grundlagen der Datenbanksysteme II
1. Suchen
R1 … Rm
B1
Bn
Header (full/empty-Bits)
Index Hauptdatei
Suche v1:
Finde im Index nach dem Block dessen erster Satz
einen Schlüssel v2 hat, der v1 überdeckt.
Suche in diesem Block nach dem Satz mit dem
Schlüssel v1. (full/empty-Bits beachten!)

Indexdateien 22
Grundlagen der Datenbanksysteme II
2. Modifizieren
Um den Satz mit dem Schlüssel v1 zu modifizieren, suche
zuerst den entsprechenden Satz.
Falls die Modifikation den Schlüssel betrifft, behandle die
Modifikation als Einfügen und Löschen.
Falls nicht, modifiziere die Daten und schreibe den Block
zurück.
Indexdateien 23
Grundlagen der Datenbanksysteme II
3. Einfügen
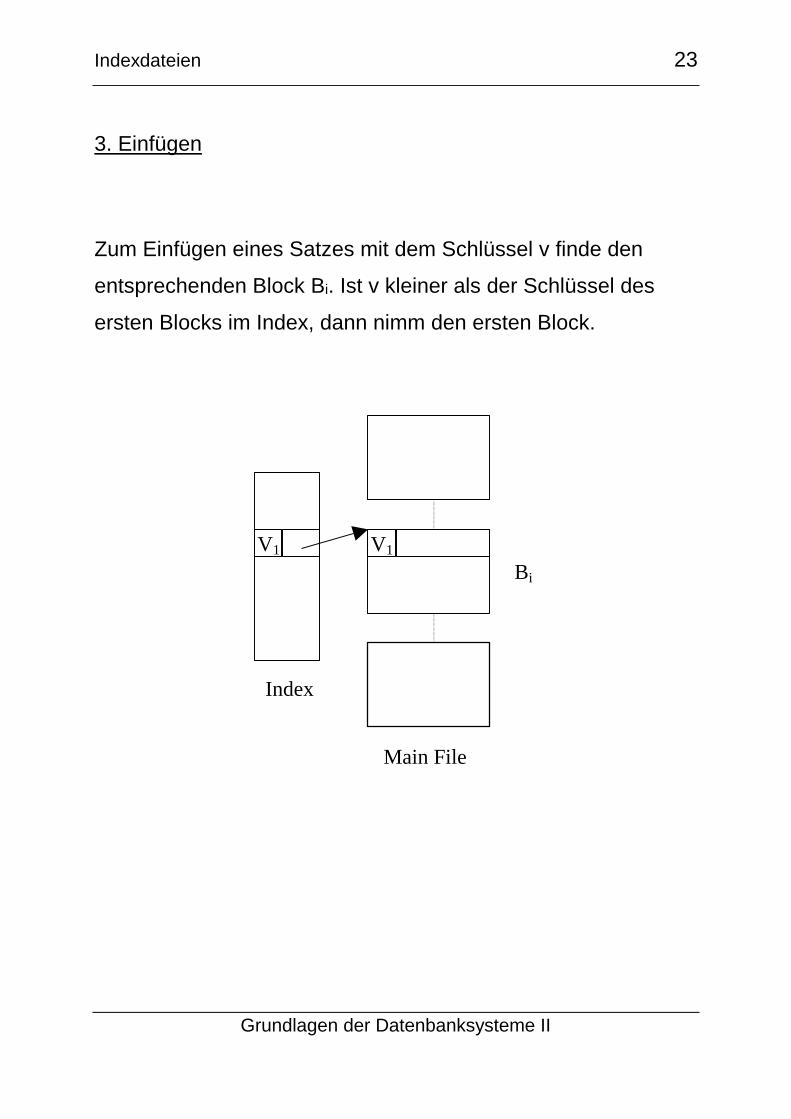
Zum Einfügen eines Satzes mit dem Schlüssel v finde den
