
Ilona Gröning Einfache Experimente zur statischen Elektrizität

AbschlussdokumentAspektorientierte Programmierung
Alexander BurgessAndreas FeldschmidHenrik Kemmesies
Abdol GholamPierre Chavaroche
21. Januar 2008

Name Arbeitspaket
Pierre Chavaroche Kapitel 1 + 2
Henrik Kemmesies Kapitel 3 + Abschlussdokument
Andreas Feldschmid Kapitel 4 + 6.5
Abdol Gholam Kapitel 5
Alexander Burgess Kapitel 6
2

Inhaltsverzeichnis
1 Was ist die Motivation AOP zu nutzen? 5
2 Grundlagen AOP 72.1 Begriffe, Grundkonzepte . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Das allgemeine Prinzip von AOP . . . . . . . . . . . . . . . . . . 72.1.2 Was genau ist ein Aspekt? . . . . . . . . . . . . . . . . . . . . . . 82.1.3 Was ist ein Join-Point? . . . . . . . . . . . . . . . . . . . . . . . . 92.1.4 Was ist ein Pointcut? . . . . . . . . . . . . . . . . . . . . . . . . . 92.1.5 Wo kann ich den nun den zusatzlichen Code definieren? (Advice) 112.1.6 Was ist eine Intertype-Declaration? . . . . . . . . . . . . . . . . . 12
2.2 Vorstellung und Einrichtung der Entwicklungstools . . . . . . . . . . . . 12
3 Laufzeitanalyse mit Hilfe von AOP 133.1 Laufzeitinformationen uber Programme . . . . . . . . . . . . . . . . . . . 143.2 Erhebung von Laufzeitinformationen uber Aspekte . . . . . . . . . . . . 163.3 Grenzen der Laufzeitinformationsbeschaffung . . . . . . . . . . . . . . . . 183.4 Anwendungsmoglichkeiten mit Laufzeitinformationen . . . . . . . . . . . 19
4 Entwurf eines prototypischen Werkzeugs 204.1 Architektur des Programms / Entscheidungen . . . . . . . . . . . . . . . 204.2 Implementierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234.3 Implementierte Aspekte . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5 Einbinden benutzerspezifischer Aspekte in den Prototyp 29
6 Benutzung des Prototyps 346.1 Was leistet das Programm? . . . . . . . . . . . . . . . . . . . . . . . . . 346.2 Wie benutzt man das Programm? . . . . . . . . . . . . . . . . . . . . . . 346.3 Einbinden in ein Eclipseprojek . . . . . . . . . . . . . . . . . . . . . . . . 356.4 Einbinden uber den Codeweaver . . . . . . . . . . . . . . . . . . . . . . . 366.5 Ausfuhren mittels Ant-Task . . . . . . . . . . . . . . . . . . . . . . . . . 396.6 Was wird Ausgegeben? . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Literaturverzeichnis 42
Abbildungsverzeichnis 43
3

Listings 44
4

1 Was ist die Motivation AOP zunutzen?
Eine der großen Herausforderungen der heutigen Softwareentwicklung ist es, die verschie-denen Verantwortlichkeiten und Aufgaben einer Software und ihrer Komponenten sauberzu trennen (Das Prinzip des
”Seperation of Concerns“). Nur so konnen Abhangigkeiten
minimiert und eine lange Lebensdauer der Software garantiert werden.
Allerdings gibt es oft nicht-funktionale Anforderungen, die uber den gesamten Codeverteilt sind (Die sogenannten
”Crosscutting Concerns“).
Abbildung 1.1: Logging in Apache Tomcat
Wie man in Abbildung 1.1 sehen kann, ist das Logging uber fast alle Module der Softwareverstreut, da es offensichtlich oft benotigt wird. Obwohl es nur eine einzige Anforderung(bzw. Aufgabe) ist, muss fur die Realisierung Code in vielen Moduln geandert werden.
Weitere Beispiele fur Crosscutting Concerns sind:
• Exception-Handling
• Performance
• Security
5

Abbildung 1.2: XML-Parsing in Apache Tomcat
Das Gegenbeispiel stellt Abbildung 1.2 dar: Das XML-Parsing ist nur in einem einzigenModul vertreten.
Eine Verteilung uber den gesamten Softwarecode (wie in Abbildung 1.1) hat zur Folge,dass
1. eine Anderung jener Anforderungen gleichzeitig eine Anderung an mehreren Stellenim Code nach sich zieht (Fehlergefahr und geringe Produktivitat).
2. der eigentliche, fachliche Code kaum mehr zu lesen ist, da er vollig von nicht-funktionalen Anforderungen durchsetzt ist.
Doch wie kann AOP hier jetzt helfen? Die Aspektorientierte Programmierung hat es sichzur Aufgabe gemacht, diese Crosscutting Concerns vom eigentlichen, fachlichen Code zukapseln und somit zu trennen.
6

2 Grundlagen AOP
AOP ist ein machtiges Werkzeug. Wir mochten hier noch einmal kurz die wichtigstenKonzepte von AspectJ vorstellen. Fur genauere Einblicke konnen wir unsere Einfuhrungs-Prasentation zum Thema AOP bzw. die AspectJ-Dokumentation unter [Aspb] sowie dieBucher [Lad03] und [Boh06] empfehlen.
2.1 Begriffe, Grundkonzepte
Wie in den meisten anderen Techniken, gibt es auch in AOP einige Begriffe und Konzeptezu erklaren, bevor man mit AOP wirklich arbeiten kann. Die Prinzipien sind aber, einmalverstanden, sehr schlussig.
2.1.1 Das allgemeine Prinzip von AOP
Eine grobe Ubersicht wie AOP funktioniert, sieht man in Abbildung 2.1. Links ist mitMethode1 und Methode2 ein sequentieller Programmablauf vorzufinden, wie man es ausProgrammen gewohnt ist. Nun gibt es in diesem Programmablauf bestimmte Punkte(Die Join-Points) an denen jetzt zusatzlicher Code hinzugefugt werden konnte. Dieserzusatzliche Code ist in sogenannten Aspekten gekapselt. Der Pointcut wahlt diejenigenJoinpoints aus, an welchen zusatzlicher Code hinzugefugt werden soll. Das Hinzufugendes Codes an die ausgewahlten Joinpoints wird in AOP
”Weaving“ (Verweben) ge-
nannt.
7

Abbildung 2.1: Wo AOP angreift
2.1.2 Was genau ist ein Aspekt?
Ein Aspekt ist einer Java-Klasse sehr ahnlich: Er besitzt genauso Methoden und Varia-blen wie man es von einer Java-Klasse gewohnt ist. Ein Aspekt enthalt aber zusatzlicheKomponenten um die AOP-Techniken anwenden zu konnen. In AspectJ kann einem dieSyntax fur einen Aspekt sehr bekannt vorkommen:
Listing 2.1: Ein Aspekt in AspectJ
public aspect KontoAspekt[ implements <something >] [ extends <something > ] [ per−Klause l ]
{//Code
}
Zusatzlich hat er die Endung .aj um sich von den normalen Java-Klassen zu unterschei-den.
8

2.1.3 Was ist ein Join-Point?
Join-Points sind uber den gesamten Code verteilt. Es sind die Punkte, an denen derCompiler die zusatzlichen Anweisungen aus den Aspekten
”einweben“ kann. Aufgrund
dessen werden sie oft auch als”Webepunkte“ bezeichnet. Ein Java-Beispiel:
Abbildung 2.2: Eine Java-Klasse Konto mit Beispiel-Join-Points
Abbildung 2.2 zeigt, wo ein Join-Point sein kann: Bei der Instanziierung einer Klasse,beim Ausfuhren einer Methode, beim Beschreiben einer Variablen, usw.
2.1.4 Was ist ein Pointcut?
Ein Pointcut fasst nun eine Menge von Join-Points zusammen und wird im jeweiligenAspekt definiert. Er kann keinen Join-Point enthalten, alle Join-Points oder im Idealfall
9

