
Information Retrieval (SS 2011) - Evaluierung von...
38
5. Evaluierung von IRSystemen
Transcript of Information Retrieval (SS 2011) - Evaluierung von...

5. Evaluierung von IR-‐Systemen

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Rückblick✦ Inver&erter Index als wich8ge Indexstruktur im IR
✦ External Memory Sort als Schlüssel zur effizienten Indexierung
✦ Anfragebearbeitung auf dokument-‐sor8erten Indexlisten (TAAT + DAAT) und wert-‐sor8erten Indexlisten (NRA)
✦ Kompression von Indexlisten wich8g für kurze Antwortzeiten
✦ Dynamische Indexierung mit logarithmischem Verschmelzen
✦ Verteile IR-‐Systeme auf Clustern mehrerer Rechner zur schnelleren Indexierung und Anfragebearbeitung
2

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Mo8va8on
✦ Wie kann man feststellen ob ein IR-‐System Ergebnisse liefert,✦ welche den Benutzer zufrieden stellen?✦ die besser sind als die Ergebnisse eines anderen IR-‐Systems?
✦ Wie kann man die Leistungsfähigkeit eines IR-‐Systems beurteilen und mit der anderer IR-‐Systeme vergleichen?
3
The test of all knowledge is experiment.
Experiment is the sole judge of scienti:ic “truth” [Richard P. Feynman]

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Inhalt
(1) Effek8vität eines IR-‐Systems Werden die rich*gen Dinge getan? (z.B. Wie gut sind die gelieferten Ergebnisse?)
(2) Effizienz eines IR-‐Systems Werden die Dinge rich*g getan? (z.B. Wie schnell werden Ergebnisse zurückgeliefert?)
4

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
5.1 Effek&vität eines IR-‐Systems✦ Im Idealfall würde man die Benutzerzufriedenheit messen
✦ Wer sind die Benutzer, die wir zufrieden stellen möchten?✦ Endbenutzer (z.B. bei Suche auf World Wide Web)✦ Unternehmen (z.B. im E-‐Commerce)
✦ Was bedeutet es, dass der Benutzer zufrieden ist?✦ schnelleres Erledigen einer Aufgabe (z.B. Urlaub buchen)✦ höherer Umsatz (z.B. im E-‐Commerce)✦ höhere Produk8vität der Mitarbeiter (z.B. in der Wissenscha[)
✦ Benutzerzufriedenheit ist schwierig direkt zu messen, daher misst man stellvertretend meist die Relevanz der Ergebnisse
5

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Messen der Relevanz von Ergebnissen✦ Um die Relevanz von Ergebnissen zu messen, benö8gt man
✦ Gütemaßeum zu quan8fizieren, wie gut ein zurückgeliefertes Ergebnis ist
✦ Dokumentensammlungauf der das verwendete IR-‐System evaluiert werden soll
✦ Informa&onsbedürfnisse und zugehörige Anfragenals repräsenta8ve Tes_älle
✦ Relevanzbewertungendarüber ob/wie relevant Dokumente zu Informa8onsbedürfnis sind
6

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Benchmark-‐Ini8a8ven✦ Benchmark-‐Ini&a&ven spielen bei der Evaluierung im
Informa8on Retrieval tradi8onell eine große Rolle
✦ TREC (Text Retrieval Evalua8on Conference) durchgeführt vonNIST (Na8onal Ins8tute of Standard and Technology) seit 1992mit wechselnden Tracks (z.B. En8ty, Efficiency und Blog Search)
✦ CLEF (Cross Language Evalua8on Forum) seit 2000 mit Schwerpunkt auf mul8lingualem Informa8on Retrieval
✦ INEX (Ini8a8ve for the Evalua8on of XML Retrieval) seit 2002mit Schwerpunkt auf semi-‐strukturierten Daten (XML)
7