entsprechenden Block Bi. Ist v kleiner als der Schlüssel des
ersten Blocks im Index, dann nimm den ersten Block.
V1 V1
Bi
Index
Main File
Indexdateien 24
Grundlagen der Datenbanksysteme II
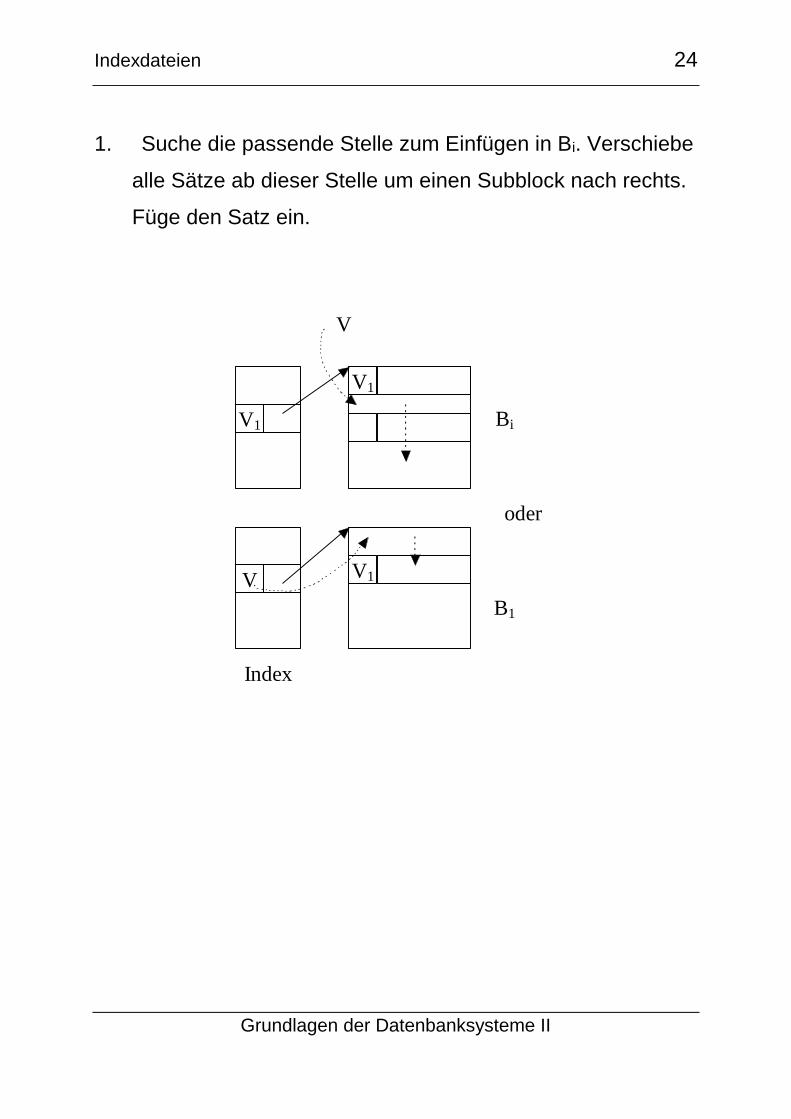
1. Suche die passende Stelle zum Einfügen in Bi. Verschiebe
alle Sätze ab dieser Stelle um einen Subblock nach rechts.
Füge den Satz ein.
V V1
B1
V1
oder
Index
V1
V
Bi
Indexdateien 25
Grundlagen der Datenbanksysteme II
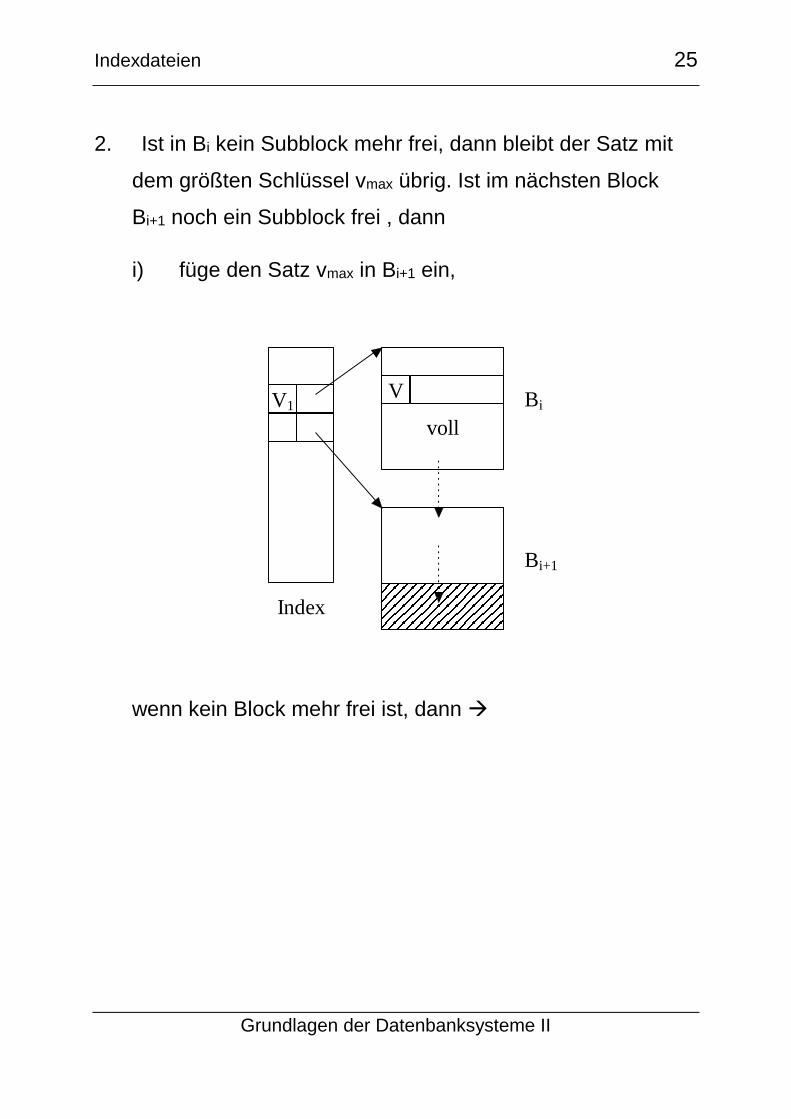
2. Ist in Bi kein Subblock mehr frei, dann bleibt der Satz mit
dem größten Schlüssel vmax übrig. Ist im nächsten Block
Bi+1 noch ein Subblock frei , dann
i) füge den Satz vmax in Bi+1 ein,
Bi+1
V
Index
V1 Bi
voll
wenn kein Block mehr frei ist, dann