genau diejenigen, die man fur seinen Aspekt benotigt. Sollte der Programmablauf zueinem Join-Point kommen und der Pointcut enthalt diesen, wird der zusatzliche Codeim Aspekt an dieser Stelle ausgefuhrt. Ein paar Java-Beispiele:
Allgemeine Syntax:
po intcut [ pointCutName ( ) ] : [ Auswahlmethode ] ;
Ein konkreter Pointcut, der einen Join-Point aus der Java-Klasse”Konto“ enthalt:
po intcut KontoSelect ( ) : c a l l ( void Konto . abheben ( int ) ) ;
Sobald die Methode abheben aus der Klasse Konto”gecallt“ (d.h. aufgerufen) wird, setzt
der dafur vorgesehene zusatzliche Code ein.
Der selbe Pointcut mit einem logischen Operator, um einen zusatzlichen Join-Point zuselektieren:
po intcut KontoSelect ( ) : c a l l ( void Konto . abheben ( int ) )| | c a l l ( void Konto . e in zah l en ( int ) ) ;
Der Pointcut trifft dann zu, wenn entweder die Methode abheben oder einzahlen aufge-rufen wird.
Diesmal mit Wildcards:
po intcut KontoSelect ( ) : c a l l (∗ Konto . abheben ( . . ) ) ;
Sollte es Uberladungen der Methode abheben geben, sind diese durch den Pointcut eben-falls betroffen.
Anmerkung: Logische Operatoren und Wildcards konnen kombiniert werden.
Neben der Pointcut-Methode call gibt es noch viele weitere Methoden:
• execution(Methoden- oder Konstruktorname)
• handler(Exception)
• args(Parameter)
• this(Instanzenname)
• get(Variable)
• set(Variable)
Dies sind nur Einige unter vielen Weiteren, worauf hier aber nicht naher eingegangenwird.
10
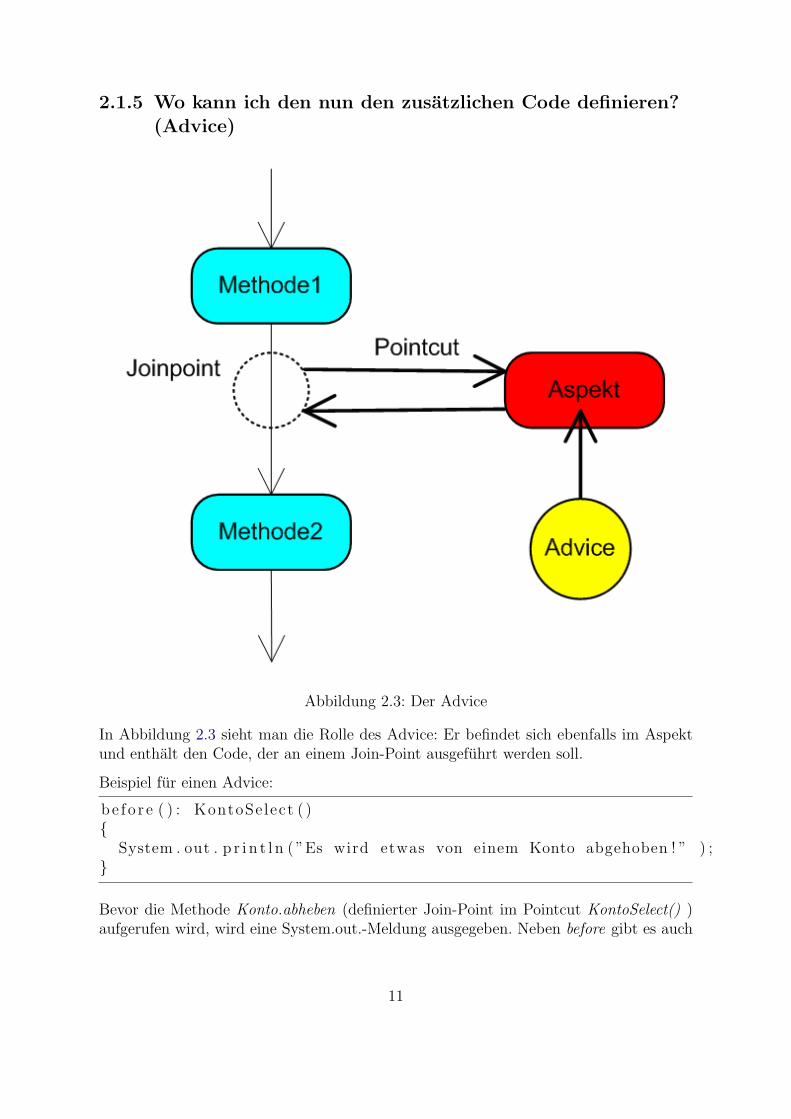
2.1.5 Wo kann ich den nun den zusatzlichen Code definieren?(Advice)
Abbildung 2.3: Der Advice
In Abbildung 2.3 sieht man die Rolle des Advice: Er befindet sich ebenfalls im Aspektund enthalt den Code, der an einem Join-Point ausgefuhrt werden soll.
Beispiel fur einen Advice:
b e f o r e ( ) : KontoSelect ( ){
System . out . p r i n t l n ( ”Es wird etwas von einem Konto abgehoben ! ” ) ;}
Bevor die Methode Konto.abheben (definierter Join-Point im Pointcut KontoSelect() )aufgerufen wird, wird eine System.out.-Meldung ausgegeben. Neben before gibt es auch
11

noch after (Ausfuhrung nach einem Join-Point) und around (umschließt einen Join-Point, bzw. kann ihn auch ersetzen).
2.1.6 Was ist eine Intertype-Declaration?
Mit der Intertype-Declaration ist es sogar moglich, zusatzliche Variablen und Methodenbestehenden Klassen hinzuzufugen.
Beispiel:
public aspect ZusatzAttr ibut {
private int Konto . z i n s s a t z = 2 ;
public int Konto . g e t Z i n s s a t z ( ) {return z i n s s a t z ;
}}
Im Aspekt ZusatzAttribut wird der Klasse Konto ein weitere Variable hinzugefugt: DerZinssatz. Zusatzlich erhalt sie eine Get-Methode.
2.2 Vorstellung und Einrichtung der
Entwicklungstools
Wie auch schon fur die Beispiele aus Kapitel 1, haben wir fur unser Projekt den Stan-dard AspectJ gewahlt. Der Vorteil von AspectJ ist die Aufwartskompatibilitat: Somitist korrekter Java-Code auch korrekter AspectJ-Code. Zusatzlich erzeugt der AspectJ-Compiler ganz normalen Java-Bytecode, d.h. es lauft auf unveranderter JVM und istsomit auch Plattformkompatibel.
Die Integration in Eclipse funktioniert wie folgt: Unter http://www.eclipse.org/ajdt/findet man die neusten AJDT (AspectJ Development Tools). Laden Sie sich hier dieentsprechende .zip-Datei herunter. Anschließend kopieren Sie die Dateien aus dem Ord-ner
”features“ und
”plugins“ in die gleichnamigen Ordner aus Ihrem Eclipse-Verzeichnis.
Naturlich ist eine Installation auch automatisch uber die Eclipse Update-Funktion moglich(die Update-Site URL ist auch auf der AJDT-Seite zu finden).
12

3 Laufzeitanalyse mit Hilfe vonAOP
”Wo gehobelt wird, da fallen Spane“ - und wo programmiert wird, da entstehen Fehler.
Dieser schlaue Satz durfte jedem heranwachsenden Informatiker wohlbekannt sein. BeiUnachtsamkeit konnen Fehler zu finanziellen oder sogar im schlimmsten Fall zu mensch-lichen Verlusten fuhren. Allein im Jahr 1999 verlor die NASA 125 Millionen Dollar durcheinen verpassten Mars-Landeanflug der Sonde
”Mars Climate Orbiter“. Der Grund: Eine
fehlerhafte Implementierung des Maßsystems [Mar].
Zur Vermeidung solcher Programmierfehler kennt die Informatik eine Antwort: Soft-waretests. Noch bevor eine Software den Unit-Tests unterzogen wird, sollte sie einerstatischen Code-Analyse unterzogen werden. Die statische Code-Analyse uberpruft denQuelltext eines Programms auf eine Reihe vorher festgelegter Regeln. Dadurch konnenbeispielsweise folgende Falle identifiziert und behoben werden:
• fehlende Vorinitialisierung von Variablen
• Identifikation von unerreichbaren Codestellen
• Uberschreitung der maximalen Lines of Code (LoC) einer Methode
• fehlendes Implementieren eines Interfaces
Teilweise wird die statische Analyse durch die Zuhilfenahme von Stylecheckern erganzt,die den Quelltext auf vorher festgelegte Programmierstile uberprufen.
Die statische Code-Analyse hat allerdings den Nachteil, dass Programmierfehler, dieerst wahrend der Programmausfuhrung
”entstehen“, nicht als solche identifiziert werden
konnen. Um diesem Problem entgegenzuwirken muss das Programm zur Laufzeit, durcheine dynamische Code-Analyse, analysiert werden. Hierbei sind nicht nur Informationenan einer ganz bestimmten Programmstelle von Interesse, sondern auch der allgemeineZustand und der Ablauf des Programms konnen eine wichtige Rolle spielen.
Dynamische Informationen uber ein laufendes Programm nennt man Laufzeitinforma-tionen. Sie konnen mit Hilfe der Aspektorientierten Programmierung aus dem Pro-grammfluss herausgeholt werden. Bevor dies allerdings durchgefuhrt werden kann, musszunachst uberlegt werden, welche Laufzeitinformationen eines Programms uberhauptvon Interesse sind.
13

3.1 Laufzeitinformationen uber Programme
Generell muss bei dem Begriff”Laufzeitinformationen“ von einem unbekannten Projekt
ausgegangen werden. Ein Projekt ist dann unbekannt, wenn der innere Aufbau und dieinnere Funktionsweise unbekannt sind. Man spricht in diesem Fall von einer Blackbox.
Abbildung 3.1: Blackbox-Ansicht eines Projekts
Betrachtet man nun eine Blackbox, wie sie in der Abbildung 3.1 zu sehen ist, so beginntman automatisch, sich Fragen uber das vorliegende Objekt und dessen Laufzeitinforma-tionen zu stellen. Mogliche Laufzeitinformationen werden nun im Folgenden strukturierterfasst. Als Grobeinteilung wurden die Strukturierungspunkte Klassen, Methoden, Ein-und Ausgaben, Threads, Exceptions, Technisches und Sonstiges gewahlt:
• Klassen
– Zahlen der Instanzen einer bestimmten Klasse
– Einhalten vorgeschriebener Schnittstellen
– Korrektes Abbilden der Instanzen auf die vorgegebene Softwarearchitektur
– Rekonstruierung der Softwarearchitektur
– Ermittlung der Aufrufreihenfolge der Komponenten(ruft obere immer untere auf?)
• Methoden
– Ermittlung der Anzahl der Aufrufe einer Methode
– Messung der Ausfuhrungszeit einer Methode
– Auffinden von ungenutzten Methoden
– Auffinden von ungenutzten Argumente
14