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Benchmark-‐Ini8a8ven✦ Track (z.B. Web) besteht aus ein oder mehreren Tasks
✦ Task (z.B. Ad-‐hoc) besteht i.d.R. aus Dokumentensammlung, Informa&onsbedürfnissen (sog. Topics) evtl. mit Anfragen sowie passenden Relevanzbewertungen (relevance assessments oder qrels)
✦ Die Teilnehmer stehen bei der Bearbeitung der Tasks im WeVbewerb zueinander
✦ Daten und Ergebnisse der Tracks sind über den WeVbewerb hinaus verfügbar, um eine Wiederholbarkeit der Experimente und Vergleichbarkeit ihrer Ergebnisse zu gewährleisten
8

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Precision & Recall✦ Precision (Präzision)
✦ Recall (Ausbeute)
✦ Relevante Ergebnisse (true posi*ves) tp✦ Irrelevante Ergebnisse (false posi*ves) fp✦ Relevante Nicht-‐Ergebnisse (false nega*ves) fn✦ Irrelevante Nicht-‐Ergebnisse (true nega*ves) tn
9
#tp
#tp+#fp=
# Relevanter Dokumente im Ergebnis
# Dokumente im Ergebnis
#tp
#tp+#fn=
# Relevanter Dokumente im Ergebnis
# Relevanter Dokumente
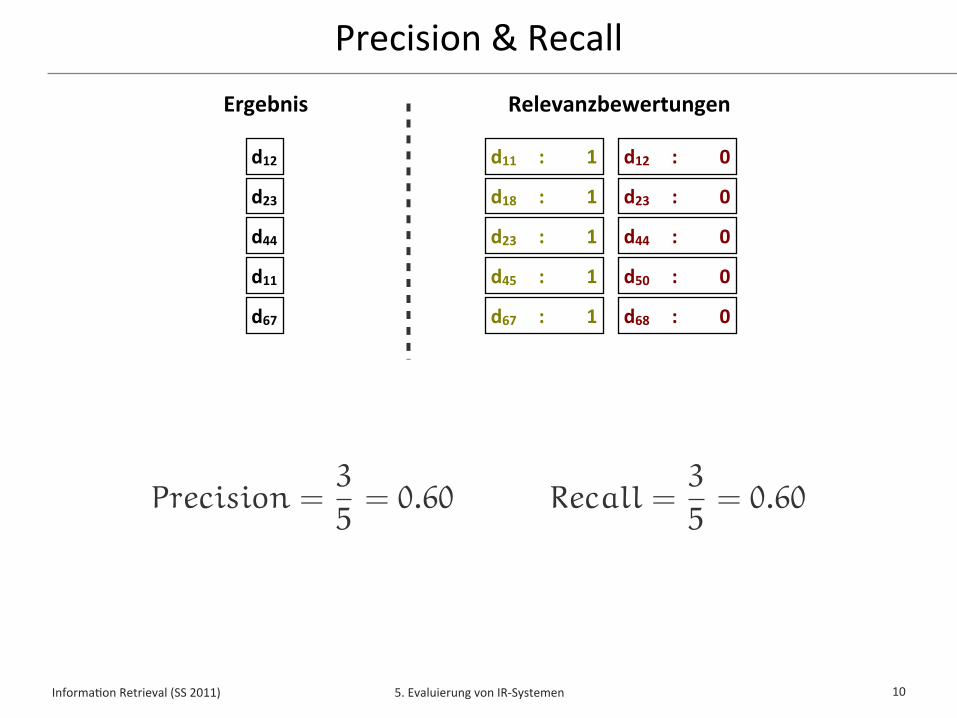
Precision =3
5= 0.60 Recall =
3
5= 0.60
Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Precision & Recall
10
RelevanzbewertungenErgebnis
d12
d23
d44
d11
d67
d11 : 1
d18 : 1
d23 : 1
d45 : 1
d67 : 1
d12 : 0
d23 : 0
d44 : 0
d50 : 0
d68 : 0

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Precision & Recall✦ Precision misst Fähigkeit nur relevante Dokumente zu finden
✦ Recall misst Fähigkeit alle relevanten Dokumente zu finden
✦ Zielkonflikt (trade-‐off) zwischen Precision und Recall✦ perfekter Recall / niedrige Precision – liefere alle Dokument zurück✦ höherer Recall geht i. Allg. mit niedrigerer Precision einher
✦ Kri&kpunkte an Precision und Recall✦ Zwei voneinander abhängige Maße schwierig zu interpre8eren✦ Rangfolge der Dokumente im Ergebnis spielt keine Rolle✦ Binärer Relevanzbegriff – Dokument ist relevant oder irrelevant
11