Indexdateien 26
Grundlagen der Datenbanksysteme II
ii) nimm einen neuen Block Bi’ , füge den Satz in Bi’ ein.
Füge einen Satz (vmax,bi’) hinter dem Eintrag für Bi in
den Index ein.
Bi’
V
Index
V1 Bi
voll Vmax
alternativ:
Index
V1

Indexdateien 27
Grundlagen der Datenbanksysteme II
4. Löschen
a) Finde den Block, der den gesuchten Satz enthält und lösche
den Satz.
b) Ist der Block leer, dann gib ihn frei und lösche den
dazugehörigen Indexeintrag.
c) Ist der Block nicht leer, rücke die nachfolgenden Sätze nach
links, um die Lücke zu füllen. War der gelöschte Satz der
erste Satz, dann ändere den Schlüsselwert im Indexeintrag.
V
Bi
full/empty
110
Indexdateien 28
Grundlagen der Datenbanksysteme II
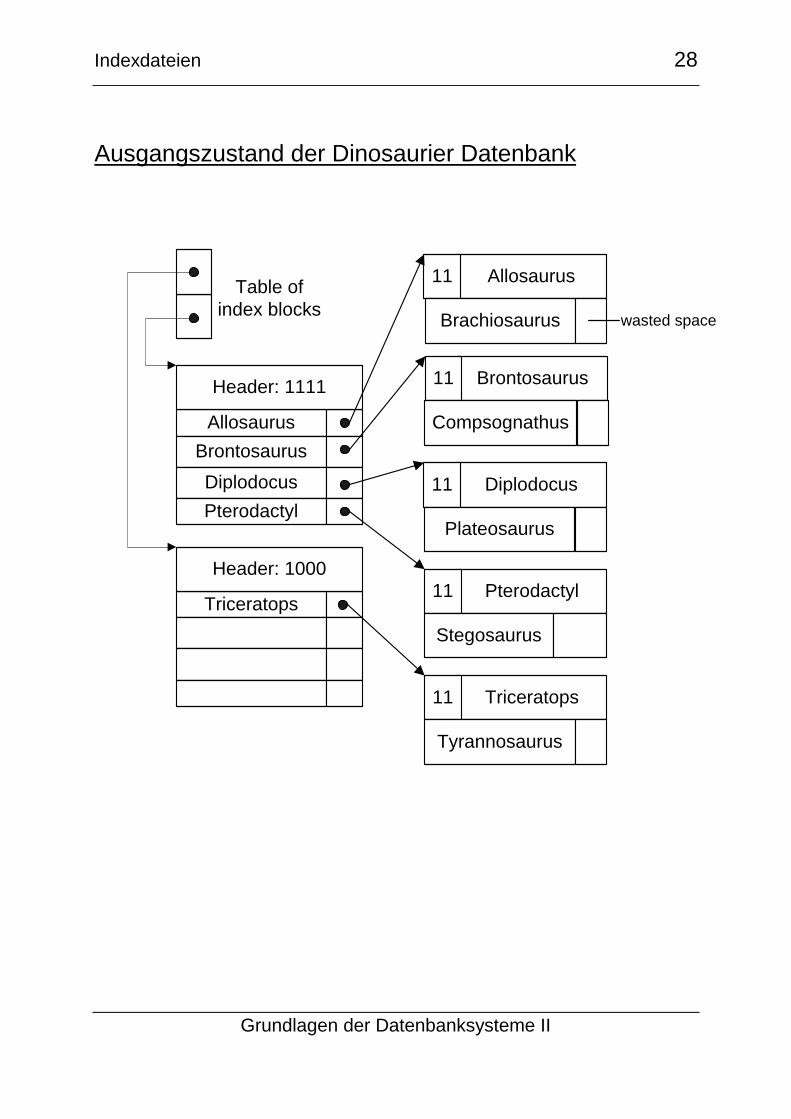
Ausgangszustand der Dinosaurier Datenbank
Allosaurus
Header: 1111
Brontosaurus
Diplodocus
Pterodactyl
Triceratops
Header: 1000
Allosaurus11
Brachiosaurus
Triceratops11
Tyrannosaurus
Pterodactyl11
Stegosaurus
Diplodocus11
Plateosaurus
Brontosaurus11
Compsognathus
wasted space
Table of
index blocks