• Threads
– Auffinden vorhandener Threads
– Ermittlung der Anzahl von Threads zu einem gewissen Zeitpunkt
– Ermittlung der Anzahl von Threads uber den Gesamtablauf des Programms
– Messen der Ausfuhrungszeit eines Threads
– Ermittlung der Große der zugeteilten Zeitscheibe an einen Thread
– Auffinden von ungenutzten Threads
– Auffinden von Deadlocks
– Messen der Wartezeit eines Threads auf gesperrte Objekte
• Ein- und Ausgaben
– Erfassen von Logging-Informationen
– Erfassen von gelesenen und geschriebenen Inhalten einer Datei
– Verwendung von Dateien
– Erfassen der Anzahl von verwendeten Dateien
– Korrektes Offnen und Schließen der Dateien
– Verwendung von Netzwerkverbindungen
– Ermittlung der Verwendungsdauer externer Quellen(Dateien und Netzwerkverbindungen)
– Ermittlung von verschickten Informationen uber das Netzwerk
– Erfassung von Benutzereingaben (Konsole / GUI)
• Exceptions
– Ermittlung aller geworfenen Exceptions
– Auffinden unvorhergesehener Exceptions
– Ermittlung der Anzahl und des Zeitpunkts von geworfenen Exceptions
• Technisches
– Ermittlung der Anzahl benotigter Speicherzellen(im Hinblick auf Embedded Systems)
– Ermittlung der Speicheradresse von Variable X
– Messen der Speicherbelastung des Programms
– Ermittlung der Belegungenen der Prozessorregister
– Auffinden von fehlenden Speicherfreigaben
• Sonstiges
– Protokollierung des detaillierten Programmablaufs(Wann hat Benutzer was gedruckt?)
15

– Erkennung von Endlosschleifen
– Ausgeben von SQL-Statements
– Ermittlung des Ausfuhrungsorts des Programms
– Ermittlung des Bauplans der GUI
– Zahlen von GUI-Elementen
Hinweis : Diese Liste hat nicht die Anforderung vollstandig zu sein. Sie soll lediglicheinen Uberblick uber mogliche Laufzeitinformationen geben.
3.2 Erhebung von Laufzeitinformationen uber
Aspekte
Nachdem nun ein Uberblick uber mogliche Laufzeitinformationen erstellt wurde, sinddiese nun aus dem Black-Box-Programm zu extrahieren. Dazu wird im Weiteren dieLaufzeitinformation
”Ausgeben von SQL-Statements“ als Erklarungsbeispiel her-
angezogen.
Wie bereits zu Beginn dieses Kapitels erwahnt, verschafft AOP mit Hilfe der Aspekte dieMoglichkeit, dieses Vorhaben umzusetzen. Das Black-Box-Projekt muss dazu im erstenSchritt in ein AspectJ-Projekt umgewandelt werden. Dies geschieht durch die Auswahldes Menupunktes
”Rechtsklick auf den Black-Box-Projektordner“ −→
”AspectJ Tools“
−→”Convert to AspectJ Project“.
Abbildung 3.2: Umwandlung eines Java-Projekts in ein AspectJ-Project
Anschließend sollte in dem Black-Box-Projektordner ein neues Package fur die zu im-plementierenden Aspekte erstellt werden. In dem Aspekt-Package muss nun im zwei-ten Schritt ein Aspekt erstellt werden. Der Aspekt wird uber
”Rechtsklick auf Aspekt-
Package −→ New −→ Other. . . −→ AspectJ −→ Aspect“ mit einem beliebigen Namen
16

erstellt. Ein Aspekt ist grundsatzlich ein Behalter fur AOP-Code und am ehesten miteiner Java-Klasse zu vergleichen – nur dass der Aspekt statt *.java auf *.aj endet.
Nach der Erstellung des Aspekts, ist in der *.aj-Datei bereits folgender Code enthalten:
Listing 3.1: Die erste Codezeile vom Aspekt SqlStatementsAspect
public aspect SqlStatementsAspect { . . . }
Nun muss geklart werden, welche Sprachkonstrukte die gesuchte Laufzeitinformationcharakterisieren. Diese Charakterisierung ist besonders fur die Erstellung der Join-Pointswichtig. Im Fall der
”Ausgeben von SQL-Statements“-Laufzeitinformation genugt ein
kurzer Blick in die Java-Dokumentation im Abschnitt java.sql.Statement unter http://java.sun.com/javase/6/docs/api/java/sql/Statement.html , woraus hervor geht,dass jedes SQL-Statement unter JDBC uber eine der execute*-Methoden des Statement-Interfaces abgesetzt wird (die addBatch()-Methode wird hier ignoriert).
Anschließend kann durch diese Charaktereigenschaften der Pointcut mit seinen Join-Points definiert werden (in unserem Laufzeitinformationen-Fall existiert nur ein Join-Point!). Dazu wird zuerst der Pointcut mit einem Namen und einem abschließenden
”:“
angegeben, gefolgt von den Join-Point-Definitionen:
Listing 3.2: Pointcut- und Join-Point-Definition im Aspekt SqlStatementsAspect
po intcut getSqlStatement ( S t r ing s q l ) :c a l l (∗ java . s q l . Statement . execute ∗ ( . . ) ) && args ( sq l , . . ) ;
Sollen weitere Join-Points angegeben werden, so geschieht dies durch das Anhangen desOder-Operators ‖ an den ersten Join-Point (nach
”&& args(sql, ..)“ ), gefolgt von den
weiteren Join-Point-Definitionen. Um nicht jede der execute*-Methoden einzeln angebenzu mussen, konnen Wildcards eingesetzt werden. Ein Stern * steht fur eine beliebigeAnzahl beliebiger Zeichen (außer dem Punkt). Zwei Punkte .. stehen fur eine beliebigeAnzahl von beliebigen Zeichen (einschließlich dem Punkt) und ein Plus + steht fursamtliche Unterklassen bzw. Interfaces des vorgegebenen Typs. Ist zusatzlich der Zugriffauf die Argumente einer Methode notig, so muss das Schlusselwort
”args“ mit Angabe
der erwarteten Argumente dem Join-Point hinzugefugt werden.
Nachdem der Einstiegspunkt unserer Interessen definiert ist, muss nun der auszufuhrendeCode an dieser Stelle definiert werden. Dies wird in einem before-, after- oder einemaround-Advice mit Angabe des Pointcuts festgelegt:
Listing 3.3: Advice-Definition im Aspekt SqlStatementsAspect
be f o r e ( S t r ing s q l ) : getSqlStatement ( s q l ) {System . out . p r i n t l n ( ”SQL−Statement ’ ”+s q l+” ’ was c a l l e d ” ) ;
}
17

Wurde alles richtig implementiert, so wird in der Entwicklungsumgebung”Eclipse“ links
neben dem Aspekt ein kleiner Pfeil angezeigt, der beim Heruberfahren mit der Maus dieanvisierte Stelle im Black-Box-Projekt anzeigt.
Abbildung 3.3: Der Aspekt Ausgeben von SQL-Statements zeigt auf eine Codestelle
Umgekehrt wird bei der anvisierten Stelle im Black-Box-Projekt ein entgegengesetzterPfeil angezeigt:
Abbildung 3.4: Main-Methode, auf die der Aspekt Ausgeben von SQL-Statements zeigt
Allerdings sind der Erfassung der Laufzeitinformationen gewisse Grenzen gesetzt, die imFolgenden untersucht werden.
3.3 Grenzen der Laufzeitinformationsbeschaffung
Mit AOP konnen keine echten Ausfuhrungszeiten einer Methode oder eines Teilbereichsdes Programms ermittelt werden. Fur eine Zeitmessung muss vor und nach dem zumessenden Code zusatzlicher AOP-Code eingefugt werden. Dieser zusatzliche Code ist,zusatzlich zum normalen Code, wahrend der Programmausfuhrung auszufuhren, wo-durch wiederum zusatzliche Zeit beansprucht wird und somit das Gesamtergebnis einergemessenen Ausfuhrungszeit verfalscht wird. Die mit AOP ermittelten Ausfuhrungszeiten
18