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
F-‐Maß✦ Kombina8on von Precision P und Recall R im F-‐Maß
als gewichtetes harmonisches MiVel der beiden
✦ Für α = 0.5 erhält man das harmonische Milel von P und R
welches auch als F1-‐Maß bezeichnet wird
12
F =1
α 1P + (1− α) 1R
F1 =2 P R
P + R

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Precision@k und Recall@k✦ Precision und Recall ignorieren Rangfolge der Ergebnisse
✦ Precision@k ermilelt Precision nur auf Top-‐k Dokumenten
✦ Recall@k ermilelt Recall nur auf Top-‐k Dokumenten
✦ Precision@k ist eines der gängigsten Gütemaße, wobei typische Werte für k in {1, 5, 10} liegen
✦ Bei Betrachtung mehrerer Informa&onsbedürfnisse oder Anfragen wird der DurchschniV (arithme8sches Milel) der Precision@k-‐Werte betrachtet
13

Precision@3 =1
3≈ 0.33 Recall@3 =
1
5= 0.2
Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Precision@k und Recall@k
14
RelevanzbewertungenErgebnis
d12
d23
d44
d11
d67
d11 : 1
d18 : 1
d23 : 1
d45 : 1
d67 : 1
d12 : 0
d23 : 0
d44 : 0
d50 : 0
d68 : 0

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Precision-‐Recall-‐Diagramm✦ Precision-‐Recall-‐Diagramm visualisiert Precision@k und
Recall@k der Top-‐k für verschiedene Werte von k
✦ Interpolierte Präzision(interpolated precision)
15
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.2 0.4 0.6 0.8 1
Prec
isio
n
Recall
non-interpolated
interpolated
P(k) = maxk �≥k P(k�)

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Mean Average Precision✦ Average Precision (AP) für Anfrage qj ist die durchschniVliche
Precision beim Zurückliefern eines relevanten Dokuments
✦ Mean Average Precision ist die millere Average Precision für eine Menge von Informa8onsbedürfnissen Q
16
AP(qj) =1
m j
m j�
k=1
Precision(Rjk)
MAP(Q) =1
|Q|
�
qj∈Q
1
m j
m j�
k=1
Precision(Rjk)

AP =1
5
�2
4+ 0+
1
2+ 0+
3
5
�= 0.32
Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Mean Average Precision
17
RelevanzbewertungenErgebnis
d12
d23
d44
d11
d67
d11 : 1
d18 : 1
d23 : 1
d45 : 1
d67 : 1
d12 : 0
d23 : 0
d44 : 0
d50 : 0
d68 : 0

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
nDCG✦ Precision, Recall und MAP für binäre Relevanzbewertungen,
d.h. Dokument relevant/irrelevant zu Informa8onsbedürfnis
✦ Normalized Discounted Cumula&ve Gain (nDCG) als Gütemaß für abgestude Relevanzbewertungen auf Grundlage der Top-‐k
✦ R(j,m) ist die Relevanzbewertung (z.B. irrelevant (0), teilweise relevant (1) oder relevant (2)) für m-‐tes Dokument im Ergebnis
✦ Konstante Zk normalisiert Werte auf Intervall [0, 1] anhand eines angenommenen bestmöglichen Ergebnis
18
NDCG(Q, k) =1
|Q|
|Q|�
j=1
Zk
k�
m=1
2R(j,m) − 1
log(1+m)

Z3 =
�22 − 1
log(1+ 1)+
22 − 1
log(1+ 2)+
21 − 1
log(1+ 3)
�−1
= (9.97+ 6.29+ 1.66)−1
= 0.06
NDCG(Q, 3) = Z3
�20 − 1
log(1+ 1)+
21 − 1
log(1+ 2)+
20 − 1
log(1+ 3)
�
= 0.06 (0+ 2.10+ 0)
= 0.13
Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
nDCG
19
RelevanzbewertungenErgebnis
d12
d23
d44
d11
d67
d11 : 2
d18 : 2
d23 : 1
d45 : 1
d67 : 1
d12 : 0
d23 : 0
d44 : 0
d50 : 0
d68 : 0