Indexdateien 29
Grundlagen der Datenbanksysteme II
Beispiel Dino-Daten:
Einfügen von „Elasmosaurus“
1. Suche den Index nach „Elasmosaurus“
„Diplodocus“
2. Nimm den entsprechen Block der Hauptdatei (Nr. 3).
3. Durchsuche den Block:
Diplodocus Plateosaurus
4. Füge „Elasmosaurus“ vor „Plateosaurus“ ein
Block ist voll.
5. Finden des nächsten Blocks über den Index, Prüfen
des 4ten Blocks voll.
6. Neuen Block bilden.
7. Indexeintrag erzeugen.

Indexdateien 30
Grundlagen der Datenbanksysteme II
Ergebnis des Einfügens von „Elasmosaurus“
Allosaurus
Header: 1111
Brontosaurus
Diplodocus
Plateosaurus
Pterodactyl
Header: 1000
Triceratops
Allosaurus11
Brachiosaurus
Triceratops11
Tyrannosaurus
Pterodactyl11
Stegosaurus
Diplodocus11
Elasmosaurus
Brontosaurus11
Compsognathus
wasted space
Table of
index blocks
Plateosaurus10

Indexdateien 31
Grundlagen der Datenbanksysteme II
Ändern von „Brontosaurus“ zu „Apatosaurus“
1. Suche im Index nach „Brontosaurus“.
2. Lösche den Satz (weil der Schlüssel geändert wird)
3. Bewege „Compsognathus“ nach links; setze die
full/empty-Bits auf „10“.
4. Modifiziere den Indexeintrag für Block 2 zu
„Compsognathus“.
5. Einfügen von „Apatosaurus“:
6. Suche im Index nach „Apatosaurus“
„Allosaurus“
7. Nimm den Block Nummer 1.
8. Füge „Apatosaurus“ ein; Block ist voll.
Allosaurus Brachiosaurus
Apatosaurus

Indexdateien 32
Grundlagen der Datenbanksysteme II
9. Prüfen des nächsten Blocks (über Index); Platz ist
vorhanden.
10. Füge den Satz „Brachiosaurus“ ein; setze die
full/empty-bits auf „11“
CompsognathusBrachiosaurus
11. Modifiziere den Indexeintrag von Block 2 zu
„Brachiosaurus“.

Indexdateien 33
Grundlagen der Datenbanksysteme II
Ergebnis: Ändern von „Brontosaurus“ zu „Apatosaurus“
Allosaurus
Header: 1111
Brachiosaurus
Diplodocus
Plateosaurus
Pterodactyl
Header: 1000
Triceratops
Allosaurus11
Apatosaurus
Triceratops11
Tyrannosaurus
Pterodactyl11
Stegosaurus
Diplodocus11
Elasmosaurus
Brachiosaurus10
Compsognathus
wasted space
Table of
index blocks
Plateosaurus10

Indexdateien 34
Grundlagen der Datenbanksysteme II
Verkettung von Blöcken
Manchmal muß bei der Operation Einfügen der „nächste“ Block
der Hauptdatei aufgesucht werden
Index
Alternativ dazu können die Blöcke untereinander mit einem
Zeiger im Header verkettet werden:
Header