sind daher immer nur Naherungswerte, die allerdings trotzdem gut fur Vergleichszweckeherangezogen werden konnen.
Mit AOP ist es zudem nicht moglich, den Code zwischen einem try- und catch-Block oderden Ausfuhrungsort eines Threads in einem Join-Point anzugeben. Auch das Erfassenvon technischen Informationen, wie z.B. die Anzahl der benotigten Speicherzellen fur einObjekt, ist beim managed Code, wie z.B. Java, nicht moglich, da AOP ebenfalls wie dermanaged Code nur in einer Sandbox ablauft und keinen Zugriff auf die Arbeitsweisender Virtual Machine hat.
3.4 Anwendungsmoglichkeiten mit
Laufzeitinformationen
Wurden einige Laufzeitinformationen aus einem Programm mit den entsprechendenAspekten extrahiert, so stellt sich nun die Frage, wie diese weiterzuverarbeiten sind.Ein besonders wichtiger Anwendungsfall ist die Grundlagenbildung fur einen Profiler.Dieser musste allerdings zusatzlich mit statischen Analysen erganzt werden, um dasvolle Spektrum der Softwareanalyse nutzen zu konnen.
Weiter konnten die Laufzeitinformationen fur die Erstellung von Sequenzdiagrammenoder zum Kennenlernen eines Programms verwendet werden. Unter Kennenlernen isthier zu verstehen, dass ein Entwickler die Aufgabe bekommen hat, eine ihm unbekannteSoftware um gewisse Funktionalitaten zu erweitern / abzuandern ohne dabei auf Softwa-redokumentation oder fruher beteiligte Entwickler zuruckzugreifen. Durch entsprechendeLaufzeitinformationen konnten hier schnell und einfach die vorhandene Softwarearchi-tektur, die dafur benotigt wird, und der Programmablauf der zu erweiternden Softwareermittelt werden.
Soll daruber hinaus ein Programm aufgrund schlechter Performance optimiert werden,so konnte es sehr wichtig sein, die Methode mit der langsten Ausfuhrungsdauer zu iden-tifizieren. Auch dies ist mit Laufzeitinformationen moglich.
Ebenfalls sind Laufzeitinformationen fur das Testen von Software geeignet: Es wird vorder Ausfuhrung eines Programms abgeschatzt, wie lange eine gewisse Methode benotigendarf. Danach wird die Software ausgefuhrt und die theoretisch ermittelte Zeit mit dertatsachlichen Ausfuhrungszeit verglichen. Unterscheiden sich diese Werte gravierend, sokonnte dies bereits ein Indiz fur fehlerhaften Code sein. Eine weitere Moglichkeit desTestens ware eine eigene Implementierung, auf Basis von Laufzeitinformationen, fur dasTracen eines Programms.
Auch konnen Laufzeitinformationen zur Softwarequalitatsicherung der Softwarearchitek-tur eingesetzt werden, indem die Soll-Architektur mit der tatsachlichen Implementierungabgeglichen wird und dabei Komponenten uberfuhrt werden, die andere Komponentenverbotener Weise ubergehen.
19

4 Entwurf eines prototypischenWerkzeugs
In diesem Abschnitt wird das von uns implementierte prototypische Werkzeug kurzvorgestellt.
Gerade beim Profiling beziehungsweise der Analyse von Methodenlaufzeiten, muss vielWert auf Performance und Skalierbarkeit gelegt werden, damit ein moglichst unverfalschtesErgebnis erzielt werden kann. Die von uns implementierten Aspekte sowie die erstellteArchitektur wurden nicht speziell auf einen performanceorientierten oder gar skalierba-ren Ansatz optimiert. Die erstellte Losung ist also eher als
”Prototyp“ oder
”Proof of
Concept“ zu verstehen – die generierten Ausgaben konnen als Richtwerte herangezogenwerden, sind aber auf jeden Fall kritisch zu hinterfragen.
4.1 Architektur des Programms / Entscheidungen
Um die Architektur des Programms verstehen zu konnen, ist es wichtig die GrundzugeAspektorientierter Programmierung zu verstehen – siehe dazu Kapitel 1.
Bei der Analyse der Architekturanforderungen an unser Programm wurde schnell klar,dass eine der Hauptanforderungen die Interoperabilitat ist, also die Moglichkeit unserWerkzeug ohne große Anpassungen auf ein beliebiges Java-Projekt anwenden zu konnen.Diese Funktion wird durch AspectJ und somit von den verschiedenen Aspekten vonHaus aus bestens Unterstutzt – wir mussten also nur noch darauf achten beim Sam-meln, Verwalten und Ausgeben der Daten keine projektspezifischen Abhangigkeiten zugenerieren.
Um die Informationen, die von den einzelnen Aspekten gesammelt werden auswertenund eventuell darstellen zu konnen, muss eine Ausgabe stattfinden. Dies konnte nunper Ausgabe in eine Datei, Schreiben in eine Datenbank, auf einen Socket oder eineMessageQueue realisiert werden. Wir entschieden uns der Einfachheit halber fur einesimple Ausgabe in eine Datei. Dabei entschieden wir uns fur eine Ausgabe im XML-Format. Auch dafur musste eine – soweit uberhaupt moglich – gemeinsame Strukturfestgelegt werden. Einer der Grunde fur das XML-Ausgabeformat war die Moglichkeitdas erzeugte XML-Dokument mittels XSLT in verschiedene andere Formate (z.B. CSV,SVG, XHTML usw.) transformieren zu konnen.
20

Ein zusatzlicher wichtiger Punkt in diesem Kontext ist die Fragestellung, wann die Aus-gabe erfolgt. Bei jedem Funktionsaufruf mehrere XML-Java-Elemente zu erstellen unddiese dann in eine XML-Datei korrekt einzuschachteln wurde eine – selbst fur einen Pro-totypen – zu hohe Beeinflussung der Laufzeit bedeuten. Selbst Ausgaben per System.outbeeinflussen die Laufzeit schon deutlich (Programmlaufzeit Normal: 6.5Sec, mit Aspek-ten 7Sec, mit System.out-Ausgabe bei jedem Methodenaufruf: 25Sec). Daher wurdevon uns eine Moglichkeit angestrebt die Informationen wahrend dem Programmablauflediglich mittels Java-Objekten vorzuhalten und nach dem Beenden des eigentlichenProgrammablaufs die Transformation in XML-Objekte und die Datei-Ausgabe in eineXML-Datei zu starten. Naturlich ergeben sich dadurch gewisse Constraints und Nach-teile. So steigt die Speichernutzung starker an und sehr lang laufende Programme mitvielen Methodenaufrufen fuhren letztendlich zum Speicheruberlauf. Um diese Nachteilezu beseitigen, musste eine ausgereiftere Logging-Methode benutzt werden, welche standigoder auch in bestimmten Intervallen die Log-Ausgabe in eine Logdatei startet und dabeidie Ausfuhrung des zu profilenden Programms moglichst wenig beeinflusst.
Eine weitere Entscheidung, die wir Treffen mussten, war die Wahl der Zeitabstandezur Methodenmessung. Sehr viele Methoden laufen außerst kurz, so dass eine Messungmit System.getCurrentTimeMillis jedes Mal 0ms ergeben hatte. System.nanoTime lie-fert zwar nicht wirklich Zeiten mit Nanosekunden-Granularitat, schafft aber durchausgenauere Messungen als Millisekunden, zusatzlich ist System.nanoTime() nicht von derBetriebssystem-Zeit abhangig, kann also nicht durch den User beeinflusst werden.
Eine sehr wichtige Funktion ist die Beschrankung des Profilings auf einen Teilbereich derApplikation. So mochte man vielleicht nur die Datenbank-Schicht profilen, wahrend derAnwendungskern und die GUI nicht von Interesse sind. Dies konnte ebenfalls mit einerAspectJ-Funktion gelost werden: Pointcuts die within(Packagename..*) beinhalten tref-fen nur auf Joinpoints zu, die im jeweiligen Package oder Unterpackage liegen (Wildcard-Bedeutung siehe [Syn]). So konnten wir mit dem Pointcut excluded: !within(cleverTec..*)auch festlegen, dass sich unsere Aspekte nicht gegenseitig profilen.
21

Abbildung 4.1: Die excluded-/included-Anweisung
Eine weitere Anforderung war es, die einzelnen Aspekte modular zu entwickeln, umwenig oder keine Abhangigkeiten zwischen den Aspekten untereinander zu generieren.Somit konnte die Implementierung unabhangig voneinander vonstatten gehen und so dieArbeit besser aufgeteilt werden. Zusatzlich konnen die Aspekte dann auch einzeln zu-oder abgeschaltet werden und neue Aspekte ohne große Probleme hinzugefugt werden.
Letztendlich konnten wir die Architektur sehr simpel und uberschaubar halten:
22

Abbildung 4.2: Die technische Architektur des Prototyps
Wie man sieht, wird ein AbstractAspect verwendet, in welchem zum einen die ange-sprochenen Pointcuts excluded()/included() vorhanden sind – welche von jedem konkre-ten Aspekt spater auch fur jeden Pointcut benutzt werden mussen – und zum anderendie Verbindung zum Logger, also der Datenhaltung hergestellt wird. Dabei wird keineSchnittstelle verwendet, sondern der Logger direkt ubernommen. Dies bedeutet, dass beieinem Austausch des Loggers samtliche Aspekte an den neuen Logger angepasst werdenmussen – dies nehmen wir aber in Kauf, da bei einer Umstellung des Loggers auf eineandere, performantere Methode gleich die gesamte Architektur sowie die Struktur derValueObjects neu uberdacht werden muss.
4.2 Implementierung
Bei der Implementierung starteten wir damit, unsere Loggerklasse zu schreiben. Der Log-ger ist dafur zustandig die Logdaten aufzunehmen und nach Ablauf des zu uberwachendenProgramms auszugeben.
23