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Dokumentensammlung✦ Verwendung allgemein verfügbarer Dokumentensammlungen
sinnvoll, um die Wiederholbarkeit von Experimenten und die Vergleichbarkeit ihrer Ergebnisse zu gewährleisten
✦ Dokumentensammlungen aus Benchmark-‐Ini8a8ven z.B.✦ Tipster/TREC – fünf CDs mit Nachrichten und öffentl. Mileilungen✦ TREC GOV2 – 25 Millionen Webseiten aus .gov Top-‐Level Domäne ✦ ClueWeb09 – 1 Milliarde Webseiten diverser Top-‐Level Domänen
✦ Weitere allgemein verfügbare Dokumentensammlungen z.B.✦ Wikipedia (sowie verwandte Projekte wie Wikinews)✦ The New York Times Annotated Corpus✦ Medline (Kurzfassungen medizinischer Fachar8kel)
20

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Informa8onsbedürfnisse und Anfragen✦ Informa&onsbedürfnisse und Anfragen als Tes_älle
✦ müssen zur verwendeten Dokumentensammlung passen✦ von Experten oder potenziellen Benutzern definiert✦ für eingesetzte Systeme abgeleitet aus tatsächlichen Anfragen
✦ Beispiel: Topic 426 from TREC 1999
21
<top><num> Number: 426<title> law enforcement dogs<desc> Description:Provide information on the use of dogs worldwide for law enforcement purposes.<narr> Narrative:Relevant items include specific information on the use of dogs during an operation. Training of dogs and their handlers are also relevant.
</top>

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Bewerten der Relevanz von Dokumenten✦ Gütemaße basieren auf Bewertungen darüber ob/wie
relevant ein Dokument zu einem Informa8onsbedürfnis ist
✦ Für welche Dokumente soll man zu einem bes8mmten Informa8onsbedürfnis die Relevanz bewerten lassen?
✦ Wie (z.B. binär) soll die Relevanz bewertet werden?
✦ Wer soll die Relevanz bewerten und wie viele unabhängige Bewertungen benö8gt man für jedes Dokument?
22

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Cranfield-‐Experimente und Pooling✦ In den Cranfield-‐Experimenten während den 1960ern wurden
für jedes Informa&onsbedürfnis alle Dokumente bewertet✦ nur für sehr kleine Dokumentensammlungen prak8kabel✦ einzige Möglichkeit wirklichen Recall zu berechnen
✦ Pooling, als heute gängige Vorgehensweise, mischt für jedes Informa8onsbedürfnis die Top-‐k Ergebnisse verschiedener IR-‐Systeme oder Standard IR-‐Modelle und lässt dann die Relevanz darin enthaltener Dokumente bewerten
✦ auch für sehr große Dokumentensammlungen prak&kabel✦ zuverlässige Evaluierung eines neuen IR-‐Systems nur dann möglich,
wenn die Relevanz aller Top-‐k Ergebnisse bewertet wurde
23

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Art der Relevanzbewertungen✦ Binäre Relevanzbewertungen noch weit verbreitet
✦ 1 : Dokument ist relevant✦ 0 : Dokument ist irrelevant
✦ Abgestude Relevanzbewertungen zunehmend verbreitet z.B.✦ 2 : Dokument ist relevant✦ 1 : Dokument ist teilweise relevant ✦ 0 : Dokument ist irrelevant
✦ Zudem macht es Sinn, den Bewertenden eine Möglichkeit zu geben, keine Relevanzbewertung abzugeben (z.B. wenn sie das Informa8onsbedürfnis oder Dokument nicht verstehen)
24