Indexdateien 35
Grundlagen der Datenbanksysteme II
Wenn dies mit ebenfalls mit dem Index gemacht wird, benötigt
man für die lineare Suche im Index keine Tabelle mehr,
sondern nur noch einen Zeiger auf den ersten Block des Index:
Index

Indexdateien 36
Grundlagen der Datenbanksysteme II
INDEX MIT PINNED RECORDS
Annahme:
Sätze der Hauptdatei sind pinned.
Folgen:
Die Sätze innerhalb eines Blocks können nicht sortiert
gehalten werden.
Es ist schwierig, sicher zu stellen, daß die Sätze eines
Blocks vor den Sätzen des folgenden Blocks liegen.

Indexdateien 37
Grundlagen der Datenbanksysteme II
Mögliche Lösung:
Anfangen mit der gleichen Organisation wie bei
unpinned Records.
Jeder Block der Hauptdatei wird als erster Block eines
Buckets gesehen.
Bei dem Einfügen von Sätzen werden zusätzliche Blocks
zum Bucket hinzugefügt; die Blocks werden
untereinander durch Zeiger verkettet.
Es wird ein leerer Block am Anfang erzeugt um ein
Bucket für die Sätze zu haben, deren Schlüssel kleiner
sind, als der des ersten Satzes der Hauptdatei. Der
entsprechende Indexeintrag hat keinen Schlüssel.
Der Index ändert sich bei dieser Organisation nie.