Zur Datenhaltung innerhalb des Loggers entschlossen wir uns parametrisierte, geschach-telte Maps zu verwenden. Im Logger selbst finden wir eine Map, welche aus String/-Map als Key/Value Paaren besteht (Map<String, Map<String, ValueObject>>). Je-der Aspekt nutzt die vom Logger angebotene Methode
”Map<String, ValueObject>
getHashMap(String)“, um eine exklusive Map zu bekommen – dafur ubergibt man alsString-Parameter Aspektname.class.getName(), um so eine Eindeutigkeit zu erlangen.In diese Map schreibt der Aspekt dann seine Daten als String, ValueObject-Paare.
Die nachste Funktionalitat die wir implementieren wollten, war die Ausgabe der Datennach Ablauf des zu uberwachenden Programms. Dies gestaltete sich als etwas schwieriger.Wie wird man daruber Informiert, dass das Programm beendet ist? Wenn es sich um einrein linear ablaufendes Programm handelt, konnte man am Ende eine Benachrichtigungeinbauen, dazu musste das Programm aber geandert werden, was wir eigentlich vermei-den wollten. Eine andere Moglichkeit ware die finalize()-Methode unseres Loggers zuuberschreiben. Jedes Objekt in Java besitzt die von Object geerbte finalize()-Methode.Diese wird aufgerufen, sobald das jeweilige Objekt explizit - also vom GarbageCollector- entfernt wird. Wann und ob Objekte vom GarbageCollector entfernt werden, ist abernicht festgelegt. Wird das Programm beendet, werden alle noch existierenden Objektezerstort, wobei die finalize()-Methode aber nicht ausgefuhrt wird.
Eine bessere Moglichkeit bietet ein sogenannter ShutdownHook.Per Runtime.getRuntime().addShutdownHook(Thread t); wird ein Thread in der Runti-me registriert, welcher ausgefuhrt wird, sobald exit(int) aufgerufen wird, keine weiterenaktiven Threads mehr am Leben sind oder die VirtualMachine vom Benutzer terminiertwird (Logoff z.B.), also kurz gesagt das Programm beendet wird. Durch diesen Mecha-nismus ist es uns moglich relativ einfach und zuverlassig die Ausgabe erst nach Beendendes Hauptprogramms zu starten.
Die verschiedenen Aspekte erheben unterschiedliche Daten, teilweise werden nur String/In-teger Paare gespeichert (z.B. zahlen der Instanzen einer Klasse), andere speichern zueinem String mehrere Zeit-Intervalle mit Anfangs und Endzeit sowie zusatzliche Infor-mationen, wie etwa die mittlere Ausfuhrungszeit. Die Struktur und das Ausgabeformatder einzelnen Aspektdaten unterscheiden sich also stark untereinander und sind auchnicht generisch darstellbar. Daher entwickelten wir unser ValueObject Interface. DasInterface beinhaltet zwei Methoden:
• public void printValues();//Gibt die Daten auf System.out aus – Debugging Zwecke etc.
• public Element toXMLElement();//Gibt ein JDOM-Element zuruck, in welchem die gesamten Daten als XML-Sturktur vorhanden sind
Wie die Implementierung des ValueObjects ansonsten aufgebaut ist und wie es seinemehr oder weniger komplexen Daten halt, interessiert uns hier nicht – das ist der Auf-gabenbereich des einzelnen Aspekts.
24

Unser Logger, welcher ja als ShutdownHook-Thread registriert ist, kann nun zunachstuber die erste Map iterieren und erhalt so fur jeden Key – welcher ja einem Aspekt-Package entspricht – als Value eine Map aus String, ValueObjects. Nun kann er uber dieseString-, ValueObjects-Paare iterieren und die toXMLElement()-Methode des ValueOb-jects benutzen, um so die gesamten Daten fur einen Aspekt zu aggregieren. So entstehtdann aus den einzelnen XML-Teilbaumen ein großes XML Gesamtdokument. Dieses liegtnun als JDOM-Document vor und kann direkt mit dem org.jdom.output.Outputter ineine Datei geschrieben werden.
Nachdem dies geschehen ist, wird uberpruft, ob in der clevertec.properties XSLT-Style-sheets angegeben wurden. Gegebenenfalls wird das JDOM-Document dann mit diesenXSLT-Stylesheets transformiert und die Ausgaben in die entsprechenden Dateien ge-schrieben. So liefern wir z.B. Templates fur das erzeugen von CSV-Dateien, welche dannin Excel weiterverarbeitet werden konnen, z.B. sortieren, selektieren und erstellen vonCharts, etc. Eine dieser CSVs wurde auch vom Team RoQuMod weiterverwendet: Eswurde ein conqat-Prozessor geschrieben, welcher das CSV einliest und so die Werte inConqat als Daten verfugbar macht und letztendlich als Tabelle ausgibt. Die erzeugtenSVG-Grafiken sind eine Art
”Proof of Concept“, dass man unsere Daten auch visuali-
sieren kann.
Der gesamte Ablauf kann etwa folgendermaßen dargestellt werden:
25

Abbildung 4.3: Programmablauf des Prototypen
4.3 Implementierte Aspekte
Folgende Aspekte haben wir in der aktuellen Version des Programms implementiert:
• ExceptionsAspect: Zahlt wie oft Exceptions aufgetreten sind und wann
26

• Instances: Zahlt wie viele Objektinstanzen erzeugt werden
• MethodExecutionNumber: Zahlt wie oft Methoden aufgerufen wurden
• MethodExecutionRuntime: Misst die Zeit, die fur eine Methodenausfuhrung benotigtwird
• MethodCallRuntime: Wie MethodExecutionRuntime, nur fur Calls, standardmaßigdisabled da sonst sehr viele Logdaten entstehen!
• ThreadCreation: Zahlt wieviele Threads erzeugt wurden
• ThreadStartup: Zahlt wie viele Threads ausgefuhrt / beendet wurden
Die Aspekte konnten alle unabhangig voneinander implementiert werden. Teilweise wur-den gemeinsame Utility-Klassen benutzt, z.B. fur das Festhalten von Zeitintervallen.
Beispielsaspekt: Instances.aj
Exemplarisch mochten wir hier nun einen Aspekt noch mal etwas genauer betrachten:Der Aspekt Instances.aj zahlt alle Objektinstanzen.
Der Aspekt leitet sich – wie jeder Aspekt – von unserem AbstractAspect ab. Dadurcherbt er die beiden Pointcuts included && excluded und den Logger log. Nun wird ausdem Logger eine fur diesen Aspekt exklusive Map geholt. Dafur wird der Aspektna-me.class.getName() – also die Packagestruktur und der eigentliche Aspektname – andie Methode Logger.getHashMap(String) ubergeben. In der Ausgabe wird spater eineSection fur diesen Aspekt erstellt, die der Packagestruktur entspricht – hier also
”clever-
Tec.aspects.instanceCounter“. Dies bedeutet, wenn man zwei Aspekte in einem Packageimplementieren wurde, wurden ihre Daten in der gleichen Sektion der XML-Ausgabelanden.
Als nachstes muss ein oder mehrere Pointcuts definiert werden. Dabei ist darauf zu ach-ten
”&& excluded() && included()“ an den Pointcut anzufugen, damit sich die Aspekte
nicht gegenseitig”matchen“ und zusatzlich eine Einschrankung der Analyse auf Teilbe-
reiche moglich ist. In unserem Fall sieht der Pointcut so aus:
po intcut InstancesCount ( ) :execut ion ( new ( . . ) ) && excluded ( ) && inc luded ( ) ;
Es werden also alle Joinpoints gematched, welche ein neues Objekt erzeugen. Nun mussnoch definiert werden was dann zu tun ist, dies geschieht im Advice. Hier benutzten wireinen before() : InstancesCount() Advice. Als nachstes wird gepruft welches Objekt gera-de instanziert wurde. Dies geschieht mittels thisJoinPoint.getTarget().getClass().getCa-nonicalName(); - was uns die Packagestruktur sowie den Klassennamen liefert. Solltegerade eine lokale oder anonyme Instanz erzeugt worden sein – liefert die Methode Null.Diese Ausnahme wird manuell behandelt und der Objektname dann auf
”localOrAnony-
mous“ gesetzt.
27

Nun kann begonnen werden diese Logdaten in die Map zu schreiben. Zunachst wird ge-pruft, ob zu dem Key – also hier dem Namen des instanzierten Objekts – bereits ein Va-lueObject vorliegt. Falls dies nicht der Fall ist, wird ein neues angelegt und in die Map ge-schrieben. Sollte bereits ein ValueObject zum jeweiligen Key vorliegen, wird dieses durchseine Methoden um den Wert 1 inkrementiert. Hier also c.setCount(c.getCount()+1).Nun sind die Daten in der Map gespeichert und somit die Aufgabe dieses Aspekts fer-tiggestellt.
28