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Bewertende✦ Relevanzbewertungen können vorgenommen werden von
✦ wenigen hochqualifizierten extra geschulten Bewertenden(gängiger Ansatz in der Industrie und bei Benchmark-‐Ini8a8ven)
✦ wenigen Studenten oder anderen Wissenschadlern(gängiger Ansatz in der akademischen Forschung)
✦ einer großen Zahl von Bewertenden mit unklarer Qualifika&on(zunehmend populärer Ansatz)
✦ Zielkonflikt zwischen Qualifika&on und Verfügbarkeit von Bewertenden – kann z.T. durch redundante Relevanzbewertungen abgeschwächt werden
25

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Crowdsourcing✦ Crowdsourcing = Crowd (Menschenmenge) + Outsourcing
lagert kleine Aufgaben an große Zahl von Teilnehmern aus
✦ Für das erfolgreiche Bearbeiten einer Aufgabe erhält der Teilnehmer i.d.R. eine kleine Vergütung (z.B. 0,05€)
✦ Crowdsourcing wurde erfolgreich angewandt z.B. zum✦ Bes8mmen der korrekten Orien&erung von Fotos✦ Verschlagworten (tagging) von Fotos ✦ Übersetzen und korrigieren kleiner Texte✦ Bewerten der Relevanz von Anfrageergebnissen
✦ Bekannteste Plasorm ist Amazon Mechanical Turk
26

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Crowdsourcing
27

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Crowdsourcing
27

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Kappa Sta8s8k✦ Kappa Sta8s8k misst Übereins&mmung von Bewertenden
✦ P(A) als beobachtete Wahrscheinlichkeit, dass die beiden Bewertenden übereins8mmen
✦ P(E) als Wahrscheinlichkeit, dass die beiden Bewertendenbei zufälliger Bewertung übereins8mmen
28
κ =P(A)− P(E)
1− P(E)
P(E) = P(R )2 + P(NR )2

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Kappa Sta8s8k✦ Beispiel:
P(A) = (300 + 70) / 400 = 0.9250P(R) = (10 + 20 + 300 + 300) / 800 = 0.7875P(NR) = (10 + 20 + 70 + 70) / 800 = 0.2125P(E) = P(R)2 + P(NR)2 = 0.6653 κ = 0.7759
29
R NR ΣR 300 20 320
NR 10 70 80
Σ 310 90 400Bewertend
er 1 Bewertender 2

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Kappa Sta8s8k✦ Interpreta&on der Kappa Sta8s8k
✦ κ > 0.8 deutliche Übereins8mmung✦ 0.8 ≥ κ > 0.67 angemessene Übereins8mmung✦ 0.67 ≥ κ ungeeignet geringe Übereins8mmung
✦ Kappa Sta8s8k kann verallgemeinert werden für Umgang mit✦ mehr als zwei Bewertenden pro Relevanzbewertung✦ abgestu[e Relevanzbewertungen
30

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Evaluierung bei Suchmaschinen✦ Suchmaschinen wenden ebenfalls die beschriebene
Vorgehensweise an, um Ergebnisgüte zu evaluieren✦ Informa8onsbedürfnisse und Anfragen als Tes_älle✦ P@10 und nDCG@10 als gängige Gütemaße und
somit Fokus auf die ersten Ergebnisseite✦ Relevanzbewertungen durch eigens angelernte Bewertende
✦ Darüber hinaus kommen weitere Verfahren/Maße zum Einsatz✦ Klick-‐Rate (clickthrough) auf erstes Ergebnis anstal Bewertungen✦ Benutzerstudien unter Laborbedingungen
(z.B. Beobachtung des Benutzerverhaltens milels Eye-‐Tracking)✦ A/B Tes&ng
31

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
A/B Tes8ng✦ Suchmaschinen bearbeiten täglich große Zahl von Anfragen,
haben viele Benutzer und beobachten deren Verhalten
✦ A/B Tes&ng evaluiert gezielt eine Veränderung (z.B. andere Parameterwahl im verwendeten IR-‐Modell), indem es
✦ Großteil der Anfragen (z.B. 99%) mit altem System bearbeitet✦ kleinen Prozentsatz (z.B. 1%) mit geändertem System bearbeitet✦ Veränderung im Verhalten der Benutzer analysiert
(z.B. die Klick-‐Rate für das erste zurückgelieferte Ergebnis)
✦ Vorteile des A/B Tes&ngs sind u.a.✦ authen8sches Benutzerverhalten – keine Bewertungssitua&on✦ universell anwendbar (z.B. visuelle Gestaltung der Ergebnisseite)
32