Indexdateien 38
Grundlagen der Datenbanksysteme II
--
B
C
D
E
X
A
B
Index,
fix bis zur Datei-Reorganisation
Indexdateien 39
Grundlagen der Datenbanksysteme II
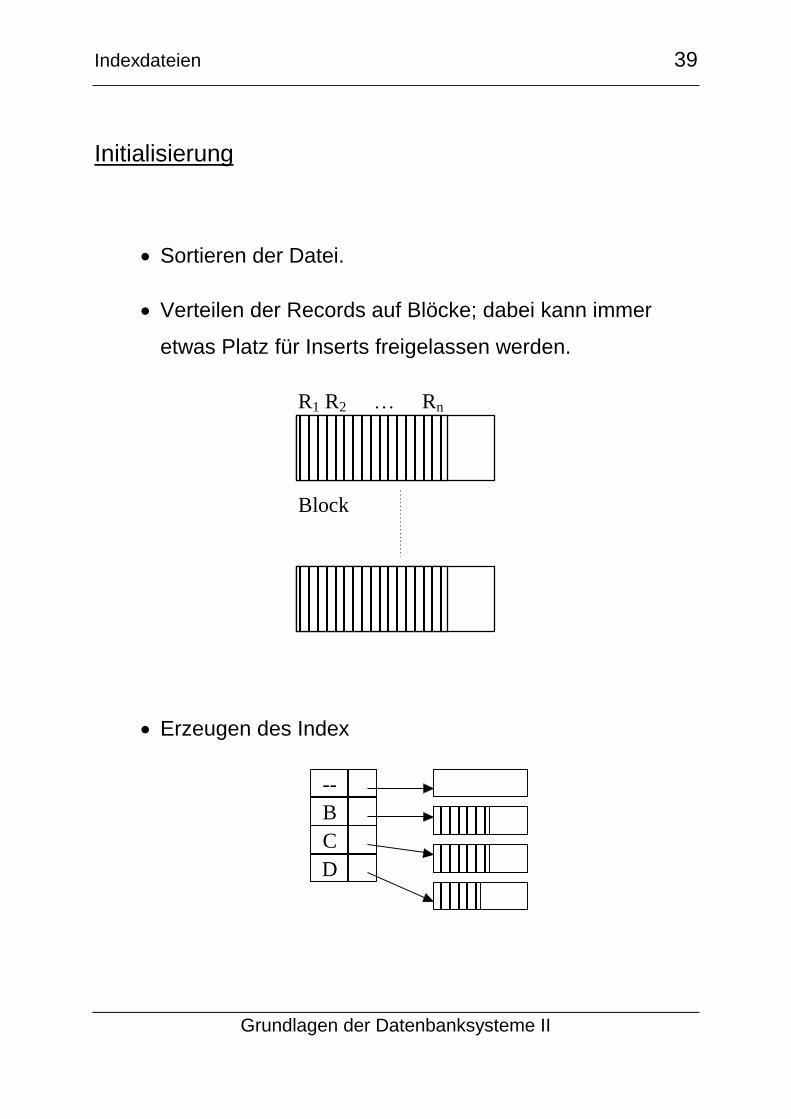
Initialisierung
Sortieren der Datei.
Verteilen der Records auf Blöcke; dabei kann immer
etwas Platz für Inserts freigelassen werden.
R1 R2 … Rn
Block
Erzeugen des Index
--
B
C
D
Indexdateien 40
Grundlagen der Datenbanksysteme II
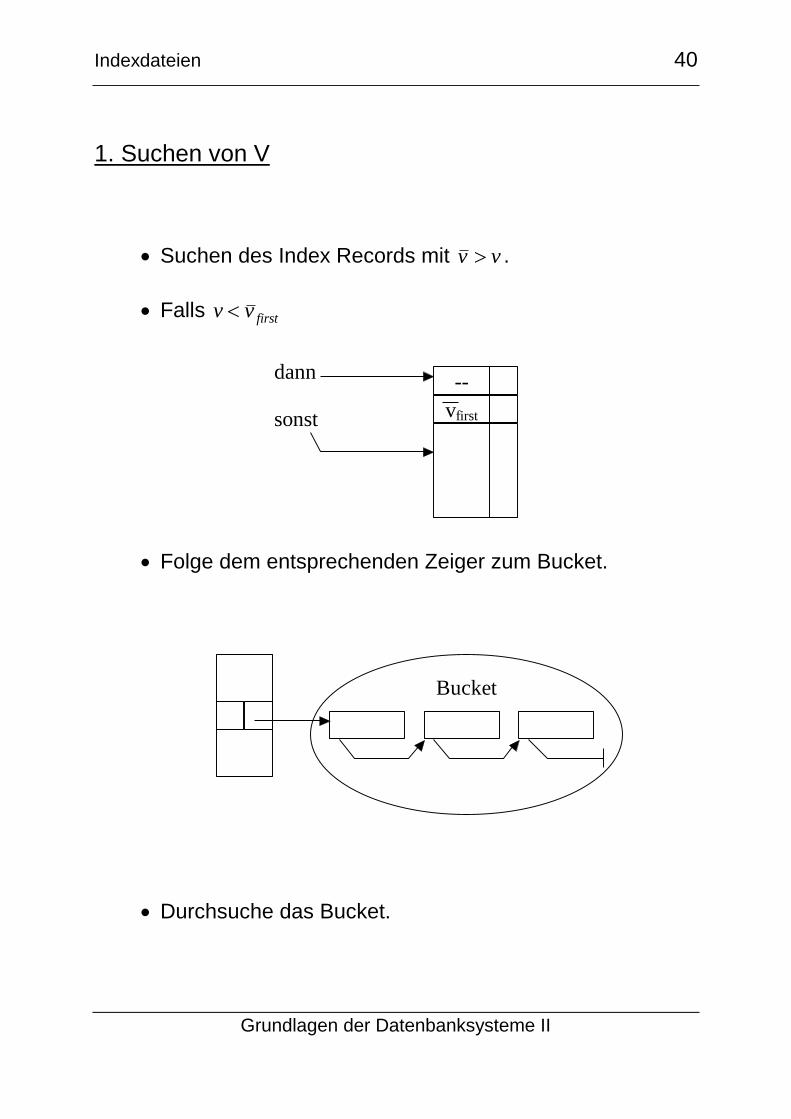
1. Suchen von V
Suchen des Index Records mit v v .
Falls v v first
--
vfirst
dann
sonst
Folge dem entsprechenden Zeiger zum Bucket.
Bucket
Durchsuche das Bucket.

Indexdateien 41
Grundlagen der Datenbanksysteme II
2. Modifikation:
Identisch mit dem Verfahren für Modifikationen bei
unpinned Records.

Indexdateien 42
Grundlagen der Datenbanksysteme II
3. Einfügen:
1. Finde den entsprechenden Indexeintrag.
2. Durchsuche die Kette der Blöcke (das Bucket) unter
diesem Eintrag nach einem freien Subblock.
3. Ist einer gefunden, dann trage den Satz dort ein. Sind
alle Blöcke voll, dann nimm einen neuen Block, trage
den Satz dort in den ersten Subblock ein und hänge
den Block ans Ende der Kette.

Indexdateien 43
Grundlagen der Datenbanksysteme II
4. Löschen:
Finde den Block, der den Satz enthält und lösche den
Satz unter Benutzung von deletion-Bits.