5 Einbinden benutzerspezifischerAspekte in den Prototyp
Nachdem die Architektur und der allgemeine Ablauf des Programms vorgestellt wordensind, wird in diesem Abschnitt ein detailliertes Beispiel fur das Einbinden eines be-nutzerspezifischen Aspekts im Programm beschrieben. Eine unaufwandige und schnelleErweiterung von Aspekten im Programm war eines der Hauptziele bei der Entwicklungdes Programms. Der Einbindevorgang wird anhand eines Beispielaspekts erlautert. DerBeispielaspekt, der in diesen Kapitel vorgestellt wird, ist fur die Zahlung von Getter-und Setter-Methoden zustandig. Die notigen Testklassen sowie die Aspektklasse befindensich im GetterSetter.jar auf der CD.
Bevor mit dem Erstellen des neuen Aspekts begonnen werden kann, ist es notig, dasProjekt in Eclipse zu importieren. Zum Einbinden des Programms in Eclipse ist ledig-lich die Installation von AJDT(AspectJ Development Tools) notwendig (siehe HowToDokument). Im einzelnen muss zunachst ein neues Projekt erstellt werden, indem inEclipse das CLeverTec Programm importiert wird. Anschliessend muss das Projekt mitHilfe von AJDT in ein AspectJ Projekt konvertiert werden, falls dies nicht automatischgeschehen ist. Das Projekt kann auch problemlos in Maven eingebunden werden, dazuist lediglich die Einbindung von JDOM-Bibliothek in der pom.xml notwendig.
Nun werden drei Testklassenn zu Testzwecken erstellt. Dazu muss zunachst ein neu-es Package test.all.aspects im Verzeichnis src/test angelegt werden. Die Klasse Kontoenthalt zwei Variablen guthaben und kontoNummer, zwei Methoden abheben(int Be-trag) und einzahlen(int betrag), sowie die fur den neu einzubindenden Aspekt relevantenGetter- und Setter-Methoden. Die Methode abheben() verursacht eine OverLimitExcep-tion, falls versucht wird, mehr Geld abzuheben als vorhanden ist. Die OverLimitEx-ception Klasse ist eine selbstgeschriebene Exception, die von der Basisklasse Exceptionabgeleitet ist. In der Mainmethode der Klasse TestKonto wird ein Konto erstellt undeine Einzahlung sowie eine Abhebung wird ausgefuhrt, am Schluss wird dann die fur re-levante getter-Methode getGuthaben() aufgerufen. Schließlich muss die Klasse Testkontoals Java Application oder AspectJ/Java kompiliert und ausgefuhrt werden. Dabei wirdein neues Verzeichnis out erstellt, die unter anderem eine XML-Datei out.xml enthalt, inder alle ausgewerteten Daten zusammengefasst sind. Um die Anderungen festzustellen,die durch die Aspekterweiterung aufgetreten sind, sollte diese generierte XML Datei inein beliebiges Verzeichnis gespeichert werden. Der Aufbau und die Struktur der XMLDatei wird in Kapitel 5 naher erlautert.
29

Innerhalb des Projekts wird nun ein Package namens cleverTec.aspects.getterandsetterund anschließend eine Klasse CountGetterAndSetter erstellt. Die Klasse CountGette-rAndSetter ist eine Implementierung des Interface ValueObject. Diese enthalt zwei Me-thoden zur Speicherung bzw. Ausgabe der entsprechenden Ergebnisse.
Dabei entspricht die Methode printValue() der Konsolenausgabe und die Methode toXM-LElement() ist fur das Festhalten der Daten in einer XML Datei verantwortlich. DesWeiteren besitzt die Klasse zwei Variablen getSetNumber die fur die Zahlung der auf-gerufenen Getter- und Setter-Methoden zustandig ist und eine Variable getSet die dieMethodennamen der Getter- und Setter-Methoden speichert. Die Methode increment()zahlt die Anzahl der Getter- und Setter-Aufrufe um eins hoch.
30

Abbildung 5.1: ValueObject-Klasse CountGetterUndSetter
Innerhalb desselben Packages muss nun eine Aspektklasse GetterAndSetter erstellt wer-den, die von AbstractAspect abgeleitet ist. In der GetterAndSetter Aspektklasse ist einpointcut definiert, der alle Getter und Setter-Methoden durchlauft. Nach jedem Aufrufeiner Getter- oder Setter-Methode, wird der Name der Methode sowie die aktualisierteAnzahl der bisherigen Aufrufe mit Hilfe des Advice in eine HashMap gespeichert, dieein Attribut der Aspektklasse ist.
31

Abbildung 5.2: Benutzerspezifisches Aspekt GetterAndSetter.aj
Nachdem nun erneut die Klasse TestKonto kompiliert und ausgefuhrt wurde, kann dieneu generierte XML mit der ursprunglichen XML Datei vor der Aspekterweiterung ver-glichen werden. Innerhalb der neuen XML Datei ist ein weiterer Tag <getandsetter> zufinden, der in der alten XML Datei nicht vorhanden war.
Abbildung 5.3: Loggerausgabe mit dem Ergebnis des benutzerspezifischen Aspekts
Zusammenfassend sind folgende Punkte bei der Erstellung eigener Aspekte zu beach-
32

ten:
• Jeder neue Aspekt muss in einem eigenen Package erstellt werden (siehe Kapitel4.3)
• Die Javaklasse implementiert das Interface ValueObject und damit dessen zweiMethoden printValues() und toXMLElement(). Dabei gibt erstere die Daten aufder Konsole aus und letztere speichert die Daten in geeignetem Format in die XMLDatei.
• Die Aspektklasse ist von der Klasse AbstracLogger abgeleitet. Von dieser erbt siedas Attribut vom Typ Logger.
33

6 Benutzung des Prototyps
Die Idee der Anwendung war, dass man jeglichen Quellcode mit Aspekten versehen kannund dadurch Messungen am Programm vornehmen kann. Dies kann auf zwei verschiedeneArten erreicht werden. Zum einen kann man dies uber Eclipse erreichen, zum anderen hatman die Moglichkeit den Quellcode uber einen Kommandozeilenaufruf mit den Aspektenversehen zu lassen und kann das Kompilat daraus wie jedes andere Javaprogramm laufenlassen. Als Ausgabe entsteht dadurch eine XML-Datei sowie eine CSV-Datei.
6.1 Was leistet das Programm?
Die Aspekte sind so gedacht, dass sie jedem beliebigem Quellcode hinzugefugt wer-den konnen und den Quellcode so erweitern, dass statistische Informationen ausgelesenwerden konnen. In der vorliegenden Version konnen bereits folgende Daten ausgelesenwerden, sind also als Aspekt vorhanden:
• Instanzen zahlen
• Methodenaufrufe zahlen, sowohl gesamt wie zu jeder spezifisch
• Methodenlaufzeiten
• Threadinstanzen zahlen
• Threadausfuhrungen (Aufrufe von start())
• Exceptions die geworfen werden
Das Programm fuhrt eine Statistik wahrend der zu untersuchende Quellcode ausgefuhrtwird und schreibt die erworbenen Daten, bei Beendigung der virtuellen Maschine, in eineXML-Datei, welche zusatzlich noch gleich mit beliebigen XSLT-Templates transformiertwerden kann (z.B. CSV oder SVG-Ausgaben). Die Sammlung der Daten passiert somit inJava nativem Code und kann daher auf jeder zur Javaspezifikation kompatiblen virtuellenMaschine laufen, wenn es entsprechend ihrer Version kompiliert wurde.
6.2 Wie benutzt man das Programm?
Das Programm kann auf zwei verschiedene Arten benutzt werden. Zum einen durch ein-binden in ein Eclipseprojekt (6.3) und zum anderen durch Aufruf des Codeweavers (6.4),
34

welchem der zu untersuchende Quellcode und die Aspekte gegeben werden und dieserdann die Aspekte an den Quellcode knupft und ein lauffahiges Programm ausgibt.
6.3 Einbinden in ein Eclipseprojek
Der einfachste Weg ist den Quellcode, den Quellcode der Aspekte und dazugehorigerKlassen in ein AspectJ-Projekt in Eclipse zu kopieren. Dann kann man die ganze Anwen-dung direkt aus Eclipse heraus laufen lassen und muss sich um nichts weiter kummern.Das Anlegen eines AspectJ-Projekts funktioniert gleich wie das Anlegen eines normalenJavaprojekts, nur das man eben als Projektbasis ein AspectJ-Projekt auswahlt. Danachist zu empfehlen zwei Quellverzeichnisse anzulegen, eins fur das Programm welches un-tersucht werden soll und eins fur die Aspekte. Jetzt ware bereits alles lauffahig, aberes konnen noch weitere Konfigurationen vorgenommen werden. In der Datei Abstrac-tAspect.aj konnen ausgeschlossene Bereiche, sowie explizit eingeschlossene Bereiche be-stimmt werden. Die hierbei relevanten Pointcuts sind folgende:
Listing 6.1: relevante Pointcuts bei der Verwendung des Prototyps
public po intcut excluded ( ) :! with in ( c l eve rTec . . ∗ ) ;
public po intcut inc luded ( ) :with in ( ∗ ) ;
Alle Dateien oder Pakete die explizit ausgeschlossen werden sollen konnen in den Klam-mern des
”excluded“-Pointcut definiert werden. Die einzelnen Teilbereiche werden uber
&& (logisches Und) oder ‖ (logisches Oder) verbunden. Wichtig hierbei ist, dass dasPaket des Prototypen sowie alle seine Unterpakete und Klassen (cleverTec..*) ausge-schlossen werden. Als Beispiel fur die Benutzung:
Listing 6.2: Benutzungsbeispiel des within() im Prototyp
! with in ( c l eve rTec . . ∗ && java . s q l . . ∗
Diese Definition wurde nun das Paket des Prototypen und dessen Unterpakete ausschlie-ßen sowie zusatzlich alle Pakete von java.sql sowie dessen Unterpakete. Ahnlich lauft diesnun mit den explizit zu inkludierenden Paketen und Dateien. Die Anderung die man hiervornehmen muss, passiert in den Klammern des within-Fragments mit den gleichen Re-geln wie oben bei den fur die explizit ausgeschlossenen Pakete. Die Grundeinstellung *bedeutet, dass alle Pakete eingeschlossen werden (außer naturlich diejenigen die ausge-schlossen sind). Das ist eigentlich auch schon alles was es zu konfigurieren gibt.
Man kann zusatzlich seine eigenen Aspekte schreiben aber sollte sie uber den geradebeschriebenen Mechanismus aus den Statistiken ausschließen.
35