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
5.2 Effizienz eines IR-‐Systems✦ Leistungsfähigkeit eines IR-‐Systems hat mehrere Aspekte z.B.
✦ Indexierungszeit, d.h. wie lange braucht das System, um eine Dokumentensammlung bes8mmter Größe zu indexieren
✦ Durchsatz, d.h. wie viele Anfragen kann das System pro gegebener Zeiteinheit bearbeiten
✦ Antwortzeit, d.h. wie lange benö8gt das System im Milel, um dem Benutzer das Ergebnis zu einer Anfrage zurückzuliefern
✦ Indexgröße, d.h. wie viel Speicherplatz nimmt der vom System verwendete Index in Anspruch
33

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Konkrete und abstrakte Effizienz-‐Maße✦ Zum Messen der verschiedenen Aspekte können entweder
konkrete oder abstrakte Effizienz-‐Maße zum Einsatz kommen
✦ Indexierungszeit (konkret: Stunden)
✦ Durchsatz (konkret: Anfragen/Sekunde)
✦ Antwortzeit (konkret: Millisekunden abstrakt: # gelesener Indexeinträge)
✦ Indexgröße(konkret: Gigabytes abstrakt: # Indexeinträge)
34

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Workload, Cache-‐Effekte und Compiler-‐Effekte✦ Insbesondere beim Messen von Antwortzeiten muss man
darauf achten, Verzerrungen zu vermeiden z.B. aufgrund von
✦ Workload (d.h. zu bearbeitende Anfragen) sollte möglichst repräsenta8v sein, um ein realis8sches Bild zu erhalten
✦ Cache-‐Effekte durch Caches seitens des Betriebssystems oder der verwendeten Hardware (z.B. Festplale)
✦ Compiler-‐Effekte durch sukzessive Op8mierungen des Compilers (z.B. bei den Just-‐In-‐Time Compilern von Java und .NET)
35

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Zusammenfassung✦ Effek&vität (z.B. Wie gut sind die Ergebnisse?)
✦ Gütemaße (Precision & Recall, MAP und nDCG)✦ Benchmark-‐Ini&a&ven (TREC, CLEF und INEX)✦ Relevanzbewertungen (z.B. milels Crowdsourcing)✦ Evaluierung bei Suchmaschinen (z.B. A/B Tes8ng)
✦ Effizienz (z.B. Wie schnell werden Anfragen beantwortet?)✦ Maße des Zeit-‐ und Speicherbedarfs (z.B. Antwortzeit)✦ Konkrete und abstrakte Effizienz-‐Maße✦ Workload, Cache-‐Effekte und Compiler-‐Effekte
36

Informa8on Retrieval (SS 2011) 5. Evaluierung von IR-‐Systemen
Quellen & Literatur[1] Amazon Mechanical Turk http://www.mturk.com[2] Cross Language Evalua8on Forum http://www.clef-campaign.org[3] Ini8a8ve for the Evalua8on of XML Retrieval http://inex.is.informatik.uni-duisburg.de[4] NIST Text REtrieval Conference http://trec.nist.gov[5] O. Alonso, D. E. Rose and B. Stewart: Crowdsourcing for Relevance Evalua*on
ACM SIGIR Forum 42(2), 2008.[6] S. Bülcher, C. L. A. Clake and G. V. Cormack: Informa*on Retrieval,
MIT Press, 2010. (Kapitel 2 + 12)[7] W. B. Cro[, D. Metzler and T. Strohman: Search Engines Addison-‐Wesley, 2010. (Kapitel 8)[8] C. D. Manning, P. Raghavan and H. Schütze: IntroducAon to InformaAon Retrieval, Cambridge University Press, 2008. (Kapitel 8)[9] J. Zobel and A. Moffat: Guidelines for presenta*on and comparison of indexing techniques ACM SIGMOD Record 25(3), 1998.
37


