Indexdateien 44
Grundlagen der Datenbanksysteme II
Beispiel Dino-Daten:
full/empty bits wasted space
Index File
00 00
11 00 Brachiosaurus Diplodocus
1111 Brachiosaurus Plateosaurus Tyrannosaurus
Fig. 2.7. Initial file organisation.
Table of index blocks
11 00 Plateosaurus Stegosaurus
Dinosaur file
Abb.: Sparse Index, pinned records
10 00 Tyrannosaurus
pointer to the next block of bucket
delition bits

Indexdateien 45
Grundlagen der Datenbanksysteme II
1. Einfügen von
i) Allosaurus
Dieser Satz kommt in den ersten Subblock des
anfänglich leeren ersten Buckets.
ii) Brontosaurus
Dieser Satz kommt in das zweite Bucket. Da der
einzige Block dieses Buckets voll ist, wird ein
neuer Block angelegt
iii) Compsognathus
Dieser Satz kommt ebenfalls in das zweite
Bucket, und dort in den zweiten Subblock des
zweiten Blocks.
iv) Elasmosaurus
Auch dieser Satz kommt in das zweite Bucket.
Da alle Blöcke voll sind, wird ein dritter Block
benötigt.
v) Pterodactylus
Dieser Satz gehört in Bucket Nummer 3, und
kommt dort in einen neuen Block.

Indexdateien 46
Grundlagen der Datenbanksysteme II
vi) Triceratops
Dieser Satz kommt in das dritte Bucket.
2. Ändern
i) Brontosaurus Apatosaurus
Der Satz für Brontosaurus im zweiten Block wird
gelöscht.
Der Satz für Apatosaurus wird im ersten Bucket
eingefügt, dort belegt er den zweiten Subblock
der ersten Blocks.

Indexdateien 47
Grundlagen der Datenbanksysteme II
11 00 Allosaurus Apatosaurus
1111 Brachiosaurus Plateosaurus Tyrannosaurus
Fig. 2.8. Final file organisation.
Table of index blocks
11 00 Plateosaurus Stegosaurus
nach Hinzufügen von: Allosaurus, Brontosaurus, Compsognathus,
Pterodactyl, Triceratops, Elasmosaurus
Ändern von Brontosaurus zu Apatosaurus
10 00 Tyrannosaurus
11 10 Brontosaurus Compsognathus
10 00 Elasmosaurus
11 00 Pterodactyl Triceratops
11 00 Brachiosaurus Diplodocus
FE/D

Indexdateien 48
Grundlagen der Datenbanksysteme II
Zusätzliche Verknüpfungen
Es ist nützlich, auch bei pinned Records die Indexblöcke
untereinander zu verknüpfen.
Auch die Buckets können in der richtigen Reihenfolge
verknüpft werden, dies kann z.B. mit einem weiteren Zeiger
im Header geschehen, oder der Zeiger im letzen Block jedes
Buckets zeigt nicht weiter auf „Null“ sondern auf den ersten
Block des folgenden Buckets (Ein Bit im Header zeigt dann
an, ob der Zeiger das nächste Bucket oder den nächsten
Block des selben Buckets referenziert).
Um die Ordnung der Records untereinander
wiederherzustellen kann zu jedem Record ein Zeiger
hinzugefügt werden, der auf den nächsten Record in der
Sortierreihenfolge verweist.

Indexdateien 49
Grundlagen der Datenbanksysteme II
01 00 Compsognathus
10 00 Elasmosaurus
11 00 Brachiosaurus Diplodocus
to first record of next bucket
from last record of previous bucket
![v Ì ] } v l Z } o ] Z v < ] v P ^ X D ] Z o U W ] v v P - kkpi.de · v Ì ] } v l Z } o ] Z v < ] v P ^ X D ] Z o U W ] v v P - kkpi.de ... í](https://static.fdokument.com/doc/165x107/5d2f93fd88c9934e178d83b4/v-i-v-l-z-o-z-v-v-p-x-d-z-o-u-w-v-v-p-kkpide-v-i-.jpg)