Zuletzt bleibt nur noch zu konfigurieren wohin die Ausgabe geschrieben werden soll undob XSLT-Templates auf sie angewendet werden sollen - dies kann man mittels der Dateiclevertec.properties im Unterverzeichnis conf erledigen. Die Erklarung zu dieser Dateiist im nachsten Abschnitt zu finden. Hat man nun dies alles gemacht kann man das zuuntersuchende Programm laufen lassen und am Ende des Laufs sind die gesammeltenDaten in den in der clevertec.properties definierten Ausgabedateien zu finden.
Das ganze wurde auch nochmal als Video beigelegt, in dem gezeigt wird wie man allesin diesem Punkt beschriebene macht.
6.4 Einbinden uber den Codeweaver
Der Codeweaver ist ein Javaprogramm, das einem letztlich den Aufruf fur den acj(AspectJ Compiler) von AspectJ abnimmt. Er baut den kompletten Aufruf auf, fuhrtihn aus und fugt dem kompilierten Projekt noch Konfigurationsdateien hinzu. Was manbraucht um ihn zu benutzen sind die Aspect Tools von AspectJ, die unter anderem dieLaufzeitumgebung von AspectJ enthalten. Diese findet man hier:http://www.eclipse.org/aspectj/downloads.php
Der Codeweaver selbst baut eigentlich nur eine Zeichenfolge auf mit welcher der ajcvon AspectJ aufgerufen wird, indem er einen Prozess dafur startet und die Zeichenfolgeausfuhrt. Die ganzen Daten, die benutzt werden um diesen Aufruf aufzubauen kom-men aus der config.properties-Datei. Das nachfolgende Bild sollte dies etwas deutlichermachen.
36

Abbildung 6.1: Die Verwendung der config.properties-Datei
Anhand der Informationen aus dieser Datei wird dann ein mit den Aspekten versehe-ner Bytecode erzeugt, welchen man wie jedes andere Javaprogramm laufen lassen kann.Zusatzlich werden noch die Verzeichnisse libs und conf, die im Arbeitsverzeichnis desCodeWeavers liegen, kopiert. Zum Schluss wird noch eine Batch- oder Skriptdatei er-zeugt, je nach unterliegender Plattform, die dann mittels Parameterubergabe des Pfadeszur main-Methode den kompilierten Code ausfuhrt.
Der Codeweaver kann sowohl unter Linux als auch unter Windows benutzt werden,dabei ist naturlich zu beachten das die Pfadangaben fur Dateien der jeweiligen Umge-bung angepasst werden mussen. Gehen wir nun Schritt fur Schritt durch, wie man ihnbenutzt.
1. Als erstes brauchen wir eine Konfigurationsdatei mit dem Namen config.propertiesim Arbeitsverzeichnis. Da man diese wahrscheinlich noch nicht hat kann man siemittels dem Aufruf
”java cleverTec.ajc.Codeweaver -makeconfig“ erzeugen lassen.
Der Aufbau der Konfigurationsdatei wird am Ende des Abschnittes erklart
2. Nachdem man die Konfigurationen gesetzt hat, u.a. wo die AspectJ-Bibliothekensowie der zu untersuchende Quellcode liegt, kann man dann den Codeweaver auf-rufen mittels: java cleverTec.ajc.Codeweaver. Dieser generiert einem dann den By-
37

tecode verwoben mit den Aspekten und zusatzlich, in dem in der Konfigurations-datei definiertem Ausgabeverzeichnis, ein Unterverzeichnis mit dem Namen conf,in welchem eine Konfigurationsdatei namens clevertec.properties fur das geradekompilierte Programm liegt.
3. Danach konnen wir in das Ausgabeverzeichnis wechseln und noch Einstellungen inder Konfigurationsdatei clevertec.properties vornehmen:xmloutfile definiert den Namen der xml-Ausgabedateixsltfiles p10cm definiert die Namen der Umwandlungsdateien, die die xml-
Ausgabe weitertransformieren. Durch”;“ getrennt – Reihenfolge
analog zu xsltoutsxsltouts definiert die Namen der zusatzlichen Ausgabedateien, die mittels
XSLT-Files generiert werden. Durch”;“ getrennt – Reihenfolge ana-
log zu xsltfiles.
4. Im letzten Schritt muss man nur noch die main-Methode des kompilierten Pro-gramms aufrufen und nach Beendigung ist sowohl die xml- als auch die csv-Ausgabevorhanden in den jeweils im clevertec.properties definierten Dateien.
Das war eigentlich schon alles was man machen muss. Es fehlt nur noch die Konfigurationdes Codeweaver uber dessen Konfigurationsdatei config.properties in dessen Arbeitsver-zeichnis. Hier ein Beispiel fur eine Windowskonfiguration und danach die Erklarungender einzelnen Variablen:
Listing 6.3: Die Konfigurationsdatei config.properties
FURTHERJAVAARGS=ACJCLASSPATH=Libs \\ jdom−1.1\\ jdom . j a r ;
C:\\Programme\\Java\\ a s p e c t j \\ l i b \\ a s p e c t j r t . j a rDESTINATION=tes tB inFURTHERACJARGS=−source 1 .5ASPECT LIB PATH=C:\\Programme\\Java\\ a s p e c t j \\ l i bJAVAFILES=t e s t s S o u r c e s \\ t e s t S o u r c e s \\ threads \\ ;\
s r c \\ c l everTec \\ l o g g e r \\ ;\s r c \\ c l everTec \\ a spec t s \\methodExecutionNumber \\ ;\s r c \\ c l everTec \\ a spec t s \\ threads \\ ;\s r c \\ c l everTec \\ u t i l \\
ACJ=org . a s p e c t j . t o o l s . a j c . MainCLASSFILESGIVEN=0
Die Konfigurationsdatei ist eine Java konforme properties-Datei. Deswegen auch die”\\“
in den Windowspfadangaben. Ansonsten gelten die ublichen Regeln fur solche Dateien.
Die Erklarung der einzelnen Variablen:
38

FURTHERJAVAARGS Hier konnen zusatzliche Argumente fur den Javakompilierer(javac) ubergeben werden, z.B. -Xstdout
ACJCLASSPATH Hier mussen die vom acj zur Ubersetzung benotigten Biblio-theken ubergeben werden. Mehrere Angaben sollten mittelsStrichpunkt getrennt werden
DESTINATION Diese Variable bestimmt das Ausgabeverzeichnis wo die kom-pilierten Dateien hingeschrieben werden sollen
FURTHERACJARGS Dies sind Argumente die dem acj zusatzlich ubergeben werdensollen, ahnlich wie FURTHERJAVAARGS
ASPECT LIB PATH Hier mussen die AspectJ-Bibliotheken angegeben werden dieu.a. den acj enthalten der zum ubersetzen der Javadateienbenutzt werden soll
JAVAFILES Hier werden sowohl der zu untersuchende Quellcode angege-ben als auch die Aspekte die man benutzen mochte. Wenn dieAngaben mit einem systemspezifischen Pfadseparator, z.B.Unix
”/“, enden, werden die verschiedenen Pfade passend um-
gebaut und als Argument an den acj ubergeben. Falls sie nichtso enden werden dem acj nur die angegebenen Dateien, welchemit .java oder .aj enden sollten, ubergeben. Wenn man meh-rere Pfade angeben will kann man diese mittels Strichpunkttrennen.
ACJ Der eigentliche Aufruf des acj selbst. Falls sich irgendwanneinmal die Struktur der AspectJ-Bibliotheken andert kann dashier angepasst werden
CLASSFILESGIVEN Entweder 0 oder 1. Bei 0 bedeutet dies, dass man nur Quell-code kompilieren will (.java), bei 1, dass man nur kompilierteDateien verweben will (.class-Dateien)
6.5 Ausfuhren mittels Ant-Task
AspectJ liefert standardmaßig Taskdefinitions fur das weitverbreitete Build-Tool Ant(siehe [The]) mit jedem Release in der
”aspectjtools.jar“ aus. Damit ist die Integration
des AspektJ-Compilers”ajc“ in Ant ein leichtes. Ein sehr einfaches compile Target fur
Ant konnte in etwa so aussehen:
Listing 6.4: Ein einfaches compile Target fur Ant
<t a r g e t name=” compile ” depends=” clean , copy”>< i a j c source=” 1 .5 ” sourceRootCopyFi l ter=” ∗∗/∗ . java ,∗∗/∗ . a j ”c l a s spa th=”${ a s p e c t j r t . j a r } ; l i b s /jdom−1.1/jdom . j a r ”destDir=”${ outd i r }”>
<s o u r c e r o o t s><pathelement l o c a t i o n=” s r c /” />
39

<pathelement l o c a t i o n=” t e s t s S o u r c e s /” /></ s o u r c e r o o t s></ i a j c>
</ t a r g e t>
Der <iajc> Aufruf kompiliert hier samtliche .java und .aj Dateien im Verzeichnis srcund testsSrouces und schreibt die kompilierten .class Dateien in das destDir-Verzeichnis– ajc agiert hier also ebenso wie javac, nur eben mit AspectJ Unterstutzung. Je nach-dem welches Projekt hier kompiliert werden soll, mussen weitere Bibliotheken im Class-path angegeben werden, oder Konfigurationsdateien mit in das destDir kopiert werden.Hierfur kann die Build-Datei beliebig erweitert werden. Fur einfache Aufgaben sind hierkaum Kentnisse der Ant-Syntax notwendig, die Build-Datei ist ausserdem fur sich sehrsprechend.
Um das volle potential des AspektJ-Compilers auszunutzen und sich so die Moglichkeitzu erschließen inkrementell zu kompilieren oder ByteCode-Weaving, also das anwendeneines Aspekts auf bereits kompilierte .class Dateien (bzw. .jar-Dateien), zu betreiben –verweisen wir auf die sehr gute Dokumentation der AspectJ-Ant-Tasks unter [Aspa].
Das aktuell enthaltene Buildfile aspectj build.xml kompiliert samtliche Aspekte undTests. Um es zu verwenden sind folgende Schritte vorzunehmen:
Zunachst sollte Ant in einer moglichst neuen Version installiert werden und das ant/bin-Verzeichnis gegebenenfalls zur Path-Variable hinzugefugt werden, um Ant direkt alsKommando in der Konsole verwenden zu konnen. Nun mussen noch die Properties imaspectj build.xml angepasst werden. Besonders wichtig sind hier die beiden Properties
<property name=”aspectjrt.jar“ value=
”C:\..\aspectjrt.jar“ />
<property name=”aspectjtools.jar“ value=
”C:\..\aspectjtools.jar“ />
Diese mussen auf den jeweiligen Pfad zeigen, in dem AspectJ installiert wurde.
Um unsere Beispiele auszufuhren ist sonst keine weitere Einstellung notig. Sollen aberandere Projekte kompiliert werden, muss das classpath compile bzw. classpath executionProperty gegebenenfalls um weitere librarys erweitert werden.
Nun kann das default-target, hier compile, per Kommandozeile gestartet werden:”ant
–f aspectj build.xml“ fuhrt das default-target aus. Zunachst, wird falls vorhanden derOrdner ant-out im relativen Verzeichnis geloscht (clean). Dann werden Librarys undKonfigurationsdateien ins ant-out Verzeichnis kopiert(copy). Zu guter letzt werden nochsamtliche java/aj Dateien compiliert, sowie alle weiteren Dateien die sich in den bei-den sourceroot-Verzeichnissen befinden ins jeweilige ant-out Unterverzeichnis kopiert(ausgeschlossen von diesem Kopieren sind .java und .aj Dateien – siehe SourceRootCo-pyFilter).
Nun konnen die kompilierten .class Dateien ganz normal per java Aufruf ausgefuhrt wer-den (zusatzlich muss man nur die aspectjrt.jar im Classpath angeben) – auch dies kann
40

per Ant erledigt werden.”ant –f aspectj build.xml run“ startet z.B. die Main-Methode
der Klasse testSources.threads.Restaurant – dies kann durch setzen des mainclass-propertiesin der XML-Datei auch geandert werden, oder per Kommandozeile direkt uberschriebenwerden:
”ant –f aspectj build.xml run -Dmainclass=testSources.svg.SVG Coordinate System Test“
fuhrt also die Klasse testScources.svg.SVG Coordinate System Test aus.
Ant bietet noch viele weitere Moglichkeiten automatische Builds und weitere Aufgabenzu realsieren. Hierfur verweisen wir auf die Ant-Dokumentation unter [Apa].
Durch die Verwendung des Ant-Build-Files ist eine nahtlose Integration in eventuell be-reits bestehende automatische Buildprozesse moglich. So konnten beispielsweise Testsmithilfe von AspectJ geschrieben werden und die von uns dabei erzeugten Ausgaben di-rekt ausgewertet, oder die SVG-Grafiken in Report-Seiten miteingebunden werden. Hierist auch zu beachten, dass weitere XSL-Transformationen direkt per clevertec.propertieseingebunden werden konnen. So konnte aus den Ergebnissen direkt eine passende XHTML-Seite generiert werden, welche dann automatisch generiert wird und weiterverarbeitetwerden kann (Maven, CruiseControl, Wikis etc..).
6.6 Was wird Ausgegeben?
Hat man nun den einen oder anderen Weg genommen um sein Programm mit denAspekten zu verweben und laufen zu lassen bekommt man als Ergebnis sowohl eineXML-Datei, sowie eventuell weitere durch XSLT erzeugte Dateien. Die XML-Datei istso aufgeteilt, dass zu jedem Unterpaket von clevertec.aspects eine Sektion aufgemachtwird und die Werte die uber die dort enthaltenen Aspekte gesammelt wurden in dieseSektion geschrieben werden. Die einzelnen Aspekte in jedem Paket wiederum bekom-men eine eigene Sektion mit dem Namen entry”welcher den Aspekt definiert. In dieserentrySektion sind dann die Werte die von dem jeweiligen Aspekt gesammelt wurden,als Kindelemente mit Attributen enthalten. Die Formatdefinition dieser Kindelemente,also welcher Wert ist ein Attribut oder sollen Werte als Elemente eingefugt werden, wirdvon dem zum Aspekt gehorigen ValueObject bestimmt. Praziser, die Methode toXM-LElement (implementiert von dem Interface ValueObject) bestimmt wie die Ausgabeinnerhalb jedes entryaussieht.
Die CSV-Datei wird eigentlich in mehreren Teilen ausgegeben (momentan). Die Ideehierbei ist, dass die CSV-Datei(en) mit Hilfe von XSLT-Datei(en) aus der produzier-ten XML-Datei erzeugt wird. Die XSLT-Datei(en) die benutzt werden soll, wird einfachin der clevertec.properties unter xsltfiles vermerkt (siehe 6.4 ). Diese Dateien werdendann zusatzlich nach Beendigung der XML-Ausgabe verarbeitet. Uber diesen Mecha-nismus kann man leicht beliebige CSV-Ausgaben erzeugen, die immer an die Umstandeangepasst werden konnen sowohl mit den Daten als auch mit dem Format.
41

Literaturverzeichnis
[Apa] Apache Ant 1.7.0 Manual. http://ant.apache.org/manual/index.html, Ab-ruf: 20. Januar 2008
[Aspa] AspectJ Ant Tasks. http://www.eclipse.org/aspectj/doc/released/
devguide/antTasks.html, Abruf: 20. Januar 2008
[Aspb] The AspectJ Programming Guide. http://www.eclipse.org/aspectj/doc/
released/progguide/index.html, Abruf: 20. Januar 2008
[Boh06] Bohm, Oliver: Aspekorientierte Programmierung mit AspectJ 5. Dpunkt-Verlag, 2006. – ISBN 3–89864–330–1
[Lad03] Laddad, Ramnivas: AspectJ In Action. Manning, 2003. – ISBN 1–930110–93–6
[Mar] Metric mishap caused loss of NASA orbiter. http://www.cnn.com/TECH/
space/9909/30/mars.metric.02/, Abruf: 20. Januar 2008
[Syn] Syntax der TypePatterns. http://www.eclipse.org/aspectj/doc/
released/progguide/semantics-pointcuts.html#type-patterns, Ab-ruf: 20. Januar 2008
[The] The Apache Ant Project. http://ant.apache.org/, Abruf: 20. Januar 2008
42

Abbildungsverzeichnis
1.1 Logging in Apache Tomcat . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2 XML-Parsing in Apache Tomcat . . . . . . . . . . . . . . . . . . . . . . . 6
2.1 Wo AOP angreift . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Eine Java-Klasse Konto mit Beispiel-Join-Points . . . . . . . . . . . . . . 9
2.3 Der Advice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1 Blackbox-Ansicht eines Projekts . . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Umwandlung eines Java-Projekts in ein AspectJ-Project . . . . . . . . . 16
3.3 Der Aspekt Ausgeben von SQL-Statements zeigt auf eine Codestelle . . . 18
3.4 Main-Methode, auf die der Aspekt Ausgeben von SQL-Statements zeigt . 18
4.1 Die excluded-/included-Anweisung . . . . . . . . . . . . . . . . . . . . . 22
4.2 Die technische Architektur des Prototyps . . . . . . . . . . . . . . . . . . 23
4.3 Programmablauf des Prototypen . . . . . . . . . . . . . . . . . . . . . . . 26
5.1 ValueObject-Klasse CountGetterUndSetter . . . . . . . . . . . . . . . . . 31
5.2 Benutzerspezifisches Aspekt GetterAndSetter.aj . . . . . . . . . . . . . . 32
5.3 Loggerausgabe mit dem Ergebnis des benutzerspezifischen Aspekts . . . . 32
6.1 Die Verwendung der config.properties-Datei . . . . . . . . . . . . . . . . 37
43

Listings
2.1 Ein Aspekt in AspectJ . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.1 Die erste Codezeile vom Aspekt SqlStatementsAspect . . . . . . . . . . . 173.2 Pointcut- und Join-Point-Definition im Aspekt SqlStatementsAspect . . . 173.3 Advice-Definition im Aspekt SqlStatementsAspect . . . . . . . . . . . . . 176.1 relevante Pointcuts bei der Verwendung des Prototyps . . . . . . . . . . . 356.2 Benutzungsbeispiel des within() im Prototyp . . . . . . . . . . . . . . . . 356.3 Die Konfigurationsdatei config.properties . . . . . . . . . . . . . . . . . . 386.4 Ein einfaches compile Target fur Ant . . . . . . . . . . . . . . . . . . . . 39
44






![VDI-Berichte, Bd. 2335 Absicherung der Umfeldwahrnehmung ... filebeispielsweise durch menschliche Unfallraten konkretisiert [1, 2, 4]. Ein wichtiger Aspekt für die Ein wichtiger Aspekt](https://static.fdokument.com/doc/165x107/5e0737234d79bb2ecf76f67a/vdi-berichte-bd-2335-absicherung-der-umfeldwahrnehmung-durch-menschliche-unfallraten.jpg)