![v l v v µ v P µ o v ] Z ] o µ v P Z o º - netzwerk-iq · ] v h v v Z u v tK d Z º ] v P v Á Á Á X ] r Z µ ] v P v X Á Á Á X Z µ ] v P v X v Ì Á l r ] X](https://static.fdokument.com/doc/165x107/5f339816706d3b22ab6d21ea/v-l-v-v-v-p-o-v-z-o-v-p-z-o-netzwerk-iq-v-h-v-v-z-u-v-tk-d-z.jpg)
![ZEICHENGENEHMIGUNG MARKS APPROVAL€¦ · 49] ELM3033 V 50] ELM3034 V 51] ELM3040 V 52] ELM3041 V 53] ELM3042 V 54] ELM3043 V 55] ELM3044 V 56] ELM3060 V 57] ELM3061 V 58] ELM3062](https://static.fdokument.com/doc/165x107/608d33d19e39f534be7102d8/zeichengenehmigung-marks-approval-49-elm3033-v-50-elm3034-v-51-elm3040-v-52.jpg)
![] v v Z v v ^ } v v P J - Heinrich Pesch House · ] ï ' u ] v ^ X Ç ] l µ X X X ' v P Á ] o o l } u u v v o o ] Z î ì ì r i Z ] P v Z v](https://static.fdokument.com/doc/165x107/5e4954f5fd078020c77fc94d/-v-v-z-v-v-v-v-p-j-heinrich-pesch-house-u-v-x-l-x-x-x.jpg)


![Präsentation HRK Dresden · 2017. 9. 27. · µ Z ( º Z µ v P c v µ } Á ] < } v ( v Ì Ì µ / v v ] } v o ] ] µ v P > Z ] o µ v P t Z v v µ v , º v v l v v µ v](https://static.fdokument.com/doc/165x107/5fe1feddce2f88140b0e25f2/prfsentation-hrk-dresden-2017-9-27-z-z-v-p-c-v-.jpg)
![Z v , o u } v W o v P µ µ U î D ] v µ v o v P µ ( º Z v µ ...](https://static.fdokument.com/doc/165x107/6179c1d8bcdce672946fa00d/z-v-o-u-v-w-o-v-p-u-d-v-v-o-v-p-z.jpg)

![W l ] l µ u / v P v ] µ ] v ( } u ] l & µ v l ] } v v U v µ u ] Z / v P ] } v · 2019-10-06 · í ð ï x î x µ Ì µ ( p ð x & µ v l ] } v v u v µ u ] z / v p ] } v lqwpdlq](https://static.fdokument.com/doc/165x107/5e79986dc6276a020c43160c/w-l-l-u-v-p-v-v-u-l-v-l-v-v-u-v-u-z-v-p.jpg)
![Jubiläumsmagazin 210x280 final 180305€¦ · „Das ist nicht nur Spielerei, } v v ] v ' µ v ] µ } v U ] alle mit Führungsverantwortung l v v v W : u µ P Z } o µ v mitgenommen](https://static.fdokument.com/doc/165x107/5f0477af7e708231d40e1d5b/jubilumsmagazin-210x280-final-180305-adas-ist-nicht-nur-spielerei-v-v-v.jpg)
![BUCHSTABEN€¦ · [vvvvvvvvvvvvv] [vvvvvvvvvvvvv] [vvvvvvvvvvvvv] Spure nach! Fahre den Buchstaben nach. Finde "v" v v v v v v v b v m n l u d f z s y x v u [] [] [] Spure nach!](https://static.fdokument.com/doc/165x107/5f06b2217e708231d41946e8/buchstaben-vvvvvvvvvvvvv-vvvvvvvvvvvvv-vvvvvvvvvvvvv-spure-nach-fahre-den.jpg)


![Gemeindebrief Mai-Aug 2015-Internet · µ ' ] u , < } v . u v v µ } v v v l v ] Z](https://static.fdokument.com/doc/165x107/5faa46fe6adf00651e0bec8f/gemeindebrief-mai-aug-2015-internet-u-v-u-v-v-v-v-v-l-v-.jpg)

![Corona Schutzkonzept PLUTO 5.8 · 2020. 9. 5. · µ P v P o P h v u > ] u } ] À ' µ v P o v P P v v µ / v ( l ] } v v Á ] Z v t ^ ] o µ u r ] D ] ] v v Á v º ^ ] v v µ v](https://static.fdokument.com/doc/165x107/603bf614fd3af3188c4e25b1/corona-schutzkonzept-pluto-58-2020-9-5-p-v-p-o-p-h-v-u-u-.jpg)
![Präsentation Stellenmarkt 2020.pptx …...c ] v Z P ] } v U ] v µ l µ v ( ^ ] Z o v ] v o u ] v W / u : Z î ì í ô ( v v ] v EZt î î X ì ì ì i µ v P D v Z v](https://static.fdokument.com/doc/165x107/5f56885fb4bd540cfe2eb414/prfsentation-stellenmarkt-2020pptx-c-v-z-p-v-u-v-l-v-.jpg)